+

+
+# ⚡ Lit-LLaMA ️
+
+
+
+ [](https://dev.azure.com/Lightning-AI/lit%20Models/_build/latest?definitionId=49&branchName=main) [](https://github.com/Lightning-AI/lit-llama/blob/master/LICENSE) [](https://discord.gg/VptPCZkGNa)
+
+
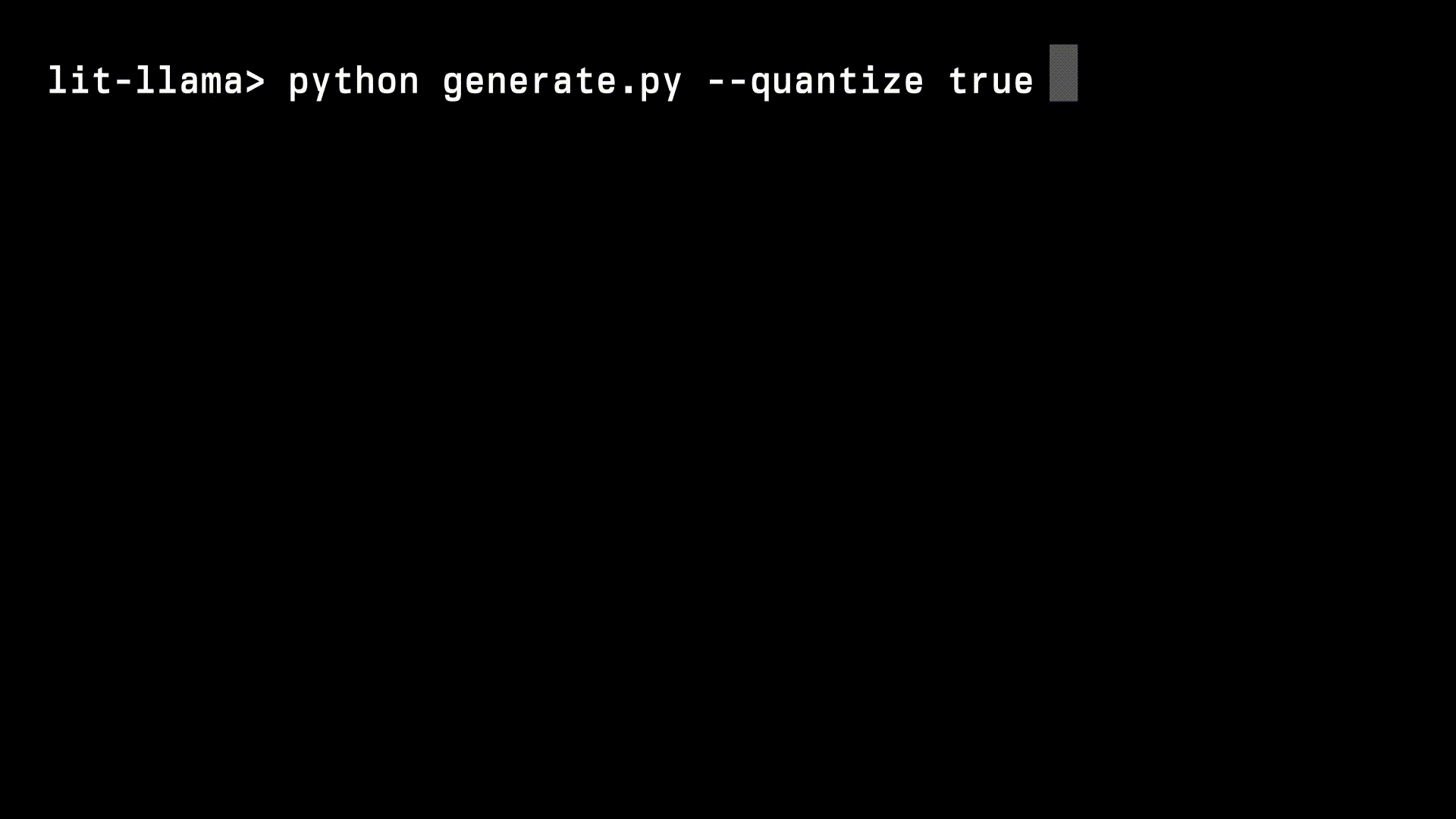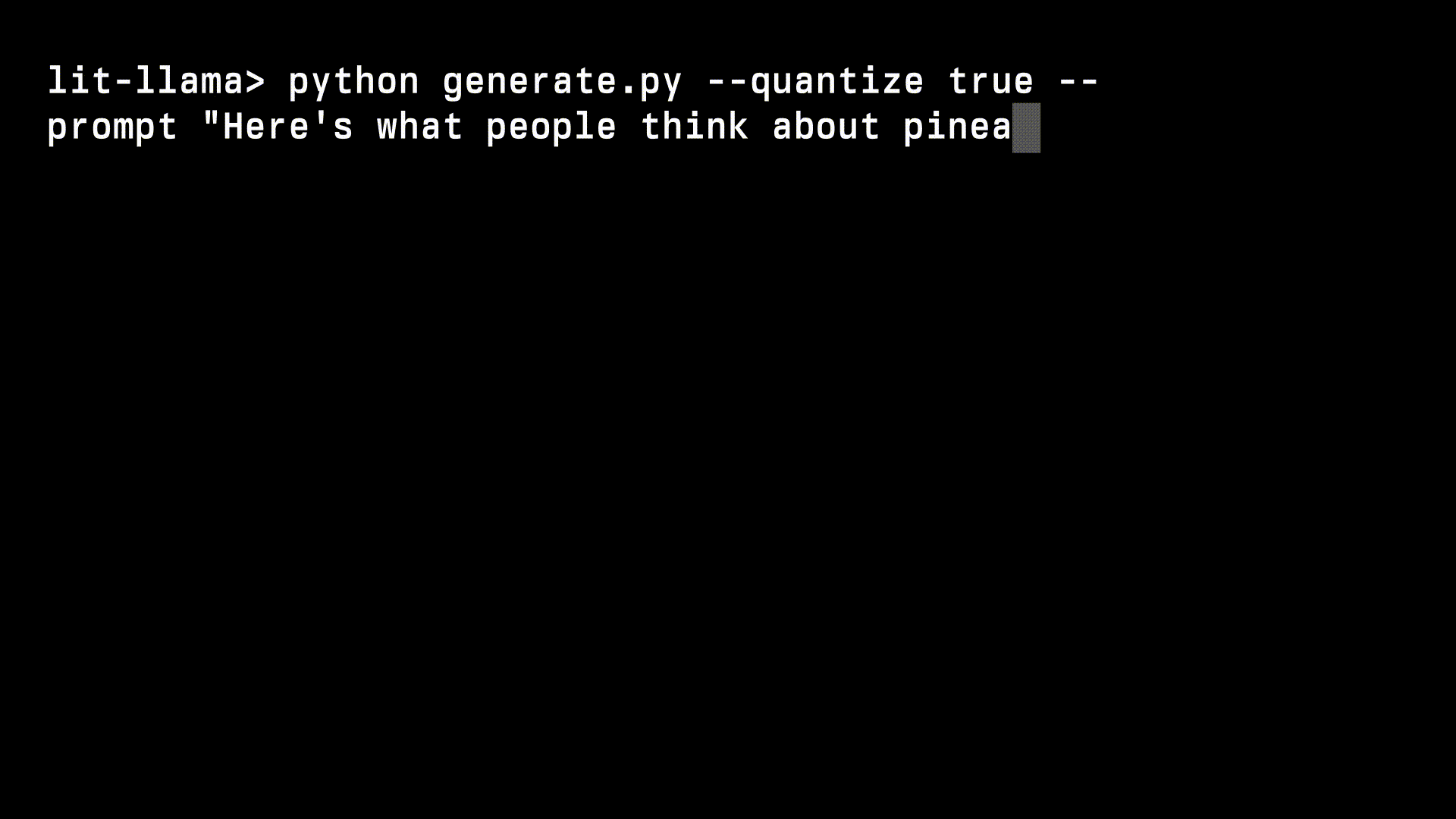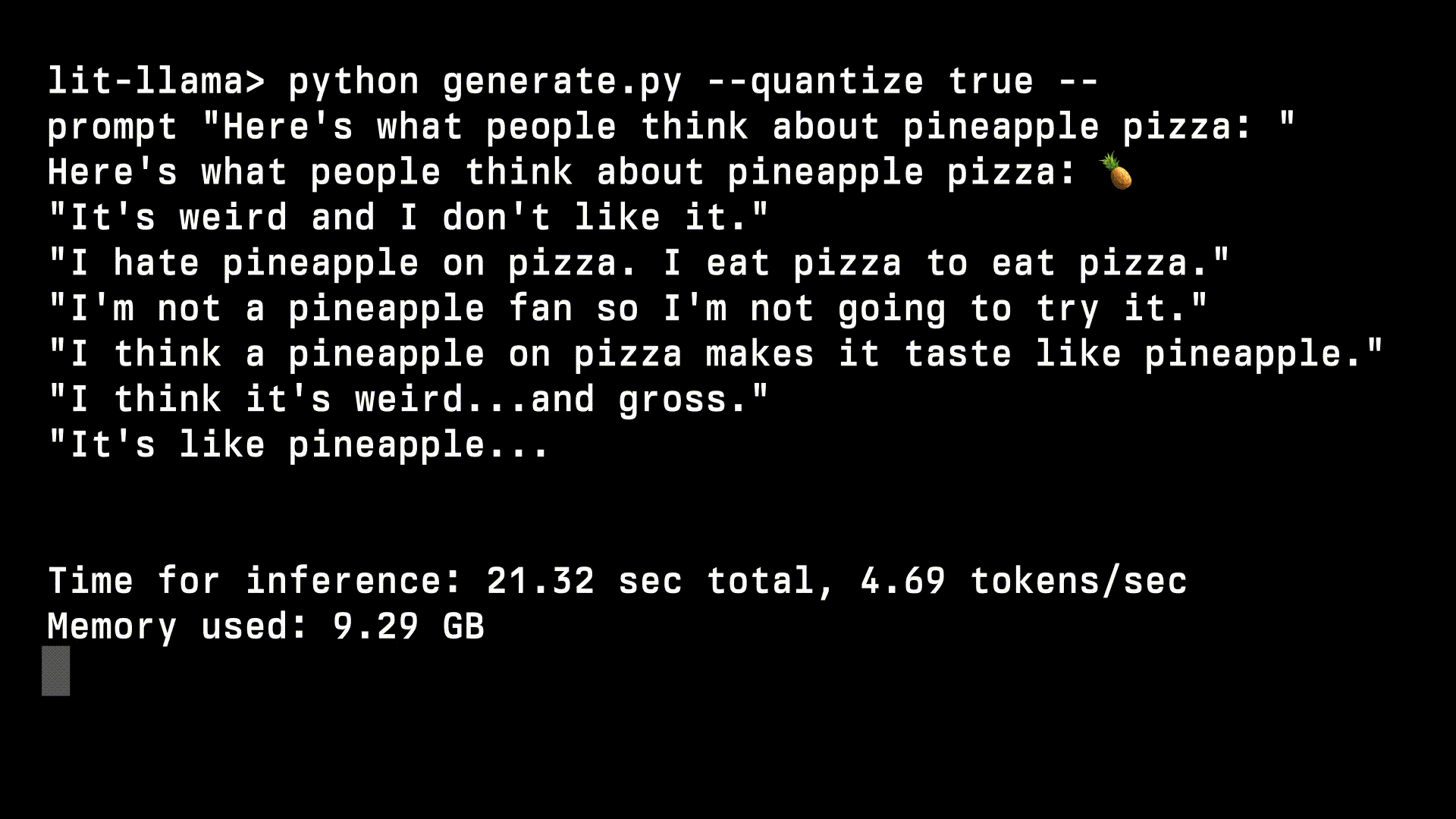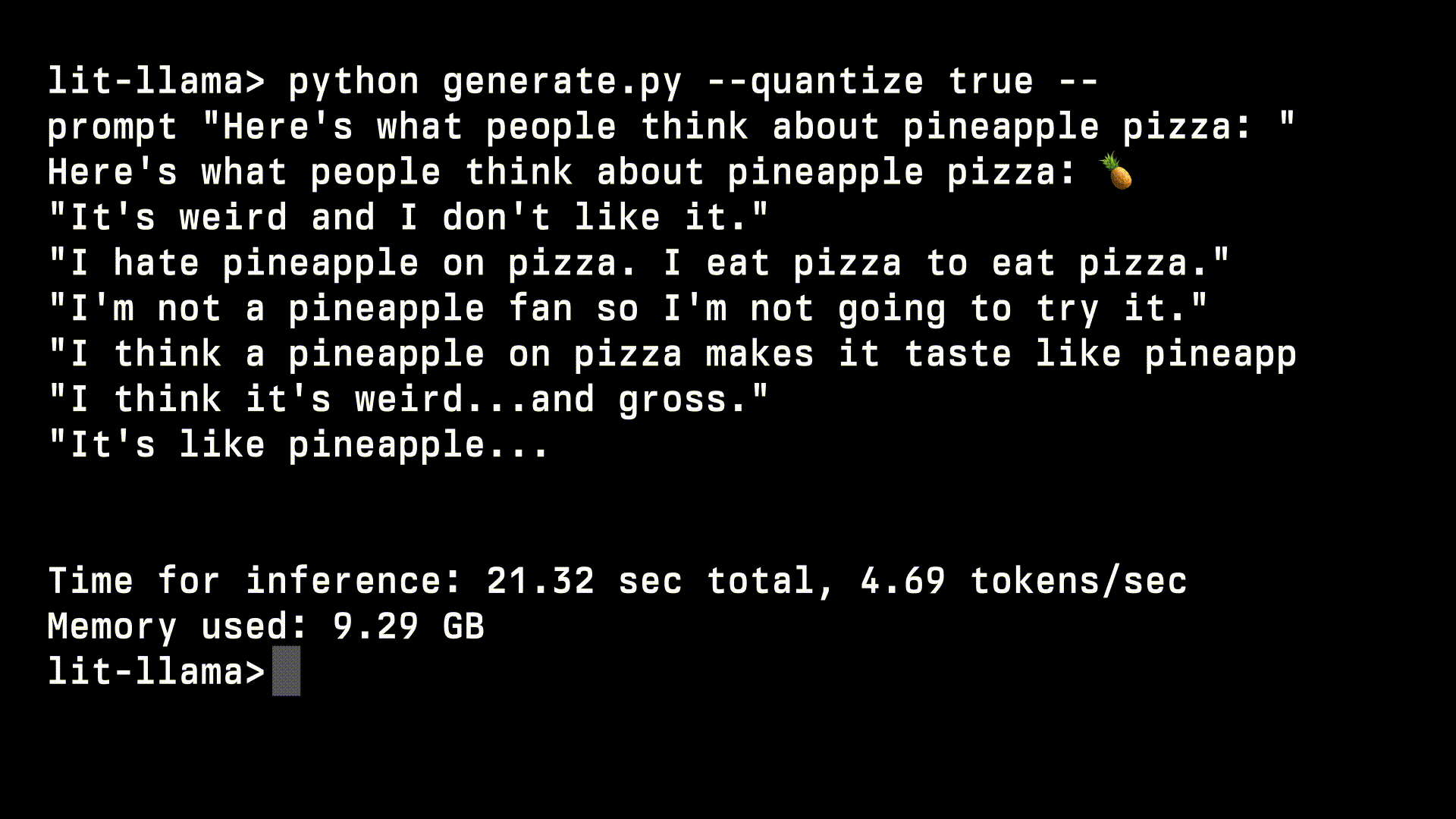
+
+
 +
+Join us and start contributing, especially on the following areas:
+
+- [ ] [Pre-training](https://github.com/Lightning-AI/lit-llama/labels/pre-training)
+- [ ] [Fine-tuning (full and LoRA)](https://github.com/Lightning-AI/lit-llama/labels/fine-tuning)
+- [ ] [Quantization](https://github.com/Lightning-AI/lit-llama/labels/quantization)
+- [ ] [Sparsification](https://github.com/Lightning-AI/lit-llama/labels/sparsification)
+
+Look at `train.py` for a starting point towards pre-training / fine-tuning using [Lightning Fabric](https://lightning.ai/docs/fabric/stable/).
