
File size: 14,295 Bytes
c499def 42af6e4 c499def 67c7760 c499def 2ecddb3 c499def 2d2b94c 4a82535 c499def 4a82535 6877568 c499def a6343cd c499def |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 |
---
license: apache-2.0
datasets:
- AIDC-AI/Ovis-dataset
library_name: transformers
tags:
- MLLM
pipeline_tag: image-text-to-text
language:
- en
- zh
---
# Ovis2-1B
<div align="center">
<img src=https://cdn-uploads.huggingface.co/production/uploads/637aebed7ce76c3b834cea37/3IK823BZ8w-mz_QfeYkDn.png width="30%"/>
</div>
## Introduction
[GitHub](https://github.com/AIDC-AI/Ovis) | [Paper](https://arxiv.org/abs/2405.20797)
We are pleased to announce the release of **Ovis2**, our latest advancement in multi-modal large language models (MLLMs). Ovis2 inherits the innovative architectural design of the Ovis series, aimed at structurally aligning visual and textual embeddings. As the successor to Ovis1.6, Ovis2 incorporates significant improvements in both dataset curation and training methodologies.
**Key Features**:
- **Small Model Performance**: Optimized training strategies enable small-scale models to achieve higher capability density, demonstrating cross-tier leading advantages.
- **Enhanced Reasoning Capabilities**: Significantly strengthens Chain-of-Thought (CoT) reasoning abilities through the combination of instruction tuning and preference learning.
- **Video and Multi-Image Processing**: Video and multi-image data are incorporated into training to enhance the ability to handle complex visual information across frames and images.
- **Multilingual Support and OCR**: Enhances multilingual OCR beyond English and Chinese and improves structured data extraction from complex visual elements like tables and charts.
<div align="center">
<img src="https://cdn-uploads.huggingface.co/production/uploads/637aebed7ce76c3b834cea37/XB-vgzDL6FshrSNGyZvzc.png" width="100%" />
</div>
## Model Zoo
| Ovis MLLMs | ViT | LLM | Model Weights | Demo |
|:-----------|:-----------------------:|:---------------------:|:-------------------------------------------------------:|:--------------------------------------------------------:|
| Ovis2-1B | aimv2-large-patch14-448 | Qwen2.5-0.5B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-1B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-1B) |
| Ovis2-2B | aimv2-large-patch14-448 | Qwen2.5-1.5B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-2B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-2B) |
| Ovis2-4B | aimv2-huge-patch14-448 | Qwen2.5-3B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-4B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-4B) |
| Ovis2-8B | aimv2-huge-patch14-448 | Qwen2.5-7B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-8B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-8B) |
