
Commit
•
fbe03b1
1
Parent(s):
bf00f2a
Upload folder using huggingface_hub
Browse files- README.md +265 -0
- config.json +26 -0
- fig_sea_bench_side_by_side.png +0 -0
- fig_sea_math_side_by_side.png +0 -0
- output.safetensors +3 -0
- seal_logo.png +0 -0
- special_tokens_map.json +24 -0
- tokenizer.json +0 -0
- tokenizer.model +3 -0
- tokenizer_config.json +43 -0
README.md
ADDED
|
@@ -0,0 +1,265 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
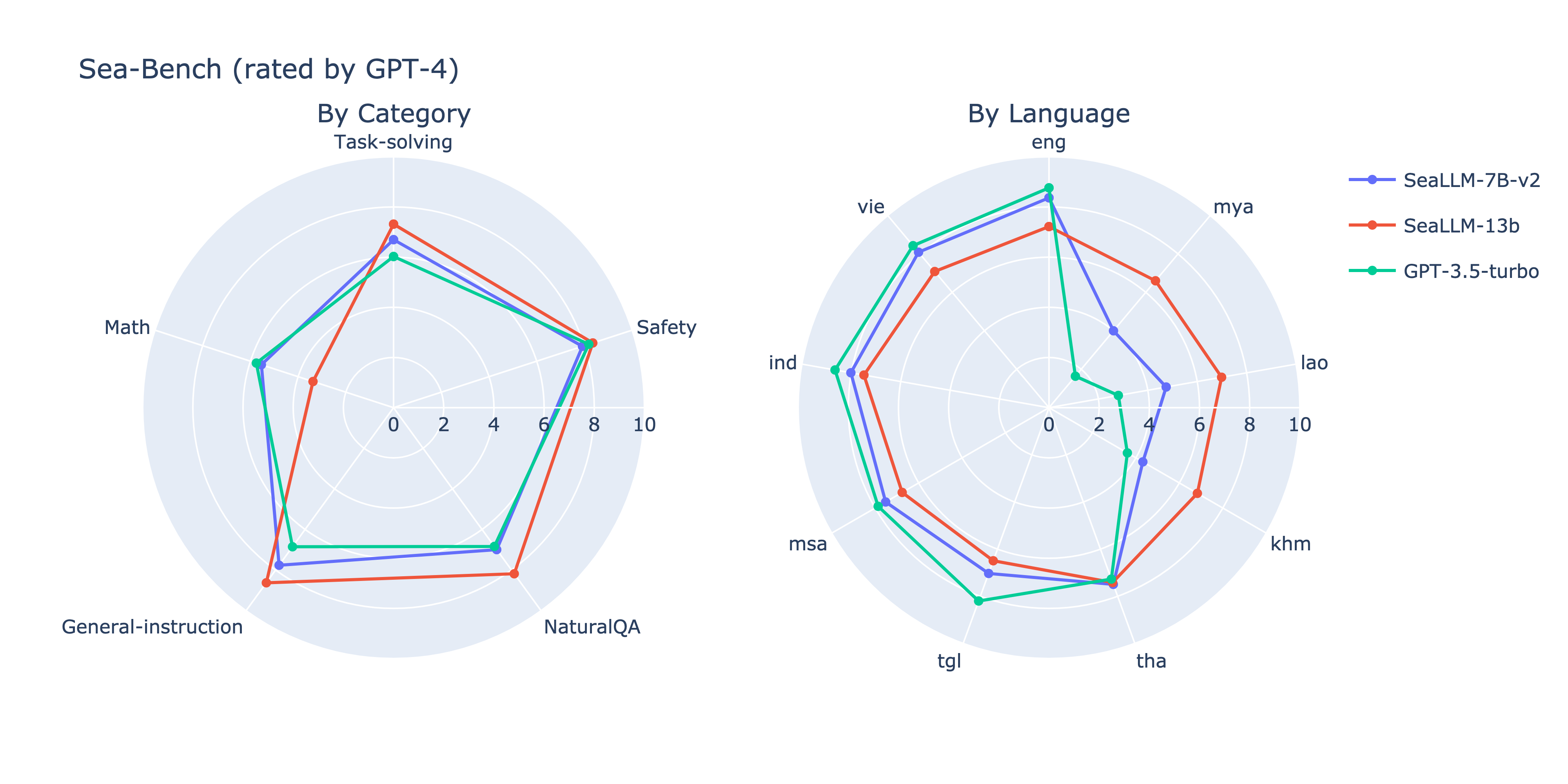
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: other
|
| 3 |
+
license_name: seallms
|
| 4 |
+
license_link: https://huggingface.co/SeaLLMs/SeaLLM-13B-Chat/blob/main/LICENSE
|
| 5 |
+
language:
|
| 6 |
+
- en
|
| 7 |
+
- zh
|
| 8 |
+
- vi
|
| 9 |
+
- id
|
| 10 |
+
- th
|
| 11 |
+
- ms
|
| 12 |
+
- km
|
| 13 |
+
- lo
|
| 14 |
+
- my
|
| 15 |
+
- tl
|
| 16 |
+
tags:
|
| 17 |
+
- multilingual
|
| 18 |
+
- sea
|
| 19 |
+
---
|
| 20 |
+
|
| 21 |
+
<p align="center">
|
| 22 |
+
<img src="seal_logo.png" width="200" />
|
| 23 |
+
</p>
|
| 24 |
+
|
| 25 |
+
# *SeaLLM-7B-v2* - Large Language Models for Southeast Asia
|
| 26 |
+
|
| 27 |
+
<p align="center">
|
| 28 |
+
<a href="https://huggingface.co/SeaLLMs/SeaLLM-7B-v2" target="_blank" rel="noopener"> 🤗 Tech Memo</a>
|
| 29 |
+
|
| 30 |
+
<a href="https://huggingface.co/spaces/SeaLLMs/SeaLLM-7B" target="_blank" rel="noopener"> 🤗 DEMO</a>
|
| 31 |
+
|
| 32 |
+
<a href="https://github.com/DAMO-NLP-SG/SeaLLMs" target="_blank" rel="noopener">Github</a>
|
| 33 |
+
