---
license: apache-2.0
language:
- id
- su
- jv
---
# **Cendol: Open Instruction-tuned Generative Large Language Models for Indonesian Languages**
Cendol is an open-source collection of fine-tuned generative large language models in Indonesian languages covering decoder-only and encoder-decoder transformer model architectures ranging in scale from 300 million to 13 billion parameters.
This is the repository for the **13B Cendol mT5-XXL Instruct model**. Links to other models can be found below.
## Model Details
*Note*: Use of Cendol is licensed under the [Apache 2.0 license](https://choosealicense.com/licenses/apache-2.0/)
**Overview**
IndoNLP developed and publicly released the Cendol family of large language models (LLMs), a collection of pretrained and fine-tuned generative text models ranging in scale from 560 million to 13 billion parameters.
Cendol models cover two instruction-tuned versions:
1. Cendol-Instruct that is instruction-tuned on tasks-specific NLP data such as sentiment analysis, topic modeling, machine translation, summarization, question answering, paraphrasing, etc
2. Cendol-Chat that is continuously instruction-tuned from **Cendol-Instruct** on general knowledge and human-centric prompts.
Both Cendol-Instruct and Cendol-Chat are designed for a single-turn conversation. Cendol outperforms open-source multilingual and region-specific LLMs on most benchmarks we tested by a huge margin, with the smaller version (<1B parameters) of Cendol being highly competitive with other LLMs with 7B parameters.
**Model Developers**: IndoNLP
**Variations**
Cendol comes from 2 base models (mT5 and LLaMA-2) each with a range of parameter sizes. mT5-based Cendol comes with 300M (mT5-small), 580M (mT5-base), 1.2B (mT5-large), 3.7B (mT5-XL), and 13B (mT5-XXL) models, while LLaMA-2-based Cendol comes with 7B (LLaMA2-7B) and 13B (LLaMA2-13B) models. Both variants come with Cendol-Instruct and Cendol-Chat variations. All 13B parameter models are tuned with LoRA, while others are fully fine-tuned.
In our paper, we showcase that adapting region-specific LLMs using LoRA is ineffective and inefficient, i.e., the 13B (mT5-XXL) Cendol models perform slightly worse than the 1.2B (mT5-large) Cendol models, while having 3x slower training time and 4x slower inference time. As an alternative to LoRA, we showcase the benefits of vocabulary substitution as an effective and efficient strategy for region-specific adaptation, where we improve the efficiency by **11.50%** and **18.71%** for training and inference times, respectively.
In terms of evaluation performance, we also showcase that the model performs on par with the Cendol model trained with the original vocabulary. We also release the Indonesian vocabulary-adapted model denoted as `Indonesian-Vocab Instruct`.
**Input-Output**: Models input and output are text only.
**Model Architecture**
|Model|Training Data|Params|Tuning Strategy|LR|
|---|---|---|---|---|
|[Cendol mT5-small Instruct](https://huggingface.co/indonlp/cendol-mt5-small-inst)|[Cendol Collection v1](https://huggingface.co/datasets/indonlp/cendol_collection_v1)|300M|Fully-Finetuned|3.0 x 10-4|
|[Cendol mT5-base Instruct](https://huggingface.co/indonlp/cendol-mt5-base-inst)|[Cendol Collection v1](https://huggingface.co/datasets/indonlp/cendol_collection_v1)|580M|Fully-Finetuned|3.0 x 10-4|
|[Cendol mT5-large Instruct](https://huggingface.co/indonlp/cendol-mt5-large-inst)|[Cendol Collection v1](https://huggingface.co/datasets/indonlp/cendol_collection_v1)|1.2B|Fully-Finetuned|3.0 x 10-4|