| Ovis2-16B | aimv2-huge-patch14-448 | Qwen2.5-14B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-16B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis2-16B) |
| Ovis2-34B | aimv2-1B-patch14-448 | Qwen2.5-32B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis2-34B) | - |
## Performance
We use [VLMEvalKit](https://github.com/open-compass/VLMEvalKit), as employed in the OpenCompass [multimodal](https://rank.opencompass.org.cn/leaderboard-multimodal) and [reasoning](https://rank.opencompass.org.cn/leaderboard-multimodal-reasoning) leaderboard, to evaluate Ovis2.
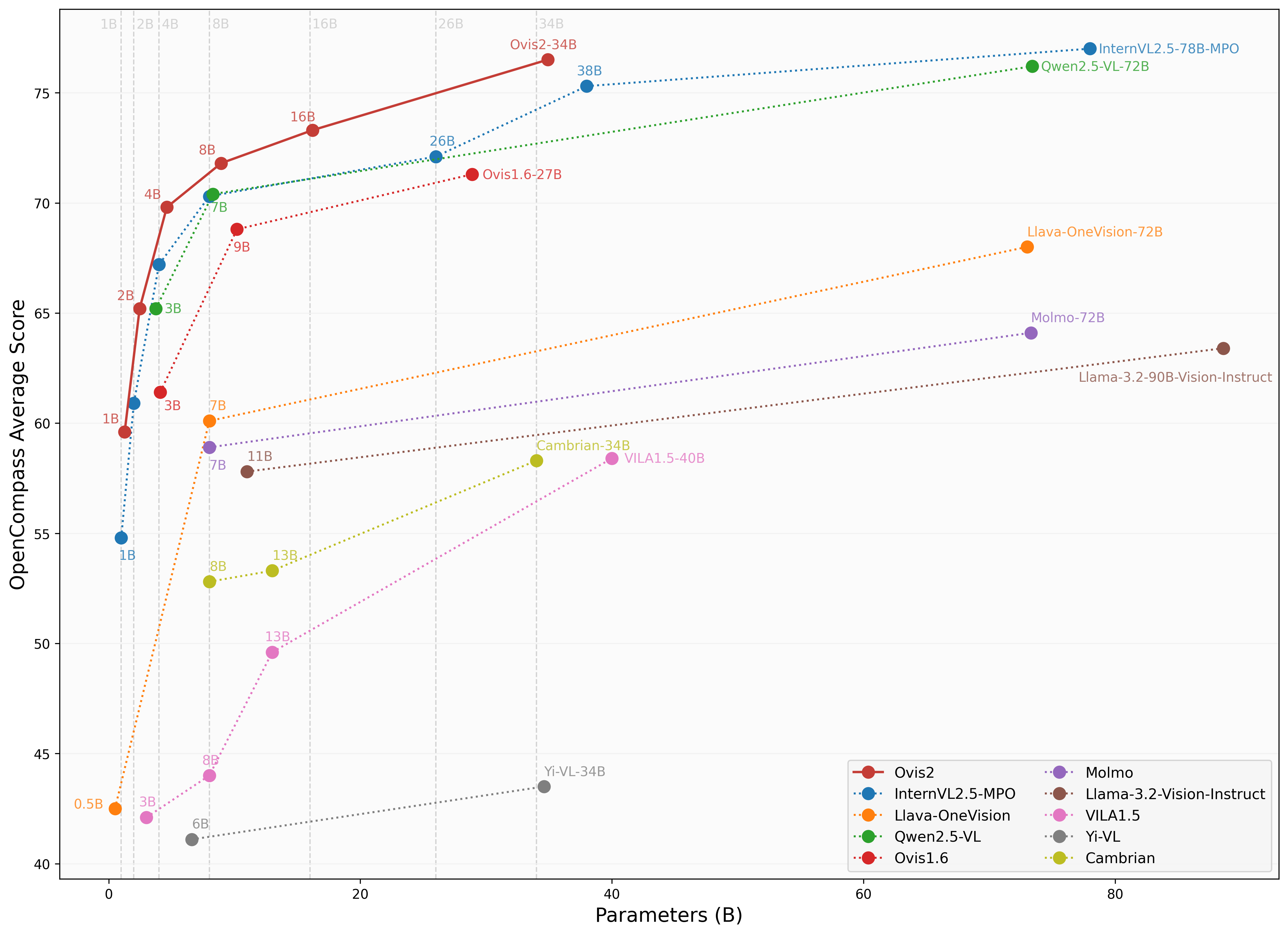
### Image Benchmark
| Benchmark | Qwen2.5-VL-3B | SAIL-VL-2B | InternVL2.5-2B-MPO | Ovis1.6-3B | InternVL2.5-1B-MPO | Ovis2-1B | Ovis2-2B |
|:-----------------------------|:---------------:|:------------:|:--------------------:|:------------:|:--------------------:|:----------:|:----------:|
| MMBench-V1.1<sub>test</sub> | **77.1** | 73.6 | 70.7 | 74.1 | 65.8 | 68.4 | 76.9 |
| MMStar | 56.5 | 56.5 | 54.9 | 52.0 | 49.5 | 52.1 | **56.7** |
| MMMU<sub>val</sub> | **51.4** | 44.1 | 44.6 | 46.7 | 40.3 | 36.1 | 45.6 |
| MathVista<sub>testmini</sub> | 60.1 | 62.8 | 53.4 | 58.9 | 47.7 | 59.4 | **64.1** |
| HallusionBench | 48.7 | 45.9 | 40.7 | 43.8 | 34.8 | 45.2 | **50.2** |
| AI2D | 81.4 | 77.4 | 75.1 | 77.8 | 68.5 | 76.4 | **82.7** |
| OCRBench | 83.1 | 83.1 | 83.8 | 80.1 | 84.3 | **89.0** | 87.3 |
| MMVet | 63.2 | 44.2 | **64.2** | 57.6 | 47.2 | 50.0 | 58.3 |
| MMBench<sub>test</sub> | 78.6 | 77 | 72.8 | 76.6 | 67.9 | 70.2 | **78.9** |
| MMT-Bench<sub>val</sub> | 60.8 | 57.1 | 54.4 | 59.2 | 50.8 | 55.5 | **61.7** |
| RealWorldQA | 66.5 | 62 | 61.3 | **66.7** | 57 | 63.9 | 66.0 |
| BLINK | **48.4** | 46.4 | 43.8 | 43.8 | 41 | 44.0 | 47.9 |
| QBench | 74.4 | 72.8 | 69.8 | 75.8 | 63.3 | 71.3 | **76.2** |
| ABench | 75.5 | 74.5 | 71.1 | 75.2 | 67.5 | 71.3 | **76.6** |
| MTVQA | 24.9 | 20.2 | 22.6 | 21.1 | 21.7 | 23.7 | **25.6** |
### Video Benchmark
| Benchmark | Qwen2.5-VL-3B | InternVL2.5-2B | InternVL2.5-1B | Ovis2-1B | Ovis2-2B |
| ------------------- |:-------------:|:--------------:|:--------------:|:---------:|:-------------:|
| VideoMME(wo/w-subs) | **61.5/67.6** | 51.9 / 54.1 | 50.3 / 52.3 | 48.6/49.5 | 57.2/60.8 |
| MVBench | 67.0 | **68.8** | 64.3 | 60.32 | 64.9 |
| MLVU(M-Avg/G-Avg) | 68.2/- | 61.4/- | 57.3/- | 58.5/3.66 | **68.6**/3.86 |
| MMBench-Video | **1.63** | 1.44 | 1.36 | 1.26 | 1.57 |
| TempCompass | **64.4** | - | - | 51.43 | 62.64 |
## Usage
Below is a code snippet demonstrating how to run Ovis with various input types. For additional usage instructions, including inference wrapper and Gradio UI, please refer to [Ovis GitHub](https://github.com/AIDC-AI/Ovis?tab=readme-ov-file#inference).
