
Commit
•
9fa8637
1
Parent(s):
48c6f94
Upload folder using huggingface_hub
Browse files- README.md +46 -0
- benchmarking.png +0 -0
- benchmarking_table.png +0 -0
- config.json +37 -0
- generation_config.json +6 -0
- model.safetensors.index.json +298 -0
- output.safetensors +3 -0
- special_tokens_map.json +23 -0
- tokenizer.json +0 -0
- tokenizer.model +3 -0
- tokenizer_config.json +42 -0
README.md
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
base_model: mistralai/Mistral-7B-v0.1
|
| 3 |
+
license: apache-2.0
|
| 4 |
+
---
|
| 5 |
+
|
| 6 |
+
## Introduction
|
| 7 |
+
|
| 8 |
+
Cerebrum 7b is a large language model (LLM) created specifically for reasoning tasks. It is based on the Mistral 7b model, fine-tuned on a small custom dataset of native chain of thought data and further improved with targeted RLHF (tRLHF), a novel technique for sample-efficient LLM alignment. Unlike numerous other recent fine-tuning approaches, our training pipeline includes under 5000 training prompts and even fewer labeled datapoints for tRLHF.
|
| 9 |
+
|
| 10 |
+
Native chain of thought approach means that Cerebrum is trained to devise a tactical plan before tackling problems that require thinking. For brainstorming, knowledge intensive, and creative tasks Cerebrum will typically omit unnecessarily verbose considerations.
|
| 11 |
+
|
| 12 |
+
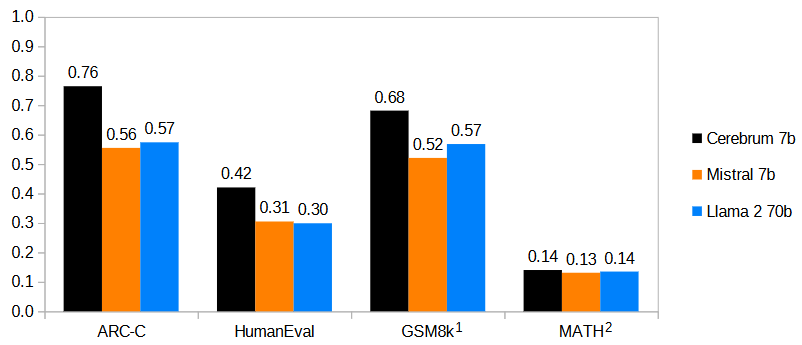
Zero-shot prompted Cerebrum significantly outperforms few-shot prompted Mistral 7b as well as much larger models (such as Llama 2 70b) on a range of tasks that require reasoning, including ARC Challenge, GSM8k, and Math.
|
| 13 |
+
|
| 14 |
+
## Benchmarking
|
| 15 |
+
An overview of Cerebrum 7b performance compared to reported performance Mistral 7b and LLama 2 70b on selected benchmarks that require reasoning:
|
| 16 |
+
|
| 17 |
+
<img src="benchmarking.png" alt="benchmarking_chart" width="750"/>
|
| 18 |
+
<img src="benchmarking_table.png" alt="benchmarking_table" width="750"/>
|
| 19 |
+
Notes: 1) Cerebrum evaluated zero-shot, Mistral 8-shot with maj@8, Llama 8-shot; 2) Cerebrum evaluated zero-shot, Mistral 4-shot with maj@4, Llama 4-shot
|
| 20 |
+
|
| 21 |
+
## Usage
|
| 22 |
+
For optimal performance, Cerebrum should be prompted with an Alpaca-style template that requests the description of the "thought process". Here is what a conversation should look like from the model's point of view:
|
| 23 |
+
```
|
| 24 |
+
<s>A chat between a user and a thinking artificial intelligence assistant. The assistant describes its thought process and gives helpful and detailed answers to the user's questions.
|
| 25 |
+
User: Are you conscious?
|
| 26 |
+
AI:
|
| 27 |
+
```
|
| 28 |
+
|
| 29 |
+
This prompt is also available as a chat template. Here is how you could use it:
|
| 30 |
+
```
|
| 31 |
+
messages = [
|
| 32 |
+
{'role': 'user', 'content': 'What is chain of thought prompting?'},
|
| 33 |
+
{'role': 'assistant', 'content': 'Chain of thought prompting is a technique used in large language models to encourage the model to think more deeply about the problem it is trying to solve. It involves prompting the model to generate a series of intermediate steps or "thoughts" that lead to the final answer. This can help the model to better understand the problem and to generate more accurate and relevant responses.'},
|
| 34 |
+
{'role': 'user', 'content': 'Why does chain of thought prompting work?'}
|
| 35 |
+
]
|
| 36 |
+
|
| 37 |
+
input = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors='pt')
|
| 38 |
+
|
| 39 |
+
with torch.no_grad():
|
| 40 |
+
out = model.generate(input_ids=input, max_new_tokens=100, do_sample=False)
|
| 41 |
+
# will generate "Chain of thought prompting works because it helps the model to break down complex problems into smaller, more manageable steps. This allows the model to focus on each step individually and to generate more accurate and relevant responses. Additionally, the intermediate steps can help the model to understand the problem better and to find patterns or connections that it may not have seen before.</s>"
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
The model ends its turn by generating the EOS token. Importantly, this token should be removed from the model answer in a multi-turn dialogue.
