Spaces:
Running

Running
Upload 1912 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +7 -0
- .gitignore +5 -0
- 1.png +0 -0
- 2.png +0 -0
- 3.png +0 -0
- 4.png +0 -0
- 5.png +0 -0
- Implementation.png +0 -0
- README.md +3 -8
- clip-baseline.png +0 -0
- clip-index.png +0 -0
- clip-online.png +0 -0
- cls_lora.png +0 -0
- cls_md_w_fbs_index.png +0 -0
- cls_md_wo_fbs.png +0 -0
- cls_online.png +0 -0
- data/README.md +94 -0
- data/__init__.py +14 -0
- data/__pycache__/__init__.cpython-38.pyc +0 -0
- data/__pycache__/dataloader.cpython-38.pyc +0 -0
- data/__pycache__/dataset.cpython-38.pyc +0 -0
- data/build/__init__.py +0 -0
- data/build/__pycache__/__init__.cpython-38.pyc +0 -0
- data/build/__pycache__/build.cpython-38.pyc +0 -0
- data/build/__pycache__/merge_alias.cpython-38.pyc +0 -0
- data/build/__pycache__/scenario.cpython-38.pyc +0 -0
- data/build/build.py +495 -0
- data/build/merge_alias.py +106 -0
- data/build/scenario.py +466 -0
- data/build_cl/__pycache__/build.cpython-38.pyc +0 -0
- data/build_cl/__pycache__/scenario.cpython-38.pyc +0 -0
- data/build_cl/build.py +161 -0
- data/build_cl/scenario.py +146 -0
- data/build_gen/__pycache__/build.cpython-38.pyc +0 -0
- data/build_gen/__pycache__/merge_alias.cpython-38.pyc +0 -0
- data/build_gen/__pycache__/scenario.cpython-38.pyc +0 -0
- data/build_gen/build.py +495 -0
- data/build_gen/merge_alias.py +106 -0
- data/build_gen/scenario.py +473 -0
- data/convert_all_load_to_single_load.py +56 -0
- data/convert_det_dataset_to_cls.py +55 -0
- data/convert_seg_dataset_to_cls.py +324 -0
- data/convert_seg_dataset_to_det.py +399 -0
- data/dataloader.py +131 -0
- data/dataset.py +43 -0
- data/datasets/__init__.py +12 -0
- data/datasets/__pycache__/__init__.cpython-38.pyc +0 -0
- data/datasets/__pycache__/ab_dataset.cpython-38.pyc +0 -0
- data/datasets/__pycache__/data_aug.cpython-38.pyc +0 -0
- data/datasets/__pycache__/dataset_cache.cpython-38.pyc +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,10 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
data/datasets/visual_question_answering/generate_c_image/imagenet_c/frost/frost1.png filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
data/datasets/visual_question_answering/generate_c_image/robustness-master/assets/spatter.gif filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
data/datasets/visual_question_answering/generate_c_image/robustness-master/assets/tilt.gif filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
data/datasets/visual_question_answering/generate_c_image/robustness-master/assets/translate.gif filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
data/datasets/visual_question_answering/generate_c_image/robustness-master/ImageNet-C/create_c/frost1.png filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
data/datasets/visual_question_answering/generate_c_image/robustness-master/ImageNet-C/imagenet_c/imagenet_c/frost/frost1.png filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
new_results.png filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
results
|
| 2 |
+
logs
|
| 3 |
+
entry_model
|
| 4 |
+
__pycache__
|
| 5 |
+
backup_codes
|
1.png
ADDED
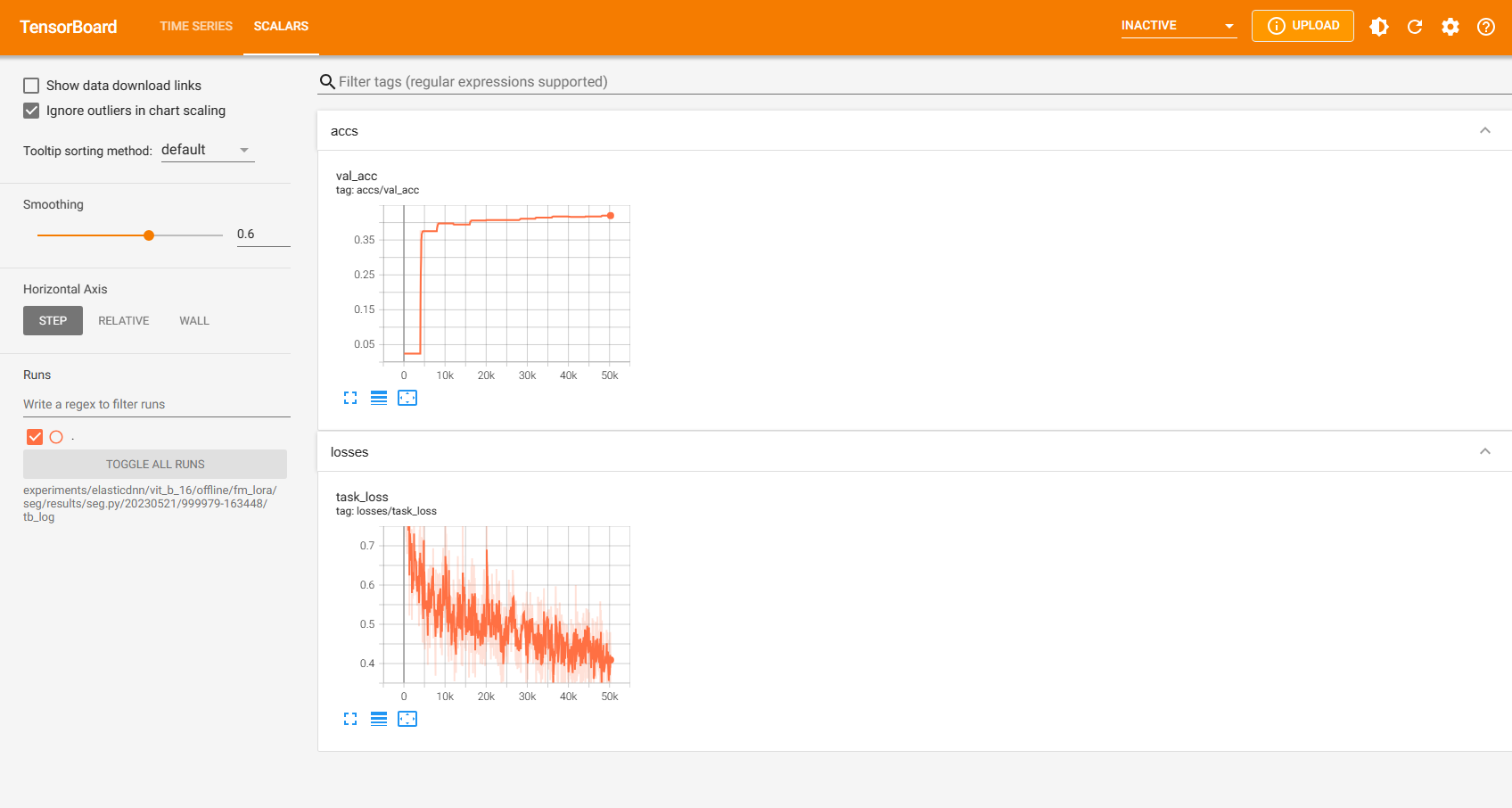
|
2.png
ADDED
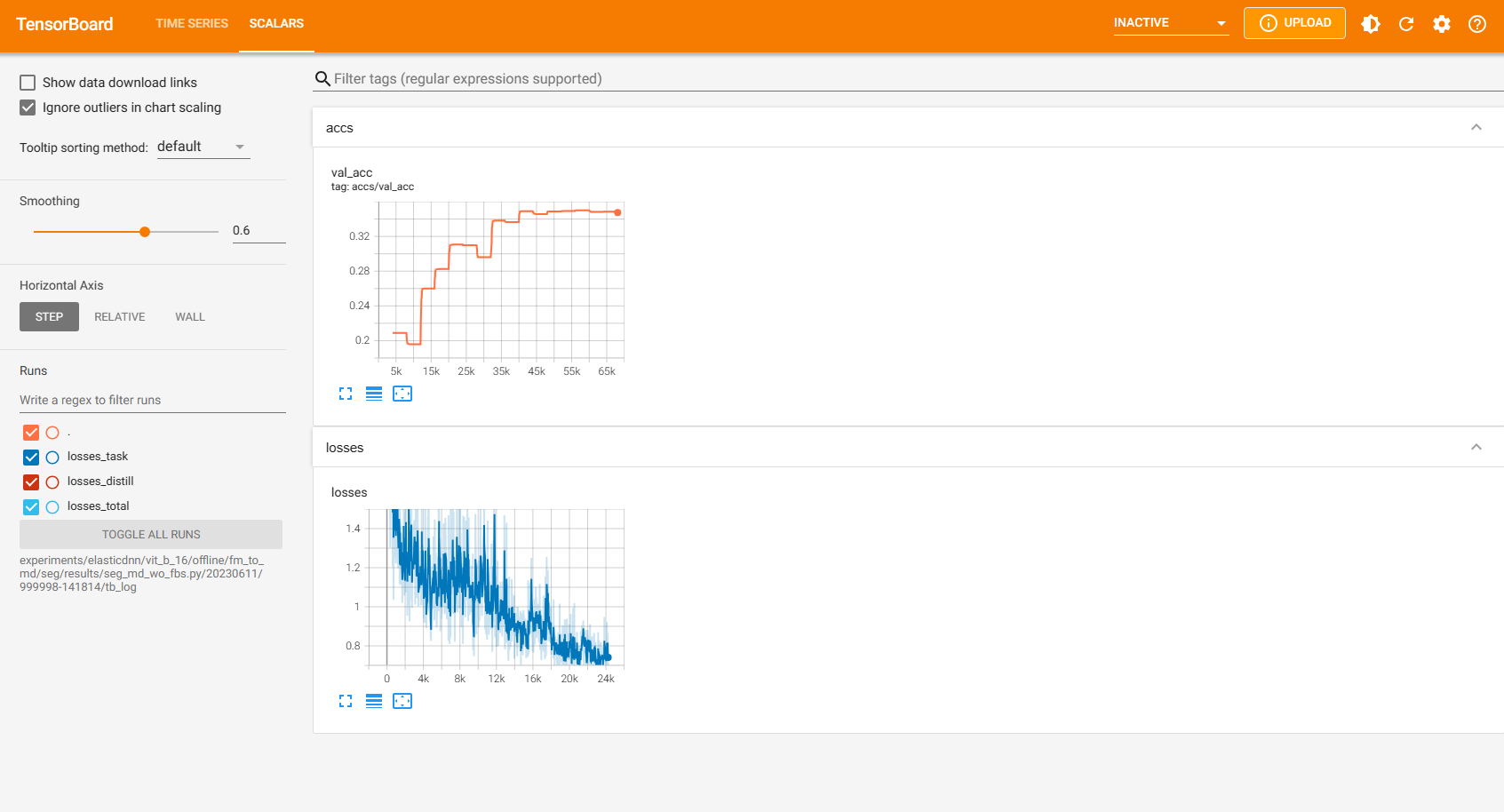
|
3.png
ADDED

|
4.png
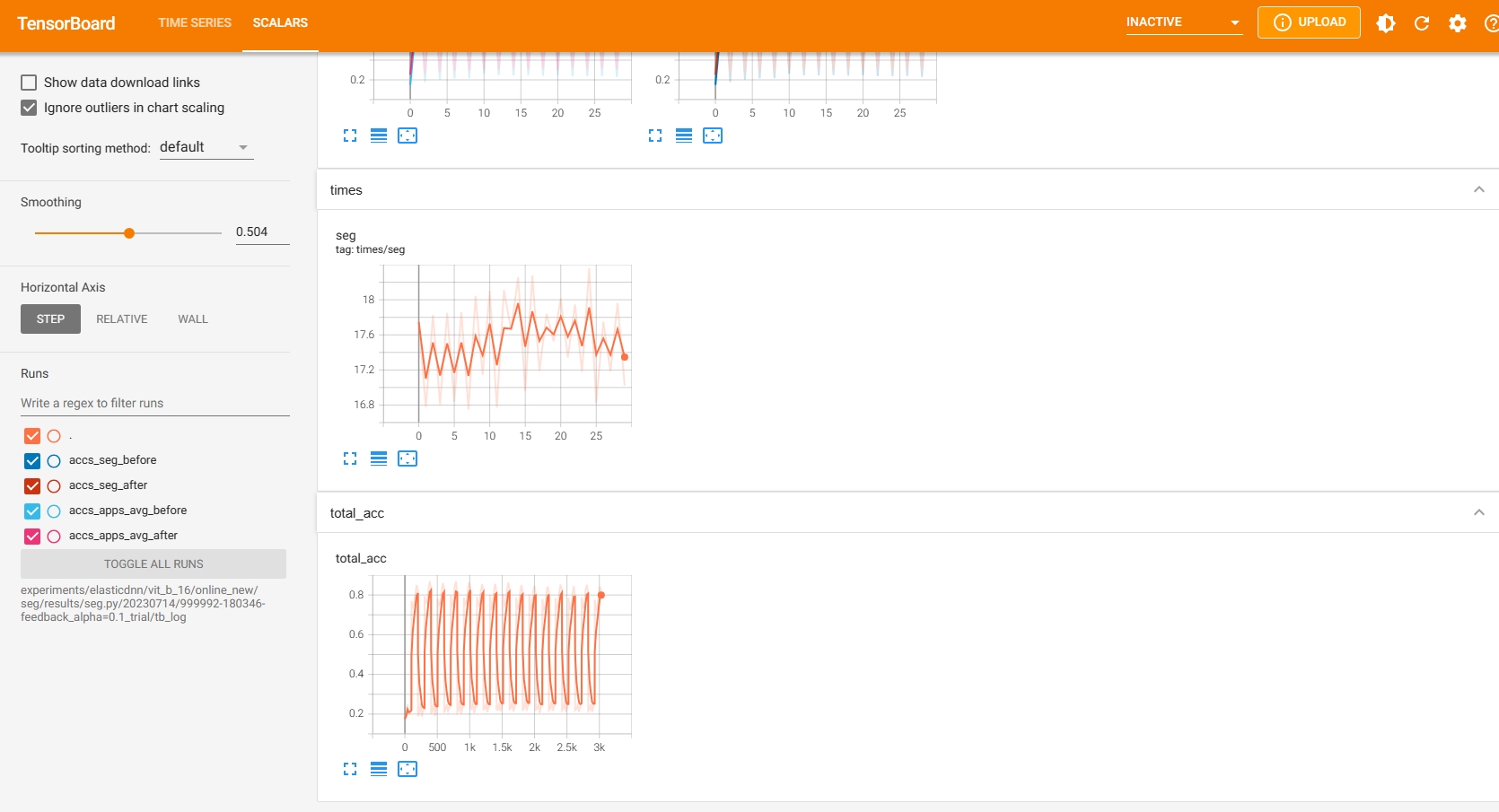
ADDED
|
5.png
ADDED
|
Implementation.png
ADDED
|
README.md
CHANGED
|
@@ -1,10 +1,5 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
emoji: 📊
|
| 4 |
-
colorFrom: green
|
| 5 |
-
colorTo: red
|
| 6 |
sdk: static
|
| 7 |
-
|
| 8 |
-
---
|
| 9 |
-
|
| 10 |
-
Check out the configuration reference at https://huggingface.co/docs/hub/spaces-config-reference
|
|
|
|
| 1 |
---
|
| 2 |
+
title: EdgeFM
|
|
|
|
|
|
|
|
|
|
| 3 |
sdk: static
|
| 4 |
+
app_file: index.html
|
| 5 |
+
---
|
|
|
|
|
|
clip-baseline.png
ADDED
|
clip-index.png
ADDED
|
clip-online.png
ADDED
|
cls_lora.png
ADDED
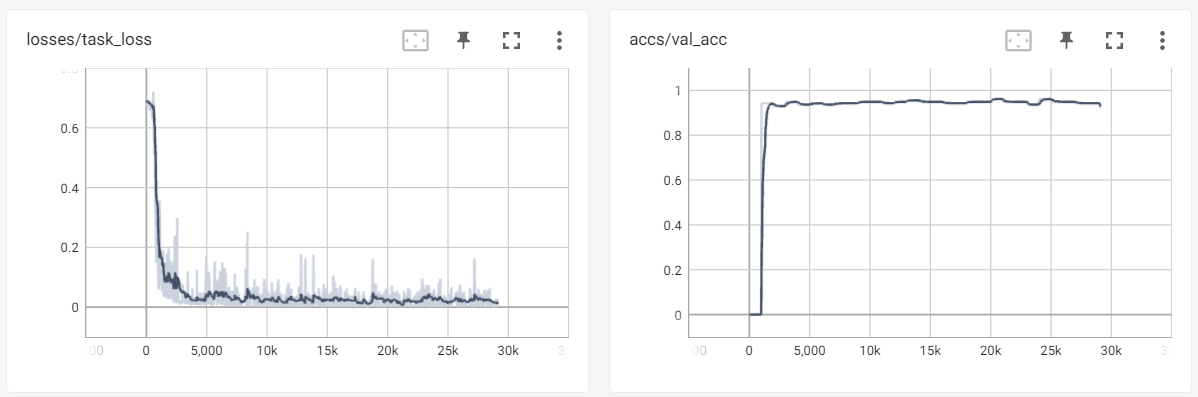
|
cls_md_w_fbs_index.png
ADDED

|
cls_md_wo_fbs.png
ADDED

|
cls_online.png
ADDED
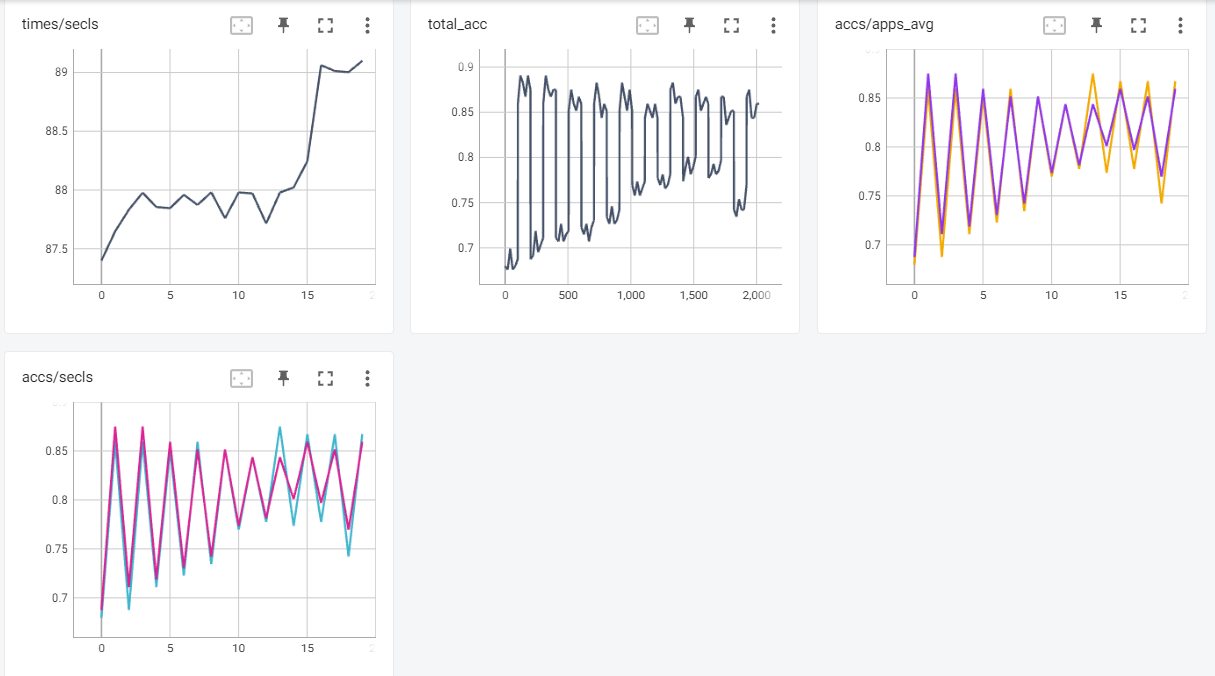
|
data/README.md
ADDED
|
@@ -0,0 +1,94 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
## How to implement a dataset?
|
| 2 |
+
|
| 3 |
+
For example, we want to implement a image classification dataset.
|
| 4 |
+
|
| 5 |
+
1. create a file in corresponding directory, i.e. `benchmark/data/datasets/image_classification`
|
| 6 |
+
|
| 7 |
+
2. create a class (inherited from `benchmark.data.datasets.ab_dataset.ABDataset`), e.g. `class YourDataset(ABDataset)`
|
| 8 |
+
|
| 9 |
+
3. register your dataset with `benchmark.data.datasets.registry.dataset_register(name, classes, classes_aliases)`, which represents the name of your dataset, the classes of your dataset, and the possible aliases of the classes. Examples refer to `benchmark/data/datasets/image_classification/cifar10.py` or other files.
|
| 10 |
+
|
| 11 |
+
Note that the order of `classes` must match the indexes. For example, `classes` of MNIST must be `['0', '1', '2', ..., '9']`, which means 0-th class is '0', 1-st class is '1', 2-nd class is '2', ...; `['1', '2', '0', ...]` is not correct because 0-th class is not '1' and 1-st class is not '2'.
|
| 12 |
+
|
| 13 |
+
How to get `classes` of a dataset? For PyTorch built-in dataset (CIFAR10, MNIST, ...) and general dataset build by `ImageFolder`, you can initialize it (e.g. `dataset = CIFAR10(...)`) and get its classes by `dataset.classes`.
|
| 14 |
+
|
| 15 |
+
```python
|
| 16 |
+
# How to get classes in CIFAR10?
|
| 17 |
+
from torchvision.datasets import CIFAR10
|
| 18 |
+
dataset = CIFAR10(...)
|
| 19 |
+
print(dataset.classes)
|
| 20 |
+
# copy this output to @dataset_register(classes=<what you copied>)
|
| 21 |
+
|
| 22 |
+
# it's not recommended to dynamically get classes, e.g.:
|
| 23 |
+
# this works but runs slowly!
|
| 24 |
+
from torchvision.datasets import CIFAR10 as RawCIFAR10
|
| 25 |
+
dataset = RawCIFAR10(...)
|
| 26 |
+
|
| 27 |
+
@dataset_register(
|
| 28 |
+
name='CIFAR10',
|
| 29 |
+
classes=dataset.classes
|
| 30 |
+
)
|
| 31 |
+
class CIFAR10(ABDataset):
|
| 32 |
+
# ...
|
| 33 |
+
```
|
| 34 |
+
|
| 35 |
+
For object detection dataset, you can read the annotation JSON file and find `categories` information in it.
|
| 36 |
+
|
| 37 |
+
4. implement abstract function `create_dataset(self, root_dir: str, split: str, transform: Optional[Compose], classes: List[str], ignore_classes: List[str], idx_map: Optional[Dict[int, int]])`.
|
| 38 |
+
|
| 39 |
+
Arguments:
|
| 40 |
+
|
| 41 |
+
- `root_dir`: the location of data
|
| 42 |
+
- `split`: `train / val / test`
|
| 43 |
+
- `transform`: preprocess function in `torchvision.transforms`
|
| 44 |
+
- `classes`: the same value with `dataset_register.classes`
|
| 45 |
+
- `ignore_classes`: **classes should be discarded. You should remove images which belong to these ignore classes.**
|
| 46 |
+
- `idx_map`: **map the original class index to new class index. For example, `{0: 2}` means the index of 0-th class will be 2 instead of 0. You should implement this by modifying the stored labels in the original dataset. **
|
| 47 |
+
|
| 48 |
+
You should do five things in this function:
|
| 49 |
+
|
| 50 |
+
1. if no user-defined transform is passed, you should implemented the default transform
|
| 51 |
+
2. create the original dataset
|
| 52 |
+
3. remove ignored classes in the original dataset if there are ignored classes
|
| 53 |
+
4. map the original class index to new class index if there is index map
|
| 54 |
+
5. split the original dataset to train / val / test dataset. If there's no val dataset in original dataset (e.g. DomainNetReal), you should split the original dataset to train / val / test dataset. If there's already val dataset in original dataset (e.g. CIFAR10 and ImageNet), regard the original val dataset as test dataset, and split the original train dataset into train / val dataset. Details just refer to existed files.
|
| 55 |
+
|
| 56 |
+
Example (`benchmark/data/datasets/image_classification/cifar10.py`):
|
| 57 |
+
|
| 58 |
+
```python
|
| 59 |
+
@dataset_register(
|
| 60 |
+
name='CIFAR10',
|
| 61 |
+
# means in the original CIFAR10, 0-th class is airplane, 1-st class is automobile, ...
|
| 62 |
+
classes=['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'],
|
| 63 |
+
# means 'automobile' and 'car' are the same thing actually
|
| 64 |
+
class_aliases=[['automobile', 'car']]
|
| 65 |
+
)
|
| 66 |
+
class CIFAR10(ABDataset):
|
| 67 |
+
def create_dataset(self, root_dir: str, split: str, transform: Optional[Compose],
|
| 68 |
+
classes: List[str], ignore_classes: List[str], idx_map: Optional[Dict[int, int]]):
|
| 69 |
+
# 1. if no user-defined transform is passed, you should implemented the default transform
|
| 70 |
+
if transform is None:
|
| 71 |
+
transform = cifar_like_image_train_aug() if split == 'train' else cifar_like_image_test_aug()
|
| 72 |
+
# 2. create the original dataset
|
| 73 |
+
dataset = RawCIFAR10(root_dir, split != 'test', transform=transform, download=True)
|
| 74 |
+
|
| 75 |
+
# 3. remove ignored classes in the original dataset if there are ignored classes
|
| 76 |
+
dataset.targets = np.asarray(dataset.targets)
|
| 77 |
+
if len(ignore_classes) > 0:
|
| 78 |
+
for ignore_class in ignore_classes:
|
| 79 |
+
dataset.data = dataset.data[dataset.targets != classes.index(ignore_class)]
|
| 80 |
+
dataset.targets = dataset.targets[dataset.targets != classes.index(ignore_class)]
|
| 81 |
+
|
| 82 |
+
# 4. map the original class index to new class index if there is index map
|
| 83 |
+
if idx_map is not None:
|
| 84 |
+
for ti, t in enumerate(dataset.targets):
|
| 85 |
+
dataset.targets[ti] = idx_map[t]
