
File size: 10,085 Bytes
e251588 097e482 ac847b2 097e482 ac847b2 097e482 ac847b2 3ef2fd3 ac847b2 3ef2fd3 ac847b2 3ef2fd3 ac847b2 3ef2fd3 ac847b2 3ef2fd3 ac847b2 e251588 85c636c f382465 cddb113 3fe691b cddb113 e251588 afab71b 3ef2fd3 e251588 85c636c e251588 85c636c fa7e665 e251588 ec6b006 e251588 5a281e6 85c636c c04ddb5 85c636c 5a281e6 e251588 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 |
---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
widget:
- text: "[Q] cengiz han binbasi olarak kim atadi"
example_title: "Örnek 1"
- text: "[Q] 2003 dunya halter sampiyonasi hangi tarihlerde yapildi"
example_title: "Örnek 2"
- text: "[Q] ahmet haldun dormen hangi tarihte dogmustur"
example_title: "Örnek 3"
- text: "[Q] ajda pekkan hangi sarkisiyla iyi cikis yakalamistir"
example_title: "Örnek 4"
- text: "[Q] kobalt camlari kim tarafindan bulunmustur"
example_title: "Örnek 5"
- text: "[Q] john turk ne zaman dogmustur"
example_title: "Örnek 6"
- text: "[Q] tayvan ne zaman kurulmustur"
example_title: "Örnek 7"
- text: "[Q] dunyanin her bolgesinden kutuphaneler hangi imkani verir"
example_title: "Örnek 8"
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
Bu model test amaçlı hazırlanmıştır ve fikir vermesi açısından geliştirilmiştir. Model için Vikipedi üzerinden üretilen 40 bin soru cevap GPT ile eğitilmiştir. Daha büyük veri setlerinde daha iyi sonuçlar alınabilir.
## Önemli Notlar
* Inference için soruların başında [Q] kullanılmalıdır.
* Sorular latin karakterlerden oluşmalıdır. ç ğ I ö ş ü gibi harfler içermemelidir.
* Sorular küçük harflerden oluşmalıdır. Büyük harf veya sembol kullanımı farklı ve istenmeyen cevaplar üretecektir.
## Model Details
## Başlıklara göre en fazla soru cevap içeren konular aşağıdadır:
* Cengiz Han: 665 adet
* Futbol rekabetleri listesi: 409 adet
* Lüleburgaz Muharebesi: 336 adet
* I. Baybars: 263 adet
* Sovyetler Birliği'nin askerî tarihi: 258 adet
* Zümrüdüanka Yoldaşlığı: 245 adet
* Gilles Deleuze: 208 adet
* Ermenistan Sovyet Sosyalist Cumhuriyeti: 195 adet
* Nâzım Hikmet: 173 adet
* Hermann Göring: 169 adet
* V. Leon: 163 adet
* Gökhan Türkmen: 156 adet
* Dumbledore'un Ordusu: 153 adet
* Ajda Pekkan: 152 adet
* Kırkpınar Yağlı Güreşleri: 152 adet
* Mehdi Savaşı: 150 adet
* İmamiye (Şiilik öğretisi): 149 adet
* Rumyantsev Harekâtı: 145 adet
* II. Dünya Savaşı tankları: 144 adet
* Emîn: 142 adet
* Boshin Savaşı: 137 adet
* Wolfgang Amadeus Mozart: 136 adet
* Faşizm: 134 adet
* Kâzım Koyuncu: 133 adet
* Suvorov Harekâtı: 128 adet
* Mao Zedong: 127 adet
* Mehdî (Abbâsî halifesi): 127 adet
* Madagaskar: 124 adet
* Oscar Niemeyer: 123 adet
* Adolf Eichmann: 123 adet
* Joachim von Ribbentrop: 121 adet
* Crystal Palace FC: 119 adet
* IV. Mihail: 111 adet
* VI. Leon: 107 adet
* Han Hanedanı: 105 adet
