# RobustVLM
[[Paper]](https://arxiv.org/abs/2402.12336) [[HuggingFace]](https://huggingface.co/collections/chs20/robust-clip-65d913e552eca001fdc41978) [[BibTeX]](#citation)
This repository contains code for the paper "Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models" (_Oral@ICML 2024_).
******

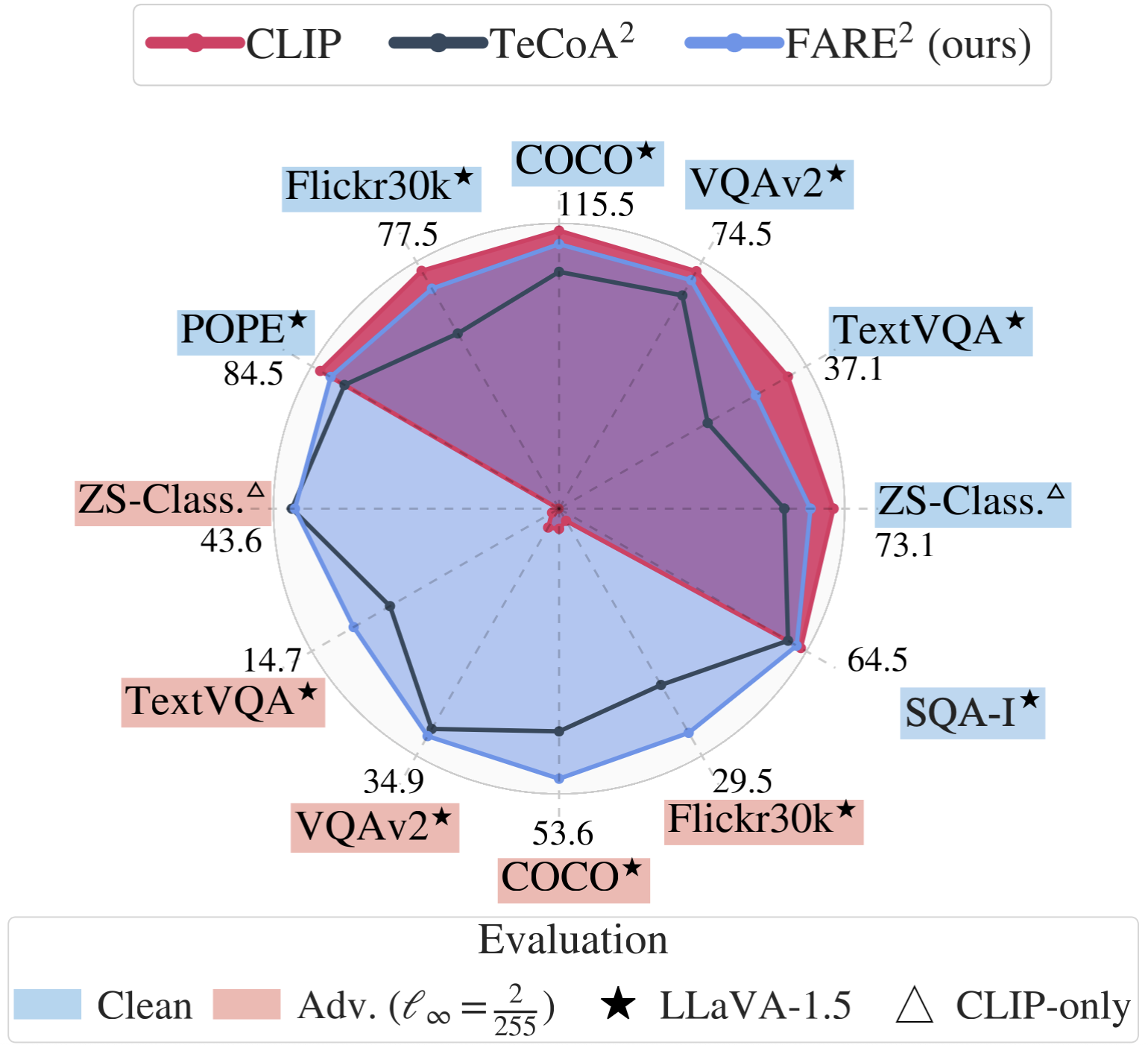
We fine-tune CLIP in an unsupervised manner to improve its robustness to visual adversarial attacks.
We show that replacing the vision encoder of large vision-language models with our fine-tuned CLIP models yields state-of-the-art
adversarial robustness on a variety of vision-language tasks, without requiring any training of the large VLMs themselves.
Moreover, we improve the robustness of CLIP to adversarial attacks in zero-shot classification settings, while maintaining
higher clean accuracy than previous adversarial fine-tuning methods.
