Hulk: A Universal Knowledge Translator for Human-centric Tasks
[Yizhou Wang](https://scholar.google.com/citations?user=CQGaGMAAAAAJ&hl=zh-CN&authuser=1)1*, [Yixuan Wu](https://scholar.google.com/citations?user=zjAxJcwAAAAJ&hl=en&oi=ao)1*,2, [Shixiang Tang](https://github.com/tangshixiang)1 :email:, [Weizhen He]()2,3,
[Xun Guo](https://github.com/Space-Xun)1,4, [Feng Zhu](https://zhufengx.github.io/)3, [Lei Bai](http://leibai.site/)1, [Rui Zhao](http://zhaorui.xyz/)3,
[Jian Wu]()2, [Tong He](http://tonghe90.github.io/)1, [Wanli Ouyang](https://wlouyang.github.io/)1
1[Shanghai AI Lab](https://www.shlab.org.cn/), 2[ZJU](https://www.zju.edu.cn/), 3[SenseTime](https://www.sensetime.com), 4[USTC](https://www.ustc.edu.cn/)
[ArXiv](https://arxiv.org/abs/2312.01697) | [Project Page](https://humancentricmodels.github.io/Hulk/)
[](https://paperswithcode.com/sota/pose-estimation-on-aic?p=hulk-a-universal-knowledge-translator-for)
[](https://paperswithcode.com/sota/human-part-segmentation-on-cihp?p=hulk-a-universal-knowledge-translator-for)
[](https://paperswithcode.com/sota/skeleton-based-action-recognition-on-ntu-rgbd?p=hulk-a-universal-knowledge-translator-for)
[](https://paperswithcode.com/sota/semantic-segmentation-on-lip-val?p=hulk-a-universal-knowledge-translator-for)
[](https://paperswithcode.com/sota/human-part-segmentation-on-human3-6m?p=hulk-a-universal-knowledge-translator-for)
[](https://paperswithcode.com/sota/pedestrian-attribute-recognition-on-rapv2?p=hulk-a-universal-knowledge-translator-for)
