

Mdels and code
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +7 -0
- .gitignore +17 -0
- README.md +36 -0
- __init__.py +0 -0
- csv/base-perplexity_quartiles_sampling.csv +33 -0
- csv/extended-perplexity_quartiles_sampling.csv +37 -0
- download_all.sh +40 -0
- histograms.py +104 -0
- kenlm/books.norm.arpa.bin +3 -0
- kenlm/books.norm.arpa.zip +3 -0
- kenlm/books.norm.sp.arpa.bin +3 -0
- kenlm/books.norm.sp.arpa.zip +3 -0
- kenlm/harmful/.keep +0 -0
- kenlm/maalfrid.norm.arpa +3 -0
- kenlm/maalfrid.norm.arpa.bin +3 -0
- kenlm/maalfrid.norm.sp.arpa +3 -0
- kenlm/maalfrid.norm.sp.arpa.bin +3 -0
- kenlm/newspapers.norm.arpa +3 -0
- kenlm/newspapers.norm.arpa.bin +3 -0
- kenlm/newspapers.norm.sp.arpa +3 -0
- kenlm/newspapers.norm.sp.arpa.bin +3 -0
- kenlm/wikipedia/.keep +0 -0
- normalization.py +154 -0
- notebooks/gaussian_sampling.ipynb +0 -0
- notebooks/gaussian_subsampling.ipynb +0 -0
- perplexity.py +449 -0
- plots/all_doc_types_plots.png +0 -0
- plots/book_no_book.png +0 -0
- plots/books_pdf_no_books_pdf.png +0 -0
- plots/combined_plots.png +0 -0
- plots/culturax_nob_all_plots.png +0 -0
- plots/culturax_nob_culturax.png +0 -0
- plots/plots_book.png +0 -0
- plots/plots_books_pdf.png +0 -0
- plots/plots_culturax.png +0 -0
- plots/plots_evalueringsrapport_pdf.png +0 -0
- plots/plots_evalueringsrapport_pdf_no.png +0 -0
- plots/plots_lovdata_cd_lokaleforskrifter_2005.png +0 -0
- plots/plots_lovdata_cd_lokaleforskrifter_2005_no.png +0 -0
- plots/plots_lovdata_cd_norgeslover_2005.png +0 -0
- plots/plots_lovdata_cd_norgeslover_2005_no.png +0 -0
- plots/plots_lovdata_cd_odelsting_2005.png +0 -0
- plots/plots_lovdata_cd_odelsting_2005_no.png +0 -0
- plots/plots_lovdata_cd_rtv_rundskriv_2005.png +0 -0
- plots/plots_lovdata_cd_rtv_rundskriv_2005_no.png +0 -0
- plots/plots_lovdata_cd_rundskriv_lovavdeling_2005.png +0 -0
- plots/plots_lovdata_cd_rundskriv_lovavdeling_2005_no.png +0 -0
- plots/plots_lovdata_cd_sentrale_forskrifter_2005.png +0 -0
- plots/plots_lovdata_cd_sentrale_forskrifter_2005_no.png +0 -0
- plots/plots_lovdata_cd_skatt_rundskriv_2005.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,10 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
*.vocab filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
texts/*.txt filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
*.arpa* filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
kenlm/*.bin filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
kenlm/*.arpa filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
samples/*.jsonl filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
*.jsonl filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
tmp/
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.pyc
|
| 4 |
+
.ipynb_checkpoints
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
samples/restricted*
|
| 8 |
+
samples/*.json*
|
| 9 |
+
kenlm/wikipedia/*
|
| 10 |
+
!kenlm/wikipedia/.keep
|
| 11 |
+
kenlm/harmful/*
|
| 12 |
+
!kenlm/harmful/.keep
|
| 13 |
+
spm/wikipedia/*
|
| 14 |
+
!spm/wikipedia/.keep
|
| 15 |
+
spm/*.txt
|
| 16 |
+
texts/*
|
| 17 |
+
!texts/.keep
|
README.md
CHANGED
|
@@ -1,3 +1,39 @@
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
---
|
| 4 |
+
|
| 5 |
+
# Perplexity tools
|
| 6 |
+
|
| 7 |
+
## 1. Create samples from `clean_json_3` sources
|
| 8 |
+
|
| 9 |
+
Between 1k and 1M documents. Read [samples/README.md](./samples/README.md). Output files must be prefixed by `doc_type` and suffixed by language code (2 letters). For example:
|
| 10 |
+
|
| 11 |
+
```bash
|
| 12 |
+
$ cat /nfsmounts/datastore/ncc_corpus/mimir/jsonl_2/nrk/nrk-articles.jsonl | shuf -n 100000 > samples/restricted-newspapers_nrk_no.json
|
| 13 |
+
```
|
| 14 |
+
|
| 15 |
+
## 2. Create the perplexity scores for each file
|
| 16 |
+
|
| 17 |
+
Example of how to create scores only for `doc_type` `restricted-newspapers_*` samples:
|
| 18 |
+
|
| 19 |
+
```bash
|
| 20 |
+
$ ls samples/restricted-newspapers_* | parallel --lb --jobs 5 python samples_scores.py {} --output_path scores/ --jobs 15
|
| 21 |
+
```
|
| 22 |
+
|
| 23 |
+
## 3. Create the quartiles CSV needed for segmenting and downsamplig
|
| 24 |
+
|
| 25 |
+
The different `doc_type`s will be grouped together. By passing the flag `--group_by_prefix_lang`, the grouping will happen on the pair `doc_type` prefix and language code, e.g., `wikipedia_en`.
|
| 26 |
+
|
| 27 |
+
Different downsampling ratios can be specified by using the `--sampling_ratio_per_lang` flag. For `mimir-base`, the downsampling by language is defined as follows: `"da:0.23,en:0.21,sv:0.08,is:0.50"`.
|
| 28 |
+
|
| 29 |
+
```bash
|
| 30 |
+
$ python samples_quartiles.py scores/ --group_by_prefix_lang --sampling_ratio_per_lang "da:0.23,en:0.21,sv:0.08,is:0.50" --output_file csv/base-perplexity_quartiles_sampling.csv
|
| 31 |
+
```
|
| 32 |
+
|
| 33 |
+
For `mimir-extended`, the downsampling by language is defined as follows: `"da:0.43,en:0.81,sv:0.15,code:0.62"`.
|
| 34 |
+
|
| 35 |
+
```bash
|
| 36 |
+
$ python samples_quartiles.py scores/ --group_by_prefix_lang --sampling_ratio_per_lang "da:0.43,en:0.81,sv:0.15,code:0.62" --output_file csv/extended-perplexity_quartiles_sampling.csv --overwrite_prefix_lang "starcoder_en:starcode_code"
|
| 37 |
+
```
|
| 38 |
+
|
| 39 |
+
More information in the [spreadsheet](https://docs.google.com/spreadsheets/d/108oGVVN-Ml-TDN59UXR96oeBBt2FbgT81zt8_1y9PUw/edit?usp=sharing).
|
__init__.py
ADDED
|
File without changes
|
csv/base-perplexity_quartiles_sampling.csv
ADDED
|
@@ -0,0 +1,33 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
doc_type,model,language,reject,bad,medium,good,norm,mean,std
|
| 2 |
+
books,books,no,542.15,301.25,219.3,165.12,0.0032422660862847633,208.18464621605895,68.02897458931068
|
| 3 |
+
culturax,wikipedia,nn,1113.2,753.4,559.9,387.7,0.001172357337862289,487.27059437715525,185.90322713836343
|
| 4 |
+
culturax,wikipedia,sv,1118.6,772.2,606.9,479.8,0.01968171485234145,580.0945047395821,142.99911605358275
|
| 5 |
+
culturax,wikipedia,da,1012.9,648.2,503.3,397.98,0.007997295965244292,488.615463864415,124.17368632962524
|
| 6 |
+
digimanus,wikipedia,no,1991.88,1226.65,989.1,830.35,0.0011146154086008851,974.7133669943673,209.08555530030617
|
| 7 |
+
culturax,wikipedia,no,1073.1,691.1,538.2,430.0,0.0017538216816248486,523.6960713940705,130.62730440702228
|
| 8 |
+
culturax,wikipedia,is,1420.0,884.5,720.2,594.5,0.0030935154995326906,693.7606785221377,147.6241796866134
|
| 9 |
+
evalueringsrapport,maalfrid,no,268.25,163.5,127.8,98.3,0.006540788722418088,117.29318501940242,34.47568292096079
|
| 10 |
+
hplt,wikipedia,nn,1539.1,980.6,772.7,627.5,0.0012826369023540814,752.0725635933572,179.13196906762977
|
| 11 |
+
lovdata,maalfrid,no,457.9,162.9,84.6,41.6,0.0038894207845140477,96.06375056993284,58.30277337274196
|
| 12 |
+
maalfrid,maalfrid,no,686.5,286.9,164.8,87.3,0.0022814356724527207,164.0258389923656,101.07016579025363
|
| 13 |
+
hplt,wikipedia,da,1445.5,829.3,616.3,493.5,0.00597386636355673,630.7049612170936,168.77191092534918
|
| 14 |
+
book,books,no,636.48,302.58,187.4,67.0,0.002034229155801576,158.1210630456195,109.45691866057511
|
| 15 |
+
hplt,wikipedia,sv,1398.0,910.9,715.8,578.5,0.0173199443667263,698.8065459625257,165.03293101814995
|
| 16 |
+
hplt,wikipedia,no,1589.0,880.7,668.5,532.6,0.0013206924407238364,671.3073940020074,174.52833317000255