|[Cendol mT5-xl Instruct](https://huggingface.co/indonlp/cendol-mt5-xl-inst)|[Cendol Collection v1](https://huggingface.co/datasets/indonlp/cendol_collection_v1)|3.7B|Fully-Finetuned|3.0 x 10-4|
|[Cendol mT5-xxl Instruct](https://huggingface.co/indonlp/cendol-mt5-xxl-merged-inst)|[Cendol Collection v1](https://huggingface.co/datasets/indonlp/cendol_collection_v1)|13B|LoRA|2.0 x 10-4|
|[Cendol LLaMA-2 (7B) Instruct](https://huggingface.co/indonlp/cendol-llama2-7b-inst)|[Cendol Collection v1](https://huggingface.co/datasets/indonlp/cendol_collection_v1)|7B|Fully-Finetuned|2.0 x 10-5|
|[Cendol LLaMA-2 (7B) Indonesian-Vocab Instruct](https://huggingface.co/indonlp/cendol-llama2-ind-vocab-inst)|[Cendol Collection v1](https://huggingface.co/datasets/indonlp/cendol_collection_v1)|7B|Fully-Finetuned|2.0 x 10-5|
|[Cendol LLaMA-2 (13B) Instruct](https://huggingface.co/indonlp/cendol-llama2-13b-merged-inst)|[Cendol Collection v1](https://huggingface.co/datasets/indonlp/cendol_collection_v1)|13B|LoRA|2.0 x 10-5|
|[Cendol mT5-small Chat](https://huggingface.co/indonlp/cendol-mt5-small-chat)|[Cendol Collection v2](https://huggingface.co/datasets/indonlp/cendol_collection_v2)|300M|Fully-Finetuned|3.0 x 10-5|
|[Cendol mT5-base Chat](https://huggingface.co/indonlp/cendol-mt5-base-chat)|[Cendol Collection v2](https://huggingface.co/datasets/indonlp/cendol_collection_v2)|580M|Fully-Finetuned|3.0 x 10-5|
|[Cendol mT5-large Chat](https://huggingface.co/indonlp/cendol-mt5-large-chat)|[Cendol Collection v2](https://huggingface.co/datasets/indonlp/cendol_collection_v2)|1.2B|Fully-Finetuned|3.0 x 10-5|
|[Cendol mT5-xl Chat](https://huggingface.co/indonlp/cendol-mt5-xl-chat)|[Cendol Collection v2](https://huggingface.co/datasets/indonlp/cendol_collection_v2)|3.7B|Fully-Finetuned|3.0 x 10-5|
|[Cendol mT5-xxl Chat](https://huggingface.co/indonlp/cendol-mt5-xxl-merged-chat)|[Cendol Collection v2](https://huggingface.co/datasets/indonlp/cendol_collection_v2)|13B|LoRA|2.0 x 10-4|
|[Cendol LLaMA-2 (7B) Chat](https://huggingface.co/indonlp/cendol-llama2-7b-chat)|[Cendol Collection v2](https://huggingface.co/datasets/indonlp/cendol_collection_v2)|7B|Fully-Finetuned|1.0 x 10-5|
|[Cendol LLaMA-2 (13B) Chat](https://huggingface.co/indonlp/cendol-llama2-13b-merged-chat)|[Cendol Collection v2](https://huggingface.co/datasets/indonlp/cendol_collection_v2)|13B|LoRA|2.0 x 10-4|
**Model Dates** Cendol was trained between October 2023 and January 2024.
**License** Use of Cendol is licensed under the [Apache 2.0 license](https://choosealicense.com/licenses/apache-2.0/)
**Research Paper** ["Cendol: Open Instruction-tuned Generative Large Language Models for Indonesian Languages"](https://arxiv.org/abs/2404.06138)
## Intended Use
**Intended Use Cases** Cendol is intended for research use especially on Indonesian languages. Cendol models are intended for a single turn instruction, with Cendol-Instruct models can be used for task-specific instruction, while Cendol-Chat models can be used for general knowledge instruction.
**Out-of-scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in languages other than English and Indonesian languages. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Cendol.
## Evaluation Results
In this section, we report the results for the Cendol models on large-scale NLU and NLG benchmarks. For all the evaluations, we use our internal evaluations library.
