Spaces:
Runtime error

Runtime error
Upload folder using huggingface_hub
Browse files- .gitattributes +1 -0
- .gitignore +173 -0
- .gradio/certificate.pem +31 -0
- LICENSE +21 -0
- README.md +119 -7
- app.py +93 -0
- demo.gif +3 -0
- docker/Dockerfile.nvidia +20 -0
- docker/run.sh +13 -0
- image.jpg +0 -0
- notebooks/Refacer_colab.ipynb +65 -0
- out/.gitkeep +0 -0
- recognition/arcface_onnx.py +91 -0
- recognition/face_align.py +141 -0
- recognition/main.py +57 -0
- recognition/scrfd.py +329 -0
- refacer.py +262 -0
- requirements-COREML.txt +12 -0
- requirements-GPU.txt +12 -0
- requirements.txt +12 -0
- script.py +41 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
demo.gif filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,173 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
share/python-wheels/
|
| 24 |
+
*.egg-info/
|
| 25 |
+
.installed.cfg
|
| 26 |
+
*.egg
|
| 27 |
+
MANIFEST
|
| 28 |
+
|
| 29 |
+
# PyInstaller
|
| 30 |
+
# Usually these files are written by a python script from a template
|
| 31 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 32 |
+
*.manifest
|
| 33 |
+
*.spec
|
| 34 |
+
|
| 35 |
+
# Installer logs
|
| 36 |
+
pip-log.txt
|
| 37 |
+
pip-delete-this-directory.txt
|
| 38 |
+
|
| 39 |
+
# Unit test / coverage reports
|
| 40 |
+
htmlcov/
|
| 41 |
+
.tox/
|
| 42 |
+
.nox/
|
| 43 |
+
.coverage
|
| 44 |
+
.coverage.*
|
| 45 |
+
.cache
|
| 46 |
+
nosetests.xml
|
| 47 |
+
coverage.xml
|
| 48 |
+
*.cover
|
| 49 |
+
*.py,cover
|
| 50 |
+
.hypothesis/
|
| 51 |
+
.pytest_cache/
|
| 52 |
+
cover/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
.pybuilder/
|
| 76 |
+
target/
|
| 77 |
+
|
| 78 |
+
# Jupyter Notebook
|
| 79 |
+
.ipynb_checkpoints
|
| 80 |
+
|
| 81 |
+
# IPython
|
| 82 |
+
profile_default/
|
| 83 |
+
ipython_config.py
|
| 84 |
+
|
| 85 |
+
# pyenv
|
| 86 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 87 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 88 |
+
# .python-version
|
| 89 |
+
|
| 90 |
+
# pipenv
|
| 91 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 92 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 93 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 94 |
+
# install all needed dependencies.
|
| 95 |
+
#Pipfile.lock
|
| 96 |
+
|
| 97 |
+
# poetry
|
| 98 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 99 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 100 |
+
# commonly ignored for libraries.
|
| 101 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 102 |
+
#poetry.lock
|
| 103 |
+
|
| 104 |
+
# pdm
|
| 105 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 106 |
+
#pdm.lock
|
| 107 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 108 |
+
# in version control.
|
| 109 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 110 |
+
.pdm.toml
|
| 111 |
+
|
| 112 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 113 |
+
__pypackages__/
|
| 114 |
+
|
| 115 |
+
# Celery stuff
|
| 116 |
+
celerybeat-schedule
|
| 117 |
+
celerybeat.pid
|
| 118 |
+
|
| 119 |
+
# SageMath parsed files
|
| 120 |
+
*.sage.py
|
| 121 |
+
|
| 122 |
+
# Environments
|
| 123 |
+
.env
|
| 124 |
+
.venv
|
| 125 |
+
env/
|
| 126 |
+
venv/
|
| 127 |
+
ENV/
|
| 128 |
+
env.bak/
|
| 129 |
+
venv.bak/
|
| 130 |
+
|
| 131 |
+
# Spyder project settings
|
| 132 |
+
.spyderproject
|
| 133 |
+
.spyproject
|
| 134 |
+
|
| 135 |
+
# Rope project settings
|
| 136 |
+
.ropeproject
|
| 137 |
+
|
| 138 |
+
# mkdocs documentation
|
| 139 |
+
/site
|
| 140 |
+
|
| 141 |
+
# mypy
|
| 142 |
+
.mypy_cache/
|
| 143 |
+
.dmypy.json
|
| 144 |
+
dmypy.json
|
| 145 |
+
|
| 146 |
+
# Pyre type checker
|
| 147 |
+
.pyre/
|
| 148 |
+
|
| 149 |
+
# pytype static type analyzer
|
| 150 |
+
.pytype/
|
| 151 |
+
|
| 152 |
+
# Cython debug symbols
|
| 153 |
+
cython_debug/
|
| 154 |
+
|
| 155 |
+
# PyCharm
|
| 156 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 157 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 158 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 159 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 160 |
+
#.idea/
|
| 161 |
+
|
| 162 |
+
out/*
|
| 163 |
+
!out/.gitkeep
|
| 164 |
+
media
|
| 165 |
+
tests
|
| 166 |
+
*.onnx
|
| 167 |
+
|
| 168 |
+
aaa.md
|
| 169 |
+
|
| 170 |
+
*_test.py
|
| 171 |
+
img.jpg
|
| 172 |
+
test_data
|
| 173 |
+
testsrc.mp4
|
.gradio/certificate.pem
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
-----BEGIN CERTIFICATE-----
|
| 2 |
+
MIIFazCCA1OgAwIBAgIRAIIQz7DSQONZRGPgu2OCiwAwDQYJKoZIhvcNAQELBQAw
|
| 3 |
+
TzELMAkGA1UEBhMCVVMxKTAnBgNVBAoTIEludGVybmV0IFNlY3VyaXR5IFJlc2Vh
|
| 4 |
+
cmNoIEdyb3VwMRUwEwYDVQQDEwxJU1JHIFJvb3QgWDEwHhcNMTUwNjA0MTEwNDM4
|
| 5 |
+
WhcNMzUwNjA0MTEwNDM4WjBPMQswCQYDVQQGEwJVUzEpMCcGA1UEChMgSW50ZXJu
|
| 6 |
+
ZXQgU2VjdXJpdHkgUmVzZWFyY2ggR3JvdXAxFTATBgNVBAMTDElTUkcgUm9vdCBY
|
| 7 |
+
MTCCAiIwDQYJKoZIhvcNAQEBBQADggIPADCCAgoCggIBAK3oJHP0FDfzm54rVygc
|
| 8 |
+
h77ct984kIxuPOZXoHj3dcKi/vVqbvYATyjb3miGbESTtrFj/RQSa78f0uoxmyF+
|
| 9 |
+
0TM8ukj13Xnfs7j/EvEhmkvBioZxaUpmZmyPfjxwv60pIgbz5MDmgK7iS4+3mX6U
|
| 10 |
+
A5/TR5d8mUgjU+g4rk8Kb4Mu0UlXjIB0ttov0DiNewNwIRt18jA8+o+u3dpjq+sW
|
| 11 |
+
T8KOEUt+zwvo/7V3LvSye0rgTBIlDHCNAymg4VMk7BPZ7hm/ELNKjD+Jo2FR3qyH
|
| 12 |
+
B5T0Y3HsLuJvW5iB4YlcNHlsdu87kGJ55tukmi8mxdAQ4Q7e2RCOFvu396j3x+UC
|
| 13 |
+
B5iPNgiV5+I3lg02dZ77DnKxHZu8A/lJBdiB3QW0KtZB6awBdpUKD9jf1b0SHzUv
|
| 14 |
+
KBds0pjBqAlkd25HN7rOrFleaJ1/ctaJxQZBKT5ZPt0m9STJEadao0xAH0ahmbWn
|
| 15 |
+
OlFuhjuefXKnEgV4We0+UXgVCwOPjdAvBbI+e0ocS3MFEvzG6uBQE3xDk3SzynTn
|
| 16 |
+
jh8BCNAw1FtxNrQHusEwMFxIt4I7mKZ9YIqioymCzLq9gwQbooMDQaHWBfEbwrbw
|
| 17 |
+
qHyGO0aoSCqI3Haadr8faqU9GY/rOPNk3sgrDQoo//fb4hVC1CLQJ13hef4Y53CI
|
| 18 |
+
rU7m2Ys6xt0nUW7/vGT1M0NPAgMBAAGjQjBAMA4GA1UdDwEB/wQEAwIBBjAPBgNV
|
| 19 |
+
HRMBAf8EBTADAQH/MB0GA1UdDgQWBBR5tFnme7bl5AFzgAiIyBpY9umbbjANBgkq
|
| 20 |
+
hkiG9w0BAQsFAAOCAgEAVR9YqbyyqFDQDLHYGmkgJykIrGF1XIpu+ILlaS/V9lZL
|
| 21 |
+
ubhzEFnTIZd+50xx+7LSYK05qAvqFyFWhfFQDlnrzuBZ6brJFe+GnY+EgPbk6ZGQ
|
| 22 |
+
3BebYhtF8GaV0nxvwuo77x/Py9auJ/GpsMiu/X1+mvoiBOv/2X/qkSsisRcOj/KK
|
| 23 |
+
NFtY2PwByVS5uCbMiogziUwthDyC3+6WVwW6LLv3xLfHTjuCvjHIInNzktHCgKQ5
|
| 24 |
+
ORAzI4JMPJ+GslWYHb4phowim57iaztXOoJwTdwJx4nLCgdNbOhdjsnvzqvHu7Ur
|
| 25 |
+
TkXWStAmzOVyyghqpZXjFaH3pO3JLF+l+/+sKAIuvtd7u+Nxe5AW0wdeRlN8NwdC
|
| 26 |
+
jNPElpzVmbUq4JUagEiuTDkHzsxHpFKVK7q4+63SM1N95R1NbdWhscdCb+ZAJzVc
|
| 27 |
+
oyi3B43njTOQ5yOf+1CceWxG1bQVs5ZufpsMljq4Ui0/1lvh+wjChP4kqKOJ2qxq
|
| 28 |
+
4RgqsahDYVvTH9w7jXbyLeiNdd8XM2w9U/t7y0Ff/9yi0GE44Za4rF2LN9d11TPA
|
| 29 |
+
mRGunUHBcnWEvgJBQl9nJEiU0Zsnvgc/ubhPgXRR4Xq37Z0j4r7g1SgEEzwxA57d
|
| 30 |
+
emyPxgcYxn/eR44/KJ4EBs+lVDR3veyJm+kXQ99b21/+jh5Xos1AnX5iItreGCc=
|
| 31 |
+
-----END CERTIFICATE-----
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 xaviviro
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
README.md
CHANGED
|
@@ -1,12 +1,124 @@
|
|
| 1 |
---
|
| 2 |
-
title:
|
| 3 |
-
|
| 4 |
-
colorFrom: gray
|
| 5 |
-
colorTo: green
|
| 6 |
sdk: gradio
|
| 7 |
sdk_version: 5.6.0
|
| 8 |
-
app_file: app.py
|
| 9 |
-
pinned: false
|
| 10 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
|
| 12 |
-
|
|
|
|
| 1 |
---
|
| 2 |
+
title: refacer
|
| 3 |
+
app_file: app.py
|
|
|
|
|
|
|
| 4 |
sdk: gradio
|
| 5 |
sdk_version: 5.6.0
|
|
|
|
|
|
|
| 6 |
---
|
| 7 |
+
# Refacer: One-Click Deepfake Multi-Face Swap Tool
|
| 8 |
+
|
| 9 |
+
[](https://colab.research.google.com/github/xaviviro/refacer/blob/master/notebooks/Refacer_colab.ipynb)
|
| 10 |
+
|
| 11 |
+
👉 [Watch demo on Youtube](https://youtu.be/mXk1Ox7B244)
|
| 12 |
+
|
| 13 |
+
Refacer, a simple tool that allows you to create deepfakes with multiple faces with just one click! This project was inspired by [Roop](https://github.com/s0md3v/roop) and is powered by the excellent [Insightface](https://github.com/deepinsight/insightface). Refacer requires no training - just one photo and you're ready to go.
