---
language:
- en
- ar
- ca
- de
- et
- fa
- id
- ja
- lv
- mn
- sl
- sv
- ta
- tr
- zh
license: mit
metrics:
- bleu
datasets:
- mozilla-foundation/common_voice_8_0
pipeline_tag: automatic-speech-recognition
tags:
- zeroswot
- speech translation
- zero-shot
- end-to-end
- nllb
- wav2vec2
---
# ZeroSwot ✨🤖✨
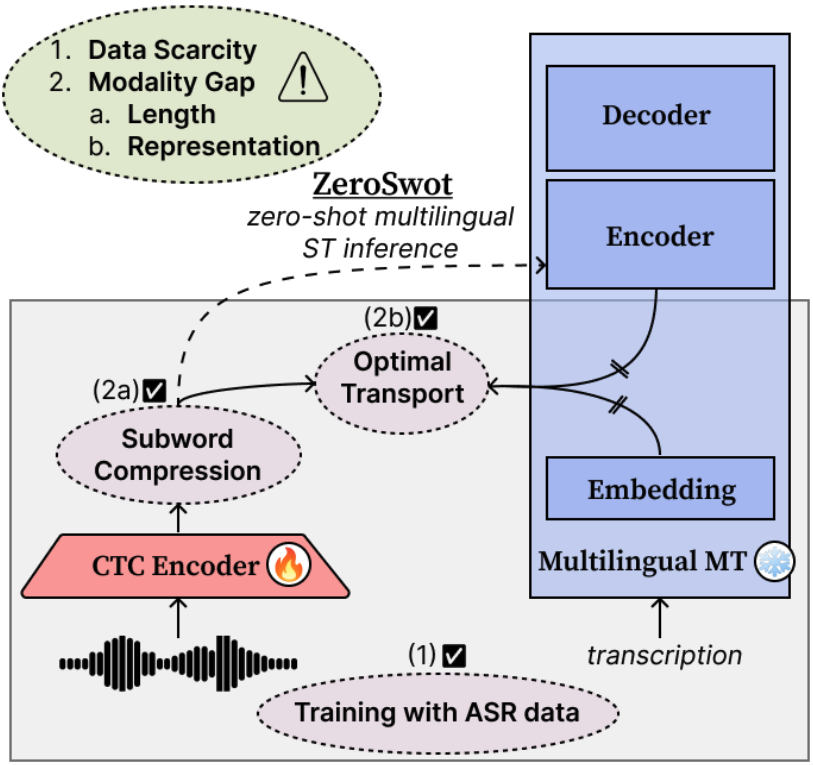
ZeroSwot is a state-of-the-art zero-shot end-to-end Speech Translation system.
The model is created by adapting a wav2vec2.0-based encoder to the embedding space of NLLB, using a novel subword compression module and Optimal Transport, while only utilizing ASR data. It thus enables **Zero-shot E2E Speech Translation to all the 200 languages supported by NLLB**.
For more details please refer to our [paper](https://arxiv.org/abs/2402.10422) and the [original repo](https://github.com/mt-upc/ZeroSwot) build on fairseq.
## Architecture
The compression module is a light-weight transformer that takes as input the hidden state of wav2vec2.0 and the corresponding CTC predictions, and compresses them to subword-like embeddings similar to those expected from NLLB and aligns them using Optimal Transport. For inference we simply pass the output of the speech encoder to NLLB encoder.
## Version
This version of ZeroSwot is trained with ASR data from CommonVoice. It adapts [wav2vec2.0-large](https://huggingface.co/facebook/wav2vec2-large-960h-lv60-self) to the embedding space of the [nllb-200-distilled-1.3B_covost2](https://huggingface.co/johntsi/nllb-200-distilled-1.3B_covost2_en-to-15) model, which is a multilingually finetuned NLLB on MuST-C MT data.
