

Upload folder using huggingface_hub (#3)
Browse files- 418a0a3d2033dd5ed3c6daec3c52f0b2041e3ed14a4cc90d07fa07df75762955 (6ca831c46f9632447654e8048855e1dc1c137c63)
- 3f0dbfbe2d7aa073e3b0b0690dd95fa604841a386d64e669e0a96008ba9d20c4 (e1208fff98bd2f23eafb4f03aa39f6ba10dc99e2)
- README.md +3 -2
- config.json +1 -1
- plots.png +0 -0
- results.json +24 -20
- smash_config.json +5 -5
README.md
CHANGED
|
@@ -1,5 +1,6 @@
|
|
| 1 |
---
|
| 2 |
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
|
|
|
|
| 3 |
metrics:
|
| 4 |
- memory_disk
|
| 5 |
- memory_inference
|
|
@@ -59,9 +60,9 @@ You can run the smashed model with these steps:
|
|
| 59 |
2. Load & run the model.
|
| 60 |
```python
|
| 61 |
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 62 |
-
|
| 63 |
|
| 64 |
-
model =
|
| 65 |
tokenizer = AutoTokenizer.from_pretrained("gradientai/Llama-3-8B-Instruct-262k")
|
| 66 |
|
| 67 |
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
|
|
|
| 1 |
---
|
| 2 |
thumbnail: "https://assets-global.website-files.com/646b351987a8d8ce158d1940/64ec9e96b4334c0e1ac41504_Logo%20with%20white%20text.svg"
|
| 3 |
+
base_model: gradientai/Llama-3-8B-Instruct-262k
|
| 4 |
metrics:
|
| 5 |
- memory_disk
|
| 6 |
- memory_inference
|
|
|
|
| 60 |
2. Load & run the model.
|
| 61 |
```python
|
| 62 |
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 63 |
+
from awq import AutoAWQForCausalLM
|
| 64 |
|
| 65 |
+
model = AutoAWQForCausalLM.from_quantized("PrunaAI/gradientai-Llama-3-8B-Instruct-262k-AWQ-4bit-smashed", trust_remote_code=True, device_map='auto')
|
| 66 |
tokenizer = AutoTokenizer.from_pretrained("gradientai/Llama-3-8B-Instruct-262k")
|
| 67 |
|
| 68 |