|
| 14 |
+
|
| 15 |
+
:warning: Please, before using the code from this repository, make sure to read the [disclaimer](https://github.com/xaviviro/refacer/tree/main#disclaimer).
|
| 16 |
+
|
| 17 |
+
## Demonstration
|
| 18 |
+
|
| 19 |
+

|
| 20 |
+
|
| 21 |
+
[](https://youtu.be/mXk1Ox7B244)
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
## System Compatibility
|
| 25 |
+
|
| 26 |
+
Refacer has been thoroughly tested on the following operating systems:
|
| 27 |
+
|
| 28 |
+
| Operating System | CPU Support | GPU Support |
|
| 29 |
+
| ---------------- | ----------- | ----------- |
|
| 30 |
+
| MacOSX | ✅ | :warning: |
|
| 31 |
+
| Windows | ✅ | ✅ |
|
| 32 |
+
| Linux | ✅ | ✅ |
|
| 33 |
+
|
| 34 |
+
The application is compatible with both CPU and GPU (Nvidia CUDA) environments, and MacOSX(CoreML)
|
| 35 |
+
|
| 36 |
+
:warning: Please note, we do not recommend using `onnxruntime-silicon` on MacOSX due to an apparent issue with memory management. If you manage to compile `onnxruntime` for Silicon, the program is prepared to use CoreML.
|
| 37 |
+
|
| 38 |
+
## Prerequisites
|
| 39 |
+
|
| 40 |
+
Ensure that you have `ffmpeg` installed and correctly configured. There are many guides available on the internet to help with this. Here are a few (note: I did not create these guides):
|
| 41 |
+
|
| 42 |
+
- [How to Install FFmpeg](https://www.hostinger.com/tutorials/how-to-install-ffmpeg)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
## Installation
|
| 46 |
+
|
| 47 |
+
Refacer has been tested and is known to work with Python 3.10.9, but it is likely to work with other Python versions as well. It is recommended to use a virtual environment for setting up and running the project to avoid potential conflicts with other Python packages you may have installed.
|
| 48 |
+
|
| 49 |
+
Follow these steps to install Refacer:
|
| 50 |
+
|
| 51 |
+
1. Clone the repository:
|
| 52 |
+
```bash
|
| 53 |
+
git clone https://github.com/xaviviro/refacer.git
|
| 54 |
+
cd refacer
|
| 55 |
+
```
|
| 56 |
+
|
| 57 |
+
2. Download the Insightface model:
|
| 58 |
+
You can manually download the model created by Insightface from this [link](https://huggingface.co/deepinsight/inswapper/resolve/main/inswapper_128.onnx) and add it to the project folder. Alternatively, if you have `wget` installed, you can use the following command:
|
| 59 |
+
```bash
|
| 60 |
+
wget --content-disposition https://huggingface.co/deepinsight/inswapper/resolve/main/inswapper_128.onnx
|
| 61 |
+
```
|
| 62 |
+
|
| 63 |
+
3. Install dependencies:
|
| 64 |
+
|
| 65 |
+
* For CPU (compatible with Windows, MacOSX, and Linux):
|
| 66 |
+
```bash
|
| 67 |
+
pip install -r requirements.txt
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
* For GPU (compatible with Windows and Linux only, requires a NVIDIA GPU with CUDA and its libraries):
|
| 71 |
+
```bash
|
| 72 |
+
pip install -r requirements-GPU.txt
|
| 73 |
+
```
|
| 74 |
+
|
| 75 |
+
* For CoreML (compatible with MacOSX, requires Silicon architecture):
|
| 76 |
+
```bash
|
| 77 |
+
pip install -r requirements-COREML.txt
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
For more information on installing the CUDA necessary to use `onnxruntime-gpu`, please refer directly to the official [ONNX Runtime repository](https://github.com/microsoft/onnxruntime/).
|
| 81 |
+
|
| 82 |
+
For more details on using the Insightface model, you can refer to their [example](https://github.com/deepinsight/insightface/tree/master/examples/in_swapper).
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
## Usage
|
| 86 |
+
|
| 87 |
+
Once you have successfully installed Refacer and its dependencies, you can run the application using the following command:
|
| 88 |
+
|
| 89 |
+
```bash
|
| 90 |
+
python app.py
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
Then, open your web browser and navigate to the following address:
|
| 94 |
+
|
| 95 |
+
```
|
| 96 |
+
http://127.0.0.1:7680
|
| 97 |
+
```
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
## Questions?
|
| 101 |
+
|
| 102 |
+
If you have any questions or issues, feel free to [open an issue](https://github.com/xaviviro/refacer/issues/new) or submit a pull request.
|
| 103 |
+
|
| 104 |
+
|
| 105 |
+
## Recognition Module
|
| 106 |
+
|
| 107 |
+
The `recognition` folder in this repository is derived from Insightface's GitHub repository. You can find the original source code here: [Insightface Recognition Source Code](https://github.com/deepinsight/insightface/tree/master/web-demos/src_recognition)
|
| 108 |
+
|
| 109 |
+
This module is used for recognizing and handling face data within the Refacer application, enabling its powerful deepfake capabilities. We are grateful to Insightface for their work and for making their code available.
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
## Disclaimer
|
| 113 |
+
|
| 114 |
+
> :warning: This software is provided "as is", without warranty of any kind, express or implied, including but not limited to the warranties of merchantability, fitness for a particular purpose and noninfringement. In no event shall the authors or copyright holders be liable for any claim, damages or other liability, whether in an action of contract, tort or otherwise, arising from, out of or in connection with the software or the use or other dealings in the software.
|
| 115 |
+
|
| 116 |
+
> :warning: This software is intended for educational and research purposes only. It is not intended for use in any malicious activities. The author of this software does not condone or support the use of this software for any harmful actions, including but not limited to identity theft, invasion of privacy, or defamation. Any use of this software for such purposes is strictly prohibited.
|
| 117 |
+
|
| 118 |
+
> :warning: You may only use this software with images for which you have the right to use and the necessary permissions. Any use of images without the proper rights and permissions is strictly prohibited.
|
| 119 |
+
|
| 120 |
+
> :warning: The author of this software is not responsible for any misuse of the software or for any violation of rights and privacy resulting from such misuse.
|
| 121 |
+
|
| 122 |
+
> :warning: To prevent misuse, the software contains an integrated protective mechanism that prevents it from working with illegal or similar types of media.
|
| 123 |
|
| 124 |
+
> :warning: By using this software, you agree to abide by all applicable laws, to respect the rights and privacy of others, and to use the software responsibly and ethically.
|
app.py
ADDED
|
@@ -0,0 +1,93 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gradio as gr
|
| 2 |
+
from refacer import Refacer
|
| 3 |
+
import argparse
|
| 4 |
+
import ngrok
|
| 5 |
+
|
| 6 |
+
parser = argparse.ArgumentParser(description='Refacer')
|
| 7 |
+
parser.add_argument("--max_num_faces", type=int, help="Max number of faces on UI", default=5)
|
| 8 |
+
parser.add_argument("--force_cpu", help="Force CPU mode", default=False, action="store_true")
|
| 9 |
+
parser.add_argument("--share_gradio", help="Share Gradio", default=False, action="store_true")
|
| 10 |
+
parser.add_argument("--server_name", type=str, help="Server IP address", default="127.0.0.1")
|
| 11 |
+
parser.add_argument("--server_port", type=int, help="Server port", default=7860)
|
| 12 |
+
parser.add_argument("--colab_performance", help="Use in colab for better performance", default=False,action="store_true")
|
| 13 |
+
parser.add_argument("--ngrok", type=str, help="Use ngrok", default=None)
|
| 14 |
+
parser.add_argument("--ngrok_region", type=str, help="ngrok region", default="us")
|
| 15 |
+
args = parser.parse_args()
|
| 16 |
+
|
| 17 |
+
refacer = Refacer(force_cpu=args.force_cpu,colab_performance=args.colab_performance)
|
| 18 |
+
|
| 19 |
+
num_faces=args.max_num_faces
|
| 20 |
+
|
| 21 |
+
# Connect to ngrok for ingress
|
| 22 |
+
def connect(token, port, options):
|
| 23 |
+
account = None
|
| 24 |
+
if token is None:
|
| 25 |
+
token = 'None'
|
| 26 |
+
else:
|
| 27 |
+
if ':' in token:
|
| 28 |
+
# token = authtoken:username:password
|
| 29 |
+
token, username, password = token.split(':', 2)
|
| 30 |
+
account = f"{username}:{password}"
|
| 31 |
+
|
| 32 |
+
# For all options see: https://github.com/ngrok/ngrok-py/blob/main/examples/ngrok-connect-full.py
|
| 33 |
+
if not options.get('authtoken_from_env'):
|
| 34 |
+
options['authtoken'] = token
|
| 35 |
+
if account:
|
| 36 |
+
options['basic_auth'] = account
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
try:
|
| 40 |
+
public_url = ngrok.connect(f"127.0.0.1:{port}", **options).url()
|
| 41 |
+
except Exception as e:
|
| 42 |
+
print(f'Invalid ngrok authtoken? ngrok connection aborted due to: {e}\n'
|
| 43 |
+
f'Your token: {token}, get the right one on https://dashboard.ngrok.com/get-started/your-authtoken')
|
| 44 |
+
else:
|
| 45 |
+
print(f'ngrok connected to localhost:{port}! URL: {public_url}\n'
|
| 46 |
+
'You can use this link after the launch is complete.')