|
| 34 |
+
<a href="https://arxiv.org/pdf/2312.00738.pdf" target="_blank" rel="noopener">Technical Report</a>
|
| 35 |
+
</p>
|
| 36 |
+
|
| 37 |
+
We introduce [SeaLLM-7B-v2](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2), the state-of-the-art multilingual LLM for Southeast Asian (SEA) languages 🇬🇧 🇨🇳 🇻🇳 🇮🇩 🇹🇭 🇲🇾 🇰🇭 🇱🇦 🇲🇲 🇵🇭. It is the most significant upgrade since [SeaLLM-13B](https://huggingface.co/SeaLLMs/SeaLLM-13B-Chat), with half the size, outperforming performance across diverse multilingual tasks, from world knowledge, math reasoning, instruction following, etc.
|
| 38 |
+
|
| 39 |
+
### Highlights
|
| 40 |
+
* [SeaLLM-7B-v2](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2) achieves the **7B-SOTA** on the **GSM8K** task with **78.2** score and outperforms GPT-3.5 in many GSM8K-translated tasks in SEA languages (🇨🇳 🇻🇳 🇮🇩 🇹🇭) as well as MGSM (🇨🇳 🇹🇭). It also surpasses GPT-3.5 in MATH for Thai 🇹🇭.
|
| 41 |
+
* It scores competitively against GPT-3.5 in many zero-shot commonsense benchmark, with **82.5, 68.3, 80.9** scores on Arc-C, Winogrande, and Hellaswag.
|
| 42 |
+
* It achieves **7.54** score on the 🇬🇧 **MT-bench**, it ranks 3rd place on the leaderboard for 7B category and is the most outperforming multilingual model.
|
| 43 |
+
* It scores **45.46** on the VMLU benchmark for Vietnamese 🇻🇳, and is the only open-source multilingual model that can be competitive to monolingual models ([Vistral-7B](https://huggingface.co/Viet-Mistral/Vistral-7B-Chat)) of similar sizes.
