
file_id
stringlengths 6
9
| content
stringlengths 1.13k
279k
| local_path
stringlengths 67
70
| kaggle_dataset_name
stringclasses 28
values | kaggle_dataset_owner
stringclasses 24
values | kversion
stringlengths 508
571
| kversion_datasetsources
stringlengths 78
322
⌀ | dataset_versions
stringclasses 29
values | datasets
stringclasses 29
values | users
stringclasses 24
values | script
stringlengths 1.1k
279k
| df_info
stringclasses 1
value | has_data_info
bool 1
class | nb_filenames
int64 0
2
| retreived_data_description
stringclasses 1
value | script_nb_tokens
int64 300
71.7k
| upvotes
int64 0
26
| tokens_description
int64 6
2.5k
| tokens_script
int64 300
71.7k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
69393429 | <kaggle_start><data_title>progresbar2-local<data_name>progresbar2local
<code># # The Bernstein Bears CRP Submission 1
# install necessary libraries from input
# import progressbar library for offline usage
# import text stat library for additional ml data prep
FAST_DEV_RUN = False
USE_CHECKPOINT = True
USE_HIDDEN_IN_RGR = False
N_FEATURES_TO_USE_HEAD = 1
N_FEATURES_TO_USE_TAIL = None
# in this kernel, run train on all data to maximize score on held out data but use what we learned about optimal parameters
# set to 16 bit precision to cut compute requirements/increase batch size capacity
USE_16_BIT_PRECISION = True
# set a seed value for consistent experimentation; optional, else leave as None
SEED_VAL = 42
# set a train-validation split, .7 means 70% of train data and 30% to validation set
TRAIN_VALID_SPLIT = 0.8 # if None, then don't split
# set hyperparameters learned from tuning: https://www.kaggle.com/justinchae/tune-roberta-pytorch-lightning-optuna
MAX_EPOCHS = 4
BATCH_SIZE = 16
GRADIENT_CLIP_VAL = 0.18318092164684585
LEARNING_RATE = 3.613894271216525e-05
TOKENIZER_MAX_LEN = 363
WARMUP_STEPS = 292
WEIGHT_DECAY = 0.004560699842170359
import kaggle_config
from kaggle_config import (
WORKFLOW_ROOT,
DATA_PATH,
CACHE_PATH,
FIG_PATH,
MODEL_PATH,
ANALYSIS_PATH,
KAGGLE_INPUT,
CHECKPOINTS_PATH,
LOGS_PATH,
)
INPUTS, DEVICE = kaggle_config.run()
KAGGLE_TRAIN_PATH = kaggle_config.get_train_path(INPUTS)
KAGGLE_TEST_PATH = kaggle_config.get_test_path(INPUTS)
import pytorch_lightning as pl
from pytorch_lightning import loggers as pl_loggers
from pytorch_lightning import seed_everything
from pytorch_lightning.callbacks import ModelCheckpoint, EarlyStopping
from pytorch_lightning.tuner.batch_size_scaling import scale_batch_size
from pytorch_lightning.tuner.lr_finder import _LRFinder, lr_find
import torchmetrics
import optuna
from optuna.integration import PyTorchLightningPruningCallback
from optuna.samplers import TPESampler, RandomSampler, CmaEsSampler
from optuna.visualization import (
plot_intermediate_values,
plot_optimization_history,
plot_param_importances,
)
import optuna.integration.lightgbm as lgb
import lightgbm as lgm
from sklearn.model_selection import (
KFold,
cross_val_score,
RepeatedKFold,
train_test_split,
)
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.decomposition import PCA
from sklearn.feature_selection import (
RFE,
f_regression,
mutual_info_regression,
SequentialFeatureSelector,
)
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error
import math
import textstat
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.dataset import random_split
import tensorflow as tf
from transformers import (
RobertaForSequenceClassification,
RobertaTokenizer,
AdamW,
get_linear_schedule_with_warmup,
)
import os
import pandas as pd
import numpy as np
import gc
from functools import partial
from typing import List, Dict
from typing import Optional
from argparse import ArgumentParser
import random
if SEED_VAL:
random.seed(SEED_VAL)
np.random.seed(SEED_VAL)
seed_everything(SEED_VAL)
NUM_DATALOADER_WORKERS = os.cpu_count()
try:
resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu="")
tf.config.experimental_connect_to_cluster(resolver)
tf.tpu.experimental.initialize_tpu_system(resolver)
n_tpus = len(tf.config.list_logical_devices("TPU"))
except ValueError:
n_tpus = 0
ACCELERATOR_TYPE = {}
ACCELERATOR_TYPE.update(
{"gpus": torch.cuda.device_count() if torch.cuda.is_available() else None}
)
ACCELERATOR_TYPE.update({"tpu_cores": n_tpus if n_tpus > 0 else None})
# still debugging how to best toggle between tpu and gpu; there's too much code to configure to work simply
print("ACCELERATOR_TYPE:\n", ACCELERATOR_TYPE)
PRETTRAINED_ROBERTA_BASE_MODEL_PATH = "/kaggle/input/pre-trained-roberta-base"
PRETRAINED_ROBERTA_BASE_TOKENIZER_PATH = "/kaggle/input/tokenizer-roberta"
PRETRAINED_ROBERTA_BASE_TOKENIZER = RobertaTokenizer.from_pretrained(
PRETRAINED_ROBERTA_BASE_TOKENIZER_PATH
)
TUNED_CHECKPOINT_PATH = "/kaggle/input/best-crp-ckpt-4/crp_roberta_trial_4.ckpt"
# from: https://www.kaggle.com/justinchae/crp-regression-with-roberta-and-lightgbm
TUNED_BEST_ROBERTA_PATH = "/kaggle/input/my-best-tuned-roberta"
"""Implementing Lightning instead of torch.nn.Module
"""
class LitRobertaLogitRegressor(pl.LightningModule):
def __init__(
self,
pre_trained_path: str,
output_hidden_states: bool = False,
num_labels: int = 1,
layer_1_output_size: int = 64,
layer_2_output_size: int = 1,
learning_rate: float = 1e-5,
task_name: Optional[str] = None,
warmup_steps: int = 100,
weight_decay: float = 0.0,
adam_epsilon: float = 1e-8,
batch_size: Optional[int] = None,
train_size: Optional[int] = None,
max_epochs: Optional[int] = None,
n_gpus: Optional[int] = 0,
n_tpus: Optional[int] = 0,
accumulate_grad_batches=None,
tokenizer=None,
do_decode=False,
):
"""refactored from: https://www.kaggle.com/justinchae/my-bert-tuner and https://www.kaggle.com/justinchae/roberta-tuner"""
super(LitRobertaLogitRegressor, self).__init__()
# this saves class params as self.hparams
self.save_hyperparameters()
self.model = RobertaForSequenceClassification.from_pretrained(
self.hparams.pre_trained_path,
output_hidden_states=self.hparams.output_hidden_states,
num_labels=self.hparams.num_labels,
)
self.accelerator_multiplier = n_gpus if n_gpus > 0 else 1
self.config = self.model.config
self.parameters = self.model.parameters
self.save_pretrained = self.model.save_pretrained
# these layers are not currently used, tbd in future iteration
self.layer_1 = torch.nn.Linear(768, layer_1_output_size)
self.layer_2 = torch.nn.Linear(layer_1_output_size, layer_2_output_size)
self.tokenizer = tokenizer
self.do_decode = do_decode
self.output_hidden_states = output_hidden_states
def rmse_loss(x, y):
criterion = F.mse_loss
loss = torch.sqrt(criterion(x, y))
return loss
# TODO: enable toggle for various loss funcs and torchmetrics package
self.loss_func = rmse_loss
# self.eval_func = rmse_loss
def setup(self, stage=None) -> None:
if stage == "fit":
# when this class is called by trainer.fit, this stage runs and so on
# Calculate total steps
tb_size = self.hparams.batch_size * self.accelerator_multiplier
ab_size = self.hparams.accumulate_grad_batches * float(
self.hparams.max_epochs
)
self.total_steps = (self.hparams.train_size // tb_size) // ab_size
def extract_logit_only(self, input_ids, attention_mask) -> float:
output = self.model(input_ids=input_ids, attention_mask=attention_mask)
logit = output.logits
logit = logit.cpu().numpy().astype(float)
return logit
def extract_hidden_only(self, input_ids, attention_mask) -> np.array:
output = self.model(input_ids=input_ids, attention_mask=input_ids)
hidden_states = output.hidden_states
x = torch.stack(hidden_states[-4:]).sum(0)
m1 = torch.nn.Sequential(self.layer_1, self.layer_2, torch.nn.Flatten())
x = m1(x)
x = torch.squeeze(x).cpu().numpy()
return x
def forward(self, input_ids, attention_mask) -> torch.Tensor:
output = self.model(input_ids=input_ids, attention_mask=attention_mask)
x = output.logits
return x
def training_step(self, batch, batch_idx: int) -> float:
# refactored from: https://www.kaggle.com/justinchae/epoch-utils
labels, encoded_batch, kaggle_ids = batch
input_ids = encoded_batch["input_ids"]
attention_mask = encoded_batch["attention_mask"]
# per docs, keep train step separate from forward call
output = self.model(input_ids=input_ids, attention_mask=attention_mask)
y_hat = output.logits
# quick reshape to align labels to predictions
labels = labels.view(-1, 1)
loss = self.loss_func(y_hat, labels)
self.log("train_loss", loss)
return loss
def validation_step(self, batch, batch_idx: int) -> float:
# refactored from: https://www.kaggle.com/justinchae/epoch-utils
labels, encoded_batch, kaggle_ids = batch
input_ids = encoded_batch["input_ids"]
attention_mask = encoded_batch["attention_mask"]
# this self call is calling the forward method
y_hat = self(input_ids, attention_mask)
# quick reshape to align labels to predictions
labels = labels.view(-1, 1)
loss = self.loss_func(y_hat, labels)
self.log("val_loss", loss)
return loss
def predict(self, batch, batch_idx: int, dataloader_idx: int = None):
# creating this predict method overrides the pl predict method
target, encoded_batch, kaggle_ids = batch
input_ids = encoded_batch["input_ids"]
attention_mask = encoded_batch["attention_mask"]
# this self call is calling the forward method
y_hat = self(input_ids, attention_mask)
# convert to numpy then list like struct to zip with ids
y_hat = y_hat.cpu().numpy().ravel()
# customizing the predict behavior to account for unique ids
if self.tokenizer is not None and self.do_decode:
target = target.cpu().numpy().ravel() if len(target) > 0 else None
excerpt = self.tokenizer.batch_decode(
input_ids.cpu().numpy(),
skip_special_tokens=True,
clean_up_tokenization_spaces=True,
)
if self.output_hidden_states:
hidden_states = self.extract_hidden_only(
input_ids=input_ids, attention_mask=attention_mask
)
else:
hidden_states = None
if target is not None:
predictions = list(
zip(
kaggle_ids,
target,
y_hat
# , hidden_states
)
)
predictions = pd.DataFrame(
predictions,
columns=[
"id",
"target",
"logit"
# , 'hidden_states'
],
)
else:
predictions = list(
zip(
kaggle_ids,
y_hat
# , hidden_states
)
)
predictions = pd.DataFrame(
predictions,
columns=[
"id",
"logit"
# , 'hidden_states'
],
)
else:
predictions = list(zip(kaggle_ids, y_hat))
predictions = pd.DataFrame(predictions, columns=["id", "target"])
return predictions
def configure_optimizers(self) -> torch.optim.Optimizer:
# Reference: https://pytorch-lightning.readthedocs.io/en/latest/notebooks/lightning_examples/text-transformers.html
model = self.model
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [
p
for n, p in model.named_parameters()
if not any(nd in n for nd in no_decay)
],
"weight_decay": self.hparams.weight_decay,
},
{
"params": [
p
for n, p in model.named_parameters()
if any(nd in n for nd in no_decay)
],
"weight_decay": 0.0,
},
]
optimizer = AdamW(
optimizer_grouped_parameters,
lr=self.hparams.learning_rate,
eps=self.hparams.adam_epsilon,
)
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=self.hparams.warmup_steps,
num_training_steps=self.total_steps,
)
scheduler = {"scheduler": scheduler, "interval": "step", "frequency": 1}
return [optimizer], [scheduler]
def my_collate_fn(
batch,
tokenizer,
max_length: int = 100,
return_tensors: str = "pt",
padding: str = "max_length",
truncation: bool = True,
):
# source: https://www.kaggle.com/justinchae/nn-utils
labels = []
batch_texts = []
kaggle_ids = []
for _label, batch_text, kaggle_id in batch:
if _label is not None:
labels.append(_label)
batch_texts.append(batch_text)
kaggle_ids.append(kaggle_id)
if _label is not None:
labels = torch.tensor(labels, dtype=torch.float)
encoded_batch = tokenizer(
batch_texts,
return_tensors=return_tensors,
padding=padding,
max_length=max_length,
truncation=truncation,
)
return labels, encoded_batch, kaggle_ids
class CommonLitDataset(Dataset):
def __init__(
self,
df,
text_col: str = "excerpt",
label_col: str = "target",
kaggle_id: str = "id",
sample_size: Optional[str] = None,
):
self.df = df if sample_size is None else df.sample(sample_size)
self.text_col = text_col
self.label_col = label_col
self.kaggle_id = kaggle_id
self.num_labels = (
len(df[label_col].unique()) if label_col in df.columns else None
)
# source: https://www.kaggle.com/justinchae/nn-utils
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
result = None
text = self.df.iloc[idx][self.text_col]
kaggle_id = self.df.iloc[idx][self.kaggle_id]
if "target" in self.df.columns:
target = self.df.iloc[idx][self.label_col]
return target, text, kaggle_id
else:
return None, text, kaggle_id
class CommonLitDataModule(pl.LightningDataModule):
def __init__(
self,
tokenizer,
train_path,
collate_fn=None,
max_length: int = 280,
batch_size: int = 16,
valid_path: Optional[str] = None,
test_path: Optional[str] = None,
train_valid_split: float = 0.6,
dtypes=None,
shuffle_dataloader: bool = True,
num_dataloader_workers: int = NUM_DATALOADER_WORKERS,
kfold: Optional[dict] = None,
):
super(CommonLitDataModule, self).__init__()
self.tokenizer = tokenizer
self.train_path = train_path
self.valid_path = valid_path
self.test_path = test_path
self.train_valid_split = train_valid_split
self.dtypes = {"id": str} if dtypes is None else dtypes
self.train_size = None
self.train_df, self.train_data = None, None
self.valid_df, self.valid_data = None, None
self.test_df, self.test_data = None, None
if collate_fn is not None:
self.collate_fn = partial(
collate_fn, tokenizer=tokenizer, max_length=max_length
)
else:
self.collate_fn = partial(
my_collate_fn, batch=batch_size, tokenizer=tokenizer
)
self.shuffle_dataloader = shuffle_dataloader
self.batch_size = batch_size
self.num_dataloader_workers = num_dataloader_workers
# refactored from: https://www.kaggle.com/justinchae/nn-utils
def _strip_extraneous(self, df):
strip_cols = ["url_legal", "license"]
if all(col in df.columns for col in strip_cols):
extraneous_data = strip_cols
return df.drop(columns=extraneous_data)
else:
return df
def prepare(self, prep_type=None):
if prep_type == "train":
# creates just an instance of the train data as a pandas df
self.train_df = (
self.train_path
if isinstance(self.train_path, pd.DataFrame)
else pd.read_csv(self.train_path, dtype=self.dtypes)
)
self.train_df = self._strip_extraneous(self.train_df)
if prep_type == "train_stage_2":
self.train_df = (
self.train_path
if isinstance(self.train_path, pd.DataFrame)
else pd.read_csv(self.train_path, dtype=self.dtypes)
)
self.train_df = self._strip_extraneous(self.train_df)
self.train_size = int(len(self.train_df))
self.train_data = CommonLitDataset(df=self.train_df)
def setup(self, stage: Optional[str] = None) -> None:
if stage == "fit":
# when this class is called by trainer.fit, this stage runs and so on
self.train_df = (
self.train_path
if isinstance(self.train_path, pd.DataFrame)
else pd.read_csv(self.train_path, dtype=self.dtypes)
)
self.train_df = self._strip_extraneous(self.train_df)
self.train_size = int(len(self.train_df))
self.train_data = CommonLitDataset(df=self.train_df)
if self.train_valid_split is not None and self.valid_path is None:
self.train_size = int(len(self.train_df) * self.train_valid_split)
self.train_data, self.valid_data = random_split(
self.train_data,
[self.train_size, len(self.train_df) - self.train_size],
)
elif self.valid_path is not None:
self.valid_df = (
self.valid_path
if isinstance(self.valid_path, pd.DataFrame)
else pd.read_csv(self.valid_path, dtype=self.dtypes)
)
self.valid_data = CommonLitDataset(df=self.valid_df)
if stage == "predict":
self.test_df = (
self.test_path
if isinstance(self.test_path, pd.DataFrame)
else pd.read_csv(self.test_path, dtype=self.dtypes)
)
self.test_df = self._strip_extraneous(self.test_df)
self.test_data = CommonLitDataset(df=self.test_df)
self.train_df = (
self.train_path
if isinstance(self.train_path, pd.DataFrame)
else pd.read_csv(self.train_path, dtype=self.dtypes)
)
self.train_df = self._strip_extraneous(self.train_df)
self.train_size = int(len(self.train_df))
self.train_data = CommonLitDataset(df=self.train_df)
def kfold_data(self):
# TODO: wondering how to integrate kfolds into the datamodule
pass
def train_dataloader(self) -> DataLoader:
return DataLoader(
self.train_data,
batch_size=self.batch_size,
shuffle=self.shuffle_dataloader,
collate_fn=self.collate_fn,
num_workers=self.num_dataloader_workers,
pin_memory=True,
)
def val_dataloader(self) -> DataLoader:
if self.valid_data is None:
return None
else:
return DataLoader(
self.valid_data,
batch_size=self.batch_size,
shuffle=False,
collate_fn=self.collate_fn,
num_workers=self.num_dataloader_workers,
pin_memory=True,
)
def predict_dataloader(self) -> DataLoader:
if self.test_data is None:
return None
else:
return DataLoader(
self.test_data,
batch_size=self.batch_size,
shuffle=False,
collate_fn=self.collate_fn,
num_workers=self.num_dataloader_workers,
pin_memory=True,
)
def add_textstat_features(df):
# adding the text standard seems to boost the accuracy score a bit
df["text_standard"] = df["excerpt"].apply(lambda x: textstat.text_standard(x))
df["text_standard_category"] = df["text_standard"].astype("category").cat.codes
# counting ratio of difficult words by lexicon count
df["difficult_words_ratio"] = df["excerpt"].apply(
lambda x: textstat.difficult_words(x)
)
df["difficult_words_ratio"] = df.apply(
lambda x: x["difficult_words_ratio"] / textstat.lexicon_count(x["excerpt"]),
axis=1,
)
df["syllable_ratio"] = df["excerpt"].apply(lambda x: textstat.syllable_count(x))
df["syllable_ratio"] = df.apply(
lambda x: x["syllable_ratio"] / textstat.lexicon_count(x["excerpt"]), axis=1
)
### You can add/remove any feature below and it will be used in training and test
df["coleman_liau_index"] = df["excerpt"].apply(
lambda x: textstat.coleman_liau_index(x)
)
df["flesch_reading_ease"] = df["excerpt"].apply(
lambda x: textstat.flesch_reading_ease(x)
)
df["smog_index"] = df["excerpt"].apply(lambda x: textstat.smog_index(x))
df["gunning_fog"] = df["excerpt"].apply(lambda x: textstat.gunning_fog(x))
df["flesch_kincaid_grade"] = df["excerpt"].apply(
lambda x: textstat.flesch_kincaid_grade(x)
)
df["automated_readability_index"] = df["excerpt"].apply(
lambda x: textstat.automated_readability_index(x)
)
df["dale_chall_readability_score"] = df["excerpt"].apply(
lambda x: textstat.dale_chall_readability_score(x)
)
df["linsear_write_formula"] = df["excerpt"].apply(
lambda x: textstat.linsear_write_formula(x)
)
###
df = df.drop(columns=["excerpt", "text_standard"])
return df
def process_hidden_states(df, drop_hidden_states=False):
# for convenience, moving hidden states to the far right of the df
if drop_hidden_states:
df.drop(columns=["hidden_states"], inplace=True)
return df
elif "hidden_states" in df.columns:
df["hidden_state"] = df["hidden_states"]
df.drop(columns=["hidden_states"], inplace=True)
temp = df["hidden_state"].apply(pd.Series)
temp = temp.rename(columns=lambda x: "hidden_state_" + str(x))
df = pd.concat([df, temp], axis=1)
df.drop(columns=["hidden_state"], inplace=True)
return df
else:
print("hidden_states not found in dataframe, skipping process_hidden_states")
return df
datamodule = CommonLitDataModule(
collate_fn=my_collate_fn,
tokenizer=PRETRAINED_ROBERTA_BASE_TOKENIZER,
train_path=KAGGLE_TRAIN_PATH,
test_path=KAGGLE_TEST_PATH,
max_length=TOKENIZER_MAX_LEN,
batch_size=BATCH_SIZE,
train_valid_split=TRAIN_VALID_SPLIT,
)
# manually calling this stage since we need some params to set up model initially
datamodule.setup(stage="fit")
if USE_CHECKPOINT:
# model = LitRobertaLogitRegressor.load_from_checkpoint(TUNED_CHECKPOINT_PATH)
trainer = pl.Trainer(
gpus=ACCELERATOR_TYPE["gpus"], tpu_cores=ACCELERATOR_TYPE["tpu_cores"]
)
model = LitRobertaLogitRegressor(
pre_trained_path=TUNED_BEST_ROBERTA_PATH,
train_size=datamodule.train_size,
batch_size=datamodule.batch_size,
output_hidden_states=USE_HIDDEN_IN_RGR,
n_gpus=ACCELERATOR_TYPE["gpus"],
accumulate_grad_batches=trainer.accumulate_grad_batches,
learning_rate=LEARNING_RATE,
warmup_steps=WARMUP_STEPS,
max_epochs=MAX_EPOCHS,
tokenizer=datamodule.tokenizer,
)
trainer = pl.Trainer(
gpus=ACCELERATOR_TYPE["gpus"], tpu_cores=ACCELERATOR_TYPE["tpu_cores"]
)
else:
checkpoint_filename = f"crp_roberta_trial_main"
checkpoint_save = ModelCheckpoint(
dirpath=CHECKPOINTS_PATH, filename=checkpoint_filename
)
early_stopping_callback = EarlyStopping(monitor="val_loss", patience=2)
trainer = pl.Trainer(
max_epochs=MAX_EPOCHS,
gpus=ACCELERATOR_TYPE["gpus"],
tpu_cores=ACCELERATOR_TYPE["tpu_cores"],
precision=16 if USE_16_BIT_PRECISION else 32,
default_root_dir=CHECKPOINTS_PATH,
gradient_clip_val=GRADIENT_CLIP_VAL,
stochastic_weight_avg=True,
callbacks=[checkpoint_save, early_stopping_callback],
fast_dev_run=FAST_DEV_RUN,
)
model = LitRobertaLogitRegressor(
pre_trained_path=PRETTRAINED_ROBERTA_BASE_MODEL_PATH,
train_size=datamodule.train_size,
batch_size=datamodule.batch_size,
n_gpus=trainer.gpus,
n_tpus=trainer.tpu_cores,
max_epochs=trainer.max_epochs,
accumulate_grad_batches=trainer.accumulate_grad_batches,
learning_rate=LEARNING_RATE,
warmup_steps=WARMUP_STEPS,
tokenizer=datamodule.tokenizer,
)
trainer.fit(model, datamodule=datamodule)
# let's also save the tuned roberta state which our model wraps around
model_file_name = f"tuned_roberta_model"
model_file_path = os.path.join(MODEL_PATH, model_file_name)
model.save_pretrained(model_file_path)
# clean up memory
torch.cuda.empty_cache()
gc.collect()
# freeze the model for prediction
model.eval()
model.freeze()
datamodule.setup(stage="predict")
model.do_decode = True
# run predict on the test data
train_data_stage_two = trainer.predict(
model=model, dataloaders=datamodule.train_dataloader()
)
train_data_stage_two = pd.concat(train_data_stage_two).reset_index(drop=True)
train_data_stage_two = pd.merge(
left=train_data_stage_two,
right=datamodule.train_df.drop(columns=["standard_error", "target"]),
left_on="id",
right_on="id",
)
print(train_data_stage_two)
# TODO: test whether we need to save and upload the fine-tuned state of roberta or if pytorch lightning checkpoints take care of it all
train_data_stage_three = add_textstat_features(train_data_stage_two)
label_data = train_data_stage_three[["id"]].copy(deep=True)
train_data = train_data_stage_three.drop(
columns=["id", "target", "text_standard_category"]
).copy(deep=True)
train_data_cols = list(train_data.columns)
target_data = train_data_stage_three[["target"]].copy(deep=True)
scaler = StandardScaler()
train_data_scaled = scaler.fit_transform(train_data)
train_data_scaled = pd.DataFrame(train_data_scaled, columns=train_data_cols)
TARGET_SCALER = StandardScaler()
target_data_scaled = TARGET_SCALER.fit_transform(target_data)
target_data_scaled = pd.DataFrame(target_data_scaled, columns=["target"])
regr = SVR(kernel="linear")
regr.fit(train_data_scaled, target_data_scaled["target"])
print(" Assessment of Features ")
print("R2 Score: ", regr.score(train_data_scaled, target_data_scaled["target"]))
print(
"RSME Score: ",
math.sqrt(
mean_squared_error(
target_data_scaled["target"], regr.predict(train_data_scaled)
)
),
)
# regr.coef_ is a array of n, 1
feats_coef = list(zip(train_data_cols, regr.coef_[0]))
feature_analysis = pd.DataFrame(feats_coef, columns=["feature_col", "coef_val"])
feature_analysis["coef_val"] = feature_analysis["coef_val"] # .abs()
feature_analysis = feature_analysis.sort_values("coef_val", ascending=False)
feature_analysis.plot.barh(
x="feature_col", y="coef_val", title="Comparison of Features and Importance"
)
# select the top n features for use in final regression approach
best_n_features = feature_analysis.head(N_FEATURES_TO_USE_HEAD)["feature_col"].to_list()
# the opposite
if N_FEATURES_TO_USE_TAIL is not None:
worst_n_features = feature_analysis.tail(N_FEATURES_TO_USE_TAIL)[
"feature_col"
].to_list()
best_n_features.extend(worst_n_features)
# manually adding this categorical feature in
if "text_standard_category" not in best_n_features:
best_n_features.append("text_standard_category")
best_n_features = list(set(best_n_features))
train_data = train_data_stage_three[best_n_features]
DATASET = train_data.copy(deep=True)
DATASET["target"] = target_data_scaled["target"]
DATASET["id"] = label_data["id"]
temp_cols = list(
DATASET.drop(columns=["id", "target", "text_standard_category"]).columns
)
DATASET_scaled = DATASET[temp_cols]
scaler = StandardScaler()
DATASET_scaled = scaler.fit_transform(DATASET_scaled)
DATASET_scaled = pd.DataFrame(DATASET_scaled, columns=temp_cols)
DATASET_scaled[["id", "target", "text_standard_category"]] = DATASET[
["id", "target", "text_standard_category"]
]
print(DATASET_scaled)
Dataset = DATASET_scaled
# https://medium.com/optuna/lightgbm-tuner-new-optuna-integration-for-hyperparameter-optimization-8b7095e99258
# https://www.kaggle.com/corochann/optuna-tutorial-for-hyperparameter-optimization
RGR_MODELS = []
def objective(trial: optuna.trial.Trial, n_folds=5, shuffle=True):
params = {
"metric": "rmse",
"boosting_type": "gbdt",
"verbose": -1,
"num_leaves": trial.suggest_int("num_leaves", 4, 512),
"max_depth": trial.suggest_int("max_depth", 4, 512),
"max_bin": trial.suggest_int("max_bin", 4, 512),
"min_data_in_leaf": trial.suggest_int("min_data_in_leaf", 64, 512),
"bagging_fraction": trial.suggest_uniform("bagging_fraction", 0.1, 1.0),
"bagging_freq": trial.suggest_int("max_bin", 5, 10),
"feature_fraction": trial.suggest_uniform("feature_fraction", 0.4, 1.0),
"learning_rate": trial.suggest_float("bagging_fraction", 0.0005, 0.01),
"n_estimators": trial.suggest_int("num_leaves", 10, 10000),
"lambda_l1": trial.suggest_loguniform("lambda_l1", 1e-8, 10.0),
"lambda_l2": trial.suggest_loguniform("lambda_l2", 1e-8, 10.0),
}
fold = KFold(
n_splits=n_folds, shuffle=shuffle, random_state=SEED_VAL if shuffle else None
)
valid_score = []
best_model_tracker = {}
for fold_idx, (train_idx, valid_idx) in enumerate(fold.split(range(len(DATASET)))):
train_data = (
Dataset.iloc[train_idx].drop(columns=["id", "target"]).copy(deep=True)
)
train_target = Dataset[["target"]].iloc[train_idx].copy(deep=True)
valid_data = (
Dataset.iloc[valid_idx].drop(columns=["id", "target"]).copy(deep=True)
)
valid_target = Dataset[["target"]].iloc[valid_idx].copy(deep=True)
lgbm_train = lgm.Dataset(
train_data,
label=train_target,
categorical_feature=["text_standard_category"],
)
lgbm_valid = lgm.Dataset(
valid_data,
label=valid_target,
categorical_feature=["text_standard_category"],
)
curr_model = lgm.train(
params,
train_set=lgbm_train,
valid_sets=[lgbm_train, lgbm_valid],
verbose_eval=-1,
)
valid_pred = curr_model.predict(
valid_data, num_iteration=curr_model.best_iteration
)
best_score = curr_model.best_score["valid_1"]["rmse"]
best_model_tracker.update({best_score: curr_model})
valid_score.append(best_score)
best_model_score = min([k for k, v in best_model_tracker.items()])
best_model = best_model_tracker[best_model_score]
RGR_MODELS.append(best_model)
# RGR_MODELS.append({best_model_score: best_model})
# worst_rgr_model_idx = max([d.keys[0] for d in RGR_MODELS])
# RGR_MODELS[worst_rgr_model_idx] = {best_model_score: None}
score = np.mean(valid_score)
return score
study = optuna.create_study(storage="sqlite:///lgm-study.db")
study.optimize(objective, n_trials=256)
plot_optimization_history(study).show()
print("Best Trial: ", study.best_trial, "\n")
# use the study parameters to create and train a lgbm regressor
lgm_train_data = DATASET_scaled.drop(columns=["id"]).copy(deep=True)
x_features = lgm_train_data.loc[:, lgm_train_data.columns != "target"]
y_train = lgm_train_data[["target"]]
lgm_train_set_full = lgm.Dataset(
data=x_features, categorical_feature=["text_standard_category"], label=y_train
)
gbm = lgm.train(
study.best_trial.params,
lgm_train_set_full,
)
model.do_decode = True
trainer = pl.Trainer(
gpus=ACCELERATOR_TYPE["gpus"], tpu_cores=ACCELERATOR_TYPE["tpu_cores"]
)
# run predict on the test data
submission_stage_1 = trainer.predict(
model=model, dataloaders=datamodule.predict_dataloader()
)
submission_stage_1 = pd.concat(submission_stage_1).reset_index(drop=True)
print(" Submission Stage 1: After RoBERTA\n")
print(submission_stage_1)
submission_stage_2 = pd.merge(
left=submission_stage_1,
right=datamodule.test_df,
left_on="id",
right_on="id",
how="left",
)
submission_stage_2 = add_textstat_features(submission_stage_2)
feature_cols = list(submission_stage_2.drop(columns=["id"]).copy(deep=True).columns)
predict_data = submission_stage_2.drop(columns=["id"]).copy(deep=True)
predict_data = predict_data[best_n_features]
temp_cols = list(predict_data.drop(columns=["text_standard_category"]).columns)
predict_data_scaled = predict_data[temp_cols]
predict_data_scaled = scaler.transform(predict_data_scaled)
predict_data_scaled = pd.DataFrame(predict_data_scaled, columns=temp_cols)
predict_data_scaled["text_standard_category"] = predict_data["text_standard_category"]
submission = submission_stage_2[["id"]].copy(deep=True)
submission["target"] = gbm.predict(predict_data_scaled)
submission["target"] = TARGET_SCALER.inverse_transform(submission["target"])
print(" Final Stage After LGBM\n")
print(submission)
submission.to_csv("submission.csv", index=False)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0069/393/69393429.ipynb | progresbar2local | justinchae | [{"Id": 69393429, "ScriptId": 18638229, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4319244, "CreationDate": "07/30/2021 12:40:32", "VersionNumber": 36.0, "Title": "The Bernstein Bears CRP Submission 1", "EvaluationDate": "07/30/2021", "IsChange": true, "TotalLines": 887.0, "LinesInsertedFromPrevious": 13.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 874.0, "LinesInsertedFromFork": 409.0, "LinesDeletedFromFork": 274.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 478.0, "TotalVotes": 0}] | [{"Id": 92503477, "KernelVersionId": 69393429, "SourceDatasetVersionId": 2311525}, {"Id": 92503478, "KernelVersionId": 69393429, "SourceDatasetVersionId": 2312589}, {"Id": 92503476, "KernelVersionId": 69393429, "SourceDatasetVersionId": 2311499}] | [{"Id": 2311525, "DatasetId": 1394642, "DatasourceVersionId": 2352908, "CreatorUserId": 4319244, "LicenseName": "Unknown", "CreationDate": "06/07/2021 14:51:02", "VersionNumber": 1.0, "Title": "progresbar2-local", "Slug": "progresbar2local", "Subtitle": "Downloaded for offline use in kaggle \"no internet\" kernels", "Description": NaN, "VersionNotes": "Initial release", "TotalCompressedBytes": 0.0, "TotalUncompressedBytes": 0.0}] | [{"Id": 1394642, "CreatorUserId": 4319244, "OwnerUserId": 4319244.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 2311525.0, "CurrentDatasourceVersionId": 2352908.0, "ForumId": 1413893, "Type": 2, "CreationDate": "06/07/2021 14:51:02", "LastActivityDate": "06/07/2021", "TotalViews": 934, "TotalDownloads": 4, "TotalVotes": 1, "TotalKernels": 3}] | [{"Id": 4319244, "UserName": "justinchae", "DisplayName": "Justin Chae", "RegisterDate": "01/12/2020", "PerformanceTier": 1}] | # # The Bernstein Bears CRP Submission 1
# install necessary libraries from input
# import progressbar library for offline usage
# import text stat library for additional ml data prep
FAST_DEV_RUN = False
USE_CHECKPOINT = True
USE_HIDDEN_IN_RGR = False
N_FEATURES_TO_USE_HEAD = 1
N_FEATURES_TO_USE_TAIL = None
# in this kernel, run train on all data to maximize score on held out data but use what we learned about optimal parameters
# set to 16 bit precision to cut compute requirements/increase batch size capacity
USE_16_BIT_PRECISION = True
# set a seed value for consistent experimentation; optional, else leave as None
SEED_VAL = 42
# set a train-validation split, .7 means 70% of train data and 30% to validation set
TRAIN_VALID_SPLIT = 0.8 # if None, then don't split
# set hyperparameters learned from tuning: https://www.kaggle.com/justinchae/tune-roberta-pytorch-lightning-optuna
MAX_EPOCHS = 4
BATCH_SIZE = 16
GRADIENT_CLIP_VAL = 0.18318092164684585
LEARNING_RATE = 3.613894271216525e-05
TOKENIZER_MAX_LEN = 363
WARMUP_STEPS = 292
WEIGHT_DECAY = 0.004560699842170359
import kaggle_config
from kaggle_config import (
WORKFLOW_ROOT,
DATA_PATH,
CACHE_PATH,
FIG_PATH,
MODEL_PATH,
ANALYSIS_PATH,
KAGGLE_INPUT,
CHECKPOINTS_PATH,
LOGS_PATH,
)
INPUTS, DEVICE = kaggle_config.run()
KAGGLE_TRAIN_PATH = kaggle_config.get_train_path(INPUTS)
KAGGLE_TEST_PATH = kaggle_config.get_test_path(INPUTS)
import pytorch_lightning as pl
from pytorch_lightning import loggers as pl_loggers
from pytorch_lightning import seed_everything
from pytorch_lightning.callbacks import ModelCheckpoint, EarlyStopping
from pytorch_lightning.tuner.batch_size_scaling import scale_batch_size
from pytorch_lightning.tuner.lr_finder import _LRFinder, lr_find
import torchmetrics
import optuna
from optuna.integration import PyTorchLightningPruningCallback
from optuna.samplers import TPESampler, RandomSampler, CmaEsSampler
from optuna.visualization import (
plot_intermediate_values,
plot_optimization_history,
plot_param_importances,
)
import optuna.integration.lightgbm as lgb
import lightgbm as lgm
from sklearn.model_selection import (
KFold,
cross_val_score,
RepeatedKFold,
train_test_split,
)
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.decomposition import PCA
from sklearn.feature_selection import (
RFE,
f_regression,
mutual_info_regression,
SequentialFeatureSelector,
)
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVR
from sklearn.metrics import mean_squared_error
import math
import textstat
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torch.utils.data.dataset import random_split
import tensorflow as tf
from transformers import (
RobertaForSequenceClassification,
RobertaTokenizer,
AdamW,
get_linear_schedule_with_warmup,
)
import os
import pandas as pd
import numpy as np
import gc
from functools import partial
from typing import List, Dict
from typing import Optional
from argparse import ArgumentParser
import random
if SEED_VAL:
random.seed(SEED_VAL)
np.random.seed(SEED_VAL)
seed_everything(SEED_VAL)
NUM_DATALOADER_WORKERS = os.cpu_count()
try:
resolver = tf.distribute.cluster_resolver.TPUClusterResolver(tpu="")
tf.config.experimental_connect_to_cluster(resolver)
tf.tpu.experimental.initialize_tpu_system(resolver)
n_tpus = len(tf.config.list_logical_devices("TPU"))
except ValueError:
n_tpus = 0
ACCELERATOR_TYPE = {}
ACCELERATOR_TYPE.update(
{"gpus": torch.cuda.device_count() if torch.cuda.is_available() else None}
)
ACCELERATOR_TYPE.update({"tpu_cores": n_tpus if n_tpus > 0 else None})
# still debugging how to best toggle between tpu and gpu; there's too much code to configure to work simply
print("ACCELERATOR_TYPE:\n", ACCELERATOR_TYPE)
PRETTRAINED_ROBERTA_BASE_MODEL_PATH = "/kaggle/input/pre-trained-roberta-base"
PRETRAINED_ROBERTA_BASE_TOKENIZER_PATH = "/kaggle/input/tokenizer-roberta"
PRETRAINED_ROBERTA_BASE_TOKENIZER = RobertaTokenizer.from_pretrained(
PRETRAINED_ROBERTA_BASE_TOKENIZER_PATH
)
TUNED_CHECKPOINT_PATH = "/kaggle/input/best-crp-ckpt-4/crp_roberta_trial_4.ckpt"
# from: https://www.kaggle.com/justinchae/crp-regression-with-roberta-and-lightgbm
TUNED_BEST_ROBERTA_PATH = "/kaggle/input/my-best-tuned-roberta"
"""Implementing Lightning instead of torch.nn.Module
"""
class LitRobertaLogitRegressor(pl.LightningModule):
def __init__(
self,
pre_trained_path: str,
output_hidden_states: bool = False,
num_labels: int = 1,
layer_1_output_size: int = 64,
layer_2_output_size: int = 1,
learning_rate: float = 1e-5,
task_name: Optional[str] = None,
warmup_steps: int = 100,
weight_decay: float = 0.0,
adam_epsilon: float = 1e-8,
batch_size: Optional[int] = None,
train_size: Optional[int] = None,
max_epochs: Optional[int] = None,
n_gpus: Optional[int] = 0,
n_tpus: Optional[int] = 0,
accumulate_grad_batches=None,
tokenizer=None,
do_decode=False,
):
"""refactored from: https://www.kaggle.com/justinchae/my-bert-tuner and https://www.kaggle.com/justinchae/roberta-tuner"""
super(LitRobertaLogitRegressor, self).__init__()
# this saves class params as self.hparams
self.save_hyperparameters()
self.model = RobertaForSequenceClassification.from_pretrained(
self.hparams.pre_trained_path,
output_hidden_states=self.hparams.output_hidden_states,
num_labels=self.hparams.num_labels,
)
self.accelerator_multiplier = n_gpus if n_gpus > 0 else 1
self.config = self.model.config
self.parameters = self.model.parameters
self.save_pretrained = self.model.save_pretrained
# these layers are not currently used, tbd in future iteration
self.layer_1 = torch.nn.Linear(768, layer_1_output_size)
self.layer_2 = torch.nn.Linear(layer_1_output_size, layer_2_output_size)
self.tokenizer = tokenizer
self.do_decode = do_decode
self.output_hidden_states = output_hidden_states
def rmse_loss(x, y):
criterion = F.mse_loss
loss = torch.sqrt(criterion(x, y))
return loss
# TODO: enable toggle for various loss funcs and torchmetrics package
self.loss_func = rmse_loss
# self.eval_func = rmse_loss
def setup(self, stage=None) -> None:
if stage == "fit":
# when this class is called by trainer.fit, this stage runs and so on
# Calculate total steps
tb_size = self.hparams.batch_size * self.accelerator_multiplier
ab_size = self.hparams.accumulate_grad_batches * float(
self.hparams.max_epochs
)
self.total_steps = (self.hparams.train_size // tb_size) // ab_size
def extract_logit_only(self, input_ids, attention_mask) -> float:
output = self.model(input_ids=input_ids, attention_mask=attention_mask)
logit = output.logits
logit = logit.cpu().numpy().astype(float)
return logit
def extract_hidden_only(self, input_ids, attention_mask) -> np.array:
output = self.model(input_ids=input_ids, attention_mask=input_ids)
hidden_states = output.hidden_states
x = torch.stack(hidden_states[-4:]).sum(0)
m1 = torch.nn.Sequential(self.layer_1, self.layer_2, torch.nn.Flatten())
x = m1(x)
x = torch.squeeze(x).cpu().numpy()
return x
def forward(self, input_ids, attention_mask) -> torch.Tensor:
output = self.model(input_ids=input_ids, attention_mask=attention_mask)
x = output.logits
return x
def training_step(self, batch, batch_idx: int) -> float:
# refactored from: https://www.kaggle.com/justinchae/epoch-utils
labels, encoded_batch, kaggle_ids = batch
input_ids = encoded_batch["input_ids"]
attention_mask = encoded_batch["attention_mask"]
# per docs, keep train step separate from forward call
output = self.model(input_ids=input_ids, attention_mask=attention_mask)
y_hat = output.logits
# quick reshape to align labels to predictions
labels = labels.view(-1, 1)
loss = self.loss_func(y_hat, labels)
self.log("train_loss", loss)
return loss
def validation_step(self, batch, batch_idx: int) -> float:
# refactored from: https://www.kaggle.com/justinchae/epoch-utils
labels, encoded_batch, kaggle_ids = batch
input_ids = encoded_batch["input_ids"]
attention_mask = encoded_batch["attention_mask"]
# this self call is calling the forward method
y_hat = self(input_ids, attention_mask)
# quick reshape to align labels to predictions
labels = labels.view(-1, 1)
loss = self.loss_func(y_hat, labels)
self.log("val_loss", loss)
return loss
def predict(self, batch, batch_idx: int, dataloader_idx: int = None):
# creating this predict method overrides the pl predict method
target, encoded_batch, kaggle_ids = batch
input_ids = encoded_batch["input_ids"]
attention_mask = encoded_batch["attention_mask"]
# this self call is calling the forward method
y_hat = self(input_ids, attention_mask)
# convert to numpy then list like struct to zip with ids
y_hat = y_hat.cpu().numpy().ravel()
# customizing the predict behavior to account for unique ids
if self.tokenizer is not None and self.do_decode:
target = target.cpu().numpy().ravel() if len(target) > 0 else None
excerpt = self.tokenizer.batch_decode(
input_ids.cpu().numpy(),
skip_special_tokens=True,
clean_up_tokenization_spaces=True,
)
if self.output_hidden_states:
hidden_states = self.extract_hidden_only(
input_ids=input_ids, attention_mask=attention_mask
)
else:
hidden_states = None
if target is not None:
predictions = list(
zip(
kaggle_ids,
target,
y_hat
# , hidden_states
)
)
predictions = pd.DataFrame(
predictions,
columns=[
"id",
"target",
"logit"
# , 'hidden_states'
],
)
else:
predictions = list(
zip(
kaggle_ids,
y_hat
# , hidden_states
)
)
predictions = pd.DataFrame(
predictions,
columns=[
"id",
"logit"
# , 'hidden_states'
],
)
else:
predictions = list(zip(kaggle_ids, y_hat))
predictions = pd.DataFrame(predictions, columns=["id", "target"])
return predictions
def configure_optimizers(self) -> torch.optim.Optimizer:
# Reference: https://pytorch-lightning.readthedocs.io/en/latest/notebooks/lightning_examples/text-transformers.html
model = self.model
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [
p
for n, p in model.named_parameters()
if not any(nd in n for nd in no_decay)
],
"weight_decay": self.hparams.weight_decay,
},
{
"params": [
p
for n, p in model.named_parameters()
if any(nd in n for nd in no_decay)
],
"weight_decay": 0.0,
},
]
optimizer = AdamW(
optimizer_grouped_parameters,
lr=self.hparams.learning_rate,
eps=self.hparams.adam_epsilon,
)
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=self.hparams.warmup_steps,
num_training_steps=self.total_steps,
)
scheduler = {"scheduler": scheduler, "interval": "step", "frequency": 1}
return [optimizer], [scheduler]
def my_collate_fn(
batch,
tokenizer,
max_length: int = 100,
return_tensors: str = "pt",
padding: str = "max_length",
truncation: bool = True,
):
# source: https://www.kaggle.com/justinchae/nn-utils
labels = []
batch_texts = []
kaggle_ids = []
for _label, batch_text, kaggle_id in batch:
if _label is not None:
labels.append(_label)
batch_texts.append(batch_text)
kaggle_ids.append(kaggle_id)
if _label is not None:
labels = torch.tensor(labels, dtype=torch.float)
encoded_batch = tokenizer(
batch_texts,
return_tensors=return_tensors,
padding=padding,
max_length=max_length,
truncation=truncation,
)
return labels, encoded_batch, kaggle_ids
class CommonLitDataset(Dataset):
def __init__(
self,
df,
text_col: str = "excerpt",
label_col: str = "target",
kaggle_id: str = "id",
sample_size: Optional[str] = None,
):
self.df = df if sample_size is None else df.sample(sample_size)
self.text_col = text_col
self.label_col = label_col
self.kaggle_id = kaggle_id
self.num_labels = (
len(df[label_col].unique()) if label_col in df.columns else None
)
# source: https://www.kaggle.com/justinchae/nn-utils
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
result = None
text = self.df.iloc[idx][self.text_col]
kaggle_id = self.df.iloc[idx][self.kaggle_id]
if "target" in self.df.columns:
target = self.df.iloc[idx][self.label_col]
return target, text, kaggle_id
else:
return None, text, kaggle_id
class CommonLitDataModule(pl.LightningDataModule):
def __init__(
self,
tokenizer,
train_path,
collate_fn=None,
max_length: int = 280,
batch_size: int = 16,
valid_path: Optional[str] = None,
test_path: Optional[str] = None,
train_valid_split: float = 0.6,
dtypes=None,
shuffle_dataloader: bool = True,
num_dataloader_workers: int = NUM_DATALOADER_WORKERS,
kfold: Optional[dict] = None,
):
super(CommonLitDataModule, self).__init__()
self.tokenizer = tokenizer
self.train_path = train_path
self.valid_path = valid_path
self.test_path = test_path
self.train_valid_split = train_valid_split
self.dtypes = {"id": str} if dtypes is None else dtypes
self.train_size = None
self.train_df, self.train_data = None, None
self.valid_df, self.valid_data = None, None
self.test_df, self.test_data = None, None
if collate_fn is not None:
self.collate_fn = partial(
collate_fn, tokenizer=tokenizer, max_length=max_length
)
else:
self.collate_fn = partial(
my_collate_fn, batch=batch_size, tokenizer=tokenizer
)
self.shuffle_dataloader = shuffle_dataloader
self.batch_size = batch_size
self.num_dataloader_workers = num_dataloader_workers
# refactored from: https://www.kaggle.com/justinchae/nn-utils
def _strip_extraneous(self, df):
strip_cols = ["url_legal", "license"]
if all(col in df.columns for col in strip_cols):
extraneous_data = strip_cols
return df.drop(columns=extraneous_data)
else:
return df
def prepare(self, prep_type=None):
if prep_type == "train":
# creates just an instance of the train data as a pandas df
self.train_df = (
self.train_path
if isinstance(self.train_path, pd.DataFrame)
else pd.read_csv(self.train_path, dtype=self.dtypes)
)
self.train_df = self._strip_extraneous(self.train_df)
if prep_type == "train_stage_2":
self.train_df = (
self.train_path
if isinstance(self.train_path, pd.DataFrame)
else pd.read_csv(self.train_path, dtype=self.dtypes)
)
self.train_df = self._strip_extraneous(self.train_df)
self.train_size = int(len(self.train_df))
self.train_data = CommonLitDataset(df=self.train_df)
def setup(self, stage: Optional[str] = None) -> None:
if stage == "fit":
# when this class is called by trainer.fit, this stage runs and so on
self.train_df = (
self.train_path
if isinstance(self.train_path, pd.DataFrame)
else pd.read_csv(self.train_path, dtype=self.dtypes)
)
self.train_df = self._strip_extraneous(self.train_df)
self.train_size = int(len(self.train_df))
self.train_data = CommonLitDataset(df=self.train_df)
if self.train_valid_split is not None and self.valid_path is None:
self.train_size = int(len(self.train_df) * self.train_valid_split)
self.train_data, self.valid_data = random_split(
self.train_data,
[self.train_size, len(self.train_df) - self.train_size],
)
elif self.valid_path is not None:
self.valid_df = (
self.valid_path
if isinstance(self.valid_path, pd.DataFrame)
else pd.read_csv(self.valid_path, dtype=self.dtypes)
)
self.valid_data = CommonLitDataset(df=self.valid_df)
if stage == "predict":
self.test_df = (
self.test_path
if isinstance(self.test_path, pd.DataFrame)
else pd.read_csv(self.test_path, dtype=self.dtypes)
)
self.test_df = self._strip_extraneous(self.test_df)
self.test_data = CommonLitDataset(df=self.test_df)
self.train_df = (
self.train_path
if isinstance(self.train_path, pd.DataFrame)
else pd.read_csv(self.train_path, dtype=self.dtypes)
)
self.train_df = self._strip_extraneous(self.train_df)
self.train_size = int(len(self.train_df))
self.train_data = CommonLitDataset(df=self.train_df)
def kfold_data(self):
# TODO: wondering how to integrate kfolds into the datamodule
pass
def train_dataloader(self) -> DataLoader:
return DataLoader(
self.train_data,
batch_size=self.batch_size,
shuffle=self.shuffle_dataloader,
collate_fn=self.collate_fn,
num_workers=self.num_dataloader_workers,
pin_memory=True,
)
def val_dataloader(self) -> DataLoader:
if self.valid_data is None:
return None
else:
return DataLoader(
self.valid_data,
batch_size=self.batch_size,
shuffle=False,
collate_fn=self.collate_fn,
num_workers=self.num_dataloader_workers,
pin_memory=True,
)
def predict_dataloader(self) -> DataLoader:
if self.test_data is None:
return None
else:
return DataLoader(
self.test_data,
batch_size=self.batch_size,
shuffle=False,
collate_fn=self.collate_fn,
num_workers=self.num_dataloader_workers,
pin_memory=True,
)
def add_textstat_features(df):
# adding the text standard seems to boost the accuracy score a bit
df["text_standard"] = df["excerpt"].apply(lambda x: textstat.text_standard(x))
df["text_standard_category"] = df["text_standard"].astype("category").cat.codes
# counting ratio of difficult words by lexicon count
df["difficult_words_ratio"] = df["excerpt"].apply(
lambda x: textstat.difficult_words(x)
)
df["difficult_words_ratio"] = df.apply(
lambda x: x["difficult_words_ratio"] / textstat.lexicon_count(x["excerpt"]),
axis=1,
)
df["syllable_ratio"] = df["excerpt"].apply(lambda x: textstat.syllable_count(x))
df["syllable_ratio"] = df.apply(
lambda x: x["syllable_ratio"] / textstat.lexicon_count(x["excerpt"]), axis=1
)
### You can add/remove any feature below and it will be used in training and test
df["coleman_liau_index"] = df["excerpt"].apply(
lambda x: textstat.coleman_liau_index(x)
)
df["flesch_reading_ease"] = df["excerpt"].apply(
lambda x: textstat.flesch_reading_ease(x)
)
df["smog_index"] = df["excerpt"].apply(lambda x: textstat.smog_index(x))
df["gunning_fog"] = df["excerpt"].apply(lambda x: textstat.gunning_fog(x))
df["flesch_kincaid_grade"] = df["excerpt"].apply(
lambda x: textstat.flesch_kincaid_grade(x)
)
df["automated_readability_index"] = df["excerpt"].apply(
lambda x: textstat.automated_readability_index(x)
)
df["dale_chall_readability_score"] = df["excerpt"].apply(
lambda x: textstat.dale_chall_readability_score(x)
)
df["linsear_write_formula"] = df["excerpt"].apply(
lambda x: textstat.linsear_write_formula(x)
)
###
df = df.drop(columns=["excerpt", "text_standard"])
return df
def process_hidden_states(df, drop_hidden_states=False):
# for convenience, moving hidden states to the far right of the df
if drop_hidden_states:
df.drop(columns=["hidden_states"], inplace=True)
return df
elif "hidden_states" in df.columns:
df["hidden_state"] = df["hidden_states"]
df.drop(columns=["hidden_states"], inplace=True)
temp = df["hidden_state"].apply(pd.Series)
temp = temp.rename(columns=lambda x: "hidden_state_" + str(x))
df = pd.concat([df, temp], axis=1)
df.drop(columns=["hidden_state"], inplace=True)
return df
else:
print("hidden_states not found in dataframe, skipping process_hidden_states")
return df
datamodule = CommonLitDataModule(
collate_fn=my_collate_fn,
tokenizer=PRETRAINED_ROBERTA_BASE_TOKENIZER,
train_path=KAGGLE_TRAIN_PATH,
test_path=KAGGLE_TEST_PATH,
max_length=TOKENIZER_MAX_LEN,
batch_size=BATCH_SIZE,
train_valid_split=TRAIN_VALID_SPLIT,
)
# manually calling this stage since we need some params to set up model initially
datamodule.setup(stage="fit")
if USE_CHECKPOINT:
# model = LitRobertaLogitRegressor.load_from_checkpoint(TUNED_CHECKPOINT_PATH)
trainer = pl.Trainer(
gpus=ACCELERATOR_TYPE["gpus"], tpu_cores=ACCELERATOR_TYPE["tpu_cores"]
)
model = LitRobertaLogitRegressor(
pre_trained_path=TUNED_BEST_ROBERTA_PATH,
train_size=datamodule.train_size,
batch_size=datamodule.batch_size,
output_hidden_states=USE_HIDDEN_IN_RGR,
n_gpus=ACCELERATOR_TYPE["gpus"],
accumulate_grad_batches=trainer.accumulate_grad_batches,
learning_rate=LEARNING_RATE,
warmup_steps=WARMUP_STEPS,
max_epochs=MAX_EPOCHS,
tokenizer=datamodule.tokenizer,
)
trainer = pl.Trainer(
gpus=ACCELERATOR_TYPE["gpus"], tpu_cores=ACCELERATOR_TYPE["tpu_cores"]
)
else:
checkpoint_filename = f"crp_roberta_trial_main"
checkpoint_save = ModelCheckpoint(
dirpath=CHECKPOINTS_PATH, filename=checkpoint_filename
)
early_stopping_callback = EarlyStopping(monitor="val_loss", patience=2)
trainer = pl.Trainer(
max_epochs=MAX_EPOCHS,
gpus=ACCELERATOR_TYPE["gpus"],
tpu_cores=ACCELERATOR_TYPE["tpu_cores"],
precision=16 if USE_16_BIT_PRECISION else 32,
default_root_dir=CHECKPOINTS_PATH,
gradient_clip_val=GRADIENT_CLIP_VAL,
stochastic_weight_avg=True,
callbacks=[checkpoint_save, early_stopping_callback],
fast_dev_run=FAST_DEV_RUN,
)
model = LitRobertaLogitRegressor(
pre_trained_path=PRETTRAINED_ROBERTA_BASE_MODEL_PATH,
train_size=datamodule.train_size,
batch_size=datamodule.batch_size,
n_gpus=trainer.gpus,
n_tpus=trainer.tpu_cores,
max_epochs=trainer.max_epochs,
accumulate_grad_batches=trainer.accumulate_grad_batches,
learning_rate=LEARNING_RATE,
warmup_steps=WARMUP_STEPS,
tokenizer=datamodule.tokenizer,
)
trainer.fit(model, datamodule=datamodule)
# let's also save the tuned roberta state which our model wraps around
model_file_name = f"tuned_roberta_model"
model_file_path = os.path.join(MODEL_PATH, model_file_name)
model.save_pretrained(model_file_path)
# clean up memory
torch.cuda.empty_cache()
gc.collect()
# freeze the model for prediction
model.eval()
model.freeze()
datamodule.setup(stage="predict")
model.do_decode = True
# run predict on the test data
train_data_stage_two = trainer.predict(
model=model, dataloaders=datamodule.train_dataloader()
)
train_data_stage_two = pd.concat(train_data_stage_two).reset_index(drop=True)
train_data_stage_two = pd.merge(
left=train_data_stage_two,
right=datamodule.train_df.drop(columns=["standard_error", "target"]),
left_on="id",
right_on="id",
)
print(train_data_stage_two)
# TODO: test whether we need to save and upload the fine-tuned state of roberta or if pytorch lightning checkpoints take care of it all
train_data_stage_three = add_textstat_features(train_data_stage_two)
label_data = train_data_stage_three[["id"]].copy(deep=True)
train_data = train_data_stage_three.drop(
columns=["id", "target", "text_standard_category"]
).copy(deep=True)
train_data_cols = list(train_data.columns)
target_data = train_data_stage_three[["target"]].copy(deep=True)
scaler = StandardScaler()
train_data_scaled = scaler.fit_transform(train_data)
train_data_scaled = pd.DataFrame(train_data_scaled, columns=train_data_cols)
TARGET_SCALER = StandardScaler()
target_data_scaled = TARGET_SCALER.fit_transform(target_data)
target_data_scaled = pd.DataFrame(target_data_scaled, columns=["target"])
regr = SVR(kernel="linear")
regr.fit(train_data_scaled, target_data_scaled["target"])
print(" Assessment of Features ")
print("R2 Score: ", regr.score(train_data_scaled, target_data_scaled["target"]))
print(
"RSME Score: ",
math.sqrt(
mean_squared_error(
target_data_scaled["target"], regr.predict(train_data_scaled)
)
),
)
# regr.coef_ is a array of n, 1
feats_coef = list(zip(train_data_cols, regr.coef_[0]))
feature_analysis = pd.DataFrame(feats_coef, columns=["feature_col", "coef_val"])
feature_analysis["coef_val"] = feature_analysis["coef_val"] # .abs()
feature_analysis = feature_analysis.sort_values("coef_val", ascending=False)
feature_analysis.plot.barh(
x="feature_col", y="coef_val", title="Comparison of Features and Importance"
)
# select the top n features for use in final regression approach
best_n_features = feature_analysis.head(N_FEATURES_TO_USE_HEAD)["feature_col"].to_list()
# the opposite
if N_FEATURES_TO_USE_TAIL is not None:
worst_n_features = feature_analysis.tail(N_FEATURES_TO_USE_TAIL)[
"feature_col"
].to_list()
best_n_features.extend(worst_n_features)
# manually adding this categorical feature in
if "text_standard_category" not in best_n_features:
best_n_features.append("text_standard_category")
best_n_features = list(set(best_n_features))
train_data = train_data_stage_three[best_n_features]
DATASET = train_data.copy(deep=True)
DATASET["target"] = target_data_scaled["target"]
DATASET["id"] = label_data["id"]
temp_cols = list(
DATASET.drop(columns=["id", "target", "text_standard_category"]).columns
)
DATASET_scaled = DATASET[temp_cols]
scaler = StandardScaler()
DATASET_scaled = scaler.fit_transform(DATASET_scaled)
DATASET_scaled = pd.DataFrame(DATASET_scaled, columns=temp_cols)
DATASET_scaled[["id", "target", "text_standard_category"]] = DATASET[
["id", "target", "text_standard_category"]
]
print(DATASET_scaled)
Dataset = DATASET_scaled
# https://medium.com/optuna/lightgbm-tuner-new-optuna-integration-for-hyperparameter-optimization-8b7095e99258
# https://www.kaggle.com/corochann/optuna-tutorial-for-hyperparameter-optimization
RGR_MODELS = []
def objective(trial: optuna.trial.Trial, n_folds=5, shuffle=True):
params = {
"metric": "rmse",
"boosting_type": "gbdt",
"verbose": -1,
"num_leaves": trial.suggest_int("num_leaves", 4, 512),
"max_depth": trial.suggest_int("max_depth", 4, 512),
"max_bin": trial.suggest_int("max_bin", 4, 512),
"min_data_in_leaf": trial.suggest_int("min_data_in_leaf", 64, 512),
"bagging_fraction": trial.suggest_uniform("bagging_fraction", 0.1, 1.0),
"bagging_freq": trial.suggest_int("max_bin", 5, 10),
"feature_fraction": trial.suggest_uniform("feature_fraction", 0.4, 1.0),
"learning_rate": trial.suggest_float("bagging_fraction", 0.0005, 0.01),
"n_estimators": trial.suggest_int("num_leaves", 10, 10000),
"lambda_l1": trial.suggest_loguniform("lambda_l1", 1e-8, 10.0),
"lambda_l2": trial.suggest_loguniform("lambda_l2", 1e-8, 10.0),
}
fold = KFold(
n_splits=n_folds, shuffle=shuffle, random_state=SEED_VAL if shuffle else None
)
valid_score = []
best_model_tracker = {}
for fold_idx, (train_idx, valid_idx) in enumerate(fold.split(range(len(DATASET)))):
train_data = (
Dataset.iloc[train_idx].drop(columns=["id", "target"]).copy(deep=True)
)
train_target = Dataset[["target"]].iloc[train_idx].copy(deep=True)
valid_data = (
Dataset.iloc[valid_idx].drop(columns=["id", "target"]).copy(deep=True)
)
valid_target = Dataset[["target"]].iloc[valid_idx].copy(deep=True)
lgbm_train = lgm.Dataset(
train_data,
label=train_target,
categorical_feature=["text_standard_category"],
)
lgbm_valid = lgm.Dataset(
valid_data,
label=valid_target,
categorical_feature=["text_standard_category"],
)
curr_model = lgm.train(
params,
train_set=lgbm_train,
valid_sets=[lgbm_train, lgbm_valid],
verbose_eval=-1,
)
valid_pred = curr_model.predict(
valid_data, num_iteration=curr_model.best_iteration
)
best_score = curr_model.best_score["valid_1"]["rmse"]
best_model_tracker.update({best_score: curr_model})
valid_score.append(best_score)
best_model_score = min([k for k, v in best_model_tracker.items()])
best_model = best_model_tracker[best_model_score]
RGR_MODELS.append(best_model)
# RGR_MODELS.append({best_model_score: best_model})
# worst_rgr_model_idx = max([d.keys[0] for d in RGR_MODELS])
# RGR_MODELS[worst_rgr_model_idx] = {best_model_score: None}
score = np.mean(valid_score)
return score
study = optuna.create_study(storage="sqlite:///lgm-study.db")
study.optimize(objective, n_trials=256)
plot_optimization_history(study).show()
print("Best Trial: ", study.best_trial, "\n")
# use the study parameters to create and train a lgbm regressor
lgm_train_data = DATASET_scaled.drop(columns=["id"]).copy(deep=True)
x_features = lgm_train_data.loc[:, lgm_train_data.columns != "target"]
y_train = lgm_train_data[["target"]]
lgm_train_set_full = lgm.Dataset(
data=x_features, categorical_feature=["text_standard_category"], label=y_train
)
gbm = lgm.train(
study.best_trial.params,
lgm_train_set_full,
)
model.do_decode = True
trainer = pl.Trainer(
gpus=ACCELERATOR_TYPE["gpus"], tpu_cores=ACCELERATOR_TYPE["tpu_cores"]
)
# run predict on the test data
submission_stage_1 = trainer.predict(
model=model, dataloaders=datamodule.predict_dataloader()
)
submission_stage_1 = pd.concat(submission_stage_1).reset_index(drop=True)
print(" Submission Stage 1: After RoBERTA\n")
print(submission_stage_1)
submission_stage_2 = pd.merge(
left=submission_stage_1,
right=datamodule.test_df,
left_on="id",
right_on="id",
how="left",
)
submission_stage_2 = add_textstat_features(submission_stage_2)
feature_cols = list(submission_stage_2.drop(columns=["id"]).copy(deep=True).columns)
predict_data = submission_stage_2.drop(columns=["id"]).copy(deep=True)
predict_data = predict_data[best_n_features]
temp_cols = list(predict_data.drop(columns=["text_standard_category"]).columns)
predict_data_scaled = predict_data[temp_cols]
predict_data_scaled = scaler.transform(predict_data_scaled)
predict_data_scaled = pd.DataFrame(predict_data_scaled, columns=temp_cols)
predict_data_scaled["text_standard_category"] = predict_data["text_standard_category"]
submission = submission_stage_2[["id"]].copy(deep=True)
submission["target"] = gbm.predict(predict_data_scaled)
submission["target"] = TARGET_SCALER.inverse_transform(submission["target"])
print(" Final Stage After LGBM\n")
print(submission)
submission.to_csv("submission.csv", index=False)
| false | 0 | 9,748 | 0 | 27 | 9,748 |
||
69716135 | <kaggle_start><data_title>ResNet-50<data_description># ResNet-50
---
## Deep Residual Learning for Image Recognition
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity.
An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.<br>
**Authors: Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun**<br>
**https://arxiv.org/abs/1512.03385**
---
Architecture visualization: http://ethereon.github.io/netscope/#/gist/db945b393d40bfa26006
![Resnet][1]
---
### What is a Pre-trained Model?
A pre-trained model has been previously trained on a dataset and contains the weights and biases that represent the features of whichever dataset it was trained on. Learned features are often transferable to different data. For example, a model trained on a large dataset of bird images will contain learned features like edges or horizontal lines that you would be transferable your dataset.
### Why use a Pre-trained Model?
Pre-trained models are beneficial to us for many reasons. By using a pre-trained model you are saving time. Someone else has already spent the time and compute resources to learn a lot of features and your model will likely benefit from it.
[1]: https://imgur.com/nyYh5xH.jpg<data_name>resnet50
<code># # Title:Skin-Lesion Segmentation
# ### Importing the Libraries
from keras.models import Model, Sequential
from keras.layers import (
Activation,
Dense,
BatchNormalization,
Dropout,
Conv2D,
Conv2DTranspose,
MaxPooling2D,
UpSampling2D,
Input,
Reshape,
)
from keras import backend as K
from keras.optimizers import Adam
import tensorflow as tf
import numpy as np
import pandas as pd
import glob
import PIL
import os
from PIL import Image, ImageEnhance, ImageFilter
import matplotlib.pyplot as plt
import cv2
from sklearn.model_selection import train_test_split
from warnings import filterwarnings
filterwarnings("ignore")
plt.rcParams["axes.grid"] = False
np.random.seed(101)
print(os.listdir("../input"))
# The ***PH2 database*** includes
# the manual segmentation, the clinical diagnosis, and the identification of several dermoscopic
# structures, performed by expert dermatologists,
# The ***PH2 database*** was built up through a joint research collaboration between the Universidade do
# Porto, T ́ecnico Lisboa, and the Dermatology service of Hospital Pedro Hispano in Matosinhos,
# Portugal.
# ## Loading the data
# [](http://)Defining a function to load the data in sorted order
import re
numbers = re.compile(r"(\d+)")
def numericalSort(value):
parts = numbers.split(value)
parts[1::2] = map(int, parts[1::2])
return parts
# * * * First we will load the filenames in a list.
filelist_trainx_ph2 = sorted(glob.glob("../input/*/*/trainx/*.bmp"), key=numericalSort)
X_train_ph2 = np.array([np.array(Image.open(fname)) for fname in filelist_trainx_ph2])
filelist_trainy_ph2 = sorted(glob.glob("../input/*/*/trainy/*.bmp"), key=numericalSort)
Y_train_ph2 = np.array([np.array(Image.open(fname)) for fname in filelist_trainy_ph2])
plt.figure(figsize=(12, 6))
plt.suptitle("Images from PH2 dataset", fontsize=25, color="blue")
plt.subplot(2, 2, 1)
plt.imshow(X_train_ph2[1])
plt.xlabel("Dimensions: " + str(np.array(X_train_ph2[1]).shape))
plt.subplot(2, 2, 2)
plt.imshow(Y_train_ph2[1], plt.cm.binary_r)
plt.xlabel("Dimensions: " + str(np.array(Y_train_ph2[1]).shape))
plt.subplot(2, 2, 3)
plt.imshow(X_train_ph2[112])
plt.xlabel("Dimensions: " + str(np.array(X_train_ph2[185]).shape))
plt.subplot(2, 2, 4)
plt.imshow(Y_train_ph2[112], plt.cm.binary_r)
plt.xlabel("Dimensions: " + str(np.array(Y_train_ph2[185]).shape))
plt.show()
# * The images are of dimensions **(572, 765)** so we will scale down the images. It will also reduce the training time of the network.
# #### Resizing
def resize(filename, size=(256, 192)):
im = Image.open(filename)
im_resized = im.resize(size, Image.ANTIALIAS)
return im_resized
X_train_ph2_resized = []
Y_train_ph2_resized = []
for i in range(len(filelist_trainx_ph2)):
X_train_ph2_resized.append(resize(filelist_trainx_ph2[i]))
Y_train_ph2_resized.append(resize(filelist_trainy_ph2[i]))
# The new resized images
plt.figure(figsize=(12, 10))
plt.suptitle("Images from PH2 dataset after Resizing", fontsize=25, color="blue")
plt.subplot(2, 2, 1)
plt.imshow(X_train_ph2_resized[1])
plt.xlabel("Dimensions: " + str(np.array(X_train_ph2_resized[1]).shape))
plt.subplot(2, 2, 2)
plt.imshow(Y_train_ph2_resized[1], plt.cm.binary_r)
plt.xlabel("Dimensions: " + str(np.array(Y_train_ph2_resized[1]).shape))
plt.subplot(2, 2, 3)
plt.imshow(X_train_ph2_resized[117])
plt.xlabel("Dimensions: " + str(np.array(X_train_ph2_resized[185]).shape))
plt.subplot(2, 2, 4)
plt.imshow(Y_train_ph2_resized[117], plt.cm.binary_r)
plt.xlabel("Dimensions: " + str(np.array(Y_train_ph2_resized[185]).shape))
plt.show()
# Converting the transformed Images into numpy arrays
X_train_ph2 = np.array([np.array(img) for img in X_train_ph2_resized])
Y_train_ph2 = np.array([np.array(img) for img in Y_train_ph2_resized])
plt.figure(figsize=(12, 6))
plt.suptitle(
"Converting the transformed Image into Numpy Array", fontsize=25, color="blue"
)
plt.subplot(1, 2, 1)
plt.imshow(X_train_ph2[117])
plt.xlabel("Dimensions: " + str(np.array(X_train_ph2_resized[180]).shape))
plt.subplot(1, 2, 2)
plt.imshow(Y_train_ph2[117], plt.cm.binary_r)
plt.xlabel("Dimensions: " + str(np.array(Y_train_ph2_resized[180]).shape))
plt.show()
# * Splitting the dataset into training set and test set to verify our model performance without any bias.
x_train, x_test, y_train, y_test = train_test_split(
X_train_ph2, Y_train_ph2, test_size=0.25, random_state=101
)
plt.figure(figsize=(25, 10))
plt.suptitle("Images from PH2 dataset", fontsize=30, color="blue")
plt.subplot(3, 5, 1)
plt.imshow(X_train_ph2[1])
plt.subplot(3, 5, 2)
plt.imshow(X_train_ph2[12])
plt.subplot(3, 5, 3)
plt.imshow(X_train_ph2[44])
plt.subplot(3, 5, 4)
plt.imshow(X_train_ph2[67])
plt.subplot(3, 5, 5)
plt.imshow(X_train_ph2[100])
plt.subplot(3, 5, 6)
plt.imshow(X_train_ph2[117])
plt.subplot(3, 5, 7)
plt.imshow(X_train_ph2[128])
plt.subplot(3, 5, 8)
plt.imshow(X_train_ph2[147])
plt.subplot(3, 5, 9)
plt.imshow(X_train_ph2[132])
plt.subplot(3, 5, 10)
plt.imshow(X_train_ph2[112])
plt.subplot(3, 5, 11)
plt.imshow(X_train_ph2[31])
plt.subplot(3, 5, 12)
plt.imshow(X_train_ph2[52])
plt.subplot(3, 5, 13)
plt.imshow(X_train_ph2[74])
plt.subplot(3, 5, 14)
plt.imshow(X_train_ph2[86])
plt.subplot(3, 5, 15)
plt.imshow(X_train_ph2[150])
plt.show()
plt.figure(figsize=(25, 10))
plt.suptitle(
"Mask of the corresponding Images from PH2 dataset", fontsize=30, color="blue"
)
plt.subplot(3, 5, 1)
plt.imshow(Y_train_ph2[1], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 2)
plt.imshow(Y_train_ph2[12], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 3)
plt.imshow(Y_train_ph2[44], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 4)
plt.imshow(Y_train_ph2[67], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 5)
plt.imshow(Y_train_ph2[100], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 6)
plt.imshow(Y_train_ph2[117], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 7)
plt.imshow(Y_train_ph2[128], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 8)
plt.imshow(Y_train_ph2[147], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 9)
plt.imshow(Y_train_ph2[132], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 10)
plt.imshow(Y_train_ph2[112], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 11)
plt.imshow(Y_train_ph2[31], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 12)
plt.imshow(Y_train_ph2[52], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 13)
plt.imshow(Y_train_ph2[74], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 14)
plt.imshow(Y_train_ph2[86], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 15)
plt.imshow(Y_train_ph2[150], cmap=plt.cm.binary_r)
plt.show()
# ## Image Augmentation
# Image augmentation artificially creates training images through different ways of processing or combination of multiple processing, such as random rotation, shifts, shear and flips, etc.
# To build a powerful image classifier using little training data, image augmentation is usually required to boost the performance of deep networks.
# We are going to define to methods for augmentation, **horizontal flipping** , **vertical flipping**, **both flipped** and **random rotation**
def horizontal_flip(x_image, y_image):
x_image = cv2.flip(x_image, 1)
y_image = cv2.flip(y_image.astype("float32"), 1)
return x_image, y_image.astype("int")
def vertical_flip(x_image, y_image):
x_image = cv2.flip(x_image, 0)
y_image = cv2.flip(y_image.astype("float32"), 0)
return x_image, y_image.astype("int")
def both_flip(x_image, y_image):
x_image = cv2.flip(x_image, -1)
y_image = cv2.flip(y_image.astype("float32"), -1)
return x_image, y_image.astype("int")
def random_rotation(x_image, y_image):
rows_x, cols_x, chl_x = x_image.shape
rows_y, cols_y = y_image.shape
rand_num = np.random.randint(-60, 60)
M1 = cv2.getRotationMatrix2D((cols_x / 2, rows_x / 2), rand_num, 1)
M2 = cv2.getRotationMatrix2D((cols_y / 2, rows_y / 2), rand_num, 1)
x_image = cv2.warpAffine(x_image, M1, (cols_x, rows_x))
y_image = cv2.warpAffine(y_image.astype("float32"), M2, (cols_y, rows_y))
return np.array(x_image), np.array(y_image.astype("int"))
def img_augmentation(x_train, y_train):
x_flip = []
y_flip = []
x_vert = []
y_vert = []
x_both = []
y_both = []
x_rotat = []
y_rotat = []
for idx in range(len(x_train)):
x, y = horizontal_flip(x_train[idx], y_train[idx])
x_flip.append(x)
y_flip.append(y)
x, y = vertical_flip(x_train[idx], y_train[idx])
x_vert.append(x)
y_vert.append(y)
x, y = both_flip(x_train[idx], y_train[idx])
x_both.append(x)
y_both.append(y)
x, y = random_rotation(x_train[idx], y_train[idx])
x_rotat.append(x)
y_rotat.append(y)
return (
np.array(x_flip),
np.array(y_flip),
np.array(x_vert),
np.array(y_vert),
np.array(x_both),
np.array(y_both),
np.array(x_rotat),
np.array(y_rotat),
)
# calling the functions for the training data.
(
x_flipped,
y_flipped,
x_vertical,
y_vertical,
x_bothed,
y_bothed,
x_rotated,
y_rotated,
) = img_augmentation(x_train, y_train)
(
x_flipped_t,
y_flipped_t,
x_vertical_t,
y_vertical_t,
x_bothed_t,
y_bothed_t,
x_rotated_t,
y_rotated_t,
) = img_augmentation(x_test, y_test)
plt.figure(figsize=(25, 16))
plt.suptitle("Image Augmentation", fontsize=25, color="blue")
plt.subplot(6, 4, 1)
plt.imshow(x_train[112])
plt.title("Original Image")
plt.subplot(6, 4, 2)
plt.imshow(y_train[112], plt.cm.binary_r)
plt.title("Original Mask")
plt.subplot(6, 4, 3)
plt.imshow(x_train[12])
plt.title("Original Image")
plt.subplot(6, 4, 4)
plt.imshow(y_train[12], plt.cm.binary_r)
plt.title("Original Mask")
plt.subplot(6, 4, 5)
plt.imshow(x_flipped[112])
plt.title("Horizontal Flipped Image")
plt.subplot(6, 4, 6)
plt.imshow(y_flipped[112], plt.cm.binary_r)
plt.title("Horizontal Flipped Mask")
plt.subplot(6, 4, 7)
plt.imshow(x_flipped[12])
plt.title("Horizontal Flipped Image")
plt.subplot(6, 4, 8)
plt.imshow(y_flipped[12], plt.cm.binary_r)
plt.title("Horizontal Flipped Mask")
plt.subplot(6, 4, 9)
plt.imshow(x_vertical[112])
plt.title("Vertical Flipped Image")
plt.subplot(6, 4, 10)
plt.imshow(y_vertical[112], plt.cm.binary_r)
plt.title("Vertical Flipped Mask")
plt.subplot(6, 4, 11)
plt.imshow(x_vertical[12])
plt.title("Vertical Flipped Image")
plt.subplot(6, 4, 12)
plt.imshow(y_vertical[12], plt.cm.binary_r)
plt.title("Vertical Flipped Mask")
plt.subplot(6, 4, 13)
plt.imshow(x_bothed[112])
plt.title("Flipped both Image")
plt.subplot(6, 4, 14)
plt.imshow(y_bothed[112], plt.cm.binary_r)
plt.title("Flipped both Mask")
plt.subplot(6, 4, 15)
plt.imshow(x_bothed[12])
plt.title("Flipped both Image")
plt.subplot(6, 4, 16)
plt.imshow(y_bothed[12], plt.cm.binary_r)
plt.title("Flipped both Mask")
plt.subplot(6, 4, 17)
plt.imshow(x_rotated[112])
plt.title("Rotated Image")
plt.subplot(6, 4, 18)
plt.imshow(y_rotated[112], plt.cm.binary_r)
plt.title("Rotated Mask")
plt.subplot(6, 4, 19)
plt.imshow(x_rotated[12])
plt.title("Rotated Image")
plt.subplot(6, 4, 20)
plt.imshow(y_rotated[12], plt.cm.binary_r)
plt.title("Rotated Mask")
plt.show()
# Now we join all the augmentations image arrays to the original training arrays.
# For training Set
x_train_full = np.concatenate([x_train, x_rotated, x_flipped, x_bothed, x_vertical])
y_train_full = np.concatenate([y_train, y_rotated, y_flipped, y_bothed, y_vertical])
# ## Defining Evaluation Metrics
# #### Intersection over Union(IOU) or Jaccard Index
# The Jaccard index, also known as Intersection over Union and the Jaccard similarity coefficient is a statistic used for gauging the similarity and diversity of sample sets. The Jaccard coefficient measures similarity between finite sample sets, and is defined as the size of the intersection divided by the size of the union of the sample sets.
# Jaccard index is popular and frequently used as a similarity index.
# The area of overlap J is
# calculated between the segmented binary image A and its ground truth G as shown:
# ***J = |A ∩ G| / |A ∪ G| × 100%.***
def iou(y_true, y_pred, smooth=100):
intersection = K.sum(K.abs(y_true * y_pred), axis=-1)
sum_ = K.sum(K.square(y_true), axis=-1) + K.sum(K.square(y_pred), axis=-1)
union = sum_ - intersection
jac = (intersection + smooth) / (union + smooth)
return jac
# #### Dice Coefficient
# The Dice score is not only a measure of how many positives you find, but it also penalizes for the false positives that the method finds, similar to precision. so it is more similar to precision than accuracy.
# The Dice coefficient can be defined as: ***D = 2 |A ∩ G| / |A + G| × 100%*** where A is the algorithm
# output and G is the ground truth.
def dice_coef(y_true, y_pred, smooth=100):
y_true_f = K.flatten(y_true)
y_pred_f = K.flatten(y_pred)
intersection = K.sum(y_true_f * y_pred_f)
return (2.0 * intersection + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth)
# #### Precision
# Precision is a good measure to determine, when the costs of False Positive is high.
# ***Precision = true-positive / (true-positive + false-positive)***
# Where,True positive is an outcome where the model correctly predicts the positive class and false positive is an outcome where the model incorrectly predicts the positive class.
#
# '''Precision calculates a metric for multi-label classification of
# how many selected items are relevant.
# '''
def precision(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
# #### Recall
# Recall actually calculates how many of the Actual Positives our model capture through labeling it as Positive (True Positive). Applying the same understanding, we know that Recall shall be the model metric we use to select our best model when there is a high cost associated with False Negative.
# ***Recall = true-positive /(true-positive + false negative)***
# Where, true positive is an outcome where the model correctly predicts the positive class and false negative is an outcome where the model incorrectly predicts the negative class.
# '''Recall calculates a metric for multi-label classification of
# how many relevant items are selected.
# '''
def recall(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
# #### Accuracy
# '''Calculates the mean accuracy rate across all predictions for binary
# classification problems.
# '''
def accuracy(y_true, y_pred):
return K.mean(K.equal(y_true, K.round(y_pred)))
# #### Making a Validation Set
x_train, x_val, y_train, y_val = train_test_split(
x_train_full, y_train_full, test_size=0.20, random_state=101
)
print("Length of the Training Set : {}".format(len(x_train)))
print("Length of the Test Set : {}".format(len(x_test)))
print("Length of the Validation Set : {}".format(len(x_val)))
# We will split our full training set into train and validation set.
# Validation dataset is used to validate the performance after each epoch
# ## The Model
# Defining the model in a function which takes two arguments when called
# * **epoch_num**: number of epochs to run
# * **savename**: the name of the model for saving after training
# ## Optimizer and Learning Rate
# * We adopt adam optimization algorithm or adaptive moments, to adjust the learning rate.
# * It is well known that learning rate is one of the critical hyperparameters that have a significant impact on classification performance.
# ### Advantages of Adam optimizer are:
# * Relatively low memory requirements (though higher than gradient descent and gradient descent with momentum).
# * Usually works well even with a little tuning of hyperparameter.
# * Adam is fairly robust to the choice of hyperparameters, and set the learning rate α as 0.003 to speed up the training procedure.
# #### Model Function
# * SegNet, a deep convolutional network architecture for semantic segmentation. The main motivation behind SegNet was the need to design an efficient architecture for road and indoor scene understanding which is efficient both in terms of memory and computational time.
# * SegNet on the other hand is more efficient since it only stores the max-pooling indices of the feature maps and uses them in its decoder network to achieve good performance.
def segnet(epochs_num, savename):
# Encoding layer
img_input = Input(shape=(192, 256, 3))
x = Conv2D(64, (3, 3), padding="same", name="conv1", strides=(1, 1))(img_input)
x = BatchNormalization(name="bn1")(x)
x = Activation("relu")(x)
x = Conv2D(64, (3, 3), padding="same", name="conv2")(x)
x = BatchNormalization(name="bn2")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Conv2D(128, (3, 3), padding="same", name="conv3")(x)
x = BatchNormalization(name="bn3")(x)
x = Activation("relu")(x)
x = Conv2D(128, (3, 3), padding="same", name="conv4")(x)
x = BatchNormalization(name="bn4")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Conv2D(256, (3, 3), padding="same", name="conv5")(x)
x = BatchNormalization(name="bn5")(x)
x = Activation("relu")(x)
x = Conv2D(256, (3, 3), padding="same", name="conv6")(x)
x = BatchNormalization(name="bn6")(x)
x = Activation("relu")(x)
x = Conv2D(256, (3, 3), padding="same", name="conv7")(x)
x = BatchNormalization(name="bn7")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Conv2D(512, (3, 3), padding="same", name="conv8")(x)
x = BatchNormalization(name="bn8")(x)
x = Activation("relu")(x)
x = Conv2D(512, (3, 3), padding="same", name="conv9")(x)
x = BatchNormalization(name="bn9")(x)
x = Activation("relu")(x)
x = Conv2D(512, (3, 3), padding="same", name="conv10")(x)
x = BatchNormalization(name="bn10")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Conv2D(512, (3, 3), padding="same", name="conv11")(x)
x = BatchNormalization(name="bn11")(x)
x = Activation("relu")(x)
x = Conv2D(512, (3, 3), padding="same", name="conv12")(x)
x = BatchNormalization(name="bn12")(x)
x = Activation("relu")(x)
x = Conv2D(512, (3, 3), padding="same", name="conv13")(x)
x = BatchNormalization(name="bn13")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Dense(1024, activation="relu", name="fc1")(x)
x = Dense(1024, activation="relu", name="fc2")(x)
# Decoding Layer
x = UpSampling2D()(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv1")(x)
x = BatchNormalization(name="bn14")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv2")(x)
x = BatchNormalization(name="bn15")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv3")(x)
x = BatchNormalization(name="bn16")(x)
x = Activation("relu")(x)
x = UpSampling2D()(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv4")(x)
x = BatchNormalization(name="bn17")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv5")(x)
x = BatchNormalization(name="bn18")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(256, (3, 3), padding="same", name="deconv6")(x)
x = BatchNormalization(name="bn19")(x)
x = Activation("relu")(x)
x = UpSampling2D()(x)
x = Conv2DTranspose(256, (3, 3), padding="same", name="deconv7")(x)
x = BatchNormalization(name="bn20")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(256, (3, 3), padding="same", name="deconv8")(x)
x = BatchNormalization(name="bn21")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(128, (3, 3), padding="same", name="deconv9")(x)
x = BatchNormalization(name="bn22")(x)
x = Activation("relu")(x)
x = UpSampling2D()(x)
x = Conv2DTranspose(128, (3, 3), padding="same", name="deconv10")(x)
x = BatchNormalization(name="bn23")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(64, (3, 3), padding="same", name="deconv11")(x)
x = BatchNormalization(name="bn24")(x)
x = Activation("relu")(x)
x = UpSampling2D()(x)
x = Conv2DTranspose(64, (3, 3), padding="same", name="deconv12")(x)
x = BatchNormalization(name="bn25")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(1, (3, 3), padding="same", name="deconv13")(x)
x = BatchNormalization(name="bn26")(x)
x = Activation("sigmoid")(x)
pred = Reshape((192, 256))(x)
model = Model(inputs=img_input, outputs=pred)
model.compile(
optimizer=Adam(lr=0.003),
loss=["binary_crossentropy"],
metrics=[iou, dice_coef, precision, recall, accuracy],
)
model.summary()
hist = model.fit(
x_train,
y_train,
epochs=epochs_num,
batch_size=32,
validation_data=(x_val, y_val),
verbose=1,
)
model.save(savename)
return model, hist
# ### Loading the Model
# Encoding layer
img_input = Input(shape=(192, 256, 3))
x = Conv2D(64, (3, 3), padding="same", name="conv1", strides=(1, 1))(img_input)
x = BatchNormalization(name="bn1")(x)
x = Activation("relu")(x)
x = Conv2D(64, (3, 3), padding="same", name="conv2")(x)
x = BatchNormalization(name="bn2")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Conv2D(128, (3, 3), padding="same", name="conv3")(x)
x = BatchNormalization(name="bn3")(x)
x = Activation("relu")(x)
x = Conv2D(128, (3, 3), padding="same", name="conv4")(x)
x = BatchNormalization(name="bn4")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Conv2D(256, (3, 3), padding="same", name="conv5")(x)
x = BatchNormalization(name="bn5")(x)
x = Activation("relu")(x)
x = Conv2D(256, (3, 3), padding="same", name="conv6")(x)
x = BatchNormalization(name="bn6")(x)
x = Activation("relu")(x)
x = Conv2D(256, (3, 3), padding="same", name="conv7")(x)
x = BatchNormalization(name="bn7")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Conv2D(512, (3, 3), padding="same", name="conv8")(x)
x = BatchNormalization(name="bn8")(x)
x = Activation("relu")(x)
x = Conv2D(512, (3, 3), padding="same", name="conv9")(x)
x = BatchNormalization(name="bn9")(x)
x = Activation("relu")(x)
x = Conv2D(512, (3, 3), padding="same", name="conv10")(x)
x = BatchNormalization(name="bn10")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Conv2D(512, (3, 3), padding="same", name="conv11")(x)
x = BatchNormalization(name="bn11")(x)
x = Activation("relu")(x)
x = Conv2D(512, (3, 3), padding="same", name="conv12")(x)
x = BatchNormalization(name="bn12")(x)
x = Activation("relu")(x)
x = Conv2D(512, (3, 3), padding="same", name="conv13")(x)
x = BatchNormalization(name="bn13")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Dense(1024, activation="relu", name="fc1")(x)
x = Dense(1024, activation="relu", name="fc2")(x)
# Decoding Layer
x = UpSampling2D()(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv1")(x)
x = BatchNormalization(name="bn14")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv2")(x)
x = BatchNormalization(name="bn15")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv3")(x)
x = BatchNormalization(name="bn16")(x)
x = Activation("relu")(x)
x = UpSampling2D()(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv4")(x)
x = BatchNormalization(name="bn17")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv5")(x)
x = BatchNormalization(name="bn18")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(256, (3, 3), padding="same", name="deconv6")(x)
x = BatchNormalization(name="bn19")(x)
x = Activation("relu")(x)
x = UpSampling2D()(x)
x = Conv2DTranspose(256, (3, 3), padding="same", name="deconv7")(x)
x = BatchNormalization(name="bn20")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(256, (3, 3), padding="same", name="deconv8")(x)
x = BatchNormalization(name="bn21")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(128, (3, 3), padding="same", name="deconv9")(x)
x = BatchNormalization(name="bn22")(x)
x = Activation("relu")(x)
x = UpSampling2D()(x)
x = Conv2DTranspose(128, (3, 3), padding="same", name="deconv10")(x)
x = BatchNormalization(name="bn23")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(64, (3, 3), padding="same", name="deconv11")(x)
x = BatchNormalization(name="bn24")(x)
x = Activation("relu")(x)
x = UpSampling2D()(x)
x = Conv2DTranspose(64, (3, 3), padding="same", name="deconv12")(x)
x = BatchNormalization(name="bn25")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(1, (3, 3), padding="same", name="deconv13")(x)
x = BatchNormalization(name="bn26")(x)
x = Activation("sigmoid")(x)
pred = Reshape((192, 256))(x)
# > #### After 120 epochs
model, hist = segnet(epochs_num=120, savename="segnet_120_epoch.h5")
model_1 = Model(inputs=img_input, outputs=pred)
model_1.compile(
optimizer=Adam(lr=0.003),
loss=["binary_crossentropy"],
metrics=[iou, dice_coef, precision, recall, accuracy],
)
model_1.load_weights("segnet_120_epoch.h5")
print("\n~~~~~~~~~~~~~~~Stats after 120 epoch~~~~~~~~~~~~~~~~~~~")
print("\n------------------On Train Set-----------------------------\n")
res = model_1.evaluate(x_train, y_train, batch_size=48)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
print("\n-----------------On Test Set-----------------------------\n")
res = model_1.evaluate(x_test, y_test, batch_size=48)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
print("\n----------------On validation Set-----------------------------\n")
res = model_1.evaluate(x_val, y_val, batch_size=48)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
# ### Plotting Training Statistics
plt.figure(figsize=(24, 14))
plt.suptitle("Training Statistics on Train Set", fontsize=30, color="blue")
plt.subplot(2, 3, 1)
plt.plot(hist.history["loss"], "red")
plt.title("Loss", fontsize=18, color="blue")
plt.subplot(2, 3, 2)
plt.plot(hist.history["iou"], "yellow")
plt.title("Jaccard Index", fontsize=18, color="blue")
plt.subplot(2, 3, 3)
plt.plot(hist.history["accuracy"], "green")
plt.title("Accuracy", fontsize=18, color="blue")
plt.subplot(2, 3, 4)
plt.plot(hist.history["val_loss"], "red")
plt.yticks(list(np.arange(0.0, 1.0, 0.10)))
plt.title("Valdiation Loss", fontsize=18, color="blue")
plt.subplot(2, 3, 5)
plt.plot(hist.history["val_iou"], "yellow")
plt.yticks(list(np.arange(0.0, 1.0, 0.10)))
plt.title("Valdiation Jaccard Index", fontsize=18, color="blue")
plt.subplot(2, 3, 6)
plt.plot(hist.history["val_accuracy"], "green")
plt.yticks(list(np.arange(0.0, 1.0, 0.10)))
plt.title("Validation Accuracy", fontsize=18, color="blue")
plt.show()
# ### Visualising Predicted Lesions
# We have trained the model on the **training set**.
# We will make predictions on the unseen **test set**
plt.figure(figsize=(20, 16))
plt.suptitle("Visualising Predicted Lesions", fontsize=30, color="blue")
img_pred = model_1.predict(x_test[49].reshape(1, 192, 256, 3))
plt.subplot(4, 3, 1)
plt.imshow(x_test[49])
plt.title("Original Image")
plt.subplot(4, 3, 2)
plt.imshow(y_test[49], plt.cm.binary_r)
plt.title("True Mask")
plt.subplot(4, 3, 3)
plt.imshow(img_pred.reshape(192, 256), plt.cm.binary_r)
plt.title("Predicted Mask")
img_pred = model_1.predict(x_test[36].reshape(1, 192, 256, 3))
plt.subplot(4, 3, 4)
plt.imshow(x_test[36])
plt.title("Original Image")
plt.subplot(4, 3, 5)
plt.imshow(y_test[36], plt.cm.binary_r)
plt.title("True Mask")
plt.subplot(4, 3, 6)
plt.imshow(img_pred.reshape(192, 256), plt.cm.binary_r)
plt.title("Predicted Mask")
img_pred = model_1.predict(x_test[32].reshape(1, 192, 256, 3))
plt.subplot(4, 3, 7)
plt.imshow(x_test[32])
plt.title("Original Image")
plt.subplot(4, 3, 8)
plt.imshow(y_test[32], plt.cm.binary_r)
plt.title("True Mask")
plt.subplot(4, 3, 9)
plt.imshow(img_pred.reshape(192, 256), plt.cm.binary_r)
plt.title("Predicted Mask")
img_pred = model_1.predict(x_test[21].reshape(1, 192, 256, 3))
plt.subplot(4, 3, 10)
plt.imshow(x_test[21])
plt.title("Original Image")
plt.subplot(4, 3, 11)
plt.imshow(y_test[21], plt.cm.binary_r)
plt.title("True Mask")
plt.subplot(4, 3, 12)
plt.imshow(img_pred.reshape(192, 256), plt.cm.binary_r)
plt.title("Predicted Mask")
plt.show()
# ### Final Enhance
# * Currently the predicted outputs are blurry because the predicted pixel values are in the range 0 - 1.
# * To make clear edge preditions we can enhance our image by rounding up the pixel values to 1 which are > 0.5 .
# * While rounding down the pixel values to 0 which are < 0.5.
# * We can enhance the image to look for absolute shape predicted by ceiling and flooring the predicted values
def enhance(img):
sub = (model_1.predict(img.reshape(1, 192, 256, 3))).flatten()
for i in range(len(sub)):
if sub[i] > 0.5:
sub[i] = 1
else:
sub[i] = 0
return sub
plt.figure(figsize=(24, 16))
plt.suptitle("Comparing the Prediction after Enhancement", fontsize=30, color="blue")
plt.subplot(4, 3, 1)
plt.imshow(x_test[21])
plt.title("Original Image")
plt.subplot(4, 3, 2)
plt.imshow(y_test[21], plt.cm.binary_r)
plt.title("True Mask")
plt.subplot(4, 3, 3)
plt.imshow(enhance(x_test[21]).reshape(192, 256), plt.cm.binary_r)
plt.title("Predicted after threshold")
plt.subplot(4, 3, 4)
plt.imshow(x_test[19])
plt.title("Original Image")
plt.subplot(4, 3, 5)
plt.imshow(y_test[19], plt.cm.binary_r)
plt.title("True Mask")
plt.subplot(4, 3, 6)
plt.imshow(enhance(x_test[19]).reshape(192, 256), plt.cm.binary_r)
plt.title("Predicted after threshold")
plt.subplot(4, 3, 7)
plt.imshow(x_test[36])
plt.title("Original Image")
plt.subplot(4, 3, 8)
plt.imshow(y_test[36], plt.cm.binary_r)
plt.title("True Mask")
plt.subplot(4, 3, 9)
plt.imshow(enhance(x_test[36]).reshape(192, 256), plt.cm.binary_r)
plt.title("Predicted after threshold")
plt.subplot(4, 3, 10)
plt.imshow(x_test[49])
plt.title("Original Image")
plt.subplot(4, 3, 11)
plt.imshow(y_test[49], plt.cm.binary_r)
plt.title("True Mask")
plt.subplot(4, 3, 12)
plt.imshow(enhance(x_test[49]).reshape(192, 256), plt.cm.binary_r)
plt.title("Predicted after threshold")
plt.show()
# # **Model: U-Net**
from keras.models import Model, Sequential
from keras.layers import (
Activation,
Dense,
BatchNormalization,
concatenate,
Dropout,
Conv2D,
Conv2DTranspose,
MaxPooling2D,
UpSampling2D,
Input,
Reshape,
)
from keras.callbacks import EarlyStopping
from keras.layers.core import SpatialDropout2D
from keras import backend as K
from keras.optimizers import Adam
import tensorflow as tf
import numpy as np
import pandas as pd
import glob
import PIL
from PIL import Image
import matplotlib.pyplot as plt
import cv2
from keras.preprocessing.image import ImageDataGenerator
from sklearn.model_selection import train_test_split
from warnings import filterwarnings
filterwarnings("ignore")
np.random.seed(101)
import re
numbers = re.compile(r"(\d+)")
def numericalSort(value):
parts = numbers.split(value)
parts[1::2] = map(int, parts[1::2])
return parts
filelist_trainx_ph2 = sorted(glob.glob("../input/*/*/trainx/*.bmp"), key=numericalSort)
X_train_ph2 = np.array([np.array(Image.open(fname)) for fname in filelist_trainx_ph2])
filelist_trainy_ph2 = sorted(glob.glob("../input/*/*/trainy/*.bmp"), key=numericalSort)
Y_train_ph2 = np.array([np.array(Image.open(fname)) for fname in filelist_trainy_ph2])
def resize(filename, size=(256, 192)):
im = Image.open(filename)
im_resized = im.resize(size, Image.ANTIALIAS)
return im_resized
X_train_ph2_resized = []
Y_train_ph2_resized = []
for i in range(len(filelist_trainx_ph2)):
X_train_ph2_resized.append(resize(filelist_trainx_ph2[i]))
Y_train_ph2_resized.append(resize(filelist_trainy_ph2[i]))
X_train = np.array([np.array(img) for img in X_train_ph2_resized])
Y_train = np.array([np.array(img) for img in Y_train_ph2_resized])
x_train, x_test, y_train, y_test = train_test_split(
X_train, Y_train, test_size=0.25, random_state=101
)
def jaccard_distance(y_true, y_pred, smooth=100):
intersection = K.sum(K.abs(y_true * y_pred), axis=-1)
sum_ = K.sum(K.square(y_true), axis=-1) + K.sum(K.square(y_pred), axis=-1)
jac = (intersection + smooth) / (sum_ - intersection + smooth)
return 1 - jac
def iou(y_true, y_pred, smooth=100):
intersection = K.sum(K.abs(y_true * y_pred), axis=-1)
sum_ = K.sum(K.square(y_true), axis=-1) + K.sum(K.square(y_pred), axis=-1)
jac = (intersection + smooth) / (sum_ - intersection + smooth)
return jac
def dice_coe(y_true, y_pred, smooth=100):
y_true_f = K.flatten(y_true)
y_pred_f = K.flatten(y_pred)
intersection = K.sum(y_true_f * y_pred_f)
return (2.0 * intersection + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth)
def precision(y_true, y_pred):
"""Calculates the precision, a metric for multi-label classification of
how many selected items are relevant.
"""
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
def recall(y_true, y_pred):
"""Calculates the recall, a metric for multi-label classification of
how many relevant items are selected.
"""
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
def accuracy(y_true, y_pred):
"""Calculates the mean accuracy rate across all predictions for binary
classification problems.
"""
return K.mean(K.equal(y_true, K.round(y_pred)))
def random_rotation(x_image, y_image):
rows_x, cols_x, chl_x = x_image.shape
rows_y, cols_y = y_image.shape
rand_num = np.random.randint(-40, 40)
M1 = cv2.getRotationMatrix2D((cols_x / 2, rows_x / 2), rand_num, 1)
M2 = cv2.getRotationMatrix2D((cols_y / 2, rows_y / 2), rand_num, 1)
x_image = cv2.warpAffine(x_image, M1, (cols_x, rows_x))
y_image = cv2.warpAffine(y_image.astype("float32"), M2, (cols_y, rows_y))
return x_image, y_image.astype("int")
def horizontal_flip(x_image, y_image):
x_image = cv2.flip(x_image, 1)
y_image = cv2.flip(y_image.astype("float32"), 1)
return x_image, y_image.astype("int")
def img_augmentation(x_train, y_train):
x_rotat = []
y_rotat = []
x_flip = []
y_flip = []
for idx in range(len(x_train)):
x, y = random_rotation(x_train[idx], y_train[idx])
x_rotat.append(x)
y_rotat.append(y)
x, y = horizontal_flip(x_train[idx], y_train[idx])
x_flip.append(x)
y_flip.append(y)
return np.array(x_rotat), np.array(y_rotat), np.array(x_flip), np.array(y_flip)
x_rotated, y_rotated, x_flipped, y_flipped = img_augmentation(x_train, y_train)
x_train_full = np.concatenate([x_train, x_rotated, x_flipped])
y_train_full = np.concatenate([y_train, y_rotated, y_flipped])
x_train, x_val, y_train, y_val = train_test_split(
x_train_full, y_train_full, test_size=0.20, random_state=101
)
print("Length of the Training Set : {}".format(len(x_train)))
print("Length of the Test Set : {}".format(len(x_test)))
print("Length of the Validation Set : {}".format(len(x_val)))
# Number of image channels (for example 3 in case of RGB, or 1 for grayscale images)
INPUT_CHANNELS = 3
# Number of output masks (1 in case you predict only one type of objects)
OUTPUT_MASK_CHANNELS = 1
# Pretrained weights
def double_conv_layer(x, size, dropout=0.40, batch_norm=True):
if K.image_data_format() == "th":
axis = 1
else:
axis = 3
conv = Conv2D(size, (3, 3), padding="same")(x)
if batch_norm is True:
conv = BatchNormalization(axis=axis)(conv)
conv = Activation("relu")(conv)
conv = Conv2D(size, (3, 3), padding="same")(conv)
if batch_norm is True:
conv = BatchNormalization(axis=axis)(conv)
conv = Activation("relu")(conv)
if dropout > 0:
conv = SpatialDropout2D(dropout)(conv)
return conv
def UNET_224(epochs_num, savename):
dropout_val = 0.50
if K.image_data_format() == "th":
inputs = Input((INPUT_CHANNELS, 192, 256))
axis = 1
else:
inputs = Input((192, 256, INPUT_CHANNELS))
axis = 3
filters = 32
conv_224 = double_conv_layer(inputs, filters)
pool_112 = MaxPooling2D(pool_size=(2, 2))(conv_224)
conv_112 = double_conv_layer(pool_112, 2 * filters)
pool_56 = MaxPooling2D(pool_size=(2, 2))(conv_112)
conv_56 = double_conv_layer(pool_56, 4 * filters)
pool_28 = MaxPooling2D(pool_size=(2, 2))(conv_56)
conv_28 = double_conv_layer(pool_28, 8 * filters)
pool_14 = MaxPooling2D(pool_size=(2, 2))(conv_28)
conv_14 = double_conv_layer(pool_14, 16 * filters)
pool_7 = MaxPooling2D(pool_size=(2, 2))(conv_14)
conv_7 = double_conv_layer(pool_7, 32 * filters)
up_14 = concatenate([UpSampling2D(size=(2, 2))(conv_7), conv_14], axis=axis)
up_conv_14 = double_conv_layer(up_14, 16 * filters)
up_28 = concatenate([UpSampling2D(size=(2, 2))(up_conv_14), conv_28], axis=axis)
up_conv_28 = double_conv_layer(up_28, 8 * filters)
up_56 = concatenate([UpSampling2D(size=(2, 2))(up_conv_28), conv_56], axis=axis)
up_conv_56 = double_conv_layer(up_56, 4 * filters)
up_112 = concatenate([UpSampling2D(size=(2, 2))(up_conv_56), conv_112], axis=axis)
up_conv_112 = double_conv_layer(up_112, 2 * filters)
up_224 = concatenate([UpSampling2D(size=(2, 2))(up_conv_112), conv_224], axis=axis)
up_conv_224 = double_conv_layer(up_224, filters, dropout_val)
conv_final = Conv2D(OUTPUT_MASK_CHANNELS, (1, 1))(up_conv_224)
conv_final = Activation("sigmoid")(conv_final)
pred = Reshape((192, 256))(conv_final)
model = Model(inputs, pred, name="UNET_224")
model.compile(
optimizer=Adam(lr=0.003),
loss=[jaccard_distance],
metrics=[iou, dice_coe, precision, recall, accuracy],
)
model.summary()
hist = model.fit(
x_train,
y_train,
epochs=epochs_num,
batch_size=18,
validation_data=(x_val, y_val),
verbose=1,
)
model.save(savename)
return model, hist
model, hist = UNET_224(1, "unet_1_epoch.h5")
dropout_val = 0.50
if K.image_data_format() == "th":
inputs = Input((INPUT_CHANNELS, 192, 256))
axis = 1
else:
inputs = Input((192, 256, INPUT_CHANNELS))
axis = 3
filters = 32
conv_224 = double_conv_layer(inputs, filters)
pool_112 = MaxPooling2D(pool_size=(2, 2))(conv_224)
conv_112 = double_conv_layer(pool_112, 2 * filters)
pool_56 = MaxPooling2D(pool_size=(2, 2))(conv_112)
conv_56 = double_conv_layer(pool_56, 4 * filters)
pool_28 = MaxPooling2D(pool_size=(2, 2))(conv_56)
conv_28 = double_conv_layer(pool_28, 8 * filters)
pool_14 = MaxPooling2D(pool_size=(2, 2))(conv_28)
conv_14 = double_conv_layer(pool_14, 16 * filters)
pool_7 = MaxPooling2D(pool_size=(2, 2))(conv_14)
conv_7 = double_conv_layer(pool_7, 32 * filters)
up_14 = concatenate([UpSampling2D(size=(2, 2))(conv_7), conv_14], axis=axis)
up_conv_14 = double_conv_layer(up_14, 16 * filters)
up_28 = concatenate([UpSampling2D(size=(2, 2))(up_conv_14), conv_28], axis=axis)
up_conv_28 = double_conv_layer(up_28, 8 * filters)
up_56 = concatenate([UpSampling2D(size=(2, 2))(up_conv_28), conv_56], axis=axis)
up_conv_56 = double_conv_layer(up_56, 4 * filters)
up_112 = concatenate([UpSampling2D(size=(2, 2))(up_conv_56), conv_112], axis=axis)
up_conv_112 = double_conv_layer(up_112, 2 * filters)
up_224 = concatenate([UpSampling2D(size=(2, 2))(up_conv_112), conv_224], axis=axis)
up_conv_224 = double_conv_layer(up_224, filters, dropout_val)
conv_final = Conv2D(OUTPUT_MASK_CHANNELS, (1, 1))(up_conv_224)
conv_final = Activation("sigmoid")(conv_final)
pred = Reshape((192, 256))(conv_final)
model_0 = Model(inputs, pred, name="UNET_224")
model_0.compile(
optimizer=Adam(lr=0.003),
loss=[jaccard_distance],
metrics=[iou, dice_coe, precision, recall, accuracy],
)
model_0.load_weights("unet_1_epoch.h5")
print("\n~~~~~~~~~~~~~~~Stats after 1 epoch~~~~~~~~~~~~~~~~~~~")
print("\n-------------On Train Set--------------------------\n")
res = model_0.evaluate(x_train, y_train, batch_size=18)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
print("\n-------------On Test Set--------------------------\n")
res = model_0.evaluate(x_test, y_test, batch_size=18)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
print("\n-------------On validation Set---------------------\n")
res = model_0.evaluate(x_val, y_val, batch_size=18)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
model, hist = UNET_224(epochs_num=100, savename="unet_100_epoch.h5")
model_1 = Model(inputs, pred, name="UNET_224")
model_1.compile(
optimizer=Adam(lr=0.003),
loss=[jaccard_distance],
metrics=[iou, dice_coe, precision, recall, accuracy],
)
model_1.load_weights("unet_100_epoch.h5")
print("\n~~~~~~~~~~~~~~~Stats after 100 epoch~~~~~~~~~~~~~~~~~~~")
print("\n-------------On Train Set--------------------------\n")
res = model_1.evaluate(x_train, y_train, batch_size=18)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
print("\n-------------On Test Set--------------------------\n")
res = model_1.evaluate(x_test, y_test, batch_size=18)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
print("\n-------------On validation Set---------------------\n")
res = model_1.evaluate(x_val, y_val, batch_size=18)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
# # **Classification: ResNet50**
import os
import cv2
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import os
from glob import glob
import seaborn as sns
from PIL import Image
from tqdm import tqdm
np.random.seed(11) # It's my lucky number
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import (
train_test_split,
KFold,
cross_val_score,
GridSearchCV,
)
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import itertools
import keras
from keras import regularizers
from keras.utils.np_utils import (
to_categorical,
) # used for converting labels to one-hot-encoding
from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2D
from keras import backend as K
from keras.layers.normalization import BatchNormalization
from keras.utils.np_utils import to_categorical # convert to one-hot-encoding
from keras.optimizers import Adam, RMSprop
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
from keras.wrappers.scikit_learn import KerasClassifier
from keras.applications.resnet50 import ResNet50
from keras import backend as K
import tensorflow as tf
# Resnet-50 has been pre_trained, weights have been saved in below path
resnet_weights_path = (
"../input/resnet50/resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5"
)
# Display the dir list
print(os.listdir("../input"))
# Transfer 'jpg' images to an array IMG
def Dataset_loader(DIR, RESIZE):
IMG = []
read = lambda imname: np.asarray(Image.open(imname).convert("RGB"))
for IMAGE_NAME in tqdm(os.listdir(DIR)):
PATH = os.path.join(DIR, IMAGE_NAME)
_, ftype = os.path.splitext(PATH)
if ftype == ".jpg":
img = read(PATH)
img = cv2.resize(img, (RESIZE, RESIZE))
IMG.append(np.array(img) / 255.0)
return IMG
X_benign = np.array(Dataset_loader("../input/skindata/train/benign", 224))
X_malignant = np.array(Dataset_loader("../input/skindata/train/malign", 224))
X_benign_test = np.array(Dataset_loader("../input/skindata/test/benign", 224))
X_malignant_test = np.array(Dataset_loader("../input/skindata/test/malign", 224))
# Create labels
y_benign = np.zeros(X_benign.shape[0])
y_malignant = np.ones(X_malignant.shape[0])
y_benign_test = np.zeros(X_benign_test.shape[0])
y_malignant_test = np.ones(X_malignant_test.shape[0])
# Merge data
X_train = np.concatenate((X_benign, X_malignant), axis=0)
y_train = np.concatenate((y_benign, y_malignant), axis=0)
X_test = np.concatenate((X_benign_test, X_malignant_test), axis=0)
y_test = np.concatenate((y_benign_test, y_malignant_test), axis=0)
# Shuffle data
s = np.arange(X_train.shape[0])
np.random.shuffle(s)
X_train = X_train[s]
y_train = y_train[s]
s = np.arange(X_test.shape[0])
np.random.shuffle(s)
X_test = X_test[s]
y_test = y_test[s]
# Display first 15 images of moles, and how they are classified
w = 40
h = 30
fig = plt.figure(figsize=(12, 8))
columns = 5
rows = 3
for i in range(1, columns * rows + 1):
ax = fig.add_subplot(rows, columns, i)
if y_train[i] == 0:
ax.title.set_text("Benign")
else:
ax.title.set_text("Malignant")
plt.imshow(X_train[i], interpolation="nearest")
plt.show()
y_train = to_categorical(y_train, num_classes=2)
y_test = to_categorical(y_test, num_classes=2)
# With data augmentation to prevent overfitting
X_train = X_train / 255.0
X_test = X_test / 255.0
# See learning curve and validation curve
def build(
input_shape=(224, 224, 3),
lr=1e-3,
num_classes=2,
init="normal",
activ="relu",
optim="adam",
):
model = Sequential()
model.add(
Conv2D(
64,
kernel_size=(3, 3),
padding="Same",
input_shape=input_shape,
activation=activ,
kernel_initializer="glorot_uniform",
)
)
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(
Conv2D(
64,
kernel_size=(3, 3),
padding="Same",
activation=activ,
kernel_initializer="glorot_uniform",
)
)
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation="relu", kernel_initializer=init))
model.add(Dense(num_classes, activation="softmax"))
model.summary()
if optim == "rmsprop":
optimizer = RMSprop(lr=lr)
else:
optimizer = Adam(lr=lr)
model.compile(optimizer=optimizer, loss="binary_crossentropy", metrics=["accuracy"])
return model
# Set a learning rate annealer
learning_rate_reduction = ReduceLROnPlateau(
monitor="val_accuracy", patience=5, verbose=1, factor=0.5, min_lr=1e-7
)
input_shape = (224, 224, 3)
lr = 1e-5
epochs = 50
batch_size = 64
model = ResNet50(
include_top=True,
weights=None,
input_tensor=None,
input_shape=input_shape,
pooling="avg",
classes=2,
)
model.compile(optimizer=Adam(lr), loss="binary_crossentropy", metrics=["accuracy"])
history = model.fit(
X_train,
y_train,
validation_split=0.2,
epochs=epochs,
batch_size=batch_size,
verbose=2,
callbacks=[learning_rate_reduction],
)
# list all data in history
print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history["accuracy"])
plt.plot(history.history["val_accuracy"])
plt.title("model accuracy")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(["train", "test"], loc="upper left")
plt.show()
# summarize history for loss
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.title("model loss")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(["train", "test"], loc="upper left")
plt.show()
# Train ResNet50 on all the data
model.fit(
X_train,
y_train,
epochs=epochs,
batch_size=epochs,
verbose=0,
callbacks=[learning_rate_reduction],
)
# Testing model on test data to evaluate
y_pred = model.predict(X_test)
print(accuracy_score(np.argmax(y_test, axis=1), np.argmax(y_pred, axis=1)))
# save model
# serialize model to JSON
resnet50_json = model.to_json()
with open("resnet50.json", "w") as json_file:
json_file.write(resnet50_json)
# serialize weights to HDF5
model.save_weights("resnet50.h5")
print("Saved model to disk")
# Testing model on test data to evaluate
lists = []
y_pred = model.predict(X_test)
for i in range(len(y_pred)):
if y_pred[i][0] > 0.5:
lists.append(1)
else:
lists.append(0)
# print(accuracy_score(np.argmax(y_test, axis=1), np.argmax(lists, axis=1)))
i = 0
prop_class = []
mis_class = []
for i in range(len(y_test)):
if y_test[i] == lists[i]:
prop_class.append(i)
if len(prop_class) == 8:
break
i = 0
for i in range(len(y_test)):
if not y_test[i] == lists[i]:
mis_class.append(i)
if len(mis_class) == 8:
break
# # Display first 8 images of benign
w = 60
h = 40
fig = plt.figure(figsize=(18, 10))
columns = 4
rows = 2
def Transfername(namecode):
if namecode == 0:
return "Benign"
else:
return "Malignant"
for i in range(len(prop_class)):
ax = fig.add_subplot(rows, columns, i + 1)
ax.set_title(
"Predicted result:"
+ Transfername(lists[prop_class[i]])
+ "\n"
+ "Actual result: "
+ Transfername(Y_test[prop_class[i]])
)
plt.imshow(X_test[prop_class[i]], interpolation="nearest")
plt.show()
base_skin_dir = os.path.join("..", "input/ph2cvs")
skin_df = pd.read_csv(os.path.join(base_skin_dir, "ph2data.csv"))
from os.path import isfile
def expand_path(p):
if isfile("../input/ph2dataset/trainx/" + p + ".bmp"):
return "../input/ph2dataset/trainx/" + p + ".bmp"
return p
skin_df["image_path"] = skin_df["Name"]
skin_df["image_path"] = skin_df["image_path"].apply(expand_path)
# 1 = Nevus, 0 = Melenoma
skin_df["cell_type_idx"] = pd.Categorical(skin_df["lesion"]).codes
skin_df["image"] = skin_df["image_path"].map(
lambda x: np.asarray(Image.open(x).resize((224, 224)))
)
skin_df.head()
n_samples = 5
fig, m_axs = plt.subplots(2, n_samples, figsize=(4 * n_samples, 6))
for n_axs, (type_name, type_rows) in zip(
m_axs, skin_df.sort_values(["lesion"]).groupby("lesion")
):
n_axs[0].set_title(type_name)
for c_ax, (_, c_row) in zip(
n_axs, type_rows.sample(n_samples, random_state=1234).iterrows()
):
c_ax.imshow(c_row["image"])
c_ax.axis("off")
skin_df["image"].map(lambda x: x.shape).value_counts()
features = skin_df.drop(columns=["cell_type_idx"], axis=1)
target = skin_df["cell_type_idx"]
x_train_o, x_test_o, y_train_o, y_test_o = train_test_split(
features, target, test_size=0.2, random_state=42
)
x_train = np.asarray(x_train_o["image"].tolist())
x_test = np.asarray(x_test_o["image"].tolist())
x_train_mean = np.mean(x_train)
x_train_std = np.std(x_train)
x_test_mean = np.mean(x_test)
x_test_std = np.std(x_test)
x_train = (x_train - x_train_mean) / x_train_std
x_test = (x_test - x_test_mean) / x_test_std
# Perform one-hot encoding on the labels
y_train = to_categorical(y_train_o, num_classes=2)
y_test = to_categorical(y_test_o, num_classes=2)
x_train, x_validate, y_train, y_validate = train_test_split(
x_train, y_train, test_size=0.1, random_state=2
)
# With data augmentation to prevent overfitting
datagen = ImageDataGenerator(
rotation_range=90, # randomly rotate images in the range (degrees, 0 to 180)
zoom_range=0.1, # Randomly zoom image
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=True, # randomly flip images
vertical_flip=True,
)
datagen.fit(x_train)
model = Sequential()
num_labels = 2
base_model = ResNet50(
include_top=False,
weights=resnet_weights_path,
input_shape=(224, 224, 3),
pooling="avg",
classes=2,
)
model = Sequential()
model.add(base_model)
model.add(Dropout(0.5))
model.add(Dense(128, activation="relu", kernel_regularizer=regularizers.l2(0.02)))
model.add(Dropout(0.5))
model.add(
Dense(num_labels, activation="softmax", kernel_regularizer=regularizers.l2(0.02))
)
for layer in base_model.layers:
layer.trainable = False
for layer in base_model.layers[-22:]:
layer.trainable = True
# Reviewing our CNN model
model.summary()
tf.keras.utils.plot_model(
model,
show_shapes=True,
show_layer_names=True,
rankdir="TB",
expand_nested=True,
dpi=100,
) # ,to_file='model.png')
early = EarlyStopping(monitor="val_accuracy", patience=4, mode="max")
# Set a learning rate annealer
learning_rate_reduction = ReduceLROnPlateau(
monitor="val_accuracy", patience=5, verbose=1, factor=0.5, min_lr=1e-7
)
from keras.callbacks import ModelCheckpoint
class CustomModelCheckPoint(keras.callbacks.Callback):
def __init__(self, **kargs):
super(CustomModelCheckPoint, self).__init__(**kargs)
self.epoch_accuracy = {} # loss at given epoch
self.epoch_loss = {} # accuracy at given epoch
def on_epoch_begin(self, epoch, logs={}):
# Things done on beginning of epoch.
return
def on_epoch_end(self, epoch, logs={}):
# things done on end of the epoch
self.epoch_accuracy[epoch] = logs.get("acc")
self.epoch_loss[epoch] = logs.get("loss")
self.model.save_weights("../output/resnet50/name-of-model-%d.h5" % epoch)
checkpointer = ModelCheckpoint(
filepath="../working/best.hdf5",
monitor="val_accuracy",
save_best_only=True,
mode="max",
)
lr = 0.001
epochs = 50
batch_size = 64
model.compile(optimizer=Adam(lr), loss="binary_crossentropy", metrics=["accuracy"])
history = model.fit_generator(
datagen.flow(x_train, y_train, batch_size=batch_size),
validation_data=(x_validate, y_validate),
epochs=epochs,
verbose=1,
steps_per_epoch=x_train.shape[0] // batch_size,
callbacks=[learning_rate_reduction],
)
# list all data in history
print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history["accuracy"])
plt.plot(history.history["val_accuracy"])
plt.title("model accuracy")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(["train", "test"], loc="upper left")
plt.show()
# summarize history for loss
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.title("model loss")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(["train", "test"], loc="upper left")
plt.show()
# Testing model on test data to evaluate
y_pred = model.predict(x_test)
print(accuracy_score(np.argmax(y_test, axis=1), np.argmax(y_pred, axis=1)))
# model.load_weights("../working/best.hdf5")
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=1)
print("test_accuracy = %f ; test_loss = %f" % (test_acc, test_loss))
# save model
# serialize model to JSON
resnet50_json = model.to_json()
with open("resnet50.json", "w") as json_file:
json_file.write(resnet50_json)
# serialize weights to HDF5
model.save_weights("resnet50.h5")
print("Saved model to disk")
# Function to plot confusion matrix
def plot_confusion_matrix(
cm, classes, normalize=False, title="Confusion matrix", cmap=plt.cm.Blues
):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
plt.imshow(cm, interpolation="nearest", cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
if normalize:
cm = cm.astype("float") / cm.sum(axis=1)[:, np.newaxis]
thresh = cm.max() / 2.0
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(
j,
i,
cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black",
)
plt.tight_layout()
plt.ylabel("True label")
plt.xlabel("Predicted label")
# Predict the values from the validation dataset
Y_pred = model.predict(x_test)
# Convert predictions classes to one hot vectors
Y_pred_classes = np.argmax(Y_pred, axis=1)
# Convert validation observations to one hot vectors
Y_true = np.argmax(y_test, axis=1)
# compute the confusion matrix
confusion_mtx = confusion_matrix(Y_true, Y_pred_classes)
cm_plot_label = ["Nevus", "Melanoma"]
# plot the confusion matrix
plot_confusion_matrix(confusion_mtx, cm_plot_label)
from sklearn.metrics import classification_report
classification_report(np.argmax(y_test, axis=1), np.argmax(Y_pred, axis=1))
from sklearn.metrics import roc_auc_score, auc
from sklearn.metrics import roc_curve
roc_log = roc_auc_score(np.argmax(y_test, axis=1), np.argmax(Y_pred, axis=1))
false_positive_rate, true_positive_rate, threshold = roc_curve(
np.argmax(y_test, axis=1), np.argmax(Y_pred, axis=1)
)
area_under_curve = auc(false_positive_rate, true_positive_rate)
plt.plot([0, 1], [0, 1], "r--")
plt.plot(
false_positive_rate,
true_positive_rate,
label="AUC = {:.3f}".format(area_under_curve),
)
plt.xlabel("False positive rate")
plt.ylabel("True positive rate")
plt.title("ROC curve")
plt.legend(loc="best")
plt.show()
# plt.savefig(ROC_PLOT_FILE, bbox_inches='tight')
plt.close()
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
df1 = skin_df.copy()
df1 = df1.drop(
columns=[
"Clinical Diagnosis",
"Histological Diagnosis",
"image_path",
"cell_type_idx",
"image",
],
axis=1,
)
name_cat = label_encoder.fit_transform(df1["Name"])
name_cat = pd.DataFrame({"Name": name_cat})
Asymmetry_cat = label_encoder.fit_transform(df1["Asymmetry"])
Asymmetry_cat = pd.DataFrame({"Asymmetry": Asymmetry_cat})
Pigment_Network_cat = label_encoder.fit_transform(df1["Pigment Network"])
Pigment_Network_cat = pd.DataFrame({"Pigment Network": Pigment_Network_cat})
Dots_Globules_cat = label_encoder.fit_transform(df1["Dots/Globules"])
Dots_Globules_cat = pd.DataFrame({"Dots/Globules": Dots_Globules_cat})
Streaks_cat = label_encoder.fit_transform(df1["Streaks"])
Streaks_cat = pd.DataFrame({"Streaks": Streaks_cat})
Regression_Areas_cat = label_encoder.fit_transform(df1["Regression Areas"])
Regression_Areas_cat = pd.DataFrame({"Regression Areas": Regression_Areas_cat})
Blue_Whitish_Veil_cat = label_encoder.fit_transform(df1["Blue-Whitish Veil"])
Blue_Whitish_Veil_cat = pd.DataFrame({"Blue-Whitish Veil": Blue_Whitish_Veil_cat})
Colors_cat = label_encoder.fit_transform(df1["Colors"])
Colors_cat = pd.DataFrame({"Colors": Colors_cat})
lesion_cat = label_encoder.fit_transform(df1["lesion"])
lesion_cat = pd.DataFrame({"lesion": lesion_cat})
df1.name = name_cat
df1.Asymmetry = Asymmetry_cat
df1.Pigment_Network = Pigment_Network_cat
df1.Dots_Globules = Dots_Globules_cat
df1.Streaks = Streaks_cat
df1.Regression_Areas = Regression_Areas_cat
df1.Blue_Whitish_Veil = Blue_Whitish_Veil_cat
df1.Colors = Colors_cat
df1.lesion = lesion_cat
df1
from sklearn.svm import SVC
model_svc = SVC()
model_svc.fit(x_train_o, y_train)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0069/716/69716135.ipynb | resnet50 | null | [{"Id": 69716135, "ScriptId": 18933277, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3956333, "CreationDate": "08/02/2021 22:56:43", "VersionNumber": 1.0, "Title": "Skin-Lesion Segmentation (SegNet Architecture).", "EvaluationDate": "08/02/2021", "IsChange": true, "TotalLines": 1771.0, "LinesInsertedFromPrevious": 877.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 894.0, "LinesInsertedFromFork": 877.0, "LinesDeletedFromFork": 0.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 894.0, "TotalVotes": 0}] | [{"Id": 93188012, "KernelVersionId": 69716135, "SourceDatasetVersionId": 9900}, {"Id": 93188013, "KernelVersionId": 69716135, "SourceDatasetVersionId": 1293025}] | [{"Id": 9900, "DatasetId": 6209, "DatasourceVersionId": 9900, "CreatorUserId": 484516, "LicenseName": "CC0: Public Domain", "CreationDate": "12/12/2017 16:54:45", "VersionNumber": 2.0, "Title": "ResNet-50", "Slug": "resnet50", "Subtitle": "ResNet-50 Pre-trained Model for Keras", "Description": "# ResNet-50\n\n---\n\n## Deep Residual Learning for Image Recognition\nDeeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. \n\nAn ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers. \n\nThe depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.<br>\n\n**Authors: Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun**<br>\n**https://arxiv.org/abs/1512.03385**\n\n---\n\n\nArchitecture visualization: http://ethereon.github.io/netscope/#/gist/db945b393d40bfa26006\n\n![Resnet][1]\n\n---\n\n### What is a Pre-trained Model?\nA pre-trained model has been previously trained on a dataset and contains the weights and biases that represent the features of whichever dataset it was trained on. Learned features are often transferable to different data. For example, a model trained on a large dataset of bird images will contain learned features like edges or horizontal lines that you would be transferable your dataset. \n\n### Why use a Pre-trained Model?\nPre-trained models are beneficial to us for many reasons. By using a pre-trained model you are saving time. Someone else has already spent the time and compute resources to learn a lot of features and your model will likely benefit from it. \n\n\n [1]: https://imgur.com/nyYh5xH.jpg", "VersionNotes": "Added imagenet_class_index.json for use with decode_predictions()", "TotalCompressedBytes": 182733298.0, "TotalUncompressedBytes": 182733298.0}] | [{"Id": 6209, "CreatorUserId": 484516, "OwnerUserId": NaN, "OwnerOrganizationId": 1202.0, "CurrentDatasetVersionId": 9900.0, "CurrentDatasourceVersionId": 9900.0, "ForumId": 12647, "Type": 2, "CreationDate": "12/06/2017 02:12:59", "LastActivityDate": "02/05/2018", "TotalViews": 267558, "TotalDownloads": 22350, "TotalVotes": 359, "TotalKernels": 752}] | null | # # Title:Skin-Lesion Segmentation
# ### Importing the Libraries
from keras.models import Model, Sequential
from keras.layers import (
Activation,
Dense,
BatchNormalization,
Dropout,
Conv2D,
Conv2DTranspose,
MaxPooling2D,
UpSampling2D,
Input,
Reshape,
)
from keras import backend as K
from keras.optimizers import Adam
import tensorflow as tf
import numpy as np
import pandas as pd
import glob
import PIL
import os
from PIL import Image, ImageEnhance, ImageFilter
import matplotlib.pyplot as plt
import cv2
from sklearn.model_selection import train_test_split
from warnings import filterwarnings
filterwarnings("ignore")
plt.rcParams["axes.grid"] = False
np.random.seed(101)
print(os.listdir("../input"))
# The ***PH2 database*** includes
# the manual segmentation, the clinical diagnosis, and the identification of several dermoscopic
# structures, performed by expert dermatologists,
# The ***PH2 database*** was built up through a joint research collaboration between the Universidade do
# Porto, T ́ecnico Lisboa, and the Dermatology service of Hospital Pedro Hispano in Matosinhos,
# Portugal.
# ## Loading the data
# [](http://)Defining a function to load the data in sorted order
import re
numbers = re.compile(r"(\d+)")
def numericalSort(value):
parts = numbers.split(value)
parts[1::2] = map(int, parts[1::2])
return parts
# * * * First we will load the filenames in a list.
filelist_trainx_ph2 = sorted(glob.glob("../input/*/*/trainx/*.bmp"), key=numericalSort)
X_train_ph2 = np.array([np.array(Image.open(fname)) for fname in filelist_trainx_ph2])
filelist_trainy_ph2 = sorted(glob.glob("../input/*/*/trainy/*.bmp"), key=numericalSort)
Y_train_ph2 = np.array([np.array(Image.open(fname)) for fname in filelist_trainy_ph2])
plt.figure(figsize=(12, 6))
plt.suptitle("Images from PH2 dataset", fontsize=25, color="blue")
plt.subplot(2, 2, 1)
plt.imshow(X_train_ph2[1])
plt.xlabel("Dimensions: " + str(np.array(X_train_ph2[1]).shape))
plt.subplot(2, 2, 2)
plt.imshow(Y_train_ph2[1], plt.cm.binary_r)
plt.xlabel("Dimensions: " + str(np.array(Y_train_ph2[1]).shape))
plt.subplot(2, 2, 3)
plt.imshow(X_train_ph2[112])
plt.xlabel("Dimensions: " + str(np.array(X_train_ph2[185]).shape))
plt.subplot(2, 2, 4)
plt.imshow(Y_train_ph2[112], plt.cm.binary_r)
plt.xlabel("Dimensions: " + str(np.array(Y_train_ph2[185]).shape))
plt.show()
# * The images are of dimensions **(572, 765)** so we will scale down the images. It will also reduce the training time of the network.
# #### Resizing
def resize(filename, size=(256, 192)):
im = Image.open(filename)
im_resized = im.resize(size, Image.ANTIALIAS)
return im_resized
X_train_ph2_resized = []
Y_train_ph2_resized = []
for i in range(len(filelist_trainx_ph2)):
X_train_ph2_resized.append(resize(filelist_trainx_ph2[i]))
Y_train_ph2_resized.append(resize(filelist_trainy_ph2[i]))
# The new resized images
plt.figure(figsize=(12, 10))
plt.suptitle("Images from PH2 dataset after Resizing", fontsize=25, color="blue")
plt.subplot(2, 2, 1)
plt.imshow(X_train_ph2_resized[1])
plt.xlabel("Dimensions: " + str(np.array(X_train_ph2_resized[1]).shape))
plt.subplot(2, 2, 2)
plt.imshow(Y_train_ph2_resized[1], plt.cm.binary_r)
plt.xlabel("Dimensions: " + str(np.array(Y_train_ph2_resized[1]).shape))
plt.subplot(2, 2, 3)
plt.imshow(X_train_ph2_resized[117])
plt.xlabel("Dimensions: " + str(np.array(X_train_ph2_resized[185]).shape))
plt.subplot(2, 2, 4)
plt.imshow(Y_train_ph2_resized[117], plt.cm.binary_r)
plt.xlabel("Dimensions: " + str(np.array(Y_train_ph2_resized[185]).shape))
plt.show()
# Converting the transformed Images into numpy arrays
X_train_ph2 = np.array([np.array(img) for img in X_train_ph2_resized])
Y_train_ph2 = np.array([np.array(img) for img in Y_train_ph2_resized])
plt.figure(figsize=(12, 6))
plt.suptitle(
"Converting the transformed Image into Numpy Array", fontsize=25, color="blue"
)
plt.subplot(1, 2, 1)
plt.imshow(X_train_ph2[117])
plt.xlabel("Dimensions: " + str(np.array(X_train_ph2_resized[180]).shape))
plt.subplot(1, 2, 2)
plt.imshow(Y_train_ph2[117], plt.cm.binary_r)
plt.xlabel("Dimensions: " + str(np.array(Y_train_ph2_resized[180]).shape))
plt.show()
# * Splitting the dataset into training set and test set to verify our model performance without any bias.
x_train, x_test, y_train, y_test = train_test_split(
X_train_ph2, Y_train_ph2, test_size=0.25, random_state=101
)
plt.figure(figsize=(25, 10))
plt.suptitle("Images from PH2 dataset", fontsize=30, color="blue")
plt.subplot(3, 5, 1)
plt.imshow(X_train_ph2[1])
plt.subplot(3, 5, 2)
plt.imshow(X_train_ph2[12])
plt.subplot(3, 5, 3)
plt.imshow(X_train_ph2[44])
plt.subplot(3, 5, 4)
plt.imshow(X_train_ph2[67])
plt.subplot(3, 5, 5)
plt.imshow(X_train_ph2[100])
plt.subplot(3, 5, 6)
plt.imshow(X_train_ph2[117])
plt.subplot(3, 5, 7)
plt.imshow(X_train_ph2[128])
plt.subplot(3, 5, 8)
plt.imshow(X_train_ph2[147])
plt.subplot(3, 5, 9)
plt.imshow(X_train_ph2[132])
plt.subplot(3, 5, 10)
plt.imshow(X_train_ph2[112])
plt.subplot(3, 5, 11)
plt.imshow(X_train_ph2[31])
plt.subplot(3, 5, 12)
plt.imshow(X_train_ph2[52])
plt.subplot(3, 5, 13)
plt.imshow(X_train_ph2[74])
plt.subplot(3, 5, 14)
plt.imshow(X_train_ph2[86])
plt.subplot(3, 5, 15)
plt.imshow(X_train_ph2[150])
plt.show()
plt.figure(figsize=(25, 10))
plt.suptitle(
"Mask of the corresponding Images from PH2 dataset", fontsize=30, color="blue"
)
plt.subplot(3, 5, 1)
plt.imshow(Y_train_ph2[1], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 2)
plt.imshow(Y_train_ph2[12], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 3)
plt.imshow(Y_train_ph2[44], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 4)
plt.imshow(Y_train_ph2[67], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 5)
plt.imshow(Y_train_ph2[100], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 6)
plt.imshow(Y_train_ph2[117], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 7)
plt.imshow(Y_train_ph2[128], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 8)
plt.imshow(Y_train_ph2[147], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 9)
plt.imshow(Y_train_ph2[132], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 10)
plt.imshow(Y_train_ph2[112], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 11)
plt.imshow(Y_train_ph2[31], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 12)
plt.imshow(Y_train_ph2[52], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 13)
plt.imshow(Y_train_ph2[74], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 14)
plt.imshow(Y_train_ph2[86], cmap=plt.cm.binary_r)
plt.subplot(3, 5, 15)
plt.imshow(Y_train_ph2[150], cmap=plt.cm.binary_r)
plt.show()
# ## Image Augmentation
# Image augmentation artificially creates training images through different ways of processing or combination of multiple processing, such as random rotation, shifts, shear and flips, etc.
# To build a powerful image classifier using little training data, image augmentation is usually required to boost the performance of deep networks.
# We are going to define to methods for augmentation, **horizontal flipping** , **vertical flipping**, **both flipped** and **random rotation**
def horizontal_flip(x_image, y_image):
x_image = cv2.flip(x_image, 1)
y_image = cv2.flip(y_image.astype("float32"), 1)
return x_image, y_image.astype("int")
def vertical_flip(x_image, y_image):
x_image = cv2.flip(x_image, 0)
y_image = cv2.flip(y_image.astype("float32"), 0)
return x_image, y_image.astype("int")
def both_flip(x_image, y_image):
x_image = cv2.flip(x_image, -1)
y_image = cv2.flip(y_image.astype("float32"), -1)
return x_image, y_image.astype("int")
def random_rotation(x_image, y_image):
rows_x, cols_x, chl_x = x_image.shape
rows_y, cols_y = y_image.shape
rand_num = np.random.randint(-60, 60)
M1 = cv2.getRotationMatrix2D((cols_x / 2, rows_x / 2), rand_num, 1)
M2 = cv2.getRotationMatrix2D((cols_y / 2, rows_y / 2), rand_num, 1)
x_image = cv2.warpAffine(x_image, M1, (cols_x, rows_x))
y_image = cv2.warpAffine(y_image.astype("float32"), M2, (cols_y, rows_y))
return np.array(x_image), np.array(y_image.astype("int"))
def img_augmentation(x_train, y_train):
x_flip = []
y_flip = []
x_vert = []
y_vert = []
x_both = []
y_both = []
x_rotat = []
y_rotat = []
for idx in range(len(x_train)):
x, y = horizontal_flip(x_train[idx], y_train[idx])
x_flip.append(x)
y_flip.append(y)
x, y = vertical_flip(x_train[idx], y_train[idx])
x_vert.append(x)
y_vert.append(y)
x, y = both_flip(x_train[idx], y_train[idx])
x_both.append(x)
y_both.append(y)
x, y = random_rotation(x_train[idx], y_train[idx])
x_rotat.append(x)
y_rotat.append(y)
return (
np.array(x_flip),
np.array(y_flip),
np.array(x_vert),
np.array(y_vert),
np.array(x_both),
np.array(y_both),
np.array(x_rotat),
np.array(y_rotat),
)
# calling the functions for the training data.
(
x_flipped,
y_flipped,
x_vertical,
y_vertical,
x_bothed,
y_bothed,
x_rotated,
y_rotated,
) = img_augmentation(x_train, y_train)
(
x_flipped_t,
y_flipped_t,
x_vertical_t,
y_vertical_t,
x_bothed_t,
y_bothed_t,
x_rotated_t,
y_rotated_t,
) = img_augmentation(x_test, y_test)
plt.figure(figsize=(25, 16))
plt.suptitle("Image Augmentation", fontsize=25, color="blue")
plt.subplot(6, 4, 1)
plt.imshow(x_train[112])
plt.title("Original Image")
plt.subplot(6, 4, 2)
plt.imshow(y_train[112], plt.cm.binary_r)
plt.title("Original Mask")
plt.subplot(6, 4, 3)
plt.imshow(x_train[12])
plt.title("Original Image")
plt.subplot(6, 4, 4)
plt.imshow(y_train[12], plt.cm.binary_r)
plt.title("Original Mask")
plt.subplot(6, 4, 5)
plt.imshow(x_flipped[112])
plt.title("Horizontal Flipped Image")
plt.subplot(6, 4, 6)
plt.imshow(y_flipped[112], plt.cm.binary_r)
plt.title("Horizontal Flipped Mask")
plt.subplot(6, 4, 7)
plt.imshow(x_flipped[12])
plt.title("Horizontal Flipped Image")
plt.subplot(6, 4, 8)
plt.imshow(y_flipped[12], plt.cm.binary_r)
plt.title("Horizontal Flipped Mask")
plt.subplot(6, 4, 9)
plt.imshow(x_vertical[112])
plt.title("Vertical Flipped Image")
plt.subplot(6, 4, 10)
plt.imshow(y_vertical[112], plt.cm.binary_r)
plt.title("Vertical Flipped Mask")
plt.subplot(6, 4, 11)
plt.imshow(x_vertical[12])
plt.title("Vertical Flipped Image")
plt.subplot(6, 4, 12)
plt.imshow(y_vertical[12], plt.cm.binary_r)
plt.title("Vertical Flipped Mask")
plt.subplot(6, 4, 13)
plt.imshow(x_bothed[112])
plt.title("Flipped both Image")
plt.subplot(6, 4, 14)
plt.imshow(y_bothed[112], plt.cm.binary_r)
plt.title("Flipped both Mask")
plt.subplot(6, 4, 15)
plt.imshow(x_bothed[12])
plt.title("Flipped both Image")
plt.subplot(6, 4, 16)
plt.imshow(y_bothed[12], plt.cm.binary_r)
plt.title("Flipped both Mask")
plt.subplot(6, 4, 17)
plt.imshow(x_rotated[112])
plt.title("Rotated Image")
plt.subplot(6, 4, 18)
plt.imshow(y_rotated[112], plt.cm.binary_r)
plt.title("Rotated Mask")
plt.subplot(6, 4, 19)
plt.imshow(x_rotated[12])
plt.title("Rotated Image")
plt.subplot(6, 4, 20)
plt.imshow(y_rotated[12], plt.cm.binary_r)
plt.title("Rotated Mask")
plt.show()
# Now we join all the augmentations image arrays to the original training arrays.
# For training Set
x_train_full = np.concatenate([x_train, x_rotated, x_flipped, x_bothed, x_vertical])
y_train_full = np.concatenate([y_train, y_rotated, y_flipped, y_bothed, y_vertical])
# ## Defining Evaluation Metrics
# #### Intersection over Union(IOU) or Jaccard Index
# The Jaccard index, also known as Intersection over Union and the Jaccard similarity coefficient is a statistic used for gauging the similarity and diversity of sample sets. The Jaccard coefficient measures similarity between finite sample sets, and is defined as the size of the intersection divided by the size of the union of the sample sets.
# Jaccard index is popular and frequently used as a similarity index.
# The area of overlap J is
# calculated between the segmented binary image A and its ground truth G as shown:
# ***J = |A ∩ G| / |A ∪ G| × 100%.***
def iou(y_true, y_pred, smooth=100):
intersection = K.sum(K.abs(y_true * y_pred), axis=-1)
sum_ = K.sum(K.square(y_true), axis=-1) + K.sum(K.square(y_pred), axis=-1)
union = sum_ - intersection
jac = (intersection + smooth) / (union + smooth)
return jac
# #### Dice Coefficient
# The Dice score is not only a measure of how many positives you find, but it also penalizes for the false positives that the method finds, similar to precision. so it is more similar to precision than accuracy.
# The Dice coefficient can be defined as: ***D = 2 |A ∩ G| / |A + G| × 100%*** where A is the algorithm
# output and G is the ground truth.
def dice_coef(y_true, y_pred, smooth=100):
y_true_f = K.flatten(y_true)
y_pred_f = K.flatten(y_pred)
intersection = K.sum(y_true_f * y_pred_f)
return (2.0 * intersection + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth)
# #### Precision
# Precision is a good measure to determine, when the costs of False Positive is high.
# ***Precision = true-positive / (true-positive + false-positive)***
# Where,True positive is an outcome where the model correctly predicts the positive class and false positive is an outcome where the model incorrectly predicts the positive class.
#
# '''Precision calculates a metric for multi-label classification of
# how many selected items are relevant.
# '''
def precision(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
# #### Recall
# Recall actually calculates how many of the Actual Positives our model capture through labeling it as Positive (True Positive). Applying the same understanding, we know that Recall shall be the model metric we use to select our best model when there is a high cost associated with False Negative.
# ***Recall = true-positive /(true-positive + false negative)***
# Where, true positive is an outcome where the model correctly predicts the positive class and false negative is an outcome where the model incorrectly predicts the negative class.
# '''Recall calculates a metric for multi-label classification of
# how many relevant items are selected.
# '''
def recall(y_true, y_pred):
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
# #### Accuracy
# '''Calculates the mean accuracy rate across all predictions for binary
# classification problems.
# '''
def accuracy(y_true, y_pred):
return K.mean(K.equal(y_true, K.round(y_pred)))
# #### Making a Validation Set
x_train, x_val, y_train, y_val = train_test_split(
x_train_full, y_train_full, test_size=0.20, random_state=101
)
print("Length of the Training Set : {}".format(len(x_train)))
print("Length of the Test Set : {}".format(len(x_test)))
print("Length of the Validation Set : {}".format(len(x_val)))
# We will split our full training set into train and validation set.
# Validation dataset is used to validate the performance after each epoch
# ## The Model
# Defining the model in a function which takes two arguments when called
# * **epoch_num**: number of epochs to run
# * **savename**: the name of the model for saving after training
# ## Optimizer and Learning Rate
# * We adopt adam optimization algorithm or adaptive moments, to adjust the learning rate.
# * It is well known that learning rate is one of the critical hyperparameters that have a significant impact on classification performance.
# ### Advantages of Adam optimizer are:
# * Relatively low memory requirements (though higher than gradient descent and gradient descent with momentum).
# * Usually works well even with a little tuning of hyperparameter.
# * Adam is fairly robust to the choice of hyperparameters, and set the learning rate α as 0.003 to speed up the training procedure.
# #### Model Function
# * SegNet, a deep convolutional network architecture for semantic segmentation. The main motivation behind SegNet was the need to design an efficient architecture for road and indoor scene understanding which is efficient both in terms of memory and computational time.
# * SegNet on the other hand is more efficient since it only stores the max-pooling indices of the feature maps and uses them in its decoder network to achieve good performance.
def segnet(epochs_num, savename):
# Encoding layer
img_input = Input(shape=(192, 256, 3))
x = Conv2D(64, (3, 3), padding="same", name="conv1", strides=(1, 1))(img_input)
x = BatchNormalization(name="bn1")(x)
x = Activation("relu")(x)
x = Conv2D(64, (3, 3), padding="same", name="conv2")(x)
x = BatchNormalization(name="bn2")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Conv2D(128, (3, 3), padding="same", name="conv3")(x)
x = BatchNormalization(name="bn3")(x)
x = Activation("relu")(x)
x = Conv2D(128, (3, 3), padding="same", name="conv4")(x)
x = BatchNormalization(name="bn4")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Conv2D(256, (3, 3), padding="same", name="conv5")(x)
x = BatchNormalization(name="bn5")(x)
x = Activation("relu")(x)
x = Conv2D(256, (3, 3), padding="same", name="conv6")(x)
x = BatchNormalization(name="bn6")(x)
x = Activation("relu")(x)
x = Conv2D(256, (3, 3), padding="same", name="conv7")(x)
x = BatchNormalization(name="bn7")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Conv2D(512, (3, 3), padding="same", name="conv8")(x)
x = BatchNormalization(name="bn8")(x)
x = Activation("relu")(x)
x = Conv2D(512, (3, 3), padding="same", name="conv9")(x)
x = BatchNormalization(name="bn9")(x)
x = Activation("relu")(x)
x = Conv2D(512, (3, 3), padding="same", name="conv10")(x)
x = BatchNormalization(name="bn10")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Conv2D(512, (3, 3), padding="same", name="conv11")(x)
x = BatchNormalization(name="bn11")(x)
x = Activation("relu")(x)
x = Conv2D(512, (3, 3), padding="same", name="conv12")(x)
x = BatchNormalization(name="bn12")(x)
x = Activation("relu")(x)
x = Conv2D(512, (3, 3), padding="same", name="conv13")(x)
x = BatchNormalization(name="bn13")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Dense(1024, activation="relu", name="fc1")(x)
x = Dense(1024, activation="relu", name="fc2")(x)
# Decoding Layer
x = UpSampling2D()(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv1")(x)
x = BatchNormalization(name="bn14")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv2")(x)
x = BatchNormalization(name="bn15")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv3")(x)
x = BatchNormalization(name="bn16")(x)
x = Activation("relu")(x)
x = UpSampling2D()(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv4")(x)
x = BatchNormalization(name="bn17")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv5")(x)
x = BatchNormalization(name="bn18")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(256, (3, 3), padding="same", name="deconv6")(x)
x = BatchNormalization(name="bn19")(x)
x = Activation("relu")(x)
x = UpSampling2D()(x)
x = Conv2DTranspose(256, (3, 3), padding="same", name="deconv7")(x)
x = BatchNormalization(name="bn20")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(256, (3, 3), padding="same", name="deconv8")(x)
x = BatchNormalization(name="bn21")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(128, (3, 3), padding="same", name="deconv9")(x)
x = BatchNormalization(name="bn22")(x)
x = Activation("relu")(x)
x = UpSampling2D()(x)
x = Conv2DTranspose(128, (3, 3), padding="same", name="deconv10")(x)
x = BatchNormalization(name="bn23")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(64, (3, 3), padding="same", name="deconv11")(x)
x = BatchNormalization(name="bn24")(x)
x = Activation("relu")(x)
x = UpSampling2D()(x)
x = Conv2DTranspose(64, (3, 3), padding="same", name="deconv12")(x)
x = BatchNormalization(name="bn25")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(1, (3, 3), padding="same", name="deconv13")(x)
x = BatchNormalization(name="bn26")(x)
x = Activation("sigmoid")(x)
pred = Reshape((192, 256))(x)
model = Model(inputs=img_input, outputs=pred)
model.compile(
optimizer=Adam(lr=0.003),
loss=["binary_crossentropy"],
metrics=[iou, dice_coef, precision, recall, accuracy],
)
model.summary()
hist = model.fit(
x_train,
y_train,
epochs=epochs_num,
batch_size=32,
validation_data=(x_val, y_val),
verbose=1,
)
model.save(savename)
return model, hist
# ### Loading the Model
# Encoding layer
img_input = Input(shape=(192, 256, 3))
x = Conv2D(64, (3, 3), padding="same", name="conv1", strides=(1, 1))(img_input)
x = BatchNormalization(name="bn1")(x)
x = Activation("relu")(x)
x = Conv2D(64, (3, 3), padding="same", name="conv2")(x)
x = BatchNormalization(name="bn2")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Conv2D(128, (3, 3), padding="same", name="conv3")(x)
x = BatchNormalization(name="bn3")(x)
x = Activation("relu")(x)
x = Conv2D(128, (3, 3), padding="same", name="conv4")(x)
x = BatchNormalization(name="bn4")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Conv2D(256, (3, 3), padding="same", name="conv5")(x)
x = BatchNormalization(name="bn5")(x)
x = Activation("relu")(x)
x = Conv2D(256, (3, 3), padding="same", name="conv6")(x)
x = BatchNormalization(name="bn6")(x)
x = Activation("relu")(x)
x = Conv2D(256, (3, 3), padding="same", name="conv7")(x)
x = BatchNormalization(name="bn7")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Conv2D(512, (3, 3), padding="same", name="conv8")(x)
x = BatchNormalization(name="bn8")(x)
x = Activation("relu")(x)
x = Conv2D(512, (3, 3), padding="same", name="conv9")(x)
x = BatchNormalization(name="bn9")(x)
x = Activation("relu")(x)
x = Conv2D(512, (3, 3), padding="same", name="conv10")(x)
x = BatchNormalization(name="bn10")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Conv2D(512, (3, 3), padding="same", name="conv11")(x)
x = BatchNormalization(name="bn11")(x)
x = Activation("relu")(x)
x = Conv2D(512, (3, 3), padding="same", name="conv12")(x)
x = BatchNormalization(name="bn12")(x)
x = Activation("relu")(x)
x = Conv2D(512, (3, 3), padding="same", name="conv13")(x)
x = BatchNormalization(name="bn13")(x)
x = Activation("relu")(x)
x = MaxPooling2D()(x)
x = Dense(1024, activation="relu", name="fc1")(x)
x = Dense(1024, activation="relu", name="fc2")(x)
# Decoding Layer
x = UpSampling2D()(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv1")(x)
x = BatchNormalization(name="bn14")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv2")(x)
x = BatchNormalization(name="bn15")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv3")(x)
x = BatchNormalization(name="bn16")(x)
x = Activation("relu")(x)
x = UpSampling2D()(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv4")(x)
x = BatchNormalization(name="bn17")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(512, (3, 3), padding="same", name="deconv5")(x)
x = BatchNormalization(name="bn18")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(256, (3, 3), padding="same", name="deconv6")(x)
x = BatchNormalization(name="bn19")(x)
x = Activation("relu")(x)
x = UpSampling2D()(x)
x = Conv2DTranspose(256, (3, 3), padding="same", name="deconv7")(x)
x = BatchNormalization(name="bn20")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(256, (3, 3), padding="same", name="deconv8")(x)
x = BatchNormalization(name="bn21")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(128, (3, 3), padding="same", name="deconv9")(x)
x = BatchNormalization(name="bn22")(x)
x = Activation("relu")(x)
x = UpSampling2D()(x)
x = Conv2DTranspose(128, (3, 3), padding="same", name="deconv10")(x)
x = BatchNormalization(name="bn23")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(64, (3, 3), padding="same", name="deconv11")(x)
x = BatchNormalization(name="bn24")(x)
x = Activation("relu")(x)
x = UpSampling2D()(x)
x = Conv2DTranspose(64, (3, 3), padding="same", name="deconv12")(x)
x = BatchNormalization(name="bn25")(x)
x = Activation("relu")(x)
x = Conv2DTranspose(1, (3, 3), padding="same", name="deconv13")(x)
x = BatchNormalization(name="bn26")(x)
x = Activation("sigmoid")(x)
pred = Reshape((192, 256))(x)
# > #### After 120 epochs
model, hist = segnet(epochs_num=120, savename="segnet_120_epoch.h5")
model_1 = Model(inputs=img_input, outputs=pred)
model_1.compile(
optimizer=Adam(lr=0.003),
loss=["binary_crossentropy"],
metrics=[iou, dice_coef, precision, recall, accuracy],
)
model_1.load_weights("segnet_120_epoch.h5")
print("\n~~~~~~~~~~~~~~~Stats after 120 epoch~~~~~~~~~~~~~~~~~~~")
print("\n------------------On Train Set-----------------------------\n")
res = model_1.evaluate(x_train, y_train, batch_size=48)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
print("\n-----------------On Test Set-----------------------------\n")
res = model_1.evaluate(x_test, y_test, batch_size=48)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
print("\n----------------On validation Set-----------------------------\n")
res = model_1.evaluate(x_val, y_val, batch_size=48)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
# ### Plotting Training Statistics
plt.figure(figsize=(24, 14))
plt.suptitle("Training Statistics on Train Set", fontsize=30, color="blue")
plt.subplot(2, 3, 1)
plt.plot(hist.history["loss"], "red")
plt.title("Loss", fontsize=18, color="blue")
plt.subplot(2, 3, 2)
plt.plot(hist.history["iou"], "yellow")
plt.title("Jaccard Index", fontsize=18, color="blue")
plt.subplot(2, 3, 3)
plt.plot(hist.history["accuracy"], "green")
plt.title("Accuracy", fontsize=18, color="blue")
plt.subplot(2, 3, 4)
plt.plot(hist.history["val_loss"], "red")
plt.yticks(list(np.arange(0.0, 1.0, 0.10)))
plt.title("Valdiation Loss", fontsize=18, color="blue")
plt.subplot(2, 3, 5)
plt.plot(hist.history["val_iou"], "yellow")
plt.yticks(list(np.arange(0.0, 1.0, 0.10)))
plt.title("Valdiation Jaccard Index", fontsize=18, color="blue")
plt.subplot(2, 3, 6)
plt.plot(hist.history["val_accuracy"], "green")
plt.yticks(list(np.arange(0.0, 1.0, 0.10)))
plt.title("Validation Accuracy", fontsize=18, color="blue")
plt.show()
# ### Visualising Predicted Lesions
# We have trained the model on the **training set**.
# We will make predictions on the unseen **test set**
plt.figure(figsize=(20, 16))
plt.suptitle("Visualising Predicted Lesions", fontsize=30, color="blue")
img_pred = model_1.predict(x_test[49].reshape(1, 192, 256, 3))
plt.subplot(4, 3, 1)
plt.imshow(x_test[49])
plt.title("Original Image")
plt.subplot(4, 3, 2)
plt.imshow(y_test[49], plt.cm.binary_r)
plt.title("True Mask")
plt.subplot(4, 3, 3)
plt.imshow(img_pred.reshape(192, 256), plt.cm.binary_r)
plt.title("Predicted Mask")
img_pred = model_1.predict(x_test[36].reshape(1, 192, 256, 3))
plt.subplot(4, 3, 4)
plt.imshow(x_test[36])
plt.title("Original Image")
plt.subplot(4, 3, 5)
plt.imshow(y_test[36], plt.cm.binary_r)
plt.title("True Mask")
plt.subplot(4, 3, 6)
plt.imshow(img_pred.reshape(192, 256), plt.cm.binary_r)
plt.title("Predicted Mask")
img_pred = model_1.predict(x_test[32].reshape(1, 192, 256, 3))
plt.subplot(4, 3, 7)
plt.imshow(x_test[32])
plt.title("Original Image")
plt.subplot(4, 3, 8)
plt.imshow(y_test[32], plt.cm.binary_r)
plt.title("True Mask")
plt.subplot(4, 3, 9)
plt.imshow(img_pred.reshape(192, 256), plt.cm.binary_r)
plt.title("Predicted Mask")
img_pred = model_1.predict(x_test[21].reshape(1, 192, 256, 3))
plt.subplot(4, 3, 10)
plt.imshow(x_test[21])
plt.title("Original Image")
plt.subplot(4, 3, 11)
plt.imshow(y_test[21], plt.cm.binary_r)
plt.title("True Mask")
plt.subplot(4, 3, 12)
plt.imshow(img_pred.reshape(192, 256), plt.cm.binary_r)
plt.title("Predicted Mask")
plt.show()
# ### Final Enhance
# * Currently the predicted outputs are blurry because the predicted pixel values are in the range 0 - 1.
# * To make clear edge preditions we can enhance our image by rounding up the pixel values to 1 which are > 0.5 .
# * While rounding down the pixel values to 0 which are < 0.5.
# * We can enhance the image to look for absolute shape predicted by ceiling and flooring the predicted values
def enhance(img):
sub = (model_1.predict(img.reshape(1, 192, 256, 3))).flatten()
for i in range(len(sub)):
if sub[i] > 0.5:
sub[i] = 1
else:
sub[i] = 0
return sub
plt.figure(figsize=(24, 16))
plt.suptitle("Comparing the Prediction after Enhancement", fontsize=30, color="blue")
plt.subplot(4, 3, 1)
plt.imshow(x_test[21])
plt.title("Original Image")
plt.subplot(4, 3, 2)
plt.imshow(y_test[21], plt.cm.binary_r)
plt.title("True Mask")
plt.subplot(4, 3, 3)
plt.imshow(enhance(x_test[21]).reshape(192, 256), plt.cm.binary_r)
plt.title("Predicted after threshold")
plt.subplot(4, 3, 4)
plt.imshow(x_test[19])
plt.title("Original Image")
plt.subplot(4, 3, 5)
plt.imshow(y_test[19], plt.cm.binary_r)
plt.title("True Mask")
plt.subplot(4, 3, 6)
plt.imshow(enhance(x_test[19]).reshape(192, 256), plt.cm.binary_r)
plt.title("Predicted after threshold")
plt.subplot(4, 3, 7)
plt.imshow(x_test[36])
plt.title("Original Image")
plt.subplot(4, 3, 8)
plt.imshow(y_test[36], plt.cm.binary_r)
plt.title("True Mask")
plt.subplot(4, 3, 9)
plt.imshow(enhance(x_test[36]).reshape(192, 256), plt.cm.binary_r)
plt.title("Predicted after threshold")
plt.subplot(4, 3, 10)
plt.imshow(x_test[49])
plt.title("Original Image")
plt.subplot(4, 3, 11)
plt.imshow(y_test[49], plt.cm.binary_r)
plt.title("True Mask")
plt.subplot(4, 3, 12)
plt.imshow(enhance(x_test[49]).reshape(192, 256), plt.cm.binary_r)
plt.title("Predicted after threshold")
plt.show()
# # **Model: U-Net**
from keras.models import Model, Sequential
from keras.layers import (
Activation,
Dense,
BatchNormalization,
concatenate,
Dropout,
Conv2D,
Conv2DTranspose,
MaxPooling2D,
UpSampling2D,
Input,
Reshape,
)
from keras.callbacks import EarlyStopping
from keras.layers.core import SpatialDropout2D
from keras import backend as K
from keras.optimizers import Adam
import tensorflow as tf
import numpy as np
import pandas as pd
import glob
import PIL
from PIL import Image
import matplotlib.pyplot as plt
import cv2
from keras.preprocessing.image import ImageDataGenerator
from sklearn.model_selection import train_test_split
from warnings import filterwarnings
filterwarnings("ignore")
np.random.seed(101)
import re
numbers = re.compile(r"(\d+)")
def numericalSort(value):
parts = numbers.split(value)
parts[1::2] = map(int, parts[1::2])
return parts
filelist_trainx_ph2 = sorted(glob.glob("../input/*/*/trainx/*.bmp"), key=numericalSort)
X_train_ph2 = np.array([np.array(Image.open(fname)) for fname in filelist_trainx_ph2])
filelist_trainy_ph2 = sorted(glob.glob("../input/*/*/trainy/*.bmp"), key=numericalSort)
Y_train_ph2 = np.array([np.array(Image.open(fname)) for fname in filelist_trainy_ph2])
def resize(filename, size=(256, 192)):
im = Image.open(filename)
im_resized = im.resize(size, Image.ANTIALIAS)
return im_resized
X_train_ph2_resized = []
Y_train_ph2_resized = []
for i in range(len(filelist_trainx_ph2)):
X_train_ph2_resized.append(resize(filelist_trainx_ph2[i]))
Y_train_ph2_resized.append(resize(filelist_trainy_ph2[i]))
X_train = np.array([np.array(img) for img in X_train_ph2_resized])
Y_train = np.array([np.array(img) for img in Y_train_ph2_resized])
x_train, x_test, y_train, y_test = train_test_split(
X_train, Y_train, test_size=0.25, random_state=101
)
def jaccard_distance(y_true, y_pred, smooth=100):
intersection = K.sum(K.abs(y_true * y_pred), axis=-1)
sum_ = K.sum(K.square(y_true), axis=-1) + K.sum(K.square(y_pred), axis=-1)
jac = (intersection + smooth) / (sum_ - intersection + smooth)
return 1 - jac
def iou(y_true, y_pred, smooth=100):
intersection = K.sum(K.abs(y_true * y_pred), axis=-1)
sum_ = K.sum(K.square(y_true), axis=-1) + K.sum(K.square(y_pred), axis=-1)
jac = (intersection + smooth) / (sum_ - intersection + smooth)
return jac
def dice_coe(y_true, y_pred, smooth=100):
y_true_f = K.flatten(y_true)
y_pred_f = K.flatten(y_pred)
intersection = K.sum(y_true_f * y_pred_f)
return (2.0 * intersection + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth)
def precision(y_true, y_pred):
"""Calculates the precision, a metric for multi-label classification of
how many selected items are relevant.
"""
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
predicted_positives = K.sum(K.round(K.clip(y_pred, 0, 1)))
precision = true_positives / (predicted_positives + K.epsilon())
return precision
def recall(y_true, y_pred):
"""Calculates the recall, a metric for multi-label classification of
how many relevant items are selected.
"""
true_positives = K.sum(K.round(K.clip(y_true * y_pred, 0, 1)))
possible_positives = K.sum(K.round(K.clip(y_true, 0, 1)))
recall = true_positives / (possible_positives + K.epsilon())
return recall
def accuracy(y_true, y_pred):
"""Calculates the mean accuracy rate across all predictions for binary
classification problems.
"""
return K.mean(K.equal(y_true, K.round(y_pred)))
def random_rotation(x_image, y_image):
rows_x, cols_x, chl_x = x_image.shape
rows_y, cols_y = y_image.shape
rand_num = np.random.randint(-40, 40)
M1 = cv2.getRotationMatrix2D((cols_x / 2, rows_x / 2), rand_num, 1)
M2 = cv2.getRotationMatrix2D((cols_y / 2, rows_y / 2), rand_num, 1)
x_image = cv2.warpAffine(x_image, M1, (cols_x, rows_x))
y_image = cv2.warpAffine(y_image.astype("float32"), M2, (cols_y, rows_y))
return x_image, y_image.astype("int")
def horizontal_flip(x_image, y_image):
x_image = cv2.flip(x_image, 1)
y_image = cv2.flip(y_image.astype("float32"), 1)
return x_image, y_image.astype("int")
def img_augmentation(x_train, y_train):
x_rotat = []
y_rotat = []
x_flip = []
y_flip = []
for idx in range(len(x_train)):
x, y = random_rotation(x_train[idx], y_train[idx])
x_rotat.append(x)
y_rotat.append(y)
x, y = horizontal_flip(x_train[idx], y_train[idx])
x_flip.append(x)
y_flip.append(y)
return np.array(x_rotat), np.array(y_rotat), np.array(x_flip), np.array(y_flip)
x_rotated, y_rotated, x_flipped, y_flipped = img_augmentation(x_train, y_train)
x_train_full = np.concatenate([x_train, x_rotated, x_flipped])
y_train_full = np.concatenate([y_train, y_rotated, y_flipped])
x_train, x_val, y_train, y_val = train_test_split(
x_train_full, y_train_full, test_size=0.20, random_state=101
)
print("Length of the Training Set : {}".format(len(x_train)))
print("Length of the Test Set : {}".format(len(x_test)))
print("Length of the Validation Set : {}".format(len(x_val)))
# Number of image channels (for example 3 in case of RGB, or 1 for grayscale images)
INPUT_CHANNELS = 3
# Number of output masks (1 in case you predict only one type of objects)
OUTPUT_MASK_CHANNELS = 1
# Pretrained weights
def double_conv_layer(x, size, dropout=0.40, batch_norm=True):
if K.image_data_format() == "th":
axis = 1
else:
axis = 3
conv = Conv2D(size, (3, 3), padding="same")(x)
if batch_norm is True:
conv = BatchNormalization(axis=axis)(conv)
conv = Activation("relu")(conv)
conv = Conv2D(size, (3, 3), padding="same")(conv)
if batch_norm is True:
conv = BatchNormalization(axis=axis)(conv)
conv = Activation("relu")(conv)
if dropout > 0:
conv = SpatialDropout2D(dropout)(conv)
return conv
def UNET_224(epochs_num, savename):
dropout_val = 0.50
if K.image_data_format() == "th":
inputs = Input((INPUT_CHANNELS, 192, 256))
axis = 1
else:
inputs = Input((192, 256, INPUT_CHANNELS))
axis = 3
filters = 32
conv_224 = double_conv_layer(inputs, filters)
pool_112 = MaxPooling2D(pool_size=(2, 2))(conv_224)
conv_112 = double_conv_layer(pool_112, 2 * filters)
pool_56 = MaxPooling2D(pool_size=(2, 2))(conv_112)
conv_56 = double_conv_layer(pool_56, 4 * filters)
pool_28 = MaxPooling2D(pool_size=(2, 2))(conv_56)
conv_28 = double_conv_layer(pool_28, 8 * filters)
pool_14 = MaxPooling2D(pool_size=(2, 2))(conv_28)
conv_14 = double_conv_layer(pool_14, 16 * filters)
pool_7 = MaxPooling2D(pool_size=(2, 2))(conv_14)
conv_7 = double_conv_layer(pool_7, 32 * filters)
up_14 = concatenate([UpSampling2D(size=(2, 2))(conv_7), conv_14], axis=axis)
up_conv_14 = double_conv_layer(up_14, 16 * filters)
up_28 = concatenate([UpSampling2D(size=(2, 2))(up_conv_14), conv_28], axis=axis)
up_conv_28 = double_conv_layer(up_28, 8 * filters)
up_56 = concatenate([UpSampling2D(size=(2, 2))(up_conv_28), conv_56], axis=axis)
up_conv_56 = double_conv_layer(up_56, 4 * filters)
up_112 = concatenate([UpSampling2D(size=(2, 2))(up_conv_56), conv_112], axis=axis)
up_conv_112 = double_conv_layer(up_112, 2 * filters)
up_224 = concatenate([UpSampling2D(size=(2, 2))(up_conv_112), conv_224], axis=axis)
up_conv_224 = double_conv_layer(up_224, filters, dropout_val)
conv_final = Conv2D(OUTPUT_MASK_CHANNELS, (1, 1))(up_conv_224)
conv_final = Activation("sigmoid")(conv_final)
pred = Reshape((192, 256))(conv_final)
model = Model(inputs, pred, name="UNET_224")
model.compile(
optimizer=Adam(lr=0.003),
loss=[jaccard_distance],
metrics=[iou, dice_coe, precision, recall, accuracy],
)
model.summary()
hist = model.fit(
x_train,
y_train,
epochs=epochs_num,
batch_size=18,
validation_data=(x_val, y_val),
verbose=1,
)
model.save(savename)
return model, hist
model, hist = UNET_224(1, "unet_1_epoch.h5")
dropout_val = 0.50
if K.image_data_format() == "th":
inputs = Input((INPUT_CHANNELS, 192, 256))
axis = 1
else:
inputs = Input((192, 256, INPUT_CHANNELS))
axis = 3
filters = 32
conv_224 = double_conv_layer(inputs, filters)
pool_112 = MaxPooling2D(pool_size=(2, 2))(conv_224)
conv_112 = double_conv_layer(pool_112, 2 * filters)
pool_56 = MaxPooling2D(pool_size=(2, 2))(conv_112)
conv_56 = double_conv_layer(pool_56, 4 * filters)
pool_28 = MaxPooling2D(pool_size=(2, 2))(conv_56)
conv_28 = double_conv_layer(pool_28, 8 * filters)
pool_14 = MaxPooling2D(pool_size=(2, 2))(conv_28)
conv_14 = double_conv_layer(pool_14, 16 * filters)
pool_7 = MaxPooling2D(pool_size=(2, 2))(conv_14)
conv_7 = double_conv_layer(pool_7, 32 * filters)
up_14 = concatenate([UpSampling2D(size=(2, 2))(conv_7), conv_14], axis=axis)
up_conv_14 = double_conv_layer(up_14, 16 * filters)
up_28 = concatenate([UpSampling2D(size=(2, 2))(up_conv_14), conv_28], axis=axis)
up_conv_28 = double_conv_layer(up_28, 8 * filters)
up_56 = concatenate([UpSampling2D(size=(2, 2))(up_conv_28), conv_56], axis=axis)
up_conv_56 = double_conv_layer(up_56, 4 * filters)
up_112 = concatenate([UpSampling2D(size=(2, 2))(up_conv_56), conv_112], axis=axis)
up_conv_112 = double_conv_layer(up_112, 2 * filters)
up_224 = concatenate([UpSampling2D(size=(2, 2))(up_conv_112), conv_224], axis=axis)
up_conv_224 = double_conv_layer(up_224, filters, dropout_val)
conv_final = Conv2D(OUTPUT_MASK_CHANNELS, (1, 1))(up_conv_224)
conv_final = Activation("sigmoid")(conv_final)
pred = Reshape((192, 256))(conv_final)
model_0 = Model(inputs, pred, name="UNET_224")
model_0.compile(
optimizer=Adam(lr=0.003),
loss=[jaccard_distance],
metrics=[iou, dice_coe, precision, recall, accuracy],
)
model_0.load_weights("unet_1_epoch.h5")
print("\n~~~~~~~~~~~~~~~Stats after 1 epoch~~~~~~~~~~~~~~~~~~~")
print("\n-------------On Train Set--------------------------\n")
res = model_0.evaluate(x_train, y_train, batch_size=18)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
print("\n-------------On Test Set--------------------------\n")
res = model_0.evaluate(x_test, y_test, batch_size=18)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
print("\n-------------On validation Set---------------------\n")
res = model_0.evaluate(x_val, y_val, batch_size=18)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
model, hist = UNET_224(epochs_num=100, savename="unet_100_epoch.h5")
model_1 = Model(inputs, pred, name="UNET_224")
model_1.compile(
optimizer=Adam(lr=0.003),
loss=[jaccard_distance],
metrics=[iou, dice_coe, precision, recall, accuracy],
)
model_1.load_weights("unet_100_epoch.h5")
print("\n~~~~~~~~~~~~~~~Stats after 100 epoch~~~~~~~~~~~~~~~~~~~")
print("\n-------------On Train Set--------------------------\n")
res = model_1.evaluate(x_train, y_train, batch_size=18)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
print("\n-------------On Test Set--------------------------\n")
res = model_1.evaluate(x_test, y_test, batch_size=18)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
print("\n-------------On validation Set---------------------\n")
res = model_1.evaluate(x_val, y_val, batch_size=18)
print("________________________")
print("IOU: | {:.2f} |".format(res[1] * 100))
print("Dice Coef: | {:.2f} |".format(res[2] * 100))
print("Precision: | {:.2f} |".format(res[3] * 100))
print("Recall: | {:.2f} |".format(res[4] * 100))
print("Accuracy: | {:.2f} |".format(res[5] * 100))
print("Loss: | {:.2f} |".format(res[0] * 100))
print("________________________")
# # **Classification: ResNet50**
import os
import cv2
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import os
from glob import glob
import seaborn as sns
from PIL import Image
from tqdm import tqdm
np.random.seed(11) # It's my lucky number
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import (
train_test_split,
KFold,
cross_val_score,
GridSearchCV,
)
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
import itertools
import keras
from keras import regularizers
from keras.utils.np_utils import (
to_categorical,
) # used for converting labels to one-hot-encoding
from keras.models import Sequential, Model
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPool2D
from keras import backend as K
from keras.layers.normalization import BatchNormalization
from keras.utils.np_utils import to_categorical # convert to one-hot-encoding
from keras.optimizers import Adam, RMSprop
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import EarlyStopping, ReduceLROnPlateau
from keras.wrappers.scikit_learn import KerasClassifier
from keras.applications.resnet50 import ResNet50
from keras import backend as K
import tensorflow as tf
# Resnet-50 has been pre_trained, weights have been saved in below path
resnet_weights_path = (
"../input/resnet50/resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5"
)
# Display the dir list
print(os.listdir("../input"))
# Transfer 'jpg' images to an array IMG
def Dataset_loader(DIR, RESIZE):
IMG = []
read = lambda imname: np.asarray(Image.open(imname).convert("RGB"))
for IMAGE_NAME in tqdm(os.listdir(DIR)):
PATH = os.path.join(DIR, IMAGE_NAME)
_, ftype = os.path.splitext(PATH)
if ftype == ".jpg":
img = read(PATH)
img = cv2.resize(img, (RESIZE, RESIZE))
IMG.append(np.array(img) / 255.0)
return IMG
X_benign = np.array(Dataset_loader("../input/skindata/train/benign", 224))
X_malignant = np.array(Dataset_loader("../input/skindata/train/malign", 224))
X_benign_test = np.array(Dataset_loader("../input/skindata/test/benign", 224))
X_malignant_test = np.array(Dataset_loader("../input/skindata/test/malign", 224))
# Create labels
y_benign = np.zeros(X_benign.shape[0])
y_malignant = np.ones(X_malignant.shape[0])
y_benign_test = np.zeros(X_benign_test.shape[0])
y_malignant_test = np.ones(X_malignant_test.shape[0])
# Merge data
X_train = np.concatenate((X_benign, X_malignant), axis=0)
y_train = np.concatenate((y_benign, y_malignant), axis=0)
X_test = np.concatenate((X_benign_test, X_malignant_test), axis=0)
y_test = np.concatenate((y_benign_test, y_malignant_test), axis=0)
# Shuffle data
s = np.arange(X_train.shape[0])
np.random.shuffle(s)
X_train = X_train[s]
y_train = y_train[s]
s = np.arange(X_test.shape[0])
np.random.shuffle(s)
X_test = X_test[s]
y_test = y_test[s]
# Display first 15 images of moles, and how they are classified
w = 40
h = 30
fig = plt.figure(figsize=(12, 8))
columns = 5
rows = 3
for i in range(1, columns * rows + 1):
ax = fig.add_subplot(rows, columns, i)
if y_train[i] == 0:
ax.title.set_text("Benign")
else:
ax.title.set_text("Malignant")
plt.imshow(X_train[i], interpolation="nearest")
plt.show()
y_train = to_categorical(y_train, num_classes=2)
y_test = to_categorical(y_test, num_classes=2)
# With data augmentation to prevent overfitting
X_train = X_train / 255.0
X_test = X_test / 255.0
# See learning curve and validation curve
def build(
input_shape=(224, 224, 3),
lr=1e-3,
num_classes=2,
init="normal",
activ="relu",
optim="adam",
):
model = Sequential()
model.add(
Conv2D(
64,
kernel_size=(3, 3),
padding="Same",
input_shape=input_shape,
activation=activ,
kernel_initializer="glorot_uniform",
)
)
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(
Conv2D(
64,
kernel_size=(3, 3),
padding="Same",
activation=activ,
kernel_initializer="glorot_uniform",
)
)
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation="relu", kernel_initializer=init))
model.add(Dense(num_classes, activation="softmax"))
model.summary()
if optim == "rmsprop":
optimizer = RMSprop(lr=lr)
else:
optimizer = Adam(lr=lr)
model.compile(optimizer=optimizer, loss="binary_crossentropy", metrics=["accuracy"])
return model
# Set a learning rate annealer
learning_rate_reduction = ReduceLROnPlateau(
monitor="val_accuracy", patience=5, verbose=1, factor=0.5, min_lr=1e-7
)
input_shape = (224, 224, 3)
lr = 1e-5
epochs = 50
batch_size = 64
model = ResNet50(
include_top=True,
weights=None,
input_tensor=None,
input_shape=input_shape,
pooling="avg",
classes=2,
)
model.compile(optimizer=Adam(lr), loss="binary_crossentropy", metrics=["accuracy"])
history = model.fit(
X_train,
y_train,
validation_split=0.2,
epochs=epochs,
batch_size=batch_size,
verbose=2,
callbacks=[learning_rate_reduction],
)
# list all data in history
print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history["accuracy"])
plt.plot(history.history["val_accuracy"])
plt.title("model accuracy")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(["train", "test"], loc="upper left")
plt.show()
# summarize history for loss
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.title("model loss")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(["train", "test"], loc="upper left")
plt.show()
# Train ResNet50 on all the data
model.fit(
X_train,
y_train,
epochs=epochs,
batch_size=epochs,
verbose=0,
callbacks=[learning_rate_reduction],
)
# Testing model on test data to evaluate
y_pred = model.predict(X_test)
print(accuracy_score(np.argmax(y_test, axis=1), np.argmax(y_pred, axis=1)))
# save model
# serialize model to JSON
resnet50_json = model.to_json()
with open("resnet50.json", "w") as json_file:
json_file.write(resnet50_json)
# serialize weights to HDF5
model.save_weights("resnet50.h5")
print("Saved model to disk")
# Testing model on test data to evaluate
lists = []
y_pred = model.predict(X_test)
for i in range(len(y_pred)):
if y_pred[i][0] > 0.5:
lists.append(1)
else:
lists.append(0)
# print(accuracy_score(np.argmax(y_test, axis=1), np.argmax(lists, axis=1)))
i = 0
prop_class = []
mis_class = []
for i in range(len(y_test)):
if y_test[i] == lists[i]:
prop_class.append(i)
if len(prop_class) == 8:
break
i = 0
for i in range(len(y_test)):
if not y_test[i] == lists[i]:
mis_class.append(i)
if len(mis_class) == 8:
break
# # Display first 8 images of benign
w = 60
h = 40
fig = plt.figure(figsize=(18, 10))
columns = 4
rows = 2
def Transfername(namecode):
if namecode == 0:
return "Benign"
else:
return "Malignant"
for i in range(len(prop_class)):
ax = fig.add_subplot(rows, columns, i + 1)
ax.set_title(
"Predicted result:"
+ Transfername(lists[prop_class[i]])
+ "\n"
+ "Actual result: "
+ Transfername(Y_test[prop_class[i]])
)
plt.imshow(X_test[prop_class[i]], interpolation="nearest")
plt.show()
base_skin_dir = os.path.join("..", "input/ph2cvs")
skin_df = pd.read_csv(os.path.join(base_skin_dir, "ph2data.csv"))
from os.path import isfile
def expand_path(p):
if isfile("../input/ph2dataset/trainx/" + p + ".bmp"):
return "../input/ph2dataset/trainx/" + p + ".bmp"
return p
skin_df["image_path"] = skin_df["Name"]
skin_df["image_path"] = skin_df["image_path"].apply(expand_path)
# 1 = Nevus, 0 = Melenoma
skin_df["cell_type_idx"] = pd.Categorical(skin_df["lesion"]).codes
skin_df["image"] = skin_df["image_path"].map(
lambda x: np.asarray(Image.open(x).resize((224, 224)))
)
skin_df.head()
n_samples = 5
fig, m_axs = plt.subplots(2, n_samples, figsize=(4 * n_samples, 6))
for n_axs, (type_name, type_rows) in zip(
m_axs, skin_df.sort_values(["lesion"]).groupby("lesion")
):
n_axs[0].set_title(type_name)
for c_ax, (_, c_row) in zip(
n_axs, type_rows.sample(n_samples, random_state=1234).iterrows()
):
c_ax.imshow(c_row["image"])
c_ax.axis("off")
skin_df["image"].map(lambda x: x.shape).value_counts()
features = skin_df.drop(columns=["cell_type_idx"], axis=1)
target = skin_df["cell_type_idx"]
x_train_o, x_test_o, y_train_o, y_test_o = train_test_split(
features, target, test_size=0.2, random_state=42
)
x_train = np.asarray(x_train_o["image"].tolist())
x_test = np.asarray(x_test_o["image"].tolist())
x_train_mean = np.mean(x_train)
x_train_std = np.std(x_train)
x_test_mean = np.mean(x_test)
x_test_std = np.std(x_test)
x_train = (x_train - x_train_mean) / x_train_std
x_test = (x_test - x_test_mean) / x_test_std
# Perform one-hot encoding on the labels
y_train = to_categorical(y_train_o, num_classes=2)
y_test = to_categorical(y_test_o, num_classes=2)
x_train, x_validate, y_train, y_validate = train_test_split(
x_train, y_train, test_size=0.1, random_state=2
)
# With data augmentation to prevent overfitting
datagen = ImageDataGenerator(
rotation_range=90, # randomly rotate images in the range (degrees, 0 to 180)
zoom_range=0.1, # Randomly zoom image
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=True, # randomly flip images
vertical_flip=True,
)
datagen.fit(x_train)
model = Sequential()
num_labels = 2
base_model = ResNet50(
include_top=False,
weights=resnet_weights_path,
input_shape=(224, 224, 3),
pooling="avg",
classes=2,
)
model = Sequential()
model.add(base_model)
model.add(Dropout(0.5))
model.add(Dense(128, activation="relu", kernel_regularizer=regularizers.l2(0.02)))
model.add(Dropout(0.5))
model.add(
Dense(num_labels, activation="softmax", kernel_regularizer=regularizers.l2(0.02))
)
for layer in base_model.layers:
layer.trainable = False
for layer in base_model.layers[-22:]:
layer.trainable = True
# Reviewing our CNN model
model.summary()
tf.keras.utils.plot_model(
model,
show_shapes=True,
show_layer_names=True,
rankdir="TB",
expand_nested=True,
dpi=100,
) # ,to_file='model.png')
early = EarlyStopping(monitor="val_accuracy", patience=4, mode="max")
# Set a learning rate annealer
learning_rate_reduction = ReduceLROnPlateau(
monitor="val_accuracy", patience=5, verbose=1, factor=0.5, min_lr=1e-7
)
from keras.callbacks import ModelCheckpoint
class CustomModelCheckPoint(keras.callbacks.Callback):
def __init__(self, **kargs):
super(CustomModelCheckPoint, self).__init__(**kargs)
self.epoch_accuracy = {} # loss at given epoch
self.epoch_loss = {} # accuracy at given epoch
def on_epoch_begin(self, epoch, logs={}):
# Things done on beginning of epoch.
return
def on_epoch_end(self, epoch, logs={}):
# things done on end of the epoch
self.epoch_accuracy[epoch] = logs.get("acc")
self.epoch_loss[epoch] = logs.get("loss")
self.model.save_weights("../output/resnet50/name-of-model-%d.h5" % epoch)
checkpointer = ModelCheckpoint(
filepath="../working/best.hdf5",
monitor="val_accuracy",
save_best_only=True,
mode="max",
)
lr = 0.001
epochs = 50
batch_size = 64
model.compile(optimizer=Adam(lr), loss="binary_crossentropy", metrics=["accuracy"])
history = model.fit_generator(
datagen.flow(x_train, y_train, batch_size=batch_size),
validation_data=(x_validate, y_validate),
epochs=epochs,
verbose=1,
steps_per_epoch=x_train.shape[0] // batch_size,
callbacks=[learning_rate_reduction],
)
# list all data in history
print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history["accuracy"])
plt.plot(history.history["val_accuracy"])
plt.title("model accuracy")
plt.ylabel("accuracy")
plt.xlabel("epoch")
plt.legend(["train", "test"], loc="upper left")
plt.show()
# summarize history for loss
plt.plot(history.history["loss"])
plt.plot(history.history["val_loss"])
plt.title("model loss")
plt.ylabel("loss")
plt.xlabel("epoch")
plt.legend(["train", "test"], loc="upper left")
plt.show()
# Testing model on test data to evaluate
y_pred = model.predict(x_test)
print(accuracy_score(np.argmax(y_test, axis=1), np.argmax(y_pred, axis=1)))
# model.load_weights("../working/best.hdf5")
test_loss, test_acc = model.evaluate(x_test, y_test, verbose=1)
print("test_accuracy = %f ; test_loss = %f" % (test_acc, test_loss))
# save model
# serialize model to JSON
resnet50_json = model.to_json()
with open("resnet50.json", "w") as json_file:
json_file.write(resnet50_json)
# serialize weights to HDF5
model.save_weights("resnet50.h5")
print("Saved model to disk")
# Function to plot confusion matrix
def plot_confusion_matrix(
cm, classes, normalize=False, title="Confusion matrix", cmap=plt.cm.Blues
):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
plt.imshow(cm, interpolation="nearest", cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
if normalize:
cm = cm.astype("float") / cm.sum(axis=1)[:, np.newaxis]
thresh = cm.max() / 2.0
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(
j,
i,
cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black",
)
plt.tight_layout()
plt.ylabel("True label")
plt.xlabel("Predicted label")
# Predict the values from the validation dataset
Y_pred = model.predict(x_test)
# Convert predictions classes to one hot vectors
Y_pred_classes = np.argmax(Y_pred, axis=1)
# Convert validation observations to one hot vectors
Y_true = np.argmax(y_test, axis=1)
# compute the confusion matrix
confusion_mtx = confusion_matrix(Y_true, Y_pred_classes)
cm_plot_label = ["Nevus", "Melanoma"]
# plot the confusion matrix
plot_confusion_matrix(confusion_mtx, cm_plot_label)
from sklearn.metrics import classification_report
classification_report(np.argmax(y_test, axis=1), np.argmax(Y_pred, axis=1))
from sklearn.metrics import roc_auc_score, auc
from sklearn.metrics import roc_curve
roc_log = roc_auc_score(np.argmax(y_test, axis=1), np.argmax(Y_pred, axis=1))
false_positive_rate, true_positive_rate, threshold = roc_curve(
np.argmax(y_test, axis=1), np.argmax(Y_pred, axis=1)
)
area_under_curve = auc(false_positive_rate, true_positive_rate)
plt.plot([0, 1], [0, 1], "r--")
plt.plot(
false_positive_rate,
true_positive_rate,
label="AUC = {:.3f}".format(area_under_curve),
)
plt.xlabel("False positive rate")
plt.ylabel("True positive rate")
plt.title("ROC curve")
plt.legend(loc="best")
plt.show()
# plt.savefig(ROC_PLOT_FILE, bbox_inches='tight')
plt.close()
from sklearn import preprocessing
label_encoder = preprocessing.LabelEncoder()
df1 = skin_df.copy()
df1 = df1.drop(
columns=[
"Clinical Diagnosis",
"Histological Diagnosis",
"image_path",
"cell_type_idx",
"image",
],
axis=1,
)
name_cat = label_encoder.fit_transform(df1["Name"])
name_cat = pd.DataFrame({"Name": name_cat})
Asymmetry_cat = label_encoder.fit_transform(df1["Asymmetry"])
Asymmetry_cat = pd.DataFrame({"Asymmetry": Asymmetry_cat})
Pigment_Network_cat = label_encoder.fit_transform(df1["Pigment Network"])
Pigment_Network_cat = pd.DataFrame({"Pigment Network": Pigment_Network_cat})
Dots_Globules_cat = label_encoder.fit_transform(df1["Dots/Globules"])
Dots_Globules_cat = pd.DataFrame({"Dots/Globules": Dots_Globules_cat})
Streaks_cat = label_encoder.fit_transform(df1["Streaks"])
Streaks_cat = pd.DataFrame({"Streaks": Streaks_cat})
Regression_Areas_cat = label_encoder.fit_transform(df1["Regression Areas"])
Regression_Areas_cat = pd.DataFrame({"Regression Areas": Regression_Areas_cat})
Blue_Whitish_Veil_cat = label_encoder.fit_transform(df1["Blue-Whitish Veil"])
Blue_Whitish_Veil_cat = pd.DataFrame({"Blue-Whitish Veil": Blue_Whitish_Veil_cat})
Colors_cat = label_encoder.fit_transform(df1["Colors"])
Colors_cat = pd.DataFrame({"Colors": Colors_cat})
lesion_cat = label_encoder.fit_transform(df1["lesion"])
lesion_cat = pd.DataFrame({"lesion": lesion_cat})
df1.name = name_cat
df1.Asymmetry = Asymmetry_cat
df1.Pigment_Network = Pigment_Network_cat
df1.Dots_Globules = Dots_Globules_cat
df1.Streaks = Streaks_cat
df1.Regression_Areas = Regression_Areas_cat
df1.Blue_Whitish_Veil = Blue_Whitish_Veil_cat
df1.Colors = Colors_cat
df1.lesion = lesion_cat
df1
from sklearn.svm import SVC
model_svc = SVC()
model_svc.fit(x_train_o, y_train)
| false | 0 | 23,035 | 0 | 608 | 23,035 |
||
69293649 | <kaggle_start><code># 生成data文件
import os
from os.path import join, isfile
import numpy as np
import h5py
from glob import glob
# from torch.utils.serialization import load_lua
import torchfile
from PIL import Image
import yaml
import io
import pdb
# images_path ='/kaggle/input/kaggle-small-data/kaggle_small_data/Birds dataset/CUB_200_2011/images'
# embedding_path ='/kaggle/input/kaggle-small-data/kaggle_small_data/Birds dataset/cub_icml'
# text_path ='/kaggle/input/kaggle-small-data/kaggle_small_data/Birds dataset/cvpr2016_cub/text_c10'
# val_classes ='/kaggle/input/kaggle-small-data/kaggle_small_data/Birds dataset/cub_icml/valclasses.txt'
# train_classes ='/kaggle/input/kaggle-small-data/kaggle_small_data/Birds dataset/cub_icml/trainclasses.txt'
# test_classes ='/kaggle/input/kaggle-small-data/kaggle_small_data/Birds dataset/cub_icml/testclasses.txt'
images_path = (
"/kaggle/input/kaggle-mid-data/kaggle_mid_data/Birds dataset/CUB_200_2011/images"
)
embedding_path = "/kaggle/input/kaggle-mid-data/kaggle_mid_data/Birds dataset/cub_icml"
text_path = (
"/kaggle/input/kaggle-mid-data/kaggle_mid_data/Birds dataset/cvpr2016_cub/text_c10"
)
val_classes = "/kaggle/input/kaggle-mid-data/kaggle_mid_data/Birds dataset/cub_icml/valclasses.txt"
train_classes = "/kaggle/input/kaggle-mid-data/kaggle_mid_data/Birds dataset/cub_icml/trainclasses.txt"
test_classes = "/kaggle/input/kaggle-mid-data/kaggle_mid_data/Birds dataset/cub_icml/testclasses.txt"
datasetDir = "/kaggle/working/birds.hdf5"
# val_classes = open(val_classes).read()
# train_classes = open(train_classes).read()
# test_classes = open(test_classes).read()
val_classes = open(val_classes).read().splitlines()
train_classes = open(train_classes).read().splitlines()
test_classes = open(test_classes).read().splitlines()
# print(val_classes)
# print(val_classes2)
if os.path.exists(datasetDir):
os.remove(datasetDir)
f = h5py.File(datasetDir, "w")
train = f.create_group("train")
valid = f.create_group("valid")
test = f.create_group("test")
# print(f)
# print(train)
# print(test)
for _class in sorted(os.listdir(embedding_path)):
split = ""
if _class in train_classes:
split = train
elif _class in val_classes:
split = valid
elif _class in test_classes:
split = test
# print(_class)
# print(type(_class))
# print(train_classes)
# print(type(train_classes))
# print(split)
# else:#它还会遍历到文件夹下的.txt文件
# print(_class)
data_path = os.path.join(embedding_path, _class) # 获取数据路径
txt_path = os.path.join(text_path, _class)
# zip将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表
# example遍历cub_icml的叶子文件
# txt_file遍历cvpr2016_cub的叶子文件
for example, txt_file in zip(
sorted(glob(data_path + "/*.t7")), sorted(glob(txt_path + "/*.txt"))
):
example_data = torchfile.load(example) # 加载t7文件
# print(example_data)
# print(type(example_data))#查看是什么类型,实际上是一个字典
# print(example_data.keys())#查看有什么键
img_path = example_data[b"img"]
# print(img_path)
embeddings = example_data[b"txt"]
# print(embeddings.shape)10*1024
# print(type(embeddings))#numpy类型
# print(embeddings)
img_path = str(img_path, "utf-8") # 将bytes转化为字符串
example_name = img_path.split("/")[-1][:-4]
# print(example_name)
f = open(txt_file, "r") # txt路径
txt = f.readlines() # txt的英文描述
f.close()
img_path = os.path.join(images_path, img_path) # 图片路径
img = open(img_path, "rb").read() # 图片以二进制方式读取
txt_choice = np.random.choice(range(10), 5) # 随机从10个里面选5个
embeddings = embeddings[txt_choice] # 从embeddings里面读取文件
txt = np.array(txt) # 转化为np类型
txt = txt[txt_choice]
dt = h5py.special_dtype(vlen=str) # object
for c, e in enumerate(embeddings): # 将embeddings转为一个可以遍历的索引序列
# 这里split是split()的意思,split在前面的split对应
ex = split.create_group(example_name + "_" + str(c))
ex.create_dataset("name", data=example_name)
ex.create_dataset("img", data=np.void(img))
ex.create_dataset("embeddings", data=e)
ex.create_dataset("class", data=_class)
ex.create_dataset("txt", data=txt[c].astype(object), dtype=dt)
# print(example_name)
print("end")
# gan.py
import torch
import torch.nn as nn
from torch.autograd import Variable
import numpy as np
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
self.image_size = 64
self.num_channels = 3
self.noise_dim = 100
self.ngf = 64
# based on: https://github.com/pytorch/examples/blob/master/dcgan/main.py
self.netG = nn.Sequential(
nn.ConvTranspose2d(self.noise_dim, self.ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(self.ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(self.ngf * 8, self.ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d(self.ngf * 4, self.ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(self.ngf * 2, self.ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d(self.ngf, self.num_channels, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (num_channels) x 64 x 64
)
def forward(self, z):
return self.netG(z)
class discriminator(nn.Module):
def __init__(self):
super(discriminator, self).__init__()
self.image_size = 64
self.num_channels = 3
self.ndf = 64
self.B_dim = 128
self.C_dim = 16
self.netD_1 = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(self.num_channels, self.ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(self.ndf, self.ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(self.ndf * 2, self.ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(self.ndf * 4, self.ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
)
self.netD_2 = nn.Sequential(
# state size. (ndf*8) x 4 x 4
nn.Conv2d(self.ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid(),
)
def forward(self, inp):
x_intermediate = self.netD_1(inp)
output = self.netD_2(x_intermediate)
return output.view(-1, 1).squeeze(1), x_intermediate
# wgan.py
import torch
import torch.nn as nn
from torch.autograd import Variable
import numpy as np
# from utils import Concat_embed, minibatch_discriminator
import pdb
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
self.image_size = 64
self.num_channels = 3
self.noise_dim = 100
self.ngf = 64
# based on: https://github.com/pytorch/examples/blob/master/dcgan/main.py
self.netG = nn.Sequential(
nn.ConvTranspose2d(self.noise_dim, self.ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(self.ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(self.ngf * 8, self.ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d(self.ngf * 4, self.ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(self.ngf * 2, self.ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d(self.ngf, self.num_channels, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (num_channels) x 64 x 64
)
def forward(self, z):
output = self.netG(z)
return output
class discriminator(nn.Module):
def __init__(self, improved=False):
super(discriminator, self).__init__()
self.image_size = 64
self.num_channels = 3
self.ndf = 64
if improved:
self.netD_1 = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(self.num_channels, self.ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(self.ndf, self.ndf * 2, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(self.ndf * 2, self.ndf * 4, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(self.ndf * 4, self.ndf * 8, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
)
else:
self.netD_1 = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(self.num_channels, self.ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(self.ndf, self.ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(self.ndf * 2, self.ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(self.ndf * 4, self.ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
)
self.netD_2 = nn.Sequential(
# nn.Conv2d(self.ndf * 8, 1, 4, 1, 0, bias=False),
nn.Conv2d(self.ndf * 8, 1, 4, 1, 0, bias=False)
)
def forward(self, inp):
x_intermediate = self.netD_1(inp)
x = self.netD_2(x_intermediate)
x = x.mean(0)
return x.view(1), x_intermediate
# visualize.py
from visdom import Visdom
import numpy as np
import torchvision
from PIL import ImageDraw, Image, ImageFont
import torch
import pdb
class VisdomPlotter(object):
"""Plots to Visdom"""
def __init__(self, env_name="gan"):
# 这里是大量出现警告的地方
self.viz = Visdom()
self.env = env_name
self.plots = {}
def plot(self, var_name, split_name, x, y, xlabel="epoch"):
if var_name not in self.plots:
self.plots[var_name] = self.viz.line(
X=np.array([x, x]),
Y=np.array([y, y]),
env=self.env,
opts=dict(
legend=[split_name], title=var_name, xlabel=xlabel, ylabel=var_name
),
)
else:
self.viz.updateTrace(
X=np.array([x]),
Y=np.array([y]),
env=self.env,
win=self.plots[var_name],
name=split_name,
)
def draw(self, var_name, images):
if var_name not in self.plots: # 这里出现大量警告
print("pause11")
# print(var_name)
# a=self.viz.images(images)#gan
# self.plots[var_name] = self.viz.images(images, env=self.env)
# print("pause12")
# input()
else:
self.viz.images(images, env=self.env, win=self.plots[var_name])
# import torch
import torch.nn as nn
from torch.autograd import Variable
import numpy as np
# from utils import Concat_embed, minibatch_discriminator
import pdb
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
self.image_size = 64
self.num_channels = 3
self.noise_dim = 100
self.embed_dim = 1024
self.projected_embed_dim = 128
self.latent_dim = self.noise_dim + self.projected_embed_dim
self.ngf = 64
self.projection = nn.Sequential(
nn.Linear(
in_features=self.embed_dim, out_features=self.projected_embed_dim
),
nn.BatchNorm1d(num_features=self.projected_embed_dim),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
)
# based on: https://github.com/pytorch/examples/blob/master/dcgan/main.py
self.netG = nn.Sequential(
nn.ConvTranspose2d(self.latent_dim, self.ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(self.ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(self.ngf * 8, self.ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d(self.ngf * 4, self.ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(self.ngf * 2, self.ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d(self.ngf, self.num_channels, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (num_channels) x 64 x 64
)
def forward(self, embed_vector, z):
projected_embed = self.projection(embed_vector).unsqueeze(2).unsqueeze(3)
latent_vector = torch.cat([projected_embed, z], 1)
output = self.netG(latent_vector)
return output
class discriminator(nn.Module):
def __init__(self, improved=False):
super(discriminator, self).__init__()
self.image_size = 64
self.num_channels = 3
self.embed_dim = 1024
self.projected_embed_dim = 128
self.ndf = 64
if improved:
self.netD_1 = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(self.num_channels, self.ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(self.ndf, self.ndf * 2, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(self.ndf * 2, self.ndf * 4, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(self.ndf * 4, self.ndf * 8, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
)
else:
self.netD_1 = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(self.num_channels, self.ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(self.ndf, self.ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(self.ndf * 2, self.ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(self.ndf * 4, self.ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
)
self.projector = Concat_embed(self.embed_dim, self.projected_embed_dim)
self.netD_2 = nn.Sequential(
# nn.Conv2d(self.ndf * 8, 1, 4, 1, 0, bias=False),
nn.Conv2d(self.ndf * 8 + self.projected_embed_dim, 1, 4, 1, 0, bias=False)
)
def forward(self, inp, embed):
x_intermediate = self.netD_1(inp)
x = self.projector(x_intermediate, embed)
x = self.netD_2(x)
x = x.mean(0)
return x.view(1), x_intermediate
# gan_cls.py
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.autograd import Variable
import numpy as np
# from utils import Concat_embed
import pdb
import yaml
from torch import nn
# from torch.utils.data import DataLoader
# from models.gan_factory import gan_factory
# from utils import Utils, Logger
from PIL import Image
import os
# utils.py
import numpy as np
from torch import autograd
# from visualize import VisdomPlotter
import os
import pdb
class Concat_embed(nn.Module):
def __init__(self, embed_dim, projected_embed_dim):
super(Concat_embed, self).__init__()
self.projection = nn.Sequential(
nn.Linear(in_features=embed_dim, out_features=projected_embed_dim),
nn.BatchNorm1d(num_features=projected_embed_dim),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
)
def forward(self, inp, embed):
projected_embed = self.projection(embed)
replicated_embed = projected_embed.repeat(4, 4, 1, 1).permute(2, 3, 0, 1)
hidden_concat = torch.cat([inp, replicated_embed], 1)
return hidden_concat
class minibatch_discriminator(nn.Module):
def __init__(self, num_channels, B_dim, C_dim):
super(minibatch_discriminator, self).__init__()
self.B_dim = B_dim
self.C_dim = C_dim
self.num_channels = num_channels
T_init = torch.randn(num_channels * 4 * 4, B_dim * C_dim) * 0.1
self.T_tensor = nn.Parameter(T_init, requires_grad=True)
def forward(self, inp):
inp = inp.view(-1, self.num_channels * 4 * 4)
M = inp.mm(self.T_tensor)
M = M.view(-1, self.B_dim, self.C_dim)
op1 = M.unsqueeze(3)
op2 = M.permute(1, 2, 0).unsqueeze(0)
output = torch.sum(torch.abs(op1 - op2), 2)
output = torch.sum(torch.exp(-output), 2)
output = output.view(M.size(0), -1)
output = torch.cat((inp, output), 1)
return output
class Utils(object):
@staticmethod
def smooth_label(tensor, offset):
return tensor + offset
@staticmethod
# based on: https://github.com/caogang/wgan-gp/blob/master/gan_cifar10.py
def compute_GP(netD, real_data, real_embed, fake_data, LAMBDA):
BATCH_SIZE = real_data.size(0)
alpha = torch.rand(BATCH_SIZE, 1)
alpha = (
alpha.expand(BATCH_SIZE, int(real_data.nelement() / BATCH_SIZE))
.contiguous()
.view(BATCH_SIZE, 3, 64, 64)
)
alpha = alpha.cuda()
interpolates = alpha * real_data + ((1 - alpha) * fake_data)
interpolates = interpolates.cuda()
interpolates = autograd.Variable(interpolates, requires_grad=True)
disc_interpolates, _ = netD(interpolates, real_embed)
gradients = autograd.grad(
outputs=disc_interpolates,
inputs=interpolates,
grad_outputs=torch.ones(disc_interpolates.size()).cuda(),
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean() * LAMBDA
return gradient_penalty
@staticmethod
def save_checkpoint(netD, netG, dir_path, subdir_path, epoch):
# 暂时不保存模型
pass
# #print("pause14")
# #保存模型
# #path = os.path.join(dir_path, subdir_path)
# path='/kaggle/working'
# # if not os.path.exists(path):
# # os.makedirs(path)
# # print("no")
# torch.save(netD.state_dict(), '{0}/disc_{1}.pth'.format(path, epoch))
# torch.save(netG.state_dict(), '{0}/gen_{1}.pth'.format(path, epoch))
@staticmethod
def weights_init(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find("BatchNorm") != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
class Logger(object):
def __init__(self, vis_screen):
# 这里是大量警告出现的地方
# print(vis_screen)#gan
# self.viz = VisdomPlotter(env_name=vis_screen)
self.hist_D = []
self.hist_G = []
self.hist_Dx = []
self.hist_DGx = []
self.i = 0
def log_iteration_wgan(
self, epoch, gen_iteration, d_loss, g_loss, real_loss, fake_loss
):
print(
"Epoch: %d, Gen_iteration: %d, d_loss= %f, g_loss= %f, real_loss= %f, fake_loss = %f"
% (
epoch,
gen_iteration,
d_loss.data.cpu().mean(),
g_loss.data.cpu().mean(),
real_loss,
fake_loss,
)
)
self.hist_D.append(d_loss.data.cpu().mean())
self.hist_G.append(g_loss.data.cpu().mean())
def log_iteration_gan(self, epoch, d_loss, g_loss, real_score, fake_score):
# 输出训练成果
# print("pause13")
print(
"Epoch: %d, d_loss= %f, g_loss= %f, D(X)= %f, D(G(X))= %f"
% (
epoch,
d_loss.data.cpu().mean(),
g_loss.data.cpu().mean(),
real_score.data.cpu().mean(),
fake_score.data.cpu().mean(),
)
)
# 每次训练以后把结果放到对应list里面
self.hist_D.append(d_loss.data.cpu().mean())
self.hist_G.append(g_loss.data.cpu().mean())
self.hist_Dx.append(real_score.data.cpu().mean())
self.hist_DGx.append(fake_score.data.cpu().mean())
def plot_epoch(self, epoch):
self.viz.plot("Discriminator", "train", epoch, np.array(self.hist_D).mean())
self.viz.plot("Generator", "train", epoch, np.array(self.hist_G).mean())
self.hist_D = []
self.hist_G = []
def plot_epoch_w_scores(self, epoch):
# viz的全部屏蔽掉
# 绘图
# 求平均值
# print(np.array(self.hist_D).mean())
# print(np.array(self.hist_G).mean())
# print(np.array(self.hist_Dx).mean())
# print(np.array(self.hist_DGx).mean())
# self.viz.plot('Discriminator', 'train', epoch, np.array(self.hist_D).mean())
# self.viz.plot('Generator', 'train', epoch, np.array(self.hist_G).mean())
# self.viz.plot('D(X)', 'train', epoch, np.array(self.hist_Dx).mean())
# self.viz.plot('D(G(X))', 'train', epoch, np.array(self.hist_DGx).mean())
path1 = r"/kaggle/working/Discriminator.txt"
path2 = r"/kaggle/working/Generator.txt"
path3 = r"/kaggle/working/D(X).txt"
path4 = r"/kaggle/working/D(G(X)).txt"
with open(path1, "a", encoding="utf-8") as f:
f.write(str(np.array(self.hist_D).mean()))
f.write("\n")
with open(path2, "a", encoding="utf-8") as f:
f.write(str(np.array(self.hist_G).mean()))
f.write("\n")
with open(path3, "a", encoding="utf-8") as f:
f.write(str(np.array(self.hist_Dx).mean()))
f.write("\n")
with open(path4, "a", encoding="utf-8") as f:
f.write(str(np.array(self.hist_DGx).mean()))
f.write("\n")
# with open(path,"a") as f:
# f.write(str(i))
# f.write('\n')
self.hist_D = []
self.hist_G = []
self.hist_Dx = []
self.hist_DGx = []
def draw(self, right_images, fake_images):
# 在Image转Tensor过程中,图片的格式会由: H * W * C的格式转为: C * H * W格式。
# 输出图片(64*3*64*64)意思是64*64*3的彩色图 第一个64对应的batchsize为64
# a=right_images.numpy()
# a=right_images.cpu().numpy()
# a=right_images.cpu().detach().numpy()
# a0=a[0]
# d=np.transpose(a0)
# c = np.transpose(a)
i = self.i
if i % 500 == 0:
a = right_images.data.cpu().numpy()[:64] * 128 + 128
np.save("/kaggle/working/npy/" + str(i) + "a.npy", a)
b = fake_images.data.cpu().numpy()[:64] * 128 + 128 # 生成的是灰色的图片
np.save("/kaggle/working/npy/" + str(i) + "b.npy", b)
self.i += 1
# print("ok")
# input()
# return
# print(c.shape)
# c0=c[0]
# print(d.shape)
# print(c0.shape)
# plt.imshow("d", d)
# plt.show()
# input()
# print("pause9")
# 这两行代码产生大量的警告
# self.viz.draw('generated images', fake_images.data.cpu().numpy()[:64] * 128 + 128)
# input()
# print("pause10")
# self.viz.draw('real images', right_images.data.cpu().numpy()[:64] * 128 + 128)
#########################################################
class gan_factory(object):
@staticmethod
def generator_factory(type):
if type == "gan":
return generator()
elif type == "wgan":
return generator()
elif type == "vanilla_gan":
return generator()
elif type == "vanilla_wgan":
return generator()
@staticmethod
def discriminator_factory(type):
if type == "gan":
return discriminator()
elif type == "wgan":
return discriminator()
elif type == "vanilla_gan":
return discriminator()
elif type == "vanilla_wgan":
return discriminator()
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
self.image_size = 64
self.num_channels = 3
self.noise_dim = 100
self.embed_dim = 1024
self.projected_embed_dim = 128
self.latent_dim = self.noise_dim + self.projected_embed_dim
self.ngf = 64
self.projection = nn.Sequential(
nn.Linear(
in_features=self.embed_dim, out_features=self.projected_embed_dim
),
nn.BatchNorm1d(num_features=self.projected_embed_dim),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
)
# based on: https://github.com/pytorch/examples/blob/master/dcgan/main.py
self.netG = nn.Sequential(
nn.ConvTranspose2d(self.latent_dim, self.ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(self.ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(self.ngf * 8, self.ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d(self.ngf * 4, self.ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(self.ngf * 2, self.ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d(self.ngf, self.num_channels, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (num_channels) x 64 x 64
)
def forward(self, embed_vector, z):
projected_embed = self.projection(embed_vector).unsqueeze(2).unsqueeze(3)
latent_vector = torch.cat([projected_embed, z], 1)
output = self.netG(latent_vector)
return output
class discriminator(nn.Module):
def __init__(self):
super(discriminator, self).__init__()
self.image_size = 64
self.num_channels = 3
self.embed_dim = 1024
self.projected_embed_dim = 128
self.ndf = 64
self.B_dim = 128
self.C_dim = 16
self.netD_1 = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(self.num_channels, self.ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(self.ndf, self.ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(self.ndf * 2, self.ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(self.ndf * 4, self.ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
)
self.projector = Concat_embed(self.embed_dim, self.projected_embed_dim)
self.netD_2 = nn.Sequential(
# state size. (ndf*8) x 4 x 4
nn.Conv2d(self.ndf * 8 + self.projected_embed_dim, 1, 4, 1, 0, bias=False),
nn.Sigmoid(),
)
def forward(self, inp, embed):
x_intermediate = self.netD_1(inp)
x = self.projector(x_intermediate, embed)
x = self.netD_2(x)
return x.view(-1, 1).squeeze(1), x_intermediate
################################################################
# trainer.py
# config
class Trainer(object):
def __init__(
self,
type,
dataset,
split,
lr,
diter,
vis_screen,
save_path,
l1_coef,
l2_coef,
pre_trained_gen,
pre_trained_disc,
batch_size,
num_workers,
epochs,
):
# with open('config.yaml', 'r') as f:
# config = yaml.load(f, Loader=yaml.FullLoader)
self.generator = torch.nn.DataParallel(
gan_factory.generator_factory(type).cuda()
)
# self.discriminator模型
self.discriminator = torch.nn.DataParallel(
gan_factory.discriminator_factory(type).cuda()
)
if pre_trained_disc:
self.discriminator.load_state_dict(torch.load(pre_trained_disc))
else:
self.discriminator.apply(Utils.weights_init)
if pre_trained_gen:
self.generator.load_state_dict(torch.load(pre_trained_gen))
else:
self.generator.apply(Utils.weights_init)
if dataset == "birds":
# self.dataset = Text2ImageDataset(config['birds_dataset_path'], split=split)
# self.dataset=Text2ImageDataset(r'/kaggle/working/birds.hdf5', split=split)
self.dataset = Text2ImageDataset(
r"/kaggle/input/birdss/birds.hdf5", split=split
) # 源数据
elif dataset == "flowers":
print("error")
return 0
# self.dataset = Text2ImageDataset(config['flowers_dataset_path'], split=split)
else:
print("Dataset not supported, please select either birds or flowers.")
