

Commit
•
4a49479
1
Parent(s):
7d3f15f
Upload 3 files
Browse files- README.md +86 -0
- img/eval-result.jpeg +0 -0
- img/pipeline.png +0 -0
README.md
CHANGED
|
@@ -1,3 +1,89 @@
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
---
|
| 4 |
+
|
| 5 |
+
## Introduction
|
| 6 |
+
|
| 7 |
+
Aquila is a large language model trained by BAAI, and AquilaMed-RL is an industry model from Aquila language model. Based on the Aquila general pre-trained model, we continued pre-training , SFT and RL in the medical domain and obtained our AquilaMed-RL model.
|
| 8 |
+
|
| 9 |
+
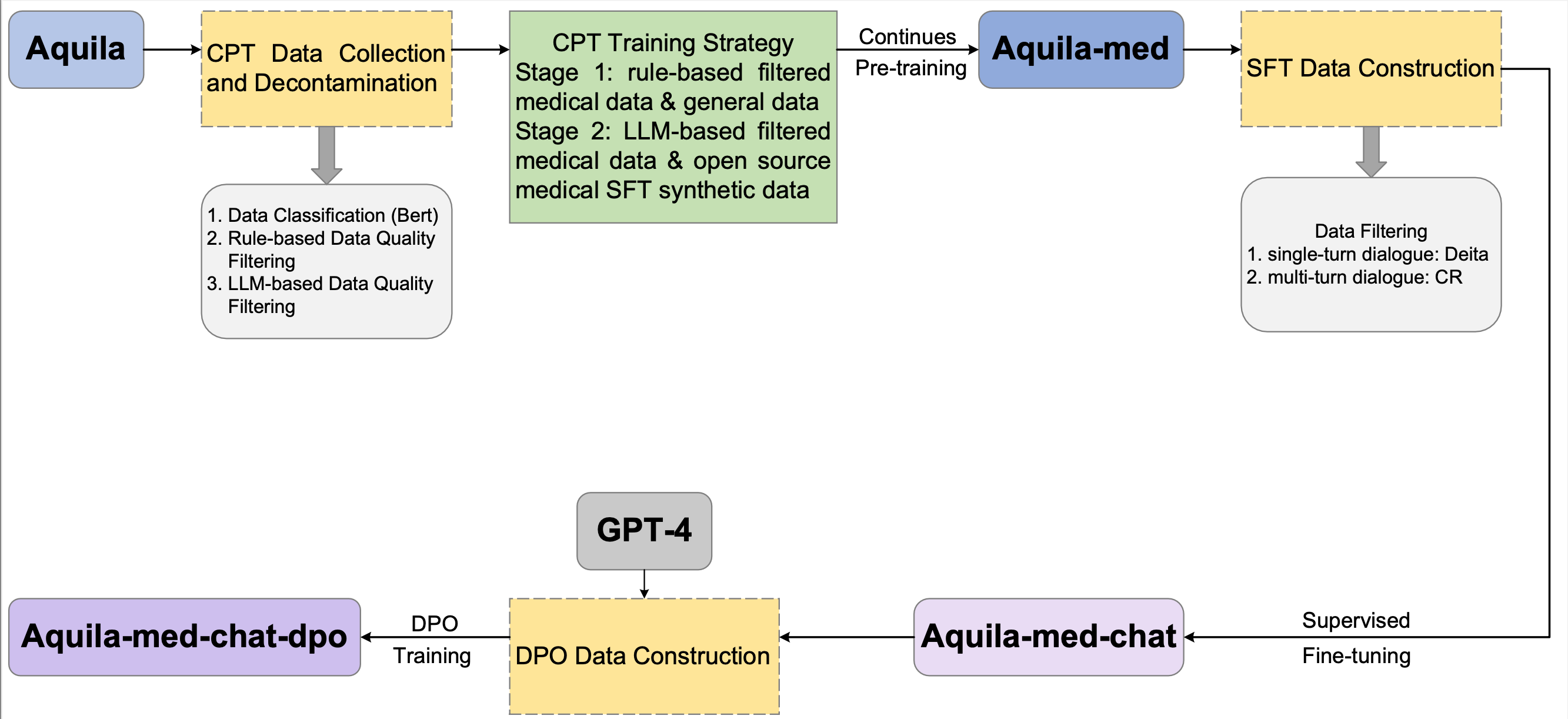
## Model Details
|
| 10 |
+
|
| 11 |
+
The pipeline of the training procedure is bellow, for more details you can read our technical report: https://github.com/FlagAI-Open/industry-application/blob/main/Aquila_med_tech-report.pdf
|
| 12 |
+
|
| 13 |
+

