Spaces:
Running
on
Zero

Running
on
Zero
Migrated from GitHub
Browse files- .gitattributes +4 -0
- LICENSE +21 -0
- ORIGINAL_README.md +153 -0
- assets/CBS_2.gif +3 -0
- assets/MLB_1.gif +3 -0
- assets/Sunny_1.gif +3 -0
- assets/Titanic_1.gif +3 -0
- assets/gazelle_arch.png +0 -0
- assets/succession.png +0 -0
- assets/the_office.png +0 -0
- data_prep/preprocess_gazefollow.py +188 -0
- data_prep/preprocess_vat.py +116 -0
- environment.yml +16 -0
- gazelle/backbone.py +55 -0
- gazelle/model.py +189 -0
- gazelle/utils.py +39 -0
- hubconf.py +28 -0
- scripts/eval_gazefollow.py +115 -0
- scripts/eval_vat.py +116 -0
- setup.py +9 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,7 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/CBS_2.gif filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/MLB_1.gif filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
assets/Sunny_1.gif filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
assets/Titanic_1.gif filter=lfs diff=lfs merge=lfs -text
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2024 Fiona Ryan
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
ORIGINAL_README.md
ADDED
|
@@ -0,0 +1,153 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Gaze-LLE
|
| 2 |
+
<div style="text-align:center;">
|
| 3 |
+
<img src="./assets/the_office.png" height="100"/>
|
| 4 |
+
<img src="./assets/MLB_1.gif" height="100"/>
|
| 5 |
+
<img src="./assets/succession.png" height="100"/>
|
| 6 |
+
<img src="./assets/CBS_2.gif" height="100"/>
|
| 7 |
+
</div>
|
| 8 |
+
|
| 9 |
+
[Gaze-LLE: Gaze Target Estimation via Large-Scale Learned Encoders](https://arxiv.org/abs/2412.09586) \
|
| 10 |
+
[Fiona Ryan](https://fkryan.github.io/), Ajay Bati, [Sangmin Lee](https://sites.google.com/view/sangmin-lee), [Daniel Bolya](https://dbolya.github.io/), [Judy Hoffman](https://faculty.cc.gatech.edu/~judy/)\*, [James M. Rehg](https://rehg.org/)\*
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
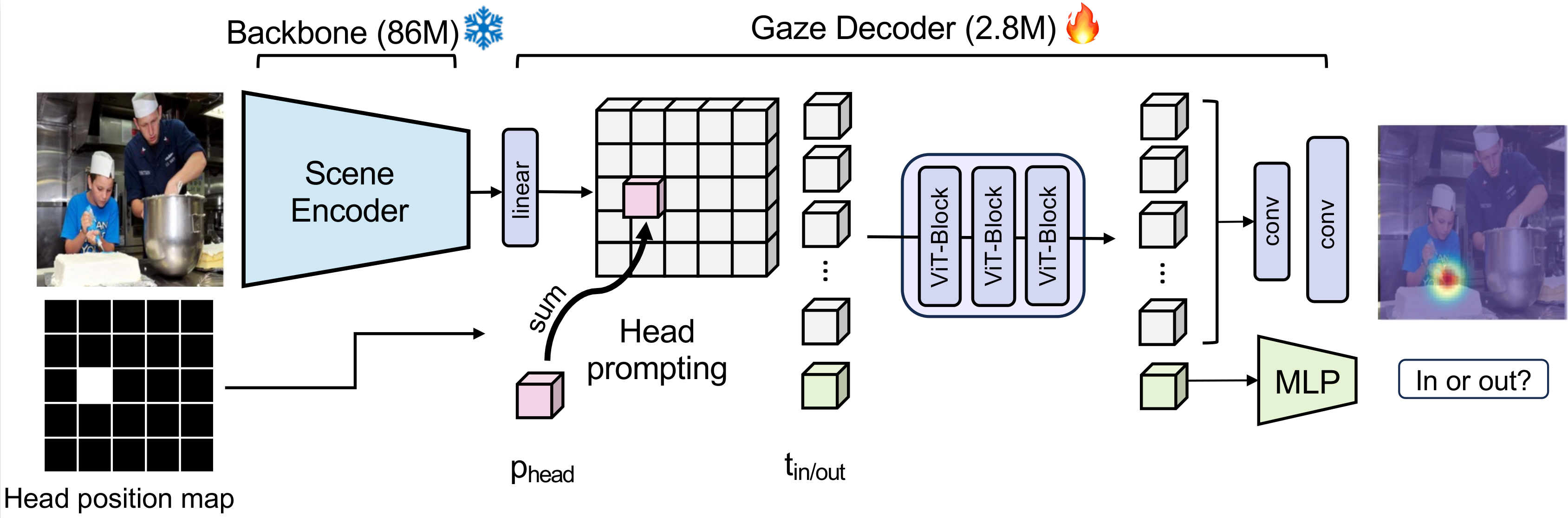
This is the official implementation for Gaze-LLE, a transformer approach for estimating gaze targets that leverages the power of pretrained visual foundation models. Gaze-LLE provides a streamlined gaze architecture that learns only a lightweight gaze decoder on top of a frozen, pretrained visual encoder (DINOv2). Gaze-LLE learns 1-2 orders of magnitude fewer parameters than prior works and doesn't require any extra input modalities like depth and pose!
|
| 14 |
+
|
| 15 |
+
<div style="text-align:center;">
|
| 16 |
+
<img src="./assets/gazelle_arch.png" height="200"/>
|
| 17 |
+
</div>
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
## Installation
|
| 21 |
+
|
| 22 |
+
Clone this repo, then create the virtual environment.
|
| 23 |
+
```
|
| 24 |
+
conda env create -f environment.yml
|
| 25 |
+
conda activate gazelle
|
| 26 |
+
pip install -e .
|
| 27 |
+
```
|
| 28 |
+
If your system supports it, consider installing [xformers](https://github.com/facebookresearch/xformers) to speed up attention computation.
|
| 29 |
+
```
|
| 30 |
+
pip3 install -U xformers --index-url https://download.pytorch.org/whl/cu118
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
## Pretrained Models
|
| 34 |
+
|
| 35 |
+
We provide the following pretrained models for download.
|
| 36 |
+
| Name | Backbone type | Backbone name | Training data | Checkpoint |
|
| 37 |
+
| ---- | ------------- | ------------- |-------------- | ---------- |
|
| 38 |
+
| ```gazelle_dinov2_vitb14``` | DINOv2 ViT-B | ```dinov2_vitb14```| GazeFollow | [Download](https://github.com/fkryan/gazelle/releases/download/v1.0.0/gazelle_dinov2_vitb14.pt) |
|
| 39 |
+
| ```gazelle_dinov2_vitl14``` | DINOv2 ViT-L | ```dinov2_vitl14``` | GazeFollow | [Download](https://github.com/fkryan/gazelle/releases/download/v1.0.0/gazelle_dinov2_vitl14.pt) |
|
| 40 |
+
| ```gazelle_dinov2_vitb14_inout``` | DINOv2 ViT-B | ```dinov2_vitb14``` | Gazefollow -> VideoAttentionTarget | [Download](https://github.com/fkryan/gazelle/releases/download/v1.0.0/gazelle_dinov2_vitb14_inout.pt) |
|
| 41 |
+
| ```gazelle_large_vitl14_inout``` | DINOv2-ViT-L | ```dinov2_vitl14``` | GazeFollow -> VideoAttentionTarget | [Download](https://github.com/fkryan/gazelle/releases/download/v1.0.0/gazelle_dinov2_vitl14_inout.pt) |
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
Note that our Gaze-LLE checkpoints contain only the gaze decoder weights - the DINOv2 backbone weights are downloaded from ```facebookresearch/dinov2``` on PyTorch Hub when the Gaze-LLE model is created in our code.
|
| 45 |
+
|
| 46 |
+
The GazeFollow-trained models output a spatial heatmap of gaze locations over the scene with values in range ```[0,1]```, where 1 represents the highest probability of the location being a gaze target. The models that are additionally finetuned on VideoAttentionTarget also predict a in/out of frame gaze score in range ```[0,1]``` where 1 represents the person's gaze target being in the frame.
|
| 47 |
+
|
| 48 |
+
### PyTorch Hub
|
| 49 |
+
|
| 50 |
+
The models are also available on PyTorch Hub for easy use without installing from source.
|
| 51 |
+
```
|
| 52 |
+
model, transform = torch.hub.load('fkryan/gazelle', 'gazelle_dinov2_vitb14')
|
| 53 |
+
model, transform = torch.hub.load('fkryan/gazelle', 'gazelle_dinov2_vitl14')
|
| 54 |
+
model, transform = torch.hub.load('fkryan/gazelle', 'gazelle_dinov2_vitb14_inout')
|
| 55 |
+
model, transform = torch.hub.load('fkryan/gazelle', 'gazelle_dinov2_vitl14_inout')
|
| 56 |
+
```
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
## Usage
|
| 60 |
+
### Colab Demo Notebook
|
| 61 |
+
Check out our [Demo Notebook](https://colab.research.google.com/drive/1TSoyFvNs1-au9kjOZN_fo5ebdzngSPDq?usp=sharing) on Google Colab for how to detect gaze for all people in an image.
