Spaces:
Sleeping

Sleeping
app created
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- app.py +124 -0
- requirements.txt +79 -0
- xyxy_converter.py +29 -0
- yolov5/CITATION.cff +14 -0
- yolov5/CONTRIBUTING.md +93 -0
- yolov5/README.md +477 -0
- yolov5/README.zh-CN.md +473 -0
- yolov5/benchmarks.py +174 -0
- yolov5/classify/predict.py +227 -0
- yolov5/classify/train.py +333 -0
- yolov5/classify/tutorial.ipynb +0 -0
- yolov5/classify/val.py +170 -0
- yolov5/data/Argoverse.yaml +74 -0
- yolov5/data/GlobalWheat2020.yaml +54 -0
- yolov5/data/ImageNet.yaml +1022 -0
- yolov5/data/ImageNet10.yaml +32 -0
- yolov5/data/ImageNet100.yaml +120 -0
- yolov5/data/ImageNet1000.yaml +1022 -0
- yolov5/data/Objects365.yaml +438 -0
- yolov5/data/SKU-110K.yaml +53 -0
- yolov5/data/VOC.yaml +100 -0
- yolov5/data/VisDrone.yaml +70 -0
- yolov5/data/coco.yaml +116 -0
- yolov5/data/coco128-seg.yaml +101 -0
- yolov5/data/coco128.yaml +101 -0
- yolov5/data/hyps/hyp.Objects365.yaml +34 -0
- yolov5/data/hyps/hyp.VOC.yaml +40 -0
- yolov5/data/hyps/hyp.no-augmentation.yaml +35 -0
- yolov5/data/hyps/hyp.scratch-high.yaml +34 -0
- yolov5/data/hyps/hyp.scratch-low.yaml +34 -0
- yolov5/data/hyps/hyp.scratch-med.yaml +34 -0
- yolov5/data/images/bus.jpg +0 -0
- yolov5/data/images/zidane.jpg +0 -0
- yolov5/data/scripts/download_weights.sh +22 -0
- yolov5/data/scripts/get_coco.sh +56 -0
- yolov5/data/scripts/get_coco128.sh +17 -0
- yolov5/data/scripts/get_imagenet.sh +51 -0
- yolov5/data/scripts/get_imagenet10.sh +29 -0
- yolov5/data/scripts/get_imagenet100.sh +29 -0
- yolov5/data/scripts/get_imagenet1000.sh +29 -0
- yolov5/data/xView.yaml +153 -0
- yolov5/detect.py +295 -0
- yolov5/export.py +880 -0
- yolov5/hubconf.py +169 -0
- yolov5/models/__init__.py +0 -0
- yolov5/models/__pycache__/__init__.cpython-310.pyc +0 -0
- yolov5/models/__pycache__/__init__.cpython-37.pyc +0 -0
- yolov5/models/__pycache__/common.cpython-310.pyc +0 -0
- yolov5/models/__pycache__/common.cpython-37.pyc +0 -0
- yolov5/models/__pycache__/experimental.cpython-310.pyc +0 -0
app.py
ADDED
|
@@ -0,0 +1,124 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import streamlit as st
|
| 2 |
+
import cv2
|
| 3 |
+
import numpy as np
|
| 4 |
+
from PIL import Image
|
| 5 |
+
import imutils
|
| 6 |
+
import easyocr
|
| 7 |
+
import os
|
| 8 |
+
import pathlib
|
| 9 |
+
import platform
|
| 10 |
+
from xyxy_converter import yolov5_to_image_coordinates
|
| 11 |
+
import shutil
|
| 12 |
+
|
| 13 |
+
system_platform = platform.system()
|
| 14 |
+
if system_platform == 'Windows': pathlib.PosixPath = pathlib.WindowsPath
|
| 15 |
+
|
| 16 |
+
CUR_DIR = os.getcwd()
|
| 17 |
+
YOLO_PATH = f"{CUR_DIR}/yolov5"
|
| 18 |
+
MODEL_PATH = "runs/train/exp/weights/best.pt"
|
| 19 |
+
|
| 20 |
+
def main():
|
| 21 |
+
st.title("Odometer value extractor with Streamlit")
|
| 22 |
+
|
| 23 |
+
# Use st.camera to capture images from the user's camera
|
| 24 |
+
img_file_buffer = st.camera_input(label='Please, take a photo of odometer', key="odometer")
|
| 25 |
+
|
| 26 |
+
# Check if an image is captured
|
| 27 |
+
if img_file_buffer is not None:
|
| 28 |
+
# Convert the image to a NumPy array
|
| 29 |
+
image = Image.open(img_file_buffer)
|
| 30 |
+
image_np = np.array(image)
|
| 31 |
+
resized_image = cv2.resize(image_np, (640, 640))
|
| 32 |
+
resized_image = resized_image.astype(np.uint8)
|
| 33 |
+
cv2.imwrite('odometer_image.jpg', resized_image)
|
| 34 |
+
|
| 35 |
+
# detect(
|
| 36 |
+
# weights='yolov5\runs\train\exp\weights\best.pt',
|
| 37 |
+
# source='odometer_image.jpg',
|
| 38 |
+
# img=640,
|
| 39 |
+
# conf=0.4,
|
| 40 |
+
# name='temp_exp',
|
| 41 |
+
# hide_labels=True,
|
| 42 |
+
# hide_conf=True,
|
| 43 |
+
# save_txt=True,
|
| 44 |
+
# exist_ok=True
|
| 45 |
+
# )
|
| 46 |
+
|
| 47 |
+
# os.system('wandb disabled')
|
| 48 |
+
|
| 49 |
+
os.chdir(YOLO_PATH)
|
| 50 |
+
|
| 51 |
+
try:
|
| 52 |
+
shutil.rmtree('runs/detect/temp_exp')
|
| 53 |
+
except:
|
| 54 |
+
pass
|
| 55 |
+
|
| 56 |
+
image_path = 'odometer_image.jpg'
|
| 57 |
+
# command = f"python detect.py --weights {MODEL_PATH} --source {image_path} --img 640 --conf 0.4 --name 'temp_exp' --hide-labels --hide-conf --save-txt --exist-ok"
|
| 58 |
+
command = f'''
|
| 59 |
+
python detect.py \
|
| 60 |
+
--weights {MODEL_PATH} \
|
| 61 |
+
--source {image_path} \
|
| 62 |
+
--img 640 \
|
| 63 |
+
--conf 0.4 \
|
| 64 |
+
--name temp_exp \
|
| 65 |
+
--hide-labels \
|
| 66 |
+
--hide-conf \
|
| 67 |
+
--save-txt \
|
| 68 |
+
--exist-ok
|
| 69 |
+
'''
|
| 70 |
+
|
| 71 |
+
# Run the command
|
| 72 |
+
os.system(command)
|
| 73 |
+
|
| 74 |
+
st.write('The detection is completed!!!')
|
| 75 |
+
|
| 76 |
+
os.chdir(CUR_DIR)
|
| 77 |
+
|
| 78 |
+
st.write(os.path.exists('yolov5/runs/detect/temp_exp'))
|
| 79 |
+
|
| 80 |
+
if os.path.exists('yolov5/runs/detect/temp_exp'):
|
| 81 |
+
processed_image = cv2.imread('yolov5/runs/detect/temp_exp/odometer_image.jpg')
|
| 82 |
+
st.write('Image boxed and loaded')
|
| 83 |
+
text_files = os.listdir('yolov5/runs/detect/temp_exp/labels')
|
| 84 |
+
original_img = cv2.imread('odometer_image.jpg')
|
| 85 |
+
gray = cv2.cvtColor(original_img, cv2.COLOR_BGR2GRAY)
|
| 86 |
+
|
| 87 |
+
if len(text_files) == 0:
|
| 88 |
+
display_text = "An odometer is not detected in the image!!!"
|
| 89 |
+
else:
|
| 90 |
+
text_file_path = f'yolov5/runs/detect/temp_exp/labels/{text_files[0]}'
|
| 91 |
+
x1, y1, x2, y2 = yolov5_to_image_coordinates(text_file_path)
|
| 92 |
+
st.write(x1, y1, x2, y2)
|
| 93 |
+
cropped_image = gray[x1:x2, y1:y2]
|
| 94 |
+
|
| 95 |
+
reader = easyocr.Reader(['en'])
|
| 96 |
+
result = reader.readtext(cropped_image)
|
| 97 |
+
|
| 98 |
+
if len(result) != 0:
|
| 99 |
+
odometer_value = sorted(result, key=lambda x: x[2], reverse=True)[0][1]
|
| 100 |
+
display_text = f"Odometer value: {odometer_value}"
|
| 101 |
+
else:
|
| 102 |
+
odometer_value = 'not detected'
|
| 103 |
+
display_text = f"The odometer value is {odometer_value}!!!"
|
| 104 |
+
try:
|
| 105 |
+
shutil.rmtree('odometer_image.jpg')
|
| 106 |
+
except:
|
| 107 |
+
pass
|
| 108 |
+
else:
|
| 109 |
+
processed_image = image_np
|
| 110 |
+
|
| 111 |
+
# Resize or preprocess the image as needed for your model
|
| 112 |
+
# For example, resizing to a specific input size
|
| 113 |
+
# processed_image = cv2.resize(image_np, (224, 224))
|
| 114 |
+
|
| 115 |
+
# Process the image using your deep learning model
|
| 116 |
+
# processed_image = process_image(image_np)
|
| 117 |
+
|
| 118 |
+
# Display the processed image
|
| 119 |
+
st.image(processed_image, caption=f"{display_text}", use_column_width=True)
|
| 120 |
+
|
| 121 |
+
st.session_state.pop("odometer")
|
| 122 |
+
|
| 123 |
+
if __name__ == "__main__":
|
| 124 |
+
main()
|
requirements.txt
ADDED
|
@@ -0,0 +1,79 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
altair==5.2.0
|
| 2 |
+
attrs==23.2.0
|
| 3 |
+
blinker==1.7.0
|
| 4 |
+
cachetools==5.3.2
|
| 5 |
+
certifi==2023.11.17
|
| 6 |
+
charset-normalizer==3.3.2
|
| 7 |
+
click==8.1.7
|
| 8 |
+
colorama==0.4.6
|
| 9 |
+
contourpy==1.2.0
|
| 10 |
+
cycler==0.12.1
|
| 11 |
+
easyocr==1.7.1
|
| 12 |
+
filelock==3.13.1
|
| 13 |
+
fonttools==4.47.0
|
| 14 |
+
fsspec==2023.12.2
|
| 15 |
+
gitdb==4.0.11
|
| 16 |
+
GitPython==3.1.40
|
| 17 |
+
idna==3.6
|
| 18 |
+
imageio==2.33.1
|
| 19 |
+
importlib-metadata==6.11.0
|
| 20 |
+
imutils==0.5.4
|
| 21 |
+
Jinja2==3.1.2
|
| 22 |
+
jsonschema==4.20.0
|
| 23 |
+
jsonschema-specifications==2023.12.1
|
| 24 |
+
kiwisolver==1.4.5
|
| 25 |
+
lazy_loader==0.3
|
| 26 |
+
markdown-it-py==3.0.0
|
| 27 |
+
MarkupSafe==2.1.3
|
| 28 |
+
matplotlib==3.8.2
|
| 29 |
+
mdurl==0.1.2
|
| 30 |
+
mpmath==1.3.0
|
| 31 |
+
networkx==3.2.1
|
| 32 |
+
ninja==1.11.1.1
|
| 33 |
+
numpy==1.26.3
|
| 34 |
+
opencv-python==4.9.0.80
|
| 35 |
+
opencv-python-headless==4.9.0.80
|
| 36 |
+
packaging==23.2
|
| 37 |
+
pandas==2.1.4
|
| 38 |
+
pillow==10.2.0
|
| 39 |
+
protobuf==4.25.1
|
| 40 |
+
psutil==5.9.7
|
| 41 |
+
py-cpuinfo==9.0.0
|
| 42 |
+
pyarrow==14.0.2
|
| 43 |
+
pyclipper==1.3.0.post5
|
| 44 |
+
pydeck==0.8.1b0
|
| 45 |
+
Pygments==2.17.2
|
| 46 |
+
pyparsing==3.1.1
|
| 47 |
+
python-bidi==0.4.2
|
| 48 |
+
python-dateutil==2.8.2
|
| 49 |
+
pytz==2023.3.post1
|
| 50 |
+
PyYAML==6.0.1
|
| 51 |
+
referencing==0.32.0
|
| 52 |
+
requests==2.31.0
|
| 53 |
+
rich==13.7.0
|
| 54 |
+
rpds-py==0.16.2
|
| 55 |
+
scikit-image==0.22.0
|
| 56 |
+
scipy==1.11.4
|
| 57 |
+
seaborn==0.13.1
|
| 58 |
+
shapely==2.0.2
|
| 59 |
+
six==1.16.0
|
| 60 |
+
smmap==5.0.1
|
| 61 |
+
streamlit==1.29.0
|
| 62 |
+
sympy==1.12
|
| 63 |
+
tenacity==8.2.3
|
| 64 |
+
thop==0.1.1.post2209072238
|
| 65 |
+
tifffile==2023.12.9
|
| 66 |
+
toml==0.10.2
|
| 67 |
+
toolz==0.12.0
|
| 68 |
+
torch==2.1.2
|
| 69 |
+
torchvision==0.16.2
|
| 70 |
+
tornado==6.4
|
| 71 |
+
tqdm==4.66.1
|
| 72 |
+
typing_extensions==4.9.0
|
| 73 |
+
tzdata==2023.4
|
| 74 |
+
tzlocal==5.2
|
| 75 |
+
ultralytics==8.0.234
|
| 76 |
+
urllib3==2.1.0
|
| 77 |
+
validators==0.22.0
|
| 78 |
+
watchdog==3.0.0
|
| 79 |
+
zipp==3.17.0
|
xyxy_converter.py
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
def yolov5_to_image_coordinates(text_file, image_width=640, image_height=640):
|
| 2 |
+
"""
|
| 3 |
+
Convert YOLOv5 bounding box coordinates to normal image coordinates.
|
| 4 |
+
|
| 5 |
+
Args:
|
| 6 |
+
box (tuple): YOLOv5 bounding box coordinates in the format (x_center, y_center, width, height).
|
| 7 |
+
image_width (int): Width of the image.
|
| 8 |
+
image_height (int): Height of the image.
|
| 9 |
+
|
| 10 |
+
Returns:
|
| 11 |
+
tuple: Normal image coordinates in the format (x_min, y_min, x_max, y_max).
|
| 12 |
+
"""
|
| 13 |
+
|
| 14 |
+
with open(text_file, 'r') as f:
|
| 15 |
+
xywh_text = f.read()
|
| 16 |
+
|
| 17 |
+
yolo_box = [float(i) for i in xywh_text.replace('\n', '').split(' ')[1:]]
|
| 18 |
+
|
| 19 |
+
x_center, y_center, width, height = yolo_box
|
| 20 |
+
|
| 21 |
+
# Convert from normalized to absolute coordinates
|
| 22 |
+
x_min = int((x_center - width / 2) * image_width)
|
| 23 |
+
y_min = int((y_center - height / 2) * image_height)
|
| 24 |
+
x_max = int((x_center + width / 2) * image_width)
|
| 25 |
+
y_max = int((y_center + height / 2) * image_height)
|
| 26 |
+
|
| 27 |
+
x1, y1, x2, y2 = y_min, x_min, y_max, x_max
|
| 28 |
+
|
| 29 |
+
return x1, y1, x2, y2
|
yolov5/CITATION.cff
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
cff-version: 1.2.0
|
| 2 |
+
preferred-citation:
|
| 3 |
+
type: software
|
| 4 |
+
message: If you use YOLOv5, please cite it as below.
|
| 5 |
+
authors:
|
| 6 |
+
- family-names: Jocher
|
| 7 |
+
given-names: Glenn
|
| 8 |
+
orcid: "https://orcid.org/0000-0001-5950-6979"
|
| 9 |
+
title: "YOLOv5 by Ultralytics"
|
| 10 |
+
version: 7.0
|
| 11 |
+
doi: 10.5281/zenodo.3908559
|
| 12 |
+
date-released: 2020-5-29
|
| 13 |
+
license: AGPL-3.0
|
| 14 |
+
url: "https://github.com/ultralytics/yolov5"
|
yolov5/CONTRIBUTING.md
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## Contributing to YOLOv5 🚀
|
| 2 |
+
|
| 3 |
+
We love your input! We want to make contributing to YOLOv5 as easy and transparent as possible, whether it's:
|
| 4 |
+
|
| 5 |
+
- Reporting a bug
|
| 6 |
+
- Discussing the current state of the code
|
| 7 |
+
- Submitting a fix
|
| 8 |
+
- Proposing a new feature
|
| 9 |
+
- Becoming a maintainer
|
| 10 |
+
|
| 11 |
+
YOLOv5 works so well due to our combined community effort, and for every small improvement you contribute you will be
|
| 12 |
+
helping push the frontiers of what's possible in AI 😃!
|
| 13 |
+
|
| 14 |
+
## Submitting a Pull Request (PR) 🛠️
|
| 15 |
+
|
| 16 |
+
Submitting a PR is easy! This example shows how to submit a PR for updating `requirements.txt` in 4 steps:
|
| 17 |
+
|
| 18 |
+
### 1. Select File to Update
|
| 19 |
+
|
| 20 |
+
Select `requirements.txt` to update by clicking on it in GitHub.
|
| 21 |
+
|
| 22 |
+
<p align="center"><img width="800" alt="PR_step1" src="https://user-images.githubusercontent.com/26833433/122260847-08be2600-ced4-11eb-828b-8287ace4136c.png"></p>
|
| 23 |
+
|
| 24 |
+
### 2. Click 'Edit this file'
|
| 25 |
+
|
| 26 |
+
The button is in the top-right corner.
|
| 27 |
+
|
| 28 |
+
<p align="center"><img width="800" alt="PR_step2" src="https://user-images.githubusercontent.com/26833433/122260844-06f46280-ced4-11eb-9eec-b8a24be519ca.png"></p>
|
| 29 |
+
|
| 30 |
+
### 3. Make Changes
|
| 31 |
+
|
| 32 |
+
Change the `matplotlib` version from `3.2.2` to `3.3`.
|
| 33 |
+
|
| 34 |
+
<p align="center"><img width="800" alt="PR_step3" src="https://user-images.githubusercontent.com/26833433/122260853-0a87e980-ced4-11eb-9fd2-3650fb6e0842.png"></p>
|
| 35 |
+
|
| 36 |
+
### 4. Preview Changes and Submit PR
|
| 37 |
+
|
| 38 |
+
Click on the **Preview changes** tab to verify your updates. At the bottom of the screen select 'Create a **new branch**
|
| 39 |
+
for this commit', assign your branch a descriptive name such as `fix/matplotlib_version` and click the green **Propose
|
| 40 |
+
changes** button. All done, your PR is now submitted to YOLOv5 for review and approval 😃!
|
| 41 |
+
|
| 42 |
+
<p align="center"><img width="800" alt="PR_step4" src="https://user-images.githubusercontent.com/26833433/122260856-0b208000-ced4-11eb-8e8e-77b6151cbcc3.png"></p>
|
| 43 |
+
|
| 44 |
+
### PR recommendations
|
| 45 |
+
|
| 46 |
+
To allow your work to be integrated as seamlessly as possible, we advise you to:
|
| 47 |
+
|
| 48 |
+
- ✅ Verify your PR is **up-to-date** with `ultralytics/yolov5` `master` branch. If your PR is behind you can update
|
| 49 |
+
your code by clicking the 'Update branch' button or by running `git pull` and `git merge master` locally.
|
| 50 |
+
|
| 51 |
+
<p align="center"><img width="751" alt="Screenshot 2022-08-29 at 22 47 15" src="https://user-images.githubusercontent.com/26833433/187295893-50ed9f44-b2c9-4138-a614-de69bd1753d7.png"></p>
|
| 52 |
+
|
| 53 |
+
- ✅ Verify all YOLOv5 Continuous Integration (CI) **checks are passing**.
|
| 54 |
+
|
| 55 |
+
<p align="center"><img width="751" alt="Screenshot 2022-08-29 at 22 47 03" src="https://user-images.githubusercontent.com/26833433/187296922-545c5498-f64a-4d8c-8300-5fa764360da6.png"></p>
|
| 56 |
+
|
| 57 |
+
- ✅ Reduce changes to the absolute **minimum** required for your bug fix or feature addition. _"It is not daily increase
|
| 58 |
+
but daily decrease, hack away the unessential. The closer to the source, the less wastage there is."_ — Bruce Lee
|
| 59 |
+
|
| 60 |
+
## Submitting a Bug Report 🐛
|
| 61 |
+
|
| 62 |
+
If you spot a problem with YOLOv5 please submit a Bug Report!
|
| 63 |
+
|
| 64 |
+
For us to start investigating a possible problem we need to be able to reproduce it ourselves first. We've created a few
|
| 65 |
+
short guidelines below to help users provide what we need to get started.
|
| 66 |
+
|
| 67 |
+
When asking a question, people will be better able to provide help if you provide **code** that they can easily
|
| 68 |
+
understand and use to **reproduce** the problem. This is referred to by community members as creating
|
| 69 |
+
a [minimum reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/). Your code that reproduces
|
| 70 |
+
the problem should be:
|
| 71 |
+
|
| 72 |
+
- ✅ **Minimal** – Use as little code as possible that still produces the same problem
|
| 73 |
+
- ✅ **Complete** – Provide **all** parts someone else needs to reproduce your problem in the question itself
|
| 74 |
+
- ✅ **Reproducible** – Test the code you're about to provide to make sure it reproduces the problem
|
| 75 |
+
|
| 76 |
+
In addition to the above requirements, for [Ultralytics](https://ultralytics.com/) to provide assistance your code
|
| 77 |
+
should be:
|
| 78 |
+
|
| 79 |
+
- ✅ **Current** – Verify that your code is up-to-date with the current
|
| 80 |
+
GitHub [master](https://github.com/ultralytics/yolov5/tree/master), and if necessary `git pull` or `git clone` a new
|
| 81 |
+
copy to ensure your problem has not already been resolved by previous commits.
|
| 82 |
+
- ✅ **Unmodified** – Your problem must be reproducible without any modifications to the codebase in this
|
| 83 |
+
repository. [Ultralytics](https://ultralytics.com/) does not provide support for custom code ⚠️.
|
| 84 |
+
|
| 85 |
+
If you believe your problem meets all of the above criteria, please close this issue and raise a new one using the 🐛
|
| 86 |
+
**Bug Report** [template](https://github.com/ultralytics/yolov5/issues/new/choose) and provide
|
| 87 |
+
a [minimum reproducible example](https://docs.ultralytics.com/help/minimum_reproducible_example/) to help us better
|
| 88 |
+
understand and diagnose your problem.
|
| 89 |
+
|
| 90 |
+
## License
|
| 91 |
+
|
| 92 |
+
By contributing, you agree that your contributions will be licensed under
|
| 93 |
+
the [AGPL-3.0 license](https://choosealicense.com/licenses/agpl-3.0/)
|
yolov5/README.md
ADDED
|
@@ -0,0 +1,477 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<p>
|
| 3 |
+
<a href="https://yolovision.ultralytics.com/" target="_blank">
|
| 4 |
+
<img width="100%" src="https://raw.githubusercontent.com/ultralytics/assets/main/im/banner-yolo-vision-2023.png"></a>
|
| 5 |
+
<!--
|
| 6 |
+
<a align="center" href="https://ultralytics.com/yolov5" target="_blank">
|
| 7 |
+
<img width="100%" src="https://raw.githubusercontent.com/ultralytics/assets/main/yolov5/v70/splash.png"></a>
|
| 8 |
+
-->
|
| 9 |
+
</p>
|
| 10 |
+
|
| 11 |
+
[中文](https://docs.ultralytics.com/zh/) | [한국어](https://docs.ultralytics.com/ko/) | [日本語](https://docs.ultralytics.com/ja/) | [Русский](https://docs.ultralytics.com/ru/) | [Deutsch](https://docs.ultralytics.com/de/) | [Français](https://docs.ultralytics.com/fr/) | [Español](https://docs.ultralytics.com/es/) | [Português](https://docs.ultralytics.com/pt/) | [हिन्दी](https://docs.ultralytics.com/hi/) | [العربية](https://docs.ultralytics.com/ar/)
|
| 12 |
+
|
| 13 |
+
<div>
|
| 14 |
+
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
| 15 |
+
<a href="https://zenodo.org/badge/latestdoi/264818686"><img src="https://zenodo.org/badge/264818686.svg" alt="YOLOv5 Citation"></a>
|
| 16 |
+
<a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
| 17 |
+
<br>
|
| 18 |
+
<a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a>
|
| 19 |
+
<a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
|
| 20 |
+
<a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
| 21 |
+
</div>
|
| 22 |
+
<br>
|
| 23 |
+
|
| 24 |
+
YOLOv5 🚀 is the world's most loved vision AI, representing <a href="https://ultralytics.com">Ultralytics</a> open-source research into future vision AI methods, incorporating lessons learned and best practices evolved over thousands of hours of research and development.
|
| 25 |
+
|
| 26 |
+
We hope that the resources here will help you get the most out of YOLOv5. Please browse the YOLOv5 <a href="https://docs.ultralytics.com/yolov5">Docs</a> for details, raise an issue on <a href="https://github.com/ultralytics/yolov5/issues/new/choose">GitHub</a> for support, and join our <a href="https://ultralytics.com/discord">Discord</a> community for questions and discussions!
|
| 27 |
+
|
| 28 |
+
To request an Enterprise License please complete the form at [Ultralytics Licensing](https://ultralytics.com/license).
|
| 29 |
+
|
| 30 |
+
<div align="center">
|
| 31 |
+
<a href="https://github.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-github.png" width="2%" alt="Ultralytics GitHub"></a>
|
| 32 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%">
|
| 33 |
+
<a href="https://www.linkedin.com/company/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-linkedin.png" width="2%" alt="Ultralytics LinkedIn"></a>
|
| 34 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%">
|
| 35 |
+
<a href="https://twitter.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-twitter.png" width="2%" alt="Ultralytics Twitter"></a>
|
| 36 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%">
|
| 37 |
+
<a href="https://youtube.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-youtube.png" width="2%" alt="Ultralytics YouTube"></a>
|
| 38 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%">
|
| 39 |
+
<a href="https://www.tiktok.com/@ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-tiktok.png" width="2%" alt="Ultralytics TikTok"></a>
|
| 40 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%">
|
| 41 |
+
<a href="https://www.instagram.com/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-instagram.png" width="2%" alt="Ultralytics Instagram"></a>
|
| 42 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%">
|
| 43 |
+
<a href="https://ultralytics.com/discord"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-discord.png" width="2%" alt="Ultralytics Discord"></a>
|
| 44 |
+
</div>
|
| 45 |
+
|
| 46 |
+
</div>
|
| 47 |
+
<br>
|
| 48 |
+
|
| 49 |
+
## <div align="center">YOLOv8 🚀 NEW</div>
|
| 50 |
+
|
| 51 |
+
We are thrilled to announce the launch of Ultralytics YOLOv8 🚀, our NEW cutting-edge, state-of-the-art (SOTA) model released at **[https://github.com/ultralytics/ultralytics](https://github.com/ultralytics/ultralytics)**. YOLOv8 is designed to be fast, accurate, and easy to use, making it an excellent choice for a wide range of object detection, image segmentation and image classification tasks.
|
| 52 |
+
|
| 53 |
+
See the [YOLOv8 Docs](https://docs.ultralytics.com) for details and get started with:
|
| 54 |
+
|
| 55 |
+
[](https://badge.fury.io/py/ultralytics) [](https://pepy.tech/project/ultralytics)
|
| 56 |
+
|
| 57 |
+
```bash
|
| 58 |
+
pip install ultralytics
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
<div align="center">
|
| 62 |
+
<a href="https://ultralytics.com/yolov8" target="_blank">
|
| 63 |
+
<img width="100%" src="https://raw.githubusercontent.com/ultralytics/assets/main/yolov8/yolo-comparison-plots.png"></a>
|
| 64 |
+
</div>
|
| 65 |
+
|
| 66 |
+
## <div align="center">Documentation</div>
|
| 67 |
+
|
| 68 |
+
See the [YOLOv5 Docs](https://docs.ultralytics.com/yolov5) for full documentation on training, testing and deployment. See below for quickstart examples.
|
| 69 |
+
|
| 70 |
+
<details open>
|
| 71 |
+
<summary>Install</summary>
|
| 72 |
+
|
| 73 |
+
Clone repo and install [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) in a
|
| 74 |
+
[**Python>=3.8.0**](https://www.python.org/) environment, including
|
| 75 |
+
[**PyTorch>=1.8**](https://pytorch.org/get-started/locally/).
|
| 76 |
+
|
| 77 |
+
```bash
|
| 78 |
+
git clone https://github.com/ultralytics/yolov5 # clone
|
| 79 |
+
cd yolov5
|
| 80 |
+
pip install -r requirements.txt # install
|
| 81 |
+
```
|
| 82 |
+
|
| 83 |
+
</details>
|
| 84 |
+
|
| 85 |
+
<details>
|
| 86 |
+
<summary>Inference</summary>
|
| 87 |
+
|
| 88 |
+
YOLOv5 [PyTorch Hub](https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading) inference. [Models](https://github.com/ultralytics/yolov5/tree/master/models) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases).
|
| 89 |
+
|
| 90 |
+
```python
|
| 91 |
+
import torch
|
| 92 |
+
|
| 93 |
+
# Model
|
| 94 |
+
model = torch.hub.load("ultralytics/yolov5", "yolov5s") # or yolov5n - yolov5x6, custom
|
| 95 |
+
|
| 96 |
+
# Images
|
| 97 |
+
img = "https://ultralytics.com/images/zidane.jpg" # or file, Path, PIL, OpenCV, numpy, list
|
| 98 |
+
|
| 99 |
+
# Inference
|
| 100 |
+
results = model(img)
|
| 101 |
+
|
| 102 |
+
# Results
|
| 103 |
+
results.print() # or .show(), .save(), .crop(), .pandas(), etc.
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
</details>
|
| 107 |
+
|
| 108 |
+
<details>
|
| 109 |
+
<summary>Inference with detect.py</summary>
|
| 110 |
+
|
| 111 |
+
`detect.py` runs inference on a variety of sources, downloading [models](https://github.com/ultralytics/yolov5/tree/master/models) automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases) and saving results to `runs/detect`.
|
| 112 |
+
|
| 113 |
+
```bash
|
| 114 |
+
python detect.py --weights yolov5s.pt --source 0 # webcam
|
| 115 |
+
img.jpg # image
|
| 116 |
+
vid.mp4 # video
|
| 117 |
+
screen # screenshot
|
| 118 |
+
path/ # directory
|
| 119 |
+
list.txt # list of images
|
| 120 |
+
list.streams # list of streams
|
| 121 |
+
'path/*.jpg' # glob
|
| 122 |
+
'https://youtu.be/LNwODJXcvt4' # YouTube
|
| 123 |
+
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
|
| 124 |
+
```
|
| 125 |
+
|
| 126 |
+
</details>
|
| 127 |
+
|
| 128 |
+
<details>
|
| 129 |
+
<summary>Training</summary>
|
| 130 |
+
|
| 131 |
+
The commands below reproduce YOLOv5 [COCO](https://github.com/ultralytics/yolov5/blob/master/data/scripts/get_coco.sh)
|
| 132 |
+
results. [Models](https://github.com/ultralytics/yolov5/tree/master/models)
|
| 133 |
+
and [datasets](https://github.com/ultralytics/yolov5/tree/master/data) download automatically from the latest YOLOv5 [release](https://github.com/ultralytics/yolov5/releases). Training times for YOLOv5n/s/m/l/x are 1/2/4/6/8 days on a V100 GPU ([Multi-GPU](https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training) times faster). Use the largest `--batch-size` possible, or pass `--batch-size -1` for YOLOv5 [AutoBatch](https://github.com/ultralytics/yolov5/pull/5092). Batch sizes shown for V100-16GB.
|
| 134 |
+
|
| 135 |
+
```bash
|
| 136 |
+
python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml --batch-size 128
|
| 137 |
+
yolov5s 64
|
| 138 |
+
yolov5m 40
|
| 139 |
+
yolov5l 24
|
| 140 |
+
yolov5x 16
|
| 141 |
+
```
|
| 142 |
+
|
| 143 |
+
<img width="800" src="https://user-images.githubusercontent.com/26833433/90222759-949d8800-ddc1-11ea-9fa1-1c97eed2b963.png">
|
| 144 |
+
|
| 145 |
+
</details>
|
| 146 |
+
|
| 147 |
+
<details open>
|
| 148 |
+
<summary>Tutorials</summary>
|
| 149 |
+
|
| 150 |
+
- [Train Custom Data](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data) 🚀 RECOMMENDED
|
| 151 |
+
- [Tips for Best Training Results](https://docs.ultralytics.com/yolov5/tutorials/tips_for_best_training_results) ☘️
|
| 152 |
+
- [Multi-GPU Training](https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training)
|
| 153 |
+
- [PyTorch Hub](https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading) 🌟 NEW
|
| 154 |
+
- [TFLite, ONNX, CoreML, TensorRT Export](https://docs.ultralytics.com/yolov5/tutorials/model_export) 🚀
|
| 155 |
+
- [NVIDIA Jetson platform Deployment](https://docs.ultralytics.com/yolov5/tutorials/running_on_jetson_nano) 🌟 NEW
|
| 156 |
+
- [Test-Time Augmentation (TTA)](https://docs.ultralytics.com/yolov5/tutorials/test_time_augmentation)
|
| 157 |
+
- [Model Ensembling](https://docs.ultralytics.com/yolov5/tutorials/model_ensembling)
|
| 158 |
+
- [Model Pruning/Sparsity](https://docs.ultralytics.com/yolov5/tutorials/model_pruning_and_sparsity)
|
| 159 |
+
- [Hyperparameter Evolution](https://docs.ultralytics.com/yolov5/tutorials/hyperparameter_evolution)
|
| 160 |
+
- [Transfer Learning with Frozen Layers](https://docs.ultralytics.com/yolov5/tutorials/transfer_learning_with_frozen_layers)
|
| 161 |
+
- [Architecture Summary](https://docs.ultralytics.com/yolov5/tutorials/architecture_description) 🌟 NEW
|
| 162 |
+
- [Roboflow for Datasets, Labeling, and Active Learning](https://docs.ultralytics.com/yolov5/tutorials/roboflow_datasets_integration)
|
| 163 |
+
- [ClearML Logging](https://docs.ultralytics.com/yolov5/tutorials/clearml_logging_integration) 🌟 NEW
|
| 164 |
+
- [YOLOv5 with Neural Magic's Deepsparse](https://docs.ultralytics.com/yolov5/tutorials/neural_magic_pruning_quantization) 🌟 NEW
|
| 165 |
+
- [Comet Logging](https://docs.ultralytics.com/yolov5/tutorials/comet_logging_integration) 🌟 NEW
|
| 166 |
+
|
| 167 |
+
</details>
|
| 168 |
+
|
| 169 |
+
## <div align="center">Integrations</div>
|
| 170 |
+
|
| 171 |
+
<br>
|
| 172 |
+
<a align="center" href="https://bit.ly/ultralytics_hub" target="_blank">
|
| 173 |
+
<img width="100%" src="https://github.com/ultralytics/assets/raw/main/im/integrations-loop.png"></a>
|
| 174 |
+
<br>
|
| 175 |
+
<br>
|
| 176 |
+
|
| 177 |
+
<div align="center">
|
| 178 |
+
<a href="https://roboflow.com/?ref=ultralytics">
|
| 179 |
+
<img src="https://github.com/ultralytics/assets/raw/main/partners/logo-roboflow.png" width="10%" /></a>
|
| 180 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="15%" height="0" alt="" />
|
| 181 |
+
<a href="https://cutt.ly/yolov5-readme-clearml">
|
| 182 |
+
<img src="https://github.com/ultralytics/assets/raw/main/partners/logo-clearml.png" width="10%" /></a>
|
| 183 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="15%" height="0" alt="" />
|
| 184 |
+
<a href="https://bit.ly/yolov5-readme-comet2">
|
| 185 |
+
<img src="https://github.com/ultralytics/assets/raw/main/partners/logo-comet.png" width="10%" /></a>
|
| 186 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="15%" height="0" alt="" />
|
| 187 |
+
<a href="https://bit.ly/yolov5-neuralmagic">
|
| 188 |
+
<img src="https://github.com/ultralytics/assets/raw/main/partners/logo-neuralmagic.png" width="10%" /></a>
|
| 189 |
+
</div>
|
| 190 |
+
|
| 191 |
+
| Roboflow | ClearML ⭐ NEW | Comet ⭐ NEW | Neural Magic ⭐ NEW |
|
| 192 |
+
| :--------------------------------------------------------------------------------------------------------------------------: | :---------------------------------------------------------------------------------------------------------------------------------: | :--------------------------------------------------------------------------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------------------------------: |
|
| 193 |
+
| Label and export your custom datasets directly to YOLOv5 for training with [Roboflow](https://roboflow.com/?ref=ultralytics) | Automatically track, visualize and even remotely train YOLOv5 using [ClearML](https://cutt.ly/yolov5-readme-clearml) (open-source!) | Free forever, [Comet](https://bit.ly/yolov5-readme-comet2) lets you save YOLOv5 models, resume training, and interactively visualise and debug predictions | Run YOLOv5 inference up to 6x faster with [Neural Magic DeepSparse](https://bit.ly/yolov5-neuralmagic) |
|
| 194 |
+
|
| 195 |
+
## <div align="center">Ultralytics HUB</div>
|
| 196 |
+
|
| 197 |
+
Experience seamless AI with [Ultralytics HUB](https://bit.ly/ultralytics_hub) ⭐, the all-in-one solution for data visualization, YOLOv5 and YOLOv8 🚀 model training and deployment, without any coding. Transform images into actionable insights and bring your AI visions to life with ease using our cutting-edge platform and user-friendly [Ultralytics App](https://ultralytics.com/app_install). Start your journey for **Free** now!
|
| 198 |
+
|
| 199 |
+
<a align="center" href="https://bit.ly/ultralytics_hub" target="_blank">
|
| 200 |
+
<img width="100%" src="https://github.com/ultralytics/assets/raw/main/im/ultralytics-hub.png"></a>
|
| 201 |
+
|
| 202 |
+
## <div align="center">Why YOLOv5</div>
|
| 203 |
+
|
| 204 |
+
YOLOv5 has been designed to be super easy to get started and simple to learn. We prioritize real-world results.
|
| 205 |
+
|
| 206 |
+
<p align="left"><img width="800" src="https://user-images.githubusercontent.com/26833433/155040763-93c22a27-347c-4e3c-847a-8094621d3f4e.png"></p>
|
| 207 |
+
<details>
|
| 208 |
+
<summary>YOLOv5-P5 640 Figure</summary>
|
| 209 |
+
|
| 210 |
+
<p align="left"><img width="800" src="https://user-images.githubusercontent.com/26833433/155040757-ce0934a3-06a6-43dc-a979-2edbbd69ea0e.png"></p>
|
| 211 |
+
</details>
|
| 212 |
+
<details>
|
| 213 |
+
<summary>Figure Notes</summary>
|
| 214 |
+
|
| 215 |
+
- **COCO AP val** denotes [email protected]:0.95 metric measured on the 5000-image [COCO val2017](http://cocodataset.org) dataset over various inference sizes from 256 to 1536.
|
| 216 |
+
- **GPU Speed** measures average inference time per image on [COCO val2017](http://cocodataset.org) dataset using a [AWS p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/) V100 instance at batch-size 32.
|
| 217 |
+
- **EfficientDet** data from [google/automl](https://github.com/google/automl) at batch size 8.
|
| 218 |
+
- **Reproduce** by `python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt`
|
| 219 |
+
|
| 220 |
+
</details>
|
| 221 |
+
|
| 222 |
+
### Pretrained Checkpoints
|
| 223 |
+
|
| 224 |
+
| Model | size<br><sup>(pixels) | mAP<sup>val<br>50-95 | mAP<sup>val<br>50 | Speed<br><sup>CPU b1<br>(ms) | Speed<br><sup>V100 b1<br>(ms) | Speed<br><sup>V100 b32<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>@640 (B) |
|
| 225 |
+
| ----------------------------------------------------------------------------------------------- | --------------------- | -------------------- | ----------------- | ---------------------------- | ----------------------------- | ------------------------------ | ------------------ | ---------------------- |
|
| 226 |
+
| [YOLOv5n](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n.pt) | 640 | 28.0 | 45.7 | **45** | **6.3** | **0.6** | **1.9** | **4.5** |
|
| 227 |
+
| [YOLOv5s](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt) | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
|
| 228 |
+
| [YOLOv5m](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m.pt) | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
|
| 229 |
+
| [YOLOv5l](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l.pt) | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
|
| 230 |
+
| [YOLOv5x](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x.pt) | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
|
| 231 |
+
| | | | | | | | | |
|
| 232 |
+
| [YOLOv5n6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n6.pt) | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
|
| 233 |
+
| [YOLOv5s6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s6.pt) | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
|
| 234 |
+
| [YOLOv5m6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m6.pt) | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
|
| 235 |
+
| [YOLOv5l6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l6.pt) | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
|
| 236 |
+
| [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x6.pt)<br>+ [TTA] | 1280<br>1536 | 55.0<br>**55.8** | 72.7<br>**72.7** | 3136<br>- | 26.2<br>- | 19.4<br>- | 140.7<br>- | 209.8<br>- |
|
| 237 |
+
|
| 238 |
+
<details>
|
| 239 |
+
<summary>Table Notes</summary>
|
| 240 |
+
|
| 241 |
+
- All checkpoints are trained to 300 epochs with default settings. Nano and Small models use [hyp.scratch-low.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-low.yaml) hyps, all others use [hyp.scratch-high.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-high.yaml).
|
| 242 |
+
- **mAP<sup>val</sup>** values are for single-model single-scale on [COCO val2017](http://cocodataset.org) dataset.<br>Reproduce by `python val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65`
|
| 243 |
+
- **Speed** averaged over COCO val images using a [AWS p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/) instance. NMS times (~1 ms/img) not included.<br>Reproduce by `python val.py --data coco.yaml --img 640 --task speed --batch 1`
|
| 244 |
+
- **TTA** [Test Time Augmentation](https://docs.ultralytics.com/yolov5/tutorials/test_time_augmentation) includes reflection and scale augmentations.<br>Reproduce by `python val.py --data coco.yaml --img 1536 --iou 0.7 --augment`
|
| 245 |
+
|
| 246 |
+
</details>
|
| 247 |
+
|
| 248 |
+
## <div align="center">Segmentation</div>
|
| 249 |
+
|
| 250 |
+
Our new YOLOv5 [release v7.0](https://github.com/ultralytics/yolov5/releases/v7.0) instance segmentation models are the fastest and most accurate in the world, beating all current [SOTA benchmarks](https://paperswithcode.com/sota/real-time-instance-segmentation-on-mscoco). We've made them super simple to train, validate and deploy. See full details in our [Release Notes](https://github.com/ultralytics/yolov5/releases/v7.0) and visit our [YOLOv5 Segmentation Colab Notebook](https://github.com/ultralytics/yolov5/blob/master/segment/tutorial.ipynb) for quickstart tutorials.
|
| 251 |
+
|
| 252 |
+
<details>
|
| 253 |
+
<summary>Segmentation Checkpoints</summary>
|
| 254 |
+
|
| 255 |
+
<div align="center">
|
| 256 |
+
<a align="center" href="https://ultralytics.com/yolov5" target="_blank">
|
| 257 |
+
<img width="800" src="https://user-images.githubusercontent.com/61612323/204180385-84f3aca9-a5e9-43d8-a617-dda7ca12e54a.png"></a>
|
| 258 |
+
</div>
|
| 259 |
+
|
| 260 |
+
We trained YOLOv5 segmentations models on COCO for 300 epochs at image size 640 using A100 GPUs. We exported all models to ONNX FP32 for CPU speed tests and to TensorRT FP16 for GPU speed tests. We ran all speed tests on Google [Colab Pro](https://colab.research.google.com/signup) notebooks for easy reproducibility.
|
| 261 |
+
|
| 262 |
+
| Model | size<br><sup>(pixels) | mAP<sup>box<br>50-95 | mAP<sup>mask<br>50-95 | Train time<br><sup>300 epochs<br>A100 (hours) | Speed<br><sup>ONNX CPU<br>(ms) | Speed<br><sup>TRT A100<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>@640 (B) |
|
| 263 |
+
| ------------------------------------------------------------------------------------------ | --------------------- | -------------------- | --------------------- | --------------------------------------------- | ------------------------------ | ------------------------------ | ------------------ | ---------------------- |
|
| 264 |
+
| [YOLOv5n-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n-seg.pt) | 640 | 27.6 | 23.4 | 80:17 | **62.7** | **1.2** | **2.0** | **7.1** |
|
| 265 |
+
| [YOLOv5s-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s-seg.pt) | 640 | 37.6 | 31.7 | 88:16 | 173.3 | 1.4 | 7.6 | 26.4 |
|
| 266 |
+
| [YOLOv5m-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m-seg.pt) | 640 | 45.0 | 37.1 | 108:36 | 427.0 | 2.2 | 22.0 | 70.8 |
|
| 267 |
+
| [YOLOv5l-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l-seg.pt) | 640 | 49.0 | 39.9 | 66:43 (2x) | 857.4 | 2.9 | 47.9 | 147.7 |
|
| 268 |
+
| [YOLOv5x-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x-seg.pt) | 640 | **50.7** | **41.4** | 62:56 (3x) | 1579.2 | 4.5 | 88.8 | 265.7 |
|
| 269 |
+
|
| 270 |
+
- All checkpoints are trained to 300 epochs with SGD optimizer with `lr0=0.01` and `weight_decay=5e-5` at image size 640 and all default settings.<br>Runs logged to https://wandb.ai/glenn-jocher/YOLOv5_v70_official
|
| 271 |
+
- **Accuracy** values are for single-model single-scale on COCO dataset.<br>Reproduce by `python segment/val.py --data coco.yaml --weights yolov5s-seg.pt`
|
| 272 |
+
- **Speed** averaged over 100 inference images using a [Colab Pro](https://colab.research.google.com/signup) A100 High-RAM instance. Values indicate inference speed only (NMS adds about 1ms per image). <br>Reproduce by `python segment/val.py --data coco.yaml --weights yolov5s-seg.pt --batch 1`
|
| 273 |
+
- **Export** to ONNX at FP32 and TensorRT at FP16 done with `export.py`. <br>Reproduce by `python export.py --weights yolov5s-seg.pt --include engine --device 0 --half`
|
| 274 |
+
|
| 275 |
+
</details>
|
| 276 |
+
|
| 277 |
+
<details>
|
| 278 |
+
<summary>Segmentation Usage Examples <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/segment/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a></summary>
|
| 279 |
+
|
| 280 |
+
### Train
|
| 281 |
+
|
| 282 |
+
YOLOv5 segmentation training supports auto-download COCO128-seg segmentation dataset with `--data coco128-seg.yaml` argument and manual download of COCO-segments dataset with `bash data/scripts/get_coco.sh --train --val --segments` and then `python train.py --data coco.yaml`.
|
| 283 |
+
|
| 284 |
+
```bash
|
| 285 |
+
# Single-GPU
|
| 286 |
+
python segment/train.py --data coco128-seg.yaml --weights yolov5s-seg.pt --img 640
|
| 287 |
+
|
| 288 |
+
# Multi-GPU DDP
|
| 289 |
+
python -m torch.distributed.run --nproc_per_node 4 --master_port 1 segment/train.py --data coco128-seg.yaml --weights yolov5s-seg.pt --img 640 --device 0,1,2,3
|
| 290 |
+
```
|
| 291 |
+
|
| 292 |
+
### Val
|
| 293 |
+
|
| 294 |
+
Validate YOLOv5s-seg mask mAP on COCO dataset:
|
| 295 |
+
|
| 296 |
+
```bash
|
| 297 |
+
bash data/scripts/get_coco.sh --val --segments # download COCO val segments split (780MB, 5000 images)
|
| 298 |
+
python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 # validate
|
| 299 |
+
```
|
| 300 |
+
|
| 301 |
+
### Predict
|
| 302 |
+
|
| 303 |
+
Use pretrained YOLOv5m-seg.pt to predict bus.jpg:
|
| 304 |
+
|
| 305 |
+
```bash
|
| 306 |
+
python segment/predict.py --weights yolov5m-seg.pt --source data/images/bus.jpg
|
| 307 |
+
```
|
| 308 |
+
|
| 309 |
+
```python
|
| 310 |
+
model = torch.hub.load(
|
| 311 |
+
"ultralytics/yolov5", "custom", "yolov5m-seg.pt"
|
| 312 |
+
) # load from PyTorch Hub (WARNING: inference not yet supported)
|
| 313 |
+
```
|
| 314 |
+
|
| 315 |
+
| 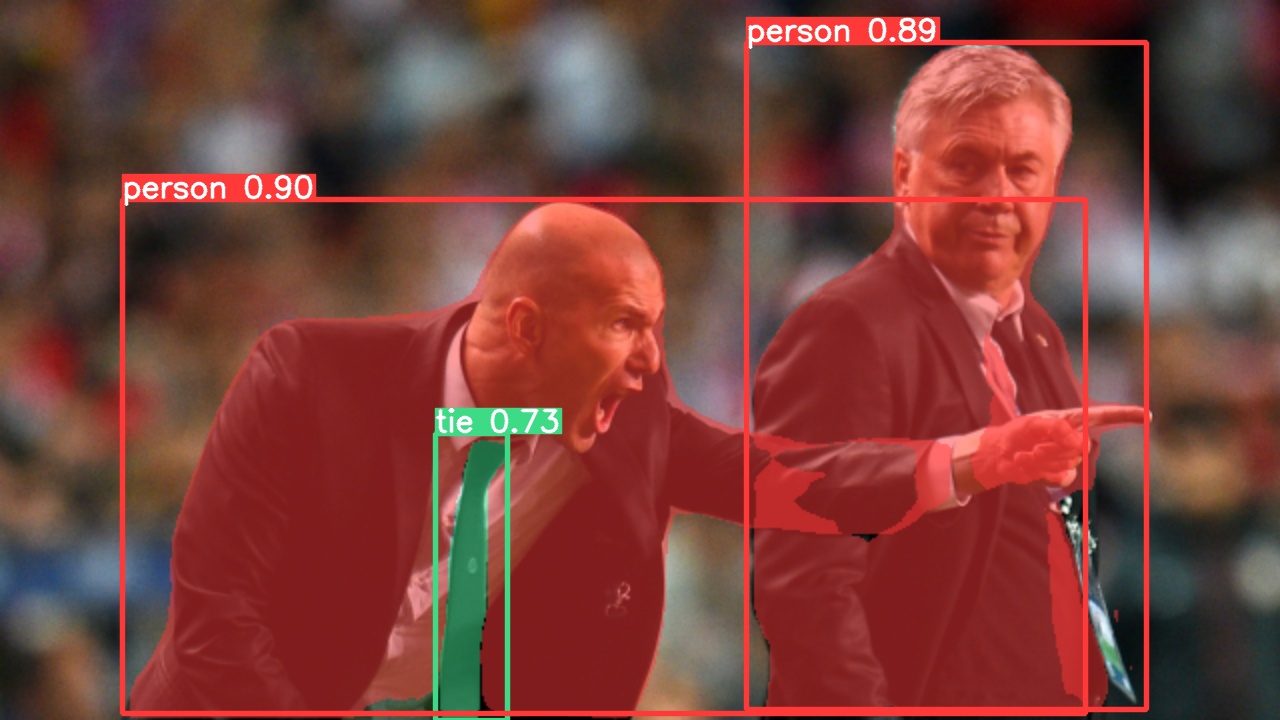 | 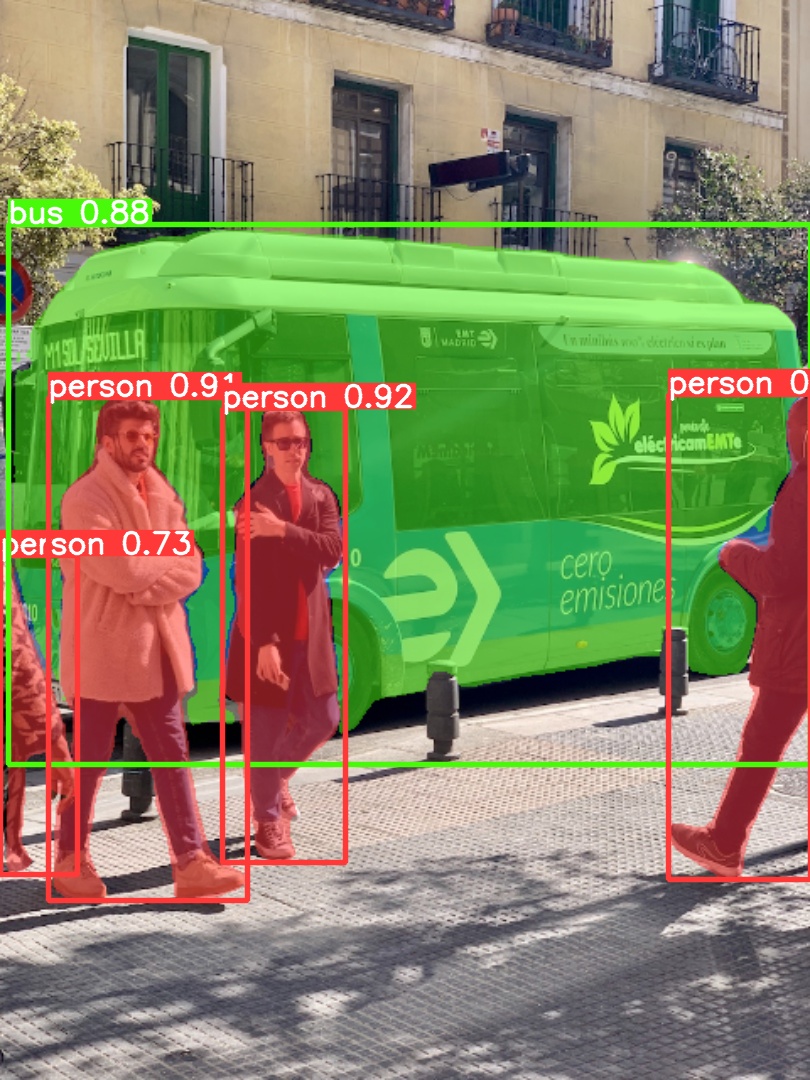 |
|
| 316 |
+
| ---------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------- |
|
| 317 |
+
|
| 318 |
+
### Export
|
| 319 |
+
|
| 320 |
+
Export YOLOv5s-seg model to ONNX and TensorRT:
|
| 321 |
+
|
| 322 |
+
```bash
|
| 323 |
+
python export.py --weights yolov5s-seg.pt --include onnx engine --img 640 --device 0
|
| 324 |
+
```
|
| 325 |
+
|
| 326 |
+
</details>
|
| 327 |
+
|
| 328 |
+
## <div align="center">Classification</div>
|
| 329 |
+
|
| 330 |
+
YOLOv5 [release v6.2](https://github.com/ultralytics/yolov5/releases) brings support for classification model training, validation and deployment! See full details in our [Release Notes](https://github.com/ultralytics/yolov5/releases/v6.2) and visit our [YOLOv5 Classification Colab Notebook](https://github.com/ultralytics/yolov5/blob/master/classify/tutorial.ipynb) for quickstart tutorials.
