
first commit
Browse files- README.md +62 -3
- all_results.json +12 -0
- config.json +29 -0
- eval_results.json +7 -0
- generation_config.json +9 -0
- model-00001-of-00003.safetensors +3 -0
- model-00002-of-00003.safetensors +3 -0
- model-00003-of-00003.safetensors +3 -0
- model.safetensors.index.json +280 -0
- special_tokens_map.json +23 -0
- tokenizer.json +0 -0
- tokenizer_config.json +140 -0
- train_results.json +8 -0
- trainer_log.jsonl +26 -0
- trainer_state.json +217 -0
- training_args.bin +3 -0
- training_loss.png +0 -0
README.md
CHANGED
|
@@ -1,3 +1,62 @@
|
|
| 1 |
-
---
|
| 2 |
-
license:
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: other
|
| 3 |
+
base_model: deepseek-ai/deepseek-llm-7b-chat
|
| 4 |
+
tags:
|
| 5 |
+
- llama-factory
|
| 6 |
+
- full
|
| 7 |
+
- generated_from_trainer
|
| 8 |
+
model-index:
|
| 9 |
+
- name: sft
|
| 10 |
+
results: []
|
| 11 |
+
---
|
| 12 |
+
|
| 13 |
+
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
|
| 14 |
+
should probably proofread and complete it, then remove this comment. -->
|
| 15 |
+
|
| 16 |
+
# sft
|
| 17 |
+
|
| 18 |
+
This model is a fine-tuned version of [deepseek-ai/deepseek-llm-7b-chat](https://huggingface.co/deepseek-ai/deepseek-llm-7b-chat) on the data dataset.
|
| 19 |
+
It achieves the following results on the evaluation set:
|
| 20 |
+
- Loss: 1.7203
|
| 21 |
+
|
| 22 |
+
## Model description
|
| 23 |
+
|
| 24 |
+
More information needed
|
| 25 |
+
|
| 26 |
+
## Intended uses & limitations
|
| 27 |
+
|
| 28 |
+
More information needed
|
| 29 |
+
|
| 30 |
+
## Training and evaluation data
|
| 31 |
+
|
| 32 |
+
More information needed
|
| 33 |
+
|
| 34 |
+
## Training procedure
|
| 35 |
+
|
| 36 |
+
### Training hyperparameters
|
| 37 |
+
|
| 38 |
+
The following hyperparameters were used during training:
|
| 39 |
+
- learning_rate: 1e-05
|
| 40 |
+
- train_batch_size: 1
|
| 41 |
+
- eval_batch_size: 1
|
| 42 |
+
- seed: 42
|
| 43 |
+
- distributed_type: multi-GPU
|
| 44 |
+
- num_devices: 4
|
| 45 |
+
- gradient_accumulation_steps: 2
|
| 46 |
+
- total_train_batch_size: 8
|
| 47 |
+
- total_eval_batch_size: 4
|
| 48 |
+
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
|
| 49 |
+
- lr_scheduler_type: cosine
|
| 50 |
+
- lr_scheduler_warmup_ratio: 0.1
|
| 51 |
+
- num_epochs: 2.0
|
| 52 |
+
|
| 53 |
+
### Training results
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
### Framework versions
|
| 58 |
+
|
| 59 |
+
- Transformers 4.43.4
|
| 60 |
+
- Pytorch 2.4.0+cu121
|
| 61 |
+
- Datasets 2.19.1
|
| 62 |
+
- Tokenizers 0.19.1
|
all_results.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.0,
|
| 3 |
+
"eval_loss": 1.7203000783920288,
|
| 4 |
+
"eval_runtime": 0.1844,
|
| 5 |
+
"eval_samples_per_second": 5.424,
|
| 6 |
+
"eval_steps_per_second": 5.424,
|
| 7 |
+
"total_flos": 4745305128960.0,
|
| 8 |
+
"train_loss": 1.6201500358581542,
|
| 9 |
+
"train_runtime": 510.1426,
|
| 10 |
+
"train_samples_per_second": 3.917,
|
| 11 |
+
"train_steps_per_second": 0.49
|
| 12 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "deepseek-ai/deepseek-llm-7b-chat",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"LlamaForCausalLM"
|
| 5 |
+
],
|
| 6 |
+
"attention_bias": false,
|
| 7 |
+
"attention_dropout": 0.0,
|
| 8 |
+
"bos_token_id": 100000,
|
| 9 |
+
"eos_token_id": 100001,
|
| 10 |
+
"hidden_act": "silu",
|
| 11 |
+
"hidden_size": 4096,
|
| 12 |
+
"initializer_range": 0.02,
|
| 13 |
+
"intermediate_size": 11008,
|
| 14 |
+
"max_position_embeddings": 4096,
|
| 15 |
+
"mlp_bias": false,
|
| 16 |
+
"model_type": "llama",
|
| 17 |
+
"num_attention_heads": 32,
|
| 18 |
+
"num_hidden_layers": 30,
|
| 19 |
+
"num_key_value_heads": 32,
|
| 20 |
+
"pretraining_tp": 1,
|
| 21 |
+
"rms_norm_eps": 1e-06,
|
| 22 |
+
"rope_scaling": null,
|
| 23 |
+
"rope_theta": 10000.0,
|
| 24 |
+
"tie_word_embeddings": false,
|
| 25 |
+
"torch_dtype": "bfloat16",
|
| 26 |
+
"transformers_version": "4.43.4",
|
| 27 |
+
"use_cache": false,
|
| 28 |
+
"vocab_size": 102400
|
| 29 |
+
}
|
eval_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.0,
|
| 3 |
+
"eval_loss": 1.7203000783920288,
|
| 4 |
+
"eval_runtime": 0.1844,
|
| 5 |
+
"eval_samples_per_second": 5.424,
|
| 6 |
+
"eval_steps_per_second": 5.424
|
| 7 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,9 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 100000,
|
| 4 |
+
"do_sample": true,
|
| 5 |
+
"eos_token_id": 100001,
|
| 6 |
+
"temperature": 0.7,
|
| 7 |
+
"top_p": 0.95,
|
| 8 |
+
"transformers_version": "4.43.4"
|
| 9 |
+
}
|
model-00001-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b4a934020ff65d6a97ce37a45b5cc4ae49856c22648b0e17c5555b16792b23e8
|
| 3 |
+
size 4987202208
|
model-00002-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:20c1f62cec09f2ab0230ec38a0dcf919da5810c45374c7b3e8cfa75d9d89adb2
|
| 3 |
+
size 4980945440
|
model-00003-of-00003.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:16a16229b93e79cae4c0cb2b228104be38b584fca61aac8aaae241d92094e1ea
|
| 3 |
+
size 3852615520
|
model.safetensors.index.json
ADDED
|
@@ -0,0 +1,280 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 13820731392
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"lm_head.weight": "model-00003-of-00003.safetensors",
|
| 7 |
+
"model.embed_tokens.weight": "model-00001-of-00003.safetensors",
|
| 8 |
+
"model.layers.0.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 9 |
+
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 10 |
+
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 11 |
+
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 12 |
+
"model.layers.0.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 13 |