|
| 17 |
+
newspapers,newspapers,nn,1685.4,1221.9,1005.4,825.2,0.0011282397163826917,951.0683339330576,197.39448542294457
|
| 18 |
+
newspaper,newspapers,no,2308.6,792.3,475.2,307.9,0.0009454270671058767,526.1389696700705,244.38110894007406
|
| 19 |
+
parlamint,maalfrid,no,129.23,104.0,93.8,84.6,0.02105587174354365,89.24246433500929,10.099393230392014
|
| 20 |
+
newspapers,newspapers,no,782.3,466.7,336.0,243.5,0.002096701749929567,326.7656126928853,108.47162732564873
|
| 21 |
+
wikipedia,wikipedia,da,1226.31,470.7,278.7,127.0,0.006116042100206995,272.5462428872027,159.55477781562297
|
| 22 |
+
wikipedia,wikipedia,is,1893.3,740.7,449.1,174.5,0.001640993616891793,429.6854374438017,283.9768832443661
|
| 23 |
+
wikipedia,wikipedia,nn,1159.86,494.45,283.1,123.6,0.0013200962342698906,280.91195392289364,167.82742834163992
|
| 24 |
+
wikipedia,wikipedia,no,2058.62,612.2,324.6,139.3,0.0009966961122328344,363.387061861549,229.2323512781706
|
| 25 |
+
slimpajama,wikipedia,en,2259.2,756.5,534.4,418.5,0.006212514831977225,569.5492667529695,179.9279253054439
|
| 26 |
+
wikipedia,wikipedia,sv,1586.56,521.5,304.0,165.4,0.016951427796527165,325.8191384990417,163.13795554088844
|
| 27 |
+
wikipedia,wikipedia,en,1815.4,671.6,455.7,331.2,0.006112968939492834,470.655891042871,184.96531992400435
|
| 28 |
+
hplt,wikipedia,is,2310.06,1484.7,1160.3,921.3,0.001632796440658896,1119.008609637535,278.2396677657607
|
| 29 |
+
pg19,wikipedia,en,865.84,540.3,473.2,419.1,0.017132607020012576,460.9763713901977,63.76307180686858
|
| 30 |
+
starcoder,wikipedia,en,6898.5,2724.5,1603.4,972.4,0.0012712203723443047,1734.1527299358695,858.6110807589087
|
| 31 |
+
slimpajama,wikipedia,no,2259.2,756.5,534.4,418.5,0.006212514831977225,569.5492667529695,179.9279253054439
|
| 32 |
+
starcoder,wikipedia,no,6898.5,2724.5,1603.4,972.4,0.0012712203723443047,1734.1527299358695,858.6110807589087
|
| 33 |
+
pg19,wikipedia,no,865.84,540.3,473.2,419.1,0.017132607020012576,460.9763713901977,63.76307180686858
|
csv/extended-perplexity_quartiles_sampling.csv
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
doc_type,model,language,reject,bad,medium,good,norm,mean,std
|
| 2 |
+
books,books,no,542.15,301.25,219.3,165.12,0.0032422660862847633,208.18464621605895,68.02897458931068
|
| 3 |
+
culturax,wikipedia,nn,1113.2,753.4,559.9,387.7,0.001172357337862289,487.27059437715525,185.90322713836343
|
| 4 |
+
culturax,wikipedia,sv,1118.6,772.2,606.9,479.8,0.01049691458791544,580.0945047395821,142.99911605358275
|
| 5 |
+
culturax,wikipedia,da,1012.9,648.2,503.3,397.98,0.004277623423270203,488.615463864415,124.17368632962524
|
| 6 |
+
digimanus,wikipedia,no,1991.88,1226.65,989.1,830.35,0.0011146154086008851,974.7133669943673,209.08555530030617
|
| 7 |
+
culturax,wikipedia,no,1073.1,691.1,538.2,430.0,0.0017538216816248486,523.6960713940705,130.62730440702228
|
| 8 |
+
culturax,wikipedia,is,1420.0,884.5,720.2,594.5,0.0015467577497663453,693.7606785221377,147.6241796866134
|
| 9 |
+
evalueringsrapport,maalfrid,no,268.25,163.5,127.8,98.3,0.006540788722418088,117.29318501940242,34.47568292096079
|
| 10 |
+
hplt,wikipedia,nn,1539.1,980.6,772.7,627.5,0.0012826369023540814,752.0725635933572,179.13196906762977
|
| 11 |
+
lovdata,maalfrid,no,457.9,162.9,84.6,41.6,0.0038894207845140477,96.06375056993284,58.30277337274196
|
| 12 |
+
maalfrid,maalfrid,no,686.5,286.9,164.8,87.3,0.0022814356724527207,164.0258389923656,101.07016579025363
|
| 13 |
+
hplt,wikipedia,da,1445.5,829.3,616.3,493.5,0.0031953238688791816,630.7049612170936,168.77191092534918
|
| 14 |
+
book,books,no,636.48,302.58,187.4,67.0,0.002034229155801576,158.1210630456195,109.45691866057511
|
| 15 |
+
hplt,wikipedia,sv,1398.0,910.9,715.8,578.5,0.009237303662254026,698.8065459625257,165.03293101814995
|
| 16 |
+
hplt,wikipedia,no,1589.0,880.7,668.5,532.6,0.0013206924407238364,671.3073940020074,174.52833317000255
|
| 17 |
+
newspapers,newspapers,nn,1685.4,1221.9,1005.4,825.2,0.0011282397163826917,951.0683339330576,197.39448542294457
|
| 18 |
+
newspaper,newspapers,no,2308.6,792.3,475.2,307.9,0.0009454270671058767,526.1389696700705,244.38110894007406
|
| 19 |
+
parlamint,maalfrid,no,129.23,104.0,93.8,84.6,0.02105587174354365,89.24246433500929,10.099393230392014
|
| 20 |
+
newspapers,newspapers,no,782.3,466.7,336.0,243.5,0.002096701749929567,326.7656126928853,108.47162732564873
|
| 21 |
+
wikipedia,wikipedia,da,1226.31,470.7,278.7,127.0,0.003271371355924672,272.5462428872027,159.55477781562297
|
| 22 |
+
wikipedia,wikipedia,is,1893.3,740.7,449.1,174.5,0.0008204968084458965,429.6854374438017,283.9768832443661
|
| 23 |
+
wikipedia,wikipedia,nn,1159.86,494.45,283.1,123.6,0.0013200962342698906,280.91195392289364,167.82742834163992
|
| 24 |
+
wikipedia,wikipedia,no,2058.62,612.2,324.6,139.3,0.0009966961122328344,363.387061861549,229.2323512781706
|
| 25 |
+
slimpajama,wikipedia,en,2259.2,756.5,534.4,418.5,0.0016106519934755766,569.5492667529695,179.9279253054439
|
| 26 |
+
wikipedia,wikipedia,sv,1586.56,521.5,304.0,165.4,0.009040761491481156,325.8191384990417,163.13795554088844
|
| 27 |
+
wikipedia,wikipedia,en,1815.4,671.6,455.7,331.2,0.0015848437991277716,470.655891042871,184.96531992400435
|
| 28 |
+
hplt,wikipedia,is,2310.06,1484.7,1160.3,921.3,0.000816398220329448,1119.008609637535,278.2396677657607
|
| 29 |
+
pg19,wikipedia,en,865.84,540.3,473.2,419.1,0.004441787005188445,460.9763713901977,63.76307180686858
|
| 30 |
+
starcoder,wikipedia,code,6898.5,2724.5,1603.4,972.4,0.0004305746422456516,1734.1527299358695,858.6110807589087
|
| 31 |
+
restricted-newspapers,newspapers,no,847.7,451.7,328.5,246.5,0.002248478883149024,325.7155732204811,102.50329419364242
|
| 32 |
+
restricted-books,books,no,636.88,375.5,282.8,216.8,0.0028282201514638694,272.19155841413874,81.36986186892527
|
| 33 |
+
restricted-book,books,no,569.8,365.9,281.7,218.6,0.0030429861768025046,267.8089800338991,74.79791679414626
|
| 34 |
+
slimpajama,wikipedia,no,2259.2,756.5,534.4,418.5,0.0016106519934755766,569.5492667529695,179.9279253054439
|
| 35 |
+
starcoder,wikipedia,no,6898.5,2724.5,1603.4,972.4,0.0004305746422456516,1734.1527299358695,858.6110807589087
|
| 36 |
+
starcoder,wikipedia,code,6898.5,2724.5,1603.4,972.4,0.0004305746422456516,1734.1527299358695,858.6110807589087
|
| 37 |
+
pg19,wikipedia,no,865.84,540.3,473.2,419.1,0.004441787005188445,460.9763713901977,63.76307180686858
|
download_all.sh
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
mkdir kenlm
|
| 2 |
+
mv *arpa* kenlm/
|
| 3 |
+
|
| 4 |
+
mkdir spm
|
| 5 |
+
mv *.model spm/
|
| 6 |
+
mv *.vocab spm/
|
| 7 |
+
|
| 8 |
+
mkdir kenlm/harmful
|
| 9 |
+
wget -O kenlm/harmful/da.arpa https://huggingface.co/oscar-corpus/harmful-kenlms/resolve/main/da.arpa
|
| 10 |
+
wget -O kenlm/harmful/da.bin https://huggingface.co/oscar-corpus/harmful-kenlms/resolve/main/da.binary
|
| 11 |
+
wget -O kenlm/harmful/sv.arpa https://huggingface.co/oscar-corpus/harmful-kenlms/resolve/main/sv.arpa
|
| 12 |
+
wget -O kenlm/harmful/sv.bin https://huggingface.co/oscar-corpus/harmful-kenlms/resolve/main/sv.binary
|
| 13 |
+
wget -O kenlm/harmful/is.arpa https://huggingface.co/oscar-corpus/harmful-kenlms/resolve/main/is.arpa
|
| 14 |
+
wget -O kenlm/harmful/is.bin https://huggingface.co/oscar-corpus/harmful-kenlms/resolve/main/is.binary
|
| 15 |
+