|
| 331 |
+
|
| 332 |
+
<details>
|
| 333 |
+
<summary>Classification Checkpoints</summary>
|
| 334 |
+
|
| 335 |
+
<br>
|
| 336 |
+
|
| 337 |
+
We trained YOLOv5-cls classification models on ImageNet for 90 epochs using a 4xA100 instance, and we trained ResNet and EfficientNet models alongside with the same default training settings to compare. We exported all models to ONNX FP32 for CPU speed tests and to TensorRT FP16 for GPU speed tests. We ran all speed tests on Google [Colab Pro](https://colab.research.google.com/signup) for easy reproducibility.
|
| 338 |
+
|
| 339 |
+
| Model | size<br><sup>(pixels) | acc<br><sup>top1 | acc<br><sup>top5 | Training<br><sup>90 epochs<br>4xA100 (hours) | Speed<br><sup>ONNX CPU<br>(ms) | Speed<br><sup>TensorRT V100<br>(ms) | params<br><sup>(M) | FLOPs<br><sup>@224 (B) |
|
| 340 |
+
| -------------------------------------------------------------------------------------------------- | --------------------- | ---------------- | ---------------- | -------------------------------------------- | ------------------------------ | ----------------------------------- | ------------------ | ---------------------- |
|
| 341 |
+
| [YOLOv5n-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n-cls.pt) | 224 | 64.6 | 85.4 | 7:59 | **3.3** | **0.5** | **2.5** | **0.5** |
|
| 342 |
+
| [YOLOv5s-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s-cls.pt) | 224 | 71.5 | 90.2 | 8:09 | 6.6 | 0.6 | 5.4 | 1.4 |
|
| 343 |
+
| [YOLOv5m-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m-cls.pt) | 224 | 75.9 | 92.9 | 10:06 | 15.5 | 0.9 | 12.9 | 3.9 |
|
| 344 |
+
| [YOLOv5l-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l-cls.pt) | 224 | 78.0 | 94.0 | 11:56 | 26.9 | 1.4 | 26.5 | 8.5 |
|
| 345 |
+
| [YOLOv5x-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x-cls.pt) | 224 | **79.0** | **94.4** | 15:04 | 54.3 | 1.8 | 48.1 | 15.9 |
|
| 346 |
+
| | | | | | | | | |
|
| 347 |
+
| [ResNet18](https://github.com/ultralytics/yolov5/releases/download/v7.0/resnet18.pt) | 224 | 70.3 | 89.5 | **6:47** | 11.2 | 0.5 | 11.7 | 3.7 |
|
| 348 |
+
| [ResNet34](https://github.com/ultralytics/yolov5/releases/download/v7.0/resnet34.pt) | 224 | 73.9 | 91.8 | 8:33 | 20.6 | 0.9 | 21.8 | 7.4 |
|
| 349 |
+
| [ResNet50](https://github.com/ultralytics/yolov5/releases/download/v7.0/resnet50.pt) | 224 | 76.8 | 93.4 | 11:10 | 23.4 | 1.0 | 25.6 | 8.5 |
|
| 350 |
+
| [ResNet101](https://github.com/ultralytics/yolov5/releases/download/v7.0/resnet101.pt) | 224 | 78.5 | 94.3 | 17:10 | 42.1 | 1.9 | 44.5 | 15.9 |
|
| 351 |
+
| | | | | | | | | |
|
| 352 |
+
| [EfficientNet_b0](https://github.com/ultralytics/yolov5/releases/download/v7.0/efficientnet_b0.pt) | 224 | 75.1 | 92.4 | 13:03 | 12.5 | 1.3 | 5.3 | 1.0 |
|
| 353 |
+
| [EfficientNet_b1](https://github.com/ultralytics/yolov5/releases/download/v7.0/efficientnet_b1.pt) | 224 | 76.4 | 93.2 | 17:04 | 14.9 | 1.6 | 7.8 | 1.5 |
|
| 354 |
+
| [EfficientNet_b2](https://github.com/ultralytics/yolov5/releases/download/v7.0/efficientnet_b2.pt) | 224 | 76.6 | 93.4 | 17:10 | 15.9 | 1.6 | 9.1 | 1.7 |
|
| 355 |
+
| [EfficientNet_b3](https://github.com/ultralytics/yolov5/releases/download/v7.0/efficientnet_b3.pt) | 224 | 77.7 | 94.0 | 19:19 | 18.9 | 1.9 | 12.2 | 2.4 |
|
| 356 |
+
|
| 357 |
+
<details>
|
| 358 |
+
<summary>Table Notes (click to expand)</summary>
|
| 359 |
+
|
| 360 |
+
- All checkpoints are trained to 90 epochs with SGD optimizer with `lr0=0.001` and `weight_decay=5e-5` at image size 224 and all default settings.<br>Runs logged to https://wandb.ai/glenn-jocher/YOLOv5-Classifier-v6-2
|
| 361 |
+
- **Accuracy** values are for single-model single-scale on [ImageNet-1k](https://www.image-net.org/index.php) dataset.<br>Reproduce by `python classify/val.py --data ../datasets/imagenet --img 224`
|
| 362 |
+
- **Speed** averaged over 100 inference images using a Google [Colab Pro](https://colab.research.google.com/signup) V100 High-RAM instance.<br>Reproduce by `python classify/val.py --data ../datasets/imagenet --img 224 --batch 1`
|
| 363 |
+
- **Export** to ONNX at FP32 and TensorRT at FP16 done with `export.py`. <br>Reproduce by `python export.py --weights yolov5s-cls.pt --include engine onnx --imgsz 224`
|
| 364 |
+
|
| 365 |
+
</details>
|
| 366 |
+
</details>
|
| 367 |
+
|
| 368 |
+
<details>
|
| 369 |
+
<summary>Classification Usage Examples <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/classify/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a></summary>
|
| 370 |
+
|
| 371 |
+
### Train
|
| 372 |
+
|
| 373 |
+
YOLOv5 classification training supports auto-download of MNIST, Fashion-MNIST, CIFAR10, CIFAR100, Imagenette, Imagewoof, and ImageNet datasets with the `--data` argument. To start training on MNIST for example use `--data mnist`.
|
| 374 |
+
|
| 375 |
+
```bash
|
| 376 |
+
# Single-GPU
|
| 377 |
+
python classify/train.py --model yolov5s-cls.pt --data cifar100 --epochs 5 --img 224 --batch 128
|
| 378 |
+
|
| 379 |
+
# Multi-GPU DDP
|
| 380 |
+
python -m torch.distributed.run --nproc_per_node 4 --master_port 1 classify/train.py --model yolov5s-cls.pt --data imagenet --epochs 5 --img 224 --device 0,1,2,3
|
| 381 |
+
```
|
| 382 |
+
|
| 383 |
+
### Val
|
| 384 |
+
|
| 385 |
+
Validate YOLOv5m-cls accuracy on ImageNet-1k dataset:
|
| 386 |
+
|
| 387 |
+
```bash
|
| 388 |
+
bash data/scripts/get_imagenet.sh --val # download ImageNet val split (6.3G, 50000 images)
|
| 389 |
+
python classify/val.py --weights yolov5m-cls.pt --data ../datasets/imagenet --img 224 # validate
|
| 390 |
+
```
|
| 391 |
+
|
| 392 |
+
### Predict
|
| 393 |
+
|
| 394 |
+
Use pretrained YOLOv5s-cls.pt to predict bus.jpg:
|
| 395 |
+
|
| 396 |
+
```bash
|
| 397 |
+
python classify/predict.py --weights yolov5s-cls.pt --source data/images/bus.jpg
|
| 398 |
+
```
|
| 399 |
+
|
| 400 |
+
```python
|
| 401 |
+
model = torch.hub.load(
|
| 402 |
+
"ultralytics/yolov5", "custom", "yolov5s-cls.pt"
|
| 403 |
+
) # load from PyTorch Hub
|
| 404 |
+
```
|
| 405 |
+
|
| 406 |
+
### Export
|
| 407 |
+
|
| 408 |
+
Export a group of trained YOLOv5s-cls, ResNet and EfficientNet models to ONNX and TensorRT:
|
| 409 |
+
|
| 410 |
+
```bash
|
| 411 |
+
python export.py --weights yolov5s-cls.pt resnet50.pt efficientnet_b0.pt --include onnx engine --img 224
|
| 412 |
+
```
|
| 413 |
+
|
| 414 |
+
</details>
|
| 415 |
+
|
| 416 |
+
## <div align="center">Environments</div>
|
| 417 |
+
|
| 418 |
+
Get started in seconds with our verified environments. Click each icon below for details.
|
| 419 |
+
|
| 420 |
+
<div align="center">
|
| 421 |
+
<a href="https://bit.ly/yolov5-paperspace-notebook">
|
| 422 |
+
<img src="https://github.com/ultralytics/yolov5/releases/download/v1.0/logo-gradient.png" width="10%" /></a>
|
| 423 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="5%" alt="" />
|
| 424 |
+
<a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb">
|
| 425 |
+
<img src="https://github.com/ultralytics/yolov5/releases/download/v1.0/logo-colab-small.png" width="10%" /></a>
|
| 426 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="5%" alt="" />
|
| 427 |
+
<a href="https://www.kaggle.com/ultralytics/yolov5">
|
| 428 |
+
<img src="https://github.com/ultralytics/yolov5/releases/download/v1.0/logo-kaggle-small.png" width="10%" /></a>
|
| 429 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="5%" alt="" />
|
| 430 |
+
<a href="https://hub.docker.com/r/ultralytics/yolov5">
|
| 431 |
+
<img src="https://github.com/ultralytics/yolov5/releases/download/v1.0/logo-docker-small.png" width="10%" /></a>
|
| 432 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="5%" alt="" />
|
| 433 |
+
<a href="https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/">
|
| 434 |
+
<img src="https://github.com/ultralytics/yolov5/releases/download/v1.0/logo-aws-small.png" width="10%" /></a>
|
| 435 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="5%" alt="" />
|
| 436 |
+
<a href="https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/">
|
| 437 |
+
<img src="https://github.com/ultralytics/yolov5/releases/download/v1.0/logo-gcp-small.png" width="10%" /></a>
|
| 438 |
+
</div>
|
| 439 |
+
|
| 440 |
+
## <div align="center">Contribute</div>
|
| 441 |
+
|
| 442 |
+
We love your input! We want to make contributing to YOLOv5 as easy and transparent as possible. Please see our [Contributing Guide](https://docs.ultralytics.com/help/contributing/) to get started, and fill out the [YOLOv5 Survey](https://ultralytics.com/survey?utm_source=github&utm_medium=social&utm_campaign=Survey) to send us feedback on your experiences. Thank you to all our contributors!
|
| 443 |
+
|
| 444 |
+
<!-- SVG image from https://opencollective.com/ultralytics/contributors.svg?width=990 -->
|
| 445 |
+
|
| 446 |
+
<a href="https://github.com/ultralytics/yolov5/graphs/contributors">
|
| 447 |
+
<img src="https://github.com/ultralytics/assets/raw/main/im/image-contributors.png" /></a>
|
| 448 |
+
|
| 449 |
+
## <div align="center">License</div>
|
| 450 |
+
|
| 451 |
+
Ultralytics offers two licensing options to accommodate diverse use cases:
|
| 452 |
+
|
| 453 |
+
- **AGPL-3.0 License**: This [OSI-approved](https://opensource.org/licenses/) open-source license is ideal for students and enthusiasts, promoting open collaboration and knowledge sharing. See the [LICENSE](https://github.com/ultralytics/yolov5/blob/master/LICENSE) file for more details.
|
| 454 |
+
- **Enterprise License**: Designed for commercial use, this license permits seamless integration of Ultralytics software and AI models into commercial goods and services, bypassing the open-source requirements of AGPL-3.0. If your scenario involves embedding our solutions into a commercial offering, reach out through [Ultralytics Licensing](https://ultralytics.com/license).
|
| 455 |
+
|
| 456 |
+
## <div align="center">Contact</div>
|
| 457 |
+
|
| 458 |
+
For YOLOv5 bug reports and feature requests please visit [GitHub Issues](https://github.com/ultralytics/yolov5/issues), and join our [Discord](https://ultralytics.com/discord) community for questions and discussions!
|
| 459 |
+
|
| 460 |
+
<br>
|
| 461 |
+
<div align="center">
|
| 462 |
+
<a href="https://github.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-github.png" width="3%" alt="Ultralytics GitHub"></a>
|
| 463 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
| 464 |
+
<a href="https://www.linkedin.com/company/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-linkedin.png" width="3%" alt="Ultralytics LinkedIn"></a>
|
| 465 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
| 466 |
+
<a href="https://twitter.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-twitter.png" width="3%" alt="Ultralytics Twitter"></a>
|
| 467 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
| 468 |
+
<a href="https://youtube.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-youtube.png" width="3%" alt="Ultralytics YouTube"></a>
|
| 469 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
| 470 |
+
<a href="https://www.tiktok.com/@ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-tiktok.png" width="3%" alt="Ultralytics TikTok"></a>
|
| 471 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
| 472 |
+
<a href="https://www.instagram.com/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-instagram.png" width="3%" alt="Ultralytics Instagram"></a>
|
| 473 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
| 474 |
+
<a href="https://ultralytics.com/discord"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-discord.png" width="3%" alt="Ultralytics Discord"></a>
|
| 475 |
+
</div>
|
| 476 |
+
|
| 477 |
+
[tta]: https://docs.ultralytics.com/yolov5/tutorials/test_time_augmentation
|
yolov5/README.zh-CN.md
ADDED
|
@@ -0,0 +1,473 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<div align="center">
|
| 2 |
+
<p>
|
| 3 |
+
<a href="https://yolovision.ultralytics.com/" target="_blank">
|
| 4 |
+
<img width="100%" src="https://raw.githubusercontent.com/ultralytics/assets/main/im/banner-yolo-vision-2023.png"></a>
|
| 5 |
+
<!--
|
| 6 |
+
<a align="center" href="https://ultralytics.com/yolov5" target="_blank">
|
| 7 |
+
<img width="100%" src="https://raw.githubusercontent.com/ultralytics/assets/main/yolov5/v70/splash.png"></a>
|
| 8 |
+
-->
|
| 9 |
+
</p>
|
| 10 |
+
|
| 11 |
+
[中文](https://docs.ultralytics.com/zh/) | [한국어](https://docs.ultralytics.com/ko/) | [日本語](https://docs.ultralytics.com/ja/) | [Русский](https://docs.ultralytics.com/ru/) | [Deutsch](https://docs.ultralytics.com/de/) | [Français](https://docs.ultralytics.com/fr/) | [Español](https://docs.ultralytics.com/es/) | [Português](https://docs.ultralytics.com/pt/) | [हिन्दी](https://docs.ultralytics.com/hi/) | [العربية](https://docs.ultralytics.com/ar/)
|
| 12 |
+
|
| 13 |
+
<div>
|
| 14 |
+
<a href="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml"><img src="https://github.com/ultralytics/yolov5/actions/workflows/ci-testing.yml/badge.svg" alt="YOLOv5 CI"></a>
|
| 15 |
+
<a href="https://zenodo.org/badge/latestdoi/264818686"><img src="https://zenodo.org/badge/264818686.svg" alt="YOLOv5 Citation"></a>
|
| 16 |
+
<a href="https://hub.docker.com/r/ultralytics/yolov5"><img src="https://img.shields.io/docker/pulls/ultralytics/yolov5?logo=docker" alt="Docker Pulls"></a>
|
| 17 |
+
<br>
|
| 18 |
+
<a href="https://bit.ly/yolov5-paperspace-notebook"><img src="https://assets.paperspace.io/img/gradient-badge.svg" alt="Run on Gradient"></a>
|
| 19 |
+
<a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a>
|
| 20 |
+
<a href="https://www.kaggle.com/ultralytics/yolov5"><img src="https://kaggle.com/static/images/open-in-kaggle.svg" alt="Open In Kaggle"></a>
|
| 21 |
+
</div>
|
| 22 |
+
<br>
|
| 23 |
+
|
| 24 |
+
YOLOv5 🚀 是世界上最受欢迎的视觉 AI,代表<a href="https://ultralytics.com"> Ultralytics </a>对未来视觉 AI 方法的开源研究,结合在数千小时的研究和开发中积累的经验教训和最佳实践。
|
| 25 |
+
|
| 26 |
+
我们希望这里的资源能帮助您充分利用 YOLOv5。请浏览 YOLOv5 <a href="https://docs.ultralytics.com/yolov5/">文档</a> 了解详细信息,在 <a href="https://github.com/ultralytics/yolov5/issues/new/choose">GitHub</a> 上提交问题以获得支持,并加入我们的 <a href="https://ultralytics.com/discord">Discord</a> 社区进行问题和讨论!
|
| 27 |
+
|
| 28 |
+
如需申请企业许可,请在 [Ultralytics Licensing](https://ultralytics.com/license) 处填写表格
|
| 29 |
+
|
| 30 |
+
<div align="center">
|
| 31 |
+
<a href="https://github.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-github.png" width="2%" alt="Ultralytics GitHub"></a>
|
| 32 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%">
|
| 33 |
+
<a href="https://www.linkedin.com/company/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-linkedin.png" width="2%" alt="Ultralytics LinkedIn"></a>
|
| 34 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%">
|
| 35 |
+
<a href="https://twitter.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-twitter.png" width="2%" alt="Ultralytics Twitter"></a>
|
| 36 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%">
|
| 37 |
+
<a href="https://youtube.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-youtube.png" width="2%" alt="Ultralytics YouTube"></a>
|
| 38 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%">
|
| 39 |
+
<a href="https://www.tiktok.com/@ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-tiktok.png" width="2%" alt="Ultralytics TikTok"></a>
|
| 40 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%">
|
| 41 |
+
<a href="https://www.instagram.com/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-instagram.png" width="2%" alt="Ultralytics Instagram"></a>
|
| 42 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="2%">
|
| 43 |
+
<a href="https://ultralytics.com/discord"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-discord.png" width="2%" alt="Ultralytics Discord"></a>
|
| 44 |
+
</div>
|
| 45 |
+
</div>
|
| 46 |
+
|
| 47 |
+
## <div align="center">YOLOv8 🚀 新品</div>
|
| 48 |
+
|
| 49 |
+
我们很高兴宣布 Ultralytics YOLOv8 🚀 的发布,这是我们新推出的领先水平、最先进的(SOTA)模型,发布于 **[https://github.com/ultralytics/ultralytics](https://github.com/ultralytics/ultralytics)**。 YOLOv8 旨在快速、准确且易于使用,使其成为广泛的物体检测、图像分割和图像分类任务的极佳选择。
|
| 50 |
+
|
| 51 |
+
请查看 [YOLOv8 文档](https://docs.ultralytics.com)了解详细信息,并开始使���:
|
| 52 |
+
|
| 53 |
+
[](https://badge.fury.io/py/ultralytics) [](https://pepy.tech/project/ultralytics)
|
| 54 |
+
|
| 55 |
+
```commandline
|
| 56 |
+
pip install ultralytics
|
| 57 |
+
```
|
| 58 |
+
|
| 59 |
+
<div align="center">
|
| 60 |
+
<a href="https://ultralytics.com/yolov8" target="_blank">
|
| 61 |
+
<img width="100%" src="https://raw.githubusercontent.com/ultralytics/assets/main/yolov8/yolo-comparison-plots.png"></a>
|
| 62 |
+
</div>
|
| 63 |
+
|
| 64 |
+
## <div align="center">文档</div>
|
| 65 |
+
|
| 66 |
+
有关训练、测试和部署的完整文档见[YOLOv5 文档](https://docs.ultralytics.com/yolov5/)。请参阅下面的快速入门示例。
|
| 67 |
+
|
| 68 |
+
<details open>
|
| 69 |
+
<summary>安装</summary>
|
| 70 |
+
|
| 71 |
+
克隆 repo,并要求在 [**Python>=3.8.0**](https://www.python.org/) 环境中安装 [requirements.txt](https://github.com/ultralytics/yolov5/blob/master/requirements.txt) ,且要求 [**PyTorch>=1.8**](https://pytorch.org/get-started/locally/) 。
|
| 72 |
+
|
| 73 |
+
```bash
|
| 74 |
+
git clone https://github.com/ultralytics/yolov5 # clone
|
| 75 |
+
cd yolov5
|
| 76 |
+
pip install -r requirements.txt # install
|
| 77 |
+
```
|
| 78 |
+
|
| 79 |
+
</details>
|
| 80 |
+
|
| 81 |
+
<details>
|
| 82 |
+
<summary>推理</summary>
|
| 83 |
+
|
| 84 |
+
使用 YOLOv5 [PyTorch Hub](https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading) 推理。最新 [模型](https://github.com/ultralytics/yolov5/tree/master/models) 将自动的从 YOLOv5 [release](https://github.com/ultralytics/yolov5/releases) 中下载。
|
| 85 |
+
|
| 86 |
+
```python
|
| 87 |
+
import torch
|
| 88 |
+
|
| 89 |
+
# Model
|
| 90 |
+
model = torch.hub.load("ultralytics/yolov5", "yolov5s") # or yolov5n - yolov5x6, custom
|
| 91 |
+
|
| 92 |
+
# Images
|
| 93 |
+
img = "https://ultralytics.com/images/zidane.jpg" # or file, Path, PIL, OpenCV, numpy, list
|
| 94 |
+
|
| 95 |
+
# Inference
|
| 96 |
+
results = model(img)
|
| 97 |
+
|
| 98 |
+
# Results
|
| 99 |
+
results.print() # or .show(), .save(), .crop(), .pandas(), etc.
|
| 100 |
+
```
|
| 101 |
+
|
| 102 |
+
</details>
|
| 103 |
+
|
| 104 |
+
<details>
|
| 105 |
+
<summary>使用 detect.py 推理</summary>
|
| 106 |
+
|
| 107 |
+
`detect.py` 在各种来源上运行推理, [模型](https://github.com/ultralytics/yolov5/tree/master/models) 自动从 最新的YOLOv5 [release](https://github.com/ultralytics/yolov5/releases) 中下载,并将结果保存到 `runs/detect` 。
|
| 108 |
+
|
| 109 |
+
```bash
|
| 110 |
+
python detect.py --weights yolov5s.pt --source 0 # webcam
|
| 111 |
+
img.jpg # image
|
| 112 |
+
vid.mp4 # video
|
| 113 |
+
screen # screenshot
|
| 114 |
+
path/ # directory
|
| 115 |
+
list.txt # list of images
|
| 116 |
+
list.streams # list of streams
|
| 117 |
+
'path/*.jpg' # glob
|
| 118 |
+
'https://youtu.be/LNwODJXcvt4' # YouTube
|
| 119 |
+
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
|
| 120 |
+
```
|
| 121 |
+
|
| 122 |
+
</details>
|
| 123 |
+
|
| 124 |
+
<details>
|
| 125 |
+
<summary>训练</summary>
|
| 126 |
+
|
| 127 |
+
下面的命令重现 YOLOv5 在 [COCO](https://github.com/ultralytics/yolov5/blob/master/data/scripts/get_coco.sh) 数据集上的结果。 最新的 [模型](https://github.com/ultralytics/yolov5/tree/master/models) 和 [数据集](https://github.com/ultralytics/yolov5/tree/master/data)
|
| 128 |
+
将自动的从 YOLOv5 [release](https://github.com/ultralytics/yolov5/releases) 中下载。 YOLOv5n/s/m/l/x 在 V100 GPU 的训练时间为 1/2/4/6/8 天( [多GPU](https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training) 训练速度更快)。 尽可能使用更大的 `--batch-size` ,或通过 `--batch-size -1` 实现 YOLOv5 [自动批处理](https://github.com/ultralytics/yolov5/pull/5092) 。下方显示的 batchsize 适用于 V100-16GB。
|
| 129 |
+
|
| 130 |
+
```bash
|
| 131 |
+
python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml --batch-size 128
|
| 132 |
+
yolov5s 64
|
| 133 |
+
yolov5m 40
|
| 134 |
+
yolov5l 24
|
| 135 |
+
yolov5x 16
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
<img width="800" src="https://user-images.githubusercontent.com/26833433/90222759-949d8800-ddc1-11ea-9fa1-1c97eed2b963.png">
|
| 139 |
+
|
| 140 |
+
</details>
|
| 141 |
+
|
| 142 |
+
<details open>
|
| 143 |
+
<summary>教程</summary>
|
| 144 |
+
|
| 145 |
+
- [训练自定义数据](https://docs.ultralytics.com/yolov5/tutorials/train_custom_data) 🚀 推荐
|
| 146 |
+
- [获得最佳训练结果的技巧](https://docs.ultralytics.com/yolov5/tutorials/tips_for_best_training_results) ☘️
|
| 147 |
+
- [多GPU训练](https://docs.ultralytics.com/yolov5/tutorials/multi_gpu_training)
|
| 148 |
+
- [PyTorch Hub](https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading) 🌟 新
|
| 149 |
+
- [TFLite,ONNX,CoreML,TensorRT导出](https://docs.ultralytics.com/yolov5/tutorials/model_export) 🚀
|
| 150 |
+
- [NVIDIA Jetson平台部署](https://docs.ultralytics.com/yolov5/tutorials/running_on_jetson_nano) 🌟 新
|
| 151 |
+
- [测试时增强 (TTA)](https://docs.ultralytics.com/yolov5/tutorials/test_time_augmentation)
|
| 152 |
+
- [模型集成](https://docs.ultralytics.com/yolov5/tutorials/model_ensembling)
|
| 153 |
+
- [模型剪枝/稀疏](https://docs.ultralytics.com/yolov5/tutorials/model_pruning_and_sparsity)
|
| 154 |
+
- [超参数进化](https://docs.ultralytics.com/yolov5/tutorials/hyperparameter_evolution)
|
| 155 |
+
- [冻结层的迁移学习](https://docs.ultralytics.com/yolov5/tutorials/transfer_learning_with_frozen_layers)
|
| 156 |
+
- [架构概述](https://docs.ultralytics.com/yolov5/tutorials/architecture_description) 🌟 新
|
| 157 |
+
- [Roboflow用于数据集、标注和主动学习](https://docs.ultralytics.com/yolov5/tutorials/roboflow_datasets_integration)
|
| 158 |
+
- [ClearML日志记录](https://docs.ultralytics.com/yolov5/tutorials/clearml_logging_integration) 🌟 新
|
| 159 |
+
- [使用Neural Magic的Deepsparse的YOLOv5](https://docs.ultralytics.com/yolov5/tutorials/neural_magic_pruning_quantization) 🌟 新
|
| 160 |
+
- [Comet日志记录](https://docs.ultralytics.com/yolov5/tutorials/comet_logging_integration) 🌟 新
|
| 161 |
+
|
| 162 |
+
</details>
|
| 163 |
+
|
| 164 |
+
## <div align="center">模块集成</div>
|
| 165 |
+
|
| 166 |
+
<br>
|
| 167 |
+
<a align="center" href="https://bit.ly/ultralytics_hub" target="_blank">
|
| 168 |
+
<img width="100%" src="https://github.com/ultralytics/assets/raw/main/im/integrations-loop.png"></a>
|
| 169 |
+
<br>
|
| 170 |
+
<br>
|
| 171 |
+
|
| 172 |
+
<div align="center">
|
| 173 |
+
<a href="https://roboflow.com/?ref=ultralytics">
|
| 174 |
+
<img src="https://github.com/ultralytics/assets/raw/main/partners/logo-roboflow.png" width="10%" /></a>
|
| 175 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="15%" height="0" alt="" />
|
| 176 |
+
<a href="https://cutt.ly/yolov5-readme-clearml">
|
| 177 |
+
<img src="https://github.com/ultralytics/assets/raw/main/partners/logo-clearml.png" width="10%" /></a>
|
| 178 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="15%" height="0" alt="" />
|
| 179 |
+
<a href="https://bit.ly/yolov5-readme-comet2">
|
| 180 |
+
<img src="https://github.com/ultralytics/assets/raw/main/partners/logo-comet.png" width="10%" /></a>
|
| 181 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="15%" height="0" alt="" />
|
| 182 |
+
<a href="https://bit.ly/yolov5-neuralmagic">
|
| 183 |
+
<img src="https://github.com/ultralytics/assets/raw/main/partners/logo-neuralmagic.png" width="10%" /></a>
|
| 184 |
+
</div>
|
| 185 |
+
|
| 186 |
+
| Roboflow | ClearML ⭐ 新 | Comet ⭐ 新 | Neural Magic ⭐ 新 |
|
| 187 |
+
| :--------------------------------------------------------------------------------: | :-------------------------------------------------------------------------: | :--------------------------------------------------------------------------------: | :------------------------------------------------------------------------------------: |
|
| 188 |
+
| 将您的自定义数据集进行标注并直接导出到 YOLOv5 以进行训练 [Roboflow](https://roboflow.com/?ref=ultralytics) | 自动跟踪、可视化甚至远程训练 YOLOv5 [ClearML](https://cutt.ly/yolov5-readme-clearml)(开源!) | 永远免费,[Comet](https://bit.ly/yolov5-readme-comet2)可让您保存 YOLOv5 模型、恢复训练以及交互式可视化和调试预测 | 使用 [Neural Magic DeepSparse](https://bit.ly/yolov5-neuralmagic),运行 YOLOv5 推理的速度最高可提高6倍 |
|
| 189 |
+
|
| 190 |
+
## <div align="center">Ultralytics HUB</div>
|
| 191 |
+
|
| 192 |
+
[Ultralytics HUB](https://bit.ly/ultralytics_hub) 是我们的⭐**新的**用于可视化数据集、训练 YOLOv5 🚀 模型并以无缝体验部署到现实世界的无代码解决方案。现在开始 **免费** 使用他!
|
| 193 |
+
|
| 194 |
+
<a align="center" href="https://bit.ly/ultralytics_hub" target="_blank">
|
| 195 |
+
<img width="100%" src="https://github.com/ultralytics/assets/raw/main/im/ultralytics-hub.png"></a>
|
| 196 |
+
|
| 197 |
+
## <div align="center">为什么选择 YOLOv5</div>
|
| 198 |
+
|
| 199 |
+
YOLOv5 超级容易上手,简单易学。我们优先考虑现实世界的结果。
|
| 200 |
+
|
| 201 |
+
<p align="left"><img width="800" src="https://user-images.githubusercontent.com/26833433/155040763-93c22a27-347c-4e3c-847a-8094621d3f4e.png"></p>
|
| 202 |
+
<details>
|
| 203 |
+
<summary>YOLOv5-P5 640 图</summary>
|
| 204 |
+
|
| 205 |
+
<p align="left"><img width="800" src="https://user-images.githubusercontent.com/26833433/155040757-ce0934a3-06a6-43dc-a979-2edbbd69ea0e.png"></p>
|
| 206 |
+
</details>
|
| 207 |
+
<details>
|
| 208 |
+
<summary>图表笔记</summary>
|
| 209 |
+
|
| 210 |
+
- **COCO AP val** 表示 [email protected]:0.95 指标,在 [COCO val2017](http://cocodataset.org) 数据集的 5000 张图像上测得, 图像包含 256 到 1536 各种推理大小。
|
| 211 |
+
- **显卡推理速度** 为在 [COCO val2017](http://cocodataset.org) 数据集上的平均推理时间,使用 [AWS p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/) V100实例,batchsize 为 32 。
|
| 212 |
+
- **EfficientDet** 数据来自 [google/automl](https://github.com/google/automl) , batchsize 为32���
|
| 213 |
+
- **复现命令** 为 `python val.py --task study --data coco.yaml --iou 0.7 --weights yolov5n6.pt yolov5s6.pt yolov5m6.pt yolov5l6.pt yolov5x6.pt`
|
| 214 |
+
|
| 215 |
+
</details>
|
| 216 |
+
|
| 217 |
+
### 预训练模型
|
| 218 |
+
|
| 219 |
+
| 模型 | 尺寸<br><sup>(像素) | mAP<sup>val<br>50-95 | mAP<sup>val<br>50 | 推理速度<br><sup>CPU b1<br>(ms) | 推理速度<br><sup>V100 b1<br>(ms) | 速度<br><sup>V100 b32<br>(ms) | 参数量<br><sup>(M) | FLOPs<br><sup>@640 (B) |
|
| 220 |
+
| ---------------------------------------------------------------------------------------------- | --------------- | -------------------- | ----------------- | --------------------------- | ---------------------------- | --------------------------- | --------------- | ---------------------- |
|
| 221 |
+
| [YOLOv5n](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n.pt) | 640 | 28.0 | 45.7 | **45** | **6.3** | **0.6** | **1.9** | **4.5** |
|
| 222 |
+
| [YOLOv5s](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt) | 640 | 37.4 | 56.8 | 98 | 6.4 | 0.9 | 7.2 | 16.5 |
|
| 223 |
+
| [YOLOv5m](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m.pt) | 640 | 45.4 | 64.1 | 224 | 8.2 | 1.7 | 21.2 | 49.0 |
|
| 224 |
+
| [YOLOv5l](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l.pt) | 640 | 49.0 | 67.3 | 430 | 10.1 | 2.7 | 46.5 | 109.1 |
|
| 225 |
+
| [YOLOv5x](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x.pt) | 640 | 50.7 | 68.9 | 766 | 12.1 | 4.8 | 86.7 | 205.7 |
|
| 226 |
+
| | | | | | | | | |
|
| 227 |
+
| [YOLOv5n6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n6.pt) | 1280 | 36.0 | 54.4 | 153 | 8.1 | 2.1 | 3.2 | 4.6 |
|
| 228 |
+
| [YOLOv5s6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s6.pt) | 1280 | 44.8 | 63.7 | 385 | 8.2 | 3.6 | 12.6 | 16.8 |
|
| 229 |
+
| [YOLOv5m6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m6.pt) | 1280 | 51.3 | 69.3 | 887 | 11.1 | 6.8 | 35.7 | 50.0 |
|
| 230 |
+
| [YOLOv5l6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l6.pt) | 1280 | 53.7 | 71.3 | 1784 | 15.8 | 10.5 | 76.8 | 111.4 |
|
| 231 |
+
| [YOLOv5x6](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x6.pt)<br>+[TTA] | 1280<br>1536 | 55.0<br>**55.8** | 72.7<br>**72.7** | 3136<br>- | 26.2<br>- | 19.4<br>- | 140.7<br>- | 209.8<br>- |
|
| 232 |
+
|
| 233 |
+
<details>
|
| 234 |
+
<summary>笔记</summary>
|
| 235 |
+
|
| 236 |
+
- 所有模型都使用默认配置,训练 300 epochs。n和s模型使用 [hyp.scratch-low.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-low.yaml) ,其他模型都使用 [hyp.scratch-high.yaml](https://github.com/ultralytics/yolov5/blob/master/data/hyps/hyp.scratch-high.yaml) 。
|
| 237 |
+
- \*\*mAP<sup>val</sup>\*\*在单模型单尺度上计算,数据集使用 [COCO val2017](http://cocodataset.org) 。<br>复现命令 `python val.py --data coco.yaml --img 640 --conf 0.001 --iou 0.65`
|
| 238 |
+
- **推理速度**在 COCO val 图像总体时间上进行平均得到,测试环境使用[AWS p3.2xlarge](https://aws.amazon.com/ec2/instance-types/p3/)实例。 NMS 时间 (大约 1 ms/img) 不包括在内。<br>复现命令 `python val.py --data coco.yaml --img 640 --task speed --batch 1`
|
| 239 |
+
- **TTA** [测试时数据增强](https://docs.ultralytics.com/yolov5/tutorials/test_time_augmentation) 包括反射和尺度变换。<br>复现命令 `python val.py --data coco.yaml --img 1536 --iou 0.7 --augment`
|
| 240 |
+
|
| 241 |
+
</details>
|
| 242 |
+
|
| 243 |
+
## <div align="center">实例分割模型 ⭐ 新</div>
|
| 244 |
+
|
| 245 |
+
我们新的 YOLOv5 [release v7.0](https://github.com/ultralytics/yolov5/releases/v7.0) 实例分割模型是世界上最快和最准确的模型,击败所有当前 [SOTA 基准](https://paperswithcode.com/sota/real-time-instance-segmentation-on-mscoco)。我们使它非常易于训练、验证和部署。更多细节请查看 [发行说明](https://github.com/ultralytics/yolov5/releases/v7.0) 或访问我们的 [YOLOv5 分割 Colab 笔记本](https://github.com/ultralytics/yolov5/blob/master/segment/tutorial.ipynb) 以快速入门。
|
| 246 |
+
|
| 247 |
+
<details>
|
| 248 |
+
<summary>实例分割模型列表</summary>
|
| 249 |
+
|
| 250 |
+
<br>
|
| 251 |
+
|
| 252 |
+
<div align="center">
|
| 253 |
+
<a align="center" href="https://ultralytics.com/yolov5" target="_blank">
|
| 254 |
+
<img width="800" src="https://user-images.githubusercontent.com/61612323/204180385-84f3aca9-a5e9-43d8-a617-dda7ca12e54a.png"></a>
|
| 255 |
+
</div>
|
| 256 |
+
|
| 257 |
+
我们使用 A100 GPU 在 COCO 上以 640 图像大小训练了 300 epochs 得到 YOLOv5 分割模型。我们将所有模型导出到 ONNX FP32 以进行 CPU 速度测试,并导出到 TensorRT FP16 以进行 GPU 速度测试。为了便于再现,我们在 Google [Colab Pro](https://colab.research.google.com/signup) 上进行了所有速度测试。
|
| 258 |
+
|
| 259 |
+
| 模型 | 尺寸<br><sup>(像素) | mAP<sup>box<br>50-95 | mAP<sup>mask<br>50-95 | 训练时长<br><sup>300 epochs<br>A100 GPU(小时) | 推理速度<br><sup>ONNX CPU<br>(ms) | 推理速度<br><sup>TRT A100<br>(ms) | 参数量<br><sup>(M) | FLOPs<br><sup>@640 (B) |
|
| 260 |
+
| ------------------------------------------------------------------------------------------ | --------------- | -------------------- | --------------------- | --------------------------------------- | ----------------------------- | ----------------------------- | --------------- | ---------------------- |
|
| 261 |
+
| [YOLOv5n-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n-seg.pt) | 640 | 27.6 | 23.4 | 80:17 | **62.7** | **1.2** | **2.0** | **7.1** |
|
| 262 |
+
| [YOLOv5s-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s-seg.pt) | 640 | 37.6 | 31.7 | 88:16 | 173.3 | 1.4 | 7.6 | 26.4 |
|
| 263 |
+
| [YOLOv5m-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m-seg.pt) | 640 | 45.0 | 37.1 | 108:36 | 427.0 | 2.2 | 22.0 | 70.8 |
|
| 264 |
+
| [YOLOv5l-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l-seg.pt) | 640 | 49.0 | 39.9 | 66:43 (2x) | 857.4 | 2.9 | 47.9 | 147.7 |
|
| 265 |
+
| [YOLOv5x-seg](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x-seg.pt) | 640 | **50.7** | **41.4** | 62:56 (3x) | 1579.2 | 4.5 | 88.8 | 265.7 |
|
| 266 |
+
|
| 267 |
+
- 所有模型使用 SGD 优化器训练, 都使用 `lr0=0.01` 和 `weight_decay=5e-5` 参数, 图像大小为 640 。<br>训练 log 可以查看 https://wandb.ai/glenn-jocher/YOLOv5_v70_official
|
| 268 |
+
- **准确性**结果都在 COCO 数据集上,使用单模型单尺度测试得到。<br>复现命令 `python segment/val.py --data coco.yaml --weights yolov5s-seg.pt`
|
| 269 |
+
- **推理速度**是使用 100 张图像推理时间进行平均得到,测试环境使用 [Colab Pro](https://colab.research.google.com/signup) 上 A100 高 RAM 实例。结果仅表示推理速度(NMS 每张图像增加约 1 毫秒)。<br>复现命令 `python segment/val.py --data coco.yaml --weights yolov5s-seg.pt --batch 1`
|
| 270 |
+
- **模型转换**到 FP32 的 ONNX 和 FP16 的 TensorRT 脚本为 `export.py`.<br>运行命令 `python export.py --weights yolov5s-seg.pt --include engine --device 0 --half`
|
| 271 |
+
|
| 272 |
+
</details>
|
| 273 |
+
|
| 274 |
+
<details>
|
| 275 |
+
<summary>分割模型使用示例 <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/segment/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a></summary>
|
| 276 |
+
|
| 277 |
+
### 训练
|
| 278 |
+
|
| 279 |
+
YOLOv5分割训练支持自动下载 COCO128-seg 分割数据集,用户仅需在启动指令中包含 `--data coco128-seg.yaml` 参数。 若要手动下载,使用命令 `bash data/scripts/get_coco.sh --train --val --segments`, 在下载完毕后,使用命令 `python train.py --data coco.yaml` 开启训练。
|
| 280 |
+
|
| 281 |
+
```bash
|
| 282 |
+
# 单 GPU
|
| 283 |
+
python segment/train.py --data coco128-seg.yaml --weights yolov5s-seg.pt --img 640
|
| 284 |
+
|
| 285 |
+
# 多 GPU, DDP 模式
|
| 286 |
+
python -m torch.distributed.run --nproc_per_node 4 --master_port 1 segment/train.py --data coco128-seg.yaml --weights yolov5s-seg.pt --img 640 --device 0,1,2,3
|
| 287 |
+
```
|
| 288 |
+
|
| 289 |
+
### 验证
|
| 290 |
+
|
| 291 |
+
在 COCO 数据集上验证 YOLOv5s-seg mask mAP:
|
| 292 |
+
|
| 293 |
+
```bash
|
| 294 |
+
bash data/scripts/get_coco.sh --val --segments # 下载 COCO val segments 数据集 (780MB, 5000 images)
|
| 295 |
+
python segment/val.py --weights yolov5s-seg.pt --data coco.yaml --img 640 # 验证
|
| 296 |
+
```
|
| 297 |
+
|
| 298 |
+
### 预测
|
| 299 |
+
|
| 300 |
+
使用预训练的 YOLOv5m-seg.pt 来预测 bus.jpg:
|
| 301 |
+
|
| 302 |
+
```bash
|
| 303 |
+
python segment/predict.py --weights yolov5m-seg.pt --source data/images/bus.jpg
|
| 304 |
+
```
|
| 305 |
+
|
| 306 |
+
```python
|
| 307 |
+
model = torch.hub.load(
|
| 308 |
+
"ultralytics/yolov5", "custom", "yolov5m-seg.pt"
|
| 309 |
+
) # 从load from PyTorch Hub 加载模型 (WARNING: 推理暂未支持)
|
| 310 |
+
```
|
| 311 |
+
|
| 312 |
+
|  |  |
|
| 313 |
+
| ---------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------- |
|
| 314 |
+
|
| 315 |
+
### 模型导出
|
| 316 |
+
|
| 317 |
+
将 YOLOv5s-seg 模型导出到 ONNX 和 TensorRT:
|
| 318 |
+
|
| 319 |
+
```bash
|
| 320 |
+
python export.py --weights yolov5s-seg.pt --include onnx engine --img 640 --device 0
|
| 321 |
+
```
|
| 322 |
+
|
| 323 |
+
</details>
|
| 324 |
+
|
| 325 |
+
## <div align="center">分类网络 ⭐ 新</div>
|
| 326 |
+
|
| 327 |
+
YOLOv5 [release v6.2](https://github.com/ultralytics/yolov5/releases) 带来对分类模型训练、验证和部署的支持!详情请查看 [发行说明](https://github.com/ultralytics/yolov5/releases/v6.2) 或访问我们的 [YOLOv5 分类 Colab 笔记本](https://github.com/ultralytics/yolov5/blob/master/classify/tutorial.ipynb) 以快速入门。
|
| 328 |
+
|
| 329 |
+
<details>
|
| 330 |
+
<summary>分类网络模型</summary>
|
| 331 |
+
|
| 332 |
+
<br>
|
| 333 |
+
|
| 334 |
+
我们使用 4xA100 实例在 ImageNet 上训练了 90 个 epochs 得到 YOLOv5-cls 分类模型,我们训练了 ResNet 和 EfficientNet 模型以及相同的默认训练设置以进行比较。我们将所有模型导出到 ONNX FP32 以进行 CPU 速度测试,并导出到 TensorRT FP16 以进行 GPU 速度测试。为了便于重现,我们在 Google 上进行了所有速度测试 [Colab Pro](https://colab.research.google.com/signup) 。
|
| 335 |
+
|
| 336 |
+
| 模型 | 尺寸<br><sup>(像素) | acc<br><sup>top1 | acc<br><sup>top5 | 训练时长<br><sup>90 epochs<br>4xA100(小时) | 推理速度<br><sup>ONNX CPU<br>(ms) | 推理速度<br><sup>TensorRT V100<br>(ms) | 参数<br><sup>(M) | FLOPs<br><sup>@640 (B) |
|
| 337 |
+
| -------------------------------------------------------------------------------------------------- | --------------- | ---------------- | ---------------- | ------------------------------------ | ----------------------------- | ---------------------------------- | -------------- | ---------------------- |
|
| 338 |
+
| [YOLOv5n-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5n-cls.pt) | 224 | 64.6 | 85.4 | 7:59 | **3.3** | **0.5** | **2.5** | **0.5** |
|
| 339 |
+
| [YOLOv5s-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s-cls.pt) | 224 | 71.5 | 90.2 | 8:09 | 6.6 | 0.6 | 5.4 | 1.4 |
|
| 340 |
+
| [YOLOv5m-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5m-cls.pt) | 224 | 75.9 | 92.9 | 10:06 | 15.5 | 0.9 | 12.9 | 3.9 |
|
| 341 |
+
| [YOLOv5l-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5l-cls.pt) | 224 | 78.0 | 94.0 | 11:56 | 26.9 | 1.4 | 26.5 | 8.5 |
|
| 342 |
+
| [YOLOv5x-cls](https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5x-cls.pt) | 224 | **79.0** | **94.4** | 15:04 | 54.3 | 1.8 | 48.1 | 15.9 |
|
| 343 |
+
| | | | | | | | | |
|
| 344 |
+
| [ResNet18](https://github.com/ultralytics/yolov5/releases/download/v7.0/resnet18.pt) | 224 | 70.3 | 89.5 | **6:47** | 11.2 | 0.5 | 11.7 | 3.7 |
|
| 345 |
+
| [Resnetzch](https://github.com/ultralytics/yolov5/releases/download/v7.0/resnet34.pt) | 224 | 73.9 | 91.8 | 8:33 | 20.6 | 0.9 | 21.8 | 7.4 |
|
| 346 |
+
| [ResNet50](https://github.com/ultralytics/yolov5/releases/download/v7.0/resnet50.pt) | 224 | 76.8 | 93.4 | 11:10 | 23.4 | 1.0 | 25.6 | 8.5 |
|
| 347 |
+
| [ResNet101](https://github.com/ultralytics/yolov5/releases/download/v7.0/resnet101.pt) | 224 | 78.5 | 94.3 | 17:10 | 42.1 | 1.9 | 44.5 | 15.9 |
|
| 348 |
+
| | | | | | | | | |
|
| 349 |
+
| [EfficientNet_b0](https://github.com/ultralytics/yolov5/releases/download/v7.0/efficientnet_b0.pt) | 224 | 75.1 | 92.4 | 13:03 | 12.5 | 1.3 | 5.3 | 1.0 |
|
| 350 |
+
| [EfficientNet_b1](https://github.com/ultralytics/yolov5/releases/download/v7.0/efficientnet_b1.pt) | 224 | 76.4 | 93.2 | 17:04 | 14.9 | 1.6 | 7.8 | 1.5 |
|
| 351 |
+
| [EfficientNet_b2](https://github.com/ultralytics/yolov5/releases/download/v7.0/efficientnet_b2.pt) | 224 | 76.6 | 93.4 | 17:10 | 15.9 | 1.6 | 9.1 | 1.7 |
|
| 352 |
+
| [EfficientNet_b3](https://github.com/ultralytics/yolov5/releases/download/v7.0/efficientnet_b3.pt) | 224 | 77.7 | 94.0 | 19:19 | 18.9 | 1.9 | 12.2 | 2.4 |
|
| 353 |
+
|
| 354 |
+
<details>
|
| 355 |
+
<summary>Table Notes (点击以展开)</summary>
|
| 356 |
+
|
| 357 |
+
- 所有模型都使用 SGD 优化器训练 90 个 epochs,都使用 `lr0=0.001` 和 `weight_decay=5e-5` 参数, 图像大小为 224 ,且都使用默认设置。<br>训练 log 可以查看 https://wandb.ai/glenn-jocher/YOLOv5-Classifier-v6-2
|
| 358 |
+
- **准确性**都在单模型单尺度上计算,数据集使用 [ImageNet-1k](https://www.image-net.org/index.php) 。<br>复现命令 `python classify/val.py --data ../datasets/imagenet --img 224`
|
| 359 |
+
- **推理速度**是使用 100 个推理图像进行平均得到,测试环境使用谷歌 [Colab Pro](https://colab.research.google.com/signup) V100 高 RAM 实例。<br>复现命令 `python classify/val.py --data ../datasets/imagenet --img 224 --batch 1`
|
| 360 |
+
- **模型导出**到 FP32 的 ONNX 和 FP16 的 TensorRT 使用 `export.py` 。<br>复现命令 `python export.py --weights yolov5s-cls.pt --include engine onnx --imgsz 224`
|
| 361 |
+
</details>
|
| 362 |
+
</details>
|
| 363 |
+
|
| 364 |
+
<details>
|
| 365 |
+
<summary>分类训练示例 <a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/classify/tutorial.ipynb"><img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"></a></summary>
|
| 366 |
+
|
| 367 |
+
### 训练
|
| 368 |
+
|
| 369 |
+
YOLOv5 分类训练支持自动下载 MNIST、Fashion-MNIST、CIFAR10、CIFAR100、Imagenette、Imagewoof 和 ImageNet 数据集,命令中使用 `--data` 即可。 MNIST 示例 `--data mnist` 。
|
| 370 |
+
|
| 371 |
+
```bash
|
| 372 |
+
# 单 GPU
|
| 373 |
+
python classify/train.py --model yolov5s-cls.pt --data cifar100 --epochs 5 --img 224 --batch 128
|
| 374 |
+
|
| 375 |
+
# 多 GPU, DDP 模式
|
| 376 |
+
python -m torch.distributed.run --nproc_per_node 4 --master_port 1 classify/train.py --model yolov5s-cls.pt --data imagenet --epochs 5 --img 224 --device 0,1,2,3
|
| 377 |
+
```
|
| 378 |
+
|
| 379 |
+
### 验证
|
| 380 |
+
|
| 381 |
+
在 ImageNet-1k 数据集上验证 YOLOv5m-cls 的准确性:
|
| 382 |
+
|
| 383 |
+
```bash
|
| 384 |
+
bash data/scripts/get_imagenet.sh --val # download ImageNet val split (6.3G, 50000 images)
|
| 385 |
+
python classify/val.py --weights yolov5m-cls.pt --data ../datasets/imagenet --img 224 # validate
|
| 386 |
+
```
|
| 387 |
+
|
| 388 |
+
### 预测
|
| 389 |
+
|
| 390 |
+
使用预训练的 YOLOv5s-cls.pt 来预测 bus.jpg:
|
| 391 |
+
|
| 392 |
+
```bash
|
| 393 |
+
python classify/predict.py --weights yolov5s-cls.pt --source data/images/bus.jpg
|
| 394 |
+
```
|
| 395 |
+
|
| 396 |
+
```python
|
| 397 |
+
model = torch.hub.load(
|
| 398 |
+
"ultralytics/yolov5", "custom", "yolov5s-cls.pt"
|
| 399 |
+
) # load from PyTorch Hub
|
| 400 |
+
```
|
| 401 |
+
|
| 402 |
+
### 模型导出
|
| 403 |
+
|
| 404 |
+
将一组经过训练的 YOLOv5s-cls、ResNet 和 EfficientNet 模型导出到 ONNX 和 TensorRT:
|
| 405 |
+
|
| 406 |
+
```bash
|
| 407 |
+
python export.py --weights yolov5s-cls.pt resnet50.pt efficientnet_b0.pt --include onnx engine --img 224
|
| 408 |
+
```
|
| 409 |
+
|
| 410 |
+
</details>
|
| 411 |
+
|
| 412 |
+
## <div align="center">环境</div>
|
| 413 |
+
|
| 414 |
+
使用下面我们经过验证的环境,在几秒钟内开始使用 YOLOv5 。单击下面的图标了解详细信息。
|
| 415 |
+
|
| 416 |
+
<div align="center">
|
| 417 |
+
<a href="https://bit.ly/yolov5-paperspace-notebook">
|
| 418 |
+
<img src="https://github.com/ultralytics/yolov5/releases/download/v1.0/logo-gradient.png" width="10%" /></a>
|
| 419 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="5%" alt="" />
|
| 420 |
+
<a href="https://colab.research.google.com/github/ultralytics/yolov5/blob/master/tutorial.ipynb">
|
| 421 |
+
<img src="https://github.com/ultralytics/yolov5/releases/download/v1.0/logo-colab-small.png" width="10%" /></a>
|
| 422 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="5%" alt="" />
|
| 423 |
+
<a href="https://www.kaggle.com/ultralytics/yolov5">
|
| 424 |
+
<img src="https://github.com/ultralytics/yolov5/releases/download/v1.0/logo-kaggle-small.png" width="10%" /></a>
|
| 425 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="5%" alt="" />
|
| 426 |
+
<a href="https://hub.docker.com/r/ultralytics/yolov5">
|
| 427 |
+
<img src="https://github.com/ultralytics/yolov5/releases/download/v1.0/logo-docker-small.png" width="10%" /></a>
|
| 428 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="5%" alt="" />
|
| 429 |
+
<a href="https://docs.ultralytics.com/yolov5/environments/aws_quickstart_tutorial/">
|
| 430 |
+
<img src="https://github.com/ultralytics/yolov5/releases/download/v1.0/logo-aws-small.png" width="10%" /></a>
|
| 431 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="5%" alt="" />
|
| 432 |
+
<a href="https://docs.ultralytics.com/yolov5/environments/google_cloud_quickstart_tutorial/">
|
| 433 |
+
<img src="https://github.com/ultralytics/yolov5/releases/download/v1.0/logo-gcp-small.png" width="10%" /></a>
|
| 434 |
+
</div>
|
| 435 |
+
|
| 436 |
+
## <div align="center">贡献</div>
|
| 437 |
+
|
| 438 |
+
我们喜欢您的意见或建议!我们希望尽可能简单和透明地为 YOLOv5 做出贡献。请看我们的 [投稿指南](https://docs.ultralytics.com/help/contributing/),并填写 [YOLOv5调查](https://ultralytics.com/survey?utm_source=github&utm_medium=social&utm_campaign=Survey) 向我们发送您的体验反馈。感谢我们所有的贡献者!
