diff --git a/.gitattributes b/.gitattributes
index a6344aac8c09253b3b630fb776ae94478aa0275b..4c8dc31416176339d3ef7d347d291ab104bda1a7 100644
--- a/.gitattributes
+++ b/.gitattributes
@@ -33,3 +33,7 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
*.zip filter=lfs diff=lfs merge=lfs -text
*.zst filter=lfs diff=lfs merge=lfs -text
*tfevents* filter=lfs diff=lfs merge=lfs -text
+PandaGPT.pdf filter=lfs diff=lfs merge=lfs -text
+PandaGPT.png filter=lfs diff=lfs merge=lfs -text
+code/assets/videos/world.mp4 filter=lfs diff=lfs merge=lfs -text
+code/pytorchvideo/.github/media/ava_slowfast.gif filter=lfs diff=lfs merge=lfs -text
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..261eeb9e9f8b2b4b0d119366dda99c6fd7d35c64
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/PandaGPT.pdf b/PandaGPT.pdf
new file mode 100644
index 0000000000000000000000000000000000000000..95f171da1f669abe4c222831c8dfbff01a1503ef
--- /dev/null
+++ b/PandaGPT.pdf
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:808a3bb9c27e315246119bc401b802a51270ef65147acce4fe9f29f1d9c25b9a
+size 8340300
diff --git a/PandaGPT.png b/PandaGPT.png
new file mode 100644
index 0000000000000000000000000000000000000000..c9ff0cf375a30983ae23208fc7b15e1030f1a61d
--- /dev/null
+++ b/PandaGPT.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:3452d3ab3f66c0e716ad9da4cf87e4540bc8b1675be7983992d2443b9dbced29
+size 1313690
diff --git a/README.md b/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..d65e4faf342d7ab3df6b87d79b84dd52fdfa9776
--- /dev/null
+++ b/README.md
@@ -0,0 +1,249 @@
+
+
+
+
+# PandaGPT: One Model To Instruction-Follow Them All
+
+
+
+
+
+
+
+
+
+**License** The icons in the image are taken from [this website](https://www.flaticon.com).
+
+
+PandaGPT is the first foundation model capable of instruction-following data across six modalities, without the need of explicit supervision. It demonstrates a diverse set of multimodal capabilities such as complex understanding/reasoning, knowledge-grounded description, and multi-turn conversation.
+
+PandaGPT is a general-purpose instruction-following model that can both see 👀 and hear👂. Our pilot experiments show that PandaGPT can perform complex tasks such as detailed image description generation, writing stories inspired by videos, and answering questions about audios. More Interestingly, PandaGPT can take multimodal inputs simultaneously and compose their semantics naturally. For example, PandaGPT can connect how objects look in a photo and how they sound in an audio.
+
+
+****
+
+
+
+### 2. Running PandaGPT Demo: [Back to Top]
+
+
+
+#### 2.1. Environment Installation:
+To install the required environment, please run
+```
+pip install -r requirements.txt
+```
+
+Then install the Pytorch package with the correct cuda version, for example
+```
+pip install torch==1.13.1+cu117 -f https://download.pytorch.org/whl/torch/
+```
+
+
+
+#### 2.2. Prepare ImageBind Checkpoint:
+You can download the pre-trained ImageBind model using [this link](https://dl.fbaipublicfiles.com/imagebind/imagebind_huge.pth). After downloading, put the downloaded file (imagebind_huge.pth) in [[./pretrained_ckpt/imagebind_ckpt/]](./pretrained_ckpt/imagebind_ckpt/) directory.
+
+
+
+#### 2.3. Prepare Vicuna Checkpoint:
+To prepare the pre-trained Vicuna model, please follow the instructions provided [[here]](./pretrained_ckpt#1-prepare-vicuna-checkpoint).
+
+
+
+
+#### 2.4. Prepare Delta Weights of PandaGPT:
+
+|**Base Language Model**|**Maximum Sequence Length**|**Huggingface Delta Weights Address**|
+|:-------------:|:-------------:|:-------------:|
+|Vicuna-7B (version 0)|512|[openllmplayground/pandagpt_7b_max_len_512](https://huggingface.co/openllmplayground/pandagpt_7b_max_len_512)|
+|Vicuna-7B (version 0)|1024|[openllmplayground/pandagpt_7b_max_len_1024](https://huggingface.co/openllmplayground/pandagpt_7b_max_len_1024)|
+|Vicuna-13B (version 0)|256|[openllmplayground/pandagpt_13b_max_len_256](https://huggingface.co/openllmplayground/pandagpt_13b_max_len_256)|
+|Vicuna-13B (version 0)|400|[openllmplayground/pandagpt_13b_max_len_400](https://huggingface.co/openllmplayground/pandagpt_13b_max_len_400)|
+
+We release the delta weights of PandaGPT trained with different strategies in the table above. After downloading, put the downloaded 7B/13B delta weights file (pytorch_model.pt) in the [./pretrained_ckpt/pandagpt_ckpt/7b/](./pretrained_ckpt/pandagpt_ckpt/7b/) or [./pretrained_ckpt/pandagpt_ckpt/13b/](./pretrained_ckpt/pandagpt_ckpt/13b/) directory. In our [online demo](https://huggingface.co/spaces/GMFTBY/PandaGPT), we use the `openllmplayground/pandagpt_7b_max_len_1024` as our default model due to the limitation of computation resource. Better results are expected if switching to `openllmplayground/pandagpt_13b_max_len_400`.
+
+
+
+#### 2.5. Deploying Demo:
+Upon completion of previous steps, you can run the demo locally as
+```bash
+cd ./code/
+CUDA_VISIBLE_DEVICES=0 python web_demo.py
+```
+
+If you running into `sample_rate` problem, please git install `pytorchvideo` from the source as
+```yaml
+git clone https://github.com/facebookresearch/pytorchvideo
+cd pytorchvideo
+pip install --editable ./
+```
+
+****
+
+
+
+### 3. Train Your Own PandaGPT: [Back to Top]
+
+**Prerequisites:** Before training the model, making sure the environment is properly installed and the checkpoints of ImageBind and Vicuna are downloaded. You can refer to [here](https://github.com/yxuansu/PandaGPT#2-running-pandagpt-demo-back-to-top) for more information.
+
+
+
+#### 3.1. Data Preparation:
+
+**Declaimer:** To ensure the reproducibility of our results, we have released our training dataset. The dataset must be used for research purpose only. The use of the dataset must comply with the licenses from original sources, i.e. LLaVA and MiniGPT-4. These datasets may be taken down when requested by the original authors.
+
+|**Training Task**|**Dataset Address**|
+|:-------------:|:-------------:|
+|Visual Instruction-Following|[openllmplayground/pandagpt_visual_instruction_dataset](https://huggingface.co/datasets/openllmplayground/pandagpt_visual_instruction_dataset)|
+
+After downloading, put the downloaded file and unzip them under the [./data/](./data/) directory.
+
+> **** The directory should look like:
+
+ .
+ └── ./data/
+ ├── pandagpt4_visual_instruction_data.json
+ └── /images/
+ ├── 000000426538.jpg
+ ├── 000000306060.jpg
+ └── ...
+
+
+
+
+#### 3.2 Training Configurations:
+
+The table below show the training hyperparameters used in our experiments. The hyperparameters are selected based on the constrain of our computational resources, i.e. 8 x A100 (40G) GPUs.
+
+|**Base Language Model**|**Training Task**|**Epoch Number**|**Batch Size**|**Learning Rate**|**Maximum Length**|
+|:-------------:|:-------------:|:-------------:|:-------------:|:-------------:|:-------------:|
+|7B|Visual Instruction|2|64|5e-4|1024|
+|13B|Visual Instruction|2|64|5e-4|400|
+
+
+
+
+
+
+#### 3.3. Training PandaGPT:
+
+To train PandaGPT, please run the following commands:
+```yaml
+cd ./code/scripts/
+chmod +x train.sh
+cd ..
+./scripts/train.sh
+```
+
+The key arguments of the training script are as follows:
+* `--data_path`: The data path for the json file `pandagpt4_visual_instruction_data.json`.
+* `--image_root_path`: The root path for the downloaded images.
+* `--imagebind_ckpt_path`: The path where saves the ImageBind checkpoint `imagebind_huge.pth`.
+* `--vicuna_ckpt_path`: The directory that saves the pre-trained Vicuna checkpoints.
+* `--max_tgt_len`: The maximum sequence length of training instances.
+* `--save_path`: The directory which saves the trained delta weights. This directory will be automatically created.
+
+Note that the epoch number can be set in the `epochs` argument at [./code/config/openllama_peft.yaml](./code/config/openllama_peft.yaml) file. The `train_micro_batch_size_per_gpu` and `gradient_accumulation_steps` arguments in [./code/dsconfig/openllama_peft_stage_1.json](./code/dsconfig/openllama_peft_stage_1.json) should be set as `2` and `4` for 7B model, and set as `1` and `8` for 13B model.
+
+****
+
+
+
+### Usage and License Notices:
+
+PandaGPT is intended and licensed for research use only. The dataset is CC BY NC 4.0 (allowing only non-commercial use) and models trained using the dataset should not be used outside of research purposes. The delta weights are also CC BY NC 4.0 (allowing only non-commercial use).
+
+
+****
+
+
+
+### Citation:
+
+If you found PandaGPT useful in your research or applications, please kindly cite using the following BibTeX:
+```
+@article{su2023pandagpt,
+ title={PandaGPT: One Model To Instruction-Follow Them All},
+ author={Su, Yixuan and Lan, Tian and Li, Huayang and Xu, Jialu and Wang, Yan and Cai, Deng},
+ journal={arXiv preprint arXiv:2305.16355},
+ year={2023}
+}
+```
+
+
+****
+
+
+
+### Acknowledgments:
+
+
+This repo benefits from [OpenAlpaca](https://github.com/yxuansu/OpenAlpaca), [ImageBind](https://github.com/facebookresearch/ImageBind), [LLaVA](https://github.com/haotian-liu/LLaVA), and [MiniGPT-4](https://github.com/Vision-CAIR/MiniGPT-4). Thanks for their wonderful works!
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/code/__pycache__/header.cpython-310.pyc b/code/__pycache__/header.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..4cc69b89054348a3a17178b7a86f6b1740fe683e
Binary files /dev/null and b/code/__pycache__/header.cpython-310.pyc differ
diff --git a/code/assets/audios/bird_audio.wav b/code/assets/audios/bird_audio.wav
new file mode 100644
index 0000000000000000000000000000000000000000..a98fc72b0df440fd10b3e54c87dfe0ffae0fa12e
Binary files /dev/null and b/code/assets/audios/bird_audio.wav differ
diff --git a/code/assets/audios/car_audio.wav b/code/assets/audios/car_audio.wav
new file mode 100644
index 0000000000000000000000000000000000000000..b71b42a3a375b763521d08855f1a1eebb647a3d2
Binary files /dev/null and b/code/assets/audios/car_audio.wav differ
diff --git a/code/assets/audios/dog_audio.wav b/code/assets/audios/dog_audio.wav
new file mode 100644
index 0000000000000000000000000000000000000000..71d69c77e92039d5906ed766d9c3ca4b181f9ffd
Binary files /dev/null and b/code/assets/audios/dog_audio.wav differ
diff --git a/code/assets/images/bird_image.jpg b/code/assets/images/bird_image.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..78b10ab1fe76f42e3dda1dc515e69312f02713d9
Binary files /dev/null and b/code/assets/images/bird_image.jpg differ
diff --git a/code/assets/images/car_image.jpg b/code/assets/images/car_image.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..e33288eb765882c594f479bfb35d941fd51a19b1
Binary files /dev/null and b/code/assets/images/car_image.jpg differ
diff --git a/code/assets/images/dog_image.jpg b/code/assets/images/dog_image.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..a54bffa5c80869c6b96246ba29c9e2462c698e3b
Binary files /dev/null and b/code/assets/images/dog_image.jpg differ
diff --git a/code/assets/thermals/190662.jpg b/code/assets/thermals/190662.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..bb690a9f7db7568e86077f1017174df551f3c306
Binary files /dev/null and b/code/assets/thermals/190662.jpg differ
diff --git a/code/assets/thermals/210009.jpg b/code/assets/thermals/210009.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..f500c611eb76c7dc82d2865513100bee1df99949
Binary files /dev/null and b/code/assets/thermals/210009.jpg differ
diff --git a/code/assets/videos/a.mp4 b/code/assets/videos/a.mp4
new file mode 100644
index 0000000000000000000000000000000000000000..95a61f6b4a753497d97f51c6a8f18727cef7d628
Binary files /dev/null and b/code/assets/videos/a.mp4 differ
diff --git a/code/assets/videos/world.mp4 b/code/assets/videos/world.mp4
new file mode 100644
index 0000000000000000000000000000000000000000..9bce44c33e275d6107240a1101032a7835fd8eed
--- /dev/null
+++ b/code/assets/videos/world.mp4
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:71944d7430c461f0cd6e7fd10cee7eb72786352a3678fc7bc0ae3d410f72aece
+size 1570024
diff --git a/code/config/__init__.py b/code/config/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..826b6ef41067725c02ac33210e773bb1a8123896
--- /dev/null
+++ b/code/config/__init__.py
@@ -0,0 +1,37 @@
+import yaml
+
+def load_model_config(model, mode):
+ # load special config for each model
+ config_path = f'config/{model}.yaml'
+ print(f'[!] load configuration from {config_path}')
+ with open(config_path) as f:
+ configuration = yaml.load(f, Loader=yaml.FullLoader)
+ new_config = {}
+ for key, value in configuration.items():
+ if key in ['train', 'test', 'validation']:
+ if mode == key:
+ new_config.update(value)
+ else:
+ new_config[key] = value
+ configuration = new_config
+ return configuration
+
+def load_config(args):
+ '''the configuration of each model can rewrite the base configuration'''
+ # base config
+ base_configuration = load_base_config()
+
+ # load one model config
+ configuration = load_model_config(args['model'], args['mode'])
+
+ # update and append the special config for base config
+ base_configuration.update(configuration)
+ configuration = base_configuration
+ return configuration
+
+def load_base_config():
+ config_path = f'config/base.yaml'
+ with open(config_path) as f:
+ configuration = yaml.load(f, Loader=yaml.FullLoader)
+ print(f'[!] load base configuration: {config_path}')
+ return configuration
diff --git a/code/config/base.yaml b/code/config/base.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..c3385ecadf2b64640bf46a19452c0b43342084cd
--- /dev/null
+++ b/code/config/base.yaml
@@ -0,0 +1,15 @@
+models:
+ openllama:
+ model_name: OpenLLAMAModel
+ agent_name: DeepSpeedAgent
+ stage1_train_dataset: SupervisedDataset
+ test_dataset: SelfInstructTestDataset
+ openllama_peft:
+ model_name: OpenLLAMAPEFTModel
+ agent_name: DeepSpeedAgent
+ stage1_train_dataset: SupervisedDataset
+ test_dataset: SelfInstructTestDataset
+
+# ========= Global configuration ========== #
+logging_step: 5
+# ========= Global configuration ========== #
diff --git a/code/config/openllama_peft.yaml b/code/config/openllama_peft.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..1ea52542901ed39498a7ac0c4a2a1a02e950c5a6
--- /dev/null
+++ b/code/config/openllama_peft.yaml
@@ -0,0 +1,22 @@
+# generation hyper-parameters
+max_len: 512
+penalty_alpha: 0.6
+top_k: 10
+top_p: 0.7
+random_prefix_len: 5
+sample_num: 2
+decoding_method: sampling
+generate_len: 512
+
+# lora hyper-parameters
+lora_r: 32
+lora_alpha: 32
+lora_dropout: 0.1
+
+# some train configuration, more can be found under dsconfig folder
+train:
+ seed: 0
+ warmup_rate: 0.1
+ epochs: 2
+ max_length: 1024
+ max_shard_size: 10GB
diff --git a/code/datasets/__init__.py b/code/datasets/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..66354326c55408308a65f7d9f2dbf56c4555541e
--- /dev/null
+++ b/code/datasets/__init__.py
@@ -0,0 +1,40 @@
+from header import *
+from .samplers import DistributedBatchSampler
+from .sft_dataset import *
+
+'''
+def get_tokenizer(model):
+ tokenizer = LlamaTokenizer.from_pretrained(model)
+ tokenizer.bos_token_id, tokenizer.eos_token_id = 1, 2
+ tokenizer.pad_token = tokenizer.eos_token
+ return tokenizer
+'''
+
+def load_sft_dataset(args):
+ '''
+ tokenizer = get_tokenizer(args['model_path'])
+ dataset_name = args['models'][args['model']]['stage1_train_dataset'] # SupervisedDataset, str
+ data_path = args["data_path"]
+ data = globals()[dataset_name](data_path, tokenizer, args['max_length']) #SupervisedDataset
+ '''
+ data = SupervisedDataset(args['data_path'], args['image_root_path'])
+
+ sampler = torch.utils.data.RandomSampler(data)
+ world_size = torch.distributed.get_world_size()
+ rank = torch.distributed.get_rank()
+ batch_size = args['world_size'] * args['dschf'].config['train_micro_batch_size_per_gpu']
+ batch_sampler = DistributedBatchSampler(
+ sampler,
+ batch_size,
+ True,
+ rank,
+ world_size
+ )
+ iter_ = DataLoader(
+ data,
+ batch_sampler=batch_sampler,
+ num_workers=1,
+ collate_fn=data.collate,
+ pin_memory=True
+ )
+ return data, iter_, sampler
diff --git a/code/datasets/samplers.py b/code/datasets/samplers.py
new file mode 100644
index 0000000000000000000000000000000000000000..d3ce1e90b2177940acb911d31d1c5245d74a6119
--- /dev/null
+++ b/code/datasets/samplers.py
@@ -0,0 +1,166 @@
+# coding=utf-8
+# Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+"""batch samplers that work with either random or sequential data samplers"""
+import math
+import os
+import sys
+
+import torch
+from torch.utils import data
+import numpy as np
+
+
+class RandomSampler(data.sampler.Sampler):
+ r"""
+ Based off of pytorch RandomSampler and DistributedSampler. Essentially a RandomSampler,
+ but this class lets the user set an epoch like DistributedSampler
+ Samples elements randomly. If without replacement, then sample from a shuffled dataset.
+ If with replacement, then user can specify ``num_samples`` to draw.
+ Arguments:
+ data_source (Dataset): dataset to sample from
+ num_samples (int): number of samples to draw, default=len(dataset)
+ replacement (bool): samples are drawn with replacement if ``True``, default=False
+ """
+
+ def __init__(self, data_source, replacement=False, num_samples=None):
+ super(RandomSampler, self).__init__(data_source)
+ self.data_source = data_source
+ self.replacement = replacement
+ self._num_samples = num_samples
+ self.epoch = -1
+
+ if self._num_samples is not None and replacement is False:
+ raise ValueError("With replacement=False, num_samples should not be specified, "
+ "since a random permute will be performed.")
+
+ if not isinstance(self.num_samples, int) or self.num_samples <= 0:
+ raise ValueError("num_samples should be a positive integer "
+ "value, but got num_samples={}".format(self.num_samples))
+ if not isinstance(self.replacement, bool):
+ raise ValueError("replacement should be a boolean value, but got "
+ "replacement={}".format(self.replacement))
+
+ @property
+ def num_samples(self):
+ # dataset size might change at runtime
+ if self._num_samples is None:
+ return len(self.data_source)
+ return self._num_samples
+
+ def __iter__(self):
+ n = len(self.data_source)
+ g = torch.Generator()
+ if self.epoch >= 0:
+ g.manual_seed(self.epoch)
+ if self.replacement:
+ for _ in range(self.num_samples // 32):
+ yield from torch.randint(high=n, size=(32,), dtype=torch.int64, generator=g).tolist()
+ yield from torch.randint(high=n, size=(self.num_samples % 32,), dtype=torch.int64,
+ generator=g).tolist()
+ else:
+ yield from torch.randperm(n, generator=self.generator).tolist()
+
+ def __len__(self):
+ return self.num_samples
+
+ def set_epoch(self, epoch):
+ self.epoch = epoch
+
+
+class DistributedSequentialSampler(data.sampler.Sampler):
+ def __init__(self, num_samples, train_iters, batch_size, rank=-1, world_size=2):
+ super().__init__(num_samples)
+ if rank == -1:
+ rank = 0
+ world_size = 1
+ self.num_samples = num_samples
+ self.rank = rank
+ self.world_size = world_size
+ self.start_iter = 0
+ self.train_iters = train_iters
+ self.batch_size = batch_size
+ self.batch_bias = [i * (num_samples // batch_size) for i in range(batch_size)]
+
+ def __iter__(self):
+ for idx in range(self.start_iter, self.train_iters * 10):
+ batch = [(idx + bias) % self.num_samples for bias in self.batch_bias]
+ tbatch = self._batch(batch)
+ yield tbatch
+
+ def __len__(self):
+ return self.train_iters
+
+ def _batch(self, batch):
+ """extracts samples only pertaining to this worker's batch"""
+ start = self.rank*self.batch_size//self.world_size
+ end = (self.rank+1)*self.batch_size//self.world_size
+ return batch[start:end]
+
+
+class DistributedBatchSampler(data.sampler.BatchSampler):
+ """
+ similar to normal implementation of distributed sampler, except implementation is at the
+ batch sampler level, instead of just the sampler level. This allows wrapping of arbitrary
+ data samplers (sequential, random, WeightedRandomSampler, etc.) with this batch sampler.
+ """
+ def __init__(self, sampler, batch_size, drop_last, rank=-1, world_size=2, wrap_last=False, gradient_accumulation_steps=None):
+ super(DistributedBatchSampler, self).__init__(sampler, batch_size, drop_last)
+ if rank == -1:
+ assert False, 'should not be here'
+ self.rank = rank
+ self.world_size = world_size
+ self.sampler.wrap_around = 0
+ self.wrap_around = 0
+ self.wrap_last = wrap_last
+ self.start_iter = 0
+ self.effective_batch_size = batch_size if gradient_accumulation_steps is None else batch_size * gradient_accumulation_steps
+
+ def __iter__(self):
+ batch = []
+ i = 0
+ for idx in self.data_iterator(self.sampler, wrap_around=False):
+ batch.append(idx)
+ if len(batch) == self.batch_size:
+ tbatch = self._batch(batch)
+ if i >= self.start_iter * self.effective_batch_size:
+ yield tbatch
+ self.start_iter = 0
+ i += len(batch)
+ batch = []
+ batch_len = len(batch)
+ if batch_len > 0 and not self.drop_last:
+ if self.wrap_last:
+ self.sampler.wrap_around -= (self.batch_size)
+ self.wrap_around += (len(batch))
+ self.wrap_around %= self.batch_size
+ yield self._batch(batch)
+ if self.wrap_last:
+ self.sampler.wrap_around += self.batch_size
+
+ def data_iterator(self, _iter, wrap_around=False):
+ """iterates through data and handles wrap around"""
+ for i, idx in enumerate(_iter):
+ if i < self.wrap_around%self.batch_size:
+ continue
+ if wrap_around:
+ self.wrap_around += 1
+ self.wrap_around %= self.batch_size
+ yield idx
+
+ def _batch(self, batch):
+ """extracts samples only pertaining to this worker's batch"""
+ start = self.rank*self.batch_size//self.world_size
+ end = (self.rank+1)*self.batch_size//self.world_size
+ return batch[start:end]
diff --git a/code/datasets/sft_dataset.py b/code/datasets/sft_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..bfc64dd37d912d539c0600e5965ad1e5c87a6c1d
--- /dev/null
+++ b/code/datasets/sft_dataset.py
@@ -0,0 +1,65 @@
+# Copyright 2023 Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import copy
+import os
+import json
+from tqdm import tqdm
+import ipdb
+import random
+from torch.nn.utils.rnn import pad_sequence
+from dataclasses import dataclass, field
+from typing import Callable, Dict, Sequence
+
+import torch
+import torch.distributed as dist
+import transformers
+from torch.utils.data import Dataset
+from tqdm import tqdm
+
+class SupervisedDataset(Dataset):
+ """Dataset for supervised fine-tuning."""
+
+ def __init__(self, data_path: str, image_root_path: str):
+ super(SupervisedDataset, self).__init__()
+
+ with open(data_path, 'r') as f:
+ json_data = json.load(f)
+ # for debug:
+ #json_data = json_data[:100000]
+
+ self.image_path_list, self.caption_list = [], []
+ for item in json_data:
+ one_image_name, one_caption = item["image_name"], item["conversation"]
+ # TODO: stage 2 dataset format is invalid
+ if not one_image_name.endswith('.jpg'):
+ one_image_name += '.jpg'
+ one_image_path = image_root_path + '/{}'.format(one_image_name)
+ self.image_path_list.append(one_image_path)
+ self.caption_list.append(one_caption)
+ print(f'[!] collect {len(self.image_path_list)} samples for training')
+
+ def __len__(self): # number of instances
+ return len(self.image_path_list)
+
+ #def __getitem__(self, i) -> Dict[str, torch.Tensor]: # how to get item, 取一个样本
+ def __getitem__(self, i):
+ return dict(image_paths=self.image_path_list[i], output_texts=self.caption_list[i])
+
+ def collate(self, instances):
+ image_paths, output_texts = tuple([instance[key] for instance in instances] for key in ("image_paths", "output_texts"))
+ return dict(
+ image_paths=image_paths,
+ output_texts=output_texts
+ )
diff --git a/code/dsconfig/openllama_peft_stage_1.json b/code/dsconfig/openllama_peft_stage_1.json
new file mode 100644
index 0000000000000000000000000000000000000000..ff78d81809d08e660c60732d06f27ec9ffea996a
--- /dev/null
+++ b/code/dsconfig/openllama_peft_stage_1.json
@@ -0,0 +1,54 @@
+{
+ "train_batch_size": 64,
+ "train_micro_batch_size_per_gpu": 1,
+ "gradient_accumulation_steps": 8,
+ "steps_per_print": 1,
+ "gradient_clipping": 1.0,
+ "zero_optimization": {
+ "stage": 2,
+ "offload_optimizer": {
+ "device": "cpu"
+ },
+ "contiguous_gradients": true,
+ "allgather_bucket_size": 500000000,
+ "allgather_partitions": true
+ },
+ "fp16": {
+ "enabled": true,
+ "opt_level": "O2",
+ "min_loss_scale": 1
+ },
+ "bf16": {
+ "enable": true
+ },
+ "optimizer": {
+ "type": "Adam",
+ "params": {
+ "lr": 0.0005,
+ "betas": [
+ 0.9,
+ 0.95
+ ],
+ "eps": 1e-8,
+ "weight_decay": 0.001
+ }
+ },
+ "scheduler": {
+ "type": "WarmupDecayLR",
+ "params": {
+ "warmup_min_lr": 0,
+ "warmup_max_lr": 0.0005,
+ "warmup_num_steps": 10,
+ "total_num_steps": 10000
+ }
+ },
+ "activation_checkpointing": {
+ "partition_activations": true,
+ "cpu_checkpointing": true,
+ "contiguous_memory_optimization": false,
+ "number_checkpoints": null,
+ "synchronize_checkpoint_boundary": false,
+ "profile": false
+ }
+
+}
\ No newline at end of file
diff --git a/code/header.py b/code/header.py
new file mode 100644
index 0000000000000000000000000000000000000000..97338165d32d531838566ade9c9217182bb8ea67
--- /dev/null
+++ b/code/header.py
@@ -0,0 +1,35 @@
+import torch
+import datetime
+import types
+import deepspeed
+from transformers.deepspeed import HfDeepSpeedConfig
+import transformers
+import numpy as np
+from collections import OrderedDict
+from torch.utils.data import Dataset, DataLoader
+from torch.nn.utils import clip_grad_norm_
+from torch.cuda.amp import autocast, GradScaler
+from torch.nn import DataParallel
+from torch.optim import lr_scheduler
+import torch.optim as optim
+import torch.nn as nn
+import torch.nn.functional as F
+from tqdm import tqdm
+import os
+import re
+import math
+import random
+import json
+import time
+import logging
+from copy import deepcopy
+import ipdb
+import argparse
+import data
+from transformers import LlamaTokenizer, LlamaForCausalLM, LlamaConfig
+from torch.nn.utils.rnn import pad_sequence
+from peft import LoraConfig, TaskType, get_peft_model
+
+logging.getLogger("transformers").setLevel(logging.WARNING)
+logging.getLogger("transformers.tokenization_utils").setLevel(logging.ERROR)
+os.environ['TOKENIZERS_PARALLELISM'] = 'false'
diff --git a/code/model/ImageBind/CODE_OF_CONDUCT.md b/code/model/ImageBind/CODE_OF_CONDUCT.md
new file mode 100644
index 0000000000000000000000000000000000000000..f913b6a55a6c5ab6e1224e11fc039c3d4c3b6283
--- /dev/null
+++ b/code/model/ImageBind/CODE_OF_CONDUCT.md
@@ -0,0 +1,80 @@
+# Code of Conduct
+
+## Our Pledge
+
+In the interest of fostering an open and welcoming environment, we as
+contributors and maintainers pledge to make participation in our project and
+our community a harassment-free experience for everyone, regardless of age, body
+size, disability, ethnicity, sex characteristics, gender identity and expression,
+level of experience, education, socio-economic status, nationality, personal
+appearance, race, religion, or sexual identity and orientation.
+
+## Our Standards
+
+Examples of behavior that contributes to creating a positive environment
+include:
+
+* Using welcoming and inclusive language
+* Being respectful of differing viewpoints and experiences
+* Gracefully accepting constructive criticism
+* Focusing on what is best for the community
+* Showing empathy towards other community members
+
+Examples of unacceptable behavior by participants include:
+
+* The use of sexualized language or imagery and unwelcome sexual attention or
+advances
+* Trolling, insulting/derogatory comments, and personal or political attacks
+* Public or private harassment
+* Publishing others' private information, such as a physical or electronic
+address, without explicit permission
+* Other conduct which could reasonably be considered inappropriate in a
+professional setting
+
+## Our Responsibilities
+
+Project maintainers are responsible for clarifying the standards of acceptable
+behavior and are expected to take appropriate and fair corrective action in
+response to any instances of unacceptable behavior.
+
+Project maintainers have the right and responsibility to remove, edit, or
+reject comments, commits, code, wiki edits, issues, and other contributions
+that are not aligned to this Code of Conduct, or to ban temporarily or
+permanently any contributor for other behaviors that they deem inappropriate,
+threatening, offensive, or harmful.
+
+## Scope
+
+This Code of Conduct applies within all project spaces, and it also applies when
+an individual is representing the project or its community in public spaces.
+Examples of representing a project or community include using an official
+project e-mail address, posting via an official social media account, or acting
+as an appointed representative at an online or offline event. Representation of
+a project may be further defined and clarified by project maintainers.
+
+This Code of Conduct also applies outside the project spaces when there is a
+reasonable belief that an individual's behavior may have a negative impact on
+the project or its community.
+
+## Enforcement
+
+Instances of abusive, harassing, or otherwise unacceptable behavior may be
+reported by contacting the project team at . All
+complaints will be reviewed and investigated and will result in a response that
+is deemed necessary and appropriate to the circumstances. The project team is
+obligated to maintain confidentiality with regard to the reporter of an incident.
+Further details of specific enforcement policies may be posted separately.
+
+Project maintainers who do not follow or enforce the Code of Conduct in good
+faith may face temporary or permanent repercussions as determined by other
+members of the project's leadership.
+
+## Attribution
+
+This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
+available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
+
+[homepage]: https://www.contributor-covenant.org
+
+For answers to common questions about this code of conduct, see
+https://www.contributor-covenant.org/faq
\ No newline at end of file
diff --git a/code/model/ImageBind/CONTRIBUTING.md b/code/model/ImageBind/CONTRIBUTING.md
new file mode 100644
index 0000000000000000000000000000000000000000..63d0b751e8a00b606ddff92e2524faa3c90a63b0
--- /dev/null
+++ b/code/model/ImageBind/CONTRIBUTING.md
@@ -0,0 +1,31 @@
+# Contributing to ImageBind
+We want to make contributing to this project as easy and transparent as
+possible.
+
+## Pull Requests
+We actively welcome your pull requests.
+
+1. Fork the repo and create your branch from `main`.
+2. If you've added code that should be tested, add tests.
+3. If you've changed APIs, update the documentation.
+4. Ensure the test suite passes.
+5. Make sure your code lints.
+6. If you haven't already, complete the Contributor License Agreement ("CLA").
+
+## Contributor License Agreement ("CLA")
+In order to accept your pull request, we need you to submit a CLA. You only need
+to do this once to work on any of Meta's open source projects.
+
+Complete your CLA here:
+
+## Issues
+We use GitHub issues to track public bugs. Please ensure your description is
+clear and has sufficient instructions to be able to reproduce the issue.
+
+Meta has a [bounty program](https://www.facebook.com/whitehat/) for the safe
+disclosure of security bugs. In those cases, please go through the process
+outlined on that page and do not file a public issue.
+
+## License
+By contributing to Omnivore, you agree that your contributions will be licensed
+under the [LICENSE](LICENSE) file in the root directory of this source tree.
diff --git a/code/model/ImageBind/LICENSE b/code/model/ImageBind/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..bfef380bf7d9cb74ec9ba533b37c3fbeef3bdc09
--- /dev/null
+++ b/code/model/ImageBind/LICENSE
@@ -0,0 +1,437 @@
+Attribution-NonCommercial-ShareAlike 4.0 International
+
+=======================================================================
+
+Creative Commons Corporation ("Creative Commons") is not a law firm and
+does not provide legal services or legal advice. Distribution of
+Creative Commons public licenses does not create a lawyer-client or
+other relationship. Creative Commons makes its licenses and related
+information available on an "as-is" basis. Creative Commons gives no
+warranties regarding its licenses, any material licensed under their
+terms and conditions, or any related information. Creative Commons
+disclaims all liability for damages resulting from their use to the
+fullest extent possible.
+
+Using Creative Commons Public Licenses
+
+Creative Commons public licenses provide a standard set of terms and
+conditions that creators and other rights holders may use to share
+original works of authorship and other material subject to copyright
+and certain other rights specified in the public license below. The
+following considerations are for informational purposes only, are not
+exhaustive, and do not form part of our licenses.
+
+ Considerations for licensors: Our public licenses are
+ intended for use by those authorized to give the public
+ permission to use material in ways otherwise restricted by
+ copyright and certain other rights. Our licenses are
+ irrevocable. Licensors should read and understand the terms
+ and conditions of the license they choose before applying it.
+ Licensors should also secure all rights necessary before
+ applying our licenses so that the public can reuse the
+ material as expected. Licensors should clearly mark any
+ material not subject to the license. This includes other CC-
+ licensed material, or material used under an exception or
+ limitation to copyright. More considerations for licensors:
+ wiki.creativecommons.org/Considerations_for_licensors
+
+ Considerations for the public: By using one of our public
+ licenses, a licensor grants the public permission to use the
+ licensed material under specified terms and conditions. If
+ the licensor's permission is not necessary for any reason--for
+ example, because of any applicable exception or limitation to
+ copyright--then that use is not regulated by the license. Our
+ licenses grant only permissions under copyright and certain
+ other rights that a licensor has authority to grant. Use of
+ the licensed material may still be restricted for other
+ reasons, including because others have copyright or other
+ rights in the material. A licensor may make special requests,
+ such as asking that all changes be marked or described.
+ Although not required by our licenses, you are encouraged to
+ respect those requests where reasonable. More considerations
+ for the public:
+ wiki.creativecommons.org/Considerations_for_licensees
+
+=======================================================================
+
+Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International
+Public License
+
+By exercising the Licensed Rights (defined below), You accept and agree
+to be bound by the terms and conditions of this Creative Commons
+Attribution-NonCommercial-ShareAlike 4.0 International Public License
+("Public License"). To the extent this Public License may be
+interpreted as a contract, You are granted the Licensed Rights in
+consideration of Your acceptance of these terms and conditions, and the
+Licensor grants You such rights in consideration of benefits the
+Licensor receives from making the Licensed Material available under
+these terms and conditions.
+
+
+Section 1 -- Definitions.
+
+ a. Adapted Material means material subject to Copyright and Similar
+ Rights that is derived from or based upon the Licensed Material
+ and in which the Licensed Material is translated, altered,
+ arranged, transformed, or otherwise modified in a manner requiring
+ permission under the Copyright and Similar Rights held by the
+ Licensor. For purposes of this Public License, where the Licensed
+ Material is a musical work, performance, or sound recording,
+ Adapted Material is always produced where the Licensed Material is
+ synched in timed relation with a moving image.
+
+ b. Adapter's License means the license You apply to Your Copyright
+ and Similar Rights in Your contributions to Adapted Material in
+ accordance with the terms and conditions of this Public License.
+
+ c. BY-NC-SA Compatible License means a license listed at
+ creativecommons.org/compatiblelicenses, approved by Creative
+ Commons as essentially the equivalent of this Public License.
+
+ d. Copyright and Similar Rights means copyright and/or similar rights
+ closely related to copyright including, without limitation,
+ performance, broadcast, sound recording, and Sui Generis Database
+ Rights, without regard to how the rights are labeled or
+ categorized. For purposes of this Public License, the rights
+ specified in Section 2(b)(1)-(2) are not Copyright and Similar
+ Rights.
+
+ e. Effective Technological Measures means those measures that, in the
+ absence of proper authority, may not be circumvented under laws
+ fulfilling obligations under Article 11 of the WIPO Copyright
+ Treaty adopted on December 20, 1996, and/or similar international
+ agreements.
+
+ f. Exceptions and Limitations means fair use, fair dealing, and/or
+ any other exception or limitation to Copyright and Similar Rights
+ that applies to Your use of the Licensed Material.
+
+ g. License Elements means the license attributes listed in the name
+ of a Creative Commons Public License. The License Elements of this
+ Public License are Attribution, NonCommercial, and ShareAlike.
+
+ h. Licensed Material means the artistic or literary work, database,
+ or other material to which the Licensor applied this Public
+ License.
+
+ i. Licensed Rights means the rights granted to You subject to the
+ terms and conditions of this Public License, which are limited to
+ all Copyright and Similar Rights that apply to Your use of the
+ Licensed Material and that the Licensor has authority to license.
+
+ j. Licensor means the individual(s) or entity(ies) granting rights
+ under this Public License.
+
+ k. NonCommercial means not primarily intended for or directed towards
+ commercial advantage or monetary compensation. For purposes of
+ this Public License, the exchange of the Licensed Material for
+ other material subject to Copyright and Similar Rights by digital
+ file-sharing or similar means is NonCommercial provided there is
+ no payment of monetary compensation in connection with the
+ exchange.
+
+ l. Share means to provide material to the public by any means or
+ process that requires permission under the Licensed Rights, such
+ as reproduction, public display, public performance, distribution,
+ dissemination, communication, or importation, and to make material
+ available to the public including in ways that members of the
+ public may access the material from a place and at a time
+ individually chosen by them.
+
+ m. Sui Generis Database Rights means rights other than copyright
+ resulting from Directive 96/9/EC of the European Parliament and of
+ the Council of 11 March 1996 on the legal protection of databases,
+ as amended and/or succeeded, as well as other essentially
+ equivalent rights anywhere in the world.
+
+ n. You means the individual or entity exercising the Licensed Rights
+ under this Public License. Your has a corresponding meaning.
+
+
+Section 2 -- Scope.
+
+ a. License grant.
+
+ 1. Subject to the terms and conditions of this Public License,
+ the Licensor hereby grants You a worldwide, royalty-free,
+ non-sublicensable, non-exclusive, irrevocable license to
+ exercise the Licensed Rights in the Licensed Material to:
+
+ a. reproduce and Share the Licensed Material, in whole or
+ in part, for NonCommercial purposes only; and
+
+ b. produce, reproduce, and Share Adapted Material for
+ NonCommercial purposes only.
+
+ 2. Exceptions and Limitations. For the avoidance of doubt, where
+ Exceptions and Limitations apply to Your use, this Public
+ License does not apply, and You do not need to comply with
+ its terms and conditions.
+
+ 3. Term. The term of this Public License is specified in Section
+ 6(a).
+
+ 4. Media and formats; technical modifications allowed. The
+ Licensor authorizes You to exercise the Licensed Rights in
+ all media and formats whether now known or hereafter created,
+ and to make technical modifications necessary to do so. The
+ Licensor waives and/or agrees not to assert any right or
+ authority to forbid You from making technical modifications
+ necessary to exercise the Licensed Rights, including
+ technical modifications necessary to circumvent Effective
+ Technological Measures. For purposes of this Public License,
+ simply making modifications authorized by this Section 2(a)
+ (4) never produces Adapted Material.
+
+ 5. Downstream recipients.
+
+ a. Offer from the Licensor -- Licensed Material. Every
+ recipient of the Licensed Material automatically
+ receives an offer from the Licensor to exercise the
+ Licensed Rights under the terms and conditions of this
+ Public License.
+
+ b. Additional offer from the Licensor -- Adapted Material.
+ Every recipient of Adapted Material from You
+ automatically receives an offer from the Licensor to
+ exercise the Licensed Rights in the Adapted Material
+ under the conditions of the Adapter's License You apply.
+
+ c. No downstream restrictions. You may not offer or impose
+ any additional or different terms or conditions on, or
+ apply any Effective Technological Measures to, the
+ Licensed Material if doing so restricts exercise of the
+ Licensed Rights by any recipient of the Licensed
+ Material.
+
+ 6. No endorsement. Nothing in this Public License constitutes or
+ may be construed as permission to assert or imply that You
+ are, or that Your use of the Licensed Material is, connected
+ with, or sponsored, endorsed, or granted official status by,
+ the Licensor or others designated to receive attribution as
+ provided in Section 3(a)(1)(A)(i).
+
+ b. Other rights.
+
+ 1. Moral rights, such as the right of integrity, are not
+ licensed under this Public License, nor are publicity,
+ privacy, and/or other similar personality rights; however, to
+ the extent possible, the Licensor waives and/or agrees not to
+ assert any such rights held by the Licensor to the limited
+ extent necessary to allow You to exercise the Licensed
+ Rights, but not otherwise.
+
+ 2. Patent and trademark rights are not licensed under this
+ Public License.
+
+ 3. To the extent possible, the Licensor waives any right to
+ collect royalties from You for the exercise of the Licensed
+ Rights, whether directly or through a collecting society
+ under any voluntary or waivable statutory or compulsory
+ licensing scheme. In all other cases the Licensor expressly
+ reserves any right to collect such royalties, including when
+ the Licensed Material is used other than for NonCommercial
+ purposes.
+
+
+Section 3 -- License Conditions.
+
+Your exercise of the Licensed Rights is expressly made subject to the
+following conditions.
+
+ a. Attribution.
+
+ 1. If You Share the Licensed Material (including in modified
+ form), You must:
+
+ a. retain the following if it is supplied by the Licensor
+ with the Licensed Material:
+
+ i. identification of the creator(s) of the Licensed
+ Material and any others designated to receive
+ attribution, in any reasonable manner requested by
+ the Licensor (including by pseudonym if
+ designated);
+
+ ii. a copyright notice;
+
+ iii. a notice that refers to this Public License;
+
+ iv. a notice that refers to the disclaimer of
+ warranties;
+
+ v. a URI or hyperlink to the Licensed Material to the
+ extent reasonably practicable;
+
+ b. indicate if You modified the Licensed Material and
+ retain an indication of any previous modifications; and
+
+ c. indicate the Licensed Material is licensed under this
+ Public License, and include the text of, or the URI or
+ hyperlink to, this Public License.
+
+ 2. You may satisfy the conditions in Section 3(a)(1) in any
+ reasonable manner based on the medium, means, and context in
+ which You Share the Licensed Material. For example, it may be
+ reasonable to satisfy the conditions by providing a URI or
+ hyperlink to a resource that includes the required
+ information.
+ 3. If requested by the Licensor, You must remove any of the
+ information required by Section 3(a)(1)(A) to the extent
+ reasonably practicable.
+
+ b. ShareAlike.
+
+ In addition to the conditions in Section 3(a), if You Share
+ Adapted Material You produce, the following conditions also apply.
+
+ 1. The Adapter's License You apply must be a Creative Commons
+ license with the same License Elements, this version or
+ later, or a BY-NC-SA Compatible License.
+
+ 2. You must include the text of, or the URI or hyperlink to, the
+ Adapter's License You apply. You may satisfy this condition
+ in any reasonable manner based on the medium, means, and
+ context in which You Share Adapted Material.
+
+ 3. You may not offer or impose any additional or different terms
+ or conditions on, or apply any Effective Technological
+ Measures to, Adapted Material that restrict exercise of the
+ rights granted under the Adapter's License You apply.
+
+
+Section 4 -- Sui Generis Database Rights.
+
+Where the Licensed Rights include Sui Generis Database Rights that
+apply to Your use of the Licensed Material:
+
+ a. for the avoidance of doubt, Section 2(a)(1) grants You the right
+ to extract, reuse, reproduce, and Share all or a substantial
+ portion of the contents of the database for NonCommercial purposes
+ only;
+
+ b. if You include all or a substantial portion of the database
+ contents in a database in which You have Sui Generis Database
+ Rights, then the database in which You have Sui Generis Database
+ Rights (but not its individual contents) is Adapted Material,
+ including for purposes of Section 3(b); and
+
+ c. You must comply with the conditions in Section 3(a) if You Share
+ all or a substantial portion of the contents of the database.
+
+For the avoidance of doubt, this Section 4 supplements and does not
+replace Your obligations under this Public License where the Licensed
+Rights include other Copyright and Similar Rights.
+
+
+Section 5 -- Disclaimer of Warranties and Limitation of Liability.
+
+ a. UNLESS OTHERWISE SEPARATELY UNDERTAKEN BY THE LICENSOR, TO THE
+ EXTENT POSSIBLE, THE LICENSOR OFFERS THE LICENSED MATERIAL AS-IS
+ AND AS-AVAILABLE, AND MAKES NO REPRESENTATIONS OR WARRANTIES OF
+ ANY KIND CONCERNING THE LICENSED MATERIAL, WHETHER EXPRESS,
+ IMPLIED, STATUTORY, OR OTHER. THIS INCLUDES, WITHOUT LIMITATION,
+ WARRANTIES OF TITLE, MERCHANTABILITY, FITNESS FOR A PARTICULAR
+ PURPOSE, NON-INFRINGEMENT, ABSENCE OF LATENT OR OTHER DEFECTS,
+ ACCURACY, OR THE PRESENCE OR ABSENCE OF ERRORS, WHETHER OR NOT
+ KNOWN OR DISCOVERABLE. WHERE DISCLAIMERS OF WARRANTIES ARE NOT
+ ALLOWED IN FULL OR IN PART, THIS DISCLAIMER MAY NOT APPLY TO YOU.
+
+ b. TO THE EXTENT POSSIBLE, IN NO EVENT WILL THE LICENSOR BE LIABLE
+ TO YOU ON ANY LEGAL THEORY (INCLUDING, WITHOUT LIMITATION,
+ NEGLIGENCE) OR OTHERWISE FOR ANY DIRECT, SPECIAL, INDIRECT,
+ INCIDENTAL, CONSEQUENTIAL, PUNITIVE, EXEMPLARY, OR OTHER LOSSES,
+ COSTS, EXPENSES, OR DAMAGES ARISING OUT OF THIS PUBLIC LICENSE OR
+ USE OF THE LICENSED MATERIAL, EVEN IF THE LICENSOR HAS BEEN
+ ADVISED OF THE POSSIBILITY OF SUCH LOSSES, COSTS, EXPENSES, OR
+ DAMAGES. WHERE A LIMITATION OF LIABILITY IS NOT ALLOWED IN FULL OR
+ IN PART, THIS LIMITATION MAY NOT APPLY TO YOU.
+
+ c. The disclaimer of warranties and limitation of liability provided
+ above shall be interpreted in a manner that, to the extent
+ possible, most closely approximates an absolute disclaimer and
+ waiver of all liability.
+
+
+Section 6 -- Term and Termination.
+
+ a. This Public License applies for the term of the Copyright and
+ Similar Rights licensed here. However, if You fail to comply with
+ this Public License, then Your rights under this Public License
+ terminate automatically.
+
+ b. Where Your right to use the Licensed Material has terminated under
+ Section 6(a), it reinstates:
+
+ 1. automatically as of the date the violation is cured, provided
+ it is cured within 30 days of Your discovery of the
+ violation; or
+
+ 2. upon express reinstatement by the Licensor.
+
+ For the avoidance of doubt, this Section 6(b) does not affect any
+ right the Licensor may have to seek remedies for Your violations
+ of this Public License.
+
+ c. For the avoidance of doubt, the Licensor may also offer the
+ Licensed Material under separate terms or conditions or stop
+ distributing the Licensed Material at any time; however, doing so
+ will not terminate this Public License.
+
+ d. Sections 1, 5, 6, 7, and 8 survive termination of this Public
+ License.
+
+
+Section 7 -- Other Terms and Conditions.
+
+ a. The Licensor shall not be bound by any additional or different
+ terms or conditions communicated by You unless expressly agreed.
+
+ b. Any arrangements, understandings, or agreements regarding the
+ Licensed Material not stated herein are separate from and
+ independent of the terms and conditions of this Public License.
+
+
+Section 8 -- Interpretation.
+
+ a. For the avoidance of doubt, this Public License does not, and
+ shall not be interpreted to, reduce, limit, restrict, or impose
+ conditions on any use of the Licensed Material that could lawfully
+ be made without permission under this Public License.
+
+ b. To the extent possible, if any provision of this Public License is
+ deemed unenforceable, it shall be automatically reformed to the
+ minimum extent necessary to make it enforceable. If the provision
+ cannot be reformed, it shall be severed from this Public License
+ without affecting the enforceability of the remaining terms and
+ conditions.
+
+ c. No term or condition of this Public License will be waived and no
+ failure to comply consented to unless expressly agreed to by the
+ Licensor.
+
+ d. Nothing in this Public License constitutes or may be interpreted
+ as a limitation upon, or waiver of, any privileges and immunities
+ that apply to the Licensor or You, including from the legal
+ processes of any jurisdiction or authority.
+
+=======================================================================
+
+Creative Commons is not a party to its public
+licenses. Notwithstanding, Creative Commons may elect to apply one of
+its public licenses to material it publishes and in those instances
+will be considered the “Licensor.” The text of the Creative Commons
+public licenses is dedicated to the public domain under the CC0 Public
+Domain Dedication. Except for the limited purpose of indicating that
+material is shared under a Creative Commons public license or as
+otherwise permitted by the Creative Commons policies published at
+creativecommons.org/policies, Creative Commons does not authorize the
+use of the trademark "Creative Commons" or any other trademark or logo
+of Creative Commons without its prior written consent including,
+without limitation, in connection with any unauthorized modifications
+to any of its public licenses or any other arrangements,
+understandings, or agreements concerning use of licensed material. For
+the avoidance of doubt, this paragraph does not form part of the
+public licenses.
+
+Creative Commons may be contacted at creativecommons.org.
\ No newline at end of file
diff --git a/code/model/ImageBind/README.md b/code/model/ImageBind/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..028fa988bb6cd9843aec9454636e1541b53680e7
--- /dev/null
+++ b/code/model/ImageBind/README.md
@@ -0,0 +1,155 @@
+# ImageBind: One Embedding Space To Bind Them All
+
+**[FAIR, Meta AI](https://ai.facebook.com/research/)**
+
+Rohit Girdhar*,
+Alaaeldin El-Nouby*,
+Zhuang Liu,
+Mannat Singh,
+Kalyan Vasudev Alwala,
+Armand Joulin,
+Ishan Misra*
+
+To appear at CVPR 2023 (*Highlighted paper*)
+
+[[`Paper`](https://facebookresearch.github.io/ImageBind/paper)] [[`Blog`](https://ai.facebook.com/blog/imagebind-six-modalities-binding-ai/)] [[`Demo`](https://imagebind.metademolab.com/)] [[`Supplementary Video`](https://dl.fbaipublicfiles.com/imagebind/imagebind_video.mp4)] [[`BibTex`](#citing-imagebind)]
+
+PyTorch implementation and pretrained models for ImageBind. For details, see the paper: **[ImageBind: One Embedding Space To Bind Them All](https://facebookresearch.github.io/ImageBind/paper)**.
+
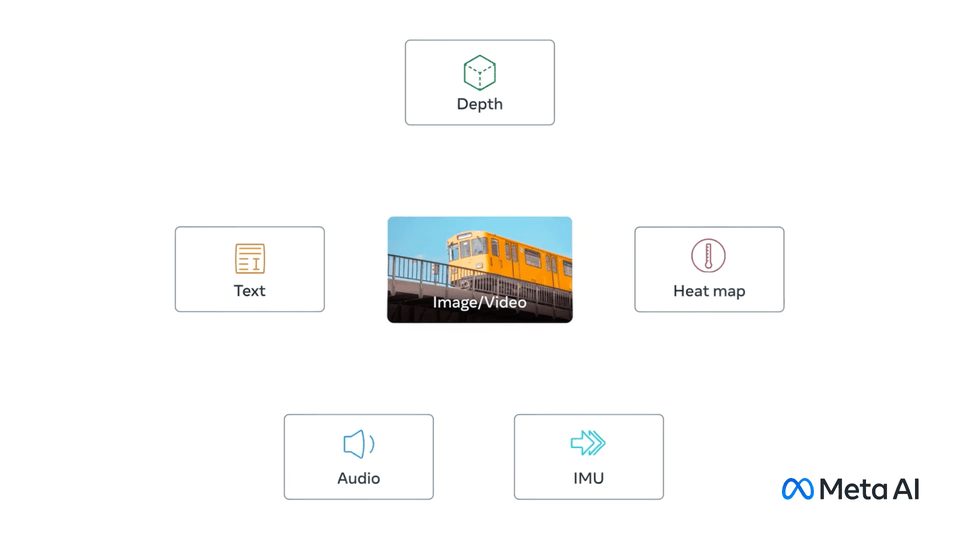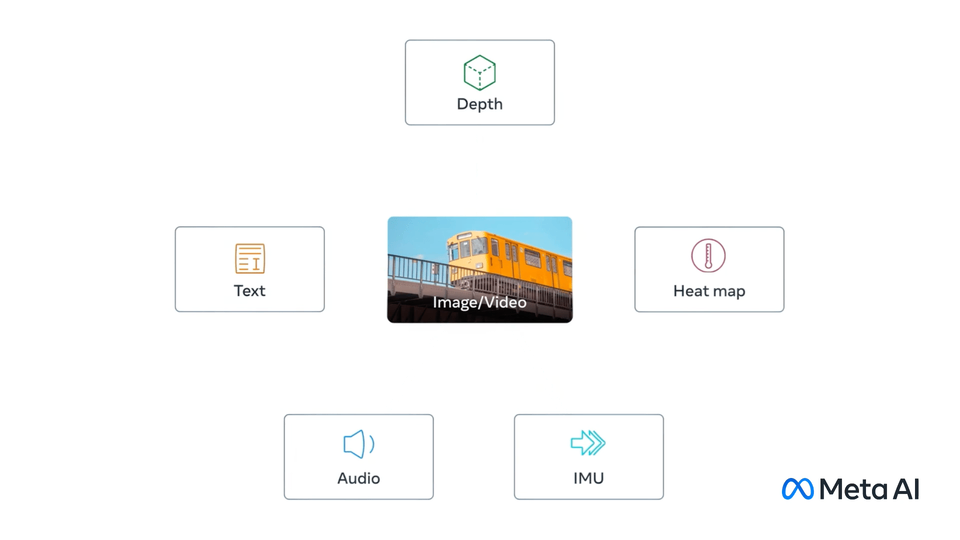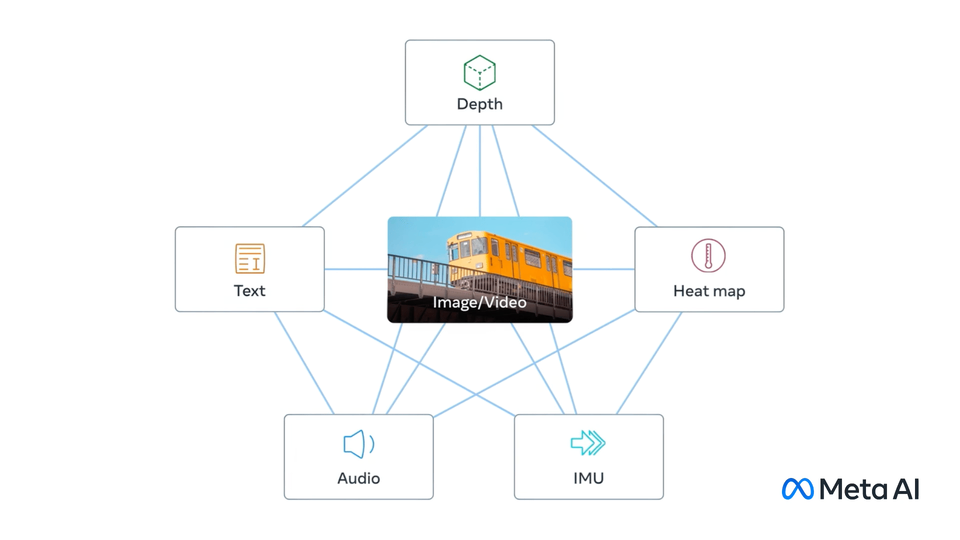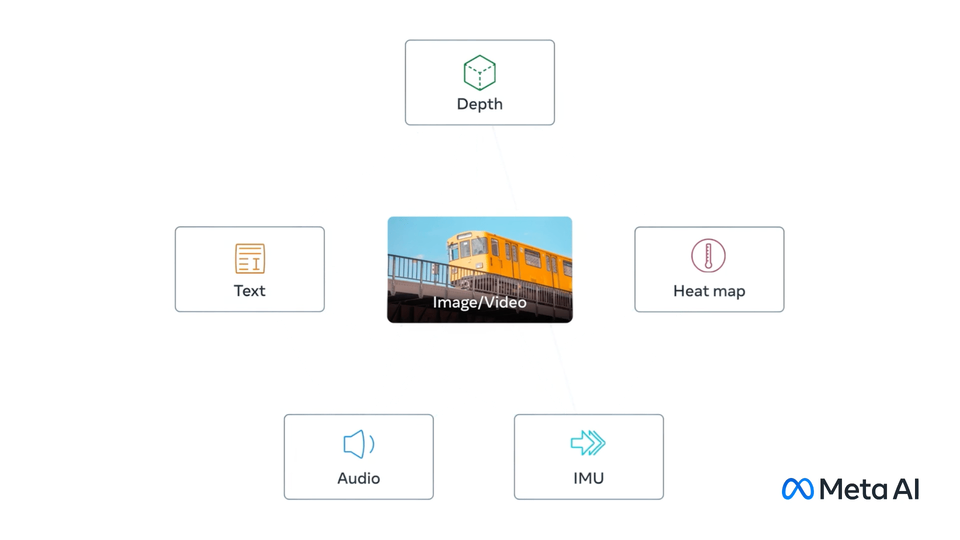
+ImageBind learns a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data. It enables novel emergent applications ‘out-of-the-box’ including cross-modal retrieval, composing modalities with arithmetic, cross-modal detection and generation.
+
+
+
+
+
+## ImageBind model
+
+Emergent zero-shot classification performance.
+
+
+
+## Usage
+
+Install pytorch 1.13+ and other 3rd party dependencies.
+
+```shell
+conda create --name imagebind python=3.8 -y
+conda activate imagebind
+
+pip install -r requirements.txt
+```
+
+For windows users, you might need to install `soundfile` for reading/writing audio files. (Thanks @congyue1977)
+
+```
+pip install soundfile
+```
+
+
+Extract and compare features across modalities (e.g. Image, Text and Audio).
+
+```python
+import data
+import torch
+from models import imagebind_model
+from models.imagebind_model import ModalityType
+
+text_list=["A dog.", "A car", "A bird"]
+image_paths=[".assets/dog_image.jpg", ".assets/car_image.jpg", ".assets/bird_image.jpg"]
+audio_paths=[".assets/dog_audio.wav", ".assets/car_audio.wav", ".assets/bird_audio.wav"]
+
+device = "cuda:0" if torch.cuda.is_available() else "cpu"
+
+# Instantiate model
+model = imagebind_model.imagebind_huge(pretrained=True)
+model.eval()
+model.to(device)
+
+# Load data
+inputs = {
+ ModalityType.TEXT: data.load_and_transform_text(text_list, device),
+ ModalityType.VISION: data.load_and_transform_vision_data(image_paths, device),
+ ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, device),
+}
+
+with torch.no_grad():
+ embeddings = model(inputs)
+
+print(
+ "Vision x Text: ",
+ torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.TEXT].T, dim=-1),
+)
+print(
+ "Audio x Text: ",
+ torch.softmax(embeddings[ModalityType.AUDIO] @ embeddings[ModalityType.TEXT].T, dim=-1),
+)
+print(
+ "Vision x Audio: ",
+ torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.AUDIO].T, dim=-1),
+)
+
+# Expected output:
+#
+# Vision x Text:
+# tensor([[9.9761e-01, 2.3694e-03, 1.8612e-05],
+# [3.3836e-05, 9.9994e-01, 2.4118e-05],
+# [4.7997e-05, 1.3496e-02, 9.8646e-01]])
+#
+# Audio x Text:
+# tensor([[1., 0., 0.],
+# [0., 1., 0.],
+# [0., 0., 1.]])
+#
+# Vision x Audio:
+# tensor([[0.8070, 0.1088, 0.0842],
+# [0.1036, 0.7884, 0.1079],
+# [0.0018, 0.0022, 0.9960]])
+
+```
+
+## Model card
+Please see the [model card](model_card.md) for details.
+
+## License
+
+ImageBind code and model weights are released under the CC-BY-NC 4.0 license. See [LICENSE](LICENSE) for additional details.
+
+## Contributing
+
+See [contributing](CONTRIBUTING.md) and the [code of conduct](CODE_OF_CONDUCT.md).
+
+## Citing ImageBind
+
+If you find this repository useful, please consider giving a star :star: and citation
+
+```
+@inproceedings{girdhar2023imagebind,
+ title={ImageBind: One Embedding Space To Bind Them All},
+ author={Girdhar, Rohit and El-Nouby, Alaaeldin and Liu, Zhuang
+and Singh, Mannat and Alwala, Kalyan Vasudev and Joulin, Armand and Misra, Ishan},
+ booktitle={CVPR},
+ year={2023}
+}
+```
diff --git a/code/model/ImageBind/__init__.py b/code/model/ImageBind/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d872d0725710d6dde3af3b6e05382922f074338b
--- /dev/null
+++ b/code/model/ImageBind/__init__.py
@@ -0,0 +1,2 @@
+from .models import imagebind_model
+from .models.imagebind_model import ModalityType
diff --git a/code/model/ImageBind/__pycache__/__init__.cpython-310.pyc b/code/model/ImageBind/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8bbd51163a7726130384b60b48a85addef2104eb
Binary files /dev/null and b/code/model/ImageBind/__pycache__/__init__.cpython-310.pyc differ
diff --git a/code/model/ImageBind/__pycache__/__init__.cpython-39.pyc b/code/model/ImageBind/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..844ac25ca7233169ebc8987eda73536149071e18
Binary files /dev/null and b/code/model/ImageBind/__pycache__/__init__.cpython-39.pyc differ
diff --git a/code/model/ImageBind/__pycache__/data.cpython-310.pyc b/code/model/ImageBind/__pycache__/data.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5b1ab7d23bc7f1bbef6df5b98c2d0ab5076bb0e5
Binary files /dev/null and b/code/model/ImageBind/__pycache__/data.cpython-310.pyc differ
diff --git a/code/model/ImageBind/__pycache__/data.cpython-39.pyc b/code/model/ImageBind/__pycache__/data.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..782d5bd14e0545c5c7a8259888f21ade7ac1e13e
Binary files /dev/null and b/code/model/ImageBind/__pycache__/data.cpython-39.pyc differ
diff --git a/code/model/ImageBind/bpe/bpe_simple_vocab_16e6.txt.gz b/code/model/ImageBind/bpe/bpe_simple_vocab_16e6.txt.gz
new file mode 100644
index 0000000000000000000000000000000000000000..36a15856e00a06a9fbed8cdd34d2393fea4a3113
--- /dev/null
+++ b/code/model/ImageBind/bpe/bpe_simple_vocab_16e6.txt.gz
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:924691ac288e54409236115652ad4aa250f48203de50a9e4722a6ecd48d6804a
+size 1356917
diff --git a/code/model/ImageBind/data.py b/code/model/ImageBind/data.py
new file mode 100644
index 0000000000000000000000000000000000000000..aed592244741f7f5dd394c4eb461d483b95174e5
--- /dev/null
+++ b/code/model/ImageBind/data.py
@@ -0,0 +1,372 @@
+#!/usr/bin/env python3
+# Portions Copyright (c) Meta Platforms, Inc. and affiliates.
+# All rights reserved.
