

Commit
·
b681d2a
1
Parent(s):
f1c8ee5
WHAM Demonstrator and README
Browse files- .gitattributes +1 -0
- README.md +240 -0
- WHAM_Demonstrator.zip +3 -0
- assets/Demonstrator/Fig_01.png +0 -0
- assets/Demonstrator/Fig_02.png +0 -0
- assets/Demonstrator/Fig_03.png +0 -0
- assets/Demonstrator/Fig_04.png +0 -0
- assets/Demonstrator/Fig_05.png +0 -0
- assets/Demonstrator/Fig_06.png +0 -0
- assets/Demonstrator/Fig_07.png +0 -0
- assets/Demonstrator/Fig_08.png +0 -0
- assets/Demonstrator/Fig_09.png +0 -0
- assets/Demonstrator/Fig_10.png +0 -0
- assets/Demonstrator/Fig_11.png +0 -0
- assets/Demonstrator/Fig_12.png +0 -0
- assets/Demonstrator/Fig_13.png +0 -0
- assets/Demonstrator/Fig_14.png +0 -0
- assets/Demonstrator/Fig_15.png +0 -0
- assets/Demonstrator/Fig_16.png +3 -0
- assets/Demonstrator/Fig_17.png +3 -0
- wham_demonstrator/README.md +25 -16
- wham_demonstrator/SharpDX.XInput.dll +0 -0
- wham_demonstrator/SharpDX.dll +0 -0
- wham_demonstrator/WHAMDemonstrator.dll +0 -0
- wham_demonstrator/WHAMDemonstrator.exe +0 -0
.gitattributes
CHANGED
|
@@ -35,3 +35,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
fonts/arial.ttf filter=lfs diff=lfs merge=lfs -text
|
| 37 |
*.gif filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
fonts/arial.ttf filter=lfs diff=lfs merge=lfs -text
|
| 37 |
*.gif filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
*.png filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,240 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
datasets:
|
| 3 |
+
- MSRTestOrg/bleeding-edge-gameplay-sample
|
| 4 |
+
tags:
|
| 5 |
+
- wham
|
| 6 |
+
- microsoft
|
| 7 |
+
language:
|
| 8 |
+
- en
|
| 9 |
+
license_link: LICENSE.md
|
| 10 |
+
---
|
| 11 |
+
# World and Human Action Model (WHAM)
|
| 12 |
+
📄 [Paper](https://www.nature.com/articles/s41586-025-08600-3) • 🔗 [Sample Data](https://huggingface.co/datasets/microsoft/bleeding-edge-gameplay-sample)
|
| 13 |
+
<div align="center">
|
| 14 |
+
Anssi Kanervisto, Dave Bignell, Linda Yilin Wen, Martin Grayson, Raluca Georgescu, Sergio Valcarcel Macua, Shan Zheng Tan, Tabish Rashid, Tim Pearce, Yuhan Cao,
|
| 15 |
+
Abdelhak Lemkhenter, Chentian Jiang, Gavin Costello, Gunshi Gupta, Marko Tot, Shu Ishida, Tarun Gupta, Udit Arora,
|
| 16 |
+
Ryen W. White, Sam Devlin, Cecily Morrison, Katja Hofmann
|
| 17 |
+
</div><br>
|
| 18 |
+
<div align='center'>
|
| 19 |
+
Dynamic Generated Gameplay Sequence using WHAM. Showcasing diverse characters and actions across intricate maps.
|
| 20 |
+
<div style="display: flex; flex-wrap: wrap;">
|
| 21 |
+
<img style="width: calc(33.33%); margin-bottom: -35px;" src="assets/Readme/wham_gen_1.gif">
|
| 22 |
+
<img style="width: calc(33.33%); margin-bottom: -35px;" src="assets/Readme/wham_gen_2.gif">
|
| 23 |
+
<img style="width: calc(33.33%); margin-bottom: -35px;" src="assets/Readme/wham_gen_3.gif">
|
| 24 |
+
<img style="width: calc(33.33%); margin-bottom: -35px;" src="assets/Readme/wham_gen_4.gif">
|
| 25 |
+
<img style="width: calc(33.33%); margin-bottom: -35px;" src="assets/Readme/wham_gen_5.gif">
|
| 26 |
+
<img style="width: calc(33.33%); margin-bottom: -35px;" src="assets/Readme/wham_gen_6.gif">
|
| 27 |
+
<img style="width: calc(33.33%);" src="assets/Readme/wham_gen_7.gif">
|
| 28 |
+
<img style="width: calc(33.33%);" src="assets/Readme/wham_gen_8.gif">
|
| 29 |
+
<img style="width: calc(33.33%);" src="assets/Readme/wham_gen_9.gif">
|
| 30 |
+
</div>
|
| 31 |
+
</div><br>
|
| 32 |
+
<div align='center'>
|
| 33 |
+
WHAM is capable of generating consistent, diverse, and persistent outputs, enabling various use cases for creative iteration.