We have more versions available:
| Models | ASR data | NLLB version |
|:------:|:--------:|:------------:|
| [ZeroSwot-Medium_asr-mustc](https://huggingface.co/johntsi/ZeroSwot-Medium_asr-mustc_en-to-200) | MuST-C v1.0 | [distilled-600M original](https://huggingface.co/facebook/nllb-200-distilled-600M)|
| [ZeroSwot-Medium_asr-mustc_mt-mustc](https://huggingface.co/johntsi/ZeroSwot-Medium_asr-mustc_mt-mustc_en-to-8) | MuST-C v1.0 | [distilled-600M finetuned w/ MuST-C](https://huggingface.co/johntsi/nllb-200-distilled-600M_mustc_en-to-8) |
| [ZeroSwot-Large_asr-mustc](https://huggingface.co/johntsi/ZeroSwot-Large_asr-mustc_en-to-200) | MuST-C v1.0 | [distilled-1.3B original](https://huggingface.co/facebook/nllb-200-distilled-1.3B) |
| [ZeroSwot-Large_asr-mustc_mt-mustc](https://huggingface.co/johntsi/ZeroSwot-Large_asr-mustc_mt-mustc_en-to-8) | MuST-C v1.0 | [distilled-1.3B finetuned w/ MuST-C](https://huggingface.co/johntsi/nllb-200-distilled-1.3B_mustc_en-to-8) |
| [ZeroSwot-Medium_asr-cv](https://huggingface.co/johntsi/ZeroSwot-Medium_asr-cv_en-to-200) | CommonVoice | [distilled-600M original](https://huggingface.co/facebook/nllb-200-distilled-600M)|
| [ZeroSwot-Medium_asr-cv_mt-covost2](https://huggingface.co/johntsi/ZeroSwot-Medium_asr-cv_mt-covost2_en-to-15) | CommonVoice | [distilled-600M finetuned w/ CoVoST2](https://huggingface.co/johntsi/nllb-200-distilled-600M_covost2_en-to-15) |
| [ZeroSwot-Large_asr-cv](https://huggingface.co/johntsi/ZeroSwot-Large_asr-cv_en-to-200) | CommonVoice | [distilled-1.3B original](https://huggingface.co/facebook/nllb-200-distilled-1.3B) |
| [ZeroSwot-Large_asr-cv_mt-covost2](https://huggingface.co/johntsi/ZeroSwot-Large_asr-cv_mt-covost2_en-to-15) | CommonVoice | [distilled-1.3B finetuned w/ CoVoST2](https://huggingface.co/johntsi/nllb-200-distilled-1.3B_covost2_en-to-15) |
## Usage
The model is tested with python 3.9.16 and Transformer v4.41.2. Install also torchaudio and sentencepiece for processing.
```bash
pip install transformers torchaudio sentencepiece
```
```python
from transformers import Wav2Vec2Processor, NllbTokenizer, AutoModel, AutoModelForSeq2SeqLM
import torchaudio
def load_and_resample_audio(audio_path, target_sr=16000):
audio, orig_freq = torchaudio.load(audio_path)
if orig_freq != target_sr:
audio = torchaudio.functional.resample(audio, orig_freq=orig_freq, new_freq=target_sr)
audio = audio.squeeze(0).numpy()
return audio
# Load processors and tokenizers
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h-lv60-self")
tokenizer = NllbTokenizer.from_pretrained("johntsi/nllb-200-distilled-1.3B_covost2_en-to-15")
# Load ZeroSwot Encoder
commit_hash = "762878c55bf91406318983c724db22590a828e96"
zeroswot_encoder = AutoModel.from_pretrained(
"johntsi/ZeroSwot-Large_asr-cv_mt-covost2_en-to-15", trust_remote_code=True, revision=commit_hash,
)
zeroswot_encoder.eval()
zeroswot_encoder.to("cuda")
# Load NLLB Model
nllb_model = AutoModelForSeq2SeqLM.from_pretrained("johntsi/nllb-200-distilled-1.3B_covost2_en-to-15")
nllb_model.eval()
nllb_model.to("cuda")
# Load audio file
audio = load_and_resample_audio(path_to_audio_file) # you can use "resources/sample.wav" for testing
input_values = processor(audio, sampling_rate=16000, return_tensors="pt").to("cuda")
# translation to German
compressed_embeds, attention_mask = zeroswot_encoder(**input_values)
predicted_ids = nllb_model.generate(
inputs_embeds=compressed_embeds,
attention_mask=attention_mask,
forced_bos_token_id=tokenizer.lang_code_to_id["deu_Latn"],
num_beams=5,
)
translation = tokenizer.decode(predicted_ids[0], skip_special_tokens=True)
print(translation)
```
## Results
BLEU scores on CoVoST-2 test compared to supervised SOTA models XLS-R-2B and SeamlessM4T-Large. You can refer to Table 5 of the Results section in the paper for more details.