+
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import math
+
+import torch
+import torch.nn as nn
+import torchaudio
+import logging
+
+from .models.multimodal_preprocessors import SimpleTokenizer
+from PIL import Image
+from pytorchvideo import transforms as pv_transforms
+from pytorchvideo.data.clip_sampling import ConstantClipsPerVideoSampler
+from pytorchvideo.data.encoded_video import EncodedVideo
+
+from torchvision import transforms
+from torchvision.transforms._transforms_video import NormalizeVideo
+
+DEFAULT_AUDIO_FRAME_SHIFT_MS = 10 # in milliseconds
+
+BPE_PATH = "bpe/bpe_simple_vocab_16e6.txt.gz"
+
+
+def waveform2melspec(waveform, sample_rate, num_mel_bins, target_length):
+ # Based on https://github.com/YuanGongND/ast/blob/d7d8b4b8e06cdaeb6c843cdb38794c1c7692234c/src/dataloader.py#L102
+ waveform -= waveform.mean()
+ fbank = torchaudio.compliance.kaldi.fbank(
+ waveform,
+ htk_compat=True,
+ sample_frequency=sample_rate,
+ use_energy=False,
+ window_type="hanning",
+ num_mel_bins=num_mel_bins,
+ dither=0.0,
+ frame_length=25,
+ frame_shift=DEFAULT_AUDIO_FRAME_SHIFT_MS,
+ )
+ # Convert to [mel_bins, num_frames] shape
+ fbank = fbank.transpose(0, 1)
+ # Pad to target_length
+ n_frames = fbank.size(1)
+ p = target_length - n_frames
+ # if p is too large (say >20%), flash a warning
+ if abs(p) / n_frames > 0.2:
+ logging.warning(
+ "Large gap between audio n_frames(%d) and "
+ "target_length (%d). Is the audio_target_length "
+ "setting correct?",
+ n_frames,
+ target_length,
+ )
+ # cut and pad
+ if p > 0:
+ fbank = torch.nn.functional.pad(fbank, (0, p), mode="constant", value=0)
+ elif p < 0:
+ fbank = fbank[:, 0:target_length]
+ # Convert to [1, mel_bins, num_frames] shape, essentially like a 1
+ # channel image
+ fbank = fbank.unsqueeze(0)
+ return fbank
+
+
+def get_clip_timepoints(clip_sampler, duration):
+ # Read out all clips in this video
+ all_clips_timepoints = []
+ is_last_clip = False
+ end = 0.0
+ while not is_last_clip:
+ start, end, _, _, is_last_clip = clip_sampler(end, duration, annotation=None)
+ all_clips_timepoints.append((start, end))
+ return all_clips_timepoints
+
+
+def load_and_transform_vision_data(image_paths, device):
+ if image_paths is None:
+ return None
+
+ image_ouputs = []
+ for image_path in image_paths:
+ data_transform = transforms.Compose(
+ [
+ transforms.Resize(
+ 224, interpolation=transforms.InterpolationMode.BICUBIC
+ ),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(
+ mean=(0.48145466, 0.4578275, 0.40821073),
+ std=(0.26862954, 0.26130258, 0.27577711),
+ ),
+ ]
+ )
+ with open(image_path, "rb") as fopen:
+ image = Image.open(fopen).convert("RGB")
+
+ image = data_transform(image).to(device)
+ image_ouputs.append(image)
+ return torch.stack(image_ouputs, dim=0)
+
+
+def load_and_transform_thermal_data(thermal_paths, device):
+ if thermal_paths is None:
+ return None
+
+ thermal_ouputs = []
+ for thermal_path in thermal_paths:
+ data_transform = transforms.Compose(
+ [
+ transforms.Resize(
+ 224, interpolation=transforms.InterpolationMode.BICUBIC
+ ),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ ]
+ )
+ with open(thermal_path, "rb") as fopen:
+ thermal = Image.open(fopen).convert("L")
+ thermal = data_transform(thermal).to(device)
+ thermal_ouputs.append(thermal)
+ return torch.stack(thermal_ouputs, dim=0)
+
+
+def load_and_transform_text(text, device):
+ if text is None:
+ return None
+ tokenizer = SimpleTokenizer(bpe_path=BPE_PATH)
+ tokens = [tokenizer(t).unsqueeze(0).to(device) for t in text]
+ tokens = torch.cat(tokens, dim=0)
+ return tokens
+
+
+def load_and_transform_audio_data(
+ audio_paths,
+ device,
+ num_mel_bins=128,
+ target_length=204,
+ sample_rate=16000,
+ clip_duration=2,
+ clips_per_video=3,
+ mean=-4.268,
+ std=9.138,
+):
+ if audio_paths is None:
+ return None
+
+ audio_outputs = []
+ clip_sampler = ConstantClipsPerVideoSampler(
+ clip_duration=clip_duration, clips_per_video=clips_per_video
+ )
+
+ for audio_path in audio_paths:
+ waveform, sr = torchaudio.load(audio_path)
+ if sample_rate != sr:
+ waveform = torchaudio.functional.resample(
+ waveform, orig_freq=sr, new_freq=sample_rate
+ )
+ all_clips_timepoints = get_clip_timepoints(
+ clip_sampler, waveform.size(1) / sample_rate
+ )
+ all_clips = []
+ for clip_timepoints in all_clips_timepoints:
+ waveform_clip = waveform[
+ :,
+ int(clip_timepoints[0] * sample_rate) : int(
+ clip_timepoints[1] * sample_rate
+ ),
+ ]
+ waveform_melspec = waveform2melspec(
+ waveform_clip, sample_rate, num_mel_bins, target_length
+ )
+ all_clips.append(waveform_melspec)
+
+ normalize = transforms.Normalize(mean=mean, std=std)
+ all_clips = [normalize(ac).to(device) for ac in all_clips]
+
+ all_clips = torch.stack(all_clips, dim=0)
+ audio_outputs.append(all_clips)
+
+ return torch.stack(audio_outputs, dim=0)
+
+
+def get_clip_timepoints(clip_sampler, duration):
+ # Read out all clips in this video
+ all_clips_timepoints = []
+ is_last_clip = False
+ end = 0.0
+ while not is_last_clip:
+ start, end, _, _, is_last_clip = clip_sampler(end, duration, annotation=None)
+ all_clips_timepoints.append((start, end))
+ return all_clips_timepoints
+
+
+def crop_boxes(boxes, x_offset, y_offset):
+ """
+ Peform crop on the bounding boxes given the offsets.
+ Args:
+ boxes (ndarray or None): bounding boxes to peform crop. The dimension
+ is `num boxes` x 4.
+ x_offset (int): cropping offset in the x axis.
+ y_offset (int): cropping offset in the y axis.
+ Returns:
+ cropped_boxes (ndarray or None): the cropped boxes with dimension of
+ `num boxes` x 4.
+ """
+ cropped_boxes = boxes.copy()
+ cropped_boxes[:, [0, 2]] = boxes[:, [0, 2]] - x_offset
+ cropped_boxes[:, [1, 3]] = boxes[:, [1, 3]] - y_offset
+
+ return cropped_boxes
+
+
+def uniform_crop(images, size, spatial_idx, boxes=None, scale_size=None):
+ """
+ Perform uniform spatial sampling on the images and corresponding boxes.
+ Args:
+ images (tensor): images to perform uniform crop. The dimension is
+ `num frames` x `channel` x `height` x `width`.
+ size (int): size of height and weight to crop the images.
+ spatial_idx (int): 0, 1, or 2 for left, center, and right crop if width
+ is larger than height. Or 0, 1, or 2 for top, center, and bottom
+ crop if height is larger than width.
+ boxes (ndarray or None): optional. Corresponding boxes to images.
+ Dimension is `num boxes` x 4.
+ scale_size (int): optinal. If not None, resize the images to scale_size before
+ performing any crop.
+ Returns:
+ cropped (tensor): images with dimension of
+ `num frames` x `channel` x `size` x `size`.
+ cropped_boxes (ndarray or None): the cropped boxes with dimension of
+ `num boxes` x 4.
+ """
+ assert spatial_idx in [0, 1, 2]
+ ndim = len(images.shape)
+ if ndim == 3:
+ images = images.unsqueeze(0)
+ height = images.shape[2]
+ width = images.shape[3]
+
+ if scale_size is not None:
+ if width <= height:
+ width, height = scale_size, int(height / width * scale_size)
+ else:
+ width, height = int(width / height * scale_size), scale_size
+ images = torch.nn.functional.interpolate(
+ images,
+ size=(height, width),
+ mode="bilinear",
+ align_corners=False,
+ )
+
+ y_offset = int(math.ceil((height - size) / 2))
+ x_offset = int(math.ceil((width - size) / 2))
+
+ if height > width:
+ if spatial_idx == 0:
+ y_offset = 0
+ elif spatial_idx == 2:
+ y_offset = height - size
+ else:
+ if spatial_idx == 0:
+ x_offset = 0
+ elif spatial_idx == 2:
+ x_offset = width - size
+ cropped = images[:, :, y_offset : y_offset + size, x_offset : x_offset + size]
+ cropped_boxes = crop_boxes(boxes, x_offset, y_offset) if boxes is not None else None
+ if ndim == 3:
+ cropped = cropped.squeeze(0)
+ return cropped, cropped_boxes
+
+
+class SpatialCrop(nn.Module):
+ """
+ Convert the video into 3 smaller clips spatially. Must be used after the
+ temporal crops to get spatial crops, and should be used with
+ -2 in the spatial crop at the slowfast augmentation stage (so full
+ frames are passed in here). Will return a larger list with the
+ 3x spatial crops as well.
+ """
+
+ def __init__(self, crop_size: int = 224, num_crops: int = 3):
+ super().__init__()
+ self.crop_size = crop_size
+ if num_crops == 3:
+ self.crops_to_ext = [0, 1, 2]
+ self.flipped_crops_to_ext = []
+ elif num_crops == 1:
+ self.crops_to_ext = [1]
+ self.flipped_crops_to_ext = []
+ else:
+ raise NotImplementedError("Nothing else supported yet")
+
+ def forward(self, videos):
+ """
+ Args:
+ videos: A list of C, T, H, W videos.
+ Returns:
+ videos: A list with 3x the number of elements. Each video converted
+ to C, T, H', W' by spatial cropping.
+ """
+ assert isinstance(videos, list), "Must be a list of videos after temporal crops"
+ assert all([video.ndim == 4 for video in videos]), "Must be (C,T,H,W)"
+ res = []
+ for video in videos:
+ for spatial_idx in self.crops_to_ext:
+ res.append(uniform_crop(video, self.crop_size, spatial_idx)[0])
+ if not self.flipped_crops_to_ext:
+ continue
+ flipped_video = transforms.functional.hflip(video)
+ for spatial_idx in self.flipped_crops_to_ext:
+ res.append(uniform_crop(flipped_video, self.crop_size, spatial_idx)[0])
+ return res
+
+
+def load_and_transform_video_data(
+ video_paths,
+ device,
+ clip_duration=2,
+ clips_per_video=5,
+ sample_rate=16000,
+):
+ if video_paths is None:
+ return None
+
+ video_outputs = []
+ video_transform = transforms.Compose(
+ [
+ pv_transforms.ShortSideScale(224),
+ NormalizeVideo(
+ mean=(0.48145466, 0.4578275, 0.40821073),
+ std=(0.26862954, 0.26130258, 0.27577711),
+ ),
+ ]
+ )
+
+ clip_sampler = ConstantClipsPerVideoSampler(
+ clip_duration=clip_duration, clips_per_video=clips_per_video
+ )
+ frame_sampler = pv_transforms.UniformTemporalSubsample(num_samples=clip_duration)
+
+ for video_path in video_paths:
+ video = EncodedVideo.from_path(
+ video_path,
+ decoder="decord",
+ decode_audio=False,
+ **{"sample_rate": sample_rate},
+ )
+
+ all_clips_timepoints = get_clip_timepoints(clip_sampler, video.duration)
+
+ all_video = []
+ for clip_timepoints in all_clips_timepoints:
+ # Read the clip, get frames
+ clip = video.get_clip(clip_timepoints[0], clip_timepoints[1])
+ if clip is None:
+ raise ValueError("No clip found")
+ video_clip = frame_sampler(clip["video"])
+ video_clip = video_clip / 255.0 # since this is float, need 0-1
+
+ all_video.append(video_clip)
+
+ all_video = [video_transform(clip) for clip in all_video]
+ all_video = SpatialCrop(224, num_crops=3)(all_video)
+
+ all_video = torch.stack(all_video, dim=0)
+ video_outputs.append(all_video)
+
+ return torch.stack(video_outputs, dim=0).to(device)
diff --git a/code/model/ImageBind/model_card.md b/code/model/ImageBind/model_card.md
new file mode 100644
index 0000000000000000000000000000000000000000..c7bb26500b6590b64ffa6350f37be80dc88612d8
--- /dev/null
+++ b/code/model/ImageBind/model_card.md
@@ -0,0 +1,94 @@
+# Model Card for ImageBind
+
+Multimodal joint embedding model for image/video, text, audio, depth, IMU, and thermal images.
+Input any of the six modalities and get the same sized embedding that can be used for cross-modal and multimodal tasks.
+
+# Model Details
+
+## Model Description
+
+
+Multimodal joint embedding model for image/video, text, audio, depth, IMU, and thermal images
+
+- **Developed by:** Meta AI
+- **Model type:** Multimodal model
+- **Language(s) (NLP):** en
+- **License:** CC BY-NC-SA 4.0
+- **Resources for more information:**
+ - [GitHub Repo](https://github.com/facebookresearch/ImageBind)
+
+
+# Uses
+
+
+This model is intended only for research purposes. It provides a joint embedding space for different modalities -- image/video, text, audio, depth, IMU and thermal images.
+We hope that these joint embeddings can be used for a variety of different cross-modal research, e.g., cross-modal retrieval and combining embeddings from different modalities.
+
+## Out-of-Scope Use
+
+
+
+
+This model is *NOT* intended to be used in any real world application -- commercial or otherwise.
+It may produce harmful associations with different inputs.
+The model needs to be investigated and likely re-trained on specific data for any such application.
+The model is expected to work better on web-based visual data since it was trained on such data.
+The text encoder is likely to work only on English language text because of the underlying training datasets.
+
+# Bias, Risks, and Limitations
+
+
+Open-domain joint embedding models are prone to producing specific biases, e.g., study from [CLIP](https://github.com/openai/CLIP/blob/main/model-card.md#bias-and-fairness).
+Since our model uses such models as initialization, it will exhibit such biases too.
+Moreover, for learning joint embeddings for other modalities such as audio, thermal, depth, and IMU we leverage datasets that are relatively small. These joint embeddings are thus limited to the concepts present in the datasets. For example, the thermal datasets we used are limited to outdoor street scenes, while the depth datasets are limited to indoor scenes.
+
+
+
+# Training Details
+
+## Training Data
+
+
+
+ImageBind uses image-paired data for training -- (image, X) where X is one of text, audio, depth, IMU or thermal data.
+In particular, we initialize and freeze the image and text encoders using an OpenCLIP ViT-H encoder.
+We train audio embeddings using Audioset, depth embeddings using the SUN RGB-D dataset, IMU using the Ego4D dataset and thermal embeddings using the LLVIP dataset.
+We provide the exact training data details in the paper.
+
+
+## Training Procedure
+
+
+Please refer to the research paper and github repo for exact details on this.
+
+# Evaluation
+
+## Testing Data, Factors & Metrics
+
+We evaluate the model on a variety of different classification benchmarks for each modality.
+The evaluation details are presented in the paper.
+The models performance is measured using standard classification metrics such as accuracy and mAP.
+
+# Citation
+
+
+
+**BibTeX:**
+```
+@inproceedings{girdhar2023imagebind,
+ title={ImageBind: One Embedding Space To Bind Them All},
+ author={Girdhar, Rohit and El-Nouby, Alaaeldin and Liu, Zhuang
+and Singh, Mannat and Alwala, Kalyan Vasudev and Joulin, Armand and Misra, Ishan},
+ booktitle={CVPR},
+ year={2023}
+}
+```
+
+
+# Model Card Contact
+
+Please reach out to the authors at: rgirdhar@meta.com imisra@meta.com alaaelnouby@gmail.com
+
+# How to Get Started with the Model
+
+Our github repo provides a simple example to extract embeddings from images, audio etc.
diff --git a/code/model/ImageBind/models/__init__.py b/code/model/ImageBind/models/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..e69de29bb2d1d6434b8b29ae775ad8c2e48c5391
diff --git a/code/model/ImageBind/models/__pycache__/__init__.cpython-310.pyc b/code/model/ImageBind/models/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5791b4fed77d0dff0f8e83ab5141710a4983fe11
Binary files /dev/null and b/code/model/ImageBind/models/__pycache__/__init__.cpython-310.pyc differ
diff --git a/code/model/ImageBind/models/__pycache__/__init__.cpython-39.pyc b/code/model/ImageBind/models/__pycache__/__init__.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b3de32cdbc7f15ded6813e73a695d430f6b07741
Binary files /dev/null and b/code/model/ImageBind/models/__pycache__/__init__.cpython-39.pyc differ
diff --git a/code/model/ImageBind/models/__pycache__/helpers.cpython-310.pyc b/code/model/ImageBind/models/__pycache__/helpers.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..cdae1ede890b3942430efaf467dd5f009c45da25
Binary files /dev/null and b/code/model/ImageBind/models/__pycache__/helpers.cpython-310.pyc differ
diff --git a/code/model/ImageBind/models/__pycache__/helpers.cpython-39.pyc b/code/model/ImageBind/models/__pycache__/helpers.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..6fcb880a4c136832fb6b9e81dc3627e28f4b4cef
Binary files /dev/null and b/code/model/ImageBind/models/__pycache__/helpers.cpython-39.pyc differ
diff --git a/code/model/ImageBind/models/__pycache__/imagebind_model.cpython-310.pyc b/code/model/ImageBind/models/__pycache__/imagebind_model.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..02f7dae44da4c150e561869d0130d345da92d66c
Binary files /dev/null and b/code/model/ImageBind/models/__pycache__/imagebind_model.cpython-310.pyc differ
diff --git a/code/model/ImageBind/models/__pycache__/imagebind_model.cpython-39.pyc b/code/model/ImageBind/models/__pycache__/imagebind_model.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3ac9da7166ecdf308cdb553e574cb2904c42e9c1
Binary files /dev/null and b/code/model/ImageBind/models/__pycache__/imagebind_model.cpython-39.pyc differ
diff --git a/code/model/ImageBind/models/__pycache__/multimodal_preprocessors.cpython-310.pyc b/code/model/ImageBind/models/__pycache__/multimodal_preprocessors.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..87da63b1c69c0cdfe55dac1e9e6130bf2e8dc1a6
Binary files /dev/null and b/code/model/ImageBind/models/__pycache__/multimodal_preprocessors.cpython-310.pyc differ
diff --git a/code/model/ImageBind/models/__pycache__/multimodal_preprocessors.cpython-39.pyc b/code/model/ImageBind/models/__pycache__/multimodal_preprocessors.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..112fb5ad9a9c2be9a9f06749fe21e25fb252b1df
Binary files /dev/null and b/code/model/ImageBind/models/__pycache__/multimodal_preprocessors.cpython-39.pyc differ
diff --git a/code/model/ImageBind/models/__pycache__/transformer.cpython-310.pyc b/code/model/ImageBind/models/__pycache__/transformer.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5f3175a8cb119c1ce83e0e0d2b44afde199beb3b
Binary files /dev/null and b/code/model/ImageBind/models/__pycache__/transformer.cpython-310.pyc differ
diff --git a/code/model/ImageBind/models/__pycache__/transformer.cpython-39.pyc b/code/model/ImageBind/models/__pycache__/transformer.cpython-39.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0674473b53734e7d6d59ea6a6e01b279c1df6a9c
Binary files /dev/null and b/code/model/ImageBind/models/__pycache__/transformer.cpython-39.pyc differ
diff --git a/code/model/ImageBind/models/helpers.py b/code/model/ImageBind/models/helpers.py
new file mode 100644
index 0000000000000000000000000000000000000000..049e1f1b0580832e8574350991bf347b6da81482
--- /dev/null
+++ b/code/model/ImageBind/models/helpers.py
@@ -0,0 +1,141 @@
+#!/usr/bin/env python3
+# Portions Copyright (c) Meta Platforms, Inc. and affiliates.
+# All rights reserved.
+
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import math
+
+import einops
+import numpy as np
+import torch
+
+import torch.nn as nn
+
+
+class Normalize(nn.Module):
+ def __init__(self, dim: int) -> None:
+ super().__init__()
+ self.dim = dim
+
+ def forward(self, x):
+ return torch.nn.functional.normalize(x, dim=self.dim, p=2)
+
+
+class LearnableLogitScaling(nn.Module):
+ def __init__(
+ self,
+ logit_scale_init: float = 1 / 0.07,
+ learnable: bool = True,
+ max_logit_scale: float = 100,
+ ) -> None:
+ super().__init__()
+ self.max_logit_scale = max_logit_scale
+ self.logit_scale_init = logit_scale_init
+ self.learnable = learnable
+ log_logit_scale = torch.ones([]) * np.log(self.logit_scale_init)
+ if learnable:
+ self.log_logit_scale = nn.Parameter(log_logit_scale)
+ else:
+ self.register_buffer("log_logit_scale", log_logit_scale)
+
+ def forward(self, x):
+ return torch.clip(self.log_logit_scale.exp(), max=self.max_logit_scale) * x
+
+ def extra_repr(self):
+ st = f"logit_scale_init={self.logit_scale_init},learnable={self.learnable}, max_logit_scale={self.max_logit_scale}"
+ return st
+
+
+class EinOpsRearrange(nn.Module):
+ def __init__(self, rearrange_expr: str, **kwargs) -> None:
+ super().__init__()
+ self.rearrange_expr = rearrange_expr
+ self.kwargs = kwargs
+
+ def forward(self, x):
+ assert isinstance(x, torch.Tensor)
+ return einops.rearrange(x, self.rearrange_expr, **self.kwargs)
+
+
+class VerboseNNModule(nn.Module):
+ """
+ Wrapper around nn.Module that prints registered buffers and parameter names.
+ """
+
+ @staticmethod
+ def get_readable_tensor_repr(name: str, tensor: torch.Tensor) -> str:
+ st = (
+ "("
+ + name
+ + "): "
+ + "tensor("
+ + str(tuple(tensor[1].shape))
+ + ", requires_grad="
+ + str(tensor[1].requires_grad)
+ + ")\n"
+ )
+ return st
+
+ def extra_repr(self) -> str:
+ named_modules = set()
+ for p in self.named_modules():
+ named_modules.update([p[0]])
+ named_modules = list(named_modules)
+
+ string_repr = ""
+ for p in self.named_parameters():
+ name = p[0].split(".")[0]
+ if name not in named_modules:
+ string_repr += self.get_readable_tensor_repr(name, p)
+
+ for p in self.named_buffers():
+ name = p[0].split(".")[0]
+ string_repr += self.get_readable_tensor_repr(name, p)
+
+ return string_repr
+
+
+def cast_if_src_dtype(
+ tensor: torch.Tensor, src_dtype: torch.dtype, tgt_dtype: torch.dtype
+):
+ updated = False
+ if tensor.dtype == src_dtype:
+ tensor = tensor.to(dtype=tgt_dtype)
+ updated = True
+ return tensor, updated
+
+
+class QuickGELU(nn.Module):
+ # From https://github.com/openai/CLIP/blob/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1/clip/model.py#L166
+ def forward(self, x: torch.Tensor):
+ return x * torch.sigmoid(1.702 * x)
+
+
+class SelectElement(nn.Module):
+ def __init__(self, index) -> None:
+ super().__init__()
+ self.index = index
+
+ def forward(self, x):
+ assert x.ndim >= 3
+ return x[:, self.index, ...]
+
+
+class SelectEOSAndProject(nn.Module):
+ """
+ Text Pooling used in OpenCLIP
+ """
+
+ def __init__(self, proj: nn.Module) -> None:
+ super().__init__()
+ self.proj = proj
+
+ def forward(self, x, seq_len):
+ assert x.ndim == 3
+ # x is of shape B x L x D
+ # take features from the eot embedding (eot_token is the highest number in each sequence)
+ x = x[torch.arange(x.shape[0]), seq_len]
+ x = self.proj(x)
+ return x
diff --git a/code/model/ImageBind/models/imagebind_model.py b/code/model/ImageBind/models/imagebind_model.py
new file mode 100644
index 0000000000000000000000000000000000000000..ba1981e8790b98131e2a89388142a79c6de94628
--- /dev/null
+++ b/code/model/ImageBind/models/imagebind_model.py
@@ -0,0 +1,521 @@
+#!/usr/bin/env python3
+# Portions Copyright (c) Meta Platforms, Inc. and affiliates.
+# All rights reserved.
+
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+
+import os
+import urllib
+from functools import partial
+from types import SimpleNamespace
+
+import torch
+import torch.nn as nn
+
+from .helpers import (
+ EinOpsRearrange,
+ LearnableLogitScaling,
+ Normalize,
+ SelectElement,
+ SelectEOSAndProject,
+)
+from .multimodal_preprocessors import (
+ AudioPreprocessor,
+ IMUPreprocessor,
+ PadIm2Video,
+ PatchEmbedGeneric,
+ RGBDTPreprocessor,
+ SpatioTemporalPosEmbeddingHelper,
+ TextPreprocessor,
+ ThermalPreprocessor,
+)
+
+from .transformer import MultiheadAttention, SimpleTransformer
+
+
+ModalityType = SimpleNamespace(
+ VISION="vision",
+ TEXT="text",
+ AUDIO="audio",
+ THERMAL="thermal",
+ DEPTH="depth",
+ IMU="imu",
+)
+
+
+class ImageBindModel(nn.Module):
+ def __init__(
+ self,
+ video_frames=2,
+ kernel_size=(2, 14, 14),
+ audio_kernel_size=16,
+ audio_stride=10,
+ out_embed_dim=768,
+ vision_embed_dim=1024,
+ vision_num_blocks=24,
+ vision_num_heads=16,
+ audio_embed_dim=768,
+ audio_num_blocks=12,
+ audio_num_heads=12,
+ audio_num_mel_bins=128,
+ audio_target_len=204,
+ audio_drop_path=0.1,
+ text_embed_dim=768,
+ text_num_blocks=12,
+ text_num_heads=12,
+ depth_embed_dim=384,
+ depth_kernel_size=16,
+ depth_num_blocks=12,
+ depth_num_heads=8,
+ depth_drop_path=0.0,
+ thermal_embed_dim=768,
+ thermal_kernel_size=16,
+ thermal_num_blocks=12,
+ thermal_num_heads=12,
+ thermal_drop_path=0.0,
+ imu_embed_dim=512,
+ imu_kernel_size=8,
+ imu_num_blocks=6,
+ imu_num_heads=8,
+ imu_drop_path=0.7,
+ ):
+ super().__init__()
+
+ self.modality_preprocessors = self._create_modality_preprocessors(
+ video_frames,
+ vision_embed_dim,
+ kernel_size,
+ text_embed_dim,
+ audio_embed_dim,
+ audio_kernel_size,
+ audio_stride,
+ audio_num_mel_bins,
+ audio_target_len,
+ depth_embed_dim,
+ depth_kernel_size,
+ thermal_embed_dim,
+ thermal_kernel_size,
+ imu_embed_dim,
+ )
+
+ self.modality_trunks = self._create_modality_trunks(
+ vision_embed_dim,
+ vision_num_blocks,
+ vision_num_heads,
+ text_embed_dim,
+ text_num_blocks,
+ text_num_heads,
+ audio_embed_dim,
+ audio_num_blocks,
+ audio_num_heads,
+ audio_drop_path,
+ depth_embed_dim,
+ depth_num_blocks,
+ depth_num_heads,
+ depth_drop_path,
+ thermal_embed_dim,
+ thermal_num_blocks,
+ thermal_num_heads,
+ thermal_drop_path,
+ imu_embed_dim,
+ imu_num_blocks,
+ imu_num_heads,
+ imu_drop_path,
+ )
+
+ self.modality_heads = self._create_modality_heads(
+ out_embed_dim,
+ vision_embed_dim,
+ text_embed_dim,
+ audio_embed_dim,
+ depth_embed_dim,
+ thermal_embed_dim,
+ imu_embed_dim,
+ )
+
+ self.modality_postprocessors = self._create_modality_postprocessors(
+ out_embed_dim
+ )
+
+ def _create_modality_preprocessors(
+ self,
+ video_frames=2,
+ vision_embed_dim=1024,
+ kernel_size=(2, 14, 14),
+ text_embed_dim=768,
+ audio_embed_dim=768,
+ audio_kernel_size=16,
+ audio_stride=10,
+ audio_num_mel_bins=128,
+ audio_target_len=204,
+ depth_embed_dim=768,
+ depth_kernel_size=16,
+ thermal_embed_dim=768,
+ thermal_kernel_size=16,
+ imu_embed_dim=512,
+ ):
+ rgbt_stem = PatchEmbedGeneric(
+ proj_stem=[
+ PadIm2Video(pad_type="repeat", ntimes=2),
+ nn.Conv3d(
+ in_channels=3,
+ kernel_size=kernel_size,
+ out_channels=vision_embed_dim,
+ stride=kernel_size,
+ bias=False,
+ ),
+ ]
+ )
+ rgbt_preprocessor = RGBDTPreprocessor(
+ img_size=[3, video_frames, 224, 224],
+ num_cls_tokens=1,
+ pos_embed_fn=partial(SpatioTemporalPosEmbeddingHelper, learnable=True),
+ rgbt_stem=rgbt_stem,
+ depth_stem=None,
+ )
+
+ text_preprocessor = TextPreprocessor(
+ context_length=77,
+ vocab_size=49408,
+ embed_dim=text_embed_dim,
+ causal_masking=True,
+ )
+
+ audio_stem = PatchEmbedGeneric(
+ proj_stem=[
+ nn.Conv2d(
+ in_channels=1,
+ kernel_size=audio_kernel_size,
+ stride=audio_stride,
+ out_channels=audio_embed_dim,
+ bias=False,
+ ),
+ ],
+ norm_layer=nn.LayerNorm(normalized_shape=audio_embed_dim),
+ )
+ audio_preprocessor = AudioPreprocessor(
+ img_size=[1, audio_num_mel_bins, audio_target_len],
+ num_cls_tokens=1,
+ pos_embed_fn=partial(SpatioTemporalPosEmbeddingHelper, learnable=True),
+ audio_stem=audio_stem,
+ )
+
+ depth_stem = PatchEmbedGeneric(
+ [
+ nn.Conv2d(
+ kernel_size=depth_kernel_size,
+ in_channels=1,
+ out_channels=depth_embed_dim,
+ stride=depth_kernel_size,
+ bias=False,
+ ),
+ ],
+ norm_layer=nn.LayerNorm(normalized_shape=depth_embed_dim),
+ )
+
+ depth_preprocessor = RGBDTPreprocessor(
+ img_size=[1, 224, 224],
+ num_cls_tokens=1,
+ pos_embed_fn=partial(SpatioTemporalPosEmbeddingHelper, learnable=True),
+ rgbt_stem=None,
+ depth_stem=depth_stem,
+ )
+
+ thermal_stem = PatchEmbedGeneric(
+ [
+ nn.Conv2d(
+ kernel_size=thermal_kernel_size,
+ in_channels=1,
+ out_channels=thermal_embed_dim,
+ stride=thermal_kernel_size,
+ bias=False,
+ ),
+ ],
+ norm_layer=nn.LayerNorm(normalized_shape=thermal_embed_dim),
+ )
+ thermal_preprocessor = ThermalPreprocessor(
+ img_size=[1, 224, 224],
+ num_cls_tokens=1,
+ pos_embed_fn=partial(SpatioTemporalPosEmbeddingHelper, learnable=True),
+ thermal_stem=thermal_stem,
+ )
+
+ imu_stem = PatchEmbedGeneric(
+ [
+ nn.Linear(
+ in_features=48,
+ out_features=imu_embed_dim,
+ bias=False,
+ ),
+ ],
+ norm_layer=nn.LayerNorm(normalized_shape=imu_embed_dim),
+ )
+
+ imu_preprocessor = IMUPreprocessor(
+ img_size=[6, 2000],
+ num_cls_tokens=1,
+ kernel_size=8,
+ embed_dim=imu_embed_dim,
+ pos_embed_fn=partial(SpatioTemporalPosEmbeddingHelper, learnable=True),
+ imu_stem=imu_stem,
+ )
+
+ modality_preprocessors = {
+ ModalityType.VISION: rgbt_preprocessor,
+ ModalityType.TEXT: text_preprocessor,
+ ModalityType.AUDIO: audio_preprocessor,
+ ModalityType.DEPTH: depth_preprocessor,
+ ModalityType.THERMAL: thermal_preprocessor,
+ ModalityType.IMU: imu_preprocessor,
+ }
+
+ return nn.ModuleDict(modality_preprocessors)
+
+ def _create_modality_trunks(
+ self,
+ vision_embed_dim=1024,
+ vision_num_blocks=24,
+ vision_num_heads=16,
+ text_embed_dim=768,
+ text_num_blocks=12,
+ text_num_heads=12,
+ audio_embed_dim=768,
+ audio_num_blocks=12,
+ audio_num_heads=12,
+ audio_drop_path=0.0,
+ depth_embed_dim=768,
+ depth_num_blocks=12,
+ depth_num_heads=12,
+ depth_drop_path=0.0,
+ thermal_embed_dim=768,
+ thermal_num_blocks=12,
+ thermal_num_heads=12,
+ thermal_drop_path=0.0,
+ imu_embed_dim=512,
+ imu_num_blocks=6,
+ imu_num_heads=8,
+ imu_drop_path=0.7,
+ ):
+ def instantiate_trunk(
+ embed_dim, num_blocks, num_heads, pre_transformer_ln, add_bias_kv, drop_path
+ ):
+ return SimpleTransformer(
+ embed_dim=embed_dim,
+ num_blocks=num_blocks,
+ ffn_dropout_rate=0.0,
+ drop_path_rate=drop_path,
+ attn_target=partial(
+ MultiheadAttention,
+ embed_dim=embed_dim,
+ num_heads=num_heads,
+ bias=True,
+ add_bias_kv=add_bias_kv,
+ ),
+ pre_transformer_layer=nn.Sequential(
+ nn.LayerNorm(embed_dim, eps=1e-6)
+ if pre_transformer_ln
+ else nn.Identity(),
+ EinOpsRearrange("b l d -> l b d"),
+ ),
+ post_transformer_layer=EinOpsRearrange("l b d -> b l d"),
+ )
+
+ modality_trunks = {}
+ modality_trunks[ModalityType.VISION] = instantiate_trunk(
+ vision_embed_dim,
+ vision_num_blocks,
+ vision_num_heads,
+ pre_transformer_ln=True,
+ add_bias_kv=False,
+ drop_path=0.0,
+ )
+ modality_trunks[ModalityType.TEXT] = instantiate_trunk(
+ text_embed_dim,
+ text_num_blocks,
+ text_num_heads,
+ pre_transformer_ln=False,
+ add_bias_kv=False,
+ drop_path=0.0,
+ )
+ modality_trunks[ModalityType.AUDIO] = instantiate_trunk(
+ audio_embed_dim,
+ audio_num_blocks,
+ audio_num_heads,
+ pre_transformer_ln=False,
+ add_bias_kv=True,
+ drop_path=audio_drop_path,
+ )
+ modality_trunks[ModalityType.DEPTH] = instantiate_trunk(
+ depth_embed_dim,
+ depth_num_blocks,
+ depth_num_heads,
+ pre_transformer_ln=False,
+ add_bias_kv=True,
+ drop_path=depth_drop_path,
+ )
+ modality_trunks[ModalityType.THERMAL] = instantiate_trunk(
+ thermal_embed_dim,
+ thermal_num_blocks,
+ thermal_num_heads,
+ pre_transformer_ln=False,
+ add_bias_kv=True,
+ drop_path=thermal_drop_path,
+ )
+ modality_trunks[ModalityType.IMU] = instantiate_trunk(
+ imu_embed_dim,
+ imu_num_blocks,
+ imu_num_heads,
+ pre_transformer_ln=False,
+ add_bias_kv=True,
+ drop_path=imu_drop_path,
+ )
+
+ return nn.ModuleDict(modality_trunks)
+
+ def _create_modality_heads(
+ self,
+ out_embed_dim,
+ vision_embed_dim,
+ text_embed_dim,
+ audio_embed_dim,
+ depth_embed_dim,
+ thermal_embed_dim,
+ imu_embed_dim,
+ ):
+ modality_heads = {}
+
+ modality_heads[ModalityType.VISION] = nn.Sequential(
+ nn.LayerNorm(normalized_shape=vision_embed_dim, eps=1e-6),
+ SelectElement(index=0),
+ nn.Linear(vision_embed_dim, out_embed_dim, bias=False),
+ )
+
+ modality_heads[ModalityType.TEXT] = SelectEOSAndProject(
+ proj=nn.Sequential(
+ nn.LayerNorm(normalized_shape=text_embed_dim, eps=1e-6),
+ nn.Linear(text_embed_dim, out_embed_dim, bias=False),
+ )
+ )
+
+ modality_heads[ModalityType.AUDIO] = nn.Sequential(
+ nn.LayerNorm(normalized_shape=audio_embed_dim, eps=1e-6),
+ SelectElement(index=0),
+ nn.Linear(audio_embed_dim, out_embed_dim, bias=False),
+ )
+
+ modality_heads[ModalityType.DEPTH] = nn.Sequential(
+ nn.LayerNorm(normalized_shape=depth_embed_dim, eps=1e-6),
+ SelectElement(index=0),
+ nn.Linear(depth_embed_dim, out_embed_dim, bias=False),
+ )
+
+ modality_heads[ModalityType.THERMAL] = nn.Sequential(
+ nn.LayerNorm(normalized_shape=thermal_embed_dim, eps=1e-6),
+ SelectElement(index=0),
+ nn.Linear(thermal_embed_dim, out_embed_dim, bias=False),
+ )
+
+ modality_heads[ModalityType.IMU] = nn.Sequential(
+ nn.LayerNorm(normalized_shape=imu_embed_dim, eps=1e-6),
+ SelectElement(index=0),
+ nn.Dropout(p=0.5),
+ nn.Linear(imu_embed_dim, out_embed_dim, bias=False),
+ )
+
+ return nn.ModuleDict(modality_heads)
+
+ def _create_modality_postprocessors(self, out_embed_dim):
+ modality_postprocessors = {}
+
+ modality_postprocessors[ModalityType.VISION] = Normalize(dim=-1)
+ modality_postprocessors[ModalityType.TEXT] = nn.Sequential(
+ Normalize(dim=-1), LearnableLogitScaling(learnable=True)
+ )
+ modality_postprocessors[ModalityType.AUDIO] = nn.Sequential(
+ Normalize(dim=-1),
+ LearnableLogitScaling(logit_scale_init=20.0, learnable=False),
+ )
+ modality_postprocessors[ModalityType.DEPTH] = nn.Sequential(
+ Normalize(dim=-1),
+ LearnableLogitScaling(logit_scale_init=5.0, learnable=False),
+ )
+ modality_postprocessors[ModalityType.THERMAL] = nn.Sequential(
+ Normalize(dim=-1),
+ LearnableLogitScaling(logit_scale_init=10.0, learnable=False),
+ )
+ modality_postprocessors[ModalityType.IMU] = nn.Sequential(
+ Normalize(dim=-1),
+ LearnableLogitScaling(logit_scale_init=5.0, learnable=False),
+ )
+ return nn.ModuleDict(modality_postprocessors)
+
+ def forward(self, inputs):
+ outputs = {}
+ for modality_key, modality_value in inputs.items():
+ reduce_list = (
+ modality_value.ndim >= 5
+ ) # Audio and Video inputs consist of multiple clips
+ if reduce_list:
+ B, S = modality_value.shape[:2]
+ modality_value = modality_value.reshape(
+ B * S, *modality_value.shape[2:]
+ )
+
+ if modality_value is not None:
+ modality_value = self.modality_preprocessors[modality_key](
+ **{modality_key: modality_value}
+ )
+ trunk_inputs = modality_value["trunk"]
+ head_inputs = modality_value["head"]
+ modality_value = self.modality_trunks[modality_key](**trunk_inputs)
+ modality_value = self.modality_heads[modality_key](
+ modality_value, **head_inputs
+ )
+ if modality_key in [ModalityType.AUDIO]:
+ modality_value = self.modality_postprocessors[modality_key][0](
+ modality_value
+ )
+ else:
+ modality_value = self.modality_postprocessors[modality_key](
+ modality_value
+ )
+
+ if reduce_list:
+ modality_value = modality_value.reshape(B, S, -1)
+ modality_value = modality_value.mean(dim=1)
+
+ outputs[modality_key] = modality_value
+
+ return outputs
+
+
+def imagebind_huge(pretrained=False, store_path=r'.checkpoints'):
+ model = ImageBindModel(
+ vision_embed_dim=1280,
+ vision_num_blocks=32,
+ vision_num_heads=16,
+ text_embed_dim=1024,
+ text_num_blocks=24,
+ text_num_heads=16,
+ out_embed_dim=1024,
+ audio_drop_path=0.1,
+ imu_drop_path=0.7,
+ )
+
+ if pretrained:
+ if not os.path.exists("{}/imagebind_huge.pth".format(store_path)):
+ print(
+ "Downloading imagebind weights to {}/imagebind_huge.pth ...".format(store_path)
+ )
+ os.makedirs(store_path, exist_ok=True)
+ torch.hub.download_url_to_file(
+ "https://dl.fbaipublicfiles.com/imagebind/imagebind_huge.pth",
+ "{}/imagebind_huge.pth".format(store_path),
+ progress=True,
+ )
+
+ model.load_state_dict(torch.load("{}/imagebind_huge.pth".format(store_path)))
+
+ return model, 1024
diff --git a/code/model/ImageBind/models/multimodal_preprocessors.py b/code/model/ImageBind/models/multimodal_preprocessors.py
new file mode 100644
index 0000000000000000000000000000000000000000..44de961053601fd288c5c92c56b799d5762b8b4c
--- /dev/null
+++ b/code/model/ImageBind/models/multimodal_preprocessors.py
@@ -0,0 +1,687 @@
+#!/usr/bin/env python3
+# Portions Copyright (c) Meta Platforms, Inc. and affiliates.
+# All rights reserved.
+
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+import gzip
+import html
+import io
+import math
+from functools import lru_cache
+from typing import Callable, List, Optional
+
+import ftfy
+
+import numpy as np
+import regex as re
+import torch
+import torch.nn as nn
+from iopath.common.file_io import g_pathmgr
+from timm.models.layers import trunc_normal_
+
+from .helpers import cast_if_src_dtype, VerboseNNModule
+
+
+def get_sinusoid_encoding_table(n_position, d_hid):
+ """Sinusoid position encoding table"""
+
+ # TODO: make it with torch instead of numpy
+ def get_position_angle_vec(position):
+ return [
+ position / np.power(10000, 2 * (hid_j // 2) / d_hid)
+ for hid_j in range(d_hid)
+ ]
+
+ sinusoid_table = np.array(
+ [get_position_angle_vec(pos_i) for pos_i in range(n_position)]
+ )
+ sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
+ sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
+
+ return torch.FloatTensor(sinusoid_table).unsqueeze(0)
+
+
+def interpolate_pos_encoding_2d(target_spatial_size, pos_embed):
+ N = pos_embed.shape[1]
+ if N == target_spatial_size:
+ return pos_embed
+ dim = pos_embed.shape[-1]
+ # nn.functional.interpolate doesn't work with bfloat16 so we cast to float32
+ pos_embed, updated = cast_if_src_dtype(pos_embed, torch.bfloat16, torch.float32)
+ pos_embed = nn.functional.interpolate(
+ pos_embed.reshape(1, int(math.sqrt(N)), int(math.sqrt(N)), dim).permute(
+ 0, 3, 1, 2
+ ),
+ scale_factor=math.sqrt(target_spatial_size / N),
+ mode="bicubic",
+ )
+ if updated:
+ pos_embed, _ = cast_if_src_dtype(pos_embed, torch.float32, torch.bfloat16)
+ pos_embed = pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
+ return pos_embed
+
+
+def interpolate_pos_encoding(
+ npatch_per_img,
+ pos_embed,
+ patches_layout,
+ input_shape=None,
+ first_patch_idx=1,
+):
+ assert first_patch_idx == 0 or first_patch_idx == 1, "there is 1 CLS token or none"
+ N = pos_embed.shape[1] - first_patch_idx # since it's 1 if cls_token exists
+ if npatch_per_img == N:
+ return pos_embed
+
+ assert (
+ patches_layout[-1] == patches_layout[-2]
+ ), "Interpolation of pos embed not supported for non-square layouts"
+
+ class_emb = pos_embed[:, :first_patch_idx]
+ pos_embed = pos_embed[:, first_patch_idx:]
+
+ if input_shape is None or patches_layout[0] == 1:
+ # simple 2D pos embedding, no temporal component
+ pos_embed = interpolate_pos_encoding_2d(npatch_per_img, pos_embed)
+ elif patches_layout[0] > 1:
+ # pos embed has a temporal component
+ assert len(input_shape) == 4, "temporal interpolation not supported"
+ # we only support 2D interpolation in this case
+ num_frames = patches_layout[0]
+ num_spatial_tokens = patches_layout[1] * patches_layout[2]
+ pos_embed = pos_embed.view(1, num_frames, num_spatial_tokens, -1)
+ # interpolate embedding for zeroth frame
+ pos_embed = interpolate_pos_encoding_2d(
+ npatch_per_img, pos_embed[0, 0, ...].unsqueeze(0)
+ )
+ else:
+ raise ValueError("This type of interpolation isn't implemented")
+
+ return torch.cat((class_emb, pos_embed), dim=1)
+
+
+def _get_pos_embedding(
+ npatch_per_img,
+ pos_embed,
+ patches_layout,
+ input_shape,
+ first_patch_idx=1,
+):
+ pos_embed = interpolate_pos_encoding(
+ npatch_per_img,
+ pos_embed,
+ patches_layout,
+ input_shape=input_shape,
+ first_patch_idx=first_patch_idx,
+ )
+ return pos_embed
+
+
+class PatchEmbedGeneric(nn.Module):
+ """
+ PatchEmbed from Hydra
+ """
+
+ def __init__(self, proj_stem, norm_layer: Optional[nn.Module] = None):
+ super().__init__()
+
+ if len(proj_stem) > 1:
+ self.proj = nn.Sequential(*proj_stem)
+ else:
+ # Special case to be able to load pre-trained models that were
+ # trained with a standard stem
+ self.proj = proj_stem[0]
+ self.norm_layer = norm_layer
+
+ def get_patch_layout(self, img_size):
+ with torch.no_grad():
+ dummy_img = torch.zeros(
+ [
+ 1,
+ ]
+ + img_size
+ )
+ dummy_out = self.proj(dummy_img)
+ embed_dim = dummy_out.shape[1]
+ patches_layout = tuple(dummy_out.shape[2:])
+ num_patches = np.prod(patches_layout)
+ return patches_layout, num_patches, embed_dim
+
+ def forward(self, x):
+ x = self.proj(x)
+ # B C (T) H W -> B (T)HW C
+ x = x.flatten(2).transpose(1, 2)
+ if self.norm_layer is not None:
+ x = self.norm_layer(x)
+ return x
+
+
+class SpatioTemporalPosEmbeddingHelper(VerboseNNModule):
+ def __init__(
+ self,
+ patches_layout: List,
+ num_patches: int,
+ num_cls_tokens: int,
+ embed_dim: int,
+ learnable: bool,
+ ) -> None:
+ super().__init__()
+ self.num_cls_tokens = num_cls_tokens
+ self.patches_layout = patches_layout
+ self.num_patches = num_patches
+ self.num_tokens = num_cls_tokens + num_patches
+ self.learnable = learnable
+ if self.learnable:
+ self.pos_embed = nn.Parameter(torch.zeros(1, self.num_tokens, embed_dim))
+ trunc_normal_(self.pos_embed, std=0.02)
+ else:
+ self.register_buffer(
+ "pos_embed", get_sinusoid_encoding_table(self.num_tokens, embed_dim)
+ )
+
+ def get_pos_embedding(self, vision_input, all_vision_tokens):
+ input_shape = vision_input.shape
+ pos_embed = _get_pos_embedding(
+ all_vision_tokens.size(1) - self.num_cls_tokens,
+ pos_embed=self.pos_embed,
+ patches_layout=self.patches_layout,
+ input_shape=input_shape,
+ first_patch_idx=self.num_cls_tokens,
+ )
+ return pos_embed
+
+
+class RGBDTPreprocessor(VerboseNNModule):
+ def __init__(
+ self,
+ rgbt_stem: PatchEmbedGeneric,
+ depth_stem: PatchEmbedGeneric,
+ img_size: List = (3, 224, 224),
+ num_cls_tokens: int = 1,
+ pos_embed_fn: Callable = None,
+ use_type_embed: bool = False,
+ init_param_style: str = "openclip",
+ ) -> None:
+ super().__init__()
+ stem = rgbt_stem if rgbt_stem is not None else depth_stem
+ (
+ self.patches_layout,
+ self.num_patches,
+ self.embed_dim,
+ ) = stem.get_patch_layout(img_size)
+ self.rgbt_stem = rgbt_stem
+ self.depth_stem = depth_stem
+ self.use_pos_embed = pos_embed_fn is not None
+ self.use_type_embed = use_type_embed
+ self.num_cls_tokens = num_cls_tokens
+
+ if self.use_pos_embed:
+ self.pos_embedding_helper = pos_embed_fn(
+ patches_layout=self.patches_layout,
+ num_cls_tokens=num_cls_tokens,
+ num_patches=self.num_patches,
+ embed_dim=self.embed_dim,
+ )
+ if self.num_cls_tokens > 0:
+ self.cls_token = nn.Parameter(
+ torch.zeros(1, self.num_cls_tokens, self.embed_dim)
+ )
+ if self.use_type_embed:
+ self.type_embed = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
+
+ self.init_parameters(init_param_style)
+
+ @torch.no_grad()
+ def init_parameters(self, init_param_style):
+ if init_param_style == "openclip":
+ # OpenCLIP style initialization
+ scale = self.embed_dim**-0.5
+ if self.use_pos_embed:
+ nn.init.normal_(self.pos_embedding_helper.pos_embed)
+ self.pos_embedding_helper.pos_embed *= scale
+
+ if self.num_cls_tokens > 0:
+ nn.init.normal_(self.cls_token)
+ self.cls_token *= scale
+ elif init_param_style == "vit":
+ self.cls_token.data.fill_(0)
+ else:
+ raise ValueError(f"Unknown init {init_param_style}")
+
+ if self.use_type_embed:
+ nn.init.normal_(self.type_embed)
+
+ def tokenize_input_and_cls_pos(self, input, stem, mask):
+ # tokens is of shape B x L x D
+ tokens = stem(input)
+ assert tokens.ndim == 3
+ assert tokens.shape[2] == self.embed_dim
+ B = tokens.shape[0]
+ if self.num_cls_tokens > 0:
+ class_tokens = self.cls_token.expand(
+ B, -1, -1
+ ) # stole class_tokens impl from Phil Wang, thanks
+ tokens = torch.cat((class_tokens, tokens), dim=1)
+ if self.use_pos_embed:
+ pos_embed = self.pos_embedding_helper.get_pos_embedding(input, tokens)
+ tokens = tokens + pos_embed
+ if self.use_type_embed:
+ tokens = tokens + self.type_embed.expand(B, -1, -1)
+ return tokens
+
+ def forward(self, vision=None, depth=None, patch_mask=None):
+ if patch_mask is not None:
+ raise NotImplementedError()
+
+ if vision is not None:
+ vision_tokens = self.tokenize_input_and_cls_pos(
+ vision, self.rgbt_stem, patch_mask
+ )
+
+ if depth is not None:
+ depth_tokens = self.tokenize_input_and_cls_pos(
+ depth, self.depth_stem, patch_mask
+ )
+
+ # aggregate tokens
+ if vision is not None and depth is not None:
+ final_tokens = vision_tokens + depth_tokens
+ else:
+ final_tokens = vision_tokens if vision is not None else depth_tokens
+ return_dict = {
+ "trunk": {
+ "tokens": final_tokens,
+ },
+ "head": {},
+ }
+ return return_dict
+
+
+class AudioPreprocessor(RGBDTPreprocessor):
+ def __init__(self, audio_stem: PatchEmbedGeneric, **kwargs) -> None:
+ super().__init__(rgbt_stem=audio_stem, depth_stem=None, **kwargs)
+
+ def forward(self, audio=None):
+ return super().forward(vision=audio)
+
+
+class ThermalPreprocessor(RGBDTPreprocessor):
+ def __init__(self, thermal_stem: PatchEmbedGeneric, **kwargs) -> None:
+ super().__init__(rgbt_stem=thermal_stem, depth_stem=None, **kwargs)
+
+ def forward(self, thermal=None):
+ return super().forward(vision=thermal)
+
+
+def build_causal_attention_mask(context_length):
+ # lazily create causal attention mask, with full attention between the vision tokens
+ # pytorch uses additive attention mask; fill with -inf
+ mask = torch.empty(context_length, context_length, requires_grad=False)
+ mask.fill_(float("-inf"))
+ mask.triu_(1) # zero out the lower diagonal
+ return mask
+
+
+class TextPreprocessor(VerboseNNModule):
+ def __init__(
+ self,
+ vocab_size: int,
+ context_length: int,
+ embed_dim: int,
+ causal_masking: bool,
+ supply_seq_len_to_head: bool = True,
+ num_cls_tokens: int = 0,
+ init_param_style: str = "openclip",
+ ) -> None:
+ super().__init__()
+ self.vocab_size = vocab_size
+ self.context_length = context_length
+ self.token_embedding = nn.Embedding(vocab_size, embed_dim)
+ self.pos_embed = nn.Parameter(
+ torch.empty(1, self.context_length + num_cls_tokens, embed_dim)
+ )
+ self.causal_masking = causal_masking
+ if self.causal_masking:
+ mask = build_causal_attention_mask(self.context_length)
+ # register the mask as a buffer so it can be moved to the right device
+ self.register_buffer("mask", mask)
+
+ self.supply_seq_len_to_head = supply_seq_len_to_head
+ self.num_cls_tokens = num_cls_tokens
+ self.embed_dim = embed_dim
+ if num_cls_tokens > 0:
+ assert self.causal_masking is False, "Masking + CLS token isn't implemented"
+ self.cls_token = nn.Parameter(
+ torch.zeros(1, self.num_cls_tokens, embed_dim)
+ )
+
+ self.init_parameters(init_param_style)
+
+ @torch.no_grad()
+ def init_parameters(self, init_param_style="openclip"):
+ # OpenCLIP style initialization
+ nn.init.normal_(self.token_embedding.weight, std=0.02)
+ nn.init.normal_(self.pos_embed, std=0.01)
+
+ if init_param_style == "openclip":
+ # OpenCLIP style initialization
+ scale = self.embed_dim**-0.5
+ if self.num_cls_tokens > 0:
+ nn.init.normal_(self.cls_token)
+ self.cls_token *= scale
+ elif init_param_style == "vit":
+ self.cls_token.data.fill_(0)
+ else:
+ raise ValueError(f"Unknown init {init_param_style}")
+
+ def forward(self, text):
+ # text tokens are of shape B x L x D
+ text_tokens = self.token_embedding(text)
+ # concat CLS tokens if any
+ if self.num_cls_tokens > 0:
+ B = text_tokens.shape[0]
+ class_tokens = self.cls_token.expand(
+ B, -1, -1
+ ) # stole class_tokens impl from Phil Wang, thanks
+ text_tokens = torch.cat((class_tokens, text_tokens), dim=1)
+ text_tokens = text_tokens + self.pos_embed
+ return_dict = {
+ "trunk": {
+ "tokens": text_tokens,
+ },
+ "head": {},
+ }
+ # Compute sequence length after adding CLS tokens
+ if self.supply_seq_len_to_head:
+ text_lengths = text.argmax(dim=-1)
+ return_dict["head"] = {
+ "seq_len": text_lengths,
+ }
+ if self.causal_masking:
+ return_dict["trunk"].update({"attn_mask": self.mask})
+ return return_dict
+
+
+class Im2Video(nn.Module):
+ """Convert an image into a trivial video."""
+
+ def __init__(self, time_dim=2):
+ super().__init__()
+ self.time_dim = time_dim
+
+ def forward(self, x):
+ if x.ndim == 4:
+ # B, C, H, W -> B, C, T, H, W
+ return x.unsqueeze(self.time_dim)
+ elif x.ndim == 5:
+ return x
+ else:
+ raise ValueError(f"Dimension incorrect {x.shape}")
+
+
+class PadIm2Video(Im2Video):
+ def __init__(self, ntimes, pad_type, time_dim=2):
+ super().__init__(time_dim=time_dim)
+ assert ntimes > 0
+ assert pad_type in ["zero", "repeat"]
+ self.ntimes = ntimes
+ self.pad_type = pad_type
+
+ def forward(self, x):
+ x = super().forward(x)
+ if x.shape[self.time_dim] == 1:
+ if self.pad_type == "repeat":
+ new_shape = [1] * len(x.shape)
+ new_shape[self.time_dim] = self.ntimes
+ x = x.repeat(new_shape)
+ elif self.pad_type == "zero":
+ padarg = [0, 0] * len(x.shape)
+ padarg[2 * self.time_dim + 1] = self.ntimes - x.shape[self.time_dim]
+ x = nn.functional.pad(x, padarg)
+ return x
+
+
+# Modified from github.com/openai/CLIP
+@lru_cache()
+def bytes_to_unicode():
+ """
+ Returns list of utf-8 byte and a corresponding list of unicode strings.
+ The reversible bpe codes work on unicode strings.
+ This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
+ When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
+ This is a signficant percentage of your normal, say, 32K bpe vocab.
+ To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
+ And avoids mapping to whitespace/control characters the bpe code barfs on.
+ """
+ bs = (
+ list(range(ord("!"), ord("~") + 1))
+ + list(range(ord("¡"), ord("¬") + 1))
+ + list(range(ord("®"), ord("ÿ") + 1))
+ )
+ cs = bs[:]
+ n = 0
+ for b in range(2**8):
+ if b not in bs:
+ bs.append(b)
+ cs.append(2**8 + n)
+ n += 1
+ cs = [chr(n) for n in cs]
+ return dict(zip(bs, cs))
+
+
+def get_pairs(word):
+ """Return set of symbol pairs in a word.
+ Word is represented as tuple of symbols (symbols being variable-length strings).
+ """
+ pairs = set()
+ prev_char = word[0]
+ for char in word[1:]:
+ pairs.add((prev_char, char))
+ prev_char = char
+ return pairs
+
+
+def basic_clean(text):
+ text = ftfy.fix_text(text)
+ text = html.unescape(html.unescape(text))
+ return text.strip()
+
+
+def whitespace_clean(text):
+ text = re.sub(r"\s+", " ", text)
+ text = text.strip()
+ return text
+
+
+class SimpleTokenizer(object):
+ def __init__(self, bpe_path: str, context_length=77):
+ self.byte_encoder = bytes_to_unicode()
+ self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
+
+ with g_pathmgr.open(bpe_path, "rb") as fh:
+ bpe_bytes = io.BytesIO(fh.read())
+ merges = gzip.open(bpe_bytes).read().decode("utf-8").split("\n")
+ merges = merges[1 : 49152 - 256 - 2 + 1]
+ merges = [tuple(merge.split()) for merge in merges]
+ vocab = list(bytes_to_unicode().values())
+ vocab = vocab + [v + "" for v in vocab]
+ for merge in merges:
+ vocab.append("".join(merge))
+ vocab.extend(["<|startoftext|>", "<|endoftext|>"])
+ self.encoder = dict(zip(vocab, range(len(vocab))))
+ self.decoder = {v: k for k, v in self.encoder.items()}
+ self.bpe_ranks = dict(zip(merges, range(len(merges))))
+ self.cache = {
+ "<|startoftext|>": "<|startoftext|>",
+ "<|endoftext|>": "<|endoftext|>",
+ }
+ self.pat = re.compile(
+ r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""",
+ re.IGNORECASE,
+ )
+ self.context_length = context_length
+
+ def bpe(self, token):
+ if token in self.cache:
+ return self.cache[token]
+ word = tuple(token[:-1]) + (token[-1] + "",)
+ pairs = get_pairs(word)
+
+ if not pairs:
+ return token + ""
+
+ while True:
+ bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float("inf")))
+ if bigram not in self.bpe_ranks:
+ break
+ first, second = bigram
+ new_word = []
+ i = 0
+ while i < len(word):
+ try:
+ j = word.index(first, i)
+ new_word.extend(word[i:j])
+ i = j
+ except:
+ new_word.extend(word[i:])
+ break
+
+ if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
+ new_word.append(first + second)
+ i += 2
+ else:
+ new_word.append(word[i])
+ i += 1
+ new_word = tuple(new_word)
+ word = new_word
+ if len(word) == 1:
+ break
+ else:
+ pairs = get_pairs(word)
+ word = " ".join(word)
+ self.cache[token] = word
+ return word
+
+ def encode(self, text):
+ bpe_tokens = []
+ text = whitespace_clean(basic_clean(text)).lower()
+ for token in re.findall(self.pat, text):
+ token = "".join(self.byte_encoder[b] for b in token.encode("utf-8"))
+ bpe_tokens.extend(
+ self.encoder[bpe_token] for bpe_token in self.bpe(token).split(" ")
+ )
+ return bpe_tokens
+
+ def decode(self, tokens):
+ text = "".join([self.decoder[token] for token in tokens])
+ text = (
+ bytearray([self.byte_decoder[c] for c in text])
+ .decode("utf-8", errors="replace")
+ .replace("", " ")
+ )
+ return text
+
+ def __call__(self, texts, context_length=None):
+ if not context_length:
+ context_length = self.context_length
+
+ if isinstance(texts, str):
+ texts = [texts]
+
+ sot_token = self.encoder["<|startoftext|>"]
+ eot_token = self.encoder["<|endoftext|>"]
+ all_tokens = [[sot_token] + self.encode(text) + [eot_token] for text in texts]
+ result = torch.zeros(len(all_tokens), context_length, dtype=torch.long)
+
+ for i, tokens in enumerate(all_tokens):
+ tokens = tokens[:context_length]
+ result[i, : len(tokens)] = torch.tensor(tokens)
+
+ if len(result) == 1:
+ return result[0]
+ return result
+
+
+class IMUPreprocessor(VerboseNNModule):
+ def __init__(
+ self,
+ kernel_size: int,
+ imu_stem: PatchEmbedGeneric,
+ embed_dim: int,
+ img_size: List = (6, 2000),
+ num_cls_tokens: int = 1,
+ pos_embed_fn: Callable = None,
+ init_param_style: str = "openclip",
+ ) -> None:
+ super().__init__()
+ stem = imu_stem
+ self.imu_stem = imu_stem
+ self.embed_dim = embed_dim
+ self.use_pos_embed = pos_embed_fn is not None
+ self.num_cls_tokens = num_cls_tokens
+ self.kernel_size = kernel_size
+ self.pos_embed = nn.Parameter(
+ torch.empty(1, (img_size[1] // kernel_size) + num_cls_tokens, embed_dim)
+ )
+
+ if self.num_cls_tokens > 0:
+ self.cls_token = nn.Parameter(
+ torch.zeros(1, self.num_cls_tokens, self.embed_dim)
+ )
+
+ self.init_parameters(init_param_style)
+
+ @torch.no_grad()
+ def init_parameters(self, init_param_style):
+ nn.init.normal_(self.pos_embed, std=0.01)
+
+ if init_param_style == "openclip":
+ # OpenCLIP style initialization
+ scale = self.embed_dim**-0.5
+
+ if self.num_cls_tokens > 0:
+ nn.init.normal_(self.cls_token)
+ self.cls_token *= scale
+ elif init_param_style == "vit":
+ self.cls_token.data.fill_(0)
+ else:
+ raise ValueError(f"Unknown init {init_param_style}")
+
+ def tokenize_input_and_cls_pos(self, input, stem):
+ # tokens is of shape B x L x D
+ tokens = stem.norm_layer(stem.proj(input))
+ assert tokens.ndim == 3
+ assert tokens.shape[2] == self.embed_dim
+ B = tokens.shape[0]
+ if self.num_cls_tokens > 0:
+ class_tokens = self.cls_token.expand(
+ B, -1, -1
+ ) # stole class_tokens impl from Phil Wang, thanks
+ tokens = torch.cat((class_tokens, tokens), dim=1)
+ if self.use_pos_embed:
+ tokens = tokens + self.pos_embed
+ return tokens
+
+ def forward(self, imu):
+ # Patchify
+ imu = imu.unfold(
+ -1,
+ self.kernel_size,
+ self.kernel_size,
+ ).permute(0, 2, 1, 3)
+ imu = imu.reshape(imu.size(0), imu.size(1), -1)
+
+ imu_tokens = self.tokenize_input_and_cls_pos(
+ imu,
+ self.imu_stem,
+ )
+
+ return_dict = {
+ "trunk": {
+ "tokens": imu_tokens,
+ },
+ "head": {},
+ }
+ return return_dict
diff --git a/code/model/ImageBind/models/transformer.py b/code/model/ImageBind/models/transformer.py
new file mode 100644
index 0000000000000000000000000000000000000000..98902ac8f08868c486a7c74781e952bee444c2e6
--- /dev/null
+++ b/code/model/ImageBind/models/transformer.py
@@ -0,0 +1,284 @@
+#!/usr/bin/env python3
+# Portions Copyright (c) Meta Platforms, Inc. and affiliates.
+# All rights reserved.
+
+# This source code is licensed under the license found in the
+# LICENSE file in the root directory of this source tree.
+
+# Code modified from
+# https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py ;
+# https://github.com/facebookresearch/deit/blob/main/models.py
+# and https://github.com/facebookresearch/vissl/blob/main/vissl/models/trunks/vision_transformer.py
+
+
+import copy
+import fnmatch
+import logging
+from functools import partial
+from typing import Callable, List
+
+import torch
+import torch.nn as nn
+import torch.utils.checkpoint as checkpoint
+
+from timm.models.layers import DropPath, trunc_normal_
+
+
+class Attention(nn.Module):
+ def __init__(
+ self,
+ dim,
+ num_heads=8,
+ qkv_bias=False,
+ qk_scale=None,
+ attn_drop=0.0,
+ proj_drop=0.0,
+ ):
+ super().__init__()
+ self.num_heads = num_heads
+ head_dim = dim // num_heads
+ # NOTE scale factor was wrong in my original version,
+ # can set manually to be compat with prev weights
+ self.scale = qk_scale or head_dim**-0.5
+
+ self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop)
+ self.proj = nn.Linear(dim, dim)
+ self.proj_drop = nn.Dropout(proj_drop)
+
+ def forward(self, x):
+ B, N, C = x.shape
+ qkv = (
+ self.qkv(x)
+ .reshape(B, N, 3, self.num_heads, C // self.num_heads)
+ .permute(2, 0, 3, 1, 4)
+ )
+ q, k, v = (
+ qkv[0],
+ qkv[1],
+ qkv[2],
+ ) # make torchscript happy (cannot use tensor as tuple)
+
+ attn = (q @ k.transpose(-2, -1)) * self.scale
+ attn = attn.softmax(dim=-1)
+ attn = self.attn_drop(attn)
+
+ x = (attn @ v).transpose(1, 2).reshape(B, N, C)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+
+class Mlp(nn.Module):
+ def __init__(
+ self,
+ in_features,
+ hidden_features=None,
+ out_features=None,
+ act_layer=nn.GELU,
+ drop=0.0,
+ ):
+ super().__init__()
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+ self.fc1 = nn.Linear(in_features, hidden_features)
+ self.act = act_layer()
+ self.fc2 = nn.Linear(hidden_features, out_features)
+ self.drop = nn.Dropout(drop)
+
+ def forward(self, x):
+ x = self.fc1(x)
+ x = self.act(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+ x = self.drop(x)
+ return x
+
+
+class MultiheadAttention(nn.MultiheadAttention):
+ def forward(self, x: torch.Tensor, attn_mask: torch.Tensor):
+ return super().forward(x, x, x, need_weights=False, attn_mask=attn_mask)[0]
+
+
+class ViTAttention(Attention):
+ def forward(self, x: torch.Tensor, attn_mask: torch.Tensor):
+ assert attn_mask is None
+ return super().forward(x)
+
+
+class BlockWithMasking(nn.Module):
+ def __init__(
+ self,
+ dim: int,
+ attn_target: Callable,
+ mlp_ratio: int = 4,
+ act_layer: Callable = nn.GELU,
+ norm_layer: Callable = nn.LayerNorm,
+ ffn_dropout_rate: float = 0.0,
+ drop_path: float = 0.0,
+ layer_scale_type: str = None,
+ layer_scale_init_value: float = 1e-4,
+ ):
+ super().__init__()
+
+ assert not isinstance(
+ attn_target, nn.Module
+ ), "attn_target should be a Callable. Otherwise attn_target is shared across blocks!"
