
Commit
•
2ed70ff
1
Parent(s):
5e2f5da
Upload folder using huggingface_hub
Browse files- .gitattributes +2 -0
- LICENSE.txt +126 -0
- NexusRaven.png +3 -0
- README.md +166 -0
- added_tokens.json +10 -0
- blog2-fc.png +3 -0
- config.json +27 -0
- generation_config.json +6 -0
- output-00001-of-00002.safetensors +3 -0
- output-00002-of-00002.safetensors +3 -0
- pytorch_model.bin.index.json +370 -0
- radar-2.png +0 -0
- special_tokens_map.json +34 -0
- tokenizer.json +0 -0
- tokenizer.model +3 -0
- tokenizer_config.json +45 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
blog2-fc.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
NexusRaven.png filter=lfs diff=lfs merge=lfs -text
|
LICENSE.txt
ADDED
|
@@ -0,0 +1,126 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
LLAMA 2 COMMUNITY LICENSE AGREEMENT
|
| 2 |
+
Llama 2 Version Release Date: July 18, 2023
|
| 3 |
+
|
| 4 |
+
"Agreement" means the terms and conditions for use, reproduction, distribution and
|
| 5 |
+
modification of the Llama Materials set forth herein.
|
| 6 |
+
|
| 7 |
+
"Documentation" means the specifications, manuals and documentation
|
| 8 |
+
accompanying Llama 2 distributed by Meta at ai.meta.com/resources/models-and-
|
| 9 |
+
libraries/llama-downloads/.
|
| 10 |
+
|
| 11 |
+
"Licensee" or "you" means you, or your employer or any other person or entity (if
|
| 12 |
+
you are entering into this Agreement on such person or entity's behalf), of the age
|
| 13 |
+
required under applicable laws, rules or regulations to provide legal consent and that
|
| 14 |
+
has legal authority to bind your employer or such other person or entity if you are
|
| 15 |
+
entering in this Agreement on their behalf.
|
| 16 |
+
|
| 17 |
+
"Llama 2" means the foundational large language models and software and
|
| 18 |
+
algorithms, including machine-learning model code, trained model weights,
|
| 19 |
+
inference-enabling code, training-enabling code, fine-tuning enabling code and other
|
| 20 |
+
elements of the foregoing distributed by Meta at ai.meta.com/resources/models-and-
|
| 21 |
+
libraries/llama-downloads/.
|
| 22 |
+
|
| 23 |
+
"Llama Materials" means, collectively, Meta's proprietary Llama 2 and
|
| 24 |
+
Documentation (and any portion thereof) made available under this Agreement.
|
| 25 |
+
|
| 26 |
+
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or, if you
|
| 27 |
+
are an entity, your principal place of business is in the EEA or Switzerland) and Meta
|
| 28 |
+
Platforms, Inc. (if you are located outside of the EEA or Switzerland).
|
| 29 |
+
|
| 30 |
+
By clicking "I Accept" below or by using or distributing any portion or element of the
|
| 31 |
+
Llama Materials, you agree to be bound by this Agreement.
|
| 32 |
+
|
| 33 |
+
1. License Rights and Redistribution.
|
| 34 |
+
|
| 35 |
+
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-
|
| 36 |
+
transferable and royalty-free limited license under Meta's intellectual property or
|
| 37 |
+
other rights owned by Meta embodied in the Llama Materials to use, reproduce,
|
| 38 |
+
distribute, copy, create derivative works of, and make modifications to the Llama
|
| 39 |
+
Materials.
|
| 40 |
+
|
| 41 |
+
b. Redistribution and Use.
|
| 42 |
+
|
| 43 |
+
i. If you distribute or make the Llama Materials, or any derivative works
|
| 44 |
+
thereof, available to a third party, you shall provide a copy of this Agreement to such
|
| 45 |
+
third party.
|
| 46 |
+
ii. If you receive Llama Materials, or any derivative works thereof, from
|
| 47 |
+
a Licensee as part of an integrated end user product, then Section 2 of this
|
| 48 |
+
Agreement will not apply to you.
|
| 49 |
+
|
| 50 |
+
iii. You must retain in all copies of the Llama Materials that you
|
| 51 |
+
distribute the following attribution notice within a "Notice" text file distributed as a
|
| 52 |
+
part of such copies: "Llama 2 is licensed under the LLAMA 2 Community License,
|
| 53 |
+
Copyright (c) Meta Platforms, Inc. All Rights Reserved."
|
| 54 |
+
|
| 55 |
+
iv. Your use of the Llama Materials must comply with applicable laws
|
| 56 |
+
and regulations (including trade compliance laws and regulations) and adhere to the
|
| 57 |
+
Acceptable Use Policy for the Llama Materials (available at
|
| 58 |
+
https://ai.meta.com/llama/use-policy), which is hereby incorporated by reference into
|
| 59 |
+
this Agreement.
|
| 60 |
+
|
| 61 |
+
v. You will not use the Llama Materials or any output or results of the
|
| 62 |
+
Llama Materials to improve any other large language model (excluding Llama 2 or
|
| 63 |
+
derivative works thereof).
|
| 64 |
+
|
| 65 |
+
2. Additional Commercial Terms. If, on the Llama 2 version release date, the
|
| 66 |
+
monthly active users of the products or services made available by or for Licensee,
|
| 67 |
+
or Licensee's affiliates, is greater than 700 million monthly active users in the
|
| 68 |
+
preceding calendar month, you must request a license from Meta, which Meta may
|
| 69 |
+
grant to you in its sole discretion, and you are not authorized to exercise any of the
|
| 70 |
+
rights under this Agreement unless or until Meta otherwise expressly grants you
|
| 71 |
+
such rights.