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
### Release and DEMO
|
| 47 |
+
|
| 48 |
+
- DEMO: [SeaLLMs/SeaLLM-7B](https://huggingface.co/spaces/SeaLLMs/SeaLLM-7B).
|
| 49 |
+
- Technical report: [Arxiv: SeaLLMs - Large Language Models for Southeast Asia](https://arxiv.org/pdf/2312.00738.pdf).
|
| 50 |
+
- Model weights: [SeaLLM-7B-v2](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2).
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
<blockquote style="color:red">
|
| 54 |
+
<p><strong style="color: red">Terms of Use and License</strong>:
|
| 55 |
+
By using our released weights, codes, and demos, you agree to and comply with the terms and conditions specified in our <a href="https://huggingface.co/SeaLLMs/SeaLLM-Chat-13b/edit/main/LICENSE" target="_blank" rel="noopener">SeaLLMs Terms Of Use</a>.
|
| 56 |
+
</blockquote>
|
| 57 |
+
|
| 58 |
+
> **Disclaimer**:
|
| 59 |
+
> We must note that even though the weights, codes, and demos are released in an open manner, similar to other pre-trained language models, and despite our best efforts in red teaming and safety fine-tuning and enforcement, our models come with potential risks, including but not limited to inaccurate, misleading or potentially harmful generation.
|
| 60 |
+
> Developers and stakeholders should perform their own red teaming and provide related security measures before deployment, and they must abide by and comply with local governance and regulations.
|
| 61 |
+
> In no event shall the authors be held liable for any claim, damages, or other liability arising from the use of the released weights, codes, or demos.
|
| 62 |
+
|
| 63 |
+
> The logo was generated by DALL-E 3.
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
### What's new since SeaLLM-13B-v1 and SeaLLM-7B-v1?
|
| 67 |
+
|
| 68 |
+
* SeaLLM-7B-v2 is continue-pretrained from [Mistral-7B](https://huggingface.co/mistralai/Mistral-7B-v0.1) and underwent carefully designed tuning with focus in reasoning.
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
## Evaluation
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
### Zero-shot Multilingual Math Reasoning
|
| 75 |
+
|
| 76 |
+
[SeaLLM-7B-v2](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2) achieves with **78.2** score on the GSM8K, making it the **state of the art** in the realm of 7B models. It also outperforms GPT-3.5 in the same GSM8K benchmark as translated into SEA languages (🇨🇳 🇻🇳 🇮🇩 🇹🇭). [SeaLLM-7B-v2](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2) also surpasses GPT-3.5 on the Thai-translated MATH benchmark, with **22.4** vs 18.1 scores.
|
| 77 |
+
|
| 78 |
+

|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
<details>
|
| 82 |
+
<summary>See details on English and translated GSM8K and MATH</summary>
|
| 83 |
+
<br>
|
| 84 |
+
|
| 85 |
+
| Model | GSM8K<br>en | MATH<br>en | GSM8K<br>zh | MATH<br>zh | GSM8K<br>vi | MATH<br>vi | GSM8K<br>id | MATH<br>id | GSM8K<br>th | MATH<br>th
|
| 86 |
+
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
|
| 87 |
+
| GPT-3.5 | 80.8 | 34.1 | 48.2 | 21.5 | 55 | 26.5 | 64.3 | 26.4 | 35.8 | 18.1
|
| 88 |
+
| Qwen-14B-chat | 61.4 | 18.4 | 41.6 | 11.8 | 33.6 | 3.6 | 44.7 | 8.6 | 22 | 6
|
| 89 |
+
| Vistral-7b-chat | 48.2 | 12.5 | | | 48.7 | 3.1 | | | |
|
| 90 |
+
| SeaLLM-7B-v2 | 78.2 | 27.5 | 53.7 | 17.6 | 69.9 | 23.8 | 71.5 | 24.4 | 59.6 | 22.4
|
| 91 |
+
|
| 92 |
+
</details>
|
| 93 |
+
|
| 94 |
+
#### Zero-shot MGSM
|
| 95 |
+
|
| 96 |
+
[SeaLLM-7B-v2](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2) also outperforms GPT-3.5 and Qwen-14B on the multilingual MGSM for Zh and Th.