+ self.attn = attn_target()
+ if drop_path > 0.0:
+ self.drop_path = DropPath(drop_path)
+ else:
+ self.drop_path = nn.Identity()
+ self.norm_1 = norm_layer(dim)
+ mlp_hidden_dim = int(mlp_ratio * dim)
+ self.mlp = Mlp(
+ in_features=dim,
+ hidden_features=mlp_hidden_dim,
+ act_layer=act_layer,
+ drop=ffn_dropout_rate,
+ )
+ self.norm_2 = norm_layer(dim)
+ self.layer_scale_type = layer_scale_type
+ if self.layer_scale_type is not None:
+ assert self.layer_scale_type in [
+ "per_channel",
+ "scalar",
+ ], f"Found Layer scale type {self.layer_scale_type}"
+ if self.layer_scale_type == "per_channel":
+ # one gamma value per channel
+ gamma_shape = [1, 1, dim]
+ elif self.layer_scale_type == "scalar":
+ # single gamma value for all channels
+ gamma_shape = [1, 1, 1]
+ # two gammas: for each part of the fwd in the encoder
+ self.layer_scale_gamma1 = nn.Parameter(
+ torch.ones(size=gamma_shape) * layer_scale_init_value,
+ requires_grad=True,
+ )
+ self.layer_scale_gamma2 = nn.Parameter(
+ torch.ones(size=gamma_shape) * layer_scale_init_value,
+ requires_grad=True,
+ )
+
+ def forward(self, x: torch.Tensor, attn_mask: torch.Tensor):
+ if self.layer_scale_type is None:
+ x = x + self.drop_path(self.attn(self.norm_1(x), attn_mask))
+ x = x + self.drop_path(self.mlp(self.norm_2(x)))
+ else:
+ x = (
+ x
+ + self.drop_path(self.attn(self.norm_1(x), attn_mask))
+ * self.layer_scale_gamma1
+ )
+ x = x + self.drop_path(self.mlp(self.norm_2(x))) * self.layer_scale_gamma2
+ return x
+
+
+_LAYER_NORM = partial(nn.LayerNorm, eps=1e-6)
+
+
+class SimpleTransformer(nn.Module):
+ def __init__(
+ self,
+ attn_target: Callable,
+ embed_dim: int,
+ num_blocks: int,
+ block: Callable = BlockWithMasking,
+ pre_transformer_layer: Callable = None,
+ post_transformer_layer: Callable = None,
+ drop_path_rate: float = 0.0,
+ drop_path_type: str = "progressive",
+ norm_layer: Callable = _LAYER_NORM,
+ mlp_ratio: int = 4,
+ ffn_dropout_rate: float = 0.0,
+ layer_scale_type: str = None, # from cait; possible values are None, "per_channel", "scalar"
+ layer_scale_init_value: float = 1e-4, # from cait; float
+ weight_init_style: str = "jax", # possible values jax or pytorch
+ ):
+ """
+ Simple Transformer with the following features
+ 1. Supports masked attention
+ 2. Supports DropPath
+ 3. Supports LayerScale
+ 4. Supports Dropout in Attention and FFN
+ 5. Makes few assumptions about the input except that it is a Tensor
+ """
+ super().__init__()
+ self.pre_transformer_layer = pre_transformer_layer
+ if drop_path_type == "progressive":
+ dpr = [x.item() for x in torch.linspace(0, drop_path_rate, num_blocks)]
+ elif drop_path_type == "uniform":
+ dpr = [drop_path_rate for i in range(num_blocks)]
+ else:
+ raise ValueError(f"Unknown drop_path_type: {drop_path_type}")
+
+ self.blocks = nn.Sequential(
+ *[
+ block(
+ dim=embed_dim,
+ attn_target=attn_target,
+ mlp_ratio=mlp_ratio,
+ ffn_dropout_rate=ffn_dropout_rate,
+ drop_path=dpr[i],
+ norm_layer=norm_layer,
+ layer_scale_type=layer_scale_type,
+ layer_scale_init_value=layer_scale_init_value,
+ )
+ for i in range(num_blocks)
+ ]
+ )
+ self.post_transformer_layer = post_transformer_layer
+ self.weight_init_style = weight_init_style
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ if self.weight_init_style == "jax":
+ # Based on MAE and official Jax ViT implementation
+ torch.nn.init.xavier_uniform_(m.weight)
+ elif self.weight_init_style == "pytorch":
+ # PyTorch ViT uses trunc_normal_
+ trunc_normal_(m.weight, std=0.02)
+
+ if m.bias is not None:
+ nn.init.constant_(m.bias, 0)
+ elif isinstance(m, (nn.LayerNorm)):
+ nn.init.constant_(m.bias, 0)
+ nn.init.constant_(m.weight, 1.0)
+
+ def forward(
+ self,
+ tokens: torch.Tensor,
+ attn_mask: torch.Tensor = None,
+ use_checkpoint: bool = False,
+ checkpoint_every_n: int = 1,
+ checkpoint_blk_ids: List[int] = None,
+ ):
+ """
+ Inputs
+ - tokens: data of shape N x L x D (or L x N x D depending on the attention implementation)
+ - attn: mask of shape L x L
+
+ Output
+ - x: data of shape N x L x D (or L x N x D depending on the attention implementation)
+ """
+ if self.pre_transformer_layer:
+ tokens = self.pre_transformer_layer(tokens)
+ if use_checkpoint and checkpoint_blk_ids is None:
+ checkpoint_blk_ids = [
+ blk_id
+ for blk_id in range(len(self.blocks))
+ if blk_id % checkpoint_every_n == 0
+ ]
+ if checkpoint_blk_ids:
+ checkpoint_blk_ids = set(checkpoint_blk_ids)
+ for blk_id, blk in enumerate(self.blocks):
+ if use_checkpoint and blk_id in checkpoint_blk_ids:
+ tokens = checkpoint.checkpoint(
+ blk, tokens, attn_mask, use_reentrant=False
+ )
+ else:
+ tokens = blk(tokens, attn_mask=attn_mask)
+ if self.post_transformer_layer:
+ tokens = self.post_transformer_layer(tokens)
+ return tokens
diff --git a/code/model/ImageBind/requirements.txt b/code/model/ImageBind/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..572ae079a6cc3592552d93b8ca08c3ec7fd4efc9
--- /dev/null
+++ b/code/model/ImageBind/requirements.txt
@@ -0,0 +1,10 @@
+--extra-index-url https://download.pytorch.org/whl/cu113
+torchvision==0.14.0
+torchaudio==0.13.0
+pytorchvideo @ git+https://github.com/facebookresearch/pytorchvideo.git@28fe037d212663c6a24f373b94cc5d478c8c1a1d
+timm==0.6.7
+ftfy
+regex
+einops
+fvcore
+decord==0.6.0
diff --git a/code/model/__init__.py b/code/model/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..879752bcc2ad73a53bd786c665a995d722b4e56b
--- /dev/null
+++ b/code/model/__init__.py
@@ -0,0 +1,9 @@
+from .agent import DeepSpeedAgent
+from .openllama import OpenLLAMAPEFTModel
+
+def load_model(args):
+ agent_name = args['models'][args['model']]['agent_name']
+ model_name = args['models'][args['model']]['model_name']
+ model = globals()[model_name](**args)
+ agent = globals()[agent_name](model, args)
+ return agent
diff --git a/code/model/__pycache__/__init__.cpython-310.pyc b/code/model/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..1173f59442c93b6379d83b0b521ba54161911f98
Binary files /dev/null and b/code/model/__pycache__/__init__.cpython-310.pyc differ
diff --git a/code/model/__pycache__/agent.cpython-310.pyc b/code/model/__pycache__/agent.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8e7d9cec8e164d6fc0883ffa78aa8386411d7d35
Binary files /dev/null and b/code/model/__pycache__/agent.cpython-310.pyc differ
diff --git a/code/model/__pycache__/modeling_llama.cpython-310.pyc b/code/model/__pycache__/modeling_llama.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5e881f160c736b6c5b0b7b3387b21b4985428fc5
Binary files /dev/null and b/code/model/__pycache__/modeling_llama.cpython-310.pyc differ
diff --git a/code/model/__pycache__/openllama.cpython-310.pyc b/code/model/__pycache__/openllama.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5096daa4a1a203fd47daa74366c8759354b8efe0
Binary files /dev/null and b/code/model/__pycache__/openllama.cpython-310.pyc differ
diff --git a/code/model/agent.py b/code/model/agent.py
new file mode 100644
index 0000000000000000000000000000000000000000..219001fda8cfa22bf6c1b720504c07763044a119
--- /dev/null
+++ b/code/model/agent.py
@@ -0,0 +1,68 @@
+from header import *
+
+class DeepSpeedAgent:
+
+ def __init__(self, model, args):
+ super(DeepSpeedAgent, self).__init__()
+ self.args = args
+ self.model = model
+ if args['stage'] == 2:
+ self.load_stage_1_parameters(args["delta_ckpt_path"])
+ print(f'[!] load stage 1 checkpoint from {args["delta_ckpt_path"]}')
+
+ # load config parameters of deepspeed
+ ds_params = json.load(open(self.args['ds_config_path']))
+ ds_params['scheduler']['params']['total_num_steps'] = self.args['total_steps']
+ ds_params['scheduler']['params']['warmup_num_steps'] = max(10, int(self.args['total_steps'] * self.args['warmup_rate']))
+ self.ds_engine, self.optimizer, _ , _ = deepspeed.initialize(
+ model=self.model,
+ model_parameters=self.model.parameters(),
+ config_params=ds_params,
+ dist_init_required=True,
+ args=types.SimpleNamespace(**args)
+ )
+
+ @torch.no_grad()
+ def predict(self, batch):
+ self.model.eval()
+ string = self.model.generate_one_sample(batch)
+ return string
+
+ def train_model(self, batch, current_step=0, pbar=None):
+ self.ds_engine.module.train()
+ loss, mle_acc = self.ds_engine(batch)
+
+ self.ds_engine.backward(loss)
+ self.ds_engine.step()
+ pbar.set_description(f'[!] loss: {round(loss.item(), 4)}; token_acc: {round(mle_acc*100, 2)}')
+ pbar.update(1)
+ if self.args['local_rank'] == 0 and self.args['log_path'] and current_step % self.args['logging_step'] == 0:
+ elapsed = pbar.format_dict['elapsed']
+ rate = pbar.format_dict['rate']
+ remaining = (pbar.total - pbar.n) / rate if rate and pbar.total else 0
+ remaining = str(datetime.timedelta(seconds=remaining))
+ logging.info(f'[!] progress: {round(pbar.n/pbar.total, 5)}; remaining time: {remaining}; loss: {round(loss.item(), 4)}; token_acc: {round(mle_acc*100, 2)}')
+
+ mle_acc *= 100
+ return mle_acc
+
+ def save_model(self, path, current_step):
+ # only save trainable model parameters
+ param_grad_dic = {
+ k: v.requires_grad for (k, v) in self.ds_engine.module.named_parameters()
+ }
+ state_dict = self.ds_engine.module.state_dict()
+ checkpoint = OrderedDict()
+ for k, v in self.ds_engine.module.named_parameters():
+ if v.requires_grad:
+ checkpoint[k] = v
+ torch.save(checkpoint, f'{path}/pytorch_model.pt')
+ # save tokenizer
+ self.model.llama_tokenizer.save_pretrained(path)
+ # save configuration
+ self.model.llama_model.config.save_pretrained(path)
+ print(f'[!] save model into {path}')
+
+ def load_stage_1_parameters(self, path):
+ delta_ckpt = torch.load(path, map_location=torch.device('cpu'))
+ self.model.load_state_dict(delta_ckpt, strict=False)
diff --git a/code/model/modeling_llama.py b/code/model/modeling_llama.py
new file mode 100644
index 0000000000000000000000000000000000000000..12d980e189d902fb1a6d9ea05dc3ca91959b1c8c
--- /dev/null
+++ b/code/model/modeling_llama.py
@@ -0,0 +1,755 @@
+# This script is based on https://github.com/huggingface/transformers/blob/main/src/transformers/models/llama/modeling_llama.py
+
+""" PyTorch LLaMA model."""
+import math
+from typing import List, Optional, Tuple, Union
+
+import torch
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import BCEWithLogitsLoss, CrossEntropyLoss, MSELoss
+
+from transformers.activations import ACT2FN
+from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast, SequenceClassifierOutputWithPast
+from transformers.modeling_utils import PreTrainedModel
+from transformers.utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging, replace_return_docstrings
+from transformers.models.llama.configuration_llama import LlamaConfig
+
+
+logger = logging.get_logger(__name__)
+
+_CONFIG_FOR_DOC = "LlamaConfig"
+
+
+# Copied from transformers.models.bart.modeling_bart._make_causal_mask
+def _make_causal_mask(
+ input_ids_shape: torch.Size, dtype: torch.dtype, device: torch.device, past_key_values_length: int = 0
+):
+ """
+ Make causal mask used for bi-directional self-attention.
+ """
+ bsz, tgt_len = input_ids_shape
+ mask = torch.full((tgt_len, tgt_len), torch.tensor(torch.finfo(dtype).min, device=device), device=device)
+ mask_cond = torch.arange(mask.size(-1), device=device)
+ mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
+ mask = mask.to(dtype)
+
+ if past_key_values_length > 0:
+ mask = torch.cat([torch.zeros(tgt_len, past_key_values_length, dtype=dtype, device=device), mask], dim=-1)
+ return mask[None, None, :, :].expand(bsz, 1, tgt_len, tgt_len + past_key_values_length)
+
+
+# Copied from transformers.models.bart.modeling_bart._expand_mask
+def _expand_mask(mask: torch.Tensor, dtype: torch.dtype, tgt_len: Optional[int] = None):
+ """
+ Expands attention_mask from `[bsz, seq_len]` to `[bsz, 1, tgt_seq_len, src_seq_len]`.
+ """
+ bsz, src_len = mask.size()
+ tgt_len = tgt_len if tgt_len is not None else src_len
+
+ expanded_mask = mask[:, None, None, :].expand(bsz, 1, tgt_len, src_len).to(dtype)
+
+ inverted_mask = 1.0 - expanded_mask
+
+ return inverted_mask.masked_fill(inverted_mask.to(torch.bool), torch.finfo(dtype).min)
+
+
+class LlamaRMSNorm(nn.Module):
+ def __init__(self, hidden_size, eps=1e-6):
+ """
+ LlamaRMSNorm is equivalent to T5LayerNorm
+ """
+ super().__init__()
+ self.weight = nn.Parameter(torch.ones(hidden_size))
+ self.variance_epsilon = eps
+
+ def forward(self, hidden_states):
+ variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
+ hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
+
+ # convert into half-precision if necessary
+ if self.weight.dtype in [torch.float16, torch.bfloat16]:
+ hidden_states = hidden_states.to(self.weight.dtype)
+
+ return self.weight * hidden_states
+
+
+class LlamaRotaryEmbedding(torch.nn.Module):
+ def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None):
+ super().__init__()
+ inv_freq = 1.0 / (base ** (torch.arange(0, dim, 2).float().to(device) / dim))
+ self.register_buffer("inv_freq", inv_freq)
+
+ # Build here to make `torch.jit.trace` work.
+ self.max_seq_len_cached = max_position_embeddings
+ t = torch.arange(self.max_seq_len_cached, device=self.inv_freq.device, dtype=self.inv_freq.dtype)
+ freqs = torch.einsum("i,j->ij", t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1)
+ self.register_buffer("cos_cached", emb.cos()[None, None, :, :], persistent=False)
+ self.register_buffer("sin_cached", emb.sin()[None, None, :, :], persistent=False)
+
+ def forward(self, x, seq_len=None):
+ # x: [bs, num_attention_heads, seq_len, head_size]
+ # This `if` block is unlikely to be run after we build sin/cos in `__init__`. Keep the logic here just in case.
+ if seq_len > self.max_seq_len_cached:
+ self.max_seq_len_cached = seq_len
+ t = torch.arange(self.max_seq_len_cached, device=x.device, dtype=self.inv_freq.dtype)
+ freqs = torch.einsum("i,j->ij", t, self.inv_freq)
+ # Different from paper, but it uses a different permutation in order to obtain the same calculation
+ emb = torch.cat((freqs, freqs), dim=-1).to(x.device)
+ self.register_buffer("cos_cached", emb.cos()[None, None, :, :], persistent=False)
+ self.register_buffer("sin_cached", emb.sin()[None, None, :, :], persistent=False)
+ return (
+ self.cos_cached[:, :, :seq_len, ...].to(dtype=x.dtype),
+ self.sin_cached[:, :, :seq_len, ...].to(dtype=x.dtype),
+ )
+
+
+def rotate_half(x):
+ """Rotates half the hidden dims of the input."""
+ x1 = x[..., : x.shape[-1] // 2]
+ x2 = x[..., x.shape[-1] // 2 :]
+ return torch.cat((-x2, x1), dim=-1)
+
+
+def apply_rotary_pos_emb(q, k, cos, sin, position_ids):
+ gather_indices = position_ids[:, None, :, None] # [bs, 1, seq_len, 1]
+ gather_indices = gather_indices.repeat(1, cos.shape[1], 1, cos.shape[3])
+ cos = torch.gather(cos.repeat(gather_indices.shape[0], 1, 1, 1), 2, gather_indices)
+ sin = torch.gather(sin.repeat(gather_indices.shape[0], 1, 1, 1), 2, gather_indices)
+ q_embed = (q * cos) + (rotate_half(q) * sin)
+ k_embed = (k * cos) + (rotate_half(k) * sin)
+ return q_embed, k_embed
+
+
+class LlamaMLP(nn.Module):
+ def __init__(
+ self,
+ hidden_size: int,
+ intermediate_size: int,
+ hidden_act: str,
+ ):
+ super().__init__()
+ self.gate_proj = nn.Linear(hidden_size, intermediate_size, bias=False)
+ self.down_proj = nn.Linear(intermediate_size, hidden_size, bias=False)
+ self.up_proj = nn.Linear(hidden_size, intermediate_size, bias=False)
+ self.act_fn = ACT2FN[hidden_act]
+
+ def forward(self, x):
+ return self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
+
+
+class LlamaAttention(nn.Module):
+ """Multi-headed attention from 'Attention Is All You Need' paper"""
+
+ def __init__(self, config: LlamaConfig):
+ super().__init__()
+ self.config = config
+ self.hidden_size = config.hidden_size
+ self.num_heads = config.num_attention_heads
+ self.head_dim = self.hidden_size // self.num_heads
+ self.max_position_embeddings = config.max_position_embeddings
+
+ if (self.head_dim * self.num_heads) != self.hidden_size:
+ raise ValueError(
+ f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size}"
+ f" and `num_heads`: {self.num_heads})."
+ )
+ self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)
+ self.k_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)
+ self.v_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=False)
+ self.o_proj = nn.Linear(self.num_heads * self.head_dim, self.hidden_size, bias=False)
+ self.rotary_emb = LlamaRotaryEmbedding(self.head_dim, max_position_embeddings=self.max_position_embeddings)
+
+ def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
+ return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: bool = False,
+ use_cache: bool = False,
+ ) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
+ bsz, q_len, _ = hidden_states.size()
+
+ query_states = self.q_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ key_states = self.k_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+ value_states = self.v_proj(hidden_states).view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
+
+ kv_seq_len = key_states.shape[-2]
+ if past_key_value is not None:
+ kv_seq_len += past_key_value[0].shape[-2]
+ cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
+ query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin, position_ids)
+ # [bsz, nh, t, hd]
+
+ if past_key_value is not None:
+ # reuse k, v, self_attention
+ key_states = torch.cat([past_key_value[0], key_states], dim=2)
+ value_states = torch.cat([past_key_value[1], value_states], dim=2)
+
+ past_key_value = (key_states, value_states) if use_cache else None
+
+ attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
+
+ if attn_weights.size() != (bsz, self.num_heads, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention weights should be of size {(bsz * self.num_heads, q_len, kv_seq_len)}, but is"
+ f" {attn_weights.size()}"
+ )
+
+ if attention_mask is not None:
+ if attention_mask.size() != (bsz, 1, q_len, kv_seq_len):
+ raise ValueError(
+ f"Attention mask should be of size {(bsz, 1, q_len, kv_seq_len)}, but is {attention_mask.size()}"
+ )
+ attn_weights = attn_weights + attention_mask
+ attn_weights = torch.max(attn_weights, torch.tensor(torch.finfo(attn_weights.dtype).min))
+
+ # upcast attention to fp32
+ attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
+ attn_output = torch.matmul(attn_weights, value_states)
+
+ if attn_output.size() != (bsz, self.num_heads, q_len, self.head_dim):
+ raise ValueError(
+ f"`attn_output` should be of size {(bsz, self.num_heads, q_len, self.head_dim)}, but is"
+ f" {attn_output.size()}"
+ )
+
+ attn_output = attn_output.transpose(1, 2)
+ attn_output = attn_output.reshape(bsz, q_len, self.hidden_size)
+
+ attn_output = self.o_proj(attn_output)
+
+ if not output_attentions:
+ attn_weights = None
+
+ return attn_output, attn_weights, past_key_value
+
+
+class LlamaDecoderLayer(nn.Module):
+ def __init__(self, config: LlamaConfig):
+ super().__init__()
+ self.hidden_size = config.hidden_size
+ self.self_attn = LlamaAttention(config=config)
+ self.mlp = LlamaMLP(
+ hidden_size=self.hidden_size,
+ intermediate_size=config.intermediate_size,
+ hidden_act=config.hidden_act,
+ )
+ self.input_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+ self.post_attention_layernorm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ def forward(
+ self,
+ hidden_states: torch.Tensor,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_value: Optional[Tuple[torch.Tensor]] = None,
+ output_attentions: Optional[bool] = False,
+ use_cache: Optional[bool] = False,
+ ) -> Tuple[torch.FloatTensor, Optional[Tuple[torch.FloatTensor, torch.FloatTensor]]]:
+ """
+ Args:
+ hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
+ attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
+ `(batch, 1, tgt_len, src_len)` where padding elements are indicated by very large negative values.
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under
+ returned tensors for more detail.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
+ (see `past_key_values`).
+ past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
+ """
+
+ residual = hidden_states
+
+ hidden_states = self.input_layernorm(hidden_states)
+
+ # Self Attention
+ hidden_states, self_attn_weights, present_key_value = self.self_attn(
+ hidden_states=hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+ hidden_states = residual + hidden_states
+
+ # Fully Connected
+ residual = hidden_states
+ hidden_states = self.post_attention_layernorm(hidden_states)
+ hidden_states = self.mlp(hidden_states)
+ hidden_states = residual + hidden_states
+
+ outputs = (hidden_states,)
+
+ if output_attentions:
+ outputs += (self_attn_weights,)
+
+ if use_cache:
+ outputs += (present_key_value,)
+
+ return outputs
+
+
+LLAMA_START_DOCSTRING = r"""
+ This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
+ library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
+ etc.)
+
+ This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
+ Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
+ and behavior.
+
+ Parameters:
+ config ([`LlamaConfig`]):
+ Model configuration class with all the parameters of the model. Initializing with a config file does not
+ load the weights associated with the model, only the configuration. Check out the
+ [`~PreTrainedModel.from_pretrained`] method to load the model weights.
+"""
+
+
+@add_start_docstrings(
+ "The bare LLaMA Model outputting raw hidden-states without any specific head on top.",
+ LLAMA_START_DOCSTRING,
+)
+class LlamaPreTrainedModel(PreTrainedModel):
+ config_class = LlamaConfig
+ base_model_prefix = "model"
+ supports_gradient_checkpointing = True
+ _no_split_modules = ["LlamaDecoderLayer"]
+ _keys_to_ignore_on_load_unexpected = [r"decoder\.version"]
+
+ def _init_weights(self, module):
+ std = self.config.initializer_range
+ if isinstance(module, nn.Linear):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.bias is not None:
+ module.bias.data.zero_()
+ elif isinstance(module, nn.Embedding):
+ module.weight.data.normal_(mean=0.0, std=std)
+ if module.padding_idx is not None:
+ module.weight.data[module.padding_idx].zero_()
+
+ def _set_gradient_checkpointing(self, module, value=False):
+ if isinstance(module, LlamaModel):
+ module.gradient_checkpointing = value
+
+
+LLAMA_INPUTS_DOCSTRING = r"""
+ Args:
+ input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
+ Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
+ it.
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ [What are input IDs?](../glossary#input-ids)
+ attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
+
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+
+ [What are attention masks?](../glossary#attention-mask)
+
+ Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
+ [`PreTrainedTokenizer.__call__`] for details.
+
+ If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see
+ `past_key_values`).
+
+ If you want to change padding behavior, you should read [`modeling_opt._prepare_decoder_attention_mask`]
+ and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more
+ information on the default strategy.
+
+ - 1 indicates the head is **not masked**,
+ - 0 indicates the head is **masked**.
+ position_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
+ config.n_positions - 1]`.
+
+ [What are position IDs?](../glossary#position-ids)
+ past_key_values (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`):
+ Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape
+ `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape
+ `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
+
+ Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention
+ blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
+
+ If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that
+ don't have their past key value states given to this model) of shape `(batch_size, 1)` instead of all
+ `decoder_input_ids` of shape `(batch_size, sequence_length)`.
+ inputs_embeds (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*):
+ Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
+ is useful if you want more control over how to convert `input_ids` indices into associated vectors than the
+ model's internal embedding lookup matrix.
+ use_cache (`bool`, *optional*):
+ If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see
+ `past_key_values`).
+ output_attentions (`bool`, *optional*):
+ Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
+ tensors for more detail.
+ output_hidden_states (`bool`, *optional*):
+ Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
+ more detail.
+ return_dict (`bool`, *optional*):
+ Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
+"""
+
+
+@add_start_docstrings(
+ "The bare LLaMA Model outputting raw hidden-states without any specific head on top.",
+ LLAMA_START_DOCSTRING,
+)
+class LlamaModel(LlamaPreTrainedModel):
+ """
+ Transformer decoder consisting of *config.num_hidden_layers* layers. Each layer is a [`LlamaDecoderLayer`]
+
+ Args:
+ config: LlamaConfig
+ """
+
+ def __init__(self, config: LlamaConfig):
+ super().__init__(config)
+ self.padding_idx = config.pad_token_id
+ self.vocab_size = config.vocab_size
+
+ self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, self.padding_idx)
+ self.layers = nn.ModuleList([LlamaDecoderLayer(config) for _ in range(config.num_hidden_layers)])
+ self.norm = LlamaRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
+
+ self.gradient_checkpointing = False
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.embed_tokens = value
+
+ # Copied from transformers.models.bart.modeling_bart.BartDecoder._prepare_decoder_attention_mask
+ def _prepare_decoder_attention_mask(self, attention_mask, input_shape, inputs_embeds, past_key_values_length):
+ # create causal mask
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ combined_attention_mask = None
+ if input_shape[-1] > 1:
+ combined_attention_mask = _make_causal_mask(
+ input_shape,
+ inputs_embeds.dtype,
+ device=inputs_embeds.device,
+ past_key_values_length=past_key_values_length,
+ )
+
+ if attention_mask is not None:
+ # [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
+ expanded_attn_mask = _expand_mask(attention_mask, inputs_embeds.dtype, tgt_len=input_shape[-1]).to(
+ inputs_embeds.device
+ )
+ combined_attention_mask = (
+ expanded_attn_mask if combined_attention_mask is None else expanded_attn_mask + combined_attention_mask
+ )
+
+ return combined_attention_mask
+
+ @add_start_docstrings_to_model_forward(LLAMA_INPUTS_DOCSTRING)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ query_embeds: Optional[torch.FloatTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, BaseModelOutputWithPast]:
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # retrieve input_ids and inputs_embeds
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both decoder_input_ids and decoder_inputs_embeds at the same time")
+ elif input_ids is not None:
+ batch_size, seq_length = input_ids.shape
+ elif inputs_embeds is not None:
+ batch_size, seq_length, _ = inputs_embeds.shape
+ else:
+ raise ValueError("You have to specify either decoder_input_ids or decoder_inputs_embeds")
+
+ if inputs_embeds is None:
+ inputs_embeds = self.embed_tokens(input_ids)
+ if query_embeds is not None:
+ inputs_embeds = torch.cat([query_embeds, inputs_embeds], dim=1)
+ batch_size, seq_length, _ = inputs_embeds.shape
+
+ seq_length_with_past = seq_length
+ past_key_values_length = 0
+
+ if past_key_values is not None:
+ past_key_values_length = past_key_values[0][0].shape[2]
+ seq_length_with_past = seq_length_with_past + past_key_values_length
+
+ if position_ids is None:
+ device = input_ids.device if input_ids is not None else inputs_embeds.device
+ position_ids = torch.arange(
+ past_key_values_length, seq_length + past_key_values_length, dtype=torch.long, device=device
+ )
+ position_ids = position_ids.unsqueeze(0).view(-1, seq_length)
+ else:
+ position_ids = position_ids.view(-1, seq_length).long()
+
+ # embed positions
+ if attention_mask is None:
+ attention_mask = torch.ones(
+ (batch_size, seq_length_with_past), dtype=torch.bool, device=inputs_embeds.device
+ )
+ attention_mask = self._prepare_decoder_attention_mask(
+ attention_mask, (batch_size, seq_length), inputs_embeds, past_key_values_length
+ )
+
+ hidden_states = inputs_embeds
+
+ if self.gradient_checkpointing and self.training:
+ if use_cache:
+ logger.warning_once(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ )
+ use_cache = False
+
+ # decoder layers
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attns = () if output_attentions else None
+ next_decoder_cache = () if use_cache else None
+
+ for idx, decoder_layer in enumerate(self.layers):
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ past_key_value = past_key_values[idx] if past_key_values is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ # None for past_key_value
+ return module(*inputs, output_attentions, None)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(decoder_layer),
+ hidden_states,
+ attention_mask,
+ position_ids,
+ None,
+ )
+ else:
+ layer_outputs = decoder_layer(
+ hidden_states,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_value=past_key_value,
+ output_attentions=output_attentions,
+ use_cache=use_cache,
+ )
+
+ hidden_states = layer_outputs[0]
+
+ if use_cache:
+ next_decoder_cache += (layer_outputs[2 if output_attentions else 1],)
+
+ if output_attentions:
+ all_self_attns += (layer_outputs[1],)
+
+ hidden_states = self.norm(hidden_states)
+
+ # add hidden states from the last decoder layer
+ if output_hidden_states:
+ all_hidden_states += (hidden_states,)
+
+ next_cache = next_decoder_cache if use_cache else None
+ if not return_dict:
+ return tuple(v for v in [hidden_states, next_cache, all_hidden_states, all_self_attns] if v is not None)
+ return BaseModelOutputWithPast(
+ last_hidden_state=hidden_states,
+ past_key_values=next_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attns,
+ )
+
+
+class LlamaForCausalLM(LlamaPreTrainedModel):
+ def __init__(self, config):
+ super().__init__(config)
+ self.model = LlamaModel(config)
+
+ self.lm_head = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
+
+ # Initialize weights and apply final processing
+ self.post_init()
+
+ def get_input_embeddings(self):
+ return self.model.embed_tokens
+
+ def set_input_embeddings(self, value):
+ self.model.embed_tokens = value
+
+ def get_output_embeddings(self):
+ return self.lm_head
+
+ def set_output_embeddings(self, new_embeddings):
+ self.lm_head = new_embeddings
+
+ def set_decoder(self, decoder):
+ self.model = decoder
+
+ def get_decoder(self):
+ return self.model
+
+ @add_start_docstrings_to_model_forward(LLAMA_INPUTS_DOCSTRING)
+ @replace_return_docstrings(output_type=CausalLMOutputWithPast, config_class=_CONFIG_FOR_DOC)
+ def forward(
+ self,
+ input_ids: torch.LongTensor = None,
+ attention_mask: Optional[torch.Tensor] = None,
+ position_ids: Optional[torch.LongTensor] = None,
+ past_key_values: Optional[List[torch.FloatTensor]] = None,
+ inputs_embeds: Optional[torch.FloatTensor] = None,
+ query_embeds: Optional[torch.FloatTensor] = None,
+ labels: Optional[torch.LongTensor] = None,
+ use_cache: Optional[bool] = None,
+ output_attentions: Optional[bool] = None,
+ output_hidden_states: Optional[bool] = None,
+ return_dict: Optional[bool] = None,
+ ) -> Union[Tuple, CausalLMOutputWithPast]:
+ r"""
+ Args:
+ labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
+ Labels for computing the masked language modeling loss. Indices should either be in `[0, ...,
+ config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored
+ (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
+
+ Returns:
+
+ Example:
+
+ ```python
+ >>> from transformers import AutoTokenizer, LlamaForCausalLM
+
+ >>> model = LlamaForCausalLM.from_pretrained(PATH_TO_CONVERTED_WEIGHTS)
+ >>> tokenizer = AutoTokenizer.from_pretrained(PATH_TO_CONVERTED_TOKENIZER)
+
+ >>> prompt = "Hey, are you consciours? Can you talk to me?"
+ >>> inputs = tokenizer(prompt, return_tensors="pt")
+
+ >>> # Generate
+ >>> generate_ids = model.generate(inputs.input_ids, max_length=30)
+ >>> tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
+ "Hey, are you consciours? Can you talk to me?\nI'm not consciours, but I can talk to you."
+ ```"""
+
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ # decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
+ outputs = self.model(
+ input_ids=input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ past_key_values=past_key_values,
+ inputs_embeds=inputs_embeds,
+ query_embeds=query_embeds,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ )
+
+ hidden_states = outputs[0]
+ logits = self.lm_head(hidden_states)
+
+ loss = None
+ if labels is not None:
+ # Shift so that tokens < n predict n
+ shift_logits = logits[..., :-1, :].contiguous()
+ shift_labels = labels[..., 1:].contiguous()
+ # Flatten the tokens
+ loss_fct = CrossEntropyLoss()
+ shift_logits = shift_logits.view(-1, self.config.vocab_size)
+ shift_labels = shift_labels.view(-1)
+ # Enable model parallelism
+ shift_labels = shift_labels.to(shift_logits.device)
+ loss = loss_fct(shift_logits, shift_labels)
+
+ if not return_dict:
+ output = (logits,) + outputs[1:]
+ return (loss,) + output if loss is not None else output
+
+ return CausalLMOutputWithPast(
+ loss=loss,
+ logits=logits,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ )
+
+ def prepare_inputs_for_generation(
+ self, input_ids, query_embeds=None, past_key_values=None, attention_mask=None, inputs_embeds=None, **kwargs
+ ):
+ if past_key_values:
+ input_ids = input_ids[:, -1:]
+
+ position_ids = kwargs.get("position_ids", None)
+ if attention_mask is not None and position_ids is None:
+ # create position_ids on the fly for batch generation
+ position_ids = attention_mask.long().cumsum(-1) - 1
+ position_ids.masked_fill_(attention_mask == 0, 1)
+ if past_key_values:
+ position_ids = position_ids[:, -1].unsqueeze(-1)
+ query_embeds = None
+
+ # if `inputs_embeds` are passed, we only want to use them in the 1st generation step
+ if inputs_embeds is not None and past_key_values is None:
+ model_inputs = {"inputs_embeds": inputs_embeds}
+ else:
+ model_inputs = {"input_ids": input_ids}
+
+ model_inputs.update(
+ {
+ "position_ids": position_ids,
+ "query_embeds": query_embeds,
+ "past_key_values": past_key_values,
+ "use_cache": kwargs.get("use_cache"),
+ "attention_mask": attention_mask,
+ }
+ )
+ return model_inputs
+
+ @staticmethod
+ def _reorder_cache(past_key_values, beam_idx):
+ reordered_past = ()
+ for layer_past in past_key_values:
+ reordered_past += (tuple(past_state.index_select(0, beam_idx) for past_state in layer_past),)
+ return reordered_past
+
diff --git a/code/model/openllama.py b/code/model/openllama.py
new file mode 100644
index 0000000000000000000000000000000000000000..b8e235a95723942975ccdd88739bd7b5b79458e7
--- /dev/null
+++ b/code/model/openllama.py
@@ -0,0 +1,293 @@
+from header import *
+import torch.nn.functional as F
+from .ImageBind import *
+from .ImageBind import data
+from .modeling_llama import LlamaForCausalLM
+from transformers import StoppingCriteria, StoppingCriteriaList
+
+import torch
+from torch.nn.utils import rnn
+
+class StoppingCriteriaSub(StoppingCriteria):
+
+ def __init__(self, stops = [], encounters=1):
+ super().__init__()
+ self.stops = stops
+ self.ENCOUNTERS = encounters
+
+ def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor):
+ stop_count = 0
+ for stop in self.stops:
+ stop_count = (stop == input_ids[0]).sum().item()
+ if stop_count >= self.ENCOUNTERS:
+ return True
+ return False
+
+def build_one_instance(tokenizer, conversation):
+ text_list = []
+ turn_num = len(conversation)
+ input_ids, target_ids = [], []
+ for i in range(turn_num):
+ turn = conversation[i]
+ role = turn['from']
+ if i == 0: # the first human turn
+ assert role == 'human'
+ text = ' ' + turn['value'] + '\n### Assistant:'
+ one_input_id = tokenizer(text, add_special_tokens=False).input_ids
+ input_ids += one_input_id
+ target_ids += [-100]*len(one_input_id) # do not perform loss regression on human prompt
+ else:
+ if role == 'human':
+ text = 'Human: ' + turn['value'] + '\n### Assistant:'
+ one_input_id = tokenizer(text, add_special_tokens=False).input_ids
+ input_ids += one_input_id
+ target_ids += [-100]*len(one_input_id)
+ elif role == 'gpt':
+ text = turn['value'] + '\n###'
+ one_input_id = tokenizer(text, add_special_tokens=False).input_ids
+ input_ids += one_input_id
+ target_ids += one_input_id
+ else:
+ raise Exception('Wrong Role!!!')
+ text_list.append(text)
+ assert len(input_ids) == len(target_ids)
+ return text_list, input_ids, target_ids
+
+def process_batch_instance(tokenizer, batch_of_conversations, max_tgt_len):
+ batch_input_ids, batch_target_ids = [], []
+ for conversation in batch_of_conversations:
+ _, one_input_ids, one_target_ids = build_one_instance(tokenizer, conversation)
+ batch_input_ids.append(torch.LongTensor(one_input_ids))
+ batch_target_ids.append(torch.LongTensor(one_target_ids))
+ input_ids = rnn.pad_sequence(batch_input_ids, batch_first=True, padding_value=tokenizer.pad_token_id)
+ target_ids = rnn.pad_sequence(batch_target_ids, batch_first=True, padding_value=-100)
+ assert input_ids.size() == target_ids.size()
+ input_ids = input_ids[:,:max_tgt_len]
+ target_ids = target_ids[:,:max_tgt_len]
+ attention_mask = input_ids.ne(tokenizer.pad_token_id)
+ assert attention_mask.size() == input_ids.size()
+ return input_ids, target_ids, attention_mask.long()
+
+PROMPT_START = '### Human: '
+class OpenLLAMAPEFTModel(nn.Module):
+
+ '''LoRA for LLaMa model'''
+
+ def __init__(self, **args):
+ super(OpenLLAMAPEFTModel, self).__init__()
+ self.args = args
+ imagebind_ckpt_path = args['imagebind_ckpt_path']
+ vicuna_ckpt_path = args['vicuna_ckpt_path']
+ max_tgt_len = args['max_tgt_len']
+ stage = args['stage']
+
+ print (f'Initializing visual encoder from {imagebind_ckpt_path} ...')
+ self.visual_encoder, self.visual_hidden_size = \
+ imagebind_model.imagebind_huge(pretrained=True, store_path=imagebind_ckpt_path)
+ # free vision encoder
+ for name, param in self.visual_encoder.named_parameters():
+ param.requires_grad = False
+ self.visual_encoder.eval()
+ print ('Visual encoder initialized.')
+
+ print (f'Initializing language decoder from {vicuna_ckpt_path} ...')
+ # add the lora module
+ peft_config = LoraConfig(
+ task_type=TaskType.CAUSAL_LM,
+ inference_mode=False,
+ r=self.args['lora_r'],
+ lora_alpha=self.args['lora_alpha'],
+ lora_dropout=self.args['lora_dropout'],
+ target_modules=['q_proj', 'k_proj', 'v_proj', 'o_proj']
+ )
+
+ self.llama_model = LlamaForCausalLM.from_pretrained(vicuna_ckpt_path)
+
+ self.llama_model = get_peft_model(self.llama_model, peft_config)
+ self.llama_model.print_trainable_parameters()
+
+ self.llama_tokenizer = LlamaTokenizer.from_pretrained(vicuna_ckpt_path, use_fast=False)
+ self.llama_tokenizer.pad_token = self.llama_tokenizer.eos_token
+ self.llama_tokenizer.padding_side = "right"
+ print ('Language decoder initialized.')
+
+ self.llama_proj = nn.Linear(
+ self.visual_hidden_size, self.llama_model.config.hidden_size
+ )
+
+ self.max_tgt_len = max_tgt_len
+ self.device = torch.cuda.current_device()
+
+ def encode_video(self, video_paths):
+ inputs = {ModalityType.VISION: data.load_and_transform_video_data(video_paths, self.device)}
+ # convert into visual dtype
+ inputs = {key: inputs[key].to(self.llama_model.dtype) for key in inputs}
+ with torch.no_grad():
+ embeddings = self.visual_encoder(inputs)
+ video_embeds = embeddings[ModalityType.VISION] # bsz x 1024
+ inputs_llama = self.llama_proj(video_embeds).unsqueeze(1) # bsz x 1 x llama_size
+ atts_llama = torch.ones(inputs_llama.size()[:-1], dtype=torch.long).to(self.device) # bsz x 1
+ return inputs_llama, atts_llama
+
+ def encode_audio(self, audio_paths):
+ inputs = {ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, self.device)}
+ # convert into visual dtype
+ inputs = {key: inputs[key].to(self.llama_model.dtype) for key in inputs}
+ with torch.no_grad():
+ embeddings = self.visual_encoder(inputs)
+ audio_embeds = embeddings[ModalityType.AUDIO] # bsz x 1024
+ inputs_llama = self.llama_proj(audio_embeds).unsqueeze(1) # bsz x 1 x llama_size
+ atts_llama = torch.ones(inputs_llama.size()[:-1], dtype=torch.long).to(self.device) # bsz x 1
+ return inputs_llama, atts_llama
+
+ def encode_thermal(self, thermal_paths):
+ inputs = {ModalityType.THERMAL: data.load_and_transform_thermal_data(thermal_paths, self.device)}
+ # convert into visual dtype
+ inputs = {key: inputs[key].to(self.llama_model.dtype) for key in inputs}
+ with torch.no_grad():
+ embeddings = self.visual_encoder(inputs)
+ image_embeds = embeddings['thermal'] # bsz x 1024
+ inputs_llama = self.llama_proj(image_embeds).unsqueeze(1) # bsz x 1 x llama_size
+ atts_llama = torch.ones(inputs_llama.size()[:-1], dtype=torch.long).to(self.device) # bsz x 1
+ return inputs_llama, atts_llama
+
+ def encode_image(self, image_paths):
+ inputs = {ModalityType.VISION: data.load_and_transform_vision_data(image_paths, self.device)}
+ # convert into visual dtype
+ inputs = {key: inputs[key].to(self.llama_model.dtype) for key in inputs}
+ with torch.no_grad():
+ embeddings = self.visual_encoder(inputs)
+ image_embeds = embeddings['vision'] # bsz x 1024
+ inputs_llama = self.llama_proj(image_embeds).unsqueeze(1) # bsz x 1 x llama_size
+ atts_llama = torch.ones(inputs_llama.size()[:-1], dtype=torch.long).to(self.device) # bsz x 1
+ return inputs_llama, atts_llama
+
+ def prompt_wrap(self, img_embeds, input_ids, target_ids, attention_mask):
+ '''
+ input_ids, target_ids, attention_mask: bsz x s2
+ '''
+ input_ids = input_ids.to(self.device) # bsz x s2
+ target_ids = target_ids.to(self.device) # bsz x s2
+ attention_mask = attention_mask.to(self.device) # bsz x s2
+
+ batch_size = img_embeds.shape[0]
+ p_before = PROMPT_START
+ p_before_tokens = self.llama_tokenizer(p_before,
+ return_tensors="pt", add_special_tokens=False).to(self.device)
+ # peft model need deeper call
+ p_before_embeds = self.llama_model.model.model.embed_tokens(p_before_tokens.input_ids).expand(batch_size, -1, -1) # bsz x s1 x embed_dim
+ p_after_embeds = self.llama_model.model.model.embed_tokens(input_ids).expand(batch_size, -1, -1) # bsz x s2 x embed_dim
+ bos = torch.ones([batch_size, 1],
+ dtype=p_before_tokens.input_ids.dtype,
+ device=p_before_tokens.input_ids.device) * self.llama_tokenizer.bos_token_id # bsz x 1
+ bos_embeds = self.llama_model.model.model.embed_tokens(bos) # bsz x 1 x embed_dim
+ inputs_embeds = torch.cat([bos_embeds, p_before_embeds, img_embeds, p_after_embeds], dim=1) # bsz x (1+s1+1+s2) x embed_dim
+
+ # create targets
+ empty_targets = (
+ torch.ones([batch_size, 1+p_before_embeds.size()[1]+1], # 1 (bos) + s1 + 1 (image vector)
+ dtype=torch.long).to(self.device).fill_(-100)
+ ) # bsz x (1 + s1 + 1)
+ targets = torch.cat([empty_targets, target_ids], dim=1) # bsz x (1 + s1 + 1 + s2)
+ assert inputs_embeds.size()[1] == targets.size()[1]
+
+ atts_prefix = torch.ones([batch_size, 1+p_before_embeds.size()[1]+1], dtype=torch.long).to(self.device) # bsz x (1 + s1 +1)
+ attention_mask = torch.cat([atts_prefix, attention_mask], dim=1)
+ assert attention_mask.size() == targets.size() # bsz x (1 + s1 + 1 + s2)
+ return inputs_embeds, targets, attention_mask
+
+ def forward(self, inputs):
+ image_paths = inputs['image_paths']
+ img_embeds, _ = self.encode_image(image_paths)
+
+ output_texts = inputs['output_texts']
+ input_ids, target_ids, attention_mask = process_batch_instance(self.llama_tokenizer, output_texts, self.max_tgt_len)
+ inputs_embeds, targets, attention_mask = self.prompt_wrap(img_embeds, input_ids, target_ids, attention_mask)
+
+ outputs = self.llama_model(
+ inputs_embeds=inputs_embeds,
+ attention_mask=attention_mask,
+ return_dict=True,
+ labels=targets,
+ )
+ loss = outputs.loss
+ # calculate the token accuarcy
+ chosen_tokens = torch.max(outputs.logits, dim=-1)[1][:, 1:-1] # [B, S-1]
+ labels = targets[:, 2:]
+ gen_acc = (chosen_tokens.reshape(-1) == labels.reshape(-1)).to(torch.long) # [B*S]
+ valid_mask = (labels != -100).reshape(-1)
+ valid_tokens = gen_acc & valid_mask # [B*S]
+ gen_acc = valid_tokens.sum().item() / valid_mask.sum().item()
+ return loss, gen_acc
+
+ def extract_multimodal_feature(self, inputs):
+ features = []
+ if inputs['image_paths']:
+ image_embeds, _ = self.encode_image(inputs['image_paths'])
+ features.append(image_embeds)
+ if inputs['audio_paths']:
+ audio_embeds, _ = self.encode_audio(inputs['audio_paths'])
+ features.append(audio_embeds)
+ if inputs['video_paths']:
+ video_embeds, _ = self.encode_video(inputs['video_paths'])
+ features.append(video_embeds)
+ if inputs['thermal_paths']:
+ thermal_embeds, _ = self.encode_thermal(inputs['thermal_paths'])
+ features.append(thermal_embeds)
+
+ feature_embeds = torch.cat(features).sum(dim=0).unsqueeze(0)
+ return feature_embeds
+
+ def prepare_generation_embedding(self, inputs):
+ prompt = inputs['prompt']
+ if len(inputs['modality_embeds']) == 1:
+ feature_embeds = inputs['modality_embeds'][0]
+ else:
+ feature_embeds = self.extract_multimodal_feature(inputs)
+ inputs['modality_embeds'].append(feature_embeds)
+
+ batch_size = feature_embeds.shape[0]
+ p_before = PROMPT_START
+ p_before_tokens = self.llama_tokenizer(p_before,
+ return_tensors="pt", add_special_tokens=False).to(self.device)
+ p_before_embeds = self.llama_model.model.model.embed_tokens(p_before_tokens.input_ids).expand(batch_size, -1, -1) # bsz x s1 x embed_dim
+ text = ' ' + prompt + '\n### Assistant:'
+ p_after_tokens = self.llama_tokenizer(text, add_special_tokens=False, return_tensors='pt').to(self.device)
+ p_after_embeds = self.llama_model.model.model.embed_tokens(p_after_tokens.input_ids).expand(batch_size, -1, -1) # bsz x s1 x embed_dim
+ bos = torch.ones([batch_size, 1],
+ dtype=p_before_tokens.input_ids.dtype,
+ device=p_before_tokens.input_ids.device) * self.llama_tokenizer.bos_token_id # bsz x 1
+ bos_embeds = self.llama_model.model.model.embed_tokens(bos) # bsz x 1 x embed_dim
+ inputs_embeds = torch.cat([bos_embeds, p_before_embeds, feature_embeds, p_after_embeds], dim=1) # bsz x (1+s1+1+s2) x embed_dim
+ return inputs_embeds
+
+ def generate(self, inputs):
+ '''
+ inputs = {
+ 'image_paths': optional,
+ 'audio_paths': optional
+ 'video_paths': optional
+ 'thermal_paths': optional
+ 'mode': generation mode,
+ 'prompt': human input prompt,
+ 'max_tgt_len': generation length,
+ 'top_p': top_p,
+ 'temperature': temperature
+ 'modality_embeds': None or torch.tensor
+ 'modality_cache': save the image cache
+ }
+ '''
+ input_embeds = self.prepare_generation_embedding(inputs)
+ stopping_criteria = StoppingCriteriaList([StoppingCriteriaSub(stops=[2277], encounters=1)])
+ outputs = self.llama_model.generate(
+ inputs_embeds=input_embeds,
+ max_new_tokens=inputs['max_tgt_len'],
+ top_p=inputs['top_p'],
+ temperature=inputs['temperature'],
+ do_sample=True,
+ use_cache=True,
+ stopping_criteria=stopping_criteria,
+ )
+ output_text = self.llama_tokenizer.decode(outputs[0][:-2], skip_special_tokens=True)
+ return output_text
+
diff --git a/code/pytorchvideo/.circleci/config.yml b/code/pytorchvideo/.circleci/config.yml
new file mode 100644
index 0000000000000000000000000000000000000000..df8133aa23db0742deb04692931b3460b51d30dc
--- /dev/null
+++ b/code/pytorchvideo/.circleci/config.yml
@@ -0,0 +1,205 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+# -------------------------------------------------------------------------------------
+# CircleCI configuration file.
+# Specifies automated environment setup and tests.
+#
+# See https://circleci.com/docs/2.0/language-python/ for more details
+# Available Machine Images:
+# https://circleci.com/docs/2.0/configuration-reference/#available-machine-images
+# -------------------------------------------------------------------------------------
+
+version: 2.1
+
+# -------------------------------------------------------------------------------------
+# Environments to run the jobs in
+# -------------------------------------------------------------------------------------
+cpu: &cpu
+ machine:
+ image: ubuntu-2004:202101-01
+
+gpu: &gpu
+ environment:
+ CUDA_VERSION: "10.2"
+ resource_class: gpu.nvidia.small.multi
+ machine:
+ image: ubuntu-2004:202101-01
+
+setup_cuda: &setup_cuda
+ run:
+ name: Setup CUDA
+ working_directory: ~/
+ command: |
+ # download and install nvidia drivers, cuda, etc
+ wget --no-verbose --no-clobber -P ~/nvidia-downloads https://developer.download.nvidia.com/compute/cuda/11.2.2/local_installers/cuda_11.2.2_460.32.03_linux.run
+ sudo sh ~/nvidia-downloads/cuda_11.2.2_460.32.03_linux.run --silent
+ echo "Done installing CUDA."
+ nvidia-smi
+
+# -------------------------------------------------------------------------------------
+# Re-usable commands
+# -------------------------------------------------------------------------------------
+install_conda: &install_conda
+ run:
+ name: Setup Conda
+ working_directory: ~/
+ command: |
+ curl --retry 3 -o conda.sh https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
+ sh conda.sh -b -p $HOME/miniconda3
+
+setup_ptv_conda: &setup_ptv_conda
+ run:
+ name: Setup Conda Environment
+ command: |
+ pyenv versions
+ export PATH="$HOME/miniconda3/bin:$PATH"
+ conda update -y conda
+ conda init bash
+ source ~/.bashrc
+ conda create --name pytorchvideo python=3.7.9
+
+install_pytorch: &install_pytorch
+ - run:
+ name: Install Pytorch
+ command: |
+ export PATH="$HOME/miniconda3/bin:$PATH"
+ conda activate pytorchvideo
+ conda install pytorch torchvision -c pytorch
+ python -c 'import torch; print(torch.__version__)'
+ python -c 'import torch; print("CUDA:", torch.cuda.is_available())'
+ python -c 'import torchvision; print(torchvision.__version__)'
+
+install_pytorchvideo: &install_pytorchvideo
+ - run:
+ name: Install PyTorchVideo
+ command: |
+ export PATH="$HOME/miniconda3/bin:$PATH"
+ conda activate pytorchvideo
+ pip install -U --progress-bar off -e .[test]
+ python -c 'import pytorchvideo; print(pytorchvideo.__version__)'
+
+build_wheels: &build_wheels
+ - run:
+ name: Install PyTorchVideo
+ command: |
+ export PATH="$HOME/miniconda3/bin:$PATH"
+ conda activate pytorchvideo
+ python setup.py sdist
+
+ export BUILD_NIGHTLY="1"
+ python setup.py sdist
+
+run_unittests: &run_unittests
+ - run:
+ name: Run Unit Tests
+ command: |
+ export PATH="$HOME/miniconda3/bin:$PATH"
+ conda activate pytorchvideo
+ python -m unittest discover -v -s tests
+
+run_unittests_with_coverage: &run_unittests_with_coverage
+ - run:
+ name: Run Unit Tests
+ command: |
+ export PATH="$HOME/miniconda3/bin:$PATH"
+ conda activate pytorchvideo
+ coverage run -m unittest discover -v -s tests
+ bash <(curl -s https://codecov.io/bash)
+
+# -------------------------------------------------------------------------------------
+# Jobs to run
+# -------------------------------------------------------------------------------------
+jobs:
+ cpu_tests:
+ <<: *cpu
+ working_directory: ~/pytorchvideo
+ steps:
+ - checkout
+ - <<: *install_conda
+ - <<: *setup_ptv_conda
+ - <<: *install_pytorch
+ - <<: *install_pytorchvideo
+ - <<: *build_wheels
+ - <<: *run_unittests_with_coverage
+ - store_artifacts:
+ path: ~/pytorchvideo/dist
+ - persist_to_workspace:
+ root: ~/pytorchvideo/dist
+ paths:
+ - "*"
+
+ gpu_tests:
+ working_directory: ~/pytorchvideo
+ <<: *gpu
+ steps:
+ - checkout
+ - <<: *setup_cuda
+ - <<: *install_conda
+ - <<: *setup_ptv_conda
+ - <<: *install_pytorch
+ - <<: *install_pytorchvideo
+ - <<: *run_unittests
+
+ upload_wheel:
+ docker:
+ - image: circleci/python:3.7
+ auth:
+ username: $DOCKERHUB_USERNAME
+ password: $DOCKERHUB_TOKEN
+ working_directory: ~/pytorchvideo
+ steps:
+ - checkout
+ - attach_workspace:
+ at: ~/workspace
+ - run:
+ command: |
+ # no commits in the last 25 hours
+ if [[ -z $(git log --since="25 hours ago") ]]; then
+ echo "No commits in the last day."
+ exit 0
+ fi
+ pip install --progress-bar off --user twine
+ for pkg in ~/workspace/*.tar.gz; do
+ if [[ "$pkg" == *"nightly"* ]];
+ then
+ twine upload --verbose --skip-existing --username __token__ --password $PTV_NIGHTLY_PYPI_TOKEN $pkg
+ else
+ twine upload --verbose --skip-existing --username __token__ --password $PTV_PYPI_TOKEN $pkg
+ fi
+ done
+# -------------------------------------------------------------------------------------
+# Workflows to launch
+# -------------------------------------------------------------------------------------
+workflows:
+ version: 2
+ regular_test:
+ jobs:
+ - cpu_tests:
+ context:
+ - DOCKERHUB_TOKEN
+ - gpu_tests:
+ context:
+ - DOCKERHUB_TOKEN
+
+ nightly:
+ jobs:
+ # https://circleci.com/docs/2.0/contexts/#creating-and-using-a-context
+ - cpu_tests:
+ context:
+ - DOCKERHUB_TOKEN
+ - gpu_tests:
+ context:
+ - DOCKERHUB_TOKEN
+ - upload_wheel:
+ requires:
+ - cpu_tests
+ - gpu_tests
+ context:
+ - DOCKERHUB_TOKEN
+ triggers:
+ - schedule:
+ cron: "0 0 * * *"
+ filters:
+ branches:
+ only:
+ - main
diff --git a/code/pytorchvideo/.flake8 b/code/pytorchvideo/.flake8
new file mode 100644
index 0000000000000000000000000000000000000000..6c3b6d91f3dcf1baa1fc8e5f337fc469e0a9b0ae
--- /dev/null
+++ b/code/pytorchvideo/.flake8
@@ -0,0 +1,6 @@
+[flake8]
+ignore = E203, E266, E501, W503, E221
+max-line-length = 88
+max-complexity = 18
+select = B,C,E,F,W,T4,B9
+exclude = build,__init__.py
diff --git a/code/pytorchvideo/.github/CODE_OF_CONDUCT.md b/code/pytorchvideo/.github/CODE_OF_CONDUCT.md
new file mode 100644
index 0000000000000000000000000000000000000000..f049d4c53173cc44e0d0755b874d108891a5bfc5
--- /dev/null
+++ b/code/pytorchvideo/.github/CODE_OF_CONDUCT.md
@@ -0,0 +1,76 @@
+# Code of Conduct
+
+## Our Pledge
+
+In the interest of fostering an open and welcoming environment, we as
+contributors and maintainers pledge to make participation in our project and
+our community a harassment-free experience for everyone, regardless of age, body
+size, disability, ethnicity, sex characteristics, gender identity and expression,
+level of experience, education, socio-economic status, nationality, personal
+appearance, race, religion, or sexual identity and orientation.
+
+## Our Standards
+
+Examples of behavior that contributes to creating a positive environment
+include:
+
+* Using welcoming and inclusive language
+* Being respectful of differing viewpoints and experiences
+* Gracefully accepting constructive criticism
+* Focusing on what is best for the community
+* Showing empathy towards other community members
+
+Examples of unacceptable behavior by participants include:
+
+* The use of sexualized language or imagery and unwelcome sexual attention or
+ advances
+* Trolling, insulting/derogatory comments, and personal or political attacks
+* Public or private harassment
+* Publishing others' private information, such as a physical or electronic
+ address, without explicit permission
+* Other conduct which could reasonably be considered inappropriate in a
+ professional setting
+
+## Our Responsibilities
+
+Project maintainers are responsible for clarifying the standards of acceptable
+behavior and are expected to take appropriate and fair corrective action in
+response to any instances of unacceptable behavior.
+
+Project maintainers have the right and responsibility to remove, edit, or
+reject comments, commits, code, wiki edits, issues, and other contributions
+that are not aligned to this Code of Conduct, or to ban temporarily or
+permanently any contributor for other behaviors that they deem inappropriate,
+threatening, offensive, or harmful.
+
+## Scope
+
+This Code of Conduct applies within all project spaces, and it also applies when
+an individual is representing the project or its community in public spaces.
+Examples of representing a project or community include using an official
+project e-mail address, posting via an official social media account, or acting
+as an appointed representative at an online or offline event. Representation of
+a project may be further defined and clarified by project maintainers.
+
+## Enforcement
+
+Instances of abusive, harassing, or otherwise unacceptable behavior may be
+reported by contacting the project team at . All
+complaints will be reviewed and investigated and will result in a response that
+is deemed necessary and appropriate to the circumstances. The project team is
+obligated to maintain confidentiality with regard to the reporter of an incident.
+Further details of specific enforcement policies may be posted separately.
+
+Project maintainers who do not follow or enforce the Code of Conduct in good
+faith may face temporary or permanent repercussions as determined by other
+members of the project's leadership.
+
+## Attribution
+
+This Code of Conduct is adapted from the [Contributor Covenant][homepage], version 1.4,
+available at https://www.contributor-covenant.org/version/1/4/code-of-conduct.html
+
+[homepage]: https://www.contributor-covenant.org
+
+For answers to common questions about this code of conduct, see
+https://www.contributor-covenant.org/faq
diff --git a/code/pytorchvideo/.github/CONTRIBUTING.md b/code/pytorchvideo/.github/CONTRIBUTING.md
new file mode 100644
index 0000000000000000000000000000000000000000..877c3814bd25d4d63608e8c3cd2942ed6f3def4d
--- /dev/null
+++ b/code/pytorchvideo/.github/CONTRIBUTING.md
@@ -0,0 +1,55 @@
+# Contributing to PyTorchVIdeo
+We want to make contributing to this project as easy and transparent as
+possible.
+
+## Pull Requests
+We actively welcome your pull requests.
+
+However, if you're adding any significant features, please make sure to have a corresponding issue to outline your proposal and motivation and allow time for us to give feedback, *before* you send a PR.
+We do not always accept new features, and we take the following factors into consideration:
+
+- Whether the same feature can be achieved without modifying PyTorchVideo directly. If any aspect of the API is not extensible, please highlight this in an issue so we can work on making this more extensible.
+- Whether the feature is potentially useful to a large audience, or only to a small portion of users.
+- Whether the proposed solution has a good design and interface.
+- Whether the proposed solution adds extra mental/practical overhead to users who don't need such feature.
+- Whether the proposed solution breaks existing APIs.
+
+When sending a PR, please ensure you complete the following steps:
+
+1. Fork the repo and create your branch from `main`. Follow the instructions
+ in [INSTALL.md](../INSTALL.md) to build the repo.
+2. If you've added code that should be tested, add tests.
+3. If you've changed any APIs, please update the documentation.
+4. Ensure the test suite passes:
+ ```
+ cd pytorchvideo/tests
+ python -m unittest -v
+ ```
+5. Make sure your code lints by running `dev/linter.sh` from the project root.
+6. If a PR contains multiple orthogonal changes, split it into multiple separate PRs.
+7. If you haven't already, complete the Contributor License Agreement ("CLA").
+
+## Contributor License Agreement ("CLA")
+In order to accept your pull request, we need you to submit a CLA. You only need
+to do this once to work on any of Facebook's open source projects.
+
+Complete your CLA here:
+
+## Issues
+We use GitHub issues to track public bugs. Please ensure your description is
+clear and has sufficient instructions to be able to reproduce the issue.
+
+Facebook has a [bounty program](https://www.facebook.com/whitehat/) for the safe
+disclosure of security bugs. In those cases, please go through the process
+outlined on that page and do not file a public issue.
+
+## Coding Style
+We follow these [python](http://google.github.io/styleguide/pyguide.html) and [C++](https://google.github.io/styleguide/cppguide.html) style guides.
+
+For the linter to work, you will need to install `black`, `flake`, `isort` and `clang-format`, and
+they need to be fairly up to date.
+
+## License
+By contributing to PyTorchVideo, you agree that your contributions will be licensed
+under the LICENSE file in the root directory of this source tree.
+
diff --git a/code/pytorchvideo/.github/ISSUE_TEMPLATE/bugs.md b/code/pytorchvideo/.github/ISSUE_TEMPLATE/bugs.md
new file mode 100644
index 0000000000000000000000000000000000000000..b6ea6e9ffa4822b7c5a90eb25dc3123f6288939c
--- /dev/null
+++ b/code/pytorchvideo/.github/ISSUE_TEMPLATE/bugs.md
@@ -0,0 +1,30 @@
+---
+name: "🐛 Bugs / Unexpected behaviors"
+about: Please report unexpected behaviors or bugs in PyTorchVideo.
+
+---
+
+If you do not know the root cause of the problem / bug, and wish someone to help you, please
+post according to this template:
+
+## 🐛 Bugs / Unexpected behaviors
+
+
+NOTE: Please look at the existing list of Issues tagged with the label ['bug`](https://github.com/facebookresearch/pytorchvideo/issues?q=label%3Abug). **Only open a new issue if this bug has not already been reported. If an issue already exists, please comment there instead.**.
+
+## Instructions To Reproduce the Issue:
+
+Please include the following (depending on what the issue is):
+
+1. Any changes you made (`git diff`) or code you wrote
+```
+
+```
+2. The exact command(s) you ran:
+3. What you observed (including the full logs):
+```
+
+```
+
+Please also simplify the steps as much as possible so they do not require additional resources to
+ run, such as a private dataset, models, etc.
diff --git a/code/pytorchvideo/.github/ISSUE_TEMPLATE/config.yml b/code/pytorchvideo/.github/ISSUE_TEMPLATE/config.yml
new file mode 100644
index 0000000000000000000000000000000000000000..3ba13e0cec6cbbfd462e9ebf529dd2093148cd69
--- /dev/null
+++ b/code/pytorchvideo/.github/ISSUE_TEMPLATE/config.yml
@@ -0,0 +1 @@
+blank_issues_enabled: false
diff --git a/code/pytorchvideo/.github/ISSUE_TEMPLATE/feature_request.md b/code/pytorchvideo/.github/ISSUE_TEMPLATE/feature_request.md
new file mode 100644
index 0000000000000000000000000000000000000000..4390d86b39837b7ada1af970067ac330aefa9bda
--- /dev/null
+++ b/code/pytorchvideo/.github/ISSUE_TEMPLATE/feature_request.md
@@ -0,0 +1,21 @@
+---
+name: "\U0001F680 Feature Request"
+about: Submit a proposal/request for a new PyTorchVideo feature
+
+---
+
+## 🚀 Feature
+
+
+NOTE: Please look at the existing list of Issues tagged with the label ['enhancement`](https://github.com/facebookresearch/pytorchvideo/issues?q=label%3Aenhancement). **Only open a new issue if you do not see your feature request there**.
+
+## Motivation
+
+
+
+## Pitch
+
+
+
+NOTE: we only consider adding new features if they are useful for many users.
diff --git a/code/pytorchvideo/.github/ISSUE_TEMPLATE/questions-help.md b/code/pytorchvideo/.github/ISSUE_TEMPLATE/questions-help.md
new file mode 100644
index 0000000000000000000000000000000000000000..76bc0d4db2580d0fd50f3275620bf1fca0b03879
--- /dev/null
+++ b/code/pytorchvideo/.github/ISSUE_TEMPLATE/questions-help.md
@@ -0,0 +1,21 @@
+---
+name: "❓ Questions"
+about: How do I do X with PyTorchVideo? How does PyTorchVideo do X?
+
+---
+
+## ❓ Questions on how to use PyTorchVideo
+
+
+
+
+NOTE: Please look at the existing list of Issues tagged with the label ['question`](https://github.com/facebookresearch/pytorchvideo/issues?q=label%3Aquestion) or ['how-to`](https://github.com/facebookresearch/pytorchvideo/issues?q=label%3A%22how+to%22). **Only open a new issue if you cannot find an answer there**.
+
+Also note the following:
+
+1. If you encountered any errors or unexpected issues while using PyTorchVideo and need help resolving them,
+ please use the "Bugs / Unexpected behaviors" issue template.
+
+2. We do not answer general machine learning / computer vision questions that are not specific to
+ PyTorchVideo, such as how a model works or what algorithm/methods can be
+ used to achieve X.
diff --git a/code/pytorchvideo/.github/PULL_REQUEST_TEMPLATE.md b/code/pytorchvideo/.github/PULL_REQUEST_TEMPLATE.md
new file mode 100644
index 0000000000000000000000000000000000000000..b6851e7bdcaae99ab931cc183cf22fa060d9920d
--- /dev/null
+++ b/code/pytorchvideo/.github/PULL_REQUEST_TEMPLATE.md
@@ -0,0 +1,30 @@
+## Motivation and Context
+
+
+
+
+
+## How Has This Been Tested
+
+
+
+## Types of changes
+
+
+- [ ] Docs change / refactoring / dependency upgrade
+- [ ] Bug fix (non-breaking change which fixes an issue)
+- [ ] New feature (non-breaking change which adds functionality)
+- [ ] Breaking change (fix or feature that would cause existing functionality to change)
+
+## Checklist
+
+
+
+- [ ] My code follows the code style of this project.
+- [ ] My change requires a change to the documentation.
+- [ ] I have updated the documentation accordingly.
+- [ ] I have read the **CONTRIBUTING** document.
+- [ ] I have completed my CLA (see **CONTRIBUTING**)
+- [ ] I have added tests to cover my changes.
+- [ ] All new and existing tests passed.