|
| 62 |
+
|
| 63 |
+
### Gaze Prediction
|
| 64 |
+
Gaze-LLE is set up for multi-person inference (e.g. for a single image, GazeLLE encodes the scene only once and then uses the features to predict the gaze of multiple people in the image). The input is a batch of image tensors and a list of bounding boxes for each image representing the heads of the people to predict gaze for in each image. The bounding boxes are tuples of form ```(xmin, ymin, xmax, ymax)``` and are in ```[0,1]``` normalized image coordinates. Below we show how to perform inference for a single person in a single image.
|
| 65 |
+
```
|
| 66 |
+
from PIL import Image
|
| 67 |
+
import torch
|
| 68 |
+
from gazelle.model import get_gazelle_model
|
| 69 |
+
|
| 70 |
+
model, transform = get_gazelle_model("gazelle_dinov2_vitl14_inout")
|
| 71 |
+
model.load_gazelle_state_dict(torch.load("/path/to/checkpoint.pt", weights_only=True))
|
| 72 |
+
model.eval()
|
| 73 |
+
|
| 74 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 75 |
+
model.to(device)
|
| 76 |
+
|
| 77 |
+
image = Image.open("path/to/image.png").convert("RGB")
|
| 78 |
+
input = {
|
| 79 |
+
"images": transform(image).unsqueeze(dim=0).to(device), # tensor of shape [1, 3, 448, 448]
|
| 80 |
+
"bboxes": [[(0.1, 0.2, 0.5, 0.7)]] # list of lists of bbox tuples
|
| 81 |
+
}
|
| 82 |
+
|
| 83 |
+
with torch.no_grad():
|
| 84 |
+
output = model(input)
|
| 85 |
+
predicted_heatmap = output["heatmap"][0][0] # access prediction for first person in first image. Tensor of size [64, 64]
|
| 86 |
+
predicted_inout = output["inout"][0][0] # in/out of frame score (1 = in frame) (output["inout"] will be None for non-inout models)
|
| 87 |
+
```
|
| 88 |
+
We empirically find that Gaze-LLE is effective without a bounding box input for scenes with just one person. However, providing a bounding box can improve results, and is necessary for scenes with multiple people to specify which person's gaze to estimate. To inference without a bounding box, use None in place of a bounding box tuple in the bbox list (e.g. ```input["bboxes"] = [[None]]``` in the example above).
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
We also provide a function to visualize the predicted heatmap for an image.
|
| 92 |
+
```
|
| 93 |
+
import matplotlib.pyplot as plt
|
| 94 |
+
from gazelle.utils import visualize_heatmap
|
| 95 |
+
|
| 96 |
+
viz = visualize_heatmap(image, predicted_heatmap)
|
| 97 |
+
plt.imshow(viz)
|
| 98 |
+
plt.show()
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
## Evaluate
|
| 103 |
+
We provide evaluation scripts for GazeFollow and VideoAttentionTarget below to reproduce our results from our checkpoints.
|
| 104 |
+
### GazeFollow
|
| 105 |
+
Download the GazeFollow dataset [here](https://github.com/ejcgt/attention-target-detection?tab=readme-ov-file#dataset). We provide a preprocessing script ```data_prep/preprocess_gazefollow.py```, which preprocesses and compiles the annotations into a JSON file for each split within the dataset folder. Run the preprocessing script as
|
| 106 |
+
```
|
| 107 |
+
python data_prep/preprocess_gazefollow.py --data_path /path/to/gazefollow/data_new
|
| 108 |
+
```
|
| 109 |
+
Download the pretrained model checkpoints above and use ```--model_name``` and ```ckpt_path``` to specify the model type and checkpoint for evaluation.
|
| 110 |
+
|
| 111 |
+
```
|
| 112 |
+
python scripts/eval_gazefollow.py
|
| 113 |
+
--data_path /path/to/gazefollow/data_new \
|
| 114 |
+
--model_name gazelle_dinov2_vitl14 \
|
| 115 |
+
--ckpt_path /path/to/checkpoint.pt \
|
| 116 |
+
--batch_size 128
|
| 117 |
+
```
|
| 118 |
+
|
| 119 |
+
|
| 120 |
+
### VideoAttentionTarget
|
| 121 |
+
Download the VideoAttentionTarget dataset [here](https://github.com/ejcgt/attention-target-detection?tab=readme-ov-file#dataset-1). We provide a preprocessing script ```data_prep/preprocess_vat.py```, which preprocesses and compiles the annotations into a JSON file for each split within the dataset folder. Run the preprocessing script as
|
| 122 |
+
```
|
| 123 |
+
python data_prep/preprocess_gazefollow.py --data_path /path/to/videoattentiontarget
|
| 124 |
+
```
|
| 125 |
+
Download the pretrained model checkpoints above and use ```--model_name``` and ```ckpt_path``` to specify the model type and checkpoint for evaluation.
|
| 126 |
+
```
|
| 127 |
+
python scripts/eval_vat.py
|
| 128 |
+
--data_path /path/to/videoattentiontarget \
|
| 129 |
+
--model_name gazelle_dinov2_vitl14_inout \
|
| 130 |
+
--ckpt_path /path/to/checkpoint.pt \
|
| 131 |
+
--batch_size 64
|
| 132 |
+
```
|
| 133 |
+
|
| 134 |
+
## Citation
|
| 135 |
+
|
| 136 |
+
```
|
| 137 |
+
@article{ryan2024gazelle,
|
| 138 |
+
author = {Ryan, Fiona and Bati, Ajay and Lee, Sangmin and Bolya, Daniel and Hoffman, Judy and Rehg, James M},
|
| 139 |
+
title = {Gaze-LLE: Gaze Target Estimation via Large-Scale Learned Encoders},
|
| 140 |
+
journal = {arXiv preprint arXiv:2412.09586},
|
| 141 |
+
year = {2024},
|
| 142 |
+
}
|
| 143 |
+
```
|
| 144 |
+
|
| 145 |
+
## References
|
| 146 |
+
|
| 147 |
+
- Our models are built on top of pretrained DINOv2 models from PyTorch Hub ([Github repo](https://github.com/facebookresearch/dinov2)).
|
| 148 |
+
|
| 149 |
+
- Our GazeFollow and VideoAttentionTarget preprocessing code is based on [Detecting Attended Targets in Video](https://github.com/ejcgt/attention-target-detection).
|
| 150 |
+
|
| 151 |
+
- We use [PyTorch Image Models (timm)](https://github.com/huggingface/pytorch-image-models) for our transformer implementation.
|
| 152 |
+
|
| 153 |
+
- We use [xFormers](https://github.com/facebookresearch/xformers) for efficient multi-head attention.