#### NLU Performance
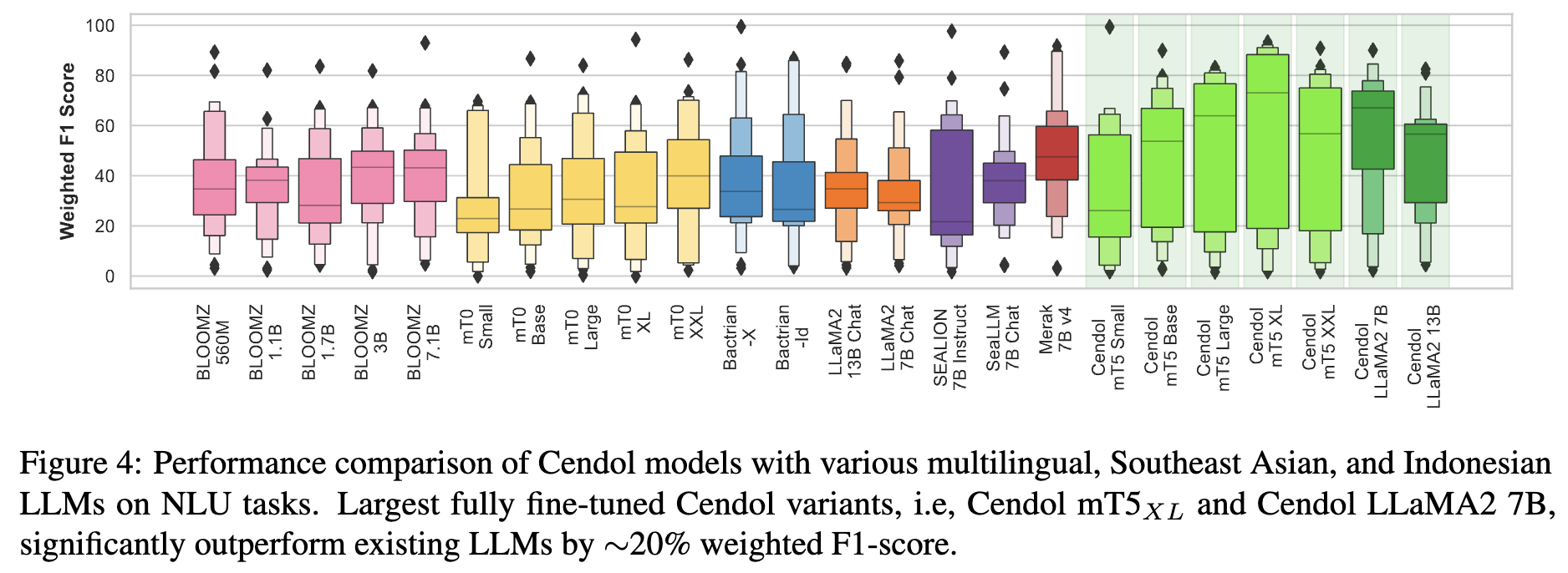 #### NLG Performance
#### NLG Performance
 #### Human evaluation
#### Human evaluation
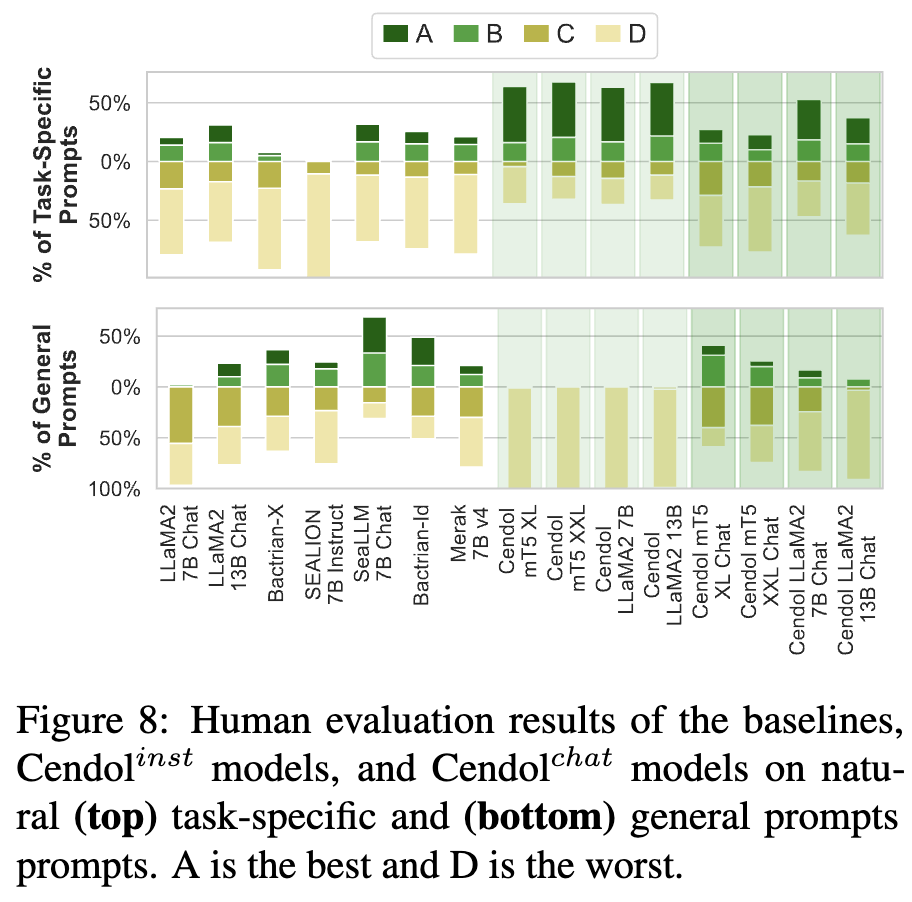 ## Ethical Considerations and Limitations
Cendol is a new technology that carries risks with its use. Testing conducted to date has been in Indonesian, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Cendol’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Cendol, developers should perform safety testing and tuning tailored to their specific applications of the model.
## Citation
If you are using any resources including Cendol models, code, or data, please cite the following articles:
```
@misc{cahyawijaya-etal-2024-cendol,
title={Cendol: Open Instruction-tuned Generative Large Language Models for Indonesian Languages},
author={Samuel Cahyawijaya and Holy Lovenia and Fajri Koto and Rifki Afina Putri and Emmanuel Dave and Jhonson Lee and Nuur Shadieq and Wawan Cenggoro and Salsabil Maulana Akbar and Muhammad Ihza Mahendra and Dea Annisayanti Putri and Bryan Wilie and Genta Indra Winata and Alham Fikri Aji and Ayu Purwarianti and Pascale Fung},
year={2024},
eprint={2404.06138},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@inproceedings{cahyawijaya-etal-2023-nusacrowd,
title = "{N}usa{C}rowd: Open Source Initiative for {I}ndonesian {NLP} Resources",
author = "Cahyawijaya, Samuel and
Lovenia, Holy and
Aji, Alham Fikri and
Winata, Genta and
Wilie, Bryan and
Koto, Fajri and
Mahendra, Rahmad and
Wibisono, Christian and
Romadhony, Ade and
Vincentio, Karissa and
Santoso, Jennifer and
Moeljadi, David and
Wirawan, Cahya and
Hudi, Frederikus and
Wicaksono, Muhammad Satrio and
Parmonangan, Ivan and
Alfina, Ika and
Putra, Ilham Firdausi and
Rahmadani, Samsul and
Oenang, Yulianti and
Septiandri, Ali and
Jaya, James and
Dhole, Kaustubh and
Suryani, Arie and
Putri, Rifki Afina and
Su, Dan and
Stevens, Keith and
Nityasya, Made Nindyatama and
Adilazuarda, Muhammad and
Hadiwijaya, Ryan and
Diandaru, Ryandito and
Yu, Tiezheng and
Ghifari, Vito and
Dai, Wenliang and
Xu, Yan and
Damapuspita, Dyah and
Wibowo, Haryo and
Tho, Cuk and
Karo Karo, Ichwanul and
Fatyanosa, Tirana and
