
Alok Pandey
commited on
Update README.md
Browse files
README.md
CHANGED
|
@@ -43,11 +43,6 @@ The model is ideal for detecting AI-generated content, particularly useful in cr
|
|
| 43 |
|
| 44 |
The model was fine-tuned using data augmentation techniques like random flips, rotations, and color jittering to improve robustness.
|
| 45 |
|
| 46 |
-
---
|
| 47 |
-
To support `.png` files and ensure that the images are rendered properly, you need to reference the correct file format in the image URLs. Additionally, you should use the appropriate image path for your hosting platform (like Hugging Face).
|
| 48 |
-
|
| 49 |
-
### Updated Model Card with Support for `.png` Images:
|
| 50 |
-
|
| 51 |
---
|
| 52 |
|
| 53 |
## **Training Metrics**
|
|
@@ -59,6 +54,21 @@ This graph shows the decrease in loss over 15 epochs, indicating the model's imp
|
|
| 59 |
|
| 60 |
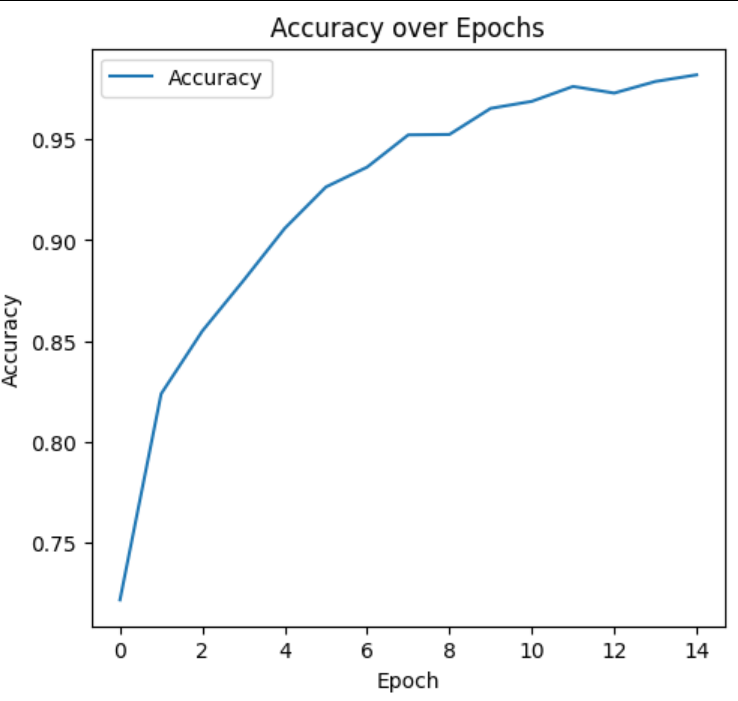
This graph shows the increase in accuracy, reflecting the model's growing ability to correctly classify images.
|
| 61 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 62 |
|
| 63 |
## **Model Output Samples**
|
| 64 |
Here are some examples of the model's predictions on various images:
|
|
@@ -97,6 +107,4 @@ You can download the fine-tuned DenseNet121 model using the following link:
|
|
| 97 |
|
| 98 |
## **References**
|
| 99 |
For more information on DenseNet, refer to the original research paper:
|
| 100 |
-
[**Densely Connected Convolutional Networks (DenseNet)**](https://arxiv.org/abs/1608.06993)
|
| 101 |
-
|
| 102 |
-
---
|
|
|
|
| 43 |
|
| 44 |
The model was fine-tuned using data augmentation techniques like random flips, rotations, and color jittering to improve robustness.
|
| 45 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 46 |
---
|
| 47 |
|
| 48 |
## **Training Metrics**
|
|
|
|
| 54 |

|
| 55 |
This graph shows the increase in accuracy, reflecting the model's growing ability to correctly classify images.
|
| 56 |
|
| 57 |
+
---
|
| 58 |
+
|
| 59 |
+
## **Sample Dataset**
|
| 60 |
+
Here is a visual representation of the dataset used for training and validation:
|
| 61 |
+
|
| 62 |
+

|
| 63 |
+
|
| 64 |
+
This image shows a collage of examples from the dataset used to fine-tune the DenseNet model. The dataset includes a diverse mix of images from three distinct categories:
|
| 65 |
+
1. **Human-Created Images** – Traditional artwork or photographs made by humans.
|
| 66 |
+
2. **DALL-E Generated Images** – Images created using DALL-E, an advanced AI model designed to generate visual content.
|
| 67 |
+
3. **Other AI-Generated Images** – Visual content generated by other AI systems, aside from DALL-E, to provide variety in the training data.
|
| 68 |
+
|
| 69 |
+
This diversity allows the model to effectively learn how to distinguish between different forms of image creation, ensuring robust performance across a range of AI-generated and human-created content.
|
| 70 |
+
|
| 71 |
+
---
|
| 72 |
|
| 73 |
## **Model Output Samples**
|
| 74 |
Here are some examples of the model's predictions on various images:
|
|
|
|
| 107 |
|
| 108 |
## **References**
|
| 109 |
For more information on DenseNet, refer to the original research paper:
|
| 110 |
+
[**Densely Connected Convolutional Networks (DenseNet)**](https://arxiv.org/abs/1608.06993)
|
|
|
|
|
|