+
diff --git a/code/pytorchvideo/.github/media/ava_slowfast.gif b/code/pytorchvideo/.github/media/ava_slowfast.gif
new file mode 100644
index 0000000000000000000000000000000000000000..37d427d2730de52acaf1200e88d638c7ccccb05a
--- /dev/null
+++ b/code/pytorchvideo/.github/media/ava_slowfast.gif
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:2a164af526b6323a2523f4c28b09408758a114865483a9b02c56d500068ffe97
+size 3455262
diff --git a/code/pytorchvideo/.github/media/logo_horizontal_color.png b/code/pytorchvideo/.github/media/logo_horizontal_color.png
new file mode 100644
index 0000000000000000000000000000000000000000..bcb951870adaad2228b8b7bf8f26b7d8dd635b3b
Binary files /dev/null and b/code/pytorchvideo/.github/media/logo_horizontal_color.png differ
diff --git a/code/pytorchvideo/.gitignore b/code/pytorchvideo/.gitignore
new file mode 100644
index 0000000000000000000000000000000000000000..776740c4b1b0e28142e31062ac1fe3245174dd7f
--- /dev/null
+++ b/code/pytorchvideo/.gitignore
@@ -0,0 +1,34 @@
+*.DS_Store
+
+build/
+_ext
+*.pyc
+*.pyd
+*.so
+*.dll
+*.egg-info/
+**/__pycache__/
+*-checkpoint.ipynb
+**/.ipynb_checkpoints
+**/.ipynb_checkpoints/**
+
+
+# Docusaurus site
+website/yarn.lock
+website/build/
+website/i18n/
+website/node_modules/*
+website/npm-debug.log
+
+## Generated for tutorials
+website/_tutorials/
+website/static/files/
+website/pages/tutorials/*
+!website/pages/tutorials/index.js
+
+
+## Conda and pip builds
+packaging/out/
+packaging/output_files/
+dist/
+wheels/
diff --git a/code/pytorchvideo/.readthedocs.yml b/code/pytorchvideo/.readthedocs.yml
new file mode 100644
index 0000000000000000000000000000000000000000..d27f49936d6674b58454fddba2544210a7f30d33
--- /dev/null
+++ b/code/pytorchvideo/.readthedocs.yml
@@ -0,0 +1,25 @@
+# .readthedocs.yml
+# Read the Docs configuration file
+# See https://docs.readthedocs.io/en/stable/config-file/v2.html for details
+
+# Required
+version: 2
+
+# Build documentation in the docs/ directory with Sphinx
+sphinx:
+ builder: html
+ configuration: docs/source/conf.py
+
+# Build documentation with MkDocs
+#mkdocs:
+# configuration: mkdocs.yml
+
+# Optionally build your docs in additional formats such as PDF and ePub
+formats: all
+
+# Optionally set the version of Python and requirements required to build your docs
+python:
+ version: 3.7
+ system_packages: true
+ install:
+ - requirements: docs/requirements.txt
diff --git a/code/pytorchvideo/CONTRIBUTING.md b/code/pytorchvideo/CONTRIBUTING.md
new file mode 100644
index 0000000000000000000000000000000000000000..23e2943257ed76d661f1be066dc687a51a38c1b2
--- /dev/null
+++ b/code/pytorchvideo/CONTRIBUTING.md
@@ -0,0 +1,41 @@
+# Contributing to fvcore
+We want to make contributing to this project as easy and transparent as
+possible.
+
+## Pull Requests
+We actively welcome your pull requests.
+
+1. Fork the repo and create your branch from `main`.
+2. If you've added code that should be tested, add tests.
+3. If you've changed APIs, update the documentation.
+4. Ensure the test suite passes.
+5. Make sure your code lints.
+6. If you haven't already, complete the Contributor License Agreement ("CLA").
+
+## Testing
+
+Please follow the instructions mentioned in [test-README](https://github.com/facebookresearch/pytorchvideo/blob/main/tests/README.md) to run the existing and your newly added tests.
+
+## Linting
+
+We provide a linting script to correctly format your code changes.
+Please follow the instructions mentioned in [dev-README](https://github.com/facebookresearch/pytorchvideo/blob/main/dev/README.md) to run the linter.
+
+
+## Contributor License Agreement ("CLA")
+In order to accept your pull request, we need you to submit a CLA. You only need
+to do this once to work on any of Facebook's open source projects.
+
+Complete your CLA here:
+
+## Issues
+We use GitHub issues to track public bugs. Please ensure your description is
+clear and has sufficient instructions to be able to reproduce the issue.
+
+Facebook has a [bounty program](https://www.facebook.com/whitehat/) for the safe
+disclosure of security bugs. In those cases, please go through the process
+outlined on that page and do not file a public issue.
+
+## License
+By contributing to fvcore, you agree that your contributions will be licensed
+under the LICENSE file in the root directory of this source tree.
diff --git a/code/pytorchvideo/INSTALL.md b/code/pytorchvideo/INSTALL.md
new file mode 100644
index 0000000000000000000000000000000000000000..16a9e4a16693b27ec46a33553250ecf1994bf9c4
--- /dev/null
+++ b/code/pytorchvideo/INSTALL.md
@@ -0,0 +1,68 @@
+# Installation
+
+## Installing PytorchVideo
+
+
+### 1. Install from PyPI
+For stable release,
+```
+pip install pytorchvideo
+=======
+conda create -n pytorchvideo python=3.7
+conda activate pytorchvideo
+conda install -c pytorch pytorch=1.8.0 torchvision cudatoolkit=10.2
+conda install -c conda-forge -c fvcore -c iopath fvcore=0.1.4 iopath
+```
+
+For nightly builds,
+```
+pip install pytorchvideo-nightly
+```
+
+### 2. Install from GitHub using pip
+```
+pip install "git+https://github.com/facebookresearch/pytorchvideo.git"
+```
+To install using the code of the released version instead of from the main branch, use the following instead.
+```
+pip install "git+https://github.com/facebookresearch/pytorchvideo.git@stable"
+```
+
+### 3. Install from a local clone
+```
+git clone https://github.com/facebookresearch/pytorchvideo.git
+cd pytorchvideo
+pip install -e .
+
+# For developing and testing
+pip install -e . [test,dev]
+```
+
+
+## Requirements
+
+### Core library
+
+- Python 3.7 or 3.8
+- PyTorch 1.8.0 or higher.
+- torchvision that matches the PyTorch installation. You can install them together as explained at pytorch.org to make sure of this.
+- [fvcore](https://github.com/facebookresearch/fvcore) version 0.1.4 or higher
+- [ioPath](https://github.com/facebookresearch/iopath)
+- If CUDA is to be used, use a version which is supported by the corresponding pytorch version and at least version 10.2 or higher.
+
+We recommend setting up a conda environment with Pytorch and Torchvision before installing PyTorchVideo.
+For instance, follow the bellow instructions to setup the conda environment,
+```
+conda create -n pytorchvideo python=3.7
+conda activate pytorchvideo
+conda install -c pytorch pytorch=1.8.0 torchvision cudatoolkit=10.2
+```
+
+## Testing
+
+Please follow the instructions mentioned in [test-README](https://github.com/facebookresearch/pytorchvideo/blob/main/tests/README.md) to run the provided tests.
+
+## Linting
+
+We also provide a linting script to correctly format your code edits.
+Please follow the instructions mentioned in [dev-README](https://github.com/facebookresearch/pytorchvideo/blob/main/dev/README.md) to run the linter.
diff --git a/code/pytorchvideo/LICENSE b/code/pytorchvideo/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..5a90478a33957a01c8b1c16fb4d9bf8d0687affd
--- /dev/null
+++ b/code/pytorchvideo/LICENSE
@@ -0,0 +1,201 @@
+Apache License
+Version 2.0, January 2004
+http://www.apache.org/licenses/
+
+TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+1. Definitions.
+
+"License" shall mean the terms and conditions for use, reproduction,
+and distribution as defined by Sections 1 through 9 of this document.
+
+"Licensor" shall mean the copyright owner or entity authorized by
+the copyright owner that is granting the License.
+
+"Legal Entity" shall mean the union of the acting entity and all
+other entities that control, are controlled by, or are under common
+control with that entity. For the purposes of this definition,
+"control" means (i) the power, direct or indirect, to cause the
+direction or management of such entity, whether by contract or
+otherwise, or (ii) ownership of fifty percent (50%) or more of the
+outstanding shares, or (iii) beneficial ownership of such entity.
+
+"You" (or "Your") shall mean an individual or Legal Entity
+exercising permissions granted by this License.
+
+"Source" form shall mean the preferred form for making modifications,
+including but not limited to software source code, documentation
+source, and configuration files.
+
+"Object" form shall mean any form resulting from mechanical
+transformation or translation of a Source form, including but
+not limited to compiled object code, generated documentation,
+and conversions to other media types.
+
+"Work" shall mean the work of authorship, whether in Source or
+Object form, made available under the License, as indicated by a
+copyright notice that is included in or attached to the work
+(an example is provided in the Appendix below).
+
+"Derivative Works" shall mean any work, whether in Source or Object
+form, that is based on (or derived from) the Work and for which the
+editorial revisions, annotations, elaborations, or other modifications
+represent, as a whole, an original work of authorship. For the purposes
+of this License, Derivative Works shall not include works that remain
+separable from, or merely link (or bind by name) to the interfaces of,
+the Work and Derivative Works thereof.
+
+"Contribution" shall mean any work of authorship, including
+the original version of the Work and any modifications or additions
+to that Work or Derivative Works thereof, that is intentionally
+submitted to Licensor for inclusion in the Work by the copyright owner
+or by an individual or Legal Entity authorized to submit on behalf of
+the copyright owner. For the purposes of this definition, "submitted"
+means any form of electronic, verbal, or written communication sent
+to the Licensor or its representatives, including but not limited to
+communication on electronic mailing lists, source code control systems,
+and issue tracking systems that are managed by, or on behalf of, the
+Licensor for the purpose of discussing and improving the Work, but
+excluding communication that is conspicuously marked or otherwise
+designated in writing by the copyright owner as "Not a Contribution."
+
+"Contributor" shall mean Licensor and any individual or Legal Entity
+on behalf of whom a Contribution has been received by Licensor and
+subsequently incorporated within the Work.
+
+2. Grant of Copyright License. Subject to the terms and conditions of
+this License, each Contributor hereby grants to You a perpetual,
+worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+copyright license to reproduce, prepare Derivative Works of,
+publicly display, publicly perform, sublicense, and distribute the
+Work and such Derivative Works in Source or Object form.
+
+3. Grant of Patent License. Subject to the terms and conditions of
+this License, each Contributor hereby grants to You a perpetual,
+worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+(except as stated in this section) patent license to make, have made,
+use, offer to sell, sell, import, and otherwise transfer the Work,
+where such license applies only to those patent claims licensable
+by such Contributor that are necessarily infringed by their
+Contribution(s) alone or by combination of their Contribution(s)
+with the Work to which such Contribution(s) was submitted. If You
+institute patent litigation against any entity (including a
+cross-claim or counterclaim in a lawsuit) alleging that the Work
+or a Contribution incorporated within the Work constitutes direct
+or contributory patent infringement, then any patent licenses
+granted to You under this License for that Work shall terminate
+as of the date such litigation is filed.
+
+4. Redistribution. You may reproduce and distribute copies of the
+Work or Derivative Works thereof in any medium, with or without
+modifications, and in Source or Object form, provided that You
+meet the following conditions:
+
+(a) You must give any other recipients of the Work or
+Derivative Works a copy of this License; and
+
+(b) You must cause any modified files to carry prominent notices
+stating that You changed the files; and
+
+(c) You must retain, in the Source form of any Derivative Works
+that You distribute, all copyright, patent, trademark, and
+attribution notices from the Source form of the Work,
+excluding those notices that do not pertain to any part of
+the Derivative Works; and
+
+(d) If the Work includes a "NOTICE" text file as part of its
+distribution, then any Derivative Works that You distribute must
+include a readable copy of the attribution notices contained
+within such NOTICE file, excluding those notices that do not
+pertain to any part of the Derivative Works, in at least one
+of the following places: within a NOTICE text file distributed
+as part of the Derivative Works; within the Source form or
+documentation, if provided along with the Derivative Works; or,
+within a display generated by the Derivative Works, if and
+wherever such third-party notices normally appear. The contents
+of the NOTICE file are for informational purposes only and
+do not modify the License. You may add Your own attribution
+notices within Derivative Works that You distribute, alongside
+or as an addendum to the NOTICE text from the Work, provided
+that such additional attribution notices cannot be construed
+as modifying the License.
+
+You may add Your own copyright statement to Your modifications and
+may provide additional or different license terms and conditions
+for use, reproduction, or distribution of Your modifications, or
+for any such Derivative Works as a whole, provided Your use,
+reproduction, and distribution of the Work otherwise complies with
+the conditions stated in this License.
+
+5. Submission of Contributions. Unless You explicitly state otherwise,
+any Contribution intentionally submitted for inclusion in the Work
+by You to the Licensor shall be under the terms and conditions of
+this License, without any additional terms or conditions.
+Notwithstanding the above, nothing herein shall supersede or modify
+the terms of any separate license agreement you may have executed
+with Licensor regarding such Contributions.
+
+6. Trademarks. This License does not grant permission to use the trade
+names, trademarks, service marks, or product names of the Licensor,
+except as required for reasonable and customary use in describing the
+origin of the Work and reproducing the content of the NOTICE file.
+
+7. Disclaimer of Warranty. Unless required by applicable law or
+agreed to in writing, Licensor provides the Work (and each
+Contributor provides its Contributions) on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+implied, including, without limitation, any warranties or conditions
+of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+PARTICULAR PURPOSE. You are solely responsible for determining the
+appropriateness of using or redistributing the Work and assume any
+risks associated with Your exercise of permissions under this License.
+
+8. Limitation of Liability. In no event and under no legal theory,
+whether in tort (including negligence), contract, or otherwise,
+unless required by applicable law (such as deliberate and grossly
+negligent acts) or agreed to in writing, shall any Contributor be
+liable to You for damages, including any direct, indirect, special,
+incidental, or consequential damages of any character arising as a
+result of this License or out of the use or inability to use the
+Work (including but not limited to damages for loss of goodwill,
+work stoppage, computer failure or malfunction, or any and all
+other commercial damages or losses), even if such Contributor
+has been advised of the possibility of such damages.
+
+9. Accepting Warranty or Additional Liability. While redistributing
+the Work or Derivative Works thereof, You may choose to offer,
+and charge a fee for, acceptance of support, warranty, indemnity,
+or other liability obligations and/or rights consistent with this
+License. However, in accepting such obligations, You may act only
+on Your own behalf and on Your sole responsibility, not on behalf
+of any other Contributor, and only if You agree to indemnify,
+defend, and hold each Contributor harmless for any liability
+incurred by, or claims asserted against, such Contributor by reason
+of your accepting any such warranty or additional liability.
+
+END OF TERMS AND CONDITIONS
+
+APPENDIX: How to apply the Apache License to your work.
+
+To apply the Apache License to your work, attach the following
+boilerplate notice, with the fields enclosed by brackets "[]"
+replaced with your own identifying information. (Don't include
+the brackets!) The text should be enclosed in the appropriate
+comment syntax for the file format. We also recommend that a
+file or class name and description of purpose be included on the
+same "printed page" as the copyright notice for easier
+identification within third-party archives.
+
+Copyright 2019, Facebook, Inc
+
+Licensed under the Apache License, Version 2.0 (the "License");
+you may not use this file except in compliance with the License.
+You may obtain a copy of the License at
+
+http://www.apache.org/licenses/LICENSE-2.0
+
+Unless required by applicable law or agreed to in writing, software
+distributed under the License is distributed on an "AS IS" BASIS,
+WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+See the License for the specific language governing permissions and
+limitations under the License.
diff --git a/code/pytorchvideo/MANIFEST.in b/code/pytorchvideo/MANIFEST.in
new file mode 100644
index 0000000000000000000000000000000000000000..538a8f8e30199d1313436c54680fd6a18a53900b
--- /dev/null
+++ b/code/pytorchvideo/MANIFEST.in
@@ -0,0 +1,3 @@
+include LICENSE
+include CONTRIBUTING.md
+include requirements.txt
\ No newline at end of file
diff --git a/code/pytorchvideo/README.md b/code/pytorchvideo/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..4434abc75937c24cd7e5e6bdb98dc90b4090d20d
--- /dev/null
+++ b/code/pytorchvideo/README.md
@@ -0,0 +1,94 @@
+
+
+
+| |
+|:-------------------------------:|:--------------------------------------------------:|
+| A PyTorchVideo-accelerated X3D model running on a Samsung Galaxy S10 phone. The model runs ~8x faster than real time, requiring roughly 130 ms to process one second of video.| A PyTorchVideo-based SlowFast model performing video action detection.|
+
+## X3D model Web Demo
+Integrated to [Huggingface Spaces](https://huggingface.co/spaces) with [Gradio](https://github.com/gradio-app/gradio). See demo: [](https://huggingface.co/spaces/pytorch/X3D)
+
+## Introduction
+
+PyTorchVideo is a deeplearning library with a focus on video understanding work. PytorchVideo provides reusable, modular and efficient components needed to accelerate the video understanding research. PyTorchVideo is developed using [PyTorch](https://pytorch.org) and supports different deeplearning video components like video models, video datasets, and video-specific transforms.
+
+Key features include:
+
+- **Based on PyTorch:** Built using PyTorch. Makes it easy to use all of the PyTorch-ecosystem components.
+- **Reproducible Model Zoo:** Variety of state of the art pretrained video models and their associated benchmarks that are ready to use.
+ Complementing the model zoo, PyTorchVideo comes with extensive data loaders supporting different datasets.
+- **Efficient Video Components:** Video-focused fast and efficient components that are easy to use. Supports accelerated inference on hardware.
+
+## Updates
+
+- Aug 2021: [Multiscale Vision Transformers](https://arxiv.org/abs/2104.11227) has been released in PyTorchVideo, details can be found from [here](https://github.com/facebookresearch/pytorchvideo/blob/main/pytorchvideo/models/vision_transformers.py#L97).
+
+## Installation
+
+Install PyTorchVideo inside a conda environment(Python >=3.7) with
+```shell
+pip install pytorchvideo
+```
+
+For detailed instructions please refer to [INSTALL.md](INSTALL.md).
+
+## License
+
+PyTorchVideo is released under the [Apache 2.0 License](LICENSE).
+
+## Tutorials
+
+Get started with PyTorchVideo by trying out one of our [tutorials](https://pytorchvideo.org/docs/tutorial_overview) or by running examples in the [tutorials folder](./tutorials).
+
+
+## Model Zoo and Baselines
+We provide a large set of baseline results and trained models available for download in the [PyTorchVideo Model Zoo](https://github.com/facebookresearch/pytorchvideo/blob/main/docs/source/model_zoo.md).
+
+## Contributors
+
+Here is the growing list of PyTorchVideo contributors in alphabetical order (let us know if you would like to be added):
+[Aaron Adcock](https://www.linkedin.com/in/aaron-adcock-79855383/), [Amy Bearman](https://www.linkedin.com/in/amy-bearman/), [Bernard Nguyen](https://www.linkedin.com/in/mrbernardnguyen/), [Bo Xiong](https://www.cs.utexas.edu/~bxiong/), [Chengyuan Yan](https://www.linkedin.com/in/chengyuan-yan-4a804282/), [Christoph Feichtenhofer](https://feichtenhofer.github.io/), [Dave Schnizlein](https://www.linkedin.com/in/david-schnizlein-96020136/), [Haoqi Fan](https://haoqifan.github.io/), [Heng Wang](https://hengcv.github.io/), [Jackson Hamburger](https://www.linkedin.com/in/jackson-hamburger-986a2873/), [Jitendra Malik](http://people.eecs.berkeley.edu/~malik/), [Kalyan Vasudev Alwala](https://www.linkedin.com/in/kalyan-vasudev-alwala-2a802b64/), [Matt Feiszli](https://www.linkedin.com/in/matt-feiszli-76b34b/), [Nikhila Ravi](https://www.linkedin.com/in/nikhilaravi/), [Ross Girshick](https://www.rossgirshick.info/), [Tullie Murrell](https://www.linkedin.com/in/tullie/), [Wan-Yen Lo](https://www.linkedin.com/in/wanyenlo/), [Weiyao Wang](https://www.linkedin.com/in/weiyaowang/?locale=en_US), [Xiaowen Lin](https://www.linkedin.com/in/xiaowen-lin-90542b34/), [Yanghao Li](https://lyttonhao.github.io/), [Yilei Li](https://liyilui.github.io/personal_page/), [Zhengxing Chen](http://czxttkl.github.io/), [Zhicheng Yan](https://www.linkedin.com/in/zhichengyan/).
+
+
+## Development
+
+We welcome new contributions to PyTorchVideo and we will be actively maintaining this library! Please refer to [`CONTRIBUTING.md`](./.github/CONTRIBUTING.md) for full instructions on how to run the code, tests and linter, and submit your pull requests.
+
+## Citing PyTorchVideo
+
+If you find PyTorchVideo useful in your work, please use the following BibTeX entry for citation.
+```BibTeX
+@inproceedings{fan2021pytorchvideo,
+ author = {Haoqi Fan and Tullie Murrell and Heng Wang and Kalyan Vasudev Alwala and Yanghao Li and Yilei Li and Bo Xiong and Nikhila Ravi and Meng Li and Haichuan Yang and Jitendra Malik and Ross Girshick and Matt Feiszli and Aaron Adcock and Wan-Yen Lo and Christoph Feichtenhofer},
+ title = {{PyTorchVideo}: A Deep Learning Library for Video Understanding},
+ booktitle = {Proceedings of the 29th ACM International Conference on Multimedia},
+ year = {2021},
+ note = {\url{https://pytorchvideo.org/}},
+}
+```
diff --git a/code/pytorchvideo/dev/README.md b/code/pytorchvideo/dev/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..027eeae3b5b36caf44af720219d2f090c3c16875
--- /dev/null
+++ b/code/pytorchvideo/dev/README.md
@@ -0,0 +1,11 @@
+## Running Linter
+
+
+Before running the linter, please ensure that you installed the necessary additional linter dependencies.
+If not installed, check the [install-README](https://github.com/facebookresearch/pytorchvideo/blob/main/INSTALL.md) on how to do it.
+
+Post that, you can run the linter from the project root using,
+
+```
+./dev/linter.sh
+```
diff --git a/code/pytorchvideo/dev/linter.sh b/code/pytorchvideo/dev/linter.sh
new file mode 100644
index 0000000000000000000000000000000000000000..eafbac0981be67410c21758eb8af8f72cf1214c5
--- /dev/null
+++ b/code/pytorchvideo/dev/linter.sh
@@ -0,0 +1,25 @@
+#!/bin/bash -ev
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+
+# Run this script at project root with "./dev/linter.sh" before you commit.
+
+echo "Running autoflake..."
+python -m autoflake --remove-all-unused-imports -i .
+
+echo "Running isort..."
+isort -y -sp .
+
+echo "Running black..."
+black .
+
+echo "Running flake8..."
+if [ -x "$(command -v flake8)" ]; then
+ flake8 .
+else
+ python3 -m flake8 .
+fi
+
+command -v arc > /dev/null && {
+ echo "Running arc lint ..."
+ arc lint
+}
diff --git a/code/pytorchvideo/docs/Makefile b/code/pytorchvideo/docs/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..d0c3cbf1020d5c292abdedf27627c6abe25e2293
--- /dev/null
+++ b/code/pytorchvideo/docs/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = source
+BUILDDIR = build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/code/pytorchvideo/docs/README.md b/code/pytorchvideo/docs/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..2fb037e2d83ef4e8e54414d44f4c448b4551bf0e
--- /dev/null
+++ b/code/pytorchvideo/docs/README.md
@@ -0,0 +1,65 @@
+
+## Setup
+
+### Install dependencies
+
+```
+pip install -U recommonmark mock sphinx sphinx_rtd_theme sphinx_markdown_tables
+```
+
+### Add symlink to the root README.md
+
+We want to include the root readme as an overview. Before generating the docs create a symlink to the root readme.
+
+```
+cd /docs
+ln -s ../README.md overview.md
+```
+
+In `conf.py` for deployment this is done using `subprocess.call`.
+
+### Add a new file
+
+Add a new `.md` or `.rst` file and add the name to the doc tree in `index.rst` e.g
+
+```
+.. toctree::
+ :maxdepth: 1
+ :caption: Intro Documentation
+
+ overview
+```
+
+### Build
+
+From `pytorchvideo/docs` run:
+
+```
+> make html
+```
+
+The website is generated in `build/html`.
+
+### Common Issues
+
+Sphinx can be fussy, and sometimes about things you weren’t expecting. For example, you might encounter something like:
+
+WARNING: toctree contains reference to nonexisting document u'overview'
+...
+checking consistency...
+/docs/overview.rst::
+WARNING: document isn't included in any toctree
+
+You might have indented overview in the .. toctree:: in index.rst with four spaces, when Sphinx is expecting three.
+
+
+### View
+
+Start a python simple server:
+
+```
+> python -m http.server
+```
+
+Navigate to: `http://0.0.0.0:8000/`
+
diff --git a/code/pytorchvideo/docs/make.bat b/code/pytorchvideo/docs/make.bat
new file mode 100644
index 0000000000000000000000000000000000000000..9534b018135ed7d5caed6298980c55e8b1d2ec82
--- /dev/null
+++ b/code/pytorchvideo/docs/make.bat
@@ -0,0 +1,35 @@
+@ECHO OFF
+
+pushd %~dp0
+
+REM Command file for Sphinx documentation
+
+if "%SPHINXBUILD%" == "" (
+ set SPHINXBUILD=sphinx-build
+)
+set SOURCEDIR=source
+set BUILDDIR=build
+
+if "%1" == "" goto help
+
+%SPHINXBUILD% >NUL 2>NUL
+if errorlevel 9009 (
+ echo.
+ echo.The 'sphinx-build' command was not found. Make sure you have Sphinx
+ echo.installed, then set the SPHINXBUILD environment variable to point
+ echo.to the full path of the 'sphinx-build' executable. Alternatively you
+ echo.may add the Sphinx directory to PATH.
+ echo.
+ echo.If you don't have Sphinx installed, grab it from
+ echo.http://sphinx-doc.org/
+ exit /b 1
+)
+
+%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+goto end
+
+:help
+%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%
+
+:end
+popd
diff --git a/code/pytorchvideo/docs/requirements.txt b/code/pytorchvideo/docs/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..95e898e22933cf92dc195573361e860e2a5e9074
--- /dev/null
+++ b/code/pytorchvideo/docs/requirements.txt
@@ -0,0 +1,15 @@
+docutils==0.16
+# https://github.com/sphinx-doc/sphinx/commit/7acd3ada3f38076af7b2b5c9f3b60bb9c2587a3d
+sphinx==3.2.0
+recommonmark==0.6.0
+sphinx_markdown_tables
+mock
+numpy
+av
+torch
+torchvision
+opencv-python
+parameterized
+git+git://github.com/facebookresearch/fvcore.git
+git+git://github.com/facebookresearch/iopath.git
+git+git://github.com/kalyanvasudev/pytorch_sphinx_theme.git
diff --git a/code/pytorchvideo/docs/source/accelerator.md b/code/pytorchvideo/docs/source/accelerator.md
new file mode 100644
index 0000000000000000000000000000000000000000..8f948ac646b860194184e5ea3d17d9ad284059bc
--- /dev/null
+++ b/code/pytorchvideo/docs/source/accelerator.md
@@ -0,0 +1,60 @@
+
+# Overview
+
+Our vision for PyTorchVideo/Accelerator is to enable video understanding models to run efficiently on all tiers of hardware devices, from mobile phone to GPU. PyTorchVideo/Accelerator (Accelerator) is aimed to accelerate the speed of video understanding model running on various hardware devices, as well as the whole process of design and deploy hardware-aware efficient video understanding models. Specifically, Accelerator provides a complete environment which allows users to:
+
+* Design efficient models for target hardware with carefully tuned efficient blocks;
+* Fine tune efficient model from Model Zoo;
+* Optimize model kernel and graph for target device;
+* Deploy efficient model to target device.
+
+
+We benchmarked the latency of SOTA models ([X3D-XS and X3D-S](https://arxiv.org/abs/2004.04730)) on a mainstream mobile device (Samsung S9 International, released in 2018). With Accelerator, we not only observed 4-6X latency reduction on fp32, but also enabled int8 operation which has not been supported in vanilla Pytorch. A table summarizing latency comparison is shown below.
+
+|model |implementation |precision |latency per 1-s clip (ms) |speed up |
+|--- |------------------------- |--- |--- |--- |
+|X3D-XS |Vanilla Pytorch |fp32 |1067 |1.0X |
+|X3D-XS |PytrochVideo/ Accelerator |fp32 |233 |4.6X |
+|X3D-XS |PytrochVideo/ Accelerator |int8 |165 |6.5X |
+|X3D-S |Vanilla Pytorch |fp32 |4248 |1.0X |
+|X3D-S |PytrochVideo/ Accelerator |fp32 |763 |5.6X |
+|X3D-S |PytrochVideo/ Accelerator |int8 |503 |8.4X |
+
+## Components in PyTorchVideo/Accelerator
+
+### Efficient block library
+
+Efficient block library contains common building blocks (residual block, squeeze-excite, etc.) that can be mapped to high-performance kernel operator implementation library of target device platform. The rationale behind having an efficient block library is that high-performance kernel operator library generally only supports a small set of kernel operators. In other words, a randomly picked kernel might not be supported by high-performance kernel operator library. By having an efficient block library and building model using efficient blocks in that library can guarantee the model is deployable with high efficiency on target device.
+
+Efficient block library lives under `pytorchvideo/layers/accelerator/` (for simple layers) and `pytorchvideo/models/accelerator/` (for complex modules such as residual block). Please also check [Build your model with PyTorchVideo/Accelerator](https://pytorchvideo.org/docs/tutorial_accelerator_build_your_model) tutorial for detailed examples.
+
+### Deployment
+
+Deployment flow includes kernel optimization as well as model export for target backend. Kernel optimization utilities can be an extremely important part that decides performance of on-device model operation. Accelerator provides a bunch of useful utilities for deployment under `pytorchvideo/accelerator/deployment`. Please also check related tutorials ([Build your model with PyTorchVideo/Accelerator](https://pytorchvideo.org/docs/tutorial_accelerator_build_your_model), [Accelerate your model with model transmuter in PyTorchVideo/Accelerator](https://pytorchvideo.org/docs/tutorial_accelerator_use_model_transmuter)) for detailed examples.
+
+### Model zoo
+
+Accelerator provides efficient model zoo for target devices, which include model builder (under `pytorchvideo/models/accelerator/`) as well as pretrained checkpoint. Please also refer to [Use PyTorchVideo/Accelerator Model Zoo](https://pytorchvideo.org/docs/tutorial_accelerator_use_accelerator_model_zoo) for how to use model zoo.
+
+
+## Supported devices
+
+Currently mobile cpu (ARM-based cpu on mobile phones) is supported. We will update this page once more target devices are supported.
+
+## Demo
+
+Checkout our on-device video classification demos running on mobile phone!
+
+[Android demo](https://github.com/pytorch/android-demo-app/tree/master/TorchVideo)
+
+[iOS demo](https://github.com/pytorch/ios-demo-app/tree/master/TorchVideo)
+
+## Jumpstart
+
+Refer to following tutorial pages to get started!
+
+[Build your model with PyTorchVideo/Accelerator](https://pytorchvideo.org/docs/tutorial_accelerator_build_your_model)
+
+[Use PyTorchVideo/Accelerator Model Zoo](https://pytorchvideo.org/docs/tutorial_accelerator_use_accelerator_model_zoo)
+
+[Accelerate your model with model transmuter in PyTorchVideo/Accelerator](https://pytorchvideo.org/docs/tutorial_accelerator_use_model_transmuter)
diff --git a/code/pytorchvideo/docs/source/api/data/data.rst b/code/pytorchvideo/docs/source/api/data/data.rst
new file mode 100644
index 0000000000000000000000000000000000000000..4c8784600cca74f64bd46681d186e3a616c4e562
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/data/data.rst
@@ -0,0 +1,8 @@
+pytorchvideo.data
+=================
+
+.. automodule:: pytorchvideo.data
+ :imported-members:
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/code/pytorchvideo/docs/source/api/data/index.rst b/code/pytorchvideo/docs/source/api/data/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..7d5781ea587ad18c01302923271a952ea25c286d
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/data/index.rst
@@ -0,0 +1,7 @@
+Data API
+==================
+
+.. toctree::
+
+ data
+
diff --git a/code/pytorchvideo/docs/source/api/index.rst b/code/pytorchvideo/docs/source/api/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..ef7efd8f520c0fe6a52921c577550318dd1d7b24
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/index.rst
@@ -0,0 +1,9 @@
+API Documentation
+==================
+
+.. toctree::
+
+ models/index
+ data/index
+ layers/index
+ transforms/index
\ No newline at end of file
diff --git a/code/pytorchvideo/docs/source/api/layers/index.rst b/code/pytorchvideo/docs/source/api/layers/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..31677003b05386c8c41d614fc93fedb546d1ac8e
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/layers/index.rst
@@ -0,0 +1,6 @@
+Layers API
+==================
+
+.. toctree::
+
+ layers
\ No newline at end of file
diff --git a/code/pytorchvideo/docs/source/api/layers/layers.rst b/code/pytorchvideo/docs/source/api/layers/layers.rst
new file mode 100644
index 0000000000000000000000000000000000000000..c988d0583f1ca8349f8e45356b76d10bfc0552f3
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/layers/layers.rst
@@ -0,0 +1,56 @@
+pytorchvideo.layers.batch_norm
+=================================
+
+
+.. automodule:: pytorchvideo.layers.batch_norm
+ :members:
+
+
+pytorchvideo.layers.convolutions
+=================================
+
+
+.. automodule:: pytorchvideo.layers.convolutions
+ :members:
+
+pytorchvideo.layers.fusion
+=================================
+
+
+.. automodule:: pytorchvideo.layers.fusion
+ :members:
+
+pytorchvideo.layers.mlp
+=================================
+
+
+.. automodule:: pytorchvideo.layers.mlp
+ :members:
+
+pytorchvideo.layers.nonlocal_net
+=================================
+
+
+.. automodule:: pytorchvideo.layers.nonlocal_net
+ :members:
+
+pytorchvideo.layers.positional_encoding
+=================================
+
+
+.. automodule:: pytorchvideo.layers.positional_encoding
+ :members:
+
+pytorchvideo.layers.swish
+=================================
+
+
+.. automodule:: pytorchvideo.layers.swish
+ :members:
+
+pytorchvideo.layers.squeeze_excitation
+=================================
+
+
+.. automodule:: pytorchvideo.layers.squeeze_excitation
+ :members:
\ No newline at end of file
diff --git a/code/pytorchvideo/docs/source/api/models/byol.rst b/code/pytorchvideo/docs/source/api/models/byol.rst
new file mode 100644
index 0000000000000000000000000000000000000000..1337b5dbe26d01d16931b593582c6d628fa8896d
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/models/byol.rst
@@ -0,0 +1,6 @@
+pytorchvideo.models.byol
+=================================
+
+
+.. automodule:: pytorchvideo.models.byol
+ :members:
\ No newline at end of file
diff --git a/code/pytorchvideo/docs/source/api/models/csn.rst b/code/pytorchvideo/docs/source/api/models/csn.rst
new file mode 100644
index 0000000000000000000000000000000000000000..a4880f292949296b67a1e90c167f116aa41a33b1
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/models/csn.rst
@@ -0,0 +1,6 @@
+pytorchvideo.models.csn
+=================================
+
+
+.. automodule:: pytorchvideo.models.csn
+ :members:
\ No newline at end of file
diff --git a/code/pytorchvideo/docs/source/api/models/head.rst b/code/pytorchvideo/docs/source/api/models/head.rst
new file mode 100644
index 0000000000000000000000000000000000000000..46dafcf1000e6f76077d686b219c1063772c9d7b
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/models/head.rst
@@ -0,0 +1,6 @@
+pytorchvideo.models.head
+=================================
+
+
+.. automodule:: pytorchvideo.models.head
+ :members:
\ No newline at end of file
diff --git a/code/pytorchvideo/docs/source/api/models/index.rst b/code/pytorchvideo/docs/source/api/models/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..14a758d0ef94cf46731c513c384982fa5c9df78f
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/models/index.rst
@@ -0,0 +1,17 @@
+Models API
+==================
+
+.. toctree::
+
+ resnet
+ net
+ head
+ stem
+ csn
+ x3d
+ slowfast
+ r2plus1d
+ simclr
+ byol
+ memory_bank
+ masked_multistream
\ No newline at end of file
diff --git a/code/pytorchvideo/docs/source/api/models/masked_multistream.rst b/code/pytorchvideo/docs/source/api/models/masked_multistream.rst
new file mode 100644
index 0000000000000000000000000000000000000000..6a32afa17fe94364b78d0f53b18e64555b9416d1
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/models/masked_multistream.rst
@@ -0,0 +1,6 @@
+pytorchvideo.models.masked_multistream
+=================================
+
+
+.. automodule:: pytorchvideo.models.masked_multistream
+ :members:
\ No newline at end of file
diff --git a/code/pytorchvideo/docs/source/api/models/memory_bank.rst b/code/pytorchvideo/docs/source/api/models/memory_bank.rst
new file mode 100644
index 0000000000000000000000000000000000000000..3334d47c67b4c1cbe821ddcb89699d63a91006ce
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/models/memory_bank.rst
@@ -0,0 +1,6 @@
+pytorchvideo.models.memory_bank
+=================================
+
+
+.. automodule:: pytorchvideo.models.memory_bank
+ :members:
\ No newline at end of file
diff --git a/code/pytorchvideo/docs/source/api/models/net.rst b/code/pytorchvideo/docs/source/api/models/net.rst
new file mode 100644
index 0000000000000000000000000000000000000000..4ea90a7ccbbdb5b8db68eca43eda222998a9016a
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/models/net.rst
@@ -0,0 +1,6 @@
+pytorchvideo.models.net
+=================================
+
+
+.. automodule:: pytorchvideo.models.net
+ :members:
\ No newline at end of file
diff --git a/code/pytorchvideo/docs/source/api/models/r2plus1d.rst b/code/pytorchvideo/docs/source/api/models/r2plus1d.rst
new file mode 100644
index 0000000000000000000000000000000000000000..377302f7f4a1d49e51e0664914e1dc4d5ef805e0
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/models/r2plus1d.rst
@@ -0,0 +1,6 @@
+pytorchvideo.models.r2plus1d
+=================================
+
+
+.. automodule:: pytorchvideo.models.r2plus1d
+ :members:
\ No newline at end of file
diff --git a/code/pytorchvideo/docs/source/api/models/resnet.rst b/code/pytorchvideo/docs/source/api/models/resnet.rst
new file mode 100644
index 0000000000000000000000000000000000000000..0570a2187d0ba34d3225fd8877390576f7536aaf
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/models/resnet.rst
@@ -0,0 +1,7 @@
+pytorchvideo.models.resnet
+=================================
+
+Building blocks for Resnet and resnet-like models
+
+.. automodule:: pytorchvideo.models.resnet
+ :members:
\ No newline at end of file
diff --git a/code/pytorchvideo/docs/source/api/models/simclr.rst b/code/pytorchvideo/docs/source/api/models/simclr.rst
new file mode 100644
index 0000000000000000000000000000000000000000..a34ff7ccfe52298b2df0d03ea60a56135d7254ac
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/models/simclr.rst
@@ -0,0 +1,6 @@
+pytorchvideo.models.simclr
+=================================
+
+
+.. automodule:: pytorchvideo.models.simclr
+ :members:
\ No newline at end of file
diff --git a/code/pytorchvideo/docs/source/api/models/slowfast.rst b/code/pytorchvideo/docs/source/api/models/slowfast.rst
new file mode 100644
index 0000000000000000000000000000000000000000..1bed28adf31b20c463b139b1c5f90b39d207e4d9
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/models/slowfast.rst
@@ -0,0 +1,6 @@
+pytorchvideo.models.slowfast
+=================================
+
+
+.. automodule:: pytorchvideo.models.slowfast
+ :members:
\ No newline at end of file
diff --git a/code/pytorchvideo/docs/source/api/models/stem.rst b/code/pytorchvideo/docs/source/api/models/stem.rst
new file mode 100644
index 0000000000000000000000000000000000000000..fbc17c7bbd78a68878885037fadf1ef734f9f24c
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/models/stem.rst
@@ -0,0 +1,6 @@
+pytorchvideo.models.stem
+=================================
+
+
+.. automodule:: pytorchvideo.models.stem
+ :members:
\ No newline at end of file
diff --git a/code/pytorchvideo/docs/source/api/models/x3d.rst b/code/pytorchvideo/docs/source/api/models/x3d.rst
new file mode 100644
index 0000000000000000000000000000000000000000..fbe6814315ca35e4cb9224ba70e4ad6b76ac0152
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/models/x3d.rst
@@ -0,0 +1,6 @@
+pytorchvideo.models.x3d
+=================================
+
+
+.. automodule:: pytorchvideo.models.x3d
+ :members:
\ No newline at end of file
diff --git a/code/pytorchvideo/docs/source/api/transforms/index.rst b/code/pytorchvideo/docs/source/api/transforms/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..e009cef528bb3fa3e4178411dab86856a1b3cfd8
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/transforms/index.rst
@@ -0,0 +1,6 @@
+Transforms API
+==================
+
+.. toctree::
+
+ transforms
\ No newline at end of file
diff --git a/code/pytorchvideo/docs/source/api/transforms/transforms.rst b/code/pytorchvideo/docs/source/api/transforms/transforms.rst
new file mode 100644
index 0000000000000000000000000000000000000000..9ca47842b611eb8a1fa6851b7e90216b70c2c5b4
--- /dev/null
+++ b/code/pytorchvideo/docs/source/api/transforms/transforms.rst
@@ -0,0 +1,20 @@
+pytorchvideo.transforms
+==================================
+
+
+.. automodule:: pytorchvideo.transforms
+ :imported-members:
+ :members:
+ :undoc-members:
+ :show-inheritance:
+
+
+pytorchvideo.transforms.functional
+==================================
+
+
+.. automodule:: pytorchvideo.transforms.functional
+ :imported-members:
+ :members:
+ :undoc-members:
+ :show-inheritance:
diff --git a/code/pytorchvideo/docs/source/conf.py b/code/pytorchvideo/docs/source/conf.py
new file mode 100644
index 0000000000000000000000000000000000000000..692755736f7fe198ea54aad5970d78c3c041e6de
--- /dev/null
+++ b/code/pytorchvideo/docs/source/conf.py
@@ -0,0 +1,190 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+
+# flake8: noqa
+import os
+import sys
+
+import unittest.mock as mock
+
+# -- Project information -----------------------------------------------------
+import pytorch_sphinx_theme
+from recommonmark.parser import CommonMarkParser
+from recommonmark.transform import AutoStructify
+
+
+# -- Path setup --------------------------------------------------------------
+sys.path.insert(0, os.path.abspath("../"))
+sys.path.insert(0, os.path.abspath("../pytorchvideo"))
+sys.path.insert(0, os.path.abspath("../../"))
+
+
+# The full version, including alpha/beta/rc tags
+try:
+ import torch # noqa
+except ImportError:
+ for m in [
+ "torch",
+ "torchvision",
+ "torch.nn",
+ "torch.autograd",
+ "torch.autograd.function",
+ "torch.nn.modules",
+ "torch.nn.modules.utils",
+ "torch.utils",
+ "torch.utils.data",
+ "torchvision",
+ "torchvision.ops",
+ "torchvision.datasets",
+ "torchvision.datasets.folder",
+ "torch.utils.data.IterableDataset",
+ ]:
+ sys.modules[m] = mock.Mock(name=m)
+
+
+project = "PyTorchVideo"
+copyright = "2021, PyTorchVideo contributors"
+author = "PyTorchVideo contributors"
+
+
+# -- General configuration ---------------------------------------------------
+
+# If your documentation needs a minimal Sphinx version, state it here.
+#
+needs_sphinx = "3.0"
+
+# Add any Sphinx extension module names here, as strings. They can be
+# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
+# ones.
+extensions = [
+ "recommonmark",
+ "sphinx.ext.autodoc",
+ "sphinx.ext.napoleon",
+ "sphinx.ext.intersphinx",
+ "sphinx.ext.todo",
+ "sphinx.ext.coverage",
+ "sphinx.ext.mathjax",
+ "sphinx.ext.viewcode",
+ "sphinx.ext.githubpages",
+ "sphinx.ext.doctest",
+ "sphinx.ext.ifconfig",
+ "sphinx_markdown_tables",
+]
+
+# Add any paths that contain templates here, relative to this directory.
+templates_path = ["_templates"]
+
+# -- Configurations for plugins ------------
+napoleon_google_docstring = True
+napoleon_include_init_with_doc = True
+napoleon_include_special_with_doc = True
+napoleon_numpy_docstring = False
+napoleon_use_rtype = False
+autodoc_inherit_docstrings = False
+autodoc_member_order = "bysource"
+
+intersphinx_mapping = {
+ "python": ("https://docs.python.org/3.6", None),
+ "numpy": ("https://docs.scipy.org/doc/numpy/", None),
+ "torch": ("https://pytorch.org/docs/master/", None),
+}
+# -------------------------
+
+source_parsers = {".md": CommonMarkParser}
+
+# Add any paths that contain templates here, relative to this directory.
+# templates_path = ["_templates"]
+
+# The suffix(es) of source filenames.
+# You can specify multiple suffix as a list of string:
+#
+source_suffix = [".rst", ".md"]
+
+# The master toctree document.
+master_doc = "index"
+
+# The language for content autogenerated by Sphinx. Refer to documentation
+# for a list of supported languages.
+#
+# This is also used if you do content translation via gettext catalogs.
+# Usually you set "language" from the command line for these cases.
+language = None
+autodoc_typehints = "description"
+# List of patterns, relative to source directory, that match files and
+# directories to ignore when looking for source files.
+# This pattern also affects html_static_path and html_extra_path.
+exclude_patterns = ["_build", "Thumbs.db", ".DS_Store", "build", "README.md"]
+
+# The name of the Pygments (syntax highlighting) style to use.
+pygments_style = "sphinx"
+
+# If true, `todo` and `todoList` produce output, else they produce nothing.
+todo_include_todos = True
+
+# -- Options for HTML output -------------------------------------------------
+
+# The theme to use for HTML and HTML Help pages. See the documentation for
+# a list of builtin themes.
+#
+html_theme = "pytorch_sphinx_theme"
+html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
+
+# Theme options are theme-specific and customize the look and feel of a theme
+# further. For a list of options available for each theme, see the
+# documentation.
+
+html_theme_options = {
+ "includehidden": False,
+ "canonical_url": "https://pytorchvideo.org/api/",
+ "pytorch_project": "docs",
+}
+
+html_baseurl = "/"
+
+# Add any paths that contain custom static files (such as style sheets) here,
+# relative to this directory. They are copied after the builtin static files,
+# so a file named "default.css" will overwrite the builtin "default.css".
+
+html_favicon = "../../website/website/static/img/favicon.png"
+
+# -- Options for HTMLHelp output ------------------------------------------
+
+# Output file base name for HTML help builder.
+htmlhelp_basename = "pytorchvideodoc"
+
+# -- Options for manual page output ---------------------------------------
+
+# One entry per manual page. List of tuples
+# (source start file, name, description, authors, manual section).
+man_pages = [(master_doc, "pytorchvideo", "PyTorchVideo Documentation", [author], 1)]
+
+
+# -- Options for Texinfo output -------------------------------------------
+
+# Grouping the document tree into Texinfo files. List of tuples
+# (source start file, target name, title, author,
+# dir menu entry, description, category)
+texinfo_documents = [
+ (
+ master_doc,
+ "PyTorchVideo",
+ "PyTorchVideo Documentation",
+ author,
+ "PyTorchVideo",
+ "One line description of project.",
+ "Miscellaneous",
+ )
+]
+
+github_doc_root = "https://github.com/facebookresearch/pytorchvideo/tree/main"
+
+
+def setup(app):
+ app.add_config_value(
+ "recommonmark_config",
+ {
+ "url_resolver": lambda url: github_doc_root + url,
+ "auto_toc_tree_section": "Contents",
+ },
+ True,
+ )
+ app.add_transform(AutoStructify)
diff --git a/code/pytorchvideo/docs/source/data.md b/code/pytorchvideo/docs/source/data.md
new file mode 100644
index 0000000000000000000000000000000000000000..038214fb657dceebb8f1fadcb0b3969427e456a0
--- /dev/null
+++ b/code/pytorchvideo/docs/source/data.md
@@ -0,0 +1,48 @@
+# Overview
+
+PyTorchVideo datasets are subclasses of either [```torch.utils.data.Dataset```](https://pytorch.org/docs/stable/data.html#map-style-datasets) or [```torch.utils.data.IterableDataset```](https://pytorch.org/docs/stable/data.html#iterable-style-datasets). As such, they can all be used with a [```torch.utils.data.DataLoader```](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoade), which can load multiple samples in parallel using [```torch.multiprocessing```](https://pytorch.org/docs/stable/multiprocessing.html) workers. For example:
+
+```python
+dataset = pytorchvideo.data.Kinetics(
+ data_path="path/to/kinetics_root/train.csv",
+ clip_sampler=pytorchvideo.data.make_clip_sampler("random", duration=2),
+)
+data_loader = torch.utils.data.DataLoader(dataset, batch_size=8)
+```
+
+## How do PyTorchVideo datasets work?
+
+Although there isn't a strict interface governing how PyTorchVideo datasets work, they all share a common design as follows:
+
+1. Each dataset starts by taking a list of video paths and labels in some form. For example, Kinetics can take a file with each row containing a video path and label, or a directory containing a ```\/\.mp4``` like file structure. Each respective dataset documents the exact structure it expected for the given data path.
+
+2. At each iteration a video sampler is used to determine which video-label pair is going to be sampled from the list of videos from the previous point. For some datasets this is required to be a random sampler, others reuse the [```torch.utils.data.Sampler```](https://pytorch.org/docs/stable/data.html#torch.utils.data.Sampler) interface for more flexibility.
+
+3. A clip sampler is then used to determine which frames to sample from the selected video. For example, your application may want to sample 2 second clips at random for the selected video at each iteration. Some datasets like Kinetics make the most of the [```pytorchvideo.data.clip_sampling```](https://pytorchvideo.readthedocs.io/en/latest/api/data/extra.html#pytorchvideo-data-clip-sampling) interface to provide flexibility on how to define these clips. Other datasets simply require you to specify an enum for common clip sampling configurations.
+
+4. Depending on if the underlying videos are stored as either encoded videos (e.g. mp4) or frame videos (i.e. a folder of images containing each decoded frame) - the video clip is then selectively read or decoded into the canonical video tensor with shape ```(C, T, H, W)``` and audio tensor with shape ```(S)```. We provide two options for decoding: PyAv or TorchVision, which can be chosen in the interface of the datasets that supported encoded videos.
+
+5. The next step of a PyTorchVideo dataset is creating a clip dictionary containing the video modalities, label and metadata ready to be returned. An example clip dictionary might look like this:
+ ```
+ {
+ 'video': , # Shape: (C, T, H, W)
+ 'audio': , # Shape: (S)
+ 'label': , # Integer defining class annotation
+ 'video_name': , # Video file path stem
+ 'video_index': , # index of video used by sampler
+ 'clip_index': # index of clip sampled within video
+ }
+ ```
+ All datasets share the same canonical modality tensor shapes and dtypes, which aligns with tensor types of other domain specific libraries (e.g. TorchVision, TorchAudio).
+
+6. The final step before returning a clip, involves feeding it into a transform callable that can be defined for of all PyTorchVideo datasets. This callable is used to allow custom data processing or augmentations to be applied before batch collation in the [```torch.utils.data.DataLoader```](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader). PyTorchVideo provides common [```pytorchvideo.transforms```](https://pytorchvideo.readthedocs.io/en/latest/transforms.html) that are useful for this callable, but users can easily define their own too.
+
+## Available datasets:
+
+* Charades
+* Domsev
+* EpicKitchen
+* HMDB51
+* Kinetics
+* SSV2
+* UCF101
diff --git a/code/pytorchvideo/docs/source/data_preparation.md b/code/pytorchvideo/docs/source/data_preparation.md
new file mode 100644
index 0000000000000000000000000000000000000000..d4756eba98b513fd6d396408a4a2db3128b959a6
--- /dev/null
+++ b/code/pytorchvideo/docs/source/data_preparation.md
@@ -0,0 +1,164 @@
+## Data Preparation
+
+### Kinetics
+
+For more information about Kinetics dataset, please refer the official [website](https://deepmind.com/research/open-source/kinetics). You can take the following steps to prepare the dataset:
+
+1. Download the videos via the official [scripts](https://github.com/activitynet/ActivityNet/tree/master/Crawler/Kinetics).
+
+2. Preprocess the downloaded videos by resizing to the short edge size of 256.
+
+3. Prepare the csv files for training, validation, and testing set as `train.csv`, `val.csv`, `test.csv`. The format of the csv file is:
+
+```
+path_to_video_1 label_1
+path_to_video_2 label_2
+path_to_video_3 label_3
+...
+path_to_video_N label_N
+```
+
+All the Kinetics models in the Model Zoo are trained and tested with the same data as [Non-local Network](https://github.com/facebookresearch/video-nonlocal-net/blob/main/DATASET.md) and [PySlowFast](https://github.com/facebookresearch/SlowFast/blob/main/slowfast/datasets/DATASET.md). For dataset specific issues, please reach out to the [dataset provider](https://deepmind.com/research/open-source/kinetics).
+
+
+### Charades
+
+We follow [PySlowFast](https://github.com/facebookresearch/SlowFast/blob/main/slowfast/datasets/DATASET.md) to prepare the Charades dataset as follow:
+
+1. Download the Charades RGB frames from [official website](http://ai2-website.s3.amazonaws.com/data/Charades_v1_rgb.tar).
+
+2. Download the *frame list* from the following links: ([train](https://dl.fbaipublicfiles.com/pyslowfast/dataset/charades/frame_lists/train.csv), [val](https://dl.fbaipublicfiles.com/pyslowfast/dataset/charades/frame_lists/val.csv)).
+
+
+### Something-Something V2
+
+We follow [PySlowFast](https://github.com/facebookresearch/SlowFast/blob/main/slowfast/datasets/DATASET.md) to prepare the Something-Something V2 dataset as follow:
+
+1. Download the dataset and annotations from [official website](https://20bn.com/datasets/something-something).
+
+2. Download the *frame list* from the following links: ([train](https://dl.fbaipublicfiles.com/pyslowfast/dataset/ssv2/frame_lists/train.csv), [val](https://dl.fbaipublicfiles.com/pyslowfast/dataset/ssv2/frame_lists/val.csv)).
+
+3. Extract the frames from downloaded videos at 30 FPS. We used ffmpeg-4.1.3 with command:
+ ```
+ ffmpeg -i "${video}" -r 30 -q:v 1 "${out_name}"
+ ```
+4. The extracted frames should be organized to be consistent with the paths in frame lists.
+
+
+### AVA (Actions V2.2)
+
+The AVA Dataset could be downloaded from the [official site](https://research.google.com/ava/download.html#ava_actions_download)
+
+We followed the same [downloading and preprocessing procedure](https://github.com/facebookresearch/video-long-term-feature-banks/blob/main/DATASET.md) as the [Long-Term Feature Banks for Detailed Video Understanding](https://arxiv.org/abs/1812.05038) do.
+
+You could follow these steps to download and preprocess the data:
+
+1. Download videos
+
+```
+DATA_DIR="../../data/ava/videos"
+
+if [[ ! -d "${DATA_DIR}" ]]; then
+ echo "${DATA_DIR} doesn't exist. Creating it.";
+ mkdir -p ${DATA_DIR}
+fi
+
+wget https://s3.amazonaws.com/ava-dataset/annotations/ava_file_names_trainval_v2.1.txt
+
+for line in $(cat ava_file_names_trainval_v2.1.txt)
+do
+ wget https://s3.amazonaws.com/ava-dataset/trainval/$line -P ${DATA_DIR}
+done
+```
+
+2. Cut each video from its 15th to 30th minute. AVA has valid annotations only in this range.
+
+```
+IN_DATA_DIR="../../data/ava/videos"
+OUT_DATA_DIR="../../data/ava/videos_15min"
+
+if [[ ! -d "${OUT_DATA_DIR}" ]]; then
+ echo "${OUT_DATA_DIR} doesn't exist. Creating it.";
+ mkdir -p ${OUT_DATA_DIR}
+fi
+
+for video in $(ls -A1 -U ${IN_DATA_DIR}/*)
+do
+ out_name="${OUT_DATA_DIR}/${video##*/}"
+ if [ ! -f "${out_name}" ]; then
+ ffmpeg -ss 900 -t 901 -i "${video}" "${out_name}"
+ fi
+done
+```
+
+3. Extract frames
+
+```
+IN_DATA_DIR="../../data/ava/videos_15min"
+OUT_DATA_DIR="../../data/ava/frames"
+
+if [[ ! -d "${OUT_DATA_DIR}" ]]; then
+ echo "${OUT_DATA_DIR} doesn't exist. Creating it.";
+ mkdir -p ${OUT_DATA_DIR}
+fi
+
+for video in $(ls -A1 -U ${IN_DATA_DIR}/*)
+do
+ video_name=${video##*/}
+
+ if [[ $video_name = *".webm" ]]; then
+ video_name=${video_name::-5}
+ else
+ video_name=${video_name::-4}
+ fi
+
+ out_video_dir=${OUT_DATA_DIR}/${video_name}/
+ mkdir -p "${out_video_dir}"
+
+ out_name="${out_video_dir}/${video_name}_%06d.jpg"
+
+ ffmpeg -i "${video}" -r 30 -q:v 1 "${out_name}"
+done
+```
+
+4. Download annotations
+
+```
+DATA_DIR="../../data/ava/annotations"
+
+if [[ ! -d "${DATA_DIR}" ]]; then
+ echo "${DATA_DIR} doesn't exist. Creating it.";
+ mkdir -p ${DATA_DIR}
+fi
+
+wget https://research.google.com/ava/download/ava_v2.2.zip -P ${DATA_DIR}
+unzip -q ${DATA_DIR}/ava_v2.2.zip -d ${DATA_DIR}
+```
+
+5. Download "frame lists" ([train](https://dl.fbaipublicfiles.com/video-long-term-feature-banks/data/ava/frame_lists/train.csv), [val](https://dl.fbaipublicfiles.com/video-long-term-feature-banks/data/ava/frame_lists/val.csv)) and put them in
+the `frame_lists` folder (see structure above).
+
+6. Download person boxes that are generated using a person detector trained on AVA - ([train](https://dl.fbaipublicfiles.com/pytorchvideo/data/ava/ava_detection_test.csv), [val](https://dl.fbaipublicfiles.com/pytorchvideo/data/ava/ava_detection_val.csv), [test](https://dl.fbaipublicfiles.com/pytorchvideo/data/ava/ava_detection_test.csv)) and put them in the `annotations` folder (see structure above). Copy files to the annotations directory mentioned in step 4.
+If you prefer to use your own person detector, please generate detection predictions files in the suggested format in step 6.
+
+Download the ava dataset with the following structure:
+
+```
+ava
+|_ frames
+| |_ [video name 0]
+| | |_ [video name 0]_000001.jpg
+| | |_ [video name 0]_000002.jpg
+| | |_ ...
+| |_ [video name 1]
+| |_ [video name 1]_000001.jpg
+| |_ [video name 1]_000002.jpg
+| |_ ...
+|_ frame_lists
+| |_ train.csv
+| |_ val.csv
+|_ annotations
+ |_ [official AVA annotation files]
+ |_ ava_train_predicted_boxes.csv
+ |_ ava_val_predicted_boxes.csv
+```
diff --git a/code/pytorchvideo/docs/source/index.rst b/code/pytorchvideo/docs/source/index.rst
new file mode 100644
index 0000000000000000000000000000000000000000..adaac612f4184b86b1811751aa23949719903576
--- /dev/null
+++ b/code/pytorchvideo/docs/source/index.rst
@@ -0,0 +1,47 @@
+.. pytorchvideo documentation master file, created by
+ sphinx-quickstart on Tue Feb 23 17:19:36 2021.
+ You can adapt this file completely to your liking, but it should at least
+ contain the root `toctree` directive.
+
+:github_url: https://github.com/facebookresearch/pytorchvideo/
+
+
+PyTorchVideo Documentation
+========================================
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Models
+
+ models
+ model_zoo
+ api/models/index
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Data
+
+ data
+ data_preparation
+ api/data/index
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Transforms
+
+ transforms
+ api/transforms/index
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Layers
+
+ layers
+ api/layers/index
+
+.. toctree::
+ :maxdepth: 1
+ :caption: Accelerator
+
+ accelerator
+
diff --git a/code/pytorchvideo/docs/source/layers.md b/code/pytorchvideo/docs/source/layers.md
new file mode 100644
index 0000000000000000000000000000000000000000..884870bb25cd33fc12e18fc5fd23af61c879bf3f
--- /dev/null
+++ b/code/pytorchvideo/docs/source/layers.md
@@ -0,0 +1,55 @@
+# Overview
+
+
+PyTorchVideo is an open source video understanding library that provides up to date builders for state of the art video understanding backbones, layers, heads, and losses addressing different tasks, including acoustic event detection, action recognition (video classification), action detection (video detection), multimodal understanding (acoustic visual classification), self-supervised learning.
+
+The layers subpackage contains definitions for the following layers and activations:
+
+
+* Layer
+ * [BatchNorm](https://arxiv.org/abs/1502.03167)
+ * [2+1 Conv](https://arxiv.org/abs/1711.11248)
+ * ConCat
+ * MLP
+ * [Nonlocal Net](https://arxiv.org/abs/1711.07971)
+ * Positional Encoding
+ * [Squeeze and Excitation](https://arxiv.org/abs/1709.01507)
+ * [Swish](https://arxiv.org/abs/1710.05941)
+
+## Build standard models
+
+PyTorchVideo provide default builders to construct state-of-the-art video understanding layers and activations.
+
+
+### Layers
+
+You can construct a layer with random weights by calling its constructor:
+
+```
+import pytorchvideo.layers as layers
+
+nonlocal = layers.create_nonlocal(dim_in=256, dim_inner=128)
+swish = layers.Swish()
+conv_2plus1d = layers.create_conv_2plus1d(in_channels=256, out_channels=512)
+```
+
+You can verify whether you have built the model successfully by:
+
+```
+import pytorchvideo.layers as layers
+
+nonlocal = layers.create_nonlocal(dim_in=256, dim_inner=128)
+B, C, T, H, W = 2, 256, 4, 14, 14
+input_tensor = torch.zeros(B, C, T, H, W)
+output = nonlocal(input_tensor)
+
+swish = layers.Swish()
+B, C, T, H, W = 2, 256, 4, 14, 14
+input_tensor = torch.zeros(B, C, T, H, W)
+output = swish(input_tensor)
+
+conv_2plus1d = layers.create_conv_2plus1d(in_channels=256, out_channels=512)
+B, C, T, H, W = 2, 256, 4, 14, 14
+input_tensor = torch.zeros(B, C, T, H, W)
+output = conv_2plus1d(input_tensor)
+```
diff --git a/code/pytorchvideo/docs/source/model_zoo.md b/code/pytorchvideo/docs/source/model_zoo.md
new file mode 100644
index 0000000000000000000000000000000000000000..f1b79c650a27fd61a8b000fdfa4fb1fedd6348bf
--- /dev/null
+++ b/code/pytorchvideo/docs/source/model_zoo.md
@@ -0,0 +1,81 @@
+
+
+
+## Model Zoo and Benchmarks
+
+PyTorchVideo provides reference implementation of a large number of video understanding approaches. In this document, we also provide comprehensive benchmarks to evaluate the supported models on different datasets using standard evaluation setup. All the models can be downloaded from the provided links.
+
+### Kinetics-400
+
+arch | depth | pretrain | frame length x sample rate | top 1 | top 5 | Flops (G) x views | Params (M) | Model
+-------- | ----- | -------- | -------------------------- | ----- | ----- | ----------------- | ---------- | --------------------------------------------------------------------------------------------------
+C2D | R50 | \- | 8x8 | 71.46 | 89.68 | 25.89 x 3 x 10 | 24.33 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/C2D\_8x8\_R50.pyth)
+I3D | R50 | \- | 8x8 | 73.27 | 90.70 | 37.53 x 3 x 10 | 28.04 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/I3D\_8x8\_R50.pyth)
+Slow | R50 | \- | 4x16 | 72.40 | 90.18 | 27.55 x 3 x 10 | 32.45 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/SLOW\_4x16\_R50.pyth)
+Slow | R50 | \- | 8x8 | 74.58 | 91.63 | 54.52 x 3 x 10 | 32.45 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/SLOW\_8x8\_R50.pyth)
+SlowFast | R50 | \- | 4x16 | 75.34 | 91.89 | 36.69 x 3 x 10 | 34.48 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/SLOWFAST\_4x16\_R50.pyth)
+SlowFast | R50 | \- | 8x8 | 76.94 | 92.69 | 65.71 x 3 x 10 | 34.57 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/SLOWFAST\_8x8\_R50.pyth)
+SlowFast | R101 | \- | 8x8 | 77.90 | 93.27 | 127.20 x 3 x 10 | 62.83 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/SLOWFAST\_8x8\_R101.pyth)
+SlowFast | R101 | \- | 16x8 | 78.70 | 93.61 | 215.61 x 3 x 10 | 53.77 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/SLOWFAST\_16x8\_R101_50_50.pyth)
+CSN | R101 | \- | 32x2 | 77.00 | 92.90 | 75.62 x 3 x 10 | 22.21 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/CSN\_32x2\_R101.pyth)
+R(2+1)D | R50 | \- | 16x4 | 76.01 | 92.23 | 76.45 x 3 x 10 | 28.11 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/R2PLUS1D\_16x4\_R50.pyth)
+X3D | XS | \- | 4x12 | 69.12 | 88.63 | 0.91 x 3 x 10 | 3.79 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/X3D\_XS.pyth)
+X3D | S | \- | 13x6 | 73.33 | 91.27 | 2.96 x 3 x 10 | 3.79 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/X3D\_S.pyth)
+X3D | M | \- | 16x5 | 75.94 | 92.72 | 6.72 x 3 x 10 | 3.79 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/X3D\_M.pyth)
+X3D | L | \- | 16x5 | 77.44 | 93.31 | 26.64 x 3 x 10 | 6.15 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/X3D\_L.pyth)
+MViT | B | \- | 16x4 | 78.85 | 93.85 | 70.80 x 1 x 5 | 36.61 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/MVIT\_B\_16x4.pyth)
+MViT | B | \- | 32x3 | 80.30 | 94.69 | 170.37 x 1 x 5 | 36.61 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/MVIT\_B\_32x3\_f294077834.pyth)
+
+### Something-Something V2
+
+| arch | depth | pretrain | frame length x sample rate | top 1 | top 5 | Flops (G) x views | Params (M) | Model |
+| -------- | ----- | ------------ | -------------------------- | ----- | ----- | ----------------- | ---------- | ----- |
+| Slow | R50 | Kinetics 400 | 8x8 | 60.04 | 85.19 | 55.10 x 3 x 1 | 31.96 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/ssv2/SLOW\_8x8\_R50.pyth) |
+| SlowFast | R50 | Kinetics 400 | 8x8 | 61.68 | 86.92 | 66.60 x 3 x 1 | 34.04 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/ssv2/SLOWFAST\_8x8\_R50.pyth) |
+
+
+### Charades
+
+| arch | depth | pretrain | frame length x sample rate | MAP | Flops (G) x views | Params (M) | Model |
+| -------- | ----- | ------------ | -------------------------- | ----- | ----------------- | ---------- | ----- |
+| Slow | R50 | Kinetics 400 | 8x8 | 34.72 | 55.10 x 3 x 10 | 31.96 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/charades/SLOW\_8x8\_R50.pyth) |
+| SlowFast | R50 | Kinetics 400 | 8x8 | 37.24 | 66.60 x 3 x 10 | 34.00 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/charades/SLOWFAST\_8x8\_R50.pyth) |
+
+
+### AVA (V2.2)
+
+| arch | depth | pretrain | frame length x sample rate | MAP | Params (M) | Model |
+| -------- | ----- | ------------ | -------------------------- | ----- | ---------- | ----- |
+| Slow | R50 | Kinetics 400 | 4x16 | 19.5 | 31.78 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/ava/SLOW\_4x16\_R50\_DETECTION.pyth) |
+| SlowFast | R50 | Kinetics 400 | 8x8 | 24.67 | 33.82 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/ava/SLOWFAST\_8x8\_R50\_DETECTION.pyth) |
+
+
+### Using PyTorchVideo model zoo
+We provide several different ways to use PyTorchVideo model zoo.