|
| 86 |
+
|
| 87 |
+
# 5. split the original dataset to train / val / test dataset.
|
| 88 |
+
# there is not val dataset in CIFAR10 dataset, so we split the val dataset from the train dataset.
|
| 89 |
+
if split != 'test':
|
| 90 |
+
dataset = train_val_split(dataset, split)
|
| 91 |
+
return dataset
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
After implementing a new dataset, you can create a test file in `example` and load the dataset by `benchmark.data.dataset.get_dataset()`. Try using this dataset to ensure it works. (Example: `example/1.py`)
|
data/__init__.py
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .dataset import get_dataset
|
| 2 |
+
from .build.build import build_scenario_manually_v2 as build_scenario
|
| 3 |
+
from .dataloader import build_dataloader
|
| 4 |
+
from .build.scenario import IndexReturnedDataset, MergedDataset
|
| 5 |
+
from .datasets.ab_dataset import ABDataset
|
| 6 |
+
from .build.scenario import Scenario
|
| 7 |
+
|
| 8 |
+
from .build_cl.build import build_cl_scenario
|
| 9 |
+
from .build_cl.scenario import Scenario as CLScenario
|
| 10 |
+
|
| 11 |
+
from .build_gen.build import build_scenario_manually_v2 as build_gen_scenario
|
| 12 |
+
from .build_gen.scenario import Scenario as GenScenario
|
| 13 |
+
|
| 14 |
+
from .datasets.dataset_split import split_dataset
|
data/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (722 Bytes). View file
|
|
|
data/__pycache__/dataloader.cpython-38.pyc
ADDED
|
Binary file (3.48 kB). View file
|
|
|
data/__pycache__/dataset.cpython-38.pyc
ADDED
|
Binary file (1.24 kB). View file
|
|
|
data/build/__init__.py
ADDED
|
File without changes
|
data/build/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (130 Bytes). View file
|
|
|
data/build/__pycache__/build.cpython-38.pyc
ADDED
|
Binary file (9.06 kB). View file
|
|
|
data/build/__pycache__/merge_alias.cpython-38.pyc
ADDED
|
Binary file (2.5 kB). View file
|
|
|
data/build/__pycache__/scenario.cpython-38.pyc
ADDED
|
Binary file (10.6 kB). View file
|
|
|
data/build/build.py
ADDED
|
@@ -0,0 +1,495 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Dict, List, Optional, Type, Union
|
| 2 |
+
from ..datasets.ab_dataset import ABDataset
|
| 3 |
+
# from benchmark.data.visualize import visualize_classes_in_object_detection
|
| 4 |
+
# from benchmark.scenario.val_domain_shift import get_val_domain_shift_transform
|
| 5 |
+
from ..dataset import get_dataset
|
| 6 |
+
import copy
|
| 7 |
+
from torchvision.transforms import Compose
|
| 8 |
+
|
| 9 |
+
from .merge_alias import merge_the_same_meaning_classes
|
| 10 |
+
from ..datasets.registery import static_dataset_registery
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
# some legacy aliases of variables:
|
| 14 |
+
# ignore_classes == discarded classes
|
| 15 |
+
# private_classes == unknown classes in partial / open-set / universal DA
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def _merge_the_same_meaning_classes(classes_info_of_all_datasets):
|
| 19 |
+
final_classes_of_all_datasets, rename_map = merge_the_same_meaning_classes(classes_info_of_all_datasets)
|
| 20 |
+
return final_classes_of_all_datasets, rename_map
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def _find_ignore_classes_when_sources_as_to_target_b(as_classes: List[List[str]], b_classes: List[str], da_mode):
|
| 24 |
+
thres = {'da': 3, 'partial_da': 2, 'open_set_da': 1, 'universal_da': 0}[da_mode]
|
| 25 |
+
|
| 26 |
+
from functools import reduce
|
| 27 |
+
a_classes = reduce(lambda res, cur: res | set(cur), as_classes, set())
|
| 28 |
+
|
| 29 |
+
if set(a_classes) == set(b_classes):
|
| 30 |
+
# a is equal to b, normal
|
| 31 |
+
# 1. no ignore classes; 2. match class idx
|
| 32 |
+
a_ignore_classes, b_ignore_classes = [], []
|
| 33 |
+
|
| 34 |
+
elif set(a_classes) > set(b_classes):
|
| 35 |
+
# a contains b, partial
|
| 36 |
+
a_ignore_classes, b_ignore_classes = [], []
|
| 37 |
+
if thres == 3 or thres == 1: # ignore extra classes in a
|
| 38 |
+
a_ignore_classes = set(a_classes) - set(b_classes)
|
| 39 |
+
|
| 40 |
+
elif set(a_classes) < set(b_classes):
|
| 41 |
+
# a is contained by b, open set
|
| 42 |
+
a_ignore_classes, b_ignore_classes = [], []
|
| 43 |
+
if thres == 3 or thres == 2: # ignore extra classes in b
|
| 44 |
+
b_ignore_classes = set(b_classes) - set(a_classes)
|
| 45 |
+
|
| 46 |
+
elif len(set(a_classes) & set(b_classes)) > 0:
|
| 47 |
+
a_ignore_classes, b_ignore_classes = [], []
|
| 48 |
+
if thres == 3:
|
| 49 |
+
a_ignore_classes = set(a_classes) - (set(a_classes) & set(b_classes))
|
| 50 |
+
b_ignore_classes = set(b_classes) - (set(a_classes) & set(b_classes))
|
| 51 |
+
elif thres == 2:
|
| 52 |
+
b_ignore_classes = set(b_classes) - (set(a_classes) & set(b_classes))
|
| 53 |
+
elif thres == 1:
|
| 54 |
+
a_ignore_classes = set(a_classes) - (set(a_classes) & set(b_classes))
|
| 55 |
+
|
| 56 |
+
else:
|
| 57 |
+
return None # a has no intersection with b, none
|
| 58 |
+
|
| 59 |
+
as_ignore_classes = [list(set(a_classes) & set(a_ignore_classes)) for a_classes in as_classes]
|
| 60 |
+
|
| 61 |
+
return as_ignore_classes, list(b_ignore_classes)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def _find_private_classes_when_sources_as_to_target_b(as_classes: List[List[str]], b_classes: List[str], da_mode):
|
| 65 |
+
thres = {'da': 3, 'partial_da': 2, 'open_set_da': 1, 'universal_da': 0}[da_mode]
|
| 66 |
+
|
| 67 |
+
from functools import reduce
|
| 68 |
+
a_classes = reduce(lambda res, cur: res | set(cur), as_classes, set())
|
| 69 |
+
|
| 70 |
+
if set(a_classes) == set(b_classes):
|
| 71 |
+
# a is equal to b, normal
|
| 72 |
+
# 1. no ignore classes; 2. match class idx
|
| 73 |
+
a_private_classes, b_private_classes = [], []
|
| 74 |
+
|
| 75 |
+
elif set(a_classes) > set(b_classes):
|
| 76 |
+
# a contains b, partial
|
| 77 |
+
a_private_classes, b_private_classes = [], []
|
| 78 |
+
# if thres == 2 or thres == 0: # ignore extra classes in a
|
| 79 |
+
# a_private_classes = set(a_classes) - set(b_classes)
|
| 80 |
+
# if thres == 0: # ignore extra classes in a
|
| 81 |
+
# a_private_classes = set(a_classes) - set(b_classes)
|
| 82 |
+
|
| 83 |
+
elif set(a_classes) < set(b_classes):
|
| 84 |
+
# a is contained by b, open set
|
| 85 |
+
a_private_classes, b_private_classes = [], []
|
| 86 |
+
if thres == 1 or thres == 0: # ignore extra classes in b
|
| 87 |
+
b_private_classes = set(b_classes) - set(a_classes)
|
| 88 |
+
|
| 89 |
+
elif len(set(a_classes) & set(b_classes)) > 0:
|
| 90 |
+
a_private_classes, b_private_classes = [], []
|
| 91 |
+
if thres == 0:
|
| 92 |
+
# a_private_classes = set(a_classes) - (set(a_classes) & set(b_classes))
|
| 93 |
+
|
| 94 |
+
b_private_classes = set(b_classes) - (set(a_classes) & set(b_classes))
|
| 95 |
+
elif thres == 1:
|
| 96 |
+
b_private_classes = set(b_classes) - (set(a_classes) & set(b_classes))
|
| 97 |
+
elif thres == 2:
|
| 98 |
+
# a_private_classes = set(a_classes) - (set(a_classes) & set(b_classes))
|
| 99 |
+
pass
|
| 100 |
+
|
| 101 |
+
else:
|
| 102 |
+
return None # a has no intersection with b, none
|
| 103 |
+
|
| 104 |
+
return list(b_private_classes)
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
class _ABDatasetMetaInfo:
|
| 108 |
+
def __init__(self, name, classes, task_type, object_type, class_aliases, shift_type):
|
| 109 |
+
self.name = name
|
| 110 |
+
self.classes = classes
|
| 111 |
+
self.class_aliases = class_aliases
|
| 112 |
+
self.shift_type = shift_type
|
| 113 |
+
self.task_type = task_type
|
| 114 |
+
self.object_type = object_type
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def _get_dist_shift_type_when_source_a_to_target_b(a: _ABDatasetMetaInfo, b: _ABDatasetMetaInfo):
|
| 118 |
+
if b.shift_type is None:
|
| 119 |
+
return 'Dataset Shifts'
|
| 120 |
+
|
| 121 |
+
if a.name in b.shift_type.keys():
|
| 122 |
+
return b.shift_type[a.name]
|
| 123 |
+
|
| 124 |
+
mid_dataset_name = list(b.shift_type.keys())[0]
|
| 125 |
+
mid_dataset_meta_info = _ABDatasetMetaInfo(mid_dataset_name, *static_dataset_registery[mid_dataset_name][1:])
|
| 126 |
+
|
| 127 |
+
return _get_dist_shift_type_when_source_a_to_target_b(a, mid_dataset_meta_info) + ' + ' + list(b.shift_type.values())[0]
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def _handle_all_datasets_v2(source_datasets: List[_ABDatasetMetaInfo], target_datasets: List[_ABDatasetMetaInfo], da_mode):
|
| 131 |
+
|
| 132 |
+
# 1. merge the same meaning classes
|
| 133 |
+
classes_info_of_all_datasets = {
|
| 134 |
+
d.name: (d.classes, d.class_aliases)
|
| 135 |
+
for d in source_datasets + target_datasets
|
| 136 |
+
}
|
| 137 |
+
final_classes_of_all_datasets, rename_map = _merge_the_same_meaning_classes(classes_info_of_all_datasets)
|
| 138 |
+
all_datasets_classes = copy.deepcopy(final_classes_of_all_datasets)
|
| 139 |
+
|
| 140 |
+
# print(all_datasets_known_classes)
|
| 141 |
+
|
| 142 |
+
# 2. find ignored classes according to DA mode
|
| 143 |
+
# source_datasets_ignore_classes, target_datasets_ignore_classes = {d.name: [] for d in source_datasets}, \
|
| 144 |
+
# {d.name: [] for d in target_datasets}
|
| 145 |
+
# source_datasets_private_classes, target_datasets_private_classes = {d.name: [] for d in source_datasets}, \
|
| 146 |
+
# {d.name: [] for d in target_datasets}
|
| 147 |
+
target_source_relationship_map = {td.name: {} for td in target_datasets}
|
| 148 |
+
# source_target_relationship_map = {sd.name: [] for sd in source_datasets}
|
| 149 |
+
|
| 150 |
+
# 1. construct target_source_relationship_map
|
| 151 |
+
for sd in source_datasets:#sd和td使列表中每一个元素(类)的实例
|
| 152 |
+
for td in target_datasets:
|
| 153 |
+
sc = all_datasets_classes[sd.name]
|
| 154 |
+
tc = all_datasets_classes[td.name]
|
| 155 |
+
|
| 156 |
+
if len(set(sc) & set(tc)) == 0:#只保留有相似类别的源域和目标域
|
| 157 |
+
continue
|
| 158 |
+
|
| 159 |
+
target_source_relationship_map[td.name][sd.name] = _get_dist_shift_type_when_source_a_to_target_b(sd, td)
|
| 160 |
+
|
| 161 |
+
# print(target_source_relationship_map)
|
| 162 |
+
# exit()
|
| 163 |
+
|
| 164 |
+
source_datasets_ignore_classes = {}
|
| 165 |
+
for td_name, v1 in target_source_relationship_map.items():
|
| 166 |
+
for sd_name, v2 in v1.items():
|
| 167 |
+
source_datasets_ignore_classes[sd_name + '|' + td_name] = []
|
| 168 |
+
target_datasets_ignore_classes = {d.name: [] for d in target_datasets}
|
| 169 |
+
target_datasets_private_classes = {d.name: [] for d in target_datasets}
|
| 170 |
+
# 保证对于每个目标域上的DA都符合给定的label shift
|
| 171 |
+
# 所以不同目标域就算对应同一个源域,该源域也可能不相同
|
| 172 |
+
|
| 173 |
+
for td_name, v1 in target_source_relationship_map.items():
|
| 174 |
+
sd_names = list(v1.keys())
|
| 175 |
+
|
| 176 |
+
sds_classes = [all_datasets_classes[sd_name] for sd_name in sd_names]
|
| 177 |
+
td_classes = all_datasets_classes[td_name]
|
| 178 |
+
ss_ignore_classes, t_ignore_classes = _find_ignore_classes_when_sources_as_to_target_b(sds_classes, td_classes, da_mode)#根据DA方式不同产生ignore_classes
|
| 179 |
+
t_private_classes = _find_private_classes_when_sources_as_to_target_b(sds_classes, td_classes, da_mode)
|
| 180 |
+
|
| 181 |
+
for sd_name, s_ignore_classes in zip(sd_names, ss_ignore_classes):
|
| 182 |
+
source_datasets_ignore_classes[sd_name + '|' + td_name] = s_ignore_classes
|
| 183 |
+
target_datasets_ignore_classes[td_name] = t_ignore_classes
|
| 184 |
+
target_datasets_private_classes[td_name] = t_private_classes
|
| 185 |
+
|
| 186 |
+
source_datasets_ignore_classes = {k: sorted(set(v), key=v.index) for k, v in source_datasets_ignore_classes.items()}
|
| 187 |
+
target_datasets_ignore_classes = {k: sorted(set(v), key=v.index) for k, v in target_datasets_ignore_classes.items()}
|
| 188 |
+
target_datasets_private_classes = {k: sorted(set(v), key=v.index) for k, v in target_datasets_private_classes.items()}
|
| 189 |
+
|
| 190 |
+
# for k, v in source_datasets_ignore_classes.items():
|
| 191 |
+
# print(k, len(v))
|
| 192 |
+
# print()
|
| 193 |
+
# for k, v in target_datasets_ignore_classes.items():
|
| 194 |
+
# print(k, len(v))
|
| 195 |
+
# print()
|
| 196 |
+
# for k, v in target_datasets_private_classes.items():
|
| 197 |
+
# print(k, len(v))
|
| 198 |
+
# print()
|
| 199 |
+
|
| 200 |
+
# print(source_datasets_private_classes, target_datasets_private_classes)
|
| 201 |
+
# 3. reparse classes idx
|
| 202 |
+
# 3.1. agg all used classes
|
| 203 |
+
# all_used_classes = []
|
| 204 |
+
# all_datasets_private_class_idx_map = {}
|
| 205 |
+
|
| 206 |
+
# source_datasets_classes_idx_map = {}
|
| 207 |
+
# for td_name, v1 in target_source_relationship_map.items():
|
| 208 |
+
# for sd_name, v2 in v1.items():
|
| 209 |
+
# source_datasets_classes_idx_map[sd_name + '|' + td_name] = []
|
| 210 |
+
# target_datasets_classes_idx_map = {}
|
| 211 |
+
|
| 212 |
+
global_idx = 0
|
| 213 |
+
all_used_classes_idx_map = {}
|
| 214 |
+
# all_datasets_known_classes = {d: [] for d in final_classes_of_all_datasets.keys()}
|
| 215 |
+
for dataset_name, classes in all_datasets_classes.items():
|
| 216 |
+
if dataset_name not in target_datasets_ignore_classes.keys():
|
| 217 |
+
ignore_classes = [0] * 100000
|
| 218 |
+
for sn, sic in source_datasets_ignore_classes.items():
|
| 219 |
+
if sn.startswith(dataset_name):
|
| 220 |
+
if len(sic) < len(ignore_classes):
|
| 221 |
+
ignore_classes = sic
|
| 222 |
+
else:
|
| 223 |
+
ignore_classes = target_datasets_ignore_classes[dataset_name]
|
| 224 |
+
private_classes = [] \
|
| 225 |
+
if dataset_name not in target_datasets_ignore_classes.keys() else target_datasets_private_classes[dataset_name]
|
| 226 |
+
|
| 227 |
+
for c in classes:
|
| 228 |
+
if c not in ignore_classes and c not in all_used_classes_idx_map.keys() and c not in private_classes:
|
| 229 |
+
all_used_classes_idx_map[c] = global_idx
|
| 230 |
+
global_idx += 1
|
| 231 |
+
|
| 232 |
+
# print(all_used_classes_idx_map)
|
| 233 |
+
|
| 234 |
+
# dataset_private_class_idx_offset = 0
|
| 235 |
+
target_private_class_idx = global_idx
|
| 236 |
+
target_datasets_private_class_idx = {d: None for d in target_datasets_private_classes.keys()}
|
| 237 |
+
|
| 238 |
+
for dataset_name, classes in final_classes_of_all_datasets.items():
|
| 239 |
+
if dataset_name not in target_datasets_private_classes.keys():
|
| 240 |
+
continue
|
| 241 |
+
|
| 242 |
+
# ignore_classes = target_datasets_ignore_classes[dataset_name]
|
| 243 |
+
private_classes = target_datasets_private_classes[dataset_name]
|
| 244 |
+
# private_classes = [] \
|
| 245 |
+
# if dataset_name in source_datasets_private_classes.keys() else target_datasets_private_classes[dataset_name]
|
| 246 |
+
# for c in classes:
|
| 247 |
+
# if c not in ignore_classes and c not in all_used_classes_idx_map.keys() and c in private_classes:
|
| 248 |
+
# all_used_classes_idx_map[c] = global_idx + dataset_private_class_idx_offset
|
| 249 |
+
|
| 250 |
+
if len(private_classes) > 0:
|
| 251 |
+
# all_datasets_private_class_idx[dataset_name] = global_idx + dataset_private_class_idx_offset
|
| 252 |
+
# dataset_private_class_idx_offset += 1
|
| 253 |
+
# if dataset_name in source_datasets_private_classes.keys():
|
| 254 |
+
# if source_private_class_idx is None:
|
| 255 |
+
# source_private_class_idx = global_idx if target_private_class_idx is None else target_private_class_idx + 1
|
| 256 |
+
# all_datasets_private_class_idx[dataset_name] = source_private_class_idx
|
| 257 |
+
# else:
|
| 258 |
+
# if target_private_class_idx is None:
|
| 259 |
+
# target_private_class_idx = global_idx if source_private_class_idx is None else source_private_class_idx + 1
|
| 260 |
+
# all_datasets_private_class_idx[dataset_name] = target_private_class_idx
|
| 261 |
+
target_datasets_private_class_idx[dataset_name] = target_private_class_idx
|
| 262 |
+
target_private_class_idx += 1
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
# all_used_classes = sorted(set(all_used_classes), key=all_used_classes.index)
|
| 266 |
+
# all_used_classes_idx_map = {c: i for i, c in enumerate(all_used_classes)}
|
| 267 |
+
|
| 268 |
+
# print('rename_map', rename_map)
|
| 269 |
+
|
| 270 |
+
# 3.2 raw_class -> rename_map[raw_classes] -> all_used_classes_idx_map
|
| 271 |
+
all_datasets_e2e_idx_map = {}
|
| 272 |
+
all_datasets_e2e_class_to_idx_map = {}
|
| 273 |
+
|
| 274 |
+
for td_name, v1 in target_source_relationship_map.items():
|
| 275 |
+
sd_names = list(v1.keys())
|
| 276 |
+
sds_classes = [all_datasets_classes[sd_name] for sd_name in sd_names]
|
| 277 |
+
td_classes = all_datasets_classes[td_name]
|
| 278 |
+
|
| 279 |
+
for sd_name, sd_classes in zip(sd_names, sds_classes):
|
| 280 |
+
cur_e2e_idx_map = {}
|
| 281 |
+
cur_e2e_class_to_idx_map = {}
|
| 282 |
+
|
| 283 |
+
for raw_ci, raw_c in enumerate(sd_classes):
|
| 284 |
+
renamed_c = raw_c if raw_c not in rename_map[dataset_name] else rename_map[dataset_name][raw_c]
|
| 285 |
+
|
| 286 |
+
ignore_classes = source_datasets_ignore_classes[sd_name + '|' + td_name]
|
| 287 |
+
if renamed_c in ignore_classes:
|
| 288 |
+
continue
|
| 289 |
+
|
| 290 |
+
idx = all_used_classes_idx_map[renamed_c]
|
| 291 |
+
|
| 292 |
+
cur_e2e_idx_map[raw_ci] = idx
|
| 293 |
+
cur_e2e_class_to_idx_map[raw_c] = idx
|
| 294 |
+
|
| 295 |
+
all_datasets_e2e_idx_map[sd_name + '|' + td_name] = cur_e2e_idx_map
|
| 296 |
+
all_datasets_e2e_class_to_idx_map[sd_name + '|' + td_name] = cur_e2e_class_to_idx_map
|
| 297 |
+
cur_e2e_idx_map = {}
|
| 298 |
+
cur_e2e_class_to_idx_map = {}
|
| 299 |
+
for raw_ci, raw_c in enumerate(td_classes):
|
| 300 |
+
renamed_c = raw_c if raw_c not in rename_map[dataset_name] else rename_map[dataset_name][raw_c]
|
| 301 |
+
|
| 302 |
+
ignore_classes = target_datasets_ignore_classes[td_name]
|
| 303 |
+
if renamed_c in ignore_classes:
|
| 304 |
+
continue
|
| 305 |
+
|
| 306 |
+
if renamed_c in target_datasets_private_classes[td_name]:
|
| 307 |
+
idx = target_datasets_private_class_idx[td_name]
|
| 308 |
+
else:
|
| 309 |
+
idx = all_used_classes_idx_map[renamed_c]
|
| 310 |
+
|
| 311 |
+
cur_e2e_idx_map[raw_ci] = idx
|
| 312 |
+
cur_e2e_class_to_idx_map[raw_c] = idx
|
| 313 |
+
|
| 314 |
+
all_datasets_e2e_idx_map[td_name] = cur_e2e_idx_map
|
| 315 |
+
all_datasets_e2e_class_to_idx_map[td_name] = cur_e2e_class_to_idx_map
|
| 316 |
+
|
| 317 |
+
all_datasets_ignore_classes = {**source_datasets_ignore_classes, **target_datasets_ignore_classes}
|
| 318 |
+
# all_datasets_private_classes = {**source_datasets_private_classes, **target_datasets_private_classes}
|
| 319 |
+
|
| 320 |
+
classes_idx_set = []
|
| 321 |
+
for d, m in all_datasets_e2e_class_to_idx_map.items():
|
| 322 |
+
classes_idx_set += list(m.values())
|
| 323 |
+
classes_idx_set = set(classes_idx_set)
|
| 324 |
+
num_classes = len(classes_idx_set)
|
| 325 |
+
|
| 326 |
+
return all_datasets_ignore_classes, target_datasets_private_classes, \
|
| 327 |
+
all_datasets_e2e_idx_map, all_datasets_e2e_class_to_idx_map, target_datasets_private_class_idx, \
|
| 328 |
+
target_source_relationship_map, rename_map, num_classes
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
def _build_scenario_info_v2(
|
| 332 |
+
source_datasets_name: List[str],
|
| 333 |
+
target_datasets_order: List[str],
|
| 334 |
+
da_mode: str
|
| 335 |
+
):
|
| 336 |
+
assert da_mode in ['close_set', 'partial', 'open_set', 'universal']
|
| 337 |
+
da_mode = {'close_set': 'da', 'partial': 'partial_da', 'open_set': 'open_set_da', 'universal': 'universal_da'}[da_mode]
|
| 338 |
+
|
| 339 |
+
source_datasets_meta_info = [_ABDatasetMetaInfo(d, *static_dataset_registery[d][1:]) for d in source_datasets_name]#获知对应的名字和对应属性,要添加数据集时,直接register就行
|
| 340 |
+
target_datasets_meta_info = [_ABDatasetMetaInfo(d, *static_dataset_registery[d][1:]) for d in list(set(target_datasets_order))]
|
| 341 |
+
|
| 342 |
+
all_datasets_ignore_classes, target_datasets_private_classes, \
|
| 343 |
+
all_datasets_e2e_idx_map, all_datasets_e2e_class_to_idx_map, target_datasets_private_class_idx, \
|
| 344 |
+
target_source_relationship_map, rename_map, num_classes \
|
| 345 |
+
= _handle_all_datasets_v2(source_datasets_meta_info, target_datasets_meta_info, da_mode)
|
| 346 |
+
|
| 347 |
+
return all_datasets_ignore_classes, target_datasets_private_classes, \
|
| 348 |
+
all_datasets_e2e_idx_map, all_datasets_e2e_class_to_idx_map, target_datasets_private_class_idx, \
|
| 349 |
+
target_source_relationship_map, rename_map, num_classes
|
| 350 |
+
|
| 351 |
+
|
| 352 |
+
def build_scenario_manually_v2(
|
| 353 |
+
source_datasets_name: List[str],
|
| 354 |
+
target_datasets_order: List[str],
|
| 355 |
+
da_mode: str,
|
| 356 |
+
data_dirs: Dict[str, str],
|
| 357 |
+
# transforms: Optional[Dict[str, Compose]] = None
|
| 358 |
+
):
|
| 359 |
+
configs = copy.deepcopy(locals())#返回当前局部变量
|
| 360 |
+
|
| 361 |
+
source_datasets_meta_info = [_ABDatasetMetaInfo(d, *static_dataset_registery[d][1:]) for d in source_datasets_name]
|
| 362 |
+
target_datasets_meta_info = [_ABDatasetMetaInfo(d, *static_dataset_registery[d][1:]) for d in list(set(target_datasets_order))]
|
| 363 |
+
|
| 364 |
+
all_datasets_ignore_classes, target_datasets_private_classes, \
|
| 365 |
+
all_datasets_e2e_idx_map, all_datasets_e2e_class_to_idx_map, target_datasets_private_class_idx, \
|
| 366 |
+
target_source_relationship_map, rename_map, num_classes \
|
| 367 |
+
= _build_scenario_info_v2(source_datasets_name, target_datasets_order, da_mode)
|
| 368 |
+
# from rich.console import Console
|
| 369 |
+
# console = Console(width=10000)
|
| 370 |
+
|
| 371 |
+
# def print_obj(_o):
|
| 372 |
+
# # import pprint
|
| 373 |
+
# # s = pprint.pformat(_o, width=140, compact=True)
|
| 374 |
+
# console.print(_o)
|
| 375 |
+
|
| 376 |
+
# console.print('configs:', style='bold red')
|
| 377 |
+
# print_obj(configs)
|
| 378 |
+
# console.print('renamed classes:', style='bold red')
|
| 379 |
+
# print_obj(rename_map)
|
| 380 |
+
# console.print('discarded classes:', style='bold red')
|
| 381 |
+
# print_obj(all_datasets_ignore_classes)
|
| 382 |
+
# console.print('unknown classes:', style='bold red')
|
| 383 |
+
# print_obj(target_datasets_private_classes)
|
| 384 |
+
# console.print('class to index map:', style='bold red')
|
| 385 |
+
# print_obj(all_datasets_e2e_class_to_idx_map)
|
| 386 |
+
# console.print('index map:', style='bold red')
|
| 387 |
+
# print_obj(all_datasets_e2e_idx_map)
|
| 388 |
+
# console = Console()
|
| 389 |
+
# # console.print('class distribution:', style='bold red')
|
| 390 |
+
# # class_dist = {
|
| 391 |
+
# # k: {
|
| 392 |
+
# # '#known classes': len(all_datasets_known_classes[k]),
|
| 393 |
+
# # '#unknown classes': len(all_datasets_private_classes[k]),
|
| 394 |
+
# # '#discarded classes': len(all_datasets_ignore_classes[k])
|
| 395 |
+
# # } for k in all_datasets_ignore_classes.keys()
|
| 396 |
+
# # }
|
| 397 |
+
# # print_obj(class_dist)
|
| 398 |
+
# console.print('corresponding sources of each target:', style='bold red')
|
| 399 |
+
# print_obj(target_source_relationship_map)
|
| 400 |
+
|
| 401 |
+
# return
|
| 402 |
+
|
| 403 |
+
# res_source_datasets_map = {d: {split: get_dataset(d, data_dirs[d], split, getattr(transforms, d, None),
|
| 404 |
+
# all_datasets_ignore_classes[d], all_datasets_e2e_idx_map[d])
|
| 405 |
+
# for split in ['train', 'val', 'test']}
|
| 406 |
+
# for d in source_datasets_name}
|
| 407 |
+
# res_target_datasets_map = {d: {'train': get_num_limited_dataset(get_dataset(d, data_dirs[d], 'test', getattr(transforms, d, None),
|
| 408 |
+
# all_datasets_ignore_classes[d], all_datasets_e2e_idx_map[d]),
|
| 409 |
+
# num_samples_in_each_target_domain),
|
| 410 |
+
# 'test': get_dataset(d, data_dirs[d], 'test', getattr(transforms, d, None),
|
| 411 |
+
# all_datasets_ignore_classes[d], all_datasets_e2e_idx_map[d])
|
| 412 |
+
# }
|
| 413 |
+
# for d in list(set(target_datasets_order))}
|
| 414 |
+
|
| 415 |
+
# res_source_datasets_map = {d: {split: get_dataset(d.split('|')[0], data_dirs[d.split('|')[0]], split,
|
| 416 |
+
# getattr(transforms, d.split('|')[0], None),
|
| 417 |
+
# all_datasets_ignore_classes[d], all_datasets_e2e_idx_map[d])
|
| 418 |
+
# for split in ['train', 'val', 'test']}
|
| 419 |
+
# for d in all_datasets_ignore_classes.keys() if d.split('|')[0] in source_datasets_name}
|
| 420 |
+
|
| 421 |
+
# from functools import reduce
|
| 422 |
+
# res_offline_train_source_datasets_map = {}
|
| 423 |
+
# res_offline_train_source_datasets_map_names = {}
|
| 424 |
+
|
| 425 |
+
# for d in source_datasets_name:
|
| 426 |
+
# source_dataset_with_max_num_classes = None
|
| 427 |
+
|
| 428 |
+
# for ed_name, ed in res_source_datasets_map.items():
|
| 429 |
+
# if not ed_name.startswith(d):
|
| 430 |
+
# continue
|
| 431 |
+
|
| 432 |
+
# if source_dataset_with_max_num_classes is None:
|
| 433 |
+
# source_dataset_with_max_num_classes = ed
|
| 434 |
+
# res_offline_train_source_datasets_map_names[d] = ed_name
|
| 435 |
+
|
| 436 |
+
# if len(ed['train'].ignore_classes) < len(source_dataset_with_max_num_classes['train'].ignore_classes):
|
| 437 |
+
# source_dataset_with_max_num_classes = ed
|
| 438 |
+
# res_offline_train_source_datasets_map_names[d] = ed_name
|
| 439 |
+
|
| 440 |
+
# res_offline_train_source_datasets_map[d] = source_dataset_with_max_num_classes
|
| 441 |
+
|
| 442 |
+
# res_target_datasets_map = {d: {split: get_dataset(d, data_dirs[d], split, getattr(transforms, d, None),
|
| 443 |
+
# all_datasets_ignore_classes[d], all_datasets_e2e_idx_map[d])
|
| 444 |
+
# for split in ['train', 'val', 'test']}
|
| 445 |
+
# for d in list(set(target_datasets_order))}
|
| 446 |
+
|
| 447 |
+
from .scenario import Scenario, DatasetMetaInfo
|
| 448 |
+
|
| 449 |
+
# test_scenario = Scenario(
|
| 450 |
+
# config=configs,
|
| 451 |
+
# offline_source_datasets_meta_info={
|
| 452 |
+
# d: DatasetMetaInfo(d,
|
| 453 |
+
# {k: v for k, v in all_datasets_e2e_class_to_idx_map[res_offline_train_source_datasets_map_names[d]].items()},
|
| 454 |
+
# None)
|
| 455 |
+
# for d in source_datasets_name
|
| 456 |
+
# },
|
| 457 |
+
# offline_source_datasets={d: res_offline_train_source_datasets_map[d] for d in source_datasets_name},
|
| 458 |
+
|
| 459 |
+
# online_datasets_meta_info=[
|
| 460 |
+
# (
|
| 461 |
+
# {sd + '|' + d: DatasetMetaInfo(d,
|
| 462 |
+
# {k: v for k, v in all_datasets_e2e_class_to_idx_map[sd + '|' + d].items()},
|
| 463 |
+
# None)
|
| 464 |
+
# for sd in target_source_relationship_map[d].keys()},
|
| 465 |
+
# DatasetMetaInfo(d,
|
| 466 |
+
# {k: v for k, v in all_datasets_e2e_class_to_idx_map[d].items() if k not in target_datasets_private_classes[d]},
|
| 467 |
+
# target_datasets_private_class_idx[d])
|
| 468 |
+
# )
|
| 469 |
+
# for d in target_datasets_order
|
| 470 |
+
# ],
|
| 471 |
+
# online_datasets={**res_source_datasets_map, **res_target_datasets_map},
|
| 472 |
+
# target_domains_order=target_datasets_order,
|
| 473 |
+
# target_source_map=target_source_relationship_map,
|
| 474 |
+
# num_classes=num_classes
|
| 475 |
+
# )
|
| 476 |
+
import os
|
| 477 |
+
os.environ['_ZQL_NUMC'] = str(num_classes)
|
| 478 |
+
|
| 479 |
+
test_scenario = Scenario(config=configs, all_datasets_ignore_classes_map=all_datasets_ignore_classes,
|
| 480 |
+
all_datasets_idx_map=all_datasets_e2e_idx_map,
|
| 481 |
+
target_domains_order=target_datasets_order,
|
| 482 |
+
target_source_map=target_source_relationship_map,
|
| 483 |
+
all_datasets_e2e_class_to_idx_map=all_datasets_e2e_class_to_idx_map,
|
| 484 |
+
num_classes=num_classes)
|
| 485 |
+
|
| 486 |
+
|
| 487 |
+
return test_scenario
|
| 488 |
+
|
| 489 |
+
|
| 490 |
+
if __name__ == '__main__':
|
| 491 |
+
test_scenario = build_scenario_manually_v2(['CIFAR10', 'SVHN'],
|
| 492 |
+
['STL10', 'MNIST', 'STL10', 'USPS', 'MNIST', 'STL10'],
|
| 493 |
+
'close_set')
|
| 494 |
+
print(test_scenario.num_classes)
|
| 495 |
+
|
data/build/merge_alias.py
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from re import L
|
| 2 |
+
from typing import Dict, List
|
| 3 |
+
from collections import Counter
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def grouping(bondlist):
|
| 7 |
+
# reference: https://blog.csdn.net/YnagShanwen/article/details/111344386
|
| 8 |
+
groups = []
|
| 9 |
+
break1 = False
|
| 10 |
+
while bondlist:
|
| 11 |
+
pair1 = bondlist.pop(0)
|
| 12 |
+
a = 11111
|
| 13 |
+
b = 10000
|
| 14 |
+
while b != a:
|
| 15 |
+
a = b
|
| 16 |
+
for atomid in pair1:
|
| 17 |
+
for i,pair2 in enumerate(bondlist):
|
| 18 |
+
if atomid in pair2:
|
| 19 |
+
pair1 = pair1 + pair2
|
| 20 |
+
bondlist.pop(i)
|
| 21 |
+
if not bondlist:
|
| 22 |
+
break1 = True
|
| 23 |
+
break
|
| 24 |
+
if break1:
|
| 25 |
+
break
|
| 26 |
+
b = len(pair1)
|
| 27 |
+
groups.append(pair1)
|
| 28 |
+
return groups
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def build_semantic_class_info(classes: List[str], aliases: List[List[str]]):
|
| 32 |
+
res = []
|
| 33 |
+
for c in classes:
|
| 34 |
+
# print(res)
|
| 35 |
+
if len(aliases) == 0:
|
| 36 |
+
res += [[c]]
|
| 37 |
+
else:
|
| 38 |
+
find_alias = False
|
| 39 |
+
for alias in aliases:
|
| 40 |
+
if c in alias:
|
| 41 |
+
res += [alias]
|
| 42 |
+
find_alias = True
|
| 43 |
+
break
|
| 44 |
+
if not find_alias:
|
| 45 |
+
res += [[c]]
|
| 46 |
+
# print(classes, res)
|
| 47 |
+
return res
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def merge_the_same_meaning_classes(classes_info_of_all_datasets):
|
| 51 |
+
# print(classes_info_of_all_datasets)
|
| 52 |
+
|
| 53 |
+
semantic_classes_of_all_datasets = []
|
| 54 |
+
all_aliases = []
|
| 55 |
+
for classes, aliases in classes_info_of_all_datasets.values():
|
| 56 |
+
all_aliases += aliases
|
| 57 |
+
for classes, aliases in classes_info_of_all_datasets.values():
|
| 58 |
+
semantic_classes_of_all_datasets += build_semantic_class_info(classes, all_aliases)
|
| 59 |
+
|
| 60 |
+
# print(semantic_classes_of_all_datasets)
|
| 61 |
+
|
| 62 |
+
grouped_classes_of_all_datasets = grouping(semantic_classes_of_all_datasets)#匹配过后的数据