wget -O kenlm/harmful/no.arpa https://huggingface.co/oscar-corpus/harmful-kenlms/resolve/main/no.arpa
|
| 16 |
+
wget -O kenlm/harmful/no.bin https://huggingface.co/oscar-corpus/harmful-kenlms/resolve/main/no.binary
|
| 17 |
+
wget -O kenlm/harmful/en.arpa https://huggingface.co/oscar-corpus/harmful-kenlms/resolve/main/en.arpa
|
| 18 |
+
wget -O kenlm/harmful/en.bin https://huggingface.co/oscar-corpus/harmful-kenlms/resolve/main/en.binary
|
| 19 |
+
|
| 20 |
+
mkdir kenlm/wikipedia
|
| 21 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O kenlm/wikipedia/da.arpa.bin https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/da.arpa.bin
|
| 22 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O kenlm/wikipedia/sv.arpa.bin https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/sv.arpa.bin
|
| 23 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O kenlm/wikipedia/is.arpa.bin https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/is.arpa.bin
|
| 24 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O kenlm/wikipedia/no.arpa.bin https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/no.arpa.bin
|
| 25 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O kenlm/wikipedia/nn.arpa.bin https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/nn.arpa.bin
|
| 26 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O kenlm/wikipedia/en.arpa.bin https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/en.arpa.bin
|
| 27 |
+
|
| 28 |
+
mkdir spm/wikipedia
|
| 29 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O spm/wikipedia/da.sp.model https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/da.sp.model
|
| 30 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O spm/wikipedia/sv.sp.model https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/sv.sp.model
|
| 31 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O spm/wikipedia/is.sp.model https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/is.sp.model
|
| 32 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O spm/wikipedia/no.sp.model https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/no.sp.model
|
| 33 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O spm/wikipedia/nn.sp.model https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/nn.sp.model
|
| 34 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O spm/wikipedia/en.sp.model https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/en.sp.model
|
| 35 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O spm/wikipedia/da.sp.vocab https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/da.sp.vocab
|
| 36 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O spm/wikipedia/sv.sp.vocab https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/sv.sp.vocab
|
| 37 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O spm/wikipedia/is.sp.vocab https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/is.sp.vocab
|
| 38 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O spm/wikipedia/no.sp.vocab https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/no.sp.vocab
|
| 39 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O spm/wikipedia/nn.sp.vocab https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/nn.sp.vocab
|
| 40 |
+
wget --header="Authorization: Bearer $(cat $HOME/.cache/huggingface/token)" -O spm/wikipedia/en.sp.vocab https://huggingface.co/uonlp/kenlm/resolve/main/wikipedia_20230501/en.sp.vocab
|
histograms.py
ADDED
|
@@ -0,0 +1,104 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import pandas as pd
|
| 2 |
+
import matplotlib.pyplot as plt
|
| 3 |
+
import seaborn as sns
|
| 4 |
+
import json
|
| 5 |
+
import argparse
|
| 6 |
+
import os
|
| 7 |
+
from scipy.stats import gaussian_kde
|
| 8 |
+
import numpy as np
|
| 9 |
+
|
| 10 |
+
def get_model_for(doc_type: str, override_model: str) -> str:
|
| 11 |
+
"""Returns model type or the override model if specified"""
|
| 12 |
+
if override_model:
|
| 13 |
+
return override_model
|
| 14 |
+
doc_type = doc_type.split("_", 1)[0]
|
| 15 |
+
if doc_type in ("book", "books", "pg19"):
|
| 16 |
+
return "books_pp"
|
| 17 |
+
elif doc_type in ("culturax", "slimpajama", "wikipedia", "digimanus"):
|
| 18 |
+
return "wikipedia_pp"
|
| 19 |
+
elif doc_type in ("newspaper", "newspapers"):
|
| 20 |
+
return "newspapers_pp"
|
| 21 |
+
elif doc_type in ("evalueringsrapport", "lovdata", "maalfrid", "parlamint"):
|
| 22 |
+
return "maalfrid_pp"
|
| 23 |
+
else:
|
| 24 |
+
return "wikipedia_pp"
|
| 25 |
+
|
| 26 |
+
def load_data(files):
|
| 27 |
+
all_data = []
|
| 28 |
+
for file_path in files:
|
| 29 |
+
with open(file_path, 'r') as file:
|
| 30 |
+
lines = file.readlines()
|
| 31 |
+
data = [json.loads(line) for line in lines]
|
| 32 |
+
all_data.extend(data)
|
| 33 |
+
return pd.DataFrame(all_data)
|
| 34 |
+
|
| 35 |
+
def plot_histograms(files, output_folder, xlim, override_model):
|
| 36 |
+
df = load_data(files)
|
| 37 |
+
doc_types = df['doctype'].unique()
|
| 38 |
+
fig, axes = plt.subplots(len(doc_types), 1, figsize=(12, 4 * len(doc_types)), squeeze=False)
|
| 39 |
+
|
| 40 |
+
# Set up a color palette
|
| 41 |
+
palette = sns.color_palette("husl", len(doc_types))
|
| 42 |
+
|
| 43 |
+
for i, doc_type in enumerate(doc_types):
|
| 44 |
+
ax = axes[i, 0]
|
| 45 |
+
group = df[df['doctype'] == doc_type]
|
| 46 |
+
languages = group['lang'].unique()
|
| 47 |
+
|
| 48 |
+
# Prepare a unique color for each language within the document type
|
| 49 |
+
colors = sns.color_palette("husl", len(languages))
|
| 50 |
+
|
| 51 |
+
for j, lang in enumerate(languages):
|
| 52 |
+
lang_group = group[group['lang'] == lang]
|
| 53 |
+
perplexity_model = get_model_for(doc_type, override_model)
|
| 54 |
+
perplexity_values = lang_group['perplexities'].apply(lambda x: x[perplexity_model]).values
|
| 55 |
+
|
| 56 |
+
series_color = colors[j]
|
| 57 |
+
|
| 58 |
+
# Plot histogram with lighter color
|
| 59 |
+
sns.histplot(perplexity_values, ax=ax, color=series_color, alpha=0.3, element="step", fill=True, stat="density", binwidth=30)
|
| 60 |
+
|
| 61 |
+
# Plot KDE without filling
|
| 62 |
+
sns.kdeplot(perplexity_values, ax=ax, bw_adjust=2, color=series_color, label=f"{lang} - {doc_type} ({perplexity_model})", linewidth=1.5)
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
kde = gaussian_kde(perplexity_values)
|
| 66 |
+
x_range = np.linspace(0, xlim, 1000)
|
| 67 |
+
y_values = kde.evaluate(x_range)
|
| 68 |
+
|
| 69 |
+
quartiles = np.quantile(perplexity_values, [0.25, 0.5, 0.75])
|
| 70 |
+
quartile_labels = ["Q1", "Q2", "Q3"]
|
| 71 |
+
for q, quartile in enumerate(quartiles):
|
| 72 |
+
idx = (np.abs(x_range-quartile)).argmin()
|
| 73 |
+
y_quartile = y_values[idx]
|
| 74 |
+
ax.plot([quartile, quartile], [0, y_quartile], color=series_color, linestyle='--', linewidth=1)
|
| 75 |
+
ax.text(quartile, y_quartile, f'{quartile_labels[q]}: {quartile:.2f}', verticalalignment='bottom', horizontalalignment='right', color=series_color, fontsize=6)
|
| 76 |
+
|
| 77 |
+
ax.set_title(f'Document Type: {doc_type} ({perplexity_model})')
|
| 78 |
+
ax.set_xlabel('Perplexity Value')
|
| 79 |
+
ax.set_ylabel('Density')
|
| 80 |
+
ax.legend()
|
| 81 |
+
ax.set_xlim(left=0, right=xlim)
|
| 82 |
+
|
| 83 |
+
plt.tight_layout()
|
| 84 |
+
output_filename = os.path.join(output_folder, "all_doc_types_plots.png")