|
| 72 |
+
|
| 73 |
+
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE
|
| 74 |
+
LLAMA MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE
|
| 75 |
+
PROVIDED ON AN "AS IS" BASIS, WITHOUT WARRANTIES OF ANY KIND,
|
| 76 |
+
EITHER EXPRESS OR IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY
|
| 77 |
+
WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR
|
| 78 |
+
FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE
|
| 79 |
+
FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING
|
| 80 |
+
THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR
|
| 81 |
+
USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.
|
| 82 |
+
|
| 83 |
+
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE
|
| 84 |
+
LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT,
|
| 85 |
+
NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS
|
| 86 |
+
AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL,
|
| 87 |
+
CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN
|
| 88 |
+
IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF
|
| 89 |
+
ANY OF THE FOREGOING.
|
| 90 |
+
|
| 91 |
+
5. Intellectual Property.
|
| 92 |
+
|
| 93 |
+
a. No trademark licenses are granted under this Agreement, and in
|
| 94 |
+
connection with the Llama Materials, neither Meta nor Licensee may use any name
|
| 95 |
+
or mark owned by or associated with the other or any of its affiliates, except as
|
| 96 |
+
required for reasonable and customary use in describing and redistributing the
|
| 97 |
+
Llama Materials.
|
| 98 |
+
|
| 99 |
+
b. Subject to Meta's ownership of Llama Materials and derivatives made by or
|
| 100 |
+
for Meta, with respect to any derivative works and modifications of the Llama
|
| 101 |
+
Materials that are made by you, as between you and Meta, you are and will be the
|
| 102 |
+
owner of such derivative works and modifications.
|
| 103 |
+
|
| 104 |
+
c. If you institute litigation or other proceedings against Meta or any entity
|
| 105 |
+
(including a cross-claim or counterclaim in a lawsuit) alleging that the Llama
|
| 106 |
+
Materials or Llama 2 outputs or results, or any portion of any of the foregoing,
|
| 107 |
+
constitutes infringement of intellectual property or other rights owned or licensable
|
| 108 |
+
by you, then any licenses granted to you under this Agreement shall terminate as of
|
| 109 |
+
the date such litigation or claim is filed or instituted. You will indemnify and hold
|
| 110 |
+
harmless Meta from and against any claim by any third party arising out of or related
|
| 111 |
+
to your use or distribution of the Llama Materials.
|
| 112 |
+
|
| 113 |
+
6. Term and Termination. The term of this Agreement will commence upon your
|
| 114 |
+
acceptance of this Agreement or access to the Llama Materials and will continue in
|
| 115 |
+
full force and effect until terminated in accordance with the terms and conditions
|
| 116 |
+
herein. Meta may terminate this Agreement if you are in breach of any term or
|
| 117 |
+
condition of this Agreement. Upon termination of this Agreement, you shall delete
|
| 118 |
+
and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the
|
| 119 |
+
termination of this Agreement.
|
| 120 |
+
|
| 121 |
+
7. Governing Law and Jurisdiction. This Agreement will be governed and
|
| 122 |
+
construed under the laws of the State of California without regard to choice of law
|
| 123 |
+
principles, and the UN Convention on Contracts for the International Sale of Goods
|
| 124 |
+
does not apply to this Agreement. The courts of California shall have exclusive
|
| 125 |
+
jurisdiction of any dispute arising out of this Agreement.
|
| 126 |
+
|
NexusRaven.png
ADDED

|
Git LFS Details
|
README.md
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: llama2
|
| 3 |
+
base_model: codellama/CodeLlama-13b-Instruct-hf
|
| 4 |
+
model-index:
|
| 5 |
+
- name: NexusRaven-13B
|
| 6 |
+
results: []
|
| 7 |
+
---
|
| 8 |
+
# NexusRaven-13B: Surpassing GPT-4 for Zero-shot Function Calling
|
| 9 |
+
<p align="center">
|
| 10 |
+
<a href="https://huggingface.co/Nexusflow" target="_blank">Nexusflow HF</a> - <a href="https://discord.gg/HDSVmNAs3y" target="_blank">Nexusflow Discord</a> - <a href="http://nexusflow.ai/blogs/ravenv2" target="_blank">NexusRaven-V2 blog post</a> - <a href="https://colab.research.google.com/drive/19JYixRPPlanmW5q49WYi_tU8rhHeCEKW?usp=sharing" target="_blank">Prompting Notebook CoLab</a> - <a href="https://huggingface.co/spaces/Nexusflow/Nexus_Function_Calling_Leaderboard" target="_blank">Leaderboard</a> - <a href="https://huggingface.co/spaces/Nexusflow/NexusRaven-V2-Demo" target="_blank">Read-World Demo</a> - <a href="https://github.com/nexusflowai/NexusRaven-V2" target="_blank">NexusRaven-V2-13B Github</a>
|
| 11 |
+
</p>
|
| 12 |
+
|
| 13 |
+
<p align="center" width="100%">
|
| 14 |
+
<a><img src="NexusRaven.png" alt="NexusRaven" style="width: 40%; min-width: 300px; display: block; margin: auto;"></a>
|
| 15 |
+
</p>
|
| 16 |
+
|
| 17 |
+
## Introducing NexusRaven-V2-13B
|
| 18 |
+
NexusRaven is an open-source and commercially viable function calling LLM that surpasses the state-of-the-art in function calling capabilities.
|
| 19 |
+
|
| 20 |
+
💪 **Versatile Function Calling Capability**: NexusRaven-V2 is capable of generating single function calls, nested calls, and parallel calls in many challenging cases.
|
| 21 |
+
|
| 22 |
+
🤓 **Fully Explainable**: NexusRaven-V2 is capable of generating very detailed explanations for the function calls it generates. This behavior can be turned off, to save tokens during inference.