+
"model.layers.0.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 14 |
+
"model.layers.0.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 15 |
+
"model.layers.0.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 16 |
+
"model.layers.0.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 17 |
+
"model.layers.1.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 18 |
+
"model.layers.1.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 19 |
+
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 20 |
+
"model.layers.1.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 21 |
+
"model.layers.1.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 22 |
+
"model.layers.1.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 23 |
+
"model.layers.1.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 24 |
+
"model.layers.1.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 25 |
+
"model.layers.1.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 26 |
+
"model.layers.10.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 27 |
+
"model.layers.10.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 28 |
+
"model.layers.10.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 29 |
+
"model.layers.10.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 30 |
+
"model.layers.10.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 31 |
+
"model.layers.10.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 32 |
+
"model.layers.10.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 33 |
+
"model.layers.10.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 34 |
+
"model.layers.10.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 35 |
+
"model.layers.11.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 36 |
+
"model.layers.11.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 37 |
+
"model.layers.11.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 38 |
+
"model.layers.11.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 39 |
+
"model.layers.11.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 40 |
+
"model.layers.11.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 41 |
+
"model.layers.11.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 42 |
+
"model.layers.11.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 43 |
+
"model.layers.11.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 44 |
+
"model.layers.12.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 45 |
+
"model.layers.12.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 46 |
+
"model.layers.12.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 47 |
+
"model.layers.12.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 48 |
+
"model.layers.12.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 49 |
+
"model.layers.12.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 50 |
+
"model.layers.12.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 51 |
+
"model.layers.12.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 52 |
+
"model.layers.12.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 53 |
+
"model.layers.13.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 54 |
+
"model.layers.13.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 55 |
+
"model.layers.13.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 56 |
+
"model.layers.13.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 57 |
+
"model.layers.13.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 58 |
+
"model.layers.13.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 59 |
+
"model.layers.13.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 60 |
+
"model.layers.13.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 61 |
+
"model.layers.13.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 62 |
+
"model.layers.14.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 63 |
+
"model.layers.14.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 64 |
+
"model.layers.14.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 65 |
+
"model.layers.14.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 66 |
+
"model.layers.14.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 67 |
+
"model.layers.14.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 68 |
+
"model.layers.14.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 69 |
+
"model.layers.14.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 70 |
+
"model.layers.14.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 71 |
+
"model.layers.15.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 72 |
+
"model.layers.15.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 73 |
+
"model.layers.15.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 74 |
+
"model.layers.15.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 75 |
+
"model.layers.15.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 76 |
+
"model.layers.15.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 77 |
+
"model.layers.15.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 78 |
+
"model.layers.15.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 79 |
+
"model.layers.15.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 80 |
+
"model.layers.16.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 81 |
+
"model.layers.16.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 82 |
+
"model.layers.16.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 83 |
+
"model.layers.16.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 84 |
+
"model.layers.16.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 85 |
+