+
+We welcome all individual contributors, regardless of their level of experience or hardware. Your contributions are valuable, and we are excited to see what you can accomplish in this collaborative and supportive environment.
+
+Unsure about contributing? Check out our [Contributing to Lit-LLaMA: A Hitchhiker’s Guide to the Quest for Fully Open-Source AI](https://lightning.ai/pages/community/tutorial/contributing-to-lit-llama-a-hitchhikers-guide-to-the-quest-for-fully-open-source-ai/) guide.
+
+Don't forget to [join our Discord](https://discord.gg/VptPCZkGNa)!
+
+## Acknowledgements
+
+- [@karpathy](https://github.com/karpathy) for [nanoGPT](https://github.com/karpathy/nanoGPT)
+- [@FacebookResearch](https://github.com/facebookresearch) for the original [LLaMA implementation](https://github.com/facebookresearch/llama)
+- [@TimDettmers](https://github.com/TimDettmers) for [bitsandbytes](https://github.com/TimDettmers/bitsandbytes)
+- [@Microsoft](https://github.com/microsoft) for [LoRA](https://github.com/microsoft/LoRA)
+- [@IST-DASLab](https://github.com/IST-DASLab) for [GPTQ](https://github.com/IST-DASLab/gptq)
+
+## License
+
+Lit-LLaMA is released under the [Apache 2.0](https://github.com/Lightning-AI/lightning-llama/blob/main/LICENSE) license.
diff --git a/checkpoints/lit-llama-bak/7B/lit-llama.pth b/checkpoints/lit-llama-bak/7B/lit-llama.pth
new file mode 100644
index 0000000000000000000000000000000000000000..2e214d1ebbc75845669768f067a130ce56286e18
--- /dev/null
+++ b/checkpoints/lit-llama-bak/7B/lit-llama.pth
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:09b6a8994e8bc8ed517e600e355a19cbe41eaf8338532ff4f88d43df6b95e3cd
+size 26953750909
diff --git a/checkpoints/lit-llama-bak/tokenizer.model b/checkpoints/lit-llama-bak/tokenizer.model
new file mode 100644
index 0000000000000000000000000000000000000000..88fe55a1de2ddca4e12292cae5273413d8b637a7
--- /dev/null
+++ b/checkpoints/lit-llama-bak/tokenizer.model
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:bc820fc43f4173d6362c16658c409ed423929a807e55a984af96cce1277d39a4
+size 772031
diff --git a/checkpoints/lit-llama/7B/lit-llama.pth b/checkpoints/lit-llama/7B/lit-llama.pth
new file mode 100644
index 0000000000000000000000000000000000000000..2e214d1ebbc75845669768f067a130ce56286e18
--- /dev/null
+++ b/checkpoints/lit-llama/7B/lit-llama.pth
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:09b6a8994e8bc8ed517e600e355a19cbe41eaf8338532ff4f88d43df6b95e3cd
+size 26953750909
diff --git a/checkpoints/lit-llama/tokenizer.model b/checkpoints/lit-llama/tokenizer.model
new file mode 100644
index 0000000000000000000000000000000000000000..88fe55a1de2ddca4e12292cae5273413d8b637a7
--- /dev/null
+++ b/checkpoints/lit-llama/tokenizer.model
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:bc820fc43f4173d6362c16658c409ed423929a807e55a984af96cce1277d39a4
+size 772031
diff --git a/checkpoints/open-llama/7B/.gitattributes b/checkpoints/open-llama/7B/.gitattributes
new file mode 100644
index 0000000000000000000000000000000000000000..9c4ed8b96533287461f2149b8a93fbf24cd5ff5a
--- /dev/null
+++ b/checkpoints/open-llama/7B/.gitattributes
@@ -0,0 +1,35 @@
+*.7z filter=lfs diff=lfs merge=lfs -text
+*.arrow filter=lfs diff=lfs merge=lfs -text
+*.bin filter=lfs diff=lfs merge=lfs -text
+*.bz2 filter=lfs diff=lfs merge=lfs -text
+*.ckpt filter=lfs diff=lfs merge=lfs -text
+*.ftz filter=lfs diff=lfs merge=lfs -text
+*.gz filter=lfs diff=lfs merge=lfs -text
+*.h5 filter=lfs diff=lfs merge=lfs -text
+*.joblib filter=lfs diff=lfs merge=lfs -text
+*.lfs.* filter=lfs diff=lfs merge=lfs -text
+*.mlmodel filter=lfs diff=lfs merge=lfs -text
+*.model filter=lfs diff=lfs merge=lfs -text
+*.msgpack filter=lfs diff=lfs merge=lfs -text
+*.npy filter=lfs diff=lfs merge=lfs -text
+*.npz filter=lfs diff=lfs merge=lfs -text
+*.onnx filter=lfs diff=lfs merge=lfs -text
+*.ot filter=lfs diff=lfs merge=lfs -text
+*.parquet filter=lfs diff=lfs merge=lfs -text
+*.pb filter=lfs diff=lfs merge=lfs -text
+*.pickle filter=lfs diff=lfs merge=lfs -text
+*.pkl filter=lfs diff=lfs merge=lfs -text
+*.pt filter=lfs diff=lfs merge=lfs -text
+*.pth filter=lfs diff=lfs merge=lfs -text
+*.rar filter=lfs diff=lfs merge=lfs -text
+*.safetensors filter=lfs diff=lfs merge=lfs -text
+saved_model/**/* filter=lfs diff=lfs merge=lfs -text
+*.tar.* filter=lfs diff=lfs merge=lfs -text
+*.tflite filter=lfs diff=lfs merge=lfs -text
+*.tgz filter=lfs diff=lfs merge=lfs -text
+*.wasm filter=lfs diff=lfs merge=lfs -text
+*.xz filter=lfs diff=lfs merge=lfs -text
+*.zip filter=lfs diff=lfs merge=lfs -text
+*.zst filter=lfs diff=lfs merge=lfs -text
+*tfevents* filter=lfs diff=lfs merge=lfs -text
+open_llama_7b_preview_300bt_easylm filter=lfs diff=lfs merge=lfs -text
diff --git a/checkpoints/open-llama/7B/LICENSE.txt b/checkpoints/open-llama/7B/LICENSE.txt
new file mode 100644
index 0000000000000000000000000000000000000000..261eeb9e9f8b2b4b0d119366dda99c6fd7d35c64
--- /dev/null
+++ b/checkpoints/open-llama/7B/LICENSE.txt
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/checkpoints/open-llama/7B/README.md b/checkpoints/open-llama/7B/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a05b0a666b1b1543b3482e726745dc489f3ba9aa
--- /dev/null
+++ b/checkpoints/open-llama/7B/README.md
@@ -0,0 +1,126 @@
+---
+license: apache-2.0
+datasets:
+ - togethercomputer/RedPajama-Data-1T
+---
+
+
+# OpenLLaMA: An Open Reproduction of LLaMA
+
+In this repo, we release a permissively licensed open source reproduction of Meta AI's [LLaMA](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/) large language model. In this release, we're releasing a public preview of the 7B OpenLLaMA model that has been trained with 200 billion tokens. We provide PyTorch and Jax weights of pre-trained OpenLLaMA models, as well as evaluation results and comparison against the original LLaMA models. Stay tuned for our updates.
