---
library_name: transformers
tags:
- depth
- absolute depth
pipeline_tag: depth-estimation
---
# Depth Anything V2 (Fine-tuned for Metric Depth Estimation) - Transformers Version
This model represents a fine-tuned version of [Depth Anything V2](https://huggingface.co/depth-anything/Depth-Anything-V2-Large-hf) for indoor metric depth estimation using the synthetic Hypersim datasets.
The model checkpoint is compatible with the transformers library.
Depth Anything V2 was introduced in [the paper of the same name](https://arxiv.org/abs/2406.09414) by Lihe Yang et al. It uses the same architecture as the original Depth Anything release but employs synthetic data and a larger capacity teacher model to achieve much finer and robust depth predictions. This fine-tuned version for metric depth estimation was first released in [this repository](https://github.com/DepthAnything/Depth-Anything-V2).
## Model description
Depth Anything V2 leverages the [DPT](https://huggingface.co/docs/transformers/model_doc/dpt) architecture with a [DINOv2](https://huggingface.co/docs/transformers/model_doc/dinov2) backbone.
The model is trained on ~600K synthetic labeled images and ~62 million real unlabeled images, obtaining state-of-the-art results for both relative and absolute depth estimation.
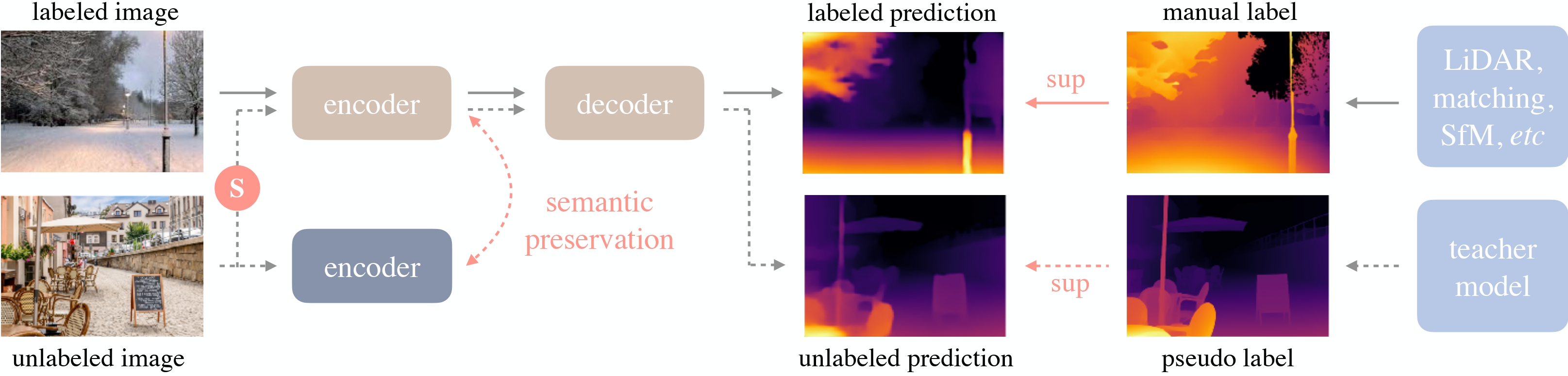 Depth Anything overview. Taken from the original paper.
## Intended uses & limitations
You can use the raw model for tasks like zero-shot depth estimation. See the [model hub](https://huggingface.co/models?search=depth-anything) to look for
other versions on a task that interests you.
### How to use
Here is how to use this model to perform zero-shot depth estimation:
```python
from transformers import pipeline
from PIL import Image
import requests
# load pipe
pipe = pipeline(task="depth-estimation", model="depth-anything/Depth-Anything-V2-Metric-Indoor-Large-hf")
# load image
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
# inference
depth = pipe(image)["depth"]
```
Alternatively, you can use the model and processor classes:
```python
from transformers import AutoImageProcessor, AutoModelForDepthEstimation
import torch
import numpy as np
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("depth-anything/Depth-Anything-V2-Metric-Indoor-Large-hf")
model = AutoModelForDepthEstimation.from_pretrained("depth-anything/Depth-Anything-V2-Metric-Indoor-Large-hf")
# prepare image for the model
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
predicted_depth = outputs.predicted_depth
# interpolate to original size
prediction = torch.nn.functional.interpolate(
predicted_depth.unsqueeze(1),
size=image.size[::-1],
mode="bicubic",
align_corners=False,
)
```
For more code examples, please refer to the [documentation](https://huggingface.co/transformers/main/model_doc/depth_anything.html#).
## Citation
```bibtex
@article{depth_anything_v2,
title={Depth Anything V2},
author={Yang, Lihe and Kang, Bingyi and Huang, Zilong and Zhao, Zhen and Xu, Xiaogang and Feng, Jiashi and Zhao, Hengshuang},
journal={arXiv:2406.09414},
year={2024}
}
@inproceedings{depth_anything_v1,
title={Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data},
author={Yang, Lihe and Kang, Bingyi and Huang, Zilong and Xu, Xiaogang and Feng, Jiashi and Zhao, Hengshuang},
booktitle={CVPR},
year={2024}
}
```
Depth Anything overview. Taken from the original paper.
## Intended uses & limitations
You can use the raw model for tasks like zero-shot depth estimation. See the [model hub](https://huggingface.co/models?search=depth-anything) to look for
other versions on a task that interests you.
### How to use
Here is how to use this model to perform zero-shot depth estimation:
```python
from transformers import pipeline
from PIL import Image
import requests
# load pipe
pipe = pipeline(task="depth-estimation", model="depth-anything/Depth-Anything-V2-Metric-Indoor-Large-hf")
# load image
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
# inference
depth = pipe(image)["depth"]
```
Alternatively, you can use the model and processor classes:
```python
from transformers import AutoImageProcessor, AutoModelForDepthEstimation
import torch
import numpy as np
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("depth-anything/Depth-Anything-V2-Metric-Indoor-Large-hf")
model = AutoModelForDepthEstimation.from_pretrained("depth-anything/Depth-Anything-V2-Metric-Indoor-Large-hf")
# prepare image for the model
inputs = image_processor(images=image, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
predicted_depth = outputs.predicted_depth
# interpolate to original size
prediction = torch.nn.functional.interpolate(
predicted_depth.unsqueeze(1),
size=image.size[::-1],
mode="bicubic",
align_corners=False,
)
```
For more code examples, please refer to the [documentation](https://huggingface.co/transformers/main/model_doc/depth_anything.html#).
## Citation
```bibtex
@article{depth_anything_v2,
title={Depth Anything V2},
author={Yang, Lihe and Kang, Bingyi and Huang, Zilong and Zhao, Zhen and Xu, Xiaogang and Feng, Jiashi and Zhao, Hengshuang},
journal={arXiv:2406.09414},
year={2024}
}
@inproceedings{depth_anything_v1,
title={Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data},
author={Yang, Lihe and Kang, Bingyi and Huang, Zilong and Xu, Xiaogang and Feng, Jiashi and Zhao, Hengshuang},
booktitle={CVPR},
year={2024}
}
```