|
| 439 |
+
|
| 440 |
+
<!-- SVG image from https://opencollective.com/ultralytics/contributors.svg?width=990 -->
|
| 441 |
+
|
| 442 |
+
<a href="https://github.com/ultralytics/yolov5/graphs/contributors">
|
| 443 |
+
<img src="https://github.com/ultralytics/assets/raw/main/im/image-contributors.png" /></a>
|
| 444 |
+
|
| 445 |
+
## <div align="center">许可证</div>
|
| 446 |
+
|
| 447 |
+
Ultralytics 提供两种许可证选项以适应各种使用场景:
|
| 448 |
+
|
| 449 |
+
- **AGPL-3.0 许可证**:这个[OSI 批准](https://opensource.org/licenses/)的开源许可证非常适合学生和爱好者,可以推动开放的协作和知识分享。请查看[LICENSE](https://github.com/ultralytics/yolov5/blob/master/LICENSE) 文件以了解更多细节。
|
| 450 |
+
- **企业许可证**:专为商业用途设计,该许可证允许将 Ultralytics 的软件和 AI 模型无缝集成到商业产品和服务中,从而绕过 AGPL-3.0 的开源要求。如果您的场景涉及将我们的解决方案嵌入到商业产品中,请通过 [Ultralytics Licensing](https://ultralytics.com/license)与我们联系。
|
| 451 |
+
|
| 452 |
+
## <div align="center">联系方式</div>
|
| 453 |
+
|
| 454 |
+
对于 Ultralytics 的错误报告和功能请求,请访问 [GitHub Issues](https://github.com/ultralytics/yolov5/issues),并加入我们的 [Discord](https://ultralytics.com/discord) 社区进行问题和讨论!
|
| 455 |
+
|
| 456 |
+
<br>
|
| 457 |
+
<div align="center">
|
| 458 |
+
<a href="https://github.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-github.png" width="3%" alt="Ultralytics GitHub"></a>
|
| 459 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
| 460 |
+
<a href="https://www.linkedin.com/company/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-linkedin.png" width="3%" alt="Ultralytics LinkedIn"></a>
|
| 461 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
| 462 |
+
<a href="https://twitter.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-twitter.png" width="3%" alt="Ultralytics Twitter"></a>
|
| 463 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
| 464 |
+
<a href="https://youtube.com/ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-youtube.png" width="3%" alt="Ultralytics YouTube"></a>
|
| 465 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
| 466 |
+
<a href="https://www.tiktok.com/@ultralytics"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-tiktok.png" width="3%" alt="Ultralytics TikTok"></a>
|
| 467 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
| 468 |
+
<a href="https://www.instagram.com/ultralytics/"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-instagram.png" width="3%" alt="Ultralytics Instagram"></a>
|
| 469 |
+
<img src="https://github.com/ultralytics/assets/raw/main/social/logo-transparent.png" width="3%">
|
| 470 |
+
<a href="https://ultralytics.com/discord"><img src="https://github.com/ultralytics/assets/raw/main/social/logo-social-discord.png" width="3%" alt="Ultralytics Discord"></a>
|
| 471 |
+
</div>
|
| 472 |
+
|
| 473 |
+
[tta]: https://docs.ultralytics.com/yolov5/tutorials/test_time_augmentation
|
yolov5/benchmarks.py
ADDED
|
@@ -0,0 +1,174 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
"""
|
| 3 |
+
Run YOLOv5 benchmarks on all supported export formats
|
| 4 |
+
|
| 5 |
+
Format | `export.py --include` | Model
|
| 6 |
+
--- | --- | ---
|
| 7 |
+
PyTorch | - | yolov5s.pt
|
| 8 |
+
TorchScript | `torchscript` | yolov5s.torchscript
|
| 9 |
+
ONNX | `onnx` | yolov5s.onnx
|
| 10 |
+
OpenVINO | `openvino` | yolov5s_openvino_model/
|
| 11 |
+
TensorRT | `engine` | yolov5s.engine
|
| 12 |
+
CoreML | `coreml` | yolov5s.mlmodel
|
| 13 |
+
TensorFlow SavedModel | `saved_model` | yolov5s_saved_model/
|
| 14 |
+
TensorFlow GraphDef | `pb` | yolov5s.pb
|
| 15 |
+
TensorFlow Lite | `tflite` | yolov5s.tflite
|
| 16 |
+
TensorFlow Edge TPU | `edgetpu` | yolov5s_edgetpu.tflite
|
| 17 |
+
TensorFlow.js | `tfjs` | yolov5s_web_model/
|
| 18 |
+
|
| 19 |
+
Requirements:
|
| 20 |
+
$ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu # CPU
|
| 21 |
+
$ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
|
| 22 |
+
$ pip install -U nvidia-tensorrt --index-url https://pypi.ngc.nvidia.com # TensorRT
|
| 23 |
+
|
| 24 |
+
Usage:
|
| 25 |
+
$ python benchmarks.py --weights yolov5s.pt --img 640
|
| 26 |
+
"""
|
| 27 |
+
|
| 28 |
+
import argparse
|
| 29 |
+
import platform
|
| 30 |
+
import sys
|
| 31 |
+
import time
|
| 32 |
+
from pathlib import Path
|
| 33 |
+
|
| 34 |
+
import pandas as pd
|
| 35 |
+
|
| 36 |
+
FILE = Path(__file__).resolve()
|
| 37 |
+
ROOT = FILE.parents[0] # YOLOv5 root directory
|
| 38 |
+
if str(ROOT) not in sys.path:
|
| 39 |
+
sys.path.append(str(ROOT)) # add ROOT to PATH
|
| 40 |
+
# ROOT = ROOT.relative_to(Path.cwd()) # relative
|
| 41 |
+
|
| 42 |
+
import export
|
| 43 |
+
from models.experimental import attempt_load
|
| 44 |
+
from models.yolo import SegmentationModel
|
| 45 |
+
from segment.val import run as val_seg
|
| 46 |
+
from utils import notebook_init
|
| 47 |
+
from utils.general import LOGGER, check_yaml, file_size, print_args
|
| 48 |
+
from utils.torch_utils import select_device
|
| 49 |
+
from val import run as val_det
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def run(
|
| 53 |
+
weights=ROOT / 'yolov5s.pt', # weights path
|
| 54 |
+
imgsz=640, # inference size (pixels)
|
| 55 |
+
batch_size=1, # batch size
|
| 56 |
+
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
|
| 57 |
+
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
|
| 58 |
+
half=False, # use FP16 half-precision inference
|
| 59 |
+
test=False, # test exports only
|
| 60 |
+
pt_only=False, # test PyTorch only
|
| 61 |
+
hard_fail=False, # throw error on benchmark failure
|
| 62 |
+
):
|
| 63 |
+
y, t = [], time.time()
|
| 64 |
+
device = select_device(device)
|
| 65 |
+
model_type = type(attempt_load(weights, fuse=False)) # DetectionModel, SegmentationModel, etc.
|
| 66 |
+
for i, (name, f, suffix, cpu, gpu) in export.export_formats().iterrows(): # index, (name, file, suffix, CPU, GPU)
|
| 67 |
+
try:
|
| 68 |
+
assert i not in (9, 10), 'inference not supported' # Edge TPU and TF.js are unsupported
|
| 69 |
+
assert i != 5 or platform.system() == 'Darwin', 'inference only supported on macOS>=10.13' # CoreML
|
| 70 |
+
if 'cpu' in device.type:
|
| 71 |
+
assert cpu, 'inference not supported on CPU'
|
| 72 |
+
if 'cuda' in device.type:
|
| 73 |
+
assert gpu, 'inference not supported on GPU'
|
| 74 |
+
|
| 75 |
+
# Export
|
| 76 |
+
if f == '-':
|
| 77 |
+
w = weights # PyTorch format
|
| 78 |
+
else:
|
| 79 |
+
w = export.run(weights=weights,
|
| 80 |
+
imgsz=[imgsz],
|
| 81 |
+
include=[f],
|
| 82 |
+
batch_size=batch_size,
|
| 83 |
+
device=device,
|
| 84 |
+
half=half)[-1] # all others
|
| 85 |
+
assert suffix in str(w), 'export failed'
|
| 86 |
+
|
| 87 |
+
# Validate
|
| 88 |
+
if model_type == SegmentationModel:
|
| 89 |
+
result = val_seg(data, w, batch_size, imgsz, plots=False, device=device, task='speed', half=half)
|
| 90 |
+
metric = result[0][7] # (box(p, r, map50, map), mask(p, r, map50, map), *loss(box, obj, cls))
|
| 91 |
+
else: # DetectionModel:
|
| 92 |
+
result = val_det(data, w, batch_size, imgsz, plots=False, device=device, task='speed', half=half)
|
| 93 |
+
metric = result[0][3] # (p, r, map50, map, *loss(box, obj, cls))
|
| 94 |
+
speed = result[2][1] # times (preprocess, inference, postprocess)
|
| 95 |
+
y.append([name, round(file_size(w), 1), round(metric, 4), round(speed, 2)]) # MB, mAP, t_inference
|
| 96 |
+
except Exception as e:
|
| 97 |
+
if hard_fail:
|
| 98 |
+
assert type(e) is AssertionError, f'Benchmark --hard-fail for {name}: {e}'
|
| 99 |
+
LOGGER.warning(f'WARNING ⚠️ Benchmark failure for {name}: {e}')
|
| 100 |
+
y.append([name, None, None, None]) # mAP, t_inference
|
| 101 |
+
if pt_only and i == 0:
|
| 102 |
+
break # break after PyTorch
|
| 103 |
+
|
| 104 |
+
# Print results
|
| 105 |
+
LOGGER.info('\n')
|
| 106 |
+
parse_opt()
|
| 107 |
+
notebook_init() # print system info
|
| 108 |
+
c = ['Format', 'Size (MB)', 'mAP50-95', 'Inference time (ms)'] if map else ['Format', 'Export', '', '']
|
| 109 |
+
py = pd.DataFrame(y, columns=c)
|
| 110 |
+
LOGGER.info(f'\nBenchmarks complete ({time.time() - t:.2f}s)')
|
| 111 |
+
LOGGER.info(str(py if map else py.iloc[:, :2]))
|
| 112 |
+
if hard_fail and isinstance(hard_fail, str):
|
| 113 |
+
metrics = py['mAP50-95'].array # values to compare to floor
|
| 114 |
+
floor = eval(hard_fail) # minimum metric floor to pass, i.e. = 0.29 mAP for YOLOv5n
|
| 115 |
+
assert all(x > floor for x in metrics if pd.notna(x)), f'HARD FAIL: mAP50-95 < floor {floor}'
|
| 116 |
+
return py
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
def test(
|
| 120 |
+
weights=ROOT / 'yolov5s.pt', # weights path
|
| 121 |
+
imgsz=640, # inference size (pixels)
|
| 122 |
+
batch_size=1, # batch size
|
| 123 |
+
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
|
| 124 |
+
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
|
| 125 |
+
half=False, # use FP16 half-precision inference
|
| 126 |
+
test=False, # test exports only
|
| 127 |
+
pt_only=False, # test PyTorch only
|
| 128 |
+
hard_fail=False, # throw error on benchmark failure
|
| 129 |
+
):
|
| 130 |
+
y, t = [], time.time()
|
| 131 |
+
device = select_device(device)
|
| 132 |
+
for i, (name, f, suffix, gpu) in export.export_formats().iterrows(): # index, (name, file, suffix, gpu-capable)
|
| 133 |
+
try:
|
| 134 |
+
w = weights if f == '-' else \
|
| 135 |
+
export.run(weights=weights, imgsz=[imgsz], include=[f], device=device, half=half)[-1] # weights
|
| 136 |
+
assert suffix in str(w), 'export failed'
|
| 137 |
+
y.append([name, True])
|
| 138 |
+
except Exception:
|
| 139 |
+
y.append([name, False]) # mAP, t_inference
|
| 140 |
+
|
| 141 |
+
# Print results
|
| 142 |
+
LOGGER.info('\n')
|
| 143 |
+
parse_opt()
|
| 144 |
+
notebook_init() # print system info
|
| 145 |
+
py = pd.DataFrame(y, columns=['Format', 'Export'])
|
| 146 |
+
LOGGER.info(f'\nExports complete ({time.time() - t:.2f}s)')
|
| 147 |
+
LOGGER.info(str(py))
|
| 148 |
+
return py
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
def parse_opt():
|
| 152 |
+
parser = argparse.ArgumentParser()
|
| 153 |
+
parser.add_argument('--weights', type=str, default=ROOT / 'yolov5s.pt', help='weights path')
|
| 154 |
+
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
|
| 155 |
+
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
|
| 156 |
+
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
|
| 157 |
+
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
|
| 158 |
+
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
|
| 159 |
+
parser.add_argument('--test', action='store_true', help='test exports only')
|
| 160 |
+
parser.add_argument('--pt-only', action='store_true', help='test PyTorch only')
|
| 161 |
+
parser.add_argument('--hard-fail', nargs='?', const=True, default=False, help='Exception on error or < min metric')
|
| 162 |
+
opt = parser.parse_args()
|
| 163 |
+
opt.data = check_yaml(opt.data) # check YAML
|
| 164 |
+
print_args(vars(opt))
|
| 165 |
+
return opt
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
def main(opt):
|
| 169 |
+
test(**vars(opt)) if opt.test else run(**vars(opt))
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
if __name__ == '__main__':
|
| 173 |
+
opt = parse_opt()
|
| 174 |
+
main(opt)
|
yolov5/classify/predict.py
ADDED
|
@@ -0,0 +1,227 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
"""
|
| 3 |
+
Run YOLOv5 classification inference on images, videos, directories, globs, YouTube, webcam, streams, etc.
|
| 4 |
+
|
| 5 |
+
Usage - sources:
|
| 6 |
+
$ python classify/predict.py --weights yolov5s-cls.pt --source 0 # webcam
|
| 7 |
+
img.jpg # image
|
| 8 |
+
vid.mp4 # video
|
| 9 |
+
screen # screenshot
|
| 10 |
+
path/ # directory
|
| 11 |
+
list.txt # list of images
|
| 12 |
+
list.streams # list of streams
|
| 13 |
+
'path/*.jpg' # glob
|
| 14 |
+
'https://youtu.be/LNwODJXcvt4' # YouTube
|
| 15 |
+
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
|
| 16 |
+
|
| 17 |
+
Usage - formats:
|
| 18 |
+
$ python classify/predict.py --weights yolov5s-cls.pt # PyTorch
|
| 19 |
+
yolov5s-cls.torchscript # TorchScript
|
| 20 |
+
yolov5s-cls.onnx # ONNX Runtime or OpenCV DNN with --dnn
|
| 21 |
+
yolov5s-cls_openvino_model # OpenVINO
|
| 22 |
+
yolov5s-cls.engine # TensorRT
|
| 23 |
+
yolov5s-cls.mlmodel # CoreML (macOS-only)
|
| 24 |
+
yolov5s-cls_saved_model # TensorFlow SavedModel
|
| 25 |
+
yolov5s-cls.pb # TensorFlow GraphDef
|
| 26 |
+
yolov5s-cls.tflite # TensorFlow Lite
|
| 27 |
+
yolov5s-cls_edgetpu.tflite # TensorFlow Edge TPU
|
| 28 |
+
yolov5s-cls_paddle_model # PaddlePaddle
|
| 29 |
+
"""
|
| 30 |
+
|
| 31 |
+
import argparse
|
| 32 |
+
import os
|
| 33 |
+
import platform
|
| 34 |
+
import sys
|
| 35 |
+
from pathlib import Path
|
| 36 |
+
|
| 37 |
+
import torch
|
| 38 |
+
import torch.nn.functional as F
|
| 39 |
+
|
| 40 |
+
FILE = Path(__file__).resolve()
|
| 41 |
+
ROOT = FILE.parents[1] # YOLOv5 root directory
|
| 42 |
+
if str(ROOT) not in sys.path:
|
| 43 |
+
sys.path.append(str(ROOT)) # add ROOT to PATH
|
| 44 |
+
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
|
| 45 |
+
|
| 46 |
+
from ultralytics.utils.plotting import Annotator
|
| 47 |
+
|
| 48 |
+
from models.common import DetectMultiBackend
|
| 49 |
+
from utils.augmentations import classify_transforms
|
| 50 |
+
from utils.dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadScreenshots, LoadStreams
|
| 51 |
+
from utils.general import (LOGGER, Profile, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
|
| 52 |
+
increment_path, print_args, strip_optimizer)
|
| 53 |
+
from utils.torch_utils import select_device, smart_inference_mode
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
@smart_inference_mode()
|
| 57 |
+
def run(
|
| 58 |
+
weights=ROOT / 'yolov5s-cls.pt', # model.pt path(s)
|
| 59 |
+
source=ROOT / 'data/images', # file/dir/URL/glob/screen/0(webcam)
|
| 60 |
+
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
|
| 61 |
+
imgsz=(224, 224), # inference size (height, width)
|
| 62 |
+
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
|
| 63 |
+
view_img=False, # show results
|
| 64 |
+
save_txt=False, # save results to *.txt
|
| 65 |
+
nosave=False, # do not save images/videos
|
| 66 |
+
augment=False, # augmented inference
|
| 67 |
+
visualize=False, # visualize features
|
| 68 |
+
update=False, # update all models
|
| 69 |
+
project=ROOT / 'runs/predict-cls', # save results to project/name
|
| 70 |
+
name='exp', # save results to project/name
|
| 71 |
+
exist_ok=False, # existing project/name ok, do not increment
|
| 72 |
+
half=False, # use FP16 half-precision inference
|
| 73 |
+
dnn=False, # use OpenCV DNN for ONNX inference
|
| 74 |
+
vid_stride=1, # video frame-rate stride
|
| 75 |
+
):
|
| 76 |
+
source = str(source)
|
| 77 |
+
save_img = not nosave and not source.endswith('.txt') # save inference images
|
| 78 |
+
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
|
| 79 |
+
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
|
| 80 |
+
webcam = source.isnumeric() or source.endswith('.streams') or (is_url and not is_file)
|
| 81 |
+
screenshot = source.lower().startswith('screen')
|
| 82 |
+
if is_url and is_file:
|
| 83 |
+
source = check_file(source) # download
|
| 84 |
+
|
| 85 |
+
# Directories
|
| 86 |
+
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
|
| 87 |
+
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
|
| 88 |
+
|
| 89 |
+
# Load model
|
| 90 |
+
device = select_device(device)
|
| 91 |
+
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
|
| 92 |
+
stride, names, pt = model.stride, model.names, model.pt
|
| 93 |
+
imgsz = check_img_size(imgsz, s=stride) # check image size
|
| 94 |
+
|
| 95 |
+
# Dataloader
|
| 96 |
+
bs = 1 # batch_size
|
| 97 |
+
if webcam:
|
| 98 |
+
view_img = check_imshow(warn=True)
|
| 99 |
+
dataset = LoadStreams(source, img_size=imgsz, transforms=classify_transforms(imgsz[0]), vid_stride=vid_stride)
|
| 100 |
+
bs = len(dataset)
|
| 101 |
+
elif screenshot:
|
| 102 |
+
dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
|
| 103 |
+
else:
|
| 104 |
+
dataset = LoadImages(source, img_size=imgsz, transforms=classify_transforms(imgsz[0]), vid_stride=vid_stride)
|
| 105 |
+
vid_path, vid_writer = [None] * bs, [None] * bs
|
| 106 |
+
|
| 107 |
+
# Run inference
|
| 108 |
+
model.warmup(imgsz=(1 if pt else bs, 3, *imgsz)) # warmup
|
| 109 |
+
seen, windows, dt = 0, [], (Profile(device=device), Profile(device=device), Profile(device=device))
|
| 110 |
+
for path, im, im0s, vid_cap, s in dataset:
|
| 111 |
+
with dt[0]:
|
| 112 |
+
im = torch.Tensor(im).to(model.device)
|
| 113 |
+
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
|
| 114 |
+
if len(im.shape) == 3:
|
| 115 |
+
im = im[None] # expand for batch dim
|
| 116 |
+
|
| 117 |
+
# Inference
|
| 118 |
+
with dt[1]:
|
| 119 |
+
results = model(im)
|
| 120 |
+
|
| 121 |
+
# Post-process
|
| 122 |
+
with dt[2]:
|
| 123 |
+
pred = F.softmax(results, dim=1) # probabilities
|
| 124 |
+
|
| 125 |
+
# Process predictions
|
| 126 |
+
for i, prob in enumerate(pred): # per image
|
| 127 |
+
seen += 1
|
| 128 |
+
if webcam: # batch_size >= 1
|
| 129 |
+
p, im0, frame = path[i], im0s[i].copy(), dataset.count
|
| 130 |
+
s += f'{i}: '
|
| 131 |
+
else:
|
| 132 |
+
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
|
| 133 |
+
|
| 134 |
+
p = Path(p) # to Path
|
| 135 |
+
save_path = str(save_dir / p.name) # im.jpg
|
| 136 |
+
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
|
| 137 |
+
|
| 138 |
+
s += '%gx%g ' % im.shape[2:] # print string
|
| 139 |
+
annotator = Annotator(im0, example=str(names), pil=True)
|
| 140 |
+
|
| 141 |
+
# Print results
|
| 142 |
+
top5i = prob.argsort(0, descending=True)[:5].tolist() # top 5 indices
|
| 143 |
+
s += f"{', '.join(f'{names[j]} {prob[j]:.2f}' for j in top5i)}, "
|
| 144 |
+
|
| 145 |
+
# Write results
|
| 146 |
+
text = '\n'.join(f'{prob[j]:.2f} {names[j]}' for j in top5i)
|
| 147 |
+
if save_img or view_img: # Add bbox to image
|
| 148 |
+
annotator.text([32, 32], text, txt_color=(255, 255, 255))
|
| 149 |
+
if save_txt: # Write to file
|
| 150 |
+
with open(f'{txt_path}.txt', 'a') as f:
|
| 151 |
+
f.write(text + '\n')
|
| 152 |
+
|
| 153 |
+
# Stream results
|
| 154 |
+
im0 = annotator.result()
|
| 155 |
+
if view_img:
|
| 156 |
+
if platform.system() == 'Linux' and p not in windows:
|
| 157 |
+
windows.append(p)
|
| 158 |
+
cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux)
|
| 159 |
+
cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
|
| 160 |
+
cv2.imshow(str(p), im0)
|
| 161 |
+
cv2.waitKey(1) # 1 millisecond
|
| 162 |
+
|
| 163 |
+
# Save results (image with detections)
|
| 164 |
+
if save_img:
|
| 165 |
+
if dataset.mode == 'image':
|
| 166 |
+
cv2.imwrite(save_path, im0)
|
| 167 |
+
else: # 'video' or 'stream'
|
| 168 |
+
if vid_path[i] != save_path: # new video
|
| 169 |
+
vid_path[i] = save_path
|
| 170 |
+
if isinstance(vid_writer[i], cv2.VideoWriter):
|
| 171 |
+
vid_writer[i].release() # release previous video writer
|
| 172 |
+
if vid_cap: # video
|
| 173 |
+
fps = vid_cap.get(cv2.CAP_PROP_FPS)
|
| 174 |
+
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
|
| 175 |
+
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
|
| 176 |
+
else: # stream
|
| 177 |
+
fps, w, h = 30, im0.shape[1], im0.shape[0]
|
| 178 |
+
save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
|
| 179 |
+
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
|
| 180 |
+
vid_writer[i].write(im0)
|
| 181 |
+
|
| 182 |
+
# Print time (inference-only)
|
| 183 |
+
LOGGER.info(f'{s}{dt[1].dt * 1E3:.1f}ms')
|
| 184 |
+
|
| 185 |
+
# Print results
|
| 186 |
+
t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
|
| 187 |
+
LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
|
| 188 |
+
if save_txt or save_img:
|
| 189 |
+
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
|
| 190 |
+
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
|
| 191 |
+
if update:
|
| 192 |
+
strip_optimizer(weights[0]) # update model (to fix SourceChangeWarning)
|
| 193 |
+
|
| 194 |
+
|
| 195 |
+
def parse_opt():
|
| 196 |
+
parser = argparse.ArgumentParser()
|
| 197 |
+
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s-cls.pt', help='model path(s)')
|
| 198 |
+
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob/screen/0(webcam)')
|
| 199 |
+
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
|
| 200 |
+
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[224], help='inference size h,w')
|
| 201 |
+
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
|
| 202 |
+
parser.add_argument('--view-img', action='store_true', help='show results')
|
| 203 |
+
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
|
| 204 |
+
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
|
| 205 |
+
parser.add_argument('--augment', action='store_true', help='augmented inference')
|
| 206 |
+
parser.add_argument('--visualize', action='store_true', help='visualize features')
|
| 207 |
+
parser.add_argument('--update', action='store_true', help='update all models')
|
| 208 |
+
parser.add_argument('--project', default=ROOT / 'runs/predict-cls', help='save results to project/name')
|
| 209 |
+
parser.add_argument('--name', default='exp', help='save results to project/name')
|
| 210 |
+
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
|
| 211 |
+
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
|
| 212 |
+
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
|
| 213 |
+
parser.add_argument('--vid-stride', type=int, default=1, help='video frame-rate stride')
|
| 214 |
+
opt = parser.parse_args()
|
| 215 |
+
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
|
| 216 |
+
print_args(vars(opt))
|
| 217 |
+
return opt
|
| 218 |
+
|
| 219 |
+
|
| 220 |
+
def main(opt):
|
| 221 |
+
check_requirements(ROOT / 'requirements.txt', exclude=('tensorboard', 'thop'))
|
| 222 |
+
run(**vars(opt))
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
if __name__ == '__main__':
|
| 226 |
+
opt = parse_opt()
|
| 227 |
+
main(opt)
|
yolov5/classify/train.py
ADDED
|
@@ -0,0 +1,333 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
"""
|
| 3 |
+
Train a YOLOv5 classifier model on a classification dataset
|
| 4 |
+
|
| 5 |
+
Usage - Single-GPU training:
|
| 6 |
+
$ python classify/train.py --model yolov5s-cls.pt --data imagenette160 --epochs 5 --img 224
|
| 7 |
+
|
| 8 |
+
Usage - Multi-GPU DDP training:
|
| 9 |
+
$ python -m torch.distributed.run --nproc_per_node 4 --master_port 2022 classify/train.py --model yolov5s-cls.pt --data imagenet --epochs 5 --img 224 --device 0,1,2,3
|
| 10 |
+
|
| 11 |
+
Datasets: --data mnist, fashion-mnist, cifar10, cifar100, imagenette, imagewoof, imagenet, or 'path/to/data'
|
| 12 |
+
YOLOv5-cls models: --model yolov5n-cls.pt, yolov5s-cls.pt, yolov5m-cls.pt, yolov5l-cls.pt, yolov5x-cls.pt
|
| 13 |
+
Torchvision models: --model resnet50, efficientnet_b0, etc. See https://pytorch.org/vision/stable/models.html
|
| 14 |
+
"""
|
| 15 |
+
|
| 16 |
+
import argparse
|
| 17 |
+
import os
|
| 18 |
+
import subprocess
|
| 19 |
+
import sys
|
| 20 |
+
import time
|
| 21 |
+
from copy import deepcopy
|
| 22 |
+
from datetime import datetime
|
| 23 |
+
from pathlib import Path
|
| 24 |
+
|
| 25 |
+
import torch
|
| 26 |
+
import torch.distributed as dist
|
| 27 |
+
import torch.hub as hub
|
| 28 |
+
import torch.optim.lr_scheduler as lr_scheduler
|
| 29 |
+
import torchvision
|
| 30 |
+
from torch.cuda import amp
|
| 31 |
+
from tqdm import tqdm
|
| 32 |
+
|
| 33 |
+
FILE = Path(__file__).resolve()
|
| 34 |
+
ROOT = FILE.parents[1] # YOLOv5 root directory
|
| 35 |
+
if str(ROOT) not in sys.path:
|
| 36 |
+
sys.path.append(str(ROOT)) # add ROOT to PATH
|
| 37 |
+
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
|
| 38 |
+
|
| 39 |
+
from classify import val as validate
|
| 40 |
+
from models.experimental import attempt_load
|
| 41 |
+
from models.yolo import ClassificationModel, DetectionModel
|
| 42 |
+
from utils.dataloaders import create_classification_dataloader
|
| 43 |
+
from utils.general import (DATASETS_DIR, LOGGER, TQDM_BAR_FORMAT, WorkingDirectory, check_git_info, check_git_status,
|
| 44 |
+
check_requirements, colorstr, download, increment_path, init_seeds, print_args, yaml_save)
|
| 45 |
+
from utils.loggers import GenericLogger
|
| 46 |
+
from utils.plots import imshow_cls
|
| 47 |
+
from utils.torch_utils import (ModelEMA, de_parallel, model_info, reshape_classifier_output, select_device, smart_DDP,
|
| 48 |
+
smart_optimizer, smartCrossEntropyLoss, torch_distributed_zero_first)
|
| 49 |
+
|
| 50 |
+
LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
|
| 51 |
+
RANK = int(os.getenv('RANK', -1))
|
| 52 |
+
WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
|
| 53 |
+
GIT_INFO = check_git_info()
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def train(opt, device):
|
| 57 |
+
init_seeds(opt.seed + 1 + RANK, deterministic=True)
|
| 58 |
+
save_dir, data, bs, epochs, nw, imgsz, pretrained = \
|
| 59 |
+
opt.save_dir, Path(opt.data), opt.batch_size, opt.epochs, min(os.cpu_count() - 1, opt.workers), \
|
| 60 |
+
opt.imgsz, str(opt.pretrained).lower() == 'true'
|
| 61 |
+
cuda = device.type != 'cpu'
|
| 62 |
+
|
| 63 |
+
# Directories
|
| 64 |
+
wdir = save_dir / 'weights'
|
| 65 |
+
wdir.mkdir(parents=True, exist_ok=True) # make dir
|
| 66 |
+
last, best = wdir / 'last.pt', wdir / 'best.pt'
|
| 67 |
+
|
| 68 |
+
# Save run settings
|
| 69 |
+
yaml_save(save_dir / 'opt.yaml', vars(opt))
|
| 70 |
+
|
| 71 |
+
# Logger
|
| 72 |
+
logger = GenericLogger(opt=opt, console_logger=LOGGER) if RANK in {-1, 0} else None
|
| 73 |
+
|
| 74 |
+
# Download Dataset
|
| 75 |
+
with torch_distributed_zero_first(LOCAL_RANK), WorkingDirectory(ROOT):
|
| 76 |
+
data_dir = data if data.is_dir() else (DATASETS_DIR / data)
|
| 77 |
+
if not data_dir.is_dir():
|
| 78 |
+
LOGGER.info(f'\nDataset not found ⚠️, missing path {data_dir}, attempting download...')
|
| 79 |
+
t = time.time()
|
| 80 |
+
if str(data) == 'imagenet':
|
| 81 |
+
subprocess.run(['bash', str(ROOT / 'data/scripts/get_imagenet.sh')], shell=True, check=True)
|
| 82 |
+
else:
|
| 83 |
+
url = f'https://github.com/ultralytics/yolov5/releases/download/v1.0/{data}.zip'
|
| 84 |
+
download(url, dir=data_dir.parent)
|
| 85 |
+
s = f"Dataset download success ✅ ({time.time() - t:.1f}s), saved to {colorstr('bold', data_dir)}\n"
|
| 86 |
+
LOGGER.info(s)
|
| 87 |
+
|
| 88 |
+
# Dataloaders
|
| 89 |
+
nc = len([x for x in (data_dir / 'train').glob('*') if x.is_dir()]) # number of classes
|
| 90 |
+
trainloader = create_classification_dataloader(path=data_dir / 'train',
|
| 91 |
+
imgsz=imgsz,
|
| 92 |
+
batch_size=bs // WORLD_SIZE,
|
| 93 |
+
augment=True,
|
| 94 |
+
cache=opt.cache,
|
| 95 |
+
rank=LOCAL_RANK,
|
| 96 |
+
workers=nw)
|
| 97 |
+
|
| 98 |
+
test_dir = data_dir / 'test' if (data_dir / 'test').exists() else data_dir / 'val' # data/test or data/val
|
| 99 |
+
if RANK in {-1, 0}:
|
| 100 |
+
testloader = create_classification_dataloader(path=test_dir,
|
| 101 |
+
imgsz=imgsz,
|
| 102 |
+
batch_size=bs // WORLD_SIZE * 2,
|
| 103 |
+
augment=False,
|
| 104 |
+
cache=opt.cache,
|
| 105 |
+
rank=-1,
|
| 106 |
+
workers=nw)
|
| 107 |
+
|
| 108 |
+
# Model
|
| 109 |
+
with torch_distributed_zero_first(LOCAL_RANK), WorkingDirectory(ROOT):
|
| 110 |
+
if Path(opt.model).is_file() or opt.model.endswith('.pt'):
|
| 111 |
+
model = attempt_load(opt.model, device='cpu', fuse=False)
|
| 112 |
+
elif opt.model in torchvision.models.__dict__: # TorchVision models i.e. resnet50, efficientnet_b0
|
| 113 |
+
model = torchvision.models.__dict__[opt.model](weights='IMAGENET1K_V1' if pretrained else None)
|
| 114 |
+
else:
|
| 115 |
+
m = hub.list('ultralytics/yolov5') # + hub.list('pytorch/vision') # models
|
| 116 |
+
raise ModuleNotFoundError(f'--model {opt.model} not found. Available models are: \n' + '\n'.join(m))
|
| 117 |
+
if isinstance(model, DetectionModel):
|
| 118 |
+
LOGGER.warning("WARNING ⚠️ pass YOLOv5 classifier model with '-cls' suffix, i.e. '--model yolov5s-cls.pt'")
|
| 119 |
+
model = ClassificationModel(model=model, nc=nc, cutoff=opt.cutoff or 10) # convert to classification model
|
| 120 |
+
reshape_classifier_output(model, nc) # update class count
|
| 121 |
+
for m in model.modules():
|
| 122 |
+
if not pretrained and hasattr(m, 'reset_parameters'):
|
| 123 |
+
m.reset_parameters()
|
| 124 |
+
if isinstance(m, torch.nn.Dropout) and opt.dropout is not None:
|
| 125 |
+
m.p = opt.dropout # set dropout
|
| 126 |
+
for p in model.parameters():
|
| 127 |
+
p.requires_grad = True # for training
|
| 128 |
+
model = model.to(device)
|
| 129 |
+
|
| 130 |
+
# Info
|
| 131 |
+
if RANK in {-1, 0}:
|
| 132 |
+
model.names = trainloader.dataset.classes # attach class names
|
| 133 |
+
model.transforms = testloader.dataset.torch_transforms # attach inference transforms
|
| 134 |
+
model_info(model)
|
| 135 |
+
if opt.verbose:
|
| 136 |
+
LOGGER.info(model)
|
| 137 |
+
images, labels = next(iter(trainloader))
|
| 138 |
+
file = imshow_cls(images[:25], labels[:25], names=model.names, f=save_dir / 'train_images.jpg')
|
| 139 |
+
logger.log_images(file, name='Train Examples')
|
| 140 |
+
logger.log_graph(model, imgsz) # log model
|
| 141 |
+
|
| 142 |
+
# Optimizer
|
| 143 |
+
optimizer = smart_optimizer(model, opt.optimizer, opt.lr0, momentum=0.9, decay=opt.decay)
|
| 144 |
+
|
| 145 |
+
# Scheduler
|
| 146 |
+
lrf = 0.01 # final lr (fraction of lr0)
|
| 147 |
+
# lf = lambda x: ((1 + math.cos(x * math.pi / epochs)) / 2) * (1 - lrf) + lrf # cosine
|
| 148 |
+
lf = lambda x: (1 - x / epochs) * (1 - lrf) + lrf # linear
|
| 149 |
+
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf)
|
| 150 |
+
# scheduler = lr_scheduler.OneCycleLR(optimizer, max_lr=lr0, total_steps=epochs, pct_start=0.1,
|
| 151 |
+
# final_div_factor=1 / 25 / lrf)
|
| 152 |
+
|
| 153 |
+
# EMA
|
| 154 |
+
ema = ModelEMA(model) if RANK in {-1, 0} else None
|
| 155 |
+
|
| 156 |
+
# DDP mode
|
| 157 |
+
if cuda and RANK != -1:
|
| 158 |
+
model = smart_DDP(model)
|
| 159 |
+
|
| 160 |
+
# Train
|
| 161 |
+
t0 = time.time()
|
| 162 |
+
criterion = smartCrossEntropyLoss(label_smoothing=opt.label_smoothing) # loss function
|
| 163 |
+
best_fitness = 0.0
|
| 164 |
+
scaler = amp.GradScaler(enabled=cuda)
|
| 165 |
+
val = test_dir.stem # 'val' or 'test'
|
| 166 |
+
LOGGER.info(f'Image sizes {imgsz} train, {imgsz} test\n'
|
| 167 |
+
f'Using {nw * WORLD_SIZE} dataloader workers\n'
|
| 168 |
+
f"Logging results to {colorstr('bold', save_dir)}\n"
|
| 169 |
+
f'Starting {opt.model} training on {data} dataset with {nc} classes for {epochs} epochs...\n\n'
|
| 170 |
+
f"{'Epoch':>10}{'GPU_mem':>10}{'train_loss':>12}{f'{val}_loss':>12}{'top1_acc':>12}{'top5_acc':>12}")
|
| 171 |
+
for epoch in range(epochs): # loop over the dataset multiple times
|
| 172 |
+
tloss, vloss, fitness = 0.0, 0.0, 0.0 # train loss, val loss, fitness
|
| 173 |
+
model.train()
|
| 174 |
+
if RANK != -1:
|
| 175 |
+
trainloader.sampler.set_epoch(epoch)
|
| 176 |
+
pbar = enumerate(trainloader)
|
| 177 |
+
if RANK in {-1, 0}:
|
| 178 |
+
pbar = tqdm(enumerate(trainloader), total=len(trainloader), bar_format=TQDM_BAR_FORMAT)
|
| 179 |
+
for i, (images, labels) in pbar: # progress bar
|
| 180 |
+
images, labels = images.to(device, non_blocking=True), labels.to(device)
|
| 181 |
+
|
| 182 |
+
# Forward
|
| 183 |
+
with amp.autocast(enabled=cuda): # stability issues when enabled
|
| 184 |
+
loss = criterion(model(images), labels)
|
| 185 |
+
|
| 186 |
+
# Backward
|
| 187 |
+
scaler.scale(loss).backward()
|
| 188 |
+
|
| 189 |
+
# Optimize
|
| 190 |
+
scaler.unscale_(optimizer) # unscale gradients
|
| 191 |
+
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=10.0) # clip gradients
|
| 192 |
+
scaler.step(optimizer)
|
| 193 |
+
scaler.update()
|
| 194 |
+
optimizer.zero_grad()
|
| 195 |
+
if ema:
|
| 196 |
+
ema.update(model)
|
| 197 |
+
|
| 198 |
+
if RANK in {-1, 0}:
|
| 199 |
+
# Print
|
| 200 |
+
tloss = (tloss * i + loss.item()) / (i + 1) # update mean losses
|
| 201 |
+
mem = '%.3gG' % (torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0) # (GB)
|
| 202 |
+
pbar.desc = f"{f'{epoch + 1}/{epochs}':>10}{mem:>10}{tloss:>12.3g}" + ' ' * 36
|
| 203 |
+
|
| 204 |
+
# Test
|
| 205 |
+
if i == len(pbar) - 1: # last batch
|
| 206 |
+
top1, top5, vloss = validate.run(model=ema.ema,
|
| 207 |
+
dataloader=testloader,
|
| 208 |
+
criterion=criterion,
|
| 209 |
+
pbar=pbar) # test accuracy, loss
|
| 210 |
+
fitness = top1 # define fitness as top1 accuracy
|
| 211 |
+
|
| 212 |
+
# Scheduler
|
| 213 |
+
scheduler.step()
|
| 214 |
+
|
| 215 |
+
# Log metrics
|
| 216 |
+
if RANK in {-1, 0}:
|
| 217 |
+
# Best fitness
|
| 218 |
+
if fitness > best_fitness:
|
| 219 |
+
best_fitness = fitness
|
| 220 |
+
|
| 221 |
+
# Log
|
| 222 |
+
metrics = {
|
| 223 |
+
'train/loss': tloss,
|
| 224 |
+
f'{val}/loss': vloss,
|
| 225 |
+
'metrics/accuracy_top1': top1,
|
| 226 |
+
'metrics/accuracy_top5': top5,
|
| 227 |
+
'lr/0': optimizer.param_groups[0]['lr']} # learning rate
|
| 228 |
+
logger.log_metrics(metrics, epoch)
|
| 229 |
+
|
| 230 |
+
# Save model
|
| 231 |
+
final_epoch = epoch + 1 == epochs
|
| 232 |
+
if (not opt.nosave) or final_epoch:
|
| 233 |
+
ckpt = {
|
| 234 |
+
'epoch': epoch,
|
| 235 |
+
'best_fitness': best_fitness,
|
| 236 |
+
'model': deepcopy(ema.ema).half(), # deepcopy(de_parallel(model)).half(),
|
| 237 |
+
'ema': None, # deepcopy(ema.ema).half(),
|
| 238 |
+
'updates': ema.updates,
|
| 239 |
+
'optimizer': None, # optimizer.state_dict(),
|
| 240 |
+
'opt': vars(opt),
|
| 241 |
+
'git': GIT_INFO, # {remote, branch, commit} if a git repo
|
| 242 |
+
'date': datetime.now().isoformat()}
|
| 243 |
+
|
| 244 |
+
# Save last, best and delete
|
| 245 |
+
torch.save(ckpt, last)
|
| 246 |
+
if best_fitness == fitness:
|
| 247 |
+
torch.save(ckpt, best)
|
| 248 |
+
del ckpt
|
| 249 |
+
|
| 250 |
+
# Train complete
|
| 251 |
+
if RANK in {-1, 0} and final_epoch:
|
| 252 |
+
LOGGER.info(f'\nTraining complete ({(time.time() - t0) / 3600:.3f} hours)'
|
| 253 |
+
f"\nResults saved to {colorstr('bold', save_dir)}"
|
| 254 |
+
f'\nPredict: python classify/predict.py --weights {best} --source im.jpg'
|
| 255 |
+
f'\nValidate: python classify/val.py --weights {best} --data {data_dir}'
|
| 256 |
+
f'\nExport: python export.py --weights {best} --include onnx'
|
| 257 |
+
f"\nPyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', '{best}')"
|
| 258 |
+
f'\nVisualize: https://netron.app\n')
|
| 259 |
+
|
| 260 |
+
# Plot examples
|
| 261 |
+
images, labels = (x[:25] for x in next(iter(testloader))) # first 25 images and labels
|
| 262 |
+
pred = torch.max(ema.ema(images.to(device)), 1)[1]
|
| 263 |
+
file = imshow_cls(images, labels, pred, de_parallel(model).names, verbose=False, f=save_dir / 'test_images.jpg')
|
| 264 |
+
|
| 265 |
+
# Log results
|
| 266 |
+
meta = {'epochs': epochs, 'top1_acc': best_fitness, 'date': datetime.now().isoformat()}
|
| 267 |
+
logger.log_images(file, name='Test Examples (true-predicted)', epoch=epoch)
|
| 268 |
+
logger.log_model(best, epochs, metadata=meta)
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
def parse_opt(known=False):
|
| 272 |
+
parser = argparse.ArgumentParser()
|
| 273 |
+
parser.add_argument('--model', type=str, default='yolov5s-cls.pt', help='initial weights path')
|
| 274 |
+
parser.add_argument('--data', type=str, default='imagenette160', help='cifar10, cifar100, mnist, imagenet, ...')