|
| 23 |
+
|
| 24 |
+
📊 **Performance Highlights**: NexusRaven-V2 surpasses GPT-4 by 7% in function calling success rates in human-generated use cases involving nested and composite functions.
|
| 25 |
+
|
| 26 |
+
🔧 **Generalization to the Unseen**: NexusRaven-V2 has never been trained on the functions used in evaluation.
|
| 27 |
+
|
| 28 |
+
🔥 **Commercially Permissive**: The training of NexusRaven-V2 does not involve any data generated by proprietary LLMs such as GPT-4. You have full control of the model when deployed in commercial applications.
|
| 29 |
+
|
| 30 |
+
Please checkout the following links!
|
| 31 |
+
- [Prompting Notebook CoLab](https://colab.research.google.com/drive/19JYixRPPlanmW5q49WYi_tU8rhHeCEKW?usp=sharing)
|
| 32 |
+
- [Evaluation Leaderboard](https://huggingface.co/spaces/Nexusflow/Nexus_Function_Calling_Leaderboard)
|
| 33 |
+
- [NexusRaven-V2 Real-World Demo](https://huggingface.co/spaces/Nexusflow/NexusRaven-V2-Demo)
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
## NexusRaven-V2 model usage
|
| 37 |
+
|
| 38 |
+
NexusRaven-V2 accepts a list of python functions. These python functions can do anything (including sending GET/POST requests to external APIs!). The two requirements include the python function signature and the appropriate docstring to generate the function call.
|
| 39 |
+
|
| 40 |
+
### NexusRaven-V2's Capabilities
|
| 41 |
+
|
| 42 |
+
NexusRaven-V2 is capable of generating deeply nested function calls, parallel function calls, and simple single calls. It can also justify the function calls it generated. If you would like to generate the call only, please set a stop criteria of \"\<bot\_end\>\". Otherwise, please allow NexusRaven-V2 to run until its stop token (i.e. "\<\/s\>").
|
| 43 |
+
|
| 44 |
+
### Quick Start Prompting Guide
|
| 45 |
+
|
| 46 |
+
Please refer to our notebook, [How-To-Prompt.ipynb](How-To-Prompt.ipynb), for more advanced tutorials on using NexusRaven-V2!
|
| 47 |
+
|
| 48 |
+
1. We strongly recommend to set sampling to False when prompting NexusRaven-V2.
|
| 49 |
+
2. We strongly recommend a very low temperature (~0.001).
|
| 50 |
+
3. We strongly recommend following the prompting style below.
|
| 51 |
+
|
| 52 |
+
### Quickstart
|
| 53 |
+
You can run the model on a GPU using the following code.
|
| 54 |
+
```python
|
| 55 |
+
# Please `pip install transformers accelerate`
|
| 56 |
+
from transformers import pipeline
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
pipeline = pipeline(
|
| 60 |
+
"text-generation",
|
| 61 |
+
model="Nexusflow/NexusRaven-V2-13B",
|
| 62 |
+
torch_dtype="auto",
|
| 63 |
+
device_map="auto",
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
prompt_template = \
|
| 67 |
+
'''
|
| 68 |
+
Function:
|
| 69 |
+
def get_weather_data(coordinates):
|
| 70 |
+
"""
|
| 71 |
+
Fetches weather data from the Open-Meteo API for the given latitude and longitude.
|
| 72 |
+
|
| 73 |
+
Args:
|
| 74 |
+
coordinates (tuple): The latitude of the location.
|
| 75 |
+
|
| 76 |
+
Returns:
|
| 77 |
+
float: The current temperature in the coordinates you've asked for
|
| 78 |
+
"""
|
| 79 |
+
|
| 80 |
+
Function:
|
| 81 |
+
def get_coordinates_from_city(city_name):
|
| 82 |
+
"""
|
| 83 |
+
Fetches the latitude and longitude of a given city name using the Maps.co Geocoding API.
|
| 84 |
+
|
| 85 |
+
Args:
|
| 86 |
+
city_name (str): The name of the city.
|
| 87 |
+
|
| 88 |
+
Returns:
|
| 89 |
+
tuple: The latitude and longitude of the city.
|
| 90 |
+
"""
|
| 91 |
+
|
| 92 |
+
User Query: {query}<human_end>
|
| 93 |
+
|
| 94 |
+
'''
|
| 95 |
+
|
| 96 |
+
prompt = prompt_template.format(query="What's the weather like in Seattle right now?")
|
| 97 |
+
|
| 98 |
+
result = pipeline(prompt, max_new_tokens=2048, return_full_text=False, do_sample=False, temperature=0.001)[0]["generated_text"]
|
| 99 |
+
print (result)
|
| 100 |
+
```
|
| 101 |
+
|
| 102 |
+
This should generate the following:
|
| 103 |
+
```
|
| 104 |
+
Call: get_weather_data(coordinates=get_coordinates_from_city(city_name='Seattle'))<bot_end>
|
| 105 |
+
Thought: The function call `get_weather_data(coordinates=get_coordinates_from_city(city_name='Seattle'))` answers the question "What's the weather like in Seattle right now?" by following these steps:
|
| 106 |
+
|
| 107 |
+
1. `get_coordinates_from_city(city_name='Seattle')`: This function call fetches the latitude and longitude of the city "Seattle" using the Maps.co Geocoding API.
|
| 108 |
+
2. `get_weather_data(coordinates=...)`: This function call fetches the current weather data for the coordinates returned by the previous function call.
|
| 109 |
+
|
| 110 |
+
Therefore, the function call `get_weather_data(coordinates=get_coordinates_from_city(city_name='Seattle'))` answers the question "What's the weather like in Seattle right now?" by first fetching the coordinates of the city "Seattle" and then fetching the current weather data for those coordinates.
