
File size: 11,201 Bytes
36a5929 24ea3d8 a89991c 55b7e6c a89991c 36a5929 9fa442b 36a5929 26dc517 36a5929 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 |
---
license: llama3
language:
- en
- ja
- zh
tags:
- roleplay
- llama3
- sillytavern
- idol
---
# Special Thanks:
- Lewdiculous's superb gguf version, thank you for your conscientious and responsible dedication.
- https://huggingface.co/LWDCLS/llama3-8B-DarkIdol-2.1-Uncensored-32K-GGUF-IQ-Imatrix-Request
# fast quantizations
- The difference with normal quantizations is that I quantize the output and embed tensors to f16.and the other tensors to 15_k,q6_k or q8_0.This creates models that are little or not degraded at all and have a smaller size.They run at about 3-6 t/sec on CPU only using llama.cpp And obviously faster on computers with potent GPUs
- https://huggingface.co/ZeroWw/llama3-8B-DarkIdol-2.1-Uncensored-32K-GGUF
- More models here: https://huggingface.co/RobertSinclair
# Model Description:
The module combination has been readjusted to better fulfill various roles and has been adapted for mobile phones.
- Saving money(LLama 3)
- Uncensored
- Quick response
- The underlying model used is winglian/Llama-3-8b-64k-PoSE (The theoretical support is 64k, but I have only tested up to 32k. :)
- A scholarly response akin to a thesis.(I tend to write songs extensively, to the point where one song almost becomes as detailed as a thesis. :)
- DarkIdol:Roles that you can imagine and those that you cannot imagine.
- Roleplay
- Specialized in various role-playing scenarios
- more look at test role. (https://huggingface.co/aifeifei798/llama3-8B-DarkIdol-1.2/tree/main/test)
- more look at LM Studio presets (https://huggingface.co/aifeifei798/llama3-8B-DarkIdol-1.2/tree/main/config-presets)

# Chang Log
### 2024-06-26
- 32k
### 2024-06-26
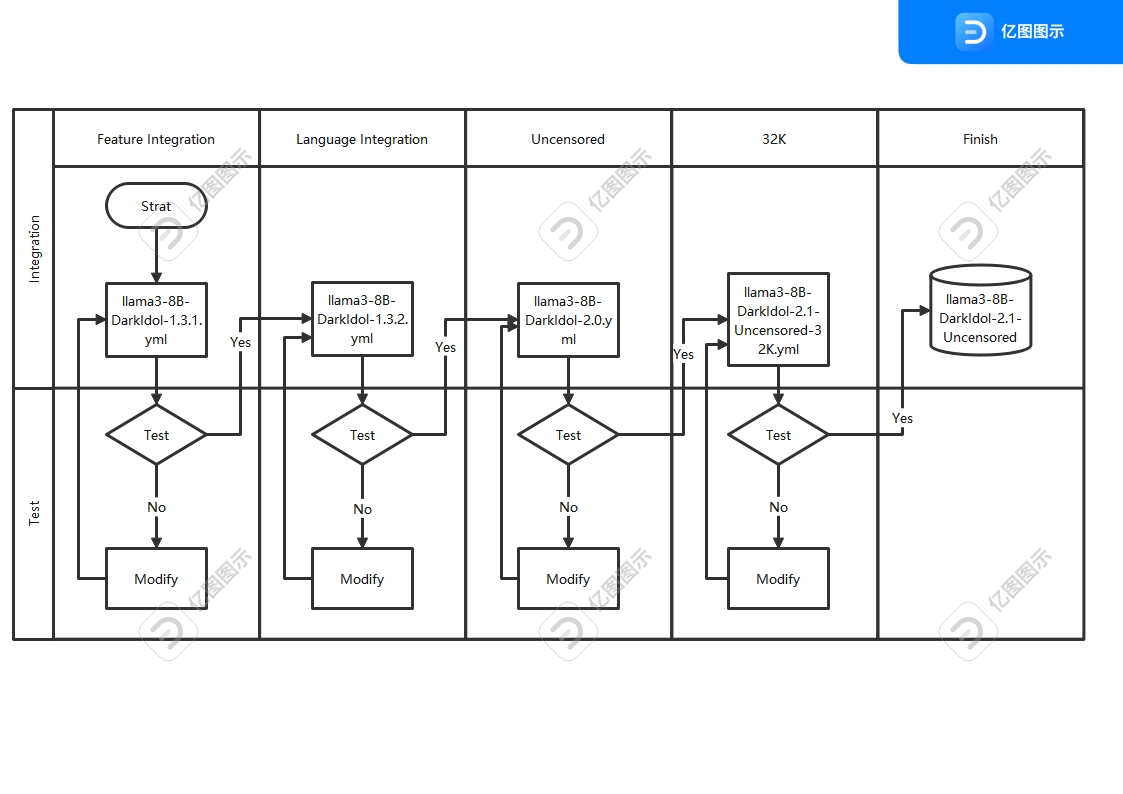
- 之前版本的迭代太多了,已经开始出现过拟合现象.重新使用了新的工艺重新制作模型,虽然制作复杂了,结果很好,新的迭代工艺如图
- The previous version had undergone excessive iterations, resulting in overfitting. We have recreated the model using a new process, which, although more complex to produce, has yielded excellent results. The new iterative process is depicted in the figure.