|
| 275 |
+
parser.add_argument('--epochs', type=int, default=10, help='total training epochs')
|
| 276 |
+
parser.add_argument('--batch-size', type=int, default=64, help='total batch size for all GPUs')
|
| 277 |
+
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=224, help='train, val image size (pixels)')
|
| 278 |
+
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
|
| 279 |
+
parser.add_argument('--cache', type=str, nargs='?', const='ram', help='--cache images in "ram" (default) or "disk"')
|
| 280 |
+
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
|
| 281 |
+
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
|
| 282 |
+
parser.add_argument('--project', default=ROOT / 'runs/train-cls', help='save to project/name')
|
| 283 |
+
parser.add_argument('--name', default='exp', help='save to project/name')
|
| 284 |
+
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
|
| 285 |
+
parser.add_argument('--pretrained', nargs='?', const=True, default=True, help='start from i.e. --pretrained False')
|
| 286 |
+
parser.add_argument('--optimizer', choices=['SGD', 'Adam', 'AdamW', 'RMSProp'], default='Adam', help='optimizer')
|
| 287 |
+
parser.add_argument('--lr0', type=float, default=0.001, help='initial learning rate')
|
| 288 |
+
parser.add_argument('--decay', type=float, default=5e-5, help='weight decay')
|
| 289 |
+
parser.add_argument('--label-smoothing', type=float, default=0.1, help='Label smoothing epsilon')
|
| 290 |
+
parser.add_argument('--cutoff', type=int, default=None, help='Model layer cutoff index for Classify() head')
|
| 291 |
+
parser.add_argument('--dropout', type=float, default=None, help='Dropout (fraction)')
|
| 292 |
+
parser.add_argument('--verbose', action='store_true', help='Verbose mode')
|
| 293 |
+
parser.add_argument('--seed', type=int, default=0, help='Global training seed')
|
| 294 |
+
parser.add_argument('--local_rank', type=int, default=-1, help='Automatic DDP Multi-GPU argument, do not modify')
|
| 295 |
+
return parser.parse_known_args()[0] if known else parser.parse_args()
|
| 296 |
+
|
| 297 |
+
|
| 298 |
+
def main(opt):
|
| 299 |
+
# Checks
|
| 300 |
+
if RANK in {-1, 0}:
|
| 301 |
+
print_args(vars(opt))
|
| 302 |
+
check_git_status()
|
| 303 |
+
check_requirements(ROOT / 'requirements.txt')
|
| 304 |
+
|
| 305 |
+
# DDP mode
|
| 306 |
+
device = select_device(opt.device, batch_size=opt.batch_size)
|
| 307 |
+
if LOCAL_RANK != -1:
|
| 308 |
+
assert opt.batch_size != -1, 'AutoBatch is coming soon for classification, please pass a valid --batch-size'
|
| 309 |
+
assert opt.batch_size % WORLD_SIZE == 0, f'--batch-size {opt.batch_size} must be multiple of WORLD_SIZE'
|
| 310 |
+
assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
|
| 311 |
+
torch.cuda.set_device(LOCAL_RANK)
|
| 312 |
+
device = torch.device('cuda', LOCAL_RANK)
|
| 313 |
+
dist.init_process_group(backend='nccl' if dist.is_nccl_available() else 'gloo')
|
| 314 |
+
|
| 315 |
+
# Parameters
|
| 316 |
+
opt.save_dir = increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok) # increment run
|
| 317 |
+
|
| 318 |
+
# Train
|
| 319 |
+
train(opt, device)
|
| 320 |
+
|
| 321 |
+
|
| 322 |
+
def run(**kwargs):
|
| 323 |
+
# Usage: from yolov5 import classify; classify.train.run(data=mnist, imgsz=320, model='yolov5m')
|
| 324 |
+
opt = parse_opt(True)
|
| 325 |
+
for k, v in kwargs.items():
|
| 326 |
+
setattr(opt, k, v)
|
| 327 |
+
main(opt)
|
| 328 |
+
return opt
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
if __name__ == '__main__':
|
| 332 |
+
opt = parse_opt()
|
| 333 |
+
main(opt)
|
yolov5/classify/tutorial.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
yolov5/classify/val.py
ADDED
|
@@ -0,0 +1,170 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
"""
|
| 3 |
+
Validate a trained YOLOv5 classification model on a classification dataset
|
| 4 |
+
|
| 5 |
+
Usage:
|
| 6 |
+
$ bash data/scripts/get_imagenet.sh --val # download ImageNet val split (6.3G, 50000 images)
|
| 7 |
+
$ python classify/val.py --weights yolov5m-cls.pt --data ../datasets/imagenet --img 224 # validate ImageNet
|
| 8 |
+
|
| 9 |
+
Usage - formats:
|
| 10 |
+
$ python classify/val.py --weights yolov5s-cls.pt # PyTorch
|
| 11 |
+
yolov5s-cls.torchscript # TorchScript
|
| 12 |
+
yolov5s-cls.onnx # ONNX Runtime or OpenCV DNN with --dnn
|
| 13 |
+
yolov5s-cls_openvino_model # OpenVINO
|
| 14 |
+
yolov5s-cls.engine # TensorRT
|
| 15 |
+
yolov5s-cls.mlmodel # CoreML (macOS-only)
|
| 16 |
+
yolov5s-cls_saved_model # TensorFlow SavedModel
|
| 17 |
+
yolov5s-cls.pb # TensorFlow GraphDef
|
| 18 |
+
yolov5s-cls.tflite # TensorFlow Lite
|
| 19 |
+
yolov5s-cls_edgetpu.tflite # TensorFlow Edge TPU
|
| 20 |
+
yolov5s-cls_paddle_model # PaddlePaddle
|
| 21 |
+
"""
|
| 22 |
+
|
| 23 |
+
import argparse
|
| 24 |
+
import os
|
| 25 |
+
import sys
|
| 26 |
+
from pathlib import Path
|
| 27 |
+
|
| 28 |
+
import torch
|
| 29 |
+
from tqdm import tqdm
|
| 30 |
+
|
| 31 |
+
FILE = Path(__file__).resolve()
|
| 32 |
+
ROOT = FILE.parents[1] # YOLOv5 root directory
|
| 33 |
+
if str(ROOT) not in sys.path:
|
| 34 |
+
sys.path.append(str(ROOT)) # add ROOT to PATH
|
| 35 |
+
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
|
| 36 |
+
|
| 37 |
+
from models.common import DetectMultiBackend
|
| 38 |
+
from utils.dataloaders import create_classification_dataloader
|
| 39 |
+
from utils.general import (LOGGER, TQDM_BAR_FORMAT, Profile, check_img_size, check_requirements, colorstr,
|
| 40 |
+
increment_path, print_args)
|
| 41 |
+
from utils.torch_utils import select_device, smart_inference_mode
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
@smart_inference_mode()
|
| 45 |
+
def run(
|
| 46 |
+
data=ROOT / '../datasets/mnist', # dataset dir
|
| 47 |
+
weights=ROOT / 'yolov5s-cls.pt', # model.pt path(s)
|
| 48 |
+
batch_size=128, # batch size
|
| 49 |
+
imgsz=224, # inference size (pixels)
|
| 50 |
+
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
|
| 51 |
+
workers=8, # max dataloader workers (per RANK in DDP mode)
|
| 52 |
+
verbose=False, # verbose output
|
| 53 |
+
project=ROOT / 'runs/val-cls', # save to project/name
|
| 54 |
+
name='exp', # save to project/name
|
| 55 |
+
exist_ok=False, # existing project/name ok, do not increment
|
| 56 |
+
half=False, # use FP16 half-precision inference
|
| 57 |
+
dnn=False, # use OpenCV DNN for ONNX inference
|
| 58 |
+
model=None,
|
| 59 |
+
dataloader=None,
|
| 60 |
+
criterion=None,
|
| 61 |
+
pbar=None,
|
| 62 |
+
):
|
| 63 |
+
# Initialize/load model and set device
|
| 64 |
+
training = model is not None
|
| 65 |
+
if training: # called by train.py
|
| 66 |
+
device, pt, jit, engine = next(model.parameters()).device, True, False, False # get model device, PyTorch model
|
| 67 |
+
half &= device.type != 'cpu' # half precision only supported on CUDA
|
| 68 |
+
model.half() if half else model.float()
|
| 69 |
+
else: # called directly
|
| 70 |
+
device = select_device(device, batch_size=batch_size)
|
| 71 |
+
|
| 72 |
+
# Directories
|
| 73 |
+
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
|
| 74 |
+
save_dir.mkdir(parents=True, exist_ok=True) # make dir
|
| 75 |
+
|
| 76 |
+
# Load model
|
| 77 |
+
model = DetectMultiBackend(weights, device=device, dnn=dnn, fp16=half)
|
| 78 |
+
stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
|
| 79 |
+
imgsz = check_img_size(imgsz, s=stride) # check image size
|
| 80 |
+
half = model.fp16 # FP16 supported on limited backends with CUDA
|
| 81 |
+
if engine:
|
| 82 |
+
batch_size = model.batch_size
|
| 83 |
+
else:
|
| 84 |
+
device = model.device
|
| 85 |
+
if not (pt or jit):
|
| 86 |
+
batch_size = 1 # export.py models default to batch-size 1
|
| 87 |
+
LOGGER.info(f'Forcing --batch-size 1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
|
| 88 |
+
|
| 89 |
+
# Dataloader
|
| 90 |
+
data = Path(data)
|
| 91 |
+
test_dir = data / 'test' if (data / 'test').exists() else data / 'val' # data/test or data/val
|
| 92 |
+
dataloader = create_classification_dataloader(path=test_dir,
|
| 93 |
+
imgsz=imgsz,
|
| 94 |
+
batch_size=batch_size,
|
| 95 |
+
augment=False,
|
| 96 |
+
rank=-1,
|
| 97 |
+
workers=workers)
|
| 98 |
+
|
| 99 |
+
model.eval()
|
| 100 |
+
pred, targets, loss, dt = [], [], 0, (Profile(device=device), Profile(device=device), Profile(device=device))
|
| 101 |
+
n = len(dataloader) # number of batches
|
| 102 |
+
action = 'validating' if dataloader.dataset.root.stem == 'val' else 'testing'
|
| 103 |
+
desc = f'{pbar.desc[:-36]}{action:>36}' if pbar else f'{action}'
|
| 104 |
+
bar = tqdm(dataloader, desc, n, not training, bar_format=TQDM_BAR_FORMAT, position=0)
|
| 105 |
+
with torch.cuda.amp.autocast(enabled=device.type != 'cpu'):
|
| 106 |
+
for images, labels in bar:
|
| 107 |
+
with dt[0]:
|
| 108 |
+
images, labels = images.to(device, non_blocking=True), labels.to(device)
|
| 109 |
+
|
| 110 |
+
with dt[1]:
|
| 111 |
+
y = model(images)
|
| 112 |
+
|
| 113 |
+
with dt[2]:
|
| 114 |
+
pred.append(y.argsort(1, descending=True)[:, :5])
|
| 115 |
+
targets.append(labels)
|
| 116 |
+
if criterion:
|
| 117 |
+
loss += criterion(y, labels)
|
| 118 |
+
|
| 119 |
+
loss /= n
|
| 120 |
+
pred, targets = torch.cat(pred), torch.cat(targets)
|
| 121 |
+
correct = (targets[:, None] == pred).float()
|
| 122 |
+
acc = torch.stack((correct[:, 0], correct.max(1).values), dim=1) # (top1, top5) accuracy
|
| 123 |
+
top1, top5 = acc.mean(0).tolist()
|
| 124 |
+
|
| 125 |
+
if pbar:
|
| 126 |
+
pbar.desc = f'{pbar.desc[:-36]}{loss:>12.3g}{top1:>12.3g}{top5:>12.3g}'
|
| 127 |
+
if verbose: # all classes
|
| 128 |
+
LOGGER.info(f"{'Class':>24}{'Images':>12}{'top1_acc':>12}{'top5_acc':>12}")
|
| 129 |
+
LOGGER.info(f"{'all':>24}{targets.shape[0]:>12}{top1:>12.3g}{top5:>12.3g}")
|
| 130 |
+
for i, c in model.names.items():
|
| 131 |
+
acc_i = acc[targets == i]
|
| 132 |
+
top1i, top5i = acc_i.mean(0).tolist()
|
| 133 |
+
LOGGER.info(f'{c:>24}{acc_i.shape[0]:>12}{top1i:>12.3g}{top5i:>12.3g}')
|
| 134 |
+
|
| 135 |
+
# Print results
|
| 136 |
+
t = tuple(x.t / len(dataloader.dataset.samples) * 1E3 for x in dt) # speeds per image
|
| 137 |
+
shape = (1, 3, imgsz, imgsz)
|
| 138 |
+
LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms post-process per image at shape {shape}' % t)
|
| 139 |
+
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}")
|
| 140 |
+
|
| 141 |
+
return top1, top5, loss
|
| 142 |
+
|
| 143 |
+
|
| 144 |
+
def parse_opt():
|
| 145 |
+
parser = argparse.ArgumentParser()
|
| 146 |
+
parser.add_argument('--data', type=str, default=ROOT / '../datasets/mnist', help='dataset path')
|
| 147 |
+
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s-cls.pt', help='model.pt path(s)')
|
| 148 |
+
parser.add_argument('--batch-size', type=int, default=128, help='batch size')
|
| 149 |
+
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=224, help='inference size (pixels)')
|
| 150 |
+
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
|
| 151 |
+
parser.add_argument('--workers', type=int, default=8, help='max dataloader workers (per RANK in DDP mode)')
|
| 152 |
+
parser.add_argument('--verbose', nargs='?', const=True, default=True, help='verbose output')
|
| 153 |
+
parser.add_argument('--project', default=ROOT / 'runs/val-cls', help='save to project/name')
|
| 154 |
+
parser.add_argument('--name', default='exp', help='save to project/name')
|
| 155 |
+
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
|
| 156 |
+
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
|
| 157 |
+
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
|
| 158 |
+
opt = parser.parse_args()
|
| 159 |
+
print_args(vars(opt))
|
| 160 |
+
return opt
|
| 161 |
+
|
| 162 |
+
|
| 163 |
+
def main(opt):
|
| 164 |
+
check_requirements(ROOT / 'requirements.txt', exclude=('tensorboard', 'thop'))
|
| 165 |
+
run(**vars(opt))
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
if __name__ == '__main__':
|
| 169 |
+
opt = parse_opt()
|
| 170 |
+
main(opt)
|
yolov5/data/Argoverse.yaml
ADDED
|
@@ -0,0 +1,74 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# Argoverse-HD dataset (ring-front-center camera) http://www.cs.cmu.edu/~mengtial/proj/streaming/ by Argo AI
|
| 3 |
+
# Example usage: python train.py --data Argoverse.yaml
|
| 4 |
+
# parent
|
| 5 |
+
# ├── yolov5
|
| 6 |
+
# └── datasets
|
| 7 |
+
# └── Argoverse ← downloads here (31.3 GB)
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
| 11 |
+
path: ../datasets/Argoverse # dataset root dir
|
| 12 |
+
train: Argoverse-1.1/images/train/ # train images (relative to 'path') 39384 images
|
| 13 |
+
val: Argoverse-1.1/images/val/ # val images (relative to 'path') 15062 images
|
| 14 |
+
test: Argoverse-1.1/images/test/ # test images (optional) https://eval.ai/web/challenges/challenge-page/800/overview
|
| 15 |
+
|
| 16 |
+
# Classes
|
| 17 |
+
names:
|
| 18 |
+
0: person
|
| 19 |
+
1: bicycle
|
| 20 |
+
2: car
|
| 21 |
+
3: motorcycle
|
| 22 |
+
4: bus
|
| 23 |
+
5: truck
|
| 24 |
+
6: traffic_light
|
| 25 |
+
7: stop_sign
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
# Download script/URL (optional) ---------------------------------------------------------------------------------------
|
| 29 |
+
download: |
|
| 30 |
+
import json
|
| 31 |
+
|
| 32 |
+
from tqdm import tqdm
|
| 33 |
+
from utils.general import download, Path
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
def argoverse2yolo(set):
|
| 37 |
+
labels = {}
|
| 38 |
+
a = json.load(open(set, "rb"))
|
| 39 |
+
for annot in tqdm(a['annotations'], desc=f"Converting {set} to YOLOv5 format..."):
|
| 40 |
+
img_id = annot['image_id']
|
| 41 |
+
img_name = a['images'][img_id]['name']
|
| 42 |
+
img_label_name = f'{img_name[:-3]}txt'
|
| 43 |
+
|
| 44 |
+
cls = annot['category_id'] # instance class id
|
| 45 |
+
x_center, y_center, width, height = annot['bbox']
|
| 46 |
+
x_center = (x_center + width / 2) / 1920.0 # offset and scale
|
| 47 |
+
y_center = (y_center + height / 2) / 1200.0 # offset and scale
|
| 48 |
+
width /= 1920.0 # scale
|
| 49 |
+
height /= 1200.0 # scale
|
| 50 |
+
|
| 51 |
+
img_dir = set.parents[2] / 'Argoverse-1.1' / 'labels' / a['seq_dirs'][a['images'][annot['image_id']]['sid']]
|
| 52 |
+
if not img_dir.exists():
|
| 53 |
+
img_dir.mkdir(parents=True, exist_ok=True)
|
| 54 |
+
|
| 55 |
+
k = str(img_dir / img_label_name)
|
| 56 |
+
if k not in labels:
|
| 57 |
+
labels[k] = []
|
| 58 |
+
labels[k].append(f"{cls} {x_center} {y_center} {width} {height}\n")
|
| 59 |
+
|
| 60 |
+
for k in labels:
|
| 61 |
+
with open(k, "w") as f:
|
| 62 |
+
f.writelines(labels[k])
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
# Download
|
| 66 |
+
dir = Path(yaml['path']) # dataset root dir
|
| 67 |
+
urls = ['https://argoverse-hd.s3.us-east-2.amazonaws.com/Argoverse-HD-Full.zip']
|
| 68 |
+
download(urls, dir=dir, delete=False)
|
| 69 |
+
|
| 70 |
+
# Convert
|
| 71 |
+
annotations_dir = 'Argoverse-HD/annotations/'
|
| 72 |
+
(dir / 'Argoverse-1.1' / 'tracking').rename(dir / 'Argoverse-1.1' / 'images') # rename 'tracking' to 'images'
|
| 73 |
+
for d in "train.json", "val.json":
|
| 74 |
+
argoverse2yolo(dir / annotations_dir / d) # convert VisDrone annotations to YOLO labels
|
yolov5/data/GlobalWheat2020.yaml
ADDED
|
@@ -0,0 +1,54 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# Global Wheat 2020 dataset http://www.global-wheat.com/ by University of Saskatchewan
|
| 3 |
+
# Example usage: python train.py --data GlobalWheat2020.yaml
|
| 4 |
+
# parent
|
| 5 |
+
# ├── yolov5
|
| 6 |
+
# └── datasets
|
| 7 |
+
# └── GlobalWheat2020 ← downloads here (7.0 GB)
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
| 11 |
+
path: ../datasets/GlobalWheat2020 # dataset root dir
|
| 12 |
+
train: # train images (relative to 'path') 3422 images
|
| 13 |
+
- images/arvalis_1
|
| 14 |
+
- images/arvalis_2
|
| 15 |
+
- images/arvalis_3
|
| 16 |
+
- images/ethz_1
|
| 17 |
+
- images/rres_1
|
| 18 |
+
- images/inrae_1
|
| 19 |
+
- images/usask_1
|
| 20 |
+
val: # val images (relative to 'path') 748 images (WARNING: train set contains ethz_1)
|
| 21 |
+
- images/ethz_1
|
| 22 |
+
test: # test images (optional) 1276 images
|
| 23 |
+
- images/utokyo_1
|
| 24 |
+
- images/utokyo_2
|
| 25 |
+
- images/nau_1
|
| 26 |
+
- images/uq_1
|
| 27 |
+
|
| 28 |
+
# Classes
|
| 29 |
+
names:
|
| 30 |
+
0: wheat_head
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
# Download script/URL (optional) ---------------------------------------------------------------------------------------
|
| 34 |
+
download: |
|
| 35 |
+
from utils.general import download, Path
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
# Download
|
| 39 |
+
dir = Path(yaml['path']) # dataset root dir
|
| 40 |
+
urls = ['https://zenodo.org/record/4298502/files/global-wheat-codalab-official.zip',
|
| 41 |
+
'https://github.com/ultralytics/yolov5/releases/download/v1.0/GlobalWheat2020_labels.zip']
|
| 42 |
+
download(urls, dir=dir)
|
| 43 |
+
|
| 44 |
+
# Make Directories
|
| 45 |
+
for p in 'annotations', 'images', 'labels':
|
| 46 |
+
(dir / p).mkdir(parents=True, exist_ok=True)
|
| 47 |
+
|
| 48 |
+
# Move
|
| 49 |
+
for p in 'arvalis_1', 'arvalis_2', 'arvalis_3', 'ethz_1', 'rres_1', 'inrae_1', 'usask_1', \
|
| 50 |
+
'utokyo_1', 'utokyo_2', 'nau_1', 'uq_1':
|
| 51 |
+
(dir / p).rename(dir / 'images' / p) # move to /images
|
| 52 |
+
f = (dir / p).with_suffix('.json') # json file
|
| 53 |
+
if f.exists():
|
| 54 |
+
f.rename((dir / 'annotations' / p).with_suffix('.json')) # move to /annotations
|
yolov5/data/ImageNet.yaml
ADDED
|
@@ -0,0 +1,1022 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# ImageNet-1k dataset https://www.image-net.org/index.php by Stanford University
|
| 3 |
+
# Simplified class names from https://github.com/anishathalye/imagenet-simple-labels
|
| 4 |
+
# Example usage: python classify/train.py --data imagenet
|
| 5 |
+
# parent
|
| 6 |
+
# ├── yolov5
|
| 7 |
+
# └── datasets
|
| 8 |
+
# └── imagenet ← downloads here (144 GB)
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
| 12 |
+
path: ../datasets/imagenet # dataset root dir
|
| 13 |
+
train: train # train images (relative to 'path') 1281167 images
|
| 14 |
+
val: val # val images (relative to 'path') 50000 images
|
| 15 |
+
test: # test images (optional)
|
| 16 |
+
|
| 17 |
+
# Classes
|
| 18 |
+
names:
|
| 19 |
+
0: tench
|
| 20 |
+
1: goldfish
|
| 21 |
+
2: great white shark
|
| 22 |
+
3: tiger shark
|
| 23 |
+
4: hammerhead shark
|
| 24 |
+
5: electric ray
|
| 25 |
+
6: stingray
|
| 26 |
+
7: cock
|
| 27 |
+
8: hen
|
| 28 |
+
9: ostrich
|
| 29 |
+
10: brambling
|
| 30 |
+
11: goldfinch
|
| 31 |
+
12: house finch
|
| 32 |
+
13: junco
|
| 33 |
+
14: indigo bunting
|
| 34 |
+
15: American robin
|
| 35 |
+
16: bulbul
|
| 36 |
+
17: jay
|
| 37 |
+
18: magpie
|
| 38 |
+
19: chickadee
|
| 39 |
+
20: American dipper
|
| 40 |
+
21: kite
|
| 41 |
+
22: bald eagle
|
| 42 |
+
23: vulture
|
| 43 |
+
24: great grey owl
|
| 44 |
+
25: fire salamander
|
| 45 |
+
26: smooth newt
|
| 46 |
+
27: newt
|
| 47 |
+
28: spotted salamander
|
| 48 |
+
29: axolotl
|
| 49 |
+
30: American bullfrog
|
| 50 |
+
31: tree frog
|
| 51 |
+
32: tailed frog
|
| 52 |
+
33: loggerhead sea turtle
|
| 53 |
+
34: leatherback sea turtle
|
| 54 |
+
35: mud turtle
|
| 55 |
+
36: terrapin
|
| 56 |
+
37: box turtle
|
| 57 |
+
38: banded gecko
|
| 58 |
+
39: green iguana
|
| 59 |
+
40: Carolina anole
|
| 60 |
+
41: desert grassland whiptail lizard
|
| 61 |
+
42: agama
|
| 62 |
+
43: frilled-necked lizard
|
| 63 |
+
44: alligator lizard
|
| 64 |
+
45: Gila monster
|
| 65 |
+
46: European green lizard
|
| 66 |
+
47: chameleon
|
| 67 |
+
48: Komodo dragon
|
| 68 |
+
49: Nile crocodile
|
| 69 |
+
50: American alligator
|
| 70 |
+
51: triceratops
|
| 71 |
+
52: worm snake
|
| 72 |
+
53: ring-necked snake
|
| 73 |
+
54: eastern hog-nosed snake
|
| 74 |
+
55: smooth green snake
|
| 75 |
+
56: kingsnake
|
| 76 |
+
57: garter snake
|
| 77 |
+
58: water snake
|
| 78 |
+
59: vine snake
|
| 79 |
+
60: night snake
|
| 80 |
+
61: boa constrictor
|
| 81 |
+
62: African rock python
|
| 82 |
+
63: Indian cobra
|
| 83 |
+
64: green mamba
|
| 84 |
+
65: sea snake
|
| 85 |
+
66: Saharan horned viper
|
| 86 |
+
67: eastern diamondback rattlesnake
|
| 87 |
+
68: sidewinder
|
| 88 |
+
69: trilobite
|
| 89 |
+
70: harvestman
|
| 90 |
+
71: scorpion
|
| 91 |
+
72: yellow garden spider
|
| 92 |
+
73: barn spider
|
| 93 |
+
74: European garden spider
|
| 94 |
+
75: southern black widow
|
| 95 |
+
76: tarantula
|
| 96 |
+
77: wolf spider
|
| 97 |
+
78: tick
|
| 98 |
+
79: centipede
|
| 99 |
+
80: black grouse
|
| 100 |
+
81: ptarmigan
|
| 101 |
+
82: ruffed grouse
|
| 102 |
+
83: prairie grouse
|
| 103 |
+
84: peacock
|
| 104 |
+
85: quail
|
| 105 |
+
86: partridge
|
| 106 |
+
87: grey parrot
|
| 107 |
+
88: macaw
|
| 108 |
+
89: sulphur-crested cockatoo
|
| 109 |
+
90: lorikeet
|
| 110 |
+
91: coucal
|
| 111 |
+
92: bee eater
|
| 112 |
+
93: hornbill
|
| 113 |
+
94: hummingbird
|
| 114 |
+
95: jacamar
|
| 115 |
+
96: toucan
|
| 116 |
+
97: duck
|
| 117 |
+
98: red-breasted merganser
|
| 118 |
+
99: goose
|
| 119 |
+
100: black swan
|
| 120 |
+
101: tusker
|
| 121 |
+
102: echidna
|
| 122 |
+
103: platypus
|
| 123 |
+
104: wallaby
|
| 124 |
+
105: koala
|
| 125 |
+
106: wombat
|
| 126 |
+
107: jellyfish
|
| 127 |
+
108: sea anemone
|
| 128 |
+
109: brain coral
|
| 129 |
+
110: flatworm
|
| 130 |
+
111: nematode
|
| 131 |
+
112: conch
|
| 132 |
+
113: snail
|
| 133 |
+
114: slug
|
| 134 |
+
115: sea slug
|
| 135 |
+
116: chiton
|
| 136 |
+
117: chambered nautilus
|
| 137 |
+
118: Dungeness crab
|
| 138 |
+
119: rock crab
|
| 139 |
+
120: fiddler crab
|
| 140 |
+
121: red king crab
|
| 141 |
+
122: American lobster
|
| 142 |
+
123: spiny lobster
|
| 143 |
+
124: crayfish
|
| 144 |
+
125: hermit crab
|
| 145 |
+
126: isopod
|
| 146 |
+
127: white stork
|
| 147 |
+
128: black stork
|
| 148 |
+
129: spoonbill
|
| 149 |
+
130: flamingo
|
| 150 |
+
131: little blue heron
|
| 151 |
+
132: great egret
|
| 152 |
+
133: bittern
|
| 153 |
+
134: crane (bird)
|
| 154 |
+
135: limpkin
|
| 155 |
+
136: common gallinule
|
| 156 |
+
137: American coot
|
| 157 |
+
138: bustard
|
| 158 |
+
139: ruddy turnstone
|
| 159 |
+
140: dunlin
|
| 160 |
+
141: common redshank
|
| 161 |
+
142: dowitcher
|
| 162 |
+
143: oystercatcher
|
| 163 |
+
144: pelican
|
| 164 |
+
145: king penguin
|
| 165 |
+
146: albatross
|
| 166 |
+
147: grey whale
|
| 167 |
+
148: killer whale
|
| 168 |
+
149: dugong
|
| 169 |
+
150: sea lion
|
| 170 |
+
151: Chihuahua
|
| 171 |
+
152: Japanese Chin
|
| 172 |
+
153: Maltese
|
| 173 |
+
154: Pekingese
|
| 174 |
+
155: Shih Tzu
|
| 175 |
+
156: King Charles Spaniel
|
| 176 |
+
157: Papillon
|
| 177 |
+
158: toy terrier
|
| 178 |
+
159: Rhodesian Ridgeback
|
| 179 |
+
160: Afghan Hound
|
| 180 |
+
161: Basset Hound
|
| 181 |
+
162: Beagle
|
| 182 |
+
163: Bloodhound
|
| 183 |
+
164: Bluetick Coonhound
|
| 184 |
+
165: Black and Tan Coonhound
|
| 185 |
+
166: Treeing Walker Coonhound
|
| 186 |
+
167: English foxhound
|
| 187 |
+
168: Redbone Coonhound
|
| 188 |
+
169: borzoi
|
| 189 |
+
170: Irish Wolfhound
|
| 190 |
+
171: Italian Greyhound
|
| 191 |
+
172: Whippet
|
| 192 |
+
173: Ibizan Hound
|
| 193 |
+
174: Norwegian Elkhound
|
| 194 |
+
175: Otterhound
|
| 195 |
+
176: Saluki
|
| 196 |
+
177: Scottish Deerhound
|
| 197 |
+
178: Weimaraner
|
| 198 |
+
179: Staffordshire Bull Terrier
|
| 199 |
+
180: American Staffordshire Terrier
|
| 200 |
+
181: Bedlington Terrier
|
| 201 |
+
182: Border Terrier
|
| 202 |
+
183: Kerry Blue Terrier
|
| 203 |
+
184: Irish Terrier
|
| 204 |
+
185: Norfolk Terrier
|
| 205 |
+
186: Norwich Terrier
|
| 206 |
+
187: Yorkshire Terrier
|
| 207 |
+
188: Wire Fox Terrier
|
| 208 |
+
189: Lakeland Terrier
|
| 209 |
+
190: Sealyham Terrier
|
| 210 |
+
191: Airedale Terrier
|
| 211 |
+
192: Cairn Terrier
|
| 212 |
+
193: Australian Terrier
|
| 213 |
+
194: Dandie Dinmont Terrier
|
| 214 |
+
195: Boston Terrier
|
| 215 |
+
196: Miniature Schnauzer
|
| 216 |
+
197: Giant Schnauzer
|
| 217 |
+
198: Standard Schnauzer
|
| 218 |
+
199: Scottish Terrier
|
| 219 |
+
200: Tibetan Terrier
|
| 220 |
+
201: Australian Silky Terrier
|
| 221 |
+
202: Soft-coated Wheaten Terrier
|
| 222 |
+
203: West Highland White Terrier
|
| 223 |
+
204: Lhasa Apso
|
| 224 |
+
205: Flat-Coated Retriever
|
| 225 |
+
206: Curly-coated Retriever
|
| 226 |
+
207: Golden Retriever
|
| 227 |
+
208: Labrador Retriever
|
| 228 |
+
209: Chesapeake Bay Retriever
|
| 229 |
+
210: German Shorthaired Pointer
|
| 230 |
+
211: Vizsla
|
| 231 |
+
212: English Setter
|
| 232 |
+
213: Irish Setter
|
| 233 |
+
214: Gordon Setter
|
| 234 |
+
215: Brittany
|
| 235 |
+
216: Clumber Spaniel
|
| 236 |
+
217: English Springer Spaniel
|
| 237 |
+
218: Welsh Springer Spaniel
|
| 238 |
+
219: Cocker Spaniels
|
| 239 |
+
220: Sussex Spaniel
|
| 240 |
+
221: Irish Water Spaniel
|
| 241 |
+
222: Kuvasz
|
| 242 |
+
223: Schipperke
|
| 243 |
+
224: Groenendael
|
| 244 |
+
225: Malinois
|
| 245 |
+
226: Briard
|
| 246 |
+
227: Australian Kelpie
|
| 247 |
+
228: Komondor
|
| 248 |
+
229: Old English Sheepdog
|
| 249 |
+
230: Shetland Sheepdog
|
| 250 |
+
231: collie
|
| 251 |
+
232: Border Collie
|
| 252 |
+
233: Bouvier des Flandres
|
| 253 |
+
234: Rottweiler
|
| 254 |
+
235: German Shepherd Dog
|
| 255 |
+
236: Dobermann
|
| 256 |
+
237: Miniature Pinscher
|
| 257 |
+
238: Greater Swiss Mountain Dog
|
| 258 |
+
239: Bernese Mountain Dog
|
| 259 |
+
240: Appenzeller Sennenhund
|
| 260 |
+
241: Entlebucher Sennenhund
|
| 261 |
+
242: Boxer
|
| 262 |
+
243: Bullmastiff
|
| 263 |
+
244: Tibetan Mastiff
|
| 264 |
+
245: French Bulldog
|
| 265 |
+
246: Great Dane
|
| 266 |
+
247: St. Bernard
|
| 267 |
+
248: husky
|
| 268 |
+
249: Alaskan Malamute
|
| 269 |
+
250: Siberian Husky
|
| 270 |
+
251: Dalmatian
|
| 271 |
+
252: Affenpinscher
|
| 272 |
+
253: Basenji
|
| 273 |
+
254: pug
|
| 274 |
+
255: Leonberger
|
| 275 |
+
256: Newfoundland
|
| 276 |
+
257: Pyrenean Mountain Dog
|
| 277 |
+
258: Samoyed
|
| 278 |
+
259: Pomeranian
|
| 279 |
+
260: Chow Chow
|
| 280 |
+
261: Keeshond
|
| 281 |
+
262: Griffon Bruxellois
|
| 282 |
+
263: Pembroke Welsh Corgi
|
| 283 |
+
264: Cardigan Welsh Corgi
|
| 284 |
+
265: Toy Poodle
|
| 285 |
+
266: Miniature Poodle
|
| 286 |
+
267: Standard Poodle
|
| 287 |
+
268: Mexican hairless dog
|
| 288 |
+
269: grey wolf
|
| 289 |
+
270: Alaskan tundra wolf
|
| 290 |
+
271: red wolf
|
| 291 |
+
272: coyote
|
| 292 |
+
273: dingo
|
| 293 |
+
274: dhole
|
| 294 |
+
275: African wild dog
|
| 295 |
+
276: hyena
|
| 296 |
+
277: red fox
|
| 297 |
+
278: kit fox
|
| 298 |
+
279: Arctic fox
|
| 299 |
+
280: grey fox
|
| 300 |
+
281: tabby cat
|
| 301 |
+
282: tiger cat
|
| 302 |
+
283: Persian cat
|
| 303 |
+
284: Siamese cat
|
| 304 |
+
285: Egyptian Mau
|
| 305 |
+
286: cougar
|
| 306 |
+
287: lynx
|
| 307 |
+
288: leopard
|
| 308 |
+
289: snow leopard
|
| 309 |
+
290: jaguar
|
| 310 |
+
291: lion
|
| 311 |
+
292: tiger
|
| 312 |
+
293: cheetah
|
| 313 |
+
294: brown bear
|
| 314 |
+
295: American black bear
|
| 315 |
+
296: polar bear
|
| 316 |
+
297: sloth bear
|
| 317 |
+
298: mongoose
|
| 318 |
+
299: meerkat
|
| 319 |
+
300: tiger beetle
|
| 320 |
+
301: ladybug
|
| 321 |
+
302: ground beetle
|
| 322 |
+
303: longhorn beetle
|
| 323 |
+
304: leaf beetle
|
| 324 |
+
305: dung beetle
|
| 325 |
+
306: rhinoceros beetle
|
| 326 |
+
307: weevil
|
| 327 |
+
308: fly
|
| 328 |
+
309: bee
|
| 329 |
+
310: ant
|
| 330 |
+
311: grasshopper
|
| 331 |
+
312: cricket
|
| 332 |
+
313: stick insect
|
| 333 |
+
314: cockroach
|
| 334 |
+
315: mantis
|
| 335 |
+
316: cicada
|
| 336 |
+
317: leafhopper
|
| 337 |
+
318: lacewing
|
| 338 |
+
319: dragonfly
|
| 339 |
+
320: damselfly
|
| 340 |
+
321: red admiral
|
| 341 |
+
322: ringlet
|
| 342 |
+
323: monarch butterfly
|
| 343 |
+
324: small white
|
| 344 |
+
325: sulphur butterfly
|
| 345 |
+
326: gossamer-winged butterfly
|
| 346 |
+
327: starfish
|
| 347 |
+
328: sea urchin
|
| 348 |
+
329: sea cucumber
|
| 349 |
+
330: cottontail rabbit
|
| 350 |
+
331: hare
|
| 351 |
+
332: Angora rabbit
|
| 352 |
+
333: hamster
|
| 353 |
+
334: porcupine
|
| 354 |
+
335: fox squirrel
|
| 355 |
+
336: marmot
|
| 356 |
+
337: beaver
|
| 357 |
+
338: guinea pig
|
| 358 |
+
339: common sorrel
|
| 359 |
+
340: zebra
|
| 360 |
+
341: pig
|
| 361 |
+
342: wild boar
|
| 362 |
+
343: warthog
|
| 363 |
+
344: hippopotamus
|
| 364 |
+
345: ox
|
| 365 |
+
346: water buffalo
|
| 366 |
+
347: bison
|
| 367 |
+
348: ram
|
| 368 |
+
349: bighorn sheep
|
| 369 |
+
350: Alpine ibex
|
| 370 |
+
351: hartebeest
|
| 371 |
+
352: impala
|
| 372 |
+
353: gazelle
|
| 373 |
+
354: dromedary
|
| 374 |
+
355: llama
|
| 375 |
+
356: weasel
|
| 376 |
+
357: mink
|
| 377 |
+
358: European polecat
|
| 378 |
+
359: black-footed ferret
|
| 379 |
+
360: otter
|
| 380 |
+
361: skunk
|
| 381 |
+
362: badger
|
| 382 |
+
363: armadillo
|
| 383 |
+
364: three-toed sloth
|
| 384 |
+
365: orangutan
|
| 385 |
+
366: gorilla
|
| 386 |
+
367: chimpanzee
|
| 387 |
+
368: gibbon
|
| 388 |
+
369: siamang
|
| 389 |
+
370: guenon
|
| 390 |
+
371: patas monkey
|
| 391 |
+
372: baboon
|
| 392 |
+
373: macaque
|
| 393 |
+
374: langur
|
| 394 |
+
375: black-and-white colobus
|
| 395 |
+
376: proboscis monkey
|
| 396 |
+
377: marmoset
|
| 397 |
+
378: white-headed capuchin
|
| 398 |
+
379: howler monkey
|
| 399 |
+
380: titi
|
| 400 |
+
381: Geoffroy's spider monkey
|
| 401 |
+
382: common squirrel monkey
|
| 402 |
+
383: ring-tailed lemur
|
| 403 |
+
384: indri
|
| 404 |
+
385: Asian elephant
|
| 405 |
+
386: African bush elephant
|
| 406 |
+
387: red panda
|
| 407 |
+
388: giant panda
|
| 408 |
+
389: snoek
|
| 409 |
+
390: eel
|
| 410 |
+
391: coho salmon
|
| 411 |
+
392: rock beauty
|
| 412 |
+
393: clownfish
|
| 413 |
+
394: sturgeon
|
| 414 |
+
395: garfish
|
| 415 |
+
396: lionfish
|
| 416 |
+
397: pufferfish
|
| 417 |
+
398: abacus
|
| 418 |
+
399: abaya
|
| 419 |
+
400: academic gown
|
| 420 |
+
401: accordion
|
| 421 |
+
402: acoustic guitar
|
| 422 |
+
403: aircraft carrier
|
| 423 |
+
404: airliner
|
| 424 |
+
405: airship
|
| 425 |
+
406: altar
|
| 426 |
+
407: ambulance
|
| 427 |
+
408: amphibious vehicle
|
| 428 |
+
409: analog clock
|
| 429 |
+
410: apiary
|
| 430 |
+
411: apron
|
| 431 |
+
412: waste container
|
| 432 |
+
413: assault rifle
|
| 433 |
+
414: backpack
|
| 434 |
+
415: bakery
|
| 435 |
+
416: balance beam
|
| 436 |
+
417: balloon
|
| 437 |
+
418: ballpoint pen
|
| 438 |
+
419: Band-Aid
|
| 439 |
+
420: banjo
|
| 440 |
+
421: baluster
|
| 441 |
+
422: barbell
|
| 442 |
+
423: barber chair
|
| 443 |
+
424: barbershop
|
| 444 |
+
425: barn
|
| 445 |
+
426: barometer
|
| 446 |
+
427: barrel
|
| 447 |
+
428: wheelbarrow
|
| 448 |
+
429: baseball
|
| 449 |
+
430: basketball
|
| 450 |
+
431: bassinet
|
| 451 |
+
432: bassoon
|
| 452 |
+
433: swimming cap
|
| 453 |
+
434: bath towel
|
| 454 |
+
435: bathtub
|
| 455 |
+
436: station wagon
|
| 456 |
+
437: lighthouse
|
| 457 |
+
438: beaker
|
| 458 |
+
439: military cap
|
| 459 |
+
440: beer bottle
|
| 460 |
+
441: beer glass
|
| 461 |
+
442: bell-cot
|
| 462 |
+
443: bib
|
| 463 |
+
444: tandem bicycle
|
| 464 |
+
445: bikini
|
| 465 |
+
446: ring binder
|
| 466 |
+
447: binoculars
|
| 467 |
+
448: birdhouse
|
| 468 |
+
449: boathouse
|
| 469 |
+
450: bobsleigh
|
| 470 |
+
451: bolo tie
|
| 471 |
+
452: poke bonnet
|
| 472 |
+
453: bookcase
|
| 473 |
+
454: bookstore
|
| 474 |
+
455: bottle cap
|
| 475 |
+
456: bow
|
| 476 |
+
457: bow tie
|
| 477 |
+
458: brass
|
| 478 |
+
459: bra
|
| 479 |
+
460: breakwater
|
| 480 |
+
461: breastplate
|
| 481 |
+
462: broom
|
| 482 |
+
463: bucket
|
| 483 |
+
464: buckle
|
| 484 |
+
465: bulletproof vest
|
| 485 |
+
466: high-speed train
|
| 486 |
+
467: butcher shop
|
| 487 |
+
468: taxicab
|
| 488 |
+
469: cauldron
|
| 489 |
+
470: candle
|
| 490 |
+
471: cannon
|
| 491 |
+
472: canoe
|
| 492 |
+
473: can opener
|
| 493 |
+
474: cardigan
|
| 494 |
+
475: car mirror
|
| 495 |
+
476: carousel
|
| 496 |
+
477: tool kit
|
| 497 |
+
478: carton
|
| 498 |
+
479: car wheel
|
| 499 |
+
480: automated teller machine
|
| 500 |
+
481: cassette
|
| 501 |
+
482: cassette player
|
| 502 |
+
483: castle
|
| 503 |
+
484: catamaran
|
| 504 |
+
485: CD player
|
| 505 |
+
486: cello
|
| 506 |
+
487: mobile phone
|
| 507 |
+
488: chain
|
| 508 |
+
489: chain-link fence
|
| 509 |
+
490: chain mail
|
| 510 |
+
491: chainsaw
|
| 511 |
+
492: chest
|
| 512 |
+
493: chiffonier
|
| 513 |
+
494: chime
|
| 514 |
+
495: china cabinet
|
| 515 |
+
496: Christmas stocking
|
| 516 |
+
497: church
|
| 517 |
+
498: movie theater
|
| 518 |
+
499: cleaver
|
| 519 |
+
500: cliff dwelling
|
| 520 |
+
501: cloak
|
| 521 |
+
502: clogs
|
| 522 |
+
503: cocktail shaker
|
| 523 |
+
504: coffee mug
|
| 524 |
+
505: coffeemaker
|
| 525 |
+
506: coil
|
| 526 |
+
507: combination lock
|
| 527 |
+
508: computer keyboard
|
| 528 |
+
509: confectionery store
|
| 529 |
+
510: container ship
|
| 530 |
+
511: convertible
|
| 531 |
+
512: corkscrew
|
| 532 |
+
513: cornet
|
| 533 |
+
514: cowboy boot
|
| 534 |
+
515: cowboy hat
|
| 535 |
+
516: cradle
|
| 536 |
+
517: crane (machine)
|
| 537 |
+
518: crash helmet
|
| 538 |
+
519: crate
|
| 539 |
+
520: infant bed
|
| 540 |
+
521: Crock Pot
|
| 541 |
+
522: croquet ball
|
| 542 |
+
523: crutch
|
| 543 |
+
524: cuirass
|
| 544 |
+
525: dam
|
| 545 |
+
526: desk
|
| 546 |
+
527: desktop computer
|
| 547 |
+
528: rotary dial telephone
|
| 548 |
+
529: diaper
|
| 549 |
+
530: digital clock
|
| 550 |
+
531: digital watch
|
| 551 |
+
532: dining table
|
| 552 |
+
533: dishcloth
|
| 553 |
+
534: dishwasher
|
| 554 |
+
535: disc brake
|
| 555 |
+
536: dock
|
| 556 |
+
537: dog sled
|
| 557 |
+
538: dome
|
| 558 |
+
539: doormat
|
| 559 |
+
540: drilling rig
|
| 560 |
+
541: drum
|
| 561 |
+
542: drumstick
|
| 562 |
+
543: dumbbell
|
| 563 |
+
544: Dutch oven
|
| 564 |
+
545: electric fan
|
| 565 |
+
546: electric guitar
|
| 566 |
+
547: electric locomotive
|
| 567 |
+
548: entertainment center
|
| 568 |
+
549: envelope
|
| 569 |
+
550: espresso machine
|
| 570 |
+
551: face powder
|
| 571 |
+
552: feather boa
|
| 572 |
+
553: filing cabinet
|
| 573 |
+
554: fireboat
|
| 574 |
+
555: fire engine
|
| 575 |
+
556: fire screen sheet
|
| 576 |
+
557: flagpole
|
| 577 |
+
558: flute
|
| 578 |
+
559: folding chair
|
| 579 |
+
560: football helmet
|
| 580 |
+
561: forklift
|
| 581 |
+
562: fountain
|
| 582 |
+
563: fountain pen
|
| 583 |
+
564: four-poster bed
|
| 584 |
+
565: freight car
|
| 585 |
+
566: French horn
|
| 586 |
+
567: frying pan
|
| 587 |
+
568: fur coat
|
| 588 |
+
569: garbage truck
|
| 589 |
+
570: gas mask
|
| 590 |
+
571: gas pump
|
| 591 |
+
572: goblet
|
| 592 |
+
573: go-kart
|
| 593 |
+
574: golf ball
|
| 594 |
+
575: golf cart
|
| 595 |
+
576: gondola
|
| 596 |
+
577: gong
|
| 597 |
+
578: gown
|
| 598 |
+
579: grand piano
|
| 599 |
+
580: greenhouse
|
| 600 |
+
581: grille
|
| 601 |
+
582: grocery store
|
| 602 |
+
583: guillotine
|
| 603 |
+
584: barrette
|
| 604 |
+
585: hair spray
|
| 605 |
+
586: half-track
|
| 606 |
+
587: hammer
|
| 607 |
+
588: hamper
|
| 608 |
+
589: hair dryer
|
| 609 |
+
590: hand-held computer
|
| 610 |
+
591: handkerchief
|
| 611 |
+
592: hard disk drive
|
| 612 |
+
593: harmonica
|
| 613 |
+
594: harp
|
| 614 |
+
595: harvester
|
| 615 |
+
596: hatchet
|
| 616 |
+
597: holster
|
| 617 |
+
598: home theater
|
| 618 |
+
599: honeycomb
|
| 619 |
+
600: hook
|
| 620 |
+
601: hoop skirt
|
| 621 |
+
602: horizontal bar
|
| 622 |
+
603: horse-drawn vehicle
|
| 623 |
+
604: hourglass
|
| 624 |
+
605: iPod
|
| 625 |
+
606: clothes iron
|
| 626 |
+
607: jack-o'-lantern
|
| 627 |
+
608: jeans
|
| 628 |
+
609: jeep
|
| 629 |
+
610: T-shirt
|
| 630 |
+
611: jigsaw puzzle
|
| 631 |
+
612: pulled rickshaw
|
| 632 |
+
613: joystick
|
| 633 |
+
614: kimono
|
| 634 |
+
615: knee pad
|
| 635 |
+
616: knot
|
| 636 |
+
617: lab coat
|
| 637 |
+
618: ladle
|
| 638 |
+
619: lampshade
|
| 639 |
+
620: laptop computer
|
| 640 |
+
621: lawn mower
|
| 641 |
+
622: lens cap
|
| 642 |
+
623: paper knife
|
| 643 |
+
624: library
|
| 644 |
+
625: lifeboat
|
| 645 |
+
626: lighter
|
| 646 |
+
627: limousine
|
| 647 |
+
628: ocean liner
|
| 648 |
+
629: lipstick
|
| 649 |
+
630: slip-on shoe
|
| 650 |
+
631: lotion
|
| 651 |
+
632: speaker
|
| 652 |
+
633: loupe
|
| 653 |
+
634: sawmill
|
| 654 |
+
635: magnetic compass
|
| 655 |
+
636: mail bag
|
| 656 |
+
637: mailbox
|
| 657 |
+
638: tights
|
| 658 |
+
639: tank suit
|
| 659 |
+
640: manhole cover
|
| 660 |
+
641: maraca
|
| 661 |
+
642: marimba
|
| 662 |
+
643: mask
|
| 663 |
+
644: match
|
| 664 |
+
645: maypole
|
| 665 |
+
646: maze
|
| 666 |
+
647: measuring cup
|
| 667 |
+
648: medicine chest
|
| 668 |
+
649: megalith
|
| 669 |
+
650: microphone
|
| 670 |
+
651: microwave oven
|
| 671 |
+
652: military uniform
|
| 672 |
+
653: milk can
|
| 673 |
+
654: minibus
|
| 674 |
+
655: miniskirt
|
| 675 |
+
656: minivan
|
| 676 |
+
657: missile
|
| 677 |
+
658: mitten
|
| 678 |
+
659: mixing bowl
|
| 679 |
+
660: mobile home
|
| 680 |
+
661: Model T
|
| 681 |
+
662: modem
|
| 682 |
+
663: monastery
|
| 683 |
+
664: monitor
|
| 684 |
+
665: moped
|
| 685 |
+
666: mortar
|
| 686 |
+
667: square academic cap
|
| 687 |
+
668: mosque
|
| 688 |
+
669: mosquito net
|
| 689 |
+
670: scooter
|
| 690 |
+
671: mountain bike
|
| 691 |
+
672: tent
|
| 692 |
+
673: computer mouse
|
| 693 |
+
674: mousetrap
|
| 694 |
+
675: moving van
|
| 695 |
+
676: muzzle
|
| 696 |
+
677: nail
|
| 697 |
+
678: neck brace
|
| 698 |
+
679: necklace
|
| 699 |
+
680: nipple
|
| 700 |
+
681: notebook computer
|
| 701 |
+
682: obelisk
|
| 702 |
+
683: oboe
|
| 703 |
+
684: ocarina
|
| 704 |
+
685: odometer
|
| 705 |
+
686: oil filter
|
| 706 |
+
687: organ
|
| 707 |
+
688: oscilloscope
|
| 708 |
+
689: overskirt
|
| 709 |
+
690: bullock cart
|
| 710 |
+
691: oxygen mask
|
| 711 |
+
692: packet
|
| 712 |
+
693: paddle
|
| 713 |
+
694: paddle wheel
|
| 714 |
+
695: padlock
|
| 715 |
+
696: paintbrush
|
| 716 |
+
697: pajamas
|
| 717 |
+
698: palace
|
| 718 |
+
699: pan flute
|
| 719 |
+
700: paper towel
|
| 720 |
+
701: parachute
|
| 721 |
+
702: parallel bars
|
| 722 |
+
703: park bench
|
| 723 |
+
704: parking meter
|
| 724 |
+
705: passenger car
|
| 725 |
+
706: patio
|
| 726 |
+
707: payphone
|
| 727 |
+
708: pedestal
|
| 728 |
+
709: pencil case
|
| 729 |
+
710: pencil sharpener
|
| 730 |
+
711: perfume
|
| 731 |
+
712: Petri dish
|
| 732 |
+
713: photocopier
|
| 733 |
+
714: plectrum
|
| 734 |
+
715: Pickelhaube
|
| 735 |
+
716: picket fence
|
| 736 |
+
717: pickup truck
|
| 737 |
+
718: pier
|
| 738 |
+
719: piggy bank
|
| 739 |
+
720: pill bottle
|
| 740 |
+
721: pillow
|
| 741 |
+
722: ping-pong ball
|
| 742 |
+
723: pinwheel
|
| 743 |
+
724: pirate ship
|
| 744 |
+
725: pitcher
|
| 745 |
+
726: hand plane
|
| 746 |
+
727: planetarium
|
| 747 |
+
728: plastic bag
|
| 748 |
+
729: plate rack
|
| 749 |
+
730: plow
|
| 750 |
+
731: plunger
|
| 751 |
+
732: Polaroid camera
|
| 752 |
+
733: pole
|
| 753 |
+
734: police van
|
| 754 |
+
735: poncho
|
| 755 |
+
736: billiard table
|
| 756 |
+
737: soda bottle
|
| 757 |
+
738: pot
|
| 758 |
+
739: potter's wheel
|
| 759 |
+
740: power drill
|
| 760 |
+
741: prayer rug
|
| 761 |
+
742: printer
|
| 762 |
+
743: prison
|
| 763 |
+
744: projectile
|
| 764 |
+
745: projector
|
| 765 |
+
746: hockey puck
|
| 766 |
+
747: punching bag
|
| 767 |
+
748: purse
|
| 768 |
+
749: quill
|
| 769 |
+
750: quilt
|
| 770 |
+
751: race car
|
| 771 |
+
752: racket
|
| 772 |
+
753: radiator
|
| 773 |
+
754: radio
|
| 774 |
+
755: radio telescope
|
| 775 |
+
756: rain barrel
|
| 776 |
+
757: recreational vehicle
|
| 777 |
+
758: reel
|
| 778 |
+
759: reflex camera
|
| 779 |
+
760: refrigerator
|
| 780 |
+
761: remote control
|
| 781 |
+
762: restaurant
|
| 782 |
+
763: revolver
|
| 783 |
+
764: rifle
|
| 784 |
+
765: rocking chair
|
| 785 |
+
766: rotisserie
|
| 786 |
+
767: eraser
|
| 787 |
+
768: rugby ball
|
| 788 |
+
769: ruler
|
| 789 |
+
770: running shoe
|
| 790 |
+
771: safe
|
| 791 |
+
772: safety pin
|
| 792 |
+
773: salt shaker
|
| 793 |
+
774: sandal
|
| 794 |
+
775: sarong
|
| 795 |
+
776: saxophone
|
| 796 |
+
777: scabbard
|
| 797 |
+
778: weighing scale
|
| 798 |
+
779: school bus
|
| 799 |
+
780: schooner
|
| 800 |
+
781: scoreboard
|
| 801 |
+
782: CRT screen
|
| 802 |
+
783: screw
|
| 803 |
+
784: screwdriver
|
| 804 |
+
785: seat belt
|
| 805 |
+
786: sewing machine
|
| 806 |
+
787: shield
|
| 807 |
+
788: shoe store
|
| 808 |
+
789: shoji
|
| 809 |
+
790: shopping basket
|
| 810 |
+
791: shopping cart
|
| 811 |
+
792: shovel
|
| 812 |
+
793: shower cap
|
| 813 |
+
794: shower curtain
|
| 814 |
+
795: ski
|
| 815 |
+
796: ski mask
|
| 816 |
+
797: sleeping bag
|
| 817 |
+
798: slide rule
|
| 818 |
+
799: sliding door
|
| 819 |
+
800: slot machine
|
| 820 |
+
801: snorkel
|
| 821 |
+
802: snowmobile
|
| 822 |
+
803: snowplow
|
| 823 |
+
804: soap dispenser
|
| 824 |
+
805: soccer ball
|
| 825 |
+
806: sock
|
| 826 |
+
807: solar thermal collector
|
| 827 |
+
808: sombrero
|
| 828 |
+
809: soup bowl
|
| 829 |
+
810: space bar
|
| 830 |
+
811: space heater
|
| 831 |
+
812: space shuttle
|
| 832 |
+
813: spatula
|
| 833 |
+
814: motorboat
|
| 834 |
+
815: spider web
|
| 835 |
+
816: spindle
|
| 836 |
+
817: sports car
|
| 837 |
+
818: spotlight
|
| 838 |
+
819: stage
|
| 839 |
+
820: steam locomotive
|
| 840 |
+
821: through arch bridge
|
| 841 |
+
822: steel drum
|
| 842 |
+
823: stethoscope
|
| 843 |
+
824: scarf
|
| 844 |
+
825: stone wall
|
| 845 |
+
826: stopwatch
|
| 846 |
+
827: stove
|
| 847 |
+
828: strainer
|
| 848 |
+
829: tram
|
| 849 |
+
830: stretcher
|
| 850 |
+
831: couch
|
| 851 |
+
832: stupa
|
| 852 |
+
833: submarine
|
| 853 |
+
834: suit
|
| 854 |
+
835: sundial
|
| 855 |
+
836: sunglass
|
| 856 |
+
837: sunglasses
|
| 857 |
+
838: sunscreen
|
| 858 |
+
839: suspension bridge
|
| 859 |
+
840: mop
|
| 860 |
+
841: sweatshirt
|
| 861 |
+
842: swimsuit
|
| 862 |
+
843: swing
|
| 863 |
+
844: switch
|
| 864 |
+
845: syringe
|
| 865 |
+
846: table lamp
|
| 866 |
+
847: tank
|
| 867 |
+
848: tape player
|
| 868 |
+
849: teapot
|
| 869 |
+
850: teddy bear
|
| 870 |
+
851: television
|
| 871 |
+
852: tennis ball
|
| 872 |
+
853: thatched roof
|
| 873 |
+
854: front curtain
|
| 874 |
+
855: thimble
|
| 875 |
+
856: threshing machine
|
| 876 |
+
857: throne
|
| 877 |
+
858: tile roof
|
| 878 |
+
859: toaster
|
| 879 |
+
860: tobacco shop
|
| 880 |
+
861: toilet seat
|
| 881 |
+
862: torch
|
| 882 |
+
863: totem pole
|
| 883 |
+
864: tow truck
|
| 884 |
+
865: toy store
|
| 885 |
+
866: tractor
|
| 886 |
+
867: semi-trailer truck
|
| 887 |
+
868: tray
|
| 888 |
+
869: trench coat
|
| 889 |
+
870: tricycle
|
| 890 |
+
871: trimaran
|
| 891 |
+
872: tripod
|
| 892 |
+
873: triumphal arch
|
| 893 |
+
874: trolleybus
|
| 894 |
+
875: trombone
|
| 895 |
+
876: tub
|
| 896 |
+
877: turnstile
|
| 897 |
+
878: typewriter keyboard
|
| 898 |
+
879: umbrella
|
| 899 |
+
880: unicycle
|
| 900 |
+
881: upright piano
|
| 901 |
+
882: vacuum cleaner
|
| 902 |
+
883: vase
|
| 903 |
+
884: vault
|
| 904 |
+
885: velvet
|
| 905 |
+
886: vending machine
|
| 906 |
+
887: vestment
|
| 907 |
+
888: viaduct
|
| 908 |
+
889: violin
|
| 909 |
+
890: volleyball
|
| 910 |
+
891: waffle iron
|
| 911 |
+
892: wall clock
|
| 912 |
+
893: wallet
|
| 913 |
+
894: wardrobe
|
| 914 |
+
895: military aircraft
|
| 915 |
+
896: sink
|
| 916 |
+
897: washing machine
|
| 917 |
+
898: water bottle
|
| 918 |
+
899: water jug
|
| 919 |
+
900: water tower
|
| 920 |
+
901: whiskey jug
|
| 921 |
+
902: whistle
|
| 922 |
+
903: wig
|
| 923 |
+
904: window screen
|
| 924 |
+
905: window shade
|
| 925 |
+
906: Windsor tie
|
| 926 |
+
907: wine bottle
|
| 927 |
+
908: wing
|
| 928 |
+
909: wok
|
| 929 |
+
910: wooden spoon
|
| 930 |
+
911: wool
|
| 931 |
+
912: split-rail fence
|
| 932 |
+
913: shipwreck
|
| 933 |
+
914: yawl
|
| 934 |
+
915: yurt
|
| 935 |
+
916: website
|
| 936 |
+
917: comic book
|
| 937 |
+
918: crossword
|
| 938 |
+
919: traffic sign
|
| 939 |
+
920: traffic light
|
| 940 |
+
921: dust jacket
|
| 941 |
+
922: menu
|
| 942 |
+
923: plate
|
| 943 |
+
924: guacamole
|
| 944 |
+
925: consomme
|
| 945 |
+
926: hot pot
|
| 946 |
+
927: trifle
|
| 947 |
+
928: ice cream
|
| 948 |
+
929: ice pop
|
| 949 |
+
930: baguette
|
| 950 |
+
931: bagel
|
| 951 |
+
932: pretzel
|
| 952 |
+
933: cheeseburger
|
| 953 |
+
934: hot dog
|
| 954 |
+
935: mashed potato
|
| 955 |
+
936: cabbage
|
| 956 |
+
937: broccoli
|
| 957 |
+
938: cauliflower
|
| 958 |
+
939: zucchini
|
| 959 |
+
940: spaghetti squash
|
| 960 |
+
941: acorn squash
|
| 961 |
+
942: butternut squash
|
| 962 |
+
943: cucumber
|
| 963 |
+
944: artichoke
|
| 964 |
+
945: bell pepper
|
| 965 |
+
946: cardoon
|
| 966 |
+
947: mushroom
|
| 967 |
+
948: Granny Smith
|
| 968 |
+
949: strawberry
|
| 969 |
+
950: orange
|
| 970 |
+
951: lemon
|
| 971 |
+
952: fig
|
| 972 |
+
953: pineapple
|
| 973 |
+
954: banana
|
| 974 |
+
955: jackfruit
|
| 975 |
+
956: custard apple
|
| 976 |
+
957: pomegranate
|
| 977 |
+
958: hay
|
| 978 |
+
959: carbonara
|
| 979 |
+
960: chocolate syrup
|
| 980 |
+
961: dough
|
| 981 |
+
962: meatloaf
|
| 982 |
+
963: pizza
|
| 983 |
+
964: pot pie
|
| 984 |
+
965: burrito
|
| 985 |
+
966: red wine
|
| 986 |
+
967: espresso
|
| 987 |
+
968: cup
|
| 988 |
+
969: eggnog
|
| 989 |
+
970: alp
|
| 990 |
+
971: bubble
|
| 991 |
+
972: cliff
|
| 992 |