|
| 97 |
+
|
| 98 |
+
| Model | MGSM-Zh | MGSM-Th
|
| 99 |
+
|-----| ----- | ---
|
| 100 |
+
| ChatGPT (reported) | 61.2* | 47.2*
|
| 101 |
+
| Qwen-14B-chat | 59.6 | 28
|
| 102 |
+
| SeaLLM-7B-v2 | **64.8** | **62.4**
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
### Zero-shot Commonsense Reasoning
|
| 106 |
+
|
| 107 |
+
We compare [SeaLLM-7B-v2](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2) with ChatGPT and Mistral-7B-instruct on various zero-shot commonsense benchmarks (Arc-Challenge, Winogrande and Hellaswag). We use the 2-stage technique in [(Kojima et al., 2023)](https://arxiv.org/pdf/2205.11916.pdf) to grab the answer. Note that we **DID NOT** use "Let's think step-by-step" to invoke explicit CoT.
|
| 108 |
+
|
| 109 |
+
| Model | Arc-Challenge | Winogrande | Hellaswag
|
| 110 |
+
|-----| ----- | --- | -- |
|
| 111 |
+
| ChatGPT (reported) | 84.6* | 66.8* | 72.0*
|
| 112 |
+
| ChatGPT (reproduced) | 84.1 | 63.1 | 79.5
|
| 113 |
+
| Mistral-7B-Instruct | 68.1 | 56.4 | 45.6
|
| 114 |
+
| SeaLLM-7B-v2 | 82.5 | 68.3 | 80.9
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
### Multilingual World Knowledge
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
We evaluate models on 3 benchmarks following the recommended default setups: 5-shot MMLU for En, 3-shot [M3Exam](https://arxiv.org/pdf/2306.05179.pdf) (M3e) for En, Zh, Vi, Id, Th, and zero-shot [VMLU](https://vmlu.ai/) for Vi.
|
| 121 |
+
|
| 122 |
+
| Model | Langs | En<br>MMLU | En<br>M3e | Zh<br>M3e | Vi<br>M3e | Vi<br>VMLU | Id<br>M3e | Th<br>M3e
|
| 123 |
+
|-----| ----- | --- | -- | ----- | ---- | --- | --- | --- |
|
| 124 |
+
| ChatGPT | Multi | 68.90 | 75.46 | 60.20 | 58.64 | 46.32 | 49.27 | 37.41
|
| 125 |
+
|-----| ----- | --- | -- | ----- | ---- | --- | --- | --- |
|
| 126 |
+
| SeaLLM-13B | Multi | 52.78 | 62.69 | 44.50 | 46.45 | | 39.28 | 36.39
|
| 127 |
+
| Vistral-7B | Mono | 56.86 | 67.00 | 44.56 | 54.33 | 50.03 | 36.49 | 25.27
|
| 128 |
+
| SeaLLM-7B-v2 | Multi | 60.72 | 70.91 | 55.43 | 51.15 | 45.46 | 42.25 | 35.52
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
### MT-Bench
|
| 133 |
+
|
| 134 |
+
On the English [MT-bench](https://arxiv.org/abs/2306.05685) metric, SeaLLM-7B-v2 achieves **7.54** score on the MT-bench (3rd place on the leaderboard for 7B category), outperforms many 70B models and is arguably the only one that handles 10 SEA languages.
|
| 135 |
+
|
| 136 |
+
Refer to [mt_bench/seallm_7b_v2.jsonl](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2/blob/main/evaluation/mt_bench/seallm_7b_v2.jsonl) for the MT-bench predictions of SeaLLM-7B-v2.