| Models | ZS | Size (B) | Ar | Ca | Cy | De | Et | Fa | Id | Ja | Lv | Mn | Sl | Sv | Ta | Tr | Zh | Average |
|:--------------:|:----:|:----------:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:-------:|
| [XLS-R-2B](https://huggingface.co/facebook/wav2vec2-xls-r-2b-en-to-15) | ✗ | 2.0 | 20.7 | 34.2 | 33.8 | 28.3 | 24.1 | 22.9 | 32.5 | 41.5 | 23.5 | 16.2 | 27.6 | 34.5 | 19.8 | 18.6 | 38.5 | 27.8 |
| [SeamlessM4T-L-v1](https://huggingface.co/facebook/seamless-m4t-large) | ✗ | 2.3 | 24.5 | 41.6 | 33.6 | 35.9 | 28.5 | 19.3 | 39.0 | 39.4 | 23.8 | 15.7 | 35.0 | 42.5 | 22.7 | 23.9 | 33.1 | 30.6 |
| [SeamlessM4T-L-v2](https://huggingface.co/facebook/seamless-m4t-v2-large) | ✗ | 2.3 | 25.4 | **43.6** | **35.5** | **37.0** | **29.3** | 19.2 | **40.2** | 39.7 | 24.8 | 16.4 | **36.2** | **43.7** | 23.4 | **24.7** | 35.9 | **31.7** |
| [ZeroSwot-Large_asr-cv](https://huggingface.co/johntsi/ZeroSwot-Large_asr-cv_en-to-200) | ✓ | 0.35/1.65 | 19.8 | 36.1 | 22.6 | 31.8 | 23.6 | 16.8 | 34.2 | 33.6 | 17.5 | 11.8 | 28.9 | 36.8 | 19.1 | 17.5 | 32.2 | 25.5 |
| [ZeroSwot-Large_asr-cv_mt-covost2](https://huggingface.co/johntsi/ZeroSwot-Large_asr-cv_mt-covost2_en-to-15) | ✓ | 0.35/1.65 | **25.7** | 40.0 | 29.0 | 32.8 | 27.2 | **26.6** | 37.1 | **47.1** | **25.7** | **18.9** | 33.2 | 39.3 | **25.3** | 19.8 | **40.5** | 31.2 |
## Citation
If you find ZeroSwot useful for your research, please cite our paper :)
```
@inproceedings{tsiamas-etal-2024-pushing,
title = {{Pushing the Limits of Zero-shot End-to-End Speech Translation}},
author = "Tsiamas, Ioannis and
G{\'a}llego, Gerard and
Fonollosa, Jos{\'e} and
Costa-juss{\`a}, Marta",
editor = "Ku, Lun-Wei and
Martins, Andre and
Srikumar, Vivek",
booktitle = "Findings of the Association for Computational Linguistics ACL 2024",
month = aug,
year = "2024",
address = "Bangkok, Thailand and virtual meeting",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-acl.847",
pages = "14245--14267",
}
```