+
+**JAX and PyTorch Weights on Huggingface Hub**
+- [200B Checkpoint](https://huggingface.co/openlm-research/open_llama_7b_preview_200bt)
+- [300B Checkpoint](https://huggingface.co/openlm-research/open_llama_7b_preview_300bt)
+
+
+## Update 5/3/2023
+We have released a new checkpoint of OpenLLaMA 7B trained on 300B tokens. In communicating
+with our users, we have realized that many existing implementations of LLaMA does not
+prepend the BOS token (id=1) at generation time. Our 200B checkpoint is sensitive
+to this and may produce degraded results without BOS token at the beginning. Hence,
+we recommend always prepending the BOS token when using our 200B checkpoint.
+
+In an effort to make our model boradly compatible with existing implementations, we have now
+released a new 300B checkpoint, which is less sensitive to BOS token and can be used
+either way.
+
+
+## Dataset and Training
+
+We train our models on the [RedPajama](https://www.together.xyz/blog/redpajama) dataset released by [Together](https://www.together.xyz/), which is a reproduction of the LLaMA training dataset containing over 1.2 trillion tokens. We follow the exactly same preprocessing steps and training hyperparameters as the original LLaMA paper, including model architecture, context length, training steps, learning rate schedule, and optimizer. The only difference between our setting and the original one is the dataset used: OpenLLaMA employs the RedPajama dataset rather than the one utilized by the original LLaMA.
+
+We train the models on cloud TPU-v4s using [EasyLM](https://github.com/young-geng/EasyLM), a JAX based training pipeline we developed for training and fine-tuning language model. We employ a combination of normal data parallelism and [fully sharded data parallelism (also know as ZeRO stage 3)](https://engineering.fb.com/2021/07/15/open-source/fsdp/) to balance the training throughput and memory usage. Overall we reach a throughput of over 1900 tokens / second / TPU-v4 chip in our training run.
+
+
+## Evaluation
+
+We evaluated OpenLLaMA on a wide range of tasks using [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness). The LLaMA results are generated by running the original LLaMA model on the same evaluation metrics. We note that our results for the LLaMA model differ slightly from the original LLaMA paper, which we believe is a result of different evaluation protocols. Similar differences have been reported in [this issue of lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness/issues/443). Additionally, we present the results of GPT-J, a 6B parameter model trained on the [Pile](https://pile.eleuther.ai/) dataset by [EleutherAI](https://www.eleuther.ai/).
+
+The original LLaMA model was trained for 1 trillion tokens and GPT-J was trained for 500 billion tokens, whereas OpenLLaMA was trained on 200 billion tokens. We present the results in the table below. OpenLLaMA exhibits comparable performance to the original LLaMA and GPT-J across a majority of tasks, and outperforms them in some tasks. We expect that the performance of OpenLLaMA, after completing its training on 1 trillion tokens, will be enhanced even further.
+
+
+| **Task/Metric** | **GPT-J 6B** | **LLaMA 7B** | **Open LLaMA 7B Preview 200B Tokens** |
+| ---------------------- | ------------ | ------------ | ------------------------------------- |
+| anli_r1/acc | 0.32 | 0.35 | 0.34 |
+| anli_r2/acc | 0.34 | 0.34 | 0.35 |
+| anli_r3/acc | 0.35 | 0.37 | 0.34 |
+| arc_challenge/acc | 0.34 | 0.39 | 0.31 |
+| arc_challenge/acc_norm | 0.37 | 0.41 | 0.34 |
+| arc_easy/acc | 0.67 | 0.68 | 0.66 |
+| arc_easy/acc_norm | 0.62 | 0.52 | 0.59 |
+| boolq/acc | 0.66 | 0.75 | 0.67 |
+| cb/acc | 0.36 | 0.36 | 0.38 |
+| cb/f1 | 0.26 | 0.24 | 0.29 |
+| hellaswag/acc | 0.50 | 0.56 | 0.47 |
+| hellaswag/acc_norm | 0.66 | 0.73 | 0.63 |
+| openbookqa/acc | 0.29 | 0.29 | 0.26 |
+| openbookqa/acc_norm | 0.38 | 0.41 | 0.37 |
+| piqa/acc | 0.75 | 0.78 | 0.74 |
+| piqa/acc_norm | 0.76 | 0.78 | 0.74 |
+| record/em | 0.88 | 0.91 | 0.87 |
+| record/f1 | 0.89 | 0.91 | 0.88 |
+| rte/acc | 0.54 | 0.56 | 0.53 |
+| truthfulqa_mc/mc1 | 0.20 | 0.21 | 0.21 |
+| truthfulqa_mc/mc2 | 0.36 | 0.34 | 0.34 |
+| wic/acc | 0.50 | 0.50 | 0.50 |
+| winogrande/acc | 0.64 | 0.68 | 0.62 |
+| wsc/acc | 0.37 | 0.35 | 0.57 |
+| Average | 0.50 | 0.52 | 0.50 |
+
+
+
+
+## Preview Weights Release and Usage
+
+To encourage the feedback from the community, we release a preview checkpoint of our weights. The checkpoint can be downloaded from [HuggingFace Hub](https://huggingface.co/openlm-research/open_llama_7b_preview_200bt). We release the weights in two formats: an EasyLM format to be use with our [EasyLM framework](https://github.com/young-geng/EasyLM), and a PyTorch format to be used with the [Huggingface Transformers](https://huggingface.co/docs/transformers/index) library.