|
| 85 |
+
plt.savefig(output_filename, dpi=300)
|
| 86 |
+
plt.close(fig)
|
| 87 |
+
print(f"All document type plots saved to {output_filename}")
|
| 88 |
+
|
| 89 |
+
def main():
|
| 90 |
+
parser = argparse.ArgumentParser(description="Plot histograms from JSON lines files.")
|
| 91 |
+
parser.add_argument('files', nargs='+', help="Path to the JSON lines files")
|
| 92 |
+
parser.add_argument('-o', '--output_folder', default=".", help="Output folder for the plots")
|
| 93 |
+
parser.add_argument('--xlim', type=int, default=2500, help="Maximum x-axis limit for the plots")
|
| 94 |
+
parser.add_argument('--model', default="", help="Override the perplexity model for all plots")
|
| 95 |
+
|
| 96 |
+
args = parser.parse_args()
|
| 97 |
+
|
| 98 |
+
if not os.path.exists(args.output_folder):
|
| 99 |
+
os.makedirs(args.output_folder, exist_ok=True)
|
| 100 |
+
|
| 101 |
+
plot_histograms(args.files, args.output_folder, args.xlim, args.model)
|
| 102 |
+
|
| 103 |
+
if __name__ == "__main__":
|
| 104 |
+
main()
|
kenlm/books.norm.arpa.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:bc2058f3fe709dcdc9e02c3094d9dba6e1d9e2846e3064fd597b632bdda7424f
|
| 3 |
+
size 26787259332
|
kenlm/books.norm.arpa.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:16934f2f95c19d22bf681552c5b667483e80915a72ed559e954914f492513604
|
| 3 |
+
size 14951532895
|
kenlm/books.norm.sp.arpa.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:582210ccef9a44feb2dde5029e3b02986ba3bb50d06152e2850a863fee8df16d
|
| 3 |
+
size 27269792294
|
kenlm/books.norm.sp.arpa.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c67bb924e8d2e0515037b1aca7c381267e7363d95ae4c5a773ae8517f9c34f81
|
| 3 |
+
size 14081165146
|
kenlm/harmful/.keep
ADDED
|
File without changes
|
kenlm/maalfrid.norm.arpa
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:9964b5a0a25e8d8f352bd85ee3de5cea80cd56cb033f4831c83e450ef42ee9b2
|
| 3 |
+
size 14095675125
|
kenlm/maalfrid.norm.arpa.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:4468f452cd224c25a7ab125f930692d415ba9a44564b6d8590ae60a697021ff8
|
| 3 |
+
size 6334870758
|
kenlm/maalfrid.norm.sp.arpa
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:12acfaf2360adec24e0456c0c9ab2a3199eda397dddb8c6b194ac7376d0811d5
|
| 3 |
+
size 15096276243
|
kenlm/maalfrid.norm.sp.arpa.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:05f2b5ee9ad6f953bcfb6ed31584706225d8390275fb78b4848b1dd697fbedb6
|
| 3 |
+
size 5938309481
|
kenlm/newspapers.norm.arpa
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d87f6044f5f3b58b94c23e556ef2fef1f2f5cee4f27f0bd81293e6d6bb2579ff
|
| 3 |
+
size 2151432996
|
kenlm/newspapers.norm.arpa.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:e63eef20ccd2a4977f1cd314e3d42ec3c04fe68ec5fb3a5ff37e2af64d966c9a
|
| 3 |
+
size 1095860943
|
kenlm/newspapers.norm.sp.arpa
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:65bb2007e807efcb548f51c18b9c7791606bd11807e292d250051efd4529ee7b
|
| 3 |
+
size 2660277943
|
kenlm/newspapers.norm.sp.arpa.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:50a79b25fc03c34278dc2cbb0b91119dfe3ba3d1e6c671b9a81127edf3746a67
|
| 3 |
+
size 1217336194
|
kenlm/wikipedia/.keep
ADDED
|
File without changes
|
normalization.py
ADDED
|
@@ -0,0 +1,154 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import unicodedata
|
| 3 |
+
import re
|
| 4 |
+
from tqdm import tqdm
|
| 5 |
+
|
| 6 |
+
# Copyright (c) Facebook, Inc. and its affiliates.
|
| 7 |
+
#
|
| 8 |
+
# This source code is licensed under the MIT license found in the
|
| 9 |
+
# LICENSE file in the root directory of this source tree.
|
| 10 |
+
#
|
| 11 |
+
|
| 12 |
+
import re
|
| 13 |
+
import unicodedata
|
| 14 |
+
|
| 15 |
+
PUNCTS = '!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~«»'
|
| 16 |
+
UNICODE_PUNCT = {
|
| 17 |
+
",": ",",
|
| 18 |
+
"。": ".",
|
| 19 |
+
"、": ",",
|
| 20 |
+
"„": '"',
|
| 21 |
+
"”": '"',
|
| 22 |
+
"“": '"',
|
| 23 |
+
"«": '"',
|
| 24 |
+
"»": '"',
|
| 25 |
+
"1": '"',
|
| 26 |
+
"」": '"',
|
| 27 |
+
"「": '"',
|
| 28 |
+
"《": '"',
|
| 29 |
+
"》": '"',
|
| 30 |
+
"´": "'",
|
| 31 |
+
"∶": ":",
|
| 32 |
+
":": ":",
|
| 33 |
+
"?": "?",
|
| 34 |
+
"!": "!",
|
| 35 |
+
"(": "(",
|
| 36 |
+
")": ")",
|
| 37 |
+
";": ";",
|
| 38 |
+
"–": "-",
|
| 39 |
+
"—": " - ",
|
| 40 |
+
".": ". ",
|
| 41 |
+
"~": "~",
|
| 42 |
+
"’": "'",
|
| 43 |
+
"…": "...",
|
| 44 |
+
"━": "-",
|
| 45 |
+
"〈": "<",
|
| 46 |
+
"〉": ">",
|
| 47 |
+
"【": "[",
|
| 48 |
+
"】": "]",
|
| 49 |
+
"%": "%",
|
| 50 |
+
"►": "-",
|
| 51 |
+
"■": " ", # added for Mimir
|
| 52 |
+
}
|
| 53 |
+
|
| 54 |
+
UNICODE_PUNCT_RE = re.compile(f"[{''.join(UNICODE_PUNCT.keys())}]")
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
def replace_unicode_punct(text: str) -> str:
|
| 58 |
+
return "".join(UNICODE_PUNCT.get(c, c) for c in text)
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def remove_unicode_punct(text: str) -> str:
|
| 62 |
+
"""More aggressive version of replace_unicode_punct but also faster."""
|
| 63 |
+
return UNICODE_PUNCT_RE.sub("", text)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def strip_accents(line: str) -> str:
|
| 67 |
+
"""Strips accents from a piece of text."""
|
| 68 |
+
nfd = unicodedata.normalize("NFD", line)
|
| 69 |
+
output = [c for c in nfd if unicodedata.category(c) != "Mn"]
|
| 70 |
+
if len(output) == line:
|
| 71 |
+
return line
|
| 72 |
+
return "".join(output)
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
# Build a regex matching all control characters.
|
| 76 |
+
NON_PRINTING_CHARS_RE = re.compile(
|
| 77 |
+
f"[{''.join(map(chr, list(range(0,32)) + list(range(127,160))))}]"
|
| 78 |
+
)
|
| 79 |
+
DIGIT_RE = re.compile(r"\d")
|
| 80 |
+
PUNCT_OR_NON_PRINTING_CHARS_RE = re.compile(
|
| 81 |
+
(UNICODE_PUNCT_RE.pattern + NON_PRINTING_CHARS_RE.pattern).replace("][", "")
|
| 82 |
+
)
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def remove_non_printing_char(text: str) -> str:
|
| 86 |
+
return NON_PRINTING_CHARS_RE.sub("", text)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def normalize(line: str, accent=True, case=True, numbers=True, punct=1) -> str:
|
| 90 |
+
line = line.strip()
|
| 91 |
+
if not line:
|
| 92 |
+
return line
|
| 93 |
+
if case:
|
| 94 |
+
line = line.lower()
|
| 95 |
+
if accent:
|
| 96 |
+
line = strip_accents(line)
|
| 97 |
+
if numbers:
|
| 98 |
+
line = DIGIT_RE.sub("0", line)
|
| 99 |
+
if punct == 1:
|
| 100 |
+
line = replace_unicode_punct(line)
|
| 101 |
+
elif punct == 2:
|
| 102 |
+
line = remove_unicode_punct(line)
|
| 103 |
+
line = remove_non_printing_char(line)
|
| 104 |
+
return line
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def slow_normalize_for_dedup(line: str) -> str:
|
| 108 |
+
return normalize(line, accent=False, case=True, numbers=True, punct=2)
|
| 109 |
+
|
| 110 |
+
|
| 111 |
+
def normalize_for_dedup(line: str) -> str:
|
| 112 |
+
line = line.strip()
|
| 113 |
+
if not line:
|
| 114 |
+
return line
|
| 115 |
+
# case
|
| 116 |
+
line = line.lower()
|
| 117 |
+
# numbers
|
| 118 |
+
line = DIGIT_RE.sub("0", line)
|
| 119 |
+
line = PUNCT_OR_NON_PRINTING_CHARS_RE.sub("", line)
|
| 120 |
+
return line
|
| 121 |
+
|
| 122 |
+
## START OF MIMIR CODE
|
| 123 |
+
def normalize_text(line):
|
| 124 |
+
normalized_line = unicodedata.normalize('NFKC', line).lower()