|
assets/CBS_2.gif
ADDED

|
Git LFS Details
|
assets/MLB_1.gif
ADDED

|
Git LFS Details
|
assets/Sunny_1.gif
ADDED

|
Git LFS Details
|
assets/Titanic_1.gif
ADDED

|
Git LFS Details
|
assets/gazelle_arch.png
ADDED
|
assets/succession.png
ADDED

|
assets/the_office.png
ADDED

|
data_prep/preprocess_gazefollow.py
ADDED
|
@@ -0,0 +1,188 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import pandas as pd
|
| 3 |
+
import json
|
| 4 |
+
from PIL import Image
|
| 5 |
+
import argparse
|
| 6 |
+
|
| 7 |
+
# preprocessing adapted from https://github.com/ejcgt/attention-target-detection/blob/master/dataset.py
|
| 8 |
+
|
| 9 |
+
parser = argparse.ArgumentParser()
|
| 10 |
+
parser.add_argument("--data_path", type=str, default="./data/gazefollow")
|
| 11 |
+
args = parser.parse_args()
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def main(DATA_PATH):
|
| 15 |
+
|
| 16 |
+
# TRAIN
|
| 17 |
+
train_csv_path = os.path.join(DATA_PATH, "train_annotations_release.txt")
|
| 18 |
+
column_names = ['path', 'idx', 'body_bbox_x', 'body_bbox_y', 'body_bbox_w', 'body_bbox_h', 'eye_x', 'eye_y',
|
| 19 |
+
'gaze_x', 'gaze_y', 'bbox_x_min', 'bbox_y_min', 'bbox_x_max', 'bbox_y_max', 'inout', 'source', 'meta']
|
| 20 |
+
df = pd.read_csv(train_csv_path, header=None, names=column_names, index_col=False)
|
| 21 |
+
df = df[df['inout'] != -1]
|
| 22 |
+
df = df.groupby("path").agg(list) # aggregate over frames
|
| 23 |
+
|
| 24 |
+
multiperson_ex = 0
|
| 25 |
+
TRAIN_FRAMES = []
|
| 26 |
+
for path, row in df.iterrows():
|
| 27 |
+
img_path = os.path.join(DATA_PATH, path)
|
| 28 |
+
img = Image.open(img_path)
|
| 29 |
+
width, height = img.size
|
| 30 |
+
|
| 31 |
+
num_people = len(row['idx'])
|
| 32 |
+
if num_people > 1:
|
| 33 |
+
multiperson_ex += 1
|
| 34 |
+
heads = []
|
| 35 |
+
crop_constraint_xs = []
|
| 36 |
+
crop_constraint_ys = []
|
| 37 |
+
|
| 38 |
+
for i in range(num_people):
|
| 39 |
+
xmin, ymin, xmax, ymax = row['bbox_x_min'][i], row['bbox_y_min'][i], row['bbox_x_max'][i], row['bbox_y_max'][i]
|
| 40 |
+
gazex = row['gaze_x'][i] * float(width)
|
| 41 |
+
gazey = row['gaze_y'][i] * float(height)
|
| 42 |
+
gazex_norm = row['gaze_x'][i]
|
| 43 |
+
gazey_norm = row['gaze_y'][i]
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
if xmin > xmax:
|
| 47 |
+
temp = xmin
|
| 48 |
+
xmin = xmax
|
| 49 |
+
xmax = temp
|
| 50 |
+
if ymin > ymax:
|
| 51 |
+
temp = ymin
|
| 52 |
+
ymin = ymax
|
| 53 |
+
ymax = temp
|
| 54 |
+
|
| 55 |
+
# move in out of frame bbox annotations
|
| 56 |
+
xmin = max(xmin, 0)
|
| 57 |
+
ymin = max(ymin, 0)
|
| 58 |
+
xmax = min(xmax, width)
|
| 59 |
+
ymax = min(ymax, height)
|
| 60 |
+
|
| 61 |
+
# precalculate feasible crop region (containing bbox and gaze target)
|
| 62 |
+
crop_xmin = min(xmin, gazex)
|
| 63 |
+
crop_ymin = min(ymin, gazey)
|
| 64 |
+
crop_xmax = max(xmax, gazex)
|
| 65 |
+
crop_ymax = max(ymax, gazey)
|
| 66 |
+
crop_constraint_xs.extend([crop_xmin, crop_xmax])
|
| 67 |
+
crop_constraint_ys.extend([crop_ymin, crop_ymax])
|
| 68 |
+
|
| 69 |
+
heads.append({
|
| 70 |
+
'bbox': [xmin, ymin, xmax, ymax],
|
| 71 |
+
'bbox_norm': [xmin / float(width), ymin / float(height), xmax / float(width), xmax / float(height)],
|
| 72 |
+
'inout': row['inout'][i],
|
| 73 |
+
'gazex': [gazex], # convert to list for consistency with multi-annotation format
|
| 74 |
+
'gazey': [gazey],
|
| 75 |
+
'gazex_norm': [gazex_norm],
|
| 76 |
+
'gazey_norm': [gazey_norm],
|
| 77 |
+
'crop_region': [crop_xmin, crop_ymin, crop_xmax, crop_ymax],
|
| 78 |
+
'crop_region_norm': [crop_xmin / float(width), crop_ymin / float(height), crop_xmin / float(width), crop_ymax / float(height)],
|
| 79 |
+
'head_id': i
|
| 80 |
+
})
|
| 81 |
+
TRAIN_FRAMES.append({
|
| 82 |
+
'path': path,
|
| 83 |
+
'heads': heads,
|
| 84 |
+
'num_heads': num_people,
|
| 85 |
+
'width': width,
|
| 86 |
+
'height': height,
|
| 87 |
+
'crop_region': [min(crop_constraint_xs), min(crop_constraint_ys), max(crop_constraint_xs), max(crop_constraint_ys)],
|
| 88 |
+
})
|
| 89 |
+
|
| 90 |
+
print("Train set: {} frames, {} multi-person".format(len(TRAIN_FRAMES), multiperson_ex))
|
| 91 |
+
out_file = open(os.path.join(DATA_PATH, "train_preprocessed.json"), "w")
|
| 92 |
+
json.dump(TRAIN_FRAMES, out_file)
|
| 93 |
+
|
| 94 |
+
# TEST
|
| 95 |
+
test_csv_path = os.path.join(DATA_PATH, "test_annotations_release.txt")
|
| 96 |
+
column_names = ['path', 'idx', 'body_bbox_x', 'body_bbox_y', 'body_bbox_w', 'body_bbox_h', 'eye_x', 'eye_y',
|
| 97 |
+
'gaze_x', 'gaze_y', 'bbox_x_min', 'bbox_y_min', 'bbox_x_max', 'bbox_y_max', 'source', 'meta']
|
| 98 |
+
df = pd.read_csv(test_csv_path, header=None, names=column_names, index_col=False)
|
| 99 |
+
|
| 100 |
+
TEST_FRAME_DICT = {}
|
| 101 |
+
df = df.groupby(["path", "eye_x"]).agg(list) # aggregate over frames
|
| 102 |
+
for id, row in df.iterrows(): # aggregate by frame
|
| 103 |
+
path, _ = id
|
| 104 |
+
if path in TEST_FRAME_DICT.keys():
|
| 105 |
+
TEST_FRAME_DICT[path].append(row)
|
| 106 |
+
else:
|
| 107 |
+
TEST_FRAME_DICT[path] = [row]
|
| 108 |
+
|
| 109 |
+
multiperson_ex = 0
|
| 110 |
+
TEST_FRAMES = []
|
| 111 |
+
for path in TEST_FRAME_DICT.keys():
|
| 112 |
+
img_path = os.path.join(DATA_PATH, path)
|
| 113 |
+
img = Image.open(img_path)
|
| 114 |
+
width, height = img.size
|
| 115 |
+
|
| 116 |
+
item = TEST_FRAME_DICT[path]
|
| 117 |
+
num_people = len(item)
|
| 118 |
+
heads = []
|
| 119 |
+
crop_constraint_xs = []
|
| 120 |
+
crop_constraint_ys = []
|
| 121 |
+
|
| 122 |
+
for i in range(num_people):
|
| 123 |
+
row = item[i]
|
| 124 |
+
assert(row['bbox_x_min'].count(row['bbox_x_min'][0]) == len(row['bbox_x_min'])) # quick check that all bboxes are equivalent
|
| 125 |
+
xmin, ymin, xmax, ymax = row['bbox_x_min'][0], row['bbox_y_min'][0], row['bbox_x_max'][0], row['bbox_y_max'][0]
|
| 126 |
+
|
| 127 |
+
if xmin > xmax:
|
| 128 |
+
temp = xmin
|
| 129 |
+
xmin = xmax
|
| 130 |
+
xmax = temp
|
| 131 |
+
if ymin > ymax:
|
| 132 |
+
temp = ymin
|
| 133 |
+
ymin = ymax
|
| 134 |
+
ymax = temp
|
| 135 |
+
|
| 136 |
+
# move in out of frame bbox annotations
|
| 137 |
+
xmin = max(xmin, 0)
|
| 138 |
+
ymin = max(ymin, 0)
|
| 139 |
+
xmax = min(xmax, width)
|
| 140 |
+
ymax = min(ymax, height)
|
| 141 |
+
|
| 142 |
+
gazex_norm = [x for x in row['gaze_x']]
|
| 143 |
+
gazey_norm = [y for y in row['gaze_y']]
|
| 144 |
+
gazex = [x * float(width) for x in row['gaze_x']]