|
| 111 |
+
```
|
| 112 |
+
|
| 113 |
+
If you would like to prevent the generation of the explanation of the function call (for example, to save on inference tokens), please set a stopping criteria of \<bot_end\>.
|
| 114 |
+
|
| 115 |
+
Please follow this prompting template to maximize the performance of RavenV2.
|
| 116 |
+
|
| 117 |
+
### Using with OpenAI FC Schematics
|
| 118 |
+
|
| 119 |
+
[If you currently have a workflow that is built around OpenAI's function calling and you want to try NexusRaven-V2, we have a package that helps you drop in NexusRaven-V2.](https://github.com/nexusflowai/nexusraven-pip)
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
## Evaluation
|
| 123 |
+
|
| 124 |
+
<p align="center" width="100%">
|
| 125 |
+
<a><img src="blog2-fc.png" alt="NexusRaven" style="width: 80%; min-width: 300px; display: block; margin: auto;"></a>
|
| 126 |
+
<a><img src="radar-2.png" alt="NexusRaven" style="width: 80%; min-width: 300px; display: block; margin: auto;"></a>
|
| 127 |
+
</p>
|
| 128 |
+
|
| 129 |
+
For a deeper dive into the results, please see our [Github README](https://github.com/nexusflowai/NexusRaven).
|
| 130 |
+
|
| 131 |
+
# Limitations
|
| 132 |
+
1. The model works best when it is connected with a retriever when there are a multitude of functions, as a large number of functions will saturate the context window of this model.
|
| 133 |
+
2. The model can be prone to generate incorrect calls. Please ensure proper guardrails to capture errant behavior is in place.
|
| 134 |
+
3. The explanations generated by NexusRaven-V2 might be incorrect. Please ensure proper guardrails are present to capture errant behavior.
|
| 135 |
+
|
| 136 |
+
## License
|
| 137 |
+
This model was trained on commercially viable data and is licensed under the [Llama 2 community license](https://huggingface.co/codellama/CodeLlama-13b-hf/blob/main/LICENSE) following the original [CodeLlama-13b-hf](https://huggingface.co/codellama/CodeLlama-13b-hf/) model.
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
## References
|
| 141 |
+
We thank the CodeLlama team for their amazing models!
|
| 142 |
+
|
| 143 |
+
```
|
| 144 |
+
@misc{rozière2023code,
|
| 145 |
+
title={Code Llama: Open Foundation Models for Code},
|
| 146 |
+
author={Baptiste Rozière and Jonas Gehring and Fabian Gloeckle and Sten Sootla and Itai Gat and Xiaoqing Ellen Tan and Yossi Adi and Jingyu Liu and Tal Remez and Jérémy Rapin and Artyom Kozhevnikov and Ivan Evtimov and Joanna Bitton and Manish Bhatt and Cristian Canton Ferrer and Aaron Grattafiori and Wenhan Xiong and Alexandre Défossez and Jade Copet and Faisal Azhar and Hugo Touvron and Louis Martin and Nicolas Usunier and Thomas Scialom and Gabriel Synnaeve},
|
| 147 |
+
year={2023},
|
| 148 |
+
eprint={2308.12950},
|
| 149 |
+
archivePrefix={arXiv},
|
| 150 |
+
primaryClass={cs.CL}
|
| 151 |
+
}
|
| 152 |
+
```
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
## Citation
|
| 156 |
+
```
|
| 157 |
+
@misc{nexusraven,
|
| 158 |
+
title={NexusRaven-V2: Surpassing GPT-4 for Zero-shot Function Calling},
|
| 159 |
+
author={Nexusflow.ai team},
|
| 160 |
+
year={2023},
|
| 161 |
+
url={https://nexusflow.ai/blogs/ravenv2}
|
| 162 |
+
}
|
| 163 |
+
```
|
| 164 |
+
|
| 165 |
+
## Contact
|
| 166 |
+
Please join our [Discord Channel](https://discord.gg/HDSVmNAs3y) to reach out for any issues and comments!
