---
license: apache-2.0
datasets:
- liuhaotian/LLaVA-CC3M-Pretrain-595K
- liuhaotian/LLaVA-Instruct-150K
- FreedomIntelligence/ALLaVA-4V-Chinese
- shareAI/ShareGPT-Chinese-English-90k
language:
- zh
- en
pipeline_tag: visual-question-answering
---
# Model Card for IAA: Inner-Adaptor Architecture
**Github**:https://github.com/360CVGroup/Inner-Adaptor-Architecture
**[IAA: Inner-Adaptor Architecture Empowers Frozen Large Language Model with Multimodal Capabilities](https://www.arxiv.org/abs/2408.12902)**
Bin Wang*, Chunyu Xie*, Dawei Leng†, Yuhui Yin(*Equal Contribution, ✝Corresponding Author)
[](https://www.arxiv.org/abs/2408.12902)
We propose a MLLM based on Inner-Adaptor Architecture (IAA). IAA demonstrates that training with a frozen language model can surpass the models with fine-tuned LLMs in both multimodal comprehension and visual grounding tasks. Moreover, after deployment, our approach incorporates multiple workflows, thereby preserving the NLP proficiency of the language model. With a single download, the model can be finetuned to cater to various task specifications. Enjoy the seamless experience of utilizing our IAA model.

## Model Performance
### Main Results on General Multimodal Benchmarks.