+
+For using the weights in our EasyLM framework, please refer to the [LLaMA documentation of EasyLM](https://github.com/young-geng/EasyLM/blob/main/docs/llama.md). Note that unlike the original LLaMA model, our OpenLLaMA tokenizer and weights are trained completely from scratch so it is no longer needed to obtain the original LLaMA tokenizer and weights. For using the weights in the transformers library, please follow the [transformers LLaMA documentation](https://huggingface.co/docs/transformers/main/model_doc/llama). Note that we use BOS (beginning of sentence) token (id=1) during training, so it is important to prepend this token for best performance during few-shot evaluation.
+
+Both our training framework EasyLM and the preview checkpoint weights are licensed permissively under the Apache 2.0 license.
+
+
+## Future Plans
+
+The current release is only a preview of what the complete OpenLLaMA release will offer. We are currently focused on completing the training process on the entire RedPajama dataset. This can gives us a good apple-to-apple comparison between the original LLaMA and our OpenLLaMA. Other than the 7B model, we are also training a smaller 3B model in hope of facilitating language model usage in low resource use cases. Please stay tuned for our upcoming releases.
+
+
+
+## Contact
+
+We would love to get feedback from the community. If you have any questions, please open an issue or contact us.
+
+OpenLLaMA is developed by:
+[Xinyang Geng](https://young-geng.xyz/)* and [Hao Liu](https://www.haoliu.site/)* from Berkeley AI Research.
+*Equal Contribution
+
+
+## Reference
+
+If you found OpenLLaMA useful in your research or applications, please cite using the following BibTeX:
+```
+@software{openlm2023openllama,
+ author = {Geng, Xinyang and Liu, Hao},
+ title = {OpenLLaMA: An Open Reproduction of LLaMA},
+ month = May,
+ year = 2023,
+ url = {https://github.com/openlm-research/open_llama}
+}
+```
+```
+@software{together2023redpajama,
+ author = {Together Computer},
+ title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
+ month = April,
+ year = 2023,
+ url = {https://github.com/togethercomputer/RedPajama-Data}
+}
+```
+```
+@article{touvron2023llama,
+ title={Llama: Open and efficient foundation language models},
+ author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{\'e}e and Rozi{\`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
+ journal={arXiv preprint arXiv:2302.13971},
+ year={2023}
+}
+```
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_easylm b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_easylm
new file mode 100644
index 0000000000000000000000000000000000000000..b06d20297811f3056bda7c6ff0bdfd1864de0b8c
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_easylm
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:63ab9d652aaf4e0e47f1d9a0321ef565b62c02921ce0b18a781ba0daac2ebb98
+size 13476851687
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/config.json b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/config.json
new file mode 100644
index 0000000000000000000000000000000000000000..cf5ef7be6f3f9c154b2cdef13ea87b9a67f60abc
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/config.json
@@ -0,0 +1,22 @@
+{
+ "architectures": [
+ "LlamaForCausalLM"
+ ],
+ "bos_token_id": 1,
+ "eos_token_id": 2,
+ "hidden_act": "silu",
+ "hidden_size": 4096,
+ "initializer_range": 0.02,
+ "intermediate_size": 11008,
+ "max_position_embeddings": 2048,
+ "model_type": "llama",
+ "num_attention_heads": 32,
+ "num_hidden_layers": 32,
+ "pad_token_id": 0,
+ "rms_norm_eps": 1e-06,
+ "tie_word_embeddings": false,
+ "torch_dtype": "float16",
+ "transformers_version": "4.28.0.dev0",
+ "use_cache": true,
+ "vocab_size": 32000
+}
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/generation_config.json b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/generation_config.json
new file mode 100644
index 0000000000000000000000000000000000000000..55d7b5b6db760f8c1963be3d56a3bc363bacdfb1
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/generation_config.json
@@ -0,0 +1,7 @@
+{
+ "_from_model_config": true,
+ "bos_token_id": 1,
+ "eos_token_id": 2,
+ "pad_token_id": 0,
+ "transformers_version": "4.28.0.dev0"
+}
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model-00001-of-00002.bin b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model-00001-of-00002.bin
new file mode 100644
index 0000000000000000000000000000000000000000..0db7ffadc89169c8f2c1267c614730585e3c7dbc
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model-00001-of-00002.bin
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:adce75e45dbad20967c0e96a83b318720a767e4b8f77aabcd01cd2b38e8f0b2e
+size 9976634558
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model-00002-of-00002.bin b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model-00002-of-00002.bin
new file mode 100644
index 0000000000000000000000000000000000000000..56bd685f09828f41347246829488a2b0e5dcb833
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model-00002-of-00002.bin
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:a80d748a6ab528f0db2249013a5d3fea17e039ad9fa1bf3e170e9070ec30f938
+size 3500315539
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model.bin.index.json b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model.bin.index.json
new file mode 100644
index 0000000000000000000000000000000000000000..db7264b24cac7a39947bb5fc02fe5c2d7ac9eaf4
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model.bin.index.json
@@ -0,0 +1,330 @@
+{
+ "metadata": {
+ "total_size": 13476839424
+ },
+ "weight_map": {
+ "lm_head.weight": "pytorch_model-00002-of-00002.bin",
+ "model.embed_tokens.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.24.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.3.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.30.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.4.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.norm.weight": "pytorch_model-00002-of-00002.bin"
+ }
+}
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/special_tokens_map.json b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/special_tokens_map.json
new file mode 100644
index 0000000000000000000000000000000000000000..9e26dfeeb6e641a33dae4961196235bdb965b21b
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/special_tokens_map.json
@@ -0,0 +1 @@
+{}
\ No newline at end of file
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/tokenizer.model b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/tokenizer.model
new file mode 100644
index 0000000000000000000000000000000000000000..88fe55a1de2ddca4e12292cae5273413d8b637a7
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/tokenizer.model
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:bc820fc43f4173d6362c16658c409ed423929a807e55a984af96cce1277d39a4
+size 772031
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/tokenizer_config.json b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/tokenizer_config.json
new file mode 100644
index 0000000000000000000000000000000000000000..a54b01aa3699f19e1aea416fc337f910f60c6839
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/tokenizer_config.json
@@ -0,0 +1 @@
+{"bos_token": "", "eos_token": "", "model_max_length": 1000000000000000019884624838656, "tokenizer_class": "LlamaTokenizer", "unk_token": ""}
\ No newline at end of file
diff --git a/checkpoints/open-llama/7B/tokenizer.model b/checkpoints/open-llama/7B/tokenizer.model
new file mode 100644
index 0000000000000000000000000000000000000000..88fe55a1de2ddca4e12292cae5273413d8b637a7
--- /dev/null
+++ b/checkpoints/open-llama/7B/tokenizer.model
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:bc820fc43f4173d6362c16658c409ed423929a807e55a984af96cce1277d39a4
+size 772031
diff --git a/checkpoints/open-llama/7B/tokenizer.vocab b/checkpoints/open-llama/7B/tokenizer.vocab
new file mode 100644
index 0000000000000000000000000000000000000000..54d6ff3ea3fa307f4920fd473f18a361be6d48e6
--- /dev/null
+++ b/checkpoints/open-llama/7B/tokenizer.vocab
@@ -0,0 +1,32000 @@
+
+
+Join us and start contributing, especially on the following areas:
+
+- [ ] [Pre-training](https://github.com/Lightning-AI/lit-llama/labels/pre-training)
+- [ ] [Fine-tuning (full and LoRA)](https://github.com/Lightning-AI/lit-llama/labels/fine-tuning)
+- [ ] [Quantization](https://github.com/Lightning-AI/lit-llama/labels/quantization)
+- [ ] [Sparsification](https://github.com/Lightning-AI/lit-llama/labels/sparsification)
+
+Look at `train.py` for a starting point towards pre-training / fine-tuning using [Lightning Fabric](https://lightning.ai/docs/fabric/stable/).