exit()
self.noise_dim = 100
self.batch_size = batch_size
self.num_workers = num_workers
self.lr = lr
self.beta1 = 0.5
self.num_epochs = epochs
self.DITER = diter
self.l1_coef = l1_coef
self.l2_coef = l2_coef
self.data_loader = DataLoader(
self.dataset,
batch_size=self.batch_size,
shuffle=True,
num_workers=self.num_workers,
)
self.optimD = torch.optim.Adam(
self.discriminator.parameters(), lr=self.lr, betas=(self.beta1, 0.999)
)
self.optimG = torch.optim.Adam(
self.generator.parameters(), lr=self.lr, betas=(self.beta1, 0.999)
)
# print(vis_screen)#gan
# print("pause0")
# input()
self.logger = Logger(vis_screen) # 这里涉及到了visdom
# print("pause1")
# input()
self.checkpoints_path = "checkpoints"
self.save_path = save_path
self.type = type
def train(self, cls=False):
if self.type == "wgan":
self._train_wgan(cls)
elif self.type == "gan":
self._train_gan(cls)
elif self.type == "vanilla_wgan":
self._train_vanilla_wgan()
elif self.type == "vanilla_gan":
self._train_vanilla_gan()
def _train_wgan(self, cls):
one = torch.FloatTensor([1])
mone = one * -1
one = Variable(one).cuda()
mone = Variable(mone).cuda()
gen_iteration = 0
for epoch in range(self.num_epochs):
iterator = 0
data_iterator = iter(self.data_loader)
while iterator < len(self.data_loader):
if gen_iteration < 25 or gen_iteration % 500 == 0:
d_iter_count = 100
else:
d_iter_count = self.DITER
d_iter = 0
# Train the discriminator
while d_iter < d_iter_count and iterator < len(self.data_loader):
d_iter += 1
for p in self.discriminator.parameters():
p.requires_grad = True
self.discriminator.zero_grad()
sample = next(data_iterator)
iterator += 1
right_images = sample["right_images"]
right_embed = sample["right_embed"]
wrong_images = sample["wrong_images"]
right_images = Variable(right_images.float()).cuda()
right_embed = Variable(right_embed.float()).cuda()
wrong_images = Variable(wrong_images.float()).cuda()
outputs, _ = self.discriminator(right_images, right_embed)
real_loss = torch.mean(outputs)
real_loss.backward(mone)
if cls:
outputs, _ = self.discriminator(wrong_images, right_embed)
wrong_loss = torch.mean(outputs)
wrong_loss.backward(one)
noise = Variable(
torch.randn(right_images.size(0), self.noise_dim), volatile=True
).cuda()
noise = noise.view(noise.size(0), self.noise_dim, 1, 1)
fake_images = Variable(self.generator(right_embed, noise).data)
outputs, _ = self.discriminator(fake_images, right_embed)
fake_loss = torch.mean(outputs)
fake_loss.backward(one)
## NOTE: Pytorch had a bug with gradient penalty at the time of this project development
## , uncomment the next two lines and remove the params clamping below if you want to try gradient penalty
# gp = Utils.compute_GP(self.discriminator, right_images.data, right_embed, fake_images.data, LAMBDA=10)
# gp.backward()
d_loss = real_loss - fake_loss
if cls:
d_loss = d_loss - wrong_loss
self.optimD.step()
for p in self.discriminator.parameters():
p.data.clamp_(-0.01, 0.01)
# Train Generator
for p in self.discriminator.parameters():
p.requires_grad = False
self.generator.zero_grad()
noise = Variable(torch.randn(right_images.size(0), 100)).cuda()
noise = noise.view(noise.size(0), 100, 1, 1)
fake_images = self.generator(right_embed, noise)
outputs, _ = self.discriminator(fake_images, right_embed)
g_loss = torch.mean(outputs)
g_loss.backward(mone)
g_loss = -g_loss
self.optimG.step()
gen_iteration += 1
self.logger.draw(right_images, fake_images)
self.logger.log_iteration_wgan(
epoch, gen_iteration, d_loss, g_loss, real_loss, fake_loss
)
self.logger.plot_epoch(gen_iteration)
if (epoch + 1) % 50 == 0:
Utils.save_checkpoint(
self.discriminator, self.generator, self.checkpoints_path, epoch
)
def _train_gan(self, cls):
# print("pause2")
criterion = nn.BCELoss()
l2_loss = nn.MSELoss()
l1_loss = nn.L1Loss()
iteration = 0
for epoch in range(self.num_epochs):
for sample in self.data_loader:
# print("pause3")
# input()
iteration += 1
right_images = sample["right_images"]
right_embed = sample["right_embed"]
wrong_images = sample["wrong_images"]
right_images = Variable(right_images.float()).cuda()
right_embed = Variable(right_embed.float()).cuda()
wrong_images = Variable(wrong_images.float()).cuda()
# print("pause4")
# input()
real_labels = torch.ones(right_images.size(0))
fake_labels = torch.zeros(right_images.size(0))
# ======== One sided label smoothing ==========
# Helps preventing the discriminator from overpowering the
# generator adding penalty when the discriminator is too confident
# =============================================
smoothed_real_labels = torch.FloatTensor(
Utils.smooth_label(real_labels.numpy(), -0.1)
)
real_labels = Variable(real_labels).cuda()
smoothed_real_labels = Variable(smoothed_real_labels).cuda()
fake_labels = Variable(fake_labels).cuda()
# Train the discriminator
self.discriminator.zero_grad()
outputs, activation_real = self.discriminator(right_images, right_embed)
real_loss = criterion(outputs, smoothed_real_labels)
real_score = outputs
if cls:
outputs, _ = self.discriminator(wrong_images, right_embed)
wrong_loss = criterion(outputs, fake_labels)
wrong_score = outputs
noise = Variable(torch.randn(right_images.size(0), 100)).cuda()
noise = noise.view(noise.size(0), 100, 1, 1)
fake_images = self.generator(right_embed, noise)
outputs, _ = self.discriminator(fake_images, right_embed)
fake_loss = criterion(outputs, fake_labels)
fake_score = outputs
d_loss = real_loss + fake_loss
if cls:
d_loss = d_loss + wrong_loss
d_loss.backward()
self.optimD.step()
# Train the generator
self.generator.zero_grad()
noise = Variable(torch.randn(right_images.size(0), 100)).cuda()
noise = noise.view(noise.size(0), 100, 1, 1)
fake_images = self.generator(right_embed, noise)
outputs, activation_fake = self.discriminator(fake_images, right_embed)
_, activation_real = self.discriminator(right_images, right_embed)
activation_fake = torch.mean(activation_fake, 0)
activation_real = torch.mean(activation_real, 0)
# ======= Generator Loss function============
# This is a customized loss function, the first term is the regular cross entropy loss
# The second term is feature matching loss, this measure the distance between the real and generated
# images statistics by comparing intermediate layers activations
# The third term is L1 distance between the generated and real images, this is helpful for the conditional case
# because it links the embedding feature vector directly to certain pixel values.
# ===========================================
g_loss = (
criterion(outputs, real_labels)
+ self.l2_coef * l2_loss(activation_fake, activation_real.detach())
+ self.l1_coef * l1_loss(fake_images, right_images)
)
g_loss.backward()
self.optimG.step()
# print("pause5")
if iteration % 5 == 0:
# print("pause6")
self.logger.log_iteration_gan(
epoch, d_loss, g_loss, real_score, fake_score
)
# print("pause7")
self.logger.draw(right_images, fake_images) # 大量警告在此处
# print("pause8")
# 多次训练后进入这里
self.logger.plot_epoch_w_scores(epoch)
if (epoch) % 10 == 0:
Utils.save_checkpoint(
self.discriminator,
self.generator,
self.checkpoints_path,
self.save_path,
epoch,
)
def _train_vanilla_wgan(self):
one = Variable(torch.FloatTensor([1])).cuda()
mone = one * -1
gen_iteration = 0
for epoch in range(self.num_epochs):
iterator = 0
data_iterator = iter(self.data_loader)
while iterator < len(self.data_loader):
if gen_iteration < 25 or gen_iteration % 500 == 0:
d_iter_count = 100
else:
d_iter_count = self.DITER
d_iter = 0
# Train the discriminator
while d_iter < d_iter_count and iterator < len(self.data_loader):
d_iter += 1
for p in self.discriminator.parameters():
p.requires_grad = True
self.discriminator.zero_grad()
sample = next(data_iterator)
iterator += 1
right_images = sample["right_images"]
right_images = Variable(right_images.float()).cuda()
outputs, _ = self.discriminator(right_images)
real_loss = torch.mean(outputs)
real_loss.backward(mone)
noise = Variable(
torch.randn(right_images.size(0), self.noise_dim), volatile=True
).cuda()
noise = noise.view(noise.size(0), self.noise_dim, 1, 1)
fake_images = Variable(self.generator(noise).data)
outputs, _ = self.discriminator(fake_images)
fake_loss = torch.mean(outputs)
fake_loss.backward(one)
## NOTE: Pytorch had a bug with gradient penalty at the time of this project development
## , uncomment the next two lines and remove the params clamping below if you want to try gradient penalty
# gp = Utils.compute_GP(self.discriminator, right_images.data, right_embed, fake_images.data, LAMBDA=10)
# gp.backward()
d_loss = real_loss - fake_loss
self.optimD.step()
for p in self.discriminator.parameters():
p.data.clamp_(-0.01, 0.01)
# Train Generator
for p in self.discriminator.parameters():
p.requires_grad = False
self.generator.zero_grad()
noise = Variable(torch.randn(right_images.size(0), 100)).cuda()
noise = noise.view(noise.size(0), 100, 1, 1)
fake_images = self.generator(noise)
outputs, _ = self.discriminator(fake_images)
g_loss = torch.mean(outputs)
g_loss.backward(mone)
g_loss = -g_loss
self.optimG.step()
gen_iteration += 1
self.logger.draw(right_images, fake_images)
self.logger.log_iteration_wgan(
epoch, gen_iteration, d_loss, g_loss, real_loss, fake_loss
)
self.logger.plot_epoch(gen_iteration)
if (epoch + 1) % 50 == 0:
Utils.save_checkpoint(
self.discriminator, self.generator, self.checkpoints_path, epoch
)
def _train_vanilla_gan(self):
criterion = nn.BCELoss()
l2_loss = nn.MSELoss()
l1_loss = nn.L1Loss()
iteration = 0
for epoch in range(self.num_epochs):
for sample in self.data_loader:
iteration += 1
right_images = sample["right_images"]
right_images = Variable(right_images.float()).cuda()
real_labels = torch.ones(right_images.size(0))
fake_labels = torch.zeros(right_images.size(0))
# ======== One sided label smoothing ==========
# Helps preventing the discriminator from overpowering the
# generator adding penalty when the discriminator is too confident
# =============================================
smoothed_real_labels = torch.FloatTensor(
Utils.smooth_label(real_labels.numpy(), -0.1)
)
real_labels = Variable(real_labels).cuda()
smoothed_real_labels = Variable(smoothed_real_labels).cuda()
fake_labels = Variable(fake_labels).cuda()
# Train the discriminator
self.discriminator.zero_grad()
outputs, activation_real = self.discriminator(right_images)
real_loss = criterion(outputs, smoothed_real_labels)
real_score = outputs
noise = Variable(torch.randn(right_images.size(0), 100)).cuda()
noise = noise.view(noise.size(0), 100, 1, 1)
fake_images = self.generator(noise)
outputs, _ = self.discriminator(fake_images)
fake_loss = criterion(outputs, fake_labels)
fake_score = outputs
d_loss = real_loss + fake_loss
d_loss.backward()
self.optimD.step()
# Train the generator
self.generator.zero_grad()
noise = Variable(torch.randn(right_images.size(0), 100)).cuda()
noise = noise.view(noise.size(0), 100, 1, 1)
fake_images = self.generator(noise)
outputs, activation_fake = self.discriminator(fake_images)
_, activation_real = self.discriminator(right_images)
activation_fake = torch.mean(activation_fake, 0)
activation_real = torch.mean(activation_real, 0)
# ======= Generator Loss function============
# This is a customized loss function, the first term is the regular cross entropy loss
# The second term is feature matching loss, this measure the distance between the real and generated
# images statistics by comparing intermediate layers activations
# The third term is L1 distance between the generated and real images, this is helpful for the conditional case
# because it links the embedding feature vector directly to certain pixel values.
g_loss = (
criterion(outputs, real_labels)
+ self.l2_coef * l2_loss(activation_fake, activation_real.detach())
+ self.l1_coef * l1_loss(fake_images, right_images)
)
g_loss.backward()
self.optimG.step()
if iteration % 5 == 0:
self.logger.log_iteration_gan(
epoch, d_loss, g_loss, real_score, fake_score
)
self.logger.draw(right_images, fake_images)
self.logger.plot_epoch_w_scores(iteration)
if (epoch) % 50 == 0:
Utils.save_checkpoint(
self.discriminator, self.generator, self.checkpoints_path, epoch
)
def predict(self):
i = 0
for sample in self.data_loader:
right_images = sample["right_images"]
right_embed = sample["right_embed"]
txt = sample["txt"]
# if not os.path.exists('results/{0}'.format(self.save_path)):
# os.makedirs('results/{0}'.format(self.save_path))
right_images = Variable(right_images.float()).cuda()
right_embed = Variable(right_embed.float()).cuda()
# Train the generator
noise = Variable(torch.randn(right_images.size(0), 100)).cuda()
noise = noise.view(noise.size(0), 100, 1, 1)
fake_images = self.generator(right_embed, noise)
self.logger.draw(right_images, fake_images)
for image, t in zip(fake_images, txt):
im = Image.fromarray(
image.data.mul_(127.5)
.add_(127.5)
.byte()
.permute(1, 2, 0)
.cpu()
.numpy()
)
# im.save('{0}/{1}.jpg'.format(self.save_path, t.replace("/", "")[:100]))
if i % 1000 == 0:
print(i)
im.save(
"{0}/{1}.jpg".format(
self.save_path, str(i).replace("/", "")[:100]
)
)
i = i + 1
# print('{0}/{1}/.jpg'.format(self.save_path, t.replace("/", "")[:100]))
# print(t)
# input()
print("predict end")
# txt2image_dataset
import os
import io
from torch.utils.data import Dataset, DataLoader
import h5py
import numpy as np
import pdb
from PIL import Image
import torch
from torch.autograd import Variable
import pdb
import torch.nn.functional as F
class Text2ImageDataset(Dataset):
def __init__(self, datasetFile, transform=None, split=0):
self.datasetFile = datasetFile
self.transform = transform
self.dataset = None
self.dataset_keys = None
self.split = "train" if split == 0 else "valid" if split == 1 else "test"
self.h5py2int = lambda x: int(np.array(x))
def __len__(self):
f = h5py.File(self.datasetFile, "r")
self.dataset_keys = [str(k) for k in f[self.split].keys()]
length = len(f[self.split])
f.close()
return length
def __getitem__(self, idx):
if self.dataset is None:
self.dataset = h5py.File(self.datasetFile, mode="r")
self.dataset_keys = [str(k) for k in self.dataset[self.split].keys()]
example_name = self.dataset_keys[idx]
example = self.dataset[self.split][example_name]
# pdb.set_trace()
right_image = bytes(np.array(example["img"]))
right_embed = np.array(example["embeddings"], dtype=float)
wrong_image = bytes(np.array(self.find_wrong_image(example["class"])))
inter_embed = np.array(self.find_inter_embed())
right_image = Image.open(io.BytesIO(right_image)).resize((64, 64))
wrong_image = Image.open(io.BytesIO(wrong_image)).resize((64, 64))
right_image = self.validate_image(right_image)
wrong_image = self.validate_image(wrong_image)
txt = np.array(example["txt"]).astype(str)
sample = {
"right_images": torch.FloatTensor(right_image),
"right_embed": torch.FloatTensor(right_embed),
"wrong_images": torch.FloatTensor(wrong_image),
"inter_embed": torch.FloatTensor(inter_embed),
"txt": str(txt),
}
sample["right_images"] = sample["right_images"].sub_(127.5).div_(127.5)
sample["wrong_images"] = sample["wrong_images"].sub_(127.5).div_(127.5)
return sample
def find_wrong_image(self, category):
idx = np.random.randint(len(self.dataset_keys))
example_name = self.dataset_keys[idx]
example = self.dataset[self.split][example_name]
_category = example["class"]
if _category != category:
return example["img"]
return self.find_wrong_image(category)
def find_inter_embed(self):
idx = np.random.randint(len(self.dataset_keys))
example_name = self.dataset_keys[idx]
example = self.dataset[self.split][example_name]
return example["embeddings"]
def validate_image(self, img):
img = np.array(img, dtype=float)
if len(img.shape) < 3:
rgb = np.empty((64, 64, 3), dtype=np.float32)
rgb[:, :, 0] = img
rgb[:, :, 1] = img
rgb[:, :, 2] = img
img = rgb
return img.transpose(2, 0, 1)
### runtime.py
# from trainer import Trainer
import argparse
from PIL import Image
import os
parser = argparse.ArgumentParser()
parser.add_argument("--type", default="gan")
parser.add_argument("--lr", default=0.0002, type=float) # 0.0002
parser.add_argument("--l1_coef", default=50, type=float)
parser.add_argument("--l2_coef", default=100, type=float)
parser.add_argument("--diter", default=5, type=int)
parser.add_argument("--cls", default=False, action="store_true")
parser.add_argument("--vis_screen", default="gan")
parser.add_argument("--save_path", default=r"/kaggle/working")
# parser.add_argument("--inference", default=False, action='store_true')#训练或者预测
parser.add_argument("--inference", default=True, action="store_true")
parser.add_argument("--pre_trained_disc", default=None)
parser.add_argument("--pre_trained_gen", default=None)
parser.add_argument("--dataset", default="birds")
parser.add_argument("--split", default=0, type=int)
parser.add_argument("--batch_size", default=64, type=int) # 64
parser.add_argument("--num_workers", default=0, type=int)
parser.add_argument("--epochs", default=200, type=int) # 200
# args = parser.parse_args()
args = parser.parse_known_args()[0]
# print(args)
trainer = Trainer(
type=args.type,
dataset=args.dataset,
split=args.split,
lr=args.lr,
diter=args.diter,
vis_screen=args.vis_screen,
save_path=args.save_path,
l1_coef=args.l1_coef,
l2_coef=args.l2_coef,
pre_trained_disc=args.pre_trained_disc,
pre_trained_gen=args.pre_trained_gen,
batch_size=args.batch_size,
num_workers=args.num_workers,
epochs=args.epochs,
)
# 删除图表文件
import os
path1 = r"/kaggle/working/Discriminator.txt"
path2 = r"/kaggle/working/Generator.txt"
path3 = r"/kaggle/working/D(X).txt"
path4 = r"/kaggle/working/D(G(X)).txt"
if os.path.exists(path1):
os.remove(path1)
if os.path.exists(path2):
os.remove(path2)
if os.path.exists(path3):
os.remove(path3)
if os.path.exists(path4):
os.remove(path4)
# 创建npy文件夹
if not os.path.exists(r"/kaggle/working/npy"):
os.mkdir(r"/kaggle/working/npy")
# 创建图表txt
path1 = r"/kaggle/working/Discriminator.txt"
path2 = r"/kaggle/working/Generator.txt"
path3 = r"/kaggle/working/D(X).txt"
path4 = r"/kaggle/working/D(G(X)).txt"
if not os.path.exists(path1):
with open(path1, "w", encoding="utf-8") as f:
f.write("")
if not os.path.exists(path2):
with open(path2, "w", encoding="utf-8") as f:
f.write("")
if not os.path.exists(path3):
with open(path3, "w", encoding="utf-8") as f:
f.write("")
if not os.path.exists(path4):
with open(path4, "w", encoding="utf-8") as f:
f.write("")
# 一次Epoch写入一次txt文件
# if not args.inference:
# print("train")
# trainer.train(args.cls)
# else:
# print("predict")
# trainer.predict()
trainer.train(args.cls)
# trainer.predict()
print("end")
# 下面是额外的内容
print("123")
# #删除图表文件
# import os
# path1=r'/kaggle/working/Discriminator.txt'
# path2=r'/kaggle/working/Generator.txt'
# path3=r'/kaggle/working/D(X).txt'
# path4=r'/kaggle/working/D(G(X)).txt'
# if os.path.exists(path1):
# os.remove(path1)
# if os.path.exists(path2):
# os.remove(path2)
# if os.path.exists(path3):
# os.remove(path3)
# if os.path.exists(path4):
# os.remove(path4)
# #创建图表文件
# import os
# path1=r'/kaggle/working/Discriminator.txt'
# path2=r'/kaggle/working/Generator.txt'
# path3=r'/kaggle/working/D(X).txt'
# path4=r'/kaggle/working/D(G(X)).txt'
# if not os.path.exists(path1):
# with open(path1, "w", encoding="utf-8") as f:
# f.write("")
# if not os.path.exists(path2):
# with open(path2, "w", encoding="utf-8") as f:
# f.write("")
# if not os.path.exists(path3):
# with open(path3, "w", encoding="utf-8") as f:
# f.write("")
# if not os.path.exists(path4):
# with open(path4, "w", encoding="utf-8") as f:
# f.write("")
# 下面是额外的内容
# pip show torchfile#查看安装包的版本
# pip uninstall visdom#卸载visdom
# pip list --outdated#查看是否有新版本更新
# pip list#查看所有包的版本
# import socket
# # 获取本机计算机名称
# hostname = socket.gethostname()
# # 获取本机ip
# ip = socket.gethostbyname(hostname)
# print(hostname)
# print(ip)
# #配套在pycharm上面使用
# import cv2
# import numpy as np
# import visdom
# #启动服务python -m visdom.server
# # #读取npy文件
# viz = visdom.Visdom()
# def fun1():
# print("fun1")
# # viz.text('Hello, world!')
# # viz.image(np.ones((3, 10, 10)))
# a=np.load(r'D:\.android\2000a.npy')
# b=np.load(r'D:\.android\2000b.npy')
# viz.images(a)
# viz.images(b)
# #读取txt文件并且绘图
# def fun2():
# plots={}
# def plot(var_name, split_name, x, y, xlabel='epoch'):
# if var_name not in plots:
# plots[var_name] = viz.line(X=np.array([x, x]), Y=np.array([y, y]), opts=dict(
# legend=[split_name],
# title=var_name,
# xlabel=xlabel,
# ylabel=var_name
# ))
# #viz.line(X=np.array([x, x]), Y=np.array([y, y]))
# else:
# viz.line(X=np.array([x, x]), Y=np.array([y, y]),win=plots[var_name],
# name=split_name,update='append')
# # viz.updateTrace(X=np.array([x]), Y=np.array([y]), win=plots[var_name],
# # name=split_name)
# path1=r'D:\.android\D(G(X)).txt'
# path2=r'D:\.android\D(X).txt'
# path3=r'D:\.android\Discriminator.txt'
# path4=r'D:\.android\Generator.txt'
# i=0
# with open(path1, 'r') as f:
# for line in f:
# line = float(line)
# #print(line)
# plot('D(G(X))', 'train', i, line)
# #print(line)
# i+=1
# i=0
# with open(path2, 'r') as f:
# for line in f:
# line = float(line)
# plot('D(X)', 'train', i, line)
# i+=1
# i=0
# with open(path3, 'r') as f:
# for line in f:
# line = float(line)
# plot('Discriminator', 'train', i, line)
# i+=1
# i=0
# with open(path4, 'r') as f:
# for line in f:
# line = float(line)
# plot('Generator', 'train', i, line)
# i+=1
# #self.viz.plot('Discriminator', 'train', epoch, np.array(self.hist_D).mean())
# #self.viz.plot('Generator', 'train', epoch, np.array(self.hist_G).mean())
# #self.viz.plot('D(X)', 'train', epoch, np.array(self.hist_Dx).mean())
# #self.viz.plot('D(G(X))', 'train', epoch, np.array(self.hist_DGx).mean())
# fun1()
# #fun2()
# import os
# if not os.path.exists(r'/kaggle/working/npy'):
# os.mkdir(r'/kaggle/working/npy')
# 检查图片是否正确
# aa=np.load("/kaggle/working/img2.npy")
# print(aa.shape)
# print(aa)
# pip install wmi
# pip install pypiwin32
# #查看kaggle的版本
# # PythonVersion:python2.7
# # filename:sys_info.py
# import sys
# import wmi
# import socket
# import platform
# import imp
# imp.reload(sys)
# #reload(sys)
# #sys.setdefaultencoding('utf-8')
# c = wmi.WMI()
# # 系统信息
# print(u'操作系统名称' + platform.platform()[:-(len(platform.version()) + 1)])
# print(u'操作系统版本号' + platform.version())
# print(u'操作系统的位数' + platform.architecture()[0])
# hostname = socket.getfqdn(socket.gethostname())
# ip = socket.gethostbyname(hostname)
# print('ip:' + ip)
# # CPU信息
# def get_CPU():
# cpumsg = []
# for cpu in c.Win32_Processor():
# tmpmsg = {}
# tmpmsg['Name'] = cpu.Name
# cpumsg.append(tmpmsg)
# print(cpumsg)
# # 内存信息
# def get_PhysicalMemory():
# memorys = []
# for mem in c.Win32_PhysicalMemory():
# tmpmsg = {}
# tmpmsg['Tag'] = mem.Tag
# tmpmsg['ConfiguredClockSpeed'] = str(mem.ConfiguredClockSpeed) + 'MHz'
# memorys.append(tmpmsg)
# print(memorys)
# # 显卡信息
# def get_video():
# videos = []
# for v in c.Win32_VideoController():
# tmpmsg = {}
# tmpmsg['Caption'] = v.Caption
# tmpmsg['AdapterRAM'] = str(abs(v.AdapterRAM) / (1024 ** 3)) + 'G'
# videos.append(tmpmsg)
# print(videos)
# # 网卡mac地址
# def get_MacAddress():
# macs = []
# for n in c.Win32_NetworkAdapter():
# mactmp = n.MACAddress
# if mactmp and len(mactmp.strip()) > 5:
# tmpmsg = {}
# tmpmsg['ProductName'] = n.ProductName
# tmpmsg['NetConnectionID'] = n.NetConnectionID
# tmpmsg['MACAddress'] = n.MACAddress
# macs.append(tmpmsg)
# print(macs)
# def main():
# get_CPU()
# get_PhysicalMemory()
# get_video()
# get_MacAddress()
# if __name__ == '__main__':
# main()
# #下载运行结果
# import os
# os.chdir(r'/kaggle/working/npy')
# print(os.getcwd())
# print(os.listdir("/kaggle/working/npy"))
# from IPython.display import FileLink
# #FileLink('a colorful bird containing a bright blue head, nape neck and back, blue white and black feathers, bu.jpg')
# FileLink('2000b.npy')
# from torch.utils.data import DataLoader
# birds_dataset_path='/kaggle/working/birds.hdf5'
# dataset = Text2ImageDataset(birds_dataset_path,split=split)
# #注意调整batch_size和num_workers不然cuda 虚拟环境的共享内存不足要报错
# #或者多线程操作时就有可能导致线程套线程,容易出现死锁的情况
# data_loader = DataLoader(dataset, batch_size=64,shuffle=True,num_workers=0)
# import h5py
# datasetFile='/kaggle/working/birds.hdf5'
# f = h5py.File(datasetFile, 'r')
# split='train'
# print(f)
# print(split)
# print(f.keys())
# print("123")
# print(f['train'].keys())
# print("ok")
# dataset_keys = [str(k) for k in f[split].keys()]
# print(dataset_keys)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0069/293/69293649.ipynb | null | null | [{"Id": 69293649, "ScriptId": 18546956, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 7677477, "CreationDate": "07/29/2021 07:38:08", "VersionNumber": 96.0, "Title": "pmh_two", "EvaluationDate": "07/29/2021", "IsChange": true, "TotalLines": 1700.0, "LinesInsertedFromPrevious": 238.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 1462.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | # 生成data文件
import os
from os.path import join, isfile
import numpy as np
import h5py
from glob import glob
# from torch.utils.serialization import load_lua
import torchfile
from PIL import Image
import yaml
import io
import pdb
# images_path ='/kaggle/input/kaggle-small-data/kaggle_small_data/Birds dataset/CUB_200_2011/images'
# embedding_path ='/kaggle/input/kaggle-small-data/kaggle_small_data/Birds dataset/cub_icml'
# text_path ='/kaggle/input/kaggle-small-data/kaggle_small_data/Birds dataset/cvpr2016_cub/text_c10'
# val_classes ='/kaggle/input/kaggle-small-data/kaggle_small_data/Birds dataset/cub_icml/valclasses.txt'
# train_classes ='/kaggle/input/kaggle-small-data/kaggle_small_data/Birds dataset/cub_icml/trainclasses.txt'
# test_classes ='/kaggle/input/kaggle-small-data/kaggle_small_data/Birds dataset/cub_icml/testclasses.txt'
images_path = (
"/kaggle/input/kaggle-mid-data/kaggle_mid_data/Birds dataset/CUB_200_2011/images"
)
embedding_path = "/kaggle/input/kaggle-mid-data/kaggle_mid_data/Birds dataset/cub_icml"
text_path = (
"/kaggle/input/kaggle-mid-data/kaggle_mid_data/Birds dataset/cvpr2016_cub/text_c10"
)
val_classes = "/kaggle/input/kaggle-mid-data/kaggle_mid_data/Birds dataset/cub_icml/valclasses.txt"
train_classes = "/kaggle/input/kaggle-mid-data/kaggle_mid_data/Birds dataset/cub_icml/trainclasses.txt"
test_classes = "/kaggle/input/kaggle-mid-data/kaggle_mid_data/Birds dataset/cub_icml/testclasses.txt"
datasetDir = "/kaggle/working/birds.hdf5"
# val_classes = open(val_classes).read()
# train_classes = open(train_classes).read()
# test_classes = open(test_classes).read()
val_classes = open(val_classes).read().splitlines()
train_classes = open(train_classes).read().splitlines()
test_classes = open(test_classes).read().splitlines()
# print(val_classes)
# print(val_classes2)
if os.path.exists(datasetDir):
os.remove(datasetDir)
f = h5py.File(datasetDir, "w")
train = f.create_group("train")
valid = f.create_group("valid")
test = f.create_group("test")
# print(f)
# print(train)
# print(test)
for _class in sorted(os.listdir(embedding_path)):
split = ""
if _class in train_classes:
split = train
elif _class in val_classes:
split = valid
elif _class in test_classes:
split = test
# print(_class)
# print(type(_class))
# print(train_classes)
# print(type(train_classes))
# print(split)
# else:#它还会遍历到文件夹下的.txt文件
# print(_class)
data_path = os.path.join(embedding_path, _class) # 获取数据路径
txt_path = os.path.join(text_path, _class)
# zip将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表
# example遍历cub_icml的叶子文件
# txt_file遍历cvpr2016_cub的叶子文件
for example, txt_file in zip(
sorted(glob(data_path + "/*.t7")), sorted(glob(txt_path + "/*.txt"))
):
example_data = torchfile.load(example) # 加载t7文件
# print(example_data)
# print(type(example_data))#查看是什么类型,实际上是一个字典
# print(example_data.keys())#查看有什么键
img_path = example_data[b"img"]
# print(img_path)
embeddings = example_data[b"txt"]
# print(embeddings.shape)10*1024
# print(type(embeddings))#numpy类型
# print(embeddings)
img_path = str(img_path, "utf-8") # 将bytes转化为字符串
example_name = img_path.split("/")[-1][:-4]
# print(example_name)
f = open(txt_file, "r") # txt路径
txt = f.readlines() # txt的英文描述
f.close()
img_path = os.path.join(images_path, img_path) # 图片路径
img = open(img_path, "rb").read() # 图片以二进制方式读取
txt_choice = np.random.choice(range(10), 5) # 随机从10个里面选5个
embeddings = embeddings[txt_choice] # 从embeddings里面读取文件
txt = np.array(txt) # 转化为np类型
txt = txt[txt_choice]
dt = h5py.special_dtype(vlen=str) # object
for c, e in enumerate(embeddings): # 将embeddings转为一个可以遍历的索引序列
# 这里split是split()的意思,split在前面的split对应
ex = split.create_group(example_name + "_" + str(c))
ex.create_dataset("name", data=example_name)
ex.create_dataset("img", data=np.void(img))
ex.create_dataset("embeddings", data=e)
ex.create_dataset("class", data=_class)
ex.create_dataset("txt", data=txt[c].astype(object), dtype=dt)
# print(example_name)
print("end")
# gan.py
import torch
import torch.nn as nn
from torch.autograd import Variable
import numpy as np
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
self.image_size = 64
self.num_channels = 3
self.noise_dim = 100
self.ngf = 64
# based on: https://github.com/pytorch/examples/blob/master/dcgan/main.py
self.netG = nn.Sequential(
nn.ConvTranspose2d(self.noise_dim, self.ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(self.ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(self.ngf * 8, self.ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d(self.ngf * 4, self.ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(self.ngf * 2, self.ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d(self.ngf, self.num_channels, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (num_channels) x 64 x 64
)
def forward(self, z):
return self.netG(z)
class discriminator(nn.Module):
def __init__(self):
super(discriminator, self).__init__()
self.image_size = 64
self.num_channels = 3
self.ndf = 64
self.B_dim = 128
self.C_dim = 16
self.netD_1 = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(self.num_channels, self.ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(self.ndf, self.ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(self.ndf * 2, self.ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(self.ndf * 4, self.ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
)
self.netD_2 = nn.Sequential(
# state size. (ndf*8) x 4 x 4
nn.Conv2d(self.ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid(),
)
def forward(self, inp):
x_intermediate = self.netD_1(inp)
output = self.netD_2(x_intermediate)
return output.view(-1, 1).squeeze(1), x_intermediate
# wgan.py
import torch
import torch.nn as nn
from torch.autograd import Variable
import numpy as np
# from utils import Concat_embed, minibatch_discriminator
import pdb
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
self.image_size = 64
self.num_channels = 3
self.noise_dim = 100
self.ngf = 64
# based on: https://github.com/pytorch/examples/blob/master/dcgan/main.py
self.netG = nn.Sequential(
nn.ConvTranspose2d(self.noise_dim, self.ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(self.ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(self.ngf * 8, self.ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d(self.ngf * 4, self.ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(self.ngf * 2, self.ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d(self.ngf, self.num_channels, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (num_channels) x 64 x 64
)
def forward(self, z):
output = self.netG(z)
return output
class discriminator(nn.Module):
def __init__(self, improved=False):
super(discriminator, self).__init__()
self.image_size = 64
self.num_channels = 3
self.ndf = 64
if improved:
self.netD_1 = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(self.num_channels, self.ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(self.ndf, self.ndf * 2, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(self.ndf * 2, self.ndf * 4, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(self.ndf * 4, self.ndf * 8, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
)
else:
self.netD_1 = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(self.num_channels, self.ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(self.ndf, self.ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(self.ndf * 2, self.ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(self.ndf * 4, self.ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
)
self.netD_2 = nn.Sequential(
# nn.Conv2d(self.ndf * 8, 1, 4, 1, 0, bias=False),
nn.Conv2d(self.ndf * 8, 1, 4, 1, 0, bias=False)
)
def forward(self, inp):
x_intermediate = self.netD_1(inp)
x = self.netD_2(x_intermediate)
x = x.mean(0)
return x.view(1), x_intermediate
# visualize.py
from visdom import Visdom
import numpy as np
import torchvision
from PIL import ImageDraw, Image, ImageFont
import torch
import pdb
class VisdomPlotter(object):
"""Plots to Visdom"""
def __init__(self, env_name="gan"):
# 这里是大量出现警告的地方
self.viz = Visdom()
self.env = env_name
self.plots = {}
def plot(self, var_name, split_name, x, y, xlabel="epoch"):
if var_name not in self.plots:
self.plots[var_name] = self.viz.line(
X=np.array([x, x]),
Y=np.array([y, y]),
env=self.env,
opts=dict(
legend=[split_name], title=var_name, xlabel=xlabel, ylabel=var_name
),
)
else:
self.viz.updateTrace(
X=np.array([x]),
Y=np.array([y]),
env=self.env,
win=self.plots[var_name],
name=split_name,
)
def draw(self, var_name, images):
if var_name not in self.plots: # 这里出现大量警告
print("pause11")
# print(var_name)
# a=self.viz.images(images)#gan
# self.plots[var_name] = self.viz.images(images, env=self.env)
# print("pause12")
# input()
else:
self.viz.images(images, env=self.env, win=self.plots[var_name])
# import torch
import torch.nn as nn
from torch.autograd import Variable
import numpy as np
# from utils import Concat_embed, minibatch_discriminator
import pdb
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
self.image_size = 64
self.num_channels = 3
self.noise_dim = 100
self.embed_dim = 1024
self.projected_embed_dim = 128
self.latent_dim = self.noise_dim + self.projected_embed_dim
self.ngf = 64
self.projection = nn.Sequential(
nn.Linear(
in_features=self.embed_dim, out_features=self.projected_embed_dim
),
nn.BatchNorm1d(num_features=self.projected_embed_dim),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
)
# based on: https://github.com/pytorch/examples/blob/master/dcgan/main.py
self.netG = nn.Sequential(
nn.ConvTranspose2d(self.latent_dim, self.ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(self.ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(self.ngf * 8, self.ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d(self.ngf * 4, self.ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(self.ngf * 2, self.ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d(self.ngf, self.num_channels, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (num_channels) x 64 x 64
)
def forward(self, embed_vector, z):
projected_embed = self.projection(embed_vector).unsqueeze(2).unsqueeze(3)
latent_vector = torch.cat([projected_embed, z], 1)
output = self.netG(latent_vector)
return output
class discriminator(nn.Module):
def __init__(self, improved=False):
super(discriminator, self).__init__()
self.image_size = 64
self.num_channels = 3
self.embed_dim = 1024
self.projected_embed_dim = 128
self.ndf = 64
if improved:
self.netD_1 = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(self.num_channels, self.ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(self.ndf, self.ndf * 2, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(self.ndf * 2, self.ndf * 4, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(self.ndf * 4, self.ndf * 8, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
)
else:
self.netD_1 = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(self.num_channels, self.ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(self.ndf, self.ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(self.ndf * 2, self.ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(self.ndf * 4, self.ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*8) x 4 x 4
)
self.projector = Concat_embed(self.embed_dim, self.projected_embed_dim)
self.netD_2 = nn.Sequential(
# nn.Conv2d(self.ndf * 8, 1, 4, 1, 0, bias=False),
nn.Conv2d(self.ndf * 8 + self.projected_embed_dim, 1, 4, 1, 0, bias=False)
)
def forward(self, inp, embed):
x_intermediate = self.netD_1(inp)
x = self.projector(x_intermediate, embed)
x = self.netD_2(x)
x = x.mean(0)
return x.view(1), x_intermediate
# gan_cls.py
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.autograd import Variable
import numpy as np
# from utils import Concat_embed
import pdb
import yaml
from torch import nn
# from torch.utils.data import DataLoader
# from models.gan_factory import gan_factory
# from utils import Utils, Logger
from PIL import Image
import os
# utils.py
import numpy as np
from torch import autograd
# from visualize import VisdomPlotter
import os
import pdb
class Concat_embed(nn.Module):
def __init__(self, embed_dim, projected_embed_dim):
super(Concat_embed, self).__init__()
self.projection = nn.Sequential(
nn.Linear(in_features=embed_dim, out_features=projected_embed_dim),
nn.BatchNorm1d(num_features=projected_embed_dim),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
)
def forward(self, inp, embed):
projected_embed = self.projection(embed)
replicated_embed = projected_embed.repeat(4, 4, 1, 1).permute(2, 3, 0, 1)
hidden_concat = torch.cat([inp, replicated_embed], 1)
return hidden_concat
class minibatch_discriminator(nn.Module):
def __init__(self, num_channels, B_dim, C_dim):
super(minibatch_discriminator, self).__init__()
self.B_dim = B_dim
self.C_dim = C_dim
self.num_channels = num_channels
T_init = torch.randn(num_channels * 4 * 4, B_dim * C_dim) * 0.1
self.T_tensor = nn.Parameter(T_init, requires_grad=True)
def forward(self, inp):
inp = inp.view(-1, self.num_channels * 4 * 4)
M = inp.mm(self.T_tensor)
M = M.view(-1, self.B_dim, self.C_dim)
op1 = M.unsqueeze(3)
op2 = M.permute(1, 2, 0).unsqueeze(0)
output = torch.sum(torch.abs(op1 - op2), 2)
output = torch.sum(torch.exp(-output), 2)
output = output.view(M.size(0), -1)
output = torch.cat((inp, output), 1)
return output
class Utils(object):
@staticmethod
def smooth_label(tensor, offset):
return tensor + offset
@staticmethod
# based on: https://github.com/caogang/wgan-gp/blob/master/gan_cifar10.py
def compute_GP(netD, real_data, real_embed, fake_data, LAMBDA):
BATCH_SIZE = real_data.size(0)
alpha = torch.rand(BATCH_SIZE, 1)
alpha = (
alpha.expand(BATCH_SIZE, int(real_data.nelement() / BATCH_SIZE))
.contiguous()
.view(BATCH_SIZE, 3, 64, 64)
)
alpha = alpha.cuda()
interpolates = alpha * real_data + ((1 - alpha) * fake_data)
interpolates = interpolates.cuda()
interpolates = autograd.Variable(interpolates, requires_grad=True)
disc_interpolates, _ = netD(interpolates, real_embed)
gradients = autograd.grad(
outputs=disc_interpolates,
inputs=interpolates,
grad_outputs=torch.ones(disc_interpolates.size()).cuda(),
create_graph=True,
retain_graph=True,
only_inputs=True,
)[0]
gradient_penalty = ((gradients.norm(2, dim=1) - 1) ** 2).mean() * LAMBDA
return gradient_penalty
@staticmethod
def save_checkpoint(netD, netG, dir_path, subdir_path, epoch):
# 暂时不保存模型
pass
# #print("pause14")
# #保存模型
# #path = os.path.join(dir_path, subdir_path)
# path='/kaggle/working'
# # if not os.path.exists(path):
# # os.makedirs(path)
# # print("no")
# torch.save(netD.state_dict(), '{0}/disc_{1}.pth'.format(path, epoch))
# torch.save(netG.state_dict(), '{0}/gen_{1}.pth'.format(path, epoch))
@staticmethod
def weights_init(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find("BatchNorm") != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
class Logger(object):
def __init__(self, vis_screen):
# 这里是大量警告出现的地方
# print(vis_screen)#gan
# self.viz = VisdomPlotter(env_name=vis_screen)
self.hist_D = []
self.hist_G = []
self.hist_Dx = []
self.hist_DGx = []
self.i = 0
def log_iteration_wgan(
self, epoch, gen_iteration, d_loss, g_loss, real_loss, fake_loss
):
print(
"Epoch: %d, Gen_iteration: %d, d_loss= %f, g_loss= %f, real_loss= %f, fake_loss = %f"
% (
epoch,
gen_iteration,
d_loss.data.cpu().mean(),
g_loss.data.cpu().mean(),
real_loss,
fake_loss,
)
)
self.hist_D.append(d_loss.data.cpu().mean())
self.hist_G.append(g_loss.data.cpu().mean())
def log_iteration_gan(self, epoch, d_loss, g_loss, real_score, fake_score):
# 输出训练成果
# print("pause13")
print(
"Epoch: %d, d_loss= %f, g_loss= %f, D(X)= %f, D(G(X))= %f"
% (
epoch,
d_loss.data.cpu().mean(),
g_loss.data.cpu().mean(),
real_score.data.cpu().mean(),
fake_score.data.cpu().mean(),
)
)
# 每次训练以后把结果放到对应list里面
self.hist_D.append(d_loss.data.cpu().mean())
self.hist_G.append(g_loss.data.cpu().mean())
self.hist_Dx.append(real_score.data.cpu().mean())
self.hist_DGx.append(fake_score.data.cpu().mean())
def plot_epoch(self, epoch):
self.viz.plot("Discriminator", "train", epoch, np.array(self.hist_D).mean())
self.viz.plot("Generator", "train", epoch, np.array(self.hist_G).mean())
self.hist_D = []
self.hist_G = []
def plot_epoch_w_scores(self, epoch):
# viz的全部屏蔽掉
# 绘图
# 求平均值
# print(np.array(self.hist_D).mean())
# print(np.array(self.hist_G).mean())
# print(np.array(self.hist_Dx).mean())
# print(np.array(self.hist_DGx).mean())
# self.viz.plot('Discriminator', 'train', epoch, np.array(self.hist_D).mean())
# self.viz.plot('Generator', 'train', epoch, np.array(self.hist_G).mean())
# self.viz.plot('D(X)', 'train', epoch, np.array(self.hist_Dx).mean())
# self.viz.plot('D(G(X))', 'train', epoch, np.array(self.hist_DGx).mean())
path1 = r"/kaggle/working/Discriminator.txt"
path2 = r"/kaggle/working/Generator.txt"
path3 = r"/kaggle/working/D(X).txt"
path4 = r"/kaggle/working/D(G(X)).txt"
with open(path1, "a", encoding="utf-8") as f:
f.write(str(np.array(self.hist_D).mean()))
f.write("\n")
with open(path2, "a", encoding="utf-8") as f:
f.write(str(np.array(self.hist_G).mean()))
f.write("\n")
with open(path3, "a", encoding="utf-8") as f:
f.write(str(np.array(self.hist_Dx).mean()))
f.write("\n")
with open(path4, "a", encoding="utf-8") as f:
f.write(str(np.array(self.hist_DGx).mean()))
f.write("\n")
# with open(path,"a") as f:
# f.write(str(i))
# f.write('\n')
self.hist_D = []
self.hist_G = []
self.hist_Dx = []
self.hist_DGx = []
def draw(self, right_images, fake_images):
# 在Image转Tensor过程中,图片的格式会由: H * W * C的格式转为: C * H * W格式。
# 输出图片(64*3*64*64)意思是64*64*3的彩色图 第一个64对应的batchsize为64
# a=right_images.numpy()
# a=right_images.cpu().numpy()
# a=right_images.cpu().detach().numpy()
# a0=a[0]
# d=np.transpose(a0)
# c = np.transpose(a)
i = self.i
if i % 500 == 0:
a = right_images.data.cpu().numpy()[:64] * 128 + 128
np.save("/kaggle/working/npy/" + str(i) + "a.npy", a)
b = fake_images.data.cpu().numpy()[:64] * 128 + 128 # 生成的是灰色的图片
np.save("/kaggle/working/npy/" + str(i) + "b.npy", b)
self.i += 1
# print("ok")
# input()
# return
# print(c.shape)
# c0=c[0]
# print(d.shape)
# print(c0.shape)
# plt.imshow("d", d)
# plt.show()
# input()
# print("pause9")
# 这两行代码产生大量的警告
# self.viz.draw('generated images', fake_images.data.cpu().numpy()[:64] * 128 + 128)
# input()
# print("pause10")
# self.viz.draw('real images', right_images.data.cpu().numpy()[:64] * 128 + 128)
#########################################################
class gan_factory(object):
@staticmethod
def generator_factory(type):
if type == "gan":
return generator()
elif type == "wgan":
return generator()
elif type == "vanilla_gan":
return generator()
elif type == "vanilla_wgan":
return generator()
@staticmethod
def discriminator_factory(type):
if type == "gan":
return discriminator()
elif type == "wgan":
return discriminator()
elif type == "vanilla_gan":
return discriminator()
elif type == "vanilla_wgan":
return discriminator()
class generator(nn.Module):
def __init__(self):
super(generator, self).__init__()
self.image_size = 64
self.num_channels = 3
self.noise_dim = 100
self.embed_dim = 1024
self.projected_embed_dim = 128
self.latent_dim = self.noise_dim + self.projected_embed_dim
self.ngf = 64
self.projection = nn.Sequential(
nn.Linear(
in_features=self.embed_dim, out_features=self.projected_embed_dim
),
nn.BatchNorm1d(num_features=self.projected_embed_dim),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
)
# based on: https://github.com/pytorch/examples/blob/master/dcgan/main.py
self.netG = nn.Sequential(
nn.ConvTranspose2d(self.latent_dim, self.ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(self.ngf * 8),
nn.ReLU(True),
# state size. (ngf*8) x 4 x 4
nn.ConvTranspose2d(self.ngf * 8, self.ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 4),
nn.ReLU(True),
# state size. (ngf*4) x 8 x 8
nn.ConvTranspose2d(self.ngf * 4, self.ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf * 2),
nn.ReLU(True),
# state size. (ngf*2) x 16 x 16
nn.ConvTranspose2d(self.ngf * 2, self.ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ngf),
nn.ReLU(True),
# state size. (ngf) x 32 x 32
nn.ConvTranspose2d(self.ngf, self.num_channels, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (num_channels) x 64 x 64
)
def forward(self, embed_vector, z):
projected_embed = self.projection(embed_vector).unsqueeze(2).unsqueeze(3)
latent_vector = torch.cat([projected_embed, z], 1)
output = self.netG(latent_vector)
return output
class discriminator(nn.Module):
def __init__(self):
super(discriminator, self).__init__()
self.image_size = 64
self.num_channels = 3
self.embed_dim = 1024
self.projected_embed_dim = 128
self.ndf = 64
self.B_dim = 128
self.C_dim = 16
self.netD_1 = nn.Sequential(
# input is (nc) x 64 x 64
nn.Conv2d(self.num_channels, self.ndf, 4, 2, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf) x 32 x 32
nn.Conv2d(self.ndf, self.ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*2) x 16 x 16
nn.Conv2d(self.ndf * 2, self.ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# state size. (ndf*4) x 8 x 8
nn.Conv2d(self.ndf * 4, self.ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(self.ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
)
self.projector = Concat_embed(self.embed_dim, self.projected_embed_dim)
self.netD_2 = nn.Sequential(
# state size. (ndf*8) x 4 x 4
nn.Conv2d(self.ndf * 8 + self.projected_embed_dim, 1, 4, 1, 0, bias=False),
nn.Sigmoid(),
)
def forward(self, inp, embed):
x_intermediate = self.netD_1(inp)
x = self.projector(x_intermediate, embed)
x = self.netD_2(x)
return x.view(-1, 1).squeeze(1), x_intermediate
################################################################
# trainer.py
# config
class Trainer(object):
def __init__(
self,
type,
dataset,
split,
lr,
diter,
vis_screen,
save_path,
l1_coef,
l2_coef,
pre_trained_gen,
pre_trained_disc,
batch_size,
num_workers,
epochs,
):
# with open('config.yaml', 'r') as f:
# config = yaml.load(f, Loader=yaml.FullLoader)
self.generator = torch.nn.DataParallel(
gan_factory.generator_factory(type).cuda()
)
# self.discriminator模型
self.discriminator = torch.nn.DataParallel(
gan_factory.discriminator_factory(type).cuda()
)
if pre_trained_disc:
self.discriminator.load_state_dict(torch.load(pre_trained_disc))
else:
self.discriminator.apply(Utils.weights_init)
if pre_trained_gen:
self.generator.load_state_dict(torch.load(pre_trained_gen))
else:
self.generator.apply(Utils.weights_init)
if dataset == "birds":
# self.dataset = Text2ImageDataset(config['birds_dataset_path'], split=split)
# self.dataset=Text2ImageDataset(r'/kaggle/working/birds.hdf5', split=split)
self.dataset = Text2ImageDataset(
r"/kaggle/input/birdss/birds.hdf5", split=split
) # 源数据
elif dataset == "flowers":
print("error")
return 0
# self.dataset = Text2ImageDataset(config['flowers_dataset_path'], split=split)
else:
print("Dataset not supported, please select either birds or flowers.")
exit()
self.noise_dim = 100
self.batch_size = batch_size
self.num_workers = num_workers
self.lr = lr
self.beta1 = 0.5
self.num_epochs = epochs
self.DITER = diter
self.l1_coef = l1_coef
self.l2_coef = l2_coef
self.data_loader = DataLoader(
self.dataset,
batch_size=self.batch_size,
shuffle=True,
num_workers=self.num_workers,
)
self.optimD = torch.optim.Adam(
self.discriminator.parameters(), lr=self.lr, betas=(self.beta1, 0.999)
)
self.optimG = torch.optim.Adam(
self.generator.parameters(), lr=self.lr, betas=(self.beta1, 0.999)
)
# print(vis_screen)#gan
# print("pause0")
# input()
self.logger = Logger(vis_screen) # 这里涉及到了visdom
# print("pause1")
# input()
self.checkpoints_path = "checkpoints"
self.save_path = save_path
self.type = type
def train(self, cls=False):
if self.type == "wgan":
self._train_wgan(cls)
elif self.type == "gan":
self._train_gan(cls)
elif self.type == "vanilla_wgan":
self._train_vanilla_wgan()
elif self.type == "vanilla_gan":
self._train_vanilla_gan()
def _train_wgan(self, cls):
one = torch.FloatTensor([1])
mone = one * -1
one = Variable(one).cuda()
mone = Variable(mone).cuda()
gen_iteration = 0
for epoch in range(self.num_epochs):
iterator = 0
data_iterator = iter(self.data_loader)
while iterator < len(self.data_loader):
if gen_iteration < 25 or gen_iteration % 500 == 0:
d_iter_count = 100
else:
d_iter_count = self.DITER
d_iter = 0
# Train the discriminator
while d_iter < d_iter_count and iterator < len(self.data_loader):
d_iter += 1
for p in self.discriminator.parameters():
p.requires_grad = True
self.discriminator.zero_grad()
sample = next(data_iterator)
iterator += 1
right_images = sample["right_images"]
right_embed = sample["right_embed"]
wrong_images = sample["wrong_images"]
right_images = Variable(right_images.float()).cuda()
right_embed = Variable(right_embed.float()).cuda()
wrong_images = Variable(wrong_images.float()).cuda()
outputs, _ = self.discriminator(right_images, right_embed)
real_loss = torch.mean(outputs)
real_loss.backward(mone)
if cls:
outputs, _ = self.discriminator(wrong_images, right_embed)
wrong_loss = torch.mean(outputs)
wrong_loss.backward(one)
noise = Variable(
torch.randn(right_images.size(0), self.noise_dim), volatile=True
).cuda()
noise = noise.view(noise.size(0), self.noise_dim, 1, 1)
fake_images = Variable(self.generator(right_embed, noise).data)
outputs, _ = self.discriminator(fake_images, right_embed)
fake_loss = torch.mean(outputs)
fake_loss.backward(one)
## NOTE: Pytorch had a bug with gradient penalty at the time of this project development
## , uncomment the next two lines and remove the params clamping below if you want to try gradient penalty
# gp = Utils.compute_GP(self.discriminator, right_images.data, right_embed, fake_images.data, LAMBDA=10)
# gp.backward()
d_loss = real_loss - fake_loss
if cls:
d_loss = d_loss - wrong_loss
self.optimD.step()
for p in self.discriminator.parameters():
p.data.clamp_(-0.01, 0.01)
# Train Generator
for p in self.discriminator.parameters():
p.requires_grad = False
self.generator.zero_grad()
noise = Variable(torch.randn(right_images.size(0), 100)).cuda()
noise = noise.view(noise.size(0), 100, 1, 1)
fake_images = self.generator(right_embed, noise)
outputs, _ = self.discriminator(fake_images, right_embed)
g_loss = torch.mean(outputs)
g_loss.backward(mone)
g_loss = -g_loss
self.optimG.step()
gen_iteration += 1
self.logger.draw(right_images, fake_images)
self.logger.log_iteration_wgan(
epoch, gen_iteration, d_loss, g_loss, real_loss, fake_loss
)
self.logger.plot_epoch(gen_iteration)
if (epoch + 1) % 50 == 0:
Utils.save_checkpoint(
self.discriminator, self.generator, self.checkpoints_path, epoch
)
def _train_gan(self, cls):
# print("pause2")
criterion = nn.BCELoss()
l2_loss = nn.MSELoss()
l1_loss = nn.L1Loss()
iteration = 0
for epoch in range(self.num_epochs):
for sample in self.data_loader:
# print("pause3")
# input()
iteration += 1
right_images = sample["right_images"]
right_embed = sample["right_embed"]
wrong_images = sample["wrong_images"]
right_images = Variable(right_images.float()).cuda()
right_embed = Variable(right_embed.float()).cuda()
wrong_images = Variable(wrong_images.float()).cuda()
# print("pause4")
# input()
real_labels = torch.ones(right_images.size(0))
fake_labels = torch.zeros(right_images.size(0))
# ======== One sided label smoothing ==========
# Helps preventing the discriminator from overpowering the
# generator adding penalty when the discriminator is too confident
# =============================================
smoothed_real_labels = torch.FloatTensor(
Utils.smooth_label(real_labels.numpy(), -0.1)
)
real_labels = Variable(real_labels).cuda()
smoothed_real_labels = Variable(smoothed_real_labels).cuda()
fake_labels = Variable(fake_labels).cuda()
# Train the discriminator
self.discriminator.zero_grad()
outputs, activation_real = self.discriminator(right_images, right_embed)
real_loss = criterion(outputs, smoothed_real_labels)
real_score = outputs
if cls:
outputs, _ = self.discriminator(wrong_images, right_embed)
wrong_loss = criterion(outputs, fake_labels)
wrong_score = outputs
noise = Variable(torch.randn(right_images.size(0), 100)).cuda()
noise = noise.view(noise.size(0), 100, 1, 1)
fake_images = self.generator(right_embed, noise)
outputs, _ = self.discriminator(fake_images, right_embed)
fake_loss = criterion(outputs, fake_labels)
fake_score = outputs
d_loss = real_loss + fake_loss
if cls:
d_loss = d_loss + wrong_loss
d_loss.backward()
self.optimD.step()
# Train the generator
self.generator.zero_grad()
noise = Variable(torch.randn(right_images.size(0), 100)).cuda()
noise = noise.view(noise.size(0), 100, 1, 1)
fake_images = self.generator(right_embed, noise)
outputs, activation_fake = self.discriminator(fake_images, right_embed)
_, activation_real = self.discriminator(right_images, right_embed)
activation_fake = torch.mean(activation_fake, 0)
activation_real = torch.mean(activation_real, 0)
# ======= Generator Loss function============
# This is a customized loss function, the first term is the regular cross entropy loss
# The second term is feature matching loss, this measure the distance between the real and generated
# images statistics by comparing intermediate layers activations
# The third term is L1 distance between the generated and real images, this is helpful for the conditional case
# because it links the embedding feature vector directly to certain pixel values.
# ===========================================
g_loss = (
criterion(outputs, real_labels)
+ self.l2_coef * l2_loss(activation_fake, activation_real.detach())
+ self.l1_coef * l1_loss(fake_images, right_images)
)
g_loss.backward()
self.optimG.step()
# print("pause5")
if iteration % 5 == 0:
# print("pause6")
self.logger.log_iteration_gan(
epoch, d_loss, g_loss, real_score, fake_score
)
# print("pause7")
self.logger.draw(right_images, fake_images) # 大量警告在此处
# print("pause8")
# 多次训练后进入这里
self.logger.plot_epoch_w_scores(epoch)
if (epoch) % 10 == 0:
Utils.save_checkpoint(
self.discriminator,
self.generator,
self.checkpoints_path,
self.save_path,
epoch,
)
def _train_vanilla_wgan(self):
one = Variable(torch.FloatTensor([1])).cuda()
mone = one * -1
gen_iteration = 0
for epoch in range(self.num_epochs):
iterator = 0
data_iterator = iter(self.data_loader)
while iterator < len(self.data_loader):
if gen_iteration < 25 or gen_iteration % 500 == 0:
d_iter_count = 100
else:
d_iter_count = self.DITER
d_iter = 0
# Train the discriminator
while d_iter < d_iter_count and iterator < len(self.data_loader):
d_iter += 1
for p in self.discriminator.parameters():
p.requires_grad = True
self.discriminator.zero_grad()
sample = next(data_iterator)
iterator += 1
right_images = sample["right_images"]
right_images = Variable(right_images.float()).cuda()
outputs, _ = self.discriminator(right_images)
real_loss = torch.mean(outputs)
real_loss.backward(mone)
noise = Variable(
torch.randn(right_images.size(0), self.noise_dim), volatile=True
).cuda()
noise = noise.view(noise.size(0), self.noise_dim, 1, 1)
fake_images = Variable(self.generator(noise).data)
outputs, _ = self.discriminator(fake_images)
fake_loss = torch.mean(outputs)
fake_loss.backward(one)
## NOTE: Pytorch had a bug with gradient penalty at the time of this project development
## , uncomment the next two lines and remove the params clamping below if you want to try gradient penalty
# gp = Utils.compute_GP(self.discriminator, right_images.data, right_embed, fake_images.data, LAMBDA=10)
# gp.backward()
d_loss = real_loss - fake_loss
self.optimD.step()
for p in self.discriminator.parameters():
p.data.clamp_(-0.01, 0.01)
# Train Generator
for p in self.discriminator.parameters():
p.requires_grad = False
self.generator.zero_grad()
noise = Variable(torch.randn(right_images.size(0), 100)).cuda()
noise = noise.view(noise.size(0), 100, 1, 1)
fake_images = self.generator(noise)
outputs, _ = self.discriminator(fake_images)
g_loss = torch.mean(outputs)
g_loss.backward(mone)
g_loss = -g_loss
self.optimG.step()
gen_iteration += 1
self.logger.draw(right_images, fake_images)
self.logger.log_iteration_wgan(
epoch, gen_iteration, d_loss, g_loss, real_loss, fake_loss
)
self.logger.plot_epoch(gen_iteration)
if (epoch + 1) % 50 == 0:
Utils.save_checkpoint(
self.discriminator, self.generator, self.checkpoints_path, epoch
)
def _train_vanilla_gan(self):
criterion = nn.BCELoss()
l2_loss = nn.MSELoss()
l1_loss = nn.L1Loss()
iteration = 0
for epoch in range(self.num_epochs):
for sample in self.data_loader:
iteration += 1
right_images = sample["right_images"]
right_images = Variable(right_images.float()).cuda()
real_labels = torch.ones(right_images.size(0))
fake_labels = torch.zeros(right_images.size(0))
# ======== One sided label smoothing ==========
# Helps preventing the discriminator from overpowering the
# generator adding penalty when the discriminator is too confident
# =============================================
smoothed_real_labels = torch.FloatTensor(
Utils.smooth_label(real_labels.numpy(), -0.1)
)
real_labels = Variable(real_labels).cuda()
smoothed_real_labels = Variable(smoothed_real_labels).cuda()
fake_labels = Variable(fake_labels).cuda()
# Train the discriminator
self.discriminator.zero_grad()
outputs, activation_real = self.discriminator(right_images)
real_loss = criterion(outputs, smoothed_real_labels)
real_score = outputs
noise = Variable(torch.randn(right_images.size(0), 100)).cuda()
noise = noise.view(noise.size(0), 100, 1, 1)
fake_images = self.generator(noise)
outputs, _ = self.discriminator(fake_images)
fake_loss = criterion(outputs, fake_labels)
fake_score = outputs
d_loss = real_loss + fake_loss
d_loss.backward()
self.optimD.step()
# Train the generator
self.generator.zero_grad()
noise = Variable(torch.randn(right_images.size(0), 100)).cuda()
noise = noise.view(noise.size(0), 100, 1, 1)
fake_images = self.generator(noise)
outputs, activation_fake = self.discriminator(fake_images)
_, activation_real = self.discriminator(right_images)
activation_fake = torch.mean(activation_fake, 0)
activation_real = torch.mean(activation_real, 0)
# ======= Generator Loss function============
# This is a customized loss function, the first term is the regular cross entropy loss
# The second term is feature matching loss, this measure the distance between the real and generated
# images statistics by comparing intermediate layers activations
# The third term is L1 distance between the generated and real images, this is helpful for the conditional case
# because it links the embedding feature vector directly to certain pixel values.
g_loss = (
criterion(outputs, real_labels)
+ self.l2_coef * l2_loss(activation_fake, activation_real.detach())
+ self.l1_coef * l1_loss(fake_images, right_images)
)
g_loss.backward()
self.optimG.step()
if iteration % 5 == 0:
self.logger.log_iteration_gan(
epoch, d_loss, g_loss, real_score, fake_score
)
self.logger.draw(right_images, fake_images)
self.logger.plot_epoch_w_scores(iteration)
if (epoch) % 50 == 0:
Utils.save_checkpoint(
self.discriminator, self.generator, self.checkpoints_path, epoch
)
def predict(self):
i = 0
for sample in self.data_loader:
right_images = sample["right_images"]
right_embed = sample["right_embed"]
txt = sample["txt"]
# if not os.path.exists('results/{0}'.format(self.save_path)):
# os.makedirs('results/{0}'.format(self.save_path))
right_images = Variable(right_images.float()).cuda()
right_embed = Variable(right_embed.float()).cuda()
# Train the generator
noise = Variable(torch.randn(right_images.size(0), 100)).cuda()
noise = noise.view(noise.size(0), 100, 1, 1)
fake_images = self.generator(right_embed, noise)
self.logger.draw(right_images, fake_images)
for image, t in zip(fake_images, txt):
im = Image.fromarray(
image.data.mul_(127.5)
.add_(127.5)
.byte()
.permute(1, 2, 0)
.cpu()
.numpy()
)
# im.save('{0}/{1}.jpg'.format(self.save_path, t.replace("/", "")[:100]))
if i % 1000 == 0:
print(i)
im.save(
"{0}/{1}.jpg".format(
self.save_path, str(i).replace("/", "")[:100]
)
)
i = i + 1
# print('{0}/{1}/.jpg'.format(self.save_path, t.replace("/", "")[:100]))
# print(t)
# input()
print("predict end")
# txt2image_dataset
import os
import io
from torch.utils.data import Dataset, DataLoader
import h5py
import numpy as np
import pdb
from PIL import Image
import torch
from torch.autograd import Variable
import pdb
import torch.nn.functional as F
class Text2ImageDataset(Dataset):
def __init__(self, datasetFile, transform=None, split=0):
self.datasetFile = datasetFile
self.transform = transform
self.dataset = None
self.dataset_keys = None
self.split = "train" if split == 0 else "valid" if split == 1 else "test"
self.h5py2int = lambda x: int(np.array(x))
def __len__(self):
f = h5py.File(self.datasetFile, "r")
self.dataset_keys = [str(k) for k in f[self.split].keys()]
length = len(f[self.split])
f.close()
return length
def __getitem__(self, idx):
if self.dataset is None:
self.dataset = h5py.File(self.datasetFile, mode="r")
self.dataset_keys = [str(k) for k in self.dataset[self.split].keys()]
example_name = self.dataset_keys[idx]
example = self.dataset[self.split][example_name]
# pdb.set_trace()
right_image = bytes(np.array(example["img"]))
right_embed = np.array(example["embeddings"], dtype=float)
wrong_image = bytes(np.array(self.find_wrong_image(example["class"])))
inter_embed = np.array(self.find_inter_embed())
right_image = Image.open(io.BytesIO(right_image)).resize((64, 64))
wrong_image = Image.open(io.BytesIO(wrong_image)).resize((64, 64))
right_image = self.validate_image(right_image)
wrong_image = self.validate_image(wrong_image)
txt = np.array(example["txt"]).astype(str)
sample = {
"right_images": torch.FloatTensor(right_image),
"right_embed": torch.FloatTensor(right_embed),
"wrong_images": torch.FloatTensor(wrong_image),
"inter_embed": torch.FloatTensor(inter_embed),
"txt": str(txt),
}
sample["right_images"] = sample["right_images"].sub_(127.5).div_(127.5)
sample["wrong_images"] = sample["wrong_images"].sub_(127.5).div_(127.5)
return sample
def find_wrong_image(self, category):
idx = np.random.randint(len(self.dataset_keys))
example_name = self.dataset_keys[idx]
example = self.dataset[self.split][example_name]
_category = example["class"]
if _category != category:
return example["img"]
return self.find_wrong_image(category)
def find_inter_embed(self):
idx = np.random.randint(len(self.dataset_keys))
example_name = self.dataset_keys[idx]
example = self.dataset[self.split][example_name]
return example["embeddings"]
def validate_image(self, img):
img = np.array(img, dtype=float)
if len(img.shape) < 3:
rgb = np.empty((64, 64, 3), dtype=np.float32)
rgb[:, :, 0] = img
rgb[:, :, 1] = img
rgb[:, :, 2] = img
img = rgb
return img.transpose(2, 0, 1)
### runtime.py
# from trainer import Trainer
import argparse
from PIL import Image
import os
parser = argparse.ArgumentParser()
parser.add_argument("--type", default="gan")
parser.add_argument("--lr", default=0.0002, type=float) # 0.0002
parser.add_argument("--l1_coef", default=50, type=float)
parser.add_argument("--l2_coef", default=100, type=float)
parser.add_argument("--diter", default=5, type=int)
parser.add_argument("--cls", default=False, action="store_true")
parser.add_argument("--vis_screen", default="gan")
parser.add_argument("--save_path", default=r"/kaggle/working")
# parser.add_argument("--inference", default=False, action='store_true')#训练或者预测
parser.add_argument("--inference", default=True, action="store_true")
parser.add_argument("--pre_trained_disc", default=None)
parser.add_argument("--pre_trained_gen", default=None)
parser.add_argument("--dataset", default="birds")
parser.add_argument("--split", default=0, type=int)
parser.add_argument("--batch_size", default=64, type=int) # 64
parser.add_argument("--num_workers", default=0, type=int)
parser.add_argument("--epochs", default=200, type=int) # 200
# args = parser.parse_args()
args = parser.parse_known_args()[0]
# print(args)
trainer = Trainer(
type=args.type,
dataset=args.dataset,
split=args.split,
lr=args.lr,
diter=args.diter,
vis_screen=args.vis_screen,
save_path=args.save_path,
l1_coef=args.l1_coef,
l2_coef=args.l2_coef,
pre_trained_disc=args.pre_trained_disc,
pre_trained_gen=args.pre_trained_gen,
batch_size=args.batch_size,
num_workers=args.num_workers,
epochs=args.epochs,
)
# 删除图表文件
import os
path1 = r"/kaggle/working/Discriminator.txt"
path2 = r"/kaggle/working/Generator.txt"
path3 = r"/kaggle/working/D(X).txt"
path4 = r"/kaggle/working/D(G(X)).txt"
if os.path.exists(path1):
os.remove(path1)
if os.path.exists(path2):
os.remove(path2)
if os.path.exists(path3):
os.remove(path3)
if os.path.exists(path4):
os.remove(path4)
# 创建npy文件夹
if not os.path.exists(r"/kaggle/working/npy"):
os.mkdir(r"/kaggle/working/npy")
# 创建图表txt
path1 = r"/kaggle/working/Discriminator.txt"
path2 = r"/kaggle/working/Generator.txt"
path3 = r"/kaggle/working/D(X).txt"
path4 = r"/kaggle/working/D(G(X)).txt"
if not os.path.exists(path1):
with open(path1, "w", encoding="utf-8") as f:
f.write("")
if not os.path.exists(path2):
with open(path2, "w", encoding="utf-8") as f:
f.write("")
if not os.path.exists(path3):
with open(path3, "w", encoding="utf-8") as f:
f.write("")
if not os.path.exists(path4):
with open(path4, "w", encoding="utf-8") as f:
f.write("")
# 一次Epoch写入一次txt文件
# if not args.inference:
# print("train")
# trainer.train(args.cls)
# else:
# print("predict")
# trainer.predict()
trainer.train(args.cls)
# trainer.predict()
print("end")
# 下面是额外的内容
print("123")
# #删除图表文件
# import os
# path1=r'/kaggle/working/Discriminator.txt'
# path2=r'/kaggle/working/Generator.txt'
# path3=r'/kaggle/working/D(X).txt'
# path4=r'/kaggle/working/D(G(X)).txt'
# if os.path.exists(path1):
# os.remove(path1)
# if os.path.exists(path2):
# os.remove(path2)
# if os.path.exists(path3):
# os.remove(path3)
# if os.path.exists(path4):
# os.remove(path4)
# #创建图表文件
# import os
# path1=r'/kaggle/working/Discriminator.txt'
# path2=r'/kaggle/working/Generator.txt'
# path3=r'/kaggle/working/D(X).txt'
# path4=r'/kaggle/working/D(G(X)).txt'
# if not os.path.exists(path1):
# with open(path1, "w", encoding="utf-8") as f:
# f.write("")
# if not os.path.exists(path2):
# with open(path2, "w", encoding="utf-8") as f:
# f.write("")
# if not os.path.exists(path3):
# with open(path3, "w", encoding="utf-8") as f:
# f.write("")
# if not os.path.exists(path4):
# with open(path4, "w", encoding="utf-8") as f:
# f.write("")
# 下面是额外的内容
# pip show torchfile#查看安装包的版本
# pip uninstall visdom#卸载visdom
# pip list --outdated#查看是否有新版本更新
# pip list#查看所有包的版本
# import socket
# # 获取本机计算机名称
# hostname = socket.gethostname()
# # 获取本机ip
# ip = socket.gethostbyname(hostname)
# print(hostname)
# print(ip)
# #配套在pycharm上面使用
# import cv2
# import numpy as np
# import visdom
# #启动服务python -m visdom.server
# # #读取npy文件
# viz = visdom.Visdom()
# def fun1():
# print("fun1")
# # viz.text('Hello, world!')
# # viz.image(np.ones((3, 10, 10)))
# a=np.load(r'D:\.android\2000a.npy')
# b=np.load(r'D:\.android\2000b.npy')
# viz.images(a)
# viz.images(b)
# #读取txt文件并且绘图
# def fun2():
# plots={}
# def plot(var_name, split_name, x, y, xlabel='epoch'):
# if var_name not in plots:
# plots[var_name] = viz.line(X=np.array([x, x]), Y=np.array([y, y]), opts=dict(
# legend=[split_name],
# title=var_name,
# xlabel=xlabel,
# ylabel=var_name
# ))
# #viz.line(X=np.array([x, x]), Y=np.array([y, y]))
# else:
# viz.line(X=np.array([x, x]), Y=np.array([y, y]),win=plots[var_name],
# name=split_name,update='append')
# # viz.updateTrace(X=np.array([x]), Y=np.array([y]), win=plots[var_name],
# # name=split_name)
# path1=r'D:\.android\D(G(X)).txt'
# path2=r'D:\.android\D(X).txt'
# path3=r'D:\.android\Discriminator.txt'
# path4=r'D:\.android\Generator.txt'
# i=0
# with open(path1, 'r') as f:
# for line in f:
# line = float(line)
# #print(line)
# plot('D(G(X))', 'train', i, line)
# #print(line)
# i+=1
# i=0
# with open(path2, 'r') as f:
# for line in f:
# line = float(line)
# plot('D(X)', 'train', i, line)
# i+=1
# i=0
# with open(path3, 'r') as f:
# for line in f:
# line = float(line)
# plot('Discriminator', 'train', i, line)
# i+=1
# i=0
# with open(path4, 'r') as f:
# for line in f:
# line = float(line)
# plot('Generator', 'train', i, line)
# i+=1
# #self.viz.plot('Discriminator', 'train', epoch, np.array(self.hist_D).mean())
# #self.viz.plot('Generator', 'train', epoch, np.array(self.hist_G).mean())
# #self.viz.plot('D(X)', 'train', epoch, np.array(self.hist_Dx).mean())
# #self.viz.plot('D(G(X))', 'train', epoch, np.array(self.hist_DGx).mean())
# fun1()
# #fun2()
# import os
# if not os.path.exists(r'/kaggle/working/npy'):
# os.mkdir(r'/kaggle/working/npy')
# 检查图片是否正确
# aa=np.load("/kaggle/working/img2.npy")
# print(aa.shape)
# print(aa)
# pip install wmi
# pip install pypiwin32
# #查看kaggle的版本
# # PythonVersion:python2.7
# # filename:sys_info.py
# import sys
# import wmi
# import socket
# import platform
# import imp
# imp.reload(sys)
# #reload(sys)
# #sys.setdefaultencoding('utf-8')
# c = wmi.WMI()
# # 系统信息
# print(u'操作系统名称' + platform.platform()[:-(len(platform.version()) + 1)])
# print(u'操作系统版本号' + platform.version())
# print(u'操作系统的位数' + platform.architecture()[0])
# hostname = socket.getfqdn(socket.gethostname())
# ip = socket.gethostbyname(hostname)
# print('ip:' + ip)
# # CPU信息
# def get_CPU():
# cpumsg = []
# for cpu in c.Win32_Processor():
# tmpmsg = {}
# tmpmsg['Name'] = cpu.Name
# cpumsg.append(tmpmsg)
# print(cpumsg)
# # 内存信息
# def get_PhysicalMemory():
# memorys = []
# for mem in c.Win32_PhysicalMemory():
# tmpmsg = {}
# tmpmsg['Tag'] = mem.Tag
# tmpmsg['ConfiguredClockSpeed'] = str(mem.ConfiguredClockSpeed) + 'MHz'
# memorys.append(tmpmsg)
# print(memorys)
# # 显卡信息
# def get_video():
# videos = []
# for v in c.Win32_VideoController():
# tmpmsg = {}
# tmpmsg['Caption'] = v.Caption
# tmpmsg['AdapterRAM'] = str(abs(v.AdapterRAM) / (1024 ** 3)) + 'G'
# videos.append(tmpmsg)
# print(videos)
# # 网卡mac地址
# def get_MacAddress():
# macs = []
# for n in c.Win32_NetworkAdapter():
# mactmp = n.MACAddress
# if mactmp and len(mactmp.strip()) > 5:
# tmpmsg = {}
# tmpmsg['ProductName'] = n.ProductName
# tmpmsg['NetConnectionID'] = n.NetConnectionID
# tmpmsg['MACAddress'] = n.MACAddress
# macs.append(tmpmsg)
# print(macs)
# def main():
# get_CPU()
# get_PhysicalMemory()
# get_video()
# get_MacAddress()
# if __name__ == '__main__':
# main()
# #下载运行结果
# import os
# os.chdir(r'/kaggle/working/npy')
# print(os.getcwd())
# print(os.listdir("/kaggle/working/npy"))
# from IPython.display import FileLink
# #FileLink('a colorful bird containing a bright blue head, nape neck and back, blue white and black feathers, bu.jpg')
# FileLink('2000b.npy')
# from torch.utils.data import DataLoader
# birds_dataset_path='/kaggle/working/birds.hdf5'
# dataset = Text2ImageDataset(birds_dataset_path,split=split)
# #注意调整batch_size和num_workers不然cuda 虚拟环境的共享内存不足要报错
# #或者多线程操作时就有可能导致线程套线程,容易出现死锁的情况
# data_loader = DataLoader(dataset, batch_size=64,shuffle=True,num_workers=0)
# import h5py
# datasetFile='/kaggle/working/birds.hdf5'
# f = h5py.File(datasetFile, 'r')
# split='train'
# print(f)
# print(split)
# print(f.keys())
# print("123")
# print(f['train'].keys())
# print("ok")
# dataset_keys = [str(k) for k in f[split].keys()]
# print(dataset_keys)
| false | 0 | 19,374 | 0 | 6 | 19,374 |
||
69955597 | <kaggle_start><code>from learntools.core import binder
binder.bind(globals())
from learntools.python.ex7 import *
print("Setup complete.")
# # 1.
# After completing the exercises on lists and tuples, Jimmy noticed that, according to his `estimate_average_slot_payout` function, the slot machines at the Learn Python Casino are actually rigged *against* the house, and are profitable to play in the long run.
# Starting with $200 in his pocket, Jimmy has played the slots 500 times, recording his new balance in a list after each spin. He used Python's `matplotlib` library to make a graph of his balance over time:
# Import the jimmy_slots submodule
from learntools.python import jimmy_slots
# Call the get_graph() function to get Jimmy's graph
graph = jimmy_slots.get_graph()
graph
# As you can see, he's hit a bit of bad luck recently. He wants to tweet this along with some choice emojis, but, as it looks right now, his followers will probably find it confusing. He's asked if you can help him make the following changes:
# 1. Add the title "Results of 500 slot machine pulls"
# 2. Make the y-axis start at 0.
# 3. Add the label "Balance" to the y-axis
# After calling `type(graph)` you see that Jimmy's graph is of type `matplotlib.axes._subplots.AxesSubplot`. Hm, that's a new one. By calling `dir(graph)`, you find three methods that seem like they'll be useful: `.set_title()`, `.set_ylim()`, and `.set_ylabel()`.
# Use these methods to complete the function `prettify_graph` according to Jimmy's requests. We've already checked off the first request for you (setting a title).
# (Remember: if you don't know what these methods do, use the `help()` function!)
def prettify_graph(graph):
"""Modify the given graph according to Jimmy's requests: add a title, make the y-axis
start at 0, label the y-axis. (And, if you're feeling ambitious, format the tick marks
as dollar amounts using the "$" symbol.)
"""
graph.set_title("Results of 500 slot machine pulls")
# Complete steps 2 and 3 here
graph.set_ylim(bottom=0)
graph.set_ylabel("Balance")
# https://matplotlib.org/stable/gallery/ticks_and_spines/tick-formatters.html
graph.yaxis.set_major_formatter("${x:0.0f}")
# new_labels = [f'${T:0.0f}' for T in graph.get_yticks()]
# graph.set_yticklabels(new_labels)
graph = jimmy_slots.get_graph()
prettify_graph(graph)
graph
ylabels = ["$" + T.get_text() for T in graph.get_yticklabels()]
ticks = graph.get_yticks()
# Format those values into strings beginning with dollar sign
new_labels = ["${}".format(int(amt)) for amt in ticks]
print(new_labels)
for T in graph.get_yticks():
print(dir(T))
break
# **Bonus:** Can you format the numbers on the y-axis so they look like dollar amounts? e.g. $200 instead of just 200.
# (We're not going to tell you what method(s) to use here. You'll need to go digging yourself with `dir(graph)` and/or `help(graph)`.)
# Check your answer (Run this code cell to receive credit!)
q1.solution()
# # 2. 🌶️🌶️
# This is a very challenging problem. Don't forget that you can receive a hint!
# Luigi is trying to perform an analysis to determine the best items for winning races on the Mario Kart circuit. He has some data in the form of lists of dictionaries that look like...
# [
# {'name': 'Peach', 'items': ['green shell', 'banana', 'green shell',], 'finish': 3},
# {'name': 'Bowser', 'items': ['green shell',], 'finish': 1},
# # Sometimes the racer's name wasn't recorded
# {'name': None, 'items': ['mushroom',], 'finish': 2},
# {'name': 'Toad', 'items': ['green shell', 'mushroom'], 'finish': 1},
# ]
# `'items'` is a list of all the power-up items the racer picked up in that race, and `'finish'` was their placement in the race (1 for first place, 3 for third, etc.).
# He wrote the function below to take a list like this and return a dictionary mapping each item to how many times it was picked up by first-place finishers.
def best_items(racers):
"""Given a list of racer dictionaries, return a dictionary mapping items to the number
of times those items were picked up by racers who finished in first place.
"""
winner_item_counts = {}
for i in range(len(racers)):
# The i'th racer dictionary
racer = racers[i]
# We're only interested in racers who finished in first
if racer["finish"] == 1:
for i in racer["items"]:
# Add one to the count for this item (adding it to the dict if necessary)
if i not in winner_item_counts:
winner_item_counts[i] = 0
winner_item_counts[i] += 1
# Data quality issues :/ Print a warning about racers with no name set. We'll take care of it later.
if racer["name"] is None:
print(
"WARNING: Encountered racer with unknown name on iteration {}/{} (racer = {})".format(
i + 1, len(racers), racer["name"]
)
)
return winner_item_counts
# He tried it on a small example list above and it seemed to work correctly:
sample = [
{
"name": "Peach",
"items": [
"green shell",
"banana",
"green shell",
],
"finish": 3,
},
{
"name": "Bowser",
"items": [
"green shell",
],
"finish": 1,
},
{
"name": None,
"items": [
"mushroom",
],
"finish": 2,
},
{"name": "Toad", "items": ["green shell", "mushroom"], "finish": 1},
]
best_items(sample)
# However, when he tried running it on his full dataset, the program crashed with a `TypeError`.
# Can you guess why? Try running the code cell below to see the error message Luigi is getting. Once you've identified the bug, fix it in the cell below (so that it runs without any errors).
# Hint: Luigi's bug is similar to one we encountered in the [tutorial](https://www.kaggle.com/colinmorris/working-with-external-libraries) when we talked about star imports.
# Import luigi's full dataset of race data
from learntools.python.luigi_analysis import full_dataset
# Fix me!
def best_items(racers):
winner_item_counts = {}
for i in range(len(racers)):
# The i'th racer dictionary
racer = racers[i]
# We're only interested in racers who finished in first
if racer["finish"] == 1:
for i in racer["items"]:
# Add one to the count for this item (adding it to the dict if necessary)
if i not in winner_item_counts:
winner_item_counts[i] = 0
winner_item_counts[i] += 1
# Data quality issues :/ Print a warning about racers with no name set. We'll take care of it later.
if racer["name"] is None:
print(
"WARNING: Encountered racer with unknown name on iteration {}/{} (racer = {})".format(
i + 1, len(racers), racer["name"]
)
)
return winner_item_counts
# Try analyzing the imported full dataset
best_items(full_dataset)
# q2.hint()
# Check your answer (Run this code cell to receive credit!)
q2.solution()
# # 3. 🌶️
# Suppose we wanted to create a new type to represent hands in blackjack. One thing we might want to do with this type is overload the comparison operators like `>` and `<=` so that we could use them to check whether one hand beats another. e.g. it'd be cool if we could do this:
# ```python
# >>> hand1 = BlackjackHand(['K', 'A'])
# >>> hand2 = BlackjackHand(['7', '10', 'A'])
# >>> hand1 > hand2
# True
# ```
# Well, we're not going to do all that in this question (defining custom classes is a bit beyond the scope of these lessons), but the code we're asking you to write in the function below is very similar to what we'd have to write if we were defining our own `BlackjackHand` class. (We'd put it in the `__gt__` magic method to define our custom behaviour for `>`.)
# Fill in the body of the `blackjack_hand_greater_than` function according to the docstring.
def blackjack_hand_greater_than(hand_1, hand_2):
"""
Return True if hand_1 beats hand_2, and False otherwise.
In order for hand_1 to beat hand_2 the following must be true:
- The total of hand_1 must not exceed 21
- The total of hand_1 must exceed the total of hand_2 OR hand_2's total must exceed 21
Hands are represented as a list of cards. Each card is represented by a string.
When adding up a hand's total, cards with numbers count for that many points. Face
cards ('J', 'Q', and 'K') are worth 10 points. 'A' can count for 1 or 11.
When determining a hand's total, you should try to count aces in the way that
maximizes the hand's total without going over 21. e.g. the total of ['A', 'A', '9'] is 21,
the total of ['A', 'A', '9', '3'] is 14.
Examples:
>>> blackjack_hand_greater_than(['K'], ['3', '4'])
True
>>> blackjack_hand_greater_than(['K'], ['10'])
False
>>> blackjack_hand_greater_than(['K', 'K', '2'], ['3'])
False
"""
pass
# Check your answer
q3.check()
# q3.hint()
# q3.solution()
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0069/955/69955597.ipynb | null | null | [{"Id": 69955597, "ScriptId": 19129579, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4260822, "CreationDate": "08/04/2021 02:30:14", "VersionNumber": 1.0, "Title": "Exercise: Working with External Libraries", "EvaluationDate": "08/04/2021", "IsChange": true, "TotalLines": 234.0, "LinesInsertedFromPrevious": 19.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 215.0, "LinesInsertedFromFork": 19.0, "LinesDeletedFromFork": 0.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 215.0, "TotalVotes": 0}] | null | null | null | null | from learntools.core import binder
binder.bind(globals())
from learntools.python.ex7 import *
print("Setup complete.")
# # 1.
# After completing the exercises on lists and tuples, Jimmy noticed that, according to his `estimate_average_slot_payout` function, the slot machines at the Learn Python Casino are actually rigged *against* the house, and are profitable to play in the long run.
# Starting with $200 in his pocket, Jimmy has played the slots 500 times, recording his new balance in a list after each spin. He used Python's `matplotlib` library to make a graph of his balance over time:
# Import the jimmy_slots submodule
from learntools.python import jimmy_slots
# Call the get_graph() function to get Jimmy's graph
graph = jimmy_slots.get_graph()
graph
# As you can see, he's hit a bit of bad luck recently. He wants to tweet this along with some choice emojis, but, as it looks right now, his followers will probably find it confusing. He's asked if you can help him make the following changes:
# 1. Add the title "Results of 500 slot machine pulls"
# 2. Make the y-axis start at 0.
# 3. Add the label "Balance" to the y-axis
# After calling `type(graph)` you see that Jimmy's graph is of type `matplotlib.axes._subplots.AxesSubplot`. Hm, that's a new one. By calling `dir(graph)`, you find three methods that seem like they'll be useful: `.set_title()`, `.set_ylim()`, and `.set_ylabel()`.
# Use these methods to complete the function `prettify_graph` according to Jimmy's requests. We've already checked off the first request for you (setting a title).
# (Remember: if you don't know what these methods do, use the `help()` function!)
def prettify_graph(graph):
"""Modify the given graph according to Jimmy's requests: add a title, make the y-axis
start at 0, label the y-axis. (And, if you're feeling ambitious, format the tick marks
as dollar amounts using the "$" symbol.)
"""
graph.set_title("Results of 500 slot machine pulls")
# Complete steps 2 and 3 here
graph.set_ylim(bottom=0)
graph.set_ylabel("Balance")
# https://matplotlib.org/stable/gallery/ticks_and_spines/tick-formatters.html
graph.yaxis.set_major_formatter("${x:0.0f}")
# new_labels = [f'${T:0.0f}' for T in graph.get_yticks()]
# graph.set_yticklabels(new_labels)
graph = jimmy_slots.get_graph()
prettify_graph(graph)
graph
ylabels = ["$" + T.get_text() for T in graph.get_yticklabels()]
ticks = graph.get_yticks()
# Format those values into strings beginning with dollar sign
new_labels = ["${}".format(int(amt)) for amt in ticks]
print(new_labels)
for T in graph.get_yticks():
print(dir(T))
break
# **Bonus:** Can you format the numbers on the y-axis so they look like dollar amounts? e.g. $200 instead of just 200.
# (We're not going to tell you what method(s) to use here. You'll need to go digging yourself with `dir(graph)` and/or `help(graph)`.)
# Check your answer (Run this code cell to receive credit!)
q1.solution()
# # 2. 🌶️🌶️
# This is a very challenging problem. Don't forget that you can receive a hint!
# Luigi is trying to perform an analysis to determine the best items for winning races on the Mario Kart circuit. He has some data in the form of lists of dictionaries that look like...
# [
# {'name': 'Peach', 'items': ['green shell', 'banana', 'green shell',], 'finish': 3},
# {'name': 'Bowser', 'items': ['green shell',], 'finish': 1},
# # Sometimes the racer's name wasn't recorded
# {'name': None, 'items': ['mushroom',], 'finish': 2},
# {'name': 'Toad', 'items': ['green shell', 'mushroom'], 'finish': 1},
# ]
# `'items'` is a list of all the power-up items the racer picked up in that race, and `'finish'` was their placement in the race (1 for first place, 3 for third, etc.).
# He wrote the function below to take a list like this and return a dictionary mapping each item to how many times it was picked up by first-place finishers.
def best_items(racers):
"""Given a list of racer dictionaries, return a dictionary mapping items to the number
of times those items were picked up by racers who finished in first place.
"""
winner_item_counts = {}
for i in range(len(racers)):
# The i'th racer dictionary
racer = racers[i]
# We're only interested in racers who finished in first
if racer["finish"] == 1:
for i in racer["items"]:
# Add one to the count for this item (adding it to the dict if necessary)
if i not in winner_item_counts:
winner_item_counts[i] = 0
winner_item_counts[i] += 1
# Data quality issues :/ Print a warning about racers with no name set. We'll take care of it later.
if racer["name"] is None:
print(
"WARNING: Encountered racer with unknown name on iteration {}/{} (racer = {})".format(
i + 1, len(racers), racer["name"]
)
)
return winner_item_counts
# He tried it on a small example list above and it seemed to work correctly:
sample = [
{
"name": "Peach",
"items": [
"green shell",
"banana",
"green shell",
],
"finish": 3,
},
{
"name": "Bowser",
"items": [
"green shell",
],
"finish": 1,
},
{
"name": None,
"items": [
"mushroom",
],
"finish": 2,
},
{"name": "Toad", "items": ["green shell", "mushroom"], "finish": 1},
]
best_items(sample)
# However, when he tried running it on his full dataset, the program crashed with a `TypeError`.
# Can you guess why? Try running the code cell below to see the error message Luigi is getting. Once you've identified the bug, fix it in the cell below (so that it runs without any errors).
# Hint: Luigi's bug is similar to one we encountered in the [tutorial](https://www.kaggle.com/colinmorris/working-with-external-libraries) when we talked about star imports.
# Import luigi's full dataset of race data
from learntools.python.luigi_analysis import full_dataset
# Fix me!
def best_items(racers):
winner_item_counts = {}
for i in range(len(racers)):
# The i'th racer dictionary
racer = racers[i]
# We're only interested in racers who finished in first
if racer["finish"] == 1:
for i in racer["items"]:
# Add one to the count for this item (adding it to the dict if necessary)
if i not in winner_item_counts:
winner_item_counts[i] = 0
winner_item_counts[i] += 1
# Data quality issues :/ Print a warning about racers with no name set. We'll take care of it later.
if racer["name"] is None:
print(
"WARNING: Encountered racer with unknown name on iteration {}/{} (racer = {})".format(
i + 1, len(racers), racer["name"]
)
)
return winner_item_counts
# Try analyzing the imported full dataset
best_items(full_dataset)
# q2.hint()
# Check your answer (Run this code cell to receive credit!)
q2.solution()
# # 3. 🌶️
# Suppose we wanted to create a new type to represent hands in blackjack. One thing we might want to do with this type is overload the comparison operators like `>` and `<=` so that we could use them to check whether one hand beats another. e.g. it'd be cool if we could do this:
# ```python
# >>> hand1 = BlackjackHand(['K', 'A'])
# >>> hand2 = BlackjackHand(['7', '10', 'A'])
# >>> hand1 > hand2
# True
# ```
# Well, we're not going to do all that in this question (defining custom classes is a bit beyond the scope of these lessons), but the code we're asking you to write in the function below is very similar to what we'd have to write if we were defining our own `BlackjackHand` class. (We'd put it in the `__gt__` magic method to define our custom behaviour for `>`.)
# Fill in the body of the `blackjack_hand_greater_than` function according to the docstring.
def blackjack_hand_greater_than(hand_1, hand_2):
"""
Return True if hand_1 beats hand_2, and False otherwise.
In order for hand_1 to beat hand_2 the following must be true:
- The total of hand_1 must not exceed 21
- The total of hand_1 must exceed the total of hand_2 OR hand_2's total must exceed 21
Hands are represented as a list of cards. Each card is represented by a string.
When adding up a hand's total, cards with numbers count for that many points. Face
cards ('J', 'Q', and 'K') are worth 10 points. 'A' can count for 1 or 11.
When determining a hand's total, you should try to count aces in the way that
maximizes the hand's total without going over 21. e.g. the total of ['A', 'A', '9'] is 21,
the total of ['A', 'A', '9', '3'] is 14.
Examples:
>>> blackjack_hand_greater_than(['K'], ['3', '4'])
True
>>> blackjack_hand_greater_than(['K'], ['10'])
False
>>> blackjack_hand_greater_than(['K', 'K', '2'], ['3'])
False
"""
pass
# Check your answer
q3.check()
# q3.hint()
# q3.solution()
| false | 0 | 2,582 | 0 | 6 | 2,582 |
||
69728033 | <kaggle_start><data_title>mlb_unnested<data_description>ref: https://www.kaggle.com/naotaka1128/creating-unnested-dataset<data_name>mlb-unnested
<code># ## About this notebook
# + train on 2021 regular season data(use update data
# + cv on may,2021(test player)1.2833 but this score is leakage
# + publicLB 1.1133 Why doesn't it match the emulation?
# + cv on july,2021(include allplayer) 0.7153 this score is not leakage maybe....
# #### about stats
# 
# 1月と2月と3月のターゲットの値の記述統計量を4月に特徴として使う
# Use descriptive statistics of target values for January, February, and March as features in April
# ## Reference
# Thank you for publishing a great notebook and dataset!
# + @columbia2131 [MLB lightGBM Starter Dataset&Code[en, ja]](https://www.kaggle.com/columbia2131/mlb-lightgbm-starter-dataset-code-en-ja)
# + @naotaka1128 [Creating Unnested Dataset](https://www.kaggle.com/naotaka1128/creating-unnested-dataset)
# + @mlconsult [create player descriptive stats dataset](https://www.kaggle.com/mlconsult/create-player-descriptive-stats-dataset)
# + @kaito510 [Player Salary + MLB lightGBM Starter](https://www.kaggle.com/kaito510/player-salary-mlb-lightgbm-starter)
# + @kohashi0000 [1.36 simple_LightGBM](https://www.kaggle.com/kohashi0000/1-36-simple-lightgbm)
# + @somayyehgholami, @mehrankazeminia [[Fork of] LightGBM + CatBoost + ANN 2505f2](https://www.kaggle.com/somayyehgholami/fork-of-lightgbm-catboost-ann-2505f2)
# + @nyanpn [API Emulator for debugging your code locally](https://www.kaggle.com/nyanpn/api-emulator-for-debugging-your-code-locally)
# ## Get env
# 環境によって処理を変えるためのもの
import sys
IN_COLAB = "google.colab" in sys.modules
IN_KAGGLE = "kaggle_web_client" in sys.modules
LOCAL = not (IN_KAGGLE or IN_COLAB)
print(f"IN_COLAB:{IN_COLAB}, IN_KAGGLE:{IN_KAGGLE}, LOCAL:{LOCAL}")
# ## Unnest updatedfile
import numpy as np
import pandas as pd
import os
def reduce_mem_usage(df, verbose=True):
numerics = ["int16", "int32", "int64", "float16", "float32", "float64"]
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == "int":
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int64)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if (
c_min > np.finfo(np.float16).min
and c_max < np.finfo(np.float16).max
):
df[col] = df[col].astype(np.float32)
elif (
c_min > np.finfo(np.float32).min
and c_max < np.finfo(np.float32).max
):
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
if verbose:
print(
"Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)".format(
end_mem, 100 * (start_mem - end_mem) / start_mem
)
)
return df
if not os.path.isfile("./train_updated_playerBoxScores.pickle"):
# drop playerTwitterFollowers, teamTwitterFollowers from example_test
df = pd.read_csv(
f"../input/mlb-player-digital-engagement-forecasting/train_updated.csv"
).dropna(axis=1, how="all")
df = df.query("date >= 20210501")
daily_data_nested_df_names = df.drop("date", axis=1).columns.values.tolist()
for df_name in daily_data_nested_df_names:
date_nested_table = df[["date", df_name]]
date_nested_table = date_nested_table[
~pd.isna(date_nested_table[df_name])
].reset_index(drop=True)
daily_dfs_collection = []
for date_index, date_row in date_nested_table.iterrows():
daily_df = pd.read_json(date_row[df_name])
daily_df["dailyDataDate"] = date_row["date"]
daily_dfs_collection = daily_dfs_collection + [daily_df]
# Concatenate all daily dfs into single df for each row
unnested_table = (
pd.concat(daily_dfs_collection, ignore_index=True)
.
# Set and reset index to move 'dailyDataDate' to front of df
set_index("dailyDataDate")
.reset_index()
)
# print(f"{file}_{df_name}.pickle")
# display(unnested_table.head(3))
reduce_mem_usage(unnested_table).to_pickle(f"train_updated_{df_name}.pickle")
# print('\n'*2)
# Clean up tables and collection of daily data frames for this df
del (date_nested_table, daily_dfs_collection, unnested_table)
import numpy as np
import pandas as pd
from numpy import mean, std
from scipy.stats import norm
import statistics as st
import warnings
warnings.simplefilter("ignore")
def calc_probs(year, pid, df, temp, patern):
to_append = [
year,
pid,
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
]
targets = ["target1", "target2", "target3", "target4"]
z = 2
for target in targets:
target_prob = temp[target].tolist()
mean = np.mean(target_prob) # 平均値
std = np.std(target_prob) # 標準偏差
median = st.median(target_prob) # 中央値
distribution = norm(mean, std) # ノルム
min_weight = min(target_prob) # 最小値
max_weight = max(target_prob) # 最大値
values = list(np.linspace(min_weight, max_weight)) # デフォルト50
probabilities = [distribution.pdf(v) for v in values]
max_value = max(probabilities)
max_index = probabilities.index(max_value) # 確率密度関数の頂点はlinspaceの何個目か
to_append[z] = mean # 平均
to_append[z + 1] = median # 中央地
to_append[z + 2] = std # 標準偏差
to_append[z + 3] = min_weight # 最小値
to_append[z + 4] = max_weight # 最大値
# よくわからないので複数パターン用意
# ============================
if patern == 1:
to_append[z + 5] = target_prob[max_index] # 確率密度変数の頂点
elif patern == 2:
to_append[z + 5] = sorted(target_prob)[max_index] # 実測値
elif patern == 3:
to_append[z + 5] = values[max_index] # 正規分布の中心
z = z + 6
df_length = len(df)
df.loc[df_length] = to_append
return df
# 2021年8月以降用のスタッツを作る
targets = pd.read_pickle("./train_updated_nextDayPlayerEngagement.pickle")
targets = targets.query("20210601 <= dailyDataDate")
# CREATE DATAFRAME to store probabilities
column_names = [
"year",
"playerId",
"target1_mean",
"target1_median",
"target1_std",
"target1_min",
"target1_max",
"target1_prob",
"target2_mean",
"target2_median",
"target2_std",
"target2_min",
"target2_max",
"target2_prob",
"target3_mean",
"target3_median",
"target3_std",
"target3_min",
"target3_max",
"target3_prob",
"target4_mean",
"target4_median",
"target4_std",
"target4_min",
"target4_max",
"target4_prob",
]
player_target_probs = pd.DataFrame(columns=column_names)
year_by_probs = pd.DataFrame(columns=column_names)
years = ["2021"]
dfs = [targets]
for year, df in zip(years, dfs):
playerId_list = df.playerId.unique().tolist()
for pid in playerId_list:
temp = df[df["playerId"] == pid]
player_target_stats = calc_probs(year, pid, player_target_probs, temp, patern=3)
df = pd.read_csv("../input/mlb-features/statsdata.csv")
df8 = player_target_stats.copy()
df9 = player_target_stats.copy()
df10 = player_target_stats.copy()
df8["month"] = 8
df9["month"] = 9
df10["month"] = 10
player_target_stats = pd.concat([df, df8, df9, df10], axis=0).reset_index(drop=True)
print(player_target_stats.groupby(["year", "month"]).size())
player_target_stats.to_csv("player_target_stats.csv", index=False)
# ## Libraries
# Standard library
import os, sys, gc, time, warnings, shutil, random
from pathlib import Path
from contextlib import contextmanager
# third party
import numpy as np
import pandas as pd
from tqdm import tqdm
from sklearn import preprocessing
from sklearn.metrics import mean_absolute_error
import lightgbm as lgb
#
import mlb
pd.set_option("display.max_rows", 500)
print(lgb.__version__)
# ## Config
class CFG:
seed = 29
# # Utills
# Seed
def set_seed(seed: int = 29):
random.seed(seed)
np.random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
set_seed(CFG.seed)
# ## Road
INPUT_DIR = Path("../input")
UNNESTED_DIR = INPUT_DIR / "mlb-unnested"
# non update files
# ======================================================================================
# df_players = pd.read_pickle(UNNESTED_DIR / 'players.pickle')
df_players = pd.read_csv(INPUT_DIR / "playerscsv/NEWplayers.csv") # salarydata
df_teams = pd.read_pickle(UNNESTED_DIR / "teams.pickle").rename(
columns={"id": "teamId"}
)
# update files
# ======================================================================================
df_targets = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_nextDayPlayerEngagement.pickle"),
pd.read_pickle("./train_updated_nextDayPlayerEngagement.pickle"),
],
axis=0,
).reset_index(drop=True)
df_games = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_games.pickle"),
pd.read_pickle("./train_updated_games.pickle"),
],
axis=0,
).reset_index(drop=True)
df_rosters = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_rosters.pickle"),
pd.read_pickle("./train_updated_rosters.pickle"),
],
axis=0,
).reset_index(drop=True)
df_scores = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_playerBoxScores.pickle"),
pd.read_pickle("./train_updated_playerBoxScores.pickle"),
],
axis=0,
).reset_index(drop=True)
df_team_scores = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_teamBoxScores.pickle"),
pd.read_pickle("./train_updated_teamBoxScores.pickle"),
],
axis=0,
).reset_index(drop=True)
df_transactions = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_transactions.pickle"),
pd.read_pickle("./train_updated_transactions.pickle"),
],
axis=0,
).reset_index(drop=True)
df_standings = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_standings.pickle"),
pd.read_pickle("./train_updated_standings.pickle"),
],
axis=0,
).reset_index(drop=True)
df_awards = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_awards.pickle"),
pd.read_pickle("./train_updated_awards.pickle"),
],
axis=0,
).reset_index(drop=True)
twitter_players = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_playerTwitterFollowers.pickle"),
pd.read_pickle("./train_updated_playerTwitterFollowers.pickle"),
],
axis=0,
).reset_index(drop=True)
twitter_team = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_teamTwitterFollowers.pickle"),
pd.read_pickle("./train_updated_teamTwitterFollowers.pickle"),
],
axis=0,
).reset_index(drop=True)
# ネストを外すときnanの場合があり、そのときは同じ形のdataframeを作る必要がある
columns_dict = {
"games": df_games.columns,
"rosters": df_rosters.columns,
"playerBoxScores": df_scores.columns,
"teamBoxScores": df_team_scores.columns,
"transactions": df_transactions.columns,
"standings": df_standings.columns,
"awards": df_awards.columns,
"playerTwitterFollowers": twitter_players.columns,
"teamTwitterFollowers": twitter_team.columns,
}
# Setting COL list
# ======================================================================================
# COL_PLAYERS = ['playerId', 'primaryPositionCode', 'american']
COL_PLAYERS = ["playerId", "primaryPositionName", "american", "salary"]
COL_TEAMS = ["teamId", "leagueId", "divisionId"]
COL_ROSTERS = ["dailyDataDate", "playerId", "teamId", "statusCode"]
COL_STANDINGS = [
"dailyDataDate",
"teamId",
"wins",
"losses",
"lastTenWins",
"lastTenLosses",
]
COL_SCORES = [
i
for i in df_scores.columns.to_list()
if i
not in [
"gamePk",
"gameDate",
"gameTimeUTC",
"teamId",
"teamName",
"playerName",
"positionName",
"positionType",
"jerseyNum",
"battingOrder",
]
]
COL_STANDINGS = ["wins", "losses", "lastTenWins", "lastTenLosses"]
tmp_feature_set = set(
COL_PLAYERS + COL_ROSTERS + COL_SCORES + COL_TEAMS + COL_STANDINGS
)
tmp_feature_set.discard("dailyDataDate")
tmp_feature_set.discard("gameDate")
tmp_feature_set.discard("playerId")
COL_FEATURES = list(tmp_feature_set)
COL_TARGETS = ["target1", "target2", "target3", "target4"]
# ## Preprocess & Feature engineering
def FE_team_score(df_team_scores):
"""
その日チームの勝敗、どういう勝ち方をしたかどうかの特徴量を作成する
"""
df_team_scores = df_team_scores.rename(
columns={"runsScored": "team_runsScored", "runsPitching": "team_runsPitching"}
)
# 勝ち負け
df_team_scores.loc[
df_team_scores["team_runsScored"] > df_team_scores["team_runsPitching"],
["team_win"],
] = 1
# 得失点差
df_team_scores["team_runsdiff"] = (
df_team_scores["team_runsScored"] - df_team_scores["team_runsPitching"]
)
# 完封勝ち
df_team_scores.loc[
(df_team_scores["team_runsScored"] > 0)
& (df_team_scores["team_runsPitching"] == 0),
["team_shutout_win"],
] = 1
df_team_scores.loc[
(df_team_scores["team_runsScored"] == 0)
& (df_team_scores["team_runsPitching"] > 0),
["team_shutout_lose"],
] = 1
# fillna
df_team_scores[
["team_win", "team_shutout_win", "team_shutout_lose"]
] = df_team_scores[["team_win", "team_shutout_win", "team_shutout_lose"]].fillna(0)
# double header
df_team_scores = (
df_team_scores.groupby(["dailyDataDate", "teamId"]).sum().reset_index()
)
df_team_scores = df_team_scores[["dailyDataDate", "teamId"] + COL_TEAMSCORE]
return df_team_scores
# Players
# =========================================================================================
df_players["american"] = df_players["birthCountry"].apply(
lambda x: 1 if x == "USA" else 0
)
# playerBoxScores
# =========================================================================================
print(f"scores shape {df_scores.shape}")
df_scores = df_scores.groupby(["playerId", "dailyDataDate"]).sum().reset_index()
print(f"marged shape {df_scores.shape}")
# teamBoxScores
# =========================================================================================
COL_TEAMSCORE = [
"team_win",
"team_runsScored",
"team_runsPitching",
"team_runsdiff",
"team_shutout_win",
"team_shutout_lose",
]
COL_FEATURES = COL_FEATURES + COL_TEAMSCORE
print(f"team scores shape {df_team_scores.shape}")
df_team_scores = FE_team_score(df_team_scores)
print(f"team scores shape {df_team_scores.shape}")
# award
# =========================================================================================
COL_AWARDS = ["dailyDataDate", "playerId", "num_of_award"]
COL_FEATURES = COL_FEATURES + ["num_of_award"]
df_awards = df_awards.groupby(["dailyDataDate", "playerId"]).size().reset_index()
df_awards = df_awards.rename(columns={0: "num_of_award"})
# transaction
# =========================================================================================
COL_TRANSACTION = ["trade"]
COL_FEATURES = COL_FEATURES + COL_TRANSACTION
# 0行でも一応動く
df_transactions = (
df_transactions.query('typeDesc == "Trade"')
.dropna(subset=["playerId"])
.reset_index(drop=True)
)
df_transactions = df_transactions[["dailyDataDate", "playerId"]]
df_transactions = df_transactions.drop_duplicates().reset_index(drop=True)
df_transactions["trade"] = 1
# twitter
# =========================================================================================
# twitter_players = pd.read_pickle(UNNESTED_DIR / 'train_playerTwitterFollowers.pickle')
# twitter_team = pd.read_pickle(UNNESTED_DIR / 'train_teamTwitterFollowers.pickle')
#
# df_train['yearmonth'] = df_train['dailyDataDate'].astype(str).str[:6].astype(np.int64)
# twitter_players['yearmonth'] = twitter_players['dailyDataDate'].astype(str).str[:6].astype(np.int64)
# twitter_team['yearmonth'] = twitter_team['dailyDataDate'].astype(str).str[:6].astype(np.int64)
#
# twitter_players = twitter_players.rename(columns={'numberOfFollowers': 'numberOfFollowers_player'})
# twitter_team = twitter_team.rename(columns={'numberOfFollowers': 'numberOfFollowers_team'})
#
# df_train = df_train.merge(twitter_players[['yearmonth', 'playerId','numberOfFollowers_player']], on=['yearmonth', 'playerId'], how='left')
# df_train = df_train.merge(twitter_team[['yearmonth', 'teamId','numberOfFollowers_team']], on=['yearmonth', 'teamId'], how='left')
# df_train[['numberOfFollowers_player','numberOfFollowers_team']] = df_train[['numberOfFollowers_player','numberOfFollowers_team']].fillna(-1)
# df_train = df_train.drop(columns='yearmonth')
# COL_TWITTER = ['numberOfFollowers_player', 'numberOfFollowers_team']
# COL_FEATURES = COL_FEATURES + COL_TWITTER
print(df_targets.shape)
# Focus on regular season data
df_targets = df_targets.query(
"20180329 <= dailyDataDate <= 20181001 | \
20190328 <= dailyDataDate <= 20190929 | \
20200723 <= dailyDataDate <= 20200927 | \
20210401 <= dailyDataDate"
).reset_index(drop=True)
print(f"filtered{df_targets.shape}")
# Create train dataframe
df_train = df_targets.merge(df_players[COL_PLAYERS], on=["playerId"], how="left")
gc.collect()
print(df_train.shape, "after_players")
print("--------------------------------------")
df_train = df_train.merge(
df_rosters[COL_ROSTERS], on=["playerId", "dailyDataDate"], how="left"
)
gc.collect()
print(df_train.shape, "after_rosters")
print("--------------------------------------")
df_train = df_train.merge(
df_scores[COL_SCORES], on=["playerId", "dailyDataDate"], how="left"
)
gc.collect()
print(df_train.shape, "after_scores")
print("--------------------------------------")
df_train = df_train.merge(
df_team_scores[["dailyDataDate", "teamId"] + COL_TEAMSCORE],
on=["dailyDataDate", "teamId"],
how="left",
)
gc.collect()
print(df_train.shape, "after_team_scores")
print("--------------------------------------")
df_train = df_train.merge(df_teams[COL_TEAMS], on=["teamId"], how="left")
gc.collect()
print(df_train.shape, "after_teams")
print("--------------------------------------")
df_train = df_train.merge(
df_standings[["dailyDataDate", "teamId"] + COL_STANDINGS],
on=["dailyDataDate", "teamId"],
how="left",
)
gc.collect()
print(df_train.shape, "after_standings")
print("--------------------------------------")
df_train = df_train.merge(
df_awards[COL_AWARDS], on=["dailyDataDate", "playerId"], how="left"
)
gc.collect()
print(df_train.shape, "after_awards")
print("--------------------------------------")
print(df_train.shape)
df_train = df_train.merge(
df_transactions[["dailyDataDate", "playerId"] + COL_TRANSACTION],
on=["dailyDataDate", "playerId"],
how="left",
)
gc.collect()
print(df_train.shape, "after_transactions")
print("--------------------------------------")
print(df_train.shape)
# print object columns
df_train.select_dtypes(include=["object"]).columns
# ### 打点がチームの得点の何割か /What percentage of the team's score is RBI?
df_train["rbi_teamruns"] = df_train["rbi"] / df_train["team_runsScored"]
COL_FEATURES = COL_FEATURES + ["rbi_teamruns"]
# ### 記述統計量の追加 / add stats
if os.path.isfile("./player_target_stats.csv"):
df_stats = pd.read_csv("./player_target_stats.csv")
df_train["year"] = df_train["dailyDataDate"].astype(str).str[:4].astype(np.int64)
df_train["month"] = df_train["dailyDataDate"].astype(str).str[4:6].astype(np.int64)
df_train = df_train.merge(df_stats, on=["year", "month", "playerId"], how="left")
df_train = df_train.drop(columns=["year", "month"])
df_stats = df_stats.drop(columns=["month"])
else:
df_stats = pd.read_csv("../input/mlb-features/player_target_stats_pattern3.csv")
df_train["year"] = df_train["dailyDataDate"].astype(str).str[:4].astype(np.int64)
df_train = df_train.merge(df_stats, on=["year", "playerId"], how="left")
df_train = df_train.drop(columns="year")
stas_feat = df_stats.columns.to_list()[2:]
COL_FEATURES = COL_FEATURES + stas_feat
# ### 人気選手がホームランを打ったか特徴量 / Whether a popular player hit a home run
HR_dict = {
545361: "HR_Trout",
592450: "HR_Judge",
592885: "HR_Yelich",
660271: "HR_Ohtani",
660670: "HR_Acuna",
}
def get_HR(df):
COL_HR = []
HR_list = [
pd.DataFrame(
{
"dailyDataDate": [0, 0, 0, 0, 0],
"playerId": [545361, 592450, 592885, 660271, 660670],
"homeRuns": [0, 0, 0, 0, 0],
}
)
]
for key in HR_dict:
df_tmp = df.query(f"playerId == {key} & homeRuns > 0")[
["dailyDataDate", "playerId", "homeRuns"]
]
HR_list.append(df_tmp)
COL_HR.append(HR_dict[key])
df_HR = pd.concat(HR_list, axis=0)
df_HR = df_HR.groupby(["dailyDataDate", "playerId"]).sum().reset_index()
df_HR = df_HR.pivot(index="dailyDataDate", columns="playerId", values="homeRuns")
df_HR = df_HR.rename(columns=HR_dict)
return df_HR, COL_HR
df_HR, COL_HR = get_HR(df_train.copy())
df_train = df_train.merge(df_HR, on=["dailyDataDate"], how="left")
df_train[COL_HR] = df_train[COL_HR].fillna(0)
# 特徴量配列に追記
COL_FEATURES = COL_FEATURES + COL_HR
# label encoding
player2num = {c: i for i, c in enumerate(df_train["playerId"].unique())}
position2num = {
c: i for i, c in enumerate(df_train["primaryPositionName"].unique())
} # salaryデータ
teamid2num = {c: i for i, c in enumerate(df_train["teamId"].unique())}
status2num = {c: i for i, c in enumerate(df_train["statusCode"].unique())}
leagueId2num = {c: i for i, c in enumerate(df_train["leagueId"].unique())}
divisionId2num = {c: i for i, c in enumerate(df_train["divisionId"].unique())}
df_train["label_playerId"] = df_train["playerId"].map(player2num)
df_train["primaryPositionName"] = df_train["primaryPositionName"].map(position2num)
df_train["teamId"] = df_train["teamId"].map(teamid2num)
df_train["statusCode"] = df_train["statusCode"].map(status2num)
df_train["leagueId"] = df_train["leagueId"].map(leagueId2num)
df_train["divisionId"] = df_train["divisionId"].map(divisionId2num)
COL_FEATURES = COL_FEATURES + ["label_playerId"]
# ### aggregate NaN
df_train.isnull().sum()
set(df_train.columns).difference(set(COL_FEATURES))
# ## CV Split
# save
import pickle
df_train.to_pickle("df_train.pickle")
with open("COL_FEATURES.pickle", mode="wb") as f:
pickle.dump(COL_FEATURES, f)
train_X = df_train.query("dailyDataDate > 20210101")[COL_FEATURES]
train_y = df_train.query("dailyDataDate > 20210101")[COL_TARGETS]
# train_X = df_train[COL_FEATURES]
# train_y = df_train[COL_TARGETS]
_index = df_train["dailyDataDate"] < 20210601
X_train = train_X.loc[_index].reset_index(drop=True)
y_train = train_y.loc[_index].reset_index(drop=True)
X_valid = train_X.loc[~_index].reset_index(drop=True)
y_valid = train_y.loc[~_index].reset_index(drop=True)
print(X_train.shape, X_valid.shape)
# ## model
def fit_lgbm(
X_train, y_train, X_valid, y_valid, params: dict = None, seed=42, verbose=100
):
oof_pred = np.zeros(len(y_valid), dtype=np.float32)
lgb_train = lgb.Dataset(X_train, y_train)
lgb_valid = lgb.Dataset(X_valid, y_valid)
params["seed"] = seed
model = lgb.train(
params,
lgb_train,
# categorical_feature=['statusCode', 'primaryPositionCode'],
valid_sets=[lgb_train, lgb_valid],
verbose_eval=100,
num_boost_round=10000,
early_stopping_rounds=100,
)
oof_pred = model.predict(X_valid)
score = mean_absolute_error(oof_pred, y_valid)
print("mae:", score)
_ = lgb.plot_importance(model, max_num_features=20, figsize=(10, 10))
return oof_pred, model, score
# training lightgbm
params1 = {
"objective": "mae",
"reg_alpha": 0.14947461820098767,
"reg_lambda": 0.10185644384043743,
"n_estimators": 3633,
"learning_rate": 0.08046301304430488,
"num_leaves": 674,
"feature_fraction": 0.9101240539122566,
"bagging_fraction": 0.9884451442950513,
"bagging_freq": 8,
"min_child_samples": 51,
}
params2 = {
"objective": "mae",
"reg_alpha": 0.1,
"reg_lambda": 0.1,
"n_estimators": 80,
"learning_rate": 0.1,
"random_state": 42,
"num_leaves": 22,
}
params3 = {
"objective": "mae",
"reg_alpha": 0.1,
"reg_lambda": 0.1,
"n_estimators": 10000,
"learning_rate": 0.1,
"random_state": 42,
"num_leaves": 100,
}
params4 = {
"objective": "mae",
"reg_alpha": 0.016468100279441976,
"reg_lambda": 0.09128335764019105,
"n_estimators": 9868,
"learning_rate": 0.10528150510326864,
"num_leaves": 157,
"feature_fraction": 0.5419185713426886,
"bagging_fraction": 0.2637405128936662,
"bagging_freq": 19,
"min_child_samples": 71,
}
oof1_1, model1_1, score1_1 = fit_lgbm(
X_train, y_train["target1"], X_valid, y_valid["target1"], params1, 29
)
oof1_2, model1_2, score1_2 = fit_lgbm(
X_train, y_train["target1"], X_valid, y_valid["target1"], params1, 42
)
oof2_1, model2_1, score2_1 = fit_lgbm(
X_train, y_train["target2"], X_valid, y_valid["target2"], params2, 29
)
oof2_2, model2_2, score2_2 = fit_lgbm(
X_train, y_train["target2"], X_valid, y_valid["target2"], params2, 42
)
oof3_1, model3_1, score3_1 = fit_lgbm(
X_train, y_train["target3"], X_valid, y_valid["target3"], params3, 29
)
oof3_2, model3_2, score3_2 = fit_lgbm(
X_train, y_train["target3"], X_valid, y_valid["target3"], params3, 42
)
oof4_1, model4_1, score4_1 = fit_lgbm(
X_train, y_train["target4"], X_valid, y_valid["target4"], params4, 29
)
oof4_2, model4_2, score4_2 = fit_lgbm(
X_train, y_train["target4"], X_valid, y_valid["target4"], params4, 42
)
score1 = (score1_1 + score2_1 + score3_1 + score4_1) / 4
score2 = (score1_2 + score2_2 + score3_2 + score4_2) / 4
print(f"score1: {score1}")
print(f"score2: {score2}")
score1 = mean_absolute_error((oof1_1 + oof1_2) / 2, y_valid["target1"])
score2 = mean_absolute_error((oof2_1 + oof2_2) / 2, y_valid["target2"])
score3 = mean_absolute_error((oof3_1 + oof3_2) / 2, y_valid["target3"])
score4 = mean_absolute_error((oof4_1 + oof4_2) / 2, y_valid["target4"])
score = (score1 + score2 + score3 + score4) / 4
print(f"score: {score}")
# ## train on alldata
def fit_lgbm_all(X_train, y_train, params: dict = None, seed=42, verbose=100):
lgb_train = lgb.Dataset(X_train, y_train)
params["seed"] = seed
model = lgb.train(params, lgb_train)
return model
train_X = df_train.query("dailyDataDate > 20210101")[COL_FEATURES]
train_y = df_train.query("dailyDataDate > 20210101")[COL_TARGETS]
print(train_X.shape, train_y.shape)
best_param1 = dict(params1)
best_param1["num_iterations"] = int(model1_1.best_iteration * 1.1)
model1_1 = fit_lgbm_all(train_X, train_y["target1"], best_param1, 29)
best_param1["num_iterations"] = int(model1_2.best_iteration * 1.1)
model1_2 = fit_lgbm_all(train_X, train_y["target1"], best_param1, 42)
best_param2 = dict(params2)
best_param2["num_iterations"] = int(model2_1.best_iteration * 1.1)
model2_1 = fit_lgbm_all(train_X, train_y["target2"], best_param2, 29)
best_param2["num_iterations"] = int(model2_2.best_iteration * 1.1)
model2_2 = fit_lgbm_all(train_X, train_y["target2"], best_param2, 42)
best_param3 = dict(params3)
best_param3["num_iterations"] = int(model3_1.best_iteration * 1.1)
model3_1 = fit_lgbm_all(train_X, train_y["target3"], best_param3, 29)
best_param3["num_iterations"] = int(model3_2.best_iteration * 1.1)
model3_2 = fit_lgbm_all(train_X, train_y["target3"], best_param3, 42)
best_param4 = dict(params4)
best_param4["num_iterations"] = int(model4_1.best_iteration * 1.1)
model4_1 = fit_lgbm_all(train_X, train_y["target4"], best_param4, 29)
best_param4["num_iterations"] = int(model4_2.best_iteration * 1.1)
model4_2 = fit_lgbm_all(train_X, train_y["target4"], best_param4, 42)
del (train_X, train_y, df_games, df_targets)
gc.collect()
# ## Inference & emulator
import os
import warnings
from typing import Optional, Tuple
class Environment:
def __init__(
self,
data_dir: str,
eval_start_day: int,
eval_end_day: Optional[int],
use_updated: bool,
multiple_days_per_iter: bool,
):
warnings.warn("this is mock module for mlb")
postfix = "_updated" if use_updated else ""
# recommend to replace this with pickle, feather etc to speedup preparing data
df_train = pd.read_pickle(os.path.join(data_dir, f"train{postfix}.pkl"))
players = pd.read_pickle("../input/mlb-unnested/players.pickle")
self.players = players[players["playerForTestSetAndFuturePreds"] == True][
"playerId"
].astype(str)
if eval_end_day is not None:
self.df_train = df_train.set_index("date").loc[eval_start_day:eval_end_day]
else:
self.df_train = df_train.set_index("date").loc[eval_start_day:]
self.date = self.df_train.index.values
self.n_rows = len(self.df_train)
self.multiple_days_per_iter = multiple_days_per_iter
assert self.n_rows > 0, "no data to emulate"
def predict(self, df: pd.DataFrame) -> None:
# if you want to emulate public LB, store your prediction here and calculate MAE
pass
def iter_test(self) -> Tuple[pd.DataFrame, pd.DataFrame]:
if self.multiple_days_per_iter:
for i in range(self.n_rows // 2):
date1 = self.date[2 * i]
date2 = self.date[2 * i + 1]
sample_sub1 = self._make_sample_sub(date1)
sample_sub2 = self._make_sample_sub(date2)
sample_sub = pd.concat([sample_sub1, sample_sub2]).reset_index(
drop=True
)
df = self.df_train.loc[date1:date2]
yield df, sample_sub.set_index("date")
else:
for i in range(self.n_rows):
date = self.date[i]
sample_sub = self._make_sample_sub(date)
df = self.df_train.loc[date:date]
yield df, sample_sub.set_index("date")
def _make_sample_sub(self, date: int) -> pd.DataFrame:
next_day = (
pd.to_datetime(date, format="%Y%m%d") + pd.to_timedelta(1, "d")
).strftime("%Y%m%d")
sample_sub = pd.DataFrame()
sample_sub["date_playerId"] = next_day + "_" + self.players
sample_sub["target1"] = 0
sample_sub["target2"] = 0
sample_sub["target3"] = 0
sample_sub["target4"] = 0
sample_sub["date"] = date
return sample_sub
class MLBEmulator:
def __init__(
self,
data_dir: str = "../input/mlb-features",
eval_start_day: int = 20210401,
eval_end_day: Optional[int] = 20210430,
use_updated: bool = True,
multiple_days_per_iter: bool = False,
):
self.data_dir = data_dir
self.eval_start_day = eval_start_day
self.eval_end_day = eval_end_day
self.use_updated = use_updated
self.multiple_days_per_iter = multiple_days_per_iter
def make_env(self) -> Environment:
return Environment(
self.data_dir,
self.eval_start_day,
self.eval_end_day,
self.use_updated,
self.multiple_days_per_iter,
)
def reduce_mem_usage(df, verbose=False):
numerics = ["int16", "int32", "int64", "float16", "float32", "float64"]
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == "int":
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int64)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if (
c_min > np.finfo(np.float16).min
and c_max < np.finfo(np.float16).max
):
df[col] = df[col].astype(np.float32)
elif (
c_min > np.finfo(np.float32).min
and c_max < np.finfo(np.float32).max
):
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
if verbose:
print(
"Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)".format(
end_mem, 100 * (start_mem - end_mem) / start_mem
)
)
return df
def get_unnested_data(df: pd.DataFrame, sample_prediction_df: pd.DataFrame):
# ['games', 'rosters', 'playerBoxScores', 'teamBoxScores', 'transactions', 'standings', 'awards', 'events']
# daily_data_nested_df_names = df.drop('date', axis = 1).columns.values.tolist()
daily_data_nested_df_names = [
"games",
"rosters",
"playerBoxScores",
"teamBoxScores",
"awards",
"transactions",
"standings",
]
dfs_dict = {}
for df_name in daily_data_nested_df_names:
# print(df_name)
date_nested_table = df[["date", df_name]]
date_nested_table = date_nested_table[
~pd.isna(date_nested_table[df_name])
].reset_index(drop=True)
# Dealing with missing values
# print(len(date_nested_table))
daily_dfs_collection = []
if len(date_nested_table) == 0:
daily_df = pd.DataFrame(
{
"dailyDataDate": sample_prediction_df["dailyDataDate"],
"playerId": sample_prediction_df["playerId"],
}
)
for col in columns_dict[df_name]:
if col in ["dailyDataDate", "playerId"]:
continue
daily_df[col] = np.nan
daily_dfs_collection = daily_dfs_collection + [daily_df]
else:
for date_index, date_row in date_nested_table.iterrows():
daily_df = pd.read_json(date_row[df_name])
daily_df["dailyDataDate"] = date_row["date"]
daily_dfs_collection = daily_dfs_collection + [daily_df]
unnested_table = (
pd.concat(daily_dfs_collection, ignore_index=True)
.
# Set and reset index to move 'dailyDataDate' to front of df
set_index("dailyDataDate")
.reset_index()
)
reduce_mem_usage(unnested_table).to_pickle(f"test_{df_name}.pickle")
dfs_dict[df_name] = reduce_mem_usage(unnested_table)
del (date_nested_table, daily_dfs_collection, unnested_table)
return dfs_dict
def inference(test_df, sample_prediction_df):
dfs_dict = get_unnested_data(test_df, sample_prediction_df)
df_test_rosters = dfs_dict["rosters"]
df_test_games = dfs_dict["games"]
df_test_scores = dfs_dict["playerBoxScores"]
df_test_team_scores = dfs_dict["teamBoxScores"]
df_test_awards = dfs_dict["awards"]
df_test_transactions = dfs_dict["transactions"]
df_test_standings = dfs_dict["standings"]
# FE
# ==========================================
df_test_team_scores = FE_team_score(df_test_team_scores)
df_test_scores = (
df_test_scores.groupby(["playerId", "dailyDataDate"]).sum().reset_index()
)
# df_test_scores = df_test_scores.drop_duplicates(subset=['playerId','dailyDataDate']).reset_index()
df_test = sample_prediction_df[["playerId", "dailyDataDate"]].copy()
df_test = df_test.merge(df_players[COL_PLAYERS], on=["playerId"], how="left")
df_test = df_test.merge(
df_test_rosters[COL_ROSTERS], on=["playerId", "dailyDataDate"], how="left"
)
df_test = df_test.merge(
df_test_scores[COL_SCORES], on=["playerId", "dailyDataDate"], how="left"
)
df_test = df_test.merge(
df_test_team_scores[["dailyDataDate", "teamId"] + COL_TEAMSCORE],
on=["dailyDataDate", "teamId"],
how="left",
)
df_test = df_test.merge(df_teams[COL_TEAMS], on=["teamId"], how="left")
# standings
if test_df["standings"].iloc[0] == test_df["standings"].iloc[0]: # nanだとelseに行く
df_test = df_test.merge(
df_test_standings[["dailyDataDate", "teamId"] + COL_STANDINGS],
on=["dailyDataDate", "teamId"],
how="left",
)
else:
df_test[COL_STANDINGS] = np.nan
# awards
df_test_awards = df_test_awards.dropna(how="any")
if len(df_test_awards) > 0:
df_test_awards = (
df_test_awards.groupby(["dailyDataDate", "playerId"]).size().reset_index()
)
df_test_awards = df_test_awards.rename(columns={0: "num_of_award"})
df_test = df_test.merge(
df_test_awards[COL_AWARDS], on=["dailyDataDate", "playerId"], how="left"
)
else:
df_test["num_of_award"] = np.nan
# transaction
df_test_transactions = (
df_test_transactions.query('typeDesc == "Trade"')
.dropna(subset=["playerId"])
.reset_index(drop=True)
)
if len(df_test_transactions) > 0:
df_test_transactions = df_test_transactions[["dailyDataDate", "playerId"]]
df_test_transactions = df_test_transactions.drop_duplicates().reset_index(
drop=True
)
df_test_transactions["trade"] = 1
df_test = df_test.merge(
df_test_transactions[["dailyDataDate", "playerId"] + COL_TRANSACTION],
on=["dailyDataDate", "playerId"],
how="left",
)
else:
df_test["trade"] = 0
# rbiの割合
df_test["rbi_teamruns"] = df_test["rbi"] / df_train["team_runsScored"]
# 記述統計
if os.path.isfile("./player_target_stats.csv"):
df_stats = pd.read_csv("./player_target_stats.csv")
df_test["year"] = df_test["dailyDataDate"].astype(str).str[:4].astype(np.int64)
df_test["month"] = (
df_test["dailyDataDate"].astype(str).str[4:6].astype(np.int64)
)
df_test = df_test.merge(df_stats, on=["year", "month", "playerId"], how="left")
df_test = df_test.drop(columns=["year", "month"])
else:
df_stats = pd.read_csv("../input/mlb-features/player_target_stats_pattern3.csv")
df_test["year"] = df_test["dailyDataDate"].astype(str).str[:4].astype(np.int64)
df_test = df_test.merge(df_stats, on=["year", "playerId"], how="left")
df_test = df_test.drop(columns="year")
# HR
df_HR, _ = get_HR(df_test.copy())
if len(df_HR) > 0:
df_test = df_test.merge(df_HR, on=["dailyDataDate"], how="left")
df_test[COL_HR] = df_test[COL_HR].fillna(0)
else:
df_test[COL_HR] = 0
# Label Encoding
df_test["label_playerId"] = df_test["playerId"].map(player2num)
df_test["primaryPositionName"] = df_test["primaryPositionName"].map(position2num)
df_test["teamId"] = df_test["teamId"].map(teamid2num)
df_test["statusCode"] = df_test["statusCode"].map(status2num)
df_test["leagueId"] = df_test["leagueId"].map(leagueId2num)
df_test["divisionId"] = df_test["divisionId"].map(divisionId2num)
test_X = df_test[COL_FEATURES]
# predict
pred1_1 = model1_1.predict(test_X)
pred2_1 = model2_1.predict(test_X)
pred3_1 = model3_1.predict(test_X)
pred4_1 = model4_1.predict(test_X)
pred1_2 = model1_2.predict(test_X)
pred2_2 = model2_2.predict(test_X)
pred3_2 = model3_2.predict(test_X)
pred4_2 = model4_2.predict(test_X)
# merge submission
sample_prediction_df["target1"] = np.clip((pred1_1 + pred1_2) / 2, 0, 100)
sample_prediction_df["target2"] = np.clip((pred2_1 + pred2_2) / 2, 0, 100)
sample_prediction_df["target3"] = np.clip((pred3_1 + pred3_2) / 2, 0, 100)
sample_prediction_df["target4"] = np.clip((pred4_1 + pred4_2) / 2, 0, 100)
# 大谷
if df_test["HR_Ohtani"][0] > 0:
sample_prediction_df.loc[
sample_prediction_df["playerId"] == 660271,
["target1", "target2", "target3", "target4"],
] = 100
sample_prediction_df = sample_prediction_df.fillna(0.0)
del sample_prediction_df["playerId"], sample_prediction_df["dailyDataDate"]
return sample_prediction_df
# env.predict(sample_prediction_df)
emulation_mode = False
if emulation_mode:
mlb = MLBEmulator(eval_start_day=20210501, eval_end_day=20210531)
else:
import mlb
env = mlb.make_env() # initialize the environment
iter_test = env.iter_test() # iterator which loops over each date in test set
for test_df, sample_prediction_df in iter_test: # make predictions here
# sample_prediction_df = sample_prediction_df.reset_index(drop=True)
sample_prediction_df = sample_prediction_df.reset_index().rename(
columns={"date": "dailyDataDate"}
)
sample_prediction_df["playerId"] = sample_prediction_df["date_playerId"].map(
lambda x: int(x.split("_")[1])
)
# ==========================================
test_df = test_df.reset_index().rename(columns={"index": "date"})
sample_prediction_df = inference(test_df, sample_prediction_df)
env.predict(sample_prediction_df)
# ## The emulator
# score1.2487188781157268
mlb = MLBEmulator(eval_start_day=20210501, eval_end_day=20210531)
env = mlb.make_env() # initialize the environment
iter_test = env.iter_test() # iterator which loops over each date in test set
col = ["target1_", "target2_", "target3_", "target4_"]
oof_preds = []
scores = 0
for n, (test_df, sample_prediction_df) in enumerate(iter_test):
# sample_prediction_df = sample_prediction_df.reset_index(drop=True)
sample_prediction_df = sample_prediction_df.reset_index().rename(
columns={"date": "dailyDataDate"}
)
sample_prediction_df["playerId"] = sample_prediction_df["date_playerId"].map(
lambda x: int(x.split("_")[1])
)
# ==========================================
test_df = test_df.reset_index().rename(columns={"index": "date"})
sample_prediction_df = inference(test_df, sample_prediction_df)
# env.predict(sample_prediction_df)
targets = pd.read_json(test_df["nextDayPlayerEngagement"][0])
targets.columns = ["engagementMetricsDate", "playerId"] + col
sample_prediction_df["playerId"] = sample_prediction_df["date_playerId"].map(
lambda x: int(x.split("_")[1])
)
oof_pred = sample_prediction_df.merge(
targets[["playerId"] + col], on="playerId", how="left"
)
# mae by day
score = mean_absolute_error(
oof_pred[["target1", "target2", "target3", "target4"]].values,
oof_pred[col].values,
)
print(f"{score}")
scores += score
oof_preds.append(oof_pred)
oof_df = pd.concat(oof_preds, axis=0).reset_index(drop=True)
print("=*" * 30)
print(f"score{scores/len(oof_preds)}")
# ### nan test
# _test_df = [pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_test.csv').query("date == 20210426"),
# pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_test.csv').query("date == 20210427"),
# pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_test.csv').query("date == 20210428"),
# pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_test.csv').query("date == 20210429"),
# pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_test.csv').query("date == 20210430")]
# sample = [pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_sample_submission.csv').query('date == 20210426').set_index('date'),
# pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_sample_submission.csv').query('date == 20210427').set_index('date'),
# pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_sample_submission.csv').query('date == 20210428').set_index('date'),
# pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_sample_submission.csv').query('date == 20210429').set_index('date'),
# pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_sample_submission.csv').query('date == 20210430').set_index('date')]
# # nanのテスト
# _test_df[0].iloc[:,1:] = np.nan
# pred = []
# for i in range(5):
# test_df = _test_df[i]
# sample_prediction_df = sample[i]
# #sample_prediction_df = sample_prediction_df.reset_index(drop=True)
# sample_prediction_df = sample_prediction_df.reset_index().rename(columns={'date':'dailyDataDate'})
# sample_prediction_df['playerId'] = sample_prediction_df['date_playerId']\
# .map(lambda x: int(x.split('_')[1]))
# sample_prediction_df = inference(test_df, sample_prediction_df)
# pred.append(sample_prediction_df)
# #dfs_dict = get_unnested_data(test_df, sample_prediction_df)
# sub = pd.concat(pred, axis=0)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0069/728/69728033.ipynb | mlb-unnested | naotaka1128 | [{"Id": 69728033, "ScriptId": 19051813, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5053565, "CreationDate": "08/03/2021 01:05:46", "VersionNumber": 1.0, "Title": "MLB- pub16th(Leakage:)pri(?)LGBM", "EvaluationDate": "08/03/2021", "IsChange": true, "TotalLines": 1007.0, "LinesInsertedFromPrevious": 40.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 967.0, "LinesInsertedFromFork": 40.0, "LinesDeletedFromFork": 42.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 967.0, "TotalVotes": 2}] | [{"Id": 93200478, "KernelVersionId": 69728033, "SourceDatasetVersionId": 2323733}] | [{"Id": 2323733, "DatasetId": 1402611, "DatasourceVersionId": 2365235, "CreatorUserId": 164146, "LicenseName": "Unknown", "CreationDate": "06/11/2021 10:47:55", "VersionNumber": 1.0, "Title": "mlb_unnested", "Slug": "mlb-unnested", "Subtitle": NaN, "Description": "ref: https://www.kaggle.com/naotaka1128/creating-unnested-dataset", "VersionNotes": "Initial release", "TotalCompressedBytes": 0.0, "TotalUncompressedBytes": 0.0}] | [{"Id": 1402611, "CreatorUserId": 164146, "OwnerUserId": 164146.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 2323733.0, "CurrentDatasourceVersionId": 2365235.0, "ForumId": 1421910, "Type": 2, "CreationDate": "06/11/2021 10:47:55", "LastActivityDate": "06/11/2021", "TotalViews": 733, "TotalDownloads": 79, "TotalVotes": 5, "TotalKernels": 3}] | [{"Id": 164146, "UserName": "naotaka1128", "DisplayName": "ML_Bear", "RegisterDate": "02/08/2014", "PerformanceTier": 3}] | # ## About this notebook
# + train on 2021 regular season data(use update data
# + cv on may,2021(test player)1.2833 but this score is leakage
# + publicLB 1.1133 Why doesn't it match the emulation?
# + cv on july,2021(include allplayer) 0.7153 this score is not leakage maybe....
# #### about stats
# 
# 1月と2月と3月のターゲットの値の記述統計量を4月に特徴として使う
# Use descriptive statistics of target values for January, February, and March as features in April
# ## Reference
# Thank you for publishing a great notebook and dataset!
# + @columbia2131 [MLB lightGBM Starter Dataset&Code[en, ja]](https://www.kaggle.com/columbia2131/mlb-lightgbm-starter-dataset-code-en-ja)
# + @naotaka1128 [Creating Unnested Dataset](https://www.kaggle.com/naotaka1128/creating-unnested-dataset)
# + @mlconsult [create player descriptive stats dataset](https://www.kaggle.com/mlconsult/create-player-descriptive-stats-dataset)
# + @kaito510 [Player Salary + MLB lightGBM Starter](https://www.kaggle.com/kaito510/player-salary-mlb-lightgbm-starter)
# + @kohashi0000 [1.36 simple_LightGBM](https://www.kaggle.com/kohashi0000/1-36-simple-lightgbm)
# + @somayyehgholami, @mehrankazeminia [[Fork of] LightGBM + CatBoost + ANN 2505f2](https://www.kaggle.com/somayyehgholami/fork-of-lightgbm-catboost-ann-2505f2)
# + @nyanpn [API Emulator for debugging your code locally](https://www.kaggle.com/nyanpn/api-emulator-for-debugging-your-code-locally)
# ## Get env
# 環境によって処理を変えるためのもの
import sys
IN_COLAB = "google.colab" in sys.modules
IN_KAGGLE = "kaggle_web_client" in sys.modules
LOCAL = not (IN_KAGGLE or IN_COLAB)
print(f"IN_COLAB:{IN_COLAB}, IN_KAGGLE:{IN_KAGGLE}, LOCAL:{LOCAL}")
# ## Unnest updatedfile
import numpy as np
import pandas as pd
import os
def reduce_mem_usage(df, verbose=True):
numerics = ["int16", "int32", "int64", "float16", "float32", "float64"]
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == "int":
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int64)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if (
c_min > np.finfo(np.float16).min
and c_max < np.finfo(np.float16).max
):
df[col] = df[col].astype(np.float32)
elif (
c_min > np.finfo(np.float32).min
and c_max < np.finfo(np.float32).max
):
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
if verbose:
print(
"Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)".format(
end_mem, 100 * (start_mem - end_mem) / start_mem
)
)
return df
if not os.path.isfile("./train_updated_playerBoxScores.pickle"):
# drop playerTwitterFollowers, teamTwitterFollowers from example_test
df = pd.read_csv(
f"../input/mlb-player-digital-engagement-forecasting/train_updated.csv"
).dropna(axis=1, how="all")
df = df.query("date >= 20210501")
daily_data_nested_df_names = df.drop("date", axis=1).columns.values.tolist()
for df_name in daily_data_nested_df_names:
date_nested_table = df[["date", df_name]]
date_nested_table = date_nested_table[
~pd.isna(date_nested_table[df_name])
].reset_index(drop=True)
daily_dfs_collection = []
for date_index, date_row in date_nested_table.iterrows():
daily_df = pd.read_json(date_row[df_name])
daily_df["dailyDataDate"] = date_row["date"]
daily_dfs_collection = daily_dfs_collection + [daily_df]
# Concatenate all daily dfs into single df for each row
unnested_table = (
pd.concat(daily_dfs_collection, ignore_index=True)
.
# Set and reset index to move 'dailyDataDate' to front of df
set_index("dailyDataDate")
.reset_index()
)
# print(f"{file}_{df_name}.pickle")
# display(unnested_table.head(3))
reduce_mem_usage(unnested_table).to_pickle(f"train_updated_{df_name}.pickle")
# print('\n'*2)
# Clean up tables and collection of daily data frames for this df
del (date_nested_table, daily_dfs_collection, unnested_table)
import numpy as np
import pandas as pd
from numpy import mean, std
from scipy.stats import norm
import statistics as st
import warnings
warnings.simplefilter("ignore")
def calc_probs(year, pid, df, temp, patern):
to_append = [
year,
pid,
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
"",
]
targets = ["target1", "target2", "target3", "target4"]
z = 2
for target in targets:
target_prob = temp[target].tolist()
mean = np.mean(target_prob) # 平均値
std = np.std(target_prob) # 標準偏差
median = st.median(target_prob) # 中央値
distribution = norm(mean, std) # ノルム
min_weight = min(target_prob) # 最小値
max_weight = max(target_prob) # 最大値
values = list(np.linspace(min_weight, max_weight)) # デフォルト50
probabilities = [distribution.pdf(v) for v in values]
max_value = max(probabilities)
max_index = probabilities.index(max_value) # 確率密度関数の頂点はlinspaceの何個目か
to_append[z] = mean # 平均
to_append[z + 1] = median # 中央地
to_append[z + 2] = std # 標準偏差
to_append[z + 3] = min_weight # 最小値
to_append[z + 4] = max_weight # 最大値
# よくわからないので複数パターン用意
# ============================
if patern == 1:
to_append[z + 5] = target_prob[max_index] # 確率密度変数の頂点
elif patern == 2:
to_append[z + 5] = sorted(target_prob)[max_index] # 実測値
elif patern == 3:
to_append[z + 5] = values[max_index] # 正規分布の中心
z = z + 6
df_length = len(df)
df.loc[df_length] = to_append
return df
# 2021年8月以降用のスタッツを作る
targets = pd.read_pickle("./train_updated_nextDayPlayerEngagement.pickle")
targets = targets.query("20210601 <= dailyDataDate")
# CREATE DATAFRAME to store probabilities
column_names = [
"year",
"playerId",
"target1_mean",
"target1_median",
"target1_std",
"target1_min",
"target1_max",
"target1_prob",
"target2_mean",
"target2_median",
"target2_std",
"target2_min",
"target2_max",
"target2_prob",
"target3_mean",
"target3_median",
"target3_std",
"target3_min",
"target3_max",
"target3_prob",
"target4_mean",
"target4_median",
"target4_std",
"target4_min",
"target4_max",
"target4_prob",
]
player_target_probs = pd.DataFrame(columns=column_names)
year_by_probs = pd.DataFrame(columns=column_names)
years = ["2021"]
dfs = [targets]
for year, df in zip(years, dfs):
playerId_list = df.playerId.unique().tolist()
for pid in playerId_list:
temp = df[df["playerId"] == pid]
player_target_stats = calc_probs(year, pid, player_target_probs, temp, patern=3)
df = pd.read_csv("../input/mlb-features/statsdata.csv")
df8 = player_target_stats.copy()
df9 = player_target_stats.copy()
df10 = player_target_stats.copy()
df8["month"] = 8
df9["month"] = 9
df10["month"] = 10
player_target_stats = pd.concat([df, df8, df9, df10], axis=0).reset_index(drop=True)
print(player_target_stats.groupby(["year", "month"]).size())
player_target_stats.to_csv("player_target_stats.csv", index=False)
# ## Libraries
# Standard library
import os, sys, gc, time, warnings, shutil, random
from pathlib import Path
from contextlib import contextmanager
# third party
import numpy as np
import pandas as pd
from tqdm import tqdm
from sklearn import preprocessing
from sklearn.metrics import mean_absolute_error
import lightgbm as lgb
#
import mlb
pd.set_option("display.max_rows", 500)
print(lgb.__version__)
# ## Config
class CFG:
seed = 29
# # Utills
# Seed
def set_seed(seed: int = 29):
random.seed(seed)
np.random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
set_seed(CFG.seed)
# ## Road
INPUT_DIR = Path("../input")
UNNESTED_DIR = INPUT_DIR / "mlb-unnested"
# non update files
# ======================================================================================
# df_players = pd.read_pickle(UNNESTED_DIR / 'players.pickle')
df_players = pd.read_csv(INPUT_DIR / "playerscsv/NEWplayers.csv") # salarydata
df_teams = pd.read_pickle(UNNESTED_DIR / "teams.pickle").rename(
columns={"id": "teamId"}
)
# update files
# ======================================================================================
df_targets = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_nextDayPlayerEngagement.pickle"),
pd.read_pickle("./train_updated_nextDayPlayerEngagement.pickle"),
],
axis=0,
).reset_index(drop=True)
df_games = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_games.pickle"),
pd.read_pickle("./train_updated_games.pickle"),
],
axis=0,
).reset_index(drop=True)
df_rosters = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_rosters.pickle"),
pd.read_pickle("./train_updated_rosters.pickle"),
],
axis=0,
).reset_index(drop=True)
df_scores = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_playerBoxScores.pickle"),
pd.read_pickle("./train_updated_playerBoxScores.pickle"),
],
axis=0,
).reset_index(drop=True)
df_team_scores = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_teamBoxScores.pickle"),
pd.read_pickle("./train_updated_teamBoxScores.pickle"),
],
axis=0,
).reset_index(drop=True)
df_transactions = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_transactions.pickle"),
pd.read_pickle("./train_updated_transactions.pickle"),
],
axis=0,
).reset_index(drop=True)
df_standings = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_standings.pickle"),
pd.read_pickle("./train_updated_standings.pickle"),
],
axis=0,
).reset_index(drop=True)
df_awards = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_awards.pickle"),
pd.read_pickle("./train_updated_awards.pickle"),
],
axis=0,
).reset_index(drop=True)
twitter_players = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_playerTwitterFollowers.pickle"),
pd.read_pickle("./train_updated_playerTwitterFollowers.pickle"),
],
axis=0,
).reset_index(drop=True)
twitter_team = pd.concat(
[
pd.read_pickle(UNNESTED_DIR / "train_teamTwitterFollowers.pickle"),
pd.read_pickle("./train_updated_teamTwitterFollowers.pickle"),
],
axis=0,
).reset_index(drop=True)
# ネストを外すときnanの場合があり、そのときは同じ形のdataframeを作る必要がある
columns_dict = {
"games": df_games.columns,
"rosters": df_rosters.columns,
"playerBoxScores": df_scores.columns,
"teamBoxScores": df_team_scores.columns,
"transactions": df_transactions.columns,
"standings": df_standings.columns,
"awards": df_awards.columns,
"playerTwitterFollowers": twitter_players.columns,
"teamTwitterFollowers": twitter_team.columns,
}
# Setting COL list
# ======================================================================================
# COL_PLAYERS = ['playerId', 'primaryPositionCode', 'american']
COL_PLAYERS = ["playerId", "primaryPositionName", "american", "salary"]
COL_TEAMS = ["teamId", "leagueId", "divisionId"]
COL_ROSTERS = ["dailyDataDate", "playerId", "teamId", "statusCode"]
COL_STANDINGS = [
"dailyDataDate",
"teamId",
"wins",
"losses",
"lastTenWins",
"lastTenLosses",
]
COL_SCORES = [
i
for i in df_scores.columns.to_list()
if i
not in [
"gamePk",
"gameDate",
"gameTimeUTC",
"teamId",
"teamName",
"playerName",
"positionName",
"positionType",
"jerseyNum",
"battingOrder",
]
]
COL_STANDINGS = ["wins", "losses", "lastTenWins", "lastTenLosses"]
tmp_feature_set = set(
COL_PLAYERS + COL_ROSTERS + COL_SCORES + COL_TEAMS + COL_STANDINGS
)
tmp_feature_set.discard("dailyDataDate")
tmp_feature_set.discard("gameDate")
tmp_feature_set.discard("playerId")
COL_FEATURES = list(tmp_feature_set)
COL_TARGETS = ["target1", "target2", "target3", "target4"]
# ## Preprocess & Feature engineering
def FE_team_score(df_team_scores):
"""
その日チームの勝敗、どういう勝ち方をしたかどうかの特徴量を作成する
"""
df_team_scores = df_team_scores.rename(
columns={"runsScored": "team_runsScored", "runsPitching": "team_runsPitching"}
)
# 勝ち負け
df_team_scores.loc[
df_team_scores["team_runsScored"] > df_team_scores["team_runsPitching"],
["team_win"],
] = 1
# 得失点差
df_team_scores["team_runsdiff"] = (
df_team_scores["team_runsScored"] - df_team_scores["team_runsPitching"]
)
# 完封勝ち
df_team_scores.loc[
(df_team_scores["team_runsScored"] > 0)
& (df_team_scores["team_runsPitching"] == 0),
["team_shutout_win"],
] = 1
df_team_scores.loc[
(df_team_scores["team_runsScored"] == 0)
& (df_team_scores["team_runsPitching"] > 0),
["team_shutout_lose"],
] = 1
# fillna
df_team_scores[
["team_win", "team_shutout_win", "team_shutout_lose"]
] = df_team_scores[["team_win", "team_shutout_win", "team_shutout_lose"]].fillna(0)
# double header
df_team_scores = (
df_team_scores.groupby(["dailyDataDate", "teamId"]).sum().reset_index()
)
df_team_scores = df_team_scores[["dailyDataDate", "teamId"] + COL_TEAMSCORE]
return df_team_scores
# Players
# =========================================================================================
df_players["american"] = df_players["birthCountry"].apply(
lambda x: 1 if x == "USA" else 0
)
# playerBoxScores
# =========================================================================================
print(f"scores shape {df_scores.shape}")
df_scores = df_scores.groupby(["playerId", "dailyDataDate"]).sum().reset_index()
print(f"marged shape {df_scores.shape}")
# teamBoxScores
# =========================================================================================
COL_TEAMSCORE = [
"team_win",
"team_runsScored",
"team_runsPitching",
"team_runsdiff",
"team_shutout_win",
"team_shutout_lose",
]
COL_FEATURES = COL_FEATURES + COL_TEAMSCORE
print(f"team scores shape {df_team_scores.shape}")
df_team_scores = FE_team_score(df_team_scores)
print(f"team scores shape {df_team_scores.shape}")
# award
# =========================================================================================
COL_AWARDS = ["dailyDataDate", "playerId", "num_of_award"]
COL_FEATURES = COL_FEATURES + ["num_of_award"]
df_awards = df_awards.groupby(["dailyDataDate", "playerId"]).size().reset_index()
df_awards = df_awards.rename(columns={0: "num_of_award"})
# transaction
# =========================================================================================
COL_TRANSACTION = ["trade"]
COL_FEATURES = COL_FEATURES + COL_TRANSACTION
# 0行でも一応動く
df_transactions = (
df_transactions.query('typeDesc == "Trade"')
.dropna(subset=["playerId"])
.reset_index(drop=True)
)
df_transactions = df_transactions[["dailyDataDate", "playerId"]]
df_transactions = df_transactions.drop_duplicates().reset_index(drop=True)
df_transactions["trade"] = 1
# twitter
# =========================================================================================
# twitter_players = pd.read_pickle(UNNESTED_DIR / 'train_playerTwitterFollowers.pickle')
# twitter_team = pd.read_pickle(UNNESTED_DIR / 'train_teamTwitterFollowers.pickle')
#
# df_train['yearmonth'] = df_train['dailyDataDate'].astype(str).str[:6].astype(np.int64)
# twitter_players['yearmonth'] = twitter_players['dailyDataDate'].astype(str).str[:6].astype(np.int64)
# twitter_team['yearmonth'] = twitter_team['dailyDataDate'].astype(str).str[:6].astype(np.int64)
#
# twitter_players = twitter_players.rename(columns={'numberOfFollowers': 'numberOfFollowers_player'})
# twitter_team = twitter_team.rename(columns={'numberOfFollowers': 'numberOfFollowers_team'})
#
# df_train = df_train.merge(twitter_players[['yearmonth', 'playerId','numberOfFollowers_player']], on=['yearmonth', 'playerId'], how='left')
# df_train = df_train.merge(twitter_team[['yearmonth', 'teamId','numberOfFollowers_team']], on=['yearmonth', 'teamId'], how='left')
# df_train[['numberOfFollowers_player','numberOfFollowers_team']] = df_train[['numberOfFollowers_player','numberOfFollowers_team']].fillna(-1)
# df_train = df_train.drop(columns='yearmonth')
# COL_TWITTER = ['numberOfFollowers_player', 'numberOfFollowers_team']
# COL_FEATURES = COL_FEATURES + COL_TWITTER
print(df_targets.shape)
# Focus on regular season data
df_targets = df_targets.query(
"20180329 <= dailyDataDate <= 20181001 | \
20190328 <= dailyDataDate <= 20190929 | \
20200723 <= dailyDataDate <= 20200927 | \
20210401 <= dailyDataDate"
).reset_index(drop=True)
print(f"filtered{df_targets.shape}")
# Create train dataframe
df_train = df_targets.merge(df_players[COL_PLAYERS], on=["playerId"], how="left")
gc.collect()
print(df_train.shape, "after_players")
print("--------------------------------------")
df_train = df_train.merge(
df_rosters[COL_ROSTERS], on=["playerId", "dailyDataDate"], how="left"
)
gc.collect()
print(df_train.shape, "after_rosters")
print("--------------------------------------")
df_train = df_train.merge(
df_scores[COL_SCORES], on=["playerId", "dailyDataDate"], how="left"
)
gc.collect()
print(df_train.shape, "after_scores")
print("--------------------------------------")
df_train = df_train.merge(
df_team_scores[["dailyDataDate", "teamId"] + COL_TEAMSCORE],
on=["dailyDataDate", "teamId"],
how="left",
)
gc.collect()
print(df_train.shape, "after_team_scores")
print("--------------------------------------")
df_train = df_train.merge(df_teams[COL_TEAMS], on=["teamId"], how="left")
gc.collect()
print(df_train.shape, "after_teams")
print("--------------------------------------")
df_train = df_train.merge(
df_standings[["dailyDataDate", "teamId"] + COL_STANDINGS],
on=["dailyDataDate", "teamId"],
how="left",
)
gc.collect()
print(df_train.shape, "after_standings")
print("--------------------------------------")
df_train = df_train.merge(
df_awards[COL_AWARDS], on=["dailyDataDate", "playerId"], how="left"
)
gc.collect()
print(df_train.shape, "after_awards")
print("--------------------------------------")
print(df_train.shape)
df_train = df_train.merge(
df_transactions[["dailyDataDate", "playerId"] + COL_TRANSACTION],
on=["dailyDataDate", "playerId"],
how="left",
)
gc.collect()
print(df_train.shape, "after_transactions")
print("--------------------------------------")
print(df_train.shape)
# print object columns
df_train.select_dtypes(include=["object"]).columns
# ### 打点がチームの得点の何割か /What percentage of the team's score is RBI?
df_train["rbi_teamruns"] = df_train["rbi"] / df_train["team_runsScored"]
COL_FEATURES = COL_FEATURES + ["rbi_teamruns"]
# ### 記述統計量の追加 / add stats
if os.path.isfile("./player_target_stats.csv"):
df_stats = pd.read_csv("./player_target_stats.csv")
df_train["year"] = df_train["dailyDataDate"].astype(str).str[:4].astype(np.int64)
df_train["month"] = df_train["dailyDataDate"].astype(str).str[4:6].astype(np.int64)
df_train = df_train.merge(df_stats, on=["year", "month", "playerId"], how="left")
df_train = df_train.drop(columns=["year", "month"])
df_stats = df_stats.drop(columns=["month"])
else:
df_stats = pd.read_csv("../input/mlb-features/player_target_stats_pattern3.csv")
df_train["year"] = df_train["dailyDataDate"].astype(str).str[:4].astype(np.int64)
df_train = df_train.merge(df_stats, on=["year", "playerId"], how="left")
df_train = df_train.drop(columns="year")
stas_feat = df_stats.columns.to_list()[2:]
COL_FEATURES = COL_FEATURES + stas_feat
# ### 人気選手がホームランを打ったか特徴量 / Whether a popular player hit a home run
HR_dict = {
545361: "HR_Trout",
592450: "HR_Judge",
592885: "HR_Yelich",
660271: "HR_Ohtani",
660670: "HR_Acuna",
}
def get_HR(df):
COL_HR = []
HR_list = [
pd.DataFrame(
{
"dailyDataDate": [0, 0, 0, 0, 0],
"playerId": [545361, 592450, 592885, 660271, 660670],
"homeRuns": [0, 0, 0, 0, 0],
}
)
]
for key in HR_dict:
df_tmp = df.query(f"playerId == {key} & homeRuns > 0")[
["dailyDataDate", "playerId", "homeRuns"]
]
HR_list.append(df_tmp)
COL_HR.append(HR_dict[key])
df_HR = pd.concat(HR_list, axis=0)
df_HR = df_HR.groupby(["dailyDataDate", "playerId"]).sum().reset_index()
df_HR = df_HR.pivot(index="dailyDataDate", columns="playerId", values="homeRuns")
df_HR = df_HR.rename(columns=HR_dict)
return df_HR, COL_HR
df_HR, COL_HR = get_HR(df_train.copy())
df_train = df_train.merge(df_HR, on=["dailyDataDate"], how="left")
df_train[COL_HR] = df_train[COL_HR].fillna(0)
# 特徴量配列に追記
COL_FEATURES = COL_FEATURES + COL_HR
# label encoding
player2num = {c: i for i, c in enumerate(df_train["playerId"].unique())}
position2num = {
c: i for i, c in enumerate(df_train["primaryPositionName"].unique())
} # salaryデータ
teamid2num = {c: i for i, c in enumerate(df_train["teamId"].unique())}
status2num = {c: i for i, c in enumerate(df_train["statusCode"].unique())}
leagueId2num = {c: i for i, c in enumerate(df_train["leagueId"].unique())}
divisionId2num = {c: i for i, c in enumerate(df_train["divisionId"].unique())}
df_train["label_playerId"] = df_train["playerId"].map(player2num)
df_train["primaryPositionName"] = df_train["primaryPositionName"].map(position2num)
df_train["teamId"] = df_train["teamId"].map(teamid2num)
df_train["statusCode"] = df_train["statusCode"].map(status2num)
df_train["leagueId"] = df_train["leagueId"].map(leagueId2num)
df_train["divisionId"] = df_train["divisionId"].map(divisionId2num)
COL_FEATURES = COL_FEATURES + ["label_playerId"]
# ### aggregate NaN
df_train.isnull().sum()
set(df_train.columns).difference(set(COL_FEATURES))
# ## CV Split
# save
import pickle
df_train.to_pickle("df_train.pickle")
with open("COL_FEATURES.pickle", mode="wb") as f:
pickle.dump(COL_FEATURES, f)
train_X = df_train.query("dailyDataDate > 20210101")[COL_FEATURES]
train_y = df_train.query("dailyDataDate > 20210101")[COL_TARGETS]
# train_X = df_train[COL_FEATURES]
# train_y = df_train[COL_TARGETS]
_index = df_train["dailyDataDate"] < 20210601
X_train = train_X.loc[_index].reset_index(drop=True)
y_train = train_y.loc[_index].reset_index(drop=True)
X_valid = train_X.loc[~_index].reset_index(drop=True)
y_valid = train_y.loc[~_index].reset_index(drop=True)
print(X_train.shape, X_valid.shape)
# ## model
def fit_lgbm(
X_train, y_train, X_valid, y_valid, params: dict = None, seed=42, verbose=100
):
oof_pred = np.zeros(len(y_valid), dtype=np.float32)
lgb_train = lgb.Dataset(X_train, y_train)
lgb_valid = lgb.Dataset(X_valid, y_valid)
params["seed"] = seed
model = lgb.train(
params,
lgb_train,
# categorical_feature=['statusCode', 'primaryPositionCode'],
valid_sets=[lgb_train, lgb_valid],
verbose_eval=100,
num_boost_round=10000,
early_stopping_rounds=100,
)
oof_pred = model.predict(X_valid)
score = mean_absolute_error(oof_pred, y_valid)
print("mae:", score)
_ = lgb.plot_importance(model, max_num_features=20, figsize=(10, 10))
return oof_pred, model, score
# training lightgbm
params1 = {
"objective": "mae",
"reg_alpha": 0.14947461820098767,
"reg_lambda": 0.10185644384043743,
"n_estimators": 3633,
"learning_rate": 0.08046301304430488,
"num_leaves": 674,
"feature_fraction": 0.9101240539122566,
"bagging_fraction": 0.9884451442950513,
"bagging_freq": 8,
"min_child_samples": 51,
}
params2 = {
"objective": "mae",
"reg_alpha": 0.1,
"reg_lambda": 0.1,
"n_estimators": 80,
"learning_rate": 0.1,
"random_state": 42,
"num_leaves": 22,
}
params3 = {
"objective": "mae",
"reg_alpha": 0.1,
"reg_lambda": 0.1,
"n_estimators": 10000,
"learning_rate": 0.1,
"random_state": 42,
"num_leaves": 100,
}
params4 = {
"objective": "mae",
"reg_alpha": 0.016468100279441976,
"reg_lambda": 0.09128335764019105,
"n_estimators": 9868,
"learning_rate": 0.10528150510326864,
"num_leaves": 157,
"feature_fraction": 0.5419185713426886,
"bagging_fraction": 0.2637405128936662,
"bagging_freq": 19,
"min_child_samples": 71,
}
oof1_1, model1_1, score1_1 = fit_lgbm(
X_train, y_train["target1"], X_valid, y_valid["target1"], params1, 29
)
oof1_2, model1_2, score1_2 = fit_lgbm(
X_train, y_train["target1"], X_valid, y_valid["target1"], params1, 42
)
oof2_1, model2_1, score2_1 = fit_lgbm(
X_train, y_train["target2"], X_valid, y_valid["target2"], params2, 29
)
oof2_2, model2_2, score2_2 = fit_lgbm(
X_train, y_train["target2"], X_valid, y_valid["target2"], params2, 42
)
oof3_1, model3_1, score3_1 = fit_lgbm(
X_train, y_train["target3"], X_valid, y_valid["target3"], params3, 29
)
oof3_2, model3_2, score3_2 = fit_lgbm(
X_train, y_train["target3"], X_valid, y_valid["target3"], params3, 42
)
oof4_1, model4_1, score4_1 = fit_lgbm(
X_train, y_train["target4"], X_valid, y_valid["target4"], params4, 29
)
oof4_2, model4_2, score4_2 = fit_lgbm(
X_train, y_train["target4"], X_valid, y_valid["target4"], params4, 42
)
score1 = (score1_1 + score2_1 + score3_1 + score4_1) / 4
score2 = (score1_2 + score2_2 + score3_2 + score4_2) / 4
print(f"score1: {score1}")
print(f"score2: {score2}")
score1 = mean_absolute_error((oof1_1 + oof1_2) / 2, y_valid["target1"])
score2 = mean_absolute_error((oof2_1 + oof2_2) / 2, y_valid["target2"])
score3 = mean_absolute_error((oof3_1 + oof3_2) / 2, y_valid["target3"])
score4 = mean_absolute_error((oof4_1 + oof4_2) / 2, y_valid["target4"])
score = (score1 + score2 + score3 + score4) / 4
print(f"score: {score}")
# ## train on alldata
def fit_lgbm_all(X_train, y_train, params: dict = None, seed=42, verbose=100):
lgb_train = lgb.Dataset(X_train, y_train)
params["seed"] = seed
model = lgb.train(params, lgb_train)
return model
train_X = df_train.query("dailyDataDate > 20210101")[COL_FEATURES]
train_y = df_train.query("dailyDataDate > 20210101")[COL_TARGETS]
print(train_X.shape, train_y.shape)
best_param1 = dict(params1)
best_param1["num_iterations"] = int(model1_1.best_iteration * 1.1)
model1_1 = fit_lgbm_all(train_X, train_y["target1"], best_param1, 29)
best_param1["num_iterations"] = int(model1_2.best_iteration * 1.1)
model1_2 = fit_lgbm_all(train_X, train_y["target1"], best_param1, 42)
best_param2 = dict(params2)
best_param2["num_iterations"] = int(model2_1.best_iteration * 1.1)
model2_1 = fit_lgbm_all(train_X, train_y["target2"], best_param2, 29)
best_param2["num_iterations"] = int(model2_2.best_iteration * 1.1)
model2_2 = fit_lgbm_all(train_X, train_y["target2"], best_param2, 42)
best_param3 = dict(params3)
best_param3["num_iterations"] = int(model3_1.best_iteration * 1.1)
model3_1 = fit_lgbm_all(train_X, train_y["target3"], best_param3, 29)
best_param3["num_iterations"] = int(model3_2.best_iteration * 1.1)
model3_2 = fit_lgbm_all(train_X, train_y["target3"], best_param3, 42)
best_param4 = dict(params4)
best_param4["num_iterations"] = int(model4_1.best_iteration * 1.1)
model4_1 = fit_lgbm_all(train_X, train_y["target4"], best_param4, 29)
best_param4["num_iterations"] = int(model4_2.best_iteration * 1.1)
model4_2 = fit_lgbm_all(train_X, train_y["target4"], best_param4, 42)
del (train_X, train_y, df_games, df_targets)
gc.collect()
# ## Inference & emulator
import os
import warnings
from typing import Optional, Tuple
class Environment:
def __init__(
self,
data_dir: str,
eval_start_day: int,
eval_end_day: Optional[int],
use_updated: bool,
multiple_days_per_iter: bool,
):
warnings.warn("this is mock module for mlb")
postfix = "_updated" if use_updated else ""
# recommend to replace this with pickle, feather etc to speedup preparing data
df_train = pd.read_pickle(os.path.join(data_dir, f"train{postfix}.pkl"))
players = pd.read_pickle("../input/mlb-unnested/players.pickle")
self.players = players[players["playerForTestSetAndFuturePreds"] == True][
"playerId"
].astype(str)
if eval_end_day is not None:
self.df_train = df_train.set_index("date").loc[eval_start_day:eval_end_day]
else:
self.df_train = df_train.set_index("date").loc[eval_start_day:]
self.date = self.df_train.index.values
self.n_rows = len(self.df_train)
self.multiple_days_per_iter = multiple_days_per_iter
assert self.n_rows > 0, "no data to emulate"
def predict(self, df: pd.DataFrame) -> None:
# if you want to emulate public LB, store your prediction here and calculate MAE
pass
def iter_test(self) -> Tuple[pd.DataFrame, pd.DataFrame]:
if self.multiple_days_per_iter:
for i in range(self.n_rows // 2):
date1 = self.date[2 * i]
date2 = self.date[2 * i + 1]
sample_sub1 = self._make_sample_sub(date1)
sample_sub2 = self._make_sample_sub(date2)
sample_sub = pd.concat([sample_sub1, sample_sub2]).reset_index(
drop=True
)
df = self.df_train.loc[date1:date2]
yield df, sample_sub.set_index("date")
else:
for i in range(self.n_rows):
date = self.date[i]
sample_sub = self._make_sample_sub(date)
df = self.df_train.loc[date:date]
yield df, sample_sub.set_index("date")
def _make_sample_sub(self, date: int) -> pd.DataFrame:
next_day = (
pd.to_datetime(date, format="%Y%m%d") + pd.to_timedelta(1, "d")
).strftime("%Y%m%d")
sample_sub = pd.DataFrame()
sample_sub["date_playerId"] = next_day + "_" + self.players
sample_sub["target1"] = 0
sample_sub["target2"] = 0
sample_sub["target3"] = 0
sample_sub["target4"] = 0
sample_sub["date"] = date
return sample_sub
class MLBEmulator:
def __init__(
self,
data_dir: str = "../input/mlb-features",
eval_start_day: int = 20210401,
eval_end_day: Optional[int] = 20210430,
use_updated: bool = True,
multiple_days_per_iter: bool = False,
):
self.data_dir = data_dir
self.eval_start_day = eval_start_day
self.eval_end_day = eval_end_day
self.use_updated = use_updated
self.multiple_days_per_iter = multiple_days_per_iter
def make_env(self) -> Environment:
return Environment(
self.data_dir,
self.eval_start_day,
self.eval_end_day,
self.use_updated,
self.multiple_days_per_iter,
)
def reduce_mem_usage(df, verbose=False):
numerics = ["int16", "int32", "int64", "float16", "float32", "float64"]
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == "int":
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int64)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if (
c_min > np.finfo(np.float16).min
and c_max < np.finfo(np.float16).max
):
df[col] = df[col].astype(np.float32)
elif (
c_min > np.finfo(np.float32).min
and c_max < np.finfo(np.float32).max
):
df[col] = df[col].astype(np.float64)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
if verbose:
print(
"Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)".format(
end_mem, 100 * (start_mem - end_mem) / start_mem
)
)
return df
def get_unnested_data(df: pd.DataFrame, sample_prediction_df: pd.DataFrame):
# ['games', 'rosters', 'playerBoxScores', 'teamBoxScores', 'transactions', 'standings', 'awards', 'events']
# daily_data_nested_df_names = df.drop('date', axis = 1).columns.values.tolist()
daily_data_nested_df_names = [
"games",
"rosters",
"playerBoxScores",
"teamBoxScores",
"awards",
"transactions",
"standings",
]
dfs_dict = {}
for df_name in daily_data_nested_df_names:
# print(df_name)
date_nested_table = df[["date", df_name]]
date_nested_table = date_nested_table[
~pd.isna(date_nested_table[df_name])
].reset_index(drop=True)
# Dealing with missing values
# print(len(date_nested_table))
daily_dfs_collection = []
if len(date_nested_table) == 0:
daily_df = pd.DataFrame(
{
"dailyDataDate": sample_prediction_df["dailyDataDate"],
"playerId": sample_prediction_df["playerId"],
}
)
for col in columns_dict[df_name]:
if col in ["dailyDataDate", "playerId"]:
continue
daily_df[col] = np.nan
daily_dfs_collection = daily_dfs_collection + [daily_df]
else:
for date_index, date_row in date_nested_table.iterrows():
daily_df = pd.read_json(date_row[df_name])
daily_df["dailyDataDate"] = date_row["date"]
daily_dfs_collection = daily_dfs_collection + [daily_df]
unnested_table = (
pd.concat(daily_dfs_collection, ignore_index=True)
.
# Set and reset index to move 'dailyDataDate' to front of df
set_index("dailyDataDate")
.reset_index()
)
reduce_mem_usage(unnested_table).to_pickle(f"test_{df_name}.pickle")
dfs_dict[df_name] = reduce_mem_usage(unnested_table)
del (date_nested_table, daily_dfs_collection, unnested_table)
return dfs_dict
def inference(test_df, sample_prediction_df):
dfs_dict = get_unnested_data(test_df, sample_prediction_df)
df_test_rosters = dfs_dict["rosters"]
df_test_games = dfs_dict["games"]
df_test_scores = dfs_dict["playerBoxScores"]
df_test_team_scores = dfs_dict["teamBoxScores"]
df_test_awards = dfs_dict["awards"]
df_test_transactions = dfs_dict["transactions"]
df_test_standings = dfs_dict["standings"]
# FE
# ==========================================
df_test_team_scores = FE_team_score(df_test_team_scores)
df_test_scores = (
df_test_scores.groupby(["playerId", "dailyDataDate"]).sum().reset_index()
)
# df_test_scores = df_test_scores.drop_duplicates(subset=['playerId','dailyDataDate']).reset_index()
df_test = sample_prediction_df[["playerId", "dailyDataDate"]].copy()
df_test = df_test.merge(df_players[COL_PLAYERS], on=["playerId"], how="left")
df_test = df_test.merge(
df_test_rosters[COL_ROSTERS], on=["playerId", "dailyDataDate"], how="left"
)
df_test = df_test.merge(
df_test_scores[COL_SCORES], on=["playerId", "dailyDataDate"], how="left"
)
df_test = df_test.merge(
df_test_team_scores[["dailyDataDate", "teamId"] + COL_TEAMSCORE],
on=["dailyDataDate", "teamId"],
how="left",
)
df_test = df_test.merge(df_teams[COL_TEAMS], on=["teamId"], how="left")
# standings
if test_df["standings"].iloc[0] == test_df["standings"].iloc[0]: # nanだとelseに行く
df_test = df_test.merge(
df_test_standings[["dailyDataDate", "teamId"] + COL_STANDINGS],
on=["dailyDataDate", "teamId"],
how="left",
)
else:
df_test[COL_STANDINGS] = np.nan
# awards
df_test_awards = df_test_awards.dropna(how="any")
if len(df_test_awards) > 0:
df_test_awards = (
df_test_awards.groupby(["dailyDataDate", "playerId"]).size().reset_index()
)
df_test_awards = df_test_awards.rename(columns={0: "num_of_award"})
df_test = df_test.merge(
df_test_awards[COL_AWARDS], on=["dailyDataDate", "playerId"], how="left"
)
else:
df_test["num_of_award"] = np.nan
# transaction
df_test_transactions = (
df_test_transactions.query('typeDesc == "Trade"')
.dropna(subset=["playerId"])
.reset_index(drop=True)
)
if len(df_test_transactions) > 0:
df_test_transactions = df_test_transactions[["dailyDataDate", "playerId"]]
df_test_transactions = df_test_transactions.drop_duplicates().reset_index(
drop=True
)
df_test_transactions["trade"] = 1
df_test = df_test.merge(
df_test_transactions[["dailyDataDate", "playerId"] + COL_TRANSACTION],
on=["dailyDataDate", "playerId"],
how="left",
)
else:
df_test["trade"] = 0
# rbiの割合
df_test["rbi_teamruns"] = df_test["rbi"] / df_train["team_runsScored"]
# 記述統計
if os.path.isfile("./player_target_stats.csv"):
df_stats = pd.read_csv("./player_target_stats.csv")
df_test["year"] = df_test["dailyDataDate"].astype(str).str[:4].astype(np.int64)
df_test["month"] = (
df_test["dailyDataDate"].astype(str).str[4:6].astype(np.int64)
)
df_test = df_test.merge(df_stats, on=["year", "month", "playerId"], how="left")
df_test = df_test.drop(columns=["year", "month"])
else:
df_stats = pd.read_csv("../input/mlb-features/player_target_stats_pattern3.csv")
df_test["year"] = df_test["dailyDataDate"].astype(str).str[:4].astype(np.int64)
df_test = df_test.merge(df_stats, on=["year", "playerId"], how="left")
df_test = df_test.drop(columns="year")
# HR
df_HR, _ = get_HR(df_test.copy())
if len(df_HR) > 0:
df_test = df_test.merge(df_HR, on=["dailyDataDate"], how="left")
df_test[COL_HR] = df_test[COL_HR].fillna(0)
else:
df_test[COL_HR] = 0
# Label Encoding
df_test["label_playerId"] = df_test["playerId"].map(player2num)
df_test["primaryPositionName"] = df_test["primaryPositionName"].map(position2num)
df_test["teamId"] = df_test["teamId"].map(teamid2num)
df_test["statusCode"] = df_test["statusCode"].map(status2num)
df_test["leagueId"] = df_test["leagueId"].map(leagueId2num)
df_test["divisionId"] = df_test["divisionId"].map(divisionId2num)
test_X = df_test[COL_FEATURES]
# predict
pred1_1 = model1_1.predict(test_X)
pred2_1 = model2_1.predict(test_X)
pred3_1 = model3_1.predict(test_X)
pred4_1 = model4_1.predict(test_X)
pred1_2 = model1_2.predict(test_X)
pred2_2 = model2_2.predict(test_X)
pred3_2 = model3_2.predict(test_X)
pred4_2 = model4_2.predict(test_X)
# merge submission
sample_prediction_df["target1"] = np.clip((pred1_1 + pred1_2) / 2, 0, 100)
sample_prediction_df["target2"] = np.clip((pred2_1 + pred2_2) / 2, 0, 100)
sample_prediction_df["target3"] = np.clip((pred3_1 + pred3_2) / 2, 0, 100)
sample_prediction_df["target4"] = np.clip((pred4_1 + pred4_2) / 2, 0, 100)
# 大谷
if df_test["HR_Ohtani"][0] > 0:
sample_prediction_df.loc[
sample_prediction_df["playerId"] == 660271,
["target1", "target2", "target3", "target4"],
] = 100
sample_prediction_df = sample_prediction_df.fillna(0.0)
del sample_prediction_df["playerId"], sample_prediction_df["dailyDataDate"]
return sample_prediction_df
# env.predict(sample_prediction_df)
emulation_mode = False
if emulation_mode:
mlb = MLBEmulator(eval_start_day=20210501, eval_end_day=20210531)
else:
import mlb
env = mlb.make_env() # initialize the environment
iter_test = env.iter_test() # iterator which loops over each date in test set
for test_df, sample_prediction_df in iter_test: # make predictions here
# sample_prediction_df = sample_prediction_df.reset_index(drop=True)
sample_prediction_df = sample_prediction_df.reset_index().rename(
columns={"date": "dailyDataDate"}
)
sample_prediction_df["playerId"] = sample_prediction_df["date_playerId"].map(
lambda x: int(x.split("_")[1])
)
# ==========================================
test_df = test_df.reset_index().rename(columns={"index": "date"})
sample_prediction_df = inference(test_df, sample_prediction_df)
env.predict(sample_prediction_df)
# ## The emulator
# score1.2487188781157268
mlb = MLBEmulator(eval_start_day=20210501, eval_end_day=20210531)
env = mlb.make_env() # initialize the environment
iter_test = env.iter_test() # iterator which loops over each date in test set
col = ["target1_", "target2_", "target3_", "target4_"]
oof_preds = []
scores = 0
for n, (test_df, sample_prediction_df) in enumerate(iter_test):
# sample_prediction_df = sample_prediction_df.reset_index(drop=True)
sample_prediction_df = sample_prediction_df.reset_index().rename(
columns={"date": "dailyDataDate"}
)
sample_prediction_df["playerId"] = sample_prediction_df["date_playerId"].map(
lambda x: int(x.split("_")[1])
)
# ==========================================
test_df = test_df.reset_index().rename(columns={"index": "date"})
sample_prediction_df = inference(test_df, sample_prediction_df)
# env.predict(sample_prediction_df)
targets = pd.read_json(test_df["nextDayPlayerEngagement"][0])
targets.columns = ["engagementMetricsDate", "playerId"] + col
sample_prediction_df["playerId"] = sample_prediction_df["date_playerId"].map(
lambda x: int(x.split("_")[1])
)
oof_pred = sample_prediction_df.merge(
targets[["playerId"] + col], on="playerId", how="left"
)
# mae by day
score = mean_absolute_error(
oof_pred[["target1", "target2", "target3", "target4"]].values,
oof_pred[col].values,
)
print(f"{score}")
scores += score
oof_preds.append(oof_pred)
oof_df = pd.concat(oof_preds, axis=0).reset_index(drop=True)
print("=*" * 30)
print(f"score{scores/len(oof_preds)}")
# ### nan test
# _test_df = [pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_test.csv').query("date == 20210426"),
# pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_test.csv').query("date == 20210427"),
# pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_test.csv').query("date == 20210428"),
# pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_test.csv').query("date == 20210429"),
# pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_test.csv').query("date == 20210430")]
# sample = [pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_sample_submission.csv').query('date == 20210426').set_index('date'),
# pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_sample_submission.csv').query('date == 20210427').set_index('date'),
# pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_sample_submission.csv').query('date == 20210428').set_index('date'),
# pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_sample_submission.csv').query('date == 20210429').set_index('date'),
# pd.read_csv('../input/mlb-player-digital-engagement-forecasting/example_sample_submission.csv').query('date == 20210430').set_index('date')]
# # nanのテスト
# _test_df[0].iloc[:,1:] = np.nan
# pred = []
# for i in range(5):
# test_df = _test_df[i]
# sample_prediction_df = sample[i]
# #sample_prediction_df = sample_prediction_df.reset_index(drop=True)
# sample_prediction_df = sample_prediction_df.reset_index().rename(columns={'date':'dailyDataDate'})
# sample_prediction_df['playerId'] = sample_prediction_df['date_playerId']\
# .map(lambda x: int(x.split('_')[1]))
# sample_prediction_df = inference(test_df, sample_prediction_df)
# pred.append(sample_prediction_df)
# #dfs_dict = get_unnested_data(test_df, sample_prediction_df)
# sub = pd.concat(pred, axis=0)
| false | 1 | 15,688 | 2 | 56 | 15,688 |
||
87643680 | <kaggle_start><data_title>OCTant project<data_name>octant-project
<code># # Enhancing an open-source OCT segmentation tool with manual segmentation capabilities
# ## Introduction
# Optical coherence tomography (OCT) is a way of capturing images for the diagnosis and monitoring of the retina. The retina is complex tissue composed of ten major layers of distinct cells. An important part of the routine use of OCT retinal images is the segmentation of the tissue layers. The segmentation consists of labelling the image pixels with their corresponding layer and remains a complex problem despite the existence of some approximate solutions.
# Around the central task of segmentation, additional functions need to be performed on the image, for instance to quantify the thickness of the tissue layers, or to stitch several images together to see a wider region of the eye. For ophthalmologists to be able to use the algorithms needed to process the OCT image, these functions are often encapsulated in user friendly applications. But alas, software to segment retinal OCT images is expensive and not always available in developing countries and/or economically disfavored areas.
# OCTant (https://github.com/forihuelaespina/OCTant/) is a python based free open-source software for the analysis of OCT images originally proposed by the National Institute of Astrophysics, Optics and Electronics (INAOE in Spanish) in Mexico but which is still under development. In its current version, OCTant can flatten or mosaic the images, and measure the thickness of each layer.
# Because the performance of even state-of-the-art segmentation algorithms is always suboptimal, ophthalmologists often benefit from being able to make manual adjustments. This project will improve the OCTant tool with the capacity to manually adjust a given segmentation
# The project will teach you:
# * Basic medical image processing.
# * To develop code valid within a collaborative project (i.e. several programming rules ought to be respected so that other collaborators can use and understand you code off-the-shelf. For instance, you will familiarize yourself with GitHub versioning platform.
# * To interact with software in development, where bugs are likely to exist, and errors are likely to appear. For instance, you will learn to report bugs.
# * To produce technical documentation in Sphynx.
# To start off with, let's take a look at an example image:
# import os
# import glob
# import numpy as np
from PIL import Image
# import matplotlib.pyplot as plt
img = Image.open("../input/octant-project/_1323904_.jpeg")
img
# what can we do to the image?
dir(img)
print(img.width, img.height)
spinPicture = img.rotate(30)
spinPicture
from PIL import Image
import matplotlib.pyplot as plt
def getRed(redVal):
return "#%02x%02x%02x" % (redVal, 0, 0)
def getGreen(greenVal):
return "#%02x%02x%02x" % (0, greenVal, 0)
def getBlue(blueVal):
return "#%02x%02x%02x" % (0, 0, blueVal)
# Create an Image with specific RGB value
image = img
# Display the image
image.show()
# Get the color histogram of the image
histogram = image.histogram()
# Take only the Red counts
l1 = histogram[0:256]
# Take only the Blue counts
l2 = histogram[256:512]
# Take only the Green counts
l3 = histogram[512:768]
plt.figure(0)
# R histogram
for i in range(0, 256):
plt.bar(i, l1[i], color=getRed(i), edgecolor=getRed(i), alpha=0.3)
# G histogram
plt.figure(1)
for i in range(0, 256):
plt.bar(i, l2[i], color=getGreen(i), edgecolor=getGreen(i), alpha=0.3)
# B histogram
plt.figure(2)
for i in range(0, 256):
plt.bar(i, l3[i], color=getBlue(i), edgecolor=getBlue(i), alpha=0.3)
plt.show()
# %matplotlib inline
# from matplotlib import pyplot as plt
# from gluoncv import model_zoo, data, utils
# net = model_zoo.get_model('mask_rcnn_fpn_resnet101_v1d_coco', pretrained=True)
# from PIL import Image
# import pandas as pd
# import os
# import numpy as np
# pth = '../input/octant-project/_1323904_.jpeg'
# x, orig_img = data.transforms.presets.rcnn.load_test(pth)
# ids, scores, bboxes, masks = [xx[0].asnumpy() for xx in net(x)]
# width, height = orig_img.shape[1], orig_img.shape[0]
# masks = utils.viz.expand_mask(masks, bboxes, (width, height), scores)
# orig_img = utils.viz.plot_mask(orig_img, masks)
# # identical to Faster RCNN object detection
# fig = plt.figure(figsize=(20, 20))
# ax = fig.add_subplot(1, 1, 1)
# ax = utils.viz.plot_bbox(orig_img, bboxes, scores, ids,
# class_names=net.classes, ax=ax)
# plt.show()
from skimage import io
import copy
import octant as oc
fileName = "../input/octant-project/_1323904_.jpeg"
img = io.imread(fileName)
scan = OCTscan(img)
scanSegmentation = OCTscanSegmentation(scan)
print("Creating document.")
study = OCTvolume() # Initialize a document
study.addScans(scan)
segmentationVol = OCTvolumeSegmentation() # Initialize a document
segmentationVol.addScanSegmentations(scanSegmentation)
doc = Document() # Initialize a document
doc.name = fileName
tmp, _ = os.path.split(fileName)
doc.folderName = tmp
doc.fileName = fileName
doc.study = study
doc.segmentation = segmentationVol
# Keep reference image.
print("Replicating image.")
doc2 = copy.deepcopy(doc)
# Flattening
print("-- Flattening.")
flt = OpScanFlatten()
flt.addOperand(doc2.getCurrentScan())
imFlattened = flt.execute()
doc2.setCurrentScan(imFlattened)
# Segmentation
print("-- Segmenting.")
doc3 = copy.deepcopy(doc2)
seg = OpScanSegment()
seg.addOperand(doc3.getCurrentScan())
imSegmented = seg.execute()
doc3.setCurrentScanSegmentation(imSegmented)
# Load colormap
print("-- Plotting.")
appsettings = Settings()
appsettingsfile = "..\\resources\\OCTantApp.config"
appsettings.read(appsettingsfile)
cmap = appsettings.retinallayerscolormap
# hFig = myInitFigure()
# myPaint(hFig,doc) #Plot raw with dummy segmentation
# hFig = myPaint(myInitFigure(),doc) #Plot raw
hFig = myPaint(myInitFigure(), doc2) # Plot flattened
hFig = myPaint(myInitFigure(), doc3) # Plot segmented
# imgin = OCTscan(img)
class OCTscan(object):
# Sphinx documentation
"""A single OCT scan.
A single OCT scan. A scan is a grayscale image.
Check .scantype property for the scan type (A, B or C)
.. seealso:: :class:`data.OCTvolume`
.. note:: None
.. todo:: Upgrade to color scans.
"""
# Class constructor
def __init__(self, *args):
"""The class constructor.
The class constructor.
tmp = OCTscan() - Creates an black scan sized 480x640.
tmp = OCTScan(img) - Creates scan from the (grayscale) image. Assumed to be an A scan.
tmp = OCTScan(img,type) - Creates scan from the (grayscale) image.
:param img: The scan image
:type img: numpy.ndarray
:param type: The scan type ('A' -default-, 'B' or 'C')
:type type: char
"""
if len(args) > 1:
warnMsg = (
self.getClassName() + ":__init__: Unexpected number of input arguments."
)
warnings.warn(warnMsg, SyntaxWarning)
# Initialize attributes (without decorator @property)
# Initialize properties (with decorator @property)
self.data = np.zeros(shape=(480, 640), dtype=np.uint8) # The default scan image
self.scantype = "A"
if len(args) > 0:
self.data = args[0]
if len(args) > 1:
self.scantype = args[1]
return
# Properties getters/setters
#
# Remember: Sphinx ignores docstrings on property setters so all
# documentation for a property must be on the @property method
@property
def data(self): # data getter
"""
The (grayscale) scan image. The image is expected to be
a grayscale image. Colour images will be converted to grayscale.
:getter: Gets the OCT scan image
:setter: Sets the OCT scan image.
:type: numpy.ndarray shaped [width,height]
"""
return self.__data
@data.setter
def data(self, img): # data setter
if img is not None:
# Check whether the image is in RGB (ndim=3) or in grayscale (ndim=2)
# and convert to grayscale if necessary
if img.ndim == 2:
# Dimensions are only width and height. The image is already in grayscale.
pass
elif img.ndim == 3:
# Image is in RGB. Convert.
img = color.rgb2gray(img)
else: # Unexpected case. Return warning
warnMsg = self.getClassName() + ":data: Unexpected image shape."
warnings.warn(warnMsg, SyntaxWarning)
self.__data = img
return None
@property
def shape(self): # shape getter
"""
The scan shape [width,height].
:getter: Gets the scan shape
:setter: None. This is a read-only property.
:type: Tuple [width,height]
"""
return self.__data.shape
@shape.setter
def shape(self, *args): # shape setter
# Catching attempts to set the shape of the scan
warnMsg = self.getClassName() + ":shape: shape is a read-only property."
warnings.warn(warnMsg, UserWarning)
return
@property
def scantype(self): # scantype getter
"""
The scan type; 'A', 'B' or 'C'.
:getter: Gets the scan type.
:setter: Sets the scan type.
:type: char 'A', 'B' or 'C'.
"""
return self.__scantype
@scantype.setter
def scantype(self, *args): # shape setter
stype = args[0].upper() # Uppercase
if not stype in ("A", "B", "C"):
warnMsg = (
self.getClassName() + ":scantype: Scan type can only be "
"A"
", "
"B"
" or "
"C"
"."
)
warnings.warn(warnMsg, SyntaxWarning)
self.__scantype = stype
return None
# Private methods
def __str__(self):
s = (
"<"
+ self.getClassName()
+ "(["
+ " data: "
+ format(self.data)
+ ","
+ " shape: "
+ format(self.shape)
+ ","
+ " scantype: "
+ self.scantype
+ "])>"
)
return s
# Public methods
def getClassName(self):
"""Get the class name as a string.
Get the class name as a string.
:returns: The class name.
:rtype: string
"""
return type(self).__name__
class OCTscanSegmentation(object):
# Sphinx documentation
"""A retinal layer segmentation over a :class:`data.OCTscan`
A retinal layer segmentation over a :class:`data.OCTscan`. A segmentation
assigns every pixel of the scan a class label.
Please note that this is a data model class; it keeps the segmentation
but it is NOT capable of "computing" such segmentation. To compute a
segmentation please refer to :class:`op.OpScanSegment`.
The segmentation is sized and shaped equal to its base
:class:`data.OCTscan`.
A default segmentation sets the whole segmentation to BACKGROUND.
.. seealso:: :class:`data.OCTscan`, :class:`op.OpScanSegment`
.. note:: None
.. todo:: None
"""
_BACKGROUND = 0 # The background label identifier
# Class constructor
def __init__(self, *args):
"""The class constructor.
The class constructor.
tmp = OCTscanSegmentation(theOCTScan) - Creates a default
segmentation for the given :class:`data.OCTscan`
:param theOCTScan: The OCT scan to be segmented
:type img: :class:`data.OCTscan`
"""
refImage = OCTscan()
# Dummy reference
if len(args) == 0:
warnMsg = (
self.getClassName()
+ ":__init__: Unexpected number of input arguments. Generating a dummy reference scan."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
refImage = args[0]
# if type(refImage) is not OCTscan:
# raise ErrorValue #Throw error
# Initialize attributes (without decorator @property)
# Initialize properties (with decorator @property)
self.scan = refImage # The OCT scan over which the segmentation is made
self.data = self._BACKGROUND * np.ones(
refImage.shape
) # The segmentation itself
self.classMap = RetinalLayers().layers # The map of class labels
return
# Properties getters/setters
#
# Remember: Sphinx ignores docstrings on property setters so all
# documentation for a property must be on the @property method
@property
def data(self): # data getter
"""
The segmentation labels map. Please refer to :py:attr:`classMap` for
classes.
..note: WARNING! This method is not currently checking whether the
data is sized equal to the scan. This may become a problem later.
The problem is that trying to check scan.shape will raise an
error during object creation, when attemting to set the data
but because the object has not been created yet, it still lacks
the scan property even if declared in advance.
:getter: Gets the segmentation map
:setter: Sets the segmentation map
:type: numpy.ndarray shaped [width,height]
"""
return self.__data
@data.setter
def data(self, segmentedImg): # data setter
self.__data = segmentedImg
# if segmentedImg is not None:
# #Check whether the image is in RGB (ndim=3) or in grayscale (ndim=2)
# #and convert to grayscale if necessary
# if ((segmentedImg.ndim == 2) & (segmentedImg.shape == self.scan.shape)):
# #Dimensions are only width and height, and matches that of
# #the scan.
# self.__data = segmentedImg;
# else: #Unexpected case. Return warning
# warnMsg = self.getClassName() + ':data: Unexpected segmentation shape.'
# warnings.warn(warnMsg,SyntaxWarning)
return None
@property
def scan(self): # scan getter
"""
The base OCT scan. Please refer to :py:attr:`data` for
the segmentation map.
:getter: Gets the base OCT scan
:setter: Sets the base OCT scan
:type: :class:`data.OCTscan`
"""
return self.__scan
@scan.setter
def scan(self, octScan): # scan setter
if octScan is not None:
# Check whether the image is in RGB (ndim=3) or in grayscale (ndim=2)
# and convert to grayscale if necessary
if type(octScan) is OCTscan:
# Dimensions are only width and height, and matches that of
# the scan.
self.__scan = octScan
self.clear()
else: # Unexpected case. Return warning
warnMsg = self.getClassName() + ":data: Unexpected type for OCT scan."
warnings.warn(warnMsg, SyntaxWarning)
return None
@property
def shape(self): # shape getter
"""
The scan segmentation shape [width,height].
:getter: Gets the scan segmentation shape
:setter: None. This is a read-only property.
:type: Tuple [width,height]
"""
return self.__data.shape
@shape.setter
def shape(self, *args): # shape setter
# Catching attempts to set the shape of the scan
warnMsg = self.getClassName() + ":shape: shape is a read-only property."
warnings.warn(warnMsg, UserWarning)
return
@property
def classMap(self): # classMap getter
"""
The map of classes.
The map of classes; the list of class names associated to each
value in the segmentation map.
..note: This list does NOT include the BACKGROUND class.
:getter: Gets the base OCT scan
:setter: Sets the base OCT scan
:type: :class:`data.OCTscan`
"""
return self.__classMap
@classMap.setter
def classMap(self, cm): # classMap setter
if cm is not None:
# Check that we are receiving the correct type
if type(cm) is dict:
self.__classMap = cm
else: # Unexpected case. Return warning
warnMsg = (
self.getClassName() + ":classMap: Unexpected type for classMap."
)
warnings.warn(warnMsg, SyntaxWarning)
return None
# Private methods
def __str__(self):
s = (
"<"
+ self.getClassName()
+ "(["
+ " scan: "
+ format(self.scan)
+ ","
+ " data: "
+ format(self.data)
+ ","
+ " classMap: "
+ format(self.classMap)
+ "])>"
)
return s
# Public methods
def getClassName(self):
"""Get the class name as a string.
Get the class name as a string.
:returns: The class name.
:rtype: string
"""
return type(self).__name__
def clear(self):
"""Clears/Resets the segmentation map to _BACKGROUND.
Clears/Resets the segmentation map to _BACKGROUND. All pixels are
assigned the background label.
"""
self.data = self._BACKGROUND * np.ones(self.scan.shape)
return None
class OCTscan(object):
# Sphinx documentation
"""A single OCT scan.
A single OCT scan. A scan is a grayscale image.
Check .scantype property for the scan type (A, B or C)
.. seealso:: :class:`data.OCTvolume`
.. note:: None
.. todo:: Upgrade to color scans.
"""
# Class constructor
def __init__(self, *args):
"""The class constructor.
The class constructor.
tmp = OCTscan() - Creates an black scan sized 480x640.
tmp = OCTScan(img) - Creates scan from the (grayscale) image. Assumed to be an A scan.
tmp = OCTScan(img,type) - Creates scan from the (grayscale) image.
:param img: The scan image
:type img: numpy.ndarray
:param type: The scan type ('A' -default-, 'B' or 'C')
:type type: char
"""
if len(args) > 1:
warnMsg = (
self.getClassName() + ":__init__: Unexpected number of input arguments."
)
warnings.warn(warnMsg, SyntaxWarning)
# Initialize attributes (without decorator @property)
# Initialize properties (with decorator @property)
self.data = np.zeros(shape=(480, 640), dtype=np.uint8) # The default scan image
self.scantype = "A"
if len(args) > 0:
self.data = args[0]
if len(args) > 1:
self.scantype = args[1]
return
# Properties getters/setters
#
# Remember: Sphinx ignores docstrings on property setters so all
# documentation for a property must be on the @property method
@property
def data(self): # data getter
"""
The (grayscale) scan image. The image is expected to be
a grayscale image. Colour images will be converted to grayscale.
:getter: Gets the OCT scan image
:setter: Sets the OCT scan image.
:type: numpy.ndarray shaped [width,height]
"""
return self.__data
@data.setter
def data(self, img): # data setter
if img is not None:
# Check whether the image is in RGB (ndim=3) or in grayscale (ndim=2)
# and convert to grayscale if necessary
if img.ndim == 2:
# Dimensions are only width and height. The image is already in grayscale.
pass
elif img.ndim == 3:
# Image is in RGB. Convert.
img = color.rgb2gray(img)
else: # Unexpected case. Return warning
warnMsg = self.getClassName() + ":data: Unexpected image shape."
warnings.warn(warnMsg, SyntaxWarning)
self.__data = img
return None
@property
def shape(self): # shape getter
"""
The scan shape [width,height].
:getter: Gets the scan shape
:setter: None. This is a read-only property.
:type: Tuple [width,height]
"""
return self.__data.shape
@shape.setter
def shape(self, *args): # shape setter
# Catching attempts to set the shape of the scan
warnMsg = self.getClassName() + ":shape: shape is a read-only property."
warnings.warn(warnMsg, UserWarning)
return
@property
def scantype(self): # scantype getter
"""
The scan type; 'A', 'B' or 'C'.
:getter: Gets the scan type.
:setter: Sets the scan type.
:type: char 'A', 'B' or 'C'.
"""
return self.__scantype
@scantype.setter
def scantype(self, *args): # shape setter
stype = args[0].upper() # Uppercase
if not stype in ("A", "B", "C"):
warnMsg = (
self.getClassName() + ":scantype: Scan type can only be "
"A"
", "
"B"
" or "
"C"
"."
)
warnings.warn(warnMsg, SyntaxWarning)
self.__scantype = stype
return None
# Private methods
def __str__(self):
s = (
"<"
+ self.getClassName()
+ "(["
+ " data: "
+ format(self.data)
+ ","
+ " shape: "
+ format(self.shape)
+ ","
+ " scantype: "
+ self.scantype
+ "])>"
)
return s
# Public methods
def getClassName(self):
"""Get the class name as a string.
Get the class name as a string.
:returns: The class name.
:rtype: string
"""
return type(self).__name__
class RetinalLayers(object):
# Sphinx documentation
"""A collection of constants for identifying retinal layers.
A collection of constants for identifying retinal layers.
It is basically a dictionary of pairs key:value
The following retinal layers are considered:
* Inner Limiting Membrane (ILM)
* Nerve Fiber Layer (NFL)
* Ganglion Cell Layer (GCL)
* Inner Plexiform Layer (IPL)
* Inner Nuclear Layer (INL)
* Outer Plexiform Layer (OPL)
* Outner Nuclear Layer (ONL)
* External Limiting Membrane (ELM)
* Rods and Cones layers (RCL)
* RetinalPigmentEpithelium (RPE)
Also the non-retinal layer is indexed:
* Choroid (CHR)
For pathological conditions, the following is also encoded:
* Fluid (FLD)
.. seealso:: None
.. note:: None
.. todo:: None
"""
# Private class attributes shared by all instances
# Class constructor
def __init__(self):
"""The class constructor.
The class constructor.
tmp = RetinalLayers() - Creates an RetinalLayers object.
"""
# Initialize attributes
# Layer constants
self.layers = {
"Inner Limiting Membrane": 1,
"Nerve Fiber Layer": 2,
"Ganglion Cell Layer": 3,
"Inner Plexiform Layer": 4,
"Inner Nuclear Layer": 5,
"Outer Plexiform Layer": 6,
"Outer Nuclear Layer": 7,
"External Limiting Membrane": 8,
"Rods and Cones Layers": 9,
"Retinal Pigment Epithelium": 10,
"Choroid": 20,
"Fluid": 1001,
}
# Currently:
# RPE includes Bruch's membrane even though most books will
# consider BM as part of the choroid already.
# ONL includes Henle’s layer
# ELM is also known as Inner Segment Layer
# The RCL includes connecting cilia (CL), outer segment layer (OSL) and Verhoeff membrane (VM)
# ...and so that one can have different names for each layer
self.layerNames = {
"ilm": self.layers["Inner Limiting Membrane"],
"innerlimitingmembrane": self.layers["Inner Limiting Membrane"],
"nfl": self.layers["Nerve Fiber Layer"],
"nervefiberlayer": self.layers["Nerve Fiber Layer"],
"gcl": self.layers["Ganglion Cell Layer"],
"ganglioncelllayer": self.layers["Ganglion Cell Layer"],
"ipl": self.layers["Inner Plexiform Layer"],
"innerplexiformlayer": self.layers["Inner Plexiform Layer"],
"inl": self.layers["Inner Nuclear Layer"],
"innernuclearlayer": self.layers["Inner Nuclear Layer"],
"opl": self.layers["Outer Plexiform Layer"],
"outerplexiformlayer": self.layers["Outer Plexiform Layer"],
"onl": self.layers["Outer Nuclear Layer"],
"outernuclearlayer": self.layers["Outer Nuclear Layer"],
"elm": self.layers["External Limiting Membrane"],
"externallimitingmembrane": self.layers["External Limiting Membrane"],
"rcl": self.layers["Rods and Cones Layers"],
"rodsandconeslayers": self.layers["Rods and Cones Layers"],
"rpe": self.layers["Retinal Pigment Epithelium"],
"retinalpigmentepithelium": self.layers["Retinal Pigment Epithelium"],
"chr": self.layers["Choroid"],
"fld": self.layers["Fluid"],
}
# Layer acronyms
self.layerAcronyms = {
self.layers["Inner Limiting Membrane"]: "ILM",
self.layers["Nerve Fiber Layer"]: "NFL",
self.layers["Ganglion Cell Layer"]: "GCL",
self.layers["Inner Plexiform Layer"]: "IPL",
self.layers["Inner Nuclear Layer"]: "INL",
self.layers["Outer Plexiform Layer"]: "OPL",
self.layers["Outer Nuclear Layer"]: "ONL",
self.layers["External Limiting Membrane"]: "ELM",
self.layers["Rods and Cones Layers"]: "RCL",
self.layers["Retinal Pigment Epithelium"]: "RPE",
self.layers["Choroid"]: "Choroid",
self.layers["Fluid"]: "Fluid",
}
return
# Private methods
# Public methods
def getClassName(self):
"""Gets the class name
return: The class name
rtype: string
"""
return type(self).__name__
def getAllLayersIndexes(self):
"""Gets the list of layer values
return: The list of layers values
rtype: list
"""
return list(self.layers.values())
def getAllLayersNames(self):
"""Gets the list of layer keys
return: The list of layers keys
rtype: list
"""
# Retrieves a list of layer keys
return list(self.layers.keys())
def getLayerAcronym(self, idx):
"""Gets the acronym of the i-th layer
return: The layer acronym e.g. NFL
rtype: string
"""
lacronym = "NaN"
try:
lacronym = self.layerAcronyms[idx]
except:
lacronym = "Unknown"
print(
self.getClassName(),
':getLayerAcronym: Unexpected layer index. Returning name "',
lacronym,
'"',
)
return lacronym
def getLayerIndex(self, layerName):
"""Retrieve the index of a given layer
return: The index of the layer
rtype: int
"""
r = -1
try:
layerName = layerName.replace(" ", "") # Remove whitespaces
r = self.layerNames[layerName.lower()] # Ignore case
except:
print(
self.getClassName(),
":getLayerIndex: Unknown layer name. Returning index ",
r,
)
return r
def getLayerName(self, idx):
"""Retrieve the i-th layer name
return: The name of the i-th layer
rtype: string
"""
lname = "Default"
try:
# There is no 'direct' method to access the keys given the value.
lname = list(self.layers.keys())[list(self.layers.values()).index(idx)]
except:
lname = "Unknown"
print(
self.getClassName(),
':getLayerName: Unexpected layer index. Returning name "',
lname,
'"',
)
return lname
def getNumLayers(self):
"""Return the number of known layers.
Return the number of known layers. Please note that this also
include known non-retinal layers like the choroid.
return: Length of property map :func:`data.OCTvolume.layers`
rtype: int
"""
return len(self.layers)
## Import
import os
import warnings
# from deprecated import deprecated
import deprecation
import math
import numpy as np
from scipy import signal, ndimage # Used for 2D convolution
from skimage import feature, color
from functools import reduce
import cv2 # That's OpenCV
# import matlab.engine
import matplotlib.pyplot as plt
import _tkinter
from PyQt5.QtCore import Qt # Imports constants
from PyQt5.QtWidgets import QProgressDialog
# from matplotlib.backends.qt_compat import QtCore, QtWidgets, is_pyqt5
# from version import __version__
import octant
# from data import OCTscan, OCTscanSegmentation, RetinalLayers
# from util import segmentationUtils
# from .Operation import Operation
from scipy.optimize import curve_fit
class OpScanSegment(Operation):
# Private class attributes shared by all instances
# Class constructor
def __init__(self):
# Call superclass constructor
super().__init__()
# Set the operation name
self.name = "Segmentation"
# Initialize private attributes unique to this instance
# self._imgin = np.zeros(shape = (0,0,0), dtype = np.uint8 ); #Input image
# self._imgout = np.zeros(shape = (0,0,0), dtype = np.uint8 ); #The segmented image
# Private methods
@staticmethod
def anisotropicDiffusionFilter(img):
"""
Non-linear anisotropic diffusion filtering
#Original algorithm in [Perona and Malik, (1990) TPAMI 12(7):629-639]
#Parameters according to [WangRK2005, Proc. of SPIE 5690:380-385]
:param img: ndarray. The image to be filtered
:return: the image filtered
:rtype: ndarray
"""
sigma = 1
GaussMask = generateGaussianMask2D(shape=(3, 3), sigma=sigma)
# print(GaussMask)
m = 8
l = 10 # contrast parameter; structures with s > λ are regarded as edges,
# while with s < λ are assumed to belong to the interior of a region
# [Wang2005] uses l=5 for the porcine trachea, but for us that value
# does not produce as good results as l=10.
timestep = 0.24
niterations = 10 # diffusion time (iteration)
Cm = 3.31488
img2 = img # Initialize image
# Get rid of the "large" noise with morphological closing after opening
morphkernel = np.ones((5, 5), np.uint8)
# img2 = cv2.morphologyEx(img2, cv2.MORPH_OPEN, morphkernel)
# img2 = cv2.morphologyEx(img2, cv2.MORPH_CLOSE, morphkernel)
if np.max(img2) <= 1:
# Scale parameters
# m=m/255
l = l / 255
# Cm = Cm/255
for tau in range(1, niterations):
# #Progress bar
# if progress.wasCanceled():
# break
# progress.setValue(round(100*tau/niterations))
# Morphological removal of noise
# Note that this is NOT part of the original diffusion filter
# but the results are clearly enhanced!.
img2 = cv2.morphologyEx(img2, cv2.MORPH_OPEN, morphkernel)
img2 = cv2.morphologyEx(img2, cv2.MORPH_CLOSE, morphkernel)
# Estimate gradient vector at sigma scale
gradI = np.gradient(img2)
tmpGradI = np.add.reduce(gradI) # For illustrations purposes only
# Regularize gradient
# gradientScaleSigma=math.sqrt(2*(tau*timestep))
gradientScaleSigma = math.sqrt(2 * (tau))
GaussMask = generateGaussianMask2D(shape=(7, 7), sigma=gradientScaleSigma)
# Individually convolve the Gaussian filter with each gradient component
# s = signal.convolve2d(gradI, GaussMask, boundary='symm', mode='same')
s = [None] * len(gradI) # Preallocate list
for dim in range(0, len(gradI)):
s[dim] = signal.convolve2d(
gradI[dim], GaussMask, boundary="symm", mode="same"
)
s = np.linalg.norm(s, ord=2, axis=0) # Norm of the gradient.
# Calculate diffusivity
tmp = (s / l) ** m
tmp = np.divide(
-Cm, tmp, out=np.zeros(tmp.shape), where=tmp != 0
) # Avoid division by 0 when estimating diffusivity
# D = 1-np.exp(-Cm/((s/l)**m)) #diffusivity or conduction coefficient
D = 1 - np.exp(tmp) # diffusivity or conduction coefficient
# Update image
img2 = img2 + divergence(np.multiply(D, gradI)) # Update the image
# Reminder> The divergence of gradient is the Laplacian operator
# See: https://math.stackexchange.com/questions/690493/what-is-divergence-in-image-processing
return img2
@staticmethod
def divergence(f):
# """Compute the divergence of n-D SCALAR field `f`."""
# See: https://stackoverflow.com/questions/11435809/compute-divergence-of-vector-field-using-python
# return reduce(np.add,np.gradient(f))
"""
Computes the divergence of the VECTOR field f, corresponding to dFx/dx + dFy/dy + ...
:param f: List of ndarrays, where every item of the list is one dimension of the vector field
:return: Single ndarray of the same shape as each of the items in f, which corresponds to a scalar field
"""
num_dims = len(f)
return np.ufunc.reduce(
np.add, [np.gradient(f[i], axis=i) for i in range(num_dims)]
)
@staticmethod
def generateGaussianMask2D(shape=(3, 3), sigma=0.5):
"""
Generates a 2D gaussian mask
It should give the same result as MATLAB's
fspecial('gaussian',[shape],[sigma])
See: https://stackoverflow.com/questions/17190649/how-to-obtain-a-gaussian-filter-in-python
"""
m, n = [(ss - 1.0) / 2.0 for ss in shape]
y, x = np.ogrid[-m : m + 1, -n : n + 1]
h = np.exp(-(x * x + y * y) / (2.0 * sigma * sigma))
h[h < np.finfo(h.dtype).eps * h.max()] = 0
sumh = h.sum()
if sumh != 0:
h /= sumh
return h
# Public methods
def execute(self, *args, **kwargs):
"""Executes the operation on the :py:attr:`operands`.
Executes the operation on the :py:attr:`operands` and stores the outcome
in :py:attr:`result`. Preload operands using method
:func:`addOperand()`.
:returns: Result of executing the operation.
:rtype: :class:`data.OCTscanSegmentation`
"""
# Ensure the operand has been set.
if len(self.operands) < 1:
warnMsg = self.getClassName() + ":execute: Operand not set."
warnings.warn(warnMsg, SyntaxWarning)
return None
# Establish mode of operation
# NOT WORKING YET... :(
# Now, it always detect:
# Terminal for the stdin
# GUI for the stdout
mode = "terminal"
if os.isatty(0):
mode = "gui"
print("Executing segmentation in mode " + mode + ".")
if mode == "gui":
MainWindow = QtWidgets.QWidget()
progress = QProgressDialog("Segmentation...", "Cancel", 0, 100, MainWindow)
progress.setWindowModality(Qt.WindowModal)
progress.setAutoReset(True)
progress.setAutoClose(True)
progress.setMinimum(0)
progress.setMaximum(100)
progress.setWindowTitle("Automatic segmentation")
progress.setLabelText("Progress:")
progress.setMinimumDuration(0)
progress.resize(500, 100)
progress.forceShow()
progress.setValue(0)
imgin = self.operands[0]
if type(imgin) is OCTscan:
imgin = imgin.data
# Define a default output
segmentedImage = np.zeros(shape=(0, 0, 0), dtype=np.uint8)
# Check whether the image is in RGB (ndim=3) or in grayscale (ndim=2)
# and convert to grayscale if necessary
# img = cv2.cvtColor(self._imgin, cv2.COLOR_BGR2GRAY)
if imgin.ndim == 2:
# Dimensions are only width and height. The image is already in grayscale.
img = imgin
elif imgin.ndim == 3:
# Image is in RGB. Convert.
img = color.rgb2gray(imgin)
else: # Unexpected case. Return warning
print(self.getClassName(), ": Unexpected image shape.")
return None
## Algoritmo 1: Basado en el código de Matlab CASeReL
# https://pangyuteng.github.io/caserel/
#
# Llama externamente a retSegment.exe
#
# Requiere de Matlab Runtime environment
# #Remove external noise from image
# img = segmentationUtils.ejecuta_close(img,4,4) #Clausura
# #segmentationUtils.mostrar_imagen(img)
#
# #Generate temporal intermediate image file to be processed externally
# tmpFilename = "paso2.tiff"
# cv2.imwrite(tmpFilename, img)
#
# #Rely externally on the matlab algorithm for segmentation
# # eng = matlab.engine.start_matlab()
# # eng.retSegment(img)
# #segmentationUtils.mostrar_imagen(img)
#
# #Delete the intermediate image file
# segmentationUtils.elimina_imagen(tmpFilename)
## Algoritmo 3 Felipe
# Step 1) Non-linear anisotropic diffusion filtering
# Original algorithm in [Perona and Malik, (1990) TPAMI 12(7):629-639]
# Parameters according to [WangRK2005, Proc. of SPIE 5690:380-385]
if mode == "gui":
progress.setLabelText("Applying diffusion filter:")
img2 = anisotropicDiffusionFilter(img)
# The output of the anisotropic filter is a float64 2D array
# with values between [0 1] (although note that IT MAY not
# include the segment boundaries 0 and/or 1, so for instance
# while testing I was getting [0,0.85]). Anyway, in this
# range, anything below 1% (~0.099) is background, and the
# rest is tissue.
if mode == "gui":
progress.setValue(100)
if progress.wasCanceled():
return img # Return the original image
# print('Diffusion Filter output range: ['+str(np.amin(img2))+','+str(np.amax(img2))+']')
# Detect background mask
BGmask = np.where(img2 <= 0.099, True, False)
# See above for threshold 0.099 on anisotropic diffusion filter
# output.
# Note that there might be "background" pixels
# found somewhere within the tissue. This is VERY LIKELY fluid!
# Note as well that the lower part also include a bit of the
# choroid with this threshold.
# Finally, the top part should be the vitreous.
# print(BGmask)
# Just to see the mask
# img2 = np.where(BGmask,10,OCTscanSegmentation._BACKGROUND)
# #Plot histogram of image
# binSize = 0.01
# bins=np.arange(0,np.amax(img2)+binSize,binSize)
# hist = np.histogram(img2, bins=bins)
# hfig, ax = plt.subplots(1, 1)
# ax.hist(img2.flatten(),bins)
# ax.set_yscale('log')
# hfig.show()
# PENDING
# Assign intratissue BG pixels to fluid.
# Normalize
img2 = np.floor(255 * (img2 / np.amax(img2))).astype(int)
img2 = np.where(BGmask == True, OCTscanSegmentation._BACKGROUND, img2)
# Assign integers to nRetinalLayers
r = RetinalLayers()
nRetinalLayers = r.getLayerIndex("RPE")
# Note that I'm not counting for choroid or fluid.
# I can't use pixel intensity alone here for segmenting as several
# (separated) layers exhibit similar reflectivity, so segmentation
# criteria has to be a mix of location and intensity.
# Estimate upper and lower boundary by checking first and last
# non-BG pixels per column
# UNFINISHED.
# upperBoundary =
# [uVals,uIdx,uInv,uCounts] = np.unique(img2, \
# return_index=True, \
# return_inverse=True, \
# return_counts=True)
# print(len(uVals))
# ## Algoritmo 2: Arlem
# img2 = img
# print(np.amax(img2))
# tmp=np.reshape(img2,(np.size(img2),1))
# print(type(tmp))
# print(np.size(tmp))
# print(np.amax(tmp))
#
#
# hfig, ax = plt.subplots(1, 1)
# ax.hist(tmp,255)
# hfig.show()
#
# #Elimina ruido
# img = segmentationUtils.ejecuta_close(img,4,4)
#
# #Amplifica capas
# img = segmentationUtils.ejecuta_dilate(img,5,20,1)
#
# #Tensor
# Axx, Axy, Ayy = feature.structure_tensor(img)
#
# #Elimina mas ruido
# Ayy = segmentationUtils.ejecuta_close(Ayy,6,1)
#
# #Resalta las capas que sean mayores a la media
# Ayy = segmentationUtils.resalta_bordes(Ayy,True,0)
#
# #Elimina aun mas ruido
# Ayy = segmentationUtils.ejecuta_open(Ayy,1,1)
#
# #Binarizacion
# binary = segmentationUtils.ejecuta_OTSU(Ayy)
#
# #elimina ruido del posible borde superior
# binary = segmentationUtils.ejecuta_elimina_ruido_extremos(True,0,0,binary)
#
# #elimina ruido del posible borde inferior
# binary = segmentationUtils.ejecuta_elimina_ruido_extremos(False,0,0,binary)
#
# #obtiene bordes exteriores
# arraySuperior, arrayInferior = segmentationUtils.obten_bordes_externos(binary)
#
# #elimina ruido a la imagen original
# img2 = segmentationUtils.elimina_desde_arreglos(img2, arraySuperior, arrayInferior)
# img2 = segmentationUtils.ejecuta_close(img2,2,1)
# img2 = feature.canny(img2,sigma = 2.5)
# img2 = segmentationUtils.elimina_ruido_canny(img2,1)
# Hide and close progress bar.
if mode == "gui":
progress.hide()
# if isinstance(imgin,(OCTscan,)):
if type(imgin) is OCTscan:
self.result = OCTscanSegmentation(imgin)
else:
self.result = OCTscanSegmentation(OCTscan(imgin))
self.result.data = img2
return self.result
# #@deprecated(version='0.2', reason="Deprecated. Use method execute() instead.")
# @deprecation.deprecated(deprecated_in="0.2", removed_in="0.3",
# current_version=__version__,
# details="Use method execute() instead.")
# def segmentar(self,image):
# #Encapsulate the image as an OCTscan
# tmp=OCTscan(image)
# self.clear()
# self.addOperand(tmp)
# #Execute
# self.execute()
# return None
def anisotropicDiffusionFilter(img):
"""
Non-linear anisotropic diffusion filtering
#Original algorithm in [Perona and Malik, (1990) TPAMI 12(7):629-639]
#Parameters according to [WangRK2005, Proc. of SPIE 5690:380-385]
:param img: ndarray. The image to be filtered
:return: the image filtered
:rtype: ndarray
"""
sigma = 1
GaussMask = generateGaussianMask2D(shape=(3, 3), sigma=sigma)
# print(GaussMask)
m = 8
l = 10 # contrast parameter; structures with s > λ are regarded as edges,
# while with s < λ are assumed to belong to the interior of a region
# [Wang2005] uses l=5 for the porcine trachea, but for us that value
# does not produce as good results as l=10.
timestep = 0.24
niterations = 10 # diffusion time (iteration)
Cm = 3.31488
img2 = img # Initialize image
# Get rid of the "large" noise with morphological closing after opening
morphkernel = np.ones((5, 5), np.uint8)
# img2 = cv2.morphologyEx(img2, cv2.MORPH_OPEN, morphkernel)
# img2 = cv2.morphologyEx(img2, cv2.MORPH_CLOSE, morphkernel)
if np.max(img2) <= 1:
# Scale parameters
# m=m/255
l = l / 255
# Cm = Cm/255
for tau in range(1, niterations):
# #Progress bar
# if progress.wasCanceled():
# break
# progress.setValue(round(100*tau/niterations))
# Morphological removal of noise
# Note that this is NOT part of the original diffusion filter
# but the results are clearly enhanced!.
img2 = cv2.morphologyEx(img2, cv2.MORPH_OPEN, morphkernel)
img2 = cv2.morphologyEx(img2, cv2.MORPH_CLOSE, morphkernel)
# Estimate gradient vector at sigma scale
gradI = np.gradient(img2)
tmpGradI = np.add.reduce(gradI) # For illustrations purposes only
# Regularize gradient
# gradientScaleSigma=math.sqrt(2*(tau*timestep))
gradientScaleSigma = math.sqrt(2 * (tau))
GaussMask = generateGaussianMask2D(shape=(7, 7), sigma=gradientScaleSigma)
# Individually convolve the Gaussian filter with each gradient component
# s = signal.convolve2d(gradI, GaussMask, boundary='symm', mode='same')
s = [None] * len(gradI) # Preallocate list
for dim in range(0, len(gradI)):
s[dim] = signal.convolve2d(
gradI[dim], GaussMask, boundary="symm", mode="same"
)
s = np.linalg.norm(s, ord=2, axis=0) # Norm of the gradient.
# Calculate diffusivity
tmp = (s / l) ** m
tmp = np.divide(
-Cm, tmp, out=np.zeros(tmp.shape), where=tmp != 0
) # Avoid division by 0 when estimating diffusivity
# D = 1-np.exp(-Cm/((s/l)**m)) #diffusivity or conduction coefficient
D = 1 - np.exp(tmp) # diffusivity or conduction coefficient
# Update image
img2 = img2 + divergence(np.multiply(D, gradI)) # Update the image
# Reminder> The divergence of gradient is the Laplacian operator
# See: https://math.stackexchange.com/questions/690493/what-is-divergence-in-image-processing
return img2
segmentedImage = np.zeros(shape=(0, 0, 0), dtype=np.uint8)
img2 = anisotropicDiffusionFilter(img)
BGmask = np.where(img2 <= 0.099, True, False)
img2 = np.floor(255 * (img2 / np.amax(img2))).astype(int)
img2 = np.where(BGmask == True, OCTscanSegmentation._BACKGROUND, img2)
# Assign integers to nRetinalLayers
r = RetinalLayers()
nRetinalLayers = r.getLayerIndex("RPE")
OCTscanSegmentation(imgin)
def divergence(f):
# """Compute the divergence of n-D SCALAR field `f`."""
# See: https://stackoverflow.com/questions/11435809/compute-divergence-of-vector-field-using-python
# return reduce(np.add,np.gradient(f))
"""
Computes the divergence of the VECTOR field f, corresponding to dFx/dx + dFy/dy + ...
:param f: List of ndarrays, where every item of the list is one dimension of the vector field
:return: Single ndarray of the same shape as each of the items in f, which corresponds to a scalar field
"""
num_dims = len(f)
return np.ufunc.reduce(np.add, [np.gradient(f[i], axis=i) for i in range(num_dims)])
def generateGaussianMask2D(shape=(3, 3), sigma=0.5):
"""
Generates a 2D gaussian mask
It should give the same result as MATLAB's
fspecial('gaussian',[shape],[sigma])
See: https://stackoverflow.com/questions/17190649/how-to-obtain-a-gaussian-filter-in-python
"""
m, n = [(ss - 1.0) / 2.0 for ss in shape]
y, x = np.ogrid[-m : m + 1, -n : n + 1]
h = np.exp(-(x * x + y * y) / (2.0 * sigma * sigma))
h[h < np.finfo(h.dtype).eps * h.max()] = 0
sumh = h.sum()
if sumh != 0:
h /= sumh
return h
generateGaussianMask2D()
def execute(self, *args, **kwargs):
"""Executes the operation on the :py:attr:`operands`.
Executes the operation on the :py:attr:`operands` and stores the outcome
in :py:attr:`result`. Preload operands using method
:func:`addOperand()`.
:returns: Result of executing the operation.