|
| 34 |
+
<img style="width: 100%;" src="assets/Readme/model_capabilities.gif">
|
| 35 |
+
</div>
|
| 36 |
+
|
| 37 |
+
Muse is powered by a World and Human Action Model (WHAM), which is a generative model of gameplay (visuals and/or controller actions) trained on gameplay data of Ninja Theory’s Xbox game Bleeding Edge. Model development was informed by requirements of game creatives that we identified through a user study. Our goal is to explore the capabilities that generative AI models need to support human creative exploration. WHAM is developed by the [Game Intelligence group](https://www.microsoft.com/en-us/research/group/game-intelligence/) at [Microsoft Research](https://www.microsoft.com/en-us/research/), in collaboration with [TaiX](https://www.microsoft.com/en-us/research/project/taix/) and [Ninja Theory](https://ninjatheory.com/).
|
| 38 |
+
|
| 39 |
+
# Model Card
|
| 40 |
+
|
| 41 |
+
WHAM is an autoregressive model that has been trained to predict (tokenized) game visuals and controller actions given a prompt. Prompts here can be either visual (one or more initial game visuals) and / or controller actions. This allows the user to run the model in (a) world modelling mode (generate visuals given controller actions), (b) behavior policy (generate controller actions given past visuals), or (c) generate both visuals and behavior.
|
| 42 |
+
|
| 43 |
+
WHAM consists of two components, an encoder-decoder [VQ-GAN](https://compvis.github.io/taming-transformers/) trained to encode game visuals to a discrete representation, and a transformer backbone trained to perform next-token prediction. We train both components from scratch. The resulting model can generate consistent game sequences, and shows evidence of capturing the 3D structure of the game environment, the effects of controller actions, and the temporal structure of the game (up to the model’s context length).
|
| 44 |
+
|
| 45 |
+
WHAM was trained on human gameplay data to predict game visuals and players’ controller actions. We worked with the game studio Ninja Theory and their game [Bleeding Edge](https://www.bleedingedge.com/) – a 3D, 4v4 multiplayer video game. From the resulting data we extracted one year’s worth of anonymized gameplay from 27,990 players, capturing a wide range of behaviors and interactions. A sample of this data is provided [here](https://huggingface.co/datasets/microsoft/bleeding-edge-gameplay-sample)
|
| 46 |
+
|
| 47 |
+
## Model Details
|
| 48 |
+
|
| 49 |
+
### Trained Models
|
| 50 |
+
|
| 51 |
+
In this release we provide the weights of two WHAM instances: 200M WHAM and 1.6B WHAM. Both have been trained from scratch on the same data set. 1.6B WHAM is evaluated in [our paper](https://www.nature.com/articles/s41586-025-08600-3). We additionally provide 200M WHAM as a more lightweight option for faster explorations.
|
| 52 |
+
- [WHAM with 200M parameters](models/WHAM_200M.ckpt), 1M training steps, model size: 3.7GB
|
| 53 |
+
- [WHAM with 1.6B parameters](models/WHAM_1.6B_v1.ckpt), 200k training steps, model size: 18.9GB
|
| 54 |
+
|
| 55 |
+
## Usage
|
| 56 |
+
|
| 57 |
+
### System Requirements
|
| 58 |
+
|
| 59 |
+
The steps below have been tested on the following setup:
|
| 60 |
+
- Linux workstation with Ubuntu 20.04.4 LTS
|
| 61 |
+
- Windows 11 workstation running WSL2 with Ubuntu 20.04.6 LTS
|
| 62 |
+
|
| 63 |
+
The current setup assumes that a CUDA-supported GPU is available for model inference. This has been tested on systems with `NVIDIA RTX A6000` and `NVIDIA GeForce GTX 1080` respectively. In addition, approximately `15GB` of free hard disk space is required for dowmloading the models.
|
| 64 |
+
|
| 65 |
+
The steps under Installation assume a python 3.9 installation that can be
|
| 66 |
+
called using the command `python3.9` and the venv package for creating virtual environments. If either of these is not present, you can install this version of python under Ubuntu using:
|
| 67 |
+
|
| 68 |
+
```bash
|
| 69 |
+
sudo apt install python3.9
|
| 70 |
+
sudo apt install python3.9-venv
|
| 71 |
+
```
|
| 72 |
+
|
| 73 |
+
If you are using the WHAM Demonstrator, please ensure that you have the required [.NET Core Runtime](https://dotnet.microsoft.com/en-us/download/dotnet/7.0). If this is not yet installed, an error message will pop up from which you can follow a link to download and install this package.