+
973: coral reef
|
| 993 |
+
974: geyser
|
| 994 |
+
975: lakeshore
|
| 995 |
+
976: promontory
|
| 996 |
+
977: shoal
|
| 997 |
+
978: seashore
|
| 998 |
+
979: valley
|
| 999 |
+
980: volcano
|
| 1000 |
+
981: baseball player
|
| 1001 |
+
982: bridegroom
|
| 1002 |
+
983: scuba diver
|
| 1003 |
+
984: rapeseed
|
| 1004 |
+
985: daisy
|
| 1005 |
+
986: yellow lady's slipper
|
| 1006 |
+
987: corn
|
| 1007 |
+
988: acorn
|
| 1008 |
+
989: rose hip
|
| 1009 |
+
990: horse chestnut seed
|
| 1010 |
+
991: coral fungus
|
| 1011 |
+
992: agaric
|
| 1012 |
+
993: gyromitra
|
| 1013 |
+
994: stinkhorn mushroom
|
| 1014 |
+
995: earth star
|
| 1015 |
+
996: hen-of-the-woods
|
| 1016 |
+
997: bolete
|
| 1017 |
+
998: ear
|
| 1018 |
+
999: toilet paper
|
| 1019 |
+
|
| 1020 |
+
|
| 1021 |
+
# Download script/URL (optional)
|
| 1022 |
+
download: data/scripts/get_imagenet.sh
|
yolov5/data/ImageNet10.yaml
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# ImageNet-1k dataset https://www.image-net.org/index.php by Stanford University
|
| 3 |
+
# Simplified class names from https://github.com/anishathalye/imagenet-simple-labels
|
| 4 |
+
# Example usage: python classify/train.py --data imagenet
|
| 5 |
+
# parent
|
| 6 |
+
# ├── yolov5
|
| 7 |
+
# └── datasets
|
| 8 |
+
# └── imagenet10 ← downloads here
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
| 12 |
+
path: ../datasets/imagenet10 # dataset root dir
|
| 13 |
+
train: train # train images (relative to 'path') 1281167 images
|
| 14 |
+
val: val # val images (relative to 'path') 50000 images
|
| 15 |
+
test: # test images (optional)
|
| 16 |
+
|
| 17 |
+
# Classes
|
| 18 |
+
names:
|
| 19 |
+
0: tench
|
| 20 |
+
1: goldfish
|
| 21 |
+
2: great white shark
|
| 22 |
+
3: tiger shark
|
| 23 |
+
4: hammerhead shark
|
| 24 |
+
5: electric ray
|
| 25 |
+
6: stingray
|
| 26 |
+
7: cock
|
| 27 |
+
8: hen
|
| 28 |
+
9: ostrich
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
# Download script/URL (optional)
|
| 32 |
+
download: data/scripts/get_imagenet10.sh
|
yolov5/data/ImageNet100.yaml
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# ImageNet-1k dataset https://www.image-net.org/index.php by Stanford University
|
| 3 |
+
# Simplified class names from https://github.com/anishathalye/imagenet-simple-labels
|
| 4 |
+
# Example usage: python classify/train.py --data imagenet
|
| 5 |
+
# parent
|
| 6 |
+
# ├── yolov5
|
| 7 |
+
# └── datasets
|
| 8 |
+
# └── imagenet100 ← downloads here
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
| 12 |
+
path: ../datasets/imagenet100 # dataset root dir
|
| 13 |
+
train: train # train images (relative to 'path') 1281167 images
|
| 14 |
+
val: val # val images (relative to 'path') 50000 images
|
| 15 |
+
test: # test images (optional)
|
| 16 |
+
|
| 17 |
+
# Classes
|
| 18 |
+
names:
|
| 19 |
+
0: tench
|
| 20 |
+
1: goldfish
|
| 21 |
+
2: great white shark
|
| 22 |
+
3: tiger shark
|
| 23 |
+
4: hammerhead shark
|
| 24 |
+
5: electric ray
|
| 25 |
+
6: stingray
|
| 26 |
+
7: cock
|
| 27 |
+
8: hen
|
| 28 |
+
9: ostrich
|
| 29 |
+
10: brambling
|
| 30 |
+
11: goldfinch
|
| 31 |
+
12: house finch
|
| 32 |
+
13: junco
|
| 33 |
+
14: indigo bunting
|
| 34 |
+
15: American robin
|
| 35 |
+
16: bulbul
|
| 36 |
+
17: jay
|
| 37 |
+
18: magpie
|
| 38 |
+
19: chickadee
|
| 39 |
+
20: American dipper
|
| 40 |
+
21: kite
|
| 41 |
+
22: bald eagle
|
| 42 |
+
23: vulture
|
| 43 |
+
24: great grey owl
|
| 44 |
+
25: fire salamander
|
| 45 |
+
26: smooth newt
|
| 46 |
+
27: newt
|
| 47 |
+
28: spotted salamander
|
| 48 |
+
29: axolotl
|
| 49 |
+
30: American bullfrog
|
| 50 |
+
31: tree frog
|
| 51 |
+
32: tailed frog
|
| 52 |
+
33: loggerhead sea turtle
|
| 53 |
+
34: leatherback sea turtle
|
| 54 |
+
35: mud turtle
|
| 55 |
+
36: terrapin
|
| 56 |
+
37: box turtle
|
| 57 |
+
38: banded gecko
|
| 58 |
+
39: green iguana
|
| 59 |
+
40: Carolina anole
|
| 60 |
+
41: desert grassland whiptail lizard
|
| 61 |
+
42: agama
|
| 62 |
+
43: frilled-necked lizard
|
| 63 |
+
44: alligator lizard
|
| 64 |
+
45: Gila monster
|
| 65 |
+
46: European green lizard
|
| 66 |
+
47: chameleon
|
| 67 |
+
48: Komodo dragon
|
| 68 |
+
49: Nile crocodile
|
| 69 |
+
50: American alligator
|
| 70 |
+
51: triceratops
|
| 71 |
+
52: worm snake
|
| 72 |
+
53: ring-necked snake
|
| 73 |
+
54: eastern hog-nosed snake
|
| 74 |
+
55: smooth green snake
|
| 75 |
+
56: kingsnake
|
| 76 |
+
57: garter snake
|
| 77 |
+
58: water snake
|
| 78 |
+
59: vine snake
|
| 79 |
+
60: night snake
|
| 80 |
+
61: boa constrictor
|
| 81 |
+
62: African rock python
|
| 82 |
+
63: Indian cobra
|
| 83 |
+
64: green mamba
|
| 84 |
+
65: sea snake
|
| 85 |
+
66: Saharan horned viper
|
| 86 |
+
67: eastern diamondback rattlesnake
|
| 87 |
+
68: sidewinder
|
| 88 |
+
69: trilobite
|
| 89 |
+
70: harvestman
|
| 90 |
+
71: scorpion
|
| 91 |
+
72: yellow garden spider
|
| 92 |
+
73: barn spider
|
| 93 |
+
74: European garden spider
|
| 94 |
+
75: southern black widow
|
| 95 |
+
76: tarantula
|
| 96 |
+
77: wolf spider
|
| 97 |
+
78: tick
|
| 98 |
+
79: centipede
|
| 99 |
+
80: black grouse
|
| 100 |
+
81: ptarmigan
|
| 101 |
+
82: ruffed grouse
|
| 102 |
+
83: prairie grouse
|
| 103 |
+
84: peacock
|
| 104 |
+
85: quail
|
| 105 |
+
86: partridge
|
| 106 |
+
87: grey parrot
|
| 107 |
+
88: macaw
|
| 108 |
+
89: sulphur-crested cockatoo
|
| 109 |
+
90: lorikeet
|
| 110 |
+
91: coucal
|
| 111 |
+
92: bee eater
|
| 112 |
+
93: hornbill
|
| 113 |
+
94: hummingbird
|
| 114 |
+
95: jacamar
|
| 115 |
+
96: toucan
|
| 116 |
+
97: duck
|
| 117 |
+
98: red-breasted merganser
|
| 118 |
+
99: goose
|
| 119 |
+
# Download script/URL (optional)
|
| 120 |
+
download: data/scripts/get_imagenet100.sh
|
yolov5/data/ImageNet1000.yaml
ADDED
|
@@ -0,0 +1,1022 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# ImageNet-1k dataset https://www.image-net.org/index.php by Stanford University
|
| 3 |
+
# Simplified class names from https://github.com/anishathalye/imagenet-simple-labels
|
| 4 |
+
# Example usage: python classify/train.py --data imagenet
|
| 5 |
+
# parent
|
| 6 |
+
# ├── yolov5
|
| 7 |
+
# └── datasets
|
| 8 |
+
# └── imagenet100 ← downloads here
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
| 12 |
+
path: ../datasets/imagenet1000 # dataset root dir
|
| 13 |
+
train: train # train images (relative to 'path') 1281167 images
|
| 14 |
+
val: val # val images (relative to 'path') 50000 images
|
| 15 |
+
test: # test images (optional)
|
| 16 |
+
|
| 17 |
+
# Classes
|
| 18 |
+
names:
|
| 19 |
+
0: tench
|
| 20 |
+
1: goldfish
|
| 21 |
+
2: great white shark
|
| 22 |
+
3: tiger shark
|
| 23 |
+
4: hammerhead shark
|
| 24 |
+
5: electric ray
|
| 25 |
+
6: stingray
|
| 26 |
+
7: cock
|
| 27 |
+
8: hen
|
| 28 |
+
9: ostrich
|
| 29 |
+
10: brambling
|
| 30 |
+
11: goldfinch
|
| 31 |
+
12: house finch
|
| 32 |
+
13: junco
|
| 33 |
+
14: indigo bunting
|
| 34 |
+
15: American robin
|
| 35 |
+
16: bulbul
|
| 36 |
+
17: jay
|
| 37 |
+
18: magpie
|
| 38 |
+
19: chickadee
|
| 39 |
+
20: American dipper
|
| 40 |
+
21: kite
|
| 41 |
+
22: bald eagle
|
| 42 |
+
23: vulture
|
| 43 |
+
24: great grey owl
|
| 44 |
+
25: fire salamander
|
| 45 |
+
26: smooth newt
|
| 46 |
+
27: newt
|
| 47 |
+
28: spotted salamander
|
| 48 |
+
29: axolotl
|
| 49 |
+
30: American bullfrog
|
| 50 |
+
31: tree frog
|
| 51 |
+
32: tailed frog
|
| 52 |
+
33: loggerhead sea turtle
|
| 53 |
+
34: leatherback sea turtle
|
| 54 |
+
35: mud turtle
|
| 55 |
+
36: terrapin
|
| 56 |
+
37: box turtle
|
| 57 |
+
38: banded gecko
|
| 58 |
+
39: green iguana
|
| 59 |
+
40: Carolina anole
|
| 60 |
+
41: desert grassland whiptail lizard
|
| 61 |
+
42: agama
|
| 62 |
+
43: frilled-necked lizard
|
| 63 |
+
44: alligator lizard
|
| 64 |
+
45: Gila monster
|
| 65 |
+
46: European green lizard
|
| 66 |
+
47: chameleon
|
| 67 |
+
48: Komodo dragon
|
| 68 |
+
49: Nile crocodile
|
| 69 |
+
50: American alligator
|
| 70 |
+
51: triceratops
|
| 71 |
+
52: worm snake
|
| 72 |
+
53: ring-necked snake
|
| 73 |
+
54: eastern hog-nosed snake
|
| 74 |
+
55: smooth green snake
|
| 75 |
+
56: kingsnake
|
| 76 |
+
57: garter snake
|
| 77 |
+
58: water snake
|
| 78 |
+
59: vine snake
|
| 79 |
+
60: night snake
|
| 80 |
+
61: boa constrictor
|
| 81 |
+
62: African rock python
|
| 82 |
+
63: Indian cobra
|
| 83 |
+
64: green mamba
|
| 84 |
+
65: sea snake
|
| 85 |
+
66: Saharan horned viper
|
| 86 |
+
67: eastern diamondback rattlesnake
|
| 87 |
+
68: sidewinder
|
| 88 |
+
69: trilobite
|
| 89 |
+
70: harvestman
|
| 90 |
+
71: scorpion
|
| 91 |
+
72: yellow garden spider
|
| 92 |
+
73: barn spider
|
| 93 |
+
74: European garden spider
|
| 94 |
+
75: southern black widow
|
| 95 |
+
76: tarantula
|
| 96 |
+
77: wolf spider
|
| 97 |
+
78: tick
|
| 98 |
+
79: centipede
|
| 99 |
+
80: black grouse
|
| 100 |
+
81: ptarmigan
|
| 101 |
+
82: ruffed grouse
|
| 102 |
+
83: prairie grouse
|
| 103 |
+
84: peacock
|
| 104 |
+
85: quail
|
| 105 |
+
86: partridge
|
| 106 |
+
87: grey parrot
|
| 107 |
+
88: macaw
|
| 108 |
+
89: sulphur-crested cockatoo
|
| 109 |
+
90: lorikeet
|
| 110 |
+
91: coucal
|
| 111 |
+
92: bee eater
|
| 112 |
+
93: hornbill
|
| 113 |
+
94: hummingbird
|
| 114 |
+
95: jacamar
|
| 115 |
+
96: toucan
|
| 116 |
+
97: duck
|
| 117 |
+
98: red-breasted merganser
|
| 118 |
+
99: goose
|
| 119 |
+
100: black swan
|
| 120 |
+
101: tusker
|
| 121 |
+
102: echidna
|
| 122 |
+
103: platypus
|
| 123 |
+
104: wallaby
|
| 124 |
+
105: koala
|
| 125 |
+
106: wombat
|
| 126 |
+
107: jellyfish
|
| 127 |
+
108: sea anemone
|
| 128 |
+
109: brain coral
|
| 129 |
+
110: flatworm
|
| 130 |
+
111: nematode
|
| 131 |
+
112: conch
|
| 132 |
+
113: snail
|
| 133 |
+
114: slug
|
| 134 |
+
115: sea slug
|
| 135 |
+
116: chiton
|
| 136 |
+
117: chambered nautilus
|
| 137 |
+
118: Dungeness crab
|
| 138 |
+
119: rock crab
|
| 139 |
+
120: fiddler crab
|
| 140 |
+
121: red king crab
|
| 141 |
+
122: American lobster
|
| 142 |
+
123: spiny lobster
|
| 143 |
+
124: crayfish
|
| 144 |
+
125: hermit crab
|
| 145 |
+
126: isopod
|
| 146 |
+
127: white stork
|
| 147 |
+
128: black stork
|
| 148 |
+
129: spoonbill
|
| 149 |
+
130: flamingo
|
| 150 |
+
131: little blue heron
|
| 151 |
+
132: great egret
|
| 152 |
+
133: bittern
|
| 153 |
+
134: crane (bird)
|
| 154 |
+
135: limpkin
|
| 155 |
+
136: common gallinule
|
| 156 |
+
137: American coot
|
| 157 |
+
138: bustard
|
| 158 |
+
139: ruddy turnstone
|
| 159 |
+
140: dunlin
|
| 160 |
+
141: common redshank
|
| 161 |
+
142: dowitcher
|
| 162 |
+
143: oystercatcher
|
| 163 |
+
144: pelican
|
| 164 |
+
145: king penguin
|
| 165 |
+
146: albatross
|
| 166 |
+
147: grey whale
|
| 167 |
+
148: killer whale
|
| 168 |
+
149: dugong
|
| 169 |
+
150: sea lion
|
| 170 |
+
151: Chihuahua
|
| 171 |
+
152: Japanese Chin
|
| 172 |
+
153: Maltese
|
| 173 |
+
154: Pekingese
|
| 174 |
+
155: Shih Tzu
|
| 175 |
+
156: King Charles Spaniel
|
| 176 |
+
157: Papillon
|
| 177 |
+
158: toy terrier
|
| 178 |
+
159: Rhodesian Ridgeback
|
| 179 |
+
160: Afghan Hound
|
| 180 |
+
161: Basset Hound
|
| 181 |
+
162: Beagle
|
| 182 |
+
163: Bloodhound
|
| 183 |
+
164: Bluetick Coonhound
|
| 184 |
+
165: Black and Tan Coonhound
|
| 185 |
+
166: Treeing Walker Coonhound
|
| 186 |
+
167: English foxhound
|
| 187 |
+
168: Redbone Coonhound
|
| 188 |
+
169: borzoi
|
| 189 |
+
170: Irish Wolfhound
|
| 190 |
+
171: Italian Greyhound
|
| 191 |
+
172: Whippet
|
| 192 |
+
173: Ibizan Hound
|
| 193 |
+
174: Norwegian Elkhound
|
| 194 |
+
175: Otterhound
|
| 195 |
+
176: Saluki
|
| 196 |
+
177: Scottish Deerhound
|
| 197 |
+
178: Weimaraner
|
| 198 |
+
179: Staffordshire Bull Terrier
|
| 199 |
+
180: American Staffordshire Terrier
|
| 200 |
+
181: Bedlington Terrier
|
| 201 |
+
182: Border Terrier
|
| 202 |
+
183: Kerry Blue Terrier
|
| 203 |
+
184: Irish Terrier
|
| 204 |
+
185: Norfolk Terrier
|
| 205 |
+
186: Norwich Terrier
|
| 206 |
+
187: Yorkshire Terrier
|
| 207 |
+
188: Wire Fox Terrier
|
| 208 |
+
189: Lakeland Terrier
|
| 209 |
+
190: Sealyham Terrier
|
| 210 |
+
191: Airedale Terrier
|
| 211 |
+
192: Cairn Terrier
|
| 212 |
+
193: Australian Terrier
|
| 213 |
+
194: Dandie Dinmont Terrier
|
| 214 |
+
195: Boston Terrier
|
| 215 |
+
196: Miniature Schnauzer
|
| 216 |
+
197: Giant Schnauzer
|
| 217 |
+
198: Standard Schnauzer
|
| 218 |
+
199: Scottish Terrier
|
| 219 |
+
200: Tibetan Terrier
|
| 220 |
+
201: Australian Silky Terrier
|
| 221 |
+
202: Soft-coated Wheaten Terrier
|
| 222 |
+
203: West Highland White Terrier
|
| 223 |
+
204: Lhasa Apso
|
| 224 |
+
205: Flat-Coated Retriever
|
| 225 |
+
206: Curly-coated Retriever
|
| 226 |
+
207: Golden Retriever
|
| 227 |
+
208: Labrador Retriever
|
| 228 |
+
209: Chesapeake Bay Retriever
|
| 229 |
+
210: German Shorthaired Pointer
|
| 230 |
+
211: Vizsla
|
| 231 |
+
212: English Setter
|
| 232 |
+
213: Irish Setter
|
| 233 |
+
214: Gordon Setter
|
| 234 |
+
215: Brittany
|
| 235 |
+
216: Clumber Spaniel
|
| 236 |
+
217: English Springer Spaniel
|
| 237 |
+
218: Welsh Springer Spaniel
|
| 238 |
+
219: Cocker Spaniels
|
| 239 |
+
220: Sussex Spaniel
|
| 240 |
+
221: Irish Water Spaniel
|
| 241 |
+
222: Kuvasz
|
| 242 |
+
223: Schipperke
|
| 243 |
+
224: Groenendael
|
| 244 |
+
225: Malinois
|
| 245 |
+
226: Briard
|
| 246 |
+
227: Australian Kelpie
|
| 247 |
+
228: Komondor
|
| 248 |
+
229: Old English Sheepdog
|
| 249 |
+
230: Shetland Sheepdog
|
| 250 |
+
231: collie
|
| 251 |
+
232: Border Collie
|
| 252 |
+
233: Bouvier des Flandres
|
| 253 |
+
234: Rottweiler
|
| 254 |
+
235: German Shepherd Dog
|
| 255 |
+
236: Dobermann
|
| 256 |
+
237: Miniature Pinscher
|
| 257 |
+
238: Greater Swiss Mountain Dog
|
| 258 |
+
239: Bernese Mountain Dog
|
| 259 |
+
240: Appenzeller Sennenhund
|
| 260 |
+
241: Entlebucher Sennenhund
|
| 261 |
+
242: Boxer
|
| 262 |
+
243: Bullmastiff
|
| 263 |
+
244: Tibetan Mastiff
|
| 264 |
+
245: French Bulldog
|
| 265 |
+
246: Great Dane
|
| 266 |
+
247: St. Bernard
|
| 267 |
+
248: husky
|
| 268 |
+
249: Alaskan Malamute
|
| 269 |
+
250: Siberian Husky
|
| 270 |
+
251: Dalmatian
|
| 271 |
+
252: Affenpinscher
|
| 272 |
+
253: Basenji
|
| 273 |
+
254: pug
|
| 274 |
+
255: Leonberger
|
| 275 |
+
256: Newfoundland
|
| 276 |
+
257: Pyrenean Mountain Dog
|
| 277 |
+
258: Samoyed
|
| 278 |
+
259: Pomeranian
|
| 279 |
+
260: Chow Chow
|
| 280 |
+
261: Keeshond
|
| 281 |
+
262: Griffon Bruxellois
|
| 282 |
+
263: Pembroke Welsh Corgi
|
| 283 |
+
264: Cardigan Welsh Corgi
|
| 284 |
+
265: Toy Poodle
|
| 285 |
+
266: Miniature Poodle
|
| 286 |
+
267: Standard Poodle
|
| 287 |
+
268: Mexican hairless dog
|
| 288 |
+
269: grey wolf
|
| 289 |
+
270: Alaskan tundra wolf
|
| 290 |
+
271: red wolf
|
| 291 |
+
272: coyote
|
| 292 |
+
273: dingo
|
| 293 |
+
274: dhole
|
| 294 |
+
275: African wild dog
|
| 295 |
+
276: hyena
|
| 296 |
+
277: red fox
|
| 297 |
+
278: kit fox
|
| 298 |
+
279: Arctic fox
|
| 299 |
+
280: grey fox
|
| 300 |
+
281: tabby cat
|
| 301 |
+
282: tiger cat
|
| 302 |
+
283: Persian cat
|
| 303 |
+
284: Siamese cat
|
| 304 |
+
285: Egyptian Mau
|
| 305 |
+
286: cougar
|
| 306 |
+
287: lynx
|
| 307 |
+
288: leopard
|
| 308 |
+
289: snow leopard
|
| 309 |
+
290: jaguar
|
| 310 |
+
291: lion
|
| 311 |
+
292: tiger
|
| 312 |
+
293: cheetah
|
| 313 |
+
294: brown bear
|
| 314 |
+
295: American black bear
|
| 315 |
+
296: polar bear
|
| 316 |
+
297: sloth bear
|
| 317 |
+
298: mongoose
|
| 318 |
+
299: meerkat
|
| 319 |
+
300: tiger beetle
|
| 320 |
+
301: ladybug
|
| 321 |
+
302: ground beetle
|
| 322 |
+
303: longhorn beetle
|
| 323 |
+
304: leaf beetle
|
| 324 |
+
305: dung beetle
|
| 325 |
+
306: rhinoceros beetle
|
| 326 |
+
307: weevil
|
| 327 |
+
308: fly
|
| 328 |
+
309: bee
|
| 329 |
+
310: ant
|
| 330 |
+
311: grasshopper
|
| 331 |
+
312: cricket
|
| 332 |
+
313: stick insect
|
| 333 |
+
314: cockroach
|
| 334 |
+
315: mantis
|
| 335 |
+
316: cicada
|
| 336 |
+
317: leafhopper
|
| 337 |
+
318: lacewing
|
| 338 |
+
319: dragonfly
|
| 339 |
+
320: damselfly
|
| 340 |
+
321: red admiral
|
| 341 |
+
322: ringlet
|
| 342 |
+
323: monarch butterfly
|
| 343 |
+
324: small white
|
| 344 |
+
325: sulphur butterfly
|
| 345 |
+
326: gossamer-winged butterfly
|
| 346 |
+
327: starfish
|
| 347 |
+
328: sea urchin
|
| 348 |
+
329: sea cucumber
|
| 349 |
+
330: cottontail rabbit
|
| 350 |
+
331: hare
|
| 351 |
+
332: Angora rabbit
|
| 352 |
+
333: hamster
|
| 353 |
+
334: porcupine
|
| 354 |
+
335: fox squirrel
|
| 355 |
+
336: marmot
|
| 356 |
+
337: beaver
|
| 357 |
+
338: guinea pig
|
| 358 |
+
339: common sorrel
|
| 359 |
+
340: zebra
|
| 360 |
+
341: pig
|
| 361 |
+
342: wild boar
|
| 362 |
+
343: warthog
|
| 363 |
+
344: hippopotamus
|
| 364 |
+
345: ox
|
| 365 |
+
346: water buffalo
|
| 366 |
+
347: bison
|
| 367 |
+
348: ram
|
| 368 |
+
349: bighorn sheep
|
| 369 |
+
350: Alpine ibex
|
| 370 |
+
351: hartebeest
|
| 371 |
+
352: impala
|
| 372 |
+
353: gazelle
|
| 373 |
+
354: dromedary
|
| 374 |
+
355: llama
|
| 375 |
+
356: weasel
|
| 376 |
+
357: mink
|
| 377 |
+
358: European polecat
|
| 378 |
+
359: black-footed ferret
|
| 379 |
+
360: otter
|
| 380 |
+
361: skunk
|
| 381 |
+
362: badger
|
| 382 |
+
363: armadillo
|
| 383 |
+
364: three-toed sloth
|
| 384 |
+
365: orangutan
|
| 385 |
+
366: gorilla
|
| 386 |
+
367: chimpanzee
|
| 387 |
+
368: gibbon
|
| 388 |
+
369: siamang
|
| 389 |
+
370: guenon
|
| 390 |
+
371: patas monkey
|
| 391 |
+
372: baboon
|
| 392 |
+
373: macaque
|
| 393 |
+
374: langur
|
| 394 |
+
375: black-and-white colobus
|
| 395 |
+
376: proboscis monkey
|
| 396 |
+
377: marmoset
|
| 397 |
+
378: white-headed capuchin
|
| 398 |
+
379: howler monkey
|
| 399 |
+
380: titi
|
| 400 |
+
381: Geoffroy's spider monkey
|
| 401 |
+
382: common squirrel monkey
|
| 402 |
+
383: ring-tailed lemur
|
| 403 |
+
384: indri
|
| 404 |
+
385: Asian elephant
|
| 405 |
+
386: African bush elephant
|
| 406 |
+
387: red panda
|
| 407 |
+
388: giant panda
|
| 408 |
+
389: snoek
|
| 409 |
+
390: eel
|
| 410 |
+
391: coho salmon
|
| 411 |
+
392: rock beauty
|
| 412 |
+
393: clownfish
|
| 413 |
+
394: sturgeon
|
| 414 |
+
395: garfish
|
| 415 |
+
396: lionfish
|
| 416 |
+
397: pufferfish
|
| 417 |
+
398: abacus
|
| 418 |
+
399: abaya
|
| 419 |
+
400: academic gown
|
| 420 |
+
401: accordion
|
| 421 |
+
402: acoustic guitar
|
| 422 |
+
403: aircraft carrier
|
| 423 |
+
404: airliner
|
| 424 |
+
405: airship
|
| 425 |
+
406: altar
|
| 426 |
+
407: ambulance
|
| 427 |
+
408: amphibious vehicle
|
| 428 |
+
409: analog clock
|
| 429 |
+
410: apiary
|
| 430 |
+
411: apron
|
| 431 |
+
412: waste container
|
| 432 |
+
413: assault rifle
|
| 433 |
+
414: backpack
|
| 434 |
+
415: bakery
|
| 435 |
+
416: balance beam
|
| 436 |
+
417: balloon
|
| 437 |
+
418: ballpoint pen
|
| 438 |
+
419: Band-Aid
|
| 439 |
+
420: banjo
|
| 440 |
+
421: baluster
|
| 441 |
+
422: barbell
|
| 442 |
+
423: barber chair
|
| 443 |
+
424: barbershop
|
| 444 |
+
425: barn
|
| 445 |
+
426: barometer
|
| 446 |
+
427: barrel
|
| 447 |
+
428: wheelbarrow
|
| 448 |
+
429: baseball
|
| 449 |
+
430: basketball
|
| 450 |
+
431: bassinet
|
| 451 |
+
432: bassoon
|
| 452 |
+
433: swimming cap
|
| 453 |
+
434: bath towel
|
| 454 |
+
435: bathtub
|
| 455 |
+
436: station wagon
|
| 456 |
+
437: lighthouse
|
| 457 |
+
438: beaker
|
| 458 |
+
439: military cap
|
| 459 |
+
440: beer bottle
|
| 460 |
+
441: beer glass
|
| 461 |
+
442: bell-cot
|
| 462 |
+
443: bib
|
| 463 |
+
444: tandem bicycle
|
| 464 |
+
445: bikini
|
| 465 |
+
446: ring binder
|
| 466 |
+
447: binoculars
|
| 467 |
+
448: birdhouse
|
| 468 |
+
449: boathouse
|
| 469 |
+
450: bobsleigh
|
| 470 |
+
451: bolo tie
|
| 471 |
+
452: poke bonnet
|
| 472 |
+
453: bookcase
|
| 473 |
+
454: bookstore
|
| 474 |
+
455: bottle cap
|
| 475 |
+
456: bow
|
| 476 |
+
457: bow tie
|
| 477 |
+
458: brass
|
| 478 |
+
459: bra
|
| 479 |
+
460: breakwater
|
| 480 |
+
461: breastplate
|
| 481 |
+
462: broom
|
| 482 |
+
463: bucket
|
| 483 |
+
464: buckle
|
| 484 |
+
465: bulletproof vest
|
| 485 |
+
466: high-speed train
|
| 486 |
+
467: butcher shop
|
| 487 |
+
468: taxicab
|
| 488 |
+
469: cauldron
|
| 489 |
+
470: candle
|
| 490 |
+
471: cannon
|
| 491 |
+
472: canoe
|
| 492 |
+
473: can opener
|
| 493 |
+
474: cardigan
|
| 494 |
+
475: car mirror
|
| 495 |
+
476: carousel
|
| 496 |
+
477: tool kit
|
| 497 |
+
478: carton
|
| 498 |
+
479: car wheel
|
| 499 |
+
480: automated teller machine
|
| 500 |
+
481: cassette
|
| 501 |
+
482: cassette player
|
| 502 |
+
483: castle
|
| 503 |
+
484: catamaran
|
| 504 |
+
485: CD player
|
| 505 |
+
486: cello
|
| 506 |
+
487: mobile phone
|
| 507 |
+
488: chain
|
| 508 |
+
489: chain-link fence
|
| 509 |
+
490: chain mail
|
| 510 |
+
491: chainsaw
|
| 511 |
+
492: chest
|
| 512 |
+
493: chiffonier
|
| 513 |
+
494: chime
|
| 514 |
+
495: china cabinet
|
| 515 |
+
496: Christmas stocking
|
| 516 |
+
497: church
|
| 517 |
+
498: movie theater
|
| 518 |
+
499: cleaver
|
| 519 |
+
500: cliff dwelling
|
| 520 |
+
501: cloak
|
| 521 |
+
502: clogs
|
| 522 |
+
503: cocktail shaker
|
| 523 |
+
504: coffee mug
|
| 524 |
+
505: coffeemaker
|
| 525 |
+
506: coil
|
| 526 |
+
507: combination lock
|
| 527 |
+
508: computer keyboard
|
| 528 |
+
509: confectionery store
|
| 529 |
+
510: container ship
|
| 530 |
+
511: convertible
|
| 531 |
+
512: corkscrew
|
| 532 |
+
513: cornet
|
| 533 |
+
514: cowboy boot
|
| 534 |
+
515: cowboy hat
|
| 535 |
+
516: cradle
|
| 536 |
+
517: crane (machine)
|
| 537 |
+
518: crash helmet
|
| 538 |
+
519: crate
|
| 539 |
+
520: infant bed
|
| 540 |
+
521: Crock Pot
|
| 541 |
+
522: croquet ball
|
| 542 |
+
523: crutch
|
| 543 |
+
524: cuirass
|
| 544 |
+
525: dam
|
| 545 |
+
526: desk
|
| 546 |
+
527: desktop computer
|
| 547 |
+
528: rotary dial telephone
|
| 548 |
+
529: diaper
|
| 549 |
+
530: digital clock
|
| 550 |
+
531: digital watch
|
| 551 |
+
532: dining table
|
| 552 |
+
533: dishcloth
|
| 553 |
+
534: dishwasher
|
| 554 |
+
535: disc brake
|
| 555 |
+
536: dock
|
| 556 |
+
537: dog sled
|
| 557 |
+
538: dome
|
| 558 |
+
539: doormat
|
| 559 |
+
540: drilling rig
|
| 560 |
+
541: drum
|
| 561 |
+
542: drumstick
|
| 562 |
+
543: dumbbell
|
| 563 |
+
544: Dutch oven
|
| 564 |
+
545: electric fan
|
| 565 |
+
546: electric guitar
|
| 566 |
+
547: electric locomotive
|
| 567 |
+
548: entertainment center
|
| 568 |
+
549: envelope
|
| 569 |
+
550: espresso machine
|
| 570 |
+
551: face powder
|
| 571 |
+
552: feather boa
|
| 572 |
+
553: filing cabinet
|
| 573 |
+
554: fireboat
|
| 574 |
+
555: fire engine
|
| 575 |
+
556: fire screen sheet
|
| 576 |
+
557: flagpole
|
| 577 |
+
558: flute
|
| 578 |
+
559: folding chair
|
| 579 |
+
560: football helmet
|
| 580 |
+
561: forklift
|
| 581 |
+
562: fountain
|
| 582 |
+
563: fountain pen
|
| 583 |
+
564: four-poster bed
|
| 584 |
+
565: freight car
|
| 585 |
+
566: French horn
|
| 586 |
+
567: frying pan
|
| 587 |
+
568: fur coat
|
| 588 |
+
569: garbage truck
|
| 589 |
+
570: gas mask
|
| 590 |
+
571: gas pump
|
| 591 |
+
572: goblet
|
| 592 |
+
573: go-kart
|
| 593 |
+
574: golf ball
|
| 594 |
+
575: golf cart
|
| 595 |
+
576: gondola
|
| 596 |
+
577: gong
|
| 597 |
+
578: gown
|
| 598 |
+
579: grand piano
|
| 599 |
+
580: greenhouse
|
| 600 |
+
581: grille
|
| 601 |
+
582: grocery store
|
| 602 |
+
583: guillotine
|
| 603 |
+
584: barrette
|
| 604 |
+
585: hair spray
|
| 605 |
+
586: half-track
|
| 606 |
+
587: hammer
|
| 607 |
+
588: hamper
|
| 608 |
+
589: hair dryer
|
| 609 |
+
590: hand-held computer
|
| 610 |
+
591: handkerchief
|
| 611 |
+
592: hard disk drive
|
| 612 |
+
593: harmonica
|
| 613 |
+
594: harp
|
| 614 |
+
595: harvester
|
| 615 |
+
596: hatchet
|
| 616 |
+
597: holster
|
| 617 |
+
598: home theater
|
| 618 |
+
599: honeycomb
|
| 619 |
+
600: hook
|
| 620 |
+
601: hoop skirt
|
| 621 |
+
602: horizontal bar
|
| 622 |
+
603: horse-drawn vehicle
|
| 623 |
+
604: hourglass
|
| 624 |
+
605: iPod
|
| 625 |
+
606: clothes iron
|
| 626 |
+
607: jack-o'-lantern
|
| 627 |
+
608: jeans
|
| 628 |
+
609: jeep
|
| 629 |
+
610: T-shirt
|
| 630 |
+
611: jigsaw puzzle
|
| 631 |
+
612: pulled rickshaw
|
| 632 |
+
613: joystick
|
| 633 |
+
614: kimono
|
| 634 |
+
615: knee pad
|
| 635 |
+
616: knot
|
| 636 |
+
617: lab coat
|
| 637 |
+
618: ladle
|
| 638 |
+
619: lampshade
|
| 639 |
+
620: laptop computer
|
| 640 |
+
621: lawn mower
|
| 641 |
+
622: lens cap
|
| 642 |
+
623: paper knife
|
| 643 |
+
624: library
|
| 644 |
+
625: lifeboat
|
| 645 |
+
626: lighter
|
| 646 |
+
627: limousine
|
| 647 |
+
628: ocean liner
|
| 648 |
+
629: lipstick
|
| 649 |
+
630: slip-on shoe
|
| 650 |
+
631: lotion
|
| 651 |
+
632: speaker
|
| 652 |
+
633: loupe
|
| 653 |
+
634: sawmill
|
| 654 |
+
635: magnetic compass
|
| 655 |
+
636: mail bag
|
| 656 |
+
637: mailbox
|
| 657 |
+
638: tights
|
| 658 |
+
639: tank suit
|
| 659 |
+
640: manhole cover
|
| 660 |
+
641: maraca
|
| 661 |
+
642: marimba
|
| 662 |
+
643: mask
|
| 663 |
+
644: match
|
| 664 |
+
645: maypole
|
| 665 |
+
646: maze
|
| 666 |
+
647: measuring cup
|
| 667 |
+
648: medicine chest
|
| 668 |
+
649: megalith
|
| 669 |
+
650: microphone
|
| 670 |
+
651: microwave oven
|
| 671 |
+
652: military uniform
|
| 672 |
+
653: milk can
|
| 673 |
+
654: minibus
|
| 674 |
+
655: miniskirt
|
| 675 |
+
656: minivan
|
| 676 |
+
657: missile
|
| 677 |
+
658: mitten
|
| 678 |
+
659: mixing bowl
|
| 679 |
+
660: mobile home
|
| 680 |
+
661: Model T
|
| 681 |
+
662: modem
|
| 682 |
+
663: monastery
|
| 683 |
+
664: monitor
|
| 684 |
+
665: moped
|
| 685 |
+
666: mortar
|
| 686 |
+
667: square academic cap
|
| 687 |
+
668: mosque
|
| 688 |
+
669: mosquito net
|
| 689 |
+
670: scooter
|
| 690 |
+
671: mountain bike
|
| 691 |
+
672: tent
|
| 692 |
+
673: computer mouse
|
| 693 |
+
674: mousetrap
|
| 694 |
+
675: moving van
|
| 695 |
+
676: muzzle
|
| 696 |
+
677: nail
|
| 697 |
+
678: neck brace
|
| 698 |
+
679: necklace
|
| 699 |
+
680: nipple
|
| 700 |
+
681: notebook computer
|
| 701 |
+
682: obelisk
|
| 702 |
+
683: oboe
|
| 703 |
+
684: ocarina
|
| 704 |
+
685: odometer
|
| 705 |
+
686: oil filter
|
| 706 |
+
687: organ
|
| 707 |
+
688: oscilloscope
|
| 708 |
+
689: overskirt
|
| 709 |
+
690: bullock cart
|
| 710 |
+
691: oxygen mask
|
| 711 |
+
692: packet
|
| 712 |
+
693: paddle
|
| 713 |
+
694: paddle wheel
|
| 714 |
+
695: padlock
|
| 715 |
+
696: paintbrush
|
| 716 |
+
697: pajamas
|
| 717 |
+
698: palace
|
| 718 |
+
699: pan flute
|
| 719 |
+
700: paper towel
|
| 720 |
+
701: parachute
|
| 721 |
+
702: parallel bars
|
| 722 |
+
703: park bench
|
| 723 |
+
704: parking meter
|
| 724 |
+
705: passenger car
|
| 725 |
+
706: patio
|
| 726 |
+
707: payphone
|
| 727 |
+
708: pedestal
|
| 728 |
+
709: pencil case
|
| 729 |
+
710: pencil sharpener
|
| 730 |
+
711: perfume
|
| 731 |
+
712: Petri dish
|
| 732 |
+
713: photocopier
|
| 733 |
+
714: plectrum
|
| 734 |
+
715: Pickelhaube
|
| 735 |
+
716: picket fence
|
| 736 |
+
717: pickup truck
|
| 737 |
+
718: pier
|
| 738 |
+
719: piggy bank
|
| 739 |
+
720: pill bottle
|
| 740 |
+
721: pillow
|
| 741 |
+
722: ping-pong ball
|
| 742 |
+
723: pinwheel
|
| 743 |
+
724: pirate ship
|
| 744 |
+
725: pitcher
|
| 745 |
+
726: hand plane
|
| 746 |
+
727: planetarium
|
| 747 |
+
728: plastic bag
|
| 748 |
+
729: plate rack
|
| 749 |
+
730: plow
|
| 750 |
+
731: plunger
|
| 751 |
+
732: Polaroid camera
|
| 752 |
+
733: pole
|
| 753 |
+
734: police van
|
| 754 |
+
735: poncho
|
| 755 |
+
736: billiard table
|
| 756 |
+
737: soda bottle
|
| 757 |
+
738: pot
|
| 758 |
+
739: potter's wheel
|
| 759 |
+
740: power drill
|
| 760 |
+
741: prayer rug
|
| 761 |
+
742: printer
|
| 762 |
+
743: prison
|
| 763 |
+
744: projectile
|
| 764 |
+
745: projector
|
| 765 |
+
746: hockey puck
|
| 766 |
+
747: punching bag
|
| 767 |
+
748: purse
|
| 768 |
+
749: quill
|
| 769 |
+
750: quilt
|
| 770 |
+
751: race car
|
| 771 |
+
752: racket
|
| 772 |
+
753: radiator
|
| 773 |
+
754: radio
|
| 774 |
+
755: radio telescope
|
| 775 |
+
756: rain barrel
|
| 776 |
+
757: recreational vehicle
|
| 777 |
+
758: reel
|
| 778 |
+
759: reflex camera
|
| 779 |
+
760: refrigerator
|
| 780 |
+
761: remote control
|
| 781 |
+
762: restaurant
|
| 782 |
+
763: revolver
|
| 783 |
+
764: rifle
|
| 784 |
+
765: rocking chair
|
| 785 |
+
766: rotisserie
|
| 786 |
+
767: eraser
|
| 787 |
+
768: rugby ball
|
| 788 |
+
769: ruler
|
| 789 |
+
770: running shoe
|
| 790 |
+
771: safe
|
| 791 |
+
772: safety pin
|
| 792 |
+
773: salt shaker
|
| 793 |
+
774: sandal
|
| 794 |
+
775: sarong
|
| 795 |
+
776: saxophone
|
| 796 |
+
777: scabbard
|
| 797 |
+
778: weighing scale
|
| 798 |
+
779: school bus
|
| 799 |
+
780: schooner
|
| 800 |
+
781: scoreboard
|
| 801 |
+
782: CRT screen
|
| 802 |
+
783: screw
|
| 803 |
+
784: screwdriver
|
| 804 |
+
785: seat belt
|
| 805 |
+
786: sewing machine
|
| 806 |
+
787: shield
|
| 807 |
+
788: shoe store
|
| 808 |
+
789: shoji
|
| 809 |
+
790: shopping basket
|
| 810 |
+
791: shopping cart
|
| 811 |
+
792: shovel
|
| 812 |
+
793: shower cap
|
| 813 |
+
794: shower curtain
|
| 814 |
+
795: ski
|
| 815 |
+
796: ski mask
|
| 816 |
+
797: sleeping bag
|
| 817 |
+
798: slide rule
|
| 818 |
+
799: sliding door
|
| 819 |
+
800: slot machine
|
| 820 |
+
801: snorkel
|
| 821 |
+
802: snowmobile
|
| 822 |
+
803: snowplow
|
| 823 |
+
804: soap dispenser
|
| 824 |
+
805: soccer ball
|
| 825 |
+
806: sock
|
| 826 |
+
807: solar thermal collector
|
| 827 |
+
808: sombrero
|
| 828 |
+
809: soup bowl
|
| 829 |
+
810: space bar
|
| 830 |
+
811: space heater
|
| 831 |
+
812: space shuttle
|
| 832 |
+
813: spatula
|
| 833 |
+
814: motorboat
|
| 834 |
+
815: spider web
|
| 835 |
+
816: spindle
|
| 836 |
+
817: sports car
|
| 837 |
+
818: spotlight
|
| 838 |
+
819: stage
|
| 839 |
+
820: steam locomotive
|
| 840 |
+
821: through arch bridge
|
| 841 |
+
822: steel drum
|
| 842 |
+
823: stethoscope
|
| 843 |
+
824: scarf
|
| 844 |
+
825: stone wall
|
| 845 |
+
826: stopwatch
|
| 846 |
+
827: stove
|
| 847 |
+
828: strainer
|
| 848 |
+
829: tram
|
| 849 |
+
830: stretcher
|
| 850 |
+
831: couch
|
| 851 |
+
832: stupa
|
| 852 |
+
833: submarine
|
| 853 |
+
834: suit
|
| 854 |
+
835: sundial
|
| 855 |
+
836: sunglass
|
| 856 |
+
837: sunglasses
|
| 857 |
+
838: sunscreen
|
| 858 |
+
839: suspension bridge
|
| 859 |
+
840: mop
|
| 860 |
+
841: sweatshirt
|
| 861 |
+
842: swimsuit
|
| 862 |
+
843: swing
|
| 863 |
+
844: switch
|
| 864 |
+
845: syringe
|
| 865 |
+
846: table lamp
|
| 866 |
+
847: tank
|
| 867 |
+
848: tape player
|
| 868 |
+
849: teapot
|
| 869 |
+
850: teddy bear
|
| 870 |
+
851: television
|
| 871 |
+
852: tennis ball
|
| 872 |
+
853: thatched roof
|
| 873 |
+
854: front curtain
|
| 874 |
+
855: thimble
|
| 875 |
+
856: threshing machine
|
| 876 |
+
857: throne
|
| 877 |
+
858: tile roof
|
| 878 |
+
859: toaster
|
| 879 |
+
860: tobacco shop
|
| 880 |
+
861: toilet seat
|
| 881 |
+
862: torch
|
| 882 |
+
863: totem pole
|
| 883 |
+
864: tow truck
|
| 884 |
+
865: toy store
|
| 885 |
+
866: tractor
|
| 886 |
+
867: semi-trailer truck
|
| 887 |
+
868: tray
|
| 888 |
+
869: trench coat
|
| 889 |
+
870: tricycle
|
| 890 |
+
871: trimaran
|
| 891 |
+
872: tripod
|
| 892 |
+
873: triumphal arch
|
| 893 |
+
874: trolleybus
|
| 894 |
+
875: trombone
|
| 895 |
+
876: tub
|
| 896 |
+
877: turnstile
|
| 897 |
+
878: typewriter keyboard
|
| 898 |
+
879: umbrella
|
| 899 |
+
880: unicycle
|
| 900 |
+
881: upright piano
|
| 901 |
+
882: vacuum cleaner
|
| 902 |
+
883: vase
|
| 903 |
+
884: vault
|
| 904 |
+
885: velvet
|
| 905 |
+
886: vending machine
|
| 906 |
+
887: vestment
|
| 907 |
+
888: viaduct
|
| 908 |
+
889: violin
|
| 909 |
+
890: volleyball
|
| 910 |
+
891: waffle iron
|
| 911 |
+
892: wall clock
|
| 912 |
+
893: wallet
|
| 913 |
+
894: wardrobe
|
| 914 |
+
895: military aircraft
|
| 915 |
+
896: sink
|
| 916 |
+
897: washing machine
|
| 917 |
+
898: water bottle
|
| 918 |
+
899: water jug
|
| 919 |
+
900: water tower
|
| 920 |
+
901: whiskey jug
|
| 921 |
+
902: whistle
|
| 922 |
+
903: wig
|
| 923 |
+
904: window screen
|
| 924 |
+
905: window shade
|
| 925 |
+
906: Windsor tie
|
| 926 |
+
907: wine bottle
|
| 927 |
+
908: wing
|
| 928 |
+
909: wok
|
| 929 |
+
910: wooden spoon
|
| 930 |
+
911: wool
|
| 931 |
+
912: split-rail fence
|
| 932 |
+
913: shipwreck
|
| 933 |
+
914: yawl
|
| 934 |
+
915: yurt
|
| 935 |
+
916: website
|
| 936 |
+
917: comic book
|
| 937 |
+
918: crossword
|
| 938 |
+
919: traffic sign
|
| 939 |
+
920: traffic light
|
| 940 |
+
921: dust jacket
|
| 941 |
+
922: menu
|
| 942 |
+
923: plate
|
| 943 |
+
924: guacamole
|
| 944 |
+
925: consomme
|
| 945 |
+
926: hot pot
|
| 946 |
+
927: trifle
|
| 947 |
+
928: ice cream
|
| 948 |
+
929: ice pop
|
| 949 |
+
930: baguette
|
| 950 |
+
931: bagel
|
| 951 |
+
932: pretzel
|
| 952 |
+
933: cheeseburger
|
| 953 |
+
934: hot dog
|
| 954 |
+
935: mashed potato
|
| 955 |
+
936: cabbage
|
| 956 |
+
937: broccoli
|
| 957 |
+
938: cauliflower
|
| 958 |
+
939: zucchini
|
| 959 |
+
940: spaghetti squash
|
| 960 |
+
941: acorn squash
|
| 961 |
+
942: butternut squash
|
| 962 |
+
943: cucumber
|
| 963 |
+
944: artichoke
|
| 964 |
+
945: bell pepper
|
| 965 |
+
946: cardoon
|
| 966 |
+
947: mushroom
|
| 967 |
+
948: Granny Smith
|
| 968 |
+
949: strawberry
|
| 969 |
+
950: orange
|
| 970 |
+
951: lemon
|
| 971 |
+
952: fig
|
| 972 |
+
953: pineapple
|
| 973 |
+
954: banana
|
| 974 |
+
955: jackfruit
|
| 975 |
+
956: custard apple
|
| 976 |
+
957: pomegranate
|
| 977 |
+
958: hay
|
| 978 |
+
959: carbonara
|
| 979 |
+
960: chocolate syrup
|
| 980 |
+
961: dough
|
| 981 |
+
962: meatloaf
|
| 982 |
+
963: pizza
|
| 983 |
+
964: pot pie
|
| 984 |
+
965: burrito
|
| 985 |
+
966: red wine
|
| 986 |
+
967: espresso
|
| 987 |
+
968: cup
|
| 988 |
+
969: eggnog
|
| 989 |
+
970: alp
|
| 990 |
+
971: bubble
|
| 991 |
+
972: cliff
|
| 992 |
+
973: coral reef
|
| 993 |
+
974: geyser
|
| 994 |
+
975: lakeshore
|
| 995 |
+
976: promontory
|
| 996 |
+
977: shoal
|
| 997 |
+
978: seashore
|
| 998 |
+
979: valley
|
| 999 |
+
980: volcano
|
| 1000 |
+
981: baseball player
|
| 1001 |
+
982: bridegroom
|
| 1002 |
+
983: scuba diver
|
| 1003 |
+
984: rapeseed
|
| 1004 |
+
985: daisy
|
| 1005 |
+
986: yellow lady's slipper
|
| 1006 |
+
987: corn
|
| 1007 |
+
988: acorn
|
| 1008 |
+
989: rose hip
|
| 1009 |
+
990: horse chestnut seed
|
| 1010 |
+
991: coral fungus
|
| 1011 |
+
992: agaric
|
| 1012 |
+
993: gyromitra
|
| 1013 |
+
994: stinkhorn mushroom
|
| 1014 |
+
995: earth star
|
| 1015 |
+
996: hen-of-the-woods
|
| 1016 |
+
997: bolete
|
| 1017 |
+
998: ear
|
| 1018 |
+
999: toilet paper
|
| 1019 |
+
|
| 1020 |
+
|
| 1021 |
+
# Download script/URL (optional)
|
| 1022 |
+
download: data/scripts/get_imagenet1000.sh
|
yolov5/data/Objects365.yaml
ADDED
|
@@ -0,0 +1,438 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# Objects365 dataset https://www.objects365.org/ by Megvii
|
| 3 |
+
# Example usage: python train.py --data Objects365.yaml
|
| 4 |
+
# parent
|
| 5 |
+
# ├── yolov5
|
| 6 |
+
# └── datasets
|
| 7 |
+
# └── Objects365 ← downloads here (712 GB = 367G data + 345G zips)
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
| 11 |
+
path: ../datasets/Objects365 # dataset root dir
|
| 12 |
+
train: images/train # train images (relative to 'path') 1742289 images
|
| 13 |
+
val: images/val # val images (relative to 'path') 80000 images
|
| 14 |
+
test: # test images (optional)
|
| 15 |
+
|
| 16 |
+
# Classes
|
| 17 |
+
names:
|
| 18 |
+
0: Person
|
| 19 |
+
1: Sneakers
|
| 20 |
+
2: Chair
|
| 21 |
+
3: Other Shoes
|
| 22 |
+
4: Hat
|
| 23 |
+
5: Car
|
| 24 |
+
6: Lamp
|
| 25 |
+
7: Glasses
|
| 26 |
+
8: Bottle
|
| 27 |
+
9: Desk
|
| 28 |
+
10: Cup
|
| 29 |
+
11: Street Lights
|
| 30 |
+
12: Cabinet/shelf
|
| 31 |
+
13: Handbag/Satchel
|
| 32 |
+
14: Bracelet
|
| 33 |
+
15: Plate
|
| 34 |
+
16: Picture/Frame
|
| 35 |
+
17: Helmet
|
| 36 |
+
18: Book
|
| 37 |
+
19: Gloves
|
| 38 |
+
20: Storage box
|
| 39 |
+
21: Boat
|
| 40 |
+
22: Leather Shoes
|
| 41 |
+
23: Flower
|
| 42 |
+
24: Bench
|
| 43 |
+
25: Potted Plant
|
| 44 |
+
26: Bowl/Basin
|
| 45 |
+
27: Flag
|
| 46 |
+
28: Pillow
|
| 47 |
+
29: Boots
|
| 48 |
+
30: Vase
|
| 49 |
+
31: Microphone
|
| 50 |
+
32: Necklace
|
| 51 |
+
33: Ring
|
| 52 |
+
34: SUV
|
| 53 |
+
35: Wine Glass
|
| 54 |
+
36: Belt
|
| 55 |
+
37: Monitor/TV
|
| 56 |
+
38: Backpack
|
| 57 |
+
39: Umbrella
|
| 58 |
+
40: Traffic Light
|
| 59 |
+
41: Speaker
|
| 60 |
+
42: Watch
|
| 61 |
+
43: Tie
|
| 62 |
+
44: Trash bin Can
|
| 63 |
+
45: Slippers
|
| 64 |
+
46: Bicycle
|
| 65 |
+
47: Stool
|
| 66 |
+
48: Barrel/bucket
|
| 67 |
+
49: Van
|
| 68 |
+
50: Couch
|
| 69 |
+
51: Sandals
|
| 70 |
+
52: Basket
|
| 71 |
+
53: Drum
|
| 72 |
+
54: Pen/Pencil
|
| 73 |
+
55: Bus
|
| 74 |
+
56: Wild Bird
|
| 75 |
+
57: High Heels
|
| 76 |
+
58: Motorcycle
|
| 77 |
+
59: Guitar
|
| 78 |
+
60: Carpet
|
| 79 |
+
61: Cell Phone
|
| 80 |
+
62: Bread
|
| 81 |
+
63: Camera
|
| 82 |
+
64: Canned
|
| 83 |
+
65: Truck
|
| 84 |
+
66: Traffic cone
|
| 85 |
+
67: Cymbal
|
| 86 |
+
68: Lifesaver
|
| 87 |
+
69: Towel
|
| 88 |
+
70: Stuffed Toy
|
| 89 |
+
71: Candle
|
| 90 |
+
72: Sailboat
|
| 91 |
+
73: Laptop
|
| 92 |
+
74: Awning
|
| 93 |
+
75: Bed
|
| 94 |
+
76: Faucet
|
| 95 |
+
77: Tent
|
| 96 |
+
78: Horse
|
| 97 |
+
79: Mirror
|
| 98 |
+
80: Power outlet
|
| 99 |
+
81: Sink
|
| 100 |
+
82: Apple
|
| 101 |
+
83: Air Conditioner
|
| 102 |
+
84: Knife
|
| 103 |
+
85: Hockey Stick
|
| 104 |
+
86: Paddle
|
| 105 |
+
87: Pickup Truck
|
| 106 |
+
88: Fork
|
| 107 |
+
89: Traffic Sign
|
| 108 |
+
90: Balloon
|
| 109 |
+
91: Tripod
|
| 110 |
+
92: Dog
|
| 111 |
+
93: Spoon
|
| 112 |
+
94: Clock
|
| 113 |
+
95: Pot
|
| 114 |
+
96: Cow
|
| 115 |
+
97: Cake
|
| 116 |
+
98: Dinning Table
|
| 117 |
+
99: Sheep
|
| 118 |
+
100: Hanger
|
| 119 |
+
101: Blackboard/Whiteboard
|
| 120 |
+
102: Napkin
|
| 121 |
+
103: Other Fish
|
| 122 |
+
104: Orange/Tangerine
|
| 123 |
+
105: Toiletry
|
| 124 |
+
106: Keyboard
|
| 125 |
+
107: Tomato
|
| 126 |
+
108: Lantern
|
| 127 |
+
109: Machinery Vehicle
|
| 128 |
+
110: Fan
|
| 129 |
+
111: Green Vegetables
|
| 130 |
+
112: Banana
|
| 131 |
+
113: Baseball Glove
|
| 132 |
+
114: Airplane
|
| 133 |
+
115: Mouse
|
| 134 |
+
116: Train
|
| 135 |
+
117: Pumpkin
|
| 136 |
+
118: Soccer
|
| 137 |
+
119: Skiboard
|
| 138 |
+
120: Luggage
|
| 139 |
+
121: Nightstand
|
| 140 |
+
122: Tea pot
|
| 141 |
+
123: Telephone
|
| 142 |
+
124: Trolley
|
| 143 |
+
125: Head Phone
|
| 144 |
+
126: Sports Car
|
| 145 |
+
127: Stop Sign
|
| 146 |
+
128: Dessert
|
| 147 |
+
129: Scooter
|
| 148 |
+
130: Stroller
|
| 149 |
+
131: Crane
|
| 150 |
+
132: Remote
|
| 151 |
+
133: Refrigerator
|
| 152 |
+
134: Oven
|
| 153 |
+
135: Lemon
|
| 154 |
+
136: Duck
|
| 155 |
+
137: Baseball Bat
|
| 156 |
+
138: Surveillance Camera
|
| 157 |
+
139: Cat
|
| 158 |
+
140: Jug
|
| 159 |
+
141: Broccoli
|
| 160 |
+
142: Piano
|
| 161 |
+
143: Pizza
|
| 162 |
+
144: Elephant
|
| 163 |
+
145: Skateboard
|
| 164 |
+
146: Surfboard
|
| 165 |
+
147: Gun
|
| 166 |
+
148: Skating and Skiing shoes
|
| 167 |
+
149: Gas stove
|
| 168 |
+
150: Donut
|
| 169 |
+
151: Bow Tie
|
| 170 |
+
152: Carrot
|
| 171 |
+
153: Toilet
|
| 172 |
+
154: Kite
|
| 173 |
+
155: Strawberry
|
| 174 |
+
156: Other Balls
|
| 175 |
+
157: Shovel
|
| 176 |
+
158: Pepper
|
| 177 |
+
159: Computer Box
|
| 178 |
+
160: Toilet Paper
|
| 179 |
+
161: Cleaning Products
|
| 180 |
+
162: Chopsticks
|
| 181 |
+
163: Microwave
|
| 182 |
+
164: Pigeon
|
| 183 |
+
165: Baseball
|
| 184 |
+
166: Cutting/chopping Board
|
| 185 |
+
167: Coffee Table
|
| 186 |
+
168: Side Table
|
| 187 |
+
169: Scissors
|
| 188 |
+
170: Marker
|
| 189 |
+
171: Pie
|
| 190 |
+
172: Ladder
|
| 191 |
+
173: Snowboard
|
| 192 |
+
174: Cookies
|
| 193 |
+
175: Radiator
|
| 194 |
+
176: Fire Hydrant
|
| 195 |
+
177: Basketball
|
| 196 |
+
178: Zebra
|
| 197 |
+
179: Grape
|
| 198 |
+
180: Giraffe
|
| 199 |
+
181: Potato
|
| 200 |
+
182: Sausage
|
| 201 |
+
183: Tricycle
|
| 202 |
+
184: Violin
|
| 203 |
+
185: Egg
|
| 204 |
+
186: Fire Extinguisher
|
| 205 |
+
187: Candy
|
| 206 |
+
188: Fire Truck
|
| 207 |
+
189: Billiards
|
| 208 |
+
190: Converter
|
| 209 |
+
191: Bathtub
|
| 210 |
+
192: Wheelchair
|
| 211 |
+
193: Golf Club
|
| 212 |
+
194: Briefcase
|
| 213 |
+
195: Cucumber
|
| 214 |
+
196: Cigar/Cigarette
|
| 215 |
+
197: Paint Brush
|
| 216 |
+
198: Pear
|
| 217 |
+
199: Heavy Truck
|
| 218 |
+
200: Hamburger
|
| 219 |
+
201: Extractor
|
| 220 |
+
202: Extension Cord
|
| 221 |
+
203: Tong
|
| 222 |
+
204: Tennis Racket
|
| 223 |
+
205: Folder
|
| 224 |
+
206: American Football
|
| 225 |
+
207: earphone
|
| 226 |
+
208: Mask
|
| 227 |
+
209: Kettle
|
| 228 |
+
210: Tennis
|
| 229 |
+
211: Ship
|
| 230 |
+
212: Swing
|
| 231 |
+
213: Coffee Machine
|
| 232 |
+
214: Slide
|
| 233 |
+
215: Carriage
|
| 234 |
+
216: Onion
|
| 235 |
+
217: Green beans
|
| 236 |
+
218: Projector
|
| 237 |
+
219: Frisbee
|
| 238 |
+
220: Washing Machine/Drying Machine
|
| 239 |
+
221: Chicken
|
| 240 |
+
222: Printer
|
| 241 |
+
223: Watermelon
|
| 242 |
+
224: Saxophone
|
| 243 |
+
225: Tissue
|
| 244 |
+
226: Toothbrush
|
| 245 |
+
227: Ice cream
|
| 246 |
+
228: Hot-air balloon
|
| 247 |
+
229: Cello
|
| 248 |
+
230: French Fries
|
| 249 |
+
231: Scale
|
| 250 |
+
232: Trophy
|
| 251 |
+
233: Cabbage
|
| 252 |
+
234: Hot dog
|
| 253 |
+
235: Blender
|
| 254 |
+
236: Peach
|
| 255 |
+
237: Rice
|
| 256 |
+
238: Wallet/Purse
|
| 257 |
+
239: Volleyball
|
| 258 |
+
240: Deer
|
| 259 |
+
241: Goose
|
| 260 |
+
242: Tape
|
| 261 |
+
243: Tablet
|
| 262 |
+
244: Cosmetics
|
| 263 |
+
245: Trumpet
|
| 264 |
+
246: Pineapple
|
| 265 |
+
247: Golf Ball
|
| 266 |
+
248: Ambulance
|
| 267 |
+
249: Parking meter
|
| 268 |
+
250: Mango
|
| 269 |
+
251: Key
|
| 270 |
+
252: Hurdle
|
| 271 |
+
253: Fishing Rod
|
| 272 |
+
254: Medal
|
| 273 |
+
255: Flute
|
| 274 |
+
256: Brush
|
| 275 |
+
257: Penguin
|
| 276 |
+
258: Megaphone
|
| 277 |
+
259: Corn
|
| 278 |
+
260: Lettuce
|
| 279 |
+
261: Garlic
|
| 280 |
+
262: Swan
|
| 281 |
+
263: Helicopter
|
| 282 |
+
264: Green Onion
|
| 283 |
+
265: Sandwich
|
| 284 |
+
266: Nuts
|
| 285 |
+
267: Speed Limit Sign
|
| 286 |
+
268: Induction Cooker
|
| 287 |
+
269: Broom
|
| 288 |
+
270: Trombone
|
| 289 |
+
271: Plum
|
| 290 |
+
272: Rickshaw
|
| 291 |
+
273: Goldfish
|
| 292 |
+
274: Kiwi fruit
|
| 293 |
+
275: Router/modem
|
| 294 |
+
276: Poker Card
|
| 295 |
+
277: Toaster
|
| 296 |
+
278: Shrimp
|
| 297 |
+
279: Sushi
|
| 298 |
+
280: Cheese
|
| 299 |
+
281: Notepaper
|
| 300 |
+
282: Cherry
|
| 301 |
+
283: Pliers
|
| 302 |
+
284: CD
|
| 303 |
+
285: Pasta
|
| 304 |
+
286: Hammer
|
| 305 |
+
287: Cue
|
| 306 |
+
288: Avocado
|
| 307 |
+
289: Hamimelon
|
| 308 |
+
290: Flask
|
| 309 |
+
291: Mushroom
|
| 310 |
+
292: Screwdriver
|
| 311 |
+
293: Soap
|
| 312 |
+
294: Recorder
|
| 313 |
+
295: Bear
|
| 314 |
+
296: Eggplant
|
| 315 |
+
297: Board Eraser
|
| 316 |
+
298: Coconut
|
| 317 |
+
299: Tape Measure/Ruler
|
| 318 |
+
300: Pig
|
| 319 |
+
301: Showerhead
|
| 320 |
+
302: Globe
|
| 321 |
+
303: Chips
|
| 322 |
+
304: Steak
|
| 323 |
+
305: Crosswalk Sign
|
| 324 |
+
306: Stapler
|
| 325 |
+
307: Camel
|
| 326 |
+
308: Formula 1
|
| 327 |
+
309: Pomegranate
|
| 328 |
+
310: Dishwasher
|
| 329 |
+
311: Crab
|
| 330 |
+
312: Hoverboard
|
| 331 |
+
313: Meat ball
|
| 332 |
+
314: Rice Cooker
|
| 333 |
+
315: Tuba
|
| 334 |
+
316: Calculator
|
| 335 |
+
317: Papaya
|
| 336 |
+
318: Antelope
|
| 337 |
+
319: Parrot
|
| 338 |
+
320: Seal
|
| 339 |
+
321: Butterfly
|
| 340 |
+
322: Dumbbell
|
| 341 |
+
323: Donkey
|
| 342 |
+
324: Lion
|
| 343 |
+
325: Urinal
|
| 344 |
+
326: Dolphin
|
| 345 |
+
327: Electric Drill
|
| 346 |
+
328: Hair Dryer
|
| 347 |
+
329: Egg tart
|
| 348 |
+
330: Jellyfish
|
| 349 |
+
331: Treadmill
|
| 350 |
+
332: Lighter
|
| 351 |
+
333: Grapefruit
|
| 352 |
+
334: Game board
|
| 353 |
+
335: Mop
|
| 354 |
+
336: Radish
|
| 355 |
+
337: Baozi
|
| 356 |
+
338: Target
|
| 357 |
+
339: French
|
| 358 |
+
340: Spring Rolls
|
| 359 |
+
341: Monkey
|
| 360 |
+
342: Rabbit
|
| 361 |
+
343: Pencil Case
|
| 362 |
+
344: Yak
|
| 363 |
+
345: Red Cabbage
|
| 364 |
+
346: Binoculars
|
| 365 |
+
347: Asparagus
|
| 366 |
+
348: Barbell
|
| 367 |
+
349: Scallop
|
| 368 |
+
350: Noddles
|
| 369 |
+
351: Comb
|
| 370 |
+
352: Dumpling
|
| 371 |
+
353: Oyster
|
| 372 |
+
354: Table Tennis paddle
|
| 373 |
+
355: Cosmetics Brush/Eyeliner Pencil
|
| 374 |
+
356: Chainsaw
|
| 375 |
+
357: Eraser
|
| 376 |
+
358: Lobster
|
| 377 |
+
359: Durian
|
| 378 |
+
360: Okra
|
| 379 |
+
361: Lipstick
|
| 380 |
+
362: Cosmetics Mirror
|
| 381 |
+
363: Curling
|
| 382 |
+
364: Table Tennis
|
| 383 |
+
|
| 384 |
+
|
| 385 |
+
# Download script/URL (optional) ---------------------------------------------------------------------------------------
|
| 386 |
+
download: |
|
| 387 |
+
from tqdm import tqdm
|
| 388 |
+
|
| 389 |
+
from utils.general import Path, check_requirements, download, np, xyxy2xywhn
|
| 390 |
+
|
| 391 |
+
check_requirements('pycocotools>=2.0')
|
| 392 |
+
from pycocotools.coco import COCO
|
| 393 |
+
|
| 394 |
+
# Make Directories
|
| 395 |
+
dir = Path(yaml['path']) # dataset root dir
|
| 396 |
+
for p in 'images', 'labels':
|
| 397 |
+
(dir / p).mkdir(parents=True, exist_ok=True)
|
| 398 |
+
for q in 'train', 'val':
|
| 399 |
+
(dir / p / q).mkdir(parents=True, exist_ok=True)
|
| 400 |
+
|
| 401 |
+
# Train, Val Splits
|
| 402 |
+
for split, patches in [('train', 50 + 1), ('val', 43 + 1)]:
|
| 403 |
+
print(f"Processing {split} in {patches} patches ...")