Ji, Ziwei and
Neubig, Graham and
Baldwin, Timothy and
Ruder, Sebastian and
Fung, Pascale and
Sujaini, Herry and
Sakti, Sakriani and
Purwarianti, Ayu",
editor = "Rogers, Anna and
Boyd-Graber, Jordan and
Okazaki, Naoaki",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2023",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-acl.868",
doi = "10.18653/v1/2023.findings-acl.868",
pages = "13745--13818"
}
```
Additionally, if you are inspired by our work on region-specific language models especially for Indonesian and its local languages, please also consider citing the following articles:
```
@inproceedings{cahyawijaya-etal-2023-nusawrites,
title = "{N}usa{W}rites: Constructing High-Quality Corpora for Underrepresented and Extremely Low-Resource Languages",
author = "Cahyawijaya, Samuel and
Lovenia, Holy and
Koto, Fajri and
Adhista, Dea and
Dave, Emmanuel and
Oktavianti, Sarah and
Akbar, Salsabil and
Lee, Jhonson and
Shadieq, Nuur and
Cenggoro, Tjeng Wawan and
Linuwih, Hanung and
Wilie, Bryan and
Muridan, Galih and
Winata, Genta and
Moeljadi, David and
Aji, Alham Fikri and
Purwarianti, Ayu and
Fung, Pascale",
editor = "Park, Jong C. and
Arase, Yuki and
Hu, Baotian and
Lu, Wei and
Wijaya, Derry and
Purwarianti, Ayu and
Krisnadhi, Adila Alfa",
booktitle = "Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = nov,
year = "2023",
address = "Nusa Dua, Bali",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.ijcnlp-main.60",
doi = "10.18653/v1/2023.ijcnlp-main.60",
pages = "921--945"
}
@inproceedings{winata-etal-2023-nusax,
title = "{N}usa{X}: Multilingual Parallel Sentiment Dataset for 10 {I}ndonesian Local Languages",
author = "Winata, Genta Indra and
Aji, Alham Fikri and
Cahyawijaya, Samuel and
Mahendra, Rahmad and
Koto, Fajri and
Romadhony, Ade and
Kurniawan, Kemal and
Moeljadi, David and
Prasojo, Radityo Eko and
Fung, Pascale and
Baldwin, Timothy and
Lau, Jey Han and
Sennrich, Rico and
Ruder, Sebastian",
editor = "Vlachos, Andreas and
Augenstein, Isabelle",
booktitle = "Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics",
month = may,
year = "2023",
address = "Dubrovnik, Croatia",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.eacl-main.57",