|
added_tokens.json
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"<bot>:": 32017,
|
| 3 |
+
"<bot_end>": 32019,
|
| 4 |
+
"<docstring_end>": 32023,
|
| 5 |
+
"<docstring_start>": 32022,
|
| 6 |
+
"<func_end>": 32021,
|
| 7 |
+
"<func_start>": 32020,
|
| 8 |
+
"<human>:": 32016,
|
| 9 |
+
"<human_end>": 32018
|
| 10 |
+
}
|
blog2-fc.png
ADDED

|
Git LFS Details
|
config.json
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "codellama/CodeLlama-13b-Instruct-hf",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"LlamaForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"bos_token_id": 1,
|
| 7 |
+
"eos_token_id": 2,
|
| 8 |
+
"hidden_act": "silu",
|
| 9 |
+
"hidden_size": 5120,
|
| 10 |
+
"initializer_range": 0.02,
|
| 11 |
+
"intermediate_size": 13824,
|
| 12 |
+
"low_cpu_mem_usage": true,
|
| 13 |
+
"max_position_embeddings": 16384,
|
| 14 |
+
"model_type": "llama",
|
| 15 |
+
"num_attention_heads": 40,
|
| 16 |
+
"num_hidden_layers": 40,
|
| 17 |
+
"num_key_value_heads": 40,
|
| 18 |
+
"pretraining_tp": 1,
|
| 19 |
+
"rms_norm_eps": 1e-05,
|
| 20 |
+
"rope_scaling": null,
|
| 21 |
+
"rope_theta": 1000000,
|
| 22 |
+
"tie_word_embeddings": false,
|
| 23 |
+
"torch_dtype": "bfloat16",
|
| 24 |
+
"transformers_version": "4.33.0",
|
| 25 |
+
"use_cache": true,
|
| 26 |
+
"vocab_size": 32024
|
| 27 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 1,
|
| 4 |
+
"eos_token_id": 2,
|
| 5 |
+
"transformers_version": "4.33.0"
|
| 6 |
+
}
|
output-00001-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9b8ebed99eb9c07bba25ced1262bedeb69a26ddc5719692ffea7266b0046192d
|
| 3 |
+
size 8571069296
|
output-00002-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8e1d9318fed92766684895df528faccf3026ad19c322fe74bcd31b9d162337c3
|
| 3 |
+
size 1412359176
|
pytorch_model.bin.index.json
ADDED
|
@@ -0,0 +1,370 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 26032220160
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "pytorch_model-00003-of-00003.bin",
|
| 7 |
+
"model.embed_tokens.weight": "pytorch_model-00001-of-00003.bin",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 14 |
+
"model.layers.0.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 15 |
+
"model.layers.0.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 16 |
+
"model.layers.0.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 17 |
+
"model.layers.1.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 18 |
+
"model.layers.1.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 19 |
+
"model.layers.1.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 20 |
+
"model.layers.1.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 21 |
+
"model.layers.1.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 22 |
+
"model.layers.1.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 23 |
+
"model.layers.1.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 24 |
+
"model.layers.1.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 25 |
+
"model.layers.1.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 26 |
+
"model.layers.10.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 27 |
+
"model.layers.10.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 28 |
+
"model.layers.10.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 29 |
+
"model.layers.10.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 30 |
+
"model.layers.10.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 31 |
+
"model.layers.10.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 32 |
+
"model.layers.10.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 33 |
+
"model.layers.10.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 34 |
+
"model.layers.10.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 35 |
+
"model.layers.11.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 36 |
+
"model.layers.11.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 37 |
+
"model.layers.11.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 38 |
+
"model.layers.11.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 39 |
+
"model.layers.11.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 40 |
+
"model.layers.11.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 41 |
+
"model.layers.11.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 42 |
+
"model.layers.11.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 43 |
+
"model.layers.11.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 44 |
+
"model.layers.12.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 45 |
+
"model.layers.12.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 46 |
+
"model.layers.12.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 47 |
+
"model.layers.12.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 48 |
+
"model.layers.12.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 49 |
+
"model.layers.12.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 50 |
+
"model.layers.12.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 51 |
+
"model.layers.12.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 52 |
+
"model.layers.12.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 53 |
+
"model.layers.13.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 54 |
+
"model.layers.13.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 55 |
+
"model.layers.13.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 56 |
+
"model.layers.13.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 57 |
+
"model.layers.13.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 58 |
+
"model.layers.13.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 59 |
+
"model.layers.13.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 60 |
+
"model.layers.13.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 61 |
+
"model.layers.13.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 62 |
+
"model.layers.14.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 63 |
+
"model.layers.14.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 64 |
+
"model.layers.14.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 65 |
+
"model.layers.14.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 66 |
+
"model.layers.14.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 67 |
+
"model.layers.14.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 68 |
+
"model.layers.14.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 69 |
+
"model.layers.14.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 70 |
+
"model.layers.14.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 71 |
+
"model.layers.15.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 72 |
+
"model.layers.15.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 73 |
+
"model.layers.15.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 74 |
+
"model.layers.15.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 75 |
+
"model.layers.15.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 76 |
+
"model.layers.15.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 77 |
+
"model.layers.15.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 78 |
+
"model.layers.15.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 79 |
+
"model.layers.15.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 80 |
+
"model.layers.16.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 81 |
+
"model.layers.16.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 82 |
+
"model.layers.16.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 83 |
+
"model.layers.16.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 84 |
+
"model.layers.16.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 85 |
+
"model.layers.16.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 86 |
+
"model.layers.16.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 87 |
+
"model.layers.16.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 88 |
+
"model.layers.16.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 89 |
+
"model.layers.17.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 90 |
+
"model.layers.17.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 91 |
+
