

Upload 5 files
Browse files- .gitattributes +3 -0
- README.md +110 -195
- assets/Sana-0.6B-laptop.gif +3 -0
- assets/dc_ae_demo.gif +3 -0
- assets/dc_ae_diffusion_demo.gif +3 -0
- assets/dc_ae_sana.jpg +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,6 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/dc_ae_demo.gif filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/dc_ae_diffusion_demo.gif filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
assets/Sana-0.6B-laptop.gif filter=lfs diff=lfs merge=lfs -text
|
README.md
CHANGED
|
@@ -1,198 +1,113 @@
|
|
| 1 |
-
|
| 2 |
-
library_name: diffusers
|
| 3 |
-
---
|
| 4 |
|
| 5 |
-
|
| 6 |
|
| 7 |
-
|
|
|
|
|
|
|
|
|
|
| 8 |
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
| 13 |
-
|
| 14 |
-
|
| 15 |
-
|
| 16 |
-
|
| 17 |
-
|
| 18 |
-
|
| 19 |
-
|
| 20 |
-
|
| 21 |
-
-
|
| 22 |
-
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
|
| 26 |
-
|
| 27 |
-
|
| 28 |
-
|
| 29 |
-
|
| 30 |
-
|
| 31 |
-
|
| 32 |
-
|
| 33 |
-
|
| 34 |
-
|
| 35 |
-
|
| 36 |
-
|
| 37 |
-
|
| 38 |
-
|
| 39 |
-
|
| 40 |
-
|
| 41 |
-
|
| 42 |
-
|
| 43 |
-
|
| 44 |
-
|
| 45 |
-
|
| 46 |
-
|
| 47 |
-
|
| 48 |
-
|
| 49 |
-
|
| 50 |
-
|
| 51 |
-
|
| 52 |
-
|
| 53 |
-
|
| 54 |
-
|
| 55 |
-
|
| 56 |
-
|
| 57 |
-
|
| 58 |
-
|
| 59 |
-
|
| 60 |
-
|
| 61 |
-
|
| 62 |
-
|
| 63 |
-
|
| 64 |
-
|
| 65 |
-
|
| 66 |
-
|
| 67 |
-
|
| 68 |
-
|
| 69 |
-
|
| 70 |
-
|
| 71 |
-
|
| 72 |
-
|
| 73 |
-
|
| 74 |
-
|
| 75 |
-
|
| 76 |
-
|
| 77 |
-
|
| 78 |
-
|
| 79 |
-
|
| 80 |
-
|
| 81 |
-
|
| 82 |
-
|
| 83 |
-
|
| 84 |
-
|
| 85 |
-
|
| 86 |
-
|
| 87 |
-
|
| 88 |
-
|
| 89 |
-
[
|
| 90 |
-
|
| 91 |
-
|
| 92 |
-
|
| 93 |
-
|
| 94 |
-
|
| 95 |
-
|
| 96 |
-
|
| 97 |
-
|
| 98 |
-
|
| 99 |
-
|
| 100 |
-
|
| 101 |
-
|
| 102 |
-
|
| 103 |
-
|
| 104 |
-
|
| 105 |
-
|
| 106 |
-
|
| 107 |
-
|
| 108 |
-
|
| 109 |
-
|
| 110 |
-
|
| 111 |
-
|
| 112 |
-
|
| 113 |
-
|
| 114 |
-
#### Factors
|
| 115 |
-
|
| 116 |
-
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
|
| 117 |
-
|
| 118 |
-
[More Information Needed]
|
| 119 |
-
|
| 120 |
-
#### Metrics
|
| 121 |
-
|
| 122 |
-
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
|
| 123 |
-
|
| 124 |
-
[More Information Needed]
|
| 125 |
-
|
| 126 |
-
### Results
|
| 127 |
-
|
| 128 |
-
[More Information Needed]
|
| 129 |
-
|
| 130 |
-
#### Summary
|
| 131 |
-
|
| 132 |
-
|
| 133 |
-
|
| 134 |
-
## Model Examination [optional]
|
| 135 |
-
|
| 136 |
-
<!-- Relevant interpretability work for the model goes here -->
|
| 137 |
-
|
| 138 |
-
[More Information Needed]
|
| 139 |
-
|
| 140 |
-
## Environmental Impact
|
| 141 |
-
|
| 142 |
-
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
|
| 143 |
-
|
| 144 |
-
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
|
| 145 |
-
|
| 146 |
-
- **Hardware Type:** [More Information Needed]
|
| 147 |
-
- **Hours used:** [More Information Needed]
|
| 148 |
-
- **Cloud Provider:** [More Information Needed]
|
| 149 |
-
- **Compute Region:** [More Information Needed]
|
| 150 |
-
- **Carbon Emitted:** [More Information Needed]
|
| 151 |
-
|
| 152 |
-
## Technical Specifications [optional]
|
| 153 |
-
|
| 154 |
-
### Model Architecture and Objective
|
| 155 |
-
|
| 156 |
-
[More Information Needed]
|
| 157 |
-
|
| 158 |
-
### Compute Infrastructure
|
| 159 |
-
|
| 160 |
-
[More Information Needed]
|
| 161 |
-
|
| 162 |
-
#### Hardware
|
| 163 |
-
|
| 164 |
-
[More Information Needed]
|
| 165 |
-
|
| 166 |
-
#### Software
|
| 167 |
-
|
| 168 |
-
[More Information Needed]
|
| 169 |
-
|
| 170 |
-
## Citation [optional]
|
| 171 |
-
|
| 172 |
-
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
|
| 173 |
-
|
| 174 |
-
**BibTeX:**
|
| 175 |
-
|
| 176 |
-
[More Information Needed]
|
| 177 |
-
|
| 178 |
-
**APA:**
|
| 179 |
-
|
| 180 |
-
[More Information Needed]
|
| 181 |
-
|
| 182 |
-
## Glossary [optional]
|
| 183 |
-
|
| 184 |
-
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
|
| 185 |
-
|
| 186 |
-
[More Information Needed]
|
| 187 |
-
|
| 188 |
-
## More Information [optional]
|
| 189 |
-
|
| 190 |
-
[More Information Needed]
|
| 191 |
-
|
| 192 |
-
## Model Card Authors [optional]
|
| 193 |
-
|
| 194 |
-
[More Information Needed]
|
| 195 |
-
|
| 196 |
-
## Model Card Contact
|
| 197 |
-
|
| 198 |
-
[More Information Needed]
|
|
|
|
| 1 |
+
# Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models
|
|
|
|
|
|
|
| 2 |
|
| 3 |
+
[[paper](https://arxiv.org/abs/2410.10733)] [[GitHub](https://github.com/mit-han-lab/efficientvit)]
|
| 4 |
|
| 5 |
+