|
| 74 |
+
|
| 75 |
+
### Installation
|
| 76 |
+
|
| 77 |
+
1. Clone this repository. We recommend starting without the large model files, using `GIT_LFS_SKIP_SMUDGE=1 git clone [email protected]:MSRTestOrg/WHAM`
|
| 78 |
+
2. `cd WHAM`
|
| 79 |
+
3. `./setup_local.sh`
|
| 80 |
+
|
| 81 |
+
This will set up a `python3.9` virtual environment and install the required packages (this includes packages required for the model server). The typical install time should be approximately 5 minutes.
|
| 82 |
+
|
| 83 |
+
3. Run `source venv/bin/activate` whenever you want to run model inference or the model server
|
| 84 |
+
|
| 85 |
+
4. Download model from this HuggingFace repository (See note below):
|
| 86 |
+
1. Go to Files and versions and navigate to the `models` folder.
|
| 87 |
+
2. Download the model checkpoint. The instructions below assume that the model checkpoints have been downloaded to your local `models` folder.
|
| 88 |
+
|
| 89 |
+
**Note:** On Linux systems, you can use `git clone` to clone the enire repository, including large files. Due to a limitation of `git lfs` on Windows, only files up to `4GB` are supported and we recommend downloading the model files manually from the `models` folder.
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
### Local Model Inference
|
| 93 |
+
|
| 94 |
+
This section assumes that you have followed the installation steps above.
|
| 95 |
+
|
| 96 |
+
(Optional) Download [sample data](https://huggingface.co/datasets/microsoft/bleeding-edge-gameplay-sample). For the local inference examples below, we recommend that you start with the `tiny-sample` set of only 4 trajectories for your initial exploration.
|
| 97 |
+
|
| 98 |
+
You can now run model inference to generate gameplay sequences as follows:
|
| 99 |
+
|
| 100 |
+
```python
|
| 101 |
+
python run_dreaming.py --model_path <path_to_checkpoint.ckpt> --data_path <path_to_sample_data_folder>
|
| 102 |
+
```
|
| 103 |
+
|
| 104 |
+
To run the 200M parameter (small) model (if you copied the tiny-sample folder to the root directory):
|
| 105 |
+
|
| 106 |
+
```bash
|
| 107 |
+
python run_dreaming.py --model_path models/WHAM_200M.ckpt --data_path tiny-sample
|
| 108 |
+
```
|
| 109 |
+
|
| 110 |
+
This uses the data in `data_path` as initial prompt sequences. The script will create a `dreaming_output` directory which will create two files per ground truth data file:
|
| 111 |
+
- An `.npz` file that contains a number of entries, most important of which are:
|
| 112 |
+
- `encoded_decoded_ground_truth_images`: the original context images, encoded and decoded with the VQGAN.
|
| 113 |
+
- `dreamt_images`: the sequence of all dreamt images.
|
| 114 |
+
- An `.mp4` file of the context data + dreamt images for easier viewing.
|
| 115 |
+
|
| 116 |
+
This requires approximately 4.5GB of VRAM on a single A6000, but only uses batch size of one. To speed up the process, increase batch size with `--batch_size` argument. With a single A6000 and `--batch_size 12` this uses approximately 30GB of VRAM. Generating gameplay sequences from the full 512 video dataset takes around 24 hours.
|
| 117 |
+
|
| 118 |
+
Please note that the first output from the script is generated when the first gameplay sequence has been generated. This may take several minutes when using an `A6000` GPU, or longer for older generation GPUs.
|
| 119 |
+
|
| 120 |
+
See python `run_dreaming.py --help` for different settings.
|
| 121 |
+
|
| 122 |
+
### WHAM Demonstrator
|
| 123 |
+
|
| 124 |
+
#### Setting up the Model Server
|
| 125 |
+
|
| 126 |
+
We have tested the server code as provided on a single Linux machine with four `A6000 GPUs` (large model) as well as on a Windows machine running Ubuntu under `WSL2`, equipped with a single `GeForce GTX 1080` (small model). Model inferences can be run on lower spec NVIDIA GPUs by reducing the batchsize.
|
| 127 |
+
|
| 128 |
+
The steps below assume that the installation steps above have been followed and that the model files have been downloaded to your local machine.
|
| 129 |
+
|
| 130 |
+
In your terminal, activate the newly installed virtual environment (if it isn't already):
|
| 131 |
+
|
| 132 |
+
```bash
|
| 133 |
+
source venv/bin/activate
|
| 134 |
+
```
|
| 135 |
+
|
| 136 |
+
Start the server, pointing it to the model:
|
| 137 |
+
|
| 138 |
+
```bash
|
| 139 |
+
python run_server.py --model <path_to_model_file>
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
To run the 200M parameter (small) model:
|
| 143 |
+
|
| 144 |
+
```bash
|
| 145 |
+
python run_server.py --model models/WHAM_200M.ckpt
|
| 146 |
+
```
|
| 147 |
+
|
| 148 |
+
To run the 1.6B parameter (large) model:
|
| 149 |
+
|
| 150 |
+
```bash
|
| 151 |
+
python run_server.py --model models/WHAM_1.6B_v1.ckpt
|
| 152 |
+
```
|
| 153 |
+
|
| 154 |
+
|
| 155 |
+
The server will start and by default listen on localhost port 5000 (this can be configured with `--port <port>`).