|
| 145 |
+
gazey = [y * float(height) for y in row['gaze_y']]
|
| 146 |
+
|
| 147 |
+
# precalculate feasible crop region (containing bbox and gaze target)
|
| 148 |
+
crop_xmin = min(xmin, *gazex)
|
| 149 |
+
crop_ymin = min(ymin, *gazey)
|
| 150 |
+
crop_xmax = max(xmax, *gazex)
|
| 151 |
+
crop_ymax = max(ymax, *gazey)
|
| 152 |
+
crop_constraint_xs.extend([crop_xmin, crop_xmax])
|
| 153 |
+
crop_constraint_ys.extend([crop_ymin, crop_ymax])
|
| 154 |
+
|
| 155 |
+
heads.append({
|
| 156 |
+
'bbox': [xmin, ymin, xmax, ymax],
|
| 157 |
+
'bbox_norm': [xmin / float(width), ymin / float(height), xmax / float(width), ymax / float(height)],
|
| 158 |
+
'gazex': gazex,
|
| 159 |
+
'gazey': gazey,
|
| 160 |
+
'gazex_norm': gazex_norm,
|
| 161 |
+
'gazey_norm': gazey_norm,
|
| 162 |
+
'inout': 1, # all test frames are in frame
|
| 163 |
+
'num_annot': len(gazex),
|
| 164 |
+
'crop_region': [crop_xmin, crop_ymin, crop_xmax, crop_ymax],
|
| 165 |
+
'crop_region_norm': [crop_xmin / float(width), crop_ymin / float(height), crop_xmax / float(width), crop_ymax / float(height)],
|
| 166 |
+
'head_id': i
|
| 167 |
+
})
|
| 168 |
+
|
| 169 |
+
# visualize_heads(img_path, heads)
|
| 170 |
+
TEST_FRAMES.append({
|
| 171 |
+
'path': path,
|
| 172 |
+
'heads': heads,
|
| 173 |
+
'num_heads': num_people,
|
| 174 |
+
'width': width,
|
| 175 |
+
'height': height,
|
| 176 |
+
'crop_region': [min(crop_constraint_xs), min(crop_constraint_ys), max(crop_constraint_xs), max(crop_constraint_ys)],
|
| 177 |
+
})
|
| 178 |
+
if num_people > 1:
|
| 179 |
+
multiperson_ex += 1
|
| 180 |
+
|
| 181 |
+
print("Test set: {} frames, {} multi-person".format(len(TEST_FRAMES), multiperson_ex))
|
| 182 |
+
out_file = open(os.path.join(DATA_PATH, "test_preprocessed.json"), "w")
|
| 183 |
+
json.dump(TEST_FRAMES, out_file)
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
if __name__ == "__main__":
|
| 188 |
+
main(args.data_path)
|
data_prep/preprocess_vat.py
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import glob
|
| 3 |
+
from functools import reduce
|
| 4 |
+
import os
|
| 5 |
+
import pandas as pd
|
| 6 |
+
import json
|
| 7 |
+
import numpy as np
|
| 8 |
+
from PIL import Image
|
| 9 |
+
|
| 10 |
+
parser = argparse.ArgumentParser()
|
| 11 |
+
parser.add_argument("--data_path", type=str, default="./data/videoattentiontarget")
|
| 12 |
+
args = parser.parse_args()
|
| 13 |
+
|
| 14 |
+
# preprocessing adapted from https://github.com/ejcgt/attention-target-detection/blob/master/dataset.py
|
| 15 |
+
|
| 16 |
+
def merge_dfs(ls):
|
| 17 |
+
for i, df in enumerate(ls): # give columns unique names
|
| 18 |
+
df.columns = [col if col == "path" else f"{col}_df{i}" for col in df.columns]
|
| 19 |
+
merged_df = reduce(
|
| 20 |
+
lambda left, right: pd.merge(left, right, on=["path"], how="outer"), ls
|
| 21 |
+
)
|
| 22 |
+
merged_df = merged_df.sort_values(by=["path"])
|
| 23 |
+
merged_df = merged_df.reset_index(drop=True)
|
| 24 |
+
return merged_df
|
| 25 |
+
|
| 26 |
+
def smooth_by_conv(window_size, df, col):
|
| 27 |
+
"""Temporal smoothing on labels to match original VideoAttTarget evaluation.
|
| 28 |
+
Adapted from https://github.com/ejcgt/attention-target-detection/blob/acd264a3c9e6002b71244dea8c1873e5c5818500/utils/myutils.py"""
|
| 29 |
+
values = df[col].values
|
| 30 |
+
padded_track = np.concatenate([values[0].repeat(window_size // 2), values, values[-1].repeat(window_size // 2)])
|
| 31 |
+
smoothed_signals = np.convolve(
|
| 32 |
+
padded_track.squeeze(), np.ones(window_size) / window_size, mode="valid"
|
| 33 |
+
)
|
| 34 |
+
return smoothed_signals
|
| 35 |
+
|
| 36 |
+
def smooth_df(window_size, df):
|
| 37 |
+
df["xmin"] = smooth_by_conv(window_size, df, "xmin")
|
| 38 |
+
df["ymin"] = smooth_by_conv(window_size, df, "ymin")
|
| 39 |
+
df["xmax"] = smooth_by_conv(window_size, df, "xmax")
|
| 40 |
+
df["ymax"] = smooth_by_conv(window_size, df, "ymax")
|
| 41 |
+
return df
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def main(PATH):
|
| 45 |
+
# preprocess by sequence and person track
|
| 46 |
+
splits = ["train", "test"]
|
| 47 |
+
|
| 48 |
+
for split in splits:
|
| 49 |
+
sequences = []
|
| 50 |
+
max_num_ppl = 0
|
| 51 |
+
seq_idx = 0
|
| 52 |
+
for seq_path in glob.glob(
|
| 53 |
+
os.path.join(PATH, "annotations", split, "*", "*")
|
| 54 |
+
):
|
| 55 |
+
seq_img_path = os.path.join("images", *seq_path.split("/")[-2:]
|
| 56 |
+
)
|
| 57 |
+
sample_image = os.path.join(PATH, seq_img_path, os.listdir(os.path.join(PATH, seq_img_path))[0])
|
| 58 |
+
width, height = Image.open(sample_image).size
|
| 59 |
+
seq_dict = {"path": seq_img_path, "width": width, "height": height}
|
| 60 |
+
frames = []
|
| 61 |
+
person_files = glob.glob(os.path.join(seq_path, "*"))
|
| 62 |
+
num_ppl = len(person_files)
|
| 63 |
+
if num_ppl > max_num_ppl:
|
| 64 |
+
max_num_ppl = num_ppl
|
| 65 |
+
person_dfs = [
|
| 66 |
+
pd.read_csv(
|
| 67 |
+
file,
|
| 68 |
+
header=None,
|
| 69 |
+
index_col=False,
|
| 70 |
+
names=["path", "xmin", "ymin", "xmax", "ymax", "gazex", "gazey"],
|
| 71 |
+
)
|
| 72 |
+
for file in person_files
|
| 73 |
+
]
|
| 74 |
+
# moving-avg smoothing to match original benchmark's evaluation
|
| 75 |
+
window_size = 11
|
| 76 |
+
person_dfs = [smooth_df(window_size, df) for df in person_dfs]
|
| 77 |
+
merged_df = merge_dfs(person_dfs) # merge annotations per person for same frames
|
| 78 |
+
for frame_idx, row in merged_df.iterrows():
|
| 79 |
+
frame_dict = {
|
| 80 |
+
"path": os.path.join(seq_img_path, row["path"]),
|
| 81 |
+
"heads": [],
|
| 82 |
+
}
|
| 83 |
+
p_idx = 0
|
| 84 |
+
for i in range(1, num_ppl * 6 + 1, 6):
|
| 85 |
+
if not np.isnan(row.iloc[i]): # if it's nan lack of continuity (one person leaving the frame for a period of time)
|
| 86 |
+
xmin, ymin, xmax, ymax, gazex, gazey = row[i: i+6].values.tolist()
|
| 87 |
+
# match original benchmark's preprocessing of annotations
|
| 88 |
+
if gazex >=0 and gazey < 0:
|
| 89 |
+
gazey = 0
|
| 90 |
+
elif gazey >=0 and gazex < 0:
|
| 91 |
+
gazex = 0
|
| 92 |
+
inout = int(gazex >= 0 and gazey >= 0)
|
| 93 |
+
frame_dict["heads"].append({
|
| 94 |
+
"bbox": [xmin, ymin, xmax, ymax],
|
| 95 |
+
"bbox_norm": [xmin / float(width), ymin / float(height), xmax / float(width), ymax / float(height)],
|
| 96 |
+
"gazex": [gazex],
|
| 97 |
+
"gazex_norm": [gazex / float(width)],
|
| 98 |
+
"gazey": [gazey],
|
| 99 |
+