* Portekiz coğrafi keşifleri: 104 adet
* II. Nikiforos: 102 adet
* III. Mihail: 98 adet
* Fidel Castro: 96 adet
* Tsushima Muharebesi: 94 adet
* I. Basileios: 93 adet
* VI. Konstantinos: 92 adet
* Bijan Muharebesi: 91 adet
* Otto Skorzeny: 90 adet
* Antimon: 89 adet
* Dijitalleştirme: 88 adet
* Theofilos: 79 adet
* Sovyet Hava Kuvvetleri: 78 adet
* IV. Henry, Bölüm 1: 77 adet
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** Cenker Sisman
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model :** redrussianarmy/gpt2-turkish-cased
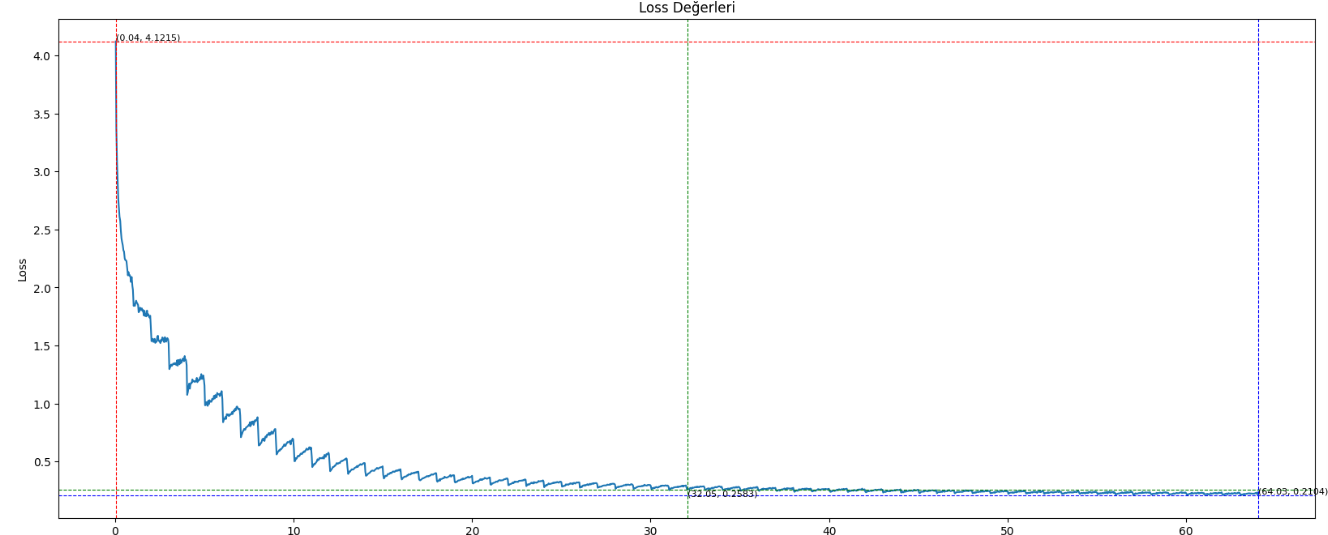
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Sınırlamalar ve Önyargılar
chatbotgpt-turkish, bir özyineli dil modeli olarak eğitildi. Bu, temel işlevinin bir metin dizisi alıp bir sonraki belirteci tahmin etmek olduğu anlamına gelir. Dil modelleri bunun dışında birçok görev için yaygın olarak kullanılsa da, bu çalışmayla ilgili birçok bilinmeyen bulunmaktadır.
chatbotgpt-turkish, küfür, açık saçıklık ve aksi davranışlara yol açan metinleri içerdiği bilinen bir veri kümesi olan Pile üzerinde eğitildi. Kullanım durumunuza bağlı olarak, chatbotgpt-turkish toplumsal olarak kabul edilemez metinler üretebilir. Pile makalesinin 5. ve 6. bölümlerinde Pile'daki önyargıların daha ayrıntılı bir analizini bulabilirsiniz.
Tüm dil modellerinde olduğu gibi, chatbotgpt-turkish'in belirli bir girişe nasıl yanıt vereceğini önceden tahmin etmek zordur ve uyarı olmaksızın saldırgan içerik ortaya çıkabilir. Sonuçları yayınlamadan önce insanların çıktıları denetlemesini veya filtrelemesini öneririz, hem istenmeyen içeriği sansürlemek hem de sonuçların kalitesini iyileştirmek için.
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
```python
"""Inference"""
from transformers import PreTrainedTokenizerFast, GPT2LMHeadModel, GPT2TokenizerFast, GPT2Tokenizer
def load_model(model_path):
model = GPT2LMHeadModel.from_pretrained(model_path)
return model
def load_tokenizer(tokenizer_path):
tokenizer = GPT2Tokenizer.from_pretrained(tokenizer_path)
return tokenizer
def generate_text(model_path, sequence, max_length):
model = load_model(model_path)
tokenizer = load_tokenizer(model_path)
ids = tokenizer.encode(sequence, return_tensors='pt')
outputs = model.generate(
ids,
do_sample=True,
max_length=max_length,
pad_token_id=model.config.eos_token_id,
top_k=1,
top_p=0.99,
)
converted = tokenizer.convert_ids_to_tokens(outputs[0])
valid_tokens = [token if token is not None else '.' for token in converted]
generated_text = tokenizer.convert_tokens_to_string(valid_tokens)
print(generated_text)
model2_path = "cenkersisman/chatbotgpt-turkish"
sequence2 = "[Q] cengiz han kimdir"
max_len = 120
generate_text(model2_path, sequence2, max_len)
```
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|