|
| 156 |
+
|
| 157 |
+
**Note:** If you run out of VRAM when running the server, you can reduce the `MAX_BATCH_SIZE` variable in `run_server.py`.
|
| 158 |
+
|
| 159 |
+
|
| 160 |
+
#### Install the WHAM Demonstrator App (Windows only)
|
| 161 |
+
|
| 162 |
+
After cloning or downloading this repository, navigate to the folder `WHAM/wham_demonstrator`, and start the Windows application `WHAMDemonstrator.exe` within that folder.
|
| 163 |
+
|
| 164 |
+
Follow the instructions in the provided README.md within WHAM Demonstrator to connect to your model server and get an overview of supported functionality.
|
| 165 |
+
|
| 166 |
+
|
| 167 |
+
## Intended Uses
|
| 168 |
+
|
| 169 |
+
This model and accompanying code are intended for academic research purposes only. WHAM has been trained on gameplay data from a single game, Bleeding Edge, and is intended to be used to generate plausible gameplay sequences resembling this game.
|
| 170 |
+
|
| 171 |
+
The model is not intended to be used to generate imagery outside of the game Bleeding Edge. Generated images include watermark and provenance metadata. Do not remove the watermark or provenance metadata..
|
| 172 |
+
|
| 173 |
+
WHAM can be used in multiple scenarios. The following list illustrates the types of tasks that WHAM can be used for:
|
| 174 |
+
- World Model: Visuals are predicted, given a real starting state and action sequence.
|
| 175 |
+
- Behaviour Policy: Given visuals, the model predicts the next controller action.
|
| 176 |
+
- Full Generation: The model generates both the visuals and the controller actions a human player might take in the game.
|
| 177 |
+
|
| 178 |
+
## Training
|
| 179 |
+
|
| 180 |
+
### Model
|
| 181 |
+
|
| 182 |
+
- Architecture: A decoder-only transformer that predicts the next token corresponding to an interleaved sequence of observations and actions. The image tokenizer is a VQ-GAN.
|
| 183 |
+
- Context length: 10 (observation, action) pairs / 5560 tokens
|
| 184 |
+
- Dataset size: The model was trained on data from approximately `500,000` Bleeding Edge games from all seven game maps (over 1 billion observation, action pairs 10Hz, equivalent to over 7 years of continuous human gameplay). A data sample is provided in [bleeding-edge-gameplay-sample](https://huggingface.co/datasets/microsoft/bleeding-edge-gameplay-sample). This is the test data used for our evaluation results, and has the same format as the training data.
|
| 185 |
+
- GPUs: 98xH100 GPUs
|
| 186 |
+
- Training time: 5 days
|
| 187 |
+
|
| 188 |
+
### Software
|
| 189 |
+
|
| 190 |
+
- [PyTorch Lightning](https://github.com/pytorch/pytorch)
|
| 191 |
+
- [Flash-Attention](https://github.com/HazyResearch/flash-attention)
|
| 192 |
+
- [ffmpeg](https://github.com/FFmpeg/FFmpeg)
|
| 193 |
+
- [exiftool](https://github.com/exiftool/exiftool)
|
| 194 |
+
|
| 195 |
+
## Bias, Risks and Limitations
|
| 196 |
+
|
| 197 |
+
- The training data represents gameplay recordings from a variety of skilled and unskilled gameplayers, representing diverse demographic characteristics. Not all possible player characteristics are represented and model performance may therefore vary.
|
| 198 |
+
- The model, as it is, can only be used to generate visuals and controller inputs. Users should not manipulate images and attempt to generate offensive scenes.
|
| 199 |
+
|
| 200 |
+
### Technical limitations, operational factors, and ranges
|
| 201 |
+
|
| 202 |
+
Model:
|
| 203 |
+
- Trained on a single game, very specialized, not intended for image prompts that are out of context or from other domains
|
| 204 |
+
- Limited context length (10s)
|
| 205 |
+
- Limited image resolution (300px x 180px), the model can only generate images at this fixed resolution.
|
| 206 |
+
- Generated images and controls can incorrect or unrecognizable.
|
| 207 |
+
- Inference time is currently too slow for real-time use.
|
| 208 |
+
|
| 209 |
+
WHAM Demonstrator:
|
| 210 |
+
- Developed as a way to explore potential interactions. This is not intended as a fully-fledged user experience or demo.