|
| 125 |
+
|
| 126 |
+
# Add a trailing dot if the line does not end with a punctuation mark
|
| 127 |
+
normalized_line = normalized_line.rstrip()
|
| 128 |
+
if normalized_line and normalized_line[-1] not in PUNCTS:
|
| 129 |
+
normalized_line += '.'
|
| 130 |
+
|
| 131 |
+
# Replace newline characters with spaces (if any remain)
|
| 132 |
+
# normalized_line = re.sub(r'\r\n|\r|\n', ' ', normalized_line)
|
| 133 |
+
normalized_line = normalize(normalized_line, accent=False, case=True, numbers=True, punct=1)
|
| 134 |
+
return normalized_line
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
def normalize_file(input_file, output_file, cutoff=None):
|
| 138 |
+
with (open(output_file, 'w', encoding='utf-8') as f,
|
| 139 |
+
open(input_file, 'r', encoding='utf-8') as lines):
|
| 140 |
+
for line_count, line in tqdm(enumerate(lines), desc="Processing"):
|
| 141 |
+
f.write(normalize_text(line) + "\n")
|
| 142 |
+
if cutoff and line_count >= cutoff:
|
| 143 |
+
break
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
if __name__ == "__main__":
|
| 147 |
+
parser = argparse.ArgumentParser(description='Normalize text file line by line, ensure trailing punctuation, replace newlines with spaces, and show progress.')
|
| 148 |
+
parser.add_argument('input_file', type=str, help='Input file path')
|
| 149 |
+
parser.add_argument('output_file', type=str, help='Output file path')
|
| 150 |
+
parser.add_argument('--cutoff', required=False, type=int, help='Max number of lines to process')
|
| 151 |
+
|
| 152 |
+
args = parser.parse_args()
|
| 153 |
+
|
| 154 |
+
normalize_file(args.input_file, args.output_file, args.cutoff)
|
notebooks/gaussian_sampling.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
notebooks/gaussian_subsampling.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
perplexity.py
ADDED
|
@@ -0,0 +1,449 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import re
|
| 4 |
+
import os
|
| 5 |
+
from functools import cache
|
| 6 |
+
from pathlib import Path
|
| 7 |
+
from typing import Iterator, List, NoReturn, Optional, Tuple, Union
|
| 8 |
+
|
| 9 |
+
import kenlm
|
| 10 |
+
import msgspec
|
| 11 |
+
import sentencepiece
|
| 12 |
+
from numpy.random import default_rng
|
| 13 |
+
from scipy.stats import norm
|
| 14 |
+
from tqdm import tqdm
|
| 15 |
+
|
| 16 |
+
from normalization import normalize_text
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
RNG = default_rng()
|
| 20 |
+
LANGS = ("no", "nn", "nob", "nno", "da", "sv", "is", "en")
|
| 21 |
+
DEFAULT_LANG = "no"
|
| 22 |
+
BASEPATH = Path(os.environ.get("PERPLEXITY_BASEPATH", "/nfsmounts/datastore/mimir/perplexity"))
|
| 23 |
+
CONFIG = {
|
| 24 |
+
"harmful": {
|
| 25 |
+
"no": {"model": BASEPATH / "kenlm" / "harmful" / "no.bin", "normalize": True},
|
| 26 |
+
"nn": {"model": BASEPATH / "kenlm" / "harmful" / "no.bin", "normalize": True},
|
| 27 |
+
"nob": {"model": BASEPATH / "kenlm" / "harmful" / "no.bin", "normalize": True},
|
| 28 |
+
"nno": {"model": BASEPATH / "kenlm" / "harmful" / "no.bin", "normalize": True},
|
| 29 |
+
"da": {"model": BASEPATH / "kenlm" / "harmful" / "da.bin", "normalize": True},
|
| 30 |
+
"sv": {"model": BASEPATH / "kenlm" / "harmful" / "sv.bin", "normalize": True},
|
| 31 |
+
"is": {"model": BASEPATH / "kenlm" / "harmful" / "is.bin", "normalize": True},
|
| 32 |
+
"en": {"model": BASEPATH / "kenlm" / "harmful" / "en.bin", "normalize": True},
|
| 33 |
+
},
|
| 34 |
+
"wikipedia": {
|
| 35 |
+
"no": {
|
| 36 |
+
"model": BASEPATH / "kenlm" / "wikipedia" / "no.arpa.bin",
|
| 37 |
+
"tokenizer": BASEPATH / "spm" / "wikipedia" / "no.sp.model",
|
| 38 |
+
"normalize": True
|
| 39 |
+
},
|
| 40 |
+
"nn": {
|
| 41 |
+
"model": BASEPATH / "kenlm" / "wikipedia" / "nn.arpa.bin",
|
| 42 |
+
"tokenizer": BASEPATH / "spm" / "wikipedia" / "nn.sp.model",
|
| 43 |
+
"normalize": True
|
| 44 |
+
},
|
| 45 |
+
"nob": {
|
| 46 |
+
"model": BASEPATH / "kenlm" / "wikipedia" / "no.arpa.bin",
|
| 47 |
+
"tokenizer": BASEPATH / "spm" / "wikipedia" / "no.sp.model",
|
| 48 |
+
"normalize": True
|
| 49 |
+
},
|
| 50 |
+
"nno": {
|
| 51 |
+
"model": BASEPATH / "kenlm" / "wikipedia" / "nn.arpa.bin",
|
| 52 |
+
"tokenizer": BASEPATH / "spm" / "wikipedia" / "nn.sp.model",
|
| 53 |
+
"normalize": True
|
| 54 |
+
},
|
| 55 |
+
"da": {
|
| 56 |
+
"model": BASEPATH / "kenlm" / "wikipedia" / "da.arpa.bin",
|
| 57 |
+
"tokenizer": BASEPATH / "spm" / "wikipedia" / "da.sp.model",
|
| 58 |
+
"normalize": True
|
| 59 |
+
},
|
| 60 |
+
"en": {
|
| 61 |
+
"model": BASEPATH / "kenlm" / "wikipedia" / "en.arpa.bin",
|
| 62 |
+
"tokenizer": BASEPATH / "spm" / "wikipedia" / "en.sp.model",
|
| 63 |
+
"normalize": True
|
| 64 |
+
},
|
| 65 |
+
"is": {
|
| 66 |
+
"model": BASEPATH / "kenlm" / "wikipedia" / "is.arpa.bin",
|
| 67 |
+
"tokenizer": BASEPATH / "spm" / "wikipedia" / "is.sp.model",
|
| 68 |
+
"normalize": True
|
| 69 |
+
},
|
| 70 |
+
"sv": {
|
| 71 |
+
"model": BASEPATH / "kenlm" / "wikipedia" / "sv.arpa.bin",
|
| 72 |
+
"tokenizer": BASEPATH / "spm" / "wikipedia" / "sv.sp.model",
|
| 73 |
+
"normalize": True
|
| 74 |
+
},
|
| 75 |
+
},
|
| 76 |
+
"books": {
|
| 77 |
+
"model": BASEPATH / "kenlm" / "books.norm.sp.arpa.bin",
|
| 78 |
+
"tokenizer": BASEPATH / "spm" / "books.norm.sp.model",
|
| 79 |
+
"normalize": True
|
| 80 |
+
},
|
| 81 |
+
"newspapers": {
|
| 82 |
+
"model": BASEPATH / "kenlm" / "newspapers.norm.sp.arpa.bin",
|
| 83 |
+
"tokenizer": BASEPATH / "spm" / "newspapers.norm.sp.model",
|
| 84 |
+
"normalize": True
|
| 85 |
+
},
|
| 86 |
+
"maalfrid": {
|
| 87 |
+
"model": BASEPATH / "kenlm" / "maalfrid.norm.sp.arpa.bin",
|
| 88 |
+
"tokenizer": BASEPATH / "spm" / "maalfrid.norm.sp.model",
|
| 89 |
+
"normalize": True
|
| 90 |
+
}
|
| 91 |
+
}
|
| 92 |
+
|
| 93 |
+
# Not used anymore, speed is almost same as naive algorithm
|
| 94 |
+
# class PerplexityDoc(msgspec.Struct):
|
| 95 |
+
# id: str
|
| 96 |
+
# doc_type: str
|
| 97 |
+
# publish_year: int
|
| 98 |
+
# lang_fasttext: str
|
| 99 |
+
# lang_fasttext_conf: Union[str, float]
|
| 100 |
+
# text: str
|
| 101 |
+
# perplexity: float | None = -1.0
|
| 102 |
+
# perplexity_model: str | None = None
|
| 103 |
+
# harmful_pp: float | None = None
|
| 104 |
+
# # wikipedia_pp: float | None = None
|
| 105 |
+
# # books_pp: float | None = None
|
| 106 |
+
# # newspapers_pp: float | None = None
|
| 107 |
+
# # maalfrid_pp: float | None = None
|
| 108 |
+
|
| 109 |
+
|
| 110 |
+
def should_keep(
|
| 111 |
+
perp: float, dist_norm: float, dist_mean: float, dist_std: float
|
| 112 |
+
) -> bool:
|
| 113 |
+
"""
|
| 114 |
+
Decide if a doc is to be retained based on its perplexity value
|
| 115 |
+
Note: set() must have been called previously
|
| 116 |
+
"""
|
| 117 |
+
p = norm.pdf(perp, loc=dist_mean, scale=dist_std) / dist_norm
|
| 118 |
+
return RNG.uniform() < p
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def fix_language(language: str) -> str:
|
| 122 |
+
if language not in LANGS:
|
| 123 |
+
return DEFAULT_LANG
|
| 124 |
+
else:
|
| 125 |
+
return language
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
def pp(log_score, length):
|
| 129 |
+
return 10.0 ** (-log_score / length)
|
| 130 |
+
|
| 131 |
+
|
| 132 |
+
@cache
|
| 133 |
+
def load_kenlm(model: str) -> kenlm.Model:
|
| 134 |
+
lm_config = kenlm.Config()
|