"model.layers.16.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 86 |
+
"model.layers.16.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 87 |
+
"model.layers.16.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 88 |
+
"model.layers.16.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 89 |
+
"model.layers.17.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 90 |
+
"model.layers.17.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 91 |
+
"model.layers.17.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 92 |
+
"model.layers.17.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 93 |
+
"model.layers.17.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 94 |
+
"model.layers.17.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 95 |
+
"model.layers.17.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 96 |
+
"model.layers.17.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 97 |
+
"model.layers.17.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 98 |
+
"model.layers.18.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 99 |
+
"model.layers.18.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 100 |
+
"model.layers.18.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 101 |
+
"model.layers.18.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 102 |
+
"model.layers.18.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 103 |
+
"model.layers.18.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 104 |
+
"model.layers.18.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 105 |
+
"model.layers.18.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 106 |
+
"model.layers.18.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 107 |
+
"model.layers.19.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 108 |
+
"model.layers.19.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 109 |
+
"model.layers.19.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 110 |
+
"model.layers.19.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 111 |
+
"model.layers.19.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 112 |
+
"model.layers.19.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 113 |
+
"model.layers.19.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 114 |
+
"model.layers.19.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 115 |
+
"model.layers.19.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 116 |
+
"model.layers.2.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 117 |
+
"model.layers.2.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 118 |
+
"model.layers.2.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 119 |
+
"model.layers.2.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 120 |
+
"model.layers.2.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 121 |
+
"model.layers.2.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 122 |
+
"model.layers.2.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 123 |
+
"model.layers.2.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 124 |
+
"model.layers.2.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 125 |
+
"model.layers.20.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 126 |
+
"model.layers.20.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 127 |
+
"model.layers.20.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 128 |
+
"model.layers.20.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 129 |
+
"model.layers.20.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 130 |
+
"model.layers.20.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 131 |
+
"model.layers.20.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 132 |
+
"model.layers.20.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 133 |
+
"model.layers.20.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 134 |
+
"model.layers.21.input_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 135 |
+
"model.layers.21.mlp.down_proj.weight": "model-00002-of-00003.safetensors",
|
| 136 |
+
"model.layers.21.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 137 |
+
"model.layers.21.mlp.up_proj.weight": "model-00002-of-00003.safetensors",
|
| 138 |
+
"model.layers.21.post_attention_layernorm.weight": "model-00002-of-00003.safetensors",
|
| 139 |
+
"model.layers.21.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 140 |
+
"model.layers.21.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 141 |
+
"model.layers.21.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 142 |
+
"model.layers.21.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 143 |
+
"model.layers.22.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 144 |
+
"model.layers.22.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 145 |
+
"model.layers.22.mlp.gate_proj.weight": "model-00002-of-00003.safetensors",
|
| 146 |
+
"model.layers.22.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 147 |
+
"model.layers.22.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 148 |
+
"model.layers.22.self_attn.k_proj.weight": "model-00002-of-00003.safetensors",
|
| 149 |
+
"model.layers.22.self_attn.o_proj.weight": "model-00002-of-00003.safetensors",
|
| 150 |
+
"model.layers.22.self_attn.q_proj.weight": "model-00002-of-00003.safetensors",
|
| 151 |
+
"model.layers.22.self_attn.v_proj.weight": "model-00002-of-00003.safetensors",
|
| 152 |
+
"model.layers.23.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 153 |
+
"model.layers.23.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 154 |
+
"model.layers.23.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 155 |
+
"model.layers.23.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 156 |