"model.layers.17.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 92 |
+
"model.layers.17.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 93 |
+
"model.layers.17.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 94 |
+
"model.layers.17.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 95 |
+
"model.layers.17.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 96 |
+
"model.layers.17.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 97 |
+
"model.layers.17.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 98 |
+
"model.layers.18.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 99 |
+
"model.layers.18.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 100 |
+
"model.layers.18.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 101 |
+
"model.layers.18.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 102 |
+
"model.layers.18.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 103 |
+
"model.layers.18.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 104 |
+
"model.layers.18.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 105 |
+
"model.layers.18.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 106 |
+
"model.layers.18.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 107 |
+
"model.layers.19.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 108 |
+
"model.layers.19.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 109 |
+
"model.layers.19.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 110 |
+
"model.layers.19.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 111 |
+
"model.layers.19.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 112 |
+
"model.layers.19.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 113 |
+
"model.layers.19.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 114 |
+
"model.layers.19.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 115 |
+
"model.layers.19.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 116 |
+
"model.layers.2.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 117 |
+
"model.layers.2.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 118 |
+
"model.layers.2.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 119 |
+
"model.layers.2.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 120 |
+
"model.layers.2.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 121 |
+
"model.layers.2.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 122 |
+
"model.layers.2.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 123 |
+
"model.layers.2.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 124 |
+
"model.layers.2.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 125 |
+
"model.layers.20.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 126 |
+
"model.layers.20.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 127 |
+
"model.layers.20.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 128 |
+
"model.layers.20.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 129 |
+
"model.layers.20.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 130 |
+
"model.layers.20.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 131 |
+
"model.layers.20.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 132 |
+
"model.layers.20.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 133 |
+
"model.layers.20.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 134 |
+
"model.layers.21.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 135 |
+
"model.layers.21.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 136 |
+
"model.layers.21.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 137 |
+
"model.layers.21.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 138 |
+
"model.layers.21.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 139 |
+
"model.layers.21.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 140 |
+
"model.layers.21.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 141 |
+
"model.layers.21.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 142 |
+
"model.layers.21.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 143 |
+
"model.layers.22.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 144 |
+
"model.layers.22.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 145 |
+
"model.layers.22.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 146 |
+
"model.layers.22.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 147 |
+
"model.layers.22.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 148 |
+
"model.layers.22.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 149 |
+
"model.layers.22.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 150 |
+
"model.layers.22.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 151 |
+
"model.layers.22.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 152 |
+
"model.layers.23.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 153 |
+
"model.layers.23.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 154 |
+
"model.layers.23.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 155 |
+
"model.layers.23.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 156 |
+
"model.layers.23.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 157 |
+
"model.layers.23.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 158 |
+
"model.layers.23.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 159 |
+
"model.layers.23.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 160 |
+
"model.layers.23.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 161 |
+
"model.layers.24.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 162 |
+
"model.layers.24.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 163 |
+
"model.layers.24.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 164 |
+
"model.layers.24.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 165 |
+
"model.layers.24.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 166 |
+
"model.layers.24.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 167 |
+
"model.layers.24.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 168 |
+
"model.layers.24.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 169 |
+
"model.layers.24.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 170 |
+
"model.layers.25.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 171 |
+
"model.layers.25.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 172 |
+
"model.layers.25.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 173 |
+
"model.layers.25.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 174 |
+
"model.layers.25.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 175 |
+
"model.layers.25.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 176 |
+
"model.layers.25.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 177 |
+
"model.layers.25.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 178 |
+
"model.layers.25.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 179 |
+
"model.layers.26.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 180 |
+
"model.layers.26.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 181 |
+
"model.layers.26.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 182 |
+
"model.layers.26.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 183 |
+
"model.layers.26.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 184 |
+
"model.layers.26.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 185 |
+
"model.layers.26.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 186 |
+
"model.layers.26.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 187 |
+
"model.layers.26.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 188 |
+
"model.layers.27.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 189 |
+
"model.layers.27.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 190 |
+
"model.layers.27.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 191 |
+
"model.layers.27.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 192 |
+
"model.layers.27.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 193 |
+
"model.layers.27.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 194 |
+
"model.layers.27.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 195 |