| 135 |
+
lm_config.load_method = 2
|
| 136 |
+
return kenlm.Model(str(model), lm_config)
|
| 137 |
+
|
| 138 |
+
|
| 139 |
+
@cache
|
| 140 |
+
def load_sentencepiece(model: str) -> sentencepiece.SentencePieceProcessor:
|
| 141 |
+
sp = sentencepiece.SentencePieceProcessor()
|
| 142 |
+
sp.load(str(model))
|
| 143 |
+
return sp
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def get_perplexity(
|
| 147 |
+
document: str,
|
| 148 |
+
model: str,
|
| 149 |
+
tokenizer: str=None,
|
| 150 |
+
normalize: bool=False
|
| 151 |
+
) -> float:
|
| 152 |
+
lines = document.split("\n")
|
| 153 |
+
model = load_kenlm(model)
|
| 154 |
+
if not lines or not model:
|
| 155 |
+
return 0.0
|
| 156 |
+
if tokenizer:
|
| 157 |
+
sp = load_sentencepiece(tokenizer)
|
| 158 |
+
doc_log_score, doc_length = 0, 0
|
| 159 |
+
for line in lines:
|
| 160 |
+
if not line:
|
| 161 |
+
continue
|
| 162 |
+
if normalize:
|
| 163 |
+
line = normalize_text(line)
|
| 164 |
+
if tokenizer:
|
| 165 |
+
line = " ".join(sp.encode_as_pieces(line))
|
| 166 |
+
log_score = model.score(line)
|
| 167 |
+
length = len(line.split()) + 1
|
| 168 |
+
doc_log_score += log_score
|
| 169 |
+
doc_length += length
|
| 170 |
+
|
| 171 |
+
return round(pp(doc_log_score, doc_length), 1)
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
def get_perplexity_local(
|
| 175 |
+
document: str,
|
| 176 |
+
model: kenlm.Model,
|
| 177 |
+
tokenizer: sentencepiece.SentencePieceProcessor=None,
|
| 178 |
+
normalize: bool=False
|
| 179 |
+
) -> float:
|
| 180 |
+
lines = document.split("\n")
|
| 181 |
+
if not lines or not model:
|
| 182 |
+
return 0.0
|
| 183 |
+
doc_log_score, doc_length = 0, 0
|
| 184 |
+
for line in lines:
|
| 185 |
+
if normalize:
|
| 186 |
+
line = normalize_text(line)
|
| 187 |
+
if tokenizer is not None:
|
| 188 |
+
line = " ".join(tokenizer.encode_as_pieces(line))
|
| 189 |
+
log_score = model.score(line)
|
| 190 |
+
length = len(line.split()) + 1
|
| 191 |
+
doc_log_score += log_score
|
| 192 |
+
doc_length += length
|
| 193 |
+
|
| 194 |
+
return round(pp(doc_log_score, doc_length), 1)
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
def harmful_perplexity(document: str, language: str) -> float:
|
| 198 |
+
params = CONFIG["harmful"][fix_lang(language)]
|
| 199 |
+
return get_perplexity(document=document, **params)
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
def wikipedia_perplexity(document: str, language: str) -> float:
|
| 203 |
+
params = CONFIG["wikipedia"][fix_lang(language)]
|
| 204 |
+
return get_perplexity(document=document, **params)
|
| 205 |
+
|
| 206 |
+
|
| 207 |
+
def books_perplexity(document: str) -> float:
|
| 208 |
+
params = CONFIG["books"]
|
| 209 |
+
return get_perplexity(document=document, **params)
|
| 210 |
+
|
| 211 |
+
|
| 212 |
+
def newspapers_perplexity(document: str) -> float:
|
| 213 |
+
params = CONFIG["newspapers"]
|
| 214 |
+
return get_perplexity(document=document, **params)
|
| 215 |
+
|
| 216 |
+
|
| 217 |
+
def maalfrid_perplexity(document: str) -> float:
|
| 218 |
+
params = CONFIG["maalfrid"]
|
| 219 |
+
return get_perplexity(document=document, **params)
|
| 220 |
+
|
| 221 |
+
|
| 222 |
+
def source_perplexities(
|
| 223 |
+
document: str,
|
| 224 |
+
language: str,
|
| 225 |
+
model: str | None = None,
|
| 226 |
+
include_harmful: bool=True) -> float:
|
| 227 |
+
"""Calculates all models perplexities at once"""
|
| 228 |
+
# Since normalization is applied to all, we normalize first and set it to False
|
| 229 |
+
normalized_document = "\n".join(normalize_text(line) for line in document.split("\n"))
|
| 230 |
+
language = fix_language(language)
|
| 231 |
+
|
| 232 |
+
if model is not None:
|
| 233 |
+
params = CONFIG[model]
|
| 234 |
+
if model == "wikipedia":
|
| 235 |
+
params = params[language]
|
| 236 |
+
params.update({"normalize": False})
|
| 237 |
+
perplexity = get_perplexity(document=normalized_document, **params)
|
| 238 |
+
perplexities = {
|
| 239 |
+
f"{model}_pp": perplexity,
|
| 240 |
+
}
|
| 241 |
+
else:
|
| 242 |
+
params = CONFIG["wikipedia"][language]
|
| 243 |
+
params.update({"normalize": False})
|
| 244 |
+
wikipedia_perplexity = get_perplexity(document=normalized_document, **params)
|
| 245 |
+
|
| 246 |
+
params = CONFIG["books"]
|
| 247 |
+
params.update({"normalize": False})
|
| 248 |
+
books_perplexity = get_perplexity(document=normalized_document, **params)
|
| 249 |
+
|
| 250 |
+
params = CONFIG["newspapers"]
|
| 251 |
+
params.update({"normalize": False})
|
| 252 |
+
newspapers_perplexity = get_perplexity(document=normalized_document, **params)
|
| 253 |
+
|
| 254 |
+
params = CONFIG["maalfrid"]
|
| 255 |
+
params.update({"normalize": False})
|
| 256 |
+
maalfrid_perplexity = get_perplexity(document=normalized_document, **params)
|
| 257 |
+
perplexities = {
|
| 258 |
+
"wikipedia_pp": wikipedia_perplexity,
|
| 259 |
+
"books_pp": books_perplexity,
|
| 260 |
+
"newspapers_pp": newspapers_perplexity,
|
| 261 |
+
"maalfrid_pp": maalfrid_perplexity,
|
| 262 |
+
}
|
| 263 |
+
if include_harmful:
|
| 264 |
+
params = CONFIG["harmful"][language]
|
| 265 |
+
params.update({"normalize": False})
|
| 266 |
+
harmful_perplexity = get_perplexity(document=normalized_document, **params)
|
| 267 |
+
perplexities.update({
|
| 268 |
+
"harmful_pp": harmful_perplexity,
|
| 269 |
+
})
|
| 270 |
+
return perplexities
|
| 271 |
+
|
| 272 |
+
|
| 273 |
+
def get_model_for(doc_type: str) -> (str, bool):
|
| 274 |
+
"""Returns model type and if it needs a language variant"""
|
| 275 |
+
doc_type = doc_type.split("_", 1)[0]
|
| 276 |
+
if "-" in doc_type:
|
| 277 |
+
doc_type = doc_type.split("-", 1)[-1]
|
| 278 |
+
if doc_type in ("book", "books"):
|
| 279 |
+
return "books", False
|
| 280 |
+
elif doc_type in ("culturax", "slimpajama", "wikipedia", "digimanus", "pg19", "hplt", "starcoder"):
|
| 281 |
+
return "wikipedia", True
|
| 282 |
+
elif doc_type in ("newspaper", "newspapers"):
|
| 283 |
+
return "newspapers", False
|
| 284 |
+
elif doc_type in ("evalueringsrapport", "lovdata", "maalfrid", "parlamint"):
|
| 285 |
+
return "maalfrid", False
|
| 286 |
+
else:
|
| 287 |
+
return "wikipedia", True
|
| 288 |
+
|
| 289 |
+
|
| 290 |
+
def preload_models_tokenizers() -> List:
|
| 291 |
+
print("Preloading models...", end=" ")
|
| 292 |
+
models = {
|
| 293 |
+
"books": (
|
| 294 |
+
load_kenlm(BASEPATH / "kenlm" / "books.norm.arpa.bin"),
|
| 295 |
+
load_sentencepiece(BASEPATH / "spm" / "books.norm.sp.model")
|
| 296 |
+
),
|
| 297 |
+
"newspapers": (
|
| 298 |
+
load_kenlm(BASEPATH / "kenlm" / "newspapers.norm.arpa.bin"),
|
| 299 |
+
load_sentencepiece(BASEPATH / "spm" / "newspapers.norm.sp.model")
|
| 300 |
+
),
|
| 301 |
+
"maalfrid": (
|
| 302 |
+
load_kenlm(BASEPATH / "kenlm" / "maalfrid.norm.arpa.bin"),
|
| 303 |
+
load_sentencepiece(BASEPATH / "spm" / "maalfrid.norm.sp.model")
|
| 304 |
+
),
|
| 305 |
+
}
|
| 306 |
+
for lang, params in CONFIG["harmful"].items():
|
| 307 |
+
model = load_kenlm(params["model"])
|
| 308 |
+
models[f"harmful-{lang}"] = model, None
|
| 309 |
+
|
| 310 |
+
for lang, params in CONFIG["wikipedia"].items():
|
| 311 |
+
model = load_kenlm(params["model"])
|
| 312 |
+
tokenizer = load_sentencepiece(params["tokenizer"])
|
| 313 |
+
models[f"wikipedia-{lang}"] = model, tokenizer
|
| 314 |
+
print("Done")
|
| 315 |
+