|
| 404 |
+
images, labels = dir / 'images' / split, dir / 'labels' / split
|
| 405 |
+
|
| 406 |
+
# Download
|
| 407 |
+
url = f"https://dorc.ks3-cn-beijing.ksyun.com/data-set/2020Objects365%E6%95%B0%E6%8D%AE%E9%9B%86/{split}/"
|
| 408 |
+
if split == 'train':
|
| 409 |
+
download([f'{url}zhiyuan_objv2_{split}.tar.gz'], dir=dir, delete=False) # annotations json
|
| 410 |
+
download([f'{url}patch{i}.tar.gz' for i in range(patches)], dir=images, curl=True, delete=False, threads=8)
|
| 411 |
+
elif split == 'val':
|
| 412 |
+
download([f'{url}zhiyuan_objv2_{split}.json'], dir=dir, delete=False) # annotations json
|
| 413 |
+
download([f'{url}images/v1/patch{i}.tar.gz' for i in range(15 + 1)], dir=images, curl=True, delete=False, threads=8)
|
| 414 |
+
download([f'{url}images/v2/patch{i}.tar.gz' for i in range(16, patches)], dir=images, curl=True, delete=False, threads=8)
|
| 415 |
+
|
| 416 |
+
# Move
|
| 417 |
+
for f in tqdm(images.rglob('*.jpg'), desc=f'Moving {split} images'):
|
| 418 |
+
f.rename(images / f.name) # move to /images/{split}
|
| 419 |
+
|
| 420 |
+
# Labels
|
| 421 |
+
coco = COCO(dir / f'zhiyuan_objv2_{split}.json')
|
| 422 |
+
names = [x["name"] for x in coco.loadCats(coco.getCatIds())]
|
| 423 |
+
for cid, cat in enumerate(names):
|
| 424 |
+
catIds = coco.getCatIds(catNms=[cat])
|
| 425 |
+
imgIds = coco.getImgIds(catIds=catIds)
|
| 426 |
+
for im in tqdm(coco.loadImgs(imgIds), desc=f'Class {cid + 1}/{len(names)} {cat}'):
|
| 427 |
+
width, height = im["width"], im["height"]
|
| 428 |
+
path = Path(im["file_name"]) # image filename
|
| 429 |
+
try:
|
| 430 |
+
with open(labels / path.with_suffix('.txt').name, 'a') as file:
|
| 431 |
+
annIds = coco.getAnnIds(imgIds=im["id"], catIds=catIds, iscrowd=False)
|
| 432 |
+
for a in coco.loadAnns(annIds):
|
| 433 |
+
x, y, w, h = a['bbox'] # bounding box in xywh (xy top-left corner)
|
| 434 |
+
xyxy = np.array([x, y, x + w, y + h])[None] # pixels(1,4)
|
| 435 |
+
x, y, w, h = xyxy2xywhn(xyxy, w=width, h=height, clip=True)[0] # normalized and clipped
|
| 436 |
+
file.write(f"{cid} {x:.5f} {y:.5f} {w:.5f} {h:.5f}\n")
|
| 437 |
+
except Exception as e:
|
| 438 |
+
print(e)
|
yolov5/data/SKU-110K.yaml
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# SKU-110K retail items dataset https://github.com/eg4000/SKU110K_CVPR19 by Trax Retail
|
| 3 |
+
# Example usage: python train.py --data SKU-110K.yaml
|
| 4 |
+
# parent
|
| 5 |
+
# ├── yolov5
|
| 6 |
+
# └── datasets
|
| 7 |
+
# └── SKU-110K ← downloads here (13.6 GB)
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
| 11 |
+
path: ../datasets/SKU-110K # dataset root dir
|
| 12 |
+
train: train.txt # train images (relative to 'path') 8219 images
|
| 13 |
+
val: val.txt # val images (relative to 'path') 588 images
|
| 14 |
+
test: test.txt # test images (optional) 2936 images
|
| 15 |
+
|
| 16 |
+
# Classes
|
| 17 |
+
names:
|
| 18 |
+
0: object
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
# Download script/URL (optional) ---------------------------------------------------------------------------------------
|
| 22 |
+
download: |
|
| 23 |
+
import shutil
|
| 24 |
+
from tqdm import tqdm
|
| 25 |
+
from utils.general import np, pd, Path, download, xyxy2xywh
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
# Download
|
| 29 |
+
dir = Path(yaml['path']) # dataset root dir
|
| 30 |
+
parent = Path(dir.parent) # download dir
|
| 31 |
+
urls = ['http://trax-geometry.s3.amazonaws.com/cvpr_challenge/SKU110K_fixed.tar.gz']
|
| 32 |
+
download(urls, dir=parent, delete=False)
|
| 33 |
+
|
| 34 |
+
# Rename directories
|
| 35 |
+
if dir.exists():
|
| 36 |
+
shutil.rmtree(dir)
|
| 37 |
+
(parent / 'SKU110K_fixed').rename(dir) # rename dir
|
| 38 |
+
(dir / 'labels').mkdir(parents=True, exist_ok=True) # create labels dir
|
| 39 |
+
|
| 40 |
+
# Convert labels
|
| 41 |
+
names = 'image', 'x1', 'y1', 'x2', 'y2', 'class', 'image_width', 'image_height' # column names
|
| 42 |
+
for d in 'annotations_train.csv', 'annotations_val.csv', 'annotations_test.csv':
|
| 43 |
+
x = pd.read_csv(dir / 'annotations' / d, names=names).values # annotations
|
| 44 |
+
images, unique_images = x[:, 0], np.unique(x[:, 0])
|
| 45 |
+
with open((dir / d).with_suffix('.txt').__str__().replace('annotations_', ''), 'w') as f:
|
| 46 |
+
f.writelines(f'./images/{s}\n' for s in unique_images)
|
| 47 |
+
for im in tqdm(unique_images, desc=f'Converting {dir / d}'):
|
| 48 |
+
cls = 0 # single-class dataset
|
| 49 |
+
with open((dir / 'labels' / im).with_suffix('.txt'), 'a') as f:
|
| 50 |
+
for r in x[images == im]:
|
| 51 |
+
w, h = r[6], r[7] # image width, height
|
| 52 |
+
xywh = xyxy2xywh(np.array([[r[1] / w, r[2] / h, r[3] / w, r[4] / h]]))[0] # instance
|
| 53 |
+
f.write(f"{cls} {xywh[0]:.5f} {xywh[1]:.5f} {xywh[2]:.5f} {xywh[3]:.5f}\n") # write label
|
yolov5/data/VOC.yaml
ADDED
|
@@ -0,0 +1,100 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# PASCAL VOC dataset http://host.robots.ox.ac.uk/pascal/VOC by University of Oxford
|
| 3 |
+
# Example usage: python train.py --data VOC.yaml
|
| 4 |
+
# parent
|
| 5 |
+
# ├── yolov5
|
| 6 |
+
# └── datasets
|
| 7 |
+
# └── VOC ← downloads here (2.8 GB)
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
| 11 |
+
path: ../datasets/VOC
|
| 12 |
+
train: # train images (relative to 'path') 16551 images
|
| 13 |
+
- images/train2012
|
| 14 |
+
- images/train2007
|
| 15 |
+
- images/val2012
|
| 16 |
+
- images/val2007
|
| 17 |
+
val: # val images (relative to 'path') 4952 images
|
| 18 |
+
- images/test2007
|
| 19 |
+
test: # test images (optional)
|
| 20 |
+
- images/test2007
|
| 21 |
+
|
| 22 |
+
# Classes
|
| 23 |
+
names:
|
| 24 |
+
0: aeroplane
|
| 25 |
+
1: bicycle
|
| 26 |
+
2: bird
|
| 27 |
+
3: boat
|
| 28 |
+
4: bottle
|
| 29 |
+
5: bus
|
| 30 |
+
6: car
|
| 31 |
+
7: cat
|
| 32 |
+
8: chair
|
| 33 |
+
9: cow
|
| 34 |
+
10: diningtable
|
| 35 |
+
11: dog
|
| 36 |
+
12: horse
|
| 37 |
+
13: motorbike
|
| 38 |
+
14: person
|
| 39 |
+
15: pottedplant
|
| 40 |
+
16: sheep
|
| 41 |
+
17: sofa
|
| 42 |
+
18: train
|
| 43 |
+
19: tvmonitor
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
# Download script/URL (optional) ---------------------------------------------------------------------------------------
|
| 47 |
+
download: |
|
| 48 |
+
import xml.etree.ElementTree as ET
|
| 49 |
+
|
| 50 |
+
from tqdm import tqdm
|
| 51 |
+
from utils.general import download, Path
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def convert_label(path, lb_path, year, image_id):
|
| 55 |
+
def convert_box(size, box):
|
| 56 |
+
dw, dh = 1. / size[0], 1. / size[1]
|
| 57 |
+
x, y, w, h = (box[0] + box[1]) / 2.0 - 1, (box[2] + box[3]) / 2.0 - 1, box[1] - box[0], box[3] - box[2]
|
| 58 |
+
return x * dw, y * dh, w * dw, h * dh
|
| 59 |
+
|
| 60 |
+
in_file = open(path / f'VOC{year}/Annotations/{image_id}.xml')
|
| 61 |
+
out_file = open(lb_path, 'w')
|
| 62 |
+
tree = ET.parse(in_file)
|
| 63 |
+
root = tree.getroot()
|
| 64 |
+
size = root.find('size')
|
| 65 |
+
w = int(size.find('width').text)
|
| 66 |
+
h = int(size.find('height').text)
|
| 67 |
+
|
| 68 |
+
names = list(yaml['names'].values()) # names list
|
| 69 |
+
for obj in root.iter('object'):
|
| 70 |
+
cls = obj.find('name').text
|
| 71 |
+
if cls in names and int(obj.find('difficult').text) != 1:
|
| 72 |
+
xmlbox = obj.find('bndbox')
|
| 73 |
+
bb = convert_box((w, h), [float(xmlbox.find(x).text) for x in ('xmin', 'xmax', 'ymin', 'ymax')])
|
| 74 |
+
cls_id = names.index(cls) # class id
|
| 75 |
+
out_file.write(" ".join([str(a) for a in (cls_id, *bb)]) + '\n')
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
# Download
|
| 79 |
+
dir = Path(yaml['path']) # dataset root dir
|
| 80 |
+
url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
|
| 81 |
+
urls = [f'{url}VOCtrainval_06-Nov-2007.zip', # 446MB, 5012 images
|
| 82 |
+
f'{url}VOCtest_06-Nov-2007.zip', # 438MB, 4953 images
|
| 83 |
+
f'{url}VOCtrainval_11-May-2012.zip'] # 1.95GB, 17126 images
|
| 84 |
+
download(urls, dir=dir / 'images', delete=False, curl=True, threads=3)
|
| 85 |
+
|
| 86 |
+
# Convert
|
| 87 |
+
path = dir / 'images/VOCdevkit'
|
| 88 |
+
for year, image_set in ('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test'):
|
| 89 |
+
imgs_path = dir / 'images' / f'{image_set}{year}'
|
| 90 |
+
lbs_path = dir / 'labels' / f'{image_set}{year}'
|
| 91 |
+
imgs_path.mkdir(exist_ok=True, parents=True)
|
| 92 |
+
lbs_path.mkdir(exist_ok=True, parents=True)
|
| 93 |
+
|
| 94 |
+
with open(path / f'VOC{year}/ImageSets/Main/{image_set}.txt') as f:
|
| 95 |
+
image_ids = f.read().strip().split()
|
| 96 |
+
for id in tqdm(image_ids, desc=f'{image_set}{year}'):
|
| 97 |
+
f = path / f'VOC{year}/JPEGImages/{id}.jpg' # old img path
|
| 98 |
+
lb_path = (lbs_path / f.name).with_suffix('.txt') # new label path
|
| 99 |
+
f.rename(imgs_path / f.name) # move image
|
| 100 |
+
convert_label(path, lb_path, year, id) # convert labels to YOLO format
|
yolov5/data/VisDrone.yaml
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# VisDrone2019-DET dataset https://github.com/VisDrone/VisDrone-Dataset by Tianjin University
|
| 3 |
+
# Example usage: python train.py --data VisDrone.yaml
|
| 4 |
+
# parent
|
| 5 |
+
# ├── yolov5
|
| 6 |
+
# └── datasets
|
| 7 |
+
# └── VisDrone ← downloads here (2.3 GB)
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
| 11 |
+
path: ../datasets/VisDrone # dataset root dir
|
| 12 |
+
train: VisDrone2019-DET-train/images # train images (relative to 'path') 6471 images
|
| 13 |
+
val: VisDrone2019-DET-val/images # val images (relative to 'path') 548 images
|
| 14 |
+
test: VisDrone2019-DET-test-dev/images # test images (optional) 1610 images
|
| 15 |
+
|
| 16 |
+
# Classes
|
| 17 |
+
names:
|
| 18 |
+
0: pedestrian
|
| 19 |
+
1: people
|
| 20 |
+
2: bicycle
|
| 21 |
+
3: car
|
| 22 |
+
4: van
|
| 23 |
+
5: truck
|
| 24 |
+
6: tricycle
|
| 25 |
+
7: awning-tricycle
|
| 26 |
+
8: bus
|
| 27 |
+
9: motor
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
# Download script/URL (optional) ---------------------------------------------------------------------------------------
|
| 31 |
+
download: |
|
| 32 |
+
from utils.general import download, os, Path
|
| 33 |
+
|
| 34 |
+
def visdrone2yolo(dir):
|
| 35 |
+
from PIL import Image
|
| 36 |
+
from tqdm import tqdm
|
| 37 |
+
|
| 38 |
+
def convert_box(size, box):
|
| 39 |
+
# Convert VisDrone box to YOLO xywh box
|
| 40 |
+
dw = 1. / size[0]
|
| 41 |
+
dh = 1. / size[1]
|
| 42 |
+
return (box[0] + box[2] / 2) * dw, (box[1] + box[3] / 2) * dh, box[2] * dw, box[3] * dh
|
| 43 |
+
|
| 44 |
+
(dir / 'labels').mkdir(parents=True, exist_ok=True) # make labels directory
|
| 45 |
+
pbar = tqdm((dir / 'annotations').glob('*.txt'), desc=f'Converting {dir}')
|
| 46 |
+
for f in pbar:
|
| 47 |
+
img_size = Image.open((dir / 'images' / f.name).with_suffix('.jpg')).size
|
| 48 |
+
lines = []
|
| 49 |
+
with open(f, 'r') as file: # read annotation.txt
|
| 50 |
+
for row in [x.split(',') for x in file.read().strip().splitlines()]:
|
| 51 |
+
if row[4] == '0': # VisDrone 'ignored regions' class 0
|
| 52 |
+
continue
|
| 53 |
+
cls = int(row[5]) - 1
|
| 54 |
+
box = convert_box(img_size, tuple(map(int, row[:4])))
|
| 55 |
+
lines.append(f"{cls} {' '.join(f'{x:.6f}' for x in box)}\n")
|
| 56 |
+
with open(str(f).replace(os.sep + 'annotations' + os.sep, os.sep + 'labels' + os.sep), 'w') as fl:
|
| 57 |
+
fl.writelines(lines) # write label.txt
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
# Download
|
| 61 |
+
dir = Path(yaml['path']) # dataset root dir
|
| 62 |
+
urls = ['https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-train.zip',
|
| 63 |
+
'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-val.zip',
|
| 64 |
+
'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-dev.zip',
|
| 65 |
+
'https://github.com/ultralytics/yolov5/releases/download/v1.0/VisDrone2019-DET-test-challenge.zip']
|
| 66 |
+
download(urls, dir=dir, curl=True, threads=4)
|
| 67 |
+
|
| 68 |
+
# Convert
|
| 69 |
+
for d in 'VisDrone2019-DET-train', 'VisDrone2019-DET-val', 'VisDrone2019-DET-test-dev':
|
| 70 |
+
visdrone2yolo(dir / d) # convert VisDrone annotations to YOLO labels
|
yolov5/data/coco.yaml
ADDED
|
@@ -0,0 +1,116 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# COCO 2017 dataset http://cocodataset.org by Microsoft
|
| 3 |
+
# Example usage: python train.py --data coco.yaml
|
| 4 |
+
# parent
|
| 5 |
+
# ├── yolov5
|
| 6 |
+
# └── datasets
|
| 7 |
+
# └── coco ← downloads here (20.1 GB)
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
| 11 |
+
path: ../datasets/coco # dataset root dir
|
| 12 |
+
train: train2017.txt # train images (relative to 'path') 118287 images
|
| 13 |
+
val: val2017.txt # val images (relative to 'path') 5000 images
|
| 14 |
+
test: test-dev2017.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
|
| 15 |
+
|
| 16 |
+
# Classes
|
| 17 |
+
names:
|
| 18 |
+
0: person
|
| 19 |
+
1: bicycle
|
| 20 |
+
2: car
|
| 21 |
+
3: motorcycle
|
| 22 |
+
4: airplane
|
| 23 |
+
5: bus
|
| 24 |
+
6: train
|
| 25 |
+
7: truck
|
| 26 |
+
8: boat
|
| 27 |
+
9: traffic light
|
| 28 |
+
10: fire hydrant
|
| 29 |
+
11: stop sign
|
| 30 |
+
12: parking meter
|
| 31 |
+
13: bench
|
| 32 |
+
14: bird
|
| 33 |
+
15: cat
|
| 34 |
+
16: dog
|
| 35 |
+
17: horse
|
| 36 |
+
18: sheep
|
| 37 |
+
19: cow
|
| 38 |
+
20: elephant
|
| 39 |
+
21: bear
|
| 40 |
+
22: zebra
|
| 41 |
+
23: giraffe
|
| 42 |
+
24: backpack
|
| 43 |
+
25: umbrella
|
| 44 |
+
26: handbag
|
| 45 |
+
27: tie
|
| 46 |
+
28: suitcase
|
| 47 |
+
29: frisbee
|
| 48 |
+
30: skis
|
| 49 |
+
31: snowboard
|
| 50 |
+
32: sports ball
|
| 51 |
+
33: kite
|
| 52 |
+
34: baseball bat
|
| 53 |
+
35: baseball glove
|
| 54 |
+
36: skateboard
|
| 55 |
+
37: surfboard
|
| 56 |
+
38: tennis racket
|
| 57 |
+
39: bottle
|
| 58 |
+
40: wine glass
|
| 59 |
+
41: cup
|
| 60 |
+
42: fork
|
| 61 |
+
43: knife
|
| 62 |
+
44: spoon
|
| 63 |
+
45: bowl
|
| 64 |
+
46: banana
|
| 65 |
+
47: apple
|
| 66 |
+
48: sandwich
|
| 67 |
+
49: orange
|
| 68 |
+
50: broccoli
|
| 69 |
+
51: carrot
|
| 70 |
+
52: hot dog
|
| 71 |
+
53: pizza
|
| 72 |
+
54: donut
|
| 73 |
+
55: cake
|
| 74 |
+
56: chair
|
| 75 |
+
57: couch
|
| 76 |
+
58: potted plant
|
| 77 |
+
59: bed
|
| 78 |
+
60: dining table
|
| 79 |
+
61: toilet
|
| 80 |
+
62: tv
|
| 81 |
+
63: laptop
|
| 82 |
+
64: mouse
|
| 83 |
+
65: remote
|
| 84 |
+
66: keyboard
|
| 85 |
+
67: cell phone
|
| 86 |
+
68: microwave
|
| 87 |
+
69: oven
|
| 88 |
+
70: toaster
|
| 89 |
+
71: sink
|
| 90 |
+
72: refrigerator
|
| 91 |
+
73: book
|
| 92 |
+
74: clock
|
| 93 |
+
75: vase
|
| 94 |
+
76: scissors
|
| 95 |
+
77: teddy bear
|
| 96 |
+
78: hair drier
|
| 97 |
+
79: toothbrush
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
# Download script/URL (optional)
|
| 101 |
+
download: |
|
| 102 |
+
from utils.general import download, Path
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
# Download labels
|
| 106 |
+
segments = False # segment or box labels
|
| 107 |
+
dir = Path(yaml['path']) # dataset root dir
|
| 108 |
+
url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
|
| 109 |
+
urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labels
|
| 110 |
+
download(urls, dir=dir.parent)
|
| 111 |
+
|
| 112 |
+
# Download data
|
| 113 |
+
urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images
|
| 114 |
+
'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images
|
| 115 |
+
'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)
|
| 116 |
+
download(urls, dir=dir / 'images', threads=3)
|
yolov5/data/coco128-seg.yaml
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# COCO128-seg dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
|
| 3 |
+
# Example usage: python train.py --data coco128.yaml
|
| 4 |
+
# parent
|
| 5 |
+
# ├── yolov5
|
| 6 |
+
# └── datasets
|
| 7 |
+
# └── coco128-seg ← downloads here (7 MB)
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
| 11 |
+
path: ../datasets/coco128-seg # dataset root dir
|
| 12 |
+
train: images/train2017 # train images (relative to 'path') 128 images
|
| 13 |
+
val: images/train2017 # val images (relative to 'path') 128 images
|
| 14 |
+
test: # test images (optional)
|
| 15 |
+
|
| 16 |
+
# Classes
|
| 17 |
+
names:
|
| 18 |
+
0: person
|
| 19 |
+
1: bicycle
|
| 20 |
+
2: car
|
| 21 |
+
3: motorcycle
|
| 22 |
+
4: airplane
|
| 23 |
+
5: bus
|
| 24 |
+
6: train
|
| 25 |
+
7: truck
|
| 26 |
+
8: boat
|
| 27 |
+
9: traffic light
|
| 28 |
+
10: fire hydrant
|
| 29 |
+
11: stop sign
|
| 30 |
+
12: parking meter
|
| 31 |
+
13: bench
|
| 32 |
+
14: bird
|
| 33 |
+
15: cat
|
| 34 |
+
16: dog
|
| 35 |
+
17: horse
|
| 36 |
+
18: sheep
|
| 37 |
+
19: cow
|
| 38 |
+
20: elephant
|
| 39 |
+
21: bear
|
| 40 |
+
22: zebra
|
| 41 |
+
23: giraffe
|
| 42 |
+
24: backpack
|
| 43 |
+
25: umbrella
|
| 44 |
+
26: handbag
|
| 45 |
+
27: tie
|
| 46 |
+
28: suitcase
|
| 47 |
+
29: frisbee
|
| 48 |
+
30: skis
|
| 49 |
+
31: snowboard
|
| 50 |
+
32: sports ball
|
| 51 |
+
33: kite
|
| 52 |
+
34: baseball bat
|
| 53 |
+
35: baseball glove
|
| 54 |
+
36: skateboard
|
| 55 |
+
37: surfboard
|
| 56 |
+
38: tennis racket
|
| 57 |
+
39: bottle
|
| 58 |
+
40: wine glass
|
| 59 |
+
41: cup
|
| 60 |
+
42: fork
|
| 61 |
+
43: knife
|
| 62 |
+
44: spoon
|
| 63 |
+
45: bowl
|
| 64 |
+
46: banana
|
| 65 |
+
47: apple
|
| 66 |
+
48: sandwich
|
| 67 |
+
49: orange
|
| 68 |
+
50: broccoli
|
| 69 |
+
51: carrot
|
| 70 |
+
52: hot dog
|
| 71 |
+
53: pizza
|
| 72 |
+
54: donut
|
| 73 |
+
55: cake
|
| 74 |
+
56: chair
|
| 75 |
+
57: couch
|
| 76 |
+
58: potted plant
|
| 77 |
+
59: bed
|
| 78 |
+
60: dining table
|
| 79 |
+
61: toilet
|
| 80 |
+
62: tv
|
| 81 |
+
63: laptop
|
| 82 |
+
64: mouse
|
| 83 |
+
65: remote
|
| 84 |
+
66: keyboard
|
| 85 |
+
67: cell phone
|
| 86 |
+
68: microwave
|
| 87 |
+
69: oven
|
| 88 |
+
70: toaster
|
| 89 |
+
71: sink
|
| 90 |
+
72: refrigerator
|
| 91 |
+
73: book
|
| 92 |
+
74: clock
|
| 93 |
+
75: vase
|
| 94 |
+
76: scissors
|
| 95 |
+
77: teddy bear
|
| 96 |
+
78: hair drier
|
| 97 |
+
79: toothbrush
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
# Download script/URL (optional)
|
| 101 |
+
download: https://ultralytics.com/assets/coco128-seg.zip
|
yolov5/data/coco128.yaml
ADDED
|
@@ -0,0 +1,101 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
|
| 3 |
+
# Example usage: python train.py --data coco128.yaml
|
| 4 |
+
# parent
|
| 5 |
+
# ├── yolov5
|
| 6 |
+
# └── datasets
|
| 7 |
+
# └── coco128 ← downloads here (7 MB)
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
| 11 |
+
path: ../datasets/coco128 # dataset root dir
|
| 12 |
+
train: images/train2017 # train images (relative to 'path') 128 images
|
| 13 |
+
val: images/train2017 # val images (relative to 'path') 128 images
|
| 14 |
+
test: # test images (optional)
|
| 15 |
+
|
| 16 |
+
# Classes
|
| 17 |
+
names:
|
| 18 |
+
0: person
|
| 19 |
+
1: bicycle
|
| 20 |
+
2: car
|
| 21 |
+
3: motorcycle
|
| 22 |
+
4: airplane
|
| 23 |
+
5: bus
|
| 24 |
+
6: train
|
| 25 |
+
7: truck
|
| 26 |
+
8: boat
|
| 27 |
+
9: traffic light
|
| 28 |
+
10: fire hydrant
|
| 29 |
+
11: stop sign
|
| 30 |
+
12: parking meter
|
| 31 |
+
13: bench
|
| 32 |
+
14: bird
|
| 33 |
+
15: cat
|
| 34 |
+
16: dog
|
| 35 |
+
17: horse
|
| 36 |
+
18: sheep
|
| 37 |
+
19: cow
|
| 38 |
+
20: elephant
|
| 39 |
+
21: bear
|
| 40 |
+
22: zebra
|
| 41 |
+
23: giraffe
|
| 42 |
+
24: backpack
|
| 43 |
+
25: umbrella
|
| 44 |
+
26: handbag
|
| 45 |
+
27: tie
|
| 46 |
+
28: suitcase
|
| 47 |
+
29: frisbee
|
| 48 |
+
30: skis
|
| 49 |
+
31: snowboard
|
| 50 |
+
32: sports ball
|
| 51 |
+
33: kite
|
| 52 |
+
34: baseball bat
|
| 53 |
+
35: baseball glove
|
| 54 |
+
36: skateboard
|
| 55 |
+
37: surfboard
|
| 56 |
+
38: tennis racket
|
| 57 |
+
39: bottle
|
| 58 |
+
40: wine glass
|
| 59 |
+
41: cup
|
| 60 |
+
42: fork
|
| 61 |
+
43: knife
|
| 62 |
+
44: spoon
|
| 63 |
+
45: bowl
|
| 64 |
+
46: banana
|
| 65 |
+
47: apple
|
| 66 |
+
48: sandwich
|
| 67 |
+
49: orange
|
| 68 |
+
50: broccoli
|
| 69 |
+
51: carrot
|
| 70 |
+
52: hot dog
|
| 71 |
+
53: pizza
|
| 72 |
+
54: donut
|
| 73 |
+
55: cake
|
| 74 |
+
56: chair
|
| 75 |
+
57: couch
|
| 76 |
+
58: potted plant
|
| 77 |
+
59: bed
|
| 78 |
+
60: dining table
|
| 79 |
+
61: toilet
|
| 80 |
+
62: tv
|
| 81 |
+
63: laptop
|
| 82 |
+
64: mouse
|
| 83 |
+
65: remote
|
| 84 |
+
66: keyboard
|
| 85 |
+
67: cell phone
|
| 86 |
+
68: microwave
|
| 87 |
+
69: oven
|
| 88 |
+
70: toaster
|
| 89 |
+
71: sink
|
| 90 |
+
72: refrigerator
|
| 91 |
+
73: book
|
| 92 |
+
74: clock
|
| 93 |
+
75: vase
|
| 94 |
+
76: scissors
|
| 95 |
+
77: teddy bear
|
| 96 |
+
78: hair drier
|
| 97 |
+
79: toothbrush
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
# Download script/URL (optional)
|
| 101 |
+
download: https://ultralytics.com/assets/coco128.zip
|
yolov5/data/hyps/hyp.Objects365.yaml
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# Hyperparameters for Objects365 training
|
| 3 |
+
# python train.py --weights yolov5m.pt --data Objects365.yaml --evolve
|
| 4 |
+
# See Hyperparameter Evolution tutorial for details https://github.com/ultralytics/yolov5#tutorials
|
| 5 |
+
|
| 6 |
+
lr0: 0.00258
|
| 7 |
+
lrf: 0.17
|
| 8 |
+
momentum: 0.779
|
| 9 |
+
weight_decay: 0.00058
|
| 10 |
+
warmup_epochs: 1.33
|
| 11 |
+
warmup_momentum: 0.86
|
| 12 |
+
warmup_bias_lr: 0.0711
|
| 13 |
+
box: 0.0539
|
| 14 |
+
cls: 0.299
|
| 15 |
+
cls_pw: 0.825
|
| 16 |
+
obj: 0.632
|
| 17 |
+
obj_pw: 1.0
|
| 18 |
+
iou_t: 0.2
|
| 19 |
+
anchor_t: 3.44
|
| 20 |
+
anchors: 3.2
|
| 21 |
+
fl_gamma: 0.0
|
| 22 |
+
hsv_h: 0.0188
|
| 23 |
+
hsv_s: 0.704
|
| 24 |
+
hsv_v: 0.36
|
| 25 |
+
degrees: 0.0
|
| 26 |
+
translate: 0.0902
|
| 27 |
+
scale: 0.491
|
| 28 |
+
shear: 0.0
|
| 29 |
+
perspective: 0.0
|
| 30 |
+
flipud: 0.0
|
| 31 |
+
fliplr: 0.5
|
| 32 |
+
mosaic: 1.0
|
| 33 |
+
mixup: 0.0
|
| 34 |
+
copy_paste: 0.0
|
yolov5/data/hyps/hyp.VOC.yaml
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# Hyperparameters for VOC training
|
| 3 |
+
# python train.py --batch 128 --weights yolov5m6.pt --data VOC.yaml --epochs 50 --img 512 --hyp hyp.scratch-med.yaml --evolve
|
| 4 |
+
# See Hyperparameter Evolution tutorial for details https://github.com/ultralytics/yolov5#tutorials
|
| 5 |
+
|
| 6 |
+
# YOLOv5 Hyperparameter Evolution Results
|
| 7 |
+
# Best generation: 467
|
| 8 |
+
# Last generation: 996
|
| 9 |
+
# metrics/precision, metrics/recall, metrics/mAP_0.5, metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss
|
| 10 |
+
# 0.87729, 0.85125, 0.91286, 0.72664, 0.0076739, 0.0042529, 0.0013865
|
| 11 |
+
|
| 12 |
+
lr0: 0.00334
|
| 13 |
+
lrf: 0.15135
|
| 14 |
+
momentum: 0.74832
|
| 15 |
+
weight_decay: 0.00025
|
| 16 |
+
warmup_epochs: 3.3835
|
| 17 |
+
warmup_momentum: 0.59462
|
| 18 |
+
warmup_bias_lr: 0.18657
|
| 19 |
+
box: 0.02
|
| 20 |
+
cls: 0.21638
|
| 21 |
+
cls_pw: 0.5
|
| 22 |
+
obj: 0.51728
|
| 23 |
+
obj_pw: 0.67198
|
| 24 |
+
iou_t: 0.2
|
| 25 |
+
anchor_t: 3.3744
|
| 26 |
+
fl_gamma: 0.0
|
| 27 |
+
hsv_h: 0.01041
|
| 28 |
+
hsv_s: 0.54703
|
| 29 |
+
hsv_v: 0.27739
|
| 30 |
+
degrees: 0.0
|
| 31 |
+
translate: 0.04591
|
| 32 |
+
scale: 0.75544
|
| 33 |
+
shear: 0.0
|
| 34 |
+
perspective: 0.0
|
| 35 |
+
flipud: 0.0
|
| 36 |
+
fliplr: 0.5
|
| 37 |
+
mosaic: 0.85834
|
| 38 |
+
mixup: 0.04266
|
| 39 |
+
copy_paste: 0.0
|
| 40 |
+
anchors: 3.412
|
yolov5/data/hyps/hyp.no-augmentation.yaml
ADDED
|
@@ -0,0 +1,35 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# Hyperparameters when using Albumentations frameworks
|
| 3 |
+
# python train.py --hyp hyp.no-augmentation.yaml
|
| 4 |
+
# See https://github.com/ultralytics/yolov5/pull/3882 for YOLOv5 + Albumentations Usage examples
|
| 5 |
+
|
| 6 |
+
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
|
| 7 |
+
lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
|
| 8 |
+
momentum: 0.937 # SGD momentum/Adam beta1
|
| 9 |
+
weight_decay: 0.0005 # optimizer weight decay 5e-4
|
| 10 |
+
warmup_epochs: 3.0 # warmup epochs (fractions ok)
|
| 11 |
+
warmup_momentum: 0.8 # warmup initial momentum
|
| 12 |
+
warmup_bias_lr: 0.1 # warmup initial bias lr
|
| 13 |
+
box: 0.05 # box loss gain
|
| 14 |
+
cls: 0.3 # cls loss gain
|
| 15 |
+
cls_pw: 1.0 # cls BCELoss positive_weight
|
| 16 |
+
obj: 0.7 # obj loss gain (scale with pixels)
|
| 17 |
+
obj_pw: 1.0 # obj BCELoss positive_weight
|
| 18 |
+
iou_t: 0.20 # IoU training threshold
|
| 19 |
+
anchor_t: 4.0 # anchor-multiple threshold
|
| 20 |
+
# anchors: 3 # anchors per output layer (0 to ignore)
|
| 21 |
+
# this parameters are all zero since we want to use albumentation framework
|
| 22 |
+
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
|
| 23 |
+
hsv_h: 0 # image HSV-Hue augmentation (fraction)
|
| 24 |
+
hsv_s: 0 # image HSV-Saturation augmentation (fraction)
|
| 25 |
+
hsv_v: 0 # image HSV-Value augmentation (fraction)
|
| 26 |
+
degrees: 0.0 # image rotation (+/- deg)
|
| 27 |
+
translate: 0 # image translation (+/- fraction)
|
| 28 |
+
scale: 0 # image scale (+/- gain)
|
| 29 |
+
shear: 0 # image shear (+/- deg)
|
| 30 |
+
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
|
| 31 |
+
flipud: 0.0 # image flip up-down (probability)
|
| 32 |
+
fliplr: 0.0 # image flip left-right (probability)
|
| 33 |
+
mosaic: 0.0 # image mosaic (probability)
|
| 34 |
+
mixup: 0.0 # image mixup (probability)
|
| 35 |
+
copy_paste: 0.0 # segment copy-paste (probability)
|
yolov5/data/hyps/hyp.scratch-high.yaml
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# Hyperparameters for high-augmentation COCO training from scratch
|
| 3 |
+
# python train.py --batch 32 --cfg yolov5m6.yaml --weights '' --data coco.yaml --img 1280 --epochs 300
|
| 4 |
+
# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
|
| 5 |
+
|
| 6 |
+
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
|
| 7 |
+
lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
|
| 8 |
+
momentum: 0.937 # SGD momentum/Adam beta1
|
| 9 |
+
weight_decay: 0.0005 # optimizer weight decay 5e-4
|
| 10 |
+
warmup_epochs: 3.0 # warmup epochs (fractions ok)
|
| 11 |
+
warmup_momentum: 0.8 # warmup initial momentum
|
| 12 |
+
warmup_bias_lr: 0.1 # warmup initial bias lr
|
| 13 |
+
box: 0.05 # box loss gain
|
| 14 |
+
cls: 0.3 # cls loss gain
|
| 15 |
+
cls_pw: 1.0 # cls BCELoss positive_weight
|
| 16 |
+
obj: 0.7 # obj loss gain (scale with pixels)
|
| 17 |
+
obj_pw: 1.0 # obj BCELoss positive_weight
|
| 18 |
+
iou_t: 0.20 # IoU training threshold
|
| 19 |
+
anchor_t: 4.0 # anchor-multiple threshold
|
| 20 |
+
# anchors: 3 # anchors per output layer (0 to ignore)
|
| 21 |
+
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
|
| 22 |
+
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
|
| 23 |
+
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
|
| 24 |
+
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
|
| 25 |
+
degrees: 0.0 # image rotation (+/- deg)
|
| 26 |
+
translate: 0.1 # image translation (+/- fraction)
|
| 27 |
+
scale: 0.9 # image scale (+/- gain)
|
| 28 |
+
shear: 0.0 # image shear (+/- deg)
|
| 29 |
+
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
|
| 30 |
+
flipud: 0.0 # image flip up-down (probability)
|
| 31 |
+
fliplr: 0.5 # image flip left-right (probability)
|
| 32 |
+
mosaic: 1.0 # image mosaic (probability)
|
| 33 |
+
mixup: 0.1 # image mixup (probability)
|
| 34 |
+
copy_paste: 0.1 # segment copy-paste (probability)
|
yolov5/data/hyps/hyp.scratch-low.yaml
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# Hyperparameters for low-augmentation COCO training from scratch
|
| 3 |
+
# python train.py --batch 64 --cfg yolov5n6.yaml --weights '' --data coco.yaml --img 640 --epochs 300 --linear
|
| 4 |
+
# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
|
| 5 |
+
|
| 6 |
+
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
|
| 7 |
+
lrf: 0.01 # final OneCycleLR learning rate (lr0 * lrf)
|
| 8 |
+
momentum: 0.937 # SGD momentum/Adam beta1
|
| 9 |
+
weight_decay: 0.0005 # optimizer weight decay 5e-4
|
| 10 |
+
warmup_epochs: 3.0 # warmup epochs (fractions ok)
|
| 11 |
+
warmup_momentum: 0.8 # warmup initial momentum
|
| 12 |
+
warmup_bias_lr: 0.1 # warmup initial bias lr
|
| 13 |
+
box: 0.05 # box loss gain
|
| 14 |
+
cls: 0.5 # cls loss gain
|
| 15 |
+
cls_pw: 1.0 # cls BCELoss positive_weight
|
| 16 |
+
obj: 1.0 # obj loss gain (scale with pixels)
|
| 17 |
+
obj_pw: 1.0 # obj BCELoss positive_weight
|
| 18 |
+
iou_t: 0.20 # IoU training threshold
|
| 19 |
+
anchor_t: 4.0 # anchor-multiple threshold
|
| 20 |
+
# anchors: 3 # anchors per output layer (0 to ignore)
|
| 21 |
+
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
|
| 22 |
+
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
|
| 23 |
+
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
|
| 24 |
+
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
|
| 25 |
+
degrees: 0.0 # image rotation (+/- deg)
|
| 26 |
+
translate: 0.1 # image translation (+/- fraction)
|
| 27 |
+
scale: 0.5 # image scale (+/- gain)
|
| 28 |
+
shear: 0.0 # image shear (+/- deg)
|
| 29 |
+
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
|
| 30 |
+
flipud: 0.0 # image flip up-down (probability)
|
| 31 |
+
fliplr: 0.5 # image flip left-right (probability)
|
| 32 |
+
mosaic: 1.0 # image mosaic (probability)
|
| 33 |
+
mixup: 0.0 # image mixup (probability)
|
| 34 |
+
copy_paste: 0.0 # segment copy-paste (probability)
|
yolov5/data/hyps/hyp.scratch-med.yaml
ADDED
|
@@ -0,0 +1,34 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# Hyperparameters for medium-augmentation COCO training from scratch
|
| 3 |
+
# python train.py --batch 32 --cfg yolov5m6.yaml --weights '' --data coco.yaml --img 1280 --epochs 300
|
| 4 |
+
# See tutorials for hyperparameter evolution https://github.com/ultralytics/yolov5#tutorials
|
| 5 |
+
|
| 6 |
+
lr0: 0.01 # initial learning rate (SGD=1E-2, Adam=1E-3)
|
| 7 |
+
lrf: 0.1 # final OneCycleLR learning rate (lr0 * lrf)
|
| 8 |
+
momentum: 0.937 # SGD momentum/Adam beta1
|
| 9 |
+
weight_decay: 0.0005 # optimizer weight decay 5e-4
|
| 10 |
+
warmup_epochs: 3.0 # warmup epochs (fractions ok)
|
| 11 |
+
warmup_momentum: 0.8 # warmup initial momentum
|
| 12 |
+
warmup_bias_lr: 0.1 # warmup initial bias lr
|
| 13 |
+
box: 0.05 # box loss gain
|
| 14 |
+
cls: 0.3 # cls loss gain
|
| 15 |
+
cls_pw: 1.0 # cls BCELoss positive_weight
|
| 16 |
+
obj: 0.7 # obj loss gain (scale with pixels)
|
| 17 |
+
obj_pw: 1.0 # obj BCELoss positive_weight
|
| 18 |
+
iou_t: 0.20 # IoU training threshold
|
| 19 |
+
anchor_t: 4.0 # anchor-multiple threshold
|
| 20 |
+
# anchors: 3 # anchors per output layer (0 to ignore)
|
| 21 |
+
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
|
| 22 |
+
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
|
| 23 |
+
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
|
| 24 |
+
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
|
| 25 |
+
degrees: 0.0 # image rotation (+/- deg)
|
| 26 |
+
translate: 0.1 # image translation (+/- fraction)
|
| 27 |
+
scale: 0.9 # image scale (+/- gain)
|
| 28 |
+
shear: 0.0 # image shear (+/- deg)
|
| 29 |
+
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
|
| 30 |
+
flipud: 0.0 # image flip up-down (probability)
|
| 31 |
+
fliplr: 0.5 # image flip left-right (probability)
|
| 32 |
+
mosaic: 1.0 # image mosaic (probability)
|
| 33 |
+
mixup: 0.1 # image mixup (probability)
|
| 34 |
+
copy_paste: 0.0 # segment copy-paste (probability)
|
yolov5/data/images/bus.jpg
ADDED

|
yolov5/data/images/zidane.jpg
ADDED

|
yolov5/data/scripts/download_weights.sh
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 3 |
+
# Download latest models from https://github.com/ultralytics/yolov5/releases
|
| 4 |
+
# Example usage: bash data/scripts/download_weights.sh
|
| 5 |
+
# parent
|
| 6 |
+
# └── yolov5
|
| 7 |
+
# ├── yolov5s.pt ← downloads here
|
| 8 |
+
# ├── yolov5m.pt
|
| 9 |
+
# └── ...
|
| 10 |
+
|
| 11 |
+
python - <<EOF
|
| 12 |
+
from utils.downloads import attempt_download
|
| 13 |
+
|
| 14 |
+
p5 = list('nsmlx') # P5 models
|
| 15 |
+
p6 = [f'{x}6' for x in p5] # P6 models
|
| 16 |
+
cls = [f'{x}-cls' for x in p5] # classification models
|
| 17 |
+
seg = [f'{x}-seg' for x in p5] # classification models
|
| 18 |
+
|
| 19 |
+
for x in p5 + p6 + cls + seg:
|
| 20 |
+
attempt_download(f'weights/yolov5{x}.pt')
|
| 21 |
+
|
| 22 |
+
EOF
|
yolov5/data/scripts/get_coco.sh
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 3 |
+
# Download COCO 2017 dataset http://cocodataset.org
|
| 4 |
+
# Example usage: bash data/scripts/get_coco.sh
|
| 5 |
+
# parent
|
| 6 |
+
# ├── yolov5
|
| 7 |
+
# └── datasets
|
| 8 |
+
# └── coco ← downloads here
|
| 9 |
+
|
| 10 |
+
# Arguments (optional) Usage: bash data/scripts/get_coco.sh --train --val --test --segments
|
| 11 |
+
if [ "$#" -gt 0 ]; then
|
| 12 |
+
for opt in "$@"; do
|
| 13 |
+
case "${opt}" in
|
| 14 |
+
--train) train=true ;;
|
| 15 |
+
--val) val=true ;;
|
| 16 |
+
--test) test=true ;;
|
| 17 |
+
--segments) segments=true ;;
|
| 18 |
+
esac
|
| 19 |
+
done
|
| 20 |
+
else
|
| 21 |
+
train=true
|
| 22 |
+
val=true
|
| 23 |
+
test=false
|
| 24 |
+
segments=false
|
| 25 |
+
fi
|
| 26 |
+
|
| 27 |
+
# Download/unzip labels
|
| 28 |
+
d='../datasets' # unzip directory
|
| 29 |
+
url=https://github.com/ultralytics/yolov5/releases/download/v1.0/
|
| 30 |
+
if [ "$segments" == "true" ]; then
|
| 31 |
+
f='coco2017labels-segments.zip' # 168 MB
|
| 32 |
+
else
|
| 33 |
+
f='coco2017labels.zip' # 46 MB
|
| 34 |
+
fi
|
| 35 |
+
echo 'Downloading' $url$f ' ...'