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
def run(*vars):
|
| 50 |
+
video_path=vars[0]
|
| 51 |
+
origins=vars[1:(num_faces+1)]
|
| 52 |
+
destinations=vars[(num_faces+1):(num_faces*2)+1]
|
| 53 |
+
thresholds=vars[(num_faces*2)+1:]
|
| 54 |
+
|
| 55 |
+
faces = []
|
| 56 |
+
for k in range(0,num_faces):
|
| 57 |
+
if origins[k] is not None and destinations[k] is not None:
|
| 58 |
+
faces.append({
|
| 59 |
+
'origin':origins[k],
|
| 60 |
+
'destination':destinations[k],
|
| 61 |
+
'threshold':thresholds[k]
|
| 62 |
+
})
|
| 63 |
+
|
| 64 |
+
return refacer.reface(video_path,faces)
|
| 65 |
+
|
| 66 |
+
origin = []
|
| 67 |
+
destination = []
|
| 68 |
+
thresholds = []
|
| 69 |
+
|
| 70 |
+
with gr.Blocks() as demo:
|
| 71 |
+
with gr.Row():
|
| 72 |
+
gr.Markdown("# Refacer")
|
| 73 |
+
with gr.Row():
|
| 74 |
+
video=gr.Video(label="Original video",format="mp4")
|
| 75 |
+
video2=gr.Video(label="Refaced video",interactive=False,format="mp4")
|
| 76 |
+
|
| 77 |
+
for i in range(0,num_faces):
|
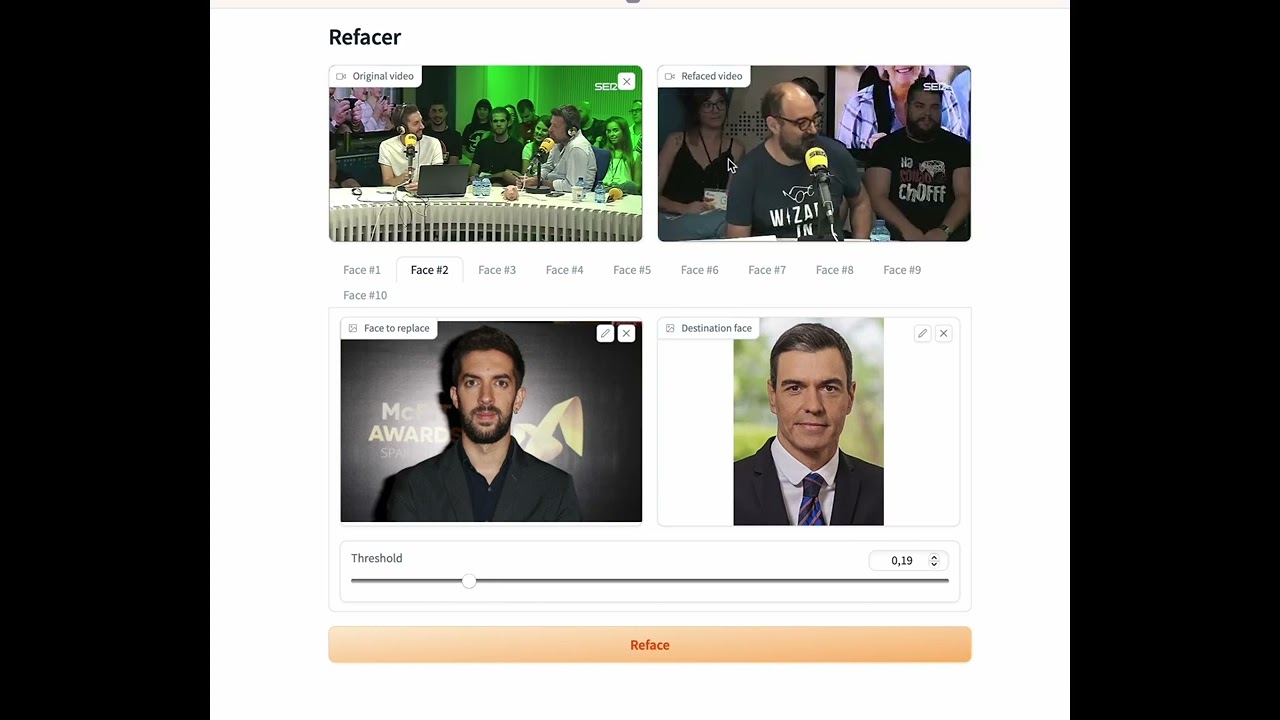
| 78 |
+
with gr.Tab(f"Face #{i+1}"):
|
| 79 |
+
with gr.Row():
|
| 80 |
+
origin.append(gr.Image(label="Face to replace"))
|
| 81 |
+
destination.append(gr.Image(label="Destination face"))
|
| 82 |
+
with gr.Row():
|
| 83 |
+
thresholds.append(gr.Slider(label="Threshold",minimum=0.0,maximum=1.0,value=0.2))
|
| 84 |
+
with gr.Row():
|
| 85 |
+
button=gr.Button("Reface", variant="primary")
|
| 86 |
+
|
| 87 |
+
button.click(fn=run,inputs=[video]+origin+destination+thresholds,outputs=[video2])
|
| 88 |
+
|
| 89 |
+
if args.ngrok is not None:
|
| 90 |
+
connect(args.ngrok, args.server_port, {'region': args.ngrok_region, 'authtoken_from_env': False})
|
| 91 |
+
|
| 92 |
+
#demo.launch(share=True,server_name="0.0.0.0", show_error=True)
|
| 93 |
+
demo.queue().launch(show_error=True,share=args.share_gradio,server_name=args.server_name,server_port=args.server_port)
|
demo.gif
ADDED

|
Git LFS Details
|
docker/Dockerfile.nvidia
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
FROM nvidia/cuda:11.8.0-cudnn8-runtime-ubuntu22.04
|
| 2 |
+
|
| 3 |
+
# Always use UTC on a server
|
| 4 |
+
RUN ln -snf /usr/share/zoneinfo/UTC /etc/localtime && echo UTC > /etc/timezone
|
| 5 |
+
|
| 6 |
+
RUN DEBIAN_FRONTEND=noninteractive apt update && apt install -y python3 python3-pip python3-tk git ffmpeg nvidia-cuda-toolkit nvidia-container-runtime libnvidia-decode-525-server wget unzip
|
| 7 |
+
RUN wget https://github.com/deepinsight/insightface/releases/download/v0.7/buffalo_l.zip -O /tmp/buffalo_l.zip && \
|
| 8 |
+
mkdir -p /root/.insightface/models/buffalo_l && \
|
| 9 |
+
cd /root/.insightface/models/buffalo_l && \
|
| 10 |
+
unzip /tmp/buffalo_l.zip && \
|
| 11 |
+
rm -f /tmp/buffalo_l.zip
|
| 12 |
+
|
| 13 |
+
RUN pip install nvidia-tensorrt
|
| 14 |
+
RUN git clone https://github.com/xaviviro/refacer && cd refacer && pip install -r requirements-GPU.txt
|
| 15 |
+
|
| 16 |
+
WORKDIR /refacer
|
| 17 |
+
|
| 18 |
+
# Test following commands in container to make sure GPU stuff works
|
| 19 |
+
# nvidia-smi
|
| 20 |
+
# python3 -c "import tensorflow as tf; print(tf.config.list_physical_devices('GPU'))"
|
docker/run.sh
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
# Run this script from within the refacer/docker folder.
|
| 3 |
+
# You'll need inswrapper_128.onnx from either:
|
| 4 |
+
# https://drive.google.com/file/d/1eu60OrRtn4WhKrzM4mQv4F3rIuyUXqfl/view?usp=drive_link
|
| 5 |
+
# or https://drive.google.com/file/d/1jbDUGrADco9A1MutWjO6d_1dwizh9w9P/view?usp=sharing
|
| 6 |
+
# or https://mega.nz/file/9l8mGDJA#FnPxHwpdhDovDo6OvbQjhHd2nDAk8_iVEgo3mpHLG6U
|
| 7 |
+
# or https://1drv.ms/u/s!AsHA3Xbnj6uAgxhb_tmQ7egHACOR?e=CPoThO
|
| 8 |
+
# or https://civitai.com/models/80324?modelVersionId=85159
|
| 9 |
+
|
| 10 |
+
docker stop -t 0 refacer
|
| 11 |
+
docker build -t refacer -f Dockerfile.nvidia . && \
|
| 12 |
+
docker run --rm --name refacer -v $(pwd)/..:/refacer -p 7860:7860 --gpus all refacer python3 app.py --server_name 0.0.0.0 &
|
| 13 |
+
sleep 2 && google-chrome --new-window "http://127.0.0.1:7860" &
|
image.jpg
ADDED
|
notebooks/Refacer_colab.ipynb
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"cells": [
|
| 3 |
+
{
|
| 4 |
+
"attachments": {},
|
| 5 |
+
"cell_type": "markdown",
|
| 6 |
+
"metadata": {
|
| 7 |
+
"id": "ghPlUjrD_xmd"
|
| 8 |
+
},
|
| 9 |
+
"source": [
|
| 10 |
+
"# Refacer\n",
|
| 11 |
+
"\n",
|
| 12 |
+
"[](https://colab.research.google.com/github/xaviviro/refacer/blob/master/notebooks/Refacer_colab.ipynb)\n",
|
| 13 |
+
"\n",
|
| 14 |
+
"[Refacer](https://github.com/xaviviro/refacer) is an amazing tool that allows you to create deepfakes with multiple faces, giving you the option to choose which face to replace, all in one click!\n",
|
| 15 |
+
"\n",
|
| 16 |
+
"If you find Refacer helpful, consider giving it a star on [GitHub](https://github.com/xaviviro/refacer) Your support helps to keep the project going!\n",
|
| 17 |
+
"\n",
|
| 18 |
+
"Before using this Colab or the Refacer tool, please make sure to read the [Disclaimer](https://github.com/xaviviro/refacer#disclaimer) in the GitHub repository. It's very important to understand the terms of use, and the ethical implications of creating deepfakes.\n",
|
| 19 |
+
"\n",
|
| 20 |
+
"In this Colab, you'll be able to try out Refacer without needing to install anything on your own machine. Enjoy!\n",
|
| 21 |
+
"\n",
|
| 22 |
+
"*If you encounter any issues or have any suggestions, feel free to [open an issue](https://github.com/xaviviro/refacer/issues/new) on the GitHub repository.*"
|
| 23 |
+
]
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"cell_type": "code",
|
| 27 |
+
"execution_count": null,
|
| 28 |
+
"metadata": {
|
| 29 |
+
"colab": {
|
| 30 |
+
"base_uri": "https://localhost:8080/"
|
| 31 |
+
},
|
| 32 |
+
"id": "r-vlpYRr_6W7",
|
| 33 |
+
"outputId": "2f2ba046-082f-422c-a391-3d6991276830"
|
| 34 |
+
},
|
| 35 |
+
"outputs": [],
|
| 36 |
+
"source": [
|
| 37 |
+
"!pip uninstall numpy -y -q\n",
|
| 38 |
+
"!pip install --disable-pip-version-check --root-user-action=ignore ngrok numpy==1.24.3 onnxruntime-gpu gradio insightface==0.7.3 ffmpeg_python opencv_python -q --force\n",
|
| 39 |
+
"\n",
|
| 40 |
+
"!git clone https://github.com/xaviviro/refacer.git\n",
|
| 41 |
+
"%cd refacer\n",
|
| 42 |
+
"\n",
|
| 43 |
+
"!wget --content-disposition \"https://huggingface.co/deepinsight/inswapper/resolve/main/inswapper_128.onnx\"\n",
|
| 44 |
+
"\n",
|
| 45 |
+
"!python app.py --share_gradio --colab_performance\n"
|
| 46 |
+
]
|
| 47 |
+
}
|
| 48 |
+
],
|
| 49 |
+
"metadata": {
|
| 50 |
+
"accelerator": "GPU",
|
| 51 |
+
"colab": {
|
| 52 |
+
"machine_shape": "hm",
|
| 53 |
+
"provenance": []
|
| 54 |
+
},
|
| 55 |