+
+We welcome all individual contributors, regardless of their level of experience or hardware. Your contributions are valuable, and we are excited to see what you can accomplish in this collaborative and supportive environment.
+
+Unsure about contributing? Check out our [Contributing to Lit-LLaMA: A Hitchhiker’s Guide to the Quest for Fully Open-Source AI](https://lightning.ai/pages/community/tutorial/contributing-to-lit-llama-a-hitchhikers-guide-to-the-quest-for-fully-open-source-ai/) guide.
+
+Don't forget to [join our Discord](https://discord.gg/VptPCZkGNa)!
+
+## Acknowledgements
+
+- [@karpathy](https://github.com/karpathy) for [nanoGPT](https://github.com/karpathy/nanoGPT)
+- [@FacebookResearch](https://github.com/facebookresearch) for the original [LLaMA implementation](https://github.com/facebookresearch/llama)
+- [@TimDettmers](https://github.com/TimDettmers) for [bitsandbytes](https://github.com/TimDettmers/bitsandbytes)
+- [@Microsoft](https://github.com/microsoft) for [LoRA](https://github.com/microsoft/LoRA)
+- [@IST-DASLab](https://github.com/IST-DASLab) for [GPTQ](https://github.com/IST-DASLab/gptq)
+
+## License
+
+Lit-LLaMA is released under the [Apache 2.0](https://github.com/Lightning-AI/lightning-llama/blob/main/LICENSE) license.
diff --git a/checkpoints/lit-llama-bak/7B/lit-llama.pth b/checkpoints/lit-llama-bak/7B/lit-llama.pth
new file mode 100644
index 0000000000000000000000000000000000000000..2e214d1ebbc75845669768f067a130ce56286e18
--- /dev/null
+++ b/checkpoints/lit-llama-bak/7B/lit-llama.pth
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:09b6a8994e8bc8ed517e600e355a19cbe41eaf8338532ff4f88d43df6b95e3cd
+size 26953750909
diff --git a/checkpoints/lit-llama-bak/tokenizer.model b/checkpoints/lit-llama-bak/tokenizer.model
new file mode 100644
index 0000000000000000000000000000000000000000..88fe55a1de2ddca4e12292cae5273413d8b637a7
--- /dev/null
+++ b/checkpoints/lit-llama-bak/tokenizer.model
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:bc820fc43f4173d6362c16658c409ed423929a807e55a984af96cce1277d39a4
+size 772031
diff --git a/checkpoints/lit-llama/7B/lit-llama.pth b/checkpoints/lit-llama/7B/lit-llama.pth
new file mode 100644
index 0000000000000000000000000000000000000000..2e214d1ebbc75845669768f067a130ce56286e18
--- /dev/null
+++ b/checkpoints/lit-llama/7B/lit-llama.pth
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:09b6a8994e8bc8ed517e600e355a19cbe41eaf8338532ff4f88d43df6b95e3cd
+size 26953750909
diff --git a/checkpoints/lit-llama/tokenizer.model b/checkpoints/lit-llama/tokenizer.model
new file mode 100644
index 0000000000000000000000000000000000000000..88fe55a1de2ddca4e12292cae5273413d8b637a7
--- /dev/null
+++ b/checkpoints/lit-llama/tokenizer.model
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:bc820fc43f4173d6362c16658c409ed423929a807e55a984af96cce1277d39a4
+size 772031
diff --git a/checkpoints/open-llama/7B/.gitattributes b/checkpoints/open-llama/7B/.gitattributes
new file mode 100644
index 0000000000000000000000000000000000000000..9c4ed8b96533287461f2149b8a93fbf24cd5ff5a
--- /dev/null
+++ b/checkpoints/open-llama/7B/.gitattributes
@@ -0,0 +1,35 @@
+*.7z filter=lfs diff=lfs merge=lfs -text
+*.arrow filter=lfs diff=lfs merge=lfs -text
+*.bin filter=lfs diff=lfs merge=lfs -text
+*.bz2 filter=lfs diff=lfs merge=lfs -text
+*.ckpt filter=lfs diff=lfs merge=lfs -text
+*.ftz filter=lfs diff=lfs merge=lfs -text
+*.gz filter=lfs diff=lfs merge=lfs -text
+*.h5 filter=lfs diff=lfs merge=lfs -text
+*.joblib filter=lfs diff=lfs merge=lfs -text
+*.lfs.* filter=lfs diff=lfs merge=lfs -text
+*.mlmodel filter=lfs diff=lfs merge=lfs -text
+*.model filter=lfs diff=lfs merge=lfs -text
+*.msgpack filter=lfs diff=lfs merge=lfs -text
+*.npy filter=lfs diff=lfs merge=lfs -text
+*.npz filter=lfs diff=lfs merge=lfs -text
+*.onnx filter=lfs diff=lfs merge=lfs -text
+*.ot filter=lfs diff=lfs merge=lfs -text
+*.parquet filter=lfs diff=lfs merge=lfs -text
+*.pb filter=lfs diff=lfs merge=lfs -text
+*.pickle filter=lfs diff=lfs merge=lfs -text
+*.pkl filter=lfs diff=lfs merge=lfs -text
+*.pt filter=lfs diff=lfs merge=lfs -text
+*.pth filter=lfs diff=lfs merge=lfs -text
+*.rar filter=lfs diff=lfs merge=lfs -text
+*.safetensors filter=lfs diff=lfs merge=lfs -text
+saved_model/**/* filter=lfs diff=lfs merge=lfs -text
+*.tar.* filter=lfs diff=lfs merge=lfs -text
+*.tflite filter=lfs diff=lfs merge=lfs -text
+*.tgz filter=lfs diff=lfs merge=lfs -text
+*.wasm filter=lfs diff=lfs merge=lfs -text
+*.xz filter=lfs diff=lfs merge=lfs -text
+*.zip filter=lfs diff=lfs merge=lfs -text
+*.zst filter=lfs diff=lfs merge=lfs -text
+*tfevents* filter=lfs diff=lfs merge=lfs -text
+open_llama_7b_preview_300bt_easylm filter=lfs diff=lfs merge=lfs -text
diff --git a/checkpoints/open-llama/7B/LICENSE.txt b/checkpoints/open-llama/7B/LICENSE.txt
new file mode 100644
index 0000000000000000000000000000000000000000..261eeb9e9f8b2b4b0d119366dda99c6fd7d35c64
--- /dev/null
+++ b/checkpoints/open-llama/7B/LICENSE.txt
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/checkpoints/open-llama/7B/README.md b/checkpoints/open-llama/7B/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..a05b0a666b1b1543b3482e726745dc489f3ba9aa
--- /dev/null
+++ b/checkpoints/open-llama/7B/README.md
@@ -0,0 +1,126 @@
+---
+license: apache-2.0
+datasets:
+ - togethercomputer/RedPajama-Data-1T
+---
+
+
+# OpenLLaMA: An Open Reproduction of LLaMA
+
+In this repo, we release a permissively licensed open source reproduction of Meta AI's [LLaMA](https://ai.facebook.com/blog/large-language-model-llama-meta-ai/) large language model. In this release, we're releasing a public preview of the 7B OpenLLaMA model that has been trained with 200 billion tokens. We provide PyTorch and Jax weights of pre-trained OpenLLaMA models, as well as evaluation results and comparison against the original LLaMA models. Stay tuned for our updates.