+
"model.layers.27.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 196 |
+
"model.layers.27.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 197 |
+
"model.layers.28.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 198 |
+
"model.layers.28.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 199 |
+
"model.layers.28.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 200 |
+
"model.layers.28.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 201 |
+
"model.layers.28.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 202 |
+
"model.layers.28.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 203 |
+
"model.layers.28.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 204 |
+
"model.layers.28.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 205 |
+
"model.layers.28.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 206 |
+
"model.layers.29.input_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 207 |
+
"model.layers.29.mlp.down_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 208 |
+
"model.layers.29.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 209 |
+
"model.layers.29.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 210 |
+
"model.layers.29.post_attention_layernorm.weight": "pytorch_model-00002-of-00003.bin",
|
| 211 |
+
"model.layers.29.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 212 |
+
"model.layers.29.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 213 |
+
"model.layers.29.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 214 |
+
"model.layers.29.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 215 |
+
"model.layers.3.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 216 |
+
"model.layers.3.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 217 |
+
"model.layers.3.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 218 |
+
"model.layers.3.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 219 |
+
"model.layers.3.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 220 |
+
"model.layers.3.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 221 |
+
"model.layers.3.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 222 |
+
"model.layers.3.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 223 |
+
"model.layers.3.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 224 |
+
"model.layers.30.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 225 |
+
"model.layers.30.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 226 |
+
"model.layers.30.mlp.gate_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 227 |
+
"model.layers.30.mlp.up_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 228 |
+
"model.layers.30.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 229 |
+
"model.layers.30.self_attn.k_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 230 |
+
"model.layers.30.self_attn.o_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 231 |
+
"model.layers.30.self_attn.q_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 232 |
+
"model.layers.30.self_attn.v_proj.weight": "pytorch_model-00002-of-00003.bin",
|
| 233 |
+
"model.layers.31.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 234 |
+
"model.layers.31.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 235 |
+
"model.layers.31.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 236 |
+
"model.layers.31.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 237 |
+
"model.layers.31.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 238 |
+
"model.layers.31.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 239 |
+
"model.layers.31.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 240 |
+
"model.layers.31.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 241 |
+
"model.layers.31.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 242 |
+
"model.layers.32.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 243 |
+
"model.layers.32.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 244 |
+
"model.layers.32.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 245 |
+
"model.layers.32.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 246 |
+
"model.layers.32.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 247 |
+
"model.layers.32.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 248 |
+
"model.layers.32.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 249 |
+
"model.layers.32.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 250 |
+
"model.layers.32.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 251 |
+
"model.layers.33.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 252 |
+
"model.layers.33.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 253 |
+
"model.layers.33.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 254 |
+
"model.layers.33.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 255 |
+
"model.layers.33.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 256 |
+
"model.layers.33.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 257 |
+
"model.layers.33.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 258 |
+
"model.layers.33.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 259 |
+
"model.layers.33.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 260 |
+
"model.layers.34.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 261 |
+
"model.layers.34.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 262 |
+
"model.layers.34.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 263 |
+
"model.layers.34.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 264 |
+
"model.layers.34.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 265 |
+
"model.layers.34.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 266 |
+
"model.layers.34.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 267 |
+
"model.layers.34.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 268 |
+
"model.layers.34.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 269 |
+
"model.layers.35.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 270 |
+
"model.layers.35.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 271 |
+
"model.layers.35.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 272 |
+
"model.layers.35.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 273 |
+
"model.layers.35.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 274 |
+
"model.layers.35.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 275 |
+
"model.layers.35.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 276 |
+
"model.layers.35.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 277 |
+
"model.layers.35.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 278 |
+
"model.layers.36.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 279 |
+
"model.layers.36.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 280 |
+
"model.layers.36.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 281 |
+
"model.layers.36.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 282 |
+
"model.layers.36.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 283 |
+
"model.layers.36.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 284 |
+
"model.layers.36.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 285 |
+
"model.layers.36.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 286 |
+
"model.layers.36.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 287 |
+
"model.layers.37.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 288 |
+
"model.layers.37.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 289 |
+
"model.layers.37.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 290 |
+
"model.layers.37.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 291 |
+
"model.layers.37.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 292 |
+
"model.layers.37.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 293 |
+
"model.layers.37.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 294 |
+
"model.layers.37.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 295 |
+
"model.layers.37.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 296 |
+
"model.layers.38.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 297 |