+
"kernelspec": {
|
| 56 |
+
"display_name": "Python 3",
|
| 57 |
+
"name": "python3"
|
| 58 |
+
},
|
| 59 |
+
"language_info": {
|
| 60 |
+
"name": "python"
|
| 61 |
+
}
|
| 62 |
+
},
|
| 63 |
+
"nbformat": 4,
|
| 64 |
+
"nbformat_minor": 0
|
| 65 |
+
}
|
out/.gitkeep
ADDED
|
File without changes
|
recognition/arcface_onnx.py
ADDED
|
@@ -0,0 +1,91 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
# @Organization : insightface.ai
|
| 3 |
+
# @Author : Jia Guo
|
| 4 |
+
# @Time : 2021-05-04
|
| 5 |
+
# @Function :
|
| 6 |
+
|
| 7 |
+
import numpy as np
|
| 8 |
+
import cv2
|
| 9 |
+
import onnx
|
| 10 |
+
import onnxruntime
|
| 11 |
+
import face_align
|
| 12 |
+
|
| 13 |
+
__all__ = [
|
| 14 |
+
'ArcFaceONNX',
|
| 15 |
+
]
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class ArcFaceONNX:
|
| 19 |
+
def __init__(self, model_file=None, session=None):
|
| 20 |
+
assert model_file is not None
|
| 21 |
+
self.model_file = model_file
|
| 22 |
+
self.session = session
|
| 23 |
+
self.taskname = 'recognition'
|
| 24 |
+
find_sub = False
|
| 25 |
+
find_mul = False
|
| 26 |
+
model = onnx.load(self.model_file)
|
| 27 |
+
graph = model.graph
|
| 28 |
+
for nid, node in enumerate(graph.node[:8]):
|
| 29 |
+
#print(nid, node.name)
|
| 30 |
+
if node.name.startswith('Sub') or node.name.startswith('_minus'):
|
| 31 |
+
find_sub = True
|
| 32 |
+
if node.name.startswith('Mul') or node.name.startswith('_mul'):
|
| 33 |
+
find_mul = True
|
| 34 |
+
if find_sub and find_mul:
|
| 35 |
+
#mxnet arcface model
|
| 36 |
+
input_mean = 0.0
|
| 37 |
+
input_std = 1.0
|
| 38 |
+
else:
|
| 39 |
+
input_mean = 127.5
|
| 40 |
+
input_std = 127.5
|
| 41 |
+
self.input_mean = input_mean
|
| 42 |
+
self.input_std = input_std
|
| 43 |
+
#print('input mean and std:', self.input_mean, self.input_std)
|
| 44 |
+
if self.session is None:
|
| 45 |
+
self.session = onnxruntime.InferenceSession(self.model_file, providers=['CoreMLExecutionProvider','CUDAExecutionProvider'])
|
| 46 |
+
input_cfg = self.session.get_inputs()[0]
|
| 47 |
+
input_shape = input_cfg.shape
|
| 48 |
+
input_name = input_cfg.name
|
| 49 |
+
self.input_size = tuple(input_shape[2:4][::-1])
|
| 50 |
+
self.input_shape = input_shape
|
| 51 |
+
outputs = self.session.get_outputs()
|
| 52 |
+
output_names = []
|
| 53 |
+
for out in outputs:
|
| 54 |
+
output_names.append(out.name)
|
| 55 |
+
self.input_name = input_name
|
| 56 |
+
self.output_names = output_names
|
| 57 |
+
assert len(self.output_names)==1
|
| 58 |
+
self.output_shape = outputs[0].shape
|
| 59 |
+
|
| 60 |
+
def prepare(self, ctx_id, **kwargs):
|
| 61 |
+
if ctx_id<0:
|
| 62 |
+
self.session.set_providers(['CPUExecutionProvider'])
|
| 63 |
+
|
| 64 |
+
def get(self, img, kps):
|
| 65 |
+
aimg = face_align.norm_crop(img, landmark=kps, image_size=self.input_size[0])
|
| 66 |
+
embedding = self.get_feat(aimg).flatten()
|
| 67 |
+
return embedding
|
| 68 |
+
|
| 69 |
+
def compute_sim(self, feat1, feat2):
|
| 70 |
+
from numpy.linalg import norm
|
| 71 |
+
feat1 = feat1.ravel()
|
| 72 |
+
feat2 = feat2.ravel()
|
| 73 |
+
sim = np.dot(feat1, feat2) / (norm(feat1) * norm(feat2))
|
| 74 |
+
return sim
|
| 75 |
+
|
| 76 |
+
def get_feat(self, imgs):
|
| 77 |
+
if not isinstance(imgs, list):
|
| 78 |
+
imgs = [imgs]
|
| 79 |
+
input_size = self.input_size
|
| 80 |
+
|
| 81 |
+
blob = cv2.dnn.blobFromImages(imgs, 1.0 / self.input_std, input_size,
|
| 82 |
+
(self.input_mean, self.input_mean, self.input_mean), swapRB=True)
|
| 83 |
+
net_out = self.session.run(self.output_names, {self.input_name: blob})[0]
|
| 84 |
+
return net_out
|
| 85 |
+
|
| 86 |
+
def forward(self, batch_data):
|
| 87 |
+
blob = (batch_data - self.input_mean) / self.input_std
|
| 88 |
+
net_out = self.session.run(self.output_names, {self.input_name: blob})[0]
|
| 89 |
+
return net_out
|
| 90 |
+
|
| 91 |
+
|
recognition/face_align.py
ADDED
|
@@ -0,0 +1,141 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import numpy as np
|
| 3 |
+
from skimage import transform as trans
|
| 4 |
+
|
| 5 |
+
src1 = np.array([[51.642, 50.115], [57.617, 49.990], [35.740, 69.007],
|
| 6 |
+
[51.157, 89.050], [57.025, 89.702]],
|
| 7 |
+
dtype=np.float32)
|
| 8 |
+
#<--left
|
| 9 |
+
src2 = np.array([[45.031, 50.118], [65.568, 50.872], [39.677, 68.111],
|
| 10 |
+
[45.177, 86.190], [64.246, 86.758]],
|
| 11 |
+
dtype=np.float32)
|
| 12 |
+
|
| 13 |
+
#---frontal
|
| 14 |
+
src3 = np.array([[39.730, 51.138], [72.270, 51.138], [56.000, 68.493],
|
| 15 |
+
[42.463, 87.010], [69.537, 87.010]],
|
| 16 |
+
dtype=np.float32)
|
| 17 |
+
|
| 18 |
+
#-->right
|
| 19 |
+
src4 = np.array([[46.845, 50.872], [67.382, 50.118], [72.737, 68.111],
|
| 20 |
+
[48.167, 86.758], [67.236, 86.190]],
|
| 21 |
+
dtype=np.float32)
|
| 22 |
+
|
| 23 |
+
#-->right profile
|
| 24 |
+
src5 = np.array([[54.796, 49.990], [60.771, 50.115], [76.673, 69.007],
|
| 25 |
+
[55.388, 89.702], [61.257, 89.050]],
|
| 26 |
+
dtype=np.float32)
|
| 27 |
+
|
| 28 |
+
src = np.array([src1, src2, src3, src4, src5])
|
| 29 |
+
src_map = {112: src, 224: src * 2}
|
| 30 |
+
|
| 31 |
+
arcface_src = np.array(
|
| 32 |
+
[[38.2946, 51.6963], [73.5318, 51.5014], [56.0252, 71.7366],
|
| 33 |
+
[41.5493, 92.3655], [70.7299, 92.2041]],
|
| 34 |
+
dtype=np.float32)
|
| 35 |
+
|
| 36 |
+
arcface_src = np.expand_dims(arcface_src, axis=0)
|
| 37 |
+
|
| 38 |
+
# In[66]:
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
# lmk is prediction; src is template
|
| 42 |
+
def estimate_norm(lmk, image_size=112, mode='arcface'):
|
| 43 |
+
assert lmk.shape == (5, 2)
|
| 44 |
+
tform = trans.SimilarityTransform()
|
| 45 |
+
lmk_tran = np.insert(lmk, 2, values=np.ones(5), axis=1)
|
| 46 |
+
min_M = []
|
| 47 |
+
min_index = []
|
| 48 |
+
min_error = float('inf')
|
| 49 |
+
if mode == 'arcface':
|
| 50 |
+
if image_size == 112:
|
| 51 |
+
src = arcface_src
|
| 52 |
+
else:
|
| 53 |
+
src = float(image_size) / 112 * arcface_src
|
| 54 |
+
else:
|
| 55 |
+
src = src_map[image_size]
|
| 56 |
+
for i in np.arange(src.shape[0]):
|
| 57 |
+
tform.estimate(lmk, src[i])
|
| 58 |
+
M = tform.params[0:2, :]
|
| 59 |
+
results = np.dot(M, lmk_tran.T)
|
| 60 |
+
results = results.T
|
| 61 |
+
error = np.sum(np.sqrt(np.sum((results - src[i])**2, axis=1)))
|
| 62 |
+
# print(error)
|
| 63 |
+
if error < min_error:
|
| 64 |
+
min_error = error
|
| 65 |
+
min_M = M
|
| 66 |
+
min_index = i
|
| 67 |
+
return min_M, min_index
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
def norm_crop(img, landmark, image_size=112, mode='arcface'):
|
| 71 |
+
M, pose_index = estimate_norm(landmark, image_size, mode)
|
| 72 |
+
warped = cv2.warpAffine(img, M, (image_size, image_size), borderValue=0.0)
|
| 73 |
+
return warped
|
| 74 |
+
|
| 75 |
+
def square_crop(im, S):
|