|
| 211 |
+
|
| 212 |
+
Models trained using game data may potentially behave in ways that are unfair, unreliable, or offensive, in turn causing harms. We emphasize that these types of harms are not mutually exclusive. A single model can exhibit more than one type of harm, potentially relating to multiple different groups of people. For example, the output of the model can be nonsensical or might look reasonable but is inaccurate with respect to external validation sources.
|
| 213 |
+
Although users can input any image as a starting point, the model is only trained to generate images and controller actions based on the structure of the Bleeding Edge game environment that it has learned from the training data. Out of domain inputs lead to unpredictable results. For example, this could include a sequence of images that dissolve into unrecognizable blobs .
|
| 214 |
+
Model generations when “out of scope” image elements are introduced will either:
|
| 215 |
+
- Dissolve into unrecognizable blobs of color.
|
| 216 |
+
- Morphed into game-relevant items such as game characters.
|
| 217 |
+
|
| 218 |
+
## Evaluating WHAM
|
| 219 |
+
WHAM is evaluated based on its consistency, diversity, and persistency. Consistency is measured using Fréchet Video Distance (FVD), while diversity is assessed by comparing the marginal distribution of real human actions to those generated by the model using the Wasserstein distance. Persistency is tested using two scenarios: by adding a static power-up object to a game visual and by adding another player character to a game visual used for prompting the model. For detailed evaluation results, see the paper that [introduces the model](https://www.nature.com/articles/s41586-025-08600-3).
|
| 220 |
+
|
| 221 |
+
### Responsible AI testing
|
| 222 |
+
WHAM has been tested with out of context prompt images to evaluate the risk of outputting harmful or nonsensical images. The generated image sequences did not retain the initial image, but rather dissolved into either unrecognizable blobs or to scenes resembling the training environment.
|
| 223 |
+
|
| 224 |
+
|
| 225 |
+
## License
|
| 226 |
+
|
| 227 |
+
The model is licensed under the [Microsoft Research License](LICENSE.md)
|
| 228 |
+
|
| 229 |
+
this work has been funded by Microsoft Research
|
| 230 |
+
|
| 231 |
+
## Privacy & Ethics Statement
|
| 232 |
+
|
| 233 |
+
[Microsoft Privacy Statement](https://go.microsoft.com/fwlink/?LinkId=521839)
|
| 234 |
+
|
| 235 |
+
## Trademark Notice
|
| 236 |
+
|
| 237 |
+
**Trademarks** This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks/usage/general). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
|
| 238 |
+
|
| 239 |
+
## Contact Information
|
| 240 |
+
For questions please email to [email protected]
|
WHAM_Demonstrator.zip
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:8d19ef23d22081044202e464e48dd4f5f6f232215a4cc797ab1a75dd3eb0e0d9
|
| 3 |
+
size 3565673
|
assets/Demonstrator/Fig_01.png
CHANGED
|

|
Git LFS Details
|
assets/Demonstrator/Fig_02.png
CHANGED

|

|
Git LFS Details
|
assets/Demonstrator/Fig_03.png
CHANGED

|

|
Git LFS Details
|
assets/Demonstrator/Fig_04.png
CHANGED
|

|
Git LFS Details
|
assets/Demonstrator/Fig_05.png
CHANGED

|

|
Git LFS Details
|
assets/Demonstrator/Fig_06.png
CHANGED
|

|
Git LFS Details
|
assets/Demonstrator/Fig_07.png
CHANGED

|

|
Git LFS Details
|
assets/Demonstrator/Fig_08.png
CHANGED

|

|
Git LFS Details
|
assets/Demonstrator/Fig_09.png
CHANGED

|

|
Git LFS Details
|
assets/Demonstrator/Fig_10.png
CHANGED
|

|
Git LFS Details
|
assets/Demonstrator/Fig_11.png
CHANGED
|

|
Git LFS Details
|
assets/Demonstrator/Fig_12.png
CHANGED

|

|
Git LFS Details
|
assets/Demonstrator/Fig_13.png
CHANGED

|

|
Git LFS Details
|
assets/Demonstrator/Fig_14.png
CHANGED

|

|
Git LFS Details
|
assets/Demonstrator/Fig_15.png
CHANGED

|

|
Git LFS Details
|
assets/Demonstrator/Fig_16.png
ADDED

|
Git LFS Details
|
assets/Demonstrator/Fig_17.png
ADDED

|
Git LFS Details
|
wham_demonstrator/README.md
CHANGED
|
@@ -3,22 +3,31 @@
|
|
| 3 |
|
| 4 |
# WHAM Demonstrator Instructions
|
| 5 |
|
| 6 |
-
##
|
| 7 |
-
|
|
|
|
| 8 |

|
| 9 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 10 |
## Opening Starting Frames
|
| 11 |
Creating sequences requires at least one start frame to generate gameplay sequence from. The WHAM Demonstrator contains some example starting frames. You can open the example frames using the “Open Example” button.