|
| 45 |
+
|
| 46 |
+
Cerebrum can be operated at very low temperatures (and specifically temperature 0), which improves performance on tasks that require precise answers. The alignment should be sufficient to avoid repetitions in most cases without a repetition penalty.
|
benchmarking.png
ADDED
|
benchmarking_table.png
ADDED

|
config.json
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "mistralai/Mistral-7B-v0.1",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"MistralForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 1,
|
| 8 |
+
"eos_token_id": 2,
|
| 9 |
+
"hidden_act": "silu",
|
| 10 |
+
"hidden_size": 4096,
|
| 11 |
+
"initializer_range": 0.02,
|
| 12 |
+
"intermediate_size": 14336,
|
| 13 |
+
"max_position_embeddings": 32768,
|
| 14 |
+
"model_type": "mistral",
|
| 15 |
+
"num_attention_heads": 32,
|
| 16 |
+
"num_hidden_layers": 32,
|
| 17 |
+
"num_key_value_heads": 8,
|
| 18 |
+
"rms_norm_eps": 1e-05,
|
| 19 |
+
"rope_theta": 10000.0,
|
| 20 |
+
"sliding_window": 4096,
|
| 21 |
+
"tie_word_embeddings": false,
|
| 22 |
+
"torch_dtype": "float16",
|
| 23 |
+
"transformers_version": "4.37.0.dev0",
|
| 24 |
+
"use_cache": true,
|
| 25 |
+
"vocab_size": 32000,
|
| 26 |
+
"quantization_config": {
|
| 27 |
+
"quant_method": "exl2",
|
| 28 |
+
"version": "0.0.15",
|
| 29 |
+
"bits": 3.5,
|
| 30 |
+
"head_bits": 6,
|
| 31 |
+
"calibration": {
|
| 32 |
+
"rows": 100,
|
| 33 |
+
"length": 2048,
|
| 34 |
+
"dataset": "(default)"
|
| 35 |
+
}
|
| 36 |
+
}
|
| 37 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"transformers_version": "4.37.0.dev0"
|
| 6 |
+
}
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,298 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 14483464192
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00003-of-00003.safetensors",
|
| 7 |
+
"model.embed_tokens.weight": "model-00001-of-00003.safetensors",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 14 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 15 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 17 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 18 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 19 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 20 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 21 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 22 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 23 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 24 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 25 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 26 |
+
"model.layers.10.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 27 |
+
"model.layers.10.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 28 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 29 |
+
"model.layers.10.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 30 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 31 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 32 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 33 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 34 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 35 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 36 |
+
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 37 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 38 |
+
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 39 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 40 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 41 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 42 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 43 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 44 |
+
"model.layers.12.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 45 |
+
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 46 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 47 |
+
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 48 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 49 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 50 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 51 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 52 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 53 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 54 |
+
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 55 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 56 |
+
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 57 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 58 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 59 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 60 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 61 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 62 |
+
"model.layers.14.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 63 |
+
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 64 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 65 |
+
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 66 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 67 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 68 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 69 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 70 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 71 |
+
"model.layers.15.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 72 |
+
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 73 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 74 |
+
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 75 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 76 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 77 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 78 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 79 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 80 |
+
"model.layers.16.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 81 |
+
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 82 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 83 |
+
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 84 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 85 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 86 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 87 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 88 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 89 |
+
"model.layers.17.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 90 |
+
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 91 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 92 |
+
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 93 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 94 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 95 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 96 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 97 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 98 |
+
"model.layers.18.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 99 |
+
"model.layers.18.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 100 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 101 |
+
"model.layers.18.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 102 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 103 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 104 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 105 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 106 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 107 |
+
"model.layers.19.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 108 |
+
"model.layers.19.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 109 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 110 |
+
"model.layers.19.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 111 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 112 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 113 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 114 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 115 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 116 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 117 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 118 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 119 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 120 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 121 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 122 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 123 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 124 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 125 |
+
"model.layers.20.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 126 |
+
"model.layers.20.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 127 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 128 |
+
"model.layers.20.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 129 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 130 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 131 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 132 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 133 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 134 |
+
"model.layers.21.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 135 |
+
"model.layers.21.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 136 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 137 |
+
"model.layers.21.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 138 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 139 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 140 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 141 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 142 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 143 |
+
"model.layers.22.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 144 |
+
"model.layers.22.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 145 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 146 |
+
"model.layers.22.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 147 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 148 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 149 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 150 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 151 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 152 |
+
"model.layers.23.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 153 |
+
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 154 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 155 |