:rtype: :class:`data.OCTscanSegmentation`
"""
# Ensure the operand has been set.
if len(self.operands) < 1:
warnMsg = self.getClassName() + ":execute: Operand not set."
warnings.warn(warnMsg, SyntaxWarning)
return None
# Establish mode of operation
# NOT WORKING YET... :(
# Now, it always detect:
# Terminal for the stdin
# GUI for the stdout
mode = "terminal"
if os.isatty(0):
mode = "gui"
print("Executing segmentation in mode " + mode + ".")
if mode == "gui":
MainWindow = QtWidgets.QWidget()
progress = QProgressDialog("Segmentation...", "Cancel", 0, 100, MainWindow)
progress.setWindowModality(Qt.WindowModal)
progress.setAutoReset(True)
progress.setAutoClose(True)
progress.setMinimum(0)
progress.setMaximum(100)
progress.setWindowTitle("Automatic segmentation")
progress.setLabelText("Progress:")
progress.setMinimumDuration(0)
progress.resize(500, 100)
progress.forceShow()
progress.setValue(0)
imgin = self.operands[0]
if type(imgin) is OCTscan:
imgin = imgin.data
# Define a default output
segmentedImage = np.zeros(shape=(0, 0, 0), dtype=np.uint8)
# Check whether the image is in RGB (ndim=3) or in grayscale (ndim=2)
# and convert to grayscale if necessary
# img = cv2.cvtColor(self._imgin, cv2.COLOR_BGR2GRAY)
if imgin.ndim == 2:
# Dimensions are only width and height. The image is already in grayscale.
img = imgin
elif imgin.ndim == 3:
# Image is in RGB. Convert.
img = color.rgb2gray(imgin)
else: # Unexpected case. Return warning
print(self.getClassName(), ": Unexpected image shape.")
return None
## Algoritmo 1: Basado en el código de Matlab CASeReL
# https://pangyuteng.github.io/caserel/
#
# Llama externamente a retSegment.exe
#
# Requiere de Matlab Runtime environment
# #Remove external noise from image
# img = segmentationUtils.ejecuta_close(img,4,4) #Clausura
# #segmentationUtils.mostrar_imagen(img)
#
# #Generate temporal intermediate image file to be processed externally
# tmpFilename = "paso2.tiff"
# cv2.imwrite(tmpFilename, img)
#
# #Rely externally on the matlab algorithm for segmentation
# # eng = matlab.engine.start_matlab()
# # eng.retSegment(img)
# #segmentationUtils.mostrar_imagen(img)
#
# #Delete the intermediate image file
# segmentationUtils.elimina_imagen(tmpFilename)
## Algoritmo 3 Felipe
# Step 1) Non-linear anisotropic diffusion filtering
# Original algorithm in [Perona and Malik, (1990) TPAMI 12(7):629-639]
# Parameters according to [WangRK2005, Proc. of SPIE 5690:380-385]
if mode == "gui":
progress.setLabelText("Applying diffusion filter:")
img2 = anisotropicDiffusionFilter(img)
# The output of the anisotropic filter is a float64 2D array
# with values between [0 1] (although note that IT MAY not
# include the segment boundaries 0 and/or 1, so for instance
# while testing I was getting [0,0.85]). Anyway, in this
# range, anything below 1% (~0.099) is background, and the
# rest is tissue.
if mode == "gui":
progress.setValue(100)
if progress.wasCanceled():
return img # Return the original image
# print('Diffusion Filter output range: ['+str(np.amin(img2))+','+str(np.amax(img2))+']')
# Detect background mask
BGmask = np.where(img2 <= 0.099, True, False)
# See above for threshold 0.099 on anisotropic diffusion filter
# output.
# Note that there might be "background" pixels
# found somewhere within the tissue. This is VERY LIKELY fluid!
# Note as well that the lower part also include a bit of the
# choroid with this threshold.
# Finally, the top part should be the vitreous.
# print(BGmask)
# Just to see the mask
# img2 = np.where(BGmask,10,OCTscanSegmentation._BACKGROUND)
# #Plot histogram of image
# binSize = 0.01
# bins=np.arange(0,np.amax(img2)+binSize,binSize)
# hist = np.histogram(img2, bins=bins)
# hfig, ax = plt.subplots(1, 1)
# ax.hist(img2.flatten(),bins)
# ax.set_yscale('log')
# hfig.show()
# PENDING
# Assign intratissue BG pixels to fluid.
# Normalize
img2 = np.floor(255 * (img2 / np.amax(img2))).astype(int)
img2 = np.where(BGmask == True, OCTscanSegmentation._BACKGROUND, img2)
# Assign integers to nRetinalLayers
r = RetinalLayers()
nRetinalLayers = r.getLayerIndex("RPE")
# Note that I'm not counting for choroid or fluid.
# I can't use pixel intensity alone here for segmenting as several
# (separated) layers exhibit similar reflectivity, so segmentation
# criteria has to be a mix of location and intensity.
# Estimate upper and lower boundary by checking first and last
# non-BG pixels per column
# UNFINISHED.
# upperBoundary =
# [uVals,uIdx,uInv,uCounts] = np.unique(img2, \
# return_index=True, \
# return_inverse=True, \
# return_counts=True)
# print(len(uVals))
# ## Algoritmo 2: Arlem
# img2 = img
# print(np.amax(img2))
# tmp=np.reshape(img2,(np.size(img2),1))
# print(type(tmp))
# print(np.size(tmp))
# print(np.amax(tmp))
#
#
# hfig, ax = plt.subplots(1, 1)
# ax.hist(tmp,255)
# hfig.show()
#
# #Elimina ruido
# img = segmentationUtils.ejecuta_close(img,4,4)
#
# #Amplifica capas
# img = segmentationUtils.ejecuta_dilate(img,5,20,1)
#
# #Tensor
# Axx, Axy, Ayy = feature.structure_tensor(img)
#
# #Elimina mas ruido
# Ayy = segmentationUtils.ejecuta_close(Ayy,6,1)
#
# #Resalta las capas que sean mayores a la media
# Ayy = segmentationUtils.resalta_bordes(Ayy,True,0)
#
# #Elimina aun mas ruido
# Ayy = segmentationUtils.ejecuta_open(Ayy,1,1)
#
# #Binarizacion
# binary = segmentationUtils.ejecuta_OTSU(Ayy)
#
# #elimina ruido del posible borde superior
# binary = segmentationUtils.ejecuta_elimina_ruido_extremos(True,0,0,binary)
#
# #elimina ruido del posible borde inferior
# binary = segmentationUtils.ejecuta_elimina_ruido_extremos(False,0,0,binary)
#
# #obtiene bordes exteriores
# arraySuperior, arrayInferior = segmentationUtils.obten_bordes_externos(binary)
#
# #elimina ruido a la imagen original
# img2 = segmentationUtils.elimina_desde_arreglos(img2, arraySuperior, arrayInferior)
# img2 = segmentationUtils.ejecuta_close(img2,2,1)
# img2 = feature.canny(img2,sigma = 2.5)
# img2 = segmentationUtils.elimina_ruido_canny(img2,1)
# Hide and close progress bar.
if mode == "gui":
progress.hide()
# if isinstance(imgin,(OCTscan,)):
if type(imgin) is OCTscan:
self.result = OCTscanSegmentation(imgin)
else:
self.result = OCTscanSegmentation(OCTscan(imgin))
self.result.data = img2
return self.result
class OCTvolume(object):
# Sphinx documentation
"""A set of :class:`data.OCTscan`
A set of :class:`data.OCTscan`
.. seealso:: :class:`data.OCTscan`
.. note:: None
.. todo:: None
"""
# Class constructor
def __init__(self):
"""The class constructor.
The class constructor.
tmp = OCTvolume() - Creates an empty volume with no scans.
"""
self.scans = list()
return
# Properties getters/setters
@property
def scans(self): # scans getter
"""
The set of OCT scans.
:getter: Gets the set of scans
:setter: Sets the set of scans
:type: list. All scans are of :class:`data.OCTscan`
.. seealso:: :func:`data.OCTvolume.addScan` , :func:`data.OCTvolume.removeScan` , :func:`data.OCTvolume.clear`
"""
return self.__scans
@scans.setter
def scans(self, *args): # scans setter
tmpScanSet = args[0]
if type(tmpScanSet) is not list:
warnMsg = (
self.getClassName() + ":scans: Unexpected type. "
"Please provide a list of data.OCTscan."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
self.__scans = list()
for x in tmpScanSet:
if type(x) is not OCTscan:
warnMsg = (
self.getClassName() + ":scans: Unexpected scan type "
"for object " + x + ". Skipping object."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
self.__scans.append(x)
return None
# Public methods
def getClassName(self):
return type(self).__name__
def clear(self):
"""
Clears the OCT volume; Removes all scans.
:return: None
"""
self.__scans = list()
return None
@deprecation.deprecated(
deprecated_in="0.3",
removed_in="1.0",
# current_version=__version__,
details="Use method addScans() instead.",
)
def addScan(self, theScan):
"""
Add an OCT scan to the volume.
:param theScan: The OCT scan.
:type theScan: :class:`data.OCTscan`
:return: None
"""
if type(theScan) is not OCTscan:
warnMsg = (
self.getClassName() + ":addScan: Unexpected scan type. "
"Nothing will be added."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
self.__scans.append(theScan)
return None
def addScans(self, theScans):
"""
Add one or more OCT scans to the volume at once.
:param theScans: The list of OCT scans.
:type theScan: list of :class:`data.OCTscan` or
single :class:`data.OCTscan`
:return: True if scans added, False otherwise.
"""
flagAllOCTscans = True
if type(theScans) is OCTscan:
self.__scans.append(theScans)
elif type(theScans) is list:
for elem in theScans:
if type(elem) is not OCTscan:
warnMsg = (
self.getClassName() + ":addScans: Unexpected scan type. "
"Nothing will be added."
)
flagAllOCTscans = False
break
if flagAllOCTscans:
self.__scans.extend(theScans)
return flagAllOCTscans
def getScans(self, t):
"""
Retrieves all scans in the volume of type t.
:param t: Scan type 'A', 'B' or 'C'
:type t: char
:return: The set of A scans in the volume
:rtype: list
.. seealso:: :func:`data.OCTvolume.getVolume`
"""
t = t.upper() # Uppercase
theScans = list()
for x in self.__scans:
if x.scantype == t:
theScans.append(x)
return theScans
def getVolume(self, t):
"""
Retrieves the (sub-)volume of scans of type t.
:param t: Scan type 'A', 'B' or 'C'
:type t: char
:return: A volume with the set of scans of type t.
:rtype: :class:`data.OCTvolume`
.. seealso:: :func:`data.OCTvolume.getScans`
"""
t = t.upper() # Uppercase
theScans = OCTvolume()
for x in self.__scans:
if x.scantype == t:
theScans.addScan(x)
return theScans
def getNScans(self, t=None):
"""Get the number of scans of a certain type.
If type is not given, then the total number of scans is given.
:param t: Scan type 'A', 'B' or 'C' or None
:type t: char
:return: The number of scans of a certain type
:rtype: int
"""
if t is None:
res = len(self.__scans)
else:
res = self.getNScans(self.getVolume(t))
return res
class OCTvolumeSegmentation(object):
# Sphinx documentation
"""A set of :class:`data.OCTscanSegmentation`
A set of :class:`data.OCTscanSegmentation`
.. seealso:: :class:`data.OCTscanSegmentation`
.. note:: None
.. todo:: None
"""
# Class constructor
def __init__(self):
"""The class constructor.
The class constructor.
tmp = OCTvolumeSegmentation() - Creates an empty segmentation volume with no scans.
"""
self.scanSegmentations = list()
return
# Properties getters/setters
@property
def scanSegmentations(self): # scans getter
"""
The set of OCT scans segmentations.
:getter: Gets the set of scans segmentations
:setter: Sets the set of scans segmentations
:type: list. All scans are of :class:`data.OCTscanSegmentation`
.. seealso:: :func:`data.OCTvolumeSegmentation.addScan` , :func:`data.OCTvolumeSegmentation.removeScan` , :func:`data.OCTvolumeSegmentation.clear`
"""
return self.__scanSegmentations
@scanSegmentations.setter
def scanSegmentations(self, *args): # scanSegmentations setter
tmpScanSet = args[0]
if type(tmpScanSet) is not list:
warnMsg = (
self.getClassName() + ":scanSegmentations: Unexpected type. "
"Please provide a list of data.OCTscanSegmentation."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
self.__scanSegmentations = list()
for x in tmpScanSet:
if type(x) is not OCTscanSegmentation:
warnMsg = (
self.getClassName()
+ ":scanSegmentations: Unexpected scan type "
"for object " + x + ". Skipping object."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
self.__scanSegmentations.append(x)
return None
# Public methods
def clear(self):
"""
Clears the OCT segmentation volume; Removes all scan segmentations.
:return: None
"""
self.__scanSegmentations = list()
return None
def addScanSegmentations(self, theScanSegmentations):
"""
Add one or multiple OCT scan segmentation to the volume.
:param theScanSegmentations: The list of OCT scan segmentations
:type theScanSegmentations: list of :class:`data.OCTscanSegmentation` or
single :class:`data.OCTscanSegmentation`
:return: None
"""
flagAllOCTscans = False
if type(theScanSegmentations) is OCTscanSegmentation:
flagAllOCTscans = True
self.__scanSegmentations.append(theScanSegmentations)
elif type(theScanSegmentations) is list:
flagAllOCTscans = True
for elem in theScans:
if type(elem) is not OCTscanSegmentation:
warnMsg = (
self.getClassName() + ":addScans: Unexpected scan type. "
"Nothing will be added."
)
flagAllOCTscans = False
break
if flagAllOCTscans:
self.__scanSegmentations.extend(theScanSegmentations)
return flagAllOCTscans
def getScanSegmentations(self, t):
"""
Retrieves all scans in the volume of type t.
:param t: Scan type 'A', 'B' or 'C' or scan indexing
:type t: str, list or int
:return: The set of scans in the volume of the chosen
:rtype: list
.. seealso:: :func:`data.OCTvolumeSegmentation.getVolume`
"""
theScans = list()
if type(t) is str:
t = t.upper() # Uppercase
for x in self.__scanSegmentations:
if x.scantype == t:
theScans.append(x)
elif type(t) is list:
for elem in t:
theScans.append(self.__scanSegmentations[elem])
elif type(t) is int:
theScans.append(self.__scanSegmentations[elem])
return theScans
def getVolume(self, t):
"""
Retrieves the (sub-)volume of scans of type t.
:param t: Scan type 'A', 'B' or 'C'
:type t: char
:return: A volume with the set of scans of type t.
:rtype: :class:`data.OCTvolume`
.. seealso:: :func:`data.OCTvolume.getScans`
"""
t = t.upper() # Uppercase
theScans = OCTvolumeSegmentation()
for x in self.__scanSegmentations:
if x.scantype == t:
theScans.addScanSegmentation(x)
return theScans
def getNScans(self):
"""Get the number of scans segmentations.
:return: The number of scans segmentations
:rtype: int
"""
return len(self.__scanSegmentations)
class Document:
# Sphinx documentation
"""The document class for
The document class for
This class represents a document in A document holds information
about a study plus some additional metadata.
Currently, a study is only an OCT image (with several scans) with or without
segmentation information.
.. seealso:: None
.. note:: None
.. todo:: None
"""
# Private class attributes shared by all instances
# Class constructor
def __init__(self):
# Call superclass constructor
# Initialize private attributes unique to this instance
self.study = OCTvolume() # The current study.
# Currently, an OCT volume
self.segmentation = OCTvolumeSegmentation() # The current study.
# Currently, an OCT volumeSegmentation
self.docsettings = Settings()
self.docsettings.selectedScan = None
# shared between study and segmentation
# Document metadata
self.folderName = "." # Folder where the document is currently stored
self.fileName = "OCTantDocument0001" # The filename of the document
self.name = "OCTantDocument0001" # A logical name for the study
return
# Properties getters/setters
#
# Remember: Sphinx ignores docstrings on property setters so all
# documentation for a property must be on the @property method
@property
def docsettings(self): # docsettings getter
"""
The application settings.
:getter: Gets the document settings
:setter: Sets the document settings
:type: class:`data.Settings`
"""
return self.__appsettings
@docsettings.setter
def docsettings(self, newSettings): # document setter
if newSettings is None:
newSettings = Settings() # Initialize settings
if type(newSettings) is Settings:
self.__appsettings = newSettings
else:
warnMsg = self.getClassName() + ":docsettings: Unexpected settings type."
warnings.warn(warnMsg, SyntaxWarning)
return None
@property
def study(self): # study getter
"""
The OCT volume being processed and analysed.
..todo: Upgrade to volume. Watch out! This will affect many
other classess using this method.
:getter: Gets the OCT volume.
:setter: Sets the OCT volume.
:type: :class:`data.OCTvolume`
"""
return self.__study
@study.setter
def study(self, vol): # study setter
if vol is None or type(vol) is OCTvolume:
self.__study = vol
# ...and reset scan
self.segmentedScan = None
elif type(vol) is OCTscan:
warnMsg = (
self.getClassName()
+ ":study: OCTvolume expected but OCTscan received. Embedding scan."
)
warnings.warn(warnMsg, SyntaxWarning)
self.__study = OCTvolume()
self.__study.addScan(vol)
else:
warnMsg = self.getClassName() + ":study: Unexpected study type."
warnings.warn(warnMsg, SyntaxWarning)
return None
@property
def segmentation(self): # segmentation getter
"""
The segmentation over the OCT study being processed and analysed.
:getter: Gets the OCT volume segmentation.
:setter: Sets the OCT volume segmentation.
:type: :class:`data.OCTvolumeSegmentation`
"""
return self.__segmentation
@segmentation.setter
def segmentation(self, newSegmentation): # segmentation setter
if (newSegmentation is None) or (
type(newSegmentation) is OCTvolumeSegmentation
):
self.__segmentation = newSegmentation
if newSegmentation is not None:
if self.study is None:
warnMsg = self.getClassName() + ":segmentation: No reference image."
warnings.warn(warnMsg, SyntaxWarning)
if not (
len(newSegmentation.scanSegmentations) == len(self.study.scans)
):
warnMsg = self.getClassName() + ":segmentation: Unexpected size."
warnings.warn(warnMsg, SyntaxWarning)
elif type(newSegmentation) is OCTscanSegmentation:
warnMsg = (
self.getClassName()
+ ":study: OCTvolumeSegmentation expected but OCTscanSegmentation received. Embedding scan."
)
warnings.warn(warnMsg, SyntaxWarning)
self.__segmentation = OCTvolumeSegmentation()
self.__segmentation.addScanSegmentations(newSegmentation)
else:
warnMsg = (
self.getClassName() + ":segmentation: Unexpected segmented scan type."
)
warnings.warn(warnMsg, SyntaxWarning)
return None
@property
def folderName(self): # folderName getter
"""
Folder where the document is currently stored.
..note: Also retrieve the py:attr:`fileName` to build the full path.
:getter: Gets the study folder name.
:setter: Sets the study folder name. If new folder is None,
the current directory '.' is chosen.
:type: str
"""
return self.__folderName
@folderName.setter
def folderName(self, d): # name setter
if d is None:
d = "." # Set to current folder
if type(d) is str:
self.__folderName = d
else:
warnMsg = self.getClassName() + ":name: Unexpected folderName type."
warnings.warn(warnMsg, SyntaxWarning)
return None
@property
def fileName(self): # fileName getter
"""
The filename of the document.
..note: Also retrieve the py:attr:`folderName` to build the full path.
:getter: Gets the the filename of the document.
:setter: Sets the The filename of the document. If new name is None,
a default name is given.
:type: str
"""
return self.__folderName
@fileName.setter
def fileName(self, newFilename): # fileName setter
if newFilename is None:
newFilename = self.defaultName # Set to default name
if type(newFilename) is str:
self.__fileName = newFilename
else:
warnMsg = self.getClassName() + ":name: Unexpected fileName type."
warnings.warn(warnMsg, SyntaxWarning)
return None
@property
def name(self): # name getter
"""
A logical name for the study.
:getter: Gets the OCT study name.
:setter: Sets the OCT study name.
:type: str
"""
return self.__name
@name.setter
def name(self, newName): # name setter
if newName is None or type(newName) is str:
self.__name = newName
else:
warnMsg = self.getClassName() + ":name: Unexpected name type."
warnings.warn(warnMsg, SyntaxWarning)
return None
# Private methods
# Public methods
def getClassName(self):
return type(self).__name__
def getCurrentScan(self):
"""Get the current working OCT scan
Change the current selection using :func:`pickScan`
:returns: The current working OCT scan.
:rtype: :class:`data.OCTscan` or None if the study contains no scans
"""
if self.docsettings.selectedScan is None:
self.docsettings.selectedScan = 0
res = None
if len(self.__study.scans) > 0:
res = self.__study.scans[self.docsettings.selectedScan]
return res
def setCurrentScan(self, newScan):
"""Sets the current working OCT scan
Change the current selection using :func:`pickScan`
:param newScan: An OCT scan to be assigned to the current working OCT scan.
:type newScan: :class:`data.OCTscan`
"""
if self.docsettings.selectedScan is None:
self.docsettings.selectedScan = 0
if newScan is None:
if self.__study.getNScans() == 0:
# do nothing.
pass
else:
warnMsg = (
self.getClassName()
+ ":setcurrentscan: Unexpected scan type NoneType."
)
warnings.warn(warnMsg, SyntaxWarning)
if type(newScan) is OCTscan:
self.__study.scans[self.docsettings.selectedScan] = newScan
else:
warnMsg = self.getClassName() + ":setcurrentscan: Unexpected scan type."
warnings.warn(warnMsg, SyntaxWarning)
return None
def pickScan(self, i):
"""Pick the i-th OCT scan (and its segmentation) for working.
Sets the docsetting.selectedScan to i checking that it does exist.
:param i: The selected scan index
:type i: int
:return: None
"""
if type(i) is int and i < self.study.getNScans() and i >= 0:
self.docsettings.selectedScan = i
else:
warnMsg = self.getClassName() + ":pickScan: Selected scan does not exist."
warnings.warn(warnMsg, SyntaxWarning)
return None
def getCurrentScanSegmentation(self):
"""Get the current working OCT scanSegmentation
Change the current selection using :func:`pickScan`
:returns: The current working OCT scanSegmentation.
:rtype: :class:`data.OCTscanSegmentation`
"""
if self.docsettings.selectedScan is None:
self.docsettings.selectedScan = 0
res = None
if len(self.__segmentation.scanSegmentations) > 0:
res = self.__segmentation.scanSegmentations[self.docsettings.selectedScan]
return res
def setCurrentScanSegmentation(self, newScan):
"""Sets the current working OCT scanSegmentation
Change the current selection using :func:`pickScan`
:param newScan: An OCT scan to be assigned to the current working OCT scan.
:type newScan: :class:`data.OCTscanSegmentation`
"""
if self.docsettings.selectedScan is None:
self.docsettings.selectedScan = 0
if newScan is None:
if self.__segmentation.getNScans() == 0:
# do nothing.
pass
else:
warnMsg = (
self.getClassName()
+ ":setcurrentscansegmentation: Unexpected scan type NoneType."
)
warnings.warn(warnMsg, SyntaxWarning)
if type(newScan) is OCTscanSegmentation:
self.__segmentation.scanSegmentations[
self.docsettings.selectedScan
] = newScan
else:
warnMsg = (
self.getClassName()
+ ":setcurrentscansegmentation: Unexpected scan type."
)
warnings.warn(warnMsg, SyntaxWarning)
return None
def readFile(self, filename):
"""Reads an OCTant document file.
This method is currently a sham, and it will be updated
when serialization is incorporated to Currently,
it returns an empty document. Nevertheless, it already
updates the document, clearing all fields to default values,
and updates the filename and folder
The file must exist or an error is generated.
The file must be in OCTant file format.
:param fileName: The file name
:type fileName: str
:return: This document
:rtype: :class:`data.Document`
"""
self = Document()
self.folderName, self.fileName = os.path.split(filename)
return self
class Settings(object):
# Sphinx documentation
"""A class to hold a list of settings.
A class to hold a list of settings. A list of settings is the classical
"dictionary" (see note below on python's dict) of pairs key:value
but with some additional capabilities. In particular, the class provides
additional file reading and writing capabilities so that settings can
be read to and from plain text files, as well as some value setting
checking capabilities.
The class is intended to behave like a dynamic struct
where properties of the class, i.e. new settings, can be declared
"on-the-fly" instead of being predefined.
Although, creating a dynamic struct class in python itself is trivial
(see https://stackoverflow.com/questions/1878710/struct-objects-in-python ),
but because of the additional capabilities, hence the convenience of
the class.
.. Background:
MATLAB's struct allows this "on-the-fly" field declaration on the fly.
Python's built-in dictionary is not exactly a match because of the
required syntax i.e. ``mySettingsObj['fieldname']`` instead of
``mySettingsObj.fieldname`` and the inability to control value settings.
.. seealso:: None
.. note:: None
.. todo:: None
"""
# Private class attributes shared by all instances
# Class constructor
def __init__(self, **kwargs):
"""The class constructor."""
# Call superclass constructor
# Initialize private attributes unique to this instance
self.__dict__.update(kwargs) # Permits direct declaration of
# key:value pairs from declaration, e.g.
# x = Settings(foo=1, bar=2)
# See: https://stackoverflow.com/questions/1878710/struct-objects-in-python
return
# Properties getters/setters
#
# Remember: Sphinx ignores docstrings on property setters so all
# documentation for a property must be on the @property method
# Private methods
def __str__(self):
"""Provides the string representation of the object.
:returns: The object representation as a string.
:rtype: str
"""
s = "<" + self.getClassName() + ": "
s = s + str(self.__dict__)
s = s + ">"
return s
# Public methods
def getClassName(self):
"""Retrieves the class name.
:returns: The class name.
:rtype: str
"""
return type(self).__name__
def read(self, filename):
"""Read settings from JSON file.
:param filename: The name of the file to be read (including path)
:type filename: str
:returns: True if file was sucessfully read. False otherwise.
:rtype: bool
"""
with open(filename, "r") as file:
contentStr = file.read()
# c=json.loads(jsonminify(content))
contentDict = json.loads(fastjsonminify(contentStr))
# c contains a dictionary that has to be
# traspassed to self
# Loop over the dictionary
for fieldName, fieldValue in contentDict.items():
setattr(self, fieldName, fieldValue)
return True
def write(self, filename):
"""Write settings to a JSON file.
:returns: True if file was sucessfully read. False otherwise.
:rtype: bool
"""
contentStr = json.dumps(self.__dict__)
with open(filename, "w") as file:
file.write("# \n")
file.write("# File: " + filename + "\n")
file.write("# \n")
file.write("# This is an OCTant settings file.\n")
file.write("# You can add, edit or remove settings manually here.\n")
file.write(
"# File format is in JSON. Although comments are permitted, but they will be lost after resaving because of minification.\n"
)
file.write(
'# If you want your comments to be persistent declared them as "__comment" fields.\n'
)
file.write("# \n")
file.write(
"# File last saved: "
+ datetime.utcnow().strftime("%d-%b-%Y %H:%M:%S UTC+0")
+ "\n"
)
file.write("# \n")
file.write("# (c) 2019. Felipe Orihuela-Espina.\n")
file.write("# \n\n")
file.write(contentStr)
return True
class OpScanFlatten(Operation):
"""A flattening operation for :class:`data.OCTscan`.
A flattening operation for :class:`data.OCTscan`.
The operation represented by this class rectifies an OCT scan.
.. seealso:: None
.. note:: None
.. todo:: None
"""
# Private class attributes shared by all instances
# Class constructor
def __init__(self):
# Call superclass constructor
super().__init__()
# Set the operation name
self.name = "Flattening"
self.__deformationMap = None
return
@property
def deformationMap(self): # name getter
"""
A logical name for the study.
This is a read only property.
:getter: Gets the deformationMap associated to the last flattening.
:type: str
"""
return self.__deformationMap
# Private methods
# def __str__(self):
# #This not working yet; it gets into an infiite recursion as
# #super().__str__() calls self.getClassName() in THIS class.
# # s = '<' + self.getClassName() + '([' \
# # + super().__str__() + '])>'
# s = '<' + self.getClassName() + '([' \
# + str(super()) + '])>'
# print(super())
# return s
@staticmethod
def fittingQuadraticModel(x, a, b, c):
# quadratic model for curve optimization
return a * x * x + b * x + c
# Public methods
def execute(self, *args, **kwargs):
"""Executes the operation on the :py:attr:`operands`.
Executes the operation on the :py:attr:`operands` and stores the outcome
in :py:attr:`result`. Preload operands using
:func:`Operation.addOperand()`.
:returns: Result of executing the operation.
:rtype: :class:`data.OCTscan`
"""
# print(self._getClasName(),": flattening: Starting flattening")
# Ensure the operand has been set.
if len(self.operands) < 1:
warnMsg = self.getClassName() + ":execute: Operand not set."
warnings.warn(warnMsg, SyntaxWarning)
return None
imgin = self.operands[0]
if type(imgin) is OCTscan:
imgin = imgin.data
# Check whether the image is in RGB (ndim=3) or in grayscale (ndim=2)
# and convert to grayscale if necessary
if imgin.ndim == 2:
# Dimensions are only width and height. The image is already in grayscale.
I2 = imgin
elif imgin.ndim == 3:
# Image is in RGB. Convert.
I2 = color.rgb2gray(imgin)
else: # Unexpected case. Return warning
print(self._getClasName(), ": Unexpected image shape.")
self.result = imgin
return self.result
aux = np.argmax(I2, axis=0)
mg = np.mean(aux)
sdg = np.std(aux)
markers = []
remover = []
x0 = np.arange(len(aux))
for i in range(0, len(aux)):
if mg - 3 * sdg <= aux[i] <= mg + 3 * sdg:
markers += [aux[i]]
else:
remover += [i]
x = np.delete(x0, remover)
modelCoeffs, pcov = curve_fit(
self.fittingQuadraticModel, x, markers, method="dogbox", loss="soft_l1"
)
a = self.fittingQuadraticModel(x0, *modelCoeffs)
shift = np.max(a)
flat = shift - a
flat = np.round(flat)
flat = np.ravel(flat).astype(int)
self.__deformationMap = flat
newgray = I2
for i in range(0, len(a)):
newgray[:, i] = np.roll(I2[:, i], flat[i], axis=0)
self.result = OCTscan(newgray)
return self.result
# #@deprecated(version='0.2', reason="Deprecated. Use method execute() instead.")
# @deprecation.deprecated(deprecated_in="0.2", removed_in="0.3",
# current_version=__version__,
# details="Use method execute() instead.")
# def flattening(self,image):
# #Encapsulate the image as an OCTscan
# tmp=OCTscan(image)
# self.clear()
# self.addOperand(tmp)
# #Execute
# self.execute()
def applyOperation(self, scanA):
"""Apply the current flattening to the given scan.
Instead of calculating the fitting again needed for the
flattening, this method applies a known fitted quadratic model to
the given parameters.
The result is NOT stored in :py:attr:`result`.
:param scanA: Image to flatten.
:type scanA: :class:`data.OCTscan`
:returns: Result of repeating the last flattening operation onto
parameter scanA.
:rtype: :class:`data.OCTscan`
"""
if type(scanA) is OCTscan:
scanA = scanA.data
newgray = scanA
for i in range(0, len(self.deformationMap)):
newgray[:, i] = np.roll(scanA[:, i], self.deformationMap[i], axis=0)
return OCTscan(newgray)
import warnings
from abc import ABC, abstractmethod
class Operation(ABC):
# Sphinx documentation
"""An abstract base class for operations on :class:`octant.data.OCTvolume` and :class:`octant.data_OCTscan` .
An abstract base class for operations on :class:`octant.data.OCTvolume` and
:class:`octant.data.OCTscan`.
:Example:
tmp = octant.data.OCTscan(img)
o = octant.op.OpScanFlattening()
o.addOperand(tmp)
o.arity() #return 1
o.execute() #Flattens the image
:Known subclasses:
* :class:`OpScanFlattening`
* :class:`OpScanMeasureLayerThickness`
* :class:`OpScanPerfilometer`
* :class:`OpScanSegment`
* :class:`OpScanStitch`
* :class:`OpSegmentationBrush`
* :class:`OpSegmentationEdit`
.. seealso:: None
.. note:: None
.. todo::
* Support to hold operand names.
"""
# Private class attributes shared by all instances
# Class constructor
#
def __init__(self, **kwargs):
"""The class constructor.
The class constructor. Creates an empty operation
"""
super().__init__()
# Initialize attributes (without decorator @property)
# Initialize properties (with decorator @property)
self.name = "Operation" # The operation name
self.operands = list() # Operands
self.parameters = list() # Parameters
self.result = None # Operation outputs (a list in case it is multivalued).
# None until executed or cleared.
if kwargs is not None:
for key, value in kwargs.items():
if key == "name":
self.name = value
return
# Properties getters/setters
#
# Remember: Sphinx ignores docstrings on property setters so all
# documentation for a property must be on the @property method
@property
def operands(self): # operands getter
"""
The list of operands.
:getter: Gets the list of operands
:setter: Sets the list of operands.
:type: list
"""
return self.__operands
@operands.setter
def operands(self, opList): # operands setter
# if (not isinstance(opList,(list,))):
if type(opList) is not list:
warnMsg = (
self.getClassName() + ":operands: Unexpected type. "
"Please provide operands as a list."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
self.__operands = opList
return None
@property
def name(self): # name getter
"""
The operation name
:getter: Gets the operation name
:setter: Sets the operation name.
:type: string
"""
return self.__name
@name.setter
def name(self, opName): # name setter
# if (not isinstance(opName,(str,))):
if type(opName) is not str:
warnMsg = (
self.getClassName() + ":name: Unexpected type. "
"Operations name must be a string."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
self.__name = opName
return None
@property
def parameters(self): # operands getter
"""
The list of parameters.
:getter: Gets the list of parameters
:setter: Sets the list of parameters.
:type: list
"""
return self.__parameters
@parameters.setter
def parameters(self, opList): # operands setter
# if (not isinstance(opList,(list,))):
if type(opList) is not list:
warnMsg = (
self.getClassName() + ":parameters: Unexpected type. "
"Please provide operands as a list."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
self.__parameters = opList
return None
@property
def result(self): # result getter
"""
The list of results.
This is a read only property. There is no setter method.
:getter: Gets the list of results
:setter: Sets the list of results
:type: list
"""
return self.__result
@result.setter
def result(self, rList): # result setter
self.__result = rList
return None
# Private methods
def __str__(self):
tmp = "["
for x in self.operands:
tmp += format(x) + ","
tmp += "]"
s = (
"<"
+ self.getClassName()
+ "(["
+ "name: "
+ self.name
+ ";"
+ " operands: "
+ tmp
+ "])>"
)
return s
# Public methods
def getClassName(self):
"""Get the class name as a string.
Get the class name as a string.
:returns: The class name.
:rtype: string
"""
return type(self).__name__
def addOperand(self, op, i=None):
"""
Add a new operand.
:param op: The operand.
:type op: object
:param i: (optional) The operand order. If given it may shift the
order of other operands already set. If not given, the operand
is appended at the end of the list of operands.
:type op: int
:return: None
"""
if i is None:
self.__operands.append(op)
else:
self.__operands.insert(i, op)
return None
def setOperand(self, op, i):
"""
Set an operand; substitutes an existing operand with a new one.
Calling setOperand when the :py:attr:`i`-th operand has not been
previously set will result in an out-of-range error.
:param op: The new operand.
:type op: object
:param i: The operand order. Operand index is zero-base i.e. the
first operand occupies i=0
:type op: int
:return: None
"""
self.__operands[i] = op
return None
def addParameter(self, param, i=None):
"""
Add a new parameter.
:param op: The parameter.
:type op: object
:param i: (optional) The paremeter order. If given it may shift the
order of other parameters already set. If not given, the parameter
is appended at the end of the list of parameters.
:type op: int
:return: None
"""
if i is None:
self.__parameters.append(op)
else:
self.__parameters.insert(i, op)
return None
def setParameter(self, op, i):
"""
Set a parameter; substitutes an existing parameter with a new one.
Calling setParameter when the :py:attr:`i`-th parameter has not been
previously set will result in an out-of-range error.
:param op: The new operand.
:type op: object
:param i: The operand order. Operand index is zero-base i.e. the
first operand occupies i=0
:type op: int
:return: None
"""
self.__operands[i] = op
return None
def arity(self):
"""Gets the operation arity (number of operands).
:return: The operation arity
:rtype: int
"""
return len(self.__operands)
def clear(self):
"""
Clears the operands; Removes all operands.
:return: None
"""
self.__operands = list()
return None
# @abstractmethod
def execute(self, *args, **kwargs):
"""Executes the operation on the operands.
This is an abstract method. Executes the operation on the .operands
and stores the outcome in .result
Operation meta-parameters may be also passed.
:returns: Result of executing the operation.
:rtype: Type of result -depends on subclass implementation-.
"""
pass
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0087/643/87643680.ipynb | octant-project | nwheeler443 | [{"Id": 87643680, "ScriptId": 24617507, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 359577, "CreationDate": "02/12/2022 13:18:33", "VersionNumber": 1.0, "Title": "OCT segmentation", "EvaluationDate": "02/12/2022", "IsChange": true, "TotalLines": 2855.0, "LinesInsertedFromPrevious": 2855.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 117988798, "KernelVersionId": 87643680, "SourceDatasetVersionId": 3175055}] | [{"Id": 3175055, "DatasetId": 1929287, "DatasourceVersionId": 3224540, "CreatorUserId": 359577, "LicenseName": "Unknown", "CreationDate": "02/12/2022 13:17:15", "VersionNumber": 2.0, "Title": "OCTant project", "Slug": "octant-project", "Subtitle": "Retinal imaging data", "Description": NaN, "VersionNotes": "Data Update 2022/02/12", "TotalCompressedBytes": 0.0, "TotalUncompressedBytes": 0.0}] | [{"Id": 1929287, "CreatorUserId": 359577, "OwnerUserId": 359577.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 3199639.0, "CurrentDatasourceVersionId": 3249374.0, "ForumId": 1952953, "Type": 2, "CreationDate": "02/12/2022 11:00:31", "LastActivityDate": "02/12/2022", "TotalViews": 998, "TotalDownloads": 4, "TotalVotes": 2, "TotalKernels": 1}] | [{"Id": 359577, "UserName": "nwheeler443", "DisplayName": "Nicole Wheeler", "RegisterDate": "05/29/2015", "PerformanceTier": 0}] | # # Enhancing an open-source OCT segmentation tool with manual segmentation capabilities
# ## Introduction
# Optical coherence tomography (OCT) is a way of capturing images for the diagnosis and monitoring of the retina. The retina is complex tissue composed of ten major layers of distinct cells. An important part of the routine use of OCT retinal images is the segmentation of the tissue layers. The segmentation consists of labelling the image pixels with their corresponding layer and remains a complex problem despite the existence of some approximate solutions.
# Around the central task of segmentation, additional functions need to be performed on the image, for instance to quantify the thickness of the tissue layers, or to stitch several images together to see a wider region of the eye. For ophthalmologists to be able to use the algorithms needed to process the OCT image, these functions are often encapsulated in user friendly applications. But alas, software to segment retinal OCT images is expensive and not always available in developing countries and/or economically disfavored areas.
# OCTant (https://github.com/forihuelaespina/OCTant/) is a python based free open-source software for the analysis of OCT images originally proposed by the National Institute of Astrophysics, Optics and Electronics (INAOE in Spanish) in Mexico but which is still under development. In its current version, OCTant can flatten or mosaic the images, and measure the thickness of each layer.
# Because the performance of even state-of-the-art segmentation algorithms is always suboptimal, ophthalmologists often benefit from being able to make manual adjustments. This project will improve the OCTant tool with the capacity to manually adjust a given segmentation
# The project will teach you:
# * Basic medical image processing.
# * To develop code valid within a collaborative project (i.e. several programming rules ought to be respected so that other collaborators can use and understand you code off-the-shelf. For instance, you will familiarize yourself with GitHub versioning platform.
# * To interact with software in development, where bugs are likely to exist, and errors are likely to appear. For instance, you will learn to report bugs.
# * To produce technical documentation in Sphynx.
# To start off with, let's take a look at an example image:
# import os
# import glob
# import numpy as np
from PIL import Image
# import matplotlib.pyplot as plt
img = Image.open("../input/octant-project/_1323904_.jpeg")
img
# what can we do to the image?
dir(img)
print(img.width, img.height)
spinPicture = img.rotate(30)
spinPicture
from PIL import Image
import matplotlib.pyplot as plt
def getRed(redVal):
return "#%02x%02x%02x" % (redVal, 0, 0)
def getGreen(greenVal):
return "#%02x%02x%02x" % (0, greenVal, 0)
def getBlue(blueVal):
return "#%02x%02x%02x" % (0, 0, blueVal)
# Create an Image with specific RGB value
image = img
# Display the image
image.show()
# Get the color histogram of the image
histogram = image.histogram()
# Take only the Red counts
l1 = histogram[0:256]
# Take only the Blue counts
l2 = histogram[256:512]
# Take only the Green counts
l3 = histogram[512:768]
plt.figure(0)
# R histogram
for i in range(0, 256):
plt.bar(i, l1[i], color=getRed(i), edgecolor=getRed(i), alpha=0.3)
# G histogram
plt.figure(1)
for i in range(0, 256):
plt.bar(i, l2[i], color=getGreen(i), edgecolor=getGreen(i), alpha=0.3)
# B histogram
plt.figure(2)
for i in range(0, 256):
plt.bar(i, l3[i], color=getBlue(i), edgecolor=getBlue(i), alpha=0.3)
plt.show()
# %matplotlib inline
# from matplotlib import pyplot as plt
# from gluoncv import model_zoo, data, utils
# net = model_zoo.get_model('mask_rcnn_fpn_resnet101_v1d_coco', pretrained=True)
# from PIL import Image
# import pandas as pd
# import os
# import numpy as np
# pth = '../input/octant-project/_1323904_.jpeg'
# x, orig_img = data.transforms.presets.rcnn.load_test(pth)
# ids, scores, bboxes, masks = [xx[0].asnumpy() for xx in net(x)]
# width, height = orig_img.shape[1], orig_img.shape[0]
# masks = utils.viz.expand_mask(masks, bboxes, (width, height), scores)
# orig_img = utils.viz.plot_mask(orig_img, masks)
# # identical to Faster RCNN object detection
# fig = plt.figure(figsize=(20, 20))
# ax = fig.add_subplot(1, 1, 1)
# ax = utils.viz.plot_bbox(orig_img, bboxes, scores, ids,
# class_names=net.classes, ax=ax)
# plt.show()
from skimage import io
import copy
import octant as oc
fileName = "../input/octant-project/_1323904_.jpeg"
img = io.imread(fileName)
scan = OCTscan(img)
scanSegmentation = OCTscanSegmentation(scan)
print("Creating document.")
study = OCTvolume() # Initialize a document
study.addScans(scan)
segmentationVol = OCTvolumeSegmentation() # Initialize a document
segmentationVol.addScanSegmentations(scanSegmentation)
doc = Document() # Initialize a document
doc.name = fileName
tmp, _ = os.path.split(fileName)
doc.folderName = tmp
doc.fileName = fileName
doc.study = study
doc.segmentation = segmentationVol
# Keep reference image.
print("Replicating image.")
doc2 = copy.deepcopy(doc)
# Flattening
print("-- Flattening.")
flt = OpScanFlatten()
flt.addOperand(doc2.getCurrentScan())
imFlattened = flt.execute()
doc2.setCurrentScan(imFlattened)
# Segmentation
print("-- Segmenting.")
doc3 = copy.deepcopy(doc2)
seg = OpScanSegment()
seg.addOperand(doc3.getCurrentScan())
imSegmented = seg.execute()
doc3.setCurrentScanSegmentation(imSegmented)
# Load colormap
print("-- Plotting.")
appsettings = Settings()
appsettingsfile = "..\\resources\\OCTantApp.config"
appsettings.read(appsettingsfile)
cmap = appsettings.retinallayerscolormap
# hFig = myInitFigure()
# myPaint(hFig,doc) #Plot raw with dummy segmentation
# hFig = myPaint(myInitFigure(),doc) #Plot raw
hFig = myPaint(myInitFigure(), doc2) # Plot flattened
hFig = myPaint(myInitFigure(), doc3) # Plot segmented
# imgin = OCTscan(img)
class OCTscan(object):
# Sphinx documentation
"""A single OCT scan.
A single OCT scan. A scan is a grayscale image.
Check .scantype property for the scan type (A, B or C)
.. seealso:: :class:`data.OCTvolume`
.. note:: None
.. todo:: Upgrade to color scans.
"""
# Class constructor
def __init__(self, *args):
"""The class constructor.
The class constructor.
tmp = OCTscan() - Creates an black scan sized 480x640.
tmp = OCTScan(img) - Creates scan from the (grayscale) image. Assumed to be an A scan.
tmp = OCTScan(img,type) - Creates scan from the (grayscale) image.
:param img: The scan image
:type img: numpy.ndarray
:param type: The scan type ('A' -default-, 'B' or 'C')
:type type: char
"""
if len(args) > 1:
warnMsg = (
self.getClassName() + ":__init__: Unexpected number of input arguments."
)
warnings.warn(warnMsg, SyntaxWarning)
# Initialize attributes (without decorator @property)
# Initialize properties (with decorator @property)
self.data = np.zeros(shape=(480, 640), dtype=np.uint8) # The default scan image
self.scantype = "A"
if len(args) > 0:
self.data = args[0]
if len(args) > 1:
self.scantype = args[1]
return
# Properties getters/setters
#
# Remember: Sphinx ignores docstrings on property setters so all
# documentation for a property must be on the @property method
@property
def data(self): # data getter
"""
The (grayscale) scan image. The image is expected to be
a grayscale image. Colour images will be converted to grayscale.
:getter: Gets the OCT scan image
:setter: Sets the OCT scan image.
:type: numpy.ndarray shaped [width,height]
"""
return self.__data
@data.setter
def data(self, img): # data setter
if img is not None:
# Check whether the image is in RGB (ndim=3) or in grayscale (ndim=2)
# and convert to grayscale if necessary
if img.ndim == 2:
# Dimensions are only width and height. The image is already in grayscale.
pass
elif img.ndim == 3:
# Image is in RGB. Convert.
img = color.rgb2gray(img)
else: # Unexpected case. Return warning
warnMsg = self.getClassName() + ":data: Unexpected image shape."
warnings.warn(warnMsg, SyntaxWarning)
self.__data = img
return None
@property
def shape(self): # shape getter
"""
The scan shape [width,height].
:getter: Gets the scan shape
:setter: None. This is a read-only property.
:type: Tuple [width,height]
"""
return self.__data.shape
@shape.setter
def shape(self, *args): # shape setter
# Catching attempts to set the shape of the scan
warnMsg = self.getClassName() + ":shape: shape is a read-only property."
warnings.warn(warnMsg, UserWarning)
return
@property
def scantype(self): # scantype getter
"""
The scan type; 'A', 'B' or 'C'.
:getter: Gets the scan type.
:setter: Sets the scan type.
:type: char 'A', 'B' or 'C'.
"""
return self.__scantype
@scantype.setter
def scantype(self, *args): # shape setter
stype = args[0].upper() # Uppercase
if not stype in ("A", "B", "C"):
warnMsg = (
self.getClassName() + ":scantype: Scan type can only be "
"A"
", "
"B"
" or "
"C"
"."
)
warnings.warn(warnMsg, SyntaxWarning)
self.__scantype = stype
return None
# Private methods
def __str__(self):
s = (
"<"
+ self.getClassName()
+ "(["
+ " data: "
+ format(self.data)
+ ","
+ " shape: "
+ format(self.shape)
+ ","
+ " scantype: "
+ self.scantype
+ "])>"
)
return s
# Public methods
def getClassName(self):
"""Get the class name as a string.
Get the class name as a string.
:returns: The class name.
:rtype: string
"""
return type(self).__name__
class OCTscanSegmentation(object):
# Sphinx documentation
"""A retinal layer segmentation over a :class:`data.OCTscan`
A retinal layer segmentation over a :class:`data.OCTscan`. A segmentation
assigns every pixel of the scan a class label.
Please note that this is a data model class; it keeps the segmentation
but it is NOT capable of "computing" such segmentation. To compute a
segmentation please refer to :class:`op.OpScanSegment`.
The segmentation is sized and shaped equal to its base
:class:`data.OCTscan`.
A default segmentation sets the whole segmentation to BACKGROUND.
.. seealso:: :class:`data.OCTscan`, :class:`op.OpScanSegment`
.. note:: None
.. todo:: None
"""
_BACKGROUND = 0 # The background label identifier
# Class constructor
def __init__(self, *args):
"""The class constructor.
The class constructor.
tmp = OCTscanSegmentation(theOCTScan) - Creates a default
segmentation for the given :class:`data.OCTscan`
:param theOCTScan: The OCT scan to be segmented
:type img: :class:`data.OCTscan`
"""
refImage = OCTscan()
# Dummy reference
if len(args) == 0:
warnMsg = (
self.getClassName()
+ ":__init__: Unexpected number of input arguments. Generating a dummy reference scan."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
refImage = args[0]
# if type(refImage) is not OCTscan:
# raise ErrorValue #Throw error
# Initialize attributes (without decorator @property)
# Initialize properties (with decorator @property)
self.scan = refImage # The OCT scan over which the segmentation is made
self.data = self._BACKGROUND * np.ones(
refImage.shape
) # The segmentation itself
self.classMap = RetinalLayers().layers # The map of class labels
return
# Properties getters/setters
#
# Remember: Sphinx ignores docstrings on property setters so all
# documentation for a property must be on the @property method
@property
def data(self): # data getter
"""
The segmentation labels map. Please refer to :py:attr:`classMap` for
classes.
..note: WARNING! This method is not currently checking whether the
data is sized equal to the scan. This may become a problem later.
The problem is that trying to check scan.shape will raise an
error during object creation, when attemting to set the data
but because the object has not been created yet, it still lacks
the scan property even if declared in advance.
:getter: Gets the segmentation map
:setter: Sets the segmentation map
:type: numpy.ndarray shaped [width,height]
"""
return self.__data
@data.setter
def data(self, segmentedImg): # data setter
self.__data = segmentedImg
# if segmentedImg is not None:
# #Check whether the image is in RGB (ndim=3) or in grayscale (ndim=2)
# #and convert to grayscale if necessary
# if ((segmentedImg.ndim == 2) & (segmentedImg.shape == self.scan.shape)):
# #Dimensions are only width and height, and matches that of
# #the scan.
# self.__data = segmentedImg;
# else: #Unexpected case. Return warning
# warnMsg = self.getClassName() + ':data: Unexpected segmentation shape.'
# warnings.warn(warnMsg,SyntaxWarning)
return None
@property
def scan(self): # scan getter
"""
The base OCT scan. Please refer to :py:attr:`data` for
the segmentation map.
:getter: Gets the base OCT scan
:setter: Sets the base OCT scan
:type: :class:`data.OCTscan`
"""
return self.__scan
@scan.setter
def scan(self, octScan): # scan setter
if octScan is not None:
# Check whether the image is in RGB (ndim=3) or in grayscale (ndim=2)
# and convert to grayscale if necessary
if type(octScan) is OCTscan:
# Dimensions are only width and height, and matches that of
# the scan.
self.__scan = octScan
self.clear()
else: # Unexpected case. Return warning
warnMsg = self.getClassName() + ":data: Unexpected type for OCT scan."
warnings.warn(warnMsg, SyntaxWarning)
return None
@property
def shape(self): # shape getter
"""
The scan segmentation shape [width,height].
:getter: Gets the scan segmentation shape
:setter: None. This is a read-only property.
:type: Tuple [width,height]
"""
return self.__data.shape
@shape.setter
def shape(self, *args): # shape setter
# Catching attempts to set the shape of the scan
warnMsg = self.getClassName() + ":shape: shape is a read-only property."
warnings.warn(warnMsg, UserWarning)
return
@property
def classMap(self): # classMap getter
"""
The map of classes.
The map of classes; the list of class names associated to each
value in the segmentation map.
..note: This list does NOT include the BACKGROUND class.
:getter: Gets the base OCT scan
:setter: Sets the base OCT scan
:type: :class:`data.OCTscan`
"""
return self.__classMap
@classMap.setter
def classMap(self, cm): # classMap setter
if cm is not None:
# Check that we are receiving the correct type
if type(cm) is dict:
self.__classMap = cm
else: # Unexpected case. Return warning
warnMsg = (
self.getClassName() + ":classMap: Unexpected type for classMap."
)
warnings.warn(warnMsg, SyntaxWarning)
return None
# Private methods
def __str__(self):
s = (
"<"
+ self.getClassName()
+ "(["
+ " scan: "
+ format(self.scan)
+ ","
+ " data: "
+ format(self.data)
+ ","
+ " classMap: "
+ format(self.classMap)
+ "])>"
)
return s
# Public methods
def getClassName(self):
"""Get the class name as a string.
Get the class name as a string.
:returns: The class name.
:rtype: string
"""
return type(self).__name__
def clear(self):
"""Clears/Resets the segmentation map to _BACKGROUND.
Clears/Resets the segmentation map to _BACKGROUND. All pixels are
assigned the background label.
"""
self.data = self._BACKGROUND * np.ones(self.scan.shape)
return None
class OCTscan(object):
# Sphinx documentation
"""A single OCT scan.
A single OCT scan. A scan is a grayscale image.
Check .scantype property for the scan type (A, B or C)
.. seealso:: :class:`data.OCTvolume`
.. note:: None
.. todo:: Upgrade to color scans.
"""
# Class constructor
def __init__(self, *args):
"""The class constructor.
The class constructor.
tmp = OCTscan() - Creates an black scan sized 480x640.
tmp = OCTScan(img) - Creates scan from the (grayscale) image. Assumed to be an A scan.
tmp = OCTScan(img,type) - Creates scan from the (grayscale) image.
:param img: The scan image
:type img: numpy.ndarray
:param type: The scan type ('A' -default-, 'B' or 'C')
:type type: char
"""
if len(args) > 1:
warnMsg = (
self.getClassName() + ":__init__: Unexpected number of input arguments."
)
warnings.warn(warnMsg, SyntaxWarning)
# Initialize attributes (without decorator @property)
# Initialize properties (with decorator @property)
self.data = np.zeros(shape=(480, 640), dtype=np.uint8) # The default scan image
self.scantype = "A"
if len(args) > 0:
self.data = args[0]
if len(args) > 1:
self.scantype = args[1]
return
# Properties getters/setters
#
# Remember: Sphinx ignores docstrings on property setters so all
# documentation for a property must be on the @property method
@property
def data(self): # data getter
"""
The (grayscale) scan image. The image is expected to be
a grayscale image. Colour images will be converted to grayscale.
:getter: Gets the OCT scan image
:setter: Sets the OCT scan image.
:type: numpy.ndarray shaped [width,height]
"""
return self.__data
@data.setter
def data(self, img): # data setter
if img is not None:
# Check whether the image is in RGB (ndim=3) or in grayscale (ndim=2)
# and convert to grayscale if necessary
if img.ndim == 2:
# Dimensions are only width and height. The image is already in grayscale.
pass
elif img.ndim == 3:
# Image is in RGB. Convert.
img = color.rgb2gray(img)
else: # Unexpected case. Return warning
warnMsg = self.getClassName() + ":data: Unexpected image shape."
warnings.warn(warnMsg, SyntaxWarning)
self.__data = img
return None
@property
def shape(self): # shape getter
"""
The scan shape [width,height].
:getter: Gets the scan shape
:setter: None. This is a read-only property.
:type: Tuple [width,height]
"""
return self.__data.shape
@shape.setter
def shape(self, *args): # shape setter
# Catching attempts to set the shape of the scan
warnMsg = self.getClassName() + ":shape: shape is a read-only property."
warnings.warn(warnMsg, UserWarning)
return
@property
def scantype(self): # scantype getter
"""
The scan type; 'A', 'B' or 'C'.
:getter: Gets the scan type.
:setter: Sets the scan type.
:type: char 'A', 'B' or 'C'.
"""
return self.__scantype
@scantype.setter
def scantype(self, *args): # shape setter
stype = args[0].upper() # Uppercase
if not stype in ("A", "B", "C"):
warnMsg = (
self.getClassName() + ":scantype: Scan type can only be "
"A"
", "
"B"
" or "
"C"
"."
)
warnings.warn(warnMsg, SyntaxWarning)
self.__scantype = stype
return None
# Private methods
def __str__(self):
s = (
"<"
+ self.getClassName()
+ "(["
+ " data: "
+ format(self.data)
+ ","
+ " shape: "
+ format(self.shape)
+ ","
+ " scantype: "
+ self.scantype
+ "])>"
)
return s
# Public methods
def getClassName(self):
"""Get the class name as a string.
Get the class name as a string.
:returns: The class name.
:rtype: string
"""
return type(self).__name__
class RetinalLayers(object):
# Sphinx documentation
"""A collection of constants for identifying retinal layers.
A collection of constants for identifying retinal layers.
It is basically a dictionary of pairs key:value
The following retinal layers are considered:
* Inner Limiting Membrane (ILM)
* Nerve Fiber Layer (NFL)
* Ganglion Cell Layer (GCL)
* Inner Plexiform Layer (IPL)
* Inner Nuclear Layer (INL)
* Outer Plexiform Layer (OPL)
* Outner Nuclear Layer (ONL)
* External Limiting Membrane (ELM)
* Rods and Cones layers (RCL)
* RetinalPigmentEpithelium (RPE)
Also the non-retinal layer is indexed:
* Choroid (CHR)
For pathological conditions, the following is also encoded:
* Fluid (FLD)
.. seealso:: None
.. note:: None
.. todo:: None
"""
# Private class attributes shared by all instances
# Class constructor
def __init__(self):
"""The class constructor.
The class constructor.
tmp = RetinalLayers() - Creates an RetinalLayers object.
"""
# Initialize attributes
# Layer constants
self.layers = {
"Inner Limiting Membrane": 1,
"Nerve Fiber Layer": 2,
"Ganglion Cell Layer": 3,
"Inner Plexiform Layer": 4,
"Inner Nuclear Layer": 5,
"Outer Plexiform Layer": 6,
"Outer Nuclear Layer": 7,
"External Limiting Membrane": 8,
"Rods and Cones Layers": 9,
"Retinal Pigment Epithelium": 10,
"Choroid": 20,
"Fluid": 1001,
}
# Currently:
# RPE includes Bruch's membrane even though most books will
# consider BM as part of the choroid already.
# ONL includes Henle’s layer
# ELM is also known as Inner Segment Layer
# The RCL includes connecting cilia (CL), outer segment layer (OSL) and Verhoeff membrane (VM)
# ...and so that one can have different names for each layer
self.layerNames = {
"ilm": self.layers["Inner Limiting Membrane"],
"innerlimitingmembrane": self.layers["Inner Limiting Membrane"],
"nfl": self.layers["Nerve Fiber Layer"],
"nervefiberlayer": self.layers["Nerve Fiber Layer"],
"gcl": self.layers["Ganglion Cell Layer"],
"ganglioncelllayer": self.layers["Ganglion Cell Layer"],
"ipl": self.layers["Inner Plexiform Layer"],
"innerplexiformlayer": self.layers["Inner Plexiform Layer"],
"inl": self.layers["Inner Nuclear Layer"],
"innernuclearlayer": self.layers["Inner Nuclear Layer"],
"opl": self.layers["Outer Plexiform Layer"],
"outerplexiformlayer": self.layers["Outer Plexiform Layer"],
"onl": self.layers["Outer Nuclear Layer"],
"outernuclearlayer": self.layers["Outer Nuclear Layer"],
"elm": self.layers["External Limiting Membrane"],
"externallimitingmembrane": self.layers["External Limiting Membrane"],
"rcl": self.layers["Rods and Cones Layers"],
"rodsandconeslayers": self.layers["Rods and Cones Layers"],
"rpe": self.layers["Retinal Pigment Epithelium"],
"retinalpigmentepithelium": self.layers["Retinal Pigment Epithelium"],
"chr": self.layers["Choroid"],
"fld": self.layers["Fluid"],
}
# Layer acronyms
self.layerAcronyms = {
self.layers["Inner Limiting Membrane"]: "ILM",
self.layers["Nerve Fiber Layer"]: "NFL",
self.layers["Ganglion Cell Layer"]: "GCL",
self.layers["Inner Plexiform Layer"]: "IPL",
self.layers["Inner Nuclear Layer"]: "INL",
self.layers["Outer Plexiform Layer"]: "OPL",
self.layers["Outer Nuclear Layer"]: "ONL",
self.layers["External Limiting Membrane"]: "ELM",
self.layers["Rods and Cones Layers"]: "RCL",
self.layers["Retinal Pigment Epithelium"]: "RPE",
self.layers["Choroid"]: "Choroid",
self.layers["Fluid"]: "Fluid",
}
return
# Private methods
# Public methods
def getClassName(self):
"""Gets the class name
return: The class name
rtype: string
"""
return type(self).__name__
def getAllLayersIndexes(self):
"""Gets the list of layer values
return: The list of layers values
rtype: list
"""
return list(self.layers.values())
def getAllLayersNames(self):
"""Gets the list of layer keys
return: The list of layers keys
rtype: list
"""
# Retrieves a list of layer keys
return list(self.layers.keys())
def getLayerAcronym(self, idx):
"""Gets the acronym of the i-th layer
return: The layer acronym e.g. NFL
rtype: string
"""
lacronym = "NaN"
try:
lacronym = self.layerAcronyms[idx]
except:
lacronym = "Unknown"
print(
self.getClassName(),
':getLayerAcronym: Unexpected layer index. Returning name "',
lacronym,
'"',
)
return lacronym
def getLayerIndex(self, layerName):
"""Retrieve the index of a given layer
return: The index of the layer
rtype: int
"""
r = -1
try:
layerName = layerName.replace(" ", "") # Remove whitespaces
r = self.layerNames[layerName.lower()] # Ignore case
except:
print(
self.getClassName(),
":getLayerIndex: Unknown layer name. Returning index ",
r,
)
return r
def getLayerName(self, idx):
"""Retrieve the i-th layer name
return: The name of the i-th layer
rtype: string
"""
lname = "Default"
try:
# There is no 'direct' method to access the keys given the value.
lname = list(self.layers.keys())[list(self.layers.values()).index(idx)]
except:
lname = "Unknown"
print(
self.getClassName(),
':getLayerName: Unexpected layer index. Returning name "',
lname,
'"',
)
return lname
def getNumLayers(self):
"""Return the number of known layers.
Return the number of known layers. Please note that this also
include known non-retinal layers like the choroid.
return: Length of property map :func:`data.OCTvolume.layers`
rtype: int
"""
return len(self.layers)
## Import
import os
import warnings
# from deprecated import deprecated
import deprecation
import math
import numpy as np
from scipy import signal, ndimage # Used for 2D convolution
from skimage import feature, color
from functools import reduce
import cv2 # That's OpenCV
# import matlab.engine
import matplotlib.pyplot as plt
import _tkinter
from PyQt5.QtCore import Qt # Imports constants
from PyQt5.QtWidgets import QProgressDialog
# from matplotlib.backends.qt_compat import QtCore, QtWidgets, is_pyqt5
# from version import __version__
import octant
# from data import OCTscan, OCTscanSegmentation, RetinalLayers
# from util import segmentationUtils
# from .Operation import Operation
from scipy.optimize import curve_fit
class OpScanSegment(Operation):
# Private class attributes shared by all instances
# Class constructor
def __init__(self):
# Call superclass constructor
super().__init__()
# Set the operation name
self.name = "Segmentation"
# Initialize private attributes unique to this instance
# self._imgin = np.zeros(shape = (0,0,0), dtype = np.uint8 ); #Input image
# self._imgout = np.zeros(shape = (0,0,0), dtype = np.uint8 ); #The segmented image
# Private methods
@staticmethod
def anisotropicDiffusionFilter(img):
"""
Non-linear anisotropic diffusion filtering
#Original algorithm in [Perona and Malik, (1990) TPAMI 12(7):629-639]
#Parameters according to [WangRK2005, Proc. of SPIE 5690:380-385]
:param img: ndarray. The image to be filtered
:return: the image filtered
:rtype: ndarray
"""
sigma = 1
GaussMask = generateGaussianMask2D(shape=(3, 3), sigma=sigma)
# print(GaussMask)
m = 8
l = 10 # contrast parameter; structures with s > λ are regarded as edges,
# while with s < λ are assumed to belong to the interior of a region
# [Wang2005] uses l=5 for the porcine trachea, but for us that value
# does not produce as good results as l=10.
timestep = 0.24
niterations = 10 # diffusion time (iteration)
Cm = 3.31488
img2 = img # Initialize image
# Get rid of the "large" noise with morphological closing after opening
morphkernel = np.ones((5, 5), np.uint8)
# img2 = cv2.morphologyEx(img2, cv2.MORPH_OPEN, morphkernel)
# img2 = cv2.morphologyEx(img2, cv2.MORPH_CLOSE, morphkernel)
if np.max(img2) <= 1:
# Scale parameters
# m=m/255
l = l / 255
# Cm = Cm/255
for tau in range(1, niterations):
# #Progress bar
# if progress.wasCanceled():
# break
# progress.setValue(round(100*tau/niterations))
# Morphological removal of noise
# Note that this is NOT part of the original diffusion filter
# but the results are clearly enhanced!.
img2 = cv2.morphologyEx(img2, cv2.MORPH_OPEN, morphkernel)
img2 = cv2.morphologyEx(img2, cv2.MORPH_CLOSE, morphkernel)
# Estimate gradient vector at sigma scale
gradI = np.gradient(img2)
tmpGradI = np.add.reduce(gradI) # For illustrations purposes only
# Regularize gradient
# gradientScaleSigma=math.sqrt(2*(tau*timestep))
gradientScaleSigma = math.sqrt(2 * (tau))
GaussMask = generateGaussianMask2D(shape=(7, 7), sigma=gradientScaleSigma)
# Individually convolve the Gaussian filter with each gradient component
# s = signal.convolve2d(gradI, GaussMask, boundary='symm', mode='same')
s = [None] * len(gradI) # Preallocate list
for dim in range(0, len(gradI)):
s[dim] = signal.convolve2d(
gradI[dim], GaussMask, boundary="symm", mode="same"
)
s = np.linalg.norm(s, ord=2, axis=0) # Norm of the gradient.
# Calculate diffusivity
tmp = (s / l) ** m
tmp = np.divide(
-Cm, tmp, out=np.zeros(tmp.shape), where=tmp != 0
) # Avoid division by 0 when estimating diffusivity
# D = 1-np.exp(-Cm/((s/l)**m)) #diffusivity or conduction coefficient
D = 1 - np.exp(tmp) # diffusivity or conduction coefficient
# Update image
img2 = img2 + divergence(np.multiply(D, gradI)) # Update the image
# Reminder> The divergence of gradient is the Laplacian operator
# See: https://math.stackexchange.com/questions/690493/what-is-divergence-in-image-processing
return img2
@staticmethod
def divergence(f):
# """Compute the divergence of n-D SCALAR field `f`."""
# See: https://stackoverflow.com/questions/11435809/compute-divergence-of-vector-field-using-python
# return reduce(np.add,np.gradient(f))
"""
Computes the divergence of the VECTOR field f, corresponding to dFx/dx + dFy/dy + ...
:param f: List of ndarrays, where every item of the list is one dimension of the vector field
:return: Single ndarray of the same shape as each of the items in f, which corresponds to a scalar field
"""
num_dims = len(f)
return np.ufunc.reduce(
np.add, [np.gradient(f[i], axis=i) for i in range(num_dims)]
)
@staticmethod
def generateGaussianMask2D(shape=(3, 3), sigma=0.5):
"""
Generates a 2D gaussian mask
It should give the same result as MATLAB's
fspecial('gaussian',[shape],[sigma])
See: https://stackoverflow.com/questions/17190649/how-to-obtain-a-gaussian-filter-in-python
"""
m, n = [(ss - 1.0) / 2.0 for ss in shape]
y, x = np.ogrid[-m : m + 1, -n : n + 1]
h = np.exp(-(x * x + y * y) / (2.0 * sigma * sigma))
h[h < np.finfo(h.dtype).eps * h.max()] = 0
sumh = h.sum()
if sumh != 0:
h /= sumh
return h
# Public methods
def execute(self, *args, **kwargs):
"""Executes the operation on the :py:attr:`operands`.
Executes the operation on the :py:attr:`operands` and stores the outcome
in :py:attr:`result`. Preload operands using method
:func:`addOperand()`.
:returns: Result of executing the operation.
:rtype: :class:`data.OCTscanSegmentation`
"""
# Ensure the operand has been set.
if len(self.operands) < 1:
warnMsg = self.getClassName() + ":execute: Operand not set."
warnings.warn(warnMsg, SyntaxWarning)
return None
# Establish mode of operation
# NOT WORKING YET... :(
# Now, it always detect:
# Terminal for the stdin
# GUI for the stdout
mode = "terminal"
if os.isatty(0):
mode = "gui"
print("Executing segmentation in mode " + mode + ".")
if mode == "gui":
MainWindow = QtWidgets.QWidget()
progress = QProgressDialog("Segmentation...", "Cancel", 0, 100, MainWindow)
progress.setWindowModality(Qt.WindowModal)
progress.setAutoReset(True)
progress.setAutoClose(True)
progress.setMinimum(0)
progress.setMaximum(100)
progress.setWindowTitle("Automatic segmentation")
progress.setLabelText("Progress:")
progress.setMinimumDuration(0)
progress.resize(500, 100)
progress.forceShow()
progress.setValue(0)
imgin = self.operands[0]
if type(imgin) is OCTscan:
imgin = imgin.data
# Define a default output
segmentedImage = np.zeros(shape=(0, 0, 0), dtype=np.uint8)
# Check whether the image is in RGB (ndim=3) or in grayscale (ndim=2)
# and convert to grayscale if necessary
# img = cv2.cvtColor(self._imgin, cv2.COLOR_BGR2GRAY)
if imgin.ndim == 2:
# Dimensions are only width and height. The image is already in grayscale.
img = imgin
elif imgin.ndim == 3:
# Image is in RGB. Convert.
img = color.rgb2gray(imgin)
else: # Unexpected case. Return warning
print(self.getClassName(), ": Unexpected image shape.")
return None
## Algoritmo 1: Basado en el código de Matlab CASeReL
# https://pangyuteng.github.io/caserel/
#
# Llama externamente a retSegment.exe
#
# Requiere de Matlab Runtime environment
# #Remove external noise from image
# img = segmentationUtils.ejecuta_close(img,4,4) #Clausura
# #segmentationUtils.mostrar_imagen(img)
#
# #Generate temporal intermediate image file to be processed externally
# tmpFilename = "paso2.tiff"
# cv2.imwrite(tmpFilename, img)
#
# #Rely externally on the matlab algorithm for segmentation
# # eng = matlab.engine.start_matlab()
# # eng.retSegment(img)
# #segmentationUtils.mostrar_imagen(img)
#
# #Delete the intermediate image file
# segmentationUtils.elimina_imagen(tmpFilename)
## Algoritmo 3 Felipe
# Step 1) Non-linear anisotropic diffusion filtering
# Original algorithm in [Perona and Malik, (1990) TPAMI 12(7):629-639]
# Parameters according to [WangRK2005, Proc. of SPIE 5690:380-385]
if mode == "gui":
progress.setLabelText("Applying diffusion filter:")
img2 = anisotropicDiffusionFilter(img)
# The output of the anisotropic filter is a float64 2D array
# with values between [0 1] (although note that IT MAY not
# include the segment boundaries 0 and/or 1, so for instance
# while testing I was getting [0,0.85]). Anyway, in this
# range, anything below 1% (~0.099) is background, and the
# rest is tissue.
if mode == "gui":
progress.setValue(100)
if progress.wasCanceled():
return img # Return the original image
# print('Diffusion Filter output range: ['+str(np.amin(img2))+','+str(np.amax(img2))+']')
# Detect background mask
BGmask = np.where(img2 <= 0.099, True, False)
# See above for threshold 0.099 on anisotropic diffusion filter
# output.
# Note that there might be "background" pixels
# found somewhere within the tissue. This is VERY LIKELY fluid!
# Note as well that the lower part also include a bit of the
# choroid with this threshold.
# Finally, the top part should be the vitreous.
# print(BGmask)
# Just to see the mask
# img2 = np.where(BGmask,10,OCTscanSegmentation._BACKGROUND)
# #Plot histogram of image
# binSize = 0.01
# bins=np.arange(0,np.amax(img2)+binSize,binSize)
# hist = np.histogram(img2, bins=bins)
# hfig, ax = plt.subplots(1, 1)
# ax.hist(img2.flatten(),bins)
# ax.set_yscale('log')
# hfig.show()
# PENDING
# Assign intratissue BG pixels to fluid.
# Normalize
img2 = np.floor(255 * (img2 / np.amax(img2))).astype(int)
img2 = np.where(BGmask == True, OCTscanSegmentation._BACKGROUND, img2)
# Assign integers to nRetinalLayers
r = RetinalLayers()
nRetinalLayers = r.getLayerIndex("RPE")
# Note that I'm not counting for choroid or fluid.
# I can't use pixel intensity alone here for segmenting as several
# (separated) layers exhibit similar reflectivity, so segmentation
# criteria has to be a mix of location and intensity.
# Estimate upper and lower boundary by checking first and last
# non-BG pixels per column
# UNFINISHED.
# upperBoundary =
# [uVals,uIdx,uInv,uCounts] = np.unique(img2, \
# return_index=True, \
# return_inverse=True, \
# return_counts=True)
# print(len(uVals))
# ## Algoritmo 2: Arlem
# img2 = img
# print(np.amax(img2))
# tmp=np.reshape(img2,(np.size(img2),1))
# print(type(tmp))
# print(np.size(tmp))
# print(np.amax(tmp))
#
#
# hfig, ax = plt.subplots(1, 1)
# ax.hist(tmp,255)
# hfig.show()
#
# #Elimina ruido
# img = segmentationUtils.ejecuta_close(img,4,4)
#
# #Amplifica capas
# img = segmentationUtils.ejecuta_dilate(img,5,20,1)
#
# #Tensor
# Axx, Axy, Ayy = feature.structure_tensor(img)
#
# #Elimina mas ruido
# Ayy = segmentationUtils.ejecuta_close(Ayy,6,1)
#
# #Resalta las capas que sean mayores a la media
# Ayy = segmentationUtils.resalta_bordes(Ayy,True,0)
#
# #Elimina aun mas ruido
# Ayy = segmentationUtils.ejecuta_open(Ayy,1,1)
#
# #Binarizacion
# binary = segmentationUtils.ejecuta_OTSU(Ayy)
#
# #elimina ruido del posible borde superior
# binary = segmentationUtils.ejecuta_elimina_ruido_extremos(True,0,0,binary)
#
# #elimina ruido del posible borde inferior
# binary = segmentationUtils.ejecuta_elimina_ruido_extremos(False,0,0,binary)
#
# #obtiene bordes exteriores
# arraySuperior, arrayInferior = segmentationUtils.obten_bordes_externos(binary)
#
# #elimina ruido a la imagen original
# img2 = segmentationUtils.elimina_desde_arreglos(img2, arraySuperior, arrayInferior)
# img2 = segmentationUtils.ejecuta_close(img2,2,1)
# img2 = feature.canny(img2,sigma = 2.5)
# img2 = segmentationUtils.elimina_ruido_canny(img2,1)
# Hide and close progress bar.
if mode == "gui":
progress.hide()
# if isinstance(imgin,(OCTscan,)):
if type(imgin) is OCTscan:
self.result = OCTscanSegmentation(imgin)
else:
self.result = OCTscanSegmentation(OCTscan(imgin))
self.result.data = img2
return self.result
# #@deprecated(version='0.2', reason="Deprecated. Use method execute() instead.")
# @deprecation.deprecated(deprecated_in="0.2", removed_in="0.3",
# current_version=__version__,
# details="Use method execute() instead.")
# def segmentar(self,image):
# #Encapsulate the image as an OCTscan
# tmp=OCTscan(image)
# self.clear()
# self.addOperand(tmp)
# #Execute
# self.execute()
# return None
def anisotropicDiffusionFilter(img):
"""
Non-linear anisotropic diffusion filtering
#Original algorithm in [Perona and Malik, (1990) TPAMI 12(7):629-639]
#Parameters according to [WangRK2005, Proc. of SPIE 5690:380-385]
:param img: ndarray. The image to be filtered
:return: the image filtered
:rtype: ndarray
"""
sigma = 1
GaussMask = generateGaussianMask2D(shape=(3, 3), sigma=sigma)
# print(GaussMask)
m = 8
l = 10 # contrast parameter; structures with s > λ are regarded as edges,
# while with s < λ are assumed to belong to the interior of a region
# [Wang2005] uses l=5 for the porcine trachea, but for us that value
# does not produce as good results as l=10.
timestep = 0.24
niterations = 10 # diffusion time (iteration)
Cm = 3.31488
img2 = img # Initialize image
# Get rid of the "large" noise with morphological closing after opening
morphkernel = np.ones((5, 5), np.uint8)
# img2 = cv2.morphologyEx(img2, cv2.MORPH_OPEN, morphkernel)
# img2 = cv2.morphologyEx(img2, cv2.MORPH_CLOSE, morphkernel)
if np.max(img2) <= 1:
# Scale parameters
# m=m/255
l = l / 255
# Cm = Cm/255
for tau in range(1, niterations):
# #Progress bar
# if progress.wasCanceled():
# break
# progress.setValue(round(100*tau/niterations))
# Morphological removal of noise
# Note that this is NOT part of the original diffusion filter
# but the results are clearly enhanced!.
img2 = cv2.morphologyEx(img2, cv2.MORPH_OPEN, morphkernel)
img2 = cv2.morphologyEx(img2, cv2.MORPH_CLOSE, morphkernel)
# Estimate gradient vector at sigma scale
gradI = np.gradient(img2)
tmpGradI = np.add.reduce(gradI) # For illustrations purposes only
# Regularize gradient
# gradientScaleSigma=math.sqrt(2*(tau*timestep))
gradientScaleSigma = math.sqrt(2 * (tau))
GaussMask = generateGaussianMask2D(shape=(7, 7), sigma=gradientScaleSigma)
# Individually convolve the Gaussian filter with each gradient component
# s = signal.convolve2d(gradI, GaussMask, boundary='symm', mode='same')
s = [None] * len(gradI) # Preallocate list
for dim in range(0, len(gradI)):
s[dim] = signal.convolve2d(
gradI[dim], GaussMask, boundary="symm", mode="same"
)
s = np.linalg.norm(s, ord=2, axis=0) # Norm of the gradient.
# Calculate diffusivity
tmp = (s / l) ** m
tmp = np.divide(
-Cm, tmp, out=np.zeros(tmp.shape), where=tmp != 0
) # Avoid division by 0 when estimating diffusivity
# D = 1-np.exp(-Cm/((s/l)**m)) #diffusivity or conduction coefficient
D = 1 - np.exp(tmp) # diffusivity or conduction coefficient
# Update image
img2 = img2 + divergence(np.multiply(D, gradI)) # Update the image
# Reminder> The divergence of gradient is the Laplacian operator
# See: https://math.stackexchange.com/questions/690493/what-is-divergence-in-image-processing
return img2
segmentedImage = np.zeros(shape=(0, 0, 0), dtype=np.uint8)
img2 = anisotropicDiffusionFilter(img)
BGmask = np.where(img2 <= 0.099, True, False)
img2 = np.floor(255 * (img2 / np.amax(img2))).astype(int)
img2 = np.where(BGmask == True, OCTscanSegmentation._BACKGROUND, img2)
# Assign integers to nRetinalLayers
r = RetinalLayers()
nRetinalLayers = r.getLayerIndex("RPE")
OCTscanSegmentation(imgin)
def divergence(f):
# """Compute the divergence of n-D SCALAR field `f`."""
# See: https://stackoverflow.com/questions/11435809/compute-divergence-of-vector-field-using-python
# return reduce(np.add,np.gradient(f))
"""
Computes the divergence of the VECTOR field f, corresponding to dFx/dx + dFy/dy + ...
:param f: List of ndarrays, where every item of the list is one dimension of the vector field
:return: Single ndarray of the same shape as each of the items in f, which corresponds to a scalar field
"""
num_dims = len(f)
return np.ufunc.reduce(np.add, [np.gradient(f[i], axis=i) for i in range(num_dims)])
def generateGaussianMask2D(shape=(3, 3), sigma=0.5):
"""
Generates a 2D gaussian mask
It should give the same result as MATLAB's
fspecial('gaussian',[shape],[sigma])
See: https://stackoverflow.com/questions/17190649/how-to-obtain-a-gaussian-filter-in-python
"""
m, n = [(ss - 1.0) / 2.0 for ss in shape]
y, x = np.ogrid[-m : m + 1, -n : n + 1]
h = np.exp(-(x * x + y * y) / (2.0 * sigma * sigma))
h[h < np.finfo(h.dtype).eps * h.max()] = 0
sumh = h.sum()
if sumh != 0:
h /= sumh
return h
generateGaussianMask2D()
def execute(self, *args, **kwargs):
"""Executes the operation on the :py:attr:`operands`.
Executes the operation on the :py:attr:`operands` and stores the outcome
in :py:attr:`result`. Preload operands using method
:func:`addOperand()`.
:returns: Result of executing the operation.
:rtype: :class:`data.OCTscanSegmentation`
"""
# Ensure the operand has been set.
if len(self.operands) < 1:
warnMsg = self.getClassName() + ":execute: Operand not set."
warnings.warn(warnMsg, SyntaxWarning)
return None
# Establish mode of operation
# NOT WORKING YET... :(
# Now, it always detect:
# Terminal for the stdin
# GUI for the stdout
mode = "terminal"
if os.isatty(0):
mode = "gui"
print("Executing segmentation in mode " + mode + ".")
if mode == "gui":
MainWindow = QtWidgets.QWidget()
progress = QProgressDialog("Segmentation...", "Cancel", 0, 100, MainWindow)
progress.setWindowModality(Qt.WindowModal)
progress.setAutoReset(True)
progress.setAutoClose(True)
progress.setMinimum(0)
progress.setMaximum(100)
progress.setWindowTitle("Automatic segmentation")
progress.setLabelText("Progress:")
progress.setMinimumDuration(0)
progress.resize(500, 100)
progress.forceShow()
progress.setValue(0)
imgin = self.operands[0]
if type(imgin) is OCTscan:
imgin = imgin.data
# Define a default output
segmentedImage = np.zeros(shape=(0, 0, 0), dtype=np.uint8)
# Check whether the image is in RGB (ndim=3) or in grayscale (ndim=2)
# and convert to grayscale if necessary
# img = cv2.cvtColor(self._imgin, cv2.COLOR_BGR2GRAY)
if imgin.ndim == 2:
# Dimensions are only width and height. The image is already in grayscale.
img = imgin
elif imgin.ndim == 3:
# Image is in RGB. Convert.
img = color.rgb2gray(imgin)
else: # Unexpected case. Return warning
print(self.getClassName(), ": Unexpected image shape.")
return None
## Algoritmo 1: Basado en el código de Matlab CASeReL
# https://pangyuteng.github.io/caserel/
#
# Llama externamente a retSegment.exe
#
# Requiere de Matlab Runtime environment
# #Remove external noise from image
# img = segmentationUtils.ejecuta_close(img,4,4) #Clausura
# #segmentationUtils.mostrar_imagen(img)
#
# #Generate temporal intermediate image file to be processed externally
# tmpFilename = "paso2.tiff"
# cv2.imwrite(tmpFilename, img)
#
# #Rely externally on the matlab algorithm for segmentation
# # eng = matlab.engine.start_matlab()
# # eng.retSegment(img)
# #segmentationUtils.mostrar_imagen(img)
#
# #Delete the intermediate image file
# segmentationUtils.elimina_imagen(tmpFilename)
## Algoritmo 3 Felipe
# Step 1) Non-linear anisotropic diffusion filtering
# Original algorithm in [Perona and Malik, (1990) TPAMI 12(7):629-639]
# Parameters according to [WangRK2005, Proc. of SPIE 5690:380-385]
if mode == "gui":
progress.setLabelText("Applying diffusion filter:")
img2 = anisotropicDiffusionFilter(img)
# The output of the anisotropic filter is a float64 2D array
# with values between [0 1] (although note that IT MAY not
# include the segment boundaries 0 and/or 1, so for instance
# while testing I was getting [0,0.85]). Anyway, in this
# range, anything below 1% (~0.099) is background, and the
# rest is tissue.
if mode == "gui":
progress.setValue(100)
if progress.wasCanceled():
return img # Return the original image
# print('Diffusion Filter output range: ['+str(np.amin(img2))+','+str(np.amax(img2))+']')
# Detect background mask
BGmask = np.where(img2 <= 0.099, True, False)
# See above for threshold 0.099 on anisotropic diffusion filter
# output.
# Note that there might be "background" pixels
# found somewhere within the tissue. This is VERY LIKELY fluid!
# Note as well that the lower part also include a bit of the
# choroid with this threshold.
# Finally, the top part should be the vitreous.
# print(BGmask)
# Just to see the mask
# img2 = np.where(BGmask,10,OCTscanSegmentation._BACKGROUND)
# #Plot histogram of image
# binSize = 0.01
# bins=np.arange(0,np.amax(img2)+binSize,binSize)
# hist = np.histogram(img2, bins=bins)
# hfig, ax = plt.subplots(1, 1)
# ax.hist(img2.flatten(),bins)
# ax.set_yscale('log')
# hfig.show()
# PENDING
# Assign intratissue BG pixels to fluid.
# Normalize
img2 = np.floor(255 * (img2 / np.amax(img2))).astype(int)
img2 = np.where(BGmask == True, OCTscanSegmentation._BACKGROUND, img2)
# Assign integers to nRetinalLayers
r = RetinalLayers()
nRetinalLayers = r.getLayerIndex("RPE")
# Note that I'm not counting for choroid or fluid.
# I can't use pixel intensity alone here for segmenting as several
# (separated) layers exhibit similar reflectivity, so segmentation
# criteria has to be a mix of location and intensity.
# Estimate upper and lower boundary by checking first and last
# non-BG pixels per column
# UNFINISHED.
# upperBoundary =
# [uVals,uIdx,uInv,uCounts] = np.unique(img2, \
# return_index=True, \
# return_inverse=True, \
# return_counts=True)
# print(len(uVals))
# ## Algoritmo 2: Arlem
# img2 = img
# print(np.amax(img2))
# tmp=np.reshape(img2,(np.size(img2),1))
# print(type(tmp))
# print(np.size(tmp))
# print(np.amax(tmp))
#
#
# hfig, ax = plt.subplots(1, 1)
# ax.hist(tmp,255)
# hfig.show()
#
# #Elimina ruido
# img = segmentationUtils.ejecuta_close(img,4,4)
#
# #Amplifica capas
# img = segmentationUtils.ejecuta_dilate(img,5,20,1)
#
# #Tensor
# Axx, Axy, Ayy = feature.structure_tensor(img)
#
# #Elimina mas ruido
# Ayy = segmentationUtils.ejecuta_close(Ayy,6,1)
#
# #Resalta las capas que sean mayores a la media
# Ayy = segmentationUtils.resalta_bordes(Ayy,True,0)
#
# #Elimina aun mas ruido
# Ayy = segmentationUtils.ejecuta_open(Ayy,1,1)
#
# #Binarizacion
# binary = segmentationUtils.ejecuta_OTSU(Ayy)
#
# #elimina ruido del posible borde superior
# binary = segmentationUtils.ejecuta_elimina_ruido_extremos(True,0,0,binary)
#
# #elimina ruido del posible borde inferior
# binary = segmentationUtils.ejecuta_elimina_ruido_extremos(False,0,0,binary)
#
# #obtiene bordes exteriores
# arraySuperior, arrayInferior = segmentationUtils.obten_bordes_externos(binary)
#
# #elimina ruido a la imagen original
# img2 = segmentationUtils.elimina_desde_arreglos(img2, arraySuperior, arrayInferior)
# img2 = segmentationUtils.ejecuta_close(img2,2,1)
# img2 = feature.canny(img2,sigma = 2.5)
# img2 = segmentationUtils.elimina_ruido_canny(img2,1)
# Hide and close progress bar.
if mode == "gui":
progress.hide()
# if isinstance(imgin,(OCTscan,)):
if type(imgin) is OCTscan:
self.result = OCTscanSegmentation(imgin)
else:
self.result = OCTscanSegmentation(OCTscan(imgin))
self.result.data = img2
return self.result
class OCTvolume(object):
# Sphinx documentation
"""A set of :class:`data.OCTscan`
A set of :class:`data.OCTscan`
.. seealso:: :class:`data.OCTscan`
.. note:: None
.. todo:: None
"""
# Class constructor
def __init__(self):
"""The class constructor.
The class constructor.
tmp = OCTvolume() - Creates an empty volume with no scans.
"""
self.scans = list()
return
# Properties getters/setters
@property
def scans(self): # scans getter
"""
The set of OCT scans.
:getter: Gets the set of scans
:setter: Sets the set of scans
:type: list. All scans are of :class:`data.OCTscan`
.. seealso:: :func:`data.OCTvolume.addScan` , :func:`data.OCTvolume.removeScan` , :func:`data.OCTvolume.clear`
"""
return self.__scans
@scans.setter
def scans(self, *args): # scans setter
tmpScanSet = args[0]
if type(tmpScanSet) is not list:
warnMsg = (
self.getClassName() + ":scans: Unexpected type. "
"Please provide a list of data.OCTscan."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
self.__scans = list()
for x in tmpScanSet:
if type(x) is not OCTscan:
warnMsg = (
self.getClassName() + ":scans: Unexpected scan type "
"for object " + x + ". Skipping object."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
self.__scans.append(x)
return None
# Public methods
def getClassName(self):
return type(self).__name__
def clear(self):
"""
Clears the OCT volume; Removes all scans.
:return: None
"""
self.__scans = list()
return None
@deprecation.deprecated(
deprecated_in="0.3",
removed_in="1.0",
# current_version=__version__,
details="Use method addScans() instead.",
)
def addScan(self, theScan):
"""
Add an OCT scan to the volume.
:param theScan: The OCT scan.
:type theScan: :class:`data.OCTscan`
:return: None
"""
if type(theScan) is not OCTscan:
warnMsg = (
self.getClassName() + ":addScan: Unexpected scan type. "
"Nothing will be added."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
self.__scans.append(theScan)
return None
def addScans(self, theScans):
"""
Add one or more OCT scans to the volume at once.
:param theScans: The list of OCT scans.
:type theScan: list of :class:`data.OCTscan` or
single :class:`data.OCTscan`
:return: True if scans added, False otherwise.
"""
flagAllOCTscans = True
if type(theScans) is OCTscan:
self.__scans.append(theScans)
elif type(theScans) is list:
for elem in theScans:
if type(elem) is not OCTscan:
warnMsg = (
self.getClassName() + ":addScans: Unexpected scan type. "
"Nothing will be added."
)
flagAllOCTscans = False
break
if flagAllOCTscans:
self.__scans.extend(theScans)
return flagAllOCTscans
def getScans(self, t):
"""
Retrieves all scans in the volume of type t.
:param t: Scan type 'A', 'B' or 'C'
:type t: char
:return: The set of A scans in the volume
:rtype: list
.. seealso:: :func:`data.OCTvolume.getVolume`
"""
t = t.upper() # Uppercase
theScans = list()
for x in self.__scans:
if x.scantype == t:
theScans.append(x)
return theScans
def getVolume(self, t):
"""
Retrieves the (sub-)volume of scans of type t.
:param t: Scan type 'A', 'B' or 'C'
:type t: char
:return: A volume with the set of scans of type t.
:rtype: :class:`data.OCTvolume`
.. seealso:: :func:`data.OCTvolume.getScans`
"""
t = t.upper() # Uppercase
theScans = OCTvolume()
for x in self.__scans:
if x.scantype == t:
theScans.addScan(x)
return theScans
def getNScans(self, t=None):
"""Get the number of scans of a certain type.
If type is not given, then the total number of scans is given.
:param t: Scan type 'A', 'B' or 'C' or None
:type t: char
:return: The number of scans of a certain type
:rtype: int
"""
if t is None:
res = len(self.__scans)
else:
res = self.getNScans(self.getVolume(t))
return res
class OCTvolumeSegmentation(object):
# Sphinx documentation
"""A set of :class:`data.OCTscanSegmentation`
A set of :class:`data.OCTscanSegmentation`
.. seealso:: :class:`data.OCTscanSegmentation`
.. note:: None
.. todo:: None
"""
# Class constructor
def __init__(self):
"""The class constructor.
The class constructor.
tmp = OCTvolumeSegmentation() - Creates an empty segmentation volume with no scans.
"""
self.scanSegmentations = list()
return
# Properties getters/setters
@property
def scanSegmentations(self): # scans getter
"""
The set of OCT scans segmentations.
:getter: Gets the set of scans segmentations
:setter: Sets the set of scans segmentations
:type: list. All scans are of :class:`data.OCTscanSegmentation`
.. seealso:: :func:`data.OCTvolumeSegmentation.addScan` , :func:`data.OCTvolumeSegmentation.removeScan` , :func:`data.OCTvolumeSegmentation.clear`
"""
return self.__scanSegmentations
@scanSegmentations.setter
def scanSegmentations(self, *args): # scanSegmentations setter
tmpScanSet = args[0]
if type(tmpScanSet) is not list:
warnMsg = (
self.getClassName() + ":scanSegmentations: Unexpected type. "
"Please provide a list of data.OCTscanSegmentation."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
self.__scanSegmentations = list()
for x in tmpScanSet:
if type(x) is not OCTscanSegmentation:
warnMsg = (
self.getClassName()
+ ":scanSegmentations: Unexpected scan type "
"for object " + x + ". Skipping object."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
self.__scanSegmentations.append(x)
return None
# Public methods
def clear(self):
"""
Clears the OCT segmentation volume; Removes all scan segmentations.
:return: None
"""
self.__scanSegmentations = list()
return None
def addScanSegmentations(self, theScanSegmentations):
"""
Add one or multiple OCT scan segmentation to the volume.
:param theScanSegmentations: The list of OCT scan segmentations
:type theScanSegmentations: list of :class:`data.OCTscanSegmentation` or
single :class:`data.OCTscanSegmentation`
:return: None
"""
flagAllOCTscans = False
if type(theScanSegmentations) is OCTscanSegmentation:
flagAllOCTscans = True
self.__scanSegmentations.append(theScanSegmentations)
elif type(theScanSegmentations) is list:
flagAllOCTscans = True
for elem in theScans:
if type(elem) is not OCTscanSegmentation:
warnMsg = (
self.getClassName() + ":addScans: Unexpected scan type. "
"Nothing will be added."
)
flagAllOCTscans = False
break
if flagAllOCTscans:
self.__scanSegmentations.extend(theScanSegmentations)
return flagAllOCTscans
def getScanSegmentations(self, t):
"""
Retrieves all scans in the volume of type t.
:param t: Scan type 'A', 'B' or 'C' or scan indexing
:type t: str, list or int
:return: The set of scans in the volume of the chosen
:rtype: list
.. seealso:: :func:`data.OCTvolumeSegmentation.getVolume`
"""
theScans = list()
if type(t) is str:
t = t.upper() # Uppercase
for x in self.__scanSegmentations:
if x.scantype == t:
theScans.append(x)
elif type(t) is list:
for elem in t:
theScans.append(self.__scanSegmentations[elem])
elif type(t) is int:
theScans.append(self.__scanSegmentations[elem])
return theScans
def getVolume(self, t):
"""
Retrieves the (sub-)volume of scans of type t.
:param t: Scan type 'A', 'B' or 'C'
:type t: char
:return: A volume with the set of scans of type t.
:rtype: :class:`data.OCTvolume`
.. seealso:: :func:`data.OCTvolume.getScans`
"""
t = t.upper() # Uppercase
theScans = OCTvolumeSegmentation()
for x in self.__scanSegmentations:
if x.scantype == t:
theScans.addScanSegmentation(x)
return theScans
def getNScans(self):
"""Get the number of scans segmentations.
:return: The number of scans segmentations
:rtype: int
"""
return len(self.__scanSegmentations)
class Document:
# Sphinx documentation
"""The document class for
The document class for
This class represents a document in A document holds information
about a study plus some additional metadata.
Currently, a study is only an OCT image (with several scans) with or without
segmentation information.
.. seealso:: None
.. note:: None
.. todo:: None
"""
# Private class attributes shared by all instances
# Class constructor
def __init__(self):
# Call superclass constructor
# Initialize private attributes unique to this instance
self.study = OCTvolume() # The current study.
# Currently, an OCT volume
self.segmentation = OCTvolumeSegmentation() # The current study.
# Currently, an OCT volumeSegmentation
self.docsettings = Settings()
self.docsettings.selectedScan = None
# shared between study and segmentation
# Document metadata
self.folderName = "." # Folder where the document is currently stored
self.fileName = "OCTantDocument0001" # The filename of the document
self.name = "OCTantDocument0001" # A logical name for the study
return
# Properties getters/setters
#
# Remember: Sphinx ignores docstrings on property setters so all
# documentation for a property must be on the @property method
@property
def docsettings(self): # docsettings getter
"""
The application settings.
:getter: Gets the document settings
:setter: Sets the document settings
:type: class:`data.Settings`
"""
return self.__appsettings
@docsettings.setter
def docsettings(self, newSettings): # document setter
if newSettings is None:
newSettings = Settings() # Initialize settings
if type(newSettings) is Settings:
self.__appsettings = newSettings
else:
warnMsg = self.getClassName() + ":docsettings: Unexpected settings type."
warnings.warn(warnMsg, SyntaxWarning)
return None
@property
def study(self): # study getter
"""
The OCT volume being processed and analysed.
..todo: Upgrade to volume. Watch out! This will affect many
other classess using this method.
:getter: Gets the OCT volume.
:setter: Sets the OCT volume.
:type: :class:`data.OCTvolume`
"""
return self.__study
@study.setter
def study(self, vol): # study setter
if vol is None or type(vol) is OCTvolume:
self.__study = vol
# ...and reset scan
self.segmentedScan = None
elif type(vol) is OCTscan:
warnMsg = (
self.getClassName()
+ ":study: OCTvolume expected but OCTscan received. Embedding scan."
)
warnings.warn(warnMsg, SyntaxWarning)
self.__study = OCTvolume()
self.__study.addScan(vol)
else:
warnMsg = self.getClassName() + ":study: Unexpected study type."
warnings.warn(warnMsg, SyntaxWarning)
return None
@property
def segmentation(self): # segmentation getter
"""
The segmentation over the OCT study being processed and analysed.
:getter: Gets the OCT volume segmentation.
:setter: Sets the OCT volume segmentation.
:type: :class:`data.OCTvolumeSegmentation`
"""
return self.__segmentation
@segmentation.setter
def segmentation(self, newSegmentation): # segmentation setter
if (newSegmentation is None) or (
type(newSegmentation) is OCTvolumeSegmentation
):
self.__segmentation = newSegmentation
if newSegmentation is not None:
if self.study is None:
warnMsg = self.getClassName() + ":segmentation: No reference image."
warnings.warn(warnMsg, SyntaxWarning)
if not (
len(newSegmentation.scanSegmentations) == len(self.study.scans)
):
warnMsg = self.getClassName() + ":segmentation: Unexpected size."
warnings.warn(warnMsg, SyntaxWarning)
elif type(newSegmentation) is OCTscanSegmentation:
warnMsg = (
self.getClassName()
+ ":study: OCTvolumeSegmentation expected but OCTscanSegmentation received. Embedding scan."
)
warnings.warn(warnMsg, SyntaxWarning)
self.__segmentation = OCTvolumeSegmentation()
self.__segmentation.addScanSegmentations(newSegmentation)
else:
warnMsg = (
self.getClassName() + ":segmentation: Unexpected segmented scan type."
)
warnings.warn(warnMsg, SyntaxWarning)
return None
@property
def folderName(self): # folderName getter
"""
Folder where the document is currently stored.
..note: Also retrieve the py:attr:`fileName` to build the full path.
:getter: Gets the study folder name.
:setter: Sets the study folder name. If new folder is None,
the current directory '.' is chosen.
:type: str
"""
return self.__folderName
@folderName.setter
def folderName(self, d): # name setter
if d is None:
d = "." # Set to current folder
if type(d) is str:
self.__folderName = d
else:
warnMsg = self.getClassName() + ":name: Unexpected folderName type."
warnings.warn(warnMsg, SyntaxWarning)
return None
@property
def fileName(self): # fileName getter
"""
The filename of the document.
..note: Also retrieve the py:attr:`folderName` to build the full path.
:getter: Gets the the filename of the document.
:setter: Sets the The filename of the document. If new name is None,
a default name is given.
:type: str
"""
return self.__folderName
@fileName.setter
def fileName(self, newFilename): # fileName setter
if newFilename is None:
newFilename = self.defaultName # Set to default name
if type(newFilename) is str:
self.__fileName = newFilename
else:
warnMsg = self.getClassName() + ":name: Unexpected fileName type."
warnings.warn(warnMsg, SyntaxWarning)
return None
@property
def name(self): # name getter
"""
A logical name for the study.
:getter: Gets the OCT study name.
:setter: Sets the OCT study name.
:type: str
"""
return self.__name
@name.setter
def name(self, newName): # name setter
if newName is None or type(newName) is str:
self.__name = newName
else:
warnMsg = self.getClassName() + ":name: Unexpected name type."
warnings.warn(warnMsg, SyntaxWarning)
return None
# Private methods
# Public methods
def getClassName(self):
return type(self).__name__
def getCurrentScan(self):
"""Get the current working OCT scan
Change the current selection using :func:`pickScan`
:returns: The current working OCT scan.
:rtype: :class:`data.OCTscan` or None if the study contains no scans
"""
if self.docsettings.selectedScan is None:
self.docsettings.selectedScan = 0
res = None
if len(self.__study.scans) > 0:
res = self.__study.scans[self.docsettings.selectedScan]
return res
def setCurrentScan(self, newScan):
"""Sets the current working OCT scan
Change the current selection using :func:`pickScan`
:param newScan: An OCT scan to be assigned to the current working OCT scan.
:type newScan: :class:`data.OCTscan`
"""
if self.docsettings.selectedScan is None:
self.docsettings.selectedScan = 0
if newScan is None:
if self.__study.getNScans() == 0:
# do nothing.
pass
else:
warnMsg = (
self.getClassName()
+ ":setcurrentscan: Unexpected scan type NoneType."
)
warnings.warn(warnMsg, SyntaxWarning)
if type(newScan) is OCTscan:
self.__study.scans[self.docsettings.selectedScan] = newScan
else:
warnMsg = self.getClassName() + ":setcurrentscan: Unexpected scan type."
warnings.warn(warnMsg, SyntaxWarning)
return None
def pickScan(self, i):
"""Pick the i-th OCT scan (and its segmentation) for working.
Sets the docsetting.selectedScan to i checking that it does exist.
:param i: The selected scan index
:type i: int
:return: None
"""
if type(i) is int and i < self.study.getNScans() and i >= 0:
self.docsettings.selectedScan = i
else:
warnMsg = self.getClassName() + ":pickScan: Selected scan does not exist."
warnings.warn(warnMsg, SyntaxWarning)
return None
def getCurrentScanSegmentation(self):
"""Get the current working OCT scanSegmentation
Change the current selection using :func:`pickScan`
:returns: The current working OCT scanSegmentation.
:rtype: :class:`data.OCTscanSegmentation`
"""
if self.docsettings.selectedScan is None:
self.docsettings.selectedScan = 0
res = None
if len(self.__segmentation.scanSegmentations) > 0:
res = self.__segmentation.scanSegmentations[self.docsettings.selectedScan]
return res
def setCurrentScanSegmentation(self, newScan):
"""Sets the current working OCT scanSegmentation
Change the current selection using :func:`pickScan`
:param newScan: An OCT scan to be assigned to the current working OCT scan.
:type newScan: :class:`data.OCTscanSegmentation`
"""
if self.docsettings.selectedScan is None:
self.docsettings.selectedScan = 0
if newScan is None:
if self.__segmentation.getNScans() == 0:
# do nothing.
pass
else:
warnMsg = (
self.getClassName()
+ ":setcurrentscansegmentation: Unexpected scan type NoneType."
)
warnings.warn(warnMsg, SyntaxWarning)
if type(newScan) is OCTscanSegmentation:
self.__segmentation.scanSegmentations[
self.docsettings.selectedScan
] = newScan
else:
warnMsg = (
self.getClassName()
+ ":setcurrentscansegmentation: Unexpected scan type."
)
warnings.warn(warnMsg, SyntaxWarning)
return None
def readFile(self, filename):
"""Reads an OCTant document file.
This method is currently a sham, and it will be updated
when serialization is incorporated to Currently,
it returns an empty document. Nevertheless, it already
updates the document, clearing all fields to default values,
and updates the filename and folder
The file must exist or an error is generated.
The file must be in OCTant file format.
:param fileName: The file name
:type fileName: str
:return: This document
:rtype: :class:`data.Document`
"""
self = Document()
self.folderName, self.fileName = os.path.split(filename)
return self
class Settings(object):
# Sphinx documentation
"""A class to hold a list of settings.
A class to hold a list of settings. A list of settings is the classical
"dictionary" (see note below on python's dict) of pairs key:value
but with some additional capabilities. In particular, the class provides
additional file reading and writing capabilities so that settings can
be read to and from plain text files, as well as some value setting
checking capabilities.
The class is intended to behave like a dynamic struct
where properties of the class, i.e. new settings, can be declared
"on-the-fly" instead of being predefined.
Although, creating a dynamic struct class in python itself is trivial
(see https://stackoverflow.com/questions/1878710/struct-objects-in-python ),
but because of the additional capabilities, hence the convenience of
the class.
.. Background:
MATLAB's struct allows this "on-the-fly" field declaration on the fly.
Python's built-in dictionary is not exactly a match because of the
required syntax i.e. ``mySettingsObj['fieldname']`` instead of
``mySettingsObj.fieldname`` and the inability to control value settings.
.. seealso:: None
.. note:: None
.. todo:: None
"""
# Private class attributes shared by all instances
# Class constructor
def __init__(self, **kwargs):
"""The class constructor."""
# Call superclass constructor
# Initialize private attributes unique to this instance
self.__dict__.update(kwargs) # Permits direct declaration of
# key:value pairs from declaration, e.g.
# x = Settings(foo=1, bar=2)
# See: https://stackoverflow.com/questions/1878710/struct-objects-in-python
return
# Properties getters/setters
#
# Remember: Sphinx ignores docstrings on property setters so all
# documentation for a property must be on the @property method
# Private methods
def __str__(self):
"""Provides the string representation of the object.
:returns: The object representation as a string.
:rtype: str
"""
s = "<" + self.getClassName() + ": "
s = s + str(self.__dict__)
s = s + ">"
return s
# Public methods
def getClassName(self):
"""Retrieves the class name.
:returns: The class name.
:rtype: str
"""
return type(self).__name__
def read(self, filename):
"""Read settings from JSON file.
:param filename: The name of the file to be read (including path)
:type filename: str
:returns: True if file was sucessfully read. False otherwise.
:rtype: bool
"""
with open(filename, "r") as file:
contentStr = file.read()
# c=json.loads(jsonminify(content))
contentDict = json.loads(fastjsonminify(contentStr))
# c contains a dictionary that has to be
# traspassed to self
# Loop over the dictionary
for fieldName, fieldValue in contentDict.items():
setattr(self, fieldName, fieldValue)
return True
def write(self, filename):
"""Write settings to a JSON file.
:returns: True if file was sucessfully read. False otherwise.
:rtype: bool
"""
contentStr = json.dumps(self.__dict__)
with open(filename, "w") as file:
file.write("# \n")
file.write("# File: " + filename + "\n")
file.write("# \n")
file.write("# This is an OCTant settings file.\n")
file.write("# You can add, edit or remove settings manually here.\n")
file.write(
"# File format is in JSON. Although comments are permitted, but they will be lost after resaving because of minification.\n"
)
file.write(
'# If you want your comments to be persistent declared them as "__comment" fields.\n'
)
file.write("# \n")
file.write(
"# File last saved: "
+ datetime.utcnow().strftime("%d-%b-%Y %H:%M:%S UTC+0")
+ "\n"
)
file.write("# \n")
file.write("# (c) 2019. Felipe Orihuela-Espina.\n")
file.write("# \n\n")
file.write(contentStr)
return True
class OpScanFlatten(Operation):
"""A flattening operation for :class:`data.OCTscan`.
A flattening operation for :class:`data.OCTscan`.
The operation represented by this class rectifies an OCT scan.
.. seealso:: None
.. note:: None
.. todo:: None
"""
# Private class attributes shared by all instances
# Class constructor
def __init__(self):
# Call superclass constructor
super().__init__()
# Set the operation name
self.name = "Flattening"
self.__deformationMap = None
return
@property
def deformationMap(self): # name getter
"""
A logical name for the study.
This is a read only property.
:getter: Gets the deformationMap associated to the last flattening.
:type: str
"""
return self.__deformationMap
# Private methods
# def __str__(self):
# #This not working yet; it gets into an infiite recursion as
# #super().__str__() calls self.getClassName() in THIS class.
# # s = '<' + self.getClassName() + '([' \
# # + super().__str__() + '])>'
# s = '<' + self.getClassName() + '([' \
# + str(super()) + '])>'
# print(super())
# return s
@staticmethod
def fittingQuadraticModel(x, a, b, c):
# quadratic model for curve optimization
return a * x * x + b * x + c
# Public methods
def execute(self, *args, **kwargs):
"""Executes the operation on the :py:attr:`operands`.
Executes the operation on the :py:attr:`operands` and stores the outcome
in :py:attr:`result`. Preload operands using
:func:`Operation.addOperand()`.
:returns: Result of executing the operation.
:rtype: :class:`data.OCTscan`
"""
# print(self._getClasName(),": flattening: Starting flattening")
# Ensure the operand has been set.
if len(self.operands) < 1:
warnMsg = self.getClassName() + ":execute: Operand not set."
warnings.warn(warnMsg, SyntaxWarning)
return None
imgin = self.operands[0]
if type(imgin) is OCTscan:
imgin = imgin.data
# Check whether the image is in RGB (ndim=3) or in grayscale (ndim=2)
# and convert to grayscale if necessary
if imgin.ndim == 2:
# Dimensions are only width and height. The image is already in grayscale.
I2 = imgin
elif imgin.ndim == 3:
# Image is in RGB. Convert.
I2 = color.rgb2gray(imgin)
else: # Unexpected case. Return warning
print(self._getClasName(), ": Unexpected image shape.")
self.result = imgin
return self.result
aux = np.argmax(I2, axis=0)
mg = np.mean(aux)
sdg = np.std(aux)
markers = []
remover = []
x0 = np.arange(len(aux))
for i in range(0, len(aux)):
if mg - 3 * sdg <= aux[i] <= mg + 3 * sdg:
markers += [aux[i]]
else:
remover += [i]
x = np.delete(x0, remover)
modelCoeffs, pcov = curve_fit(
self.fittingQuadraticModel, x, markers, method="dogbox", loss="soft_l1"
)
a = self.fittingQuadraticModel(x0, *modelCoeffs)
shift = np.max(a)
flat = shift - a
flat = np.round(flat)
flat = np.ravel(flat).astype(int)
self.__deformationMap = flat
newgray = I2
for i in range(0, len(a)):
newgray[:, i] = np.roll(I2[:, i], flat[i], axis=0)
self.result = OCTscan(newgray)
return self.result
# #@deprecated(version='0.2', reason="Deprecated. Use method execute() instead.")
# @deprecation.deprecated(deprecated_in="0.2", removed_in="0.3",
# current_version=__version__,
# details="Use method execute() instead.")
# def flattening(self,image):
# #Encapsulate the image as an OCTscan
# tmp=OCTscan(image)
# self.clear()
# self.addOperand(tmp)
# #Execute
# self.execute()
def applyOperation(self, scanA):
"""Apply the current flattening to the given scan.
Instead of calculating the fitting again needed for the
flattening, this method applies a known fitted quadratic model to
the given parameters.
The result is NOT stored in :py:attr:`result`.
:param scanA: Image to flatten.
:type scanA: :class:`data.OCTscan`
:returns: Result of repeating the last flattening operation onto
parameter scanA.
:rtype: :class:`data.OCTscan`
"""
if type(scanA) is OCTscan:
scanA = scanA.data
newgray = scanA
for i in range(0, len(self.deformationMap)):
newgray[:, i] = np.roll(scanA[:, i], self.deformationMap[i], axis=0)
return OCTscan(newgray)
import warnings
from abc import ABC, abstractmethod
class Operation(ABC):
# Sphinx documentation
"""An abstract base class for operations on :class:`octant.data.OCTvolume` and :class:`octant.data_OCTscan` .
An abstract base class for operations on :class:`octant.data.OCTvolume` and
:class:`octant.data.OCTscan`.
:Example:
tmp = octant.data.OCTscan(img)
o = octant.op.OpScanFlattening()
o.addOperand(tmp)
o.arity() #return 1
o.execute() #Flattens the image
:Known subclasses:
* :class:`OpScanFlattening`
* :class:`OpScanMeasureLayerThickness`
* :class:`OpScanPerfilometer`
* :class:`OpScanSegment`
* :class:`OpScanStitch`
* :class:`OpSegmentationBrush`
* :class:`OpSegmentationEdit`
.. seealso:: None
.. note:: None
.. todo::
* Support to hold operand names.
"""
# Private class attributes shared by all instances
# Class constructor
#
def __init__(self, **kwargs):
"""The class constructor.
The class constructor. Creates an empty operation
"""
super().__init__()
# Initialize attributes (without decorator @property)
# Initialize properties (with decorator @property)
self.name = "Operation" # The operation name
self.operands = list() # Operands
self.parameters = list() # Parameters
self.result = None # Operation outputs (a list in case it is multivalued).
# None until executed or cleared.
if kwargs is not None:
for key, value in kwargs.items():
if key == "name":
self.name = value
return
# Properties getters/setters
#
# Remember: Sphinx ignores docstrings on property setters so all
# documentation for a property must be on the @property method
@property
def operands(self): # operands getter
"""
The list of operands.
:getter: Gets the list of operands
:setter: Sets the list of operands.
:type: list
"""
return self.__operands
@operands.setter
def operands(self, opList): # operands setter
# if (not isinstance(opList,(list,))):
if type(opList) is not list:
warnMsg = (
self.getClassName() + ":operands: Unexpected type. "
"Please provide operands as a list."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
self.__operands = opList
return None
@property
def name(self): # name getter
"""
The operation name
:getter: Gets the operation name
:setter: Sets the operation name.
:type: string
"""
return self.__name
@name.setter
def name(self, opName): # name setter
# if (not isinstance(opName,(str,))):
if type(opName) is not str:
warnMsg = (
self.getClassName() + ":name: Unexpected type. "
"Operations name must be a string."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
self.__name = opName
return None
@property
def parameters(self): # operands getter
"""
The list of parameters.
:getter: Gets the list of parameters
:setter: Sets the list of parameters.
:type: list
"""
return self.__parameters
@parameters.setter
def parameters(self, opList): # operands setter
# if (not isinstance(opList,(list,))):
if type(opList) is not list:
warnMsg = (
self.getClassName() + ":parameters: Unexpected type. "
"Please provide operands as a list."
)
warnings.warn(warnMsg, SyntaxWarning)
else:
self.__parameters = opList
return None
@property
def result(self): # result getter
"""
The list of results.
This is a read only property. There is no setter method.
:getter: Gets the list of results
:setter: Sets the list of results
:type: list
"""
return self.__result
@result.setter
def result(self, rList): # result setter
self.__result = rList
return None
# Private methods
def __str__(self):
tmp = "["
for x in self.operands:
tmp += format(x) + ","
tmp += "]"
s = (
"<"
+ self.getClassName()
+ "(["
+ "name: "
+ self.name
+ ";"
+ " operands: "
+ tmp
+ "])>"
)
return s
# Public methods
def getClassName(self):
"""Get the class name as a string.
Get the class name as a string.
:returns: The class name.
:rtype: string
"""
return type(self).__name__
def addOperand(self, op, i=None):
"""
Add a new operand.
:param op: The operand.
:type op: object
:param i: (optional) The operand order. If given it may shift the
order of other operands already set. If not given, the operand
is appended at the end of the list of operands.
:type op: int
:return: None
"""
if i is None:
self.__operands.append(op)
else:
self.__operands.insert(i, op)
return None
def setOperand(self, op, i):
"""
Set an operand; substitutes an existing operand with a new one.
Calling setOperand when the :py:attr:`i`-th operand has not been
previously set will result in an out-of-range error.
:param op: The new operand.
:type op: object
:param i: The operand order. Operand index is zero-base i.e. the
first operand occupies i=0
:type op: int
:return: None
"""
self.__operands[i] = op
return None
def addParameter(self, param, i=None):
"""
Add a new parameter.
:param op: The parameter.
:type op: object
:param i: (optional) The paremeter order. If given it may shift the
order of other parameters already set. If not given, the parameter
is appended at the end of the list of parameters.
:type op: int
:return: None
"""
if i is None:
self.__parameters.append(op)
else:
self.__parameters.insert(i, op)
return None
def setParameter(self, op, i):
"""
Set a parameter; substitutes an existing parameter with a new one.
Calling setParameter when the :py:attr:`i`-th parameter has not been
previously set will result in an out-of-range error.
:param op: The new operand.
:type op: object
:param i: The operand order. Operand index is zero-base i.e. the
first operand occupies i=0
:type op: int
:return: None
"""
self.__operands[i] = op
return None
def arity(self):
"""Gets the operation arity (number of operands).
:return: The operation arity
:rtype: int
"""
return len(self.__operands)
def clear(self):
"""
Clears the operands; Removes all operands.
:return: None
"""
self.__operands = list()
return None
# @abstractmethod
def execute(self, *args, **kwargs):
"""Executes the operation on the operands.
This is an abstract method. Executes the operation on the .operands
and stores the outcome in .result
Operation meta-parameters may be also passed.
:returns: Result of executing the operation.
:rtype: Type of result -depends on subclass implementation-.
"""
pass
| false | 0 | 24,379 | 0 | 23 | 24,379 |
||
87084457 | <kaggle_start><code># # Objective of first fast YOLO inspired network
# The first network will generate a square where we will be abble to find the real starfish. It means that I need a very good recall without lose too much accuracy...
# I choose for a fast network to avoid overfitting.
# **Important to notice: it is not a real fast YOLO implementation but just inspired in YOLO.**
# # Libraries
# Data analysis and processing
import pandas as pd
import numpy as np
# Tensor processing tool
import tensorflow as tf
import tensorflow_addons as tfa
from tensorflow import keras
# # Help Functions
def image_path(video_id, video_frame):
return f"/kaggle/input/tensorflow-great-barrier-reef/train_images/video_{video_id}/{video_frame}.jpg"
def cocoincode(cocobboxdict):
"""COCO incode is a np array like ['x' 'y' 'width' 'height']"""
return np.array(
[
cocobboxdict["x"],
cocobboxdict["y"],
cocobboxdict["width"],
cocobboxdict["height"],
],
dtype=np.int32,
)
def coco2yolo(cocobbox):
"""Transform a COCO np array like ['x' 'y' 'width' 'height'] in a YOLO np array like ['x' 'y' 'width' 'height']"""
return np.array(
[
(cocobbox[0] + cocobbox[2] // 2 + cocobbox[2] % 2),
(cocobbox[1] + cocobbox[3] // 2 + cocobbox[3] % 2),
cocobbox[2],
cocobbox[3],
],
dtype=np.int32,
)
def yolo2yolosquared(yolobbox):
"""Transform a YOLO np array like ['x' 'y' 'width' 'height'] to a YOLO np array like ['x' 'y' 'side']"""
return np.array(
[yolobbox[0], yolobbox[1], max(yolobbox[2], yolobbox[3])], dtype=np.int32
)
def yolosquared2yolo(yolosquaredbbox):
"""Transform a YOLO np array like ['x' 'y' 'side'] to a YOLO np array like ['x' 'y' 'width' 'height']"""
return np.array(
[
yolosquaredbbox[0],
yolosquaredbbox[1],
yolosquaredbbox[2],
yolosquaredbbox[2],
],
dtype=np.int32,
)
def yolo2coco(yolobboxes):
pass
from tensorflow.keras.utils import load_img
from tensorflow.keras.utils import img_to_array
def my_load_image(image_path):
return np.array(img_to_array(load_img(image_path)) / 255, np.float)
# # Training Functions and classes
# ## YOLO Squared Transformer
class YOLOSquaredTransformer:
def __init__(self, S, B, img_width, img_height):
self.S = S
self.B = B
self.img_width = img_width
self.img_height = img_height
self.l_x = img_width // S + (1 if img_width % S != 0 else 0)
self.l_y = img_height // S + (1 if img_height % S != 0 else 0)
self.img_big_side = max([img_width, img_height])
def batch_from_cocodictlist(self, cocodictlistbatch):
"""
Receive a batch of cocodictlists where labels are 'x_left', 'y_top', 'width' and 'height' creating a numpy batch
output in format of YOLO Squared where shape is (batch_size, S, S, B, 4) being ['prob', 'x_center', 'y_center', 'side'] -> normalized
"""
batch_size = len(cocodictlistbatch)
bboxes_in_square = np.zeros((batch_size, S, S), dtype=np.int32)
output = np.zeros((batch_size, S, S, B, 4), dtype=np.float)
for batch_pos, cocodictlist in enumerate(cocodictlistbatch):
for cocodict in cocodictlist:
coco = cocoincode(cocodict)
yolo = coco2yolo(coco)
yolosquared = yolo2yolosquared(yolo)
S_x = yolosquared[0] // self.l_x - (
1 if yolosquared[0] % self.l_x == 0 else 0
)
S_y = yolosquared[1] // self.l_y - (
1 if yolosquared[1] % self.l_y == 0 else 0
)
if S_x < self.S and S_y < self.S:
n = bboxes_in_square[batch_pos, S_y, S_x]
if n < B:
output[batch_pos, S_y, S_x, n, 0] = 1
output[batch_pos, S_y, S_x, n, 1] = (
yolosquared[0] - S_x * self.l_x
) / self.l_x
output[batch_pos, S_y, S_x, n, 2] = (
yolosquared[1] - S_y * self.l_y
) / self.l_y
output[batch_pos, S_y, S_x, n, 3] = (
yolosquared[2] / self.img_big_side
)
bboxes_in_square[batch_pos, S_y, S_x] = n + 1
return output
def cocolistbatch_from_yolosquaredbatch(self, y, cut_prob):
"""
Take a batch of tensors representing a yolo output (['prob', 'x_center', 'y_center', 'side'] -> normalized) whit shape: (batch_size, S, S, B, 4)
and transforms it in a list of a list of coco values (['prob', 'x_lefttop', 'y_lefttop', 'width', 'height']) with shape: (batch_size, variable, 4)
where prob is bigger than cut_prob.
"""
pass
def iou(self, y_true, y_pred):
"""
We only know that tensor have rank 5 and the shape is: (batch_size, S, S, B, 4)
bbox are: ['prob' 'x' 'y' 'side'] -> normalized
"""
side_scale = max([img_width, img_height])
l_true = y_true[:, :, :, 3:4] * self.img_big_side
l_pred = y_pred[:, :, :, 3:4] * self.img_big_side
x_true = y_true[:, :, :, 1:2] * self.l_x
x_pred = y_pred[:, :, :, 1:2] * self.l_x
yc_true = y_true[:, :, :, 2:3] * self.l_y
yc_pred = y_pred[:, :, :, 2:3] * self.l_y
dx = tf.math.abs(x_true - x_pred)
dy = tf.math.abs(yc_true - yc_pred)
l_x = tf.math.maximum(
tf.math.maximum(l_true / 2 + l_pred / 2 + dx, l_true), l_pred
)
l_y = tf.math.maximum(
tf.math.maximum(l_true / 2 + l_pred / 2 + dy, l_true), l_pred
)
I_area = tf.nn.relu(l_true + l_pred - l_x) * tf.nn.relu(l_true + l_pred - l_x)
U_area = tf.pow(l_true, 2) + tf.pow(l_pred, 2) - I_area
IoU = I_area / U_area
return IoU
# ## Batch generator
from tensorflow.keras.utils import Sequence
from json import loads
class YoloSquaredSequence(Sequence):
def __init__(self, train_df, batch_size, transformer):
self.train_df = train_df
self.batch_size = batch_size
self.transformer = transformer
def __len__(self):
return len(self.train_df) // self.batch_size
def __getitem__(self, idx):
batch_df = self.train_df[idx * self.batch_size : (idx + 1) * (self.batch_size)]
X = self.get_x(batch_df)
y = self.get_y(batch_df)
return X, y
def get_x(self, batch_df):
return np.array(
[my_load_image(image_path) for image_path in batch_df["image_path"]]
)
def get_y(self, batch_df):
cocodictlistbatch = [
loads(annotations.replace("'", '"'))
for annotations in batch_df["annotations"]
]
return self.transformer.batch_from_cocodictlist(cocodictlistbatch)
# ## Loss Function
from tensorflow.keras.losses import Loss
class SquaredYoloLoss(Loss):
"""We only know that tensor have rank 5 and the shape is: (batch_size, S, S, B, 4)"""
def __init__(self, lambda_coord, lambda_noobj, transformer, *args, **kwargs):
self.lambda_coord = lambda_coord
self.lambda_noobj = lambda_noobj
self.transformer = transformer
super(SquaredYoloLoss, self).__init__(*args, **kwargs)
def call(self, y_true, y_pred):
# Necessario achar qual objeto é par de qual...
# Look at y_true if we have bbox
obj_exists = y_true[:, :, :, 0:1]
obj_noexists = 1 - obj_exists
iou = self.transformer.iou(y_true, y_pred)
sum_exists_coord = self.lambda_coord * tf.reduce_sum(
obj_exists * (tf.pow(y_pred[:, :, :, 1:4] - y_true[:, :, :, 1:4], 2))
) + tf.reduce_sum(tf.nn.relu(y_true[:, :, :, 3:4] - y_pred[:, :, :, 3:4]))
sum_predict = tf.reduce_sum(obj_exists * tf.pow(y_pred[:, :, :, 0:1] - iou, 2))
sum_noexists = self.lambda_noobj * tf.reduce_sum(
obj_noexists * (tf.pow(y_pred[:, :, :, 0:1], 2))
)
return sum_exists_coord + sum_predict + sum_noexists
# ## Metric Function
from tensorflow.keras.metrics import Metric
class YOLOSquaredMetric(Metric):
def __init__(self, transformer, name="YOLO Recall Squared Metric", **kwargs):
super(YOLOSquaredMetric, self).__init__(name=name, **kwargs)
self.recall = self.add_weight(name="yoloRecall", initializer="zeros")
self.objects = self.add_weight(name="objects", initializer="zeros")
self.finds = self.add_weight(name="finds", initializer="zeros")
self.transformer = transformer
def update_state(self, y_true, y_pred, sample_weight=None):
obj_exists = y_true[:, :, :, 0:1]
iou = self.transformer.iou(y_true, y_pred)
self.objects = tf.reduce_sum(obj_exists)
def result(self):
return self.objects
# # Training Specifications
# ## Constants - Hyperparameters
# grid size SxS:
S = 7
# bboxes per cell in grid
B = 2
# batch size
batch_size = 40
# image shape
img_shape = (720, 1280, 3)
img_height = img_shape[0]
img_width = img_shape[1]
# ## Preprocessing data to train
def load_train_df():
# Load train.csv:
complete_train_df = pd.read_csv(
"/kaggle/input/tensorflow-great-barrier-reef/train.csv"
)
# Only use images where we have starfish
complete_train_df = complete_train_df[complete_train_df["annotations"] != "[]"]
# Create column image_path -> too expensive in memory
complete_train_df["image_path"] = complete_train_df.apply(
lambda row: image_path(row["video_id"], row["video_frame"]), axis=1
)
# Shuffle dataframe
complete_train_df = complete_train_df.sample(frac=1)
return complete_train_df
train_df = load_train_df()
# ## Model Definition
transformer = YOLOSquaredTransformer(S, B, img_width, img_height)
batch_sequence = YoloSquaredSequence(train_df, batch_size, transformer)
model = keras.models.Sequential(
[
keras.layers.Conv2D(
128,
9,
strides=(2, 4),
activation="relu",
padding="same",
input_shape=img_shape,
),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(128, 3, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(128, 1, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(128, 3, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(256, 1, activation="relu", padding="same"),
keras.layers.Conv2D(256, 3, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Flatten(),
keras.layers.Dense(S * S * B * 4, activation="relu"),
keras.layers.Dropout(0.5),
keras.layers.Dense(S * S * B * 4, activation="sigmoid"),
keras.layers.Reshape((S, S, B, 4)),
]
)
model.summary()
loss_function = SquaredYoloLoss(5, 0.5, transformer)
yolo_recall = YOLOSquaredMetric(transformer)
model.compile(
optimizer="rmsprop", loss=loss_function, metrics=["accuracy", yolo_recall]
)
model.fit(x=batch_sequence, batch_size=batch_size, epochs=30)
model.save("fastLazyYOLO")
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0087/084/87084457.ipynb | null | null | [{"Id": 87084457, "ScriptId": 24134606, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5464089, "CreationDate": "02/06/2022 02:11:17", "VersionNumber": 7.0, "Title": "COTs - Train the first fast network", "EvaluationDate": "02/06/2022", "IsChange": true, "TotalLines": 295.0, "LinesInsertedFromPrevious": 138.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 157.0, "LinesInsertedFromFork": 295.0, "LinesDeletedFromFork": 0.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 0.0, "TotalVotes": 0}] | null | null | null | null | # # Objective of first fast YOLO inspired network
# The first network will generate a square where we will be abble to find the real starfish. It means that I need a very good recall without lose too much accuracy...
# I choose for a fast network to avoid overfitting.
# **Important to notice: it is not a real fast YOLO implementation but just inspired in YOLO.**
# # Libraries
# Data analysis and processing
import pandas as pd
import numpy as np
# Tensor processing tool
import tensorflow as tf
import tensorflow_addons as tfa
from tensorflow import keras
# # Help Functions
def image_path(video_id, video_frame):
return f"/kaggle/input/tensorflow-great-barrier-reef/train_images/video_{video_id}/{video_frame}.jpg"
def cocoincode(cocobboxdict):
"""COCO incode is a np array like ['x' 'y' 'width' 'height']"""
return np.array(
[
cocobboxdict["x"],
cocobboxdict["y"],
cocobboxdict["width"],
cocobboxdict["height"],
],
dtype=np.int32,
)
def coco2yolo(cocobbox):
"""Transform a COCO np array like ['x' 'y' 'width' 'height'] in a YOLO np array like ['x' 'y' 'width' 'height']"""
return np.array(
[
(cocobbox[0] + cocobbox[2] // 2 + cocobbox[2] % 2),
(cocobbox[1] + cocobbox[3] // 2 + cocobbox[3] % 2),
cocobbox[2],
cocobbox[3],
],
dtype=np.int32,
)
def yolo2yolosquared(yolobbox):
"""Transform a YOLO np array like ['x' 'y' 'width' 'height'] to a YOLO np array like ['x' 'y' 'side']"""
return np.array(
[yolobbox[0], yolobbox[1], max(yolobbox[2], yolobbox[3])], dtype=np.int32
)
def yolosquared2yolo(yolosquaredbbox):
"""Transform a YOLO np array like ['x' 'y' 'side'] to a YOLO np array like ['x' 'y' 'width' 'height']"""
return np.array(
[
yolosquaredbbox[0],
yolosquaredbbox[1],
yolosquaredbbox[2],
yolosquaredbbox[2],
],
dtype=np.int32,
)
def yolo2coco(yolobboxes):
pass
from tensorflow.keras.utils import load_img
from tensorflow.keras.utils import img_to_array
def my_load_image(image_path):
return np.array(img_to_array(load_img(image_path)) / 255, np.float)
# # Training Functions and classes
# ## YOLO Squared Transformer
class YOLOSquaredTransformer:
def __init__(self, S, B, img_width, img_height):
self.S = S
self.B = B
self.img_width = img_width
self.img_height = img_height
self.l_x = img_width // S + (1 if img_width % S != 0 else 0)
self.l_y = img_height // S + (1 if img_height % S != 0 else 0)
self.img_big_side = max([img_width, img_height])
def batch_from_cocodictlist(self, cocodictlistbatch):
"""
Receive a batch of cocodictlists where labels are 'x_left', 'y_top', 'width' and 'height' creating a numpy batch
output in format of YOLO Squared where shape is (batch_size, S, S, B, 4) being ['prob', 'x_center', 'y_center', 'side'] -> normalized
"""
batch_size = len(cocodictlistbatch)
bboxes_in_square = np.zeros((batch_size, S, S), dtype=np.int32)
output = np.zeros((batch_size, S, S, B, 4), dtype=np.float)
for batch_pos, cocodictlist in enumerate(cocodictlistbatch):
for cocodict in cocodictlist:
coco = cocoincode(cocodict)
yolo = coco2yolo(coco)
yolosquared = yolo2yolosquared(yolo)
S_x = yolosquared[0] // self.l_x - (
1 if yolosquared[0] % self.l_x == 0 else 0
)
S_y = yolosquared[1] // self.l_y - (
1 if yolosquared[1] % self.l_y == 0 else 0
)
if S_x < self.S and S_y < self.S:
n = bboxes_in_square[batch_pos, S_y, S_x]
if n < B:
output[batch_pos, S_y, S_x, n, 0] = 1
output[batch_pos, S_y, S_x, n, 1] = (
yolosquared[0] - S_x * self.l_x
) / self.l_x
output[batch_pos, S_y, S_x, n, 2] = (
yolosquared[1] - S_y * self.l_y
) / self.l_y
output[batch_pos, S_y, S_x, n, 3] = (
yolosquared[2] / self.img_big_side
)
bboxes_in_square[batch_pos, S_y, S_x] = n + 1
return output
def cocolistbatch_from_yolosquaredbatch(self, y, cut_prob):
"""
Take a batch of tensors representing a yolo output (['prob', 'x_center', 'y_center', 'side'] -> normalized) whit shape: (batch_size, S, S, B, 4)
and transforms it in a list of a list of coco values (['prob', 'x_lefttop', 'y_lefttop', 'width', 'height']) with shape: (batch_size, variable, 4)
where prob is bigger than cut_prob.
"""
pass
def iou(self, y_true, y_pred):
"""
We only know that tensor have rank 5 and the shape is: (batch_size, S, S, B, 4)
bbox are: ['prob' 'x' 'y' 'side'] -> normalized
"""
side_scale = max([img_width, img_height])
l_true = y_true[:, :, :, 3:4] * self.img_big_side
l_pred = y_pred[:, :, :, 3:4] * self.img_big_side
x_true = y_true[:, :, :, 1:2] * self.l_x
x_pred = y_pred[:, :, :, 1:2] * self.l_x
yc_true = y_true[:, :, :, 2:3] * self.l_y
yc_pred = y_pred[:, :, :, 2:3] * self.l_y
dx = tf.math.abs(x_true - x_pred)
dy = tf.math.abs(yc_true - yc_pred)
l_x = tf.math.maximum(
tf.math.maximum(l_true / 2 + l_pred / 2 + dx, l_true), l_pred
)
l_y = tf.math.maximum(
tf.math.maximum(l_true / 2 + l_pred / 2 + dy, l_true), l_pred
)
I_area = tf.nn.relu(l_true + l_pred - l_x) * tf.nn.relu(l_true + l_pred - l_x)
U_area = tf.pow(l_true, 2) + tf.pow(l_pred, 2) - I_area
IoU = I_area / U_area
return IoU
# ## Batch generator
from tensorflow.keras.utils import Sequence
from json import loads
class YoloSquaredSequence(Sequence):
def __init__(self, train_df, batch_size, transformer):
self.train_df = train_df
self.batch_size = batch_size
self.transformer = transformer
def __len__(self):
return len(self.train_df) // self.batch_size
def __getitem__(self, idx):
batch_df = self.train_df[idx * self.batch_size : (idx + 1) * (self.batch_size)]
X = self.get_x(batch_df)
y = self.get_y(batch_df)
return X, y
def get_x(self, batch_df):
return np.array(
[my_load_image(image_path) for image_path in batch_df["image_path"]]
)
def get_y(self, batch_df):
cocodictlistbatch = [
loads(annotations.replace("'", '"'))
for annotations in batch_df["annotations"]
]
return self.transformer.batch_from_cocodictlist(cocodictlistbatch)
# ## Loss Function
from tensorflow.keras.losses import Loss
class SquaredYoloLoss(Loss):
"""We only know that tensor have rank 5 and the shape is: (batch_size, S, S, B, 4)"""
def __init__(self, lambda_coord, lambda_noobj, transformer, *args, **kwargs):
self.lambda_coord = lambda_coord
self.lambda_noobj = lambda_noobj
self.transformer = transformer
super(SquaredYoloLoss, self).__init__(*args, **kwargs)
def call(self, y_true, y_pred):
# Necessario achar qual objeto é par de qual...
# Look at y_true if we have bbox
obj_exists = y_true[:, :, :, 0:1]
obj_noexists = 1 - obj_exists
iou = self.transformer.iou(y_true, y_pred)
sum_exists_coord = self.lambda_coord * tf.reduce_sum(
obj_exists * (tf.pow(y_pred[:, :, :, 1:4] - y_true[:, :, :, 1:4], 2))
) + tf.reduce_sum(tf.nn.relu(y_true[:, :, :, 3:4] - y_pred[:, :, :, 3:4]))
sum_predict = tf.reduce_sum(obj_exists * tf.pow(y_pred[:, :, :, 0:1] - iou, 2))
sum_noexists = self.lambda_noobj * tf.reduce_sum(
obj_noexists * (tf.pow(y_pred[:, :, :, 0:1], 2))
)
return sum_exists_coord + sum_predict + sum_noexists
# ## Metric Function
from tensorflow.keras.metrics import Metric
class YOLOSquaredMetric(Metric):
def __init__(self, transformer, name="YOLO Recall Squared Metric", **kwargs):
super(YOLOSquaredMetric, self).__init__(name=name, **kwargs)
self.recall = self.add_weight(name="yoloRecall", initializer="zeros")
self.objects = self.add_weight(name="objects", initializer="zeros")
self.finds = self.add_weight(name="finds", initializer="zeros")
self.transformer = transformer
def update_state(self, y_true, y_pred, sample_weight=None):
obj_exists = y_true[:, :, :, 0:1]
iou = self.transformer.iou(y_true, y_pred)
self.objects = tf.reduce_sum(obj_exists)
def result(self):
return self.objects
# # Training Specifications
# ## Constants - Hyperparameters
# grid size SxS:
S = 7
# bboxes per cell in grid
B = 2
# batch size
batch_size = 40
# image shape
img_shape = (720, 1280, 3)
img_height = img_shape[0]
img_width = img_shape[1]
# ## Preprocessing data to train
def load_train_df():
# Load train.csv:
complete_train_df = pd.read_csv(
"/kaggle/input/tensorflow-great-barrier-reef/train.csv"
)
# Only use images where we have starfish
complete_train_df = complete_train_df[complete_train_df["annotations"] != "[]"]
# Create column image_path -> too expensive in memory
complete_train_df["image_path"] = complete_train_df.apply(
lambda row: image_path(row["video_id"], row["video_frame"]), axis=1
)
# Shuffle dataframe
complete_train_df = complete_train_df.sample(frac=1)
return complete_train_df
train_df = load_train_df()
# ## Model Definition
transformer = YOLOSquaredTransformer(S, B, img_width, img_height)
batch_sequence = YoloSquaredSequence(train_df, batch_size, transformer)
model = keras.models.Sequential(
[
keras.layers.Conv2D(
128,
9,
strides=(2, 4),
activation="relu",
padding="same",
input_shape=img_shape,
),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(128, 3, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(128, 1, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(128, 3, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Conv2D(256, 1, activation="relu", padding="same"),
keras.layers.Conv2D(256, 3, activation="relu", padding="same"),
keras.layers.MaxPooling2D(2),
keras.layers.Flatten(),
keras.layers.Dense(S * S * B * 4, activation="relu"),
keras.layers.Dropout(0.5),
keras.layers.Dense(S * S * B * 4, activation="sigmoid"),
keras.layers.Reshape((S, S, B, 4)),
]
)
model.summary()
loss_function = SquaredYoloLoss(5, 0.5, transformer)
yolo_recall = YOLOSquaredMetric(transformer)
model.compile(
optimizer="rmsprop", loss=loss_function, metrics=["accuracy", yolo_recall]
)
model.fit(x=batch_sequence, batch_size=batch_size, epochs=30)
model.save("fastLazyYOLO")
| false | 0 | 3,597 | 0 | 6 | 3,597 |
||
87964295 | <kaggle_start><code># !curl https://raw.githubusercontent.com/pytorch/xla/master/contrib/scripts/env-setup.py -o pytorch-xla-env-setup.py
# !python pytorch-xla-env-setup.py --version 1.7 --apt-packages libomp5 libopenblas-dev
# !pip install -U pytorch-lightning albumentations
import pandas as pd
from PIL import Image
import os
import numpy as np
from io import BytesIO
from matplotlib import pyplot as plt
from tqdm.notebook import tqdm
import traceback
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
from torchvision import models
import cv2
from pytorch_lightning import LightningModule, Trainer, seed_everything
from pytorch_lightning.callbacks import ModelCheckpoint, LearningRateMonitor
from pytorch_lightning.profiler import AdvancedProfiler
from pytorch_lightning.loggers import TensorBoardLogger
import time
import sys
import gc
import pickle
batch_size = 128
gradient_accum = 1
epoch = 20
lr = 5e-3
wd = 5e-4
MODEL = "tf_efficientnet_b4_ns"
from collections import defaultdict
words = defaultdict(int)
for fn in tqdm(
os.listdir("../input/dcic-2022-ocr/training_dataset-909058/training_dataset")
):
for c in fn.split(".")[0]:
words[c] += 1
sorted(list(words.items())), len(words)
vocab = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
class Tokenizer:
def __init__(self):
self.vocab = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
self.vocab_lookup = {}
for i, c in enumerate(self.vocab):
self.vocab_lookup[c] = i
def __call__(self, s):
ret = np.zeros(len(s), dtype=np.int64)
for i, c in enumerate(s):
ret[i] = self.vocab_lookup[c]
return ret
def untokenize(self, s):
ret = []
for i in range(len(s)):
ret.append(self.vocab[s[i]])
return "".join(ret)
tokenizer = Tokenizer()
tokenizer.untokenize(tokenizer("123jik"))
imgs = os.listdir("../input/dcic-2022-ocr/training_dataset-909058/training_dataset")
import timm
from torchvision import transforms
cfg = timm.data.resolve_data_config({}, MODEL)
cfg
import aug_lib
aug_train = transforms.Compose(
[
timm.data.RandomResizedCropAndInterpolation(
(128, 256), scale=(0.9, 1.2), ratio=(2, 3), interpolation="random"
),
aug_lib.TrivialAugment(),
transforms.ToTensor(),
transforms.Normalize(mean=cfg["mean"], std=cfg["std"]),
]
)
aug_val = timm.data.create_transform(
input_size=(128, 256),
crop_pct=1,
is_training=False,
interpolation="bilinear",
)
class MyDataset(Dataset):
def __init__(self, imgs, tokenizer, aug):
self.path = "../input/dcic-2022-ocr/training_dataset-909058/training_dataset"
self.imgs = imgs
self.tokenizer = tokenizer
self.aug = aug
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
img = Image.open(os.path.join(self.path, self.imgs[idx])).convert("RGB")
img = self.aug(img)
label = self.imgs[idx].split(".")[0]
return img, self.tokenizer(label)
def reverse_transform(a):
r = a[0]
g = a[1]
b = a[2]
return torch.stack([r * 0.229 + 0.485, g * 0.224 + 0.456, b * 0.225 + 0.406], dim=0)
import random
import IPython
ds = MyDataset(imgs, tokenizer, aug_train)
for i in range(5):
d = ds[random.randrange(0, len(ds))]
IPython.display.display(transforms.ToPILImage()(reverse_transform(d[0])))
print(tokenizer.untokenize(d[1]))
def one_hot(x, num_classes, on_value=1.0, off_value=0.0, device="cuda"):
x = x.long().view(-1, 1)
return torch.full((x.size()[0], num_classes), off_value, device=device).scatter_(
1, x, on_value
)
import torch
import torch.nn as nn
import torch.nn.functional as F
# +
class Model(LightningModule):
def __init__(self, n_classes, lr, wd):
super().__init__()
self.save_hyperparameters()
self.lr = lr
self.cnn = timm.create_model(MODEL, pretrained=True) # resnet 50
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.out = nn.Linear(self.cnn.num_features, n_classes * 4)
self.crit = nn.CrossEntropyLoss()
def forward(self, input_):
x = self.cnn.forward_features(input_)
x = self.avgpool(x).flatten(1)
x = self.out(x).view(-1, 4, self.hparams.n_classes)
return x
def training_step(self, batch, batch_idx):
self.train()
crit = nn.MultiLabelSoftMarginLoss()
input_tensor, target_tensor = batch
with torch.no_grad():
target = one_hot(target_tensor, self.hparams.n_classes).view(
input_tensor.size(0), -1
)
decoder_out = self(input_tensor) # N x L x C
loss = crit(decoder_out.flatten(1), target)
with torch.no_grad():
target_tensor = target_tensor
preds = decoder_out.argmax(2)
acc_char = (preds == target_tensor).float().mean()
acc_sent = (preds == target_tensor).all(dim=1).float().mean()
self.log("train_loss", loss)
self.log("train_acc_char", acc_char)
self.log("train_acc_sent", acc_sent)
return loss
def configure_optimizers(self):
optimizer = torch.optim.AdamW(
self.parameters(), lr=0, weight_decay=self.hparams.wd
)
scheduler = {
"scheduler": torch.optim.lr_scheduler.OneCycleLR(
optimizer,
max_lr=self.lr,
total_steps=self.trainer.max_steps,
anneal_strategy="linear",
cycle_momentum=False,
pct_start=0.1,
),
"interval": "step",
"frequency": 1,
}
return [optimizer], [scheduler]
def validation_step(self, batch, batch_idx):
self.eval()
with torch.no_grad():
input_tensor, target_tensor = batch
decoder_out = self(input_tensor) # N x L x C
loss = self.crit(decoder_out.permute(0, 2, 1), target_tensor)
target_tensor = target_tensor
preds = decoder_out.argmax(2)
acc_char = (preds == target_tensor).float().mean()
acc_sent = (preds == target_tensor).all(dim=1).float().mean()
self.log("val_loss", loss)
self.log("val_acc_char", acc_char)
self.log("val_acc_sent", acc_sent)
from sklearn.model_selection import train_test_split, KFold
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score
imgs = np.array(imgs)
imgs
from pytorch_lightning.utilities import rank_zero_only
from pytorch_lightning.loggers import LightningLoggerBase
from pytorch_lightning.loggers.base import rank_zero_experiment
from collections import defaultdict
class ConsoleLogger(LightningLoggerBase):
def __init__(self):
super().__init__()
self.metrics = defaultdict(list)
@property
def name(self):
return ""
@property
@rank_zero_experiment
def experiment(self):
# Return the experiment object associated with this logger.
pass
@property
def version(self):
# Return the experiment version, int or str.
return ""
@rank_zero_only
def log_hyperparams(self, params):
# params is an argparse.Namespace
# your code to record hyperparameters goes here
pass
@rank_zero_only
def log_metrics(self, metrics, step):
# metrics is a dictionary of metric names and values
# your code to record metrics goes here
print("=" * 80)
if "epoch" in metrics:
print(f'epoch: {metrics["epoch"]}, steps: {step}')
else:
print(f"steps: {step}")
for k, v in metrics.items():
if k == "epoch":
continue
if isinstance(v, torch.Tensor):
v = v.item()
print(f"{k}: {v}")
self.metrics[k].append((step, v))
import pytorch_lightning
kf = KFold(n_splits=20, random_state=42, shuffle=True)
val_data = []
fold_idx = 0
for train, val in kf.split(imgs):
def train_func():
train_imgs = imgs[train]
val_imgs = imgs[val]
ds_train = MyDataset(train_imgs, tokenizer, aug_train)
train_loader = DataLoader(
ds_train,
batch_size=batch_size,
num_workers=4,
shuffle=True,
pin_memory=True,
drop_last=True,
)
ds_val = MyDataset(val_imgs, tokenizer, aug_val)
val_loader = DataLoader(
ds_val,
batch_size=batch_size,
num_workers=4,
pin_memory=True,
)
max_steps = epoch * int(np.ceil(len(train_loader) / gradient_accum))
print("*" * 80)
print("training fold", fold_idx)
print("train samples:", len(train_imgs), "max steps:", max_steps)
checkpoint_callback = ModelCheckpoint(
save_top_k=1,
verbose=True,
monitor="val_acc_sent",
mode="max",
filename="epoch{epoch}-step{step}-val_acc_sent{val_acc_sent:.2f}",
auto_insert_metric_name=False,
save_weights_only=True,
save_last=True,
)
logger = ConsoleLogger()
tb_logger = TensorBoardLogger(
save_dir=".", version=f"fold_{fold_idx}", name="lightning_logs"
)
trainer = Trainer(
logger=[logger, tb_logger],
accumulate_grad_batches=gradient_accum,
gpus=-1,
callbacks=[LearningRateMonitor(), checkpoint_callback],
flush_logs_every_n_steps=50,
log_every_n_steps=50,
max_steps=max_steps,
benchmark=True,
precision=16,
)
model = Model(len(vocab), lr, wd)
# lr_finder = trainer.tuner.lr_find(model, train_loader)
# lr_finder.plot(suggest=True)
trainer.fit(model, train_dataloaders=train_loader, val_dataloaders=val_loader)
train_func()
gc.collect()
pytorch_lightning.utilities.memory.garbage_collection_cuda()
break
class MyTestDataset(Dataset):
def __init__(self, imgs, aug):
self.path = "../input/dcic-2022-ocr/test_dataset-220406/test_dataset/"
self.imgs = imgs
self.tokenizer = tokenizer
self.aug = aug
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
img = Image.open(os.path.join(self.path, self.imgs[idx])).convert("RGB")
img = self.aug(img)
return img
test_imgs = os.listdir("../input/dcic-2022-ocr/test_dataset-220406/test_dataset")
test_imgs = sorted(test_imgs, key=lambda x: int(x.split(".")[0]))
ds_test = MyTestDataset(test_imgs, aug_val)
test_loader = DataLoader(
ds_test, batch_size=32, num_workers=4, pin_memory=True, shuffle=False
)
model = Model.load_from_checkpoint(
"./_lightning_logs/_fold_0/checkpoints/last.ckpt"
).cuda()
tmp = []
with torch.no_grad():
for batch in tqdm(test_loader):
batch = batch.cuda()
model.eval()
pred = model(batch).argmax(2).cpu().numpy()
tmp.append(pred)
preds = np.concatenate(tmp, axis=0)
df_preds = pd.DataFrame()
df_preds["num"] = [x.split(".")[0] for x in test_imgs] # [:len(tags)]
df_preds["tag"] = [tokenizer.untokenize(x) for x in preds]
df_preds.to_csv("result.csv", index=None)
df_preds
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0087/964/87964295.ipynb | null | null | [{"Id": 87964295, "ScriptId": 24700958, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3508829, "CreationDate": "02/16/2022 06:26:06", "VersionNumber": 3.0, "Title": "dcic ocr effnet multilabel", "EvaluationDate": "02/16/2022", "IsChange": true, "TotalLines": 409.0, "LinesInsertedFromPrevious": 16.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 393.0, "LinesInsertedFromFork": 32.0, "LinesDeletedFromFork": 85.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 377.0, "TotalVotes": 0}] | null | null | null | null | # !curl https://raw.githubusercontent.com/pytorch/xla/master/contrib/scripts/env-setup.py -o pytorch-xla-env-setup.py
# !python pytorch-xla-env-setup.py --version 1.7 --apt-packages libomp5 libopenblas-dev
# !pip install -U pytorch-lightning albumentations
import pandas as pd
from PIL import Image
import os
import numpy as np
from io import BytesIO
from matplotlib import pyplot as plt
from tqdm.notebook import tqdm
import traceback
import pandas as pd
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset
from torchvision import models
import cv2
from pytorch_lightning import LightningModule, Trainer, seed_everything
from pytorch_lightning.callbacks import ModelCheckpoint, LearningRateMonitor
from pytorch_lightning.profiler import AdvancedProfiler
from pytorch_lightning.loggers import TensorBoardLogger
import time
import sys
import gc
import pickle
batch_size = 128
gradient_accum = 1
epoch = 20
lr = 5e-3
wd = 5e-4
MODEL = "tf_efficientnet_b4_ns"
from collections import defaultdict
words = defaultdict(int)
for fn in tqdm(
os.listdir("../input/dcic-2022-ocr/training_dataset-909058/training_dataset")
):
for c in fn.split(".")[0]:
words[c] += 1
sorted(list(words.items())), len(words)
vocab = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
class Tokenizer:
def __init__(self):
self.vocab = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
self.vocab_lookup = {}
for i, c in enumerate(self.vocab):
self.vocab_lookup[c] = i
def __call__(self, s):
ret = np.zeros(len(s), dtype=np.int64)
for i, c in enumerate(s):
ret[i] = self.vocab_lookup[c]
return ret
def untokenize(self, s):
ret = []
for i in range(len(s)):
ret.append(self.vocab[s[i]])
return "".join(ret)
tokenizer = Tokenizer()
tokenizer.untokenize(tokenizer("123jik"))
imgs = os.listdir("../input/dcic-2022-ocr/training_dataset-909058/training_dataset")
import timm
from torchvision import transforms
cfg = timm.data.resolve_data_config({}, MODEL)
cfg
import aug_lib
aug_train = transforms.Compose(
[
timm.data.RandomResizedCropAndInterpolation(
(128, 256), scale=(0.9, 1.2), ratio=(2, 3), interpolation="random"
),
aug_lib.TrivialAugment(),
transforms.ToTensor(),
transforms.Normalize(mean=cfg["mean"], std=cfg["std"]),
]
)
aug_val = timm.data.create_transform(
input_size=(128, 256),
crop_pct=1,
is_training=False,
interpolation="bilinear",
)
class MyDataset(Dataset):
def __init__(self, imgs, tokenizer, aug):
self.path = "../input/dcic-2022-ocr/training_dataset-909058/training_dataset"
self.imgs = imgs
self.tokenizer = tokenizer
self.aug = aug
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
img = Image.open(os.path.join(self.path, self.imgs[idx])).convert("RGB")
img = self.aug(img)
label = self.imgs[idx].split(".")[0]
return img, self.tokenizer(label)
def reverse_transform(a):
r = a[0]
g = a[1]
b = a[2]
return torch.stack([r * 0.229 + 0.485, g * 0.224 + 0.456, b * 0.225 + 0.406], dim=0)
import random
import IPython
ds = MyDataset(imgs, tokenizer, aug_train)
for i in range(5):
d = ds[random.randrange(0, len(ds))]
IPython.display.display(transforms.ToPILImage()(reverse_transform(d[0])))
print(tokenizer.untokenize(d[1]))
def one_hot(x, num_classes, on_value=1.0, off_value=0.0, device="cuda"):
x = x.long().view(-1, 1)
return torch.full((x.size()[0], num_classes), off_value, device=device).scatter_(
1, x, on_value
)
import torch
import torch.nn as nn
import torch.nn.functional as F
# +
class Model(LightningModule):
def __init__(self, n_classes, lr, wd):
super().__init__()
self.save_hyperparameters()
self.lr = lr
self.cnn = timm.create_model(MODEL, pretrained=True) # resnet 50
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.out = nn.Linear(self.cnn.num_features, n_classes * 4)
self.crit = nn.CrossEntropyLoss()
def forward(self, input_):
x = self.cnn.forward_features(input_)
x = self.avgpool(x).flatten(1)
x = self.out(x).view(-1, 4, self.hparams.n_classes)
return x
def training_step(self, batch, batch_idx):
self.train()
crit = nn.MultiLabelSoftMarginLoss()
input_tensor, target_tensor = batch
with torch.no_grad():
target = one_hot(target_tensor, self.hparams.n_classes).view(
input_tensor.size(0), -1
)
decoder_out = self(input_tensor) # N x L x C
loss = crit(decoder_out.flatten(1), target)
with torch.no_grad():
target_tensor = target_tensor
preds = decoder_out.argmax(2)
acc_char = (preds == target_tensor).float().mean()
acc_sent = (preds == target_tensor).all(dim=1).float().mean()
self.log("train_loss", loss)
self.log("train_acc_char", acc_char)
self.log("train_acc_sent", acc_sent)
return loss
def configure_optimizers(self):
optimizer = torch.optim.AdamW(
self.parameters(), lr=0, weight_decay=self.hparams.wd
)
scheduler = {
"scheduler": torch.optim.lr_scheduler.OneCycleLR(
optimizer,
max_lr=self.lr,
total_steps=self.trainer.max_steps,
anneal_strategy="linear",
cycle_momentum=False,
pct_start=0.1,
),
"interval": "step",
"frequency": 1,
}
return [optimizer], [scheduler]
def validation_step(self, batch, batch_idx):
self.eval()
with torch.no_grad():
input_tensor, target_tensor = batch
decoder_out = self(input_tensor) # N x L x C
loss = self.crit(decoder_out.permute(0, 2, 1), target_tensor)
target_tensor = target_tensor
preds = decoder_out.argmax(2)
acc_char = (preds == target_tensor).float().mean()
acc_sent = (preds == target_tensor).all(dim=1).float().mean()
self.log("val_loss", loss)
self.log("val_acc_char", acc_char)
self.log("val_acc_sent", acc_sent)
from sklearn.model_selection import train_test_split, KFold
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score
imgs = np.array(imgs)
imgs
from pytorch_lightning.utilities import rank_zero_only
from pytorch_lightning.loggers import LightningLoggerBase
from pytorch_lightning.loggers.base import rank_zero_experiment
from collections import defaultdict
class ConsoleLogger(LightningLoggerBase):
def __init__(self):
super().__init__()
self.metrics = defaultdict(list)
@property
def name(self):
return ""
@property
@rank_zero_experiment
def experiment(self):
# Return the experiment object associated with this logger.
pass
@property
def version(self):
# Return the experiment version, int or str.
return ""
@rank_zero_only
def log_hyperparams(self, params):
# params is an argparse.Namespace
# your code to record hyperparameters goes here
pass
@rank_zero_only
def log_metrics(self, metrics, step):
# metrics is a dictionary of metric names and values
# your code to record metrics goes here
print("=" * 80)
if "epoch" in metrics:
print(f'epoch: {metrics["epoch"]}, steps: {step}')
else:
print(f"steps: {step}")
for k, v in metrics.items():
if k == "epoch":
continue
if isinstance(v, torch.Tensor):
v = v.item()
print(f"{k}: {v}")
self.metrics[k].append((step, v))
import pytorch_lightning
kf = KFold(n_splits=20, random_state=42, shuffle=True)
val_data = []
fold_idx = 0
for train, val in kf.split(imgs):
def train_func():
train_imgs = imgs[train]
val_imgs = imgs[val]
ds_train = MyDataset(train_imgs, tokenizer, aug_train)
train_loader = DataLoader(
ds_train,
batch_size=batch_size,
num_workers=4,
shuffle=True,
pin_memory=True,
drop_last=True,
)
ds_val = MyDataset(val_imgs, tokenizer, aug_val)
val_loader = DataLoader(
ds_val,
batch_size=batch_size,
num_workers=4,
pin_memory=True,
)
max_steps = epoch * int(np.ceil(len(train_loader) / gradient_accum))
print("*" * 80)
print("training fold", fold_idx)
print("train samples:", len(train_imgs), "max steps:", max_steps)
checkpoint_callback = ModelCheckpoint(
save_top_k=1,
verbose=True,
monitor="val_acc_sent",
mode="max",
filename="epoch{epoch}-step{step}-val_acc_sent{val_acc_sent:.2f}",
auto_insert_metric_name=False,
save_weights_only=True,
save_last=True,
)
logger = ConsoleLogger()
tb_logger = TensorBoardLogger(
save_dir=".", version=f"fold_{fold_idx}", name="lightning_logs"
)
trainer = Trainer(
logger=[logger, tb_logger],
accumulate_grad_batches=gradient_accum,
gpus=-1,
callbacks=[LearningRateMonitor(), checkpoint_callback],
flush_logs_every_n_steps=50,
log_every_n_steps=50,
max_steps=max_steps,
benchmark=True,
precision=16,
)
model = Model(len(vocab), lr, wd)
# lr_finder = trainer.tuner.lr_find(model, train_loader)
# lr_finder.plot(suggest=True)
trainer.fit(model, train_dataloaders=train_loader, val_dataloaders=val_loader)
train_func()
gc.collect()
pytorch_lightning.utilities.memory.garbage_collection_cuda()
break
class MyTestDataset(Dataset):
def __init__(self, imgs, aug):
self.path = "../input/dcic-2022-ocr/test_dataset-220406/test_dataset/"
self.imgs = imgs
self.tokenizer = tokenizer
self.aug = aug
def __len__(self):
return len(self.imgs)
def __getitem__(self, idx):
img = Image.open(os.path.join(self.path, self.imgs[idx])).convert("RGB")
img = self.aug(img)
return img
test_imgs = os.listdir("../input/dcic-2022-ocr/test_dataset-220406/test_dataset")
test_imgs = sorted(test_imgs, key=lambda x: int(x.split(".")[0]))
ds_test = MyTestDataset(test_imgs, aug_val)
test_loader = DataLoader(
ds_test, batch_size=32, num_workers=4, pin_memory=True, shuffle=False
)
model = Model.load_from_checkpoint(
"./_lightning_logs/_fold_0/checkpoints/last.ckpt"
).cuda()
tmp = []
with torch.no_grad():
for batch in tqdm(test_loader):
batch = batch.cuda()
model.eval()
pred = model(batch).argmax(2).cpu().numpy()
tmp.append(pred)
preds = np.concatenate(tmp, axis=0)
df_preds = pd.DataFrame()
df_preds["num"] = [x.split(".")[0] for x in test_imgs] # [:len(tags)]
df_preds["tag"] = [tokenizer.untokenize(x) for x in preds]
df_preds.to_csv("result.csv", index=None)
df_preds
| false | 0 | 3,368 | 0 | 6 | 3,368 |
||
87597153 | <kaggle_start><code># # HW2B: Neural Machine Translation
# In this project, you will build a neural machine translation system using modern techniques for sequence-to-sequence modeling. You will first implement a baseline encoder-decoder architecture, then improve upon the baseline by adding an attention mechanism and implementing beam search. The end result will be a fully functional translation system capable of translating simple German sentences into English.
# ## Setup
# First we install and import the required dependencies. These include:
# * `torch` for modeling and training
# * `torchtext` for data collection
# * `sentencepiece` for subword tokenization
# * `sacrebleu` for BLEU score evaluation
# Standard library imports
import json
import math
import random
import pdb
# Third party imports
import matplotlib.pyplot as plt
import numpy as np
import sacrebleu
import sentencepiece
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchtext
import tqdm.notebook
# Before proceeding, let's verify that we're connected to a GPU runtime and that `torch` can detect the GPU.
# We'll define a variable `device` here to use throughout the code so that we can easily change to run on CPU for debugging.
assert torch.cuda.is_available()
device = torch.device("cuda")
print("Using device:", device)
# ## Data
# The data for this assignment comes from the [Multi30K dataset](https://arxiv.org/abs/1605.00459), which contains English and German captions for images from Flickr. We can download and unpack it using `torchtext`. We use the Multi30K dataset because it is simpler than standard translation benchmark datasets and allows for models to be trained and evaluated in a matter of minutes rather than days.
# We will be translating from German to English in this assignment, but the same techniques apply equally well to any language pair.
#
extensions = [".de", ".en"]
source_field = torchtext.data.Field(tokenize=lambda x: x)
target_field = torchtext.data.Field(tokenize=lambda x: x)
training_data, validation_data, test_data = torchtext.datasets.Multi30k.splits(
extensions, [source_field, target_field], root="."
)
# Now that we have the data, let's see how large each split is and look at a few examples.
print("Number of training examples:", len(training_data))
print("Number of validation examples:", len(validation_data))
print("Number of test examples:", len(test_data))
print()
for example in training_data[:10]:
print(example.src)
print(example.trg)
print()
# ## Vocabulary
# We can use `sentencepiece` to create a joint German-English subword vocabulary from the training corpus. Because the number of training examples is small, we choose a smaller vocabulary size than would be used for large-scale NMT.
args = {
"pad_id": 0,
"bos_id": 1,
"eos_id": 2,
"unk_id": 3,
"input": "multi30k/train.de,multi30k/train.en",
"vocab_size": 8000,
"model_prefix": "multi30k",
}
combined_args = " ".join("--{}={}".format(key, value) for key, value in args.items())
sentencepiece.SentencePieceTrainer.Train(combined_args)
# This creates two files: `multi30k.model` and `multi30k.vocab`. The first is a binary file containing the relevant data for the vocabulary. The second is a human-readable listing of each subword and its associated score.
# We can preview the contents of the vocabulary by looking at the first few rows from the human-readable file.
# As we can see, the vocabulary consists of four special tokens (`` for padding, `` for beginning of sentence (BOS), `` for end of sentence (EOS), `` for unknown) and a mixture of German and English words and subwords. In order to ensure reversability, word boundaries are encoded with a special unicode character "▁" (U+2581).
# To use the vocabulary, we first need to load it from the binary file produced above.
vocab = sentencepiece.SentencePieceProcessor()
vocab.Load("multi30k.model")
# The vocabulary object includes a number of methods for working with full sequences or individual pieces. We explore the most relevant ones below. A complete interface can be found on [GitHub](https://github.com/google/sentencepiece/tree/master/python#usage) for reference.
print("Vocabulary size:", vocab.GetPieceSize())
print()
for example in training_data[:3]:
sentence = example.trg
pieces = vocab.EncodeAsPieces(sentence)
indices = vocab.EncodeAsIds(sentence)
print(sentence)
print(pieces)
print(vocab.DecodePieces(pieces))
print(indices)
print(vocab.DecodeIds(indices))
print()
piece = vocab.EncodeAsPieces("the")[0]
index = vocab.PieceToId(piece)
print(piece)
print(index)
print(vocab.IdToPiece(index))
# We define some constants here for the first three special tokens that you may find useful in the following sections.
pad_id = vocab.PieceToId("<pad>")
bos_id = vocab.PieceToId("<s>")
eos_id = vocab.PieceToId("</s>")
# Note that these tokens will be stripped from the output when converting from word pieces to text. This may be helpful when implementing greedy search and beam search.
sentence = training_data[0].trg
indices = vocab.EncodeAsIds(sentence)
indices_augmented = [bos_id] + indices + [eos_id, pad_id, pad_id, pad_id]
print(vocab.DecodeIds(indices))
print(vocab.DecodeIds(indices_augmented))
print(vocab.DecodeIds(indices) == vocab.DecodeIds(indices_augmented))
# ## Baseline sequence-to-sequence model
# With our data and vocabulary loaded, we're now ready to build a baseline sequence-to-sequence model. Later on we'll add an attention mechanism to the model.
# Let's begin by defining a batch iterator for the training data. Given a dataset and a batch size, it will iterate over the dataset and yield pairs of tensors containing the subword indices for the source and target sentences in the batch, respectively. Fill in `make_batch` below.
def make_batch(sentences):
"""Convert a list of sentences into a batch of subword indices.
Args:
sentences: A list of sentences, each of which is a string.
Returns:
A LongTensor of size (max_sequence_length, batch_size) containing the
subword indices for the sentences, where max_sequence_length is the length
of the longest sentence as encoded by the subword vocabulary and batch_size
is the number of sentences in the batch. A beginning-of-sentence token
should be included before each sequence, and an end-of-sentence token should
be included after each sequence. Empty slots at the end of shorter sequences
should be filled with padding tokens. The tensor should be located on the
device defined at the beginning of the notebook.
"""
# Implementation tip: You can use the nn.utils.rnn.pad_sequence utility
# function to combine a list of variable-length sequences with padding.
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
def make_batch_iterator(dataset, batch_size, shuffle=False):
"""Make a batch iterator that yields source-target pairs.
Args:
dataset: A torchtext dataset object.
batch_size: An integer batch size.
shuffle: A boolean indicating whether to shuffle the examples.
Yields:
Pairs of tensors constructed by calling the make_batch function on the
source and target sentences in the current group of examples. The max
sequence length can differ between the source and target tensor, but the
batch size will be the same. The final batch may be smaller than the given
batch size.
"""
examples = list(dataset)
if shuffle:
random.shuffle(examples)
for start_index in range(0, len(examples), batch_size):
example_batch = examples[start_index : start_index + batch_size]
source_sentences = [example.src for example in example_batch]
target_sentences = [example.trg for example in example_batch]
yield make_batch(source_sentences), make_batch(target_sentences)
test_batch = make_batch(["a test input", "a longer input than the first"])
print("Example batch tensor:")
print(test_batch)
assert test_batch.shape[1] == 2
assert test_batch[0, 0] == bos_id
assert test_batch[0, 1] == bos_id
assert test_batch[-1, 0] == pad_id
assert test_batch[-1, 1] == eos_id
# Now we will define the model itself. It should consist of a bidirectional LSTM encoder that encodes the input sentence into a fixed-size representation, and an LSTM decoder that uses this representation to produce the output sentence.
class Seq2seqBaseline(nn.Module):
def __init__(self):
super().__init__()
# Initialize your model's parameters here. To get started, we suggest
# setting all embedding and hidden dimensions to 256, using encoder and
# decoder LSTMs with 2 layers, and using a dropout rate of 0.5.
# Implementation tip: To create a bidirectional LSTM, you don't need to
# create two LSTM networks. Instead use nn.LSTM(..., bidirectional=True).
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
def encode(self, source):
"""Encode the source batch using a bidirectional LSTM encoder.
Args:
source: An integer tensor with shape (max_source_sequence_length,
batch_size) containing subword indices for the source sentences.
Returns:
A tuple with three elements:
encoder_output: The output of the bidirectional LSTM with shape
(max_source_sequence_length, batch_size, 2 * hidden_size).
encoder_mask: A boolean tensor with shape (max_source_sequence_length,
batch_size) indicating which encoder outputs correspond to padding
tokens. Its elements should be True at positions corresponding to
padding tokens and False elsewhere.
encoder_hidden: The final hidden states of the bidirectional LSTM (after
a suitable projection) that will be used to initialize the decoder.
This should be a pair of tensors (h_n, c_n), each with shape
(num_layers, batch_size, hidden_size). Note that the hidden state
returned by the LSTM cannot be used directly. Its initial dimension is
twice the required size because it contains state from two directions.
The first two return values are not required for the baseline model and will
only be used later in the attention model. If desired, they can be replaced
with None for the initial implementation.
"""
# Implementation tip: consider using packed sequences to more easily work
# with the variable-length sequences represented by the source tensor.
# See https://pytorch.org/docs/stable/nn.html#torch.nn.utils.rnn.PackedSequence.
# Implementation tip: there are many simple ways to combine the forward
# and backward portions of the final hidden state, e.g. addition, averaging,
# or a linear transformation of the appropriate size. Any of these
# should let you reach the required performance.
# Compute a tensor containing the length of each source sequence.
lengths = torch.sum(source != pad_id, axis=0)
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
def decode(self, decoder_input, initial_hidden, encoder_output, encoder_mask):
"""Run the decoder LSTM starting from an initial hidden state.
The third and fourth arguments are not used in the baseline model, but are
included for compatibility with the attention model in the next section.
Args:
decoder_input: An integer tensor with shape (max_decoder_sequence_length,
batch_size) containing the subword indices for the decoder input. During
evaluation, where decoding proceeds one step at a time, the initial
dimension should be 1.
initial_hidden: A pair of tensors (h_0, c_0) representing the initial
state of the decoder, each with shape (num_layers, batch_size,
hidden_size).
encoder_output: The output of the encoder with shape
(max_source_sequence_length, batch_size, 2 * hidden_size).
encoder_mask: The output mask from the encoder with shape
(max_source_sequence_length, batch_size). Encoder outputs at positions
with a True value correspond to padding tokens and should be ignored.
Returns:
A tuple with three elements:
logits: A tensor with shape (max_decoder_sequence_length, batch_size,
vocab_size) containing unnormalized scores for the next-word
predictions at each position.
decoder_hidden: A pair of tensors (h_n, c_n) with the same shape as
initial_hidden representing the updated decoder state after processing
the decoder input.
attention_weights: This will be implemented later in the attention
model, but in order to maintain compatible type signatures, we also
include it here. This can be None or any other placeholder value.
"""
# These arguments are not used in the baseline model.
del encoder_output
del encoder_mask
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
def compute_loss(self, source, target):
"""Run the model on the source and compute the loss on the target.
Args:
source: An integer tensor with shape (max_source_sequence_length,
batch_size) containing subword indices for the source sentences.
target: An integer tensor with shape (max_target_sequence_length,
batch_size) containing subword indices for the target sentences.
Returns:
A scalar float tensor representing cross-entropy loss on the current batch.
"""
# Implementation tip: don't feed the target tensor directly to the decoder.
# To see why, note that for a target sequence like <s> A B C </s>, you would
# want to run the decoder on the prefix <s> A B C and have it predict the
# suffix A B C </s>.
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
# We define the following functions for training. This code will run as provided, but you are welcome to modify the training loop to adjust the optimizer settings, add learning rate decay, etc.
def train(model, num_epochs, batch_size, model_file):
"""Train the model and save its best checkpoint.
Model performance across epochs is evaluated using token-level accuracy on the
validation set. The best checkpoint obtained during training will be stored on
disk and loaded back into the model at the end of training.
"""
optimizer = torch.optim.Adam(model.parameters())
best_accuracy = 0.0
for epoch in tqdm.notebook.trange(num_epochs, desc="training", unit="epoch"):
with tqdm.notebook.tqdm(
make_batch_iterator(training_data, batch_size, shuffle=True),
desc="epoch {}".format(epoch + 1),
unit="batch",
total=math.ceil(len(training_data) / batch_size),
) as batch_iterator:
model.train()
total_loss = 0.0
for i, (source, target) in enumerate(batch_iterator, start=1):
optimizer.zero_grad()
loss = model.compute_loss(source, target)
total_loss += loss.item()
loss.backward()
optimizer.step()
batch_iterator.set_postfix(mean_loss=total_loss / i)
validation_perplexity, validation_accuracy = evaluate_next_token(
model, validation_data
)
batch_iterator.set_postfix(
mean_loss=total_loss / i,
validation_perplexity=validation_perplexity,
validation_token_accuracy=validation_accuracy,
)
if validation_accuracy > best_accuracy:
print(
"Obtained a new best validation accuracy of {:.2f}, saving model "
"checkpoint to {}...".format(validation_accuracy, model_file)
)
torch.save(model.state_dict(), model_file)
best_accuracy = validation_accuracy
print("Reloading best model checkpoint from {}...".format(model_file))
model.load_state_dict(torch.load(model_file))
def evaluate_next_token(model, dataset, batch_size=64):
"""Compute token-level perplexity and accuracy metrics.
Note that the perplexity here is over subwords, not words.
This function is used for validation set evaluation at the end of each epoch
and should not be modified.
"""
model.eval()
total_cross_entropy = 0.0
total_predictions = 0
correct_predictions = 0
with torch.no_grad():
for source, target in make_batch_iterator(dataset, batch_size):
encoder_output, encoder_mask, encoder_hidden = model.encode(source)
decoder_input, decoder_target = target[:-1], target[1:]
logits, decoder_hidden, attention_weights = model.decode(
decoder_input, encoder_hidden, encoder_output, encoder_mask
)
total_cross_entropy += F.cross_entropy(
logits.permute(1, 2, 0),
decoder_target.permute(1, 0),
ignore_index=pad_id,
reduction="sum",
).item()
total_predictions += (decoder_target != pad_id).sum().item()
correct_predictions += (
((decoder_target != pad_id) & (decoder_target == logits.argmax(2)))
.sum()
.item()
)
perplexity = math.exp(total_cross_entropy / total_predictions)
accuracy = 100 * correct_predictions / total_predictions
return perplexity, accuracy
# We can now train the baseline model.
# Since we haven't yet defined a decoding method to output an entire string, we will measure performance for now by computing perplexity and the accuracy of predicting the next token given a gold prefix of the output. A correct implementation should get a validation token accuracy above 55%. The training code will automatically save the model with the highest validation accuracy and reload that checkpoint's parameters at the end of training.
# You are welcome to adjust these parameters based on your model implementation.
num_epochs = 10
batch_size = 16
baseline_model = Seq2seqBaseline().to(device)
train(baseline_model, num_epochs, batch_size, "baseline_model.pt")
# **Download your baseline model here.** Once you have a model you are happy with, you are encouraged to download it or save it to your Google Drive in case your session disconnects. The best baseline model has been saved to `baseline_model.pt` in the local filesystem. You will need a trained model while implementing inference below and to generate your final predictions. To download session files from Kaggle, please click the data tab on the right side of the screen and expand the `/kaggle/working` folder
# For evaluation, we also need to be able to generate entire strings from the model. We'll first define a greedy inference procedure here. Later on, we'll implement beam search.
# A correct implementation of greedy decoding should get above 20 BLEU on the validation set.
def predict_greedy(model, sentences, max_length=100):
"""Make predictions for the given inputs using greedy inference.
Args:
model: A sequence-to-sequence model.
sentences: A list of input sentences, represented as strings.
max_length: The maximum length at which to truncate outputs in order to
avoid non-terminating inference.
Returns:
A list of predicted translations, represented as strings.
"""
# Requirement: your implementation must be batched. This means that you should
# make only one call to model.encode() at the start of the function, and make
# only one call to model.decode() per inference step.
# Implementation tip: once an EOS token has been generated, force the output
# for that example to be padding tokens in all subsequent time steps by
# adding a large positive number like 1e9 to the appropriate logits.
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
def evaluate(model, dataset, batch_size=64, method="greedy"):
assert method in {"greedy", "beam"}
source_sentences = [example.src for example in dataset]
target_sentences = [example.trg for example in dataset]
model.eval()
predictions = []
with torch.no_grad():
for start_index in range(0, len(source_sentences), batch_size):
if method == "greedy":
prediction_batch = predict_greedy(
model, source_sentences[start_index : start_index + batch_size]
)
else:
prediction_batch = predict_beam(
model, source_sentences[start_index : start_index + batch_size]
)
prediction_batch = [candidates[0] for candidates in prediction_batch]
predictions.extend(prediction_batch)
return sacrebleu.corpus_bleu(predictions, [target_sentences]).score
print(
"Baseline model validation BLEU using greedy search:",
evaluate(baseline_model, validation_data),
)
def show_predictions(model, num_examples=4, include_beam=False):
for example in validation_data[:num_examples]:
print("Input:")
print(" ", example.src)
print("Target:")
print(" ", example.trg)
print("Greedy prediction:")
print(" ", predict_greedy(model, [example.src])[0])
if include_beam:
print("Beam predictions:")
for candidate in predict_beam(model, [example.src])[0]:
print(" ", candidate)
print()
print("Baseline model sample predictions:")
print()
show_predictions(baseline_model)
# ## Sequence-to-sequence model with attention
# Next, we extend the baseline model to include an attention mechanism in the decoder. This circumvents the need to store all information about the source sentence in a fixed-size representation, and should substantially improve performance and convergence time.
# Your implementation should use bilinear attention, where the attention distribution over the encoder outputs $e_1, \dots, e_n$ given a decoder LSTM output $d$ is obtained via a softmax of the dot products after a suitable projection to get them to the same size: $w_i \propto \exp ( d^\top W e_i )$. The unnormalized attention logits for encoder outputs corresponding to padding tokens should be offset with a large negative value to ensure that the corresponding attention weights are $0$.
# After computing the attention distribution, take a weighted sum of the projected encoder outputs to obtain the attention context $c = \sum_i w_i We_i$, and add this to the decoder output $d$ to obtain the final representation to be passed to the vocabulary projection layer.
class Seq2seqAttention(Seq2seqBaseline):
def __init__(self):
super().__init__()
# Initialize any additional parameters needed for this model that are not
# already included in the baseline model.
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
def decode(self, decoder_input, initial_hidden, encoder_output, encoder_mask):
"""Run the decoder LSTM starting from an initial hidden state.
The third and fourth arguments are not used in the baseline model, but are
included for compatibility with the attention model in the next section.
Args:
decoder_input: An integer tensor with shape (max_decoder_sequence_length,
batch_size) containing the subword indices for the decoder input. During
evaluation, where decoding proceeds one step at a time, the initial
dimension should be 1.
initial_hidden: A pair of tensors (h_0, c_0) representing the initial
state of the decoder, each with shape (num_layers, batch_size,
hidden_size).
encoder_output: The output of the encoder with shape
(max_source_sequence_length, batch_size, 2 * hidden_size).
encoder_mask: The output mask from the encoder with shape
(max_source_sequence_length, batch_size). Encoder outputs at positions
with a True value correspond to padding tokens and should be ignored.
Returns:
A tuple with three elements:
logits: A tensor with shape (max_decoder_sequence_length, batch_size,
vocab_size) containing unnormalized scores for the next-word
predictions at each position.
decoder_hidden: A pair of tensors (h_n, c_n) with the same shape as
initial_hidden representing the updated decoder state after processing
the decoder input.
attention_weights: A tensor with shape (max_decoder_sequence_length,
batch_size, max_source_sequence_length) representing the normalized
attention weights. This should sum to 1 along the last dimension.
"""
# Implementation tip: use a large negative number like -1e9 instead of
# float("-inf") when masking logits to avoid numerical issues.
# Implementation tip: the function torch.einsum may be useful here.
# See https://rockt.github.io/2018/04/30/einsum for a tutorial.
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
# As before, we can train an attention model using the provided training code.
# A correct implementation should get a validation token accuracy above 64 and a validation BLEU above 36 with greedy search.
# You are welcome to adjust these parameters based on your model implementation.
num_epochs = 10
batch_size = 16
attention_model = Seq2seqAttention().to(device)
train(attention_model, num_epochs, batch_size, "attention_model.pt")
print(
"Attention model validation BLEU using greedy search:",
evaluate(attention_model, validation_data),
)
# **Download your attention model here.** Once you have a model you are happy with, you are encouraged to download it or save it to your Google Drive in case your session disconnects. The best attention model has been saved to `attention_model.pt` in the local filesystem. You will need a trained model while implementing beam search below and to generate your final predictions.
print(
"Attention model validation BLEU using greedy search:",
evaluate(attention_model, validation_data),
)
print()
print("Attention model sample predictions:")
print()
show_predictions(attention_model)
# ## Beam Search
# Now it's time to implement beam search.
# Similar to greedy search, beam search generates one token at a time. However, rather than keeping only the single best hypothesis, we instead keep the top $k$ candidates at each time step. This is accomplished by computing the set of next-token extensions for each item on the beam and finding the top $k$ across all candidates according to total log-probability.
# Candidates that are finished should stay on the beam through the end of inference. The search process concludes once all $k$ items on the beam are complete.
# With beam search, you should get an improvement of at least 0.5 BLEU over greedy search, and should reach above 21 BLEU without attention and above 37 BLEU with attention.
# **Tips:**
# 1) A good general strategy when doing complex code like this is to carefully annotate each line with a comment saying what each dimension represents.
# 2) You should only need one call to topk per step. You do not need to have a topk just over vocabulary first, you can directly go from vocab_size*beam_size to beam_size items.
# 3) Be sure you are correctly keeping track of which beam item a candidate is selected from and updating the beam states, such as LSTM hidden state, accordingly. A single state from the previous time step may need to be used for multiple new beam items or not at all. This includes all state associated with a beam, including all past tokens output by the beam and any extra tensors such as ones remembering when a beam is finished.
# 4) Pay attention to how you interleave things when using a single dimension to represent multiple things. It will make a difference when you start reshaping to separate them out. It may be easier to start with everything separate, then temporarily combine as needed.
# 5) For efficiency, we suggest that you implement all beam manipulations using batched PyTorch computations rather than Python for-loops.
# 6) Once an EOS token has been generated, force the output for that candidate to be padding tokens in all subsequent time steps by adding a large positive number like 1e9 to the appropriate logits. This will ensure that the candidate stays on the beam, as its probability will be very close to 1 and its score will effectively remain the same as when it was first completed. All other (invalid) token continuations will have extremely low log probability and will not make it onto the beam.
# 7) While you are encouraged to keep your tensor dimensions constant for simplicity (aside from the sequence length), some special care will need to be taken on the first iteration to ensure that your beam doesn't fill up with k identical copies of the same candidate.
#
def predict_beam(model, sentences, k=5, max_length=100):
"""Make predictions for the given inputs using beam search.
Args:
model: A sequence-to-sequence model.
sentences: A list of input sentences, represented as strings.
k: The size of the beam.
max_length: The maximum length at which to truncate outputs in order to
avoid non-terminating inference.
Returns:
A list of beam predictions. Each element in the list should be a list of k
strings corresponding to the top k predictions for the corresponding input,
sorted in descending order by score.
"""
# Requirement: your implementation must be batched. This means that you should
# make only one call to model.encode() at the start of the function, and make
# only one call to model.decode() per inference step.
# Does top-k return relative ordering, if not how to return at end of method?
# EOS candidate getting knocked.
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
print(
"Baseline model validation BLEU using beam search:",
evaluate(baseline_model, validation_data, method="beam"),
)
print()
print("Baseline model sample predictions:")
print()
show_predictions(baseline_model, include_beam=True)
print(
"Attention model validation BLEU using beam search:",
evaluate(attention_model, validation_data, method="beam"),
)
print()
print("Attention model sample predictions:")
print()
show_predictions(attention_model, include_beam=True)
# ## Attention visualization: 1-Page Analysis
# Once you have everything working in the sections above, add some code here to visualize the decoder attention learned by the attention model using `matplotlib`.
# You may visualize decoder attention on gold source-target pairs from the validation data. You do not need to run any inference.
# For this section, you will submit a write-up interpreting attention maps generated by your model. Your write-up should be 1-page maximum in length and should be submitted in PDF format. You may use any editor you like, but we recommend using LaTeX and working in an environment like Overleaf. For full credit, your write-up should include:
# * A figure with attention map plots for 4 sentence pairs from the validation set (the method `imshow`, or equivalent, will likely be useful here). We encourage you to look through more maps to aid your analysis, but please only include 4 representative plots in the figure.
# * A brief discussion over trends you discover in the plots. Do the maps line up with your intuition, are there any surprising alignments? Are there any many-to-one or many-to-many alignments, or mainly one-to-one? Using a tool like Google Translate on substrings may help give some insight into this.
# When you submit the file, please name it report.pdf.
# You may find the following annotated heatmap tutorial helpful:
# https://matplotlib.org/3.1.3/gallery/images_contours_and_fields/image_annotated_heatmap.html.
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
# \* Describe your findings in this text cell. \*
# ## Submission
# Turn in the following files on Gradescope:
# * proj_2.ipynb (this file; please rename to match)
# * predictions.json (the predictions file generated by running the cell below)
# * report.pdf
# Be sure to check the output of the autograder after it runs. It should confirm that no files are missing and that the output files have the correct format.
# The code below will generate the required predictions file. **Note** that it is designed to create the file even if some required elements are missing so that you can submit for partial credit. If you want full credit, you should check the output to make sure there are no warnings indicating missing portions.
# Run this cell to generate the predictions.json file required for submission.
def get_raw_predictions(model, dataset, method, batch_size=64):
assert method in {"greedy", "beam"}
source_sentences = [example.src for example in dataset]
target_sentences = [example.trg for example in dataset]
model.eval()
predictions = []
with torch.no_grad():
for start_index in range(0, len(source_sentences), batch_size):
if method == "greedy":
prediction_batch = predict_greedy(
model, source_sentences[start_index : start_index + batch_size]
)
else:
prediction_batch = predict_beam(
model, source_sentences[start_index : start_index + batch_size]
)
predictions.extend(prediction_batch)
return predictions
def generate_predictions_file_for_submission(filepath):
models = {"baseline": baseline_model, "attention": attention_model}
datasets = {"validation": validation_data, "test": test_data}
methods = ["greedy", "beam"]
predictions = {}
for model_name, model in models.items():
for dataset_name, dataset in datasets.items():
for method in methods:
print(
"Getting predictions for {} model on {} set using {} "
"search...".format(model_name, dataset_name, method)
)
if model_name not in predictions:
predictions[model_name] = {}
if dataset_name not in predictions[model_name]:
predictions[model_name][dataset_name] = {}
try:
predictions[model_name][dataset_name][method] = get_raw_predictions(
model, dataset, method
)
except:
print(
"!!! WARNING: An exception was raised, setting predictions to None !!!"
)
predictions[model_name][dataset_name][method] = None
print("Writing predictions to {}...".format(filepath))
with open(filepath, "w") as outfile:
json.dump(predictions, outfile, indent=2)
print("Finished writing predictions to {}.".format(filepath))
generate_predictions_file_for_submission("predictions.json")
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0087/597/87597153.ipynb | null | null | [{"Id": 87597153, "ScriptId": 24604634, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 9564005, "CreationDate": "02/11/2022 21:51:40", "VersionNumber": 1.0, "Title": "cs288-hw2b-public", "EvaluationDate": "02/11/2022", "IsChange": false, "TotalLines": 733.0, "LinesInsertedFromPrevious": 0.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 733.0, "LinesInsertedFromFork": 0.0, "LinesDeletedFromFork": 0.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 733.0, "TotalVotes": 0}] | null | null | null | null | # # HW2B: Neural Machine Translation
# In this project, you will build a neural machine translation system using modern techniques for sequence-to-sequence modeling. You will first implement a baseline encoder-decoder architecture, then improve upon the baseline by adding an attention mechanism and implementing beam search. The end result will be a fully functional translation system capable of translating simple German sentences into English.
# ## Setup
# First we install and import the required dependencies. These include:
# * `torch` for modeling and training
# * `torchtext` for data collection
# * `sentencepiece` for subword tokenization
# * `sacrebleu` for BLEU score evaluation
# Standard library imports
import json
import math
import random
import pdb
# Third party imports
import matplotlib.pyplot as plt
import numpy as np
import sacrebleu
import sentencepiece
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchtext
import tqdm.notebook
# Before proceeding, let's verify that we're connected to a GPU runtime and that `torch` can detect the GPU.
# We'll define a variable `device` here to use throughout the code so that we can easily change to run on CPU for debugging.
assert torch.cuda.is_available()
device = torch.device("cuda")
print("Using device:", device)
# ## Data
# The data for this assignment comes from the [Multi30K dataset](https://arxiv.org/abs/1605.00459), which contains English and German captions for images from Flickr. We can download and unpack it using `torchtext`. We use the Multi30K dataset because it is simpler than standard translation benchmark datasets and allows for models to be trained and evaluated in a matter of minutes rather than days.
# We will be translating from German to English in this assignment, but the same techniques apply equally well to any language pair.
#
extensions = [".de", ".en"]
source_field = torchtext.data.Field(tokenize=lambda x: x)
target_field = torchtext.data.Field(tokenize=lambda x: x)
training_data, validation_data, test_data = torchtext.datasets.Multi30k.splits(
extensions, [source_field, target_field], root="."
)
# Now that we have the data, let's see how large each split is and look at a few examples.
print("Number of training examples:", len(training_data))
print("Number of validation examples:", len(validation_data))
print("Number of test examples:", len(test_data))
print()
for example in training_data[:10]:
print(example.src)
print(example.trg)
print()
# ## Vocabulary
# We can use `sentencepiece` to create a joint German-English subword vocabulary from the training corpus. Because the number of training examples is small, we choose a smaller vocabulary size than would be used for large-scale NMT.
args = {
"pad_id": 0,
"bos_id": 1,
"eos_id": 2,
"unk_id": 3,
"input": "multi30k/train.de,multi30k/train.en",
"vocab_size": 8000,
"model_prefix": "multi30k",
}
combined_args = " ".join("--{}={}".format(key, value) for key, value in args.items())
sentencepiece.SentencePieceTrainer.Train(combined_args)
# This creates two files: `multi30k.model` and `multi30k.vocab`. The first is a binary file containing the relevant data for the vocabulary. The second is a human-readable listing of each subword and its associated score.
# We can preview the contents of the vocabulary by looking at the first few rows from the human-readable file.
# As we can see, the vocabulary consists of four special tokens (`` for padding, `` for beginning of sentence (BOS), `` for end of sentence (EOS), `` for unknown) and a mixture of German and English words and subwords. In order to ensure reversability, word boundaries are encoded with a special unicode character "▁" (U+2581).
# To use the vocabulary, we first need to load it from the binary file produced above.
vocab = sentencepiece.SentencePieceProcessor()
vocab.Load("multi30k.model")
# The vocabulary object includes a number of methods for working with full sequences or individual pieces. We explore the most relevant ones below. A complete interface can be found on [GitHub](https://github.com/google/sentencepiece/tree/master/python#usage) for reference.
print("Vocabulary size:", vocab.GetPieceSize())
print()
for example in training_data[:3]:
sentence = example.trg
pieces = vocab.EncodeAsPieces(sentence)
indices = vocab.EncodeAsIds(sentence)
print(sentence)
print(pieces)
print(vocab.DecodePieces(pieces))
print(indices)
print(vocab.DecodeIds(indices))
print()
piece = vocab.EncodeAsPieces("the")[0]
index = vocab.PieceToId(piece)
print(piece)
print(index)
print(vocab.IdToPiece(index))
# We define some constants here for the first three special tokens that you may find useful in the following sections.
pad_id = vocab.PieceToId("<pad>")
bos_id = vocab.PieceToId("<s>")
eos_id = vocab.PieceToId("</s>")
# Note that these tokens will be stripped from the output when converting from word pieces to text. This may be helpful when implementing greedy search and beam search.
sentence = training_data[0].trg
indices = vocab.EncodeAsIds(sentence)
indices_augmented = [bos_id] + indices + [eos_id, pad_id, pad_id, pad_id]
print(vocab.DecodeIds(indices))
print(vocab.DecodeIds(indices_augmented))
print(vocab.DecodeIds(indices) == vocab.DecodeIds(indices_augmented))
# ## Baseline sequence-to-sequence model
# With our data and vocabulary loaded, we're now ready to build a baseline sequence-to-sequence model. Later on we'll add an attention mechanism to the model.
# Let's begin by defining a batch iterator for the training data. Given a dataset and a batch size, it will iterate over the dataset and yield pairs of tensors containing the subword indices for the source and target sentences in the batch, respectively. Fill in `make_batch` below.
def make_batch(sentences):
"""Convert a list of sentences into a batch of subword indices.
Args:
sentences: A list of sentences, each of which is a string.
Returns:
A LongTensor of size (max_sequence_length, batch_size) containing the
subword indices for the sentences, where max_sequence_length is the length
of the longest sentence as encoded by the subword vocabulary and batch_size
is the number of sentences in the batch. A beginning-of-sentence token
should be included before each sequence, and an end-of-sentence token should
be included after each sequence. Empty slots at the end of shorter sequences
should be filled with padding tokens. The tensor should be located on the
device defined at the beginning of the notebook.
"""
# Implementation tip: You can use the nn.utils.rnn.pad_sequence utility
# function to combine a list of variable-length sequences with padding.
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
def make_batch_iterator(dataset, batch_size, shuffle=False):
"""Make a batch iterator that yields source-target pairs.
Args:
dataset: A torchtext dataset object.
batch_size: An integer batch size.
shuffle: A boolean indicating whether to shuffle the examples.
Yields:
Pairs of tensors constructed by calling the make_batch function on the
source and target sentences in the current group of examples. The max
sequence length can differ between the source and target tensor, but the
batch size will be the same. The final batch may be smaller than the given
batch size.
"""
examples = list(dataset)
if shuffle:
random.shuffle(examples)
for start_index in range(0, len(examples), batch_size):
example_batch = examples[start_index : start_index + batch_size]
source_sentences = [example.src for example in example_batch]
target_sentences = [example.trg for example in example_batch]
yield make_batch(source_sentences), make_batch(target_sentences)
test_batch = make_batch(["a test input", "a longer input than the first"])
print("Example batch tensor:")
print(test_batch)
assert test_batch.shape[1] == 2
assert test_batch[0, 0] == bos_id
assert test_batch[0, 1] == bos_id
assert test_batch[-1, 0] == pad_id
assert test_batch[-1, 1] == eos_id
# Now we will define the model itself. It should consist of a bidirectional LSTM encoder that encodes the input sentence into a fixed-size representation, and an LSTM decoder that uses this representation to produce the output sentence.
class Seq2seqBaseline(nn.Module):
def __init__(self):
super().__init__()
# Initialize your model's parameters here. To get started, we suggest
# setting all embedding and hidden dimensions to 256, using encoder and
# decoder LSTMs with 2 layers, and using a dropout rate of 0.5.
# Implementation tip: To create a bidirectional LSTM, you don't need to
# create two LSTM networks. Instead use nn.LSTM(..., bidirectional=True).
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
def encode(self, source):
"""Encode the source batch using a bidirectional LSTM encoder.
Args:
source: An integer tensor with shape (max_source_sequence_length,
batch_size) containing subword indices for the source sentences.
Returns:
A tuple with three elements:
encoder_output: The output of the bidirectional LSTM with shape
(max_source_sequence_length, batch_size, 2 * hidden_size).
encoder_mask: A boolean tensor with shape (max_source_sequence_length,
batch_size) indicating which encoder outputs correspond to padding
tokens. Its elements should be True at positions corresponding to
padding tokens and False elsewhere.
encoder_hidden: The final hidden states of the bidirectional LSTM (after
a suitable projection) that will be used to initialize the decoder.
This should be a pair of tensors (h_n, c_n), each with shape
(num_layers, batch_size, hidden_size). Note that the hidden state
returned by the LSTM cannot be used directly. Its initial dimension is
twice the required size because it contains state from two directions.
The first two return values are not required for the baseline model and will
only be used later in the attention model. If desired, they can be replaced
with None for the initial implementation.
"""
# Implementation tip: consider using packed sequences to more easily work
# with the variable-length sequences represented by the source tensor.
# See https://pytorch.org/docs/stable/nn.html#torch.nn.utils.rnn.PackedSequence.
# Implementation tip: there are many simple ways to combine the forward
# and backward portions of the final hidden state, e.g. addition, averaging,
# or a linear transformation of the appropriate size. Any of these
# should let you reach the required performance.
# Compute a tensor containing the length of each source sequence.
lengths = torch.sum(source != pad_id, axis=0)
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
def decode(self, decoder_input, initial_hidden, encoder_output, encoder_mask):
"""Run the decoder LSTM starting from an initial hidden state.
The third and fourth arguments are not used in the baseline model, but are
included for compatibility with the attention model in the next section.
Args:
decoder_input: An integer tensor with shape (max_decoder_sequence_length,
batch_size) containing the subword indices for the decoder input. During
evaluation, where decoding proceeds one step at a time, the initial
dimension should be 1.
initial_hidden: A pair of tensors (h_0, c_0) representing the initial
state of the decoder, each with shape (num_layers, batch_size,
hidden_size).
encoder_output: The output of the encoder with shape
(max_source_sequence_length, batch_size, 2 * hidden_size).
encoder_mask: The output mask from the encoder with shape
(max_source_sequence_length, batch_size). Encoder outputs at positions
with a True value correspond to padding tokens and should be ignored.
Returns:
A tuple with three elements:
logits: A tensor with shape (max_decoder_sequence_length, batch_size,
vocab_size) containing unnormalized scores for the next-word
predictions at each position.
decoder_hidden: A pair of tensors (h_n, c_n) with the same shape as
initial_hidden representing the updated decoder state after processing
the decoder input.
attention_weights: This will be implemented later in the attention
model, but in order to maintain compatible type signatures, we also
include it here. This can be None or any other placeholder value.
"""
# These arguments are not used in the baseline model.
del encoder_output
del encoder_mask
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
def compute_loss(self, source, target):
"""Run the model on the source and compute the loss on the target.
Args:
source: An integer tensor with shape (max_source_sequence_length,
batch_size) containing subword indices for the source sentences.
target: An integer tensor with shape (max_target_sequence_length,
batch_size) containing subword indices for the target sentences.
Returns:
A scalar float tensor representing cross-entropy loss on the current batch.
"""
# Implementation tip: don't feed the target tensor directly to the decoder.
# To see why, note that for a target sequence like <s> A B C </s>, you would
# want to run the decoder on the prefix <s> A B C and have it predict the
# suffix A B C </s>.
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
# We define the following functions for training. This code will run as provided, but you are welcome to modify the training loop to adjust the optimizer settings, add learning rate decay, etc.
def train(model, num_epochs, batch_size, model_file):
"""Train the model and save its best checkpoint.
Model performance across epochs is evaluated using token-level accuracy on the
validation set. The best checkpoint obtained during training will be stored on
disk and loaded back into the model at the end of training.
"""
optimizer = torch.optim.Adam(model.parameters())
best_accuracy = 0.0
for epoch in tqdm.notebook.trange(num_epochs, desc="training", unit="epoch"):
with tqdm.notebook.tqdm(
make_batch_iterator(training_data, batch_size, shuffle=True),
desc="epoch {}".format(epoch + 1),
unit="batch",
total=math.ceil(len(training_data) / batch_size),
) as batch_iterator:
model.train()
total_loss = 0.0
for i, (source, target) in enumerate(batch_iterator, start=1):
optimizer.zero_grad()
loss = model.compute_loss(source, target)
total_loss += loss.item()
loss.backward()
optimizer.step()
batch_iterator.set_postfix(mean_loss=total_loss / i)
validation_perplexity, validation_accuracy = evaluate_next_token(
model, validation_data
)
batch_iterator.set_postfix(
mean_loss=total_loss / i,
validation_perplexity=validation_perplexity,
validation_token_accuracy=validation_accuracy,
)
if validation_accuracy > best_accuracy:
print(
"Obtained a new best validation accuracy of {:.2f}, saving model "
"checkpoint to {}...".format(validation_accuracy, model_file)
)
torch.save(model.state_dict(), model_file)
best_accuracy = validation_accuracy
print("Reloading best model checkpoint from {}...".format(model_file))
model.load_state_dict(torch.load(model_file))
def evaluate_next_token(model, dataset, batch_size=64):
"""Compute token-level perplexity and accuracy metrics.
Note that the perplexity here is over subwords, not words.
This function is used for validation set evaluation at the end of each epoch
and should not be modified.
"""
model.eval()
total_cross_entropy = 0.0
total_predictions = 0
correct_predictions = 0
with torch.no_grad():
for source, target in make_batch_iterator(dataset, batch_size):
encoder_output, encoder_mask, encoder_hidden = model.encode(source)
decoder_input, decoder_target = target[:-1], target[1:]
logits, decoder_hidden, attention_weights = model.decode(
decoder_input, encoder_hidden, encoder_output, encoder_mask
)
total_cross_entropy += F.cross_entropy(
logits.permute(1, 2, 0),
decoder_target.permute(1, 0),
ignore_index=pad_id,
reduction="sum",
).item()
total_predictions += (decoder_target != pad_id).sum().item()
correct_predictions += (
((decoder_target != pad_id) & (decoder_target == logits.argmax(2)))
.sum()
.item()
)
perplexity = math.exp(total_cross_entropy / total_predictions)
accuracy = 100 * correct_predictions / total_predictions
return perplexity, accuracy
# We can now train the baseline model.
# Since we haven't yet defined a decoding method to output an entire string, we will measure performance for now by computing perplexity and the accuracy of predicting the next token given a gold prefix of the output. A correct implementation should get a validation token accuracy above 55%. The training code will automatically save the model with the highest validation accuracy and reload that checkpoint's parameters at the end of training.
# You are welcome to adjust these parameters based on your model implementation.
num_epochs = 10
batch_size = 16
baseline_model = Seq2seqBaseline().to(device)
train(baseline_model, num_epochs, batch_size, "baseline_model.pt")
# **Download your baseline model here.** Once you have a model you are happy with, you are encouraged to download it or save it to your Google Drive in case your session disconnects. The best baseline model has been saved to `baseline_model.pt` in the local filesystem. You will need a trained model while implementing inference below and to generate your final predictions. To download session files from Kaggle, please click the data tab on the right side of the screen and expand the `/kaggle/working` folder
# For evaluation, we also need to be able to generate entire strings from the model. We'll first define a greedy inference procedure here. Later on, we'll implement beam search.
# A correct implementation of greedy decoding should get above 20 BLEU on the validation set.
def predict_greedy(model, sentences, max_length=100):
"""Make predictions for the given inputs using greedy inference.
Args:
model: A sequence-to-sequence model.
sentences: A list of input sentences, represented as strings.
max_length: The maximum length at which to truncate outputs in order to
avoid non-terminating inference.
Returns:
A list of predicted translations, represented as strings.
"""
# Requirement: your implementation must be batched. This means that you should
# make only one call to model.encode() at the start of the function, and make
# only one call to model.decode() per inference step.
# Implementation tip: once an EOS token has been generated, force the output
# for that example to be padding tokens in all subsequent time steps by
# adding a large positive number like 1e9 to the appropriate logits.
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
def evaluate(model, dataset, batch_size=64, method="greedy"):
assert method in {"greedy", "beam"}
source_sentences = [example.src for example in dataset]
target_sentences = [example.trg for example in dataset]
model.eval()
predictions = []
with torch.no_grad():
for start_index in range(0, len(source_sentences), batch_size):
if method == "greedy":
prediction_batch = predict_greedy(
model, source_sentences[start_index : start_index + batch_size]
)
else:
prediction_batch = predict_beam(
model, source_sentences[start_index : start_index + batch_size]
)
prediction_batch = [candidates[0] for candidates in prediction_batch]
predictions.extend(prediction_batch)
return sacrebleu.corpus_bleu(predictions, [target_sentences]).score
print(
"Baseline model validation BLEU using greedy search:",
evaluate(baseline_model, validation_data),
)
def show_predictions(model, num_examples=4, include_beam=False):
for example in validation_data[:num_examples]:
print("Input:")
print(" ", example.src)
print("Target:")
print(" ", example.trg)
print("Greedy prediction:")
print(" ", predict_greedy(model, [example.src])[0])
if include_beam:
print("Beam predictions:")
for candidate in predict_beam(model, [example.src])[0]:
print(" ", candidate)
print()
print("Baseline model sample predictions:")
print()
show_predictions(baseline_model)
# ## Sequence-to-sequence model with attention
# Next, we extend the baseline model to include an attention mechanism in the decoder. This circumvents the need to store all information about the source sentence in a fixed-size representation, and should substantially improve performance and convergence time.
# Your implementation should use bilinear attention, where the attention distribution over the encoder outputs $e_1, \dots, e_n$ given a decoder LSTM output $d$ is obtained via a softmax of the dot products after a suitable projection to get them to the same size: $w_i \propto \exp ( d^\top W e_i )$. The unnormalized attention logits for encoder outputs corresponding to padding tokens should be offset with a large negative value to ensure that the corresponding attention weights are $0$.
# After computing the attention distribution, take a weighted sum of the projected encoder outputs to obtain the attention context $c = \sum_i w_i We_i$, and add this to the decoder output $d$ to obtain the final representation to be passed to the vocabulary projection layer.
class Seq2seqAttention(Seq2seqBaseline):
def __init__(self):
super().__init__()
# Initialize any additional parameters needed for this model that are not
# already included in the baseline model.
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
def decode(self, decoder_input, initial_hidden, encoder_output, encoder_mask):
"""Run the decoder LSTM starting from an initial hidden state.
The third and fourth arguments are not used in the baseline model, but are
included for compatibility with the attention model in the next section.
Args:
decoder_input: An integer tensor with shape (max_decoder_sequence_length,
batch_size) containing the subword indices for the decoder input. During
evaluation, where decoding proceeds one step at a time, the initial
dimension should be 1.
initial_hidden: A pair of tensors (h_0, c_0) representing the initial
state of the decoder, each with shape (num_layers, batch_size,
hidden_size).
encoder_output: The output of the encoder with shape
(max_source_sequence_length, batch_size, 2 * hidden_size).
encoder_mask: The output mask from the encoder with shape
(max_source_sequence_length, batch_size). Encoder outputs at positions
with a True value correspond to padding tokens and should be ignored.
Returns:
A tuple with three elements:
logits: A tensor with shape (max_decoder_sequence_length, batch_size,
vocab_size) containing unnormalized scores for the next-word
predictions at each position.
decoder_hidden: A pair of tensors (h_n, c_n) with the same shape as
initial_hidden representing the updated decoder state after processing
the decoder input.
attention_weights: A tensor with shape (max_decoder_sequence_length,
batch_size, max_source_sequence_length) representing the normalized
attention weights. This should sum to 1 along the last dimension.
"""
# Implementation tip: use a large negative number like -1e9 instead of
# float("-inf") when masking logits to avoid numerical issues.
# Implementation tip: the function torch.einsum may be useful here.
# See https://rockt.github.io/2018/04/30/einsum for a tutorial.
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
# As before, we can train an attention model using the provided training code.
# A correct implementation should get a validation token accuracy above 64 and a validation BLEU above 36 with greedy search.
# You are welcome to adjust these parameters based on your model implementation.
num_epochs = 10
batch_size = 16
attention_model = Seq2seqAttention().to(device)
train(attention_model, num_epochs, batch_size, "attention_model.pt")
print(
"Attention model validation BLEU using greedy search:",
evaluate(attention_model, validation_data),
)
# **Download your attention model here.** Once you have a model you are happy with, you are encouraged to download it or save it to your Google Drive in case your session disconnects. The best attention model has been saved to `attention_model.pt` in the local filesystem. You will need a trained model while implementing beam search below and to generate your final predictions.
print(
"Attention model validation BLEU using greedy search:",
evaluate(attention_model, validation_data),
)
print()
print("Attention model sample predictions:")
print()
show_predictions(attention_model)
# ## Beam Search
# Now it's time to implement beam search.
# Similar to greedy search, beam search generates one token at a time. However, rather than keeping only the single best hypothesis, we instead keep the top $k$ candidates at each time step. This is accomplished by computing the set of next-token extensions for each item on the beam and finding the top $k$ across all candidates according to total log-probability.
# Candidates that are finished should stay on the beam through the end of inference. The search process concludes once all $k$ items on the beam are complete.
# With beam search, you should get an improvement of at least 0.5 BLEU over greedy search, and should reach above 21 BLEU without attention and above 37 BLEU with attention.
# **Tips:**
# 1) A good general strategy when doing complex code like this is to carefully annotate each line with a comment saying what each dimension represents.
# 2) You should only need one call to topk per step. You do not need to have a topk just over vocabulary first, you can directly go from vocab_size*beam_size to beam_size items.
# 3) Be sure you are correctly keeping track of which beam item a candidate is selected from and updating the beam states, such as LSTM hidden state, accordingly. A single state from the previous time step may need to be used for multiple new beam items or not at all. This includes all state associated with a beam, including all past tokens output by the beam and any extra tensors such as ones remembering when a beam is finished.
# 4) Pay attention to how you interleave things when using a single dimension to represent multiple things. It will make a difference when you start reshaping to separate them out. It may be easier to start with everything separate, then temporarily combine as needed.
# 5) For efficiency, we suggest that you implement all beam manipulations using batched PyTorch computations rather than Python for-loops.
# 6) Once an EOS token has been generated, force the output for that candidate to be padding tokens in all subsequent time steps by adding a large positive number like 1e9 to the appropriate logits. This will ensure that the candidate stays on the beam, as its probability will be very close to 1 and its score will effectively remain the same as when it was first completed. All other (invalid) token continuations will have extremely low log probability and will not make it onto the beam.
# 7) While you are encouraged to keep your tensor dimensions constant for simplicity (aside from the sequence length), some special care will need to be taken on the first iteration to ensure that your beam doesn't fill up with k identical copies of the same candidate.
#
def predict_beam(model, sentences, k=5, max_length=100):
"""Make predictions for the given inputs using beam search.
Args:
model: A sequence-to-sequence model.
sentences: A list of input sentences, represented as strings.
k: The size of the beam.
max_length: The maximum length at which to truncate outputs in order to
avoid non-terminating inference.
Returns:
A list of beam predictions. Each element in the list should be a list of k
strings corresponding to the top k predictions for the corresponding input,
sorted in descending order by score.
"""
# Requirement: your implementation must be batched. This means that you should
# make only one call to model.encode() at the start of the function, and make
# only one call to model.decode() per inference step.
# Does top-k return relative ordering, if not how to return at end of method?
# EOS candidate getting knocked.
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
print(
"Baseline model validation BLEU using beam search:",
evaluate(baseline_model, validation_data, method="beam"),
)
print()
print("Baseline model sample predictions:")
print()
show_predictions(baseline_model, include_beam=True)
print(
"Attention model validation BLEU using beam search:",
evaluate(attention_model, validation_data, method="beam"),
)
print()
print("Attention model sample predictions:")
print()
show_predictions(attention_model, include_beam=True)
# ## Attention visualization: 1-Page Analysis
# Once you have everything working in the sections above, add some code here to visualize the decoder attention learned by the attention model using `matplotlib`.
# You may visualize decoder attention on gold source-target pairs from the validation data. You do not need to run any inference.
# For this section, you will submit a write-up interpreting attention maps generated by your model. Your write-up should be 1-page maximum in length and should be submitted in PDF format. You may use any editor you like, but we recommend using LaTeX and working in an environment like Overleaf. For full credit, your write-up should include:
# * A figure with attention map plots for 4 sentence pairs from the validation set (the method `imshow`, or equivalent, will likely be useful here). We encourage you to look through more maps to aid your analysis, but please only include 4 representative plots in the figure.
# * A brief discussion over trends you discover in the plots. Do the maps line up with your intuition, are there any surprising alignments? Are there any many-to-one or many-to-many alignments, or mainly one-to-one? Using a tool like Google Translate on substrings may help give some insight into this.
# When you submit the file, please name it report.pdf.
# You may find the following annotated heatmap tutorial helpful:
# https://matplotlib.org/3.1.3/gallery/images_contours_and_fields/image_annotated_heatmap.html.
# YOUR CODE HERE
...
# BEGIN SOLUTION
# END SOLUTION
# \* Describe your findings in this text cell. \*
# ## Submission
# Turn in the following files on Gradescope:
# * proj_2.ipynb (this file; please rename to match)
# * predictions.json (the predictions file generated by running the cell below)
# * report.pdf
# Be sure to check the output of the autograder after it runs. It should confirm that no files are missing and that the output files have the correct format.
# The code below will generate the required predictions file. **Note** that it is designed to create the file even if some required elements are missing so that you can submit for partial credit. If you want full credit, you should check the output to make sure there are no warnings indicating missing portions.
# Run this cell to generate the predictions.json file required for submission.
def get_raw_predictions(model, dataset, method, batch_size=64):
assert method in {"greedy", "beam"}
source_sentences = [example.src for example in dataset]
target_sentences = [example.trg for example in dataset]
model.eval()
predictions = []
with torch.no_grad():
for start_index in range(0, len(source_sentences), batch_size):
if method == "greedy":
prediction_batch = predict_greedy(
model, source_sentences[start_index : start_index + batch_size]
)
else:
prediction_batch = predict_beam(
model, source_sentences[start_index : start_index + batch_size]
)
predictions.extend(prediction_batch)
return predictions
def generate_predictions_file_for_submission(filepath):
models = {"baseline": baseline_model, "attention": attention_model}
datasets = {"validation": validation_data, "test": test_data}
methods = ["greedy", "beam"]
predictions = {}
for model_name, model in models.items():
for dataset_name, dataset in datasets.items():
for method in methods:
print(
"Getting predictions for {} model on {} set using {} "
"search...".format(model_name, dataset_name, method)
)
if model_name not in predictions:
predictions[model_name] = {}
if dataset_name not in predictions[model_name]:
predictions[model_name][dataset_name] = {}
try:
predictions[model_name][dataset_name][method] = get_raw_predictions(
model, dataset, method
)
except:
print(
"!!! WARNING: An exception was raised, setting predictions to None !!!"