doi = "10.18653/v1/2023.eacl-main.57",
pages = "815--834"
}
@inproceedings{aji-etal-2022-one,
title = "One Country, 700+ Languages: {NLP} Challenges for Underrepresented Languages and Dialects in {I}ndonesia",
author = "Aji, Alham Fikri and
Winata, Genta Indra and
Koto, Fajri and
Cahyawijaya, Samuel and
Romadhony, Ade and
Mahendra, Rahmad and
Kurniawan, Kemal and
Moeljadi, David and
Prasojo, Radityo Eko and
Baldwin, Timothy and
Lau, Jey Han and
Ruder, Sebastian",
editor = "Muresan, Smaranda and
Nakov, Preslav and
Villavicencio, Aline",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.500",
doi = "10.18653/v1/2022.acl-long.500",
pages = "7226--7249"
}
@inproceedings{cahyawijaya-etal-2021-indonlg,
title = "{I}ndo{NLG}: Benchmark and Resources for Evaluating {I}ndonesian Natural Language Generation",
author = "Cahyawijaya, Samuel and
Winata, Genta Indra and
Wilie, Bryan and
Vincentio, Karissa and
Li, Xiaohong and
Kuncoro, Adhiguna and
Ruder, Sebastian and
Lim, Zhi Yuan and
Bahar, Syafri and
Khodra, Masayu and
Purwarianti, Ayu and
Fung, Pascale",
editor = "Moens, Marie-Francine and
Huang, Xuanjing and
Specia, Lucia and
Yih, Scott Wen-tau",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.699",
doi = "10.18653/v1/2021.emnlp-main.699",
pages = "8875--8898"
}
@inproceedings{wilie-etal-2020-indonlu,
title = "{I}ndo{NLU}: Benchmark and Resources for Evaluating {I}ndonesian Natural Language Understanding",
author = "Wilie, Bryan and
Vincentio, Karissa and
Winata, Genta Indra and
Cahyawijaya, Samuel and
Li, Xiaohong and
Lim, Zhi Yuan and
Soleman, Sidik and
Mahendra, Rahmad and
Fung, Pascale and
Bahar, Syafri and
Purwarianti, Ayu",
editor = "Wong, Kam-Fai and
Knight, Kevin and
Wu, Hua",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-main.85",
pages = "843--857"
}
```
## Ethical Considerations and Limitations
Cendol is a new technology that carries risks with its use. Testing conducted to date has been in Indonesian, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Cendol’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Cendol, developers should perform safety testing and tuning tailored to their specific applications of the model.