|
| 6 |
+
<p align="center">
|
| 7 |
+
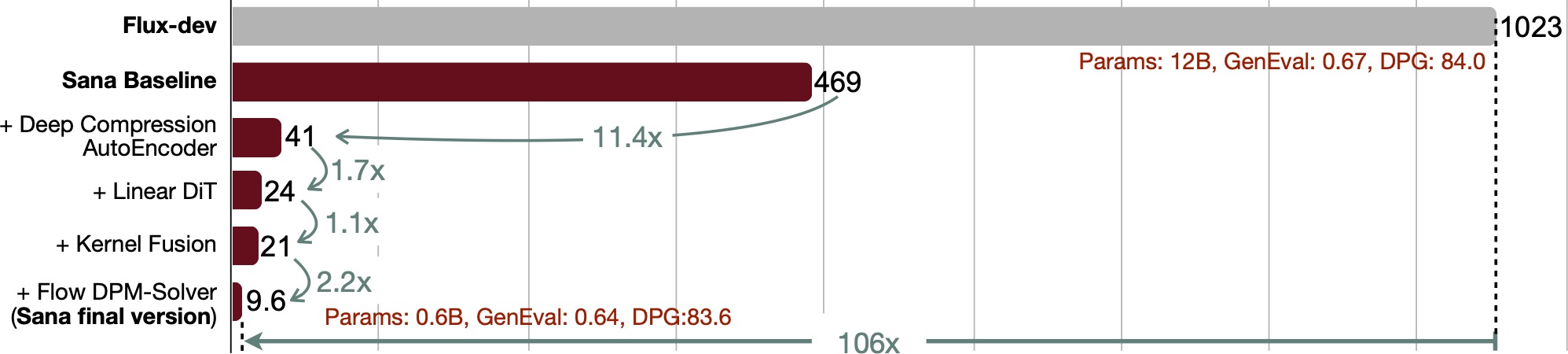
<b> Figure 1: We address the reconstruction accuracy drop of high spatial-compression autoencoders.
|
| 8 |
+
</p>
|
| 9 |
|
| 10 |
+