+
+**JAX and PyTorch Weights on Huggingface Hub**
+- [200B Checkpoint](https://huggingface.co/openlm-research/open_llama_7b_preview_200bt)
+- [300B Checkpoint](https://huggingface.co/openlm-research/open_llama_7b_preview_300bt)
+
+
+## Update 5/3/2023
+We have released a new checkpoint of OpenLLaMA 7B trained on 300B tokens. In communicating
+with our users, we have realized that many existing implementations of LLaMA does not
+prepend the BOS token (id=1) at generation time. Our 200B checkpoint is sensitive
+to this and may produce degraded results without BOS token at the beginning. Hence,
+we recommend always prepending the BOS token when using our 200B checkpoint.
+
+In an effort to make our model boradly compatible with existing implementations, we have now
+released a new 300B checkpoint, which is less sensitive to BOS token and can be used
+either way.
+
+
+## Dataset and Training
+
+We train our models on the [RedPajama](https://www.together.xyz/blog/redpajama) dataset released by [Together](https://www.together.xyz/), which is a reproduction of the LLaMA training dataset containing over 1.2 trillion tokens. We follow the exactly same preprocessing steps and training hyperparameters as the original LLaMA paper, including model architecture, context length, training steps, learning rate schedule, and optimizer. The only difference between our setting and the original one is the dataset used: OpenLLaMA employs the RedPajama dataset rather than the one utilized by the original LLaMA.
+
+We train the models on cloud TPU-v4s using [EasyLM](https://github.com/young-geng/EasyLM), a JAX based training pipeline we developed for training and fine-tuning language model. We employ a combination of normal data parallelism and [fully sharded data parallelism (also know as ZeRO stage 3)](https://engineering.fb.com/2021/07/15/open-source/fsdp/) to balance the training throughput and memory usage. Overall we reach a throughput of over 1900 tokens / second / TPU-v4 chip in our training run.
+
+
+## Evaluation
+
+We evaluated OpenLLaMA on a wide range of tasks using [lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness). The LLaMA results are generated by running the original LLaMA model on the same evaluation metrics. We note that our results for the LLaMA model differ slightly from the original LLaMA paper, which we believe is a result of different evaluation protocols. Similar differences have been reported in [this issue of lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness/issues/443). Additionally, we present the results of GPT-J, a 6B parameter model trained on the [Pile](https://pile.eleuther.ai/) dataset by [EleutherAI](https://www.eleuther.ai/).
+
+The original LLaMA model was trained for 1 trillion tokens and GPT-J was trained for 500 billion tokens, whereas OpenLLaMA was trained on 200 billion tokens. We present the results in the table below. OpenLLaMA exhibits comparable performance to the original LLaMA and GPT-J across a majority of tasks, and outperforms them in some tasks. We expect that the performance of OpenLLaMA, after completing its training on 1 trillion tokens, will be enhanced even further.
+
+
+| **Task/Metric** | **GPT-J 6B** | **LLaMA 7B** | **Open LLaMA 7B Preview 200B Tokens** |
+| ---------------------- | ------------ | ------------ | ------------------------------------- |
+| anli_r1/acc | 0.32 | 0.35 | 0.34 |
+| anli_r2/acc | 0.34 | 0.34 | 0.35 |
+| anli_r3/acc | 0.35 | 0.37 | 0.34 |
+| arc_challenge/acc | 0.34 | 0.39 | 0.31 |
+| arc_challenge/acc_norm | 0.37 | 0.41 | 0.34 |
+| arc_easy/acc | 0.67 | 0.68 | 0.66 |
+| arc_easy/acc_norm | 0.62 | 0.52 | 0.59 |
+| boolq/acc | 0.66 | 0.75 | 0.67 |
+| cb/acc | 0.36 | 0.36 | 0.38 |
+| cb/f1 | 0.26 | 0.24 | 0.29 |
+| hellaswag/acc | 0.50 | 0.56 | 0.47 |
+| hellaswag/acc_norm | 0.66 | 0.73 | 0.63 |
+| openbookqa/acc | 0.29 | 0.29 | 0.26 |
+| openbookqa/acc_norm | 0.38 | 0.41 | 0.37 |
+| piqa/acc | 0.75 | 0.78 | 0.74 |
+| piqa/acc_norm | 0.76 | 0.78 | 0.74 |
+| record/em | 0.88 | 0.91 | 0.87 |
+| record/f1 | 0.89 | 0.91 | 0.88 |
+| rte/acc | 0.54 | 0.56 | 0.53 |
+| truthfulqa_mc/mc1 | 0.20 | 0.21 | 0.21 |
+| truthfulqa_mc/mc2 | 0.36 | 0.34 | 0.34 |
+| wic/acc | 0.50 | 0.50 | 0.50 |
+| winogrande/acc | 0.64 | 0.68 | 0.62 |
+| wsc/acc | 0.37 | 0.35 | 0.57 |
+| Average | 0.50 | 0.52 | 0.50 |
+
+
+
+
+## Preview Weights Release and Usage
+
+To encourage the feedback from the community, we release a preview checkpoint of our weights. The checkpoint can be downloaded from [HuggingFace Hub](https://huggingface.co/openlm-research/open_llama_7b_preview_200bt). We release the weights in two formats: an EasyLM format to be use with our [EasyLM framework](https://github.com/young-geng/EasyLM), and a PyTorch format to be used with the [Huggingface Transformers](https://huggingface.co/docs/transformers/index) library.
+
+For using the weights in our EasyLM framework, please refer to the [LLaMA documentation of EasyLM](https://github.com/young-geng/EasyLM/blob/main/docs/llama.md). Note that unlike the original LLaMA model, our OpenLLaMA tokenizer and weights are trained completely from scratch so it is no longer needed to obtain the original LLaMA tokenizer and weights. For using the weights in the transformers library, please follow the [transformers LLaMA documentation](https://huggingface.co/docs/transformers/main/model_doc/llama). Note that we use BOS (beginning of sentence) token (id=1) during training, so it is important to prepend this token for best performance during few-shot evaluation.
+
+Both our training framework EasyLM and the preview checkpoint weights are licensed permissively under the Apache 2.0 license.
+
+
+## Future Plans
+
+The current release is only a preview of what the complete OpenLLaMA release will offer. We are currently focused on completing the training process on the entire RedPajama dataset. This can gives us a good apple-to-apple comparison between the original LLaMA and our OpenLLaMA. Other than the 7B model, we are also training a smaller 3B model in hope of facilitating language model usage in low resource use cases. Please stay tuned for our upcoming releases.
+
+
+
+## Contact
+
+We would love to get feedback from the community. If you have any questions, please open an issue or contact us.
+
+OpenLLaMA is developed by:
+[Xinyang Geng](https://young-geng.xyz/)* and [Hao Liu](https://www.haoliu.site/)* from Berkeley AI Research.
