

Commit
•
35b54f7
1
Parent(s):
98d5982
Upload files
Browse files- .DS_Store +0 -0
- .gitattributes +1 -0
- config.json +96 -0
- img/.DS_Store +0 -0
- img/classify.png +0 -0
- img/classify_exp.png +0 -0
- model.safetensors +3 -0
- readme.md +67 -0
- sentencepiece.bpe.model +3 -0
- special_tokens_map.json +51 -0
- tokenizer.json +3 -0
- tokenizer_config.json +55 -0
- trainer_state.json +0 -0
- training_args.bin +3 -0
.DS_Store
ADDED
|
Binary file (8.2 kB). View file
|
|
|
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
tokenizer.json filter=lfs diff=lfs merge=lfs -text
|
config.json
ADDED
|
@@ -0,0 +1,96 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"XLMRobertaForSequenceClassification"
|
| 5 |
+
],
|
| 6 |
+
"attention_probs_dropout_prob": 0.1,
|
| 7 |
+
"bos_token_id": 0,
|
| 8 |
+
"classifier_dropout": 0.1,
|
| 9 |
+
"eos_token_id": 2,
|
| 10 |
+
"finetuning_task": "text-classification",
|
| 11 |
+
"hidden_act": "gelu",
|
| 12 |
+
"hidden_dropout_prob": 0.0,
|
| 13 |
+
"hidden_size": 1024,
|
| 14 |
+
"id2label": {
|
| 15 |
+
"0": "\u4ea4\u901a\u8fd0\u8f93",
|
| 16 |
+
"1": "\u4eba\u5de5\u667a\u80fd_\u673a\u5668\u5b66\u4e60",
|
| 17 |
+
"2": "\u4f4f\u5bbf_\u9910\u996e_\u9152\u5e97",
|
| 18 |
+
"3": "\u4f53\u80b2",
|
| 19 |
+
"4": "\u5176\u4ed6",
|
| 20 |
+
"5": "\u5176\u4ed6\u4fe1\u606f\u670d\u52a1_\u4fe1\u606f\u5b89\u5168",
|
| 21 |
+
"6": "\u5176\u4ed6\u5236\u9020",
|
| 22 |
+
"7": "\u519c\u6797\u7267\u6e14",
|
| 23 |
+
"8": "\u533b\u5b66_\u5065\u5eb7_\u5fc3\u7406_\u4e2d\u533b",
|
| 24 |
+
"9": "\u5b66\u79d1\u6559\u80b2_\u6559\u80b2",
|
| 25 |
+
"10": "\u5f71\u89c6_\u5a31\u4e50",
|
| 26 |
+
"11": "\u623f\u5730\u4ea7_\u5efa\u7b51",
|
| 27 |
+
"12": "\u6570\u5b66_\u7edf\u8ba1\u5b66",
|
| 28 |
+
"13": "\u6587\u5b66_\u60c5\u611f",
|
| 29 |
+
"14": "\u65b0\u95fb\u4f20\u5a92",
|
| 30 |
+
"15": "\u65c5\u6e38_\u5730\u7406",
|
| 31 |
+
"16": "\u65f6\u653f_\u653f\u52a1_\u884c\u653f",
|
| 32 |
+
"17": "\u6c34\u5229_\u6d77\u6d0b",
|
| 33 |
+
"18": "\u6c7d\u8f66",
|
| 34 |
+
"19": "\u6cd5\u5f8b_\u53f8\u6cd5",
|
| 35 |
+
"20": "\u6d88\u9632\u5b89\u5168_\u98df\u54c1\u5b89\u5168",
|
| 36 |
+
"21": "\u6e38\u620f",
|
| 37 |
+
"22": "\u751f\u7269\u533b\u836f",
|
| 38 |
+
"23": "\u7535\u529b\u80fd\u6e90",
|
| 39 |
+