|
| 11 |
+
<p align="center">
|
| 12 |
+
<b> Figure 2: DC-AE delivers significant training and inference speedup without performance drop.
|
| 13 |
+
</p>
|
| 14 |
+
|
| 15 |
+

|
| 16 |
+
|
| 17 |
+
<p align="center">
|
| 18 |
+
<img src="assets/dc_ae_sana.jpg" width="1200">
|
| 19 |
+
</p>
|
| 20 |
+
|
| 21 |
+
<p align="center">
|
| 22 |
+
<b> Figure 3: DC-AE enables efficient text-to-image generation on the laptop.
|
| 23 |
+
</p>
|
| 24 |
+
|
| 25 |
+
## Abstract
|
| 26 |
+
|
| 27 |
+
We present Deep Compression Autoencoder (DC-AE), a new family of autoencoder models for accelerating high-resolution diffusion models. Existing autoencoder models have demonstrated impressive results at a moderate spatial compression ratio (e.g., 8x), but fail to maintain satisfactory reconstruction accuracy for high spatial compression ratios (e.g., 64x). We address this challenge by introducing two key techniques: (1) Residual Autoencoding, where we design our models to learn residuals based on the space-to-channel transformed features to alleviate the optimization difficulty of high spatial-compression autoencoders; (2) Decoupled High-Resolution Adaptation, an efficient decoupled three-phases training strategy for mitigating the generalization penalty of high spatial-compression autoencoders. With these designs, we improve the autoencoder's spatial compression ratio up to 128 while maintaining the reconstruction quality. Applying our DC-AE to latent diffusion models, we achieve significant speedup without accuracy drop. For example, on ImageNet 512x512, our DC-AE provides 19.1x inference speedup and 17.9x training speedup on H100 GPU for UViT-H while achieving a better FID, compared with the widely used SD-VAE-f8 autoencoder.
|
| 28 |
+
|
| 29 |
+
## Usage
|
| 30 |
+
|
| 31 |
+
### Deep Compression Autoencoder
|
| 32 |
+
|
| 33 |
+
```python
|
| 34 |
+
# build DC-AE models
|
| 35 |
+
# full DC-AE model list: https://huggingface.co/collections/mit-han-lab/dc-ae-670085b9400ad7197bb1009b
|
| 36 |
+
from efficientvit.ae_model_zoo import DCAE_HF
|
| 37 |
+
|
| 38 |
+
dc_ae = DCAE_HF.from_pretrained(f"mit-han-lab/dc-ae-f64c128-in-1.0")
|
| 39 |
+
|
| 40 |
+
# encode
|
| 41 |
+
from PIL import Image
|
| 42 |
+
import torch
|
| 43 |
+
import torchvision.transforms as transforms
|
| 44 |
+
from torchvision.utils import save_image
|
| 45 |
+
from efficientvit.apps.utils.image import DMCrop
|
| 46 |
+
|
| 47 |
+
device = torch.device("cuda")
|
| 48 |
+
dc_ae = dc_ae.to(device).eval()
|
| 49 |
+
|
| 50 |
+
transform = transforms.Compose([
|
| 51 |
+
DMCrop(512), # resolution
|
| 52 |
+
transforms.ToTensor(),
|
| 53 |
+
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
|
| 54 |
+
])
|
| 55 |
+
image = Image.open("assets/fig/girl.png")
|
| 56 |
+
x = transform(image)[None].to(device)