|
| 63 |
+
|
| 64 |
+
# print(grouped_classes_of_all_datasets)
|
| 65 |
+
|
| 66 |
+
# final_grouped_classes_of_all_datasets = [Counter(c).most_common()[0][0] for c in grouped_classes_of_all_datasets]
|
| 67 |
+
# use most common class name; if the same common, use shortest class name!
|
| 68 |
+
final_grouped_classes_of_all_datasets = []
|
| 69 |
+
for c in grouped_classes_of_all_datasets:
|
| 70 |
+
counter = Counter(c).most_common()
|
| 71 |
+
max_times = counter[0][1]
|
| 72 |
+
candidate_class_names = []
|
| 73 |
+
for item, times in counter:
|
| 74 |
+
if times < max_times:
|
| 75 |
+
break
|
| 76 |
+
candidate_class_names += [item]
|
| 77 |
+
candidate_class_names.sort(key=lambda x: len(x))
|
| 78 |
+
|
| 79 |
+
final_grouped_classes_of_all_datasets += [candidate_class_names[0]]
|
| 80 |
+
res = {}
|
| 81 |
+
res_map = {d: {} for d in classes_info_of_all_datasets.keys()}
|
| 82 |
+
|
| 83 |
+
for dataset_name, (classes, _) in classes_info_of_all_datasets.items():
|
| 84 |
+
final_classes = []
|
| 85 |
+
for c in classes:
|
| 86 |
+
for grouped_names, final_name in zip(grouped_classes_of_all_datasets, final_grouped_classes_of_all_datasets):
|
| 87 |
+
if c in grouped_names:
|
| 88 |
+
final_classes += [final_name]
|
| 89 |
+
if final_name != c:
|
| 90 |
+
res_map[dataset_name][c] = final_name
|
| 91 |
+
break
|
| 92 |
+
res[dataset_name] = sorted(set(final_classes), key=final_classes.index)
|
| 93 |
+
return res, res_map
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
if __name__ == '__main__':
|
| 97 |
+
cifar10_classes = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
|
| 98 |
+
cifar10_aliases = [['automobile', 'car']]
|
| 99 |
+
stl10_classes = ['airplane', 'bird', 'car', 'cat', 'deer', 'dog', 'horse', 'monkey', 'ship', 'truck']
|
| 100 |
+
|
| 101 |
+
final_classes_of_all_datasets, rename_map = merge_the_same_meaning_classes({
|
| 102 |
+
'CIFAR10': (cifar10_classes, cifar10_aliases),
|
| 103 |
+
'STL10': (stl10_classes, [])
|
| 104 |
+
})
|
| 105 |
+
|
| 106 |
+
print(final_classes_of_all_datasets, rename_map)
|
data/build/scenario.py
ADDED
|
@@ -0,0 +1,466 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import enum
|
| 2 |
+
from functools import reduce
|
| 3 |
+
from typing import Dict, List, Tuple
|
| 4 |
+
import numpy as np
|
| 5 |
+
import copy
|
| 6 |
+
from utils.common.log import logger
|
| 7 |
+
from ..datasets.ab_dataset import ABDataset
|
| 8 |
+
from ..dataloader import FastDataLoader, InfiniteDataLoader, build_dataloader
|
| 9 |
+
from data import get_dataset
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class DatasetMetaInfo:
|
| 13 |
+
def __init__(self, name,
|
| 14 |
+
known_classes_name_idx_map, unknown_class_idx):
|
| 15 |
+
|
| 16 |
+
assert unknown_class_idx not in known_classes_name_idx_map.keys()
|
| 17 |
+
|
| 18 |
+
self.name = name
|
| 19 |
+
self.unknown_class_idx = unknown_class_idx
|
| 20 |
+
self.known_classes_name_idx_map = known_classes_name_idx_map
|
| 21 |
+
|
| 22 |
+
@property
|
| 23 |
+
def num_classes(self):
|
| 24 |
+
return len(self.known_classes_idx) + 1
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class MergedDataset:
|
| 28 |
+
def __init__(self, datasets: List[ABDataset]):
|
| 29 |
+
self.datasets = datasets
|
| 30 |
+
self.datasets_len = [len(i) for i in self.datasets]
|
| 31 |
+
logger.info(f'create MergedDataset: len of datasets {self.datasets_len}')
|
| 32 |
+
self.datasets_cum_len = np.cumsum(self.datasets_len)
|
| 33 |
+
|
| 34 |
+
def __getitem__(self, idx):
|
| 35 |
+
for i, cum_len in enumerate(self.datasets_cum_len):
|
| 36 |
+
if idx < cum_len:
|
| 37 |
+
return self.datasets[i][idx - sum(self.datasets_len[0: i])]
|
| 38 |
+
|
| 39 |
+
def __len__(self):
|
| 40 |
+
return sum(self.datasets_len)
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
class IndexReturnedDataset:
|
| 44 |
+
def __init__(self, dataset: ABDataset):
|
| 45 |
+
self.dataset = dataset
|
| 46 |
+
|
| 47 |
+
def __getitem__(self, idx):
|
| 48 |
+
res = self.dataset[idx]
|
| 49 |
+
|
| 50 |
+
if isinstance(res, (tuple, list)):
|
| 51 |
+
return (*res, idx)
|
| 52 |
+
else:
|
| 53 |
+
return res, idx
|
| 54 |
+
|
| 55 |
+
def __len__(self):
|
| 56 |
+
return len(self.dataset)
|
| 57 |
+
|
| 58 |
+
|
| 59 |
+
# class Scenario:
|
| 60 |
+
# def __init__(self, config,
|
| 61 |
+
# source_datasets_meta_info: Dict[str, DatasetMetaInfo], target_datasets_meta_info: Dict[str, DatasetMetaInfo],
|
| 62 |
+
# target_source_map: Dict[str, Dict[str, str]],
|
| 63 |
+
# target_domains_order: List[str],
|
| 64 |
+
# source_datasets: Dict[str, Dict[str, ABDataset]], target_datasets: Dict[str, Dict[str, ABDataset]]):
|
| 65 |
+
|
| 66 |
+
# self.__config = config
|
| 67 |
+
# self.__source_datasets_meta_info = source_datasets_meta_info
|
| 68 |
+
# self.__target_datasets_meta_info = target_datasets_meta_info
|
| 69 |
+
# self.__target_source_map = target_source_map
|
| 70 |
+
# self.__target_domains_order = target_domains_order
|
| 71 |
+
# self.__source_datasets = source_datasets
|
| 72 |
+
# self.__target_datasets = target_datasets
|
| 73 |
+
|
| 74 |
+
# # 1. basic
|
| 75 |
+
# def get_config(self):
|
| 76 |
+
# return copy.deepcopy(self.__config)
|
| 77 |
+
|
| 78 |
+
# def get_task_type(self):
|
| 79 |
+
# return list(self.__source_datasets.values())[0]['train'].task_type
|
| 80 |
+
|
| 81 |
+
# def get_num_classes(self):
|
| 82 |
+
# known_classes_idx = []
|
| 83 |
+
# unknown_classes_idx = []
|
| 84 |
+
# for v in self.__source_datasets_meta_info.values():
|
| 85 |
+
# known_classes_idx += list(v.known_classes_name_idx_map.values())
|
| 86 |
+
# unknown_classes_idx += [v.unknown_class_idx]
|
| 87 |
+
# for v in self.__target_datasets_meta_info.values():
|
| 88 |
+
# known_classes_idx += list(v.known_classes_name_idx_map.values())
|
| 89 |
+
# unknown_classes_idx += [v.unknown_class_idx]
|
| 90 |
+
# unknown_classes_idx = [i for i in unknown_classes_idx if i is not None]
|
| 91 |
+
# # print(known_classes_idx, unknown_classes_idx)
|
| 92 |
+
# res = len(set(known_classes_idx)), len(set(unknown_classes_idx)), len(set(known_classes_idx + unknown_classes_idx))
|
| 93 |
+
# # print(res)
|
| 94 |
+
# assert res[0] + res[1] == res[2]
|
| 95 |
+
# return res
|
| 96 |
+
|
| 97 |
+
# def build_dataloader(self, dataset: ABDataset, batch_size: int, num_workers: int, infinite: bool, shuffle_when_finite: bool):
|
| 98 |
+
# if infinite:
|
| 99 |
+
# dataloader = InfiniteDataLoader(
|
| 100 |
+
# dataset, None, batch_size, num_workers=num_workers)
|
| 101 |
+
# else:
|
| 102 |
+
# dataloader = FastDataLoader(
|
| 103 |
+
# dataset, batch_size, num_workers, shuffle=shuffle_when_finite)
|
| 104 |
+
|
| 105 |
+
# return dataloader
|
| 106 |
+
|
| 107 |
+
# def build_sub_dataset(self, dataset: ABDataset, indexes: List[int]):
|
| 108 |
+
# from ..data.datasets.dataset_split import _SplitDataset
|
| 109 |
+
# dataset.dataset = _SplitDataset(dataset.dataset, indexes)
|
| 110 |
+
# return dataset
|
| 111 |
+
|
| 112 |
+
# def build_index_returned_dataset(self, dataset: ABDataset):
|
| 113 |
+
# return IndexReturnedDataset(dataset)
|
| 114 |
+
|
| 115 |
+
# # 2. source
|
| 116 |
+
# def get_source_datasets_meta_info(self):
|
| 117 |
+
# return self.__source_datasets_meta_info
|
| 118 |
+
|
| 119 |
+
# def get_source_datasets_name(self):
|
| 120 |
+
# return list(self.__source_datasets.keys())
|
| 121 |
+
|
| 122 |
+
# def get_merged_source_dataset(self, split):
|
| 123 |
+
# source_train_datasets = {n: d[split] for n, d in self.__source_datasets.items()}
|
| 124 |
+
# return MergedDataset(list(source_train_datasets.values()))
|
| 125 |
+
|
| 126 |
+
# def get_source_datasets(self, split):
|
| 127 |
+
# source_train_datasets = {n: d[split] for n, d in self.__source_datasets.items()}
|
| 128 |
+
# return source_train_datasets
|
| 129 |
+
|
| 130 |
+
# # 3. target **domain**
|
| 131 |
+
# # (do we need such API `get_ith_target_domain()`?)
|
| 132 |
+
# def get_target_domains_meta_info(self):
|
| 133 |
+
# return self.__source_datasets_meta_info
|
| 134 |
+
|
| 135 |
+
# def get_target_domains_order(self):
|
| 136 |
+
# return self.__target_domains_order
|
| 137 |
+
|
| 138 |
+
# def get_corr_source_datasets_name_of_target_domain(self, target_domain_name):
|
| 139 |
+
# return self.__target_source_map[target_domain_name]
|
| 140 |
+
|
| 141 |
+
# def get_limited_target_train_dataset(self):
|
| 142 |
+
# if len(self.__target_domains_order) > 1:
|
| 143 |
+
# raise RuntimeError('this API is only for pass-in scenario in user-defined online DA algorithm')
|
| 144 |
+
# return list(self.__target_datasets.values())[0]['train']
|
| 145 |
+
|
| 146 |
+
# def get_target_domains_iterator(self, split):
|
| 147 |
+
# for target_domain_index, target_domain_name in enumerate(self.__target_domains_order):
|
| 148 |
+
# target_dataset = self.__target_datasets[target_domain_name]
|
| 149 |
+
# target_domain_meta_info = self.__target_datasets_meta_info[target_domain_name]
|
| 150 |
+
|
| 151 |
+
# yield target_domain_index, target_domain_name, target_dataset[split], target_domain_meta_info
|
| 152 |
+
|
| 153 |
+
# # 4. permission management
|
| 154 |
+
# def get_sub_scenario(self, source_datasets_name, source_splits, target_domains_order, target_splits):
|
| 155 |
+
# def get_split(dataset, splits):
|
| 156 |
+
# res = {}
|
| 157 |
+
# for s, d in dataset.items():
|
| 158 |
+
# if s in splits:
|
| 159 |
+
# res[s] = d
|
| 160 |
+
# return res
|
| 161 |
+
|
| 162 |
+
# return Scenario(
|
| 163 |
+
# config=self.__config,
|
| 164 |
+
# source_datasets_meta_info={k: v for k, v in self.__source_datasets_meta_info.items() if k in source_datasets_name},
|
| 165 |
+
# target_datasets_meta_info={k: v for k, v in self.__target_datasets_meta_info.items() if k in target_domains_order},
|
| 166 |
+
# target_source_map={k: v for k, v in self.__target_source_map.items() if k in target_domains_order},
|
| 167 |
+
# target_domains_order=target_domains_order,
|
| 168 |
+
# source_datasets={k: get_split(v, source_splits) for k, v in self.__source_datasets.items() if k in source_datasets_name},
|
| 169 |
+
# target_datasets={k: get_split(v, target_splits) for k, v in self.__target_datasets.items() if k in target_domains_order}
|
| 170 |
+
# )
|
| 171 |
+
|
| 172 |
+
# def get_only_source_sub_scenario_for_exp_tracker(self):
|
| 173 |
+
# return self.get_sub_scenario(self.get_source_datasets_name(), ['train', 'val', 'test'], [], [])
|
| 174 |
+
|
| 175 |
+
# def get_only_source_sub_scenario_for_alg(self):
|
| 176 |
+
# return self.get_sub_scenario(self.get_source_datasets_name(), ['train'], [], [])
|
| 177 |
+
|
| 178 |
+
# def get_one_da_sub_scenario_for_alg(self, target_domain_name):
|
| 179 |
+
# return self.get_sub_scenario(self.get_corr_source_datasets_name_of_target_domain(target_domain_name),
|
| 180 |
+
# ['train', 'val'], [target_domain_name], ['train'])
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
# class Scenario:
|
| 184 |
+
# def __init__(self, config,
|
| 185 |
+
|
| 186 |
+
# offline_source_datasets_meta_info: Dict[str, DatasetMetaInfo],
|
| 187 |
+
# offline_source_datasets: Dict[str, ABDataset],
|
| 188 |
+
|
| 189 |
+
# online_datasets_meta_info: List[Tuple[Dict[str, DatasetMetaInfo], DatasetMetaInfo]],
|
| 190 |
+
# online_datasets: Dict[str, ABDataset],
|
| 191 |
+
# target_domains_order: List[str],
|
| 192 |
+
# target_source_map: Dict[str, Dict[str, str]],
|
| 193 |
+
|
| 194 |
+
# num_classes: int):
|
| 195 |
+
|
| 196 |
+
# self.config = config
|
| 197 |
+
|
| 198 |
+
# self.offline_source_datasets_meta_info = offline_source_datasets_meta_info
|
| 199 |
+
# self.offline_source_datasets = offline_source_datasets
|
| 200 |
+
|
| 201 |
+
# self.online_datasets_meta_info = online_datasets_meta_info
|
| 202 |
+
# self.online_datasets = online_datasets
|
| 203 |
+
|
| 204 |
+
# self.target_domains_order = target_domains_order
|
| 205 |
+
# self.target_source_map = target_source_map
|
| 206 |
+
|
| 207 |
+
# self.num_classes = num_classes
|
| 208 |
+
|
| 209 |
+
# def get_offline_source_datasets(self, split):
|
| 210 |
+
# return {n: d[split] for n, d in self.offline_source_datasets.items()}
|
| 211 |
+
|
| 212 |
+
# def get_offline_source_merged_dataset(self, split):
|
| 213 |
+
# return MergedDataset([d[split] for d in self.offline_source_datasets.values()])
|
| 214 |
+
|
| 215 |
+
# def get_online_current_corresponding_source_datasets(self, domain_index, split):
|
| 216 |
+
# cur_target_domain_name = self.target_domains_order[domain_index]
|
| 217 |
+
# cur_source_datasets_name = list(self.target_source_map[cur_target_domain_name].keys())
|
| 218 |
+
# cur_source_datasets = {n: self.online_datasets[n + '|' + cur_target_domain_name][split] for n in cur_source_datasets_name}
|
| 219 |
+
# return cur_source_datasets
|
| 220 |
+
|
| 221 |
+
# def get_online_current_corresponding_merged_source_dataset(self, domain_index, split):
|
| 222 |
+
# cur_target_domain_name = self.target_domains_order[domain_index]
|
| 223 |
+
# cur_source_datasets_name = list(self.target_source_map[cur_target_domain_name].keys())
|
| 224 |
+
# cur_source_datasets = {n: self.online_datasets[n + '|' + cur_target_domain_name][split] for n in cur_source_datasets_name}
|
| 225 |
+
# return MergedDataset([d for d in cur_source_datasets.values()])
|
| 226 |
+
|
| 227 |
+
# def get_online_current_target_dataset(self, domain_index, split):
|
| 228 |
+
# cur_target_domain_name = self.target_domains_order[domain_index]
|
| 229 |
+
# return self.online_datasets[cur_target_domain_name][split]
|
| 230 |
+
|
| 231 |
+
# def build_dataloader(self, dataset: ABDataset, batch_size: int, num_workers: int,
|
| 232 |
+
# infinite: bool, shuffle_when_finite: bool, to_iterator: bool):
|
| 233 |
+
# if infinite:
|
| 234 |
+
# dataloader = InfiniteDataLoader(
|
| 235 |
+
# dataset, None, batch_size, num_workers=num_workers)
|
| 236 |
+
# else:
|
| 237 |
+
# dataloader = FastDataLoader(
|
| 238 |
+
# dataset, batch_size, num_workers, shuffle=shuffle_when_finite)
|
| 239 |
+
|
| 240 |
+
# if to_iterator:
|
| 241 |
+
# dataloader = iter(dataloader)
|
| 242 |
+
|
| 243 |
+
# return dataloader
|
| 244 |
+
|
| 245 |
+
# def build_sub_dataset(self, dataset: ABDataset, indexes: List[int]):
|
| 246 |
+
# from data.datasets.dataset_split import _SplitDataset
|
| 247 |
+
# dataset.dataset = _SplitDataset(dataset.dataset, indexes)
|
| 248 |
+
# return dataset
|
| 249 |
+
|
| 250 |
+
# def build_index_returned_dataset(self, dataset: ABDataset):
|
| 251 |
+
# return IndexReturnedDataset(dataset)
|
| 252 |
+
|
| 253 |
+
# def get_config(self):
|
| 254 |
+
# return copy.deepcopy(self.config)
|
| 255 |
+
|
| 256 |
+
# def get_task_type(self):
|
| 257 |
+
# return list(self.online_datasets.values())[0]['train'].task_type
|
| 258 |
+
|
| 259 |
+
# def get_num_classes(self):
|
| 260 |
+
# return self.num_classes
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
class Scenario:
|
| 264 |
+
def __init__(self, config, all_datasets_ignore_classes_map, all_datasets_idx_map, target_domains_order, target_source_map,
|
| 265 |
+
all_datasets_e2e_class_to_idx_map,
|
| 266 |
+
num_classes):
|
| 267 |
+
self.config = config
|
| 268 |
+
self.all_datasets_ignore_classes_map = all_datasets_ignore_classes_map
|
| 269 |
+
self.all_datasets_idx_map = all_datasets_idx_map
|
| 270 |
+
self.target_domains_order = target_domains_order
|
| 271 |
+
self.target_source_map = target_source_map
|
| 272 |
+
self.all_datasets_e2e_class_to_idx_map = all_datasets_e2e_class_to_idx_map
|
| 273 |
+
self.num_classes = num_classes
|
| 274 |
+
self.cur_domain_index = 0
|
| 275 |
+
|
| 276 |
+
logger.info(f'[scenario build] # classes: {num_classes}')
|
| 277 |
+
logger.debug(f'[scenario build] idx map: {all_datasets_idx_map}')
|
| 278 |
+
|
| 279 |
+
def to_json(self):
|
| 280 |
+
return dict(
|
| 281 |
+
config=self.config, all_datasets_ignore_classes_map=self.all_datasets_ignore_classes_map,
|
| 282 |
+
all_datasets_idx_map=self.all_datasets_idx_map, target_domains_order=self.target_domains_order,
|
| 283 |
+
target_source_map=self.target_source_map,
|
| 284 |
+
all_datasets_e2e_class_to_idx_map=self.all_datasets_e2e_class_to_idx_map,
|
| 285 |
+
num_classes=self.num_classes
|
| 286 |
+
)
|
| 287 |
+
|
| 288 |
+
def __str__(self):
|
| 289 |
+
return f'Scenario({self.to_json()})'
|
| 290 |
+
|
| 291 |
+
def get_offline_datasets(self, transform=None):
|
| 292 |
+
# make source datasets which contains all unioned classes
|
| 293 |
+
res_offline_train_source_datasets_map = {}
|
| 294 |
+
|
| 295 |
+
from .. import get_dataset
|
| 296 |
+
data_dirs = self.config['data_dirs']
|
| 297 |
+
|
| 298 |
+
source_datasets_name = self.config['source_datasets_name']
|
| 299 |
+
res_source_datasets_map = {d: {split: get_dataset(d.split('|')[0], data_dirs[d.split('|')[0]], split,
|
| 300 |
+
transform,
|
| 301 |
+
self.all_datasets_ignore_classes_map[d], self.all_datasets_idx_map[d])
|
| 302 |
+
for split in ['train', 'val', 'test']}
|
| 303 |
+
for d in self.all_datasets_ignore_classes_map.keys() if d.split('|')[0] in source_datasets_name}
|
| 304 |
+
|
| 305 |
+
for source_dataset_name in self.config['source_datasets_name']:
|
| 306 |
+
source_datasets = [v for k, v in res_source_datasets_map.items() if source_dataset_name in k]
|
| 307 |
+
|
| 308 |
+
# how to merge idx map?
|
| 309 |
+
# 35 79 97
|
| 310 |
+
idx_maps = [d['train'].idx_map for d in source_datasets]
|
| 311 |
+
ignore_classes_list = [d['train'].ignore_classes for d in source_datasets]
|
| 312 |
+
|
| 313 |
+
union_idx_map = {}
|
| 314 |
+
for idx_map in idx_maps:
|
| 315 |
+
for k, v in idx_map.items():
|
| 316 |
+
if k not in union_idx_map:
|
| 317 |
+
union_idx_map[k] = v
|
| 318 |
+
else:
|
| 319 |
+
assert union_idx_map[k] == v
|
| 320 |
+
|
| 321 |
+
union_ignore_classes = reduce(lambda res, cur: res & set(cur), ignore_classes_list, set(ignore_classes_list[0]))
|
| 322 |
+
assert len(union_ignore_classes) + len(union_idx_map) == len(source_datasets[0]['train'].raw_classes)
|
| 323 |
+
|
| 324 |
+
logger.info(f'[scenario build] {source_dataset_name} has {len(union_idx_map)} classes in offline training')
|
| 325 |
+
|
| 326 |
+
d = source_dataset_name
|
| 327 |
+
res_offline_train_source_datasets_map[d] = {split: get_dataset(d, data_dirs[d], split,
|
| 328 |
+
transform,
|
| 329 |
+
union_ignore_classes, union_idx_map)
|
| 330 |
+
for split in ['train', 'val', 'test']}
|
| 331 |
+
|
| 332 |
+
return res_offline_train_source_datasets_map
|
| 333 |
+
|
| 334 |
+
def get_offline_datasets_args(self):
|
| 335 |
+
# make source datasets which contains all unioned classes
|
| 336 |
+
res_offline_train_source_datasets_map = {}
|
| 337 |
+
|
| 338 |
+
from .. import get_dataset
|
| 339 |
+
data_dirs = self.config['data_dirs']
|
| 340 |
+
|
| 341 |
+
source_datasets_name = self.config['source_datasets_name']
|
| 342 |
+
res_source_datasets_map = {d: {split: get_dataset(d.split('|')[0], data_dirs[d.split('|')[0]], split,
|
| 343 |
+
None,
|
| 344 |
+
self.all_datasets_ignore_classes_map[d], self.all_datasets_idx_map[d])
|
| 345 |
+
for split in ['train', 'val', 'test']}
|
| 346 |
+
for d in self.all_datasets_ignore_classes_map.keys() if d.split('|')[0] in source_datasets_name}
|
| 347 |
+
|
| 348 |
+
for source_dataset_name in self.config['source_datasets_name']:
|
| 349 |
+
source_datasets = [v for k, v in res_source_datasets_map.items() if source_dataset_name in k]