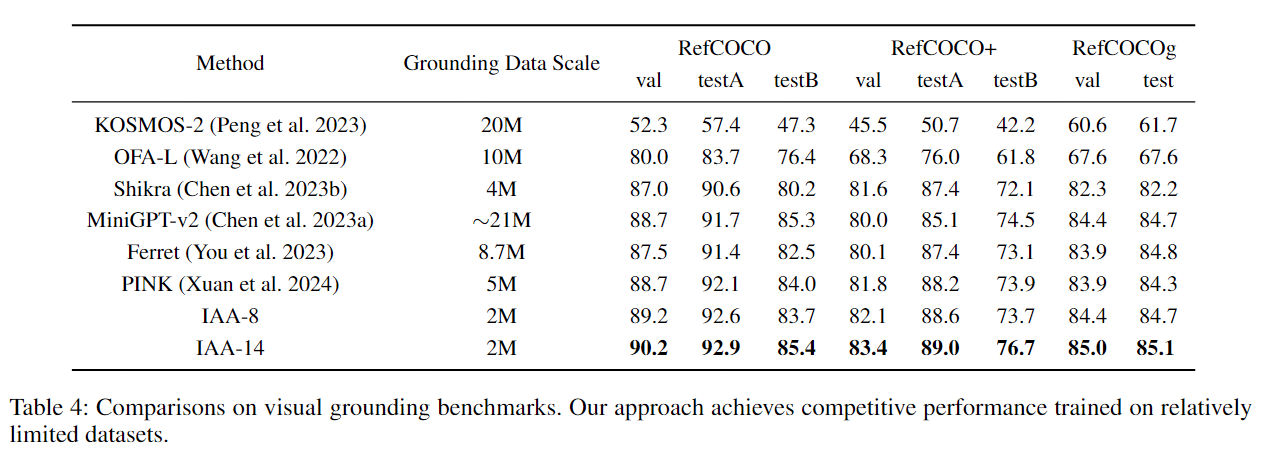
### Results on Visual Grounding Benchmarks.
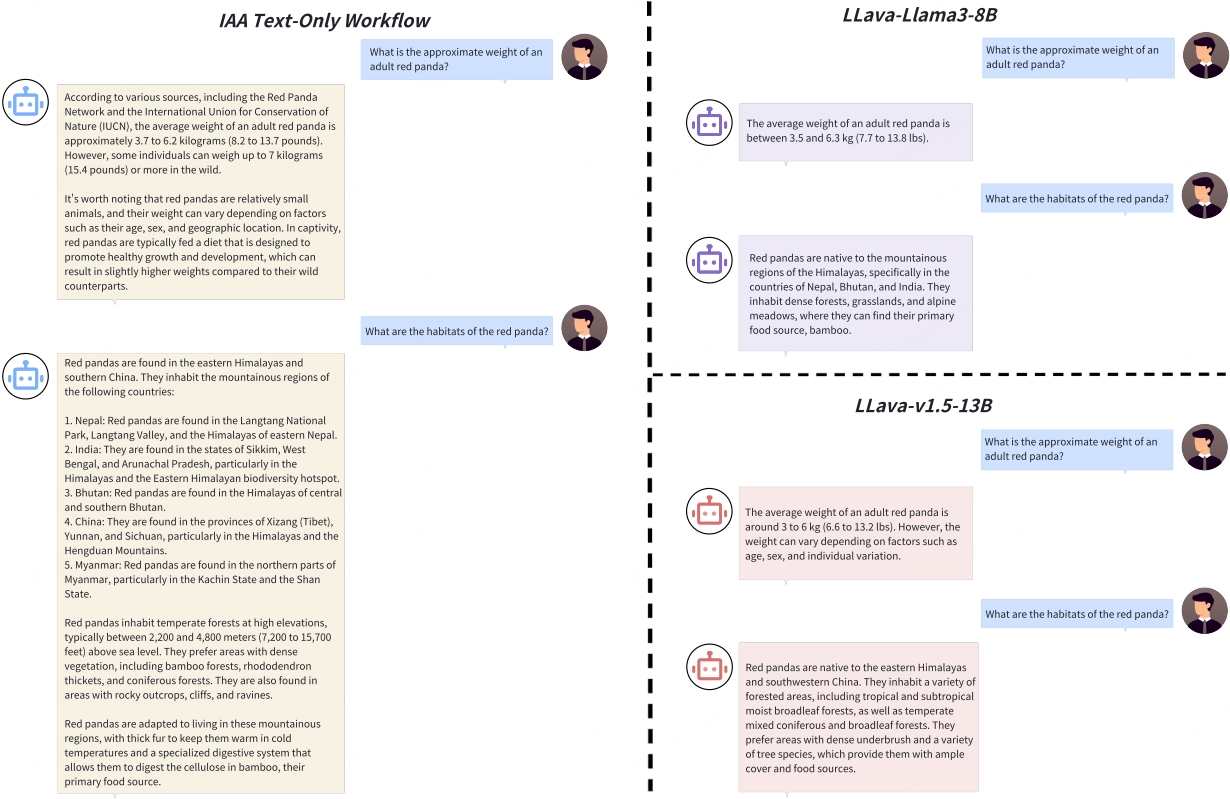
### Comparison on text-only question answering.
## Quick Start 🤗
### First pull off our model
```Shell
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
from PIL import Image
checkpoint = "qihoo360/Inner-Adaptor-Architecture"
model = AutoModelForCausalLM.from_pretrained(checkpoint, torch_dtype=torch.float16, device_map='cuda', trust_remote_code=True).eval()
tokenizer = AutoTokenizer.from_pretrained(checkpoint, trust_remote_code=True)
vision_tower = model.get_vision_tower()
vision_tower.load_model()
vision_tower.to(device="cuda", dtype=torch.float16)
image_processor = vision_tower.image_processor
tokenizer.pad_token = tokenizer.eos_token
terminators = [
tokenizer.convert_tokens_to_ids("<|eot_id|>",)
]
```
### Multimodal Workflow: task_type="MM"
```Shell
image = Image.open("readpanda.jpg").convert('RGB')
query = "What animal is in the picture?"
inputs = model.build_conversation_input_ids(tokenizer, query=query, image=image, image_processor=image_processor)
input_ids = inputs["input_ids"].to(device='cuda', non_blocking=True)
images = inputs["image"].to(dtype=torch.float16, device='cuda', non_blocking=True)
output_ids = model.generate(
input_ids,
task_type="MM",
images=images,
do_sample=False,
eos_token_id=terminators,
num_beams=1,
max_new_tokens=512,
use_cache=True)
input_token_len = input_ids.shape[1]
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
outputs = outputs.strip()
print(outputs)
```
### Grounding Workflow: task_type="G"
```Shell
image = Image.open("COCO_train2014_000000014502.jpg").convert('RGB')
query = "Please provide the bounding box coordinate of the region this sentence describes: dude with black shirt says circa."
inputs = model.build_conversation_input_ids(tokenizer, query=query, image=image, image_processor=image_processor)
input_ids = inputs["input_ids"].to(device='cuda', non_blocking=True)
images = inputs["image"].to(dtype=torch.float16, device='cuda', non_blocking=True)
output_ids = model.generate(
input_ids,
task_type="G",
images=images,
do_sample=False,
eos_token_id=terminators,
num_beams=1,
max_new_tokens=512,
use_cache=True)
input_token_len = input_ids.shape[1]
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
outputs = outputs.strip()
print(outputs)
```
### Text-only Workflow: task_type="Text"
```Shell
query = "What is the approximate weight of an adult red panda?"
inputs = model.build_conversation_input_ids(tokenizer, query=query)
input_ids = inputs["input_ids"].to(device='cuda', non_blocking=True)
images = None
output_ids = model.generate(
input_ids,
task_type="Text",
images=images,
do_sample=False,
eos_token_id=terminators,
num_beams=1,
max_new_tokens=512,
use_cache=True)
input_token_len = input_ids.shape[1]
outputs = tokenizer.batch_decode(output_ids[:, input_token_len:], skip_special_tokens=True)[0]
outputs = outputs.strip()
print(outputs)
```
## We Are Hiring
We are seeking academic interns in the Multimodal field. If interested, please send your resume to xiechunyu@360.cn.
## Citation
If you find IAA useful for your research and applications, please cite using this BibTeX:
```
@article{Wang2024IAA,
title={IAA: Inner-Adaptor Architecture Empowers Frozen Large Language Model with Multimodal Capabilities},
author={Bin Wang and Chunyu Xie and Dawei Leng and Yuhui Yin},
journal={arXiv preprint arXiv:2408.12902},
year={2024},
}
```
## License
This project utilizes certain datasets and checkpoints that are subject to their respective original licenses. Users must comply with all terms and conditions of these original licenses.
The content of this project itself is licensed under the [Apache license 2.0]
**Where to send questions or comments about the model:**
https://github.com/360CVGroup/Inner-Adaptor-Architecture
## Related Projects
This work wouldn't be possible without the incredible open-source code of these projects. Huge thanks!
- [Meta Llama 3](https://github.com/meta-llama/llama3)
- [LLaVA: Large Language and Vision Assistant](https://github.com/haotian-liu/LLaVA)
- [360VL](https://github.com/360CVGroup/360VL)