## Table of Contents
- [Installation](#installation)
- [Models](#models)
- [Loading pretrained models](#loading-pretrained-models)
- [Summary of results](#summary-of-results)
- [Training](#training)
- [Evaluation](#evaluation)
## Installation
The code is tested with Python 3.11. To install the required packages, run:
```shell
pip install -r requirements.txt
```
## Models
We provide the following adversarially fine-tuned ViT-L/14 CLIP models (approx. 1.1 GB each):
| Model | Link | Proposed by | Notes |
|-------------------|--------------------------------------------------------------------------------------------------|--------------------------------------------------------|-------------------------------------------------------------------------------------------|
| TeCoA2 | [Link](https://nc.mlcloud.uni-tuebingen.de/index.php/s/5SQzfAbp8JHS3o7/download/tecoa_eps_2.pt) | [Mao et al. (2023)](https://arxiv.org/abs/2212.07016) | Supervised adversarial fine-tuning with $\ell_\infty$ norm, $\varepsilon=\frac{2}{255}$ |
| TeCoA4 | [Link](https://nc.mlcloud.uni-tuebingen.de/index.php/s/92req4Pak5i56tX/download/tecoa_eps_4.pt) | [Mao et al. (2023)](https://arxiv.org/abs/2212.07016) | Supervised adversarial fine-tuning with $\ell_\infty$ norm, $\varepsilon=\frac{4}{255}$ |
| FARE2 | [Link](https://nc.mlcloud.uni-tuebingen.de/index.php/s/d83Lqm8Jpowxp4m/download/fare_eps_2.pt) | ours | Unsupervised adversarial fine-tuning with $\ell_\infty$ norm, $\varepsilon=\frac{2}{255}$ |
| FARE4 | [Link](https://nc.mlcloud.uni-tuebingen.de/index.php/s/jnQ2qmp9tst8kyQ/download/fare_eps_4.pt) | ours | Unsupervised adversarial fine-tuning with $\ell_\infty$ norm, $\varepsilon=\frac{4}{255}$ |
The models are also available on [HuggingFace](https://huggingface.co/collections/chs20/robust-clip-65d913e552eca001fdc41978).
All models are adversarially fine-tuned for two epochs on ImageNet. TeCoA is trained in a supervised fashion, utilizing ImageNet class labels. FARE, in contrast, does not require any labels for training.
### Loading pretrained models
The provided checkpoints correspond to the vision encoder of CLIP. To load the full CLIP model (including the text encoder), you can use the following code:
```python
import torch
from open_clip import create_model_and_transforms
model, _, image_processor = create_model_and_transforms(
'ViT-L-14', pretrained='openai', device='cpu'
)
checkpoint = torch.load('/path/to/fare_eps_2.pt', map_location=torch.device('cpu'))
model.visual.load_state_dict(checkpoint)
```
Alternatively load directly from HuggingFace:
```python
from open_clip import create_model_and_transforms
model, _, image_processor = open_clip.create_model_and_transforms('hf-hub:chs20/fare2-clip')
```
### Summary of results
We show a summary of results on zero-shot classification and vision-language tasks for original and fine-tuned ViT-L/14 CLIP models. *CLIP-only* means that we evaluate
the respective CLIP model in a standalone fashion for zero-shot classification, whereas *OpenFlamingo* and *LLaVA* evaluation means that we use the respective CLIP model
as a vision encoder as part of these large vision-language models. Results for individual zero-shot datasets and more VLM tasks
are provided in the paper.
- Clean evaluation:
|
CLIP-only |
OpenFlamingo 9B |
LLaVA 1.5 7B |
| Model |
Avg. zero-shot |
COCO |
TextVQA |
COCO |
TextVQA |
| OpenAI |
73.1 |
79.7 |
23.8 |
115.5 |
37.1 |
| TeCoA2 |
60.0 |
73.5 |
16.6 |
98.4 |
24.1 |
| FARE2 |
67.0 |
79.1 |
21.6 |
109.9 |
31.9 |
| TeCoA4 |
54.2 |
66.9 |
15.4 |
88.3 |
20.7 |
| FARE4 |
61.1 |
74.1 |
18.6 |
102.4 |
27.6 |
- Adversarial evaluation ($\ell_\infty, ~ \varepsilon=\frac{2}{255}$):
|
CLIP-only |
OpenFlamingo 9B |
LLaVA 1.5 7B |
| Model |
Avg. zero-shot |
COCO |
TextVQA |
COCO |
TextVQA |
| Openai |
0.0 |
1.5 |
0.0 |
4.0 |
0.5 |
| TeCoA2 |
43.6 |
31.6 |
3.5 |
44.2 |
12.1 |
| FARE2 |
43.1 |
34.2 |
4.1 |
53.6 |
14.7 |
| TeCoA4 |
42.3 |
28.5 |
2.1 |
50.9 |
12.6 |
| FARE4 |
45.9 |
30.9 |
3.4 |
57.1 |
15.8 |
- Adversarial evaluation ($\ell_\infty, ~ \varepsilon=\frac{4}{255}$):
|
CLIP-only |
OpenFlamingo 9B |
LLaVA 1.5 7B |
| Model |
Avg. zero-shot |
COCO |
TextVQA |
COCO |