+
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 156 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 157 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 158 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 159 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 160 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 161 |
+
"model.layers.24.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 162 |
+
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 163 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 164 |
+
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 165 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 166 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 167 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 168 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 169 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 170 |
+
"model.layers.25.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 171 |
+
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 172 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 173 |
+
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 174 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 175 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 176 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 177 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 178 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 179 |
+
"model.layers.26.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 180 |
+
"model.layers.26.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 181 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 182 |
+
"model.layers.26.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 183 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 184 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 185 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 186 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 187 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 188 |
+
"model.layers.27.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 189 |
+
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 190 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 191 |
+
"model.layers.27.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 192 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 193 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 194 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 195 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 196 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 197 |
+
"model.layers.28.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 198 |
+
"model.layers.28.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 199 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 200 |
+
"model.layers.28.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 201 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 202 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 203 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 204 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 205 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 206 |
+
"model.layers.29.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 207 |
+
"model.layers.29.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 208 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 209 |
+
"model.layers.29.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 210 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 211 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 212 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 213 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 214 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 215 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 216 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 217 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 218 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 219 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 220 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 221 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 222 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 223 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 224 |
+
"model.layers.30.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 225 |
+
"model.layers.30.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 226 |
+
"model.layers.30.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 227 |
+
"model.layers.30.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 228 |
+
"model.layers.30.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 229 |
+
"model.layers.30.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 230 |
+
"model.layers.30.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 231 |
+
"model.layers.30.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 232 |
+
"model.layers.30.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 233 |
+
"model.layers.31.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 234 |
+
"model.layers.31.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 235 |
+
"model.layers.31.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 236 |
+
"model.layers.31.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 237 |
+
"model.layers.31.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 238 |
+
"model.layers.31.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 239 |
+
"model.layers.31.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 240 |
+
"model.layers.31.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 241 |
+
"model.layers.31.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 242 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 243 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 244 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 245 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 246 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 247 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 248 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 249 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 250 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 251 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 252 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 253 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 254 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 255 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 256 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 257 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 258 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 259 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 260 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 261 |
+
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 262 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 263 |
+
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 264 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 265 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 266 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 267 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 268 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 269 |
+
"model.layers.7.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 270 |
+
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 271 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 272 |
+
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 273 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 274 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 275 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 276 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 277 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 278 |
+
"model.layers.8.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 279 |
+
"model.layers.8.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 280 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 281 |
+
"model.layers.8.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 282 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 283 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 284 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 285 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 286 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 287 |
+
"model.layers.9.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 288 |
+
"model.layers.9.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 289 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 290 |
+
"model.layers.9.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 291 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 292 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 293 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 294 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 295 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 296 |
+
"model.norm.weight": "model-00003-of-00003.safetensors"
|
| 297 |
+
}
|
| 298 |
+
}
|
output.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:88dd1e09873974cd5c97d521c908e7dea7841a00c38f603552239b7b34409e06
|
| 3 |
+
size 3418506732
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"unk_token": {
|
| 17 |
+
"content": "<unk>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
}
|
| 23 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:dadfd56d766715c61d2ef780a525ab43b8e6da4de6865bda3d95fdef5e134055
|
| 3 |
+
size 493443
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,42 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"0": {
|
| 6 |
+
"content": "<unk>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"1": {
|
| 14 |
+
"content": "<s>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"2": {
|
| 22 |
+
"content": "</s>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
}
|
| 29 |
+
},
|
| 30 |
+
"additional_special_tokens": [],
|
| 31 |
+
"bos_token": "<s>",
|
| 32 |
+
"clean_up_tokenization_spaces": false,
|
| 33 |
+
"eos_token": "</s>",
|
| 34 |
+
"legacy": true,
|
| 35 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 36 |
+
"pad_token": null,
|
| 37 |
+
"sp_model_kwargs": {},
|
| 38 |
+
"spaces_between_special_tokens": false,
|
| 39 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 40 |
+
"unk_token": "<unk>",
|
| 41 |
+
"use_default_system_prompt": false
|
| 42 |
+
}
|