+
"model.layers.23.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 157 |
+
"model.layers.23.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 158 |
+
"model.layers.23.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 159 |
+
"model.layers.23.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 160 |
+
"model.layers.23.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 161 |
+
"model.layers.24.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 162 |
+
"model.layers.24.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 163 |
+
"model.layers.24.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 164 |
+
"model.layers.24.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 165 |
+
"model.layers.24.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 166 |
+
"model.layers.24.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 167 |
+
"model.layers.24.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 168 |
+
"model.layers.24.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 169 |
+
"model.layers.24.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 170 |
+
"model.layers.25.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 171 |
+
"model.layers.25.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 172 |
+
"model.layers.25.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 173 |
+
"model.layers.25.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 174 |
+
"model.layers.25.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 175 |
+
"model.layers.25.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 176 |
+
"model.layers.25.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 177 |
+
"model.layers.25.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 178 |
+
"model.layers.25.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 179 |
+
"model.layers.26.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 180 |
+
"model.layers.26.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 181 |
+
"model.layers.26.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 182 |
+
"model.layers.26.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 183 |
+
"model.layers.26.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 184 |
+
"model.layers.26.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 185 |
+
"model.layers.26.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 186 |
+
"model.layers.26.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 187 |
+
"model.layers.26.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 188 |
+
"model.layers.27.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 189 |
+
"model.layers.27.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 190 |
+
"model.layers.27.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 191 |
+
"model.layers.27.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 192 |
+
"model.layers.27.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 193 |
+
"model.layers.27.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 194 |
+
"model.layers.27.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 195 |
+
"model.layers.27.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 196 |
+
"model.layers.27.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 197 |
+
"model.layers.28.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 198 |
+
"model.layers.28.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 199 |
+
"model.layers.28.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 200 |
+
"model.layers.28.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 201 |
+
"model.layers.28.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 202 |
+
"model.layers.28.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 203 |
+
"model.layers.28.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 204 |
+
"model.layers.28.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 205 |
+
"model.layers.28.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 206 |
+
"model.layers.29.input_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 207 |
+
"model.layers.29.mlp.down_proj.weight": "model-00003-of-00003.safetensors",
|
| 208 |
+
"model.layers.29.mlp.gate_proj.weight": "model-00003-of-00003.safetensors",
|
| 209 |
+
"model.layers.29.mlp.up_proj.weight": "model-00003-of-00003.safetensors",
|
| 210 |
+
"model.layers.29.post_attention_layernorm.weight": "model-00003-of-00003.safetensors",
|
| 211 |
+
"model.layers.29.self_attn.k_proj.weight": "model-00003-of-00003.safetensors",
|
| 212 |
+
"model.layers.29.self_attn.o_proj.weight": "model-00003-of-00003.safetensors",
|
| 213 |
+
"model.layers.29.self_attn.q_proj.weight": "model-00003-of-00003.safetensors",
|
| 214 |
+
"model.layers.29.self_attn.v_proj.weight": "model-00003-of-00003.safetensors",
|
| 215 |
+
"model.layers.3.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 216 |
+
"model.layers.3.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 217 |
+
"model.layers.3.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 218 |
+
"model.layers.3.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 219 |
+
"model.layers.3.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 220 |
+
"model.layers.3.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 221 |
+
"model.layers.3.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 222 |
+
"model.layers.3.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 223 |
+
"model.layers.3.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 224 |
+
"model.layers.4.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 225 |
+
"model.layers.4.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 226 |
+