| 76 |
+
if im.shape[0] > im.shape[1]:
|
| 77 |
+
height = S
|
| 78 |
+
width = int(float(im.shape[1]) / im.shape[0] * S)
|
| 79 |
+
scale = float(S) / im.shape[0]
|
| 80 |
+
else:
|
| 81 |
+
width = S
|
| 82 |
+
height = int(float(im.shape[0]) / im.shape[1] * S)
|
| 83 |
+
scale = float(S) / im.shape[1]
|
| 84 |
+
resized_im = cv2.resize(im, (width, height))
|
| 85 |
+
det_im = np.zeros((S, S, 3), dtype=np.uint8)
|
| 86 |
+
det_im[:resized_im.shape[0], :resized_im.shape[1], :] = resized_im
|
| 87 |
+
return det_im, scale
|
| 88 |
+
|
| 89 |
+
|
| 90 |
+
def transform(data, center, output_size, scale, rotation):
|
| 91 |
+
scale_ratio = scale
|
| 92 |
+
rot = float(rotation) * np.pi / 180.0
|
| 93 |
+
#translation = (output_size/2-center[0]*scale_ratio, output_size/2-center[1]*scale_ratio)
|
| 94 |
+
t1 = trans.SimilarityTransform(scale=scale_ratio)
|
| 95 |
+
cx = center[0] * scale_ratio
|
| 96 |
+
cy = center[1] * scale_ratio
|
| 97 |
+
t2 = trans.SimilarityTransform(translation=(-1 * cx, -1 * cy))
|
| 98 |
+
t3 = trans.SimilarityTransform(rotation=rot)
|
| 99 |
+
t4 = trans.SimilarityTransform(translation=(output_size / 2,
|
| 100 |
+
output_size / 2))
|
| 101 |
+
t = t1 + t2 + t3 + t4
|
| 102 |
+
M = t.params[0:2]
|
| 103 |
+
cropped = cv2.warpAffine(data,
|
| 104 |
+
M, (output_size, output_size),
|
| 105 |
+
borderValue=0.0)
|
| 106 |
+
return cropped, M
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def trans_points2d(pts, M):
|
| 110 |
+
new_pts = np.zeros(shape=pts.shape, dtype=np.float32)
|
| 111 |
+
for i in range(pts.shape[0]):
|
| 112 |
+
pt = pts[i]
|
| 113 |
+
new_pt = np.array([pt[0], pt[1], 1.], dtype=np.float32)
|
| 114 |
+
new_pt = np.dot(M, new_pt)
|
| 115 |
+
#print('new_pt', new_pt.shape, new_pt)
|
| 116 |
+
new_pts[i] = new_pt[0:2]
|
| 117 |
+
|
| 118 |
+
return new_pts
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def trans_points3d(pts, M):
|
| 122 |
+
scale = np.sqrt(M[0][0] * M[0][0] + M[0][1] * M[0][1])
|
| 123 |
+
#print(scale)
|
| 124 |
+
new_pts = np.zeros(shape=pts.shape, dtype=np.float32)
|
| 125 |
+
for i in range(pts.shape[0]):
|
| 126 |
+
pt = pts[i]
|
| 127 |
+
new_pt = np.array([pt[0], pt[1], 1.], dtype=np.float32)
|
| 128 |
+
new_pt = np.dot(M, new_pt)
|
| 129 |
+
#print('new_pt', new_pt.shape, new_pt)
|
| 130 |
+
new_pts[i][0:2] = new_pt[0:2]
|
| 131 |
+
new_pts[i][2] = pts[i][2] * scale
|
| 132 |
+
|
| 133 |
+
return new_pts
|
| 134 |
+
|
| 135 |
+
|
| 136 |
+
def trans_points(pts, M):
|
| 137 |
+
if pts.shape[1] == 2:
|
| 138 |
+
return trans_points2d(pts, M)
|
| 139 |
+
else:
|
| 140 |
+
return trans_points3d(pts, M)
|
| 141 |
+
|
recognition/main.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/usr/bin/env python
|
| 2 |
+
|
| 3 |
+
import os
|
| 4 |
+
import os.path as osp
|
| 5 |
+
import argparse
|
| 6 |
+
import cv2
|
| 7 |
+
import numpy as np
|
| 8 |
+
import onnxruntime
|
| 9 |
+
from scrfd import SCRFD
|
| 10 |
+
from arcface_onnx import ArcFaceONNX
|
| 11 |
+
|
| 12 |
+
onnxruntime.set_default_logger_severity(5)
|
| 13 |
+
|
| 14 |
+
assets_dir = osp.expanduser('~/.insightface/models/buffalo_l')
|
| 15 |
+
|
| 16 |
+
detector = SCRFD(os.path.join(assets_dir, 'det_10g.onnx'))
|
| 17 |
+
detector.prepare(0)
|
| 18 |
+
model_path = os.path.join(assets_dir, 'w600k_r50.onnx')
|
| 19 |
+
rec = ArcFaceONNX(model_path)
|
| 20 |
+
rec.prepare(0)
|
| 21 |
+
|
| 22 |
+
def parse_args() -> argparse.Namespace:
|
| 23 |
+
parser = argparse.ArgumentParser()
|
| 24 |
+
parser.add_argument('img1', type=str)
|
| 25 |
+
parser.add_argument('img2', type=str)
|
| 26 |
+
return parser.parse_args()
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def func(args):
|
| 30 |
+
image1 = cv2.imread(args.img1)
|
| 31 |
+
image2 = cv2.imread(args.img2)
|
| 32 |
+
bboxes1, kpss1 = detector.autodetect(image1, max_num=1)
|
| 33 |
+
if bboxes1.shape[0]==0:
|
| 34 |
+
return -1.0, "Face not found in Image-1"
|
| 35 |
+
bboxes2, kpss2 = detector.autodetect(image2, max_num=1)
|
| 36 |
+
if bboxes2.shape[0]==0:
|
| 37 |
+
return -1.0, "Face not found in Image-2"
|
| 38 |
+
kps1 = kpss1[0]
|
| 39 |
+
kps2 = kpss2[0]
|
| 40 |
+
feat1 = rec.get(image1, kps1)
|
| 41 |
+
feat2 = rec.get(image2, kps2)
|
| 42 |
+
sim = rec.compute_sim(feat1, feat2)
|
| 43 |
+
if sim<0.2:
|
| 44 |
+
conclu = 'They are NOT the same person'
|
| 45 |
+
elif sim>=0.2 and sim<0.28:
|
| 46 |
+
conclu = 'They are LIKELY TO be the same person'
|
| 47 |
+
else:
|
| 48 |
+
conclu = 'They ARE the same person'
|
| 49 |
+
return sim, conclu
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
if __name__ == '__main__':
|
| 54 |
+
args = parse_args()
|
| 55 |
+
output = func(args)
|
| 56 |
+
print('sim: %.4f, message: %s'%(output[0], output[1]))
|
| 57 |
+
|
recognition/scrfd.py
ADDED
|
@@ -0,0 +1,329 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
from __future__ import division
|
| 3 |
+
import datetime
|
| 4 |
+
import numpy as np
|
| 5 |
+
#import onnx
|
| 6 |
+
import onnxruntime
|
| 7 |
+
import os
|
| 8 |
+
import os.path as osp
|
| 9 |
+
import cv2
|
| 10 |
+
import sys
|
| 11 |
+
|
| 12 |
+
def softmax(z):
|
| 13 |
+
assert len(z.shape) == 2
|
| 14 |
+
s = np.max(z, axis=1)
|
| 15 |
+
s = s[:, np.newaxis] # necessary step to do broadcasting
|
| 16 |
+
e_x = np.exp(z - s)
|
| 17 |
+
div = np.sum(e_x, axis=1)
|
| 18 |
+
div = div[:, np.newaxis] # dito
|
| 19 |
+
return e_x / div
|
| 20 |
+
|
| 21 |
+
def distance2bbox(points, distance, max_shape=None):
|
| 22 |
+
"""Decode distance prediction to bounding box.
|
| 23 |
+
|
| 24 |
+
Args:
|
| 25 |
+
points (Tensor): Shape (n, 2), [x, y].
|
| 26 |
+
distance (Tensor): Distance from the given point to 4
|
| 27 |
+
boundaries (left, top, right, bottom).
|
| 28 |
+
max_shape (tuple): Shape of the image.
|
| 29 |
+
|
| 30 |
+
Returns:
|
| 31 |
+
Tensor: Decoded bboxes.
|
| 32 |
+
"""
|
| 33 |
+
x1 = points[:, 0] - distance[:, 0]
|
| 34 |
+
y1 = points[:, 1] - distance[:, 1]
|
| 35 |
+
x2 = points[:, 0] + distance[:, 2]
|
| 36 |
+
y2 = points[:, 1] + distance[:, 3]
|
| 37 |
+
if max_shape is not None:
|
| 38 |
+
x1 = x1.clamp(min=0, max=max_shape[1])
|
| 39 |
+
y1 = y1.clamp(min=0, max=max_shape[0])
|
| 40 |
+
x2 = x2.clamp(min=0, max=max_shape[1])
|
| 41 |
+
y2 = y2.clamp(min=0, max=max_shape[0])
|
| 42 |
+
return np.stack([x1, y1, x2, y2], axis=-1)
|
| 43 |
+
|
| 44 |
+
def distance2kps(points, distance, max_shape=None):
|
| 45 |
+
"""Decode distance prediction to bounding box.
|
| 46 |
+
|
| 47 |
+
Args:
|
| 48 |
+
points (Tensor): Shape (n, 2), [x, y].
|
| 49 |
+
distance (Tensor): Distance from the given point to 4
|
| 50 |
+
boundaries (left, top, right, bottom).
|
| 51 |
+
max_shape (tuple): Shape of the image.
|
| 52 |
+
|
| 53 |
+
Returns:
|
| 54 |
+
Tensor: Decoded bboxes.