)
predictions[model_name][dataset_name][method] = None
print("Writing predictions to {}...".format(filepath))
with open(filepath, "w") as outfile:
json.dump(predictions, outfile, indent=2)
print("Finished writing predictions to {}.".format(filepath))
generate_predictions_file_for_submission("predictions.json")
| false | 0 | 8,157 | 0 | 6 | 8,157 |
||
87030978 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import datatable as dt # Fast data reading/writing
import seaborn as sns
import matplotlib.pyplot as plt
# First, we load the asset details so that we can load the data in the order of their asset id. Filenames are based on asset names.
asset_details = pd.read_csv(
"/kaggle/input/g-research-crypto-forecasting/asset_details.csv",
index_col="Asset_ID",
)
names = asset_details.sort_index().Asset_Name.values
ids = asset_details.sort_index().index
# Since all the dataframes are too big to be stored, trained and evaluated at once, we define a function to do it in one go:
from lightgbm import LGBMRegressor
from scipy.stats import pearsonr
from glob import iglob
from datetime import datetime
params = {
"lambda_l1": 0.004498875792752676,
"lambda_l2": 0.03243290696956152,
"num_leaves": 60,
"max_depth": 6,
"min_data_in_leaf": 2496,
"learning_rate": 0.18502752618241153,
"n_estimators": 100,
"boosting_type": "goss",
"random_state": 1,
}
used_features = [
"RSI",
"MACD_crossover_norm",
"stochastic_crossover",
"log_ret1",
"log_ret30",
"log_ret240",
"log_ret1440",
"mfi",
]
def train(asset_name):
df = dt.fread(
f"/kaggle/input/crypto-challenge-mlii-project-feature-eng-2/{asset_name.lower().replace(' ', '_')}.jay"
).to_pandas() # Load asset data
df.drop("index", axis=1, inplace=True)
df.set_index("timestamp", inplace=True)
X, y = (
df.drop(["Target"], axis=1)[used_features],
df.Target,
) # Separate into features and labels
# Training the model
model = LGBMRegressor(**params)
model.fit(X, y)
print(f"Trained model for {asset_name}")
return model
def global_train():
all_df = []
for filename in iglob(
"/kaggle/input/crypto-challenge-mlii-project-feature-eng-2/*.jay"
):
all_df.append(dt.fread(filename).to_pandas()) # Load asset data
all_df = pd.concat(all_df)
X_all, y_all = all_df.drop("Target", axis=1)[used_features], all_df.Target
global_model = LGBMRegressor(**params)
global_model.fit(X_all, y_all)
return global_model
# ### Feature engineering functions
from collections import deque
class DynamicSimpleMovingAverage:
def __init__(self, column, window_size):
# Dynamically shift moving averages over column
# Column should be columns with values from training data
self.window_size = window_size
self.window = deque(column.iloc[-window_size:].to_numpy())
self.sum = np.sum(self.window)
def get_sma(self, new_values):
mas = np.full(len(new_values), np.nan)
for i, value in enumerate(new_values):
self.sum -= self.window.popleft()
self.sum += value
self.window.append(value)
mas[i] = self.sum / self.window_size
return mas
class DynamicExponentialMovingAverage:
def __init__(self, column, window_size):
# Dynamically shift exponential moving averages over column
# Unlike simple moving average, instead of sums we need to keep track of only the previous EMA.
# Column should be column with previous emas from training data
self.prev_ema = column[-1]
self.alpha = 2 / (1 + window_size)
def get_ema(self, new_values):
emas = np.full(len(new_values), np.nan)
for i in range(len(new_values)):
ema = self.alpha * new_values[i] + self.prev_ema * (1 - self.alpha)
self.prev_ema = ema
emas[i] = ema
return emas
class Feature:
# An interface for dynamic feature computations
def __init__(self, name):
self.name = name
def get(self, new_values):
# Compute the feature based on dataframe of new values
pass
class RSI(Feature):
def __init__(self, name, close_col, gain_mean, loss_mean, period):
super().__init__(name)
used_col = close_col.to_numpy()[-period:]
self.gain_mean = gain_mean[-1]
self.loss_mean = loss_mean[-1]
self.last_val = used_col[-1]
self.period = period
def get_diff(self, new_value):
gain = 0
loss = 0
if new_value < self.last_val:
gain = 0
loss = abs(new_value - self.last_val)
else:
gain = new_value - self.last_val
loss = 0
self.last_val = new_value
return gain, loss
def get(self, new_values):
close_col = new_values["Close"].to_numpy()
rsis = np.zeros(len(close_col))
for i in range(len(close_col)):
gain, loss = self.get_diff(close_col[i])
self.gain_mean = (self.gain_mean * (self.period - 1) + gain) / self.period
self.loss_mean = (self.loss_mean * (self.period - 1) + loss) / self.period
rs = self.gain_mean / self.loss_mean
rsis[i] = 100 - 100 / (1 + rs)
return rsis
class MFI(Feature):
def __init__(self, name, close_col, volume_col, period):
super().__init__(name)
used_close = close_col.to_numpy()[-(period + 1) :]
used_vol = volume_col.to_numpy()[-(period + 1) :]
sign_diffs = np.sign(used_close[1:] - used_close[:-1])
self.money_flow = sign_diffs * used_close[1:] * used_vol[1:]
self.pos = self.money_flow.clip(min=0).sum()
self.neg = -1 * self.money_flow.clip(max=0).sum()
self.last_val = used_close[-1]
def get(self, new_values):
close_col = new_values["VWAP"].to_numpy()
vol_col = new_values["Volume"].to_numpy()
mfis = np.zeros(len(close_col))
for i in range(len(close_col)):
# Remove first element of window in sums
self.pos -= self.money_flow[0].clip(min=0)
self.neg -= -1 * self.money_flow[0].clip(max=0)
# Slide window
self.money_flow = np.roll(self.money_flow, -1)
curr_close = close_col[i]
curr_vol = vol_col[i]
if curr_close < self.last_val:
self.money_flow[-1] = -1 * curr_close * curr_vol
self.neg += -1 * self.money_flow[-1]
else:
self.money_flow[-1] = curr_close * curr_vol
self.pos += self.money_flow[-1]
if self.neg == 0: # to prevent div by zero
mfis[i] = 50
else:
mfis[i] = 100 - 100 / (1 + self.pos / self.neg)
return mfis
class MACD(Feature):
def __init__(
self,
name,
macd_long_period,
macd_long_col,
macd_short_period,
macd_short_col,
signal_period,
macd_col,
):
super().__init__(name)
self.macd_long_ema = DynamicExponentialMovingAverage(
macd_long_col.to_numpy(), macd_long_period
)
self.macd_short_ema = DynamicExponentialMovingAverage(
macd_short_col.to_numpy(), macd_short_period
)
self.signal_ema = DynamicExponentialMovingAverage(
macd_col.to_numpy(), signal_period
)
def get(self, new_values):
close_col = new_values["Close"].to_numpy()
macd = self.macd_short_ema.get_ema(close_col) - self.macd_long_ema.get_ema(
close_col
)
signal = self.signal_ema.get_ema(macd)
macd_crossovers = (macd - signal) / signal # Normalize with signal
return macd_crossovers
class Stochastic(Feature):
def __init__(self, name, close_col, k_col, period):
super().__init__(name)
self.window = deque(close_col.iloc[-period:].to_numpy())
self.low = np.min(self.window)
self.high = np.max(self.window)
self.d_sma = DynamicSimpleMovingAverage(
k_col, 3
) # needs K% column of training data
def get(self, new_values):
close_col = new_values["Close"].to_numpy()
k = np.zeros(len(close_col))
for i in range(len(close_col)):
self.window.popleft()
self.window.append(close_col[i])
self.low = np.min(self.window)
self.high = np.max(self.window)
k[i] = (close_col[i] - self.low) / (self.high - self.low) * 100
d = self.d_sma.get_sma(k)
return k - d
class CumLogReturns(Feature):
def __init__(self, name, close_col, period):
super().__init__(name)
used_col = close_col.to_numpy()[-(period + 1) :]
self.window = np.log(used_col[1:] / used_col[:-1])
self.sum = self.window.sum()
self.last_val = used_col[-1]
def get(self, new_values):
close_col = new_values["Close"].to_numpy()
ret = np.zeros(len(close_col))
for i in range(len(close_col)):
self.sum -= self.window[0]
new_ret = np.log(close_col[i] / self.last_val)
self.sum += new_ret
self.window = np.roll(self.window, -1)
self.window[-1] = new_ret
self.last_val = close_col[i]
ret[i] = self.sum
return ret
# ### Functions for processing incoming data
def get_last_train_rows():
# Get rows of all assets in one dataframe, of the last timestamp seen
last_rows = []
for name in names:
last_rows.append(
dt.fread(
f"/kaggle/input/crypto-challenge-mlii-project-feature-eng-2/{name.lower().replace(' ', '_')}.jay"
)
.to_pandas()
.iloc[-1]
)
concat = pd.concat(last_rows)
concat.index = sorted(asset_details.index)
def get_window(asset_dfs, window_size):
# Get rows of the current window, as a list of dataframes for every asset
return [asset_df[:-window_size] for asset_df in asset_dfs]
from datetime import timedelta
def interpolate(test_batch, prev_timestamp_rows):
prev_timestamp_rows[
"row_id"
] = -1 # Add row_id column as dummy so they match columns
asset_dfs = {}
for asset_id in prev_timestamp_rows["Asset_ID"].unique():
prev_row = prev_timestamp_rows[prev_timestamp_rows["Asset_ID"] == asset_id]
if asset_id not in test_batch["Asset_ID"].values:
# If this asset is not included in new data at all, create a new row filled with nans for it, to be interpolated later.
asset_df = pd.DataFrame(
columns=prev_timestamp_rows.columns,
index=[prev_timestamp_rows["Asset_ID"].index[0] + timedelta(minutes=1)],
)
asset_df["Asset_ID"] = asset_id
else:
asset_df = test_batch.loc[test_batch["Asset_ID"] == asset_id, :]
# if asset_df.index.value_counts()[0] > 1:
# return {} # In case of some weird event where the timestamp is the same as the previous iteration, just return an empty dict to skip this iteration entirely
asset_df.replace([np.inf, -np.inf], 0, inplace=True) # Replace infs with zeros
asset_df.loc[
asset_df.Volume == 0.0, "Volume"
] = np.nan # Zero volume seems unlikely, so interpolate this instead
if asset_df.index[0] == prev_row.index[0]:
asset_df.reset_index(inplace=True)
asset_df["timestamp"][0] += timedelta(
minutes=1
) # If somehow the timestamp remain the same, add 1 minute to it so asfreq() doesnt break
asset_df.set_index("timestamp", inplace=True)
if asset_df.index[0] >= prev_row.index[0]:
asset_df = pd.concat([prev_row, asset_df]).asfreq(
freq="60S"
) # Adds nans to missing minutes using previous row
asset_df["row_id"] = asset_df["row_id"].fillna(
-1
) # So that we can recognize interpolated rows and skip them for prediction
asset_df["Asset_ID"] = asset_df["Asset_ID"].fillna(
asset_id
) # This should not be interpolated
asset_df = asset_df.interpolate(
method="linear", axis=0
) # Interpolate and forward fill potential missing values at the end
asset_df = asset_df.iloc[1:] # Remove the previous row again
asset_dfs[asset_id] = asset_df.fillna(method="ffill")
return asset_dfs
def engineer_features(batch_assets, features):
engineered = {}
start_time = time.time()
for asset_id in batch_assets.keys():
df = batch_assets[asset_id]
init_timestamp = df.index[0]
for feature in features[asset_id]:
df[f"{feature.name}"] = feature.get(df)
df = df.drop(
["Count", "High", "Low", "Open", "Close", "Volume", "VWAP"], axis=1
)
# engineered[asset_id] = window.loc[init_timestamp:]
engineered[asset_id] = df
# print(f'Engineering took {time.time()-start_time} seconds.')
return engineered
def get_new_windows(old_windows, curr_batch, window_size):
# Get the new window to be the last rows that fit in the window
if len(curr_batch) == 0:
return old_windows
else:
return {
asset_id: pd.concat([old_windows[asset_id], curr_batch[asset_id]]).iloc[
-window_size:
]
for asset_id in old_windows.keys()
}
def predict_targets(asset_dfs, models, global_model, global_weight=0.5):
targets = []
for asset_id in asset_dfs.keys():
asset_df = asset_dfs[asset_id]
model = models[asset_id]
features = asset_df.drop(
["row_id", "Asset_ID", "Target", "group_num"], axis=1, errors="ignore"
).to_numpy()
targets.extend(
(
zip(
asset_df["row_id"].to_numpy(),
global_weight * global_model.predict(features)
+ (1 - global_weight) * model.predict(features),
)
)
)
targets = sorted(
filter((lambda tup: tup[0] >= 0), targets), key=(lambda tup: tup[0])
) # Remove interpolated rows and sort by id
return list(
map((lambda tup: tup[1]), targets)
) # Get the target values and add them to the predictions.
# Training the models:
models = {}
for asset_id, asset_name in zip(ids, names):
models[asset_id] = train(asset_name)
global_model = global_train()
# example_rsi = [[26.9, 2.7, -7.5/37_595.2]] # Bitcoin - 29 jan 18:36 UTC
# prediction = models[1].predict(example_rsi, pred_contrib = True)
# print(prediction)
window_size = 1441
# Retrieve the first window
windows = {}
features = {}
sma_dict = {}
for asset_name, asset_id in zip(names, ids):
engineered_window = dt.fread(
f"/kaggle/input/crypto-challenge-mlii-project-feature-eng-2/{asset_name.lower().replace(' ', '_')}.jay"
).to_pandas()
engineered_window = engineered_window.set_index("timestamp").iloc[-window_size:]
preprocessed_window = dt.fread(
f"../input/crypto-challenge-mlii-project-preprocessing-2/{asset_name.lower().replace(' ', '_')}.jay"
).to_pandas()
preprocessed_window = preprocessed_window.set_index("timestamp").iloc[-window_size:]
windows[asset_id] = preprocessed_window
close_col = preprocessed_window["Close"]
vwap_col = preprocessed_window["VWAP"]
vol_col = preprocessed_window["Volume"]
asset_features = [
RSI(
"RSI",
close_col,
engineered_window["gain_mean"],
engineered_window["loss_mean"],
28,
),
MACD(
"MACD_crossover_norm",
52,
engineered_window["ema_52"],
24,
engineered_window["ema_24"],
18,
engineered_window["MACD_signal"],
),
Stochastic(
"stochastic_crossover", close_col, engineered_window["stochastic_k"], 28
),
CumLogReturns("log_ret1", close_col, 1),
CumLogReturns("log_ret30", close_col, 30),
CumLogReturns("log_ret240", close_col, 240),
CumLogReturns("log_ret1440", close_col, 1440),
MFI("mfi", vwap_col, vol_col, 28),
]
features[asset_id] = asset_features
import gresearch_crypto
env = gresearch_crypto.make_env()
iter_test = env.iter_test()
# For testing without using API
# copy1 = dummy_test.copy()
# copy2 = dummy_test.copy()
# copy2['timestamp'] += 60
# copy2.drop(copy2.index[copy2['Asset_ID'] == 2], inplace=True)
# copy3 = dummy_test.copy()
# copy3['timestamp'] += 180
# copy3.drop(copy3.index[copy3['Asset_ID'] == 2], inplace=True) # Test what happens when assets are not all provided
# test_data = [(copy1, pd.DataFrame()), (copy2, pd.DataFrame()), (copy3, pd.DataFrame())]
# for i, (test_batch, sample_preds) in enumerate(test_data):
# start_time = time.time()
# test_batch['timestamp'] = pd.to_datetime(test_batch['timestamp'], unit='s')
# test_batch.set_index('timestamp', inplace=True)
# #TODO last rows should include interpolated ones
# last_rows = pd.concat([asset.iloc[-1:] for asset in windows.values()]) # Slice [-1:] so we get a DataFrame instead of Series
# asset_dfs = interpolate(test_batch, last_rows) # Use the final rows from the previous time to determine if there are any gaps
# engineered_dfs = engineer_features(asset_dfs, features, sma_dict)
# print(engineered_dfs[1])
# sns.lineplot(data=engineered_dfs[3], x='timestamp', y='RSI')
# windows = get_new_windows(windows, asset_dfs, window_size)
# targets = predict_targets(engineered_dfs, models)
# sample_preds['Target'] = predict_targets(engineered_dfs, models)
# print(f'Predicted {len(test_batch)} values! Took {time.time()-start_time} seconds.')
# TODO: train on new data
import time
# dummy_test = None
for test_batch, sample_preds in iter_test:
start_time = time.time()
test_batch["timestamp"] = pd.to_datetime(test_batch["timestamp"], unit="s")
test_batch.set_index("timestamp", inplace=True)
test_batch.index = test_batch.index.ceil("min") # Round up to nearest minute
last_rows = pd.concat(
[asset.iloc[-1:] for asset in windows.values()]
) # Slice [-1:] so we get a DataFrame instead of Series
asset_dfs = interpolate(
test_batch, last_rows
) # Use the final rows from the previous time to determine if there are any gaps
engineered_dfs = engineer_features(asset_dfs, features)
windows = get_new_windows(windows, asset_dfs, 1)
targets = predict_targets(engineered_dfs, models, global_model)
targets = np.clip(np.nan_to_num(targets), -0.99, 0.99)
sample_preds["Target"] = targets
env.predict(sample_preds) # Call the predict function to pass it through the API.
# print(f'Predicted {len(test_batch)} values! Took {time.time()-start_time} seconds.')
# start = datetime.fromtimestamp(1623542340)
# end = datetime.fromtimestamp(1623542520)
# df = dt.fread(f"/kaggle/input/crypto-challenge-mlii-project-feature-eng-2/bitcoin.jay").to_pandas().set_index('timestamp').loc[start:end]
# display(df)
# from datetime import datetime
# from datatable import dt
# import pandas as pd
# display(dt.fread(f"/kaggle/input/crypto-challenge-mlii-project-preprocessing-2/bitcoin.jay").to_pandas().set_index('timestamp').loc[datetime.fromtimestamp(1623540000):datetime.fromtimestamp(1623542520)])
# display(dt.fread(f"/kaggle/input/crypto-challenge-mlii-project-feature-eng-2/bitcoin.jay").to_pandas().set_index('timestamp').loc[datetime.fromtimestamp(1623540000):datetime.fromtimestamp(1623542520)])
# orig = pd.read_csv('../input/g-research-crypto-forecasting/train.csv')
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0087/030/87030978.ipynb | null | null | [{"Id": 87030978, "ScriptId": 23915017, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 7356290, "CreationDate": "02/05/2022 09:42:57", "VersionNumber": 50.0, "Title": "Crypto Challenge MLII Project: Submission", "EvaluationDate": "02/05/2022", "IsChange": true, "TotalLines": 404.0, "LinesInsertedFromPrevious": 6.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 398.0, "LinesInsertedFromFork": 386.0, "LinesDeletedFromFork": 121.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 18.0, "TotalVotes": 0}] | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import datatable as dt # Fast data reading/writing
import seaborn as sns
import matplotlib.pyplot as plt
# First, we load the asset details so that we can load the data in the order of their asset id. Filenames are based on asset names.
asset_details = pd.read_csv(
"/kaggle/input/g-research-crypto-forecasting/asset_details.csv",
index_col="Asset_ID",
)
names = asset_details.sort_index().Asset_Name.values
ids = asset_details.sort_index().index
# Since all the dataframes are too big to be stored, trained and evaluated at once, we define a function to do it in one go:
from lightgbm import LGBMRegressor
from scipy.stats import pearsonr
from glob import iglob
from datetime import datetime
params = {
"lambda_l1": 0.004498875792752676,
"lambda_l2": 0.03243290696956152,
"num_leaves": 60,
"max_depth": 6,
"min_data_in_leaf": 2496,
"learning_rate": 0.18502752618241153,
"n_estimators": 100,
"boosting_type": "goss",
"random_state": 1,
}
used_features = [
"RSI",
"MACD_crossover_norm",
"stochastic_crossover",
"log_ret1",
"log_ret30",
"log_ret240",
"log_ret1440",
"mfi",
]
def train(asset_name):
df = dt.fread(
f"/kaggle/input/crypto-challenge-mlii-project-feature-eng-2/{asset_name.lower().replace(' ', '_')}.jay"
).to_pandas() # Load asset data
df.drop("index", axis=1, inplace=True)
df.set_index("timestamp", inplace=True)
X, y = (
df.drop(["Target"], axis=1)[used_features],
df.Target,
) # Separate into features and labels
# Training the model
model = LGBMRegressor(**params)
model.fit(X, y)
print(f"Trained model for {asset_name}")
return model
def global_train():
all_df = []
for filename in iglob(
"/kaggle/input/crypto-challenge-mlii-project-feature-eng-2/*.jay"
):
all_df.append(dt.fread(filename).to_pandas()) # Load asset data
all_df = pd.concat(all_df)
X_all, y_all = all_df.drop("Target", axis=1)[used_features], all_df.Target
global_model = LGBMRegressor(**params)
global_model.fit(X_all, y_all)
return global_model
# ### Feature engineering functions
from collections import deque
class DynamicSimpleMovingAverage:
def __init__(self, column, window_size):
# Dynamically shift moving averages over column
# Column should be columns with values from training data
self.window_size = window_size
self.window = deque(column.iloc[-window_size:].to_numpy())
self.sum = np.sum(self.window)
def get_sma(self, new_values):
mas = np.full(len(new_values), np.nan)
for i, value in enumerate(new_values):
self.sum -= self.window.popleft()
self.sum += value
self.window.append(value)
mas[i] = self.sum / self.window_size
return mas
class DynamicExponentialMovingAverage:
def __init__(self, column, window_size):
# Dynamically shift exponential moving averages over column
# Unlike simple moving average, instead of sums we need to keep track of only the previous EMA.
# Column should be column with previous emas from training data
self.prev_ema = column[-1]
self.alpha = 2 / (1 + window_size)
def get_ema(self, new_values):
emas = np.full(len(new_values), np.nan)
for i in range(len(new_values)):
ema = self.alpha * new_values[i] + self.prev_ema * (1 - self.alpha)
self.prev_ema = ema
emas[i] = ema
return emas
class Feature:
# An interface for dynamic feature computations
def __init__(self, name):
self.name = name
def get(self, new_values):
# Compute the feature based on dataframe of new values
pass
class RSI(Feature):
def __init__(self, name, close_col, gain_mean, loss_mean, period):
super().__init__(name)
used_col = close_col.to_numpy()[-period:]
self.gain_mean = gain_mean[-1]
self.loss_mean = loss_mean[-1]
self.last_val = used_col[-1]
self.period = period
def get_diff(self, new_value):
gain = 0
loss = 0
if new_value < self.last_val:
gain = 0
loss = abs(new_value - self.last_val)
else:
gain = new_value - self.last_val
loss = 0
self.last_val = new_value
return gain, loss
def get(self, new_values):
close_col = new_values["Close"].to_numpy()
rsis = np.zeros(len(close_col))
for i in range(len(close_col)):
gain, loss = self.get_diff(close_col[i])
self.gain_mean = (self.gain_mean * (self.period - 1) + gain) / self.period
self.loss_mean = (self.loss_mean * (self.period - 1) + loss) / self.period
rs = self.gain_mean / self.loss_mean
rsis[i] = 100 - 100 / (1 + rs)
return rsis
class MFI(Feature):
def __init__(self, name, close_col, volume_col, period):
super().__init__(name)
used_close = close_col.to_numpy()[-(period + 1) :]
used_vol = volume_col.to_numpy()[-(period + 1) :]
sign_diffs = np.sign(used_close[1:] - used_close[:-1])
self.money_flow = sign_diffs * used_close[1:] * used_vol[1:]
self.pos = self.money_flow.clip(min=0).sum()
self.neg = -1 * self.money_flow.clip(max=0).sum()
self.last_val = used_close[-1]
def get(self, new_values):
close_col = new_values["VWAP"].to_numpy()
vol_col = new_values["Volume"].to_numpy()
mfis = np.zeros(len(close_col))
for i in range(len(close_col)):
# Remove first element of window in sums
self.pos -= self.money_flow[0].clip(min=0)
self.neg -= -1 * self.money_flow[0].clip(max=0)
# Slide window
self.money_flow = np.roll(self.money_flow, -1)
curr_close = close_col[i]
curr_vol = vol_col[i]
if curr_close < self.last_val:
self.money_flow[-1] = -1 * curr_close * curr_vol
self.neg += -1 * self.money_flow[-1]
else:
self.money_flow[-1] = curr_close * curr_vol
self.pos += self.money_flow[-1]
if self.neg == 0: # to prevent div by zero
mfis[i] = 50
else:
mfis[i] = 100 - 100 / (1 + self.pos / self.neg)
return mfis
class MACD(Feature):
def __init__(
self,
name,
macd_long_period,
macd_long_col,
macd_short_period,
macd_short_col,
signal_period,
macd_col,
):
super().__init__(name)
self.macd_long_ema = DynamicExponentialMovingAverage(
macd_long_col.to_numpy(), macd_long_period
)
self.macd_short_ema = DynamicExponentialMovingAverage(
macd_short_col.to_numpy(), macd_short_period
)
self.signal_ema = DynamicExponentialMovingAverage(
macd_col.to_numpy(), signal_period
)
def get(self, new_values):
close_col = new_values["Close"].to_numpy()
macd = self.macd_short_ema.get_ema(close_col) - self.macd_long_ema.get_ema(
close_col
)
signal = self.signal_ema.get_ema(macd)
macd_crossovers = (macd - signal) / signal # Normalize with signal
return macd_crossovers
class Stochastic(Feature):
def __init__(self, name, close_col, k_col, period):
super().__init__(name)
self.window = deque(close_col.iloc[-period:].to_numpy())
self.low = np.min(self.window)
self.high = np.max(self.window)
self.d_sma = DynamicSimpleMovingAverage(
k_col, 3
) # needs K% column of training data
def get(self, new_values):
close_col = new_values["Close"].to_numpy()
k = np.zeros(len(close_col))
for i in range(len(close_col)):
self.window.popleft()
self.window.append(close_col[i])
self.low = np.min(self.window)
self.high = np.max(self.window)
k[i] = (close_col[i] - self.low) / (self.high - self.low) * 100
d = self.d_sma.get_sma(k)
return k - d
class CumLogReturns(Feature):
def __init__(self, name, close_col, period):
super().__init__(name)
used_col = close_col.to_numpy()[-(period + 1) :]
self.window = np.log(used_col[1:] / used_col[:-1])
self.sum = self.window.sum()
self.last_val = used_col[-1]
def get(self, new_values):
close_col = new_values["Close"].to_numpy()
ret = np.zeros(len(close_col))
for i in range(len(close_col)):
self.sum -= self.window[0]
new_ret = np.log(close_col[i] / self.last_val)
self.sum += new_ret
self.window = np.roll(self.window, -1)
self.window[-1] = new_ret
self.last_val = close_col[i]
ret[i] = self.sum
return ret
# ### Functions for processing incoming data
def get_last_train_rows():
# Get rows of all assets in one dataframe, of the last timestamp seen
last_rows = []
for name in names:
last_rows.append(
dt.fread(
f"/kaggle/input/crypto-challenge-mlii-project-feature-eng-2/{name.lower().replace(' ', '_')}.jay"
)
.to_pandas()
.iloc[-1]
)
concat = pd.concat(last_rows)
concat.index = sorted(asset_details.index)
def get_window(asset_dfs, window_size):
# Get rows of the current window, as a list of dataframes for every asset
return [asset_df[:-window_size] for asset_df in asset_dfs]
from datetime import timedelta
def interpolate(test_batch, prev_timestamp_rows):
prev_timestamp_rows[
"row_id"
] = -1 # Add row_id column as dummy so they match columns
asset_dfs = {}
for asset_id in prev_timestamp_rows["Asset_ID"].unique():
prev_row = prev_timestamp_rows[prev_timestamp_rows["Asset_ID"] == asset_id]
if asset_id not in test_batch["Asset_ID"].values:
# If this asset is not included in new data at all, create a new row filled with nans for it, to be interpolated later.
asset_df = pd.DataFrame(
columns=prev_timestamp_rows.columns,
index=[prev_timestamp_rows["Asset_ID"].index[0] + timedelta(minutes=1)],
)
asset_df["Asset_ID"] = asset_id
else:
asset_df = test_batch.loc[test_batch["Asset_ID"] == asset_id, :]
# if asset_df.index.value_counts()[0] > 1:
# return {} # In case of some weird event where the timestamp is the same as the previous iteration, just return an empty dict to skip this iteration entirely
asset_df.replace([np.inf, -np.inf], 0, inplace=True) # Replace infs with zeros
asset_df.loc[
asset_df.Volume == 0.0, "Volume"
] = np.nan # Zero volume seems unlikely, so interpolate this instead
if asset_df.index[0] == prev_row.index[0]:
asset_df.reset_index(inplace=True)
asset_df["timestamp"][0] += timedelta(
minutes=1
) # If somehow the timestamp remain the same, add 1 minute to it so asfreq() doesnt break
asset_df.set_index("timestamp", inplace=True)
if asset_df.index[0] >= prev_row.index[0]:
asset_df = pd.concat([prev_row, asset_df]).asfreq(
freq="60S"
) # Adds nans to missing minutes using previous row
asset_df["row_id"] = asset_df["row_id"].fillna(
-1
) # So that we can recognize interpolated rows and skip them for prediction
asset_df["Asset_ID"] = asset_df["Asset_ID"].fillna(
asset_id
) # This should not be interpolated
asset_df = asset_df.interpolate(
method="linear", axis=0
) # Interpolate and forward fill potential missing values at the end
asset_df = asset_df.iloc[1:] # Remove the previous row again
asset_dfs[asset_id] = asset_df.fillna(method="ffill")
return asset_dfs
def engineer_features(batch_assets, features):
engineered = {}
start_time = time.time()
for asset_id in batch_assets.keys():
df = batch_assets[asset_id]
init_timestamp = df.index[0]
for feature in features[asset_id]:
df[f"{feature.name}"] = feature.get(df)
df = df.drop(
["Count", "High", "Low", "Open", "Close", "Volume", "VWAP"], axis=1
)
# engineered[asset_id] = window.loc[init_timestamp:]
engineered[asset_id] = df
# print(f'Engineering took {time.time()-start_time} seconds.')
return engineered
def get_new_windows(old_windows, curr_batch, window_size):
# Get the new window to be the last rows that fit in the window
if len(curr_batch) == 0:
return old_windows
else:
return {
asset_id: pd.concat([old_windows[asset_id], curr_batch[asset_id]]).iloc[
-window_size:
]
for asset_id in old_windows.keys()
}
def predict_targets(asset_dfs, models, global_model, global_weight=0.5):
targets = []
for asset_id in asset_dfs.keys():
asset_df = asset_dfs[asset_id]
model = models[asset_id]
features = asset_df.drop(
["row_id", "Asset_ID", "Target", "group_num"], axis=1, errors="ignore"
).to_numpy()
targets.extend(
(
zip(
asset_df["row_id"].to_numpy(),
global_weight * global_model.predict(features)
+ (1 - global_weight) * model.predict(features),
)
)
)
targets = sorted(
filter((lambda tup: tup[0] >= 0), targets), key=(lambda tup: tup[0])
) # Remove interpolated rows and sort by id
return list(
map((lambda tup: tup[1]), targets)
) # Get the target values and add them to the predictions.
# Training the models:
models = {}
for asset_id, asset_name in zip(ids, names):
models[asset_id] = train(asset_name)
global_model = global_train()
# example_rsi = [[26.9, 2.7, -7.5/37_595.2]] # Bitcoin - 29 jan 18:36 UTC
# prediction = models[1].predict(example_rsi, pred_contrib = True)
# print(prediction)
window_size = 1441
# Retrieve the first window
windows = {}
features = {}
sma_dict = {}
for asset_name, asset_id in zip(names, ids):
engineered_window = dt.fread(
f"/kaggle/input/crypto-challenge-mlii-project-feature-eng-2/{asset_name.lower().replace(' ', '_')}.jay"
).to_pandas()
engineered_window = engineered_window.set_index("timestamp").iloc[-window_size:]
preprocessed_window = dt.fread(
f"../input/crypto-challenge-mlii-project-preprocessing-2/{asset_name.lower().replace(' ', '_')}.jay"
).to_pandas()
preprocessed_window = preprocessed_window.set_index("timestamp").iloc[-window_size:]
windows[asset_id] = preprocessed_window
close_col = preprocessed_window["Close"]
vwap_col = preprocessed_window["VWAP"]
vol_col = preprocessed_window["Volume"]
asset_features = [
RSI(
"RSI",
close_col,
engineered_window["gain_mean"],
engineered_window["loss_mean"],
28,
),
MACD(
"MACD_crossover_norm",
52,
engineered_window["ema_52"],
24,
engineered_window["ema_24"],
18,
engineered_window["MACD_signal"],
),
Stochastic(
"stochastic_crossover", close_col, engineered_window["stochastic_k"], 28
),
CumLogReturns("log_ret1", close_col, 1),
CumLogReturns("log_ret30", close_col, 30),
CumLogReturns("log_ret240", close_col, 240),
CumLogReturns("log_ret1440", close_col, 1440),
MFI("mfi", vwap_col, vol_col, 28),
]
features[asset_id] = asset_features
import gresearch_crypto
env = gresearch_crypto.make_env()
iter_test = env.iter_test()
# For testing without using API
# copy1 = dummy_test.copy()
# copy2 = dummy_test.copy()
# copy2['timestamp'] += 60
# copy2.drop(copy2.index[copy2['Asset_ID'] == 2], inplace=True)
# copy3 = dummy_test.copy()
# copy3['timestamp'] += 180
# copy3.drop(copy3.index[copy3['Asset_ID'] == 2], inplace=True) # Test what happens when assets are not all provided
# test_data = [(copy1, pd.DataFrame()), (copy2, pd.DataFrame()), (copy3, pd.DataFrame())]
# for i, (test_batch, sample_preds) in enumerate(test_data):
# start_time = time.time()
# test_batch['timestamp'] = pd.to_datetime(test_batch['timestamp'], unit='s')
# test_batch.set_index('timestamp', inplace=True)
# #TODO last rows should include interpolated ones
# last_rows = pd.concat([asset.iloc[-1:] for asset in windows.values()]) # Slice [-1:] so we get a DataFrame instead of Series
# asset_dfs = interpolate(test_batch, last_rows) # Use the final rows from the previous time to determine if there are any gaps
# engineered_dfs = engineer_features(asset_dfs, features, sma_dict)
# print(engineered_dfs[1])
# sns.lineplot(data=engineered_dfs[3], x='timestamp', y='RSI')
# windows = get_new_windows(windows, asset_dfs, window_size)
# targets = predict_targets(engineered_dfs, models)
# sample_preds['Target'] = predict_targets(engineered_dfs, models)
# print(f'Predicted {len(test_batch)} values! Took {time.time()-start_time} seconds.')
# TODO: train on new data
import time
# dummy_test = None
for test_batch, sample_preds in iter_test:
start_time = time.time()
test_batch["timestamp"] = pd.to_datetime(test_batch["timestamp"], unit="s")
test_batch.set_index("timestamp", inplace=True)
test_batch.index = test_batch.index.ceil("min") # Round up to nearest minute
last_rows = pd.concat(
[asset.iloc[-1:] for asset in windows.values()]
) # Slice [-1:] so we get a DataFrame instead of Series
asset_dfs = interpolate(
test_batch, last_rows
) # Use the final rows from the previous time to determine if there are any gaps
engineered_dfs = engineer_features(asset_dfs, features)
windows = get_new_windows(windows, asset_dfs, 1)
targets = predict_targets(engineered_dfs, models, global_model)
targets = np.clip(np.nan_to_num(targets), -0.99, 0.99)
sample_preds["Target"] = targets
env.predict(sample_preds) # Call the predict function to pass it through the API.
# print(f'Predicted {len(test_batch)} values! Took {time.time()-start_time} seconds.')
# start = datetime.fromtimestamp(1623542340)
# end = datetime.fromtimestamp(1623542520)
# df = dt.fread(f"/kaggle/input/crypto-challenge-mlii-project-feature-eng-2/bitcoin.jay").to_pandas().set_index('timestamp').loc[start:end]
# display(df)
# from datetime import datetime
# from datatable import dt
# import pandas as pd
# display(dt.fread(f"/kaggle/input/crypto-challenge-mlii-project-preprocessing-2/bitcoin.jay").to_pandas().set_index('timestamp').loc[datetime.fromtimestamp(1623540000):datetime.fromtimestamp(1623542520)])
# display(dt.fread(f"/kaggle/input/crypto-challenge-mlii-project-feature-eng-2/bitcoin.jay").to_pandas().set_index('timestamp').loc[datetime.fromtimestamp(1623540000):datetime.fromtimestamp(1623542520)])
# orig = pd.read_csv('../input/g-research-crypto-forecasting/train.csv')
| false | 0 | 5,933 | 0 | 6 | 5,933 |
||
113042082 | <kaggle_start><data_title>PlantVillage Dataset<data_description>Human society needs to increase food production by an estimated 70% by 2050 to feed an expected population size that is predicted to be over 9 billion people. Currently, infectious diseases reduce the potential yield by an average of 40% with many farmers in the developing world experiencing yield losses as high as 100%. The widespread distribution of smartphones among crop growers around the world with an expected 5 billion smartphones by 2020 offers the potential of turning the smartphone into a valuable tool for diverse communities growing food. One potential application is the development of mobile disease diagnostics through machine learning and crowdsourcing. Here we announce the release of over 50,000 expertly curated images on healthy and infected leaves of crops plants through the existing online platform PlantVillage. We describe both the data and the platform. These data are the beginning of an on-going, crowdsourcing effort to enable computer vision approaches to help solve the problem of yield losses in crop plants due to infectious diseases.<data_name>plantvillage-dataset
<code># # Knowledge Distillation
# **Author:** [Aminu Musa]
# **Date created:** 2022/09/01
# **Last modified:** 2020/10/17
# **Description:** Lighweight Plant Disease Detection Model for Embedded Device Using Knowledge Distillation Technique.
# This work is from a paper titled "Low-Power Deep Learning Model for Plant Disease Detection for Smart-Hydroponics Using Knowledge Distillation Techniques" link to the paper: https://www.mdpi.com/1605040
# the Techniques of Knowledge Distillation was a from a paper by Geofrey Hinton.https://arxiv.org/abs/1503.02531
# # **INTRODUCTION**
# In this work We tried to implement Knowledge Distillation(KD) technique as proposed by Geofrey Hinton in thier paper titled "Distilling the Knowledge in a Neural Network" the technique was adopted in our paper called Lighweight Plant Disease Detection Model for Embedded Device with the aim of achieving a lighter CNN model for plant disease detection.
# * **Goal**:
# Our aim is to developed a deep learning model that will aid African farmers in detecting diseases that are affecting thier crops using thier smartphones.the start of the art CNN models are not suitable for deployment on smartphones due to thier sizes and huge number of parametres. We therefore, compressed the model using KD to reduce model parameters while keeping the performance. we use open source plant disease detection dataset organized by PlantVIllage to train and validate our model.
# * **Contribution:**
# To obtain a lighweight model that will be suitable for deployment on embedded devices such as smartphone
# # 1- Uplaoding necessary libraries
import os
import pickle
import zipfile
import random
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from shutil import copyfile
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import (
BatchNormalization,
Conv2D,
MaxPooling2D,
Activation,
Flatten,
Dropout,
Dense,
)
from tensorflow.keras import backend as K
from sklearn.preprocessing import LabelBinarizer
from keras.preprocessing import image
import matplotlib.pyplot as plt
# # 2- How Does Knowledge Distillation Works?
# Knowledge distillation is a technique of model compression that employs teacher-student learning. In this technique, a large, cumbersome pre-trained model called the teacher model is trained first on a large dataset. The knowledge learned by the teacher model is transferred (distilled) to a shallow lightweight model called the student model, whereby the student mimics the performance of the teacher model despite its shallow nature. The student model size is relatively reduced without sacrificing accuracy. Figure.1 presents the architecture of the knowledge distillation technique.
# 
# # 3- Creating Distiller Class
# ## Construct `Distiller()` class
# This custom class`Distiller()` was used to overrides the original Model methods namely:`train_step`, `test_step`,
# and `compile()`.
# * **Train_step:** A training step is one gradient update. In one step batch_size many examples are processed. An epoch consists of one full cycle through the training data. This is usually many steps. As an example, if you have 2,000 images and use a batch size of 10 an epoch consists of 2,000 images / (10 images / step) = 200 steps
# * **Compile method:** It specifies a loss, metrics, and an optimizer. To train a model with fit(), you need to specify a loss function, an optimizer, and optionally, some metrics to monitor. We can pass these variables to the model as arguments to the compile() method.
# In order to use the distiller, we need:
# - A trained teacher model
# - A student model to train
# - A student loss function on the difference between student predictions and ground-truth
# - A distillation loss function, along with a `temperature`, on the difference between the
# soft student predictions and the soft teacher labels
# - An `alpha` factor to weight the student and distillation loss
# - An optimizer for the student and (optional) metrics to evaluate performance
# In the `train_step` method, we perform a forward pass of both the teacher and student,
# calculate the loss with weighting of the `student_loss` and `distillation_loss` by `alpha` and
# `1 - alpha`, respectively, and perform the backward pass. Note: only the student weights are updated,
# and therefore we only calculate the gradients for the student weights.
# In the `test_step` method, we evaluate the student model on the provided dataset.
class Distiller(keras.Model):
def __init__(self, student, teacher):
super(Distiller, self).__init__()
self.teacher = teacher
self.student = student
def compile(
self,
optimizer,
metrics,
student_loss_fn,
distillation_loss_fn,
alpha=0.1,
temperature=3,
):
"""Configure the distiller.
Args:
optimizer: Keras optimizer for the student weights
metrics: Keras metrics for evaluation
student_loss_fn: Loss function of difference between student
predictions and ground-truth
distillation_loss_fn: Loss function of difference between soft
student predictions and soft teacher predictions
alpha: weight to student_loss_fn and 1-alpha to distillation_loss_fn
temperature: Temperature for softening probability distributions.
Larger temperature gives softer distributions.
"""
super(Distiller, self).compile(optimizer=optimizer, metrics=metrics)
self.student_loss_fn = student_loss_fn
self.distillation_loss_fn = distillation_loss_fn
self.alpha = alpha
self.temperature = temperature
def train_step(self, data):
# Unpack data
x, y = data
# Forward pass of teacher
teacher_predictions = self.teacher(x, training=False)
with tf.GradientTape() as tape:
# Forward pass of student
student_predictions = self.student(x, training=True)
# Compute losses
student_loss = self.student_loss_fn(y, student_predictions)
distillation_loss = self.distillation_loss_fn(
tf.nn.softmax(teacher_predictions / self.temperature, axis=1),
tf.nn.softmax(student_predictions / self.temperature, axis=1),
)
loss = self.alpha * student_loss + (1 - self.alpha) * distillation_loss
# Compute gradients
trainable_vars = self.student.trainable_variables
gradients = tape.gradient(loss, trainable_vars)
# Update weights
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
# Update the metrics configured in `compile()`.
self.compiled_metrics.update_state(y, student_predictions)
# Return a dict of performance
results = {m.name: m.result() for m in self.metrics}
results.update(
{"student_loss": student_loss, "distillation_loss": distillation_loss}
)
return results
def test_step(self, data):
# Unpack the data
x, y = data
# Compute predictions
y_prediction = self.student(x, training=False)
# Calculate the loss
student_loss = self.student_loss_fn(y, y_prediction)
# Update the metrics.
self.compiled_metrics.update_state(y, y_prediction)
# Return a dict of performance
results = {m.name: m.result() for m in self.metrics}
results.update({"student_loss": student_loss})
return results
def call(self, data, training=False):
# You don't need this method for training.
# So just pass.
pass
import splitfolders
splitfolders.ratio(
"../input/plantvillage-dataset/color",
output="output",
seed=1337,
ratio=(0.8, 0.1, 0.1),
)
# # 4- Flowing Images from directory
# In step 4, the traning and validation datasets are flown from the directory to a variables called train_generator and validation_genearator. we also specify the batch size and resize all the images to 250 by 250px.
TRAINING_DIR = "./output/train"
train_datagen = ImageDataGenerator(rescale=1.0 / 255)
train_generator = train_datagen.flow_from_directory(
TRAINING_DIR, class_mode="categorical", batch_size=250, target_size=(250, 250)
)
VALIDATION_DIR = "./output/test"
validation_datagen = ImageDataGenerator(rescale=1.0 / 255.0)
validation_generator = validation_datagen.flow_from_directory(
VALIDATION_DIR, class_mode="categorical", batch_size=250, target_size=(250, 250)
)
# # Sample Images From the Dataset
# The code below defines a method plotImages which defined how to plot sample images from the dataset using matplotlib library and imshow() method. The Imagedatagenerator output array train_generator was used as input array to the method and then five images were selected from it.
def plotImages(images_arr):
fig, axes = plt.subplots(1, 5, figsize=(20, 20))
axes = axes.flatten()
for img, ax in zip(images_arr, axes):
ax.imshow(img)
plt.tight_layout()
plt.show()
augmented_images = [train_generator[0][0][0] for i in range(5)]
plotImages(augmented_images)
# # 5- Getting Categorical Labels
# We obtained the the labels associated with each images that is all the directories name from our dataset and assign it to a varaible called train_y
train_y = train_generator.classes
# # 6- Converting categorical labels to binary otherwise called (Encoding)
# Label Binarizer is an SciKit Learn class that accepts Categorical data as input and returns an Numpy array. Unlike Label Encoder, it encodes the data into dummy variables indicating the presence of a particular label or not. Encoding make column data using Label Binarizer
label_binarizer = LabelBinarizer()
image_labels = label_binarizer.fit_transform(train_y)
pickle.dump(label_binarizer, open("label_transform.pkl", "wb"))
n_classes = len(label_binarizer.classes_)
# ## 7- Create student and teacher models
# Initialy, we create a teacher model and a smaller student model using keras. Both models are
# convolutional neural networks and created using `Sequential()`,
# but could be any Keras model.
# Create the teacher
teacher = keras.Sequential(
name="teacher",
)
inputShape = (250, 250, 3)
chanDim = -1
if K.image_data_format() == "channels_first":
inputShape = (3, 250, 250)
chanDim = 1
teacher.add(Conv2D(32, (3, 3), padding="same", input_shape=inputShape))
teacher.add(Activation("relu"))
teacher.add(BatchNormalization(axis=chanDim))
teacher.add(MaxPooling2D(pool_size=(3, 3)))
teacher.add(Dropout(0.25))
teacher.add(Conv2D(64, (3, 3), padding="same"))
teacher.add(Activation("relu"))
teacher.add(BatchNormalization(axis=chanDim))
teacher.add(Conv2D(64, (3, 3), padding="same"))
teacher.add(Activation("relu"))
teacher.add(BatchNormalization(axis=chanDim))
teacher.add(MaxPooling2D(pool_size=(2, 2)))
teacher.add(Dropout(0.25))
teacher.add(Conv2D(128, (3, 3), padding="same"))
teacher.add(Activation("relu"))
teacher.add(BatchNormalization(axis=chanDim))
teacher.add(Conv2D(128, (3, 3), padding="same"))
teacher.add(Activation("relu"))
teacher.add(BatchNormalization(axis=chanDim))
teacher.add(MaxPooling2D(pool_size=(2, 2)))
teacher.add(Dropout(0.25))
teacher.add(Flatten())
teacher.add(Dense(1024))
teacher.add(Activation("relu"))
teacher.add(BatchNormalization())
teacher.add(Dropout(0.5))
teacher.add(Dense(n_classes))
# Create the student
student = keras.Sequential(
[
keras.Input(shape=(250, 250, 3)),
layers.Conv2D(16, (3, 3), strides=(2, 2), padding="same"),
layers.LeakyReLU(alpha=0.2),
layers.MaxPooling2D(pool_size=(2, 2), strides=(1, 1), padding="same"),
layers.Conv2D(32, (3, 3), strides=(2, 2), padding="same"),
layers.LeakyReLU(alpha=0.2),
layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding="same"),
layers.Flatten(),
layers.Dense(n_classes),
],
name="student",
)
# Clone student for later comparison
student_scratch = keras.models.clone_model(student)
# # 8- Displaying the model summary
# the custom method 'summary' allows us to diplay the architecture of the models described above, this allows us to know thw number parameters avaible in our defined model.
teacher.summary()
student.summary()
# # 9- Compiling Teacher Model for training
# The teacher model is first compile using custom compile method to achieve better accucaracy and learn more information
# Train teacher as usual
teacher.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=["acc"],
)
# ## 10- Train the teacher
# During training Step, the model sifts through preexisting data and draws conclusions based on what it “thinks” the data represents. Every time it comes to an incorrect conclusion, that result is fed back to the system so that it “learns” from its mistake.
# This process makes connections between the artificial neurons stronger over time and increases the likelihood that the system will make accurate predictions in the future. As it’s presented with novel data, the DNN should be able to categorize and analyze new and possibly more complex information. Ultimately, it will continue to learn from its encounters and become more intuitive over time.
# * ** to train a model a fit() method is called on the model, fit takes arguments such as trainig data, validation data, epoch, train step and valudation step.
#
teacher_history = teacher.fit(
train_generator, validation_data=validation_generator, epochs=5
)
# # 11- Plotting Teacher Model Accuracy and loss Curves
# * **Accruacy curve:** The accuracy curve describes the accuracy of test and validation sets. The X-axis is the iteration step. The Y-axis is the prediction accuracy. The blue curve is the accuracy on a batch of training examples from the training set, the orange curve is the accuracy for the test set.
# * **Loss curve:** One of the most used plots to debug a neural network is a Loss curve during training. It gives us a snapshot of the training process and the direction in which the network learns
import matplotlib.pyplot as plt
acc = teacher_history.history["acc"]
val_acc = teacher_history.history["val_acc"]
loss = teacher_history.history["loss"]
val_loss = teacher_history.history["val_loss"]
print(range(1, len(acc) + 1))
epochs = range(1, len(acc) + 1)
# Train and validation accuracy
plt.plot(epochs, acc, "b", label="Training accurarcy")
plt.plot(epochs, val_acc, "r", label="Validation accurarcy")
plt.title("Training and Validation accurarcy")
plt.legend()
plt.figure()
# Train and validation loss
plt.plot(epochs, loss, "b", label="Training loss")
plt.plot(epochs, val_loss, "r", label="Validation loss")
plt.title("Training and Validation loss")
plt.legend()
plt.show()
# ## 12 Distilling teacher knowledge to student Model
# We have already trained the teacher model, and we only need to initialize a
# `Distiller(student, teacher)` instance, `compile()` it with the desired losses,
# hyperparameters and optimizer, and distill the teacher to the student.
# Here we are trying to calculate the general loss by conputing KL divergence between student loss and distillation using the following relation.
# Dist_loss= 1/m ∑_(j=0)^m〖(2t^2 αD_KL (p^j,q^j )-(1-α)∑_(i=1)^cyi〗^(j ) log(1-〖yhat〗^j)〗
# where:
# P: is the soft labels from the teacher network
# q: is the softmax scores of student model
# Dkl: is the Kullback- Liebler (KL) divergence between p and q
# α: is the relative importance of the teacher’s guidance
# The distillation loss was minimized using the KL divergence between soft labels of a teacher p, and student model score q
#
# Initialize and compile distiller
distiller = Distiller(student=student, teacher=teacher)
distiller.compile(
optimizer=keras.optimizers.Adam(),
metrics=["acc"],
student_loss_fn=keras.losses.CategoricalCrossentropy(from_logits=True),
distillation_loss_fn=keras.losses.KLDivergence(),
alpha=0.1,
temperature=10,
)
# Distill teacher to student
student_history = distiller.fit(
train_generator, validation_data=validation_generator, epochs=3
)
# # Plotting Student model Accuracy and loss curves
# to investigate the performance of the student model for comparison with teacher model, an accaucry and validation curve was plotted below.
import matplotlib.pyplot as plt
acc = student_history.history["acc"]
val_acc = student_history.history["val_acc"]
loss = student_history.history["distillation_loss"]
val_loss = student_history.history["student_loss"]
print(range(1, len(acc) + 1))
epochs = range(1, len(acc) + 1)
# Train and validation accuracy
plt.plot(epochs, acc, "b", label="Training accurarcy")
plt.plot(epochs, val_acc, "r", label="Validation accurarcy")
plt.title("Training and Validation accurarcy")
plt.legend()
plt.figure()
# Train and validation loss
plt.plot(epochs, loss, "b", label="Training loss")
plt.plot(epochs, val_loss, "r", label="Validation loss")
plt.title("Training and Validation loss")
plt.legend()
plt.show()
# ## Train student from scratch for comparison
# We can also train an equivalent student model from scratch without the teacher, in order
# to evaluate the performance gain obtained by knowledge distillation.
# Train student as doen usually
student_scratch.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=["acc"],
)
# Train and evaluate student trained from scratch.
student_scratch.fit(train_generator, epochs=1)
std_history = student_scratch.evaluate(validation_generator)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0113/042/113042082.ipynb | plantvillage-dataset | abdallahalidev | [{"Id": 113042082, "ScriptId": 29154796, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4773887, "CreationDate": "12/05/2022 22:39:12", "VersionNumber": 2.0, "Title": "Lightweight Model of Disease Detection", "EvaluationDate": "12/05/2022", "IsChange": true, "TotalLines": 408.0, "LinesInsertedFromPrevious": 108.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 300.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 3}] | [{"Id": 158070707, "KernelVersionId": 113042082, "SourceDatasetVersionId": 658267}] | [{"Id": 658267, "DatasetId": 277323, "DatasourceVersionId": 677630, "CreatorUserId": 3478941, "LicenseName": "CC BY-NC-SA 4.0", "CreationDate": "09/01/2019 11:52:26", "VersionNumber": 3.0, "Title": "PlantVillage Dataset", "Slug": "plantvillage-dataset", "Subtitle": "Dataset of diseased plant leaf images and corresponding labels", "Description": "Human society needs to increase food production by an estimated 70% by 2050 to feed an expected population size that is predicted to be over 9 billion people. Currently, infectious diseases reduce the potential yield by an average of 40% with many farmers in the developing world experiencing yield losses as high as 100%. The widespread distribution of smartphones among crop growers around the world with an expected 5 billion smartphones by 2020 offers the potential of turning the smartphone into a valuable tool for diverse communities growing food. One potential application is the development of mobile disease diagnostics through machine learning and crowdsourcing. Here we announce the release of over 50,000 expertly curated images on healthy and infected leaves of crops plants through the existing online platform PlantVillage. We describe both the data and the platform. These data are the beginning of an on-going, crowdsourcing effort to enable computer vision approaches to help solve the problem of yield losses in crop plants due to infectious diseases.", "VersionNotes": "PlantVillage Dataset", "TotalCompressedBytes": 0.0, "TotalUncompressedBytes": 2184925679.0}] | [{"Id": 277323, "CreatorUserId": 3478941, "OwnerUserId": 3682811.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 658267.0, "CurrentDatasourceVersionId": 677630.0, "ForumId": 288696, "Type": 2, "CreationDate": "07/26/2019 10:40:16", "LastActivityDate": "07/26/2019", "TotalViews": 107780, "TotalDownloads": 13555, "TotalVotes": 322, "TotalKernels": 45}] | [{"Id": 3682811, "UserName": "abdallahalidev", "DisplayName": "Abdallah Ali", "RegisterDate": "09/09/2019", "PerformanceTier": 0}] | # # Knowledge Distillation
# **Author:** [Aminu Musa]
# **Date created:** 2022/09/01
# **Last modified:** 2020/10/17
# **Description:** Lighweight Plant Disease Detection Model for Embedded Device Using Knowledge Distillation Technique.
# This work is from a paper titled "Low-Power Deep Learning Model for Plant Disease Detection for Smart-Hydroponics Using Knowledge Distillation Techniques" link to the paper: https://www.mdpi.com/1605040
# the Techniques of Knowledge Distillation was a from a paper by Geofrey Hinton.https://arxiv.org/abs/1503.02531
# # **INTRODUCTION**
# In this work We tried to implement Knowledge Distillation(KD) technique as proposed by Geofrey Hinton in thier paper titled "Distilling the Knowledge in a Neural Network" the technique was adopted in our paper called Lighweight Plant Disease Detection Model for Embedded Device with the aim of achieving a lighter CNN model for plant disease detection.
# * **Goal**:
# Our aim is to developed a deep learning model that will aid African farmers in detecting diseases that are affecting thier crops using thier smartphones.the start of the art CNN models are not suitable for deployment on smartphones due to thier sizes and huge number of parametres. We therefore, compressed the model using KD to reduce model parameters while keeping the performance. we use open source plant disease detection dataset organized by PlantVIllage to train and validate our model.
# * **Contribution:**
# To obtain a lighweight model that will be suitable for deployment on embedded devices such as smartphone
# # 1- Uplaoding necessary libraries
import os
import pickle
import zipfile
import random
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.optimizers import RMSprop
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from shutil import copyfile
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import (
BatchNormalization,
Conv2D,
MaxPooling2D,
Activation,
Flatten,
Dropout,
Dense,
)
from tensorflow.keras import backend as K
from sklearn.preprocessing import LabelBinarizer
from keras.preprocessing import image
import matplotlib.pyplot as plt
# # 2- How Does Knowledge Distillation Works?
# Knowledge distillation is a technique of model compression that employs teacher-student learning. In this technique, a large, cumbersome pre-trained model called the teacher model is trained first on a large dataset. The knowledge learned by the teacher model is transferred (distilled) to a shallow lightweight model called the student model, whereby the student mimics the performance of the teacher model despite its shallow nature. The student model size is relatively reduced without sacrificing accuracy. Figure.1 presents the architecture of the knowledge distillation technique.
# 
# # 3- Creating Distiller Class
# ## Construct `Distiller()` class
# This custom class`Distiller()` was used to overrides the original Model methods namely:`train_step`, `test_step`,
# and `compile()`.
# * **Train_step:** A training step is one gradient update. In one step batch_size many examples are processed. An epoch consists of one full cycle through the training data. This is usually many steps. As an example, if you have 2,000 images and use a batch size of 10 an epoch consists of 2,000 images / (10 images / step) = 200 steps
# * **Compile method:** It specifies a loss, metrics, and an optimizer. To train a model with fit(), you need to specify a loss function, an optimizer, and optionally, some metrics to monitor. We can pass these variables to the model as arguments to the compile() method.
# In order to use the distiller, we need:
# - A trained teacher model
# - A student model to train
# - A student loss function on the difference between student predictions and ground-truth
# - A distillation loss function, along with a `temperature`, on the difference between the
# soft student predictions and the soft teacher labels
# - An `alpha` factor to weight the student and distillation loss
# - An optimizer for the student and (optional) metrics to evaluate performance
# In the `train_step` method, we perform a forward pass of both the teacher and student,
# calculate the loss with weighting of the `student_loss` and `distillation_loss` by `alpha` and
# `1 - alpha`, respectively, and perform the backward pass. Note: only the student weights are updated,
# and therefore we only calculate the gradients for the student weights.
# In the `test_step` method, we evaluate the student model on the provided dataset.
class Distiller(keras.Model):
def __init__(self, student, teacher):
super(Distiller, self).__init__()
self.teacher = teacher
self.student = student
def compile(
self,
optimizer,
metrics,
student_loss_fn,
distillation_loss_fn,
alpha=0.1,
temperature=3,
):
"""Configure the distiller.
Args:
optimizer: Keras optimizer for the student weights
metrics: Keras metrics for evaluation
student_loss_fn: Loss function of difference between student
predictions and ground-truth
distillation_loss_fn: Loss function of difference between soft
student predictions and soft teacher predictions
alpha: weight to student_loss_fn and 1-alpha to distillation_loss_fn
temperature: Temperature for softening probability distributions.
Larger temperature gives softer distributions.
"""
super(Distiller, self).compile(optimizer=optimizer, metrics=metrics)
self.student_loss_fn = student_loss_fn
self.distillation_loss_fn = distillation_loss_fn
self.alpha = alpha
self.temperature = temperature
def train_step(self, data):
# Unpack data
x, y = data
# Forward pass of teacher
teacher_predictions = self.teacher(x, training=False)
with tf.GradientTape() as tape:
# Forward pass of student
student_predictions = self.student(x, training=True)
# Compute losses
student_loss = self.student_loss_fn(y, student_predictions)
distillation_loss = self.distillation_loss_fn(
tf.nn.softmax(teacher_predictions / self.temperature, axis=1),
tf.nn.softmax(student_predictions / self.temperature, axis=1),
)
loss = self.alpha * student_loss + (1 - self.alpha) * distillation_loss
# Compute gradients
trainable_vars = self.student.trainable_variables
gradients = tape.gradient(loss, trainable_vars)
# Update weights
self.optimizer.apply_gradients(zip(gradients, trainable_vars))
# Update the metrics configured in `compile()`.
self.compiled_metrics.update_state(y, student_predictions)
# Return a dict of performance
results = {m.name: m.result() for m in self.metrics}
results.update(
{"student_loss": student_loss, "distillation_loss": distillation_loss}
)
return results
def test_step(self, data):
# Unpack the data
x, y = data
# Compute predictions
y_prediction = self.student(x, training=False)
# Calculate the loss
student_loss = self.student_loss_fn(y, y_prediction)
# Update the metrics.
self.compiled_metrics.update_state(y, y_prediction)
# Return a dict of performance
results = {m.name: m.result() for m in self.metrics}
results.update({"student_loss": student_loss})
return results
def call(self, data, training=False):
# You don't need this method for training.
# So just pass.
pass
import splitfolders
splitfolders.ratio(
"../input/plantvillage-dataset/color",
output="output",
seed=1337,
ratio=(0.8, 0.1, 0.1),
)
# # 4- Flowing Images from directory
# In step 4, the traning and validation datasets are flown from the directory to a variables called train_generator and validation_genearator. we also specify the batch size and resize all the images to 250 by 250px.
TRAINING_DIR = "./output/train"
train_datagen = ImageDataGenerator(rescale=1.0 / 255)
train_generator = train_datagen.flow_from_directory(
TRAINING_DIR, class_mode="categorical", batch_size=250, target_size=(250, 250)
)
VALIDATION_DIR = "./output/test"
validation_datagen = ImageDataGenerator(rescale=1.0 / 255.0)
validation_generator = validation_datagen.flow_from_directory(
VALIDATION_DIR, class_mode="categorical", batch_size=250, target_size=(250, 250)
)
# # Sample Images From the Dataset
# The code below defines a method plotImages which defined how to plot sample images from the dataset using matplotlib library and imshow() method. The Imagedatagenerator output array train_generator was used as input array to the method and then five images were selected from it.
def plotImages(images_arr):
fig, axes = plt.subplots(1, 5, figsize=(20, 20))
axes = axes.flatten()
for img, ax in zip(images_arr, axes):
ax.imshow(img)
plt.tight_layout()
plt.show()
augmented_images = [train_generator[0][0][0] for i in range(5)]
plotImages(augmented_images)
# # 5- Getting Categorical Labels
# We obtained the the labels associated with each images that is all the directories name from our dataset and assign it to a varaible called train_y
train_y = train_generator.classes
# # 6- Converting categorical labels to binary otherwise called (Encoding)
# Label Binarizer is an SciKit Learn class that accepts Categorical data as input and returns an Numpy array. Unlike Label Encoder, it encodes the data into dummy variables indicating the presence of a particular label or not. Encoding make column data using Label Binarizer
label_binarizer = LabelBinarizer()
image_labels = label_binarizer.fit_transform(train_y)
pickle.dump(label_binarizer, open("label_transform.pkl", "wb"))
n_classes = len(label_binarizer.classes_)
# ## 7- Create student and teacher models
# Initialy, we create a teacher model and a smaller student model using keras. Both models are
# convolutional neural networks and created using `Sequential()`,
# but could be any Keras model.
# Create the teacher
teacher = keras.Sequential(
name="teacher",
)
inputShape = (250, 250, 3)
chanDim = -1
if K.image_data_format() == "channels_first":
inputShape = (3, 250, 250)
chanDim = 1
teacher.add(Conv2D(32, (3, 3), padding="same", input_shape=inputShape))
teacher.add(Activation("relu"))
teacher.add(BatchNormalization(axis=chanDim))
teacher.add(MaxPooling2D(pool_size=(3, 3)))
teacher.add(Dropout(0.25))
teacher.add(Conv2D(64, (3, 3), padding="same"))
teacher.add(Activation("relu"))
teacher.add(BatchNormalization(axis=chanDim))
teacher.add(Conv2D(64, (3, 3), padding="same"))
teacher.add(Activation("relu"))
teacher.add(BatchNormalization(axis=chanDim))
teacher.add(MaxPooling2D(pool_size=(2, 2)))
teacher.add(Dropout(0.25))
teacher.add(Conv2D(128, (3, 3), padding="same"))
teacher.add(Activation("relu"))
teacher.add(BatchNormalization(axis=chanDim))
teacher.add(Conv2D(128, (3, 3), padding="same"))
teacher.add(Activation("relu"))
teacher.add(BatchNormalization(axis=chanDim))
teacher.add(MaxPooling2D(pool_size=(2, 2)))
teacher.add(Dropout(0.25))
teacher.add(Flatten())
teacher.add(Dense(1024))
teacher.add(Activation("relu"))
teacher.add(BatchNormalization())
teacher.add(Dropout(0.5))
teacher.add(Dense(n_classes))
# Create the student
student = keras.Sequential(
[
keras.Input(shape=(250, 250, 3)),
layers.Conv2D(16, (3, 3), strides=(2, 2), padding="same"),
layers.LeakyReLU(alpha=0.2),
layers.MaxPooling2D(pool_size=(2, 2), strides=(1, 1), padding="same"),
layers.Conv2D(32, (3, 3), strides=(2, 2), padding="same"),
layers.LeakyReLU(alpha=0.2),
layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding="same"),
layers.Flatten(),
layers.Dense(n_classes),
],
name="student",
)
# Clone student for later comparison
student_scratch = keras.models.clone_model(student)
# # 8- Displaying the model summary
# the custom method 'summary' allows us to diplay the architecture of the models described above, this allows us to know thw number parameters avaible in our defined model.
teacher.summary()
student.summary()
# # 9- Compiling Teacher Model for training
# The teacher model is first compile using custom compile method to achieve better accucaracy and learn more information
# Train teacher as usual
teacher.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=["acc"],
)
# ## 10- Train the teacher
# During training Step, the model sifts through preexisting data and draws conclusions based on what it “thinks” the data represents. Every time it comes to an incorrect conclusion, that result is fed back to the system so that it “learns” from its mistake.
# This process makes connections between the artificial neurons stronger over time and increases the likelihood that the system will make accurate predictions in the future. As it’s presented with novel data, the DNN should be able to categorize and analyze new and possibly more complex information. Ultimately, it will continue to learn from its encounters and become more intuitive over time.
# * ** to train a model a fit() method is called on the model, fit takes arguments such as trainig data, validation data, epoch, train step and valudation step.
#
teacher_history = teacher.fit(
train_generator, validation_data=validation_generator, epochs=5
)
# # 11- Plotting Teacher Model Accuracy and loss Curves
# * **Accruacy curve:** The accuracy curve describes the accuracy of test and validation sets. The X-axis is the iteration step. The Y-axis is the prediction accuracy. The blue curve is the accuracy on a batch of training examples from the training set, the orange curve is the accuracy for the test set.
# * **Loss curve:** One of the most used plots to debug a neural network is a Loss curve during training. It gives us a snapshot of the training process and the direction in which the network learns
import matplotlib.pyplot as plt
acc = teacher_history.history["acc"]
val_acc = teacher_history.history["val_acc"]
loss = teacher_history.history["loss"]
val_loss = teacher_history.history["val_loss"]
print(range(1, len(acc) + 1))
epochs = range(1, len(acc) + 1)
# Train and validation accuracy
plt.plot(epochs, acc, "b", label="Training accurarcy")
plt.plot(epochs, val_acc, "r", label="Validation accurarcy")
plt.title("Training and Validation accurarcy")
plt.legend()
plt.figure()
# Train and validation loss
plt.plot(epochs, loss, "b", label="Training loss")
plt.plot(epochs, val_loss, "r", label="Validation loss")
plt.title("Training and Validation loss")
plt.legend()
plt.show()
# ## 12 Distilling teacher knowledge to student Model
# We have already trained the teacher model, and we only need to initialize a
# `Distiller(student, teacher)` instance, `compile()` it with the desired losses,
# hyperparameters and optimizer, and distill the teacher to the student.
# Here we are trying to calculate the general loss by conputing KL divergence between student loss and distillation using the following relation.
# Dist_loss= 1/m ∑_(j=0)^m〖(2t^2 αD_KL (p^j,q^j )-(1-α)∑_(i=1)^cyi〗^(j ) log(1-〖yhat〗^j)〗
# where:
# P: is the soft labels from the teacher network
# q: is the softmax scores of student model
# Dkl: is the Kullback- Liebler (KL) divergence between p and q
# α: is the relative importance of the teacher’s guidance
# The distillation loss was minimized using the KL divergence between soft labels of a teacher p, and student model score q
#
# Initialize and compile distiller
distiller = Distiller(student=student, teacher=teacher)
distiller.compile(
optimizer=keras.optimizers.Adam(),
metrics=["acc"],
student_loss_fn=keras.losses.CategoricalCrossentropy(from_logits=True),
distillation_loss_fn=keras.losses.KLDivergence(),
alpha=0.1,
temperature=10,
)
# Distill teacher to student
student_history = distiller.fit(
train_generator, validation_data=validation_generator, epochs=3
)
# # Plotting Student model Accuracy and loss curves
# to investigate the performance of the student model for comparison with teacher model, an accaucry and validation curve was plotted below.
import matplotlib.pyplot as plt
acc = student_history.history["acc"]
val_acc = student_history.history["val_acc"]
loss = student_history.history["distillation_loss"]
val_loss = student_history.history["student_loss"]
print(range(1, len(acc) + 1))
epochs = range(1, len(acc) + 1)
# Train and validation accuracy
plt.plot(epochs, acc, "b", label="Training accurarcy")
plt.plot(epochs, val_acc, "r", label="Validation accurarcy")
plt.title("Training and Validation accurarcy")
plt.legend()
plt.figure()
# Train and validation loss
plt.plot(epochs, loss, "b", label="Training loss")
plt.plot(epochs, val_loss, "r", label="Validation loss")
plt.title("Training and Validation loss")
plt.legend()
plt.show()
# ## Train student from scratch for comparison
# We can also train an equivalent student model from scratch without the teacher, in order
# to evaluate the performance gain obtained by knowledge distillation.
# Train student as doen usually
student_scratch.compile(
optimizer=keras.optimizers.Adam(),
loss=keras.losses.CategoricalCrossentropy(from_logits=True),
metrics=["acc"],
)
# Train and evaluate student trained from scratch.
student_scratch.fit(train_generator, epochs=1)
std_history = student_scratch.evaluate(validation_generator)
| false | 0 | 4,817 | 3 | 271 | 4,817 |
||
113527804 | <kaggle_start><code># import module
import os
import glob
import random
from datetime import datetime
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch import optim
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
import numpy as np
import logging
from tqdm import tqdm
# ### 设置随机种子
# seed setting
def same_seeds(seed):
# Python built-in random module
random.seed(seed)
# Numpy
np.random.seed(seed)
# Torch
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
same_seeds(2022)
workspace_dir = "/kaggle/input/bao-ke-meng-img"
# ### 数据集
# In order to unified image information, we use the transform function to:
# - Resize image to 64x64
# - Normalize the image
# This CrypkoDataset class will be use in Section 4
# prepare for CrypkoDataset
class CrypkoDataset(Dataset):
def __init__(self, fnames, transform):
self.transform = transform
self.fnames = fnames
self.num_samples = len(self.fnames)
def __getitem__(self, idx):
fname = self.fnames[idx]
img = torchvision.io.read_image(fname)
img = self.transform(img)
return img
def __len__(self):
return self.num_samples
def get_dataset(root):
fnames = glob.glob(os.path.join(root, "*"))
compose = [
transforms.ToPILImage(),
transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
]
transform = transforms.Compose(compose)
dataset = CrypkoDataset(fnames, transform)
return dataset
def get_dataset(root):
fnames = glob.glob(os.path.join(root, "*"))
compose = [
transforms.ToPILImage(),
transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
]
transform = transforms.Compose(compose)
dataset = CrypkoDataset(fnames, transform)
return dataset
# ### 展示图片
#
temp_dataset = get_dataset(os.path.join(workspace_dir, "faces"))
images = [temp_dataset[i] for i in range(4)]
grid_img = torchvision.utils.make_grid(images, nrow=4)
plt.figure(figsize=(10, 10))
plt.imshow(grid_img.permute(1, 2, 0))
plt.show()
# ### 模型配置
# #### 创建模型
class Generator(nn.Module):
"""
Input shape: (batch, in_dim)
Output shape: (batch, 3, 64, 64)
"""
def __init__(self, in_dim, feature_dim=64):
super().__init__()
# input: (batch, 100)
self.l1 = nn.Sequential(
nn.Linear(in_dim, feature_dim * 8 * 4 * 4, bias=False),
nn.BatchNorm1d(feature_dim * 8 * 4 * 4),
nn.ReLU(),
)
self.l2 = nn.Sequential(
self.dconv_bn_relu(
feature_dim * 8, feature_dim * 4
), # (batch, feature_dim * 16, 8, 8)
self.dconv_bn_relu(
feature_dim * 4, feature_dim * 2
), # (batch, feature_dim * 16, 16, 16)
self.dconv_bn_relu(
feature_dim * 2, feature_dim
), # (batch, feature_dim * 16, 32, 32)
)
self.l3 = nn.Sequential(
nn.ConvTranspose2d(
feature_dim,
3,
kernel_size=5,
stride=2,
padding=2,
output_padding=1,
bias=False,
),
nn.Tanh(),
)
self.apply(weights_init)
def dconv_bn_relu(self, in_dim, out_dim):
return nn.Sequential(
nn.ConvTranspose2d(
in_dim,
out_dim,
kernel_size=5,
stride=2,
padding=2,
output_padding=1,
bias=False,
), # double height and width
nn.BatchNorm2d(out_dim),
nn.ReLU(True),
)
def forward(self, x):
y = self.l1(x)
y = y.view(y.size(0), -1, 4, 4)
y = self.l2(y)
y = self.l3(y)
return y
# Discriminator
class Discriminator(nn.Module):
"""
Input shape: (batch, 3, 64, 64)
Output shape: (batch)
"""
def __init__(self, in_dim, feature_dim=64):
super(Discriminator, self).__init__()
# input: (batch, 3, 64, 64)
"""
NOTE FOR SETTING DISCRIMINATOR:
Remove last sigmoid layer for WGAN
"""
self.l1 = nn.Sequential(
nn.Conv2d(
in_dim, feature_dim, kernel_size=4, stride=2, padding=1
), # (batch, 3, 32, 32)
nn.LeakyReLU(0.2),
self.conv_bn_lrelu(feature_dim, feature_dim * 2), # (batch, 3, 16, 16)
self.conv_bn_lrelu(feature_dim * 2, feature_dim * 4), # (batch, 3, 8, 8)
self.conv_bn_lrelu(feature_dim * 4, feature_dim * 8), # (batch, 3, 4, 4)
nn.Conv2d(feature_dim * 8, 1, kernel_size=4, stride=1, padding=0),
# nn.Sigmoid()
)
self.apply(weights_init)
def conv_bn_lrelu(self, in_dim, out_dim):
"""
NOTE FOR SETTING DISCRIMINATOR:
You can't use nn.Batchnorm for WGAN-GP
Use nn.InstanceNorm2d instead
"""
return nn.Sequential(
nn.Conv2d(in_dim, out_dim, 4, 2, 1),
nn.BatchNorm2d(out_dim),
nn.LeakyReLU(0.2),
)
def forward(self, x):
y = self.l1(x)
y = y.view(-1)
return y
# setting for weight init function
def weights_init(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find("BatchNorm") != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
class TrainerGAN:
def __init__(self, config):
self.config = config
self.G = Generator(100)
self.D = Discriminator(3)
self.loss = nn.BCELoss()
"""
NOTE FOR SETTING OPTIMIZER:
GAN: use Adam optimizer
WGAN: use RMSprop optimizer
WGAN-GP: use Adam optimizer
"""
self.opt_D = torch.optim.Adam(
self.D.parameters(), lr=self.config["lr"], betas=(0.5, 0.999)
)
self.opt_G = torch.optim.Adam(
self.G.parameters(), lr=self.config["lr"], betas=(0.5, 0.999)
)
self.dataloader = None
self.log_dir = os.path.join(self.config["model_dir"], "logs")
self.ckpt_dir = os.path.join(self.config["model_dir"], "checkpoints")
FORMAT = "%(asctime)s - %(levelname)s: %(message)s"
logging.basicConfig(level=logging.INFO, format=FORMAT, datefmt="%Y-%m-%d %H:%M")
self.steps = 0
self.z_samples = Variable(torch.randn(100, self.config["z_dim"])).cuda()
def prepare_environment(self):
"""
Use this funciton to prepare function
"""
os.makedirs(self.log_dir, exist_ok=True)
os.makedirs(self.ckpt_dir, exist_ok=True)
# update dir by time
time = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
self.log_dir = os.path.join(
self.log_dir, time + f'_{self.config["model_type"]}'
)
self.ckpt_dir = os.path.join(
self.ckpt_dir, time + f'_{self.config["model_type"]}'
)
os.makedirs(self.log_dir)
os.makedirs(self.ckpt_dir)
# create dataset by the above function
dataset = get_dataset(os.path.join(self.config["workspace_dir"], "faces"))
self.dataloader = DataLoader(
dataset, batch_size=self.config["batch_size"], shuffle=True, num_workers=2
)
# model preparation
self.G = self.G.cuda()
self.D = self.D.cuda()
self.G.train()
self.D.train()
def gp(self):
"""
Implement gradient penalty function
"""
pass
def train(self):
"""
Use this function to train generator and discriminator
"""
self.prepare_environment()
for e, epoch in enumerate(range(self.config["n_epoch"])):
progress_bar = tqdm(self.dataloader)
progress_bar.set_description(f"Epoch {e+1}")
for i, data in enumerate(progress_bar):
imgs = data.cuda()
bs = imgs.size(0)
# *********************
# * Train D *
# *********************
z = Variable(torch.randn(bs, self.config["z_dim"])).cuda()
r_imgs = Variable(imgs).cuda()
f_imgs = self.G(z)
r_label = torch.ones((bs)).cuda()
f_label = torch.zeros((bs)).cuda()
# Discriminator forwarding
r_logit = self.D(r_imgs)
f_logit = self.D(f_imgs)
"""
NOTE FOR SETTING DISCRIMINATOR LOSS:
GAN:
loss_D = (r_loss + f_loss)/2
WGAN:
loss_D = -torch.mean(r_logit) + torch.mean(f_logit)
WGAN-GP:
gradient_penalty = self.gp(r_imgs, f_imgs)
loss_D = -torch.mean(r_logit) + torch.mean(f_logit) + gradient_penalty
"""
# Loss for discriminator
if self.config["model_type"] == "GAN":
r_loss = self.loss(r_logit, r_label)
f_loss = self.loss(f_logit, f_label)
loss_D = (r_loss + f_loss) / 2
elif self.config["model_type"] == "WGAN":
loss_D = -torch.mean(r_logit) + torch.mean(f_logit)
# Discriminator backwarding
self.D.zero_grad()
loss_D.backward()
self.opt_D.step()
"""
NOTE FOR SETTING WEIGHT CLIP:
WGAN: below code
"""
# for p in self.D.parameters():
# p.data.clamp_(-self.config["clip_value"], self.config["clip_value"])
# *********************
# * Train G *
# *********************
if self.steps % self.config["n_critic"] == 0:
# Generate some fake images.
z = Variable(torch.randn(bs, self.config["z_dim"])).cuda()
f_imgs = self.G(z)
# Generator forwarding
f_logit = self.D(f_imgs)
"""
NOTE FOR SETTING LOSS FOR GENERATOR:
GAN: loss_G = self.loss(f_logit, r_label)
WGAN: loss_G = -torch.mean(self.D(f_imgs))
WGAN-GP: loss_G = -torch.mean(self.D(f_imgs))
"""
# Loss for the generator.
if self.config["model_type"] == "GAN":
loss_G = self.loss(f_logit, r_label)
elif self.config["model_type"] == "WGAN":
loss_G = -torch.mean(f_logit)
# Generator backwarding
self.G.zero_grad()
loss_G.backward()
self.opt_G.step()
if self.steps % 10 == 0:
progress_bar.set_postfix(loss_G=loss_G.item(), loss_D=loss_D.item())
self.steps += 1
self.G.eval()
# f_imgs_sample = (self.G(self.z_samples).data + 1) / 2.0
f_imgs_sample = self.G(self.z_samples).data
filename = os.path.join(self.log_dir, f"Epoch_{epoch+1:03d}.jpg")
torchvision.utils.save_image(f_imgs_sample, filename, nrow=10)
# logging.info(f'Save some samples to {filename}.')
# Show some images during training.
grid_img = torchvision.utils.make_grid(f_imgs_sample.cpu(), nrow=10)
plt.figure(figsize=(10, 10))
plt.imshow(grid_img.permute(1, 2, 0))
plt.show()
self.G.train()
if (e + 1) % 5 == 0 or e == 0:
# Save the checkpoints.
torch.save(
self.G.state_dict(), os.path.join(self.ckpt_dir, f"G_{e}.pth")
)
torch.save(
self.D.state_dict(), os.path.join(self.ckpt_dir, f"D_{e}.pth")
)
logging.info("Finish training")
def inference(self, G_path, n_generate=1000, n_output=30, show=False):
"""
1. G_path is the path for Generator ckpt
2. You can use this function to generate final answer
"""
self.G.load_state_dict(torch.load(G_path))
self.G.cuda()
self.G.eval()
z = Variable(torch.randn(n_generate, self.config["z_dim"])).cuda()
imgs = (self.G(z).data + 1) / 2.0
os.makedirs("output", exist_ok=True)
for i in range(n_generate):
torchvision.utils.save_image(imgs[i], f"output/{i+1}.jpg")
if show:
row, col = n_output // 10 + 1, 10
grid_img = torchvision.utils.make_grid(imgs[:n_output].cpu(), nrow=row)
plt.figure(figsize=(row, col))
plt.imshow(grid_img.permute(1, 2, 0))
plt.show()
workspace_dir = "/kaggle/input/bao-ke-meng-img"
config = {
"model_type": "WGAN",
"batch_size": 64,
"lr": 1e-4,
"n_epoch": 10,
"n_critic": 1,
"z_dim": 100,
"workspace_dir": workspace_dir, # define in the environment setting
"model_dir": "/kaggle/working/",
}
trainer = TrainerGAN(config)
trainer.train()
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0113/527/113527804.ipynb | null | null | [{"Id": 113527804, "ScriptId": 32903951, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 6717967, "CreationDate": "12/11/2022 13:26:07", "VersionNumber": 1.0, "Title": "wgan_demo", "EvaluationDate": "12/11/2022", "IsChange": true, "TotalLines": 413.0, "LinesInsertedFromPrevious": 413.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | # import module
import os
import glob
import random
from datetime import datetime
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from torch import optim
from torch.autograd import Variable
from torch.utils.data import Dataset, DataLoader
import matplotlib.pyplot as plt
import numpy as np
import logging
from tqdm import tqdm
# ### 设置随机种子
# seed setting
def same_seeds(seed):
# Python built-in random module
random.seed(seed)
# Numpy
np.random.seed(seed)
# Torch
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
same_seeds(2022)
workspace_dir = "/kaggle/input/bao-ke-meng-img"
# ### 数据集
# In order to unified image information, we use the transform function to:
# - Resize image to 64x64
# - Normalize the image
# This CrypkoDataset class will be use in Section 4
# prepare for CrypkoDataset
class CrypkoDataset(Dataset):
def __init__(self, fnames, transform):
self.transform = transform
self.fnames = fnames
self.num_samples = len(self.fnames)
def __getitem__(self, idx):
fname = self.fnames[idx]
img = torchvision.io.read_image(fname)
img = self.transform(img)
return img
def __len__(self):
return self.num_samples
def get_dataset(root):
fnames = glob.glob(os.path.join(root, "*"))
compose = [
transforms.ToPILImage(),
transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
]
transform = transforms.Compose(compose)
dataset = CrypkoDataset(fnames, transform)
return dataset
def get_dataset(root):
fnames = glob.glob(os.path.join(root, "*"))
compose = [
transforms.ToPILImage(),
transforms.Resize((64, 64)),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5)),
]
transform = transforms.Compose(compose)
dataset = CrypkoDataset(fnames, transform)
return dataset
# ### 展示图片
#
temp_dataset = get_dataset(os.path.join(workspace_dir, "faces"))
images = [temp_dataset[i] for i in range(4)]
grid_img = torchvision.utils.make_grid(images, nrow=4)
plt.figure(figsize=(10, 10))
plt.imshow(grid_img.permute(1, 2, 0))
plt.show()
# ### 模型配置
# #### 创建模型
class Generator(nn.Module):
"""
Input shape: (batch, in_dim)
Output shape: (batch, 3, 64, 64)
"""
def __init__(self, in_dim, feature_dim=64):
super().__init__()
# input: (batch, 100)
self.l1 = nn.Sequential(
nn.Linear(in_dim, feature_dim * 8 * 4 * 4, bias=False),
nn.BatchNorm1d(feature_dim * 8 * 4 * 4),
nn.ReLU(),
)
self.l2 = nn.Sequential(
self.dconv_bn_relu(
feature_dim * 8, feature_dim * 4
), # (batch, feature_dim * 16, 8, 8)
self.dconv_bn_relu(
feature_dim * 4, feature_dim * 2
), # (batch, feature_dim * 16, 16, 16)
self.dconv_bn_relu(
feature_dim * 2, feature_dim
), # (batch, feature_dim * 16, 32, 32)
)
self.l3 = nn.Sequential(
nn.ConvTranspose2d(
feature_dim,
3,
kernel_size=5,
stride=2,
padding=2,
output_padding=1,
bias=False,
),
nn.Tanh(),
)
self.apply(weights_init)
def dconv_bn_relu(self, in_dim, out_dim):
return nn.Sequential(
nn.ConvTranspose2d(
in_dim,
out_dim,
kernel_size=5,
stride=2,
padding=2,
output_padding=1,
bias=False,
), # double height and width
nn.BatchNorm2d(out_dim),
nn.ReLU(True),
)
def forward(self, x):
y = self.l1(x)
y = y.view(y.size(0), -1, 4, 4)
y = self.l2(y)
y = self.l3(y)
return y
# Discriminator
class Discriminator(nn.Module):
"""
Input shape: (batch, 3, 64, 64)
Output shape: (batch)
"""
def __init__(self, in_dim, feature_dim=64):
super(Discriminator, self).__init__()
# input: (batch, 3, 64, 64)
"""
NOTE FOR SETTING DISCRIMINATOR:
Remove last sigmoid layer for WGAN
"""
self.l1 = nn.Sequential(
nn.Conv2d(
in_dim, feature_dim, kernel_size=4, stride=2, padding=1
), # (batch, 3, 32, 32)
nn.LeakyReLU(0.2),
self.conv_bn_lrelu(feature_dim, feature_dim * 2), # (batch, 3, 16, 16)
self.conv_bn_lrelu(feature_dim * 2, feature_dim * 4), # (batch, 3, 8, 8)
self.conv_bn_lrelu(feature_dim * 4, feature_dim * 8), # (batch, 3, 4, 4)
nn.Conv2d(feature_dim * 8, 1, kernel_size=4, stride=1, padding=0),
# nn.Sigmoid()
)
self.apply(weights_init)
def conv_bn_lrelu(self, in_dim, out_dim):
"""
NOTE FOR SETTING DISCRIMINATOR:
You can't use nn.Batchnorm for WGAN-GP
Use nn.InstanceNorm2d instead
"""
return nn.Sequential(
nn.Conv2d(in_dim, out_dim, 4, 2, 1),
nn.BatchNorm2d(out_dim),
nn.LeakyReLU(0.2),
)
def forward(self, x):
y = self.l1(x)
y = y.view(-1)
return y
# setting for weight init function
def weights_init(m):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
m.weight.data.normal_(0.0, 0.02)
elif classname.find("BatchNorm") != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
class TrainerGAN:
def __init__(self, config):
self.config = config
self.G = Generator(100)
self.D = Discriminator(3)
self.loss = nn.BCELoss()
"""
NOTE FOR SETTING OPTIMIZER:
GAN: use Adam optimizer
WGAN: use RMSprop optimizer
WGAN-GP: use Adam optimizer
"""
self.opt_D = torch.optim.Adam(
self.D.parameters(), lr=self.config["lr"], betas=(0.5, 0.999)
)
self.opt_G = torch.optim.Adam(
self.G.parameters(), lr=self.config["lr"], betas=(0.5, 0.999)
)
self.dataloader = None
self.log_dir = os.path.join(self.config["model_dir"], "logs")
self.ckpt_dir = os.path.join(self.config["model_dir"], "checkpoints")
FORMAT = "%(asctime)s - %(levelname)s: %(message)s"
logging.basicConfig(level=logging.INFO, format=FORMAT, datefmt="%Y-%m-%d %H:%M")
self.steps = 0
self.z_samples = Variable(torch.randn(100, self.config["z_dim"])).cuda()
def prepare_environment(self):
"""
Use this funciton to prepare function
"""
os.makedirs(self.log_dir, exist_ok=True)
os.makedirs(self.ckpt_dir, exist_ok=True)
# update dir by time
time = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
self.log_dir = os.path.join(
self.log_dir, time + f'_{self.config["model_type"]}'
)
self.ckpt_dir = os.path.join(
self.ckpt_dir, time + f'_{self.config["model_type"]}'
)
os.makedirs(self.log_dir)
os.makedirs(self.ckpt_dir)
# create dataset by the above function
dataset = get_dataset(os.path.join(self.config["workspace_dir"], "faces"))
self.dataloader = DataLoader(
dataset, batch_size=self.config["batch_size"], shuffle=True, num_workers=2
)
# model preparation
self.G = self.G.cuda()
self.D = self.D.cuda()
self.G.train()
self.D.train()
def gp(self):
"""
Implement gradient penalty function
"""
pass
def train(self):
"""
Use this function to train generator and discriminator
"""
self.prepare_environment()
for e, epoch in enumerate(range(self.config["n_epoch"])):
progress_bar = tqdm(self.dataloader)
progress_bar.set_description(f"Epoch {e+1}")
for i, data in enumerate(progress_bar):
imgs = data.cuda()
bs = imgs.size(0)
# *********************
# * Train D *
# *********************
z = Variable(torch.randn(bs, self.config["z_dim"])).cuda()
r_imgs = Variable(imgs).cuda()
f_imgs = self.G(z)
r_label = torch.ones((bs)).cuda()
f_label = torch.zeros((bs)).cuda()
# Discriminator forwarding
r_logit = self.D(r_imgs)
f_logit = self.D(f_imgs)
"""
NOTE FOR SETTING DISCRIMINATOR LOSS:
GAN:
loss_D = (r_loss + f_loss)/2
WGAN:
loss_D = -torch.mean(r_logit) + torch.mean(f_logit)
WGAN-GP:
gradient_penalty = self.gp(r_imgs, f_imgs)
loss_D = -torch.mean(r_logit) + torch.mean(f_logit) + gradient_penalty
"""
# Loss for discriminator
if self.config["model_type"] == "GAN":
r_loss = self.loss(r_logit, r_label)
f_loss = self.loss(f_logit, f_label)
loss_D = (r_loss + f_loss) / 2
elif self.config["model_type"] == "WGAN":
loss_D = -torch.mean(r_logit) + torch.mean(f_logit)
# Discriminator backwarding
self.D.zero_grad()
loss_D.backward()
self.opt_D.step()
"""
NOTE FOR SETTING WEIGHT CLIP:
WGAN: below code
"""
# for p in self.D.parameters():
# p.data.clamp_(-self.config["clip_value"], self.config["clip_value"])
# *********************
# * Train G *
# *********************
if self.steps % self.config["n_critic"] == 0:
# Generate some fake images.
z = Variable(torch.randn(bs, self.config["z_dim"])).cuda()
f_imgs = self.G(z)
# Generator forwarding
f_logit = self.D(f_imgs)
"""
NOTE FOR SETTING LOSS FOR GENERATOR:
GAN: loss_G = self.loss(f_logit, r_label)
WGAN: loss_G = -torch.mean(self.D(f_imgs))
WGAN-GP: loss_G = -torch.mean(self.D(f_imgs))
"""
# Loss for the generator.
if self.config["model_type"] == "GAN":
loss_G = self.loss(f_logit, r_label)
elif self.config["model_type"] == "WGAN":
loss_G = -torch.mean(f_logit)
# Generator backwarding
self.G.zero_grad()
loss_G.backward()
self.opt_G.step()
if self.steps % 10 == 0:
progress_bar.set_postfix(loss_G=loss_G.item(), loss_D=loss_D.item())
self.steps += 1
self.G.eval()
# f_imgs_sample = (self.G(self.z_samples).data + 1) / 2.0
f_imgs_sample = self.G(self.z_samples).data
filename = os.path.join(self.log_dir, f"Epoch_{epoch+1:03d}.jpg")
torchvision.utils.save_image(f_imgs_sample, filename, nrow=10)
# logging.info(f'Save some samples to {filename}.')
# Show some images during training.
grid_img = torchvision.utils.make_grid(f_imgs_sample.cpu(), nrow=10)
plt.figure(figsize=(10, 10))
plt.imshow(grid_img.permute(1, 2, 0))
plt.show()
self.G.train()
if (e + 1) % 5 == 0 or e == 0:
# Save the checkpoints.
torch.save(
self.G.state_dict(), os.path.join(self.ckpt_dir, f"G_{e}.pth")
)
torch.save(
self.D.state_dict(), os.path.join(self.ckpt_dir, f"D_{e}.pth")
)
logging.info("Finish training")
def inference(self, G_path, n_generate=1000, n_output=30, show=False):
"""
1. G_path is the path for Generator ckpt
2. You can use this function to generate final answer
"""
self.G.load_state_dict(torch.load(G_path))
self.G.cuda()
self.G.eval()
z = Variable(torch.randn(n_generate, self.config["z_dim"])).cuda()
imgs = (self.G(z).data + 1) / 2.0
os.makedirs("output", exist_ok=True)
for i in range(n_generate):
torchvision.utils.save_image(imgs[i], f"output/{i+1}.jpg")
if show:
row, col = n_output // 10 + 1, 10
grid_img = torchvision.utils.make_grid(imgs[:n_output].cpu(), nrow=row)
plt.figure(figsize=(row, col))
plt.imshow(grid_img.permute(1, 2, 0))
plt.show()
workspace_dir = "/kaggle/input/bao-ke-meng-img"
config = {
"model_type": "WGAN",
"batch_size": 64,
"lr": 1e-4,
"n_epoch": 10,
"n_critic": 1,
"z_dim": 100,
"workspace_dir": workspace_dir, # define in the environment setting
"model_dir": "/kaggle/working/",
}
trainer = TrainerGAN(config)
trainer.train()
| false | 0 | 4,068 | 0 | 6 | 4,068 |
||
113664182 | <kaggle_start><data_title>Premier League 2016-2017 and 2017-2018<data_description>The players included in this dataset played in both the 2016-2017 and 2017-2018 seasons<data_name>premier-league-20162017-and-20172018
<code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
filepath = "/kaggle/input/premier-league-20162017-and-20172018/PremierLeagueData2016-2017and2017-2018.csv"
raw_data = pd.read_csv(filepath, encoding="cp1252")
data = raw_data.loc[1:, :].reset_index(drop=True).copy()
desc = raw_data.loc[0, :].copy()
desc
def preprocess_df(df: pd.DataFrame):
"""
Preprocess input dataframe - feature engineering.
Input:
df -> pandas.DataFrame
Output:
df -> pandas.DataFrame (preprocessed)
"""
pass
df = data.copy()
# drop `Variable`
if "Variable" in df.columns:
df = df.drop("Variable", axis=1)
# clean column `Nationality`
df.loc[:, "Nationality"] = df["Nationality"].str.replace("\xa0", "")
df.loc[:, "Nationality"] = df["Nationality"].str.replace(" ", "_")
# turn rare nationalities into `Other`
max_count_nats = 3
other_nationalities = (
df["Nationality"]
.value_counts()[df["Nationality"].value_counts() <= max_count_nats]
.index.tolist()
)
df.loc[df["Nationality"].isin(other_nationalities), "Nationality"] = "Other"
# one hot encode nationalities
nationalities_df = pd.get_dummies(df["Nationality"], prefix="NAT").astype(bool)
df = df.drop("Nationality", axis=1)
df = pd.concat([df, nationalities_df], axis=1)
# data = preprocess_df(data)
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
target = "Position"
le = LabelEncoder()
y = le.fit_transform(df[target])
X = df.loc[:, df.columns != target]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=2023
)
# le.classes_
# le.inverse_transform([0, 0, 1, 2])
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
# Define a list of transformers to use in the pipeline
transformers = [("scaler", StandardScaler()), ("clf", RandomForestClassifier())]
# Create a classification pipeline
pipeline = Pipeline(transformers)
# Train the pipeline on the training data
pipeline.fit(X_train, y_train)
# Use the pipeline to make predictions on the test data
predictions = pipeline.predict(X_test)
# Create a Confusion Matrix
cm = confusion_matrix(y_test, predictions)
cm
y_hat = le.inverse_transform(predictions)
y_hat
from sklearn.metrics import accuracy_score
from sklearn.model_selection import StratifiedKFold
k = 5
cv = StratifiedKFold(n_splits=k, random_state=2023, shuffle=True)
params = {
"n_estimators": 100,
"criterion": "gini",
"max_depth": 8,
"min_samples_split": 2,
"min_samples_leaf": 1,
"min_weight_fraction_leaf": 0.0,
"max_features": "sqrt",
"max_leaf_nodes": None,
"min_impurity_decrease": 0.0,
"bootstrap": True,
"oob_score": False,
"n_jobs": 4,
"random_state": None,
"verbose": 0,
"warm_start": False,
"class_weight": None,
"ccp_alpha": 0.0,
"max_samples": None,
}
clf = RandomForestClassifier(**params)
scores = []
for (train, test), i in zip(cv.split(X, y), range(k)):
X_train = X.iloc[train]
y_train = y[train]
X_test = X.iloc[test]
y_test = y[test]
clf.fit(X_train, y_train)
preds = clf.predict(X_test)
scores.append(accuracy_score(y_test, preds))
scores = np.array(scores)
np.mean(scores), np.std(scores)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0113/664/113664182.ipynb | premier-league-20162017-and-20172018 | andrewsundberg | [{"Id": 113664182, "ScriptId": 33162490, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1141571, "CreationDate": "12/13/2022 01:05:22", "VersionNumber": 2.0, "Title": "DSBA2022-23", "EvaluationDate": "12/13/2022", "IsChange": true, "TotalLines": 135.0, "LinesInsertedFromPrevious": 125.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 10.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 158934569, "KernelVersionId": 113664182, "SourceDatasetVersionId": 193628}] | [{"Id": 193628, "DatasetId": 83417, "DatasourceVersionId": 204764, "CreatorUserId": 2192630, "LicenseName": "Unknown", "CreationDate": "11/27/2018 23:24:10", "VersionNumber": 1.0, "Title": "Premier League 2016-2017 and 2017-2018", "Slug": "premier-league-20162017-and-20172018", "Subtitle": "2016-2017 and 2017-2018 Seasons", "Description": "The players included in this dataset played in both the 2016-2017 and 2017-2018 seasons", "VersionNotes": "Initial release", "TotalCompressedBytes": 80644.0, "TotalUncompressedBytes": 80644.0}] | [{"Id": 83417, "CreatorUserId": 2192630, "OwnerUserId": 2192630.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 193628.0, "CurrentDatasourceVersionId": 204764.0, "ForumId": 92884, "Type": 2, "CreationDate": "11/27/2018 23:24:10", "LastActivityDate": "11/27/2018", "TotalViews": 2249, "TotalDownloads": 109, "TotalVotes": 3, "TotalKernels": 2}] | [{"Id": 2192630, "UserName": "andrewsundberg", "DisplayName": "Andrew Sundberg", "RegisterDate": "08/29/2018", "PerformanceTier": 1}] | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
filepath = "/kaggle/input/premier-league-20162017-and-20172018/PremierLeagueData2016-2017and2017-2018.csv"
raw_data = pd.read_csv(filepath, encoding="cp1252")
data = raw_data.loc[1:, :].reset_index(drop=True).copy()
desc = raw_data.loc[0, :].copy()
desc
def preprocess_df(df: pd.DataFrame):
"""
Preprocess input dataframe - feature engineering.
Input:
df -> pandas.DataFrame
Output:
df -> pandas.DataFrame (preprocessed)
"""
pass
df = data.copy()
# drop `Variable`
if "Variable" in df.columns:
df = df.drop("Variable", axis=1)
# clean column `Nationality`
df.loc[:, "Nationality"] = df["Nationality"].str.replace("\xa0", "")
df.loc[:, "Nationality"] = df["Nationality"].str.replace(" ", "_")
# turn rare nationalities into `Other`
max_count_nats = 3
other_nationalities = (
df["Nationality"]
.value_counts()[df["Nationality"].value_counts() <= max_count_nats]
.index.tolist()
)
df.loc[df["Nationality"].isin(other_nationalities), "Nationality"] = "Other"
# one hot encode nationalities
nationalities_df = pd.get_dummies(df["Nationality"], prefix="NAT").astype(bool)
df = df.drop("Nationality", axis=1)
df = pd.concat([df, nationalities_df], axis=1)
# data = preprocess_df(data)
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
target = "Position"
le = LabelEncoder()
y = le.fit_transform(df[target])
X = df.loc[:, df.columns != target]
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=2023
)
# le.classes_
# le.inverse_transform([0, 0, 1, 2])
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
# Define a list of transformers to use in the pipeline
transformers = [("scaler", StandardScaler()), ("clf", RandomForestClassifier())]
# Create a classification pipeline
pipeline = Pipeline(transformers)
# Train the pipeline on the training data
pipeline.fit(X_train, y_train)
# Use the pipeline to make predictions on the test data
predictions = pipeline.predict(X_test)
# Create a Confusion Matrix
cm = confusion_matrix(y_test, predictions)
cm
y_hat = le.inverse_transform(predictions)
y_hat
from sklearn.metrics import accuracy_score
from sklearn.model_selection import StratifiedKFold
k = 5
cv = StratifiedKFold(n_splits=k, random_state=2023, shuffle=True)
params = {
"n_estimators": 100,
"criterion": "gini",
"max_depth": 8,
"min_samples_split": 2,
"min_samples_leaf": 1,
"min_weight_fraction_leaf": 0.0,
"max_features": "sqrt",
"max_leaf_nodes": None,
"min_impurity_decrease": 0.0,
"bootstrap": True,
"oob_score": False,
"n_jobs": 4,
"random_state": None,
"verbose": 0,
"warm_start": False,
"class_weight": None,
"ccp_alpha": 0.0,
"max_samples": None,
}
clf = RandomForestClassifier(**params)
scores = []
for (train, test), i in zip(cv.split(X, y), range(k)):
X_train = X.iloc[train]
y_train = y[train]
X_test = X.iloc[test]
y_test = y[test]
clf.fit(X_train, y_train)
preds = clf.predict(X_test)
scores.append(accuracy_score(y_test, preds))
scores = np.array(scores)
np.mean(scores), np.std(scores)
| false | 0 | 1,163 | 0 | 102 | 1,163 |
||
63571785 | <kaggle_start><code># # Introduction
#
# Dans ce notebook, nous allons analyser la signification et l'intuition derrière chaque composante du jeu de données, y compris les images, le LiDAR(aser imaging detection and ranging : La télédétection par laser ou lidar) et les nuages de points. Après avoir plongé dans la théorie qui sous-tend ces concepts, je montrerai comment cet ensemble de données peut être conditionné dans un format compact qui facilite l'interrogation des informations de l'ensemble de données. Enfin, je montrerai comment visualiser et explorer ces données à l'aide la visualization *matplotlib*.
# # Acknowledgements
# * [NuScences DevKit ~ by Lyft](https://github.com/lyft/nuscenes-devkit)
# * [EDA - 3D Object Detection Challenge ~ by beluga](https://www.kaggle.com/gaborfodor/eda-3d-object-detection-challenge)
# * [Lyft: EDA, Animations, generating CSVs ~ by xhulu](https://www.kaggle.com/xhlulu/lyft-eda-animations-generating-csvs)
# * [Lidar - Wikipedia](https://en.wikipedia.org/wiki/Lidar)
# If you find this kernel interesting, please drop an upvote. It motivates me to produce more quality content :)
# ### Une voiture conduite par l'intelligence artificielle !
## Importer la librairie HTML pour lire la vidéo
from IPython.display import HTML
HTML(
'<center><iframe width="700" height="400" src="https://www.youtube.com/embed/tlThdr3O5Qo?rel=0&controls=0&showinfo=0" frameborder="0" allowfullscreen></iframe></center>'
)
# On peut voir dans la vidéo que la voiture est capable de prendre des virages, de changer de voie, de s'arrêter aux feux rouges, etc. sans effort. Cela est possible parce que la voiture est capable de reconnaître avec précision les objets dans l'espace 3D en utilisant les informations de ses capteurs, comme les données d'image et LiDAR. Je vais maintenant examiner la signification théorique de ces formes de données, puis je visualiserai ces informations plus tard dans le noyau.
# # Structure du dataset
# 1. `scene` - Consiste en 25 à 45 secondes de trajet d'une voiture dans un environnement donné. Chaque scence est composée de plusieurs échantillons.
# 2. `sample` - Un instantané d'une scène à un moment précis dans le temps. Chaque échantillon est annoté avec les objets présents.
# 3. `sample_data` - Contient les données collectées à partir d'un capteur particulier de la voiture.
# 4. `sample_annotation` - Une instance annotée d'un objet qui nous intéresse.
# 5. `instance` - Une énumération de toutes les instances d'objets que nous avons observées.
# 6. `category` - Plusieurs catégories d'objets (e.g. véhicule, humain).
# 7. `attribute` - Propriété d'une instance qui peut changer alors que la catégorie reste la même.
# 8. `visibility` -
# 9. `sensor` - Un type de capteur spécifique.
# 10. `calibrated sensor` - Définition d'un capteur particulier tel qu'étalonné sur un véhicule particulier.
# 11. `ego_pose` - Le véhicule Ego pose à un moment précis.
# 12. `log` - Informations sur le journal à partir duquel les données ont été extraites.
# 13. `map` - Cartographier les données stockées sous forme de masques sémantiques binaires à partir d'une vue de haut en bas.
# Nous distinguons deux types d'informations: **image data and LiDAR data**.
# Les données de l'image sont dans le format habituel *.jpeg*, qui est assez simple à comprendre. Chaque image se compose simplement de trois canaux de couleur : Rouge (R), Bleu (B) et Vert (G) qui forment le format d'image couleur RVB. Ces canaux de couleur se superposent pour former l'image colorée finale. Ces images peuvent donc être stockées dans un tenseur quadridimensionnel dont les dimensions sont les suivantes: **(batch_size, channels, width, height)**.
# # What is LiDAR?
# Le LiDAR (Light Detection and Ranging) est une méthode utilisée pour générer des représentations 3D précises de l'environnement, et il utilise la lumière laser pour y parvenir. En gros, la cible 3D est éclairée par une lumière laser (un faisceau de lumière focalisé et dirigé) et la lumière réfléchie est collectée par des capteurs. Le temps nécessaire pour que la lumière soit réfléchie vers le capteur est calculé.
# **Des capteurs différents collectent la lumière de différentes parties de l'objet, et les temps enregistrés par les capteurs seront différents. Cette différence de temps calculée par les capteurs peut être utilisée pour calculer la profondeur de l'objet. Cette information de profondeur, combinée à la représentation 2D de l'image, fournit une représentation 3D précise de l'objet. Ce processus est similaire à la vision humaine réelle. Deux yeux font des observations en 2D et ces deux informations sont combinées pour former une carte 3D (perception de la profondeur). C'est ainsi que les humains perçoivent le monde qui les entoure**.
# Cette technologie est utilisée pour créer des représentations 3D dans de nombreux scénarios du monde réel. Par exemple, elle est utilisée dans les fermes pour aider à semer les graines et à enlever les mauvaises herbes. Un robot en mouvement utilise le LiDAR pour créer une carte en 3D de son environnement. Grâce à cette carte, il évite les obstacles et accomplit ses tâches. Cette technologie est également utilisée en archéologie. Le LiDAR est utilisé pour créer des rendus 3D à partir de scans 2D d'artefacts. Cela donne une idée précise de la forme 3D de l'artefact lorsque celui-ci ne peut être fouillé pour une raison quelconque. Enfin, le LiDAR peut également être utilisé pour produire des cartes 3D de haute qualité des fonds marins et d'autres terrains inaccessibles, ce qui le rend très utile aux géologues et aux océanographes. Ci-dessous, la carte 3D d'un plancher océanique générée à l'aide du LiDAR :
# Et, bien sûr, les voitures à conduite autonome utilisent cette technologie pour identifier les objets qui les entourent en 3D, ainsi que pour estimer la vitesse et l'orientation de ces objets. Cette carte 3D complète fournit à la voiture des informations détaillées qui lui permettent de naviguer même dans des environnements complexes. Vous trouverez ci-dessous une vidéo présentant un drone équipé d'un LiDAR. Il crée automatiquement une carte 3D du monde qui l'entoure en utilisant le processus mentionné ci-dessus.
HTML(
'<center><iframe width="700" height="400" src="https://www.youtube.com/embed/x7De3tCb3_A?rel=0&controls=0&showinfo=0" frameborder="0" allowfullscreen></iframe></center>'
)
# # Démonstration de fonctionnement de LiDAR
# des faisceaux laser sont tirés dans toutes les sens par un laser. Les faisceaux laser se réfléchissent sur les objets qui se trouvent sur leur chemin et les faisceaux réfléchis sont collectés par un capteur. Maintenant, un dispositif spécial appelé **caméra flash LiDAR** est utilisé pour créer des cartes en 3D en utilisant les informations de ces capteurs.
# ### Flash LiDAR Camera
# L'appareil présenté dans l'image ci-dessus s'appelle une caméra Flash LiDAR. Le plan focal d'une caméra Flash LiDAR comporte des rangées et des colonnes de pixels ayant une "profondeur" et une "intensité" suffisantes pour créer des modèles de paysage en 3D. Chaque pixel enregistre le temps que met chaque impulsion laser à atteindre la cible et à revenir au capteur, ainsi que la profondeur, l'emplacement et l'intensité de réflexion de l'objet touché par l'impulsion laser.
# Le Flash LiDAR utilise une seule source lumineuse qui illumine le champ de vision en une seule impulsion. Tout comme un appareil photo qui prend des photos de la distance, au lieu des couleurs.
# La source d'illumination embarquée fait du Flash LiDAR un capteur actif. Le signal renvoyé est traité par des algorithmes intégrés pour produire un rendu 3D quasi instantané des objets et des caractéristiques du terrain dans le champ de vision du capteur. La fréquence de répétition des impulsions laser est suffisante pour générer des vidéos 3D avec une résolution et une précision élevées. La fréquence d'images élevée du capteur en fait un outil utile pour une variété d'applications qui bénéficient d'une visualisation en temps réel, comme la conduite autonome des véhicules. En renvoyant immédiatement un maillage d'élévation 3D des paysages cibles, un capteur flash peut être utilisé par un véhicule autonome pour prendre des décisions concernant le réglage de la vitesse, le freinage, la direction, etc.
# Ce type de caméra est fixé au sommet des voitures autonomes, et ces voitures l'utilisent pour naviguer tout en conduisant.
# # Visualisation de données
# ### Install *lyft_dataset_sdk* and import the necessary libraries
# Nous aurons besoin de la bibliothèque *lyft_dataset_sdk* car elle nous aidera à visualiser facilement l'image et les données LiDAR. Une simple commande *pip install* est nécessaire. J'utiliserai également l'installation de la bibliothèque *chart_studio* pour générer des graphiques interactifs.
import os
import gc
import numpy as np
import pandas as pd
import json
import math
import sys
import time
from datetime import datetime
from typing import Tuple, List
import cv2
import matplotlib.pyplot as plt
import sklearn.metrics
from PIL import Image
from matplotlib.axes import Axes
from matplotlib import animation, rc
import plotly.graph_objs as go
import plotly.tools as tls
from plotly.offline import plot, init_notebook_mode
import plotly.figure_factory as ff
init_notebook_mode(connected=True)
import seaborn as sns
from pyquaternion import Quaternion
from tqdm import tqdm
from lyft_dataset_sdk.utils.map_mask import MapMask
from lyft_dataset_sdk.lyftdataset import LyftDataset
from lyft_dataset_sdk.utils.geometry_utils import (
view_points,
box_in_image,
BoxVisibility,
)
from lyft_dataset_sdk.utils.geometry_utils import view_points, transform_matrix
from pathlib import Path
import struct
from abc import ABC, abstractmethod
from functools import reduce
from typing import Tuple, List, Dict
import copy
# ### le chemin de données
DATA_PATH = "../input/3d-object-detection-for-autonomous-vehicles/"
# ### Importer les données de training
train = pd.read_csv(DATA_PATH + "train.csv")
sample_submission = pd.read_csv(DATA_PATH + "sample_submission.csv")
#
# ### Regrouper les données par catégorie d'objet
# Taken from https://www.kaggle.com/gaborfodor/eda-3d-object-detection-challenge
object_columns = [
"sample_id",
"object_id",
"center_x",
"center_y",
"center_z",
"width",
"length",
"height",
"yaw",
"class_name",
]
objects = []
for sample_id, ps in tqdm(train.values[:]):
object_params = ps.split()
n_objects = len(object_params)
for i in range(n_objects // 8):
x, y, z, w, l, h, yaw, c = tuple(object_params[i * 8 : (i + 1) * 8])
objects.append([sample_id, i, x, y, z, w, l, h, yaw, c])
train_objects = pd.DataFrame(objects, columns=object_columns)
# ### Convertir les colonnes de type string en numérique (float32)
numerical_cols = [
"object_id",
"center_x",
"center_y",
"center_z",
"width",
"length",
"height",
"yaw",
]
train_objects[numerical_cols] = np.float32(train_objects[numerical_cols].values)
train_objects.head()
train_objects.info()
# ### First Exploration
# ### center_x and center_y
# **center_x** et **center_y** correspondent aux coordonnées *x* et *y* du centre de l'emplacement d'un objet (volume limite). Ces coordonnées représentent l'emplacement d'un objet sur le plan *x-y*.
# ### Distributions *center_x* and *center_y*
fig, ax = plt.subplots(figsize=(10, 10))
sns.distplot(train_objects["center_x"], color="darkorange", ax=ax).set_title(
"center_x and center_y", fontsize=16
)
sns.distplot(train_objects["center_y"], color="purple", ax=ax).set_title(
"center_x and center_y", fontsize=16
)
plt.xlabel("center_x and center_y", fontsize=15)
plt.show()
# Sur ce graphique ci-dessus, la distribution violette est celle de *center_y* et la distribution orange est celle de *center_x*. Le diagramme ci-dessus montre que les distributions de *centre_x* et de *centre_y* ont plusieurs pics et sont donc multimodales. Les deux distributions présentent également une nette inclinaison vers la droite ou une inclinaison positive. Mais, la distribution de *center_y* (violet) a un biais significativement plus élevé que la distribution de *center_x* (orange). La distribution *center_x* est plus uniformément répartie.
# Cela indique que les objets sont répartis très uniformément le long de l'axe *x*, mais pas de la même manière le long de l'axe *y*. Cela est probablement dû au fait que la caméra de la voiture peut facilement détecter des objets à gauche ou à droite (le long de l'axe *x*) en raison de la faible largeur de la route. Mais, comme la longueur de la route est beaucoup plus grande que sa largeur, et qu'il y a plus de chances que la vue de la caméra soit bloquée depuis cet angle, la caméra ne peut trouver que des objets situés juste devant ou juste derrière (et pas plus loin).
# ### Relation entre *center_x* and *center_y*
# ### KDE Plot
new_train_objects = train_objects.query('class_name == "car"')
plot = sns.jointplot(
x=new_train_objects["center_x"][:1000],
y=new_train_objects["center_y"][:1000],
kind="kde",
color="blueviolet",
)
plot.set_axis_labels("center_x", "center_y", fontsize=16)
plt.show()
# Dans le graphique KDE ci-dessus, nous pouvons voir que *center_x* et *center_y* semblent avoir une corrélation quelque peu négative. Cela est probablement dû, une fois de plus, aux limites du système de caméra. La caméra peut détecter des objets qui sont loin devant, mais pas trop loin sur le côté. Et elle peut également détecter des objets qui sont loin sur le côté, mais pas trop loin devant. Mais **la caméra ne peut pas détecter les objets qui sont à la fois loin devant et loin sur le côté**. Pour cette raison, les objets situés loin devant et loin sur le côté ne sont pas du tout détectés, et seuls les objets qui remplissent une (ou aucune) de ces conditions sont détectés. Il en résulte une relation négative entre *center_x* et *center_y*.
# ### center_z
# **center_z** correspond à la coordonnée *xz* du centre de l'emplacement d'un objet (volume limite). Cette coordonnée représente la hauteur de l'objet au-dessus du plan *x-y*.
# ### Distribution *center_z*
fig, ax = plt.subplots(figsize=(10, 10))
sns.distplot(train_objects["center_z"], color="navy", ax=ax).set_title(
"center_z", fontsize=16
)
plt.xlabel("center_z", fontsize=15)
plt.show()
# Dans le diagramme ci-dessus, nous pouvons voir que la distribution de *center_z* a une asymétrie positive (vers la droite) extrêmement élevée et qu'elle est regroupée autour de la marque -20 (qui est proche de sa valeur moyenne). La variation (dispersion) de *center_z* est nettement plus faible que celle de *center_x* et *center_y*. Cela s'explique probablement par le fait que la plupart des objets sont très proches du plan plat de la route et qu'il n'y a donc pas de grande variation de la hauteur des objets au-dessus (ou au-dessous) de la caméra. Il y a naturellement une variation beaucoup plus grande dans les coordonnées *x* et *y* de l'objet.
# De plus, la plupart des coordonnées *z* sont négatives car la caméra est fixée au sommet de la voiture. Ainsi, la plupart du temps, la caméra doit "regarder vers le bas" pour voir les objets. Par conséquent, la hauteur ou les coordonnées *z* des objets par rapport à la caméra sont généralement négatives.
# ### yaw
# **yaw** est l'angle du volume autour de l'axe *z*, ce qui fait que le "lacet" est la direction vers laquelle l'avant du véhicule/boîte englobante est dirigé lorsqu'il est au sol.
# ### Distribution de *yaw*
fig, ax = plt.subplots(figsize=(10, 10))
sns.distplot(train_objects["yaw"], color="darkgreen", ax=ax).set_title(
"yaw", fontsize=16
)
plt.xlabel("yaw", fontsize=15)
plt.show()
# Dans le diagramme ci-dessus, nous pouvons voir que la distribution de *yaw* est grossièrement bimodale, *c'est-à-dire qu'il y a deux pics majeurs dans la distribution. L'un des pics se situe autour de 0,5 et l'autre autour de 2,5. On peut estimer que la moyenne se situe entre 1 et 2 (autour de 1,5). La distribution ne présente pas d'asymétrie nette. La présence des deux pics à des positions symétriques réduit l'asymétrie dans les deux directions (et ils s'annulent), ce qui rend la distribution plus équilibrée que les distributions de *centre_x*, *centre_y* et *centre_z*.
# ### width
# **width** est simplement la largeur du volume délimité dans lequel se trouve l'objet.
fig, ax = plt.subplots(figsize=(10, 10))
sns.distplot(train_objects["width"], color="magenta", ax=ax).set_title(
"width", fontsize=16
)
plt.xlabel("width", fontsize=15)
plt.show()
# Dans le diagramme ci-dessus, nous pouvons voir que la *largeur* est distribuée à peu près normalement avec une moyenne d'environ 2, avec quelques valeurs aberrantes de chaque côté. La majorité des objets sont des voitures (comme nous le verrons plus tard), et celles-ci constituent une largeur d'environ 2 (au sommet). Les valeurs aberrantes à droite représentent des objets plus grands comme les camions et les camionnettes, et les valeurs aberrantes à gauche représentent des objets plus petits comme les piétons et les bicyclettes.
# ### length
# **length** est simplement la longueur du volume délimité dans lequel se trouve l'objet.
fig, ax = plt.subplots(figsize=(10, 10))
sns.distplot(train_objects["length"], color="crimson", ax=ax).set_title(
"length", fontsize=16
)
plt.xlabel("length", fontsize=15)
plt.show()
# Dans le diagramme ci-dessus, nous pouvons voir que la *longueur* a une distribution fortement positive (skew vers la droite) avec une moyenne d'environ 5, avec quelques valeurs aberrantes de chaque côté. La majorité des objets sont des voitures (comme nous le verrons plus tard), et celles-ci constituent une longueur d'environ 5 (au sommet). Les valeurs aberrantes sur la droite représentent des objets plus grands comme les camions et les camionnettes, et les valeurs aberrantes sur la gauche représentent des objets plus petits comme les piétons et les bicyclettes.
# ### height
# **height** est simplement la hauteur du volume délimité dans lequel se trouve l'objet.
fig, ax = plt.subplots(figsize=(10, 10))
sns.distplot(train_objects["height"], color="indigo", ax=ax).set_title(
"height", fontsize=16
)
plt.xlabel("height", fontsize=15)
plt.show()
# Dans le diagramme ci-dessus, nous pouvons voir que la *hauteur* a une distribution fortement positive (skew vers la droite) avec une moyenne d'environ 2, avec quelques aberrations de part et d'autre. La majorité des objets sont des voitures (comme nous le verrons plus tard), et celles-ci constituent une longueur d'environ 2 (au sommet). Les valeurs aberrantes sur la droite représentent des objets plus grands comme les camions et les camionnettes, et les valeurs aberrantes sur la gauche représentent des objets plus petits comme les piétons et les bicyclettes.
# ### Fréquence des objets
fig, ax = plt.subplots(figsize=(10, 10))
plot = sns.countplot(
y="class_name",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
),
palette=["navy", "darkblue", "blue", "dodgerblue", "skyblue", "lightblue"],
).set_title("Object Frequencies", fontsize=16)
plt.yticks(fontsize=14)
plt.xlabel("Count", fontsize=15)
plt.ylabel("Class Name", fontsize=15)
plt.show(plot)
# Le diagramme ci-dessus montre que la classe d'objets la plus courante dans l'ensemble de données est la "voiture". Cela n'est pas surprenant car les images sont prises dans les rues de Palo Alto, dans la Silicon Valley, en Californie. Et le véhicule (ou l'entité, d'ailleurs) le plus communément visible sur ces routes est la voiture. Toutes les autres classes d'objets sont loin d'être proches des voitures en termes de fréquence.
# ### center_x *vs.* class_name
# Dans les graphiques ci-dessous, je vais explorer comment la distribution de **center_x** change pour différents **nom de classe_des objets.**.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.violinplot(
x="class_name",
y="center_x",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
),
palette="YlGnBu",
split=True,
ax=ax,
).set_title("center_x (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("center_x", fontsize=15)
plt.show(plot)
# Dans les diagrammes de violon ci-dessus, nous pouvons voir que les distributions de *center_x* pour les grands véhicules, y compris les camions, les bus et autres véhicules, sont bien réparties. Elles ne présentent pratiquement pas d'asymétrie et ont des moyennes plus élevées que les distributions des piétons et des bicyclettes. Cela s'explique probablement par le fait que ces gros véhicules ont tendance à garder une plus grande distance avec les autres véhicules, et que les petits véhicules ne restent pas trop près de ces gros véhicules afin d'éviter les accidents. Par conséquent, la moyenne *center_x* est nettement supérieure pour les gros véhicules comme les bus et les camions.
# En revanche, les objets plus petits comme les piétons et les bicyclettes ont des distributions *center_x* fortement inclinées vers la droite. Ces distributions ont également des moyennes nettement plus faibles que celles des véhicules plus grands. Cela est probablement dû au fait que les piétons (qui traversent la route) et les cyclistes n'ont pas besoin de maintenir de grandes distances avec les voitures et les camions pour éviter les accidents. Ils traversent généralement la route pendant un feu rouge, lorsque le trafic s'arrête.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.boxplot(
x="class_name",
y="center_x",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
),
palette="YlGnBu",
ax=ax,
).set_title("center_x (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("center_x", fontsize=15)
plt.show(plot)
# In the box plots above, we can notice the same observation as in the violin plot above. The *center_x* distributions for smaller objects like pedestrians and bicycles have very low mean and quartile values as compared to larger objects like cars, trucks, and buses.
# ### center_y *vs.* class_name
# In the plots below, I will explore how the distribution of **center_y** changes for different object **class_names**.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.violinplot(
x="class_name",
y="center_y",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
),
palette="YlOrRd",
split=True,
ax=ax,
).set_title("center_y (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("center_y", fontsize=15)
plt.show(plot)
# In the violin plots above, we can see that the distributions of *center_y* for small objects including pedestrians and bicycles have a greater mean value than large objects like trucks and buses. The distributions for the small objects have much greater probability density concentrated at higher values of *center_y* as compared to large objects. This signifies that small objects, in general, have greater *center_y* values than large objects.
# This is probably because the large vehicles tend to be within the field of view of the camera due to their large size. But, smaller objects like bicycles and pedestrians cannot remain in the field of view of the camera when they are too close. Therefore, most pedestrains and bicycles that are detected tend to be far away. This causes the *center_y* to be greater (on average) for small objects as compared to large objects.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.boxplot(
x="class_name",
y="center_y",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
),
palette="YlOrRd",
ax=ax,
).set_title("center_y (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("center_y", fontsize=15)
plt.show(plot)
# In the box plots above, we can notice the same observation as in the violin plot above. The *center_y* distributions for smaller objects like pedestrians and bicycles have much larger mean and quartile values as compared to larger objects like cars, trucks, and buses.
# ### center_z *vs.* class_name
# In the plots below, I will explore how the distribution of **center_z** changes for different object **class_names**.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.violinplot(
x="class_name",
y="center_z",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
).query("center_z <= -5"),
palette="RdPu",
split=True,
ax=ax,
).set_title("center_z (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("center_z", fontsize=15)
plt.show(plot)
# In the violin plots above, we can see that the distributions of *center_z* for small objects including pedestrians and bicycles have a significantly smaller mean value than large objects like trucks and buses. The distributions for the small objects have much greater probability density concentrated at lower values of *center_z* as compared to large objects. This signifies that small objects, in general, have smaller *center_y* values than large objects.
# This is probably because smaller objects like pedestrians and bicycles tend to have a lower height with repsect to the camera. And, on the other hand, larger objects like cars, trucks, and buses tend to have a greater height with respect to the camera.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.boxplot(
x="class_name",
y="center_z",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
).query("center_z <= -5"),
palette="RdPu",
ax=ax,
).set_title("center_z (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("center_z", fontsize=15)
plt.show(plot)
# In the box plots above, we can notice the same observation as in the violin plot above. The *center_z* distributions for smaller objects like pedestrians and bicycles have much smaller mean and quartile values as compared to larger objects like cars, trucks, and buses.
# ### width *vs.* class_name
# In the plots below, I will explore how the distribution of **width** changes for different object **class_names**.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.violinplot(
x="class_name",
y="width",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
),
palette="YlGn",
split=True,
ax=ax,
).set_title("width (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("width", fontsize=15)
plt.show(plot)
# In the violin plots, we can clearly see that the *width* distributions for large vehicles like cars, buses, and trucks have much larger means as compared to small objects like pedestrians and bicycles. This is not surprising because trucks, buses, and cars almost always have much greater width than pedestrians and bicycles.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.boxplot(
x="class_name",
y="width",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
),
palette="YlGn",
ax=ax,
).set_title("width (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("width", fontsize=15)
plt.show(plot)
# In the box plots above, we can notice the same observation as in the violin plot above. The *width* distributions for smaller objects like pedestrians and bicycles have much smaller mean and quartile values as compared to larger objects like cars, trucks, and buses.
# ### length *vs.* class_name
# In the plots below, I will explore how the distribution of **length** changes for different object **class_names**.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.violinplot(
x="class_name",
y="length",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal" and length < 15'
),
palette="Purples",
split=True,
ax=ax,
).set_title("length (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("length", fontsize=15)
plt.show(plot)
# In the violin plots, we can clearly see that the *length* distributions for large vehicles like cars, buses, and trucks have much larger means as compared to small objects like pedestrians and bicycles. This is not surprising because trucks, buses, and cars almost always have much greater length than pedestrians and bicycles.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.boxplot(
x="class_name",
y="length",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal" and length < 15'
),
palette="Purples",
ax=ax,
).set_title("length (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("length", fontsize=15)
plt.show(plot)
# In the box plots above, we can notice the same observation as in the violin plot above. The *length* distributions for smaller objects like pedestrians and bicycles have much smaller mean and quartile values as compared to larger objects like cars, trucks, and buses.
# ### height *vs.* class_name
# In the plots below, I will explore how the distribution of **height** changes for different object **class_names**.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.violinplot(
x="class_name",
y="height",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal" and height < 6'
),
palette="Reds",
split=True,
ax=ax,
).set_title("height (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("height", fontsize=15)
plt.show(plot)
# In the violin plots, we can clearly see that the *length* distributions for large vehicles like buses and trucks have much larger means as compared to small objects like pedestrians and bicycles. This is not surprising because trucks and buses almost always have much greater length than pedestrians and bicycles.
# The only exception to this trend are the cars. They tend to have a similar height to that of pedestrians.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.boxplot(
x="class_name",
y="height",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal" and height < 6'
),
palette="Reds",
ax=ax,
).set_title("height (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("height", fontsize=15)
plt.show(plot)
# In the box plots above, we can notice the same observation as in the violin plot above. The *height* distributions for smaller objects like pedestrians and bicycles have much smaller mean and quartile values as compared to larger objects like cars, trucks, and buses.
# Once again, the only exception to this trend are the cars. They tend to have a similar height to that of pedestrians.
# # Digging into the image and LiDAR data
# ### Define some functions to help create the *LyftDataset* class
# #### (click CODE on the right side)
# Lyft Dataset SDK dev-kit.
# Code written by Oscar Beijbom, 2018.
# Licensed under the Creative Commons [see licence.txt]
# Modified by Vladimir Iglovikov 2019.
class PointCloud(ABC):
"""
Abstract class for manipulating and viewing point clouds.
Every point cloud (lidar and radar) consists of points where:
- Dimensions 0, 1, 2 represent x, y, z coordinates.
These are modified when the point cloud is rotated or translated.
- All other dimensions are optional. Hence these have to be manually modified if the reference frame changes.
"""
def __init__(self, points: np.ndarray):
"""
Initialize a point cloud and check it has the correct dimensions.
:param points: <np.float: d, n>. d-dimensional input point cloud matrix.
"""
assert points.shape[0] == self.nbr_dims(), (
"Error: Pointcloud points must have format: %d x n" % self.nbr_dims()
)
self.points = points
@staticmethod
@abstractmethod
def nbr_dims() -> int:
"""Returns the number of dimensions.
Returns: Number of dimensions.
"""
pass
@classmethod
@abstractmethod
def from_file(cls, file_name: str) -> "PointCloud":
"""Loads point cloud from disk.
Args:
file_name: Path of the pointcloud file on disk.
Returns: PointCloud instance.
"""
pass
@classmethod
def from_file_multisweep(
cls,
lyftd,
sample_rec: Dict,
chan: str,
ref_chan: str,
num_sweeps: int = 26,
min_distance: float = 1.0,
) -> Tuple["PointCloud", np.ndarray]:
"""Return a point cloud that aggregates multiple sweeps.
As every sweep is in a different coordinate frame, we need to map the coordinates to a single reference frame.
As every sweep has a different timestamp, we need to account for that in the transformations and timestamps.
Args:
lyftd: A LyftDataset instance.
sample_rec: The current sample.
chan: The radar channel from which we track back n sweeps to aggregate the point cloud.
ref_chan: The reference channel of the current sample_rec that the point clouds are mapped to.
num_sweeps: Number of sweeps to aggregated.
min_distance: Distance below which points are discarded.
Returns: (all_pc, all_times). The aggregated point cloud and timestamps.
"""
# Init
points = np.zeros((cls.nbr_dims(), 0))
all_pc = cls(points)
all_times = np.zeros((1, 0))
# Get reference pose and timestamp
ref_sd_token = sample_rec["data"][ref_chan]
ref_sd_rec = lyftd.get("sample_data", ref_sd_token)
ref_pose_rec = lyftd.get("ego_pose", ref_sd_rec["ego_pose_token"])
ref_cs_rec = lyftd.get(
"calibrated_sensor", ref_sd_rec["calibrated_sensor_token"]
)
ref_time = 1e-6 * ref_sd_rec["timestamp"]
# Homogeneous transform from ego car frame to reference frame
ref_from_car = transform_matrix(
ref_cs_rec["translation"], Quaternion(ref_cs_rec["rotation"]), inverse=True
)
# Homogeneous transformation matrix from global to _current_ ego car frame
car_from_global = transform_matrix(
ref_pose_rec["translation"],
Quaternion(ref_pose_rec["rotation"]),
inverse=True,
)
# Aggregate current and previous sweeps.
sample_data_token = sample_rec["data"][chan]
current_sd_rec = lyftd.get("sample_data", sample_data_token)
for _ in range(num_sweeps):
# Load up the pointcloud.
current_pc = cls.from_file(
lyftd.data_path / ("train_" + current_sd_rec["filename"])
)
# Get past pose.
current_pose_rec = lyftd.get("ego_pose", current_sd_rec["ego_pose_token"])
global_from_car = transform_matrix(
current_pose_rec["translation"],
Quaternion(current_pose_rec["rotation"]),
inverse=False,
)
# Homogeneous transformation matrix from sensor coordinate frame to ego car frame.
current_cs_rec = lyftd.get(
"calibrated_sensor", current_sd_rec["calibrated_sensor_token"]
)
car_from_current = transform_matrix(
current_cs_rec["translation"],
Quaternion(current_cs_rec["rotation"]),
inverse=False,
)
# Fuse four transformation matrices into one and perform transform.
trans_matrix = reduce(
np.dot,
[ref_from_car, car_from_global, global_from_car, car_from_current],
)
current_pc.transform(trans_matrix)
# Remove close points and add timevector.
current_pc.remove_close(min_distance)
time_lag = (
ref_time - 1e-6 * current_sd_rec["timestamp"]
) # positive difference
times = time_lag * np.ones((1, current_pc.nbr_points()))
all_times = np.hstack((all_times, times))
# Merge with key pc.
all_pc.points = np.hstack((all_pc.points, current_pc.points))
# Abort if there are no previous sweeps.
if current_sd_rec["prev"] == "":
break
else:
current_sd_rec = lyftd.get("sample_data", current_sd_rec["prev"])
return all_pc, all_times
def nbr_points(self) -> int:
"""Returns the number of points."""
return self.points.shape[1]
def subsample(self, ratio: float) -> None:
"""Sub-samples the pointcloud.
Args:
ratio: Fraction to keep.
"""
selected_ind = np.random.choice(
np.arange(0, self.nbr_points()), size=int(self.nbr_points() * ratio)
)
self.points = self.points[:, selected_ind]
def remove_close(self, radius: float) -> None:
"""Removes point too close within a certain radius from origin.
Args:
radius: Radius below which points are removed.
Returns:
"""
x_filt = np.abs(self.points[0, :]) < radius
y_filt = np.abs(self.points[1, :]) < radius
not_close = np.logical_not(np.logical_and(x_filt, y_filt))
self.points = self.points[:, not_close]
def translate(self, x: np.ndarray) -> None:
"""Applies a translation to the point cloud.
Args:
x: <np.float: 3, 1>. Translation in x, y, z.
"""
for i in range(3):
self.points[i, :] = self.points[i, :] + x[i]
def rotate(self, rot_matrix: np.ndarray) -> None:
"""Applies a rotation.
Args:
rot_matrix: <np.float: 3, 3>. Rotation matrix.
Returns:
"""
self.points[:3, :] = np.dot(rot_matrix, self.points[:3, :])
def transform(self, transf_matrix: np.ndarray) -> None:
"""Applies a homogeneous transform.
Args:
transf_matrix: transf_matrix: <np.float: 4, 4>. Homogenous transformation matrix.
"""
self.points[:3, :] = transf_matrix.dot(
np.vstack((self.points[:3, :], np.ones(self.nbr_points())))
)[:3, :]
def render_height(
self,
ax: Axes,
view: np.ndarray = np.eye(4),
x_lim: Tuple = (-20, 20),
y_lim: Tuple = (-20, 20),
marker_size: float = 1,
) -> None:
"""Simple method that applies a transformation and then scatter plots the points colored by height (z-value).
Args:
ax: Axes on which to render the points.
view: <np.float: n, n>. Defines an arbitrary projection (n <= 4).
x_lim: (min <float>, max <float>). x range for plotting.
y_lim: (min <float>, max <float>). y range for plotting.
marker_size: Marker size.
"""
self._render_helper(2, ax, view, x_lim, y_lim, marker_size)
def render_intensity(
self,
ax: Axes,
view: np.ndarray = np.eye(4),
x_lim: Tuple = (-20, 20),
y_lim: Tuple = (-20, 20),
marker_size: float = 1,
) -> None:
"""Very simple method that applies a transformation and then scatter plots the points colored by intensity.
Args:
ax: Axes on which to render the points.
view: <np.float: n, n>. Defines an arbitrary projection (n <= 4).
x_lim: (min <float>, max <float>).
y_lim: (min <float>, max <float>).
marker_size: Marker size.
Returns:
"""
self._render_helper(3, ax, view, x_lim, y_lim, marker_size)
def _render_helper(
self,
color_channel: int,
ax: Axes,
view: np.ndarray,
x_lim: Tuple,
y_lim: Tuple,
marker_size: float,
) -> None:
"""Helper function for rendering.
Args:
color_channel: Point channel to use as color.
ax: Axes on which to render the points.
view: <np.float: n, n>. Defines an arbitrary projection (n <= 4).
x_lim: (min <float>, max <float>).
y_lim: (min <float>, max <float>).
marker_size: Marker size.
"""
points = view_points(self.points[:3, :], view, normalize=False)
ax.scatter(
points[0, :], points[1, :], c=self.points[color_channel, :], s=marker_size
)
ax.set_xlim(x_lim[0], x_lim[1])
ax.set_ylim(y_lim[0], y_lim[1])
class LidarPointCloud(PointCloud):
@staticmethod
def nbr_dims() -> int:
"""Returns the number of dimensions.
Returns: Number of dimensions.
"""
return 4
@classmethod
def from_file(cls, file_name: Path) -> "LidarPointCloud":
"""Loads LIDAR data from binary numpy format. Data is stored as (x, y, z, intensity, ring index).
Args:
file_name: Path of the pointcloud file on disk.
Returns: LidarPointCloud instance (x, y, z, intensity).
"""
assert file_name.suffix == ".bin", "Unsupported filetype {}".format(file_name)
scan = np.fromfile(str(file_name), dtype=np.float32)
points = scan.reshape((-1, 5))[:, : cls.nbr_dims()]
return cls(points.T)
class RadarPointCloud(PointCloud):
# Class-level settings for radar pointclouds, see from_file().
invalid_states = [0] # type: List[int]
dynprop_states = range(
7
) # type: List[int] # Use [0, 2, 6] for moving objects only.
ambig_states = [3] # type: List[int]
@staticmethod
def nbr_dims() -> int:
"""Returns the number of dimensions.
Returns: Number of dimensions.
"""
return 18
@classmethod
def from_file(
cls,
file_name: Path,
invalid_states: List[int] = None,
dynprop_states: List[int] = None,
ambig_states: List[int] = None,
) -> "RadarPointCloud":
"""Loads RADAR data from a Point Cloud Data file. See details below.
Args:
file_name: The path of the pointcloud file.
invalid_states: Radar states to be kept. See details below.
dynprop_states: Radar states to be kept. Use [0, 2, 6] for moving objects only. See details below.
ambig_states: Radar states to be kept. See details below. To keep all radar returns,
set each state filter to range(18).
Returns: <np.float: d, n>. Point cloud matrix with d dimensions and n points.
Example of the header fields:
# .PCD v0.7 - Point Cloud Data file format
VERSION 0.7
FIELDS x y z dyn_prop id rcs vx vy vx_comp vy_comp is_quality_valid ambig_
state x_rms y_rms invalid_state pdh0 vx_rms vy_rms
SIZE 4 4 4 1 2 4 4 4 4 4 1 1 1 1 1 1 1 1
TYPE F F F I I F F F F F I I I I I I I I
COUNT 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
WIDTH 125
HEIGHT 1
VIEWPOINT 0 0 0 1 0 0 0
POINTS 125
DATA binary
Below some of the fields are explained in more detail:
x is front, y is left
vx, vy are the velocities in m/s.
vx_comp, vy_comp are the velocities in m/s compensated by the ego motion.
We recommend using the compensated velocities.
invalid_state: state of Cluster validity state.
(Invalid states)
0x01 invalid due to low RCS
0x02 invalid due to near-field artefact
0x03 invalid far range cluster because not confirmed in near range
0x05 reserved
0x06 invalid cluster due to high mirror probability
0x07 Invalid cluster because outside sensor field of view
0x0d reserved
0x0e invalid cluster because it is a harmonics
(Valid states)
0x00 valid
0x04 valid cluster with low RCS
0x08 valid cluster with azimuth correction due to elevation
0x09 valid cluster with high child probability
0x0a valid cluster with high probability of being a 50 deg artefact
0x0b valid cluster but no local maximum
0x0c valid cluster with high artefact probability
0x0f valid cluster with above 95m in near range
0x10 valid cluster with high multi-target probability
0x11 valid cluster with suspicious angle
dynProp: Dynamic property of cluster to indicate if is moving or not.
0: moving
1: stationary
2: oncoming
3: stationary candidate
4: unknown
5: crossing stationary
6: crossing moving
7: stopped
ambig_state: State of Doppler (radial velocity) ambiguity solution.
0: invalid
1: ambiguous
2: staggered ramp
3: unambiguous
4: stationary candidates
pdh0: False alarm probability of cluster (i.e. probability of being an artefact caused
by multipath or similar).
0: invalid
1: <25%
2: 50%
3: 75%
4: 90%
5: 99%
6: 99.9%
7: <=100%
"""
assert file_name.suffix == ".pcd", "Unsupported filetype {}".format(file_name)
meta = []
with open(str(file_name), "rb") as f:
for line in f:
line = line.strip().decode("utf-8")
meta.append(line)
if line.startswith("DATA"):
break
data_binary = f.read()
# Get the header rows and check if they appear as expected.
assert meta[0].startswith("#"), "First line must be comment"
assert meta[1].startswith("VERSION"), "Second line must be VERSION"
sizes = meta[3].split(" ")[1:]
types = meta[4].split(" ")[1:]
counts = meta[5].split(" ")[1:]
width = int(meta[6].split(" ")[1])
height = int(meta[7].split(" ")[1])
data = meta[10].split(" ")[1]
feature_count = len(types)
assert width > 0
assert len([c for c in counts if c != c]) == 0, "Error: COUNT not supported!"
assert height == 1, "Error: height != 0 not supported!"
assert data == "binary"
# Lookup table for how to decode the binaries.
unpacking_lut = {
"F": {2: "e", 4: "f", 8: "d"},
"I": {1: "b", 2: "h", 4: "i", 8: "q"},
"U": {1: "B", 2: "H", 4: "I", 8: "Q"},
}
types_str = "".join([unpacking_lut[t][int(s)] for t, s in zip(types, sizes)])
# Decode each point.
offset = 0
point_count = width
points = []
for i in range(point_count):
point = []
for p in range(feature_count):
start_p = offset
end_p = start_p + int(sizes[p])
assert end_p < len(data_binary)
point_p = struct.unpack(types_str[p], data_binary[start_p:end_p])[0]
point.append(point_p)
offset = end_p
points.append(point)
# A NaN in the first point indicates an empty pointcloud.
point = np.array(points[0])
if np.any(np.isnan(point)):
return cls(np.zeros((feature_count, 0)))
# Convert to numpy matrix.
points = np.array(points).transpose()
# If no parameters are provided, use default settings.
invalid_states = (
cls.invalid_states if invalid_states is None else invalid_states
)
dynprop_states = (
cls.dynprop_states if dynprop_states is None else dynprop_states
)
ambig_states = cls.ambig_states if ambig_states is None else ambig_states
# Filter points with an invalid state.
valid = [p in invalid_states for p in points[-4, :]]
points = points[:, valid]
# Filter by dynProp.
valid = [p in dynprop_states for p in points[3, :]]
points = points[:, valid]
# Filter by ambig_state.
valid = [p in ambig_states for p in points[11, :]]
points = points[:, valid]
return cls(points)
class Box:
"""Simple data class representing a 3d box including, label, score and velocity."""
def __init__(
self,
center: List[float],
size: List[float],
orientation: Quaternion,
label: int = np.nan,
score: float = np.nan,
velocity: Tuple = (np.nan, np.nan, np.nan),
name: str = None,
token: str = None,
):
"""
Args:
center: Center of box given as x, y, z.
size: Size of box in width, length, height.
orientation: Box orientation.
label: Integer label, optional.
score: Classification score, optional.
velocity: Box velocity in x, y, z direction.
name: Box name, optional. Can be used e.g. for denote category name.
token: Unique string identifier from DB.
"""
assert not np.any(np.isnan(center))
assert not np.any(np.isnan(size))
assert len(center) == 3
assert len(size) == 3
assert type(orientation) == Quaternion
self.center = np.array(center)
self.wlh = np.array(size)
self.orientation = orientation
self.label = int(label) if not np.isnan(label) else label
self.score = float(score) if not np.isnan(score) else score
self.velocity = np.array(velocity)
self.name = name
self.token = token
def __eq__(self, other):
center = np.allclose(self.center, other.center)
wlh = np.allclose(self.wlh, other.wlh)
orientation = np.allclose(self.orientation.elements, other.orientation.elements)
label = (self.label == other.label) or (
np.isnan(self.label) and np.isnan(other.label)
)
score = (self.score == other.score) or (
np.isnan(self.score) and np.isnan(other.score)
)
vel = np.allclose(self.velocity, other.velocity) or (
np.all(np.isnan(self.velocity)) and np.all(np.isnan(other.velocity))
)
return center and wlh and orientation and label and score and vel
def __repr__(self):
repr_str = (
"label: {}, score: {:.2f}, xyz: [{:.2f}, {:.2f}, {:.2f}], wlh: [{:.2f}, {:.2f}, {:.2f}], "
"rot axis: [{:.2f}, {:.2f}, {:.2f}], ang(degrees): {:.2f}, ang(rad): {:.2f}, "
"vel: {:.2f}, {:.2f}, {:.2f}, name: {}, token: {}"
)
return repr_str.format(
self.label,
self.score,
self.center[0],
self.center[1],
self.center[2],
self.wlh[0],
self.wlh[1],
self.wlh[2],
self.orientation.axis[0],
self.orientation.axis[1],
self.orientation.axis[2],
self.orientation.degrees,
self.orientation.radians,
self.velocity[0],
self.velocity[1],
self.velocity[2],
self.name,
self.token,
)
@property
def rotation_matrix(self) -> np.ndarray:
"""Return a rotation matrix.
Returns: <np.float: 3, 3>. The box's rotation matrix.
"""
return self.orientation.rotation_matrix
def translate(self, x: np.ndarray) -> None:
"""Applies a translation.
Args:
x: <np.float: 3, 1>. Translation in x, y, z direction.
"""
self.center += x
def rotate(self, quaternion: Quaternion) -> None:
"""Rotates box.
Args:
quaternion: Rotation to apply.
"""
self.center = np.dot(quaternion.rotation_matrix, self.center)
self.orientation = quaternion * self.orientation
self.velocity = np.dot(quaternion.rotation_matrix, self.velocity)
def corners(self, wlh_factor: float = 1.0) -> np.ndarray:
"""Returns the bounding box corners.
Args:
wlh_factor: Multiply width, length, height by a factor to scale the box.
Returns: First four corners are the ones facing forward.
The last four are the ones facing backwards.
"""
width, length, height = self.wlh * wlh_factor
# 3D bounding box corners. (Convention: x points forward, y to the left, z up.)
x_corners = length / 2 * np.array([1, 1, 1, 1, -1, -1, -1, -1])
y_corners = width / 2 * np.array([1, -1, -1, 1, 1, -1, -1, 1])
z_corners = height / 2 * np.array([1, 1, -1, -1, 1, 1, -1, -1])
corners = np.vstack((x_corners, y_corners, z_corners))
# Rotate
corners = np.dot(self.orientation.rotation_matrix, corners)
# Translate
x, y, z = self.center
corners[0, :] = corners[0, :] + x
corners[1, :] = corners[1, :] + y
corners[2, :] = corners[2, :] + z
return corners
def bottom_corners(self) -> np.ndarray:
"""Returns the four bottom corners.
Returns: <np.float: 3, 4>. Bottom corners. First two face forward, last two face backwards.
"""
return self.corners()[:, [2, 3, 7, 6]]
def render(
self,
axis: Axes,
view: np.ndarray = np.eye(3),
normalize: bool = False,
colors: Tuple = ("b", "r", "k"),
linewidth: float = 2,
):
"""Renders the box in the provided Matplotlib axis.
Args:
axis: Axis onto which the box should be drawn.
view: <np.array: 3, 3>. Define a projection in needed (e.g. for drawing projection in an image).
normalize: Whether to normalize the remaining coordinate.
colors: (<Matplotlib.colors>: 3). Valid Matplotlib colors (<str> or normalized RGB tuple) for front,
back and sides.
linewidth: Width in pixel of the box sides.
"""
corners = view_points(self.corners(), view, normalize=normalize)[:2, :]
def draw_rect(selected_corners, color):
prev = selected_corners[-1]
for corner in selected_corners:
axis.plot(
[prev[0], corner[0]],
[prev[1], corner[1]],
color=color,
linewidth=linewidth,
)
prev = corner
# Draw the sides
for i in range(4):
axis.plot(
[corners.T[i][0], corners.T[i + 4][0]],
[corners.T[i][1], corners.T[i + 4][1]],
color=colors[2],
linewidth=linewidth,
)
# Draw front (first 4 corners) and rear (last 4 corners) rectangles(3d)/lines(2d)
draw_rect(corners.T[:4], colors[0])
draw_rect(corners.T[4:], colors[1])
# Draw line indicating the front
center_bottom_forward = np.mean(corners.T[2:4], axis=0)
center_bottom = np.mean(corners.T[[2, 3, 7, 6]], axis=0)
axis.plot(
[center_bottom[0], center_bottom_forward[0]],
[center_bottom[1], center_bottom_forward[1]],
color=colors[0],
linewidth=linewidth,
)
def render_cv2(
self,
image: np.ndarray,
view: np.ndarray = np.eye(3),
normalize: bool = False,
colors: Tuple = ((0, 0, 255), (255, 0, 0), (155, 155, 155)),
linewidth: int = 2,
) -> None:
"""Renders box using OpenCV2.
Args:
image: <np.array: width, height, 3>. Image array. Channels are in BGR order.
view: <np.array: 3, 3>. Define a projection if needed (e.g. for drawing projection in an image).
normalize: Whether to normalize the remaining coordinate.
colors: ((R, G, B), (R, G, B), (R, G, B)). Colors for front, side & rear.
linewidth: Linewidth for plot.
Returns:
"""
corners = view_points(self.corners(), view, normalize=normalize)[:2, :]
def draw_rect(selected_corners, color):
prev = selected_corners[-1]
for corner in selected_corners:
cv2.line(
image,
(int(prev[0]), int(prev[1])),
(int(corner[0]), int(corner[1])),
color,
linewidth,
)
prev = corner
# Draw the sides
for i in range(4):
cv2.line(
image,
(int(corners.T[i][0]), int(corners.T[i][1])),
(int(corners.T[i + 4][0]), int(corners.T[i + 4][1])),
colors[2][::-1],
linewidth,
)
# Draw front (first 4 corners) and rear (last 4 corners) rectangles(3d)/lines(2d)
draw_rect(corners.T[:4], colors[0][::-1])
draw_rect(corners.T[4:], colors[1][::-1])
# Draw line indicating the front
center_bottom_forward = np.mean(corners.T[2:4], axis=0)
center_bottom = np.mean(corners.T[[2, 3, 7, 6]], axis=0)
cv2.line(
image,
(int(center_bottom[0]), int(center_bottom[1])),
(int(center_bottom_forward[0]), int(center_bottom_forward[1])),
colors[0][::-1],
linewidth,
)
def copy(self) -> "Box":
"""Create a copy of self.
Returns: A copy.
"""
return copy.deepcopy(self)
# ### Create a class called *LyftDataset* to package the dataset in a convenient form
# #### (click CODE on the right side)
# Lyft Dataset SDK dev-kit.
# Code written by Oscar Beijbom, 2018.
# Licensed under the Creative Commons [see licence.txt]
# Modified by Vladimir Iglovikov 2019.
PYTHON_VERSION = sys.version_info[0]
if not PYTHON_VERSION == 3:
raise ValueError("LyftDataset sdk only supports Python version 3.")
class LyftDataset:
"""Database class for Lyft Dataset to help query and retrieve information from the database."""
def __init__(
self,
data_path: str,
json_path: str,
verbose: bool = True,
map_resolution: float = 0.1,
):
"""Loads database and creates reverse indexes and shortcuts.
Args:
data_path: Path to the tables and data.
json_path: Path to the folder with json files
verbose: Whether to print status messages during load.
map_resolution: Resolution of maps (meters).
"""
self.data_path = Path(data_path).expanduser().absolute()
self.json_path = Path(json_path)
self.table_names = [
"category",
"attribute",
"visibility",
"instance",
"sensor",
"calibrated_sensor",
"ego_pose",
"log",
"scene",
"sample",
"sample_data",
"sample_annotation",
"map",
]
start_time = time.time()
# Explicitly assign tables to help the IDE determine valid class members.
self.category = self.__load_table__("category")
self.attribute = self.__load_table__("attribute")
self.visibility = self.__load_table__("visibility")
self.instance = self.__load_table__("instance")
self.sensor = self.__load_table__("sensor")
self.calibrated_sensor = self.__load_table__("calibrated_sensor")
self.ego_pose = self.__load_table__("ego_pose")
self.log = self.__load_table__("log")
self.scene = self.__load_table__("scene")
self.sample = self.__load_table__("sample")
self.sample_data = self.__load_table__("sample_data")
self.sample_annotation = self.__load_table__("sample_annotation")
self.map = self.__load_table__("map")
# Initialize map mask for each map record.
for map_record in self.map:
map_record["mask"] = MapMask(
self.data_path / "train_maps/map_raster_palo_alto.png",
resolution=map_resolution,
)
if verbose:
for table in self.table_names:
print("{} {},".format(len(getattr(self, table)), table))
print(
"Done loading in {:.1f} seconds.\n======".format(
time.time() - start_time
)
)
# Make reverse indexes for common lookups.
self.__make_reverse_index__(verbose)
# Initialize LyftDatasetExplorer class
self.explorer = LyftDatasetExplorer(self)
def __load_table__(self, table_name) -> dict:
"""Loads a table."""
with open(str(self.json_path.joinpath("{}.json".format(table_name)))) as f:
table = json.load(f)
return table
def __make_reverse_index__(self, verbose: bool) -> None:
"""De-normalizes database to create reverse indices for common cases.
Args:
verbose: Whether to print outputs.
"""
start_time = time.time()
if verbose:
print("Reverse indexing ...")
# Store the mapping from token to table index for each table.
self._token2ind = dict()
for table in self.table_names:
self._token2ind[table] = dict()
for ind, member in enumerate(getattr(self, table)):
self._token2ind[table][member["token"]] = ind
# Decorate (adds short-cut) sample_annotation table with for category name.
for record in self.sample_annotation:
inst = self.get("instance", record["instance_token"])
record["category_name"] = self.get("category", inst["category_token"])[
"name"
]
# Decorate (adds short-cut) sample_data with sensor information.
for record in self.sample_data:
cs_record = self.get("calibrated_sensor", record["calibrated_sensor_token"])
sensor_record = self.get("sensor", cs_record["sensor_token"])
record["sensor_modality"] = sensor_record["modality"]
record["channel"] = sensor_record["channel"]
# Reverse-index samples with sample_data and annotations.
for record in self.sample:
record["data"] = {}
record["anns"] = []
for record in self.sample_data:
if record["is_key_frame"]:
sample_record = self.get("sample", record["sample_token"])
sample_record["data"][record["channel"]] = record["token"]
for ann_record in self.sample_annotation:
sample_record = self.get("sample", ann_record["sample_token"])
sample_record["anns"].append(ann_record["token"])
# Add reverse indices from log records to map records.
if "log_tokens" not in self.map[0].keys():
raise Exception(
"Error: log_tokens not in map table. This code is not compatible with the teaser dataset."
)
log_to_map = dict()
for map_record in self.map:
for log_token in map_record["log_tokens"]:
log_to_map[log_token] = map_record["token"]
for log_record in self.log:
log_record["map_token"] = log_to_map[log_record["token"]]
if verbose:
print(
"Done reverse indexing in {:.1f} seconds.\n======".format(
time.time() - start_time
)
)
def get(self, table_name: str, token: str) -> dict:
"""Returns a record from table in constant runtime.
Args:
table_name: Table name.
token: Token of the record.
Returns: Table record.
"""
assert table_name in self.table_names, "Table {} not found".format(table_name)
return getattr(self, table_name)[self.getind(table_name, token)]
def getind(self, table_name: str, token: str) -> int:
"""Returns the index of the record in a table in constant runtime.
Args:
table_name: Table name.
token: The index of the record in table, table is an array.
Returns:
"""
return self._token2ind[table_name][token]
def field2token(self, table_name: str, field: str, query) -> List[str]:
"""Query all records for a certain field value, and returns the tokens for the matching records.
Runs in linear time.
Args:
table_name: Table name.
field: Field name.
query: Query to match against. Needs to type match the content of the query field.
Returns: List of tokens for the matching records.
"""
matches = []
for member in getattr(self, table_name):
if member[field] == query:
matches.append(member["token"])
return matches
def get_sample_data_path(self, sample_data_token: str) -> Path:
"""Returns the path to a sample_data.
Args:
sample_data_token:
Returns:
"""
sd_record = self.get("sample_data", sample_data_token)
return self.data_path / sd_record["filename"]
def get_sample_data(
self,
sample_data_token: str,
box_vis_level: BoxVisibility = BoxVisibility.ANY,
selected_anntokens: List[str] = None,
flat_vehicle_coordinates: bool = False,
) -> Tuple[Path, List[Box], np.array]:
"""Returns the data path as well as all annotations related to that sample_data.
The boxes are transformed into the current sensor's coordinate frame.
Args:
sample_data_token: Sample_data token.
box_vis_level: If sample_data is an image, this sets required visibility for boxes.
selected_anntokens: If provided only return the selected annotation.
flat_vehicle_coordinates: Instead of current sensor's coordinate frame, use vehicle frame which is
aligned to z-plane in world
Returns: (data_path, boxes, camera_intrinsic <np.array: 3, 3>)
"""
# Retrieve sensor & pose records
sd_record = self.get("sample_data", sample_data_token)
cs_record = self.get("calibrated_sensor", sd_record["calibrated_sensor_token"])
sensor_record = self.get("sensor", cs_record["sensor_token"])
pose_record = self.get("ego_pose", sd_record["ego_pose_token"])
data_path = self.get_sample_data_path(sample_data_token)
if sensor_record["modality"] == "camera":
cam_intrinsic = np.array(cs_record["camera_intrinsic"])
imsize = (sd_record["width"], sd_record["height"])
else:
cam_intrinsic = None
imsize = None
# Retrieve all sample annotations and map to sensor coordinate system.
if selected_anntokens is not None:
boxes = list(map(self.get_box, selected_anntokens))
else:
boxes = self.get_boxes(sample_data_token)
# Make list of Box objects including coord system transforms.
box_list = []
for box in boxes:
if flat_vehicle_coordinates:
# Move box to ego vehicle coord system parallel to world z plane
ypr = Quaternion(pose_record["rotation"]).yaw_pitch_roll
yaw = ypr[0]
box.translate(-np.array(pose_record["translation"]))
box.rotate(
Quaternion(
scalar=np.cos(yaw / 2), vector=[0, 0, np.sin(yaw / 2)]
).inverse
)
else:
# Move box to ego vehicle coord system
box.translate(-np.array(pose_record["translation"]))
box.rotate(Quaternion(pose_record["rotation"]).inverse)
# Move box to sensor coord system
box.translate(-np.array(cs_record["translation"]))
box.rotate(Quaternion(cs_record["rotation"]).inverse)
if sensor_record["modality"] == "camera" and not box_in_image(
box, cam_intrinsic, imsize, vis_level=box_vis_level
):
continue
box_list.append(box)
return data_path, box_list, cam_intrinsic
def get_box(self, sample_annotation_token: str) -> Box:
"""Instantiates a Box class from a sample annotation record.
Args:
sample_annotation_token: Unique sample_annotation identifier.
Returns:
"""
record = self.get("sample_annotation", sample_annotation_token)
return Box(
record["translation"],
record["size"],
Quaternion(record["rotation"]),
name=record["category_name"],
token=record["token"],
)
def get_boxes(self, sample_data_token: str) -> List[Box]:
"""Instantiates Boxes for all annotation for a particular sample_data record. If the sample_data is a
keyframe, this returns the annotations for that sample. But if the sample_data is an intermediate
sample_data, a linear interpolation is applied to estimate the location of the boxes at the time the
sample_data was captured.
Args:
sample_data_token: Unique sample_data identifier.
Returns:
"""
# Retrieve sensor & pose records
sd_record = self.get("sample_data", sample_data_token)
curr_sample_record = self.get("sample", sd_record["sample_token"])
if curr_sample_record["prev"] == "" or sd_record["is_key_frame"]:
# If no previous annotations available, or if sample_data is keyframe just return the current ones.
boxes = list(map(self.get_box, curr_sample_record["anns"]))
else:
prev_sample_record = self.get("sample", curr_sample_record["prev"])
curr_ann_recs = [
self.get("sample_annotation", token)
for token in curr_sample_record["anns"]
]
prev_ann_recs = [
self.get("sample_annotation", token)
for token in prev_sample_record["anns"]
]
# Maps instance tokens to prev_ann records
prev_inst_map = {entry["instance_token"]: entry for entry in prev_ann_recs}
t0 = prev_sample_record["timestamp"]
t1 = curr_sample_record["timestamp"]
t = sd_record["timestamp"]
# There are rare situations where the timestamps in the DB are off so ensure that t0 < t < t1.
t = max(t0, min(t1, t))
boxes = []
for curr_ann_rec in curr_ann_recs:
if curr_ann_rec["instance_token"] in prev_inst_map:
# If the annotated instance existed in the previous frame, interpolate center & orientation.
prev_ann_rec = prev_inst_map[curr_ann_rec["instance_token"]]
# Interpolate center.
center = [
np.interp(t, [t0, t1], [c0, c1])
for c0, c1 in zip(
prev_ann_rec["translation"], curr_ann_rec["translation"]
)
]
# Interpolate orientation.
rotation = Quaternion.slerp(
q0=Quaternion(prev_ann_rec["rotation"]),
q1=Quaternion(curr_ann_rec["rotation"]),
amount=(t - t0) / (t1 - t0),
)
box = Box(
center,
curr_ann_rec["size"],
rotation,
name=curr_ann_rec["category_name"],
token=curr_ann_rec["token"],
)
else:
# If not, simply grab the current annotation.
box = self.get_box(curr_ann_rec["token"])
boxes.append(box)
return boxes
def box_velocity(
self, sample_annotation_token: str, max_time_diff: float = 1.5
) -> np.ndarray:
"""Estimate the velocity for an annotation.
If possible, we compute the centered difference between the previous and next frame.
Otherwise we use the difference between the current and previous/next frame.
If the velocity cannot be estimated, values are set to np.nan.
Args:
sample_annotation_token: Unique sample_annotation identifier.
max_time_diff: Max allowed time diff between consecutive samples that are used to estimate velocities.
Returns: <np.float: 3>. Velocity in x/y/z direction in m/s.
"""
current = self.get("sample_annotation", sample_annotation_token)
has_prev = current["prev"] != ""
has_next = current["next"] != ""
# Cannot estimate velocity for a single annotation.
if not has_prev and not has_next:
return np.array([np.nan, np.nan, np.nan])
if has_prev:
first = self.get("sample_annotation", current["prev"])
else:
first = current
if has_next:
last = self.get("sample_annotation", current["next"])
else:
last = current
pos_last = np.array(last["translation"])
pos_first = np.array(first["translation"])
pos_diff = pos_last - pos_first
time_last = 1e-6 * self.get("sample", last["sample_token"])["timestamp"]
time_first = 1e-6 * self.get("sample", first["sample_token"])["timestamp"]
time_diff = time_last - time_first
if has_next and has_prev:
# If doing centered difference, allow for up to double the max_time_diff.
max_time_diff *= 2
if time_diff > max_time_diff:
# If time_diff is too big, don't return an estimate.
return np.array([np.nan, np.nan, np.nan])
else:
return pos_diff / time_diff
def list_categories(self) -> None:
self.explorer.list_categories()
def list_attributes(self) -> None:
self.explorer.list_attributes()
def list_scenes(self) -> None:
self.explorer.list_scenes()
def list_sample(self, sample_token: str) -> None:
self.explorer.list_sample(sample_token)
def render_pointcloud_in_image(
self,
sample_token: str,
dot_size: int = 5,
pointsensor_channel: str = "LIDAR_TOP",
camera_channel: str = "CAM_FRONT",
out_path: str = None,
) -> None:
self.explorer.render_pointcloud_in_image(
sample_token,
dot_size,
pointsensor_channel=pointsensor_channel,
camera_channel=camera_channel,
out_path=out_path,
)
def render_sample(
self,
sample_token: str,
box_vis_level: BoxVisibility = BoxVisibility.ANY,
nsweeps: int = 1,
out_path: str = None,
) -> None:
self.explorer.render_sample(
sample_token, box_vis_level, nsweeps=nsweeps, out_path=out_path
)
def render_sample_data(
self,
sample_data_token: str,
with_anns: bool = True,
box_vis_level: BoxVisibility = BoxVisibility.ANY,
axes_limit: float = 40,
ax: Axes = None,
nsweeps: int = 1,
out_path: str = None,
underlay_map: bool = False,
) -> None:
return self.explorer.render_sample_data(
sample_data_token,
with_anns,
box_vis_level,
axes_limit,
ax,
num_sweeps=nsweeps,
out_path=out_path,
underlay_map=underlay_map,
)
def render_annotation(
self,
sample_annotation_token: str,
margin: float = 10,
view: np.ndarray = np.eye(4),
box_vis_level: BoxVisibility = BoxVisibility.ANY,
out_path: str = None,
) -> None:
self.explorer.render_annotation(
sample_annotation_token, margin, view, box_vis_level, out_path
)
def render_instance(self, instance_token: str, out_path: str = None) -> None:
self.explorer.render_instance(instance_token, out_path=out_path)
def render_scene(
self,
scene_token: str,
freq: float = 10,
imwidth: int = 640,
out_path: str = None,
) -> None:
self.explorer.render_scene(
scene_token, freq, image_width=imwidth, out_path=out_path
)
def render_scene_channel(
self,
scene_token: str,
channel: str = "CAM_FRONT",
freq: float = 10,
imsize: Tuple[float, float] = (640, 360),
out_path: str = None,
) -> None:
self.explorer.render_scene_channel(
scene_token=scene_token,
channel=channel,
freq=freq,
image_size=imsize,
out_path=out_path,
)
def render_egoposes_on_map(
self, log_location: str, scene_tokens: List = None, out_path: str = None
) -> None:
self.explorer.render_egoposes_on_map(
log_location, scene_tokens, out_path=out_path
)
# ### Create another class called *LyftDatasetExplorer* which will help us to visualize the data
# #### (click CODE on the right side)
class LyftDatasetExplorer:
"""Helper class to list and visualize Lyft Dataset data. These are meant to serve as tutorials and templates for
working with the data."""
def __init__(self, lyftd: LyftDataset):
self.lyftd = lyftd
@staticmethod
def get_color(category_name: str) -> Tuple[int, int, int]:
"""Provides the default colors based on the category names.
This method works for the general Lyft Dataset categories, as well as the Lyft Dataset detection categories.
Args:
category_name:
Returns:
"""
if "bicycle" in category_name or "motorcycle" in category_name:
return 255, 61, 99 # Red
elif "vehicle" in category_name or category_name in [
"bus",
"car",
"construction_vehicle",
"trailer",
"truck",
]:
return 255, 158, 0 # Orange
elif "pedestrian" in category_name:
return 0, 0, 230 # Blue
elif "cone" in category_name or "barrier" in category_name:
return 0, 0, 0 # Black
else:
return 255, 0, 255 # Magenta
def list_categories(self) -> None:
"""Print categories, counts and stats."""
print("Category stats")
# Add all annotations
categories = dict()
for record in self.lyftd.sample_annotation:
if record["category_name"] not in categories:
categories[record["category_name"]] = []
categories[record["category_name"]].append(
record["size"] + [record["size"][1] / record["size"][0]]
)
# Print stats
for name, stats in sorted(categories.items()):
stats = np.array(stats)
print(
"{:27} n={:5}, width={:5.2f}\u00B1{:.2f}, len={:5.2f}\u00B1{:.2f}, height={:5.2f}\u00B1{:.2f}, "
"lw_aspect={:5.2f}\u00B1{:.2f}".format(
name[:27],
stats.shape[0],
np.mean(stats[:, 0]),
np.std(stats[:, 0]),
np.mean(stats[:, 1]),
np.std(stats[:, 1]),
np.mean(stats[:, 2]),
np.std(stats[:, 2]),
np.mean(stats[:, 3]),
np.std(stats[:, 3]),
)
)
def list_attributes(self) -> None:
"""Prints attributes and counts."""
attribute_counts = dict()
for record in self.lyftd.sample_annotation:
for attribute_token in record["attribute_tokens"]:
att_name = self.lyftd.get("attribute", attribute_token)["name"]
if att_name not in attribute_counts:
attribute_counts[att_name] = 0
attribute_counts[att_name] += 1
for name, count in sorted(attribute_counts.items()):
print("{}: {}".format(name, count))
def list_scenes(self) -> None:
"""Lists all scenes with some meta data."""
def ann_count(record):
count = 0
sample = self.lyftd.get("sample", record["first_sample_token"])
while not sample["next"] == "":
count += len(sample["anns"])
sample = self.lyftd.get("sample", sample["next"])
return count
recs = [
(
self.lyftd.get("sample", record["first_sample_token"])["timestamp"],
record,
)
for record in self.lyftd.scene
]
for start_time, record in sorted(recs):
start_time = (
self.lyftd.get("sample", record["first_sample_token"])["timestamp"]
/ 1000000
)
length_time = (
self.lyftd.get("sample", record["last_sample_token"])["timestamp"]
/ 1000000
- start_time
)
location = self.lyftd.get("log", record["log_token"])["location"]
desc = record["name"] + ", " + record["description"]
if len(desc) > 55:
desc = desc[:51] + "..."
if len(location) > 18:
location = location[:18]
print(
"{:16} [{}] {:4.0f}s, {}, #anns:{}".format(
desc,
datetime.utcfromtimestamp(start_time).strftime("%y-%m-%d %H:%M:%S"),
length_time,
location,
ann_count(record),
)
)
def list_sample(self, sample_token: str) -> None:
"""Prints sample_data tokens and sample_annotation tokens related to the sample_token."""
sample_record = self.lyftd.get("sample", sample_token)
print("Sample: {}\n".format(sample_record["token"]))
for sd_token in sample_record["data"].values():
sd_record = self.lyftd.get("sample_data", sd_token)
print(
"sample_data_token: {}, mod: {}, channel: {}".format(
sd_token, sd_record["sensor_modality"], sd_record["channel"]
)
)
print("")
for ann_token in sample_record["anns"]:
ann_record = self.lyftd.get("sample_annotation", ann_token)
print(
"sample_annotation_token: {}, category: {}".format(
ann_record["token"], ann_record["category_name"]
)
)
def map_pointcloud_to_image(
self, pointsensor_token: str, camera_token: str
) -> Tuple:
"""Given a point sensor (lidar/radar) token and camera sample_data token, load point-cloud and map it to
the image plane.
Args:
pointsensor_token: Lidar/radar sample_data token.
camera_token: Camera sample_data token.
Returns: (pointcloud <np.float: 2, n)>, coloring <np.float: n>, image <Image>).
"""
cam = self.lyftd.get("sample_data", camera_token)
pointsensor = self.lyftd.get("sample_data", pointsensor_token)
pcl_path = self.lyftd.data_path / ("train_" + pointsensor["filename"])
if pointsensor["sensor_modality"] == "lidar":
pc = LidarPointCloud.from_file(pcl_path)
else:
pc = RadarPointCloud.from_file(pcl_path)
im = Image.open(str(self.lyftd.data_path / ("train_" + cam["filename"])))
# Points live in the point sensor frame. So they need to be transformed via global to the image plane.
# First step: transform the point-cloud to the ego vehicle frame for the timestamp of the sweep.
cs_record = self.lyftd.get(
"calibrated_sensor", pointsensor["calibrated_sensor_token"]
)
pc.rotate(Quaternion(cs_record["rotation"]).rotation_matrix)
pc.translate(np.array(cs_record["translation"]))
# Second step: transform to the global frame.
poserecord = self.lyftd.get("ego_pose", pointsensor["ego_pose_token"])
pc.rotate(Quaternion(poserecord["rotation"]).rotation_matrix)
pc.translate(np.array(poserecord["translation"]))
# Third step: transform into the ego vehicle frame for the timestamp of the image.
poserecord = self.lyftd.get("ego_pose", cam["ego_pose_token"])
pc.translate(-np.array(poserecord["translation"]))
pc.rotate(Quaternion(poserecord["rotation"]).rotation_matrix.T)
# Fourth step: transform into the camera.
cs_record = self.lyftd.get("calibrated_sensor", cam["calibrated_sensor_token"])
pc.translate(-np.array(cs_record["translation"]))
pc.rotate(Quaternion(cs_record["rotation"]).rotation_matrix.T)
# Fifth step: actually take a "picture" of the point cloud.
# Grab the depths (camera frame z axis points away from the camera).
depths = pc.points[2, :]
# Retrieve the color from the depth.
coloring = depths
# Take the actual picture (matrix multiplication with camera-matrix + renormalization).
points = view_points(
pc.points[:3, :], np.array(cs_record["camera_intrinsic"]), normalize=True
)
# Remove points that are either outside or behind the camera. Leave a margin of 1 pixel for aesthetic reasons.
mask = np.ones(depths.shape[0], dtype=bool)
mask = np.logical_and(mask, depths > 0)
mask = np.logical_and(mask, points[0, :] > 1)
mask = np.logical_and(mask, points[0, :] < im.size[0] - 1)
mask = np.logical_and(mask, points[1, :] > 1)
mask = np.logical_and(mask, points[1, :] < im.size[1] - 1)
points = points[:, mask]
coloring = coloring[mask]
return points, coloring, im
def render_pointcloud_in_image(
self,
sample_token: str,
dot_size: int = 2,
pointsensor_channel: str = "LIDAR_TOP",
camera_channel: str = "CAM_FRONT",
out_path: str = None,
) -> None:
"""Scatter-plots a point-cloud on top of image.
Args:
sample_token: Sample token.
dot_size: Scatter plot dot size.
pointsensor_channel: RADAR or LIDAR channel name, e.g. 'LIDAR_TOP'.
camera_channel: Camera channel name, e.g. 'CAM_FRONT'.
out_path: Optional path to save the rendered figure to disk.
Returns:
"""
sample_record = self.lyftd.get("sample", sample_token)
# Here we just grab the front camera and the point sensor.
pointsensor_token = sample_record["data"][pointsensor_channel]
camera_token = sample_record["data"][camera_channel]
points, coloring, im = self.map_pointcloud_to_image(
pointsensor_token, camera_token
)
plt.figure(figsize=(9, 16))
plt.imshow(im)
plt.scatter(points[0, :], points[1, :], c=coloring, s=dot_size)
plt.axis("off")
if out_path is not None:
plt.savefig(out_path)
def render_sample(
self,
token: str,
box_vis_level: BoxVisibility = BoxVisibility.ANY,
nsweeps: int = 1,
out_path: str = None,
) -> None:
"""Render all LIDAR and camera sample_data in sample along with annotations.
Args:
token: Sample token.
box_vis_level: If sample_data is an image, this sets required visibility for boxes.
nsweeps: Number of sweeps for lidar and radar.
out_path: Optional path to save the rendered figure to disk.
Returns:
"""
record = self.lyftd.get("sample", token)
# Separate RADAR from LIDAR and vision.
radar_data = {}
nonradar_data = {}
for channel, token in record["data"].items():
sd_record = self.lyftd.get("sample_data", token)
sensor_modality = sd_record["sensor_modality"]
if sensor_modality in ["lidar", "camera"]:
nonradar_data[channel] = token
else:
radar_data[channel] = token
num_radar_plots = 1 if len(radar_data) > 0 else 0
# Create plots.
n = num_radar_plots + len(nonradar_data)
cols = 2
fig, axes = plt.subplots(int(np.ceil(n / cols)), cols, figsize=(16, 24))
if len(radar_data) > 0:
# Plot radar into a single subplot.
ax = axes[0, 0]
for i, (_, sd_token) in enumerate(radar_data.items()):
self.render_sample_data(
sd_token,
with_anns=i == 0,
box_vis_level=box_vis_level,
ax=ax,
num_sweeps=nsweeps,
)
ax.set_title("Fused RADARs")
# Plot camera and lidar in separate subplots.
for (_, sd_token), ax in zip(
nonradar_data.items(), axes.flatten()[num_radar_plots:]
):
self.render_sample_data(
sd_token, box_vis_level=box_vis_level, ax=ax, num_sweeps=nsweeps
)
axes.flatten()[-1].axis("off")
plt.tight_layout()
fig.subplots_adjust(wspace=0, hspace=0)
if out_path is not None:
plt.savefig(out_path)
def render_ego_centric_map(
self, sample_data_token: str, axes_limit: float = 40, ax: Axes = None
) -> None:
"""Render map centered around the associated ego pose.
Args:
sample_data_token: Sample_data token.
axes_limit: Axes limit measured in meters.
ax: Axes onto which to render.
"""
def crop_image(
image: np.array, x_px: int, y_px: int, axes_limit_px: int
) -> np.array:
x_min = int(x_px - axes_limit_px)
x_max = int(x_px + axes_limit_px)
y_min = int(y_px - axes_limit_px)
y_max = int(y_px + axes_limit_px)
cropped_image = image[y_min:y_max, x_min:x_max]
return cropped_image
sd_record = self.lyftd.get("sample_data", sample_data_token)
# Init axes.
if ax is None:
_, ax = plt.subplots(1, 1, figsize=(9, 9))
sample = self.lyftd.get("sample", sd_record["sample_token"])
scene = self.lyftd.get("scene", sample["scene_token"])
log = self.lyftd.get("log", scene["log_token"])
map = self.lyftd.get("map", log["map_token"])
map_mask = map["mask"]
pose = self.lyftd.get("ego_pose", sd_record["ego_pose_token"])
pixel_coords = map_mask.to_pixel_coords(
pose["translation"][0], pose["translation"][1]
)
scaled_limit_px = int(axes_limit * (1.0 / map_mask.resolution))
mask_raster = map_mask.mask()
cropped = crop_image(
mask_raster,
pixel_coords[0],
pixel_coords[1],
int(scaled_limit_px * math.sqrt(2)),
)
ypr_rad = Quaternion(pose["rotation"]).yaw_pitch_roll
yaw_deg = -math.degrees(ypr_rad[0])
rotated_cropped = np.array(Image.fromarray(cropped).rotate(yaw_deg))
ego_centric_map = crop_image(
rotated_cropped,
rotated_cropped.shape[1] / 2,
rotated_cropped.shape[0] / 2,
scaled_limit_px,
)
ax.imshow(
ego_centric_map,
extent=[-axes_limit, axes_limit, -axes_limit, axes_limit],
cmap="gray",
vmin=0,
vmax=150,
)
def render_sample_data(
self,
sample_data_token: str,
with_anns: bool = True,
box_vis_level: BoxVisibility = BoxVisibility.ANY,
axes_limit: float = 40,
ax: Axes = None,
num_sweeps: int = 1,
out_path: str = None,
underlay_map: bool = False,
):
"""Render sample data onto axis.
Args:
sample_data_token: Sample_data token.
with_anns: Whether to draw annotations.
box_vis_level: If sample_data is an image, this sets required visibility for boxes.
axes_limit: Axes limit for lidar and radar (measured in meters).
ax: Axes onto which to render.
num_sweeps: Number of sweeps for lidar and radar.
out_path: Optional path to save the rendered figure to disk.
underlay_map: When set to true, LIDAR data is plotted onto the map. This can be slow.
"""
# Get sensor modality.
sd_record = self.lyftd.get("sample_data", sample_data_token)
sensor_modality = sd_record["sensor_modality"]
if sensor_modality == "lidar":
# Get boxes in lidar frame.
_, boxes, _ = self.lyftd.get_sample_data(
sample_data_token,
box_vis_level=box_vis_level,
flat_vehicle_coordinates=True,
)
# Get aggregated point cloud in lidar frame.
sample_rec = self.lyftd.get("sample", sd_record["sample_token"])
chan = sd_record["channel"]
ref_chan = "LIDAR_TOP"
pc, times = LidarPointCloud.from_file_multisweep(
self.lyftd, sample_rec, chan, ref_chan, num_sweeps=num_sweeps
)
# Compute transformation matrices for lidar point cloud
cs_record = self.lyftd.get(
"calibrated_sensor", sd_record["calibrated_sensor_token"]
)
pose_record = self.lyftd.get("ego_pose", sd_record["ego_pose_token"])
vehicle_from_sensor = np.eye(4)
vehicle_from_sensor[:3, :3] = Quaternion(
cs_record["rotation"]
).rotation_matrix
vehicle_from_sensor[:3, 3] = cs_record["translation"]
ego_yaw = Quaternion(pose_record["rotation"]).yaw_pitch_roll[0]
rot_vehicle_flat_from_vehicle = np.dot(
Quaternion(
scalar=np.cos(ego_yaw / 2), vector=[0, 0, np.sin(ego_yaw / 2)]
).rotation_matrix,
Quaternion(pose_record["rotation"]).inverse.rotation_matrix,
)
vehicle_flat_from_vehicle = np.eye(4)
vehicle_flat_from_vehicle[:3, :3] = rot_vehicle_flat_from_vehicle
# Init axes.
if ax is None:
_, ax = plt.subplots(1, 1, figsize=(9, 9))
if underlay_map:
self.render_ego_centric_map(
sample_data_token=sample_data_token, axes_limit=axes_limit, ax=ax
)
# Show point cloud.
points = view_points(
pc.points[:3, :],
np.dot(vehicle_flat_from_vehicle, vehicle_from_sensor),
normalize=False,
)
dists = np.sqrt(np.sum(pc.points[:2, :] ** 2, axis=0))
colors = np.minimum(1, dists / axes_limit / np.sqrt(2))
ax.scatter(points[0, :], points[1, :], c=colors, s=0.2)
# Show ego vehicle.
ax.plot(0, 0, "x", color="red")
# Show boxes.
if with_anns:
for box in boxes:
c = np.array(self.get_color(box.name)) / 255.0
box.render(ax, view=np.eye(4), colors=(c, c, c))
# Limit visible range.
ax.set_xlim(-axes_limit, axes_limit)
ax.set_ylim(-axes_limit, axes_limit)
elif sensor_modality == "radar":
# Get boxes in lidar frame.
sample_rec = self.lyftd.get("sample", sd_record["sample_token"])
lidar_token = sample_rec["data"]["LIDAR_TOP"]
_, boxes, _ = self.lyftd.get_sample_data(
lidar_token, box_vis_level=box_vis_level
)
# Get aggregated point cloud in lidar frame.
# The point cloud is transformed to the lidar frame for visualization purposes.
chan = sd_record["channel"]
ref_chan = "LIDAR_TOP"
pc, times = RadarPointCloud.from_file_multisweep(
self.lyftd, sample_rec, chan, ref_chan, num_sweeps=num_sweeps
)
# Transform radar velocities (x is front, y is left), as these are not transformed when loading the point
# cloud.
radar_cs_record = self.lyftd.get(
"calibrated_sensor", sd_record["calibrated_sensor_token"]
)
lidar_sd_record = self.lyftd.get("sample_data", lidar_token)
lidar_cs_record = self.lyftd.get(
"calibrated_sensor", lidar_sd_record["calibrated_sensor_token"]
)
velocities = pc.points[8:10, :] # Compensated velocity
velocities = np.vstack((velocities, np.zeros(pc.points.shape[1])))
velocities = np.dot(
Quaternion(radar_cs_record["rotation"]).rotation_matrix, velocities
)
velocities = np.dot(
Quaternion(lidar_cs_record["rotation"]).rotation_matrix.T, velocities
)
velocities[2, :] = np.zeros(pc.points.shape[1])
# Init axes.
if ax is None:
_, ax = plt.subplots(1, 1, figsize=(9, 9))
# Show point cloud.
points = view_points(pc.points[:3, :], np.eye(4), normalize=False)
dists = np.sqrt(np.sum(pc.points[:2, :] ** 2, axis=0))
colors = np.minimum(1, dists / axes_limit / np.sqrt(2))
sc = ax.scatter(points[0, :], points[1, :], c=colors, s=3)
# Show velocities.
points_vel = view_points(
pc.points[:3, :] + velocities, np.eye(4), normalize=False
)
max_delta = 10
deltas_vel = points_vel - points
deltas_vel = 3 * deltas_vel # Arbitrary scaling
deltas_vel = np.clip(
deltas_vel, -max_delta, max_delta
) # Arbitrary clipping
colors_rgba = sc.to_rgba(colors)
for i in range(points.shape[1]):
ax.arrow(
points[0, i],
points[1, i],
deltas_vel[0, i],
deltas_vel[1, i],
color=colors_rgba[i],
)
# Show ego vehicle.
ax.plot(0, 0, "x", color="black")
# Show boxes.
if with_anns:
for box in boxes:
c = np.array(self.get_color(box.name)) / 255.0
box.render(ax, view=np.eye(4), colors=(c, c, c))
# Limit visible range.
ax.set_xlim(-axes_limit, axes_limit)
ax.set_ylim(-axes_limit, axes_limit)
elif sensor_modality == "camera":
# Load boxes and image.
data_path, boxes, camera_intrinsic = self.lyftd.get_sample_data(
sample_data_token, box_vis_level=box_vis_level
)
data = Image.open(
str(data_path)[: len(str(data_path)) - 46]
+ "train_images/"
+ str(data_path)[len(str(data_path)) - 39 : len(str(data_path))]
)
# Init axes.
if ax is None:
_, ax = plt.subplots(1, 1, figsize=(9, 16))
# Show image.
ax.imshow(data)
# Show boxes.
if with_anns:
for box in boxes:
c = np.array(self.get_color(box.name)) / 255.0
box.render(
ax, view=camera_intrinsic, normalize=True, colors=(c, c, c)
)
# Limit visible range.
ax.set_xlim(0, data.size[0])
ax.set_ylim(data.size[1], 0)
else:
raise ValueError("Error: Unknown sensor modality!")
ax.axis("off")
ax.set_title(sd_record["channel"])
ax.set_aspect("equal")
if out_path is not None:
num = len([name for name in os.listdir(out_path)])
out_path = out_path + str(num).zfill(5) + "_" + sample_data_token + ".png"
plt.savefig(out_path)
plt.close("all")
return out_path
def render_annotation(
self,
ann_token: str,
margin: float = 10,
view: np.ndarray = np.eye(4),
box_vis_level: BoxVisibility = BoxVisibility.ANY,
out_path: str = None,
) -> None:
"""Render selected annotation.
Args:
ann_token: Sample_annotation token.
margin: How many meters in each direction to include in LIDAR view.
view: LIDAR view point.
box_vis_level: If sample_data is an image, this sets required visibility for boxes.
out_path: Optional path to save the rendered figure to disk.
"""
ann_record = self.lyftd.get("sample_annotation", ann_token)
sample_record = self.lyftd.get("sample", ann_record["sample_token"])
assert (
"LIDAR_TOP" in sample_record["data"].keys()
), "No LIDAR_TOP in data, cant render"
fig, axes = plt.subplots(1, 2, figsize=(18, 9))
# Figure out which camera the object is fully visible in (this may return nothing)
boxes, cam = [], []
cams = [key for key in sample_record["data"].keys() if "CAM" in key]
for cam in cams:
_, boxes, _ = self.lyftd.get_sample_data(
sample_record["data"][cam],
box_vis_level=box_vis_level,
selected_anntokens=[ann_token],
)
if len(boxes) > 0:
break # We found an image that matches. Let's abort.
assert (
len(boxes) > 0
), "Could not find image where annotation is visible. Try using e.g. BoxVisibility.ANY."
assert len(boxes) < 2, "Found multiple annotations. Something is wrong!"
cam = sample_record["data"][cam]
# Plot LIDAR view
lidar = sample_record["data"]["LIDAR_TOP"]
data_path, boxes, camera_intrinsic = self.lyftd.get_sample_data(
lidar, selected_anntokens=[ann_token]
)
LidarPointCloud.from_file(
Path(
str(data_path)[: len(str(data_path)) - 46]
+ "train_lidar/"
+ str(data_path)[len(str(data_path)) - 40 : len(str(data_path))]
)
).render_height(axes[0], view=view)
for box in boxes:
c = np.array(self.get_color(box.name)) / 255.0
box.render(axes[0], view=view, colors=(c, c, c))
corners = view_points(boxes[0].corners(), view, False)[:2, :]
axes[0].set_xlim(
[np.min(corners[0, :]) - margin, np.max(corners[0, :]) + margin]
)
axes[0].set_ylim(
[np.min(corners[1, :]) - margin, np.max(corners[1, :]) + margin]
)
axes[0].axis("off")
axes[0].set_aspect("equal")
# Plot CAMERA view
data_path, boxes, camera_intrinsic = self.lyftd.get_sample_data(
cam, selected_anntokens=[ann_token]
)
im = Image.open(
Path(
str(data_path)[: len(str(data_path)) - 46]
+ "train_images/"
+ str(data_path)[len(str(data_path)) - 39 : len(str(data_path))]
)
)
axes[1].imshow(im)
axes[1].set_title(self.lyftd.get("sample_data", cam)["channel"])
axes[1].axis("off")
axes[1].set_aspect("equal")
for box in boxes:
c = np.array(self.get_color(box.name)) / 255.0
box.render(axes[1], view=camera_intrinsic, normalize=True, colors=(c, c, c))
if out_path is not None:
plt.savefig(out_path)
def render_instance(self, instance_token: str, out_path: str = None) -> None:
"""Finds the annotation of the given instance that is closest to the vehicle, and then renders it.
Args:
instance_token: The instance token.
out_path: Optional path to save the rendered figure to disk.
Returns:
"""
ann_tokens = self.lyftd.field2token(
"sample_annotation", "instance_token", instance_token
)
closest = [np.inf, None]
for ann_token in ann_tokens:
ann_record = self.lyftd.get("sample_annotation", ann_token)
sample_record = self.lyftd.get("sample", ann_record["sample_token"])
sample_data_record = self.lyftd.get(
"sample_data", sample_record["data"]["LIDAR_TOP"]
)
pose_record = self.lyftd.get(
"ego_pose", sample_data_record["ego_pose_token"]
)
dist = np.linalg.norm(
np.array(pose_record["translation"])
- np.array(ann_record["translation"])
)
if dist < closest[0]:
closest[0] = dist
closest[1] = ann_token
self.render_annotation(closest[1], out_path=out_path)
def render_scene(
self,
scene_token: str,
freq: float = 10,
image_width: int = 640,
out_path: Path = None,
) -> None:
"""Renders a full scene with all surround view camera channels.
Args:
scene_token: Unique identifier of scene to render.
freq: Display frequency (Hz).
image_width: Width of image to render. Height is determined automatically to preserve aspect ratio.
out_path: Optional path to write a video file of the rendered frames.
"""
if out_path is not None:
assert out_path.suffix == ".avi"
# Get records from DB.
scene_rec = self.lyftd.get("scene", scene_token)
first_sample_rec = self.lyftd.get("sample", scene_rec["first_sample_token"])
last_sample_rec = self.lyftd.get("sample", scene_rec["last_sample_token"])
channels = [
"CAM_FRONT_LEFT",
"CAM_FRONT",
"CAM_FRONT_RIGHT",
"CAM_BACK_LEFT",
"CAM_BACK",
"CAM_BACK_RIGHT",
]
horizontal_flip = [
"CAM_BACK_LEFT",
"CAM_BACK",
"CAM_BACK_RIGHT",
] # Flip these for aesthetic reasons.
time_step = 1 / freq * 1e6 # Time-stamps are measured in micro-seconds.
window_name = "{}".format(scene_rec["name"])
cv2.namedWindow(window_name)
cv2.moveWindow(window_name, 0, 0)
# Load first sample_data record for each channel
current_recs = {} # Holds the current record to be displayed by channel.
prev_recs = {} # Hold the previous displayed record by channel.
for channel in channels:
current_recs[channel] = self.lyftd.get(
"sample_data", first_sample_rec["data"][channel]
)
prev_recs[channel] = None
# We assume that the resolution is the same for all surround view cameras.
image_height = int(
image_width
* current_recs[channels[0]]["height"]
/ current_recs[channels[0]]["width"]
)
image_size = (image_width, image_height)
# Set some display parameters
layout = {
"CAM_FRONT_LEFT": (0, 0),
"CAM_FRONT": (image_size[0], 0),
"CAM_FRONT_RIGHT": (2 * image_size[0], 0),
"CAM_BACK_LEFT": (0, image_size[1]),
"CAM_BACK": (image_size[0], image_size[1]),
"CAM_BACK_RIGHT": (2 * image_size[0], image_size[1]),
}
canvas = np.ones((2 * image_size[1], 3 * image_size[0], 3), np.uint8)
if out_path is not None:
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
out = cv2.VideoWriter(out_path, fourcc, freq, canvas.shape[1::-1])
else:
out = None
current_time = first_sample_rec["timestamp"]
while current_time < last_sample_rec["timestamp"]:
current_time += time_step
# For each channel, find first sample that has time > current_time.
for channel, sd_rec in current_recs.items():
while sd_rec["timestamp"] < current_time and sd_rec["next"] != "":
sd_rec = self.lyftd.get("sample_data", sd_rec["next"])
current_recs[channel] = sd_rec
# Now add to canvas
for channel, sd_rec in current_recs.items():
# Only update canvas if we have not already rendered this one.
if not sd_rec == prev_recs[channel]:
# Get annotations and params from DB.
image_path, boxes, camera_intrinsic = self.lyftd.get_sample_data(
sd_rec["token"], box_vis_level=BoxVisibility.ANY
)
# Load and render
if not image_path.exists():
raise Exception("Error: Missing image %s" % image_path)
im = cv2.imread(str(image_path))
for box in boxes:
c = self.get_color(box.name)
box.render_cv2(
im, view=camera_intrinsic, normalize=True, colors=(c, c, c)
)
im = cv2.resize(im, image_size)
if channel in horizontal_flip:
im = im[:, ::-1, :]
canvas[
layout[channel][1] : layout[channel][1] + image_size[1],
layout[channel][0] : layout[channel][0] + image_size[0],
:,
] = im
prev_recs[
channel
] = sd_rec # Store here so we don't render the same image twice.
# Show updated canvas.
cv2.imshow(window_name, canvas)
if out_path is not None:
out.write(canvas)
key = cv2.waitKey(1) # Wait a very short time (1 ms).
if key == 32: # if space is pressed, pause.
key = cv2.waitKey()
if key == 27: # if ESC is pressed, exit.
cv2.destroyAllWindows()
break
cv2.destroyAllWindows()
if out_path is not None:
out.release()
def render_scene_channel(
self,
scene_token: str,
channel: str = "CAM_FRONT",
freq: float = 10,
image_size: Tuple[float, float] = (640, 360),
out_path: Path = None,
) -> None:
"""Renders a full scene for a particular camera channel.
Args:
scene_token: Unique identifier of scene to render.
channel: Channel to render.
freq: Display frequency (Hz).
image_size: Size of image to render. The larger the slower this will run.
out_path: Optional path to write a video file of the rendered frames.
"""
valid_channels = [
"CAM_FRONT_LEFT",
"CAM_FRONT",
"CAM_FRONT_RIGHT",
"CAM_BACK_LEFT",
"CAM_BACK",
"CAM_BACK_RIGHT",
]
assert image_size[0] / image_size[1] == 16 / 9, "Aspect ratio should be 16/9."
assert channel in valid_channels, "Input channel {} not valid.".format(channel)
if out_path is not None:
assert out_path.suffix == ".avi"
# Get records from DB
scene_rec = self.lyftd.get("scene", scene_token)
sample_rec = self.lyftd.get("sample", scene_rec["first_sample_token"])
sd_rec = self.lyftd.get("sample_data", sample_rec["data"][channel])
# Open CV init
name = "{}: {} (Space to pause, ESC to exit)".format(scene_rec["name"], channel)
cv2.namedWindow(name)
cv2.moveWindow(name, 0, 0)
if out_path is not None:
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
out = cv2.VideoWriter(out_path, fourcc, freq, image_size)
else:
out = None
has_more_frames = True
while has_more_frames:
# Get data from DB
image_path, boxes, camera_intrinsic = self.lyftd.get_sample_data(
sd_rec["token"], box_vis_level=BoxVisibility.ANY
)
# Load and render
if not image_path.exists():
raise Exception("Error: Missing image %s" % image_path)
image = cv2.imread(str(image_path))
for box in boxes:
c = self.get_color(box.name)
box.render_cv2(
image, view=camera_intrinsic, normalize=True, colors=(c, c, c)
)
# Render
image = cv2.resize(image, image_size)
cv2.imshow(name, image)
if out_path is not None:
out.write(image)
key = cv2.waitKey(10) # Images stored at approx 10 Hz, so wait 10 ms.
if key == 32: # If space is pressed, pause.
key = cv2.waitKey()
if key == 27: # if ESC is pressed, exit
cv2.destroyAllWindows()
break
if not sd_rec["next"] == "":
sd_rec = self.lyftd.get("sample_data", sd_rec["next"])
else:
has_more_frames = False
cv2.destroyAllWindows()
if out_path is not None:
out.release()
def render_egoposes_on_map(
self,
log_location: str,
scene_tokens: List = None,
close_dist: float = 100,
color_fg: Tuple[int, int, int] = (167, 174, 186),
color_bg: Tuple[int, int, int] = (255, 255, 255),
out_path: Path = None,
) -> None:
"""Renders ego poses a the map. These can be filtered by location or scene.
Args:
log_location: Name of the location, e.g. "singapore-onenorth", "singapore-hollandvillage",
"singapore-queenstown' and "boston-seaport".
scene_tokens: Optional list of scene tokens.
close_dist: Distance in meters for an ego pose to be considered within range of another ego pose.
color_fg: Color of the semantic prior in RGB format (ignored if map is RGB).
color_bg: Color of the non-semantic prior in RGB format (ignored if map is RGB).
out_path: Optional path to save the rendered figure to disk.
Returns:
"""
# Get logs by location
log_tokens = [
l["token"] for l in self.lyftd.log if l["location"] == log_location
]
assert len(log_tokens) > 0, (
"Error: This split has 0 scenes for location %s!" % log_location
)
# Filter scenes
scene_tokens_location = [
e["token"] for e in self.lyftd.scene if e["log_token"] in log_tokens
]
if scene_tokens is not None:
scene_tokens_location = [
t for t in scene_tokens_location if t in scene_tokens
]
if len(scene_tokens_location) == 0:
print("Warning: Found 0 valid scenes for location %s!" % log_location)
map_poses = []
map_mask = None
print("Adding ego poses to map...")
for scene_token in tqdm(scene_tokens_location):
# Get records from the database.
scene_record = self.lyftd.get("scene", scene_token)
log_record = self.lyftd.get("log", scene_record["log_token"])
map_record = self.lyftd.get("map", log_record["map_token"])
map_mask = map_record["mask"]
# For each sample in the scene, store the ego pose.
sample_tokens = self.lyftd.field2token("sample", "scene_token", scene_token)
for sample_token in sample_tokens:
sample_record = self.lyftd.get("sample", sample_token)
# Poses are associated with the sample_data. Here we use the lidar sample_data.
sample_data_record = self.lyftd.get(
"sample_data", sample_record["data"]["LIDAR_TOP"]
)
pose_record = self.lyftd.get(
"ego_pose", sample_data_record["ego_pose_token"]
)
# Calculate the pose on the map and append
map_poses.append(
np.concatenate(
map_mask.to_pixel_coords(
pose_record["translation"][0], pose_record["translation"][1]
)
)
)
# Compute number of close ego poses.
print("Creating plot...")
map_poses = np.vstack(map_poses)
dists = sklearn.metrics.pairwise.euclidean_distances(
map_poses * map_mask.resolution
)
close_poses = np.sum(dists < close_dist, axis=0)
if (
len(np.array(map_mask.mask()).shape) == 3
and np.array(map_mask.mask()).shape[2] == 3
):
# RGB Colour maps
mask = map_mask.mask()
else:
# Monochrome maps
# Set the colors for the mask.
mask = Image.fromarray(map_mask.mask())
mask = np.array(mask)
maskr = color_fg[0] * np.ones(np.shape(mask), dtype=np.uint8)
maskr[mask == 0] = color_bg[0]
maskg = color_fg[1] * np.ones(np.shape(mask), dtype=np.uint8)
maskg[mask == 0] = color_bg[1]
maskb = color_fg[2] * np.ones(np.shape(mask), dtype=np.uint8)
maskb[mask == 0] = color_bg[2]
mask = np.concatenate(
(
np.expand_dims(maskr, axis=2),
np.expand_dims(maskg, axis=2),
np.expand_dims(maskb, axis=2),
),
axis=2,
)
# Plot.
_, ax = plt.subplots(1, 1, figsize=(10, 10))
ax.imshow(mask)
title = "Number of ego poses within {}m in {}".format(close_dist, log_location)
ax.set_title(title, color="k")
sc = ax.scatter(map_poses[:, 0], map_poses[:, 1], s=10, c=close_poses)
color_bar = plt.colorbar(sc, fraction=0.025, pad=0.04)
plt.rcParams["figure.facecolor"] = "black"
color_bar_ticklabels = plt.getp(color_bar.ax.axes, "yticklabels")
plt.setp(color_bar_ticklabels, color="k")
plt.rcParams["figure.facecolor"] = "white" # Reset for future plots
if out_path is not None:
plt.savefig(out_path)
plt.close("all")
# ### Create a *LyftDataset* object from the existing dataset
lyft_dataset = LyftDataset(data_path=DATA_PATH, json_path=DATA_PATH + "train_data")
# The dataset consists of several scences, which are 25-45 second clips of image of LiDAR data from a self-driving car. We can extract and look at the first scence as follows:
my_scene = lyft_dataset.scene[179]
my_scene
# As it can be seen above, each scence consists of a dictionary of information. There are a few token IDs and a name for each scene. The "name" matches with the name of the LiDAR data file associated with the given scene. Here, the LiDAR file's name is:
# **host-a101-lidar0-1241893239199111666-1241893264098084346**.
# *Note:* You can list all the scenes in the dataset using:
# **lyft_dataset.list_scenes()**
# Now, let us visualize some of the image and LiDAR data.
# ### Create a function to render scences in the dataset
def render_scene(index):
my_scene = lyft_dataset.scene[index]
my_sample_token = my_scene["first_sample_token"]
lyft_dataset.render_sample(my_sample_token)
# ### Render the first scence (image and LiDAR)
render_scene(179)
# ### Render the second scence (image and LiDAR)
render_scene(1)
# These images above display the image and LiDAR data collected using the cameras and sensors from various angles on the car. The yellow boxes around the objects in the images are the bounding boxes or bounding volumes that show the location of the objects in the image.
# Note that a sample is a snapshot of the data at a given point in time during the scene. Therefore, each scence is made up of several samples.
# Now, let us extract the first sample sample from the first scence.
my_sample_token = my_scene["first_sample_token"]
my_sample = lyft_dataset.get("sample", my_sample_token)
# *Note :* You can list all samples in a scence using:
# **lyft_dataset.list_sample(my_sample['token'])**
# Next, let us render a pointcloud for a sample image in the dataset. The pointcloud is basically a set of contours that represent the distance of various objects as measured by the LiDAR. Basically, the LiDAR uses light beams to measure the distance of various objects (as discussed earlier) and this distance information can be visualized as a set of 3D contours. The colours of these contour lines represent the distance. The darker purple and blue contour lines represent the closer objects and the lighter green and yellow lines represent the far away objects. Basically, the higher the wavelength of the color of the contour line, the greater the distance of the object from the camera.
lyft_dataset.render_pointcloud_in_image(
sample_token=my_sample["token"], dot_size=1, camera_channel="CAM_FRONT"
)
# We can also print all annotations across all sample data for a given sample, as shown below:
my_sample["data"]
# We can also render the image data from particular sensors, as follows:
# ### Front Camera
# Images from the front camera
sensor_channel = "CAM_FRONT"
my_sample_data = lyft_dataset.get("sample_data", my_sample["data"][sensor_channel])
lyft_dataset.render_sample_data(my_sample_data["token"])
# ### Back Camera
# Images from the back camera
sensor_channel = "CAM_BACK"
my_sample_data = lyft_dataset.get("sample_data", my_sample["data"][sensor_channel])
lyft_dataset.render_sample_data(my_sample_data["token"])
# ### Front-Left Camera
# Images from the front-left camera
sensor_channel = "CAM_FRONT_LEFT"
my_sample_data = lyft_dataset.get("sample_data", my_sample["data"][sensor_channel])
lyft_dataset.render_sample_data(my_sample_data["token"])
# ### Front-Right Camera
# Images from the front-right camera
sensor_channel = "CAM_FRONT_RIGHT"
my_sample_data = lyft_dataset.get("sample_data", my_sample["data"][sensor_channel])
lyft_dataset.render_sample_data(my_sample_data["token"])
# ### Back-Left Camera
# Images from the back-left camera
sensor_channel = "CAM_BACK_LEFT"
my_sample_data = lyft_dataset.get("sample_data", my_sample["data"][sensor_channel])
lyft_dataset.render_sample_data(my_sample_data["token"])
# ### Back-Right Camera
# Images from the back-right camera
sensor_channel = "CAM_BACK_RIGHT"
my_sample_data = lyft_dataset.get("sample_data", my_sample["data"][sensor_channel])
lyft_dataset.render_sample_data(my_sample_data["token"])
# We can pick a given annotation from a sample in the data and render only that annotation, as shown below:
my_annotation_token = my_sample["anns"][10]
my_annotation = my_sample_data.get("sample_annotation", my_annotation_token)
lyft_dataset.render_annotation(my_annotation_token)
# We can also pick a given instance from the dataset and render only that instance, as shown below:
my_instance = lyft_dataset.instance[100]
my_instance
instance_token = my_instance["token"]
lyft_dataset.render_instance(instance_token)
lyft_dataset.render_annotation(my_instance["last_annotation_token"])
# We can also get the LiDAR data collected from various LIDAR sensors on the car as follows:
# ### Top LiDAR
# LiDAR data from the top sensor
my_scene = lyft_dataset.scene[0]
my_sample_token = my_scene["first_sample_token"]
my_sample = lyft_dataset.get("sample", my_sample_token)
lyft_dataset.render_sample_data(my_sample["data"]["LIDAR_TOP"], nsweeps=5)
# ### Front-Left LiDAR
# LiDAR data from the front-left sensor
my_scene = lyft_dataset.scene[0]
my_sample_token = my_scene["first_sample_token"]
my_sample = lyft_dataset.get("sample", my_sample_token)
lyft_dataset.render_sample_data(my_sample["data"]["LIDAR_FRONT_LEFT"], nsweeps=5)
# ### Front-Right LiDAR
# LiDAR data from the front-right sensor
my_scene = lyft_dataset.scene[0]
my_sample_token = my_scene["first_sample_token"]
my_sample = lyft_dataset.get("sample", my_sample_token)
lyft_dataset.render_sample_data(my_sample["data"]["LIDAR_FRONT_RIGHT"], nsweeps=5)
# ### Image and LiDAR animation
# This section is from [@xhulu](https://www.kaggle.com/xhlulu)'s brilliant [animation kernel](https://www.kaggle.com/xhlulu/lyft-eda-animations-generating-csvs). I use functions from that kernel to animate the image and LiDAR data.
# Please upvote [xhulu's kernel](https://www.kaggle.com/xhlulu/lyft-eda-animations-generating-csvs) if you find this interesting.
def generate_next_token(scene):
scene = lyft_dataset.scene[scene]
sample_token = scene["first_sample_token"]
sample_record = lyft_dataset.get("sample", sample_token)
while sample_record["next"]:
sample_token = sample_record["next"]
sample_record = lyft_dataset.get("sample", sample_token)
yield sample_token
def animate_images(scene, frames, pointsensor_channel="LIDAR_TOP", interval=1):
cams = [
"CAM_FRONT",
"CAM_FRONT_RIGHT",
"CAM_BACK_RIGHT",
"CAM_BACK",
"CAM_BACK_LEFT",
"CAM_FRONT_LEFT",
]
generator = generate_next_token(scene)
fig, axs = plt.subplots(
2,
len(cams),
figsize=(3 * len(cams), 6),
sharex=True,
sharey=True,
gridspec_kw={"wspace": 0, "hspace": 0.1},
)
plt.close(fig)
def animate_fn(i):
for _ in range(interval):
sample_token = next(generator)
for c, camera_channel in enumerate(cams):
sample_record = lyft_dataset.get("sample", sample_token)
pointsensor_token = sample_record["data"][pointsensor_channel]
camera_token = sample_record["data"][camera_channel]
axs[0, c].clear()
axs[1, c].clear()
lyft_dataset.render_sample_data(camera_token, with_anns=False, ax=axs[0, c])
lyft_dataset.render_sample_data(camera_token, with_anns=True, ax=axs[1, c])
axs[0, c].set_title("")
axs[1, c].set_title("")
anim = animation.FuncAnimation(fig, animate_fn, frames=frames, interval=interval)
return anim
# ### Animate image data (for 3 scences)
# ### Scence 1
anim = animate_images(scene=3, frames=100, interval=1)
HTML(anim.to_jshtml(fps=8))
# ### Scence 2
anim = animate_images(scene=7, frames=100, interval=1)
HTML(anim.to_jshtml(fps=8))
# ### Scence 3
anim = animate_images(scene=4, frames=100, interval=1)
HTML(anim.to_jshtml(fps=8))
# ### Animate LiDAR data (for 3 scences)
def animate_lidar(
scene, frames, pointsensor_channel="LIDAR_TOP", with_anns=True, interval=1
):
generator = generate_next_token(scene)
fig, axs = plt.subplots(1, 1, figsize=(8, 8))
plt.close(fig)
def animate_fn(i):
for _ in range(interval):
sample_token = next(generator)
axs.clear()
sample_record = lyft_dataset.get("sample", sample_token)
pointsensor_token = sample_record["data"][pointsensor_channel]
lyft_dataset.render_sample_data(pointsensor_token, with_anns=with_anns, ax=axs)
anim = animation.FuncAnimation(fig, animate_fn, frames=frames, interval=interval)
return anim
# ### Scence 1
anim = animate_lidar(scene=5, frames=100, interval=1)
HTML(anim.to_jshtml(fps=8))
# ### Scence 2
anim = animate_lidar(scene=25, frames=100, interval=1)
HTML(anim.to_jshtml(fps=8))
# ### Scence 3
anim = animate_lidar(scene=10, frames=100, interval=1)
HTML(anim.to_jshtml(fps=8))
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0063/571/63571785.ipynb | null | null | [{"Id": 63571785, "ScriptId": 16999857, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1314776, "CreationDate": "05/21/2021 23:58:04", "VersionNumber": 2.0, "Title": "TP_coursSignal", "EvaluationDate": "05/21/2021", "IsChange": true, "TotalLines": 2771.0, "LinesInsertedFromPrevious": 88.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 2683.0, "LinesInsertedFromFork": 92.0, "LinesDeletedFromFork": 90.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 2679.0, "TotalVotes": 0}] | null | null | null | null | # # Introduction
#
# Dans ce notebook, nous allons analyser la signification et l'intuition derrière chaque composante du jeu de données, y compris les images, le LiDAR(aser imaging detection and ranging : La télédétection par laser ou lidar) et les nuages de points. Après avoir plongé dans la théorie qui sous-tend ces concepts, je montrerai comment cet ensemble de données peut être conditionné dans un format compact qui facilite l'interrogation des informations de l'ensemble de données. Enfin, je montrerai comment visualiser et explorer ces données à l'aide la visualization *matplotlib*.
# # Acknowledgements
# * [NuScences DevKit ~ by Lyft](https://github.com/lyft/nuscenes-devkit)
# * [EDA - 3D Object Detection Challenge ~ by beluga](https://www.kaggle.com/gaborfodor/eda-3d-object-detection-challenge)
# * [Lyft: EDA, Animations, generating CSVs ~ by xhulu](https://www.kaggle.com/xhlulu/lyft-eda-animations-generating-csvs)
# * [Lidar - Wikipedia](https://en.wikipedia.org/wiki/Lidar)
# If you find this kernel interesting, please drop an upvote. It motivates me to produce more quality content :)
# ### Une voiture conduite par l'intelligence artificielle !
## Importer la librairie HTML pour lire la vidéo
from IPython.display import HTML
HTML(
'<center><iframe width="700" height="400" src="https://www.youtube.com/embed/tlThdr3O5Qo?rel=0&controls=0&showinfo=0" frameborder="0" allowfullscreen></iframe></center>'
)
# On peut voir dans la vidéo que la voiture est capable de prendre des virages, de changer de voie, de s'arrêter aux feux rouges, etc. sans effort. Cela est possible parce que la voiture est capable de reconnaître avec précision les objets dans l'espace 3D en utilisant les informations de ses capteurs, comme les données d'image et LiDAR. Je vais maintenant examiner la signification théorique de ces formes de données, puis je visualiserai ces informations plus tard dans le noyau.
# # Structure du dataset
# 1. `scene` - Consiste en 25 à 45 secondes de trajet d'une voiture dans un environnement donné. Chaque scence est composée de plusieurs échantillons.
# 2. `sample` - Un instantané d'une scène à un moment précis dans le temps. Chaque échantillon est annoté avec les objets présents.
# 3. `sample_data` - Contient les données collectées à partir d'un capteur particulier de la voiture.
# 4. `sample_annotation` - Une instance annotée d'un objet qui nous intéresse.
# 5. `instance` - Une énumération de toutes les instances d'objets que nous avons observées.
# 6. `category` - Plusieurs catégories d'objets (e.g. véhicule, humain).
# 7. `attribute` - Propriété d'une instance qui peut changer alors que la catégorie reste la même.
# 8. `visibility` -
# 9. `sensor` - Un type de capteur spécifique.
# 10. `calibrated sensor` - Définition d'un capteur particulier tel qu'étalonné sur un véhicule particulier.
# 11. `ego_pose` - Le véhicule Ego pose à un moment précis.
# 12. `log` - Informations sur le journal à partir duquel les données ont été extraites.
# 13. `map` - Cartographier les données stockées sous forme de masques sémantiques binaires à partir d'une vue de haut en bas.
# Nous distinguons deux types d'informations: **image data and LiDAR data**.
# Les données de l'image sont dans le format habituel *.jpeg*, qui est assez simple à comprendre. Chaque image se compose simplement de trois canaux de couleur : Rouge (R), Bleu (B) et Vert (G) qui forment le format d'image couleur RVB. Ces canaux de couleur se superposent pour former l'image colorée finale. Ces images peuvent donc être stockées dans un tenseur quadridimensionnel dont les dimensions sont les suivantes: **(batch_size, channels, width, height)**.
# # What is LiDAR?
# Le LiDAR (Light Detection and Ranging) est une méthode utilisée pour générer des représentations 3D précises de l'environnement, et il utilise la lumière laser pour y parvenir. En gros, la cible 3D est éclairée par une lumière laser (un faisceau de lumière focalisé et dirigé) et la lumière réfléchie est collectée par des capteurs. Le temps nécessaire pour que la lumière soit réfléchie vers le capteur est calculé.
# **Des capteurs différents collectent la lumière de différentes parties de l'objet, et les temps enregistrés par les capteurs seront différents. Cette différence de temps calculée par les capteurs peut être utilisée pour calculer la profondeur de l'objet. Cette information de profondeur, combinée à la représentation 2D de l'image, fournit une représentation 3D précise de l'objet. Ce processus est similaire à la vision humaine réelle. Deux yeux font des observations en 2D et ces deux informations sont combinées pour former une carte 3D (perception de la profondeur). C'est ainsi que les humains perçoivent le monde qui les entoure**.
# Cette technologie est utilisée pour créer des représentations 3D dans de nombreux scénarios du monde réel. Par exemple, elle est utilisée dans les fermes pour aider à semer les graines et à enlever les mauvaises herbes. Un robot en mouvement utilise le LiDAR pour créer une carte en 3D de son environnement. Grâce à cette carte, il évite les obstacles et accomplit ses tâches. Cette technologie est également utilisée en archéologie. Le LiDAR est utilisé pour créer des rendus 3D à partir de scans 2D d'artefacts. Cela donne une idée précise de la forme 3D de l'artefact lorsque celui-ci ne peut être fouillé pour une raison quelconque. Enfin, le LiDAR peut également être utilisé pour produire des cartes 3D de haute qualité des fonds marins et d'autres terrains inaccessibles, ce qui le rend très utile aux géologues et aux océanographes. Ci-dessous, la carte 3D d'un plancher océanique générée à l'aide du LiDAR :
# Et, bien sûr, les voitures à conduite autonome utilisent cette technologie pour identifier les objets qui les entourent en 3D, ainsi que pour estimer la vitesse et l'orientation de ces objets. Cette carte 3D complète fournit à la voiture des informations détaillées qui lui permettent de naviguer même dans des environnements complexes. Vous trouverez ci-dessous une vidéo présentant un drone équipé d'un LiDAR. Il crée automatiquement une carte 3D du monde qui l'entoure en utilisant le processus mentionné ci-dessus.
HTML(
'<center><iframe width="700" height="400" src="https://www.youtube.com/embed/x7De3tCb3_A?rel=0&controls=0&showinfo=0" frameborder="0" allowfullscreen></iframe></center>'
)
# # Démonstration de fonctionnement de LiDAR
# des faisceaux laser sont tirés dans toutes les sens par un laser. Les faisceaux laser se réfléchissent sur les objets qui se trouvent sur leur chemin et les faisceaux réfléchis sont collectés par un capteur. Maintenant, un dispositif spécial appelé **caméra flash LiDAR** est utilisé pour créer des cartes en 3D en utilisant les informations de ces capteurs.
# ### Flash LiDAR Camera
# L'appareil présenté dans l'image ci-dessus s'appelle une caméra Flash LiDAR. Le plan focal d'une caméra Flash LiDAR comporte des rangées et des colonnes de pixels ayant une "profondeur" et une "intensité" suffisantes pour créer des modèles de paysage en 3D. Chaque pixel enregistre le temps que met chaque impulsion laser à atteindre la cible et à revenir au capteur, ainsi que la profondeur, l'emplacement et l'intensité de réflexion de l'objet touché par l'impulsion laser.
# Le Flash LiDAR utilise une seule source lumineuse qui illumine le champ de vision en une seule impulsion. Tout comme un appareil photo qui prend des photos de la distance, au lieu des couleurs.
# La source d'illumination embarquée fait du Flash LiDAR un capteur actif. Le signal renvoyé est traité par des algorithmes intégrés pour produire un rendu 3D quasi instantané des objets et des caractéristiques du terrain dans le champ de vision du capteur. La fréquence de répétition des impulsions laser est suffisante pour générer des vidéos 3D avec une résolution et une précision élevées. La fréquence d'images élevée du capteur en fait un outil utile pour une variété d'applications qui bénéficient d'une visualisation en temps réel, comme la conduite autonome des véhicules. En renvoyant immédiatement un maillage d'élévation 3D des paysages cibles, un capteur flash peut être utilisé par un véhicule autonome pour prendre des décisions concernant le réglage de la vitesse, le freinage, la direction, etc.
# Ce type de caméra est fixé au sommet des voitures autonomes, et ces voitures l'utilisent pour naviguer tout en conduisant.
# # Visualisation de données
# ### Install *lyft_dataset_sdk* and import the necessary libraries
# Nous aurons besoin de la bibliothèque *lyft_dataset_sdk* car elle nous aidera à visualiser facilement l'image et les données LiDAR. Une simple commande *pip install* est nécessaire. J'utiliserai également l'installation de la bibliothèque *chart_studio* pour générer des graphiques interactifs.
import os
import gc
import numpy as np
import pandas as pd
import json
import math
import sys
import time
from datetime import datetime
from typing import Tuple, List
import cv2
import matplotlib.pyplot as plt
import sklearn.metrics
from PIL import Image
from matplotlib.axes import Axes
from matplotlib import animation, rc
import plotly.graph_objs as go
import plotly.tools as tls
from plotly.offline import plot, init_notebook_mode
import plotly.figure_factory as ff
init_notebook_mode(connected=True)
import seaborn as sns
from pyquaternion import Quaternion
from tqdm import tqdm
from lyft_dataset_sdk.utils.map_mask import MapMask
from lyft_dataset_sdk.lyftdataset import LyftDataset
from lyft_dataset_sdk.utils.geometry_utils import (
view_points,
box_in_image,
BoxVisibility,
)
from lyft_dataset_sdk.utils.geometry_utils import view_points, transform_matrix
from pathlib import Path
import struct
from abc import ABC, abstractmethod
from functools import reduce
from typing import Tuple, List, Dict
import copy
# ### le chemin de données
DATA_PATH = "../input/3d-object-detection-for-autonomous-vehicles/"
# ### Importer les données de training
train = pd.read_csv(DATA_PATH + "train.csv")
sample_submission = pd.read_csv(DATA_PATH + "sample_submission.csv")
#
# ### Regrouper les données par catégorie d'objet
# Taken from https://www.kaggle.com/gaborfodor/eda-3d-object-detection-challenge
object_columns = [
"sample_id",
"object_id",
"center_x",
"center_y",
"center_z",
"width",
"length",
"height",
"yaw",
"class_name",
]
objects = []
for sample_id, ps in tqdm(train.values[:]):
object_params = ps.split()
n_objects = len(object_params)
for i in range(n_objects // 8):
x, y, z, w, l, h, yaw, c = tuple(object_params[i * 8 : (i + 1) * 8])
objects.append([sample_id, i, x, y, z, w, l, h, yaw, c])
train_objects = pd.DataFrame(objects, columns=object_columns)
# ### Convertir les colonnes de type string en numérique (float32)
numerical_cols = [
"object_id",
"center_x",
"center_y",
"center_z",
"width",
"length",
"height",
"yaw",
]
train_objects[numerical_cols] = np.float32(train_objects[numerical_cols].values)
train_objects.head()
train_objects.info()
# ### First Exploration
# ### center_x and center_y
# **center_x** et **center_y** correspondent aux coordonnées *x* et *y* du centre de l'emplacement d'un objet (volume limite). Ces coordonnées représentent l'emplacement d'un objet sur le plan *x-y*.
# ### Distributions *center_x* and *center_y*
fig, ax = plt.subplots(figsize=(10, 10))
sns.distplot(train_objects["center_x"], color="darkorange", ax=ax).set_title(
"center_x and center_y", fontsize=16
)
sns.distplot(train_objects["center_y"], color="purple", ax=ax).set_title(
"center_x and center_y", fontsize=16
)
plt.xlabel("center_x and center_y", fontsize=15)
plt.show()
# Sur ce graphique ci-dessus, la distribution violette est celle de *center_y* et la distribution orange est celle de *center_x*. Le diagramme ci-dessus montre que les distributions de *centre_x* et de *centre_y* ont plusieurs pics et sont donc multimodales. Les deux distributions présentent également une nette inclinaison vers la droite ou une inclinaison positive. Mais, la distribution de *center_y* (violet) a un biais significativement plus élevé que la distribution de *center_x* (orange). La distribution *center_x* est plus uniformément répartie.
# Cela indique que les objets sont répartis très uniformément le long de l'axe *x*, mais pas de la même manière le long de l'axe *y*. Cela est probablement dû au fait que la caméra de la voiture peut facilement détecter des objets à gauche ou à droite (le long de l'axe *x*) en raison de la faible largeur de la route. Mais, comme la longueur de la route est beaucoup plus grande que sa largeur, et qu'il y a plus de chances que la vue de la caméra soit bloquée depuis cet angle, la caméra ne peut trouver que des objets situés juste devant ou juste derrière (et pas plus loin).
# ### Relation entre *center_x* and *center_y*
# ### KDE Plot
new_train_objects = train_objects.query('class_name == "car"')
plot = sns.jointplot(
x=new_train_objects["center_x"][:1000],
y=new_train_objects["center_y"][:1000],
kind="kde",
color="blueviolet",
)
plot.set_axis_labels("center_x", "center_y", fontsize=16)
plt.show()
# Dans le graphique KDE ci-dessus, nous pouvons voir que *center_x* et *center_y* semblent avoir une corrélation quelque peu négative. Cela est probablement dû, une fois de plus, aux limites du système de caméra. La caméra peut détecter des objets qui sont loin devant, mais pas trop loin sur le côté. Et elle peut également détecter des objets qui sont loin sur le côté, mais pas trop loin devant. Mais **la caméra ne peut pas détecter les objets qui sont à la fois loin devant et loin sur le côté**. Pour cette raison, les objets situés loin devant et loin sur le côté ne sont pas du tout détectés, et seuls les objets qui remplissent une (ou aucune) de ces conditions sont détectés. Il en résulte une relation négative entre *center_x* et *center_y*.
# ### center_z
# **center_z** correspond à la coordonnée *xz* du centre de l'emplacement d'un objet (volume limite). Cette coordonnée représente la hauteur de l'objet au-dessus du plan *x-y*.