input_ids = tokenizer("What is the color of prunes?,", return_tensors='pt').to(model.device)["input_ids"]
|
config.json
CHANGED
|
@@ -1,5 +1,5 @@
|
|
| 1 |
{
|
| 2 |
-
"_name_or_path": "/tmp/
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
|
|
|
| 1 |
{
|
| 2 |
+
"_name_or_path": "/tmp/tmp4pr25txe",
|
| 3 |
"architectures": [
|
| 4 |
"LlamaForCausalLM"
|
| 5 |
],
|
plots.png
CHANGED
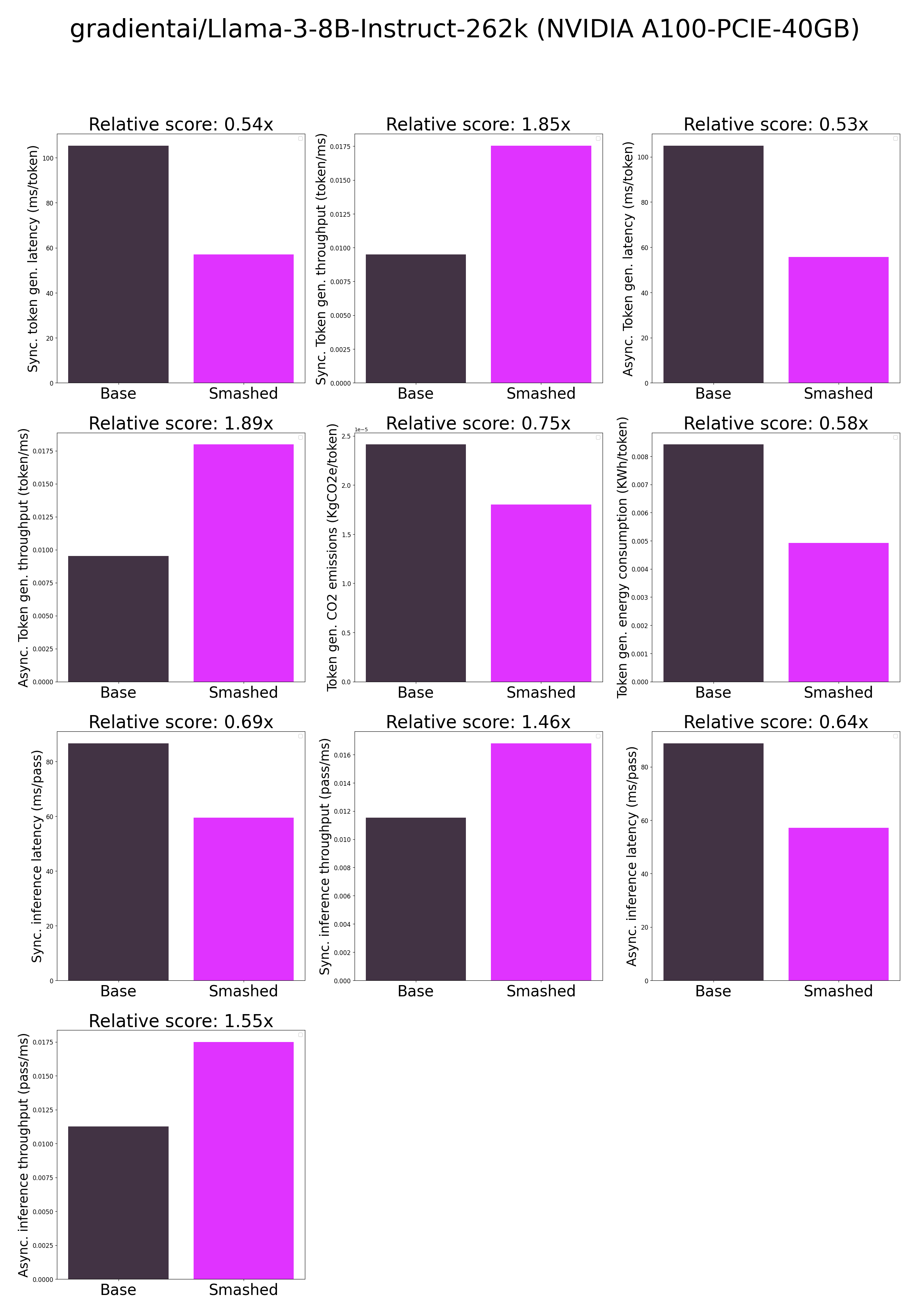
|

|
results.json
CHANGED
|
@@ -1,26 +1,30 @@
|
|
| 1 |
{
|
| 2 |
"base_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 3 |
"base_current_gpu_total_memory": 40339.3125,
|
| 4 |
-
"base_token_generation_latency_sync":
|
| 5 |
-
"base_token_generation_latency_async":
|
| 6 |
-
"base_token_generation_throughput_sync": 0.
|
| 7 |
-
"base_token_generation_throughput_async": 0.
|
| 8 |
-
"base_token_generation_CO2_emissions":
|
| 9 |
-
"base_token_generation_energy_consumption":
|
| 10 |
-
"base_inference_latency_sync":
|
| 11 |
-
"base_inference_latency_async":
|
| 12 |
-
"base_inference_throughput_sync": 0.
|
| 13 |
-
"base_inference_throughput_async": 0.
|
|
|
|
|
|
|
| 14 |
"smashed_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 15 |
"smashed_current_gpu_total_memory": 40339.3125,
|
| 16 |
-
"smashed_token_generation_latency_sync":
|
| 17 |
-
"smashed_token_generation_latency_async":
|
| 18 |
-
"smashed_token_generation_throughput_sync": 0.
|
| 19 |
-
"smashed_token_generation_throughput_async": 0.
|
| 20 |
-
"smashed_token_generation_CO2_emissions":
|
| 21 |
-
"smashed_token_generation_energy_consumption":
|
| 22 |
-
"smashed_inference_latency_sync":
|
| 23 |
-
"smashed_inference_latency_async":
|
| 24 |
-
"smashed_inference_throughput_sync": 0.
|
| 25 |
-
"smashed_inference_throughput_async": 0.