|
| 55 |
+
"""
|
| 56 |
+
preds = []
|
| 57 |
+
for i in range(0, distance.shape[1], 2):
|
| 58 |
+
px = points[:, i%2] + distance[:, i]
|
| 59 |
+
py = points[:, i%2+1] + distance[:, i+1]
|
| 60 |
+
if max_shape is not None:
|
| 61 |
+
px = px.clamp(min=0, max=max_shape[1])
|
| 62 |
+
py = py.clamp(min=0, max=max_shape[0])
|
| 63 |
+
preds.append(px)
|
| 64 |
+
preds.append(py)
|
| 65 |
+
return np.stack(preds, axis=-1)
|
| 66 |
+
|
| 67 |
+
class SCRFD:
|
| 68 |
+
def __init__(self, model_file=None, session=None):
|
| 69 |
+
import onnxruntime
|
| 70 |
+
self.model_file = model_file
|
| 71 |
+
self.session = session
|
| 72 |
+
self.taskname = 'detection'
|
| 73 |
+
self.batched = False
|
| 74 |
+
if self.session is None:
|
| 75 |
+
assert self.model_file is not None
|
| 76 |
+
assert osp.exists(self.model_file)
|
| 77 |
+
self.session = onnxruntime.InferenceSession(self.model_file, providers=['CoreMLExecutionProvider','CUDAExecutionProvider'])
|
| 78 |
+
self.center_cache = {}
|
| 79 |
+
self.nms_thresh = 0.4
|
| 80 |
+
self.det_thresh = 0.5
|
| 81 |
+
self._init_vars()
|
| 82 |
+
|
| 83 |
+
def _init_vars(self):
|
| 84 |
+
input_cfg = self.session.get_inputs()[0]
|
| 85 |
+
input_shape = input_cfg.shape
|
| 86 |
+
#print(input_shape)
|
| 87 |
+
if isinstance(input_shape[2], str):
|
| 88 |
+
self.input_size = None
|
| 89 |
+
else:
|
| 90 |
+
self.input_size = tuple(input_shape[2:4][::-1])
|
| 91 |
+
#print('image_size:', self.image_size)
|
| 92 |
+
input_name = input_cfg.name
|
| 93 |
+
self.input_shape = input_shape
|
| 94 |
+
outputs = self.session.get_outputs()
|
| 95 |
+
if len(outputs[0].shape) == 3:
|
| 96 |
+
self.batched = True
|
| 97 |
+
output_names = []
|
| 98 |
+
for o in outputs:
|
| 99 |
+
output_names.append(o.name)
|
| 100 |
+
self.input_name = input_name
|
| 101 |
+
self.output_names = output_names
|
| 102 |
+
self.input_mean = 127.5
|
| 103 |
+
self.input_std = 128.0
|
| 104 |
+
#print(self.output_names)
|
| 105 |
+
#assert len(outputs)==10 or len(outputs)==15
|
| 106 |
+
self.use_kps = False
|
| 107 |
+
self._anchor_ratio = 1.0
|
| 108 |
+
self._num_anchors = 1
|
| 109 |
+
if len(outputs)==6:
|
| 110 |
+
self.fmc = 3
|
| 111 |
+
self._feat_stride_fpn = [8, 16, 32]
|
| 112 |
+
self._num_anchors = 2
|
| 113 |
+
elif len(outputs)==9:
|
| 114 |
+
self.fmc = 3
|
| 115 |
+
self._feat_stride_fpn = [8, 16, 32]
|
| 116 |
+
self._num_anchors = 2
|
| 117 |
+
self.use_kps = True
|
| 118 |
+
elif len(outputs)==10:
|
| 119 |
+
self.fmc = 5
|
| 120 |
+
self._feat_stride_fpn = [8, 16, 32, 64, 128]
|
| 121 |
+
self._num_anchors = 1
|
| 122 |
+
elif len(outputs)==15:
|
| 123 |
+
self.fmc = 5
|
| 124 |
+
self._feat_stride_fpn = [8, 16, 32, 64, 128]
|
| 125 |
+
self._num_anchors = 1
|
| 126 |
+
self.use_kps = True
|
| 127 |
+
|
| 128 |
+
def prepare(self, ctx_id, **kwargs):
|
| 129 |
+
if ctx_id<0:
|
| 130 |
+
self.session.set_providers(['CPUExecutionProvider'])
|
| 131 |
+
nms_thresh = kwargs.get('nms_thresh', None)
|
| 132 |
+
if nms_thresh is not None:
|
| 133 |
+
self.nms_thresh = nms_thresh
|
| 134 |
+
det_thresh = kwargs.get('det_thresh', None)
|
| 135 |
+
if det_thresh is not None:
|
| 136 |
+
self.det_thresh = det_thresh
|
| 137 |
+
input_size = kwargs.get('input_size', None)
|
| 138 |
+
if input_size is not None:
|
| 139 |
+
if self.input_size is not None:
|
| 140 |
+
print('warning: det_size is already set in scrfd model, ignore')
|
| 141 |
+
else:
|
| 142 |
+
self.input_size = input_size
|
| 143 |
+
|
| 144 |
+
def forward(self, img, threshold):
|
| 145 |
+
scores_list = []
|
| 146 |
+
bboxes_list = []
|
| 147 |
+
kpss_list = []
|
| 148 |
+
input_size = tuple(img.shape[0:2][::-1])
|
| 149 |
+
blob = cv2.dnn.blobFromImage(img, 1.0/self.input_std, input_size, (self.input_mean, self.input_mean, self.input_mean), swapRB=True)
|
| 150 |
+
net_outs = self.session.run(self.output_names, {self.input_name : blob})
|
| 151 |
+
|
| 152 |
+
input_height = blob.shape[2]
|
| 153 |
+
input_width = blob.shape[3]
|
| 154 |
+
fmc = self.fmc
|
| 155 |
+
for idx, stride in enumerate(self._feat_stride_fpn):
|
| 156 |
+
# If model support batch dim, take first output
|
| 157 |
+
if self.batched:
|
| 158 |
+
scores = net_outs[idx][0]
|
| 159 |
+
bbox_preds = net_outs[idx + fmc][0]
|
| 160 |
+
bbox_preds = bbox_preds * stride
|
| 161 |
+
if self.use_kps:
|
| 162 |
+
kps_preds = net_outs[idx + fmc * 2][0] * stride
|
| 163 |
+
# If model doesn't support batching take output as is
|
| 164 |
+
else:
|
| 165 |
+
scores = net_outs[idx]
|
| 166 |
+
bbox_preds = net_outs[idx + fmc]
|
| 167 |
+
bbox_preds = bbox_preds * stride
|
| 168 |
+
if self.use_kps:
|
| 169 |
+
kps_preds = net_outs[idx + fmc * 2] * stride
|
| 170 |
+
|
| 171 |
+
height = input_height // stride
|
| 172 |
+
width = input_width // stride
|
| 173 |
+
K = height * width
|
| 174 |
+
key = (height, width, stride)
|
| 175 |
+
if key in self.center_cache:
|
| 176 |
+
anchor_centers = self.center_cache[key]
|
| 177 |
+
else:
|
| 178 |
+
#solution-1, c style:
|
| 179 |
+
#anchor_centers = np.zeros( (height, width, 2), dtype=np.float32 )
|
| 180 |
+
#for i in range(height):
|
| 181 |
+
# anchor_centers[i, :, 1] = i
|
| 182 |
+
#for i in range(width):
|
| 183 |
+
# anchor_centers[:, i, 0] = i
|
| 184 |
+
|
| 185 |
+
#solution-2:
|
| 186 |
+
#ax = np.arange(width, dtype=np.float32)
|
| 187 |
+
#ay = np.arange(height, dtype=np.float32)
|
| 188 |
+
#xv, yv = np.meshgrid(np.arange(width), np.arange(height))
|
| 189 |
+
#anchor_centers = np.stack([xv, yv], axis=-1).astype(np.float32)
|
| 190 |
+
|
| 191 |
+
#solution-3:
|
| 192 |
+
anchor_centers = np.stack(np.mgrid[:height, :width][::-1], axis=-1).astype(np.float32)
|
| 193 |
+
#print(anchor_centers.shape)
|
| 194 |
+
|
| 195 |
+
anchor_centers = (anchor_centers * stride).reshape( (-1, 2) )
|
| 196 |
+
if self._num_anchors>1:
|
| 197 |
+
anchor_centers = np.stack([anchor_centers]*self._num_anchors, axis=1).reshape( (-1,2) )
|
| 198 |
+
if len(self.center_cache)<100:
|
| 199 |
+
self.center_cache[key] = anchor_centers
|
| 200 |
+
|
| 201 |
+
pos_inds = np.where(scores>=threshold)[0]
|
| 202 |
+
bboxes = distance2bbox(anchor_centers, bbox_preds)
|
| 203 |
+
pos_scores = scores[pos_inds]
|
| 204 |
+
pos_bboxes = bboxes[pos_inds]
|
| 205 |
+
scores_list.append(pos_scores)
|
| 206 |
+
bboxes_list.append(pos_bboxes)
|
| 207 |
+
if self.use_kps:
|
| 208 |
+
kpss = distance2kps(anchor_centers, kps_preds)
|
| 209 |
+
#kpss = kps_preds
|
| 210 |
+
kpss = kpss.reshape( (kpss.shape[0], -1, 2) )
|
| 211 |
+
pos_kpss = kpss[pos_inds]
|
| 212 |
+
kpss_list.append(pos_kpss)
|
| 213 |
+
return scores_list, bboxes_list, kpss_list
|
| 214 |
+
|
| 215 |
+
def detect(self, img, input_size = None, thresh=None, max_num=0, metric='default'):
|
| 216 |
+
assert input_size is not None or self.input_size is not None
|
| 217 |
+
input_size = self.input_size if input_size is None else input_size
|
| 218 |
+
|
| 219 |
+
im_ratio = float(img.shape[0]) / img.shape[1]
|
| 220 |
+
model_ratio = float(input_size[1]) / input_size[0]
|
| 221 |
+
if im_ratio>model_ratio:
|
| 222 |
+
new_height = input_size[1]
|
| 223 |
+
new_width = int(new_height / im_ratio)
|
| 224 |
+
else:
|
| 225 |
+
new_width = input_size[0]
|
| 226 |
+
new_height = int(new_width * im_ratio)
|
| 227 |
+
det_scale = float(new_height) / img.shape[0]
|
| 228 |
+
resized_img = cv2.resize(img, (new_width, new_height))
|
| 229 |
+
det_img = np.zeros( (input_size[1], input_size[0], 3), dtype=np.uint8 )
|
| 230 |
+
det_img[:new_height, :new_width, :] = resized_img
|
| 231 |
+
det_thresh = thresh if thresh is not None else self.det_thresh
|
| 232 |
+
|
| 233 |
+
scores_list, bboxes_list, kpss_list = self.forward(det_img, det_thresh)
|
| 234 |
+
|
| 235 |
+
scores = np.vstack(scores_list)
|
| 236 |
+
scores_ravel = scores.ravel()
|
| 237 |
+
order = scores_ravel.argsort()[::-1]
|
| 238 |
+
bboxes = np.vstack(bboxes_list) / det_scale
|
| 239 |
+
if self.use_kps:
|
| 240 |
+
kpss = np.vstack(kpss_list) / det_scale
|
| 241 |
+
pre_det = np.hstack((bboxes, scores)).astype(np.float32, copy=False)
|
| 242 |
+
pre_det = pre_det[order, :]
|
| 243 |
+
keep = self.nms(pre_det)
|
| 244 |
+
det = pre_det[keep, :]
|
| 245 |
+
if self.use_kps:
|
| 246 |
+
kpss = kpss[order,:,:]
|
| 247 |
+
kpss = kpss[keep,:,:]
|
| 248 |
+
else:
|
| 249 |
+
kpss = None
|
| 250 |
+
if max_num > 0 and det.shape[0] > max_num:
|
| 251 |
+
area = (det[:, 2] - det[:, 0]) * (det[:, 3] -
|
| 252 |
+
det[:, 1])
|
| 253 |
+
img_center = img.shape[0] // 2, img.shape[1] // 2
|
| 254 |
+
offsets = np.vstack([
|
| 255 |
+
(det[:, 0] + det[:, 2]) / 2 - img_center[1],