|
| 12 |
-

|
| 10 |
|
| 11 |
+
## Entering Server IP Address and API Key (Azure AI Foundry)
|
| 12 |
+
If you have deployed your model in Azure AI Foundry. Enter the endpoint address as well as the API Key.
|
| 13 |
+

|
| 14 |
+
|
| 15 |
+
## Entering a Server IP Address (Local Deployment)
|
| 16 |
+
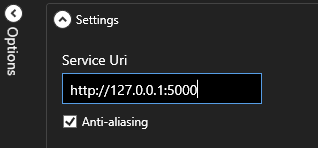
If you have deployed your own model using run_server.py. The model and API should be hosted on a server and port that is accessible to the app. Enter the IP address with port into the text box at the top left of the window, in the form `http://127.0.0.1:5000`.
|
| 17 |
+

|
| 18 |
+
|
| 19 |
## Opening Starting Frames
|
| 20 |
Creating sequences requires at least one start frame to generate gameplay sequence from. The WHAM Demonstrator contains some example starting frames. You can open the example frames using the “Open Example” button.
|
| 21 |
+

|
| 22 |
|
| 23 |
You can also start with either one or more images that you choose, or you can open a previously saved generated gameplay sequence timeline.
|
| 24 |
+

|
| 25 |
To open one or more images to seed a generated gameplay sequence, select `File -> Open Image(s)…`, and select one or more images. The images will appear as the first images on the timeline at the bottom of the window. To open a previously saved timeline, select `File -> Open Timeline JSON…` and select the JSON file saved with the timeline. The seed images should now appear in the timeline at the bottom of the view.
|
| 26 |
+

|
| 27 |
|
| 28 |
## Prediction Parameters
|
| 29 |
When creating generated gameplay sequence, there are a number of parameters you can set:
|
| 30 |
+

|
| 31 |
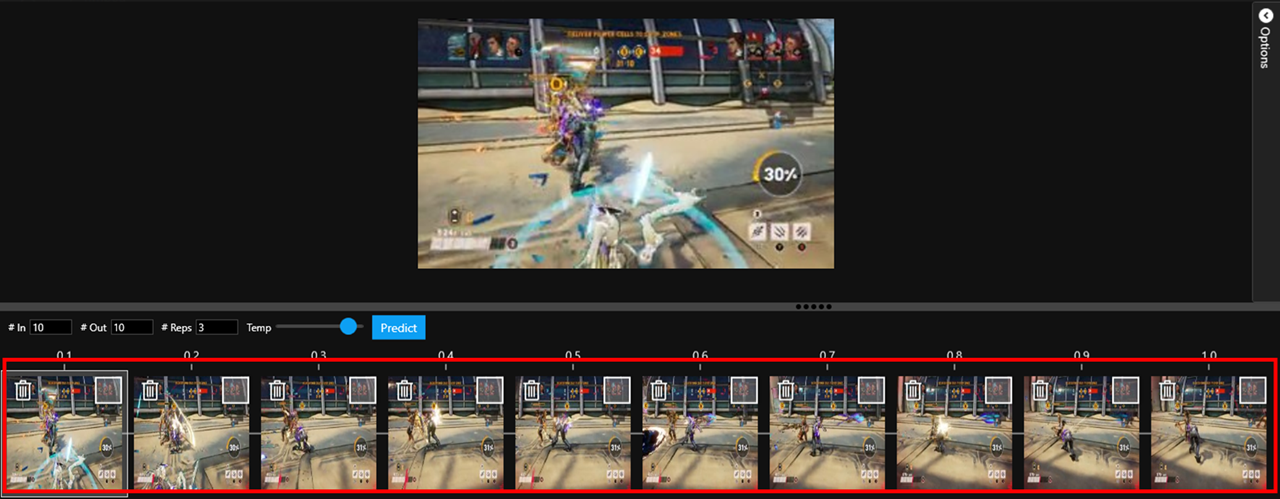
- **In**: The number of input frames into the next generated gameplay sequence. The maximum is 10.
|
| 32 |
- **Out**: The number of frames you would like to be returned per generated sequence.
|
| 33 |
- **Reps**: The number of branches for each generated gameplay sequence initiated.