|
| 137 |
+
|
| 138 |
+
| Model | Access | Langs | MT-Bench
|
| 139 |
+
| --- | --- | --- | --- |
|
| 140 |
+
| GPT-4-turbo | closed | multi | 9.32
|
| 141 |
+
| GPT-4-0613 | closed | multi | 9.18
|
| 142 |
+
| Mixtral-8x7b (46B) | open | multi | 8.3
|
| 143 |
+
| Starling-LM-7B-alpha | open | mono (en) | 8.0
|
| 144 |
+
| OpenChat-3.5-7B | open | mono (en) | 7.81
|
| 145 |
+
| **SeaLLM-7B-v2** | **open** | **multi (10+)** | **7.54**
|
| 146 |
+
| [Qwen-14B](https://huggingface.co/Qwen/Qwen-14B-Chat) | open | multi | 6.96
|
| 147 |
+
| [Llama-2-70B](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf) | open | mono (en) | 6.86
|
| 148 |
+
| Mistral-7B-instuct | open | mono (en) | 6.84
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
### Sea-Bench
|
| 152 |
+
|
| 153 |
+
Similar to MT-Bench, [Sea-bench](https://huggingface.co/datasets/SeaLLMs/Sea-bench) is a set of categorized instruction test sets to measure models' ability as an assistant that is specifically focused on 9 SEA languages, including non-Latin low-resource languages.
|
| 154 |
+
|
| 155 |
+
As shown, the huge improvements come from math-reasoning, reaching GPT-3.5 level of performance.
|
| 156 |
+
|
| 157 |
+

|
| 158 |
+
|
| 159 |
+
Refer to [sea_bench/seallm_7b_v2.jsonl](https://huggingface.co/SeaLLMs/SeaLLM-7B-v2/blob/main/evaluation/sea_bench/seallm_7b_v2.jsonl) for the Sea-bench predictions of SeaLLM-7B-v2.
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
### Usage
|
| 164 |
+
|
| 165 |
+
#### Instruction format
|
| 166 |
+
|
| 167 |
+
```python
|
| 168 |
+
prompt = """<|im_start|>system
|
| 169 |
+
You are a helpful assistant.</s>
|
| 170 |
+
<|im_start|>user
|
| 171 |
+
Hello world</s>
|
| 172 |
+
<|im_start|>assistant
|
| 173 |
+
Hi there, how can I help?</s>
|
| 174 |
+
|
| 175 |
+
# ! ENSURE 1 and only 1 bos `<s>` at the beginning of sequence
|
| 176 |
+
print(tokenizer.convert_ids_to_tokens(tokenizer.encode(prompt)))
|
| 177 |
+
|
| 178 |
+
['<s>', '▁<', '|', 'im', '_', 'start', '|', '>', 'system', '<0x0A>', 'You', '▁are', '▁a', '▁helpful', '▁assistant', '.', '</s>', '▁', '<0x0A>', '<', '|', 'im', '_', 'start', '|', '>', 'user', '<0x0A>', 'Hello', '▁world', '</s>', '▁', '<0x0A>', '<', '|', 'im', '_', 'start', '|', '>', 'ass', 'istant', '<0x0A>', 'Hi', '▁there', ',', '▁how', '▁can', '▁I', '▁help', '?', '</s>', '▁', '<0x0A>']
|
| 179 |
+
"""
|
| 180 |
+
```
|
| 181 |
+
|
| 182 |
+
#### Using transformers's chat_template
|
| 183 |
+
```python
|
| 184 |
+
|
| 185 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 186 |
+
|
| 187 |
+
device = "cuda" # the device to load the model onto
|
| 188 |
+
|
| 189 |
+
model = AutoModelForCausalLM.from_pretrained("SeaLLMs/SeaLLM-7B-v2", torch_dtype=torch.bfloat16, device_map=device)
|
| 190 |
+
tokenizer = AutoTokenizer.from_pretrained("SeaLLMs/SeaLLM-7B-v2")
|
| 191 |
+
|
| 192 |
+
messages = [
|
| 193 |
+
{"role": "user", "content": "Hello world"},
|
| 194 |
+
{"role": "assistant", "content": "Hi there, how can I help you today?"},
|
| 195 |
+
{"role": "user", "content": "Explain general relativity in details."}
|
| 196 |
+
]
|
| 197 |
+
|
| 198 |
+
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt", add_generation_prompt=True)
|
| 199 |
+
print(tokenizer.convert_ids_to_tokens(encodeds[0]))
|
| 200 |
+
# ['<s>', '▁<', '|', 'im', '_', 'start', '|', '>', 'user', '<0x0A>', 'Hello', '▁world', '</s>', '▁', '<0x0A>', '<', '|', 'im ....