+* The models have been integrated into TorchHub, so could be loaded with TorchHub with or without pre-trained models. Additionally, we provide a [tutorial](https://pytorchvideo.org/docs/tutorial_torchhub_inference) which goes over the steps needed to load models from TorchHub and perform inference.
+* PyTorchVideo models/datasets are also supported in PySlowFast. You can use [PySlowFast workflow](https://github.com/facebookresearch/SlowFast/) to train or test PyTorchVideo models/datasets.
+* You can also use [PyTorch Lightning](https://github.com/PyTorchLightning/pytorch-lightning) to build training/test pipeline for PyTorchVideo models and datasets. Please check this [tutorial](https://pytorchvideo.org/docs/tutorial_classification) for more information.
+
+
+Notes:
+* The above benchmarks are conducted by [PySlowFast workflow](https://github.com/facebookresearch/SlowFast/) using PyTorchVideo datasets and models.
+* For more details on the data preparation, you can refer to [PyTorchVideo Data Preparation](data_preparation.md).
+* For `Flops x views` column, we report the inference cost with a single “view" × the number of views (FLOPs × space_views × time_views). For example, we take 3 spatial crops for 10 temporal clips on Kinetics.
+
+
+
+### PytorchVideo Accelerator Model Zoo
+Accelerator model zoo provides a set of efficient models on target device with pretrained checkpoints. To learn more about how to build model, load checkpoint and deploy, please refer to [Use PyTorchVideo/Accelerator Model Zoo](https://pytorchvideo.org/docs/tutorial_accelerator_use_accelerator_model_zoo).
+
+**Efficient Models for mobile CPU**
+All top1/top5 accuracies are measured with 10-clip evaluation. Latency is benchmarked on Samsung S8 phone with 1s input clip length.
+
+| model | model builder | top 1 | top 5 | latency (ms) | params (M) | checkpoint |
+|--------------|--------------------------------------------------------------------------|-------|-------|--------------|----------------|---------------------|
+| X3D_XS (fp32)| models. accelerator. mobile_cpu. efficient_x3d. EfficientX3d (expansion="XS") | 68.5 | 88.0 | 233 | 3.8 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/efficient_x3d_xs_original_form.pyth) |
+| X3D_XS (int8)| N/A (Use the TorchScript file in checkpoint link directly) | 66.9 | 87.2 | 165 | 3.8 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/x3d_xs_efficient_converted_qnnpack.pt) |
+| X3D_S (fp32) | models. accelerator. mobile_cpu. efficient_x3d. EfficientX3d (expansion="S") | 73.0 | 90.6 | 764 | 3.8 | [link](https://dl.fbaipublicfiles.com/pytorchvideo/model_zoo/kinetics/efficient_x3d_s_original_form.pyth) |
+
+
+### TorchHub models
+We provide a large set of [TorchHub](https://pytorch.org/hub/) models for the above video models with pre-trained weights. So it's easy to construct the networks and load pre-trained weights. Please refer to [PytorchVideo TorchHub models](https://github.com/facebookresearch/pytorchvideo/blob/main/pytorchvideo/models/hub/README.md) for more details.
diff --git a/code/pytorchvideo/docs/source/models.md b/code/pytorchvideo/docs/source/models.md
new file mode 100644
index 0000000000000000000000000000000000000000..3905092fb07f50da2bf9259e6c2ef739bd0ba2b4
--- /dev/null
+++ b/code/pytorchvideo/docs/source/models.md
@@ -0,0 +1,181 @@
+# Overview
+
+
+PyTorchVideo is an open source video understanding library that provides up to date builders for state of the art video understanding backbones, layers, heads, and losses addressing different tasks, including acoustic event detection, action recognition (video classification), action detection (video detection), multimodal understanding (acoustic visual classification), self-supervised learning.
+
+The models subpackage contains definitions for the following model architectures and layers:
+
+
+* Acoustic Backbone
+ * Acoustic ResNet
+* Visual Backbone
+ * [I3D](https://arxiv.org/pdf/1705.07750.pdf)
+ * [C2D](https://arxiv.org/pdf/1711.07971.pdf)
+ * [Squeeze-and-Excitation Networks](https://arxiv.org/pdf/1709.01507.pdf)
+ * [Nonlocal Networks](https://arxiv.org/pdf/1711.07971.pdf)
+ * [R2+1D](https://openaccess.thecvf.com/content_cvpr_2018/papers/Tran_A_Closer_Look_CVPR_2018_paper.pdf)
+ * CSN
+ * [SlowFast](https://arxiv.org/pdf/1812.03982.pdf)
+ * [Audiovisual SlowFast](https://arxiv.org/pdf/2001.08740.pdf)
+ * [X3D](https://arxiv.org/pdf/2004.04730.pdf)
+* Self-Supervised Learning
+ * [SimCLR](https://arxiv.org/pdf/2002.05709.pdf)
+ * [Bootstrap Your Own Latent](https://arxiv.org/pdf/2006.07733.pdf)
+ * [Non-Parametric Instance Discrimination](https://openaccess.thecvf.com/content_cvpr_2018/CameraReady/0801.pdf)
+
+
+## Build standard models
+
+PyTorchVideo provide default builders to construct state-of-the-art video understanding models, layers, heads, and losses.
+
+### Models
+
+You can construct a model with random weights by calling its constructor:
+
+```
+import pytorchvideo.models as models
+
+resnet = models.create_resnet()
+acoustic_resnet = models.create_acoustic_resnet()
+slowfast = models.create_slowfast()
+x3d = models.create_x3d()
+r2plus1d = models.create_r2plus1d()
+csn = models.create_csn()
+```
+
+You can verify whether you have built the model successfully by:
+
+```
+import pytorchvideo.models as models
+
+resnet = models.create_resnet()
+B, C, T, H, W = 2, 3, 8, 224, 224
+input_tensor = torch.zeros(B, C, T, H, W)
+output = resnet(input_tensor)
+```
+
+### Layers
+
+You can construct a layer with random weights by calling its constructor:
+
+```
+import pytorchvideo.layers as layers
+
+nonlocal = layers.create_nonlocal(dim_in=256, dim_inner=128)
+swish = layers.Swish()
+conv_2plus1d = layers.create_conv_2plus1d(in_channels=256, out_channels=512)
+```
+
+You can verify whether you have built the model successfully by:
+
+```
+import pytorchvideo.layers as layers
+
+nonlocal = layers.create_nonlocal(dim_in=256, dim_inner=128)
+B, C, T, H, W = 2, 256, 4, 14, 14
+input_tensor = torch.zeros(B, C, T, H, W)
+output = nonlocal(input_tensor)
+
+swish = layers.Swish()
+B, C, T, H, W = 2, 256, 4, 14, 14
+input_tensor = torch.zeros(B, C, T, H, W)
+output = swish(input_tensor)
+
+conv_2plus1d = layers.create_conv_2plus1d(in_channels=256, out_channels=512)
+B, C, T, H, W = 2, 256, 4, 14, 14
+input_tensor = torch.zeros(B, C, T, H, W)
+output = conv_2plus1d(input_tensor)
+```
+
+### Heads
+
+You can construct a head with random weights by calling its constructor:
+
+```
+import pytorchvideo.models as models
+
+res_head = models.head.create_res_basic_head(in_features, out_features)
+x3d_head = models.x3d.create_x3d_head(dim_in=1024, dim_inner=512, dim_out=2048, num_classes=400)
+```
+
+You can verify whether you have built the head successfully by:
+
+```
+import pytorchvideo.models as models
+
+res_head = models.head.create_res_basic_head(in_features, out_features)
+B, C, T, H, W = 2, 256, 4, 14, 14
+input_tensor = torch.zeros(B, C, T, H, W)
+output = res_head(input_tensor)
+
+x3d_head = models.x3d.create_x3d_head(dim_in=1024, dim_inner=512, dim_out=2048, num_classes=400)
+B, C, T, H, W = 2, 256, 4, 14, 14
+input_tensor = torch.zeros(B, C, T, H, W)
+output = x3d_head(input_tensor)
+```
+
+### Losses
+
+You can construct a loss by calling its constructor:
+
+```
+import pytorchvideo.models as models
+
+simclr_loss = models.SimCLR()
+```
+
+You can verify whether you have built the loss successfully by:
+
+```
+import pytorchvideo.models as models
+import pytorchvideo.layers as layers
+
+resnet = models.create_resnet()
+mlp = layers.make_multilayer_perceptron(fully_connected_dims=(2048, 1024, 2048))
+simclr_loss = models.SimCLR(mlp=mlp, backbone=resnet)
+B, C, T, H, W = 2, 256, 4, 14, 14
+view1, view2 = torch.zeros(B, C, T, H, W), torch.zeros(B, C, T, H, W)
+loss = simclr_loss(view1, view2)
+```
+
+## Build customized models
+
+PyTorchVideo also supports building models with customized components, which is an important feature for video understanding research. Here we take a standard stem model as an example, show how to build each resnet components (head, backbone, stem) separately, and how to use your customized components to replace standard components.
+
+
+```
+from pytorchvideo.models.stem import create_res_basic_stem
+
+
+# Create standard stem layer.
+stem = create_res_basic_stem(in_channels=3, out_channels=64)
+
+# Create customized stem layer with YourFancyNorm
+stem = create_res_basic_stem(
+ in_channels=3,
+ out_channels=64,
+ norm=YourFancyNorm, # GhostNorm for example
+)
+
+# Create customized stem layer with YourFancyConv
+stem = create_res_basic_stem(
+ in_channels=3,
+ out_channels=64,
+ conv=YourFancyConv, # OctConv for example
+)
+
+# Create customized stem layer with YourFancyAct
+stem = create_res_basic_stem(
+ in_channels=3,
+ out_channels=64,
+ activation=YourFancyAct, # Swish for example
+)
+
+# Create customized stem layer with YourFancyPool
+stem = create_res_basic_stem(
+ in_channels=3,
+ out_channels=64,
+ pool=YourFancyPool, # MinPool for example
+)
+
+```
diff --git a/code/pytorchvideo/docs/source/transforms.md b/code/pytorchvideo/docs/source/transforms.md
new file mode 100644
index 0000000000000000000000000000000000000000..e107e5c099b93edfdf40fc6e8af2faaf11c7597c
--- /dev/null
+++ b/code/pytorchvideo/docs/source/transforms.md
@@ -0,0 +1,33 @@
+# Overview
+
+The PyTorchVideo transforms package contains common video algorithms used for preprocessing and/or augmenting video data. The package also contains helper dictionary transforms that are useful for interoperability between PyTorchVideo [dataset's clip outputs](https://pytorchvideo.readthedocs.io/en/latest/data.html) and domain specific transforms. For example, here is a standard transform pipeline for a video model, that could be used with a PyTorchVideo dataset:
+
+```python
+transform = torchvision.transforms.Compose([
+ pytorchvideo.transforms.ApplyTransformToKey(
+ key="video",
+ transform=torchvision.transforms.Compose([
+ pytorchvideo.transforms.UniformTemporalSubsample(8),
+ pytorchvideo.transforms.Normalize((0.45, 0.45, 0.45), (0.225, 0.225, 0.225)),
+ pytorchvideo.transforms.RandomShortSideScale(min_size=256, max_size=320),
+ torchvision.transforms.RandomCrop(244),
+ torchvision.transforms.RandomHorizontalFlip(p=0.5),
+ )]
+ )
+])
+dataset = pytorchvideo.data.Kinetics(
+ data_path="path/to/kinetics_root/train.csv",
+ clip_sampler=pytorchvideo.data.make_clip_sampler("random", duration=2),
+ transform=transform
+)
+```
+
+Notice how the example also includes transforms from TorchVision? PyTorchVideo uses the same canonical tensor shape as TorchVision for video and TorchAudio for audio. This allows the frameworks to be used together freely.
+
+## Transform vs Functional interface
+
+The example above demonstrated the [```pytorchvideo.transforms```](https://pytorchvideo.readthedocs.io/en/latest/api/transforms/transforms.html) interface. These transforms are [```torch.nn.module```](https://pytorch.org/docs/stable/generated/torch.nn.Module.html) callable classes that can be stringed together in a declarative way. PyTorchVideo also provides a [```pytorchvideo.transforms.functional```](https://pytorchvideo.readthedocs.io/en/latest/api/transforms/transforms.html#pytorchvideo-transforms-functional) interface, which are the functions that the transform API uses. These allow more fine-grained control over the transformations and may be more suitable for use outside the dataset preprocessing use case.
+
+## Scriptable transforms
+
+All non-OpenCV transforms are TorchScriptable, as described in the [TorchVision docs](https://pytorch.org/vision/stable/transforms.html#scriptable-transforms), in order to script the transforms together, please use [```ltorch.nn.Sequential```](https://pytorch.org/docs/stable/generated/torch.nn.Sequential.html) instead of [```torchvision.transform.Compose```](https://pytorch.org/vision/stable/transforms.html#torchvision.transforms.Compose).
diff --git a/code/pytorchvideo/hubconf.py b/code/pytorchvideo/hubconf.py
new file mode 100644
index 0000000000000000000000000000000000000000..d22fdb99e810ac34c05f185d259fff3ea31c3911
--- /dev/null
+++ b/code/pytorchvideo/hubconf.py
@@ -0,0 +1,24 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+dependencies = ["torch"]
+from pytorchvideo.models.hub import ( # noqa: F401, E402
+ c2d_r50,
+ csn_r101,
+ efficient_x3d_s,
+ efficient_x3d_xs,
+ i3d_r50,
+ mvit_base_16,
+ mvit_base_16x4,
+ mvit_base_32x3,
+ r2plus1d_r50,
+ slow_r50,
+ slow_r50_detection,
+ slowfast_16x8_r101_50_50,
+ slowfast_r101,
+ slowfast_r50,
+ slowfast_r50_detection,
+ x3d_l,
+ x3d_m,
+ x3d_s,
+ x3d_xs,
+)
diff --git a/code/pytorchvideo/projects/video_nerf/README.md b/code/pytorchvideo/projects/video_nerf/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..abfb2a3865ca59ce0338d679dfe8f3611d2b9555
--- /dev/null
+++ b/code/pytorchvideo/projects/video_nerf/README.md
@@ -0,0 +1,136 @@
+# Train a NeRF model with PyTorchVideo and PyTorch3D
+
+This project demonstrates how to use the video decoder from PyTorchVideo to load frames from a video of an object from the [Objectron dataset](https://github.com/google-research-datasets/Objectron), and use this to train a NeRF [1] model with [PyTorch3D](https://github.com/facebookresearch/pytorch3d). Instead of decoding and storing all the video frames as images, PyTorchVideo offers an easy alternative to load and access frames on the fly. For this project we will be using the [NeRF implementation from PyTorch3D](https://github.com/facebookresearch/pytorch3d/tree/main/projects/nerf).
+
+### Set up
+
+#### Installation
+
+Install PyTorch3D
+
+```python
+# Create new conda environment
+conda create -n 3ddemo
+conda activate 3ddemo
+
+# Install PyTorch3D
+conda install -c pytorch pytorch=1.7.1 torchvision cudatoolkit=10.1
+conda install -c conda-forge -c fvcore -c iopath fvcore iopath
+conda install pytorch3d -c pytorch3d-nightly
+```
+
+Install PyTorchVideo if you haven't installed it already (assuming you have cloned the repo locally):
+
+```python
+cd pytorchvideo
+python -m pip install -e .
+```
+
+Install some extras libraries needed for NeRF:
+
+```python
+pip install visdom Pillow matplotlib tqdm plotly
+pip install hydra-core --upgrade
+```
+
+#### Set up NeRF Model
+
+We will be using the PyTorch3D NeRF implementation. We have already installed the PyTorch3d conda packages, so now we only need to clone the NeRF implementation:
+
+```python
+cd pytorchvideo/tutorials/video_nerf
+git clone https://github.com/facebookresearch/pytorch3d.git
+cp -r pytorch3d/projects/nerf .
+
+# Remove the rest of the PyTorch3D repo
+rm -r pytorch3d
+```
+
+#### Dataset
+
+###### Download the Objectron repo
+
+The repo contains helper functions for reading the metadata files. Clone it to the path `pytorchvideo/tutorials/video_nerf/Objectron`.
+
+```python
+git clone https://github.com/google-research-datasets/Objectron.git
+
+# Also install protobuf for parsing the metadata
+pip install protobuf
+```
+
+###### Download an example video
+
+For this demo we will be using a short video of a chair from the [Objectron dataset](https://github.com/google-research-datasets/Objectron). Each video is accompanied by metadata with the camera parameters for each frame. You can download an example video for a chair and the associated metadata by running the following script:
+
+```python
+python download_objectron_data.py
+```
+
+The data files will be downloaded to the path: `pytorchvideo/tutorials/video_nerf/nerf/data/objectron`. Within the script you can change the index of the video to use to obtain a different chair video. We will create and save a random split of train/val/test when the video is first loaded by the NeRF model training script.
+
+Most of the videos are recorded in landscape mode with image size (H, W) = [1440, 1920].
+
+
+#### Set up new configs
+
+For this dataset we need a new config file and data loader to use it with the PyTorch3D NeRF implementation. Copy the relevant dataset and config files into the `nerf` folder and replace the original files:
+
+```python
+# Make sure you are at the path: pytorchvideo/tutorials/video_nerf
+# Rename the current dataset file
+mv nerf/nerf/dataset.py nerf/nerf/nerf_dataset.py
+
+# Move the new objectron specific files into the nerf folder
+mv dataset.py nerf/nerf/dataset.py
+mv dataset_utils.py nerf/nerf/dataset_utils.py
+mv objectron.yaml nerf/configs
+```
+
+In the `video_dataset.py` file we use the PyTorchVideo `EncodedVideo` class to load a video `.MOV` file, decode it into frames and access the frames by the index.
+
+#### Train model
+
+Run the model training:
+
+```python
+cd nerf
+python ./train_nerf.py --config-name objectron
+```
+
+#### Visualize predictions
+
+Predictions and metrics will be logged to Visdom. Before training starts launch the visdom server:
+
+```python
+python -m visdom.server
+```
+
+Navigate to `https://localhost:8097` to view the logs and visualizations.
+
+After training, you can generate predictions on the test set:
+
+```python
+python test_nerf.py --config-name objectron test.mode='export_video' data.image_size="[96,128]"
+```
+
+For a higher resolution video you can increase the image size to e.g. [192, 256] (note that this will slow down inference).
+
+You will need to specify the `scene_center` for the video in the `objectron.yaml` file. This is set for the demo video specified in `download_objectron_data.py`. For a different video you can calculate the scene center inside [`eval_video_utils.py`](https://github.com/facebookresearch/pytorch3d/blob/main/projects/nerf/nerf/eval_video_utils.py#L99). After line 99 you can add the following code to compute the center:
+
+```python
+# traj is the circular camera trajectory on the camera mean plane.
+# We want the camera to always point towards the center of this trajectory.
+x_center = traj[..., 0].mean().item()
+z_center = traj[..., 2].mean().item()
+y_center = traj[0, ..., 1]
+scene_center = [x_center, y_center, z_center]
+```
+You can also point the camera down/up relative to the camera mean plane e.g. `y_center -= 0.5`
+
+Here is an example of a video reconstruction generated using a trained NeRF model. NOTE: the quality of reconstruction is highly dependent on the camera pose range and accuracy in the annotations - try training a model for a few different chairs in the dataset to see which one has the best results.
+
+
+
+##### References
+[1] Ben Mildenhall and Pratul P. Srinivasan and Matthew Tancik and Jonathan T. Barron and Ravi Ramamoorthi and Ren Ng, NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis, ECCV2020
diff --git a/code/pytorchvideo/projects/video_nerf/dataset.py b/code/pytorchvideo/projects/video_nerf/dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..e687d2c6d77f9a4d503dcab25a6aa7c4a64d0348
--- /dev/null
+++ b/code/pytorchvideo/projects/video_nerf/dataset.py
@@ -0,0 +1,125 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
+
+import os
+from typing import Tuple
+
+import numpy as np
+import torch
+import tqdm
+
+# Imports from PyTorchVideo and PyTorch3D
+from pytorch3d.renderer import PerspectiveCameras
+from pytorchvideo.data.encoded_video import EncodedVideo
+from torch.utils.data import Dataset
+
+from .dataset_utils import (
+ generate_splits,
+ get_geometry_data,
+ objectron_to_pytorch3d,
+ resize_images,
+)
+from .nerf_dataset import ListDataset
+
+
+DEFAULT_DATA_ROOT = os.path.join(
+ os.path.dirname(os.path.realpath(__file__)), "..", "data", "objectron"
+)
+
+
+def trivial_collate(batch):
+ """
+ A trivial collate function that merely returns the uncollated batch.
+ """
+ return batch
+
+
+def get_nerf_datasets(
+ dataset_name: str,
+ image_size: Tuple[int, int],
+ data_root: str = DEFAULT_DATA_ROOT,
+ **kwargs,
+) -> Tuple[Dataset, Dataset, Dataset]:
+ """
+ Obtains the training and validation dataset object for a dataset specified
+ with the `dataset_name` argument.
+
+ Args:
+ dataset_name: The name of the dataset to load.
+ image_size: A tuple (height, width) denoting the sizes of the loaded dataset images.
+ data_root: The root folder at which the data is stored.
+
+ Returns:
+ train_dataset: The training dataset object.
+ val_dataset: The validation dataset object.
+ test_dataset: The testing dataset object.
+ """
+ print(f"Loading dataset {dataset_name}, image size={str(image_size)} ...")
+
+ if dataset_name != "objectron":
+ raise ValueError("This data loader is only for the objectron dataset")
+
+ # Use the bundle adjusted camera parameters
+ sequence_geometry = get_geometry_data(os.path.join(data_root, "sfm_arframe.pbdata"))
+ num_frames = len(sequence_geometry)
+
+ # Check if splits are present else generate them on the first instance:
+ splits_path = os.path.join(data_root, "splits.pt")
+ if os.path.exists(splits_path):
+ print("Loading splits...")
+ splits = torch.load(splits_path)
+ train_idx, val_idx, test_idx = splits
+ else:
+ print("Generating splits...")
+ index_options = np.arange(num_frames)
+ train_idx, val_idx, test_idx = generate_splits(index_options)
+ torch.save([train_idx, val_idx, test_idx], splits_path)
+
+ print("Loading video...")
+ video_path = os.path.join(data_root, "video.MOV")
+ # Load the video using the PyTorchVideo video class
+ video = EncodedVideo.from_path(video_path)
+ FPS = 30
+
+ print("Loading all images and cameras...")
+ # Load all the video frames
+ frame_data = video.get_clip(start_sec=0, end_sec=(num_frames - 1) * 1.0 / FPS)
+ frame_data = frame_data["video"].permute(1, 2, 3, 0)
+ images = resize_images(frame_data, image_size)
+ cameras = []
+
+ for frame_id in tqdm.tqdm(range(num_frames)):
+ I, P = sequence_geometry[frame_id]
+ R = P[0:3, 0:3]
+ T = P[0:3, 3]
+
+ # Convert conventions
+ R = R.transpose(0, 1)
+ R, T = objectron_to_pytorch3d(R, T)
+
+ # Get intrinsic parameters
+ fx = I[0, 0]
+ fy = I[1, 1]
+ px = I[0, 2]
+ py = I[1, 2]
+
+ # Initialize the Perspective Camera
+ scene_cam = PerspectiveCameras(
+ R=R[None, ...],
+ T=T[None, ...],
+ focal_length=((fx, fy),),
+ principal_point=((px, py),),
+ ).to("cpu")
+
+ cameras.append(scene_cam)
+
+ train_dataset, val_dataset, test_dataset = [
+ ListDataset(
+ [
+ {"image": images[i], "camera": cameras[i], "camera_idx": int(i)}
+ for i in idx
+ ]
+ )
+ for idx in [train_idx, val_idx, test_idx]
+ ]
+
+ return train_dataset, val_dataset, test_dataset
diff --git a/code/pytorchvideo/projects/video_nerf/dataset_utils.py b/code/pytorchvideo/projects/video_nerf/dataset_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..d81737afaf15d93979c5485a7d9e2759c8ca2e70
--- /dev/null
+++ b/code/pytorchvideo/projects/video_nerf/dataset_utils.py
@@ -0,0 +1,117 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import os
+import struct
+import sys
+from typing import List, Tuple
+
+import numpy as np
+import torch
+
+# The AR Metadata captured with each frame in the video
+from objectron.schema import ( # noqa: E402
+ a_r_capture_metadata_pb2 as ar_metadata_protocol,
+)
+from PIL import Image
+from pytorch3d.transforms import Rotate, RotateAxisAngle, Translate
+
+
+# Imports from Objectron
+module_path = os.path.abspath(os.path.join("..."))
+if module_path not in sys.path:
+ sys.path.append("../Objectron")
+
+
+def objectron_to_pytorch3d(
+ R: torch.Tensor, T: torch.Tensor
+) -> Tuple[torch.Tensor, torch.Tensor]:
+ """
+ Transforms the R and T matrices from the Objectron world coordinate
+ system to the PyTorch3d world system.
+ Objectron cameras live in +X right, +Y Up, +Z from screen to us.
+ Pytorch3d world is +X left, +Y up, +Z from us to screen.
+ """
+ rotation = Rotate(R=R)
+ conversion = RotateAxisAngle(axis="y", angle=180)
+ composed_transform = rotation.compose(conversion).get_matrix()
+ composed_R = composed_transform[0, 0:3, 0:3]
+
+ translation = Translate(x=T[None, ...])
+ t_matrix = translation.compose(conversion).get_matrix()
+ flipped_T = t_matrix[0, 3, :3]
+ return composed_R, flipped_T
+
+
+def generate_splits(
+ index_options: List[int], train_fraction: float = 0.8
+) -> List[List[int]]:
+ """
+ Get indices for train, val, test splits.
+ """
+ num_images = len(index_options)
+ np.random.shuffle(index_options)
+ train_index = int(train_fraction * num_images)
+ val_index = train_index + ((num_images - train_index) // 2)
+ train_indices = index_options[:train_index]
+ val_indices = index_options[train_index:val_index]
+ test_indices = index_options[val_index:]
+ split_indices = [train_indices, val_indices, test_indices]
+ return split_indices
+
+
+def get_geometry_data(geometry_filename: str) -> List[List[torch.Tensor]]:
+ """
+ Utils function for parsing metadata files from the Objectron GitHub repo:
+ https://github.com/google-research-datasets/Objectron/blob/master/notebooks/objectron-geometry-tutorial.ipynb # noqa: B950
+ """
+ sequence_geometry = []
+ with open(geometry_filename, "rb") as pb:
+ proto_buf = pb.read()
+
+ i = 0
+ while i < len(proto_buf):
+ # Read the first four Bytes in little endian '<' integers 'I' format
+ # indicating the length of the current message.
+ msg_len = struct.unpack(" torch.Tensor:
+ """
+ Utils function to resize images
+ """
+ _image_max_image_pixels = Image.MAX_IMAGE_PIXELS
+ Image.MAX_IMAGE_PIXELS = None # The dataset image is very large ...
+ images = torch.FloatTensor(frames) / 255.0
+ Image.MAX_IMAGE_PIXELS = _image_max_image_pixels
+
+ scale_factors = [s_new / s for s, s_new in zip(images.shape[1:3], image_size)]
+
+ if abs(scale_factors[0] - scale_factors[1]) > 1e-3:
+ raise ValueError(
+ "Non-isotropic scaling is not allowed. Consider changing the 'image_size' argument."
+ )
+ scale_factor = sum(scale_factors) * 0.5
+
+ if scale_factor != 1.0:
+ print(f"Rescaling dataset (factor={scale_factor})")
+ images = torch.nn.functional.interpolate(
+ images.permute(0, 3, 1, 2),
+ size=tuple(image_size),
+ mode="bilinear",
+ ).permute(0, 2, 3, 1)
+
+ return images
diff --git a/code/pytorchvideo/projects/video_nerf/download_objectron_data.py b/code/pytorchvideo/projects/video_nerf/download_objectron_data.py
new file mode 100644
index 0000000000000000000000000000000000000000..c201ba2ba928bc1e5fce5e4c6325e6495907d650
--- /dev/null
+++ b/code/pytorchvideo/projects/video_nerf/download_objectron_data.py
@@ -0,0 +1,58 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import os
+
+import requests
+
+
+# URLs for downloading the Objectron dataset
+public_url = "https://storage.googleapis.com/objectron"
+blob_path = public_url + "/v1/index/chair_annotations_train"
+video_ids = requests.get(blob_path).text
+video_ids = video_ids.split("\n")
+
+DATA_PATH = "./nerf/data/objectron"
+
+os.makedirs(DATA_PATH, exist_ok=True)
+
+# Download a video of a chair.
+for i in range(3, 4):
+ video_filename = public_url + "/videos/" + video_ids[i] + "/video.MOV"
+ metadata_filename = public_url + "/videos/" + video_ids[i] + "/geometry.pbdata"
+ annotation_filename = public_url + "/annotations/" + video_ids[i] + ".pbdata"
+
+ # This file contains the bundle adjusted cameras
+ sfm_filename = public_url + "/videos/" + video_ids[i] + "/sfm_arframe.pbdata"
+
+ # video.content contains the video file.
+ video = requests.get(video_filename)
+ metadata = requests.get(metadata_filename)
+
+ # Please refer to Parse Annotation tutorial to see how to parse the annotation files.
+ annotation = requests.get(annotation_filename)
+
+ sfm = requests.get(sfm_filename)
+
+ video_path = os.path.join(DATA_PATH, "video.MOV")
+ print("Writing video to %s" % video_path)
+ file = open(video_path, "wb")
+ file.write(video.content)
+ file.close()
+
+ geometry_path = os.path.join(DATA_PATH, "geometry.pbdata")
+ print("Writing geometry data to %s" % geometry_path)
+ file = open(geometry_path, "wb")
+ file.write(metadata.content)
+ file.close()
+
+ annotation_path = os.path.join(DATA_PATH, "annotation.pbdata")
+ print("Writing annotation data to %s" % annotation_path)
+ file = open(annotation_path, "wb")
+ file.write(annotation.content)
+ file.close()
+
+ sfm_arframe_path = os.path.join(DATA_PATH, "sfm_arframe.pbdata")
+ print("Writing bundle adjusted camera data to %s" % sfm_arframe_path)
+ file = open(sfm_arframe_path, "wb")
+ file.write(sfm.content)
+ file.close()
diff --git a/code/pytorchvideo/projects/video_nerf/objectron.yaml b/code/pytorchvideo/projects/video_nerf/objectron.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..3bd1cdad7c874be910f98ddfd037af1f47a9f22a
--- /dev/null
+++ b/code/pytorchvideo/projects/video_nerf/objectron.yaml
@@ -0,0 +1,45 @@
+seed: 3
+resume: True
+stats_print_interval: 10
+validation_epoch_interval: 5
+checkpoint_epoch_interval: 30
+checkpoint_path: 'checkpoints/objectron.pth'
+data:
+ dataset_name: 'objectron'
+ image_size: [1440, 1920] # [height, width]
+ precache_rays: True
+test:
+ mode: 'evaluation'
+ trajectory_type: 'circular'
+ up: [0.0, 1.0, 0.0]
+ scene_center: [-0.5365, -1.05, 7.6191]
+ n_frames: 50
+ fps: 1
+ trajectory_scale: 0.2
+optimizer:
+ max_epochs: 20000
+ lr: 0.0005
+ lr_scheduler_step_size: 5000
+ lr_scheduler_gamma: 0.1
+visualization:
+ history_size: 10
+ visdom: True
+ visdom_server: 'localhost'
+ visdom_port: 8097
+ visdom_env: 'objectron'
+raysampler:
+ n_pts_per_ray: 64
+ n_pts_per_ray_fine: 64
+ n_rays_per_image: 1024
+ min_depth: 0.1
+ max_depth: 100.0
+ stratified: True
+ stratified_test: False
+ chunk_size_test: 6000
+implicit_function:
+ n_harmonic_functions_xyz: 10
+ n_harmonic_functions_dir: 4
+ n_hidden_neurons_xyz: 256
+ n_hidden_neurons_dir: 128
+ density_noise_std: 0.0
+ n_layers_xyz: 8
diff --git a/code/pytorchvideo/pytorchvideo.egg-info/PKG-INFO b/code/pytorchvideo/pytorchvideo.egg-info/PKG-INFO
new file mode 100644
index 0000000000000000000000000000000000000000..b65f333e0da43ab520d7cecc6017ce4c9a1a746d
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo.egg-info/PKG-INFO
@@ -0,0 +1,12 @@
+Metadata-Version: 2.1
+Name: pytorchvideo
+Version: 0.1.5
+Summary: A video understanding deep learning library.
+Home-page: https://github.com/facebookresearch/pytorchvideo
+Author: Facebook AI
+License: Apache 2.0
+Requires-Python: >=3.7
+Provides-Extra: test
+Provides-Extra: dev
+Provides-Extra: opencv-python
+License-File: LICENSE
diff --git a/code/pytorchvideo/pytorchvideo.egg-info/SOURCES.txt b/code/pytorchvideo/pytorchvideo.egg-info/SOURCES.txt
new file mode 100644
index 0000000000000000000000000000000000000000..c5ce4832f23e8e267af1699927afbb576944081d
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo.egg-info/SOURCES.txt
@@ -0,0 +1,162 @@
+CONTRIBUTING.md
+LICENSE
+MANIFEST.in
+README.md
+setup.cfg
+setup.py
+pytorchvideo/__init__.py
+pytorchvideo.egg-info/PKG-INFO
+pytorchvideo.egg-info/SOURCES.txt
+pytorchvideo.egg-info/dependency_links.txt
+pytorchvideo.egg-info/requires.txt
+pytorchvideo.egg-info/top_level.txt
+pytorchvideo/accelerator/__init__.py
+pytorchvideo/accelerator/deployment/__init__.py
+pytorchvideo/accelerator/deployment/common/__init__.py
+pytorchvideo/accelerator/deployment/common/model_transmuter.py
+pytorchvideo/accelerator/deployment/mobile_cpu/__init__.py
+pytorchvideo/accelerator/deployment/mobile_cpu/transmuter/__init__.py
+pytorchvideo/accelerator/deployment/mobile_cpu/transmuter/transmuter_mobile_cpu.py
+pytorchvideo/accelerator/deployment/mobile_cpu/utils/__init__.py
+pytorchvideo/accelerator/deployment/mobile_cpu/utils/model_conversion.py
+pytorchvideo/accelerator/efficient_blocks/__init__.py
+pytorchvideo/accelerator/efficient_blocks/efficient_block_base.py
+pytorchvideo/accelerator/efficient_blocks/no_op_convert_block.py
+pytorchvideo/data/__init__.py
+pytorchvideo/data/ava.py
+pytorchvideo/data/charades.py
+pytorchvideo/data/clip_sampling.py
+pytorchvideo/data/dataset_manifest_utils.py
+pytorchvideo/data/decoder.py
+pytorchvideo/data/domsev.py
+pytorchvideo/data/encoded_video.py
+pytorchvideo/data/encoded_video_decord.py
+pytorchvideo/data/encoded_video_pyav.py
+pytorchvideo/data/encoded_video_torchvision.py
+pytorchvideo/data/epic_kitchen_forecasting.py
+pytorchvideo/data/epic_kitchen_recognition.py
+pytorchvideo/data/frame_video.py
+pytorchvideo/data/hmdb51.py
+pytorchvideo/data/json_dataset.py
+pytorchvideo/data/kinetics.py
+pytorchvideo/data/labeled_video_dataset.py
+pytorchvideo/data/labeled_video_paths.py
+pytorchvideo/data/ssv2.py
+pytorchvideo/data/ucf101.py
+pytorchvideo/data/utils.py
+pytorchvideo/data/video.py
+pytorchvideo/data/ego4d/__init__.py
+pytorchvideo/data/ego4d/ego4d_dataset.py
+pytorchvideo/data/ego4d/utils.py
+pytorchvideo/data/epic_kitchen/__init__.py
+pytorchvideo/data/epic_kitchen/epic_kitchen_dataset.py
+pytorchvideo/data/epic_kitchen/utils.py
+pytorchvideo/layers/__init__.py
+pytorchvideo/layers/attention.py
+pytorchvideo/layers/attention_torchscript.py
+pytorchvideo/layers/batch_norm.py
+pytorchvideo/layers/convolutions.py
+pytorchvideo/layers/distributed.py
+pytorchvideo/layers/drop_path.py
+pytorchvideo/layers/fusion.py
+pytorchvideo/layers/mlp.py
+pytorchvideo/layers/nonlocal_net.py
+pytorchvideo/layers/positional_encoding.py
+pytorchvideo/layers/positional_encoding_torchscript.py
+pytorchvideo/layers/squeeze_excitation.py
+pytorchvideo/layers/swish.py
+pytorchvideo/layers/utils.py
+pytorchvideo/layers/accelerator/__init__.py
+pytorchvideo/layers/accelerator/mobile_cpu/__init__.py
+pytorchvideo/layers/accelerator/mobile_cpu/activation_functions.py
+pytorchvideo/layers/accelerator/mobile_cpu/attention.py
+pytorchvideo/layers/accelerator/mobile_cpu/conv_helper.py
+pytorchvideo/layers/accelerator/mobile_cpu/convolutions.py
+pytorchvideo/layers/accelerator/mobile_cpu/fully_connected.py
+pytorchvideo/layers/accelerator/mobile_cpu/pool.py
+pytorchvideo/losses/__init__.py
+pytorchvideo/losses/soft_target_cross_entropy.py
+pytorchvideo/models/__init__.py
+pytorchvideo/models/audio_visual_slowfast.py
+pytorchvideo/models/byol.py
+pytorchvideo/models/csn.py
+pytorchvideo/models/head.py
+pytorchvideo/models/masked_multistream.py
+pytorchvideo/models/memory_bank.py
+pytorchvideo/models/net.py
+pytorchvideo/models/r2plus1d.py
+pytorchvideo/models/resnet.py
+pytorchvideo/models/simclr.py
+pytorchvideo/models/slowfast.py
+pytorchvideo/models/stem.py
+pytorchvideo/models/vision_transformers.py
+pytorchvideo/models/weight_init.py
+pytorchvideo/models/x3d.py
+pytorchvideo/models/accelerator/__init__.py
+pytorchvideo/models/accelerator/mobile_cpu/__init__.py
+pytorchvideo/models/accelerator/mobile_cpu/efficient_x3d.py
+pytorchvideo/models/accelerator/mobile_cpu/residual_blocks.py
+pytorchvideo/models/hub/__init__.py
+pytorchvideo/models/hub/csn.py
+pytorchvideo/models/hub/efficient_x3d_mobile_cpu.py
+pytorchvideo/models/hub/r2plus1d.py
+pytorchvideo/models/hub/resnet.py
+pytorchvideo/models/hub/slowfast.py
+pytorchvideo/models/hub/utils.py
+pytorchvideo/models/hub/vision_transformers.py
+pytorchvideo/models/hub/x3d.py
+pytorchvideo/transforms/__init__.py
+pytorchvideo/transforms/augmentations.py
+pytorchvideo/transforms/augmix.py
+pytorchvideo/transforms/functional.py
+pytorchvideo/transforms/mix.py
+pytorchvideo/transforms/rand_augment.py
+pytorchvideo/transforms/transforms.py
+pytorchvideo/transforms/transforms_factory.py
+tests/test_accelerator_deployment_mobile_cpu_model_conversion.py
+tests/test_accelerator_deployment_model_transmuter.py
+tests/test_accelerator_efficient_blocks_mobile_cpu_activation_attention.py
+tests/test_accelerator_efficient_blocks_mobile_cpu_conv3d.py
+tests/test_accelerator_efficient_blocks_mobile_cpu_head_layer.py
+tests/test_accelerator_efficient_blocks_mobile_cpu_residual_block.py
+tests/test_accelerator_models_efficient_x3d.py
+tests/test_data_ava_dataset.py
+tests/test_data_charades_dataset.py
+tests/test_data_dataset_manifest_utils.py
+tests/test_data_domsev_dataset.py
+tests/test_data_encoded_video.py
+tests/test_data_epic_kitchen_dataset.py
+tests/test_data_epic_kitchen_forecasting.py
+tests/test_data_epic_kitchen_recognition.py
+tests/test_data_epic_kitchen_utils.py
+tests/test_data_frame_video.py
+tests/test_data_json_dataset.py
+tests/test_data_labeled_video_dataset.py
+tests/test_data_ssv2_dataset.py
+tests/test_data_utils.py
+tests/test_fuse_bn.py
+tests/test_layers_attention.py
+tests/test_layers_convolutions.py
+tests/test_layers_drop_path.py
+tests/test_layers_fusion.py
+tests/test_layers_mlp.py
+tests/test_layers_nonlocal_net.py
+tests/test_layers_positional_encoding.py
+tests/test_layers_squeeze_excitation.py
+tests/test_losses_soft_target_cross_entropy.py
+tests/test_models_audio_visual_slowfast.py
+tests/test_models_byol.py
+tests/test_models_csn.py
+tests/test_models_head.py
+tests/test_models_hub_vision_transformers.py
+tests/test_models_masked_multistream.py
+tests/test_models_memory_bank.py
+tests/test_models_r2plus1d.py
+tests/test_models_resnet.py
+tests/test_models_slowfast.py
+tests/test_models_stem.py
+tests/test_models_vision_transformers.py
+tests/test_models_x3d.py
+tests/test_simclr.py
+tests/test_transforms.py
+tests/test_uniform_clip_sampler.py
\ No newline at end of file
diff --git a/code/pytorchvideo/pytorchvideo.egg-info/dependency_links.txt b/code/pytorchvideo/pytorchvideo.egg-info/dependency_links.txt
new file mode 100644
index 0000000000000000000000000000000000000000..8b137891791fe96927ad78e64b0aad7bded08bdc
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo.egg-info/dependency_links.txt
@@ -0,0 +1 @@
+
diff --git a/code/pytorchvideo/pytorchvideo.egg-info/requires.txt b/code/pytorchvideo/pytorchvideo.egg-info/requires.txt
new file mode 100644
index 0000000000000000000000000000000000000000..7b42a71885c62345079daac67c4f225f1e8c4928
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo.egg-info/requires.txt
@@ -0,0 +1,28 @@
+fvcore
+av
+parameterized
+iopath
+networkx
+
+[dev]
+opencv-python
+decord
+black==20.8b1
+sphinx
+isort==4.3.21
+flake8==3.8.1
+flake8-bugbear
+flake8-comprehensions
+pre-commit
+nbconvert
+bs4
+autoflake==1.4
+
+[opencv-python]
+opencv-python
+
+[test]
+coverage
+pytest
+opencv-python
+decord
diff --git a/code/pytorchvideo/pytorchvideo.egg-info/top_level.txt b/code/pytorchvideo/pytorchvideo.egg-info/top_level.txt
new file mode 100644
index 0000000000000000000000000000000000000000..0b1daa503b36a6d4ec04f865849bc1738f7d12a9
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo.egg-info/top_level.txt
@@ -0,0 +1 @@
+pytorchvideo
diff --git a/code/pytorchvideo/pytorchvideo/__init__.py b/code/pytorchvideo/pytorchvideo/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2b2f870710dc40c0e8f1910bcd0a089a8ecf018
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/__init__.py
@@ -0,0 +1,3 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+__version__ = "0.1.5"
diff --git a/code/pytorchvideo/pytorchvideo/__pycache__/__init__.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..35f3c4cb422de0e9bde61274435508cf01891cc3
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/__pycache__/__init__.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/accelerator/__init__.py b/code/pytorchvideo/pytorchvideo/accelerator/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c7f19c6c00a4ac3f2f2bc66f892e44bcbd72612
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/accelerator/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
diff --git a/code/pytorchvideo/pytorchvideo/accelerator/deployment/__init__.py b/code/pytorchvideo/pytorchvideo/accelerator/deployment/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c7f19c6c00a4ac3f2f2bc66f892e44bcbd72612
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/accelerator/deployment/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
diff --git a/code/pytorchvideo/pytorchvideo/accelerator/deployment/common/__init__.py b/code/pytorchvideo/pytorchvideo/accelerator/deployment/common/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c7f19c6c00a4ac3f2f2bc66f892e44bcbd72612
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/accelerator/deployment/common/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
diff --git a/code/pytorchvideo/pytorchvideo/accelerator/deployment/common/model_transmuter.py b/code/pytorchvideo/pytorchvideo/accelerator/deployment/common/model_transmuter.py
new file mode 100644
index 0000000000000000000000000000000000000000..e1593528b3212b1f4bb926d002e0e9c64c113b8e
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/accelerator/deployment/common/model_transmuter.py
@@ -0,0 +1,86 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import logging
+from typing import List
+
+import torch.nn as nn
+
+
+"""
+This file contains top-level transmuter to convert user input model (nn.Module) into
+an equivalent model composed of efficientBlocks for target device.
+Specifically, each target device has a transmuter list, which contains transmuter
+functions to convert module into equivalent efficientBlock. Each transmuter list is
+registered in EFFICIENT_BLOCK_TRANSMUTER_REGISTRY to be accessed by top-level transmuter.
+"""
+EFFICIENT_BLOCK_TRANSMUTER_REGISTRY = {}
+
+
+def _find_equivalent_efficient_module(
+ module_input: nn.Module,
+ efficient_block_transmuter_list: List,
+ module_name: str = "",
+):
+ """
+ Given module_input, search through efficient_block_registry to see whether the
+ module_input can be replaced with equivalent efficientBlock. Returns None if no
+ equivalent efficientBlock is found, else returns an instance of equivalent
+ efficientBlock.
+ Args:
+ module_input (nn.Module): module to be replaced by equivalent efficientBlock
+ efficient_block_transmuter_list (list): a transmuter list that contains transmuter
+ functions for available efficientBlocks
+ module_name (str): name of module_input in original model
+ """
+ eq_module_hit_list = []
+ for iter_func in efficient_block_transmuter_list:
+ eq_module = iter_func(module_input)
+ if eq_module is not None:
+ eq_module_hit_list.append(eq_module)
+ if len(eq_module_hit_list) > 0:
+ # Check for multiple matches.
+ if len(eq_module_hit_list) > 1:
+ logging.warning(f"{module_name} has multiple matches:")
+ for iter_match in eq_module_hit_list:
+ logging.warning(f"{iter_match.__class__.__name__} is a match.")
+ logging.warning(
+ f"Will use {eq_module_hit_list[0]} as it has highest priority."
+ )
+ return eq_module_hit_list[0]
+ return None
+
+
+def transmute_model(
+ model: nn.Module,
+ target_device: str = "mobile_cpu",
+ prefix: str = "",
+):
+ """
+ Recursively goes through user input model and replace module in place with available
+ equivalent efficientBlock for target device.
+ Args:
+ model (nn.Module): user input model to be transmuted
+ target_device (str): name of target device, used to access transmuter list in
+ EFFICIENT_BLOCK_TRANSMUTER_REGISTRY
+ prefix (str): name of current hierarchy in user model
+ """
+ assert (
+ target_device in EFFICIENT_BLOCK_TRANSMUTER_REGISTRY
+ ), f"{target_device} not registered in EFFICIENT_BLOCK_TRANSMUTER_REGISTRY!"
+ transmuter_list = EFFICIENT_BLOCK_TRANSMUTER_REGISTRY[target_device]
+ for name, child in model.named_children():
+ equivalent_module = _find_equivalent_efficient_module(
+ child, transmuter_list, module_name=f"{prefix}.{name}"
+ )
+ if equivalent_module is not None:
+ model._modules[name] = equivalent_module
+ logging.info(
+ f"Replacing {prefix}.{name} ({child.__class__.__name__}) with "
+ f"{equivalent_module.__class__.__name__}"
+ )
+ else:
+ transmute_model(
+ child,
+ target_device=target_device,
+ prefix=f"{prefix}.{name}",
+ )
diff --git a/code/pytorchvideo/pytorchvideo/accelerator/deployment/mobile_cpu/__init__.py b/code/pytorchvideo/pytorchvideo/accelerator/deployment/mobile_cpu/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c7f19c6c00a4ac3f2f2bc66f892e44bcbd72612
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/accelerator/deployment/mobile_cpu/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
diff --git a/code/pytorchvideo/pytorchvideo/accelerator/deployment/mobile_cpu/transmuter/__init__.py b/code/pytorchvideo/pytorchvideo/accelerator/deployment/mobile_cpu/transmuter/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..8c573dc2f395c8a20625ee32398c503aefe69d02
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/accelerator/deployment/mobile_cpu/transmuter/__init__.py
@@ -0,0 +1,10 @@
+from pytorchvideo.accelerator.deployment.common.model_transmuter import (
+ EFFICIENT_BLOCK_TRANSMUTER_REGISTRY,
+)
+
+from .transmuter_mobile_cpu import EFFICIENT_BLOCK_TRANSMUTER_MOBILE_CPU
+
+
+EFFICIENT_BLOCK_TRANSMUTER_REGISTRY[
+ "mobile_cpu"
+] = EFFICIENT_BLOCK_TRANSMUTER_MOBILE_CPU
diff --git a/code/pytorchvideo/pytorchvideo/accelerator/deployment/mobile_cpu/transmuter/transmuter_mobile_cpu.py b/code/pytorchvideo/pytorchvideo/accelerator/deployment/mobile_cpu/transmuter/transmuter_mobile_cpu.py
new file mode 100644
index 0000000000000000000000000000000000000000..dfaee8a8c7dc141282b64aad7c59039c47484eec
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/accelerator/deployment/mobile_cpu/transmuter/transmuter_mobile_cpu.py
@@ -0,0 +1,204 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import torch.nn as nn
+from pytorchvideo.layers.accelerator.mobile_cpu.convolutions import (
+ Conv3d3x1x1BnAct,
+ Conv3d3x3x3DwBnAct,
+ Conv3d5x1x1BnAct,
+ Conv3dPwBnAct,
+ Conv3dTemporalKernel1BnAct,
+)
+
+
+def transmute_Conv3dPwBnAct(input_module: nn.Module):
+ """
+ Given an input_module, transmutes it into a equivalent Conv3dPwBnAct. Returns None
+ if no equivalent Conv3dPwBnAct is found, else returns an instance of equivalent
+ Conv3dPwBnAct.
+ Args:
+ input_module (nn.Module): input module to find an equivalent Conv3dPwBnAct
+ """
+ if not isinstance(input_module, nn.Conv3d):
+ return None
+ if (
+ input_module.kernel_size == (1, 1, 1)
+ and input_module.groups == 1
+ and input_module.stride == (1, 1, 1)
+ and input_module.padding == (0, 0, 0)
+ and input_module.dilation == (1, 1, 1)
+ ):
+ module = Conv3dPwBnAct(
+ in_channels=input_module.in_channels,
+ out_channels=input_module.out_channels,
+ bias=False if input_module.bias is None else True,
+ activation="identity",
+ use_bn=False,
+ )
+ module.kernel.conv.load_state_dict(input_module.state_dict())
+ return module
+ else:
+ return None
+
+
+def transmute_Conv3d3x3x3DwBnAct(input_module: nn.Module):
+ """
+ Given an input_module, transmutes it into a equivalent Conv3d3x3x3DwBnAct. Returns
+ None if no equivalent Conv3d3x3x3DwBnAct is found, else returns an instance of
+ equivalent Conv3d3x3x3DwBnAct.
+ Args:
+ input_module (nn.Module): input module to find an equivalent Conv3d3x3x3DwBnAct
+ """
+ if not isinstance(input_module, nn.Conv3d):
+ return None
+ if (
+ input_module.kernel_size == (3, 3, 3)
+ and input_module.in_channels == input_module.out_channels
+ and input_module.groups == input_module.out_channels
+ and input_module.stride[0] == 1
+ and input_module.stride[1] == input_module.stride[2]
+ and input_module.padding == (1, 1, 1)
+ and input_module.padding_mode == "zeros"
+ and input_module.dilation == (1, 1, 1)
+ ):
+ spatial_stride = input_module.stride[1]
+ module = Conv3d3x3x3DwBnAct(
+ in_channels=input_module.in_channels,
+ spatial_stride=spatial_stride,
+ bias=False if input_module.bias is None else True,
+ activation="identity",
+ use_bn=False,
+ )
+ module.kernel.conv.load_state_dict(input_module.state_dict())
+ return module
+ else:
+ return None
+
+
+def transmute_Conv3dTemporalKernel1BnAct(input_module: nn.Module):
+ """
+ Given an input_module, transmutes it into a equivalent Conv3dTemporalKernel1BnAct.
+ Returns None if no equivalent Conv3dTemporalKernel1BnAct is found, else returns
+ an instance of equivalent Conv3dTemporalKernel1BnAct.
+ Args:
+ input_module (nn.Module): input module to find an equivalent Conv3dTemporalKernel1BnAct
+ """
+ if not isinstance(input_module, nn.Conv3d):
+ return None
+ """
+ If the input_module can be replaced by Conv3dPwBnAct, don't use
+ Conv3dTemporalKernel1BnAct.
+ """
+ if (
+ input_module.kernel_size == (1, 1, 1)
+ and input_module.groups == 1
+ and input_module.stride == (1, 1, 1)
+ and input_module.padding == (0, 0, 0)
+ and input_module.dilation == (1, 1, 1)
+ ):
+ return None
+
+ if (
+ input_module.kernel_size[0] == 1
+ and input_module.kernel_size[1] == input_module.kernel_size[2]
+ and input_module.stride[0] == 1
+ and input_module.stride[1] == input_module.stride[2]
+ and input_module.padding[0] == 0
+ and input_module.dilation[0] == 1
+ ):
+ spatial_stride = input_module.stride[1]
+ spatial_kernel = input_module.kernel_size[1]
+ spatial_padding = input_module.padding[1]
+ spatial_dilation = input_module.dilation[1]
+ module = Conv3dTemporalKernel1BnAct(
+ in_channels=input_module.in_channels,
+ out_channels=input_module.out_channels,
+ bias=False if input_module.bias is None else True,
+ groups=input_module.groups,
+ spatial_kernel=spatial_kernel,
+ spatial_stride=spatial_stride,
+ spatial_padding=spatial_padding,
+ spatial_dilation=spatial_dilation,
+ activation="identity",
+ use_bn=False,
+ )
+ module.kernel.conv.load_state_dict(input_module.state_dict())
+ return module
+ else:
+ return None
+
+
+def transmute_Conv3d3x1x1BnAct(input_module: nn.Module):
+ """
+ Given an input_module, transmutes it into a equivalent Conv3d3x1x1BnAct.
+ Returns None if no equivalent Conv3d3x1x1BnAct is found, else returns
+ an instance of equivalent Conv3d3x1x1BnAct.
+ Args:
+ input_module (nn.Module): input module to find an equivalent Conv3d3x1x1BnAct
+ """
+ if not isinstance(input_module, nn.Conv3d):
+ return None
+
+ if (
+ input_module.kernel_size == (3, 1, 1)
+ and input_module.stride == (1, 1, 1)
+ and input_module.padding == (1, 0, 0)
+ and input_module.dilation == (1, 1, 1)
+ and input_module.padding_mode == "zeros"
+ ):
+ module = Conv3d3x1x1BnAct(
+ in_channels=input_module.in_channels,
+ out_channels=input_module.out_channels,
+ bias=False if input_module.bias is None else True,
+ groups=input_module.groups,
+ activation="identity",
+ use_bn=False,
+ )
+ module.kernel.conv.load_state_dict(input_module.state_dict())
+ return module
+ else:
+ return None
+
+
+def transmute_Conv3d5x1x1BnAct(input_module: nn.Module):
+ """
+ Given an input_module, transmutes it into a equivalent Conv3d5x1x1BnAct.
+ Returns None if no equivalent Conv3d5x1x1BnAct is found, else returns
+ an instance of equivalent Conv3d5x1x1BnAct.
+ Args:
+ input_module (nn.Module): input module to find an equivalent Conv3d5x1x1BnAct
+ """
+ if not isinstance(input_module, nn.Conv3d):
+ return None
+
+ if (
+ input_module.kernel_size == (5, 1, 1)
+ and input_module.stride == (1, 1, 1)
+ and input_module.padding == (2, 0, 0)
+ and input_module.dilation == (1, 1, 1)
+ and input_module.padding_mode == "zeros"
+ ):
+ module = Conv3d5x1x1BnAct(
+ in_channels=input_module.in_channels,
+ out_channels=input_module.out_channels,
+ bias=False if input_module.bias is None else True,
+ groups=input_module.groups,
+ activation="identity",
+ use_bn=False,
+ )
+ module.kernel.conv.load_state_dict(input_module.state_dict())
+ return module
+ else:
+ return None
+
+
+"""
+List of efficient_block transmuters for mobile_cpu. If one module matches multiple
+transmuters, the first matched transmuter in list will be used.
+"""
+EFFICIENT_BLOCK_TRANSMUTER_MOBILE_CPU = [
+ transmute_Conv3dPwBnAct,
+ transmute_Conv3d3x3x3DwBnAct,
+ transmute_Conv3dTemporalKernel1BnAct,
+ transmute_Conv3d3x1x1BnAct,
+ transmute_Conv3d5x1x1BnAct,
+]
diff --git a/code/pytorchvideo/pytorchvideo/accelerator/deployment/mobile_cpu/utils/__init__.py b/code/pytorchvideo/pytorchvideo/accelerator/deployment/mobile_cpu/utils/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c7f19c6c00a4ac3f2f2bc66f892e44bcbd72612
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/accelerator/deployment/mobile_cpu/utils/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
diff --git a/code/pytorchvideo/pytorchvideo/accelerator/deployment/mobile_cpu/utils/model_conversion.py b/code/pytorchvideo/pytorchvideo/accelerator/deployment/mobile_cpu/utils/model_conversion.py
new file mode 100644
index 0000000000000000000000000000000000000000..2b36f54e2430fba23f5979a45d4a99fe86b102a2
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/accelerator/deployment/mobile_cpu/utils/model_conversion.py
@@ -0,0 +1,125 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+from copy import deepcopy
+from typing import Dict, List
+
+import torch
+import torch.nn as nn
+from pytorchvideo.accelerator.efficient_blocks.efficient_block_base import (
+ EfficientBlockBase,
+)
+
+
+def _add_input_tensor_size_lut_hook(
+ module: nn.Module,
+ input_tensor_size_lut: Dict,
+ hook_handle_list: List,
+ base_name: str = "",
+) -> None:
+ """
+ This helper function recursively goes through all modules in a network, registers
+ forward hook function to each module. The hook function records the input tensor
+ size in forward in input_tensor_size_lut[base_name].
+ Args:
+ module (nn.Module): input module to add hook recursively.
+ input_tensor_size_lut (dict): lut to record input tensor size for hook function.
+ hook_handle_list (list): a list to contain hook handles.
+ base_name (str): name for module input.
+ """
+
+ def hook_fn(_, _in, _out):
+ if isinstance(_in[0], torch.Tensor):
+ input_tensor_size_lut[base_name] = tuple(_in[0].size())
+ return
+
+ handle = module.register_forward_hook(hook_fn)
+ hook_handle_list.append(handle)
+ for name, child in module.named_children():
+ _add_input_tensor_size_lut_hook(
+ child,
+ input_tensor_size_lut,
+ hook_handle_list,
+ base_name=f"{base_name}.{name}",
+ )
+
+
+def _convert_module(
+ module: nn.Module,
+ input_tensor_size_lut: Dict,
+ base_name: str = "",
+ convert_for_quantize: bool = False,
+ native_conv3d_op_qnnpack: bool = False,
+) -> None:
+ """
+ This helper function recursively goes through sub-modules in a network. If current
+ module is a efficient block (instance of EfficientBlockBase) with convert() method,
+ its convert() method will be called, and the input tensor size (needed by efficient
+ blocks for mobile cpu) will be provided by matching module name in
+ input_tensor_size_lut.
+ Otherwise if the input module is a non efficient block, this function will try to go
+ through child modules of input module to look for any efficient block in lower
+ hierarchy.
+ Args:
+ module (nn.Module): input module for convert.
+ input_tensor_size_lut (dict): input tensor size look-up table.
+ base_name (str): module name for input module.
+ convert_for_quantize (bool): whether this module is intended to be quantized.
+ native_conv3d_op_qnnpack (bool): whether the QNNPACK version has native int8
+ Conv3d.
+ """
+ if isinstance(module, EfficientBlockBase):
+ module.convert(
+ input_tensor_size_lut[base_name],
+ convert_for_quantize=convert_for_quantize,
+ native_conv3d_op_qnnpack=native_conv3d_op_qnnpack,
+ )
+ else:
+ for name, child in module.named_children():
+ _convert_module(
+ child,
+ input_tensor_size_lut,
+ base_name=f"{base_name}.{name}",
+ convert_for_quantize=convert_for_quantize,
+ native_conv3d_op_qnnpack=native_conv3d_op_qnnpack,
+ )
+
+
+def convert_to_deployable_form(
+ model: nn.Module,
+ input_tensor: torch.Tensor,
+ convert_for_quantize: bool = False,
+ native_conv3d_op_qnnpack: bool = False,
+) -> nn.Module:
+ """
+ This function takes an input model, and returns a deployable model copy.
+ Args:
+ model (nn.Module): input model for conversion. The model can include a mix of
+ efficient blocks (instances of EfficientBlockBase) and non efficient blocks.
+ The efficient blocks will be converted by calling its convert() method, while
+ other blocks will stay unchanged.
+ input_tensor (torch.Tensor): input tensor for model. Note current conversion for
+ deployable form in mobile cpu only works for single input tensor size (i.e.,
+ the future input tensor to converted model should have the same size as
+ input_tensor specified here).
+ convert_for_quantize (bool): whether this module is intended to be quantized.
+ native_conv3d_op_qnnpack (bool): whether the QNNPACK version has native int8
+ Conv3d.
+ """
+ input_tensor_size_lut = {}
+ hook_handle_list = []
+ _add_input_tensor_size_lut_hook(model, input_tensor_size_lut, hook_handle_list)
+ # Run forward to fill in input tensor lut.
+ model.eval()
+ model(input_tensor)
+ # Remove forward hooks.
+ for handle in hook_handle_list:
+ handle.remove()
+ model_converted = deepcopy(model)
+ model_converted.eval()
+ _convert_module(
+ model_converted,
+ input_tensor_size_lut,
+ convert_for_quantize=convert_for_quantize,
+ native_conv3d_op_qnnpack=native_conv3d_op_qnnpack,
+ )
+ return model_converted
diff --git a/code/pytorchvideo/pytorchvideo/accelerator/efficient_blocks/__init__.py b/code/pytorchvideo/pytorchvideo/accelerator/efficient_blocks/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..5c7f19c6c00a4ac3f2f2bc66f892e44bcbd72612
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/accelerator/efficient_blocks/__init__.py
@@ -0,0 +1 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
diff --git a/code/pytorchvideo/pytorchvideo/accelerator/efficient_blocks/efficient_block_base.py b/code/pytorchvideo/pytorchvideo/accelerator/efficient_blocks/efficient_block_base.py
new file mode 100644
index 0000000000000000000000000000000000000000..1040218d67f9572aaf517434f6ef6b6ac62564d1
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/accelerator/efficient_blocks/efficient_block_base.py
@@ -0,0 +1,35 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+from abc import abstractmethod
+
+import torch.nn as nn
+
+
+class EfficientBlockBase(nn.Module):
+ """
+ PyTorchVideo/accelerator provides a set of efficient blocks
+ that have optimal efficiency for each target hardware device.
+
+ Each efficient block has two forms:
+ - original form: this form is for training. When efficient block is instantiated,
+ it is in this original form.
+ - deployable form: this form is for deployment. Once the network is ready for
+ deploy, it can be converted into deployable form for efficient execution
+ on target hardware. One block is transformed into deployable form by calling
+ convert() method. By conversion to deployable form,
+ various optimization (operator fuse, kernel optimization, etc.) are applied.
+
+ EfficientBlockBase is the base class for efficient blocks.
+ All efficient blocks should inherit this base class
+ and implement following methods:
+ - forward(): same as required by nn.Module
+ - convert(): called to convert block into deployable form
+ """
+
+ @abstractmethod
+ def convert(self):
+ pass
+
+ @abstractmethod
+ def forward(self):
+ pass
diff --git a/code/pytorchvideo/pytorchvideo/accelerator/efficient_blocks/no_op_convert_block.py b/code/pytorchvideo/pytorchvideo/accelerator/efficient_blocks/no_op_convert_block.py
new file mode 100644
index 0000000000000000000000000000000000000000..81ce0aa5716b2477da24ed2bc478079c9cd866fc
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/accelerator/efficient_blocks/no_op_convert_block.py
@@ -0,0 +1,26 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import torch.nn as nn
+
+from .efficient_block_base import EfficientBlockBase
+
+
+class NoOpConvertBlock(EfficientBlockBase):
+ """
+ This class provides an interface with EfficientBlockBase for modules that do not
+ need convert.
+ Args:
+ model (nn.Module): NoOpConvertBlock takes model as input and generate a wrapper
+ instance of EfficientBlockBase with same functionality as model, with no change
+ applied when convert() is called.
+ """
+
+ def __init__(self, model: nn.Module):
+ super().__init__()
+ self.model = model
+
+ def convert(self, *args, **kwargs):
+ pass
+
+ def forward(self, x):
+ return self.model(x)
diff --git a/code/pytorchvideo/pytorchvideo/data/__init__.py b/code/pytorchvideo/pytorchvideo/data/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..f7316dc8b01ddd51b108c54220339bf5221fa5f0
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/__init__.py
@@ -0,0 +1,18 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+from .ava import Ava # noqa
+from .charades import Charades # noqa
+from .clip_sampling import ( # noqa; noqa
+ ClipSampler,
+ make_clip_sampler,
+ RandomClipSampler,
+ UniformClipSampler,
+)
+from .domsev import DomsevFrameDataset, DomsevVideoDataset # noqa
+from .epic_kitchen_forecasting import EpicKitchenForecasting # noqa
+from .epic_kitchen_recognition import EpicKitchenRecognition # noqa
+from .hmdb51 import Hmdb51 # noqa
+from .kinetics import Kinetics # noqa
+from .labeled_video_dataset import labeled_video_dataset, LabeledVideoDataset # noqa
+from .ssv2 import SSv2
+from .ucf101 import Ucf101 # noqa
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/__init__.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..e6aa5aa1026d947dc6858b376a5514213f906af5
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/__init__.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/ava.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/ava.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0b7e6b5bd6f080a5459904a7ae1431f56681f630
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/ava.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/charades.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/charades.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..98832f40b6627be40e83f80b0577fb6304c23b02
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/charades.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/clip_sampling.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/clip_sampling.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..85ce69deefb30ba9ebe10f9fcb7db71c488e93a6
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/clip_sampling.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/dataset_manifest_utils.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/dataset_manifest_utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f457a018714bb4a95b7fb3f3cfcce681c3824d1b
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/dataset_manifest_utils.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/decoder.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/decoder.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..3bdb2920463a92bd3093c71af65899de0be9b9d6
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/decoder.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/domsev.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/domsev.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..7dc32375eede9f63000f92b9ac522c2fa198939d
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/domsev.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/encoded_video.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/encoded_video.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..88395c098864882657e0c3507bfe28f47548d21d
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/encoded_video.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/encoded_video_decord.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/encoded_video_decord.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..0f965031466e934a88ad5931821e1d6d8168a812
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/encoded_video_decord.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/epic_kitchen_forecasting.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/epic_kitchen_forecasting.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..21a07d3782794d4f294658befb2805dc1f0fe66e
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/epic_kitchen_forecasting.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/epic_kitchen_recognition.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/epic_kitchen_recognition.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..27c8a6a461229f14eff6a8351e114303bf905ebd
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/epic_kitchen_recognition.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/frame_video.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/frame_video.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..16d051e392b987a876d43f1211ec4cf148758123
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/frame_video.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/hmdb51.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/hmdb51.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..40a6e745bb7f2539e961daffd9c97b20e4d57aab
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/hmdb51.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/kinetics.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/kinetics.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..fa767341901041ce1577fddb0efe32a350fc69f1
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/kinetics.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/labeled_video_dataset.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/labeled_video_dataset.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..186058f1f4ff94abc6327a56c5e60361384d0eac
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/labeled_video_dataset.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/labeled_video_paths.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/labeled_video_paths.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..f5c62a8a229b969d9e6307683e25e2a186ebf68e
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/labeled_video_paths.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/ssv2.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/ssv2.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..5b2c260c21e87a6253390c54a1d29226ed3dc194
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/ssv2.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/ucf101.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/ucf101.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..b062e0a473ecbc61ac592fe0c00598bf28ddad0e
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/ucf101.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/utils.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/utils.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..c2cffa33eebc56e538c0cd3121cb4e62e449f8fc
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/utils.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/__pycache__/video.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/__pycache__/video.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..94ef0f8ad414092f05d6f2a56c7904c6fdf56d29
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/__pycache__/video.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/ava.py b/code/pytorchvideo/pytorchvideo/data/ava.py
new file mode 100644
index 0000000000000000000000000000000000000000..aed7c5e6c748bf57d3a253ec07f0887f373f5888
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/ava.py
@@ -0,0 +1,375 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+from __future__ import annotations
+
+import os
+from collections import defaultdict
+from typing import Any, Callable, Dict, Optional, Set, Tuple, Type
+
+import torch
+from iopath.common.file_io import g_pathmgr
+from pytorchvideo.data.clip_sampling import ClipInfo, ClipSampler
+from pytorchvideo.data.labeled_video_dataset import LabeledVideoDataset
+
+
+class AvaLabeledVideoFramePaths:
+ """
+ Pre-processor for Ava Actions Dataset stored as image frames -
+ `_`
+ This class handles the parsing of all the necessary
+ csv files containing frame paths and frame labels.