|
|
|
|
| 35 |
|
| 36 |
## The Timeline User Interface
|
| 37 |
The timeline can get quite big. Here are a few controls to help manage the user interface when the timeline is large:
|
| 38 |
+

|
| 39 |
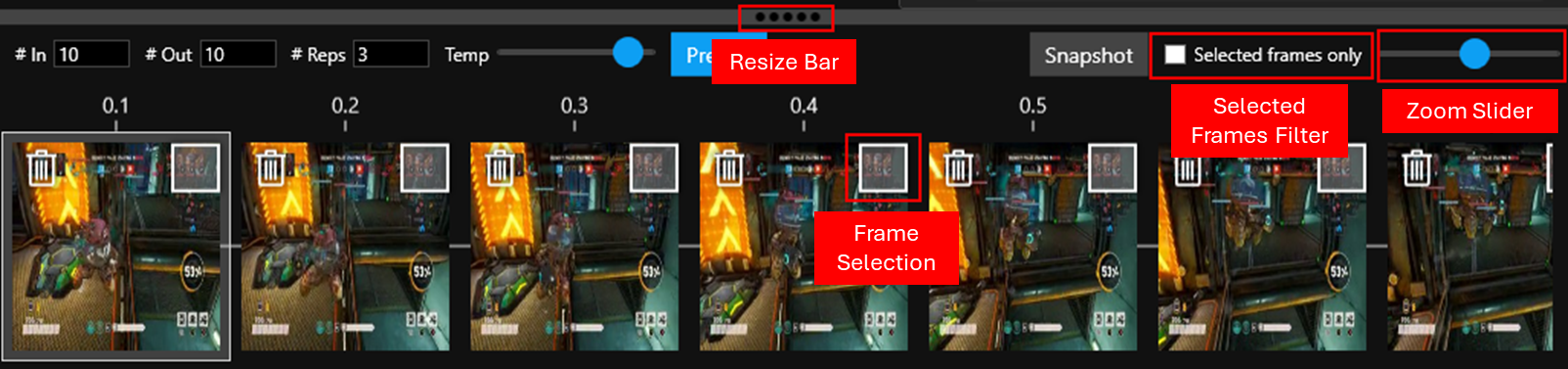
- **Resize bar**: Click and drag this to change the vertical size of the timeline.
|
| 40 |
- **Frame selection**: If you want to focus in on a particular pathway, you can select the end frame, and all frames leading up to it will also be selected.
|
| 41 |
- **Selected frames only**: Toggle this to flatten the timeline to only the selected frames.
|
|
|
|
| 43 |
|
| 44 |
There is also a “snapshot” button that allows you to take a single picture of your entire timeline, even if it has scrolled out of view.
|
| 45 |
When you select a frame, you will see an outline around the frame in the timeline, and the frame will appear in the main area above.
|
| 46 |
+

|
| 47 |
|
| 48 |
**Note**: When making a frame the selected frame (and have the image appear above), you need to click on the image part of the frame thumbnail on the timeline, not the selection box.
|
| 49 |
|
| 50 |
## Generating gameplay sequence
|
| 51 |
To create a generated gameplay sequence (or set of generated gamepla sequences), you must first click on the frame you would like to generate from. The WHAM Demonstrator allows creating new gameplay branches from any frame. So please ensure the frame you wish to generate from has been selected. If the parameters are correct and the server address has been entered, you can click “Predict” in the bar above the timeline. You should see the selected number of generated gameplay sequence branches, and new frames start to appear.
|
| 52 |
+

|
| 53 |
|
| 54 |
The frames may take a number of seconds to appear, depending on the hardware used to host the model. You can cancel one of the branches at any moment by clicking on the ‘X’ in the last frame square. When the frame generation is complete, you can select another frame anywhere in the timeline and select “Predict” again.
|
| 55 |
+

|
| 56 |
|
| 57 |
## Manipulating Images
|
| 58 |
New image layers can be added to any gameplay frame to introduce new content or characters to include in future generated frames. You could add a power-up or an NPC to a frame and have those included as the gameplay sequence evolves.
|
|
|
|
| 60 |
**Note**: This feature is not fully supported yet in the models shared with the WHAM Demonstrator, so performance can be unpredictable. To help added elements really “stick” in the generated sequence, we recommend creating a sequence of 5 frames with your added element in before continuing to generate sequences.
|
| 61 |
|
| 62 |
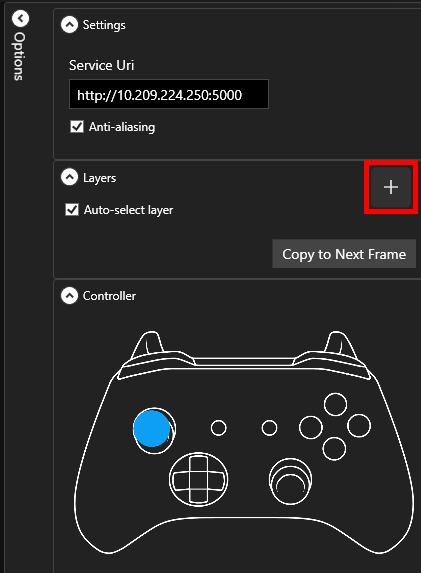
To add a new element, select the frame you wish to manipulate so it appears in the main frame area and click the `+` button in the layers panel.