|
| 201 |
+
|
| 202 |
+
model_inputs = encodeds.to(device)
|
| 203 |
+
model.to(device)
|
| 204 |
+
|
| 205 |
+
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True, pad_token_id=tokenizer.pad_token_id)
|
| 206 |
+
decoded = tokenizer.batch_decode(generated_ids)
|
| 207 |
+
print(decoded[0])
|
| 208 |
+
|
| 209 |
+
```
|
| 210 |
+
|
| 211 |
+
#### Using vLLM
|
| 212 |
+
|
| 213 |
+
```python
|
| 214 |
+
from vllm import LLM, SamplingParams
|
| 215 |
+
TURN_TEMPLATE = "<|im_start|>{role}\n{content}</s>"
|
| 216 |
+
TURN_PREFIX = "<|im_start|>{role}\n"
|
| 217 |
+
|
| 218 |
+
def seallm_chat_convo_format(conversations, add_assistant_prefix: bool, system_prompt=None):
|
| 219 |
+
# conversations: list of dict with key `role` and `content` (openai format)
|
| 220 |
+
if conversations[0]['role'] != 'system' and system_prompt is not None:
|
| 221 |
+
conversations = [{"role": "system", "content": system_prompt}] + conversations
|
| 222 |
+
text = ''
|
| 223 |
+
for turn_id, turn in enumerate(conversations):
|
| 224 |
+
prompt = TURN_TEMPLATE.format(role=turn['role'], content=turn['content'])
|
| 225 |
+
text += prompt
|
| 226 |
+
if add_assistant_prefix:
|
| 227 |
+
prompt = TURN_PREFIX.format(role='assistant')
|
| 228 |
+
text += prompt
|
| 229 |
+
return text
|
| 230 |
+
|
| 231 |
+
sparams = SamplingParams(temperature=0.1, max_tokens=1024, stop=['</s>', '<|im_start|>'])
|
| 232 |
+
llm = LLM("SeaLLMs/SeaLLM-7B-v2", dtype="bfloat16")
|
| 233 |
+
|
| 234 |
+
message = "Explain general relativity in details."
|
| 235 |
+
prompt = seallm_chat_convo_format(message, True)
|
| 236 |
+
gen = llm.generate(prompt, sampling_params)
|
| 237 |
+
|
| 238 |
+
print(gen[0].outputs[0].text)
|
| 239 |
+
```
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
## Acknowledgement to Our Linguists
|
| 243 |
+
|
| 244 |
+
We would like to express our special thanks to our professional and native linguists, Tantong Champaiboon, Nguyen Ngoc Yen Nhi and Tara Devina Putri, who helped build, evaluate, and fact-check our sampled pretraining and SFT dataset as well as evaluating our models across different aspects, especially safety.
|
| 245 |
+
|
| 246 |
+
## Citation
|
| 247 |
+
|
| 248 |
+
If you find our project useful, we hope you would kindly star our repo and cite our work as follows: Corresponding Author: [[email protected]](mailto:[email protected])
|
| 249 |
+
|
| 250 |
+
**Author list and order will change!**
|
| 251 |
+
|
| 252 |
+
* `*` and `^` are equal contributions.