[](https://paperswithcode.com/sota/pedestrian-attribute-recognition-on-pa-100k?p=hulk-a-universal-knowledge-translator-for)
[](https://paperswithcode.com/sota/pose-estimation-on-coco?p=hulk-a-universal-knowledge-translator-for)
[](https://paperswithcode.com/sota/object-detection-on-crowdhuman-full-body?p=hulk-a-universal-knowledge-translator-for)
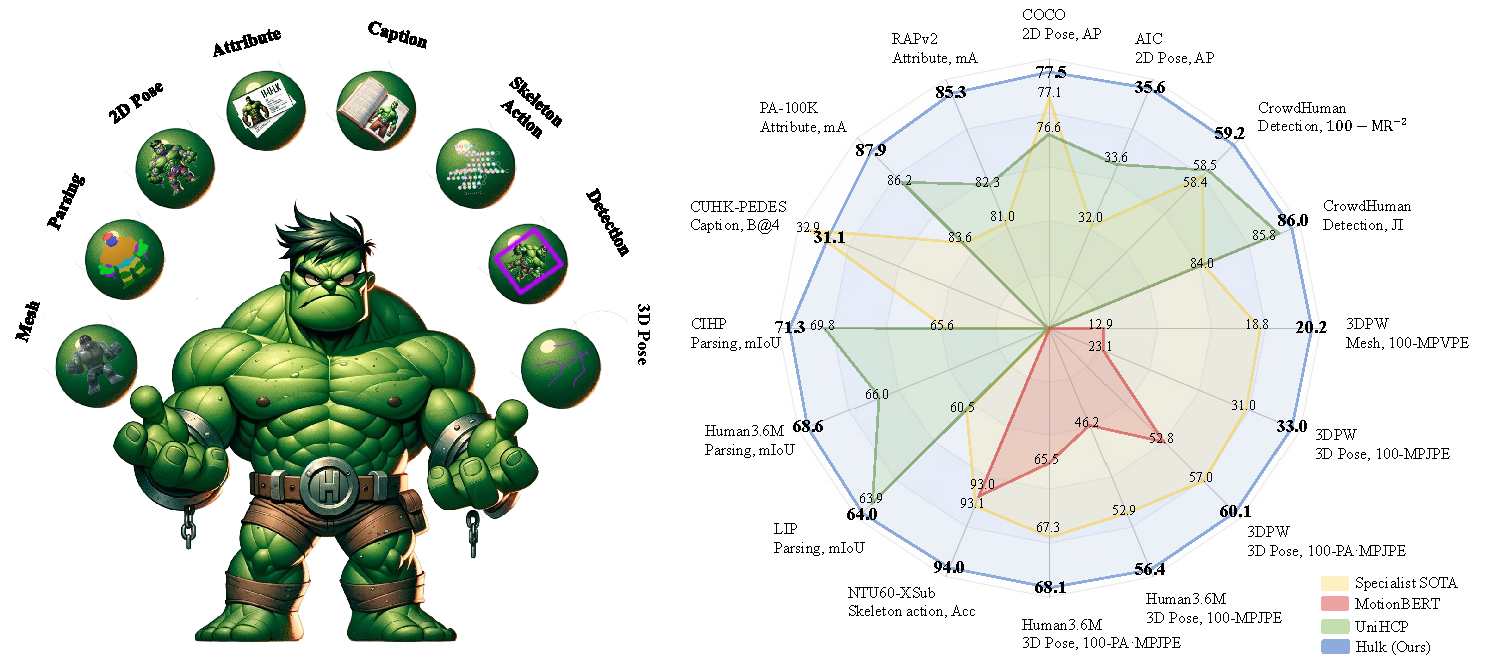
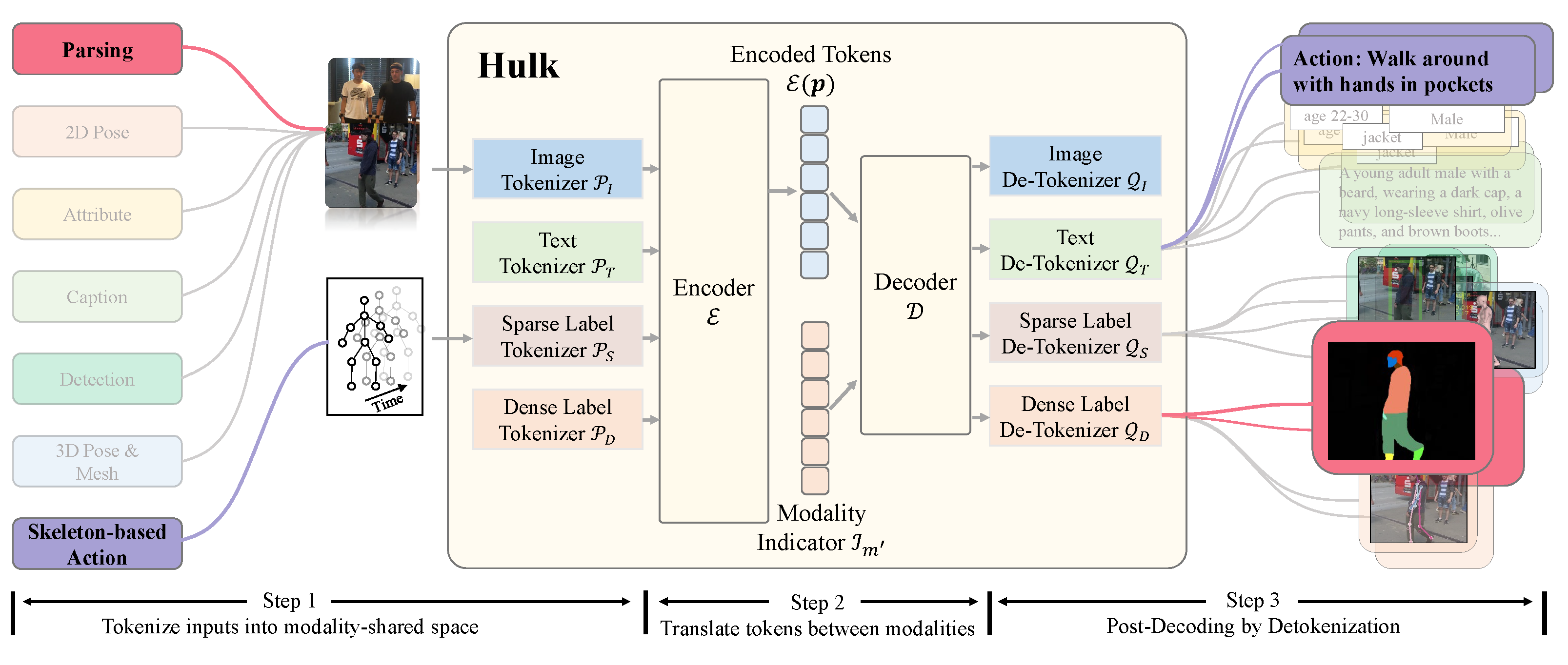
Welcome to **Hulk**! Hulk is a multimodel human-centric generalist model, capable of addressing 2D vision, 3D vision, skeleton-based, and vision-language human-centric tasks. Unlike many existing human-centric foundation models that
did not explore 3D and vision-language tasks for human-centric and required task-specific finetuning, Hulk condensed various task-specific heads into two general heads, one for discrete representations, e.g., languages,
and the other for continuous representations, e.g., location coordinates. Unifying these tasks enables Hulk to treat diverse human-centric tasks as modality translation, integrating knowledge across a wide range of tasks.
For more details, please take a look at our paper [Hulk: A Universal Knowledge Translator for Human-centric Tasks](https://arxiv.org/abs/2312.01697).
## News
- _Apr. 2024_ A pretrained Hulk is released on [🤗 Hugging Face Models](https://huggingface.co/OpenGVLab/Hulk/tree/main)!
- _Apr. 2024_ Project page with demos is released at [Hulk](https://humancentricmodels.github.io/Hulk/).