|
| 36 |
+
curl -L $url$f -o $f -# && unzip -q $f -d $d && rm $f &
|
| 37 |
+
|
| 38 |
+
# Download/unzip images
|
| 39 |
+
d='../datasets/coco/images' # unzip directory
|
| 40 |
+
url=http://images.cocodataset.org/zips/
|
| 41 |
+
if [ "$train" == "true" ]; then
|
| 42 |
+
f='train2017.zip' # 19G, 118k images
|
| 43 |
+
echo 'Downloading' $url$f '...'
|
| 44 |
+
curl -L $url$f -o $f -# && unzip -q $f -d $d && rm $f &
|
| 45 |
+
fi
|
| 46 |
+
if [ "$val" == "true" ]; then
|
| 47 |
+
f='val2017.zip' # 1G, 5k images
|
| 48 |
+
echo 'Downloading' $url$f '...'
|
| 49 |
+
curl -L $url$f -o $f -# && unzip -q $f -d $d && rm $f &
|
| 50 |
+
fi
|
| 51 |
+
if [ "$test" == "true" ]; then
|
| 52 |
+
f='test2017.zip' # 7G, 41k images (optional)
|
| 53 |
+
echo 'Downloading' $url$f '...'
|
| 54 |
+
curl -L $url$f -o $f -# && unzip -q $f -d $d && rm $f &
|
| 55 |
+
fi
|
| 56 |
+
wait # finish background tasks
|
yolov5/data/scripts/get_coco128.sh
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 3 |
+
# Download COCO128 dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017)
|
| 4 |
+
# Example usage: bash data/scripts/get_coco128.sh
|
| 5 |
+
# parent
|
| 6 |
+
# ├── yolov5
|
| 7 |
+
# └── datasets
|
| 8 |
+
# └── coco128 ← downloads here
|
| 9 |
+
|
| 10 |
+
# Download/unzip images and labels
|
| 11 |
+
d='../datasets' # unzip directory
|
| 12 |
+
url=https://github.com/ultralytics/yolov5/releases/download/v1.0/
|
| 13 |
+
f='coco128.zip' # or 'coco128-segments.zip', 68 MB
|
| 14 |
+
echo 'Downloading' $url$f ' ...'
|
| 15 |
+
curl -L $url$f -o $f -# && unzip -q $f -d $d && rm $f &
|
| 16 |
+
|
| 17 |
+
wait # finish background tasks
|
yolov5/data/scripts/get_imagenet.sh
ADDED
|
@@ -0,0 +1,51 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 3 |
+
# Download ILSVRC2012 ImageNet dataset https://image-net.org
|
| 4 |
+
# Example usage: bash data/scripts/get_imagenet.sh
|
| 5 |
+
# parent
|
| 6 |
+
# ├── yolov5
|
| 7 |
+
# └── datasets
|
| 8 |
+
# └── imagenet ← downloads here
|
| 9 |
+
|
| 10 |
+
# Arguments (optional) Usage: bash data/scripts/get_imagenet.sh --train --val
|
| 11 |
+
if [ "$#" -gt 0 ]; then
|
| 12 |
+
for opt in "$@"; do
|
| 13 |
+
case "${opt}" in
|
| 14 |
+
--train) train=true ;;
|
| 15 |
+
--val) val=true ;;
|
| 16 |
+
esac
|
| 17 |
+
done
|
| 18 |
+
else
|
| 19 |
+
train=true
|
| 20 |
+
val=true
|
| 21 |
+
fi
|
| 22 |
+
|
| 23 |
+
# Make dir
|
| 24 |
+
d='../datasets/imagenet' # unzip directory
|
| 25 |
+
mkdir -p $d && cd $d
|
| 26 |
+
|
| 27 |
+
# Download/unzip train
|
| 28 |
+
if [ "$train" == "true" ]; then
|
| 29 |
+
wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_train.tar # download 138G, 1281167 images
|
| 30 |
+
mkdir train && mv ILSVRC2012_img_train.tar train/ && cd train
|
| 31 |
+
tar -xf ILSVRC2012_img_train.tar && rm -f ILSVRC2012_img_train.tar
|
| 32 |
+
find . -name "*.tar" | while read NAME; do
|
| 33 |
+
mkdir -p "${NAME%.tar}"
|
| 34 |
+
tar -xf "${NAME}" -C "${NAME%.tar}"
|
| 35 |
+
rm -f "${NAME}"
|
| 36 |
+
done
|
| 37 |
+
cd ..
|
| 38 |
+
fi
|
| 39 |
+
|
| 40 |
+
# Download/unzip val
|
| 41 |
+
if [ "$val" == "true" ]; then
|
| 42 |
+
wget https://image-net.org/data/ILSVRC/2012/ILSVRC2012_img_val.tar # download 6.3G, 50000 images
|
| 43 |
+
mkdir val && mv ILSVRC2012_img_val.tar val/ && cd val && tar -xf ILSVRC2012_img_val.tar
|
| 44 |
+
wget -qO- https://raw.githubusercontent.com/soumith/imagenetloader.torch/master/valprep.sh | bash # move into subdirs
|
| 45 |
+
fi
|
| 46 |
+
|
| 47 |
+
# Delete corrupted image (optional: PNG under JPEG name that may cause dataloaders to fail)
|
| 48 |
+
# rm train/n04266014/n04266014_10835.JPEG
|
| 49 |
+
|
| 50 |
+
# TFRecords (optional)
|
| 51 |
+
# wget https://raw.githubusercontent.com/tensorflow/models/master/research/slim/datasets/imagenet_lsvrc_2015_synsets.txt
|
yolov5/data/scripts/get_imagenet10.sh
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 3 |
+
# Download ILSVRC2012 ImageNet dataset https://image-net.org
|
| 4 |
+
# Example usage: bash data/scripts/get_imagenet.sh
|
| 5 |
+
# parent
|
| 6 |
+
# ├── yolov5
|
| 7 |
+
# └── datasets
|
| 8 |
+
# └── imagenet ← downloads here
|
| 9 |
+
|
| 10 |
+
# Arguments (optional) Usage: bash data/scripts/get_imagenet.sh --train --val
|
| 11 |
+
if [ "$#" -gt 0 ]; then
|
| 12 |
+
for opt in "$@"; do
|
| 13 |
+
case "${opt}" in
|
| 14 |
+
--train) train=true ;;
|
| 15 |
+
--val) val=true ;;
|
| 16 |
+
esac
|
| 17 |
+
done
|
| 18 |
+
else
|
| 19 |
+
train=true
|
| 20 |
+
val=true
|
| 21 |
+
fi
|
| 22 |
+
|
| 23 |
+
# Make dir
|
| 24 |
+
d='../datasets/imagenet10' # unzip directory
|
| 25 |
+
mkdir -p $d && cd $d
|
| 26 |
+
|
| 27 |
+
# Download/unzip train
|
| 28 |
+
wget https://github.com/ultralytics/yolov5/releases/download/v1.0/imagenet10.zip
|
| 29 |
+
unzip imagenet10.zip && rm imagenet10.zip
|
yolov5/data/scripts/get_imagenet100.sh
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 3 |
+
# Download ILSVRC2012 ImageNet dataset https://image-net.org
|
| 4 |
+
# Example usage: bash data/scripts/get_imagenet.sh
|
| 5 |
+
# parent
|
| 6 |
+
# ├── yolov5
|
| 7 |
+
# └── datasets
|
| 8 |
+
# └── imagenet ← downloads here
|
| 9 |
+
|
| 10 |
+
# Arguments (optional) Usage: bash data/scripts/get_imagenet.sh --train --val
|
| 11 |
+
if [ "$#" -gt 0 ]; then
|
| 12 |
+
for opt in "$@"; do
|
| 13 |
+
case "${opt}" in
|
| 14 |
+
--train) train=true ;;
|
| 15 |
+
--val) val=true ;;
|
| 16 |
+
esac
|
| 17 |
+
done
|
| 18 |
+
else
|
| 19 |
+
train=true
|
| 20 |
+
val=true
|
| 21 |
+
fi
|
| 22 |
+
|
| 23 |
+
# Make dir
|
| 24 |
+
d='../datasets/imagenet100' # unzip directory
|
| 25 |
+
mkdir -p $d && cd $d
|
| 26 |
+
|
| 27 |
+
# Download/unzip train
|
| 28 |
+
wget https://github.com/ultralytics/yolov5/releases/download/v1.0/imagenet100.zip
|
| 29 |
+
unzip imagenet100.zip && rm imagenet100.zip
|
yolov5/data/scripts/get_imagenet1000.sh
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 3 |
+
# Download ILSVRC2012 ImageNet dataset https://image-net.org
|
| 4 |
+
# Example usage: bash data/scripts/get_imagenet.sh
|
| 5 |
+
# parent
|
| 6 |
+
# ├── yolov5
|
| 7 |
+
# └── datasets
|
| 8 |
+
# └── imagenet ← downloads here
|
| 9 |
+
|
| 10 |
+
# Arguments (optional) Usage: bash data/scripts/get_imagenet.sh --train --val
|
| 11 |
+
if [ "$#" -gt 0 ]; then
|
| 12 |
+
for opt in "$@"; do
|
| 13 |
+
case "${opt}" in
|
| 14 |
+
--train) train=true ;;
|
| 15 |
+
--val) val=true ;;
|
| 16 |
+
esac
|
| 17 |
+
done
|
| 18 |
+
else
|
| 19 |
+
train=true
|
| 20 |
+
val=true
|
| 21 |
+
fi
|
| 22 |
+
|
| 23 |
+
# Make dir
|
| 24 |
+
d='../datasets/imagenet1000' # unzip directory
|
| 25 |
+
mkdir -p $d && cd $d
|
| 26 |
+
|
| 27 |
+
# Download/unzip train
|
| 28 |
+
wget https://github.com/ultralytics/yolov5/releases/download/v1.0/imagenet1000.zip
|
| 29 |
+
unzip imagenet1000.zip && rm imagenet1000.zip
|
yolov5/data/xView.yaml
ADDED
|
@@ -0,0 +1,153 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
# DIUx xView 2018 Challenge https://challenge.xviewdataset.org by U.S. National Geospatial-Intelligence Agency (NGA)
|
| 3 |
+
# -------- DOWNLOAD DATA MANUALLY and jar xf val_images.zip to 'datasets/xView' before running train command! --------
|
| 4 |
+
# Example usage: python train.py --data xView.yaml
|
| 5 |
+
# parent
|
| 6 |
+
# ├── yolov5
|
| 7 |
+
# └── datasets
|
| 8 |
+
# └── xView ← downloads here (20.7 GB)
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
|
| 12 |
+
path: ../datasets/xView # dataset root dir
|
| 13 |
+
train: images/autosplit_train.txt # train images (relative to 'path') 90% of 847 train images
|
| 14 |
+
val: images/autosplit_val.txt # train images (relative to 'path') 10% of 847 train images
|
| 15 |
+
|
| 16 |
+
# Classes
|
| 17 |
+
names:
|
| 18 |
+
0: Fixed-wing Aircraft
|
| 19 |
+
1: Small Aircraft
|
| 20 |
+
2: Cargo Plane
|
| 21 |
+
3: Helicopter
|
| 22 |
+
4: Passenger Vehicle
|
| 23 |
+
5: Small Car
|
| 24 |
+
6: Bus
|
| 25 |
+
7: Pickup Truck
|
| 26 |
+
8: Utility Truck
|
| 27 |
+
9: Truck
|
| 28 |
+
10: Cargo Truck
|
| 29 |
+
11: Truck w/Box
|
| 30 |
+
12: Truck Tractor
|
| 31 |
+
13: Trailer
|
| 32 |
+
14: Truck w/Flatbed
|
| 33 |
+
15: Truck w/Liquid
|
| 34 |
+
16: Crane Truck
|
| 35 |
+
17: Railway Vehicle
|
| 36 |
+
18: Passenger Car
|
| 37 |
+
19: Cargo Car
|
| 38 |
+
20: Flat Car
|
| 39 |
+
21: Tank car
|
| 40 |
+
22: Locomotive
|
| 41 |
+
23: Maritime Vessel
|
| 42 |
+
24: Motorboat
|
| 43 |
+
25: Sailboat
|
| 44 |
+
26: Tugboat
|
| 45 |
+
27: Barge
|
| 46 |
+
28: Fishing Vessel
|
| 47 |
+
29: Ferry
|
| 48 |
+
30: Yacht
|
| 49 |
+
31: Container Ship
|
| 50 |
+
32: Oil Tanker
|
| 51 |
+
33: Engineering Vehicle
|
| 52 |
+
34: Tower crane
|
| 53 |
+
35: Container Crane
|
| 54 |
+
36: Reach Stacker
|
| 55 |
+
37: Straddle Carrier
|
| 56 |
+
38: Mobile Crane
|
| 57 |
+
39: Dump Truck
|
| 58 |
+
40: Haul Truck
|
| 59 |
+
41: Scraper/Tractor
|
| 60 |
+
42: Front loader/Bulldozer
|
| 61 |
+
43: Excavator
|
| 62 |
+
44: Cement Mixer
|
| 63 |
+
45: Ground Grader
|
| 64 |
+
46: Hut/Tent
|
| 65 |
+
47: Shed
|
| 66 |
+
48: Building
|
| 67 |
+
49: Aircraft Hangar
|
| 68 |
+
50: Damaged Building
|
| 69 |
+
51: Facility
|
| 70 |
+
52: Construction Site
|
| 71 |
+
53: Vehicle Lot
|
| 72 |
+
54: Helipad
|
| 73 |
+
55: Storage Tank
|
| 74 |
+
56: Shipping container lot
|
| 75 |
+
57: Shipping Container
|
| 76 |
+
58: Pylon
|
| 77 |
+
59: Tower
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
# Download script/URL (optional) ---------------------------------------------------------------------------------------
|
| 81 |
+
download: |
|
| 82 |
+
import json
|
| 83 |
+
import os
|
| 84 |
+
from pathlib import Path
|
| 85 |
+
|
| 86 |
+
import numpy as np
|
| 87 |
+
from PIL import Image
|
| 88 |
+
from tqdm import tqdm
|
| 89 |
+
|
| 90 |
+
from utils.dataloaders import autosplit
|
| 91 |
+
from utils.general import download, xyxy2xywhn
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
def convert_labels(fname=Path('xView/xView_train.geojson')):
|
| 95 |
+
# Convert xView geoJSON labels to YOLO format
|
| 96 |
+
path = fname.parent
|
| 97 |
+
with open(fname) as f:
|
| 98 |
+
print(f'Loading {fname}...')
|
| 99 |
+
data = json.load(f)
|
| 100 |
+
|
| 101 |
+
# Make dirs
|
| 102 |
+
labels = Path(path / 'labels' / 'train')
|
| 103 |
+
os.system(f'rm -rf {labels}')
|
| 104 |
+
labels.mkdir(parents=True, exist_ok=True)
|
| 105 |
+
|
| 106 |
+
# xView classes 11-94 to 0-59
|
| 107 |
+
xview_class2index = [-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, -1, 3, -1, 4, 5, 6, 7, 8, -1, 9, 10, 11,
|
| 108 |
+
12, 13, 14, 15, -1, -1, 16, 17, 18, 19, 20, 21, 22, -1, 23, 24, 25, -1, 26, 27, -1, 28, -1,
|
| 109 |
+
29, 30, 31, 32, 33, 34, 35, 36, 37, -1, 38, 39, 40, 41, 42, 43, 44, 45, -1, -1, -1, -1, 46,
|
| 110 |
+
47, 48, 49, -1, 50, 51, -1, 52, -1, -1, -1, 53, 54, -1, 55, -1, -1, 56, -1, 57, -1, 58, 59]
|
| 111 |
+
|
| 112 |
+
shapes = {}
|
| 113 |
+
for feature in tqdm(data['features'], desc=f'Converting {fname}'):
|
| 114 |
+
p = feature['properties']
|
| 115 |
+
if p['bounds_imcoords']:
|
| 116 |
+
id = p['image_id']
|
| 117 |
+
file = path / 'train_images' / id
|
| 118 |
+
if file.exists(): # 1395.tif missing
|
| 119 |
+
try:
|
| 120 |
+
box = np.array([int(num) for num in p['bounds_imcoords'].split(",")])
|
| 121 |
+
assert box.shape[0] == 4, f'incorrect box shape {box.shape[0]}'
|
| 122 |
+
cls = p['type_id']
|
| 123 |
+
cls = xview_class2index[int(cls)] # xView class to 0-60
|
| 124 |
+
assert 59 >= cls >= 0, f'incorrect class index {cls}'
|
| 125 |
+
|
| 126 |
+
# Write YOLO label
|
| 127 |
+
if id not in shapes:
|
| 128 |
+
shapes[id] = Image.open(file).size
|
| 129 |
+
box = xyxy2xywhn(box[None].astype(np.float), w=shapes[id][0], h=shapes[id][1], clip=True)
|
| 130 |
+
with open((labels / id).with_suffix('.txt'), 'a') as f:
|
| 131 |
+
f.write(f"{cls} {' '.join(f'{x:.6f}' for x in box[0])}\n") # write label.txt
|
| 132 |
+
except Exception as e:
|
| 133 |
+
print(f'WARNING: skipping one label for {file}: {e}')
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
# Download manually from https://challenge.xviewdataset.org
|
| 137 |
+
dir = Path(yaml['path']) # dataset root dir
|
| 138 |
+
# urls = ['https://d307kc0mrhucc3.cloudfront.net/train_labels.zip', # train labels
|
| 139 |
+
# 'https://d307kc0mrhucc3.cloudfront.net/train_images.zip', # 15G, 847 train images
|
| 140 |
+
# 'https://d307kc0mrhucc3.cloudfront.net/val_images.zip'] # 5G, 282 val images (no labels)
|
| 141 |
+
# download(urls, dir=dir, delete=False)
|
| 142 |
+
|
| 143 |
+
# Convert labels
|
| 144 |
+
convert_labels(dir / 'xView_train.geojson')
|
| 145 |
+
|
| 146 |
+
# Move images
|
| 147 |
+
images = Path(dir / 'images')
|
| 148 |
+
images.mkdir(parents=True, exist_ok=True)
|
| 149 |
+
Path(dir / 'train_images').rename(dir / 'images' / 'train')
|
| 150 |
+
Path(dir / 'val_images').rename(dir / 'images' / 'val')
|
| 151 |
+
|
| 152 |
+
# Split
|
| 153 |
+
autosplit(dir / 'images' / 'train')
|
yolov5/detect.py
ADDED
|
@@ -0,0 +1,295 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
"""
|
| 3 |
+
Run YOLOv5 detection inference on images, videos, directories, globs, YouTube, webcam, streams, etc.
|
| 4 |
+
|
| 5 |
+
Usage - sources:
|
| 6 |
+
$ python detect.py --weights yolov5s.pt --source 0 # webcam
|
| 7 |
+
img.jpg # image
|
| 8 |
+
vid.mp4 # video
|
| 9 |
+
screen # screenshot
|
| 10 |
+
path/ # directory
|
| 11 |
+
list.txt # list of images
|
| 12 |
+
list.streams # list of streams
|
| 13 |
+
'path/*.jpg' # glob
|
| 14 |
+
'https://youtu.be/LNwODJXcvt4' # YouTube
|
| 15 |
+
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
|
| 16 |
+
|
| 17 |
+
Usage - formats:
|
| 18 |
+
$ python detect.py --weights yolov5s.pt # PyTorch
|
| 19 |
+
yolov5s.torchscript # TorchScript
|
| 20 |
+
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
|
| 21 |
+
yolov5s_openvino_model # OpenVINO
|
| 22 |
+
yolov5s.engine # TensorRT
|
| 23 |
+
yolov5s.mlmodel # CoreML (macOS-only)
|
| 24 |
+
yolov5s_saved_model # TensorFlow SavedModel
|
| 25 |
+
yolov5s.pb # TensorFlow GraphDef
|
| 26 |
+
yolov5s.tflite # TensorFlow Lite
|
| 27 |
+
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
|
| 28 |
+
yolov5s_paddle_model # PaddlePaddle
|
| 29 |
+
"""
|
| 30 |
+
|
| 31 |
+
import argparse
|
| 32 |
+
import csv
|
| 33 |
+
import os
|
| 34 |
+
import platform
|
| 35 |
+
import sys
|
| 36 |
+
from pathlib import Path
|
| 37 |
+
|
| 38 |
+
import torch
|
| 39 |
+
|
| 40 |
+
FILE = Path(__file__).resolve()
|
| 41 |
+
ROOT = FILE.parents[0] # YOLOv5 root directory
|
| 42 |
+
if str(ROOT) not in sys.path:
|
| 43 |
+
sys.path.append(str(ROOT)) # add ROOT to PATH
|
| 44 |
+
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
|
| 45 |
+
|
| 46 |
+
from ultralytics.utils.plotting import Annotator, colors, save_one_box
|
| 47 |
+
|
| 48 |
+
from models.common import DetectMultiBackend
|
| 49 |
+
from utils.dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadScreenshots, LoadStreams
|
| 50 |
+
from utils.general import (LOGGER, Profile, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
|
| 51 |
+
increment_path, non_max_suppression, print_args, scale_boxes, strip_optimizer, xyxy2xywh)
|
| 52 |
+
from utils.torch_utils import select_device, smart_inference_mode
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
@smart_inference_mode()
|
| 56 |
+
def run(
|
| 57 |
+
weights=ROOT / 'yolov5s.pt', # model path or triton URL
|
| 58 |
+
source=ROOT / 'data/images', # file/dir/URL/glob/screen/0(webcam)
|
| 59 |
+
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
|
| 60 |
+
imgsz=(640, 640), # inference size (height, width)
|
| 61 |
+
conf_thres=0.25, # confidence threshold
|
| 62 |
+
iou_thres=0.45, # NMS IOU threshold
|
| 63 |
+
max_det=1000, # maximum detections per image
|
| 64 |
+
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
|
| 65 |
+
view_img=False, # show results
|
| 66 |
+
save_txt=False, # save results to *.txt
|
| 67 |
+
save_csv=False, # save results in CSV format
|
| 68 |
+
save_conf=False, # save confidences in --save-txt labels
|
| 69 |
+
save_crop=False, # save cropped prediction boxes
|
| 70 |
+
nosave=False, # do not save images/videos
|
| 71 |
+
classes=None, # filter by class: --class 0, or --class 0 2 3
|
| 72 |
+
agnostic_nms=False, # class-agnostic NMS
|
| 73 |
+
augment=False, # augmented inference
|
| 74 |
+
visualize=False, # visualize features
|
| 75 |
+
update=False, # update all models
|
| 76 |
+
project=ROOT / 'runs/detect', # save results to project/name
|
| 77 |
+
name='exp', # save results to project/name
|
| 78 |
+
exist_ok=False, # existing project/name ok, do not increment
|
| 79 |
+
line_thickness=3, # bounding box thickness (pixels)
|
| 80 |
+
hide_labels=False, # hide labels
|
| 81 |
+
hide_conf=False, # hide confidences
|
| 82 |
+
half=False, # use FP16 half-precision inference
|
| 83 |
+
dnn=False, # use OpenCV DNN for ONNX inference
|
| 84 |
+
vid_stride=1, # video frame-rate stride
|
| 85 |
+
):
|
| 86 |
+
source = str(source)
|
| 87 |
+
save_img = not nosave and not source.endswith('.txt') # save inference images
|
| 88 |
+
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
|
| 89 |
+
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
|
| 90 |
+
webcam = source.isnumeric() or source.endswith('.streams') or (is_url and not is_file)
|
| 91 |
+
screenshot = source.lower().startswith('screen')
|
| 92 |
+
if is_url and is_file:
|
| 93 |
+
source = check_file(source) # download
|
| 94 |
+
|
| 95 |
+
# Directories
|
| 96 |
+
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
|
| 97 |
+
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
|
| 98 |
+
|
| 99 |
+
# Load model
|
| 100 |
+
device = select_device(device)
|
| 101 |
+
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
|
| 102 |
+
stride, names, pt = model.stride, model.names, model.pt
|
| 103 |
+
imgsz = check_img_size(imgsz, s=stride) # check image size
|
| 104 |
+
|
| 105 |
+
# Dataloader
|
| 106 |
+
bs = 1 # batch_size
|
| 107 |
+
if webcam:
|
| 108 |
+
view_img = check_imshow(warn=True)
|
| 109 |
+
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
|
| 110 |
+
bs = len(dataset)
|
| 111 |
+
elif screenshot:
|
| 112 |
+
dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
|
| 113 |
+
else:
|
| 114 |
+
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
|
| 115 |
+
vid_path, vid_writer = [None] * bs, [None] * bs
|
| 116 |
+
|
| 117 |
+
# Run inference
|
| 118 |
+
model.warmup(imgsz=(1 if pt or model.triton else bs, 3, *imgsz)) # warmup
|
| 119 |
+
seen, windows, dt = 0, [], (Profile(device=device), Profile(device=device), Profile(device=device))
|
| 120 |
+
for path, im, im0s, vid_cap, s in dataset:
|
| 121 |
+
with dt[0]:
|
| 122 |
+
im = torch.from_numpy(im).to(model.device)
|
| 123 |
+
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
|
| 124 |
+
im /= 255 # 0 - 255 to 0.0 - 1.0
|
| 125 |
+
if len(im.shape) == 3:
|
| 126 |
+
im = im[None] # expand for batch dim
|
| 127 |
+
if model.xml and im.shape[0] > 1:
|
| 128 |
+
ims = torch.chunk(im, im.shape[0], 0)
|
| 129 |
+
|
| 130 |
+
# Inference
|
| 131 |
+
with dt[1]:
|
| 132 |
+
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
|
| 133 |
+
if model.xml and im.shape[0] > 1:
|
| 134 |
+
pred = None
|
| 135 |
+
for image in ims:
|
| 136 |
+
if pred is None:
|
| 137 |
+
pred = model(image, augment=augment, visualize=visualize).unsqueeze(0)
|
| 138 |
+
else:
|
| 139 |
+
pred = torch.cat((pred, model(image, augment=augment, visualize=visualize).unsqueeze(0)), dim=0)
|
| 140 |
+
pred = [pred, None]
|
| 141 |
+
else:
|
| 142 |
+
pred = model(im, augment=augment, visualize=visualize)
|
| 143 |
+
# NMS
|
| 144 |
+
with dt[2]:
|
| 145 |
+
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
|
| 146 |
+
|
| 147 |
+
# Second-stage classifier (optional)
|
| 148 |
+
# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
|
| 149 |
+
|
| 150 |
+
# Define the path for the CSV file
|
| 151 |
+
csv_path = save_dir / 'predictions.csv'
|
| 152 |
+
|
| 153 |
+
# Create or append to the CSV file
|
| 154 |
+
def write_to_csv(image_name, prediction, confidence):
|
| 155 |
+
data = {'Image Name': image_name, 'Prediction': prediction, 'Confidence': confidence}
|
| 156 |
+
with open(csv_path, mode='a', newline='') as f:
|
| 157 |
+
writer = csv.DictWriter(f, fieldnames=data.keys())
|
| 158 |
+
if not csv_path.is_file():
|
| 159 |
+
writer.writeheader()
|
| 160 |
+
writer.writerow(data)
|
| 161 |
+
|
| 162 |
+
# Process predictions
|
| 163 |
+
for i, det in enumerate(pred): # per image
|
| 164 |
+
seen += 1
|
| 165 |
+
if webcam: # batch_size >= 1
|
| 166 |
+
p, im0, frame = path[i], im0s[i].copy(), dataset.count
|
| 167 |
+
s += f'{i}: '
|
| 168 |
+
else:
|
| 169 |
+
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
|
| 170 |
+
|
| 171 |
+
p = Path(p) # to Path
|
| 172 |
+
save_path = str(save_dir / p.name) # im.jpg
|
| 173 |
+
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
|
| 174 |
+
s += '%gx%g ' % im.shape[2:] # print string
|
| 175 |
+
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
|
| 176 |
+
imc = im0.copy() if save_crop else im0 # for save_crop
|
| 177 |
+
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
|
| 178 |
+
if len(det):
|
| 179 |
+
# Rescale boxes from img_size to im0 size
|
| 180 |
+
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()
|
| 181 |
+
|
| 182 |
+
# Print results
|
| 183 |
+
for c in det[:, 5].unique():
|
| 184 |
+
n = (det[:, 5] == c).sum() # detections per class
|
| 185 |
+
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
|
| 186 |
+
|
| 187 |
+
# Write results
|
| 188 |
+
for *xyxy, conf, cls in reversed(det):
|
| 189 |
+
c = int(cls) # integer class
|
| 190 |
+
label = names[c] if hide_conf else f'{names[c]}'
|
| 191 |
+
confidence = float(conf)
|
| 192 |
+
confidence_str = f'{confidence:.2f}'
|
| 193 |
+
|
| 194 |
+
if save_csv:
|
| 195 |
+
write_to_csv(p.name, label, confidence_str)
|
| 196 |
+
|
| 197 |
+
if save_txt: # Write to file
|
| 198 |
+
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
|
| 199 |
+
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
|
| 200 |
+
with open(f'{txt_path}.txt', 'a') as f:
|
| 201 |
+
f.write(('%g ' * len(line)).rstrip() % line + '\n')
|
| 202 |
+
|
| 203 |
+
if save_img or save_crop or view_img: # Add bbox to image
|
| 204 |
+
c = int(cls) # integer class
|
| 205 |
+
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
|
| 206 |
+
annotator.box_label(xyxy, label, color=colors(c, True))
|
| 207 |
+
if save_crop:
|
| 208 |
+
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
|
| 209 |
+
|
| 210 |
+
# Stream results
|
| 211 |
+
im0 = annotator.result()
|
| 212 |
+
if view_img:
|
| 213 |
+
if platform.system() == 'Linux' and p not in windows:
|
| 214 |
+
windows.append(p)
|
| 215 |
+
cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux)
|
| 216 |
+
cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
|
| 217 |
+
cv2.imshow(str(p), im0)
|
| 218 |
+
cv2.waitKey(1) # 1 millisecond
|
| 219 |
+
|
| 220 |
+
# Save results (image with detections)
|
| 221 |
+
if save_img:
|
| 222 |
+
if dataset.mode == 'image':
|
| 223 |
+
cv2.imwrite(save_path, im0)
|
| 224 |
+
else: # 'video' or 'stream'
|
| 225 |
+
if vid_path[i] != save_path: # new video
|
| 226 |
+
vid_path[i] = save_path
|
| 227 |
+
if isinstance(vid_writer[i], cv2.VideoWriter):
|
| 228 |
+
vid_writer[i].release() # release previous video writer
|
| 229 |
+
if vid_cap: # video
|
| 230 |
+
fps = vid_cap.get(cv2.CAP_PROP_FPS)
|
| 231 |
+
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
|
| 232 |
+
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
|
| 233 |
+
else: # stream
|
| 234 |
+
fps, w, h = 30, im0.shape[1], im0.shape[0]
|
| 235 |
+
save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
|
| 236 |
+
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
|
| 237 |
+
vid_writer[i].write(im0)
|
| 238 |
+
|
| 239 |
+
# Print time (inference-only)
|
| 240 |
+
LOGGER.info(f"{s}{'' if len(det) else '(no detections), '}{dt[1].dt * 1E3:.1f}ms")
|
| 241 |
+
|
| 242 |
+
# Print results
|
| 243 |
+
t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
|
| 244 |
+
LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
|
| 245 |
+
if save_txt or save_img:
|
| 246 |
+
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
|
| 247 |
+
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
|
| 248 |
+
if update:
|
| 249 |
+
strip_optimizer(weights[0]) # update model (to fix SourceChangeWarning)
|
| 250 |
+
|
| 251 |
+
|
| 252 |
+
def parse_opt():
|
| 253 |
+
parser = argparse.ArgumentParser()
|
| 254 |
+
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path or triton URL')
|
| 255 |
+
parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob/screen/0(webcam)')
|
| 256 |
+
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
|
| 257 |
+
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
|
| 258 |
+
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
|
| 259 |
+
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
|
| 260 |
+
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
|
| 261 |
+
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
|
| 262 |
+
parser.add_argument('--view-img', action='store_true', help='show results')
|
| 263 |
+
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
|
| 264 |
+
parser.add_argument('--save-csv', action='store_true', help='save results in CSV format')
|
| 265 |
+
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
|
| 266 |
+
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
|
| 267 |
+
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
|
| 268 |
+
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
|
| 269 |
+
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
|
| 270 |
+
parser.add_argument('--augment', action='store_true', help='augmented inference')
|
| 271 |
+
parser.add_argument('--visualize', action='store_true', help='visualize features')
|
| 272 |
+
parser.add_argument('--update', action='store_true', help='update all models')
|
| 273 |
+
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
|
| 274 |
+
parser.add_argument('--name', default='exp', help='save results to project/name')
|
| 275 |
+
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
|
| 276 |
+
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
|
| 277 |
+
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
|
| 278 |
+
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
|
| 279 |
+
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
|
| 280 |
+
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
|
| 281 |
+
parser.add_argument('--vid-stride', type=int, default=1, help='video frame-rate stride')
|
| 282 |
+
opt = parser.parse_args()
|
| 283 |
+
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
|
| 284 |
+
print_args(vars(opt))
|
| 285 |
+
return opt
|
| 286 |
+
|
| 287 |
+
|
| 288 |
+
def main(opt):
|
| 289 |
+
check_requirements(ROOT / 'requirements.txt', exclude=('tensorboard', 'thop'))
|
| 290 |
+
run(**vars(opt))
|
| 291 |
+
|
| 292 |
+
|
| 293 |
+
if __name__ == '__main__':
|
| 294 |
+
opt = parse_opt()
|
| 295 |
+
main(opt)
|
yolov5/export.py
ADDED
|
@@ -0,0 +1,880 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
"""
|
| 3 |
+
Export a YOLOv5 PyTorch model to other formats. TensorFlow exports authored by https://github.com/zldrobit
|
| 4 |
+
|
| 5 |
+
Format | `export.py --include` | Model
|
| 6 |
+
--- | --- | ---
|
| 7 |
+
PyTorch | - | yolov5s.pt
|
| 8 |
+
TorchScript | `torchscript` | yolov5s.torchscript
|
| 9 |
+
ONNX | `onnx` | yolov5s.onnx
|
| 10 |
+
OpenVINO | `openvino` | yolov5s_openvino_model/
|
| 11 |
+
TensorRT | `engine` | yolov5s.engine
|
| 12 |
+
CoreML | `coreml` | yolov5s.mlmodel
|
| 13 |
+
TensorFlow SavedModel | `saved_model` | yolov5s_saved_model/
|
| 14 |
+
TensorFlow GraphDef | `pb` | yolov5s.pb
|
| 15 |
+
TensorFlow Lite | `tflite` | yolov5s.tflite
|
| 16 |
+
TensorFlow Edge TPU | `edgetpu` | yolov5s_edgetpu.tflite
|
| 17 |
+
TensorFlow.js | `tfjs` | yolov5s_web_model/
|
| 18 |
+
PaddlePaddle | `paddle` | yolov5s_paddle_model/
|
| 19 |
+
|
| 20 |
+
Requirements:
|
| 21 |
+
$ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime openvino-dev tensorflow-cpu # CPU
|
| 22 |
+
$ pip install -r requirements.txt coremltools onnx onnx-simplifier onnxruntime-gpu openvino-dev tensorflow # GPU
|
| 23 |
+
|
| 24 |
+
Usage:
|
| 25 |
+
$ python export.py --weights yolov5s.pt --include torchscript onnx openvino engine coreml tflite ...
|
| 26 |
+
|
| 27 |
+
Inference:
|
| 28 |
+
$ python detect.py --weights yolov5s.pt # PyTorch
|
| 29 |
+
yolov5s.torchscript # TorchScript
|
| 30 |
+
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
|
| 31 |
+
yolov5s_openvino_model # OpenVINO
|
| 32 |
+
yolov5s.engine # TensorRT
|
| 33 |
+
yolov5s.mlmodel # CoreML (macOS-only)
|
| 34 |
+
yolov5s_saved_model # TensorFlow SavedModel
|
| 35 |
+
yolov5s.pb # TensorFlow GraphDef
|
| 36 |
+
yolov5s.tflite # TensorFlow Lite
|
| 37 |
+
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
|
| 38 |
+
yolov5s_paddle_model # PaddlePaddle
|
| 39 |
+
|
| 40 |
+
TensorFlow.js:
|
| 41 |
+
$ cd .. && git clone https://github.com/zldrobit/tfjs-yolov5-example.git && cd tfjs-yolov5-example
|
| 42 |
+
$ npm install
|
| 43 |
+
$ ln -s ../../yolov5/yolov5s_web_model public/yolov5s_web_model
|
| 44 |
+
$ npm start
|
| 45 |
+
"""
|
| 46 |
+
|
| 47 |
+
import argparse
|
| 48 |
+
import contextlib
|
| 49 |
+
import json
|
| 50 |
+
import os
|
| 51 |
+
import platform
|
| 52 |
+
import re
|
| 53 |
+
import subprocess
|
| 54 |
+
import sys
|
| 55 |
+
import time
|
| 56 |
+
import warnings
|
| 57 |
+
from pathlib import Path
|
| 58 |
+
|
| 59 |
+
import pandas as pd
|
| 60 |
+
import torch
|
| 61 |
+
from torch.utils.mobile_optimizer import optimize_for_mobile
|
| 62 |
+
|
| 63 |
+
FILE = Path(__file__).resolve()
|
| 64 |
+
ROOT = FILE.parents[0] # YOLOv5 root directory
|
| 65 |
+
if str(ROOT) not in sys.path:
|
| 66 |
+
sys.path.append(str(ROOT)) # add ROOT to PATH
|
| 67 |
+
if platform.system() != 'Windows':
|
| 68 |
+
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
|
| 69 |
+
|
| 70 |
+
from models.experimental import attempt_load
|
| 71 |
+
from models.yolo import ClassificationModel, Detect, DetectionModel, SegmentationModel
|
| 72 |
+
from utils.dataloaders import LoadImages
|
| 73 |
+
from utils.general import (LOGGER, Profile, check_dataset, check_img_size, check_requirements, check_version,
|
| 74 |
+
check_yaml, colorstr, file_size, get_default_args, print_args, url2file, yaml_save)
|
| 75 |
+
from utils.torch_utils import select_device, smart_inference_mode
|
| 76 |
+
|
| 77 |
+
MACOS = platform.system() == 'Darwin' # macOS environment
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
class iOSModel(torch.nn.Module):
|
| 81 |
+
|
| 82 |
+
def __init__(self, model, im):
|
| 83 |
+
super().__init__()
|
| 84 |
+
b, c, h, w = im.shape # batch, channel, height, width
|
| 85 |
+
self.model = model
|
| 86 |
+
self.nc = model.nc # number of classes
|
| 87 |
+
if w == h:
|
| 88 |
+
self.normalize = 1. / w
|
| 89 |
+
else:
|
| 90 |
+
self.normalize = torch.tensor([1. / w, 1. / h, 1. / w, 1. / h]) # broadcast (slower, smaller)
|
| 91 |
+
# np = model(im)[0].shape[1] # number of points
|
| 92 |
+
# self.normalize = torch.tensor([1. / w, 1. / h, 1. / w, 1. / h]).expand(np, 4) # explicit (faster, larger)
|
| 93 |
+
|
| 94 |
+
def forward(self, x):
|
| 95 |
+
xywh, conf, cls = self.model(x)[0].squeeze().split((4, 1, self.nc), 1)
|
| 96 |
+
return cls * conf, xywh * self.normalize # confidence (3780, 80), coordinates (3780, 4)
|
| 97 |
+
|
| 98 |
+
|
| 99 |
+
def export_formats():
|
| 100 |
+
# YOLOv5 export formats
|
| 101 |
+
x = [
|
| 102 |
+
['PyTorch', '-', '.pt', True, True],
|
| 103 |
+
['TorchScript', 'torchscript', '.torchscript', True, True],
|
| 104 |
+
['ONNX', 'onnx', '.onnx', True, True],
|
| 105 |
+
['OpenVINO', 'openvino', '_openvino_model', True, False],
|
| 106 |
+
['TensorRT', 'engine', '.engine', False, True],
|
| 107 |
+
['CoreML', 'coreml', '.mlmodel', True, False],
|
| 108 |
+
['TensorFlow SavedModel', 'saved_model', '_saved_model', True, True],
|
| 109 |
+
['TensorFlow GraphDef', 'pb', '.pb', True, True],
|
| 110 |
+
['TensorFlow Lite', 'tflite', '.tflite', True, False],
|
| 111 |
+
['TensorFlow Edge TPU', 'edgetpu', '_edgetpu.tflite', False, False],
|
| 112 |
+
['TensorFlow.js', 'tfjs', '_web_model', False, False],
|
| 113 |
+
['PaddlePaddle', 'paddle', '_paddle_model', True, True], ]
|
| 114 |
+
return pd.DataFrame(x, columns=['Format', 'Argument', 'Suffix', 'CPU', 'GPU'])
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def try_export(inner_func):
|
| 118 |
+
# YOLOv5 export decorator, i..e @try_export
|
| 119 |
+
inner_args = get_default_args(inner_func)
|
| 120 |
+
|
| 121 |
+
def outer_func(*args, **kwargs):
|
| 122 |
+
prefix = inner_args['prefix']
|
| 123 |
+
try:
|
| 124 |
+
with Profile() as dt:
|
| 125 |
+
f, model = inner_func(*args, **kwargs)
|
| 126 |
+
LOGGER.info(f'{prefix} export success ✅ {dt.t:.1f}s, saved as {f} ({file_size(f):.1f} MB)')
|
| 127 |
+
return f, model
|
| 128 |
+
except Exception as e:
|
| 129 |
+
LOGGER.info(f'{prefix} export failure ❌ {dt.t:.1f}s: {e}')
|
| 130 |
+
return None, None
|
| 131 |
+
|
| 132 |
+
return outer_func
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
@try_export
|
| 136 |
+
def export_torchscript(model, im, file, optimize, prefix=colorstr('TorchScript:')):
|
| 137 |
+
# YOLOv5 TorchScript model export
|
| 138 |
+
LOGGER.info(f'\n{prefix} starting export with torch {torch.__version__}...')
|
| 139 |
+
f = file.with_suffix('.torchscript')
|
| 140 |
+
|
| 141 |
+
ts = torch.jit.trace(model, im, strict=False)
|
| 142 |
+
d = {'shape': im.shape, 'stride': int(max(model.stride)), 'names': model.names}
|
| 143 |
+
extra_files = {'config.txt': json.dumps(d)} # torch._C.ExtraFilesMap()
|
| 144 |
+
if optimize: # https://pytorch.org/tutorials/recipes/mobile_interpreter.html
|
| 145 |
+
optimize_for_mobile(ts)._save_for_lite_interpreter(str(f), _extra_files=extra_files)
|
| 146 |
+
else:
|
| 147 |
+
ts.save(str(f), _extra_files=extra_files)
|
| 148 |
+
return f, None
|
| 149 |
+
|
| 150 |
+
|
| 151 |
+
@try_export
|
| 152 |
+
def export_onnx(model, im, file, opset, dynamic, simplify, prefix=colorstr('ONNX:')):
|
| 153 |
+
# YOLOv5 ONNX export
|
| 154 |
+
check_requirements('onnx>=1.12.0')
|
| 155 |
+
import onnx
|
| 156 |
+
|
| 157 |
+
LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')
|
| 158 |
+
f = str(file.with_suffix('.onnx'))
|
| 159 |
+
|
| 160 |
+
output_names = ['output0', 'output1'] if isinstance(model, SegmentationModel) else ['output0']
|
| 161 |
+
if dynamic:
|
| 162 |
+
dynamic = {'images': {0: 'batch', 2: 'height', 3: 'width'}} # shape(1,3,640,640)
|
| 163 |
+
if isinstance(model, SegmentationModel):
|
| 164 |
+
dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
|
| 165 |
+
dynamic['output1'] = {0: 'batch', 2: 'mask_height', 3: 'mask_width'} # shape(1,32,160,160)
|
| 166 |
+
elif isinstance(model, DetectionModel):
|
| 167 |
+
dynamic['output0'] = {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
|
| 168 |
+
|
| 169 |
+
torch.onnx.export(
|
| 170 |
+
model.cpu() if dynamic else model, # --dynamic only compatible with cpu
|
| 171 |
+
im.cpu() if dynamic else im,
|
| 172 |
+
f,
|
| 173 |
+
verbose=False,
|
| 174 |
+
opset_version=opset,
|
| 175 |
+
do_constant_folding=True, # WARNING: DNN inference with torch>=1.12 may require do_constant_folding=False
|
| 176 |
+
input_names=['images'],
|
| 177 |
+
output_names=output_names,
|
| 178 |
+
dynamic_axes=dynamic or None)
|
| 179 |
+
|
| 180 |
+
# Checks
|
| 181 |
+
model_onnx = onnx.load(f) # load onnx model
|
| 182 |
+
onnx.checker.check_model(model_onnx) # check onnx model
|
| 183 |
+
|
| 184 |
+
# Metadata
|
| 185 |
+
d = {'stride': int(max(model.stride)), 'names': model.names}
|
| 186 |
+
for k, v in d.items():
|
| 187 |
+
meta = model_onnx.metadata_props.add()
|
| 188 |
+
meta.key, meta.value = k, str(v)
|
| 189 |
+
onnx.save(model_onnx, f)
|
| 190 |
+
|
| 191 |
+
# Simplify
|
| 192 |
+
if simplify:
|
| 193 |
+
try:
|
| 194 |
+
cuda = torch.cuda.is_available()
|
| 195 |
+
check_requirements(('onnxruntime-gpu' if cuda else 'onnxruntime', 'onnx-simplifier>=0.4.1'))
|
| 196 |
+
import onnxsim
|
| 197 |
+
|
| 198 |
+
LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
|
| 199 |
+
model_onnx, check = onnxsim.simplify(model_onnx)
|
| 200 |
+
assert check, 'assert check failed'
|
| 201 |
+
onnx.save(model_onnx, f)
|
| 202 |
+
except Exception as e:
|
| 203 |
+
LOGGER.info(f'{prefix} simplifier failure: {e}')
|
| 204 |
+
return f, model_onnx
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
@try_export
|
| 208 |
+
def export_openvino(file, metadata, half, int8, data, prefix=colorstr('OpenVINO:')):
|
| 209 |
+
# YOLOv5 OpenVINO export
|
| 210 |
+
check_requirements('openvino-dev>=2023.0') # requires openvino-dev: https://pypi.org/project/openvino-dev/
|
| 211 |
+
import openvino.runtime as ov # noqa
|
| 212 |
+
from openvino.tools import mo # noqa
|
| 213 |
+
|
| 214 |
+
LOGGER.info(f'\n{prefix} starting export with openvino {ov.__version__}...')
|
| 215 |
+
f = str(file).replace(file.suffix, f'_openvino_model{os.sep}')
|
| 216 |
+
f_onnx = file.with_suffix('.onnx')
|
| 217 |
+
f_ov = str(Path(f) / file.with_suffix('.xml').name)
|
| 218 |
+
if int8:
|
| 219 |
+
check_requirements('nncf>=2.4.0') # requires at least version 2.4.0 to use the post-training quantization
|
| 220 |
+
import nncf
|
| 221 |
+
import numpy as np
|
| 222 |
+
from openvino.runtime import Core
|
| 223 |
+
|
| 224 |
+
from utils.dataloaders import create_dataloader
|
| 225 |
+
core = Core()
|
| 226 |
+
onnx_model = core.read_model(f_onnx) # export
|
| 227 |
+
|
| 228 |
+
def prepare_input_tensor(image: np.ndarray):
|
| 229 |
+
input_tensor = image.astype(np.float32) # uint8 to fp16/32
|
| 230 |
+
input_tensor /= 255.0 # 0 - 255 to 0.0 - 1.0
|
| 231 |
+
|
| 232 |
+
if input_tensor.ndim == 3:
|
| 233 |
+
input_tensor = np.expand_dims(input_tensor, 0)
|
| 234 |
+
return input_tensor
|
| 235 |
+
|
| 236 |
+
def gen_dataloader(yaml_path, task='train', imgsz=640, workers=4):
|
| 237 |
+
data_yaml = check_yaml(yaml_path)
|
| 238 |
+
data = check_dataset(data_yaml)
|
| 239 |
+
dataloader = create_dataloader(data[task],
|
| 240 |
+
imgsz=imgsz,
|
| 241 |
+
batch_size=1,
|
| 242 |
+
stride=32,
|
| 243 |
+
pad=0.5,
|
| 244 |
+
single_cls=False,
|
| 245 |
+
rect=False,
|
| 246 |
+
workers=workers)[0]
|
| 247 |
+
return dataloader
|
| 248 |
+
|
| 249 |
+
# noqa: F811
|
| 250 |
+
|
| 251 |
+
def transform_fn(data_item):
|
| 252 |
+
"""
|
| 253 |
+
Quantization transform function. Extracts and preprocess input data from dataloader item for quantization.