"24": "\u77f3\u6cb9\u5316\u5de5",
|
| 40 |
+
"25": "\u79d1\u6280_\u79d1\u5b66\u7814\u7a76",
|
| 41 |
+
"26": "\u822a\u7a7a\u822a\u5929",
|
| 42 |
+
"27": "\u8ba1\u7b97\u673a_\u901a\u4fe1",
|
| 43 |
+
"28": "\u8ba1\u7b97\u673a\u7f16\u7a0b_\u4ee3\u7801",
|
| 44 |
+
"29": "\u91c7\u77ff",
|
| 45 |
+
"30": "\u91d1\u878d_\u7ecf\u6d4e"
|
| 46 |
+
},
|
| 47 |
+
"initializer_range": 0.02,
|
| 48 |
+
"intermediate_size": 4096,
|
| 49 |
+
"label2id": {
|
| 50 |
+
"\u4ea4\u901a\u8fd0\u8f93": 0,
|
| 51 |
+
"\u4eba\u5de5\u667a\u80fd_\u673a\u5668\u5b66\u4e60": 1,
|
| 52 |
+
"\u4f4f\u5bbf_\u9910\u996e_\u9152\u5e97": 2,
|
| 53 |
+
"\u4f53\u80b2": 3,
|
| 54 |
+
"\u5176\u4ed6": 4,
|
| 55 |
+
"\u5176\u4ed6\u4fe1\u606f\u670d\u52a1_\u4fe1\u606f\u5b89\u5168": 5,
|
| 56 |
+
"\u5176\u4ed6\u5236\u9020": 6,
|
| 57 |
+
"\u519c\u6797\u7267\u6e14": 7,
|
| 58 |
+
"\u533b\u5b66_\u5065\u5eb7_\u5fc3\u7406_\u4e2d\u533b": 8,
|
| 59 |
+
"\u5b66\u79d1\u6559\u80b2_\u6559\u80b2": 9,
|
| 60 |
+
"\u5f71\u89c6_\u5a31\u4e50": 10,
|
| 61 |
+
"\u623f\u5730\u4ea7_\u5efa\u7b51": 11,
|
| 62 |
+
"\u6570\u5b66_\u7edf\u8ba1\u5b66": 12,
|
| 63 |
+
"\u6587\u5b66_\u60c5\u611f": 13,
|
| 64 |
+
"\u65b0\u95fb\u4f20\u5a92": 14,
|
| 65 |
+
"\u65c5\u6e38_\u5730\u7406": 15,
|
| 66 |
+
"\u65f6\u653f_\u653f\u52a1_\u884c\u653f": 16,
|
| 67 |
+
"\u6c34\u5229_\u6d77\u6d0b": 17,
|
| 68 |
+
"\u6c7d\u8f66": 18,
|
| 69 |
+
"\u6cd5\u5f8b_\u53f8\u6cd5": 19,
|
| 70 |
+
"\u6d88\u9632\u5b89\u5168_\u98df\u54c1\u5b89\u5168": 20,
|
| 71 |
+
"\u6e38\u620f": 21,
|
| 72 |
+
"\u751f\u7269\u533b\u836f": 22,
|
| 73 |
+
"\u7535\u529b\u80fd\u6e90": 23,
|
| 74 |
+
"\u77f3\u6cb9\u5316\u5de5": 24,
|
| 75 |
+
"\u79d1\u6280_\u79d1\u5b66\u7814\u7a76": 25,
|
| 76 |
+
"\u822a\u7a7a\u822a\u5929": 26,
|
| 77 |
+
"\u8ba1\u7b97\u673a_\u901a\u4fe1": 27,
|
| 78 |
+
"\u8ba1\u7b97\u673a\u7f16\u7a0b_\u4ee3\u7801": 28,
|
| 79 |
+
"\u91c7\u77ff": 29,
|
| 80 |
+
"\u91d1\u878d_\u7ecf\u6d4e": 30
|
| 81 |
+
},
|
| 82 |
+
"layer_norm_eps": 1e-05,
|
| 83 |
+
"max_position_embeddings": 8194,
|
| 84 |
+
"model_type": "xlm-roberta",
|
| 85 |
+
"num_attention_heads": 16,
|
| 86 |
+
"num_hidden_layers": 24,
|
| 87 |
+
"output_past": true,
|
| 88 |
+
"pad_token_id": 1,
|
| 89 |
+
"position_embedding_type": "absolute",
|
| 90 |
+