"gazey_norm": [gazey / float(height)],
|
| 100 |
+
"inout": inout
|
| 101 |
+
})
|
| 102 |
+
p_idx = p_idx + 1
|
| 103 |
+
|
| 104 |
+
frames.append(frame_dict)
|
| 105 |
+
seq_dict["frames"] = frames
|
| 106 |
+
sequences.append(seq_dict)
|
| 107 |
+
seq_idx += 1
|
| 108 |
+
|
| 109 |
+
print("{} max people per image {}".format(split, max_num_ppl))
|
| 110 |
+
print("{} num unique video sequences {}".format(split, len(sequences)))
|
| 111 |
+
|
| 112 |
+
out_file = open(os.path.join(PATH, "{}_preprocessed.json".format(split)), "w")
|
| 113 |
+
json.dump(sequences, out_file)
|
| 114 |
+
|
| 115 |
+
if __name__ == "__main__":
|
| 116 |
+
main(args.data_path)
|
environment.yml
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: gazelle
|
| 2 |
+
channels:
|
| 3 |
+
- nvidia
|
| 4 |
+
- pytorch
|
| 5 |
+
- conda-forge
|
| 6 |
+
- defaults
|
| 7 |
+
dependencies:
|
| 8 |
+
- python=3.9
|
| 9 |
+
- pytorch=2.5.1
|
| 10 |
+
- torchvision=0.20.1
|
| 11 |
+
- torchaudio=2.5.1
|
| 12 |
+
- pytorch-cuda=11.8
|
| 13 |
+
- timm
|
| 14 |
+
- scikit-learn
|
| 15 |
+
- matplotlib
|
| 16 |
+
- pandas
|
gazelle/backbone.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import ABC, abstractmethod
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import torchvision.transforms as transforms
|
| 5 |
+
|
| 6 |
+
# Abstract Backbone class
|
| 7 |
+
class Backbone(nn.Module, ABC):
|
| 8 |
+
def __init__(self):
|
| 9 |
+
super(Backbone, self).__init__()
|
| 10 |
+
|
| 11 |
+
@abstractmethod
|
| 12 |
+
def forward(self, x):
|
| 13 |
+
pass
|
| 14 |
+
|
| 15 |
+
@abstractmethod
|
| 16 |
+
def get_dimension(self):
|
| 17 |
+
pass
|
| 18 |
+
|
| 19 |
+
@abstractmethod
|
| 20 |
+
def get_out_size(self, in_size):
|
| 21 |
+
pass
|
| 22 |
+
|
| 23 |
+
def get_transform(self):
|
| 24 |
+
pass
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
# Official DINOv2 backbones from torch hub (https://github.com/facebookresearch/dinov2#pretrained-backbones-via-pytorch-hub)
|
| 28 |
+
class DinoV2Backbone(Backbone):
|
| 29 |
+
def __init__(self, model_name):
|
| 30 |
+
super(DinoV2Backbone, self).__init__()
|
| 31 |
+
self.model = torch.hub.load('facebookresearch/dinov2', model_name)
|
| 32 |
+
|
| 33 |
+
def forward(self, x):
|
| 34 |
+
b, c, h, w = x.shape
|
| 35 |
+
out_h, out_w = self.get_out_size((h, w))
|
| 36 |
+
x = self.model.forward_features(x)['x_norm_patchtokens']
|
| 37 |
+
x = x.view(x.size(0), out_h, out_w, -1).permute(0, 3, 1, 2) # "b (out_h out_w) c -> b c out_h out_w"
|
| 38 |
+
return x
|
| 39 |
+
|
| 40 |
+
def get_dimension(self):
|
| 41 |
+
return self.model.embed_dim
|
| 42 |
+
|
| 43 |
+
def get_out_size(self, in_size):
|
| 44 |
+
h, w = in_size
|
| 45 |
+
return (h // self.model.patch_size, w // self.model.patch_size)
|
| 46 |
+
|
| 47 |
+
def get_transform(self, in_size):
|
| 48 |
+
return transforms.Compose([
|
| 49 |
+
transforms.ToTensor(),
|
| 50 |
+
transforms.Normalize(
|
| 51 |
+
mean=[0.485,0.456,0.406],
|
| 52 |
+
std=[0.229,0.224,0.225]
|
| 53 |
+
),
|
| 54 |
+
transforms.Resize(in_size),
|
| 55 |
+
])
|
gazelle/model.py
ADDED
|
@@ -0,0 +1,189 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
import torchvision
|
| 4 |
+
from timm.models.vision_transformer import Block
|
| 5 |
+
import math
|
| 6 |
+
|
| 7 |
+
import gazelle.utils as utils
|
| 8 |
+
from gazelle.backbone import DinoV2Backbone
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class GazeLLE(nn.Module):
|
| 12 |
+
def __init__(self, backbone, inout=False, dim=256, num_layers=3, in_size=(448, 448), out_size=(64, 64)):
|
| 13 |
+
super().__init__()
|
| 14 |
+
self.backbone = backbone
|
| 15 |
+
self.dim = dim
|
| 16 |
+
self.num_layers = num_layers
|
| 17 |
+
self.featmap_h, self.featmap_w = backbone.get_out_size(in_size)
|
| 18 |
+
self.in_size = in_size
|
| 19 |
+
self.out_size = out_size
|
| 20 |
+
self.inout = inout
|
| 21 |
+
|
| 22 |
+
self.linear = nn.Conv2d(backbone.get_dimension(), self.dim, 1)
|
| 23 |
+
self.register_buffer("pos_embed", positionalencoding2d(self.dim, self.featmap_h, self.featmap_w).squeeze(dim=0).squeeze(dim=0))
|
| 24 |
+
self.transformer = nn.Sequential(*[
|
| 25 |
+
Block(
|
| 26 |
+
dim=self.dim,
|
| 27 |
+
num_heads=8,
|
| 28 |
+
mlp_ratio=4,
|
| 29 |
+
drop_path=0.1)
|
| 30 |
+
for i in range(num_layers)
|
| 31 |
+
])
|
| 32 |
+
self.heatmap_head = nn.Sequential(
|
| 33 |
+
nn.ConvTranspose2d(dim, dim, kernel_size=2, stride=2),
|
| 34 |
+
nn.Conv2d(dim, 1, kernel_size=1, bias=False),
|
| 35 |
+
nn.Sigmoid()
|
| 36 |
+
)
|
| 37 |
+
self.head_token = nn.Embedding(1, self.dim)
|
| 38 |
+
if self.inout:
|
| 39 |
+
self.inout_head = nn.Sequential(
|
| 40 |
+
nn.Linear(self.dim, 128),
|
| 41 |
+
nn.ReLU(),
|
| 42 |
+
nn.Dropout(0.1),
|
| 43 |
+
nn.Linear(128, 1),
|
| 44 |
+
nn.Sigmoid()
|
| 45 |
+
)
|
| 46 |
+
self.inout_token = nn.Embedding(1, self.dim)
|
| 47 |
+
|
| 48 |
+
def forward(self, input):
|
| 49 |
+
# input["images"]: [B, 3, H, W] tensor of images
|
| 50 |
+
# input["bboxes"]: list of lists of bbox tuples [[(xmin, ymin, xmax, ymax)]] per image in normalized image coords
|
| 51 |
+
|
| 52 |
+
num_ppl_per_img = [len(bbox_list) for bbox_list in input["bboxes"]]
|
| 53 |
+
x = self.backbone.forward(input["images"])
|
| 54 |
+
x = self.linear(x)
|
| 55 |
+
x = x + self.pos_embed
|
| 56 |
+
x = utils.repeat_tensors(x, num_ppl_per_img) # repeat image features along people dimension per image
|
| 57 |
+
head_maps = torch.cat(self.get_input_head_maps(input["bboxes"]), dim=0).to(x.device) # [sum(N_p), 32, 32]
|
| 58 |
+
head_map_embeddings = head_maps.unsqueeze(dim=1) * self.head_token.weight.unsqueeze(-1).unsqueeze(-1)
|
| 59 |
+
x = x + head_map_embeddings
|
| 60 |
+
x = x.flatten(start_dim=2).permute(0, 2, 1) # "b c h w -> b (h w) c"
|
| 61 |
+
|
| 62 |
+
if self.inout:
|
| 63 |
+
x = torch.cat([self.inout_token.weight.unsqueeze(dim=0).repeat(x.shape[0], 1, 1), x], dim=1)
|
| 64 |
+
|
| 65 |
+
x = self.transformer(x)
|
| 66 |
+
|
| 67 |
+
if self.inout:
|
| 68 |
+
inout_tokens = x[:, 0, :]
|
| 69 |
+
inout_preds = self.inout_head(inout_tokens).squeeze(dim=-1)
|
| 70 |
+
inout_preds = utils.split_tensors(inout_preds, num_ppl_per_img)
|
| 71 |
+
x = x[:, 1:, :] # slice off inout tokens from scene tokens
|
| 72 |
+
|
| 73 |
+
x = x.reshape(x.shape[0], self.featmap_h, self.featmap_w, x.shape[2]).permute(0, 3, 1, 2) # b (h w) c -> b c h w
|
| 74 |
+
x = self.heatmap_head(x).squeeze(dim=1)
|