+*Equal Contribution
+
+
+## Reference
+
+If you found OpenLLaMA useful in your research or applications, please cite using the following BibTeX:
+```
+@software{openlm2023openllama,
+ author = {Geng, Xinyang and Liu, Hao},
+ title = {OpenLLaMA: An Open Reproduction of LLaMA},
+ month = May,
+ year = 2023,
+ url = {https://github.com/openlm-research/open_llama}
+}
+```
+```
+@software{together2023redpajama,
+ author = {Together Computer},
+ title = {RedPajama-Data: An Open Source Recipe to Reproduce LLaMA training dataset},
+ month = April,
+ year = 2023,
+ url = {https://github.com/togethercomputer/RedPajama-Data}
+}
+```
+```
+@article{touvron2023llama,
+ title={Llama: Open and efficient foundation language models},
+ author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{\'e}e and Rozi{\`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and others},
+ journal={arXiv preprint arXiv:2302.13971},
+ year={2023}
+}
+```
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_easylm b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_easylm
new file mode 100644
index 0000000000000000000000000000000000000000..b06d20297811f3056bda7c6ff0bdfd1864de0b8c
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_easylm
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:63ab9d652aaf4e0e47f1d9a0321ef565b62c02921ce0b18a781ba0daac2ebb98
+size 13476851687
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/config.json b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/config.json
new file mode 100644
index 0000000000000000000000000000000000000000..cf5ef7be6f3f9c154b2cdef13ea87b9a67f60abc
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/config.json
@@ -0,0 +1,22 @@
+{
+ "architectures": [
+ "LlamaForCausalLM"
+ ],
+ "bos_token_id": 1,
+ "eos_token_id": 2,
+ "hidden_act": "silu",
+ "hidden_size": 4096,
+ "initializer_range": 0.02,
+ "intermediate_size": 11008,
+ "max_position_embeddings": 2048,
+ "model_type": "llama",
+ "num_attention_heads": 32,
+ "num_hidden_layers": 32,
+ "pad_token_id": 0,
+ "rms_norm_eps": 1e-06,
+ "tie_word_embeddings": false,
+ "torch_dtype": "float16",
+ "transformers_version": "4.28.0.dev0",
+ "use_cache": true,
+ "vocab_size": 32000
+}
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/generation_config.json b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/generation_config.json
new file mode 100644
index 0000000000000000000000000000000000000000..55d7b5b6db760f8c1963be3d56a3bc363bacdfb1
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/generation_config.json
@@ -0,0 +1,7 @@
+{
+ "_from_model_config": true,
+ "bos_token_id": 1,
+ "eos_token_id": 2,
+ "pad_token_id": 0,
+ "transformers_version": "4.28.0.dev0"
+}
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model-00001-of-00002.bin b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model-00001-of-00002.bin
new file mode 100644
index 0000000000000000000000000000000000000000..0db7ffadc89169c8f2c1267c614730585e3c7dbc
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model-00001-of-00002.bin
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:adce75e45dbad20967c0e96a83b318720a767e4b8f77aabcd01cd2b38e8f0b2e
+size 9976634558
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model-00002-of-00002.bin b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model-00002-of-00002.bin
new file mode 100644
index 0000000000000000000000000000000000000000..56bd685f09828f41347246829488a2b0e5dcb833
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model-00002-of-00002.bin
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:a80d748a6ab528f0db2249013a5d3fea17e039ad9fa1bf3e170e9070ec30f938
+size 3500315539
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model.bin.index.json b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model.bin.index.json
new file mode 100644
index 0000000000000000000000000000000000000000..db7264b24cac7a39947bb5fc02fe5c2d7ac9eaf4
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/pytorch_model.bin.index.json
@@ -0,0 +1,330 @@
+{
+ "metadata": {
+ "total_size": 13476839424
+ },
+ "weight_map": {
+ "lm_head.weight": "pytorch_model-00002-of-00002.bin",
+ "model.embed_tokens.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.0.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.1.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.10.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.11.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.12.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.13.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.14.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.15.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.16.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.17.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.18.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.19.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.2.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.20.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.21.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.22.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.23.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.24.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
+ "model.layers.24.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
+ "model.layers.25.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
+ "model.layers.26.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
+ "model.layers.27.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
+ "model.layers.28.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
+ "model.layers.29.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.3.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.3.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.30.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
+ "model.layers.30.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.input_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.mlp.down_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.mlp.gate_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.mlp.up_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.post_attention_layernorm.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.self_attn.k_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.self_attn.o_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.self_attn.q_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.self_attn.rotary_emb.inv_freq": "pytorch_model-00002-of-00002.bin",
+ "model.layers.31.self_attn.v_proj.weight": "pytorch_model-00002-of-00002.bin",
+ "model.layers.4.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.4.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.5.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.6.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.7.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.8.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.input_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.mlp.down_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.mlp.gate_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.mlp.up_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.post_attention_layernorm.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.self_attn.k_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.self_attn.o_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.self_attn.q_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.self_attn.rotary_emb.inv_freq": "pytorch_model-00001-of-00002.bin",
+ "model.layers.9.self_attn.v_proj.weight": "pytorch_model-00001-of-00002.bin",
+ "model.norm.weight": "pytorch_model-00002-of-00002.bin"
+ }
+}
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/special_tokens_map.json b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/special_tokens_map.json
new file mode 100644
index 0000000000000000000000000000000000000000..9e26dfeeb6e641a33dae4961196235bdb965b21b
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/special_tokens_map.json
@@ -0,0 +1 @@
+{}
\ No newline at end of file
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/tokenizer.model b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/tokenizer.model
new file mode 100644
index 0000000000000000000000000000000000000000..88fe55a1de2ddca4e12292cae5273413d8b637a7
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/tokenizer.model
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:bc820fc43f4173d6362c16658c409ed423929a807e55a984af96cce1277d39a4
+size 772031
diff --git a/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/tokenizer_config.json b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/tokenizer_config.json
new file mode 100644
index 0000000000000000000000000000000000000000..a54b01aa3699f19e1aea416fc337f910f60c6839
--- /dev/null
+++ b/checkpoints/open-llama/7B/open_llama_7b_preview_300bt_transformers_weights/tokenizer_config.json
@@ -0,0 +1 @@
+{"bos_token": "", "eos_token": "", "model_max_length": 1000000000000000019884624838656, "tokenizer_class": "LlamaTokenizer", "unk_token": ""}
\ No newline at end of file
diff --git a/checkpoints/open-llama/7B/tokenizer.model b/checkpoints/open-llama/7B/tokenizer.model
new file mode 100644
index 0000000000000000000000000000000000000000..88fe55a1de2ddca4e12292cae5273413d8b637a7
--- /dev/null
+++ b/checkpoints/open-llama/7B/tokenizer.model
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:bc820fc43f4173d6362c16658c409ed423929a807e55a984af96cce1277d39a4
+size 772031
diff --git a/checkpoints/open-llama/7B/tokenizer.vocab b/checkpoints/open-llama/7B/tokenizer.vocab
new file mode 100644
index 0000000000000000000000000000000000000000..54d6ff3ea3fa307f4920fd473f18a361be6d48e6
--- /dev/null
+++ b/checkpoints/open-llama/7B/tokenizer.vocab
@@ -0,0 +1,32000 @@
+