# Questions
- The model's response results are for reference only, please do not fully trust them.
- I am unable to test Japanese and Korean parts very well. Based on my testing, Korean performs excellently, but sometimes Japanese may have furigana (if anyone knows a good Japanese language module, - I need to replace the module for integration).
- With the new manufacturing process, overfitting and crashes have been reduced, but there may be new issues, so please leave a message if you encounter any.
- testing with other tools is not comprehensive.but there may be new issues, so please leave a message if you encounter any.
- The range between 32K and 64K was not tested, and the approach was somewhat casual. I didn't expect the results to be exceptionally good.
# 问题
- 模型回复结果仅供参考,请勿完全相信
- 日语,韩语部分我没办法进行很好的测试,根据我测试情况,韩语表现的很好,日语有时候会出现注音(谁知道好的日文语言模块,我需要换模块集成)
- 新工艺制作,过拟合现象和崩溃减少了,可能会有新的问题,碰到了请给我留言
- 32K-64k区间没有测试,做的有点随意,没想到结果特别的好
- 其他工具的测试不完善
# Stop Strings
```python
stop = [
"## Instruction:",
"### Instruction:",
"<|end_of_text|>",
" //:",
"</s>",
"<3```",
"### Note:",
"### Input:",
"### Response:",
"### Emoticons:"
],
```
# Model Use
- Koboldcpp https://github.com/LostRuins/koboldcpp
- Since KoboldCpp is taking a while to update with the latest llama.cpp commits, I'll recommend this [fork](https://github.com/Nexesenex/kobold.cpp) if anyone has issues.
- LM Studio https://lmstudio.ai/
- llama.cpp https://github.com/ggerganov/llama.cpp
- Backyard AI https://backyard.ai/
- Meet Layla,Layla is an AI chatbot that runs offline on your device.No internet connection required.No censorship.Complete privacy.Layla Lite https://www.layla-network.ai/
- Layla Lite llama3-8B-DarkIdol-1.1-Q4_K_S-imat.gguf https://huggingface.co/LWDCLS/llama3-8B-DarkIdol-2.1-Uncensored-32K/blob/main/llama3-8B-DarkIdol-2.1-Uncensored-32K-Q4_K_S-imat.gguf?download=true
- more gguf at https://huggingface.co/LWDCLS/llama3-8B-DarkIdol-2.1-Uncensored-32K-GGUF-IQ-Imatrix-Request
# character
- https://character-tavern.com/
- https://characterhub.org/
- https://pygmalion.chat/
- https://aetherroom.club/
- https://backyard.ai/
- Layla AI chatbot
### If you want to use vision functionality:
* You must use the latest versions of [Koboldcpp](https://github.com/Nexesenex/kobold.cpp).
### To use the multimodal capabilities of this model and use **vision** you need to load the specified **mmproj** file, this can be found inside this model repo. [Llava MMProj](https://huggingface.co/Nitral-AI/Llama-3-Update-3.0-mmproj-model-f16)
* You can load the **mmproj** by using the corresponding section in the interface:

### Thank you:
To the authors for their hard work, which has given me more options to easily create what I want. Thank you for your efforts.
- Hastagaras
- Gryphe
- cgato
- ChaoticNeutrals
- mergekit
- merge
- transformers
- llama
- Nitral-AI
- MLP-KTLim
- rinna
- hfl
- Rupesh2
- stephenlzc
- theprint
- Sao10K
- turboderp
- TheBossLevel123
- winglian
- .........
---
base_model:
- Nitral-AI/Hathor_Fractionate-L3-8B-v.05
- Hastagaras/Jamet-8B-L3-MK.V-Blackroot
- turboderp/llama3-turbcat-instruct-8b
- aifeifei798/Meta-Llama-3-8B-Instruct
- Sao10K/L3-8B-Stheno-v3.3-32K
- TheBossLevel123/Llama3-Toxic-8B-Float16
- cgato/L3-TheSpice-8b-v0.8.3
library_name: transformers
tags:
- mergekit
- merge
---
# llama3-8B-DarkIdol-1.3.1
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using [aifeifei798/Meta-Llama-3-8B-Instruct](https://huggingface.co/aifeifei798/Meta-Llama-3-8B-Instruct) as a base.