|
| 57 |
+
latent = dc_ae.encode(x)
|
| 58 |
+
print(latent.shape)
|
| 59 |
+
|
| 60 |
+
# decode
|
| 61 |
+
y = dc_ae.decode(latent)
|
| 62 |
+
save_image(y * 0.5 + 0.5, "demo_dc_ae.png")
|
| 63 |
+
```
|
| 64 |
+
|
| 65 |
+
### Efficient Diffusion Models with DC-AE
|
| 66 |
+
|
| 67 |
+
```python
|
| 68 |
+
# build DC-AE-Diffusion models
|
| 69 |
+
# full DC-AE-Diffusion model list: https://huggingface.co/collections/mit-han-lab/dc-ae-diffusion-670dbb8d6b6914cf24c1a49d
|
| 70 |
+
from efficientvit.diffusion_model_zoo import DCAE_Diffusion_HF
|
| 71 |
+
|
| 72 |
+
dc_ae_diffusion = DCAE_Diffusion_HF.from_pretrained(f"mit-han-lab/dc-ae-f64c128-in-1.0-uvit-h-in-512px-train2000k")
|
| 73 |
+
|
| 74 |
+
# denoising on the latent space
|
| 75 |
+
import torch
|
| 76 |
+
import numpy as np
|
| 77 |
+
from torchvision.utils import save_image
|
| 78 |
+
|
| 79 |
+
torch.set_grad_enabled(False)
|
| 80 |
+
device = torch.device("cuda")
|
| 81 |
+
dc_ae_diffusion = dc_ae_diffusion.to(device).eval()
|
| 82 |
+
|
| 83 |
+
seed = 0
|
| 84 |
+
torch.manual_seed(seed)
|
| 85 |
+
torch.cuda.manual_seed_all(seed)
|
| 86 |
+
eval_generator = torch.Generator(device=device)
|
| 87 |
+
eval_generator.manual_seed(seed)
|
| 88 |
+
|
| 89 |
+
prompts = torch.tensor(
|
| 90 |
+
[279, 333, 979, 936, 933, 145, 497, 1, 248, 360, 793, 12, 387, 437, 938, 978], dtype=torch.int, device=device
|
| 91 |
+
)
|
| 92 |
+
num_samples = prompts.shape[0]
|
| 93 |
+
prompts_null = 1000 * torch.ones((num_samples,), dtype=torch.int, device=device)
|
| 94 |
+
latent_samples = dc_ae_diffusion.diffusion_model.generate(prompts, prompts_null, 6.0, eval_generator)
|
| 95 |
+
latent_samples = latent_samples / dc_ae_diffusion.scaling_factor
|
| 96 |
+
|
| 97 |
+
# decode
|
| 98 |
+
image_samples = dc_ae_diffusion.autoencoder.decode(latent_samples)
|
| 99 |
+
save_image(image_samples * 0.5 + 0.5, "demo_dc_ae_diffusion.png", nrow=int(np.sqrt(num_samples)))
|
| 100 |
+
```
|
| 101 |
+
|
| 102 |
+
## Reference
|
| 103 |
+
|
| 104 |
+
If DC-AE is useful or relevant to your research, please kindly recognize our contributions by citing our papers:
|
| 105 |
+
|
| 106 |
+
```
|
| 107 |
+
@article{chen2024deep,
|
| 108 |
+
title={Deep Compression Autoencoder for Efficient High-Resolution Diffusion Models},
|
| 109 |
+
author={Chen, Junyu and Cai, Han and Chen, Junsong and Xie, Enze and Yang, Shang and Tang, Haotian and Li, Muyang and Lu, Yao and Han, Song},
|
| 110 |
+
journal={arXiv preprint arXiv:2410.10733},
|
| 111 |
+
year={2024}
|
| 112 |
+
}
|
| 113 |
+
```
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
assets/Sana-0.6B-laptop.gif
ADDED

|
Git LFS Details
|
assets/dc_ae_demo.gif
ADDED

|
Git LFS Details
|
assets/dc_ae_diffusion_demo.gif
ADDED

|
Git LFS Details
|
assets/dc_ae_sana.jpg
ADDED
|