# ### Distribution *center_z*
fig, ax = plt.subplots(figsize=(10, 10))
sns.distplot(train_objects["center_z"], color="navy", ax=ax).set_title(
"center_z", fontsize=16
)
plt.xlabel("center_z", fontsize=15)
plt.show()
# Dans le diagramme ci-dessus, nous pouvons voir que la distribution de *center_z* a une asymétrie positive (vers la droite) extrêmement élevée et qu'elle est regroupée autour de la marque -20 (qui est proche de sa valeur moyenne). La variation (dispersion) de *center_z* est nettement plus faible que celle de *center_x* et *center_y*. Cela s'explique probablement par le fait que la plupart des objets sont très proches du plan plat de la route et qu'il n'y a donc pas de grande variation de la hauteur des objets au-dessus (ou au-dessous) de la caméra. Il y a naturellement une variation beaucoup plus grande dans les coordonnées *x* et *y* de l'objet.
# De plus, la plupart des coordonnées *z* sont négatives car la caméra est fixée au sommet de la voiture. Ainsi, la plupart du temps, la caméra doit "regarder vers le bas" pour voir les objets. Par conséquent, la hauteur ou les coordonnées *z* des objets par rapport à la caméra sont généralement négatives.
# ### yaw
# **yaw** est l'angle du volume autour de l'axe *z*, ce qui fait que le "lacet" est la direction vers laquelle l'avant du véhicule/boîte englobante est dirigé lorsqu'il est au sol.
# ### Distribution de *yaw*
fig, ax = plt.subplots(figsize=(10, 10))
sns.distplot(train_objects["yaw"], color="darkgreen", ax=ax).set_title(
"yaw", fontsize=16
)
plt.xlabel("yaw", fontsize=15)
plt.show()
# Dans le diagramme ci-dessus, nous pouvons voir que la distribution de *yaw* est grossièrement bimodale, *c'est-à-dire qu'il y a deux pics majeurs dans la distribution. L'un des pics se situe autour de 0,5 et l'autre autour de 2,5. On peut estimer que la moyenne se situe entre 1 et 2 (autour de 1,5). La distribution ne présente pas d'asymétrie nette. La présence des deux pics à des positions symétriques réduit l'asymétrie dans les deux directions (et ils s'annulent), ce qui rend la distribution plus équilibrée que les distributions de *centre_x*, *centre_y* et *centre_z*.
# ### width
# **width** est simplement la largeur du volume délimité dans lequel se trouve l'objet.
fig, ax = plt.subplots(figsize=(10, 10))
sns.distplot(train_objects["width"], color="magenta", ax=ax).set_title(
"width", fontsize=16
)
plt.xlabel("width", fontsize=15)
plt.show()
# Dans le diagramme ci-dessus, nous pouvons voir que la *largeur* est distribuée à peu près normalement avec une moyenne d'environ 2, avec quelques valeurs aberrantes de chaque côté. La majorité des objets sont des voitures (comme nous le verrons plus tard), et celles-ci constituent une largeur d'environ 2 (au sommet). Les valeurs aberrantes à droite représentent des objets plus grands comme les camions et les camionnettes, et les valeurs aberrantes à gauche représentent des objets plus petits comme les piétons et les bicyclettes.
# ### length
# **length** est simplement la longueur du volume délimité dans lequel se trouve l'objet.
fig, ax = plt.subplots(figsize=(10, 10))
sns.distplot(train_objects["length"], color="crimson", ax=ax).set_title(
"length", fontsize=16
)
plt.xlabel("length", fontsize=15)
plt.show()
# Dans le diagramme ci-dessus, nous pouvons voir que la *longueur* a une distribution fortement positive (skew vers la droite) avec une moyenne d'environ 5, avec quelques valeurs aberrantes de chaque côté. La majorité des objets sont des voitures (comme nous le verrons plus tard), et celles-ci constituent une longueur d'environ 5 (au sommet). Les valeurs aberrantes sur la droite représentent des objets plus grands comme les camions et les camionnettes, et les valeurs aberrantes sur la gauche représentent des objets plus petits comme les piétons et les bicyclettes.
# ### height
# **height** est simplement la hauteur du volume délimité dans lequel se trouve l'objet.
fig, ax = plt.subplots(figsize=(10, 10))
sns.distplot(train_objects["height"], color="indigo", ax=ax).set_title(
"height", fontsize=16
)
plt.xlabel("height", fontsize=15)
plt.show()
# Dans le diagramme ci-dessus, nous pouvons voir que la *hauteur* a une distribution fortement positive (skew vers la droite) avec une moyenne d'environ 2, avec quelques aberrations de part et d'autre. La majorité des objets sont des voitures (comme nous le verrons plus tard), et celles-ci constituent une longueur d'environ 2 (au sommet). Les valeurs aberrantes sur la droite représentent des objets plus grands comme les camions et les camionnettes, et les valeurs aberrantes sur la gauche représentent des objets plus petits comme les piétons et les bicyclettes.
# ### Fréquence des objets
fig, ax = plt.subplots(figsize=(10, 10))
plot = sns.countplot(
y="class_name",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
),
palette=["navy", "darkblue", "blue", "dodgerblue", "skyblue", "lightblue"],
).set_title("Object Frequencies", fontsize=16)
plt.yticks(fontsize=14)
plt.xlabel("Count", fontsize=15)
plt.ylabel("Class Name", fontsize=15)
plt.show(plot)
# Le diagramme ci-dessus montre que la classe d'objets la plus courante dans l'ensemble de données est la "voiture". Cela n'est pas surprenant car les images sont prises dans les rues de Palo Alto, dans la Silicon Valley, en Californie. Et le véhicule (ou l'entité, d'ailleurs) le plus communément visible sur ces routes est la voiture. Toutes les autres classes d'objets sont loin d'être proches des voitures en termes de fréquence.
# ### center_x *vs.* class_name
# Dans les graphiques ci-dessous, je vais explorer comment la distribution de **center_x** change pour différents **nom de classe_des objets.**.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.violinplot(
x="class_name",
y="center_x",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
),
palette="YlGnBu",
split=True,
ax=ax,
).set_title("center_x (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("center_x", fontsize=15)
plt.show(plot)
# Dans les diagrammes de violon ci-dessus, nous pouvons voir que les distributions de *center_x* pour les grands véhicules, y compris les camions, les bus et autres véhicules, sont bien réparties. Elles ne présentent pratiquement pas d'asymétrie et ont des moyennes plus élevées que les distributions des piétons et des bicyclettes. Cela s'explique probablement par le fait que ces gros véhicules ont tendance à garder une plus grande distance avec les autres véhicules, et que les petits véhicules ne restent pas trop près de ces gros véhicules afin d'éviter les accidents. Par conséquent, la moyenne *center_x* est nettement supérieure pour les gros véhicules comme les bus et les camions.
# En revanche, les objets plus petits comme les piétons et les bicyclettes ont des distributions *center_x* fortement inclinées vers la droite. Ces distributions ont également des moyennes nettement plus faibles que celles des véhicules plus grands. Cela est probablement dû au fait que les piétons (qui traversent la route) et les cyclistes n'ont pas besoin de maintenir de grandes distances avec les voitures et les camions pour éviter les accidents. Ils traversent généralement la route pendant un feu rouge, lorsque le trafic s'arrête.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.boxplot(
x="class_name",
y="center_x",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
),
palette="YlGnBu",
ax=ax,
).set_title("center_x (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("center_x", fontsize=15)
plt.show(plot)
# In the box plots above, we can notice the same observation as in the violin plot above. The *center_x* distributions for smaller objects like pedestrians and bicycles have very low mean and quartile values as compared to larger objects like cars, trucks, and buses.
# ### center_y *vs.* class_name
# In the plots below, I will explore how the distribution of **center_y** changes for different object **class_names**.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.violinplot(
x="class_name",
y="center_y",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
),
palette="YlOrRd",
split=True,
ax=ax,
).set_title("center_y (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("center_y", fontsize=15)
plt.show(plot)
# In the violin plots above, we can see that the distributions of *center_y* for small objects including pedestrians and bicycles have a greater mean value than large objects like trucks and buses. The distributions for the small objects have much greater probability density concentrated at higher values of *center_y* as compared to large objects. This signifies that small objects, in general, have greater *center_y* values than large objects.
# This is probably because the large vehicles tend to be within the field of view of the camera due to their large size. But, smaller objects like bicycles and pedestrians cannot remain in the field of view of the camera when they are too close. Therefore, most pedestrains and bicycles that are detected tend to be far away. This causes the *center_y* to be greater (on average) for small objects as compared to large objects.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.boxplot(
x="class_name",
y="center_y",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
),
palette="YlOrRd",
ax=ax,
).set_title("center_y (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("center_y", fontsize=15)
plt.show(plot)
# In the box plots above, we can notice the same observation as in the violin plot above. The *center_y* distributions for smaller objects like pedestrians and bicycles have much larger mean and quartile values as compared to larger objects like cars, trucks, and buses.
# ### center_z *vs.* class_name
# In the plots below, I will explore how the distribution of **center_z** changes for different object **class_names**.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.violinplot(
x="class_name",
y="center_z",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
).query("center_z <= -5"),
palette="RdPu",
split=True,
ax=ax,
).set_title("center_z (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("center_z", fontsize=15)
plt.show(plot)
# In the violin plots above, we can see that the distributions of *center_z* for small objects including pedestrians and bicycles have a significantly smaller mean value than large objects like trucks and buses. The distributions for the small objects have much greater probability density concentrated at lower values of *center_z* as compared to large objects. This signifies that small objects, in general, have smaller *center_y* values than large objects.
# This is probably because smaller objects like pedestrians and bicycles tend to have a lower height with repsect to the camera. And, on the other hand, larger objects like cars, trucks, and buses tend to have a greater height with respect to the camera.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.boxplot(
x="class_name",
y="center_z",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
).query("center_z <= -5"),
palette="RdPu",
ax=ax,
).set_title("center_z (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("center_z", fontsize=15)
plt.show(plot)
# In the box plots above, we can notice the same observation as in the violin plot above. The *center_z* distributions for smaller objects like pedestrians and bicycles have much smaller mean and quartile values as compared to larger objects like cars, trucks, and buses.
# ### width *vs.* class_name
# In the plots below, I will explore how the distribution of **width** changes for different object **class_names**.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.violinplot(
x="class_name",
y="width",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
),
palette="YlGn",
split=True,
ax=ax,
).set_title("width (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("width", fontsize=15)
plt.show(plot)
# In the violin plots, we can clearly see that the *width* distributions for large vehicles like cars, buses, and trucks have much larger means as compared to small objects like pedestrians and bicycles. This is not surprising because trucks, buses, and cars almost always have much greater width than pedestrians and bicycles.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.boxplot(
x="class_name",
y="width",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal"'
),
palette="YlGn",
ax=ax,
).set_title("width (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("width", fontsize=15)
plt.show(plot)
# In the box plots above, we can notice the same observation as in the violin plot above. The *width* distributions for smaller objects like pedestrians and bicycles have much smaller mean and quartile values as compared to larger objects like cars, trucks, and buses.
# ### length *vs.* class_name
# In the plots below, I will explore how the distribution of **length** changes for different object **class_names**.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.violinplot(
x="class_name",
y="length",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal" and length < 15'
),
palette="Purples",
split=True,
ax=ax,
).set_title("length (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("length", fontsize=15)
plt.show(plot)
# In the violin plots, we can clearly see that the *length* distributions for large vehicles like cars, buses, and trucks have much larger means as compared to small objects like pedestrians and bicycles. This is not surprising because trucks, buses, and cars almost always have much greater length than pedestrians and bicycles.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.boxplot(
x="class_name",
y="length",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal" and length < 15'
),
palette="Purples",
ax=ax,
).set_title("length (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("length", fontsize=15)
plt.show(plot)
# In the box plots above, we can notice the same observation as in the violin plot above. The *length* distributions for smaller objects like pedestrians and bicycles have much smaller mean and quartile values as compared to larger objects like cars, trucks, and buses.
# ### height *vs.* class_name
# In the plots below, I will explore how the distribution of **height** changes for different object **class_names**.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.violinplot(
x="class_name",
y="height",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal" and height < 6'
),
palette="Reds",
split=True,
ax=ax,
).set_title("height (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("height", fontsize=15)
plt.show(plot)
# In the violin plots, we can clearly see that the *length* distributions for large vehicles like buses and trucks have much larger means as compared to small objects like pedestrians and bicycles. This is not surprising because trucks and buses almost always have much greater length than pedestrians and bicycles.
# The only exception to this trend are the cars. They tend to have a similar height to that of pedestrians.
fig, ax = plt.subplots(figsize=(15, 15))
plot = sns.boxplot(
x="class_name",
y="height",
data=train_objects.query(
'class_name != "motorcycle" and class_name != "emergency_vehicle" and class_name != "animal" and height < 6'
),
palette="Reds",
ax=ax,
).set_title("height (for different objects)", fontsize=16)
plt.yticks(fontsize=14)
plt.xticks(fontsize=14)
plt.xlabel("Class Name", fontsize=15)
plt.ylabel("height", fontsize=15)
plt.show(plot)
# In the box plots above, we can notice the same observation as in the violin plot above. The *height* distributions for smaller objects like pedestrians and bicycles have much smaller mean and quartile values as compared to larger objects like cars, trucks, and buses.
# Once again, the only exception to this trend are the cars. They tend to have a similar height to that of pedestrians.
# # Digging into the image and LiDAR data
# ### Define some functions to help create the *LyftDataset* class
# #### (click CODE on the right side)
# Lyft Dataset SDK dev-kit.
# Code written by Oscar Beijbom, 2018.
# Licensed under the Creative Commons [see licence.txt]
# Modified by Vladimir Iglovikov 2019.
class PointCloud(ABC):
"""
Abstract class for manipulating and viewing point clouds.
Every point cloud (lidar and radar) consists of points where:
- Dimensions 0, 1, 2 represent x, y, z coordinates.
These are modified when the point cloud is rotated or translated.
- All other dimensions are optional. Hence these have to be manually modified if the reference frame changes.
"""
def __init__(self, points: np.ndarray):
"""
Initialize a point cloud and check it has the correct dimensions.
:param points: <np.float: d, n>. d-dimensional input point cloud matrix.
"""
assert points.shape[0] == self.nbr_dims(), (
"Error: Pointcloud points must have format: %d x n" % self.nbr_dims()
)
self.points = points
@staticmethod
@abstractmethod
def nbr_dims() -> int:
"""Returns the number of dimensions.
Returns: Number of dimensions.
"""
pass
@classmethod
@abstractmethod
def from_file(cls, file_name: str) -> "PointCloud":
"""Loads point cloud from disk.
Args:
file_name: Path of the pointcloud file on disk.
Returns: PointCloud instance.
"""
pass
@classmethod
def from_file_multisweep(
cls,
lyftd,
sample_rec: Dict,
chan: str,
ref_chan: str,
num_sweeps: int = 26,
min_distance: float = 1.0,
) -> Tuple["PointCloud", np.ndarray]:
"""Return a point cloud that aggregates multiple sweeps.
As every sweep is in a different coordinate frame, we need to map the coordinates to a single reference frame.
As every sweep has a different timestamp, we need to account for that in the transformations and timestamps.
Args:
lyftd: A LyftDataset instance.
sample_rec: The current sample.
chan: The radar channel from which we track back n sweeps to aggregate the point cloud.
ref_chan: The reference channel of the current sample_rec that the point clouds are mapped to.
num_sweeps: Number of sweeps to aggregated.
min_distance: Distance below which points are discarded.
Returns: (all_pc, all_times). The aggregated point cloud and timestamps.
"""
# Init
points = np.zeros((cls.nbr_dims(), 0))
all_pc = cls(points)
all_times = np.zeros((1, 0))
# Get reference pose and timestamp
ref_sd_token = sample_rec["data"][ref_chan]
ref_sd_rec = lyftd.get("sample_data", ref_sd_token)
ref_pose_rec = lyftd.get("ego_pose", ref_sd_rec["ego_pose_token"])
ref_cs_rec = lyftd.get(
"calibrated_sensor", ref_sd_rec["calibrated_sensor_token"]
)
ref_time = 1e-6 * ref_sd_rec["timestamp"]
# Homogeneous transform from ego car frame to reference frame
ref_from_car = transform_matrix(
ref_cs_rec["translation"], Quaternion(ref_cs_rec["rotation"]), inverse=True
)
# Homogeneous transformation matrix from global to _current_ ego car frame
car_from_global = transform_matrix(
ref_pose_rec["translation"],
Quaternion(ref_pose_rec["rotation"]),
inverse=True,
)
# Aggregate current and previous sweeps.
sample_data_token = sample_rec["data"][chan]
current_sd_rec = lyftd.get("sample_data", sample_data_token)
for _ in range(num_sweeps):
# Load up the pointcloud.
current_pc = cls.from_file(
lyftd.data_path / ("train_" + current_sd_rec["filename"])
)
# Get past pose.
current_pose_rec = lyftd.get("ego_pose", current_sd_rec["ego_pose_token"])
global_from_car = transform_matrix(
current_pose_rec["translation"],
Quaternion(current_pose_rec["rotation"]),
inverse=False,
)
# Homogeneous transformation matrix from sensor coordinate frame to ego car frame.
current_cs_rec = lyftd.get(
"calibrated_sensor", current_sd_rec["calibrated_sensor_token"]
)
car_from_current = transform_matrix(
current_cs_rec["translation"],
Quaternion(current_cs_rec["rotation"]),
inverse=False,
)
# Fuse four transformation matrices into one and perform transform.
trans_matrix = reduce(
np.dot,
[ref_from_car, car_from_global, global_from_car, car_from_current],
)
current_pc.transform(trans_matrix)
# Remove close points and add timevector.
current_pc.remove_close(min_distance)
time_lag = (
ref_time - 1e-6 * current_sd_rec["timestamp"]
) # positive difference
times = time_lag * np.ones((1, current_pc.nbr_points()))
all_times = np.hstack((all_times, times))
# Merge with key pc.
all_pc.points = np.hstack((all_pc.points, current_pc.points))
# Abort if there are no previous sweeps.
if current_sd_rec["prev"] == "":
break
else:
current_sd_rec = lyftd.get("sample_data", current_sd_rec["prev"])
return all_pc, all_times
def nbr_points(self) -> int:
"""Returns the number of points."""
return self.points.shape[1]
def subsample(self, ratio: float) -> None:
"""Sub-samples the pointcloud.
Args:
ratio: Fraction to keep.
"""
selected_ind = np.random.choice(
np.arange(0, self.nbr_points()), size=int(self.nbr_points() * ratio)
)
self.points = self.points[:, selected_ind]
def remove_close(self, radius: float) -> None:
"""Removes point too close within a certain radius from origin.
Args:
radius: Radius below which points are removed.
Returns:
"""
x_filt = np.abs(self.points[0, :]) < radius
y_filt = np.abs(self.points[1, :]) < radius
not_close = np.logical_not(np.logical_and(x_filt, y_filt))
self.points = self.points[:, not_close]
def translate(self, x: np.ndarray) -> None:
"""Applies a translation to the point cloud.
Args:
x: <np.float: 3, 1>. Translation in x, y, z.
"""
for i in range(3):
self.points[i, :] = self.points[i, :] + x[i]
def rotate(self, rot_matrix: np.ndarray) -> None:
"""Applies a rotation.
Args:
rot_matrix: <np.float: 3, 3>. Rotation matrix.
Returns:
"""
self.points[:3, :] = np.dot(rot_matrix, self.points[:3, :])
def transform(self, transf_matrix: np.ndarray) -> None:
"""Applies a homogeneous transform.
Args:
transf_matrix: transf_matrix: <np.float: 4, 4>. Homogenous transformation matrix.
"""
self.points[:3, :] = transf_matrix.dot(
np.vstack((self.points[:3, :], np.ones(self.nbr_points())))
)[:3, :]
def render_height(
self,
ax: Axes,
view: np.ndarray = np.eye(4),
x_lim: Tuple = (-20, 20),
y_lim: Tuple = (-20, 20),
marker_size: float = 1,
) -> None:
"""Simple method that applies a transformation and then scatter plots the points colored by height (z-value).
Args:
ax: Axes on which to render the points.
view: <np.float: n, n>. Defines an arbitrary projection (n <= 4).
x_lim: (min <float>, max <float>). x range for plotting.
y_lim: (min <float>, max <float>). y range for plotting.
marker_size: Marker size.
"""
self._render_helper(2, ax, view, x_lim, y_lim, marker_size)
def render_intensity(
self,
ax: Axes,
view: np.ndarray = np.eye(4),
x_lim: Tuple = (-20, 20),
y_lim: Tuple = (-20, 20),
marker_size: float = 1,
) -> None:
"""Very simple method that applies a transformation and then scatter plots the points colored by intensity.
Args:
ax: Axes on which to render the points.
view: <np.float: n, n>. Defines an arbitrary projection (n <= 4).
x_lim: (min <float>, max <float>).
y_lim: (min <float>, max <float>).
marker_size: Marker size.
Returns:
"""
self._render_helper(3, ax, view, x_lim, y_lim, marker_size)
def _render_helper(
self,
color_channel: int,
ax: Axes,
view: np.ndarray,
x_lim: Tuple,
y_lim: Tuple,
marker_size: float,
) -> None:
"""Helper function for rendering.
Args:
color_channel: Point channel to use as color.
ax: Axes on which to render the points.
view: <np.float: n, n>. Defines an arbitrary projection (n <= 4).
x_lim: (min <float>, max <float>).
y_lim: (min <float>, max <float>).
marker_size: Marker size.
"""
points = view_points(self.points[:3, :], view, normalize=False)
ax.scatter(
points[0, :], points[1, :], c=self.points[color_channel, :], s=marker_size
)
ax.set_xlim(x_lim[0], x_lim[1])
ax.set_ylim(y_lim[0], y_lim[1])
class LidarPointCloud(PointCloud):
@staticmethod
def nbr_dims() -> int:
"""Returns the number of dimensions.
Returns: Number of dimensions.
"""
return 4
@classmethod
def from_file(cls, file_name: Path) -> "LidarPointCloud":
"""Loads LIDAR data from binary numpy format. Data is stored as (x, y, z, intensity, ring index).
Args:
file_name: Path of the pointcloud file on disk.
Returns: LidarPointCloud instance (x, y, z, intensity).
"""
assert file_name.suffix == ".bin", "Unsupported filetype {}".format(file_name)
scan = np.fromfile(str(file_name), dtype=np.float32)
points = scan.reshape((-1, 5))[:, : cls.nbr_dims()]
return cls(points.T)
class RadarPointCloud(PointCloud):
# Class-level settings for radar pointclouds, see from_file().
invalid_states = [0] # type: List[int]
dynprop_states = range(
7
) # type: List[int] # Use [0, 2, 6] for moving objects only.
ambig_states = [3] # type: List[int]
@staticmethod
def nbr_dims() -> int:
"""Returns the number of dimensions.
Returns: Number of dimensions.
"""
return 18
@classmethod
def from_file(
cls,
file_name: Path,
invalid_states: List[int] = None,
dynprop_states: List[int] = None,
ambig_states: List[int] = None,
) -> "RadarPointCloud":
"""Loads RADAR data from a Point Cloud Data file. See details below.
Args:
file_name: The path of the pointcloud file.
invalid_states: Radar states to be kept. See details below.
dynprop_states: Radar states to be kept. Use [0, 2, 6] for moving objects only. See details below.
ambig_states: Radar states to be kept. See details below. To keep all radar returns,
set each state filter to range(18).
Returns: <np.float: d, n>. Point cloud matrix with d dimensions and n points.
Example of the header fields:
# .PCD v0.7 - Point Cloud Data file format
VERSION 0.7
FIELDS x y z dyn_prop id rcs vx vy vx_comp vy_comp is_quality_valid ambig_
state x_rms y_rms invalid_state pdh0 vx_rms vy_rms
SIZE 4 4 4 1 2 4 4 4 4 4 1 1 1 1 1 1 1 1
TYPE F F F I I F F F F F I I I I I I I I
COUNT 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
WIDTH 125
HEIGHT 1
VIEWPOINT 0 0 0 1 0 0 0
POINTS 125
DATA binary
Below some of the fields are explained in more detail:
x is front, y is left
vx, vy are the velocities in m/s.
vx_comp, vy_comp are the velocities in m/s compensated by the ego motion.
We recommend using the compensated velocities.
invalid_state: state of Cluster validity state.
(Invalid states)
0x01 invalid due to low RCS
0x02 invalid due to near-field artefact
0x03 invalid far range cluster because not confirmed in near range
0x05 reserved
0x06 invalid cluster due to high mirror probability
0x07 Invalid cluster because outside sensor field of view
0x0d reserved
0x0e invalid cluster because it is a harmonics
(Valid states)
0x00 valid
0x04 valid cluster with low RCS
0x08 valid cluster with azimuth correction due to elevation
0x09 valid cluster with high child probability
0x0a valid cluster with high probability of being a 50 deg artefact
0x0b valid cluster but no local maximum
0x0c valid cluster with high artefact probability
0x0f valid cluster with above 95m in near range
0x10 valid cluster with high multi-target probability
0x11 valid cluster with suspicious angle
dynProp: Dynamic property of cluster to indicate if is moving or not.
0: moving
1: stationary
2: oncoming
3: stationary candidate
4: unknown
5: crossing stationary
6: crossing moving
7: stopped
ambig_state: State of Doppler (radial velocity) ambiguity solution.
0: invalid
1: ambiguous
2: staggered ramp
3: unambiguous
4: stationary candidates
pdh0: False alarm probability of cluster (i.e. probability of being an artefact caused
by multipath or similar).
0: invalid
1: <25%
2: 50%
3: 75%
4: 90%
5: 99%
6: 99.9%
7: <=100%
"""
assert file_name.suffix == ".pcd", "Unsupported filetype {}".format(file_name)
meta = []
with open(str(file_name), "rb") as f:
for line in f:
line = line.strip().decode("utf-8")
meta.append(line)
if line.startswith("DATA"):
break
data_binary = f.read()
# Get the header rows and check if they appear as expected.
assert meta[0].startswith("#"), "First line must be comment"
assert meta[1].startswith("VERSION"), "Second line must be VERSION"
sizes = meta[3].split(" ")[1:]
types = meta[4].split(" ")[1:]
counts = meta[5].split(" ")[1:]
width = int(meta[6].split(" ")[1])
height = int(meta[7].split(" ")[1])
data = meta[10].split(" ")[1]
feature_count = len(types)
assert width > 0
assert len([c for c in counts if c != c]) == 0, "Error: COUNT not supported!"
assert height == 1, "Error: height != 0 not supported!"
assert data == "binary"
# Lookup table for how to decode the binaries.
unpacking_lut = {
"F": {2: "e", 4: "f", 8: "d"},
"I": {1: "b", 2: "h", 4: "i", 8: "q"},
"U": {1: "B", 2: "H", 4: "I", 8: "Q"},
}
types_str = "".join([unpacking_lut[t][int(s)] for t, s in zip(types, sizes)])
# Decode each point.
offset = 0
point_count = width
points = []
for i in range(point_count):
point = []
for p in range(feature_count):
start_p = offset
end_p = start_p + int(sizes[p])
assert end_p < len(data_binary)
point_p = struct.unpack(types_str[p], data_binary[start_p:end_p])[0]
point.append(point_p)
offset = end_p
points.append(point)
# A NaN in the first point indicates an empty pointcloud.
point = np.array(points[0])
if np.any(np.isnan(point)):
return cls(np.zeros((feature_count, 0)))
# Convert to numpy matrix.
points = np.array(points).transpose()
# If no parameters are provided, use default settings.
invalid_states = (
cls.invalid_states if invalid_states is None else invalid_states
)
dynprop_states = (
cls.dynprop_states if dynprop_states is None else dynprop_states
)
ambig_states = cls.ambig_states if ambig_states is None else ambig_states
# Filter points with an invalid state.
valid = [p in invalid_states for p in points[-4, :]]
points = points[:, valid]
# Filter by dynProp.
valid = [p in dynprop_states for p in points[3, :]]
points = points[:, valid]
# Filter by ambig_state.
valid = [p in ambig_states for p in points[11, :]]
points = points[:, valid]
return cls(points)
class Box:
"""Simple data class representing a 3d box including, label, score and velocity."""
def __init__(
self,
center: List[float],
size: List[float],
orientation: Quaternion,
label: int = np.nan,
score: float = np.nan,
velocity: Tuple = (np.nan, np.nan, np.nan),
name: str = None,
token: str = None,
):
"""
Args:
center: Center of box given as x, y, z.
size: Size of box in width, length, height.
orientation: Box orientation.
label: Integer label, optional.
score: Classification score, optional.
velocity: Box velocity in x, y, z direction.
name: Box name, optional. Can be used e.g. for denote category name.
token: Unique string identifier from DB.
"""
assert not np.any(np.isnan(center))
assert not np.any(np.isnan(size))
assert len(center) == 3
assert len(size) == 3
assert type(orientation) == Quaternion
self.center = np.array(center)
self.wlh = np.array(size)
self.orientation = orientation
self.label = int(label) if not np.isnan(label) else label
self.score = float(score) if not np.isnan(score) else score
self.velocity = np.array(velocity)
self.name = name
self.token = token
def __eq__(self, other):
center = np.allclose(self.center, other.center)
wlh = np.allclose(self.wlh, other.wlh)
orientation = np.allclose(self.orientation.elements, other.orientation.elements)
label = (self.label == other.label) or (
np.isnan(self.label) and np.isnan(other.label)
)
score = (self.score == other.score) or (
np.isnan(self.score) and np.isnan(other.score)
)
vel = np.allclose(self.velocity, other.velocity) or (
np.all(np.isnan(self.velocity)) and np.all(np.isnan(other.velocity))
)
return center and wlh and orientation and label and score and vel
def __repr__(self):
repr_str = (
"label: {}, score: {:.2f}, xyz: [{:.2f}, {:.2f}, {:.2f}], wlh: [{:.2f}, {:.2f}, {:.2f}], "
"rot axis: [{:.2f}, {:.2f}, {:.2f}], ang(degrees): {:.2f}, ang(rad): {:.2f}, "
"vel: {:.2f}, {:.2f}, {:.2f}, name: {}, token: {}"
)
return repr_str.format(
self.label,
self.score,
self.center[0],
self.center[1],
self.center[2],
self.wlh[0],
self.wlh[1],
self.wlh[2],
self.orientation.axis[0],
self.orientation.axis[1],
self.orientation.axis[2],
self.orientation.degrees,
self.orientation.radians,
self.velocity[0],
self.velocity[1],
self.velocity[2],
self.name,
self.token,
)
@property
def rotation_matrix(self) -> np.ndarray:
"""Return a rotation matrix.
Returns: <np.float: 3, 3>. The box's rotation matrix.
"""
return self.orientation.rotation_matrix
def translate(self, x: np.ndarray) -> None:
"""Applies a translation.
Args:
x: <np.float: 3, 1>. Translation in x, y, z direction.
"""
self.center += x
def rotate(self, quaternion: Quaternion) -> None:
"""Rotates box.
Args:
quaternion: Rotation to apply.
"""
self.center = np.dot(quaternion.rotation_matrix, self.center)
self.orientation = quaternion * self.orientation
self.velocity = np.dot(quaternion.rotation_matrix, self.velocity)
def corners(self, wlh_factor: float = 1.0) -> np.ndarray:
"""Returns the bounding box corners.
Args:
wlh_factor: Multiply width, length, height by a factor to scale the box.
Returns: First four corners are the ones facing forward.
The last four are the ones facing backwards.
"""
width, length, height = self.wlh * wlh_factor
# 3D bounding box corners. (Convention: x points forward, y to the left, z up.)
x_corners = length / 2 * np.array([1, 1, 1, 1, -1, -1, -1, -1])
y_corners = width / 2 * np.array([1, -1, -1, 1, 1, -1, -1, 1])
z_corners = height / 2 * np.array([1, 1, -1, -1, 1, 1, -1, -1])
corners = np.vstack((x_corners, y_corners, z_corners))
# Rotate
corners = np.dot(self.orientation.rotation_matrix, corners)
# Translate
x, y, z = self.center
corners[0, :] = corners[0, :] + x
corners[1, :] = corners[1, :] + y
corners[2, :] = corners[2, :] + z
return corners
def bottom_corners(self) -> np.ndarray:
"""Returns the four bottom corners.
Returns: <np.float: 3, 4>. Bottom corners. First two face forward, last two face backwards.
"""
return self.corners()[:, [2, 3, 7, 6]]
def render(
self,
axis: Axes,
view: np.ndarray = np.eye(3),
normalize: bool = False,
colors: Tuple = ("b", "r", "k"),
linewidth: float = 2,
):
"""Renders the box in the provided Matplotlib axis.
Args:
axis: Axis onto which the box should be drawn.
view: <np.array: 3, 3>. Define a projection in needed (e.g. for drawing projection in an image).
normalize: Whether to normalize the remaining coordinate.
colors: (<Matplotlib.colors>: 3). Valid Matplotlib colors (<str> or normalized RGB tuple) for front,
back and sides.
linewidth: Width in pixel of the box sides.
"""
corners = view_points(self.corners(), view, normalize=normalize)[:2, :]
def draw_rect(selected_corners, color):
prev = selected_corners[-1]
for corner in selected_corners:
axis.plot(
[prev[0], corner[0]],
[prev[1], corner[1]],
color=color,
linewidth=linewidth,
)
prev = corner
# Draw the sides
for i in range(4):
axis.plot(
[corners.T[i][0], corners.T[i + 4][0]],
[corners.T[i][1], corners.T[i + 4][1]],
color=colors[2],
linewidth=linewidth,
)
# Draw front (first 4 corners) and rear (last 4 corners) rectangles(3d)/lines(2d)
draw_rect(corners.T[:4], colors[0])
draw_rect(corners.T[4:], colors[1])
# Draw line indicating the front
center_bottom_forward = np.mean(corners.T[2:4], axis=0)
center_bottom = np.mean(corners.T[[2, 3, 7, 6]], axis=0)
axis.plot(
[center_bottom[0], center_bottom_forward[0]],
[center_bottom[1], center_bottom_forward[1]],
color=colors[0],
linewidth=linewidth,
)
def render_cv2(
self,
image: np.ndarray,
view: np.ndarray = np.eye(3),
normalize: bool = False,
colors: Tuple = ((0, 0, 255), (255, 0, 0), (155, 155, 155)),
linewidth: int = 2,
) -> None:
"""Renders box using OpenCV2.
Args:
image: <np.array: width, height, 3>. Image array. Channels are in BGR order.
view: <np.array: 3, 3>. Define a projection if needed (e.g. for drawing projection in an image).
normalize: Whether to normalize the remaining coordinate.
colors: ((R, G, B), (R, G, B), (R, G, B)). Colors for front, side & rear.
linewidth: Linewidth for plot.
Returns:
"""
corners = view_points(self.corners(), view, normalize=normalize)[:2, :]
def draw_rect(selected_corners, color):
prev = selected_corners[-1]
for corner in selected_corners:
cv2.line(
image,
(int(prev[0]), int(prev[1])),
(int(corner[0]), int(corner[1])),
color,
linewidth,
)
prev = corner
# Draw the sides
for i in range(4):
cv2.line(
image,
(int(corners.T[i][0]), int(corners.T[i][1])),
(int(corners.T[i + 4][0]), int(corners.T[i + 4][1])),
colors[2][::-1],
linewidth,
)
# Draw front (first 4 corners) and rear (last 4 corners) rectangles(3d)/lines(2d)
draw_rect(corners.T[:4], colors[0][::-1])
draw_rect(corners.T[4:], colors[1][::-1])
# Draw line indicating the front
center_bottom_forward = np.mean(corners.T[2:4], axis=0)
center_bottom = np.mean(corners.T[[2, 3, 7, 6]], axis=0)
cv2.line(
image,
(int(center_bottom[0]), int(center_bottom[1])),
(int(center_bottom_forward[0]), int(center_bottom_forward[1])),
colors[0][::-1],
linewidth,
)
def copy(self) -> "Box":
"""Create a copy of self.
Returns: A copy.
"""
return copy.deepcopy(self)
# ### Create a class called *LyftDataset* to package the dataset in a convenient form
# #### (click CODE on the right side)
# Lyft Dataset SDK dev-kit.
# Code written by Oscar Beijbom, 2018.
# Licensed under the Creative Commons [see licence.txt]
# Modified by Vladimir Iglovikov 2019.
PYTHON_VERSION = sys.version_info[0]
if not PYTHON_VERSION == 3:
raise ValueError("LyftDataset sdk only supports Python version 3.")
class LyftDataset:
"""Database class for Lyft Dataset to help query and retrieve information from the database."""
def __init__(
self,
data_path: str,
json_path: str,
verbose: bool = True,
map_resolution: float = 0.1,
):
"""Loads database and creates reverse indexes and shortcuts.
Args:
data_path: Path to the tables and data.
json_path: Path to the folder with json files
verbose: Whether to print status messages during load.
map_resolution: Resolution of maps (meters).
"""
self.data_path = Path(data_path).expanduser().absolute()
self.json_path = Path(json_path)
self.table_names = [
"category",
"attribute",
"visibility",
"instance",
"sensor",
"calibrated_sensor",
"ego_pose",
"log",
"scene",
"sample",
"sample_data",
"sample_annotation",
"map",
]
start_time = time.time()
# Explicitly assign tables to help the IDE determine valid class members.
self.category = self.__load_table__("category")
self.attribute = self.__load_table__("attribute")
self.visibility = self.__load_table__("visibility")
self.instance = self.__load_table__("instance")
self.sensor = self.__load_table__("sensor")
self.calibrated_sensor = self.__load_table__("calibrated_sensor")
self.ego_pose = self.__load_table__("ego_pose")
self.log = self.__load_table__("log")
self.scene = self.__load_table__("scene")
self.sample = self.__load_table__("sample")
self.sample_data = self.__load_table__("sample_data")
self.sample_annotation = self.__load_table__("sample_annotation")
self.map = self.__load_table__("map")
# Initialize map mask for each map record.
for map_record in self.map:
map_record["mask"] = MapMask(
self.data_path / "train_maps/map_raster_palo_alto.png",
resolution=map_resolution,
)
if verbose:
for table in self.table_names:
print("{} {},".format(len(getattr(self, table)), table))
print(
"Done loading in {:.1f} seconds.\n======".format(
time.time() - start_time
)
)
# Make reverse indexes for common lookups.
self.__make_reverse_index__(verbose)
# Initialize LyftDatasetExplorer class
self.explorer = LyftDatasetExplorer(self)
def __load_table__(self, table_name) -> dict:
"""Loads a table."""
with open(str(self.json_path.joinpath("{}.json".format(table_name)))) as f:
table = json.load(f)
return table
def __make_reverse_index__(self, verbose: bool) -> None:
"""De-normalizes database to create reverse indices for common cases.
Args:
verbose: Whether to print outputs.
"""
start_time = time.time()
if verbose:
print("Reverse indexing ...")
# Store the mapping from token to table index for each table.
self._token2ind = dict()
for table in self.table_names:
self._token2ind[table] = dict()
for ind, member in enumerate(getattr(self, table)):
self._token2ind[table][member["token"]] = ind
# Decorate (adds short-cut) sample_annotation table with for category name.
for record in self.sample_annotation:
inst = self.get("instance", record["instance_token"])
record["category_name"] = self.get("category", inst["category_token"])[
"name"
]
# Decorate (adds short-cut) sample_data with sensor information.
for record in self.sample_data:
cs_record = self.get("calibrated_sensor", record["calibrated_sensor_token"])
sensor_record = self.get("sensor", cs_record["sensor_token"])
record["sensor_modality"] = sensor_record["modality"]
record["channel"] = sensor_record["channel"]
# Reverse-index samples with sample_data and annotations.
for record in self.sample:
record["data"] = {}
record["anns"] = []
for record in self.sample_data:
if record["is_key_frame"]:
sample_record = self.get("sample", record["sample_token"])
sample_record["data"][record["channel"]] = record["token"]
for ann_record in self.sample_annotation:
sample_record = self.get("sample", ann_record["sample_token"])
sample_record["anns"].append(ann_record["token"])
# Add reverse indices from log records to map records.
if "log_tokens" not in self.map[0].keys():
raise Exception(
"Error: log_tokens not in map table. This code is not compatible with the teaser dataset."
)
log_to_map = dict()
for map_record in self.map:
for log_token in map_record["log_tokens"]:
log_to_map[log_token] = map_record["token"]
for log_record in self.log:
log_record["map_token"] = log_to_map[log_record["token"]]
if verbose:
print(
"Done reverse indexing in {:.1f} seconds.\n======".format(
time.time() - start_time
)
)
def get(self, table_name: str, token: str) -> dict:
"""Returns a record from table in constant runtime.
Args:
table_name: Table name.
token: Token of the record.
Returns: Table record.
"""
assert table_name in self.table_names, "Table {} not found".format(table_name)
return getattr(self, table_name)[self.getind(table_name, token)]
def getind(self, table_name: str, token: str) -> int:
"""Returns the index of the record in a table in constant runtime.
Args:
table_name: Table name.
token: The index of the record in table, table is an array.
Returns:
"""
return self._token2ind[table_name][token]
def field2token(self, table_name: str, field: str, query) -> List[str]:
"""Query all records for a certain field value, and returns the tokens for the matching records.
Runs in linear time.
Args:
table_name: Table name.
field: Field name.
query: Query to match against. Needs to type match the content of the query field.
Returns: List of tokens for the matching records.
"""
matches = []
for member in getattr(self, table_name):
if member[field] == query:
matches.append(member["token"])
return matches
def get_sample_data_path(self, sample_data_token: str) -> Path:
"""Returns the path to a sample_data.
Args:
sample_data_token:
Returns:
"""
sd_record = self.get("sample_data", sample_data_token)
return self.data_path / sd_record["filename"]
def get_sample_data(
self,
sample_data_token: str,
box_vis_level: BoxVisibility = BoxVisibility.ANY,
selected_anntokens: List[str] = None,
flat_vehicle_coordinates: bool = False,
) -> Tuple[Path, List[Box], np.array]:
"""Returns the data path as well as all annotations related to that sample_data.
The boxes are transformed into the current sensor's coordinate frame.
Args:
sample_data_token: Sample_data token.
box_vis_level: If sample_data is an image, this sets required visibility for boxes.
selected_anntokens: If provided only return the selected annotation.
flat_vehicle_coordinates: Instead of current sensor's coordinate frame, use vehicle frame which is
aligned to z-plane in world
Returns: (data_path, boxes, camera_intrinsic <np.array: 3, 3>)
"""
# Retrieve sensor & pose records
sd_record = self.get("sample_data", sample_data_token)
cs_record = self.get("calibrated_sensor", sd_record["calibrated_sensor_token"])
sensor_record = self.get("sensor", cs_record["sensor_token"])
pose_record = self.get("ego_pose", sd_record["ego_pose_token"])
data_path = self.get_sample_data_path(sample_data_token)
if sensor_record["modality"] == "camera":
cam_intrinsic = np.array(cs_record["camera_intrinsic"])
imsize = (sd_record["width"], sd_record["height"])
else:
cam_intrinsic = None
imsize = None
# Retrieve all sample annotations and map to sensor coordinate system.
if selected_anntokens is not None:
boxes = list(map(self.get_box, selected_anntokens))
else:
boxes = self.get_boxes(sample_data_token)
# Make list of Box objects including coord system transforms.
box_list = []
for box in boxes:
if flat_vehicle_coordinates:
# Move box to ego vehicle coord system parallel to world z plane
ypr = Quaternion(pose_record["rotation"]).yaw_pitch_roll
yaw = ypr[0]
box.translate(-np.array(pose_record["translation"]))
box.rotate(
Quaternion(
scalar=np.cos(yaw / 2), vector=[0, 0, np.sin(yaw / 2)]
).inverse
)
else:
# Move box to ego vehicle coord system
box.translate(-np.array(pose_record["translation"]))
box.rotate(Quaternion(pose_record["rotation"]).inverse)
# Move box to sensor coord system
box.translate(-np.array(cs_record["translation"]))
box.rotate(Quaternion(cs_record["rotation"]).inverse)
if sensor_record["modality"] == "camera" and not box_in_image(
box, cam_intrinsic, imsize, vis_level=box_vis_level
):
continue
box_list.append(box)
return data_path, box_list, cam_intrinsic
def get_box(self, sample_annotation_token: str) -> Box:
"""Instantiates a Box class from a sample annotation record.
Args:
sample_annotation_token: Unique sample_annotation identifier.
Returns:
"""
record = self.get("sample_annotation", sample_annotation_token)
return Box(
record["translation"],
record["size"],
Quaternion(record["rotation"]),
name=record["category_name"],
token=record["token"],
)
def get_boxes(self, sample_data_token: str) -> List[Box]:
"""Instantiates Boxes for all annotation for a particular sample_data record. If the sample_data is a
keyframe, this returns the annotations for that sample. But if the sample_data is an intermediate
sample_data, a linear interpolation is applied to estimate the location of the boxes at the time the
sample_data was captured.
Args:
sample_data_token: Unique sample_data identifier.
Returns:
"""
# Retrieve sensor & pose records
sd_record = self.get("sample_data", sample_data_token)
curr_sample_record = self.get("sample", sd_record["sample_token"])
if curr_sample_record["prev"] == "" or sd_record["is_key_frame"]:
# If no previous annotations available, or if sample_data is keyframe just return the current ones.
boxes = list(map(self.get_box, curr_sample_record["anns"]))
else:
prev_sample_record = self.get("sample", curr_sample_record["prev"])
curr_ann_recs = [
self.get("sample_annotation", token)
for token in curr_sample_record["anns"]
]
prev_ann_recs = [
self.get("sample_annotation", token)
for token in prev_sample_record["anns"]
]
# Maps instance tokens to prev_ann records
prev_inst_map = {entry["instance_token"]: entry for entry in prev_ann_recs}
t0 = prev_sample_record["timestamp"]
t1 = curr_sample_record["timestamp"]
t = sd_record["timestamp"]
# There are rare situations where the timestamps in the DB are off so ensure that t0 < t < t1.
t = max(t0, min(t1, t))
boxes = []
for curr_ann_rec in curr_ann_recs:
if curr_ann_rec["instance_token"] in prev_inst_map:
# If the annotated instance existed in the previous frame, interpolate center & orientation.
prev_ann_rec = prev_inst_map[curr_ann_rec["instance_token"]]
# Interpolate center.
center = [
np.interp(t, [t0, t1], [c0, c1])
for c0, c1 in zip(
prev_ann_rec["translation"], curr_ann_rec["translation"]
)
]
# Interpolate orientation.
rotation = Quaternion.slerp(
q0=Quaternion(prev_ann_rec["rotation"]),
q1=Quaternion(curr_ann_rec["rotation"]),
amount=(t - t0) / (t1 - t0),
)
box = Box(
center,
curr_ann_rec["size"],
rotation,
name=curr_ann_rec["category_name"],
token=curr_ann_rec["token"],
)
else:
# If not, simply grab the current annotation.
box = self.get_box(curr_ann_rec["token"])
boxes.append(box)
return boxes
def box_velocity(
self, sample_annotation_token: str, max_time_diff: float = 1.5
) -> np.ndarray:
"""Estimate the velocity for an annotation.
If possible, we compute the centered difference between the previous and next frame.
Otherwise we use the difference between the current and previous/next frame.
If the velocity cannot be estimated, values are set to np.nan.
Args:
sample_annotation_token: Unique sample_annotation identifier.
max_time_diff: Max allowed time diff between consecutive samples that are used to estimate velocities.
Returns: <np.float: 3>. Velocity in x/y/z direction in m/s.
"""
current = self.get("sample_annotation", sample_annotation_token)
has_prev = current["prev"] != ""
has_next = current["next"] != ""
# Cannot estimate velocity for a single annotation.
if not has_prev and not has_next:
return np.array([np.nan, np.nan, np.nan])
if has_prev:
first = self.get("sample_annotation", current["prev"])
else:
first = current
if has_next:
last = self.get("sample_annotation", current["next"])
else:
last = current
pos_last = np.array(last["translation"])
pos_first = np.array(first["translation"])
pos_diff = pos_last - pos_first
time_last = 1e-6 * self.get("sample", last["sample_token"])["timestamp"]
time_first = 1e-6 * self.get("sample", first["sample_token"])["timestamp"]
time_diff = time_last - time_first
if has_next and has_prev:
# If doing centered difference, allow for up to double the max_time_diff.
max_time_diff *= 2
if time_diff > max_time_diff:
# If time_diff is too big, don't return an estimate.
return np.array([np.nan, np.nan, np.nan])
else:
return pos_diff / time_diff
def list_categories(self) -> None:
self.explorer.list_categories()
def list_attributes(self) -> None:
self.explorer.list_attributes()
def list_scenes(self) -> None:
self.explorer.list_scenes()
def list_sample(self, sample_token: str) -> None:
self.explorer.list_sample(sample_token)
def render_pointcloud_in_image(
self,
sample_token: str,
dot_size: int = 5,
pointsensor_channel: str = "LIDAR_TOP",
camera_channel: str = "CAM_FRONT",
out_path: str = None,
) -> None:
self.explorer.render_pointcloud_in_image(
sample_token,
dot_size,
pointsensor_channel=pointsensor_channel,
camera_channel=camera_channel,
out_path=out_path,
)
def render_sample(
self,
sample_token: str,
box_vis_level: BoxVisibility = BoxVisibility.ANY,
nsweeps: int = 1,
out_path: str = None,
) -> None:
self.explorer.render_sample(
sample_token, box_vis_level, nsweeps=nsweeps, out_path=out_path
)
def render_sample_data(
self,
sample_data_token: str,
with_anns: bool = True,
box_vis_level: BoxVisibility = BoxVisibility.ANY,
axes_limit: float = 40,
ax: Axes = None,
nsweeps: int = 1,
out_path: str = None,
underlay_map: bool = False,
) -> None:
return self.explorer.render_sample_data(
sample_data_token,
with_anns,
box_vis_level,
axes_limit,
ax,
num_sweeps=nsweeps,
out_path=out_path,
underlay_map=underlay_map,
)
def render_annotation(
self,
sample_annotation_token: str,
margin: float = 10,
view: np.ndarray = np.eye(4),
box_vis_level: BoxVisibility = BoxVisibility.ANY,
out_path: str = None,
) -> None:
self.explorer.render_annotation(
sample_annotation_token, margin, view, box_vis_level, out_path
)
def render_instance(self, instance_token: str, out_path: str = None) -> None:
self.explorer.render_instance(instance_token, out_path=out_path)
def render_scene(
self,
scene_token: str,
freq: float = 10,
imwidth: int = 640,
out_path: str = None,
) -> None:
self.explorer.render_scene(
scene_token, freq, image_width=imwidth, out_path=out_path
)
def render_scene_channel(
self,
scene_token: str,
channel: str = "CAM_FRONT",
freq: float = 10,
imsize: Tuple[float, float] = (640, 360),
out_path: str = None,
) -> None:
self.explorer.render_scene_channel(
scene_token=scene_token,
channel=channel,
freq=freq,
image_size=imsize,
out_path=out_path,
)
def render_egoposes_on_map(
self, log_location: str, scene_tokens: List = None, out_path: str = None
) -> None:
self.explorer.render_egoposes_on_map(
log_location, scene_tokens, out_path=out_path
)
# ### Create another class called *LyftDatasetExplorer* which will help us to visualize the data
# #### (click CODE on the right side)
class LyftDatasetExplorer:
"""Helper class to list and visualize Lyft Dataset data. These are meant to serve as tutorials and templates for
working with the data."""
def __init__(self, lyftd: LyftDataset):
self.lyftd = lyftd
@staticmethod
def get_color(category_name: str) -> Tuple[int, int, int]:
"""Provides the default colors based on the category names.
This method works for the general Lyft Dataset categories, as well as the Lyft Dataset detection categories.
Args:
category_name:
Returns:
"""
if "bicycle" in category_name or "motorcycle" in category_name:
return 255, 61, 99 # Red
elif "vehicle" in category_name or category_name in [
"bus",
"car",
"construction_vehicle",
"trailer",
"truck",
]:
return 255, 158, 0 # Orange
elif "pedestrian" in category_name:
return 0, 0, 230 # Blue
elif "cone" in category_name or "barrier" in category_name:
return 0, 0, 0 # Black
else:
return 255, 0, 255 # Magenta
def list_categories(self) -> None:
"""Print categories, counts and stats."""
print("Category stats")
# Add all annotations
categories = dict()
for record in self.lyftd.sample_annotation:
if record["category_name"] not in categories:
categories[record["category_name"]] = []
categories[record["category_name"]].append(
record["size"] + [record["size"][1] / record["size"][0]]
)
# Print stats
for name, stats in sorted(categories.items()):
stats = np.array(stats)
print(
"{:27} n={:5}, width={:5.2f}\u00B1{:.2f}, len={:5.2f}\u00B1{:.2f}, height={:5.2f}\u00B1{:.2f}, "
"lw_aspect={:5.2f}\u00B1{:.2f}".format(
name[:27],
stats.shape[0],
np.mean(stats[:, 0]),
np.std(stats[:, 0]),
np.mean(stats[:, 1]),
np.std(stats[:, 1]),
np.mean(stats[:, 2]),
np.std(stats[:, 2]),
np.mean(stats[:, 3]),
np.std(stats[:, 3]),
)
)
def list_attributes(self) -> None:
"""Prints attributes and counts."""
attribute_counts = dict()
for record in self.lyftd.sample_annotation:
for attribute_token in record["attribute_tokens"]:
att_name = self.lyftd.get("attribute", attribute_token)["name"]
if att_name not in attribute_counts:
attribute_counts[att_name] = 0
attribute_counts[att_name] += 1
for name, count in sorted(attribute_counts.items()):
print("{}: {}".format(name, count))
def list_scenes(self) -> None:
"""Lists all scenes with some meta data."""
def ann_count(record):
count = 0
sample = self.lyftd.get("sample", record["first_sample_token"])
while not sample["next"] == "":
count += len(sample["anns"])
sample = self.lyftd.get("sample", sample["next"])
return count
recs = [
(
self.lyftd.get("sample", record["first_sample_token"])["timestamp"],
record,
)
for record in self.lyftd.scene
]
for start_time, record in sorted(recs):
start_time = (
self.lyftd.get("sample", record["first_sample_token"])["timestamp"]
/ 1000000
)
length_time = (
self.lyftd.get("sample", record["last_sample_token"])["timestamp"]
/ 1000000
- start_time
)
location = self.lyftd.get("log", record["log_token"])["location"]
desc = record["name"] + ", " + record["description"]
if len(desc) > 55:
desc = desc[:51] + "..."
if len(location) > 18:
location = location[:18]
print(
"{:16} [{}] {:4.0f}s, {}, #anns:{}".format(
desc,
datetime.utcfromtimestamp(start_time).strftime("%y-%m-%d %H:%M:%S"),
length_time,
location,
ann_count(record),
)
)
def list_sample(self, sample_token: str) -> None:
"""Prints sample_data tokens and sample_annotation tokens related to the sample_token."""
sample_record = self.lyftd.get("sample", sample_token)
print("Sample: {}\n".format(sample_record["token"]))
for sd_token in sample_record["data"].values():
sd_record = self.lyftd.get("sample_data", sd_token)
print(
"sample_data_token: {}, mod: {}, channel: {}".format(
sd_token, sd_record["sensor_modality"], sd_record["channel"]
)
)
print("")
for ann_token in sample_record["anns"]:
ann_record = self.lyftd.get("sample_annotation", ann_token)
print(
"sample_annotation_token: {}, category: {}".format(
ann_record["token"], ann_record["category_name"]
)
)
def map_pointcloud_to_image(
self, pointsensor_token: str, camera_token: str
) -> Tuple:
"""Given a point sensor (lidar/radar) token and camera sample_data token, load point-cloud and map it to
the image plane.
Args:
pointsensor_token: Lidar/radar sample_data token.
camera_token: Camera sample_data token.
Returns: (pointcloud <np.float: 2, n)>, coloring <np.float: n>, image <Image>).
"""
cam = self.lyftd.get("sample_data", camera_token)
pointsensor = self.lyftd.get("sample_data", pointsensor_token)
pcl_path = self.lyftd.data_path / ("train_" + pointsensor["filename"])
if pointsensor["sensor_modality"] == "lidar":
pc = LidarPointCloud.from_file(pcl_path)
else:
pc = RadarPointCloud.from_file(pcl_path)
im = Image.open(str(self.lyftd.data_path / ("train_" + cam["filename"])))
# Points live in the point sensor frame. So they need to be transformed via global to the image plane.
# First step: transform the point-cloud to the ego vehicle frame for the timestamp of the sweep.
cs_record = self.lyftd.get(
"calibrated_sensor", pointsensor["calibrated_sensor_token"]
)
pc.rotate(Quaternion(cs_record["rotation"]).rotation_matrix)
pc.translate(np.array(cs_record["translation"]))
# Second step: transform to the global frame.
poserecord = self.lyftd.get("ego_pose", pointsensor["ego_pose_token"])
pc.rotate(Quaternion(poserecord["rotation"]).rotation_matrix)
pc.translate(np.array(poserecord["translation"]))
# Third step: transform into the ego vehicle frame for the timestamp of the image.
poserecord = self.lyftd.get("ego_pose", cam["ego_pose_token"])
pc.translate(-np.array(poserecord["translation"]))
pc.rotate(Quaternion(poserecord["rotation"]).rotation_matrix.T)
# Fourth step: transform into the camera.
cs_record = self.lyftd.get("calibrated_sensor", cam["calibrated_sensor_token"])
pc.translate(-np.array(cs_record["translation"]))
pc.rotate(Quaternion(cs_record["rotation"]).rotation_matrix.T)
# Fifth step: actually take a "picture" of the point cloud.
# Grab the depths (camera frame z axis points away from the camera).
depths = pc.points[2, :]
# Retrieve the color from the depth.
coloring = depths
# Take the actual picture (matrix multiplication with camera-matrix + renormalization).
points = view_points(
pc.points[:3, :], np.array(cs_record["camera_intrinsic"]), normalize=True
)
# Remove points that are either outside or behind the camera. Leave a margin of 1 pixel for aesthetic reasons.
mask = np.ones(depths.shape[0], dtype=bool)
mask = np.logical_and(mask, depths > 0)
mask = np.logical_and(mask, points[0, :] > 1)
mask = np.logical_and(mask, points[0, :] < im.size[0] - 1)
mask = np.logical_and(mask, points[1, :] > 1)
mask = np.logical_and(mask, points[1, :] < im.size[1] - 1)
points = points[:, mask]
coloring = coloring[mask]
return points, coloring, im
def render_pointcloud_in_image(
self,
sample_token: str,
dot_size: int = 2,
pointsensor_channel: str = "LIDAR_TOP",
camera_channel: str = "CAM_FRONT",
out_path: str = None,
) -> None:
"""Scatter-plots a point-cloud on top of image.
Args:
sample_token: Sample token.
dot_size: Scatter plot dot size.
pointsensor_channel: RADAR or LIDAR channel name, e.g. 'LIDAR_TOP'.
camera_channel: Camera channel name, e.g. 'CAM_FRONT'.
out_path: Optional path to save the rendered figure to disk.
Returns:
"""
sample_record = self.lyftd.get("sample", sample_token)
# Here we just grab the front camera and the point sensor.
pointsensor_token = sample_record["data"][pointsensor_channel]
camera_token = sample_record["data"][camera_channel]
points, coloring, im = self.map_pointcloud_to_image(
pointsensor_token, camera_token
)
plt.figure(figsize=(9, 16))
plt.imshow(im)
plt.scatter(points[0, :], points[1, :], c=coloring, s=dot_size)
plt.axis("off")
if out_path is not None:
plt.savefig(out_path)
def render_sample(
self,
token: str,
box_vis_level: BoxVisibility = BoxVisibility.ANY,
nsweeps: int = 1,
out_path: str = None,
) -> None:
"""Render all LIDAR and camera sample_data in sample along with annotations.
Args:
token: Sample token.
box_vis_level: If sample_data is an image, this sets required visibility for boxes.
nsweeps: Number of sweeps for lidar and radar.
out_path: Optional path to save the rendered figure to disk.
Returns:
"""
record = self.lyftd.get("sample", token)
# Separate RADAR from LIDAR and vision.
radar_data = {}
nonradar_data = {}
for channel, token in record["data"].items():
sd_record = self.lyftd.get("sample_data", token)
sensor_modality = sd_record["sensor_modality"]
if sensor_modality in ["lidar", "camera"]:
nonradar_data[channel] = token
else:
radar_data[channel] = token
num_radar_plots = 1 if len(radar_data) > 0 else 0
# Create plots.
n = num_radar_plots + len(nonradar_data)
cols = 2
fig, axes = plt.subplots(int(np.ceil(n / cols)), cols, figsize=(16, 24))
if len(radar_data) > 0:
# Plot radar into a single subplot.
ax = axes[0, 0]
for i, (_, sd_token) in enumerate(radar_data.items()):
self.render_sample_data(
sd_token,
with_anns=i == 0,
box_vis_level=box_vis_level,
ax=ax,
num_sweeps=nsweeps,
)
ax.set_title("Fused RADARs")
# Plot camera and lidar in separate subplots.
for (_, sd_token), ax in zip(
nonradar_data.items(), axes.flatten()[num_radar_plots:]
):
self.render_sample_data(
sd_token, box_vis_level=box_vis_level, ax=ax, num_sweeps=nsweeps
)
axes.flatten()[-1].axis("off")
plt.tight_layout()
fig.subplots_adjust(wspace=0, hspace=0)
if out_path is not None:
plt.savefig(out_path)
def render_ego_centric_map(
self, sample_data_token: str, axes_limit: float = 40, ax: Axes = None
) -> None:
"""Render map centered around the associated ego pose.
Args:
sample_data_token: Sample_data token.
axes_limit: Axes limit measured in meters.
ax: Axes onto which to render.
"""
def crop_image(
image: np.array, x_px: int, y_px: int, axes_limit_px: int
) -> np.array:
x_min = int(x_px - axes_limit_px)
x_max = int(x_px + axes_limit_px)
y_min = int(y_px - axes_limit_px)
y_max = int(y_px + axes_limit_px)
cropped_image = image[y_min:y_max, x_min:x_max]
return cropped_image
sd_record = self.lyftd.get("sample_data", sample_data_token)
# Init axes.
if ax is None:
_, ax = plt.subplots(1, 1, figsize=(9, 9))
sample = self.lyftd.get("sample", sd_record["sample_token"])
scene = self.lyftd.get("scene", sample["scene_token"])
log = self.lyftd.get("log", scene["log_token"])
map = self.lyftd.get("map", log["map_token"])
map_mask = map["mask"]
pose = self.lyftd.get("ego_pose", sd_record["ego_pose_token"])
pixel_coords = map_mask.to_pixel_coords(
pose["translation"][0], pose["translation"][1]
)
scaled_limit_px = int(axes_limit * (1.0 / map_mask.resolution))
mask_raster = map_mask.mask()
cropped = crop_image(
mask_raster,
pixel_coords[0],
pixel_coords[1],
int(scaled_limit_px * math.sqrt(2)),
)
ypr_rad = Quaternion(pose["rotation"]).yaw_pitch_roll
yaw_deg = -math.degrees(ypr_rad[0])
rotated_cropped = np.array(Image.fromarray(cropped).rotate(yaw_deg))
ego_centric_map = crop_image(
rotated_cropped,
rotated_cropped.shape[1] / 2,
rotated_cropped.shape[0] / 2,
scaled_limit_px,
)
ax.imshow(
ego_centric_map,
extent=[-axes_limit, axes_limit, -axes_limit, axes_limit],
cmap="gray",
vmin=0,
vmax=150,
)
def render_sample_data(
self,
sample_data_token: str,
with_anns: bool = True,
box_vis_level: BoxVisibility = BoxVisibility.ANY,
axes_limit: float = 40,
ax: Axes = None,
num_sweeps: int = 1,
out_path: str = None,
underlay_map: bool = False,
):
"""Render sample data onto axis.
Args:
sample_data_token: Sample_data token.
with_anns: Whether to draw annotations.
box_vis_level: If sample_data is an image, this sets required visibility for boxes.
axes_limit: Axes limit for lidar and radar (measured in meters).
ax: Axes onto which to render.
num_sweeps: Number of sweeps for lidar and radar.
out_path: Optional path to save the rendered figure to disk.
underlay_map: When set to true, LIDAR data is plotted onto the map. This can be slow.
"""
# Get sensor modality.
sd_record = self.lyftd.get("sample_data", sample_data_token)
sensor_modality = sd_record["sensor_modality"]
if sensor_modality == "lidar":
# Get boxes in lidar frame.
_, boxes, _ = self.lyftd.get_sample_data(
sample_data_token,
box_vis_level=box_vis_level,
flat_vehicle_coordinates=True,
)
# Get aggregated point cloud in lidar frame.
sample_rec = self.lyftd.get("sample", sd_record["sample_token"])
chan = sd_record["channel"]
ref_chan = "LIDAR_TOP"
pc, times = LidarPointCloud.from_file_multisweep(
self.lyftd, sample_rec, chan, ref_chan, num_sweeps=num_sweeps
)
# Compute transformation matrices for lidar point cloud
cs_record = self.lyftd.get(
"calibrated_sensor", sd_record["calibrated_sensor_token"]
)
pose_record = self.lyftd.get("ego_pose", sd_record["ego_pose_token"])
vehicle_from_sensor = np.eye(4)
vehicle_from_sensor[:3, :3] = Quaternion(
cs_record["rotation"]
).rotation_matrix
vehicle_from_sensor[:3, 3] = cs_record["translation"]
ego_yaw = Quaternion(pose_record["rotation"]).yaw_pitch_roll[0]
rot_vehicle_flat_from_vehicle = np.dot(
Quaternion(
scalar=np.cos(ego_yaw / 2), vector=[0, 0, np.sin(ego_yaw / 2)]
).rotation_matrix,
Quaternion(pose_record["rotation"]).inverse.rotation_matrix,
)
vehicle_flat_from_vehicle = np.eye(4)
vehicle_flat_from_vehicle[:3, :3] = rot_vehicle_flat_from_vehicle
# Init axes.
if ax is None:
_, ax = plt.subplots(1, 1, figsize=(9, 9))
if underlay_map:
self.render_ego_centric_map(
sample_data_token=sample_data_token, axes_limit=axes_limit, ax=ax
)
# Show point cloud.
points = view_points(
pc.points[:3, :],
np.dot(vehicle_flat_from_vehicle, vehicle_from_sensor),
normalize=False,
)
dists = np.sqrt(np.sum(pc.points[:2, :] ** 2, axis=0))
colors = np.minimum(1, dists / axes_limit / np.sqrt(2))
ax.scatter(points[0, :], points[1, :], c=colors, s=0.2)
# Show ego vehicle.
ax.plot(0, 0, "x", color="red")
# Show boxes.
if with_anns:
for box in boxes:
c = np.array(self.get_color(box.name)) / 255.0
box.render(ax, view=np.eye(4), colors=(c, c, c))
# Limit visible range.
ax.set_xlim(-axes_limit, axes_limit)
ax.set_ylim(-axes_limit, axes_limit)
elif sensor_modality == "radar":
# Get boxes in lidar frame.
sample_rec = self.lyftd.get("sample", sd_record["sample_token"])
lidar_token = sample_rec["data"]["LIDAR_TOP"]
_, boxes, _ = self.lyftd.get_sample_data(
lidar_token, box_vis_level=box_vis_level
)
# Get aggregated point cloud in lidar frame.
# The point cloud is transformed to the lidar frame for visualization purposes.
chan = sd_record["channel"]
ref_chan = "LIDAR_TOP"
pc, times = RadarPointCloud.from_file_multisweep(
self.lyftd, sample_rec, chan, ref_chan, num_sweeps=num_sweeps
)
# Transform radar velocities (x is front, y is left), as these are not transformed when loading the point
# cloud.
radar_cs_record = self.lyftd.get(
"calibrated_sensor", sd_record["calibrated_sensor_token"]
)
lidar_sd_record = self.lyftd.get("sample_data", lidar_token)
lidar_cs_record = self.lyftd.get(
"calibrated_sensor", lidar_sd_record["calibrated_sensor_token"]
)
velocities = pc.points[8:10, :] # Compensated velocity
velocities = np.vstack((velocities, np.zeros(pc.points.shape[1])))
velocities = np.dot(
Quaternion(radar_cs_record["rotation"]).rotation_matrix, velocities
)
velocities = np.dot(
Quaternion(lidar_cs_record["rotation"]).rotation_matrix.T, velocities
)
velocities[2, :] = np.zeros(pc.points.shape[1])
# Init axes.
if ax is None:
_, ax = plt.subplots(1, 1, figsize=(9, 9))
# Show point cloud.
points = view_points(pc.points[:3, :], np.eye(4), normalize=False)
dists = np.sqrt(np.sum(pc.points[:2, :] ** 2, axis=0))
colors = np.minimum(1, dists / axes_limit / np.sqrt(2))
sc = ax.scatter(points[0, :], points[1, :], c=colors, s=3)
# Show velocities.
points_vel = view_points(
pc.points[:3, :] + velocities, np.eye(4), normalize=False
)
max_delta = 10
deltas_vel = points_vel - points
deltas_vel = 3 * deltas_vel # Arbitrary scaling
deltas_vel = np.clip(
deltas_vel, -max_delta, max_delta
) # Arbitrary clipping
colors_rgba = sc.to_rgba(colors)
for i in range(points.shape[1]):
ax.arrow(
points[0, i],
points[1, i],
deltas_vel[0, i],
deltas_vel[1, i],
color=colors_rgba[i],
)
# Show ego vehicle.
ax.plot(0, 0, "x", color="black")
# Show boxes.
if with_anns:
for box in boxes:
c = np.array(self.get_color(box.name)) / 255.0
box.render(ax, view=np.eye(4), colors=(c, c, c))
# Limit visible range.
ax.set_xlim(-axes_limit, axes_limit)
ax.set_ylim(-axes_limit, axes_limit)
elif sensor_modality == "camera":
# Load boxes and image.
data_path, boxes, camera_intrinsic = self.lyftd.get_sample_data(
sample_data_token, box_vis_level=box_vis_level
)
data = Image.open(
str(data_path)[: len(str(data_path)) - 46]
+ "train_images/"
+ str(data_path)[len(str(data_path)) - 39 : len(str(data_path))]
)
# Init axes.
if ax is None:
_, ax = plt.subplots(1, 1, figsize=(9, 16))
# Show image.
ax.imshow(data)
# Show boxes.
if with_anns:
for box in boxes:
c = np.array(self.get_color(box.name)) / 255.0
box.render(
ax, view=camera_intrinsic, normalize=True, colors=(c, c, c)
)
# Limit visible range.
ax.set_xlim(0, data.size[0])
ax.set_ylim(data.size[1], 0)
else:
raise ValueError("Error: Unknown sensor modality!")
ax.axis("off")
ax.set_title(sd_record["channel"])
ax.set_aspect("equal")
if out_path is not None:
num = len([name for name in os.listdir(out_path)])
out_path = out_path + str(num).zfill(5) + "_" + sample_data_token + ".png"
plt.savefig(out_path)
plt.close("all")
return out_path
def render_annotation(
self,
ann_token: str,
margin: float = 10,
view: np.ndarray = np.eye(4),
box_vis_level: BoxVisibility = BoxVisibility.ANY,
out_path: str = None,
) -> None:
"""Render selected annotation.
Args:
ann_token: Sample_annotation token.
margin: How many meters in each direction to include in LIDAR view.
view: LIDAR view point.
box_vis_level: If sample_data is an image, this sets required visibility for boxes.
out_path: Optional path to save the rendered figure to disk.
"""
ann_record = self.lyftd.get("sample_annotation", ann_token)
sample_record = self.lyftd.get("sample", ann_record["sample_token"])
assert (
"LIDAR_TOP" in sample_record["data"].keys()
), "No LIDAR_TOP in data, cant render"
fig, axes = plt.subplots(1, 2, figsize=(18, 9))
# Figure out which camera the object is fully visible in (this may return nothing)
boxes, cam = [], []
cams = [key for key in sample_record["data"].keys() if "CAM" in key]
for cam in cams:
_, boxes, _ = self.lyftd.get_sample_data(
sample_record["data"][cam],
box_vis_level=box_vis_level,
selected_anntokens=[ann_token],
)
if len(boxes) > 0:
break # We found an image that matches. Let's abort.
assert (
len(boxes) > 0
), "Could not find image where annotation is visible. Try using e.g. BoxVisibility.ANY."
assert len(boxes) < 2, "Found multiple annotations. Something is wrong!"
cam = sample_record["data"][cam]
# Plot LIDAR view
lidar = sample_record["data"]["LIDAR_TOP"]
data_path, boxes, camera_intrinsic = self.lyftd.get_sample_data(
lidar, selected_anntokens=[ann_token]
)
LidarPointCloud.from_file(
Path(
str(data_path)[: len(str(data_path)) - 46]
+ "train_lidar/"
+ str(data_path)[len(str(data_path)) - 40 : len(str(data_path))]
)
).render_height(axes[0], view=view)
for box in boxes:
c = np.array(self.get_color(box.name)) / 255.0
box.render(axes[0], view=view, colors=(c, c, c))
corners = view_points(boxes[0].corners(), view, False)[:2, :]
axes[0].set_xlim(
[np.min(corners[0, :]) - margin, np.max(corners[0, :]) + margin]
)
axes[0].set_ylim(
[np.min(corners[1, :]) - margin, np.max(corners[1, :]) + margin]
)
axes[0].axis("off")
axes[0].set_aspect("equal")
# Plot CAMERA view
data_path, boxes, camera_intrinsic = self.lyftd.get_sample_data(
cam, selected_anntokens=[ann_token]
)
im = Image.open(
Path(
str(data_path)[: len(str(data_path)) - 46]
+ "train_images/"
+ str(data_path)[len(str(data_path)) - 39 : len(str(data_path))]
)
)
axes[1].imshow(im)
axes[1].set_title(self.lyftd.get("sample_data", cam)["channel"])
axes[1].axis("off")
axes[1].set_aspect("equal")
for box in boxes:
c = np.array(self.get_color(box.name)) / 255.0
box.render(axes[1], view=camera_intrinsic, normalize=True, colors=(c, c, c))
if out_path is not None:
plt.savefig(out_path)
def render_instance(self, instance_token: str, out_path: str = None) -> None:
"""Finds the annotation of the given instance that is closest to the vehicle, and then renders it.
Args:
instance_token: The instance token.
out_path: Optional path to save the rendered figure to disk.
Returns:
"""
ann_tokens = self.lyftd.field2token(
"sample_annotation", "instance_token", instance_token
)
closest = [np.inf, None]
for ann_token in ann_tokens:
ann_record = self.lyftd.get("sample_annotation", ann_token)
sample_record = self.lyftd.get("sample", ann_record["sample_token"])
sample_data_record = self.lyftd.get(
"sample_data", sample_record["data"]["LIDAR_TOP"]
)
pose_record = self.lyftd.get(
"ego_pose", sample_data_record["ego_pose_token"]
)
dist = np.linalg.norm(
np.array(pose_record["translation"])
- np.array(ann_record["translation"])
)
if dist < closest[0]:
closest[0] = dist
closest[1] = ann_token
self.render_annotation(closest[1], out_path=out_path)
def render_scene(
self,
scene_token: str,
freq: float = 10,
image_width: int = 640,
out_path: Path = None,
) -> None:
"""Renders a full scene with all surround view camera channels.
Args:
scene_token: Unique identifier of scene to render.
freq: Display frequency (Hz).
image_width: Width of image to render. Height is determined automatically to preserve aspect ratio.
out_path: Optional path to write a video file of the rendered frames.
"""
if out_path is not None:
assert out_path.suffix == ".avi"
# Get records from DB.
scene_rec = self.lyftd.get("scene", scene_token)
first_sample_rec = self.lyftd.get("sample", scene_rec["first_sample_token"])
last_sample_rec = self.lyftd.get("sample", scene_rec["last_sample_token"])
channels = [
"CAM_FRONT_LEFT",
"CAM_FRONT",
"CAM_FRONT_RIGHT",
"CAM_BACK_LEFT",
"CAM_BACK",
"CAM_BACK_RIGHT",
]
horizontal_flip = [
"CAM_BACK_LEFT",
"CAM_BACK",
"CAM_BACK_RIGHT",
] # Flip these for aesthetic reasons.
time_step = 1 / freq * 1e6 # Time-stamps are measured in micro-seconds.
window_name = "{}".format(scene_rec["name"])
cv2.namedWindow(window_name)
cv2.moveWindow(window_name, 0, 0)
# Load first sample_data record for each channel
current_recs = {} # Holds the current record to be displayed by channel.
prev_recs = {} # Hold the previous displayed record by channel.
for channel in channels:
current_recs[channel] = self.lyftd.get(
"sample_data", first_sample_rec["data"][channel]
)
prev_recs[channel] = None
# We assume that the resolution is the same for all surround view cameras.
image_height = int(
image_width
* current_recs[channels[0]]["height"]
/ current_recs[channels[0]]["width"]
)
image_size = (image_width, image_height)
# Set some display parameters
layout = {
"CAM_FRONT_LEFT": (0, 0),
"CAM_FRONT": (image_size[0], 0),
"CAM_FRONT_RIGHT": (2 * image_size[0], 0),
"CAM_BACK_LEFT": (0, image_size[1]),
"CAM_BACK": (image_size[0], image_size[1]),
"CAM_BACK_RIGHT": (2 * image_size[0], image_size[1]),
}
canvas = np.ones((2 * image_size[1], 3 * image_size[0], 3), np.uint8)
if out_path is not None:
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
out = cv2.VideoWriter(out_path, fourcc, freq, canvas.shape[1::-1])
else:
out = None
current_time = first_sample_rec["timestamp"]
while current_time < last_sample_rec["timestamp"]:
current_time += time_step
# For each channel, find first sample that has time > current_time.
for channel, sd_rec in current_recs.items():
while sd_rec["timestamp"] < current_time and sd_rec["next"] != "":
sd_rec = self.lyftd.get("sample_data", sd_rec["next"])
current_recs[channel] = sd_rec
# Now add to canvas
for channel, sd_rec in current_recs.items():
# Only update canvas if we have not already rendered this one.
if not sd_rec == prev_recs[channel]:
# Get annotations and params from DB.
image_path, boxes, camera_intrinsic = self.lyftd.get_sample_data(
sd_rec["token"], box_vis_level=BoxVisibility.ANY
)
# Load and render
if not image_path.exists():
raise Exception("Error: Missing image %s" % image_path)
im = cv2.imread(str(image_path))
for box in boxes:
c = self.get_color(box.name)
box.render_cv2(
im, view=camera_intrinsic, normalize=True, colors=(c, c, c)
)
im = cv2.resize(im, image_size)
if channel in horizontal_flip:
im = im[:, ::-1, :]
canvas[
layout[channel][1] : layout[channel][1] + image_size[1],
layout[channel][0] : layout[channel][0] + image_size[0],
:,
] = im
prev_recs[
channel
] = sd_rec # Store here so we don't render the same image twice.
# Show updated canvas.
cv2.imshow(window_name, canvas)
if out_path is not None:
out.write(canvas)
key = cv2.waitKey(1) # Wait a very short time (1 ms).
if key == 32: # if space is pressed, pause.
key = cv2.waitKey()
if key == 27: # if ESC is pressed, exit.
cv2.destroyAllWindows()
break
cv2.destroyAllWindows()
if out_path is not None:
out.release()
def render_scene_channel(
self,
scene_token: str,
channel: str = "CAM_FRONT",
freq: float = 10,
image_size: Tuple[float, float] = (640, 360),
out_path: Path = None,
) -> None:
"""Renders a full scene for a particular camera channel.
Args:
scene_token: Unique identifier of scene to render.
channel: Channel to render.
freq: Display frequency (Hz).
image_size: Size of image to render. The larger the slower this will run.
out_path: Optional path to write a video file of the rendered frames.
"""
valid_channels = [
"CAM_FRONT_LEFT",
"CAM_FRONT",
"CAM_FRONT_RIGHT",
"CAM_BACK_LEFT",
"CAM_BACK",
"CAM_BACK_RIGHT",
]
assert image_size[0] / image_size[1] == 16 / 9, "Aspect ratio should be 16/9."
assert channel in valid_channels, "Input channel {} not valid.".format(channel)
if out_path is not None:
assert out_path.suffix == ".avi"
# Get records from DB
scene_rec = self.lyftd.get("scene", scene_token)
sample_rec = self.lyftd.get("sample", scene_rec["first_sample_token"])
sd_rec = self.lyftd.get("sample_data", sample_rec["data"][channel])
# Open CV init
name = "{}: {} (Space to pause, ESC to exit)".format(scene_rec["name"], channel)
cv2.namedWindow(name)
cv2.moveWindow(name, 0, 0)
if out_path is not None:
fourcc = cv2.VideoWriter_fourcc(*"MJPG")
out = cv2.VideoWriter(out_path, fourcc, freq, image_size)
else:
out = None
has_more_frames = True
while has_more_frames:
# Get data from DB
image_path, boxes, camera_intrinsic = self.lyftd.get_sample_data(
sd_rec["token"], box_vis_level=BoxVisibility.ANY
)
# Load and render
if not image_path.exists():
raise Exception("Error: Missing image %s" % image_path)
image = cv2.imread(str(image_path))
for box in boxes:
c = self.get_color(box.name)
box.render_cv2(
image, view=camera_intrinsic, normalize=True, colors=(c, c, c)
)
# Render
image = cv2.resize(image, image_size)
cv2.imshow(name, image)
if out_path is not None:
out.write(image)
key = cv2.waitKey(10) # Images stored at approx 10 Hz, so wait 10 ms.
if key == 32: # If space is pressed, pause.
key = cv2.waitKey()
if key == 27: # if ESC is pressed, exit
cv2.destroyAllWindows()
break
if not sd_rec["next"] == "":
sd_rec = self.lyftd.get("sample_data", sd_rec["next"])
else:
has_more_frames = False
cv2.destroyAllWindows()
if out_path is not None:
out.release()
def render_egoposes_on_map(
self,
log_location: str,
scene_tokens: List = None,
close_dist: float = 100,
color_fg: Tuple[int, int, int] = (167, 174, 186),
color_bg: Tuple[int, int, int] = (255, 255, 255),
out_path: Path = None,
) -> None:
"""Renders ego poses a the map. These can be filtered by location or scene.
Args:
log_location: Name of the location, e.g. "singapore-onenorth", "singapore-hollandvillage",
"singapore-queenstown' and "boston-seaport".
scene_tokens: Optional list of scene tokens.
close_dist: Distance in meters for an ego pose to be considered within range of another ego pose.
color_fg: Color of the semantic prior in RGB format (ignored if map is RGB).
color_bg: Color of the non-semantic prior in RGB format (ignored if map is RGB).
out_path: Optional path to save the rendered figure to disk.
Returns:
"""
# Get logs by location
log_tokens = [
l["token"] for l in self.lyftd.log if l["location"] == log_location
]
assert len(log_tokens) > 0, (
"Error: This split has 0 scenes for location %s!" % log_location
)
# Filter scenes
scene_tokens_location = [
e["token"] for e in self.lyftd.scene if e["log_token"] in log_tokens
]
if scene_tokens is not None:
scene_tokens_location = [
t for t in scene_tokens_location if t in scene_tokens
]
if len(scene_tokens_location) == 0:
print("Warning: Found 0 valid scenes for location %s!" % log_location)
map_poses = []
map_mask = None
print("Adding ego poses to map...")
for scene_token in tqdm(scene_tokens_location):
# Get records from the database.
scene_record = self.lyftd.get("scene", scene_token)
log_record = self.lyftd.get("log", scene_record["log_token"])
map_record = self.lyftd.get("map", log_record["map_token"])
map_mask = map_record["mask"]
# For each sample in the scene, store the ego pose.
sample_tokens = self.lyftd.field2token("sample", "scene_token", scene_token)
for sample_token in sample_tokens:
sample_record = self.lyftd.get("sample", sample_token)
# Poses are associated with the sample_data. Here we use the lidar sample_data.
sample_data_record = self.lyftd.get(
"sample_data", sample_record["data"]["LIDAR_TOP"]
)
pose_record = self.lyftd.get(
"ego_pose", sample_data_record["ego_pose_token"]
)
# Calculate the pose on the map and append
map_poses.append(
np.concatenate(
map_mask.to_pixel_coords(
pose_record["translation"][0], pose_record["translation"][1]
)
)
)
# Compute number of close ego poses.
print("Creating plot...")
map_poses = np.vstack(map_poses)
dists = sklearn.metrics.pairwise.euclidean_distances(
map_poses * map_mask.resolution
)
close_poses = np.sum(dists < close_dist, axis=0)
if (
len(np.array(map_mask.mask()).shape) == 3
and np.array(map_mask.mask()).shape[2] == 3
):
# RGB Colour maps
mask = map_mask.mask()
else:
# Monochrome maps
# Set the colors for the mask.
mask = Image.fromarray(map_mask.mask())
mask = np.array(mask)
maskr = color_fg[0] * np.ones(np.shape(mask), dtype=np.uint8)
maskr[mask == 0] = color_bg[0]
maskg = color_fg[1] * np.ones(np.shape(mask), dtype=np.uint8)
maskg[mask == 0] = color_bg[1]
maskb = color_fg[2] * np.ones(np.shape(mask), dtype=np.uint8)
maskb[mask == 0] = color_bg[2]
mask = np.concatenate(
(
np.expand_dims(maskr, axis=2),
np.expand_dims(maskg, axis=2),
np.expand_dims(maskb, axis=2),
),
axis=2,
)
# Plot.
_, ax = plt.subplots(1, 1, figsize=(10, 10))
ax.imshow(mask)
title = "Number of ego poses within {}m in {}".format(close_dist, log_location)
ax.set_title(title, color="k")
sc = ax.scatter(map_poses[:, 0], map_poses[:, 1], s=10, c=close_poses)
color_bar = plt.colorbar(sc, fraction=0.025, pad=0.04)
plt.rcParams["figure.facecolor"] = "black"
color_bar_ticklabels = plt.getp(color_bar.ax.axes, "yticklabels")
plt.setp(color_bar_ticklabels, color="k")
plt.rcParams["figure.facecolor"] = "white" # Reset for future plots
if out_path is not None:
plt.savefig(out_path)
plt.close("all")
# ### Create a *LyftDataset* object from the existing dataset
lyft_dataset = LyftDataset(data_path=DATA_PATH, json_path=DATA_PATH + "train_data")
# The dataset consists of several scences, which are 25-45 second clips of image of LiDAR data from a self-driving car. We can extract and look at the first scence as follows:
my_scene = lyft_dataset.scene[179]
my_scene
# As it can be seen above, each scence consists of a dictionary of information. There are a few token IDs and a name for each scene. The "name" matches with the name of the LiDAR data file associated with the given scene. Here, the LiDAR file's name is:
# **host-a101-lidar0-1241893239199111666-1241893264098084346**.
# *Note:* You can list all the scenes in the dataset using:
# **lyft_dataset.list_scenes()**
# Now, let us visualize some of the image and LiDAR data.
# ### Create a function to render scences in the dataset
def render_scene(index):
my_scene = lyft_dataset.scene[index]
my_sample_token = my_scene["first_sample_token"]
lyft_dataset.render_sample(my_sample_token)
# ### Render the first scence (image and LiDAR)
render_scene(179)
# ### Render the second scence (image and LiDAR)
render_scene(1)
# These images above display the image and LiDAR data collected using the cameras and sensors from various angles on the car. The yellow boxes around the objects in the images are the bounding boxes or bounding volumes that show the location of the objects in the image.
# Note that a sample is a snapshot of the data at a given point in time during the scene. Therefore, each scence is made up of several samples.
# Now, let us extract the first sample sample from the first scence.
my_sample_token = my_scene["first_sample_token"]
my_sample = lyft_dataset.get("sample", my_sample_token)
# *Note :* You can list all samples in a scence using:
# **lyft_dataset.list_sample(my_sample['token'])**
# Next, let us render a pointcloud for a sample image in the dataset. The pointcloud is basically a set of contours that represent the distance of various objects as measured by the LiDAR. Basically, the LiDAR uses light beams to measure the distance of various objects (as discussed earlier) and this distance information can be visualized as a set of 3D contours. The colours of these contour lines represent the distance. The darker purple and blue contour lines represent the closer objects and the lighter green and yellow lines represent the far away objects. Basically, the higher the wavelength of the color of the contour line, the greater the distance of the object from the camera.
lyft_dataset.render_pointcloud_in_image(
sample_token=my_sample["token"], dot_size=1, camera_channel="CAM_FRONT"
)
# We can also print all annotations across all sample data for a given sample, as shown below:
my_sample["data"]
# We can also render the image data from particular sensors, as follows:
# ### Front Camera
# Images from the front camera
sensor_channel = "CAM_FRONT"
my_sample_data = lyft_dataset.get("sample_data", my_sample["data"][sensor_channel])
lyft_dataset.render_sample_data(my_sample_data["token"])
# ### Back Camera
# Images from the back camera
sensor_channel = "CAM_BACK"
my_sample_data = lyft_dataset.get("sample_data", my_sample["data"][sensor_channel])
lyft_dataset.render_sample_data(my_sample_data["token"])
# ### Front-Left Camera
# Images from the front-left camera
sensor_channel = "CAM_FRONT_LEFT"
my_sample_data = lyft_dataset.get("sample_data", my_sample["data"][sensor_channel])
lyft_dataset.render_sample_data(my_sample_data["token"])
# ### Front-Right Camera
# Images from the front-right camera
sensor_channel = "CAM_FRONT_RIGHT"
my_sample_data = lyft_dataset.get("sample_data", my_sample["data"][sensor_channel])
lyft_dataset.render_sample_data(my_sample_data["token"])
# ### Back-Left Camera
# Images from the back-left camera
sensor_channel = "CAM_BACK_LEFT"
my_sample_data = lyft_dataset.get("sample_data", my_sample["data"][sensor_channel])
lyft_dataset.render_sample_data(my_sample_data["token"])
# ### Back-Right Camera
# Images from the back-right camera
sensor_channel = "CAM_BACK_RIGHT"
my_sample_data = lyft_dataset.get("sample_data", my_sample["data"][sensor_channel])
lyft_dataset.render_sample_data(my_sample_data["token"])
# We can pick a given annotation from a sample in the data and render only that annotation, as shown below:
my_annotation_token = my_sample["anns"][10]
my_annotation = my_sample_data.get("sample_annotation", my_annotation_token)
lyft_dataset.render_annotation(my_annotation_token)
# We can also pick a given instance from the dataset and render only that instance, as shown below:
my_instance = lyft_dataset.instance[100]
my_instance
instance_token = my_instance["token"]
lyft_dataset.render_instance(instance_token)
lyft_dataset.render_annotation(my_instance["last_annotation_token"])
# We can also get the LiDAR data collected from various LIDAR sensors on the car as follows:
# ### Top LiDAR
# LiDAR data from the top sensor
my_scene = lyft_dataset.scene[0]
my_sample_token = my_scene["first_sample_token"]
my_sample = lyft_dataset.get("sample", my_sample_token)
lyft_dataset.render_sample_data(my_sample["data"]["LIDAR_TOP"], nsweeps=5)
# ### Front-Left LiDAR
# LiDAR data from the front-left sensor
my_scene = lyft_dataset.scene[0]
my_sample_token = my_scene["first_sample_token"]
my_sample = lyft_dataset.get("sample", my_sample_token)
lyft_dataset.render_sample_data(my_sample["data"]["LIDAR_FRONT_LEFT"], nsweeps=5)
# ### Front-Right LiDAR
# LiDAR data from the front-right sensor
my_scene = lyft_dataset.scene[0]
my_sample_token = my_scene["first_sample_token"]
my_sample = lyft_dataset.get("sample", my_sample_token)
lyft_dataset.render_sample_data(my_sample["data"]["LIDAR_FRONT_RIGHT"], nsweeps=5)
# ### Image and LiDAR animation
# This section is from [@xhulu](https://www.kaggle.com/xhlulu)'s brilliant [animation kernel](https://www.kaggle.com/xhlulu/lyft-eda-animations-generating-csvs). I use functions from that kernel to animate the image and LiDAR data.
# Please upvote [xhulu's kernel](https://www.kaggle.com/xhlulu/lyft-eda-animations-generating-csvs) if you find this interesting.
def generate_next_token(scene):
scene = lyft_dataset.scene[scene]
sample_token = scene["first_sample_token"]
sample_record = lyft_dataset.get("sample", sample_token)
while sample_record["next"]:
sample_token = sample_record["next"]
sample_record = lyft_dataset.get("sample", sample_token)
yield sample_token
def animate_images(scene, frames, pointsensor_channel="LIDAR_TOP", interval=1):
cams = [
"CAM_FRONT",
"CAM_FRONT_RIGHT",
"CAM_BACK_RIGHT",
"CAM_BACK",
"CAM_BACK_LEFT",
"CAM_FRONT_LEFT",
]
generator = generate_next_token(scene)
fig, axs = plt.subplots(
2,
len(cams),
figsize=(3 * len(cams), 6),
sharex=True,
sharey=True,
gridspec_kw={"wspace": 0, "hspace": 0.1},
)
plt.close(fig)
def animate_fn(i):
for _ in range(interval):
sample_token = next(generator)
for c, camera_channel in enumerate(cams):
sample_record = lyft_dataset.get("sample", sample_token)
pointsensor_token = sample_record["data"][pointsensor_channel]
camera_token = sample_record["data"][camera_channel]
axs[0, c].clear()
axs[1, c].clear()
lyft_dataset.render_sample_data(camera_token, with_anns=False, ax=axs[0, c])
lyft_dataset.render_sample_data(camera_token, with_anns=True, ax=axs[1, c])
axs[0, c].set_title("")
axs[1, c].set_title("")
anim = animation.FuncAnimation(fig, animate_fn, frames=frames, interval=interval)
return anim
# ### Animate image data (for 3 scences)
# ### Scence 1
anim = animate_images(scene=3, frames=100, interval=1)
HTML(anim.to_jshtml(fps=8))
# ### Scence 2
anim = animate_images(scene=7, frames=100, interval=1)
HTML(anim.to_jshtml(fps=8))
# ### Scence 3
anim = animate_images(scene=4, frames=100, interval=1)
HTML(anim.to_jshtml(fps=8))
# ### Animate LiDAR data (for 3 scences)
def animate_lidar(
scene, frames, pointsensor_channel="LIDAR_TOP", with_anns=True, interval=1
):
generator = generate_next_token(scene)
fig, axs = plt.subplots(1, 1, figsize=(8, 8))
plt.close(fig)
def animate_fn(i):
for _ in range(interval):
sample_token = next(generator)
axs.clear()
sample_record = lyft_dataset.get("sample", sample_token)
pointsensor_token = sample_record["data"][pointsensor_channel]
lyft_dataset.render_sample_data(pointsensor_token, with_anns=with_anns, ax=axs)
anim = animation.FuncAnimation(fig, animate_fn, frames=frames, interval=interval)
return anim
# ### Scence 1
anim = animate_lidar(scene=5, frames=100, interval=1)
HTML(anim.to_jshtml(fps=8))
# ### Scence 2
anim = animate_lidar(scene=25, frames=100, interval=1)
HTML(anim.to_jshtml(fps=8))
# ### Scence 3
anim = animate_lidar(scene=10, frames=100, interval=1)
HTML(anim.to_jshtml(fps=8))
| false | 0 | 36,048 | 0 | 6 | 36,048 |
||
63434456 | <kaggle_start><data_title>BMS-train-full<data_name>bmstrainpart1
<code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
inputDir = "/kaggle/input"
def _walkdir(dirPath):
for dirname, _, filenames in os.walk(dirPath):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
import gc
# gc.collect()
# # Refference
# 1. frog dudes masterpieces https://www.kaggle.com/c/bms-molecular-translation/discussion/231190
# ## 待研究
# - 青蛙做了什么优化
# 1. cnn(tnt) + tokenizer + transformer decoder 为什么比 cnn + lstm 好 ?
# ans: Ranger
# 2. 青蛙的tnt结构可以直接迁移到tpu上吗? 似乎是可以的,结构中并没有啥np的结构
# 3. 什么样的情况下模型可以反复训练
# 4. 似乎结构上只有预处理 padding mask 上有优化
# - 为什么内存会超
# 1. dataloader 里有什么增加了内存
# 2. transformer 训练过程中有什么变量一直没释放
# 3. dataloader 太大,可以分批小范围load
# 4. 训练过程中做do_valid 不合适 非常占资源
# - 如果
# 1. 如果不做patch会省内存嘛?
# 2. 我能不能搭建个vit
# 3. 如果不处理内存爆掉的问题会如何
# - 结论
# 1. 想来想去,这个版本实在是太慢了,而且有包内存的问题,即使不做do validate 也只能持续20k个batch左右
# 2. 后面还是根据这个博客 手动搭建一下transformer https://www.kaggle.com/drzhuzhe/training-on-gpu-bms/
import math
import gc
import torch
from torch.utils.data.dataset import Dataset
from torch.utils.data import DataLoader
from torch.utils.data.sampler import *
import torch.nn.functional as F
from torch.nn.parallel.data_parallel import data_parallel
import random
import pickle
import time
from timeit import default_timer as timer
import cv2
# %pylab inline
import matplotlib.pyplot as plt
# import matplotlib.image as mpimg
import collections
from collections import defaultdict
# # Set up Torch
def seed_py(seed):
random.seed(seed)
np.random.seed(seed)
return seed
def seed_torch(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
return seed
seed = int(time.time()) # 335202 #5202 #123 #
seed_py(seed)
seed_torch(seed)
torch.backends.cudnn.benchmark = False ##uses the inbuilt cudnn auto-tuner to find the fastest convolution algorithms. -
torch.backends.cudnn.enabled = True
torch.backends.cudnn.deterministic = True
COMMON_STRING = "\tpytorch\n"
COMMON_STRING += "\t\tseed = %d\n" % seed
COMMON_STRING += "\t\ttorch.__version__ = %s\n" % torch.__version__
COMMON_STRING += "\t\ttorch.version.cuda = %s\n" % torch.version.cuda
COMMON_STRING += (
"\t\ttorch.backends.cudnn.version() = %s\n" % torch.backends.cudnn.version()
)
try:
COMMON_STRING += (
"\t\tos['CUDA_VISIBLE_DEVICES'] = %s\n" % os.environ["CUDA_VISIBLE_DEVICES"]
)
NUM_CUDA_DEVICES = len(os.environ["CUDA_VISIBLE_DEVICES"].split(","))
except Exception:
COMMON_STRING += "\t\tos['CUDA_VISIBLE_DEVICES'] = None\n"
NUM_CUDA_DEVICES = 1
COMMON_STRING += "\t\ttorch.cuda.device_count() = %d\n" % torch.cuda.device_count()
COMMON_STRING += (
"\t\ttorch.cuda.get_device_properties() = %s\n"
% str(torch.cuda.get_device_properties(0))[21:]
)
COMMON_STRING += "\n"
# # Configure
origin_data_dir = "../input/bms-molecular-translation"
data_dir = "../input/bmstrainpart1/bms-moleular-translation"
csv_data_dir = "../input/bmd-mate-csv/csv"
STOI = {
"<sos>": 190,
"<eos>": 191,
"<pad>": 192,
}
patch_size = 16
pixel_pad = 3
pixel_scale = 0.8 # 1.0 #0.62=36/58 #1.0
max_length = 300 # 278 #275
pixel_stride = 4
pixel_dim = 24
patch_dim = 384
_walkdir(csv_data_dir)
# # Utils
def read_pickle_from_file(pickle_file):
with open(pickle_file, "rb") as f:
x = pickle.load(f)
return x
def uncompress_array(compressed_k):
compressed_k.seek(0)
k = np.load(compressed_k, allow_pickle=True)["arr_0"]
return k
# draw -----------------------------------
def image_show(name, image, resize=0.1):
H, W = image.shape[0:2]
plt.figure(figsize=(round(resize * W), round(resize * H)), dpi=20)
# fig = plt.figure(figsize = (500,500), dpi=20)
# ax = fig.add_subplot(1)
plt.imshow(image, cmap=plt.cm.gray)
# ax.imshow(image)
# image = cv2.resize(image, (round(resize*W), round(resize*H)), interpolation = cv2.INTER_AREA)
# plt.imshow(image)
def resize_image(image, scale=1):
if scale == 1:
f = pixel_scale * 58 / 36 # 1.2414 #0.80555
b = int(round(36 * 0.5))
if scale == 2:
f = pixel_scale * 1
b = int(round(58 * 0.5))
image = image[b:-b, b:-b] # remove border
if not np.isclose(1, f, rtol=1e-02, atol=1e-02):
h, w = image.shape
fw = int(round(f * w))
fh = int(round(f * h))
image = cv2.resize(image, dsize=(fw, fh), interpolation=cv2.INTER_AREA)
return image
def repad_image(image, multiplier=16):
h, w = image.shape
fh = int(np.ceil(h / multiplier)) * multiplier
fw = int(np.ceil(w / multiplier)) * multiplier
m = np.full((fh, fw), 255, np.uint8)
m[0:h, 0:w] = image
return m
# it seems to fill patches to Images
def patch_to_image(patch, coord, width, height):
image = np.full((height, width), 255, np.uint8)
p = pixel_pad
patch = patch[:, p:-p, p:-p]
num_patch = len(patch)
for i in range(num_patch):
y, x = coord[i]
x = x * patch_size
y = y * patch_size
image[y : y + patch_size, x : x + patch_size] = patch[i]
cv2.rectangle(image, (x, y), (x + patch_size, y + patch_size), 128, 1)
return image
def image_to_patch(image, patch_size, pixel_pad, threshold=0):
p = pixel_pad
h, w = image.shape
x, y = np.meshgrid(np.arange(w // patch_size), np.arange(h // patch_size))
yx = np.stack([y, x], 2).reshape(-1, 2)
s = patch_size + 2 * p
m = torch.from_numpy(image).reshape(1, 1, h, w).float()
k = F.unfold(m, kernel_size=s, stride=patch_size, padding=p)
k = k.permute(0, 2, 1).reshape(-1, s * s)
k = k.data.cpu().numpy().reshape(-1, s, s)
# print(k.shape)
sum = (1 - k[:, p:-p, p:-p] / 255).reshape(len(k), -1).sum(-1)
# only store patches
i = np.where(sum > threshold)
# print(sum)
patch = k[i]
coord = yx[i]
return patch, coord
"""
# check folder data
#df = pd.read_csv('../input/tarfile/df_train_patch_s0.800.csv')
df = read_pickle_from_file(csv_data_dir+'/df_train.more.csv.pickle')
df_fold = pd.read_csv(csv_data_dir+'/df_fold.fine.csv')
df_meta = pd.read_csv(csv_data_dir+'/df_train_image_meta.csv')
df = df.merge(df_fold, on='image_id')
df = df.merge(df_meta, on='image_id')
print(len(df), len(df_fold), len(df_meta))
print(len(df['fold'].unique()))
df.head(10)
"""
# divide dataset into training and validate
def make_fold(mode="train-1"):
if "train" in mode:
df = read_pickle_from_file(csv_data_dir + "/df_train.more.csv.pickle")
# df = pd.read_csv('../input/tarfile/df_train_patch_s0.800.csv')
# df_fold = pd.read_csv(data_dir+'/df_fold.csv')
df_fold = pd.read_csv(csv_data_dir + "/df_fold.fine.csv")
df_meta = pd.read_csv(csv_data_dir + "/df_train_image_meta.csv")
df = df.merge(df_fold, on="image_id")
df = df.merge(df_meta, on="image_id")
df.loc[:, "path"] = "train_patch16_s0.800"
df["fold"] = df["fold"].astype(int)
# print(df.groupby(['fold']).size()) #404_031
# print(df.columns)
fold = int(mode[-1]) * 10
# print(fold)
df_train = df[df.fold != fold].reset_index(drop=True)
df_valid = df[df.fold == fold].reset_index(drop=True)
return df_train, df_valid
# Index(['image_id', 'InChI'], dtype='object')
if "test" in mode:
# df = pd.read_csv(data_dir+'/sample_submission.csv')
df = pd.read_csv(data_dir + "/submit_lb3.80.csv")
df_meta = pd.read_csv(data_dir + "/df_test_image_meta.csv")
df = df.merge(df_meta, on="image_id")
df.loc[:, "path"] = "test"
# df.loc[:, 'InChI'] = '0'
df.loc[:, "formula"] = "0"
df.loc[:, "text"] = "0"
df.loc[:, "sequence"] = pd.Series([[0]] * len(df))
df.loc[:, "length"] = df.InChI.str.len()
df_test = df
return df_test
# df_train, df_valid = make_fold()
# print(len(df_train), len(df_valid))
# -----------------------------------------------------------------------
# tokenization, padding, ...
def pad_sequence_to_max_length(sequence, max_length, padding_value):
batch_size = len(sequence)
pad_sequence = np.full((batch_size, max_length), padding_value, np.int32)
for b, s in enumerate(sequence):
L = len(s)
pad_sequence[b, :L, ...] = s
return pad_sequence
def load_tokenizer():
tokenizer = YNakamaTokenizer(is_load=True)
print("len(tokenizer) : vocab_size", len(tokenizer))
for k, v in STOI.items():
assert tokenizer.stoi[k] == v
return tokenizer
def null_augment(r):
return r
# getDataset
class BmsDataset(Dataset):
def __init__(self, df, tokenizer, augment=null_augment):
super().__init__()
self.tokenizer = tokenizer
self.df = df
self.augment = augment
self.length = len(self.df)
def __str__(self):
string = ""
string += "\tlen = %d\n" % len(self)
string += "\tdf = %s\n" % str(self.df.shape)
g = self.df["length"].values.astype(np.int32) // 20
g = np.bincount(g, minlength=14)
string += "\tlength distribution\n"
for n in range(14):
string += "\t\t %3d = %8d (%0.4f)\n" % ((n + 1) * 20, g[n], g[n] / g.sum())
return string
def __len__(self):
return self.length
def __getitem__(self, index):
d = self.df.iloc[index]
token = d.sequence
patch_file = data_dir + "/%s/%s/%s/%s/%s.pickle" % (
d.path,
d.image_id[0],
d.image_id[1],
d.image_id[2],
d.image_id,
)
k = read_pickle_from_file(patch_file)
patch = uncompress_array(k["patch"])
patch = np.concatenate(
[
np.zeros(
(1, patch_size + 2 * pixel_pad, patch_size + 2 * pixel_pad),
np.uint8,
),
patch,
],
0,
) # cls token
coord = k["coord"]
w = k["width"]
h = k["height"]
h = h // patch_size - 1
w = w // patch_size - 1
coord = np.insert(coord, 0, [h, w], 0) # cls token
# debug
# image = patch_to_image(patch, coord, k['width' ], k['height'])
# image_show('image', image, resize=1)
# cv2.waitKey(0)
# image = cv2.imread(image_file,cv2.IMREAD_GRAYSCALE) #
r = {
"index": index,
"image_id": d.image_id,
"InChI": d.InChI,
"d": d,
"token": token,
#'image' : image,
"patch": patch,
"coord": coord,
}
if self.augment is not None:
r = self.augment(r)
# Warrning runtime keep this variable shall cause Out of memery crash
del patch_file, patch, coord, k
# gc.collect()
return r
# set up tokenizer
class YNakamaTokenizer(object):
def __init__(self, is_load=True):
self.stoi = {}
self.itos = {}
if is_load:
self.stoi = _TOKENIZER_
self.itos = {k: v for v, k in self.stoi.items()}
def __len__(self):
return len(self.stoi)
def build_vocab(self, text):
vocab = set()
for t in text:
vocab.update(t.split(" "))
vocab = sorted(vocab)
vocab.append("<sos>")
vocab.append("<eos>")
vocab.append("<pad>")
for i, s in enumerate(vocab):
self.stoi[s] = i
self.itos = {k: v for v, k in self.stoi.items()}
def one_text_to_sequence(self, text):
sequence = []
sequence.append(self.stoi["<sos>"])
for s in text.split(" "):
sequence.append(self.stoi[s])
sequence.append(self.stoi["<eos>"])
return sequence
def one_sequence_to_text(self, sequence):
return "".join(list(map(lambda i: self.itos[i], sequence)))
def one_predict_to_inchi(self, predict):
inchi = "InChI=1S/"
for p in predict:
if p == self.stoi["<eos>"] or p == self.stoi["<pad>"]:
break
inchi += self.itos[p]
return inchi
# ---
def text_to_sequence(self, text):
sequence = [self.one_text_to_sequence(t) for t in text]
return sequence
def sequence_to_text(self, sequence):
text = [self.one_sequence_to_text(s) for s in sequence]
return text
def predict_to_inchi(self, predict):
inchi = [self.one_predict_to_inchi(p) for p in predict]
return inchi
def null_collate(batch, is_sort_decreasing_length=True):
collate = defaultdict(list)
if is_sort_decreasing_length: # sort by decreasing length
sort = np.argsort([-len(r["token"]) for r in batch])
batch = [batch[s] for s in sort]
for r in batch:
for k, v in r.items():
collate[k].append(v)
# ----
batch_size = len(batch)
collate["length"] = [len(l) for l in collate["token"]]
token = [np.array(t, np.int32) for t in collate["token"]]
token = pad_sequence_to_max_length(
token, max_length=max_length, padding_value=STOI["<pad>"]
)
collate["token"] = torch.from_numpy(token).long()
max_of_length = max(collate["length"])
token_pad_mask = np.zeros((batch_size, max_of_length, max_of_length))
for b in range(batch_size):
L = collate["length"][b]
token_pad_mask[b, :L, :L] = 1 # +1 for cls_token
collate["token_pad_mask"] = torch.from_numpy(token_pad_mask).byte()
# -----
# image = np.stack(collate['image'])
# image = image.astype(np.float32) / 255
# collate['image'] = torch.from_numpy(image).unsqueeze(1).repeat(1,3,1,1)
# -----
collate["num_patch"] = [len(l) for l in collate["patch"]]
max_of_num_patch = max(collate["num_patch"])
patch_pad_mask = np.zeros((batch_size, max_of_num_patch, max_of_num_patch))
patch = np.full(
(
batch_size,
max_of_num_patch,
patch_size + 2 * pixel_pad,
patch_size + 2 * pixel_pad,
),
255,
) # pad as 255
coord = np.zeros((batch_size, max_of_num_patch, 2))
for b in range(batch_size):
N = collate["num_patch"][b]
patch[b, :N] = collate["patch"][b]
coord[b, :N] = collate["coord"][b]
patch_pad_mask[b, :N, :N] = 1 # +1 for cls_token
collate["patch"] = torch.from_numpy(patch).half() / 255
collate["coord"] = torch.from_numpy(coord).long()
collate["patch_pad_mask"] = torch.from_numpy(patch_pad_mask).byte()
del patch_pad_mask, patch, coord, token_pad_mask, batch
return collate
def run_check_dataset():
tokenizer = load_tokenizer()
df_train, df_valid = make_fold("train-1")
# df_train = make_fold('test') #1616107
# dataset = BmsDataset(df_train, tokenizer, remote_augment)
# dataset = BmsDataset(df_valid, tokenizer)
# print(dataset)
train_dataset = BmsDataset(df_train, tokenizer)
# for i in range(len(dataset)):
"""
for i in range(5):
#i = np.random.choice(len(dataset))
r = dataset[i]
print(r['index'])
print(r['image_id'])
#print(r['formula'])
print(r['InChI'])
print(r['token'])
print('image : ')
#print('\t', r['image'].shape)
print('')
#---
image = patch_to_image(r['patch'], r['coord'], width=1024, height=1024)
#image_show('image', image, resize=.1)
del image
gc.collect()
#cv2.waitKey(0)
"""
# exit(0)
# """
loader = DataLoader(
train_dataset,
# sampler = RandomSampler(train_dataset),
batch_size=8,
drop_last=True,
num_workers=8,
pin_memory=True,
collate_fn=null_collate,
)
for t, batch in enumerate(loader):
# if t>30: break
print(t, "-----------")
# print('index : ', batch['index'])
"""
print('image : ')
#print('\t', batch['image'].shape, batch['image'].is_contiguous())
print('\t', batch['patch'].shape, batch['patch'].is_contiguous())
print('\t', batch['coord'].shape, batch['coord'].is_contiguous())
#print('\t', batch['mask'].shape, batch['mask'].is_contiguous())
print('length : ')
print('\t',len( batch['length']))
print('\t', batch['length'])
print('token : ')
print('\t', batch['token'].shape, batch['token'].is_contiguous())
"""
# print('\t', batch['token'])
# print('')
del t, batch
del loader, train_dataset, df_train, df_valid, tokenizer
# """
# 数据load到4000 条 左右就会挂 , 讲道理 load数据应该不会不断加内存吧
# run_check_dataset()
# # Net Modeules
# ## 1D Encoder and Decoder
from typing import Tuple, Dict
import torch.nn as nn
from fairseq import utils
from fairseq.models import *
from fairseq.modules import *
# ------------------------------------------------------
# https://kazemnejad.com/blog/transformer_architecture_positional_encoding/
# https://stackoverflow.com/questions/46452020/sinusoidal-embedding-attention-is-all-you-need
class PositionEncode1D(nn.Module):
def __init__(self, dim, max_length):
super().__init__()
assert dim % 2 == 0
self.max_length = max_length
d = torch.exp(torch.arange(0.0, dim, 2) * (-math.log(10000.0) / dim))
position = torch.arange(0.0, max_length).unsqueeze(1)
pos = torch.zeros(1, max_length, dim)
pos[0, :, 0::2] = torch.sin(position * d)
pos[0, :, 1::2] = torch.cos(position * d)
self.register_buffer("pos", pos)
def forward(self, x):
batch_size, T, dim = x.shape
x = x + self.pos[:, :T]
return x
"""
# https://gitlab.maastrichtuniversity.nl/dsri-examples/dsri-pytorch-workspace/-/blob/c8a88cdeb8e1a0f3a2ccd3c6119f43743cbb01e9/examples/transformer/fairseq/models/transformer.py
#https://github.com/pytorch/fairseq/issues/568
# fairseq/fairseq/models/fairseq_encoder.py
# https://github.com/pytorch/fairseq/blob/master/fairseq/modules/transformer_layer.py
class TransformerEncode(FairseqEncoder):
def __init__(self, dim, ff_dim, num_head, num_layer):
super().__init__({})
#print('my TransformerEncode()')
self.layer = nn.ModuleList([
TransformerEncoderLayer(Namespace({
'encoder_embed_dim': dim,
'encoder_attention_heads': num_head,
'attention_dropout': 0.1,
'dropout': 0.1,
'encoder_normalize_before': True,
'encoder_ffn_embed_dim': ff_dim,
})) for i in range(num_layer)
])
self.layer_norm = nn.LayerNorm(dim)
def forward(self, x):# T x B x C
#print('my TransformerEncode forward()')
for layer in self.layer:
x = layer(x)
x = self.layer_norm(x)
return x
"""
# https://mt.cs.upc.edu/2020/12/21/the-transformer-fairseq-edition/
# for debug
# class TransformerDecode(FairseqDecoder):
# def __init__(self, dim, ff_dim, num_head, num_layer):
# super().__init__({})
# print('my TransformerDecode()')
#
# self.layer = nn.ModuleList([
# TransformerDecoderLayer(Namespace({
# 'decoder_embed_dim': dim,
# 'decoder_attention_heads': num_head,
# 'attention_dropout': 0.1,
# 'dropout': 0.1,
# 'decoder_normalize_before': True,
# 'decoder_ffn_embed_dim': ff_dim,
# })) for i in range(num_layer)
# ])
# self.layer_norm = nn.LayerNorm(dim)
#
#
# def forward(self, x, mem, x_mask):# T x B x C
# print('my TransformerDecode forward()')
# for layer in self.layer:
# x = layer(x, mem, self_attn_mask=x_mask)[0]
# x = self.layer_norm(x)
# return x # T x B x C
# https://stackoverflow.com/questions/4984647/accessing-dict-keys-like-an-attribute
class Namespace(object):
def __init__(self, adict):
self.__dict__.update(adict)
# https://fairseq.readthedocs.io/en/latest/tutorial_simple_lstm.html
# see https://gitlab.maastrichtuniversity.nl/dsri-examples/dsri-pytorch-workspace/-/blob/c8a88cdeb8e1a0f3a2ccd3c6119f43743cbb01e9/examples/transformer/fairseq/models/transformer.py
class TransformerDecode(FairseqIncrementalDecoder):
def __init__(self, dim, ff_dim, num_head, num_layer):
super().__init__({})
# print('my TransformerDecode()')
self.layer = nn.ModuleList(
[
TransformerDecoderLayer(
Namespace(
{
"decoder_embed_dim": dim,
"decoder_attention_heads": num_head,
"attention_dropout": 0.1,
"dropout": 0.1,
"decoder_normalize_before": True,
"decoder_ffn_embed_dim": ff_dim,
}
)
)
for i in range(num_layer)
]
)
self.layer_norm = nn.LayerNorm(dim)
def forward(self, x, mem, x_mask, x_pad_mask, mem_pad_mask):
# print('my TransformerDecode forward()')
for layer in self.layer:
x = layer(
x,
mem,
self_attn_mask=x_mask,
self_attn_padding_mask=x_pad_mask,
encoder_padding_mask=mem_pad_mask,
)[0]
x = self.layer_norm(x)
return x # T x B x C
# def forward_one(self, x, mem, incremental_state):
def forward_one(
self,
x: Tensor,
mem: Tensor,
incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]],
) -> Tensor:
x = x[-1:]
for layer in self.layer:
x = layer(x, mem, incremental_state=incremental_state)[0]
x = self.layer_norm(x)
return x
"""
https://fairseq.readthedocs.io/en/latest/_modules/fairseq/modules/transformer_layer.html
class TransformerDecoderLayer(nn.Module):
def forward(
self,
x,
encoder_out: Optional[torch.Tensor] = None,
encoder_padding_mask: Optional[torch.Tensor] = None,
incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]] = None,
prev_self_attn_state: Optional[List[torch.Tensor]] = None,
prev_attn_state: Optional[List[torch.Tensor]] = None,
self_attn_mask: Optional[torch.Tensor] = None,
self_attn_padding_mask: Optional[torch.Tensor] = None,
need_attn: bool = False,
need_head_weights: bool = False,
):
https://github.com/pytorch/fairseq/blob/05b86005bcca0155319fa9b81abfd69f63c06906/examples/simultaneous_translation/utils/data_utils.py#L31
"""
# ## TNT
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence, PackedSequence
# https://github.com/pytorch/pytorch/issues/1788
# https://stackoverflow.com/questions/51030782/why-do-we-pack-the-sequences-in-pytorch
from timm.models.vision_transformer import Mlp
from timm.models.layers import DropPath, trunc_normal_
# from timm.models.tnt import *
# 这个多头注意力会造成内存不断增加吗?
class Attention(nn.Module):
"""Multi-Head Attention"""
def __init__(
self, dim, hidden_dim, num_heads=8, qkv_bias=False, attn_drop=0.0, proj_drop=0.0
):
super().__init__()
self.hidden_dim = hidden_dim
self.num_heads = num_heads
head_dim = hidden_dim // num_heads
self.head_dim = head_dim
self.scale = head_dim**-0.5
self.qk = nn.Linear(dim, hidden_dim * 2, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop, inplace=True)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop, inplace=True)
def forward(self, x: Tensor, mask: Optional[Tensor] = None) -> Tensor:
B, N, C = x.shape
qk = (
self.qk(x)
.reshape(B, N, 2, self.num_heads, self.head_dim)
.permute(2, 0, 3, 1, 4)
)
q, k = qk[0], qk[1] # make torchscript happy (cannot use tensor as tuple)
v = self.v(x).reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3)
# ---
attn = (q @ k.transpose(-2, -1)) * self.scale # B x self.num_heads x NxN
if mask is not None:
# mask = mask.unsqueeze(1).repeat(1,self.num_heads,1,1)
mask = mask.unsqueeze(1).expand(-1, self.num_heads, -1, -1)
attn = attn.masked_fill(mask == 0, -6e4)
# attn = attn.masked_fill(mask == 0, -half('inf'))
# https://github.com/NVIDIA/apex/issues/93
# How to use fp16 training with masked operations
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, -1)
x = self.proj(x)
x = self.proj_drop(x)
del mask, attn
return x
class Block(nn.Module):
def __init__(
self,
dim,
in_dim,
num_pixel,
num_heads=12,
in_num_head=4,
mlp_ratio=4.0,
qkv_bias=False,
drop=0.0,
attn_drop=0.0,
drop_path=0.0,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm,
):
super().__init__()
# Inner transformer
self.norm_in = norm_layer(in_dim)
self.attn_in = Attention(
in_dim,
in_dim,
num_heads=in_num_head,
qkv_bias=qkv_bias,
attn_drop=attn_drop,
proj_drop=drop,
)
self.norm_mlp_in = norm_layer(in_dim)
self.mlp_in = Mlp(
in_features=in_dim,
hidden_features=int(in_dim * 4),
out_features=in_dim,
act_layer=act_layer,
drop=drop,
)
self.norm1_proj = norm_layer(in_dim)
self.proj = nn.Linear(in_dim * num_pixel, dim, bias=True)
# Outer transformer
self.norm_out = norm_layer(dim)
self.attn_out = Attention(
dim,
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
attn_drop=attn_drop,
proj_drop=drop,
)
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
self.norm_mlp = norm_layer(dim)
self.mlp = Mlp(
in_features=dim,
hidden_features=int(dim * mlp_ratio),
out_features=dim,
act_layer=act_layer,
drop=drop,
)
def forward(self, pixel_embed, patch_embed, mask):
# inner
pixel_embed = pixel_embed + self.drop_path(
self.attn_in(self.norm_in(pixel_embed))
)
pixel_embed = pixel_embed + self.drop_path(
self.mlp_in(self.norm_mlp_in(pixel_embed))
)
# outer
B, N, C = patch_embed.size()
patch_embed[:, 1:] = (
patch_embed[:, 1:]
+ self.proj(self.norm1_proj(pixel_embed).reshape(B, N, -1))[:, 1:]
)
patch_embed = patch_embed + self.drop_path(
self.attn_out(self.norm_out(patch_embed), mask)
)
patch_embed = patch_embed + self.drop_path(self.mlp(self.norm_mlp(patch_embed)))
return pixel_embed, patch_embed
# ---------------------------------
class PixelEmbed(nn.Module):
def __init__(self, patch_size=16, in_dim=48, stride=4):
super().__init__()
self.in_dim = in_dim
self.proj = nn.Conv2d(3, self.in_dim, kernel_size=7, padding=0, stride=stride)
def forward(self, patch, pixel_pos):
BN = len(patch)
x = patch
x = self.proj(x)
# x = x.transpose(1, 2).reshape(B * self.num_patches, self.in_dim, self.new_patch_size, self.new_patch_size)
x = x + pixel_pos
x = x.reshape(BN, self.in_dim, -1).transpose(1, 2)
return x
# ---------------------------------
class TNT(nn.Module):
"""Transformer in Transformer - https://arxiv.org/abs/2103.00112"""
def __init__(
self,
patch_size=patch_size,
embed_dim=patch_dim,
in_dim=pixel_dim,
depth=12,
num_heads=6,
in_num_head=4,
mlp_ratio=4.0,
qkv_bias=False,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.0,
norm_layer=nn.LayerNorm,
first_stride=pixel_stride,
):
super().__init__()
self.num_features = (
self.embed_dim
) = embed_dim # num_features for consistency with other models
self.pixel_embed = PixelEmbed(
patch_size=patch_size, in_dim=in_dim, stride=first_stride
)
# num_patches = self.pixel_embed.num_patches
# self.num_patches = num_patches
new_patch_size = 4 # self.pixel_embed.new_patch_size
num_pixel = new_patch_size**2
self.norm1_proj = norm_layer(num_pixel * in_dim)
self.proj = nn.Linear(num_pixel * in_dim, embed_dim)
self.norm2_proj = norm_layer(embed_dim)
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.patch_pos = nn.Embedding(
100 * 100, embed_dim
) # nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.pixel_pos = nn.Parameter(
torch.zeros(1, in_dim, new_patch_size, new_patch_size)
)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [
x.item() for x in torch.linspace(0, drop_path_rate, depth)
] # stochastic depth decay rule
blocks = []
for i in range(depth):
blocks.append(
Block(
dim=embed_dim,
in_dim=in_dim,
num_pixel=num_pixel,
num_heads=num_heads,
in_num_head=in_num_head,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[i],
norm_layer=norm_layer,
)
)
self.blocks = nn.ModuleList(blocks)
self.norm = norm_layer(embed_dim)
trunc_normal_(self.cls_token, std=0.02)
# trunc_normal_(self.patch_pos, std=.02)
trunc_normal_(self.pixel_pos, std=0.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=0.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {"patch_pos", "pixel_pos", "cls_token"}
def forward(self, patch, coord, mask):
B = len(patch)
batch_size, max_of_num_patch, s, s = patch.shape
patch = patch.reshape(batch_size * max_of_num_patch, 1, s, s).repeat(1, 3, 1, 1)
pixel_embed = self.pixel_embed(patch, self.pixel_pos)
patch_embed = self.norm2_proj(
self.proj(self.norm1_proj(pixel_embed.reshape(B, max_of_num_patch, -1)))
)
# patch_embed = torch.cat((self.cls_token.expand(B, -1, -1), patch_embed), dim=1)
# patch_embed = patch_embed + self.patch_pos
# patch_embed[:, 1:] = patch_embed[:, 1:] + self.patch_pos(coord[:, :, 0] * 100 + coord[:, :, 1])
patch_embed[:, :1] = self.cls_token.expand(B, -1, -1)
patch_embed = patch_embed + self.patch_pos(
coord[:, :, 0] * 100 + coord[:, :, 1]
)
patch_embed = self.pos_drop(patch_embed)
for blk in self.blocks:
pixel_embed, patch_embed = blk(pixel_embed, patch_embed, mask)
patch_embed = self.norm(patch_embed)
del patch, mask
return patch_embed
def make_dummy_data():
# make dummy data
# image_id,width,height,scale,orientation
meta = [
[
"000011a64c74",
325,
229,
2,
0,
],
[
"000019cc0cd2",
288,
148,
1,
0,
],
[
"0000252b6d2b",
509,
335,
2,
0,
],
[
"000026b49b7e",
243,
177,
1,
0,
],
[
"000026fc6c36",
294,
112,
1,
0,
],
[
"000028818203",
402,
328,
2,
0,
],
[
"000029a61c01",
395,
294,
2,
0,
],
[
"000035624718",
309,
145,
1,
0,
],
]
batch_size = 8
# <todo> check border for padding
# <todo> pepper noise
batch = {
"num_patch": [],
"patch": [],
"coord": [],
}
for b in range(batch_size):
image_id = meta[b][0]
scale = meta[b][3]
image_file = origin_data_dir + "/%s/%s/%s/%s/%s.png" % (
"train",
image_id[0],
image_id[1],
image_id[2],
image_id,
)
# print(image_file)
image = cv2.imread(image_file, cv2.IMREAD_GRAYSCALE)
image = resize_image(image, scale)
image = repad_image(image, patch_size) # remove border and repad
# print(image.shape)
k, yx = image_to_patch(image, patch_size, pixel_pad, threshold=0)
for y, x in yx:
# cv2.circle(image,(x,y),8,128,1)
x = x * patch_size
y = y * patch_size
cv2.rectangle(image, (x, y), (x + patch_size, y + patch_size), 128, 1)
# image_show('image-%d' % b, image, resize=1)
del image
# cv2.waitKey(1)
batch["patch"].append(k)
batch["coord"].append(yx)
batch["num_patch"].append(len(k))
# ----
max_of_num_patch = max(batch["num_patch"])
mask = np.zeros((batch_size, max_of_num_patch, max_of_num_patch))
patch = np.zeros(
(
batch_size,
max_of_num_patch,
patch_size + 2 * pixel_pad,
patch_size + 2 * pixel_pad,
)
)
coord = np.zeros((batch_size, max_of_num_patch, 2))
for b in range(batch_size):
N = batch["num_patch"][b]
patch[b, :N] = batch["patch"][b]
coord[b, :N] = batch["coord"][b]
mask[b, :N, :N] = 1
num_patch = batch["num_patch"]
patch = torch.from_numpy(patch).float()
coord = torch.from_numpy(coord).long()
mask = torch.from_numpy(mask).byte()
return patch, coord, num_patch, mask
def run_check_tnt_patch():
patch, coord, num_patch, mask = make_dummy_data()
tnt = TNT()
patch_embed = tnt(patch, coord, mask)
print(patch_embed.shape)
# run_check_tnt_patch()
# ## TNT + PositionEncode1D + Transformer Decoder
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence, PackedSequence
vocab_size = 193
text_dim = 384
decoder_dim = 384
num_layer = 3
num_head = 8
ff_dim = 1024
class Net(nn.Module):
def __init__(
self,
):
super(Net, self).__init__()
self.cnn = TNT()
self.image_encode = nn.Identity()
# ---
self.text_pos = PositionEncode1D(text_dim, max_length)
self.token_embed = nn.Embedding(vocab_size, text_dim)
self.text_decode = TransformerDecode(decoder_dim, ff_dim, num_head, num_layer)
# ---
self.logit = nn.Linear(decoder_dim, vocab_size)
self.dropout = nn.Dropout(p=0.5)
# ----
# initialization
self.token_embed.weight.data.uniform_(-0.1, 0.1)
self.logit.bias.data.fill_(0)
self.logit.weight.data.uniform_(-0.1, 0.1)
@torch.jit.unused
def forward(self, patch, coord, token, patch_pad_mask, token_pad_mask):
device = patch.device
batch_size = len(patch)
# ---
patch = patch * 2 - 1
image_embed = self.cnn(patch, coord, patch_pad_mask)
image_embed = self.image_encode(image_embed).permute(1, 0, 2).contiguous()
text_embed = self.token_embed(token)
text_embed = self.text_pos(text_embed).permute(1, 0, 2).contiguous()
max_of_length = token_pad_mask.shape[-1]
text_mask = np.triu(np.ones((max_of_length, max_of_length)), k=1).astype(
np.uint8
)
text_mask = torch.autograd.Variable(torch.from_numpy(text_mask) == 1).to(device)
# ----
# <todo> perturb mask as aug
text_pad_mask = token_pad_mask[:, :, 0] == 0
image_pad_mask = patch_pad_mask[:, :, 0] == 0
x = self.text_decode(
text_embed[:max_of_length],
image_embed,
text_mask,
text_pad_mask,
image_pad_mask,
)
x = x.permute(1, 0, 2).contiguous()
l = self.logit(x)
logit = torch.zeros((batch_size, max_length, vocab_size), device=device)
logit[:, :max_of_length] = l
del image_embed, text_mask, text_pad_mask, image_pad_mask
return logit
# submit function has not been coded. i will leave it as an exercise for the kaggler
# @torch.jit.export
# def forward_argmax_decode(self, patch, coord, mask):
#
# image_dim = 384
# text_dim = 384
# decoder_dim = 384
# num_layer = 3
# num_head = 8
# ff_dim = 1024
#
# STOI = {
# '<sos>': 190,
# '<eos>': 191,
# '<pad>': 192,
# }
# max_length = 278 # 275
#
#
# #---------------------------------
# device = patch.device
# batch_size = len(patch)
#
# patch = patch*2-1
# image_embed = self.cnn(patch, coord, mask)
# image_embed = self.image_encode(image_embed).permute(1,0,2).contiguous()
#
# token = torch.full((batch_size, max_length), STOI['<pad>'],dtype=torch.long, device=device)
# text_pos = self.text_pos.pos
# token[:,0] = STOI['<sos>']
#
#
# #-------------------------------------
# eos = STOI['<eos>']
# pad = STOI['<pad>']
# # https://github.com/alexmt-scale/causal-transformer-decoder/blob/master/tests/test_consistency.py
# # slow version
# # if 0:
# # for t in range(max_length-1):
# # last_token = token [:,:(t+1)]
# # text_embed = self.token_embed(last_token)
# # text_embed = self.text_pos(text_embed).permute(1,0,2).contiguous() #text_embed + text_pos[:,:(t+1)] #
# #
# # text_mask = np.triu(np.ones((t+1, t+1)), k=1).astype(np.uint8)
# # text_mask = torch.autograd.Variable(torch.from_numpy(text_mask)==1).to(device)
# #
# # x = self.text_decode(text_embed, image_embed, text_mask)
# # x = x.permute(1,0,2).contiguous()
# #
# # l = self.logit(x[:,-1])
# # k = torch.argmax(l, -1) # predict max
# # token[:, t+1] = k
# # if ((k == eos) | (k == pad)).all(): break
#
# # fast version
# if 1:
# #incremental_state = {}
# incremental_state = torch.jit.annotate(
# Dict[str, Dict[str, Optional[Tensor]]],
# torch.jit.annotate(Dict[str, Dict[str, Optional[Tensor]]], {}),
# )
# for t in range(max_length-1):
# #last_token = token [:,:(t+1)]
# #text_embed = self.token_embed(last_token)
# #text_embed = self.text_pos(text_embed) #text_embed + text_pos[:,:(t+1)] #
#
# last_token = token[:, t]
# text_embed = self.token_embed(last_token)
# text_embed = text_embed + text_pos[:,t] #
# text_embed = text_embed.reshape(1,batch_size,text_dim)
#
# x = self.text_decode.forward_one(text_embed, image_embed, incremental_state)
# x = x.reshape(batch_size,decoder_dim)
# #print(incremental_state.keys())
#
# l = self.logit(x)
# k = torch.argmax(l, -1) # predict max
# token[:, t+1] = k
# if ((k == eos) | (k == pad)).all(): break
#
# predict = token[:, 1:]
# return predict
# loss #################################################################
def seq_cross_entropy_loss(logit, token, length):
truth = token[:, 1:]
L = [l - 1 for l in length]
logit = pack_padded_sequence(logit, L, batch_first=True).data
truth = pack_padded_sequence(truth, L, batch_first=True).data
loss = F.cross_entropy(logit, truth, ignore_index=STOI["<pad>"])
return loss
# https://www.aclweb.org/anthology/2020.findings-emnlp.276.pdf
def seq_focal_cross_entropy_loss(logit, token, length):
gamma = 0.5 # {0.5,1.0}
# label_smooth = 0.90
# ---
truth = token[:, 1:]
L = [l - 1 for l in length]
logit = pack_padded_sequence(logit, L, batch_first=True).data
truth = pack_padded_sequence(truth, L, batch_first=True).data
# loss = F.cross_entropy(logit, truth, ignore_index=STOI['<pad>'])
# non_pad = torch.where(truth != STOI['<pad>'])[0] # & (t!=STOI['<sos>'])
# ---
# p = F.softmax(logit,-1)
# logp = - torch.log(torch.clamp(p, 1e-4, 1 - 1e-4))
logp = F.log_softmax(logit, -1)
logp = logp.gather(1, truth.reshape(-1, 1)).reshape(-1)
p = logp.exp()
loss = -((1 - p) ** gamma) * logp # focal
# loss = - ((1 + p) ** gamma)*logp #anti-focal
loss = loss.mean()
return loss
def np_loss_cross_entropy(probability, truth):
batch_size = len(probability)
truth = truth.reshape(-1)
p = probability[np.arange(batch_size), truth]
loss = -np.log(np.clip(p, 1e-6, 1))
loss = loss.mean()
return loss
# check #################################################################
def run_check_net():
patch, coord, num_patch, patch_pad_mask = make_dummy_data()
batch_size = len(patch)
token = np.full((batch_size, max_length), STOI["<pad>"], np.int64) # token
length = np.random.randint(5, max_length - 2, batch_size)
length = np.sort(length)[::-1].copy()
max_of_length = max(length)
token_pad_mask = np.zeros((batch_size, max_of_length, max_of_length))
for b in range(batch_size):
l = length[b]
t = np.random.choice(vocab_size, l)
t = np.insert(t, 0, STOI["<sos>"])
t = np.insert(t, len(t), STOI["<eos>"])
L = len(t)
token[b, :L] = t
token_pad_mask[b, :L, :L] = 1
token = torch.from_numpy(token).long()
token_pad_mask = torch.from_numpy(token_pad_mask).byte()
# ---
net = Net()
net.train()
logit = net(patch, coord, token, patch_pad_mask, token_pad_mask)
loss = seq_cross_entropy_loss(logit, token, length)
print("vocab_size", vocab_size)
print("max_length", max_length)
print("")
print(length)
print(length.shape)
print(token.shape)
print("---")
print(logit.shape)
print(loss)
print("---")
del net
# ---
# print('torch.jit.script(net)')
# net.eval()
# net = torch.jit.script(net)
#
# predict = net.forward_argmax_decode(patch, coord, mask)
# print(predict.shape)
# run_check_net()
"""
import sys
local_vars = list(locals().items())
for var, obj in local_vars:
print(var, sys.getsizeof(obj))
"""
# ----------------
is_mixed_precision = True # False #
###################################################################################################
import torch.cuda.amp as amp
if is_mixed_precision:
class AmpNet(Net):
@torch.cuda.amp.autocast()
def forward(self, *args):
return super(AmpNet, self).forward(*args)
else:
AmpNet = Net
import sys
from datetime import datetime
import Levenshtein
IDENTIFIER = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
# http://stackoverflow.com/questions/34950201/pycharm-print-end-r-statement-not-working
class Logger(object):
def __init__(self):
self.terminal = sys.stdout # stdout
self.file = None
def open(self, file, mode=None):
if mode is None:
mode = "w"
self.file = open(file, mode)
def write(self, message, is_terminal=1, is_file=1):
if "\r" in message:
is_file = 0
if is_terminal == 1:
self.terminal.write(message)
self.terminal.flush()
# time.sleep(1)
if is_file == 1:
self.file.write(message)
self.file.flush()
def flush(self):
# this flush method is needed for python 3 compatibility.
# this handles the flush command by doing nothing.
# you might want to specify some extra behavior here.
pass
# etc ------------------------------------
def time_to_str(t, mode="min"):
if mode == "min":
t = int(t) / 60
hr = t // 60
min = t % 60
return "%2d hr %02d min" % (hr, min)
elif mode == "sec":
t = int(t)
min = t // 60
sec = t % 60
return "%2d min %02d sec" % (min, sec)
else:
raise NotImplementedError
# ## Optimizer
from torch.optim.optimizer import Optimizer
import itertools as it
def get_learning_rate(optimizer):
lr = []
for param_group in optimizer.param_groups:
lr += [param_group["lr"]]
assert len(lr) == 1 # we support only one param_group
lr = lr[0]
return lr
class RAdam(Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0):
defaults = dict(lr=lr, betas=betas, eps=eps, weight_decay=weight_decay)
self.buffer = [[None, None, None] for ind in range(10)]
super(RAdam, self).__init__(params, defaults)
def __setstate__(self, state):
super(RAdam, self).__setstate__(state)
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
for p in group["params"]:
if p.grad is None:
continue
grad = p.grad.data.float()
if grad.is_sparse:
raise RuntimeError("RAdam does not support sparse gradients")
p_data_fp32 = p.data.float()
state = self.state[p]
if len(state) == 0:
state["step"] = 0
state["exp_avg"] = torch.zeros_like(p_data_fp32)
state["exp_avg_sq"] = torch.zeros_like(p_data_fp32)
else:
state["exp_avg"] = state["exp_avg"].type_as(p_data_fp32)
state["exp_avg_sq"] = state["exp_avg_sq"].type_as(p_data_fp32)
exp_avg, exp_avg_sq = state["exp_avg"], state["exp_avg_sq"]
beta1, beta2 = group["betas"]
exp_avg_sq.mul_(beta2).addcmul_(grad, grad, value=1 - beta2)
exp_avg.mul_(beta1).add_(grad, alpha=1 - beta1)
state["step"] += 1
buffered = self.buffer[int(state["step"] % 10)]
if state["step"] == buffered[0]:
N_sma, step_size = buffered[1], buffered[2]
else:
buffered[0] = state["step"]
beta2_t = beta2 ** state["step"]
N_sma_max = 2 / (1 - beta2) - 1
N_sma = N_sma_max - 2 * state["step"] * beta2_t / (1 - beta2_t)
buffered[1] = N_sma
# more conservative since it's an approximated value
if N_sma >= 5:
step_size = math.sqrt(
(1 - beta2_t)
* (N_sma - 4)
/ (N_sma_max - 4)
* (N_sma - 2)
/ N_sma
* N_sma_max
/ (N_sma_max - 2)
) / (1 - beta1 ** state["step"])
else:
step_size = 1.0 / (1 - beta1 ** state["step"])
buffered[2] = step_size
if group["weight_decay"] != 0:
p_data_fp32.add_(-group["weight_decay"] * group["lr"], p_data_fp32)
# more conservative since it's an approximated value
if N_sma >= 5:
denom = exp_avg_sq.sqrt().add_(group["eps"])
p_data_fp32.addcdiv_(exp_avg, denom, value=-step_size * group["lr"])
else:
p_data_fp32.add_(exp_avg, alpha=-step_size * group["lr"])
p.data.copy_(p_data_fp32)
return loss
class Lookahead(Optimizer):
def __init__(self, optimizer, alpha=0.5, k=6):
if not 0.0 <= alpha <= 1.0:
raise ValueError(f"Invalid slow update rate: {alpha}")
if not 1 <= k:
raise ValueError(f"Invalid lookahead steps: {k}")
self.optimizer = optimizer
self.param_groups = self.optimizer.param_groups
self.alpha = alpha
self.k = k
for group in self.param_groups:
group["step_counter"] = 0
self.slow_weights = [
[p.clone().detach() for p in group["params"]] for group in self.param_groups
]
for w in it.chain(*self.slow_weights):
w.requires_grad = False
self.state = optimizer.state
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
loss = self.optimizer.step()
for group, slow_weights in zip(self.param_groups, self.slow_weights):
group["step_counter"] += 1
if group["step_counter"] % self.k != 0:
continue
for p, q in zip(group["params"], slow_weights):
if p.grad is None:
continue
q.data.add_(p.data - q.data, alpha=self.alpha)
p.data.copy_(q.data)
return loss
# ## Training
def do_valid(net, tokenizer, valid_loader):
valid_probability = []
valid_truth = []
valid_length = []
valid_num = 0
net.eval()
start_timer = timer()
for t, batch in enumerate(valid_loader):
batch_size = len(batch["index"])
length = batch["length"]
token = batch["token"].cuda()
token_pad_mask = batch["token_pad_mask"].cuda()
# image = batch['image' ].cuda()
num_patch = batch["num_patch"]
patch = batch["patch"].cuda()
coord = batch["coord"].cuda()
patch_pad_mask = batch["patch_pad_mask"].cuda()
with torch.no_grad():
logit = data_parallel(
net, (patch, coord, token, patch_pad_mask, token_pad_mask)
) # net(image, token, length)
probability = F.softmax(logit, -1)
valid_num += batch_size
valid_probability.append(probability.data.cpu().numpy())
valid_truth.append(token.data.cpu().numpy())
valid_length.extend(length)
print(
"\r %8d / %d %s"
% (
valid_num,
len(valid_loader.sampler),
time_to_str(timer() - start_timer, "sec"),
),
end="",
flush=True,
)
del t, batch
assert valid_num == len(valid_loader.sampler) # len(valid_loader.dataset))
# print('')
# ----------------------
probability = np.concatenate(valid_probability)
predict = probability.argmax(-1)
truth = np.concatenate(valid_truth)
length = valid_length
# ----
p = probability[:, :-1].reshape(-1, vocab_size)
t = truth[:, 1:].reshape(-1)
non_pad = np.where(t != STOI["<pad>"])[0] # & (t!=STOI['<sos>'])
p = p[non_pad]
t = t[non_pad]
loss = np_loss_cross_entropy(p, t)
# ----
lb_score = 0
if 1:
score = []
for i, (p, t) in enumerate(zip(predict, truth)):
t = truth[i][1 : length[i] - 1]
p = predict[i][1 : length[i] - 1]
t = tokenizer.one_predict_to_inchi(t)
p = tokenizer.one_predict_to_inchi(p)
s = Levenshtein.distance(p, t)
score.append(s)
lb_score = np.mean(score)
"""
if 1:
score = []
for i, (p, t) in enumerate(zip(predict, truth)):
t = truth[i][1:length[i]-1] # in the buggy version, i have used 1 instead of i
p = predict[i][1:length[i]-1]
t = tokenizer.one_predict_to_inchi(t)
p = tokenizer.one_predict_to_inchi(p)
s = Levenshtein.distance(p, t)
score.append(s)
lb_score = np.mean(score)
"""
# lb_score = compute_lb_score(k, t)
del (
valid_loader,
net,
predict,
truth,
valid_probability,
valid_truth,
valid_length,
valid_num,
)
return [loss, lb_score]
def run_train():
fold = 3
out_dir = "./tnt-patch1-s0.8/fold%d" % fold
initial_checkpoint = None
# initial_checkpoint = \
# out_dir + '/checkpoint/00755000_model.pth'#None #
#'/root/share1/kaggle/2021/bms-moleular-translation/result/try22/tnt-patch1/fold3/checkpoint/00697000_model.pth'
debug = 0
start_lr = 0.00001 # 1
batch_size = 32 # 24
## setup ----------------------------------------
for f in ["checkpoint", "train", "valid", "backup"]:
os.makedirs(out_dir + "/" + f, exist_ok=True)
# backup_project_as_zip(PROJECT_PATH, out_dir +'/backup/code.train.%s.zip'%IDENTIFIER)
log = Logger()
log.open(out_dir + "/log.train.txt", mode="a")
log.write("\n--- [START %s] %s\n\n" % (IDENTIFIER, "-" * 64))
log.write("\t%s\n" % COMMON_STRING)
# log.write('\t__file__ = %s\n' % __file__)
log.write("\tout_dir = %s\n" % out_dir)
log.write("\n")
## dataset ------------------------------------
df_train, df_valid = make_fold("train-%d" % fold)
df_valid = df_valid.iloc[:5_000]
tokenizer = load_tokenizer()
train_dataset = BmsDataset(df_train, tokenizer)
valid_dataset = BmsDataset(df_valid, tokenizer)
train_loader = DataLoader(
train_dataset,
sampler=RandomSampler(train_dataset),
# sampler=UniformLengthSampler(train_dataset, is_shuffle=True), #200_000
batch_size=batch_size,
drop_last=True,
num_workers=8,
pin_memory=True,
worker_init_fn=lambda id: np.random.seed(torch.initial_seed() // 2**32 + id),
collate_fn=null_collate,
)
valid_loader = DataLoader(
valid_dataset,
# sampler=UniformLengthSampler(valid_dataset, 5_000),
sampler=SequentialSampler(valid_dataset),
batch_size=32,
drop_last=False,
num_workers=8,
pin_memory=True,
collate_fn=null_collate,
)
log.write("train_dataset : \n%s\n" % (train_dataset))
log.write("valid_dataset : \n%s\n" % (valid_dataset))
log.write("\n")
## net ----------------------------------------
log.write("** net setting **\n")
scaler = amp.GradScaler()
net = AmpNet().cuda()
if initial_checkpoint is not None:
f = torch.load(initial_checkpoint, map_location=lambda storage, loc: storage)
start_iteration = f["iteration"]
start_epoch = f["epoch"]
state_dict = f["state_dict"]
# ---
# state_dict = {k.replace('cnn.e.','cnn.'):v for k,v in state_dict.items()}
# del state_dict['text_pos.pos']
# del state_dict['cnn.head.weight']
# del state_dict['cnn.head.bias']
# net.load_state_dict(state_dict, strict=False)
# ---
net.load_state_dict(state_dict, strict=True) # True
else:
start_iteration = 0
start_epoch = 0
log.write("\tinitial_checkpoint = %s\n" % initial_checkpoint)
log.write("\n")
# -----------------------------------------------
if 0: ##freeze
for p in net.encoder.parameters():
p.requires_grad = False
optimizer = Lookahead(
RAdam(filter(lambda p: p.requires_grad, net.parameters()), lr=start_lr),
alpha=0.5,
k=5,
)
# optimizer = RAdam(filter(lambda p: p.requires_grad, net.parameters()),lr=start_lr)
num_iteration = 10 * 1000
# num_iteration = 10
iter_log = 1000
iter_valid = 1000
iter_save = list(range(0, num_iteration, 1000)) # 1*1000
# iter_save = [0]
log.write("optimizer\n %s\n" % (optimizer))
log.write("\n")
## start training here! ##############################################
log.write("** start training here! **\n")
log.write(" is_mixed_precision = %s \n" % str(is_mixed_precision))
log.write(" batch_size = %d\n" % (batch_size))
# log.write(' experiment = %s\n' % str(__file__.split('/')[-2:]))
log.write(
" |----- VALID ---|---- TRAIN/BATCH --------------\n"
)
log.write(
"rate iter epoch | loss lb(lev) | loss0 loss1 | time \n"
)
log.write(
"----------------------------------------------------------------------\n"
)
# 0.00000 0.00* 0.00 | 0.000 0.000 | 0.000 0.000 | 0 hr 00 min
def message(mode="print"):
if mode == ("print"):
asterisk = " "
loss = batch_loss
if mode == ("log"):
asterisk = "*" if iteration in iter_save else " "
loss = train_loss
#'%4.3f %5.2f | ' % (*valid_loss,) + \
text = (
"%0.5f %5.4f%s %4.2f | "
% (
rate,
iteration / 10000,
asterisk,
epoch,
)
+ "%4.3f %4.3f %4.3f | " % (*loss,)
+ "%s" % (time_to_str(timer() - start_timer, "min"))
)
return text
# ----
valid_loss = np.zeros(2, np.float32)
train_loss = np.zeros(3, np.float32)
batch_loss = np.zeros_like(train_loss)
sum_train_loss = np.zeros_like(train_loss)
sum_train = 0
loss0 = torch.FloatTensor([0]).cuda().sum()
loss1 = torch.FloatTensor([0]).cuda().sum()
loss2 = torch.FloatTensor([0]).cuda().sum()
start_timer = timer()
iteration = start_iteration
epoch = start_epoch
rate = 0
# while iteration < num_iteration:
for t, batch in enumerate(train_loader):
if iteration in iter_save:
if iteration != start_iteration:
torch.save(
{
"state_dict": net.state_dict(),
"iteration": iteration,
"epoch": epoch,
},
out_dir + "/checkpoint/%08d_model.pth" % (iteration),
)
pass
"""
if (iteration % iter_valid == 0):
if iteration != start_iteration:
valid_loss = do_valid(net, tokenizer, valid_loader) #
pass
"""
if iteration % iter_log == 0:
print("\r", end="", flush=True)
log.write(message(mode="log") + "\n")
# learning rate schduler ------------
rate = get_learning_rate(optimizer)
# one iteration update -------------
batch_size = len(batch["index"])
length = batch["length"]
token = batch["token"].cuda()
token_pad_mask = batch["token_pad_mask"].cuda()
# image = batch['image' ].cuda()
num_patch = batch["num_patch"]
patch = batch["patch"].cuda()
coord = batch["coord"].cuda()
patch_pad_mask = batch["patch_pad_mask"].cuda()
# ----
net.train()
optimizer.zero_grad()
if is_mixed_precision:
with amp.autocast():
# assert(False)
logit = data_parallel(
net, (patch, coord, token, patch_pad_mask, token_pad_mask)
) # net(image, token, length)
loss0 = seq_cross_entropy_loss(logit, token, length)
# loss0 = seq_anti_focal_cross_entropy_loss(logit, token, length)
scaler.scale(loss0).backward()
# scaler.unscale_(optimizer)
# torch.nn.utils.clip_grad_norm_(net.parameters(), 2)
scaler.step(optimizer)
scaler.update()
else:
assert False
# print('fp32')
# image_embed = encoder(image)
logit, weight = decoder(image_embed, token, length)
(loss0).backward()
optimizer.step()
# print statistics --------
epoch += 1 / len(train_loader)
iteration += 1
batch_loss = np.array([loss0.item(), loss1.item(), loss2.item()])
sum_train_loss += batch_loss
sum_train += 1
if iteration % 100 == 0:
train_loss = sum_train_loss / (sum_train + 1e-12)
sum_train_loss[...] = 0
sum_train = 0
print("\r", end="", flush=True)
print(message(mode="print"), end="", flush=True)
# debug--------------------------
if debug:
pass
# delete per batch
del (
batch_size,
length,
token,
token_pad_mask,
num_patch,
patch,
coord,
patch_pad_mask,
t,
batch,
)
if iteration > num_iteration:
break
log.write("\n")
run_train()
#!ls ./tnt-patch1-s0.8/fold3/checkpoint/
# list(range(0, 3000, 1000))
"""
import sys
# These are the usual ipython objects, including this one you are creating
ipython_vars = ['In', 'Out', 'exit', 'quit', 'get_ipython', 'ipython_vars']
# Get a sorted list of the objects and their sizes
sorted([(x, sys.getsizeof(globals().get(x))) for x in dir() if not x.startswith('_') and x not in sys.modules and x not in ipython_vars], key=lambda x: x[1], reverse=True)
"""
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0063/434/63434456.ipynb | bmstrainpart1 | drzhuzhe | [{"Id": 63434456, "ScriptId": 17031148, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4321793, "CreationDate": "05/20/2021 12:54:39", "VersionNumber": 7.0, "Title": "Training on GPU - BMS", "EvaluationDate": "05/20/2021", "IsChange": true, "TotalLines": 1818.0, "LinesInsertedFromPrevious": 147.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 1671.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 2}] | [{"Id": 83325210, "KernelVersionId": 63434456, "SourceDatasetVersionId": 2239678}, {"Id": 83325211, "KernelVersionId": 63434456, "SourceDatasetVersionId": 2240275}] | [{"Id": 2239678, "DatasetId": 1343985, "DatasourceVersionId": 2281534, "CreatorUserId": 4321793, "LicenseName": "Unknown", "CreationDate": "05/17/2021 08:17:11", "VersionNumber": 3.0, "Title": "BMS-train-full", "Slug": "bmstrainpart1", "Subtitle": NaN, "Description": NaN, "VersionNotes": "tar.gz.file", "TotalCompressedBytes": 0.0, "TotalUncompressedBytes": 0.0}] | [{"Id": 1343985, "CreatorUserId": 4321793, "OwnerUserId": 4321793.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 2239678.0, "CurrentDatasourceVersionId": 2281534.0, "ForumId": 1362981, "Type": 2, "CreationDate": "05/16/2021 11:02:38", "LastActivityDate": "05/16/2021", "TotalViews": 898, "TotalDownloads": 1, "TotalVotes": 1, "TotalKernels": 1}] | [{"Id": 4321793, "UserName": "drzhuzhe", "DisplayName": "Drzhuzhe", "RegisterDate": "01/13/2020", "PerformanceTier": 2}] | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
inputDir = "/kaggle/input"
def _walkdir(dirPath):
for dirname, _, filenames in os.walk(dirPath):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
import gc
# gc.collect()
# # Refference
# 1. frog dudes masterpieces https://www.kaggle.com/c/bms-molecular-translation/discussion/231190
# ## 待研究
# - 青蛙做了什么优化
# 1. cnn(tnt) + tokenizer + transformer decoder 为什么比 cnn + lstm 好 ?
# ans: Ranger
# 2. 青蛙的tnt结构可以直接迁移到tpu上吗? 似乎是可以的,结构中并没有啥np的结构
# 3. 什么样的情况下模型可以反复训练
# 4. 似乎结构上只有预处理 padding mask 上有优化
# - 为什么内存会超
# 1. dataloader 里有什么增加了内存
# 2. transformer 训练过程中有什么变量一直没释放
# 3. dataloader 太大,可以分批小范围load
# 4. 训练过程中做do_valid 不合适 非常占资源
# - 如果
# 1. 如果不做patch会省内存嘛?
# 2. 我能不能搭建个vit
# 3. 如果不处理内存爆掉的问题会如何
# - 结论
# 1. 想来想去,这个版本实在是太慢了,而且有包内存的问题,即使不做do validate 也只能持续20k个batch左右
# 2. 后面还是根据这个博客 手动搭建一下transformer https://www.kaggle.com/drzhuzhe/training-on-gpu-bms/
import math
import gc
import torch
from torch.utils.data.dataset import Dataset
from torch.utils.data import DataLoader
from torch.utils.data.sampler import *
import torch.nn.functional as F
from torch.nn.parallel.data_parallel import data_parallel
import random
import pickle
import time
from timeit import default_timer as timer
import cv2
# %pylab inline
import matplotlib.pyplot as plt
# import matplotlib.image as mpimg
import collections
from collections import defaultdict
# # Set up Torch
def seed_py(seed):
random.seed(seed)
np.random.seed(seed)
return seed
def seed_torch(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
return seed
seed = int(time.time()) # 335202 #5202 #123 #
seed_py(seed)
seed_torch(seed)
torch.backends.cudnn.benchmark = False ##uses the inbuilt cudnn auto-tuner to find the fastest convolution algorithms. -
torch.backends.cudnn.enabled = True
torch.backends.cudnn.deterministic = True
COMMON_STRING = "\tpytorch\n"
COMMON_STRING += "\t\tseed = %d\n" % seed
COMMON_STRING += "\t\ttorch.__version__ = %s\n" % torch.__version__
COMMON_STRING += "\t\ttorch.version.cuda = %s\n" % torch.version.cuda
COMMON_STRING += (
"\t\ttorch.backends.cudnn.version() = %s\n" % torch.backends.cudnn.version()
)
try:
COMMON_STRING += (
"\t\tos['CUDA_VISIBLE_DEVICES'] = %s\n" % os.environ["CUDA_VISIBLE_DEVICES"]
)
NUM_CUDA_DEVICES = len(os.environ["CUDA_VISIBLE_DEVICES"].split(","))
except Exception:
COMMON_STRING += "\t\tos['CUDA_VISIBLE_DEVICES'] = None\n"
NUM_CUDA_DEVICES = 1
COMMON_STRING += "\t\ttorch.cuda.device_count() = %d\n" % torch.cuda.device_count()
COMMON_STRING += (
"\t\ttorch.cuda.get_device_properties() = %s\n"
% str(torch.cuda.get_device_properties(0))[21:]
)
COMMON_STRING += "\n"
# # Configure
origin_data_dir = "../input/bms-molecular-translation"
data_dir = "../input/bmstrainpart1/bms-moleular-translation"
csv_data_dir = "../input/bmd-mate-csv/csv"
STOI = {
"<sos>": 190,
"<eos>": 191,
"<pad>": 192,
}
patch_size = 16
pixel_pad = 3
pixel_scale = 0.8 # 1.0 #0.62=36/58 #1.0
max_length = 300 # 278 #275
pixel_stride = 4
pixel_dim = 24
patch_dim = 384
_walkdir(csv_data_dir)
# # Utils
def read_pickle_from_file(pickle_file):
with open(pickle_file, "rb") as f:
x = pickle.load(f)
return x
def uncompress_array(compressed_k):
compressed_k.seek(0)
k = np.load(compressed_k, allow_pickle=True)["arr_0"]
return k
# draw -----------------------------------
def image_show(name, image, resize=0.1):
H, W = image.shape[0:2]
plt.figure(figsize=(round(resize * W), round(resize * H)), dpi=20)
# fig = plt.figure(figsize = (500,500), dpi=20)
# ax = fig.add_subplot(1)
plt.imshow(image, cmap=plt.cm.gray)
# ax.imshow(image)
# image = cv2.resize(image, (round(resize*W), round(resize*H)), interpolation = cv2.INTER_AREA)
# plt.imshow(image)
def resize_image(image, scale=1):
if scale == 1:
f = pixel_scale * 58 / 36 # 1.2414 #0.80555
b = int(round(36 * 0.5))
if scale == 2:
f = pixel_scale * 1
b = int(round(58 * 0.5))
image = image[b:-b, b:-b] # remove border
if not np.isclose(1, f, rtol=1e-02, atol=1e-02):
h, w = image.shape
fw = int(round(f * w))
fh = int(round(f * h))
image = cv2.resize(image, dsize=(fw, fh), interpolation=cv2.INTER_AREA)
return image
def repad_image(image, multiplier=16):
h, w = image.shape
fh = int(np.ceil(h / multiplier)) * multiplier
fw = int(np.ceil(w / multiplier)) * multiplier
m = np.full((fh, fw), 255, np.uint8)
m[0:h, 0:w] = image
return m
# it seems to fill patches to Images
def patch_to_image(patch, coord, width, height):
image = np.full((height, width), 255, np.uint8)
p = pixel_pad
patch = patch[:, p:-p, p:-p]
num_patch = len(patch)
for i in range(num_patch):
y, x = coord[i]
x = x * patch_size
y = y * patch_size
image[y : y + patch_size, x : x + patch_size] = patch[i]
cv2.rectangle(image, (x, y), (x + patch_size, y + patch_size), 128, 1)
return image
def image_to_patch(image, patch_size, pixel_pad, threshold=0):
p = pixel_pad
h, w = image.shape
x, y = np.meshgrid(np.arange(w // patch_size), np.arange(h // patch_size))
yx = np.stack([y, x], 2).reshape(-1, 2)
s = patch_size + 2 * p
m = torch.from_numpy(image).reshape(1, 1, h, w).float()
k = F.unfold(m, kernel_size=s, stride=patch_size, padding=p)
k = k.permute(0, 2, 1).reshape(-1, s * s)
k = k.data.cpu().numpy().reshape(-1, s, s)
# print(k.shape)
sum = (1 - k[:, p:-p, p:-p] / 255).reshape(len(k), -1).sum(-1)
# only store patches
i = np.where(sum > threshold)
# print(sum)
patch = k[i]
coord = yx[i]
return patch, coord
"""
# check folder data
#df = pd.read_csv('../input/tarfile/df_train_patch_s0.800.csv')
df = read_pickle_from_file(csv_data_dir+'/df_train.more.csv.pickle')
df_fold = pd.read_csv(csv_data_dir+'/df_fold.fine.csv')
df_meta = pd.read_csv(csv_data_dir+'/df_train_image_meta.csv')
df = df.merge(df_fold, on='image_id')
df = df.merge(df_meta, on='image_id')
print(len(df), len(df_fold), len(df_meta))
print(len(df['fold'].unique()))
df.head(10)
"""
# divide dataset into training and validate
def make_fold(mode="train-1"):
if "train" in mode:
df = read_pickle_from_file(csv_data_dir + "/df_train.more.csv.pickle")
# df = pd.read_csv('../input/tarfile/df_train_patch_s0.800.csv')
# df_fold = pd.read_csv(data_dir+'/df_fold.csv')
df_fold = pd.read_csv(csv_data_dir + "/df_fold.fine.csv")
df_meta = pd.read_csv(csv_data_dir + "/df_train_image_meta.csv")
df = df.merge(df_fold, on="image_id")
df = df.merge(df_meta, on="image_id")
df.loc[:, "path"] = "train_patch16_s0.800"
df["fold"] = df["fold"].astype(int)
# print(df.groupby(['fold']).size()) #404_031
# print(df.columns)
fold = int(mode[-1]) * 10
# print(fold)
df_train = df[df.fold != fold].reset_index(drop=True)
df_valid = df[df.fold == fold].reset_index(drop=True)
return df_train, df_valid
# Index(['image_id', 'InChI'], dtype='object')
if "test" in mode:
# df = pd.read_csv(data_dir+'/sample_submission.csv')
df = pd.read_csv(data_dir + "/submit_lb3.80.csv")
df_meta = pd.read_csv(data_dir + "/df_test_image_meta.csv")
df = df.merge(df_meta, on="image_id")
df.loc[:, "path"] = "test"
# df.loc[:, 'InChI'] = '0'
df.loc[:, "formula"] = "0"
df.loc[:, "text"] = "0"
df.loc[:, "sequence"] = pd.Series([[0]] * len(df))
df.loc[:, "length"] = df.InChI.str.len()
df_test = df
return df_test
# df_train, df_valid = make_fold()
# print(len(df_train), len(df_valid))
# -----------------------------------------------------------------------
# tokenization, padding, ...
def pad_sequence_to_max_length(sequence, max_length, padding_value):
batch_size = len(sequence)
pad_sequence = np.full((batch_size, max_length), padding_value, np.int32)
for b, s in enumerate(sequence):
L = len(s)
pad_sequence[b, :L, ...] = s
return pad_sequence
def load_tokenizer():
tokenizer = YNakamaTokenizer(is_load=True)
print("len(tokenizer) : vocab_size", len(tokenizer))
for k, v in STOI.items():
assert tokenizer.stoi[k] == v
return tokenizer
def null_augment(r):
return r
# getDataset
class BmsDataset(Dataset):
def __init__(self, df, tokenizer, augment=null_augment):
super().__init__()
self.tokenizer = tokenizer
self.df = df
self.augment = augment
self.length = len(self.df)
def __str__(self):
string = ""
string += "\tlen = %d\n" % len(self)
string += "\tdf = %s\n" % str(self.df.shape)
g = self.df["length"].values.astype(np.int32) // 20
g = np.bincount(g, minlength=14)
string += "\tlength distribution\n"
for n in range(14):
string += "\t\t %3d = %8d (%0.4f)\n" % ((n + 1) * 20, g[n], g[n] / g.sum())
return string
def __len__(self):
return self.length
def __getitem__(self, index):
d = self.df.iloc[index]
token = d.sequence
patch_file = data_dir + "/%s/%s/%s/%s/%s.pickle" % (
d.path,
d.image_id[0],
d.image_id[1],
d.image_id[2],
d.image_id,
)
k = read_pickle_from_file(patch_file)
patch = uncompress_array(k["patch"])
patch = np.concatenate(
[
np.zeros(
(1, patch_size + 2 * pixel_pad, patch_size + 2 * pixel_pad),
np.uint8,
),
patch,
],
0,
) # cls token
coord = k["coord"]
w = k["width"]
h = k["height"]
h = h // patch_size - 1
w = w // patch_size - 1
coord = np.insert(coord, 0, [h, w], 0) # cls token
# debug
# image = patch_to_image(patch, coord, k['width' ], k['height'])
# image_show('image', image, resize=1)
# cv2.waitKey(0)
# image = cv2.imread(image_file,cv2.IMREAD_GRAYSCALE) #
r = {
"index": index,
"image_id": d.image_id,
"InChI": d.InChI,
"d": d,
"token": token,
#'image' : image,
"patch": patch,
"coord": coord,
}
if self.augment is not None:
r = self.augment(r)
# Warrning runtime keep this variable shall cause Out of memery crash
del patch_file, patch, coord, k
# gc.collect()
return r
# set up tokenizer
class YNakamaTokenizer(object):
def __init__(self, is_load=True):
self.stoi = {}
self.itos = {}
if is_load:
self.stoi = _TOKENIZER_
self.itos = {k: v for v, k in self.stoi.items()}
def __len__(self):
return len(self.stoi)
def build_vocab(self, text):
vocab = set()
for t in text:
vocab.update(t.split(" "))
vocab = sorted(vocab)
vocab.append("<sos>")
vocab.append("<eos>")
vocab.append("<pad>")
for i, s in enumerate(vocab):
self.stoi[s] = i
self.itos = {k: v for v, k in self.stoi.items()}
def one_text_to_sequence(self, text):
sequence = []
sequence.append(self.stoi["<sos>"])
for s in text.split(" "):
sequence.append(self.stoi[s])
sequence.append(self.stoi["<eos>"])
return sequence
def one_sequence_to_text(self, sequence):
return "".join(list(map(lambda i: self.itos[i], sequence)))
def one_predict_to_inchi(self, predict):
inchi = "InChI=1S/"
for p in predict:
if p == self.stoi["<eos>"] or p == self.stoi["<pad>"]:
break
inchi += self.itos[p]
return inchi
# ---
def text_to_sequence(self, text):
sequence = [self.one_text_to_sequence(t) for t in text]
return sequence
def sequence_to_text(self, sequence):
text = [self.one_sequence_to_text(s) for s in sequence]
return text
def predict_to_inchi(self, predict):
inchi = [self.one_predict_to_inchi(p) for p in predict]
return inchi
def null_collate(batch, is_sort_decreasing_length=True):
collate = defaultdict(list)
if is_sort_decreasing_length: # sort by decreasing length
sort = np.argsort([-len(r["token"]) for r in batch])
batch = [batch[s] for s in sort]
for r in batch:
for k, v in r.items():
collate[k].append(v)
# ----
batch_size = len(batch)
collate["length"] = [len(l) for l in collate["token"]]
token = [np.array(t, np.int32) for t in collate["token"]]
token = pad_sequence_to_max_length(
token, max_length=max_length, padding_value=STOI["<pad>"]
)
collate["token"] = torch.from_numpy(token).long()
max_of_length = max(collate["length"])
token_pad_mask = np.zeros((batch_size, max_of_length, max_of_length))
for b in range(batch_size):
L = collate["length"][b]
token_pad_mask[b, :L, :L] = 1 # +1 for cls_token
collate["token_pad_mask"] = torch.from_numpy(token_pad_mask).byte()
# -----
# image = np.stack(collate['image'])
# image = image.astype(np.float32) / 255
# collate['image'] = torch.from_numpy(image).unsqueeze(1).repeat(1,3,1,1)
# -----
collate["num_patch"] = [len(l) for l in collate["patch"]]
max_of_num_patch = max(collate["num_patch"])
patch_pad_mask = np.zeros((batch_size, max_of_num_patch, max_of_num_patch))
patch = np.full(
(
batch_size,
max_of_num_patch,
patch_size + 2 * pixel_pad,
patch_size + 2 * pixel_pad,
),
255,
) # pad as 255
coord = np.zeros((batch_size, max_of_num_patch, 2))
for b in range(batch_size):
N = collate["num_patch"][b]
patch[b, :N] = collate["patch"][b]
coord[b, :N] = collate["coord"][b]
patch_pad_mask[b, :N, :N] = 1 # +1 for cls_token
collate["patch"] = torch.from_numpy(patch).half() / 255
collate["coord"] = torch.from_numpy(coord).long()
collate["patch_pad_mask"] = torch.from_numpy(patch_pad_mask).byte()
del patch_pad_mask, patch, coord, token_pad_mask, batch
return collate
def run_check_dataset():
tokenizer = load_tokenizer()
df_train, df_valid = make_fold("train-1")
# df_train = make_fold('test') #1616107
# dataset = BmsDataset(df_train, tokenizer, remote_augment)
# dataset = BmsDataset(df_valid, tokenizer)
# print(dataset)
train_dataset = BmsDataset(df_train, tokenizer)
# for i in range(len(dataset)):
"""
for i in range(5):
#i = np.random.choice(len(dataset))
r = dataset[i]
print(r['index'])
print(r['image_id'])
#print(r['formula'])
print(r['InChI'])
print(r['token'])
print('image : ')
#print('\t', r['image'].shape)
print('')
#---
image = patch_to_image(r['patch'], r['coord'], width=1024, height=1024)
#image_show('image', image, resize=.1)
del image
gc.collect()
#cv2.waitKey(0)
"""
# exit(0)
# """
loader = DataLoader(
train_dataset,
# sampler = RandomSampler(train_dataset),
batch_size=8,
drop_last=True,
num_workers=8,
pin_memory=True,
collate_fn=null_collate,
)
for t, batch in enumerate(loader):
# if t>30: break
print(t, "-----------")
# print('index : ', batch['index'])
"""
print('image : ')
#print('\t', batch['image'].shape, batch['image'].is_contiguous())
print('\t', batch['patch'].shape, batch['patch'].is_contiguous())
print('\t', batch['coord'].shape, batch['coord'].is_contiguous())
#print('\t', batch['mask'].shape, batch['mask'].is_contiguous())
print('length : ')
print('\t',len( batch['length']))
print('\t', batch['length'])
print('token : ')
print('\t', batch['token'].shape, batch['token'].is_contiguous())
"""
# print('\t', batch['token'])
# print('')
del t, batch
del loader, train_dataset, df_train, df_valid, tokenizer
# """
# 数据load到4000 条 左右就会挂 , 讲道理 load数据应该不会不断加内存吧
# run_check_dataset()
# # Net Modeules
# ## 1D Encoder and Decoder
from typing import Tuple, Dict
import torch.nn as nn
from fairseq import utils
from fairseq.models import *
from fairseq.modules import *
# ------------------------------------------------------
# https://kazemnejad.com/blog/transformer_architecture_positional_encoding/
# https://stackoverflow.com/questions/46452020/sinusoidal-embedding-attention-is-all-you-need
class PositionEncode1D(nn.Module):
def __init__(self, dim, max_length):
super().__init__()
assert dim % 2 == 0
self.max_length = max_length
d = torch.exp(torch.arange(0.0, dim, 2) * (-math.log(10000.0) / dim))
position = torch.arange(0.0, max_length).unsqueeze(1)
pos = torch.zeros(1, max_length, dim)
pos[0, :, 0::2] = torch.sin(position * d)
pos[0, :, 1::2] = torch.cos(position * d)
self.register_buffer("pos", pos)
def forward(self, x):
batch_size, T, dim = x.shape
x = x + self.pos[:, :T]
return x
"""
# https://gitlab.maastrichtuniversity.nl/dsri-examples/dsri-pytorch-workspace/-/blob/c8a88cdeb8e1a0f3a2ccd3c6119f43743cbb01e9/examples/transformer/fairseq/models/transformer.py
#https://github.com/pytorch/fairseq/issues/568
# fairseq/fairseq/models/fairseq_encoder.py
# https://github.com/pytorch/fairseq/blob/master/fairseq/modules/transformer_layer.py
class TransformerEncode(FairseqEncoder):
def __init__(self, dim, ff_dim, num_head, num_layer):
super().__init__({})
#print('my TransformerEncode()')
self.layer = nn.ModuleList([
TransformerEncoderLayer(Namespace({
'encoder_embed_dim': dim,
'encoder_attention_heads': num_head,
'attention_dropout': 0.1,
'dropout': 0.1,
'encoder_normalize_before': True,
'encoder_ffn_embed_dim': ff_dim,
})) for i in range(num_layer)
])
self.layer_norm = nn.LayerNorm(dim)
def forward(self, x):# T x B x C
#print('my TransformerEncode forward()')
for layer in self.layer:
x = layer(x)
x = self.layer_norm(x)
return x
"""
# https://mt.cs.upc.edu/2020/12/21/the-transformer-fairseq-edition/
# for debug
# class TransformerDecode(FairseqDecoder):
# def __init__(self, dim, ff_dim, num_head, num_layer):
# super().__init__({})
# print('my TransformerDecode()')
#
# self.layer = nn.ModuleList([
# TransformerDecoderLayer(Namespace({
# 'decoder_embed_dim': dim,
# 'decoder_attention_heads': num_head,
# 'attention_dropout': 0.1,
# 'dropout': 0.1,
# 'decoder_normalize_before': True,
# 'decoder_ffn_embed_dim': ff_dim,
# })) for i in range(num_layer)
# ])
# self.layer_norm = nn.LayerNorm(dim)
#
#
# def forward(self, x, mem, x_mask):# T x B x C
# print('my TransformerDecode forward()')
# for layer in self.layer:
# x = layer(x, mem, self_attn_mask=x_mask)[0]
# x = self.layer_norm(x)
# return x # T x B x C
# https://stackoverflow.com/questions/4984647/accessing-dict-keys-like-an-attribute
class Namespace(object):
def __init__(self, adict):
self.__dict__.update(adict)
# https://fairseq.readthedocs.io/en/latest/tutorial_simple_lstm.html
# see https://gitlab.maastrichtuniversity.nl/dsri-examples/dsri-pytorch-workspace/-/blob/c8a88cdeb8e1a0f3a2ccd3c6119f43743cbb01e9/examples/transformer/fairseq/models/transformer.py
class TransformerDecode(FairseqIncrementalDecoder):
def __init__(self, dim, ff_dim, num_head, num_layer):
super().__init__({})
# print('my TransformerDecode()')
self.layer = nn.ModuleList(
[
TransformerDecoderLayer(
Namespace(
{
"decoder_embed_dim": dim,
"decoder_attention_heads": num_head,
"attention_dropout": 0.1,
"dropout": 0.1,
"decoder_normalize_before": True,
"decoder_ffn_embed_dim": ff_dim,
}
)
)
for i in range(num_layer)
]
)
self.layer_norm = nn.LayerNorm(dim)
def forward(self, x, mem, x_mask, x_pad_mask, mem_pad_mask):
# print('my TransformerDecode forward()')
for layer in self.layer:
x = layer(
x,
mem,
self_attn_mask=x_mask,
self_attn_padding_mask=x_pad_mask,
encoder_padding_mask=mem_pad_mask,
)[0]
x = self.layer_norm(x)
return x # T x B x C
# def forward_one(self, x, mem, incremental_state):
def forward_one(
self,
x: Tensor,
mem: Tensor,
incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]],
) -> Tensor:
x = x[-1:]
for layer in self.layer:
x = layer(x, mem, incremental_state=incremental_state)[0]
x = self.layer_norm(x)
return x
"""
https://fairseq.readthedocs.io/en/latest/_modules/fairseq/modules/transformer_layer.html
class TransformerDecoderLayer(nn.Module):
def forward(
self,
x,
encoder_out: Optional[torch.Tensor] = None,
encoder_padding_mask: Optional[torch.Tensor] = None,
incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]] = None,
prev_self_attn_state: Optional[List[torch.Tensor]] = None,
prev_attn_state: Optional[List[torch.Tensor]] = None,
self_attn_mask: Optional[torch.Tensor] = None,
self_attn_padding_mask: Optional[torch.Tensor] = None,
need_attn: bool = False,
need_head_weights: bool = False,
):
https://github.com/pytorch/fairseq/blob/05b86005bcca0155319fa9b81abfd69f63c06906/examples/simultaneous_translation/utils/data_utils.py#L31
"""
# ## TNT
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence, PackedSequence
# https://github.com/pytorch/pytorch/issues/1788
# https://stackoverflow.com/questions/51030782/why-do-we-pack-the-sequences-in-pytorch
from timm.models.vision_transformer import Mlp
from timm.models.layers import DropPath, trunc_normal_
# from timm.models.tnt import *
# 这个多头注意力会造成内存不断增加吗?
class Attention(nn.Module):
"""Multi-Head Attention"""
def __init__(
self, dim, hidden_dim, num_heads=8, qkv_bias=False, attn_drop=0.0, proj_drop=0.0
):
super().__init__()
self.hidden_dim = hidden_dim
self.num_heads = num_heads
head_dim = hidden_dim // num_heads
self.head_dim = head_dim
self.scale = head_dim**-0.5
self.qk = nn.Linear(dim, hidden_dim * 2, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop, inplace=True)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop, inplace=True)
def forward(self, x: Tensor, mask: Optional[Tensor] = None) -> Tensor:
B, N, C = x.shape
qk = (
self.qk(x)
.reshape(B, N, 2, self.num_heads, self.head_dim)
.permute(2, 0, 3, 1, 4)
)
q, k = qk[0], qk[1] # make torchscript happy (cannot use tensor as tuple)
v = self.v(x).reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3)
# ---
attn = (q @ k.transpose(-2, -1)) * self.scale # B x self.num_heads x NxN
if mask is not None:
# mask = mask.unsqueeze(1).repeat(1,self.num_heads,1,1)
mask = mask.unsqueeze(1).expand(-1, self.num_heads, -1, -1)
attn = attn.masked_fill(mask == 0, -6e4)
# attn = attn.masked_fill(mask == 0, -half('inf'))
# https://github.com/NVIDIA/apex/issues/93
# How to use fp16 training with masked operations
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, -1)
x = self.proj(x)
x = self.proj_drop(x)
del mask, attn
return x
class Block(nn.Module):
def __init__(
self,
dim,
in_dim,
num_pixel,
num_heads=12,
in_num_head=4,
mlp_ratio=4.0,
qkv_bias=False,
drop=0.0,
attn_drop=0.0,
drop_path=0.0,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm,
):
super().__init__()
# Inner transformer
self.norm_in = norm_layer(in_dim)
self.attn_in = Attention(
in_dim,
in_dim,
num_heads=in_num_head,
qkv_bias=qkv_bias,
attn_drop=attn_drop,
proj_drop=drop,
)
self.norm_mlp_in = norm_layer(in_dim)
self.mlp_in = Mlp(
in_features=in_dim,
hidden_features=int(in_dim * 4),
out_features=in_dim,
act_layer=act_layer,
drop=drop,
)
self.norm1_proj = norm_layer(in_dim)
self.proj = nn.Linear(in_dim * num_pixel, dim, bias=True)
# Outer transformer
self.norm_out = norm_layer(dim)
self.attn_out = Attention(
dim,
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
attn_drop=attn_drop,
proj_drop=drop,
)
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
self.norm_mlp = norm_layer(dim)
self.mlp = Mlp(
in_features=dim,
hidden_features=int(dim * mlp_ratio),
out_features=dim,
act_layer=act_layer,
drop=drop,
)
def forward(self, pixel_embed, patch_embed, mask):
# inner
pixel_embed = pixel_embed + self.drop_path(
self.attn_in(self.norm_in(pixel_embed))
)
pixel_embed = pixel_embed + self.drop_path(
self.mlp_in(self.norm_mlp_in(pixel_embed))
)
# outer
B, N, C = patch_embed.size()
patch_embed[:, 1:] = (
patch_embed[:, 1:]
+ self.proj(self.norm1_proj(pixel_embed).reshape(B, N, -1))[:, 1:]
)
patch_embed = patch_embed + self.drop_path(
self.attn_out(self.norm_out(patch_embed), mask)
)
patch_embed = patch_embed + self.drop_path(self.mlp(self.norm_mlp(patch_embed)))
return pixel_embed, patch_embed
# ---------------------------------
class PixelEmbed(nn.Module):
def __init__(self, patch_size=16, in_dim=48, stride=4):
super().__init__()
self.in_dim = in_dim
self.proj = nn.Conv2d(3, self.in_dim, kernel_size=7, padding=0, stride=stride)
def forward(self, patch, pixel_pos):
BN = len(patch)
x = patch
x = self.proj(x)
# x = x.transpose(1, 2).reshape(B * self.num_patches, self.in_dim, self.new_patch_size, self.new_patch_size)
x = x + pixel_pos
x = x.reshape(BN, self.in_dim, -1).transpose(1, 2)
return x
# ---------------------------------
class TNT(nn.Module):
"""Transformer in Transformer - https://arxiv.org/abs/2103.00112"""
def __init__(
self,
patch_size=patch_size,
embed_dim=patch_dim,
in_dim=pixel_dim,
depth=12,
num_heads=6,
in_num_head=4,
mlp_ratio=4.0,
qkv_bias=False,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.0,
norm_layer=nn.LayerNorm,
first_stride=pixel_stride,
):
super().__init__()
self.num_features = (
self.embed_dim
) = embed_dim # num_features for consistency with other models
self.pixel_embed = PixelEmbed(
patch_size=patch_size, in_dim=in_dim, stride=first_stride
)
# num_patches = self.pixel_embed.num_patches
# self.num_patches = num_patches
new_patch_size = 4 # self.pixel_embed.new_patch_size
num_pixel = new_patch_size**2
self.norm1_proj = norm_layer(num_pixel * in_dim)
self.proj = nn.Linear(num_pixel * in_dim, embed_dim)
self.norm2_proj = norm_layer(embed_dim)
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.patch_pos = nn.Embedding(
100 * 100, embed_dim
) # nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.pixel_pos = nn.Parameter(
torch.zeros(1, in_dim, new_patch_size, new_patch_size)
)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [
x.item() for x in torch.linspace(0, drop_path_rate, depth)
] # stochastic depth decay rule
blocks = []
for i in range(depth):
blocks.append(
Block(
dim=embed_dim,
in_dim=in_dim,
num_pixel=num_pixel,
num_heads=num_heads,
in_num_head=in_num_head,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[i],
norm_layer=norm_layer,
)
)
self.blocks = nn.ModuleList(blocks)
self.norm = norm_layer(embed_dim)
trunc_normal_(self.cls_token, std=0.02)
# trunc_normal_(self.patch_pos, std=.02)
trunc_normal_(self.pixel_pos, std=0.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=0.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {"patch_pos", "pixel_pos", "cls_token"}
def forward(self, patch, coord, mask):
B = len(patch)
batch_size, max_of_num_patch, s, s = patch.shape
patch = patch.reshape(batch_size * max_of_num_patch, 1, s, s).repeat(1, 3, 1, 1)
pixel_embed = self.pixel_embed(patch, self.pixel_pos)
patch_embed = self.norm2_proj(
self.proj(self.norm1_proj(pixel_embed.reshape(B, max_of_num_patch, -1)))
)
# patch_embed = torch.cat((self.cls_token.expand(B, -1, -1), patch_embed), dim=1)
# patch_embed = patch_embed + self.patch_pos
# patch_embed[:, 1:] = patch_embed[:, 1:] + self.patch_pos(coord[:, :, 0] * 100 + coord[:, :, 1])
patch_embed[:, :1] = self.cls_token.expand(B, -1, -1)
patch_embed = patch_embed + self.patch_pos(
coord[:, :, 0] * 100 + coord[:, :, 1]
)
patch_embed = self.pos_drop(patch_embed)
for blk in self.blocks:
pixel_embed, patch_embed = blk(pixel_embed, patch_embed, mask)
patch_embed = self.norm(patch_embed)
del patch, mask
return patch_embed
def make_dummy_data():
# make dummy data
# image_id,width,height,scale,orientation
meta = [
[
"000011a64c74",
325,
229,
2,
0,
],
[
"000019cc0cd2",
288,
148,
1,
0,
],
[
"0000252b6d2b",
509,
335,
2,
0,
],
[
"000026b49b7e",
243,
177,
1,
0,
],
[
"000026fc6c36",
294,
112,
1,
0,
],
[
"000028818203",
402,
328,
2,
0,
],
[
"000029a61c01",
395,
294,
2,
0,
],
[
"000035624718",
309,
145,
1,
0,
],
]
batch_size = 8
# <todo> check border for padding
# <todo> pepper noise
batch = {
"num_patch": [],
"patch": [],
"coord": [],
}
for b in range(batch_size):
image_id = meta[b][0]
scale = meta[b][3]
image_file = origin_data_dir + "/%s/%s/%s/%s/%s.png" % (
"train",
image_id[0],
image_id[1],
image_id[2],
image_id,
)
# print(image_file)
image = cv2.imread(image_file, cv2.IMREAD_GRAYSCALE)
image = resize_image(image, scale)
image = repad_image(image, patch_size) # remove border and repad
# print(image.shape)
k, yx = image_to_patch(image, patch_size, pixel_pad, threshold=0)
for y, x in yx:
# cv2.circle(image,(x,y),8,128,1)
x = x * patch_size
y = y * patch_size
cv2.rectangle(image, (x, y), (x + patch_size, y + patch_size), 128, 1)
# image_show('image-%d' % b, image, resize=1)
del image
# cv2.waitKey(1)
batch["patch"].append(k)
batch["coord"].append(yx)
batch["num_patch"].append(len(k))
# ----
max_of_num_patch = max(batch["num_patch"])
mask = np.zeros((batch_size, max_of_num_patch, max_of_num_patch))
patch = np.zeros(
(
batch_size,
max_of_num_patch,
patch_size + 2 * pixel_pad,
patch_size + 2 * pixel_pad,
)
)
coord = np.zeros((batch_size, max_of_num_patch, 2))
for b in range(batch_size):
N = batch["num_patch"][b]
patch[b, :N] = batch["patch"][b]
coord[b, :N] = batch["coord"][b]
mask[b, :N, :N] = 1
num_patch = batch["num_patch"]
patch = torch.from_numpy(patch).float()
coord = torch.from_numpy(coord).long()
mask = torch.from_numpy(mask).byte()
return patch, coord, num_patch, mask
def run_check_tnt_patch():
patch, coord, num_patch, mask = make_dummy_data()
tnt = TNT()
patch_embed = tnt(patch, coord, mask)
print(patch_embed.shape)
# run_check_tnt_patch()
# ## TNT + PositionEncode1D + Transformer Decoder
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence, PackedSequence
vocab_size = 193
text_dim = 384
decoder_dim = 384
num_layer = 3
num_head = 8
ff_dim = 1024
class Net(nn.Module):
def __init__(
self,
):
super(Net, self).__init__()
self.cnn = TNT()
self.image_encode = nn.Identity()
# ---
self.text_pos = PositionEncode1D(text_dim, max_length)
self.token_embed = nn.Embedding(vocab_size, text_dim)
self.text_decode = TransformerDecode(decoder_dim, ff_dim, num_head, num_layer)
# ---
self.logit = nn.Linear(decoder_dim, vocab_size)
self.dropout = nn.Dropout(p=0.5)
# ----
# initialization
self.token_embed.weight.data.uniform_(-0.1, 0.1)
self.logit.bias.data.fill_(0)
self.logit.weight.data.uniform_(-0.1, 0.1)
@torch.jit.unused
def forward(self, patch, coord, token, patch_pad_mask, token_pad_mask):
device = patch.device
batch_size = len(patch)
# ---
patch = patch * 2 - 1
image_embed = self.cnn(patch, coord, patch_pad_mask)
image_embed = self.image_encode(image_embed).permute(1, 0, 2).contiguous()
text_embed = self.token_embed(token)
text_embed = self.text_pos(text_embed).permute(1, 0, 2).contiguous()
max_of_length = token_pad_mask.shape[-1]
text_mask = np.triu(np.ones((max_of_length, max_of_length)), k=1).astype(
np.uint8
)
text_mask = torch.autograd.Variable(torch.from_numpy(text_mask) == 1).to(device)
# ----
# <todo> perturb mask as aug
text_pad_mask = token_pad_mask[:, :, 0] == 0
image_pad_mask = patch_pad_mask[:, :, 0] == 0
x = self.text_decode(
text_embed[:max_of_length],
image_embed,
text_mask,
text_pad_mask,
image_pad_mask,
)
x = x.permute(1, 0, 2).contiguous()
l = self.logit(x)
logit = torch.zeros((batch_size, max_length, vocab_size), device=device)
logit[:, :max_of_length] = l
del image_embed, text_mask, text_pad_mask, image_pad_mask
return logit
# submit function has not been coded. i will leave it as an exercise for the kaggler
# @torch.jit.export
# def forward_argmax_decode(self, patch, coord, mask):
#
# image_dim = 384
# text_dim = 384
# decoder_dim = 384
# num_layer = 3
# num_head = 8
# ff_dim = 1024
#
# STOI = {
# '<sos>': 190,
# '<eos>': 191,
# '<pad>': 192,
# }
# max_length = 278 # 275
#
#
# #---------------------------------
# device = patch.device
# batch_size = len(patch)
#
# patch = patch*2-1
# image_embed = self.cnn(patch, coord, mask)
# image_embed = self.image_encode(image_embed).permute(1,0,2).contiguous()
#
# token = torch.full((batch_size, max_length), STOI['<pad>'],dtype=torch.long, device=device)
# text_pos = self.text_pos.pos
# token[:,0] = STOI['<sos>']
#
#
# #-------------------------------------
# eos = STOI['<eos>']
# pad = STOI['<pad>']
# # https://github.com/alexmt-scale/causal-transformer-decoder/blob/master/tests/test_consistency.py
# # slow version
# # if 0:
# # for t in range(max_length-1):
# # last_token = token [:,:(t+1)]
# # text_embed = self.token_embed(last_token)
# # text_embed = self.text_pos(text_embed).permute(1,0,2).contiguous() #text_embed + text_pos[:,:(t+1)] #
# #
# # text_mask = np.triu(np.ones((t+1, t+1)), k=1).astype(np.uint8)
# # text_mask = torch.autograd.Variable(torch.from_numpy(text_mask)==1).to(device)
# #
# # x = self.text_decode(text_embed, image_embed, text_mask)
# # x = x.permute(1,0,2).contiguous()
# #
# # l = self.logit(x[:,-1])
# # k = torch.argmax(l, -1) # predict max
# # token[:, t+1] = k
# # if ((k == eos) | (k == pad)).all(): break
#
# # fast version
# if 1:
# #incremental_state = {}
# incremental_state = torch.jit.annotate(
# Dict[str, Dict[str, Optional[Tensor]]],
# torch.jit.annotate(Dict[str, Dict[str, Optional[Tensor]]], {}),
# )
# for t in range(max_length-1):
# #last_token = token [:,:(t+1)]
# #text_embed = self.token_embed(last_token)
# #text_embed = self.text_pos(text_embed) #text_embed + text_pos[:,:(t+1)] #
#
# last_token = token[:, t]
# text_embed = self.token_embed(last_token)
# text_embed = text_embed + text_pos[:,t] #
# text_embed = text_embed.reshape(1,batch_size,text_dim)
#
# x = self.text_decode.forward_one(text_embed, image_embed, incremental_state)
# x = x.reshape(batch_size,decoder_dim)
# #print(incremental_state.keys())
#
# l = self.logit(x)
# k = torch.argmax(l, -1) # predict max
# token[:, t+1] = k
# if ((k == eos) | (k == pad)).all(): break
#
# predict = token[:, 1:]
# return predict
# loss #################################################################
def seq_cross_entropy_loss(logit, token, length):
truth = token[:, 1:]
L = [l - 1 for l in length]
logit = pack_padded_sequence(logit, L, batch_first=True).data
truth = pack_padded_sequence(truth, L, batch_first=True).data
loss = F.cross_entropy(logit, truth, ignore_index=STOI["<pad>"])
return loss
# https://www.aclweb.org/anthology/2020.findings-emnlp.276.pdf
def seq_focal_cross_entropy_loss(logit, token, length):
gamma = 0.5 # {0.5,1.0}
# label_smooth = 0.90
# ---
truth = token[:, 1:]
L = [l - 1 for l in length]
logit = pack_padded_sequence(logit, L, batch_first=True).data
truth = pack_padded_sequence(truth, L, batch_first=True).data
# loss = F.cross_entropy(logit, truth, ignore_index=STOI['<pad>'])
# non_pad = torch.where(truth != STOI['<pad>'])[0] # & (t!=STOI['<sos>'])
# ---
# p = F.softmax(logit,-1)
# logp = - torch.log(torch.clamp(p, 1e-4, 1 - 1e-4))
logp = F.log_softmax(logit, -1)
logp = logp.gather(1, truth.reshape(-1, 1)).reshape(-1)
p = logp.exp()
loss = -((1 - p) ** gamma) * logp # focal
# loss = - ((1 + p) ** gamma)*logp #anti-focal
loss = loss.mean()
return loss
def np_loss_cross_entropy(probability, truth):
batch_size = len(probability)
truth = truth.reshape(-1)
p = probability[np.arange(batch_size), truth]
loss = -np.log(np.clip(p, 1e-6, 1))
loss = loss.mean()
return loss
# check #################################################################
def run_check_net():
patch, coord, num_patch, patch_pad_mask = make_dummy_data()
batch_size = len(patch)
token = np.full((batch_size, max_length), STOI["<pad>"], np.int64) # token
length = np.random.randint(5, max_length - 2, batch_size)
length = np.sort(length)[::-1].copy()
max_of_length = max(length)
token_pad_mask = np.zeros((batch_size, max_of_length, max_of_length))
for b in range(batch_size):
l = length[b]
t = np.random.choice(vocab_size, l)
t = np.insert(t, 0, STOI["<sos>"])
t = np.insert(t, len(t), STOI["<eos>"])
L = len(t)
token[b, :L] = t
token_pad_mask[b, :L, :L] = 1
token = torch.from_numpy(token).long()
token_pad_mask = torch.from_numpy(token_pad_mask).byte()
# ---
net = Net()
net.train()
logit = net(patch, coord, token, patch_pad_mask, token_pad_mask)
loss = seq_cross_entropy_loss(logit, token, length)
print("vocab_size", vocab_size)
print("max_length", max_length)
print("")
print(length)
print(length.shape)
print(token.shape)
print("---")
print(logit.shape)
print(loss)
print("---")
del net
# ---
# print('torch.jit.script(net)')
# net.eval()
# net = torch.jit.script(net)
#
# predict = net.forward_argmax_decode(patch, coord, mask)
# print(predict.shape)
# run_check_net()
"""
import sys
local_vars = list(locals().items())
for var, obj in local_vars:
print(var, sys.getsizeof(obj))
"""
# ----------------
is_mixed_precision = True # False #
###################################################################################################
import torch.cuda.amp as amp
if is_mixed_precision:
class AmpNet(Net):
@torch.cuda.amp.autocast()
def forward(self, *args):
return super(AmpNet, self).forward(*args)
else:
AmpNet = Net
import sys
from datetime import datetime
import Levenshtein
IDENTIFIER = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
# http://stackoverflow.com/questions/34950201/pycharm-print-end-r-statement-not-working
class Logger(object):
def __init__(self):
self.terminal = sys.stdout # stdout
self.file = None
def open(self, file, mode=None):
if mode is None:
mode = "w"
self.file = open(file, mode)
def write(self, message, is_terminal=1, is_file=1):
if "\r" in message:
is_file = 0
if is_terminal == 1:
self.terminal.write(message)
self.terminal.flush()
# time.sleep(1)
if is_file == 1:
self.file.write(message)
self.file.flush()
def flush(self):
# this flush method is needed for python 3 compatibility.
# this handles the flush command by doing nothing.
# you might want to specify some extra behavior here.
pass
# etc ------------------------------------
def time_to_str(t, mode="min"):
if mode == "min":
t = int(t) / 60
hr = t // 60
min = t % 60
return "%2d hr %02d min" % (hr, min)
elif mode == "sec":
t = int(t)
min = t // 60
sec = t % 60
return "%2d min %02d sec" % (min, sec)
else:
raise NotImplementedError
# ## Optimizer
from torch.optim.optimizer import Optimizer
import itertools as it
def get_learning_rate(optimizer):
lr = []
for param_group in optimizer.param_groups:
lr += [param_group["lr"]]
assert len(lr) == 1 # we support only one param_group
lr = lr[0]
return lr
class RAdam(Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0):
defaults = dict(lr=lr, betas=betas, eps=eps, weight_decay=weight_decay)
self.buffer = [[None, None, None] for ind in range(10)]
super(RAdam, self).__init__(params, defaults)
def __setstate__(self, state):
super(RAdam, self).__setstate__(state)
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
for p in group["params"]:
if p.grad is None:
continue
grad = p.grad.data.float()
if grad.is_sparse:
raise RuntimeError("RAdam does not support sparse gradients")
p_data_fp32 = p.data.float()
state = self.state[p]
if len(state) == 0:
state["step"] = 0
state["exp_avg"] = torch.zeros_like(p_data_fp32)
state["exp_avg_sq"] = torch.zeros_like(p_data_fp32)
else:
state["exp_avg"] = state["exp_avg"].type_as(p_data_fp32)
state["exp_avg_sq"] = state["exp_avg_sq"].type_as(p_data_fp32)
exp_avg, exp_avg_sq = state["exp_avg"], state["exp_avg_sq"]
beta1, beta2 = group["betas"]
exp_avg_sq.mul_(beta2).addcmul_(grad, grad, value=1 - beta2)
exp_avg.mul_(beta1).add_(grad, alpha=1 - beta1)
state["step"] += 1
buffered = self.buffer[int(state["step"] % 10)]
if state["step"] == buffered[0]:
N_sma, step_size = buffered[1], buffered[2]
else:
buffered[0] = state["step"]
beta2_t = beta2 ** state["step"]
N_sma_max = 2 / (1 - beta2) - 1
N_sma = N_sma_max - 2 * state["step"] * beta2_t / (1 - beta2_t)
buffered[1] = N_sma
# more conservative since it's an approximated value
if N_sma >= 5:
step_size = math.sqrt(
(1 - beta2_t)
* (N_sma - 4)
/ (N_sma_max - 4)
* (N_sma - 2)
/ N_sma
* N_sma_max
/ (N_sma_max - 2)
) / (1 - beta1 ** state["step"])
else:
step_size = 1.0 / (1 - beta1 ** state["step"])
buffered[2] = step_size
if group["weight_decay"] != 0:
p_data_fp32.add_(-group["weight_decay"] * group["lr"], p_data_fp32)
# more conservative since it's an approximated value
if N_sma >= 5:
denom = exp_avg_sq.sqrt().add_(group["eps"])
p_data_fp32.addcdiv_(exp_avg, denom, value=-step_size * group["lr"])
else:
p_data_fp32.add_(exp_avg, alpha=-step_size * group["lr"])
p.data.copy_(p_data_fp32)
return loss
class Lookahead(Optimizer):
def __init__(self, optimizer, alpha=0.5, k=6):
if not 0.0 <= alpha <= 1.0:
raise ValueError(f"Invalid slow update rate: {alpha}")
if not 1 <= k:
raise ValueError(f"Invalid lookahead steps: {k}")
self.optimizer = optimizer
self.param_groups = self.optimizer.param_groups
self.alpha = alpha
self.k = k
for group in self.param_groups:
group["step_counter"] = 0
self.slow_weights = [
[p.clone().detach() for p in group["params"]] for group in self.param_groups
]
for w in it.chain(*self.slow_weights):
w.requires_grad = False
self.state = optimizer.state
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
loss = self.optimizer.step()
for group, slow_weights in zip(self.param_groups, self.slow_weights):
group["step_counter"] += 1
if group["step_counter"] % self.k != 0:
continue
for p, q in zip(group["params"], slow_weights):
if p.grad is None:
continue
q.data.add_(p.data - q.data, alpha=self.alpha)
p.data.copy_(q.data)
return loss
# ## Training
def do_valid(net, tokenizer, valid_loader):
valid_probability = []
valid_truth = []
valid_length = []
valid_num = 0
net.eval()
start_timer = timer()
for t, batch in enumerate(valid_loader):
batch_size = len(batch["index"])
length = batch["length"]
token = batch["token"].cuda()
token_pad_mask = batch["token_pad_mask"].cuda()
# image = batch['image' ].cuda()
num_patch = batch["num_patch"]
patch = batch["patch"].cuda()
coord = batch["coord"].cuda()
patch_pad_mask = batch["patch_pad_mask"].cuda()
with torch.no_grad():
logit = data_parallel(
net, (patch, coord, token, patch_pad_mask, token_pad_mask)
) # net(image, token, length)
probability = F.softmax(logit, -1)
valid_num += batch_size
valid_probability.append(probability.data.cpu().numpy())
valid_truth.append(token.data.cpu().numpy())
valid_length.extend(length)
print(
"\r %8d / %d %s"
% (
valid_num,
len(valid_loader.sampler),
time_to_str(timer() - start_timer, "sec"),
),
end="",
flush=True,
)
del t, batch
assert valid_num == len(valid_loader.sampler) # len(valid_loader.dataset))
# print('')
# ----------------------
probability = np.concatenate(valid_probability)
predict = probability.argmax(-1)
truth = np.concatenate(valid_truth)
length = valid_length
# ----
p = probability[:, :-1].reshape(-1, vocab_size)
t = truth[:, 1:].reshape(-1)
non_pad = np.where(t != STOI["<pad>"])[0] # & (t!=STOI['<sos>'])
p = p[non_pad]
t = t[non_pad]
loss = np_loss_cross_entropy(p, t)
# ----
lb_score = 0
if 1:
score = []
for i, (p, t) in enumerate(zip(predict, truth)):
t = truth[i][1 : length[i] - 1]
p = predict[i][1 : length[i] - 1]
t = tokenizer.one_predict_to_inchi(t)
p = tokenizer.one_predict_to_inchi(p)
s = Levenshtein.distance(p, t)
score.append(s)
lb_score = np.mean(score)
"""
if 1:
score = []
for i, (p, t) in enumerate(zip(predict, truth)):
t = truth[i][1:length[i]-1] # in the buggy version, i have used 1 instead of i
p = predict[i][1:length[i]-1]
t = tokenizer.one_predict_to_inchi(t)
p = tokenizer.one_predict_to_inchi(p)
s = Levenshtein.distance(p, t)
score.append(s)
lb_score = np.mean(score)
"""
# lb_score = compute_lb_score(k, t)
del (
valid_loader,
net,
predict,
truth,
valid_probability,
valid_truth,
valid_length,
valid_num,
)
return [loss, lb_score]
def run_train():
fold = 3
out_dir = "./tnt-patch1-s0.8/fold%d" % fold
initial_checkpoint = None
# initial_checkpoint = \
# out_dir + '/checkpoint/00755000_model.pth'#None #
#'/root/share1/kaggle/2021/bms-moleular-translation/result/try22/tnt-patch1/fold3/checkpoint/00697000_model.pth'
debug = 0
start_lr = 0.00001 # 1
batch_size = 32 # 24
## setup ----------------------------------------
for f in ["checkpoint", "train", "valid", "backup"]:
os.makedirs(out_dir + "/" + f, exist_ok=True)
# backup_project_as_zip(PROJECT_PATH, out_dir +'/backup/code.train.%s.zip'%IDENTIFIER)
log = Logger()
log.open(out_dir + "/log.train.txt", mode="a")
log.write("\n--- [START %s] %s\n\n" % (IDENTIFIER, "-" * 64))
log.write("\t%s\n" % COMMON_STRING)
# log.write('\t__file__ = %s\n' % __file__)
log.write("\tout_dir = %s\n" % out_dir)
log.write("\n")
## dataset ------------------------------------
df_train, df_valid = make_fold("train-%d" % fold)
df_valid = df_valid.iloc[:5_000]
tokenizer = load_tokenizer()
train_dataset = BmsDataset(df_train, tokenizer)
valid_dataset = BmsDataset(df_valid, tokenizer)
train_loader = DataLoader(
train_dataset,
sampler=RandomSampler(train_dataset),
# sampler=UniformLengthSampler(train_dataset, is_shuffle=True), #200_000
batch_size=batch_size,
drop_last=True,
num_workers=8,
pin_memory=True,
worker_init_fn=lambda id: np.random.seed(torch.initial_seed() // 2**32 + id),
collate_fn=null_collate,
)
valid_loader = DataLoader(
valid_dataset,
# sampler=UniformLengthSampler(valid_dataset, 5_000),
sampler=SequentialSampler(valid_dataset),
batch_size=32,
drop_last=False,
num_workers=8,
pin_memory=True,
collate_fn=null_collate,
)
log.write("train_dataset : \n%s\n" % (train_dataset))
log.write("valid_dataset : \n%s\n" % (valid_dataset))
log.write("\n")
## net ----------------------------------------
log.write("** net setting **\n")
scaler = amp.GradScaler()
net = AmpNet().cuda()
if initial_checkpoint is not None:
f = torch.load(initial_checkpoint, map_location=lambda storage, loc: storage)
start_iteration = f["iteration"]
start_epoch = f["epoch"]
state_dict = f["state_dict"]
# ---
# state_dict = {k.replace('cnn.e.','cnn.'):v for k,v in state_dict.items()}
# del state_dict['text_pos.pos']
# del state_dict['cnn.head.weight']
# del state_dict['cnn.head.bias']
# net.load_state_dict(state_dict, strict=False)
# ---
net.load_state_dict(state_dict, strict=True) # True
else:
start_iteration = 0
start_epoch = 0
log.write("\tinitial_checkpoint = %s\n" % initial_checkpoint)
log.write("\n")
# -----------------------------------------------
if 0: ##freeze
for p in net.encoder.parameters():
p.requires_grad = False
optimizer = Lookahead(
RAdam(filter(lambda p: p.requires_grad, net.parameters()), lr=start_lr),
alpha=0.5,
k=5,
)
# optimizer = RAdam(filter(lambda p: p.requires_grad, net.parameters()),lr=start_lr)
num_iteration = 10 * 1000
# num_iteration = 10
iter_log = 1000
iter_valid = 1000
iter_save = list(range(0, num_iteration, 1000)) # 1*1000
# iter_save = [0]
log.write("optimizer\n %s\n" % (optimizer))
log.write("\n")
## start training here! ##############################################
log.write("** start training here! **\n")
log.write(" is_mixed_precision = %s \n" % str(is_mixed_precision))
log.write(" batch_size = %d\n" % (batch_size))
# log.write(' experiment = %s\n' % str(__file__.split('/')[-2:]))
log.write(
" |----- VALID ---|---- TRAIN/BATCH --------------\n"
)
log.write(
"rate iter epoch | loss lb(lev) | loss0 loss1 | time \n"
)
log.write(
"----------------------------------------------------------------------\n"
)
# 0.00000 0.00* 0.00 | 0.000 0.000 | 0.000 0.000 | 0 hr 00 min
def message(mode="print"):
if mode == ("print"):
asterisk = " "
loss = batch_loss
if mode == ("log"):
asterisk = "*" if iteration in iter_save else " "
loss = train_loss
#'%4.3f %5.2f | ' % (*valid_loss,) + \
text = (
"%0.5f %5.4f%s %4.2f | "
% (
rate,
iteration / 10000,
asterisk,
epoch,
)
+ "%4.3f %4.3f %4.3f | " % (*loss,)
+ "%s" % (time_to_str(timer() - start_timer, "min"))
)
return text
# ----
valid_loss = np.zeros(2, np.float32)
train_loss = np.zeros(3, np.float32)
batch_loss = np.zeros_like(train_loss)
sum_train_loss = np.zeros_like(train_loss)
sum_train = 0
loss0 = torch.FloatTensor([0]).cuda().sum()
loss1 = torch.FloatTensor([0]).cuda().sum()
loss2 = torch.FloatTensor([0]).cuda().sum()
start_timer = timer()
iteration = start_iteration
epoch = start_epoch
rate = 0
# while iteration < num_iteration:
for t, batch in enumerate(train_loader):
if iteration in iter_save:
if iteration != start_iteration:
torch.save(
{
"state_dict": net.state_dict(),
"iteration": iteration,
"epoch": epoch,
},
out_dir + "/checkpoint/%08d_model.pth" % (iteration),
)
pass
"""
if (iteration % iter_valid == 0):
if iteration != start_iteration:
valid_loss = do_valid(net, tokenizer, valid_loader) #
pass
"""
if iteration % iter_log == 0:
print("\r", end="", flush=True)
log.write(message(mode="log") + "\n")
# learning rate schduler ------------
rate = get_learning_rate(optimizer)
# one iteration update -------------
batch_size = len(batch["index"])
length = batch["length"]
token = batch["token"].cuda()
token_pad_mask = batch["token_pad_mask"].cuda()
# image = batch['image' ].cuda()
num_patch = batch["num_patch"]
patch = batch["patch"].cuda()
coord = batch["coord"].cuda()
patch_pad_mask = batch["patch_pad_mask"].cuda()
# ----
net.train()
optimizer.zero_grad()
if is_mixed_precision:
with amp.autocast():
# assert(False)
logit = data_parallel(
net, (patch, coord, token, patch_pad_mask, token_pad_mask)
) # net(image, token, length)
loss0 = seq_cross_entropy_loss(logit, token, length)
# loss0 = seq_anti_focal_cross_entropy_loss(logit, token, length)
scaler.scale(loss0).backward()
# scaler.unscale_(optimizer)
# torch.nn.utils.clip_grad_norm_(net.parameters(), 2)
scaler.step(optimizer)
scaler.update()
else:
assert False
# print('fp32')
# image_embed = encoder(image)
logit, weight = decoder(image_embed, token, length)
(loss0).backward()
optimizer.step()
# print statistics --------
epoch += 1 / len(train_loader)
iteration += 1
batch_loss = np.array([loss0.item(), loss1.item(), loss2.item()])
sum_train_loss += batch_loss
sum_train += 1
if iteration % 100 == 0:
train_loss = sum_train_loss / (sum_train + 1e-12)
sum_train_loss[...] = 0
sum_train = 0
print("\r", end="", flush=True)
print(message(mode="print"), end="", flush=True)
# debug--------------------------
if debug:
pass
# delete per batch
del (
batch_size,
length,
token,
token_pad_mask,
num_patch,
patch,
coord,
patch_pad_mask,
t,
batch,
)
if iteration > num_iteration:
break
log.write("\n")
run_train()
#!ls ./tnt-patch1-s0.8/fold3/checkpoint/
# list(range(0, 3000, 1000))
"""
import sys
# These are the usual ipython objects, including this one you are creating
ipython_vars = ['In', 'Out', 'exit', 'quit', 'get_ipython', 'ipython_vars']
# Get a sorted list of the objects and their sizes
sorted([(x, sys.getsizeof(globals().get(x))) for x in dir() if not x.startswith('_') and x not in sys.modules and x not in ipython_vars], key=lambda x: x[1], reverse=True)
"""
| false | 0 | 19,683 | 2 | 27 | 19,683 |
||
63841560 | <kaggle_start><code># ### This file was made by me while I was teaching myself Python and I would be happy if this can help someone on Kaggle who wants to learn Python.
# # PYTHON PROGRAMMING FUNDAMENTALS
# ## CONDITIONS AND BRANCHING
# ### Comparison Operators:
a = 5
print(a == 6) # in this case '==' determines wether the two values are equal or not
print(a == 5)
print(a > 7) # checking for one value greater than the other
print(a > 4)
print(a >= 5) # greater than or equal to
print(a < 4) # checking for one value less than the other
print(a < 8)
print(a <= 5) # less than or equal to
print(a != 8) # not equal to
print(a != 5)
print("salman" == "khan") # can compare strings too
print("salman" != "khan")
print("khan" == "khan")
print("A" == "a")
print("A" > "B") # actually comparing ascii values here
print("B" > "A")
# ### Branching:
# #### The IF Statement:
age = 21
if age >= 18: # if this statement qualifies the person can enter
print("You can enter,")
print(
"move on!"
) # this statement will run no matter what, since it is out of the if block
age = 12
if age >= 18:
print("You can enter,")
print("move on!")
# #### The ELSE Statement:
age = 13
if age >= 18: # if this statement qualifies, the person can enter
print("You can enter,")
else: # if the above statement doesn't qualify, the person will be suggested another place
print("Go see Meat Loaf,")
print("move on!")
age = 31
if age >= 18:
print("You can enter,")
else:
print("Go see Meat Loaf,")
print("move on!")
# #### The ELIF Statement:
age = 13
if age > 18: # if this statement qualifies, the person can enter
print("You can enter,")
# if the above one doesnt qualify, program will run this "ELIF" statement and do as it says on qualification
elif age == 18:
print("Please visit Pink Floyd,")
else: # if both of the above don't work, it will run this one
print("Go see Meat Loaf,")
print("move on!")
age = 31
if age > 18: # if this statement qualifies, the person can enter
print("You can enter,")
# if the above one doesnt qualify, program will run this "ELIF" statement and do as it says on qualification
elif age == 18:
print("Please visit Pink Floyd,")
else: # if both of the above don't work, it will run this one
print("Go see Meat Loaf,")
print("move on!")
age = 18
if age > 18: # if this statement qualifies, the person can enter
print("You can enter,")
# if the above one doesnt qualify, program will run this "ELIF" statement and do as it says on qualification
elif age == 18:
print("Please visit Pink Floyd,")
else: # if both of the above don't work, it will run this one
print("Go see Meat Loaf,")
print("move on!")
# ### Logic Operators:
# NOT operator inverses the boolean value
print(not True)
print(not False)
# OR operator comes in between multiple boolean values and will be resulted in single
# for the resulted boolean value to be true, any one of those multiple values must be a true
# for the resulted boolean value to be false, all of the input multiple values must be false
print(True or True)
print(True or False)
print(False or True)
print(False or False) # here both input values are false, hence reslted in false
# can be used in the if statements like below!
movie_release_year = 1985
if movie_release_year < 2000 or movie_release_year > 2010:
print("Yeah! I have watched it!")
else:
print("No! I have not seen any movie released in that decade!")
movie_release_year = 2008
if movie_release_year < 2000 or movie_release_year > 2010:
print("Yeah! I have watched it!")
else:
print("No! I have not seen any movie released in that decade!")
movie_release_year = 2015
if movie_release_year < 2000 or movie_release_year > 2010:
print("Yeah! I have watched it!")
else:
print("No! I have not seen any movie released in that decade!")
# AND operator comes in between multiple boolean values and will be resulted in single (just like OR)
# for the resulted boolean value to be true, all of the multiple values must be a true
# for the resulted boolean value to be false, any one of the input multiple values must be false
print(True and True) # all are true
print(True and False)
print(False and True)
print(False and False)
birth_year = 1990
if birth_year >= 1981 and birth_year <= 1996:
print("You're a Millennial!")
else:
print("You're not a Millennial!")
birth_year = 2000
if birth_year >= 1981 and birth_year <= 1996:
print("You're a Millennial!")
else:
print("You're not a Millennial!")
birth_year = 1973
if birth_year >= 1981 and birth_year <= 1996:
print("You're a Millennial!")
else:
print("You're not a Millennial!")
# ## LOOPS
# range generates an ordered sequences
# if its provided with one integer, it will range from zero to a number 1 less than that number
# if its provided with two integers, it will range from first to a number 1 less than second integer
print(range(3))
print(range(10, 34))
# we can generate a list from range
print(list(range(3)))
print(list(range(10, 23)))
# ### FOR Loops:
# here in this example, we have 5 different colored squares, we want to paint all 5 squares with white
# we will use loops here
# for loop is used here 5 time, because we want to paint each square one by one
# with each turn of loop, one square is painted white and the program will rum 5 times
# these 5 times are achieved by the range provided by us 'range(0, 5)'
# this range will also serve as the index of list
squares = ["red", "yellow", "green", "purple", "blue"]
for i in range(0, 5):
squares[i] = "white"
print(squares)
squares = ["red", "yellow", "green", "purple", "blue"]
for square in squares:
print(square)
# square = "white" will also do the work done in the above cell
# as square here will one-by-one call the items of the list i.e. "red", "yellow", etc
# no need to use indexes this way
# no need to manually give the range too, as it will automatically run for all of the items of list
# enumerate is the function that is used to obtain the index and value of the sequence
boxes = ("red", "yellow", "green")
for i, box in enumerate(boxes):
print(i, box)
# ### WHILE Loops:
# here we have a list of colors, we want to pick only reds from here
# while loop will work until we are getting reds
# loop will break once we would encounter a color that is not red and we will be then out of the loop
colors = ["red", "red", "red", "yellow", "green", "red", "orange", "green", "red"]
red = []
i = 0
while colors[i] == "red":
red.append(colors[i])
i += 1
print(red)
# ## FUNCTIONS
# ### Built in Functions
# len() funtion takes a sequence and tells length of that sequence
# can be used on strings, lists, sets and dictionaries
print(len("salman"))
print(len([2, 1, 0, 10, 45]))
# sum() fuction takes numbers in sequence and returns their total sum
# can find sums for integers, floats and complex numbers
print(sum([2 + 5j, 9 + 13j]))
print(sum([2, 1, 0, 10, 45]))
print(sum((3.7, 67)))
# #### SORTED VS SORT
list_forsort = [123, 1200, 24, 6, 28, 12] # example list
# sorted() sorts the list in ascending order, if haven't instructed otherwise
# generates another list, does not alter the original list
print(sorted(list_forsort))
print(list_forsort)
# sort is a function that will alter the orginal list as it does not generate another list
print("Initial list:", list_forsort)
list_forsort.sort()
print("After 'sort()' function:", list_forsort)
# ### Making Functions
def give_double(x): # how to define function
x_doubled = 2 * x # function body
return x_doubled # return value
print(give_double(34)) # calling a function
doubled_4 = give_double(4) # assigning return of function to a variable
print(doubled_4)
# Statement in triple double/single quotes is Documentation String, helps to document the purpose of the function
def squared(a):
"""
squares the given number"
"""
b = a**2
return b
c = squared(4)
print(c)
help(squared)
# Multiple Parameter, a function can have more than 1 arguments
def product(x, y):
z = x * y
return z
print(product(23, 56))
def product(w, x, y):
z = w * x * y
return z
print(product(12, 56.87, 5))
# it is not a must for a function to return a value
# there can be an equally workable and normal function with no return value
def SK():
print("Salman")
print("Khan")
SK()
def no_work():
pass # Python doesnt allow a function to have no body, here pass will fill in that requirement and will be doing nothing
print(no_work()) # when we dont return a vlue for a function, python saves a None in it
def no_work_none(): # Equilvalent to the above function
return None
print(no_work_none())
def add1(a):
b = a + 1
print(a, "+ 1 =", b)
return b
add1(34)
a_list = [10, 9, 8, 7, 6, 5]
def printStuff(Stuff):
for i, s in enumerate(Stuff): # using a loop inside a function
print("Album", i, "Rating is", s)
printStuff(a_list)
def collectnames(
*name,
): # if we put * before argument, the function collects the argument
for name in name:
print(name)
collectnames(
"salman", "khan", "m"
) # no matter how much names, we put in the argument, the function will print it
def show_dict(**kv): # same can be applied on dictionaries as well
for key in kv:
print(key, kv[key])
show_dict(name="salman", age=26, city="karachi")
# #### Global and Local Variables
# variables defined outside the function are called gloabal variables
def AddDC(x):
x = (
x + "DC"
) # we have called a variable that hasnt been asssinged yet inside of function as well
print(x)
return x
x = "AC" # we are assigning the variable here
z = AddDC(x)
# local variables only exsists only within the scope of the function
def Thriller():
Date = "1897"
return Date
Date = "1982"
print(Thriller())
print(Date)
def PinkFloyd():
global ClaimedSales # a way how we can create a global variable inside a function
ClaimedSales = "45M"
return ClaimedSales
PinkFloyd()
print(ClaimedSales)
# ## OBJECTS AND CLASSES
# importing the library, for later use
# library not explained now
# we will just use this library for methods on objects
import matplotlib.pyplot as plt
class Circle(object): # how to create a class
def __init__(self, radius, color):
"""
__init__ is a special method or constructor to initialize data attributes
self defines an object and is unique for each object
radius and color in this case are the attributes of the objects that will be created in this class
"""
self.radius = radius
self.color = color
def add_radius(
self, radius_inc
): # creating a fuction for the class, to modify the object's radius
self.radius += radius_inc
return self.radius
def reduce_radius(self, radius_dec):
self.radius -= radius_dec
return self.radius
def draw_circle(self):
"""
using matplotlib to draw the circle
just copied the body of this function for now
this will somehow print the drawn circle on screen
"""
plt.gca().add_patch(plt.Circle((0, 0), radius=self.radius, fc=self.color))
plt.axis("scaled")
return plt.show
class Rectangle(object):
def __init__(self, height, width, color):
self.height = height
self.width = width
self.color - color
cr10 = Circle(10, "red") # creating a new object in class "Circle"
cb4 = Circle(4, "blue") # creating another
print(cr10.color)
print(cb4.radius)
print(cr10.draw_circle())
cb4.radius = 40 # changing the attribute
print(cb4.radius)
cb4.add_radius(-36) # calling method to increase the radius of the cirlce
print(cb4.radius)
cb4.reduce_radius(2) # calling method to reduce the radius of the cirlce
print(cb4.radius)
dir(cb4) # helps getting a list of methods that we can apply on a certain object
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0063/841/63841560.ipynb | null | null | [{"Id": 63841560, "ScriptId": 17200474, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 7112435, "CreationDate": "05/24/2021 21:45:31", "VersionNumber": 1.0, "Title": "Python Conditions, Loops and Functions", "EvaluationDate": "05/24/2021", "IsChange": true, "TotalLines": 406.0, "LinesInsertedFromPrevious": 406.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 5}] | null | null | null | null | # ### This file was made by me while I was teaching myself Python and I would be happy if this can help someone on Kaggle who wants to learn Python.