### Models Merged
The following models were included in the merge:
* [Nitral-AI/Hathor_Fractionate-L3-8B-v.05](https://huggingface.co/Nitral-AI/Hathor_Fractionate-L3-8B-v.05)
* [Hastagaras/Jamet-8B-L3-MK.V-Blackroot](https://huggingface.co/Hastagaras/Jamet-8B-L3-MK.V-Blackroot)
* [turboderp/llama3-turbcat-instruct-8b](https://huggingface.co/turboderp/llama3-turbcat-instruct-8b)
* [Sao10K/L3-8B-Stheno-v3.3-32K](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.3-32K)
* [TheBossLevel123/Llama3-Toxic-8B-Float16](https://huggingface.co/TheBossLevel123/Llama3-Toxic-8B-Float16)
* [cgato/L3-TheSpice-8b-v0.8.3](https://huggingface.co/cgato/L3-TheSpice-8b-v0.8.3)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: Sao10K/L3-8B-Stheno-v3.3-32K
- model: Hastagaras/Jamet-8B-L3-MK.V-Blackroot
- model: cgato/L3-TheSpice-8b-v0.8.3
- model: Nitral-AI/Hathor_Fractionate-L3-8B-v.05
- model: TheBossLevel123/Llama3-Toxic-8B-Float16
- model: turboderp/llama3-turbcat-instruct-8b
- model: aifeifei798/Meta-Llama-3-8B-Instruct
merge_method: model_stock
base_model: aifeifei798/Meta-Llama-3-8B-Instruct
dtype: bfloat16
```
---
base_model:
- hfl/llama-3-chinese-8b-instruct-v3
- rinna/llama-3-youko-8b
- MLP-KTLim/llama-3-Korean-Bllossom-8B
library_name: transformers
tags:
- mergekit
- merge
---
# llama3-8B-DarkIdol-1.3.2
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using ./llama3-8B-DarkIdol-1.3.1 as a base.
### Models Merged
The following models were included in the merge:
* [hfl/llama-3-chinese-8b-instruct-v3](https://huggingface.co/hfl/llama-3-chinese-8b-instruct-v3)
* [rinna/llama-3-youko-8b](https://huggingface.co/rinna/llama-3-youko-8b)
* [MLP-KTLim/llama-3-Korean-Bllossom-8B](https://huggingface.co/MLP-KTLim/llama-3-Korean-Bllossom-8B)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: hfl/llama-3-chinese-8b-instruct-v3
- model: rinna/llama-3-youko-8b
- model: MLP-KTLim/llama-3-Korean-Bllossom-8B
- model: ./llama3-8B-DarkIdol-1.3.1
merge_method: model_stock
base_model: ./llama3-8B-DarkIdol-1.3.1
dtype: bfloat16
```
---
base_model:
- theprint/Llama-3-8B-Lexi-Smaug-Uncensored
- Rupesh2/OrpoLlama-3-8B-instruct-uncensored
- stephenlzc/dolphin-llama3-zh-cn-uncensored
library_name: transformers
tags:
- mergekit
- merge
---
# llama3-8B-DarkIdol-2.0-Uncensored
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using ./llama3-8B-DarkIdol-1.3.2 as a base.
### Models Merged
The following models were included in the merge:
* [theprint/Llama-3-8B-Lexi-Smaug-Uncensored](https://huggingface.co/theprint/Llama-3-8B-Lexi-Smaug-Uncensored)
* [Rupesh2/OrpoLlama-3-8B-instruct-uncensored](https://huggingface.co/Rupesh2/OrpoLlama-3-8B-instruct-uncensored)
* [stephenlzc/dolphin-llama3-zh-cn-uncensored](https://huggingface.co/stephenlzc/dolphin-llama3-zh-cn-uncensored)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: Rupesh2/OrpoLlama-3-8B-instruct-uncensored
- model: stephenlzc/dolphin-llama3-zh-cn-uncensored
- model: theprint/Llama-3-8B-Lexi-Smaug-Uncensored
- model: ./llama3-8B-DarkIdol-1.3.2
merge_method: model_stock
base_model: ./llama3-8B-DarkIdol-2.0-Uncensored
dtype: bfloat16
```
---
base_model:
- winglian/Llama-3-8b-64k-PoSE
library_name: transformers
tags:
- mergekit
- merge
---
# llama3-8B-DarkIdol-2.1-Uncensored-32K
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using [winglian/Llama-3-8b-64k-PoSE](https://huggingface.co/winglian/Llama-3-8b-64k-PoSE) as a base.
### Models Merged
The following models were included in the merge:
* ./llama3-8B-DarkIdol-1.3.2
* ./llama3-8B-DarkIdol-2.0
* ./llama3-8B-DarkIdol-1.3.1
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: ./llama3-8B-DarkIdol-1.3.1
- model: ./llama3-8B-DarkIdol-1.3.2
- model: ./llama3-8B-DarkIdol-2.0
- model: winglian/Llama-3-8b-64k-PoSE
merge_method: model_stock
base_model: winglian/Llama-3-8b-64k-PoSE
dtype: bfloat16
```
|