|
| 256 |
+
(det[:, 1] + det[:, 3]) / 2 - img_center[0]
|
| 257 |
+
])
|
| 258 |
+
offset_dist_squared = np.sum(np.power(offsets, 2.0), 0)
|
| 259 |
+
if metric=='max':
|
| 260 |
+
values = area
|
| 261 |
+
else:
|
| 262 |
+
values = area - offset_dist_squared * 2.0 # some extra weight on the centering
|
| 263 |
+
bindex = np.argsort(
|
| 264 |
+
values)[::-1] # some extra weight on the centering
|
| 265 |
+
bindex = bindex[0:max_num]
|
| 266 |
+
det = det[bindex, :]
|
| 267 |
+
if kpss is not None:
|
| 268 |
+
kpss = kpss[bindex, :]
|
| 269 |
+
return det, kpss
|
| 270 |
+
|
| 271 |
+
def autodetect(self, img, max_num=0, metric='max'):
|
| 272 |
+
bboxes, kpss = self.detect(img, input_size=(640, 640), thresh=0.5)
|
| 273 |
+
bboxes2, kpss2 = self.detect(img, input_size=(128, 128), thresh=0.5)
|
| 274 |
+
bboxes_all = np.concatenate([bboxes, bboxes2], axis=0)
|
| 275 |
+
kpss_all = np.concatenate([kpss, kpss2], axis=0)
|
| 276 |
+
keep = self.nms(bboxes_all)
|
| 277 |
+
det = bboxes_all[keep,:]
|
| 278 |
+
kpss = kpss_all[keep,:]
|
| 279 |
+
if max_num > 0 and det.shape[0] > max_num:
|
| 280 |
+
area = (det[:, 2] - det[:, 0]) * (det[:, 3] -
|
| 281 |
+
det[:, 1])
|
| 282 |
+
img_center = img.shape[0] // 2, img.shape[1] // 2
|
| 283 |
+
offsets = np.vstack([
|
| 284 |
+
(det[:, 0] + det[:, 2]) / 2 - img_center[1],
|
| 285 |
+
(det[:, 1] + det[:, 3]) / 2 - img_center[0]
|
| 286 |
+
])
|
| 287 |
+
offset_dist_squared = np.sum(np.power(offsets, 2.0), 0)
|
| 288 |
+
if metric=='max':
|
| 289 |
+
values = area
|
| 290 |
+
else:
|
| 291 |
+
values = area - offset_dist_squared * 2.0 # some extra weight on the centering
|
| 292 |
+
bindex = np.argsort(
|
| 293 |
+
values)[::-1] # some extra weight on the centering
|
| 294 |
+
bindex = bindex[0:max_num]
|
| 295 |
+
det = det[bindex, :]
|
| 296 |
+
if kpss is not None:
|
| 297 |
+
kpss = kpss[bindex, :]
|
| 298 |
+
return det, kpss
|
| 299 |
+
|
| 300 |
+
def nms(self, dets):
|
| 301 |
+
thresh = self.nms_thresh
|
| 302 |
+
x1 = dets[:, 0]
|
| 303 |
+
y1 = dets[:, 1]
|
| 304 |
+
x2 = dets[:, 2]
|
| 305 |
+
y2 = dets[:, 3]
|
| 306 |
+
scores = dets[:, 4]
|
| 307 |
+
|
| 308 |
+
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
|
| 309 |
+
order = scores.argsort()[::-1]
|
| 310 |
+
|
| 311 |
+
keep = []
|
| 312 |
+
while order.size > 0:
|
| 313 |
+
i = order[0]
|
| 314 |
+
keep.append(i)
|
| 315 |
+
xx1 = np.maximum(x1[i], x1[order[1:]])
|
| 316 |
+
yy1 = np.maximum(y1[i], y1[order[1:]])
|
| 317 |
+
xx2 = np.minimum(x2[i], x2[order[1:]])
|
| 318 |
+
yy2 = np.minimum(y2[i], y2[order[1:]])
|
| 319 |
+
|
| 320 |
+
w = np.maximum(0.0, xx2 - xx1 + 1)
|
| 321 |
+
h = np.maximum(0.0, yy2 - yy1 + 1)
|
| 322 |
+
inter = w * h
|
| 323 |
+
ovr = inter / (areas[i] + areas[order[1:]] - inter)
|
| 324 |
+
|
| 325 |
+
inds = np.where(ovr <= thresh)[0]
|
| 326 |
+
order = order[inds + 1]
|
| 327 |
+
|
| 328 |
+
return keep
|
| 329 |
+
|
refacer.py
ADDED
|
@@ -0,0 +1,262 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import cv2
|
| 2 |
+
import onnxruntime as rt
|
| 3 |
+
import sys
|
| 4 |
+
from insightface.app import FaceAnalysis
|
| 5 |
+
sys.path.insert(1, './recognition')
|
| 6 |
+
from scrfd import SCRFD
|
| 7 |
+
from arcface_onnx import ArcFaceONNX
|
| 8 |
+
import os.path as osp
|
| 9 |
+
import os
|
| 10 |
+
from pathlib import Path
|
| 11 |
+
from tqdm import tqdm
|
| 12 |
+
import ffmpeg
|
| 13 |
+
import random
|
| 14 |
+
import multiprocessing as mp
|
| 15 |
+
from concurrent.futures import ThreadPoolExecutor
|
| 16 |
+
from insightface.model_zoo.inswapper import INSwapper
|
| 17 |
+
import psutil
|
| 18 |
+
from enum import Enum
|
| 19 |
+
from insightface.app.common import Face
|
| 20 |
+
from insightface.utils.storage import ensure_available
|
| 21 |
+
import re
|
| 22 |
+
import subprocess
|
| 23 |
+
|
| 24 |
+
class RefacerMode(Enum):
|
| 25 |
+
CPU, CUDA, COREML, TENSORRT = range(1, 5)
|
| 26 |
+
|
| 27 |
+
class Refacer:
|
| 28 |
+
def __init__(self,force_cpu=False,colab_performance=False):
|
| 29 |
+
self.first_face = False
|
| 30 |
+
self.force_cpu = force_cpu
|
| 31 |
+
self.colab_performance = colab_performance
|
| 32 |
+
self.__check_encoders()
|
| 33 |
+
self.__check_providers()
|
| 34 |
+
self.total_mem = psutil.virtual_memory().total
|
| 35 |
+
self.__init_apps()
|
| 36 |
+
|
| 37 |
+
def __check_providers(self):
|
| 38 |
+
if self.force_cpu :
|
| 39 |
+
self.providers = ['CPUExecutionProvider']
|
| 40 |
+
else:
|
| 41 |
+
self.providers = rt.get_available_providers()
|
| 42 |
+
rt.set_default_logger_severity(4)
|
| 43 |
+
self.sess_options = rt.SessionOptions()
|
| 44 |
+
self.sess_options.execution_mode = rt.ExecutionMode.ORT_SEQUENTIAL
|
| 45 |
+
self.sess_options.graph_optimization_level = rt.GraphOptimizationLevel.ORT_ENABLE_ALL
|
| 46 |
+
|
| 47 |
+
if len(self.providers) == 1 and 'CPUExecutionProvider' in self.providers:
|
| 48 |
+
self.mode = RefacerMode.CPU
|
| 49 |
+
self.use_num_cpus = mp.cpu_count()-1
|
| 50 |
+
self.sess_options.intra_op_num_threads = int(self.use_num_cpus/3)
|
| 51 |
+
print(f"CPU mode with providers {self.providers}")
|
| 52 |
+
elif self.colab_performance:
|
| 53 |
+
self.mode = RefacerMode.TENSORRT
|
| 54 |
+
self.use_num_cpus = mp.cpu_count()-1
|
| 55 |
+
self.sess_options.intra_op_num_threads = int(self.use_num_cpus/3)
|
| 56 |
+
print(f"TENSORRT mode with providers {self.providers}")
|
| 57 |
+
elif 'CoreMLExecutionProvider' in self.providers:
|
| 58 |
+
self.mode = RefacerMode.COREML
|
| 59 |
+
self.use_num_cpus = mp.cpu_count()-1
|
| 60 |
+
self.sess_options.intra_op_num_threads = int(self.use_num_cpus/3)
|
| 61 |
+
print(f"CoreML mode with providers {self.providers}")
|
| 62 |
+
elif 'CUDAExecutionProvider' in self.providers:
|
| 63 |
+
self.mode = RefacerMode.CUDA
|
| 64 |
+
self.use_num_cpus = 2
|
| 65 |
+
self.sess_options.intra_op_num_threads = 1
|
| 66 |
+
if 'TensorrtExecutionProvider' in self.providers:
|
| 67 |
+
self.providers.remove('TensorrtExecutionProvider')
|
| 68 |
+
print(f"CUDA mode with providers {self.providers}")
|
| 69 |
+
"""
|
| 70 |
+
elif 'TensorrtExecutionProvider' in self.providers:
|
| 71 |
+
self.mode = RefacerMode.TENSORRT
|
| 72 |
+
#self.use_num_cpus = 1
|
| 73 |
+
#self.sess_options.intra_op_num_threads = 1
|
| 74 |
+
self.use_num_cpus = mp.cpu_count()-1
|
| 75 |
+
self.sess_options.intra_op_num_threads = int(self.use_num_cpus/3)
|
| 76 |
+
print(f"TENSORRT mode with providers {self.providers}")
|
| 77 |
+
"""
|
| 78 |
+
|
| 79 |
+
|
| 80 |
+
def __init_apps(self):
|
| 81 |
+
assets_dir = ensure_available('models', 'buffalo_l', root='~/.insightface')
|
| 82 |
+
|
| 83 |
+
model_path = os.path.join(assets_dir, 'det_10g.onnx')
|
| 84 |
+
sess_face = rt.InferenceSession(model_path, self.sess_options, providers=self.providers)
|
| 85 |
+
self.face_detector = SCRFD(model_path,sess_face)
|
| 86 |
+
self.face_detector.prepare(0,input_size=(640, 640))
|
| 87 |
+
|
| 88 |
+
model_path = os.path.join(assets_dir , 'w600k_r50.onnx')
|
| 89 |
+
sess_rec = rt.InferenceSession(model_path, self.sess_options, providers=self.providers)
|
| 90 |
+
self.rec_app = ArcFaceONNX(model_path,sess_rec)
|
| 91 |
+
self.rec_app.prepare(0)
|
| 92 |
+
|
| 93 |
+
model_path = 'inswapper_128.onnx'
|
| 94 |
+
sess_swap = rt.InferenceSession(model_path, self.sess_options, providers=self.providers)
|
| 95 |
+
self.face_swapper = INSwapper(model_path,sess_swap)
|
| 96 |
+
|
| 97 |
+
def prepare_faces(self, faces):
|
| 98 |
+
self.replacement_faces=[]
|
| 99 |
+
for face in faces:
|
| 100 |
+
#image1 = cv2.imread(face.origin)
|
| 101 |
+
if "origin" in face:
|
| 102 |
+
face_threshold = face['threshold']
|
| 103 |
+
bboxes1, kpss1 = self.face_detector.autodetect(face['origin'], max_num=1)
|
| 104 |
+
if len(kpss1)<1:
|
| 105 |
+
raise Exception('No face detected on "Face to replace" image')
|
| 106 |
+
feat_original = self.rec_app.get(face['origin'], kpss1[0])
|
| 107 |
+
else:
|
| 108 |
+
face_threshold = 0
|
| 109 |
+
self.first_face = True
|
| 110 |
+
feat_original = None
|
| 111 |
+
print('No origin image: First face change')
|
| 112 |
+
#image2 = cv2.imread(face.destination)
|
| 113 |
+
_faces = self.__get_faces(face['destination'],max_num=1)
|
| 114 |
+
if len(_faces)<1:
|
| 115 |
+
raise Exception('No face detected on "Destination face" image')
|
| 116 |
+
self.replacement_faces.append((feat_original,_faces[0],face_threshold))
|
| 117 |
+
|
| 118 |
+
def __convert_video(self,video_path,output_video_path):
|
| 119 |
+
if self.video_has_audio:
|
| 120 |
+
print("Merging audio with the refaced video...")