# # PYTHON PROGRAMMING FUNDAMENTALS
# ## CONDITIONS AND BRANCHING
# ### Comparison Operators:
a = 5
print(a == 6) # in this case '==' determines wether the two values are equal or not
print(a == 5)
print(a > 7) # checking for one value greater than the other
print(a > 4)
print(a >= 5) # greater than or equal to
print(a < 4) # checking for one value less than the other
print(a < 8)
print(a <= 5) # less than or equal to
print(a != 8) # not equal to
print(a != 5)
print("salman" == "khan") # can compare strings too
print("salman" != "khan")
print("khan" == "khan")
print("A" == "a")
print("A" > "B") # actually comparing ascii values here
print("B" > "A")
# ### Branching:
# #### The IF Statement:
age = 21
if age >= 18: # if this statement qualifies the person can enter
print("You can enter,")
print(
"move on!"
) # this statement will run no matter what, since it is out of the if block
age = 12
if age >= 18:
print("You can enter,")
print("move on!")
# #### The ELSE Statement:
age = 13
if age >= 18: # if this statement qualifies, the person can enter
print("You can enter,")
else: # if the above statement doesn't qualify, the person will be suggested another place
print("Go see Meat Loaf,")
print("move on!")
age = 31
if age >= 18:
print("You can enter,")
else:
print("Go see Meat Loaf,")
print("move on!")
# #### The ELIF Statement:
age = 13
if age > 18: # if this statement qualifies, the person can enter
print("You can enter,")
# if the above one doesnt qualify, program will run this "ELIF" statement and do as it says on qualification
elif age == 18:
print("Please visit Pink Floyd,")
else: # if both of the above don't work, it will run this one
print("Go see Meat Loaf,")
print("move on!")
age = 31
if age > 18: # if this statement qualifies, the person can enter
print("You can enter,")
# if the above one doesnt qualify, program will run this "ELIF" statement and do as it says on qualification
elif age == 18:
print("Please visit Pink Floyd,")
else: # if both of the above don't work, it will run this one
print("Go see Meat Loaf,")
print("move on!")
age = 18
if age > 18: # if this statement qualifies, the person can enter
print("You can enter,")
# if the above one doesnt qualify, program will run this "ELIF" statement and do as it says on qualification
elif age == 18:
print("Please visit Pink Floyd,")
else: # if both of the above don't work, it will run this one
print("Go see Meat Loaf,")
print("move on!")
# ### Logic Operators:
# NOT operator inverses the boolean value
print(not True)
print(not False)
# OR operator comes in between multiple boolean values and will be resulted in single
# for the resulted boolean value to be true, any one of those multiple values must be a true
# for the resulted boolean value to be false, all of the input multiple values must be false
print(True or True)
print(True or False)
print(False or True)
print(False or False) # here both input values are false, hence reslted in false
# can be used in the if statements like below!
movie_release_year = 1985
if movie_release_year < 2000 or movie_release_year > 2010:
print("Yeah! I have watched it!")
else:
print("No! I have not seen any movie released in that decade!")
movie_release_year = 2008
if movie_release_year < 2000 or movie_release_year > 2010:
print("Yeah! I have watched it!")
else:
print("No! I have not seen any movie released in that decade!")
movie_release_year = 2015
if movie_release_year < 2000 or movie_release_year > 2010:
print("Yeah! I have watched it!")
else:
print("No! I have not seen any movie released in that decade!")
# AND operator comes in between multiple boolean values and will be resulted in single (just like OR)
# for the resulted boolean value to be true, all of the multiple values must be a true
# for the resulted boolean value to be false, any one of the input multiple values must be false
print(True and True) # all are true
print(True and False)
print(False and True)
print(False and False)
birth_year = 1990
if birth_year >= 1981 and birth_year <= 1996:
print("You're a Millennial!")
else:
print("You're not a Millennial!")
birth_year = 2000
if birth_year >= 1981 and birth_year <= 1996:
print("You're a Millennial!")
else:
print("You're not a Millennial!")
birth_year = 1973
if birth_year >= 1981 and birth_year <= 1996:
print("You're a Millennial!")
else:
print("You're not a Millennial!")
# ## LOOPS
# range generates an ordered sequences
# if its provided with one integer, it will range from zero to a number 1 less than that number
# if its provided with two integers, it will range from first to a number 1 less than second integer
print(range(3))
print(range(10, 34))
# we can generate a list from range
print(list(range(3)))
print(list(range(10, 23)))
# ### FOR Loops:
# here in this example, we have 5 different colored squares, we want to paint all 5 squares with white
# we will use loops here
# for loop is used here 5 time, because we want to paint each square one by one
# with each turn of loop, one square is painted white and the program will rum 5 times
# these 5 times are achieved by the range provided by us 'range(0, 5)'
# this range will also serve as the index of list
squares = ["red", "yellow", "green", "purple", "blue"]
for i in range(0, 5):
squares[i] = "white"
print(squares)
squares = ["red", "yellow", "green", "purple", "blue"]
for square in squares:
print(square)
# square = "white" will also do the work done in the above cell
# as square here will one-by-one call the items of the list i.e. "red", "yellow", etc
# no need to use indexes this way
# no need to manually give the range too, as it will automatically run for all of the items of list
# enumerate is the function that is used to obtain the index and value of the sequence
boxes = ("red", "yellow", "green")
for i, box in enumerate(boxes):
print(i, box)
# ### WHILE Loops:
# here we have a list of colors, we want to pick only reds from here
# while loop will work until we are getting reds
# loop will break once we would encounter a color that is not red and we will be then out of the loop
colors = ["red", "red", "red", "yellow", "green", "red", "orange", "green", "red"]
red = []
i = 0
while colors[i] == "red":
red.append(colors[i])
i += 1
print(red)
# ## FUNCTIONS
# ### Built in Functions
# len() funtion takes a sequence and tells length of that sequence
# can be used on strings, lists, sets and dictionaries
print(len("salman"))
print(len([2, 1, 0, 10, 45]))
# sum() fuction takes numbers in sequence and returns their total sum
# can find sums for integers, floats and complex numbers
print(sum([2 + 5j, 9 + 13j]))
print(sum([2, 1, 0, 10, 45]))
print(sum((3.7, 67)))
# #### SORTED VS SORT
list_forsort = [123, 1200, 24, 6, 28, 12] # example list
# sorted() sorts the list in ascending order, if haven't instructed otherwise
# generates another list, does not alter the original list
print(sorted(list_forsort))
print(list_forsort)
# sort is a function that will alter the orginal list as it does not generate another list
print("Initial list:", list_forsort)
list_forsort.sort()
print("After 'sort()' function:", list_forsort)
# ### Making Functions
def give_double(x): # how to define function
x_doubled = 2 * x # function body
return x_doubled # return value
print(give_double(34)) # calling a function
doubled_4 = give_double(4) # assigning return of function to a variable
print(doubled_4)
# Statement in triple double/single quotes is Documentation String, helps to document the purpose of the function
def squared(a):
"""
squares the given number"
"""
b = a**2
return b
c = squared(4)
print(c)
help(squared)
# Multiple Parameter, a function can have more than 1 arguments
def product(x, y):
z = x * y
return z
print(product(23, 56))
def product(w, x, y):
z = w * x * y
return z
print(product(12, 56.87, 5))
# it is not a must for a function to return a value
# there can be an equally workable and normal function with no return value
def SK():
print("Salman")
print("Khan")
SK()
def no_work():
pass # Python doesnt allow a function to have no body, here pass will fill in that requirement and will be doing nothing
print(no_work()) # when we dont return a vlue for a function, python saves a None in it
def no_work_none(): # Equilvalent to the above function
return None
print(no_work_none())
def add1(a):
b = a + 1
print(a, "+ 1 =", b)
return b
add1(34)
a_list = [10, 9, 8, 7, 6, 5]
def printStuff(Stuff):
for i, s in enumerate(Stuff): # using a loop inside a function
print("Album", i, "Rating is", s)
printStuff(a_list)
def collectnames(
*name,
): # if we put * before argument, the function collects the argument
for name in name:
print(name)
collectnames(
"salman", "khan", "m"
) # no matter how much names, we put in the argument, the function will print it
def show_dict(**kv): # same can be applied on dictionaries as well
for key in kv:
print(key, kv[key])
show_dict(name="salman", age=26, city="karachi")
# #### Global and Local Variables
# variables defined outside the function are called gloabal variables
def AddDC(x):
x = (
x + "DC"
) # we have called a variable that hasnt been asssinged yet inside of function as well
print(x)
return x
x = "AC" # we are assigning the variable here
z = AddDC(x)
# local variables only exsists only within the scope of the function
def Thriller():
Date = "1897"
return Date
Date = "1982"
print(Thriller())
print(Date)
def PinkFloyd():
global ClaimedSales # a way how we can create a global variable inside a function
ClaimedSales = "45M"
return ClaimedSales
PinkFloyd()
print(ClaimedSales)
# ## OBJECTS AND CLASSES
# importing the library, for later use
# library not explained now
# we will just use this library for methods on objects
import matplotlib.pyplot as plt
class Circle(object): # how to create a class
def __init__(self, radius, color):
"""
__init__ is a special method or constructor to initialize data attributes
self defines an object and is unique for each object
radius and color in this case are the attributes of the objects that will be created in this class
"""
self.radius = radius
self.color = color
def add_radius(
self, radius_inc
): # creating a fuction for the class, to modify the object's radius
self.radius += radius_inc
return self.radius
def reduce_radius(self, radius_dec):
self.radius -= radius_dec
return self.radius
def draw_circle(self):
"""
using matplotlib to draw the circle
just copied the body of this function for now
this will somehow print the drawn circle on screen
"""
plt.gca().add_patch(plt.Circle((0, 0), radius=self.radius, fc=self.color))
plt.axis("scaled")
return plt.show
class Rectangle(object):
def __init__(self, height, width, color):
self.height = height
self.width = width
self.color - color
cr10 = Circle(10, "red") # creating a new object in class "Circle"
cb4 = Circle(4, "blue") # creating another
print(cr10.color)
print(cb4.radius)
print(cr10.draw_circle())
cb4.radius = 40 # changing the attribute
print(cb4.radius)
cb4.add_radius(-36) # calling method to increase the radius of the cirlce
print(cb4.radius)
cb4.reduce_radius(2) # calling method to reduce the radius of the cirlce
print(cb4.radius)
dir(cb4) # helps getting a list of methods that we can apply on a certain object
| false | 0 | 3,658 | 5 | 6 | 3,658 |
||
14245203 | <kaggle_start><data_title>Keras Pretrained models<data_description>### Context
Kaggle has more and more computer vision challenges. Although Kernel resources were increased recently we still can not train useful CNNs without GPU. The other main problem is that Kernels can't use network connection to download pretrained keras model weights. This dataset helps you to apply your favorite pretrained model in the Kaggle Kernel environment.
Happy data exploration and transfer learning!
### Content
Model (Top-1 Accuracy | Top -5 Accuracy)
- [Xception][2] (0.790 | 0.945)
- [VGG16][3] (0.715 | 0.901)
- [VGG19][4] (0.727 | 0.910)
- [ResNet50][5] (0.759 | 0.929)
- [InceptionV3][6] (0.788 | 0.944)
- [InceptionResNetV2][7] (0.804 | 0.953) (could not upload due to 500 MB limit)
For more information see https://keras.io/applications/<data_name>keras-pretrained-models
<code># # FROM REFERENCEE
# **Catatan penting pada versi ini:**
# 1. Preprocess diganti dari *keras.applications.mobilenet.preprocess_input* menjadi *keras.applications.inception_v3.preprocess_input*
import keras
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
import os
print(os.listdir("../input"))
# Any results you write to the current directory are saved as output.
import pandas as pd
df_data = pd.read_csv("../input/metadata/metadata.csv")
df_data.head()
df_data["dx"].unique()
import matplotlib.pyplot as plt
# exp = pd.Series.to_frame(df1.groupby('dx').sex.value_counts())
df_data["dx"].value_counts().plot.bar(rot=0)
plt.title("Number of images for different dx type")
plt.xlabel("dx")
plt.ylabel("Counts")
plt.grid(axis="y")
# # 1. Create several more columns for the dataframe 'df'
# 1. Create 'num_images' to record the number of images belonging to the same 'lesion_id'
# 2. Create 'dx_id' convert the 'dx' to integer label
# 3. Create 'image_path' to store the path to access the image
# 4. Create 'images' to store the resized image as arrays
# Memberi informasi berapa banyak citra yang dikaitkan dengan setiap lesion_id
df = df_data.groupby("lesion_id").count()
# Memfilter lesion_id yang hanya memiliki satu citra yang terkait dengannya
df = df[df["image_id"] == 1]
df.reset_index(inplace=True)
df_data.head()
# identifikasi lesion_id yg mempunyai duplikat citra atau tidak.
def identify_duplicates(x):
unique_list = list(df["lesion_id"])
if x in unique_list:
return "no_duplicates"
else:
return "has_duplicates"
# buat kolom baru yang merupakan salinan dari kolom lesi _id
df_data["duplicates"] = df_data["lesion_id"]
# terapkan fungsi ke kolom baru ini
df_data["duplicates"] = df_data["duplicates"].apply(identify_duplicates)
df_data.head(50)
df_data["duplicates"].value_counts()
# filter citra yang tidak memiliki duplikat
df = df_data[df_data["duplicates"] == "no_duplicates"]
print("Citra yang tidak memiliki duplikat berjumlah")
df.shape
# df yang telah dipastikan tidak memiliki duplikat displit kemudian dijadikan set val (validasi)
y = df["dx"]
import tensorflow
from sklearn.model_selection import train_test_split
_, df_val = train_test_split(df, test_size=0.17, random_state=101, stratify=y)
# train_size -> If float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the train split
# randostate -> If int, random_state is the seed used by the random number generator
# stratif -> If not None, data is split in a stratified fashion
print("Jumlah citra sebagai validasi")
df_val.shape
# Membuat set train yg tidak termasuk images yg ada di set val
# Fungsi ini mengidentifikasi apakah gambar adalah bagian dari set train atau set val
def identify_val_rows(x):
# create a list of all the lesion_id's in the val set
val_list = list(df_val["image_id"])
if str(x) in val_list:
return "val"
else:
return "train"
# buat kolom baru yang merupakan salinan dari kolom image_id
df_data["train_or_val"] = df_data["image_id"]
# terapkan fungsi ke kolom baru ini
df_data["train_or_val"] = df_data["train_or_val"].apply(identify_val_rows)
# filter baris set train
df_train = df_data[df_data["train_or_val"] == "train"]
print("Jumlah citra yang akan dijadikan set train:")
print(len(df_train))
print("Jumlah citra yang akan dijadikan set validasi:")
print(len(df_val))
print("Jumlah citra yang tiap class yang akan dijadikan set train sebelum augmanted")
print(df_train["dx"].value_counts())
print("Jumlah citra yang tiap class yang akan dijadikan set validas")
print(df_val["dx"].value_counts())
# cek berapa banyak image di set train setiap class
print("Jumlah data citra setelah dilakukan Augmanted")
print(len(os.listdir("../input/basedir/base_dir/base_dir/train_dir/nv")))
print(len(os.listdir("../input/basedir/base_dir/base_dir/train_dir/mel")))
print(len(os.listdir("../input/basedir/base_dir/base_dir/train_dir/bkl")))
print(len(os.listdir("../input/basedir/base_dir/base_dir/train_dir/bcc")))
print(len(os.listdir("../input/basedir/base_dir/base_dir/train_dir/akiec")))
print(len(os.listdir("../input/basedir/base_dir/base_dir/train_dir/vasc")))
print(len(os.listdir("../input/basedir/base_dir/base_dir/train_dir/df")))
train_path = "../input/basedir/base_dir/base_dir/train_dir"
valid_path = "../input/basedir/base_dir/base_dir/val_dir"
num_train_samples = len(df_train)
num_val_samples = len(df_val)
train_batch_size = 10
val_batch_size = 10
image_size = 224
train_steps = np.ceil(num_train_samples / train_batch_size)
val_steps = np.ceil(num_val_samples / val_batch_size)
print(train_steps)
print(val_steps)
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
preprocessing_function=keras.applications.inception_v3.preprocess_input
)
train_batches = datagen.flow_from_directory(
train_path, target_size=(image_size, image_size), batch_size=train_batch_size
)
valid_batches = datagen.flow_from_directory(
valid_path, target_size=(image_size, image_size), batch_size=val_batch_size
)
# Note: shuffle=False causes the test dataset to not be shuffled
test_batches = datagen.flow_from_directory(
valid_path, target_size=(image_size, image_size), batch_size=1, shuffle=False
)
# # 5. Build CNN model -- InceptionV3
import keras
from keras.applications import InceptionV3
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras import regularizers
input_shape = (224, 224, 3)
num_labels = 7
base_model = InceptionV3(
include_top=False,
input_shape=(224, 224, 3),
pooling="avg",
weights="../input/keras-pretrained-models/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5",
)
model = Sequential()
model.add(base_model)
model.add(Dropout(0.5))
model.add(Dense(128, activation="relu", kernel_regularizer=regularizers.l2(0.02)))
model.add(Dropout(0.5))
model.add(Dense(7, activation="softmax", kernel_regularizer=regularizers.l2(0.02)))
for layer in base_model.layers:
layer.trainable = True
# for layer in base_model.layers[-30:]:
# layer.trainable = True
# model.add(ResNet50(include_top = False, pooling = 'max', weights = '../input/resnet50/resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5'))
model.summary()
print(valid_batches.class_indices)
class_weights = {
0: 1.0, # akiec
1: 1.0, # bcc
2: 1.0, # bkl
3: 1.0, # df
4: 3.0, # mel # Try to make the model more sensitive to Melanoma.
5: 1.0, # nv
6: 1.0, # vasc
}
from keras.optimizers import Adam
optimizer = Adam(
lr=0.0005, beta_1=0.9, beta_2=0.999, epsilon=None, decay=5e-7, amsgrad=False
)
model.compile(
optimizer=optimizer, loss="categorical_crossentropy", metrics=["accuracy"]
)
# Fit the model
from keras.callbacks import ReduceLROnPlateau, ModelCheckpoint, EarlyStopping
class CustomModelCheckPoint(keras.callbacks.Callback):
def __init__(self, **kargs):
super(CustomModelCheckPoint, self).__init__(**kargs)
self.epoch_accuracy = {} # loss at given epoch
self.epoch_loss = {} # accuracy at given epoch
def on_epoch_begin(self, epoch, logs={}):
# Things done on beginning of epoch.
return
def on_epoch_end(self, epoch, logs={}):
# things done on end of the epoch
self.epoch_accuracy[epoch] = logs.get("acc")
self.epoch_loss[epoch] = logs.get("loss")
self.model.save_weights("name-of-model-%d.h5" % epoch)
checkpoint = CustomModelCheckPoint()
cb_early_stopper = ReduceLROnPlateau(
monitor="val_loss",
factor=0.1,
patience=10,
verbose=0,
mode="auto",
min_delta=0.0001,
cooldown=0,
min_lr=0,
)
cb_checkpointer = ModelCheckpoint(
filepath="../working/best.h5", monitor="val_loss", save_best_only=True, mode="auto"
)
callbacks_list = [cb_checkpointer, cb_early_stopper]
epochs = 30
trainhistory = model.fit_generator(
train_batches,
validation_steps=val_steps,
class_weight=class_weights,
epochs=epochs,
validation_data=valid_batches,
verbose=1,
steps_per_epoch=train_steps,
callbacks=callbacks_list,
)
# # 6. Plot the accuracy and loss of both training and validation dataset
import matplotlib.pyplot as plt
acc = trainhistory.history["acc"]
val_acc = trainhistory.history["val_acc"]
loss = trainhistory.history["loss"]
val_loss = trainhistory.history["val_loss"]
epochs = range(1, len(acc) + 1)
plt.plot(epochs, loss, "", label="Training loss")
plt.plot(epochs, val_loss, "", label="Validation loss")
plt.title("InceptionV3 -- Training and validation loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.figure()
plt.plot(epochs, acc, "", label="Training accuracy")
plt.plot(epochs, val_acc, "", label="Validation accuracy")
plt.title("InceptionV3 -- Training and validation accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
model.load_weights("../working/best.h5")
test_loss, test_acc = model.evaluate_generator(
test_batches, steps=len(df_val), verbose=1
)
print("test_accuracy = %f ; test_loss = %f" % (test_acc, test_loss))
# Source: Scikit Learn website
# http://scikit-learn.org/stable/auto_examples/
# model_selection/plot_confusion_matrix.html#sphx-glr-auto-examples-model-
# selection-plot-confusion-matrix-py
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
import itertools
def plot_confusion_matrix(
cm, classes, normalize=False, title="Confusion matrix", cmap=plt.cm.Blues
):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
if normalize:
cm = cm.astype("float") / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print("Confusion matrix, without normalization")
print(cm)
plt.imshow(cm, interpolation="nearest", cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = ".2f" if normalize else "d"
thresh = cm.max() / 2.0
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(
j,
i,
format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black",
)
plt.ylabel("True label")
plt.xlabel("Predicted label")
plt.tight_layout()
test_labels = test_batches.classes
test_labels
test_labels.shape
predictions = model.predict_generator(test_batches, steps=len(df_val), verbose=1)
# argmax returns the index of the max value in a row
cm = confusion_matrix(test_labels, predictions.argmax(axis=1))
# Define the labels of the class indices. These need to match the
# order shown above.
cm_plot_labels = ["akiec", "bcc", "bkl", "df", "mel", "nv", "vasc"]
plot_confusion_matrix(cm, cm_plot_labels, title="Confusion Matrix")
# Get the index of the class with the highest probability score
y_pred = np.argmax(predictions, axis=1)
# Get the labels of the test images.
y_true = test_batches.classes
from sklearn.metrics import classification_report
# Generate a classification report
report = classification_report(y_true, y_pred, target_names=cm_plot_labels)
print(report)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0014/245/14245203.ipynb | keras-pretrained-models | gaborfodor | [{"Id": 14245203, "ScriptId": 3445997, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2864532, "CreationDate": "05/16/2019 09:33:41", "VersionNumber": 5.0, "Title": "Klasifikasi Penyakit Kulit (InceptionV3)", "EvaluationDate": "05/16/2019", "IsChange": true, "TotalLines": 341.0, "LinesInsertedFromPrevious": 4.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 337.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 1}] | [{"Id": 9388674, "KernelVersionId": 14245203, "SourceDatasetVersionId": 7251}, {"Id": 9388676, "KernelVersionId": 14245203, "SourceDatasetVersionId": 332046}, {"Id": 9388675, "KernelVersionId": 14245203, "SourceDatasetVersionId": 104884}] | [{"Id": 7251, "DatasetId": 2798, "DatasourceVersionId": 7251, "CreatorUserId": 18102, "LicenseName": "CC BY-SA 4.0", "CreationDate": "11/16/2017 21:13:35", "VersionNumber": 11.0, "Title": "Keras Pretrained models", "Slug": "keras-pretrained-models", "Subtitle": "This dataset helps to use pretrained keras models in Kernels.", "Description": "### Context\n\nKaggle has more and more computer vision challenges. Although Kernel resources were increased recently we still can not train useful CNNs without GPU. The other main problem is that Kernels can't use network connection to download pretrained keras model weights. This dataset helps you to apply your favorite pretrained model in the Kaggle Kernel environment. \n\nHappy data exploration and transfer learning!\n\n### Content\n\n Model (Top-1 Accuracy | Top -5 Accuracy)\n\n - [Xception][2] (0.790 | 0.945)\n - [VGG16][3] (0.715 | 0.901)\n - [VGG19][4] (0.727 | 0.910)\n - [ResNet50][5] (0.759 | 0.929)\n - [InceptionV3][6] (0.788 | 0.944)\n - [InceptionResNetV2][7] (0.804 | 0.953) (could not upload due to 500 MB limit)\n\nFor more information see https://keras.io/applications/\n\n### Acknowledgements\nThanks to Fran\u00e7ois Chollet for collecting these models and for the awesome keras.\n\n\n [1]: https://www.kaggle.io/svf/1567125/6050f9f4b59e20afee8b68c84f79ea6c/__results___files/__results___7_0.png\n [2]: https://keras.io/applications/#xception\n [3]: https://keras.io/applications/#vgg16\n [4]: https://keras.io/applications/#vgg19\n [5]: https://keras.io/applications/#resnet50\n [6]: https://keras.io/applications/#inceptionv3\n [7]: https://keras.io/applications/#inceptionresnetv2", "VersionNotes": "Removed VGGs", "TotalCompressedBytes": 989270724.0, "TotalUncompressedBytes": 989270724.0}] | [{"Id": 2798, "CreatorUserId": 18102, "OwnerUserId": 18102.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 7251.0, "CurrentDatasourceVersionId": 7251.0, "ForumId": 7260, "Type": 2, "CreationDate": "10/03/2017 16:57:14", "LastActivityDate": "02/06/2018", "TotalViews": 87437, "TotalDownloads": 22618, "TotalVotes": 450, "TotalKernels": 651}] | [{"Id": 18102, "UserName": "gaborfodor", "DisplayName": "beluga", "RegisterDate": "10/05/2011", "PerformanceTier": 4}] | # # FROM REFERENCEE
# **Catatan penting pada versi ini:**
# 1. Preprocess diganti dari *keras.applications.mobilenet.preprocess_input* menjadi *keras.applications.inception_v3.preprocess_input*
import keras
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
import os
print(os.listdir("../input"))
# Any results you write to the current directory are saved as output.
import pandas as pd
df_data = pd.read_csv("../input/metadata/metadata.csv")
df_data.head()
df_data["dx"].unique()
import matplotlib.pyplot as plt
# exp = pd.Series.to_frame(df1.groupby('dx').sex.value_counts())
df_data["dx"].value_counts().plot.bar(rot=0)
plt.title("Number of images for different dx type")
plt.xlabel("dx")
plt.ylabel("Counts")
plt.grid(axis="y")
# # 1. Create several more columns for the dataframe 'df'
# 1. Create 'num_images' to record the number of images belonging to the same 'lesion_id'
# 2. Create 'dx_id' convert the 'dx' to integer label
# 3. Create 'image_path' to store the path to access the image
# 4. Create 'images' to store the resized image as arrays
# Memberi informasi berapa banyak citra yang dikaitkan dengan setiap lesion_id
df = df_data.groupby("lesion_id").count()
# Memfilter lesion_id yang hanya memiliki satu citra yang terkait dengannya
df = df[df["image_id"] == 1]
df.reset_index(inplace=True)
df_data.head()
# identifikasi lesion_id yg mempunyai duplikat citra atau tidak.
def identify_duplicates(x):
unique_list = list(df["lesion_id"])
if x in unique_list:
return "no_duplicates"
else:
return "has_duplicates"
# buat kolom baru yang merupakan salinan dari kolom lesi _id
df_data["duplicates"] = df_data["lesion_id"]
# terapkan fungsi ke kolom baru ini
df_data["duplicates"] = df_data["duplicates"].apply(identify_duplicates)
df_data.head(50)
df_data["duplicates"].value_counts()
# filter citra yang tidak memiliki duplikat
df = df_data[df_data["duplicates"] == "no_duplicates"]
print("Citra yang tidak memiliki duplikat berjumlah")
df.shape
# df yang telah dipastikan tidak memiliki duplikat displit kemudian dijadikan set val (validasi)
y = df["dx"]
import tensorflow
from sklearn.model_selection import train_test_split
_, df_val = train_test_split(df, test_size=0.17, random_state=101, stratify=y)
# train_size -> If float, should be between 0.0 and 1.0 and represent the proportion of the dataset to include in the train split
# randostate -> If int, random_state is the seed used by the random number generator
# stratif -> If not None, data is split in a stratified fashion
print("Jumlah citra sebagai validasi")
df_val.shape
# Membuat set train yg tidak termasuk images yg ada di set val
# Fungsi ini mengidentifikasi apakah gambar adalah bagian dari set train atau set val
def identify_val_rows(x):
# create a list of all the lesion_id's in the val set
val_list = list(df_val["image_id"])
if str(x) in val_list:
return "val"
else:
return "train"
# buat kolom baru yang merupakan salinan dari kolom image_id
df_data["train_or_val"] = df_data["image_id"]
# terapkan fungsi ke kolom baru ini
df_data["train_or_val"] = df_data["train_or_val"].apply(identify_val_rows)
# filter baris set train
df_train = df_data[df_data["train_or_val"] == "train"]
print("Jumlah citra yang akan dijadikan set train:")
print(len(df_train))
print("Jumlah citra yang akan dijadikan set validasi:")
print(len(df_val))
print("Jumlah citra yang tiap class yang akan dijadikan set train sebelum augmanted")
print(df_train["dx"].value_counts())
print("Jumlah citra yang tiap class yang akan dijadikan set validas")
print(df_val["dx"].value_counts())
# cek berapa banyak image di set train setiap class
print("Jumlah data citra setelah dilakukan Augmanted")
print(len(os.listdir("../input/basedir/base_dir/base_dir/train_dir/nv")))
print(len(os.listdir("../input/basedir/base_dir/base_dir/train_dir/mel")))
print(len(os.listdir("../input/basedir/base_dir/base_dir/train_dir/bkl")))
print(len(os.listdir("../input/basedir/base_dir/base_dir/train_dir/bcc")))
print(len(os.listdir("../input/basedir/base_dir/base_dir/train_dir/akiec")))
print(len(os.listdir("../input/basedir/base_dir/base_dir/train_dir/vasc")))
print(len(os.listdir("../input/basedir/base_dir/base_dir/train_dir/df")))
train_path = "../input/basedir/base_dir/base_dir/train_dir"
valid_path = "../input/basedir/base_dir/base_dir/val_dir"
num_train_samples = len(df_train)
num_val_samples = len(df_val)
train_batch_size = 10
val_batch_size = 10
image_size = 224
train_steps = np.ceil(num_train_samples / train_batch_size)
val_steps = np.ceil(num_val_samples / val_batch_size)
print(train_steps)
print(val_steps)
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(
preprocessing_function=keras.applications.inception_v3.preprocess_input
)
train_batches = datagen.flow_from_directory(
train_path, target_size=(image_size, image_size), batch_size=train_batch_size
)
valid_batches = datagen.flow_from_directory(
valid_path, target_size=(image_size, image_size), batch_size=val_batch_size
)
# Note: shuffle=False causes the test dataset to not be shuffled
test_batches = datagen.flow_from_directory(
valid_path, target_size=(image_size, image_size), batch_size=1, shuffle=False
)
# # 5. Build CNN model -- InceptionV3
import keras
from keras.applications import InceptionV3
from keras.models import Sequential
from keras.layers import Dense, Dropout
from keras import regularizers
input_shape = (224, 224, 3)
num_labels = 7
base_model = InceptionV3(
include_top=False,
input_shape=(224, 224, 3),
pooling="avg",
weights="../input/keras-pretrained-models/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5",
)
model = Sequential()
model.add(base_model)
model.add(Dropout(0.5))
model.add(Dense(128, activation="relu", kernel_regularizer=regularizers.l2(0.02)))
model.add(Dropout(0.5))
model.add(Dense(7, activation="softmax", kernel_regularizer=regularizers.l2(0.02)))
for layer in base_model.layers:
layer.trainable = True
# for layer in base_model.layers[-30:]:
# layer.trainable = True
# model.add(ResNet50(include_top = False, pooling = 'max', weights = '../input/resnet50/resnet50_weights_tf_dim_ordering_tf_kernels_notop.h5'))
model.summary()
print(valid_batches.class_indices)
class_weights = {
0: 1.0, # akiec
1: 1.0, # bcc
2: 1.0, # bkl
3: 1.0, # df
4: 3.0, # mel # Try to make the model more sensitive to Melanoma.
5: 1.0, # nv
6: 1.0, # vasc
}
from keras.optimizers import Adam
optimizer = Adam(
lr=0.0005, beta_1=0.9, beta_2=0.999, epsilon=None, decay=5e-7, amsgrad=False
)
model.compile(
optimizer=optimizer, loss="categorical_crossentropy", metrics=["accuracy"]
)
# Fit the model
from keras.callbacks import ReduceLROnPlateau, ModelCheckpoint, EarlyStopping
class CustomModelCheckPoint(keras.callbacks.Callback):
def __init__(self, **kargs):
super(CustomModelCheckPoint, self).__init__(**kargs)
self.epoch_accuracy = {} # loss at given epoch
self.epoch_loss = {} # accuracy at given epoch
def on_epoch_begin(self, epoch, logs={}):
# Things done on beginning of epoch.
return
def on_epoch_end(self, epoch, logs={}):
# things done on end of the epoch
self.epoch_accuracy[epoch] = logs.get("acc")
self.epoch_loss[epoch] = logs.get("loss")
self.model.save_weights("name-of-model-%d.h5" % epoch)
checkpoint = CustomModelCheckPoint()
cb_early_stopper = ReduceLROnPlateau(
monitor="val_loss",
factor=0.1,
patience=10,
verbose=0,
mode="auto",
min_delta=0.0001,
cooldown=0,
min_lr=0,
)
cb_checkpointer = ModelCheckpoint(
filepath="../working/best.h5", monitor="val_loss", save_best_only=True, mode="auto"
)
callbacks_list = [cb_checkpointer, cb_early_stopper]
epochs = 30
trainhistory = model.fit_generator(
train_batches,
validation_steps=val_steps,
class_weight=class_weights,
epochs=epochs,
validation_data=valid_batches,
verbose=1,
steps_per_epoch=train_steps,
callbacks=callbacks_list,
)
# # 6. Plot the accuracy and loss of both training and validation dataset
import matplotlib.pyplot as plt
acc = trainhistory.history["acc"]
val_acc = trainhistory.history["val_acc"]
loss = trainhistory.history["loss"]
val_loss = trainhistory.history["val_loss"]
epochs = range(1, len(acc) + 1)
plt.plot(epochs, loss, "", label="Training loss")
plt.plot(epochs, val_loss, "", label="Validation loss")
plt.title("InceptionV3 -- Training and validation loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.figure()
plt.plot(epochs, acc, "", label="Training accuracy")
plt.plot(epochs, val_acc, "", label="Validation accuracy")
plt.title("InceptionV3 -- Training and validation accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
model.load_weights("../working/best.h5")
test_loss, test_acc = model.evaluate_generator(
test_batches, steps=len(df_val), verbose=1
)
print("test_accuracy = %f ; test_loss = %f" % (test_acc, test_loss))
# Source: Scikit Learn website
# http://scikit-learn.org/stable/auto_examples/
# model_selection/plot_confusion_matrix.html#sphx-glr-auto-examples-model-
# selection-plot-confusion-matrix-py
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
import itertools
def plot_confusion_matrix(
cm, classes, normalize=False, title="Confusion matrix", cmap=plt.cm.Blues
):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
if normalize:
cm = cm.astype("float") / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print("Confusion matrix, without normalization")
print(cm)
plt.imshow(cm, interpolation="nearest", cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = ".2f" if normalize else "d"
thresh = cm.max() / 2.0
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(
j,
i,
format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black",
)
plt.ylabel("True label")
plt.xlabel("Predicted label")
plt.tight_layout()
test_labels = test_batches.classes
test_labels
test_labels.shape
predictions = model.predict_generator(test_batches, steps=len(df_val), verbose=1)
# argmax returns the index of the max value in a row
cm = confusion_matrix(test_labels, predictions.argmax(axis=1))
# Define the labels of the class indices. These need to match the
# order shown above.
cm_plot_labels = ["akiec", "bcc", "bkl", "df", "mel", "nv", "vasc"]
plot_confusion_matrix(cm, cm_plot_labels, title="Confusion Matrix")
# Get the index of the class with the highest probability score
y_pred = np.argmax(predictions, axis=1)
# Get the labels of the test images.
y_true = test_batches.classes
from sklearn.metrics import classification_report
# Generate a classification report
report = classification_report(y_true, y_pred, target_names=cm_plot_labels)
print(report)
| false | 1 | 3,703 | 1 | 295 | 3,703 |
||
14970735 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt # Visualisation Tool
import seaborn as sns # Visualisation Tool
import sys
import math
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
import os
print(os.listdir("../input"))
# Any results you write to the current directory are saved as output.
# Display Available Line/Cell Magics
cities = pd.read_csv("../input/cities.csv")
cities.head()
print(len(cities))
# Show Scatter Plot of Original Data
plt.figure(figsize=(15, 10))
plt.scatter(cities.X, cities.Y, s=1)
plt.scatter(cities.iloc[0:1, 1], cities.iloc[0:1, 2], s=10, c="red")
plt.grid(False)
plt.show()
# Reference: https://www.kaggle.com/seshadrikolluri/understanding-the-problem-and-some-sample-paths
# Reference: https://www.kaggle.com/seshadrikolluri/understanding-the-problem-and-some-sample-paths
# To improve the performance, instead of checking whether each member is a prime,
# we first a generate a list where each element tells whether the number indicated
# by the position is a prime or not.
# using sieve of eratosthenes
def sieve_of_eratosthenes(n):
primes = [True for i in range(n + 1)] # Start assuming all numbers are primes
primes[0] = False # 0 is not a prime
primes[1] = False # 1 is not a prime
for i in range(2, int(np.sqrt(n)) + 1):
if primes[i]:
k = 2
while i * k <= n:
primes[i * k] = False
k += 1
return primes
prime_cities = sieve_of_eratosthenes(max(cities.CityId))
sub1 = cities.copy()
sub2 = cities.copy()
# # Algorithm 1: Merge Sort
# # Data Structure 1: Map
# # Import classes from TextbookSampleCode
# * MapBase
from collections import MutableMapping
class MapBase(MutableMapping):
"""Our own abstract base class that includes a nonpublic _Item class."""
# ------------------------------- nested _Item class -------------------------------
class _Item:
"""Lightweight composite to store key-value pairs as map items."""
__slots__ = "_key", "_value"
def __init__(self, k, v):
self._key = k
self._value = v
def __eq__(self, other):
return self._key == other._key # compare items based on their keys
def __ne__(self, other):
return not (self == other) # opposite of __eq__
def __lt__(self, other):
return self._key < other._key # compare items based on their keys
# * SortedTableMap
class SortedTableMap(MapBase):
"""Map implementation using a sorted table."""
# ----------------------------- nonpublic behaviors -----------------------------
def _find_index(self, k, low, high):
"""Return index of the leftmost item with key greater than or equal to k.
Return high + 1 if no such item qualifies.
That is, j will be returned such that:
all items of slice table[low:j] have key < k
all items of slice table[j:high+1] have key >= k
"""
if high < low:
return high + 1 # no element qualifies
else:
mid = (low + high) // 2
if k == self._table[mid]._key:
return mid # found exact match
elif k < self._table[mid]._key:
return self._find_index(k, low, mid - 1) # Note: may return mid
else:
return self._find_index(k, mid + 1, high) # answer is right of mid
# ----------------------------- public behaviors -----------------------------
def __init__(self):
"""Create an empty map."""
self._table = []
def __len__(self):
"""Return number of items in the map."""
return len(self._table)
def __getitem__(self, k):
"""Return value associated with key k (raise KeyError if not found)."""
j = self._find_index(k, 0, len(self._table) - 1)
if j == len(self._table) or self._table[j]._key != k:
raise KeyError("Key Error: " + repr(k))
return self._table[j]._value
def __setitem__(self, k, v):
"""Assign value v to key k, overwriting existing value if present."""
j = self._find_index(k, 0, len(self._table) - 1)
if j < len(self._table) and self._table[j]._key == k:
self._table[j]._value = v # reassign value
else:
self._table.insert(j, self._Item(k, v)) # adds new item
def __delitem__(self, k):
"""Remove item associated with key k (raise KeyError if not found)."""
j = self._find_index(k, 0, len(self._table) - 1)
if j == len(self._table) or self._table[j]._key != k:
raise KeyError("Key Error: " + repr(k))
self._table.pop(j) # delete item
def __iter__(self):
"""Generate keys of the map ordered from minimum to maximum."""
for item in self._table:
yield item._key
def __reversed__(self):
"""Generate keys of the map ordered from maximum to minimum."""
for item in reversed(self._table):
yield item._key
def find_min(self):
"""Return (key,value) pair with minimum key (or None if empty)."""
if len(self._table) > 0:
return (self._table[0]._key, self._table[0]._value)
else:
return None
def find_max(self):
"""Return (key,value) pair with maximum key (or None if empty)."""
if len(self._table) > 0:
return (self._table[-1]._key, self._table[-1]._value)
else:
return None
def find_le(self, k):
"""Return (key,value) pair with greatest key less than or equal to k.
Return None if there does not exist such a key.
"""
j = self._find_index(k, 0, len(self._table) - 1) # j's key >= k
if j < len(self._table) and self._table[j]._key == k:
return (self._table[j]._key, self._table[j]._value) # exact match
elif j > 0:
return (
self._table[j - 1]._key,
self._table[j - 1]._value,
) # Note use of j-1
else:
return None
def find_ge(self, k):
"""Return (key,value) pair with least key greater than or equal to k.
Return None if there does not exist such a key.
"""
j = self._find_index(k, 0, len(self._table) - 1) # j's key >= k
if j < len(self._table):
return (self._table[j]._key, self._table[j]._value)
else:
return None
def find_lt(self, k):
"""Return (key,value) pair with greatest key strictly less than k.
Return None if there does not exist such a key.
"""
j = self._find_index(k, 0, len(self._table) - 1) # j's key >= k
if j > 0:
return (
self._table[j - 1]._key,
self._table[j - 1]._value,
) # Note use of j-1
else:
return None
def find_gt(self, k):
"""Return (key,value) pair with least key strictly greater than k.
Return None if there does not exist such a key.
"""
j = self._find_index(k, 0, len(self._table) - 1) # j's key >= k
if j < len(self._table) and self._table[j]._key == k:
j += 1 # advanced past match
if j < len(self._table):
return (self._table[j]._key, self._table[j]._value)
else:
return None
def find_range(self, start, stop):
"""Iterate all (key,value) pairs such that start <= key < stop.
If start is None, iteration begins with minimum key of map.
If stop is None, iteration continues through the maximum key of map.
"""
if start is None:
j = 0
else:
j = self._find_index(start, 0, len(self._table) - 1) # find first result
while j < len(self._table) and (stop is None or self._table[j]._key < stop):
yield (self._table[j]._key, self._table[j]._value)
j += 1
# # Sort Path in X,Y Order Using MergeSort and Record Time Taken
# Use Merge Sort Algorithm to create sorted cities path
sorted_cities_path = list(
sub1.iloc[1:,].sort_values(["X", "Y"], kind="mergesort")["CityId"]
)
sorted_cities_path = [0] + sorted_cities_path + [0]
# Record Time Taken
# Altered function from: https://www.kaggle.com/seshadrikolluri/understanding-the-problem-and-some-sample-paths
# Calculate euclidean distance and store in a Sorted Map
def calculate_distance(dfcity, path):
prev_city = path[0]
distance = 0
distances = SortedTableMap()
step_num = 1
for city_num in path[1:]:
next_city = city_num
distance = np.sqrt(
pow((dfcity.X[city_num] - dfcity.X[prev_city]), 2)
+ pow((dfcity.Y[city_num] - dfcity.Y[prev_city]), 2)
) * (1 + 0.1 * ((step_num % 10 == 0) * int(not (prime_cities[prev_city]))))
distances.__setitem__(city_num, distance)
prev_city = next_city
step_num = step_num + 1
return distances
distances_sub1 = calculate_distance(sub1, sorted_cities_path)
# Time function creating Map with calculated distances
# Calculate Total Distance from Map
def total_distance(distances):
total_distance = 0
for i in distances:
total_distance += distances[i]
return total_distance
print("Total distance is " + "{:,}".format(total_distance(distances_sub1)))
# Time function calculating total distance
# # **Algorithm Analysis: Merge Sort**
# * Using MergeSort to sort the cities in X, Y order, takes O(n lg n) time regarding total running time.
# * The height of MergeSort results in O(lg n) time as each recursive call is dividing the sequence in half.
# * The operations executed at each node at such depth results in O(n) time.
# # Chosen DataStructure: SortedMapTable
# * A SortedMapTable was implemented to store the calculated distances in.
# * By adding a key, value pair by using the __setitem__ function takes O(1) time, however, calculating the total distance took a total running time of O(n).
# # Algorithm 2: QuickSort
# # Data Structure 2: BinarySearchTree
# # Import classes from TextbookSampleCode
# * Tree
class Tree:
"""Abstract base class representing a tree structure."""
# ------------------------------- nested Position class -------------------------------
class Position:
"""An abstraction representing the location of a single element within a tree.
Note that two position instaces may represent the same inherent location in a tree.
Therefore, users should always rely on syntax 'p == q' rather than 'p is q' when testing
equivalence of positions.
"""
def element(self):
"""Return the element stored at this Position."""
raise NotImplementedError("must be implemented by subclass")
def __eq__(self, other):
"""Return True if other Position represents the same location."""
raise NotImplementedError("must be implemented by subclass")
def __ne__(self, other):
"""Return True if other does not represent the same location."""
return not (self == other) # opposite of __eq__
# ---------- abstract methods that concrete subclass must support ----------
def root(self):
"""Return Position representing the tree's root (or None if empty)."""
raise NotImplementedError("must be implemented by subclass")
def parent(self, p):
"""Return Position representing p's parent (or None if p is root)."""
raise NotImplementedError("must be implemented by subclass")
def num_children(self, p):
"""Return the number of children that Position p has."""
raise NotImplementedError("must be implemented by subclass")
def children(self, p):
"""Generate an iteration of Positions representing p's children."""
raise NotImplementedError("must be implemented by subclass")
def __len__(self):
"""Return the total number of elements in the tree."""
raise NotImplementedError("must be implemented by subclass")
# ---------- concrete methods implemented in this class ----------
def is_root(self, p):
"""Return True if Position p represents the root of the tree."""
return self.root() == p
def is_leaf(self, p):
"""Return True if Position p does not have any children."""
return self.num_children(p) == 0
def is_empty(self):
"""Return True if the tree is empty."""
return len(self) == 0
def depth(self, p):
"""Return the number of levels separating Position p from the root."""
if self.is_root(p):
return 0
else:
return 1 + self.depth(self.parent(p))
def _height1(self): # works, but O(n^2) worst-case time
"""Return the height of the tree."""
return max(self.depth(p) for p in self.positions() if self.is_leaf(p))
def _height2(self, p): # time is linear in size of subtree
"""Return the height of the subtree rooted at Position p."""
if self.is_leaf(p):
return 0
else:
return 1 + max(self._height2(c) for c in self.children(p))
def height(self, p=None):
"""Return the height of the subtree rooted at Position p.
If p is None, return the height of the entire tree.
"""
if p is None:
p = self.root()
return self._height2(p) # start _height2 recursion
def __iter__(self):
"""Generate an iteration of the tree's elements."""
for p in self.positions(): # use same order as positions()
yield p.element() # but yield each element
def positions(self):
"""Generate an iteration of the tree's positions."""
return self.preorder() # return entire preorder iteration
def preorder(self):
"""Generate a preorder iteration of positions in the tree."""
if not self.is_empty():
for p in self._subtree_preorder(self.root()): # start recursion
yield p
def _subtree_preorder(self, p):
"""Generate a preorder iteration of positions in subtree rooted at p."""
yield p # visit p before its subtrees
for c in self.children(p): # for each child c
for other in self._subtree_preorder(c): # do preorder of c's subtree
yield other # yielding each to our caller
def postorder(self):
"""Generate a postorder iteration of positions in the tree."""
if not self.is_empty():
for p in self._subtree_postorder(self.root()): # start recursion
yield p
def _subtree_postorder(self, p):
"""Generate a postorder iteration of positions in subtree rooted at p."""
for c in self.children(p): # for each child c
for other in self._subtree_postorder(c): # do postorder of c's subtree
yield other # yielding each to our caller
yield p # visit p after its subtrees
def breadthfirst(self):
"""Generate a breadth-first iteration of the positions of the tree."""
if not self.is_empty():
fringe = LinkedQueue() # known positions not yet yielded
fringe.enqueue(self.root()) # starting with the root
while not fringe.is_empty():
p = fringe.dequeue() # remove from front of the queue
yield p # report this position
for c in self.children(p):
fringe.enqueue(c) # add children to back of queue
# BinaryTree
class BinaryTree(Tree):
"""Abstract base class representing a binary tree structure."""
# --------------------- additional abstract methods ---------------------
def left(self, p):
"""Return a Position representing p's left child.
Return None if p does not have a left child.
"""
raise NotImplementedError("must be implemented by subclass")
def right(self, p):
"""Return a Position representing p's right child.
Return None if p does not have a right child.
"""
raise NotImplementedError("must be implemented by subclass")
# ---------- concrete methods implemented in this class ----------
def sibling(self, p):
"""Return a Position representing p's sibling (or None if no sibling)."""
parent = self.parent(p)
if parent is None: # p must be the root
return None # root has no sibling
else:
if p == self.left(parent):
return self.right(parent) # possibly None
else:
return self.left(parent) # possibly None
def children(self, p):
"""Generate an iteration of Positions representing p's children."""
if self.left(p) is not None:
yield self.left(p)
if self.right(p) is not None:
yield self.right(p)
def inorder(self):
"""Generate an inorder iteration of positions in the tree."""
if not self.is_empty():
for p in self._subtree_inorder(self.root()):
yield p
def _subtree_inorder(self, p):
"""Generate an inorder iteration of positions in subtree rooted at p."""
if self.left(p) is not None: # if left child exists, traverse its subtree
for other in self._subtree_inorder(self.left(p)):
yield other
yield p # visit p between its subtrees
if self.right(p) is not None: # if right child exists, traverse its subtree
for other in self._subtree_inorder(self.right(p)):
yield other
# override inherited version to make inorder the default
def positions(self):
"""Generate an iteration of the tree's positions."""
return self.inorder() # make inorder the default
# * LinkedBinaryTree
class LinkedBinaryTree(BinaryTree):
"""Linked representation of a binary tree structure."""
# -------------------------- nested _Node class --------------------------
class _Node:
"""Lightweight, nonpublic class for storing a node."""
__slots__ = "_element", "_parent", "_left", "_right" # streamline memory usage
def __init__(self, element, parent=None, left=None, right=None):
self._element = element
self._parent = parent
self._left = left
self._right = right
# -------------------------- nested Position class --------------------------
class Position(BinaryTree.Position):
"""An abstraction representing the location of a single element."""
def __init__(self, container, node):
"""Constructor should not be invoked by user."""
self._container = container
self._node = node
def element(self):
"""Return the element stored at this Position."""
return self._node._element
def __eq__(self, other):
"""Return True if other is a Position representing the same location."""
return type(other) is type(self) and other._node is self._node
# ------------------------------- utility methods -------------------------------
def _validate(self, p):
"""Return associated node, if position is valid."""
if not isinstance(p, self.Position):
raise TypeError("p must be proper Position type")
if p._container is not self:
raise ValueError("p does not belong to this container")
if p._node._parent is p._node: # convention for deprecated nodes
raise ValueError("p is no longer valid")
return p._node
def _make_position(self, node):
"""Return Position instance for given node (or None if no node)."""
return self.Position(self, node) if node is not None else None
# -------------------------- binary tree constructor --------------------------
def __init__(self):
"""Create an initially empty binary tree."""
self._root = None
self._size = 0
# -------------------------- public accessors --------------------------
def __len__(self):
"""Return the total number of elements in the tree."""
return self._size
def root(self):
"""Return the root Position of the tree (or None if tree is empty)."""
return self._make_position(self._root)
def parent(self, p):
"""Return the Position of p's parent (or None if p is root)."""
node = self._validate(p)
return self._make_position(node._parent)
def left(self, p):
"""Return the Position of p's left child (or None if no left child)."""
node = self._validate(p)
return self._make_position(node._left)
def right(self, p):
"""Return the Position of p's right child (or None if no right child)."""
node = self._validate(p)
return self._make_position(node._right)
def num_children(self, p):
"""Return the number of children of Position p."""
node = self._validate(p)
count = 0
if node._left is not None: # left child exists
count += 1
if node._right is not None: # right child exists
count += 1
return count
# -------------------------- nonpublic mutators --------------------------
def _add_root(self, e):
"""Place element e at the root of an empty tree and return new Position.
Raise ValueError if tree nonempty.
"""
if self._root is not None:
raise ValueError("Root exists")
self._size = 1
self._root = self._Node(e)
return self._make_position(self._root)
def _add_left(self, p, e):
"""Create a new left child for Position p, storing element e.
Return the Position of new node.
Raise ValueError if Position p is invalid or p already has a left child.
"""
node = self._validate(p)
if node._left is not None:
raise ValueError("Left child exists")
self._size += 1
node._left = self._Node(e, node) # node is its parent
return self._make_position(node._left)
def _add_right(self, p, e):
"""Create a new right child for Position p, storing element e.
Return the Position of new node.
Raise ValueError if Position p is invalid or p already has a right child.
"""
node = self._validate(p)
if node._right is not None:
raise ValueError("Right child exists")
self._size += 1
node._right = self._Node(e, node) # node is its parent
return self._make_position(node._right)
def _replace(self, p, e):
"""Replace the element at position p with e, and return old element."""
node = self._validate(p)
old = node._element
node._element = e
return old
def _delete(self, p):
"""Delete the node at Position p, and replace it with its child, if any.
Return the element that had been stored at Position p.
Raise ValueError if Position p is invalid or p has two children.
"""
node = self._validate(p)
if self.num_children(p) == 2:
raise ValueError("Position has two children")
child = node._left if node._left else node._right # might be None
if child is not None:
child._parent = node._parent # child's grandparent becomes parent
if node is self._root:
self._root = child # child becomes root
else:
parent = node._parent
if node is parent._left:
parent._left = child
else:
parent._right = child
self._size -= 1
node._parent = node # convention for deprecated node
return node._element
def _attach(self, p, t1, t2):
"""Attach trees t1 and t2, respectively, as the left and right subtrees of the external Position p.
As a side effect, set t1 and t2 to empty.
Raise TypeError if trees t1 and t2 do not match type of this tree.
Raise ValueError if Position p is invalid or not external.
"""
node = self._validate(p)
if not self.is_leaf(p):
raise ValueError("position must be leaf")
if not type(self) is type(t1) is type(t2): # all 3 trees must be same type
raise TypeError("Tree types must match")
self._size += len(t1) + len(t2)
if not t1.is_empty(): # attached t1 as left subtree of node
t1._root._parent = node
node._left = t1._root
t1._root = None # set t1 instance to empty
t1._size = 0
if not t2.is_empty(): # attached t2 as right subtree of node
t2._root._parent = node
node._right = t2._root
t2._root = None # set t2 instance to empty
t2._size = 0
# * TreeMap
class TreeMap(LinkedBinaryTree, MapBase):
"""Sorted map implementation using a binary search tree."""
# ---------------------------- override Position class ----------------------------
class Position(LinkedBinaryTree.Position):
def key(self):
"""Return key of map's key-value pair."""
return self.element()._key
def value(self):
"""Return value of map's key-value pair."""
return self.element()._value
# ------------------------------- nonpublic utilities -------------------------------
def _subtree_search(self, p, k):
"""Return Position of p's subtree having key k, or last node searched."""
if k == p.key(): # found match
return p
elif k < p.key(): # search left subtree
if self.left(p) is not None:
return self._subtree_search(self.left(p), k)
else: # search right subtree
if self.right(p) is not None:
return self._subtree_search(self.right(p), k)
return p # unsucessful search
def _subtree_first_position(self, p):
"""Return Position of first item in subtree rooted at p."""
walk = p
while self.left(walk) is not None: # keep walking left
walk = self.left(walk)
return walk
def _subtree_last_position(self, p):
"""Return Position of last item in subtree rooted at p."""
walk = p
while self.right(walk) is not None: # keep walking right
walk = self.right(walk)
return walk
# --------------------- public methods providing "positional" support ---------------------
def first(self):
"""Return the first Position in the tree (or None if empty)."""
return self._subtree_first_position(self.root()) if len(self) > 0 else None
def last(self):
"""Return the last Position in the tree (or None if empty)."""
return self._subtree_last_position(self.root()) if len(self) > 0 else None
def before(self, p):
"""Return the Position just before p in the natural order.
Return None if p is the first position.
"""
self._validate(p) # inherited from LinkedBinaryTree
if self.left(p):
return self._subtree_last_position(self.left(p))
else:
# walk upward
walk = p
above = self.parent(walk)
while above is not None and walk == self.left(above):
walk = above
above = self.parent(walk)
return above
def after(self, p):
"""Return the Position just after p in the natural order.
Return None if p is the last position.
"""
self._validate(p) # inherited from LinkedBinaryTree
if self.right(p):
return self._subtree_first_position(self.right(p))
else:
walk = p
above = self.parent(walk)
while above is not None and walk == self.right(above):
walk = above
above = self.parent(walk)
return above
def find_position(self, k):
"""Return position with key k, or else neighbor (or None if empty)."""
if self.is_empty():
return None
else:
p = self._subtree_search(self.root(), k)
self._rebalance_access(p) # hook for balanced tree subclasses
return p
def delete(self, p):
"""Remove the item at given Position."""
self._validate(p) # inherited from LinkedBinaryTree
if self.left(p) and self.right(p): # p has two children
replacement = self._subtree_last_position(self.left(p))
self._replace(p, replacement.element()) # from LinkedBinaryTree
p = replacement
# now p has at most one child
parent = self.parent(p)
self._delete(p) # inherited from LinkedBinaryTree
self._rebalance_delete(parent) # if root deleted, parent is None
# --------------------- public methods for (standard) map interface ---------------------
def __getitem__(self, k):
"""Return value associated with key k (raise KeyError if not found)."""
if self.is_empty():
raise KeyError("Key Error: " + repr(k))
else:
p = self._subtree_search(self.root(), k)
self._rebalance_access(p) # hook for balanced tree subclasses
if k != p.key():
raise KeyError("Key Error: " + repr(k))
return p.value()
def __setitem__(self, k, v):
"""Assign value v to key k, overwriting existing value if present."""
if self.is_empty():
leaf = self._add_root(self._Item(k, v)) # from LinkedBinaryTree
else:
p = self._subtree_search(self.root(), k)
if p.key() == k:
p.element()._value = v # replace existing item's value
self._rebalance_access(p) # hook for balanced tree subclasses
return
else:
item = self._Item(k, v)
if p.key() < k:
leaf = self._add_right(p, item) # inherited from LinkedBinaryTree
else:
leaf = self._add_left(p, item) # inherited from LinkedBinaryTree
self._rebalance_insert(leaf) # hook for balanced tree subclasses
def __delitem__(self, k):
"""Remove item associated with key k (raise KeyError if not found)."""
if not self.is_empty():
p = self._subtree_search(self.root(), k)
if k == p.key():
self.delete(p) # rely on positional version
return # successful deletion complete
self._rebalance_access(p) # hook for balanced tree subclasses
raise KeyError("Key Error: " + repr(k))
def __iter__(self):
"""Generate an iteration of all keys in the map in order."""
p = self.first()
while p is not None:
yield p.key()
p = self.after(p)
# --------------------- public methods for sorted map interface ---------------------
def __reversed__(self):
"""Generate an iteration of all keys in the map in reverse order."""
p = self.last()
while p is not None:
yield p.key()
p = self.before(p)
def find_min(self):
"""Return (key,value) pair with minimum key (or None if empty)."""
if self.is_empty():
return None
else:
p = self.first()
return (p.key(), p.value())
def find_max(self):
"""Return (key,value) pair with maximum key (or None if empty)."""
if self.is_empty():
return None
else:
p = self.last()
return (p.key(), p.value())
def find_le(self, k):
"""Return (key,value) pair with greatest key less than or equal to k.
Return None if there does not exist such a key.
"""
if self.is_empty():
return None
else:
p = self.find_position(k)
if k < p.key():
p = self.before(p)
return (p.key(), p.value()) if p is not None else None
def find_lt(self, k):
"""Return (key,value) pair with greatest key strictly less than k.
Return None if there does not exist such a key.
"""
if self.is_empty():
return None
else:
p = self.find_position(k)
if not p.key() < k:
p = self.before(p)
return (p.key(), p.value()) if p is not None else None
def find_ge(self, k):
"""Return (key,value) pair with least key greater than or equal to k.
Return None if there does not exist such a key.
"""
if self.is_empty():
return None
else:
p = self.find_position(k) # may not find exact match
if p.key() < k: # p's key is too small
p = self.after(p)
return (p.key(), p.value()) if p is not None else None
def find_gt(self, k):
"""Return (key,value) pair with least key strictly greater than k.
Return None if there does not exist such a key.
"""
if self.is_empty():
return None
else:
p = self.find_position(k)
if not k < p.key():
p = self.after(p)
return (p.key(), p.value()) if p is not None else None
def find_range(self, start, stop):
"""Iterate all (key,value) pairs such that start <= key < stop.
If start is None, iteration begins with minimum key of map.
If stop is None, iteration continues through the maximum key of map.
"""
if not self.is_empty():
if start is None:
p = self.first()
else:
# we initialize p with logic similar to find_ge
p = self.find_position(start)
if p.key() < start:
p = self.after(p)
while p is not None and (stop is None or p.key() < stop):
yield (p.key(), p.value())
p = self.after(p)
# --------------------- hooks used by subclasses to balance a tree ---------------------
def _rebalance_insert(self, p):
"""Call to indicate that position p is newly added."""
pass
def _rebalance_delete(self, p):
"""Call to indicate that a child of p has been removed."""
pass
def _rebalance_access(self, p):
"""Call to indicate that position p was recently accessed."""
pass
# --------------------- nonpublic methods to support tree balancing ---------------------
def _relink(self, parent, child, make_left_child):
"""Relink parent node with child node (we allow child to be None)."""
if make_left_child: # make it a left child
parent._left = child
else: # make it a right child
parent._right = child
if child is not None: # make child point to parent
child._parent = parent
def _rotate(self, p):
"""Rotate Position p above its parent.
Switches between these configurations, depending on whether p==a or p==b.
b a
/ \ / \
a t2 t0 b
/ \ / \
t0 t1 t1 t2
Caller should ensure that p is not the root.
"""
"""Rotate Position p above its parent."""
x = p._node
y = x._parent # we assume this exists
z = y._parent # grandparent (possibly None)
if z is None:
self._root = x # x becomes root
x._parent = None
else:
self._relink(z, x, y == z._left) # x becomes a direct child of z
# now rotate x and y, including transfer of middle subtree
if x == y._left:
self._relink(y, x._right, True) # x._right becomes left child of y
self._relink(x, y, False) # y becomes right child of x
else:
self._relink(y, x._left, False) # x._left becomes right child of y
self._relink(x, y, True) # y becomes left child of x
def _restructure(self, x):
"""Perform a trinode restructure among Position x, its parent, and its grandparent.
Return the Position that becomes root of the restructured subtree.
Assumes the nodes are in one of the following configurations:
z=a z=c z=a z=c
/ \ / \ / \ / \
t0 y=b y=b t3 t0 y=c y=a t3
/ \ / \ / \ / \
t1 x=c x=a t2 x=b t3 t0 x=b
/ \ / \ / \ / \
t2 t3 t0 t1 t1 t2 t1 t2
The subtree will be restructured so that the node with key b becomes its root.
b
/ \
a c
/ \ / \
t0 t1 t2 t3
Caller should ensure that x has a grandparent.
"""
"""Perform trinode restructure of Position x with parent/grandparent."""
y = self.parent(x)
z = self.parent(y)
if (x == self.right(y)) == (y == self.right(z)): # matching alignments
self._rotate(y) # single rotation (of y)
return y # y is new subtree root
else: # opposite alignments
self._rotate(x) # double rotation (of x)
self._rotate(x)
return x # x is new subtree root
# # Sort Path in X,Y Order Using QuickSort and Record Time Taken
# Use Quick Sort Algorithm to create sorted cities path
sorted_cities_path2 = list(
sub2.iloc[1:,].sort_values(["X", "Y"], kind="quicksort")["CityId"]
)
sorted_cities_path2 = [0] + sorted_cities_path2 + [0]
# Record Time Taken
# Altered function from: https://www.kaggle.com/seshadrikolluri/understanding-the-problem-and-some-sample-paths
# Calculate euclidean distance and store in a Map
def calculate_distance(dfcity, path):
prev_city = path[0]
distance = 0
distances = TreeMap()
step_num = 1
for city_num in path[1:]:
next_city = city_num
distance = np.sqrt(
pow((dfcity.X[city_num] - dfcity.X[prev_city]), 2)
+ pow((dfcity.Y[city_num] - dfcity.Y[prev_city]), 2)
) * (1 + 0.1 * ((step_num % 10 == 0) * int(not (prime_cities[prev_city]))))
distances.__setitem__(city_num, distance)
prev_city = next_city
step_num = step_num + 1
return distances
distances_sub2 = calculate_distance(sub2, sorted_cities_path2)
# Calculate Total Distance from TreeMap
def total_distance(distances):
total_distance = 0
for i in distances:
total_distance += distances[i]
return total_distance
print("Total distance is " + "{:,}".format(total_distance(distances_sub2)))
# Time function calculating total distance
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0014/970/14970735.ipynb | null | null | [{"Id": 14970735, "ScriptId": 4036531, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2875114, "CreationDate": "05/31/2019 10:32:05", "VersionNumber": 7.0, "Title": "CP2410 - A2 Algorithms & Data Structures", "EvaluationDate": "05/31/2019", "IsChange": true, "TotalLines": 1064.0, "LinesInsertedFromPrevious": 9.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 1055.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt # Visualisation Tool
import seaborn as sns # Visualisation Tool
import sys
import math
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
import os
print(os.listdir("../input"))
# Any results you write to the current directory are saved as output.
# Display Available Line/Cell Magics
cities = pd.read_csv("../input/cities.csv")
cities.head()
print(len(cities))
# Show Scatter Plot of Original Data
plt.figure(figsize=(15, 10))
plt.scatter(cities.X, cities.Y, s=1)
plt.scatter(cities.iloc[0:1, 1], cities.iloc[0:1, 2], s=10, c="red")
plt.grid(False)
plt.show()
# Reference: https://www.kaggle.com/seshadrikolluri/understanding-the-problem-and-some-sample-paths
# Reference: https://www.kaggle.com/seshadrikolluri/understanding-the-problem-and-some-sample-paths
# To improve the performance, instead of checking whether each member is a prime,
# we first a generate a list where each element tells whether the number indicated
# by the position is a prime or not.
# using sieve of eratosthenes
def sieve_of_eratosthenes(n):
primes = [True for i in range(n + 1)] # Start assuming all numbers are primes
primes[0] = False # 0 is not a prime
primes[1] = False # 1 is not a prime
for i in range(2, int(np.sqrt(n)) + 1):
if primes[i]:
k = 2
while i * k <= n:
primes[i * k] = False
k += 1
return primes
prime_cities = sieve_of_eratosthenes(max(cities.CityId))
sub1 = cities.copy()
sub2 = cities.copy()
# # Algorithm 1: Merge Sort
# # Data Structure 1: Map
# # Import classes from TextbookSampleCode
# * MapBase
from collections import MutableMapping
class MapBase(MutableMapping):
"""Our own abstract base class that includes a nonpublic _Item class."""
# ------------------------------- nested _Item class -------------------------------
class _Item:
"""Lightweight composite to store key-value pairs as map items."""
__slots__ = "_key", "_value"
def __init__(self, k, v):
self._key = k
self._value = v
def __eq__(self, other):
return self._key == other._key # compare items based on their keys
def __ne__(self, other):
return not (self == other) # opposite of __eq__
def __lt__(self, other):
return self._key < other._key # compare items based on their keys
# * SortedTableMap
class SortedTableMap(MapBase):
"""Map implementation using a sorted table."""
# ----------------------------- nonpublic behaviors -----------------------------
def _find_index(self, k, low, high):
"""Return index of the leftmost item with key greater than or equal to k.
Return high + 1 if no such item qualifies.
That is, j will be returned such that:
all items of slice table[low:j] have key < k
all items of slice table[j:high+1] have key >= k
"""
if high < low:
return high + 1 # no element qualifies
else:
mid = (low + high) // 2
if k == self._table[mid]._key:
return mid # found exact match
elif k < self._table[mid]._key:
return self._find_index(k, low, mid - 1) # Note: may return mid
else:
return self._find_index(k, mid + 1, high) # answer is right of mid
# ----------------------------- public behaviors -----------------------------
def __init__(self):
"""Create an empty map."""
self._table = []
def __len__(self):
"""Return number of items in the map."""
return len(self._table)
def __getitem__(self, k):
"""Return value associated with key k (raise KeyError if not found)."""
j = self._find_index(k, 0, len(self._table) - 1)
if j == len(self._table) or self._table[j]._key != k:
raise KeyError("Key Error: " + repr(k))
return self._table[j]._value
def __setitem__(self, k, v):
"""Assign value v to key k, overwriting existing value if present."""
j = self._find_index(k, 0, len(self._table) - 1)
if j < len(self._table) and self._table[j]._key == k:
self._table[j]._value = v # reassign value
else:
self._table.insert(j, self._Item(k, v)) # adds new item
def __delitem__(self, k):
"""Remove item associated with key k (raise KeyError if not found)."""
j = self._find_index(k, 0, len(self._table) - 1)
if j == len(self._table) or self._table[j]._key != k:
raise KeyError("Key Error: " + repr(k))
self._table.pop(j) # delete item
def __iter__(self):
"""Generate keys of the map ordered from minimum to maximum."""
for item in self._table:
yield item._key
def __reversed__(self):
"""Generate keys of the map ordered from maximum to minimum."""
for item in reversed(self._table):
yield item._key
def find_min(self):
"""Return (key,value) pair with minimum key (or None if empty)."""
if len(self._table) > 0:
return (self._table[0]._key, self._table[0]._value)
else:
return None
def find_max(self):
"""Return (key,value) pair with maximum key (or None if empty)."""
if len(self._table) > 0:
return (self._table[-1]._key, self._table[-1]._value)
else:
return None
def find_le(self, k):
"""Return (key,value) pair with greatest key less than or equal to k.
Return None if there does not exist such a key.
"""
j = self._find_index(k, 0, len(self._table) - 1) # j's key >= k
if j < len(self._table) and self._table[j]._key == k:
return (self._table[j]._key, self._table[j]._value) # exact match
elif j > 0:
return (
self._table[j - 1]._key,
self._table[j - 1]._value,
) # Note use of j-1
else:
return None
def find_ge(self, k):
"""Return (key,value) pair with least key greater than or equal to k.
Return None if there does not exist such a key.
"""
j = self._find_index(k, 0, len(self._table) - 1) # j's key >= k
if j < len(self._table):
return (self._table[j]._key, self._table[j]._value)
else:
return None
def find_lt(self, k):
"""Return (key,value) pair with greatest key strictly less than k.
Return None if there does not exist such a key.
"""
j = self._find_index(k, 0, len(self._table) - 1) # j's key >= k
if j > 0:
return (
self._table[j - 1]._key,
self._table[j - 1]._value,
) # Note use of j-1
else:
return None
def find_gt(self, k):
"""Return (key,value) pair with least key strictly greater than k.
Return None if there does not exist such a key.
"""
j = self._find_index(k, 0, len(self._table) - 1) # j's key >= k
if j < len(self._table) and self._table[j]._key == k:
j += 1 # advanced past match
if j < len(self._table):
return (self._table[j]._key, self._table[j]._value)
else:
return None
def find_range(self, start, stop):
"""Iterate all (key,value) pairs such that start <= key < stop.
If start is None, iteration begins with minimum key of map.
If stop is None, iteration continues through the maximum key of map.
"""
if start is None:
j = 0
else:
j = self._find_index(start, 0, len(self._table) - 1) # find first result
while j < len(self._table) and (stop is None or self._table[j]._key < stop):
yield (self._table[j]._key, self._table[j]._value)
j += 1
# # Sort Path in X,Y Order Using MergeSort and Record Time Taken
# Use Merge Sort Algorithm to create sorted cities path
sorted_cities_path = list(
sub1.iloc[1:,].sort_values(["X", "Y"], kind="mergesort")["CityId"]
)
sorted_cities_path = [0] + sorted_cities_path + [0]
# Record Time Taken
# Altered function from: https://www.kaggle.com/seshadrikolluri/understanding-the-problem-and-some-sample-paths
# Calculate euclidean distance and store in a Sorted Map
def calculate_distance(dfcity, path):
prev_city = path[0]
distance = 0
distances = SortedTableMap()
step_num = 1
for city_num in path[1:]:
next_city = city_num
distance = np.sqrt(
pow((dfcity.X[city_num] - dfcity.X[prev_city]), 2)
+ pow((dfcity.Y[city_num] - dfcity.Y[prev_city]), 2)
) * (1 + 0.1 * ((step_num % 10 == 0) * int(not (prime_cities[prev_city]))))
distances.__setitem__(city_num, distance)
prev_city = next_city
step_num = step_num + 1
return distances
distances_sub1 = calculate_distance(sub1, sorted_cities_path)
# Time function creating Map with calculated distances
# Calculate Total Distance from Map
def total_distance(distances):
total_distance = 0
for i in distances:
total_distance += distances[i]
return total_distance
print("Total distance is " + "{:,}".format(total_distance(distances_sub1)))
# Time function calculating total distance
# # **Algorithm Analysis: Merge Sort**
# * Using MergeSort to sort the cities in X, Y order, takes O(n lg n) time regarding total running time.
# * The height of MergeSort results in O(lg n) time as each recursive call is dividing the sequence in half.
# * The operations executed at each node at such depth results in O(n) time.
# # Chosen DataStructure: SortedMapTable
# * A SortedMapTable was implemented to store the calculated distances in.
# * By adding a key, value pair by using the __setitem__ function takes O(1) time, however, calculating the total distance took a total running time of O(n).
# # Algorithm 2: QuickSort
# # Data Structure 2: BinarySearchTree
# # Import classes from TextbookSampleCode
# * Tree
class Tree:
"""Abstract base class representing a tree structure."""
# ------------------------------- nested Position class -------------------------------
class Position:
"""An abstraction representing the location of a single element within a tree.
Note that two position instaces may represent the same inherent location in a tree.
Therefore, users should always rely on syntax 'p == q' rather than 'p is q' when testing
equivalence of positions.
"""
def element(self):
"""Return the element stored at this Position."""
raise NotImplementedError("must be implemented by subclass")
def __eq__(self, other):
"""Return True if other Position represents the same location."""
raise NotImplementedError("must be implemented by subclass")
def __ne__(self, other):
"""Return True if other does not represent the same location."""
return not (self == other) # opposite of __eq__
# ---------- abstract methods that concrete subclass must support ----------
def root(self):
"""Return Position representing the tree's root (or None if empty)."""
raise NotImplementedError("must be implemented by subclass")
def parent(self, p):
"""Return Position representing p's parent (or None if p is root)."""
raise NotImplementedError("must be implemented by subclass")
def num_children(self, p):
"""Return the number of children that Position p has."""
raise NotImplementedError("must be implemented by subclass")
def children(self, p):
"""Generate an iteration of Positions representing p's children."""
raise NotImplementedError("must be implemented by subclass")
def __len__(self):
"""Return the total number of elements in the tree."""
raise NotImplementedError("must be implemented by subclass")
# ---------- concrete methods implemented in this class ----------
def is_root(self, p):
"""Return True if Position p represents the root of the tree."""
return self.root() == p
def is_leaf(self, p):
"""Return True if Position p does not have any children."""
return self.num_children(p) == 0
def is_empty(self):
"""Return True if the tree is empty."""
return len(self) == 0
def depth(self, p):
"""Return the number of levels separating Position p from the root."""
if self.is_root(p):
return 0
else:
return 1 + self.depth(self.parent(p))
def _height1(self): # works, but O(n^2) worst-case time
"""Return the height of the tree."""
return max(self.depth(p) for p in self.positions() if self.is_leaf(p))
def _height2(self, p): # time is linear in size of subtree
"""Return the height of the subtree rooted at Position p."""
if self.is_leaf(p):
return 0
else:
return 1 + max(self._height2(c) for c in self.children(p))
def height(self, p=None):
"""Return the height of the subtree rooted at Position p.
If p is None, return the height of the entire tree.
"""
if p is None:
p = self.root()
return self._height2(p) # start _height2 recursion
def __iter__(self):
"""Generate an iteration of the tree's elements."""
for p in self.positions(): # use same order as positions()
yield p.element() # but yield each element
def positions(self):
"""Generate an iteration of the tree's positions."""
return self.preorder() # return entire preorder iteration
def preorder(self):
"""Generate a preorder iteration of positions in the tree."""
if not self.is_empty():
for p in self._subtree_preorder(self.root()): # start recursion
yield p
def _subtree_preorder(self, p):
"""Generate a preorder iteration of positions in subtree rooted at p."""
yield p # visit p before its subtrees
for c in self.children(p): # for each child c
for other in self._subtree_preorder(c): # do preorder of c's subtree
yield other # yielding each to our caller
def postorder(self):
"""Generate a postorder iteration of positions in the tree."""
if not self.is_empty():
for p in self._subtree_postorder(self.root()): # start recursion
yield p
def _subtree_postorder(self, p):
"""Generate a postorder iteration of positions in subtree rooted at p."""
for c in self.children(p): # for each child c
for other in self._subtree_postorder(c): # do postorder of c's subtree
yield other # yielding each to our caller
yield p # visit p after its subtrees
def breadthfirst(self):
"""Generate a breadth-first iteration of the positions of the tree."""
if not self.is_empty():
fringe = LinkedQueue() # known positions not yet yielded
fringe.enqueue(self.root()) # starting with the root
while not fringe.is_empty():
p = fringe.dequeue() # remove from front of the queue
yield p # report this position
for c in self.children(p):
fringe.enqueue(c) # add children to back of queue
# BinaryTree
class BinaryTree(Tree):
"""Abstract base class representing a binary tree structure."""
# --------------------- additional abstract methods ---------------------
def left(self, p):
"""Return a Position representing p's left child.
Return None if p does not have a left child.
"""
raise NotImplementedError("must be implemented by subclass")
def right(self, p):
"""Return a Position representing p's right child.
Return None if p does not have a right child.
"""
raise NotImplementedError("must be implemented by subclass")
# ---------- concrete methods implemented in this class ----------
def sibling(self, p):
"""Return a Position representing p's sibling (or None if no sibling)."""
parent = self.parent(p)
if parent is None: # p must be the root
return None # root has no sibling
else:
if p == self.left(parent):
return self.right(parent) # possibly None
else:
return self.left(parent) # possibly None
def children(self, p):
"""Generate an iteration of Positions representing p's children."""
if self.left(p) is not None:
yield self.left(p)
if self.right(p) is not None:
yield self.right(p)
def inorder(self):
"""Generate an inorder iteration of positions in the tree."""
if not self.is_empty():
for p in self._subtree_inorder(self.root()):
yield p
def _subtree_inorder(self, p):
"""Generate an inorder iteration of positions in subtree rooted at p."""
if self.left(p) is not None: # if left child exists, traverse its subtree
for other in self._subtree_inorder(self.left(p)):
yield other
yield p # visit p between its subtrees
if self.right(p) is not None: # if right child exists, traverse its subtree
for other in self._subtree_inorder(self.right(p)):
yield other
# override inherited version to make inorder the default
def positions(self):
"""Generate an iteration of the tree's positions."""
return self.inorder() # make inorder the default
# * LinkedBinaryTree
class LinkedBinaryTree(BinaryTree):
"""Linked representation of a binary tree structure."""
# -------------------------- nested _Node class --------------------------
class _Node:
"""Lightweight, nonpublic class for storing a node."""
__slots__ = "_element", "_parent", "_left", "_right" # streamline memory usage
def __init__(self, element, parent=None, left=None, right=None):
self._element = element
self._parent = parent
self._left = left
self._right = right
# -------------------------- nested Position class --------------------------
class Position(BinaryTree.Position):
"""An abstraction representing the location of a single element."""
def __init__(self, container, node):
"""Constructor should not be invoked by user."""
self._container = container
self._node = node
def element(self):
"""Return the element stored at this Position."""
return self._node._element
def __eq__(self, other):
"""Return True if other is a Position representing the same location."""
return type(other) is type(self) and other._node is self._node
# ------------------------------- utility methods -------------------------------
def _validate(self, p):
"""Return associated node, if position is valid."""
if not isinstance(p, self.Position):
raise TypeError("p must be proper Position type")
if p._container is not self:
raise ValueError("p does not belong to this container")
if p._node._parent is p._node: # convention for deprecated nodes
raise ValueError("p is no longer valid")
return p._node
def _make_position(self, node):
"""Return Position instance for given node (or None if no node)."""
return self.Position(self, node) if node is not None else None
# -------------------------- binary tree constructor --------------------------
def __init__(self):
"""Create an initially empty binary tree."""
self._root = None
self._size = 0
# -------------------------- public accessors --------------------------
def __len__(self):
"""Return the total number of elements in the tree."""
return self._size
def root(self):
"""Return the root Position of the tree (or None if tree is empty)."""
return self._make_position(self._root)
def parent(self, p):
"""Return the Position of p's parent (or None if p is root)."""
node = self._validate(p)
return self._make_position(node._parent)
def left(self, p):
"""Return the Position of p's left child (or None if no left child)."""
node = self._validate(p)
return self._make_position(node._left)
def right(self, p):
"""Return the Position of p's right child (or None if no right child)."""
node = self._validate(p)
return self._make_position(node._right)
def num_children(self, p):
"""Return the number of children of Position p."""
node = self._validate(p)
count = 0
if node._left is not None: # left child exists
count += 1
if node._right is not None: # right child exists
count += 1
return count
# -------------------------- nonpublic mutators --------------------------
def _add_root(self, e):
"""Place element e at the root of an empty tree and return new Position.
Raise ValueError if tree nonempty.
"""
if self._root is not None:
raise ValueError("Root exists")
self._size = 1
self._root = self._Node(e)
return self._make_position(self._root)
def _add_left(self, p, e):
"""Create a new left child for Position p, storing element e.
Return the Position of new node.
Raise ValueError if Position p is invalid or p already has a left child.
"""
node = self._validate(p)
if node._left is not None:
raise ValueError("Left child exists")
self._size += 1
node._left = self._Node(e, node) # node is its parent
return self._make_position(node._left)
def _add_right(self, p, e):
"""Create a new right child for Position p, storing element e.
Return the Position of new node.
Raise ValueError if Position p is invalid or p already has a right child.
"""
node = self._validate(p)
if node._right is not None:
raise ValueError("Right child exists")
self._size += 1
node._right = self._Node(e, node) # node is its parent
return self._make_position(node._right)
def _replace(self, p, e):
"""Replace the element at position p with e, and return old element."""
node = self._validate(p)
old = node._element
node._element = e
return old
def _delete(self, p):
"""Delete the node at Position p, and replace it with its child, if any.
Return the element that had been stored at Position p.
Raise ValueError if Position p is invalid or p has two children.
"""
node = self._validate(p)
if self.num_children(p) == 2:
raise ValueError("Position has two children")
child = node._left if node._left else node._right # might be None
if child is not None:
child._parent = node._parent # child's grandparent becomes parent
if node is self._root:
self._root = child # child becomes root
else:
parent = node._parent
if node is parent._left:
parent._left = child
else:
parent._right = child
self._size -= 1
node._parent = node # convention for deprecated node
return node._element
def _attach(self, p, t1, t2):
"""Attach trees t1 and t2, respectively, as the left and right subtrees of the external Position p.
As a side effect, set t1 and t2 to empty.
Raise TypeError if trees t1 and t2 do not match type of this tree.
Raise ValueError if Position p is invalid or not external.
"""
node = self._validate(p)
if not self.is_leaf(p):
raise ValueError("position must be leaf")
if not type(self) is type(t1) is type(t2): # all 3 trees must be same type
raise TypeError("Tree types must match")
self._size += len(t1) + len(t2)
if not t1.is_empty(): # attached t1 as left subtree of node
t1._root._parent = node
node._left = t1._root
t1._root = None # set t1 instance to empty
t1._size = 0
if not t2.is_empty(): # attached t2 as right subtree of node
t2._root._parent = node
node._right = t2._root
t2._root = None # set t2 instance to empty
t2._size = 0
# * TreeMap
class TreeMap(LinkedBinaryTree, MapBase):
"""Sorted map implementation using a binary search tree."""
# ---------------------------- override Position class ----------------------------
class Position(LinkedBinaryTree.Position):
def key(self):
"""Return key of map's key-value pair."""
return self.element()._key
def value(self):
"""Return value of map's key-value pair."""
return self.element()._value
# ------------------------------- nonpublic utilities -------------------------------
def _subtree_search(self, p, k):
"""Return Position of p's subtree having key k, or last node searched."""
if k == p.key(): # found match
return p
elif k < p.key(): # search left subtree
if self.left(p) is not None:
return self._subtree_search(self.left(p), k)
else: # search right subtree
if self.right(p) is not None:
return self._subtree_search(self.right(p), k)
return p # unsucessful search
def _subtree_first_position(self, p):
"""Return Position of first item in subtree rooted at p."""
walk = p
while self.left(walk) is not None: # keep walking left
walk = self.left(walk)
return walk
def _subtree_last_position(self, p):
"""Return Position of last item in subtree rooted at p."""
walk = p
while self.right(walk) is not None: # keep walking right
walk = self.right(walk)
return walk
# --------------------- public methods providing "positional" support ---------------------
def first(self):
"""Return the first Position in the tree (or None if empty)."""
return self._subtree_first_position(self.root()) if len(self) > 0 else None
def last(self):
"""Return the last Position in the tree (or None if empty)."""
return self._subtree_last_position(self.root()) if len(self) > 0 else None
def before(self, p):
"""Return the Position just before p in the natural order.
Return None if p is the first position.
"""
self._validate(p) # inherited from LinkedBinaryTree
if self.left(p):
return self._subtree_last_position(self.left(p))
else:
# walk upward
walk = p
above = self.parent(walk)
while above is not None and walk == self.left(above):
walk = above
above = self.parent(walk)
return above
def after(self, p):
"""Return the Position just after p in the natural order.
Return None if p is the last position.
"""
self._validate(p) # inherited from LinkedBinaryTree
if self.right(p):
return self._subtree_first_position(self.right(p))
else:
walk = p
above = self.parent(walk)
while above is not None and walk == self.right(above):
walk = above
above = self.parent(walk)
return above
def find_position(self, k):
"""Return position with key k, or else neighbor (or None if empty)."""
if self.is_empty():
return None
else:
p = self._subtree_search(self.root(), k)
self._rebalance_access(p) # hook for balanced tree subclasses
return p
def delete(self, p):
"""Remove the item at given Position."""
self._validate(p) # inherited from LinkedBinaryTree
if self.left(p) and self.right(p): # p has two children
replacement = self._subtree_last_position(self.left(p))
self._replace(p, replacement.element()) # from LinkedBinaryTree
p = replacement
# now p has at most one child
parent = self.parent(p)
self._delete(p) # inherited from LinkedBinaryTree
self._rebalance_delete(parent) # if root deleted, parent is None
# --------------------- public methods for (standard) map interface ---------------------
def __getitem__(self, k):
"""Return value associated with key k (raise KeyError if not found)."""
if self.is_empty():
raise KeyError("Key Error: " + repr(k))
else:
p = self._subtree_search(self.root(), k)
self._rebalance_access(p) # hook for balanced tree subclasses
if k != p.key():
raise KeyError("Key Error: " + repr(k))
return p.value()
def __setitem__(self, k, v):
"""Assign value v to key k, overwriting existing value if present."""
if self.is_empty():
leaf = self._add_root(self._Item(k, v)) # from LinkedBinaryTree
else:
p = self._subtree_search(self.root(), k)
if p.key() == k:
p.element()._value = v # replace existing item's value
self._rebalance_access(p) # hook for balanced tree subclasses
return
else:
item = self._Item(k, v)
if p.key() < k:
leaf = self._add_right(p, item) # inherited from LinkedBinaryTree
else:
leaf = self._add_left(p, item) # inherited from LinkedBinaryTree
self._rebalance_insert(leaf) # hook for balanced tree subclasses
def __delitem__(self, k):
"""Remove item associated with key k (raise KeyError if not found)."""
if not self.is_empty():
p = self._subtree_search(self.root(), k)
if k == p.key():
self.delete(p) # rely on positional version
return # successful deletion complete
self._rebalance_access(p) # hook for balanced tree subclasses
raise KeyError("Key Error: " + repr(k))
def __iter__(self):
"""Generate an iteration of all keys in the map in order."""
p = self.first()
while p is not None:
yield p.key()
p = self.after(p)
# --------------------- public methods for sorted map interface ---------------------
def __reversed__(self):
"""Generate an iteration of all keys in the map in reverse order."""
p = self.last()
while p is not None:
yield p.key()
p = self.before(p)
def find_min(self):
"""Return (key,value) pair with minimum key (or None if empty)."""
if self.is_empty():
return None
else:
p = self.first()
return (p.key(), p.value())
def find_max(self):
"""Return (key,value) pair with maximum key (or None if empty)."""
if self.is_empty():
return None
else:
p = self.last()
return (p.key(), p.value())
def find_le(self, k):
"""Return (key,value) pair with greatest key less than or equal to k.
Return None if there does not exist such a key.
"""
if self.is_empty():
return None
else:
p = self.find_position(k)
if k < p.key():
p = self.before(p)
return (p.key(), p.value()) if p is not None else None
def find_lt(self, k):
"""Return (key,value) pair with greatest key strictly less than k.
Return None if there does not exist such a key.
"""
if self.is_empty():
return None
else:
p = self.find_position(k)
if not p.key() < k:
p = self.before(p)
return (p.key(), p.value()) if p is not None else None
def find_ge(self, k):
"""Return (key,value) pair with least key greater than or equal to k.
Return None if there does not exist such a key.
"""
if self.is_empty():
return None
else:
p = self.find_position(k) # may not find exact match
if p.key() < k: # p's key is too small
p = self.after(p)
return (p.key(), p.value()) if p is not None else None
def find_gt(self, k):
"""Return (key,value) pair with least key strictly greater than k.
Return None if there does not exist such a key.
"""
if self.is_empty():
return None
else:
p = self.find_position(k)
if not k < p.key():
p = self.after(p)
return (p.key(), p.value()) if p is not None else None
def find_range(self, start, stop):
"""Iterate all (key,value) pairs such that start <= key < stop.
If start is None, iteration begins with minimum key of map.
If stop is None, iteration continues through the maximum key of map.
"""
if not self.is_empty():
if start is None:
p = self.first()
else:
# we initialize p with logic similar to find_ge
p = self.find_position(start)
if p.key() < start:
p = self.after(p)
while p is not None and (stop is None or p.key() < stop):
yield (p.key(), p.value())
p = self.after(p)
# --------------------- hooks used by subclasses to balance a tree ---------------------
def _rebalance_insert(self, p):
"""Call to indicate that position p is newly added."""
pass
def _rebalance_delete(self, p):
"""Call to indicate that a child of p has been removed."""
pass
def _rebalance_access(self, p):
"""Call to indicate that position p was recently accessed."""
pass
# --------------------- nonpublic methods to support tree balancing ---------------------
def _relink(self, parent, child, make_left_child):
"""Relink parent node with child node (we allow child to be None)."""
if make_left_child: # make it a left child
parent._left = child
else: # make it a right child
parent._right = child
if child is not None: # make child point to parent
child._parent = parent
def _rotate(self, p):
"""Rotate Position p above its parent.
Switches between these configurations, depending on whether p==a or p==b.
b a
/ \ / \
a t2 t0 b
/ \ / \
t0 t1 t1 t2
Caller should ensure that p is not the root.
"""
"""Rotate Position p above its parent."""
x = p._node
y = x._parent # we assume this exists
z = y._parent # grandparent (possibly None)
if z is None:
self._root = x # x becomes root
x._parent = None
else:
self._relink(z, x, y == z._left) # x becomes a direct child of z
# now rotate x and y, including transfer of middle subtree
if x == y._left:
self._relink(y, x._right, True) # x._right becomes left child of y
self._relink(x, y, False) # y becomes right child of x
else:
self._relink(y, x._left, False) # x._left becomes right child of y
self._relink(x, y, True) # y becomes left child of x
def _restructure(self, x):
"""Perform a trinode restructure among Position x, its parent, and its grandparent.
Return the Position that becomes root of the restructured subtree.
Assumes the nodes are in one of the following configurations:
z=a z=c z=a z=c
/ \ / \ / \ / \
t0 y=b y=b t3 t0 y=c y=a t3
/ \ / \ / \ / \
t1 x=c x=a t2 x=b t3 t0 x=b
/ \ / \ / \ / \
t2 t3 t0 t1 t1 t2 t1 t2
The subtree will be restructured so that the node with key b becomes its root.
b
/ \
a c
/ \ / \
t0 t1 t2 t3
Caller should ensure that x has a grandparent.
"""
"""Perform trinode restructure of Position x with parent/grandparent."""
y = self.parent(x)
z = self.parent(y)
if (x == self.right(y)) == (y == self.right(z)): # matching alignments
self._rotate(y) # single rotation (of y)
return y # y is new subtree root
else: # opposite alignments
self._rotate(x) # double rotation (of x)
self._rotate(x)
return x # x is new subtree root
# # Sort Path in X,Y Order Using QuickSort and Record Time Taken
# Use Quick Sort Algorithm to create sorted cities path
sorted_cities_path2 = list(
sub2.iloc[1:,].sort_values(["X", "Y"], kind="quicksort")["CityId"]
)
sorted_cities_path2 = [0] + sorted_cities_path2 + [0]
# Record Time Taken
# Altered function from: https://www.kaggle.com/seshadrikolluri/understanding-the-problem-and-some-sample-paths
# Calculate euclidean distance and store in a Map
def calculate_distance(dfcity, path):
prev_city = path[0]
distance = 0
distances = TreeMap()
step_num = 1
for city_num in path[1:]:
next_city = city_num
distance = np.sqrt(
pow((dfcity.X[city_num] - dfcity.X[prev_city]), 2)
+ pow((dfcity.Y[city_num] - dfcity.Y[prev_city]), 2)
) * (1 + 0.1 * ((step_num % 10 == 0) * int(not (prime_cities[prev_city]))))
distances.__setitem__(city_num, distance)
prev_city = next_city
step_num = step_num + 1
return distances
distances_sub2 = calculate_distance(sub2, sorted_cities_path2)
# Calculate Total Distance from TreeMap
def total_distance(distances):
total_distance = 0
for i in distances:
total_distance += distances[i]
return total_distance
print("Total distance is " + "{:,}".format(total_distance(distances_sub2)))
# Time function calculating total distance
| false | 0 | 9,669 | 0 | 6 | 9,669 |
||
14064907 | <kaggle_start><data_title>mlcourse.ai<data_description>Open Machine Learning Course [mlcourse.ai](http://mlcourse.ai/) is designed to perfectly balance theory and practice; therefore, each topic is followed by an assignment with a deadline in a week. You can also take part in several Kaggle Inclass competitions held during the course and write your own tutorials. The next session starts on **October 1, 2018**. Fill in [this form](https://docs.google.com/forms/d/1_pDNuVHwBxV5wuOcdaXoxBZneyAQcqfOl4V2qkqKbNQ/) to participate. More info in [GitHub repo](https://github.com/Yorko/mlcourse.ai).
### Outline
This is the list of published articles on [medium.com](https://medium.com/open-machine-learning-course) (English), [habr.com](https://habr.com/company/ods/blog/344044/) (Russian), and [jqr.com](https://www.jqr.com/) (Chinese). See Kernels of this Dataset for the same material in English.
1. Exploratory Data Analysis with Pandas [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-1-exploratory-data-analysis-with-pandas-de57880f1a68) [ru](https://habrahabr.ru/company/ods/blog/322626/), [cn](https://www.jqr.com/article/000079), [Kaggle Kernel](https://www.kaggle.com/kashnitsky/topic-1-exploratory-data-analysis-with-pandas)
2. Visual Data Analysis with Python [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-2-visual-data-analysis-in-python-846b989675cd) [ru](https://habrahabr.ru/company/ods/blog/323210/), [cn](https://www.jqr.com/article/000086), Kaggle Kernels: [part1](https://www.kaggle.com/kashnitsky/topic-2-visual-data-analysis-in-python), [part2](https://www.kaggle.com/kashnitsky/topic-2-part-2-seaborn-and-plotly)
3. Classification, Decision Trees and k Nearest Neighbors [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-3-classification-decision-trees-and-k-nearest-neighbors-8613c6b6d2cd), [ru](https://habrahabr.ru/company/ods/blog/322534/), [cn](https://www.jqr.com/article/000139), [Kaggle Kernel](https://www.kaggle.com/kashnitsky/topic-3-decision-trees-and-knn)
4. Linear Classification and Regression [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-4-linear-classification-and-regression-44a41b9b5220), [ru](https://habrahabr.ru/company/ods/blog/323890/), [cn](https://www.jqr.com/article/000175), Kaggle Kernels: [part1](https://www.kaggle.com/kashnitsky/topic-4-linear-models-part-1-ols), [part2](https://www.kaggle.com/kashnitsky/topic-4-linear-models-part-2-classification), [part3](https://www.kaggle.com/kashnitsky/topic-4-linear-models-part-3-regularization), [part4](https://www.kaggle.com/kashnitsky/topic-4-linear-models-part-4-more-of-logit), [part5](https://www.kaggle.com/kashnitsky/topic-4-linear-models-part-5-validation)
5. Bagging and Random Forest [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-5-ensembles-of-algorithms-and-random-forest-8e05246cbba7), [ru](https://habrahabr.ru/company/ods/blog/324402/), [cn](https://www.jqr.com/article/000241), Kaggle Kernels: [part1](https://www.kaggle.com/kashnitsky/topic-5-ensembles-part-1-bagging), [part2](https://www.kaggle.com/kashnitsky/topic-5-ensembles-part-2-random-forest), [part3](https://www.kaggle.com/kashnitsky/topic-5-ensembles-part-3-feature-importance)
6. Feature Engineering and Feature Selection [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-6-feature-engineering-and-feature-selection-8b94f870706a), [ru](https://habrahabr.ru/company/ods/blog/325422/), [cn](https://www.jqr.com/article/000249), [Kaggle Kernel](https://www.kaggle.com/kashnitsky/topic-6-feature-engineering-and-feature-selection)
7. Unsupervised Learning: Principal Component Analysis and Clustering [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-7-unsupervised-learning-pca-and-clustering-db7879568417), [ru](https://habrahabr.ru/company/ods/blog/325654/), [cn](https://www.jqr.com/article/000336), [Kaggle Kernel](https://www.kaggle.com/kashnitsky/topic-7-unsupervised-learning-pca-and-clustering)
8. Vowpal Wabbit: Learning with Gigabytes of Data [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-8-vowpal-wabbit-fast-learning-with-gigabytes-of-data-60f750086237), [ru](https://habrahabr.ru/company/ods/blog/326418/), [cn](https://www.jqr.com/article/000348), [Kaggle Kernel](https://www.kaggle.com/kashnitsky/topic-8-online-learning-and-vowpal-wabbit)
9. Time Series Analysis with Python, part 1 [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-9-time-series-analysis-in-python-a270cb05e0b3), [ru](https://habrahabr.ru/company/ods/blog/327242/), [cn](https://www.jqr.com/article/000450). Predicting future with Facebook Prophet, part 2 [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-9-part-3-predicting-the-future-with-facebook-prophet-3f3af145cdc), [cn](https://www.jqr.com/article/000598) Kaggle Kernels: [part1](https://www.kaggle.com/kashnitsky/topic-9-part-1-time-series-analysis-in-python), [part2](https://www.kaggle.com/kashnitsky/topic-9-part-2-time-series-with-facebook-prophet)
10. Gradient Boosting [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-10-gradient-boosting-c751538131ac), [ru](https://habrahabr.ru/company/ods/blog/327250/), [cn](https://www.jqr.com/article/000573), [Kaggle Kernel](https://www.kaggle.com/kashnitsky/topic-10-gradient-boosting)
### Assignments
Each topic is followed by an assignment. See demo versions in this Dataset. Solutions will be discussed in the upcoming run of the course.
### Kaggle competitions
1. Catch Me If You Can: Intruder Detection through Webpage Session Tracking. [Kaggle Inclass](https://www.kaggle.com/c/catch-me-if-you-can-intruder-detection-through-webpage-session-tracking2)
2. How good is your Medium article? [Kaggle Inclass](https://www.kaggle.com/c/how-good-is-your-medium-article/)
### Rating
Throughout the course we are maintaining a student rating. It takes into account credits scored in assignments and Kaggle competitions. Top students (according to the final rating) will be listed on a special Wiki page.
### Community
Discussions between students are held in the **#mlcourse_ai** channel of the OpenDataScience Slack team. Fill in [this form](https://drive.google.com/open?id=1_pDNuVHwBxV5wuOcdaXoxBZneyAQcqfOl4V2qkqKbNQ) to get an invitation (to be sent in September 2018). The form will also ask you some personal questions, don't hesitate
### Collaboration
You can publish Kernels using this Dataset. But please respect others' interests: don't share solutions to assignments and well-performing solutions for Kaggle Inclass competitions. If you notice any typos/errors in course material, please open an [Issue](https://github.com/Yorko/mlcourse.ai/issues) or make a pull request in course [repo](https://github.com/Yorko/mlcourse.ai).<data_name>mlcourse
<code>#
#
# ## [mlcourse.ai](https://mlcourse.ai) - Open Machine Learning Course
# Authors: [Maria Sumarokova](https://www.linkedin.com/in/mariya-sumarokova-230b4054/), and [Yury Kashnitsky](https://www.linkedin.com/in/festline/). Translated and edited by Gleb Filatov, Aleksey Kiselev, [Anastasia Manokhina](https://www.linkedin.com/in/anastasiamanokhina/), [Egor Polusmak](https://www.linkedin.com/in/egor-polusmak/), and [Yuanyuan Pao](https://www.linkedin.com/in/yuanyuanpao/). All content is distributed under the [Creative Commons CC BY-NC-SA 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/) license.
# # Assignment #3 (demo)
# ## Decision trees with a toy task and the UCI Adult dataset
# Same assignment as a [Kaggle Kernel](https://www.kaggle.com/kashnitsky/a3-demo-decision-trees) + [solution](https://www.kaggle.com/kashnitsky/a3-demo-decision-trees-solution). Fill in the answers in the [web-form](https://docs.google.com/forms/d/1wfWYYoqXTkZNOPy1wpewACXaj2MZjBdLOL58htGWYBA/edit).
# Let's start by loading all necessary libraries:
from matplotlib import pyplot as plt
plt.rcParams["figure.figsize"] = (10, 8)
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import collections
from sklearn.model_selection import GridSearchCV
from sklearn import preprocessing
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from ipywidgets import Image
from io import StringIO
import pydotplus # pip install pydotplus
# ### Part 1. Toy dataset "Will They? Won't They?"
# Your goal is to figure out how decision trees work by walking through a toy problem. While a single decision tree does not yield outstanding results, other performant algorithms like gradient boosting and random forests are based on the same idea. That is why knowing how decision trees work might be useful.
# We'll go through a toy example of binary classification - Person A is deciding whether they will go on a second date with Person B. It will depend on their looks, eloquence, alcohol consumption (only for example), and how much money was spent on the first date.
# #### Creating the dataset
# Create dataframe with dummy variables
def create_df(dic, feature_list):
out = pd.DataFrame(dic)
out = pd.concat([out, pd.get_dummies(out[feature_list])], axis=1)
out.drop(feature_list, axis=1, inplace=True)
return out
# Some feature values are present in train and absent in test and vice-versa.
def intersect_features(train, test):
common_feat = list(set(train.keys()) & set(test.keys()))
return train[common_feat], test[common_feat]
features = ["Looks", "Alcoholic_beverage", "Eloquence", "Money_spent"]
# #### Training data
df_train = {}
df_train["Looks"] = [
"handsome",
"handsome",
"handsome",
"repulsive",
"repulsive",
"repulsive",
"handsome",
]
df_train["Alcoholic_beverage"] = ["yes", "yes", "no", "no", "yes", "yes", "yes"]
df_train["Eloquence"] = ["high", "low", "average", "average", "low", "high", "average"]
df_train["Money_spent"] = ["lots", "little", "lots", "little", "lots", "lots", "lots"]
df_train["Will_go"] = LabelEncoder().fit_transform(["+", "-", "+", "-", "-", "+", "+"])
df_train = create_df(df_train, features)
df_train
# #### Test data
df_test = {}
df_test["Looks"] = ["handsome", "handsome", "repulsive"]
df_test["Alcoholic_beverage"] = ["no", "yes", "yes"]
df_test["Eloquence"] = ["average", "high", "average"]
df_test["Money_spent"] = ["lots", "little", "lots"]
df_test = create_df(df_test, features)
df_test
# Some feature values are present in train and absent in test and vice-versa.
y = df_train["Will_go"]
df_train, df_test = intersect_features(train=df_train, test=df_test)
df_train
df_test
# #### Draw a decision tree (by hand or in any graphics editor) for this dataset. Optionally you can also implement tree construction and draw it here.
# 1\. What is the entropy $S_0$ of the initial system? By system states, we mean values of the binary feature "Will_go" - 0 or 1 - two states in total.
# you code here
# 2\. Let's split the data by the feature "Looks_handsome". What is the entropy $S_1$ of the left group - the one with "Looks_handsome". What is the entropy $S_2$ in the opposite group? What is the information gain (IG) if we consider such a split?
# you code here
# #### Train a decision tree using sklearn on the training data. You may choose any depth for the tree.
# you code here
# #### Additional: display the resulting tree using graphviz. You can use pydot or [web-service](https://www.coolutils.com/ru/online/DOT-to-PNG) dot2png.
# you code here
# ### Part 2. Functions for calculating entropy and information gain.
# Consider the following warm-up example: we have 9 blue balls and 11 yellow balls. Let ball have label **1** if it is blue, **0** otherwise.
balls = [1 for i in range(9)] + [0 for i in range(11)]
#
# Next split the balls into two groups:
#
# two groups
balls_left = [1 for i in range(8)] + [0 for i in range(5)] # 8 blue and 5 yellow
balls_right = [1 for i in range(1)] + [0 for i in range(6)] # 1 blue and 6 yellow
# #### Implement a function to calculate the Shannon Entropy
def entropy(a_list):
# you code here
pass
# Tests
print(entropy(balls)) # 9 blue и 11 yellow
print(entropy(balls_left)) # 8 blue и 5 yellow
print(entropy(balls_right)) # 1 blue и 6 yellow
print(entropy([1, 2, 3, 4, 5, 6])) # entropy of a fair 6-sided die
# 3\. What is the entropy of the state given by the list **balls_left**?
# 4\. What is the entropy of a fair dice? (where we look at a dice as a system with 6 equally probable states)?
# information gain calculation
def information_gain(root, left, right):
"""root - initial data, left and right - two partitions of initial data"""
# you code here
pass
# 5\. What is the information gain from splitting the initial dataset into **balls_left** and **balls_right** ?
def best_feature_to_split(X, y):
"""Outputs information gain when splitting on best feature"""
# you code here
pass
# #### Optional:
# - Implement a decision tree building algorithm by calling **best_feature_to_split** recursively
# - Plot the resulting tree
# ### Part 3. The "Adult" dataset
# #### Dataset description:
# [Dataset](http://archive.ics.uci.edu/ml/machine-learning-databases/adult) UCI Adult (no need to download it, we have a copy in the course repository): classify people using demographical data - whether they earn more than \$50,000 per year or not.
# Feature descriptions:
# - **Age** – continuous feature
# - **Workclass** – continuous feature
# - **fnlwgt** – final weight of object, continuous feature
# - **Education** – categorical feature
# - **Education_Num** – number of years of education, continuous feature
# - **Martial_Status** – categorical feature
# - **Occupation** – categorical feature
# - **Relationship** – categorical feature
# - **Race** – categorical feature
# - **Sex** – categorical feature
# - **Capital_Gain** – continuous feature
# - **Capital_Loss** – continuous feature
# - **Hours_per_week** – continuous feature
# - **Country** – categorical feature
# **Target** – earnings level, categorical (binary) feature.
# #### Reading train and test data
data_train = pd.read_csv("../../data/adult_train.csv", sep=";")
data_train.tail()
data_test = pd.read_csv("../../data/adult_test.csv", sep=";")
data_test.tail()
# necessary to remove rows with incorrect labels in test dataset
data_test = data_test[
(data_test["Target"] == " >50K.") | (data_test["Target"] == " <=50K.")
]
# encode target variable as integer
data_train.loc[data_train["Target"] == " <=50K", "Target"] = 0
data_train.loc[data_train["Target"] == " >50K", "Target"] = 1
data_test.loc[data_test["Target"] == " <=50K.", "Target"] = 0
data_test.loc[data_test["Target"] == " >50K.", "Target"] = 1
# #### Primary data analysis
data_test.describe(include="all").T
data_train["Target"].value_counts()
fig = plt.figure(figsize=(25, 15))
cols = 5
rows = np.ceil(float(data_train.shape[1]) / cols)
for i, column in enumerate(data_train.columns):
ax = fig.add_subplot(rows, cols, i + 1)
ax.set_title(column)
if data_train.dtypes[column] == np.object:
data_train[column].value_counts().plot(kind="bar", axes=ax)
else:
data_train[column].hist(axes=ax)
plt.xticks(rotation="vertical")
plt.subplots_adjust(hspace=0.7, wspace=0.2)
# #### Checking data types
data_train.dtypes
data_test.dtypes
# As we see, in the test data, age is treated as type **object**. We need to fix this.
data_test["Age"] = data_test["Age"].astype(int)
# Also we'll cast all **float** features to **int** type to keep types consistent between our train and test data.
data_test["fnlwgt"] = data_test["fnlwgt"].astype(int)
data_test["Education_Num"] = data_test["Education_Num"].astype(int)
data_test["Capital_Gain"] = data_test["Capital_Gain"].astype(int)
data_test["Capital_Loss"] = data_test["Capital_Loss"].astype(int)
data_test["Hours_per_week"] = data_test["Hours_per_week"].astype(int)
# #### Fill in missing data for continuous features with their median values, for categorical features with their mode.
# choose categorical and continuous features from data
categorical_columns = [
c for c in data_train.columns if data_train[c].dtype.name == "object"
]
numerical_columns = [
c for c in data_train.columns if data_train[c].dtype.name != "object"
]
print("categorical_columns:", categorical_columns)
print("numerical_columns:", numerical_columns)
# we see some missing values
data_train.info()
# fill missing data
for c in categorical_columns:
data_train[c].fillna(data_train[c].mode()[0], inplace=True)
data_test[c].fillna(data_train[c].mode()[0], inplace=True)
for c in numerical_columns:
data_train[c].fillna(data_train[c].median(), inplace=True)
data_test[c].fillna(data_train[c].median(), inplace=True)
# no more missing values
data_train.info()
# We'll dummy code some categorical features: **Workclass**, **Education**, **Martial_Status**, **Occupation**, **Relationship**, **Race**, **Sex**, **Country**. It can be done via pandas method **get_dummies**
data_train = pd.concat(
[data_train[numerical_columns], pd.get_dummies(data_train[categorical_columns])],
axis=1,
)
data_test = pd.concat(
[data_test[numerical_columns], pd.get_dummies(data_test[categorical_columns])],
axis=1,
)
set(data_train.columns) - set(data_test.columns)
data_train.shape, data_test.shape
# #### There is no Holland in the test data. Create new zero-valued feature.
data_test["Country_ Holand-Netherlands"] = 0
set(data_train.columns) - set(data_test.columns)
data_train.head(2)
data_test.head(2)
X_train = data_train.drop(["Target"], axis=1)
y_train = data_train["Target"]
X_test = data_test.drop(["Target"], axis=1)
y_test = data_test["Target"]
# ### 3.1 Decision tree without parameter tuning
# Train a decision tree **(DecisionTreeClassifier)** with a maximum depth of 3, and evaluate the accuracy metric on the test data. Use parameter **random_state = 17** for results reproducibility.
# you code here
# tree =
# tree.fit
# Make a prediction with the trained model on the test data.
# you code here
# tree_predictions = tree.predict
# you code here
# accuracy_score
# 6\. What is the test set accuracy of a decision tree with maximum tree depth of 3 and **random_state = 17**?
# ### 3.2 Decision tree with parameter tuning
# Train a decision tree **(DecisionTreeClassifier, random_state = 17).** Find the optimal maximum depth using 5-fold cross-validation **(GridSearchCV)**.
tree_params = {"max_depth": range(2, 11)}
locally_best_tree = GridSearchCV # you code here
locally_best_tree.fit
# you code here
# Train a decision tree with maximum depth of 9 (it is the best **max_depth** in my case), and compute the test set accuracy. Use parameter **random_state = 17** for reproducibility.
# you code here
# tuned_tree =
# tuned_tree.fit
# tuned_tree_predictions = tuned_tree.predict
# accuracy_score
# 7\. What is the test set accuracy of a decision tree with maximum depth of 9 and **random_state = 17**?
# ### 3.3 (Optional) Random forest without parameter tuning
# Let's take a sneak peek of upcoming lectures and try to use a random forest for our task. For now, you can imagine a random forest as a bunch of decision trees, trained on slightly different subsets of the training data.
# Train a random forest **(RandomForestClassifier)**. Set the number of trees to 100 and use **random_state = 17**.
# you code here
# rf =
# rf.fit # you code here
# Make predictions for the test data and assess accuracy.
# you code here
# ### 3.4 (Optional) Random forest with parameter tuning
# Train a random forest **(RandomForestClassifier)**. Tune the maximum depth and maximum number of features for each tree using **GridSearchCV**.
# forest_params = {'max_depth': range(10, 21),
# 'max_features': range(5, 105, 20)}
# locally_best_forest = GridSearchCV # you code here
# locally_best_forest.fit # you code here
# Make predictions for the test data and assess accuracy.
# you code here
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0014/064/14064907.ipynb | mlcourse | kashnitsky | [{"Id": 14064907, "ScriptId": 1215902, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 178864, "CreationDate": "05/12/2019 07:28:41", "VersionNumber": 7.0, "Title": "A3 (demo). Decision trees", "EvaluationDate": "05/12/2019", "IsChange": true, "TotalLines": 359.0, "LinesInsertedFromPrevious": 14.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 345.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 2}] | [{"Id": 9170963, "KernelVersionId": 14064907, "SourceDatasetVersionId": 117853}] | [{"Id": 117853, "DatasetId": 32132, "DatasourceVersionId": 128405, "CreatorUserId": 178864, "LicenseName": "CC BY-NC-SA 4.0", "CreationDate": "10/07/2018 17:25:09", "VersionNumber": 16.0, "Title": "mlcourse.ai", "Slug": "mlcourse", "Subtitle": "Open Machine Learning Course by OpenDataScience", "Description": "Open Machine Learning Course [mlcourse.ai](http://mlcourse.ai/) is designed to perfectly balance theory and practice; therefore, each topic is followed by an assignment with a deadline in a week. You can also take part in several Kaggle Inclass competitions held during the course and write your own tutorials. The next session starts on **October 1, 2018**. Fill in [this form](https://docs.google.com/forms/d/1_pDNuVHwBxV5wuOcdaXoxBZneyAQcqfOl4V2qkqKbNQ/) to participate. More info in [GitHub repo](https://github.com/Yorko/mlcourse.ai). \n\n### Outline\nThis is the list of published articles on [medium.com](https://medium.com/open-machine-learning-course) (English), [habr.com](https://habr.com/company/ods/blog/344044/) (Russian), and [jqr.com](https://www.jqr.com/) (Chinese). See Kernels of this Dataset for the same material in English. \n\n1. Exploratory Data Analysis with Pandas [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-1-exploratory-data-analysis-with-pandas-de57880f1a68) [ru](https://habrahabr.ru/company/ods/blog/322626/), [cn](https://www.jqr.com/article/000079), [Kaggle Kernel](https://www.kaggle.com/kashnitsky/topic-1-exploratory-data-analysis-with-pandas)\n2. Visual Data Analysis with Python [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-2-visual-data-analysis-in-python-846b989675cd) [ru](https://habrahabr.ru/company/ods/blog/323210/), [cn](https://www.jqr.com/article/000086), Kaggle Kernels: [part1](https://www.kaggle.com/kashnitsky/topic-2-visual-data-analysis-in-python), [part2](https://www.kaggle.com/kashnitsky/topic-2-part-2-seaborn-and-plotly)\n3. Classification, Decision Trees and k Nearest Neighbors [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-3-classification-decision-trees-and-k-nearest-neighbors-8613c6b6d2cd), [ru](https://habrahabr.ru/company/ods/blog/322534/), [cn](https://www.jqr.com/article/000139), [Kaggle Kernel](https://www.kaggle.com/kashnitsky/topic-3-decision-trees-and-knn)\n4. Linear Classification and Regression [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-4-linear-classification-and-regression-44a41b9b5220), [ru](https://habrahabr.ru/company/ods/blog/323890/), [cn](https://www.jqr.com/article/000175), Kaggle Kernels: [part1](https://www.kaggle.com/kashnitsky/topic-4-linear-models-part-1-ols), [part2](https://www.kaggle.com/kashnitsky/topic-4-linear-models-part-2-classification), [part3](https://www.kaggle.com/kashnitsky/topic-4-linear-models-part-3-regularization), [part4](https://www.kaggle.com/kashnitsky/topic-4-linear-models-part-4-more-of-logit), [part5](https://www.kaggle.com/kashnitsky/topic-4-linear-models-part-5-validation)\n5. Bagging and Random Forest [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-5-ensembles-of-algorithms-and-random-forest-8e05246cbba7), [ru](https://habrahabr.ru/company/ods/blog/324402/), [cn](https://www.jqr.com/article/000241), Kaggle Kernels: [part1](https://www.kaggle.com/kashnitsky/topic-5-ensembles-part-1-bagging), [part2](https://www.kaggle.com/kashnitsky/topic-5-ensembles-part-2-random-forest), [part3](https://www.kaggle.com/kashnitsky/topic-5-ensembles-part-3-feature-importance)\n6. Feature Engineering and Feature Selection [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-6-feature-engineering-and-feature-selection-8b94f870706a), [ru](https://habrahabr.ru/company/ods/blog/325422/), [cn](https://www.jqr.com/article/000249), [Kaggle Kernel](https://www.kaggle.com/kashnitsky/topic-6-feature-engineering-and-feature-selection)\n7. Unsupervised Learning: Principal Component Analysis and Clustering [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-7-unsupervised-learning-pca-and-clustering-db7879568417), [ru](https://habrahabr.ru/company/ods/blog/325654/), [cn](https://www.jqr.com/article/000336), [Kaggle Kernel](https://www.kaggle.com/kashnitsky/topic-7-unsupervised-learning-pca-and-clustering)\n8. Vowpal Wabbit: Learning with Gigabytes of Data [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-8-vowpal-wabbit-fast-learning-with-gigabytes-of-data-60f750086237), [ru](https://habrahabr.ru/company/ods/blog/326418/), [cn](https://www.jqr.com/article/000348), [Kaggle Kernel](https://www.kaggle.com/kashnitsky/topic-8-online-learning-and-vowpal-wabbit)\n9. Time Series Analysis with Python, part 1 [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-9-time-series-analysis-in-python-a270cb05e0b3), [ru](https://habrahabr.ru/company/ods/blog/327242/), [cn](https://www.jqr.com/article/000450). Predicting future with Facebook Prophet, part 2 [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-9-part-3-predicting-the-future-with-facebook-prophet-3f3af145cdc), [cn](https://www.jqr.com/article/000598) Kaggle Kernels: [part1](https://www.kaggle.com/kashnitsky/topic-9-part-1-time-series-analysis-in-python), [part2](https://www.kaggle.com/kashnitsky/topic-9-part-2-time-series-with-facebook-prophet)\n10. Gradient Boosting [uk](https://medium.com/open-machine-learning-course/open-machine-learning-course-topic-10-gradient-boosting-c751538131ac), [ru](https://habrahabr.ru/company/ods/blog/327250/), [cn](https://www.jqr.com/article/000573), [Kaggle Kernel](https://www.kaggle.com/kashnitsky/topic-10-gradient-boosting)\n\n### Assignments\nEach topic is followed by an assignment. See demo versions in this Dataset. Solutions will be discussed in the upcoming run of the course. \n\n### Kaggle competitions\n1. Catch Me If You Can: Intruder Detection through Webpage Session Tracking. [Kaggle Inclass](https://www.kaggle.com/c/catch-me-if-you-can-intruder-detection-through-webpage-session-tracking2)\n2. How good is your Medium article? [Kaggle Inclass](https://www.kaggle.com/c/how-good-is-your-medium-article/)\n\n### Rating\nThroughout the course we are maintaining a student rating. It takes into account credits scored in assignments and Kaggle competitions. Top students (according to the final rating) will be listed on a special Wiki page.\n\n### Community\nDiscussions between students are held in the **#mlcourse_ai** channel of the OpenDataScience Slack team. Fill in [this form](https://drive.google.com/open?id=1_pDNuVHwBxV5wuOcdaXoxBZneyAQcqfOl4V2qkqKbNQ) to get an invitation (to be sent in September 2018). The form will also ask you some personal questions, don't hesitate\n\n### Collaboration\nYou can publish Kernels using this Dataset. But please respect others' interests: don't share solutions to assignments and well-performing solutions for Kaggle Inclass competitions. If you notice any typos/errors in course material, please open an [Issue](https://github.com/Yorko/mlcourse.ai/issues) or make a pull request in course [repo](https://github.com/Yorko/mlcourse.ai).", "VersionNotes": "add beauty.csv", "TotalCompressedBytes": 211086036.0, "TotalUncompressedBytes": 53878942.0}] | [{"Id": 32132, "CreatorUserId": 178864, "OwnerUserId": 178864.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 205932.0, "CurrentDatasourceVersionId": 217276.0, "ForumId": 40462, "Type": 2, "CreationDate": "06/18/2018 06:56:16", "LastActivityDate": "06/18/2018", "TotalViews": 267148, "TotalDownloads": 39410, "TotalVotes": 1585, "TotalKernels": 523}] | [{"Id": 178864, "UserName": "kashnitsky", "DisplayName": "Yury Kashnitsky", "RegisterDate": "03/27/2014", "PerformanceTier": 4}] | #
#
# ## [mlcourse.ai](https://mlcourse.ai) - Open Machine Learning Course
# Authors: [Maria Sumarokova](https://www.linkedin.com/in/mariya-sumarokova-230b4054/), and [Yury Kashnitsky](https://www.linkedin.com/in/festline/). Translated and edited by Gleb Filatov, Aleksey Kiselev, [Anastasia Manokhina](https://www.linkedin.com/in/anastasiamanokhina/), [Egor Polusmak](https://www.linkedin.com/in/egor-polusmak/), and [Yuanyuan Pao](https://www.linkedin.com/in/yuanyuanpao/). All content is distributed under the [Creative Commons CC BY-NC-SA 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/) license.
# # Assignment #3 (demo)
# ## Decision trees with a toy task and the UCI Adult dataset
# Same assignment as a [Kaggle Kernel](https://www.kaggle.com/kashnitsky/a3-demo-decision-trees) + [solution](https://www.kaggle.com/kashnitsky/a3-demo-decision-trees-solution). Fill in the answers in the [web-form](https://docs.google.com/forms/d/1wfWYYoqXTkZNOPy1wpewACXaj2MZjBdLOL58htGWYBA/edit).
# Let's start by loading all necessary libraries:
from matplotlib import pyplot as plt
plt.rcParams["figure.figsize"] = (10, 8)
import seaborn as sns
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelEncoder
import collections
from sklearn.model_selection import GridSearchCV
from sklearn import preprocessing
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from ipywidgets import Image
from io import StringIO
import pydotplus # pip install pydotplus
# ### Part 1. Toy dataset "Will They? Won't They?"
# Your goal is to figure out how decision trees work by walking through a toy problem. While a single decision tree does not yield outstanding results, other performant algorithms like gradient boosting and random forests are based on the same idea. That is why knowing how decision trees work might be useful.
# We'll go through a toy example of binary classification - Person A is deciding whether they will go on a second date with Person B. It will depend on their looks, eloquence, alcohol consumption (only for example), and how much money was spent on the first date.
# #### Creating the dataset
# Create dataframe with dummy variables
def create_df(dic, feature_list):
out = pd.DataFrame(dic)
out = pd.concat([out, pd.get_dummies(out[feature_list])], axis=1)
out.drop(feature_list, axis=1, inplace=True)
return out
# Some feature values are present in train and absent in test and vice-versa.
def intersect_features(train, test):
common_feat = list(set(train.keys()) & set(test.keys()))
return train[common_feat], test[common_feat]
features = ["Looks", "Alcoholic_beverage", "Eloquence", "Money_spent"]
# #### Training data
df_train = {}
df_train["Looks"] = [
"handsome",
"handsome",
"handsome",
"repulsive",
"repulsive",
"repulsive",
"handsome",
]
df_train["Alcoholic_beverage"] = ["yes", "yes", "no", "no", "yes", "yes", "yes"]
df_train["Eloquence"] = ["high", "low", "average", "average", "low", "high", "average"]
df_train["Money_spent"] = ["lots", "little", "lots", "little", "lots", "lots", "lots"]
df_train["Will_go"] = LabelEncoder().fit_transform(["+", "-", "+", "-", "-", "+", "+"])
df_train = create_df(df_train, features)
df_train
# #### Test data
df_test = {}
df_test["Looks"] = ["handsome", "handsome", "repulsive"]
df_test["Alcoholic_beverage"] = ["no", "yes", "yes"]
df_test["Eloquence"] = ["average", "high", "average"]
df_test["Money_spent"] = ["lots", "little", "lots"]
df_test = create_df(df_test, features)
df_test
# Some feature values are present in train and absent in test and vice-versa.
y = df_train["Will_go"]
df_train, df_test = intersect_features(train=df_train, test=df_test)
df_train
df_test
# #### Draw a decision tree (by hand or in any graphics editor) for this dataset. Optionally you can also implement tree construction and draw it here.
# 1\. What is the entropy $S_0$ of the initial system? By system states, we mean values of the binary feature "Will_go" - 0 or 1 - two states in total.
# you code here
# 2\. Let's split the data by the feature "Looks_handsome". What is the entropy $S_1$ of the left group - the one with "Looks_handsome". What is the entropy $S_2$ in the opposite group? What is the information gain (IG) if we consider such a split?
# you code here
# #### Train a decision tree using sklearn on the training data. You may choose any depth for the tree.
# you code here
# #### Additional: display the resulting tree using graphviz. You can use pydot or [web-service](https://www.coolutils.com/ru/online/DOT-to-PNG) dot2png.
# you code here
# ### Part 2. Functions for calculating entropy and information gain.
# Consider the following warm-up example: we have 9 blue balls and 11 yellow balls. Let ball have label **1** if it is blue, **0** otherwise.
balls = [1 for i in range(9)] + [0 for i in range(11)]
#
# Next split the balls into two groups:
#
# two groups
balls_left = [1 for i in range(8)] + [0 for i in range(5)] # 8 blue and 5 yellow
balls_right = [1 for i in range(1)] + [0 for i in range(6)] # 1 blue and 6 yellow
# #### Implement a function to calculate the Shannon Entropy
def entropy(a_list):
# you code here
pass
# Tests
print(entropy(balls)) # 9 blue и 11 yellow
print(entropy(balls_left)) # 8 blue и 5 yellow
print(entropy(balls_right)) # 1 blue и 6 yellow
print(entropy([1, 2, 3, 4, 5, 6])) # entropy of a fair 6-sided die
# 3\. What is the entropy of the state given by the list **balls_left**?
# 4\. What is the entropy of a fair dice? (where we look at a dice as a system with 6 equally probable states)?
# information gain calculation
def information_gain(root, left, right):
"""root - initial data, left and right - two partitions of initial data"""
# you code here
pass
# 5\. What is the information gain from splitting the initial dataset into **balls_left** and **balls_right** ?
def best_feature_to_split(X, y):
"""Outputs information gain when splitting on best feature"""
# you code here
pass
# #### Optional:
# - Implement a decision tree building algorithm by calling **best_feature_to_split** recursively
# - Plot the resulting tree
# ### Part 3. The "Adult" dataset
# #### Dataset description:
# [Dataset](http://archive.ics.uci.edu/ml/machine-learning-databases/adult) UCI Adult (no need to download it, we have a copy in the course repository): classify people using demographical data - whether they earn more than \$50,000 per year or not.
# Feature descriptions:
# - **Age** – continuous feature
# - **Workclass** – continuous feature
# - **fnlwgt** – final weight of object, continuous feature
# - **Education** – categorical feature
# - **Education_Num** – number of years of education, continuous feature
# - **Martial_Status** – categorical feature
# - **Occupation** – categorical feature
# - **Relationship** – categorical feature
# - **Race** – categorical feature
# - **Sex** – categorical feature
# - **Capital_Gain** – continuous feature
# - **Capital_Loss** – continuous feature
# - **Hours_per_week** – continuous feature
# - **Country** – categorical feature
# **Target** – earnings level, categorical (binary) feature.
# #### Reading train and test data
data_train = pd.read_csv("../../data/adult_train.csv", sep=";")
data_train.tail()
data_test = pd.read_csv("../../data/adult_test.csv", sep=";")
data_test.tail()
# necessary to remove rows with incorrect labels in test dataset
data_test = data_test[
(data_test["Target"] == " >50K.") | (data_test["Target"] == " <=50K.")
]
# encode target variable as integer
data_train.loc[data_train["Target"] == " <=50K", "Target"] = 0
data_train.loc[data_train["Target"] == " >50K", "Target"] = 1
data_test.loc[data_test["Target"] == " <=50K.", "Target"] = 0
data_test.loc[data_test["Target"] == " >50K.", "Target"] = 1
# #### Primary data analysis
data_test.describe(include="all").T
data_train["Target"].value_counts()
fig = plt.figure(figsize=(25, 15))
cols = 5
rows = np.ceil(float(data_train.shape[1]) / cols)
for i, column in enumerate(data_train.columns):
ax = fig.add_subplot(rows, cols, i + 1)
ax.set_title(column)
if data_train.dtypes[column] == np.object:
data_train[column].value_counts().plot(kind="bar", axes=ax)
else:
data_train[column].hist(axes=ax)
plt.xticks(rotation="vertical")
plt.subplots_adjust(hspace=0.7, wspace=0.2)
# #### Checking data types
data_train.dtypes
data_test.dtypes
# As we see, in the test data, age is treated as type **object**. We need to fix this.
data_test["Age"] = data_test["Age"].astype(int)
# Also we'll cast all **float** features to **int** type to keep types consistent between our train and test data.
data_test["fnlwgt"] = data_test["fnlwgt"].astype(int)
data_test["Education_Num"] = data_test["Education_Num"].astype(int)
data_test["Capital_Gain"] = data_test["Capital_Gain"].astype(int)
data_test["Capital_Loss"] = data_test["Capital_Loss"].astype(int)
data_test["Hours_per_week"] = data_test["Hours_per_week"].astype(int)
# #### Fill in missing data for continuous features with their median values, for categorical features with their mode.
# choose categorical and continuous features from data
categorical_columns = [
c for c in data_train.columns if data_train[c].dtype.name == "object"
]
numerical_columns = [
c for c in data_train.columns if data_train[c].dtype.name != "object"
]
print("categorical_columns:", categorical_columns)
print("numerical_columns:", numerical_columns)
# we see some missing values
data_train.info()
# fill missing data
for c in categorical_columns:
data_train[c].fillna(data_train[c].mode()[0], inplace=True)
data_test[c].fillna(data_train[c].mode()[0], inplace=True)
for c in numerical_columns:
data_train[c].fillna(data_train[c].median(), inplace=True)
data_test[c].fillna(data_train[c].median(), inplace=True)
# no more missing values
data_train.info()
# We'll dummy code some categorical features: **Workclass**, **Education**, **Martial_Status**, **Occupation**, **Relationship**, **Race**, **Sex**, **Country**. It can be done via pandas method **get_dummies**
data_train = pd.concat(
[data_train[numerical_columns], pd.get_dummies(data_train[categorical_columns])],
axis=1,
)
data_test = pd.concat(
[data_test[numerical_columns], pd.get_dummies(data_test[categorical_columns])],
axis=1,
)
set(data_train.columns) - set(data_test.columns)
data_train.shape, data_test.shape
# #### There is no Holland in the test data. Create new zero-valued feature.
data_test["Country_ Holand-Netherlands"] = 0
set(data_train.columns) - set(data_test.columns)
data_train.head(2)
data_test.head(2)
X_train = data_train.drop(["Target"], axis=1)
y_train = data_train["Target"]
X_test = data_test.drop(["Target"], axis=1)
y_test = data_test["Target"]
# ### 3.1 Decision tree without parameter tuning
# Train a decision tree **(DecisionTreeClassifier)** with a maximum depth of 3, and evaluate the accuracy metric on the test data. Use parameter **random_state = 17** for results reproducibility.
# you code here
# tree =
# tree.fit
# Make a prediction with the trained model on the test data.
# you code here
# tree_predictions = tree.predict
# you code here
# accuracy_score
# 6\. What is the test set accuracy of a decision tree with maximum tree depth of 3 and **random_state = 17**?
# ### 3.2 Decision tree with parameter tuning
# Train a decision tree **(DecisionTreeClassifier, random_state = 17).** Find the optimal maximum depth using 5-fold cross-validation **(GridSearchCV)**.
tree_params = {"max_depth": range(2, 11)}
locally_best_tree = GridSearchCV # you code here
locally_best_tree.fit
# you code here
# Train a decision tree with maximum depth of 9 (it is the best **max_depth** in my case), and compute the test set accuracy. Use parameter **random_state = 17** for reproducibility.
# you code here
# tuned_tree =
# tuned_tree.fit
# tuned_tree_predictions = tuned_tree.predict
# accuracy_score
# 7\. What is the test set accuracy of a decision tree with maximum depth of 9 and **random_state = 17**?
# ### 3.3 (Optional) Random forest without parameter tuning
# Let's take a sneak peek of upcoming lectures and try to use a random forest for our task. For now, you can imagine a random forest as a bunch of decision trees, trained on slightly different subsets of the training data.
# Train a random forest **(RandomForestClassifier)**. Set the number of trees to 100 and use **random_state = 17**.
# you code here
# rf =
# rf.fit # you code here
# Make predictions for the test data and assess accuracy.
# you code here
# ### 3.4 (Optional) Random forest with parameter tuning
# Train a random forest **(RandomForestClassifier)**. Tune the maximum depth and maximum number of features for each tree using **GridSearchCV**.
# forest_params = {'max_depth': range(10, 21),
# 'max_features': range(5, 105, 20)}
# locally_best_forest = GridSearchCV # you code here
# locally_best_forest.fit # you code here
# Make predictions for the test data and assess accuracy.
# you code here
| false | 0 | 4,041 | 2 | 2,503 | 4,041 |
||
14044587 | <kaggle_start><data_title>MNIST in CSV<data_description># The MNIST dataset provided in a easy-to-use CSV format
The [original dataset](http://yann.lecun.com/exdb/mnist/) is in a format that is difficult for beginners to use. This dataset uses the work of [Joseph Redmon](https://pjreddie.com/) to provide the [MNIST dataset in a CSV format](https://pjreddie.com/projects/mnist-in-csv/).
The dataset consists of two files:
1. `mnist_train.csv`
2. `mnist_test.csv`
The `mnist_train.csv` file contains the 60,000 training examples and labels. The `mnist_test.csv` contains 10,000 test examples and labels. Each row consists of 785 values: the first value is the label (a number from 0 to 9) and the remaining 784 values are the pixel values (a number from 0 to 255).<data_name>mnist-in-csv
<code># # A conditional Conv-GAN using MXNet on the MNIST dataset
# 
import numpy as np
import mxnet as mx
import pandas as pd
import matplotlib.pyplot as plt
import os
print(os.listdir("../input"))
# Any results you write to the current directory are saved as output.
# ## Figuring out the data format and making it usable
train_data_ = pd.read_csv("../input/mnist_train.csv")
test_data_ = pd.read_csv("../input/mnist_test.csv")
print(train_data_.head())
train_label = train_data_["label"]
test_label = test_data_["label"]
train_data = train_data_.drop(columns="label").values
test_data = test_data_.drop(columns="label").values
print(train_data.shape)
# ### Trying to recreate the images
def get_image(mat):
mat = mat.reshape((28, 28))
print(mat.shape)
plt.imshow(mat, cmap="gray")
plt.show
def get_sturctured_images(data):
# convert to batch_size X width X height form
data = data.reshape((-1, 28, 28))
return data
# plot the image at this index:
idx = 4
get_image(train_data[idx])
#
# ***
# ## The Conditional Conv-GAN model
# The model specifics
ctx = mx.gpu(0)
# The Generator Module
def gen_module():
# just create the generator module and return it
# it would generate an image from some random number
no_bias = True
fix_gamma = True
epsilon = 1e-5 + 1e-12
rand = mx.sym.Variable("rand")
g1 = mx.sym.Deconvolution(
rand, name="g1", kernel=(4, 4), num_filter=1024, no_bias=no_bias
)
gbn1 = mx.sym.BatchNorm(g1, name="gbn1", fix_gamma=fix_gamma, eps=epsilon)
gact1 = mx.sym.Activation(gbn1, name="gact1", act_type="relu")
g2 = mx.sym.Deconvolution(
gact1,
name="g2",
kernel=(4, 4),
stride=(2, 2),
pad=(1, 1),
num_filter=512,
no_bias=no_bias,
)
gbn2 = mx.sym.BatchNorm(g2, name="gbn2", fix_gamma=fix_gamma, eps=epsilon)
gact2 = mx.sym.Activation(gbn2, name="gact2", act_type="relu")
g3 = mx.sym.Deconvolution(
gact2,
name="g3",
kernel=(4, 4),
stride=(2, 2),
pad=(1, 1),
num_filter=256,
no_bias=no_bias,
)
gbn3 = mx.sym.BatchNorm(g3, name="gbn3", fix_gamma=fix_gamma, eps=epsilon)
gact3 = mx.sym.Activation(gbn3, name="gact3", act_type="relu")
g4 = mx.sym.Deconvolution(
gact3,
name="g4",
kernel=(4, 4),
stride=(2, 2),
pad=(1, 1),
num_filter=128,
no_bias=no_bias,
)
gbn4 = mx.sym.BatchNorm(g4, name="gbn4", fix_gamma=fix_gamma, eps=epsilon)
gact4 = mx.sym.Activation(gbn4, name="gact4", act_type="relu")
g5 = mx.sym.Deconvolution(
gact4,
name="g5",
kernel=(4, 4),
stride=(2, 2),
pad=(1, 1),
num_filter=3,
no_bias=no_bias,
)
generatorSymbol = mx.sym.Activation(g5, name="gact5", act_type="tanh")
# The discriminator module:
def discr_module():
# creat the discriminator
pass
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0014/044/14044587.ipynb | mnist-in-csv | oddrationale | [{"Id": 14044587, "ScriptId": 3865422, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1077425, "CreationDate": "05/11/2019 15:32:13", "VersionNumber": 1.0, "Title": "conditional_GAN_using_MXNet", "EvaluationDate": "05/11/2019", "IsChange": true, "TotalLines": 87.0, "LinesInsertedFromPrevious": 87.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 9146264, "KernelVersionId": 14044587, "SourceDatasetVersionId": 34877}] | [{"Id": 34877, "DatasetId": 27352, "DatasourceVersionId": 35935, "CreatorUserId": 1352634, "LicenseName": "CC0: Public Domain", "CreationDate": "05/19/2018 02:24:20", "VersionNumber": 2.0, "Title": "MNIST in CSV", "Slug": "mnist-in-csv", "Subtitle": "The MNIST dataset provided in a easy-to-use CSV format", "Description": "# The MNIST dataset provided in a easy-to-use CSV format\nThe [original dataset](http://yann.lecun.com/exdb/mnist/) is in a format that is difficult for beginners to use. This dataset uses the work of [Joseph Redmon](https://pjreddie.com/) to provide the [MNIST dataset in a CSV format](https://pjreddie.com/projects/mnist-in-csv/).\n\nThe dataset consists of two files:\n\n1. `mnist_train.csv`\n2. `mnist_test.csv`\n\nThe `mnist_train.csv` file contains the 60,000 training examples and labels. The `mnist_test.csv` contains 10,000 test examples and labels. Each row consists of 785 values: the first value is the label (a number from 0 to 9) and the remaining 784 values are the pixel values (a number from 0 to 255).", "VersionNotes": "Added column headers", "TotalCompressedBytes": 127943851.0, "TotalUncompressedBytes": 15970538.0}] | [{"Id": 27352, "CreatorUserId": 1352634, "OwnerUserId": 1352634.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 34877.0, "CurrentDatasourceVersionId": 35935.0, "ForumId": 35558, "Type": 2, "CreationDate": "05/19/2018 00:53:44", "LastActivityDate": "05/19/2018", "TotalViews": 422443, "TotalDownloads": 111721, "TotalVotes": 678, "TotalKernels": 503}] | [{"Id": 1352634, "UserName": "oddrationale", "DisplayName": "Dariel Dato-on", "RegisterDate": "10/22/2017", "PerformanceTier": 0}] | # # A conditional Conv-GAN using MXNet on the MNIST dataset
# 
import numpy as np
import mxnet as mx
import pandas as pd
import matplotlib.pyplot as plt
import os
print(os.listdir("../input"))
# Any results you write to the current directory are saved as output.
# ## Figuring out the data format and making it usable
train_data_ = pd.read_csv("../input/mnist_train.csv")
test_data_ = pd.read_csv("../input/mnist_test.csv")
print(train_data_.head())
train_label = train_data_["label"]
test_label = test_data_["label"]
train_data = train_data_.drop(columns="label").values
test_data = test_data_.drop(columns="label").values
print(train_data.shape)
# ### Trying to recreate the images
def get_image(mat):
mat = mat.reshape((28, 28))
print(mat.shape)
plt.imshow(mat, cmap="gray")
plt.show
def get_sturctured_images(data):
# convert to batch_size X width X height form
data = data.reshape((-1, 28, 28))
return data
# plot the image at this index:
idx = 4
get_image(train_data[idx])
#
# ***
# ## The Conditional Conv-GAN model
# The model specifics
ctx = mx.gpu(0)
# The Generator Module
def gen_module():
# just create the generator module and return it
# it would generate an image from some random number
no_bias = True
fix_gamma = True
epsilon = 1e-5 + 1e-12
rand = mx.sym.Variable("rand")
g1 = mx.sym.Deconvolution(
rand, name="g1", kernel=(4, 4), num_filter=1024, no_bias=no_bias
)
gbn1 = mx.sym.BatchNorm(g1, name="gbn1", fix_gamma=fix_gamma, eps=epsilon)
gact1 = mx.sym.Activation(gbn1, name="gact1", act_type="relu")
g2 = mx.sym.Deconvolution(
gact1,
name="g2",
kernel=(4, 4),
stride=(2, 2),
pad=(1, 1),
num_filter=512,
no_bias=no_bias,
)
gbn2 = mx.sym.BatchNorm(g2, name="gbn2", fix_gamma=fix_gamma, eps=epsilon)
gact2 = mx.sym.Activation(gbn2, name="gact2", act_type="relu")
g3 = mx.sym.Deconvolution(
gact2,
name="g3",
kernel=(4, 4),
stride=(2, 2),
pad=(1, 1),
num_filter=256,
no_bias=no_bias,
)
gbn3 = mx.sym.BatchNorm(g3, name="gbn3", fix_gamma=fix_gamma, eps=epsilon)
gact3 = mx.sym.Activation(gbn3, name="gact3", act_type="relu")
g4 = mx.sym.Deconvolution(
gact3,
name="g4",
kernel=(4, 4),
stride=(2, 2),
pad=(1, 1),
num_filter=128,
no_bias=no_bias,
)
gbn4 = mx.sym.BatchNorm(g4, name="gbn4", fix_gamma=fix_gamma, eps=epsilon)
gact4 = mx.sym.Activation(gbn4, name="gact4", act_type="relu")
g5 = mx.sym.Deconvolution(
gact4,
name="g5",
kernel=(4, 4),
stride=(2, 2),
pad=(1, 1),
num_filter=3,
no_bias=no_bias,
)
generatorSymbol = mx.sym.Activation(g5, name="gact5", act_type="tanh")
# The discriminator module:
def discr_module():
# creat the discriminator
pass
| false | 0 | 1,026 | 0 | 252 | 1,026 |
||
14324727 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from IPython.display import Image
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
from collections import MutableMapping
import os
print(os.listdir("../input"))
# Any results you write to the current directory are saved as output.
# # Use classes from TextbookSampleCode
class MapBase(MutableMapping):
"""Our own abstract base class that includes a nonpublic _Item class."""
# ------------------------------- nested _Item class -------------------------------
class _Item:
"""Lightweight composite to store key-value pairs as map items."""
__slots__ = "_key", "_value"
def __init__(self, k, v):
self._key = k
self._value = v
def __eq__(self, other):
return self._key == other._key # compare items based on their keys
def __ne__(self, other):
return not (self == other) # opposite of __eq__
def __lt__(self, other):
return self._key < other._key # compare items based on their keys
class Tree:
"""Abstract base class representing a tree structure."""
# ------------------------------- nested Position class -------------------------------
class Position:
"""An abstraction representing the location of a single element within a tree.
Note that two position instaces may represent the same inherent location in a tree.
Therefore, users should always rely on syntax 'p == q' rather than 'p is q' when testing
equivalence of positions.
"""
def element(self):
"""Return the element stored at this Position."""
raise NotImplementedError("must be implemented by subclass")
def __eq__(self, other):
"""Return True if other Position represents the same location."""
raise NotImplementedError("must be implemented by subclass")
def __ne__(self, other):
"""Return True if other does not represent the same location."""
return not (self == other) # opposite of __eq__
# ---------- abstract methods that concrete subclass must support ----------
def root(self):
"""Return Position representing the tree's root (or None if empty)."""
raise NotImplementedError("must be implemented by subclass")
def parent(self, p):
"""Return Position representing p's parent (or None if p is root)."""
raise NotImplementedError("must be implemented by subclass")
def num_children(self, p):
"""Return the number of children that Position p has."""
raise NotImplementedError("must be implemented by subclass")
def children(self, p):
"""Generate an iteration of Positions representing p's children."""
raise NotImplementedError("must be implemented by subclass")
def __len__(self):
"""Return the total number of elements in the tree."""
raise NotImplementedError("must be implemented by subclass")
# ---------- concrete methods implemented in this class ----------
def is_root(self, p):
"""Return True if Position p represents the root of the tree."""
return self.root() == p
def is_leaf(self, p):
"""Return True if Position p does not have any children."""
return self.num_children(p) == 0
def is_empty(self):
"""Return True if the tree is empty."""
return len(self) == 0
def depth(self, p):
"""Return the number of levels separating Position p from the root."""
if self.is_root(p):
return 0
else:
return 1 + self.depth(self.parent(p))
def _height1(self): # works, but O(n^2) worst-case time
"""Return the height of the tree."""
return max(self.depth(p) for p in self.positions() if self.is_leaf(p))
def _height2(self, p): # time is linear in size of subtree
"""Return the height of the subtree rooted at Position p."""
if self.is_leaf(p):
return 0
else:
return 1 + max(self._height2(c) for c in self.children(p))
def height(self, p=None):
"""Return the height of the subtree rooted at Position p.
If p is None, return the height of the entire tree.
"""
if p is None:
p = self.root()
return self._height2(p) # start _height2 recursion
def __iter__(self):
"""Generate an iteration of the tree's elements."""
for p in self.positions(): # use same order as positions()
yield p.element() # but yield each element
def positions(self):
"""Generate an iteration of the tree's positions."""
return self.preorder() # return entire preorder iteration
def preorder(self):
"""Generate a preorder iteration of positions in the tree."""
if not self.is_empty():
for p in self._subtree_preorder(self.root()): # start recursion
yield p
def _subtree_preorder(self, p):
"""Generate a preorder iteration of positions in subtree rooted at p."""
yield p # visit p before its subtrees
for c in self.children(p): # for each child c
for other in self._subtree_preorder(c): # do preorder of c's subtree
yield other # yielding each to our caller
def postorder(self):
"""Generate a postorder iteration of positions in the tree."""
if not self.is_empty():
for p in self._subtree_postorder(self.root()): # start recursion
yield p
def _subtree_postorder(self, p):
"""Generate a postorder iteration of positions in subtree rooted at p."""
for c in self.children(p): # for each child c
for other in self._subtree_postorder(c): # do postorder of c's subtree
yield other # yielding each to our caller
yield p # visit p after its subtrees
def breadthfirst(self):
"""Generate a breadth-first iteration of the positions of the tree."""
if not self.is_empty():
fringe = LinkedQueue() # known positions not yet yielded
fringe.enqueue(self.root()) # starting with the root
while not fringe.is_empty():
p = fringe.dequeue() # remove from front of the queue
yield p # report this position
for c in self.children(p):
fringe.enqueue(c) # add children to back of queue
class BinaryTree(Tree):
"""Abstract base class representing a binary tree structure."""
# --------------------- additional abstract methods ---------------------
def left(self, p):
"""Return a Position representing p's left child.
Return None if p does not have a left child.
"""
raise NotImplementedError("must be implemented by subclass")
def right(self, p):
"""Return a Position representing p's right child.
Return None if p does not have a right child.
"""
raise NotImplementedError("must be implemented by subclass")
# ---------- concrete methods implemented in this class ----------
def sibling(self, p):
"""Return a Position representing p's sibling (or None if no sibling)."""
parent = self.parent(p)
if parent is None: # p must be the root
return None # root has no sibling
else:
if p == self.left(parent):
return self.right(parent) # possibly None
else:
return self.left(parent) # possibly None
def children(self, p):
"""Generate an iteration of Positions representing p's children."""
if self.left(p) is not None:
yield self.left(p)
if self.right(p) is not None:
yield self.right(p)
def inorder(self):
"""Generate an inorder iteration of positions in the tree."""
if not self.is_empty():
for p in self._subtree_inorder(self.root()):
yield p
def _subtree_inorder(self, p):
"""Generate an inorder iteration of positions in subtree rooted at p."""
if self.left(p) is not None: # if left child exists, traverse its subtree
for other in self._subtree_inorder(self.left(p)):
yield other
yield p # visit p between its subtrees
if self.right(p) is not None: # if right child exists, traverse its subtree
for other in self._subtree_inorder(self.right(p)):
yield other
# override inherited version to make inorder the default
def positions(self):
"""Generate an iteration of the tree's positions."""
return self.inorder() # make inorder the default
class LinkedBinaryTree(BinaryTree):
"""Linked representation of a binary tree structure."""
# -------------------------- nested _Node class --------------------------
class _Node:
"""Lightweight, nonpublic class for storing a node."""
__slots__ = "_element", "_parent", "_left", "_right" # streamline memory usage
def __init__(self, element, parent=None, left=None, right=None):
self._element = element
self._parent = parent
self._left = left
self._right = right
# -------------------------- nested Position class --------------------------
class Position(BinaryTree.Position):
"""An abstraction representing the location of a single element."""
def __init__(self, container, node):
"""Constructor should not be invoked by user."""
self._container = container
self._node = node
def element(self):
"""Return the element stored at this Position."""
return self._node._element
def __eq__(self, other):
"""Return True if other is a Position representing the same location."""
return type(other) is type(self) and other._node is self._node
# ------------------------------- utility methods -------------------------------
def _validate(self, p):
"""Return associated node, if position is valid."""
if not isinstance(p, self.Position):
raise TypeError("p must be proper Position type")
if p._container is not self:
raise ValueError("p does not belong to this container")
if p._node._parent is p._node: # convention for deprecated nodes
raise ValueError("p is no longer valid")
return p._node
def _make_position(self, node):
"""Return Position instance for given node (or None if no node)."""
return self.Position(self, node) if node is not None else None
# -------------------------- binary tree constructor --------------------------
def __init__(self):
"""Create an initially empty binary tree."""
self._root = None
self._size = 0
# -------------------------- public accessors --------------------------
def __len__(self):
"""Return the total number of elements in the tree."""
return self._size
def root(self):
"""Return the root Position of the tree (or None if tree is empty)."""
return self._make_position(self._root)
def parent(self, p):
"""Return the Position of p's parent (or None if p is root)."""
node = self._validate(p)
return self._make_position(node._parent)
def left(self, p):
"""Return the Position of p's left child (or None if no left child)."""
node = self._validate(p)
return self._make_position(node._left)
def right(self, p):
"""Return the Position of p's right child (or None if no right child)."""
node = self._validate(p)
return self._make_position(node._right)
def num_children(self, p):
"""Return the number of children of Position p."""
node = self._validate(p)
count = 0
if node._left is not None: # left child exists
count += 1
if node._right is not None: # right child exists
count += 1
return count
# -------------------------- nonpublic mutators --------------------------
def _add_root(self, e):
"""Place element e at the root of an empty tree and return new Position.
Raise ValueError if tree nonempty.
"""
if self._root is not None:
raise ValueError("Root exists")
self._size = 1
self._root = self._Node(e)
return self._make_position(self._root)
def _add_left(self, p, e):
"""Create a new left child for Position p, storing element e.
Return the Position of new node.
Raise ValueError if Position p is invalid or p already has a left child.
"""
node = self._validate(p)
if node._left is not None:
raise ValueError("Left child exists")
self._size += 1
node._left = self._Node(e, node) # node is its parent
return self._make_position(node._left)
def _add_right(self, p, e):
"""Create a new right child for Position p, storing element e.
Return the Position of new node.
Raise ValueError if Position p is invalid or p already has a right child.
"""
node = self._validate(p)
if node._right is not None:
raise ValueError("Right child exists")
self._size += 1
node._right = self._Node(e, node) # node is its parent
return self._make_position(node._right)
def _replace(self, p, e):
"""Replace the element at position p with e, and return old element."""
node = self._validate(p)
old = node._element
node._element = e
return old
def _delete(self, p):
"""Delete the node at Position p, and replace it with its child, if any.
Return the element that had been stored at Position p.
Raise ValueError if Position p is invalid or p has two children.
"""
node = self._validate(p)
if self.num_children(p) == 2:
raise ValueError("Position has two children")
child = node._left if node._left else node._right # might be None
if child is not None:
child._parent = node._parent # child's grandparent becomes parent
if node is self._root:
self._root = child # child becomes root
else:
parent = node._parent
if node is parent._left:
parent._left = child
else:
parent._right = child
self._size -= 1
node._parent = node # convention for deprecated node
return node._element
def _attach(self, p, t1, t2):
"""Attach trees t1 and t2, respectively, as the left and right subtrees of the external Position p.
As a side effect, set t1 and t2 to empty.
Raise TypeError if trees t1 and t2 do not match type of this tree.
Raise ValueError if Position p is invalid or not external.
"""
node = self._validate(p)
if not self.is_leaf(p):
raise ValueError("position must be leaf")
if not type(self) is type(t1) is type(t2): # all 3 trees must be same type
raise TypeError("Tree types must match")
self._size += len(t1) + len(t2)
if not t1.is_empty(): # attached t1 as left subtree of node
t1._root._parent = node
node._left = t1._root
t1._root = None # set t1 instance to empty
t1._size = 0
if not t2.is_empty(): # attached t2 as right subtree of node
t2._root._parent = node
node._right = t2._root
t2._root = None # set t2 instance to empty
t2._size = 0
class TreeMap(LinkedBinaryTree, MapBase):
"""Sorted map implementation using a binary search tree."""
# ---------------------------- override Position class ----------------------------
class Position(LinkedBinaryTree.Position):
def key(self):
"""Return key of map's key-value pair."""
return self.element()._key
def value(self):
"""Return value of map's key-value pair."""
return self.element()._value
# ------------------------------- nonpublic utilities -------------------------------
def _subtree_search(self, p, k):
"""Return Position of p's subtree having key k, or last node searched."""
if k == p.key(): # found match
return p
elif k < p.key(): # search left subtree
if self.left(p) is not None:
return self._subtree_search(self.left(p), k)
else: # search right subtree
if self.right(p) is not None:
return self._subtree_search(self.right(p), k)
return p # unsucessful search
def _subtree_first_position(self, p):
"""Return Position of first item in subtree rooted at p."""
walk = p
while self.left(walk) is not None: # keep walking left
walk = self.left(walk)
return walk
def _subtree_last_position(self, p):
"""Return Position of last item in subtree rooted at p."""
walk = p
while self.right(walk) is not None: # keep walking right
walk = self.right(walk)
return walk
# --------------------- public methods providing "positional" support ---------------------
def first(self):
"""Return the first Position in the tree (or None if empty)."""
return self._subtree_first_position(self.root()) if len(self) > 0 else None
def last(self):
"""Return the last Position in the tree (or None if empty)."""
return self._subtree_last_position(self.root()) if len(self) > 0 else None
def before(self, p):
"""Return the Position just before p in the natural order.
Return None if p is the first position.
"""
self._validate(p) # inherited from LinkedBinaryTree
if self.left(p):
return self._subtree_last_position(self.left(p))
else:
# walk upward
walk = p
above = self.parent(walk)
while above is not None and walk == self.left(above):
walk = above
above = self.parent(walk)
return above
def after(self, p):
"""Return the Position just after p in the natural order.
Return None if p is the last position.
"""
self._validate(p) # inherited from LinkedBinaryTree
if self.right(p):
return self._subtree_first_position(self.right(p))
else:
walk = p
above = self.parent(walk)
while above is not None and walk == self.right(above):
walk = above
above = self.parent(walk)
return above
def find_position(self, k):
"""Return position with key k, or else neighbor (or None if empty)."""
if self.is_empty():
return None
else:
p = self._subtree_search(self.root(), k)
self._rebalance_access(p) # hook for balanced tree subclasses
return p
def delete(self, p):
"""Remove the item at given Position."""
self._validate(p) # inherited from LinkedBinaryTree
if self.left(p) and self.right(p): # p has two children
replacement = self._subtree_last_position(self.left(p))
self._replace(p, replacement.element()) # from LinkedBinaryTree
p = replacement
# now p has at most one child
parent = self.parent(p)
self._delete(p) # inherited from LinkedBinaryTree
self._rebalance_delete(parent) # if root deleted, parent is None
# --------------------- public methods for (standard) map interface ---------------------
def __getitem__(self, k):
"""Return value associated with key k (raise KeyError if not found)."""
if self.is_empty():
raise KeyError("Key Error: " + repr(k))
else:
p = self._subtree_search(self.root(), k)
self._rebalance_access(p) # hook for balanced tree subclasses
if k != p.key():
raise KeyError("Key Error: " + repr(k))
return p.value()
def __setitem__(self, k, v):
"""Assign value v to key k, overwriting existing value if present."""
if self.is_empty():
leaf = self._add_root(self._Item(k, v)) # from LinkedBinaryTree
else:
p = self._subtree_search(self.root(), k)
if p.key() == k:
p.element()._value = v # replace existing item's value
self._rebalance_access(p) # hook for balanced tree subclasses
return
else:
item = self._Item(k, v)
if p.key() < k:
leaf = self._add_right(p, item) # inherited from LinkedBinaryTree
else:
leaf = self._add_left(p, item) # inherited from LinkedBinaryTree
self._rebalance_insert(leaf) # hook for balanced tree subclasses
def __delitem__(self, k):
"""Remove item associated with key k (raise KeyError if not found)."""
if not self.is_empty():
p = self._subtree_search(self.root(), k)
if k == p.key():
self.delete(p) # rely on positional version
return # successful deletion complete
self._rebalance_access(p) # hook for balanced tree subclasses
raise KeyError("Key Error: " + repr(k))
def __iter__(self):
"""Generate an iteration of all keys in the map in order."""
p = self.first()
while p is not None:
yield p.key()
p = self.after(p)
# --------------------- public methods for sorted map interface ---------------------
def __reversed__(self):
"""Generate an iteration of all keys in the map in reverse order."""
p = self.last()
while p is not None:
yield p.key()
p = self.before(p)
def find_min(self):
"""Return (key,value) pair with minimum key (or None if empty)."""
if self.is_empty():
return None
else:
p = self.first()
return (p.key(), p.value())
def find_max(self):
"""Return (key,value) pair with maximum key (or None if empty)."""
if self.is_empty():
return None
else:
p = self.last()
return (p.key(), p.value())
def find_le(self, k):
"""Return (key,value) pair with greatest key less than or equal to k.
Return None if there does not exist such a key.
"""
if self.is_empty():
return None
else:
p = self.find_position(k)
if k < p.key():
p = self.before(p)
return (p.key(), p.value()) if p is not None else None
def find_lt(self, k):
"""Return (key,value) pair with greatest key strictly less than k.
Return None if there does not exist such a key.
"""
if self.is_empty():
return None
else:
p = self.find_position(k)
if not p.key() < k:
p = self.before(p)
return (p.key(), p.value()) if p is not None else None
def find_ge(self, k):
"""Return (key,value) pair with least key greater than or equal to k.
Return None if there does not exist such a key.
"""
if self.is_empty():
return None
else:
p = self.find_position(k) # may not find exact match
if p.key() < k: # p's key is too small
p = self.after(p)
return (p.key(), p.value()) if p is not None else None
def find_gt(self, k):
"""Return (key,value) pair with least key strictly greater than k.
Return None if there does not exist such a key.
"""
if self.is_empty():
return None
else:
p = self.find_position(k)
if not k < p.key():
p = self.after(p)
return (p.key(), p.value()) if p is not None else None
def find_range(self, start, stop):
"""Iterate all (key,value) pairs such that start <= key < stop.
If start is None, iteration begins with minimum key of map.
If stop is None, iteration continues through the maximum key of map.
"""
if not self.is_empty():
if start is None:
p = self.first()
else:
# we initialize p with logic similar to find_ge
p = self.find_position(start)
if p.key() < start:
p = self.after(p)
while p is not None and (stop is None or p.key() < stop):
yield (p.key(), p.value())
p = self.after(p)
# --------------------- hooks used by subclasses to balance a tree ---------------------
def _rebalance_insert(self, p):
"""Call to indicate that position p is newly added."""
pass
def _rebalance_delete(self, p):
"""Call to indicate that a child of p has been removed."""
pass
def _rebalance_access(self, p):
"""Call to indicate that position p was recently accessed."""
pass
# --------------------- nonpublic methods to support tree balancing ---------------------
def _relink(self, parent, child, make_left_child):
"""Relink parent node with child node (we allow child to be None)."""
if make_left_child: # make it a left child
parent._left = child
else: # make it a right child
parent._right = child
if child is not None: # make child point to parent
child._parent = parent
def _rotate(self, p):
"""Rotate Position p above its parent.
Switches between these configurations, depending on whether p==a or p==b.
b a
/ \ / \
a t2 t0 b
/ \ / \
t0 t1 t1 t2
Caller should ensure that p is not the root.
"""
"""Rotate Position p above its parent."""
x = p._node
y = x._parent # we assume this exists
z = y._parent # grandparent (possibly None)
if z is None:
self._root = x # x becomes root
x._parent = None
else:
self._relink(z, x, y == z._left) # x becomes a direct child of z
# now rotate x and y, including transfer of middle subtree
if x == y._left:
self._relink(y, x._right, True) # x._right becomes left child of y
self._relink(x, y, False) # y becomes right child of x
else:
self._relink(y, x._left, False) # x._left becomes right child of y
self._relink(x, y, True) # y becomes left child of x
def _restructure(self, x):
"""Perform a trinode restructure among Position x, its parent, and its grandparent.
Return the Position that becomes root of the restructured subtree.
Assumes the nodes are in one of the following configurations:
z=a z=c z=a z=c
/ \ / \ / \ / \
t0 y=b y=b t3 t0 y=c y=a t3
/ \ / \ / \ / \
t1 x=c x=a t2 x=b t3 t0 x=b
/ \ / \ / \ / \
t2 t3 t0 t1 t1 t2 t1 t2
The subtree will be restructured so that the node with key b becomes its root.
b
/ \
a c
/ \ / \
t0 t1 t2 t3
Caller should ensure that x has a grandparent.
"""
"""Perform trinode restructure of Position x with parent/grandparent."""
y = self.parent(x)
z = self.parent(y)
if (x == self.right(y)) == (y == self.right(z)): # matching alignments
self._rotate(y) # single rotation (of y)
return y # y is new subtree root
else: # opposite alignments
self._rotate(x) # double rotation (of x)
self._rotate(x)
return x # x is new subtree root
class SplayTreeMap(TreeMap):
"""Sorted map implementation using a splay tree."""
# --------------------------------- splay operation --------------------------------
def _splay(self, p):
while p != self.root():
parent = self.parent(p)
grand = self.parent(parent)
if grand is None:
# zig case
self._rotate(p)
elif (parent == self.left(grand)) == (p == self.left(parent)):
# zig-zig case
self._rotate(parent) # move PARENT up
self._rotate(p) # then move p up
else:
# zig-zag case
self._rotate(p) # move p up
self._rotate(p) # move p up again
# ---------------------------- override balancing hooks ----------------------------
def _rebalance_insert(self, p):
self._splay(p)
def _rebalance_delete(self, p):
if p is not None:
self._splay(p)
def _rebalance_access(self, p):
self._splay(p)
# # 1. Insert, into an empty binary search tree, entries with keys 30, 40, 24, 58, 48, 26, 25 (in this order). Draw the tree after each insertion.
# # Drawn Stages
Image("../input/q1.jpg")
# # Code Implementation
tree = TreeMap()
root = tree._add_root(30)
print("Root Element: ", root.element(), "\n")
node_40 = tree._add_right(root, 40)
print("Right of Root Element: ", tree.right(root).element())
node_24 = tree._add_left(root, 24)
print("Left of Root Element: ", tree.left(root).element(), "\n")
node_58 = tree._add_right(node_40, 58)
print("Right of Node 40 Element: ", tree.right(node_40).element())
node_48 = tree._add_left(node_58, 48)
print("Left of Node 58 Element: ", tree.left(node_58).element())
node_26 = tree._add_right(node_24, 26)
print("Right of Node 24 Element: ", tree.right(node_24).element())
node_25 = tree._add_left(node_26, 25)
print("Left of Node 26 Element: ", tree.left(node_26).element(), "\n")
print("Number of elements: ", len(tree), "\n")
# # 2. (R-11.3) How many different binary search trees can store the keys {1,2,3}?
# # Drawn Stages
Image("../input/q2.jpg")
# # Code Implementation
print("Different Binary Trees \n")
print("Binary Tree 1")
tree1 = TreeMap()
root = tree1._add_root(2)
print("Root Element: ", root.element())
node_3 = tree1._add_right(root, 3)
print("Right of Root Element: ", tree1.right(root).element())
node_1 = tree1._add_left(root, 1)
print("Left of Root Element: ", tree1.left(root).element(), "\n")
print("Binary Tree 2")
tree2 = TreeMap()
root = tree2._add_root(1)
print("Root Element: ", root.element())
node_2 = tree2._add_right(root, 2)
print("Right of Root Element: ", tree2.right(root).element())
node_3 = tree2._add_right(node_2, 3)
print("Right of Node 2 Element: ", tree2.right(node_2).element(), "\n")
print("Binary Tree 3")
tree3 = TreeMap()
root = tree3._add_root(3)
print("Root Element: ", root.element())
node_2 = tree3._add_left(root, 2)
print("Left of Root Element: ", tree3.left(root).element())
node_1 = tree3._add_left(node_2, 1)
print("Left of Node 2 Element: ", tree3.left(node_2).element(), "\n")
print("Binary Tree 4")
tree4 = TreeMap()
root = tree4._add_root(3)
print("Root Element: ", root.element())
node_1 = tree4._add_left(root, 1)
print("Left of Root Element: ", tree4.left(root).element())
node_2 = tree4._add_right(node_1, 2)
print("Right of Node 1 Element: ", tree4.right(node_1).element(), "\n")
print("Binary Tree 5")
tree5 = TreeMap()
root = tree5._add_root(1)
print("Root Element: ", root.element())
node_3 = tree5._add_right(root, 3)
print("Right of Root Element: ", tree5.right(root).element())
node_2 = tree5._add_left(node_3, 2)
print("Left of Node 3 Element: ", tree5.left(node_3).element(), "\n")
# 3. Draw an AVL tree resulting from the insertion of an entry with key 52 into the AVL tree below:
# 
# # Drawn Stages
Image("../input/q3.jpg")
# # Code Implementation
# Initial Tree
avltree = TreeMap()
root = avltree._add_root(62)
print("Initial Tree: \n")
print("Root Element: ", root.element(), "\n")
node_78 = avltree._add_right(root, 78) # First Right subtree
node_88 = avltree._add_right(node_78, 88) # Right Child of first right subtree
print("Right of Root Element: ", avltree.right(root).element())
print("Right of Node 78 Element: ", avltree.right(node_78).element(), "\n")
node_44 = avltree._add_left(root, 44) # First Left subtree
node_17 = avltree._add_left(node_44, 17) # Left child of first left subtree
node_50 = avltree._add_right(
node_44, 50
) # Right child of first left subtree, start of second left subtree
print("Left of Root Element: ", avltree.left(root).element())
print("Left child of first left subtree: ", avltree.left(node_44).element())
print("Right child of first left subtree: ", avltree.right(node_44).element(), "\n")
node_48 = avltree._add_left(node_50, 48) # Left child of second left subtree
node_54 = avltree._add_right(node_50, 54) # Right child of second left subtree
print("Left child of second left subtree: ", avltree.left(node_50).element())
print("Right child of second left subtree: ", avltree.right(node_50).element(), "\n")
print("Insert key 52:")
node_52 = avltree._add_left(node_54, 52)
print("Left child of third left subtree: ", avltree.left(node_54).element())
print("Restructure tree:", "\n")
avltree._restructure(node_54)
print("Display left path for restructered Tree \n")
print("Root Element:", root.element())
print("Left of Root Element:", avltree.left(root).element(), "\n")
print("Left child of first left subtree:", avltree.left(node_50).element())
print("Right child of first left subtree:", avltree.right(node_50).element(), "\n")
print(
"Left grandchild of first left subtree on left side",
avltree.left(node_44).element(),
)
print(
"Right grandchild of first left subtree on left side:",
avltree.right(node_44).element(),
"\n",
)
print(
"Left grandchild of first left subtree on right side:",
avltree.left(node_54).element(),
)
# 4. Consider the set of keys K = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15}. Draw a (2, 4) tree
# storing K as its keys using the fewest number of nodes.
# # Drawn Stages
Image("../input/q4.jpg")
# # Code Implementation
# 5. Insert into an empty (2, 4) tree, entries with keys 5, 16, 22, 45, 2, 10, 18, 30, 50, 12, 1 (in this order).
# Draw the tree after each insertion.
#
Image("../input/q5.jpg")
# 6. Insert into an empty splay tree entries with keys 10, 16, 12, 14, 13 (in this order). Draw the tree after
# each insertion.
# # Drawn Stages
Image("../input/q6.jpg")
# # Code Implementation
splay = SplayTreeMap()
print("Stage 1: Add Root")
root = splay._add_root(10)
print("Root node added:", root.element(), "\n")
print("Stage 2: Insert 16")
node16 = splay._add_right(root, 16).element()
pos16 = splay.right(root)
print("Right node of root added:", splay.right(root).element(), "\n")
splay._splay(pos16)
print("Splaying.. \n")
new_root = splay.root().element()
left_root = splay.left(splay.root()).element()
print("Root node:", new_root)
print("Left of root node:", left_root, "\n")
print("Stage 3: Insert 12")
node12 = splay._add_right(splay.left(splay.root()), 12).element()
pos12 = splay.right(splay.left(splay.root()))
print("Node added:", node12, "\n")
splay._splay(pos12)
print("Splaying.. \n")
new_root = splay.root().element()
left_root = splay.left(splay.root()).element()
right_root = splay.right(splay.root()).element()
print("Root node:", new_root)
print("Left of root node:", left_root)
print("Right of root node:", right_root, "\n")
print("Stage 4: Insert 14")
node14 = splay._add_left(splay.right(splay.root()), 14).element()
pos14 = splay.left(splay.right(splay.root()))
print("Node added:", node14, "\n")
splay._splay(pos14)
print("Splaying.. \n")
new_root = splay.root().element()
left_root = splay.left(splay.root()).element()
right_root = splay.right(splay.root()).element()
left_gchild_root = splay.left(splay.left(splay.root())).element()
print("Root node:", new_root)
print("Left of root node:", left_root)
print("Right of root node:", right_root)
print("Left grandchild of root node:", left_gchild_root, "\n")
print("Stage 5: Insert 13")
node13 = splay._add_right(splay.left(splay.root()), 13).element()
pos13 = splay.right(splay.left(splay.root()))
print("Node added:", node13, "\n")
splay._splay(pos13)
print("Splaying.. \n")
new_root = splay.root().element()
left_root = splay.left(splay.root()).element()
right_root = splay.right(splay.root()).element()
left_gchild_root = splay.left(splay.left(splay.root())).element()
right_gchild_root = splay.right(splay.right(splay.root())).element()
print("Root node:", new_root)
print("Left of root node:", left_root)
print("Right of root node:", right_root)
print("Left grandchild of root node:", left_gchild_root)
print("Right grandchild of root node:", right_gchild_root)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0014/324/14324727.ipynb | null | null | [{"Id": 14324727, "ScriptId": 3696559, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2875114, "CreationDate": "05/18/2019 06:32:16", "VersionNumber": 4.0, "Title": "CP2410 Practical 09 - Search Trees", "EvaluationDate": "05/18/2019", "IsChange": true, "TotalLines": 1020.0, "LinesInsertedFromPrevious": 114.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 906.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from IPython.display import Image
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
from collections import MutableMapping
import os
print(os.listdir("../input"))
# Any results you write to the current directory are saved as output.
# # Use classes from TextbookSampleCode
class MapBase(MutableMapping):
"""Our own abstract base class that includes a nonpublic _Item class."""
# ------------------------------- nested _Item class -------------------------------
class _Item:
"""Lightweight composite to store key-value pairs as map items."""
__slots__ = "_key", "_value"
def __init__(self, k, v):
self._key = k
self._value = v
def __eq__(self, other):
return self._key == other._key # compare items based on their keys
def __ne__(self, other):
return not (self == other) # opposite of __eq__
def __lt__(self, other):
return self._key < other._key # compare items based on their keys
class Tree:
"""Abstract base class representing a tree structure."""
# ------------------------------- nested Position class -------------------------------
class Position:
"""An abstraction representing the location of a single element within a tree.
Note that two position instaces may represent the same inherent location in a tree.
Therefore, users should always rely on syntax 'p == q' rather than 'p is q' when testing
equivalence of positions.
"""
def element(self):
"""Return the element stored at this Position."""
raise NotImplementedError("must be implemented by subclass")
def __eq__(self, other):
"""Return True if other Position represents the same location."""
raise NotImplementedError("must be implemented by subclass")
def __ne__(self, other):
"""Return True if other does not represent the same location."""
return not (self == other) # opposite of __eq__
# ---------- abstract methods that concrete subclass must support ----------
def root(self):
"""Return Position representing the tree's root (or None if empty)."""
raise NotImplementedError("must be implemented by subclass")
def parent(self, p):
"""Return Position representing p's parent (or None if p is root)."""
raise NotImplementedError("must be implemented by subclass")
def num_children(self, p):
"""Return the number of children that Position p has."""
raise NotImplementedError("must be implemented by subclass")
def children(self, p):
"""Generate an iteration of Positions representing p's children."""
raise NotImplementedError("must be implemented by subclass")
def __len__(self):
"""Return the total number of elements in the tree."""
raise NotImplementedError("must be implemented by subclass")
# ---------- concrete methods implemented in this class ----------
def is_root(self, p):
"""Return True if Position p represents the root of the tree."""
return self.root() == p
def is_leaf(self, p):
"""Return True if Position p does not have any children."""
return self.num_children(p) == 0
def is_empty(self):
"""Return True if the tree is empty."""
return len(self) == 0
def depth(self, p):
"""Return the number of levels separating Position p from the root."""
if self.is_root(p):
return 0
else:
return 1 + self.depth(self.parent(p))
def _height1(self): # works, but O(n^2) worst-case time
"""Return the height of the tree."""
return max(self.depth(p) for p in self.positions() if self.is_leaf(p))
def _height2(self, p): # time is linear in size of subtree
"""Return the height of the subtree rooted at Position p."""
if self.is_leaf(p):
return 0
else:
return 1 + max(self._height2(c) for c in self.children(p))
def height(self, p=None):
"""Return the height of the subtree rooted at Position p.
If p is None, return the height of the entire tree.
"""
if p is None:
p = self.root()
return self._height2(p) # start _height2 recursion
def __iter__(self):
"""Generate an iteration of the tree's elements."""
for p in self.positions(): # use same order as positions()
yield p.element() # but yield each element
def positions(self):
"""Generate an iteration of the tree's positions."""
return self.preorder() # return entire preorder iteration
def preorder(self):
"""Generate a preorder iteration of positions in the tree."""
if not self.is_empty():
for p in self._subtree_preorder(self.root()): # start recursion
yield p
def _subtree_preorder(self, p):
"""Generate a preorder iteration of positions in subtree rooted at p."""
yield p # visit p before its subtrees
for c in self.children(p): # for each child c
for other in self._subtree_preorder(c): # do preorder of c's subtree
yield other # yielding each to our caller
def postorder(self):
"""Generate a postorder iteration of positions in the tree."""
if not self.is_empty():
for p in self._subtree_postorder(self.root()): # start recursion
yield p
def _subtree_postorder(self, p):
"""Generate a postorder iteration of positions in subtree rooted at p."""
for c in self.children(p): # for each child c
for other in self._subtree_postorder(c): # do postorder of c's subtree
yield other # yielding each to our caller
yield p # visit p after its subtrees
def breadthfirst(self):
"""Generate a breadth-first iteration of the positions of the tree."""
if not self.is_empty():
fringe = LinkedQueue() # known positions not yet yielded
fringe.enqueue(self.root()) # starting with the root
while not fringe.is_empty():
p = fringe.dequeue() # remove from front of the queue
yield p # report this position
for c in self.children(p):
fringe.enqueue(c) # add children to back of queue
class BinaryTree(Tree):
"""Abstract base class representing a binary tree structure."""
# --------------------- additional abstract methods ---------------------
def left(self, p):
"""Return a Position representing p's left child.
Return None if p does not have a left child.
"""
raise NotImplementedError("must be implemented by subclass")
def right(self, p):
"""Return a Position representing p's right child.
Return None if p does not have a right child.
"""
raise NotImplementedError("must be implemented by subclass")
# ---------- concrete methods implemented in this class ----------
def sibling(self, p):
"""Return a Position representing p's sibling (or None if no sibling)."""
parent = self.parent(p)
if parent is None: # p must be the root
return None # root has no sibling
else:
if p == self.left(parent):
return self.right(parent) # possibly None
else:
return self.left(parent) # possibly None
def children(self, p):
"""Generate an iteration of Positions representing p's children."""
if self.left(p) is not None:
yield self.left(p)
if self.right(p) is not None:
yield self.right(p)
def inorder(self):
"""Generate an inorder iteration of positions in the tree."""
if not self.is_empty():
for p in self._subtree_inorder(self.root()):
yield p
def _subtree_inorder(self, p):
"""Generate an inorder iteration of positions in subtree rooted at p."""
if self.left(p) is not None: # if left child exists, traverse its subtree
for other in self._subtree_inorder(self.left(p)):
yield other
yield p # visit p between its subtrees
if self.right(p) is not None: # if right child exists, traverse its subtree
for other in self._subtree_inorder(self.right(p)):
yield other
# override inherited version to make inorder the default
def positions(self):
"""Generate an iteration of the tree's positions."""
return self.inorder() # make inorder the default
class LinkedBinaryTree(BinaryTree):
"""Linked representation of a binary tree structure."""
# -------------------------- nested _Node class --------------------------
class _Node:
"""Lightweight, nonpublic class for storing a node."""
__slots__ = "_element", "_parent", "_left", "_right" # streamline memory usage
def __init__(self, element, parent=None, left=None, right=None):
self._element = element
self._parent = parent
self._left = left
self._right = right
# -------------------------- nested Position class --------------------------
class Position(BinaryTree.Position):
"""An abstraction representing the location of a single element."""
def __init__(self, container, node):
"""Constructor should not be invoked by user."""
self._container = container
self._node = node
def element(self):
"""Return the element stored at this Position."""
return self._node._element
def __eq__(self, other):
"""Return True if other is a Position representing the same location."""
return type(other) is type(self) and other._node is self._node
# ------------------------------- utility methods -------------------------------
def _validate(self, p):
"""Return associated node, if position is valid."""
if not isinstance(p, self.Position):
raise TypeError("p must be proper Position type")
if p._container is not self:
raise ValueError("p does not belong to this container")
if p._node._parent is p._node: # convention for deprecated nodes
raise ValueError("p is no longer valid")
return p._node
def _make_position(self, node):
"""Return Position instance for given node (or None if no node)."""
return self.Position(self, node) if node is not None else None
# -------------------------- binary tree constructor --------------------------
def __init__(self):
"""Create an initially empty binary tree."""
self._root = None
self._size = 0
# -------------------------- public accessors --------------------------
def __len__(self):
"""Return the total number of elements in the tree."""
return self._size
def root(self):
"""Return the root Position of the tree (or None if tree is empty)."""
return self._make_position(self._root)
def parent(self, p):
"""Return the Position of p's parent (or None if p is root)."""
node = self._validate(p)
return self._make_position(node._parent)
def left(self, p):
"""Return the Position of p's left child (or None if no left child)."""
node = self._validate(p)
return self._make_position(node._left)
def right(self, p):
"""Return the Position of p's right child (or None if no right child)."""
node = self._validate(p)
return self._make_position(node._right)
def num_children(self, p):
"""Return the number of children of Position p."""
node = self._validate(p)
count = 0
if node._left is not None: # left child exists
count += 1
if node._right is not None: # right child exists
count += 1
return count
# -------------------------- nonpublic mutators --------------------------
def _add_root(self, e):
"""Place element e at the root of an empty tree and return new Position.
Raise ValueError if tree nonempty.
"""
if self._root is not None:
raise ValueError("Root exists")
self._size = 1
self._root = self._Node(e)
return self._make_position(self._root)
def _add_left(self, p, e):
"""Create a new left child for Position p, storing element e.
Return the Position of new node.
Raise ValueError if Position p is invalid or p already has a left child.
"""
node = self._validate(p)
if node._left is not None:
raise ValueError("Left child exists")
self._size += 1
node._left = self._Node(e, node) # node is its parent
return self._make_position(node._left)
def _add_right(self, p, e):
"""Create a new right child for Position p, storing element e.
Return the Position of new node.
Raise ValueError if Position p is invalid or p already has a right child.
"""
node = self._validate(p)
if node._right is not None:
raise ValueError("Right child exists")
self._size += 1
node._right = self._Node(e, node) # node is its parent
return self._make_position(node._right)
def _replace(self, p, e):
"""Replace the element at position p with e, and return old element."""
node = self._validate(p)
old = node._element
node._element = e
return old
def _delete(self, p):
"""Delete the node at Position p, and replace it with its child, if any.
Return the element that had been stored at Position p.
Raise ValueError if Position p is invalid or p has two children.
"""
node = self._validate(p)
if self.num_children(p) == 2:
raise ValueError("Position has two children")
child = node._left if node._left else node._right # might be None
if child is not None:
child._parent = node._parent # child's grandparent becomes parent
if node is self._root:
self._root = child # child becomes root
else:
parent = node._parent
if node is parent._left:
parent._left = child
else:
parent._right = child
self._size -= 1
node._parent = node # convention for deprecated node
return node._element
def _attach(self, p, t1, t2):
"""Attach trees t1 and t2, respectively, as the left and right subtrees of the external Position p.
As a side effect, set t1 and t2 to empty.
Raise TypeError if trees t1 and t2 do not match type of this tree.
Raise ValueError if Position p is invalid or not external.
"""
node = self._validate(p)
if not self.is_leaf(p):
raise ValueError("position must be leaf")
if not type(self) is type(t1) is type(t2): # all 3 trees must be same type
raise TypeError("Tree types must match")
self._size += len(t1) + len(t2)
if not t1.is_empty(): # attached t1 as left subtree of node
t1._root._parent = node
node._left = t1._root
t1._root = None # set t1 instance to empty
t1._size = 0
if not t2.is_empty(): # attached t2 as right subtree of node
t2._root._parent = node
node._right = t2._root
t2._root = None # set t2 instance to empty
t2._size = 0
class TreeMap(LinkedBinaryTree, MapBase):
"""Sorted map implementation using a binary search tree."""
# ---------------------------- override Position class ----------------------------
class Position(LinkedBinaryTree.Position):
def key(self):
"""Return key of map's key-value pair."""
return self.element()._key
def value(self):
"""Return value of map's key-value pair."""
return self.element()._value
# ------------------------------- nonpublic utilities -------------------------------
def _subtree_search(self, p, k):
"""Return Position of p's subtree having key k, or last node searched."""
if k == p.key(): # found match
return p
elif k < p.key(): # search left subtree
if self.left(p) is not None:
return self._subtree_search(self.left(p), k)
else: # search right subtree
if self.right(p) is not None:
return self._subtree_search(self.right(p), k)
return p # unsucessful search
def _subtree_first_position(self, p):
"""Return Position of first item in subtree rooted at p."""
walk = p
while self.left(walk) is not None: # keep walking left
walk = self.left(walk)
return walk
def _subtree_last_position(self, p):
"""Return Position of last item in subtree rooted at p."""
walk = p
while self.right(walk) is not None: # keep walking right
walk = self.right(walk)
return walk
# --------------------- public methods providing "positional" support ---------------------
def first(self):
"""Return the first Position in the tree (or None if empty)."""
return self._subtree_first_position(self.root()) if len(self) > 0 else None
def last(self):
"""Return the last Position in the tree (or None if empty)."""
return self._subtree_last_position(self.root()) if len(self) > 0 else None
def before(self, p):
"""Return the Position just before p in the natural order.
Return None if p is the first position.
"""
self._validate(p) # inherited from LinkedBinaryTree
if self.left(p):
return self._subtree_last_position(self.left(p))
else:
# walk upward
walk = p
above = self.parent(walk)
while above is not None and walk == self.left(above):
walk = above
above = self.parent(walk)
return above
def after(self, p):
"""Return the Position just after p in the natural order.
Return None if p is the last position.
"""
self._validate(p) # inherited from LinkedBinaryTree
if self.right(p):
return self._subtree_first_position(self.right(p))
else:
walk = p
above = self.parent(walk)
while above is not None and walk == self.right(above):
walk = above
above = self.parent(walk)
return above
def find_position(self, k):
"""Return position with key k, or else neighbor (or None if empty)."""
if self.is_empty():
return None
else:
p = self._subtree_search(self.root(), k)
self._rebalance_access(p) # hook for balanced tree subclasses
return p
def delete(self, p):
"""Remove the item at given Position."""
self._validate(p) # inherited from LinkedBinaryTree
if self.left(p) and self.right(p): # p has two children
replacement = self._subtree_last_position(self.left(p))
self._replace(p, replacement.element()) # from LinkedBinaryTree
p = replacement
# now p has at most one child
parent = self.parent(p)
self._delete(p) # inherited from LinkedBinaryTree
self._rebalance_delete(parent) # if root deleted, parent is None
# --------------------- public methods for (standard) map interface ---------------------
def __getitem__(self, k):
"""Return value associated with key k (raise KeyError if not found)."""
if self.is_empty():
raise KeyError("Key Error: " + repr(k))
else:
p = self._subtree_search(self.root(), k)
self._rebalance_access(p) # hook for balanced tree subclasses
if k != p.key():
raise KeyError("Key Error: " + repr(k))
return p.value()
def __setitem__(self, k, v):
"""Assign value v to key k, overwriting existing value if present."""
if self.is_empty():
leaf = self._add_root(self._Item(k, v)) # from LinkedBinaryTree
else:
p = self._subtree_search(self.root(), k)
if p.key() == k:
p.element()._value = v # replace existing item's value
self._rebalance_access(p) # hook for balanced tree subclasses
return
else:
item = self._Item(k, v)
if p.key() < k:
leaf = self._add_right(p, item) # inherited from LinkedBinaryTree
else:
leaf = self._add_left(p, item) # inherited from LinkedBinaryTree
self._rebalance_insert(leaf) # hook for balanced tree subclasses
def __delitem__(self, k):
"""Remove item associated with key k (raise KeyError if not found)."""
if not self.is_empty():
p = self._subtree_search(self.root(), k)
if k == p.key():
self.delete(p) # rely on positional version
return # successful deletion complete
self._rebalance_access(p) # hook for balanced tree subclasses
raise KeyError("Key Error: " + repr(k))
def __iter__(self):
"""Generate an iteration of all keys in the map in order."""
p = self.first()
while p is not None:
yield p.key()
p = self.after(p)
# --------------------- public methods for sorted map interface ---------------------
def __reversed__(self):
"""Generate an iteration of all keys in the map in reverse order."""
p = self.last()
while p is not None:
yield p.key()
p = self.before(p)
def find_min(self):
"""Return (key,value) pair with minimum key (or None if empty)."""
if self.is_empty():
return None
else:
p = self.first()
return (p.key(), p.value())
def find_max(self):
"""Return (key,value) pair with maximum key (or None if empty)."""
if self.is_empty():
return None
else:
p = self.last()
return (p.key(), p.value())
def find_le(self, k):
"""Return (key,value) pair with greatest key less than or equal to k.
Return None if there does not exist such a key.
"""
if self.is_empty():
return None
else:
p = self.find_position(k)
if k < p.key():
p = self.before(p)
return (p.key(), p.value()) if p is not None else None
def find_lt(self, k):
"""Return (key,value) pair with greatest key strictly less than k.
Return None if there does not exist such a key.
"""
if self.is_empty():
return None
else:
p = self.find_position(k)
if not p.key() < k:
p = self.before(p)
return (p.key(), p.value()) if p is not None else None
def find_ge(self, k):
"""Return (key,value) pair with least key greater than or equal to k.
Return None if there does not exist such a key.
"""
if self.is_empty():
return None
else:
p = self.find_position(k) # may not find exact match
if p.key() < k: # p's key is too small
p = self.after(p)
return (p.key(), p.value()) if p is not None else None
def find_gt(self, k):
"""Return (key,value) pair with least key strictly greater than k.
Return None if there does not exist such a key.
"""
if self.is_empty():
return None
else:
p = self.find_position(k)
if not k < p.key():
p = self.after(p)
return (p.key(), p.value()) if p is not None else None
def find_range(self, start, stop):
"""Iterate all (key,value) pairs such that start <= key < stop.
If start is None, iteration begins with minimum key of map.
If stop is None, iteration continues through the maximum key of map.
"""
if not self.is_empty():
if start is None:
p = self.first()
else:
# we initialize p with logic similar to find_ge
p = self.find_position(start)
if p.key() < start:
p = self.after(p)
while p is not None and (stop is None or p.key() < stop):
yield (p.key(), p.value())
p = self.after(p)
# --------------------- hooks used by subclasses to balance a tree ---------------------
def _rebalance_insert(self, p):
"""Call to indicate that position p is newly added."""
pass
def _rebalance_delete(self, p):
"""Call to indicate that a child of p has been removed."""
pass
def _rebalance_access(self, p):
"""Call to indicate that position p was recently accessed."""
pass
# --------------------- nonpublic methods to support tree balancing ---------------------
def _relink(self, parent, child, make_left_child):
"""Relink parent node with child node (we allow child to be None)."""
if make_left_child: # make it a left child
parent._left = child
else: # make it a right child
parent._right = child
if child is not None: # make child point to parent
child._parent = parent
def _rotate(self, p):
"""Rotate Position p above its parent.
Switches between these configurations, depending on whether p==a or p==b.
b a
/ \ / \
a t2 t0 b
/ \ / \
t0 t1 t1 t2
Caller should ensure that p is not the root.
"""
"""Rotate Position p above its parent."""
x = p._node
y = x._parent # we assume this exists
z = y._parent # grandparent (possibly None)
if z is None:
self._root = x # x becomes root
x._parent = None
else:
self._relink(z, x, y == z._left) # x becomes a direct child of z
# now rotate x and y, including transfer of middle subtree
if x == y._left:
self._relink(y, x._right, True) # x._right becomes left child of y
self._relink(x, y, False) # y becomes right child of x
else:
self._relink(y, x._left, False) # x._left becomes right child of y
self._relink(x, y, True) # y becomes left child of x
def _restructure(self, x):
"""Perform a trinode restructure among Position x, its parent, and its grandparent.
Return the Position that becomes root of the restructured subtree.
Assumes the nodes are in one of the following configurations:
z=a z=c z=a z=c
/ \ / \ / \ / \
t0 y=b y=b t3 t0 y=c y=a t3
/ \ / \ / \ / \
t1 x=c x=a t2 x=b t3 t0 x=b
/ \ / \ / \ / \
t2 t3 t0 t1 t1 t2 t1 t2
The subtree will be restructured so that the node with key b becomes its root.
b
/ \
a c
/ \ / \
t0 t1 t2 t3
Caller should ensure that x has a grandparent.
"""
"""Perform trinode restructure of Position x with parent/grandparent."""
y = self.parent(x)
z = self.parent(y)
if (x == self.right(y)) == (y == self.right(z)): # matching alignments
self._rotate(y) # single rotation (of y)
return y # y is new subtree root
else: # opposite alignments
self._rotate(x) # double rotation (of x)
self._rotate(x)
return x # x is new subtree root
class SplayTreeMap(TreeMap):
"""Sorted map implementation using a splay tree."""
# --------------------------------- splay operation --------------------------------
def _splay(self, p):
while p != self.root():
parent = self.parent(p)
grand = self.parent(parent)
if grand is None:
# zig case
self._rotate(p)
elif (parent == self.left(grand)) == (p == self.left(parent)):
# zig-zig case
self._rotate(parent) # move PARENT up
self._rotate(p) # then move p up
else:
# zig-zag case
self._rotate(p) # move p up
self._rotate(p) # move p up again
# ---------------------------- override balancing hooks ----------------------------
def _rebalance_insert(self, p):
self._splay(p)
def _rebalance_delete(self, p):
if p is not None:
self._splay(p)
def _rebalance_access(self, p):
self._splay(p)
# # 1. Insert, into an empty binary search tree, entries with keys 30, 40, 24, 58, 48, 26, 25 (in this order). Draw the tree after each insertion.
# # Drawn Stages
Image("../input/q1.jpg")
# # Code Implementation
tree = TreeMap()
root = tree._add_root(30)
print("Root Element: ", root.element(), "\n")
node_40 = tree._add_right(root, 40)
print("Right of Root Element: ", tree.right(root).element())
node_24 = tree._add_left(root, 24)
print("Left of Root Element: ", tree.left(root).element(), "\n")
node_58 = tree._add_right(node_40, 58)
print("Right of Node 40 Element: ", tree.right(node_40).element())
node_48 = tree._add_left(node_58, 48)
print("Left of Node 58 Element: ", tree.left(node_58).element())
node_26 = tree._add_right(node_24, 26)
print("Right of Node 24 Element: ", tree.right(node_24).element())
node_25 = tree._add_left(node_26, 25)
print("Left of Node 26 Element: ", tree.left(node_26).element(), "\n")
print("Number of elements: ", len(tree), "\n")
# # 2. (R-11.3) How many different binary search trees can store the keys {1,2,3}?
# # Drawn Stages
Image("../input/q2.jpg")
# # Code Implementation
print("Different Binary Trees \n")
print("Binary Tree 1")
tree1 = TreeMap()
root = tree1._add_root(2)
print("Root Element: ", root.element())
node_3 = tree1._add_right(root, 3)
print("Right of Root Element: ", tree1.right(root).element())
node_1 = tree1._add_left(root, 1)
print("Left of Root Element: ", tree1.left(root).element(), "\n")
print("Binary Tree 2")
tree2 = TreeMap()
root = tree2._add_root(1)
print("Root Element: ", root.element())
node_2 = tree2._add_right(root, 2)
print("Right of Root Element: ", tree2.right(root).element())
node_3 = tree2._add_right(node_2, 3)
print("Right of Node 2 Element: ", tree2.right(node_2).element(), "\n")
print("Binary Tree 3")
tree3 = TreeMap()
root = tree3._add_root(3)
print("Root Element: ", root.element())
node_2 = tree3._add_left(root, 2)
print("Left of Root Element: ", tree3.left(root).element())
node_1 = tree3._add_left(node_2, 1)
print("Left of Node 2 Element: ", tree3.left(node_2).element(), "\n")
print("Binary Tree 4")
tree4 = TreeMap()
root = tree4._add_root(3)
print("Root Element: ", root.element())
node_1 = tree4._add_left(root, 1)
print("Left of Root Element: ", tree4.left(root).element())
node_2 = tree4._add_right(node_1, 2)
print("Right of Node 1 Element: ", tree4.right(node_1).element(), "\n")
print("Binary Tree 5")
tree5 = TreeMap()
root = tree5._add_root(1)
print("Root Element: ", root.element())
node_3 = tree5._add_right(root, 3)
print("Right of Root Element: ", tree5.right(root).element())
node_2 = tree5._add_left(node_3, 2)
print("Left of Node 3 Element: ", tree5.left(node_3).element(), "\n")
# 3. Draw an AVL tree resulting from the insertion of an entry with key 52 into the AVL tree below:
# 
# # Drawn Stages
Image("../input/q3.jpg")
# # Code Implementation
# Initial Tree
avltree = TreeMap()
root = avltree._add_root(62)
print("Initial Tree: \n")
print("Root Element: ", root.element(), "\n")
node_78 = avltree._add_right(root, 78) # First Right subtree
node_88 = avltree._add_right(node_78, 88) # Right Child of first right subtree
print("Right of Root Element: ", avltree.right(root).element())
print("Right of Node 78 Element: ", avltree.right(node_78).element(), "\n")
node_44 = avltree._add_left(root, 44) # First Left subtree
node_17 = avltree._add_left(node_44, 17) # Left child of first left subtree
node_50 = avltree._add_right(
node_44, 50
) # Right child of first left subtree, start of second left subtree
print("Left of Root Element: ", avltree.left(root).element())
print("Left child of first left subtree: ", avltree.left(node_44).element())
print("Right child of first left subtree: ", avltree.right(node_44).element(), "\n")
node_48 = avltree._add_left(node_50, 48) # Left child of second left subtree
node_54 = avltree._add_right(node_50, 54) # Right child of second left subtree
print("Left child of second left subtree: ", avltree.left(node_50).element())
print("Right child of second left subtree: ", avltree.right(node_50).element(), "\n")
print("Insert key 52:")
node_52 = avltree._add_left(node_54, 52)
print("Left child of third left subtree: ", avltree.left(node_54).element())
print("Restructure tree:", "\n")
avltree._restructure(node_54)
print("Display left path for restructered Tree \n")
print("Root Element:", root.element())
print("Left of Root Element:", avltree.left(root).element(), "\n")
print("Left child of first left subtree:", avltree.left(node_50).element())
print("Right child of first left subtree:", avltree.right(node_50).element(), "\n")
print(
"Left grandchild of first left subtree on left side",
avltree.left(node_44).element(),
)
print(
"Right grandchild of first left subtree on left side:",
avltree.right(node_44).element(),
"\n",
)
print(
"Left grandchild of first left subtree on right side:",
avltree.left(node_54).element(),
)
# 4. Consider the set of keys K = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15}. Draw a (2, 4) tree
# storing K as its keys using the fewest number of nodes.
# # Drawn Stages
Image("../input/q4.jpg")
# # Code Implementation
# 5. Insert into an empty (2, 4) tree, entries with keys 5, 16, 22, 45, 2, 10, 18, 30, 50, 12, 1 (in this order).
# Draw the tree after each insertion.
#
Image("../input/q5.jpg")
# 6. Insert into an empty splay tree entries with keys 10, 16, 12, 14, 13 (in this order). Draw the tree after
# each insertion.
# # Drawn Stages
Image("../input/q6.jpg")
# # Code Implementation
splay = SplayTreeMap()
print("Stage 1: Add Root")
root = splay._add_root(10)
print("Root node added:", root.element(), "\n")
print("Stage 2: Insert 16")
node16 = splay._add_right(root, 16).element()
pos16 = splay.right(root)
print("Right node of root added:", splay.right(root).element(), "\n")
splay._splay(pos16)
print("Splaying.. \n")
new_root = splay.root().element()
left_root = splay.left(splay.root()).element()
print("Root node:", new_root)
print("Left of root node:", left_root, "\n")
print("Stage 3: Insert 12")
node12 = splay._add_right(splay.left(splay.root()), 12).element()
pos12 = splay.right(splay.left(splay.root()))
print("Node added:", node12, "\n")
splay._splay(pos12)
print("Splaying.. \n")
new_root = splay.root().element()
left_root = splay.left(splay.root()).element()
right_root = splay.right(splay.root()).element()
print("Root node:", new_root)
print("Left of root node:", left_root)
print("Right of root node:", right_root, "\n")
print("Stage 4: Insert 14")
node14 = splay._add_left(splay.right(splay.root()), 14).element()
pos14 = splay.left(splay.right(splay.root()))
print("Node added:", node14, "\n")
splay._splay(pos14)
print("Splaying.. \n")
new_root = splay.root().element()
left_root = splay.left(splay.root()).element()
right_root = splay.right(splay.root()).element()
left_gchild_root = splay.left(splay.left(splay.root())).element()
print("Root node:", new_root)
print("Left of root node:", left_root)
print("Right of root node:", right_root)
print("Left grandchild of root node:", left_gchild_root, "\n")
print("Stage 5: Insert 13")
node13 = splay._add_right(splay.left(splay.root()), 13).element()
pos13 = splay.right(splay.left(splay.root()))
print("Node added:", node13, "\n")
splay._splay(pos13)
print("Splaying.. \n")
new_root = splay.root().element()
left_root = splay.left(splay.root()).element()
right_root = splay.right(splay.root()).element()
left_gchild_root = splay.left(splay.left(splay.root())).element()
right_gchild_root = splay.right(splay.right(splay.root())).element()
print("Root node:", new_root)
print("Left of root node:", left_root)
print("Right of root node:", right_root)
print("Left grandchild of root node:", left_gchild_root)
print("Right grandchild of root node:", right_gchild_root)
| false | 0 | 9,798 | 0 | 6 | 9,798 |
||
14071740 | <kaggle_start><data_title>Google Play Store Apps<data_description>### Context
While many public datasets (on Kaggle and the like) provide Apple App Store data, there are not many counterpart datasets available for Google Play Store apps anywhere on the web. On digging deeper, I found out that iTunes App Store page deploys a nicely indexed appendix-like structure to allow for simple and easy web scraping. On the other hand, Google Play Store uses sophisticated modern-day techniques (like dynamic page load) using JQuery making scraping more challenging.
### Content
Each app (row) has values for catergory, rating, size, and more.<data_name>google-play-store-apps
<code># Teaching Python Programming Language For Data Scientists
# Introduction
#
# What is Python Programming Language?
# Why Python Programming Language?
# Required Libraries
#
# Python for Beginners
#
# Python Installation
# Maths Operations
# Strings Operation
# Lists Operation
# if-elif-else
# While Statement
# For Statement
# Range
# Break and Continue
# Introduction to Functions
# Lambda Expressions
# Documentation Strings
# Data Structure
# Dictionaries
# Modules
# Input and Output
# Reading and Writing Files
# Errors and Exceptions
# Classes
#
# Data Preparation and Processing
#
# Pandas
#
# Create Data
# Get Data
# Prepare Data
# Analyze Data
# Presedent Data
#
#
# NumPy
#
# The Basics
# Array Creation
# Printing Arrays
# Basic Operations
# Universal Functions
# Indexing, Slicing and Iterating
# Shape Manipulation
# Deep Copy
#
#
#
# Feature Work
# References
# Conclusion
# if you like it,please UPVOTE
# Last Update : 12.05.2019
# Introduction
# What is Python Programming Language?
# Python is the programming language. Kdnuggets is the most used programming language in data science with 65.5% according to Analytics data. Open source is free and free software. Python is a programming language that supports the object-oriented programming paradigm. Web, mobile and socket programming etc. is a scripting language with many features. However, it can operate independently on every platform. This is an indispensable programming language for data scientists and other programmers thanks to their diversity. In addition, it has a clear and easy-to-read format compared to other programming languages. With its wide library, it helps us in all kinds of software works. All software will be written in this programming language.
# Link: https://www.python.org/downloads/
# Why Python Programming Language?
# It is one of the most used programming languages by data scientists. Because there are developers all around the world. In this way, a wide variety of operations are performed. In addition, very few transactions can be performed with very little code. More than one operation is performed.Python is a powerful programming language that is easy to learn. It has a simple but effective approach to effective high-level data structures and object-oriented programming. Python's exquisite syntax and dynamic writing, combined with its interpreted nature, has made it an ideal language for scripting and rapid application development across many platforms.
# The Python interpreter can be easily expanded with new functions and data types implemented in C or C ++ (or other languages that can be called from C). Python is also available as an extension language for customizable applications.
# Required Libraries
# Numpy
# It is a Python library that allows us to perform multiple operations on arrays, including multidimensional arrays, various derived objects (such as masked arrays and matrices) and lots of mathematical, logical, shape manipulation, sorting, sorting, discrete Fourier. Statistical procedures and simulations can be performed using NumPy. NumPy library with C ++ does not cause any loss of performance.
# Pandas
# Pandas is an open source, BSD licensed library, offering high-performance, easy-to-use data structures and data analysis tools for the Python programming language. It is a library designed to work with data, allowing you to run your non-structural data as in structural databases. Pandas is designed for fast and easy data processing, collection and visualization. Therefore, it is a very preferred library for data scientists. In addition, with its own data-editing functions, you can convert your data into any format. Thanks to Pandas, we make preliminary work for our model and make it ready for the model. As a preliminary study, it is necessary to carry out editing studies by detecting missing, slingshot, incompatible and repetitive data. In this way, you can train your model smoothly and get the results properly. To use the Pandas library, we need to upload it to Anaconda.
# Scikit-Learn
# It includes many machine learning algorithms such as classification, regression, clustering, size reduction, model selection and data removal. It is an open source library with BSD license. Together with the algorithms it contains, it creates a fast and secure coding structure. It includes the functions of expressing frequently used mathematical and physical problems in computer environment. In addition, thanks to its own web site you can look at the working principle of the algorithm you want. However, you can learn the mathematical infrastructure of the algorithm. In this way, according to your own data set you can develop the mathematical model of the algorithm yourself. By applying the model you have made on the data set, results can be obtained. Which of these results is effective in the mathematical model you will make out. In addition, you must install the scikit-learn library to Anaconda to use it.
# Seaborn
# Seaborn is a library in Python for making interesting and informative statistical graphs. Built on Matplotlib, numpy has been tightly integrated with the PyData stack, providing support for statistical templates from scipy, statsmodel, pandas data structures. It is used for graphs depicting general distributions that summarize data as in heat maps. Thanks to the many methods included in the content of high-level analysis can be made. However, the user can perform analyzes in interactive and animation structure. Today's data scientists put the seaborn library in place where the matplotlib library is missing. Thanks to Seaborn, interactive plots can be removed. In this way, we will show the dimensions of inter-feature interaction more clearly. Thanks to the different types of plots within itself, we are able to make analyzes in every format.
# Matplotlib
# Matplotlib graphical drawing package is one of the most important tools of scientific programming. With Matplotlib, a very powerful package, data can be visualized interactively, and high quality printouts are available for publishing. Both two- and three-dimensional graphics can be created. However, it is very simple to use. In addition, there are a lot of information about this package on the internet, but for data scientists can take all kinds of analysis. As a result of your analysis, you can save the resulting graph as output. You can then add it as an addition to the report you made later. It will be used to explain the results obtained from various analyzes and evaluations in the application orally and graphically. So much so that we use the algorithm to show us the most accurate results. In this way, we will guide us for further analysis. In addition, our corporate website helps us for all the plots we will use.
# Scipy
# SciPy refers to several related but distinct entities:The SciPy ecosystem, a collection of open source software for scientific computing in Python.The community of people who use and develop this stack.Several conferences dedicated to scientific computing in Python - SciPy, EuroSciPy and SciPy.in.The SciPy library, one component of the SciPy stack, providing many numerical routines.
# Python for Beginners
# Python Installation
# Link: https://www.youtube.com/watch?v=dX2-V2BocqQ
# There is very good expression in this section.
# Maths Operations
# Python can do a variety of mathematical operations. In this case, we do not need to define any variables. This is described in the examples below for this situation.
# The following mathematical operations are given 3 kinds of examples. In the first example, only data from the variable definition are given. Thus, results were obtained. In the second example, a variable is defined. In this example, the operations were performed. In the last example, a decimal data is obtained by dividing int data with decimal data.**
# Before continue with pandas, we need to learn logic, control flow and filtering.
# Comparison operator: ==, , <=
# Boolean operators: and, or ,not
# Filtering pandas
# Comparison operator
print(3 > 2)
print(5 < 4)
print("Apple" in ["App", "Appl", "Apple"])
print(3 != 2)
# Boolean operators
print(True and False)
print(True or False)
# Example 1
print(2 + 2)
# Example 2
a = (50 - 5 * 6) / 4
print(a)
# Example 3
print(8 / 5.0)
# Example 4
print(10 + 80)
print(10 - (25 - 85) + 45)
print(5 * 6 - (2 - 8))
# Example 5
print(17 // 3.0) # explicit floor division discards the fractional part
# Example 6
print(18 // 4.0)
# The // operator is also provided for doing floor division no
# matter what the operands are.
# Example 7
print(17 % 3)
# Example 6 Mode operation; between the first number and the second number.
# As a result of this operation, the remaining number is obtained.
# With Python, it is possible to use the ** operator to calculate powers
# Example 8
print(5**2) # 5 squared
# Example 9
print(2**8) # 2 to power of 8
# The equal sign (=) is used to assign a value to a variable.
# Example 10
width = 8
height = 10
print(width * height)
# Strings Operation
# Besides numbers, Python can also manipulate strings, which can be expressed in several ways. They can be enclosed in single quotes ('...') or double quotes ("...") with the same result. \ can be used to escape quotes:
s1 = "string"
s2 = "data"
print(s1 + " " + s2)
# Strings can be concatenated (glued together) with the
# + operator, and repeated with *:
index = 3
print("un " * index)
# Two or more string literals
print("Py" "thon")
prefix = "Py"
# prefix='thon'
prefix + "thon"
# Strings can be indexed (subscripted)
word = "Python"
print(word[0]) # character in position 0
print(word[5]) # character in position 5
print(word[-1]) # last character
print(word[-2]) # second-last character
# In addition to indexing, slicing is also supported.
# While indexing is used to obtain individual characters,
# slicing allows you to obtain a substring:
print(word[0:2]) # characters from position 0 (included) to 2 (excluded)
print(word[2:5]) # characters from position 2 (included) to 5 (excluded)
# Note how the start is always included, and the end always
# excluded. This makes sure that s[:i] + s[i:] is always equal to s:
print(word[:2] + word[2:])
print(word[:4] + word[4:])
# Slice indices have useful defaults; an omitted first index defaults
# to zero, an omitted second index defaults to the size of the
# string being sliced.
print(word[:2]) # character from the beginning to position 2 (excluded)
print(word[4:])
print(word[-2:])
print(word[1:3]) # character from the beginning to position 3 (excluded)
print("J" + word[1:])
print(word[:2] + "py")
# Lists Operation
# Python knows a number of compound data types, used to group together other values. The most versatile is the list, which can be written as a list of comma-separated values (items) between square brackets. Lists might contain items of different types, but usually the items all have the same type.
squares = [1, 4, 9, 16, 25]
squares
# Like strings (and all other built-in sequence type),
# lists can be indexed and sliced:
print(squares[0]) # indexing returns the item
print(squares[-1])
print(squares[-3:]) # slicing returns a new list
print(squares[:]) # all
# All slice operations return a new list containing the requested
# elements. This means that the following slice returns a new
# (shallow) copy of the list:
squares + [36, 49, 64, 81, 100]
cubes = [1, 8, 27, 65, 125]
4**3
cubes[3] = 64 # replace the wrong value
cubes
# You can also add new items at the end of the list, by using the
# append() method (we will see more about methods later):
cubes.append(216) # add the cube of 6
cubes.append(7**3) # and the cube of 7
cubes
# Assignment to slices is also possible, and this can even change
# the size of the list or clear it entirely:
letters = ["a", "b", "c", "d", "e", "f", "g"]
print(letters)
# replace some values
letters[2:5] = ["C", "D", "E"]
print(letters)
# now remove them
letters[2:5] = []
letters
# clear the list by replacing all the elements with an empty list
letters[:] = []
letters
# The built-in function len() also applies to lists:
letters = ["a", "b", "c", "d"]
len(letters)
# if-elif-else
# Decision making is required when we want to execute a code only if a certain condition is satisfied.
# [i + 1 for i in num1 ]: list of comprehension
# i +1: list comprehension syntax
# for i in num1: for loop syntax
# i: iterator
# num1: iterable object
# The if…elif…else statement is used in Python for decision making.
# Perhaps the most well-known statement type is the if statement. For example:
# We use list comprehension for data analysis often.
# list comprehension: collapse for loops for building lists into a single line
# Ex: num1 = [1,2,3] and we want to make it num2 = [2,3,4]. This can be done with for loop. However it is unnecessarily long. We can make it one line code that is list comprehension.
# Example of list comprehension
num1 = [1, 2, 3]
num2 = [i + 1 for i in num1]
print(num2)
# Conditionals on iterable
num1 = [5, 10, 15]
num2 = [i**2 if i == 10 else i - 5 if i < 7 else i + 5 for i in num1]
print(num2)
# If the number is positive, we print an appropriate message
num = 3
if num > 0:
print(num, " is a positive number")
print("This is always printed")
num = -1
if num > 0:
print(num, " is a positive number")
print("This is also always printed")
# Program checks if the number is positive or negative
# And displays an appropriate message
num = 3
# Try these two variations as well.
# num = -5
# num = 0
if num >= 0:
print("Positive or Zero")
else:
print("Negative number")
# In this program,
# we check if the number is positive or
# negative or zero and
# display an appropriate message
num = 3.4
# Try these two variations as well:
# num = 0
# num = -4.5
if num > 0:
print("Positive number")
elif num == 0:
print("Zero")
else:
print("Negative number")
# In this program, we input a number
# check if the number is positive or
# negative or zero and display
# an appropriate message
# This time we use nested if
num = float(input("Enter a number: "))
if num >= 0:
if num == 0:
print("Zero")
else:
print("Positive number")
else:
print("Negative number")
var = 100
if var == 100:
print("Value of expression is 100")
print("Good bye!")
# While
# With the while loop we can execute a set of statements as long as a condition is true.
# Stay in loop if condition( i is not equal 5) is true
i = 0
while i != 5:
print("i is: ", i)
i += 1
print(i, " is equal to 5")
# Stay in loop if condition( i is not equal 5) is true
lis = [1, 2, 3, 4, 5]
for i in lis:
print("i is: ", i)
print("")
# Enumerate index and value of list
# index : value = 0:1, 1:2, 2:3, 3:4, 4:5
for index, value in enumerate(lis):
print(index, " : ", value)
print("")
# For dictionaries
# We can use for loop to achive key and value of dictionary. We learnt key and value at dictionary part.
dictionary = {"spain": "madrid", "france": "paris"}
for key, value in dictionary.items():
print(key, " : ", value)
print("")
i = 1
while i < 6:
print(i)
i += 1
# With the break statement we can stop the loop even if the while condition is true:
i = 1
while i < 6:
print(i)
if i == 3:
break
i += 1
# With the continue statement we can stop the current iteration, and continue with the next:
i = 0
while i < 6:
i += 1
if i == 3:
continue
print(i)
# For Statements
# The for statement in Python differs a bit from what you may be used to in C or Pascal. Rather than always iterating over an arithmetic progression of numbers (like in Pascal), or giving the user the ability to define both the iteration step and halting condition (as C), Python’s for statement iterates over the items of any sequence (a list or a string), in the order that they appear in the sequence. For example (no pun intended):
words = ["cats", "window", "defenstrate"]
for w in words:
print(w, len(w))
# If you need to modify the sequence you are iterating over while inside the loop (for example to duplicate selected items), it is recommended that you first make a copy. Iterating over a sequence does not implicitly make a copy. The slice notation makes this especially convenient:
for w in words[:]:
if len(w) > 6:
words.insert(0, w)
for i, w in enumerate(words):
print((i + 1), ":", w)
# Loop through the letters in the word "banana":
for x in "banana":
print(x)
# Range
# If you do need to iterate over a sequence of numbers, the built-in function range() comes in handy. It generates lists containing arithmetic progressions:
# To loop through a set of code a specified number of times, we can use the range() function,
# The range() function returns a sequence of numbers, starting from 0 by default, and increments by 1 (by default), and ends at a specified number.
for i in range(10):
print(i)
# The given end point is never part of the generated list; range(10) generates a list of 10 values, the legal indices for items of a sequence of length 10. It is possible to let the range start at another number, or to specify a different increment (even negative; sometimes this is called the ‘step’):
for i in range(5, 10):
print(i)
print("#" * 30)
for i in range(0, 10, 3): # 0 start 10 finish 3 step
print(i)
print("#" * 30)
for i in range(-10, -100, -30): # 0 start 10 finish 3 step
print(i)
a = ["Mary", "had", "a", "little", "lamb"]
for i in range(len(a)):
print(i, a[i])
import numpy as np
new_list = np.arange(1, 20)
for i in np.arange(1, 30, 2):
print(i)
# The else keyword in a for loop specifies a block of code to be executed when the loop is finished:
for x in range(6):
print(x)
else:
print("Finish")
# Break and Continue
# The break statement, like in C, breaks out of the innermost enclosing for or while loop.
# Loop statements may have an else clause; it is executed when the loop terminates through exhaustion of the list (with for) or when the condition becomes false (with while), but not when the loop is terminated by a break statement. This is exemplified by the following loop, which searches for prime numbers:
for n in range(2, 10):
for x in range(2, n):
if n % x == 0:
print(n, " equal", x, "*", n / x)
break
else:
# loop fell through without finding a factor
print(n, " is a prime number")
# (Yes, this is the correct code. Look closely: the else clause belongs to the for loop, not the if statement.)
# When used with a loop, the else clause has more in common with the else clause of a try statement than it does that of if statements: a try statement’s else clause runs when no exception occurs, and a loop’s else clause runs when no break occurs. For more on the try statement and exceptions, see Handling Exceptions.
# The continue statement, also borrowed from C, continues with the next iteration of the loop:
# iteration example
name = "ronaldo"
it = iter(name)
print(next(it)) # print next iteration
print(*it) # print remaining iteration
#
# ITERATORS
# iterable is an object that can return an iterator
# iterable: an object with an associated iter() method
# example: list, strings and dictionaries
# iterator: produces next value with next() method
#
for num in range(2, 10):
if num % 2 == 0:
print("Found an even number", num)
continue
print("Found a number", num)
# Introduction to Functions
# We can create a function that writes the Fibonacci series to an arbitrary boundary:
def fib(n):
# print a fibonacci series up to n
a, b = 0, 1
while a < n:
print(a)
a, b = b, a + b
fib(2000)
def my_function1(country="Turkey"):
print("I am from " + country)
my_function1()
my_function1("Canada")
# The keyword def introduces a function definition. It must be followed by the function name and the parenthesized list of formal parameters. The statements that form the body of the function start at the next line, and must be indented.
# The most useful form is to specify a default value for one or more arguments. This creates a function that can be called with fewer arguments than it is defined to allow. For example:
def ask_ok(prompt, retries=4, complaint="Yes or no, please!"):
while True:
ok = raw_input(prompt)
if ok in ("y", "ye", "yes"):
return True
if ok in ("n", "no", "nop", "nope"):
return False
retries = retries - 1
if retries < 0:
raise IOError("refusenik user")
print(complaint)
# This function can be called in several ways:
# giving only the mandatory argument: ask_ok('Do you really want to quit?')
# giving one of the optional arguments: ask_ok('OK to overwrite the file?', 2)
# or even giving all arguments: ask_ok('OK to overwrite the file?', 2, 'Come on, only yes or no!')
# The default values are evaluated at the point of function definition in the defining scope, so that
i = 5
def f(arg=i):
print(arg)
i = 6
f()
# Important warning: The default value is evaluated only once. This makes a difference when the default is a mutable object such as a list, dictionary, or instances of most classes. For example, the following function accumulates the arguments passed to it on subsequent calls:
def f(a, L=[]):
L.append(a)
return L
print(f(1))
print(f(2))
print(f(3))
# If you don’t want the default to be shared between subsequent calls, you can write the function like this instead:
def f(a, L=None):
if L is None:
L = []
L.append(a)
return L
f([5, 4, 3])
# Functions can also be called using keyword arguments of the form kwarg=value. For instance, the following function:
def parrot(voltage, state="a stiff", action="voom", type="Norwegian Blue"):
print(
"-- This parrot wouldn't",
action,
)
print("if you put", voltage, "volts through it.")
print("-- Lovely plumage, the", type)
print("-- It's", state, "!")