```bash
pip install torch==2.4.0 transformers==4.46.2 numpy==1.25.0 pillow==10.3.0
pip install flash-attn==2.7.0.post2 --no-build-isolation
```
```python
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-1B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# single-image input
image_path = '/data/images/example_1.jpg'
images = [Image.open(image_path)]
max_partition = 9
text = 'Describe the image.'
query = f'<image>\n{text}'
## cot-style input
# cot_suffix = "Provide a step-by-step solution to the problem, and conclude with 'the answer is' followed by the final solution."
# image_path = '/data/images/example_1.jpg'
# images = [Image.open(image_path)]
# max_partition = 9
# text = "What's the area of the shape?"
# query = f'<image>\n{text}\n{cot_suffix}'
## multiple-images input
# image_paths = [
# '/data/images/example_1.jpg',
# '/data/images/example_2.jpg',
# '/data/images/example_3.jpg'
# ]
# images = [Image.open(image_path) for image_path in image_paths]
# max_partition = 4
# text = 'Describe each image.'
# query = '\n'.join([f'Image {i+1}: <image>' for i in range(len(images))]) + '\n' + text
## video input (require `pip install moviepy==1.0.3`)
# from moviepy.editor import VideoFileClip
# video_path = '/data/videos/example_1.mp4'
# num_frames = 12
# max_partition = 1
# text = 'Describe the video.'
# with VideoFileClip(video_path) as clip:
# total_frames = int(clip.fps * clip.duration)
# if total_frames <= num_frames:
# sampled_indices = range(total_frames)
# else:
# stride = total_frames / num_frames
# sampled_indices = [min(total_frames - 1, int((stride * i + stride * (i + 1)) / 2)) for i in range(num_frames)]
# frames = [clip.get_frame(index / clip.fps) for index in sampled_indices]
# frames = [Image.fromarray(frame, mode='RGB') for frame in frames]
# images = frames
# query = '\n'.join(['<image>'] * len(images)) + '\n' + text
## text-only input
# images = []
# max_partition = None
# text = 'Hello'
# query = text
# format conversation
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'Output:\n{output}')
```
<details>
<summary>Batch Inference</summary>
```python
import torch
from PIL import Image
from transformers import AutoModelForCausalLM
# load model
model = AutoModelForCausalLM.from_pretrained("AIDC-AI/Ovis2-1B",
torch_dtype=torch.bfloat16,
multimodal_max_length=32768,
trust_remote_code=True).cuda()
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# preprocess inputs
batch_inputs = [
('/data/images/example_1.jpg', 'What colors dominate the image?'),
('/data/images/example_2.jpg', 'What objects are depicted in this image?'),
('/data/images/example_3.jpg', 'Is there any text in the image?')
]
batch_input_ids = []
batch_attention_mask = []
batch_pixel_values = []
for image_path, text in batch_inputs:
image = Image.open(image_path)
query = f'<image>\n{text}'
prompt, input_ids, pixel_values = model.preprocess_inputs(query, [image], max_partition=9)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
batch_input_ids.append(input_ids.to(device=model.device))
batch_attention_mask.append(attention_mask.to(device=model.device))
batch_pixel_values.append(pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device))
batch_input_ids = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_input_ids], batch_first=True,
padding_value=0.0).flip(dims=[1])
batch_input_ids = batch_input_ids[:, -model.config.multimodal_max_length:]
batch_attention_mask = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_attention_mask],
batch_first=True, padding_value=False).flip(dims=[1])
batch_attention_mask = batch_attention_mask[:, -model.config.multimodal_max_length:]
# generate outputs
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(batch_input_ids, pixel_values=batch_pixel_values, attention_mask=batch_attention_mask,
**gen_kwargs)
for i in range(len(batch_inputs)):
output = text_tokenizer.decode(output_ids[i], skip_special_tokens=True)
print(f'Output {i + 1}:\n{output}\n')
```
</details>
## Citation
If you find Ovis useful, please consider citing the paper
```
@article{lu2024ovis,
title={Ovis: Structural Embedding Alignment for Multimodal Large Language Model},
author={Shiyin Lu and Yang Li and Qing-Guo Chen and Zhao Xu and Weihua Luo and Kaifu Zhang and Han-Jia Ye},
year={2024},
journal={arXiv:2405.20797}
}
```
## License
This project is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt) (SPDX-License-Identifier: Apache-2.0).
## Disclaimer
We used compliance-checking algorithms during the training process, to ensure the compliance of the trained model to the best of our ability. Due to the complexity of the data and the diversity of language model usage scenarios, we cannot guarantee that the model is completely free of copyright issues or improper content. If you believe anything infringes on your rights or generates improper content, please contact us, and we will promptly address the matter. |