"model.layers.4.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 227 |
+
"model.layers.4.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 228 |
+
"model.layers.4.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 229 |
+
"model.layers.4.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 230 |
+
"model.layers.4.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 231 |
+
"model.layers.4.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 232 |
+
"model.layers.4.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 233 |
+
"model.layers.5.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 234 |
+
"model.layers.5.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 235 |
+
"model.layers.5.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 236 |
+
"model.layers.5.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 237 |
+
"model.layers.5.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 238 |
+
"model.layers.5.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 239 |
+
"model.layers.5.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 240 |
+
"model.layers.5.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 241 |
+
"model.layers.5.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 242 |
+
"model.layers.6.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 243 |
+
"model.layers.6.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 244 |
+
"model.layers.6.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 245 |
+
"model.layers.6.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 246 |
+
"model.layers.6.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 247 |
+
"model.layers.6.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 248 |
+
"model.layers.6.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 249 |
+
"model.layers.6.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 250 |
+
"model.layers.6.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 251 |
+
"model.layers.7.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 252 |
+
"model.layers.7.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 253 |
+
"model.layers.7.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 254 |
+
"model.layers.7.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 255 |
+
"model.layers.7.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 256 |
+
"model.layers.7.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 257 |
+
"model.layers.7.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 258 |
+
"model.layers.7.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 259 |
+
"model.layers.7.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 260 |
+
"model.layers.8.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 261 |
+
"model.layers.8.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 262 |
+
"model.layers.8.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 263 |
+
"model.layers.8.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 264 |
+
"model.layers.8.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 265 |
+
"model.layers.8.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 266 |
+
"model.layers.8.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 267 |
+
"model.layers.8.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 268 |
+
"model.layers.8.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 269 |
+
"model.layers.9.input_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 270 |
+
"model.layers.9.mlp.down_proj.weight": "model-00001-of-00003.safetensors",
|
| 271 |
+
"model.layers.9.mlp.gate_proj.weight": "model-00001-of-00003.safetensors",
|
| 272 |
+
"model.layers.9.mlp.up_proj.weight": "model-00001-of-00003.safetensors",
|
| 273 |
+
"model.layers.9.post_attention_layernorm.weight": "model-00001-of-00003.safetensors",
|
| 274 |
+
"model.layers.9.self_attn.k_proj.weight": "model-00001-of-00003.safetensors",
|
| 275 |
+
"model.layers.9.self_attn.o_proj.weight": "model-00001-of-00003.safetensors",
|
| 276 |
+
"model.layers.9.self_attn.q_proj.weight": "model-00001-of-00003.safetensors",
|
| 277 |
+
"model.layers.9.self_attn.v_proj.weight": "model-00001-of-00003.safetensors",
|
| 278 |
+
"model.norm.weight": "model-00003-of-00003.safetensors"
|
| 279 |
+
}
|
| 280 |
+
}
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": {
|
| 3 |
+
"content": "<|begin▁of▁sentence|>",
|
| 4 |
+
"lstrip": false,
|
| 5 |
+
"normalized": true,
|
| 6 |
+
"rstrip": false,
|
| 7 |
+
"single_word": false
|
| 8 |
+
},
|
| 9 |
+
"eos_token": {
|
| 10 |
+
"content": "<|end▁of▁sentence|>",
|
| 11 |
+
"lstrip": false,
|
| 12 |
+
"normalized": true,
|
| 13 |
+
"rstrip": false,
|
| 14 |
+
"single_word": false
|
| 15 |
+
},
|
| 16 |
+
"pad_token": {
|
| 17 |
+
"content": "<|end▁of▁sentence|>",
|
| 18 |
+
"lstrip": false,
|
| 19 |
+
"normalized": true,
|
| 20 |
+
"rstrip": false,
|
| 21 |
+
"single_word": false
|
| 22 |
+
}
|
| 23 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,140 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_bos_token": true,
|
| 3 |
+
"add_eos_token": false,
|
| 4 |
+
"add_prefix_space": null,
|
| 5 |
+
"added_tokens_decoder": {
|
| 6 |
+
"100000": {
|
| 7 |
+
"content": "<|begin▁of▁sentence|>",
|
| 8 |
+
"lstrip": false,
|
| 9 |
+
"normalized": true,
|
| 10 |
+
"rstrip": false,
|
| 11 |
+
"single_word": false,
|
| 12 |
+
"special": true
|
| 13 |
+
},
|
| 14 |
+
"100001": {
|
| 15 |
+
"content": "<|end▁of▁sentence|>",
|
| 16 |
+
"lstrip": false,
|
| 17 |
+
"normalized": true,
|
| 18 |
+
"rstrip": false,
|
| 19 |
+
"single_word": false,
|
| 20 |
+
"special": true
|
| 21 |
+
},
|
| 22 |
+
"100002": {
|
| 23 |
+
"content": "ø",
|
| 24 |
+