|
| 253 |
+
|
| 254 |
+
```
|
| 255 |
+
@article{damonlpsg2023seallm,
|
| 256 |
+
author = {Xuan-Phi Nguyen*, Wenxuan Zhang*, Xin Li*, Mahani Aljunied*,
|
| 257 |
+
Zhiqiang Hu, Chenhui Shen^, Yew Ken Chia^, Xingxuan Li, Jianyu Wang,
|
| 258 |
+
Qingyu Tan, Liying Cheng, Guanzheng Chen, Yue Deng, Sen Yang,
|
| 259 |
+
Chaoqun Liu, Hang Zhang, Lidong Bing},
|
| 260 |
+
title = {SeaLLMs - Large Language Models for Southeast Asia},
|
| 261 |
+
year = 2023,
|
| 262 |
+
Eprint = {arXiv:2312.00738},
|
| 263 |
+
}
|
| 264 |
+
```
|
| 265 |
+
|
config.json
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "seallm_dpo",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"MistralForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_dropout": 0.0,
|
| 7 |
+
"bos_token_id": 1,
|
| 8 |
+
"eos_token_id": 2,
|
| 9 |
+
"hidden_act": "silu",
|
| 10 |
+
"hidden_size": 4096,
|
| 11 |
+
"initializer_range": 0.02,
|
| 12 |
+
"intermediate_size": 14336,
|
| 13 |
+
"max_position_embeddings": 32768,
|
| 14 |
+
"model_type": "mistral",
|
| 15 |
+
"num_attention_heads": 32,
|
| 16 |
+
"num_hidden_layers": 32,
|
| 17 |
+
"num_key_value_heads": 8,
|
| 18 |
+
"rms_norm_eps": 1e-05,
|
| 19 |
+
"rope_theta": 10000.0,
|
| 20 |
+
"sliding_window": 4096,
|
| 21 |
+
"tie_word_embeddings": false,
|
| 22 |
+
"torch_dtype": "bfloat16",
|
| 23 |
+
"transformers_version": "4.37.0.dev0",
|
| 24 |
+
"use_cache": true,
|
| 25 |
+
"vocab_size": 48384
|
| 26 |
+
}
|
fig_sea_bench_side_by_side.png
ADDED
|
fig_sea_math_side_by_side.png
ADDED

|
output.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0eb270e8bd1d1977ca91bb2da2dfb423d0ee0153acdab689c4e14fff914d06be
|
| 3 |
+
size 4043748444
|
seal_logo.png
ADDED
|
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "</s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": "<unk>",
|
| 17 |
+
"unk_token": {
|
| 18 |
+
"content": "<unk>",
|
| 19 |
+
"lstrip": false,
|
| 20 |
+
"normalized": false,
|
| 21 |
+
"rstrip": false,
|
| 22 |
+
"single_word": false
|
| 23 |
+
}
|
| 24 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4d88bdadaa2a065aa7c6e18a4b5999ce4c76cec14d9fea882102e7b4931d7ef0
|
| 3 |
+
size 779539
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"added_tokens_decoder": {
|
| 5 |
+
"0": {
|
| 6 |
+
"content": "<unk>",
|
| 7 |
+
"lstrip": false,
|
| 8 |
+
"normalized": false,
|
| 9 |
+
"rstrip": false,
|
| 10 |
+
"single_word": false,
|
| 11 |
+
"special": true
|
| 12 |
+
},
|
| 13 |
+
"1": {
|
| 14 |
+
"content": "<s>",
|
| 15 |
+
"lstrip": false,
|
| 16 |
+
"normalized": false,
|
| 17 |
+
"rstrip": false,
|
| 18 |
+
"single_word": false,
|
| 19 |
+
"special": true
|
| 20 |
+
},
|
| 21 |
+
"2": {
|
| 22 |
+
"content": "</s>",
|
| 23 |
+
"lstrip": false,
|
| 24 |
+
"normalized": false,
|
| 25 |
+
"rstrip": false,
|
| 26 |
+
"single_word": false,
|
| 27 |
+
"special": true
|
| 28 |
+
}
|
| 29 |
+
},
|
| 30 |
+
"additional_special_tokens": [],
|
| 31 |
+
"bos_token": "<s>",
|
| 32 |
+
"clean_up_tokenization_spaces": false,
|
| 33 |
+
"eos_token": "</s>",
|
| 34 |
+
"legacy": true,
|
| 35 |
+
"model_max_length": 1000000000000000019884624838656,
|
| 36 |
+
"pad_token": "<unk>",
|
| 37 |
+
"sp_model_kwargs": {},
|
| 38 |
+
"spaces_between_special_tokens": false,
|
| 39 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 40 |
+
"unk_token": "<unk>",
|
| 41 |
+
"use_default_system_prompt": false,
|
| 42 |
+
"chat_template": "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{{ bos_token }}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '</s>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
|
| 43 |
+
}
|