|
| 254 |
+
Parameters:
|
| 255 |
+
data_item: Tuple with data item produced by DataLoader during iteration
|
| 256 |
+
Returns:
|
| 257 |
+
input_tensor: Input data for quantization
|
| 258 |
+
"""
|
| 259 |
+
img = data_item[0].numpy()
|
| 260 |
+
input_tensor = prepare_input_tensor(img)
|
| 261 |
+
return input_tensor
|
| 262 |
+
|
| 263 |
+
ds = gen_dataloader(data)
|
| 264 |
+
quantization_dataset = nncf.Dataset(ds, transform_fn)
|
| 265 |
+
ov_model = nncf.quantize(onnx_model, quantization_dataset, preset=nncf.QuantizationPreset.MIXED)
|
| 266 |
+
else:
|
| 267 |
+
ov_model = mo.convert_model(f_onnx, model_name=file.stem, framework='onnx', compress_to_fp16=half) # export
|
| 268 |
+
|
| 269 |
+
ov.serialize(ov_model, f_ov) # save
|
| 270 |
+
yaml_save(Path(f) / file.with_suffix('.yaml').name, metadata) # add metadata.yaml
|
| 271 |
+
return f, None
|
| 272 |
+
|
| 273 |
+
|
| 274 |
+
@try_export
|
| 275 |
+
def export_paddle(model, im, file, metadata, prefix=colorstr('PaddlePaddle:')):
|
| 276 |
+
# YOLOv5 Paddle export
|
| 277 |
+
check_requirements(('paddlepaddle', 'x2paddle'))
|
| 278 |
+
import x2paddle
|
| 279 |
+
from x2paddle.convert import pytorch2paddle
|
| 280 |
+
|
| 281 |
+
LOGGER.info(f'\n{prefix} starting export with X2Paddle {x2paddle.__version__}...')
|
| 282 |
+
f = str(file).replace('.pt', f'_paddle_model{os.sep}')
|
| 283 |
+
|
| 284 |
+
pytorch2paddle(module=model, save_dir=f, jit_type='trace', input_examples=[im]) # export
|
| 285 |
+
yaml_save(Path(f) / file.with_suffix('.yaml').name, metadata) # add metadata.yaml
|
| 286 |
+
return f, None
|
| 287 |
+
|
| 288 |
+
|
| 289 |
+
@try_export
|
| 290 |
+
def export_coreml(model, im, file, int8, half, nms, prefix=colorstr('CoreML:')):
|
| 291 |
+
# YOLOv5 CoreML export
|
| 292 |
+
check_requirements('coremltools')
|
| 293 |
+
import coremltools as ct
|
| 294 |
+
|
| 295 |
+
LOGGER.info(f'\n{prefix} starting export with coremltools {ct.__version__}...')
|
| 296 |
+
f = file.with_suffix('.mlmodel')
|
| 297 |
+
|
| 298 |
+
if nms:
|
| 299 |
+
model = iOSModel(model, im)
|
| 300 |
+
ts = torch.jit.trace(model, im, strict=False) # TorchScript model
|
| 301 |
+
ct_model = ct.convert(ts, inputs=[ct.ImageType('image', shape=im.shape, scale=1 / 255, bias=[0, 0, 0])])
|
| 302 |
+
bits, mode = (8, 'kmeans_lut') if int8 else (16, 'linear') if half else (32, None)
|
| 303 |
+
if bits < 32:
|
| 304 |
+
if MACOS: # quantization only supported on macOS
|
| 305 |
+
with warnings.catch_warnings():
|
| 306 |
+
warnings.filterwarnings('ignore', category=DeprecationWarning) # suppress numpy==1.20 float warning
|
| 307 |
+
ct_model = ct.models.neural_network.quantization_utils.quantize_weights(ct_model, bits, mode)
|
| 308 |
+
else:
|
| 309 |
+
print(f'{prefix} quantization only supported on macOS, skipping...')
|
| 310 |
+
ct_model.save(f)
|
| 311 |
+
return f, ct_model
|
| 312 |
+
|
| 313 |
+
|
| 314 |
+
@try_export
|
| 315 |
+
def export_engine(model, im, file, half, dynamic, simplify, workspace=4, verbose=False, prefix=colorstr('TensorRT:')):
|
| 316 |
+
# YOLOv5 TensorRT export https://developer.nvidia.com/tensorrt
|
| 317 |
+
assert im.device.type != 'cpu', 'export running on CPU but must be on GPU, i.e. `python export.py --device 0`'
|
| 318 |
+
try:
|
| 319 |
+
import tensorrt as trt
|
| 320 |
+
except Exception:
|
| 321 |
+
if platform.system() == 'Linux':
|
| 322 |
+
check_requirements('nvidia-tensorrt', cmds='-U --index-url https://pypi.ngc.nvidia.com')
|
| 323 |
+
import tensorrt as trt
|
| 324 |
+
|
| 325 |
+
if trt.__version__[0] == '7': # TensorRT 7 handling https://github.com/ultralytics/yolov5/issues/6012
|
| 326 |
+
grid = model.model[-1].anchor_grid
|
| 327 |
+
model.model[-1].anchor_grid = [a[..., :1, :1, :] for a in grid]
|
| 328 |
+
export_onnx(model, im, file, 12, dynamic, simplify) # opset 12
|
| 329 |
+
model.model[-1].anchor_grid = grid
|
| 330 |
+
else: # TensorRT >= 8
|
| 331 |
+
check_version(trt.__version__, '8.0.0', hard=True) # require tensorrt>=8.0.0
|
| 332 |
+
export_onnx(model, im, file, 12, dynamic, simplify) # opset 12
|
| 333 |
+
onnx = file.with_suffix('.onnx')
|
| 334 |
+
|
| 335 |
+
LOGGER.info(f'\n{prefix} starting export with TensorRT {trt.__version__}...')
|
| 336 |
+
assert onnx.exists(), f'failed to export ONNX file: {onnx}'
|
| 337 |
+
f = file.with_suffix('.engine') # TensorRT engine file
|
| 338 |
+
logger = trt.Logger(trt.Logger.INFO)
|
| 339 |
+
if verbose:
|
| 340 |
+
logger.min_severity = trt.Logger.Severity.VERBOSE
|
| 341 |
+
|
| 342 |
+
builder = trt.Builder(logger)
|
| 343 |
+
config = builder.create_builder_config()
|
| 344 |
+
config.max_workspace_size = workspace * 1 << 30
|
| 345 |
+
# config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, workspace << 30) # fix TRT 8.4 deprecation notice
|
| 346 |
+
|
| 347 |
+
flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
|
| 348 |
+
network = builder.create_network(flag)
|
| 349 |
+
parser = trt.OnnxParser(network, logger)
|
| 350 |
+
if not parser.parse_from_file(str(onnx)):
|
| 351 |
+
raise RuntimeError(f'failed to load ONNX file: {onnx}')
|
| 352 |
+
|
| 353 |
+
inputs = [network.get_input(i) for i in range(network.num_inputs)]
|
| 354 |
+
outputs = [network.get_output(i) for i in range(network.num_outputs)]
|
| 355 |
+
for inp in inputs:
|
| 356 |
+
LOGGER.info(f'{prefix} input "{inp.name}" with shape{inp.shape} {inp.dtype}')
|
| 357 |
+
for out in outputs:
|
| 358 |
+
LOGGER.info(f'{prefix} output "{out.name}" with shape{out.shape} {out.dtype}')
|
| 359 |
+
|
| 360 |
+
if dynamic:
|
| 361 |
+
if im.shape[0] <= 1:
|
| 362 |
+
LOGGER.warning(f'{prefix} WARNING ⚠️ --dynamic model requires maximum --batch-size argument')
|
| 363 |
+
profile = builder.create_optimization_profile()
|
| 364 |
+
for inp in inputs:
|
| 365 |
+
profile.set_shape(inp.name, (1, *im.shape[1:]), (max(1, im.shape[0] // 2), *im.shape[1:]), im.shape)
|
| 366 |
+
config.add_optimization_profile(profile)
|
| 367 |
+
|
| 368 |
+
LOGGER.info(f'{prefix} building FP{16 if builder.platform_has_fast_fp16 and half else 32} engine as {f}')
|
| 369 |
+
if builder.platform_has_fast_fp16 and half:
|
| 370 |
+
config.set_flag(trt.BuilderFlag.FP16)
|
| 371 |
+
with builder.build_engine(network, config) as engine, open(f, 'wb') as t:
|
| 372 |
+
t.write(engine.serialize())
|
| 373 |
+
return f, None
|
| 374 |
+
|
| 375 |
+
|
| 376 |
+
@try_export
|
| 377 |
+
def export_saved_model(model,
|
| 378 |
+
im,
|
| 379 |
+
file,
|
| 380 |
+
dynamic,
|
| 381 |
+
tf_nms=False,
|
| 382 |
+
agnostic_nms=False,
|
| 383 |
+
topk_per_class=100,
|
| 384 |
+
topk_all=100,
|
| 385 |
+
iou_thres=0.45,
|
| 386 |
+
conf_thres=0.25,
|
| 387 |
+
keras=False,
|
| 388 |
+
prefix=colorstr('TensorFlow SavedModel:')):
|
| 389 |
+
# YOLOv5 TensorFlow SavedModel export
|
| 390 |
+
try:
|
| 391 |
+
import tensorflow as tf
|
| 392 |
+
except Exception:
|
| 393 |
+
check_requirements(f"tensorflow{'' if torch.cuda.is_available() else '-macos' if MACOS else '-cpu'}")
|
| 394 |
+
import tensorflow as tf
|
| 395 |
+
from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
|
| 396 |
+
|
| 397 |
+
from models.tf import TFModel
|
| 398 |
+
|
| 399 |
+
LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
|
| 400 |
+
if tf.__version__ > '2.13.1':
|
| 401 |
+
helper_url = 'https://github.com/ultralytics/yolov5/issues/12489'
|
| 402 |
+
LOGGER.info(
|
| 403 |
+
f'WARNING ⚠️ using Tensorflow {tf.__version__} > 2.13.1 might cause issue when exporting the model to tflite {helper_url}'
|
| 404 |
+
) # handling issue https://github.com/ultralytics/yolov5/issues/12489
|
| 405 |
+
f = str(file).replace('.pt', '_saved_model')
|
| 406 |
+
batch_size, ch, *imgsz = list(im.shape) # BCHW
|
| 407 |
+
|
| 408 |
+
tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
|
| 409 |
+
im = tf.zeros((batch_size, *imgsz, ch)) # BHWC order for TensorFlow
|
| 410 |
+
_ = tf_model.predict(im, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
|
| 411 |
+
inputs = tf.keras.Input(shape=(*imgsz, ch), batch_size=None if dynamic else batch_size)
|
| 412 |
+
outputs = tf_model.predict(inputs, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
|
| 413 |
+
keras_model = tf.keras.Model(inputs=inputs, outputs=outputs)
|
| 414 |
+
keras_model.trainable = False
|
| 415 |
+
keras_model.summary()
|
| 416 |
+
if keras:
|
| 417 |
+
keras_model.save(f, save_format='tf')
|
| 418 |
+
else:
|
| 419 |
+
spec = tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype)
|
| 420 |
+
m = tf.function(lambda x: keras_model(x)) # full model
|
| 421 |
+
m = m.get_concrete_function(spec)
|
| 422 |
+
frozen_func = convert_variables_to_constants_v2(m)
|
| 423 |
+
tfm = tf.Module()
|
| 424 |
+
tfm.__call__ = tf.function(lambda x: frozen_func(x)[:4] if tf_nms else frozen_func(x), [spec])
|
| 425 |
+
tfm.__call__(im)
|
| 426 |
+
tf.saved_model.save(tfm,
|
| 427 |
+
f,
|
| 428 |
+
options=tf.saved_model.SaveOptions(experimental_custom_gradients=False) if check_version(
|
| 429 |
+
tf.__version__, '2.6') else tf.saved_model.SaveOptions())
|
| 430 |
+
return f, keras_model
|
| 431 |
+
|
| 432 |
+
|
| 433 |
+
@try_export
|
| 434 |
+
def export_pb(keras_model, file, prefix=colorstr('TensorFlow GraphDef:')):
|
| 435 |
+
# YOLOv5 TensorFlow GraphDef *.pb export https://github.com/leimao/Frozen_Graph_TensorFlow
|
| 436 |
+
import tensorflow as tf
|
| 437 |
+
from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
|
| 438 |
+
|
| 439 |
+
LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
|
| 440 |
+
f = file.with_suffix('.pb')
|
| 441 |
+
|
| 442 |
+
m = tf.function(lambda x: keras_model(x)) # full model
|
| 443 |
+
m = m.get_concrete_function(tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype))
|
| 444 |
+
frozen_func = convert_variables_to_constants_v2(m)
|
| 445 |
+
frozen_func.graph.as_graph_def()
|
| 446 |
+
tf.io.write_graph(graph_or_graph_def=frozen_func.graph, logdir=str(f.parent), name=f.name, as_text=False)
|
| 447 |
+
return f, None
|
| 448 |
+
|
| 449 |
+
|
| 450 |
+
@try_export
|
| 451 |
+
def export_tflite(keras_model, im, file, int8, per_tensor, data, nms, agnostic_nms,
|
| 452 |
+
prefix=colorstr('TensorFlow Lite:')):
|
| 453 |
+
# YOLOv5 TensorFlow Lite export
|
| 454 |
+
import tensorflow as tf
|
| 455 |
+
|
| 456 |
+
LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
|
| 457 |
+
batch_size, ch, *imgsz = list(im.shape) # BCHW
|
| 458 |
+
f = str(file).replace('.pt', '-fp16.tflite')
|
| 459 |
+
|
| 460 |
+
converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
|
| 461 |
+
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS]
|
| 462 |
+
converter.target_spec.supported_types = [tf.float16]
|
| 463 |
+
converter.optimizations = [tf.lite.Optimize.DEFAULT]
|
| 464 |
+
if int8:
|
| 465 |
+
from models.tf import representative_dataset_gen
|
| 466 |
+
dataset = LoadImages(check_dataset(check_yaml(data))['train'], img_size=imgsz, auto=False)
|
| 467 |
+
converter.representative_dataset = lambda: representative_dataset_gen(dataset, ncalib=100)
|
| 468 |
+
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
|
| 469 |
+
converter.target_spec.supported_types = []
|
| 470 |
+
converter.inference_input_type = tf.uint8 # or tf.int8
|
| 471 |
+
converter.inference_output_type = tf.uint8 # or tf.int8
|
| 472 |
+
converter.experimental_new_quantizer = True
|
| 473 |
+
if per_tensor:
|
| 474 |
+
converter._experimental_disable_per_channel = True
|
| 475 |
+
f = str(file).replace('.pt', '-int8.tflite')
|
| 476 |
+
if nms or agnostic_nms:
|
| 477 |
+
converter.target_spec.supported_ops.append(tf.lite.OpsSet.SELECT_TF_OPS)
|
| 478 |
+
|
| 479 |
+
tflite_model = converter.convert()
|
| 480 |
+
open(f, 'wb').write(tflite_model)
|
| 481 |
+
return f, None
|
| 482 |
+
|
| 483 |
+
|
| 484 |
+
@try_export
|
| 485 |
+
def export_edgetpu(file, prefix=colorstr('Edge TPU:')):
|
| 486 |
+
# YOLOv5 Edge TPU export https://coral.ai/docs/edgetpu/models-intro/
|
| 487 |
+
cmd = 'edgetpu_compiler --version'
|
| 488 |
+
help_url = 'https://coral.ai/docs/edgetpu/compiler/'
|
| 489 |
+
assert platform.system() == 'Linux', f'export only supported on Linux. See {help_url}'
|
| 490 |
+
if subprocess.run(f'{cmd} > /dev/null 2>&1', shell=True).returncode != 0:
|
| 491 |
+
LOGGER.info(f'\n{prefix} export requires Edge TPU compiler. Attempting install from {help_url}')
|
| 492 |
+
sudo = subprocess.run('sudo --version >/dev/null', shell=True).returncode == 0 # sudo installed on system
|
| 493 |
+
for c in (
|
| 494 |
+
'curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -',
|
| 495 |
+
'echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list',
|
| 496 |
+
'sudo apt-get update', 'sudo apt-get install edgetpu-compiler'):
|
| 497 |
+
subprocess.run(c if sudo else c.replace('sudo ', ''), shell=True, check=True)
|
| 498 |
+
ver = subprocess.run(cmd, shell=True, capture_output=True, check=True).stdout.decode().split()[-1]
|
| 499 |
+
|
| 500 |
+
LOGGER.info(f'\n{prefix} starting export with Edge TPU compiler {ver}...')
|
| 501 |
+
f = str(file).replace('.pt', '-int8_edgetpu.tflite') # Edge TPU model
|
| 502 |
+
f_tfl = str(file).replace('.pt', '-int8.tflite') # TFLite model
|
| 503 |
+
|
| 504 |
+
subprocess.run([
|
| 505 |
+
'edgetpu_compiler',
|
| 506 |
+
'-s',
|
| 507 |
+
'-d',
|
| 508 |
+
'-k',
|
| 509 |
+
'10',
|
| 510 |
+
'--out_dir',
|
| 511 |
+
str(file.parent),
|
| 512 |
+
f_tfl, ], check=True)
|
| 513 |
+
return f, None
|
| 514 |
+
|
| 515 |
+
|
| 516 |
+
@try_export
|
| 517 |
+
def export_tfjs(file, int8, prefix=colorstr('TensorFlow.js:')):
|
| 518 |
+
# YOLOv5 TensorFlow.js export
|
| 519 |
+
check_requirements('tensorflowjs')
|
| 520 |
+
import tensorflowjs as tfjs
|
| 521 |
+
|
| 522 |
+
LOGGER.info(f'\n{prefix} starting export with tensorflowjs {tfjs.__version__}...')
|
| 523 |
+
f = str(file).replace('.pt', '_web_model') # js dir
|
| 524 |
+
f_pb = file.with_suffix('.pb') # *.pb path
|
| 525 |
+
f_json = f'{f}/model.json' # *.json path
|
| 526 |
+
|
| 527 |
+
args = [
|
| 528 |
+
'tensorflowjs_converter',
|
| 529 |
+
'--input_format=tf_frozen_model',
|
| 530 |
+
'--quantize_uint8' if int8 else '',
|
| 531 |
+
'--output_node_names=Identity,Identity_1,Identity_2,Identity_3',
|
| 532 |
+
str(f_pb),
|
| 533 |
+
str(f), ]
|
| 534 |
+
subprocess.run([arg for arg in args if arg], check=True)
|
| 535 |
+
|
| 536 |
+
json = Path(f_json).read_text()
|
| 537 |
+
with open(f_json, 'w') as j: # sort JSON Identity_* in ascending order
|
| 538 |
+
subst = re.sub(
|
| 539 |
+
r'{"outputs": {"Identity.?.?": {"name": "Identity.?.?"}, '
|
| 540 |
+
r'"Identity.?.?": {"name": "Identity.?.?"}, '
|
| 541 |
+
r'"Identity.?.?": {"name": "Identity.?.?"}, '
|
| 542 |
+
r'"Identity.?.?": {"name": "Identity.?.?"}}}', r'{"outputs": {"Identity": {"name": "Identity"}, '
|
| 543 |
+
r'"Identity_1": {"name": "Identity_1"}, '
|
| 544 |
+
r'"Identity_2": {"name": "Identity_2"}, '
|
| 545 |
+
r'"Identity_3": {"name": "Identity_3"}}}', json)
|
| 546 |
+
j.write(subst)
|
| 547 |
+
return f, None
|
| 548 |
+
|
| 549 |
+
|
| 550 |
+
def add_tflite_metadata(file, metadata, num_outputs):
|
| 551 |
+
# Add metadata to *.tflite models per https://www.tensorflow.org/lite/models/convert/metadata
|
| 552 |
+
with contextlib.suppress(ImportError):
|
| 553 |
+
# check_requirements('tflite_support')
|
| 554 |
+
from tflite_support import flatbuffers
|
| 555 |
+
from tflite_support import metadata as _metadata
|
| 556 |
+
from tflite_support import metadata_schema_py_generated as _metadata_fb
|
| 557 |
+
|
| 558 |
+
tmp_file = Path('/tmp/meta.txt')
|
| 559 |
+
with open(tmp_file, 'w') as meta_f:
|
| 560 |
+
meta_f.write(str(metadata))
|
| 561 |
+
|
| 562 |
+
model_meta = _metadata_fb.ModelMetadataT()
|
| 563 |
+
label_file = _metadata_fb.AssociatedFileT()
|
| 564 |
+
label_file.name = tmp_file.name
|
| 565 |
+
model_meta.associatedFiles = [label_file]
|
| 566 |
+
|
| 567 |
+
subgraph = _metadata_fb.SubGraphMetadataT()
|
| 568 |
+
subgraph.inputTensorMetadata = [_metadata_fb.TensorMetadataT()]
|
| 569 |
+
subgraph.outputTensorMetadata = [_metadata_fb.TensorMetadataT()] * num_outputs
|
| 570 |
+
model_meta.subgraphMetadata = [subgraph]
|
| 571 |
+
|
| 572 |
+
b = flatbuffers.Builder(0)
|
| 573 |
+
b.Finish(model_meta.Pack(b), _metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
|
| 574 |
+
metadata_buf = b.Output()
|
| 575 |
+
|
| 576 |
+
populator = _metadata.MetadataPopulator.with_model_file(file)
|
| 577 |
+
populator.load_metadata_buffer(metadata_buf)
|
| 578 |
+
populator.load_associated_files([str(tmp_file)])
|
| 579 |
+
populator.populate()
|
| 580 |
+
tmp_file.unlink()
|
| 581 |
+
|
| 582 |
+
|
| 583 |
+
def pipeline_coreml(model, im, file, names, y, prefix=colorstr('CoreML Pipeline:')):
|
| 584 |
+
# YOLOv5 CoreML pipeline
|
| 585 |
+
import coremltools as ct
|
| 586 |
+
from PIL import Image
|
| 587 |
+
|
| 588 |
+
print(f'{prefix} starting pipeline with coremltools {ct.__version__}...')
|
| 589 |
+
batch_size, ch, h, w = list(im.shape) # BCHW
|
| 590 |
+
t = time.time()
|
| 591 |
+
|
| 592 |
+
# YOLOv5 Output shapes
|
| 593 |
+
spec = model.get_spec()
|
| 594 |
+
out0, out1 = iter(spec.description.output)
|
| 595 |
+
if platform.system() == 'Darwin':
|
| 596 |
+
img = Image.new('RGB', (w, h)) # img(192 width, 320 height)
|
| 597 |
+
# img = torch.zeros((*opt.img_size, 3)).numpy() # img size(320,192,3) iDetection
|
| 598 |
+
out = model.predict({'image': img})
|
| 599 |
+
out0_shape, out1_shape = out[out0.name].shape, out[out1.name].shape
|
| 600 |
+
else: # linux and windows can not run model.predict(), get sizes from pytorch output y
|
| 601 |
+
s = tuple(y[0].shape)
|
| 602 |
+
out0_shape, out1_shape = (s[1], s[2] - 5), (s[1], 4) # (3780, 80), (3780, 4)
|
| 603 |
+
|
| 604 |
+
# Checks
|
| 605 |
+
nx, ny = spec.description.input[0].type.imageType.width, spec.description.input[0].type.imageType.height
|
| 606 |
+
na, nc = out0_shape
|
| 607 |
+
# na, nc = out0.type.multiArrayType.shape # number anchors, classes
|
| 608 |
+
assert len(names) == nc, f'{len(names)} names found for nc={nc}' # check
|
| 609 |
+
|
| 610 |
+
# Define output shapes (missing)
|
| 611 |
+
out0.type.multiArrayType.shape[:] = out0_shape # (3780, 80)
|
| 612 |
+
out1.type.multiArrayType.shape[:] = out1_shape # (3780, 4)
|
| 613 |
+
# spec.neuralNetwork.preprocessing[0].featureName = '0'
|
| 614 |
+
|
| 615 |
+
# Flexible input shapes
|
| 616 |
+
# from coremltools.models.neural_network import flexible_shape_utils
|
| 617 |
+
# s = [] # shapes
|
| 618 |
+
# s.append(flexible_shape_utils.NeuralNetworkImageSize(320, 192))
|
| 619 |
+
# s.append(flexible_shape_utils.NeuralNetworkImageSize(640, 384)) # (height, width)
|
| 620 |
+
# flexible_shape_utils.add_enumerated_image_sizes(spec, feature_name='image', sizes=s)
|
| 621 |
+
# r = flexible_shape_utils.NeuralNetworkImageSizeRange() # shape ranges
|
| 622 |
+
# r.add_height_range((192, 640))
|
| 623 |
+
# r.add_width_range((192, 640))
|
| 624 |
+
# flexible_shape_utils.update_image_size_range(spec, feature_name='image', size_range=r)
|
| 625 |
+
|
| 626 |
+
# Print
|
| 627 |
+
print(spec.description)
|
| 628 |
+
|
| 629 |
+
# Model from spec
|
| 630 |
+
model = ct.models.MLModel(spec)
|
| 631 |
+
|
| 632 |
+
# 3. Create NMS protobuf
|
| 633 |
+
nms_spec = ct.proto.Model_pb2.Model()
|
| 634 |
+
nms_spec.specificationVersion = 5
|
| 635 |
+
for i in range(2):
|
| 636 |
+
decoder_output = model._spec.description.output[i].SerializeToString()
|
| 637 |
+
nms_spec.description.input.add()
|
| 638 |
+
nms_spec.description.input[i].ParseFromString(decoder_output)
|
| 639 |
+
nms_spec.description.output.add()
|
| 640 |
+
nms_spec.description.output[i].ParseFromString(decoder_output)
|
| 641 |
+
|
| 642 |
+
nms_spec.description.output[0].name = 'confidence'
|
| 643 |
+
nms_spec.description.output[1].name = 'coordinates'
|
| 644 |
+
|
| 645 |
+
output_sizes = [nc, 4]
|
| 646 |
+
for i in range(2):
|
| 647 |
+
ma_type = nms_spec.description.output[i].type.multiArrayType
|
| 648 |
+
ma_type.shapeRange.sizeRanges.add()
|
| 649 |
+
ma_type.shapeRange.sizeRanges[0].lowerBound = 0
|
| 650 |
+
ma_type.shapeRange.sizeRanges[0].upperBound = -1
|
| 651 |
+
ma_type.shapeRange.sizeRanges.add()
|
| 652 |
+
ma_type.shapeRange.sizeRanges[1].lowerBound = output_sizes[i]
|
| 653 |
+
ma_type.shapeRange.sizeRanges[1].upperBound = output_sizes[i]
|
| 654 |
+
del ma_type.shape[:]
|
| 655 |
+
|
| 656 |
+
nms = nms_spec.nonMaximumSuppression
|
| 657 |
+
nms.confidenceInputFeatureName = out0.name # 1x507x80
|
| 658 |
+
nms.coordinatesInputFeatureName = out1.name # 1x507x4
|
| 659 |
+
nms.confidenceOutputFeatureName = 'confidence'
|
| 660 |
+
nms.coordinatesOutputFeatureName = 'coordinates'
|
| 661 |
+
nms.iouThresholdInputFeatureName = 'iouThreshold'
|
| 662 |
+
nms.confidenceThresholdInputFeatureName = 'confidenceThreshold'
|
| 663 |
+
nms.iouThreshold = 0.45
|
| 664 |
+
nms.confidenceThreshold = 0.25
|
| 665 |
+
nms.pickTop.perClass = True
|
| 666 |
+
nms.stringClassLabels.vector.extend(names.values())
|
| 667 |
+
nms_model = ct.models.MLModel(nms_spec)
|
| 668 |
+
|
| 669 |
+
# 4. Pipeline models together
|
| 670 |
+
pipeline = ct.models.pipeline.Pipeline(input_features=[('image', ct.models.datatypes.Array(3, ny, nx)),
|
| 671 |
+
('iouThreshold', ct.models.datatypes.Double()),
|
| 672 |
+
('confidenceThreshold', ct.models.datatypes.Double())],
|
| 673 |
+
output_features=['confidence', 'coordinates'])
|
| 674 |
+
pipeline.add_model(model)
|
| 675 |
+
pipeline.add_model(nms_model)
|
| 676 |
+
|
| 677 |
+
# Correct datatypes
|
| 678 |
+
pipeline.spec.description.input[0].ParseFromString(model._spec.description.input[0].SerializeToString())
|
| 679 |
+
pipeline.spec.description.output[0].ParseFromString(nms_model._spec.description.output[0].SerializeToString())
|
| 680 |
+
pipeline.spec.description.output[1].ParseFromString(nms_model._spec.description.output[1].SerializeToString())
|
| 681 |
+
|
| 682 |
+
# Update metadata
|
| 683 |
+
pipeline.spec.specificationVersion = 5
|
| 684 |
+
pipeline.spec.description.metadata.versionString = 'https://github.com/ultralytics/yolov5'
|
| 685 |
+
pipeline.spec.description.metadata.shortDescription = 'https://github.com/ultralytics/yolov5'
|
| 686 |
+
pipeline.spec.description.metadata.author = '[email protected]'
|
| 687 |
+
pipeline.spec.description.metadata.license = 'https://github.com/ultralytics/yolov5/blob/master/LICENSE'
|
| 688 |
+
pipeline.spec.description.metadata.userDefined.update({
|
| 689 |
+
'classes': ','.join(names.values()),
|
| 690 |
+
'iou_threshold': str(nms.iouThreshold),
|
| 691 |
+
'confidence_threshold': str(nms.confidenceThreshold)})
|
| 692 |
+
|
| 693 |
+
# Save the model
|
| 694 |
+
f = file.with_suffix('.mlmodel') # filename
|
| 695 |
+
model = ct.models.MLModel(pipeline.spec)
|
| 696 |
+
model.input_description['image'] = 'Input image'
|
| 697 |
+
model.input_description['iouThreshold'] = f'(optional) IOU Threshold override (default: {nms.iouThreshold})'
|
| 698 |
+
model.input_description['confidenceThreshold'] = \
|
| 699 |
+
f'(optional) Confidence Threshold override (default: {nms.confidenceThreshold})'
|
| 700 |
+
model.output_description['confidence'] = 'Boxes × Class confidence (see user-defined metadata "classes")'
|
| 701 |
+
model.output_description['coordinates'] = 'Boxes × [x, y, width, height] (relative to image size)'
|
| 702 |
+
model.save(f) # pipelined
|
| 703 |
+
print(f'{prefix} pipeline success ({time.time() - t:.2f}s), saved as {f} ({file_size(f):.1f} MB)')
|
| 704 |
+
|
| 705 |
+
|
| 706 |
+
@smart_inference_mode()
|
| 707 |
+
def run(
|
| 708 |
+
data=ROOT / 'data/coco128.yaml', # 'dataset.yaml path'
|
| 709 |
+
weights=ROOT / 'yolov5s.pt', # weights path
|
| 710 |
+
imgsz=(640, 640), # image (height, width)
|
| 711 |
+
batch_size=1, # batch size
|
| 712 |
+
device='cpu', # cuda device, i.e. 0 or 0,1,2,3 or cpu
|
| 713 |
+
include=('torchscript', 'onnx'), # include formats
|
| 714 |
+
half=False, # FP16 half-precision export
|
| 715 |
+
inplace=False, # set YOLOv5 Detect() inplace=True
|
| 716 |
+
keras=False, # use Keras
|
| 717 |
+
optimize=False, # TorchScript: optimize for mobile
|
| 718 |
+
int8=False, # CoreML/TF INT8 quantization
|
| 719 |
+
per_tensor=False, # TF per tensor quantization
|
| 720 |
+
dynamic=False, # ONNX/TF/TensorRT: dynamic axes
|
| 721 |
+
simplify=False, # ONNX: simplify model
|
| 722 |
+
opset=12, # ONNX: opset version
|
| 723 |
+
verbose=False, # TensorRT: verbose log
|
| 724 |
+
workspace=4, # TensorRT: workspace size (GB)
|
| 725 |
+
nms=False, # TF: add NMS to model
|
| 726 |
+
agnostic_nms=False, # TF: add agnostic NMS to model
|
| 727 |
+
topk_per_class=100, # TF.js NMS: topk per class to keep
|
| 728 |
+
topk_all=100, # TF.js NMS: topk for all classes to keep
|
| 729 |
+
iou_thres=0.45, # TF.js NMS: IoU threshold
|
| 730 |
+
conf_thres=0.25, # TF.js NMS: confidence threshold
|
| 731 |
+
):
|
| 732 |
+
t = time.time()
|
| 733 |
+
include = [x.lower() for x in include] # to lowercase
|
| 734 |
+
fmts = tuple(export_formats()['Argument'][1:]) # --include arguments
|
| 735 |
+
flags = [x in include for x in fmts]
|
| 736 |
+
assert sum(flags) == len(include), f'ERROR: Invalid --include {include}, valid --include arguments are {fmts}'
|
| 737 |
+
jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle = flags # export booleans
|
| 738 |
+
file = Path(url2file(weights) if str(weights).startswith(('http:/', 'https:/')) else weights) # PyTorch weights
|
| 739 |
+
|
| 740 |
+
# Load PyTorch model
|
| 741 |
+
device = select_device(device)
|
| 742 |
+
if half:
|
| 743 |
+
assert device.type != 'cpu' or coreml, '--half only compatible with GPU export, i.e. use --device 0'
|
| 744 |
+
assert not dynamic, '--half not compatible with --dynamic, i.e. use either --half or --dynamic but not both'
|
| 745 |
+
model = attempt_load(weights, device=device, inplace=True, fuse=True) # load FP32 model
|
| 746 |
+
|
| 747 |
+
# Checks
|
| 748 |
+
imgsz *= 2 if len(imgsz) == 1 else 1 # expand
|
| 749 |
+
if optimize:
|
| 750 |
+
assert device.type == 'cpu', '--optimize not compatible with cuda devices, i.e. use --device cpu'
|
| 751 |
+
|
| 752 |
+
# Input
|
| 753 |
+
gs = int(max(model.stride)) # grid size (max stride)
|
| 754 |
+
imgsz = [check_img_size(x, gs) for x in imgsz] # verify img_size are gs-multiples
|
| 755 |
+
im = torch.zeros(batch_size, 3, *imgsz).to(device) # image size(1,3,320,192) BCHW iDetection
|
| 756 |
+
|
| 757 |
+
# Update model
|
| 758 |
+
model.eval()
|
| 759 |
+
for k, m in model.named_modules():
|
| 760 |
+
if isinstance(m, Detect):
|
| 761 |
+
m.inplace = inplace
|
| 762 |
+
m.dynamic = dynamic
|
| 763 |
+
m.export = True
|
| 764 |
+
|
| 765 |
+
for _ in range(2):
|
| 766 |
+
y = model(im) # dry runs
|
| 767 |
+
if half and not coreml:
|
| 768 |
+
im, model = im.half(), model.half() # to FP16
|
| 769 |
+
shape = tuple((y[0] if isinstance(y, tuple) else y).shape) # model output shape
|
| 770 |
+
metadata = {'stride': int(max(model.stride)), 'names': model.names} # model metadata
|
| 771 |
+
LOGGER.info(f"\n{colorstr('PyTorch:')} starting from {file} with output shape {shape} ({file_size(file):.1f} MB)")
|
| 772 |
+
|
| 773 |
+
# Exports
|
| 774 |
+
f = [''] * len(fmts) # exported filenames
|
| 775 |
+
warnings.filterwarnings(action='ignore', category=torch.jit.TracerWarning) # suppress TracerWarning
|
| 776 |
+
if jit: # TorchScript
|
| 777 |
+
f[0], _ = export_torchscript(model, im, file, optimize)
|
| 778 |
+
if engine: # TensorRT required before ONNX
|
| 779 |
+
f[1], _ = export_engine(model, im, file, half, dynamic, simplify, workspace, verbose)
|
| 780 |
+
if onnx or xml: # OpenVINO requires ONNX
|
| 781 |
+
f[2], _ = export_onnx(model, im, file, opset, dynamic, simplify)
|
| 782 |
+
if xml: # OpenVINO
|
| 783 |
+
f[3], _ = export_openvino(file, metadata, half, int8, data)
|
| 784 |
+
if coreml: # CoreML
|
| 785 |
+
f[4], ct_model = export_coreml(model, im, file, int8, half, nms)
|
| 786 |
+
if nms:
|
| 787 |
+
pipeline_coreml(ct_model, im, file, model.names, y)
|
| 788 |
+
if any((saved_model, pb, tflite, edgetpu, tfjs)): # TensorFlow formats
|
| 789 |
+
assert not tflite or not tfjs, 'TFLite and TF.js models must be exported separately, please pass only one type.'
|
| 790 |
+
assert not isinstance(model, ClassificationModel), 'ClassificationModel export to TF formats not yet supported.'
|
| 791 |
+
f[5], s_model = export_saved_model(model.cpu(),
|
| 792 |
+
im,
|
| 793 |
+
file,
|
| 794 |
+
dynamic,
|
| 795 |
+
tf_nms=nms or agnostic_nms or tfjs,
|
| 796 |
+
agnostic_nms=agnostic_nms or tfjs,
|
| 797 |
+
topk_per_class=topk_per_class,
|
| 798 |
+
topk_all=topk_all,
|
| 799 |
+
iou_thres=iou_thres,
|
| 800 |
+
conf_thres=conf_thres,
|
| 801 |
+
keras=keras)
|
| 802 |
+
if pb or tfjs: # pb prerequisite to tfjs
|
| 803 |
+
f[6], _ = export_pb(s_model, file)
|
| 804 |
+
if tflite or edgetpu:
|
| 805 |
+
f[7], _ = export_tflite(s_model,
|
| 806 |
+
im,
|
| 807 |
+
file,
|
| 808 |
+
int8 or edgetpu,
|
| 809 |
+
per_tensor,
|
| 810 |
+
data=data,
|
| 811 |
+
nms=nms,
|
| 812 |
+
agnostic_nms=agnostic_nms)
|
| 813 |
+
if edgetpu:
|
| 814 |
+
f[8], _ = export_edgetpu(file)
|
| 815 |
+
add_tflite_metadata(f[8] or f[7], metadata, num_outputs=len(s_model.outputs))
|
| 816 |
+
if tfjs:
|
| 817 |
+
f[9], _ = export_tfjs(file, int8)
|
| 818 |
+
if paddle: # PaddlePaddle
|
| 819 |
+
f[10], _ = export_paddle(model, im, file, metadata)
|
| 820 |
+
|
| 821 |
+
# Finish
|
| 822 |
+
f = [str(x) for x in f if x] # filter out '' and None
|
| 823 |
+
if any(f):
|
| 824 |
+
cls, det, seg = (isinstance(model, x) for x in (ClassificationModel, DetectionModel, SegmentationModel)) # type
|
| 825 |
+
det &= not seg # segmentation models inherit from SegmentationModel(DetectionModel)
|
| 826 |
+
dir = Path('segment' if seg else 'classify' if cls else '')
|
| 827 |
+
h = '--half' if half else '' # --half FP16 inference arg
|
| 828 |
+
s = '# WARNING ⚠️ ClassificationModel not yet supported for PyTorch Hub AutoShape inference' if cls else \
|
| 829 |
+
'# WARNING ⚠️ SegmentationModel not yet supported for PyTorch Hub AutoShape inference' if seg else ''
|
| 830 |
+
LOGGER.info(f'\nExport complete ({time.time() - t:.1f}s)'
|
| 831 |
+
f"\nResults saved to {colorstr('bold', file.parent.resolve())}"
|
| 832 |
+
f"\nDetect: python {dir / ('detect.py' if det else 'predict.py')} --weights {f[-1]} {h}"
|
| 833 |
+
f"\nValidate: python {dir / 'val.py'} --weights {f[-1]} {h}"
|
| 834 |
+
f"\nPyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', '{f[-1]}') {s}"
|
| 835 |
+
f'\nVisualize: https://netron.app')
|
| 836 |
+
return f # return list of exported files/dirs
|
| 837 |
+
|
| 838 |
+
|
| 839 |
+
def parse_opt(known=False):
|
| 840 |
+
parser = argparse.ArgumentParser()
|
| 841 |
+
parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='dataset.yaml path')
|
| 842 |
+
parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model.pt path(s)')
|
| 843 |
+
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640, 640], help='image (h, w)')
|
| 844 |
+
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
|
| 845 |
+
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
|
| 846 |
+
parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
|
| 847 |
+
parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
|
| 848 |
+
parser.add_argument('--keras', action='store_true', help='TF: use Keras')
|
| 849 |
+
parser.add_argument('--optimize', action='store_true', help='TorchScript: optimize for mobile')
|
| 850 |
+
parser.add_argument('--int8', action='store_true', help='CoreML/TF/OpenVINO INT8 quantization')
|
| 851 |
+
parser.add_argument('--per-tensor', action='store_true', help='TF per-tensor quantization')
|
| 852 |
+
parser.add_argument('--dynamic', action='store_true', help='ONNX/TF/TensorRT: dynamic axes')
|
| 853 |
+
parser.add_argument('--simplify', action='store_true', help='ONNX: simplify model')
|
| 854 |
+
parser.add_argument('--opset', type=int, default=17, help='ONNX: opset version')
|
| 855 |
+
parser.add_argument('--verbose', action='store_true', help='TensorRT: verbose log')
|
| 856 |
+
parser.add_argument('--workspace', type=int, default=4, help='TensorRT: workspace size (GB)')
|
| 857 |
+
parser.add_argument('--nms', action='store_true', help='TF: add NMS to model')
|
| 858 |
+
parser.add_argument('--agnostic-nms', action='store_true', help='TF: add agnostic NMS to model')
|
| 859 |
+
parser.add_argument('--topk-per-class', type=int, default=100, help='TF.js NMS: topk per class to keep')
|
| 860 |
+
parser.add_argument('--topk-all', type=int, default=100, help='TF.js NMS: topk for all classes to keep')
|
| 861 |
+
parser.add_argument('--iou-thres', type=float, default=0.45, help='TF.js NMS: IoU threshold')
|
| 862 |
+
parser.add_argument('--conf-thres', type=float, default=0.25, help='TF.js NMS: confidence threshold')
|
| 863 |
+
parser.add_argument(
|
| 864 |
+
'--include',
|
| 865 |
+
nargs='+',
|
| 866 |
+
default=['torchscript'],
|
| 867 |
+
help='torchscript, onnx, openvino, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs, paddle')
|
| 868 |
+
opt = parser.parse_known_args()[0] if known else parser.parse_args()
|
| 869 |
+
print_args(vars(opt))
|
| 870 |
+
return opt
|
| 871 |
+
|
| 872 |
+
|
| 873 |
+
def main(opt):
|
| 874 |
+
for opt.weights in (opt.weights if isinstance(opt.weights, list) else [opt.weights]):
|
| 875 |
+
run(**vars(opt))
|
| 876 |
+
|
| 877 |
+
|
| 878 |
+
if __name__ == '__main__':
|
| 879 |
+
opt = parse_opt()
|
| 880 |
+
main(opt)
|
yolov5/hubconf.py
ADDED
|
@@ -0,0 +1,169 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license
|
| 2 |
+
"""
|
| 3 |
+
PyTorch Hub models https://pytorch.org/hub/ultralytics_yolov5
|
| 4 |
+
|
| 5 |
+
Usage:
|
| 6 |
+
import torch
|
| 7 |
+
model = torch.hub.load('ultralytics/yolov5', 'yolov5s') # official model
|
| 8 |
+
model = torch.hub.load('ultralytics/yolov5:master', 'yolov5s') # from branch
|
| 9 |
+
model = torch.hub.load('ultralytics/yolov5', 'custom', 'yolov5s.pt') # custom/local model
|
| 10 |
+
model = torch.hub.load('.', 'custom', 'yolov5s.pt', source='local') # local repo
|
| 11 |
+
"""
|
| 12 |
+
|
| 13 |
+
import torch
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def _create(name, pretrained=True, channels=3, classes=80, autoshape=True, verbose=True, device=None):
|
| 17 |
+
"""Creates or loads a YOLOv5 model
|
| 18 |
+
|
| 19 |
+
Arguments:
|
| 20 |
+
name (str): model name 'yolov5s' or path 'path/to/best.pt'
|
| 21 |
+
pretrained (bool): load pretrained weights into the model
|
| 22 |
+
channels (int): number of input channels
|
| 23 |
+
classes (int): number of model classes
|
| 24 |
+
autoshape (bool): apply YOLOv5 .autoshape() wrapper to model
|
| 25 |
+
verbose (bool): print all information to screen
|
| 26 |
+
device (str, torch.device, None): device to use for model parameters
|
| 27 |
+
|
| 28 |
+
Returns:
|
| 29 |
+
YOLOv5 model
|
| 30 |
+
"""
|
| 31 |
+
from pathlib import Path
|
| 32 |
+
|
| 33 |
+
from models.common import AutoShape, DetectMultiBackend
|
| 34 |
+
from models.experimental import attempt_load
|
| 35 |
+
from models.yolo import ClassificationModel, DetectionModel, SegmentationModel
|
| 36 |
+
from utils.downloads import attempt_download
|
| 37 |
+
from utils.general import LOGGER, ROOT, check_requirements, intersect_dicts, logging
|
| 38 |
+
from utils.torch_utils import select_device
|
| 39 |
+
|
| 40 |
+
if not verbose:
|
| 41 |
+
LOGGER.setLevel(logging.WARNING)
|
| 42 |
+
check_requirements(ROOT / 'requirements.txt', exclude=('opencv-python', 'tensorboard', 'thop'))
|
| 43 |
+
name = Path(name)
|
| 44 |
+
path = name.with_suffix('.pt') if name.suffix == '' and not name.is_dir() else name # checkpoint path
|
| 45 |
+
try:
|
| 46 |
+
device = select_device(device)
|
| 47 |
+
if pretrained and channels == 3 and classes == 80:
|
| 48 |
+
try:
|
| 49 |
+
model = DetectMultiBackend(path, device=device, fuse=autoshape) # detection model
|
| 50 |
+
if autoshape:
|
| 51 |
+
if model.pt and isinstance(model.model, ClassificationModel):
|
| 52 |
+
LOGGER.warning('WARNING ⚠️ YOLOv5 ClassificationModel is not yet AutoShape compatible. '
|
| 53 |
+
'You must pass torch tensors in BCHW to this model, i.e. shape(1,3,224,224).')
|
| 54 |
+
elif model.pt and isinstance(model.model, SegmentationModel):
|
| 55 |
+
LOGGER.warning('WARNING ⚠️ YOLOv5 SegmentationModel is not yet AutoShape compatible. '
|
| 56 |
+
'You will not be able to run inference with this model.')
|
| 57 |
+
else:
|
| 58 |
+
model = AutoShape(model) # for file/URI/PIL/cv2/np inputs and NMS
|
| 59 |
+
except Exception:
|
| 60 |
+
model = attempt_load(path, device=device, fuse=False) # arbitrary model
|
| 61 |
+
else:
|
| 62 |
+
cfg = list((Path(__file__).parent / 'models').rglob(f'{path.stem}.yaml'))[0] # model.yaml path
|
| 63 |
+
model = DetectionModel(cfg, channels, classes) # create model
|
| 64 |
+
if pretrained:
|
| 65 |
+
ckpt = torch.load(attempt_download(path), map_location=device) # load
|
| 66 |
+
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
|
| 67 |
+
csd = intersect_dicts(csd, model.state_dict(), exclude=['anchors']) # intersect
|
| 68 |
+
model.load_state_dict(csd, strict=False) # load
|
| 69 |
+
if len(ckpt['model'].names) == classes:
|
| 70 |
+
model.names = ckpt['model'].names # set class names attribute
|
| 71 |
+
if not verbose:
|
| 72 |
+
LOGGER.setLevel(logging.INFO) # reset to default
|
| 73 |
+
return model.to(device)
|
| 74 |
+
|
| 75 |
+
except Exception as e:
|
| 76 |
+
help_url = 'https://docs.ultralytics.com/yolov5/tutorials/pytorch_hub_model_loading'
|
| 77 |
+
s = f'{e}. Cache may be out of date, try `force_reload=True` or see {help_url} for help.'
|
| 78 |
+
raise Exception(s) from e
|
| 79 |
+
|
| 80 |
+
|
| 81 |
+
def custom(path='path/to/model.pt', autoshape=True, _verbose=True, device=None):
|
| 82 |
+
# YOLOv5 custom or local model
|
| 83 |
+
return _create(path, autoshape=autoshape, verbose=_verbose, device=device)
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
def yolov5n(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
|
| 87 |
+
# YOLOv5-nano model https://github.com/ultralytics/yolov5
|
| 88 |
+
return _create('yolov5n', pretrained, channels, classes, autoshape, _verbose, device)
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
def yolov5s(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
|
| 92 |
+
# YOLOv5-small model https://github.com/ultralytics/yolov5
|
| 93 |
+
return _create('yolov5s', pretrained, channels, classes, autoshape, _verbose, device)
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
def yolov5m(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
|
| 97 |
+
# YOLOv5-medium model https://github.com/ultralytics/yolov5
|
| 98 |
+
return _create('yolov5m', pretrained, channels, classes, autoshape, _verbose, device)
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def yolov5l(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
|
| 102 |
+
# YOLOv5-large model https://github.com/ultralytics/yolov5
|
| 103 |
+
return _create('yolov5l', pretrained, channels, classes, autoshape, _verbose, device)
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
def yolov5x(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
|
| 107 |
+
# YOLOv5-xlarge model https://github.com/ultralytics/yolov5
|
| 108 |
+
return _create('yolov5x', pretrained, channels, classes, autoshape, _verbose, device)
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def yolov5n6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
|
| 112 |
+
# YOLOv5-nano-P6 model https://github.com/ultralytics/yolov5
|
| 113 |
+
return _create('yolov5n6', pretrained, channels, classes, autoshape, _verbose, device)
|
| 114 |
+
|
| 115 |
+
|
| 116 |
+
def yolov5s6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
|
| 117 |
+
# YOLOv5-small-P6 model https://github.com/ultralytics/yolov5
|
| 118 |
+
return _create('yolov5s6', pretrained, channels, classes, autoshape, _verbose, device)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def yolov5m6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
|
| 122 |
+
# YOLOv5-medium-P6 model https://github.com/ultralytics/yolov5
|
| 123 |
+
return _create('yolov5m6', pretrained, channels, classes, autoshape, _verbose, device)
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
def yolov5l6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
|
| 127 |
+
# YOLOv5-large-P6 model https://github.com/ultralytics/yolov5
|
| 128 |
+
return _create('yolov5l6', pretrained, channels, classes, autoshape, _verbose, device)
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
def yolov5x6(pretrained=True, channels=3, classes=80, autoshape=True, _verbose=True, device=None):
|
| 132 |
+
# YOLOv5-xlarge-P6 model https://github.com/ultralytics/yolov5
|
| 133 |
+
return _create('yolov5x6', pretrained, channels, classes, autoshape, _verbose, device)
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
if __name__ == '__main__':
|
| 137 |
+
import argparse
|
| 138 |
+
from pathlib import Path
|
| 139 |
+
|
| 140 |
+
import numpy as np
|
| 141 |
+
from PIL import Image
|
| 142 |
+
|
| 143 |
+
from utils.general import cv2, print_args
|
| 144 |
+
|
| 145 |
+
# Argparser
|
| 146 |
+
parser = argparse.ArgumentParser()
|
| 147 |
+
parser.add_argument('--model', type=str, default='yolov5s', help='model name')
|
| 148 |
+
opt = parser.parse_args()
|
| 149 |
+
print_args(vars(opt))
|
| 150 |
+
|
| 151 |
+
# Model
|
| 152 |
+
model = _create(name=opt.model, pretrained=True, channels=3, classes=80, autoshape=True, verbose=True)
|
| 153 |
+
# model = custom(path='path/to/model.pt') # custom
|
| 154 |
+
|
| 155 |
+
# Images
|
| 156 |
+
imgs = [
|
| 157 |
+
'data/images/zidane.jpg', # filename
|
| 158 |
+
Path('data/images/zidane.jpg'), # Path
|
| 159 |
+
'https://ultralytics.com/images/zidane.jpg', # URI
|
| 160 |
+
cv2.imread('data/images/bus.jpg')[:, :, ::-1], # OpenCV
|
| 161 |
+
Image.open('data/images/bus.jpg'), # PIL
|
| 162 |
+
np.zeros((320, 640, 3))] # numpy
|
| 163 |
+
|
| 164 |
+
# Inference
|
| 165 |
+
results = model(imgs, size=320) # batched inference
|
| 166 |
+
|
| 167 |
+
# Results
|
| 168 |
+
results.print()
|
| 169 |
+
results.save()
|
yolov5/models/__init__.py
ADDED
|
File without changes
|
yolov5/models/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (187 Bytes). View file
|
|
|
yolov5/models/__pycache__/__init__.cpython-37.pyc
ADDED
|
Binary file (124 Bytes). View file
|
|
|
yolov5/models/__pycache__/common.cpython-310.pyc
ADDED
|
Binary file (37.2 kB). View file
|
|
|
yolov5/models/__pycache__/common.cpython-37.pyc
ADDED
|
Binary file (38.4 kB). View file
|
|
|
yolov5/models/__pycache__/experimental.cpython-310.pyc
ADDED
|
Binary file (5.01 kB). View file
|
|
|