return models
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
# Not used anymore, speed is almost same as naive algorithm
|
| 319 |
+
# def process_file_binary(input_file, output_path, cutoff=None, overwrite_output=True):
|
| 320 |
+
# input_file = Path(input_file)
|
| 321 |
+
# output_file = Path(output_path) / input_file.name
|
| 322 |
+
# if not overwrite_output and output_file.exists():
|
| 323 |
+
# print(f"Skipping {output_file} as it already exists")
|
| 324 |
+
# return
|
| 325 |
+
# models = preload_models_tokenizers()
|
| 326 |
+
# encoder = msgspec.json.Encoder()
|
| 327 |
+
# decoder = msgspec.json.Decoder(PerplexityDoc)
|
| 328 |
+
# buffer = bytearray(64)
|
| 329 |
+
# with (open(output_file, 'wb') as f,
|
| 330 |
+
# open(input_file, 'r', encoding='utf-8') as lines):
|
| 331 |
+
# for line_count, line in tqdm(enumerate(lines), desc=f"Processing {input_file.name}"):
|
| 332 |
+
# doc = decoder.decode(line)
|
| 333 |
+
# if "code" not in doc.doc_type:
|
| 334 |
+
# # Perplexity
|
| 335 |
+
# model_type, needs_lang = get_model_for(doc.doc_type)
|
| 336 |
+
# if needs_lang:
|
| 337 |
+
# model_key = f"{model_type}-{fix_language(doc.lang_fasttext)}"
|
| 338 |
+
# else:
|
| 339 |
+
# model_key = model_type
|
| 340 |
+
# model, tokenizer = models[model_key]
|
| 341 |
+
# text = "\n".join(normalize_text(line) for line in doc.text.split("\n"))
|
| 342 |
+
# score = get_perplexity_local(
|
| 343 |
+
# text, model=model, tokenizer=tokenizer, normalize=False
|
| 344 |
+
# )
|
| 345 |
+
# doc.perplexity = score
|
| 346 |
+
# doc.perplexity_model = model_type
|
| 347 |
+
# # Harmfulness
|
| 348 |
+
# harmful_key = f"harmful-{fix_language(doc.lang_fasttext)}"
|
| 349 |
+
# harmful_model, harmful_tokenizer = models[harmful_key]
|
| 350 |
+
# harmful_pp = get_perplexity_local(
|
| 351 |
+
# text, model=harmful_model, tokenizer=harmful_tokenizer, normalize=False
|
| 352 |
+
# )
|
| 353 |
+
# doc.harmful_pp = harmful_pp
|
| 354 |
+
|
| 355 |
+
# encoder.encode_into(doc, buffer)
|
| 356 |
+
# buffer.extend(b"\n")
|
| 357 |
+
# f.write(buffer)
|
| 358 |
+
# if cutoff is not None and line_count >= cutoff:
|
| 359 |
+
# break
|
| 360 |
+
|
| 361 |
+
|
| 362 |
+
def process_file(input_file, output_path, cutoff=None, model=None, overwrite_output=True):
|
| 363 |
+
"""
|
| 364 |
+
Processes a file by reading its contents, analyzing each line for language and document type,
|
| 365 |
+
computing perplexities using specified models, and writing the modified content to a new file.
|
| 366 |
+
|
| 367 |
+
This function performs several steps:
|
| 368 |
+
1. Determines the output file path and checks for its existence if overwrite is not desired.
|
| 369 |
+
2. Reads the input file line by line, processing each line as a separate JSON document.
|
| 370 |
+
3. For each document, identifies its language using a fastText model. If the document type is "starcoder",
|
| 371 |
+
it defaults the language to English.
|
| 372 |
+
4. Depending on the model parameter, computes perplexities for the document text either using a
|
| 373 |
+
single document type model or a specified general model.
|
| 374 |
+
5. Updates the document with computed perplexities and writes it to the output file in JSON format.
|
| 375 |
+
6. Optionally stops processing after a specified number of lines determined by the cutoff parameter.
|
| 376 |
+
|
| 377 |
+
Parameters:
|
| 378 |
+
- input_file (str or Path): Path to the input file to be processed.
|
| 379 |
+
- output_path (str or Path): Directory path where the output file will be saved. The output file
|
| 380 |
+
will have the same name as the input file.
|
| 381 |
+
- cutoff (int, optional): If provided, processing will stop after this number of lines. Defaults to None.
|
| 382 |
+
- model (str, optional): Specifies the model to use for computing perplexities. If 'single', uses a
|
| 383 |
+
model specific to the document's type. Otherwise, uses the model specified.
|
| 384 |
+
Defaults to None.
|
| 385 |
+
- overwrite_output (bool): If True, will overwrite the output file if it already exists. If False,
|
| 386 |
+
will skip processing if the output file exists. Defaults to True.
|
| 387 |
+
|
| 388 |
+
Returns:
|
| 389 |
+
None. Writes processed documents to an output file in the specified output path.
|
| 390 |
+
"""
|
| 391 |
+
input_file = Path(input_file)
|
| 392 |
+
output_file = Path(output_path) / input_file.name
|
| 393 |
+
if not overwrite_output and output_file.exists():
|
| 394 |
+
print(f"Skipping {output_file} as it already exists")
|
| 395 |
+
return
|
| 396 |
+
with (open(output_file, 'w', encoding='utf-8') as f,
|
| 397 |
+
open(input_file, 'r', encoding='utf-8') as lines):
|
| 398 |
+
for line_count, line in tqdm(enumerate(lines), desc=f"Processing {input_file.name}"):
|
| 399 |
+
doc = json.loads(line)
|
| 400 |
+
language = doc["lang_fasttext"]
|
| 401 |
+
if doc["doc_type"] == "starcoder":
|
| 402 |
+
language = "en"
|
| 403 |
+
if model == "single":
|
| 404 |
+
doc_type_model, _ = get_model_for(doc["doc_type"])
|
| 405 |
+
perplexities = source_perplexities(doc["text"], language, model=doc_type_model)
|
| 406 |
+
perplexities["perplexity"] = perplexities.pop(f"{doc_type_model}_pp")
|
| 407 |
+
perplexities["perplexity_model"] = doc_type_model
|
| 408 |
+
else:
|
| 409 |
+
perplexities = source_perplexities(doc["text"], language, model=model)
|
| 410 |
+
doc.update(perplexities)
|
| 411 |
+
f.write(json.dumps(doc) + "\n")
|
| 412 |
+
if cutoff is not None and line_count >= cutoff:
|
| 413 |
+
break
|
| 414 |
+
|
| 415 |
+
|
| 416 |
+
if __name__ == "__main__":
|
| 417 |
+
parser = argparse.ArgumentParser(description='Calculate perplexity values for a given JSON Lines file and output the result to a new file.')
|
| 418 |
+
parser.add_argument('-i', '--input_file', type=str,
|
| 419 |
+
help='Input file path')
|
| 420 |
+
parser.add_argument('-o', '--output_path', type=str,
|
| 421 |
+
help='Output path to write enriched file')
|
| 422 |
+
parser.add_argument('-c', '--cutoff', required=False, type=int,
|
| 423 |
+
help='Max number of lines to process')
|
| 424 |
+
parser.add_argument('-m', '--model', required=False, type=str,
|
| 425 |
+
help='Run "single" model per doc type, "all" the models, '
|
| 426 |
+
'or a specific model to choose from '
|
| 427 |
+
'"books", "wikipedia", "newspapers" or "maalfrid". '
|
| 428 |
+
'Defaults to "single"')
|
| 429 |
+
parser.add_argument('--overwrite_output',
|
| 430 |
+
action=argparse.BooleanOptionalAction, default=True,
|
| 431 |
+
help="Whether to overwrite the output file if exists.")
|
| 432 |
+
|
| 433 |
+
args = parser.parse_args()
|
| 434 |
+
|
| 435 |
+
if args.model == "single":
|
| 436 |
+
process_file(
|
| 437 |
+
args.input_file, args.output_path, args.cutoff,
|
| 438 |
+
model="single", overwrite_output=args.overwrite_output,
|
| 439 |
+
)
|
| 440 |
+
elif args.model in ("books", "wikipedia", "newspapers", "maalfrid"):
|
| 441 |
+
process_file(
|
| 442 |
+
args.input_file, args.output_path, args.cutoff,
|
| 443 |
+
model=args.model, overwrite_output=args.overwrite_output,
|
| 444 |
+
)
|
| 445 |
+
else:
|
| 446 |
+
process_file(
|
| 447 |
+
args.input_file, args.output_path, args.cutoff,
|
| 448 |
+
overwrite_output=args.overwrite_output,
|
| 449 |
+
)
|
plots/all_doc_types_plots.png
ADDED