TextVQA |
| Openai |
0.0 |
1.1 |
0.0 |
3.1 |
0.0 |
| TeCoA2 |
27.0 |
21.2 |
2.1 |
30.3 |
8.8 |
| FARE2 |
20.5 |
19.5 |
1.9 |
31.0 |
9.1 |
| TeCoA4 |
31.9 |
21.6 |
1.8 |
35.3 |
9.3 |
| FARE4 |
32.4 |
22.8 |
2.9 |
40.9 |
10.9 |
## Training
- TeCoA4
```shell
python -m train.adversarial_training_clip --clip_model_name ViT-L-14 --pretrained openai --dataset imagenet --imagenet_root /path/to/imagenet --template std --output_normalize True --steps 20000 --warmup 1400 --batch_size 128 --loss ce --opt adamw --lr 1e-5 --wd 1e-4 --attack pgd --inner_loss ce --norm linf --eps 4 --iterations_adv 10 --stepsize_adv 1 --wandb False --output_dir /path/to/out/dir --experiment_name TECOA4 --log_freq 10 --eval_freq 10```
```
- FARE4
```shell
python -m train.adversarial_training_clip --clip_model_name ViT-L-14 --pretrained openai --dataset imagenet --imagenet_root /path/to/imagenet --template std --output_normalize False --steps 20000 --warmup 1400 --batch_size 128 --loss l2 --opt adamw --lr 1e-5 --wd 1e-4 --attack pgd --inner_loss l2 --norm linf --eps 4 --iterations_adv 10 --stepsize_adv 1 --wandb False --output_dir /path/to/out/dir --experiment_name FARE4 --log_freq 10 --eval_freq 10
```
Set `--eps 2` to obtain TeCoA2 and FARE2 models.
## Evaluation
Make sure files in `bash` directory are executable: `chmod +x bash/*`
### CLIP ImageNet
```shell
python -m CLIP_eval.clip_robustbench --clip_model_name ViT-L-14 --pretrained /path/to/ckpt.pt --dataset imagenet --imagenet_root /path/to/imagenet --wandb False --norm linf --eps 2
```
### CLIP Zero-Shot
Set models to be evaluated in `CLIP_benchmark/benchmark/models.txt` and datasets in `CLIP_benchmark/benchmark/datasets.txt`
(the datasets are downloaded from HuggingFace). Then run
```shell
cd CLIP_benchmark
./bash/run_benchmark_adv.sh
```
### VLM Captioning and VQA
#### LLaVA
In `/bash/llava_eval.sh` supply paths for the datasets. The required annotation files for the datasets can be obtained from this [HuggingFace repository](https://huggingface.co/datasets/openflamingo/eval_benchmark/tree/main).
Set `--vision_encoder_pretrained` to `openai` or supply path to fine-tuned CLIP model checkpoint.
Then run
```shell
./bash/llava_eval.sh
```
The LLaVA model will be automatically downloaded from HuggingFace.
#### OpenFlamingo
Download the OpenFlamingo 9B [model](https://huggingface.co/openflamingo/OpenFlamingo-9B-vitl-mpt7b/tree/main), supply paths in `/bash/of_eval_9B.sh` and run
```shell
./bash/of_eval_9B.sh
```
Some non-standard annotation files are supplied [here](https://nc.mlcloud.uni-tuebingen.de/index.php/s/mtRnQFaZJkR9zaX) and [here](https://github.com/mlfoundations/open_flamingo/tree/main/open_flamingo/eval/data).
### VLM Stealthy Targeted Attacks
For targeted attacks on COCO, run
```shell
./bash/llava_eval_targeted.sh
```
For targeted attacks on self-selected images, set images and target captions in `vlm_eval/run_evaluation_qualitative.py` and run
```shell
python -m vlm_eval.run_evaluation_qualitative --precision float32 --attack apgd --eps 2 --steps 10000 --vlm_model_name llava --vision_encoder_pretrained openai --verbose
```
With 10,000 iterations it takes about 2 hours per image on an A100 GPU.
### POPE
```shell
./bash/eval_pope.sh openai # for clean model evaluation
./bash/eval_pope.sh # for robust model evaluation - add path_to_ckpt in bash file
```
### SQA
```shell
./bash/eval_scienceqa.sh openai # for clean model evaluation
./bash/eval_scienceqa.sh # for robust model evaluation - add path_to_ckpt in bash file
```
## Acknowledgements
This repository gratefully forks from
- [OpenFlamingo](https://github.com/mlfoundations/open_flamingo)
- [LLaVA](https://github.com/haotian-liu/LLaVA)
- [CLIP Benchmark](https://github.com/LAION-AI/CLIP_benchmark)
- [AutoAttack](https://github.com/fra31/auto-attack)
## Citation
If you find this repository useful, please consider citing our paper:
```bibtex
@article{schlarmann2024robustclip,
title={Robust CLIP: Unsupervised Adversarial Fine-Tuning of Vision Embeddings for Robust Large Vision-Language Models},
author={Christian Schlarmann and Naman Deep Singh and Francesco Croce and Matthias Hein},
year={2024},
journal={ICML}
}
```