|
| 350 |
+
|
| 351 |
+
# how to merge idx map?
|
| 352 |
+
# 35 79 97
|
| 353 |
+
idx_maps = [d['train'].idx_map for d in source_datasets]
|
| 354 |
+
ignore_classes_list = [d['train'].ignore_classes for d in source_datasets]
|
| 355 |
+
|
| 356 |
+
union_idx_map = {}
|
| 357 |
+
for idx_map in idx_maps:
|
| 358 |
+
for k, v in idx_map.items():
|
| 359 |
+
if k not in union_idx_map:
|
| 360 |
+
union_idx_map[k] = v
|
| 361 |
+
else:
|
| 362 |
+
assert union_idx_map[k] == v
|
| 363 |
+
|
| 364 |
+
union_ignore_classes = reduce(lambda res, cur: res & set(cur), ignore_classes_list, set(ignore_classes_list[0]))
|
| 365 |
+
assert len(union_ignore_classes) + len(union_idx_map) == len(source_datasets[0]['train'].raw_classes)
|
| 366 |
+
|
| 367 |
+
logger.info(f'[scenario build] {source_dataset_name} has {len(union_idx_map)} classes in offline training')
|
| 368 |
+
|
| 369 |
+
d = source_dataset_name
|
| 370 |
+
res_offline_train_source_datasets_map[d] = {split: dict(d, data_dirs[d], split,
|
| 371 |
+
None,
|
| 372 |
+
union_ignore_classes, union_idx_map)
|
| 373 |
+
for split in ['train', 'val', 'test']}
|
| 374 |
+
|
| 375 |
+
return res_offline_train_source_datasets_map
|
| 376 |
+
|
| 377 |
+
# for d in source_datasets_name:
|
| 378 |
+
# source_dataset_with_max_num_classes = None
|
| 379 |
+
|
| 380 |
+
# for ed_name, ed in res_source_datasets_map.items():
|
| 381 |
+
# if not ed_name.startswith(d):
|
| 382 |
+
# continue
|
| 383 |
+
|
| 384 |
+
# if source_dataset_with_max_num_classes is None:
|
| 385 |
+
# source_dataset_with_max_num_classes = ed
|
| 386 |
+
# res_offline_train_source_datasets_map_names[d] = ed_name
|
| 387 |
+
|
| 388 |
+
# if len(ed['train'].ignore_classes) < len(source_dataset_with_max_num_classes['train'].ignore_classes):
|
| 389 |
+
# source_dataset_with_max_num_classes = ed
|
| 390 |
+
# res_offline_train_source_datasets_map_names[d] = ed_name
|
| 391 |
+
|
| 392 |
+
# res_offline_train_source_datasets_map[d] = source_dataset_with_max_num_classes
|
| 393 |
+
|
| 394 |
+
# return res_offline_train_source_datasets_map
|
| 395 |
+
|
| 396 |
+
def get_online_ith_domain_datasets_args_for_inference(self, domain_index):
|
| 397 |
+
target_dataset_name = self.target_domains_order[domain_index]
|
| 398 |
+
# dataset_name: Any, root_dir: Any, split: Any, transform: Any | None = None, ignore_classes: Any = [], idx_map: Any | None = None
|
| 399 |
+
|
| 400 |
+
if 'MM-CityscapesDet' in self.target_domains_order or 'CityscapesDet' in self.target_domains_order or 'BaiduPersonDet' in self.target_domains_order:
|
| 401 |
+
logger.info(f'use val split for inference test (only Det workload)')
|
| 402 |
+
split = 'test'
|
| 403 |
+
else:
|
| 404 |
+
split = 'train'
|
| 405 |
+
|
| 406 |
+
return dict(dataset_name=target_dataset_name,
|
| 407 |
+
root_dir=self.config['data_dirs'][target_dataset_name],
|
| 408 |
+
split=split,
|
| 409 |
+
transform=None,
|
| 410 |
+
ignore_classes=self.all_datasets_ignore_classes_map[target_dataset_name],
|
| 411 |
+
idx_map=self.all_datasets_idx_map[target_dataset_name])
|
| 412 |
+
|
| 413 |
+
def get_online_ith_domain_datasets_args_for_training(self, domain_index):
|
| 414 |
+
target_dataset_name = self.target_domains_order[domain_index]
|
| 415 |
+
source_datasets_name = list(self.target_source_map[target_dataset_name].keys())
|
| 416 |
+
|
| 417 |
+
res = {}
|
| 418 |
+
# dataset_name: Any, root_dir: Any, split: Any, transform: Any | None = None, ignore_classes: Any = [], idx_map: Any | None = None
|
| 419 |
+
res[target_dataset_name] = {split: dict(dataset_name=target_dataset_name,
|
| 420 |
+
root_dir=self.config['data_dirs'][target_dataset_name],
|
| 421 |
+
split=split,
|
| 422 |
+
transform=None,
|
| 423 |
+
ignore_classes=self.all_datasets_ignore_classes_map[target_dataset_name],
|
| 424 |
+
idx_map=self.all_datasets_idx_map[target_dataset_name]) for split in ['train', 'val']}
|
| 425 |
+
for d in source_datasets_name:
|
| 426 |
+
res[d] = {split: dict(dataset_name=d,
|
| 427 |
+
root_dir=self.config['data_dirs'][d],
|
| 428 |
+
split=split,
|
| 429 |
+
transform=None,
|
| 430 |
+
ignore_classes=self.all_datasets_ignore_classes_map[d + '|' + target_dataset_name],
|
| 431 |
+
idx_map=self.all_datasets_idx_map[d + '|' + target_dataset_name]) for split in ['train', 'val']}
|
| 432 |
+
|
| 433 |
+
return res
|
| 434 |
+
|
| 435 |
+
def get_online_cur_domain_datasets_args_for_inference(self):
|
| 436 |
+
return self.get_online_ith_domain_datasets_args_for_inference(self.cur_domain_index)
|
| 437 |
+
|
| 438 |
+
def get_online_cur_domain_datasets_args_for_training(self):
|
| 439 |
+
return self.get_online_ith_domain_datasets_args_for_training(self.cur_domain_index)
|
| 440 |
+
|
| 441 |
+
def get_online_cur_domain_datasets_for_training(self, transform=None):
|
| 442 |
+
res = {}
|
| 443 |
+
datasets_args = self.get_online_ith_domain_datasets_args_for_training(self.cur_domain_index)
|
| 444 |
+
for dataset_name, dataset_args in datasets_args.items():
|
| 445 |
+
res[dataset_name] = {}
|
| 446 |
+
for split, args in dataset_args.items():
|
| 447 |
+
if transform is not None:
|
| 448 |
+
args['transform'] = transform
|
| 449 |
+
dataset = get_dataset(**args)
|
| 450 |
+
res[dataset_name][split] = dataset
|
| 451 |
+
return res
|
| 452 |
+
|
| 453 |
+
def get_online_cur_domain_datasets_for_inference(self, transform=None):
|
| 454 |
+
datasets_args = self.get_online_ith_domain_datasets_args_for_inference(self.cur_domain_index)
|
| 455 |
+
if transform is not None:
|
| 456 |
+
datasets_args['transform'] = transform
|
| 457 |
+
return get_dataset(**datasets_args)
|
| 458 |
+
|
| 459 |
+
def get_online_cur_domain_samples_for_training(self, num_samples, transform=None, collate_fn=None):
|
| 460 |
+
dataset = self.get_online_cur_domain_datasets_for_training(transform=transform)
|
| 461 |
+
dataset = dataset[self.target_domains_order[self.cur_domain_index]]['train']
|
| 462 |
+
return next(iter(build_dataloader(dataset, num_samples, 0, True, None, collate_fn=collate_fn)))[0]
|
| 463 |
+
|
| 464 |
+
def next_domain(self):
|
| 465 |
+
self.cur_domain_index += 1
|
| 466 |
+
|
data/build_cl/__pycache__/build.cpython-38.pyc
ADDED
|
Binary file (4.31 kB). View file
|
|
|
data/build_cl/__pycache__/scenario.cpython-38.pyc
ADDED
|
Binary file (5.42 kB). View file
|
|
|
data/build_cl/build.py
ADDED
|
@@ -0,0 +1,161 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Dict, List, Optional, Type, Union
|
| 2 |
+
from ..datasets.ab_dataset import ABDataset
|
| 3 |
+
# from benchmark.data.visualize import visualize_classes_in_object_detection
|
| 4 |
+
# from benchmark.scenario.val_domain_shift import get_val_domain_shift_transform
|
| 5 |
+
from ..dataset import get_dataset
|
| 6 |
+
import copy
|
| 7 |
+
from torchvision.transforms import Compose
|
| 8 |
+
from ..datasets.registery import static_dataset_registery
|
| 9 |
+
from ..build.scenario import Scenario as DAScenario
|
| 10 |
+
from copy import deepcopy
|
| 11 |
+
from utils.common.log import logger
|
| 12 |
+
import random
|
| 13 |
+
from .scenario import _ABDatasetMetaInfo, Scenario
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def _check(source_datasets_meta_info: List[_ABDatasetMetaInfo], target_datasets_meta_info: List[_ABDatasetMetaInfo]):
|
| 17 |
+
# requirements for simplity
|
| 18 |
+
# 1. no same class in source datasets
|
| 19 |
+
|
| 20 |
+
source_datasets_class = [i.classes for i in source_datasets_meta_info]
|
| 21 |
+
for ci1, c1 in enumerate(source_datasets_class):
|
| 22 |
+
for ci2, c2 in enumerate(source_datasets_class):
|
| 23 |
+
if ci1 == ci2:
|
| 24 |
+
continue
|
| 25 |
+
|
| 26 |
+
c1_name = source_datasets_meta_info[ci1].name
|
| 27 |
+
c2_name = source_datasets_meta_info[ci2].name
|
| 28 |
+
intersection = set(c1).intersection(set(c2))
|
| 29 |
+
assert len(intersection) == 0, f'{c1_name} has intersection with {c2_name}: {intersection}'
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
def build_cl_scenario(
|
| 33 |
+
da_scenario: DAScenario,
|
| 34 |
+
target_datasets_name: List[str],
|
| 35 |
+
num_classes_per_task: int,
|
| 36 |
+
max_num_tasks: int,
|
| 37 |
+
data_dirs,
|
| 38 |
+
sanity_check=False
|
| 39 |
+
):
|
| 40 |
+
config = deepcopy(locals())
|
| 41 |
+
|
| 42 |
+
source_datasets_idx_map = {}
|
| 43 |
+
source_class_idx_max = 0
|
| 44 |
+
|
| 45 |
+
for sd in da_scenario.config['source_datasets_name']:
|
| 46 |
+
da_scenario_idx_map = None
|
| 47 |
+
for k, v in da_scenario.all_datasets_idx_map.items():
|
| 48 |
+
if k.startswith(sd):
|
| 49 |
+
da_scenario_idx_map = v
|
| 50 |
+
break
|
| 51 |
+
|
| 52 |
+
source_datasets_idx_map[sd] = da_scenario_idx_map
|
| 53 |
+
source_class_idx_max = max(source_class_idx_max, max(list(da_scenario_idx_map.values())))
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
target_class_idx_start = source_class_idx_max + 1
|
| 57 |
+
|
| 58 |
+
target_datasets_meta_info = [_ABDatasetMetaInfo(d, *static_dataset_registery[d][1:], None, None) for d in target_datasets_name]
|
| 59 |
+
|
| 60 |
+
task_datasets_seq = []
|
| 61 |
+
|
| 62 |
+
num_tasks_per_dataset = {}
|
| 63 |
+
|
| 64 |
+
for td_info_i, td_info in enumerate(target_datasets_meta_info):
|
| 65 |
+
|
| 66 |
+
if td_info_i >= 1:
|
| 67 |
+
for _td_info_i, _td_info in enumerate(target_datasets_meta_info[0: td_info_i]):
|
| 68 |
+
if _td_info.name == td_info.name:
|
| 69 |
+
# print(111)
|
| 70 |
+
# class_idx_offset = sum([len(t.classes) for t in target_datasets_meta_info[0: td_info_i]])
|
| 71 |
+
print(len(task_datasets_seq))
|
| 72 |
+
|
| 73 |
+
task_index_offset = sum([v if __i < _td_info_i else 0 for __i, v in enumerate(num_tasks_per_dataset.values())])
|
| 74 |
+
|
| 75 |
+
task_datasets_seq += task_datasets_seq[task_index_offset: task_index_offset + num_tasks_per_dataset[_td_info_i]]
|
| 76 |
+
print(len(task_datasets_seq))
|
| 77 |
+
break
|
| 78 |
+
continue
|
| 79 |
+
|
| 80 |
+
td_classes = td_info.classes
|
| 81 |
+
num_tasks_per_dataset[td_info_i] = 0
|
| 82 |
+
|
| 83 |
+
for ci in range(0, len(td_classes), num_classes_per_task):
|
| 84 |
+
task_i = ci // num_classes_per_task
|
| 85 |
+
task_datasets_seq += [_ABDatasetMetaInfo(
|
| 86 |
+
f'{td_info.name}|task-{task_i}|ci-{ci}-{ci + num_classes_per_task - 1}',
|
| 87 |
+
td_classes[ci: ci + num_classes_per_task],
|
| 88 |
+
td_info.task_type,
|
| 89 |
+
td_info.object_type,
|
| 90 |
+
td_info.class_aliases,
|
| 91 |
+
td_info.shift_type,
|
| 92 |
+
|
| 93 |
+
td_classes[:ci] + td_classes[ci + num_classes_per_task: ],
|
| 94 |
+
{cii: cii + target_class_idx_start for cii in range(ci, ci + num_classes_per_task)}
|
| 95 |
+
)]
|
| 96 |
+
num_tasks_per_dataset[td_info_i] += 1
|
| 97 |
+
|
| 98 |
+
if ci + num_classes_per_task < len(td_classes) - 1:
|
| 99 |
+
task_datasets_seq += [_ABDatasetMetaInfo(
|
| 100 |
+
f'{td_info.name}-task-{task_i + 1}|ci-{ci}-{ci + num_classes_per_task - 1}',
|
| 101 |
+
td_classes[ci: len(td_classes)],
|
| 102 |
+
td_info.task_type,
|
| 103 |
+
td_info.object_type,
|
| 104 |
+
td_info.class_aliases,
|
| 105 |
+
td_info.shift_type,
|
| 106 |
+
|
| 107 |
+
td_classes[:ci],
|
| 108 |
+
{cii: cii + target_class_idx_start for cii in range(ci, len(td_classes))}
|
| 109 |
+
)]
|
| 110 |
+
num_tasks_per_dataset[td_info_i] += 1
|
| 111 |
+
|
| 112 |
+
target_class_idx_start += len(td_classes)
|
| 113 |
+
|
| 114 |
+
if len(task_datasets_seq) < max_num_tasks:
|
| 115 |
+
print(len(task_datasets_seq), max_num_tasks)
|
| 116 |
+
raise RuntimeError()
|
| 117 |
+
|
| 118 |
+
task_datasets_seq = task_datasets_seq[0: max_num_tasks]
|
| 119 |
+
target_class_idx_start = max([max(list(td.idx_map.values())) + 1 for td in task_datasets_seq])
|
| 120 |
+
|
| 121 |
+
scenario = Scenario(config, task_datasets_seq, target_class_idx_start, source_class_idx_max + 1, data_dirs)
|
| 122 |
+
|
| 123 |
+
if sanity_check:
|
| 124 |
+
selected_tasks_index = []
|
| 125 |
+
for task_index, _ in enumerate(scenario.target_tasks_order):
|
| 126 |
+
cur_datasets = scenario.get_cur_task_train_datasets()
|
| 127 |
+
|
| 128 |
+
if len(cur_datasets) < 300:
|
| 129 |
+
# empty_tasks_index += [task_index]
|
| 130 |
+
# while True:
|
| 131 |
+
# replaced_task_index = random.randint(0, task_index - 1) # ensure no random
|
| 132 |
+
replaced_task_index = task_index // 2
|
| 133 |
+
assert replaced_task_index != task_index
|
| 134 |
+
while replaced_task_index in selected_tasks_index:
|
| 135 |
+
replaced_task_index += 1
|
| 136 |
+
|
| 137 |
+
task_datasets_seq[task_index] = deepcopy(task_datasets_seq[replaced_task_index])
|
| 138 |
+
selected_tasks_index += [replaced_task_index]
|
| 139 |
+
|
| 140 |
+
logger.warning(f'replace {task_index}-th task with {replaced_task_index}-th task')
|
| 141 |
+
|
| 142 |
+
# print(task_index, [t.name for t in task_datasets_seq])
|
| 143 |
+
|
| 144 |
+
scenario.next_task()
|
| 145 |
+
|
| 146 |
+
# print([t.name for t in task_datasets_seq])
|
| 147 |
+
|
| 148 |
+
if len(selected_tasks_index) > 0:
|
| 149 |
+
target_class_idx_start = max([max(list(td.idx_map.values())) + 1 for td in task_datasets_seq])
|
| 150 |
+
scenario = Scenario(config, task_datasets_seq, target_class_idx_start, source_class_idx_max + 1, data_dirs)
|
| 151 |
+
|
| 152 |
+
for task_index, _ in enumerate(scenario.target_tasks_order):
|
| 153 |
+
cur_datasets = scenario.get_cur_task_train_datasets()
|
| 154 |
+
logger.info(f'task {task_index}, len {len(cur_datasets)}')
|
| 155 |
+
assert len(cur_datasets) > 0
|
| 156 |
+
|
| 157 |
+
scenario.next_task()
|
| 158 |
+
|
| 159 |
+
scenario = Scenario(config, task_datasets_seq, target_class_idx_start, source_class_idx_max + 1, data_dirs)
|
| 160 |
+
|
| 161 |
+
return scenario
|
data/build_cl/scenario.py
ADDED
|
@@ -0,0 +1,146 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import enum
|
| 2 |
+
from functools import reduce
|
| 3 |
+
from typing import Dict, List, Tuple
|
| 4 |
+
import numpy as np
|
| 5 |
+
import copy
|
| 6 |
+
from utils.common.log import logger
|
| 7 |
+
from ..datasets.ab_dataset import ABDataset
|
| 8 |
+
from ..dataloader import FastDataLoader, InfiniteDataLoader, build_dataloader
|
| 9 |
+
from data import get_dataset, MergedDataset, Scenario as DAScenario
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class _ABDatasetMetaInfo:
|
| 13 |
+
def __init__(self, name, classes, task_type, object_type, class_aliases, shift_type, ignore_classes, idx_map):
|
| 14 |
+
self.name = name
|
| 15 |
+
self.classes = classes
|
| 16 |
+
self.class_aliases = class_aliases
|
| 17 |
+
self.shift_type = shift_type
|
| 18 |
+
self.task_type = task_type
|
| 19 |
+
self.object_type = object_type
|
| 20 |
+
|
| 21 |
+
self.ignore_classes = ignore_classes
|
| 22 |
+
self.idx_map = idx_map
|
| 23 |
+
|
| 24 |
+
def __repr__(self) -> str:
|
| 25 |
+
return f'({self.name}, {self.classes}, {self.idx_map})'
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class Scenario:
|
| 29 |
+
def __init__(self, config, target_datasets_info: List[_ABDatasetMetaInfo], num_classes: int, num_source_classes: int, data_dirs):
|
| 30 |
+
self.config = config
|
| 31 |
+
self.target_datasets_info = target_datasets_info
|
| 32 |
+
self.num_classes = num_classes
|
| 33 |
+
self.cur_task_index = 0
|
| 34 |
+
self.num_source_classes = num_source_classes
|
| 35 |
+
self.cur_class_offset = num_source_classes
|
| 36 |
+
self.data_dirs = data_dirs
|
| 37 |
+
|
| 38 |
+
self.target_tasks_order = [i.name for i in self.target_datasets_info]
|
| 39 |
+
self.num_tasks_to_be_learn = sum([len(i.classes) for i in target_datasets_info])
|
| 40 |
+
|
| 41 |
+
logger.info(f'[scenario build] # classes: {num_classes}, # tasks to be learnt: {len(target_datasets_info)}, '
|
| 42 |
+
f'# classes per task: {config["num_classes_per_task"]}')
|
| 43 |
+
|
| 44 |
+
def to_json(self):
|
| 45 |
+
config = copy.deepcopy(self.config)
|
| 46 |
+
config['da_scenario'] = config['da_scenario'].to_json()
|
| 47 |
+
target_datasets_info = [str(i) for i in self.target_datasets_info]
|
| 48 |
+
return dict(
|
| 49 |
+
config=config, target_datasets_info=target_datasets_info,
|
| 50 |
+
num_classes=self.num_classes
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
def __str__(self):
|
| 54 |
+
return f'Scenario({self.to_json()})'
|
| 55 |
+
|
| 56 |
+
def get_cur_class_offset(self):
|
| 57 |
+
return self.cur_class_offset
|
| 58 |
+
|
| 59 |
+
def get_cur_num_class(self):
|
| 60 |
+
return len(self.target_datasets_info[self.cur_task_index].classes)
|
| 61 |
+
|
| 62 |
+
def get_nc_per_task(self):
|
| 63 |
+
return len(self.target_datasets_info[0].classes)
|
| 64 |
+
|
| 65 |
+
def next_task(self):
|
| 66 |
+
self.cur_class_offset += len(self.target_datasets_info[self.cur_task_index].classes)
|
| 67 |
+
self.cur_task_index += 1
|
| 68 |
+
|
| 69 |
+
print(f'now, cur task: {self.cur_task_index}, cur_class_offset: {self.cur_class_offset}')
|
| 70 |
+
|
| 71 |
+
def get_cur_task_datasets(self):
|
| 72 |
+
dataset_info = self.target_datasets_info[self.cur_task_index]
|
| 73 |
+
dataset_name = dataset_info.name.split('|')[0]
|
| 74 |
+
# print()
|
| 75 |
+
|
| 76 |
+
# source_datasets_info = []
|
| 77 |
+
|
| 78 |
+
res ={ **{split: get_dataset(dataset_name=dataset_name,
|
| 79 |
+
root_dir=self.data_dirs[dataset_name],
|
| 80 |
+
split=split,
|
| 81 |
+
transform=None,
|
| 82 |
+
ignore_classes=dataset_info.ignore_classes,
|
| 83 |
+
idx_map=dataset_info.idx_map) for split in ['train']},
|
| 84 |
+
|
| 85 |
+
**{split: MergedDataset([get_dataset(dataset_name=dataset_name,
|
| 86 |
+
root_dir=self.data_dirs[dataset_name],
|
| 87 |
+
split=split,
|
| 88 |
+
transform=None,
|
| 89 |
+
ignore_classes=di.ignore_classes,
|
| 90 |
+
idx_map=di.idx_map) for di in self.target_datasets_info[0: self.cur_task_index + 1]])
|
| 91 |
+
for split in ['val', 'test']}
|
| 92 |
+
}
|
| 93 |
+
|
| 94 |
+
# if len(res['train']) < 200 or len(res['val']) < 200 or len(res['test']) < 200:
|
| 95 |
+
# return None
|
| 96 |
+
|
| 97 |
+
|
| 98 |
+
if len(res['train']) < 1000:
|
| 99 |
+
res['train'] = MergedDataset([res['train']] * 5)
|
| 100 |
+
logger.info('aug train dataset')
|
| 101 |
+
if len(res['val']) < 1000:
|
| 102 |
+
res['val'] = MergedDataset(res['val'].datasets * 5)
|
| 103 |
+
logger.info('aug val dataset')
|
| 104 |
+
if len(res['test']) < 1000:
|
| 105 |
+
res['test'] = MergedDataset(res['test'].datasets * 5)
|
| 106 |
+
logger.info('aug test dataset')
|
| 107 |
+
# da_scenario: DAScenario = self.config['da_scenario']
|
| 108 |
+
# offline_datasets = da_scenario.get_offline_datasets()
|
| 109 |
+
|
| 110 |
+
for k, v in res.items():
|
| 111 |
+
logger.info(f'{k} dataset: {len(v)}')
|
| 112 |
+
|
| 113 |
+
# new_val_datasets = [
|
| 114 |
+
# *[d['val'] for d in offline_datasets.values()],
|
| 115 |
+
# res['val']
|
| 116 |
+
# ]
|
| 117 |
+
# res['val'] = MergedDataset(new_val_datasets)
|
| 118 |
+
|
| 119 |
+
# new_test_datasets = [
|
| 120 |
+
# *[d['test'] for d in offline_datasets.values()],
|
| 121 |
+
# res['test']
|
| 122 |
+
# ]
|
| 123 |
+
# res['test'] = MergedDataset(new_test_datasets)
|
| 124 |
+
|
| 125 |
+
return res
|
| 126 |
+
|
| 127 |
+
def get_cur_task_train_datasets(self):
|
| 128 |
+
dataset_info = self.target_datasets_info[self.cur_task_index]
|
| 129 |
+
dataset_name = dataset_info.name.split('|')[0]
|
| 130 |
+
# print()
|
| 131 |
+
|
| 132 |
+
# source_datasets_info = []
|
| 133 |
+
|
| 134 |
+
res = get_dataset(dataset_name=dataset_name,
|
| 135 |
+
root_dir=self.data_dirs[dataset_name],
|
| 136 |
+
split='train',
|
| 137 |
+
transform=None,
|
| 138 |
+
ignore_classes=dataset_info.ignore_classes,
|
| 139 |
+
idx_map=dataset_info.idx_map)
|
| 140 |
+
|
| 141 |
+
return res
|
| 142 |
+
|
| 143 |
+
def get_online_cur_task_samples_for_training(self, num_samples):
|
| 144 |
+
dataset = self.get_cur_task_datasets()
|
| 145 |
+
dataset = dataset['train']
|
| 146 |
+
return next(iter(build_dataloader(dataset, num_samples, 0, True, None)))[0]
|
data/build_gen/__pycache__/build.cpython-38.pyc
ADDED
|
Binary file (9.07 kB). View file
|
|
|
data/build_gen/__pycache__/merge_alias.cpython-38.pyc
ADDED
|
Binary file (2.5 kB). View file
|
|
|
data/build_gen/__pycache__/scenario.cpython-38.pyc
ADDED
|
Binary file (9.65 kB). View file
|
|
|
data/build_gen/build.py
ADDED
|
@@ -0,0 +1,495 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from typing import Dict, List, Optional, Type, Union
|
| 2 |
+
from ..datasets.ab_dataset import ABDataset
|
| 3 |
+
# from benchmark.data.visualize import visualize_classes_in_object_detection
|
| 4 |
+
# from benchmark.scenario.val_domain_shift import get_val_domain_shift_transform
|
| 5 |
+
from ..dataset import get_dataset
|
| 6 |
+
import copy
|
| 7 |
+
from torchvision.transforms import Compose
|
| 8 |
+
|
| 9 |
+
from .merge_alias import merge_the_same_meaning_classes
|
| 10 |
+
from ..datasets.registery import static_dataset_registery
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
# some legacy aliases of variables:
|
| 14 |
+
# ignore_classes == discarded classes
|
| 15 |
+
# private_classes == unknown classes in partial / open-set / universal DA
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
def _merge_the_same_meaning_classes(classes_info_of_all_datasets):
|
| 19 |
+
final_classes_of_all_datasets, rename_map = merge_the_same_meaning_classes(classes_info_of_all_datasets)
|
| 20 |
+
return final_classes_of_all_datasets, rename_map
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def _find_ignore_classes_when_sources_as_to_target_b(as_classes: List[List[str]], b_classes: List[str], da_mode):
|
| 24 |
+
thres = {'da': 3, 'partial_da': 2, 'open_set_da': 1, 'universal_da': 0}[da_mode]
|
| 25 |
+
|
| 26 |
+
from functools import reduce
|
| 27 |
+
a_classes = reduce(lambda res, cur: res | set(cur), as_classes, set())
|
| 28 |
+
|
| 29 |
+
if set(a_classes) == set(b_classes):
|
| 30 |
+
# a is equal to b, normal
|
| 31 |
+
# 1. no ignore classes; 2. match class idx
|
| 32 |
+
a_ignore_classes, b_ignore_classes = [], []
|
| 33 |
+
|
| 34 |
+
elif set(a_classes) > set(b_classes):
|
| 35 |
+
# a contains b, partial
|
| 36 |
+
a_ignore_classes, b_ignore_classes = [], []
|
| 37 |
+
if thres == 3 or thres == 1: # ignore extra classes in a
|
| 38 |
+
a_ignore_classes = set(a_classes) - set(b_classes)
|
| 39 |
+
|
| 40 |
+
elif set(a_classes) < set(b_classes):
|
| 41 |
+
# a is contained by b, open set
|
| 42 |
+
a_ignore_classes, b_ignore_classes = [], []
|
| 43 |
+
if thres == 3 or thres == 2: # ignore extra classes in b
|
| 44 |
+
b_ignore_classes = set(b_classes) - set(a_classes)
|
| 45 |
+
|
| 46 |
+
elif len(set(a_classes) & set(b_classes)) > 0:
|
| 47 |
+
a_ignore_classes, b_ignore_classes = [], []
|
| 48 |
+
if thres == 3:
|
| 49 |
+
a_ignore_classes = set(a_classes) - (set(a_classes) & set(b_classes))
|
| 50 |
+
b_ignore_classes = set(b_classes) - (set(a_classes) & set(b_classes))
|
| 51 |
+
elif thres == 2:
|
| 52 |
+
b_ignore_classes = set(b_classes) - (set(a_classes) & set(b_classes))
|
| 53 |
+
elif thres == 1:
|
| 54 |
+
a_ignore_classes = set(a_classes) - (set(a_classes) & set(b_classes))
|
| 55 |
+
|
| 56 |
+
else:
|
| 57 |
+
return None # a has no intersection with b, none
|
| 58 |
+
|
| 59 |
+
as_ignore_classes = [list(set(a_classes) & set(a_ignore_classes)) for a_classes in as_classes]
|
| 60 |
+
|
| 61 |
+
return as_ignore_classes, list(b_ignore_classes)
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
def _find_private_classes_when_sources_as_to_target_b(as_classes: List[List[str]], b_classes: List[str], da_mode):
|
| 65 |
+
thres = {'da': 3, 'partial_da': 2, 'open_set_da': 1, 'universal_da': 0}[da_mode]
|
| 66 |
+
|
| 67 |
+
from functools import reduce
|
| 68 |
+
a_classes = reduce(lambda res, cur: res | set(cur), as_classes, set())
|
| 69 |
+
|
| 70 |
+
if set(a_classes) == set(b_classes):
|
| 71 |
+
# a is equal to b, normal
|
| 72 |
+
# 1. no ignore classes; 2. match class idx
|
| 73 |
+
a_private_classes, b_private_classes = [], []
|
| 74 |
+
|
| 75 |
+
elif set(a_classes) > set(b_classes):
|
| 76 |
+
# a contains b, partial
|
| 77 |
+