|
| 14 |
+
|
| 15 |
+
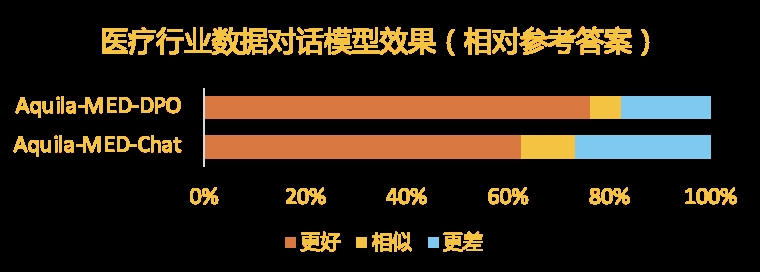
## Evaluation
|
| 16 |
+
|
| 17 |
+

|
| 18 |
+
|
| 19 |
+
## usage
|
| 20 |
+
|
| 21 |
+
when you have downloaded the model, you can use the bellow code to run the model
|
| 22 |
+
|
| 23 |
+
```python
|
| 24 |
+
|
| 25 |
+
import torch
|
| 26 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoConfig
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
model_dir = "xxx"
|
| 30 |
+
|
| 31 |
+
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
|
| 32 |
+
|
| 33 |
+
config = AutoConfig.from_pretrained(model_dir, trust_remote_code=True)
|
| 34 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 35 |
+
model_dir, config=config, trust_remote_code=True
|
| 36 |
+
)
|
| 37 |
+
model.cuda()
|
| 38 |
+
model.eval()
|
| 39 |
+
|
| 40 |
+
template = "<|im_start|>system\nYou are a helpful assistant in medical domain.<|im_end|>\n<|im_start|>user\n{question}<|im_end|>\n<|im_start|>assistant\n"
|
| 41 |
+
|
| 42 |
+
text = "我肚子疼怎么办?"
|
| 43 |
+
|
| 44 |
+
item_instruction = template.format(question=text)
|
| 45 |
+
|
| 46 |
+
inputs = tokenizer(item_instruction, return_tensors="pt").to("cuda")
|
| 47 |
+
input_ids = inputs["input_ids"]
|
| 48 |
+
prompt_length = len(input_ids[0])
|
| 49 |
+
generate_output = model.generate(
|
| 50 |
+
input_ids=input_ids, do_sample=False, max_length=1024, return_dict_in_generate=True
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
response_ids = generate_output.sequences[0][prompt_length:]
|
| 54 |
+
predicts = tokenizer.decode(
|
| 55 |
+
response_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True
|
| 56 |
+
)
|
| 57 |
+
|
| 58 |
+
print("predict:", predicts)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
"""
|
| 62 |
+
predict: 肚子疼可能是多种原因引起的,例如消化不良、胃炎、胃溃疡、胆囊炎、胰腺炎、肠道感染等。如果疼痛持续或加重,或者伴随有呕吐、腹泻、发热等症状,建议尽快就医。如果疼痛轻微,可以尝试以下方法缓解:
|
| 63 |
+
|
| 64 |
+
1. 饮食调整:避免油腻、辛辣、刺激性食物,多喝水,多吃易消化的食物,如米粥、面条、饼干等。
|
| 65 |
+
|
| 66 |
+
2. 休息:避免剧烈运动,保持充足的睡眠。
|
| 67 |
+
|
| 68 |
+
3. 热敷:用热水袋或毛巾敷在肚子上,可以缓解疼痛。
|
| 69 |
+
|
| 70 |
+
4. 药物:可以尝试一些非处方药,如布洛芬、阿司匹林等,但请务必在医生的指导下使用。
|
| 71 |
+
|
| 72 |
+
如果疼痛持续或加重,或者伴随有其他症状,建议尽快就医。
|
| 73 |
+
|
| 74 |
+
希望我的回答对您有所帮助。如果您还有其他问题,欢迎随时向我提问。
|
| 75 |
+
"""
|
| 76 |
+
```
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
## Citation
|
| 81 |
+
|
| 82 |
+
If you find our work helpful, feel free to give us a cite.
|
| 83 |
+
|
| 84 |
+
```
|
| 85 |
+
@article{AquilaMed,
|
| 86 |
+
title={AquilaMed Technical Report},
|
| 87 |
+
year={2024}
|
| 88 |
+
}
|
| 89 |
+
```
|
img/eval-result.jpeg
ADDED
|
img/pipeline.png
ADDED
|