- _Mar. 2024_ Training and inference code are released!
- _Dec. 2023_ Hulk is released on [ArXiv](https://arxiv.org/abs/2312.01697)!
## Installation
This codebase has been developed with python version 3.9, pytorch 2.0.0, cuda 11.8 and torchvision 0.15.0.
We recommend using the same version to avoid potential issues.
```bash
pip install -r requirements.txt
```
Also, download [bert-base-uncased](https://huggingface.co/google-bert/bert-base-uncased) from huggingface and put it under `experiments/release/`.
## Datasets
Please refer to the [datasets](docs/datasets.md) for more details.
## Training
Download pre-trained MAE weights from [here](https://dl.fbaipublicfiles.com/mae/pretrain/mae_pretrain_vit_base.pth) and put it under `core/models/backbones/pretrain_weights/`.
We use 10 nodes (80 A100 GPUs) for training with the following command:
```bash
cd experiments/release
sh train.sh 80 Hulk_vit-B
```
## Evaluation
A pretrained Hulk will be soon available at [🤗 Hugging Face Models](https://huggingface.co/OpenGVLab/Hulk/tree/main).
Download it, put it under the folder `experiments/release/checkpoints/Hulk_vit-B` (first `mkdir -p experiments/release/checkpoints/Hulk_vit-B`), then use the following command to evaluate the model on the test set.
```bash
cd experiments/release
sh batch_eval.sh 1 Hulk_vit-B
```
## Model Performance
We use the plain ViT as our backbone, develop four modality-specific tokenizers and de-tokenizers
to cover 2D vision, 3D vision, skeleton-based, and vision-language human-centric tasks.
Hulk has achieved state-of-the-art results on various human-centric tasks.
### Direct Evaluation
| Task | pedestrian detection | 2D pose | skeleton-based action | human parsing | attribute recognition | image caption | monocular 3D human pose and mesh recovery |
| Dataset | CrowdHuman | COCO | AIC | NTU60-XSub | H3.6M | LIP | CIHP | PA-100k | RAPv2 | CUHK-PEDES | 3DPW | H3.6M |
| Metric | mAP | MR-2 | JI | AP | AP | acc. | mIoU | mIoU | mIoU | mA | mA | B@4 | MPVPE↓ | MPJPE↓ | PA-MPJPE↓ | MPJPE↓ | PA-MPJPE↓ |
| Hulk (ViT-B) | 90.7 | 43.8 | 84.0 | 77.0 | 34.5 | 93.8 | 68.08 | 63.95 | 70.58 | 82.85 | 80.90 | 31.1 | 79.8 | 67.0 | 39.9 | 43.6 | 31.9 |
| Hulk (ViT-L) | 92.2 | 40.1 | 85.8 | 78.3 | 36.3 | 94.1 | 69.31 | 65.86 | 72.33 | 84.36 | 82.85 | 31.6 | 77.4 | 66.3 | 38.5 | 40.3 | 28.8 |
### Finetune Performance
| Task | pedestrian detection | 2D pose | skeleton-based action | human parsing | attribute recognition | image caption ♣ | monocular 3D human pose and mesh recovery ♣ |
| Dataset | CrowdHuman | COCO | AIC | NTU60-XSub | H3.6M | LIP | CIHP | PA-100k | RAPv2 | CUHK-PEDES | 3DPW | H3.6M |
| Metric | mAP | MR-2 | JI | AP | AP | acc. | mIoU | mIoU | mIoU | mA | mA | B@4 | MPVPE↓ | MPJPE↓ | PA-MPJPE↓ | MPJPE↓ | PA-MPJPE↓ |
| Hulk (ViT-B) | 92.4 | 40.7 | 86.0 | 77.5 | 35.6 | 94.0 | 68.56 | 63.98 | 71.26 | 87.85 | 85.26 | 28.3 | 80.7 | 68.9 | 41.3 | 44.9 | 32.0 |
| Hulk (ViT-L) | 93.0 | 36.5 | 87.0 | 78.7 | 37.1 | 94.3 | 69.89 | 66.02 | 72.68 | 88.97 | 85.86 | 30.5 | 79.9 | 68.3 | 40.6 | 41.4 | 30.2 |
♣: We find that the performance of image caption and monocular 3D human pose and mesh recovery is not as good as the direct evaluation, indicating that overfitting may occur during finetuning.
## Contact
If you have any problem about our paper & code, feel free to contact [Yizhou Wang](wangyizhou@pjlab.org.cn) and [Yixuan Wu](wyx_chloe@zju.edu.cn).
## Citation
If you find this work useful, please consider citing:
```bibtex
@article{wang2023hulk,
title={Hulk: A Universal Knowledge Translator for Human-Centric Tasks},
author={Wang, Yizhou and Wu, Yixuan and Tang, Shixiang and He, Weizhen and Guo, Xun and Zhu, Feng and Bai, Lei and Zhao, Rui and Wu, Jian and He, Tong and others},
journal={arXiv preprint arXiv:2312.01697},
year={2023}
}
```