| 75 |
+
x = torchvision.transforms.functional.resize(x, self.out_size)
|
| 76 |
+
heatmap_preds = utils.split_tensors(x, num_ppl_per_img) # resplit per image
|
| 77 |
+
|
| 78 |
+
return {"heatmap": heatmap_preds, "inout": inout_preds if self.inout else None}
|
| 79 |
+
|
| 80 |
+
def get_input_head_maps(self, bboxes):
|
| 81 |
+
# bboxes: [[(xmin, ymin, xmax, ymax)]] - list of list of head bboxes per image
|
| 82 |
+
head_maps = []
|
| 83 |
+
for bbox_list in bboxes:
|
| 84 |
+
img_head_maps = []
|
| 85 |
+
for bbox in bbox_list:
|
| 86 |
+
if bbox is None: # no bbox provided, use empty head map
|
| 87 |
+
img_head_maps.append(torch.zeros(self.featmap_h, self.featmap_w))
|
| 88 |
+
else:
|
| 89 |
+
xmin, ymin, xmax, ymax = bbox
|
| 90 |
+
width, height = self.featmap_w, self.featmap_h
|
| 91 |
+
xmin = round(xmin * width)
|
| 92 |
+
ymin = round(ymin * height)
|
| 93 |
+
xmax = round(xmax * width)
|
| 94 |
+
ymax = round(ymax * height)
|
| 95 |
+
head_map = torch.zeros((height, width))
|
| 96 |
+
head_map[ymin:ymax, xmin:xmax] = 1
|
| 97 |
+
img_head_maps.append(head_map)
|
| 98 |
+
head_maps.append(torch.stack(img_head_maps))
|
| 99 |
+
return head_maps
|
| 100 |
+
|
| 101 |
+
def get_gazelle_state_dict(self, include_backbone=False):
|
| 102 |
+
if include_backbone:
|
| 103 |
+
return self.state_dict()
|
| 104 |
+
else:
|
| 105 |
+
return {k: v for k, v in self.state_dict().items() if not k.startswith("backbone")}
|
| 106 |
+
|
| 107 |
+
def load_gazelle_state_dict(self, ckpt_state_dict, include_backbone=False):
|
| 108 |
+
current_state_dict = self.state_dict()
|
| 109 |
+
keys1 = current_state_dict.keys()
|
| 110 |
+
keys2 = ckpt_state_dict.keys()
|
| 111 |
+
|
| 112 |
+
if not include_backbone:
|
| 113 |
+
keys1 = set([k for k in keys1 if not k.startswith("backbone")])
|
| 114 |
+
keys2 = set([k for k in keys2 if not k.startswith("backbone")])
|
| 115 |
+
else:
|
| 116 |
+
keys1 = set(keys1)
|
| 117 |
+
keys2 = set(keys2)
|
| 118 |
+
|
| 119 |
+
if len(keys2 - keys1) > 0:
|
| 120 |
+
print("WARNING unused keys in provided state dict: ", keys2 - keys1)
|
| 121 |
+
if len(keys1 - keys2) > 0:
|
| 122 |
+
print("WARNING provided state dict does not have values for keys: ", keys1 - keys2)
|
| 123 |
+
|
| 124 |
+
for k in list(keys1 & keys2):
|
| 125 |
+
current_state_dict[k] = ckpt_state_dict[k]
|
| 126 |
+
|
| 127 |
+
self.load_state_dict(current_state_dict, strict=False)
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
# From https://github.com/wzlxjtu/PositionalEncoding2D/blob/master/positionalembedding2d.py
|
| 131 |
+
def positionalencoding2d(d_model, height, width):
|
| 132 |
+
"""
|
| 133 |
+
:param d_model: dimension of the model
|
| 134 |
+
:param height: height of the positions
|
| 135 |
+
:param width: width of the positions
|
| 136 |
+
:return: d_model*height*width position matrix
|
| 137 |
+
"""
|
| 138 |
+
if d_model % 4 != 0:
|
| 139 |
+
raise ValueError("Cannot use sin/cos positional encoding with "
|
| 140 |
+
"odd dimension (got dim={:d})".format(d_model))
|
| 141 |
+
pe = torch.zeros(d_model, height, width)
|
| 142 |
+
# Each dimension use half of d_model
|
| 143 |
+
d_model = int(d_model / 2)
|
| 144 |
+
div_term = torch.exp(torch.arange(0., d_model, 2) *
|
| 145 |
+
-(math.log(10000.0) / d_model))
|
| 146 |
+
pos_w = torch.arange(0., width).unsqueeze(1)
|
| 147 |
+
pos_h = torch.arange(0., height).unsqueeze(1)
|
| 148 |
+
pe[0:d_model:2, :, :] = torch.sin(pos_w * div_term).transpose(0, 1).unsqueeze(1).repeat(1, height, 1)
|
| 149 |
+
pe[1:d_model:2, :, :] = torch.cos(pos_w * div_term).transpose(0, 1).unsqueeze(1).repeat(1, height, 1)
|
| 150 |
+
pe[d_model::2, :, :] = torch.sin(pos_h * div_term).transpose(0, 1).unsqueeze(2).repeat(1, 1, width)
|
| 151 |
+
pe[d_model + 1::2, :, :] = torch.cos(pos_h * div_term).transpose(0, 1).unsqueeze(2).repeat(1, 1, width)
|
| 152 |
+
|
| 153 |
+
return pe
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
# models
|
| 157 |
+
def get_gazelle_model(model_name):
|
| 158 |
+
factory = {
|
| 159 |
+
"gazelle_dinov2_vitb14": gazelle_dinov2_vitb14,
|
| 160 |
+
"gazelle_dinov2_vitl14": gazelle_dinov2_vitl14,
|
| 161 |
+
"gazelle_dinov2_vitb14_inout": gazelle_dinov2_vitb14_inout,
|
| 162 |
+
"gazelle_dinov2_vitl14_inout": gazelle_dinov2_vitl14_inout,
|
| 163 |
+
}
|
| 164 |
+
assert model_name in factory.keys(), "invalid model name"
|
| 165 |
+
return factory[model_name]()
|
| 166 |
+
|
| 167 |
+
def gazelle_dinov2_vitb14():
|
| 168 |
+
backbone = DinoV2Backbone('dinov2_vitb14')
|
| 169 |
+
transform = backbone.get_transform((448, 448))
|
| 170 |
+
model = GazeLLE(backbone)
|
| 171 |
+
return model, transform
|
| 172 |
+
|
| 173 |
+
def gazelle_dinov2_vitl14():
|
| 174 |
+
backbone = DinoV2Backbone('dinov2_vitl14')
|
| 175 |
+
transform = backbone.get_transform((448, 448))
|
| 176 |
+
model = GazeLLE(backbone)
|
| 177 |
+
return model, transform
|
| 178 |
+
|
| 179 |
+
def gazelle_dinov2_vitb14_inout():
|
| 180 |
+
backbone = DinoV2Backbone('dinov2_vitb14')
|
| 181 |
+
transform = backbone.get_transform((448, 448))
|
| 182 |
+
model = GazeLLE(backbone, inout=True)
|
| 183 |
+
return model, transform
|
| 184 |
+
|
| 185 |
+
def gazelle_dinov2_vitl14_inout():
|
| 186 |
+
backbone = DinoV2Backbone('dinov2_vitl14')
|
| 187 |
+
transform = backbone.get_transform((448, 448))
|
| 188 |
+
model = GazeLLE(backbone, inout=True)
|
| 189 |
+
return model, transform
|
gazelle/utils.py
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
from PIL import Image, ImageDraw
|
| 3 |
+
import numpy as np
|
| 4 |
+
import matplotlib.pyplot as plt
|
| 5 |
+
|
| 6 |
+
def repeat_tensors(tensor, repeat_counts):
|
| 7 |
+
repeated_tensors = [tensor[i:i+1].repeat(repeat, *[1] * (tensor.ndim - 1)) for i, repeat in enumerate(repeat_counts)]
|
| 8 |
+
return torch.cat(repeated_tensors, dim=0)
|
| 9 |
+
|
| 10 |
+
def split_tensors(tensor, split_counts):
|
| 11 |
+
indices = torch.cumsum(torch.tensor([0] + split_counts), dim=0)
|
| 12 |
+
return [tensor[indices[i]:indices[i+1]] for i in range(len(split_counts))]
|
| 13 |
+
|
| 14 |
+
def visualize_heatmap(pil_image, heatmap, bbox=None):
|
| 15 |
+
if isinstance(heatmap, torch.Tensor):
|
| 16 |
+
heatmap = heatmap.detach().cpu().numpy()
|
| 17 |
+
heatmap = Image.fromarray((heatmap * 255).astype(np.uint8)).resize(pil_image.size, Image.Resampling.BILINEAR)
|
| 18 |
+
heatmap = plt.cm.jet(np.array(heatmap) / 255.)