## Citation
If you are using any resources including Cendol models, code, or data, please cite the following articles:
```
@misc{cahyawijaya-etal-2024-cendol,
title={Cendol: Open Instruction-tuned Generative Large Language Models for Indonesian Languages},
author={Samuel Cahyawijaya and Holy Lovenia and Fajri Koto and Rifki Afina Putri and Emmanuel Dave and Jhonson Lee and Nuur Shadieq and Wawan Cenggoro and Salsabil Maulana Akbar and Muhammad Ihza Mahendra and Dea Annisayanti Putri and Bryan Wilie and Genta Indra Winata and Alham Fikri Aji and Ayu Purwarianti and Pascale Fung},
year={2024},
eprint={2404.06138},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@inproceedings{cahyawijaya-etal-2023-nusacrowd,
title = "{N}usa{C}rowd: Open Source Initiative for {I}ndonesian {NLP} Resources",
author = "Cahyawijaya, Samuel and
Lovenia, Holy and
Aji, Alham Fikri and
Winata, Genta and
Wilie, Bryan and
Koto, Fajri and
Mahendra, Rahmad and
Wibisono, Christian and
Romadhony, Ade and
Vincentio, Karissa and
Santoso, Jennifer and
Moeljadi, David and
Wirawan, Cahya and
Hudi, Frederikus and
Wicaksono, Muhammad Satrio and
Parmonangan, Ivan and
Alfina, Ika and
Putra, Ilham Firdausi and
Rahmadani, Samsul and
Oenang, Yulianti and
Septiandri, Ali and
Jaya, James and
Dhole, Kaustubh and
Suryani, Arie and
Putri, Rifki Afina and
Su, Dan and
Stevens, Keith and
Nityasya, Made Nindyatama and
Adilazuarda, Muhammad and
Hadiwijaya, Ryan and
Diandaru, Ryandito and
Yu, Tiezheng and
Ghifari, Vito and
Dai, Wenliang and
Xu, Yan and
Damapuspita, Dyah and
Wibowo, Haryo and
Tho, Cuk and
Karo Karo, Ichwanul and
Fatyanosa, Tirana and
Ji, Ziwei and
Neubig, Graham and
Baldwin, Timothy and
Ruder, Sebastian and
Fung, Pascale and
Sujaini, Herry and
Sakti, Sakriani and
Purwarianti, Ayu",
editor = "Rogers, Anna and
Boyd-Graber, Jordan and
Okazaki, Naoaki",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2023",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.findings-acl.868",
doi = "10.18653/v1/2023.findings-acl.868",
pages = "13745--13818"
}
```
Additionally, if you are inspired by our work on region-specific language models especially for Indonesian and its local languages, please also consider citing the following articles:
```
@inproceedings{cahyawijaya-etal-2023-nusawrites,
title = "{N}usa{W}rites: Constructing High-Quality Corpora for Underrepresented and Extremely Low-Resource Languages",
author = "Cahyawijaya, Samuel and
Lovenia, Holy and
Koto, Fajri and
Adhista, Dea and
Dave, Emmanuel and
Oktavianti, Sarah and
Akbar, Salsabil and
Lee, Jhonson and
Shadieq, Nuur and
Cenggoro, Tjeng Wawan and
Linuwih, Hanung and
Wilie, Bryan and
Muridan, Galih and
Winata, Genta and
Moeljadi, David and
Aji, Alham Fikri and
Purwarianti, Ayu and
Fung, Pascale",
editor = "Park, Jong C. and
Arase, Yuki and
Hu, Baotian and
Lu, Wei and
Wijaya, Derry and
Purwarianti, Ayu and
Krisnadhi, Adila Alfa",