# accepts one required argument (voltage) and three optional arguments (state, action, and type). This function can be called in any of the following ways:
# accepts one required argument (voltage) and three optional arguments (state, action, and type). This function can be called in any of the following ways:
parrot(1000) # 1 positional argument
parrot(voltage=1000) # 1 keyword argument
parrot(voltage=1000000, action="VOOOOOM") # 2 keyword arguments
parrot(action="VOOOOOM", voltage=1000000) # 2 keyword arguments
parrot("a million", "bereft of life", "jump") # 3 positional arguments
parrot("a thousand", state="pushing up the daisies") # 1 positional, 1 keyword
# When a final formal parameter of the form **name is present, it receives a dictionary (see Mapping Types — dict) containing all keyword arguments except for those corresponding to a formal parameter. This may be combined with a formal parameter of the form *name (described in the next subsection) which receives a tuple containing the positional arguments beyond the formal parameter list. (*name must occur before **name.) For example, if we define a function like this:
def cheeseshop(kind, *arguments, **keywords):
print("-- Do you have any", kind, "?")
print("-- I'm sorry, we're all out of", kind)
for arg in arguments:
print(arg)
print("-" * 40)
keys = sorted(keywords.keys())
for kw in keys:
print(kw, ":", keywords[kw])
"""cheeseshop("Limburger", "It's very runny, sir.",
"It's really very, VERY runny, sir.",
shopkeeper='Michael Palin',
client="John Cleese",
sketch="Cheese Shop Sketch")"""
# The reverse situation occurs when the arguments are already in a list or tuple but need to be unpacked for a function call requiring separate positional arguments. For instance, the built-in range() function expects separate start and stop arguments. If they are not available separately, write the function call with the *-operator to unpack the arguments out of a list or tuple:
print(list(range(3, 6))) # normal call with separate arguments
args = [3, 6]
list(range(*args)) # call with arguments unpacked from a list
def tri_recursion(k):
if k > 0:
result = k + tri_recursion(k - 1)
print(result)
else:
result = 0
return result
tri_recursion(6)
# Lambda Expressions
# Small anonymous functions can be created with the lambda keyword. This function returns the sum of its two arguments: lambda a, b: a+b. Lambda functions can be used wherever function objects are required. They are syntactically restricted to a single expression. Semantically, they are just syntactic sugar for a normal function definition. Like nested function definitions, lambda functions can reference variables from the containing scope:
def make_incrementor(n):
return lambda x: x + n
f = make_incrementor(50)
print(f(2))
print(f(1))
# The above example uses a lambda expression to return a function. Another use is to pass a small function as an argument:
pairs = [(1, "one"), (2, "two"), (3, "three"), (4, "four")]
pairs.sort(key=lambda pair: pair[1])
pairs
# A lambda function that adds 10 to the number passed in as an argument, and print the result:
x = lambda a: a + 10
print(x(5))
x = 5
y = lambda x: x**2
y(10)
# A lambda function that adds 10 to the number passed in as an argument, and print the result:
x = lambda a: a + 120
print(x(15))
# A lambda function that multiplies argument a with argument b and print the result:
x = lambda a, b, c: a + b + c
print(x(5, 6, 2))
number_list = [1, 2, 3]
y = map(lambda x: x**2, number_list)
print(list(y))
# The power of lambda is better shown when you use them as an anonymous function inside another function.
# Say you have a function definition that takes one argument, and that argument will be multiplied with an unknown number:
def myfunc(n):
return lambda a: a * n
mydoubler = myfunc(2)
print(mydoubler(11))
# Documentation Strings
# There are emerging conventions about the content and formatting of documentation strings.
# The first line should always be a short, concise summary of the object’s purpose. For brevity, it should not explicitly state the object’s name or type, since these are available by other means (except if the name happens to be a verb describing a function’s operation). This line should begin with a capital letter and end with a period.
# If there are more lines in the documentation string, the second line should be blank, visually separating the summary from the rest of the description. The following lines should be one or more paragraphs describing the object’s calling conventions, its side effects, etc.
# Here is an example of a multi-line docstring:
def my_fucntion():
"""Do nothing, but document it
No,really, it doesn't do anything.
"""
pass
print(my_fucntion)
# Data Structures
# This chapter describes some things you’ve learned about already in more detail, and adds some new things as well.
a = [66.25, 333, 333, 1, 12, 154, 789]
print(a.count(333), a.count(66.25), a.count("x"))
a.insert(2, -1)
a.append(333)
print(a)
a.index(333)
a.remove(333)
a.reverse()
print(a)
a.sort()
print(a.pop())
a
# The list methods make it very easy to use a list as a stack, where the last element added is the first element retrieved (“last-in, first-out”). To add an item to the top of the stack, use append(). To retrieve an item from the top of the stack, use pop() without an explicit index. For example:
stack = [3, 4, 5]
stack.append(6)
stack.append(7)
print(stack)
print(stack.pop())
print(stack.pop())
print(stack)
def f(x):
return x % 3 == 0 or x % 5 == 0
f(9)
# map(function, sequence) calls function(item) for each of the sequence’s items and returns a list of the return values. For example, to compute some cubes:
def cube(x):
return x * x * x
cube(5)
# More than one sequence may be passed; the function must then have as many arguments as there are sequences and is called with the corresponding item from each sequence (or None if some sequence is shorter than another). For example:
seq = range(1, 8)
list(seq)
def add(x, y):
return x + y
add(5, 7)
# List comprehensions provide a concise way to create lists. Common applications are to make new lists where each element is the result of some operations applied to each member of another sequence or iterable, or to create a subsequence of those elements that satisfy a certain condition.
# For example, assume we want to create a list of squares, like:
squares = []
for x in range(10):
squares.append(x**2)
squares
for x in range(0, 18, 2):
print(x)
# We can obtain the same result with:
squares = [i * 2 for i in range(1, 10, 1)]
squares
[(x, y) for x in [1, 2, 3] for y in [3, 1, 4] if x != y]
a = [-1, 1, 66, 45, 87, 65, 12, 65]
del a[0]
print(a)
del a[2:4]
print(a)
del a[:]
print(a)
t = 123, 45, 65, 78, "hi!"
print(t[0])
print(t)
# Tuples may be nested:
u = t, (1, 2, 3, 4, 5, 6)
u
# A special problem is the construction of tuples containing 0 or 1 items: the syntax has some extra quirks to accommodate these. Empty tuples are constructed by an empty pair of parentheses; a tuple with one item is constructed by following a value with a comma (it is not sufficient to enclose a single value in parentheses). Ugly, but effective. For example:
empty = ()
singleton = ("hello",)
len(empty)
len(singleton)
print(singleton)
# Dictionaries
# Another useful data type built into Python is the dictionary (see Mapping Types — dict). Dictionaries are sometimes found in other languages as “associative memories” or “associative arrays”. Unlike sequences, which are indexed by a range of numbers, dictionaries are indexed by keys, which can be any immutable type; strings and numbers can always be keys. Tuples can be used as keys if they contain only strings, numbers, or tuples; if a tuple contains any mutable object either directly or indirectly, it cannot be used as a key. You can’t use lists as keys, since lists can be modified in place using index assignments, slice assignments, or methods like append() and extend().
# create dictionary and look its keys and values
dictionary = {"spain": "madrid", "usa": "vegas"}
print(dictionary.keys())
print(dictionary.values())
# Keys have to be immutable objects like string, boolean, float, integer or tubles
# List is not immutable
# Keys are unique
dictionary["spain"] = "barcelona" # update existing entry
print(dictionary)
dictionary["france"] = "paris" # Add new entry
print(dictionary)
del dictionary["spain"] # remove entry with key 'spain'
print(dictionary)
print("france" in dictionary) # check include or not
dictionary.clear() # remove all entries in dict
print(dictionary)
tel = {"jack": 4098, "sape": 4139}
tel["guido"] = 4127
print(tel)
print(tel["jack"])
del tel["sape"]
tel["irv"] = 4127
print(tel)
print(tel.keys())
print(tel.values())
"jack" in tel
# The dict() constructor builds dictionaries directly from sequences of key-value pairs:
dict([("sape", 4139), ("guido", 4127), ("jack", 4098)])
# In addition, dict comprehensions can be used to create dictionaries from arbitrary key and value expressions:
{x: x**2 for x in (2, 4, 6)}
for i, v in enumerate(["tic", "tac", "toe"]):
print(i, v)
# Modules
# If you quit from the Python interpreter and enter it again, the definitions you have made (functions and variables) are lost. Therefore, if you want to write a somewhat longer program, you are better off using a text editor to prepare the input for the interpreter and running it with that file as input instead. This is known as creating a script. As your program gets longer, you may want to split it into several files for easier maintenance. You may also want to use a handy function that you’ve written in several programs without copying its definition into each program.
# A module is a file containing Python definitions and statements. The file name is the module name with the suffix .py appended. Within a module, the module’s name (as a string) is available as the value of the global variable __name__. For instance, use your favorite text editor to create a file called fibo.py in the current directory with the following contents:
# Fibonacci numbers module
def fib(n): # write Fibonacci series up to n
a, b = 0, 1
while b < n:
print(b),
a, b = b, a + b
def fib2(n): # return Fibonacci series up to n
result = []
a, b = 0, 1
while b < n:
result.append(b)
a, b = b, a + b
return result
#
# What we need to know about functions:
# docstrings: documentation for functions. Example:
# for f():
# """This is docstring for documentation of function f"""
# tuble: sequence of immutable python objects.
# cant modify values
# tuble uses paranthesis like tuble = (1,2,3)
# unpack tuble into several variables like a,b,c = tuble
#
# How can we learn what is built in scope
import builtins
dir(builtins)
# example of what we learn above
def tuble_ex():
"""return defined t tuble"""
t = (1, 2, 3)
return t
a, b, c = tuble_ex()
print(a, b, c)
import sys
"""
The built-in function dir() is used to find out which names a
module defines. It returns a sorted list of strings:
"""
print(dir(sys))
# Input and Output
# There are several ways to present the output of a program; data can be printed in a human-readable form, or written to a file for future use. This chapter will discuss some of the possibilities.
s = "Hello world"
print(str(s))
print(repr(s))
print(str(1.0 / 7.0))
x = 10 * 3.25
y = 200 * 200
s = "The value of x is " + repr(x) + ", and y is " + repr(y) + "..."
print(s)
# Reading and Writing Files
# open() returns a file object, and is most commonly used with two arguments: open(filename, mode).
# Errors and Exceptions
# Until now error messages haven’t been more than mentioned, but if you have tried out the examples you have probably seen some. There are (at least) two distinguishable kinds of errors: syntax errors and exceptions.
# while True:print('Hello World')
# Syntax errors, also known as parsing errors, are perhaps
# he most common kind of complaint you get while you are still
# earning Python:
# It is possible to write programs that handle selected exceptions. Look at the following example, which asks the user for input until a valid integer has been entered, but allows the user to interrupt the program (using Control-C or whatever the operating system supports); note that a user-generated interruption is signalled by raising the KeyboardInterrupt exception.
# while True:
# try:
# x=int(input('Please enter a number :'))
# break
# except ValueError:
# print('Stop!')
# If an exception has an argument, it is printed as the last part (‘detail’) of the message for unhandled exceptions.
# Exception handlers don’t just handle exceptions if they occur immediately in the try clause, but also if they occur inside functions that are called (even indirectly) in the try clause. For example:
def this_fails():
x = 1 / 10
try:
this_fails()
except ZeroDivisonError as detail:
print("Handling run-time error :", detail)
# Classes
# Compared with other programming languages, Python’s class mechanism adds classes with a minimum of new syntax and semantics. It is a mixture of the class mechanisms found in C++ and Modula-3. Python classes provide all the standard features of Object Oriented Programming: the class inheritance mechanism allows multiple base classes, a derived class can override any methods of its base class or classes, and a method can call the method of a base class with the same name. Objects can contain arbitrary amounts and kinds of data. As is true for modules, classes partake of the dynamic nature of Python: they are created at runtime, and can be modified further after creation.
# Class objects support two kinds of operations: attribute references and instantiation.
# Attribute references use the standard syntax used for all attribute references in Python: obj.name. Valid attribute names are all the names that were in the class’s namespace when the class object was created. So, if the class definition looked like this:
class MyClass:
"""A simple example class"""
i = 12345
def f(self):
return "hello world"
# Class instantiation uses function notation. Just pretend that the class object is a parameterless function that returns a new instance of the class. For example (assuming the above class):
x = MyClass()
# Of course, the __init__() method may have arguments for greater flexibility. In that case, arguments given to the class instantiation operator are passed on to __init__(). For example,
class Complex:
def __init__(self, realpart, imagpart):
self.r = realpart
self.i = imagpart
x = Complex(3.0, -4.5)
print(x.i, x.r)
# Now what can we do with instance objects? The only operations understood by instance objects are attribute references. There are two kinds of valid attribute names, data attributes and methods.
# data attributes correspond to “instance variables” in Smalltalk, and to “data members” in C++. Data attributes need not be declared; like local variables, they spring into existence when they are first assigned to. For example, if x is the instance of MyClass created above, the following piece of code will print the value 16, without leaving a trace:
x.counter = 1
while x.counter < 10:
x.counter = x.counter * 2
print(x.counter)
del x.counter
# Generally speaking, instance variables are for data unique to each instance and class variables are for attributes and methods shared by all instances of the class:
class Dog:
trick = []
kind = "canine"
def __init__(self, name):
self.name = name
def add_trick(self, trick):
self.tricks.append(trick)
d = Dog("Fibo")
e = Dog("Buddy")
print(d.kind)
print(e.kind)
print(d.name)
print(e.name)
class Dog:
tricks = [] # mistaken use of a class variable
def __init__(self, name):
self.name = name
def add_trick(self, trick):
self.tricks.append(trick)
d = Dog("Fido")
e = Dog("Buddy")
d.add_trick("roll over")
e.add_trick("play dead")
d.tricks # unexpectedly shared by all dogs
["roll over", "play dead"]
# Data Preparation and Processing
# Pandas
# import pandas as pd
# Create Data
# The data set will consist of 5 baby names and the number of births recorded for that year (1880).
import pandas as pd # import library as pd
names = ["Bob", "Jessica", "Mary", "Jhon", "Mel"]
births = [968, 45, 756, 12, 65]
# To merge these two lists together we will use the zip function.
BabyDataSet = list(zip(names, births))
print(BabyDataSet)
# We are basically done creating the data set. We now will use the pandas library to export this data set into a csv file.
# df will be a DataFrame object. You can think of this object holding the contents of the BabyDataSet in a format similar to a sql table or an excel spreadsheet. Lets take a look below at the contents inside df.
df = pd.DataFrame(data=BabyDataSet, columns=["Names", "Births"])
df
# Export the dataframe to a csv file. We can name the file births1880.csv. The function to_csv will be used to export the file. The file will be saved in the same location of the notebook unless specified otherwise.
# df.to_csv('C:\\Users\\aAa\\Desktop\\Kaggle-Python-Learn\\biths.csv',index=False,header=False)
# Merge the names and the births data set using the zip function.
BabyDataSet = list(zip(names, births))
BabyDataSet[:10]
# Lets add a column
df["Year"] = 2019
# using loc accessor
df.loc[1:5, ["Names"]]
# Slicing and indexing series
df.loc[1:10, "Names":] # 10 and "Defense" are inclusive
# replaces the deprecated ix function
# df.ix[5:,'col']
df.loc[df.index[1:], "Names"]
# replaces the deprecated ix function
# df.ix[:3,['col', 'test']]
df.loc[df.index[:3], ["Names", "Year"]]
# Get Data
# To pull in the csv file, we will use the pandas function read_csv. Let us take a look at this function and what inputs it takes.
# df=pd.read_csv('C:\\Users\\aAa\\Desktop\\Kaggle-Python-Learn\\biths.csv')
df
# This brings us to the first problem of the exercise. The read_csv function treated the first record in the csv file as the header names. This is obviously not correct since the text file did not provide us with header names.
# To correct this we will pass the header parameter to the read_csv function and set it to None (means null in python).
##df=pd.read_csv('C:\\Users\\aAa\\Desktop\\Kaggle-Python-Learn\\biths.csv',header=None)
print(df)
# df=pd.read_csv('C:\\Users\\aAa\\Desktop\\Kaggle-Python-Learn\\biths.csv',names=['Name','Birth'])
print(df)
df.info()
# Info says:
# There are 999 records in the data set
# There is a column named Mary with 999 values
# There is a column named 968 with 999 values
# Out of the two columns, one is numeric, the other is non numericli>
# To actually see the contents of the dataframe we can use the head() function which by default will return the first five records. You can also pass in a number n to return the top n records of the dataframe.
df.head(4)
# Now lets take a look at the last five records of the dataframe
df.tail(4)
df.sample()
# Prepare Data
# The data we have consists of baby names and the number of births in the year 1880. We already know that we have 5 records and none of the records are missing (non-null values).
# Realize that aside from the check we did on the "Names" column, briefly looking at the data inside the dataframe should be as far as we need to go at this stage of the game. As we continue in the data analysis life cycle we will have plenty of opportunities to find any issues with the data set.
# Check data type of the columns
df.dtypes
# Check data type of births column
df.Births.dtype
# We can use the unique property of the dataframe to find all the unique records of the "Names" column.
df["Names"].unique()
# If you actually want to print the unique values:
for x in df["Names"].unique():
print(x)
print(df["Names"].describe())
# Since we have multiple values per baby name, we need to aggregate this data so we only have a baby name appear once. This means the 1,000 rows will need to become 5. We can accomplish this by using the groupby function.
# clean name column convert to upper
df["Names"] = df.Names.apply(lambda x: x.upper())
df
# clean name column convert to upper
df["Names"] = df.Names.apply(lambda x: x.lower())
df
data_filter = data.copy()
data_filter.Genres.apply(lambda x: x.strip("&")).sample(5)
name = df.groupby("Names")
df1 = name.sum()
df1
df
# Analyze Data
# To find the most popular name or the baby name with the higest birth rate, we can do one of the following.
# Sort the dataframe and select the top row
# Use the max() attribute to find the maximum value
#
sorted = df.sort_values(["Births"], ascending=False)
sorted.head(1)
df["Births"].max()
# Present Data
# Here we can plot the Births column and label the graph to show the end user the highest point on the graph. In conjunction with the table, the end user has a clear picture that Mel is the most popular baby name in the data set.
# plot() is a convinient attribute where pandas lets you painlessly plot the data in your dataframe. We learned how to find the maximum value of the Births column in the previous section. Now to find the actual baby name of the 973 value looks a bit tricky, so lets go over it.s
# NumPy
# The Basic
# NumPy’s main object is the homogeneous multidimensional array. It is a table of elements (usually numbers), all of the same type, indexed by a tuple of positive integers. In NumPy dimensions are called axes.
import numpy as np
a = np.arange(15).reshape(3, 5)
a
a.shape
a.ndim
a.dtype.name
a.itemsize
# Array Creation
# There are several ways to create arrays.
# For example, you can create an array from a regular Python list or tuple using the array function. The type of the resulting array is deduced from the type of the elements in the sequences.
a = np.array([2, 3, 4])
a
a.dtype
b = np.array([1.2, 3.5, 5.1])
b.dtype
# A frequent error consists in calling array with multiple numeric arguments, rather than providing a single list of numbers as an argument.
# a=np.array(1,2,3,4) #that's not true
a = np.array([1, 2, 3, 4]) # that's true
# array transforms sequences of sequences into two-dimensional
# arrays, sequences of sequences of sequences into three-dimensional arrays, and so on.
b = np.array([(1.5, 2, 3), (4, 5, 6)])
b
# The function zeros creates an array full of zeros, the function ones creates an array full of ones, and the function empty creates an array whose initial content is random and depends on the state of the memory. By default, the dtype of the created array is float64.
np.zeros((3, 4))
np.eye(4, 4)
eyes = np.eye(5, 5)
np.diagonal(eyes)
array = np.array([[2, 3, 4], [6, 7, 8], [10, 11, 12]])
array.T
np.ones((2, 3, 4), dtype=np.int16)
np.empty((2, 3))
# To create sequences of numbers, NumPy provides a function analogous to range that returns arrays instead of lists.
np.arange(10, 30, 5)
np.arange(-1, 1, 0.1)
np.arange(0, 2, 0.3)
# When arange is used with floating point arguments, it is generally not possible to predict the number of elements obtained, due to the finite floating point precision. For this reason, it is usually better to use the function linspace that receives as an argument the number of elements that we want, instead of the step:
np.linspace(0, 2, 9)
np.linspace(0, 2, 10)
from numpy import pi
x = np.linspace(0, 2 * pi, 100)
f = np.sin(x)
# Printing Arrays
# When you print an array, NumPy displays it in a similar way to nested lists, but with the following layout:
# the last axis is printed from left to right,
# the second-to-last is printed from top to bottom,
# the rest are also printed from top to bottom, with each slice separated from the next by an empty line.
#
a = np.arange(6) # 1d array
print(a)
b = np.arange(12).reshape(4, 3) # 2d array
print(b)
c = np.arange(24).reshape(2, 3, 4) # 3d array
print(c)
print(np.arange(10000))
print(np.arange(10000).reshape(100, 100))
# Basic Operations
# Arithmetic operators on arrays apply elementwise. A new array is created and filled with the result.
a = np.array([20, 30, 40, 50])
b = np.arange(4)
print(b)
c = a - b
print(c)
print(b**2)
print(10 * np.sin(a))
print(a < 35)
# Universal Functions
# NumPy provides familiar mathematical functions such as sin, cos, and exp. In NumPy, these are called “universal functions”(ufunc). Within NumPy, these functions operate elementwise on an array, producing an array as output.
B = np.arange(3)
print(B)
np.exp(B)
np.sqrt(B)
C = np.array([2.0, -1.0, 4.0])
np.add(B, C)
np.abs(-100)
# Indexing, Slicing and Iterating
# One-dimensional arrays can be indexed, sliced and iterated over, much like lists and other Python sequences.
a = np.arange(10) ** 3
print(a)
print(a[2])
print(a[2:5])
a[:6:2] = -1100
print(a)
# Shape Manipulation
a = np.floor(10 * np.random.random((3, 4)))
print(a)
a.shape
print(a.shape[0])
# The shape of an array can be changed with various commands. Note that the following three commands all return a modified array, but do not change the original array:
a.ravel() # returns the array,flattend
a.shape
b.T
b.T.shape
# Deep Copy
# The copy method makes a complete copy of the array and its data.
d = a.copy()
print(d)
print(d is a)
print(d.base is a)
a = np.arange(12) ** 2
i = np.array([1, 1, 3, 8, 5])
print(a[i])
j = np.array([[3, 4], [9, 7]])
print(a[j])
# Scipy
# There are two (interchangeable) ways to deal with 1-d polynomials in SciPy. The first is to use the poly1d class from Numpy. This class accepts coefficients or polynomial roots to initialize a polynomial. The polynomial object can then be manipulated in algebraic expressions, integrated, differentiated, and evaluated. It even prints like a polynomial:
from numpy import poly1d
p = poly1d([3, 4, 5])
print(p)
print(p * p)
print(p.integ(k=6))
print(p.deriv())
p([4, 5])
# The main feature of the scipy.special package is the definition of numerous special functions of mathematical physics. Available functions include airy, elliptic, bessel, gamma, beta, hypergeometric, parabolic cylinder, mathieu, spheroidal wave, struve, and kelvin. There are also some low-level stats functions that are not intended for general use as an easier interface to these functions is provided by the stats module. Most of these functions can take array arguments and return array results following the same broadcasting rules as other math functions in Numerical Python. Many of these functions also accept complex numbers as input. For a complete list of the available functions with a one-line description type >>> help(special). Each function also has its own documentation accessible using help. If you don’t see a function you need, consider writing it and contributing it to the library. You can write the function in either C, Fortran, or Python. Look in the source code of the library for examples of each of these kinds of functions.
from scipy import special
def drumhead_height(n, k, distance, angle, t):
kth_zero = special.jn_zeros(n, k)[-1]
return np.cos(t) * np.cos(n * angle) * special.jn(n, distance * kth_zero)
theta = np.r_[0 : 2 * np.pi : 50j]
radius = np.r_[0:1:50j]
x = np.array([r * np.cos(theta) for r in radius])
y = np.array([r * np.sin(theta) for r in radius])
z = np.array([drumhead_height(1, 1, r, theta, 0.5) for r in radius])
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
fig = plt.figure()
ax = Axes3D(fig)
ax.plot_surface(x, y, z, rstride=1, cstride=1, cmap=cm.jet)
ax.set_xlabel("X")
ax.set_ylabel("Y")
ax.set_zlabel("Z")
plt.show()
# FIR Filter
# The function firwin designs filters according to the window method. Depending on the provided arguments, the function returns different filter types (e.g. low-pass, band-pass…).
# The example below designs a low-pass and a band-stop filter, respectively.
import numpy as np
import scipy.signal as signal
import matplotlib.pyplot as plt
b1 = signal.firwin(40, 0.5)
b2 = signal.firwin(41, [0.3, 0.8])
w1, h1 = signal.freqz(b1)
w2, h2 = signal.freqz(b2)
plt.title("Digital filter frequency response")
plt.plot(w1, 20 * np.log10(np.abs(h1)), "b")
plt.plot(w2, 20 * np.log10(np.abs(h2)), "r")
plt.ylabel("Amplitude Response (dB)")
plt.xlabel("Frequency (rad/sample)")
plt.grid()
plt.show()
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import seaborn as sns
import matplotlib.pyplot as plt
import os
print(os.listdir("../input"))
# read_csv load data
data = pd.read_csv("../input/googleplaystore.csv")
# first 5 rows
data.head()
# last 5 rows
data.tail()
data.sample(5)
data.sample(frac=0.1)
# Can you show your data's columns?
data.columns
# so data's info
data.info()
# Empty fields within the data set
data.isnull().sum()
# It appears that the value of the rating is a little empty. We're gonna have to fill it.
from sklearn.preprocessing import Imputer
im = Imputer(missing_values="NaN", strategy="mean")
data.iloc[:, 2:3] = im.fit_transform(data.iloc[:, 2:3])
# so,We've done adding implants to the empty spaces by taking the mean.
data.isnull().sum()
data.head()
# value_counts(): Frequency counts
# outliers: the value that is considerably higher or lower from rest of the data
# Lets say value at 75% is Q3 and value at 25% is Q1.
# Outlier are smaller than Q1 - 1.5(Q3-Q1) and bigger than Q3 + 1.5(Q3-Q1). (Q3-Q1) = IQR
# We will use describe() method. Describe method includes:
# count: number of entries
# mean: average of entries
# std: standart deviation
# min: minimum entry
# 25%: first quantile
# 50%: median or second quantile
# 75%: third quantile
# max: maximum entry
# What is quantile?
# 1,4,5,6,8,9,11,12,13,14,15,16,17
# The median is the number that is in middle of the sequence. In this case it would be 11.
# The lower quartile is the median in between the smallest number and the median i.e. in between 1 and 11, which is 6.
# The upper quartile, you find the median between the median and the largest number i.e. between 11 and 17, which will be 14 according to the question above.
#
# For example lets look frequency of pokemom types
print(
data["Category"].value_counts(dropna=False)
) # if there are nan values that also be counted
# As it can be seen below there are 112 water pokemon or 70 grass pokemon
# Category Analysis
sns.barplot(
x=data["Category"].value_counts().index, y=data["Category"].value_counts().values
)
plt.xlabel("Category")
plt.ylabel("Count")
plt.title("Category Count Operation")
plt.xticks(rotation=90)
plt.show()
# It seems that the most family and game categories are traded.
fig, ax = plt.subplots()
ax.scatter(
x=data.groupby("Category")["Rating"].mean()[1:].index,
y=data.groupby("Category")["Rating"].mean()[1:].values,
)
plt.ylabel("Category", fontsize=13)
plt.xlabel("Rating", fontsize=13)
plt.xticks(rotation=90)
plt.show()
ax = sns.boxplot(x="Rating", y="Size", data=data)
plt.show()
data[data["Reviews"] == max(data.Reviews)]
# most viewed and displayed application
data[data["Reviews"] == min(data.Reviews)]
# least viewed and displayed application
# scaling and cleaning size of installation
def change_size(size):
if "M" in size:
x = size[:-1]
x = float(x) * 1000000
return x
elif "k" == size[-1:]:
x = size[:-1]
x = float(x) * 1000
return x
else:
return None
data["Size"] = data["Size"].map(change_size)
# filling Size which had NA
data.Size.fillna(method="ffill", inplace=True)
data.head()
filter_data = data[data["Size"] > int(data["Size"].mean())]
filter_data.Reviews = filter_data.Reviews.astype(float)
filter_data[filter_data["Reviews"] > 15].Type.value_counts()
sns.countplot(filter_data[filter_data["Reviews"] > 15].Type)
plt.title("Free vs Paid")
plt.show()
filter_data[(filter_data["Reviews"] > 15) & (filter_data["Type"] == "Paid")]
# The value of the type in the data we filter is analyzed for payment. For this, the total price value will be calculated.
# For this, we need to remove the $ symbol from the charge column. In addition, it is necessary to change the type of milk.
filter_data["Price"] = filter_data.Price.str.replace("$", "")
filter_data.Price = filter_data.Price.astype("float")
# Calculating the total fee
(
str(
sum(
filter_data[
(filter_data["Reviews"] > 15) & (filter_data["Type"] == "Paid")
].Price
)
)
+ " $"
)
# filter_data[(filter_data['Reviews']>15)&(filter_data['Type']=='Paid')]
df_filter = filter_data.groupby("Category")["Price"].sum()
# sum and display of paid products for the filtered area in terms of categorical
d1 = pd.DataFrame(df_filter.index, columns=["Category"])
d2 = pd.DataFrame(df_filter.values, columns=["Price"])
df_data_filter = pd.concat([d1, d2], axis=1)
df_data_filter = df_data_filter.sort_values(by="Price", ascending=False)
df_data_filter
cmap = sns.diverging_palette(220, 10, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(
data.corr(),
cmap=cmap,
vmax=0.3,
center=0,
square=True,
linewidths=0.5,
cbar_kws={"shrink": 0.5},
annot=True,
)
plt.show()
plt.figure(figsize=(5, 5))
plt.pie(
df_data_filter.Price[0:5],
labels=df_data_filter.Category[0:5],
autopct="%1.1f%%",
shadow=True,
startangle=90,
)
# ax.axis('Price') # Equal aspect ratio ensures that pie is drawn as a circle.
# plt.legend()
plt.show()
# sns.relplot(x="Rating",y="Reviews",data=data)
# plt.show()
# sns.lmplot(x="Review", y="Rating", hue="Category",data=data)
# plt.show()
data.dropna(inplace=True)
everyone = []
teen = []
everyone10 = []
mature17 = []
adults18 = []
unrates = []
everyone.append(sum(data[(data["Content Rating"] == "Everyone")].Size))
teen.append(sum(data[(data["Content Rating"] == "Teen")].Size))
mature17.append(sum(data[(data["Content Rating"] == "Mature 17+")].Size))
adults18.append(sum(data[(data["Content Rating"] == "Adults only 18+")].Size))
unrates.append(sum(data[(data["Content Rating"] == "Unrated")].Size))
everyone10.append(sum(data[(data["Content Rating"] == "Everyone 10+")].Size))
# data.groupby('Content Rating')['Size'].mean().values
plt.plot(
data["Content Rating"].unique(),
[everyone, teen, mature17, adults18, unrates, everyone10],
)
plt.xlabel("Content Rating")
plt.ylabel("Sum Of Size")
plt.xticks(rotation=90)
plt.show()
data["Content Rating"].unique()
# everyone
data.head()
len(data[data["Category"] == "FAMILY"])
sns.barplot(
x=data["Category"].unique(), y=data.groupby("Category")["Rating"].mean().values
)
plt.xticks(rotation=90)
plt.xlabel("Category")
plt.ylabel("Mean")
plt.show()
data.head()
data.Price = data.Price.str.replace("$", "")
print(max(data[data["Type"] == "Paid"].Price.values))
print(min(data[data["Type"] == "Paid"].Price.values))
paid_filter = data[data["Type"] == "Paid"]
paid_filter.Price = paid_filter.Price.astype(float)
paid_filter.Reviews = paid_filter.Reviews.astype(float)
paid_filter.groupby("Category")["Reviews"].sum().values
plt.scatter(
x=paid_filter.Category.unique(),
y=paid_filter.groupby("Category")["Reviews"].sum().values,
)
plt.xticks(rotation=90)
plt.show()
data.Genres.unique()
countplot = data.Genres.value_counts()
plt.figure(figsize=(10, 10))
sns.barplot(x=countplot.index[:50], y=countplot[:50])
plt.xticks(rotation=90)
plt.title("Count Genres of DataSet")
plt.show()
data[data["Genres"] == "Tools"].Type.value_counts().index
explode = [0, 0.1]
labels = ["Free", "Paid"]
plt.figure(figsize=(5, 5))
plt.pie(
data[data["Genres"] == "Tools"].Type.value_counts().values,
labels=data[data["Genres"] == "Tools"].Type.value_counts().index,
explode=explode,
autopct="%1.1f%%",
)
plt.title("Genres Tools Type System")
plt.show()
# Show the joint distribution using kernel density estimation
g = sns.jointplot(data.Rating, data.Reviews, kind="kde", height=7, space=0)
plt.show()
data.head()
data.Reviews = data.Reviews.astype(float)
s = paid_filter[paid_filter["Price"] == 0.99].Category.unique()
paid_filter[paid_filter["Price"] == 0.99].groupby("Category")["Rating"].mean()
plt.figure(1, figsize=(15, 7))
plt.subplot(131)
plt.bar(
paid_filter[paid_filter["Price"] == 0.99]
.groupby("Category")["Rating"]
.mean()
.index,
paid_filter[paid_filter["Price"] == 0.99]
.groupby("Category")["Rating"]
.mean()
.values,
)
plt.xticks(rotation=90)
plt.subplot(132)
plt.scatter(
paid_filter[paid_filter["Price"] == 0.99]
.groupby("Category")["Rating"]
.mean()
.index,
paid_filter[paid_filter["Price"] == 0.99]
.groupby("Category")["Rating"]
.mean()
.values,
)
plt.xticks(rotation=90)
plt.subplot(133)
plt.plot(
paid_filter[paid_filter["Price"] == 0.99]
.groupby("Category")["Rating"]
.mean()
.index,
paid_filter[paid_filter["Price"] == 0.99]
.groupby("Category")["Rating"]
.mean()
.values,
)
plt.suptitle("Categorical Plotting")
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
data.head()
# Plot miles per gallon against horsepower with other semantics
sns.relplot(
x="Rating",
y="Reviews",
hue="Type",
sizes=(40, 400),
alpha=0.5,
palette="muted",
height=6,
data=data,
)
plt.show()
g = sns.PairGrid(data, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_upper(sns.scatterplot)
g.map_diag(sns.kdeplot, lw=3)
plt.show()
ax = sns.kdeplot(data.Rating, data.Size, cmap="Blues", shade=True)
plt.show()
data.head()
data.Type = [1 if type == "Free" else 0 for type in data.Type]
data.head(2)
data.columns
col = {
"Content Rating": "ContentRating",
"Last Updated": "LastUpdated",
"Current Ver": "CurrentVer",
"Android Ver": "AndroidVer",
}
data.rename(columns=col, inplace=True)
def showColumns(data):
for i, col in enumerate(data):
print("{} . columns {}".format(i, col))
showColumns(data.columns)
data.dtypes
data.Price = data.Price.astype("float")
data.Price = [1 if price > 0 else -1 for price in data.Price]
np.mean(data.Price)
np.eye(5)
np.std(data[:5], axis=1)
np.var(data)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0014/071/14071740.ipynb | google-play-store-apps | lava18 | [{"Id": 14071740, "ScriptId": 2821193, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1712516, "CreationDate": "05/12/2019 11:37:31", "VersionNumber": 44.0, "Title": "Python Programming Language For Data Scientists", "EvaluationDate": "05/12/2019", "IsChange": true, "TotalLines": 1676.0, "LinesInsertedFromPrevious": 4.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 1672.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 2}] | [{"Id": 9179491, "KernelVersionId": 14071740, "SourceDatasetVersionId": 274957}] | [{"Id": 274957, "DatasetId": 49864, "DatasourceVersionId": 287262, "CreatorUserId": 2115707, "LicenseName": "Unknown", "CreationDate": "02/03/2019 13:55:47", "VersionNumber": 6.0, "Title": "Google Play Store Apps", "Slug": "google-play-store-apps", "Subtitle": "Web scraped data of 10k Play Store apps for analysing the Android market.", "Description": "### Context\n\nWhile many public datasets (on Kaggle and the like) provide Apple App Store data, there are not many counterpart datasets available for Google Play Store apps anywhere on the web. On digging deeper, I found out that iTunes App Store page deploys a nicely indexed appendix-like structure to allow for simple and easy web scraping. On the other hand, Google Play Store uses sophisticated modern-day techniques (like dynamic page load) using JQuery making scraping more challenging.\n\n\n### Content\n\nEach app (row) has values for catergory, rating, size, and more.\n\n\n### Acknowledgements\n\nThis information is scraped from the Google Play Store. This app information would not be available without it.\n\n\n### Inspiration\n\nThe Play Store apps data has enormous potential to drive app-making businesses to success. Actionable insights can be drawn for developers to work on and capture the Android market!", "VersionNotes": "Insert CC license", "TotalCompressedBytes": 165.0, "TotalUncompressedBytes": 2013308.0}] | [{"Id": 49864, "CreatorUserId": 2115707, "OwnerUserId": 2115707.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 274957.0, "CurrentDatasourceVersionId": 287262.0, "ForumId": 58489, "Type": 2, "CreationDate": "09/04/2018 18:19:51", "LastActivityDate": "09/04/2018", "TotalViews": 1687374, "TotalDownloads": 222127, "TotalVotes": 4501, "TotalKernels": 921}] | [{"Id": 2115707, "UserName": "lava18", "DisplayName": "Lavanya", "RegisterDate": "07/31/2018", "PerformanceTier": 1}] | # Teaching Python Programming Language For Data Scientists
# Introduction
#
# What is Python Programming Language?
# Why Python Programming Language?
# Required Libraries
#
# Python for Beginners
#
# Python Installation
# Maths Operations
# Strings Operation
# Lists Operation
# if-elif-else
# While Statement
# For Statement
# Range
# Break and Continue
# Introduction to Functions
# Lambda Expressions
# Documentation Strings
# Data Structure
# Dictionaries
# Modules
# Input and Output
# Reading and Writing Files
# Errors and Exceptions
# Classes
#
# Data Preparation and Processing
#
# Pandas
#
# Create Data
# Get Data
# Prepare Data
# Analyze Data
# Presedent Data
#
#
# NumPy
#
# The Basics
# Array Creation
# Printing Arrays
# Basic Operations
# Universal Functions
# Indexing, Slicing and Iterating
# Shape Manipulation
# Deep Copy
#
#
#
# Feature Work
# References
# Conclusion
# if you like it,please UPVOTE
# Last Update : 12.05.2019
# Introduction
# What is Python Programming Language?
# Python is the programming language. Kdnuggets is the most used programming language in data science with 65.5% according to Analytics data. Open source is free and free software. Python is a programming language that supports the object-oriented programming paradigm. Web, mobile and socket programming etc. is a scripting language with many features. However, it can operate independently on every platform. This is an indispensable programming language for data scientists and other programmers thanks to their diversity. In addition, it has a clear and easy-to-read format compared to other programming languages. With its wide library, it helps us in all kinds of software works. All software will be written in this programming language.
# Link: https://www.python.org/downloads/
# Why Python Programming Language?
# It is one of the most used programming languages by data scientists. Because there are developers all around the world. In this way, a wide variety of operations are performed. In addition, very few transactions can be performed with very little code. More than one operation is performed.Python is a powerful programming language that is easy to learn. It has a simple but effective approach to effective high-level data structures and object-oriented programming. Python's exquisite syntax and dynamic writing, combined with its interpreted nature, has made it an ideal language for scripting and rapid application development across many platforms.
# The Python interpreter can be easily expanded with new functions and data types implemented in C or C ++ (or other languages that can be called from C). Python is also available as an extension language for customizable applications.
# Required Libraries
# Numpy
# It is a Python library that allows us to perform multiple operations on arrays, including multidimensional arrays, various derived objects (such as masked arrays and matrices) and lots of mathematical, logical, shape manipulation, sorting, sorting, discrete Fourier. Statistical procedures and simulations can be performed using NumPy. NumPy library with C ++ does not cause any loss of performance.
# Pandas
# Pandas is an open source, BSD licensed library, offering high-performance, easy-to-use data structures and data analysis tools for the Python programming language. It is a library designed to work with data, allowing you to run your non-structural data as in structural databases. Pandas is designed for fast and easy data processing, collection and visualization. Therefore, it is a very preferred library for data scientists. In addition, with its own data-editing functions, you can convert your data into any format. Thanks to Pandas, we make preliminary work for our model and make it ready for the model. As a preliminary study, it is necessary to carry out editing studies by detecting missing, slingshot, incompatible and repetitive data. In this way, you can train your model smoothly and get the results properly. To use the Pandas library, we need to upload it to Anaconda.
# Scikit-Learn
# It includes many machine learning algorithms such as classification, regression, clustering, size reduction, model selection and data removal. It is an open source library with BSD license. Together with the algorithms it contains, it creates a fast and secure coding structure. It includes the functions of expressing frequently used mathematical and physical problems in computer environment. In addition, thanks to its own web site you can look at the working principle of the algorithm you want. However, you can learn the mathematical infrastructure of the algorithm. In this way, according to your own data set you can develop the mathematical model of the algorithm yourself. By applying the model you have made on the data set, results can be obtained. Which of these results is effective in the mathematical model you will make out. In addition, you must install the scikit-learn library to Anaconda to use it.
# Seaborn
# Seaborn is a library in Python for making interesting and informative statistical graphs. Built on Matplotlib, numpy has been tightly integrated with the PyData stack, providing support for statistical templates from scipy, statsmodel, pandas data structures. It is used for graphs depicting general distributions that summarize data as in heat maps. Thanks to the many methods included in the content of high-level analysis can be made. However, the user can perform analyzes in interactive and animation structure. Today's data scientists put the seaborn library in place where the matplotlib library is missing. Thanks to Seaborn, interactive plots can be removed. In this way, we will show the dimensions of inter-feature interaction more clearly. Thanks to the different types of plots within itself, we are able to make analyzes in every format.
# Matplotlib
# Matplotlib graphical drawing package is one of the most important tools of scientific programming. With Matplotlib, a very powerful package, data can be visualized interactively, and high quality printouts are available for publishing. Both two- and three-dimensional graphics can be created. However, it is very simple to use. In addition, there are a lot of information about this package on the internet, but for data scientists can take all kinds of analysis. As a result of your analysis, you can save the resulting graph as output. You can then add it as an addition to the report you made later. It will be used to explain the results obtained from various analyzes and evaluations in the application orally and graphically. So much so that we use the algorithm to show us the most accurate results. In this way, we will guide us for further analysis. In addition, our corporate website helps us for all the plots we will use.
# Scipy
# SciPy refers to several related but distinct entities:The SciPy ecosystem, a collection of open source software for scientific computing in Python.The community of people who use and develop this stack.Several conferences dedicated to scientific computing in Python - SciPy, EuroSciPy and SciPy.in.The SciPy library, one component of the SciPy stack, providing many numerical routines.
# Python for Beginners
# Python Installation
# Link: https://www.youtube.com/watch?v=dX2-V2BocqQ
# There is very good expression in this section.
# Maths Operations
# Python can do a variety of mathematical operations. In this case, we do not need to define any variables. This is described in the examples below for this situation.
# The following mathematical operations are given 3 kinds of examples. In the first example, only data from the variable definition are given. Thus, results were obtained. In the second example, a variable is defined. In this example, the operations were performed. In the last example, a decimal data is obtained by dividing int data with decimal data.**
# Before continue with pandas, we need to learn logic, control flow and filtering.
# Comparison operator: ==, , <=
# Boolean operators: and, or ,not
# Filtering pandas
# Comparison operator
print(3 > 2)
print(5 < 4)
print("Apple" in ["App", "Appl", "Apple"])
print(3 != 2)
# Boolean operators
print(True and False)
print(True or False)
# Example 1
print(2 + 2)
# Example 2
a = (50 - 5 * 6) / 4
print(a)
# Example 3
print(8 / 5.0)
# Example 4
print(10 + 80)
print(10 - (25 - 85) + 45)
print(5 * 6 - (2 - 8))
# Example 5
print(17 // 3.0) # explicit floor division discards the fractional part
# Example 6
print(18 // 4.0)
# The // operator is also provided for doing floor division no
# matter what the operands are.
# Example 7
print(17 % 3)
# Example 6 Mode operation; between the first number and the second number.
# As a result of this operation, the remaining number is obtained.
# With Python, it is possible to use the ** operator to calculate powers
# Example 8
print(5**2) # 5 squared
# Example 9
print(2**8) # 2 to power of 8
# The equal sign (=) is used to assign a value to a variable.
# Example 10
width = 8
height = 10
print(width * height)
# Strings Operation
# Besides numbers, Python can also manipulate strings, which can be expressed in several ways. They can be enclosed in single quotes ('...') or double quotes ("...") with the same result. \ can be used to escape quotes:
s1 = "string"
s2 = "data"
print(s1 + " " + s2)
# Strings can be concatenated (glued together) with the
# + operator, and repeated with *:
index = 3
print("un " * index)
# Two or more string literals
print("Py" "thon")
prefix = "Py"
# prefix='thon'
prefix + "thon"
# Strings can be indexed (subscripted)
word = "Python"
print(word[0]) # character in position 0
print(word[5]) # character in position 5
print(word[-1]) # last character
print(word[-2]) # second-last character
# In addition to indexing, slicing is also supported.
# While indexing is used to obtain individual characters,
# slicing allows you to obtain a substring:
print(word[0:2]) # characters from position 0 (included) to 2 (excluded)
print(word[2:5]) # characters from position 2 (included) to 5 (excluded)
# Note how the start is always included, and the end always
# excluded. This makes sure that s[:i] + s[i:] is always equal to s:
print(word[:2] + word[2:])
print(word[:4] + word[4:])
# Slice indices have useful defaults; an omitted first index defaults
# to zero, an omitted second index defaults to the size of the
# string being sliced.
print(word[:2]) # character from the beginning to position 2 (excluded)
print(word[4:])
print(word[-2:])
print(word[1:3]) # character from the beginning to position 3 (excluded)
print("J" + word[1:])
print(word[:2] + "py")
# Lists Operation
# Python knows a number of compound data types, used to group together other values. The most versatile is the list, which can be written as a list of comma-separated values (items) between square brackets. Lists might contain items of different types, but usually the items all have the same type.
squares = [1, 4, 9, 16, 25]
squares
# Like strings (and all other built-in sequence type),
# lists can be indexed and sliced:
print(squares[0]) # indexing returns the item
print(squares[-1])
print(squares[-3:]) # slicing returns a new list
print(squares[:]) # all
# All slice operations return a new list containing the requested
# elements. This means that the following slice returns a new
# (shallow) copy of the list:
squares + [36, 49, 64, 81, 100]
cubes = [1, 8, 27, 65, 125]
4**3
cubes[3] = 64 # replace the wrong value
cubes
# You can also add new items at the end of the list, by using the
# append() method (we will see more about methods later):
cubes.append(216) # add the cube of 6
cubes.append(7**3) # and the cube of 7
cubes
# Assignment to slices is also possible, and this can even change
# the size of the list or clear it entirely:
letters = ["a", "b", "c", "d", "e", "f", "g"]
print(letters)
# replace some values
letters[2:5] = ["C", "D", "E"]
print(letters)
# now remove them
letters[2:5] = []
letters
# clear the list by replacing all the elements with an empty list
letters[:] = []
letters
# The built-in function len() also applies to lists:
letters = ["a", "b", "c", "d"]
len(letters)
# if-elif-else
# Decision making is required when we want to execute a code only if a certain condition is satisfied.
# [i + 1 for i in num1 ]: list of comprehension
# i +1: list comprehension syntax
# for i in num1: for loop syntax
# i: iterator
# num1: iterable object
# The if…elif…else statement is used in Python for decision making.
# Perhaps the most well-known statement type is the if statement. For example:
# We use list comprehension for data analysis often.
# list comprehension: collapse for loops for building lists into a single line
# Ex: num1 = [1,2,3] and we want to make it num2 = [2,3,4]. This can be done with for loop. However it is unnecessarily long. We can make it one line code that is list comprehension.
# Example of list comprehension
num1 = [1, 2, 3]
num2 = [i + 1 for i in num1]
print(num2)
# Conditionals on iterable
num1 = [5, 10, 15]
num2 = [i**2 if i == 10 else i - 5 if i < 7 else i + 5 for i in num1]
print(num2)
# If the number is positive, we print an appropriate message
num = 3
if num > 0:
print(num, " is a positive number")
print("This is always printed")
num = -1
if num > 0:
print(num, " is a positive number")
print("This is also always printed")
# Program checks if the number is positive or negative
# And displays an appropriate message
num = 3
# Try these two variations as well.
# num = -5
# num = 0
if num >= 0:
print("Positive or Zero")
else:
print("Negative number")
# In this program,
# we check if the number is positive or
# negative or zero and
# display an appropriate message
num = 3.4
# Try these two variations as well:
# num = 0
# num = -4.5
if num > 0:
print("Positive number")
elif num == 0:
print("Zero")
else:
print("Negative number")
# In this program, we input a number
# check if the number is positive or
# negative or zero and display
# an appropriate message
# This time we use nested if
num = float(input("Enter a number: "))
if num >= 0:
if num == 0:
print("Zero")
else:
print("Positive number")
else:
print("Negative number")
var = 100
if var == 100:
print("Value of expression is 100")
print("Good bye!")
# While
# With the while loop we can execute a set of statements as long as a condition is true.
# Stay in loop if condition( i is not equal 5) is true
i = 0
while i != 5:
print("i is: ", i)
i += 1
print(i, " is equal to 5")
# Stay in loop if condition( i is not equal 5) is true
lis = [1, 2, 3, 4, 5]
for i in lis:
print("i is: ", i)
print("")
# Enumerate index and value of list
# index : value = 0:1, 1:2, 2:3, 3:4, 4:5
for index, value in enumerate(lis):
print(index, " : ", value)
print("")
# For dictionaries
# We can use for loop to achive key and value of dictionary. We learnt key and value at dictionary part.
dictionary = {"spain": "madrid", "france": "paris"}
for key, value in dictionary.items():
print(key, " : ", value)
print("")
i = 1
while i < 6:
print(i)
i += 1
# With the break statement we can stop the loop even if the while condition is true:
i = 1
while i < 6:
print(i)
if i == 3:
break
i += 1
# With the continue statement we can stop the current iteration, and continue with the next:
i = 0
while i < 6:
i += 1
if i == 3:
continue
print(i)
# For Statements
# The for statement in Python differs a bit from what you may be used to in C or Pascal. Rather than always iterating over an arithmetic progression of numbers (like in Pascal), or giving the user the ability to define both the iteration step and halting condition (as C), Python’s for statement iterates over the items of any sequence (a list or a string), in the order that they appear in the sequence. For example (no pun intended):
words = ["cats", "window", "defenstrate"]
for w in words:
print(w, len(w))
# If you need to modify the sequence you are iterating over while inside the loop (for example to duplicate selected items), it is recommended that you first make a copy. Iterating over a sequence does not implicitly make a copy. The slice notation makes this especially convenient:
for w in words[:]:
if len(w) > 6:
words.insert(0, w)
for i, w in enumerate(words):
print((i + 1), ":", w)
# Loop through the letters in the word "banana":
for x in "banana":
print(x)
# Range
# If you do need to iterate over a sequence of numbers, the built-in function range() comes in handy. It generates lists containing arithmetic progressions:
# To loop through a set of code a specified number of times, we can use the range() function,
# The range() function returns a sequence of numbers, starting from 0 by default, and increments by 1 (by default), and ends at a specified number.
for i in range(10):
print(i)
# The given end point is never part of the generated list; range(10) generates a list of 10 values, the legal indices for items of a sequence of length 10. It is possible to let the range start at another number, or to specify a different increment (even negative; sometimes this is called the ‘step’):
for i in range(5, 10):
print(i)
print("#" * 30)
for i in range(0, 10, 3): # 0 start 10 finish 3 step
print(i)
print("#" * 30)
for i in range(-10, -100, -30): # 0 start 10 finish 3 step
print(i)
a = ["Mary", "had", "a", "little", "lamb"]
for i in range(len(a)):
print(i, a[i])
import numpy as np
new_list = np.arange(1, 20)
for i in np.arange(1, 30, 2):
print(i)
# The else keyword in a for loop specifies a block of code to be executed when the loop is finished:
for x in range(6):
print(x)
else:
print("Finish")
# Break and Continue
# The break statement, like in C, breaks out of the innermost enclosing for or while loop.
# Loop statements may have an else clause; it is executed when the loop terminates through exhaustion of the list (with for) or when the condition becomes false (with while), but not when the loop is terminated by a break statement. This is exemplified by the following loop, which searches for prime numbers:
for n in range(2, 10):
for x in range(2, n):
if n % x == 0:
print(n, " equal", x, "*", n / x)
break
else:
# loop fell through without finding a factor
print(n, " is a prime number")
# (Yes, this is the correct code. Look closely: the else clause belongs to the for loop, not the if statement.)
# When used with a loop, the else clause has more in common with the else clause of a try statement than it does that of if statements: a try statement’s else clause runs when no exception occurs, and a loop’s else clause runs when no break occurs. For more on the try statement and exceptions, see Handling Exceptions.
# The continue statement, also borrowed from C, continues with the next iteration of the loop:
# iteration example
name = "ronaldo"
it = iter(name)
print(next(it)) # print next iteration
print(*it) # print remaining iteration
#
# ITERATORS
# iterable is an object that can return an iterator
# iterable: an object with an associated iter() method
# example: list, strings and dictionaries
# iterator: produces next value with next() method
#
for num in range(2, 10):
if num % 2 == 0:
print("Found an even number", num)
continue
print("Found a number", num)
# Introduction to Functions
# We can create a function that writes the Fibonacci series to an arbitrary boundary:
def fib(n):
# print a fibonacci series up to n
a, b = 0, 1
while a < n:
print(a)
a, b = b, a + b
fib(2000)
def my_function1(country="Turkey"):
print("I am from " + country)
my_function1()
my_function1("Canada")
# The keyword def introduces a function definition. It must be followed by the function name and the parenthesized list of formal parameters. The statements that form the body of the function start at the next line, and must be indented.
# The most useful form is to specify a default value for one or more arguments. This creates a function that can be called with fewer arguments than it is defined to allow. For example:
def ask_ok(prompt, retries=4, complaint="Yes or no, please!"):
while True:
ok = raw_input(prompt)
if ok in ("y", "ye", "yes"):
return True
if ok in ("n", "no", "nop", "nope"):
return False
retries = retries - 1
if retries < 0:
raise IOError("refusenik user")
print(complaint)
# This function can be called in several ways:
# giving only the mandatory argument: ask_ok('Do you really want to quit?')
# giving one of the optional arguments: ask_ok('OK to overwrite the file?', 2)
# or even giving all arguments: ask_ok('OK to overwrite the file?', 2, 'Come on, only yes or no!')
# The default values are evaluated at the point of function definition in the defining scope, so that
i = 5
def f(arg=i):
print(arg)
i = 6
f()
# Important warning: The default value is evaluated only once. This makes a difference when the default is a mutable object such as a list, dictionary, or instances of most classes. For example, the following function accumulates the arguments passed to it on subsequent calls:
def f(a, L=[]):
L.append(a)
return L
print(f(1))
print(f(2))
print(f(3))
# If you don’t want the default to be shared between subsequent calls, you can write the function like this instead:
def f(a, L=None):
if L is None:
L = []
L.append(a)
return L
f([5, 4, 3])
# Functions can also be called using keyword arguments of the form kwarg=value. For instance, the following function:
def parrot(voltage, state="a stiff", action="voom", type="Norwegian Blue"):
print(
"-- This parrot wouldn't",
action,
)
print("if you put", voltage, "volts through it.")
print("-- Lovely plumage, the", type)
print("-- It's", state, "!")
# accepts one required argument (voltage) and three optional arguments (state, action, and type). This function can be called in any of the following ways:
# accepts one required argument (voltage) and three optional arguments (state, action, and type). This function can be called in any of the following ways:
parrot(1000) # 1 positional argument
parrot(voltage=1000) # 1 keyword argument
parrot(voltage=1000000, action="VOOOOOM") # 2 keyword arguments
parrot(action="VOOOOOM", voltage=1000000) # 2 keyword arguments
parrot("a million", "bereft of life", "jump") # 3 positional arguments
parrot("a thousand", state="pushing up the daisies") # 1 positional, 1 keyword
# When a final formal parameter of the form **name is present, it receives a dictionary (see Mapping Types — dict) containing all keyword arguments except for those corresponding to a formal parameter. This may be combined with a formal parameter of the form *name (described in the next subsection) which receives a tuple containing the positional arguments beyond the formal parameter list. (*name must occur before **name.) For example, if we define a function like this:
def cheeseshop(kind, *arguments, **keywords):
print("-- Do you have any", kind, "?")
print("-- I'm sorry, we're all out of", kind)
for arg in arguments:
print(arg)
print("-" * 40)
keys = sorted(keywords.keys())
for kw in keys:
print(kw, ":", keywords[kw])
"""cheeseshop("Limburger", "It's very runny, sir.",
"It's really very, VERY runny, sir.",
shopkeeper='Michael Palin',
client="John Cleese",
sketch="Cheese Shop Sketch")"""
# The reverse situation occurs when the arguments are already in a list or tuple but need to be unpacked for a function call requiring separate positional arguments. For instance, the built-in range() function expects separate start and stop arguments. If they are not available separately, write the function call with the *-operator to unpack the arguments out of a list or tuple:
print(list(range(3, 6))) # normal call with separate arguments
args = [3, 6]
list(range(*args)) # call with arguments unpacked from a list
def tri_recursion(k):
if k > 0:
result = k + tri_recursion(k - 1)
print(result)
else:
result = 0
return result
tri_recursion(6)
# Lambda Expressions
# Small anonymous functions can be created with the lambda keyword. This function returns the sum of its two arguments: lambda a, b: a+b. Lambda functions can be used wherever function objects are required. They are syntactically restricted to a single expression. Semantically, they are just syntactic sugar for a normal function definition. Like nested function definitions, lambda functions can reference variables from the containing scope:
def make_incrementor(n):
return lambda x: x + n
f = make_incrementor(50)
print(f(2))
print(f(1))
# The above example uses a lambda expression to return a function. Another use is to pass a small function as an argument:
pairs = [(1, "one"), (2, "two"), (3, "three"), (4, "four")]
pairs.sort(key=lambda pair: pair[1])
pairs
# A lambda function that adds 10 to the number passed in as an argument, and print the result:
x = lambda a: a + 10
print(x(5))
x = 5
y = lambda x: x**2
y(10)
# A lambda function that adds 10 to the number passed in as an argument, and print the result:
x = lambda a: a + 120
print(x(15))
# A lambda function that multiplies argument a with argument b and print the result:
x = lambda a, b, c: a + b + c
print(x(5, 6, 2))
number_list = [1, 2, 3]
y = map(lambda x: x**2, number_list)
print(list(y))
# The power of lambda is better shown when you use them as an anonymous function inside another function.
# Say you have a function definition that takes one argument, and that argument will be multiplied with an unknown number:
def myfunc(n):
return lambda a: a * n
mydoubler = myfunc(2)
print(mydoubler(11))
# Documentation Strings
# There are emerging conventions about the content and formatting of documentation strings.
# The first line should always be a short, concise summary of the object’s purpose. For brevity, it should not explicitly state the object’s name or type, since these are available by other means (except if the name happens to be a verb describing a function’s operation). This line should begin with a capital letter and end with a period.
# If there are more lines in the documentation string, the second line should be blank, visually separating the summary from the rest of the description. The following lines should be one or more paragraphs describing the object’s calling conventions, its side effects, etc.
# Here is an example of a multi-line docstring:
def my_fucntion():
"""Do nothing, but document it
No,really, it doesn't do anything.
"""
pass
print(my_fucntion)
# Data Structures
# This chapter describes some things you’ve learned about already in more detail, and adds some new things as well.
a = [66.25, 333, 333, 1, 12, 154, 789]
print(a.count(333), a.count(66.25), a.count("x"))
a.insert(2, -1)
a.append(333)
print(a)
a.index(333)
a.remove(333)
a.reverse()
print(a)
a.sort()
print(a.pop())
a
# The list methods make it very easy to use a list as a stack, where the last element added is the first element retrieved (“last-in, first-out”). To add an item to the top of the stack, use append(). To retrieve an item from the top of the stack, use pop() without an explicit index. For example:
stack = [3, 4, 5]
stack.append(6)
stack.append(7)
print(stack)
print(stack.pop())
print(stack.pop())
print(stack)
def f(x):
return x % 3 == 0 or x % 5 == 0
f(9)
# map(function, sequence) calls function(item) for each of the sequence’s items and returns a list of the return values. For example, to compute some cubes:
def cube(x):
return x * x * x
cube(5)
# More than one sequence may be passed; the function must then have as many arguments as there are sequences and is called with the corresponding item from each sequence (or None if some sequence is shorter than another). For example:
seq = range(1, 8)
list(seq)
def add(x, y):
return x + y
add(5, 7)
# List comprehensions provide a concise way to create lists. Common applications are to make new lists where each element is the result of some operations applied to each member of another sequence or iterable, or to create a subsequence of those elements that satisfy a certain condition.
# For example, assume we want to create a list of squares, like:
squares = []
for x in range(10):
squares.append(x**2)
squares
for x in range(0, 18, 2):
print(x)
# We can obtain the same result with:
squares = [i * 2 for i in range(1, 10, 1)]
squares
[(x, y) for x in [1, 2, 3] for y in [3, 1, 4] if x != y]
a = [-1, 1, 66, 45, 87, 65, 12, 65]
del a[0]
print(a)
del a[2:4]
print(a)
del a[:]
print(a)
t = 123, 45, 65, 78, "hi!"
print(t[0])
print(t)
# Tuples may be nested:
u = t, (1, 2, 3, 4, 5, 6)
u
# A special problem is the construction of tuples containing 0 or 1 items: the syntax has some extra quirks to accommodate these. Empty tuples are constructed by an empty pair of parentheses; a tuple with one item is constructed by following a value with a comma (it is not sufficient to enclose a single value in parentheses). Ugly, but effective. For example:
empty = ()
singleton = ("hello",)
len(empty)
len(singleton)
print(singleton)
# Dictionaries
# Another useful data type built into Python is the dictionary (see Mapping Types — dict). Dictionaries are sometimes found in other languages as “associative memories” or “associative arrays”. Unlike sequences, which are indexed by a range of numbers, dictionaries are indexed by keys, which can be any immutable type; strings and numbers can always be keys. Tuples can be used as keys if they contain only strings, numbers, or tuples; if a tuple contains any mutable object either directly or indirectly, it cannot be used as a key. You can’t use lists as keys, since lists can be modified in place using index assignments, slice assignments, or methods like append() and extend().
# create dictionary and look its keys and values
dictionary = {"spain": "madrid", "usa": "vegas"}
print(dictionary.keys())
print(dictionary.values())
# Keys have to be immutable objects like string, boolean, float, integer or tubles
# List is not immutable
# Keys are unique
dictionary["spain"] = "barcelona" # update existing entry
print(dictionary)
dictionary["france"] = "paris" # Add new entry
print(dictionary)
del dictionary["spain"] # remove entry with key 'spain'
print(dictionary)
print("france" in dictionary) # check include or not
dictionary.clear() # remove all entries in dict
print(dictionary)
tel = {"jack": 4098, "sape": 4139}
tel["guido"] = 4127
print(tel)
print(tel["jack"])
del tel["sape"]
tel["irv"] = 4127
print(tel)
print(tel.keys())
print(tel.values())
"jack" in tel
# The dict() constructor builds dictionaries directly from sequences of key-value pairs:
dict([("sape", 4139), ("guido", 4127), ("jack", 4098)])
# In addition, dict comprehensions can be used to create dictionaries from arbitrary key and value expressions:
{x: x**2 for x in (2, 4, 6)}
for i, v in enumerate(["tic", "tac", "toe"]):
print(i, v)
# Modules
# If you quit from the Python interpreter and enter it again, the definitions you have made (functions and variables) are lost. Therefore, if you want to write a somewhat longer program, you are better off using a text editor to prepare the input for the interpreter and running it with that file as input instead. This is known as creating a script. As your program gets longer, you may want to split it into several files for easier maintenance. You may also want to use a handy function that you’ve written in several programs without copying its definition into each program.
# A module is a file containing Python definitions and statements. The file name is the module name with the suffix .py appended. Within a module, the module’s name (as a string) is available as the value of the global variable __name__. For instance, use your favorite text editor to create a file called fibo.py in the current directory with the following contents:
# Fibonacci numbers module
def fib(n): # write Fibonacci series up to n
a, b = 0, 1
while b < n:
print(b),
a, b = b, a + b
def fib2(n): # return Fibonacci series up to n
result = []
a, b = 0, 1
while b < n:
result.append(b)
a, b = b, a + b
return result
#
# What we need to know about functions:
# docstrings: documentation for functions. Example:
# for f():
# """This is docstring for documentation of function f"""
# tuble: sequence of immutable python objects.
# cant modify values
# tuble uses paranthesis like tuble = (1,2,3)
# unpack tuble into several variables like a,b,c = tuble
#
# How can we learn what is built in scope
import builtins
dir(builtins)
# example of what we learn above
def tuble_ex():
"""return defined t tuble"""
t = (1, 2, 3)
return t
a, b, c = tuble_ex()
print(a, b, c)
import sys
"""
The built-in function dir() is used to find out which names a
module defines. It returns a sorted list of strings:
"""
print(dir(sys))
# Input and Output
# There are several ways to present the output of a program; data can be printed in a human-readable form, or written to a file for future use. This chapter will discuss some of the possibilities.
s = "Hello world"
print(str(s))
print(repr(s))
print(str(1.0 / 7.0))
x = 10 * 3.25
y = 200 * 200
s = "The value of x is " + repr(x) + ", and y is " + repr(y) + "..."
print(s)
# Reading and Writing Files
# open() returns a file object, and is most commonly used with two arguments: open(filename, mode).
# Errors and Exceptions
# Until now error messages haven’t been more than mentioned, but if you have tried out the examples you have probably seen some. There are (at least) two distinguishable kinds of errors: syntax errors and exceptions.
# while True:print('Hello World')
# Syntax errors, also known as parsing errors, are perhaps
# he most common kind of complaint you get while you are still
# earning Python:
# It is possible to write programs that handle selected exceptions. Look at the following example, which asks the user for input until a valid integer has been entered, but allows the user to interrupt the program (using Control-C or whatever the operating system supports); note that a user-generated interruption is signalled by raising the KeyboardInterrupt exception.
# while True:
# try:
# x=int(input('Please enter a number :'))
# break
# except ValueError:
# print('Stop!')
# If an exception has an argument, it is printed as the last part (‘detail’) of the message for unhandled exceptions.
# Exception handlers don’t just handle exceptions if they occur immediately in the try clause, but also if they occur inside functions that are called (even indirectly) in the try clause. For example:
def this_fails():
x = 1 / 10
try:
this_fails()
except ZeroDivisonError as detail:
print("Handling run-time error :", detail)
# Classes
# Compared with other programming languages, Python’s class mechanism adds classes with a minimum of new syntax and semantics. It is a mixture of the class mechanisms found in C++ and Modula-3. Python classes provide all the standard features of Object Oriented Programming: the class inheritance mechanism allows multiple base classes, a derived class can override any methods of its base class or classes, and a method can call the method of a base class with the same name. Objects can contain arbitrary amounts and kinds of data. As is true for modules, classes partake of the dynamic nature of Python: they are created at runtime, and can be modified further after creation.
# Class objects support two kinds of operations: attribute references and instantiation.
# Attribute references use the standard syntax used for all attribute references in Python: obj.name. Valid attribute names are all the names that were in the class’s namespace when the class object was created. So, if the class definition looked like this:
class MyClass:
"""A simple example class"""
i = 12345
def f(self):
return "hello world"
# Class instantiation uses function notation. Just pretend that the class object is a parameterless function that returns a new instance of the class. For example (assuming the above class):
x = MyClass()
# Of course, the __init__() method may have arguments for greater flexibility. In that case, arguments given to the class instantiation operator are passed on to __init__(). For example,
class Complex:
def __init__(self, realpart, imagpart):
self.r = realpart
self.i = imagpart
x = Complex(3.0, -4.5)
print(x.i, x.r)
# Now what can we do with instance objects? The only operations understood by instance objects are attribute references. There are two kinds of valid attribute names, data attributes and methods.
# data attributes correspond to “instance variables” in Smalltalk, and to “data members” in C++. Data attributes need not be declared; like local variables, they spring into existence when they are first assigned to. For example, if x is the instance of MyClass created above, the following piece of code will print the value 16, without leaving a trace:
x.counter = 1
while x.counter < 10:
x.counter = x.counter * 2
print(x.counter)
del x.counter
# Generally speaking, instance variables are for data unique to each instance and class variables are for attributes and methods shared by all instances of the class:
class Dog:
trick = []
kind = "canine"
def __init__(self, name):
self.name = name
def add_trick(self, trick):
self.tricks.append(trick)
d = Dog("Fibo")
e = Dog("Buddy")
print(d.kind)
print(e.kind)
print(d.name)
print(e.name)
class Dog:
tricks = [] # mistaken use of a class variable
def __init__(self, name):
self.name = name
def add_trick(self, trick):
self.tricks.append(trick)
d = Dog("Fido")
e = Dog("Buddy")
d.add_trick("roll over")
e.add_trick("play dead")
d.tricks # unexpectedly shared by all dogs
["roll over", "play dead"]
# Data Preparation and Processing
# Pandas
# import pandas as pd
# Create Data
# The data set will consist of 5 baby names and the number of births recorded for that year (1880).
import pandas as pd # import library as pd
names = ["Bob", "Jessica", "Mary", "Jhon", "Mel"]
births = [968, 45, 756, 12, 65]
# To merge these two lists together we will use the zip function.
BabyDataSet = list(zip(names, births))
print(BabyDataSet)
# We are basically done creating the data set. We now will use the pandas library to export this data set into a csv file.
# df will be a DataFrame object. You can think of this object holding the contents of the BabyDataSet in a format similar to a sql table or an excel spreadsheet. Lets take a look below at the contents inside df.
df = pd.DataFrame(data=BabyDataSet, columns=["Names", "Births"])
df
# Export the dataframe to a csv file. We can name the file births1880.csv. The function to_csv will be used to export the file. The file will be saved in the same location of the notebook unless specified otherwise.
# df.to_csv('C:\\Users\\aAa\\Desktop\\Kaggle-Python-Learn\\biths.csv',index=False,header=False)
# Merge the names and the births data set using the zip function.
BabyDataSet = list(zip(names, births))
BabyDataSet[:10]
# Lets add a column
df["Year"] = 2019
# using loc accessor
df.loc[1:5, ["Names"]]
# Slicing and indexing series
df.loc[1:10, "Names":] # 10 and "Defense" are inclusive
# replaces the deprecated ix function
# df.ix[5:,'col']
df.loc[df.index[1:], "Names"]
# replaces the deprecated ix function
# df.ix[:3,['col', 'test']]
df.loc[df.index[:3], ["Names", "Year"]]
# Get Data
# To pull in the csv file, we will use the pandas function read_csv. Let us take a look at this function and what inputs it takes.
# df=pd.read_csv('C:\\Users\\aAa\\Desktop\\Kaggle-Python-Learn\\biths.csv')
df
# This brings us to the first problem of the exercise. The read_csv function treated the first record in the csv file as the header names. This is obviously not correct since the text file did not provide us with header names.
# To correct this we will pass the header parameter to the read_csv function and set it to None (means null in python).
##df=pd.read_csv('C:\\Users\\aAa\\Desktop\\Kaggle-Python-Learn\\biths.csv',header=None)
print(df)
# df=pd.read_csv('C:\\Users\\aAa\\Desktop\\Kaggle-Python-Learn\\biths.csv',names=['Name','Birth'])
print(df)
df.info()
# Info says:
# There are 999 records in the data set
# There is a column named Mary with 999 values
# There is a column named 968 with 999 values
# Out of the two columns, one is numeric, the other is non numericli>
# To actually see the contents of the dataframe we can use the head() function which by default will return the first five records. You can also pass in a number n to return the top n records of the dataframe.
df.head(4)
# Now lets take a look at the last five records of the dataframe
df.tail(4)
df.sample()
# Prepare Data
# The data we have consists of baby names and the number of births in the year 1880. We already know that we have 5 records and none of the records are missing (non-null values).
# Realize that aside from the check we did on the "Names" column, briefly looking at the data inside the dataframe should be as far as we need to go at this stage of the game. As we continue in the data analysis life cycle we will have plenty of opportunities to find any issues with the data set.
# Check data type of the columns
df.dtypes
# Check data type of births column
df.Births.dtype
# We can use the unique property of the dataframe to find all the unique records of the "Names" column.
df["Names"].unique()
# If you actually want to print the unique values:
for x in df["Names"].unique():
print(x)
print(df["Names"].describe())
# Since we have multiple values per baby name, we need to aggregate this data so we only have a baby name appear once. This means the 1,000 rows will need to become 5. We can accomplish this by using the groupby function.
# clean name column convert to upper
df["Names"] = df.Names.apply(lambda x: x.upper())
df
# clean name column convert to upper
df["Names"] = df.Names.apply(lambda x: x.lower())
df
data_filter = data.copy()
data_filter.Genres.apply(lambda x: x.strip("&")).sample(5)
name = df.groupby("Names")
df1 = name.sum()
df1
df
# Analyze Data
# To find the most popular name or the baby name with the higest birth rate, we can do one of the following.
# Sort the dataframe and select the top row
# Use the max() attribute to find the maximum value
#
sorted = df.sort_values(["Births"], ascending=False)
sorted.head(1)
df["Births"].max()
# Present Data
# Here we can plot the Births column and label the graph to show the end user the highest point on the graph. In conjunction with the table, the end user has a clear picture that Mel is the most popular baby name in the data set.
# plot() is a convinient attribute where pandas lets you painlessly plot the data in your dataframe. We learned how to find the maximum value of the Births column in the previous section. Now to find the actual baby name of the 973 value looks a bit tricky, so lets go over it.s
# NumPy
# The Basic
# NumPy’s main object is the homogeneous multidimensional array. It is a table of elements (usually numbers), all of the same type, indexed by a tuple of positive integers. In NumPy dimensions are called axes.
import numpy as np
a = np.arange(15).reshape(3, 5)
a
a.shape
a.ndim
a.dtype.name
a.itemsize
# Array Creation
# There are several ways to create arrays.
# For example, you can create an array from a regular Python list or tuple using the array function. The type of the resulting array is deduced from the type of the elements in the sequences.
a = np.array([2, 3, 4])
a
a.dtype
b = np.array([1.2, 3.5, 5.1])
b.dtype
# A frequent error consists in calling array with multiple numeric arguments, rather than providing a single list of numbers as an argument.
# a=np.array(1,2,3,4) #that's not true
a = np.array([1, 2, 3, 4]) # that's true
# array transforms sequences of sequences into two-dimensional
# arrays, sequences of sequences of sequences into three-dimensional arrays, and so on.
b = np.array([(1.5, 2, 3), (4, 5, 6)])
b
# The function zeros creates an array full of zeros, the function ones creates an array full of ones, and the function empty creates an array whose initial content is random and depends on the state of the memory. By default, the dtype of the created array is float64.
np.zeros((3, 4))
np.eye(4, 4)
eyes = np.eye(5, 5)
np.diagonal(eyes)
array = np.array([[2, 3, 4], [6, 7, 8], [10, 11, 12]])
array.T
np.ones((2, 3, 4), dtype=np.int16)
np.empty((2, 3))
# To create sequences of numbers, NumPy provides a function analogous to range that returns arrays instead of lists.
np.arange(10, 30, 5)
np.arange(-1, 1, 0.1)
np.arange(0, 2, 0.3)
# When arange is used with floating point arguments, it is generally not possible to predict the number of elements obtained, due to the finite floating point precision. For this reason, it is usually better to use the function linspace that receives as an argument the number of elements that we want, instead of the step:
np.linspace(0, 2, 9)
np.linspace(0, 2, 10)
from numpy import pi
x = np.linspace(0, 2 * pi, 100)
f = np.sin(x)
# Printing Arrays
# When you print an array, NumPy displays it in a similar way to nested lists, but with the following layout:
# the last axis is printed from left to right,
# the second-to-last is printed from top to bottom,
# the rest are also printed from top to bottom, with each slice separated from the next by an empty line.
#
a = np.arange(6) # 1d array
print(a)
b = np.arange(12).reshape(4, 3) # 2d array
print(b)
c = np.arange(24).reshape(2, 3, 4) # 3d array
print(c)
print(np.arange(10000))
print(np.arange(10000).reshape(100, 100))
# Basic Operations
# Arithmetic operators on arrays apply elementwise. A new array is created and filled with the result.
a = np.array([20, 30, 40, 50])
b = np.arange(4)
print(b)
c = a - b
print(c)
print(b**2)
print(10 * np.sin(a))
print(a < 35)
# Universal Functions
# NumPy provides familiar mathematical functions such as sin, cos, and exp. In NumPy, these are called “universal functions”(ufunc). Within NumPy, these functions operate elementwise on an array, producing an array as output.
B = np.arange(3)
print(B)
np.exp(B)
np.sqrt(B)
C = np.array([2.0, -1.0, 4.0])
np.add(B, C)
np.abs(-100)
# Indexing, Slicing and Iterating
# One-dimensional arrays can be indexed, sliced and iterated over, much like lists and other Python sequences.
a = np.arange(10) ** 3
print(a)
print(a[2])
print(a[2:5])
a[:6:2] = -1100
print(a)
# Shape Manipulation
a = np.floor(10 * np.random.random((3, 4)))
print(a)
a.shape
print(a.shape[0])
# The shape of an array can be changed with various commands. Note that the following three commands all return a modified array, but do not change the original array:
a.ravel() # returns the array,flattend
a.shape
b.T
b.T.shape
# Deep Copy
# The copy method makes a complete copy of the array and its data.
d = a.copy()
print(d)
print(d is a)
print(d.base is a)
a = np.arange(12) ** 2
i = np.array([1, 1, 3, 8, 5])
print(a[i])
j = np.array([[3, 4], [9, 7]])
print(a[j])
# Scipy
# There are two (interchangeable) ways to deal with 1-d polynomials in SciPy. The first is to use the poly1d class from Numpy. This class accepts coefficients or polynomial roots to initialize a polynomial. The polynomial object can then be manipulated in algebraic expressions, integrated, differentiated, and evaluated. It even prints like a polynomial:
from numpy import poly1d
p = poly1d([3, 4, 5])
print(p)
print(p * p)
print(p.integ(k=6))
print(p.deriv())
p([4, 5])
# The main feature of the scipy.special package is the definition of numerous special functions of mathematical physics. Available functions include airy, elliptic, bessel, gamma, beta, hypergeometric, parabolic cylinder, mathieu, spheroidal wave, struve, and kelvin. There are also some low-level stats functions that are not intended for general use as an easier interface to these functions is provided by the stats module. Most of these functions can take array arguments and return array results following the same broadcasting rules as other math functions in Numerical Python. Many of these functions also accept complex numbers as input. For a complete list of the available functions with a one-line description type >>> help(special). Each function also has its own documentation accessible using help. If you don’t see a function you need, consider writing it and contributing it to the library. You can write the function in either C, Fortran, or Python. Look in the source code of the library for examples of each of these kinds of functions.
from scipy import special
def drumhead_height(n, k, distance, angle, t):
kth_zero = special.jn_zeros(n, k)[-1]
return np.cos(t) * np.cos(n * angle) * special.jn(n, distance * kth_zero)
theta = np.r_[0 : 2 * np.pi : 50j]
radius = np.r_[0:1:50j]
x = np.array([r * np.cos(theta) for r in radius])
y = np.array([r * np.sin(theta) for r in radius])
z = np.array([drumhead_height(1, 1, r, theta, 0.5) for r in radius])
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
fig = plt.figure()
ax = Axes3D(fig)
ax.plot_surface(x, y, z, rstride=1, cstride=1, cmap=cm.jet)
ax.set_xlabel("X")
ax.set_ylabel("Y")
ax.set_zlabel("Z")
plt.show()
# FIR Filter
# The function firwin designs filters according to the window method. Depending on the provided arguments, the function returns different filter types (e.g. low-pass, band-pass…).
# The example below designs a low-pass and a band-stop filter, respectively.
import numpy as np
import scipy.signal as signal
import matplotlib.pyplot as plt
b1 = signal.firwin(40, 0.5)
b2 = signal.firwin(41, [0.3, 0.8])
w1, h1 = signal.freqz(b1)
w2, h2 = signal.freqz(b2)
plt.title("Digital filter frequency response")
plt.plot(w1, 20 * np.log10(np.abs(h1)), "b")
plt.plot(w2, 20 * np.log10(np.abs(h2)), "r")
plt.ylabel("Amplitude Response (dB)")
plt.xlabel("Frequency (rad/sample)")
plt.grid()
plt.show()
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import seaborn as sns
import matplotlib.pyplot as plt
import os
print(os.listdir("../input"))
# read_csv load data
data = pd.read_csv("../input/googleplaystore.csv")
# first 5 rows
data.head()
# last 5 rows
data.tail()
data.sample(5)
data.sample(frac=0.1)
# Can you show your data's columns?
data.columns
# so data's info
data.info()
# Empty fields within the data set
data.isnull().sum()
# It appears that the value of the rating is a little empty. We're gonna have to fill it.
from sklearn.preprocessing import Imputer
im = Imputer(missing_values="NaN", strategy="mean")
data.iloc[:, 2:3] = im.fit_transform(data.iloc[:, 2:3])
# so,We've done adding implants to the empty spaces by taking the mean.
data.isnull().sum()
data.head()
# value_counts(): Frequency counts
# outliers: the value that is considerably higher or lower from rest of the data
# Lets say value at 75% is Q3 and value at 25% is Q1.
# Outlier are smaller than Q1 - 1.5(Q3-Q1) and bigger than Q3 + 1.5(Q3-Q1). (Q3-Q1) = IQR
# We will use describe() method. Describe method includes:
# count: number of entries
# mean: average of entries
# std: standart deviation
# min: minimum entry
# 25%: first quantile
# 50%: median or second quantile
# 75%: third quantile
# max: maximum entry
# What is quantile?
# 1,4,5,6,8,9,11,12,13,14,15,16,17
# The median is the number that is in middle of the sequence. In this case it would be 11.
# The lower quartile is the median in between the smallest number and the median i.e. in between 1 and 11, which is 6.
# The upper quartile, you find the median between the median and the largest number i.e. between 11 and 17, which will be 14 according to the question above.
#
# For example lets look frequency of pokemom types
print(
data["Category"].value_counts(dropna=False)
) # if there are nan values that also be counted
# As it can be seen below there are 112 water pokemon or 70 grass pokemon
# Category Analysis
sns.barplot(
x=data["Category"].value_counts().index, y=data["Category"].value_counts().values
)
plt.xlabel("Category")
plt.ylabel("Count")
plt.title("Category Count Operation")
plt.xticks(rotation=90)
plt.show()
# It seems that the most family and game categories are traded.
fig, ax = plt.subplots()
ax.scatter(
x=data.groupby("Category")["Rating"].mean()[1:].index,
y=data.groupby("Category")["Rating"].mean()[1:].values,
)
plt.ylabel("Category", fontsize=13)
plt.xlabel("Rating", fontsize=13)
plt.xticks(rotation=90)
plt.show()
ax = sns.boxplot(x="Rating", y="Size", data=data)
plt.show()
data[data["Reviews"] == max(data.Reviews)]
# most viewed and displayed application
data[data["Reviews"] == min(data.Reviews)]
# least viewed and displayed application
# scaling and cleaning size of installation
def change_size(size):
if "M" in size:
x = size[:-1]
x = float(x) * 1000000
return x
elif "k" == size[-1:]:
x = size[:-1]
x = float(x) * 1000
return x
else:
return None
data["Size"] = data["Size"].map(change_size)
# filling Size which had NA
data.Size.fillna(method="ffill", inplace=True)
data.head()
filter_data = data[data["Size"] > int(data["Size"].mean())]
filter_data.Reviews = filter_data.Reviews.astype(float)
filter_data[filter_data["Reviews"] > 15].Type.value_counts()
sns.countplot(filter_data[filter_data["Reviews"] > 15].Type)
plt.title("Free vs Paid")
plt.show()
filter_data[(filter_data["Reviews"] > 15) & (filter_data["Type"] == "Paid")]
# The value of the type in the data we filter is analyzed for payment. For this, the total price value will be calculated.
# For this, we need to remove the $ symbol from the charge column. In addition, it is necessary to change the type of milk.
filter_data["Price"] = filter_data.Price.str.replace("$", "")
filter_data.Price = filter_data.Price.astype("float")
# Calculating the total fee
(
str(
sum(
filter_data[
(filter_data["Reviews"] > 15) & (filter_data["Type"] == "Paid")
].Price
)
)
+ " $"
)
# filter_data[(filter_data['Reviews']>15)&(filter_data['Type']=='Paid')]
df_filter = filter_data.groupby("Category")["Price"].sum()
# sum and display of paid products for the filtered area in terms of categorical
d1 = pd.DataFrame(df_filter.index, columns=["Category"])
d2 = pd.DataFrame(df_filter.values, columns=["Price"])
df_data_filter = pd.concat([d1, d2], axis=1)
df_data_filter = df_data_filter.sort_values(by="Price", ascending=False)
df_data_filter
cmap = sns.diverging_palette(220, 10, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(
data.corr(),
cmap=cmap,
vmax=0.3,
center=0,
square=True,
linewidths=0.5,
cbar_kws={"shrink": 0.5},
annot=True,
)
plt.show()
plt.figure(figsize=(5, 5))
plt.pie(
df_data_filter.Price[0:5],
labels=df_data_filter.Category[0:5],
autopct="%1.1f%%",
shadow=True,
startangle=90,
)
# ax.axis('Price') # Equal aspect ratio ensures that pie is drawn as a circle.
# plt.legend()
plt.show()
# sns.relplot(x="Rating",y="Reviews",data=data)
# plt.show()
# sns.lmplot(x="Review", y="Rating", hue="Category",data=data)
# plt.show()
data.dropna(inplace=True)
everyone = []
teen = []
everyone10 = []
mature17 = []
adults18 = []
unrates = []
everyone.append(sum(data[(data["Content Rating"] == "Everyone")].Size))
teen.append(sum(data[(data["Content Rating"] == "Teen")].Size))
mature17.append(sum(data[(data["Content Rating"] == "Mature 17+")].Size))
adults18.append(sum(data[(data["Content Rating"] == "Adults only 18+")].Size))
unrates.append(sum(data[(data["Content Rating"] == "Unrated")].Size))
everyone10.append(sum(data[(data["Content Rating"] == "Everyone 10+")].Size))
# data.groupby('Content Rating')['Size'].mean().values
plt.plot(
data["Content Rating"].unique(),
[everyone, teen, mature17, adults18, unrates, everyone10],
)
plt.xlabel("Content Rating")
plt.ylabel("Sum Of Size")
plt.xticks(rotation=90)
plt.show()
data["Content Rating"].unique()
# everyone
data.head()
len(data[data["Category"] == "FAMILY"])
sns.barplot(
x=data["Category"].unique(), y=data.groupby("Category")["Rating"].mean().values
)
plt.xticks(rotation=90)
plt.xlabel("Category")
plt.ylabel("Mean")
plt.show()
data.head()
data.Price = data.Price.str.replace("$", "")
print(max(data[data["Type"] == "Paid"].Price.values))
print(min(data[data["Type"] == "Paid"].Price.values))
paid_filter = data[data["Type"] == "Paid"]
paid_filter.Price = paid_filter.Price.astype(float)
paid_filter.Reviews = paid_filter.Reviews.astype(float)
paid_filter.groupby("Category")["Reviews"].sum().values
plt.scatter(
x=paid_filter.Category.unique(),
y=paid_filter.groupby("Category")["Reviews"].sum().values,
)
plt.xticks(rotation=90)
plt.show()
data.Genres.unique()
countplot = data.Genres.value_counts()
plt.figure(figsize=(10, 10))
sns.barplot(x=countplot.index[:50], y=countplot[:50])
plt.xticks(rotation=90)
plt.title("Count Genres of DataSet")
plt.show()
data[data["Genres"] == "Tools"].Type.value_counts().index
explode = [0, 0.1]
labels = ["Free", "Paid"]
plt.figure(figsize=(5, 5))
plt.pie(
data[data["Genres"] == "Tools"].Type.value_counts().values,
labels=data[data["Genres"] == "Tools"].Type.value_counts().index,
explode=explode,
autopct="%1.1f%%",
)
plt.title("Genres Tools Type System")
plt.show()
# Show the joint distribution using kernel density estimation
g = sns.jointplot(data.Rating, data.Reviews, kind="kde", height=7, space=0)
plt.show()
data.head()
data.Reviews = data.Reviews.astype(float)
s = paid_filter[paid_filter["Price"] == 0.99].Category.unique()
paid_filter[paid_filter["Price"] == 0.99].groupby("Category")["Rating"].mean()
plt.figure(1, figsize=(15, 7))
plt.subplot(131)
plt.bar(
paid_filter[paid_filter["Price"] == 0.99]
.groupby("Category")["Rating"]
.mean()
.index,
paid_filter[paid_filter["Price"] == 0.99]
.groupby("Category")["Rating"]
.mean()
.values,
)
plt.xticks(rotation=90)
plt.subplot(132)
plt.scatter(
paid_filter[paid_filter["Price"] == 0.99]
.groupby("Category")["Rating"]
.mean()
.index,
paid_filter[paid_filter["Price"] == 0.99]
.groupby("Category")["Rating"]
.mean()
.values,
)
plt.xticks(rotation=90)
plt.subplot(133)
plt.plot(
paid_filter[paid_filter["Price"] == 0.99]
.groupby("Category")["Rating"]
.mean()
.index,
paid_filter[paid_filter["Price"] == 0.99]
.groupby("Category")["Rating"]
.mean()
.values,
)
plt.suptitle("Categorical Plotting")
plt.xticks(rotation=90)
plt.tight_layout()
plt.show()
data.head()
# Plot miles per gallon against horsepower with other semantics
sns.relplot(
x="Rating",
y="Reviews",
hue="Type",
sizes=(40, 400),
alpha=0.5,
palette="muted",
height=6,
data=data,
)
plt.show()
g = sns.PairGrid(data, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_upper(sns.scatterplot)
g.map_diag(sns.kdeplot, lw=3)
plt.show()
ax = sns.kdeplot(data.Rating, data.Size, cmap="Blues", shade=True)
plt.show()
data.head()
data.Type = [1 if type == "Free" else 0 for type in data.Type]
data.head(2)
data.columns
col = {
"Content Rating": "ContentRating",
"Last Updated": "LastUpdated",
"Current Ver": "CurrentVer",
"Android Ver": "AndroidVer",
}
data.rename(columns=col, inplace=True)
def showColumns(data):
for i, col in enumerate(data):
print("{} . columns {}".format(i, col))
showColumns(data.columns)
data.dtypes
data.Price = data.Price.astype("float")
data.Price = [1 if price > 0 else -1 for price in data.Price]
np.mean(data.Price)
np.eye(5)
np.std(data[:5], axis=1)
np.var(data)
| false | 0 | 17,663 | 2 | 167 | 17,663 |
||
119399350 | <kaggle_start><code>import pandas as pd
import sklearn
# importing dataset
df_train = pd.read_csv("/kaggle/input/home-data-for-ml-course/train.csv")
df_test = pd.read_csv("/kaggle/input/home-data-for-ml-course/test.csv")
# to simplify calling the dataframes each time
df1 = df_train
df2 = df_test
class primitive_analysis:
def __init__(self):
print("---train dataset overview:--- \n")
print(df1.head(5))
print(df1.tail(5))
def info(self, df1, df2):
print("\n---train dataset info :---\n")
print(df1.info())
print("\n---test dataset info :---\n")
print(df2.info())
def dimensions(self, df1, df2):
print("\n---no. of dimensions [train] = ", df1.ndim)
print("---no. of dimensions [test] = ", df2.ndim)
def size(self, df1, df2):
print("\n---size of dataset [train] = ", df1.size)
print("---size of dataset [test] = ", df2.size)
def axes(self, df1, df2):
print("\n---list of the labels [train] ", df1.axes)
print("\n---list of the labels [test] ", df2.axes)
def empty(self, df1, df2):
print("is dataset empty? [train] ", df1.empty)
print("is dataset empty? [test] ", df2.empty)
obj_primitive = primitive_analysis()
obj_primitive.info(df1, df2)
obj_primitive.dimensions(df1, df2)
obj_primitive.axes(df1, df2)
obj_primitive.empty(df1, df2)
class data_cleaning:
def __init__(self):
pass
def drop_columns(self, df1, df2):
# df1["Alley"].fillna("Unknown", inplace = True)
# drop df1["Alley"] column because of 1369/1459 null values
if "Alley" in df1.columns:
df1.drop(["Alley"], axis=1, inplace=True)
# drop df1["PoolQC"] column because of 1453/1459 null values
if "PoolQC" in df1.columns:
df1.drop(["PoolQC"], axis=1, inplace=True)
# drop df1["MiscFeature"] column because of 1406/1459 null values
if "MiscFeature" in df1.columns:
df1.drop(["MiscFeature"], axis=1, inplace=True)
# drop df1["Fence"] column because of 1179/1459 null values
if "Fence" in df1.columns:
df1.drop(["Fence"], axis=1, inplace=True)
# drop df1["FireplaceQu"] column because of 690/1459 null values
if "FireplaceQu" in df1.columns:
df1.drop(["FireplaceQu"], axis=1, inplace=True)
return df1, df2
"""
df1.dropna(inplace = True)
df2.dropna(inplace = True)
return df1, df2
"""
def view_row_column_count(self, df1, df2):
# view and print the row & column count of the dataset
print(f"\n --- view the rows and column count of the dataset --- \n")
print("[train] = ", df1.shape)
print("[test] =", df2.shape)
def check_missing_values(self, df1, df2):
# check and print missing values
print(f"\n --- check missing values --- \n")
total_nulls = df1.isnull().sum()
for key, value in total_nulls.iteritems():
print(key, ",", value)
def check_duplicate(self, df1, df2):
print("\n--- Duplicate items :---\n")
duplicate = df1[df1.duplicated()]
print(duplicate)
def analyze_missing_values(self, df1, df2):
# most of them are obj except for LotFrontage / GarageYrBlt which are float
# consider best approaches to handle missing values in float and string
# float
# calculating mode for columns with missing values
LotFrontage = df1["LotFrontage"].mode()
MasVnrType = df1["MasVnrType"].mode()
MasVnrArea = df1["MasVnrArea"].mode()
BsmtQual = df1["BsmtQual"].mode()
BsmtCond = df1["BsmtCond"].mode()
BsmtExposure = df1["BsmtExposure"].mode()
BsmtFinType1 = df1["BsmtFinType1"].mode()
BsmtFinType2 = df1["BsmtFinType2"].mode()
GarageType = df1["GarageType"].mode()
GarageYrBlt = df1["GarageYrBlt"].mode()
GarageFinish = df1["GarageFinish"].mode()
GarageQual = df1["GarageQual"].mode()
GarageCond = df1["GarageCond"].mode()
"""
print("LotFrontage = ", LotFrontage) #0.351799
print("MasVnrType = ", MasVnrType)
print("MasVnrArea = ", MasVnrArea) #0.477493
print("BsmtQual = ", BsmtQual)
print("BsmtCond = ", BsmtCond)
print("BsmtExposure = ", BsmtExposure)
print("BsmtFinType1 = ", BsmtFinType1)
print("BsmtFinType2 = ", BsmtFinType2)
print("GarageType = ", GarageType)
print("GarageYrBlt = ", GarageYrBlt) #0.486362
print("GarageFinish = ", GarageFinish)
print("GarageQual = ", GarageQual)
print("GarageCond = ", GarageCond)
"""
# create new df > as one of the approaches for missing values
df1_sample1 = df1
# handling missing values in > LotFrontage , GarageYrBlt
mean_LotFrontage = df1_sample1["LotFrontage"].mean()
mean_GarageYrBlt = int(df1_sample1["GarageYrBlt"].mean())
print("mean[GarageYrBlt] = ", mean_GarageYrBlt)
print("mean[mean_LotFrontage] = ", mean_LotFrontage)
# insert mean values in > LotFrontage , GarageYrBlt
df1_sample1["LotFrontage"] = mean_LotFrontage
df1_sample1["GarageYrBlt"] = mean_GarageYrBlt
# df1_sample1 = df1_sample1.fillna(df.mean())
df1_sample1.fillna({"LotFrontage": mean_LotFrontage}, inplace=True)
# print(df1_sample1["MasVnrType"].to_string())
# corr=df1_sample1['LotFrontage'].corr(df1_sample1['SalePrice'])
# print(corr)
# print(df1_sample1)
# covariance
# print("\n--- covariance ---\n")
# print(df1.cov())
# correlation
print("\n--- correlation ---\n")
print(df1.corr())
# avg, mean,
# print(statistics.mode(df1["MasVnrType"]))
# print(MasVnrType[0] , "," , MasVnrArea[0] , "," , )
# return df1, df2
obj_cleaning = data_cleaning()
obj_cleaning.view_row_column_count(df1, df2)
obj_cleaning.check_missing_values(df1, df2)
obj_cleaning.check_duplicate(df1, df2)
df1, df2 = obj_cleaning.drop_columns(df1, df2)
# df1, df2 = obj_cleaning.fill_na_fileds(df1, df2)
# obj_cleaning.analyze_missing_values(df1, df2)
print(df1.corr())
class EDA:
def __init__(self):
# print(df1.info())
pass
def convert_obj_cols_to_numeric(self, df1, df2):
df1_sample1 = df1
# print(df1_sample1["MasVnrType"].to_string())
MSZoning_values = df1_sample1["MSZoning"].unique()
Street_values = df1_sample1["Street"].unique()
LotShape_values = df1_sample1["LotShape"].unique()
LandContour_values = df1_sample1["LandContour"].unique()
Utilities_values = df1_sample1["Utilities"].unique()
LotConfig_values = df1_sample1["LotConfig"].unique()
LandSlope_values = df1_sample1["LandSlope"].unique()
Neighborhood_values = df1_sample1["Neighborhood"].unique()
Condition1_values = df1_sample1["Condition1"].unique()
Condition2_values = df1_sample1["Condition2"].unique()
BldgType_values = df1_sample1["BldgType"].unique()
HouseStyle_values = df1_sample1["HouseStyle"].unique()
RoofStyle_values = df1_sample1["RoofStyle"].unique()
RoofMatl_values = df1_sample1["RoofMatl"].unique()
Exterior1st_values = df1_sample1["Exterior1st"].unique()
Exterior2nd_values = df1_sample1["Exterior2nd"].unique()
ExterQual_values = df1_sample1["ExterQual"].unique()
ExterCond_values = df1_sample1["ExterCond"].unique()
Foundation_values = df1_sample1["Foundation"].unique()
BsmtQual_values = df1_sample1["BsmtQual"].unique()
BsmtCond_values = df1_sample1["BsmtCond"].unique()
BsmtExposure_values = df1_sample1["BsmtExposure"].unique()
BsmtFinType1_values = df1_sample1["BsmtFinType1"].unique()
BsmtFinType2_values = df1_sample1["BsmtFinType2"].unique()
Heating_values = df1_sample1["Heating"].unique()
HeatingQC_values = df1_sample1["HeatingQC"].unique()
CentralAir_values = df1_sample1["CentralAir"].unique()
Electrical_values = df1_sample1["Electrical"].unique()
KitchenQual_values = df1_sample1["KitchenQual"].unique()
Functional_values = df1_sample1["Functional"].unique()
GarageType_values = df1_sample1["GarageType"].unique()
GarageFinish_values = df1_sample1["GarageFinish"].unique()
GarageQual_values = df1_sample1["GarageQual"].unique()
GarageCond_values = df1_sample1["GarageCond"].unique()
PavedDrive_values = df1_sample1["PavedDrive"].unique()
SaleType_values = df1_sample1["SaleType"].unique()
SaleCondition_values = df1_sample1["SaleCondition"].unique()
# create a dictionary to keep obj values as a numeric
df1_sample1["MasVnrType"] = df1_sample1["MasVnrType"].replace(
["None", "Stone", "BrkCmn", "BrkFace"], [0, 1, 2, 3]
)
df1_sample1["MSZoning"] = df1_sample1["MSZoning"].replace(
["RL", "RM", "C (all)", "FV", "RH"], [0, 1, 2, 3, 4]
)
df1_sample1["Street"] = df1_sample1["Street"].replace(["Pave", "Grvl"], [0, 1])
df1_sample1["LotShape"] = df1_sample1["LotShape"].replace(
["Reg", "IR1", "IR2", "IR3"], [0, 1, 2, 3]
)
df1_sample1["LandContour"] = df1_sample1["LandContour"].replace(
["Lvl", "Bnk", "Low", "HLS"], [0, 1, 2, 3]
)
df1_sample1["Utilities"] = df1_sample1["Utilities"].replace(
["AllPub", "NoSeWa"], [0, 1]
)
df1_sample1["LotConfig"] = df1_sample1["LotConfig"].replace(
["Inside", "FR2", "Corner", "CulDSac", "FR3"], [0, 1, 2, 3, 4]
)
df1_sample1["LandSlope"] = df1_sample1["LandSlope"].replace(
["Gtl", "Mod", "Sev"], [0, 1, 2]
)
df1_sample1["Neighborhood"] = df1_sample1["Neighborhood"].replace(
[
"CollgCr",
"Veenker",
"Crawfor",
"NoRidge",
"Mitchel",
"Somerst",
"NWAmes",
"OldTown",
"BrkSide",
"Sawyer",
"NridgHt",
"NAmes",
"SawyerW",
"IDOTRR",
"MeadowV",
"Edwards",
"Timber",
"Gilbert",
"StoneBr",
"ClearCr",
"NPkVill",
"Blmngtn",
"BrDale",
"SWISU",
"Blueste",
],
[
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
],
)
df1_sample1["Condition1"] = df1_sample1["Condition1"].replace(
["Norm", "Feedr", "PosN", "Artery", "RRAe", "RRNn", "RRAn", "PosA", "RRNe"],
[0, 1, 2, 3, 4, 5, 6, 7, 8],
)
df1_sample1["Condition2"] = df1_sample1["Condition2"].replace(
["Norm", "Artery", "RRNn", "Feedr", "PosN", "PosA", "RRAn", "RRAe"],
[0, 1, 2, 3, 4, 5, 6, 7],
)
df1_sample1["BldgType"] = df1_sample1["BldgType"].replace(
["1Fam", "2fmCon", "Duplex", "TwnhsE", "Twnhs"], [0, 1, 2, 3, 4]
)
df1_sample1["HouseStyle"] = df1_sample1["HouseStyle"].replace(
[
"2Story",
"1Story",
"1.5Fin",
"1.5Unf",
"SFoyer",
"SLvl",
"2.5Unf",
"2.5Fin",
],
[0, 1, 2, 3, 4, 5, 6, 7],
)
df1_sample1["RoofStyle"] = df1_sample1["RoofStyle"].replace(
["Gable", "Hip", "Gambrel", "Mansard", "Flat", "Shed"], [0, 1, 2, 3, 4, 5]
)
df1_sample1["RoofMatl"] = df1_sample1["RoofMatl"].replace(
[
"CompShg",
"WdShngl",
"Metal",
"WdShake",
"Membran",
"Tar&Grv",
"Roll",
"ClyTile",
],
[0, 1, 2, 3, 4, 5, 6, 7],
)
df1_sample1["Exterior1st"] = df1_sample1["Exterior1st"].replace(
[
"VinylSd",
"MetalSd",
"Wd Sdng",
"HdBoard",
"BrkFace",
"WdShing",
"CemntBd",
"Plywood",
"AsbShng",
"Stucco",
"BrkComm",
"AsphShn",
"Stone",
"ImStucc",
"CBlock",
],
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
)
df1_sample1["Exterior2nd"] = df1_sample1["Exterior2nd"].replace(
[
"VinylSd",
"MetalSd",
"Wd Shng",
"HdBoard",
"Plywood",
"Wd Sdng",
"CmentBd",
"BrkFace",
"Stucco",
"AsbShng",
"Brk Cmn",
"ImStucc",
"AsphShn",
"Stone",
"Other",
"CBlock",
],
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15],
)
# df1_sample1['ExterQual'] = df1_sample1['ExterQual'].replace(['Gd' ,'TA', 'Ex', 'Fa'], [0,1,2,3])
# df1_sample1['ExterCond'] = df1_sample1['ExterCond'].replace(['TA', 'Gd', 'Fa', 'Po', 'Ex'], [0,1,2,3,4])
# df1_sample1['Foundation'] = df1_sample1['Foundation'].replace(['PConc' ,'CBlock', 'BrkTil', 'Wood', 'Slab', 'Stone'], [0,1,2,3,4,5])
# df1_sample1['BsmtQual'] = df1_sample1['BsmtQual'].replace(['Gd' ,'TA', 'Ex','Fa'], [0,1,2,3])
# df1_sample1['BsmtQual'] = df1_sample1['BsmtQual'].replace(['Gd' ,'TA', 'Ex','Fa'], [0,1,2,3])
# df1_sample1['BsmtCond'] = df1_sample1['BsmtCond'].replace(['TA', 'Gd','Fa', 'Po'], [0,1,2,3])
# df1_sample1['BsmtExposure'] = df1_sample1['BsmtExposure'].replace(['No','Gd', 'Mn', 'Av'], [0,1,2,3])
# df1_sample1['BsmtFinType1'] = df1_sample1['BsmtFinType1'].replace(['GLQ','ALQ', 'Unf', 'Rec', 'BLQ', 'LwQ'], [0,1,2,3,4,5])
# df1_sample1['BsmtFinType2'] = df1_sample1['BsmtFinType2'].replace(['Unf' ,'BLQ','ALQ', 'Rec', 'LwQ', 'GLQ'], [0,1,2,3,4,5])
# df1_sample1['BsmtExposure'] = df1_sample1['BsmtExposure'].replace(['No','Gd', 'Mn', 'Av'], [0,1,2,3])
# df1_sample1['Heating'] = df1_sample1['Heating'].replace(['GasA', 'GasW', 'Grav', 'Wall', 'OthW', 'Floor'], [0,1,2,3,4,5])
# df1_sample1['HeatingQC'] = df1_sample1['HeatingQC'].replace(['Ex' ,'Gd', 'TA', 'Fa', 'Po'], [0,1,2,3,4])
# df1_sample1['CentralAir'] = df1_sample1['CentralAir'].replace(['Y' ,'N'], [0,1])
# df1_sample1['Electrical'] = df1_sample1['Electrical'].replace(['SBrkr', 'FuseF', 'FuseA', 'FuseP', 'Mix'], [0,1,2,3,4])
# df1_sample1['KitchenQual'] = df1_sample1['KitchenQual'].replace(['Gd', 'TA', 'Ex', 'Fa'], [0,1,2,3])
# df1_sample1['Functional'] = df1_sample1['Functional'].replace(['Typ', 'Min1', 'Maj1', 'Min2', 'Mod', 'Maj2', 'Sev'], [0,1,2,3,4,5,6])
# df1_sample1['GarageType'] = df1_sample1['GarageType'].replace(['Attchd', 'Detchd', 'BuiltIn', 'CarPort', 'Basment', '2Types'], [0,1,2,3,4,5])
# df1_sample1['GarageFinish'] = df1_sample1['GarageFinish'].replace(['RFn' ,'Unf', 'Fin'], [0,1,2])
# df1_sample1['GarageQual'] = df1_sample1['GarageQual'].replace(['TA','Fa', 'Gd','Ex', 'Po'], [0,1,2,3,4])
# df1_sample1['PavedDrive'] = df1_sample1['PavedDrive'].replace(['Y', 'N', 'P'], [0,1,2])
df1_sample1["SaleType"] = df1_sample1["SaleType"].replace(
["WD", "New", "COD", "ConLD", "ConLI", "CWD", "ConLw", "Con", "Oth"],
[0, 1, 2, 3, 4, 5, 6, 7, 8],
)
df1_sample1["SaleCondition"] = df1_sample1["SaleCondition"].replace(
["Normal", "Abnorml", "Partial", "AdjLand", "Alloca", "Family"],
[0, 1, 2, 3, 4, 5],
)
dic_columns = {
"MasVnrType": ["None", "Stone", "BrkCmn", "BrkFace"],
"MSZoning": ["RL", "RM", "C (all)", "FV", "RH"],
"Street": ["Pave", "Grvl"],
"LotShape": ["Reg", "IR1", "IR2", "IR3"],
"LandContour": ["Lvl", "Bnk", "Low", "HLS"],
"Utilities": ["AllPub", "NoSeWa"],
"LotConfig": ["Inside", "FR2", "Corner", "CulDSac", "FR3"],
"LandSlope": ["Gtl", "Mod", "Sev"],
"RoofStyle": ["Gable", "Hip", "Gambrel", "Mansard", "Flat", "Shed"],
"BsmtExposure": ["No", "Gd", "Mn", "Av"],
"GarageFinish": ["RFn", "Unf", "Fin"],
"SaleType": [
"WD",
"New",
"COD",
"ConLD",
"ConLI",
"CWD",
"ConLw",
"Con",
"Oth",
],
"SaleCondition": [
"Normal",
"Abnorml",
"Partial",
"AdjLand",
"Alloca",
"Family",
],
}
# print(df1_sample1.corr())
print(df1_sample1.corr())
def correlation(self, df1, df2):
print(df1.corr())
# [OverallQual / YearBuilt / YearRemodAdd / MasVnrArea] / BsmtFinSF1 / LotFrontage / WoodDeckSF / OpenPorchSF
obj_eda = EDA()
# obj_eda.correlation(df1, df2)
obj_eda.convert_obj_cols_to_numeric(df1, df2)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0119/399/119399350.ipynb | null | null | [{"Id": 119399350, "ScriptId": 35008370, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 13475265, "CreationDate": "02/16/2023 19:53:21", "VersionNumber": 8.0, "Title": "Housing-Prices-Competition", "EvaluationDate": "02/16/2023", "IsChange": true, "TotalLines": 312.0, "LinesInsertedFromPrevious": 27.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 285.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | import pandas as pd
import sklearn
# importing dataset
df_train = pd.read_csv("/kaggle/input/home-data-for-ml-course/train.csv")
df_test = pd.read_csv("/kaggle/input/home-data-for-ml-course/test.csv")
# to simplify calling the dataframes each time
df1 = df_train
df2 = df_test
class primitive_analysis:
def __init__(self):
print("---train dataset overview:--- \n")
print(df1.head(5))
print(df1.tail(5))
def info(self, df1, df2):
print("\n---train dataset info :---\n")
print(df1.info())
print("\n---test dataset info :---\n")
print(df2.info())
def dimensions(self, df1, df2):
print("\n---no. of dimensions [train] = ", df1.ndim)
print("---no. of dimensions [test] = ", df2.ndim)
def size(self, df1, df2):
print("\n---size of dataset [train] = ", df1.size)
print("---size of dataset [test] = ", df2.size)
def axes(self, df1, df2):
print("\n---list of the labels [train] ", df1.axes)
print("\n---list of the labels [test] ", df2.axes)
def empty(self, df1, df2):
print("is dataset empty? [train] ", df1.empty)
print("is dataset empty? [test] ", df2.empty)
obj_primitive = primitive_analysis()
obj_primitive.info(df1, df2)
obj_primitive.dimensions(df1, df2)
obj_primitive.axes(df1, df2)
obj_primitive.empty(df1, df2)
class data_cleaning:
def __init__(self):
pass
def drop_columns(self, df1, df2):
# df1["Alley"].fillna("Unknown", inplace = True)
# drop df1["Alley"] column because of 1369/1459 null values
if "Alley" in df1.columns:
df1.drop(["Alley"], axis=1, inplace=True)
# drop df1["PoolQC"] column because of 1453/1459 null values
if "PoolQC" in df1.columns:
df1.drop(["PoolQC"], axis=1, inplace=True)
# drop df1["MiscFeature"] column because of 1406/1459 null values
if "MiscFeature" in df1.columns:
df1.drop(["MiscFeature"], axis=1, inplace=True)
# drop df1["Fence"] column because of 1179/1459 null values
if "Fence" in df1.columns:
df1.drop(["Fence"], axis=1, inplace=True)
# drop df1["FireplaceQu"] column because of 690/1459 null values
if "FireplaceQu" in df1.columns:
df1.drop(["FireplaceQu"], axis=1, inplace=True)
return df1, df2
"""
df1.dropna(inplace = True)
df2.dropna(inplace = True)
return df1, df2
"""
def view_row_column_count(self, df1, df2):
# view and print the row & column count of the dataset
print(f"\n --- view the rows and column count of the dataset --- \n")
print("[train] = ", df1.shape)
print("[test] =", df2.shape)
def check_missing_values(self, df1, df2):
# check and print missing values
print(f"\n --- check missing values --- \n")
total_nulls = df1.isnull().sum()
for key, value in total_nulls.iteritems():
print(key, ",", value)
def check_duplicate(self, df1, df2):
print("\n--- Duplicate items :---\n")
duplicate = df1[df1.duplicated()]
print(duplicate)
def analyze_missing_values(self, df1, df2):
# most of them are obj except for LotFrontage / GarageYrBlt which are float
# consider best approaches to handle missing values in float and string
# float
# calculating mode for columns with missing values
LotFrontage = df1["LotFrontage"].mode()
MasVnrType = df1["MasVnrType"].mode()
MasVnrArea = df1["MasVnrArea"].mode()
BsmtQual = df1["BsmtQual"].mode()
BsmtCond = df1["BsmtCond"].mode()
BsmtExposure = df1["BsmtExposure"].mode()
BsmtFinType1 = df1["BsmtFinType1"].mode()
BsmtFinType2 = df1["BsmtFinType2"].mode()
GarageType = df1["GarageType"].mode()
GarageYrBlt = df1["GarageYrBlt"].mode()
GarageFinish = df1["GarageFinish"].mode()
GarageQual = df1["GarageQual"].mode()
GarageCond = df1["GarageCond"].mode()
"""
print("LotFrontage = ", LotFrontage) #0.351799
print("MasVnrType = ", MasVnrType)
print("MasVnrArea = ", MasVnrArea) #0.477493
print("BsmtQual = ", BsmtQual)
print("BsmtCond = ", BsmtCond)
print("BsmtExposure = ", BsmtExposure)
print("BsmtFinType1 = ", BsmtFinType1)
print("BsmtFinType2 = ", BsmtFinType2)
print("GarageType = ", GarageType)
print("GarageYrBlt = ", GarageYrBlt) #0.486362
print("GarageFinish = ", GarageFinish)
print("GarageQual = ", GarageQual)
print("GarageCond = ", GarageCond)
"""
# create new df > as one of the approaches for missing values
df1_sample1 = df1
# handling missing values in > LotFrontage , GarageYrBlt
mean_LotFrontage = df1_sample1["LotFrontage"].mean()
mean_GarageYrBlt = int(df1_sample1["GarageYrBlt"].mean())
print("mean[GarageYrBlt] = ", mean_GarageYrBlt)
print("mean[mean_LotFrontage] = ", mean_LotFrontage)
# insert mean values in > LotFrontage , GarageYrBlt
df1_sample1["LotFrontage"] = mean_LotFrontage
df1_sample1["GarageYrBlt"] = mean_GarageYrBlt
# df1_sample1 = df1_sample1.fillna(df.mean())
df1_sample1.fillna({"LotFrontage": mean_LotFrontage}, inplace=True)
# print(df1_sample1["MasVnrType"].to_string())
# corr=df1_sample1['LotFrontage'].corr(df1_sample1['SalePrice'])
# print(corr)
# print(df1_sample1)
# covariance
# print("\n--- covariance ---\n")
# print(df1.cov())
# correlation
print("\n--- correlation ---\n")
print(df1.corr())
# avg, mean,
# print(statistics.mode(df1["MasVnrType"]))
# print(MasVnrType[0] , "," , MasVnrArea[0] , "," , )
# return df1, df2
obj_cleaning = data_cleaning()
obj_cleaning.view_row_column_count(df1, df2)
obj_cleaning.check_missing_values(df1, df2)
obj_cleaning.check_duplicate(df1, df2)
df1, df2 = obj_cleaning.drop_columns(df1, df2)
# df1, df2 = obj_cleaning.fill_na_fileds(df1, df2)
# obj_cleaning.analyze_missing_values(df1, df2)
print(df1.corr())
class EDA:
def __init__(self):
# print(df1.info())
pass
def convert_obj_cols_to_numeric(self, df1, df2):
df1_sample1 = df1
# print(df1_sample1["MasVnrType"].to_string())
MSZoning_values = df1_sample1["MSZoning"].unique()
Street_values = df1_sample1["Street"].unique()
LotShape_values = df1_sample1["LotShape"].unique()
LandContour_values = df1_sample1["LandContour"].unique()
Utilities_values = df1_sample1["Utilities"].unique()
LotConfig_values = df1_sample1["LotConfig"].unique()
LandSlope_values = df1_sample1["LandSlope"].unique()
Neighborhood_values = df1_sample1["Neighborhood"].unique()
Condition1_values = df1_sample1["Condition1"].unique()
Condition2_values = df1_sample1["Condition2"].unique()
BldgType_values = df1_sample1["BldgType"].unique()
HouseStyle_values = df1_sample1["HouseStyle"].unique()
RoofStyle_values = df1_sample1["RoofStyle"].unique()
RoofMatl_values = df1_sample1["RoofMatl"].unique()
Exterior1st_values = df1_sample1["Exterior1st"].unique()
Exterior2nd_values = df1_sample1["Exterior2nd"].unique()
ExterQual_values = df1_sample1["ExterQual"].unique()
ExterCond_values = df1_sample1["ExterCond"].unique()
Foundation_values = df1_sample1["Foundation"].unique()
BsmtQual_values = df1_sample1["BsmtQual"].unique()
BsmtCond_values = df1_sample1["BsmtCond"].unique()
BsmtExposure_values = df1_sample1["BsmtExposure"].unique()
BsmtFinType1_values = df1_sample1["BsmtFinType1"].unique()
BsmtFinType2_values = df1_sample1["BsmtFinType2"].unique()
Heating_values = df1_sample1["Heating"].unique()
HeatingQC_values = df1_sample1["HeatingQC"].unique()
CentralAir_values = df1_sample1["CentralAir"].unique()
Electrical_values = df1_sample1["Electrical"].unique()
KitchenQual_values = df1_sample1["KitchenQual"].unique()
Functional_values = df1_sample1["Functional"].unique()
GarageType_values = df1_sample1["GarageType"].unique()
GarageFinish_values = df1_sample1["GarageFinish"].unique()
GarageQual_values = df1_sample1["GarageQual"].unique()
GarageCond_values = df1_sample1["GarageCond"].unique()
PavedDrive_values = df1_sample1["PavedDrive"].unique()
SaleType_values = df1_sample1["SaleType"].unique()
SaleCondition_values = df1_sample1["SaleCondition"].unique()
# create a dictionary to keep obj values as a numeric
df1_sample1["MasVnrType"] = df1_sample1["MasVnrType"].replace(
["None", "Stone", "BrkCmn", "BrkFace"], [0, 1, 2, 3]
)
df1_sample1["MSZoning"] = df1_sample1["MSZoning"].replace(
["RL", "RM", "C (all)", "FV", "RH"], [0, 1, 2, 3, 4]
)
df1_sample1["Street"] = df1_sample1["Street"].replace(["Pave", "Grvl"], [0, 1])
df1_sample1["LotShape"] = df1_sample1["LotShape"].replace(
["Reg", "IR1", "IR2", "IR3"], [0, 1, 2, 3]
)
df1_sample1["LandContour"] = df1_sample1["LandContour"].replace(
["Lvl", "Bnk", "Low", "HLS"], [0, 1, 2, 3]
)
df1_sample1["Utilities"] = df1_sample1["Utilities"].replace(
["AllPub", "NoSeWa"], [0, 1]
)
df1_sample1["LotConfig"] = df1_sample1["LotConfig"].replace(
["Inside", "FR2", "Corner", "CulDSac", "FR3"], [0, 1, 2, 3, 4]
)
df1_sample1["LandSlope"] = df1_sample1["LandSlope"].replace(
["Gtl", "Mod", "Sev"], [0, 1, 2]
)
df1_sample1["Neighborhood"] = df1_sample1["Neighborhood"].replace(
[
"CollgCr",
"Veenker",
"Crawfor",
"NoRidge",
"Mitchel",
"Somerst",
"NWAmes",
"OldTown",
"BrkSide",
"Sawyer",
"NridgHt",
"NAmes",
"SawyerW",
"IDOTRR",
"MeadowV",
"Edwards",
"Timber",
"Gilbert",
"StoneBr",
"ClearCr",
"NPkVill",
"Blmngtn",
"BrDale",
"SWISU",
"Blueste",
],
[
0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
],
)
df1_sample1["Condition1"] = df1_sample1["Condition1"].replace(
["Norm", "Feedr", "PosN", "Artery", "RRAe", "RRNn", "RRAn", "PosA", "RRNe"],
[0, 1, 2, 3, 4, 5, 6, 7, 8],
)
df1_sample1["Condition2"] = df1_sample1["Condition2"].replace(
["Norm", "Artery", "RRNn", "Feedr", "PosN", "PosA", "RRAn", "RRAe"],
[0, 1, 2, 3, 4, 5, 6, 7],
)
df1_sample1["BldgType"] = df1_sample1["BldgType"].replace(
["1Fam", "2fmCon", "Duplex", "TwnhsE", "Twnhs"], [0, 1, 2, 3, 4]
)
df1_sample1["HouseStyle"] = df1_sample1["HouseStyle"].replace(
[
"2Story",
"1Story",
"1.5Fin",
"1.5Unf",
"SFoyer",
"SLvl",
"2.5Unf",
"2.5Fin",
],
[0, 1, 2, 3, 4, 5, 6, 7],
)
df1_sample1["RoofStyle"] = df1_sample1["RoofStyle"].replace(
["Gable", "Hip", "Gambrel", "Mansard", "Flat", "Shed"], [0, 1, 2, 3, 4, 5]
)
df1_sample1["RoofMatl"] = df1_sample1["RoofMatl"].replace(
[
"CompShg",
"WdShngl",
"Metal",
"WdShake",
"Membran",
"Tar&Grv",
"Roll",
"ClyTile",
],
[0, 1, 2, 3, 4, 5, 6, 7],
)
df1_sample1["Exterior1st"] = df1_sample1["Exterior1st"].replace(
[
"VinylSd",
"MetalSd",
"Wd Sdng",
"HdBoard",
"BrkFace",
"WdShing",
"CemntBd",
"Plywood",
"AsbShng",
"Stucco",
"BrkComm",
"AsphShn",
"Stone",
"ImStucc",
"CBlock",
],
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14],
)
df1_sample1["Exterior2nd"] = df1_sample1["Exterior2nd"].replace(
[
"VinylSd",
"MetalSd",
"Wd Shng",
"HdBoard",
"Plywood",
"Wd Sdng",
"CmentBd",
"BrkFace",
"Stucco",
"AsbShng",
"Brk Cmn",
"ImStucc",
"AsphShn",
"Stone",
"Other",
"CBlock",
],
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15],
)
# df1_sample1['ExterQual'] = df1_sample1['ExterQual'].replace(['Gd' ,'TA', 'Ex', 'Fa'], [0,1,2,3])
# df1_sample1['ExterCond'] = df1_sample1['ExterCond'].replace(['TA', 'Gd', 'Fa', 'Po', 'Ex'], [0,1,2,3,4])
# df1_sample1['Foundation'] = df1_sample1['Foundation'].replace(['PConc' ,'CBlock', 'BrkTil', 'Wood', 'Slab', 'Stone'], [0,1,2,3,4,5])
# df1_sample1['BsmtQual'] = df1_sample1['BsmtQual'].replace(['Gd' ,'TA', 'Ex','Fa'], [0,1,2,3])
# df1_sample1['BsmtQual'] = df1_sample1['BsmtQual'].replace(['Gd' ,'TA', 'Ex','Fa'], [0,1,2,3])
# df1_sample1['BsmtCond'] = df1_sample1['BsmtCond'].replace(['TA', 'Gd','Fa', 'Po'], [0,1,2,3])
# df1_sample1['BsmtExposure'] = df1_sample1['BsmtExposure'].replace(['No','Gd', 'Mn', 'Av'], [0,1,2,3])
# df1_sample1['BsmtFinType1'] = df1_sample1['BsmtFinType1'].replace(['GLQ','ALQ', 'Unf', 'Rec', 'BLQ', 'LwQ'], [0,1,2,3,4,5])
# df1_sample1['BsmtFinType2'] = df1_sample1['BsmtFinType2'].replace(['Unf' ,'BLQ','ALQ', 'Rec', 'LwQ', 'GLQ'], [0,1,2,3,4,5])
# df1_sample1['BsmtExposure'] = df1_sample1['BsmtExposure'].replace(['No','Gd', 'Mn', 'Av'], [0,1,2,3])
# df1_sample1['Heating'] = df1_sample1['Heating'].replace(['GasA', 'GasW', 'Grav', 'Wall', 'OthW', 'Floor'], [0,1,2,3,4,5])
# df1_sample1['HeatingQC'] = df1_sample1['HeatingQC'].replace(['Ex' ,'Gd', 'TA', 'Fa', 'Po'], [0,1,2,3,4])
# df1_sample1['CentralAir'] = df1_sample1['CentralAir'].replace(['Y' ,'N'], [0,1])
# df1_sample1['Electrical'] = df1_sample1['Electrical'].replace(['SBrkr', 'FuseF', 'FuseA', 'FuseP', 'Mix'], [0,1,2,3,4])
# df1_sample1['KitchenQual'] = df1_sample1['KitchenQual'].replace(['Gd', 'TA', 'Ex', 'Fa'], [0,1,2,3])
# df1_sample1['Functional'] = df1_sample1['Functional'].replace(['Typ', 'Min1', 'Maj1', 'Min2', 'Mod', 'Maj2', 'Sev'], [0,1,2,3,4,5,6])
# df1_sample1['GarageType'] = df1_sample1['GarageType'].replace(['Attchd', 'Detchd', 'BuiltIn', 'CarPort', 'Basment', '2Types'], [0,1,2,3,4,5])
# df1_sample1['GarageFinish'] = df1_sample1['GarageFinish'].replace(['RFn' ,'Unf', 'Fin'], [0,1,2])
# df1_sample1['GarageQual'] = df1_sample1['GarageQual'].replace(['TA','Fa', 'Gd','Ex', 'Po'], [0,1,2,3,4])
# df1_sample1['PavedDrive'] = df1_sample1['PavedDrive'].replace(['Y', 'N', 'P'], [0,1,2])
df1_sample1["SaleType"] = df1_sample1["SaleType"].replace(
["WD", "New", "COD", "ConLD", "ConLI", "CWD", "ConLw", "Con", "Oth"],
[0, 1, 2, 3, 4, 5, 6, 7, 8],
)
df1_sample1["SaleCondition"] = df1_sample1["SaleCondition"].replace(
["Normal", "Abnorml", "Partial", "AdjLand", "Alloca", "Family"],
[0, 1, 2, 3, 4, 5],
)
dic_columns = {
"MasVnrType": ["None", "Stone", "BrkCmn", "BrkFace"],
"MSZoning": ["RL", "RM", "C (all)", "FV", "RH"],
"Street": ["Pave", "Grvl"],
"LotShape": ["Reg", "IR1", "IR2", "IR3"],
"LandContour": ["Lvl", "Bnk", "Low", "HLS"],
"Utilities": ["AllPub", "NoSeWa"],
"LotConfig": ["Inside", "FR2", "Corner", "CulDSac", "FR3"],
"LandSlope": ["Gtl", "Mod", "Sev"],
"RoofStyle": ["Gable", "Hip", "Gambrel", "Mansard", "Flat", "Shed"],
"BsmtExposure": ["No", "Gd", "Mn", "Av"],
"GarageFinish": ["RFn", "Unf", "Fin"],
"SaleType": [
"WD",
"New",
"COD",
"ConLD",
"ConLI",
"CWD",
"ConLw",
"Con",
"Oth",
],
"SaleCondition": [
"Normal",
"Abnorml",
"Partial",
"AdjLand",
"Alloca",
"Family",
],
}
# print(df1_sample1.corr())
print(df1_sample1.corr())
def correlation(self, df1, df2):
print(df1.corr())
# [OverallQual / YearBuilt / YearRemodAdd / MasVnrArea] / BsmtFinSF1 / LotFrontage / WoodDeckSF / OpenPorchSF
obj_eda = EDA()
# obj_eda.correlation(df1, df2)
obj_eda.convert_obj_cols_to_numeric(df1, df2)
| false | 0 | 5,864 | 0 | 6 | 5,864 |
||
119553423 | <kaggle_start><data_title>Large Movie review<data_name>large-movie-review
<code># Run this cell! It sets some things up for you.
import matplotlib.pyplot as plt
import os
import math
import zipfile
import time
import operator
from collections import defaultdict, Counter
plt.rcParams["figure.figsize"] = (5, 4) # set default size of plots
if not os.path.isdir("data"):
os.mkdir("data") # make the data directory
if not os.path.isdir("./checkpoints"):
os.mkdir("./checkpoints") # directory to save checkpoints
PATH_TO_DATA = "/kaggle/input/large-movie-review/large_movie_review_dataset" # path to the data directory
POS_LABEL = "pos"
NEG_LABEL = "neg"
TRAIN_DIR = os.path.join(PATH_TO_DATA, "train")
TEST_DIR = os.path.join(PATH_TO_DATA, "test")
for label in [POS_LABEL, NEG_LABEL]:
if len(os.listdir(TRAIN_DIR + "/" + label)) == 12500:
print(
"Great! You have 12500 {} reviews in {}".format(
label, TRAIN_DIR + "/" + label
)
)
else:
print("Oh no! Something is wrong. Check your code which loads the reviews")
###### PREPROCESSING BLOCK ######
###### DO NOT MODIFY THIS FUNCTION #####
def tokenize_doc(doc):
"""
Tokenize a document and return its bag-of-words representation.
doc - a string representing a document.
returns a dictionary mapping each word to the number of times it appears in doc.
"""
bow = defaultdict(float)
tokens = doc.split()
lowered_tokens = map(lambda t: t.lower(), tokens)
for token in lowered_tokens:
bow[token] += 1.0
return dict(bow)
###### END FUNCTION #####
def n_word_types(word_counts):
"""
Implement Me!
return a count of all word types in the corpus
using information from word_counts
"""
pass
def n_word_tokens(word_counts):
"""
Implement Me!
return a count of all word tokens in the corpus
using information from word_counts
"""
pass
###### NAIVE BAYES BLOCK ######
class NaiveBayes:
"""A Naive Bayes model for text classification."""
def __init__(self, path_to_data, tokenizer):
# Vocabulary is a set that stores every word seen in the training data
self.vocab = set()
self.path_to_data = path_to_data
self.tokenize_doc = tokenizer
self.train_dir = os.path.join(path_to_data, "train")
self.test_dir = os.path.join(path_to_data, "test")
# class_total_doc_counts is a dictionary that maps a class (i.e., pos/neg) to
# the number of documents in the trainning set of that class
self.class_total_doc_counts = {POS_LABEL: 0.0, NEG_LABEL: 0.0}
# class_total_word_counts is a dictionary that maps a class (i.e., pos/neg) to
# the number of words in the training set in documents of that class
self.class_total_word_counts = {POS_LABEL: 0.0, NEG_LABEL: 0.0}
# class_word_counts is a dictionary of dictionaries. It maps a class (i.e.,
# pos/neg) to a dictionary of word counts. For example:
# self.class_word_counts[POS_LABEL]['awesome']
# stores the number of times the word 'awesome' appears in documents
# of the positive class in the training documents.
self.class_word_counts = {
POS_LABEL: defaultdict(float),
NEG_LABEL: defaultdict(float),
}
def train_model(self):
"""
This function processes the entire training set using the global PATH
variable above. It makes use of the tokenize_doc and update_model
functions you will implement.
"""
pos_path = os.path.join(self.train_dir, POS_LABEL)
neg_path = os.path.join(self.train_dir, NEG_LABEL)
for p, label in [(pos_path, POS_LABEL), (neg_path, NEG_LABEL)]:
for f in os.listdir(p):
with open(os.path.join(p, f), "r") as doc:
content = doc.read()
self.tokenize_and_update_model(content, label)
self.report_statistics_after_training()
def report_statistics_after_training(self):
"""
Report a number of statistics after training.
"""
print("REPORTING CORPUS STATISTICS")
print(
"NUMBER OF DOCUMENTS IN POSITIVE CLASS:",
self.class_total_doc_counts[POS_LABEL],
)
print(
"NUMBER OF DOCUMENTS IN NEGATIVE CLASS:",
self.class_total_doc_counts[NEG_LABEL],
)
print(
"NUMBER OF TOKENS IN POSITIVE CLASS:",
self.class_total_word_counts[POS_LABEL],
)
print(
"NUMBER OF TOKENS IN NEGATIVE CLASS:",
self.class_total_word_counts[NEG_LABEL],
)
print(
"VOCABULARY SIZE: NUMBER OF UNIQUE WORDTYPES IN TRAINING CORPUS:",
len(self.vocab),
)
def update_model(self, bow, label):
"""
IMPLEMENT ME!
Update internal statistics given a document represented as a bag-of-words
bow - a map from words to their counts
label - the class of the document whose bag-of-words representation was input
This function doesn't return anything but should update a number of internal
statistics. Specifically, it updates:
- the internal map the counts, per class, how many times each word was
seen (self.class_word_counts)
- the number of words seen for each label (self.class_total_word_counts)
- the vocabulary seen so far (self.vocab)
- the number of documents seen of each label (self.class_total_doc_counts)
"""
pass
def tokenize_and_update_model(self, doc, label):
"""
Implement me!
Tokenizes a document doc and updates internal count statistics.
doc - a string representing a document.
label - the sentiment of the document (either postive or negative)
stop_word - a boolean flag indicating whether to stop word or not
Make sure when tokenizing to lower case all of the tokens!
"""
pass
def top_n(self, label, n):
"""
Implement me!
Returns the most frequent n tokens for documents with class 'label'.
"""
pass
def p_word_given_label(self, word, label):
"""
Implement me!
Returns the probability of word given label
according to this NB model.
"""
pass
def p_word_given_label_and_alpha(self, word, label, alpha):
"""
Implement me!
Returns the probability of word given label wrt psuedo counts.
alpha - pseudocount parameter
"""
pass
def log_likelihood(self, bow, label, alpha):
"""
Implement me!
Computes the log likelihood of a set of words given a label and pseudocount.
bow - a bag of words (i.e., a tokenized document)
label - either the positive or negative label
alpha - float; pseudocount parameter
"""
pass
def log_prior(self, label):
"""
Implement me!
Returns the log prior of a document having the class 'label'.
"""
pass
def unnormalized_log_posterior(self, bow, label, alpha):
"""
Implement me!
Computes the unnormalized log posterior (of doc being of class 'label').
bow - a bag of words (i.e., a tokenized document)
"""
pass
def classify(self, bow, alpha):
"""
Implement me!
Compares the unnormalized log posterior for doc for both the positive
and negative classes and returns the either POS_LABEL or NEG_LABEL
(depending on which resulted in the higher unnormalized log posterior)
bow - a bag of words (i.e., a tokenized document)
"""
pass
def likelihood_ratio(self, word, alpha):
"""
Implement me!
Returns the ratio of P(word|pos) to P(word|neg).
"""
pass
def evaluate_classifier_accuracy(self, alpha):
"""
DO NOT MODIFY THIS FUNCTION
alpha - pseudocount parameter.
This function should go through the test data, classify each instance and
compute the accuracy of the classifier (the fraction of classifications
the classifier gets right.
"""
correct = 0.0
total = 0.0
pos_path = os.path.join(self.test_dir, POS_LABEL)
neg_path = os.path.join(self.test_dir, NEG_LABEL)
for p, label in [(pos_path, POS_LABEL), (neg_path, NEG_LABEL)]:
for f in os.listdir(p):
with open(os.path.join(p, f), "r") as doc:
content = doc.read()
bow = self.tokenize_doc(content)
if self.classify(bow, alpha) == label:
correct += 1.0
total += 1.0
return 100 * correct / total
# ### Question 1.1 (5 points)
# Complete the cell below to fill out the `word_counts` dictionary variable. `word_counts` keeps track of how many times a word type appears across the corpus. For instance, `word_counts["movie"]` should store the number 61492, the count of how many times the word `movie` appears in the corpus.
import glob
import codecs
word_counts = Counter() # Counters are often useful for NLP in python
for label in [POS_LABEL, NEG_LABEL]:
for directory in [TRAIN_DIR, TEST_DIR]:
for fn in glob.glob(directory + "/" + label + "/*txt"):
doc = codecs.open(fn, "r", "utf8") # Open the file with UTF-8 encoding
# IMPLEMENT ME
pass
if word_counts["movie"] == 61492:
print(
"yay! there are {} total instances of the word type movie in the corpus".format(
word_counts["movie"]
)
)
else:
print("hmm. Something seems off. Double check your code")
# ### Question 1.2 (5 points)
# Fill out the functions `n_word_types`, `n_word_tokens` in the [Preprocessing Block](#Preprocessing-Block).
# ***Note: you will have to rerun the `Preprocessing Block` cell every time you change its code for it to have any effect!***
print("there are {} word types in the corpus".format(n_word_types(word_counts)))
print("there are {} word tokens in the corpus".format(n_word_tokens(word_counts)))
# What is the difference between word types and tokens? Why are the number of tokens much higher than the number of types?
# ***Answer in one or two lines here.***
# ### Question 1.3 (5 points)
# Using the `word_counts` dictionary you just created, make a new dictionary called `sorted_dict` where the words are sorted according to their counts, in decending order:
sorted_dict = dict(sorted(word_counts.items(), key=lambda item: item[1], reverse=True))
# Now print the first 30 values from sorted_dict.
for i, (word, count) in enumerate(sorted_dict.items()):
if i < 30:
print(f"{word}: {count}")
else:
break
# ## Zipf's Law
# ### Question 1.4 (10 points)
# In this section, you will verify a key statistical property of text: [Zipf's Law](https://en.wikipedia.org/wiki/Zipf%27s_law).
# Zipf's Law describes the relations between the frequency rank of words and frequency value of words. For a word $w$, its frequency is inversely proportional to its rank:
# $$count_w = K \frac{1}{rank_w}$$
# $K$ is a constant, specific to the corpus and how words are being defined.
# What would this look like if you took the log of both sides of the equation?
# ***Answer in one or two lines here.***
# The log of word frequency and log of word rank have a linear connection when we take the log of both sides of the equation, giving us log(count w) = log(K) - log(rank w).
# Therefore, if Zipf's Law holds, after sorting the words descending on frequency, word frequency decreases in an approximately linear fashion under a log-log scale.
# Now, please make such a log-log plot by plotting the rank versus frequency
# *Hint: Make use of the sorted dictionary you just created.*
# Use a scatter plot where the x-axis is the *log(rank)*, and y-axis is *log(frequency)*. You should get this information from `word_counts`; for example, you can take the individual word counts and sort them. dict methods `.items()` and/or `values()` may be useful. (Note that it doesn't really matter whether ranks start at 1 or 0 in terms of how the plot comes out.) You can check your results by comparing your plots to ones on Wikipedia; they should look qualitatively similar.
# *Please remember to label the meaning of the x-axis and y-axis.*
import math
import operator
x = []
y = []
X_LABEL = "log(rank)"
Y_LABEL = "log(frequency)"
# Add your code here
# You should fill the x and y arrays.
# Running this cell should produce your plot below.
plt.scatter(x, y)
plt.xlabel(X_LABEL)
plt.ylabel(Y_LABEL)
# # Part Two: Naive Bayes
# This section of the homework will walk you through coding a Naive Bayes classifier that can distinguish between positive and negative reviews (with some level of accuracy).
# ## Question 2.1 (10 pts)
# To start, implement the `update_model` and `tokenize_and_update_model` functions in the [Naive Bayes Block](#Naive-Bayes-Block). Make sure to read the functions' comments so you know what to update. Also review the `NaiveBayes` class variables in the `def __init__` method of the `NaiveBayes class` to get a sense of which statistics are important to keep track of. Once you have implemented `update_model`, run the train model function using the code below.
nb = NaiveBayes(PATH_TO_DATA, tokenizer=tokenize_doc)
nb.train_model()
if len(nb.vocab) == 251637:
print("Great! The vocabulary size is {}".format(251637))
else:
print(
"Oh no! Something seems off. Double check your code before continuing. Maybe a mistake in update_model?"
)
# ## Exploratory analysis
# Let’s begin to explore the count statistics stored by the update model function. Implement the provided `top_n` function in the [Naive Bayes Block](#Naive-Bayes-Block) to find the top 10 most common words in the positive class and top 10 most common words in the negative class.
print("TOP 10 WORDS FOR CLASS " + POS_LABEL + ":")
for tok, count in nb.top_n(POS_LABEL, 10):
print("", tok, count)
print()
print("TOP 10 WORDS FOR CLASS " + NEG_LABEL + ":")
for tok, count in nb.top_n(NEG_LABEL, 10):
print("", tok, count)
print()
# ### Question 2.2 (5 points)
# What is the first thing that you notice when you look at the top 10 words for the 2 classes? Are these words helpful for discriminating between the two classes? Do you imagine that processing other English text will result in a similar phenomenon? What about other languages?
# ***Answer in one or two lines here.***
# The top words for both classes are stop words, which make it difficult to distinguish between the two classes. This is the first thing to note. Both favorable and bad evaluations may have a lot of these exclamation points. It's likely that reading other English work would cause a similar occurrence, although it may depend on the text's particular subject matter or genre. Depending on the syntax and vocabulary of the respective language, the top words in other languages may also vary.
# ### Question 2.3 (5 points)
# The Naive Bayes model assumes that all features are conditionally independent given the class label. For our purposes, this means that the probability of seeing a particular word in a document with class label $y$ is independent of the rest of the words in that document. Implement the `p_word_given_label` function in the [Naive Bayes Block](#Naive-Bayes-Block). This function calculates P (w|y) (i.e., the probability of seeing word w in a document given the label of that document is y).
# Use your `p_word_given_label` function to compute the probability of seeing the word “amazing” given each sentiment label. Repeat the computation for the word “dull.”
print("P('amazing'|pos):", nb.p_word_given_label("amazing", POS_LABEL))
print("P('amazing'|neg):", nb.p_word_given_label("amazing", NEG_LABEL))
print("P('dull'|pos):", nb.p_word_given_label("dull", POS_LABEL))
print("P('dull'|neg):", nb.p_word_given_label("dull", NEG_LABEL))
# Which word has a higher probability, given the positive class? Which word has a higher probability, given the negative class? Is this behavior expected?
# ***Answer in one or two lines here.***
# ### Question 2.4 (5 points)
# In the next cell, compute the probability of the word "car-thievery" in the positive training data and negative training data.
print("P('car-thievery'|pos):", nb.p_word_given_label("car-thievery", POS_LABEL))
print("P('car-thievery'|neg):", nb.p_word_given_label("car-thievery", NEG_LABEL))
# What is unusual about P('car-thievery'|neg)? What would happen if we took the log of "P('car-thievery'|neg)"? What would happen if we multiplied "P('car-thievery'|neg)" by "P('dull'|neg)"? Why might these operations cause problems for a Naive Bayes classifier?
# ***Answer in one or two lines here.***
# ### Question 2.5 (5 points)
# We can address the issues from question 2.4 with add-$\alpha$ smoothing (like add-1 smoothing except instead of adding 1 we add $\alpha$). Implement
# `p_word_given_label_and_alpha` in the [Naive Bayes Block](#Naive-Bayes-Block) and then run the next cell.
# **Hint:** look at the slides from the lecture on add-1 smoothing.
print(
"P('stop-sign.'|pos):",
nb.p_word_given_label_and_alpha("stop-sign.", POS_LABEL, 0.2),
)
# ### Question 2.6 (5 points)
# *Prior and Likelihood*
# As noted before, the Naive Bayes model assumes that all words in a document are independent of one another given the document’s label. Because of this we can write the likelihood of a document as:
# $P(w_{d1},\cdots,w_{dn}|y_d) = \prod_{i=1}^{n}P(w_{di}|y_d)$
# However, if a document has a lot of words, the likelihood will become extremely small and we’ll encounter numerical underflow. Underflow is a common problem when dealing with probabilistic models; if you are unfamiliar with it, you can get a brief overview on [Wikipedia](https:/en.wikipedia.org/wiki/Arithmetic_underflow). To deal with underflow, a common transformation is to work in log-space.
# $\log[P(w_{d1},\cdots,w_{dn}|y_d)] = \sum_{i=1}^{n}\log[P(w_{di}|y_d)]$
# Implement the `log_likelihood` function in the [Naive Bayes Block](#Naive-Bayes-Block). **Hint:** it should make calls to the p word given label and alpha function.
# Implement the `log_prior` function in the [Naive Bayes Block](#Naive-Bayes-Block). This function takes a class label and returns the log of the fraction of the training documents that are of that label.
# ### Question 2.7 (5 points)
# Naive Bayes is a model that tells us how to compute the posterior
# probability of a document being of some label (i.e.,
# $P(y_d|\mathbf{w_d})$). Specifically, we do so using bayes rule:
# $P(y_d|\mathbf{w_d}) = \frac{P(y_d)P(\mathbf{w_d}|y_d)}{P(\mathbf{w_d})}$
# In the previous section you implemented functions to compute both
# the log prior ($\log[P(y_d)]$) and the log likelihood
# ($\log[P( \mathbf{w_d} |y_d)]$ ). Now, all you're missing is the
# *normalizer*, $P(\mathbf{w_d})$.
# Derive the normalizer by expanding $P(\mathbf{w_d})$.
# ***Answer in one or two lines here. Provide the formula and define each term in this formula.***
# ### Question 2.8 (5 points)
# One way to classify a document is to compute the unnormalized log posterior for both labels and take the argmax (i.e., the label that yields the higher unnormalized log posterior). The unnormalized log posterior is the sum of the log prior and the log likelihood of the document. Why don’t we need to compute the log normalizer here?
# ***Answer in one or two lines here.***
# ### Question 2.9 (10 points)
# As we saw earlier, the top 10 words from each class do not give us much to go on when classifying a document. A much more powerful metric is the likelihood ratio, which is defined as
# $LR(w)=\frac{P(w|y=\mathrm{pos})}{P(w|y=\mathrm{neg})}$
# A word with LR 3 is 3 times more likely to appear in the positive class than in the negative. A word with LR 0.3 is one-third as likely to appear in the positive class as opposed to the negative class.
# Implement the nb.likelihod_ratio function and use it to investigate the likelihood ratio of "amazing" and "dull"
print("LIKELIHOOD RATIO OF 'amazing':", nb.likelihood_ratio("amazing", 0.2))
print("LIKELIHOOD RATIO OF 'dull':", nb.likelihood_ratio("dull", 0.2))
print("LIKELIHOOD RATIO OF 'and':", nb.likelihood_ratio("and", 0.2))
print("LIKELIHOOD RATIO OF 'to':", nb.likelihood_ratio("to", 0.2))
# What is the minimum and maximum possible values the likelihood ratio can take? Does it make sense that $LR('amazing') > LR('to')$?
# ***Answer in one or two lines here.***
# Find the word in the vocabulary with the highest liklihood ratio below.
# Add your code here
# ### Question 2.10 (5 points)
# The unnormalized log posterior is the sum of the log prior and the log likelihood of the document. Implement the `unnormalized_log_posterior` function and the `classify` function in the [Naive Bayes Block](#Naive-Bayes-Block). The `classify` function should use the unnormalized log posteriors but should not compute the normalizer. Once you implement the `classify` function, we'd like to evaluate its accuracy.
print(nb.evaluate_classifier_accuracy(0.2))
# ### Question 2.11 (5 points)
# Try evaluating your model again with a smoothing parameter of 1000.
print(nb.evaluate_classifier_accuracy(1000.0))
# Does the accuracy go up or down when alpha is raised to 1000? Why do you think this is?
# ***Answer in one or two lines here.***
# ### Question 2.12 (5 points)
# Find a review that your classifier got wrong.
# In this cell, print out a review your classifier got wrong, along with its label.
# What are two reasons your system might have misclassified this example? What improvements could you make that may help your system classify this example correctly?
# ***Answer in one or two lines here.***
# ### Question 2.13 (5 points)
# Often times we care about multi-class classification rather than binary classification.
# How many counts would we need to keep track of if the model were modified to support 5-class classification?
# ***Answer in one or two lines here.***
#
# Use your own code or an external library such as nltk to perform tokenization,
# text normalization, word filtering, etc.
# Fill out your work in def tokenize_doc_and_more (below) and then show improvement by
# running the cells below.
def tokenize_doc_and_more(doc):
"""
Return some representation of a document.
At a minimum, you need to perform tokenization, the rest is up to you.
"""
# Implement me!
bow = defaultdict(float)
# your code goes here
return bow
nb = NaiveBayes(PATH_TO_DATA, tokenizer=tokenize_doc_and_more)
nb.train_model()
nb.evaluate_classifier_accuracy(1.0)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0119/553/119553423.ipynb | large-movie-review | kazimushfiqrafid | [{"Id": 119553423, "ScriptId": 35192466, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 7676061, "CreationDate": "02/18/2023 12:39:05", "VersionNumber": 1.0, "Title": "This one", "EvaluationDate": "02/18/2023", "IsChange": true, "TotalLines": 554.0, "LinesInsertedFromPrevious": 554.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 169373332, "KernelVersionId": 119553423, "SourceDatasetVersionId": 5019693}] | [{"Id": 5019693, "DatasetId": 2912825, "DatasourceVersionId": 5089756, "CreatorUserId": 7676061, "LicenseName": "Unknown", "CreationDate": "02/18/2023 08:51:26", "VersionNumber": 1.0, "Title": "Large Movie review", "Slug": "large-movie-review", "Subtitle": NaN, "Description": NaN, "VersionNotes": "Initial release", "TotalCompressedBytes": 0.0, "TotalUncompressedBytes": 0.0}] | [{"Id": 2912825, "CreatorUserId": 7676061, "OwnerUserId": 7676061.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 5019693.0, "CurrentDatasourceVersionId": 5089756.0, "ForumId": 2950169, "Type": 2, "CreationDate": "02/18/2023 08:51:26", "LastActivityDate": "02/18/2023", "TotalViews": 124, "TotalDownloads": 3, "TotalVotes": 0, "TotalKernels": 0}] | [{"Id": 7676061, "UserName": "kazimushfiqrafid", "DisplayName": "Kazi Mushfiq Rafid", "RegisterDate": "06/14/2021", "PerformanceTier": 0}] | # Run this cell! It sets some things up for you.
import matplotlib.pyplot as plt
import os
import math
import zipfile
import time
import operator
from collections import defaultdict, Counter
plt.rcParams["figure.figsize"] = (5, 4) # set default size of plots
if not os.path.isdir("data"):
os.mkdir("data") # make the data directory
if not os.path.isdir("./checkpoints"):
os.mkdir("./checkpoints") # directory to save checkpoints
PATH_TO_DATA = "/kaggle/input/large-movie-review/large_movie_review_dataset" # path to the data directory
POS_LABEL = "pos"
NEG_LABEL = "neg"
TRAIN_DIR = os.path.join(PATH_TO_DATA, "train")
TEST_DIR = os.path.join(PATH_TO_DATA, "test")
for label in [POS_LABEL, NEG_LABEL]:
if len(os.listdir(TRAIN_DIR + "/" + label)) == 12500:
print(
"Great! You have 12500 {} reviews in {}".format(
label, TRAIN_DIR + "/" + label
)
)
else:
print("Oh no! Something is wrong. Check your code which loads the reviews")
###### PREPROCESSING BLOCK ######
###### DO NOT MODIFY THIS FUNCTION #####
def tokenize_doc(doc):
"""
Tokenize a document and return its bag-of-words representation.
doc - a string representing a document.
returns a dictionary mapping each word to the number of times it appears in doc.
"""
bow = defaultdict(float)
tokens = doc.split()
lowered_tokens = map(lambda t: t.lower(), tokens)
for token in lowered_tokens:
bow[token] += 1.0
return dict(bow)
###### END FUNCTION #####
def n_word_types(word_counts):
"""
Implement Me!
return a count of all word types in the corpus
using information from word_counts
"""
pass
def n_word_tokens(word_counts):
"""
Implement Me!
return a count of all word tokens in the corpus
using information from word_counts
"""
pass
###### NAIVE BAYES BLOCK ######
class NaiveBayes:
"""A Naive Bayes model for text classification."""
def __init__(self, path_to_data, tokenizer):
# Vocabulary is a set that stores every word seen in the training data
self.vocab = set()
self.path_to_data = path_to_data
self.tokenize_doc = tokenizer
self.train_dir = os.path.join(path_to_data, "train")
self.test_dir = os.path.join(path_to_data, "test")
# class_total_doc_counts is a dictionary that maps a class (i.e., pos/neg) to
# the number of documents in the trainning set of that class
self.class_total_doc_counts = {POS_LABEL: 0.0, NEG_LABEL: 0.0}
# class_total_word_counts is a dictionary that maps a class (i.e., pos/neg) to
# the number of words in the training set in documents of that class
self.class_total_word_counts = {POS_LABEL: 0.0, NEG_LABEL: 0.0}
# class_word_counts is a dictionary of dictionaries. It maps a class (i.e.,
# pos/neg) to a dictionary of word counts. For example:
# self.class_word_counts[POS_LABEL]['awesome']
# stores the number of times the word 'awesome' appears in documents
# of the positive class in the training documents.
self.class_word_counts = {
POS_LABEL: defaultdict(float),
NEG_LABEL: defaultdict(float),
}
def train_model(self):
"""
This function processes the entire training set using the global PATH
variable above. It makes use of the tokenize_doc and update_model
functions you will implement.
"""
pos_path = os.path.join(self.train_dir, POS_LABEL)
neg_path = os.path.join(self.train_dir, NEG_LABEL)
for p, label in [(pos_path, POS_LABEL), (neg_path, NEG_LABEL)]:
for f in os.listdir(p):
with open(os.path.join(p, f), "r") as doc:
content = doc.read()
self.tokenize_and_update_model(content, label)
self.report_statistics_after_training()
def report_statistics_after_training(self):
"""
Report a number of statistics after training.
"""
print("REPORTING CORPUS STATISTICS")
print(
"NUMBER OF DOCUMENTS IN POSITIVE CLASS:",
self.class_total_doc_counts[POS_LABEL],
)
print(
"NUMBER OF DOCUMENTS IN NEGATIVE CLASS:",
self.class_total_doc_counts[NEG_LABEL],
)
print(
"NUMBER OF TOKENS IN POSITIVE CLASS:",
self.class_total_word_counts[POS_LABEL],
)
print(
"NUMBER OF TOKENS IN NEGATIVE CLASS:",
self.class_total_word_counts[NEG_LABEL],
)
print(
"VOCABULARY SIZE: NUMBER OF UNIQUE WORDTYPES IN TRAINING CORPUS:",
len(self.vocab),
)
def update_model(self, bow, label):
"""
IMPLEMENT ME!
Update internal statistics given a document represented as a bag-of-words
bow - a map from words to their counts
label - the class of the document whose bag-of-words representation was input
This function doesn't return anything but should update a number of internal
statistics. Specifically, it updates:
- the internal map the counts, per class, how many times each word was
seen (self.class_word_counts)
- the number of words seen for each label (self.class_total_word_counts)
- the vocabulary seen so far (self.vocab)
- the number of documents seen of each label (self.class_total_doc_counts)
"""
pass
def tokenize_and_update_model(self, doc, label):
"""
Implement me!
Tokenizes a document doc and updates internal count statistics.
doc - a string representing a document.
label - the sentiment of the document (either postive or negative)
stop_word - a boolean flag indicating whether to stop word or not
Make sure when tokenizing to lower case all of the tokens!
"""
pass
def top_n(self, label, n):
"""
Implement me!
Returns the most frequent n tokens for documents with class 'label'.
"""
pass
def p_word_given_label(self, word, label):
"""
Implement me!
Returns the probability of word given label
according to this NB model.
"""
pass
def p_word_given_label_and_alpha(self, word, label, alpha):
"""
Implement me!
Returns the probability of word given label wrt psuedo counts.
alpha - pseudocount parameter
"""
pass
def log_likelihood(self, bow, label, alpha):
"""
Implement me!
Computes the log likelihood of a set of words given a label and pseudocount.
bow - a bag of words (i.e., a tokenized document)
label - either the positive or negative label
alpha - float; pseudocount parameter
"""
pass
def log_prior(self, label):
"""
Implement me!
Returns the log prior of a document having the class 'label'.
"""
pass
def unnormalized_log_posterior(self, bow, label, alpha):
"""
Implement me!
Computes the unnormalized log posterior (of doc being of class 'label').
bow - a bag of words (i.e., a tokenized document)
"""
pass
def classify(self, bow, alpha):
"""
Implement me!
Compares the unnormalized log posterior for doc for both the positive
and negative classes and returns the either POS_LABEL or NEG_LABEL
(depending on which resulted in the higher unnormalized log posterior)
bow - a bag of words (i.e., a tokenized document)
"""
pass
def likelihood_ratio(self, word, alpha):
"""
Implement me!
Returns the ratio of P(word|pos) to P(word|neg).
"""
pass
def evaluate_classifier_accuracy(self, alpha):
"""
DO NOT MODIFY THIS FUNCTION
alpha - pseudocount parameter.
This function should go through the test data, classify each instance and
compute the accuracy of the classifier (the fraction of classifications
the classifier gets right.
"""
correct = 0.0
total = 0.0
pos_path = os.path.join(self.test_dir, POS_LABEL)
neg_path = os.path.join(self.test_dir, NEG_LABEL)
for p, label in [(pos_path, POS_LABEL), (neg_path, NEG_LABEL)]:
for f in os.listdir(p):
with open(os.path.join(p, f), "r") as doc:
content = doc.read()
bow = self.tokenize_doc(content)
if self.classify(bow, alpha) == label:
correct += 1.0
total += 1.0
return 100 * correct / total
# ### Question 1.1 (5 points)
# Complete the cell below to fill out the `word_counts` dictionary variable. `word_counts` keeps track of how many times a word type appears across the corpus. For instance, `word_counts["movie"]` should store the number 61492, the count of how many times the word `movie` appears in the corpus.
import glob
import codecs
word_counts = Counter() # Counters are often useful for NLP in python
for label in [POS_LABEL, NEG_LABEL]:
for directory in [TRAIN_DIR, TEST_DIR]:
for fn in glob.glob(directory + "/" + label + "/*txt"):
doc = codecs.open(fn, "r", "utf8") # Open the file with UTF-8 encoding
# IMPLEMENT ME
pass
if word_counts["movie"] == 61492:
print(
"yay! there are {} total instances of the word type movie in the corpus".format(
word_counts["movie"]
)
)
else:
print("hmm. Something seems off. Double check your code")
# ### Question 1.2 (5 points)
# Fill out the functions `n_word_types`, `n_word_tokens` in the [Preprocessing Block](#Preprocessing-Block).
# ***Note: you will have to rerun the `Preprocessing Block` cell every time you change its code for it to have any effect!***
print("there are {} word types in the corpus".format(n_word_types(word_counts)))
print("there are {} word tokens in the corpus".format(n_word_tokens(word_counts)))
# What is the difference between word types and tokens? Why are the number of tokens much higher than the number of types?
# ***Answer in one or two lines here.***
# ### Question 1.3 (5 points)
# Using the `word_counts` dictionary you just created, make a new dictionary called `sorted_dict` where the words are sorted according to their counts, in decending order:
sorted_dict = dict(sorted(word_counts.items(), key=lambda item: item[1], reverse=True))
# Now print the first 30 values from sorted_dict.
for i, (word, count) in enumerate(sorted_dict.items()):
if i < 30:
print(f"{word}: {count}")
else:
break
# ## Zipf's Law
# ### Question 1.4 (10 points)
# In this section, you will verify a key statistical property of text: [Zipf's Law](https://en.wikipedia.org/wiki/Zipf%27s_law).
# Zipf's Law describes the relations between the frequency rank of words and frequency value of words. For a word $w$, its frequency is inversely proportional to its rank:
# $$count_w = K \frac{1}{rank_w}$$
# $K$ is a constant, specific to the corpus and how words are being defined.
# What would this look like if you took the log of both sides of the equation?
# ***Answer in one or two lines here.***
# The log of word frequency and log of word rank have a linear connection when we take the log of both sides of the equation, giving us log(count w) = log(K) - log(rank w).
# Therefore, if Zipf's Law holds, after sorting the words descending on frequency, word frequency decreases in an approximately linear fashion under a log-log scale.
# Now, please make such a log-log plot by plotting the rank versus frequency
# *Hint: Make use of the sorted dictionary you just created.*
# Use a scatter plot where the x-axis is the *log(rank)*, and y-axis is *log(frequency)*. You should get this information from `word_counts`; for example, you can take the individual word counts and sort them. dict methods `.items()` and/or `values()` may be useful. (Note that it doesn't really matter whether ranks start at 1 or 0 in terms of how the plot comes out.) You can check your results by comparing your plots to ones on Wikipedia; they should look qualitatively similar.
# *Please remember to label the meaning of the x-axis and y-axis.*
import math
import operator
x = []
y = []
X_LABEL = "log(rank)"
Y_LABEL = "log(frequency)"
# Add your code here
# You should fill the x and y arrays.
# Running this cell should produce your plot below.
plt.scatter(x, y)
plt.xlabel(X_LABEL)
plt.ylabel(Y_LABEL)
# # Part Two: Naive Bayes
# This section of the homework will walk you through coding a Naive Bayes classifier that can distinguish between positive and negative reviews (with some level of accuracy).
# ## Question 2.1 (10 pts)
# To start, implement the `update_model` and `tokenize_and_update_model` functions in the [Naive Bayes Block](#Naive-Bayes-Block). Make sure to read the functions' comments so you know what to update. Also review the `NaiveBayes` class variables in the `def __init__` method of the `NaiveBayes class` to get a sense of which statistics are important to keep track of. Once you have implemented `update_model`, run the train model function using the code below.
nb = NaiveBayes(PATH_TO_DATA, tokenizer=tokenize_doc)
nb.train_model()
if len(nb.vocab) == 251637:
print("Great! The vocabulary size is {}".format(251637))
else:
print(
"Oh no! Something seems off. Double check your code before continuing. Maybe a mistake in update_model?"
)
# ## Exploratory analysis
# Let’s begin to explore the count statistics stored by the update model function. Implement the provided `top_n` function in the [Naive Bayes Block](#Naive-Bayes-Block) to find the top 10 most common words in the positive class and top 10 most common words in the negative class.
print("TOP 10 WORDS FOR CLASS " + POS_LABEL + ":")
for tok, count in nb.top_n(POS_LABEL, 10):
print("", tok, count)
print()
print("TOP 10 WORDS FOR CLASS " + NEG_LABEL + ":")
for tok, count in nb.top_n(NEG_LABEL, 10):
print("", tok, count)
print()
# ### Question 2.2 (5 points)
# What is the first thing that you notice when you look at the top 10 words for the 2 classes? Are these words helpful for discriminating between the two classes? Do you imagine that processing other English text will result in a similar phenomenon? What about other languages?
# ***Answer in one or two lines here.***
# The top words for both classes are stop words, which make it difficult to distinguish between the two classes. This is the first thing to note. Both favorable and bad evaluations may have a lot of these exclamation points. It's likely that reading other English work would cause a similar occurrence, although it may depend on the text's particular subject matter or genre. Depending on the syntax and vocabulary of the respective language, the top words in other languages may also vary.
# ### Question 2.3 (5 points)
# The Naive Bayes model assumes that all features are conditionally independent given the class label. For our purposes, this means that the probability of seeing a particular word in a document with class label $y$ is independent of the rest of the words in that document. Implement the `p_word_given_label` function in the [Naive Bayes Block](#Naive-Bayes-Block). This function calculates P (w|y) (i.e., the probability of seeing word w in a document given the label of that document is y).
# Use your `p_word_given_label` function to compute the probability of seeing the word “amazing” given each sentiment label. Repeat the computation for the word “dull.”
print("P('amazing'|pos):", nb.p_word_given_label("amazing", POS_LABEL))
print("P('amazing'|neg):", nb.p_word_given_label("amazing", NEG_LABEL))
print("P('dull'|pos):", nb.p_word_given_label("dull", POS_LABEL))
print("P('dull'|neg):", nb.p_word_given_label("dull", NEG_LABEL))
# Which word has a higher probability, given the positive class? Which word has a higher probability, given the negative class? Is this behavior expected?
# ***Answer in one or two lines here.***
# ### Question 2.4 (5 points)
# In the next cell, compute the probability of the word "car-thievery" in the positive training data and negative training data.
print("P('car-thievery'|pos):", nb.p_word_given_label("car-thievery", POS_LABEL))
print("P('car-thievery'|neg):", nb.p_word_given_label("car-thievery", NEG_LABEL))
# What is unusual about P('car-thievery'|neg)? What would happen if we took the log of "P('car-thievery'|neg)"? What would happen if we multiplied "P('car-thievery'|neg)" by "P('dull'|neg)"? Why might these operations cause problems for a Naive Bayes classifier?
# ***Answer in one or two lines here.***
# ### Question 2.5 (5 points)
# We can address the issues from question 2.4 with add-$\alpha$ smoothing (like add-1 smoothing except instead of adding 1 we add $\alpha$). Implement
# `p_word_given_label_and_alpha` in the [Naive Bayes Block](#Naive-Bayes-Block) and then run the next cell.
# **Hint:** look at the slides from the lecture on add-1 smoothing.
print(
"P('stop-sign.'|pos):",
nb.p_word_given_label_and_alpha("stop-sign.", POS_LABEL, 0.2),
)
# ### Question 2.6 (5 points)
# *Prior and Likelihood*
# As noted before, the Naive Bayes model assumes that all words in a document are independent of one another given the document’s label. Because of this we can write the likelihood of a document as:
# $P(w_{d1},\cdots,w_{dn}|y_d) = \prod_{i=1}^{n}P(w_{di}|y_d)$
# However, if a document has a lot of words, the likelihood will become extremely small and we’ll encounter numerical underflow. Underflow is a common problem when dealing with probabilistic models; if you are unfamiliar with it, you can get a brief overview on [Wikipedia](https:/en.wikipedia.org/wiki/Arithmetic_underflow). To deal with underflow, a common transformation is to work in log-space.
# $\log[P(w_{d1},\cdots,w_{dn}|y_d)] = \sum_{i=1}^{n}\log[P(w_{di}|y_d)]$
# Implement the `log_likelihood` function in the [Naive Bayes Block](#Naive-Bayes-Block). **Hint:** it should make calls to the p word given label and alpha function.
# Implement the `log_prior` function in the [Naive Bayes Block](#Naive-Bayes-Block). This function takes a class label and returns the log of the fraction of the training documents that are of that label.
# ### Question 2.7 (5 points)
# Naive Bayes is a model that tells us how to compute the posterior
# probability of a document being of some label (i.e.,
# $P(y_d|\mathbf{w_d})$). Specifically, we do so using bayes rule:
# $P(y_d|\mathbf{w_d}) = \frac{P(y_d)P(\mathbf{w_d}|y_d)}{P(\mathbf{w_d})}$
# In the previous section you implemented functions to compute both
# the log prior ($\log[P(y_d)]$) and the log likelihood
# ($\log[P( \mathbf{w_d} |y_d)]$ ). Now, all you're missing is the
# *normalizer*, $P(\mathbf{w_d})$.
# Derive the normalizer by expanding $P(\mathbf{w_d})$.
# ***Answer in one or two lines here. Provide the formula and define each term in this formula.***
# ### Question 2.8 (5 points)
# One way to classify a document is to compute the unnormalized log posterior for both labels and take the argmax (i.e., the label that yields the higher unnormalized log posterior). The unnormalized log posterior is the sum of the log prior and the log likelihood of the document. Why don’t we need to compute the log normalizer here?
# ***Answer in one or two lines here.***
# ### Question 2.9 (10 points)
# As we saw earlier, the top 10 words from each class do not give us much to go on when classifying a document. A much more powerful metric is the likelihood ratio, which is defined as
# $LR(w)=\frac{P(w|y=\mathrm{pos})}{P(w|y=\mathrm{neg})}$
# A word with LR 3 is 3 times more likely to appear in the positive class than in the negative. A word with LR 0.3 is one-third as likely to appear in the positive class as opposed to the negative class.
# Implement the nb.likelihod_ratio function and use it to investigate the likelihood ratio of "amazing" and "dull"
print("LIKELIHOOD RATIO OF 'amazing':", nb.likelihood_ratio("amazing", 0.2))
print("LIKELIHOOD RATIO OF 'dull':", nb.likelihood_ratio("dull", 0.2))
print("LIKELIHOOD RATIO OF 'and':", nb.likelihood_ratio("and", 0.2))
print("LIKELIHOOD RATIO OF 'to':", nb.likelihood_ratio("to", 0.2))
# What is the minimum and maximum possible values the likelihood ratio can take? Does it make sense that $LR('amazing') > LR('to')$?
# ***Answer in one or two lines here.***
# Find the word in the vocabulary with the highest liklihood ratio below.
# Add your code here
# ### Question 2.10 (5 points)
# The unnormalized log posterior is the sum of the log prior and the log likelihood of the document. Implement the `unnormalized_log_posterior` function and the `classify` function in the [Naive Bayes Block](#Naive-Bayes-Block). The `classify` function should use the unnormalized log posteriors but should not compute the normalizer. Once you implement the `classify` function, we'd like to evaluate its accuracy.
print(nb.evaluate_classifier_accuracy(0.2))
# ### Question 2.11 (5 points)
# Try evaluating your model again with a smoothing parameter of 1000.
print(nb.evaluate_classifier_accuracy(1000.0))
# Does the accuracy go up or down when alpha is raised to 1000? Why do you think this is?
# ***Answer in one or two lines here.***
# ### Question 2.12 (5 points)
# Find a review that your classifier got wrong.
# In this cell, print out a review your classifier got wrong, along with its label.
# What are two reasons your system might have misclassified this example? What improvements could you make that may help your system classify this example correctly?
# ***Answer in one or two lines here.***
# ### Question 2.13 (5 points)
# Often times we care about multi-class classification rather than binary classification.
# How many counts would we need to keep track of if the model were modified to support 5-class classification?
# ***Answer in one or two lines here.***
#
# Use your own code or an external library such as nltk to perform tokenization,
# text normalization, word filtering, etc.
# Fill out your work in def tokenize_doc_and_more (below) and then show improvement by
# running the cells below.
def tokenize_doc_and_more(doc):
"""
Return some representation of a document.
At a minimum, you need to perform tokenization, the rest is up to you.
"""
# Implement me!
bow = defaultdict(float)
# your code goes here
return bow
nb = NaiveBayes(PATH_TO_DATA, tokenizer=tokenize_doc_and_more)
nb.train_model()
nb.evaluate_classifier_accuracy(1.0)
| false | 0 | 6,190 | 0 | 24 | 6,190 |
||
119205695 | <kaggle_start><code># # Lab 42
# - 7 Examples of Pythonisms:
# - Iterators and Generators
# - Data Model Methods
# - Decorators
# ## Iterators and Generators
# - Iterators and generators are both used to produce sequences of values.
# - Iterators are objects that implement the __iter__() and __next__() methods
# - Generators are functions that use the yield keyword to produce a sequence of values
def my_generator(start, end):
current = start
while current < end:
yield current
current += 1
def my_infinite_generator(start):
current = start
while True:
yield current
current += 1
# When you call this function, it will return a generator object that you can
# iterate over to get an infinite sequence of values:
gen = my_infinite_generator(10)
for i in range(5):
print(next(gen)) # prints 10, 11, 12, 13, 14
# Note that you can't simply use a for loop to iterate over an infinite generator,
# since it would never terminate. You can, however, use the itertools module to
# extract a finite number of values:
import itertools
gen = my_infinite_generator(10)
values = itertools.islice(gen, 5)
for value in values:
print(value) # prints 10, 11, 12, 13, 14
class MyIterator:
def __init__(self, start, end):
self.current = start
self.end = end
def __iter__(self):
return self
def __next__(self):
if self.current < self.end:
value = self.current
self.current += 1
return value
else:
raise StopIteration
# ## Data Model Methods
# - Data model methods are methods that allow you to define how your objects behave in various contexts,
# - such as when they are compared, printed, or used in mathematical operations.
# - Here are a few examples of data model methods:
class MyClass:
def __init__(self, value):
self.value = value
def __eq__(self, other):
return self.value == other.value
def __str__(self):
return f"MyClass({self.value})"
def __add__(self, other):
return MyClass(self.value + other.value)
# ## Decorators
# - Decorators are functions that modify the behavior of other functions.
# - They are often used to add functionality such as logging, caching, or authentication to existing functions.
# - Here are a few examples of decorators:
import time
def timer(func):
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print(f"{func.__name__} took {end_time - start_time} seconds")
return result
return wrapper
@timer
def slow_function():
time.sleep(2)
return "done"
def authenticated(func):
def wrapper(*args, **kwargs):
if check_authentication():
return func(*args, **kwargs)
else:
raise Exception("Not authenticated")
return wrapper
@authenticated
def secure_function():
# this function will only run if the user is authenticated
pass
def memoize(func):
cache = {}
def wrapper(*args):
if args in cache:
return cache[args]
else:
result = func(*args)
cache[args] = result
return result
return wrapper
@memoize
def fibonacci(n):
if n < 2:
return n
else:
return fibonacci(n - 1) + fibonacci(n - 2)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0119/205/119205695.ipynb | null | null | [{"Id": 119205695, "ScriptId": 35084581, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 13129125, "CreationDate": "02/15/2023 03:22:12", "VersionNumber": 1.0, "Title": "Lab 42", "EvaluationDate": "02/15/2023", "IsChange": true, "TotalLines": 129.0, "LinesInsertedFromPrevious": 129.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | # # Lab 42
# - 7 Examples of Pythonisms:
# - Iterators and Generators
# - Data Model Methods
# - Decorators
# ## Iterators and Generators
# - Iterators and generators are both used to produce sequences of values.
# - Iterators are objects that implement the __iter__() and __next__() methods
# - Generators are functions that use the yield keyword to produce a sequence of values
def my_generator(start, end):
current = start
while current < end:
yield current
current += 1
def my_infinite_generator(start):
current = start
while True:
yield current
current += 1
# When you call this function, it will return a generator object that you can
# iterate over to get an infinite sequence of values:
gen = my_infinite_generator(10)
for i in range(5):
print(next(gen)) # prints 10, 11, 12, 13, 14
# Note that you can't simply use a for loop to iterate over an infinite generator,
# since it would never terminate. You can, however, use the itertools module to
# extract a finite number of values:
import itertools
gen = my_infinite_generator(10)
values = itertools.islice(gen, 5)
for value in values:
print(value) # prints 10, 11, 12, 13, 14
class MyIterator:
def __init__(self, start, end):
self.current = start
self.end = end
def __iter__(self):
return self
def __next__(self):
if self.current < self.end:
value = self.current
self.current += 1
return value
else:
raise StopIteration
# ## Data Model Methods
# - Data model methods are methods that allow you to define how your objects behave in various contexts,
# - such as when they are compared, printed, or used in mathematical operations.
# - Here are a few examples of data model methods:
class MyClass:
def __init__(self, value):
self.value = value
def __eq__(self, other):
return self.value == other.value
def __str__(self):
return f"MyClass({self.value})"
def __add__(self, other):
return MyClass(self.value + other.value)
# ## Decorators
# - Decorators are functions that modify the behavior of other functions.
# - They are often used to add functionality such as logging, caching, or authentication to existing functions.
# - Here are a few examples of decorators:
import time
def timer(func):
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
print(f"{func.__name__} took {end_time - start_time} seconds")
return result
return wrapper
@timer
def slow_function():
time.sleep(2)
return "done"
def authenticated(func):
def wrapper(*args, **kwargs):
if check_authentication():
return func(*args, **kwargs)
else:
raise Exception("Not authenticated")
return wrapper
@authenticated
def secure_function():
# this function will only run if the user is authenticated
pass
def memoize(func):
cache = {}
def wrapper(*args):
if args in cache:
return cache[args]
else:
result = func(*args)
cache[args] = result
return result
return wrapper
@memoize
def fibonacci(n):
if n < 2:
return n
else:
return fibonacci(n - 1) + fibonacci(n - 2)
| false | 0 | 870 | 0 | 6 | 870 |
||
121748209 | <kaggle_start><code># ## Aşağıdakı kod, kagglein verdiyi hazir koddur. Meqsedi competitionda yüklənmiş bütün faylları göstərməkdir
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Aşagıdaki import etdiyim modullar,
# 1. pandas --> faylları oxumaq üçün
# 2. CountVectorizer --> text inputlarını vectora çevirmek üçün
# 3. accuracy_score --> accuracy metricini hesablamaq üçün
# 4. precision_recall_fscore_support --> precision, recall ve fscore metriclerini hesablamaq üçün
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
# Aşağıda torch ile bağlı modulları import etmişem
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# Aşağıda SpamModel 2 layerli ve arasinda relu activation function olan neural network qururuq
class SpamModel(nn.Module):
def __init__(self):
super().__init__()
# Please Fill 3 commented lines
# 1. first feed forward layer, input size len(vectorizer.vocabulary), output_size 256
# 2. relu activation function
# 3. second feed forward layer input size output size of first feedforward layer, output size number of target labels
def forward(self, x):
x = x.view(-1, len(vectorizer.vocabulary_))
x = self.fc1(x)
x = self.relu(x)
return self.fc2(x)
# Aşağıda Training Data üçün sentiment dataset adlı dataset yaradırıq
class SentimentDataset(Dataset):
def __init__(self, emails, labels, vectorizer):
self.emails = emails
self.labels = labels
self.vectorizer = vectorizer
def __len__(self):
# 1. please fill this line
pass
def __getitem__(self, idx):
email = self.emails[idx].lower()
label = self.labels[idx]
# 1. fill this line convert labels so that spam is 1 and ham is 0
features = vectorizer.transform([email]).todense()
return {
"features": torch.tensor(features, dtype=torch.float32),
"labels": torch.tensor(label, dtype=torch.long),
}
class SentimentTestDataset(Dataset):
def __init__(self, emails, vectorizer):
self.emails = emails
self.vectorizer = vectorizer
def __len__(self):
# 1. please fill this line
pass
def __getitem__(self, idx):
email = self.emails[idx].lower()
# fill this line to convert email to necessary format
# fill this line, return necessary object
train_data = pd.read_csv("/kaggle/input/spam-detection-competition/train.csv")
test_data = pd.read_csv("/kaggle/input/spam-detection-competition/test.csv")
train_features = train_data["email"]
train_labels = train_data["label"]
test_features = test_data["email"]
# Bu setirde evvel count vectorizer instanceni yaradırıq
# sonra onu training datasetin featurelarına fit edirik.
# Yeni ki vectorizerin Vocabularysini training datasetimiz ile qururuq.
count_vect = CountVectorizer(stop_words="english")
vectorizer = count_vect.fit(train_features)
train_dataset = SentimentDataset(train_features, train_labels, vectorizer)
test_dataset = SentimentTestDataset(test_features, vectorizer)
train_data_loader = DataLoader(dataset=train_dataset, batch_size=256, shuffle=True)
test_data_loader = DataLoader(dataset=test_dataset, batch_size=256, shuffle=False)
model = SpamModel()
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=2e-3)
for epoch in range(10):
total_train_loss = 0.0
for batch in train_data_loader:
labels = batch["labels"]
features = batch["features"]
logits = model(features)
loss_train = loss_fn(logits, labels)
optimizer.zero_grad()
loss_train.backward()
optimizer.step()
total_train_loss += loss_train.item()
print(total_train_loss / len(train_data_loader))
# Evaluation aşaması. Bu aşamada modelin test data üzerinde nece işlediyini görürük
model = model.eval()
all_predicted = []
with torch.no_grad():
for data in test_data_loader:
features = data["features"]
predicted = model(features)
predicted = torch.sigmoid(predicted).detach().numpy()
predicted = predicted.argmax(axis=1)
all_predicted.extend(predicted.tolist())
# Neticeleri csv fayla yazıb submit edirik
df = pd.DataFrame({"id": list(range(len(test_dataset))), "label": all_predicted})
df.to_csv("submission_count-vector.csv", index=None)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0121/748/121748209.ipynb | null | null | [{"Id": 121748209, "ScriptId": 35906894, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1092846, "CreationDate": "03/11/2023 08:13:55", "VersionNumber": 1.0, "Title": "Example Template To Fill - dummy", "EvaluationDate": "03/11/2023", "IsChange": false, "TotalLines": 141.0, "LinesInsertedFromPrevious": 0.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 141.0, "LinesInsertedFromFork": 0.0, "LinesDeletedFromFork": 0.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 141.0, "TotalVotes": 0}] | null | null | null | null | # ## Aşağıdakı kod, kagglein verdiyi hazir koddur. Meqsedi competitionda yüklənmiş bütün faylları göstərməkdir
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Aşagıdaki import etdiyim modullar,
# 1. pandas --> faylları oxumaq üçün
# 2. CountVectorizer --> text inputlarını vectora çevirmek üçün
# 3. accuracy_score --> accuracy metricini hesablamaq üçün
# 4. precision_recall_fscore_support --> precision, recall ve fscore metriclerini hesablamaq üçün
import pandas as pd
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics import accuracy_score, precision_recall_fscore_support
# Aşağıda torch ile bağlı modulları import etmişem
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# Aşağıda SpamModel 2 layerli ve arasinda relu activation function olan neural network qururuq
class SpamModel(nn.Module):
def __init__(self):
super().__init__()
# Please Fill 3 commented lines
# 1. first feed forward layer, input size len(vectorizer.vocabulary), output_size 256
# 2. relu activation function
# 3. second feed forward layer input size output size of first feedforward layer, output size number of target labels
def forward(self, x):
x = x.view(-1, len(vectorizer.vocabulary_))
x = self.fc1(x)
x = self.relu(x)
return self.fc2(x)
# Aşağıda Training Data üçün sentiment dataset adlı dataset yaradırıq
class SentimentDataset(Dataset):
def __init__(self, emails, labels, vectorizer):
self.emails = emails
self.labels = labels
self.vectorizer = vectorizer
def __len__(self):
# 1. please fill this line
pass
def __getitem__(self, idx):
email = self.emails[idx].lower()
label = self.labels[idx]
# 1. fill this line convert labels so that spam is 1 and ham is 0
features = vectorizer.transform([email]).todense()
return {
"features": torch.tensor(features, dtype=torch.float32),
"labels": torch.tensor(label, dtype=torch.long),
}
class SentimentTestDataset(Dataset):
def __init__(self, emails, vectorizer):
self.emails = emails
self.vectorizer = vectorizer
def __len__(self):
# 1. please fill this line
pass
def __getitem__(self, idx):
email = self.emails[idx].lower()
# fill this line to convert email to necessary format
# fill this line, return necessary object
train_data = pd.read_csv("/kaggle/input/spam-detection-competition/train.csv")
test_data = pd.read_csv("/kaggle/input/spam-detection-competition/test.csv")
train_features = train_data["email"]
train_labels = train_data["label"]
test_features = test_data["email"]
# Bu setirde evvel count vectorizer instanceni yaradırıq
# sonra onu training datasetin featurelarına fit edirik.
# Yeni ki vectorizerin Vocabularysini training datasetimiz ile qururuq.
count_vect = CountVectorizer(stop_words="english")
vectorizer = count_vect.fit(train_features)
train_dataset = SentimentDataset(train_features, train_labels, vectorizer)
test_dataset = SentimentTestDataset(test_features, vectorizer)
train_data_loader = DataLoader(dataset=train_dataset, batch_size=256, shuffle=True)
test_data_loader = DataLoader(dataset=test_dataset, batch_size=256, shuffle=False)
model = SpamModel()
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=2e-3)
for epoch in range(10):
total_train_loss = 0.0
for batch in train_data_loader:
labels = batch["labels"]
features = batch["features"]
logits = model(features)
loss_train = loss_fn(logits, labels)
optimizer.zero_grad()
loss_train.backward()
optimizer.step()
total_train_loss += loss_train.item()
print(total_train_loss / len(train_data_loader))
# Evaluation aşaması. Bu aşamada modelin test data üzerinde nece işlediyini görürük
model = model.eval()
all_predicted = []
with torch.no_grad():
for data in test_data_loader:
features = data["features"]
predicted = model(features)
predicted = torch.sigmoid(predicted).detach().numpy()
predicted = predicted.argmax(axis=1)
all_predicted.extend(predicted.tolist())
# Neticeleri csv fayla yazıb submit edirik
df = pd.DataFrame({"id": list(range(len(test_dataset))), "label": all_predicted})
df.to_csv("submission_count-vector.csv", index=None)
| false | 0 | 1,349 | 0 | 6 | 1,349 |
||
121651668 | <kaggle_start><data_title>ECG Heartbeat Categorization Dataset<data_description># Context
# ECG Heartbeat Categorization Dataset
## Abstract
This dataset is composed of two collections of heartbeat signals derived from two famous datasets in heartbeat classification, [the MIT-BIH Arrhythmia Dataset](https://www.physionet.org/physiobank/database/mitdb/) and [The PTB Diagnostic ECG Database](https://www.physionet.org/physiobank/database/ptbdb/). The number of samples in both collections is large enough for training a deep neural network.
This dataset has been used in exploring heartbeat classification using deep neural network architectures, and observing some of the capabilities of transfer learning on it. The signals correspond to electrocardiogram (ECG) shapes of heartbeats for the normal case and the cases affected by different arrhythmias and myocardial infarction. These signals are preprocessed and segmented, with each segment corresponding to a heartbeat.
## Content
### Arrhythmia Dataset
<ul>
<li> Number of Samples: 109446</li>
<li> Number of Categories: 5</li>
<li> Sampling Frequency: 125Hz</li>
<li> Data Source: Physionet's MIT-BIH Arrhythmia Dataset</li>
<li> Classes: ['N': 0, 'S': 1, 'V': 2, 'F': 3, 'Q': 4]</li>
</ul>
### The PTB Diagnostic ECG Database
<ul>
<li> Number of Samples: 14552</li>
<li> Number of Categories: 2</li>
<li> Sampling Frequency: 125Hz</li>
<li> Data Source: Physionet's PTB Diagnostic Database</li>
</ul>
**Remark**: *All the samples are cropped, downsampled and padded with zeroes if necessary to the fixed dimension of 188*.
## Data Files
This dataset consists of a series of CSV files. Each of these CSV files contain a matrix, with each row representing an example in that portion of the dataset. The final element of each row denotes the class to which that example belongs.
## Acknowledgements
Mohammad Kachuee, Shayan Fazeli, and Majid Sarrafzadeh. "ECG Heartbeat Classification: A Deep Transferable Representation." [*arXiv preprint arXiv:1805.00794 (2018)*](https://arxiv.org/abs/1805.00794).
# Inspiration
Can you identify myocardial infarction?<data_name>heartbeat
<code># # TODO-List
# * Read train and test data
# * Data preprocessing (how data should look like to be passed to RNN model)
# * Create simple(for the first time) RNN class in PyTorch
# * Implement Genetic Algorithm for weights update
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
# '/kaggle/input/heartbeat/ptbdb_abnormal.csv'
# '/kaggle/input/heartbeat/ptbdb_normal.csv'
path_test = "/kaggle/input/heartbeat/mitbih_test.csv"
path_train = "/kaggle/input/heartbeat/mitbih_train.csv"
df_train = pd.read_csv(path_train, header=None)
df_test = pd.read_csv(path_test, header=None)
df_train.head()
# # Data Preprocessing
# * Normalizing (to converge faster)
# * Resampling (each category appears equally in training)
# * Transforming? (Fourier/Spectral analysis)
from sklearn.utils import resample
import torch.utils.data as data_utils
df_train[187] = df_train[187].astype(int)
df_test[187] = df_test[187].astype(int)
df_normal = df_train[df_train[187] == 0]
df_supraventricular = df_train[df_train[187] == 1]
df_ventricular = df_train[df_train[187] == 2]
df_fusion = df_train[df_train[187] == 3]
df_unknown = df_train[df_train[187] == 4]
n = 10000
normal_train = resample(df_normal, replace=True, n_samples=n)
supraventricular_train = resample(df_supraventricular, replace=True, n_samples=n)
ventricular_train = resample(df_ventricular, replace=True, n_samples=n)
fusion_train = resample(df_fusion, replace=True, n_samples=n)
unknown_train = resample(df_unknown, replace=True, n_samples=n)
train = pd.concat(
(
normal_train,
supraventricular_train,
ventricular_train,
fusion_train,
unknown_train,
)
)
X_train = train.iloc[:, 0:-1]
y_train = train.iloc[:, -1]
print(train[187].value_counts())
print(train.shape)
# ecg values vary from 0.0 to 1.0, so normalizing is not necessary
print(train.min(), train.max())
# # Classification using RNNs
# * Simple Vanilla RNN
# * LSTM
# * GRU
# * ConvRNN
# * Own architecture
# importing necessary modules
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
class EcgSequentialLoader(Dataset):
def __init__(self, data, seq_len, input_size, num_classes):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.data = torch.tensor(data.to_numpy(), dtype=torch.float32).to(device=device)
self.seq_len = seq_len
self.input_size = input_size
self.num_classes = num_classes
def __len__(self):
# return len(self.data) // self.seq_len
return len(self.data)
def __getitem__(self, index):
x = self.data[index, :-1]
y = self.data[index, -1].floor().long()
x = x.reshape(-1, self.seq_len, self.input_size)
# OH-encoded ECG classification categories
# y = torch.nn.functional.one_hot(y.to(torch.int64), num_classes=self.num_classes)
# print(x.shape, y.shape)
return x, y
class VanillaRNN(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(VanillaRNN, self).__init__()
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.hidden_size = hidden_size # hidden state size
# rnn
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
# fully connected layer (goes after rnn computations)
# for inputs is the last hidden state of the rnn, output logits to softmax
self.fc_layer = nn.Linear(hidden_size, num_classes)
# self.sm_layer = nn.Softmax(dim=1)
def forward(self, x):
# because dataloader adds new axis=1 and we get 4D tensor
x = x.squeeze(1)
# initial state (null-state)
h0 = self.init_hidden(x.size(0)).to(self.device)
out, hidden = self.rnn(x, h0)
logits = self.fc_layer(hidden[-1, :, :])
# out = self.sm_layer(logit)
return logits
def init_hidden(self, batch_size):
hidden = torch.zeros(1, batch_size, self.hidden_size)
return hidden
class ClassifierLSTM:
def __init__():
pass
class ClassifierGRU:
def __init__():
pass
class ClassifierConvRNN:
def __init__():
pass
class OwnArchitectureRNN:
def __init__(self):
pass
def get_train_loader(dataset, batch_size):
return DataLoader(dataset=dataset, batch_size=batch_size, shuffle=True)
batch_size = 32
input_size = 11 # input size of input vectors
seq_len = 17 # iterations inside RNN
hidden_size = 10
num_classes = 5
ecg_dataset = EcgSequentialLoader(train, seq_len, input_size, num_classes)
dataloader = get_train_loader(ecg_dataset, batch_size)
vrnn = VanillaRNN(input_size, hidden_size, num_classes)
# vrnn.forward(few_signals)
for batch_idx, (x, y) in enumerate(dataloader):
print(x.shape, y.shape)
print(y)
print(vrnn.forward(x))
break
vrnn.state_dict()
# # Implementation of Genetic Algorithm Helper functions
# * Create initial population
# * Individual evaluation using environmental function (CrossEntropy or LogSoftmax?)
# * Selection (choose parents of the next generation)
# * Crossing-over (biology) of chromosomes
# * Mutations
# imports
import numpy as np
import random
import itertools
import functools
from typing import Callable, Iterable, Tuple, List, Union
def selection():
pass
def crossover():
pass
def mutation():
pass
class GeneticAlgorithm:
def __init__(
self,
model_class,
model_params: Union[Tuple, List],
population_size: int,
mutation_rate: float,
selection_method=None,
crossover_method=None,
mutation_method=None,
):
"""
Genetic Algorithm parameters description
population_size:
mutation_rate:
generations:
environment_func:
selection_method:
crossover_method:
mutation_method:
"""
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.model_class = model_class
self.model_params = model_params
self.population_size = population_size
self.mutation_rate = mutation_rate
self.selection_method = selection_method
self.crossover_method = crossover_method
self.mutation_method = mutation_method
# ======
self.population = [] # models
self.fitness_values = (
[]
) # corresponding (by index) fitness values for each individual
self.parent_pairs = []
# ==========================================
def init_population(self):
self.population = [
self.model_class(*self.model_params).to(device=self.device)
for _ in range(self.population_size)
]
def fitness_evaluation(self, train_loader, individual, fitness_function):
# fitness_function (e.g. torch.nn.CrossEntropyLoss)
total_loss = 0
for x, y in train_loader:
out = individual.forward(x)
# print(out.shape, y.shape)
# print(type(out), type(y))
loss = fitness_function(out, y)
total_loss += loss.item()
# Compute the average loss and convert to fitness score
avg_loss = total_loss / len(train_loader)
# fitness_score = 1 / (1 + avg_loss)
# return fitness_score
return avg_loss
def selection(self):
# Implement selection method here
pass
def crossover(self):
# Implement crossover method here
pass
def mutation(self):
# Implement mutation method here
pass
def evolve(self, train_loader, n_generations, fitness_function, strategy):
# Implement genetic algorithm methods here
# returns best model after all passed generations
self.init_population()
for i in range(n_generations):
# evaluation (compute fitness value for each individual)
self.fitness_values = list(
map(
lambda individual: self.fitness_evaluation(
train_loader, individual, fitness_function
),
self.population,
)
)
# print(self.fitness_values)
print(f"gen {i}.....best fitness value", min(self.fitness_values))
# selection (form parent pairs)
parent_pairs = self.selection_tournament(strategy)
# crossover (for each parent pair compute children)
offspring = list(
map(lambda ps: self.crossover_weights_exchange(*ps), parent_pairs)
)
# print(type(offspring), type(offspring[0]))
offspring = list(itertools.chain(*offspring))
# print(type(offspring), type(offspring[0]))
# mutation
offspring = list(
map(lambda child: self.mutation_gaussian(child), offspring)
)
# replace existing population with a new one
self.population = offspring.copy()
# return the fittest
return
# ==========================================
def mutation_gaussian(self, model, mean=0.0, std=0.033):
weights = self.model_get_weights(model)
keys_ = model.state_dict().keys()
# 0 - no mutation, 1 - mutate
mutate = [
(torch.rand(w.shape).to(device=self.device) < self.mutation_rate).int()
for w in weights
]
gaussian = [
torch.normal(
mean=torch.ones(w.shape) * mean, std=torch.ones(w.shape) * std
).to(device=self.device)
for w in weights
]
# Hadamard product of gaussian values and mutations
mutation_values = [mut * gauss for mut, gauss in zip(mutate, gaussian)]
# add small mutation values to child's weights
new_weights = [w + m for w, m in zip(weights, mutation_values)]
model = self.model_update_weights(model, new_weights)
return model
def mutation_uniform(self, model, lo, hi):
weights = self.model_get_weights(model)
keys_ = model.state_dict().keys()
# 0 - no mutation, 1 - mutate
mutate = [(torch.rand(w.shape) < self.mutation_rate).int() for w in weights]
uniform = [(hi - lo) * (torch.rand(w.shape)) + lo for w in weights]
# Hadamard product of gaussian values and mutations
mutation_values = [mut * uni for mut, uni in zip(mutate, uniform)]
# add small mutation values to child weights
new_weights = [w + m for w, m in zip(weights, mutation_values)]
model = self.model_update_weights(model, new_weights)
return model
def mutation_bit_flip(self):
pass
# =============================
def crossover_weights_exchange(self, parent1, parent2):
p1_weights = self.model_get_weights(parent1)
p2_weights = self.model_get_weights(parent2)
# print(type(p1_weights))
assert len(p1_weights) == len(p2_weights)
# p1 = [w1, w2, ..., wn]
# p2 = [v1, v2, ..., vn]
# initialize children models
child1 = self.model_class(*self.model_params).to(device=self.device)
child2 = self.model_class(*self.model_params).to(device=self.device)
c1_new_weights = []
c2_new_weights = []
for i in range(len(p1_weights)):
# probabilities for each child to inherit some gene (weight)
rand1 = torch.rand(1)
rand2 = torch.rand(1)
if rand1 < 0.5:
c1_new_weights.append(p1_weights[i])
else:
c1_new_weights.append(p2_weights[i])
if rand2 < 0.5:
c2_new_weights.append(p1_weights[i])
else:
c2_new_weights.append(p2_weights[i])
# assign new weights to children
child1 = self.model_update_weights(child1, c1_new_weights)
child2 = self.model_update_weights(child2, c2_new_weights)
# print(type(child1), type(child2))
return child1, child2
# ============================
@staticmethod
def selection_random():
pass
def selection_roulette(self):
pass
def selection_tournament(self, strategy):
tournament_pool = self.population.copy()
fit_values = self.fitness_values.copy()
zipped = zip(tournament_pool, fit_values)
sorted_zipped = sorted(
zipped, key=lambda x: x[1], reverse=False if strategy == "min" else True
)
# sort tournament_pool by fitness value (in asc order)
# sorted_ = sorted(tournament_pool, key=lambda k: fit_values[k], reverse=False if strategy=='min' else True)
# generate pairs of the fittest individuals
sorted_ = [individual for individual, _ in sorted_zipped]
pairs = [(sorted_[2 * i], sorted_[2 * i + 1]) for i in range(len(sorted_) // 2)]
return pairs
# ====== HELPER METHODS =======
@staticmethod
def model_get_weights(model) -> List[torch.tensor]:
# get state dictionary
return list(model.state_dict().values())
@staticmethod
def model_update_weights(model, new_weights): # -> nn.Module inherited obj
state = model.state_dict()
keys_ = state.keys()
assert len(keys_) == len(new_weights)
new_state = dict(zip(keys_, new_weights))
model.load_state_dict(new_state)
return model
# ======== additional ideas
# use when some fuzzy rule (e.g. population stuck at local extrema)
def genocide(self):
# reinitialize some population
pass
# ????
def regulizer(self):
pass
batch_size = 1024
input_size = 11 # size of input vectors
seq_len = 17 # iterations inside RNN
hidden_size = 20
num_classes = 5
ecg_dataset = EcgSequentialLoader(train, seq_len, input_size, num_classes)
dataloader = get_train_loader(ecg_dataset, batch_size)
# GA parameters
population_size = 50
mutation_rate = 3e-2 # mutation probability
n_generations = 50
fitness_function = nn.CrossEntropyLoss()
vanilla_rnn_params = (input_size, hidden_size, num_classes)
gen_alg_1 = GeneticAlgorithm(
VanillaRNN, vanilla_rnn_params, population_size, mutation_rate
)
gen_alg_1.evolve(dataloader, n_generations, fitness_function, "min")
vrnn.state_dict()
# # RNN Training using Genetic Algorithms (GA)
# Questions:
# * How to update weights using GA?
# * What to modify in already existing GA implementations?
# * What should i use as chromosomes in GA?
# Genetic Algorithm:
# 1. Initialize population
# 2. Measure each individual's cost in environment(some error function)
# 3. Select best individuals
# 4. Generate new population from the best genes adding some mutations
# 5. Repeat steps 2-4 until the last epoch (generation) and select the best one of them
# GA parameters
population_sz = 20
mutation_rate = 1e-1 # mutation probability
n_generations = 10
def simple_genetic_algorithm(data):
# initialize population
# run loop for generations
# evaluate population
# select best
# crossing-over parents to create new population with some mutations
return
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0121/651/121651668.ipynb | heartbeat | shayanfazeli | [{"Id": 121651668, "ScriptId": 35750855, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 6614265, "CreationDate": "03/10/2023 09:01:12", "VersionNumber": 1.0, "Title": "ecg_rnn_genetic_algorithm_classification", "EvaluationDate": "03/10/2023", "IsChange": true, "TotalLines": 460.0, "LinesInsertedFromPrevious": 460.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 174018505, "KernelVersionId": 121651668, "SourceDatasetVersionId": 37484}] | [{"Id": 37484, "DatasetId": 29414, "DatasourceVersionId": 39061, "CreatorUserId": 1700398, "LicenseName": "Unknown", "CreationDate": "05/31/2018 18:47:34", "VersionNumber": 1.0, "Title": "ECG Heartbeat Categorization Dataset", "Slug": "heartbeat", "Subtitle": "Segmented and Preprocessed ECG Signals for Heartbeat Classification", "Description": "# Context\n\n# ECG Heartbeat Categorization Dataset\n\n## Abstract\n\nThis dataset is composed of two collections of heartbeat signals derived from two famous datasets in heartbeat classification, [the MIT-BIH Arrhythmia Dataset](https://www.physionet.org/physiobank/database/mitdb/) and [The PTB Diagnostic ECG Database](https://www.physionet.org/physiobank/database/ptbdb/). The number of samples in both collections is large enough for training a deep neural network. \n\nThis dataset has been used in exploring heartbeat classification using deep neural network architectures, and observing some of the capabilities of transfer learning on it. The signals correspond to electrocardiogram (ECG) shapes of heartbeats for the normal case and the cases affected by different arrhythmias and myocardial infarction. These signals are preprocessed and segmented, with each segment corresponding to a heartbeat.\n\n## Content\n\n### Arrhythmia Dataset\n<ul>\n <li> Number of Samples: 109446</li>\n <li> Number of Categories: 5</li>\n <li> Sampling Frequency: 125Hz</li>\n <li> Data Source: Physionet's MIT-BIH Arrhythmia Dataset</li>\n <li> Classes: ['N': 0, 'S': 1, 'V': 2, 'F': 3, 'Q': 4]</li>\n</ul>\n\n### The PTB Diagnostic ECG Database\n<ul>\n <li> Number of Samples: 14552</li>\n <li> Number of Categories: 2</li>\n <li> Sampling Frequency: 125Hz</li>\n <li> Data Source: Physionet's PTB Diagnostic Database</li>\n</ul>\n\n\n**Remark**: *All the samples are cropped, downsampled and padded with zeroes if necessary to the fixed dimension of 188*.\n\n## Data Files\n\nThis dataset consists of a series of CSV files. Each of these CSV files contain a matrix, with each row representing an example in that portion of the dataset. The final element of each row denotes the class to which that example belongs.\n\n## Acknowledgements\n\nMohammad Kachuee, Shayan Fazeli, and Majid Sarrafzadeh. \"ECG Heartbeat Classification: A Deep Transferable Representation.\" [*arXiv preprint arXiv:1805.00794 (2018)*](https://arxiv.org/abs/1805.00794).\n\n# Inspiration\n\nCan you identify myocardial infarction?", "VersionNotes": "Initial release", "TotalCompressedBytes": 582790600.0, "TotalUncompressedBytes": 103633674.0}] | [{"Id": 29414, "CreatorUserId": 1700398, "OwnerUserId": 1700398.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 37484.0, "CurrentDatasourceVersionId": 39061.0, "ForumId": 37684, "Type": 2, "CreationDate": "05/31/2018 18:47:34", "LastActivityDate": "05/31/2018", "TotalViews": 479385, "TotalDownloads": 61615, "TotalVotes": 739, "TotalKernels": 204}] | [{"Id": 1700398, "UserName": "shayanfazeli", "DisplayName": "Shayan Fazeli", "RegisterDate": "03/07/2018", "PerformanceTier": 0}] | # # TODO-List
# * Read train and test data
# * Data preprocessing (how data should look like to be passed to RNN model)
# * Create simple(for the first time) RNN class in PyTorch
# * Implement Genetic Algorithm for weights update
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
# '/kaggle/input/heartbeat/ptbdb_abnormal.csv'
# '/kaggle/input/heartbeat/ptbdb_normal.csv'
path_test = "/kaggle/input/heartbeat/mitbih_test.csv"
path_train = "/kaggle/input/heartbeat/mitbih_train.csv"
df_train = pd.read_csv(path_train, header=None)
df_test = pd.read_csv(path_test, header=None)
df_train.head()
# # Data Preprocessing
# * Normalizing (to converge faster)
# * Resampling (each category appears equally in training)
# * Transforming? (Fourier/Spectral analysis)
from sklearn.utils import resample
import torch.utils.data as data_utils
df_train[187] = df_train[187].astype(int)
df_test[187] = df_test[187].astype(int)
df_normal = df_train[df_train[187] == 0]
df_supraventricular = df_train[df_train[187] == 1]
df_ventricular = df_train[df_train[187] == 2]
df_fusion = df_train[df_train[187] == 3]
df_unknown = df_train[df_train[187] == 4]
n = 10000
normal_train = resample(df_normal, replace=True, n_samples=n)
supraventricular_train = resample(df_supraventricular, replace=True, n_samples=n)
ventricular_train = resample(df_ventricular, replace=True, n_samples=n)
fusion_train = resample(df_fusion, replace=True, n_samples=n)
unknown_train = resample(df_unknown, replace=True, n_samples=n)
train = pd.concat(
(
normal_train,
supraventricular_train,
ventricular_train,
fusion_train,
unknown_train,
)
)
X_train = train.iloc[:, 0:-1]
y_train = train.iloc[:, -1]
print(train[187].value_counts())
print(train.shape)
# ecg values vary from 0.0 to 1.0, so normalizing is not necessary
print(train.min(), train.max())
# # Classification using RNNs
# * Simple Vanilla RNN
# * LSTM
# * GRU
# * ConvRNN
# * Own architecture
# importing necessary modules
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
class EcgSequentialLoader(Dataset):
def __init__(self, data, seq_len, input_size, num_classes):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.data = torch.tensor(data.to_numpy(), dtype=torch.float32).to(device=device)
self.seq_len = seq_len
self.input_size = input_size
self.num_classes = num_classes
def __len__(self):
# return len(self.data) // self.seq_len
return len(self.data)
def __getitem__(self, index):
x = self.data[index, :-1]
y = self.data[index, -1].floor().long()
x = x.reshape(-1, self.seq_len, self.input_size)
# OH-encoded ECG classification categories
# y = torch.nn.functional.one_hot(y.to(torch.int64), num_classes=self.num_classes)
# print(x.shape, y.shape)
return x, y
class VanillaRNN(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(VanillaRNN, self).__init__()
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.hidden_size = hidden_size # hidden state size
# rnn
self.rnn = nn.RNN(input_size, hidden_size, batch_first=True)
# fully connected layer (goes after rnn computations)
# for inputs is the last hidden state of the rnn, output logits to softmax
self.fc_layer = nn.Linear(hidden_size, num_classes)
# self.sm_layer = nn.Softmax(dim=1)
def forward(self, x):
# because dataloader adds new axis=1 and we get 4D tensor
x = x.squeeze(1)
# initial state (null-state)
h0 = self.init_hidden(x.size(0)).to(self.device)
out, hidden = self.rnn(x, h0)
logits = self.fc_layer(hidden[-1, :, :])
# out = self.sm_layer(logit)
return logits
def init_hidden(self, batch_size):
hidden = torch.zeros(1, batch_size, self.hidden_size)
return hidden
class ClassifierLSTM:
def __init__():
pass
class ClassifierGRU:
def __init__():
pass
class ClassifierConvRNN:
def __init__():
pass
class OwnArchitectureRNN:
def __init__(self):
pass
def get_train_loader(dataset, batch_size):
return DataLoader(dataset=dataset, batch_size=batch_size, shuffle=True)
batch_size = 32
input_size = 11 # input size of input vectors
seq_len = 17 # iterations inside RNN
hidden_size = 10
num_classes = 5
ecg_dataset = EcgSequentialLoader(train, seq_len, input_size, num_classes)
dataloader = get_train_loader(ecg_dataset, batch_size)
vrnn = VanillaRNN(input_size, hidden_size, num_classes)
# vrnn.forward(few_signals)
for batch_idx, (x, y) in enumerate(dataloader):
print(x.shape, y.shape)
print(y)
print(vrnn.forward(x))
break
vrnn.state_dict()
# # Implementation of Genetic Algorithm Helper functions
# * Create initial population
# * Individual evaluation using environmental function (CrossEntropy or LogSoftmax?)
# * Selection (choose parents of the next generation)
# * Crossing-over (biology) of chromosomes
# * Mutations
# imports
import numpy as np
import random
import itertools
import functools
from typing import Callable, Iterable, Tuple, List, Union
def selection():
pass
def crossover():
pass
def mutation():
pass
class GeneticAlgorithm:
def __init__(
self,
model_class,
model_params: Union[Tuple, List],
population_size: int,
mutation_rate: float,
selection_method=None,
crossover_method=None,
mutation_method=None,
):
"""
Genetic Algorithm parameters description
population_size:
mutation_rate:
generations:
environment_func:
selection_method:
crossover_method:
mutation_method:
"""
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.model_class = model_class
self.model_params = model_params
self.population_size = population_size
self.mutation_rate = mutation_rate
self.selection_method = selection_method
self.crossover_method = crossover_method
self.mutation_method = mutation_method
# ======
self.population = [] # models
self.fitness_values = (
[]
) # corresponding (by index) fitness values for each individual
self.parent_pairs = []
# ==========================================
def init_population(self):
self.population = [
self.model_class(*self.model_params).to(device=self.device)
for _ in range(self.population_size)
]
def fitness_evaluation(self, train_loader, individual, fitness_function):
# fitness_function (e.g. torch.nn.CrossEntropyLoss)
total_loss = 0
for x, y in train_loader:
out = individual.forward(x)
# print(out.shape, y.shape)
# print(type(out), type(y))
loss = fitness_function(out, y)
total_loss += loss.item()
# Compute the average loss and convert to fitness score
avg_loss = total_loss / len(train_loader)
# fitness_score = 1 / (1 + avg_loss)
# return fitness_score
return avg_loss
def selection(self):
# Implement selection method here
pass
def crossover(self):
# Implement crossover method here
pass
def mutation(self):
# Implement mutation method here
pass
def evolve(self, train_loader, n_generations, fitness_function, strategy):
# Implement genetic algorithm methods here
# returns best model after all passed generations
self.init_population()
for i in range(n_generations):
# evaluation (compute fitness value for each individual)
self.fitness_values = list(
map(
lambda individual: self.fitness_evaluation(
train_loader, individual, fitness_function
),
self.population,
)
)
# print(self.fitness_values)
print(f"gen {i}.....best fitness value", min(self.fitness_values))
# selection (form parent pairs)
parent_pairs = self.selection_tournament(strategy)
# crossover (for each parent pair compute children)
offspring = list(
map(lambda ps: self.crossover_weights_exchange(*ps), parent_pairs)
)
# print(type(offspring), type(offspring[0]))
offspring = list(itertools.chain(*offspring))
# print(type(offspring), type(offspring[0]))
# mutation
offspring = list(
map(lambda child: self.mutation_gaussian(child), offspring)
)
# replace existing population with a new one
self.population = offspring.copy()
# return the fittest
return
# ==========================================
def mutation_gaussian(self, model, mean=0.0, std=0.033):
weights = self.model_get_weights(model)
keys_ = model.state_dict().keys()
# 0 - no mutation, 1 - mutate
mutate = [
(torch.rand(w.shape).to(device=self.device) < self.mutation_rate).int()
for w in weights
]
gaussian = [
torch.normal(
mean=torch.ones(w.shape) * mean, std=torch.ones(w.shape) * std
).to(device=self.device)
for w in weights
]
# Hadamard product of gaussian values and mutations
mutation_values = [mut * gauss for mut, gauss in zip(mutate, gaussian)]
# add small mutation values to child's weights
new_weights = [w + m for w, m in zip(weights, mutation_values)]
model = self.model_update_weights(model, new_weights)
return model
def mutation_uniform(self, model, lo, hi):
weights = self.model_get_weights(model)
keys_ = model.state_dict().keys()
# 0 - no mutation, 1 - mutate
mutate = [(torch.rand(w.shape) < self.mutation_rate).int() for w in weights]
uniform = [(hi - lo) * (torch.rand(w.shape)) + lo for w in weights]
# Hadamard product of gaussian values and mutations
mutation_values = [mut * uni for mut, uni in zip(mutate, uniform)]
# add small mutation values to child weights
new_weights = [w + m for w, m in zip(weights, mutation_values)]
model = self.model_update_weights(model, new_weights)
return model
def mutation_bit_flip(self):
pass
# =============================
def crossover_weights_exchange(self, parent1, parent2):
p1_weights = self.model_get_weights(parent1)
p2_weights = self.model_get_weights(parent2)
# print(type(p1_weights))
assert len(p1_weights) == len(p2_weights)
# p1 = [w1, w2, ..., wn]
# p2 = [v1, v2, ..., vn]
# initialize children models
child1 = self.model_class(*self.model_params).to(device=self.device)
child2 = self.model_class(*self.model_params).to(device=self.device)
c1_new_weights = []
c2_new_weights = []
for i in range(len(p1_weights)):
# probabilities for each child to inherit some gene (weight)
rand1 = torch.rand(1)
rand2 = torch.rand(1)
if rand1 < 0.5:
c1_new_weights.append(p1_weights[i])
else:
c1_new_weights.append(p2_weights[i])
if rand2 < 0.5:
c2_new_weights.append(p1_weights[i])
else:
c2_new_weights.append(p2_weights[i])
# assign new weights to children
child1 = self.model_update_weights(child1, c1_new_weights)
child2 = self.model_update_weights(child2, c2_new_weights)
# print(type(child1), type(child2))
return child1, child2
# ============================
@staticmethod
def selection_random():
pass
def selection_roulette(self):
pass
def selection_tournament(self, strategy):
tournament_pool = self.population.copy()
fit_values = self.fitness_values.copy()
zipped = zip(tournament_pool, fit_values)
sorted_zipped = sorted(
zipped, key=lambda x: x[1], reverse=False if strategy == "min" else True
)
# sort tournament_pool by fitness value (in asc order)
# sorted_ = sorted(tournament_pool, key=lambda k: fit_values[k], reverse=False if strategy=='min' else True)
# generate pairs of the fittest individuals
sorted_ = [individual for individual, _ in sorted_zipped]
pairs = [(sorted_[2 * i], sorted_[2 * i + 1]) for i in range(len(sorted_) // 2)]
return pairs
# ====== HELPER METHODS =======
@staticmethod
def model_get_weights(model) -> List[torch.tensor]:
# get state dictionary
return list(model.state_dict().values())
@staticmethod
def model_update_weights(model, new_weights): # -> nn.Module inherited obj
state = model.state_dict()
keys_ = state.keys()
assert len(keys_) == len(new_weights)
new_state = dict(zip(keys_, new_weights))
model.load_state_dict(new_state)
return model
# ======== additional ideas
# use when some fuzzy rule (e.g. population stuck at local extrema)
def genocide(self):
# reinitialize some population
pass
# ????
def regulizer(self):
pass
batch_size = 1024
input_size = 11 # size of input vectors
seq_len = 17 # iterations inside RNN
hidden_size = 20
num_classes = 5
ecg_dataset = EcgSequentialLoader(train, seq_len, input_size, num_classes)
dataloader = get_train_loader(ecg_dataset, batch_size)
# GA parameters
population_size = 50
mutation_rate = 3e-2 # mutation probability
n_generations = 50
fitness_function = nn.CrossEntropyLoss()
vanilla_rnn_params = (input_size, hidden_size, num_classes)
gen_alg_1 = GeneticAlgorithm(
VanillaRNN, vanilla_rnn_params, population_size, mutation_rate
)
gen_alg_1.evolve(dataloader, n_generations, fitness_function, "min")
vrnn.state_dict()
# # RNN Training using Genetic Algorithms (GA)
# Questions:
# * How to update weights using GA?
# * What to modify in already existing GA implementations?
# * What should i use as chromosomes in GA?
# Genetic Algorithm:
# 1. Initialize population
# 2. Measure each individual's cost in environment(some error function)
# 3. Select best individuals
# 4. Generate new population from the best genes adding some mutations
# 5. Repeat steps 2-4 until the last epoch (generation) and select the best one of them
# GA parameters
population_sz = 20
mutation_rate = 1e-1 # mutation probability
n_generations = 10
def simple_genetic_algorithm(data):
# initialize population
# run loop for generations
# evaluate population
# select best
# crossing-over parents to create new population with some mutations
return
| false | 0 | 4,374 | 0 | 639 | 4,374 |
||
121679071 | <kaggle_start><data_title>Danish Golf Courses Orthophotos<data_description>## Context:
This dataset contains 1123 orthophotos of Danish golf courses during spring with a scale of 1:1000 and a resolution of 1600x900 pixels. The orthophotos are captured from 107 different Danish golf courses, where each orthophoto captures a broad portion of the physical layout and features of the golf course. The images can contain between 1 to 4 golf holes each with some remaining parts of other converging holes.
### Content:
The data has been annotated to form the ground truth for semantic segmentation using CVAT.