"lstrip": false,
|
| 25 |
+
"normalized": true,
|
| 26 |
+
"rstrip": false,
|
| 27 |
+
"single_word": false,
|
| 28 |
+
"special": false
|
| 29 |
+
},
|
| 30 |
+
"100003": {
|
| 31 |
+
"content": "ö",
|
| 32 |
+
"lstrip": false,
|
| 33 |
+
"normalized": true,
|
| 34 |
+
"rstrip": false,
|
| 35 |
+
"single_word": false,
|
| 36 |
+
"special": false
|
| 37 |
+
},
|
| 38 |
+
"100004": {
|
| 39 |
+
"content": "ú",
|
| 40 |
+
"lstrip": false,
|
| 41 |
+
"normalized": true,
|
| 42 |
+
"rstrip": false,
|
| 43 |
+
"single_word": false,
|
| 44 |
+
"special": false
|
| 45 |
+
},
|
| 46 |
+
"100005": {
|
| 47 |
+
"content": "ÿ",
|
| 48 |
+
"lstrip": false,
|
| 49 |
+
"normalized": true,
|
| 50 |
+
"rstrip": false,
|
| 51 |
+
"single_word": false,
|
| 52 |
+
"special": false
|
| 53 |
+
},
|
| 54 |
+
"100006": {
|
| 55 |
+
"content": "õ",
|
| 56 |
+
"lstrip": false,
|
| 57 |
+
"normalized": true,
|
| 58 |
+
"rstrip": false,
|
| 59 |
+
"single_word": false,
|
| 60 |
+
"special": false
|
| 61 |
+
},
|
| 62 |
+
"100007": {
|
| 63 |
+
"content": "÷",
|
| 64 |
+
"lstrip": false,
|
| 65 |
+
"normalized": true,
|
| 66 |
+
"rstrip": false,
|
| 67 |
+
"single_word": false,
|
| 68 |
+
"special": false
|
| 69 |
+
},
|
| 70 |
+
"100008": {
|
| 71 |
+
"content": "û",
|
| 72 |
+
"lstrip": false,
|
| 73 |
+
"normalized": true,
|
| 74 |
+
"rstrip": false,
|
| 75 |
+
"single_word": false,
|
| 76 |
+
"special": false
|
| 77 |
+
},
|
| 78 |
+
"100009": {
|
| 79 |
+
"content": "ý",
|
| 80 |
+
"lstrip": false,
|
| 81 |
+
"normalized": true,
|
| 82 |
+
"rstrip": false,
|
| 83 |
+
"single_word": false,
|
| 84 |
+
"special": false
|
| 85 |
+
},
|
| 86 |
+
"100010": {
|
| 87 |
+
"content": "À",
|
| 88 |
+
"lstrip": false,
|
| 89 |
+
"normalized": true,
|
| 90 |
+
"rstrip": false,
|
| 91 |
+
"single_word": false,
|
| 92 |
+
"special": false
|
| 93 |
+
},
|
| 94 |
+
"100011": {
|
| 95 |
+
"content": "ù",
|
| 96 |
+
"lstrip": false,
|
| 97 |
+
"normalized": true,
|
| 98 |
+
"rstrip": false,
|
| 99 |
+
"single_word": false,
|
| 100 |
+
"special": false
|
| 101 |
+
},
|
| 102 |
+
"100012": {
|
| 103 |
+
"content": "Á",
|
| 104 |
+
"lstrip": false,
|
| 105 |
+
"normalized": true,
|
| 106 |
+
"rstrip": false,
|
| 107 |
+
"single_word": false,
|
| 108 |
+
"special": false
|
| 109 |
+
},
|
| 110 |
+
"100013": {
|
| 111 |
+
"content": "þ",
|
| 112 |
+
"lstrip": false,
|
| 113 |
+
"normalized": true,
|
| 114 |
+
"rstrip": false,
|
| 115 |
+
"single_word": false,
|
| 116 |
+
"special": false
|
| 117 |
+
},
|
| 118 |
+
"100014": {
|
| 119 |
+
"content": "ü",
|
| 120 |
+
"lstrip": false,
|
| 121 |
+
"normalized": true,
|
| 122 |
+
"rstrip": false,
|
| 123 |
+
"single_word": false,
|
| 124 |
+
"special": false
|
| 125 |
+
}
|
| 126 |
+
},
|
| 127 |
+
"bos_token": "<|begin▁of▁sentence|>",
|
| 128 |
+
"chat_template": "{{ '<|begin▁of▁sentence|>' }}{% if messages[0]['role'] == 'system' %}{% set system_message = messages[0]['content'] %}{% endif %}{% if system_message is defined %}{{ system_message + '\n\n' }}{% endif %}{% for message in messages %}{% set content = message['content'] %}{% if message['role'] == 'user' %}{{ 'User: ' + content + '\n\nAssistant:' }}{% elif message['role'] == 'assistant' %}{{ content + '<|end▁of▁sentence|>' }}{% endif %}{% endfor %}",
|
| 129 |
+
"clean_up_tokenization_spaces": false,
|
| 130 |
+
"eos_token": "<|end▁of▁sentence|>",
|
| 131 |
+
"legacy": true,
|
| 132 |
+
"model_max_length": 4096,
|
| 133 |
+
"pad_token": "<|end▁of▁sentence|>",
|
| 134 |
+
"padding_side": "right",
|
| 135 |
+
"sp_model_kwargs": {},
|
| 136 |
+
"split_special_tokens": false,
|
| 137 |
+
"tokenizer_class": "LlamaTokenizer",
|
| 138 |
+
"unk_token": null,
|
| 139 |
+
"use_default_system_prompt": false
|
| 140 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 2.0,
|
| 3 |
+
"total_flos": 4745305128960.0,
|
| 4 |
+
"train_loss": 1.6201500358581542,
|
| 5 |
+
"train_runtime": 510.1426,
|
| 6 |
+
"train_samples_per_second": 3.917,
|
| 7 |
+
"train_steps_per_second": 0.49
|
| 8 |
+
}
|
trainer_log.jsonl
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{"current_steps": 10, "total_steps": 250, "loss": 2.124, "learning_rate": 4.000000000000001e-06, "epoch": 0.08, "percentage": 4.0, "elapsed_time": "0:00:21", "remaining_time": "0:08:24", "throughput": "0.00", "total_tokens": 0}
|
| 2 |
+
{"current_steps": 20, "total_steps": 250, "loss": 1.971, "learning_rate": 8.000000000000001e-06, "epoch": 0.16, "percentage": 8.0, "elapsed_time": "0:00:38", "remaining_time": "0:07:25", "throughput": "0.00", "total_tokens": 0}
|
| 3 |
+
{"current_steps": 30, "total_steps": 250, "loss": 1.8813, "learning_rate": 9.987820251299121e-06, "epoch": 0.24, "percentage": 12.0, "elapsed_time": "0:00:56", "remaining_time": "0:06:56", "throughput": "0.00", "total_tokens": 0}
|
| 4 |
+
{"current_steps": 40, "total_steps": 250, "loss": 1.8264, "learning_rate": 9.890738003669029e-06, "epoch": 0.32, "percentage": 16.0, "elapsed_time": "0:01:14", "remaining_time": "0:06:30", "throughput": "0.00", "total_tokens": 0}
|
| 5 |
+
{"current_steps": 50, "total_steps": 250, "loss": 1.7815, "learning_rate": 9.698463103929542e-06, "epoch": 0.4, "percentage": 20.0, "elapsed_time": "0:01:31", "remaining_time": "0:06:04", "throughput": "0.00", "total_tokens": 0}
|
| 6 |
+
{"current_steps": 60, "total_steps": 250, "loss": 1.7795, "learning_rate": 9.414737964294636e-06, "epoch": 0.48, "percentage": 24.0, "elapsed_time": "0:01:48", "remaining_time": "0:05:44", "throughput": "0.00", "total_tokens": 0}
|
| 7 |
+
{"current_steps": 70, "total_steps": 250, "loss": 1.7885, "learning_rate": 9.045084971874738e-06, "epoch": 0.56, "percentage": 28.0, "elapsed_time": "0:02:05", "remaining_time": "0:05:23", "throughput": "0.00", "total_tokens": 0}