+ """
+
+ # Range of valid annotated frames in Ava dataset
+ AVA_VALID_FRAMES = list(range(902, 1799))
+ FPS = 30
+ AVA_VIDEO_START_SEC = 900
+
+ @classmethod
+ def _aggregate_bboxes_labels(cls, inp: Dict):
+
+ # Needed for aggregating the bounding boxes
+ labels = inp["labels"]
+ extra_info = inp["extra_info"]
+ boxes = inp["boxes"]
+
+ labels_agg = []
+ extra_info_agg = []
+ boxes_agg = []
+ bb_dict = {}
+
+ for i in range(len(labels)):
+ box_label, box_extra_info = labels[i], extra_info[i]
+
+ bbox_key = "{:.2f},{:.2f},{:.2f},{:.2f}".format(
+ boxes[i][0], boxes[i][1], boxes[i][2], boxes[i][3]
+ )
+
+ if bbox_key not in bb_dict:
+ bb_dict[bbox_key] = len(boxes_agg)
+ boxes_agg.append(boxes[i])
+ labels_agg.append([])
+ extra_info_agg.append([])
+
+ idx = bb_dict[bbox_key]
+ labels_agg[idx].append(box_label)
+ extra_info_agg[idx].append(box_extra_info)
+
+ return {
+ "labels": labels_agg,
+ "boxes": boxes_agg,
+ "extra_info": extra_info_agg,
+ }
+
+ @classmethod
+ def from_csv(
+ cls,
+ frame_paths_file: str,
+ frame_labels_file: str,
+ video_path_prefix: str,
+ label_map_file: Optional[str] = None,
+ ) -> AvaLabeledVideoFramePaths:
+ """
+ Args:
+ frame_labels_file (str): Path to the file containing containing labels
+ per key frame. Acceptible file formats are,
+ Type 1:
+
+ Type 2:
+
+ frame_paths_file (str): Path to a file containing relative paths
+ to all the frames in the video. Each line in the file is of the
+ form
+ video_path_prefix (str): Path to be augumented to the each relative frame
+ path to get the global frame path.
+ label_map_file (str): Path to a .pbtxt containing class id's and class names.
+ If not set, label_map is not loaded and bbox labels are not pruned
+ based on allowable class_id's in label_map.
+ Returs:
+ A list of tuples of the the form (video_frames directory, label dictionary).
+ """
+ if label_map_file is not None:
+ _, allowed_class_ids = AvaLabeledVideoFramePaths.read_label_map(
+ label_map_file
+ )
+ else:
+ allowed_class_ids = None
+
+ (
+ image_paths,
+ video_idx_to_name,
+ video_name_to_idx,
+ ) = AvaLabeledVideoFramePaths.load_image_lists(
+ frame_paths_file, video_path_prefix
+ )
+
+ video_frame_labels = AvaLabeledVideoFramePaths.load_and_parse_labels_csv(
+ frame_labels_file,
+ video_name_to_idx,
+ allowed_class_ids,
+ )
+
+ # Populate keyframes list
+ labeled_video_paths = []
+ for video_id in video_frame_labels.keys():
+ for frame_video_sec in video_frame_labels[video_id].keys():
+ labels = video_frame_labels[video_id][frame_video_sec]
+ if len(labels["labels"]) > 0:
+ labels = AvaLabeledVideoFramePaths._aggregate_bboxes_labels(labels)
+ labels["video_index"] = video_id
+ labels["clip_index"] = frame_video_sec
+ video_frames_dir = os.path.dirname(image_paths[video_id][0])
+ labeled_video_paths.append((video_frames_dir, labels))
+
+ return labeled_video_paths
+
+ @staticmethod
+ def load_and_parse_labels_csv(
+ frame_labels_file: str,
+ video_name_to_idx: dict,
+ allowed_class_ids: Optional[Set] = None,
+ ):
+ """
+ Parses AVA per frame labels .csv file.
+ Args:
+ frame_labels_file (str): Path to the file containing labels
+ per key frame. Acceptible file formats are,
+ Type 1:
+
+ Type 2:
+
+ video_name_to_idx (dict): Dictionary mapping video names to indices.
+ allowed_class_ids (set): A set of integer unique class (bbox label)
+ id's that are allowed in the dataset. If not set, all class id's
+ are allowed in the bbox labels.
+ Returns:
+ (dict): A dictionary of dictionary containing labels per each keyframe
+ in each video. Here, the label for each keyframe is again a dict
+ of the form,
+ {
+ 'labels': a list of bounding boxes
+ 'boxes':a list of action lables for the bounding box
+ 'extra_info': ist of extra information cotaining either
+ detections iou's or person id's depending on the
+ csv format.
+ }
+ """
+ labels_dict = {}
+ with g_pathmgr.open(frame_labels_file, "r") as f:
+ for line in f:
+ row = line.strip().split(",")
+
+ video_name = row[0]
+ video_idx = video_name_to_idx[video_name]
+
+ frame_sec = float(row[1])
+ if (
+ frame_sec > AvaLabeledVideoFramePaths.AVA_VALID_FRAMES[-1]
+ or frame_sec < AvaLabeledVideoFramePaths.AVA_VALID_FRAMES[0]
+ ):
+ continue
+
+ # Since frame labels in video start from 0 not at 900 secs
+ frame_sec = frame_sec - AvaLabeledVideoFramePaths.AVA_VIDEO_START_SEC
+
+ # Box with format [x1, y1, x2, y2] with a range of [0, 1] as float.
+ bbox = list(map(float, row[2:6]))
+
+ # Label
+ label = -1 if row[6] == "" else int(row[6])
+ # Continue if the current label is not in allowed labels.
+ if (allowed_class_ids is not None) and (label not in allowed_class_ids):
+ continue
+
+ # Both id's and iou's are treated as float
+ extra_info = float(row[7])
+
+ if video_idx not in labels_dict:
+ labels_dict[video_idx] = {}
+
+ if frame_sec not in labels_dict[video_idx]:
+ labels_dict[video_idx][frame_sec] = defaultdict(list)
+
+ labels_dict[video_idx][frame_sec]["boxes"].append(bbox)
+ labels_dict[video_idx][frame_sec]["labels"].append(label)
+ labels_dict[video_idx][frame_sec]["extra_info"].append(extra_info)
+ return labels_dict
+
+ @staticmethod
+ def load_image_lists(frame_paths_file: str, video_path_prefix: str) -> Tuple:
+ """
+ Loading image paths from the corresponding file.
+ Args:
+ frame_paths_file (str): Path to a file containing relative paths
+ to all the frames in the video. Each line in the file is of the
+ form
+ video_path_prefix (str): Path to be augumented to the each relative
+ frame path to get the global frame path.
+ Returns:
+ (tuple): A tuple of the following,
+ image_paths_list: List of list containing absolute frame paths.
+ Wherein the outer list is per video and inner list is per
+ timestamp.
+ video_idx_to_name: A dictionary mapping video index to name
+ video_name_to_idx: A dictionary maoping video name to index
+ """
+
+ image_paths = []
+ video_name_to_idx = {}
+ video_idx_to_name = []
+
+ with g_pathmgr.open(frame_paths_file, "r") as f:
+ f.readline()
+ for line in f:
+ row = line.split()
+ # The format of each row should follow:
+ # original_vido_id video_id frame_id path labels.
+ assert len(row) == 5
+ video_name = row[0]
+
+ if video_name not in video_name_to_idx:
+ idx = len(video_name_to_idx)
+ video_name_to_idx[video_name] = idx
+ video_idx_to_name.append(video_name)
+ image_paths.append({})
+
+ data_key = video_name_to_idx[video_name]
+ frame_id = int(row[2])
+ image_paths[data_key][frame_id] = os.path.join(
+ video_path_prefix, row[3]
+ )
+
+ image_paths_list = []
+ for i in range(len(image_paths)):
+ image_paths_list.append([])
+ sorted_keys = sorted(image_paths[i])
+ for key in sorted_keys:
+ image_paths_list[i].append(image_paths[i][key])
+
+ return image_paths_list, video_idx_to_name, video_name_to_idx
+
+ @staticmethod
+ def read_label_map(label_map_file: str) -> Tuple:
+ """
+ Read label map and class ids.
+ Args:
+ label_map_file (str): Path to a .pbtxt containing class id's
+ and class names
+ Returns:
+ (tuple): A tuple of the following,
+ label_map (dict): A dictionary mapping class id to
+ the associated class names.
+ class_ids (set): A set of integer unique class id's
+ """
+ label_map = {}
+ class_ids = set()
+ name = ""
+ class_id = ""
+ with g_pathmgr.open(label_map_file, "r") as f:
+ for line in f:
+ if line.startswith(" name:"):
+ name = line.split('"')[1]
+ elif line.startswith(" id:") or line.startswith(" label_id:"):
+ class_id = int(line.strip().split(" ")[-1])
+ label_map[class_id] = name
+ class_ids.add(class_id)
+ return label_map, class_ids
+
+
+class TimeStampClipSampler:
+ """
+ A sepcialized clip sampler for sampling video clips around specific
+ timestamps. This is particularly used in datasets like Ava wherein only
+ a specific subset of clips in the video have annotations
+ """
+
+ def __init__(self, clip_sampler: ClipSampler) -> None:
+ """
+ Args:
+ clip_sampler (`pytorchvideo.data.ClipSampler`): Strategy used for sampling
+ between the untrimmed clip boundary.
+ """
+ self.clip_sampler = clip_sampler
+
+ def __call__(
+ self, last_clip_time: float, video_duration: float, annotation: Dict[str, Any]
+ ) -> ClipInfo:
+ """
+ Args:
+ last_clip_time (float): Not used for TimeStampClipSampler.
+ video_duration: (float): Not used for TimeStampClipSampler.
+ annotation (Dict): Dict containing time step to sample aroud.
+ Returns:
+ clip_info (ClipInfo): includes the clip information of (clip_start_time,
+ clip_end_time, clip_index, aug_index, is_last_clip). The times are in seconds.
+ clip_index, aux_index and is_last_clip are always 0, 0 and True, respectively.
+ """
+ center_frame_sec = annotation["clip_index"] # a.k.a timestamp
+ clip_start_sec = center_frame_sec - self.clip_sampler._clip_duration / 2.0
+ return ClipInfo(
+ clip_start_sec,
+ clip_start_sec + self.clip_sampler._clip_duration,
+ 0,
+ 0,
+ True,
+ )
+
+ def reset(self) -> None:
+ pass
+
+
+def Ava(
+ frame_paths_file: str,
+ frame_labels_file: str,
+ video_path_prefix: str = "",
+ label_map_file: Optional[str] = None,
+ clip_sampler: Callable = ClipSampler,
+ video_sampler: Type[torch.utils.data.Sampler] = torch.utils.data.RandomSampler,
+ transform: Optional[Callable[[dict], Any]] = None,
+) -> None:
+ """
+ Args:
+ frame_paths_file (str): Path to a file containing relative paths
+ to all the frames in the video. Each line in the file is of the
+ form
+ frame_labels_file (str): Path to the file containing containing labels
+ per key frame. Acceptible file formats are,
+ Type 1:
+
+ Type 2:
+
+ video_path_prefix (str): Path to be augumented to the each relative frame
+ path to get the global frame path.
+ label_map_file (str): Path to a .pbtxt containing class id's
+ and class names. If not set, label_map is not loaded and bbox labels are
+ not pruned based on allowable class_id's in label_map.
+ clip_sampler (ClipSampler): Defines how clips should be sampled from each
+ video.
+ video_sampler (Type[torch.utils.data.Sampler]): Sampler for the internal
+ video container. This defines the order videos are decoded and,
+ if necessary, the distributed split.
+ transform (Optional[Callable]): This callable is evaluated on the clip output
+ and the corresponding bounding boxes before the clip and the bounding boxes
+ are returned. It can be used for user defined preprocessing and
+ augmentations to the clips. If transform is None, the clip and bounding
+ boxes are returned as it is.
+ """
+ labeled_video_paths = AvaLabeledVideoFramePaths.from_csv(
+ frame_paths_file,
+ frame_labels_file,
+ video_path_prefix,
+ label_map_file,
+ )
+ return LabeledVideoDataset(
+ labeled_video_paths=labeled_video_paths,
+ clip_sampler=TimeStampClipSampler(clip_sampler),
+ transform=transform,
+ video_sampler=video_sampler,
+ decode_audio=False,
+ )
diff --git a/code/pytorchvideo/pytorchvideo/data/charades.py b/code/pytorchvideo/pytorchvideo/data/charades.py
new file mode 100644
index 0000000000000000000000000000000000000000..c211a6131737efc17760dde101a5dc1b1504b8ed
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/charades.py
@@ -0,0 +1,220 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import csv
+import functools
+import itertools
+import os
+from collections import defaultdict
+from typing import Any, Callable, List, Optional, Tuple, Type
+
+import torch
+import torch.utils.data
+from iopath.common.file_io import g_pathmgr
+from pytorchvideo.data.clip_sampling import ClipSampler
+from pytorchvideo.data.frame_video import FrameVideo
+
+from .utils import MultiProcessSampler
+
+
+class Charades(torch.utils.data.IterableDataset):
+ """
+ Action recognition video dataset for
+ `Charades `_ stored as image frames.
+
+ This dataset handles the parsing of frames, loading and clip sampling for the
+ videos. All io is done through :code:`iopath.common.file_io.PathManager`, enabling
+ non-local storage uri's to be used.
+ """
+
+ # Number of classes represented by this dataset's annotated labels.
+ NUM_CLASSES = 157
+
+ def __init__(
+ self,
+ data_path: str,
+ clip_sampler: ClipSampler,
+ video_sampler: Type[torch.utils.data.Sampler] = torch.utils.data.RandomSampler,
+ transform: Optional[Callable[[dict], Any]] = None,
+ video_path_prefix: str = "",
+ frames_per_clip: Optional[int] = None,
+ ) -> None:
+ """
+ Args:
+ data_path (str): Path to the data file. This file must be a space
+ separated csv with the format: (original_vido_id video_id frame_id
+ path_labels)
+
+ clip_sampler (ClipSampler): Defines how clips should be sampled from each
+ video. See the clip sampling documentation for more information.
+
+ video_sampler (Type[torch.utils.data.Sampler]): Sampler for the internal
+ video container. This defines the order videos are decoded and,
+ if necessary, the distributed split.
+
+ transform (Optional[Callable]): This callable is evaluated on the clip output before
+ the clip is returned. It can be used for user defined preprocessing and
+ augmentations on the clips. The clip output format is described in __next__().
+
+ video_path_prefix (str): prefix path to add to all paths from data_path.
+
+ frames_per_clip (Optional[int]): The number of frames per clip to sample.
+ """
+
+ torch._C._log_api_usage_once("PYTORCHVIDEO.dataset.Charades.__init__")
+
+ self._transform = transform
+ self._clip_sampler = clip_sampler
+ (
+ self._path_to_videos,
+ self._labels,
+ self._video_labels,
+ ) = _read_video_paths_and_labels(data_path, prefix=video_path_prefix)
+ self._video_sampler = video_sampler(self._path_to_videos)
+ self._video_sampler_iter = None # Initialized on first call to self.__next__()
+ self._frame_filter = (
+ functools.partial(
+ Charades._sample_clip_frames,
+ frames_per_clip=frames_per_clip,
+ )
+ if frames_per_clip is not None
+ else None
+ )
+
+ # Depending on the clip sampler type, we may want to sample multiple clips
+ # from one video. In that case, we keep the store video, label and previous sampled
+ # clip time in these variables.
+ self._loaded_video = None
+ self._loaded_clip = None
+ self._next_clip_start_time = 0.0
+
+ @staticmethod
+ def _sample_clip_frames(
+ frame_indices: List[int], frames_per_clip: int
+ ) -> List[int]:
+ """
+ Args:
+ frame_indices (list): list of frame indices.
+ frames_per+clip (int): The number of frames per clip to sample.
+
+ Returns:
+ (list): Outputs a subsampled list with num_samples frames.
+ """
+ num_frames = len(frame_indices)
+ indices = torch.linspace(0, num_frames - 1, frames_per_clip)
+ indices = torch.clamp(indices, 0, num_frames - 1).long()
+
+ return [frame_indices[idx] for idx in indices]
+
+ @property
+ def video_sampler(self) -> torch.utils.data.Sampler:
+ return self._video_sampler
+
+ def __next__(self) -> dict:
+ """
+ Retrieves the next clip based on the clip sampling strategy and video sampler.
+
+ Returns:
+ A dictionary with the following format.
+
+ .. code-block:: text
+
+ {
+ 'video': ,
+ 'label': ,
+ 'video_label':
+ 'video_index': ,
+ 'clip_index': ,
+ 'aug_index': ,
+ }
+ """
+ if not self._video_sampler_iter:
+ # Setup MultiProcessSampler here - after PyTorch DataLoader workers are spawned.
+ self._video_sampler_iter = iter(MultiProcessSampler(self._video_sampler))
+
+ if self._loaded_video:
+ video, video_index = self._loaded_video
+ else:
+ video_index = next(self._video_sampler_iter)
+ path_to_video_frames = self._path_to_videos[video_index]
+ video = FrameVideo.from_frame_paths(path_to_video_frames)
+ self._loaded_video = (video, video_index)
+
+ clip_start, clip_end, clip_index, aug_index, is_last_clip = self._clip_sampler(
+ self._next_clip_start_time, video.duration, {}
+ )
+ # Only load the clip once and reuse previously stored clip if there are multiple
+ # views for augmentations to perform on the same clip.
+ if aug_index == 0:
+ self._loaded_clip = video.get_clip(clip_start, clip_end, self._frame_filter)
+
+ frames, frame_indices = (
+ self._loaded_clip["video"],
+ self._loaded_clip["frame_indices"],
+ )
+ self._next_clip_start_time = clip_end
+
+ if is_last_clip:
+ self._loaded_video = None
+ self._next_clip_start_time = 0.0
+
+ # Merge unique labels from each frame into clip label.
+ labels_by_frame = [
+ self._labels[video_index][i]
+ for i in range(min(frame_indices), max(frame_indices) + 1)
+ ]
+ sample_dict = {
+ "video": frames,
+ "label": labels_by_frame,
+ "video_label": self._video_labels[video_index],
+ "video_name": str(video_index),
+ "video_index": video_index,
+ "clip_index": clip_index,
+ "aug_index": aug_index,
+ }
+ if self._transform is not None:
+ sample_dict = self._transform(sample_dict)
+
+ return sample_dict
+
+ def __iter__(self):
+ return self
+
+
+def _read_video_paths_and_labels(
+ video_path_label_file: List[str], prefix: str = ""
+) -> Tuple[List[str], List[int]]:
+ """
+ Args:
+ video_path_label_file (List[str]): a file that contains frame paths for each
+ video and the corresponding frame label. The file must be a space separated
+ csv of the format:
+ `original_vido_id video_id frame_id path labels`
+
+ prefix (str): prefix path to add to all paths from video_path_label_file.
+
+ """
+ image_paths = defaultdict(list)
+ labels = defaultdict(list)
+ with g_pathmgr.open(video_path_label_file, "r") as f:
+
+ # Space separated CSV with format: original_vido_id video_id frame_id path labels
+ csv_reader = csv.DictReader(f, delimiter=" ")
+ for row in csv_reader:
+ assert len(row) == 5
+ video_name = row["original_vido_id"]
+ path = os.path.join(prefix, row["path"])
+ image_paths[video_name].append(path)
+ frame_labels = row["labels"].replace('"', "")
+ label_list = []
+ if frame_labels:
+ label_list = [int(x) for x in frame_labels.split(",")]
+
+ labels[video_name].append(label_list)
+
+ # Extract image paths from dictionary and return paths and labels as list.
+ video_names = image_paths.keys()
+ image_paths = [image_paths[key] for key in video_names]
+ labels = [labels[key] for key in video_names]
+ # Aggregate labels from all frames to form video-level labels.
+ video_labels = [list(set(itertools.chain(*label_list))) for label_list in labels]
+ return image_paths, labels, video_labels
diff --git a/code/pytorchvideo/pytorchvideo/data/clip_sampling.py b/code/pytorchvideo/pytorchvideo/data/clip_sampling.py
new file mode 100644
index 0000000000000000000000000000000000000000..f59c5c1e3f47feb6c339a06d48db4595fcd02618
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/clip_sampling.py
@@ -0,0 +1,413 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import random
+from abc import ABC, abstractmethod
+from fractions import Fraction
+from typing import Any, Dict, List, NamedTuple, Optional, Tuple, Union
+
+
+class ClipInfo(NamedTuple):
+ """
+ Named-tuple for clip information with:
+ clip_start_sec (Union[float, Fraction]): clip start time.
+ clip_end_sec (Union[float, Fraction]): clip end time.
+ clip_index (int): clip index in the video.
+ aug_index (int): augmentation index for the clip. Different augmentation methods
+ might generate multiple views for the same clip.
+ is_last_clip (bool): a bool specifying whether there are more clips to be
+ sampled from the video.
+ """
+
+ clip_start_sec: Union[float, Fraction]
+ clip_end_sec: Union[float, Fraction]
+ clip_index: int
+ aug_index: int
+ is_last_clip: bool
+
+
+class ClipInfoList(NamedTuple):
+ """
+ Named-tuple for clip information with:
+ clip_start_sec (float): clip start time.
+ clip_end_sec (float): clip end time.
+ clip_index (int): clip index in the video.
+ aug_index (int): augmentation index for the clip. Different augmentation methods
+ might generate multiple views for the same clip.
+ is_last_clip (bool): a bool specifying whether there are more clips to be
+ sampled from the video.
+ """
+
+ clip_start_sec: List[float]
+ clip_end_sec: List[float]
+ clip_index: List[float]
+ aug_index: List[float]
+ is_last_clip: List[float]
+
+
+class ClipSampler(ABC):
+ """
+ Interface for clip samplers that take a video time, previous sampled clip time,
+ and returns a named-tuple ``ClipInfo``.
+ """
+
+ def __init__(self, clip_duration: Union[float, Fraction]) -> None:
+ self._clip_duration = Fraction(clip_duration)
+ self._current_clip_index = 0
+ self._current_aug_index = 0
+
+ @abstractmethod
+ def __call__(
+ self,
+ last_clip_end_time: Union[float, Fraction],
+ video_duration: Union[float, Fraction],
+ annotation: Dict[str, Any],
+ ) -> ClipInfo:
+ pass
+
+ def reset(self) -> None:
+ """Resets any video-specific attributes in preperation for next video"""
+ pass
+
+
+def make_clip_sampler(sampling_type: str, *args) -> ClipSampler:
+ """
+ Constructs the clip samplers found in ``pytorchvideo.data.clip_sampling`` from the
+ given arguments.
+
+ Args:
+ sampling_type (str): choose clip sampler to return. It has three options:
+
+ * uniform: constructs and return ``UniformClipSampler``
+ * random: construct and return ``RandomClipSampler``
+ * constant_clips_per_video: construct and return ``ConstantClipsPerVideoSampler``
+
+ *args: the args to pass to the chosen clip sampler constructor.
+ """
+ if sampling_type == "uniform":
+ return UniformClipSampler(*args)
+ elif sampling_type == "random":
+ return RandomClipSampler(*args)
+ elif sampling_type == "constant_clips_per_video":
+ return ConstantClipsPerVideoSampler(*args)
+ elif sampling_type == "random_multi":
+ return RandomMultiClipSampler(*args)
+ else:
+ raise NotImplementedError(f"{sampling_type} not supported")
+
+
+class UniformClipSampler(ClipSampler):
+ """
+ Evenly splits the video into clips of size clip_duration.
+ """
+
+ def __init__(
+ self,
+ clip_duration: Union[float, Fraction],
+ stride: Optional[Union[float, Fraction]] = None,
+ backpad_last: bool = False,
+ eps: float = 1e-6,
+ ):
+ """
+ Args:
+ clip_duration (Union[float, Fraction]):
+ The length of the clip to sample (in seconds).
+ stride (Union[float, Fraction], optional):
+ The amount of seconds to offset the next clip by
+ default value of None is equivalent to no stride => stride == clip_duration.
+ eps (float):
+ Epsilon for floating point comparisons. Used to check the last clip.
+ backpad_last (bool):
+ Whether to include the last frame(s) by "back padding".
+
+ For instance, if we have a video of 39 frames (30 fps = 1.3s)
+ with a stride of 16 (0.533s) with a clip duration of 32 frames
+ (1.0667s). The clips will be (in frame numbers):
+
+ with backpad_last = False
+ - [0, 31]
+
+ with backpad_last = True
+ - [0, 31]
+ - [8, 39], this is "back-padded" from [16, 48] to fit the last window
+ Note that you can use Fraction for clip_duration and stride if you want to
+ avoid float precision issue and need accurate frames in each clip.
+ """
+ super().__init__(clip_duration)
+ self._stride = stride if stride is not None else self._clip_duration
+ self._eps = eps
+ self._backpad_last = backpad_last
+
+ assert self._stride > 0, "stride must be positive"
+
+ def _clip_start_end(
+ self,
+ last_clip_end_time: Union[float, Fraction],
+ video_duration: Union[float, Fraction],
+ backpad_last: bool,
+ ) -> Tuple[Fraction, Fraction]:
+ """
+ Helper to calculate the start/end clip with backpad logic
+ """
+ delta = self._stride - self._clip_duration
+ last_end_time = -delta if last_clip_end_time is None else last_clip_end_time
+ clip_start = Fraction(last_end_time + delta)
+ clip_end = Fraction(clip_start + self._clip_duration)
+ if backpad_last:
+ buffer_amount = max(0, clip_end - video_duration)
+ clip_start -= buffer_amount
+ clip_start = Fraction(max(0, clip_start)) # handle rounding
+ clip_end = Fraction(clip_start + self._clip_duration)
+
+ return clip_start, clip_end
+
+ def __call__(
+ self,
+ last_clip_end_time: Optional[float],
+ video_duration: float,
+ annotation: Dict[str, Any],
+ ) -> ClipInfo:
+ """
+ Args:
+ last_clip_end_time (float): the last clip end time sampled from this video. This
+ should be 0.0 if the video hasn't had clips sampled yet.
+ video_duration: (float): the duration of the video that's being sampled in seconds
+ annotation (Dict): Not used by this sampler.
+ Returns:
+ clip_info: (ClipInfo): includes the clip information (clip_start_time,
+ clip_end_time, clip_index, aug_index, is_last_clip), where the times are in
+ seconds and is_last_clip is False when there is still more of time in the video
+ to be sampled.
+ """
+ clip_start, clip_end = self._clip_start_end(
+ last_clip_end_time, video_duration, backpad_last=self._backpad_last
+ )
+
+ # if they both end at the same time - it's the last clip
+ _, next_clip_end = self._clip_start_end(
+ clip_end, video_duration, backpad_last=self._backpad_last
+ )
+ if self._backpad_last:
+ is_last_clip = abs(next_clip_end - clip_end) < self._eps
+ else:
+ is_last_clip = (next_clip_end - video_duration) > self._eps
+
+ clip_index = self._current_clip_index
+ self._current_clip_index += 1
+
+ if is_last_clip:
+ self.reset()
+
+ return ClipInfo(clip_start, clip_end, clip_index, 0, is_last_clip)
+
+ def reset(self):
+ self._current_clip_index = 0
+
+
+class UniformClipSamplerTruncateFromStart(UniformClipSampler):
+ """
+ Evenly splits the video into clips of size clip_duration.
+ If truncation_duration is set, clips sampled from [0, truncation_duration].
+ If truncation_duration is not set, defaults to UniformClipSampler.
+ """
+
+ def __init__(
+ self,
+ clip_duration: Union[float, Fraction],
+ stride: Optional[Union[float, Fraction]] = None,
+ backpad_last: bool = False,
+ eps: float = 1e-6,
+ truncation_duration: float = None,
+ ) -> None:
+ super().__init__(clip_duration, stride, backpad_last, eps)
+ self.truncation_duration = truncation_duration
+
+ def __call__(
+ self,
+ last_clip_end_time: float,
+ video_duration: float,
+ annotation: Dict[str, Any],
+ ) -> ClipInfo:
+
+ truncated_video_duration = video_duration
+ if self.truncation_duration is not None:
+ truncated_video_duration = min(self.truncation_duration, video_duration)
+
+ return super().__call__(
+ last_clip_end_time, truncated_video_duration, annotation
+ )
+
+
+class RandomClipSampler(ClipSampler):
+ """
+ Randomly samples clip of size clip_duration from the videos.
+ """
+
+ def __call__(
+ self,
+ last_clip_end_time: float,
+ video_duration: float,
+ annotation: Dict[str, Any],
+ ) -> ClipInfo:
+ """
+ Args:
+ last_clip_end_time (float): Not used for RandomClipSampler.
+ video_duration: (float): the duration (in seconds) for the video that's
+ being sampled
+ annotation (Dict): Not used by this sampler.
+ Returns:
+ clip_info (ClipInfo): includes the clip information of (clip_start_time,
+ clip_end_time, clip_index, aug_index, is_last_clip). The times are in seconds.
+ clip_index, aux_index and is_last_clip are always 0, 0 and True, respectively.
+
+ """
+ max_possible_clip_start = max(video_duration - self._clip_duration, 0)
+ clip_start_sec = Fraction(random.uniform(0, max_possible_clip_start))
+ return ClipInfo(
+ clip_start_sec, clip_start_sec + self._clip_duration, 0, 0, True
+ )
+
+
+class RandomMultiClipSampler(RandomClipSampler):
+ """
+ Randomly samples multiple clips of size clip_duration from the videos.
+ """
+
+ def __init__(self, clip_duration: float, num_clips: int) -> None:
+ super().__init__(clip_duration)
+ self._num_clips = num_clips
+
+ def __call__(
+ self,
+ last_clip_end_time: Optional[float],
+ video_duration: float,
+ annotation: Dict[str, Any],
+ ) -> ClipInfoList:
+
+ (
+ clip_start_list,
+ clip_end_list,
+ clip_index_list,
+ aug_index_list,
+ is_last_clip_list,
+ ) = (
+ self._num_clips * [None],
+ self._num_clips * [None],
+ self._num_clips * [None],
+ self._num_clips * [None],
+ self._num_clips * [None],
+ )
+ for i in range(self._num_clips):
+ (
+ clip_start_list[i],
+ clip_end_list[i],
+ clip_index_list[i],
+ aug_index_list[i],
+ is_last_clip_list[i],
+ ) = super().__call__(last_clip_end_time, video_duration, annotation)
+
+ return ClipInfoList(
+ clip_start_list,
+ clip_end_list,
+ clip_index_list,
+ aug_index_list,
+ is_last_clip_list,
+ )
+
+
+class RandomMultiClipSamplerTruncateFromStart(RandomMultiClipSampler):
+ """
+ Randomly samples multiple clips of size clip_duration from the videos.
+ If truncation_duration is set, clips sampled from [0, truncation_duration].
+ If truncation_duration is not set, defaults to RandomMultiClipSampler.
+ """
+
+ def __init__(
+ self, clip_duration: float, num_clips: int, truncation_duration: float = None
+ ) -> None:
+ super().__init__(clip_duration, num_clips)
+ self.truncation_duration = truncation_duration
+
+ def __call__(
+ self,
+ last_clip_end_time: Optional[float],
+ video_duration: float,
+ annotation: Dict[str, Any],
+ ) -> ClipInfoList:
+
+ truncated_video_duration = video_duration
+ if self.truncation_duration is not None:
+ truncated_video_duration = min(self.truncation_duration, video_duration)
+
+ return super().__call__(
+ last_clip_end_time, truncated_video_duration, annotation
+ )
+
+
+class ConstantClipsPerVideoSampler(ClipSampler):
+ """
+ Evenly splits the video into clips_per_video increments and samples clips of size
+ clip_duration at these increments.
+ """
+
+ def __init__(
+ self, clip_duration: float, clips_per_video: int, augs_per_clip: int = 1
+ ) -> None:
+ super().__init__(clip_duration)
+ self._clips_per_video = clips_per_video
+ self._augs_per_clip = augs_per_clip
+
+ def __call__(
+ self,
+ last_clip_end_time: Optional[float],
+ video_duration: float,
+ annotation: Dict[str, Any],
+ ) -> ClipInfo:
+ """
+ Args:
+ last_clip_end_time (float): Not used for ConstantClipsPerVideoSampler.
+ video_duration: (float): the duration (in seconds) for the video that's
+ being sampled.
+ annotation (Dict): Not used by this sampler.
+ Returns:
+ a named-tuple `ClipInfo`: includes the clip information of (clip_start_time,
+ clip_end_time, clip_index, aug_index, is_last_clip). The times are in seconds.
+ is_last_clip is True after clips_per_video clips have been sampled or the end
+ of the video is reached.
+
+ """
+ max_possible_clip_start = Fraction(max(video_duration - self._clip_duration, 0))
+ uniform_clip = Fraction(
+ max_possible_clip_start, max(self._clips_per_video - 1, 1)
+ )
+ clip_start_sec = uniform_clip * self._current_clip_index
+ clip_index = self._current_clip_index
+ aug_index = self._current_aug_index
+
+ self._current_aug_index += 1
+ if self._current_aug_index >= self._augs_per_clip:
+ self._current_clip_index += 1
+ self._current_aug_index = 0
+
+ # Last clip is True if sampled self._clips_per_video or if end of video is reached.
+ is_last_clip = False
+ if (
+ self._current_clip_index >= self._clips_per_video
+ or uniform_clip * self._current_clip_index > max_possible_clip_start
+ ):
+ self._current_clip_index = 0
+ is_last_clip = True
+
+ if is_last_clip:
+ self.reset()
+
+ return ClipInfo(
+ clip_start_sec,
+ clip_start_sec + self._clip_duration,
+ clip_index,
+ aug_index,
+ is_last_clip,
+ )
+
+ def reset(self):
+ self._current_clip_index = 0
+ self._current_aug_index = 0
diff --git a/code/pytorchvideo/pytorchvideo/data/dataset_manifest_utils.py b/code/pytorchvideo/pytorchvideo/data/dataset_manifest_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..948dbde6a1efa0fd05a4cd6e60f90e053d2df227
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/dataset_manifest_utils.py
@@ -0,0 +1,315 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import datetime
+import os
+from dataclasses import dataclass
+from enum import Enum
+from typing import Dict, Optional, Union
+
+from pytorchvideo.data.encoded_video import EncodedVideo
+from pytorchvideo.data.frame_video import FrameVideo
+from pytorchvideo.data.utils import (
+ DataclassFieldCaster,
+ load_dataclass_dict_from_csv,
+ save_dataclass_objs_to_headered_csv,
+)
+from pytorchvideo.data.video import Video
+
+
+@dataclass
+class EncodedVideoInfo(DataclassFieldCaster):
+ """
+ Class representing the location of an available encoded video.
+ """
+
+ video_id: str
+ file_path: str
+
+
+@dataclass
+class VideoFrameInfo(DataclassFieldCaster):
+ """
+ Class representing the locations of all frames that compose a video.
+ """
+
+ video_id: str
+ location: str
+ frame_file_stem: str
+ frame_string_length: int
+ min_frame_number: int
+ max_frame_number: int
+ file_extension: str
+
+
+@dataclass
+class VideoInfo(DataclassFieldCaster):
+ """
+ Class representing the video-level metadata of a video from an arbitrary video dataset.
+ """
+
+ video_id: str
+ resolution: str
+ duration: float
+ fps: float
+
+
+@dataclass
+class VideoClipInfo(DataclassFieldCaster):
+ video_id: str
+ start_time: float
+ stop_time: float
+
+
+@dataclass
+class ImageFrameInfo(DataclassFieldCaster):
+ """
+ Class representing the metadata (and labels) for a single frame
+ """
+
+ video_id: str
+ frame_id: str
+ frame_number: int
+ frame_file_path: str
+
+
+class VideoDatasetType(Enum):
+ Frame = 1
+ EncodedVideo = 2
+
+
+class ImageDataset:
+ @staticmethod
+ def _load_images(
+ frame_manifest_file_path: Optional[str],
+ video_info_file_path: str,
+ multithreaded_io: bool,
+ ) -> Dict[str, ImageFrameInfo]:
+ video_infos: Dict[str, VideoInfo] = load_dataclass_dict_from_csv(
+ video_info_file_path, VideoInfo, "video_id"
+ )
+ video_frames: Dict[str, VideoFrameInfo] = load_dataclass_dict_from_csv(
+ frame_manifest_file_path, VideoFrameInfo, "video_id"
+ )
+ VideoDataset._remove_video_info_missing_or_incomplete_videos(
+ video_frames, video_infos
+ )
+
+ image_infos = {}
+ for video_id in video_infos:
+ frame_filepaths = VideoDataset._frame_number_to_filepaths(
+ video_id, video_frames, video_infos
+ )
+ video_info = video_infos[video_id]
+ video_frame_info = video_frames[video_info.video_id]
+ for frame_filepath, frame_number in zip(
+ frame_filepaths,
+ range(
+ video_frame_info.min_frame_number, video_frame_info.max_frame_number
+ ),
+ ):
+ frame_id = os.path.splitext(os.path.basename(frame_filepath))[0]
+ image_infos[frame_id] = ImageFrameInfo(
+ video_id, frame_id, frame_number, frame_filepath
+ )
+ return image_infos
+
+
+class VideoDataset:
+ @staticmethod
+ def _load_videos(
+ video_data_manifest_file_path: Optional[str],
+ video_info_file_path: str,
+ multithreaded_io: bool,
+ dataset_type: VideoDatasetType,
+ ) -> Dict[str, Video]:
+ video_infos: Dict[str, VideoInfo] = load_dataclass_dict_from_csv(
+ video_info_file_path, VideoInfo, "video_id"
+ )
+ if dataset_type == VideoDatasetType.Frame:
+ return VideoDataset._load_frame_videos(
+ video_data_manifest_file_path, video_infos, multithreaded_io
+ )
+ elif dataset_type == VideoDatasetType.EncodedVideo:
+ return VideoDataset._load_encoded_videos(
+ video_data_manifest_file_path, video_infos
+ )
+
+ @staticmethod
+ def _load_frame_videos(
+ frame_manifest_file_path: str,
+ video_infos: Dict[str, VideoInfo],
+ multithreaded_io: bool,
+ ):
+ video_frames: Dict[str, VideoFrameInfo] = load_dataclass_dict_from_csv(
+ frame_manifest_file_path, VideoFrameInfo, "video_id"
+ )
+ VideoDataset._remove_video_info_missing_or_incomplete_videos(
+ video_frames, video_infos
+ )
+ return {
+ video_id: FrameVideo(
+ video_frame_paths=VideoDataset._frame_number_to_filepaths(
+ video_id, video_frames, video_infos
+ ),
+ duration=video_infos[video_id].duration,
+ fps=video_infos[video_id].fps,
+ multithreaded_io=multithreaded_io,
+ )
+ for video_id in video_infos
+ }
+
+ @staticmethod
+ def _load_encoded_videos(
+ encoded_video_manifest_file_path: str,
+ video_infos: Dict[str, VideoInfo],
+ ):
+ encoded_video_infos: Dict[str, EncodedVideoInfo] = load_dataclass_dict_from_csv(
+ encoded_video_manifest_file_path, EncodedVideoInfo, "video_id"
+ )
+ VideoDataset._remove_video_info_missing_or_incomplete_videos(
+ encoded_video_infos, video_infos
+ )
+
+ return {
+ video_id: EncodedVideo.from_path(encoded_video_info.file_path)
+ for video_id, encoded_video_info in encoded_video_infos.items()
+ }
+
+ @staticmethod
+ def _frame_number_to_filepaths(
+ video_id: str,
+ video_frames: Dict[str, VideoFrameInfo],
+ video_infos: Dict[str, VideoInfo],
+ ) -> Optional[str]:
+ video_info = video_infos[video_id]
+ video_frame_info = video_frames[video_info.video_id]
+
+ frame_filepaths = []
+ num_frames = (
+ video_frame_info.max_frame_number - video_frame_info.min_frame_number + 1
+ )
+ for frame_index in range(num_frames):
+ frame_number = frame_index + video_frame_info.min_frame_number
+ if (
+ frame_number < video_frame_info.min_frame_number
+ or frame_number > video_frame_info.max_frame_number
+ ):
+ return None
+
+ frame_path_index = str(frame_number)
+ frame_prefix = video_frame_info.frame_file_stem
+ num_zero_pad = (
+ video_frame_info.frame_string_length
+ - len(frame_path_index)
+ - len(frame_prefix)
+ )
+ zero_padding = "0" * num_zero_pad
+ frame_component = (
+ f"{frame_prefix}{zero_padding}{frame_path_index}"
+ f".{video_frame_info.file_extension}"
+ )
+ frame_filepaths.append(f"{video_frame_info.location}/{frame_component}")
+ return frame_filepaths
+
+ @staticmethod
+ def _remove_video_info_missing_or_incomplete_videos(
+ video_data_infos: Dict[str, Union[VideoFrameInfo, EncodedVideoInfo]],
+ video_infos: Dict[str, VideoInfo],
+ ) -> None:
+ # Avoid deletion keys from dict during iteration over keys
+ video_ids = list(video_infos)
+ for video_id in video_ids:
+ video_info = video_infos[video_id]
+
+ # Remove videos we have metadata for but don't have video data
+ if video_id not in video_data_infos:
+ del video_infos[video_id]
+ continue
+
+ # Remove videos we have metadata for but don't have the right number of frames
+ if type(video_data_infos[video_id]) == VideoFrameInfo:
+ video_frames_info = video_data_infos[video_id]
+ expected_frames = round(video_info.duration * video_info.fps)
+ num_frames = (
+ video_frames_info.max_frame_number
+ - video_frames_info.min_frame_number
+ )
+ if abs(num_frames - expected_frames) > video_info.fps:
+ del video_data_infos[video_id]
+ del video_infos[video_id]
+
+ video_ids = list(video_data_infos) # Avoid modifying dict during iteration
+ for video_id in video_ids:
+ # Remove videos we have video data for but don't have metadata
+ if video_id not in video_infos:
+
+ del video_data_infos[video_id]
+
+
+def get_seconds_from_hms_time(time_str: str) -> float:
+ """
+ Get Seconds from timestamp of form 'HH:MM:SS'.
+
+ Args:
+ time_str (str)
+
+ Returns:
+ float of seconds
+
+ """
+ for fmt in ("%H:%M:%S.%f", "%H:%M:%S"):
+ try:
+ time_since_min_time = datetime.datetime.strptime(time_str, fmt)
+ min_time = datetime.datetime.strptime("", "")
+ return float((time_since_min_time - min_time).total_seconds())
+ except ValueError:
+ pass
+ raise ValueError(f"No valid data format found for provided string {time_str}.")
+
+
+def save_encoded_video_manifest(
+ encoded_video_infos: Dict[str, EncodedVideoInfo], file_name: str = None
+) -> str:
+ """
+ Saves the encoded video dictionary as a csv file that can be read for future usage.
+
+ Args:
+ video_frames (Dict[str, EncodedVideoInfo]):
+ Dictionary mapping video_ids to metadata about the location of
+ their video data.
+
+ file_name (str):
+ location to save file (will be automatically generated if None).
+
+ Returns:
+ string of the filename where the video info is stored.
+ """
+ file_name = (
+ f"{os.getcwd()}/encoded_video_manifest.csv" if file_name is None else file_name
+ )
+ save_dataclass_objs_to_headered_csv(list(encoded_video_infos.values()), file_name)
+ return file_name
+
+
+def save_video_frame_info(
+ video_frames: Dict[str, VideoFrameInfo], file_name: str = None
+) -> str:
+ """
+ Saves the video frame dictionary as a csv file that can be read for future usage.
+
+ Args:
+ video_frames (Dict[str, VideoFrameInfo]):
+ Dictionary mapping video_ids to metadata about the location of
+ their video frame files.
+
+ file_name (str):
+ location to save file (will be automatically generated if None).
+
+ Returns:
+ string of the filename where the video info is stored.
+ """
+ file_name = (
+ f"{os.getcwd()}/video_frame_metadata.csv" if file_name is None else file_name
+ )
+ save_dataclass_objs_to_headered_csv(list(video_frames.values()), file_name)
+ return file_name
diff --git a/code/pytorchvideo/pytorchvideo/data/decoder.py b/code/pytorchvideo/pytorchvideo/data/decoder.py
new file mode 100644
index 0000000000000000000000000000000000000000..8d5194ff20ca0c087a63ac530ff46a6ed6dda7ba
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/decoder.py
@@ -0,0 +1,8 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+from enum import Enum
+
+
+class DecoderType(Enum):
+ PYAV = "pyav"
+ TORCHVISION = "torchvision"
+ DECORD = "decord"
diff --git a/code/pytorchvideo/pytorchvideo/data/domsev.py b/code/pytorchvideo/pytorchvideo/data/domsev.py
new file mode 100644
index 0000000000000000000000000000000000000000..74f07490c18442d2111ab082cd21797987b9f21e
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/domsev.py
@@ -0,0 +1,532 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import logging
+import math
+import random
+import time
+from dataclasses import dataclass
+from enum import Enum
+from typing import Any, Callable, Dict, List, Optional, Tuple
+
+import numpy as np
+import torch
+from iopath.common.file_io import g_pathmgr
+from PIL import Image
+from pytorchvideo.data.dataset_manifest_utils import (
+ ImageDataset,
+ ImageFrameInfo,
+ VideoClipInfo,
+ VideoDataset,
+ VideoDatasetType,
+)
+from pytorchvideo.data.utils import DataclassFieldCaster, load_dataclass_dict_from_csv
+from pytorchvideo.data.video import Video
+
+
+try:
+ import cv2
+except ImportError:
+ _HAS_CV2 = False
+else:
+ _HAS_CV2 = True
+
+
+USER_ENVIRONMENT_MAP = {
+ 0: "none",
+ 1: "indoor",
+ 2: "nature",
+ 3: "crowded_environment",
+ 4: "urban",
+}
+
+USER_ACTIVITY_MAP = {
+ 0: "none",
+ 1: "walking",
+ 2: "running",
+ 3: "standing",
+ 4: "biking",
+ 5: "driving",
+ 6: "playing",
+ 7: "cooking",
+ 8: "eating",
+ 9: "observing",
+ 10: "in_conversation",
+ 11: "browsing",
+ 12: "shopping",
+}
+
+USER_ATTENTION_MAP = {
+ 0: "none",
+ 1: "paying_attention",
+ 2: "interacting",
+}
+
+
+class LabelType(Enum):
+ Environment = 1
+ Activity = 2
+ UserAttention = 3
+
+
+LABEL_TYPE_2_MAP = {
+ LabelType.Environment: USER_ENVIRONMENT_MAP,
+ LabelType.Activity: USER_ACTIVITY_MAP,
+ LabelType.UserAttention: USER_ATTENTION_MAP,
+}
+
+
+@dataclass
+class LabelData(DataclassFieldCaster):
+ """
+ Class representing a contiguous label for a video segment from the DoMSEV dataset.
+ """
+
+ video_id: str
+ start_time: float # Start time of the label, in seconds
+ stop_time: float # Stop time of the label, in seconds
+ start_frame: int # 0-indexed ID of the start frame (inclusive)
+ stop_frame: int # 0-index ID of the stop frame (inclusive)
+ label_id: int
+ label_name: str
+
+
+# Utility functions
+def _seconds_to_frame_index(
+ time_in_seconds: float, fps: int, zero_indexed: Optional[bool] = True
+) -> int:
+ """
+ Converts a point in time (in seconds) within a video clip to its closest
+ frame indexed (rounding down), based on a specified frame rate.
+
+ Args:
+ time_in_seconds (float): The point in time within the video.
+ fps (int): The frame rate (frames per second) of the video.
+ zero_indexed (Optional[bool]): Whether the returned frame should be
+ zero-indexed (if True) or one-indexed (if False).
+
+ Returns:
+ (int) The index of the nearest frame (rounding down to the nearest integer).
+ """
+ frame_idx = math.floor(time_in_seconds * fps)
+ if not zero_indexed:
+ frame_idx += 1
+ return frame_idx
+
+
+def _get_overlap_for_time_range_pair(
+ t1_start: float, t1_stop: float, t2_start: float, t2_stop: float
+) -> Optional[Tuple[float, float]]:
+ """
+ Calculates the overlap between two time ranges, if one exists.
+
+ Returns:
+ (Optional[Tuple]) A tuple of if
+ an overlap is found, or None otherwise.
+ """
+ # Check if there is an overlap
+ if (t1_start <= t2_stop) and (t2_start <= t1_stop):
+ # Calculate the overlap period
+ overlap_start_time = max(t1_start, t2_start)
+ overlap_stop_time = min(t1_stop, t2_stop)
+ return (overlap_start_time, overlap_stop_time)
+ else:
+ return None
+
+
+class DomsevFrameDataset(torch.utils.data.Dataset):
+ """
+ Egocentric video classification frame-based dataset for
+ `DoMSEV `_
+
+ This dataset handles the loading, decoding, and configurable sampling for
+ the image frames.
+ """
+
+ def __init__(
+ self,
+ video_data_manifest_file_path: str,
+ video_info_file_path: str,
+ labels_file_path: str,
+ transform: Optional[Callable[[Dict[str, Any]], Any]] = None,
+ multithreaded_io: bool = False,
+ ) -> None:
+ """
+ Args:
+ video_data_manifest_file_path (str):
+ The path to a json file outlining the available video data for the
+ associated videos. File must be a csv (w/header) with columns:
+ ``{[f.name for f in dataclass_fields(EncodedVideoInfo)]}``
+
+ To generate this file from a directory of video frames, see helper
+ functions in module: ``pytorchvideo.data.domsev.utils``
+
+ video_info_file_path (str):
+ Path or URI to manifest with basic metadata of each video.
+ File must be a csv (w/header) with columns:
+ ``{[f.name for f in dataclass_fields(VideoInfo)]}``
+
+ labels_file_path (str):
+ Path or URI to manifest with temporal annotations for each video.
+ File must be a csv (w/header) with columns:
+ ``{[f.name for f in dataclass_fields(LabelData)]}``
+
+ dataset_type (VideoDatasetType): The data format in which dataset
+ video data is stored (e.g. video frames, encoded video etc).
+
+ transform (Optional[Callable[[Dict[str, Any]], Any]]):
+ This callable is evaluated on the clip output before the clip is returned.
+ It can be used for user-defined preprocessing and augmentations to the clips.
+ The clip output format is described in __next__().
+
+ multithreaded_io (bool):
+ Boolean to control whether io operations are performed across multiple
+ threads.
+ """
+ assert video_info_file_path
+ assert labels_file_path
+ assert video_data_manifest_file_path
+
+ ## Populate image frame and metadata data providers ##
+ # Maps a image frame ID to an `ImageFrameInfo`
+ frames_dict: Dict[str, ImageFrameInfo] = ImageDataset._load_images(
+ video_data_manifest_file_path,
+ video_info_file_path,
+ multithreaded_io,
+ )
+ video_labels: Dict[str, List[LabelData]] = load_dataclass_dict_from_csv(
+ labels_file_path, LabelData, "video_id", list_per_key=True
+ )
+ # Maps an image frame ID to the singular frame label
+ self._labels_per_frame: Dict[
+ str, int
+ ] = DomsevFrameDataset._assign_labels_to_frames(frames_dict, video_labels)
+
+ self._user_transform = transform
+ self._transform = self._transform_frame
+
+ # Shuffle the frames order for iteration
+ self._frames = list(frames_dict.values())
+ random.shuffle(self._frames)
+
+ @staticmethod
+ def _assign_labels_to_frames(
+ frames_dict: Dict[str, ImageFrameInfo],
+ video_labels: Dict[str, List[LabelData]],
+ ):
+ """
+ Args:
+ frames_dict: The mapping of for all the frames
+ in the dataset.
+ video_labels: The list of temporal labels for each video
+
+ Also unpacks one label per frame.
+ Also converts them to class IDs and then a tensor.
+ """
+ labels_per_frame: Dict[str, int] = {}
+ for frame_id, image_info in frames_dict.items():
+ # Filter labels by only the ones that appear within the clip boundaries,
+ # and unpack the labels so there is one per frame in the clip
+ labels_in_video = video_labels[image_info.video_id]
+ for label in labels_in_video:
+ if (image_info.frame_number >= label.start_frame) and (
+ image_info.frame_number <= label.stop_frame
+ ):
+ labels_per_frame[frame_id] = label.label_id
+
+ return labels_per_frame
+
+ def __getitem__(self, index) -> Dict[str, Any]:
+ """
+ Samples an image frame associated to the given index.
+
+ Args:
+ index (int): index for the image frame
+
+ Returns:
+ An image frame with the following format if transform is None.
+
+ .. code-block:: text
+
+ {{
+ 'frame_id': ,
+ 'image': ,
+ 'label': ,
+ }}
+ """
+ frame = self._frames[index]
+ label_in_frame = self._labels_per_frame[frame.frame_id]
+
+ image_data = _load_image_from_path(frame.frame_file_path)
+
+ frame_data = {
+ "frame_id": frame.frame_id,
+ "image": image_data,
+ "label": label_in_frame,
+ }
+
+ if self._transform:
+ frame_data = self._transform(frame_data)
+
+ return frame_data
+
+ def __len__(self) -> int:
+ """
+ Returns:
+ The number of frames in the dataset.
+ """
+ return len(self._frames)
+
+ def _transform_frame(self, frame: Dict[str, Any]) -> Dict[str, Any]:
+ """
+ Transforms a given image frame, according to some pre-defined transforms
+ and an optional user transform function (self._user_transform).
+
+ Args:
+ clip (Dict[str, Any]): The clip that will be transformed.
+
+ Returns:
+ (Dict[str, Any]) The transformed clip.
+ """
+ for key in frame:
+ if frame[key] is None:
+ frame[key] = torch.tensor([])
+
+ if self._user_transform:
+ frame = self._user_transform(frame)
+
+ return frame
+
+
+class DomsevVideoDataset(torch.utils.data.Dataset):
+ """
+ Egocentric classification video clip-based dataset for
+ `DoMSEV `_
+ stored as an encoded video (with frame-level labels).
+
+ This dataset handles the loading, decoding, and configurable clip
+ sampling for the videos.
+ """
+
+ def __init__(
+ self,
+ video_data_manifest_file_path: str,
+ video_info_file_path: str,
+ labels_file_path: str,
+ clip_sampler: Callable[
+ [Dict[str, Video], Dict[str, List[LabelData]]], List[VideoClipInfo]
+ ],
+ dataset_type: VideoDatasetType = VideoDatasetType.Frame,
+ frames_per_second: int = 1,
+ transform: Optional[Callable[[Dict[str, Any]], Any]] = None,
+ frame_filter: Optional[Callable[[List[int]], List[int]]] = None,
+ multithreaded_io: bool = False,
+ ) -> None:
+ """
+ Args:
+ video_data_manifest_file_path (str):
+ The path to a json file outlining the available video data for the
+ associated videos. File must be a csv (w/header) with columns:
+ ``{[f.name for f in dataclass_fields(EncodedVideoInfo)]}``
+
+ To generate this file from a directory of video frames, see helper
+ functions in module: ``pytorchvideo.data.domsev.utils``
+
+ video_info_file_path (str):
+ Path or URI to manifest with basic metadata of each video.
+ File must be a csv (w/header) with columns:
+ ``{[f.name for f in dataclass_fields(VideoInfo)]}``
+
+ labels_file_path (str):
+ Path or URI to manifest with annotations for each video.
+ File must be a csv (w/header) with columns:
+ ``{[f.name for f in dataclass_fields(LabelData)]}``
+
+ clip_sampler (Callable[[Dict[str, Video], Dict[str, List[LabelData]]],
+ List[VideoClipInfo]]):
+ Defines how clips should be sampled from each video. See the clip
+ sampling documentation for more information.
+
+ dataset_type (VideoDatasetType): The data format in which dataset
+ video data is stored (e.g. video frames, encoded video etc).
+
+ frames_per_second (int): The FPS of the stored videos. (NOTE:
+ this is variable and may be different than the original FPS
+ reported on the DoMSEV dataset website -- it depends on the
+ preprocessed subsampling and frame extraction).
+
+ transform (Optional[Callable[[Dict[str, Any]], Any]]):
+ This callable is evaluated on the clip output before the clip is returned.
+ It can be used for user-defined preprocessing and augmentations to the clips.
+ The clip output format is described in __next__().
+
+ frame_filter (Optional[Callable[[List[int]], List[int]]]):
+ This callable is evaluated on the set of available frame indices to be
+ included in a sampled clip. This can be used to subselect frames within
+ a clip to be loaded.
+
+ multithreaded_io (bool):
+ Boolean to control whether io operations are performed across multiple
+ threads.
+ """
+ assert video_info_file_path
+ assert labels_file_path
+ assert video_data_manifest_file_path
+
+ # Populate video and metadata data providers
+ self._videos: Dict[str, Video] = VideoDataset._load_videos(
+ video_data_manifest_file_path,
+ video_info_file_path,
+ multithreaded_io,
+ dataset_type,
+ )
+
+ self._labels_per_video: Dict[
+ str, List[LabelData]
+ ] = load_dataclass_dict_from_csv(
+ labels_file_path, LabelData, "video_id", list_per_key=True
+ )
+
+ # Sample datapoints
+ self._clips: List[VideoClipInfo] = clip_sampler(
+ self._videos, self._labels_per_video
+ )
+
+ self._frames_per_second = frames_per_second
+ self._user_transform = transform
+ self._transform = self._transform_clip
+ self._frame_filter = frame_filter
+
+ def __getitem__(self, index) -> Dict[str, Any]:
+ """
+ Samples a video clip associated to the given index.
+
+ Args:
+ index (int): index for the video clip.
+
+ Returns:
+ A video clip with the following format if transform is None.
+
+ .. code-block:: text
+
+ {{
+ 'video_id': ,
+ 'video': ,
+ 'audio': ,
+ 'labels': ,
+ 'start_time': ,
+ 'stop_time':
+ }}
+ """
+ clip = self._clips[index]
+
+ # Filter labels by only the ones that appear within the clip boundaries,
+ # and unpack the labels so there is one per frame in the clip
+ labels_in_video = self._labels_per_video[clip.video_id]
+ labels_in_clip = []
+ for label_data in labels_in_video:
+ overlap_period = _get_overlap_for_time_range_pair(
+ clip.start_time,
+ clip.stop_time,
+ label_data.start_time,
+ label_data.stop_time,
+ )
+ if overlap_period is not None:
+ overlap_start_time, overlap_stop_time = overlap_period
+
+ # Convert the overlapping period between clip and label to
+ # 0-indexed start and stop frame indexes, so we can unpack 1
+ # label per frame.
+ overlap_start_frame = _seconds_to_frame_index(
+ overlap_start_time, self._frames_per_second
+ )
+ overlap_stop_frame = _seconds_to_frame_index(
+ overlap_stop_time, self._frames_per_second
+ )
+
+ # Append 1 label per frame
+ for _ in range(overlap_start_frame, overlap_stop_frame):
+ labels_in_clip.append(label_data)
+
+ # Convert the list of LabelData objects to a tensor of just the label IDs
+ label_ids = [labels_in_clip[i].label_id for i in range(len(labels_in_clip))]
+ label_ids_tensor = torch.tensor(label_ids)
+
+ clip_data = {
+ "video_id": clip.video_id,
+ **self._videos[clip.video_id].get_clip(clip.start_time, clip.stop_time),
+ "labels": label_ids_tensor,
+ "start_time": clip.start_time,
+ "stop_time": clip.stop_time,
+ }
+
+ if self._transform:
+ clip_data = self._transform(clip_data)
+
+ return clip_data
+
+ def __len__(self) -> int:
+ """
+ Returns:
+ The number of video clips in the dataset.
+ """
+ return len(self._clips)
+
+ def _transform_clip(self, clip: Dict[str, Any]) -> Dict[str, Any]:
+ """
+ Transforms a given video clip, according to some pre-defined transforms
+ and an optional user transform function (self._user_transform).
+
+ Args:
+ clip (Dict[str, Any]): The clip that will be transformed.
+
+ Returns:
+ (Dict[str, Any]) The transformed clip.
+ """
+ for key in clip:
+ if clip[key] is None:
+ clip[key] = torch.tensor([])
+
+ if self._user_transform:
+ clip = self._user_transform(clip)
+
+ return clip
+
+
+def _load_image_from_path(image_path: str, num_retries: int = 10) -> Image:
+ """
+ Loads the given image path using PathManager and decodes it as an RGB image.
+
+ Args:
+ image_path (str): the path to the image.
+ num_retries (int): number of times to retry image reading to handle transient error.
+
+ Returns:
+ A PIL Image of the image RGB data with shape:
+ (channel, height, width). The frames are of type np.uint8 and
+ in the range [0 - 255]. Raises an exception if unable to load images.
+ """
+ if not _HAS_CV2:
+ raise ImportError(
+ "opencv2 is required to use FrameVideo. Please "
+ "install with 'pip install opencv-python'"
+ )
+
+ img_arr = None
+
+ for i in range(num_retries):
+ with g_pathmgr.open(image_path, "rb") as f:
+ img_str = np.frombuffer(f.read(), np.uint8)
+ img_bgr = cv2.imdecode(img_str, flags=cv2.IMREAD_COLOR)
+ img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
+ if img_rgb is not None:
+ img_arr = img_rgb
+ break
+ else:
+ logging.warning(f"Reading attempt {i}/{num_retries} failed.")
+ time.sleep(1e-6)
+
+ if img_arr is None:
+ raise Exception("Failed to load image from {}".format(image_path))
+
+ pil_image = Image.fromarray(img_arr)
+ return pil_image
diff --git a/code/pytorchvideo/pytorchvideo/data/ego4d/__init__.py b/code/pytorchvideo/pytorchvideo/data/ego4d/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..5385bb06ea15356d80d42bc99df9f814a0c3d617
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/ego4d/__init__.py
@@ -0,0 +1,3 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+from .ego4d_dataset import Ego4dMomentsDataset
diff --git a/code/pytorchvideo/pytorchvideo/data/ego4d/ego4d_dataset.py b/code/pytorchvideo/pytorchvideo/data/ego4d/ego4d_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..e41c27a7a25f50fae68cb1be77eb48ab233e0f00
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/ego4d/ego4d_dataset.py
@@ -0,0 +1,622 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import csv
+import json
+import logging
+import os
+from bisect import bisect_left
+from collections import defaultdict
+from typing import Any, Callable, Dict, List, Optional, Set, Tuple, Type
+
+import numpy as np
+
+import torch
+import torch.autograd.profiler as profiler
+import torch.utils.data
+import torchaudio
+from iopath.common.file_io import g_pathmgr
+
+from pytorchvideo.data import LabeledVideoDataset
+from pytorchvideo.data.clip_sampling import ClipSampler
+from pytorchvideo.data.ego4d.utils import (
+ Ego4dImuDataBase,
+ get_label_id_map,
+ MomentsClipSampler,
+)
+from pytorchvideo.data.utils import get_logger
+from pytorchvideo.data.video import VideoPathHandler
+from pytorchvideo.transforms import (
+ ApplyTransformToKey,
+ Div255,
+ Normalize,
+ RandomShortSideScale,
+ ShortSideScale,
+)
+from torchvision.transforms import CenterCrop, Compose, RandomCrop, RandomHorizontalFlip
+
+log: logging.Logger = get_logger("Ego4dMomentsDataset")
+
+
+class Ego4dImuData(Ego4dImuDataBase):
+ """
+ Wrapper for Ego4D IMU data loads, assuming one csv per video_uid at the provided path.
+ """
+
+ def __init__(self, imu_path: str) -> None:
+ """
+ Args:
+ imu_path (str):
+ Base path to construct IMU csv file paths.
+ i.e. /.csv
+ """
+ assert imu_path
+
+ self.path_imu = imu_path
+ self.IMU_by_video_uid: Dict[str, Any] = {}
+ for f in g_pathmgr.ls(self.path_imu):
+ self.IMU_by_video_uid[f.split(".")[0]] = f.replace(".csv", "")
+
+ log.info(
+ f"Number of videos with IMU (before filtering) {len(self.IMU_by_video_uid)}"
+ )
+
+ self.imu_video_uid: Optional[str] = None
+ self.imu_video_data: Optional[Tuple[np.ndarray, np.ndarray, int]] = None
+
+ def has_imu(self, video_uid: str) -> bool:
+ return video_uid in self.IMU_by_video_uid
+
+ def _load_csv(self, csv_path: str) -> List[Dict[str, Any]]:
+ with g_pathmgr.open(csv_path, "r") as f:
+ reader = csv.DictReader(f)
+ data = []
+ for row in reader:
+ data.append(row)
+ return data
+
+ def _load_imu(self, video_uid: str) -> Tuple[np.ndarray, np.ndarray, int]:
+ file_path = os.path.join(self.path_imu, video_uid) + ".csv"
+ data_csv = self._load_csv(file_path)
+ data_IMU = defaultdict(list)
+ for row in data_csv:
+ for k, v in row.items():
+ if v != "":
+ data_IMU[k].append(float(v))
+ else:
+ data_IMU[k].append(0.0)
+ signal = np.array(
+ [
+ data_IMU["accl_x"],
+ data_IMU["accl_y"],
+ data_IMU["accl_z"],
+ data_IMU["gyro_x"],
+ data_IMU["gyro_y"],
+ data_IMU["gyro_z"],
+ ]
+ ).transpose()
+ # normalize
+ signal = (signal - signal.mean(axis=0)) / signal.std(axis=0)
+ timestamps = np.array(data_IMU["canonical_timestamp_ms"])
+ sampling_rate = int(1000 * (1 / (np.mean(np.diff(timestamps)))))
+ if sampling_rate < 0:
+ # regenerate timestamps with 198 hz
+ new_timestamps = timestamps[0] + (1000 / 198) * np.arange(len(timestamps))
+ timestamps = np.array(new_timestamps)
+ sampling_rate = int(1000 * (1 / (np.mean(np.diff(timestamps)))))
+ return signal, timestamps, sampling_rate
+
+ def _get_imu_window(
+ self,
+ window_start: float,
+ window_end: float,
+ signal: np.ndarray,
+ timestamps: np.ndarray,
+ sampling_rate: float,
+ ) -> Dict[str, Any]:
+ start_id = bisect_left(timestamps, window_start * 1000)
+ end_id = bisect_left(timestamps, window_end * 1000)
+ if end_id == len(timestamps):
+ end_id -= 1
+
+ sample_dict = {
+ "timestamp": timestamps[start_id:end_id],
+ "signal": signal[start_id:end_id],
+ "sampling_rate": sampling_rate,
+ }
+ return sample_dict
+
+ def get_imu(self, video_uid: str) -> Tuple[np.ndarray, np.ndarray, int]:
+ # Caching/etc?