|
| 19 |
+
heatmap = (heatmap[:, :, :3] * 255).astype(np.uint8)
|
| 20 |
+
heatmap = Image.fromarray(heatmap).convert("RGBA")
|
| 21 |
+
heatmap.putalpha(128)
|
| 22 |
+
overlay_image = Image.alpha_composite(pil_image.convert("RGBA"), heatmap)
|
| 23 |
+
|
| 24 |
+
if bbox is not None:
|
| 25 |
+
width, height = pil_image.size
|
| 26 |
+
xmin, ymin, xmax, ymax = bbox
|
| 27 |
+
draw = ImageDraw.Draw(overlay_image)
|
| 28 |
+
draw.rectangle([xmin * width, ymin * height, xmax * width, ymax * height], outline="green", width=3)
|
| 29 |
+
return overlay_image
|
| 30 |
+
|
| 31 |
+
def stack_and_pad(tensor_list):
|
| 32 |
+
max_size = max([t.shape[0] for t in tensor_list])
|
| 33 |
+
padded_list = []
|
| 34 |
+
for t in tensor_list:
|
| 35 |
+
if t.shape[0] == max_size:
|
| 36 |
+
padded_list.append(t)
|
| 37 |
+
else:
|
| 38 |
+
padded_list.append(torch.cat([t, torch.zeros(max_size - t.shape[0], *t.shape[1:])], dim=0))
|
| 39 |
+
return torch.stack(padded_list)
|
hubconf.py
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
dependencies = ['torch', 'timm']
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
from gazelle.model import get_gazelle_model
|
| 5 |
+
|
| 6 |
+
def gazelle_dinov2_vitb14():
|
| 7 |
+
model, transform = get_gazelle_model('gazelle_dinov2_vitb14')
|
| 8 |
+
ckpt_path = "https://github.com/fkryan/gazelle/releases/download/v1.0.0/gazelle_dinov2_vitb14_hub.pt"
|
| 9 |
+
model.load_gazelle_state_dict(torch.hub.load_state_dict_from_url(ckpt_path))
|
| 10 |
+
return model, transform
|
| 11 |
+
|
| 12 |
+
def gazelle_dinov2_vitl14():
|
| 13 |
+
model, transform = get_gazelle_model('gazelle_dinov2_vitl14')
|
| 14 |
+
ckpt_path = "https://github.com/fkryan/gazelle/releases/download/v1.0.0/gazelle_dinov2_vitl14.pt"
|
| 15 |
+
model.load_gazelle_state_dict(torch.hub.load_state_dict_from_url(ckpt_path))
|
| 16 |
+
return model, transform
|
| 17 |
+
|
| 18 |
+
def gazelle_dinov2_vitb14_inout():
|
| 19 |
+
model, transform = get_gazelle_model('gazelle_dinov2_vitb14_inout')
|
| 20 |
+
ckpt_path = "https://github.com/fkryan/gazelle/releases/download/v1.0.0/gazelle_dinov2_vitb14_inout.pt"
|
| 21 |
+
model.load_gazelle_state_dict(torch.hub.load_state_dict_from_url(ckpt_path))
|
| 22 |
+
return model, transform
|
| 23 |
+
|
| 24 |
+
def gazelle_dinov2_vitl14_inout():
|
| 25 |
+
model, transform = get_gazelle_model('gazelle_dinov2_vitl14_inout')
|
| 26 |
+
ckpt_path = "https://github.com/fkryan/gazelle/releases/download/v1.0.0/gazelle_dinov2_vitl14_inout.pt"
|
| 27 |
+
model.load_gazelle_state_dict(torch.hub.load_state_dict_from_url(ckpt_path))
|
| 28 |
+
return model, transform
|
scripts/eval_gazefollow.py
ADDED
|
@@ -0,0 +1,115 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import torch
|
| 3 |
+
from PIL import Image
|
| 4 |
+
import json
|
| 5 |
+
import os
|
| 6 |
+
import numpy as np
|
| 7 |
+
from sklearn.metrics import roc_auc_score
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
|
| 10 |
+
from gazelle.model import get_gazelle_model
|
| 11 |
+
from gazelle.model import GazeLLE
|
| 12 |
+
from gazelle.backbone import DinoV2Backbone
|
| 13 |
+
|
| 14 |
+
parser = argparse.ArgumentParser()
|
| 15 |
+
parser.add_argument("--data_path", type=str, default="./data/gazefollow")
|
| 16 |
+
parser.add_argument("--model_name", type=str, default="gazelle_dinov2_vitl14_inout")
|
| 17 |
+
parser.add_argument("--ckpt_path", type=str, default="./checkpoints/gazelle_dinov2_vitl14_inout.pt")
|
| 18 |
+
parser.add_argument("--batch_size", type=int, default=128)
|
| 19 |
+
args = parser.parse_args()
|
| 20 |
+
|
| 21 |
+
class GazeFollow(torch.utils.data.Dataset):
|
| 22 |
+
def __init__(self, path, img_transform):
|
| 23 |
+
self.images = json.load(open(os.path.join(path, "test_preprocessed.json"), "rb"))
|
| 24 |
+
self.path = path
|
| 25 |
+
self.transform = img_transform
|
| 26 |
+
|
| 27 |
+
def __getitem__(self, idx):
|
| 28 |
+
item = self.images[idx]
|
| 29 |
+
image = self.transform(Image.open(os.path.join(self.path, item['path'])).convert("RGB"))
|
| 30 |
+
height = item['height']
|
| 31 |
+
width = item['width']
|
| 32 |
+
bboxes = [head['bbox_norm'] for head in item['heads']]
|
| 33 |
+
gazex = [head['gazex_norm'] for head in item['heads']]
|
| 34 |
+
gazey = [head['gazey_norm'] for head in item['heads']]
|
| 35 |
+
|
| 36 |
+
return image, bboxes, gazex, gazey, height, width
|
| 37 |
+
|
| 38 |
+
def __len__(self):
|
| 39 |
+
return len(self.images)
|
| 40 |
+
|
| 41 |
+
def collate(batch):
|
| 42 |
+
images, bboxes, gazex, gazey, height, width = zip(*batch)
|
| 43 |
+
return torch.stack(images), list(bboxes), list(gazex), list(gazey), list(height), list(width)
|
| 44 |
+
|
| 45 |
+
# GazeFollow calculates AUC using original image size with GT (x,y) coordinates set to 1 and everything else as 0
|
| 46 |
+
# References:
|
| 47 |
+
# https://github.com/ejcgt/attention-target-detection/blob/acd264a3c9e6002b71244dea8c1873e5c5818500/eval_on_gazefollow.py#L78
|
| 48 |
+
# https://github.com/ejcgt/attention-target-detection/blob/acd264a3c9e6002b71244dea8c1873e5c5818500/utils/imutils.py#L67
|
| 49 |
+
# https://github.com/ejcgt/attention-target-detection/blob/acd264a3c9e6002b71244dea8c1873e5c5818500/utils/evaluation.py#L7
|
| 50 |
+
def gazefollow_auc(heatmap, gt_gazex, gt_gazey, height, width):
|
| 51 |
+
target_map = np.zeros((height, width))
|
| 52 |
+
for point in zip(gt_gazex, gt_gazey):
|
| 53 |
+
if point[0] >= 0:
|
| 54 |
+
x, y = map(int, [point[0]*float(width), point[1]*float(height)])
|
| 55 |
+
x = min(x, width - 1)
|
| 56 |
+
y = min(y, height - 1)
|
| 57 |
+
target_map[y, x] = 1
|
| 58 |
+
resized_heatmap = torch.nn.functional.interpolate(heatmap.unsqueeze(dim=0).unsqueeze(dim=0), (height, width), mode='bilinear').squeeze()
|
| 59 |
+
auc = roc_auc_score(target_map.flatten(), resized_heatmap.cpu().flatten())
|
| 60 |
+
|
| 61 |
+
return auc
|
| 62 |
+
|
| 63 |
+
# Reference: https://github.com/ejcgt/attention-target-detection/blob/acd264a3c9e6002b71244dea8c1873e5c5818500/eval_on_gazefollow.py#L81
|
| 64 |
+
def gazefollow_l2(heatmap, gt_gazex, gt_gazey):
|
| 65 |
+
argmax = heatmap.flatten().argmax().item()
|
| 66 |
+
pred_y, pred_x = np.unravel_index(argmax, (64, 64))
|
| 67 |
+
pred_x = pred_x / 64.
|
| 68 |
+
pred_y = pred_y / 64.