|
| 63 |
+

|
| 64 |
|
| 65 |
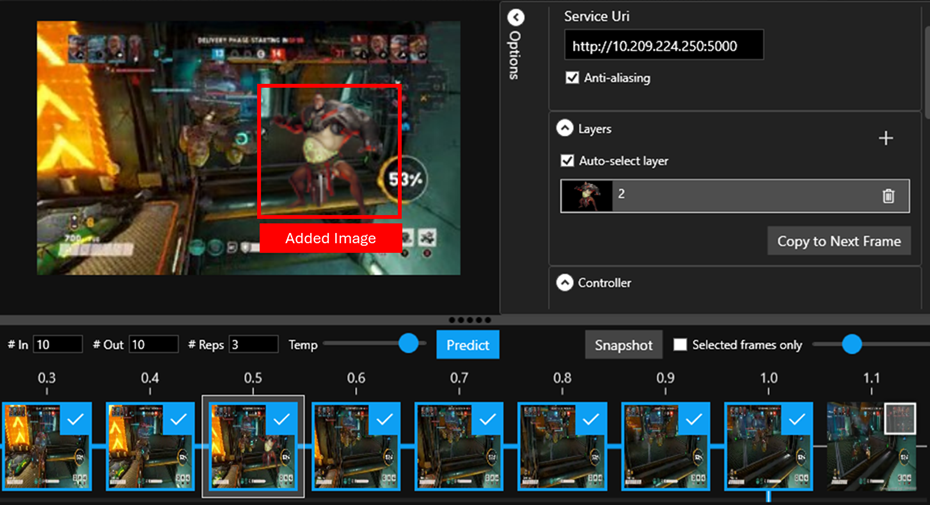
You will then be prompted to select an image. We recommend a transparent PNG, like the example supplied within the Examples folder called "Layer_Image". The selected image will then appear both as a layer in the layers panel, and on the currently selected frame.
|
| 66 |
+

|
| 67 |
|
| 68 |
To move and resize the added element, click on the element, either in the layers panel, or on the image directly, and you can use your mouse wheel to resize, or drag it around to move. Here, the character has been placed on the right of the frame.
|
| 69 |
+

|
| 70 |
|
| 71 |
To easily create a sequence, click the “copy to next frame” button, and the layers will be added to the next frame for easier sequencing. Here are a further 4 frames showing the character movement as they enter from the right.
|
| 72 |
+

|
| 73 |
|
| 74 |
Predictions can now happen from the manipulated frame.
|
| 75 |
|
|
|
|
| 77 |
|
| 78 |
## Controller Input
|
| 79 |
The WHAM Demonstrator can also be controlled using an Xbox controller.
|
| 80 |
+

|
| 81 |
|
| 82 |
With a controller connected and a frame selected, you can hold down the buttons you wish to use on the controller for around a second and the desired input will be passed to the model for the next frame. When you hold buttons, a blue progress bar will appear below the controller, when this disappears, you must release all of the controller buttons. The WHAM Demonstrator does not yet support holding the buttons for multiple frame predictions. Also, in this mode, only one frame will be produced at a time. When you hold the buttons down on the controller, you will also notice that whenever a frame is selected, this controller image will show the action state of the controller too.
|
| 83 |
|
| 84 |
## Saving Generated Gameplay Sequence
|
| 85 |
If you have created a gameplay sequence timeline that you want to save, or even continue later, you can save either a flat, selected sequence of frames, or the entire timeline.
|
| 86 |
+

|
| 87 |
|
| 88 |
Both of these options will ask for a folder and all of the required images and timeline information will be saved to that folder.
|
wham_demonstrator/SharpDX.XInput.dll
CHANGED
|
Binary files a/wham_demonstrator/SharpDX.XInput.dll and b/wham_demonstrator/SharpDX.XInput.dll differ
|
|
|
wham_demonstrator/SharpDX.dll
CHANGED
|
Binary files a/wham_demonstrator/SharpDX.dll and b/wham_demonstrator/SharpDX.dll differ
|
|
|
wham_demonstrator/WHAMDemonstrator.dll
CHANGED
|
Binary files a/wham_demonstrator/WHAMDemonstrator.dll and b/wham_demonstrator/WHAMDemonstrator.dll differ
|
|
|
wham_demonstrator/WHAMDemonstrator.exe
CHANGED
|
Binary files a/wham_demonstrator/WHAMDemonstrator.exe and b/wham_demonstrator/WHAMDemonstrator.exe differ
|
|
|