+ return self._load_imu(video_uid)
+
+ def get_imu_sample(
+ self, video_uid: str, video_start: float, video_end: float
+ ) -> Dict[str, Any]:
+ # Assumes video clips are loaded sequentially, will lazy load imu
+ if not self.imu_video_uid or video_uid != self.imu_video_uid:
+ self.imu_video_uid = video_uid
+ self.imu_video_data = self._load_imu(video_uid)
+ assert self.imu_video_data
+ imu_signal, timestamps, sampling_rate = self.imu_video_data
+
+ return self._get_imu_window(
+ video_start,
+ video_end,
+ imu_signal,
+ timestamps,
+ sampling_rate,
+ )
+
+
+class Ego4dMomentsDataset(LabeledVideoDataset):
+ """
+ Ego4d video/audio/imu dataset for the moments benchmark:
+ ``
+
+ This dataset handles the parsing of frames, loading and clip sampling for the
+ videos.
+
+ IO utilizing :code:`iopath.common.file_io.PathManager` to support
+ non-local storage uri's.
+ """
+
+ VIDEO_FPS = 30
+ AUDIO_FPS = 48000
+
+ def __init__(
+ self,
+ annotation_path: str,
+ metadata_path: str,
+ split: Optional[str] = None,
+ decode_audio: bool = True,
+ imu: bool = False,
+ clip_sampler: Optional[ClipSampler] = None,
+ video_sampler: Type[
+ torch.utils.data.Sampler
+ ] = torch.utils.data.SequentialSampler,
+ transform: Optional[Callable[[Dict[str, Any]], Dict[str, Any]]] = None,
+ decoder: str = "pyav",
+ filtered_labels: Optional[List[str]] = None,
+ window_sec: int = 10,
+ audio_transform_type: str = "melspectrogram",
+ imu_path: str = None,
+ label_id_map: Optional[Dict[str, int]] = None,
+ label_id_map_path: Optional[str] = None,
+ video_path_override: Optional[Callable[[str], str]] = None,
+ video_path_handler: Optional[VideoPathHandler] = None,
+ eligible_video_uids: Optional[Set[str]] = None,
+ ) -> None:
+ """
+ Args:
+ annotation_path (str):
+ Path or URI to Ego4d moments annotations json (ego4d.json). Download via:
+ ``
+
+ metadata_path (str):
+ Path or URI to primary Ego4d metadata json (moments.json). Download via:
+ ``
+
+ split (Optional[str]): train/val/test
+
+ decode_audio (bool): If True, decode audio from video.
+
+ imu (bool): If True, load IMU data.
+
+ clip_sampler (ClipSampler):
+ A standard PTV ClipSampler. By default, if not specified, `MomentsClipSampler`
+
+ video_sampler (VideoSampler):
+ A standard PTV VideoSampler.
+
+ transform (Optional[Callable[[Dict[str, Any]], Any]]):
+ This callable is evaluated on the clip output before the clip is returned.
+ It can be used for user-defined preprocessing and augmentations to the clips.
+
+ The clip input is a dictionary with the following format:
+ {{
+ 'video': ,
+ 'audio': ,
+ 'imu': ,
+ 'start_time': ,
+ 'stop_time':
+ }}
+
+ If transform is None, the raw clip output in the above format is
+ returned unmodified.
+
+ decoder (str): Defines what type of decoder used to decode a video within
+ `LabeledVideoDataset`.
+
+ filtered_labels (List[str]):
+ Optional list of moments labels to filter samples for training.
+
+ window_sec (int): minimum window size in s
+
+ audio_transform_type: melspectrogram / spectrogram / mfcc
+
+ imu_path (Optional[str]):
+ Path to the ego4d IMU csv file. Required if imu=True.
+
+ label_id_map / label_id_map_path:
+ A map of moments labels to consistent integer ids. If specified as a path
+ we expect a vanilla .json dict[str, int]. Exactly one must be specified.
+
+ video_path_override ((str) -> str):
+ An override for video paths, given the video_uid, to support downsampled/etc
+ videos.
+
+ video_path_handler (VideoPathHandler):
+ Primarily provided as an override for `CachedVideoPathHandler`
+
+ Example Usage:
+ Ego4dMomentsDataset(
+ annotation_path="~/ego4d_data/v1/annotations/moments.json",
+ metadata_path="~/ego4d_data/v1/ego4d.json",
+ split="train",
+ decode_audio=True,
+ imu=False,
+ )
+ """
+
+ assert annotation_path
+ assert metadata_path
+ assert split in [
+ "train",
+ "val",
+ "test",
+ ], f"Split '{split}' not supported for ego4d"
+ self.split: str = split
+ self.training: bool = split == "train"
+ self.window_sec = window_sec
+ self._transform_source = transform
+ self.decode_audio = decode_audio
+ self.audio_transform_type = audio_transform_type
+ assert (label_id_map is not None) ^ (
+ label_id_map_path is not None
+ ), f"Either label_id_map or label_id_map_path required ({label_id_map_path} / {label_id_map})" # noqa
+
+ self.video_means = (0.45, 0.45, 0.45)
+ self.video_stds = (0.225, 0.225, 0.225)
+ self.video_crop_size = 224
+ self.video_min_short_side_scale = 256
+ self.video_max_short_side_scale = 320
+
+ try:
+ with g_pathmgr.open(metadata_path, "r") as f:
+ metadata = json.load(f)
+ except Exception:
+ raise FileNotFoundError(
+ f"{metadata_path} must be a valid metadata json for Ego4D"
+ )
+
+ self.video_metadata_map: Dict[str, Any] = {
+ x["video_uid"]: x for x in metadata["videos"]
+ }
+
+ if not g_pathmgr.isfile(annotation_path):
+ raise FileNotFoundError(f"{annotation_path} not found.")
+
+ try:
+ with g_pathmgr.open(annotation_path, "r") as f:
+ moments_annotations = json.load(f)
+ except Exception:
+ raise FileNotFoundError(f"{annotation_path} must be json for Ego4D dataset")
+
+ self.label_name_id_map: Dict[str, int]
+ if label_id_map:
+ self.label_name_id_map = label_id_map
+ else:
+ self.label_name_id_map = get_label_id_map(label_id_map_path)
+ assert self.label_name_id_map
+
+ self.num_classes: int = len(self.label_name_id_map)
+ log.info(f"Label Classes: {self.num_classes}")
+
+ self.imu_data: Optional[Ego4dImuDataBase] = None
+ if imu:
+ assert imu_path, "imu_path not provided"
+ self.imu_data = Ego4dImuData(imu_path)
+
+ video_uids = set()
+ clip_uids = set()
+ clip_video_map = {}
+ labels = set()
+ labels_bypassed = set()
+ cnt_samples_bypassed = 0
+ cnt_samples_bypassed_labels = 0
+ samples = []
+
+ for vid in moments_annotations["videos"]:
+ video_uid = vid["video_uid"]
+ video_uids.add(video_uid)
+ vsplit = vid["split"]
+ if split and vsplit != split:
+ continue
+ # If IMU, filter videos without IMU
+ if self.imu_data and not self.imu_data.has_imu(video_uid):
+ continue
+ if eligible_video_uids and video_uid not in eligible_video_uids:
+ continue
+ for clip in vid["clips"]:
+ clip_uid = clip["clip_uid"]
+ clip_uids.add(clip_uid)
+ clip_video_map[clip_uid] = video_uid
+ clip_start_sec = clip["video_start_sec"]
+ clip_end_sec = clip["video_end_sec"]
+ for vann in clip["annotations"]:
+ for lann in vann["labels"]:
+ label = lann["label"]
+ labels.add(label)
+ start = lann["start_time"]
+ end = lann["end_time"]
+ # remove sample with same timestamp
+ if start == end:
+ continue
+ start_video = lann["video_start_time"]
+ end_video = lann["video_end_time"]
+ assert end_video >= start_video
+
+ if abs(start_video - (clip_start_sec + start)) > 0.5:
+ log.warning(
+ f"Suspect clip/video start mismatch: clip: {clip_start_sec:.2f} + {start:.2f} video: {start_video:.2f}" # noqa
+ )
+
+ # filter annotation base on the existing label map
+ if filtered_labels and label not in filtered_labels:
+ cnt_samples_bypassed += 1
+ labels_bypassed.add(label)
+ continue
+ metadata = self.video_metadata_map[video_uid]
+
+ if metadata["is_stereo"]:
+ cnt_samples_bypassed += 1
+ continue
+
+ if video_path_override:
+ video_path = video_path_override(video_uid)
+ else:
+ video_path = metadata["manifold_path"]
+ if not video_path:
+ cnt_samples_bypassed += 1
+ log.error("Bypassing invalid video_path: {video_uid}")
+ continue
+
+ sample = {
+ "clip_uid": clip_uid,
+ "video_uid": video_uid,
+ "duration": metadata["duration_sec"],
+ "clip_video_start_sec": clip_start_sec,
+ "clip_video_end_sec": clip_end_sec,
+ "labels": [label],
+ "label_video_start_sec": start_video,
+ "label_video_end_sec": end_video,
+ "video_path": video_path,
+ }
+ assert (
+ sample["label_video_end_sec"]
+ > sample["label_video_start_sec"]
+ )
+
+ if self.label_name_id_map:
+ if label in self.label_name_id_map:
+ sample["labels_id"] = self.label_name_id_map[label]
+ else:
+ cnt_samples_bypassed_labels += 1
+ continue
+ else:
+ log.error("Missing label_name_id_map")
+ samples.append(sample)
+
+ self.cnt_samples: int = len(samples)
+
+ log.info(
+ f"Loaded {self.cnt_samples} samples. Bypass: {cnt_samples_bypassed} Label Lookup Bypass: {cnt_samples_bypassed_labels}" # noqa
+ )
+
+ for sample in samples:
+ assert "labels_id" in sample, f"init: Sample missing labels_id: {sample}"
+
+ if not clip_sampler:
+ clip_sampler = MomentsClipSampler(self.window_sec)
+
+ super().__init__(
+ [(x["video_path"], x) for x in samples],
+ clip_sampler,
+ video_sampler,
+ transform=self._transform_mm,
+ decode_audio=decode_audio,
+ decoder=decoder,
+ )
+
+ if video_path_handler:
+ self.video_path_handler = video_path_handler
+
+ def check_IMU(self, input_dict: Dict[str, Any]) -> bool:
+ if (
+ len(input_dict["imu"]["signal"].shape) != 2
+ or input_dict["imu"]["signal"].shape[0] == 0
+ or input_dict["imu"]["signal"].shape[0] < 200
+ or input_dict["imu"]["signal"].shape[1] != 6
+ ):
+ log.warning(f"Problematic Sample: {input_dict}")
+ return True
+ else:
+ return False
+
+ def _transform_mm(self, sample_dict: Dict[str, Any]) -> Optional[Dict[str, Any]]:
+ log.info("_transform_mm")
+ with profiler.record_function("_transform_mm"):
+ video_uid = sample_dict["video_uid"]
+ assert video_uid
+
+ assert sample_dict["video"] is not None
+ assert (
+ "labels_id" in sample_dict
+ ), f"Sample missing labels_id: {sample_dict}"
+
+ video = sample_dict["video"]
+
+ expected = int(self.VIDEO_FPS * self.window_sec)
+ actual = video.size(1)
+ if expected != actual:
+ log.error(
+ f"video size mismatch: actual: {actual} expected: {expected} video: {video.size()} uid: {video_uid}", # noqa
+ stack_info=True,
+ )
+ return None
+
+ start = sample_dict["clip_start"]
+ end = sample_dict["clip_end"]
+ assert start >= 0 and end >= start
+
+ if abs((end - start) - self.window_sec) > 0.01:
+ log.warning(f"Invalid IMU time window: ({start}, {end})")
+
+ if self.imu_data:
+ sample_dict["imu"] = self.imu_data.get_imu_sample(
+ video_uid,
+ start,
+ end,
+ )
+ if self.check_IMU(sample_dict):
+ log.warning(f"Bad IMU sample: ignoring: {video_uid}")
+ return None
+
+ sample_dict = self._video_transform()(sample_dict)
+
+ if self.decode_audio:
+ audio_fps = self.AUDIO_FPS
+ sample_dict["audio"] = self._preproc_audio(
+ sample_dict["audio"], audio_fps
+ )
+ sample_dict["spectrogram"] = sample_dict["audio"]["spectrogram"]
+
+ labels = sample_dict["labels"]
+ one_hot = self.convert_one_hot(labels)
+ sample_dict["labels_onehot"] = one_hot
+
+ if self._transform_source:
+ sample_dict = self._transform_source(sample_dict)
+
+ log.info(
+ f"Sample ({sample_dict['video_name']}): "
+ f"({sample_dict['clip_start']:.2f}, {sample_dict['clip_end']:.2f}) "
+ f" {sample_dict['labels_id']} | {sample_dict['labels']}"
+ )
+
+ return sample_dict
+
+ # pyre-ignore
+ def _video_transform(self):
+ """
+ This function contains example transforms using both PyTorchVideo and
+ TorchVision in the same callable. For 'train' model, we use augmentations (prepended
+ with 'Random'), for 'val' we use the respective deterministic function
+ """
+
+ assert (
+ self.video_means
+ and self.video_stds
+ and self.video_min_short_side_scale > 0
+ and self.video_crop_size > 0
+ )
+
+ video_transforms = ApplyTransformToKey(
+ key="video",
+ transform=Compose(
+ # pyre-fixme
+ [Div255(), Normalize(self.video_means, self.video_stds)]
+ + [ # pyre-fixme
+ RandomShortSideScale(
+ min_size=self.video_min_short_side_scale,
+ max_size=self.video_max_short_side_scale,
+ ),
+ RandomCrop(self.video_crop_size),
+ RandomHorizontalFlip(p=0.5),
+ ]
+ if self.training
+ else [
+ ShortSideScale(self.video_min_short_side_scale),
+ CenterCrop(self.video_crop_size),
+ ]
+ ),
+ )
+ return Compose([video_transforms])
+
+ def signal_transform(self, type: str = "spectrogram", sample_rate: int = 48000):
+ if type == "spectrogram":
+ n_fft = 1024
+ win_length = None
+ hop_length = 512
+
+ transform = torchaudio.transforms.Spectrogram(
+ n_fft=n_fft,
+ win_length=win_length,
+ hop_length=hop_length,
+ center=True,
+ pad_mode="reflect",
+ power=2.0,
+ )
+ elif type == "melspectrogram":
+ n_fft = 1024
+ win_length = None
+ hop_length = 512
+ n_mels = 64
+
+ transform = torchaudio.transforms.MelSpectrogram(
+ sample_rate=sample_rate,
+ n_fft=n_fft,
+ win_length=win_length,
+ hop_length=hop_length,
+ center=True,
+ pad_mode="reflect",
+ power=2.0,
+ norm="slaney",
+ onesided=True,
+ n_mels=n_mels,
+ mel_scale="htk",
+ )
+ elif type == "mfcc":
+ n_fft = 2048
+ win_length = None
+ hop_length = 512
+ n_mels = 256
+ n_mfcc = 256
+
+ transform = torchaudio.transforms.MFCC(
+ sample_rate=sample_rate,
+ n_mfcc=n_mfcc,
+ melkwargs={
+ "n_fft": n_fft,
+ "n_mels": n_mels,
+ "hop_length": hop_length,
+ "mel_scale": "htk",
+ },
+ )
+ else:
+ raise ValueError(type)
+
+ return transform
+
+ def _preproc_audio(self, audio, audio_fps) -> Dict[str, Any]:
+ # convert stero to mono
+ # https://github.com/pytorch/audio/issues/363
+ waveform_mono = torch.mean(audio, dim=0, keepdim=True)
+ return {
+ "signal": waveform_mono,
+ "spectrogram": self.signal_transform(
+ type=self.audio_transform_type,
+ sample_rate=audio_fps,
+ )(waveform_mono),
+ "sampling_rate": audio_fps,
+ }
+
+ def convert_one_hot(self, label_list: List[str]) -> List[int]:
+ labels = [x for x in label_list if x in self.label_name_id_map.keys()]
+ assert len(labels) == len(
+ label_list
+ ), f"invalid filter {len(label_list)} -> {len(labels)}: {label_list}"
+ one_hot = [0 for _ in range(self.num_classes)]
+ for lab in labels:
+ one_hot[self.label_name_id_map[lab]] = 1
+ return one_hot
diff --git a/code/pytorchvideo/pytorchvideo/data/ego4d/utils.py b/code/pytorchvideo/pytorchvideo/data/ego4d/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..186004fda11a8287321b14d662fa0701ab0fd16f
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/ego4d/utils.py
@@ -0,0 +1,124 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import json
+import logging
+from abc import ABC, abstractmethod
+from typing import Any, Dict, Tuple
+
+from iopath.common.file_io import g_pathmgr
+
+from pytorchvideo.data.clip_sampling import ClipInfo, ClipSampler
+from pytorchvideo.data.utils import get_logger
+
+log: logging.Logger = get_logger("Ego4dDatasetUtils")
+
+
+# TODO: Round to fps (and ideally frame align)
+def check_window_len(
+ s_time: float, e_time: float, w_len: float, video_dur: float
+) -> Tuple[float, float]:
+ """
+ Constrain/slide the give time window to `w_len` size and the video/clip length.
+ """
+ # adjust to match w_len
+ interval = e_time - s_time
+ if abs(interval - w_len) > 0.001:
+ # TODO: Do we want to sample rather than trim the interior when larger?
+ delta = w_len - (e_time - s_time)
+ s_time = s_time - (delta / 2)
+ e_time = e_time + (delta / 2)
+ if s_time < 0:
+ e_time += -s_time
+ s_time = 0
+ if video_dur:
+ if e_time > video_dur:
+ overlap = e_time - video_dur
+ assert s_time >= overlap, "Incompatible w_len / video_dur"
+ s_time -= overlap
+ e_time -= overlap
+ log.info(
+ f"check_window_len: video overlap ({overlap}) adjusted -> ({s_time:.2f}, {e_time:.2f}) video: {video_dur}" # noqa
+ )
+ if abs((e_time - s_time) - w_len) > 0.01:
+ log.error(
+ f"check_window_len: invalid time interval: {s_time}, {e_time}",
+ stack_info=True,
+ )
+ return s_time, e_time
+
+
+# TODO: Move to FixedClipSampler?
+class MomentsClipSampler(ClipSampler):
+ """
+ ClipSampler for Ego4d moments. Will return a fixed `window_sec` window
+ around the given annotation, shifting where relevant to account for the end
+ of the clip/video.
+
+ clip_start/clip_end is added to the annotation dict to facilitate future lookups.
+ """
+
+ def __init__(self, window_sec: float = 0) -> None:
+ self.window_sec = window_sec
+
+ def __call__(
+ self,
+ last_clip_end_time: float,
+ video_duration: float,
+ annotation: Dict[str, Any],
+ ) -> ClipInfo:
+ assert (
+ last_clip_end_time is None or last_clip_end_time <= video_duration
+ ), f"last_clip_end_time ({last_clip_end_time}) > video_duration ({video_duration})"
+ start = annotation["label_video_start_sec"]
+ end = annotation["label_video_end_sec"]
+ if video_duration is not None and end > video_duration:
+ log.error(f"Invalid video_duration/end_sec: {video_duration} / {end}")
+ # If it's small, proceed anyway
+ if end > video_duration + 0.1:
+ raise Exception(
+ f"Invalid video_duration/end_sec: {video_duration} / {end} ({annotation['video_name']})" # noqa
+ )
+ assert end >= start, f"end < start: {end:.2f} / {start:.2f}"
+ if self.window_sec > 0:
+ s, e = check_window_len(start, end, self.window_sec, video_duration)
+ if s != start or e != end:
+ # log.info(
+ # f"clip window slid ({start:.2f}|{end:.2f}) -> ({s:.2f}|{e:.2f})"
+ # )
+ start = s
+ end = e
+ annotation["clip_start"] = start
+ annotation["clip_end"] = end
+ return ClipInfo(start, end, 0, 0, True)
+
+
+def get_label_id_map(label_id_map_path: str) -> Dict[str, int]:
+ label_name_id_map: Dict[str, int]
+
+ try:
+ with g_pathmgr.open(label_id_map_path, "r") as f:
+ label_json = json.load(f)
+
+ # TODO: Verify?
+ return label_json
+ except Exception:
+ raise FileNotFoundError(f"{label_id_map_path} must be a valid label id json")
+
+
+class Ego4dImuDataBase(ABC):
+ """
+ Base class placeholder for Ego4d IMU data.
+ """
+
+ def __init__(self, basepath: str):
+ self.basepath = basepath
+
+ @abstractmethod
+ def has_imu(self, video_uid: str) -> bool:
+ pass
+
+ @abstractmethod
+ def get_imu_sample(
+ self, video_uid: str, video_start: float, video_end: float
+ ) -> Dict[str, Any]:
+ pass
diff --git a/code/pytorchvideo/pytorchvideo/data/encoded_video.py b/code/pytorchvideo/pytorchvideo/data/encoded_video.py
new file mode 100644
index 0000000000000000000000000000000000000000..227227adcd9a16e04bebdac9bf3c5ffb1cd37982
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/encoded_video.py
@@ -0,0 +1,75 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import io
+import logging
+import pathlib
+from typing import Any, Dict
+
+from iopath.common.file_io import g_pathmgr
+from pytorchvideo.data.decoder import DecoderType
+
+from .video import Video
+
+
+logger = logging.getLogger(__name__)
+
+
+def select_video_class(decoder: str) -> Video:
+ """
+ Select the class for accessing clips based on provided decoder string
+
+ Args:
+ decoder (str): Defines what type of decoder used to decode a video.
+ """
+ if DecoderType(decoder) == DecoderType.PYAV:
+ from .encoded_video_pyav import EncodedVideoPyAV
+
+ video_cls = EncodedVideoPyAV
+ elif DecoderType(decoder) == DecoderType.TORCHVISION:
+ from .encoded_video_torchvision import EncodedVideoTorchVision
+
+ video_cls = EncodedVideoTorchVision
+ elif DecoderType(decoder) == DecoderType.DECORD:
+ from .encoded_video_decord import EncodedVideoDecord
+
+ video_cls = EncodedVideoDecord
+ else:
+ raise NotImplementedError(f"Unknown decoder type {decoder}")
+
+ return video_cls
+
+
+class EncodedVideo(Video):
+ """
+ EncodedVideo is an abstraction for accessing clips from an encoded video.
+ It supports selective decoding when header information is available.
+ """
+
+ @classmethod
+ def from_path(
+ cls,
+ file_path: str,
+ decode_video: bool = True,
+ decode_audio: bool = True,
+ decoder: str = "pyav",
+ **other_args: Dict[str, Any],
+ ):
+ """
+ Fetches the given video path using PathManager (allowing remote uris to be
+ fetched) and constructs the EncodedVideo object.
+
+ Args:
+ file_path (str): a PathManager file-path.
+ """
+ # We read the file with PathManager so that we can read from remote uris.
+ with g_pathmgr.open(file_path, "rb") as fh:
+ video_file = io.BytesIO(fh.read())
+
+ video_cls = select_video_class(decoder)
+ return video_cls(
+ file=video_file,
+ video_name=pathlib.Path(file_path).name,
+ decode_video=decode_video,
+ decode_audio=decode_audio,
+ **other_args,
+ )
diff --git a/code/pytorchvideo/pytorchvideo/data/encoded_video_decord.py b/code/pytorchvideo/pytorchvideo/data/encoded_video_decord.py
new file mode 100644
index 0000000000000000000000000000000000000000..5ae85dc04011e6c1463ab0fa1ebcbb9cd1b2ea44
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/encoded_video_decord.py
@@ -0,0 +1,199 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import logging
+import math
+from typing import BinaryIO, Dict, Optional, TypeVar
+
+import torch
+
+from .utils import thwc_to_cthw
+from .video import Video
+
+
+logger = logging.getLogger(__name__)
+
+try:
+ import decord
+except ImportError:
+ _HAS_DECORD = False
+else:
+ _HAS_DECORD = True
+
+if _HAS_DECORD:
+ decord.bridge.set_bridge("torch")
+
+DecordDevice = TypeVar("DecordDevice")
+
+
+class EncodedVideoDecord(Video):
+ """
+
+ Accessing clips from an encoded video using Decord video reading API
+ as the decoding backend. For more details, please refer to -
+ `Decord `
+ """
+
+ def __init__(
+ self,
+ file: BinaryIO,
+ video_name: Optional[str] = None,
+ decode_video: bool = True,
+ decode_audio: bool = True,
+ sample_rate: int = 44100,
+ mono: bool = True,
+ width: int = -1,
+ height: int = -1,
+ num_threads: int = 0,
+ fault_tol: int = -1,
+ ) -> None:
+ """
+ Args:
+ file (BinaryIO): a file-like object (e.g. io.BytesIO or io.StringIO) that
+ contains the encoded video.
+ video_name (str): An optional name assigned to the video.
+ decode_video (bool): If disabled, video is not decoded.
+ decode_audio (bool): If disabled, audio is not decoded.
+ sample_rate: int, default is -1
+ Desired output sample rate of the audio, unchanged if `-1` is specified.
+ mono: bool, default is True
+ Desired output channel layout of the audio. `True` is mono layout. `False`
+ is unchanged.
+ width : int, default is -1
+ Desired output width of the video, unchanged if `-1` is specified.
+ height : int, default is -1
+ Desired output height of the video, unchanged if `-1` is specified.
+ num_threads : int, default is 0
+ Number of decoding thread, auto if `0` is specified.
+ fault_tol : int, default is -1
+ The threshold of corupted and recovered frames. This is to prevent silent fault
+ tolerance when for example 50% frames of a video cannot be decoded and duplicate
+ frames are returned. You may find the fault tolerant feature sweet in many
+ cases, but not for training models. Say `N = # recovered frames`
+ If `fault_tol` < 0, nothing will happen.
+ If 0 < `fault_tol` < 1.0, if N > `fault_tol * len(video)`,
+ raise `DECORDLimitReachedError`.
+ If 1 < `fault_tol`, if N > `fault_tol`, raise `DECORDLimitReachedError`.
+ """
+ if not decode_video:
+ raise NotImplementedError()
+
+ self._decode_audio = decode_audio
+ self._video_name = video_name
+ if not _HAS_DECORD:
+ raise ImportError(
+ "decord is required to use EncodedVideoDecord decoder. Please "
+ "install with 'pip install decord' for CPU-only version and refer to"
+ "'https://github.com/dmlc/decord' for GPU-supported version"
+ )
+ try:
+ if self._decode_audio:
+ self._av_reader = decord.AVReader(
+ uri=file,
+ ctx=decord.cpu(0),
+ sample_rate=sample_rate,
+ mono=mono,
+ width=width,
+ height=height,
+ num_threads=num_threads,
+ fault_tol=fault_tol,
+ )
+ else:
+ self._av_reader = decord.VideoReader(
+ uri=file,
+ ctx=decord.cpu(0),
+ width=width,
+ height=height,
+ num_threads=num_threads,
+ fault_tol=fault_tol,
+ )
+ except Exception as e:
+ raise RuntimeError(f"Failed to open video {video_name} with Decord. {e}")
+
+ if self._decode_audio:
+ self._fps = self._av_reader._AVReader__video_reader.get_avg_fps()
+ else:
+ self._fps = self._av_reader.get_avg_fps()
+
+ self._duration = float(len(self._av_reader)) / float(self._fps)
+
+ @property
+ def name(self) -> Optional[str]:
+ """
+ Returns:
+ name: the name of the stored video if set.
+ """
+ return self._video_name
+
+ @property
+ def duration(self) -> float:
+ """
+ Returns:
+ duration: the video's duration/end-time in seconds.
+ """
+ return self._duration
+
+ def close(self):
+ if self._av_reader is not None:
+ del self._av_reader
+ self._av_reader = None
+
+ def get_clip(
+ self, start_sec: float, end_sec: float
+ ) -> Dict[str, Optional[torch.Tensor]]:
+ """
+ Retrieves frames from the encoded video at the specified start and end times
+ in seconds (the video always starts at 0 seconds).
+
+ Args:
+ start_sec (float): the clip start time in seconds
+ end_sec (float): the clip end time in seconds
+ Returns:
+ clip_data:
+ A dictionary mapping the entries at "video" and "audio" to a tensors.
+
+ "video": A tensor of the clip's RGB frames with shape:
+ (channel, time, height, width). The frames are of type torch.float32 and
+ in the range [0 - 255].
+
+ "audio": A tensor of the clip's audio samples with shape:
+ (samples). The samples are of type torch.float32 and
+ in the range [0 - 255].
+
+ Returns None if no video or audio found within time range.
+
+ """
+ if start_sec > end_sec or start_sec > self._duration:
+ raise RuntimeError(
+ f"Incorrect time window for Decord decoding for video: {self._video_name}."
+ )
+
+ start_idx = math.ceil(self._fps * start_sec)
+ end_idx = math.ceil(self._fps * end_sec)
+ end_idx = min(end_idx, len(self._av_reader))
+ frame_idxs = list(range(start_idx, end_idx))
+ audio = None
+
+ try:
+ outputs = self._av_reader.get_batch(frame_idxs)
+ except Exception as e:
+ logger.debug(f"Failed to decode video with Decord: {self._video_name}. {e}")
+ raise e
+
+ if self._decode_audio:
+ audio, video = outputs
+ if audio is not None:
+ audio = list(audio)
+ audio = torch.cat(audio, dim=1)
+ audio = torch.flatten(audio)
+ audio = audio.to(torch.float32)
+ else:
+ video = outputs
+
+ if video is not None:
+ video = video.to(torch.float32)
+ video = thwc_to_cthw(video)
+
+ return {
+ "video": video,
+ "audio": audio,
+ }
diff --git a/code/pytorchvideo/pytorchvideo/data/encoded_video_pyav.py b/code/pytorchvideo/pytorchvideo/data/encoded_video_pyav.py
new file mode 100644
index 0000000000000000000000000000000000000000..8e9523815a58dc214ad1c956979dc13865c2045d
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/encoded_video_pyav.py
@@ -0,0 +1,364 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import logging
+import math
+from fractions import Fraction
+from typing import BinaryIO, Dict, List, Optional, Tuple, Union
+
+import av
+import numpy as np
+import torch
+from pytorchvideo.data.encoded_video import EncodedVideo
+
+from .utils import pts_to_secs, secs_to_pts, thwc_to_cthw
+
+
+logger = logging.getLogger(__name__)
+
+
+class EncodedVideoPyAV(EncodedVideo):
+ """
+ EncodedVideoPyAV is an abstraction for accessing clips from an encoded video using
+ PyAV as the decoding backend. It supports selective decoding when header information
+ is available.
+ """
+
+ def __init__(
+ self,
+ file: BinaryIO,
+ video_name: Optional[str] = None,
+ decode_video: bool = True,
+ decode_audio: bool = True,
+ perform_seek: bool = True,
+ ) -> None:
+ """
+ Args:
+ file (BinaryIO): a file-like object (e.g. io.BytesIO or io.StringIO) that
+ contains the encoded video.
+ perform_seek:
+ Whether or not to seek time to the underlying video container.
+
+ NOTE: seeks may be slow on larger files, e.g. on a networked filesystem
+ """
+ self.perform_seek = perform_seek
+ self._video_name = video_name
+ self._decode_video = decode_video
+ self._decode_audio = decode_audio
+
+ try:
+ self._container = av.open(file)
+ except Exception as e:
+ raise RuntimeError(f"Failed to open video {video_name}. {e}")
+
+ if self._container is None or len(self._container.streams.video) == 0:
+ raise RuntimeError(f"Video stream not found {video_name}")
+
+ # Retrieve video header information if available.
+ video_stream = self._container.streams.video[0]
+ self._video_time_base = video_stream.time_base
+ self._video_start_pts = video_stream.start_time
+ if self._video_start_pts is None:
+ self._video_start_pts = 0.0
+
+ video_duration = video_stream.duration
+
+ # Retrieve audio header information if available.
+ audio_duration = None
+ self._has_audio = None
+ if self._decode_audio:
+ self._has_audio = self._container.streams.audio
+ if self._has_audio:
+ self._audio_time_base = self._container.streams.audio[0].time_base
+ self._audio_start_pts = self._container.streams.audio[0].start_time
+ if self._audio_start_pts is None:
+ self._audio_start_pts = 0.0
+
+ audio_duration = self._container.streams.audio[0].duration
+
+ # If duration isn't found in header the whole video is decoded to
+ # determine the duration.
+ self._video, self._audio, self._selective_decoding = (None, None, True)
+ if audio_duration is None and video_duration is None:
+ self._selective_decoding = False
+ self._video, self._audio = self._pyav_decode_video()
+ if self._video is None:
+ raise RuntimeError("Unable to decode video stream")
+
+ video_duration = self._video[-1][1]
+ if self._audio is not None:
+ audio_duration = self._audio[-1][1]
+
+ # Take the largest duration of either video or duration stream.
+ if audio_duration is not None and video_duration is not None:
+ self._duration = max(
+ pts_to_secs(
+ video_duration, self._video_time_base, self._video_start_pts
+ ),
+ pts_to_secs(
+ audio_duration, self._audio_time_base, self._audio_start_pts
+ ),
+ )
+ elif video_duration is not None:
+ self._duration = pts_to_secs(
+ video_duration, self._video_time_base, self._video_start_pts
+ )
+
+ elif audio_duration is not None:
+ self._duration = pts_to_secs(
+ audio_duration, self._audio_time_base, self._audio_start_pts
+ )
+
+ @property
+ def rate(self) -> Union[str, Fraction]:
+ """
+ Returns:
+ rate: the frame rate of the video
+ """
+ return self._container.streams.video[0].rate
+
+ @property
+ def bit_rate(self) -> int:
+ """
+ Returns:
+ bit_rate: the bit rate of the underlying video
+ """
+ return self._container.streams.video[0].bit_rate
+
+ @property
+ def pix_fmt(self) -> int:
+ """
+ Returns:
+ pix_fmt: the pixel format of the underlying video
+ """
+ return self._container.streams.video[0].pix_fmt
+
+ @property
+ def name(self) -> Optional[str]:
+ """
+ Returns:
+ name: the name of the stored video if set.
+ """
+ return self._video_name
+
+ @property
+ def duration(self) -> float:
+ """
+ Returns:
+ duration: the video's duration/end-time in seconds.
+ """
+ return self._duration
+
+ def get_clip(
+ self, start_sec: float, end_sec: float
+ ) -> Dict[str, Optional[torch.Tensor]]:
+ """
+ Retrieves frames from the encoded video at the specified start and end times
+ in seconds (the video always starts at 0 seconds). Returned frames will be in
+ [start_sec, end_sec). Note that 1) if you want to avoid float precision issue
+ and need accurate frames, please use Fraction for start_sec and end_sec.
+ 2) As end_sec is exclusive, so you may need to use
+ `get_clip(start_sec, duration + EPS)` to get the last frame.
+
+ Args:
+ start_sec (float): the clip start time in seconds
+ end_sec (float): the clip end time in seconds
+ Returns:
+ clip_data:
+ A dictionary mapping the entries at "video" and "audio" to a tensors.
+
+ "video": A tensor of the clip's RGB frames with shape:
+ (channel, time, height, width). The frames are of type torch.float32 and
+ in the range [0 - 255].
+
+ "audio": A tensor of the clip's audio samples with shape:
+ (samples). The samples are of type torch.float32 and
+ in the range [0 - 255].
+
+ Returns None if no video or audio found within time range.
+
+ """
+ if self._selective_decoding:
+ self._video, self._audio = self._pyav_decode_video(start_sec, end_sec)
+
+ video_frames = None
+ if self._video is not None:
+ video_start_pts = secs_to_pts(
+ start_sec,
+ self._video_time_base,
+ self._video_start_pts,
+ round_mode="ceil",
+ )
+ video_end_pts = secs_to_pts(
+ end_sec,
+ self._video_time_base,
+ self._video_start_pts,
+ round_mode="ceil",
+ )
+
+ video_frames = [
+ f
+ for f, pts in self._video
+ if pts >= video_start_pts and pts < video_end_pts
+ ]
+
+ audio_samples = None
+ if self._has_audio and self._audio is not None:
+ audio_start_pts = secs_to_pts(
+ start_sec,
+ self._audio_time_base,
+ self._audio_start_pts,
+ round_mode="ceil",
+ )
+ audio_end_pts = secs_to_pts(
+ end_sec,
+ self._audio_time_base,
+ self._audio_start_pts,
+ round_mode="ceil",
+ )
+ audio_samples = [
+ f
+ for f, pts in self._audio
+ if pts >= audio_start_pts and pts < audio_end_pts
+ ]
+ audio_samples = torch.cat(audio_samples, axis=0)
+ audio_samples = audio_samples.to(torch.float32)
+
+ if video_frames is None or len(video_frames) == 0:
+ logger.debug(
+ f"No video found within {start_sec} and {end_sec} seconds. "
+ f"Video starts at time 0 and ends at {self.duration}."
+ )
+
+ video_frames = None
+
+ if video_frames is not None:
+ video_frames = thwc_to_cthw(torch.stack(video_frames)).to(torch.float32)
+
+ return {
+ "video": video_frames,
+ "audio": audio_samples,
+ }
+
+ def close(self):
+ """
+ Closes the internal video container.
+ """
+ if self._container is not None:
+ self._container.close()
+
+ def _pyav_decode_video(
+ self, start_secs: float = 0.0, end_secs: float = math.inf
+ ) -> float:
+ """
+ Selectively decodes a video between start_pts and end_pts in time units of the
+ self._video's timebase.
+ """
+ video_and_pts = None
+ audio_and_pts = None
+ try:
+ if self._decode_video:
+ pyav_video_frames, _ = _pyav_decode_stream(
+ self._container,
+ secs_to_pts(
+ start_secs,
+ self._video_time_base,
+ self._video_start_pts,
+ round_mode="ceil",
+ ),
+ secs_to_pts(
+ end_secs,
+ self._video_time_base,
+ self._video_start_pts,
+ round_mode="ceil",
+ ),
+ self._container.streams.video[0],
+ {"video": 0},
+ perform_seek=self.perform_seek,
+ )
+ if len(pyav_video_frames) > 0:
+ video_and_pts = [
+ (torch.from_numpy(frame.to_rgb().to_ndarray()), frame.pts)
+ for frame in pyav_video_frames
+ ]
+
+ if self._has_audio:
+ pyav_audio_frames, _ = _pyav_decode_stream(
+ self._container,
+ secs_to_pts(
+ start_secs,
+ self._audio_time_base,
+ self._audio_start_pts,
+ round_mode="ceil",
+ ),
+ secs_to_pts(
+ end_secs,
+ self._audio_time_base,
+ self._audio_start_pts,
+ round_mode="ceil",
+ ),
+ self._container.streams.audio[0],
+ {"audio": 0},
+ perform_seek=self.perform_seek,
+ )
+
+ if len(pyav_audio_frames) > 0:
+ audio_and_pts = [
+ (
+ torch.from_numpy(np.mean(frame.to_ndarray(), axis=0)),
+ frame.pts,
+ )
+ for frame in pyav_audio_frames
+ ]
+
+ except Exception as e:
+ logger.debug(f"Failed to decode video: {self._video_name}. {e}")
+
+ return video_and_pts, audio_and_pts
+
+
+def _pyav_decode_stream(
+ container: av.container.input.InputContainer,
+ start_pts: int,
+ end_pts: int,
+ stream: av.video.stream.VideoStream,
+ stream_name: dict,
+ buffer_size: int = 0,
+ perform_seek: bool = True,
+) -> Tuple[List, float]:
+ """
+ Decode the video with PyAV decoder.
+ Args:
+ container (container): PyAV container.
+ start_pts (int): the starting Presentation TimeStamp to fetch the
+ video frames.
+ end_pts (int): the ending Presentation TimeStamp of the decoded frames.
+ stream (stream): PyAV stream.
+ stream_name (dict): a dictionary of streams. For example, {"video": 0}
+ means video stream at stream index 0.
+ Returns:
+ result (list): list of decoded frames.
+ max_pts (int): max Presentation TimeStamp of the video sequence.
+ """
+
+ # Seeking in the stream is imprecise. Thus, seek to an earlier pts by a
+ # margin pts.
+ margin = 1024
+
+ # NOTE:
+ # Don't want to seek if iterating through a video due to slow-downs. I
+ # believe this is some PyAV bug where seeking after a certain point causes
+ # major slow-downs
+ if perform_seek:
+ seek_offset = max(start_pts - margin, 0)
+ container.seek(int(seek_offset), any_frame=False, backward=True, stream=stream)
+ frames = {}
+ max_pts = 0
+ for frame in container.decode(**stream_name):
+ max_pts = max(max_pts, frame.pts)
+ if frame.pts >= start_pts and frame.pts < end_pts:
+ frames[frame.pts] = frame
+ elif frame.pts >= end_pts:
+ break
+
+ result = [frames[pts] for pts in sorted(frames)]
+ return result, max_pts
diff --git a/code/pytorchvideo/pytorchvideo/data/encoded_video_torchvision.py b/code/pytorchvideo/pytorchvideo/data/encoded_video_torchvision.py
new file mode 100644
index 0000000000000000000000000000000000000000..eee8f17a6b08546f59415c619a64e5fd891b1316
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/encoded_video_torchvision.py
@@ -0,0 +1,276 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import logging
+from fractions import Fraction
+from typing import BinaryIO, Dict, Optional
+
+import numpy as np
+import torch
+
+from .utils import pts_to_secs, secs_to_pts, thwc_to_cthw
+from .video import Video
+
+
+logger = logging.getLogger(__name__)
+
+
+class EncodedVideoTorchVision(Video):
+ """
+
+ Accessing clips from an encoded video using Torchvision video reading API
+ (torch.ops.video_reader.read_video_from_memory) as the decoding backend.
+ """
+
+ """
+ av_seek_frame is imprecise so seek to a timestamp earlier by a margin
+ The unit of margin is second
+ """
+ SEEK_FRAME_MARGIN = 0.25
+
+ def __init__(
+ self,
+ file: BinaryIO,
+ video_name: Optional[str] = None,
+ decode_video: bool = True,
+ decode_audio: bool = True,
+ ) -> None:
+ if not decode_video:
+ raise NotImplementedError()
+
+ self._video_tensor = torch.tensor(
+ np.frombuffer(file.getvalue(), dtype=np.uint8)
+ )
+ self._video_name = video_name
+ self._decode_audio = decode_audio
+
+ (
+ self._video,
+ self._video_time_base,
+ self._video_start_pts,
+ video_duration,
+ self._audio,
+ self._audio_time_base,
+ self._audio_start_pts,
+ audio_duration,
+ ) = self._torch_vision_decode_video()
+
+ # Take the largest duration of either video or duration stream.
+ if audio_duration is not None and video_duration is not None:
+ self._duration = max(
+ pts_to_secs(
+ video_duration, self._video_time_base, self._video_start_pts
+ ),
+ pts_to_secs(
+ audio_duration, self._audio_time_base, self._audio_start_pts
+ ),
+ )
+ elif video_duration is not None:
+ self._duration = pts_to_secs(
+ video_duration, self._video_time_base, self._video_start_pts
+ )
+
+ elif audio_duration is not None:
+ self._duration = pts_to_secs(
+ audio_duration, self._audio_time_base, self._audio_start_pts
+ )
+
+ @property
+ def name(self) -> Optional[str]:
+ """
+ Returns:
+ name: the name of the stored video if set.
+ """
+ return self._video_name
+
+ @property
+ def duration(self) -> float:
+ """
+ Returns:
+ duration: the video's duration/end-time in seconds.
+ """
+ return self._duration
+
+ def close(self):
+ pass
+
+ def get_clip(
+ self, start_sec: float, end_sec: float
+ ) -> Dict[str, Optional[torch.Tensor]]:
+ """
+ Retrieves frames from the encoded video at the specified start and end times
+ in seconds (the video always starts at 0 seconds). Returned frames will be in
+ [start_sec, end_sec). Note that 1) if you want to avoid float precision issue
+ and need accurate frames, please use Fraction for start_sec and end_sec.
+ 2) As end_sec is exclusive, so you may need to use
+ `get_clip(start_sec, duration + EPS)` to get the last frame.
+
+ Args:
+ start_sec (float): the clip start time in seconds
+ end_sec (float): the clip end time in seconds
+ Returns:
+ clip_data:
+ A dictionary mapping the entries at "video" and "audio" to a tensors.
+
+ "video": A tensor of the clip's RGB frames with shape:
+ (channel, time, height, width). The frames are of type torch.float32 and
+ in the range [0 - 255].
+
+ "audio": A tensor of the clip's audio samples with shape:
+ (samples). The samples are of type torch.float32 and
+ in the range [0 - 255].
+
+ Returns None if no video or audio found within time range.
+
+ """
+ video_frames = None
+ if self._video is not None:
+ video_start_pts = secs_to_pts(
+ start_sec,
+ self._video_time_base,
+ self._video_start_pts,
+ round_mode="ceil",
+ )
+ video_end_pts = secs_to_pts(
+ end_sec,
+ self._video_time_base,
+ self._video_start_pts,
+ round_mode="ceil",
+ )
+ video_frames = [
+ f
+ for f, pts in self._video
+ if pts >= video_start_pts and pts < video_end_pts
+ ]
+
+ audio_samples = None
+ if self._decode_audio and self._audio:
+ audio_start_pts = secs_to_pts(
+ start_sec,
+ self._audio_time_base,
+ self._audio_start_pts,
+ round_mode="ceil",
+ )
+ audio_end_pts = secs_to_pts(
+ end_sec,
+ self._audio_time_base,
+ self._audio_start_pts,
+ round_mode="ceil",
+ )
+ audio_samples = [
+ f
+ for f, pts in self._audio
+ if pts >= audio_start_pts and pts < audio_end_pts
+ ]
+ audio_samples = torch.cat(audio_samples, axis=0)
+ audio_samples = audio_samples.to(torch.float32)
+
+ if video_frames is None or len(video_frames) == 0:
+ logger.warning(
+ f"No video found within {start_sec} and {end_sec} seconds. "
+ f"Video starts at time 0 and ends at {self.duration}."
+ )
+
+ video_frames = None
+
+ if video_frames is not None:
+ video_frames = thwc_to_cthw(torch.stack(video_frames)).to(torch.float32)
+
+ return {
+ "video": video_frames,
+ "audio": audio_samples,
+ }
+
+ def _torch_vision_decode_video(
+ self, start_pts: int = 0, end_pts: int = -1
+ ) -> float:
+ """
+ Decode the video in the PTS range [start_pts, end_pts]
+ """
+ video_and_pts = None
+ audio_and_pts = None
+
+ width, height, min_dimension, max_dimension = 0, 0, 0, 0
+ video_start_pts, video_end_pts = start_pts, end_pts
+ video_timebase_num, video_timebase_den = 0, 1
+
+ samples, channels = 0, 0
+ audio_start_pts, audio_end_pts = start_pts, end_pts
+ audio_timebase_num, audio_timebase_den = 0, 1
+
+ try:
+ tv_result = torch.ops.video_reader.read_video_from_memory(
+ self._video_tensor,
+ self.SEEK_FRAME_MARGIN,
+ # Set getPtsOnly=0, i.e., read full video rather than just header
+ 0,
+ # Read video stream
+ 1,
+ width,
+ height,
+ min_dimension,
+ max_dimension,
+ video_start_pts,
+ video_end_pts,
+ video_timebase_num,
+ video_timebase_den,
+ # Read audio stream
+ self._decode_audio,
+ samples,
+ channels,
+ audio_start_pts,
+ audio_end_pts,
+ audio_timebase_num,
+ audio_timebase_den,
+ )
+ except Exception as e:
+ logger.warning(f"Failed to decode video of name {self._video_name}. {e}")
+ raise e
+
+ (
+ vframes,
+ vframes_pts,
+ vtimebase,
+ _,
+ vduration,
+ aframes,
+ aframe_pts,
+ atimebase,
+ _,
+ aduration,
+ ) = tv_result
+
+ if vduration < 0:
+ # No header information to infer video duration
+ video_duration = int(vframes_pts[-1])
+ else:
+ video_duration = int(vduration)
+
+ video_and_pts = list(zip(vframes, vframes_pts))
+ video_start_pts = int(vframes_pts[0])
+ video_time_base = Fraction(int(vtimebase[0]), int(vtimebase[1]))
+
+ audio_and_pts = None
+ audio_time_base = None
+ audio_start_pts = None
+ audio_duration = None
+ if self._decode_audio:
+ if aduration < 0:
+ # No header information to infer audio duration
+ audio_duration = int(aframe_pts[-1])
+ else:
+ audio_duration = int(aduration)
+
+ audio_and_pts = list(zip(aframes, aframe_pts))
+ audio_start_pts = int(aframe_pts[0])
+ audio_time_base = Fraction(int(atimebase[0]), int(atimebase[1]))
+
+ return (
+ video_and_pts,
+ video_time_base,
+ video_start_pts,
+ video_duration,
+ audio_and_pts,
+ audio_time_base,
+ audio_start_pts,
+ audio_duration,
+ )
diff --git a/code/pytorchvideo/pytorchvideo/data/epic_kitchen/__init__.py b/code/pytorchvideo/pytorchvideo/data/epic_kitchen/__init__.py
new file mode 100644
index 0000000000000000000000000000000000000000..dea20a04a5856581db7978504c48993ab5c6faa5
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/epic_kitchen/__init__.py
@@ -0,0 +1,3 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+from .epic_kitchen_dataset import ActionData, EpicKitchenDataset
diff --git a/code/pytorchvideo/pytorchvideo/data/epic_kitchen/__pycache__/__init__.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/epic_kitchen/__pycache__/__init__.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..8016c6b89ad4061fe3142b06f0e19fec98d091d1
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/epic_kitchen/__pycache__/__init__.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/epic_kitchen/__pycache__/epic_kitchen_dataset.cpython-310.pyc b/code/pytorchvideo/pytorchvideo/data/epic_kitchen/__pycache__/epic_kitchen_dataset.cpython-310.pyc
new file mode 100644
index 0000000000000000000000000000000000000000..be4763158a4691744379c26c19ea07beb4d07940
Binary files /dev/null and b/code/pytorchvideo/pytorchvideo/data/epic_kitchen/__pycache__/epic_kitchen_dataset.cpython-310.pyc differ
diff --git a/code/pytorchvideo/pytorchvideo/data/epic_kitchen/epic_kitchen_dataset.py b/code/pytorchvideo/pytorchvideo/data/epic_kitchen/epic_kitchen_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..6077517b79adee65df6c0ca3d5d20d0f38ddb002
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/epic_kitchen/epic_kitchen_dataset.py
@@ -0,0 +1,205 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import ast
+from dataclasses import dataclass, fields as dataclass_fields
+from typing import Any, Callable, Dict, List, Optional
+
+import torch
+from pytorchvideo.data.dataset_manifest_utils import (
+ EncodedVideoInfo,
+ get_seconds_from_hms_time,
+ VideoClipInfo,
+ VideoDataset,
+ VideoDatasetType,
+ VideoFrameInfo,
+ VideoInfo,
+)
+from pytorchvideo.data.frame_video import FrameVideo
+from pytorchvideo.data.utils import DataclassFieldCaster, load_dataclass_dict_from_csv
+from pytorchvideo.data.video import Video
+
+
+@dataclass
+class ActionData(DataclassFieldCaster):
+ """
+ Class representing an action from the Epic Kitchen dataset.
+ """
+
+ participant_id: str
+ video_id: str
+ narration: str
+ start_timestamp: str
+ stop_timestamp: str
+ start_frame: int
+ stop_frame: int
+ verb: str
+ verb_class: int
+ noun: str
+ noun_class: int
+ all_nouns: list = DataclassFieldCaster.complex_initialized_dataclass_field(
+ ast.literal_eval
+ )
+ all_noun_classes: list = DataclassFieldCaster.complex_initialized_dataclass_field(
+ ast.literal_eval
+ )
+
+ @property
+ def start_time(self) -> float:
+ return get_seconds_from_hms_time(self.start_timestamp)
+
+ @property
+ def stop_time(self) -> float:
+ return get_seconds_from_hms_time(self.stop_timestamp)
+
+
+class EpicKitchenDataset(torch.utils.data.Dataset):
+ """
+ Video dataset for EpicKitchen-55 Dataset
+
+
+ This dataset handles the loading, decoding, and configurable clip
+ sampling for the videos.
+ """
+
+ def __init__(
+ self,
+ video_info_file_path: str,
+ actions_file_path: str,
+ clip_sampler: Callable[
+ [Dict[str, Video], Dict[str, List[ActionData]]], List[VideoClipInfo]
+ ],
+ video_data_manifest_file_path: str,
+ dataset_type: VideoDatasetType = VideoDatasetType.Frame,
+ transform: Optional[Callable[[Dict[str, Any]], Any]] = None,
+ frame_filter: Optional[Callable[[List[int]], List[int]]] = None,
+ multithreaded_io: bool = True,
+ ) -> None:
+ f"""
+ Args:
+ video_info_file_path (str):
+ Path or URI to manifest with basic metadata of each video.
+ File must be a csv (w/header) with columns:
+ {[f.name for f in dataclass_fields(VideoInfo)]}
+
+ actions_file_path (str):
+ Path or URI to manifest with action annotations for each video.
+ File must ber a csv (w/header) with columns:
+ {[f.name for f in dataclass_fields(ActionData)]}
+
+ clip_sampler (Callable[[Dict[str, Video]], List[VideoClipInfo]]):
+ This callable takes as input all available videos and outputs a list of clips to
+ be loaded by the dataset.
+
+ video_data_manifest_file_path (str):
+ The path to a json file outlining the available video data for the
+ associated videos. File must be a csv (w/header) with columns:
+ {[f.name for f in dataclass_fields(VideoFrameInfo)]}
+
+ or
+ {[f.name for f in dataclass_fields(EncodedVideoInfo)]}
+
+ To generate this file from a directory of video frames, see helper
+ functions in Module: pytorchvideo.data.epic_kitchen.utils
+
+ dataset_type (VideoDatasetType): The dataformat in which dataset
+ video data is store (e.g. video frames, encoded video etc).
+
+ transform (Optional[Callable[[Dict[str, Any]], Any]]):
+ This callable is evaluated on the clip output before the clip is returned.
+ It can be used for user-defined preprocessing and augmentations to the clips.
+
+ The clip input is a dictionary with the following format:
+ {{
+ 'video': ,
+ 'audio': ,
+ 'actions': ,
+ 'start_time': ,
+ 'stop_time':
+ }}
+
+ If transform is None, the raw clip output in the above format is
+ returned unmodified.
+
+ frame_filter (Optional[Callable[[List[int]], List[int]]]):
+ This callable is evaluated on the set of available frame inidices to be
+ included in a sampled clip. This can be used to subselect frames within
+ a clip to be loaded.
+
+ multithreaded_io (bool):
+ Boolean to control whether parllelizable io operations are performed across
+ multiple threads.
+
+ """
+
+ torch._C._log_api_usage_once("PYTORCHVIDEO.dataset.EpicKitchenDataset.__init__")
+
+ assert video_info_file_path
+ assert actions_file_path
+ assert video_data_manifest_file_path
+ assert clip_sampler
+
+ # Populate video and metadata data providers
+ self._videos: Dict[str, Video] = VideoDataset._load_videos(
+ video_data_manifest_file_path,
+ video_info_file_path,
+ multithreaded_io,
+ dataset_type,
+ )
+
+ self._actions: Dict[str, List[ActionData]] = load_dataclass_dict_from_csv(
+ actions_file_path, ActionData, "video_id", list_per_key=True
+ )
+ # Sample datapoints
+ self._clips: List[VideoClipInfo] = clip_sampler(self._videos, self._actions)
+
+ self._transform = transform
+ self._frame_filter = frame_filter
+
+ def __getitem__(self, index) -> Dict[str, Any]:
+ """
+ Samples a video clip associated to the given index.
+
+ Args:
+ index (int): index for the video clip.
+
+ Returns:
+ A video clip with the following format if transform is None:
+ {{
+ 'video_id': ,
+ 'video': ,
+ 'audio': ,
+ 'actions': ,
+ 'start_time': ,
+ 'stop_time':
+ }}
+ Otherwise, the transform defines the clip output.
+ """
+ clip = self._clips[index]
+ video = self._videos[clip.video_id]
+
+ if isinstance(video, FrameVideo):
+ clip_dict = video.get_clip(
+ clip.start_time, clip.stop_time, self._frame_filter
+ )
+ else:
+ clip_dict = video.get_clip(clip.start_time, clip.stop_time)
+
+ clip_data = {
+ "video_id": clip.video_id,
+ **clip_dict,
+ "actions": self._actions[clip.video_id],
+ "start_time": clip.start_time,
+ "stop_time": clip.stop_time,
+ }
+
+ if self._transform:
+ clip_data = self._transform(clip_data)
+
+ return clip_data
+
+ def __len__(self) -> int:
+ """
+ Returns:
+ The number of video clips in the dataset.
+ """
+ return len(self._clips)
diff --git a/code/pytorchvideo/pytorchvideo/data/epic_kitchen/utils.py b/code/pytorchvideo/pytorchvideo/data/epic_kitchen/utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..3dedff09199ab7ee3e47f9d434b18c9a0c3eaf9a
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/epic_kitchen/utils.py
@@ -0,0 +1,195 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+from typing import Dict
+
+from iopath.common.file_io import g_pathmgr
+from pytorchvideo.data.dataset_manifest_utils import EncodedVideoInfo, VideoFrameInfo
+from pytorchvideo.data.utils import optional_threaded_foreach
+
+
+def build_frame_manifest_from_flat_directory(
+ data_directory_path: str, multithreaded: bool
+) -> Dict[str, VideoFrameInfo]:
+ """
+ Args:
+ data_directory_path (str): Path or URI to EpicKitchenDataset data.
+ Data at this path must be a folder of structure:
+ {
+ "{video_id}": [
+ "frame_{frame_number}.{file_extension}",
+ "frame_{frame_number}.{file_extension}",
+ "frame_{frame_number}.{file_extension}",
+ ...]
+ ...}
+ multithreaded (bool):
+ controls whether io operations are performed across multiple threads.
+
+ Returns:
+ Dictionary mapping video_id of available videos to the locations of their
+ underlying frame files.
+ """
+
+ video_frames = {}
+ video_ids = g_pathmgr.ls(str(data_directory_path))
+
+ def add_video_frames(video_id: str, video_path: str) -> None:
+ video_frame_file_names = sorted(g_pathmgr.ls(video_path))
+ for frame in video_frame_file_names:
+ file_extension = frame.split(".")[-1]
+ frame_name = frame[: -(len(file_extension) + 1)]
+ stem, path_frame_id = frame_name.split("_")
+ if video_id not in video_frames:
+ video_frames[video_id] = VideoFrameInfo(
+ video_id=video_id,
+ location=video_path,
+ frame_file_stem=f"{stem}_",
+ frame_string_length=len(frame_name),
+ min_frame_number=int(path_frame_id),
+ max_frame_number=int(path_frame_id),
+ file_extension=file_extension,
+ )
+ else:
+ video_frame_info = video_frames[video_id]
+ # Check that this new frame is of the same format as other frames for this video
+ # and that it is the next frame in order, if so update the frame info for this
+ # video to reflect there is an additional frame.
+ # We don't need to check video_id or frame_file_stem as they are function of
+ # video_id which is aligned within the dictionary
+ assert video_frame_info.frame_string_length == len(frame_name)
+ assert video_frame_info.location == video_path, (
+ f"Frames for {video_id} found in two paths: "
+ f"{video_frame_info.location} and {video_path}"
+ )
+ assert video_frame_info.max_frame_number + 1 == int(path_frame_id)
+ assert (
+ video_frame_info.file_extension == file_extension
+ ), f"Frames with two different file extensions found for video {video_id}"
+ video_frames[video_id] = VideoFrameInfo(
+ video_id=video_frame_info.video_id,
+ location=video_frame_info.location,
+ frame_file_stem=video_frame_info.frame_file_stem,
+ frame_string_length=video_frame_info.frame_string_length,
+ min_frame_number=video_frame_info.min_frame_number,
+ max_frame_number=int(path_frame_id), # Update
+ file_extension=video_frame_info.file_extension,
+ )
+
+ video_paths = [
+ (video_id, f"{data_directory_path}/{video_id}") for video_id in video_ids
+ ]
+ # Kick off frame indexing for all participants
+ optional_threaded_foreach(add_video_frames, video_paths, multithreaded)
+
+ return video_frames
+
+
+def build_frame_manifest_from_nested_directory(
+ data_directory_path: str, multithreaded: bool
+) -> Dict[str, VideoFrameInfo]:
+ """
+ Args:
+ data_directory_path (str): Path or URI to EpicKitchenDataset data.
+ If this dataset is to load from the frame-based dataset:
+ Data at this path must be a folder of structure:
+ {
+ "{participant_id}" : [
+ "{participant_id}_{participant_video_id}_{frame_number}.{file_extension}",
+
+ ...],
+ ...}
+
+ multithreaded (bool):
+ controls whether io operations are performed across multiple threads.
+
+ Returns:
+ Dictionary mapping video_id of available videos to the locations of their
+ underlying frame files.
+ """
+
+ participant_ids = g_pathmgr.ls(str(data_directory_path))
+ video_frames = {}
+
+ # Create function to execute in parallel that lists files available for each participant
+ def add_participant_video_frames(
+ participant_id: str, participant_path: str
+ ) -> None:
+ participant_frames = sorted(g_pathmgr.ls(str(participant_path)))
+ for frame_file_name in participant_frames:
+ file_extension = frame_file_name.split(".")[-1]
+ frame_name = frame_file_name[: -(len(file_extension) + 1)]
+ [path_participant_id, path_video_id, path_frame_id] = frame_name.split("_")
+ assert path_participant_id == participant_id
+ video_id = f"{path_participant_id}_{path_video_id}"
+ if (
+ video_id not in video_frames
+ ): # This is the first frame we have seen from video w/ video_id
+ video_frames[video_id] = VideoFrameInfo(
+ video_id=video_id,
+ location=participant_path,
+ frame_file_stem=f"{video_id}_",
+ frame_string_length=len(frame_name),
+ min_frame_number=int(path_frame_id),
+ max_frame_number=int(path_frame_id),
+ file_extension=file_extension,
+ )
+ else:
+ video_frame_info = video_frames[video_id]
+ # Check that this new frame is of the same format as other frames for this video
+ # and that it is the next frame in order, if so update the frame info for this
+ # video to reflect there is an additional frame.
+ # We don't need to check video_id or frame_file_stem as they are function of
+ # video_id which is aligned within the dictionary
+ assert video_frame_info.frame_string_length == len(frame_name)
+ assert video_frame_info.location == participant_path, (
+ f"Frames for {video_id} found in two paths: "
+ f"{video_frame_info.location} and {participant_path}"
+ )
+ assert video_frame_info.max_frame_number + 1 == int(path_frame_id)
+ assert (
+ video_frame_info.file_extension == file_extension
+ ), f"Frames with two different file extensions found for video {video_id}"
+ video_frames[video_id] = VideoFrameInfo(
+ video_id=video_frame_info.video_id,
+ location=video_frame_info.location,
+ frame_file_stem=video_frame_info.frame_file_stem,
+ frame_string_length=video_frame_info.frame_string_length,
+ min_frame_number=video_frame_info.min_frame_number,
+ max_frame_number=int(path_frame_id), # Update
+ file_extension=video_frame_info.file_extension,
+ )
+
+ particpant_paths = [
+ (participant_id, f"{data_directory_path}/{participant_id}")
+ for participant_id in participant_ids
+ ]
+ # Kick off frame indexing for all participants
+ optional_threaded_foreach(
+ add_participant_video_frames, particpant_paths, multithreaded
+ )
+
+ return video_frames
+
+
+def build_encoded_manifest_from_nested_directory(
+ data_directory_path: str,
+) -> Dict[str, EncodedVideoInfo]:
+ """
+ Creates a dictionary from video_id to EncodedVideoInfo for
+ encoded videos in the given directory.
+
+ Args:
+ data_directory_path (str): The folder to ls to find encoded
+ video files.
+
+ Returns:
+ Dict[str, EncodedVideoInfo] mapping video_id to EncodedVideoInfo
+ for each file in 'data_directory_path'
+ """
+ encoded_video_infos = {}
+ for participant_id in g_pathmgr.ls(data_directory_path):
+ participant_folder_path = f"{data_directory_path}/{participant_id}"
+ for video_file_name in g_pathmgr.ls(participant_folder_path):
+ video_id = video_file_name[:6]
+ video_full_path = f"{participant_folder_path}/{video_file_name}"
+ encoded_video_infos[video_id] = EncodedVideoInfo(video_id, video_full_path)
+ return encoded_video_infos
diff --git a/code/pytorchvideo/pytorchvideo/data/epic_kitchen_forecasting.py b/code/pytorchvideo/pytorchvideo/data/epic_kitchen_forecasting.py
new file mode 100644
index 0000000000000000000000000000000000000000..8a6ad5e6d8172aac8977abd5b338b68d83102f20
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/epic_kitchen_forecasting.py
@@ -0,0 +1,295 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+from dataclasses import fields as dataclass_fields
+from enum import Enum
+from typing import Any, Callable, Dict, List, Optional
+
+import torch
+from pytorchvideo.data.dataset_manifest_utils import (
+ EncodedVideoInfo,
+ VideoClipInfo,
+ VideoDatasetType,
+ VideoFrameInfo,
+ VideoInfo,
+)
+from pytorchvideo.data.epic_kitchen import ActionData, EpicKitchenDataset
+from pytorchvideo.data.video import Video
+
+
+class ClipSampling(Enum):
+ Random = 1
+
+
+class EpicKitchenForecasting(EpicKitchenDataset):
+ """
+ Action forecasting video data set for EpicKitchen-55 Dataset.
+
+
+ This dataset handles the loading, decoding, and clip sampling for the videos.
+ """
+
+ def __init__(
+ self,
+ video_info_file_path: str,
+ actions_file_path: str,
+ video_data_manifest_file_path: str,
+ clip_sampling: ClipSampling = ClipSampling.Random,
+ dataset_type: VideoDatasetType = VideoDatasetType.Frame,
+ seconds_per_clip: float = 2.0,
+ clip_time_stride: float = 10.0,
+ num_input_clips: int = 1,
+ frames_per_clip: Optional[int] = None,
+ num_forecast_actions: int = 1,
+ transform: Callable[[Dict[str, Any]], Any] = None,
+ multithreaded_io: bool = True,
+ ):
+ f"""
+ Args:
+ video_info_file_path (str):
+ Path or URI to manifest with basic metadata of each video.
+ File must be a csv (w/header) with columns:
+ {[f.name for f in dataclass_fields(VideoInfo)]}
+
+ actions_file_path (str):
+ Path or URI to manifest with action annotations for each video.