booktitle = "Proceedings of the 13th International Joint Conference on Natural Language Processing and the 3rd Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = nov,
year = "2023",
address = "Nusa Dua, Bali",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.ijcnlp-main.60",
doi = "10.18653/v1/2023.ijcnlp-main.60",
pages = "921--945"
}
@inproceedings{winata-etal-2023-nusax,
title = "{N}usa{X}: Multilingual Parallel Sentiment Dataset for 10 {I}ndonesian Local Languages",
author = "Winata, Genta Indra and
Aji, Alham Fikri and
Cahyawijaya, Samuel and
Mahendra, Rahmad and
Koto, Fajri and
Romadhony, Ade and
Kurniawan, Kemal and
Moeljadi, David and
Prasojo, Radityo Eko and
Fung, Pascale and
Baldwin, Timothy and
Lau, Jey Han and
Sennrich, Rico and
Ruder, Sebastian",
editor = "Vlachos, Andreas and
Augenstein, Isabelle",
booktitle = "Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics",
month = may,
year = "2023",
address = "Dubrovnik, Croatia",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.eacl-main.57",
doi = "10.18653/v1/2023.eacl-main.57",
pages = "815--834"
}
@inproceedings{aji-etal-2022-one,
title = "One Country, 700+ Languages: {NLP} Challenges for Underrepresented Languages and Dialects in {I}ndonesia",
author = "Aji, Alham Fikri and
Winata, Genta Indra and
Koto, Fajri and
Cahyawijaya, Samuel and
Romadhony, Ade and
Mahendra, Rahmad and
Kurniawan, Kemal and
Moeljadi, David and
Prasojo, Radityo Eko and
Baldwin, Timothy and
Lau, Jey Han and
Ruder, Sebastian",
editor = "Muresan, Smaranda and
Nakov, Preslav and
Villavicencio, Aline",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = may,
year = "2022",
address = "Dublin, Ireland",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.acl-long.500",
doi = "10.18653/v1/2022.acl-long.500",
pages = "7226--7249"
}
@inproceedings{cahyawijaya-etal-2021-indonlg,
title = "{I}ndo{NLG}: Benchmark and Resources for Evaluating {I}ndonesian Natural Language Generation",
author = "Cahyawijaya, Samuel and
Winata, Genta Indra and
Wilie, Bryan and
Vincentio, Karissa and
Li, Xiaohong and
Kuncoro, Adhiguna and
Ruder, Sebastian and
Lim, Zhi Yuan and
Bahar, Syafri and
Khodra, Masayu and
Purwarianti, Ayu and
Fung, Pascale",
editor = "Moens, Marie-Francine and
Huang, Xuanjing and
Specia, Lucia and
Yih, Scott Wen-tau",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.699",
doi = "10.18653/v1/2021.emnlp-main.699",
pages = "8875--8898"
}
@inproceedings{wilie-etal-2020-indonlu,
title = "{I}ndo{NLU}: Benchmark and Resources for Evaluating {I}ndonesian Natural Language Understanding",
author = "Wilie, Bryan and
Vincentio, Karissa and
Winata, Genta Indra and
Cahyawijaya, Samuel and
Li, Xiaohong and
Lim, Zhi Yuan and
Soleman, Sidik and
Mahendra, Rahmad and
Fung, Pascale and
Bahar, Syafri and
Purwarianti, Ayu",
editor = "Wong, Kam-Fai and
Knight, Kevin and
Wu, Hua",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-main.85",
pages = "843--857"
}
```