|
| 8 |
+
{"current_steps": 80, "total_steps": 250, "loss": 1.771, "learning_rate": 8.596699001693257e-06, "epoch": 0.64, "percentage": 32.0, "elapsed_time": "0:02:24", "remaining_time": "0:05:06", "throughput": "0.00", "total_tokens": 0}
|
| 9 |
+
{"current_steps": 90, "total_steps": 250, "loss": 1.7706, "learning_rate": 8.078307376628292e-06, "epoch": 0.72, "percentage": 36.0, "elapsed_time": "0:02:41", "remaining_time": "0:04:47", "throughput": "0.00", "total_tokens": 0}
|
| 10 |
+
{"current_steps": 100, "total_steps": 250, "loss": 1.7634, "learning_rate": 7.500000000000001e-06, "epoch": 0.8, "percentage": 40.0, "elapsed_time": "0:02:59", "remaining_time": "0:04:29", "throughput": "0.00", "total_tokens": 0}
|
| 11 |
+
{"current_steps": 110, "total_steps": 250, "loss": 1.7241, "learning_rate": 6.873032967079562e-06, "epoch": 0.88, "percentage": 44.0, "elapsed_time": "0:03:16", "remaining_time": "0:04:10", "throughput": "0.00", "total_tokens": 0}
|
| 12 |
+
{"current_steps": 120, "total_steps": 250, "loss": 1.7287, "learning_rate": 6.209609477998339e-06, "epoch": 0.96, "percentage": 48.0, "elapsed_time": "0:03:33", "remaining_time": "0:03:51", "throughput": "0.00", "total_tokens": 0}
|
| 13 |
+
{"current_steps": 130, "total_steps": 250, "loss": 1.6224, "learning_rate": 5.522642316338268e-06, "epoch": 1.04, "percentage": 52.0, "elapsed_time": "0:03:52", "remaining_time": "0:03:34", "throughput": "0.00", "total_tokens": 0}
|
| 14 |
+
{"current_steps": 140, "total_steps": 250, "loss": 1.4283, "learning_rate": 4.825502516487497e-06, "epoch": 1.12, "percentage": 56.0, "elapsed_time": "0:04:09", "remaining_time": "0:03:16", "throughput": "0.00", "total_tokens": 0}
|
| 15 |
+
{"current_steps": 150, "total_steps": 250, "loss": 1.4763, "learning_rate": 4.131759111665349e-06, "epoch": 1.2, "percentage": 60.0, "elapsed_time": "0:04:28", "remaining_time": "0:02:58", "throughput": "0.00", "total_tokens": 0}
|
| 16 |
+
{"current_steps": 160, "total_steps": 250, "loss": 1.4036, "learning_rate": 3.4549150281252635e-06, "epoch": 1.28, "percentage": 64.0, "elapsed_time": "0:04:45", "remaining_time": "0:02:40", "throughput": "0.00", "total_tokens": 0}
|
| 17 |
+
{"current_steps": 170, "total_steps": 250, "loss": 1.4223, "learning_rate": 2.8081442660546126e-06, "epoch": 1.3599999999999999, "percentage": 68.0, "elapsed_time": "0:05:03", "remaining_time": "0:02:22", "throughput": "0.00", "total_tokens": 0}
|
| 18 |
+
{"current_steps": 180, "total_steps": 250, "loss": 1.416, "learning_rate": 2.204035482646267e-06, "epoch": 1.44, "percentage": 72.0, "elapsed_time": "0:05:21", "remaining_time": "0:02:04", "throughput": "0.00", "total_tokens": 0}
|
| 19 |
+
{"current_steps": 190, "total_steps": 250, "loss": 1.4118, "learning_rate": 1.6543469682057105e-06, "epoch": 1.52, "percentage": 76.0, "elapsed_time": "0:05:38", "remaining_time": "0:01:46", "throughput": "0.00", "total_tokens": 0}
|
| 20 |
+
{"current_steps": 200, "total_steps": 250, "loss": 1.4386, "learning_rate": 1.1697777844051105e-06, "epoch": 1.6, "percentage": 80.0, "elapsed_time": "0:05:56", "remaining_time": "0:01:29", "throughput": "0.00", "total_tokens": 0}
|
| 21 |
+
{"current_steps": 210, "total_steps": 250, "loss": 1.4189, "learning_rate": 7.597595192178702e-07, "epoch": 1.6800000000000002, "percentage": 84.0, "elapsed_time": "0:06:14", "remaining_time": "0:01:11", "throughput": "0.00", "total_tokens": 0}
|
| 22 |
+
{"current_steps": 220, "total_steps": 250, "loss": 1.4129, "learning_rate": 4.322727117869951e-07, "epoch": 1.76, "percentage": 88.0, "elapsed_time": "0:06:32", "remaining_time": "0:00:53", "throughput": "0.00", "total_tokens": 0}
|
| 23 |
+
{"current_steps": 230, "total_steps": 250, "loss": 1.388, "learning_rate": 1.9369152030840553e-07, "epoch": 1.8399999999999999, "percentage": 92.0, "elapsed_time": "0:06:50", "remaining_time": "0:00:35", "throughput": "0.00", "total_tokens": 0}
|
| 24 |
+
{"current_steps": 240, "total_steps": 250, "loss": 1.3457, "learning_rate": 4.865965629214819e-08, "epoch": 1.92, "percentage": 96.0, "elapsed_time": "0:07:06", "remaining_time": "0:00:17", "throughput": "0.00", "total_tokens": 0}
|
| 25 |
+
{"current_steps": 250, "total_steps": 250, "loss": 1.4088, "learning_rate": 0.0, "epoch": 2.0, "percentage": 100.0, "elapsed_time": "0:07:24", "remaining_time": "0:00:00", "throughput": "0.00", "total_tokens": 0}
|
| 26 |
+
{"current_steps": 250, "total_steps": 250, "epoch": 2.0, "percentage": 100.0, "elapsed_time": "0:08:23", "remaining_time": "0:00:00", "throughput": "0.00", "total_tokens": 0}
|
trainer_state.json
ADDED
|
@@ -0,0 +1,217 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"best_metric": null,
|
| 3 |
+
"best_model_checkpoint": null,
|
| 4 |
+
"epoch": 2.0,
|
| 5 |
+
"eval_steps": 5000,
|
| 6 |
+
"global_step": 250,
|
| 7 |
+
"is_hyper_param_search": false,
|
| 8 |
+
"is_local_process_zero": true,
|
| 9 |
+
"is_world_process_zero": true,
|
| 10 |
+
"log_history": [
|
| 11 |
+
{
|
| 12 |
+
"epoch": 0.08,
|
| 13 |
+
"grad_norm": 3.1430612111542,
|
| 14 |
+
"learning_rate": 4.000000000000001e-06,
|
| 15 |
+
"loss": 2.124,
|
| 16 |
+
"step": 10
|
| 17 |
+
},
|
| 18 |
+
{
|
| 19 |
+
"epoch": 0.16,
|
| 20 |
+
"grad_norm": 1.9096499041651624,
|
| 21 |
+
"learning_rate": 8.000000000000001e-06,
|
| 22 |
+
"loss": 1.971,
|
| 23 |
+
"step": 20
|
| 24 |
+
},
|
| 25 |
+
{
|
| 26 |
+
"epoch": 0.24,
|
| 27 |
+
"grad_norm": 1.963357152408043,
|
| 28 |
+
"learning_rate": 9.987820251299121e-06,
|
| 29 |
+
"loss": 1.8813,
|
| 30 |
+
"step": 30
|
| 31 |
+
},
|