"problem_type": "single_label_classification",
|
| 91 |
+
"torch_dtype": "float32",
|
| 92 |
+
"transformers_version": "4.39.0",
|
| 93 |
+
"type_vocab_size": 1,
|
| 94 |
+
"use_cache": true,
|
| 95 |
+
"vocab_size": 250002
|
| 96 |
+
}
|
img/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
img/classify.png
ADDED

|
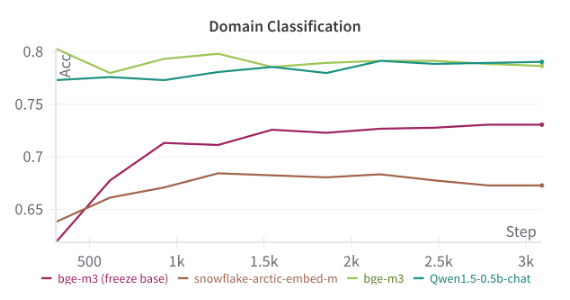
img/classify_exp.png
ADDED
|
model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:0597708ae15fdcce27850e947653857d31f2e161a0ff46c53185ad58b644908c
|
| 3 |
+
size 2271194860
|
readme.md
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
模型是数据集[BAAI/IndustryCorpus2](https://huggingface.co/datasets/BAAI/IndustryCorpus2)中用来进行行业分类分类
|
| 2 |
+
|
| 3 |
+
模型细节:
|
| 4 |
+
|
| 5 |
+
为了提升数据集中行业划分对实际行业的覆盖,并对齐国家标准中定义的行业目录,我们参考国家统计局制定的国民经济行业分类体系和世界知识体系,进行类目的合并和整合,设计了覆盖中英文的最终的31个行业类目。类目表名称如下所示
|
| 6 |
+
|
| 7 |
+
```
|
| 8 |
+
{
|
| 9 |
+
"数学_统计": {"zh": "数学与统计", "en": "Math & Statistics"},
|
| 10 |
+
"体育": {"zh": "体育", "en": "Sports"},
|
| 11 |
+
"农林牧渔": {"zh": "农业与渔业", "en": "Agriculture & Fisheries"},
|
| 12 |
+
"房地产_建筑": {"zh": "房地产与建筑", "en": "Real Estate & Construction"},
|
| 13 |
+
"时政_政务_行政": {"zh": "政治与行政", "en": "Politics & Administration"},
|
| 14 |
+
"消防安全_食品安全": {"zh": "安全管理", "en": "Safety Management"},
|
| 15 |
+
"石油化工": {"zh": "石油化工", "en": "Petrochemicals"},
|
| 16 |
+
"计算机_通信": {"zh": "计算机与通信", "en": "Computing & Telecommunications"},
|
| 17 |
+
"交通运输": {"zh": "交通运输", "en": "Transportation"},
|
| 18 |
+
"其他": {"zh": "其他", "en": "Others"},
|
| 19 |
+
"医学_健康_心理_中医": {"zh": "健康与医学", "en": "Health & Medicine"},
|
| 20 |
+
"文学_情感": {"zh": "文学与情感", "en": "Literature & Emotions"},
|
| 21 |
+
"水利_海洋": {"zh": "水利与海洋", "en": "Water Resources & Marine"},
|
| 22 |
+
"游戏": {"zh": "游戏", "en": "Gaming"},
|
| 23 |
+
"科技_科学研究": {"zh": "科技与研究", "en": "Technology & Research"},
|
| 24 |
+
"采矿": {"zh": "采矿", "en": "Mining"},
|
| 25 |
+
"人工智能_机器学习": {"zh": "人工智能", "en": "Artificial Intelligence"},
|
| 26 |
+
"其他信息服务_信息安全": {"zh": "信息服务", "en": "Information Services"},
|
| 27 |
+
"学科教育_教育": {"zh": "学科教育", "en": "Subject Education"},
|
| 28 |
+
"新闻传媒": {"zh": "新闻传媒", "en": "Media & Journalism"},
|
| 29 |
+
"汽车": {"zh": "汽车", "en": "Automobiles"},
|
| 30 |
+
"生物医药": {"zh": "生物医药", "en": "Biopharmaceuticals"},