+
"model.layers.38.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 298 |
+
"model.layers.38.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 299 |
+
"model.layers.38.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 300 |
+
"model.layers.38.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 301 |
+
"model.layers.38.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 302 |
+
"model.layers.38.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 303 |
+
"model.layers.38.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 304 |
+
"model.layers.38.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 305 |
+
"model.layers.39.input_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 306 |
+
"model.layers.39.mlp.down_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 307 |
+
"model.layers.39.mlp.gate_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 308 |
+
"model.layers.39.mlp.up_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 309 |
+
"model.layers.39.post_attention_layernorm.weight": "pytorch_model-00003-of-00003.bin",
|
| 310 |
+
"model.layers.39.self_attn.k_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 311 |
+
"model.layers.39.self_attn.o_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 312 |
+
"model.layers.39.self_attn.q_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 313 |
+
"model.layers.39.self_attn.v_proj.weight": "pytorch_model-00003-of-00003.bin",
|
| 314 |
+
"model.layers.4.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 315 |
+
"model.layers.4.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 316 |
+
"model.layers.4.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 317 |
+
"model.layers.4.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 318 |
+
"model.layers.4.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 319 |
+
"model.layers.4.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 320 |
+
"model.layers.4.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 321 |
+
"model.layers.4.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 322 |
+
"model.layers.4.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 323 |
+
"model.layers.5.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 324 |
+
"model.layers.5.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 325 |
+
"model.layers.5.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 326 |
+
"model.layers.5.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 327 |
+
"model.layers.5.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 328 |
+
"model.layers.5.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 329 |
+
"model.layers.5.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 330 |
+
"model.layers.5.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 331 |
+
"model.layers.5.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 332 |
+
"model.layers.6.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 333 |
+
"model.layers.6.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 334 |
+
"model.layers.6.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 335 |
+
"model.layers.6.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 336 |
+
"model.layers.6.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 337 |
+
"model.layers.6.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 338 |
+
"model.layers.6.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 339 |
+
"model.layers.6.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 340 |
+
"model.layers.6.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 341 |
+
"model.layers.7.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 342 |
+
"model.layers.7.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 343 |
+
"model.layers.7.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 344 |
+
"model.layers.7.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 345 |
+
"model.layers.7.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 346 |
+
"model.layers.7.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 347 |
+
"model.layers.7.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 348 |
+
"model.layers.7.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 349 |
+
"model.layers.7.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 350 |
+
"model.layers.8.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 351 |
+
"model.layers.8.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 352 |
+
"model.layers.8.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 353 |
+
"model.layers.8.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 354 |
+
"model.layers.8.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 355 |
+
"model.layers.8.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 356 |
+
"model.layers.8.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 357 |
+
"model.layers.8.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 358 |
+
"model.layers.8.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 359 |
+
"model.layers.9.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 360 |
+
"model.layers.9.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 361 |
+
"model.layers.9.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 362 |
+
"model.layers.9.mlp.up_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 363 |
+
"model.layers.9.post_attention_layernorm.weight": "pytorch_model-00001-of-00003.bin",
|
| 364 |
+
"model.layers.9.self_attn.k_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 365 |
+
"model.layers.9.self_attn.o_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 366 |
+
"model.layers.9.self_attn.q_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 367 |
+
"model.layers.9.self_attn.v_proj.weight": "pytorch_model-00001-of-00003.bin",
|
| 368 |
+
"model.norm.weight": "pytorch_model-00003-of-00003.bin"
|
| 369 |
+
}
|
| 370 |
+
}
|
radar-2.png
ADDED
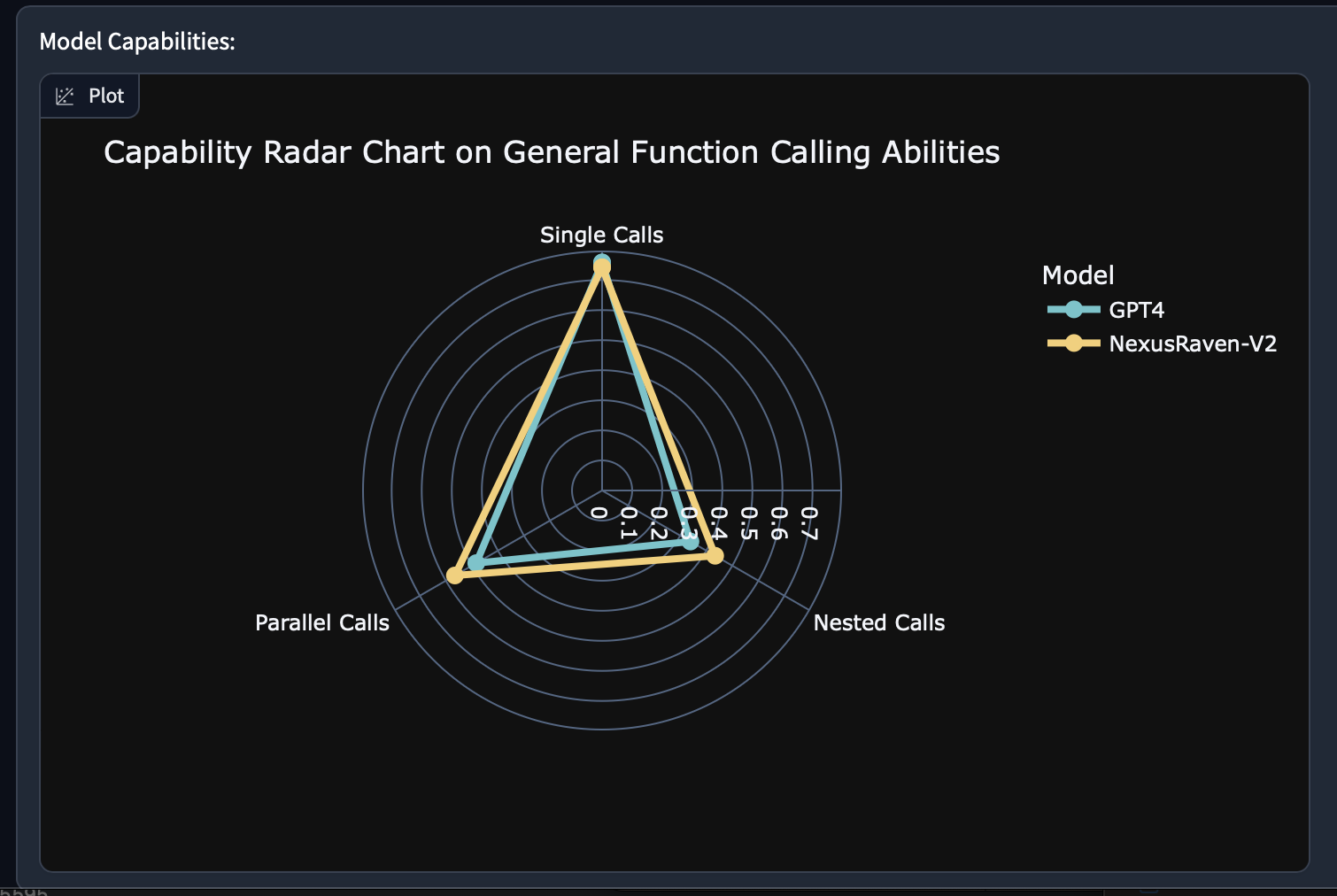
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<human>:",
|
| 4 |
+
"<bot>:",
|
| 5 |
+
"<human_end>",
|
| 6 |
+
"<bot_end>",
|
| 7 |
+
"<func_start>",
|
| 8 |
+
"<func_end>",
|
| 9 |
+
"<docstring_start>",
|
| 10 |
+
"<docstring_end>"
|
| 11 |
+
],
|
| 12 |
+
"bos_token": {
|
| 13 |
+
"content": "<s>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": true,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false
|
| 18 |
+
},
|
| 19 |
+
"eos_token": {
|
| 20 |
+
"content": "</s>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": true,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false
|
| 25 |
+
},
|
| 26 |
+
"pad_token": "</s>",
|
| 27 |
+
"unk_token": {
|
| 28 |
+
"content": "<unk>",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": true,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false
|
| 33 |
+
}
|
| 34 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:45ccb9c8b6b561889acea59191d66986d314e7cbd6a78abc6e49b139ca91c1e6
|
| 3 |
+
size 500058
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"▁<PRE>",
|
| 4 |
+
"▁<MID>",
|
| 5 |
+
"▁<SUF>",
|
| 6 |
+
"▁<EOT>"
|
| 7 |
+
],
|
| 8 |
+
"bos_token": {
|
| 9 |
+
"__type": "AddedToken",
|
| 10 |
+
"content": "<s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": true,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"clean_up_tokenization_spaces": false,
|
| 17 |
+
"eos_token": {
|
| 18 |
+
"__type": "AddedToken",
|
| 19 |
+
"content": "</s>",
|
| 20 |
+
"lstrip": false,
|
| 21 |
+
"normalized": true,
|
| 22 |
+
"rstrip": false,
|
| 23 |
+
"single_word": false
|
| 24 |
+
},
|
| 25 |
+
"eot_token": "▁<EOT>",
|
| 26 |
+
"fill_token": "<FILL_ME>",
|
| 27 |
+
"legacy": null,
|
| 28 |
+
"middle_token": "▁<MID>",
|
| 29 |
+
"model_max_length": 8192,
|
| 30 |
+
"pad_token": null,
|
| 31 |
+
"prefix_token": "▁<PRE>",
|
| 32 |
+
"sp_model_kwargs": {},
|
| 33 |
+
"suffix_token": "▁<SUF>",
|
| 34 |
+
"tokenizer_class": "CodeLlamaTokenizer",
|
| 35 |
+
"truncation_side": "left",
|
| 36 |
+
"unk_token": {
|
| 37 |
+
"__type": "AddedToken",
|
| 38 |
+
"content": "<unk>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": true,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false
|
| 43 |
+
},
|
| 44 |
+
"use_default_system_prompt": false
|
| 45 |
+
}
|