a_private_classes, b_private_classes = [], []
|
| 78 |
+
# if thres == 2 or thres == 0: # ignore extra classes in a
|
| 79 |
+
# a_private_classes = set(a_classes) - set(b_classes)
|
| 80 |
+
# if thres == 0: # ignore extra classes in a
|
| 81 |
+
# a_private_classes = set(a_classes) - set(b_classes)
|
| 82 |
+
|
| 83 |
+
elif set(a_classes) < set(b_classes):
|
| 84 |
+
# a is contained by b, open set
|
| 85 |
+
a_private_classes, b_private_classes = [], []
|
| 86 |
+
if thres == 1 or thres == 0: # ignore extra classes in b
|
| 87 |
+
b_private_classes = set(b_classes) - set(a_classes)
|
| 88 |
+
|
| 89 |
+
elif len(set(a_classes) & set(b_classes)) > 0:
|
| 90 |
+
a_private_classes, b_private_classes = [], []
|
| 91 |
+
if thres == 0:
|
| 92 |
+
# a_private_classes = set(a_classes) - (set(a_classes) & set(b_classes))
|
| 93 |
+
|
| 94 |
+
b_private_classes = set(b_classes) - (set(a_classes) & set(b_classes))
|
| 95 |
+
elif thres == 1:
|
| 96 |
+
b_private_classes = set(b_classes) - (set(a_classes) & set(b_classes))
|
| 97 |
+
elif thres == 2:
|
| 98 |
+
# a_private_classes = set(a_classes) - (set(a_classes) & set(b_classes))
|
| 99 |
+
pass
|
| 100 |
+
|
| 101 |
+
else:
|
| 102 |
+
return None # a has no intersection with b, none
|
| 103 |
+
|
| 104 |
+
return list(b_private_classes)
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
class _ABDatasetMetaInfo:
|
| 108 |
+
def __init__(self, name, classes, task_type, object_type, class_aliases, shift_type):
|
| 109 |
+
self.name = name
|
| 110 |
+
self.classes = classes
|
| 111 |
+
self.class_aliases = class_aliases
|
| 112 |
+
self.shift_type = shift_type
|
| 113 |
+
self.task_type = task_type
|
| 114 |
+
self.object_type = object_type
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def _get_dist_shift_type_when_source_a_to_target_b(a: _ABDatasetMetaInfo, b: _ABDatasetMetaInfo):
|
| 118 |
+
if b.shift_type is None:
|
| 119 |
+
return 'Dataset Shifts'
|
| 120 |
+
|
| 121 |
+
if a.name in b.shift_type.keys():
|
| 122 |
+
return b.shift_type[a.name]
|
| 123 |
+
|
| 124 |
+
mid_dataset_name = list(b.shift_type.keys())[0]
|
| 125 |
+
mid_dataset_meta_info = _ABDatasetMetaInfo(mid_dataset_name, *static_dataset_registery[mid_dataset_name][1:])
|
| 126 |
+
|
| 127 |
+
return _get_dist_shift_type_when_source_a_to_target_b(a, mid_dataset_meta_info) + ' + ' + list(b.shift_type.values())[0]
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
def _handle_all_datasets_v2(source_datasets: List[_ABDatasetMetaInfo], target_datasets: List[_ABDatasetMetaInfo], da_mode):
|
| 131 |
+
|
| 132 |
+
# 1. merge the same meaning classes
|
| 133 |
+
classes_info_of_all_datasets = {
|
| 134 |
+
d.name: (d.classes, d.class_aliases)
|
| 135 |
+
for d in source_datasets + target_datasets
|
| 136 |
+
}
|
| 137 |
+
final_classes_of_all_datasets, rename_map = _merge_the_same_meaning_classes(classes_info_of_all_datasets)
|
| 138 |
+
all_datasets_classes = copy.deepcopy(final_classes_of_all_datasets)
|
| 139 |
+
|
| 140 |
+
# print(all_datasets_known_classes)
|
| 141 |
+
|
| 142 |
+
# 2. find ignored classes according to DA mode
|
| 143 |
+
# source_datasets_ignore_classes, target_datasets_ignore_classes = {d.name: [] for d in source_datasets}, \
|
| 144 |
+
# {d.name: [] for d in target_datasets}
|
| 145 |
+
# source_datasets_private_classes, target_datasets_private_classes = {d.name: [] for d in source_datasets}, \
|
| 146 |
+
# {d.name: [] for d in target_datasets}
|
| 147 |
+
target_source_relationship_map = {td.name: {} for td in target_datasets}
|
| 148 |
+
# source_target_relationship_map = {sd.name: [] for sd in source_datasets}
|
| 149 |
+
|
| 150 |
+
# 1. construct target_source_relationship_map
|
| 151 |
+
for sd in source_datasets:#sd和td使列表中每一个元素(类)的实例
|
| 152 |
+
for td in target_datasets:
|
| 153 |
+
sc = all_datasets_classes[sd.name]
|
| 154 |
+
tc = all_datasets_classes[td.name]
|
| 155 |
+
|
| 156 |
+
if len(set(sc) & set(tc)) == 0:#只保留有相似类别的源域和目标域
|
| 157 |
+
continue
|
| 158 |
+
|
| 159 |
+
target_source_relationship_map[td.name][sd.name] = _get_dist_shift_type_when_source_a_to_target_b(sd, td)
|
| 160 |
+
|
| 161 |
+
# print(target_source_relationship_map)
|
| 162 |
+
# exit()
|
| 163 |
+
|
| 164 |
+
source_datasets_ignore_classes = {}
|
| 165 |
+
for td_name, v1 in target_source_relationship_map.items():
|
| 166 |
+
for sd_name, v2 in v1.items():
|
| 167 |
+
source_datasets_ignore_classes[sd_name + '|' + td_name] = []
|
| 168 |
+
target_datasets_ignore_classes = {d.name: [] for d in target_datasets}
|
| 169 |
+
target_datasets_private_classes = {d.name: [] for d in target_datasets}
|
| 170 |
+
# 保证对于每个目标域上的DA都符合给定的label shift
|
| 171 |
+
# 所以不同目标域就算对应同一个源域,该源域也可能不相同
|
| 172 |
+
|
| 173 |
+
for td_name, v1 in target_source_relationship_map.items():
|
| 174 |
+
sd_names = list(v1.keys())
|
| 175 |
+
|
| 176 |
+
sds_classes = [all_datasets_classes[sd_name] for sd_name in sd_names]
|
| 177 |
+
td_classes = all_datasets_classes[td_name]
|
| 178 |
+
ss_ignore_classes, t_ignore_classes = _find_ignore_classes_when_sources_as_to_target_b(sds_classes, td_classes, da_mode)#根据DA方式不同产生ignore_classes
|
| 179 |
+
t_private_classes = _find_private_classes_when_sources_as_to_target_b(sds_classes, td_classes, da_mode)
|
| 180 |
+
|
| 181 |
+
for sd_name, s_ignore_classes in zip(sd_names, ss_ignore_classes):
|
| 182 |
+
source_datasets_ignore_classes[sd_name + '|' + td_name] = s_ignore_classes
|
| 183 |
+
target_datasets_ignore_classes[td_name] = t_ignore_classes
|
| 184 |
+
target_datasets_private_classes[td_name] = t_private_classes
|
| 185 |
+
|
| 186 |
+
source_datasets_ignore_classes = {k: sorted(set(v), key=v.index) for k, v in source_datasets_ignore_classes.items()}
|
| 187 |
+
target_datasets_ignore_classes = {k: sorted(set(v), key=v.index) for k, v in target_datasets_ignore_classes.items()}
|
| 188 |
+
target_datasets_private_classes = {k: sorted(set(v), key=v.index) for k, v in target_datasets_private_classes.items()}
|
| 189 |
+
|
| 190 |
+
# for k, v in source_datasets_ignore_classes.items():
|
| 191 |
+
# print(k, len(v))
|
| 192 |
+
# print()
|
| 193 |
+
# for k, v in target_datasets_ignore_classes.items():
|
| 194 |
+
# print(k, len(v))
|
| 195 |
+
# print()
|
| 196 |
+
# for k, v in target_datasets_private_classes.items():
|
| 197 |
+
# print(k, len(v))
|
| 198 |
+
# print()
|
| 199 |
+
|
| 200 |
+
# print(source_datasets_private_classes, target_datasets_private_classes)
|
| 201 |
+
# 3. reparse classes idx
|
| 202 |
+
# 3.1. agg all used classes
|
| 203 |
+
# all_used_classes = []
|
| 204 |
+
# all_datasets_private_class_idx_map = {}
|
| 205 |
+
|
| 206 |
+
# source_datasets_classes_idx_map = {}
|
| 207 |
+
# for td_name, v1 in target_source_relationship_map.items():
|
| 208 |
+
# for sd_name, v2 in v1.items():
|
| 209 |
+
# source_datasets_classes_idx_map[sd_name + '|' + td_name] = []
|
| 210 |
+
# target_datasets_classes_idx_map = {}
|
| 211 |
+
|
| 212 |
+
global_idx = 0
|
| 213 |
+
all_used_classes_idx_map = {}
|
| 214 |
+
# all_datasets_known_classes = {d: [] for d in final_classes_of_all_datasets.keys()}
|
| 215 |
+
for dataset_name, classes in all_datasets_classes.items():
|
| 216 |
+
if dataset_name not in target_datasets_ignore_classes.keys():
|
| 217 |
+
ignore_classes = [0] * 100000
|
| 218 |
+
for sn, sic in source_datasets_ignore_classes.items():
|
| 219 |
+
if sn.startswith(dataset_name):
|
| 220 |
+
if len(sic) < len(ignore_classes):
|
| 221 |
+
ignore_classes = sic
|
| 222 |
+
else:
|
| 223 |
+
ignore_classes = target_datasets_ignore_classes[dataset_name]
|
| 224 |
+
private_classes = [] \
|
| 225 |
+
if dataset_name not in target_datasets_ignore_classes.keys() else target_datasets_private_classes[dataset_name]
|
| 226 |
+
|
| 227 |
+
for c in classes:
|
| 228 |
+
if c not in ignore_classes and c not in all_used_classes_idx_map.keys() and c not in private_classes:
|
| 229 |
+
all_used_classes_idx_map[c] = global_idx
|
| 230 |
+
global_idx += 1
|
| 231 |
+
|
| 232 |
+
# print(all_used_classes_idx_map)
|
| 233 |
+
|
| 234 |
+
# dataset_private_class_idx_offset = 0
|
| 235 |
+
target_private_class_idx = global_idx
|
| 236 |
+
target_datasets_private_class_idx = {d: None for d in target_datasets_private_classes.keys()}
|
| 237 |
+
|
| 238 |
+
for dataset_name, classes in final_classes_of_all_datasets.items():
|
| 239 |
+
if dataset_name not in target_datasets_private_classes.keys():
|
| 240 |
+
continue
|
| 241 |
+
|
| 242 |
+
# ignore_classes = target_datasets_ignore_classes[dataset_name]
|
| 243 |
+
private_classes = target_datasets_private_classes[dataset_name]
|
| 244 |
+
# private_classes = [] \
|
| 245 |
+
# if dataset_name in source_datasets_private_classes.keys() else target_datasets_private_classes[dataset_name]
|
| 246 |
+
# for c in classes:
|
| 247 |
+
# if c not in ignore_classes and c not in all_used_classes_idx_map.keys() and c in private_classes:
|
| 248 |
+
# all_used_classes_idx_map[c] = global_idx + dataset_private_class_idx_offset
|
| 249 |
+
|
| 250 |
+
if len(private_classes) > 0:
|
| 251 |
+
# all_datasets_private_class_idx[dataset_name] = global_idx + dataset_private_class_idx_offset
|
| 252 |
+
# dataset_private_class_idx_offset += 1
|
| 253 |
+
# if dataset_name in source_datasets_private_classes.keys():
|
| 254 |
+
# if source_private_class_idx is None:
|
| 255 |
+
# source_private_class_idx = global_idx if target_private_class_idx is None else target_private_class_idx + 1
|
| 256 |
+
# all_datasets_private_class_idx[dataset_name] = source_private_class_idx
|
| 257 |
+
# else:
|
| 258 |
+
# if target_private_class_idx is None:
|
| 259 |
+
# target_private_class_idx = global_idx if source_private_class_idx is None else source_private_class_idx + 1
|
| 260 |
+
# all_datasets_private_class_idx[dataset_name] = target_private_class_idx
|
| 261 |
+
target_datasets_private_class_idx[dataset_name] = target_private_class_idx
|
| 262 |
+
target_private_class_idx += 1
|
| 263 |
+
|
| 264 |
+
|
| 265 |
+
# all_used_classes = sorted(set(all_used_classes), key=all_used_classes.index)
|
| 266 |
+
# all_used_classes_idx_map = {c: i for i, c in enumerate(all_used_classes)}
|
| 267 |
+
|
| 268 |
+
# print('rename_map', rename_map)
|
| 269 |
+
|
| 270 |
+
# 3.2 raw_class -> rename_map[raw_classes] -> all_used_classes_idx_map
|
| 271 |
+
all_datasets_e2e_idx_map = {}
|
| 272 |
+
all_datasets_e2e_class_to_idx_map = {}
|
| 273 |
+
|
| 274 |
+
for td_name, v1 in target_source_relationship_map.items():
|
| 275 |
+
sd_names = list(v1.keys())
|
| 276 |
+
sds_classes = [all_datasets_classes[sd_name] for sd_name in sd_names]
|
| 277 |
+
td_classes = all_datasets_classes[td_name]
|
| 278 |
+
|
| 279 |
+
for sd_name, sd_classes in zip(sd_names, sds_classes):
|
| 280 |
+
cur_e2e_idx_map = {}
|
| 281 |
+
cur_e2e_class_to_idx_map = {}
|
| 282 |
+
|
| 283 |
+
for raw_ci, raw_c in enumerate(sd_classes):
|
| 284 |
+
renamed_c = raw_c if raw_c not in rename_map[dataset_name] else rename_map[dataset_name][raw_c]
|
| 285 |
+
|
| 286 |
+
ignore_classes = source_datasets_ignore_classes[sd_name + '|' + td_name]
|
| 287 |
+
if renamed_c in ignore_classes:
|
| 288 |
+
continue
|
| 289 |
+
|
| 290 |
+
idx = all_used_classes_idx_map[renamed_c]
|
| 291 |
+
|
| 292 |
+
cur_e2e_idx_map[raw_ci] = idx
|
| 293 |
+
cur_e2e_class_to_idx_map[raw_c] = idx
|
| 294 |
+
|
| 295 |
+
all_datasets_e2e_idx_map[sd_name + '|' + td_name] = cur_e2e_idx_map
|
| 296 |
+
all_datasets_e2e_class_to_idx_map[sd_name + '|' + td_name] = cur_e2e_class_to_idx_map
|
| 297 |
+
cur_e2e_idx_map = {}
|
| 298 |
+
cur_e2e_class_to_idx_map = {}
|
| 299 |
+
for raw_ci, raw_c in enumerate(td_classes):
|
| 300 |
+
renamed_c = raw_c if raw_c not in rename_map[dataset_name] else rename_map[dataset_name][raw_c]
|
| 301 |
+
|
| 302 |
+
ignore_classes = target_datasets_ignore_classes[td_name]
|
| 303 |
+
if renamed_c in ignore_classes:
|
| 304 |
+
continue
|
| 305 |
+
|
| 306 |
+
if renamed_c in target_datasets_private_classes[td_name]:
|
| 307 |
+
idx = target_datasets_private_class_idx[td_name]
|
| 308 |
+
else:
|
| 309 |
+
idx = all_used_classes_idx_map[renamed_c]
|
| 310 |
+
|
| 311 |
+
cur_e2e_idx_map[raw_ci] = idx
|
| 312 |
+
cur_e2e_class_to_idx_map[raw_c] = idx
|
| 313 |
+
|
| 314 |
+
all_datasets_e2e_idx_map[td_name] = cur_e2e_idx_map
|
| 315 |
+
all_datasets_e2e_class_to_idx_map[td_name] = cur_e2e_class_to_idx_map
|
| 316 |
+
|
| 317 |
+
all_datasets_ignore_classes = {**source_datasets_ignore_classes, **target_datasets_ignore_classes}
|
| 318 |
+
# all_datasets_private_classes = {**source_datasets_private_classes, **target_datasets_private_classes}
|
| 319 |
+
|
| 320 |
+
classes_idx_set = []
|
| 321 |
+
for d, m in all_datasets_e2e_class_to_idx_map.items():
|
| 322 |
+
classes_idx_set += list(m.values())
|
| 323 |
+
classes_idx_set = set(classes_idx_set)
|
| 324 |
+
num_classes = len(classes_idx_set)
|
| 325 |
+
|
| 326 |
+
return all_datasets_ignore_classes, target_datasets_private_classes, \
|
| 327 |
+
all_datasets_e2e_idx_map, all_datasets_e2e_class_to_idx_map, target_datasets_private_class_idx, \
|
| 328 |
+
target_source_relationship_map, rename_map, num_classes
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
def _build_scenario_info_v2(
|
| 332 |
+
source_datasets_name: List[str],
|
| 333 |
+
target_datasets_order: List[str],
|
| 334 |
+
da_mode: str
|
| 335 |
+
):
|
| 336 |
+
assert da_mode in ['close_set', 'partial', 'open_set', 'universal']
|
| 337 |
+
da_mode = {'close_set': 'da', 'partial': 'partial_da', 'open_set': 'open_set_da', 'universal': 'universal_da'}[da_mode]
|
| 338 |
+
|
| 339 |
+
source_datasets_meta_info = [_ABDatasetMetaInfo(d, *static_dataset_registery[d][1:]) for d in source_datasets_name]#获知对应的名字和对应属性,要添加数据集时,直接register就行
|
| 340 |
+
target_datasets_meta_info = [_ABDatasetMetaInfo(d, *static_dataset_registery[d][1:]) for d in list(set(target_datasets_order))]
|
| 341 |
+
|
| 342 |
+
all_datasets_ignore_classes, target_datasets_private_classes, \
|
| 343 |
+
all_datasets_e2e_idx_map, all_datasets_e2e_class_to_idx_map, target_datasets_private_class_idx, \
|
| 344 |
+
target_source_relationship_map, rename_map, num_classes \
|
| 345 |
+
= _handle_all_datasets_v2(source_datasets_meta_info, target_datasets_meta_info, da_mode)
|
| 346 |
+
|
| 347 |
+
return all_datasets_ignore_classes, target_datasets_private_classes, \
|
| 348 |
+
all_datasets_e2e_idx_map, all_datasets_e2e_class_to_idx_map, target_datasets_private_class_idx, \
|
| 349 |
+
target_source_relationship_map, rename_map, num_classes
|
| 350 |
+
|
| 351 |
+
|
| 352 |
+
def build_scenario_manually_v2(
|
| 353 |
+
source_datasets_name: List[str],
|
| 354 |
+
target_datasets_order: List[str],
|
| 355 |
+
da_mode: str,
|
| 356 |
+
data_dirs: Dict[str, str],
|
| 357 |
+
# transforms: Optional[Dict[str, Compose]] = None
|
| 358 |
+
):
|
| 359 |
+
configs = copy.deepcopy(locals())#返回当前局部变量
|
| 360 |
+
|
| 361 |
+
source_datasets_meta_info = [_ABDatasetMetaInfo(d, *static_dataset_registery[d][1:]) for d in source_datasets_name]
|
| 362 |
+
target_datasets_meta_info = [_ABDatasetMetaInfo(d, *static_dataset_registery[d][1:]) for d in list(set(target_datasets_order))]
|
| 363 |
+
|
| 364 |
+
all_datasets_ignore_classes, target_datasets_private_classes, \
|
| 365 |
+
all_datasets_e2e_idx_map, all_datasets_e2e_class_to_idx_map, target_datasets_private_class_idx, \
|
| 366 |
+
target_source_relationship_map, rename_map, num_classes \
|
| 367 |
+
= _build_scenario_info_v2(source_datasets_name, target_datasets_order, da_mode)
|
| 368 |
+
# from rich.console import Console
|
| 369 |
+
# console = Console(width=10000)
|
| 370 |
+
|
| 371 |
+
# def print_obj(_o):
|
| 372 |
+
# # import pprint
|
| 373 |
+
# # s = pprint.pformat(_o, width=140, compact=True)
|
| 374 |
+
# console.print(_o)
|
| 375 |
+
|
| 376 |
+
# console.print('configs:', style='bold red')
|
| 377 |
+
# print_obj(configs)
|
| 378 |
+
# console.print('renamed classes:', style='bold red')
|
| 379 |
+
# print_obj(rename_map)
|
| 380 |
+
# console.print('discarded classes:', style='bold red')
|
| 381 |
+
# print_obj(all_datasets_ignore_classes)
|
| 382 |
+
# console.print('unknown classes:', style='bold red')
|
| 383 |
+
# print_obj(target_datasets_private_classes)
|
| 384 |
+
# console.print('class to index map:', style='bold red')
|
| 385 |
+
# print_obj(all_datasets_e2e_class_to_idx_map)
|
| 386 |
+
# console.print('index map:', style='bold red')
|
| 387 |
+
# print_obj(all_datasets_e2e_idx_map)
|
| 388 |
+
# console = Console()
|
| 389 |
+
# # console.print('class distribution:', style='bold red')
|
| 390 |
+
# # class_dist = {
|
| 391 |
+
# # k: {
|
| 392 |
+
# # '#known classes': len(all_datasets_known_classes[k]),
|
| 393 |
+
# # '#unknown classes': len(all_datasets_private_classes[k]),
|
| 394 |
+
# # '#discarded classes': len(all_datasets_ignore_classes[k])
|
| 395 |
+
# # } for k in all_datasets_ignore_classes.keys()
|
| 396 |
+
# # }
|
| 397 |
+
# # print_obj(class_dist)
|
| 398 |
+
# console.print('corresponding sources of each target:', style='bold red')
|
| 399 |
+
# print_obj(target_source_relationship_map)
|
| 400 |
+
|
| 401 |
+
# return
|
| 402 |
+
|
| 403 |
+
# res_source_datasets_map = {d: {split: get_dataset(d, data_dirs[d], split, getattr(transforms, d, None),
|
| 404 |
+
# all_datasets_ignore_classes[d], all_datasets_e2e_idx_map[d])
|
| 405 |
+
# for split in ['train', 'val', 'test']}
|
| 406 |
+
# for d in source_datasets_name}
|
| 407 |
+
# res_target_datasets_map = {d: {'train': get_num_limited_dataset(get_dataset(d, data_dirs[d], 'test', getattr(transforms, d, None),
|
| 408 |
+
# all_datasets_ignore_classes[d], all_datasets_e2e_idx_map[d]),
|
| 409 |
+
# num_samples_in_each_target_domain),
|
| 410 |
+
# 'test': get_dataset(d, data_dirs[d], 'test', getattr(transforms, d, None),
|
| 411 |
+
# all_datasets_ignore_classes[d], all_datasets_e2e_idx_map[d])
|
| 412 |
+
# }
|
| 413 |
+
# for d in list(set(target_datasets_order))}
|
| 414 |
+
|
| 415 |
+
# res_source_datasets_map = {d: {split: get_dataset(d.split('|')[0], data_dirs[d.split('|')[0]], split,
|
| 416 |
+
# getattr(transforms, d.split('|')[0], None),
|
| 417 |
+
# all_datasets_ignore_classes[d], all_datasets_e2e_idx_map[d])
|
| 418 |
+
# for split in ['train', 'val', 'test']}
|
| 419 |
+
# for d in all_datasets_ignore_classes.keys() if d.split('|')[0] in source_datasets_name}
|
| 420 |
+
|
| 421 |
+
# from functools import reduce
|
| 422 |
+
# res_offline_train_source_datasets_map = {}
|
| 423 |
+
# res_offline_train_source_datasets_map_names = {}
|
| 424 |
+
|
| 425 |
+
# for d in source_datasets_name:
|
| 426 |
+
# source_dataset_with_max_num_classes = None
|
| 427 |
+
|
| 428 |
+
# for ed_name, ed in res_source_datasets_map.items():
|
| 429 |
+
# if not ed_name.startswith(d):
|
| 430 |
+
# continue
|
| 431 |
+
|
| 432 |
+
# if source_dataset_with_max_num_classes is None:
|
| 433 |
+
# source_dataset_with_max_num_classes = ed
|
| 434 |
+
# res_offline_train_source_datasets_map_names[d] = ed_name
|
| 435 |
+
|
| 436 |
+
# if len(ed['train'].ignore_classes) < len(source_dataset_with_max_num_classes['train'].ignore_classes):
|
| 437 |
+
# source_dataset_with_max_num_classes = ed
|
| 438 |
+
# res_offline_train_source_datasets_map_names[d] = ed_name
|
| 439 |
+
|
| 440 |
+
# res_offline_train_source_datasets_map[d] = source_dataset_with_max_num_classes
|
| 441 |
+
|
| 442 |
+
# res_target_datasets_map = {d: {split: get_dataset(d, data_dirs[d], split, getattr(transforms, d, None),
|
| 443 |
+
# all_datasets_ignore_classes[d], all_datasets_e2e_idx_map[d])
|
| 444 |
+
# for split in ['train', 'val', 'test']}
|
| 445 |
+
# for d in list(set(target_datasets_order))}
|
| 446 |
+
|
| 447 |
+
from .scenario import Scenario, DatasetMetaInfo
|
| 448 |
+
|
| 449 |
+
# test_scenario = Scenario(
|
| 450 |
+
# config=configs,
|
| 451 |
+
# offline_source_datasets_meta_info={
|
| 452 |
+
# d: DatasetMetaInfo(d,
|
| 453 |
+
# {k: v for k, v in all_datasets_e2e_class_to_idx_map[res_offline_train_source_datasets_map_names[d]].items()},
|
| 454 |
+
# None)
|
| 455 |
+
# for d in source_datasets_name
|
| 456 |
+
# },
|
| 457 |
+
# offline_source_datasets={d: res_offline_train_source_datasets_map[d] for d in source_datasets_name},
|
| 458 |
+
|
| 459 |
+
# online_datasets_meta_info=[
|
| 460 |
+
# (
|
| 461 |
+
# {sd + '|' + d: DatasetMetaInfo(d,
|
| 462 |
+
# {k: v for k, v in all_datasets_e2e_class_to_idx_map[sd + '|' + d].items()},
|
| 463 |
+
# None)
|
| 464 |
+
# for sd in target_source_relationship_map[d].keys()},
|
| 465 |
+
# DatasetMetaInfo(d,
|
| 466 |
+
# {k: v for k, v in all_datasets_e2e_class_to_idx_map[d].items() if k not in target_datasets_private_classes[d]},
|
| 467 |
+
# target_datasets_private_class_idx[d])
|
| 468 |
+
# )
|
| 469 |
+
# for d in target_datasets_order
|
| 470 |
+
# ],
|
| 471 |
+
# online_datasets={**res_source_datasets_map, **res_target_datasets_map},
|
| 472 |
+
# target_domains_order=target_datasets_order,
|
| 473 |
+
# target_source_map=target_source_relationship_map,
|
| 474 |
+
# num_classes=num_classes
|
| 475 |
+
# )
|
| 476 |
+
import os
|
| 477 |
+
os.environ['_ZQL_NUMC'] = str(num_classes)
|
| 478 |
+
|
| 479 |
+
test_scenario = Scenario(config=configs, all_datasets_ignore_classes_map=all_datasets_ignore_classes,
|
| 480 |
+
all_datasets_idx_map=all_datasets_e2e_idx_map,
|
| 481 |
+
target_domains_order=target_datasets_order,
|
| 482 |
+
target_source_map=target_source_relationship_map,
|
| 483 |
+
all_datasets_e2e_class_to_idx_map=all_datasets_e2e_class_to_idx_map,
|
| 484 |
+
num_classes=num_classes)
|
| 485 |
+
|
| 486 |
+
|
| 487 |
+
return test_scenario
|
| 488 |
+
|
| 489 |
+
|
| 490 |
+
if __name__ == '__main__':
|
| 491 |
+
test_scenario = build_scenario_manually_v2(['CIFAR10', 'SVHN'],
|
| 492 |
+
['STL10', 'MNIST', 'STL10', 'USPS', 'MNIST', 'STL10'],
|
| 493 |
+
'close_set')
|
| 494 |
+
print(test_scenario.num_classes)
|
| 495 |
+
|
data/build_gen/merge_alias.py
ADDED
|
@@ -0,0 +1,106 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from re import L
|
| 2 |
+
from typing import Dict, List
|
| 3 |
+
from collections import Counter
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
def grouping(bondlist):
|
| 7 |
+
# reference: https://blog.csdn.net/YnagShanwen/article/details/111344386
|
| 8 |
+
groups = []
|
| 9 |
+
break1 = False
|
| 10 |
+
while bondlist:
|
| 11 |
+
pair1 = bondlist.pop(0)
|
| 12 |
+
a = 11111
|
| 13 |
+
b = 10000
|
| 14 |
+
while b != a:
|
| 15 |
+
a = b
|
| 16 |
+
for atomid in pair1:
|
| 17 |
+
for i,pair2 in enumerate(bondlist):
|
| 18 |
+
if atomid in pair2:
|
| 19 |
+
pair1 = pair1 + pair2
|
| 20 |
+
bondlist.pop(i)
|
| 21 |
+
if not bondlist:
|
| 22 |
+
break1 = True
|
| 23 |
+
break
|
| 24 |
+
if break1:
|
| 25 |
+
break
|
| 26 |
+
b = len(pair1)
|
| 27 |
+
groups.append(pair1)
|
| 28 |
+
return groups
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
def build_semantic_class_info(classes: List[str], aliases: List[List[str]]):
|
| 32 |
+
res = []
|
| 33 |
+
for c in classes:
|
| 34 |
+
# print(res)
|
| 35 |
+
if len(aliases) == 0:
|
| 36 |
+
res += [[c]]
|
| 37 |
+
else:
|
| 38 |
+
find_alias = False
|
| 39 |
+
for alias in aliases:
|
| 40 |
+
if c in alias:
|
| 41 |
+
res += [alias]
|
| 42 |
+
find_alias = True
|
| 43 |
+
break
|
| 44 |
+
if not find_alias:
|
| 45 |
+
res += [[c]]
|
| 46 |
+
# print(classes, res)
|
| 47 |
+
return res
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
def merge_the_same_meaning_classes(classes_info_of_all_datasets):
|
| 51 |
+
# print(classes_info_of_all_datasets)
|
| 52 |
+
|
| 53 |
+
semantic_classes_of_all_datasets = []
|
| 54 |
+
all_aliases = []
|
| 55 |
+
for classes, aliases in classes_info_of_all_datasets.values():
|
| 56 |
+
all_aliases += aliases
|
| 57 |
+
for classes, aliases in classes_info_of_all_datasets.values():
|
| 58 |
+
semantic_classes_of_all_datasets += build_semantic_class_info(classes, all_aliases)
|
| 59 |
+
|
| 60 |
+
# print(semantic_classes_of_all_datasets)
|
| 61 |
+
|
| 62 |
+
grouped_classes_of_all_datasets = grouping(semantic_classes_of_all_datasets)#匹配过后的数据