|
|
|
|
|
|
|
| 26 |
}
|
|
|
|
| 1 |
{
|
| 2 |
"base_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 3 |
"base_current_gpu_total_memory": 40339.3125,
|
| 4 |
+
"base_token_generation_latency_sync": 53.581108474731444,
|
| 5 |
+
"base_token_generation_latency_async": 53.849875181913376,
|
| 6 |
+
"base_token_generation_throughput_sync": 0.018663294367483915,
|
| 7 |
+
"base_token_generation_throughput_async": 0.01857014517901559,
|
| 8 |
+
"base_token_generation_CO2_emissions": null,
|
| 9 |
+
"base_token_generation_energy_consumption": null,
|
| 10 |
+
"base_inference_latency_sync": 51.79688911437988,
|
| 11 |
+
"base_inference_latency_async": 51.439499855041504,
|
| 12 |
+
"base_inference_throughput_sync": 0.019306178751232753,
|
| 13 |
+
"base_inference_throughput_async": 0.019440313432635206,
|
| 14 |
+
"base_inference_CO2_emissions": null,
|
| 15 |
+
"base_inference_energy_consumption": null,
|
| 16 |
"smashed_current_gpu_type": "NVIDIA A100-PCIE-40GB",
|
| 17 |
"smashed_current_gpu_total_memory": 40339.3125,
|
| 18 |
+
"smashed_token_generation_latency_sync": 40.933387756347656,
|
| 19 |
+
"smashed_token_generation_latency_async": 41.39378983527422,
|
| 20 |
+
"smashed_token_generation_throughput_sync": 0.024429934945829818,
|
| 21 |
+
"smashed_token_generation_throughput_async": 0.024158213200083406,
|
| 22 |
+
"smashed_token_generation_CO2_emissions": null,
|
| 23 |
+
"smashed_token_generation_energy_consumption": null,
|
| 24 |
+
"smashed_inference_latency_sync": 52.317081451416016,
|
| 25 |
+
"smashed_inference_latency_async": 39.870476722717285,
|
| 26 |
+
"smashed_inference_throughput_sync": 0.019114216088843655,
|
| 27 |
+
"smashed_inference_throughput_async": 0.02508121502922043,
|
| 28 |
+
"smashed_inference_CO2_emissions": null,
|
| 29 |
+
"smashed_inference_energy_consumption": null
|
| 30 |
}
|
smash_config.json
CHANGED
|
@@ -2,19 +2,19 @@
|
|
| 2 |
"api_key": null,
|
| 3 |
"verify_url": "http://johnrachwan.pythonanywhere.com",
|
| 4 |
"smash_config": {
|
| 5 |
-
"pruners": "
|
| 6 |
"pruning_ratio": 0.0,
|
| 7 |
-
"factorizers": "
|
| 8 |
"quantizers": "['awq']",
|
| 9 |
"weight_quantization_bits": 4,
|
| 10 |
-
"output_deviation": 0.
|
| 11 |
-
"compilers": "
|
| 12 |
"static_batch": true,
|
| 13 |
"static_shape": true,
|
| 14 |
"controlnet": "None",
|
| 15 |
"unet_dim": 4,
|
| 16 |
"device": "cuda",
|
| 17 |
-
"cache_dir": "/ceph/hdd/staff/charpent/.cache/
|
| 18 |
"batch_size": 1,
|
| 19 |
"model_name": "gradientai/Llama-3-8B-Instruct-262k",
|
| 20 |
"task": "text_text_generation",
|
|
|
|
| 2 |
"api_key": null,
|
| 3 |
"verify_url": "http://johnrachwan.pythonanywhere.com",
|
| 4 |
"smash_config": {
|
| 5 |
+
"pruners": "None",
|
| 6 |
"pruning_ratio": 0.0,
|
| 7 |
+
"factorizers": "None",
|
| 8 |
"quantizers": "['awq']",
|
| 9 |
"weight_quantization_bits": 4,
|
| 10 |
+
"output_deviation": 0.005,
|
| 11 |
+
"compilers": "None",
|
| 12 |
"static_batch": true,
|
| 13 |
"static_shape": true,
|
| 14 |
"controlnet": "None",
|
| 15 |
"unet_dim": 4,
|
| 16 |
"device": "cuda",
|
| 17 |
+
"cache_dir": "/ceph/hdd/staff/charpent/.cache/modelsnqte778j",
|
| 18 |
"batch_size": 1,
|
| 19 |
"model_name": "gradientai/Llama-3-8B-Instruct-262k",
|
| 20 |
"task": "text_text_generation",
|