|
| 31 |
+
"航空航天": {"zh": "航空航天", "en": "Aerospace"},
|
| 32 |
+
"金融_经济": {"zh": "金融与经济", "en": "Finance & Economics"},
|
| 33 |
+
"住宿_餐饮_酒店": {"zh": "住宿与餐饮", "en": "Hospitality & Catering"},
|
| 34 |
+
"其他制造": {"zh": "制造业", "en": "Manufacturing"},
|
| 35 |
+
"影视_娱乐": {"zh": "影视与娱乐", "en": "Film & Entertainment"},
|
| 36 |
+
"旅游_地理": {"zh": "旅游与地理", "en": "Travel & Geography"},
|
| 37 |
+
"法律_司法": {"zh": "法律与司法", "en": "Law & Justice"},
|
| 38 |
+
"电力能源": {"zh": "电力与能源", "en": "Power & Energy"},
|
| 39 |
+
"计算机编程_代码": {"zh": "编程", "en": "Programming"},
|
| 40 |
+
}
|
| 41 |
+
```
|
| 42 |
+
|
| 43 |
+
- 行业分类模型的数据构造
|
| 44 |
+
|
| 45 |
+
- 数据构建
|
| 46 |
+
|
| 47 |
+
数据来源:预训练预训练语料抽样和开源文本分类数据,其中预训练语料占比90%,通过数据采样,保证中英文数据占比为1:1
|
| 48 |
+
|
| 49 |
+
标签构造:使用LLM模型对数据进行多次分类判定,筛选多次判定一致的数据作为训练数据
|
| 50 |
+
|
| 51 |
+
数据规模:36K
|
| 52 |
+
|
| 53 |
+
数据构造的整体流程如下:
|
| 54 |
+
|
| 55 |
+

|
| 56 |
+
|
| 57 |
+
- 模型训练:
|
| 58 |
+
|
| 59 |
+
参数更新:在预训练的bert模型上添加分类头进行文本分类模型训练
|
| 60 |
+
|
| 61 |
+
模型选型:考虑的模型性能和推理效率,我们选用了0.5b规模的模型,通过对比实验最终最终选择了bge-m3并全参数训练的方式,作为我们的基座模型
|
| 62 |
+
|
| 63 |
+
训练超参:全参数训练,max_length = 2048,lr=1e-5,batch_size=64,,验证集评估acc:86%
|
| 64 |
+
|
| 65 |
+

|
| 66 |
+
|
| 67 |
+
###
|
sentencepiece.bpe.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:cfc8146abe2a0488e9e2a0c56de7952f7c11ab059eca145a0a727afce0db2865
|
| 3 |
+
size 5069051
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<s>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": false,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"cls_token": {
|
| 10 |
+
"content": "<s>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": false,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"eos_token": {
|
| 17 |
+
"content": "</s>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": false,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
},
|
| 23 |
+
"mask_token": {
|
| 24 |
+
"content": "<mask>",
|
| 25 |
+
"lstrip": true,
|
| 26 |
+
"normalized": false,
|
| 27 |
+
"rstrip": false,
|
| 28 |
+
"single_word": false
|
| 29 |
+
},
|
| 30 |
+
"pad_token": {
|
| 31 |
+
"content": "<pad>",
|
| 32 |
+
"lstrip": false,
|
| 33 |
+
"normalized": false,
|
| 34 |
+
"rstrip": false,
|
| 35 |
+
"single_word": false
|
| 36 |
+
},
|