| 32 |
+
{
|
| 33 |
+
"epoch": 0.32,
|
| 34 |
+
"grad_norm": 1.931497009564988,
|
| 35 |
+
"learning_rate": 9.890738003669029e-06,
|
| 36 |
+
"loss": 1.8264,
|
| 37 |
+
"step": 40
|
| 38 |
+
},
|
| 39 |
+
{
|
| 40 |
+
"epoch": 0.4,
|
| 41 |
+
"grad_norm": 2.014420552850295,
|
| 42 |
+
"learning_rate": 9.698463103929542e-06,
|
| 43 |
+
"loss": 1.7815,
|
| 44 |
+
"step": 50
|
| 45 |
+
},
|
| 46 |
+
{
|
| 47 |
+
"epoch": 0.48,
|
| 48 |
+
"grad_norm": 1.7693673411468296,
|
| 49 |
+
"learning_rate": 9.414737964294636e-06,
|
| 50 |
+
"loss": 1.7795,
|
| 51 |
+
"step": 60
|
| 52 |
+
},
|
| 53 |
+
{
|
| 54 |
+
"epoch": 0.56,
|
| 55 |
+
"grad_norm": 1.5985741500266653,
|
| 56 |
+
"learning_rate": 9.045084971874738e-06,
|
| 57 |
+
"loss": 1.7885,
|
| 58 |
+
"step": 70
|
| 59 |
+
},
|
| 60 |
+
{
|
| 61 |
+
"epoch": 0.64,
|
| 62 |
+
"grad_norm": 1.5468022654000388,
|
| 63 |
+
"learning_rate": 8.596699001693257e-06,
|
| 64 |
+
"loss": 1.771,
|
| 65 |
+
"step": 80
|
| 66 |
+
},
|
| 67 |
+
{
|
| 68 |
+
"epoch": 0.72,
|
| 69 |
+
"grad_norm": 1.6447937843717773,
|
| 70 |
+
"learning_rate": 8.078307376628292e-06,
|
| 71 |
+
"loss": 1.7706,
|
| 72 |
+
"step": 90
|
| 73 |
+
},
|
| 74 |
+
{
|
| 75 |
+
"epoch": 0.8,
|
| 76 |
+
"grad_norm": 1.566629345204418,
|
| 77 |
+
"learning_rate": 7.500000000000001e-06,
|
| 78 |
+
"loss": 1.7634,
|
| 79 |
+
"step": 100
|
| 80 |
+
},
|
| 81 |
+
{
|
| 82 |
+
"epoch": 0.88,
|
| 83 |
+
"grad_norm": 1.6089870593659625,
|
| 84 |
+
"learning_rate": 6.873032967079562e-06,
|
| 85 |
+
"loss": 1.7241,
|
| 86 |
+
"step": 110
|
| 87 |
+
},
|
| 88 |
+
{
|
| 89 |
+
"epoch": 0.96,
|
| 90 |
+
"grad_norm": 1.5484779186475413,
|
| 91 |
+
"learning_rate": 6.209609477998339e-06,
|
| 92 |
+
"loss": 1.7287,
|
| 93 |
+
"step": 120
|
| 94 |
+
},
|
| 95 |
+
{
|
| 96 |
+
"epoch": 1.04,
|
| 97 |
+
"grad_norm": 1.5850310588338916,
|
| 98 |
+
"learning_rate": 5.522642316338268e-06,
|
| 99 |
+
"loss": 1.6224,
|
| 100 |
+
"step": 130
|
| 101 |
+
},
|
| 102 |
+
{
|
| 103 |
+
"epoch": 1.12,
|
| 104 |
+
"grad_norm": 1.7746427733728092,
|
| 105 |
+
"learning_rate": 4.825502516487497e-06,
|
| 106 |
+
"loss": 1.4283,
|
| 107 |
+
"step": 140
|
| 108 |
+
},
|
| 109 |
+
{
|
| 110 |
+
"epoch": 1.2,
|
| 111 |
+
"grad_norm": 1.7232081953947909,
|
| 112 |
+
"learning_rate": 4.131759111665349e-06,
|
| 113 |
+
"loss": 1.4763,
|
| 114 |
+
"step": 150
|
| 115 |
+
},
|
| 116 |
+
{
|
| 117 |
+
"epoch": 1.28,
|
| 118 |
+
"grad_norm": 1.7024573641927823,
|
| 119 |
+
"learning_rate": 3.4549150281252635e-06,
|
| 120 |
+
"loss": 1.4036,
|
| 121 |
+
"step": 160
|
| 122 |
+
},
|
| 123 |
+
{
|
| 124 |
+
"epoch": 1.3599999999999999,
|
| 125 |
+
"grad_norm": 1.681053350335325,
|
| 126 |
+
"learning_rate": 2.8081442660546126e-06,
|
| 127 |
+
"loss": 1.4223,
|
| 128 |
+
"step": 170
|
| 129 |
+
},
|
| 130 |
+
{
|
| 131 |
+
"epoch": 1.44,
|
| 132 |
+
"grad_norm": 1.5805323673193001,
|
| 133 |
+
"learning_rate": 2.204035482646267e-06,
|
| 134 |
+
"loss": 1.416,
|
| 135 |
+
"step": 180
|
| 136 |
+
},
|
| 137 |
+
{
|
| 138 |
+
"epoch": 1.52,
|
| 139 |
+
"grad_norm": 1.8952832093764047,
|
| 140 |
+
"learning_rate": 1.6543469682057105e-06,
|
| 141 |
+
"loss": 1.4118,
|
| 142 |
+
"step": 190
|
| 143 |
+
},
|
| 144 |
+
{
|
| 145 |
+
"epoch": 1.6,
|
| 146 |
+
"grad_norm": 1.7448747247813432,
|
| 147 |
+
"learning_rate": 1.1697777844051105e-06,
|
| 148 |
+
"loss": 1.4386,
|
| 149 |
+
"step": 200
|
| 150 |
+
},
|
| 151 |
+
{
|
| 152 |
+
"epoch": 1.6800000000000002,
|
| 153 |
+
"grad_norm": 1.6558543089408067,
|
| 154 |
+
"learning_rate": 7.597595192178702e-07,
|
| 155 |
+
"loss": 1.4189,
|
| 156 |
+
"step": 210
|
| 157 |
+
},
|
| 158 |
+
{
|
| 159 |
+
"epoch": 1.76,
|
| 160 |
+
"grad_norm": 1.9939504796568306,
|
| 161 |
+
"learning_rate": 4.322727117869951e-07,
|
| 162 |
+
"loss": 1.4129,
|
| 163 |
+
"step": 220
|
| 164 |
+
},
|
| 165 |
+
{
|
| 166 |
+
"epoch": 1.8399999999999999,
|
| 167 |
+
"grad_norm": 1.7587188318416578,
|
| 168 |
+
"learning_rate": 1.9369152030840553e-07,
|
| 169 |
+
"loss": 1.388,
|
| 170 |
+
"step": 230
|
| 171 |
+
},
|
| 172 |
+
{
|
| 173 |
+
"epoch": 1.92,
|
| 174 |
+
"grad_norm": 1.9110466730907998,
|
| 175 |
+
"learning_rate": 4.865965629214819e-08,
|
| 176 |
+
"loss": 1.3457,
|
| 177 |
+
"step": 240
|
| 178 |
+
},
|
| 179 |
+
{
|
| 180 |
+
"epoch": 2.0,
|
| 181 |
+
"grad_norm": 1.7323350066509577,
|
| 182 |
+
"learning_rate": 0.0,
|
| 183 |
+
"loss": 1.4088,
|
| 184 |
+
"step": 250
|
| 185 |
+
},
|
| 186 |
+
{
|
| 187 |
+
"epoch": 2.0,
|
| 188 |
+
"step": 250,
|
| 189 |
+
"total_flos": 4745305128960.0,
|
| 190 |
+
"train_loss": 1.6201500358581542,
|
| 191 |
+
"train_runtime": 510.1426,
|
| 192 |
+
"train_samples_per_second": 3.917,
|
| 193 |
+
"train_steps_per_second": 0.49
|
| 194 |
+
}
|
| 195 |
+
],
|
| 196 |
+
"logging_steps": 10,
|
| 197 |
+
"max_steps": 250,
|
| 198 |
+
"num_input_tokens_seen": 0,
|
| 199 |
+
"num_train_epochs": 2,
|
| 200 |
+
"save_steps": 5000,
|
| 201 |
+
"stateful_callbacks": {
|
| 202 |
+
"TrainerControl": {
|
| 203 |
+
"args": {
|
| 204 |
+
"should_epoch_stop": false,
|
| 205 |
+
"should_evaluate": false,
|
| 206 |
+
"should_log": false,
|
| 207 |
+
"should_save": true,
|
| 208 |
+
"should_training_stop": true
|
| 209 |
+
},
|
| 210 |
+
"attributes": {}
|
| 211 |
+
}
|
| 212 |
+
},
|
| 213 |
+
"total_flos": 4745305128960.0,
|
| 214 |
+
"train_batch_size": 1,
|
| 215 |
+
"trial_name": null,
|
| 216 |
+
"trial_params": null
|
| 217 |
+
}
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:693cb8ed1a7762557df4accd6089b983c9b75098174b601652bd94f6f5abb74d
|
| 3 |
+
size 7032
|
training_loss.png
ADDED
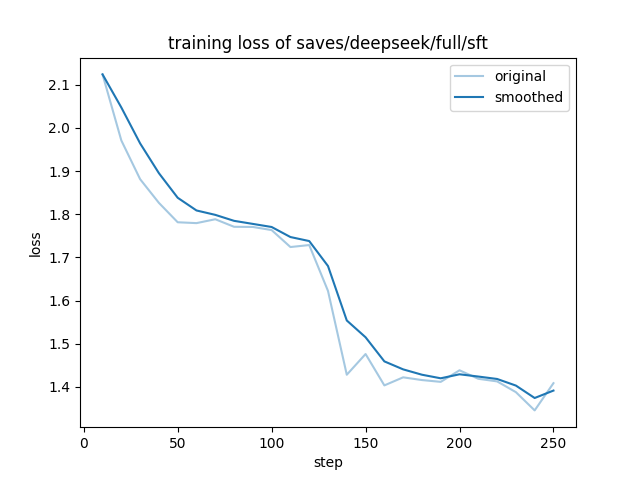
|