|
| 69 |
+
|
| 70 |
+
gazex = np.array(gt_gazex)
|
| 71 |
+
gazey = np.array(gt_gazey)
|
| 72 |
+
|
| 73 |
+
avg_l2 = np.sqrt((pred_x - gazex.mean())**2 + (pred_y - gazey.mean())**2)
|
| 74 |
+
all_l2s = np.sqrt((pred_x - gazex)**2 + (pred_y - gazey)**2)
|
| 75 |
+
min_l2 = all_l2s.min().item()
|
| 76 |
+
|
| 77 |
+
return avg_l2, min_l2
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
@torch.no_grad()
|
| 81 |
+
def main():
|
| 82 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 83 |
+
print("Running on {}".format(device))
|
| 84 |
+
|
| 85 |
+
model, transform = get_gazelle_model(args.model_name)
|
| 86 |
+
model.load_gazelle_state_dict(torch.load(args.ckpt_path, weights_only=True))
|
| 87 |
+
model.to(device)
|
| 88 |
+
model.eval()
|
| 89 |
+
|
| 90 |
+
dataset = GazeFollow(args.data_path, transform)
|
| 91 |
+
dataloader = torch.utils.data.DataLoader(dataset, batch_size=args.batch_size, collate_fn=collate)
|
| 92 |
+
|
| 93 |
+
aucs = []
|
| 94 |
+
min_l2s = []
|
| 95 |
+
avg_l2s = []
|
| 96 |
+
|
| 97 |
+
for _, (images, bboxes, gazex, gazey, height, width) in tqdm(enumerate(dataloader), desc="Evaluating", total=len(dataloader)):
|
| 98 |
+
preds = model.forward({"images": images.to(device), "bboxes": bboxes})
|
| 99 |
+
|
| 100 |
+
# eval each instance (head)
|
| 101 |
+
for i in range(images.shape[0]): # per image
|
| 102 |
+
for j in range(len(bboxes[i])): # per head
|
| 103 |
+
auc = gazefollow_auc(preds['heatmap'][i][j], gazex[i][j], gazey[i][j], height[i], width[i])
|
| 104 |
+
avg_l2, min_l2 = gazefollow_l2(preds['heatmap'][i][j], gazex[i][j], gazey[i][j])
|
| 105 |
+
aucs.append(auc)
|
| 106 |
+
avg_l2s.append(avg_l2)
|
| 107 |
+
min_l2s.append(min_l2)
|
| 108 |
+
|
| 109 |
+
print("AUC: {}".format(np.array(aucs).mean()))
|
| 110 |
+
print("Avg L2: {}".format(np.array(avg_l2s).mean()))
|
| 111 |
+
print("Min L2: {}".format(np.array(min_l2s).mean()))
|
| 112 |
+
|
| 113 |
+
|
| 114 |
+
if __name__ == "__main__":
|
| 115 |
+
main()
|
scripts/eval_vat.py
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import torch
|
| 3 |
+
from PIL import Image
|
| 4 |
+
import json
|
| 5 |
+
import os
|
| 6 |
+
import numpy as np
|
| 7 |
+
from sklearn.metrics import roc_auc_score, average_precision_score
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
|
| 10 |
+
from gazelle.model import get_gazelle_model
|
| 11 |
+
|
| 12 |
+
parser = argparse.ArgumentParser()
|
| 13 |
+
parser.add_argument("--data_path", type=str, default="./data/videoattentiontarget")
|
| 14 |
+
parser.add_argument("--model_name", type=str, default="gazelle_dinov2_vitl14_inout")
|
| 15 |
+
parser.add_argument("--ckpt_path", type=str, default="./checkpoints/gazelle_dinov2_vitl14_inout.pt")
|
| 16 |
+
parser.add_argument("--batch_size", type=int, default=64)
|
| 17 |
+
args = parser.parse_args()
|
| 18 |
+
|
| 19 |
+
class VideoAttentionTarget(torch.utils.data.Dataset):
|
| 20 |
+
def __init__(self, path, img_transform):
|
| 21 |
+
self.sequences = json.load(open(os.path.join(path, "test_preprocessed.json"), "rb"))
|
| 22 |
+
self.frames = []
|
| 23 |
+
for i in range(len(self.sequences)):
|
| 24 |
+
for j in range(len(self.sequences[i]['frames'])):
|
| 25 |
+
self.frames.append((i, j))
|
| 26 |
+
self.path = path
|
| 27 |
+
self.transform = img_transform
|
| 28 |
+
|
| 29 |
+
def __getitem__(self, idx):
|
| 30 |
+
seq_idx, frame_idx = self.frames[idx]
|
| 31 |
+
seq = self.sequences[seq_idx]
|
| 32 |
+
frame = seq['frames'][frame_idx]
|
| 33 |
+
image = self.transform(Image.open(os.path.join(self.path, frame['path'])).convert("RGB"))
|
| 34 |
+
bboxes = [head['bbox_norm'] for head in frame['heads']]
|
| 35 |
+
gazex = [head['gazex_norm'] for head in frame['heads']]
|
| 36 |
+
gazey = [head['gazey_norm'] for head in frame['heads']]
|
| 37 |
+
inout = [head['inout'] for head in frame['heads']]
|
| 38 |
+
|
| 39 |
+
return image, bboxes, gazex, gazey, inout
|
| 40 |
+
|
| 41 |
+
def __len__(self):
|
| 42 |
+
return len(self.frames)
|
| 43 |
+
|
| 44 |
+
def collate(batch):
|
| 45 |
+
images, bboxes, gazex, gazey, inout = zip(*batch)
|
| 46 |
+
return torch.stack(images), list(bboxes), list(gazex), list(gazey), list(inout)
|
| 47 |
+
|
| 48 |
+
# VideoAttentionTarget calculates AUC on 64x64 heatmap, defining a rectangular tolerance region of 6*(sigma=3) + 1 (uses 2D Gaussian code but binary thresholds > 0 resulting in rectangle)
|
| 49 |
+
# References:
|
| 50 |
+
# https://github.com/ejcgt/attention-target-detection/blob/acd264a3c9e6002b71244dea8c1873e5c5818500/eval_on_videoatttarget.py#L106
|
| 51 |
+
# https://github.com/ejcgt/attention-target-detection/blob/acd264a3c9e6002b71244dea8c1873e5c5818500/utils/imutils.py#L31
|
| 52 |
+
def vat_auc(heatmap, gt_gazex, gt_gazey):
|
| 53 |
+
res = 64
|
| 54 |
+
sigma = 3
|
| 55 |
+
assert heatmap.shape[0] == res and heatmap.shape[1] == res
|
| 56 |
+
target_map = np.zeros((res, res))
|
| 57 |
+
gazex = gt_gazex * res
|
| 58 |
+
gazey = gt_gazey * res
|
| 59 |
+
ul = [max(0, int(gazex - 3 * sigma)), max(0, int(gazey - 3 * sigma))]
|
| 60 |
+
br = [min(int(gazex + 3 * sigma + 1), res-1), min(int(gazey + 3 * sigma + 1), res-1)]
|
| 61 |
+
target_map[ul[1]:br[1], ul[0]:br[0]] = 1
|
| 62 |
+
auc = roc_auc_score(target_map.flatten(), heatmap.cpu().flatten())
|
| 63 |
+
return auc
|
| 64 |
+
|
| 65 |
+
# Reference: https://github.com/ejcgt/attention-target-detection/blob/acd264a3c9e6002b71244dea8c1873e5c5818500/eval_on_videoatttarget.py#L118
|
| 66 |
+
def vat_l2(heatmap, gt_gazex, gt_gazey):
|
| 67 |
+
argmax = heatmap.flatten().argmax().item()
|
| 68 |
+
pred_y, pred_x = np.unravel_index(argmax, (64, 64))
|
| 69 |
+
pred_x = pred_x / 64.
|
| 70 |
+
pred_y = pred_y / 64.
|
| 71 |
+
|
| 72 |
+
l2 = np.sqrt((pred_x - gt_gazex)**2 + (pred_y - gt_gazey)**2)
|
| 73 |
+
|
| 74 |
+
return l2
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
@torch.no_grad()
|
| 78 |
+
def main():
|
| 79 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 80 |
+
print("Running on {}".format(device))
|
| 81 |
+
|
| 82 |
+
model, transform = get_gazelle_model(args.model_name)
|
| 83 |
+
model.load_gazelle_state_dict(torch.load(args.ckpt_path, weights_only=True))
|
| 84 |
+
model.to(device)
|
| 85 |
+
model.eval()
|
| 86 |
+
|
| 87 |
+
dataset = VideoAttentionTarget(args.data_path, transform)
|
| 88 |
+
dataloader = torch.utils.data.DataLoader(dataset, batch_size=args.batch_size, collate_fn=collate)
|
| 89 |
+
|
| 90 |
+
aucs = []
|
| 91 |
+
l2s = []
|
| 92 |
+
inout_preds = []
|
| 93 |
+
inout_gts = []
|
| 94 |
+
|
| 95 |
+
for _, (images, bboxes, gazex, gazey, inout) in tqdm(enumerate(dataloader), desc="Evaluating", total=len(dataloader)):
|
| 96 |
+
preds = model.forward({"images": images.to(device), "bboxes": bboxes})
|
| 97 |
+
|
| 98 |
+
# eval each instance (head)
|
| 99 |
+
for i in range(images.shape[0]): # per image
|
| 100 |
+
for j in range(len(bboxes[i])): # per head
|
| 101 |
+
if inout[i][j] == 1: # in frame
|
| 102 |
+
auc = vat_auc(preds['heatmap'][i][j], gazex[i][j][0], gazey[i][j][0])
|
| 103 |
+
l2 = vat_l2(preds['heatmap'][i][j], gazex[i][j][0], gazey[i][j][0])
|
| 104 |
+
aucs.append(auc)
|
| 105 |
+
l2s.append(l2)
|
| 106 |
+
inout_preds.append(preds['inout'][i][j].item())
|
| 107 |
+
inout_gts.append(inout[i][j])
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
print("AUC: {}".format(np.array(aucs).mean()))
|
| 111 |
+
print("Avg L2: {}".format(np.array(l2s).mean()))
|
| 112 |
+
print("Inout AP: {}".format(average_precision_score(inout_gts, inout_preds)))
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
if __name__ == "__main__":
|
| 116 |
+
main()
|
setup.py
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import setuptools
|
| 2 |
+
|
| 3 |
+
setuptools.setup(
|
| 4 |
+
name="gazelle",
|
| 5 |
+
version="0.0.1",
|
| 6 |
+
author="Fiona Ryan",
|
| 7 |
+
description="Gaze-LLE: Gaze Target Estimation via Large-Scale Learned Encoders",
|
| 8 |
+
packages=setuptools.find_packages()
|
| 9 |
+
)
|