|
| 63 |
+
|
| 64 |
+
# print(grouped_classes_of_all_datasets)
|
| 65 |
+
|
| 66 |
+
# final_grouped_classes_of_all_datasets = [Counter(c).most_common()[0][0] for c in grouped_classes_of_all_datasets]
|
| 67 |
+
# use most common class name; if the same common, use shortest class name!
|
| 68 |
+
final_grouped_classes_of_all_datasets = []
|
| 69 |
+
for c in grouped_classes_of_all_datasets:
|
| 70 |
+
counter = Counter(c).most_common()
|
| 71 |
+
max_times = counter[0][1]
|
| 72 |
+
candidate_class_names = []
|
| 73 |
+
for item, times in counter:
|
| 74 |
+
if times < max_times:
|
| 75 |
+
break
|
| 76 |
+
candidate_class_names += [item]
|
| 77 |
+
candidate_class_names.sort(key=lambda x: len(x))
|
| 78 |
+
|
| 79 |
+
final_grouped_classes_of_all_datasets += [candidate_class_names[0]]
|
| 80 |
+
res = {}
|
| 81 |
+
res_map = {d: {} for d in classes_info_of_all_datasets.keys()}
|
| 82 |
+
|
| 83 |
+
for dataset_name, (classes, _) in classes_info_of_all_datasets.items():
|
| 84 |
+
final_classes = []
|
| 85 |
+
for c in classes:
|
| 86 |
+
for grouped_names, final_name in zip(grouped_classes_of_all_datasets, final_grouped_classes_of_all_datasets):
|
| 87 |
+
if c in grouped_names:
|
| 88 |
+
final_classes += [final_name]
|
| 89 |
+
if final_name != c:
|
| 90 |
+
res_map[dataset_name][c] = final_name
|
| 91 |
+
break
|
| 92 |
+
res[dataset_name] = sorted(set(final_classes), key=final_classes.index)
|
| 93 |
+
return res, res_map
|
| 94 |
+
|
| 95 |
+
|
| 96 |
+
if __name__ == '__main__':
|
| 97 |
+
cifar10_classes = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
|
| 98 |
+
cifar10_aliases = [['automobile', 'car']]
|
| 99 |
+
stl10_classes = ['airplane', 'bird', 'car', 'cat', 'deer', 'dog', 'horse', 'monkey', 'ship', 'truck']
|
| 100 |
+
|
| 101 |
+
final_classes_of_all_datasets, rename_map = merge_the_same_meaning_classes({
|
| 102 |
+
'CIFAR10': (cifar10_classes, cifar10_aliases),
|
| 103 |
+
'STL10': (stl10_classes, [])
|
| 104 |
+
})
|
| 105 |
+
|
| 106 |
+
print(final_classes_of_all_datasets, rename_map)
|
data/build_gen/scenario.py
ADDED
|
@@ -0,0 +1,473 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import enum
|
| 2 |
+
from functools import reduce
|
| 3 |
+
from typing import Dict, List, Tuple
|
| 4 |
+
import numpy as np
|
| 5 |
+
import copy
|
| 6 |
+
from utils.common.log import logger
|
| 7 |
+
from ..datasets.ab_dataset import ABDataset
|
| 8 |
+
from ..datasets.dataset_split import train_val_split
|
| 9 |
+
from ..dataloader import FastDataLoader, InfiniteDataLoader, build_dataloader
|
| 10 |
+
from data import get_dataset
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
class DatasetMetaInfo:
|
| 14 |
+
def __init__(self, name,
|
| 15 |
+
known_classes_name_idx_map, unknown_class_idx):
|
| 16 |
+
|
| 17 |
+
assert unknown_class_idx not in known_classes_name_idx_map.keys()
|
| 18 |
+
|
| 19 |
+
self.name = name
|
| 20 |
+
self.unknown_class_idx = unknown_class_idx
|
| 21 |
+
self.known_classes_name_idx_map = known_classes_name_idx_map
|
| 22 |
+
|
| 23 |
+
@property
|
| 24 |
+
def num_classes(self):
|
| 25 |
+
return len(self.known_classes_idx) + 1
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
class MergedDataset:
|
| 29 |
+
def __init__(self, datasets: List[ABDataset]):
|
| 30 |
+
self.datasets = datasets
|
| 31 |
+
self.datasets_len = [len(i) for i in self.datasets]
|
| 32 |
+
logger.info(f'create MergedDataset: len of datasets {self.datasets_len}')
|
| 33 |
+
self.datasets_cum_len = np.cumsum(self.datasets_len)
|
| 34 |
+
|
| 35 |
+
def __getitem__(self, idx):
|
| 36 |
+
for i, cum_len in enumerate(self.datasets_cum_len):
|
| 37 |
+
if idx < cum_len:
|
| 38 |
+
return self.datasets[i][idx - sum(self.datasets_len[0: i])]
|
| 39 |
+
|
| 40 |
+
def __len__(self):
|
| 41 |
+
return sum(self.datasets_len)
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class IndexReturnedDataset:
|
| 45 |
+
def __init__(self, dataset: ABDataset):
|
| 46 |
+
self.dataset = dataset
|
| 47 |
+
|
| 48 |
+
def __getitem__(self, idx):
|
| 49 |
+
res = self.dataset[idx]
|
| 50 |
+
|
| 51 |
+
if isinstance(res, (tuple, list)):
|
| 52 |
+
return (*res, idx)
|
| 53 |
+
else:
|
| 54 |
+
return res, idx
|
| 55 |
+
|
| 56 |
+
def __len__(self):
|
| 57 |
+
return len(self.dataset)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
# class Scenario:
|
| 61 |
+
# def __init__(self, config,
|
| 62 |
+
# source_datasets_meta_info: Dict[str, DatasetMetaInfo], target_datasets_meta_info: Dict[str, DatasetMetaInfo],
|
| 63 |
+
# target_source_map: Dict[str, Dict[str, str]],
|
| 64 |
+
# target_domains_order: List[str],
|
| 65 |
+
# source_datasets: Dict[str, Dict[str, ABDataset]], target_datasets: Dict[str, Dict[str, ABDataset]]):
|
| 66 |
+
|
| 67 |
+
# self.__config = config
|
| 68 |
+
# self.__source_datasets_meta_info = source_datasets_meta_info
|
| 69 |
+
# self.__target_datasets_meta_info = target_datasets_meta_info
|
| 70 |
+
# self.__target_source_map = target_source_map
|
| 71 |
+
# self.__target_domains_order = target_domains_order
|
| 72 |
+
# self.__source_datasets = source_datasets
|
| 73 |
+
# self.__target_datasets = target_datasets
|
| 74 |
+
|
| 75 |
+
# # 1. basic
|
| 76 |
+
# def get_config(self):
|
| 77 |
+
# return copy.deepcopy(self.__config)
|
| 78 |
+
|
| 79 |
+
# def get_task_type(self):
|
| 80 |
+
# return list(self.__source_datasets.values())[0]['train'].task_type
|
| 81 |
+
|
| 82 |
+
# def get_num_classes(self):
|
| 83 |
+
# known_classes_idx = []
|
| 84 |
+
# unknown_classes_idx = []
|
| 85 |
+
# for v in self.__source_datasets_meta_info.values():
|
| 86 |
+
# known_classes_idx += list(v.known_classes_name_idx_map.values())
|
| 87 |
+
# unknown_classes_idx += [v.unknown_class_idx]
|
| 88 |
+
# for v in self.__target_datasets_meta_info.values():
|
| 89 |
+
# known_classes_idx += list(v.known_classes_name_idx_map.values())
|
| 90 |
+
# unknown_classes_idx += [v.unknown_class_idx]
|
| 91 |
+
# unknown_classes_idx = [i for i in unknown_classes_idx if i is not None]
|
| 92 |
+
# # print(known_classes_idx, unknown_classes_idx)
|
| 93 |
+
# res = len(set(known_classes_idx)), len(set(unknown_classes_idx)), len(set(known_classes_idx + unknown_classes_idx))
|
| 94 |
+
# # print(res)
|
| 95 |
+
# assert res[0] + res[1] == res[2]
|
| 96 |
+
# return res
|
| 97 |
+
|
| 98 |
+
# def build_dataloader(self, dataset: ABDataset, batch_size: int, num_workers: int, infinite: bool, shuffle_when_finite: bool):
|
| 99 |
+
# if infinite:
|
| 100 |
+
# dataloader = InfiniteDataLoader(
|
| 101 |
+
# dataset, None, batch_size, num_workers=num_workers)
|
| 102 |
+
# else:
|
| 103 |
+
# dataloader = FastDataLoader(
|
| 104 |
+
# dataset, batch_size, num_workers, shuffle=shuffle_when_finite)
|
| 105 |
+
|
| 106 |
+
# return dataloader
|
| 107 |
+
|
| 108 |
+
# def build_sub_dataset(self, dataset: ABDataset, indexes: List[int]):
|
| 109 |
+
# from ..data.datasets.dataset_split import _SplitDataset
|
| 110 |
+
# dataset.dataset = _SplitDataset(dataset.dataset, indexes)
|
| 111 |
+
# return dataset
|
| 112 |
+
|
| 113 |
+
# def build_index_returned_dataset(self, dataset: ABDataset):
|
| 114 |
+
# return IndexReturnedDataset(dataset)
|
| 115 |
+
|
| 116 |
+
# # 2. source
|
| 117 |
+
# def get_source_datasets_meta_info(self):
|
| 118 |
+
# return self.__source_datasets_meta_info
|
| 119 |
+
|
| 120 |
+
# def get_source_datasets_name(self):
|
| 121 |
+
# return list(self.__source_datasets.keys())
|
| 122 |
+
|
| 123 |
+
# def get_merged_source_dataset(self, split):
|
| 124 |
+
# source_train_datasets = {n: d[split] for n, d in self.__source_datasets.items()}
|
| 125 |
+
# return MergedDataset(list(source_train_datasets.values()))
|
| 126 |
+
|
| 127 |
+
# def get_source_datasets(self, split):
|
| 128 |
+
# source_train_datasets = {n: d[split] for n, d in self.__source_datasets.items()}
|
| 129 |
+
# return source_train_datasets
|
| 130 |
+
|
| 131 |
+
# # 3. target **domain**
|
| 132 |
+
# # (do we need such API `get_ith_target_domain()`?)
|
| 133 |
+
# def get_target_domains_meta_info(self):
|
| 134 |
+
# return self.__source_datasets_meta_info
|
| 135 |
+
|
| 136 |
+
# def get_target_domains_order(self):
|
| 137 |
+
# return self.__target_domains_order
|
| 138 |
+
|
| 139 |
+
# def get_corr_source_datasets_name_of_target_domain(self, target_domain_name):
|
| 140 |
+
# return self.__target_source_map[target_domain_name]
|
| 141 |
+
|
| 142 |
+
# def get_limited_target_train_dataset(self):
|
| 143 |
+
# if len(self.__target_domains_order) > 1:
|
| 144 |
+
# raise RuntimeError('this API is only for pass-in scenario in user-defined online DA algorithm')
|
| 145 |
+
# return list(self.__target_datasets.values())[0]['train']
|
| 146 |
+
|
| 147 |
+
# def get_target_domains_iterator(self, split):
|
| 148 |
+
# for target_domain_index, target_domain_name in enumerate(self.__target_domains_order):
|
| 149 |
+
# target_dataset = self.__target_datasets[target_domain_name]
|
| 150 |
+
# target_domain_meta_info = self.__target_datasets_meta_info[target_domain_name]
|
| 151 |
+
|
| 152 |
+
# yield target_domain_index, target_domain_name, target_dataset[split], target_domain_meta_info
|
| 153 |
+
|
| 154 |
+
# # 4. permission management
|
| 155 |
+
# def get_sub_scenario(self, source_datasets_name, source_splits, target_domains_order, target_splits):
|
| 156 |
+
# def get_split(dataset, splits):
|
| 157 |
+
# res = {}
|
| 158 |
+
# for s, d in dataset.items():
|
| 159 |
+
# if s in splits:
|
| 160 |
+
# res[s] = d
|
| 161 |
+
# return res
|
| 162 |
+
|
| 163 |
+
# return Scenario(
|
| 164 |
+
# config=self.__config,
|
| 165 |
+
# source_datasets_meta_info={k: v for k, v in self.__source_datasets_meta_info.items() if k in source_datasets_name},
|
| 166 |
+
# target_datasets_meta_info={k: v for k, v in self.__target_datasets_meta_info.items() if k in target_domains_order},
|
| 167 |
+
# target_source_map={k: v for k, v in self.__target_source_map.items() if k in target_domains_order},
|
| 168 |
+
# target_domains_order=target_domains_order,
|
| 169 |
+
# source_datasets={k: get_split(v, source_splits) for k, v in self.__source_datasets.items() if k in source_datasets_name},
|
| 170 |
+
# target_datasets={k: get_split(v, target_splits) for k, v in self.__target_datasets.items() if k in target_domains_order}
|
| 171 |
+
# )
|
| 172 |
+
|
| 173 |
+
# def get_only_source_sub_scenario_for_exp_tracker(self):
|
| 174 |
+
# return self.get_sub_scenario(self.get_source_datasets_name(), ['train', 'val', 'test'], [], [])
|
| 175 |
+
|
| 176 |
+
# def get_only_source_sub_scenario_for_alg(self):
|
| 177 |
+
# return self.get_sub_scenario(self.get_source_datasets_name(), ['train'], [], [])
|
| 178 |
+
|
| 179 |
+
# def get_one_da_sub_scenario_for_alg(self, target_domain_name):
|
| 180 |
+
# return self.get_sub_scenario(self.get_corr_source_datasets_name_of_target_domain(target_domain_name),
|
| 181 |
+
# ['train', 'val'], [target_domain_name], ['train'])
|
| 182 |
+
|
| 183 |
+
|
| 184 |
+
# class Scenario:
|
| 185 |
+
# def __init__(self, config,
|
| 186 |
+
|
| 187 |
+
# offline_source_datasets_meta_info: Dict[str, DatasetMetaInfo],
|
| 188 |
+
# offline_source_datasets: Dict[str, ABDataset],
|
| 189 |
+
|
| 190 |
+
# online_datasets_meta_info: List[Tuple[Dict[str, DatasetMetaInfo], DatasetMetaInfo]],
|
| 191 |
+
# online_datasets: Dict[str, ABDataset],
|
| 192 |
+
# target_domains_order: List[str],
|
| 193 |
+
# target_source_map: Dict[str, Dict[str, str]],
|
| 194 |
+
|
| 195 |
+
# num_classes: int):
|
| 196 |
+
|
| 197 |
+
# self.config = config
|
| 198 |
+
|
| 199 |
+
# self.offline_source_datasets_meta_info = offline_source_datasets_meta_info
|
| 200 |
+
# self.offline_source_datasets = offline_source_datasets
|
| 201 |
+
|
| 202 |
+
# self.online_datasets_meta_info = online_datasets_meta_info
|
| 203 |
+
# self.online_datasets = online_datasets
|
| 204 |
+
|
| 205 |
+
# self.target_domains_order = target_domains_order
|
| 206 |
+
# self.target_source_map = target_source_map
|
| 207 |
+
|
| 208 |
+
# self.num_classes = num_classes
|
| 209 |
+
|
| 210 |
+
# def get_offline_source_datasets(self, split):
|
| 211 |
+
# return {n: d[split] for n, d in self.offline_source_datasets.items()}
|
| 212 |
+
|
| 213 |
+
# def get_offline_source_merged_dataset(self, split):
|
| 214 |
+
# return MergedDataset([d[split] for d in self.offline_source_datasets.values()])
|
| 215 |
+
|
| 216 |
+
# def get_online_current_corresponding_source_datasets(self, domain_index, split):
|
| 217 |
+
# cur_target_domain_name = self.target_domains_order[domain_index]
|
| 218 |
+
# cur_source_datasets_name = list(self.target_source_map[cur_target_domain_name].keys())
|
| 219 |
+
# cur_source_datasets = {n: self.online_datasets[n + '|' + cur_target_domain_name][split] for n in cur_source_datasets_name}
|
| 220 |
+
# return cur_source_datasets
|
| 221 |
+
|
| 222 |
+
# def get_online_current_corresponding_merged_source_dataset(self, domain_index, split):
|
| 223 |
+
# cur_target_domain_name = self.target_domains_order[domain_index]
|
| 224 |
+
# cur_source_datasets_name = list(self.target_source_map[cur_target_domain_name].keys())
|
| 225 |
+
# cur_source_datasets = {n: self.online_datasets[n + '|' + cur_target_domain_name][split] for n in cur_source_datasets_name}
|
| 226 |
+
# return MergedDataset([d for d in cur_source_datasets.values()])
|
| 227 |
+
|
| 228 |
+
# def get_online_current_target_dataset(self, domain_index, split):
|
| 229 |
+
# cur_target_domain_name = self.target_domains_order[domain_index]
|
| 230 |
+
# return self.online_datasets[cur_target_domain_name][split]
|
| 231 |
+
|
| 232 |
+
# def build_dataloader(self, dataset: ABDataset, batch_size: int, num_workers: int,
|
| 233 |
+
# infinite: bool, shuffle_when_finite: bool, to_iterator: bool):
|
| 234 |
+
# if infinite:
|
| 235 |
+
# dataloader = InfiniteDataLoader(
|
| 236 |
+
# dataset, None, batch_size, num_workers=num_workers)
|
| 237 |
+
# else:
|
| 238 |
+
# dataloader = FastDataLoader(
|
| 239 |
+
# dataset, batch_size, num_workers, shuffle=shuffle_when_finite)
|
| 240 |
+
|
| 241 |
+
# if to_iterator:
|
| 242 |
+
# dataloader = iter(dataloader)
|
| 243 |
+
|
| 244 |
+
# return dataloader
|
| 245 |
+
|
| 246 |
+
# def build_sub_dataset(self, dataset: ABDataset, indexes: List[int]):
|
| 247 |
+
# from data.datasets.dataset_split import _SplitDataset
|
| 248 |
+
# dataset.dataset = _SplitDataset(dataset.dataset, indexes)
|
| 249 |
+
# return dataset
|
| 250 |
+
|
| 251 |
+
# def build_index_returned_dataset(self, dataset: ABDataset):
|
| 252 |
+
# return IndexReturnedDataset(dataset)
|
| 253 |
+
|
| 254 |
+
# def get_config(self):
|
| 255 |
+
# return copy.deepcopy(self.config)
|
| 256 |
+
|
| 257 |
+
# def get_task_type(self):
|
| 258 |
+
# return list(self.online_datasets.values())[0]['train'].task_type
|
| 259 |
+
|
| 260 |
+
# def get_num_classes(self):
|
| 261 |
+
# return self.num_classes
|
| 262 |
+
|
| 263 |
+
|
| 264 |
+
class Scenario:
|
| 265 |
+
def __init__(self, config, all_datasets_ignore_classes_map, all_datasets_idx_map, target_domains_order, target_source_map,
|
| 266 |
+
all_datasets_e2e_class_to_idx_map,
|
| 267 |
+
num_classes):
|
| 268 |
+
self.config = config
|
| 269 |
+
self.all_datasets_ignore_classes_map = all_datasets_ignore_classes_map
|
| 270 |
+
self.all_datasets_idx_map = all_datasets_idx_map
|
| 271 |
+
self.target_domains_order = target_domains_order
|
| 272 |
+
self.target_source_map = target_source_map
|
| 273 |
+
self.all_datasets_e2e_class_to_idx_map = all_datasets_e2e_class_to_idx_map
|
| 274 |
+
self.num_classes = num_classes
|
| 275 |
+
self.cur_domain_index = 0
|
| 276 |
+
|
| 277 |
+
logger.info(f'[scenario build] # classes: {num_classes}')
|
| 278 |
+
logger.debug(f'[scenario build] idx map: {all_datasets_idx_map}')
|
| 279 |
+
|
| 280 |
+
def to_json(self):
|
| 281 |
+
return dict(
|
| 282 |
+
config=self.config, all_datasets_ignore_classes_map=self.all_datasets_ignore_classes_map,
|
| 283 |
+
all_datasets_idx_map=self.all_datasets_idx_map, target_domains_order=self.target_domains_order,
|
| 284 |
+
target_source_map=self.target_source_map,
|
| 285 |
+
all_datasets_e2e_class_to_idx_map=self.all_datasets_e2e_class_to_idx_map,
|
| 286 |
+
num_classes=self.num_classes
|
| 287 |
+
)
|
| 288 |
+
|
| 289 |
+
def __str__(self):
|
| 290 |
+
return f'Scenario({self.to_json()})'
|
| 291 |
+
|
| 292 |
+
def get_offline_datasets(self, transform=None):
|
| 293 |
+
# make source datasets which contains all unioned classes
|
| 294 |
+
res_offline_train_source_datasets_map = {}
|
| 295 |
+
|
| 296 |
+
from .. import get_dataset
|
| 297 |
+
data_dirs = self.config['data_dirs']
|
| 298 |
+
|
| 299 |
+
source_datasets_name = self.config['source_datasets_name']
|
| 300 |
+
|
| 301 |
+
# ori_datasets_map = {d: get_dataset(d, data_dirs[d], None, None, None, None) for d in source_datasets_name}
|
| 302 |
+
# res_source_datasets_map = {k: {split: train_val_split(copy.deepcopy(v), split, rate=0.97) for split in ['train', 'val']} for k, v in ori_datasets_map.items()}
|
| 303 |
+
# for ds in res_source_datasets_map.values():
|
| 304 |
+
# for k, v in ds.items():
|
| 305 |
+
# v.underlying_dataset.dataset.setSplit(k)
|
| 306 |
+
res_source_datasets_map = {d: {split: get_dataset(d, data_dirs[d], split,
|
| 307 |
+
transform,
|
| 308 |
+
self.all_datasets_ignore_classes_map[d], self.all_datasets_idx_map[d])
|
| 309 |
+
for split in ['train', 'val', 'test']}
|
| 310 |
+
for d in self.all_datasets_ignore_classes_map.keys() if d in source_datasets_name}
|
| 311 |
+
|
| 312 |
+
# for source_dataset_name in self.config['source_datasets_name']:
|
| 313 |
+
# source_datasets = [v for k, v in res_source_datasets_map.items() if source_dataset_name in k]
|
| 314 |
+
|
| 315 |
+
# # how to merge idx map?
|
| 316 |
+
# # 35 79 97
|
| 317 |
+
# idx_maps = [d['train'].idx_map for d in source_datasets]
|
| 318 |
+
# ignore_classes_list = [d['train'].ignore_classes for d in source_datasets]
|
| 319 |
+
|
| 320 |
+
# union_idx_map = {}
|
| 321 |
+
# for idx_map in idx_maps:
|
| 322 |
+
# for k, v in idx_map.items():
|
| 323 |
+
# if k not in union_idx_map:
|
| 324 |
+
# union_idx_map[k] = v
|
| 325 |
+
# else:
|
| 326 |
+
# assert union_idx_map[k] == v
|
| 327 |
+
|
| 328 |
+
# union_ignore_classes = reduce(lambda res, cur: res & set(cur), ignore_classes_list, set(ignore_classes_list[0]))
|
| 329 |
+
# assert len(union_ignore_classes) + len(union_idx_map) == len(source_datasets[0]['train'].raw_classes)
|
| 330 |
+
|
| 331 |
+
# logger.info(f'[scenario build] {source_dataset_name} has {len(union_idx_map)} classes in offline training')
|
| 332 |
+
|
| 333 |
+
# d = source_dataset_name
|
| 334 |
+
# res_offline_train_source_datasets_map[d] = {split: get_dataset(d, data_dirs[d], split,
|
| 335 |
+
# transform,
|
| 336 |
+
# union_ignore_classes, union_idx_map)
|
| 337 |
+
# for split in ['train', 'val', 'test']}
|
| 338 |
+
|
| 339 |
+
return res_source_datasets_map
|
| 340 |
+
|
| 341 |
+
def get_offline_datasets_args(self):
|
| 342 |
+
# make source datasets which contains all unioned classes
|
| 343 |
+
res_offline_train_source_datasets_map = {}
|
| 344 |
+
|
| 345 |
+
from .. import get_dataset
|
| 346 |
+
data_dirs = self.config['data_dirs']
|
| 347 |
+
|
| 348 |
+
source_datasets_name = self.config['source_datasets_name']
|
| 349 |
+
res_source_datasets_map = {d: {split: get_dataset(d.split('|')[0], data_dirs[d.split('|')[0]], split,
|
| 350 |
+
None,
|
| 351 |
+
self.all_datasets_ignore_classes_map[d], self.all_datasets_idx_map[d])
|
| 352 |
+
for split in ['train', 'val', 'test']}
|
| 353 |
+
for d in self.all_datasets_ignore_classes_map.keys() if d.split('|')[0] in source_datasets_name}
|
| 354 |
+
|
| 355 |
+
for source_dataset_name in self.config['source_datasets_name']:
|
| 356 |
+
source_datasets = [v for k, v in res_source_datasets_map.items() if source_dataset_name in k]
