Евалуација XLMR-base модела за српски језик |
Serbian XLMR-base models evaluation results |
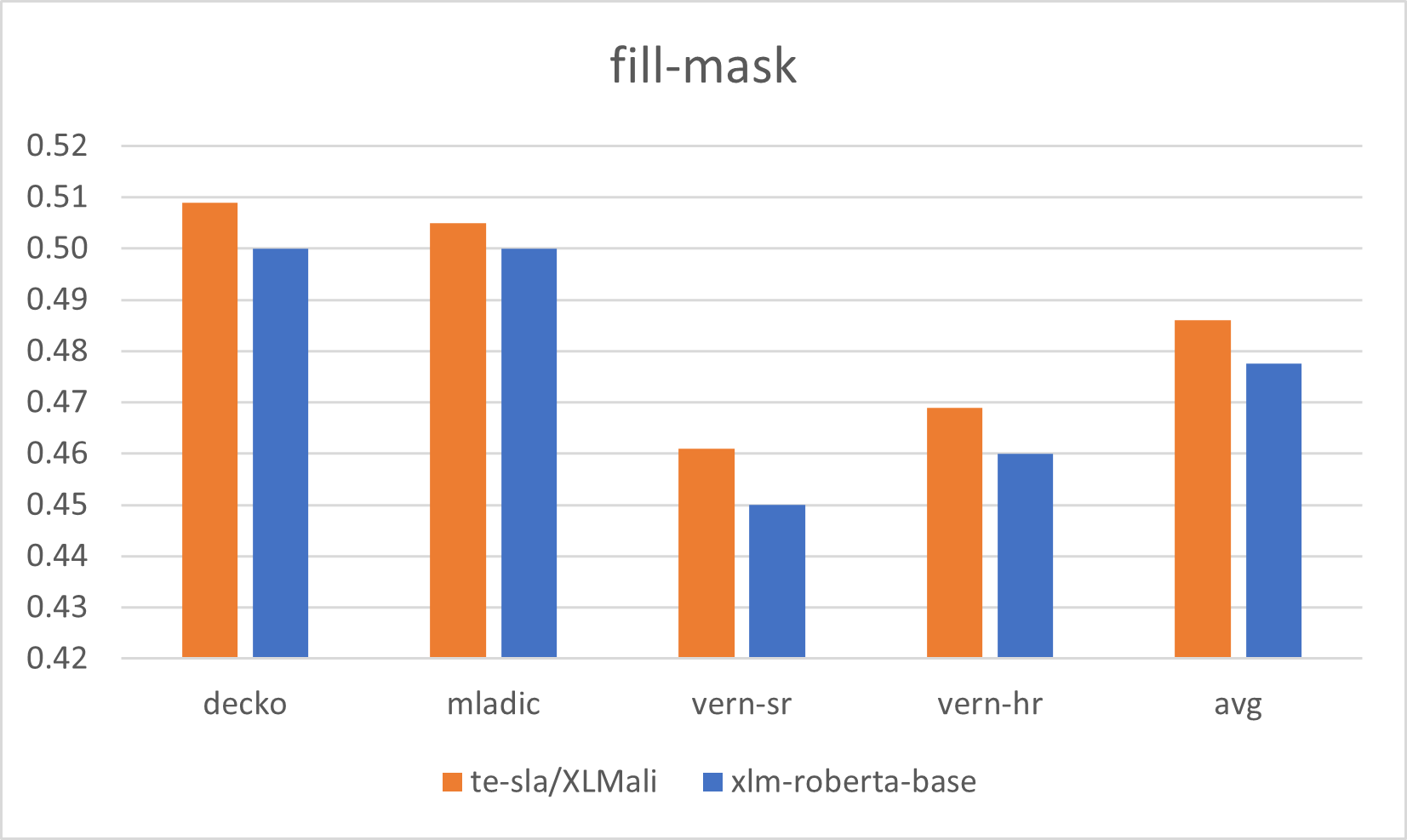
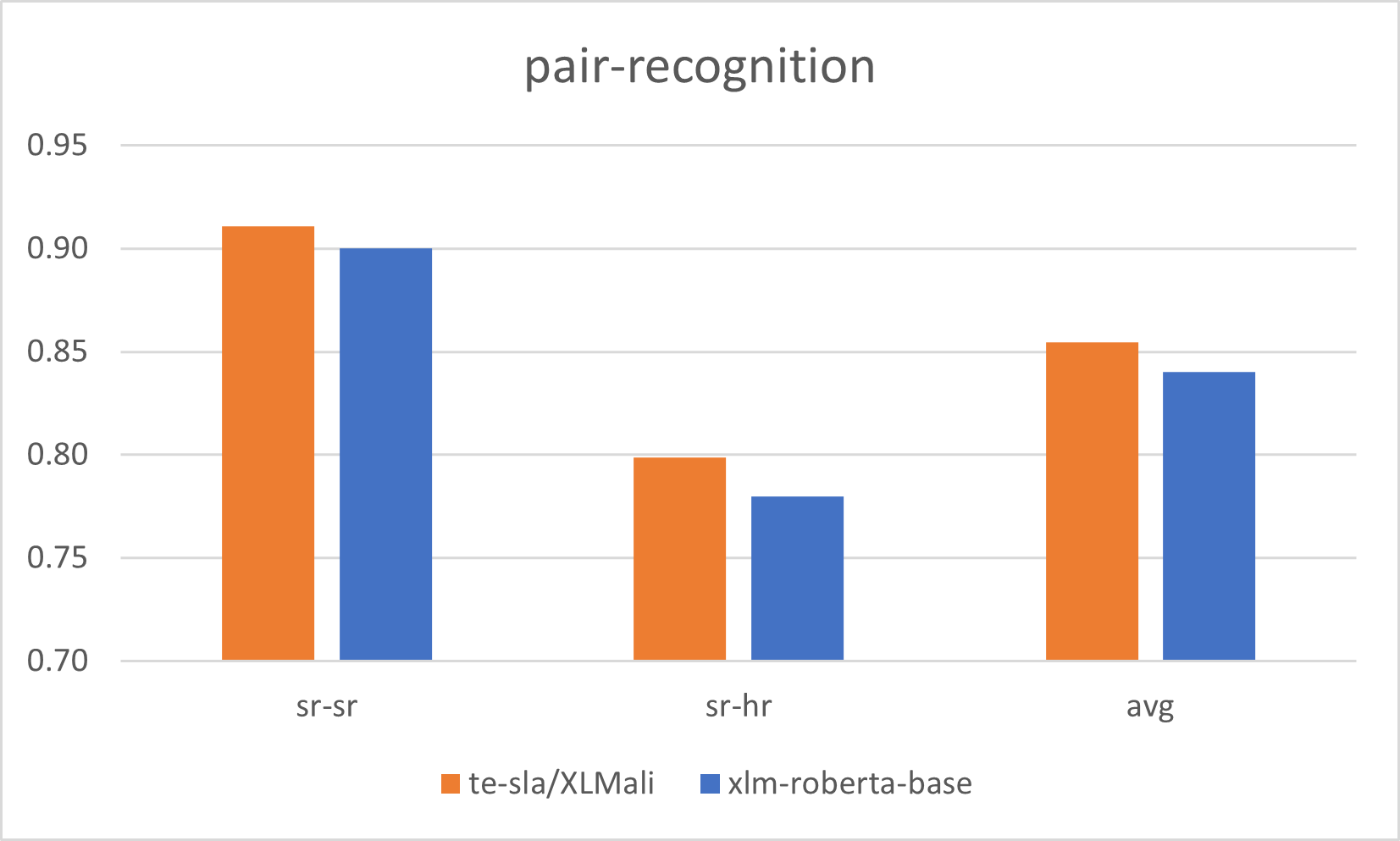
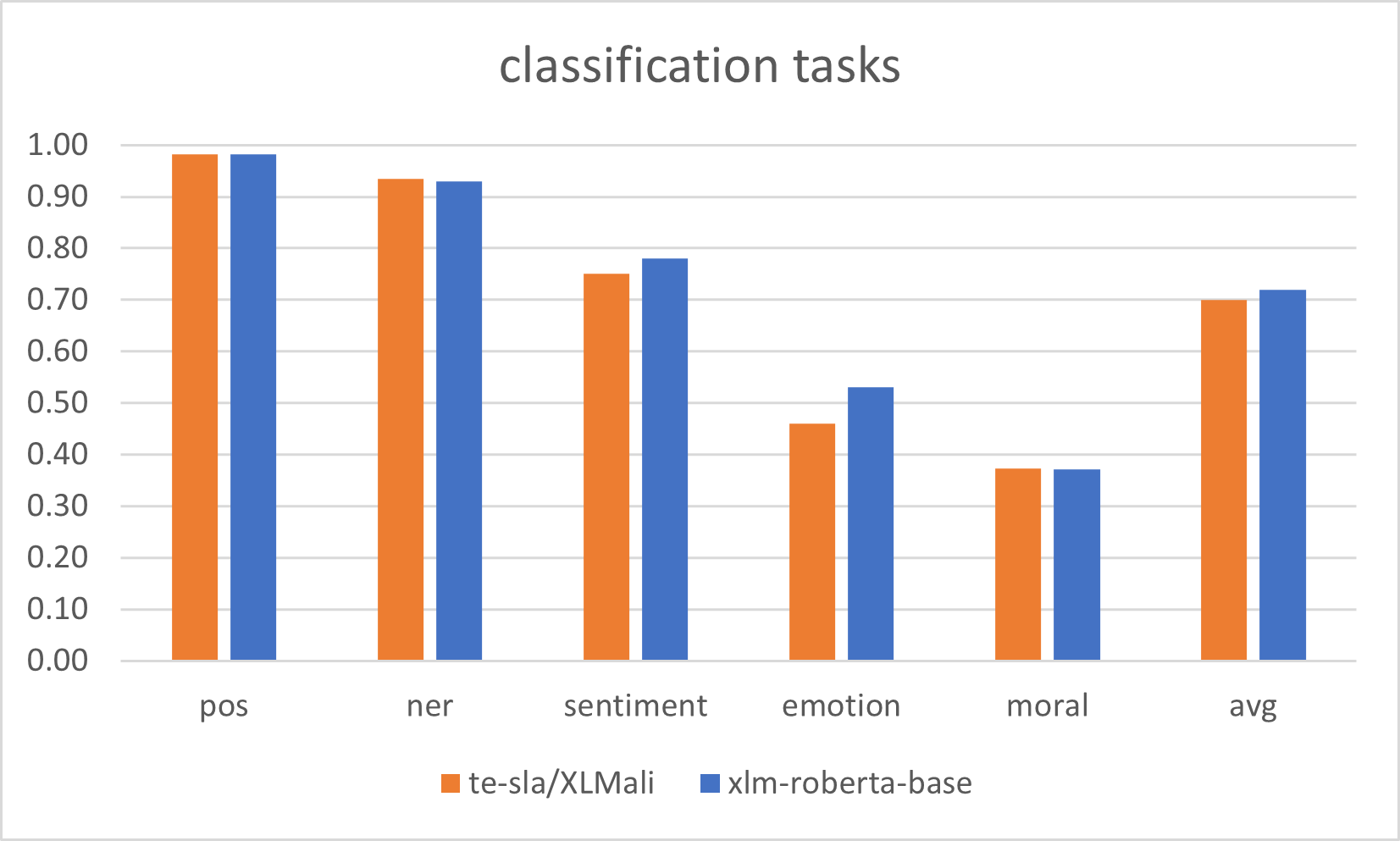
|
|
## Cit. ```bibtex @inproceedings{skoricxlm, author = {Mihailo Škorić, Saša Petalinkar}, title = {New XLM-R-based language models for Serbian and Serbo-Croatian}, booktitle = {ARTIFICAL INTELLIGENCE CONFERENCE}, year = {2024}, address = {Belgrade} publisher = {SASA, Belgrade}, url = {} } ```
|
Истраживање jе спроведено уз подршку Фонда за науку Републике Србиjе, #7276, Text Embeddings – Serbian Language Applications – TESLA |
This research was supported by the Science Fund of the Republic of Serbia, #7276, Text Embeddings - Serbian Language Applications - TESLA |