| 37 |
+
"sep_token": {
|
| 38 |
+
"content": "</s>",
|
| 39 |
+
"lstrip": false,
|
| 40 |
+
"normalized": false,
|
| 41 |
+
"rstrip": false,
|
| 42 |
+
"single_word": false
|
| 43 |
+
},
|
| 44 |
+
"unk_token": {
|
| 45 |
+
"content": "<unk>",
|
| 46 |
+
"lstrip": false,
|
| 47 |
+
"normalized": false,
|
| 48 |
+
"rstrip": false,
|
| 49 |
+
"single_word": false
|
| 50 |
+
}
|
| 51 |
+
}
|
tokenizer.json
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6710678b12670bc442b99edc952c4d996ae309a7020c1fa0096dd245c2faf790
|
| 3 |
+
size 17082821
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"added_tokens_decoder": {
|
| 3 |
+
"0": {
|
| 4 |
+
"content": "<s>",
|
| 5 |
+
"lstrip": false,
|
| 6 |
+
"normalized": false,
|
| 7 |
+
"rstrip": false,
|
| 8 |
+
"single_word": false,
|
| 9 |
+
"special": true
|
| 10 |
+
},
|
| 11 |
+
"1": {
|
| 12 |
+
"content": "<pad>",
|
| 13 |
+
"lstrip": false,
|
| 14 |
+
"normalized": false,
|
| 15 |
+
"rstrip": false,
|
| 16 |
+
"single_word": false,
|
| 17 |
+
"special": true
|
| 18 |
+
},
|
| 19 |
+
"2": {
|
| 20 |
+
"content": "</s>",
|
| 21 |
+
"lstrip": false,
|
| 22 |
+
"normalized": false,
|
| 23 |
+
"rstrip": false,
|
| 24 |
+
"single_word": false,
|
| 25 |
+
"special": true
|
| 26 |
+
},
|
| 27 |
+
"3": {
|
| 28 |
+
"content": "<unk>",
|
| 29 |
+
"lstrip": false,
|
| 30 |
+
"normalized": false,
|
| 31 |
+
"rstrip": false,
|
| 32 |
+
"single_word": false,
|
| 33 |
+
"special": true
|
| 34 |
+
},
|
| 35 |
+
"250001": {
|
| 36 |
+
"content": "<mask>",
|
| 37 |
+
"lstrip": true,
|
| 38 |
+
"normalized": false,
|
| 39 |
+
"rstrip": false,
|
| 40 |
+
"single_word": false,
|
| 41 |
+
"special": true
|
| 42 |
+
}
|
| 43 |
+
},
|
| 44 |
+
"bos_token": "<s>",
|
| 45 |
+
"clean_up_tokenization_spaces": true,
|
| 46 |
+
"cls_token": "<s>",
|
| 47 |
+
"eos_token": "</s>",
|
| 48 |
+
"mask_token": "<mask>",
|
| 49 |
+
"model_max_length": 8192,
|
| 50 |
+
"pad_token": "<pad>",
|
| 51 |
+
"sep_token": "</s>",
|
| 52 |
+
"sp_model_kwargs": {},
|
| 53 |
+
"tokenizer_class": "XLMRobertaTokenizer",
|
| 54 |
+
"unk_token": "<unk>"
|
| 55 |
+
}
|
trainer_state.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:16a60324779f4561552c1e524383f6591f97b80e0adc5098445a110a72360d23
|
| 3 |
+
size 5240
|