|
| 357 |
+
|
| 358 |
+
# how to merge idx map?
|
| 359 |
+
# 35 79 97
|
| 360 |
+
idx_maps = [d['train'].idx_map for d in source_datasets]
|
| 361 |
+
ignore_classes_list = [d['train'].ignore_classes for d in source_datasets]
|
| 362 |
+
|
| 363 |
+
union_idx_map = {}
|
| 364 |
+
for idx_map in idx_maps:
|
| 365 |
+
for k, v in idx_map.items():
|
| 366 |
+
if k not in union_idx_map:
|
| 367 |
+
union_idx_map[k] = v
|
| 368 |
+
else:
|
| 369 |
+
assert union_idx_map[k] == v
|
| 370 |
+
|
| 371 |
+
union_ignore_classes = reduce(lambda res, cur: res & set(cur), ignore_classes_list, set(ignore_classes_list[0]))
|
| 372 |
+
assert len(union_ignore_classes) + len(union_idx_map) == len(source_datasets[0]['train'].raw_classes)
|
| 373 |
+
|
| 374 |
+
logger.info(f'[scenario build] {source_dataset_name} has {len(union_idx_map)} classes in offline training')
|
| 375 |
+
|
| 376 |
+
d = source_dataset_name
|
| 377 |
+
res_offline_train_source_datasets_map[d] = {split: dict(d, data_dirs[d], split,
|
| 378 |
+
None,
|
| 379 |
+
union_ignore_classes, union_idx_map)
|
| 380 |
+
for split in ['train', 'val', 'test']}
|
| 381 |
+
|
| 382 |
+
return res_offline_train_source_datasets_map
|
| 383 |
+
|
| 384 |
+
# for d in source_datasets_name:
|
| 385 |
+
# source_dataset_with_max_num_classes = None
|
| 386 |
+
|
| 387 |
+
# for ed_name, ed in res_source_datasets_map.items():
|
| 388 |
+
# if not ed_name.startswith(d):
|
| 389 |
+
# continue
|
| 390 |
+
|
| 391 |
+
# if source_dataset_with_max_num_classes is None:
|
| 392 |
+
# source_dataset_with_max_num_classes = ed
|
| 393 |
+
# res_offline_train_source_datasets_map_names[d] = ed_name
|
| 394 |
+
|
| 395 |
+
# if len(ed['train'].ignore_classes) < len(source_dataset_with_max_num_classes['train'].ignore_classes):
|
| 396 |
+
# source_dataset_with_max_num_classes = ed
|
| 397 |
+
# res_offline_train_source_datasets_map_names[d] = ed_name
|
| 398 |
+
|
| 399 |
+
# res_offline_train_source_datasets_map[d] = source_dataset_with_max_num_classes
|
| 400 |
+
|
| 401 |
+
# return res_offline_train_source_datasets_map
|
| 402 |
+
|
| 403 |
+
def get_online_ith_domain_datasets_args_for_inference(self, domain_index):
|
| 404 |
+
target_dataset_name = self.target_domains_order[domain_index]
|
| 405 |
+
# dataset_name: Any, root_dir: Any, split: Any, transform: Any | None = None, ignore_classes: Any = [], idx_map: Any | None = None
|
| 406 |
+
|
| 407 |
+
if 'MM-CityscapesDet' in self.target_domains_order or 'CityscapesDet' in self.target_domains_order or 'BaiduPersonDet' in self.target_domains_order:
|
| 408 |
+
logger.info(f'use val split for inference test (only Det workload)')
|
| 409 |
+
split = 'test'
|
| 410 |
+
else:
|
| 411 |
+
split = 'train'
|
| 412 |
+
|
| 413 |
+
return dict(dataset_name=target_dataset_name,
|
| 414 |
+
root_dir=self.config['data_dirs'][target_dataset_name],
|
| 415 |
+
split=split,
|
| 416 |
+
transform=None,
|
| 417 |
+
ignore_classes=self.all_datasets_ignore_classes_map[target_dataset_name],
|
| 418 |
+
idx_map=self.all_datasets_idx_map[target_dataset_name])
|
| 419 |
+
|
| 420 |
+
def get_online_ith_domain_datasets_args_for_training(self, domain_index):
|
| 421 |
+
target_dataset_name = self.target_domains_order[domain_index]
|
| 422 |
+
source_datasets_name = list(self.target_source_map[target_dataset_name].keys())
|
| 423 |
+
|
| 424 |
+
res = {}
|
| 425 |
+
# dataset_name: Any, root_dir: Any, split: Any, transform: Any | None = None, ignore_classes: Any = [], idx_map: Any | None = None
|
| 426 |
+
res[target_dataset_name] = {split: dict(dataset_name=target_dataset_name,
|
| 427 |
+
root_dir=self.config['data_dirs'][target_dataset_name],
|
| 428 |
+
split=split,
|
| 429 |
+
transform=None,
|
| 430 |
+
ignore_classes=self.all_datasets_ignore_classes_map[target_dataset_name],
|
| 431 |
+
idx_map=self.all_datasets_idx_map[target_dataset_name]) for split in ['train', 'val']}
|
| 432 |
+
for d in source_datasets_name:
|
| 433 |
+
res[d] = {split: dict(dataset_name=d,
|
| 434 |
+
root_dir=self.config['data_dirs'][d],
|
| 435 |
+
split=split,
|
| 436 |
+
transform=None,
|
| 437 |
+
ignore_classes=self.all_datasets_ignore_classes_map[d + '|' + target_dataset_name],
|
| 438 |
+
idx_map=self.all_datasets_idx_map[d + '|' + target_dataset_name]) for split in ['train', 'val']}
|
| 439 |
+
|
| 440 |
+
return res
|
| 441 |
+
|
| 442 |
+
def get_online_cur_domain_datasets_args_for_inference(self):
|
| 443 |
+
return self.get_online_ith_domain_datasets_args_for_inference(self.cur_domain_index)
|
| 444 |
+
|
| 445 |
+
def get_online_cur_domain_datasets_args_for_training(self):
|
| 446 |
+
return self.get_online_ith_domain_datasets_args_for_training(self.cur_domain_index)
|
| 447 |
+
|
| 448 |
+
def get_online_cur_domain_datasets_for_training(self, transform=None):
|
| 449 |
+
res = {}
|
| 450 |
+
datasets_args = self.get_online_ith_domain_datasets_args_for_training(self.cur_domain_index)
|
| 451 |
+
for dataset_name, dataset_args in datasets_args.items():
|
| 452 |
+
res[dataset_name] = {}
|
| 453 |
+
for split, args in dataset_args.items():
|
| 454 |
+
if transform is not None:
|
| 455 |
+
args['transform'] = transform
|
| 456 |
+
dataset = get_dataset(**args)
|
| 457 |
+
res[dataset_name][split] = dataset
|
| 458 |
+
return res
|
| 459 |
+
|
| 460 |
+
def get_online_cur_domain_datasets_for_inference(self, transform=None):
|
| 461 |
+
datasets_args = self.get_online_ith_domain_datasets_args_for_inference(self.cur_domain_index)
|
| 462 |
+
if transform is not None:
|
| 463 |
+
datasets_args['transform'] = transform
|
| 464 |
+
return get_dataset(**datasets_args)
|
| 465 |
+
|
| 466 |
+
def get_online_cur_domain_samples_for_training(self, num_samples, transform=None, collate_fn=None):
|
| 467 |
+
dataset = self.get_online_cur_domain_datasets_for_training(transform=transform)
|
| 468 |
+
dataset = dataset[self.target_domains_order[self.cur_domain_index]]['train']
|
| 469 |
+
return next(iter(build_dataloader(dataset, num_samples, 0, True, None, collate_fn=collate_fn)))[0]
|
| 470 |
+
|
| 471 |
+
def next_domain(self):
|
| 472 |
+
self.cur_domain_index += 1
|
| 473 |
+
|
data/convert_all_load_to_single_load.py
ADDED
|
@@ -0,0 +1,56 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
convert load-all-images-into-memory-before-training dataset
|
| 3 |
+
to load-when-training-dataset
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
from torchvision.datasets import CIFAR10, STL10, MNIST, USPS, SVHN
|
| 10 |
+
import os
|
| 11 |
+
import tqdm
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def convert(datasets_of_split, new_dir):
|
| 15 |
+
img_idx = {}
|
| 16 |
+
|
| 17 |
+
for d in datasets_of_split:
|
| 18 |
+
for x, y in tqdm.tqdm(d, total=len(d), dynamic_ncols=True):
|
| 19 |
+
# print(type(x), type(y))
|
| 20 |
+
# break
|
| 21 |
+
# y = str(y)
|
| 22 |
+
if y not in img_idx:
|
| 23 |
+
img_idx[y] = -1
|
| 24 |
+
img_idx[y] += 1
|
| 25 |
+
|
| 26 |
+
p = os.path.join(new_dir, f'{y:06d}', f'{img_idx[y]:06d}' + '.png')
|
| 27 |
+
os.makedirs(os.path.dirname(p), exist_ok=True)
|
| 28 |
+
|
| 29 |
+
x.save(p)
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
if __name__ == '__main__':
|
| 33 |
+
# convert(
|
| 34 |
+
# [CIFAR10('/data/zql/datasets/CIFAR10', True, download=True), CIFAR10('/data/zql/datasets/CIFAR10', False, download=True)],
|
| 35 |
+
# '/data/zql/datasets/CIFAR10-single'
|
| 36 |
+
# )
|
| 37 |
+
|
| 38 |
+
# convert(
|
| 39 |
+
# [STL10('/data/zql/datasets/STL10', 'train', download=False), STL10('/data/zql/datasets/STL10', 'test', download=False)],
|
| 40 |
+
# '/data/zql/datasets/STL10-single'
|
| 41 |
+
# )
|
| 42 |
+
|
| 43 |
+
# convert(
|
| 44 |
+
# [MNIST('/data/zql/datasets/MNIST', True, download=True), MNIST('/data/zql/datasets/MNIST', False, download=True)],
|
| 45 |
+
# '/data/zql/datasets/MNIST-single'
|
| 46 |
+
# )
|
| 47 |
+
|
| 48 |
+
convert(
|
| 49 |
+
[SVHN('/data/zql/datasets/SVHN', 'train', download=True), SVHN('/data/zql/datasets/SVHN', 'test', download=True)],
|
| 50 |
+
'/data/zql/datasets/SVHN-single'
|
| 51 |
+
)
|
| 52 |
+
|
| 53 |
+
# convert(
|
| 54 |
+
# [USPS('/data/zql/datasets/USPS', True, download=False), USPS('/data/zql/datasets/USPS', False, download=False)],
|
| 55 |
+
# '/data/zql/datasets/USPS-single'
|
| 56 |
+
# )
|
data/convert_det_dataset_to_cls.py
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from data import ABDataset
|
| 2 |
+
from utils.common.data_record import read_json, write_json
|
| 3 |
+
from PIL import Image
|
| 4 |
+
import os
|
| 5 |
+
from utils.common.file import ensure_dir
|
| 6 |
+
import numpy as np
|
| 7 |
+
from itertools import groupby
|
| 8 |
+
from skimage import morphology, measure
|
| 9 |
+
from PIL import Image
|
| 10 |
+
from scipy import misc
|
| 11 |
+
import tqdm
|
| 12 |
+
from PIL import ImageFile
|
| 13 |
+
ImageFile.LOAD_TRUNCATED_IMAGES = True
|
| 14 |
+
import shutil
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def convert_det_dataset_to_det(coco_ann_json_path, data_dir, target_data_dir, min_img_size=224):
|
| 18 |
+
|
| 19 |
+
coco_ann = read_json(coco_ann_json_path)
|
| 20 |
+
|
| 21 |
+
img_id_to_path = {}
|
| 22 |
+
for img in coco_ann['images']:
|
| 23 |
+
img_id_to_path[img['id']] = os.path.join(data_dir, img['file_name'])
|
| 24 |
+
|
| 25 |
+
classes_imgs_id_map = {}
|
| 26 |
+
for ann in tqdm.tqdm(coco_ann['annotations'], total=len(coco_ann['annotations']), dynamic_ncols=True):
|
| 27 |
+
img_id = ann['image_id']
|
| 28 |
+
img_path = img_id_to_path[img_id]
|
| 29 |
+
img = Image.open(img_path)
|
| 30 |
+
|
| 31 |
+
bbox = ann['bbox']
|
| 32 |
+
if bbox[2] < min_img_size or bbox[3] < min_img_size:
|
| 33 |
+
continue
|
| 34 |
+
|
| 35 |
+
bbox = [bbox[0], bbox[1], bbox[0] + bbox[2], bbox[1] + bbox[3]]
|
| 36 |
+
|
| 37 |
+
class_idx = str(ann['category_id'])
|
| 38 |
+
if class_idx not in classes_imgs_id_map.keys():
|
| 39 |
+
classes_imgs_id_map[class_idx] = 0
|
| 40 |
+
target_cropped_img_path = os.path.join(target_data_dir, class_idx,
|
| 41 |
+
f'{classes_imgs_id_map[class_idx]}.{img_path.split(".")[-1]}')
|
| 42 |
+
classes_imgs_id_map[class_idx] += 1
|
| 43 |
+
|
| 44 |
+
ensure_dir(target_cropped_img_path)
|
| 45 |
+
img.crop(bbox).save(target_cropped_img_path)
|
| 46 |
+
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
if __name__ == '__main__':
|
| 50 |
+
convert_det_dataset_to_det(
|
| 51 |
+
coco_ann_json_path='/data/zql/datasets/coco2017/train2017/coco_ann.json',
|
| 52 |
+
data_dir='/data/zql/datasets/coco2017/train2017',
|
| 53 |
+
target_data_dir='/data/zql/datasets/coco2017_for_cls_task',
|
| 54 |
+
min_img_size=224
|
| 55 |
+
)
|
data/convert_seg_dataset_to_cls.py
ADDED
|
@@ -0,0 +1,324 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from data import ABDataset
|
| 2 |
+
from utils.common.data_record import read_json
|
| 3 |
+
from PIL import Image
|
| 4 |
+
import os
|
| 5 |
+
from utils.common.file import ensure_dir
|
| 6 |
+
import numpy as np
|
| 7 |
+
from itertools import groupby
|
| 8 |
+
from skimage import morphology, measure
|
| 9 |
+
from PIL import Image
|
| 10 |
+
from scipy import misc
|
| 11 |
+
import tqdm
|
| 12 |
+
from PIL import ImageFile
|
| 13 |
+
ImageFile.LOAD_TRUNCATED_IMAGES = True
|
| 14 |
+
import shutil
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def convert_seg_dataset_to_cls(seg_imgs_path, seg_labels_path, target_cls_data_dir, ignore_classes_idx, thread_i, min_img_size=224, label_after_hook=lambda x: x):
|
| 18 |
+
"""
|
| 19 |
+
Reference: https://blog.csdn.net/lizaijinsheng/article/details/119889946
|
| 20 |
+
|
| 21 |
+
NOTE:
|
| 22 |
+
Background class should not be considered.
|
| 23 |
+
However, if a seg dataset has only one valid class, so that the generated cls dataset also has only one class and
|
| 24 |
+
the cls accuracy will be 100% forever. But we do not use the generated cls dataset alone, so it is ok.
|
| 25 |
+
"""
|
| 26 |
+
assert len(seg_imgs_path) == len(seg_labels_path)
|
| 27 |
+
|
| 28 |
+
classes_imgs_id_map = {}
|
| 29 |
+
|
| 30 |
+
for seg_img_path, seg_label_path in tqdm.tqdm(zip(seg_imgs_path, seg_labels_path), total=len(seg_imgs_path),
|
| 31 |
+
dynamic_ncols=True, leave=False, desc=f'thread {thread_i}'):
|
| 32 |
+
|
| 33 |
+
try:
|
| 34 |
+
seg_img = Image.open(seg_img_path)
|
| 35 |
+
seg_label = Image.open(seg_label_path).convert('L')
|
| 36 |
+
seg_label = np.array(seg_label)
|
| 37 |
+
seg_label = label_after_hook(seg_label)
|
| 38 |
+
except Exception as e:
|
| 39 |
+
print(e)
|
| 40 |
+
print(f'file {seg_img_path} error, skip')
|
| 41 |
+
exit()
|
| 42 |
+
# seg_img = Image.open(seg_img_path)
|
| 43 |
+
# seg_label = Image.open(seg_label_path).convert('L')
|
| 44 |
+
# seg_label = np.array(seg_label)
|
| 45 |
+
|
| 46 |
+
this_img_classes = set(seg_label.reshape(-1).tolist())
|
| 47 |
+
# print(this_img_classes)
|
| 48 |
+
|
| 49 |
+
for class_idx in this_img_classes:
|
| 50 |
+
if class_idx in ignore_classes_idx:
|
| 51 |
+
continue
|
| 52 |
+
|
| 53 |
+
if class_idx not in classes_imgs_id_map.keys():
|
| 54 |
+
classes_imgs_id_map[class_idx] = 0
|
| 55 |
+
|
| 56 |
+
mask = np.zeros((seg_label.shape[0], seg_label.shape[1]), dtype=np.uint8)
|
| 57 |
+
mask[seg_label == class_idx] = 1
|
| 58 |
+
mask_without_small = morphology.remove_small_objects(mask, min_size=10, connectivity=2)
|
| 59 |
+
label_image = measure.label(mask_without_small)
|
| 60 |
+
|
| 61 |
+
for region in measure.regionprops(label_image):
|
| 62 |
+
bbox = region.bbox # (top, left, bottom, right)
|
| 63 |
+
bbox = [bbox[1], bbox[0], bbox[3], bbox[2]] # (left, top, right, bottom)
|
| 64 |
+
|
| 65 |
+
width, height = bbox[2] - bbox[0], bbox[3] - bbox[1]
|
| 66 |
+
if width < min_img_size or height < min_img_size:
|
| 67 |
+
continue
|
| 68 |
+
|
| 69 |
+
target_cropped_img_path = os.path.join(target_cls_data_dir, str(class_idx),
|
| 70 |
+
f'{classes_imgs_id_map[class_idx]}.{seg_img_path.split(".")[-1]}')
|
| 71 |
+
ensure_dir(target_cropped_img_path)
|
| 72 |
+
seg_img.crop(bbox).save(target_cropped_img_path)
|
| 73 |
+
# print(target_cropped_img_path)
|
| 74 |
+
# exit()
|
| 75 |
+
|
| 76 |
+
classes_imgs_id_map[class_idx] += 1
|
| 77 |
+
|
| 78 |
+
num_cls_imgs = 0
|
| 79 |
+
for k, v in classes_imgs_id_map.items():
|
| 80 |
+
# print(f'# class {k}: {v + 1}')
|
| 81 |
+
num_cls_imgs += v
|
| 82 |
+
# print(f'total: {num_cls_imgs}')
|
| 83 |
+
|
| 84 |
+
return classes_imgs_id_map
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
from concurrent.futures import ThreadPoolExecutor
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
# def convert_seg_dataset_to_cls_multi_thread(seg_imgs_path, seg_labels_path, target_cls_data_dir, ignore_classes_idx, num_threads):
|
| 92 |
+
# if os.path.exists(target_cls_data_dir):
|
| 93 |
+
# shutil.rmtree(target_cls_data_dir)
|
| 94 |
+
|
| 95 |
+
# assert len(seg_imgs_path) == len(seg_labels_path)
|
| 96 |
+
# n = len(seg_imgs_path) // num_threads
|
| 97 |
+
|
| 98 |
+
# pool = ThreadPoolExecutor(max_workers=num_threads)
|
| 99 |
+
# # threads = []
|
| 100 |
+
# futures = []
|
| 101 |
+
# for thread_i in range(num_threads):
|
| 102 |
+
# # thread = threading.Thread(target=convert_seg_dataset_to_cls,
|
| 103 |
+
# # args=(seg_imgs_path[thread_i * n: (thread_i + 1) * n],
|
| 104 |
+
# # seg_labels_path[thread_i * n: (thread_i + 1) * n],
|
| 105 |
+
# # target_cls_data_dir, ignore_classes_idx))
|
| 106 |
+
# # threads += [thread]
|
| 107 |
+
# future = pool.submit(convert_seg_dataset_to_cls, *(seg_imgs_path[thread_i * n: (thread_i + 1) * n],
|
| 108 |
+
# seg_labels_path[thread_i * n: (thread_i + 1) * n],
|
| 109 |
+
# target_cls_data_dir, ignore_classes_idx, thread_i))
|
| 110 |
+
# futures += [future]
|
| 111 |
+
|
| 112 |
+
# futures += [
|
| 113 |
+
# pool.submit(convert_seg_dataset_to_cls, *(seg_imgs_path[(thread_i + 1) * n: ],
|
| 114 |
+
# seg_labels_path[(thread_i + 1) * n: ],
|
| 115 |
+
# target_cls_data_dir, ignore_classes_idx, thread_i))
|
| 116 |
+
# ]
|
| 117 |
+
|
| 118 |
+
# for f in futures:
|
| 119 |
+
# f.done()
|
| 120 |
+
|
| 121 |
+
# res = []
|
| 122 |
+
# for f in futures:
|
| 123 |
+
# res += [f.result()]
|
| 124 |
+
# print(res[-1])
|
| 125 |
+
|
| 126 |
+
# res_dist = {}
|
| 127 |
+
# for r in res:
|
| 128 |
+
# for k, v in r.items():
|
| 129 |
+
# if k in res_dist.keys():
|
| 130 |
+
# res_dist[k] += v
|
| 131 |
+
# else:
|
| 132 |
+
# res_dist[k] = v
|
| 133 |
+
|
| 134 |
+
# print('results:')
|
| 135 |
+
# print(res_dist)
|
| 136 |
+
|
| 137 |
+
# pool.shutdown()
|
| 138 |
+
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
import random
|
| 142 |
+
def random_crop_aug(target_dir):
|
| 143 |
+
for class_dir in os.listdir(target_dir):
|
| 144 |
+
class_dir = os.path.join(target_dir, class_dir)
|
| 145 |
+
|
| 146 |
+
for img_path in os.listdir(class_dir):
|
| 147 |
+
img_path = os.path.join(class_dir, img_path)
|
| 148 |
+
|
| 149 |
+
img = Image.open(img_path)
|
| 150 |
+
|
| 151 |
+
w, h = img.width, img.height
|
| 152 |
+
|
| 153 |
+
for ri in range(5):
|
| 154 |
+
img.crop(
|
| 155 |
+
[
|
| 156 |
+
random.randint(0, w // 5),
|
| 157 |
+
random.randint(0, h // 5),
|
| 158 |
+
random.randint(w // 5 * 4, w),
|
| 159 |
+
random.randint(h // 5 * 4, h)
|
| 160 |
+
]
|
| 161 |
+
).save(
|
| 162 |
+
os.path.join(os.path.dirname(img_path), f'randaug_{ri}_' + os.path.basename(img_path))
|
| 163 |
+
)
|
| 164 |
+
# print(img_path)
|
| 165 |
+
# exit()
|
| 166 |
+
|
| 167 |
+
|
| 168 |
+
if __name__ == '__main__':
|
| 169 |
+
# SuperviselyPerson
|
| 170 |
+
# root_dir = '/data/zql/datasets/supervisely_person/Supervisely Person Dataset'
|
| 171 |
+
|
| 172 |
+
# images_path, labels_path = [], []
|
| 173 |
+
# for p in os.listdir(root_dir):
|
| 174 |
+
# if p.startswith('ds'):
|
| 175 |
+
# p1 = os.path.join(root_dir, p, 'img')
|
| 176 |
+
# images_path += [(p, os.path.join(p1, n)) for n in os.listdir(p1)]
|
| 177 |
+
# for dsi, img_p in images_path:
|
| 178 |
+
# target_p = os.path.join(root_dir, p, dsi, img_p.split('/')[-1])
|
| 179 |
+
# labels_path += [target_p]
|
| 180 |
+
# images_path = [i[1] for i in images_path]
|
| 181 |
+
|
| 182 |
+
# target_dir = '/data/zql/datasets/supervisely_person_for_cls_task'
|
| 183 |
+
# if os.path.exists(target_dir):
|
| 184 |
+
# shutil.rmtree(target_dir)
|
| 185 |
+
# convert_seg_dataset_to_cls(
|
| 186 |
+
# seg_imgs_path=images_path,
|
| 187 |
+
# seg_labels_path=labels_path,
|
| 188 |
+
# target_cls_data_dir=target_dir,
|
| 189 |
+
# ignore_classes_idx=[0, 2],
|
| 190 |
+
# # num_threads=8
|
| 191 |
+
# thread_i=0
|
| 192 |
+
# )
|
| 193 |
+
|
| 194 |
+
# random_crop_aug('/data/zql/datasets/supervisely_person_for_cls_task')
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
# GTA5
|
| 198 |
+
# root_dir = '/data/zql/datasets/GTA-ls-copy/GTA5'
|
| 199 |
+
# images_path, labels_path = [], []
|
| 200 |
+
# for p in os.listdir(os.path.join(root_dir, 'images')):
|
| 201 |
+
# p = os.path.join(root_dir, 'images', p)
|
| 202 |
+
# if not p.endswith('png'):
|
| 203 |
+
# continue
|
| 204 |
+
# images_path += [p]
|
| 205 |
+
# labels_path += [p.replace('images', 'labels_gt')]
|
| 206 |
+
|
| 207 |
+
# target_dir = '/data/zql/datasets/gta5_for_cls_task'
|
| 208 |
+
# if os.path.exists(target_dir):
|
| 209 |
+
# shutil.rmtree(target_dir)
|
| 210 |
+
|
| 211 |
+
# convert_seg_dataset_to_cls(
|
| 212 |
+
# seg_imgs_path=images_path,
|
| 213 |
+
# seg_labels_path=labels_path,
|
| 214 |
+
# target_cls_data_dir=target_dir,
|
| 215 |
+
# ignore_classes_idx=[],
|
| 216 |
+
# thread_i=0
|
| 217 |
+
# )
|
| 218 |
+
|
| 219 |
+
# cityscapes
|
| 220 |
+
# root_dir = '/data/zql/datasets/cityscape/'
|
| 221 |
+
|
| 222 |
+
# def _get_target_suffix(mode: str, target_type: str) -> str:
|
| 223 |
+
# if target_type == 'instance':
|
| 224 |
+
# return '{}_instanceIds.png'.format(mode)
|
| 225 |
+
# elif target_type == 'semantic':
|
| 226 |
+
# return '{}_labelIds.png'.format(mode)
|
| 227 |
+
# elif target_type == 'color':
|
| 228 |
+
# return '{}_color.png'.format(mode)
|
| 229 |
+
# else:
|
| 230 |
+
# return '{}_polygons.json'.format(mode)
|
| 231 |
+
|
| 232 |
+
|
| 233 |
+
# images_path, labels_path = [], []
|
| 234 |
+
# split = 'train'
|
| 235 |
+
# images_dir = os.path.join(root_dir, 'leftImg8bit', split)
|
| 236 |
+
# targets_dir = os.path.join(root_dir, 'gtFine', split)
|
| 237 |
+
# for city in os.listdir(images_dir):
|
| 238 |
+
# img_dir = os.path.join(images_dir, city)
|
| 239 |
+
# target_dir = os.path.join(targets_dir, city)
|
| 240 |
+
# for file_name in os.listdir(img_dir):
|
| 241 |
+
# target_types = []
|
| 242 |
+
# for t in ['semantic']:
|
| 243 |
+
# target_name = '{}_{}'.format(file_name.split('_leftImg8bit')[0],
|
| 244 |
+
# _get_target_suffix('gtFine', t))
|
| 245 |
+
# target_types.append(os.path.join(target_dir, target_name))
|
| 246 |
+
|
| 247 |
+
# images_path.append(os.path.join(img_dir, file_name))
|
| 248 |
+
# labels_path.append(target_types[0])
|
| 249 |
+
|
| 250 |
+
# print(images_path[0: 5], '\n', labels_path[0: 5])
|
| 251 |
+
|
| 252 |
+
# target_dir = '/data/zql/datasets/cityscapes_for_cls_task'
|
| 253 |
+
# if os.path.exists(target_dir):
|
| 254 |
+
# shutil.rmtree(target_dir)
|
| 255 |
+
# convert_seg_dataset_to_cls(
|
| 256 |
+
# seg_imgs_path=images_path,
|
| 257 |
+
# seg_labels_path=labels_path,
|
| 258 |
+
# target_cls_data_dir=target_dir,
|
| 259 |
+
# ignore_classes_idx=[],
|
| 260 |
+
# # num_threads=8
|
| 261 |
+
# thread_i=0
|
| 262 |
+
# )
|
| 263 |
+
|
| 264 |
+
# import shutil
|
| 265 |
+
|
| 266 |
+
# ignore_target_dir = '/data/zql/datasets/cityscapes_for_cls_task_ignored'
|
| 267 |
+
|
| 268 |
+
# ignore_label = 255
|
| 269 |
+
# raw_idx_map_in_y_transform = {-1: ignore_label, 0: ignore_label, 1: ignore_label, 2: ignore_label,
|
| 270 |
+
# 3: ignore_label, 4: ignore_label, 5: ignore_label, 6: ignore_label,
|
| 271 |
+
# 7: 0, 8: 1, 9: ignore_label, 10: ignore_label, 11: 2, 12: 3, 13: 4,
|
| 272 |
+
# 14: ignore_label, 15: ignore_label, 16: ignore_label, 17: 5,
|
| 273 |
+
# 18: ignore_label, 19: 6, 20: 7, 21: 8, 22: 9, 23: 10, 24: 11, 25: 12, 26: 13, 27: 14,
|
| 274 |
+
# 28: 15, 29: ignore_label, 30: ignore_label, 31: 16, 32: 17, 33: 18}
|
| 275 |
+
# ignore_classes_idx = [k for k, v in raw_idx_map_in_y_transform.items() if v == ignore_label]
|
| 276 |
+
# ignore_classes_idx = sorted(ignore_classes_idx)
|
| 277 |
+
|
| 278 |
+
# for class_dir in os.listdir(target_dir):
|
| 279 |
+
# if int(class_dir) in ignore_classes_idx:
|
| 280 |
+
# continue
|
| 281 |
+
# shutil.move(
|
| 282 |
+
# os.path.join(target_dir, class_dir),
|
| 283 |
+
# os.path.join(ignore_target_dir, class_dir)
|
| 284 |
+
# )
|
| 285 |
+
# else:
|
| 286 |
+
# shutil.move(
|
| 287 |
+
# os.path.join(target_dir, class_dir),
|
| 288 |
+
# os.path.join(target_dir, str(raw_idx_map_in_y_transform[int(class_dir)]))
|
| 289 |
+
# )
|
| 290 |
+
# continue
|
| 291 |
+
# print(class_dir)
|
| 292 |
+
# exit()
|
| 293 |
+
|
| 294 |
+
|
| 295 |
+
|
| 296 |
+
# baidu person
|
| 297 |
+
# root_dir = '/data/zql/datasets/baidu_person/clean_images/'
|
| 298 |
+
|
| 299 |
+
# images_path, labels_path = [], []
|
| 300 |
+
# for p in os.listdir(os.path.join(root_dir, 'images')):
|
| 301 |
+
# images_path += [os.path.join(root_dir, 'images', p)]
|
| 302 |
+
# labels_path += [os.path.join(root_dir, 'profiles', p.split('.')[0] + '-profile.jpg')]
|
| 303 |
+
|
| 304 |
+
# target_dir = '/data/zql/datasets/baiduperson_for_cls_task'
|
| 305 |
+
# # if os.path.exists(target_dir):
|
| 306 |
+
# # shutil.rmtree(target_dir)
|
| 307 |
+
|
| 308 |
+
# def label_after_hook(x):
|
| 309 |
+
# x[x > 1] = 1
|
| 310 |
+
# return x
|
| 311 |
+
|
| 312 |
+
# convert_seg_dataset_to_cls(
|
| 313 |
+
# seg_imgs_path=images_path,
|
| 314 |
+
# seg_labels_path=labels_path,
|
| 315 |
+
# target_cls_data_dir=target_dir,
|
| 316 |
+
# ignore_classes_idx=[1],
|
| 317 |
+
# # num_threads=8
|
| 318 |
+
# thread_i=1,
|
| 319 |
+
# min_img_size=224,
|
| 320 |
+
# label_after_hook=label_after_hook
|
| 321 |
+
# )
|
| 322 |
+
|
| 323 |
+
|
| 324 |
+
|
data/convert_seg_dataset_to_det.py
ADDED
|
@@ -0,0 +1,399 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from data import ABDataset
|
| 2 |
+
from utils.common.data_record import read_json, write_json
|
| 3 |
+
from PIL import Image
|
| 4 |
+
import os
|
| 5 |
+
from utils.common.file import ensure_dir
|
| 6 |
+
import numpy as np
|
| 7 |
+
from itertools import groupby
|
| 8 |
+
from skimage import morphology, measure
|
| 9 |
+
from PIL import Image
|
| 10 |
+
from scipy import misc
|
| 11 |
+
import tqdm
|
| 12 |
+
from PIL import ImageFile
|
| 13 |
+
ImageFile.LOAD_TRUNCATED_IMAGES = True
|
| 14 |
+
import shutil
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def convert_seg_dataset_to_det(seg_imgs_path, seg_labels_path, root_dir, target_coco_ann_path, ignore_classes_idx, thread_i, min_img_size=224, label_after_hook=lambda x: x):
|
| 18 |
+
"""
|
| 19 |
+
Reference: https://blog.csdn.net/lizaijinsheng/article/details/119889946
|
| 20 |
+
|
| 21 |
+
NOTE:
|
| 22 |
+
Background class should not be considered.
|
| 23 |
+
However, if a seg dataset has only one valid class, so that the generated cls dataset also has only one class and
|
| 24 |
+
the cls accuracy will be 100% forever. But we do not use the generated cls dataset alone, so it is ok.