+ File must ber a csv (w/header) with columns:
+ {[f.name for f in dataclass_fields(ActionData)]}
+
+ video_data_manifest_file_path (str):
+ The path to a json file outlining the available video data for the
+ associated videos. File must be a csv (w/header) with columns either:
+
+ For Frame Videos:
+ {[f.name for f in dataclass_fields(VideoFrameInfo)]}
+
+ For Encoded Videos:
+ {[f.name for f in dataclass_fields(EncodedVideoInfo)]}
+
+ To generate this file from a directory of video frames, see helper
+ functions in Module: pytorchvideo.data.epic_kitchen.utils
+
+ clip_sampling (ClipSampling):
+ The type of sampling to perform to perform on the videos of the dataset.
+
+ dataset_type (VideoDatasetType): The dataformat in which dataset
+ video data is store (e.g. video frames, encoded video etc).
+
+ seconds_per_clip (float): The length of each sampled subclip in seconds.
+
+ clip_time_stride (float): The time difference in seconds between the start of
+ each input subclip.
+
+ num_input_clips (int): The number of subclips to be included in the input
+ video data.
+
+ frames_per_clip (Optional[int]): The number of frames per clip to sample.
+ If None, all frames in the clip will be included.
+
+ num_forecast_actions (int): The number of actions to be included in the
+ action vector.
+
+ transform (Callable[[Dict[str, Any]], Any]):
+ This callable is evaluated on the clip output before the clip is returned.
+ It can be used for user-defined preprocessing and augmentations to the clips.
+ The clip input is a dictionary with the following format:
+ {{
+ 'video_id': ,
+ 'video': ,
+ 'audio': ,
+ 'label': ,
+ 'start_time': ,
+ 'stop_time':
+ }}
+
+ If transform is None, the raw clip output in the above format is
+ returned unmodified.
+
+ multithreaded_io (bool):
+ Boolean to control whether parllelizable io operations are performed across
+ multiple threads.
+ """
+ define_clip_structure_fn = (
+ EpicKitchenForecasting._define_clip_structure_generator(
+ clip_sampling,
+ seconds_per_clip,
+ clip_time_stride,
+ num_input_clips,
+ num_forecast_actions,
+ )
+ )
+ frame_filter = (
+ EpicKitchenForecasting._frame_filter_generator(
+ frames_per_clip, seconds_per_clip, clip_time_stride, num_input_clips
+ )
+ if frames_per_clip is not None
+ else None
+ )
+ transform = EpicKitchenForecasting._transform_generator(
+ transform, num_forecast_actions, frames_per_clip, num_input_clips
+ )
+
+ super().__init__(
+ video_info_file_path=video_info_file_path,
+ actions_file_path=actions_file_path,
+ video_data_manifest_file_path=video_data_manifest_file_path,
+ dataset_type=dataset_type,
+ transform=transform,
+ frame_filter=frame_filter,
+ clip_sampler=define_clip_structure_fn,
+ multithreaded_io=multithreaded_io,
+ )
+
+ @staticmethod
+ def _transform_generator(
+ transform: Callable[[Dict[str, Any]], Dict[str, Any]],
+ num_forecast_actions: int,
+ frames_per_clip: int,
+ num_input_clips: int,
+ ) -> Callable[[Dict[str, Any]], Dict[str, Any]]:
+ """
+ Args:
+ transform (Callable[[Dict[str, Any]], Dict[str, Any]]): A function that performs
+ any operation on a clip before it is returned in the default transform function.
+ num_forecast_actions: (int) The number of actions to be included in the
+ action vector.
+ frames_per_clip (int): The number of frames per clip to sample.
+ num_input_clips (int): The number of subclips to be included in the video data.
+
+ Returns:
+ A function that performs any operation on a clip and returns the transformed clip.
+ """
+
+ def transform_clip(clip: Dict[str, Any]) -> Dict[str, Any]:
+ assert all(
+ clip["actions"][i].start_time <= clip["actions"][i + 1].start_time
+ for i in range(len(clip["actions"]) - 1)
+ ), "Actions must be sorted"
+ next_k_actions: List[ActionData] = [
+ a for a in clip["actions"] if (a.start_time > clip["stop_time"])
+ ][:num_forecast_actions]
+ clip["actions"] = next_k_actions
+
+ assert clip["video"].size()[1] == num_input_clips * frames_per_clip
+ clip_video_tensor = torch.stack(
+ [
+ clip["video"][
+ :, (i * frames_per_clip) : ((i + 1) * frames_per_clip), :, :
+ ]
+ for i in range(num_input_clips)
+ ]
+ )
+ clip["video"] = clip_video_tensor
+
+ for key in clip:
+ if clip[key] is None:
+ clip[key] = torch.tensor([])
+
+ if transform:
+ clip = transform(clip)
+
+ return clip
+
+ return transform_clip
+
+ @staticmethod
+ def _frame_filter_generator(
+ frames_per_clip: int,
+ seconds_per_clip: float,
+ clip_time_stride: float,
+ num_input_clips: int,
+ ) -> Callable[[List[int]], List[int]]:
+ """
+ Args:
+ frames_per_clip (int): The number of frames per clip to sample.
+ seconds_per_clip (float): The length of each sampled subclip in seconds.
+ clip_time_stride (float): The time difference in seconds between the start of
+ each input subclip.
+ num_input_clips (int): The number of subclips to be included in the video data.
+
+ Returns:
+ A function that takes in a list of frame indicies and outputs a subsampled list.
+ """
+ time_window_length = seconds_per_clip + (num_input_clips - 1) * clip_time_stride
+ desired_frames_per_second = frames_per_clip / seconds_per_clip
+
+ def frame_filter(frame_indices: List[int]) -> List[int]:
+ num_available_frames_for_all_clips = len(frame_indices)
+ available_frames_per_second = (
+ num_available_frames_for_all_clips / time_window_length
+ )
+ intra_clip_sampling_stride = int(
+ available_frames_per_second // desired_frames_per_second
+ )
+ selected_frames = set()
+ for i in range(num_input_clips):
+ clip_start_index = int(
+ i * clip_time_stride * available_frames_per_second
+ )
+ for j in range(frames_per_clip):
+ selected_frames.add(
+ clip_start_index + j * intra_clip_sampling_stride
+ )
+ return [x for i, x in enumerate(frame_indices) if i in selected_frames]
+
+ return frame_filter
+
+ @staticmethod
+ def _define_clip_structure_generator(
+ clip_sampling: str,
+ seconds_per_clip: float,
+ clip_time_stride: float,
+ num_input_clips: int,
+ num_forecast_actions: int,
+ ) -> Callable[[Dict[str, Video], Dict[str, List[ActionData]]], List[VideoClipInfo]]:
+ """
+ Args:
+ clip_sampling (ClipSampling):
+ The type of sampling to perform to perform on the videos of the dataset.
+ seconds_per_clip (float): The length of each sampled clip in seconds.
+ clip_time_stride: The time difference in seconds between the start of
+ each input subclip.
+ num_input_clips (int): The number of subclips to be included in the video data.
+ num_forecast_actions (int): The number of actions to be included in the
+ action vector.
+
+ Returns:
+ A function that takes a dictionary of videos and outputs a list of sampled
+ clips.
+ """
+ # TODO(T77683480)
+ if not clip_sampling == ClipSampling.Random:
+ raise NotImplementedError(
+ f"Only {ClipSampling.Random} is implemented. "
+ f"{clip_sampling} not implemented."
+ )
+
+ time_window_length = seconds_per_clip + (num_input_clips - 1) * clip_time_stride
+
+ def define_clip_structure(
+ videos: Dict[str, Video], video_actions: Dict[str, List[ActionData]]
+ ) -> List[VideoClipInfo]:
+ candidate_sample_clips = []
+ for video_id, actions in video_actions.items():
+ for i, action in enumerate(actions[: (-1 * num_forecast_actions)]):
+ # Only actions with num_forecast_actions after to predict
+ # Confirm there are >= num_forecast_actions available
+ # (it is possible for actions to overlap)
+ number_valid_actions = 0
+ for j in range(i + 1, len(actions)):
+ if actions[j].start_time > action.stop_time:
+ number_valid_actions += 1
+ if number_valid_actions == num_forecast_actions:
+ if (
+ action.start_time - time_window_length >= 0
+ ): # Only add clips that have the full input video available
+ candidate_sample_clips.append(
+ VideoClipInfo(
+ video_id,
+ action.stop_time - time_window_length,
+ action.stop_time,
+ )
+ )
+ break
+ return candidate_sample_clips
+
+ return define_clip_structure
diff --git a/code/pytorchvideo/pytorchvideo/data/epic_kitchen_recognition.py b/code/pytorchvideo/pytorchvideo/data/epic_kitchen_recognition.py
new file mode 100644
index 0000000000000000000000000000000000000000..8a6f688e1bcef6ededf07d37185038c2e0a71781
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/epic_kitchen_recognition.py
@@ -0,0 +1,212 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import random
+from dataclasses import fields as dataclass_fields
+from enum import Enum
+from typing import Any, Callable, Dict, List, Optional
+
+import torch
+from pytorchvideo.data.dataset_manifest_utils import (
+ EncodedVideoInfo,
+ VideoClipInfo,
+ VideoDatasetType,
+ VideoFrameInfo,
+ VideoInfo,
+)
+from pytorchvideo.data.epic_kitchen import ActionData, EpicKitchenDataset
+from pytorchvideo.data.video import Video
+
+
+class ClipSampling(Enum):
+ RandomOffsetUniform = 1
+
+
+class EpicKitchenRecognition(EpicKitchenDataset):
+ """
+ Action recognition video data set for EpicKitchen-55 Dataset.
+
+
+ This dataset handles the loading, decoding, and clip sampling for the videos.
+ """
+
+ def __init__(
+ self,
+ video_info_file_path: str,
+ actions_file_path: str,
+ video_data_manifest_file_path: str,
+ clip_sampling: ClipSampling = ClipSampling.RandomOffsetUniform,
+ dataset_type: VideoDatasetType = VideoDatasetType.Frame,
+ seconds_per_clip: float = 2.0,
+ frames_per_clip: Optional[int] = None,
+ transform: Callable[[Dict[str, Any]], Any] = None,
+ multithreaded_io: bool = True,
+ ):
+ f"""
+ Args:
+ video_info_file_path (str):
+ Path or URI to manifest with basic metadata of each video.
+ File must be a csv (w/header) with columns:
+ {[f.name for f in dataclass_fields(VideoInfo)]}
+
+ actions_file_path (str):
+ Path or URI to manifest with action annotations for each video.
+ File must ber a csv (w/header) with columns:
+ {[f.name for f in dataclass_fields(ActionData)]}
+
+ video_data_manifest_file_path (str):
+ The path to a json file outlining the available video data for the
+ associated videos. File must be a csv (w/header) with columns either:
+
+ For Frame Videos:
+ {[f.name for f in dataclass_fields(VideoFrameInfo)]}
+
+ For Encoded Videos:
+ {[f.name for f in dataclass_fields(EncodedVideoInfo)]}
+
+ To generate this file from a directory of video frames, see helper
+ functions in Module: pytorchvideo.data.epic_kitchen.utils
+
+ clip_sampling (ClipSampling):
+ The type of sampling to perform to perform on the videos of the dataset.
+
+ dataset_type (VideoDatasetType): The dataformat in which dataset
+ video data is store (e.g. video frames, encoded video etc).
+
+ seconds_per_clip (float): The length of each sampled clip in seconds.
+
+ frames_per_clip (Optional[int]): The number of frames per clip to sample.
+
+ transform (Callable[[Dict[str, Any]], Any]):
+ This callable is evaluated on the clip output before the clip is returned.
+ It can be used for user-defined preprocessing and augmentations to the clips.
+ The clip input is a dictionary with the following format:
+ {{
+ 'video_id': ,
+ 'video': ,
+ 'audio': ,
+ 'label': ,
+ 'start_time': ,
+ 'stop_time':
+ }}
+
+ If transform is None, the raw clip output in the above format is
+ returned unmodified.
+
+ multithreaded_io (bool):
+ Boolean to control whether parllelizable io operations are performed across
+ multiple threads.
+ """
+ define_clip_structure_fn = (
+ EpicKitchenRecognition._define_clip_structure_generator(
+ seconds_per_clip, clip_sampling
+ )
+ )
+ transform = EpicKitchenRecognition._transform_generator(transform)
+ frame_filter = (
+ EpicKitchenRecognition._frame_filter_generator(frames_per_clip)
+ if frames_per_clip is not None
+ else None
+ )
+
+ super().__init__(
+ video_info_file_path=video_info_file_path,
+ actions_file_path=actions_file_path,
+ dataset_type=dataset_type,
+ video_data_manifest_file_path=video_data_manifest_file_path,
+ transform=transform,
+ frame_filter=frame_filter,
+ clip_sampler=define_clip_structure_fn,
+ multithreaded_io=multithreaded_io,
+ )
+
+ @staticmethod
+ def _transform_generator(
+ transform: Callable[[Dict[str, Any]], Dict[str, Any]]
+ ) -> Callable[[Dict[str, Any]], Dict[str, Any]]:
+ """
+ Args:
+ transform (Callable[[Dict[str, Any]], Dict[str, Any]]): A function that performs
+ any operation on a clip before it is returned in the default transform function.
+
+ Returns:
+ A function that performs any operation on a clip and returns the transformed clip.
+ """
+
+ def transform_clip(clip: Dict[str, Any]) -> Dict[str, Any]:
+ actions_in_clip: List[ActionData] = [
+ a
+ for a in clip["actions"]
+ if (
+ a.start_time <= clip["stop_time"]
+ and a.stop_time >= clip["start_time"]
+ )
+ ]
+ clip["actions"] = actions_in_clip
+
+ for key in clip:
+ if clip[key] is None:
+ clip[key] = torch.tensor([])
+
+ if transform:
+ clip = transform(clip)
+
+ return clip
+
+ return transform_clip
+
+ @staticmethod
+ def _frame_filter_generator(
+ frames_per_clip: int,
+ ) -> Callable[[List[int]], List[int]]:
+ """
+ Args:
+ frames_per_clip (int): The number of frames per clip to sample.
+
+ Returns:
+ A function that takes in a list of frame indicies and outputs a subsampled list.
+ """
+
+ def frame_filer(frame_indices: List[int]) -> List[int]:
+ num_frames = len(frame_indices)
+ frame_step = int(num_frames // frames_per_clip)
+ selected_frames = set(range(0, num_frames, frame_step))
+ return [x for i, x in enumerate(frame_indices) if i in selected_frames]
+
+ return frame_filer
+
+ @staticmethod
+ def _define_clip_structure_generator(
+ seconds_per_clip: float, clip_sampling: ClipSampling
+ ) -> Callable[[Dict[str, Video], Dict[str, List[ActionData]]], List[VideoClipInfo]]:
+ """
+ Args:
+ seconds_per_clip (float): The length of each sampled clip in seconds.
+ clip_sampling (ClipSampling):
+ The type of sampling to perform to perform on the videos of the dataset.
+
+ Returns:
+ A function that takes a dictionary of videos and a dictionary of the actions
+ for each video and outputs a list of sampled clips.
+ """
+ if not clip_sampling == ClipSampling.RandomOffsetUniform:
+ raise NotImplementedError(
+ f"Only {ClipSampling.RandomOffsetUniform} is implemented. "
+ f"{clip_sampling} not implemented."
+ )
+
+ def define_clip_structure(
+ videos: Dict[str, Video], actions: Dict[str, List[ActionData]]
+ ) -> List[VideoClipInfo]:
+ clips = []
+ for video_id, video in videos.items():
+ offset = random.random() * seconds_per_clip
+ num_clips = int((video.duration - offset) // seconds_per_clip)
+
+ for i in range(num_clips):
+ start_time = i * seconds_per_clip + offset
+ stop_time = start_time + seconds_per_clip
+ clip = VideoClipInfo(video_id, start_time, stop_time)
+ clips.append(clip)
+ return clips
+
+ return define_clip_structure
diff --git a/code/pytorchvideo/pytorchvideo/data/frame_video.py b/code/pytorchvideo/pytorchvideo/data/frame_video.py
new file mode 100644
index 0000000000000000000000000000000000000000..d3aacf2f293e5cc138027979aa2d31340c5d6fe1
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/frame_video.py
@@ -0,0 +1,258 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+from __future__ import annotations
+
+import logging
+import math
+import os
+import re
+import time
+from typing import Callable, Dict, List, Optional
+
+import numpy as np
+import torch
+import torch.utils.data
+from iopath.common.file_io import g_pathmgr
+from pytorchvideo.data.utils import optional_threaded_foreach
+
+from .utils import thwc_to_cthw
+from .video import Video
+
+
+try:
+ import cv2
+except ImportError:
+ _HAS_CV2 = False
+else:
+ _HAS_CV2 = True
+
+
+logger = logging.getLogger(__name__)
+
+
+class FrameVideo(Video):
+ """
+ FrameVideo is an abstractions for accessing clips based on their start and end
+ time for a video where each frame is stored as an image. PathManager is used for
+ frame image reading, allowing non-local uri's to be used.
+ """
+
+ def __init__(
+ self,
+ duration: float,
+ fps: float,
+ video_frame_to_path_fn: Callable[[int], str] = None,
+ video_frame_paths: List[str] = None,
+ multithreaded_io: bool = False,
+ ) -> None:
+ """
+ Args:
+ duration (float): the duration of the video in seconds.
+ fps (float): the target fps for the video. This is needed to link the frames
+ to a second timestamp in the video.
+ video_frame_to_path_fn (Callable[[int], str]): a function that maps from a frame
+ index integer to the file path where the frame is located.
+ video_frame_paths (List[str]): Dictionary of frame paths for each index of a video.
+ multithreaded_io (bool): controls whether parllelizable io operations are
+ performed across multiple threads.
+ """
+ if not _HAS_CV2:
+ raise ImportError(
+ "opencv2 is required to use FrameVideo. Please "
+ "install with 'pip install opencv-python'"
+ )
+
+ self._duration = duration
+ self._fps = fps
+ self._multithreaded_io = multithreaded_io
+
+ assert (video_frame_to_path_fn is None) != (
+ video_frame_paths is None
+ ), "Only one of video_frame_to_path_fn or video_frame_paths can be provided"
+ self._video_frame_to_path_fn = video_frame_to_path_fn
+ self._video_frame_paths = video_frame_paths
+
+ # Set the pathname to the parent directory of the first frame.
+ self._name = os.path.basename(
+ os.path.dirname(self._video_frame_to_path(frame_index=0))
+ )
+
+ @classmethod
+ def from_directory(
+ cls,
+ path: str,
+ fps: float = 30.0,
+ multithreaded_io=False,
+ path_order_cache: Optional[Dict[str, List[str]]] = None,
+ ):
+ """
+ Args:
+ path (str): path to frame video directory.
+ fps (float): the target fps for the video. This is needed to link the frames
+ to a second timestamp in the video.
+ multithreaded_io (bool): controls whether parllelizable io operations are
+ performed across multiple threads.
+ path_order_cache (dict): An optional mapping from directory-path to list
+ of frames in the directory in numerical order. Used for speedup by
+ caching the frame paths.
+ """
+ if path_order_cache is not None and path in path_order_cache:
+ return cls.from_frame_paths(path_order_cache[path], fps, multithreaded_io)
+
+ assert g_pathmgr.isdir(path), f"{path} is not a directory"
+ rel_frame_paths = g_pathmgr.ls(path)
+
+ def natural_keys(text):
+ return [int(c) if c.isdigit() else c for c in re.split("(\d+)", text)]
+
+ rel_frame_paths.sort(key=natural_keys)
+ frame_paths = [os.path.join(path, f) for f in rel_frame_paths]
+ if path_order_cache is not None:
+ path_order_cache[path] = frame_paths
+ return cls.from_frame_paths(frame_paths, fps, multithreaded_io)
+
+ @classmethod
+ def from_frame_paths(
+ cls,
+ video_frame_paths: List[str],
+ fps: float = 30.0,
+ multithreaded_io: bool = False,
+ ):
+ """
+ Args:
+ video_frame_paths (List[str]): a list of paths to each frames in the video.
+ fps (float): the target fps for the video. This is needed to link the frames
+ to a second timestamp in the video.
+ multithreaded_io (bool): controls whether parllelizable io operations are
+ performed across multiple threads.
+ """
+ assert len(video_frame_paths) != 0, "video_frame_paths is empty"
+ return cls(
+ len(video_frame_paths) / fps,
+ fps,
+ video_frame_paths=video_frame_paths,
+ multithreaded_io=multithreaded_io,
+ )
+
+ @property
+ def name(self) -> float:
+ return self._name
+
+ @property
+ def duration(self) -> float:
+ """
+ Returns:
+ duration: the video's duration/end-time in seconds.
+ """
+ return self._duration
+
+ def _get_frame_index_for_time(self, time_sec: float) -> int:
+ return math.ceil(self._fps * time_sec)
+
+ def get_clip(
+ self,
+ start_sec: float,
+ end_sec: float,
+ frame_filter: Optional[Callable[[List[int]], List[int]]] = None,
+ ) -> Dict[str, Optional[torch.Tensor]]:
+ """
+ Retrieves frames from the stored video at the specified start and end times
+ in seconds (the video always starts at 0 seconds). Returned frames will be
+ in [start_sec, end_sec). Given that PathManager may
+ be fetching the frames from network storage, to handle transient errors, frame
+ reading is retried N times. Note that as end_sec is exclusive, so you may need
+ to use `get_clip(start_sec, duration + EPS)` to get the last frame.
+
+ Args:
+ start_sec (float): the clip start time in seconds
+ end_sec (float): the clip end time in seconds
+ frame_filter (Optional[Callable[List[int], List[int]]]):
+ function to subsample frames in a clip before loading.
+ If None, no subsampling is peformed.
+ Returns:
+ clip_frames: A tensor of the clip's RGB frames with shape:
+ (channel, time, height, width). The frames are of type torch.float32 and
+ in the range [0 - 255]. Raises an exception if unable to load images.
+
+ clip_data:
+ "video": A tensor of the clip's RGB frames with shape:
+ (channel, time, height, width). The frames are of type torch.float32 and
+ in the range [0 - 255]. Raises an exception if unable to load images.
+
+ "frame_indices": A list of indices for each frame relative to all frames in the
+ video.
+
+ Returns None if no frames are found.
+ """
+ if start_sec < 0 or start_sec > self._duration:
+ logger.warning(
+ f"No frames found within {start_sec} and {end_sec} seconds. Video starts"
+ f"at time 0 and ends at {self._duration}."
+ )
+ return None
+
+ end_sec = min(end_sec, self._duration)
+
+ start_frame_index = self._get_frame_index_for_time(start_sec)
+ end_frame_index = min(
+ self._get_frame_index_for_time(end_sec), len(self._video_frame_paths)
+ )
+ frame_indices = list(range(start_frame_index, end_frame_index))
+ # Frame filter function to allow for subsampling before loading
+ if frame_filter:
+ frame_indices = frame_filter(frame_indices)
+
+ clip_paths = [self._video_frame_to_path(i) for i in frame_indices]
+ clip_frames = _load_images_with_retries(
+ clip_paths, multithreaded=self._multithreaded_io
+ )
+ clip_frames = thwc_to_cthw(clip_frames).to(torch.float32)
+ return {"video": clip_frames, "frame_indices": frame_indices, "audio": None}
+
+ def _video_frame_to_path(self, frame_index: int) -> str:
+ if self._video_frame_to_path_fn:
+ return self._video_frame_to_path_fn(frame_index)
+ elif self._video_frame_paths:
+ return self._video_frame_paths[frame_index]
+ else:
+ raise Exception(
+ "One of _video_frame_to_path_fn or _video_frame_paths must be set"
+ )
+
+
+def _load_images_with_retries(
+ image_paths: List[str], num_retries: int = 10, multithreaded: bool = True
+) -> torch.Tensor:
+ """
+ Loads the given image paths using PathManager, decodes them as RGB images and
+ returns them as a stacked tensors.
+ Args:
+ image_paths (List[str]): a list of paths to images.
+ num_retries (int): number of times to retry image reading to handle transient error.
+ multithreaded (bool): if images are fetched via multiple threads in parallel.
+ Returns:
+ A tensor of the clip's RGB frames with shape:
+ (time, height, width, channel). The frames are of type torch.uint8 and
+ in the range [0 - 255]. Raises an exception if unable to load images.
+ """
+ imgs = [None for i in image_paths]
+
+ def fetch_image(image_index: int, image_path: str) -> None:
+ for i in range(num_retries):
+ with g_pathmgr.open(image_path, "rb") as f:
+ img_str = np.frombuffer(f.read(), np.uint8)
+ img_bgr = cv2.imdecode(img_str, flags=cv2.IMREAD_COLOR)
+ img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
+ if img_rgb is not None:
+ imgs[image_index] = img_rgb
+ return
+ else:
+ logging.warning(f"Reading attempt {i}/{num_retries} failed.")
+ time.sleep(1e-6)
+
+ optional_threaded_foreach(fetch_image, enumerate(image_paths), multithreaded)
+
+ if any((img is None for img in imgs)):
+ raise Exception("Failed to load images from {}".format(image_paths))
+
+ return torch.as_tensor(np.stack(imgs))
diff --git a/code/pytorchvideo/pytorchvideo/data/hmdb51.py b/code/pytorchvideo/pytorchvideo/data/hmdb51.py
new file mode 100644
index 0000000000000000000000000000000000000000..eb87eb3b6d95986138ac298437923c411f1360dd
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/hmdb51.py
@@ -0,0 +1,231 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+from __future__ import annotations
+
+import logging
+import os
+import pathlib
+from typing import Any, Callable, List, Optional, Tuple, Type, Union
+
+import torch
+import torch.utils.data
+from iopath.common.file_io import g_pathmgr
+
+from .clip_sampling import ClipSampler
+from .labeled_video_dataset import LabeledVideoDataset
+
+
+logger = logging.getLogger(__name__)
+
+
+class Hmdb51LabeledVideoPaths:
+ """
+ Pre-processor for Hmbd51 dataset mentioned here -
+ https://serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database/
+
+ This dataset consists of classwise folds with each class consisting of 3
+ folds (splits).
+
+ The videos directory is of the format,
+ video_dir_path/class_x/.avi
+ ...
+ video_dir_path/class_y/.avi
+
+ The splits/fold directory is of the format,
+ folds_dir_path/class_x_test_split_1.txt
+ folds_dir_path/class_x_test_split_2.txt
+ folds_dir_path/class_x_test_split_3.txt
+ ...
+ folds_dir_path/class_y_test_split_1.txt
+ folds_dir_path/class_y_test_split_2.txt
+ folds_dir_path/class_y_test_split_3.txt
+
+ And each text file in the splits directory class_x_test_split_<1 or 2 or 3>.txt
+ <0 or 1 or 2>
+ where 0,1,2 corresponds to unused, train split respectively.
+
+ Each video has name of format
+ ______.avi
+ For more details on tags -
+ https://serre-lab.clps.brown.edu/resource/hmdb-a-large-human-motion-database/
+ """
+
+ _allowed_splits = [1, 2, 3]
+ _split_type_dict = {"train": 1, "test": 2, "unused": 0}
+
+ @classmethod
+ def from_dir(
+ cls, data_path: str, split_id: int = 1, split_type: str = "train"
+ ) -> Hmdb51LabeledVideoPaths:
+ """
+ Factory function that creates Hmdb51LabeledVideoPaths object form a splits/folds
+ directory.
+
+ Args:
+ data_path (str): The path to the splits/folds directory of HMDB51.
+ split_id (int): Fold id to be loaded. Belongs to [1,2,3]
+ split_type (str): Split/Fold type to be loaded. It belongs to one of the
+ following,
+ - "train"
+ - "test"
+ - "unused" (This is a small set of videos that are neither
+ of part of test or train fold.)
+ """
+ data_path = pathlib.Path(data_path)
+ if not data_path.is_dir():
+ return RuntimeError(f"{data_path} not found or is not a directory.")
+ if not int(split_id) in cls._allowed_splits:
+ return RuntimeError(
+ f"{split_id} not found in allowed split id's {cls._allowed_splits}."
+ )
+ file_name_format = "_test_split" + str(int(split_id))
+ file_paths = sorted(
+ (
+ f
+ for f in data_path.iterdir()
+ if f.is_file() and f.suffix == ".txt" and file_name_format in f.stem
+ )
+ )
+ return cls.from_csvs(file_paths, split_type)
+
+ @classmethod
+ def from_csvs(
+ cls, file_paths: List[Union[pathlib.Path, str]], split_type: str = "train"
+ ) -> Hmdb51LabeledVideoPaths:
+ """
+ Factory function that creates Hmdb51LabeledVideoPaths object form a list of
+ split files of .txt type
+
+ Args:
+ file_paths (List[Union[pathlib.Path, str]]) : The path to the splits/folds
+ directory of HMDB51.
+ split_type (str): Split/Fold type to be loaded.
+ - "train"
+ - "test"
+ - "unused"
+ """
+ video_paths_and_label = []
+ for file_path in file_paths:
+ file_path = pathlib.Path(file_path)
+ assert g_pathmgr.exists(file_path), f"{file_path} not found."
+ if not (file_path.suffix == ".txt" and "_test_split" in file_path.stem):
+ return RuntimeError(f"Ivalid file: {file_path}")
+
+ action_name = "_"
+ action_name = action_name.join((file_path.stem).split("_")[:-2])
+ with g_pathmgr.open(file_path, "r") as f:
+ for path_label in f.read().splitlines():
+ line_split = path_label.rsplit(None, 1)
+
+ if not int(line_split[1]) == cls._split_type_dict[split_type]:
+ continue
+
+ file_path = os.path.join(action_name, line_split[0])
+ meta_tags = line_split[0].split("_")[-6:-1]
+ video_paths_and_label.append(
+ (file_path, {"label": action_name, "meta_tags": meta_tags})
+ )
+
+ assert (
+ len(video_paths_and_label) > 0
+ ), f"Failed to load dataset from {file_path}."
+ return cls(video_paths_and_label)
+
+ def __init__(
+ self, paths_and_labels: List[Tuple[str, Optional[dict]]], path_prefix=""
+ ) -> None:
+ """
+ Args:
+ paths_and_labels [(str, int)]: a list of tuples containing the video
+ path and integer label.
+ """
+ self._paths_and_labels = paths_and_labels
+ self._path_prefix = path_prefix
+
+ def path_prefix(self, prefix):
+ self._path_prefix = prefix
+
+ path_prefix = property(None, path_prefix)
+
+ def __getitem__(self, index: int) -> Tuple[str, dict]:
+ """
+ Args:
+ index (int): the path and label index.
+
+ Returns:
+ The path and label tuple for the given index.
+ """
+ path, label = self._paths_and_labels[index]
+ return (os.path.join(self._path_prefix, path), label)
+
+ def __len__(self) -> int:
+ """
+ Returns:
+ The number of video paths and label pairs.
+ """
+ return len(self._paths_and_labels)
+
+
+def Hmdb51(
+ data_path: pathlib.Path,
+ clip_sampler: ClipSampler,
+ video_sampler: Type[torch.utils.data.Sampler] = torch.utils.data.RandomSampler,
+ transform: Optional[Callable[[dict], Any]] = None,
+ video_path_prefix: str = "",
+ split_id: int = 1,
+ split_type: str = "train",
+ decode_audio=True,
+ decoder: str = "pyav",
+) -> LabeledVideoDataset:
+ """
+ A helper function to create ``LabeledVideoDataset`` object for HMDB51 dataset
+
+ Args:
+ data_path (pathlib.Path): Path to the data. The path type defines how the data
+ should be read:
+
+ * For a file path, the file is read and each line is parsed into a
+ video path and label.
+ * For a directory, the directory structure defines the classes
+ (i.e. each subdirectory is a class).
+
+ clip_sampler (ClipSampler): Defines how clips should be sampled from each
+ video. See the clip sampling documentation for more information.
+
+ video_sampler (Type[torch.utils.data.Sampler]): Sampler for the internal
+ video container. This defines the order videos are decoded and,
+ if necessary, the distributed split.
+
+ transform (Callable): This callable is evaluated on the clip output before
+ the clip is returned. It can be used for user defined preprocessing and
+ augmentations to the clips. See the ``LabeledVideoDataset`` class for
+ clip output format.
+
+ video_path_prefix (str): Path to root directory with the videos that are
+ loaded in LabeledVideoDataset. All the video paths before loading
+ are prefixed with this path.
+
+ split_id (int): Fold id to be loaded. Options are 1, 2 or 3
+
+ split_type (str): Split/Fold type to be loaded. Options are ("train", "test" or
+ "unused")
+
+ decoder (str): Defines which backend should be used to decode videos.
+ """
+
+ torch._C._log_api_usage_once("PYTORCHVIDEO.dataset.Hmdb51")
+
+ labeled_video_paths = Hmdb51LabeledVideoPaths.from_dir(
+ data_path, split_id=split_id, split_type=split_type
+ )
+ labeled_video_paths.path_prefix = video_path_prefix
+ dataset = LabeledVideoDataset(
+ labeled_video_paths,
+ clip_sampler,
+ video_sampler,
+ transform,
+ decode_audio=decode_audio,
+ decoder=decoder,
+ )
+
+ return dataset
diff --git a/code/pytorchvideo/pytorchvideo/data/json_dataset.py b/code/pytorchvideo/pytorchvideo/data/json_dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..c86c1b51a0edaa6c8199b650dc27d40c7bae08a8
--- /dev/null
+++ b/code/pytorchvideo/pytorchvideo/data/json_dataset.py
@@ -0,0 +1,254 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import json
+import logging
+import os
+from typing import Any, Callable, Dict, Optional, Type
+
+import torch
+from iopath.common.file_io import g_pathmgr
+from pytorchvideo.data.clip_sampling import ClipInfo, ClipSampler
+from pytorchvideo.data.labeled_video_dataset import LabeledVideoDataset
+
+
+logger = logging.getLogger(__name__)
+
+
+def video_only_dataset(
+ data_path: str,
+ clip_sampler: ClipSampler,
+ video_sampler: Type[torch.utils.data.Sampler] = torch.utils.data.RandomSampler,
+ transform: Optional[Callable[[Dict[str, Any]], Dict[str, Any]]] = None,
+ video_path_prefix: str = "",
+ decode_audio: bool = True,
+ decoder: str = "pyav",
+):
+ """
+ Builds a LabeledVideoDataset with no annotations from a json file with the following
+ format:
+
+ .. code-block:: text
+
+ {
+ "video_name1": {...}
+ "video_name2": {...}
+ ....
+ "video_nameN": {...}
+ }
+
+ Args:
+ labeled_video_paths (List[Tuple[str, Optional[dict]]]): List containing
+ video file paths and associated labels. If video paths are a folder
+ it's interpreted as a frame video, otherwise it must be an encoded
+ video.
+
+ clip_sampler (ClipSampler): Defines how clips should be sampled from each
+ video. See the clip sampling documentation for more information.
+
+ video_sampler (Type[torch.utils.data.Sampler]): Sampler for the internal
+ video container. This defines the order videos are decoded and,
+ if necessary, the distributed split.
+
+ transform (Callable): This callable is evaluated on the clip output before
+ the clip is returned. It can be used for user defined preprocessing and
+ augmentations on the clips. The clip output format is described in __next__().
+
+ decode_audio (bool): If True, also decode audio from video.
+
+ decoder (str): Defines what type of decoder used to decode a video. Not used for
+ frame videos.
+ """
+
+ torch._C._log_api_usage_once("PYTORCHVIDEO.dataset.json_dataset.video_only_dataset")
+
+ if g_pathmgr.isfile(data_path):
+ try:
+ with g_pathmgr.open(data_path, "r") as f:
+ annotations = json.load(f)
+ except Exception:
+ raise FileNotFoundError(f"{data_path} must be json for Ego4D dataset")
+
+ # LabeledVideoDataset requires the data to be list of tuples with format:
+ # (video_paths, annotation_dict), for no annotations we just pass in an empty dict.
+ video_paths = [
+ (os.path.join(video_path_prefix, x), {}) for x in annotations.keys()
+ ]
+ else:
+ raise FileNotFoundError(f"{data_path} not found.")
+
+ dataset = LabeledVideoDataset(
+ video_paths,
+ clip_sampler,
+ video_sampler,
+ transform,
+ decode_audio=decode_audio,
+ decoder=decoder,
+ )
+ return dataset
+
+
+def clip_recognition_dataset(
+ data_path: str,
+ clip_sampler: ClipSampler,
+ video_sampler: Type[torch.utils.data.Sampler] = torch.utils.data.RandomSampler,
+ transform: Optional[Callable[[Dict[str, Any]], Dict[str, Any]]] = None,
+ video_path_prefix: str = "",
+ decode_audio: bool = True,
+ decoder: str = "pyav",
+):
+ """
+ Builds a LabeledVideoDataset with noun, verb annotations from a json file with the following
+ format:
+
+ .. code-block:: text
+
+ {
+ "video_name1": {
+ {
+ "benchmarks": {
+ "forecasting_hands_objects": [
+ {
+ "critical_frame_selection_parent_start_sec":
+ "critical_frame_selection_parent_end_sec":
+ {
+ "taxonomy: {
+ "noun":
 +
+ +
+ +
+ +
+



 |
|  +|:-------------------------------:|:--------------------------------------------------:|
+| A PyTorchVideo-accelerated X3D model running on a Samsung Galaxy S10 phone. The model runs ~8x faster than real time, requiring roughly 130 ms to process one second of video.| A PyTorchVideo-based SlowFast model performing video action detection.|
+
+## X3D model Web Demo
+Integrated to [Huggingface Spaces](https://huggingface.co/spaces) with [Gradio](https://github.com/gradio-app/gradio). See demo: [](https://huggingface.co/spaces/pytorch/X3D)
+
+## Introduction
+
+PyTorchVideo is a deeplearning library with a focus on video understanding work. PytorchVideo provides reusable, modular and efficient components needed to accelerate the video understanding research. PyTorchVideo is developed using [PyTorch](https://pytorch.org) and supports different deeplearning video components like video models, video datasets, and video-specific transforms.
+
+Key features include:
+
+- **Based on PyTorch:** Built using PyTorch. Makes it easy to use all of the PyTorch-ecosystem components.
+- **Reproducible Model Zoo:** Variety of state of the art pretrained video models and their associated benchmarks that are ready to use.
+ Complementing the model zoo, PyTorchVideo comes with extensive data loaders supporting different datasets.
+- **Efficient Video Components:** Video-focused fast and efficient components that are easy to use. Supports accelerated inference on hardware.
+
+## Updates
+
+- Aug 2021: [Multiscale Vision Transformers](https://arxiv.org/abs/2104.11227) has been released in PyTorchVideo, details can be found from [here](https://github.com/facebookresearch/pytorchvideo/blob/main/pytorchvideo/models/vision_transformers.py#L97).
+
+## Installation
+
+Install PyTorchVideo inside a conda environment(Python >=3.7) with
+```shell
+pip install pytorchvideo
+```
+
+For detailed instructions please refer to [INSTALL.md](INSTALL.md).
+
+## License
+
+PyTorchVideo is released under the [Apache 2.0 License](LICENSE).
+
+## Tutorials
+
+Get started with PyTorchVideo by trying out one of our [tutorials](https://pytorchvideo.org/docs/tutorial_overview) or by running examples in the [tutorials folder](./tutorials).
+
+
+## Model Zoo and Baselines
+We provide a large set of baseline results and trained models available for download in the [PyTorchVideo Model Zoo](https://github.com/facebookresearch/pytorchvideo/blob/main/docs/source/model_zoo.md).
+
+## Contributors
+
+Here is the growing list of PyTorchVideo contributors in alphabetical order (let us know if you would like to be added):
+[Aaron Adcock](https://www.linkedin.com/in/aaron-adcock-79855383/), [Amy Bearman](https://www.linkedin.com/in/amy-bearman/), [Bernard Nguyen](https://www.linkedin.com/in/mrbernardnguyen/), [Bo Xiong](https://www.cs.utexas.edu/~bxiong/), [Chengyuan Yan](https://www.linkedin.com/in/chengyuan-yan-4a804282/), [Christoph Feichtenhofer](https://feichtenhofer.github.io/), [Dave Schnizlein](https://www.linkedin.com/in/david-schnizlein-96020136/), [Haoqi Fan](https://haoqifan.github.io/), [Heng Wang](https://hengcv.github.io/), [Jackson Hamburger](https://www.linkedin.com/in/jackson-hamburger-986a2873/), [Jitendra Malik](http://people.eecs.berkeley.edu/~malik/), [Kalyan Vasudev Alwala](https://www.linkedin.com/in/kalyan-vasudev-alwala-2a802b64/), [Matt Feiszli](https://www.linkedin.com/in/matt-feiszli-76b34b/), [Nikhila Ravi](https://www.linkedin.com/in/nikhilaravi/), [Ross Girshick](https://www.rossgirshick.info/), [Tullie Murrell](https://www.linkedin.com/in/tullie/), [Wan-Yen Lo](https://www.linkedin.com/in/wanyenlo/), [Weiyao Wang](https://www.linkedin.com/in/weiyaowang/?locale=en_US), [Xiaowen Lin](https://www.linkedin.com/in/xiaowen-lin-90542b34/), [Yanghao Li](https://lyttonhao.github.io/), [Yilei Li](https://liyilui.github.io/personal_page/), [Zhengxing Chen](http://czxttkl.github.io/), [Zhicheng Yan](https://www.linkedin.com/in/zhichengyan/).
+
+
+## Development
+
+We welcome new contributions to PyTorchVideo and we will be actively maintaining this library! Please refer to [`CONTRIBUTING.md`](./.github/CONTRIBUTING.md) for full instructions on how to run the code, tests and linter, and submit your pull requests.
+
+## Citing PyTorchVideo
+
+If you find PyTorchVideo useful in your work, please use the following BibTeX entry for citation.
+```BibTeX
+@inproceedings{fan2021pytorchvideo,
+ author = {Haoqi Fan and Tullie Murrell and Heng Wang and Kalyan Vasudev Alwala and Yanghao Li and Yilei Li and Bo Xiong and Nikhila Ravi and Meng Li and Haichuan Yang and Jitendra Malik and Ross Girshick and Matt Feiszli and Aaron Adcock and Wan-Yen Lo and Christoph Feichtenhofer},
+ title = {{PyTorchVideo}: A Deep Learning Library for Video Understanding},
+ booktitle = {Proceedings of the 29th ACM International Conference on Multimedia},
+ year = {2021},
+ note = {\url{https://pytorchvideo.org/}},
+}
+```
diff --git a/code/pytorchvideo/dev/README.md b/code/pytorchvideo/dev/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..027eeae3b5b36caf44af720219d2f090c3c16875
--- /dev/null
+++ b/code/pytorchvideo/dev/README.md
@@ -0,0 +1,11 @@
+## Running Linter
+
+
+Before running the linter, please ensure that you installed the necessary additional linter dependencies.
+If not installed, check the [install-README](https://github.com/facebookresearch/pytorchvideo/blob/main/INSTALL.md) on how to do it.
+
+Post that, you can run the linter from the project root using,
+
+```
+./dev/linter.sh
+```
diff --git a/code/pytorchvideo/dev/linter.sh b/code/pytorchvideo/dev/linter.sh
new file mode 100644
index 0000000000000000000000000000000000000000..eafbac0981be67410c21758eb8af8f72cf1214c5
--- /dev/null
+++ b/code/pytorchvideo/dev/linter.sh
@@ -0,0 +1,25 @@
+#!/bin/bash -ev
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+
+# Run this script at project root with "./dev/linter.sh" before you commit.
+
+echo "Running autoflake..."
+python -m autoflake --remove-all-unused-imports -i .
+
+echo "Running isort..."
+isort -y -sp .
+
+echo "Running black..."
+black .
+
+echo "Running flake8..."
+if [ -x "$(command -v flake8)" ]; then
+ flake8 .
+else
+ python3 -m flake8 .
+fi
+
+command -v arc > /dev/null && {
+ echo "Running arc lint ..."
+ arc lint
+}
diff --git a/code/pytorchvideo/docs/Makefile b/code/pytorchvideo/docs/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..d0c3cbf1020d5c292abdedf27627c6abe25e2293
--- /dev/null
+++ b/code/pytorchvideo/docs/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = source
+BUILDDIR = build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/code/pytorchvideo/docs/README.md b/code/pytorchvideo/docs/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..2fb037e2d83ef4e8e54414d44f4c448b4551bf0e
--- /dev/null
+++ b/code/pytorchvideo/docs/README.md
@@ -0,0 +1,65 @@
+
+## Setup
+
+### Install dependencies
+
+```
+pip install -U recommonmark mock sphinx sphinx_rtd_theme sphinx_markdown_tables
+```
+
+### Add symlink to the root README.md
+
+We want to include the root readme as an overview. Before generating the docs create a symlink to the root readme.
+
+```
+cd
+|:-------------------------------:|:--------------------------------------------------:|
+| A PyTorchVideo-accelerated X3D model running on a Samsung Galaxy S10 phone. The model runs ~8x faster than real time, requiring roughly 130 ms to process one second of video.| A PyTorchVideo-based SlowFast model performing video action detection.|
+
+## X3D model Web Demo
+Integrated to [Huggingface Spaces](https://huggingface.co/spaces) with [Gradio](https://github.com/gradio-app/gradio). See demo: [](https://huggingface.co/spaces/pytorch/X3D)
+
+## Introduction
+
+PyTorchVideo is a deeplearning library with a focus on video understanding work. PytorchVideo provides reusable, modular and efficient components needed to accelerate the video understanding research. PyTorchVideo is developed using [PyTorch](https://pytorch.org) and supports different deeplearning video components like video models, video datasets, and video-specific transforms.
+
+Key features include:
+
+- **Based on PyTorch:** Built using PyTorch. Makes it easy to use all of the PyTorch-ecosystem components.
+- **Reproducible Model Zoo:** Variety of state of the art pretrained video models and their associated benchmarks that are ready to use.
+ Complementing the model zoo, PyTorchVideo comes with extensive data loaders supporting different datasets.
+- **Efficient Video Components:** Video-focused fast and efficient components that are easy to use. Supports accelerated inference on hardware.
+
+## Updates
+
+- Aug 2021: [Multiscale Vision Transformers](https://arxiv.org/abs/2104.11227) has been released in PyTorchVideo, details can be found from [here](https://github.com/facebookresearch/pytorchvideo/blob/main/pytorchvideo/models/vision_transformers.py#L97).
+
+## Installation
+
+Install PyTorchVideo inside a conda environment(Python >=3.7) with
+```shell
+pip install pytorchvideo
+```
+
+For detailed instructions please refer to [INSTALL.md](INSTALL.md).
+
+## License
+
+PyTorchVideo is released under the [Apache 2.0 License](LICENSE).
+
+## Tutorials
+
+Get started with PyTorchVideo by trying out one of our [tutorials](https://pytorchvideo.org/docs/tutorial_overview) or by running examples in the [tutorials folder](./tutorials).
+
+
+## Model Zoo and Baselines
+We provide a large set of baseline results and trained models available for download in the [PyTorchVideo Model Zoo](https://github.com/facebookresearch/pytorchvideo/blob/main/docs/source/model_zoo.md).
+
+## Contributors
+
+Here is the growing list of PyTorchVideo contributors in alphabetical order (let us know if you would like to be added):
+[Aaron Adcock](https://www.linkedin.com/in/aaron-adcock-79855383/), [Amy Bearman](https://www.linkedin.com/in/amy-bearman/), [Bernard Nguyen](https://www.linkedin.com/in/mrbernardnguyen/), [Bo Xiong](https://www.cs.utexas.edu/~bxiong/), [Chengyuan Yan](https://www.linkedin.com/in/chengyuan-yan-4a804282/), [Christoph Feichtenhofer](https://feichtenhofer.github.io/), [Dave Schnizlein](https://www.linkedin.com/in/david-schnizlein-96020136/), [Haoqi Fan](https://haoqifan.github.io/), [Heng Wang](https://hengcv.github.io/), [Jackson Hamburger](https://www.linkedin.com/in/jackson-hamburger-986a2873/), [Jitendra Malik](http://people.eecs.berkeley.edu/~malik/), [Kalyan Vasudev Alwala](https://www.linkedin.com/in/kalyan-vasudev-alwala-2a802b64/), [Matt Feiszli](https://www.linkedin.com/in/matt-feiszli-76b34b/), [Nikhila Ravi](https://www.linkedin.com/in/nikhilaravi/), [Ross Girshick](https://www.rossgirshick.info/), [Tullie Murrell](https://www.linkedin.com/in/tullie/), [Wan-Yen Lo](https://www.linkedin.com/in/wanyenlo/), [Weiyao Wang](https://www.linkedin.com/in/weiyaowang/?locale=en_US), [Xiaowen Lin](https://www.linkedin.com/in/xiaowen-lin-90542b34/), [Yanghao Li](https://lyttonhao.github.io/), [Yilei Li](https://liyilui.github.io/personal_page/), [Zhengxing Chen](http://czxttkl.github.io/), [Zhicheng Yan](https://www.linkedin.com/in/zhichengyan/).
+
+
+## Development
+
+We welcome new contributions to PyTorchVideo and we will be actively maintaining this library! Please refer to [`CONTRIBUTING.md`](./.github/CONTRIBUTING.md) for full instructions on how to run the code, tests and linter, and submit your pull requests.
+
+## Citing PyTorchVideo
+
+If you find PyTorchVideo useful in your work, please use the following BibTeX entry for citation.
+```BibTeX
+@inproceedings{fan2021pytorchvideo,
+ author = {Haoqi Fan and Tullie Murrell and Heng Wang and Kalyan Vasudev Alwala and Yanghao Li and Yilei Li and Bo Xiong and Nikhila Ravi and Meng Li and Haichuan Yang and Jitendra Malik and Ross Girshick and Matt Feiszli and Aaron Adcock and Wan-Yen Lo and Christoph Feichtenhofer},
+ title = {{PyTorchVideo}: A Deep Learning Library for Video Understanding},
+ booktitle = {Proceedings of the 29th ACM International Conference on Multimedia},
+ year = {2021},
+ note = {\url{https://pytorchvideo.org/}},
+}
+```
diff --git a/code/pytorchvideo/dev/README.md b/code/pytorchvideo/dev/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..027eeae3b5b36caf44af720219d2f090c3c16875
--- /dev/null
+++ b/code/pytorchvideo/dev/README.md
@@ -0,0 +1,11 @@
+## Running Linter
+
+
+Before running the linter, please ensure that you installed the necessary additional linter dependencies.
+If not installed, check the [install-README](https://github.com/facebookresearch/pytorchvideo/blob/main/INSTALL.md) on how to do it.
+
+Post that, you can run the linter from the project root using,
+
+```
+./dev/linter.sh
+```
diff --git a/code/pytorchvideo/dev/linter.sh b/code/pytorchvideo/dev/linter.sh
new file mode 100644
index 0000000000000000000000000000000000000000..eafbac0981be67410c21758eb8af8f72cf1214c5
--- /dev/null
+++ b/code/pytorchvideo/dev/linter.sh
@@ -0,0 +1,25 @@
+#!/bin/bash -ev
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
+
+# Run this script at project root with "./dev/linter.sh" before you commit.
+
+echo "Running autoflake..."
+python -m autoflake --remove-all-unused-imports -i .
+
+echo "Running isort..."
+isort -y -sp .
+
+echo "Running black..."
+black .
+
+echo "Running flake8..."
+if [ -x "$(command -v flake8)" ]; then
+ flake8 .
+else
+ python3 -m flake8 .
+fi
+
+command -v arc > /dev/null && {
+ echo "Running arc lint ..."
+ arc lint
+}
diff --git a/code/pytorchvideo/docs/Makefile b/code/pytorchvideo/docs/Makefile
new file mode 100644
index 0000000000000000000000000000000000000000..d0c3cbf1020d5c292abdedf27627c6abe25e2293
--- /dev/null
+++ b/code/pytorchvideo/docs/Makefile
@@ -0,0 +1,20 @@
+# Minimal makefile for Sphinx documentation
+#
+
+# You can set these variables from the command line, and also
+# from the environment for the first two.
+SPHINXOPTS ?=
+SPHINXBUILD ?= sphinx-build
+SOURCEDIR = source
+BUILDDIR = build
+
+# Put it first so that "make" without argument is like "make help".
+help:
+ @$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
+
+.PHONY: help Makefile
+
+# Catch-all target: route all unknown targets to Sphinx using the new
+# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
+%: Makefile
+ @$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
diff --git a/code/pytorchvideo/docs/README.md b/code/pytorchvideo/docs/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..2fb037e2d83ef4e8e54414d44f4c448b4551bf0e
--- /dev/null
+++ b/code/pytorchvideo/docs/README.md
@@ -0,0 +1,65 @@
+
+## Setup
+
+### Install dependencies
+
+```
+pip install -U recommonmark mock sphinx sphinx_rtd_theme sphinx_markdown_tables
+```
+
+### Add symlink to the root README.md
+
+We want to include the root readme as an overview. Before generating the docs create a symlink to the root readme.
+
+```
+cd  +
+##### References
+[1] Ben Mildenhall and Pratul P. Srinivasan and Matthew Tancik and Jonathan T. Barron and Ravi Ramamoorthi and Ren Ng, NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis, ECCV2020
diff --git a/code/pytorchvideo/projects/video_nerf/dataset.py b/code/pytorchvideo/projects/video_nerf/dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..e687d2c6d77f9a4d503dcab25a6aa7c4a64d0348
--- /dev/null
+++ b/code/pytorchvideo/projects/video_nerf/dataset.py
@@ -0,0 +1,125 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
+
+import os
+from typing import Tuple
+
+import numpy as np
+import torch
+import tqdm
+
+# Imports from PyTorchVideo and PyTorch3D
+from pytorch3d.renderer import PerspectiveCameras
+from pytorchvideo.data.encoded_video import EncodedVideo
+from torch.utils.data import Dataset
+
+from .dataset_utils import (
+ generate_splits,
+ get_geometry_data,
+ objectron_to_pytorch3d,
+ resize_images,
+)
+from .nerf_dataset import ListDataset
+
+
+DEFAULT_DATA_ROOT = os.path.join(
+ os.path.dirname(os.path.realpath(__file__)), "..", "data", "objectron"
+)
+
+
+def trivial_collate(batch):
+ """
+ A trivial collate function that merely returns the uncollated batch.
+ """
+ return batch
+
+
+def get_nerf_datasets(
+ dataset_name: str,
+ image_size: Tuple[int, int],
+ data_root: str = DEFAULT_DATA_ROOT,
+ **kwargs,
+) -> Tuple[Dataset, Dataset, Dataset]:
+ """
+ Obtains the training and validation dataset object for a dataset specified
+ with the `dataset_name` argument.
+
+ Args:
+ dataset_name: The name of the dataset to load.
+ image_size: A tuple (height, width) denoting the sizes of the loaded dataset images.
+ data_root: The root folder at which the data is stored.
+
+ Returns:
+ train_dataset: The training dataset object.
+ val_dataset: The validation dataset object.
+ test_dataset: The testing dataset object.
+ """
+ print(f"Loading dataset {dataset_name}, image size={str(image_size)} ...")
+
+ if dataset_name != "objectron":
+ raise ValueError("This data loader is only for the objectron dataset")
+
+ # Use the bundle adjusted camera parameters
+ sequence_geometry = get_geometry_data(os.path.join(data_root, "sfm_arframe.pbdata"))
+ num_frames = len(sequence_geometry)
+
+ # Check if splits are present else generate them on the first instance:
+ splits_path = os.path.join(data_root, "splits.pt")
+ if os.path.exists(splits_path):
+ print("Loading splits...")
+ splits = torch.load(splits_path)
+ train_idx, val_idx, test_idx = splits
+ else:
+ print("Generating splits...")
+ index_options = np.arange(num_frames)
+ train_idx, val_idx, test_idx = generate_splits(index_options)
+ torch.save([train_idx, val_idx, test_idx], splits_path)
+
+ print("Loading video...")
+ video_path = os.path.join(data_root, "video.MOV")
+ # Load the video using the PyTorchVideo video class
+ video = EncodedVideo.from_path(video_path)
+ FPS = 30
+
+ print("Loading all images and cameras...")
+ # Load all the video frames
+ frame_data = video.get_clip(start_sec=0, end_sec=(num_frames - 1) * 1.0 / FPS)
+ frame_data = frame_data["video"].permute(1, 2, 3, 0)
+ images = resize_images(frame_data, image_size)
+ cameras = []
+
+ for frame_id in tqdm.tqdm(range(num_frames)):
+ I, P = sequence_geometry[frame_id]
+ R = P[0:3, 0:3]
+ T = P[0:3, 3]
+
+ # Convert conventions
+ R = R.transpose(0, 1)
+ R, T = objectron_to_pytorch3d(R, T)
+
+ # Get intrinsic parameters
+ fx = I[0, 0]
+ fy = I[1, 1]
+ px = I[0, 2]
+ py = I[1, 2]
+
+ # Initialize the Perspective Camera
+ scene_cam = PerspectiveCameras(
+ R=R[None, ...],
+ T=T[None, ...],
+ focal_length=((fx, fy),),
+ principal_point=((px, py),),
+ ).to("cpu")
+
+ cameras.append(scene_cam)
+
+ train_dataset, val_dataset, test_dataset = [
+ ListDataset(
+ [
+ {"image": images[i], "camera": cameras[i], "camera_idx": int(i)}
+ for i in idx
+ ]
+ )
+ for idx in [train_idx, val_idx, test_idx]
+ ]
+
+ return train_dataset, val_dataset, test_dataset
diff --git a/code/pytorchvideo/projects/video_nerf/dataset_utils.py b/code/pytorchvideo/projects/video_nerf/dataset_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..d81737afaf15d93979c5485a7d9e2759c8ca2e70
--- /dev/null
+++ b/code/pytorchvideo/projects/video_nerf/dataset_utils.py
@@ -0,0 +1,117 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import os
+import struct
+import sys
+from typing import List, Tuple
+
+import numpy as np
+import torch
+
+# The AR Metadata captured with each frame in the video
+from objectron.schema import ( # noqa: E402
+ a_r_capture_metadata_pb2 as ar_metadata_protocol,
+)
+from PIL import Image
+from pytorch3d.transforms import Rotate, RotateAxisAngle, Translate
+
+
+# Imports from Objectron
+module_path = os.path.abspath(os.path.join("..."))
+if module_path not in sys.path:
+ sys.path.append("../Objectron")
+
+
+def objectron_to_pytorch3d(
+ R: torch.Tensor, T: torch.Tensor
+) -> Tuple[torch.Tensor, torch.Tensor]:
+ """
+ Transforms the R and T matrices from the Objectron world coordinate
+ system to the PyTorch3d world system.
+ Objectron cameras live in +X right, +Y Up, +Z from screen to us.
+ Pytorch3d world is +X left, +Y up, +Z from us to screen.
+ """
+ rotation = Rotate(R=R)
+ conversion = RotateAxisAngle(axis="y", angle=180)
+ composed_transform = rotation.compose(conversion).get_matrix()
+ composed_R = composed_transform[0, 0:3, 0:3]
+
+ translation = Translate(x=T[None, ...])
+ t_matrix = translation.compose(conversion).get_matrix()
+ flipped_T = t_matrix[0, 3, :3]
+ return composed_R, flipped_T
+
+
+def generate_splits(
+ index_options: List[int], train_fraction: float = 0.8
+) -> List[List[int]]:
+ """
+ Get indices for train, val, test splits.
+ """
+ num_images = len(index_options)
+ np.random.shuffle(index_options)
+ train_index = int(train_fraction * num_images)
+ val_index = train_index + ((num_images - train_index) // 2)
+ train_indices = index_options[:train_index]
+ val_indices = index_options[train_index:val_index]
+ test_indices = index_options[val_index:]
+ split_indices = [train_indices, val_indices, test_indices]
+ return split_indices
+
+
+def get_geometry_data(geometry_filename: str) -> List[List[torch.Tensor]]:
+ """
+ Utils function for parsing metadata files from the Objectron GitHub repo:
+ https://github.com/google-research-datasets/Objectron/blob/master/notebooks/objectron-geometry-tutorial.ipynb # noqa: B950
+ """
+ sequence_geometry = []
+ with open(geometry_filename, "rb") as pb:
+ proto_buf = pb.read()
+
+ i = 0
+ while i < len(proto_buf):
+ # Read the first four Bytes in little endian '<' integers 'I' format
+ # indicating the length of the current message.
+ msg_len = struct.unpack("
+
+##### References
+[1] Ben Mildenhall and Pratul P. Srinivasan and Matthew Tancik and Jonathan T. Barron and Ravi Ramamoorthi and Ren Ng, NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis, ECCV2020
diff --git a/code/pytorchvideo/projects/video_nerf/dataset.py b/code/pytorchvideo/projects/video_nerf/dataset.py
new file mode 100644
index 0000000000000000000000000000000000000000..e687d2c6d77f9a4d503dcab25a6aa7c4a64d0348
--- /dev/null
+++ b/code/pytorchvideo/projects/video_nerf/dataset.py
@@ -0,0 +1,125 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All rights reserved.
+
+import os
+from typing import Tuple
+
+import numpy as np
+import torch
+import tqdm
+
+# Imports from PyTorchVideo and PyTorch3D
+from pytorch3d.renderer import PerspectiveCameras
+from pytorchvideo.data.encoded_video import EncodedVideo
+from torch.utils.data import Dataset
+
+from .dataset_utils import (
+ generate_splits,
+ get_geometry_data,
+ objectron_to_pytorch3d,
+ resize_images,
+)
+from .nerf_dataset import ListDataset
+
+
+DEFAULT_DATA_ROOT = os.path.join(
+ os.path.dirname(os.path.realpath(__file__)), "..", "data", "objectron"
+)
+
+
+def trivial_collate(batch):
+ """
+ A trivial collate function that merely returns the uncollated batch.
+ """
+ return batch
+
+
+def get_nerf_datasets(
+ dataset_name: str,
+ image_size: Tuple[int, int],
+ data_root: str = DEFAULT_DATA_ROOT,
+ **kwargs,
+) -> Tuple[Dataset, Dataset, Dataset]:
+ """
+ Obtains the training and validation dataset object for a dataset specified
+ with the `dataset_name` argument.
+
+ Args:
+ dataset_name: The name of the dataset to load.
+ image_size: A tuple (height, width) denoting the sizes of the loaded dataset images.
+ data_root: The root folder at which the data is stored.
+
+ Returns:
+ train_dataset: The training dataset object.
+ val_dataset: The validation dataset object.
+ test_dataset: The testing dataset object.
+ """
+ print(f"Loading dataset {dataset_name}, image size={str(image_size)} ...")
+
+ if dataset_name != "objectron":
+ raise ValueError("This data loader is only for the objectron dataset")
+
+ # Use the bundle adjusted camera parameters
+ sequence_geometry = get_geometry_data(os.path.join(data_root, "sfm_arframe.pbdata"))
+ num_frames = len(sequence_geometry)
+
+ # Check if splits are present else generate them on the first instance:
+ splits_path = os.path.join(data_root, "splits.pt")
+ if os.path.exists(splits_path):
+ print("Loading splits...")
+ splits = torch.load(splits_path)
+ train_idx, val_idx, test_idx = splits
+ else:
+ print("Generating splits...")
+ index_options = np.arange(num_frames)
+ train_idx, val_idx, test_idx = generate_splits(index_options)
+ torch.save([train_idx, val_idx, test_idx], splits_path)
+
+ print("Loading video...")
+ video_path = os.path.join(data_root, "video.MOV")
+ # Load the video using the PyTorchVideo video class
+ video = EncodedVideo.from_path(video_path)
+ FPS = 30
+
+ print("Loading all images and cameras...")
+ # Load all the video frames
+ frame_data = video.get_clip(start_sec=0, end_sec=(num_frames - 1) * 1.0 / FPS)
+ frame_data = frame_data["video"].permute(1, 2, 3, 0)
+ images = resize_images(frame_data, image_size)
+ cameras = []
+
+ for frame_id in tqdm.tqdm(range(num_frames)):
+ I, P = sequence_geometry[frame_id]
+ R = P[0:3, 0:3]
+ T = P[0:3, 3]
+
+ # Convert conventions
+ R = R.transpose(0, 1)
+ R, T = objectron_to_pytorch3d(R, T)
+
+ # Get intrinsic parameters
+ fx = I[0, 0]
+ fy = I[1, 1]
+ px = I[0, 2]
+ py = I[1, 2]
+
+ # Initialize the Perspective Camera
+ scene_cam = PerspectiveCameras(
+ R=R[None, ...],
+ T=T[None, ...],
+ focal_length=((fx, fy),),
+ principal_point=((px, py),),
+ ).to("cpu")
+
+ cameras.append(scene_cam)
+
+ train_dataset, val_dataset, test_dataset = [
+ ListDataset(
+ [
+ {"image": images[i], "camera": cameras[i], "camera_idx": int(i)}
+ for i in idx
+ ]
+ )
+ for idx in [train_idx, val_idx, test_idx]
+ ]
+
+ return train_dataset, val_dataset, test_dataset
diff --git a/code/pytorchvideo/projects/video_nerf/dataset_utils.py b/code/pytorchvideo/projects/video_nerf/dataset_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..d81737afaf15d93979c5485a7d9e2759c8ca2e70
--- /dev/null
+++ b/code/pytorchvideo/projects/video_nerf/dataset_utils.py
@@ -0,0 +1,117 @@
+# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
+
+import os
+import struct
+import sys
+from typing import List, Tuple
+
+import numpy as np
+import torch
+
+# The AR Metadata captured with each frame in the video
+from objectron.schema import ( # noqa: E402
+ a_r_capture_metadata_pb2 as ar_metadata_protocol,
+)
+from PIL import Image
+from pytorch3d.transforms import Rotate, RotateAxisAngle, Translate
+
+
+# Imports from Objectron
+module_path = os.path.abspath(os.path.join("..."))
+if module_path not in sys.path:
+ sys.path.append("../Objectron")
+
+
+def objectron_to_pytorch3d(
+ R: torch.Tensor, T: torch.Tensor
+) -> Tuple[torch.Tensor, torch.Tensor]:
+ """
+ Transforms the R and T matrices from the Objectron world coordinate
+ system to the PyTorch3d world system.
+ Objectron cameras live in +X right, +Y Up, +Z from screen to us.
+ Pytorch3d world is +X left, +Y up, +Z from us to screen.
+ """
+ rotation = Rotate(R=R)
+ conversion = RotateAxisAngle(axis="y", angle=180)
+ composed_transform = rotation.compose(conversion).get_matrix()
+ composed_R = composed_transform[0, 0:3, 0:3]
+
+ translation = Translate(x=T[None, ...])
+ t_matrix = translation.compose(conversion).get_matrix()
+ flipped_T = t_matrix[0, 3, :3]
+ return composed_R, flipped_T
+
+
+def generate_splits(
+ index_options: List[int], train_fraction: float = 0.8
+) -> List[List[int]]:
+ """
+ Get indices for train, val, test splits.
+ """
+ num_images = len(index_options)
+ np.random.shuffle(index_options)
+ train_index = int(train_fraction * num_images)
+ val_index = train_index + ((num_images - train_index) // 2)
+ train_indices = index_options[:train_index]
+ val_indices = index_options[train_index:val_index]
+ test_indices = index_options[val_index:]
+ split_indices = [train_indices, val_indices, test_indices]
+ return split_indices
+
+
+def get_geometry_data(geometry_filename: str) -> List[List[torch.Tensor]]:
+ """
+ Utils function for parsing metadata files from the Objectron GitHub repo:
+ https://github.com/google-research-datasets/Objectron/blob/master/notebooks/objectron-geometry-tutorial.ipynb # noqa: B950
+ """
+ sequence_geometry = []
+ with open(geometry_filename, "rb") as pb:
+ proto_buf = pb.read()
+
+ i = 0
+ while i < len(proto_buf):
+ # Read the first four Bytes in little endian '<' integers 'I' format
+ # indicating the length of the current message.
+ msg_len = struct.unpack("