|
plots/book_no_book.png
ADDED

|
plots/books_pdf_no_books_pdf.png
ADDED

|
plots/combined_plots.png
ADDED

|
plots/culturax_nob_all_plots.png
ADDED

|
plots/culturax_nob_culturax.png
ADDED

|
plots/plots_book.png
ADDED

|
plots/plots_books_pdf.png
ADDED

|
plots/plots_culturax.png
ADDED

|
plots/plots_evalueringsrapport_pdf.png
ADDED

|
plots/plots_evalueringsrapport_pdf_no.png
ADDED
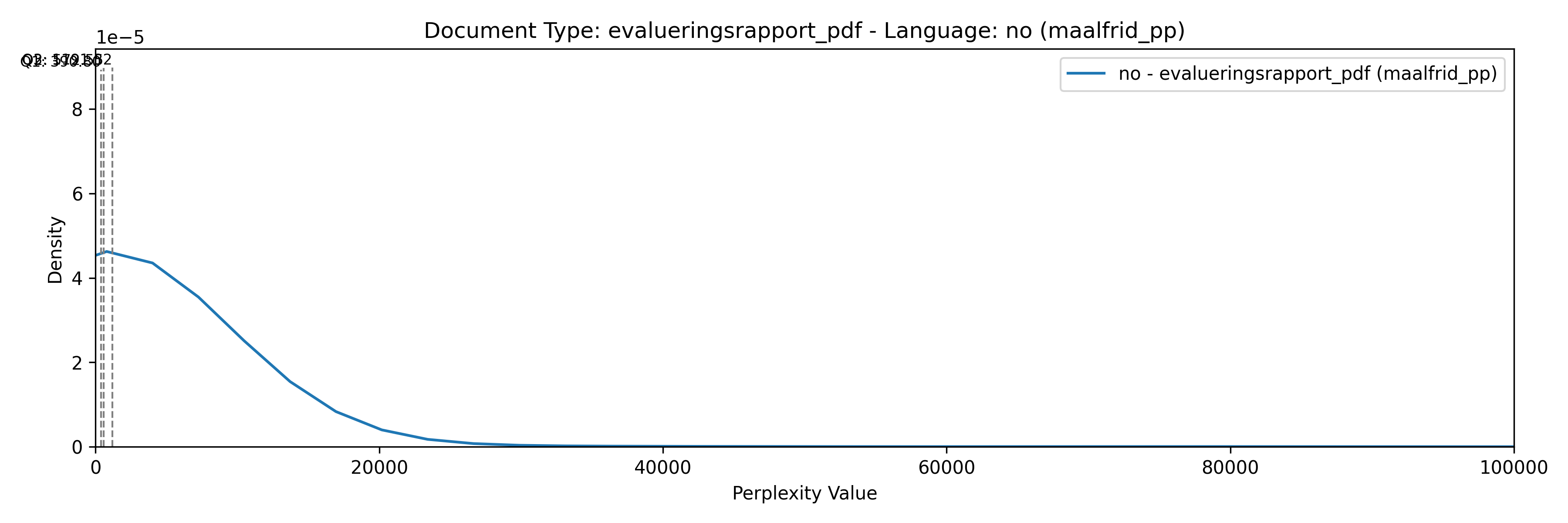
|
plots/plots_lovdata_cd_lokaleforskrifter_2005.png
ADDED
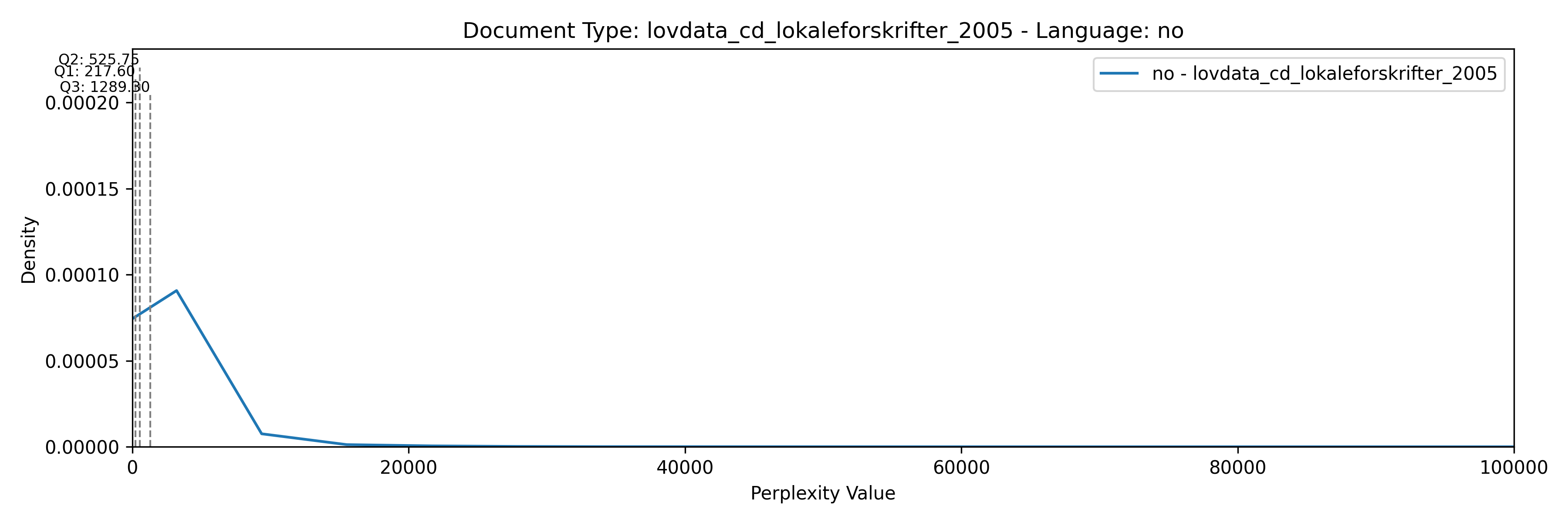
|
plots/plots_lovdata_cd_lokaleforskrifter_2005_no.png
ADDED

|
plots/plots_lovdata_cd_norgeslover_2005.png
ADDED

|
plots/plots_lovdata_cd_norgeslover_2005_no.png
ADDED

|
plots/plots_lovdata_cd_odelsting_2005.png
ADDED

|
plots/plots_lovdata_cd_odelsting_2005_no.png
ADDED

|
plots/plots_lovdata_cd_rtv_rundskriv_2005.png
ADDED

|
plots/plots_lovdata_cd_rtv_rundskriv_2005_no.png
ADDED

|
plots/plots_lovdata_cd_rundskriv_lovavdeling_2005.png
ADDED

|
plots/plots_lovdata_cd_rundskriv_lovavdeling_2005_no.png
ADDED

|
plots/plots_lovdata_cd_sentrale_forskrifter_2005.png
ADDED

|
plots/plots_lovdata_cd_sentrale_forskrifter_2005_no.png
ADDED

|
plots/plots_lovdata_cd_skatt_rundskriv_2005.png
ADDED

|