|
| 121 |
+
new_path = output_video_path + str(random.randint(0,999)) + "_c.mp4"
|
| 122 |
+
#stream = ffmpeg.input(output_video_path)
|
| 123 |
+
in1 = ffmpeg.input(output_video_path)
|
| 124 |
+
in2 = ffmpeg.input(video_path)
|
| 125 |
+
out = ffmpeg.output(in1.video, in2.audio, new_path,video_bitrate=self.ffmpeg_video_bitrate,vcodec=self.ffmpeg_video_encoder)
|
| 126 |
+
out.run(overwrite_output=True,quiet=True)
|
| 127 |
+
else:
|
| 128 |
+
new_path = output_video_path
|
| 129 |
+
print("The video doesn't have audio, so post-processing is not necessary")
|
| 130 |
+
|
| 131 |
+
print(f"The process has finished.\nThe refaced video can be found at {os.path.abspath(new_path)}")
|
| 132 |
+
return new_path
|
| 133 |
+
|
| 134 |
+
def __get_faces(self,frame,max_num=0):
|
| 135 |
+
|
| 136 |
+
bboxes, kpss = self.face_detector.detect(frame,max_num=max_num,metric='default')
|
| 137 |
+
|
| 138 |
+
if bboxes.shape[0] == 0:
|
| 139 |
+
return []
|
| 140 |
+
ret = []
|
| 141 |
+
for i in range(bboxes.shape[0]):
|
| 142 |
+
bbox = bboxes[i, 0:4]
|
| 143 |
+
det_score = bboxes[i, 4]
|
| 144 |
+
kps = None
|
| 145 |
+
if kpss is not None:
|
| 146 |
+
kps = kpss[i]
|
| 147 |
+
face = Face(bbox=bbox, kps=kps, det_score=det_score)
|
| 148 |
+
face.embedding = self.rec_app.get(frame, kps)
|
| 149 |
+
ret.append(face)
|
| 150 |
+
return ret
|
| 151 |
+
|
| 152 |
+
def process_first_face(self,frame):
|
| 153 |
+
faces = self.__get_faces(frame,max_num=1)
|
| 154 |
+
if len(faces) != 0:
|
| 155 |
+
frame = self.face_swapper.get(frame, faces[0], self.replacement_faces[0][1], paste_back=True)
|
| 156 |
+
return frame
|
| 157 |
+
|
| 158 |
+
def process_faces(self,frame):
|
| 159 |
+
faces = self.__get_faces(frame,max_num=0)
|
| 160 |
+
for rep_face in self.replacement_faces:
|
| 161 |
+
for i in range(len(faces) - 1, -1, -1):
|
| 162 |
+
sim = self.rec_app.compute_sim(rep_face[0], faces[i].embedding)
|
| 163 |
+
if sim>=rep_face[2]:
|
| 164 |
+
frame = self.face_swapper.get(frame, faces[i], rep_face[1], paste_back=True)
|
| 165 |
+
del faces[i]
|
| 166 |
+
break
|
| 167 |
+
return frame
|
| 168 |
+
|
| 169 |
+
def __check_video_has_audio(self,video_path):
|
| 170 |
+
self.video_has_audio = False
|
| 171 |
+
probe = ffmpeg.probe(video_path)
|
| 172 |
+
audio_stream = next((stream for stream in probe['streams'] if stream['codec_type'] == 'audio'), None)
|
| 173 |
+
if audio_stream is not None:
|
| 174 |
+
self.video_has_audio = True
|
| 175 |
+
|
| 176 |
+
def reface_group(self, faces, frames, output):
|
| 177 |
+
with ThreadPoolExecutor(max_workers = self.use_num_cpus) as executor:
|
| 178 |
+
if self.first_face:
|
| 179 |
+
results = list(tqdm(executor.map(self.process_first_face, frames), total=len(frames),desc="Processing frames"))
|
| 180 |
+
else:
|
| 181 |
+
results = list(tqdm(executor.map(self.process_faces, frames), total=len(frames),desc="Processing frames"))
|
| 182 |
+
for result in results:
|
| 183 |
+
output.write(result)
|
| 184 |
+
|
| 185 |
+
def reface(self, video_path, faces):
|
| 186 |
+
self.__check_video_has_audio(video_path)
|
| 187 |
+
output_video_path = os.path.join('out',Path(video_path).name)
|
| 188 |
+
self.prepare_faces(faces)
|
| 189 |
+
|
| 190 |
+
cap = cv2.VideoCapture(video_path)
|
| 191 |
+
total_frames = int(cap.get(cv2.CAP_PROP_FRAME_COUNT))
|
| 192 |
+
print(f"Total frames: {total_frames}")
|
| 193 |
+
|
| 194 |
+
fps = cap.get(cv2.CAP_PROP_FPS)
|
| 195 |
+
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
|
| 196 |
+
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
|
| 197 |
+
|
| 198 |
+
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
|
| 199 |
+
output = cv2.VideoWriter(output_video_path, fourcc, fps, (frame_width, frame_height))
|
| 200 |
+
|
| 201 |
+
frames=[]
|
| 202 |
+
self.k = 1
|
| 203 |
+
with tqdm(total=total_frames,desc="Extracting frames") as pbar:
|
| 204 |
+
while cap.isOpened():
|
| 205 |
+
flag, frame = cap.read()
|
| 206 |
+
if flag and len(frame)>0:
|
| 207 |
+
frames.append(frame.copy())
|
| 208 |
+
pbar.update()
|
| 209 |
+
else:
|
| 210 |
+
break
|
| 211 |
+
if (len(frames) > 1000):
|
| 212 |
+
self.reface_group(faces,frames,output)
|
| 213 |
+
frames=[]
|
| 214 |
+
|
| 215 |
+
cap.release()
|
| 216 |
+
pbar.close()
|
| 217 |
+
|
| 218 |
+
self.reface_group(faces,frames,output)
|
| 219 |
+
frames=[]
|
| 220 |
+
output.release()
|
| 221 |
+
|
| 222 |
+
return self.__convert_video(video_path,output_video_path)
|
| 223 |
+
|
| 224 |
+
def __try_ffmpeg_encoder(self, vcodec):
|
| 225 |
+
print(f"Trying FFMPEG {vcodec} encoder")
|
| 226 |
+
command = ['ffmpeg', '-y', '-f','lavfi','-i','testsrc=duration=1:size=1280x720:rate=30','-vcodec',vcodec,'testsrc.mp4']
|
| 227 |
+
try:
|
| 228 |
+
subprocess.run(command, check=True, capture_output=True).stderr
|
| 229 |
+
except subprocess.CalledProcessError as e:
|
| 230 |
+
print(f"FFMPEG {vcodec} encoder doesn't work -> Disabled.")
|
| 231 |
+
return False
|
| 232 |
+
print(f"FFMPEG {vcodec} encoder works")
|
| 233 |
+
return True
|
| 234 |
+
|
| 235 |
+
def __check_encoders(self):
|
| 236 |
+
self.ffmpeg_video_encoder='libx264'
|
| 237 |
+
self.ffmpeg_video_bitrate='0'
|
| 238 |
+
|
| 239 |
+
pattern = r"encoders: ([a-zA-Z0-9_]+(?: [a-zA-Z0-9_]+)*)"
|
| 240 |
+
command = ['ffmpeg', '-codecs', '--list-encoders']
|
| 241 |
+
commandout = subprocess.run(command, check=True, capture_output=True).stdout
|
| 242 |
+
result = commandout.decode('utf-8').split('\n')
|
| 243 |
+
for r in result:
|
| 244 |
+
if "264" in r:
|
| 245 |
+
encoders = re.search(pattern, r).group(1).split(' ')
|
| 246 |
+
for v_c in Refacer.VIDEO_CODECS:
|
| 247 |
+
for v_k in encoders:
|
| 248 |
+
if v_c == v_k:
|
| 249 |
+
if self.__try_ffmpeg_encoder(v_k):
|
| 250 |
+
self.ffmpeg_video_encoder=v_k
|
| 251 |
+
self.ffmpeg_video_bitrate=Refacer.VIDEO_CODECS[v_k]
|
| 252 |
+
print(f"Video codec for FFMPEG: {self.ffmpeg_video_encoder}")
|
| 253 |
+
return
|
| 254 |
+
|
| 255 |
+
VIDEO_CODECS = {
|
| 256 |
+
'h264_videotoolbox':'0', #osx HW acceleration
|
| 257 |
+
'h264_nvenc':'0', #NVIDIA HW acceleration
|
| 258 |
+
#'h264_qsv', #Intel HW acceleration
|
| 259 |
+
#'h264_vaapi', #Intel HW acceleration
|
| 260 |
+
#'h264_omx', #HW acceleration
|
| 261 |
+
'libx264':'0' #No HW acceleration
|
| 262 |
+
}
|
requirements-COREML.txt
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ffmpeg_python==0.2.0
|
| 2 |
+
gradio==3.33.1
|
| 3 |
+
insightface==0.7.3
|
| 4 |
+
numpy==1.24.3
|
| 5 |
+
onnx==1.14.0
|
| 6 |
+
onnxruntime-silicon
|
| 7 |
+
opencv_python==4.7.0.72
|
| 8 |
+
opencv_python_headless==4.7.0.72
|
| 9 |
+
scikit-image==0.20.0
|
| 10 |
+
tqdm
|
| 11 |
+
psutil
|
| 12 |
+
ngrok
|
requirements-GPU.txt
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ffmpeg_python==0.2.0
|
| 2 |
+
gradio==3.33.1
|
| 3 |
+
insightface==0.7.3
|
| 4 |
+
numpy==1.24.3
|
| 5 |
+
onnx==1.14.0
|
| 6 |
+
onnxruntime_gpu==1.15.0
|
| 7 |
+
opencv_python==4.7.0.72
|
| 8 |
+
opencv_python_headless==4.7.0.72
|
| 9 |
+
scikit-image==0.20.0
|
| 10 |
+
tqdm
|
| 11 |
+
psutil
|
| 12 |
+
ngrok
|
requirements.txt
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
ffmpeg_python==0.2.0
|
| 2 |
+
gradio==3.33.1
|
| 3 |
+
insightface==0.7.3
|
| 4 |
+
numpy==1.24.3
|
| 5 |
+
onnx==1.14.0
|
| 6 |
+
onnxruntime==1.15.0
|
| 7 |
+
opencv_python==4.7.0.72
|
| 8 |
+
opencv_python_headless==4.7.0.72
|
| 9 |
+
scikit-image==0.20.0
|
| 10 |
+
tqdm
|
| 11 |
+
psutil
|
| 12 |
+
ngrok
|
script.py
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from refacer import Refacer
|
| 2 |
+
from os.path import exists
|
| 3 |
+
import argparse
|
| 4 |
+
import cv2
|
| 5 |
+
|
| 6 |
+
parser = argparse.ArgumentParser(description='Refacer')
|
| 7 |
+
parser.add_argument("--force_cpu", help="Force CPU mode", default=False, action="store_true")
|
| 8 |
+
parser.add_argument("--colab_performance", help="Use in colab for better performance", default=False,action="store_true")
|
| 9 |
+
parser.add_argument("--face", help="Face to replace (ex: <src>,<dst>,<thresh=0.2>)", nargs='+', action="append", required=True)
|
| 10 |
+
parser.add_argument("--video", help="Video to parse", required=True)
|
| 11 |
+
args = parser.parse_args()
|
| 12 |
+
|
| 13 |
+
refacer = Refacer(force_cpu=args.force_cpu,colab_performance=args.colab_performance)
|
| 14 |
+
|
| 15 |
+
def run(video_path,faces):
|
| 16 |
+
video_path_exists = exists(video_path)
|
| 17 |
+
if video_path_exists == False:
|
| 18 |
+
print ("Can't find " + video_path)
|
| 19 |
+
return
|
| 20 |
+
|
| 21 |
+
faces_out = []
|
| 22 |
+
for face in faces:
|
| 23 |
+
face_str = face[0].split(",")
|
| 24 |
+
origin = exists(face_str[0])
|
| 25 |
+
if origin == False:
|
| 26 |
+
print ("Can't find " + face_str[0])
|
| 27 |
+
return
|
| 28 |
+
destination = exists(face_str[1])
|
| 29 |
+
if destination == False:
|
| 30 |
+
print ("Can't find " + face_str[1])
|
| 31 |
+
return
|
| 32 |
+
|
| 33 |
+
faces_out.append({
|
| 34 |
+
'origin':cv2.imread(face_str[0]),
|
| 35 |
+
'destination':cv2.imread(face_str[1]),
|
| 36 |
+
'threshold':float(face_str[2])
|
| 37 |
+
})
|
| 38 |
+
|
| 39 |
+
return refacer.reface(video_path,faces_out)
|
| 40 |
+
|
| 41 |
+
run(args.video, args.face)
|