|
| 25 |
+
"""
|
| 26 |
+
assert len(seg_imgs_path) == len(seg_labels_path)
|
| 27 |
+
|
| 28 |
+
classes_imgs_id_map = {}
|
| 29 |
+
|
| 30 |
+
coco_ann = {
|
| 31 |
+
'categories': [],
|
| 32 |
+
"type": "instances",
|
| 33 |
+
'images': [],
|
| 34 |
+
'annotations': []
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
image_id = 0
|
| 38 |
+
ann_id = 0
|
| 39 |
+
|
| 40 |
+
pbar = tqdm.tqdm(zip(seg_imgs_path, seg_labels_path), total=len(seg_imgs_path),
|
| 41 |
+
dynamic_ncols=True, leave=False, desc=f'thread {thread_i}')
|
| 42 |
+
for seg_img_path, seg_label_path in pbar:
|
| 43 |
+
|
| 44 |
+
try:
|
| 45 |
+
seg_img = Image.open(seg_img_path)
|
| 46 |
+
seg_label = Image.open(seg_label_path).convert('L')
|
| 47 |
+
seg_label = np.array(seg_label)
|
| 48 |
+
seg_label = label_after_hook(seg_label)
|
| 49 |
+
except Exception as e:
|
| 50 |
+
print(e)
|
| 51 |
+
print(f'file {seg_img_path} error, skip')
|
| 52 |
+
exit()
|
| 53 |
+
# seg_img = Image.open(seg_img_path)
|
| 54 |
+
# seg_label = Image.open(seg_label_path).convert('L')
|
| 55 |
+
# seg_label = np.array(seg_label)
|
| 56 |
+
|
| 57 |
+
image_coco_info = {'file_name': os.path.relpath(seg_img_path, root_dir), 'height': seg_img.height, 'width': seg_img.width,
|
| 58 |
+
'id':image_id}
|
| 59 |
+
image_id += 1
|
| 60 |
+
coco_ann['images'] += [image_coco_info]
|
| 61 |
+
|
| 62 |
+
this_img_classes = set(seg_label.reshape(-1).tolist())
|
| 63 |
+
# print(this_img_classes)
|
| 64 |
+
|
| 65 |
+
for class_idx in this_img_classes:
|
| 66 |
+
if class_idx in ignore_classes_idx:
|
| 67 |
+
continue
|
| 68 |
+
|
| 69 |
+
if class_idx not in classes_imgs_id_map.keys():
|
| 70 |
+
classes_imgs_id_map[class_idx] = 0
|
| 71 |
+
|
| 72 |
+
mask = np.zeros((seg_label.shape[0], seg_label.shape[1]), dtype=np.uint8)
|
| 73 |
+
mask[seg_label == class_idx] = 1
|
| 74 |
+
mask_without_small = morphology.remove_small_objects(mask, min_size=10, connectivity=2)
|
| 75 |
+
label_image = measure.label(mask_without_small)
|
| 76 |
+
|
| 77 |
+
for region in measure.regionprops(label_image):
|
| 78 |
+
bbox = region.bbox # (top, left, bottom, right)
|
| 79 |
+
bbox = [bbox[1], bbox[0], bbox[3], bbox[2]] # (left, top, right, bottom)
|
| 80 |
+
|
| 81 |
+
width, height = bbox[2] - bbox[0], bbox[3] - bbox[1]
|
| 82 |
+
if width < min_img_size or height < min_img_size:
|
| 83 |
+
continue
|
| 84 |
+
|
| 85 |
+
# target_cropped_img_path = os.path.join(target_cls_data_dir, str(class_idx),
|
| 86 |
+
# f'{classes_imgs_id_map[class_idx]}.{seg_img_path.split(".")[-1]}')
|
| 87 |
+
# ensure_dir(target_cropped_img_path)
|
| 88 |
+
# seg_img.crop(bbox).save(target_cropped_img_path)
|
| 89 |
+
# print(target_cropped_img_path)
|
| 90 |
+
# exit()
|
| 91 |
+
|
| 92 |
+
ann_coco_info = {'area': width*height, 'iscrowd': 0, 'image_id':
|
| 93 |
+
image_id - 1, 'bbox': [bbox[0], bbox[1], width, height],
|
| 94 |
+
'category_id': class_idx,
|
| 95 |
+
'id': ann_id, 'ignore': 0,
|
| 96 |
+
'segmentation': []}
|
| 97 |
+
ann_id += 1
|
| 98 |
+
|
| 99 |
+
coco_ann['annotations'] += [ann_coco_info]
|
| 100 |
+
|
| 101 |
+
classes_imgs_id_map[class_idx] += 1
|
| 102 |
+
|
| 103 |
+
pbar.set_description(f'# ann: {ann_id}')
|
| 104 |
+
|
| 105 |
+
coco_ann['categories'] = [
|
| 106 |
+
{'id': ci, 'name': f'class_{c}_in_seg'} for ci, c in enumerate(classes_imgs_id_map.keys())
|
| 107 |
+
]
|
| 108 |
+
c_to_ci_map = {c: ci for ci, c in enumerate(classes_imgs_id_map.keys())}
|
| 109 |
+
for ann in coco_ann['annotations']:
|
| 110 |
+
ann['category_id'] = c_to_ci_map[
|
| 111 |
+
ann['category_id']
|
| 112 |
+
]
|
| 113 |
+
|
| 114 |
+
write_json(target_coco_ann_path, coco_ann, indent=0, backup=True)
|
| 115 |
+
write_json(os.path.join(root_dir, 'coco_ann.json'), coco_ann, indent=0, backup=True)
|
| 116 |
+
|
| 117 |
+
num_cls_imgs = 0
|
| 118 |
+
for k, v in classes_imgs_id_map.items():
|
| 119 |
+
# print(f'# class {k}: {v + 1}')
|
| 120 |
+
num_cls_imgs += v
|
| 121 |
+
# print(f'total: {num_cls_imgs}')
|
| 122 |
+
|
| 123 |
+
return classes_imgs_id_map
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
from concurrent.futures import ThreadPoolExecutor
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
# def convert_seg_dataset_to_cls_multi_thread(seg_imgs_path, seg_labels_path, target_cls_data_dir, ignore_classes_idx, num_threads):
|
| 131 |
+
# if os.path.exists(target_cls_data_dir):
|
| 132 |
+
# shutil.rmtree(target_cls_data_dir)
|
| 133 |
+
|
| 134 |
+
# assert len(seg_imgs_path) == len(seg_labels_path)
|
| 135 |
+
# n = len(seg_imgs_path) // num_threads
|
| 136 |
+
|
| 137 |
+
# pool = ThreadPoolExecutor(max_workers=num_threads)
|
| 138 |
+
# # threads = []
|
| 139 |
+
# futures = []
|
| 140 |
+
# for thread_i in range(num_threads):
|
| 141 |
+
# # thread = threading.Thread(target=convert_seg_dataset_to_cls,
|
| 142 |
+
# # args=(seg_imgs_path[thread_i * n: (thread_i + 1) * n],
|
| 143 |
+
# # seg_labels_path[thread_i * n: (thread_i + 1) * n],
|
| 144 |
+
# # target_cls_data_dir, ignore_classes_idx))
|
| 145 |
+
# # threads += [thread]
|
| 146 |
+
# future = pool.submit(convert_seg_dataset_to_cls, *(seg_imgs_path[thread_i * n: (thread_i + 1) * n],
|
| 147 |
+
# seg_labels_path[thread_i * n: (thread_i + 1) * n],
|
| 148 |
+
# target_cls_data_dir, ignore_classes_idx, thread_i))
|
| 149 |
+
# futures += [future]
|
| 150 |
+
|
| 151 |
+
# futures += [
|
| 152 |
+
# pool.submit(convert_seg_dataset_to_cls, *(seg_imgs_path[(thread_i + 1) * n: ],
|
| 153 |
+
# seg_labels_path[(thread_i + 1) * n: ],
|
| 154 |
+
# target_cls_data_dir, ignore_classes_idx, thread_i))
|
| 155 |
+
# ]
|
| 156 |
+
|
| 157 |
+
# for f in futures:
|
| 158 |
+
# f.done()
|
| 159 |
+
|
| 160 |
+
# res = []
|
| 161 |
+
# for f in futures:
|
| 162 |
+
# res += [f.result()]
|
| 163 |
+
# print(res[-1])
|
| 164 |
+
|
| 165 |
+
# res_dist = {}
|
| 166 |
+
# for r in res:
|
| 167 |
+
# for k, v in r.items():
|
| 168 |
+
# if k in res_dist.keys():
|
| 169 |
+
# res_dist[k] += v
|
| 170 |
+
# else:
|
| 171 |
+
# res_dist[k] = v
|
| 172 |
+
|
| 173 |
+
# print('results:')
|
| 174 |
+
# print(res_dist)
|
| 175 |
+
|
| 176 |
+
# pool.shutdown()
|
| 177 |
+
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
# import random
|
| 181 |
+
# def random_crop_aug(target_dir):
|
| 182 |
+
# for class_dir in os.listdir(target_dir):
|
| 183 |
+
# class_dir = os.path.join(target_dir, class_dir)
|
| 184 |
+
|
| 185 |
+
# for img_path in os.listdir(class_dir):
|
| 186 |
+
# img_path = os.path.join(class_dir, img_path)
|
| 187 |
+
|
| 188 |
+
# img = Image.open(img_path)
|
| 189 |
+
|
| 190 |
+
# w, h = img.width, img.height
|
| 191 |
+
|
| 192 |
+
# for ri in range(5):
|
| 193 |
+
# img.crop(
|
| 194 |
+
# [
|
| 195 |
+
# random.randint(0, w // 5),
|
| 196 |
+
# random.randint(0, h // 5),
|
| 197 |
+
# random.randint(w // 5 * 4, w),
|
| 198 |
+
# random.randint(h // 5 * 4, h)
|
| 199 |
+
# ]
|
| 200 |
+
# ).save(
|
| 201 |
+
# os.path.join(os.path.dirname(img_path), f'randaug_{ri}_' + os.path.basename(img_path))
|
| 202 |
+
# )
|
| 203 |
+
# # print(img_path)
|
| 204 |
+
# # exit()
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
def post_ignore_classes(coco_ann_json_path):
|
| 208 |
+
# from data.datasets.object_detection.yolox_data_util.api import remap_dataset
|
| 209 |
+
# remap_dataset(coco_ann_json_path, [], {})
|
| 210 |
+
pass
|
| 211 |
+
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
if __name__ == '__main__':
|
| 215 |
+
# SuperviselyPerson
|
| 216 |
+
# root_dir = '/data/zql/datasets/supervisely_person_full_20230635/Supervisely Person Dataset'
|
| 217 |
+
|
| 218 |
+
# images_path, labels_path = [], []
|
| 219 |
+
# for p in os.listdir(root_dir):
|
| 220 |
+
# if p.startswith('ds'):
|
| 221 |
+
# p1 = os.path.join(root_dir, p, 'img')
|
| 222 |
+
# images_path += [(p, os.path.join(p1, n)) for n in os.listdir(p1)]
|
| 223 |
+
# for dsi, img_p in images_path:
|
| 224 |
+
# target_p = os.path.join(root_dir, p, dsi, img_p.split('/')[-1])
|
| 225 |
+
# labels_path += [target_p]
|
| 226 |
+
# images_path = [i[1] for i in images_path]
|
| 227 |
+
|
| 228 |
+
# target_coco_ann_path = '/data/zql/datasets/supervisely_person_for_det_task/coco_ann.json'
|
| 229 |
+
# if os.path.exists(target_coco_ann_path):
|
| 230 |
+
# os.remove(target_coco_ann_path)
|
| 231 |
+
# convert_seg_dataset_to_det(
|
| 232 |
+
# seg_imgs_path=images_path,
|
| 233 |
+
# seg_labels_path=labels_path,
|
| 234 |
+
# root_dir=root_dir,
|
| 235 |
+
# target_coco_ann_path=target_coco_ann_path,
|
| 236 |
+
# ignore_classes_idx=[0, 2],
|
| 237 |
+
# # num_threads=8
|
| 238 |
+
# thread_i=0
|
| 239 |
+
# )
|
| 240 |
+
|
| 241 |
+
# random_crop_aug('/data/zql/datasets/supervisely_person_for_cls_task')
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
# GTA5
|
| 245 |
+
# root_dir = '/data/zql/datasets/GTA-ls-copy/GTA5'
|
| 246 |
+
# images_path, labels_path = [], []
|
| 247 |
+
# for p in os.listdir(os.path.join(root_dir, 'images')):
|
| 248 |
+
# p = os.path.join(root_dir, 'images', p)
|
| 249 |
+
# if not p.endswith('png'):
|
| 250 |
+
# continue
|
| 251 |
+
# images_path += [p]
|
| 252 |
+
# labels_path += [p.replace('images', 'labels_gt')]
|
| 253 |
+
|
| 254 |
+
# target_coco_ann_path = '/data/zql/datasets/gta5_for_det_task/coco_ann.json'
|
| 255 |
+
# if os.path.exists(target_coco_ann_path):
|
| 256 |
+
# os.remove(target_coco_ann_path)
|
| 257 |
+
|
| 258 |
+
# """
|
| 259 |
+
# [
|
| 260 |
+
# 'road', 'sidewalk', 'building', 'wall',
|
| 261 |
+
# 'fence', 'pole', 'light', 'sign',
|
| 262 |
+
# 'vegetation', 'terrain', 'sky', 'people', # person
|
| 263 |
+
# 'rider', 'car', 'truck', 'bus', 'train',
|
| 264 |
+
# 'motocycle', 'bicycle'
|
| 265 |
+
# ]
|
| 266 |
+
# """
|
| 267 |
+
# need_classes_idx = [13, 15]
|
| 268 |
+
# convert_seg_dataset_to_det(
|
| 269 |
+
# seg_imgs_path=images_path,
|
| 270 |
+
# seg_labels_path=labels_path,
|
| 271 |
+
# root_dir=root_dir,
|
| 272 |
+
# target_coco_ann_path=target_coco_ann_path,
|
| 273 |
+
# ignore_classes_idx=[i for i in range(20) if i not in need_classes_idx],
|
| 274 |
+
# thread_i=0
|
| 275 |
+
# )
|
| 276 |
+
|
| 277 |
+
# from data.datasets.object_detection.yolox_data_util.api import remap_dataset
|
| 278 |
+
# new_coco_ann_json_path = remap_dataset('/data/zql/datasets/GTA-ls-copy/GTA5/coco_ann.json', [-1], {0: 0, 1:-1, 2:-1, 3: 1, 4:-1, 5:-1})
|
| 279 |
+
# print(new_coco_ann_json_path)
|
| 280 |
+
|
| 281 |
+
# cityscapes
|
| 282 |
+
# root_dir = '/data/zql/datasets/cityscape/'
|
| 283 |
+
|
| 284 |
+
# def _get_target_suffix(mode: str, target_type: str) -> str:
|
| 285 |
+
# if target_type == 'instance':
|
| 286 |
+
# return '{}_instanceIds.png'.format(mode)
|
| 287 |
+
# elif target_type == 'semantic':
|
| 288 |
+
# return '{}_labelIds.png'.format(mode)
|
| 289 |
+
# elif target_type == 'color':
|
| 290 |
+
# return '{}_color.png'.format(mode)
|
| 291 |
+
# else:
|
| 292 |
+
# return '{}_polygons.json'.format(mode)
|
| 293 |
+
|
| 294 |
+
|
| 295 |
+
# images_path, labels_path = [], []
|
| 296 |
+
# split = 'train'
|
| 297 |
+
# images_dir = os.path.join(root_dir, 'leftImg8bit', split)
|
| 298 |
+
# targets_dir = os.path.join(root_dir, 'gtFine', split)
|
| 299 |
+
# for city in os.listdir(images_dir):
|
| 300 |
+
# img_dir = os.path.join(images_dir, city)
|
| 301 |
+
# target_dir = os.path.join(targets_dir, city)
|
| 302 |
+
# for file_name in os.listdir(img_dir):
|
| 303 |
+
# target_types = []
|
| 304 |
+
# for t in ['semantic']:
|
| 305 |
+
# target_name = '{}_{}'.format(file_name.split('_leftImg8bit')[0],
|
| 306 |
+
# _get_target_suffix('gtFine', t))
|
| 307 |
+
# target_types.append(os.path.join(target_dir, target_name))
|
| 308 |
+
|
| 309 |
+
# images_path.append(os.path.join(img_dir, file_name))
|
| 310 |
+
# labels_path.append(target_types[0])
|
| 311 |
+
|
| 312 |
+
# # print(images_path[0: 5], '\n', labels_path[0: 5])
|
| 313 |
+
|
| 314 |
+
# target_coco_ann_path = '/data/zql/datasets/cityscape/coco_ann.json'
|
| 315 |
+
# # if os.path.exists(target_dir):
|
| 316 |
+
# # shutil.rmtree(target_dir)
|
| 317 |
+
|
| 318 |
+
# need_classes_idx = [26, 28]
|
| 319 |
+
# convert_seg_dataset_to_det(
|
| 320 |
+
# seg_imgs_path=images_path,
|
| 321 |
+
# seg_labels_path=labels_path,
|
| 322 |
+
# root_dir=root_dir,
|
| 323 |
+
# target_coco_ann_path=target_coco_ann_path,
|
| 324 |
+
# ignore_classes_idx=[i for i in range(80) if i not in need_classes_idx],
|
| 325 |
+
# # num_threads=8
|
| 326 |
+
# thread_i=0
|
| 327 |
+
# )
|
| 328 |
+
|
| 329 |
+
# import shutil
|
| 330 |
+
|
| 331 |
+
# ignore_target_dir = '/data/zql/datasets/cityscapes_for_cls_task_ignored'
|
| 332 |
+
|
| 333 |
+
# ignore_label = 255
|
| 334 |
+
# raw_idx_map_in_y_transform = {-1: ignore_label, 0: ignore_label, 1: ignore_label, 2: ignore_label,
|
| 335 |
+
# 3: ignore_label, 4: ignore_label, 5: ignore_label, 6: ignore_label,
|
| 336 |
+
# 7: 0, 8: 1, 9: ignore_label, 10: ignore_label, 11: 2, 12: 3, 13: 4,
|
| 337 |
+
# 14: ignore_label, 15: ignore_label, 16: ignore_label, 17: 5,
|
| 338 |
+
# 18: ignore_label, 19: 6, 20: 7, 21: 8, 22: 9, 23: 10, 24: 11, 25: 12, 26: 13, 27: 14,
|
| 339 |
+
# 28: 15, 29: ignore_label, 30: ignore_label, 31: 16, 32: 17, 33: 18}
|
| 340 |
+
# ignore_classes_idx = [k for k, v in raw_idx_map_in_y_transform.items() if v == ignore_label]
|
| 341 |
+
# ignore_classes_idx = sorted(ignore_classes_idx)
|
| 342 |
+
|
| 343 |
+
# for class_dir in os.listdir(target_dir):
|
| 344 |
+
# if int(class_dir) in ignore_classes_idx:
|
| 345 |
+
# continue
|
| 346 |
+
# shutil.move(
|
| 347 |
+
# os.path.join(target_dir, class_dir),
|
| 348 |
+
# os.path.join(ignore_target_dir, class_dir)
|
| 349 |
+
# )
|
| 350 |
+
# else:
|
| 351 |
+
# shutil.move(
|
| 352 |
+
# os.path.join(target_dir, class_dir),
|
| 353 |
+
# os.path.join(target_dir, str(raw_idx_map_in_y_transform[int(class_dir)]))
|
| 354 |
+
# )
|
| 355 |
+
# continue
|
| 356 |
+
# print(class_dir)
|
| 357 |
+
# exit()
|
| 358 |
+
|
| 359 |
+
|
| 360 |
+
|
| 361 |
+
# baidu person
|
| 362 |
+
# root_dir = '/data/zql/datasets/baidu_person/clean_images/'
|
| 363 |
+
|
| 364 |
+
# images_path, labels_path = [], []
|
| 365 |
+
# for p in os.listdir(os.path.join(root_dir, 'images')):
|
| 366 |
+
# images_path += [os.path.join(root_dir, 'images', p)]
|
| 367 |
+
# labels_path += [os.path.join(root_dir, 'profiles', p.split('.')[0] + '-profile.jpg')]
|
| 368 |
+
|
| 369 |
+
# target_dir = '/data/zql/datasets/baiduperson_for_cls_task'
|
| 370 |
+
# # if os.path.exists(target_dir):
|
| 371 |
+
# # shutil.rmtree(target_dir)
|
| 372 |
+
|
| 373 |
+
# def label_after_hook(x):
|
| 374 |
+
# x[x > 1] = 1
|
| 375 |
+
# return x
|
| 376 |
+
|
| 377 |
+
# convert_seg_dataset_to_det(
|
| 378 |
+
# seg_imgs_path=images_path,
|
| 379 |
+
# seg_labels_path=labels_path,
|
| 380 |
+
# root_dir=root_dir,
|
| 381 |
+
# target_coco_ann_path='/data/zql/datasets/baidu_person/clean_images/coco_ann_zql.json',
|
| 382 |
+
# ignore_classes_idx=[1],
|
| 383 |
+
# # num_threads=8
|
| 384 |
+
# thread_i=1,
|
| 385 |
+
# min_img_size=224,
|
| 386 |
+
# label_after_hook=label_after_hook
|
| 387 |
+
# )
|
| 388 |
+
|
| 389 |
+
|
| 390 |
+
# from data.visualize import visualize_classes_in_object_detection
|
| 391 |
+
# from data import get_dataset
|
| 392 |
+
# d = get_dataset('CityscapesDet', '/data/zql/datasets/cityscape/', 'val', None, [], None)
|
| 393 |
+
# visualize_classes_in_object_detection(d, {'car': 0, 'bus': 1}, {}, 'debug.png')
|
| 394 |
+
|
| 395 |
+
# d = get_dataset('GTA5Det', '/data/zql/datasets/GTA-ls-copy/GTA5', 'val', None, [], None)
|
| 396 |
+
# visualize_classes_in_object_detection(d, {'car': 0, 'bus': 1}, {}, 'debug.png')
|
| 397 |
+
|
| 398 |
+
# d = get_dataset('BaiduPersonDet', '/data/zql/datasets/baidu_person/clean_images/', 'val', None, [], None)
|
| 399 |
+
# visualize_classes_in_object_detection(d, {'person': 0}, {}, 'debug.png')
|
data/dataloader.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
|
| 2 |
+
# domainbed/lib/fast_data_loader.py
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from .datasets.ab_dataset import ABDataset
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
class _InfiniteSampler(torch.utils.data.Sampler):
|
| 9 |
+
"""Wraps another Sampler to yield an infinite stream."""
|
| 10 |
+
|
| 11 |
+
def __init__(self, sampler):
|
| 12 |
+
self.sampler = sampler
|
| 13 |
+
|
| 14 |
+
def __iter__(self):
|
| 15 |
+
while True:
|
| 16 |
+
for batch in self.sampler:
|
| 17 |
+
yield batch
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class InfiniteDataLoader:
|
| 21 |
+
def __init__(self, dataset, weights, batch_size, num_workers, collate_fn=None):
|
| 22 |
+
super().__init__()
|
| 23 |
+
|
| 24 |
+
if weights:
|
| 25 |
+
sampler = torch.utils.data.WeightedRandomSampler(
|
| 26 |
+
weights, replacement=True, num_samples=batch_size
|
| 27 |
+
)
|
| 28 |
+
else:
|
| 29 |
+
sampler = torch.utils.data.RandomSampler(dataset, replacement=True)
|
| 30 |
+
|
| 31 |
+
batch_sampler = torch.utils.data.BatchSampler(
|
| 32 |
+
sampler, batch_size=batch_size, drop_last=True
|
| 33 |
+
)
|
| 34 |
+
|
| 35 |
+
if collate_fn is not None:
|
| 36 |
+
self._infinite_iterator = iter(
|
| 37 |
+
torch.utils.data.DataLoader(
|
| 38 |
+
dataset,
|
| 39 |
+
num_workers=num_workers,
|
| 40 |
+
batch_sampler=_InfiniteSampler(batch_sampler),
|
| 41 |
+
pin_memory=False,
|
| 42 |
+
collate_fn=collate_fn
|
| 43 |
+
)
|
| 44 |
+
)
|
| 45 |
+
else:
|
| 46 |
+
self._infinite_iterator = iter(
|
| 47 |
+
torch.utils.data.DataLoader(
|
| 48 |
+
dataset,
|
| 49 |
+
num_workers=num_workers,
|
| 50 |
+
batch_sampler=_InfiniteSampler(batch_sampler),
|
| 51 |
+
pin_memory=False
|
| 52 |
+
)
|
| 53 |
+
)
|
| 54 |
+
self.dataset = dataset
|
| 55 |
+
|
| 56 |
+
def __iter__(self):
|
| 57 |
+
while True:
|
| 58 |
+
yield next(self._infinite_iterator)
|
| 59 |
+
|
| 60 |
+
def __len__(self):
|
| 61 |
+
raise ValueError
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
class FastDataLoader:
|
| 65 |
+
"""
|
| 66 |
+
DataLoader wrapper with slightly improved speed by not respawning worker
|
| 67 |
+
processes at every epoch.
|
| 68 |
+
"""
|
| 69 |
+
|
| 70 |
+
def __init__(self, dataset, batch_size, num_workers, shuffle=False, collate_fn=None):
|
| 71 |
+
super().__init__()
|
| 72 |
+
|
| 73 |
+
self.num_workers = num_workers
|
| 74 |
+
|
| 75 |
+
if shuffle:
|
| 76 |
+
sampler = torch.utils.data.RandomSampler(dataset, replacement=False)
|
| 77 |
+
else:
|
| 78 |
+
sampler = torch.utils.data.SequentialSampler(dataset)
|
| 79 |
+
|
| 80 |
+
batch_sampler = torch.utils.data.BatchSampler(
|
| 81 |
+
sampler,
|
| 82 |
+
batch_size=batch_size,
|
| 83 |
+
drop_last=False,
|
| 84 |
+
)
|
| 85 |
+
if collate_fn is not None:
|
| 86 |
+
self._infinite_iterator = iter(
|
| 87 |
+
torch.utils.data.DataLoader(
|
| 88 |
+
dataset,
|
| 89 |
+
num_workers=num_workers,
|
| 90 |
+
batch_sampler=_InfiniteSampler(batch_sampler),
|
| 91 |
+
pin_memory=False,
|
| 92 |
+
collate_fn=collate_fn
|
| 93 |
+
)
|
| 94 |
+
)
|
| 95 |
+
else:
|
| 96 |
+
self._infinite_iterator = iter(
|
| 97 |
+
torch.utils.data.DataLoader(
|
| 98 |
+
dataset,
|
| 99 |
+
num_workers=num_workers,
|
| 100 |
+
batch_sampler=_InfiniteSampler(batch_sampler),
|
| 101 |
+
pin_memory=False,
|
| 102 |
+
)
|
| 103 |
+
)
|
| 104 |
+
|
| 105 |
+
self.dataset = dataset
|
| 106 |
+
self.batch_size = batch_size
|
| 107 |
+
self._length = len(batch_sampler)
|
| 108 |
+
|
| 109 |
+
def __iter__(self):
|
| 110 |
+
for _ in range(len(self)):
|
| 111 |
+
yield next(self._infinite_iterator)
|
| 112 |
+
|
| 113 |
+
def __len__(self):
|
| 114 |
+
return self._length
|
| 115 |
+
|
| 116 |
+
|
| 117 |
+
def build_dataloader(dataset: ABDataset, batch_size: int, num_workers: int, infinite: bool, shuffle_when_finite: bool, collate_fn=None):
|
| 118 |
+
assert batch_size <= len(dataset), len(dataset)
|
| 119 |
+
if infinite:
|
| 120 |
+
dataloader = InfiniteDataLoader(
|
| 121 |
+
dataset, None, batch_size, num_workers=num_workers, collate_fn=collate_fn)
|
| 122 |
+
else:
|
| 123 |
+
dataloader = FastDataLoader(
|
| 124 |
+
dataset, batch_size, num_workers, shuffle=shuffle_when_finite, collate_fn=collate_fn)
|
| 125 |
+
|
| 126 |
+
return dataloader
|
| 127 |
+
|
| 128 |
+
|
| 129 |
+
def get_a_batch_dataloader(dataset: ABDataset, batch_size: int, num_workers: int, infinite: bool, shuffle_when_finite: bool):
|
| 130 |
+
pass
|
| 131 |
+
|
data/dataset.py
ADDED
|
@@ -0,0 +1,43 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import importlib
|
| 2 |
+
from typing import Type
|
| 3 |
+
import torch
|
| 4 |
+
from torch.utils.data import TensorDataset
|
| 5 |
+
from torch.utils.data.dataloader import DataLoader
|
| 6 |
+
|
| 7 |
+
from .datasets.ab_dataset import ABDataset
|
| 8 |
+
|
| 9 |
+
from .datasets import * # import all datasets
|
| 10 |
+
from .datasets.registery import static_dataset_registery
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def get_dataset(dataset_name, root_dir, split, transform=None, ignore_classes=[], idx_map=None) -> ABDataset:
|
| 14 |
+
dataset_cls = static_dataset_registery[dataset_name][0]
|
| 15 |
+
dataset = dataset_cls(root_dir, split, transform, ignore_classes, idx_map)
|
| 16 |
+
|
| 17 |
+
return dataset
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def get_num_limited_dataset(dataset: ABDataset, num_samples: int, discard_label=True):
|
| 21 |
+
dataloader = iter(DataLoader(dataset, num_samples // 2, shuffle=True))
|
| 22 |
+
x, y = [], []
|
| 23 |
+
cur_num_samples = 0
|
| 24 |
+
while True:
|
| 25 |
+
batch = next(dataloader)
|
| 26 |
+
cur_x, cur_y = batch[0], batch[1]
|
| 27 |
+
|
| 28 |
+
x += [cur_x]
|
| 29 |
+
y += [cur_y]
|
| 30 |
+
cur_num_samples += cur_x.size(0)
|
| 31 |
+
|
| 32 |
+
if cur_num_samples >= num_samples:
|
| 33 |
+
break
|
| 34 |
+
|
| 35 |
+
x, y = torch.cat(x)[0: num_samples], torch.cat(y)[0: num_samples]
|
| 36 |
+
if discard_label:
|
| 37 |
+
new_dataset = TensorDataset(x)
|
| 38 |
+
else:
|
| 39 |
+
new_dataset = TensorDataset(x, y)
|
| 40 |
+
|
| 41 |
+
dataset.dataset = new_dataset
|
| 42 |
+
|
| 43 |
+
return dataset
|
data/datasets/__init__.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from .image_classification import *
|
| 2 |
+
from .object_detection import *
|
| 3 |
+
from .semantic_segmentation import *
|
| 4 |
+
from .action_recognition import *
|
| 5 |
+
|
| 6 |
+
from .sentiment_classification import *
|
| 7 |
+
from .text_generation import *
|
| 8 |
+
from .machine_translation import *
|
| 9 |
+
from .pos_tagging import *
|
| 10 |
+
|
| 11 |
+
from .mm_image_classification import *
|
| 12 |
+
from .visual_question_answering import *
|
data/datasets/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (450 Bytes). View file
|
|
|
data/datasets/__pycache__/ab_dataset.cpython-38.pyc
ADDED
|
Binary file (2.14 kB). View file
|
|
|
data/datasets/__pycache__/data_aug.cpython-38.pyc
ADDED
|
Binary file (3.18 kB). View file
|
|
|
data/datasets/__pycache__/dataset_cache.cpython-38.pyc
ADDED
|
Binary file (1.62 kB). View file
|
|
|