The different classes annotated are:
- Background
- Fairway
- Green
- Tee
- Bunker
- Water
This dataset is divided into 3 folders:
1. Orthophotos: RGB images
2. Segmentation masks: annotated images
3. Class masks: annotated images where each pixel value is between 0 to 5 depending on the class<data_name>danish-golf-courses-orthophotos
<code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import pytorch_lightning as pl
from torch.utils.data import random_split, DataLoader, Dataset
from torchvision.io import read_image
import torch
from torch import nn
from torchvision import transforms
import torchvision.transforms.functional as TF # Used for transforms (resize)
import torch.nn.functional as F
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
IMAGES_DIR = "/kaggle/input/danish-golf-courses-orthophotos/1. orthophotos/"
MASKS_DIR = "/kaggle/input/danish-golf-courses-orthophotos/3. class masks/"
import os
# for dirname, _, filenames in os.walk('/kaggle/input'):
# for filename in filenames:
# pass
##print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
# Hyperparameters
BATCH_SIZE = 1
IMAGE_SIZE = (256, 256) # Images get resized to a smaller resolution
IN_CHANNELS = 3 # There are 3 channels for RGB
# A Dataset class is created to load
class GolfDataset(Dataset):
def __init__(self, images_dir, masks_dir):
self.images_dir = images_dir
self.masks_dir = masks_dir
self.images_dir_list = os.listdir(images_dir)
def __len__(self):
return len(self.images_dir_list)
def __getitem__(self, idx):
image_path = os.path.join(self.images_dir, self.images_dir_list[idx])
image = read_image(image_path)
image = image.float()
mask_path = os.path.join(self.masks_dir, self.images_dir_list[idx])
mask = read_image(image_path)
# Apply transformations to the images
image = TF.resize(image, IMAGE_SIZE) # Apply resize transform
mask = TF.resize(mask, IMAGE_SIZE) # Apply resize transform
mask = TF.rgb_to_grayscale(mask) # Apply grayscaling to go from 3->1 channels.
mask = mask.float()
return image, mask
gds = GolfDataset(IMAGES_DIR, MASKS_DIR)
print(gds.__getitem__(0)[1])
class GolfDataModule(pl.LightningDataModule):
def __init__(self, batch_size):
super().__init__()
self.batch_size = batch_size
self.all_images = []
def prepare_data(self):
# We don't use this function for loading the data as
# WARNING
# prepare_data is called from a single GPU. Do not use it to assign state (self.x = y).
pass
def setup(self, stage=None):
# Data is loaded from the image and mask directories
self.all_images = GolfDataset(IMAGES_DIR, MASKS_DIR)
# The data is split into train, val and test with a 70/20/10 split
self.train_data, self.val_data, self.test_data = random_split(
self.all_images, [0.7, 0.2, 0.1]
)
def train_dataloader(self):
return DataLoader(self.train_data, batch_size=self.batch_size)
def val_dataloader(self):
return DataLoader(self.val_data, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.test_data, batch_size=self.batch_size)
module = GolfDataModule(BATCH_SIZE)
print(module)
# Visualize the data in the golf dataset.
# A random orthophoto is shown along with its mask.
class UNetModel(pl.LightningModule):
def __init__(self):
super().__init__()
def double_conv(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(),
)
def down(in_channels, out_channels):
return nn.Sequential(
nn.MaxPool2d(kernel_size=2), double_conv(in_channels, out_channels)
)
def up(in_channels, out_channels):
print("up in out", in_channels, " ", out_channels)
return nn.Sequential(
nn.ConvTranspose2d(in_channels, out_channels, kernel_size=2, stride=2),
double_conv(in_channels, out_channels),
)
# The encoder part of UNet
self.l1 = double_conv(3, 64)
self.l2 = down(64, 128)
self.l3 = down(128, 256)
self.l4 = down(256, 512)
self.l5 = down(512, 1024)
# The decoder part of UNet
# self.l6 = up(1024, 512)
# self.l7 = up(512, 256)
# self.l8 = up(256, 128)
# self.l9 = up(128, 64)
# self.l10 = double_conv(64, 64)
# Final (1x1) convolution to go from 64 -> 6 channels as we have 6 classes
self.final = nn.Conv2d(1024, 6, kernel_size=1)
self.loss_fn = nn.CrossEntropyLoss()
self.softmax = nn.Softmax2d()
def forward(self, x):
x1 = self.l1(x)
print("shape of x1", x1.shape)
x2 = self.l2(x1)
print("shape of x2", x2.shape)
x3 = self.l3(x2)
print("shape of x3", x3.shape)
x4 = self.l4(x3)
print("shape of x4", x4.shape)
x5 = self.l5(x4)
print("shape of x5", x5.shape)
# x6 = self.l6(x5)
# print("shape of x6", x6.shape)
# x7 = self.l7(x6)
# print("shape of x7", x7.shape)
# x8 = self.l8(x7)
# print("shape of x8", x8.shape)
# x9 = self.l9(x8)
# print("shape of x9", x9.shape)
# x10 = self.l10(x9)
# print("shape of x10", x10.shape)
return self.final(x5)
def training_step(self, batch, batch_idx):
x, y = batch
x = x.float()
y = y.float()
y_pred = self.forward(x)
y_pred = torch.argmax(y_pred, dim=1)
# print("bru", y_pred.shape)
print(y)
print(y_pred)
loss = self.loss_fn(y_pred, y)
return loss
def validation_step(self, batch, batch_idx):
pass
def validation_epoch_end(self, validation_step_outputs):
pass
def configure_optimizers(self):
return torch.optim.AdamW(self.parameters(), lr=0.001)
train_loader = GolfDataModule(BATCH_SIZE)
trainer = pl.Trainer(max_epochs=2, accelerator="gpu", devices=1)
model = UNetModel()
trainer.fit(model, train_loader)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0121/679/121679071.ipynb | danish-golf-courses-orthophotos | jacotaco | [{"Id": 121679071, "ScriptId": 35882420, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 12923738, "CreationDate": "03/10/2023 14:10:30", "VersionNumber": 1.0, "Title": "HEJsa eftggfs", "EvaluationDate": "03/10/2023", "IsChange": true, "TotalLines": 202.0, "LinesInsertedFromPrevious": 202.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 174059423, "KernelVersionId": 121679071, "SourceDatasetVersionId": 4727518}] | [{"Id": 4727518, "DatasetId": 2735624, "DatasourceVersionId": 4790362, "CreatorUserId": 6407631, "LicenseName": "Database: Open Database, Contents: \u00a9 Original Authors", "CreationDate": "12/15/2022 13:54:25", "VersionNumber": 1.0, "Title": "Danish Golf Courses Orthophotos", "Slug": "danish-golf-courses-orthophotos", "Subtitle": "1123 orthophotos of Danish golf courses", "Description": "## Context:\nThis dataset contains 1123 orthophotos of Danish golf courses during spring with a scale of 1:1000 and a resolution of 1600x900 pixels. The orthophotos are captured from 107 different Danish golf courses, where each orthophoto captures a broad portion of the physical layout and features of the golf course. The images can contain between 1 to 4 golf holes each with some remaining parts of other converging holes.\n\n### Content:\nThe data has been annotated to form the ground truth for semantic segmentation using CVAT.\nThe different classes annotated are:\n\n- Background\n- Fairway\n- Green\n- Tee\n- Bunker\n- Water\n\nThis dataset is divided into 3 folders:\n1. Orthophotos: RGB images \n2. Segmentation masks: annotated images\n3. Class masks: annotated images where each pixel value is between 0 to 5 depending on the class\n\n### Acknowledgements:\nThis data was collected from the Danish national database \u201dDataforsyningen\".", "VersionNotes": "Initial release", "TotalCompressedBytes": 0.0, "TotalUncompressedBytes": 0.0}] | [{"Id": 2735624, "CreatorUserId": 6407631, "OwnerUserId": 6407631.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 4727518.0, "CurrentDatasourceVersionId": 4790362.0, "ForumId": 2768924, "Type": 2, "CreationDate": "12/15/2022 13:54:25", "LastActivityDate": "12/15/2022", "TotalViews": 1667, "TotalDownloads": 79, "TotalVotes": 23, "TotalKernels": 2}] | [{"Id": 6407631, "UserName": "jacotaco", "DisplayName": "Jacobo Gonz\u00e1lez de Frutos", "RegisterDate": "12/19/2020", "PerformanceTier": 1}] | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import pytorch_lightning as pl
from torch.utils.data import random_split, DataLoader, Dataset
from torchvision.io import read_image
import torch
from torch import nn
from torchvision import transforms
import torchvision.transforms.functional as TF # Used for transforms (resize)
import torch.nn.functional as F
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
IMAGES_DIR = "/kaggle/input/danish-golf-courses-orthophotos/1. orthophotos/"
MASKS_DIR = "/kaggle/input/danish-golf-courses-orthophotos/3. class masks/"
import os
# for dirname, _, filenames in os.walk('/kaggle/input'):
# for filename in filenames:
# pass
##print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
# Hyperparameters
BATCH_SIZE = 1
IMAGE_SIZE = (256, 256) # Images get resized to a smaller resolution
IN_CHANNELS = 3 # There are 3 channels for RGB
# A Dataset class is created to load
class GolfDataset(Dataset):
def __init__(self, images_dir, masks_dir):
self.images_dir = images_dir
self.masks_dir = masks_dir
self.images_dir_list = os.listdir(images_dir)
def __len__(self):
return len(self.images_dir_list)
def __getitem__(self, idx):
image_path = os.path.join(self.images_dir, self.images_dir_list[idx])
image = read_image(image_path)
image = image.float()
mask_path = os.path.join(self.masks_dir, self.images_dir_list[idx])
mask = read_image(image_path)
# Apply transformations to the images
image = TF.resize(image, IMAGE_SIZE) # Apply resize transform
mask = TF.resize(mask, IMAGE_SIZE) # Apply resize transform
mask = TF.rgb_to_grayscale(mask) # Apply grayscaling to go from 3->1 channels.
mask = mask.float()
return image, mask
gds = GolfDataset(IMAGES_DIR, MASKS_DIR)
print(gds.__getitem__(0)[1])
class GolfDataModule(pl.LightningDataModule):
def __init__(self, batch_size):
super().__init__()
self.batch_size = batch_size
self.all_images = []
def prepare_data(self):
# We don't use this function for loading the data as
# WARNING
# prepare_data is called from a single GPU. Do not use it to assign state (self.x = y).
pass
def setup(self, stage=None):
# Data is loaded from the image and mask directories
self.all_images = GolfDataset(IMAGES_DIR, MASKS_DIR)
# The data is split into train, val and test with a 70/20/10 split
self.train_data, self.val_data, self.test_data = random_split(
self.all_images, [0.7, 0.2, 0.1]
)
def train_dataloader(self):
return DataLoader(self.train_data, batch_size=self.batch_size)
def val_dataloader(self):
return DataLoader(self.val_data, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.test_data, batch_size=self.batch_size)
module = GolfDataModule(BATCH_SIZE)
print(module)
# Visualize the data in the golf dataset.
# A random orthophoto is shown along with its mask.
class UNetModel(pl.LightningModule):
def __init__(self):
super().__init__()
def double_conv(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(),
)
def down(in_channels, out_channels):
return nn.Sequential(
nn.MaxPool2d(kernel_size=2), double_conv(in_channels, out_channels)
)
def up(in_channels, out_channels):
print("up in out", in_channels, " ", out_channels)
return nn.Sequential(
nn.ConvTranspose2d(in_channels, out_channels, kernel_size=2, stride=2),
double_conv(in_channels, out_channels),
)
# The encoder part of UNet
self.l1 = double_conv(3, 64)
self.l2 = down(64, 128)
self.l3 = down(128, 256)
self.l4 = down(256, 512)
self.l5 = down(512, 1024)
# The decoder part of UNet
# self.l6 = up(1024, 512)
# self.l7 = up(512, 256)
# self.l8 = up(256, 128)
# self.l9 = up(128, 64)
# self.l10 = double_conv(64, 64)
# Final (1x1) convolution to go from 64 -> 6 channels as we have 6 classes
self.final = nn.Conv2d(1024, 6, kernel_size=1)
self.loss_fn = nn.CrossEntropyLoss()
self.softmax = nn.Softmax2d()
def forward(self, x):
x1 = self.l1(x)
print("shape of x1", x1.shape)
x2 = self.l2(x1)
print("shape of x2", x2.shape)
x3 = self.l3(x2)
print("shape of x3", x3.shape)
x4 = self.l4(x3)
print("shape of x4", x4.shape)
x5 = self.l5(x4)
print("shape of x5", x5.shape)
# x6 = self.l6(x5)
# print("shape of x6", x6.shape)
# x7 = self.l7(x6)
# print("shape of x7", x7.shape)
# x8 = self.l8(x7)
# print("shape of x8", x8.shape)
# x9 = self.l9(x8)
# print("shape of x9", x9.shape)
# x10 = self.l10(x9)
# print("shape of x10", x10.shape)
return self.final(x5)
def training_step(self, batch, batch_idx):
x, y = batch
x = x.float()
y = y.float()
y_pred = self.forward(x)
y_pred = torch.argmax(y_pred, dim=1)
# print("bru", y_pred.shape)
print(y)
print(y_pred)
loss = self.loss_fn(y_pred, y)
return loss
def validation_step(self, batch, batch_idx):
pass
def validation_epoch_end(self, validation_step_outputs):
pass
def configure_optimizers(self):
return torch.optim.AdamW(self.parameters(), lr=0.001)
train_loader = GolfDataModule(BATCH_SIZE)
trainer = pl.Trainer(max_epochs=2, accelerator="gpu", devices=1)
model = UNetModel()
trainer.fit(model, train_loader)
| false | 0 | 2,005 | 0 | 269 | 2,005 |
||
121873780 | <kaggle_start><data_title>Danish Golf Courses Orthophotos<data_description>## Context:
This dataset contains 1123 orthophotos of Danish golf courses during spring with a scale of 1:1000 and a resolution of 1600x900 pixels. The orthophotos are captured from 107 different Danish golf courses, where each orthophoto captures a broad portion of the physical layout and features of the golf course. The images can contain between 1 to 4 golf holes each with some remaining parts of other converging holes.
### Content:
The data has been annotated to form the ground truth for semantic segmentation using CVAT.
The different classes annotated are:
- Background
- Fairway
- Green
- Tee
- Bunker
- Water
This dataset is divided into 3 folders:
1. Orthophotos: RGB images
2. Segmentation masks: annotated images
3. Class masks: annotated images where each pixel value is between 0 to 5 depending on the class<data_name>danish-golf-courses-orthophotos
<code>import os
import numpy as np
import pytorch_lightning as pl
import torch
import torchmetrics
from torch import nn
import torch.nn.functional as F
from torch.utils.data import random_split, DataLoader, Dataset
from torchvision import transforms
from torchvision.io import read_image
import torchvision.transforms as T
import torchvision.transforms.functional as TF
# Plotting images
from PIL import Image
import matplotlib.pyplot as plt
# Hyperparameters
BATCH_SIZE = 16
IMAGE_SIZE = (256, 256) # Images get resized to a smaller resolution
IN_CHANNELS = 3 # There are 3 channels for RGB
IMAGES_DIR = "/kaggle/input/danish-golf-courses-orthophotos/1. orthophotos/"
SEGMASKS_DIR = "/kaggle/input/danish-golf-courses-orthophotos/2. segmentation masks/"
LABELMASKS_DIR = "/kaggle/input/danish-golf-courses-orthophotos/3. class masks/"
# A Dataset class is created to load
class GolfDataset(Dataset):
def __init__(self, images_dir, labelmasks_dir, segmasks_dir):
self.images_dir = images_dir
self.labelmasks_dir = labelmasks_dir
self.images_dir_list = os.listdir(
images_dir
) # We create a list PATHs to every file in the orthophotos directory.
def __len__(self):
# return 10
return len(self.images_dir_list)
def __getitem__(self, idx):
image_path = os.path.join(self.images_dir, self.images_dir_list[idx])
image = read_image(image_path)
image = image.float()
labelmask_path = os.path.join(
self.labelmasks_dir, self.images_dir_list[idx]
).replace(
".jpg", ".png"
) # The class masks are png instead of jpg
labelmask = read_image(labelmask_path)
# Apply transformations to the images
image = TF.resize(image, IMAGE_SIZE) # Apply resize transform
labelmask = TF.resize(labelmask, IMAGE_SIZE) # Apply resize transform
labelmask = TF.rgb_to_grayscale(
labelmask
) # Apply grayscaling to go from 3->1 channels.
labelmask = labelmask.float()
return image, labelmask
# Loading the data
orthophoto_list = os.listdir(IMAGES_DIR)
# Load image with index of 5 (I prefer this image as it shows all the classes)
idx = 5
golf_image = Image.open(os.path.join(IMAGES_DIR, orthophoto_list[idx]))
golf_segmask = Image.open(
os.path.join(SEGMASKS_DIR, orthophoto_list[idx].replace(".jpg", ".png"))
) # The class masks are png instead of jpg
# Plot using matplotlib
fig, axes = plt.subplots(1, 2)
axes[0].set_title("Orthophoto")
axes[1].set_title("Segmentation Mask")
axes[0].imshow(golf_image)
axes[1].imshow(golf_segmask)
class GolfDataModule(pl.LightningDataModule):
def __init__(self, batch_size):
super().__init__()
self.batch_size = batch_size
self.all_images = []
def prepare_data(self):
# We don't use this function for loading the data as
# WARNING
# prepare_data is called from a single GPU. Do not use it to assign state (self.x = y).
pass
def setup(self, stage=None):
# Data is loaded from the image and mask directories
self.all_images = GolfDataset(IMAGES_DIR, LABELMASKS_DIR, SEGMASKS_DIR)
# The data is split into train, val and test with a 70/20/10 split
self.train_data, self.val_data, self.test_data = random_split(
self.all_images, [0.7, 0.2, 0.1]
)
def train_dataloader(self):
return DataLoader(self.train_data, batch_size=self.batch_size)
def val_dataloader(self):
return DataLoader(self.val_data, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.test_data, batch_size=self.batch_size)
# Visualize the data in the golf dataset.
# A random orthophoto is shown along with its mask.
class UNetModel(pl.LightningModule):
def __init__(self):
super().__init__()
def double_conv(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(),
)
def down(in_channels, out_channels):
return nn.Sequential(
nn.MaxPool2d(kernel_size=2), double_conv(in_channels, out_channels)
)
def up(in_channels, out_channels):
return nn.Sequential(
nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True),
double_conv(in_channels, out_channels),
)
# The encoder part of UNet
self.l1 = double_conv(3, 64)
self.l2 = down(64, 128)
self.l3 = down(128, 256)
self.l4 = down(256, 512)
self.l5 = down(512, 1024)
# The decoder part of UNet
self.l6 = up(1024, 512)
self.l7 = up(512, 256)
self.l8 = up(256, 128)
self.l9 = up(128, 64)
self.l10 = double_conv(64, 64)
# Final (1x1) convolution to go from 64 -> 6 channels as we have 6 classes
self.final = nn.Conv2d(64, 6, kernel_size=1)
self.loss_fn = nn.CrossEntropyLoss()
self.softmax = nn.Softmax2d()
self.train_acc = torchmetrics.Accuracy(task="multiclass", num_classes=6)
self.valid_acc = torchmetrics.Accuracy(task="multiclass", num_classes=6)
def prepare_prediction_tensor(self, pred):
pred = self.softmax(pred)
pred = torch.argmax(pred, dim=1)
pred = pred.float()
pred = pred.unsqueeze(1)
pred.requires_grad_()
return pred
def forward(self, x):
x1 = self.l1(x)
x2 = self.l2(x1)
x3 = self.l3(x2)
x4 = self.l4(x3)
x5 = self.l5(x4)
x6 = self.l6(x5)
x7 = self.l7(x6)
x8 = self.l8(x7)
x9 = self.l9(x8)
x10 = self.l10(x9)
return self.final(x10)
def training_step(self, batch, batch_idx):
x, y = batch
y_pred = self.forward(x)
y_pred = self.prepare_prediction_tensor(y_pred)
loss = self.loss_fn(y_pred, y)
self.train_acc(y_pred, y)
self.log("train_acc", self.train_acc, on_step=True, on_epoch=False)
return loss
def training_epoch_end(self, outs):
pass
def validation_step(self, batch, batch_idx):
x, y = batch
y_pred = self.forward(x)
y_pred = self.prepare_prediction_tensor(y_pred)
loss = self.loss_fn(y_pred, y)
self.valid_acc(y_pred, y)
self.log("valid_acc", self.valid_acc, on_step=True, on_epoch=True)
return loss
def save_predictions_as_imgs(
self, x, y, preds, folder="/kaggle/working/", counter=0, names=[]
):
x = x.to(self.device)
y = y.to(self.device)
preds = preds.to(self.device)
class_to_color = [
torch.tensor([0.0, 0.0, 0.0], device=self.device),
torch.tensor([0.0, 140.0 / 255, 0.0], device=self.device),
torch.tensor([0.0, 1.0, 0.0], device=self.device),
torch.tensor([1.0, 0.0, 0.0], device=self.device),
torch.tensor([217.0 / 255, 230.0 / 255, 122.0 / 255], device=self.device),
torch.tensor([7.0 / 255, 15.0 / 255, 247.0 / 255], device=self.device),
]
output = torch.zeros(
preds.shape[0], 3, preds.size(-2), preds.size(-1), dtype=torch.float
) # Output size is set to preds.shape[0] as the size automatically changes to fit the remaining batch_size.
for class_idx, color in enumerate(class_to_color):
mask = preds[:, class_idx, :, :] == torch.max(preds, dim=1)[0]
mask = mask.unsqueeze(1)
curr_color = color.reshape(1, 3, 1, 1)
segment = mask * curr_color
output += segment
y_output = torch.zeros(
y.shape[0],
3,
preds.size(-2),
preds.size(-1),
dtype=torch.float,
device=self.device,
)
for class_idx, color in enumerate(class_to_color):
mask = y[:, :, :] == class_idx
mask = mask.unsqueeze(1)
# print("mask shape", mask.shape)
curr_color = color.reshape(1, 3, 1, 1)
segment = mask * curr_color
y_output += segment
# Save images to our saved_images folder
torchvision.utils.save_image(output, f"{folder}/{idx+1}_prediction.png")
# if counter == 0: #Only save original and grountruth on the first tine (no reason to re-save it if they dont change)
torchvision.utils.save_image(y_output, f"{folder}/{idx+1}_groundtruth.png")
torchvision.utils.save_image(x, f"{folder}/{idx+1}_figure_.png")
def configure_optimizers(self):
return torch.optim.AdamW(self.parameters(), lr=0.001)
train_loader = GolfDataModule(BATCH_SIZE)
trainer = pl.Trainer(max_epochs=100, accelerator="gpu", devices=2)
model = UNetModel()
trainer.fit(model, train_loader)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0121/873/121873780.ipynb | danish-golf-courses-orthophotos | jacotaco | [{"Id": 121873780, "ScriptId": 35882420, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 12923738, "CreationDate": "03/12/2023 14:06:11", "VersionNumber": 6.0, "Title": "HEJsa eftggfs", "EvaluationDate": "03/12/2023", "IsChange": false, "TotalLines": 250.0, "LinesInsertedFromPrevious": 0.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 250.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 174360921, "KernelVersionId": 121873780, "SourceDatasetVersionId": 4727518}] | [{"Id": 4727518, "DatasetId": 2735624, "DatasourceVersionId": 4790362, "CreatorUserId": 6407631, "LicenseName": "Database: Open Database, Contents: \u00a9 Original Authors", "CreationDate": "12/15/2022 13:54:25", "VersionNumber": 1.0, "Title": "Danish Golf Courses Orthophotos", "Slug": "danish-golf-courses-orthophotos", "Subtitle": "1123 orthophotos of Danish golf courses", "Description": "## Context:\nThis dataset contains 1123 orthophotos of Danish golf courses during spring with a scale of 1:1000 and a resolution of 1600x900 pixels. The orthophotos are captured from 107 different Danish golf courses, where each orthophoto captures a broad portion of the physical layout and features of the golf course. The images can contain between 1 to 4 golf holes each with some remaining parts of other converging holes.\n\n### Content:\nThe data has been annotated to form the ground truth for semantic segmentation using CVAT.\nThe different classes annotated are:\n\n- Background\n- Fairway\n- Green\n- Tee\n- Bunker\n- Water\n\nThis dataset is divided into 3 folders:\n1. Orthophotos: RGB images \n2. Segmentation masks: annotated images\n3. Class masks: annotated images where each pixel value is between 0 to 5 depending on the class\n\n### Acknowledgements:\nThis data was collected from the Danish national database \u201dDataforsyningen\".", "VersionNotes": "Initial release", "TotalCompressedBytes": 0.0, "TotalUncompressedBytes": 0.0}] | [{"Id": 2735624, "CreatorUserId": 6407631, "OwnerUserId": 6407631.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 4727518.0, "CurrentDatasourceVersionId": 4790362.0, "ForumId": 2768924, "Type": 2, "CreationDate": "12/15/2022 13:54:25", "LastActivityDate": "12/15/2022", "TotalViews": 1667, "TotalDownloads": 79, "TotalVotes": 23, "TotalKernels": 2}] | [{"Id": 6407631, "UserName": "jacotaco", "DisplayName": "Jacobo Gonz\u00e1lez de Frutos", "RegisterDate": "12/19/2020", "PerformanceTier": 1}] | import os
import numpy as np
import pytorch_lightning as pl
import torch
import torchmetrics
from torch import nn
import torch.nn.functional as F
from torch.utils.data import random_split, DataLoader, Dataset
from torchvision import transforms
from torchvision.io import read_image
import torchvision.transforms as T
import torchvision.transforms.functional as TF
# Plotting images
from PIL import Image
import matplotlib.pyplot as plt
# Hyperparameters
BATCH_SIZE = 16
IMAGE_SIZE = (256, 256) # Images get resized to a smaller resolution
IN_CHANNELS = 3 # There are 3 channels for RGB
IMAGES_DIR = "/kaggle/input/danish-golf-courses-orthophotos/1. orthophotos/"
SEGMASKS_DIR = "/kaggle/input/danish-golf-courses-orthophotos/2. segmentation masks/"
LABELMASKS_DIR = "/kaggle/input/danish-golf-courses-orthophotos/3. class masks/"
# A Dataset class is created to load
class GolfDataset(Dataset):
def __init__(self, images_dir, labelmasks_dir, segmasks_dir):
self.images_dir = images_dir
self.labelmasks_dir = labelmasks_dir
self.images_dir_list = os.listdir(
images_dir
) # We create a list PATHs to every file in the orthophotos directory.
def __len__(self):
# return 10
return len(self.images_dir_list)
def __getitem__(self, idx):
image_path = os.path.join(self.images_dir, self.images_dir_list[idx])
image = read_image(image_path)
image = image.float()
labelmask_path = os.path.join(
self.labelmasks_dir, self.images_dir_list[idx]
).replace(
".jpg", ".png"
) # The class masks are png instead of jpg
labelmask = read_image(labelmask_path)
# Apply transformations to the images
image = TF.resize(image, IMAGE_SIZE) # Apply resize transform
labelmask = TF.resize(labelmask, IMAGE_SIZE) # Apply resize transform
labelmask = TF.rgb_to_grayscale(
labelmask
) # Apply grayscaling to go from 3->1 channels.
labelmask = labelmask.float()
return image, labelmask
# Loading the data
orthophoto_list = os.listdir(IMAGES_DIR)
# Load image with index of 5 (I prefer this image as it shows all the classes)
idx = 5
golf_image = Image.open(os.path.join(IMAGES_DIR, orthophoto_list[idx]))
golf_segmask = Image.open(
os.path.join(SEGMASKS_DIR, orthophoto_list[idx].replace(".jpg", ".png"))
) # The class masks are png instead of jpg
# Plot using matplotlib
fig, axes = plt.subplots(1, 2)
axes[0].set_title("Orthophoto")
axes[1].set_title("Segmentation Mask")
axes[0].imshow(golf_image)
axes[1].imshow(golf_segmask)
class GolfDataModule(pl.LightningDataModule):
def __init__(self, batch_size):
super().__init__()
self.batch_size = batch_size
self.all_images = []
def prepare_data(self):
# We don't use this function for loading the data as
# WARNING
# prepare_data is called from a single GPU. Do not use it to assign state (self.x = y).
pass
def setup(self, stage=None):
# Data is loaded from the image and mask directories
self.all_images = GolfDataset(IMAGES_DIR, LABELMASKS_DIR, SEGMASKS_DIR)
# The data is split into train, val and test with a 70/20/10 split
self.train_data, self.val_data, self.test_data = random_split(
self.all_images, [0.7, 0.2, 0.1]
)
def train_dataloader(self):
return DataLoader(self.train_data, batch_size=self.batch_size)
def val_dataloader(self):
return DataLoader(self.val_data, batch_size=self.batch_size)
def test_dataloader(self):
return DataLoader(self.test_data, batch_size=self.batch_size)
# Visualize the data in the golf dataset.
# A random orthophoto is shown along with its mask.
class UNetModel(pl.LightningModule):
def __init__(self):
super().__init__()
def double_conv(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(),
)
def down(in_channels, out_channels):
return nn.Sequential(
nn.MaxPool2d(kernel_size=2), double_conv(in_channels, out_channels)
)
def up(in_channels, out_channels):
return nn.Sequential(
nn.Upsample(scale_factor=2, mode="bilinear", align_corners=True),
double_conv(in_channels, out_channels),
)
# The encoder part of UNet
self.l1 = double_conv(3, 64)
self.l2 = down(64, 128)
self.l3 = down(128, 256)
self.l4 = down(256, 512)
self.l5 = down(512, 1024)
# The decoder part of UNet
self.l6 = up(1024, 512)
self.l7 = up(512, 256)
self.l8 = up(256, 128)
self.l9 = up(128, 64)
self.l10 = double_conv(64, 64)
# Final (1x1) convolution to go from 64 -> 6 channels as we have 6 classes
self.final = nn.Conv2d(64, 6, kernel_size=1)
self.loss_fn = nn.CrossEntropyLoss()
self.softmax = nn.Softmax2d()
self.train_acc = torchmetrics.Accuracy(task="multiclass", num_classes=6)
self.valid_acc = torchmetrics.Accuracy(task="multiclass", num_classes=6)
def prepare_prediction_tensor(self, pred):
pred = self.softmax(pred)
pred = torch.argmax(pred, dim=1)
pred = pred.float()
pred = pred.unsqueeze(1)
pred.requires_grad_()
return pred
def forward(self, x):
x1 = self.l1(x)
x2 = self.l2(x1)
x3 = self.l3(x2)
x4 = self.l4(x3)
x5 = self.l5(x4)
x6 = self.l6(x5)
x7 = self.l7(x6)
x8 = self.l8(x7)
x9 = self.l9(x8)
x10 = self.l10(x9)
return self.final(x10)
def training_step(self, batch, batch_idx):
x, y = batch
y_pred = self.forward(x)
y_pred = self.prepare_prediction_tensor(y_pred)
loss = self.loss_fn(y_pred, y)
self.train_acc(y_pred, y)
self.log("train_acc", self.train_acc, on_step=True, on_epoch=False)
return loss
def training_epoch_end(self, outs):
pass
def validation_step(self, batch, batch_idx):
x, y = batch
y_pred = self.forward(x)
y_pred = self.prepare_prediction_tensor(y_pred)
loss = self.loss_fn(y_pred, y)
self.valid_acc(y_pred, y)
self.log("valid_acc", self.valid_acc, on_step=True, on_epoch=True)
return loss
def save_predictions_as_imgs(
self, x, y, preds, folder="/kaggle/working/", counter=0, names=[]
):
x = x.to(self.device)
y = y.to(self.device)
preds = preds.to(self.device)
class_to_color = [
torch.tensor([0.0, 0.0, 0.0], device=self.device),
torch.tensor([0.0, 140.0 / 255, 0.0], device=self.device),
torch.tensor([0.0, 1.0, 0.0], device=self.device),
torch.tensor([1.0, 0.0, 0.0], device=self.device),
torch.tensor([217.0 / 255, 230.0 / 255, 122.0 / 255], device=self.device),
torch.tensor([7.0 / 255, 15.0 / 255, 247.0 / 255], device=self.device),
]
output = torch.zeros(
preds.shape[0], 3, preds.size(-2), preds.size(-1), dtype=torch.float
) # Output size is set to preds.shape[0] as the size automatically changes to fit the remaining batch_size.
for class_idx, color in enumerate(class_to_color):
mask = preds[:, class_idx, :, :] == torch.max(preds, dim=1)[0]
mask = mask.unsqueeze(1)
curr_color = color.reshape(1, 3, 1, 1)
segment = mask * curr_color
output += segment
y_output = torch.zeros(
y.shape[0],
3,
preds.size(-2),
preds.size(-1),
dtype=torch.float,
device=self.device,
)
for class_idx, color in enumerate(class_to_color):
mask = y[:, :, :] == class_idx
mask = mask.unsqueeze(1)
# print("mask shape", mask.shape)
curr_color = color.reshape(1, 3, 1, 1)
segment = mask * curr_color
y_output += segment
# Save images to our saved_images folder
torchvision.utils.save_image(output, f"{folder}/{idx+1}_prediction.png")
# if counter == 0: #Only save original and grountruth on the first tine (no reason to re-save it if they dont change)
torchvision.utils.save_image(y_output, f"{folder}/{idx+1}_groundtruth.png")
torchvision.utils.save_image(x, f"{folder}/{idx+1}_figure_.png")
def configure_optimizers(self):
return torch.optim.AdamW(self.parameters(), lr=0.001)
train_loader = GolfDataModule(BATCH_SIZE)
trainer = pl.Trainer(max_epochs=100, accelerator="gpu", devices=2)
model = UNetModel()
trainer.fit(model, train_loader)
| false | 0 | 2,809 | 0 | 269 | 2,809 |
||
121063973 | <kaggle_start><code># # NLP Disaster Tweets Kaggle Mini-Project
# ## Overview
# This notebook is a practice of utilizing the TensorFlow and Keras to build a Neural Network (NN) to identify false and real emergency alert from the post on Twitter. The practice is based on a Kaggle competition, and the data can be obtained from the competition website at https://www.kaggle.com/competitions/nlp-getting-started/data.
# This notebook can also be found at https://github.com/Lorby04/msds/tree/main/dl/week4 and https://www.kaggle.com/code/lorbybi/nlp-disaster-tweets
# 1. Data preparing
# Downloading data from the source, extract the compressed files to local disk.
# The data includes 3 csv files, one includes the training data, and one includes the testing data, another one is a sample file.
# We will use the training data to train the model and then make estimation on the testing data.
# import required libraries
import pathlib
import os
import sys
import concurrent.futures
import pandas as pd
import numpy as np
import random as rn
import tensorflow as tf
import tensorflow_datasets as tfds
import matplotlib.pyplot as plt
from timeit import default_timer as timer
import re
import shutil
import string
class Constants:
QUICK_TEST = False
MAX_FILES = sys.maxsize
TARGET_SIZE = [96, 96]
BATCH_SIZE = 32
RETRAIN_MODEL = False
MAX_FEATURES = 1000
SEQUENCE_LEN = 10
class Config:
def __init__(self):
self.dataset_url = (
"https://www.kaggle.com/competitions/histopathologic-cancer-detection/data"
)
self.data_root_dir = "/kaggle/input/mayo-clinic-strip-ai/"
self.working_dir = "/kaggle/working/"
self.temp_dir = "/kaggle/working/temp/"
if os.path.exists("/kaggle"):
print("Working in kaggle notebook enviorment")
else:
print("Working locally")
self.data_root_dir = "./nlp-getting-started/"
self.working_dir = self.data_root_dir
self.temp_dir = "./nlp-getting-started/"
self.temp_train_dir = self.temp_dir + "train/"
self.temp_test_dir = self.temp_dir + "test/"
self.data_dir = self.data_root_dir
self.train_csv = self.data_dir + "train.csv"
self.test_csv = self.data_dir + "test.csv"
self.origin_train_dir = "././nlp-getting-started/train/"
self.origin_test_dir = "././nlp-getting-started/test/"
self.train_dir = self.temp_train_dir # self.data_dir + "train/"
self.test_dir = self.temp_test_dir # self.data_dir + "test/"
self.dir_true = self.train_dir + "1/"
self.dir_false = self.train_dir + "0/"
self.origin_train_path = pathlib.Path(self.origin_train_dir).with_suffix("")
self.origin_test_path = pathlib.Path(self.origin_test_dir).with_suffix("")
self.train_path = pathlib.Path(self.train_dir).with_suffix("")
self.test_path = pathlib.Path(self.test_dir).with_suffix("")
# Convert the image from tif to jpg
# Move train data to subclass directory
def new_dir(directory):
cmd = "mkdir " + directory
os.system(cmd)
def download_data(self):
if not os.path.exists(self.data_dir):
cmd = "pip install opendatasets"
os.system(cmd)
import opendatasets as od
od.download(self.dataset_url)
new_dir(data_dir)
new_dir(train_dir)
new_dir(test_dir)
new_dir(dir_true)
new_dir(dir_false)
# Download data, create pandas dataframe from the csv files.
class Df:
def __init__(self, cfg: Config):
self.train_df = pd.read_csv(cfg.train_csv)
self.test_df = None if cfg.test_csv == None else pd.read_csv(cfg.test_csv)
def combine_train_set(self):
pass
def glance_at(self, df):
print("\nQuick view of {} data set".format(df))
if df == "train":
print(self.train_df)
self.train_df.info()
print("Target values:")
vc = self.train_df["target"].value_counts()
print(vc)
labels = ["Fake", "Real"]
plt.pie(vc, autopct="%1.1f%%", labels=labels)
plt.legend(vc.index, loc="best")
plt.show()
elif df == "test" and self.test_df is not None:
print(self.test_df)
self.test_df.info()
else:
pass
def glance(self):
self.glance_at("train")
self.glance_at("test")
config = Config()
config.download_data()
df = Df(config)
# ## Exploratory Data Analysis (EDA)
# Firstly, have a glance on the training data. It includes 7613 observations and 5 features. Among these features, most of the observations of 'keywords' and 'location' are not available. So these 2 features will not be considered in the training. The 'id' field is for indexing only, it is not needed for training.
# The 'text' is the input data and the 'target' field is output data.
# Further check on the values of the feature 'target', it has 2 unique values: 0 means false alert and 1 means true alert.
# There are 3263 rows of data for testing.
# From the statistics information, 57% of the training data are false alerts and the other 43% are true alerts.
df.glance_at("train")
df.train_df[df.train_df["target"] == 1]["text"].values[100]
df.train_df[df.train_df["target"] != 1]["text"].values[100]
df.glance_at("test")
# The tensorflow dataset API text_dataset_from_directory requires the training data to be organized in a hierarchical structure with the sundir name being the name of the category. To follow the requirement of the API, the 'text' field in the dataframe are copied to txt file respectively.
# Cross check the raw data with the files in the traning directory. The data matches with the csv file.
list(config.train_path.iterdir())
def check_create_dir(path):
if not os.path.exists(path):
os.makedirs(path)
else:
pass
class TextRawDataInDisk:
def __init__(self, df, to_path, quick_test=Constants.QUICK_TEST):
self.df = df # List of df
self.to_path = to_path
self.max_files = min(len(df), Constants.MAX_FILES)
self.quick_test = quick_test
if quick_test:
self.max_files = min(4, len(df))
self.loaded_files = 0
self.skipped_files = 0
self.is_training = "target" in df.columns
class TextLoaderToDisk:
def build(df, to_path, quick_test=Constants.QUICK_TEST):
owner = TextRawDataInDisk(df, to_path, quick_test)
check_create_dir(to_path)
loader = TextLoaderToDisk(owner)
loader.load()
return loader
def __init__(self, owner=None):
self._owner = owner
def reset_owner(self, owner):
self._owner = owner
def owner(self):
return self._owner
def load(self):
start = timer()
self.owner().loaded_files = 0
loop_start = timer()
to_dir = self.owner().to_path
for row in self.owner().df.itertuples(index=False):
txt = "/" + str(row.id) + ".txt"
if self.owner().is_training:
label = str(row.target)
to_dir = self.owner().to_path + label + "/"
else:
assert to_dir == self.owner().to_path
to_file = to_dir + str(row.id) + ".txt"
if os.path.exists(to_file):
self.owner().skipped_files += 1
self.owner().loaded_files += 1
continue
check_create_dir(to_dir)
with open(to_file, "w") as f:
f.write(row.text)
self.owner().loaded_files += 1
if self.owner().loaded_files % 50 == 0:
print(".", end=" ")
elapsed = timer() - start
print(
"{} files are stored to {} in {} seconds, {} are skipped among which.".format(
self.owner().loaded_files,
self.owner().to_path,
elapsed,
self.owner().skipped_files,
)
)
def statistics(self):
print(
"{} file are stored to {} , {} are skipped among which.".format(
self.owner().loaded_files,
self.owner().to_path,
self.owner().skipped_files,
)
)
class DatasetFromDisk:
def __init__(self, td, training_ratio=0.8):
self.ds_from = td.to_path
assert self.ds_from != None
self.is_training = td.is_training
self.training_ratio = (
training_ratio if training_ratio > 0 and training_ratio <= 1 else 0.8
)
self.train_ds_ = None
self.val_ds_ = None
self.test_ds_ = None
self.is_preprocessed = False
class DatasetBuilderFromDisk:
def build(td, training_ratio=0.8):
owner = DatasetFromDisk(td, training_ratio)
builder = DatasetBuilderFromDisk(owner)
builder.build_dataset()
return builder
def __init__(self, owner=None): # MUST set owner before using
self._owner = owner
def reset_owner(self, owner):
self._owner = owner
def owner(self):
return self._owner
def build_dataset(self):
if self.owner().is_training:
self.owner().train_ds_ = tf.keras.utils.text_dataset_from_directory(
self.owner().ds_from,
validation_split=0.2,
subset="training",
seed=123,
batch_size=Constants.BATCH_SIZE,
)
self.owner().val_ds_ = tf.keras.utils.text_dataset_from_directory(
self.owner().ds_from,
validation_split=1 - self.owner().training_ratio,
subset="validation",
seed=123,
batch_size=Constants.BATCH_SIZE,
)
else:
pass
self.pre_process()
def pre_process(self):
return # Don't perform preprocess
def train_ds(self):
return self.owner().train_ds_
def val_ds(self):
return self.owner().val_ds_
def test_ds(self):
return self.owner().test_ds_
def show_train_texts(self, ds, number):
assert ds != None and number >= 1
i = 0
for txts, labels in ds:
# print(imgs)
# print(labels)
for txt in txts:
print(txt)
i += 1
if i >= number:
return
def show_test_texts(self, ds, number):
i = 0
for b in ds:
for t in b:
print(t)
i += 1
if i >= number:
return
def show_texts(self):
if self.owner().train_ds_ != None:
self.show_train_texts(self.owner().train_ds_, 3)
assert self.owner().val_ds_ != None
self.show_train_texts(self.owner().val_ds_, 3)
else:
assert self.owner().test_ds_ != None
self.show_test_texts(self.owner().test_ds_, 3)
def statistics(self):
if self.owner().train_ds_ != None:
for i, target in enumerate(self.owner().train_ds_.class_names):
print("Index:", i, "corresponds to:", target)
for text_batch, target_batch in self.owner().train_ds_.take(1):
for i in range(3):
print("Statement: ", text_batch.numpy()[i])
print("Target:", target_batch.numpy()[i])
for text_batch, target_batch in self.owner().val_ds_.take(1):
for i in range(3):
print("Statement: ", text_batch.numpy()[i])
print("Target:", target_batch.numpy()[i])
else:
for text_batch in self.owner().test_ds_.take(1):
for i in range(4):
print("Statement: ", text_batch.numpy()[i])
# Use alias to try different options
TextData = TextRawDataInDisk
TextLoader = TextLoaderToDisk
Dataset = DatasetFromDisk
DatasetBuilder = DatasetBuilderFromDisk
# Generate training and validation dataset with text_dataset_from_directory
train_texts = TextLoader.build(df.train_df, config.temp_train_dir).owner()
train_text_loader = TextLoader(train_texts)
ds = DatasetBuilder.build(train_texts).owner()
ds_loader = DatasetBuilder(ds)
ds_loader.show_texts()
# Check the dataset is as expected.
ds_loader.statistics()
# ## Model Architecture
# The high level architecture of the training network are referring to the tensorflow training material for text classification.
# The model includes the following layers:
# 1. Input layer
# 2. Vectorization layer: This layer is to standardize, tokenize, and vectorize the data. The vectorization layer is from the tf.keras.layers.TextVectorization
# 3. Hidden network layers, including embedding pooling and dense layer for respective model.
# 4. SparseCategoricalCrossentropy is used as loss function
# 5. Optimize with Adam function
# 6. Accuracy as the metric parameter
# 7. Early stop if validation accuracy is not increasing for continuous 3 epochs
# Two models, int vectorization base and binary vectorization base, are tried. The hyper-parameters are adjusted with multiple running to avoid overfitting and underfitting with reasonable accuracy.
#
from tensorflow.keras.optimizers.legacy import Adam
class Model:
def __init__(self, ds):
self.ds = ds
self.history = None
self.opt = Adam()
self.loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
self.metrics = ["accuracy"]
self.callbacks = [
tf.keras.callbacks.EarlyStopping(monitor="val_accuracy", patience=5)
]
self.model = self.build_model()
def fit(self, ds=None, epochs=10):
if ds == None:
ds = self.ds
self.history = self.model.fit(
ds.train_ds_,
validation_data=ds.val_ds_,
epochs=epochs,
callbacks=self.callbacks,
)
def build_model(self):
import tensorflow.strings as tfs
from tensorflow.strings import regex_replace as rr
# Prepare the vectorization layer
normalization = lambda s: rr(
rr(tfs.lower(s), "<br />", " "), "[%s]" % re.escape(string.punctuation), ""
)
extraction = lambda x, y: x
vectorize_layer = tf.keras.layers.TextVectorization(
standardize=normalization,
max_tokens=Constants.MAX_FEATURES,
output_mode="binary",
)
texts = ds.train_ds_.map(extraction)
vectorize_layer.adapt(texts)
model = tf.keras.Sequential(
[vectorize_layer, tf.keras.layers.Dense(len(self.ds.train_ds_.class_names))]
)
model.compile(loss=self.loss, optimizer=self.opt, metrics=["accuracy"])
return model
class ModelVisualization:
def __init__(self, model: Model):
self.model = model
def show_history(self):
history = self.model.history.history
fig = plt.figure(figsize=(6, 10))
fig_width = 1
fig_height = 2
ax = fig.subplots(fig_height, fig_width)
ax[0].plot(history["accuracy"], "*-")
ax[0].plot(history["val_accuracy"], "x-")
ax[0].legend(["train", "validation"])
ax[0].set_xlabel("epoch")
ax[0].set_ylabel("accuracy")
ax[0].set_title("Accuracies")
ax[1].plot(history["loss"], "*-")
ax[1].plot(history["val_loss"], "x-")
ax[1].legend(["train", "validation"])
ax[1].set_title("Losses")
ax[1].set_xlabel("epoch")
ax[1].set_ylabel("loss")
plt.show()
def summary(self):
self.model.model.summary()
self.model.model.get_metrics_result()
m = Model(ds)
m.fit(epochs=100)
vm = ModelVisualization(m)
vm.show_history()
vm.summary()
# ## Test
# From the training result, the binary model has higher validation accuracy and there is no significant indication of overfitting.
# So the binary model will be used for the testing.
# Before testing, a softmax layer is added to the model to make the probability more obvious.
# The test images are from the previously prepared test directory.
# To make the result clearer, a pandas dataframe is created for the record.
class Predictor:
def __init__(self, model: tf.keras.Model, test_df):
self.model = model
# self.model.add(tf.keras.layers.Softmax())
self.test_df = test_df
self.df = None
self.pred = self.predict()
self.pred_df = None
self.build_result_df()
self.submit()
def predict(self):
y_pred_prob = self.model.model.predict(np.array(self.test_df.text))
return tf.keras.activations.softmax(tf.convert_to_tensor(y_pred_prob))
def build_result_df(self):
self.pred_df = pd.DataFrame(self.test_df["id"])
self.pred_df["target"] = pd.DataFrame(self.pred).apply(np.argmax, axis=1)
def submit(self):
self.pred_df.to_csv("submission.csv", index=False)
class PredictorDisplay:
def __init__(self, owner):
self.owner = owner
def dump(self):
print("Prediction possibilities:")
print(self.owner.pred_df)
print(self.owner.pred_df.target.value_counts())
def show_result(self):
labels = ["Fake", "Real"]
plt.pie(
self.owner.pred_df["target"].value_counts(),
autopct="%1.1f%%",
labels=labels,
)
plt.show()
pred = Predictor(m, df.test_df)
disp = PredictorDisplay(pred)
disp.dump()
disp.show_result()
labels = ["Fake", "Real"]
plt.pie(df.train_df["target"].value_counts(), autopct="%1.1f%%", labels=labels)
plt.show()
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0121/063/121063973.ipynb | null | null | [{"Id": 121063973, "ScriptId": 35176022, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 11726793, "CreationDate": "03/04/2023 21:45:31", "VersionNumber": 2.0, "Title": "NLP Disaster Tweets", "EvaluationDate": "03/04/2023", "IsChange": true, "TotalLines": 563.0, "LinesInsertedFromPrevious": 485.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 78.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | # # NLP Disaster Tweets Kaggle Mini-Project
# ## Overview
# This notebook is a practice of utilizing the TensorFlow and Keras to build a Neural Network (NN) to identify false and real emergency alert from the post on Twitter. The practice is based on a Kaggle competition, and the data can be obtained from the competition website at https://www.kaggle.com/competitions/nlp-getting-started/data.
# This notebook can also be found at https://github.com/Lorby04/msds/tree/main/dl/week4 and https://www.kaggle.com/code/lorbybi/nlp-disaster-tweets
# 1. Data preparing
# Downloading data from the source, extract the compressed files to local disk.
# The data includes 3 csv files, one includes the training data, and one includes the testing data, another one is a sample file.
# We will use the training data to train the model and then make estimation on the testing data.
# import required libraries
import pathlib
import os
import sys
import concurrent.futures
import pandas as pd
import numpy as np
import random as rn
import tensorflow as tf
import tensorflow_datasets as tfds
import matplotlib.pyplot as plt
from timeit import default_timer as timer
import re
import shutil
import string
class Constants:
QUICK_TEST = False
MAX_FILES = sys.maxsize
TARGET_SIZE = [96, 96]
BATCH_SIZE = 32
RETRAIN_MODEL = False
MAX_FEATURES = 1000
SEQUENCE_LEN = 10
class Config:
def __init__(self):
self.dataset_url = (
"https://www.kaggle.com/competitions/histopathologic-cancer-detection/data"
)
self.data_root_dir = "/kaggle/input/mayo-clinic-strip-ai/"
self.working_dir = "/kaggle/working/"
self.temp_dir = "/kaggle/working/temp/"
if os.path.exists("/kaggle"):
print("Working in kaggle notebook enviorment")
else:
print("Working locally")
self.data_root_dir = "./nlp-getting-started/"
self.working_dir = self.data_root_dir
self.temp_dir = "./nlp-getting-started/"
self.temp_train_dir = self.temp_dir + "train/"
self.temp_test_dir = self.temp_dir + "test/"
self.data_dir = self.data_root_dir
self.train_csv = self.data_dir + "train.csv"
self.test_csv = self.data_dir + "test.csv"
self.origin_train_dir = "././nlp-getting-started/train/"
self.origin_test_dir = "././nlp-getting-started/test/"
self.train_dir = self.temp_train_dir # self.data_dir + "train/"
self.test_dir = self.temp_test_dir # self.data_dir + "test/"
self.dir_true = self.train_dir + "1/"
self.dir_false = self.train_dir + "0/"
self.origin_train_path = pathlib.Path(self.origin_train_dir).with_suffix("")
self.origin_test_path = pathlib.Path(self.origin_test_dir).with_suffix("")
self.train_path = pathlib.Path(self.train_dir).with_suffix("")
self.test_path = pathlib.Path(self.test_dir).with_suffix("")
# Convert the image from tif to jpg
# Move train data to subclass directory
def new_dir(directory):
cmd = "mkdir " + directory
os.system(cmd)
def download_data(self):
if not os.path.exists(self.data_dir):
cmd = "pip install opendatasets"
os.system(cmd)
import opendatasets as od
od.download(self.dataset_url)
new_dir(data_dir)
new_dir(train_dir)
new_dir(test_dir)
new_dir(dir_true)
new_dir(dir_false)
# Download data, create pandas dataframe from the csv files.
class Df:
def __init__(self, cfg: Config):
self.train_df = pd.read_csv(cfg.train_csv)
self.test_df = None if cfg.test_csv == None else pd.read_csv(cfg.test_csv)
def combine_train_set(self):
pass
def glance_at(self, df):
print("\nQuick view of {} data set".format(df))
if df == "train":
print(self.train_df)
self.train_df.info()
print("Target values:")
vc = self.train_df["target"].value_counts()
print(vc)
labels = ["Fake", "Real"]
plt.pie(vc, autopct="%1.1f%%", labels=labels)
plt.legend(vc.index, loc="best")
plt.show()
elif df == "test" and self.test_df is not None:
print(self.test_df)
self.test_df.info()
else:
pass
def glance(self):
self.glance_at("train")
self.glance_at("test")
config = Config()
config.download_data()
df = Df(config)
# ## Exploratory Data Analysis (EDA)
# Firstly, have a glance on the training data. It includes 7613 observations and 5 features. Among these features, most of the observations of 'keywords' and 'location' are not available. So these 2 features will not be considered in the training. The 'id' field is for indexing only, it is not needed for training.
# The 'text' is the input data and the 'target' field is output data.
# Further check on the values of the feature 'target', it has 2 unique values: 0 means false alert and 1 means true alert.
# There are 3263 rows of data for testing.
# From the statistics information, 57% of the training data are false alerts and the other 43% are true alerts.
df.glance_at("train")
df.train_df[df.train_df["target"] == 1]["text"].values[100]
df.train_df[df.train_df["target"] != 1]["text"].values[100]
df.glance_at("test")
# The tensorflow dataset API text_dataset_from_directory requires the training data to be organized in a hierarchical structure with the sundir name being the name of the category. To follow the requirement of the API, the 'text' field in the dataframe are copied to txt file respectively.
# Cross check the raw data with the files in the traning directory. The data matches with the csv file.
list(config.train_path.iterdir())
def check_create_dir(path):
if not os.path.exists(path):
os.makedirs(path)
else:
pass
class TextRawDataInDisk:
def __init__(self, df, to_path, quick_test=Constants.QUICK_TEST):
self.df = df # List of df
self.to_path = to_path
self.max_files = min(len(df), Constants.MAX_FILES)
self.quick_test = quick_test
if quick_test:
self.max_files = min(4, len(df))
self.loaded_files = 0
self.skipped_files = 0
self.is_training = "target" in df.columns
class TextLoaderToDisk:
def build(df, to_path, quick_test=Constants.QUICK_TEST):
owner = TextRawDataInDisk(df, to_path, quick_test)
check_create_dir(to_path)
loader = TextLoaderToDisk(owner)
loader.load()
return loader
def __init__(self, owner=None):
self._owner = owner
def reset_owner(self, owner):
self._owner = owner
def owner(self):
return self._owner
def load(self):
start = timer()
self.owner().loaded_files = 0
loop_start = timer()
to_dir = self.owner().to_path
for row in self.owner().df.itertuples(index=False):
txt = "/" + str(row.id) + ".txt"
if self.owner().is_training:
label = str(row.target)
to_dir = self.owner().to_path + label + "/"
else:
assert to_dir == self.owner().to_path
to_file = to_dir + str(row.id) + ".txt"
if os.path.exists(to_file):
self.owner().skipped_files += 1
self.owner().loaded_files += 1
continue
check_create_dir(to_dir)
with open(to_file, "w") as f:
f.write(row.text)
self.owner().loaded_files += 1
if self.owner().loaded_files % 50 == 0:
print(".", end=" ")
elapsed = timer() - start
print(
"{} files are stored to {} in {} seconds, {} are skipped among which.".format(
self.owner().loaded_files,
self.owner().to_path,
elapsed,
self.owner().skipped_files,
)
)
def statistics(self):
print(
"{} file are stored to {} , {} are skipped among which.".format(
self.owner().loaded_files,
self.owner().to_path,
self.owner().skipped_files,
)
)
class DatasetFromDisk:
def __init__(self, td, training_ratio=0.8):
self.ds_from = td.to_path
assert self.ds_from != None
self.is_training = td.is_training
self.training_ratio = (
training_ratio if training_ratio > 0 and training_ratio <= 1 else 0.8
)
self.train_ds_ = None
self.val_ds_ = None
self.test_ds_ = None
self.is_preprocessed = False
class DatasetBuilderFromDisk:
def build(td, training_ratio=0.8):
owner = DatasetFromDisk(td, training_ratio)
builder = DatasetBuilderFromDisk(owner)
builder.build_dataset()
return builder
def __init__(self, owner=None): # MUST set owner before using
self._owner = owner
def reset_owner(self, owner):
self._owner = owner
def owner(self):
return self._owner
def build_dataset(self):
if self.owner().is_training:
self.owner().train_ds_ = tf.keras.utils.text_dataset_from_directory(
self.owner().ds_from,
validation_split=0.2,
subset="training",
seed=123,
batch_size=Constants.BATCH_SIZE,
)
self.owner().val_ds_ = tf.keras.utils.text_dataset_from_directory(
self.owner().ds_from,
validation_split=1 - self.owner().training_ratio,
subset="validation",
seed=123,
batch_size=Constants.BATCH_SIZE,
)
else:
pass
self.pre_process()
def pre_process(self):
return # Don't perform preprocess
def train_ds(self):
return self.owner().train_ds_
def val_ds(self):
return self.owner().val_ds_
def test_ds(self):
return self.owner().test_ds_
def show_train_texts(self, ds, number):
assert ds != None and number >= 1
i = 0
for txts, labels in ds:
# print(imgs)
# print(labels)
for txt in txts:
print(txt)
i += 1
if i >= number:
return
def show_test_texts(self, ds, number):
i = 0
for b in ds:
for t in b:
print(t)
i += 1
if i >= number:
return
def show_texts(self):
if self.owner().train_ds_ != None:
self.show_train_texts(self.owner().train_ds_, 3)
assert self.owner().val_ds_ != None
self.show_train_texts(self.owner().val_ds_, 3)
else:
assert self.owner().test_ds_ != None
self.show_test_texts(self.owner().test_ds_, 3)
def statistics(self):
if self.owner().train_ds_ != None:
for i, target in enumerate(self.owner().train_ds_.class_names):
print("Index:", i, "corresponds to:", target)
for text_batch, target_batch in self.owner().train_ds_.take(1):
for i in range(3):
print("Statement: ", text_batch.numpy()[i])
print("Target:", target_batch.numpy()[i])
for text_batch, target_batch in self.owner().val_ds_.take(1):
for i in range(3):
print("Statement: ", text_batch.numpy()[i])
print("Target:", target_batch.numpy()[i])
else:
for text_batch in self.owner().test_ds_.take(1):
for i in range(4):
print("Statement: ", text_batch.numpy()[i])
# Use alias to try different options
TextData = TextRawDataInDisk
TextLoader = TextLoaderToDisk
Dataset = DatasetFromDisk
DatasetBuilder = DatasetBuilderFromDisk
# Generate training and validation dataset with text_dataset_from_directory
train_texts = TextLoader.build(df.train_df, config.temp_train_dir).owner()
train_text_loader = TextLoader(train_texts)
ds = DatasetBuilder.build(train_texts).owner()
ds_loader = DatasetBuilder(ds)
ds_loader.show_texts()
# Check the dataset is as expected.
ds_loader.statistics()
# ## Model Architecture
# The high level architecture of the training network are referring to the tensorflow training material for text classification.
# The model includes the following layers:
# 1. Input layer
# 2. Vectorization layer: This layer is to standardize, tokenize, and vectorize the data. The vectorization layer is from the tf.keras.layers.TextVectorization
# 3. Hidden network layers, including embedding pooling and dense layer for respective model.
# 4. SparseCategoricalCrossentropy is used as loss function
# 5. Optimize with Adam function
# 6. Accuracy as the metric parameter
# 7. Early stop if validation accuracy is not increasing for continuous 3 epochs
# Two models, int vectorization base and binary vectorization base, are tried. The hyper-parameters are adjusted with multiple running to avoid overfitting and underfitting with reasonable accuracy.
#
from tensorflow.keras.optimizers.legacy import Adam
class Model:
def __init__(self, ds):
self.ds = ds
self.history = None
self.opt = Adam()
self.loss = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
self.metrics = ["accuracy"]
self.callbacks = [
tf.keras.callbacks.EarlyStopping(monitor="val_accuracy", patience=5)
]
self.model = self.build_model()
def fit(self, ds=None, epochs=10):
if ds == None:
ds = self.ds
self.history = self.model.fit(
ds.train_ds_,
validation_data=ds.val_ds_,
epochs=epochs,
callbacks=self.callbacks,
)
def build_model(self):
import tensorflow.strings as tfs
from tensorflow.strings import regex_replace as rr
# Prepare the vectorization layer
normalization = lambda s: rr(
rr(tfs.lower(s), "<br />", " "), "[%s]" % re.escape(string.punctuation), ""
)
extraction = lambda x, y: x
vectorize_layer = tf.keras.layers.TextVectorization(
standardize=normalization,
max_tokens=Constants.MAX_FEATURES,
output_mode="binary",
)
texts = ds.train_ds_.map(extraction)
vectorize_layer.adapt(texts)
model = tf.keras.Sequential(
[vectorize_layer, tf.keras.layers.Dense(len(self.ds.train_ds_.class_names))]
)
model.compile(loss=self.loss, optimizer=self.opt, metrics=["accuracy"])
return model
class ModelVisualization:
def __init__(self, model: Model):
self.model = model
def show_history(self):
history = self.model.history.history
fig = plt.figure(figsize=(6, 10))
fig_width = 1
fig_height = 2
ax = fig.subplots(fig_height, fig_width)
ax[0].plot(history["accuracy"], "*-")
ax[0].plot(history["val_accuracy"], "x-")
ax[0].legend(["train", "validation"])
ax[0].set_xlabel("epoch")
ax[0].set_ylabel("accuracy")
ax[0].set_title("Accuracies")
ax[1].plot(history["loss"], "*-")
ax[1].plot(history["val_loss"], "x-")
ax[1].legend(["train", "validation"])
ax[1].set_title("Losses")
ax[1].set_xlabel("epoch")
ax[1].set_ylabel("loss")
plt.show()
def summary(self):
self.model.model.summary()
self.model.model.get_metrics_result()
m = Model(ds)
m.fit(epochs=100)
vm = ModelVisualization(m)
vm.show_history()
vm.summary()
# ## Test
# From the training result, the binary model has higher validation accuracy and there is no significant indication of overfitting.
# So the binary model will be used for the testing.
# Before testing, a softmax layer is added to the model to make the probability more obvious.
# The test images are from the previously prepared test directory.
# To make the result clearer, a pandas dataframe is created for the record.
class Predictor:
def __init__(self, model: tf.keras.Model, test_df):
self.model = model
# self.model.add(tf.keras.layers.Softmax())
self.test_df = test_df
self.df = None
self.pred = self.predict()
self.pred_df = None
self.build_result_df()
self.submit()
def predict(self):
y_pred_prob = self.model.model.predict(np.array(self.test_df.text))
return tf.keras.activations.softmax(tf.convert_to_tensor(y_pred_prob))
def build_result_df(self):
self.pred_df = pd.DataFrame(self.test_df["id"])
self.pred_df["target"] = pd.DataFrame(self.pred).apply(np.argmax, axis=1)
def submit(self):
self.pred_df.to_csv("submission.csv", index=False)
class PredictorDisplay:
def __init__(self, owner):
self.owner = owner
def dump(self):
print("Prediction possibilities:")
print(self.owner.pred_df)
print(self.owner.pred_df.target.value_counts())
def show_result(self):
labels = ["Fake", "Real"]
plt.pie(
self.owner.pred_df["target"].value_counts(),
autopct="%1.1f%%",
labels=labels,
)
plt.show()
pred = Predictor(m, df.test_df)
disp = PredictorDisplay(pred)
disp.dump()
disp.show_result()
labels = ["Fake", "Real"]
plt.pie(df.train_df["target"].value_counts(), autopct="%1.1f%%", labels=labels)
plt.show()
| false | 0 | 4,806 | 0 | 6 | 4,806 |
||
26763336 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import xgboost as xgb
from xgboost import XGBClassifier, XGBRegressor
from xgboost import plot_importance
from catboost import CatBoostRegressor
from matplotlib import pyplot
import shap
from time import time
from tqdm import tqdm_notebook as tqdm
from collections import Counter
from scipy import stats
import lightgbm as lgb
from sklearn.metrics import cohen_kappa_score, mean_squared_error
from sklearn.model_selection import KFold, StratifiedKFold
import gc
import json
from pandas.io.json import json_normalize
import json
train = pd.read_csv("/kaggle/input/data-science-bowl-2019/train.csv")
test = pd.read_csv("/kaggle/input/data-science-bowl-2019/test.csv")
train_labels = pd.read_csv("/kaggle/input/data-science-bowl-2019/train_labels.csv")
specs = pd.read_csv("/kaggle/input/data-science-bowl-2019/specs.csv")
train = train[train.installation_id.isin(train_labels.installation_id.unique())]
def json_parser(dataframe, column):
dataframe.reset_index(drop=True, inplace=True)
parsed_set = dataframe[column].apply(json.loads)
parsed_set = json_normalize(parsed_set)
parsed_set.drop(columns=["event_count", "event_code", "game_time"], inplace=True)
merged_set = pd.merge(
dataframe, parsed_set, how="inner", left_index=True, right_index=True
)
del merged_set[column]
return merged_set
def encode_title(train, test):
train["title_event_code"] = list(
map(lambda x, y: str(x) + "_" + str(y), train["title"], train["event_code"])
)
test["title_event_code"] = list(
map(lambda x, y: str(x) + "_" + str(y), test["title"], test["event_code"])
)
unique_title_event_code = list(
set(train["title_event_code"].unique()).union(
set(test["title_event_code"].unique())
)
)
unique_titles = list(
set(train["title"].unique()).union(set(test["title"].unique()))
)
unique_event_codes = list(
set(train["event_code"].unique()).union(set(test["event_code"].unique()))
)
unique_worlds = list(
set(train["world"].unique()).union(set(test["world"].unique()))
)
unique_event_ids = list(
set(train["event_id"].unique()).union(set(test["event_id"].unique()))
)
unique_assessments = list(
set(train[train["type"] == "Assessment"]["title"].value_counts().index).union(
set(test[test["type"] == "Assessment"]["title"].value_counts().index)
)
)
unique_games = list(
set(train[train["type"] == "Game"]["title"].value_counts().index).union(
set(test[test["type"] == "Game"]["title"].value_counts().index)
)
)
unique_clips = list(
set(train[train["type"] == "Clip"]["title"].value_counts().index).union(
set(test[test["type"] == "Clip"]["title"].value_counts().index)
)
)
unique_activitys = list(
set(train[train["type"] == "Activity"]["title"].value_counts().index).union(
set(test[test["type"] == "Activity"]["title"].value_counts().index)
)
)
# convert text into datetime
train["timestamp"] = pd.to_datetime(train["timestamp"])
test["timestamp"] = pd.to_datetime(test["timestamp"])
unique_data = {
"unique_title_event_code": unique_title_event_code,
"unique_titles": unique_titles,
"unique_event_codes": unique_event_codes,
"unique_worlds": unique_worlds,
"unique_event_ids": unique_event_ids,
"unique_assessments": unique_assessments,
"unique_games": unique_games,
"unique_clips": unique_clips,
"unique_activitys": unique_activitys,
}
return train, test, unique_data
train, test, unique_data = encode_title(train, test)
def get_data(user_sample, unique_data, test=False):
final_features = []
features = {}
Assessments_count = {"count_" + ass: 0 for ass in unique_data["unique_assessments"]}
Clips_count = {"count_" + clip: 0 for clip in unique_data["unique_clips"]}
Games_count = {"count_" + game: 0 for game in unique_data["unique_games"]}
Activitys_count = {
"count_" + activity: 0 for activity in unique_data["unique_activitys"]
}
Worlds_count = {"count_" + world: 0 for world in unique_data["unique_worlds"]}
# Title_event_code_count = {"count_"+etc:0 for etc in unique_data["unique_title_event_code"]}
accuracy_groups = {0: 0, 1: 0, 2: 0, 3: 0}
accuracy_groups_game = {"game_0": 0, "game_1": 0, "game_2": 0, "game_3": 0}
features["accumulated_false"] = 0
features["accumulated_true"] = 0
features["accumulated_false_ass"] = 0
features["accumulated_true_ass"] = 0
Clip_duration_accumulated = {
"accu_duration_" + clip: 0 for clip in unique_data["unique_clips"]
}
Clip_duration = {"duration_" + clip: 0 for clip in unique_data["unique_clips"]}
Games_duration_accumulated = {
"accu_duration_" + game: 0 for game in unique_data["unique_games"]
}
Games_duration = {"duration_" + game: 0 for game in unique_data["unique_games"]}
Activitys_duration_accumulated = {
"accu_duration_" + activity: 0 for activity in unique_data["unique_activitys"]
}
Activitys_duration = {
"duration_" + activity: 0 for activity in unique_data["unique_activitys"]
}
Assessments_duration_accumulated = {
"accu_duration_" + ass: 0 for ass in unique_data["unique_assessments"]
}
Assessments_duration = {
"duration_" + ass: 0 for ass in unique_data["unique_assessments"]
}
features.update(accuracy_groups)
features.update(accuracy_groups_game)
for i, session in user_sample.groupby("game_session", sort=False):
# i = game_session_id
session_type = session.type.iloc[0]
session_title = session.title.iloc[0]
session_world = session.world.iloc[0]
Worlds_count["count_" + session_world] += 1
if session_type == "Clip":
# count
Clips_count["count_" + session_title] += 1
# duration
try:
index = session.index.values[0]
duration = (
user_sample.timestamp.loc[index + 1]
- user_sample.timestamp.loc[index]
).seconds
Clip_duration["duration_" + session_title] = duration
Clip_duration_accumulated["accu_duration_" + session_title] += duration
except:
pass
if session_type == "Activity":
# count
Activitys_count["count_" + session_title] += 1
# duration
duration = round(session.game_time.iloc[-1] / 1000, 2)
Activitys_duration["duration_" + session_title] = duration
Activitys_duration_accumulated["accu_duration_" + session_title] += duration
if session_type == "Game":
# count
Games_count["count_" + session_title] += 1
# duration
duration = round(session.game_time.iloc[-1] / 1000, 2)
Games_duration["duration_" + session_title] = duration
Games_duration_accumulated["accu_duration_" + session_title] += duration
if (session_type == "Assessment") & (test or len(session) > 1):
predicted_title = session["title"].iloc[0]
predicted_game_session = session["game_session"].iloc[0]
predicted_timestamp_session = session["timestamp"].iloc[0]
features["predicted_title"] = predicted_title
features["installation_id"] = session["installation_id"].iloc[0]
features["game_session"] = predicted_game_session
features["timestamp_session"] = predicted_timestamp_session
pred_title_df = user_sample[user_sample.title == predicted_title]
pred_title_df = pred_title_df[
pred_title_df.timestamp < predicted_timestamp_session
]
predicted_assessment = {
"pred_bef_attampt": 0,
"pred_bef_true": np.nan,
"pred_bef_false": np.nan,
"pred_bef_acc_group": np.nan,
"pred_bef_accuracy": np.nan,
"pred_bef_timespent": np.nan,
"pred_bef_time_diff": np.nan,
}
try:
if len(pred_title_df) > 2:
for i, pred_session in pred_title_df.groupby(
"game_session", sort=False
):
predicted_assessment["pred_bef_attampt"] += 1
predicted_assessment["pred_bef_timespent"] = round(
pred_session.game_time.iloc[-1] / 1000, 2
)
if predicted_title == "Bird Measurer (Assessment)":
predicted_data = pred_session[
pred_session.event_code == 4110
]
else:
predicted_data = pred_session[
pred_session.event_code == 4100
]
true_attempts = predicted_data[predicted_data.correct == True][
"correct"
].count()
false_attempts = predicted_data[
predicted_data.correct == False
]["correct"].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
group = accuracy_groups_def(accuracy)
predicted_assessment["pred_bef_true"] = true_attempts
predicted_assessment["pred_bef_false"] = false_attempts
predicted_assessment["pred_bef_accuracy"] = accuracy
predicted_assessment["pred_bef_acc_group"] = group
predicted_assessment["pred_bef_time_diff"] = (
predicted_timestamp_session - pred_title_df.timestamp.iloc[-1]
).seconds
except:
pass
features.update(predicted_assessment.copy())
features.update(Clips_count.copy())
features.update(Clip_duration.copy())
features.update(Clip_duration_accumulated.copy())
features.update(Games_count.copy())
features.update(Games_duration.copy())
features.update(Games_duration_accumulated.copy())
features.update(Activitys_count.copy())
features.update(Activitys_duration.copy())
features.update(Activitys_duration_accumulated.copy())
features.update(Assessments_count.copy())
features.update(Assessments_duration.copy())
features.update(Assessments_duration_accumulated.copy())
final_features.append(features.copy())
try:
# last Assessment
last_assessment = {
"last_bef_true": np.nan,
"last_bef_false": np.nan,
"last_bef_acc_group": np.nan,
"last_bef_accuracy": np.nan,
"last_bef_timespent": np.nan,
"last_bef_title": np.nan,
}
last_assessment["last_bef_timespent"] = round(
session.game_time.iloc[-1] / 1000, 2
)
if predicted_title == "Bird Measurer (Assessment)":
predicted_data = session[session.event_code == 4110]
else:
predicted_data = session[session.event_code == 4100]
true_attempts = predicted_data[predicted_data.correct == True][
"correct"
].count()
false_attempts = predicted_data[predicted_data.correct == False][
"correct"
].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
group = accuracy_groups_def(accuracy)
last_assessment["last_bef_true"] = true_attempts
last_assessment["last_bef_false"] = false_attempts
last_assessment["last_bef_accuracy"] = accuracy
last_assessment["last_bef_acc_group"] = group
last_assessment["last_bef_title"] = predicted_title
features.update(last_assessment.copy())
except:
pass
# count
Assessments_count["count_" + session_title] += 1
# duration
duration = round(session.game_time.iloc[-1] / 1000, 2)
Assessments_duration["duration_" + session_title] = duration
Assessments_duration_accumulated[
"accu_duration_" + session_title
] += duration
ed = EventDataFeatures(
features, session, user_sample, session_type, session_title
)
try:
ed.event_code_2000()
ed.event_code_2010()
ed.event_code_2020()
ed.event_code_2030()
ed.event_code_2025()
ed.event_code_2035()
ed.event_code_2040()
ed.event_code_2050()
ed.event_code_2060()
ed.event_code_2070()
ed.event_code_2075()
ed.event_code_2080()
ed.event_code_2081()
ed.event_code_2083()
ed.event_code_3010()
ed.event_code_3020()
ed.event_code_3021()
ed.event_code_3110()
ed.event_code_3120()
ed.event_code_3121()
ed.event_code_4010()
ed.event_code_4020()
ed.event_code_4021()
ed.event_code_4022()
ed.event_code_4025()
ed.event_code_4030()
ed.event_code_4031()
ed.event_code_4035()
ed.event_code_4040()
ed.event_code_4045()
ed.event_code_4050()
ed.event_code_4070()
ed.event_code_4080()
ed.event_code_4090()
ed.event_code_4095()
ed.event_code_4100()
ed.event_code_4110()
ed.event_code_4220()
ed.event_code_4230()
ed.event_code_4235()
ed.event_code_5000()
ed.event_code_5010()
except:
pass
try:
edf = ed.Event_features
features_ed = ed.features
features.update(edf.copy())
features.update(features_ed.copy())
except:
pass
if test:
return final_features[-1]
else:
return final_features
def accuracy_groups_def(accuracy):
if accuracy == 0:
return 0
elif accuracy == 1:
return 3
elif accuracy == 0.5:
return 2
else:
return 1
class EventDataFeatures(object):
def __init__(self, features, session, user_sample, session_type, session_title):
self.features = features
self.session = session
self.user_sample = user_sample
self.session_type = session_type
self.session_title = session_title
self.Event_features = {}
self.unique_event_codes = self.session.event_code.unique()
def event_code_2000(self):
pass
def event_code_2010(self):
"""
['The exit game event is triggered when the game is quit.
This is used to compute things like time spent in game.
Depending on platform this may / may not be possible.
NOTE: “quit” also means navigating away from game.']
"""
if 2010 in self.unique_event_codes:
session_duration = self.session[self.session.event_code == 2010][
"session_duration"
].values[0]
self.Event_features[
"session_duration_" + self.session_title
] = session_duration
def event_code_2020(self):
"""
['The start round event is triggered at the start of a round when
the player is prompted to weigh and arrange the chests. There is only one round per playthrough.
This event provides information about the game characteristics of the round (i.e. resources, objectives, setup).
It is used in calculating things like time spent in a round (for speed and accuracy), attempts at
solving a round, and the number of rounds the player has visited (exposures).']
"""
pass
def event_code_2025(self):
"""
['The reset dinosaurs event is triggered when the player has placed the last dinosaur,
but not all dinosaurs are in the correct position.
This event provides information about the game characteristics of the round (i.e. resources, objectives, setup).
It is used to indicate a significant change in state during play.']
This event is used for calculating time spent in a round and
the number of rounds the player has completed (completion).
"""
pass
def event_code_2030(self):
"""
['The beat round event is triggered when the player finishes a round by filling the jar.
This event is used for calculating time spent in a round and
the number of rounds the player has completed (completion).']
"""
if 2030 in self.unique_event_codes:
rounds = self.session[self.session.event_code == 2030]
round_duration = rounds["duration"].values
self.Event_features[
"round_duration_2030_sum_" + self.session_title
] = round_duration.sum()
self.Event_features[
"round_duration_2030_avg_" + self.session_title
] = round_duration.mean()
self.Event_features[
"round_duration_2030_std_" + self.session_title
] = round_duration.std()
self.Event_features[
"round_duration_2030_max_" + self.session_title
] = round_duration.max()
self.Event_features[
"round_duration_2030_min_" + self.session_title
] = round_duration.min()
try:
round_rounds = rounds["round"].values
self.Event_features[
"round_2030_max_" + self.session_title
] = round_rounds.max()
except:
pass
try:
round_misses = rounds["misses"].values
self.Event_features[
"misses_2030_sum_" + self.session_title
] = round_misses.sum()
self.Event_features[
"misses_2030_avg_" + self.session_title
] = round_misses.mean()
self.Event_features[
"misses_2030_max_" + self.session_title
] = round_misses.max()
except:
pass
def event_code_2035(self):
"""
['The finish filling tub event is triggered after the player finishes filling up the tub.
It is used to separate a section of gameplay that is different from the estimation section of the game.']
"""
if 2035 in self.unique_event_codes:
rounds = self.session[self.session.event_code == 2035]
round_duration = rounds["duration"].values
self.Event_features[
"round_duration_2035_sum_" + self.session_title
] = round_duration.sum()
self.Event_features[
"round_duration_2035_avg_" + self.session_title
] = round_duration.mean()
def event_code_2040(self):
"""
['The start level event is triggered when a new level begins
(at the same time as the start round event for the first round in the level).
This event is used for calculating time spent in a level (for speed and accuracy),
and the number of levels the player has completed (completion).']
"""
pass
def event_code_2050(self):
"""
['The beat level event is triggered when a level has been completed and
the player has cleared all rounds in the current layout (occurs at the same time as
the beat round event for the last round in the previous level). This event is used for
calculating time spent in a level (for speed and accuracy),
and the number of levels the player has completed (completion).']
"""
if 2050 in self.unique_event_codes:
level = self.session[self.session.event_code == 2050]
level_duration = level["duration"].values
self.Event_features[
"level_duration_2050_sum_" + self.session_title
] = level_duration.sum()
self.Event_features[
"level_duration_2050_avg_" + self.session_title
] = level_duration.mean()
self.Event_features[
"level_duration_2050_std_" + self.session_title
] = level_duration.std()
self.Event_features[
"level_duration_2050_max_" + self.session_title
] = level_duration.max()
self.Event_features[
"level_duration_2050_min_" + self.session_title
] = level_duration.min()
try:
level_rounds = level["level"].values
self.Event_features[
"level_2050_max_" + self.session_title
] = level_rounds.max()
except:
pass
try:
level_misses = level["misses"].values
self.Event_features[
"level_misses_2050_sum_" + self.session_title
] = level_misses.sum()
self.Event_features[
"level_misses_2050_avg_" + self.session_title
] = level_misses.mean()
self.Event_features[
"level_misses_2050_sum_" + self.session_title
] = level_misses.std()
except:
pass
def event_code_2060(self):
"""
['The start tutorial event is triggered at the start of the tutorial.
It is used in calculating time spent in the tutorial.']
"""
pass
def event_code_2070(self):
"""
['The beat round event is triggered when the player finishes the tutorial.
This event is used for calculating time spent in the tutorial.']
"""
if 2070 in self.unique_event_codes:
tutorial = self.session[self.session.event_code == 2070]
tutorial_duration = tutorial["duration"].values
self.Event_features[
"tutorial_duration_2070_sum_" + self.session_title
] = tutorial_duration.sum()
self.Event_features[
"tutorial_duration_2070_avg_" + self.session_title
] = tutorial_duration.mean()
self.Event_features[
"tutorial_duration_2070_std_" + self.session_title
] = tutorial_duration.std()
self.Event_features[
"tutorial_duration_2070_max_" + self.session_title
] = tutorial_duration.max()
self.Event_features[
"tutorial_duration_2070_min_" + self.session_title
] = tutorial_duration.min()
def event_code_2075(self):
"""
['The beat round event is triggered when the player skips the tutorial by clicking on the skip button.
This event is used for calculating time spent in the tutorial.']
"""
if 2075 in self.unique_event_codes:
tutorial = self.session[self.session.event_code == 2075]
self.Event_features[
"tutorial_skiping_count_2075_" + self.session_title
] = tutorial["duration"].count()
def event_code_2080(self):
"""
['The movie started event triggers when an intro or outro movie starts to play.
It identifies the movie being played. This is used to determine how long players
spend watching the movies (more relevant after the first play
through when the skip option is available).']
"""
if 2080 in self.unique_event_codes:
movie = self.session[self.session.event_code == 2080]
movie_duration = movie["duration"].values
self.Event_features[
"movie_duration_2080_sum_" + self.session_title
] = movie_duration.sum()
self.Event_features[
"movie_duration_2080_avg_" + self.session_title
] = movie_duration.mean()
self.Event_features[
"movie_duration_2080_std_" + self.session_title
] = movie_duration.std()
self.Event_features[
"movie_duration_2080_max_" + self.session_title
] = movie_duration.max()
self.Event_features[
"movie_duration_2080_min_" + self.session_title
] = movie_duration.min()
def event_code_2081(self):
"""
['The movie started event triggers when an intro or outro movie starts to play.
It identifies the movie being played. This is used to determine how long players
spend watching the movies (more relevant after the first play
through when the skip option is available).']
"""
if 2081 in self.unique_event_codes:
movie = self.session[self.session.event_code == 2081]
self.Event_features[
"movie_skiping_count_2081_" + self.session_title
] = movie["duration"].count()
def event_code_2083(self):
"""
['The movie started event triggers when an intro or outro movie starts to play.
It identifies the movie being played. This is used to determine how long players
spend watching the movies (more relevant after the first play
through when the skip option is available).']
"""
if 2083 in self.unique_event_codes:
movie = self.session[self.session.event_code == 2083]
movie_duration = movie["duration"].values
self.Event_features[
"movie_duration_2083_sum_" + self.session_title
] = movie_duration.sum()
self.Event_features[
"movie_duration_2083_avg_" + self.session_title
] = movie_duration.mean()
def event_code_3010(self):
"""
['The system-initiated instruction event occurs when the game delivers instructions to the player.
It contains information that describes the content of the instruction. This event differs from events 3020
and 3021 as it captures instructions that are not given in response to player action.
These events are used to determine the effectiveness of the instructions. We can answer questions like,
"did players who received instruction X do better than those who did not?"']
"""
if 3010 in self.unique_event_codes:
instruction = self.session[self.session.event_code == 3010]
instruction_duration = instruction["total_duration"].values
self.Event_features[
"instruction_duration_3010_sum_" + self.session_title
] = instruction_duration.sum()
self.Event_features[
"instruction_duration_3010_avg_" + self.session_title
] = instruction_duration.mean()
# self.Event_features["instruction_media_type_3010_"+self.session_title] = instruction["media_type"].values_count().index[0]
self.Event_features[
"instruction_media_type_3010_count_" + self.session_title
] = instruction["media_type"].count()
def event_code_3020(self):
"""
['The system-initiated feedback (Incorrect) event occurs when the game starts delivering feedback
to the player in response to an incorrect round attempt (pressing the go button with the incorrect answer).
It contains information that describes the content of the instruction. These events are used to determine
the effectiveness of the feedback. We can answer questions like
"did players who received feedback X do better than those who did not?"']
"""
if 3020 in self.unique_event_codes:
Incorrect = self.session[self.session.event_code == 3020]
Incorrect_duration = Incorrect["total_duration"].values
self.Event_features[
"Incorrect_duration_3020_sum_" + self.session_title
] = Incorrect_duration.sum()
self.Event_features[
"Incorrect_duration_3020_avg_" + self.session_title
] = Incorrect_duration.mean()
# self.Event_features["Incorrect_duration_3020_std_"+self.session_title] = Incorrect_duration.std()
# self.Event_features["Incorrect_duration_3020_max_"+self.session_title] = Incorrect_duration.max()
# self.Event_features["Incorrect_duration_3020_min_"+self.session_title] = Incorrect_duration.min()
# self.Event_features["Incorrect_media_type_3020_"+self.session_title] = Incorrect["media_type"].values[0]
self.Event_features[
"Incorrect_media_type_3020_count_" + self.session_title
] = Incorrect["media_type"].count()
def event_code_3021(self):
"""
['The system-initiated feedback (Correct) event occurs when the game
starts delivering feedback to the player in response to a correct round attempt
(pressing the go button with the correct answer). It contains information that describes the
content of the instruction, and will likely occur in conjunction with a beat round event.
These events are used to determine the effectiveness of the feedback. We can answer questions like,
"did players who received feedback X do better than those who did not?"']
"""
if 3021 in self.unique_event_codes:
Correct = self.session[self.session.event_code == 3021]
Correct_duration = Correct["total_duration"].values
self.Event_features[
"Correct_duration_3021_sum_" + self.session_title
] = Correct_duration.sum()
self.Event_features[
"Correct_duration_3021_avg_" + self.session_title
] = Correct_duration.mean()
# self.Event_features["Correct_duration_3021_std_"+self.session_title] = Correct_duration.std()
# self.Event_features["Correct_duration_3021_max_"+self.session_title] = Correct_duration.max()
# self.Event_features["Correct_duration_3021_min_"+self.session_title] = Correct_duration.min()
# self.Event_features["Correct_media_type_3021_"+self.session_title] = Correct["media_type"].values[0]
self.Event_features[
"Correct_media_type_3021_count_" + self.session_title
] = Correct["media_type"].count()
def event_code_3110(self):
"""
['The end of system-initiated instruction event occurs when the game finishes
delivering instructions to the player. It contains information that describes the
content of the instruction including duration. These events are used to determine the
effectiveness of the instructions and the amount of time they consume. We can answer questions like,
"how much time elapsed while the game was presenting instruction?"']
"""
if 3110 in self.unique_event_codes:
Instuction = self.session[self.session.event_code == 3110]
Instuction_duration = Instuction["duration"].values
self.Event_features[
"Instuction_duration_3110_sum_" + self.session_title
] = Instuction_duration.sum()
self.Event_features[
"Instuction_duration_3110_avg_" + self.session_title
] = Instuction_duration.mean()
# self.Event_features["Instuction_duration_3110_std_"+self.session_title] = Instuction_duration.std()
# self.Event_features["Instuction_duration_3110_max_"+self.session_title] = Instuction_duration.max()
# self.Event_features["Instuction_duration_3110_min_"+self.session_title] = Instuction_duration.min()
# self.Event_features["Instuction_media_type_3110_"+self.session_title] = Instuction["media_type"].values[0]
self.Event_features[
"Instuction_media_type_3110_count_" + self.session_title
] = Instuction["media_type"].count()
def event_code_3120(self):
"""
['The end of system-initiated feedback (Incorrect) event
occurs when the game finishes delivering feedback to the player in response
to an incorrect round attempt (pressing the go button with the incorrect answer).
It contains information that describes the content of the instruction.
These events are used to determine the effectiveness of the feedback. We can answer questions like,
“how much time elapsed while the game was presenting feedback?”']
"""
if 3120 in self.unique_event_codes:
IncorrectInstruction = self.session[self.session.event_code == 3120]
IncorrectInstruction_duration = IncorrectInstruction["duration"].values
self.Event_features[
"IncorrectInstruction_duration_3120_sum_" + self.session_title
] = IncorrectInstruction_duration.sum()
self.Event_features[
"IncorrectInstruction_duration_3120_avg_" + self.session_title
] = IncorrectInstruction_duration.mean()
# self.Event_features["IncorrectInstruction_duration_3120_std_"+self.session_title] = IncorrectInstruction_duration.std()
# self.Event_features["IncorrectInstruction_duration_3120_max_"+self.session_title] = IncorrectInstruction_duration.max()
# self.Event_features["IncorrectInstruction_duration_3120_min_"+self.session_title] = IncorrectInstruction_duration.min()
# self.Event_features["IncorrectInstruction_media_type_3120_"+self.session_title] = IncorrectInstruction["media_type"].values[0]
self.Event_features[
"IncorrectInstruction_media_type_3120_count_" + self.session_title
] = IncorrectInstruction["media_type"].count()
def event_code_3121(self):
"""
['The end of system-initiated feedback (Correct) event
occurs when the game finishes delivering feedback to the player in response
to an incorrect round attempt (pressing the go button with the incorrect answer).
It contains information that describes the content of the instruction.
These events are used to determine the effectiveness of the feedback. We can answer questions like,
“how much time elapsed while the game was presenting feedback?”']
"""
if 3121 in self.unique_event_codes:
CorrectInstruction = self.session[self.session.event_code == 3121]
CorrectInstruction_duration = CorrectInstruction["duration"].values
self.Event_features[
"CorrectInstruction_duration_3121_sum_" + self.session_title
] = CorrectInstruction_duration.sum()
self.Event_features[
"CorrectInstruction_duration_3121_avg_" + self.session_title
] = CorrectInstruction_duration.mean()
# self.Event_features["CorrectInstruction_duration_3121_std_"+self.session_title] = CorrectInstruction_duration.std()
# self.Event_features["CorrectInstruction_duration_3121_max_"+self.session_title] = CorrectInstruction_duration.max()
# self.Event_features["CorrectInstruction_duration_3121_min_"+self.session_title] = CorrectInstruction_duration.min()
# self.Event_features["CorrectInstruction_media_type_3121_"+self.session_title] = CorrectInstruction["media_type"].values[0]
self.Event_features[
"CorrectInstruction_media_type_3121_count_" + self.session_title
] = CorrectInstruction["media_type"].count()
def event_code_4010(self):
"""
['This event occurs when the player clicks to start
the game from the starting screen.']
"""
if 4010 in self.unique_event_codes:
click_start = self.session[self.session.event_code == 4010]
index = click_start.index.values[0]
duration = (
self.user_sample.timestamp.loc[index]
- self.user_sample.timestamp.loc[index - 1]
).seconds
self.Event_features[
"click_start_duration_4010_" + self.session_title
] = duration
def event_code_4020(self):
"""
['This event occurs when the player
clicks a group of objects. It contains information
about the group clicked, the state of the game, and the
correctness of the action. This event is
to diagnose player strategies and understanding.']
It contains information about the state of the game and the correctness of the action. This event is used
to diagnose player strategies and understanding.
"""
if 4020 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4020]
if self.session_title == "Bottle Filler (Activity)":
true_attempts = event_data[event_data.jar_filled == True][
"jar_filled"
].count()
false_attempts = event_data[event_data.jar_filled == False][
"jar_filled"
].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"True_attempts_4020_" + self.session_title
] = true_attempts
self.Event_features[
"False_attempts_4020_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4020_" + self.session_title
] = accuracy
group = accuracy_groups_def(accuracy)
self.features["game_" + str(group)] += 1
self.features["accumulated_false"] += false_attempts
self.features["accumulated_true"] += true_attempts
elif self.session_title == "Sandcastle Builder (Activity)":
sandcastle_duration = event_data["duration"].values
self.Event_features[
"sandcastle_duration_4020_sum_" + self.session_title
] = sandcastle_duration.sum()
self.Event_features[
"sandcastle_duration_4020_avg_" + self.session_title
] = sandcastle_duration.mean()
# self.Event_features["sandcastle_duration_4020_std_"+self.session_title] = sandcastle_duration.std()
# self.Event_features["sandcastle_duration_4020_max_"+self.session_title] = sandcastle_duration.max()
# self.Event_features["sandcastle_duration_4020_min_"+self.session_title] = sandcastle_duration.min()
elif self.session_title == "Cart Balancer (Assessment)":
try:
true_attempts = event_data[event_data.size == "left"][
"size"
].count()
false_attempts = event_data[event_data.size == "right"][
"size"
].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"Left_attempts_4020_" + self.session_title
] = true_attempts
self.Event_features[
"Right_attempts_4020_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4020_" + self.session_title
] = accuracy
group = accuracy_groups_def(accuracy)
self.features["game_" + str(group)] += 1
self.features["accumulated_false"] += false_attempts
self.features["accumulated_true"] += true_attempts
except:
pass
elif self.session_title == "Fireworks (Activity)":
true_attempts = event_data[event_data.launched == True][
"launched"
].count()
false_attempts = event_data[event_data.launched == False][
"launched"
].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"True_attempts_4020_" + self.session_title
] = true_attempts
self.Event_features[
"False_attempts_4020_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4020_" + self.session_title
] = accuracy
group = accuracy_groups_def(accuracy)
self.features["game_" + str(group)] += 1
self.features["accumulated_false"] += false_attempts
self.features["accumulated_true"] += true_attempts
rocket_duration = event_data["duration"].values
self.Event_features[
"rocket_duration_4020_sum_" + self.session_title
] = rocket_duration.sum()
self.Event_features[
"rocket_duration_4020_avg_" + self.session_title
] = rocket_duration.mean()
self.Event_features[
"rocket_duration_4020_std_" + self.session_title
] = rocket_duration.std()
self.Event_features[
"rocket_duration_4020_max_" + self.session_title
] = rocket_duration.max()
self.Event_features[
"rocket_duration_4020_min_" + self.session_title
] = rocket_duration.min()
rocket_height = event_data["height"].values
self.Event_features[
"rocket_height_4020_sum_" + self.session_title
] = rocket_height.sum()
self.Event_features[
"rocket_height_4020_avg_" + self.session_title
] = rocket_height.mean()
self.Event_features[
"rocket_height_4020_std_" + self.session_title
] = rocket_height.std()
self.Event_features[
"rocket_height_4020_max_" + self.session_title
] = rocket_height.max()
self.Event_features[
"rocket_height_4020_min_" + self.session_title
] = rocket_height.min()
elif self.session_title == "Watering Hole (Activity)":
water_level = event_data["water_level"].values
self.Event_features[
"water_level_4020_sum_" + self.session_title
] = water_level.sum()
self.Event_features[
"water_level_4020_avg_" + self.session_title
] = water_level.mean()
self.Event_features[
"water_level_4020_std_" + self.session_title
] = water_level.std()
self.Event_features[
"water_level_4020_max_" + self.session_title
] = water_level.max()
self.Event_features[
"water_level_4020_min_" + self.session_title
] = water_level.min()
elif self.session_title == "Chicken Balancer (Activity)":
true_attempts = event_data[event_data["layout.right.pig"] == True][
"layout.right.pig"
].count()
false_attempts = event_data[event_data["layout.right.pig"] == False][
"layout.right.pig"
].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"True_attempts_4020_" + self.session_title
] = true_attempts
self.Event_features[
"False_attempts_4020_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4020_" + self.session_title
] = accuracy
elif self.session_title == "Flower Waterer (Activity)":
flower_duration = event_data["duration"].values
self.Event_features[
"flower_duration_4020_sum_" + self.session_title
] = flower_duration.sum()
self.Event_features[
"flower_duration_4020_avg_" + self.session_title
] = flower_duration.mean()
# self.Event_features["flower_duration_4020_std_"+self.session_title] = flower_duration.std()
# self.Event_features["flower_duration_4020_max_"+self.session_title] = flower_duration.max()
# self.Event_features["flower_duration_4020_min_"+self.session_title] = flower_duration.min()
elif self.session_title == "Egg Dropper (Activity)":
true_attempts = event_data[event_data["gate.side"] == "left"][
"gate.side"
].count()
false_attempts = event_data[event_data["gate.side"] == "right"][
"gate.side"
].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"Left_attempts_4020_" + self.session_title
] = true_attempts
self.Event_features[
"Right_attempts_4020_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4020_" + self.session_title
] = accuracy
else:
true_attempts = event_data[event_data.correct == True][
"correct"
].count()
false_attempts = event_data[event_data.correct == False][
"correct"
].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"True_attempts_4020_" + self.session_title
] = true_attempts
self.Event_features[
"False_attempts_4020_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4020_" + self.session_title
] = accuracy
group = accuracy_groups_def(accuracy)
self.features["game_" + str(group)] += 1
self.features["accumulated_false"] += false_attempts
self.features["accumulated_true"] += true_attempts
def event_code_4021(self):
if 4021 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4021]
if self.session_title == "Sandcastle Builder (Activity)":
amount_sand = event_data["sand"].values
self.Event_features[
"amount_sand_4020_sum_" + self.session_title
] = amount_sand.sum()
self.Event_features[
"amount_sand_4020_avg_" + self.session_title
] = amount_sand.mean()
# self.Event_features["amount_sand_4020_std_"+self.session_title] = amount_sand.std()
self.Event_features[
"amount_sand_4020_max_" + self.session_title
] = amount_sand.max()
# self.Event_features["amount_sand_4020_min_"+self.session_title] = amount_sand.min()
elif self.session_title == "Watering Hole (Activity)":
cloud_size = event_data["cloud_size"].values
self.Event_features[
"cloud_size_4020_sum_" + self.session_title
] = cloud_size.sum()
self.Event_features[
"cloud_size_4020_avg_" + self.session_title
] = cloud_size.mean()
# self.Event_features["cloud_size_4020_std_"+self.session_title] = cloud_size.std()
self.Event_features[
"cloud_size_4020_max_" + self.session_title
] = cloud_size.max()
# self.Event_features["cloud_size_4020_min_"+self.session_title] = cloud_size.min()
else:
pass
def event_code_4022(self):
pass
def event_code_4025(self):
if 4025 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4025]
if self.session_title == "Cauldron Filler (Assessment)":
true_attempts = event_data[event_data.correct == True][
"correct"
].count()
false_attempts = event_data[event_data.correct == False][
"correct"
].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"True_attempts_4025_" + self.session_title
] = true_attempts
self.Event_features[
"False_attempts_4025_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4025_" + self.session_title
] = accuracy
group = accuracy_groups_def(accuracy)
self.features["game_" + str(group)] += 1
self.features["accumulated_false"] += false_attempts
self.features["accumulated_true"] += true_attempts
elif self.session_title == "Bug Measurer (Activity)":
self.Event_features[
"Bug_length_max_4025_" + self.session_title
] = event_data["buglength"].max()
self.Event_features[
"Number_of_Bugs_4025_" + self.session_title
] = event_data["buglength"].count()
else:
pass
def event_code_4030(self):
pass
def event_code_4031(self):
pass
def event_code_4035(self):
if 4035 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4035]
self.Event_features["wrong_place_count_4035_" + self.session_title] = len(
event_data
)
if self.session_title == "All Star Sorting":
wrong_place = event_data["duration"].values
self.Event_features[
"wrong_place_duration_4035_sum_" + self.session_title
] = wrong_place.sum()
self.Event_features[
"wrong_place_duration_4035_avg_" + self.session_title
] = wrong_place.mean()
# self.Event_features["wrong_place_duration_4035_std_"+self.session_title] = wrong_place.std()
# self.Event_features["wrong_place_duration_4035_max_"+self.session_title] = wrong_place.max()
# self.Event_features["wrong_place_duration_4035_min_"+self.session_title] = wrong_place.min()
elif self.session_title == "Bug Measurer (Activity)":
wrong_place = event_data["duration"].values
self.Event_features[
"wrong_place_duration_4035_sum_" + self.session_title
] = wrong_place.sum()
self.Event_features[
"wrong_place_duration_4035_avg_" + self.session_title
] = wrong_place.mean()
# self.Event_features["wrong_place_duration_4035_std_"+self.session_title] = wrong_place.std()
# self.Event_features["wrong_place_duration_4035_max_"+self.session_title] = wrong_place.max()
# self.Event_features["wrong_place_duration_4035_min_"+self.session_title] = wrong_place.min()
elif self.session_title == "Pan Balance":
pass
elif self.session_title == "Chicken Balancer (Activity)":
wrong_place = event_data["duration"].values
self.Event_features[
"wrong_place_duration_4035_sum_" + self.session_title
] = wrong_place.sum()
self.Event_features[
"wrong_place_duration_4035_avg_" + self.session_title
] = wrong_place.mean()
# self.Event_features["wrong_place_duration_4035_std_"+self.session_title] = wrong_place.std()
# self.Event_features["wrong_place_duration_4035_max_"+self.session_title] = wrong_place.max()
# self.Event_features["wrong_place_duration_4035_min_"+self.session_title] = wrong_place.min()
elif self.session_title == "Chest Sorter (Assessment)":
wrong_place = event_data["duration"].values
self.Event_features[
"wrong_place_duration_4035_sum_" + self.session_title
] = wrong_place.sum()
self.Event_features[
"wrong_place_duration_4035_avg_" + self.session_title
] = wrong_place.mean()
# self.Event_features["wrong_place_duration_4035_std_"+self.session_title] = wrong_place.std()
# self.Event_features["wrong_place_duration_4035_max_"+self.session_title] = wrong_place.max()
# self.Event_features["wrong_place_duration_4035_min_"+self.session_title] = wrong_place.min()
else:
try:
wrong_place = event_data["duration"].values
self.Event_features[
"wrong_place_duration_4035_sum_" + self.session_title
] = wrong_place.sum()
self.Event_features[
"wrong_place_duration_4035_avg_" + self.session_title
] = wrong_place.mean()
# self.Event_features["wrong_place_duration_4035_std_"+self.session_title] = wrong_place.std()
# self.Event_features["wrong_place_duration_4035_max_"+self.session_title] = wrong_place.max()
# self.Event_features["wrong_place_duration_4035_min_"+self.session_title] = wrong_place.min()
except:
pass
def event_code_4040(self):
pass
def event_code_4045(self):
pass
def event_code_4050(self):
pass
def event_code_4070(self):
"""
['This event occurs when the player clicks on
something that isn’t covered elsewhere.
It can be useful in determining if there are
attractive distractions (things the player think
should do something, but don’t) in the game, or
diagnosing players
who are having mechanical difficulties (near misses).']
"""
if 4070 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4070]
self.Event_features[
"something_not_covered_count_4070_" + self.session_title
] = len(event_data)
def event_code_4080(self):
if 4080 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4080]
self.Event_features["mouse_over_count_4080_" + self.session_title] = len(
event_data
)
try:
dwell_time = event_data["dwell_time"].values
self.Event_features[
"dwell_time_duration_4080_sum_" + self.session_title
] = dwell_time.sum()
self.Event_features[
"dwell_time_duration_4080_avg_" + self.session_title
] = dwell_time.mean()
self.Event_features[
"dwell_time_duration_4080_std_" + self.session_title
] = dwell_time.std()
self.Event_features[
"dwell_time_duration_4080_max_" + self.session_title
] = dwell_time.max()
self.Event_features[
"dwell_time_duration_4080_min_" + self.session_title
] = dwell_time.min()
except:
pass
def event_code_4090(self):
if 4090 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4090]
self.Event_features["Player_help_count_4090_" + self.session_title] = len(
event_data
)
def event_code_4095(self):
if 4095 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4095]
self.Event_features["Plage_again_4095_" + self.session_title] = len(
event_data
)
def event_code_4100(self):
if 4100 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4100]
true_attempts = event_data[event_data.correct == True]["correct"].count()
false_attempts = event_data[event_data.correct == False]["correct"].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"True_attempts_4100_" + self.session_title
] = true_attempts
self.Event_features[
"False_attempts_4100_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4100_" + self.session_title
] = accuracy
group = accuracy_groups_def(accuracy)
self.features[group] += 1
self.features["accumulated_false_ass"] += false_attempts
self.features["accumulated_true_ass"] += true_attempts
def event_code_4110(self):
if 4110 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4110]
true_attempts = event_data[event_data.correct == True]["correct"].count()
false_attempts = event_data[event_data.correct == False]["correct"].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"True_attempts_4110_" + self.session_title
] = true_attempts
self.Event_features[
"False_attempts_4110_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4110_" + self.session_title
] = accuracy
group = accuracy_groups_def(accuracy)
self.features[group] += 1
self.features["accumulated_false_ass"] += false_attempts
self.features["accumulated_true_ass"] += true_attempts
def event_code_4220(self):
pass
def event_code_4230(self):
pass
def event_code_4235(self):
pass
def event_code_5000(self):
pass
def event_code_5010(self):
pass
def get_train_test(train, test, unique_data):
compiled_train = []
compiled_test = []
if os.path.exists("../input/amma-reduce-train/amma_reduce_train.csv"):
reduce_train_file = True
reduce_train = pd.read_csv("../input/amma-reduce-train/amma_reduce_train.csv")
else:
for i, (ins_id, user_sample) in tqdm(
enumerate(train.groupby("installation_id", sort=False)),
total=len(train.installation_id.unique()),
):
if "Assessment" in user_sample.type.unique():
temp_df = json_parser(user_sample, "event_data")
temp_df.sort_values("timestamp", inplace=True)
temp_df.reset_index(inplace=True, drop=True)
temp_df["index"] = temp_df.index.values
compiled_train.extend(get_data(temp_df, unique_data))
reduce_train = pd.DataFrame(compiled_train)
for i, (ins_id, user_sample) in tqdm(
enumerate(test.groupby("installation_id", sort=False)),
total=len(test.installation_id.unique()),
):
if "Assessment" in user_sample.type.unique():
temp_df = json_parser(user_sample, "event_data")
temp_df.sort_values("timestamp", inplace=True)
temp_df.reset_index(inplace=True, drop=True)
temp_df["index"] = temp_df.index.values
compiled_test.append(get_data(temp_df, unique_data, test=True))
reduce_test = pd.DataFrame(compiled_test)
return reduce_train, reduce_test
reduce_train, reduce_test = get_train_test(train, test, unique_data)
reduce_train.shape, reduce_test.shape
reduce_train = reduce_train[
reduce_train.game_session.isin(train_labels.game_session.unique())
]
reduce_train.shape
reduce_train.columns = [
"".join(c if c.isalnum() else "_" for c in str(x)) for x in reduce_train.columns
]
reduce_test.columns = [
"".join(c if c.isalnum() else "_" for c in str(x)) for x in reduce_test.columns
]
rem = list(set(reduce_train.columns).intersection(set(reduce_test)))
reduce_train = reduce_train[rem]
reduce_test = reduce_test[rem]
reduce_train.shape, reduce_test.shape
import numpy as np
import pandas as pd
from functools import partial
from sklearn import metrics
import scipy as sp
from sklearn.preprocessing import OneHotEncoder
from scipy.stats import boxcox, skew, randint, uniform
from sklearn.model_selection import KFold, StratifiedKFold
from sklearn.linear_model import Lasso, ElasticNet, Ridge, LinearRegression
from sklearn.kernel_ridge import KernelRidge
from sklearn.feature_selection import RFECV
from sklearn.preprocessing import StandardScaler, RobustScaler
from sklearn.metrics import mean_squared_error
import warnings
warnings.filterwarnings("ignore")
categorical_cols = []
for col in reduce_train.columns:
if reduce_train[col].dtype == "object":
categorical_cols.append(col)
categorical_cols
def tree_based_models(train, test, columns_map):
for col in columns_map:
list_of_values = list(set(train[col].unique()).union(set(test[col].unique())))
list_of_values_map = dict(zip(list_of_values, np.arange(len(list_of_values))))
train[col] = train[col].map(list_of_values_map)
test[col] = test[col].map(list_of_values_map)
return train, test
def merge_with_labels(train, train_labels):
train = train[train.game_session.isin(train_labels.game_session.unique())]
tld = train_labels[
[
"game_session",
"installation_id",
"num_correct",
"num_incorrect",
"accuracy",
"accuracy_group",
]
]
final_train = pd.merge(
tld,
train,
left_on=["game_session", "installation_id"],
right_on=["game_session", "installation_id"],
how="inner",
)
final_train.sort_values("timestamp_session", inplace=True)
col_drop = tld.columns.values
col_drop = np.append(col_drop, "timestamp_session")
return final_train, col_drop
final_train, col_drop = merge_with_labels(reduce_train, train_labels)
cat_cols = []
for col in categorical_cols:
if col not in col_drop:
cat_cols.append(col)
len(cat_cols)
cat_drop_com = cat_cols + col_drop.tolist()
numaric_cols = list(set(final_train.columns.values) - set(cat_drop_com))
final_train, final_test = tree_based_models(final_train, reduce_test, cat_cols)
final_train.shape, final_test.shape
def eval_qwk_lgb_regr2(y_true, y_pred, train):
"""
Fast cappa eval function for lgb.
"""
dist = Counter(train["accuracy_group"])
for k in dist:
dist[k] /= len(train)
train["accuracy_group"].hist()
acum = 0
bound = {}
for i in range(3):
acum += dist[i]
bound[i] = np.percentile(y_pred, acum * 100)
def classify(x):
if x <= bound[0]:
return 0
elif x <= bound[1]:
return 1
elif x <= bound[2]:
return 2
else:
return 3
y_pred = np.array(list(map(classify, y_pred))).reshape(y_true.shape)
return "cappa", cohen_kappa_score(y_true, y_pred, weights="quadratic"), True
def qwk(a1, a2):
"""
Source: https://www.kaggle.com/c/data-science-bowl-2019/discussion/114133#latest-660168
:param a1:
:param a2:
:param max_rat:
:return:
"""
max_rat = 3
a1 = np.asarray(a1, dtype=int)
a2 = np.asarray(a2, dtype=int)
hist1 = np.zeros((max_rat + 1,))
hist2 = np.zeros((max_rat + 1,))
o = 0
for k in range(a1.shape[0]):
i, j = a1[k], a2[k]
hist1[i] += 1
hist2[j] += 1
o += (i - j) * (i - j)
e = 0
for i in range(max_rat + 1):
for j in range(max_rat + 1):
e += hist1[i] * hist2[j] * (i - j) * (i - j)
e = e / a1.shape[0]
return 1 - o / e
def eval_qwk_lgb_regr(y_true, y_pred):
"""
Fast cappa eval function for lgb.
"""
y_pred[y_pred <= 1.12232214] = 0
y_pred[np.where(np.logical_and(y_pred > 1.12232214, y_pred <= 1.73925866))] = 1
y_pred[np.where(np.logical_and(y_pred > 1.73925866, y_pred <= 2.22506454))] = 2
y_pred[y_pred > 2.22506454] = 3
# y_pred = y_pred.reshape(len(np.unique(y_true)), -1).argmax(axis=0)
return "cappa", qwk(y_true, y_pred), True
from sklearn.metrics import confusion_matrix, accuracy_score
def confusion_matrix_reg(y_true, y_pred):
y_pred[y_pred <= 1.12232214] = 0
y_pred[np.where(np.logical_and(y_pred > 1.12232214, y_pred <= 1.73925866))] = 1
y_pred[np.where(np.logical_and(y_pred > 1.73925866, y_pred <= 2.22506454))] = 2
y_pred[y_pred > 2.22506454] = 3
print("Accuracy : ", accuracy_score(y_true=y_true, y_pred=y_pred))
print("Confussion_matrix \n", confusion_matrix(y_true, y_pred))
print("\n\n")
col_drop
col_drop1 = col_drop
class OptimizedRounder(object):
def __init__(self):
self.coef_ = 0
def _kappa_loss(self, coef, X, y):
X_p = np.copy(X)
for i, pred in enumerate(X_p):
if pred < coef[0]:
X_p[i] = 0
elif pred >= coef[0] and pred < coef[1]:
X_p[i] = 1
elif pred >= coef[1] and pred < coef[2]:
X_p[i] = 2
else:
X_p[i] = 3
ll = quadratic_weighted_kappa(y, X_p)
return -ll
def fit(self, X, y):
loss_partial = partial(self._kappa_loss, X=X, y=y)
initial_coef = [1.1, 1.7, 2.2]
self.coef_ = sp.optimize.minimize(
loss_partial, initial_coef, method="nelder-mead"
)
def predict(self, X, coef):
X_p = np.copy(X)
for i, pred in enumerate(X_p):
if pred < coef[0]:
X_p[i] = 0
elif pred >= coef[0] and pred < coef[1]:
X_p[i] = 1
elif pred >= coef[1] and pred < coef[2]:
X_p[i] = 2
else:
X_p[i] = 3
return X_p
def coefficients(self):
return self.coef_["x"]
# The following 3 functions have been taken from Ben Hamner's github repository
# https://github.com/benhamner/Metrics
def confusion_matrix(rater_a, rater_b, min_rating=None, max_rating=None):
"""
Returns the confusion matrix between rater's ratings
"""
assert len(rater_a) == len(rater_b)
if min_rating is None:
min_rating = min(rater_a + rater_b)
if max_rating is None:
max_rating = max(rater_a + rater_b)
num_ratings = int(max_rating - min_rating + 1)
conf_mat = [[0 for i in range(num_ratings)] for j in range(num_ratings)]
for a, b in zip(rater_a, rater_b):
conf_mat[a - min_rating][b - min_rating] += 1
return conf_mat
def histogram(ratings, min_rating=None, max_rating=None):
"""
Returns the counts of each type of rating that a rater made
"""
if min_rating is None:
min_rating = min(ratings)
if max_rating is None:
max_rating = max(ratings)
num_ratings = int(max_rating - min_rating + 1)
hist_ratings = [0 for x in range(num_ratings)]
for r in ratings:
hist_ratings[r - min_rating] += 1
return hist_ratings
def quadratic_weighted_kappa(y, y_pred):
"""
Calculates the quadratic weighted kappa
axquadratic_weighted_kappa calculates the quadratic weighted kappa
value, which is a measure of inter-rater agreement between two raters
that provide discrete numeric ratings. Potential values range from -1
(representing complete disagreement) to 1 (representing complete
agreement). A kappa value of 0 is expected if all agreement is due to
chance.
quadratic_weighted_kappa(rater_a, rater_b), where rater_a and rater_b
each correspond to a list of integer ratings. These lists must have the
same length.
The ratings should be integers, and it is assumed that they contain
the complete range of possible ratings.
quadratic_weighted_kappa(X, min_rating, max_rating), where min_rating
is the minimum possible rating, and max_rating is the maximum possible
rating
"""
rater_a = y
rater_b = y_pred
min_rating = None
max_rating = None
rater_a = np.array(rater_a, dtype=int)
rater_b = np.array(rater_b, dtype=int)
assert len(rater_a) == len(rater_b)
if min_rating is None:
min_rating = min(min(rater_a), min(rater_b))
if max_rating is None:
max_rating = max(max(rater_a), max(rater_b))
conf_mat = confusion_matrix(rater_a, rater_b, min_rating, max_rating)
num_ratings = len(conf_mat)
num_scored_items = float(len(rater_a))
hist_rater_a = histogram(rater_a, min_rating, max_rating)
hist_rater_b = histogram(rater_b, min_rating, max_rating)
numerator = 0.0
denominator = 0.0
for i in range(num_ratings):
for j in range(num_ratings):
expected_count = hist_rater_a[i] * hist_rater_b[j] / num_scored_items
d = pow(i - j, 2.0) / pow(num_ratings - 1, 2.0)
numerator += d * conf_mat[i][j] / num_scored_items
denominator += d * expected_count / num_scored_items
return 1.0 - numerator / denominator
def qwk(a1, a2):
"""
Source: https://www.kaggle.com/c/data-science-bowl-2019/discussion/114133#latest-660168
:param a1:
:param a2:
:param max_rat:
:return:
"""
max_rat = 3
a1 = np.asarray(a1, dtype=int)
a2 = np.asarray(a2, dtype=int)
hist1 = np.zeros((max_rat + 1,))
hist2 = np.zeros((max_rat + 1,))
o = 0
for k in range(a1.shape[0]):
i, j = a1[k], a2[k]
hist1[i] += 1
hist2[j] += 1
o += (i - j) * (i - j)
e = 0
for i in range(max_rat + 1):
for j in range(max_rat + 1):
e += hist1[i] * hist2[j] * (i - j) * (i - j)
e = e / a1.shape[0]
return 1 - o / e
def eval_qwk_lgb_regr(y_true, y_pred):
"""
Fast cappa eval function for lgb.
"""
y_pred[y_pred <= 1.12232214] = 0
y_pred[np.where(np.logical_and(y_pred > 1.12232214, y_pred <= 1.73925866))] = 1
y_pred[np.where(np.logical_and(y_pred > 1.73925866, y_pred <= 2.22506454))] = 2
y_pred[y_pred > 2.22506454] = 3
# y_pred = y_pred.reshape(len(np.unique(y_true)), -1).argmax(axis=0)
return "cappa", qwk(y_true, y_pred), True
from sklearn.metrics import confusion_matrix, accuracy_score
def confusion_matrix_reg(y_true, y_pred):
y_pred[y_pred <= 1.12232214] = 0
y_pred[np.where(np.logical_and(y_pred > 1.12232214, y_pred <= 1.73925866))] = 1
y_pred[np.where(np.logical_and(y_pred > 1.73925866, y_pred <= 2.22506454))] = 2
y_pred[y_pred > 2.22506454] = 3
print("Accuracy : ", accuracy_score(y_true=y_true, y_pred=y_pred))
print("Confussion_matrix \n", confusion_matrix(y_true, y_pred))
print("\n\n")
def eval_qwk_lgb_regr2(y_true, y_pred):
"""
Fast cappa eval function for lgb.
"""
dist = Counter(final_train["accuracy_group"])
for k in dist:
dist[k] /= len(final_train)
final_train["accuracy_group"].hist()
acum = 0
bound = {}
for i in range(3):
acum += dist[i]
bound[i] = np.percentile(y_pred, acum * 100)
def classify(x):
if x <= bound[0]:
return 0
elif x <= bound[1]:
return 1
elif x <= bound[2]:
return 2
else:
return 3
y_pred = np.array(list(map(classify, y_pred))).reshape(y_true.shape)
return "cappa", cohen_kappa_score(y_true, y_pred, weights="quadratic"), True
def cohenkappa(ypred, y):
y = y.get_label().astype("int")
ypred = ypred.reshape((4, -1)).argmax(axis=0)
loss = cohenkappascore(y, y_pred, weights="quadratic")
return "cappa", loss, True
# The following 3 functions have been taken from Ben Hamner's github repository
# https://github.com/benhamner/Metrics
def confusion_matrix(rater_a, rater_b, min_rating=None, max_rating=None):
"""
Returns the confusion matrix between rater's ratings
"""
assert len(rater_a) == len(rater_b)
if min_rating is None:
min_rating = min(rater_a + rater_b)
if max_rating is None:
max_rating = max(rater_a + rater_b)
num_ratings = int(max_rating - min_rating + 1)
conf_mat = [[0 for i in range(num_ratings)] for j in range(num_ratings)]
for a, b in zip(rater_a, rater_b):
conf_mat[a - min_rating][b - min_rating] += 1
return conf_mat
def histogram(ratings, min_rating=None, max_rating=None):
"""
Returns the counts of each type of rating that a rater made
"""
if min_rating is None:
min_rating = min(ratings)
if max_rating is None:
max_rating = max(ratings)
num_ratings = int(max_rating - min_rating + 1)
hist_ratings = [0 for x in range(num_ratings)]
for r in ratings:
hist_ratings[r - min_rating] += 1
return hist_ratings
def quadratic_weighted_kappa(y, y_pred):
"""
Calculates the quadratic weighted kappa
axquadratic_weighted_kappa calculates the quadratic weighted kappa
value, which is a measure of inter-rater agreement between two raters
that provide discrete numeric ratings. Potential values range from -1
(representing complete disagreement) to 1 (representing complete
agreement). A kappa value of 0 is expected if all agreement is due to
chance.
quadratic_weighted_kappa(rater_a, rater_b), where rater_a and rater_b
each correspond to a list of integer ratings. These lists must have the
same length.
The ratings should be integers, and it is assumed that they contain
the complete range of possible ratings.
quadratic_weighted_kappa(X, min_rating, max_rating), where min_rating
is the minimum possible rating, and max_rating is the maximum possible
rating
"""
rater_a = y
rater_b = y_pred
min_rating = None
max_rating = None
rater_a = np.array(rater_a, dtype=int)
rater_b = np.array(rater_b, dtype=int)
assert len(rater_a) == len(rater_b)
if min_rating is None:
min_rating = min(min(rater_a), min(rater_b))
if max_rating is None:
max_rating = max(max(rater_a), max(rater_b))
conf_mat = confusion_matrix(rater_a, rater_b, min_rating, max_rating)
num_ratings = len(conf_mat)
num_scored_items = float(len(rater_a))
hist_rater_a = histogram(rater_a, min_rating, max_rating)
hist_rater_b = histogram(rater_b, min_rating, max_rating)
numerator = 0.0
denominator = 0.0
for i in range(num_ratings):
for j in range(num_ratings):
expected_count = hist_rater_a[i] * hist_rater_b[j] / num_scored_items
d = pow(i - j, 2.0) / pow(num_ratings - 1, 2.0)
numerator += d * conf_mat[i][j] / num_scored_items
denominator += d * expected_count / num_scored_items
return 1.0 - numerator / denominator
from sklearn.model_selection import KFold, StratifiedKFold
train_predictions = np.zeros((len(final_train), 1))
train_predictions_y = np.zeros((len(final_train), 1))
test_predictions = np.zeros((final_test.shape[0], 1))
zero_test_predictions = np.zeros((final_test.shape[0], 1))
FOLDS = 5
print("stratified k-folds")
train = final_train
y = final_train.accuracy_group
skf = StratifiedKFold(n_splits=FOLDS, random_state=42, shuffle=True)
skf.get_n_splits(train, y)
cv_scores = []
fold = 1
coefficients = np.zeros((FOLDS, 3))
for train_ids_indx, test_ids_indx in skf.split(train, y):
# train_ids = unique_installation_ids[train_ids_indx]
# test_ids = unique_installation_ids[test_ids_indx]
# print(train_ids.shape, test_ids.shape)
train_X = train.iloc[train_ids_indx]
test_X = train.iloc[test_ids_indx]
x_train = train_X.drop(columns=col_drop1)
y_train = train_X["accuracy_group"]
x_test = test_X.drop(columns=col_drop1)
y_test = test_X["accuracy_group"]
w = y_test.value_counts()
weights = {i: np.sum(w) / w[i] for i in w.index}
print(weights)
lgb_params = {
"boosting_type": "gbdt",
"objective": "regression",
"learning_rate": 0.005,
"subsample": 0.8,
"colsample_bytree": 0.8,
"min_split_gain": 0.006,
"min_child_samples": 150,
"min_child_weight": 0.1,
"max_depth": 17,
"n_estimators": 10000,
"num_leaves": 80,
"silent": -1,
"verbose": -1,
"max_depth": 15,
"random_state": 2018,
}
model = lgb.LGBMRegressor(**lgb_params)
model.fit(
x_train,
y_train,
eval_set=[(x_test, y_test)],
eval_metric="rmse",
verbose=100,
early_stopping_rounds=150,
)
valid_preds = model.predict(x_test, num_iteration=model.best_iteration_)
train_predictions[test_ids_indx] = valid_preds.reshape(-1, 1)
train_predictions_y[test_ids_indx] = y_test.values.reshape(-1, 1)
optR = OptimizedRounder()
optR.fit(valid_preds, y_test.values)
coefficients[fold - 1, :] = optR.coefficients()
print("Coefficients : ", optR.coefficients())
valid_p = optR.predict(valid_preds, coefficients[fold - 1, :])
valid_preds1 = valid_preds.copy()
print("non optimized qwk : ", eval_qwk_lgb_regr(y_test, valid_preds1))
print("optimized qwk : ", qwk(y_test, valid_p))
print("Valid Counts = ", Counter(y_test.values))
print("Predicted Counts = ", Counter(valid_p))
test_preds = model.predict(
final_test[x_train.columns], num_iteration=model.best_iteration_
)
scr = quadratic_weighted_kappa(y_test.values, valid_p)
cv_scores.append(scr)
print("Fold = {}. QWK = {}. Coef = {}".format(fold, scr, coefficients[fold - 1, :]))
print("\n")
test_predictions += test_preds.reshape(-1, 1)
fold += 1
test_predictions = test_predictions * 1.0 / FOLDS
print(
"Mean Score: {}. Std Dev: {}. Mean Coeff: {}".format(
np.mean(cv_scores), np.std(cv_scores), np.mean(coefficients, axis=0)
)
)
optR = OptimizedRounder()
train_predictions1 = np.array(
[item for sublist in train_predictions for item in sublist]
)
y1 = np.array([item for sublist in train_predictions_y for item in sublist])
optR.fit(train_predictions1, y1)
coefficients = optR.coefficients()
print(quadratic_weighted_kappa(y1, optR.predict(train_predictions1, coefficients)))
predictions = optR.predict(test_predictions, coefficients).astype(int)
predictions = [item for sublist in predictions for item in sublist]
n = pd.Series(optR.predict(train_predictions1, coefficients))
n.value_counts(normalize=True)
sample_submission = pd.read_csv(
"/kaggle/input/data-science-bowl-2019/sample_submission.csv"
)
sample_submission["accuracy_group"] = predictions
sample_submission.to_csv("submission.csv", index=False)
sample_submission["accuracy_group"].value_counts(normalize=True)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0026/763/26763336.ipynb | null | null | [{"Id": 26763336, "ScriptId": 7495391, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2058044, "CreationDate": "01/12/2020 17:19:57", "VersionNumber": 2.0, "Title": "datahack-amma", "EvaluationDate": "01/12/2020", "IsChange": true, "TotalLines": 1733.0, "LinesInsertedFromPrevious": 18.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 1715.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import xgboost as xgb
from xgboost import XGBClassifier, XGBRegressor
from xgboost import plot_importance
from catboost import CatBoostRegressor
from matplotlib import pyplot
import shap
from time import time
from tqdm import tqdm_notebook as tqdm
from collections import Counter
from scipy import stats
import lightgbm as lgb
from sklearn.metrics import cohen_kappa_score, mean_squared_error
from sklearn.model_selection import KFold, StratifiedKFold
import gc
import json
from pandas.io.json import json_normalize
import json
train = pd.read_csv("/kaggle/input/data-science-bowl-2019/train.csv")
test = pd.read_csv("/kaggle/input/data-science-bowl-2019/test.csv")
train_labels = pd.read_csv("/kaggle/input/data-science-bowl-2019/train_labels.csv")
specs = pd.read_csv("/kaggle/input/data-science-bowl-2019/specs.csv")
train = train[train.installation_id.isin(train_labels.installation_id.unique())]
def json_parser(dataframe, column):
dataframe.reset_index(drop=True, inplace=True)
parsed_set = dataframe[column].apply(json.loads)
parsed_set = json_normalize(parsed_set)
parsed_set.drop(columns=["event_count", "event_code", "game_time"], inplace=True)
merged_set = pd.merge(
dataframe, parsed_set, how="inner", left_index=True, right_index=True
)
del merged_set[column]
return merged_set
def encode_title(train, test):
train["title_event_code"] = list(
map(lambda x, y: str(x) + "_" + str(y), train["title"], train["event_code"])
)
test["title_event_code"] = list(
map(lambda x, y: str(x) + "_" + str(y), test["title"], test["event_code"])
)
unique_title_event_code = list(
set(train["title_event_code"].unique()).union(
set(test["title_event_code"].unique())
)
)
unique_titles = list(
set(train["title"].unique()).union(set(test["title"].unique()))
)
unique_event_codes = list(
set(train["event_code"].unique()).union(set(test["event_code"].unique()))
)
unique_worlds = list(
set(train["world"].unique()).union(set(test["world"].unique()))
)
unique_event_ids = list(
set(train["event_id"].unique()).union(set(test["event_id"].unique()))
)
unique_assessments = list(
set(train[train["type"] == "Assessment"]["title"].value_counts().index).union(
set(test[test["type"] == "Assessment"]["title"].value_counts().index)
)
)
unique_games = list(
set(train[train["type"] == "Game"]["title"].value_counts().index).union(
set(test[test["type"] == "Game"]["title"].value_counts().index)
)
)
unique_clips = list(
set(train[train["type"] == "Clip"]["title"].value_counts().index).union(
set(test[test["type"] == "Clip"]["title"].value_counts().index)
)
)
unique_activitys = list(
set(train[train["type"] == "Activity"]["title"].value_counts().index).union(
set(test[test["type"] == "Activity"]["title"].value_counts().index)
)
)
# convert text into datetime
train["timestamp"] = pd.to_datetime(train["timestamp"])
test["timestamp"] = pd.to_datetime(test["timestamp"])
unique_data = {
"unique_title_event_code": unique_title_event_code,
"unique_titles": unique_titles,
"unique_event_codes": unique_event_codes,
"unique_worlds": unique_worlds,
"unique_event_ids": unique_event_ids,
"unique_assessments": unique_assessments,
"unique_games": unique_games,
"unique_clips": unique_clips,
"unique_activitys": unique_activitys,
}
return train, test, unique_data
train, test, unique_data = encode_title(train, test)
def get_data(user_sample, unique_data, test=False):
final_features = []
features = {}
Assessments_count = {"count_" + ass: 0 for ass in unique_data["unique_assessments"]}
Clips_count = {"count_" + clip: 0 for clip in unique_data["unique_clips"]}
Games_count = {"count_" + game: 0 for game in unique_data["unique_games"]}
Activitys_count = {
"count_" + activity: 0 for activity in unique_data["unique_activitys"]
}
Worlds_count = {"count_" + world: 0 for world in unique_data["unique_worlds"]}
# Title_event_code_count = {"count_"+etc:0 for etc in unique_data["unique_title_event_code"]}
accuracy_groups = {0: 0, 1: 0, 2: 0, 3: 0}
accuracy_groups_game = {"game_0": 0, "game_1": 0, "game_2": 0, "game_3": 0}
features["accumulated_false"] = 0
features["accumulated_true"] = 0
features["accumulated_false_ass"] = 0
features["accumulated_true_ass"] = 0
Clip_duration_accumulated = {
"accu_duration_" + clip: 0 for clip in unique_data["unique_clips"]
}
Clip_duration = {"duration_" + clip: 0 for clip in unique_data["unique_clips"]}
Games_duration_accumulated = {
"accu_duration_" + game: 0 for game in unique_data["unique_games"]
}
Games_duration = {"duration_" + game: 0 for game in unique_data["unique_games"]}
Activitys_duration_accumulated = {
"accu_duration_" + activity: 0 for activity in unique_data["unique_activitys"]
}
Activitys_duration = {
"duration_" + activity: 0 for activity in unique_data["unique_activitys"]
}
Assessments_duration_accumulated = {
"accu_duration_" + ass: 0 for ass in unique_data["unique_assessments"]
}
Assessments_duration = {
"duration_" + ass: 0 for ass in unique_data["unique_assessments"]
}
features.update(accuracy_groups)
features.update(accuracy_groups_game)
for i, session in user_sample.groupby("game_session", sort=False):
# i = game_session_id
session_type = session.type.iloc[0]
session_title = session.title.iloc[0]
session_world = session.world.iloc[0]
Worlds_count["count_" + session_world] += 1
if session_type == "Clip":
# count
Clips_count["count_" + session_title] += 1
# duration
try:
index = session.index.values[0]
duration = (
user_sample.timestamp.loc[index + 1]
- user_sample.timestamp.loc[index]
).seconds
Clip_duration["duration_" + session_title] = duration
Clip_duration_accumulated["accu_duration_" + session_title] += duration
except:
pass
if session_type == "Activity":
# count
Activitys_count["count_" + session_title] += 1
# duration
duration = round(session.game_time.iloc[-1] / 1000, 2)
Activitys_duration["duration_" + session_title] = duration
Activitys_duration_accumulated["accu_duration_" + session_title] += duration
if session_type == "Game":
# count
Games_count["count_" + session_title] += 1
# duration
duration = round(session.game_time.iloc[-1] / 1000, 2)
Games_duration["duration_" + session_title] = duration
Games_duration_accumulated["accu_duration_" + session_title] += duration
if (session_type == "Assessment") & (test or len(session) > 1):
predicted_title = session["title"].iloc[0]
predicted_game_session = session["game_session"].iloc[0]
predicted_timestamp_session = session["timestamp"].iloc[0]
features["predicted_title"] = predicted_title
features["installation_id"] = session["installation_id"].iloc[0]
features["game_session"] = predicted_game_session
features["timestamp_session"] = predicted_timestamp_session
pred_title_df = user_sample[user_sample.title == predicted_title]
pred_title_df = pred_title_df[
pred_title_df.timestamp < predicted_timestamp_session
]
predicted_assessment = {
"pred_bef_attampt": 0,
"pred_bef_true": np.nan,
"pred_bef_false": np.nan,
"pred_bef_acc_group": np.nan,
"pred_bef_accuracy": np.nan,
"pred_bef_timespent": np.nan,
"pred_bef_time_diff": np.nan,
}
try:
if len(pred_title_df) > 2:
for i, pred_session in pred_title_df.groupby(
"game_session", sort=False
):
predicted_assessment["pred_bef_attampt"] += 1
predicted_assessment["pred_bef_timespent"] = round(
pred_session.game_time.iloc[-1] / 1000, 2
)
if predicted_title == "Bird Measurer (Assessment)":
predicted_data = pred_session[
pred_session.event_code == 4110
]
else:
predicted_data = pred_session[
pred_session.event_code == 4100
]
true_attempts = predicted_data[predicted_data.correct == True][
"correct"
].count()
false_attempts = predicted_data[
predicted_data.correct == False
]["correct"].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
group = accuracy_groups_def(accuracy)
predicted_assessment["pred_bef_true"] = true_attempts
predicted_assessment["pred_bef_false"] = false_attempts
predicted_assessment["pred_bef_accuracy"] = accuracy
predicted_assessment["pred_bef_acc_group"] = group
predicted_assessment["pred_bef_time_diff"] = (
predicted_timestamp_session - pred_title_df.timestamp.iloc[-1]
).seconds
except:
pass
features.update(predicted_assessment.copy())
features.update(Clips_count.copy())
features.update(Clip_duration.copy())
features.update(Clip_duration_accumulated.copy())
features.update(Games_count.copy())
features.update(Games_duration.copy())
features.update(Games_duration_accumulated.copy())
features.update(Activitys_count.copy())
features.update(Activitys_duration.copy())
features.update(Activitys_duration_accumulated.copy())
features.update(Assessments_count.copy())
features.update(Assessments_duration.copy())
features.update(Assessments_duration_accumulated.copy())
final_features.append(features.copy())
try:
# last Assessment
last_assessment = {
"last_bef_true": np.nan,
"last_bef_false": np.nan,
"last_bef_acc_group": np.nan,
"last_bef_accuracy": np.nan,
"last_bef_timespent": np.nan,
"last_bef_title": np.nan,
}
last_assessment["last_bef_timespent"] = round(
session.game_time.iloc[-1] / 1000, 2
)
if predicted_title == "Bird Measurer (Assessment)":
predicted_data = session[session.event_code == 4110]
else:
predicted_data = session[session.event_code == 4100]
true_attempts = predicted_data[predicted_data.correct == True][
"correct"
].count()
false_attempts = predicted_data[predicted_data.correct == False][
"correct"
].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
group = accuracy_groups_def(accuracy)
last_assessment["last_bef_true"] = true_attempts
last_assessment["last_bef_false"] = false_attempts
last_assessment["last_bef_accuracy"] = accuracy
last_assessment["last_bef_acc_group"] = group
last_assessment["last_bef_title"] = predicted_title
features.update(last_assessment.copy())
except:
pass
# count
Assessments_count["count_" + session_title] += 1
# duration
duration = round(session.game_time.iloc[-1] / 1000, 2)
Assessments_duration["duration_" + session_title] = duration
Assessments_duration_accumulated[
"accu_duration_" + session_title
] += duration
ed = EventDataFeatures(
features, session, user_sample, session_type, session_title
)
try:
ed.event_code_2000()
ed.event_code_2010()
ed.event_code_2020()
ed.event_code_2030()
ed.event_code_2025()
ed.event_code_2035()
ed.event_code_2040()
ed.event_code_2050()
ed.event_code_2060()
ed.event_code_2070()
ed.event_code_2075()
ed.event_code_2080()
ed.event_code_2081()
ed.event_code_2083()
ed.event_code_3010()
ed.event_code_3020()
ed.event_code_3021()
ed.event_code_3110()
ed.event_code_3120()
ed.event_code_3121()
ed.event_code_4010()
ed.event_code_4020()
ed.event_code_4021()
ed.event_code_4022()
ed.event_code_4025()
ed.event_code_4030()
ed.event_code_4031()
ed.event_code_4035()
ed.event_code_4040()
ed.event_code_4045()
ed.event_code_4050()
ed.event_code_4070()
ed.event_code_4080()
ed.event_code_4090()
ed.event_code_4095()
ed.event_code_4100()
ed.event_code_4110()
ed.event_code_4220()
ed.event_code_4230()
ed.event_code_4235()
ed.event_code_5000()
ed.event_code_5010()
except:
pass
try:
edf = ed.Event_features
features_ed = ed.features
features.update(edf.copy())
features.update(features_ed.copy())
except:
pass
if test:
return final_features[-1]
else:
return final_features
def accuracy_groups_def(accuracy):
if accuracy == 0:
return 0
elif accuracy == 1:
return 3
elif accuracy == 0.5:
return 2
else:
return 1
class EventDataFeatures(object):
def __init__(self, features, session, user_sample, session_type, session_title):
self.features = features
self.session = session
self.user_sample = user_sample
self.session_type = session_type
self.session_title = session_title
self.Event_features = {}
self.unique_event_codes = self.session.event_code.unique()
def event_code_2000(self):
pass
def event_code_2010(self):
"""
['The exit game event is triggered when the game is quit.
This is used to compute things like time spent in game.
Depending on platform this may / may not be possible.
NOTE: “quit” also means navigating away from game.']
"""
if 2010 in self.unique_event_codes:
session_duration = self.session[self.session.event_code == 2010][
"session_duration"
].values[0]
self.Event_features[
"session_duration_" + self.session_title
] = session_duration
def event_code_2020(self):
"""
['The start round event is triggered at the start of a round when
the player is prompted to weigh and arrange the chests. There is only one round per playthrough.
This event provides information about the game characteristics of the round (i.e. resources, objectives, setup).
It is used in calculating things like time spent in a round (for speed and accuracy), attempts at
solving a round, and the number of rounds the player has visited (exposures).']
"""
pass
def event_code_2025(self):
"""
['The reset dinosaurs event is triggered when the player has placed the last dinosaur,
but not all dinosaurs are in the correct position.
This event provides information about the game characteristics of the round (i.e. resources, objectives, setup).
It is used to indicate a significant change in state during play.']
This event is used for calculating time spent in a round and
the number of rounds the player has completed (completion).
"""
pass
def event_code_2030(self):
"""
['The beat round event is triggered when the player finishes a round by filling the jar.
This event is used for calculating time spent in a round and
the number of rounds the player has completed (completion).']
"""
if 2030 in self.unique_event_codes:
rounds = self.session[self.session.event_code == 2030]
round_duration = rounds["duration"].values
self.Event_features[
"round_duration_2030_sum_" + self.session_title
] = round_duration.sum()
self.Event_features[
"round_duration_2030_avg_" + self.session_title
] = round_duration.mean()
self.Event_features[
"round_duration_2030_std_" + self.session_title
] = round_duration.std()
self.Event_features[
"round_duration_2030_max_" + self.session_title
] = round_duration.max()
self.Event_features[
"round_duration_2030_min_" + self.session_title
] = round_duration.min()
try:
round_rounds = rounds["round"].values
self.Event_features[
"round_2030_max_" + self.session_title
] = round_rounds.max()
except:
pass
try:
round_misses = rounds["misses"].values
self.Event_features[
"misses_2030_sum_" + self.session_title
] = round_misses.sum()
self.Event_features[
"misses_2030_avg_" + self.session_title
] = round_misses.mean()
self.Event_features[
"misses_2030_max_" + self.session_title
] = round_misses.max()
except:
pass
def event_code_2035(self):
"""
['The finish filling tub event is triggered after the player finishes filling up the tub.
It is used to separate a section of gameplay that is different from the estimation section of the game.']
"""
if 2035 in self.unique_event_codes:
rounds = self.session[self.session.event_code == 2035]
round_duration = rounds["duration"].values
self.Event_features[
"round_duration_2035_sum_" + self.session_title
] = round_duration.sum()
self.Event_features[
"round_duration_2035_avg_" + self.session_title
] = round_duration.mean()
def event_code_2040(self):
"""
['The start level event is triggered when a new level begins
(at the same time as the start round event for the first round in the level).
This event is used for calculating time spent in a level (for speed and accuracy),
and the number of levels the player has completed (completion).']
"""
pass
def event_code_2050(self):
"""
['The beat level event is triggered when a level has been completed and
the player has cleared all rounds in the current layout (occurs at the same time as
the beat round event for the last round in the previous level). This event is used for
calculating time spent in a level (for speed and accuracy),
and the number of levels the player has completed (completion).']
"""
if 2050 in self.unique_event_codes:
level = self.session[self.session.event_code == 2050]
level_duration = level["duration"].values
self.Event_features[
"level_duration_2050_sum_" + self.session_title
] = level_duration.sum()
self.Event_features[
"level_duration_2050_avg_" + self.session_title
] = level_duration.mean()
self.Event_features[
"level_duration_2050_std_" + self.session_title
] = level_duration.std()
self.Event_features[
"level_duration_2050_max_" + self.session_title
] = level_duration.max()
self.Event_features[
"level_duration_2050_min_" + self.session_title
] = level_duration.min()
try:
level_rounds = level["level"].values
self.Event_features[
"level_2050_max_" + self.session_title
] = level_rounds.max()
except:
pass
try:
level_misses = level["misses"].values
self.Event_features[
"level_misses_2050_sum_" + self.session_title
] = level_misses.sum()
self.Event_features[
"level_misses_2050_avg_" + self.session_title
] = level_misses.mean()
self.Event_features[
"level_misses_2050_sum_" + self.session_title
] = level_misses.std()
except:
pass
def event_code_2060(self):
"""
['The start tutorial event is triggered at the start of the tutorial.
It is used in calculating time spent in the tutorial.']
"""
pass
def event_code_2070(self):
"""
['The beat round event is triggered when the player finishes the tutorial.
This event is used for calculating time spent in the tutorial.']
"""
if 2070 in self.unique_event_codes:
tutorial = self.session[self.session.event_code == 2070]
tutorial_duration = tutorial["duration"].values
self.Event_features[
"tutorial_duration_2070_sum_" + self.session_title
] = tutorial_duration.sum()
self.Event_features[
"tutorial_duration_2070_avg_" + self.session_title
] = tutorial_duration.mean()
self.Event_features[
"tutorial_duration_2070_std_" + self.session_title
] = tutorial_duration.std()
self.Event_features[
"tutorial_duration_2070_max_" + self.session_title
] = tutorial_duration.max()
self.Event_features[
"tutorial_duration_2070_min_" + self.session_title
] = tutorial_duration.min()
def event_code_2075(self):
"""
['The beat round event is triggered when the player skips the tutorial by clicking on the skip button.
This event is used for calculating time spent in the tutorial.']
"""
if 2075 in self.unique_event_codes:
tutorial = self.session[self.session.event_code == 2075]
self.Event_features[
"tutorial_skiping_count_2075_" + self.session_title
] = tutorial["duration"].count()
def event_code_2080(self):
"""
['The movie started event triggers when an intro or outro movie starts to play.
It identifies the movie being played. This is used to determine how long players
spend watching the movies (more relevant after the first play
through when the skip option is available).']
"""
if 2080 in self.unique_event_codes:
movie = self.session[self.session.event_code == 2080]
movie_duration = movie["duration"].values
self.Event_features[
"movie_duration_2080_sum_" + self.session_title
] = movie_duration.sum()
self.Event_features[
"movie_duration_2080_avg_" + self.session_title
] = movie_duration.mean()
self.Event_features[
"movie_duration_2080_std_" + self.session_title
] = movie_duration.std()
self.Event_features[
"movie_duration_2080_max_" + self.session_title
] = movie_duration.max()
self.Event_features[
"movie_duration_2080_min_" + self.session_title
] = movie_duration.min()
def event_code_2081(self):
"""
['The movie started event triggers when an intro or outro movie starts to play.
It identifies the movie being played. This is used to determine how long players
spend watching the movies (more relevant after the first play
through when the skip option is available).']
"""
if 2081 in self.unique_event_codes:
movie = self.session[self.session.event_code == 2081]
self.Event_features[
"movie_skiping_count_2081_" + self.session_title
] = movie["duration"].count()
def event_code_2083(self):
"""
['The movie started event triggers when an intro or outro movie starts to play.
It identifies the movie being played. This is used to determine how long players
spend watching the movies (more relevant after the first play
through when the skip option is available).']
"""
if 2083 in self.unique_event_codes:
movie = self.session[self.session.event_code == 2083]
movie_duration = movie["duration"].values
self.Event_features[
"movie_duration_2083_sum_" + self.session_title
] = movie_duration.sum()
self.Event_features[
"movie_duration_2083_avg_" + self.session_title
] = movie_duration.mean()
def event_code_3010(self):
"""
['The system-initiated instruction event occurs when the game delivers instructions to the player.
It contains information that describes the content of the instruction. This event differs from events 3020
and 3021 as it captures instructions that are not given in response to player action.
These events are used to determine the effectiveness of the instructions. We can answer questions like,
"did players who received instruction X do better than those who did not?"']
"""
if 3010 in self.unique_event_codes:
instruction = self.session[self.session.event_code == 3010]
instruction_duration = instruction["total_duration"].values
self.Event_features[
"instruction_duration_3010_sum_" + self.session_title
] = instruction_duration.sum()
self.Event_features[
"instruction_duration_3010_avg_" + self.session_title
] = instruction_duration.mean()
# self.Event_features["instruction_media_type_3010_"+self.session_title] = instruction["media_type"].values_count().index[0]
self.Event_features[
"instruction_media_type_3010_count_" + self.session_title
] = instruction["media_type"].count()
def event_code_3020(self):
"""
['The system-initiated feedback (Incorrect) event occurs when the game starts delivering feedback
to the player in response to an incorrect round attempt (pressing the go button with the incorrect answer).
It contains information that describes the content of the instruction. These events are used to determine
the effectiveness of the feedback. We can answer questions like
"did players who received feedback X do better than those who did not?"']
"""
if 3020 in self.unique_event_codes:
Incorrect = self.session[self.session.event_code == 3020]
Incorrect_duration = Incorrect["total_duration"].values
self.Event_features[
"Incorrect_duration_3020_sum_" + self.session_title
] = Incorrect_duration.sum()
self.Event_features[
"Incorrect_duration_3020_avg_" + self.session_title
] = Incorrect_duration.mean()
# self.Event_features["Incorrect_duration_3020_std_"+self.session_title] = Incorrect_duration.std()
# self.Event_features["Incorrect_duration_3020_max_"+self.session_title] = Incorrect_duration.max()
# self.Event_features["Incorrect_duration_3020_min_"+self.session_title] = Incorrect_duration.min()
# self.Event_features["Incorrect_media_type_3020_"+self.session_title] = Incorrect["media_type"].values[0]
self.Event_features[
"Incorrect_media_type_3020_count_" + self.session_title
] = Incorrect["media_type"].count()
def event_code_3021(self):
"""
['The system-initiated feedback (Correct) event occurs when the game
starts delivering feedback to the player in response to a correct round attempt
(pressing the go button with the correct answer). It contains information that describes the
content of the instruction, and will likely occur in conjunction with a beat round event.
These events are used to determine the effectiveness of the feedback. We can answer questions like,
"did players who received feedback X do better than those who did not?"']
"""
if 3021 in self.unique_event_codes:
Correct = self.session[self.session.event_code == 3021]
Correct_duration = Correct["total_duration"].values
self.Event_features[
"Correct_duration_3021_sum_" + self.session_title
] = Correct_duration.sum()
self.Event_features[
"Correct_duration_3021_avg_" + self.session_title
] = Correct_duration.mean()
# self.Event_features["Correct_duration_3021_std_"+self.session_title] = Correct_duration.std()
# self.Event_features["Correct_duration_3021_max_"+self.session_title] = Correct_duration.max()
# self.Event_features["Correct_duration_3021_min_"+self.session_title] = Correct_duration.min()
# self.Event_features["Correct_media_type_3021_"+self.session_title] = Correct["media_type"].values[0]
self.Event_features[
"Correct_media_type_3021_count_" + self.session_title
] = Correct["media_type"].count()
def event_code_3110(self):
"""
['The end of system-initiated instruction event occurs when the game finishes
delivering instructions to the player. It contains information that describes the
content of the instruction including duration. These events are used to determine the
effectiveness of the instructions and the amount of time they consume. We can answer questions like,
"how much time elapsed while the game was presenting instruction?"']
"""
if 3110 in self.unique_event_codes:
Instuction = self.session[self.session.event_code == 3110]
Instuction_duration = Instuction["duration"].values
self.Event_features[
"Instuction_duration_3110_sum_" + self.session_title
] = Instuction_duration.sum()
self.Event_features[
"Instuction_duration_3110_avg_" + self.session_title
] = Instuction_duration.mean()
# self.Event_features["Instuction_duration_3110_std_"+self.session_title] = Instuction_duration.std()
# self.Event_features["Instuction_duration_3110_max_"+self.session_title] = Instuction_duration.max()
# self.Event_features["Instuction_duration_3110_min_"+self.session_title] = Instuction_duration.min()
# self.Event_features["Instuction_media_type_3110_"+self.session_title] = Instuction["media_type"].values[0]
self.Event_features[
"Instuction_media_type_3110_count_" + self.session_title
] = Instuction["media_type"].count()
def event_code_3120(self):
"""
['The end of system-initiated feedback (Incorrect) event
occurs when the game finishes delivering feedback to the player in response
to an incorrect round attempt (pressing the go button with the incorrect answer).
It contains information that describes the content of the instruction.
These events are used to determine the effectiveness of the feedback. We can answer questions like,
“how much time elapsed while the game was presenting feedback?”']
"""
if 3120 in self.unique_event_codes:
IncorrectInstruction = self.session[self.session.event_code == 3120]
IncorrectInstruction_duration = IncorrectInstruction["duration"].values
self.Event_features[
"IncorrectInstruction_duration_3120_sum_" + self.session_title
] = IncorrectInstruction_duration.sum()
self.Event_features[
"IncorrectInstruction_duration_3120_avg_" + self.session_title
] = IncorrectInstruction_duration.mean()
# self.Event_features["IncorrectInstruction_duration_3120_std_"+self.session_title] = IncorrectInstruction_duration.std()
# self.Event_features["IncorrectInstruction_duration_3120_max_"+self.session_title] = IncorrectInstruction_duration.max()
# self.Event_features["IncorrectInstruction_duration_3120_min_"+self.session_title] = IncorrectInstruction_duration.min()
# self.Event_features["IncorrectInstruction_media_type_3120_"+self.session_title] = IncorrectInstruction["media_type"].values[0]
self.Event_features[
"IncorrectInstruction_media_type_3120_count_" + self.session_title
] = IncorrectInstruction["media_type"].count()
def event_code_3121(self):
"""
['The end of system-initiated feedback (Correct) event
occurs when the game finishes delivering feedback to the player in response
to an incorrect round attempt (pressing the go button with the incorrect answer).
It contains information that describes the content of the instruction.
These events are used to determine the effectiveness of the feedback. We can answer questions like,
“how much time elapsed while the game was presenting feedback?”']
"""
if 3121 in self.unique_event_codes:
CorrectInstruction = self.session[self.session.event_code == 3121]
CorrectInstruction_duration = CorrectInstruction["duration"].values
self.Event_features[
"CorrectInstruction_duration_3121_sum_" + self.session_title
] = CorrectInstruction_duration.sum()
self.Event_features[
"CorrectInstruction_duration_3121_avg_" + self.session_title
] = CorrectInstruction_duration.mean()
# self.Event_features["CorrectInstruction_duration_3121_std_"+self.session_title] = CorrectInstruction_duration.std()
# self.Event_features["CorrectInstruction_duration_3121_max_"+self.session_title] = CorrectInstruction_duration.max()
# self.Event_features["CorrectInstruction_duration_3121_min_"+self.session_title] = CorrectInstruction_duration.min()
# self.Event_features["CorrectInstruction_media_type_3121_"+self.session_title] = CorrectInstruction["media_type"].values[0]
self.Event_features[
"CorrectInstruction_media_type_3121_count_" + self.session_title
] = CorrectInstruction["media_type"].count()
def event_code_4010(self):
"""
['This event occurs when the player clicks to start
the game from the starting screen.']
"""
if 4010 in self.unique_event_codes:
click_start = self.session[self.session.event_code == 4010]
index = click_start.index.values[0]
duration = (
self.user_sample.timestamp.loc[index]
- self.user_sample.timestamp.loc[index - 1]
).seconds
self.Event_features[
"click_start_duration_4010_" + self.session_title
] = duration
def event_code_4020(self):
"""
['This event occurs when the player
clicks a group of objects. It contains information
about the group clicked, the state of the game, and the
correctness of the action. This event is
to diagnose player strategies and understanding.']
It contains information about the state of the game and the correctness of the action. This event is used
to diagnose player strategies and understanding.
"""
if 4020 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4020]
if self.session_title == "Bottle Filler (Activity)":
true_attempts = event_data[event_data.jar_filled == True][
"jar_filled"
].count()
false_attempts = event_data[event_data.jar_filled == False][
"jar_filled"
].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"True_attempts_4020_" + self.session_title
] = true_attempts
self.Event_features[
"False_attempts_4020_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4020_" + self.session_title
] = accuracy
group = accuracy_groups_def(accuracy)
self.features["game_" + str(group)] += 1
self.features["accumulated_false"] += false_attempts
self.features["accumulated_true"] += true_attempts
elif self.session_title == "Sandcastle Builder (Activity)":
sandcastle_duration = event_data["duration"].values
self.Event_features[
"sandcastle_duration_4020_sum_" + self.session_title
] = sandcastle_duration.sum()
self.Event_features[
"sandcastle_duration_4020_avg_" + self.session_title
] = sandcastle_duration.mean()
# self.Event_features["sandcastle_duration_4020_std_"+self.session_title] = sandcastle_duration.std()
# self.Event_features["sandcastle_duration_4020_max_"+self.session_title] = sandcastle_duration.max()
# self.Event_features["sandcastle_duration_4020_min_"+self.session_title] = sandcastle_duration.min()
elif self.session_title == "Cart Balancer (Assessment)":
try:
true_attempts = event_data[event_data.size == "left"][
"size"
].count()
false_attempts = event_data[event_data.size == "right"][
"size"
].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"Left_attempts_4020_" + self.session_title
] = true_attempts
self.Event_features[
"Right_attempts_4020_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4020_" + self.session_title
] = accuracy
group = accuracy_groups_def(accuracy)
self.features["game_" + str(group)] += 1
self.features["accumulated_false"] += false_attempts
self.features["accumulated_true"] += true_attempts
except:
pass
elif self.session_title == "Fireworks (Activity)":
true_attempts = event_data[event_data.launched == True][
"launched"
].count()
false_attempts = event_data[event_data.launched == False][
"launched"
].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"True_attempts_4020_" + self.session_title
] = true_attempts
self.Event_features[
"False_attempts_4020_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4020_" + self.session_title
] = accuracy
group = accuracy_groups_def(accuracy)
self.features["game_" + str(group)] += 1
self.features["accumulated_false"] += false_attempts
self.features["accumulated_true"] += true_attempts
rocket_duration = event_data["duration"].values
self.Event_features[
"rocket_duration_4020_sum_" + self.session_title
] = rocket_duration.sum()
self.Event_features[
"rocket_duration_4020_avg_" + self.session_title
] = rocket_duration.mean()
self.Event_features[
"rocket_duration_4020_std_" + self.session_title
] = rocket_duration.std()
self.Event_features[
"rocket_duration_4020_max_" + self.session_title
] = rocket_duration.max()
self.Event_features[
"rocket_duration_4020_min_" + self.session_title
] = rocket_duration.min()
rocket_height = event_data["height"].values
self.Event_features[
"rocket_height_4020_sum_" + self.session_title
] = rocket_height.sum()
self.Event_features[
"rocket_height_4020_avg_" + self.session_title
] = rocket_height.mean()
self.Event_features[
"rocket_height_4020_std_" + self.session_title
] = rocket_height.std()
self.Event_features[
"rocket_height_4020_max_" + self.session_title
] = rocket_height.max()
self.Event_features[
"rocket_height_4020_min_" + self.session_title
] = rocket_height.min()
elif self.session_title == "Watering Hole (Activity)":
water_level = event_data["water_level"].values
self.Event_features[
"water_level_4020_sum_" + self.session_title
] = water_level.sum()
self.Event_features[
"water_level_4020_avg_" + self.session_title
] = water_level.mean()
self.Event_features[
"water_level_4020_std_" + self.session_title
] = water_level.std()
self.Event_features[
"water_level_4020_max_" + self.session_title
] = water_level.max()
self.Event_features[
"water_level_4020_min_" + self.session_title
] = water_level.min()
elif self.session_title == "Chicken Balancer (Activity)":
true_attempts = event_data[event_data["layout.right.pig"] == True][
"layout.right.pig"
].count()
false_attempts = event_data[event_data["layout.right.pig"] == False][
"layout.right.pig"
].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"True_attempts_4020_" + self.session_title
] = true_attempts
self.Event_features[
"False_attempts_4020_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4020_" + self.session_title
] = accuracy
elif self.session_title == "Flower Waterer (Activity)":
flower_duration = event_data["duration"].values
self.Event_features[
"flower_duration_4020_sum_" + self.session_title
] = flower_duration.sum()
self.Event_features[
"flower_duration_4020_avg_" + self.session_title
] = flower_duration.mean()
# self.Event_features["flower_duration_4020_std_"+self.session_title] = flower_duration.std()
# self.Event_features["flower_duration_4020_max_"+self.session_title] = flower_duration.max()
# self.Event_features["flower_duration_4020_min_"+self.session_title] = flower_duration.min()
elif self.session_title == "Egg Dropper (Activity)":
true_attempts = event_data[event_data["gate.side"] == "left"][
"gate.side"
].count()
false_attempts = event_data[event_data["gate.side"] == "right"][
"gate.side"
].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"Left_attempts_4020_" + self.session_title
] = true_attempts
self.Event_features[
"Right_attempts_4020_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4020_" + self.session_title
] = accuracy
else:
true_attempts = event_data[event_data.correct == True][
"correct"
].count()
false_attempts = event_data[event_data.correct == False][
"correct"
].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"True_attempts_4020_" + self.session_title
] = true_attempts
self.Event_features[
"False_attempts_4020_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4020_" + self.session_title
] = accuracy
group = accuracy_groups_def(accuracy)
self.features["game_" + str(group)] += 1
self.features["accumulated_false"] += false_attempts
self.features["accumulated_true"] += true_attempts
def event_code_4021(self):
if 4021 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4021]
if self.session_title == "Sandcastle Builder (Activity)":
amount_sand = event_data["sand"].values
self.Event_features[
"amount_sand_4020_sum_" + self.session_title
] = amount_sand.sum()
self.Event_features[
"amount_sand_4020_avg_" + self.session_title
] = amount_sand.mean()
# self.Event_features["amount_sand_4020_std_"+self.session_title] = amount_sand.std()
self.Event_features[
"amount_sand_4020_max_" + self.session_title
] = amount_sand.max()
# self.Event_features["amount_sand_4020_min_"+self.session_title] = amount_sand.min()
elif self.session_title == "Watering Hole (Activity)":
cloud_size = event_data["cloud_size"].values
self.Event_features[
"cloud_size_4020_sum_" + self.session_title
] = cloud_size.sum()
self.Event_features[
"cloud_size_4020_avg_" + self.session_title
] = cloud_size.mean()
# self.Event_features["cloud_size_4020_std_"+self.session_title] = cloud_size.std()
self.Event_features[
"cloud_size_4020_max_" + self.session_title
] = cloud_size.max()
# self.Event_features["cloud_size_4020_min_"+self.session_title] = cloud_size.min()
else:
pass
def event_code_4022(self):
pass
def event_code_4025(self):
if 4025 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4025]
if self.session_title == "Cauldron Filler (Assessment)":
true_attempts = event_data[event_data.correct == True][
"correct"
].count()
false_attempts = event_data[event_data.correct == False][
"correct"
].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"True_attempts_4025_" + self.session_title
] = true_attempts
self.Event_features[
"False_attempts_4025_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4025_" + self.session_title
] = accuracy
group = accuracy_groups_def(accuracy)
self.features["game_" + str(group)] += 1
self.features["accumulated_false"] += false_attempts
self.features["accumulated_true"] += true_attempts
elif self.session_title == "Bug Measurer (Activity)":
self.Event_features[
"Bug_length_max_4025_" + self.session_title
] = event_data["buglength"].max()
self.Event_features[
"Number_of_Bugs_4025_" + self.session_title
] = event_data["buglength"].count()
else:
pass
def event_code_4030(self):
pass
def event_code_4031(self):
pass
def event_code_4035(self):
if 4035 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4035]
self.Event_features["wrong_place_count_4035_" + self.session_title] = len(
event_data
)
if self.session_title == "All Star Sorting":
wrong_place = event_data["duration"].values
self.Event_features[
"wrong_place_duration_4035_sum_" + self.session_title
] = wrong_place.sum()
self.Event_features[
"wrong_place_duration_4035_avg_" + self.session_title
] = wrong_place.mean()
# self.Event_features["wrong_place_duration_4035_std_"+self.session_title] = wrong_place.std()
# self.Event_features["wrong_place_duration_4035_max_"+self.session_title] = wrong_place.max()
# self.Event_features["wrong_place_duration_4035_min_"+self.session_title] = wrong_place.min()
elif self.session_title == "Bug Measurer (Activity)":
wrong_place = event_data["duration"].values
self.Event_features[
"wrong_place_duration_4035_sum_" + self.session_title
] = wrong_place.sum()
self.Event_features[
"wrong_place_duration_4035_avg_" + self.session_title
] = wrong_place.mean()
# self.Event_features["wrong_place_duration_4035_std_"+self.session_title] = wrong_place.std()
# self.Event_features["wrong_place_duration_4035_max_"+self.session_title] = wrong_place.max()
# self.Event_features["wrong_place_duration_4035_min_"+self.session_title] = wrong_place.min()
elif self.session_title == "Pan Balance":
pass
elif self.session_title == "Chicken Balancer (Activity)":
wrong_place = event_data["duration"].values
self.Event_features[
"wrong_place_duration_4035_sum_" + self.session_title
] = wrong_place.sum()
self.Event_features[
"wrong_place_duration_4035_avg_" + self.session_title
] = wrong_place.mean()
# self.Event_features["wrong_place_duration_4035_std_"+self.session_title] = wrong_place.std()
# self.Event_features["wrong_place_duration_4035_max_"+self.session_title] = wrong_place.max()
# self.Event_features["wrong_place_duration_4035_min_"+self.session_title] = wrong_place.min()
elif self.session_title == "Chest Sorter (Assessment)":
wrong_place = event_data["duration"].values
self.Event_features[
"wrong_place_duration_4035_sum_" + self.session_title
] = wrong_place.sum()
self.Event_features[
"wrong_place_duration_4035_avg_" + self.session_title
] = wrong_place.mean()
# self.Event_features["wrong_place_duration_4035_std_"+self.session_title] = wrong_place.std()
# self.Event_features["wrong_place_duration_4035_max_"+self.session_title] = wrong_place.max()
# self.Event_features["wrong_place_duration_4035_min_"+self.session_title] = wrong_place.min()
else:
try:
wrong_place = event_data["duration"].values
self.Event_features[
"wrong_place_duration_4035_sum_" + self.session_title
] = wrong_place.sum()
self.Event_features[
"wrong_place_duration_4035_avg_" + self.session_title
] = wrong_place.mean()
# self.Event_features["wrong_place_duration_4035_std_"+self.session_title] = wrong_place.std()
# self.Event_features["wrong_place_duration_4035_max_"+self.session_title] = wrong_place.max()
# self.Event_features["wrong_place_duration_4035_min_"+self.session_title] = wrong_place.min()
except:
pass
def event_code_4040(self):
pass
def event_code_4045(self):
pass
def event_code_4050(self):
pass
def event_code_4070(self):
"""
['This event occurs when the player clicks on
something that isn’t covered elsewhere.
It can be useful in determining if there are
attractive distractions (things the player think
should do something, but don’t) in the game, or
diagnosing players
who are having mechanical difficulties (near misses).']
"""
if 4070 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4070]
self.Event_features[
"something_not_covered_count_4070_" + self.session_title
] = len(event_data)
def event_code_4080(self):
if 4080 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4080]
self.Event_features["mouse_over_count_4080_" + self.session_title] = len(
event_data
)
try:
dwell_time = event_data["dwell_time"].values
self.Event_features[
"dwell_time_duration_4080_sum_" + self.session_title
] = dwell_time.sum()
self.Event_features[
"dwell_time_duration_4080_avg_" + self.session_title
] = dwell_time.mean()
self.Event_features[
"dwell_time_duration_4080_std_" + self.session_title
] = dwell_time.std()
self.Event_features[
"dwell_time_duration_4080_max_" + self.session_title
] = dwell_time.max()
self.Event_features[
"dwell_time_duration_4080_min_" + self.session_title
] = dwell_time.min()
except:
pass
def event_code_4090(self):
if 4090 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4090]
self.Event_features["Player_help_count_4090_" + self.session_title] = len(
event_data
)
def event_code_4095(self):
if 4095 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4095]
self.Event_features["Plage_again_4095_" + self.session_title] = len(
event_data
)
def event_code_4100(self):
if 4100 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4100]
true_attempts = event_data[event_data.correct == True]["correct"].count()
false_attempts = event_data[event_data.correct == False]["correct"].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"True_attempts_4100_" + self.session_title
] = true_attempts
self.Event_features[
"False_attempts_4100_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4100_" + self.session_title
] = accuracy
group = accuracy_groups_def(accuracy)
self.features[group] += 1
self.features["accumulated_false_ass"] += false_attempts
self.features["accumulated_true_ass"] += true_attempts
def event_code_4110(self):
if 4110 in self.unique_event_codes:
event_data = self.session[self.session.event_code == 4110]
true_attempts = event_data[event_data.correct == True]["correct"].count()
false_attempts = event_data[event_data.correct == False]["correct"].count()
accuracy = (
true_attempts / (true_attempts + false_attempts)
if (true_attempts + false_attempts) != 0
else 0
)
self.Event_features[
"True_attempts_4110_" + self.session_title
] = true_attempts
self.Event_features[
"False_attempts_4110_" + self.session_title
] = false_attempts
self.Event_features[
"Accuracy_attempts_4110_" + self.session_title
] = accuracy
group = accuracy_groups_def(accuracy)
self.features[group] += 1
self.features["accumulated_false_ass"] += false_attempts
self.features["accumulated_true_ass"] += true_attempts
def event_code_4220(self):
pass
def event_code_4230(self):
pass
def event_code_4235(self):
pass
def event_code_5000(self):
pass
def event_code_5010(self):
pass
def get_train_test(train, test, unique_data):
compiled_train = []
compiled_test = []
if os.path.exists("../input/amma-reduce-train/amma_reduce_train.csv"):
reduce_train_file = True
reduce_train = pd.read_csv("../input/amma-reduce-train/amma_reduce_train.csv")
else:
for i, (ins_id, user_sample) in tqdm(
enumerate(train.groupby("installation_id", sort=False)),
total=len(train.installation_id.unique()),
):
if "Assessment" in user_sample.type.unique():
temp_df = json_parser(user_sample, "event_data")
temp_df.sort_values("timestamp", inplace=True)
temp_df.reset_index(inplace=True, drop=True)
temp_df["index"] = temp_df.index.values
compiled_train.extend(get_data(temp_df, unique_data))
reduce_train = pd.DataFrame(compiled_train)
for i, (ins_id, user_sample) in tqdm(
enumerate(test.groupby("installation_id", sort=False)),
total=len(test.installation_id.unique()),
):
if "Assessment" in user_sample.type.unique():
temp_df = json_parser(user_sample, "event_data")
temp_df.sort_values("timestamp", inplace=True)
temp_df.reset_index(inplace=True, drop=True)
temp_df["index"] = temp_df.index.values
compiled_test.append(get_data(temp_df, unique_data, test=True))
reduce_test = pd.DataFrame(compiled_test)
return reduce_train, reduce_test
reduce_train, reduce_test = get_train_test(train, test, unique_data)
reduce_train.shape, reduce_test.shape
reduce_train = reduce_train[
reduce_train.game_session.isin(train_labels.game_session.unique())
]
reduce_train.shape
reduce_train.columns = [
"".join(c if c.isalnum() else "_" for c in str(x)) for x in reduce_train.columns
]
reduce_test.columns = [
"".join(c if c.isalnum() else "_" for c in str(x)) for x in reduce_test.columns
]
rem = list(set(reduce_train.columns).intersection(set(reduce_test)))
reduce_train = reduce_train[rem]
reduce_test = reduce_test[rem]
reduce_train.shape, reduce_test.shape
import numpy as np
import pandas as pd
from functools import partial
from sklearn import metrics
import scipy as sp
from sklearn.preprocessing import OneHotEncoder
from scipy.stats import boxcox, skew, randint, uniform
from sklearn.model_selection import KFold, StratifiedKFold
from sklearn.linear_model import Lasso, ElasticNet, Ridge, LinearRegression
from sklearn.kernel_ridge import KernelRidge
from sklearn.feature_selection import RFECV
from sklearn.preprocessing import StandardScaler, RobustScaler
from sklearn.metrics import mean_squared_error
import warnings
warnings.filterwarnings("ignore")
categorical_cols = []
for col in reduce_train.columns:
if reduce_train[col].dtype == "object":
categorical_cols.append(col)
categorical_cols
def tree_based_models(train, test, columns_map):
for col in columns_map:
list_of_values = list(set(train[col].unique()).union(set(test[col].unique())))
list_of_values_map = dict(zip(list_of_values, np.arange(len(list_of_values))))
train[col] = train[col].map(list_of_values_map)
test[col] = test[col].map(list_of_values_map)
return train, test
def merge_with_labels(train, train_labels):
train = train[train.game_session.isin(train_labels.game_session.unique())]
tld = train_labels[
[
"game_session",
"installation_id",
"num_correct",
"num_incorrect",
"accuracy",
"accuracy_group",
]
]
final_train = pd.merge(
tld,
train,
left_on=["game_session", "installation_id"],
right_on=["game_session", "installation_id"],
how="inner",
)
final_train.sort_values("timestamp_session", inplace=True)
col_drop = tld.columns.values
col_drop = np.append(col_drop, "timestamp_session")
return final_train, col_drop
final_train, col_drop = merge_with_labels(reduce_train, train_labels)
cat_cols = []
for col in categorical_cols:
if col not in col_drop:
cat_cols.append(col)
len(cat_cols)
cat_drop_com = cat_cols + col_drop.tolist()
numaric_cols = list(set(final_train.columns.values) - set(cat_drop_com))
final_train, final_test = tree_based_models(final_train, reduce_test, cat_cols)
final_train.shape, final_test.shape
def eval_qwk_lgb_regr2(y_true, y_pred, train):
"""
Fast cappa eval function for lgb.
"""
dist = Counter(train["accuracy_group"])
for k in dist:
dist[k] /= len(train)
train["accuracy_group"].hist()
acum = 0
bound = {}
for i in range(3):
acum += dist[i]
bound[i] = np.percentile(y_pred, acum * 100)
def classify(x):
if x <= bound[0]:
return 0
elif x <= bound[1]:
return 1
elif x <= bound[2]:
return 2
else:
return 3
y_pred = np.array(list(map(classify, y_pred))).reshape(y_true.shape)
return "cappa", cohen_kappa_score(y_true, y_pred, weights="quadratic"), True
def qwk(a1, a2):
"""
Source: https://www.kaggle.com/c/data-science-bowl-2019/discussion/114133#latest-660168
:param a1:
:param a2:
:param max_rat:
:return:
"""
max_rat = 3
a1 = np.asarray(a1, dtype=int)
a2 = np.asarray(a2, dtype=int)
hist1 = np.zeros((max_rat + 1,))
hist2 = np.zeros((max_rat + 1,))
o = 0
for k in range(a1.shape[0]):
i, j = a1[k], a2[k]
hist1[i] += 1
hist2[j] += 1
o += (i - j) * (i - j)
e = 0
for i in range(max_rat + 1):
for j in range(max_rat + 1):
e += hist1[i] * hist2[j] * (i - j) * (i - j)
e = e / a1.shape[0]
return 1 - o / e
def eval_qwk_lgb_regr(y_true, y_pred):
"""
Fast cappa eval function for lgb.
"""
y_pred[y_pred <= 1.12232214] = 0
y_pred[np.where(np.logical_and(y_pred > 1.12232214, y_pred <= 1.73925866))] = 1
y_pred[np.where(np.logical_and(y_pred > 1.73925866, y_pred <= 2.22506454))] = 2
y_pred[y_pred > 2.22506454] = 3
# y_pred = y_pred.reshape(len(np.unique(y_true)), -1).argmax(axis=0)
return "cappa", qwk(y_true, y_pred), True
from sklearn.metrics import confusion_matrix, accuracy_score
def confusion_matrix_reg(y_true, y_pred):
y_pred[y_pred <= 1.12232214] = 0
y_pred[np.where(np.logical_and(y_pred > 1.12232214, y_pred <= 1.73925866))] = 1
y_pred[np.where(np.logical_and(y_pred > 1.73925866, y_pred <= 2.22506454))] = 2
y_pred[y_pred > 2.22506454] = 3
print("Accuracy : ", accuracy_score(y_true=y_true, y_pred=y_pred))
print("Confussion_matrix \n", confusion_matrix(y_true, y_pred))
print("\n\n")
col_drop
col_drop1 = col_drop
class OptimizedRounder(object):
def __init__(self):
self.coef_ = 0
def _kappa_loss(self, coef, X, y):
X_p = np.copy(X)
for i, pred in enumerate(X_p):
if pred < coef[0]:
X_p[i] = 0
elif pred >= coef[0] and pred < coef[1]:
X_p[i] = 1
elif pred >= coef[1] and pred < coef[2]:
X_p[i] = 2
else:
X_p[i] = 3
ll = quadratic_weighted_kappa(y, X_p)
return -ll
def fit(self, X, y):
loss_partial = partial(self._kappa_loss, X=X, y=y)
initial_coef = [1.1, 1.7, 2.2]
self.coef_ = sp.optimize.minimize(
loss_partial, initial_coef, method="nelder-mead"
)
def predict(self, X, coef):
X_p = np.copy(X)
for i, pred in enumerate(X_p):
if pred < coef[0]:
X_p[i] = 0
elif pred >= coef[0] and pred < coef[1]:
X_p[i] = 1
elif pred >= coef[1] and pred < coef[2]:
X_p[i] = 2
else:
X_p[i] = 3
return X_p
def coefficients(self):
return self.coef_["x"]
# The following 3 functions have been taken from Ben Hamner's github repository
# https://github.com/benhamner/Metrics
def confusion_matrix(rater_a, rater_b, min_rating=None, max_rating=None):
"""
Returns the confusion matrix between rater's ratings
"""
assert len(rater_a) == len(rater_b)
if min_rating is None:
min_rating = min(rater_a + rater_b)
if max_rating is None:
max_rating = max(rater_a + rater_b)
num_ratings = int(max_rating - min_rating + 1)
conf_mat = [[0 for i in range(num_ratings)] for j in range(num_ratings)]
for a, b in zip(rater_a, rater_b):
conf_mat[a - min_rating][b - min_rating] += 1
return conf_mat
def histogram(ratings, min_rating=None, max_rating=None):
"""
Returns the counts of each type of rating that a rater made
"""
if min_rating is None:
min_rating = min(ratings)
if max_rating is None:
max_rating = max(ratings)
num_ratings = int(max_rating - min_rating + 1)
hist_ratings = [0 for x in range(num_ratings)]
for r in ratings:
hist_ratings[r - min_rating] += 1
return hist_ratings
def quadratic_weighted_kappa(y, y_pred):
"""
Calculates the quadratic weighted kappa
axquadratic_weighted_kappa calculates the quadratic weighted kappa
value, which is a measure of inter-rater agreement between two raters
that provide discrete numeric ratings. Potential values range from -1
(representing complete disagreement) to 1 (representing complete
agreement). A kappa value of 0 is expected if all agreement is due to
chance.
quadratic_weighted_kappa(rater_a, rater_b), where rater_a and rater_b
each correspond to a list of integer ratings. These lists must have the
same length.
The ratings should be integers, and it is assumed that they contain
the complete range of possible ratings.
quadratic_weighted_kappa(X, min_rating, max_rating), where min_rating
is the minimum possible rating, and max_rating is the maximum possible
rating
"""
rater_a = y
rater_b = y_pred
min_rating = None
max_rating = None
rater_a = np.array(rater_a, dtype=int)
rater_b = np.array(rater_b, dtype=int)
assert len(rater_a) == len(rater_b)
if min_rating is None:
min_rating = min(min(rater_a), min(rater_b))
if max_rating is None:
max_rating = max(max(rater_a), max(rater_b))
conf_mat = confusion_matrix(rater_a, rater_b, min_rating, max_rating)
num_ratings = len(conf_mat)
num_scored_items = float(len(rater_a))
hist_rater_a = histogram(rater_a, min_rating, max_rating)
hist_rater_b = histogram(rater_b, min_rating, max_rating)
numerator = 0.0
denominator = 0.0
for i in range(num_ratings):
for j in range(num_ratings):
expected_count = hist_rater_a[i] * hist_rater_b[j] / num_scored_items
d = pow(i - j, 2.0) / pow(num_ratings - 1, 2.0)
numerator += d * conf_mat[i][j] / num_scored_items
denominator += d * expected_count / num_scored_items
return 1.0 - numerator / denominator
def qwk(a1, a2):
"""
Source: https://www.kaggle.com/c/data-science-bowl-2019/discussion/114133#latest-660168
:param a1:
:param a2:
:param max_rat:
:return:
"""
max_rat = 3
a1 = np.asarray(a1, dtype=int)
a2 = np.asarray(a2, dtype=int)
hist1 = np.zeros((max_rat + 1,))
hist2 = np.zeros((max_rat + 1,))
o = 0
for k in range(a1.shape[0]):
i, j = a1[k], a2[k]
hist1[i] += 1
hist2[j] += 1
o += (i - j) * (i - j)
e = 0
for i in range(max_rat + 1):
for j in range(max_rat + 1):
e += hist1[i] * hist2[j] * (i - j) * (i - j)
e = e / a1.shape[0]
return 1 - o / e
def eval_qwk_lgb_regr(y_true, y_pred):
"""
Fast cappa eval function for lgb.
"""
y_pred[y_pred <= 1.12232214] = 0
y_pred[np.where(np.logical_and(y_pred > 1.12232214, y_pred <= 1.73925866))] = 1
y_pred[np.where(np.logical_and(y_pred > 1.73925866, y_pred <= 2.22506454))] = 2
y_pred[y_pred > 2.22506454] = 3
# y_pred = y_pred.reshape(len(np.unique(y_true)), -1).argmax(axis=0)
return "cappa", qwk(y_true, y_pred), True
from sklearn.metrics import confusion_matrix, accuracy_score
def confusion_matrix_reg(y_true, y_pred):
y_pred[y_pred <= 1.12232214] = 0
y_pred[np.where(np.logical_and(y_pred > 1.12232214, y_pred <= 1.73925866))] = 1
y_pred[np.where(np.logical_and(y_pred > 1.73925866, y_pred <= 2.22506454))] = 2
y_pred[y_pred > 2.22506454] = 3
print("Accuracy : ", accuracy_score(y_true=y_true, y_pred=y_pred))
print("Confussion_matrix \n", confusion_matrix(y_true, y_pred))
print("\n\n")
def eval_qwk_lgb_regr2(y_true, y_pred):
"""
Fast cappa eval function for lgb.
"""
dist = Counter(final_train["accuracy_group"])
for k in dist:
dist[k] /= len(final_train)
final_train["accuracy_group"].hist()
acum = 0
bound = {}
for i in range(3):
acum += dist[i]
bound[i] = np.percentile(y_pred, acum * 100)
def classify(x):
if x <= bound[0]:
return 0
elif x <= bound[1]:
return 1
elif x <= bound[2]:
return 2
else:
return 3
y_pred = np.array(list(map(classify, y_pred))).reshape(y_true.shape)
return "cappa", cohen_kappa_score(y_true, y_pred, weights="quadratic"), True
def cohenkappa(ypred, y):
y = y.get_label().astype("int")
ypred = ypred.reshape((4, -1)).argmax(axis=0)
loss = cohenkappascore(y, y_pred, weights="quadratic")
return "cappa", loss, True
# The following 3 functions have been taken from Ben Hamner's github repository
# https://github.com/benhamner/Metrics
def confusion_matrix(rater_a, rater_b, min_rating=None, max_rating=None):
"""
Returns the confusion matrix between rater's ratings
"""
assert len(rater_a) == len(rater_b)
if min_rating is None:
min_rating = min(rater_a + rater_b)
if max_rating is None:
max_rating = max(rater_a + rater_b)
num_ratings = int(max_rating - min_rating + 1)
conf_mat = [[0 for i in range(num_ratings)] for j in range(num_ratings)]
for a, b in zip(rater_a, rater_b):
conf_mat[a - min_rating][b - min_rating] += 1
return conf_mat
def histogram(ratings, min_rating=None, max_rating=None):
"""
Returns the counts of each type of rating that a rater made
"""
if min_rating is None:
min_rating = min(ratings)
if max_rating is None:
max_rating = max(ratings)
num_ratings = int(max_rating - min_rating + 1)
hist_ratings = [0 for x in range(num_ratings)]
for r in ratings:
hist_ratings[r - min_rating] += 1
return hist_ratings
def quadratic_weighted_kappa(y, y_pred):
"""
Calculates the quadratic weighted kappa
axquadratic_weighted_kappa calculates the quadratic weighted kappa
value, which is a measure of inter-rater agreement between two raters
that provide discrete numeric ratings. Potential values range from -1
(representing complete disagreement) to 1 (representing complete
agreement). A kappa value of 0 is expected if all agreement is due to
chance.
quadratic_weighted_kappa(rater_a, rater_b), where rater_a and rater_b
each correspond to a list of integer ratings. These lists must have the
same length.
The ratings should be integers, and it is assumed that they contain
the complete range of possible ratings.
quadratic_weighted_kappa(X, min_rating, max_rating), where min_rating
is the minimum possible rating, and max_rating is the maximum possible
rating
"""
rater_a = y
rater_b = y_pred
min_rating = None
max_rating = None
rater_a = np.array(rater_a, dtype=int)
rater_b = np.array(rater_b, dtype=int)
assert len(rater_a) == len(rater_b)
if min_rating is None:
min_rating = min(min(rater_a), min(rater_b))
if max_rating is None:
max_rating = max(max(rater_a), max(rater_b))
conf_mat = confusion_matrix(rater_a, rater_b, min_rating, max_rating)
num_ratings = len(conf_mat)
num_scored_items = float(len(rater_a))
hist_rater_a = histogram(rater_a, min_rating, max_rating)
hist_rater_b = histogram(rater_b, min_rating, max_rating)
numerator = 0.0
denominator = 0.0
for i in range(num_ratings):
for j in range(num_ratings):
expected_count = hist_rater_a[i] * hist_rater_b[j] / num_scored_items
d = pow(i - j, 2.0) / pow(num_ratings - 1, 2.0)
numerator += d * conf_mat[i][j] / num_scored_items
denominator += d * expected_count / num_scored_items
return 1.0 - numerator / denominator
from sklearn.model_selection import KFold, StratifiedKFold
train_predictions = np.zeros((len(final_train), 1))
train_predictions_y = np.zeros((len(final_train), 1))
test_predictions = np.zeros((final_test.shape[0], 1))
zero_test_predictions = np.zeros((final_test.shape[0], 1))
FOLDS = 5
print("stratified k-folds")
train = final_train
y = final_train.accuracy_group
skf = StratifiedKFold(n_splits=FOLDS, random_state=42, shuffle=True)
skf.get_n_splits(train, y)
cv_scores = []
fold = 1
coefficients = np.zeros((FOLDS, 3))
for train_ids_indx, test_ids_indx in skf.split(train, y):
# train_ids = unique_installation_ids[train_ids_indx]
# test_ids = unique_installation_ids[test_ids_indx]
# print(train_ids.shape, test_ids.shape)
train_X = train.iloc[train_ids_indx]
test_X = train.iloc[test_ids_indx]
x_train = train_X.drop(columns=col_drop1)
y_train = train_X["accuracy_group"]
x_test = test_X.drop(columns=col_drop1)
y_test = test_X["accuracy_group"]
w = y_test.value_counts()
weights = {i: np.sum(w) / w[i] for i in w.index}
print(weights)
lgb_params = {
"boosting_type": "gbdt",
"objective": "regression",
"learning_rate": 0.005,
"subsample": 0.8,
"colsample_bytree": 0.8,
"min_split_gain": 0.006,
"min_child_samples": 150,
"min_child_weight": 0.1,
"max_depth": 17,
"n_estimators": 10000,
"num_leaves": 80,
"silent": -1,
"verbose": -1,
"max_depth": 15,
"random_state": 2018,
}
model = lgb.LGBMRegressor(**lgb_params)
model.fit(
x_train,
y_train,
eval_set=[(x_test, y_test)],
eval_metric="rmse",
verbose=100,
early_stopping_rounds=150,
)
valid_preds = model.predict(x_test, num_iteration=model.best_iteration_)
train_predictions[test_ids_indx] = valid_preds.reshape(-1, 1)
train_predictions_y[test_ids_indx] = y_test.values.reshape(-1, 1)
optR = OptimizedRounder()
optR.fit(valid_preds, y_test.values)
coefficients[fold - 1, :] = optR.coefficients()
print("Coefficients : ", optR.coefficients())
valid_p = optR.predict(valid_preds, coefficients[fold - 1, :])
valid_preds1 = valid_preds.copy()
print("non optimized qwk : ", eval_qwk_lgb_regr(y_test, valid_preds1))
print("optimized qwk : ", qwk(y_test, valid_p))
print("Valid Counts = ", Counter(y_test.values))
print("Predicted Counts = ", Counter(valid_p))
test_preds = model.predict(
final_test[x_train.columns], num_iteration=model.best_iteration_
)
scr = quadratic_weighted_kappa(y_test.values, valid_p)
cv_scores.append(scr)
print("Fold = {}. QWK = {}. Coef = {}".format(fold, scr, coefficients[fold - 1, :]))
print("\n")
test_predictions += test_preds.reshape(-1, 1)
fold += 1
test_predictions = test_predictions * 1.0 / FOLDS
print(
"Mean Score: {}. Std Dev: {}. Mean Coeff: {}".format(
np.mean(cv_scores), np.std(cv_scores), np.mean(coefficients, axis=0)
)
)
optR = OptimizedRounder()
train_predictions1 = np.array(
[item for sublist in train_predictions for item in sublist]
)
y1 = np.array([item for sublist in train_predictions_y for item in sublist])
optR.fit(train_predictions1, y1)
coefficients = optR.coefficients()
print(quadratic_weighted_kappa(y1, optR.predict(train_predictions1, coefficients)))
predictions = optR.predict(test_predictions, coefficients).astype(int)
predictions = [item for sublist in predictions for item in sublist]
n = pd.Series(optR.predict(train_predictions1, coefficients))
n.value_counts(normalize=True)
sample_submission = pd.read_csv(
"/kaggle/input/data-science-bowl-2019/sample_submission.csv"
)
sample_submission["accuracy_group"] = predictions
sample_submission.to_csv("submission.csv", index=False)
sample_submission["accuracy_group"].value_counts(normalize=True)
| false | 0 | 22,346 | 0 | 6 | 22,346 |
||
51274129 | <kaggle_start><data_title>2017 Kaggle Machine Learning & Data Science Survey<data_description>### Context
For the first time, Kaggle conducted an industry-wide survey to establish a comprehensive view of the state of data science and machine learning. The survey received over 16,000 responses and we learned a ton about who is working with data, what’s happening at the cutting edge of machine learning across industries, and how new data scientists can best break into the field.
To share some of the initial insights from the survey, we’ve worked with the folks from [The Pudding](https://pudding.cool/) to put together [this interactive report](https://kaggle.com/surveys/2017). They’ve shared all of the kernels used in the report [here](https://www.kaggle.com/amberthomas/kaggle-2017-survey-results).
### Content
The data includes 5 files:
- `schema.csv`: a CSV file with survey schema. This schema includes the questions that correspond to each column name in both the `multipleChoiceResponses.csv` and `freeformResponses.csv`.
- `multipleChoiceResponses.csv`: Respondents' answers to multiple choice and ranking questions. These are non-randomized and thus a single row does correspond to all of a single user's answers.
-`freeformResponses.csv`: Respondents' freeform answers to Kaggle's survey questions. These responses are randomized within a column, so that reading across a single row does not give a single user's answers.
- `conversionRates.csv`: Currency conversion rates (to USD) as accessed from the R package "quantmod" on September 14, 2017
- `RespondentTypeREADME.txt`: This is a schema for decoding the responses in the "Asked" column of the `schema.csv` file.
### Kernel Awards in November
In the month of November, we’re awarding $1000 a week for code and analyses shared on this dataset via [Kaggle Kernels](https://www.kaggle.com/kaggle/kaggle-survey-2017/kernels). Read more about this month’s [Kaggle Kernels Awards](https://www.kaggle.com/about/datasets-awards/kernels) and help us advance the state of machine learning and data science by exploring this one of a kind dataset.
### Methodology
- This survey received 16,716 usable respondents from 171 countries and territories. If a country or territory received less than 50 respondents, we grouped them into a group named “Other” for anonymity.
- We excluded respondents who were flagged by our survey system as “Spam” or who did not answer the question regarding their employment status (this question was the first required question, so not answering it indicates that the respondent did not proceed past the 5th question in our survey).
- Most of our respondents were found primarily through Kaggle channels, like our email list, discussion forums and social media channels.
- The survey was live from August 7th to August 25th. The median response time for those who participated in the survey was 16.4 minutes. We allowed respondents to complete the survey at any time during that window.
- We received salary data by first asking respondents for their day-to-day currency, and then asking them to write in either their total compensation.
- We’ve provided a csv with an exchange rate to USD for you to calculate the salary in US dollars on your own.
- The question was optional
- Not every question was shown to every respondent. In an attempt to ask relevant questions to each respondent, we generally asked work related questions to employed data scientists and learning related questions to students. There is a column in the `schema.csv` file called "Asked" that describes who saw each question. You can learn more about the different segments we used in the `schema.csv` file and `RespondentTypeREADME.txt` in the data tab.
- To protect the respondents’ identity, the answers to multiple choice questions have been separated into a separate data file from the open-ended responses. We do not provide a key to match up the multiple choice and free form responses. Further, the free form responses have been randomized column-wise such that the responses that appear on the same row did not necessarily come from the same survey-taker.<data_name>kaggle-survey-2017
<code># # One chart, many answers: Kaggle Surveys in Slopes
# 
# On previous surveys I explored [What Makes a Kaggler Valuable](https://www.kaggle.com/andresionek/what-makes-a-kaggler-valuable) and a comparison between job posts and survey answers on [Is there any job out there? Kaggle vs Glassdoor](https://www.kaggle.com/andresionek/is-there-any-job-out-there-kaggle-vs-glassdoor).
# This is the 4th Kaggle Survey, so I decided to explore trends over time. Unfortunately The 2017 survey was very different from the others, so I decided to exclude it from the analysis. I was left with the 2018, 2019 and 2020 surveys and tried to extract as much value as possible.
# With one extra challenge: use only one chart type.
# I present to you Kaggle Surveys in Slopes! Enjoy!
# ## Slopegraphs - How to read them?
# Despite the fancy name, slopegraphs are simple line charts, the ones you are already familiar with. But lets give you an intro to how to read the charts I'm presenting here. I promise you only need to learn it only once!
# Let's look at this example:
# Here we have two slopegraphs, one for women and another for men. Note that they share the y axis.
#
# Each line in this chart represents a country. This information is available in the subtitle and also when you hover you mouse over the datapoints.
#
#
# Warning! For all charts in this study we applied a filter to select only Professionals (people who are actively working).
# Non-professionals were defined as those who answered Job Title (Q5) as either:
# Student
# Currently not employed
# those who didn't answer the question (NaN)
# Professionals were defined as everyone but the non-professionals.
# Now let's start the fun part!
#
"""
Prior to starting I created a spreadsheets mapping all questions from the 4 years of survey.
https://docs.google.com/spreadsheets/d/1HpVi0ipElWYxwXali7QlIbMWjCQWk6nuaZRAZLcksn4/edit?usp=sharing
Some questions were the same through the years and had exactly the same wording.
Others had changes that did not compromise too much the question meaning. For example:
2020 - For how many years have you been writing code and/or programming?
2019 - How long have you been writing code to analyze data (at work or at school)?
Or
2020 - Which of the following big data products (relational databases, data warehouses, data lakes, or similar) do you use on a regular basis?
2019 - Which specific big data / analytics products do you use on a regular basis?
Or
2020 - Which of the following big data products (relational databases, data warehouses, data lakes, or similar) do you use on a regular basis?
2019 - Which specific big data / analytics products do you use on a regular basis?
2018 - Which of the following big data and analytics products have you used at work or school in the last 5 years?
---
Other questions had a different wording that implied in a different meaning, so they were excluded from this analysis.
I picked only questions that were the same over the last 3 years (2020, 2019 and 2018).
The 2017 survey was very different from the others and only a few questions were useful, so I decided to exclude 2017 from the analysis.
## ## ## ## ##
I suggest that Kaggle keeps the survey consistent over the following years to allow better time-series analysis.
## ## ## ## ##
Note: I'm trying to write functions for all transformations following the single responsability principle.
"""
pass
from enum import Enum
import numpy as np
class Mapping(Enum):
"""
Contains dicts mapping values found in the surveys to values we want to replace with.
"""
COMPENSATION = {
"$0-999": "0-10k",
"1,000-1,999": "0-10k",
"2,000-2,999": "0-10k",
"3,000-3,999": "0-10k",
"4,000-4,999": "0-10k",
"5,000-7,499": "0-10k",
"7,500-9,999": "0-10k",
"10,000-14,999": "10-20k",
"15,000-19,999": "10-20k",
"20,000-24,999": "20-30k",
"25,000-29,999": "20-30k",
"30,000-39,999": "30-40k",
"40,000-49,999": "40-50k",
"50,000-59,999": "50-60k",
"60,000-69,999": "60-70k",
"70,000-79,999": "70-80k",
"80,000-89,999": "80-90k",
"90,000-99,999": "90-100k",
"100,000-124,999": "100-125k",
"125,000-149,999": "125-150k",
"150,000-199,999": "150-200k",
"200,000-249,999": "200-250k",
"300,000-500,000": "300-500k",
"> $500,000": np.nan,
"0-10,000": "0-10k",
"10-20,000": "10-20k",
"20-30,000": "20-30k",
"30-40,000": "30-40k",
"40-50,000": "40-50k",
"50-60,000": "50-60k",
"60-70,000": "60-70k",
"70-80,000": "70-80k",
"80-90,000": "80-90k",
"90-100,000": "90-100k",
"100-125,000": "100-125k",
"125-150,000": "125-150k",
"150-200,00": "150-200k",
"200-250,000": "200-250k",
"300-400,000": "300-500k",
"400-500,000": "300-500k",
"500,000+": np.nan,
"I do not wish to disclose my approximate yearly compensation": np.nan,
}
JOB_TITLE = {
"Data Scientist": "Data Scientist",
"Software Engineer": "Software Engineer",
"Data Analyst": "Data Analyst",
"Other": "Other",
"Research Scientist": "Research Scientist/Statistician",
"Business Analyst": "Business Analyst",
"Product/Project Manager": "Product/Project Manager",
"Data Engineer": "Data Engineer/DBA",
"Not employed": "Currently not employed",
"Machine Learning Engineer": "Machine Learning Engineer",
"Statistician": "Research Scientist/Statistician",
"Consultant": "Other",
"Research Assistant": "Research Scientist/Statistician",
"Manager": "Manager/C-level",
"DBA/Database Engineer": "Data Engineer/DBA",
"Chief Officer": "Manager/C-level",
"Developer Advocate": "Other",
"Marketing Analyst": "Business Analyst",
"Salesperson": "Other",
"Principal Investigator": "Research Scientist/Statistician",
"Data Journalist": "Other",
"Currently not employed": "Currently not employed",
"Student": "Student",
}
GENDER = {
"Male": "Men",
"Female": "Women",
"Man": "Men",
"Woman": "Women",
"Prefer not to say": np.nan, # Very few answers on those categories to do any meaningful analysis
"Prefer to self-describe": np.nan, # Very few answers on those categories to do any meaningful analysis
"Nonbinary": np.nan, # Very few answers on those categories to do any meaningful analysis
}
AGE = {
"18-21": "18-21",
"22-24": "22-24",
"25-29": "25-29",
"30-34": "30-34",
"35-39": "35-39",
"40-44": "40-44",
"45-49": "45-49",
"50-54": "50-54",
"55-59": "55-59",
"60-69": "60-69",
"70+": "70+",
"70-79": "70+",
"80+": "70+",
}
EDUCATION = {
"Master’s degree": "Master’s",
"Bachelor’s degree": "Bachelor’s",
"Some college/university study without earning a bachelor’s degree": "Some college",
"Doctoral degree": "Doctoral",
"Professional degree": "Professional",
"I prefer not to answer": np.nan,
"No formal education past high school": "High school",
}
YEARS_WRITING_CODE = {
"3-5 years": "3-5 years",
"1-2 years": "1-3 years",
"2-3 years": "1-3 years",
"5-10 years": "5-10 years",
"10-20 years": "10+ years",
"< 1 years": "< 1 year",
"< 1 year": "< 1 year",
"20+ years": "10+ years",
np.nan: "None",
"I have never written code": "None",
"I have never written code but I want to learn": "None",
"20-30 years": "10+ years",
"30-40 years": "10+ years",
"40+ years": "10+ years",
}
YEARS_WRITING_CODE_PROFILES = {
"3-5 years": "3-10 years",
"1-2 years": "1-2 years",
"2-3 years": "2-3 years",
"5-10 years": "3-10 years",
"10-20 years": "10+ years",
"< 1 years": "0-1 years",
"< 1 year": "0-1 years",
"20+ years": "10+ years",
np.nan: "None",
"I have never written code": "None",
"I have never written code but I want to learn": "None",
"20-30 years": "10+ years",
"30-40 years": "10+ years",
"40+ years": "10+ years",
}
RECOMMENDED_LANGUAGE = {
"Python": "Python",
"R": "R",
"SQL": "SQL",
"C++": "C++",
"MATLAB": "MATLAB",
"Other": "Other",
"Java": "Java",
"C": "C",
"None": "None",
"Javascript": "Javascript",
"Julia": "Julia",
"Scala": "Other",
"SAS": "Other",
"Bash": "Bash",
"VBA": "Other",
"Go": "Other",
"Swift": "Swift",
"TypeScript": "Other",
}
LANGUAGES = {
"SQL": "SQL",
"R": "R",
"Java": "Java",
"MATLAB": "MATLAB",
"Python": "Python",
"Javascript/Typescript": "Javascript/Typescript",
"Bash": "Bash",
"Visual Basic/VBA": "VBA",
"Scala": "Scala",
"PHP": "Other",
"C/C++": "C/C++",
"Other": "Other",
"C#/.NET": "Other",
"Go": "Other",
"SAS/STATA": "Other",
"Ruby": "Other",
"Julia": "Julia",
"None": "None",
np.nan: "None",
"Javascript": "Javascript/Typescript",
"C": "C/C++",
"TypeScript": "Javascript/Typescript",
"C++": "C/C++",
"Swift": "Swift",
}
YEARS_USING_ML = {
"1-2 years": "1-3 years",
"2-3 years": "1-3 years",
"< 1 year": "< 1 year",
"Under 1 year": "< 1 year",
"< 1 years": "< 1 year",
"3-4 years": "3-5 years",
"5-10 years": "5+ years",
"4-5 years": "3-5 years",
np.nan: "None",
"I have never studied machine learning but plan to learn in the future": "None",
"I do not use machine learning methods": "None",
"10-15 years": "5+ years",
"20+ years": "5+ years",
"10-20 years": "5+ years",
"20 or more years": "5+ years",
"I have never studied machine learning and I do not plan to": "None",
}
YEARS_USING_ML_PROFILES = {
"1-2 years": "1-2 years",
"2-3 years": "2-3 years",
"< 1 year": "0-1 years",
"Under 1 year": "0-3 years",
"< 1 years": "0-1 years",
"3-4 years": "3-10 years",
"5-10 years": "3-10 years",
"4-5 years": "3-10 years",
np.nan: "None",
"I have never studied machine learning but plan to learn in the future": "None",
"I do not use machine learning methods": "None",
"10-15 years": "10+ years",
"20+ years": "10+ years",
"10-20 years": "10+ years",
"20 or more years": "10+ years",
"I have never studied machine learning and I do not plan to": "None",
}
PRIMARY_TOOL = {
"Local development environments (RStudio, JupyterLab, etc.)": "Local or hosted development environments",
"Basic statistical software (Microsoft Excel, Google Sheets, etc.)": "Basic statistical software",
"Local or hosted development environments (RStudio, JupyterLab, etc.)": "Local or hosted development environments",
"Cloud-based data software & APIs (AWS, GCP, Azure, etc.)": "Cloud-based data software & APIs",
"Other": "Other",
"Advanced statistical software (SPSS, SAS, etc.)": "Advanced statistical software",
"Business intelligence software (Salesforce, Tableau, Spotfire, etc.)": "Business intelligence software",
}
COUNTRY = {
"India": "India",
"United States of America": "United States",
"Other": "Other",
"Brazil": "Brazil",
"Russia": "Russia",
"Japan": "Japan",
"United Kingdom of Great Britain and Northern Ireland": "United Kingdom",
"Germany": "Germany",
"China": "China",
"Spain": "Spain",
"France": "France",
"Canada": "Canada",
"Italy": "Italy",
"Nigeria": "Nigeria",
"Turkey": "Turkey",
"Australia": "Australia",
}
IDE = {
"None": "None",
"MATLAB": "MATLAB",
"RStudio": "RStudio",
"Jupyter/IPython": "Jupyter/IPython",
"PyCharm": "PyCharm",
"Atom": "Vim/Emacs/Atom",
"Visual Studio": "Visual Studio",
"Notepad++": "Notepad++/Sublime",
"Sublime Text": "Notepad++/Sublime",
"IntelliJ": "PyCharm",
"Spyder": "Spyder",
"Visual Studio Code": "Visual Studio",
"Vim": "Vim/Emacs/Atom",
"Other": "Other",
"nteract": "Other",
np.nan: "Other",
"Jupyter (JupyterLab, Jupyter Notebooks, etc) ": "Jupyter/IPython",
" RStudio ": "RStudio",
" PyCharm ": "PyCharm",
" MATLAB ": "MATLAB",
" Spyder ": "Spyder",
" Notepad++ ": "Notepad++/Sublime",
" Sublime Text ": "Notepad++/Sublime",
" Atom ": "Vim/Emacs/Atom",
" Visual Studio / Visual Studio Code ": "Visual Studio",
" Vim / Emacs ": "Vim/Emacs/Atom",
"Visual Studio Code (VSCode)": "Visual Studio",
}
CLOUD = {
"I have not used any cloud providers": "None",
"Microsoft Azure": "Azure",
"Google Cloud Platform (GCP)": "GCP",
"Amazon Web Services (AWS)": "AWS",
"IBM Cloud": "IBM/Red Hat",
"Other": "Other",
"Alibaba Cloud": "Alibaba",
np.nan: "None",
" Amazon Web Services (AWS) ": "AWS",
" Google Cloud Platform (GCP) ": "GCP",
" Microsoft Azure ": "Azure",
"None": "None",
" Salesforce Cloud ": "Other",
" Red Hat Cloud ": "IBM/Red Hat",
" VMware Cloud ": "Other",
" Alibaba Cloud ": "Alibaba",
" SAP Cloud ": "Other",
" IBM Cloud ": "IBM/Red Hat",
" Oracle Cloud ": "Other",
" IBM Cloud / Red Hat ": "IBM/Red Hat",
" Tencent Cloud ": "Other",
}
ML_STATUS = {
"No (we do not use ML methods)": "Do not use ML / Do not know",
"I do not know": "Do not use ML / Do not know",
"We recently started using ML methods (i.e., models in production for less than 2 years)": "Recently started using ML",
"We have well established ML methods (i.e., models in production for more than 2 years)": "Well established ML",
"We are exploring ML methods (and may one day put a model into production)": "Exploring ML",
"We use ML methods for generating insights (but do not put working models into production)": "Use ML for generating insights",
np.nan: "Do not use ML / Do not know",
}
ML_FRAMEWORKS = {
"None": "None",
"Prophet": "Prophet",
"Scikit-Learn": "Scikit-learn",
"Keras": "Keras",
"TensorFlow": "TensorFlow",
"Spark MLlib": "Other",
"Xgboost": "Xgboost",
"randomForest": "Other",
"lightgbm": "LightGBM",
"Caret": "Caret",
"mlr": "Other",
"PyTorch": "PyTorch",
"Mxnet": "Other",
"CNTK": "Other",
"Caffe": "Other",
"H20": "H2O",
"catboost": "CatBoost",
"Fastai": "Fast.ai",
"Other": "Other",
np.nan: "None",
" Scikit-learn ": "Scikit-learn",
" RandomForest": "Other",
" Xgboost ": "Xgboost",
" LightGBM ": "LightGBM",
" TensorFlow ": "TensorFlow",
" Keras ": "Keras",
" Caret ": "Caret",
" PyTorch ": "PyTorch",
" Spark MLib ": "Spark MLlib",
" Fast.ai ": "Fast.ai",
" Tidymodels ": "Other",
" CatBoost ": "CatBoost",
" JAX ": "Other",
" Prophet ": "Prophet",
" H2O 3 ": "H2O",
" MXNet ": "Other",
}
class Category(Enum):
COMPENSATION = [
"Not Disclosed",
"0-10k",
"10-20k",
"20-30k",
"30-40k",
"40-50k",
"50-60k",
"60-70k",
"70-80k",
"80-90k",
"90-100k",
"100-125k",
"125-150k",
"150-200k",
"200-250k",
"300-500k",
]
JOB_TITLE = [
"Other",
"Manager/C-level",
"Product/Project Manager",
"Business Analyst",
"Data Analyst",
"Research Scientist/Statistician",
"Data Scientist",
"Machine Learning Engineer",
"Data Engineer/DBA",
"Software Engineer",
]
GENDER = ["Women", "Men"]
AGE = [
"18-21",
"22-24",
"25-29",
"30-34",
"35-39",
"40-44",
"45-49",
"50-54",
"55-59",
"60-69",
"70+",
]
YEARS_WRITING_CODE = [
"None",
"< 1 year",
"1-3 years",
"3-5 years",
"5-10 years",
"10+ years",
]
YEARS_USING_ML = ["None", "< 1 year", "1-3 years", "3-5 years", "5+ years"]
SURVEY_YEAR = [2018, 2019, 2020]
EDUCATION = [
"High school",
"Some college",
"Professional",
"Bachelor’s",
"Master’s",
"Doctoral",
]
PROFILES = ["Beginners", "Others", "Modern DS", "Coders", "ML Veterans"]
COLORS = {
"India": "#FE9933",
"Brazil": "#179B3A",
"United States": "#002366",
"China": "#ED2124",
"Average": "blueviolet",
"Canada": "#F60B00",
"Data Scientist": "#13A4B4",
"Product/Project Manager": "#D70947",
"Software Engineer": "#E8743B",
"Data Analyst": "#BF399E",
"Data Engineer/DBA": "#144B7F",
"< 1 year": "lightgreen",
"10+ years": "green",
"Women": "hotpink",
"Men": "midnightblue",
"Python": "#FEC331",
"SQL": "#66B900",
"R": "#2063b7",
"C/C++": "slateblue",
"Basic statistical software": "#0D7036",
"Local or hosted development environments": "#36B5E2",
"Visual Studio": "#349FED",
"Jupyter/IPython": "#EC7426",
"AWS": "#F79500",
"GCP": "#1AA746",
"Azure": "#3278B1",
"Well established ML": "dodgerblue",
"Exploring ML": "slategrey",
"PyTorch": "orangered",
"Scikit-learn": "goldenrod",
"None": "darkblue",
}
from typing import List, Type, Tuple
import pandas as pd
from abc import ABC, abstractmethod
class BaseKaggle(ABC):
"""
Base class to handle cleaning and transformation of datasets from different years.
"""
def __init__(self) -> None:
self.df = None
self.non_professionals = ["Student", "Currently not employed", np.nan]
self.mapping = {}
self.questions_to_combine = []
self.survey_year = None
@property
def questions_to_keep(self) -> List[str]:
"""
Select which questions we should keep in the dataframe using the mapping keys
"""
return [key for key, value in self.mapping.items()]
def remove_non_professionals(self) -> pd.DataFrame:
"""
Non-professionals were defined as students, unemployed and NaNs.
Also removed those who didn't disclose compensation.
"""
self.df = self.df.drop(
self.df[self.df["Job Title"].isin(self.non_professionals)].index
)
self.df.dropna(subset=["Yearly Compensation"], inplace=True)
return self.df
@abstractmethod
def filter_question_columns(columns: List[str], question: str) -> List[str]:
pass
@staticmethod
def remove_nans_from_list(answers: List[str]) -> List[str]:
"""
This function removes all nans from a list
"""
return [x for x in answers if pd.notnull(x)]
def combine_answers_into_list(self, question: str) -> pd.DataFrame:
"""
This function will create a new column in the dataframe adding
all answers to a list and removing nans.
"""
filtered_columns = self.filter_question_columns(list(self.df.columns), question)
self.df[question] = self.df[filtered_columns].values.tolist()
self.df[question] = self.df[question].apply(self.remove_nans_from_list)
return self.df
def batch_combine_answers_into_list(
self, questions_to_combine: List[str]
) -> pd.DataFrame:
"""
Applyes combine_answers_into_list to multiple columns
"""
for question in questions_to_combine:
self.combine_answers_into_list(question=question)
return self.df
def rename_columns(self) -> pd.DataFrame:
"""
Renames columns using mapping
"""
self.df = self.df.rename(columns=self.mapping)
return self.df
def do_mapping(self, column: str, mapping: Mapping) -> pd.DataFrame:
"""
Maps values to have same classes accross all years
"""
self.df[column] = self.df[column].map(mapping.value)
return self.df
def do_list_mapping(self, column: str, mapping: Mapping) -> pd.DataFrame:
"""
Maps values to have same classes accross all years for columns that are list type
"""
mapping_dict = mapping.value
self.df[column] = self.df[column].apply(
lambda x: [mapping_dict[val] for val in x]
)
return self.df
def add_numeric_average_compensation(self) -> pd.DataFrame:
"""
Create a numeric value for compensation, taking the average between the max and min values for each class
We are summing up the lowest and highest value for each category, and then dividing by 2.
Some regex needed to clean the text
"""
compensation = (
self.df["Yearly Compensation"]
.str.replace(r"(?:(?!\d|\-).)*", "")
.str.replace("500", "500-500")
.str.split("-")
)
self.df["Yearly Compensation Numeric"] = compensation.apply(
lambda x: (int(x[0]) + int(x[1])) / 2
) # it is calculated in thousand of dollars
return self.df
def add_survey_year_column(self) -> pd.DataFrame:
"""
Adds the year the survey was taken as a column
"""
self.df["Survey Year"] = self.survey_year
return self.df
def add_dummy_column(self) -> pd.DataFrame:
"""
Adds Dummy = 1 to make easier to perform group by
"""
self.df["Dummy"] = 1
return self.df
def select_questions(self) -> pd.DataFrame:
"""
Selects only the relevant questions from each survey year
"""
self.df = self.df[self.questions_to_keep]
return self.df
def fill_na(self, column: str, value: str) -> pd.DataFrame:
"""
Fill column NaNs with a given value
"""
self.df[column] = self.df[column].fillna(value)
return self.df
def calculate_profile(self, values: tuple) -> str:
"""
This function creates profiles for professionals adapted from the work developed by Teresa Kubacka on last years survey
https://www.kaggle.com/tkubacka/a-story-told-through-a-heatmap
"""
years_code, years_ml = values
if years_code in ["0-1 years", "1-2 years"] and years_ml in [
"0-1 years",
"1-2 years",
]:
return "Beginners"
elif years_code in ["2-3 years", "3-10 years"] and years_ml in [
"1-2 years",
"2-3 years",
"3-10 years",
]:
return "Modern DS"
elif years_code == "10+ years" and years_ml in ["0-1 years", "1-2 years"]:
return "Coders"
elif years_code == "10+ years" and years_ml == "10+ years":
return "ML Veterans"
else:
return "Others"
def create_profiles(self) -> None:
"""
This function creates a new columns with profiles for professionals adapted from the work developed by Teresa Kubacka on last years survey
https://www.kaggle.com/tkubacka/a-story-told-through-a-heatmap
"""
self.df["Years Writing Code Profile"] = self.df[
"Tenure: Years Writing Code"
].map(Mapping.YEARS_WRITING_CODE_PROFILES.value)
self.df["Years Using ML Profile"] = self.df[
"Tenure: Years Using Machine Learning Methods"
].map(Mapping.YEARS_USING_ML_PROFILES.value)
self.df["Profile"] = self.df[
["Years Writing Code Profile", "Years Using ML Profile"]
].apply(self.calculate_profile, axis=1)
def transform(self) -> pd.DataFrame:
"""
Process and clean the dataset
"""
self.df.drop(
0, axis=0, inplace=True
) # dropping first row (questions) from processed data
self.batch_combine_answers_into_list(
questions_to_combine=self.questions_to_combine
)
self.select_questions()
self.rename_columns()
self.create_profiles()
self.do_mapping(column="Yearly Compensation", mapping=Mapping.COMPENSATION)
self.do_mapping(column="Job Title", mapping=Mapping.JOB_TITLE)
self.do_mapping(column="Gender", mapping=Mapping.GENDER)
self.do_mapping(column="Age", mapping=Mapping.AGE)
self.do_mapping(column="Education", mapping=Mapping.EDUCATION)
self.do_mapping(
column="Tenure: Years Writing Code", mapping=Mapping.YEARS_WRITING_CODE
)
self.do_mapping(
column="Recommended Programming Language",
mapping=Mapping.RECOMMENDED_LANGUAGE,
)
self.do_mapping(
column="Tenure: Years Using Machine Learning Methods",
mapping=Mapping.YEARS_USING_ML,
)
self.do_mapping(
column="Primary Tool to Analyze Data", mapping=Mapping.PRIMARY_TOOL
)
self.do_mapping(column="Country", mapping=Mapping.COUNTRY)
self.do_mapping(
column="Machine Learning Status in Company", mapping=Mapping.ML_STATUS
)
self.do_list_mapping(
column="Machine Learning Frameworks", mapping=Mapping.ML_FRAMEWORKS
)
self.do_list_mapping(column="Programming Languages", mapping=Mapping.LANGUAGES)
self.do_list_mapping(column="IDEs", mapping=Mapping.IDE)
self.do_list_mapping(column="Cloud Computing Platforms", mapping=Mapping.CLOUD)
self.fill_na(column="Country", value="Other")
self.remove_non_professionals()
self.add_numeric_average_compensation()
self.add_survey_year_column()
self.add_dummy_column()
self.df.reset_index(drop=True, inplace=True)
return self.df
class Kaggle2020(BaseKaggle):
"""
Processing and cleaning 2020 Dataset
Here we do the following:
* Group all multiple choice answers into a list in a single column.
* Remove Non-Professionals from the data set. Non-professionals were defined as students, unemployed and NaNs.
* Select the questions we want to keep, based on the spreadsheet analysis done previously.
* Remove all non-multiple choice answers
"""
def __init__(self) -> None:
super().__init__()
self.survey_year = 2020
self.df = pd.read_csv(
"/kaggle/input/kaggle-survey-2020/kaggle_survey_2020_responses.csv",
low_memory=False,
)
self.mapping = {
"Q1": "Age",
"Q2": "Gender",
"Q3": "Country",
"Q4": "Education",
"Q5": "Job Title",
"Q6": "Tenure: Years Writing Code",
"Q7": "Programming Languages",
"Q8": "Recommended Programming Language",
"Q9": "IDEs",
"Q10": "Hosted Notebooks",
"Q14": "Data Visualization Libraries",
"Q15": "Tenure: Years Using Machine Learning Methods",
"Q16": "Machine Learning Frameworks",
"Q22": "Machine Learning Status in Company",
"Q23": "Daily activities",
"Q24": "Yearly Compensation",
"Q26_A": "Cloud Computing Platforms",
"Q27_A": "Cloud Computing Products",
"Q28_A": "Machine Learning Products",
"Q29_A": "Big Data Products",
"Q37": "Data Science Courses",
"Q38": "Primary Tool to Analyze Data",
"Q39": "Media Sources",
}
self.questions_to_combine = [
"Q7",
"Q9",
"Q10",
"Q14",
"Q16",
"Q23",
"Q26_A",
"Q27_A",
"Q28_A",
"Q29_A",
"Q37",
"Q39",
]
@staticmethod
def filter_question_columns(columns: List[str], question: str) -> List[str]:
"""
Filters only questions that starts with the question_number and do not end with the string _OTHER
"""
return [
col
for col in columns
if col.startswith(f"{question}_P") and not col.endswith("_OTHER")
]
class Kaggle2019(BaseKaggle):
"""
Processing and cleaning 2019 Dataset
"""
def __init__(self) -> None:
super().__init__()
self.survey_year = 2019
self.df = pd.read_csv(
"/kaggle/input/kaggle-survey-2019/multiple_choice_responses.csv",
low_memory=False,
)
self.mapping = {
"Q1": "Age",
"Q2": "Gender",
"Q3": "Country",
"Q4": "Education",
"Q5": "Job Title",
"Q15": "Tenure: Years Writing Code",
"Q18": "Programming Languages",
"Q19": "Recommended Programming Language",
"Q16": "IDEs",
"Q17": "Hosted Notebooks",
"Q20": "Data Visualization Libraries",
"Q23": "Tenure: Years Using Machine Learning Methods",
"Q28": "Machine Learning Frameworks",
"Q8": "Machine Learning Status in Company",
"Q9": "Daily activities",
"Q10": "Yearly Compensation",
"Q29": "Cloud Computing Platforms",
"Q30": "Cloud Computing Products",
"Q32": "Machine Learning Products",
"Q31": "Big Data Products",
"Q13": "Data Science Courses",
"Q14": "Primary Tool to Analyze Data",
"Q12": "Media Sources",
}
self.questions_to_combine = [
"Q18",
"Q16",
"Q17",
"Q20",
"Q28",
"Q9",
"Q29",
"Q30",
"Q32",
"Q31",
"Q13",
"Q12",
]
@staticmethod
def filter_question_columns(columns: List[str], question: str) -> List[str]:
"""
Filters only questions that starts with the question_number and do not end with the string _OTHER_TEXT
"""
return [
col
for col in columns
if col.startswith(f"{question}_P") and not col.endswith("_OTHER_TEXT")
]
class Kaggle2018(BaseKaggle):
"""
Processing and cleaning 2019 Dataset
"""
def __init__(self) -> None:
super().__init__()
self.survey_year = 2018
self.df = pd.read_csv(
"/kaggle/input/kaggle-survey-2018/multipleChoiceResponses.csv",
low_memory=False,
)
self.mapping = {
"Q2": "Age",
"Q1": "Gender",
"Q3": "Country",
"Q4": "Education",
"Q6": "Job Title",
"Q24": "Tenure: Years Writing Code",
"Q16": "Programming Languages",
"Q18": "Recommended Programming Language",
"Q13": "IDEs",
"Q14": "Hosted Notebooks",
"Q21": "Data Visualization Libraries",
"Q25": "Tenure: Years Using Machine Learning Methods",
"Q19": "Machine Learning Frameworks",
"Q10": "Machine Learning Status in Company",
"Q11": "Daily activities",
"Q9": "Yearly Compensation",
"Q15": "Cloud Computing Platforms",
"Q27": "Cloud Computing Products",
"Q28": "Machine Learning Products",
"Q30": "Big Data Products",
"Q36": "Data Science Courses",
"Q12_MULTIPLE_CHOICE": "Primary Tool to Analyze Data",
"Q38": "Media Sources",
}
self.questions_to_combine = [
"Q16",
"Q13",
"Q14",
"Q21",
"Q19",
"Q11",
"Q15",
"Q27",
"Q28",
"Q30",
"Q36",
"Q38",
]
@staticmethod
def filter_question_columns(columns: List[str], question: str) -> List[str]:
"""
Filters only questions that starts with the question_number and do not end with the string _OTHER_TEXT
"""
return [
col
for col in columns
if col.startswith(f"{question}_P") and not col.endswith("_OTHER_TEXT")
]
class KaggleCombinedSurvey:
"""
This class combines surveys from multiple years into a concatenated dataframe.
"""
def __init__(self, surveys: List[Type[BaseKaggle]]) -> None:
self.surveys = surveys
self._cached_df = None
@property
def df(self) -> pd.DataFrame:
"""
If df was already processed get it from cache, otherwise process it and saves to cache.
"""
if isinstance(self._cached_df, type(None)):
self._cached_df = self._concatenate()
return self._cached_df
def _get_surveys_dfs(self) -> List[pd.DataFrame]:
"""
Applies the transform method for each survey and return the dfs in a list
"""
return [survey().transform() for survey in self.surveys]
def _concatenate(self) -> pd.DataFrame:
"""
Concatenate survey dataframes into a single dataframe
"""
df = pd.concat(self._get_surveys_dfs())
df = df.reset_index(drop=True)
return df
import plotly.graph_objects as go
import plotly.offline as pyo
import plotly.express as px
from plotly.subplots import make_subplots
from collections import namedtuple
MetricData = namedtuple(
"MetricData",
[
"subplot_name",
"trace_name",
"y_values",
"x_values",
"subplot_y_position",
"subplot_x_position",
"highlighted_traces",
],
)
class BaseMetric(ABC):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(
self,
survey: KaggleCombinedSurvey,
traces_col: str,
y_col: str,
x_col: str,
explode: bool = False,
) -> None:
"""
traces: the column name we want to creaate traces from
y: the column name we will be ploting
x: Will always be survey year for our slopegraphs.
"""
self.traces_col = traces_col
self.y_col = y_col
self.x_col = x_col
self.survey = survey
self.traces = []
self.explode = explode
self.metric_df = None
@property
def traces_names(self) -> List[str]:
"""
Calculate unique values of traces_col
"""
return self.metric_df[self.traces_col].cat.categories
@property
def subplots_names(self) -> List[str]:
"""
Calculate unique values of traces_col
"""
return self.metric_df[self.y_col].cat.categories
@property
def subplots_qty(self):
return len(self.subplots_names)
@property
def traces_qty(self):
return len(self.traces_names)
def apply_filter(self, df: pd.DataFrame, column: str, value: str) -> pd.DataFrame:
"""
filters data for a single trace
"""
return df[df[column] == value]
@abstractmethod
def calculate(self) -> pd.DataFrame:
"""
Group the data by y_col, perform count and convert it to a list
Transforms absolute values into percentages
Yeld the metrics for a given trace
"""
pass
def groupby(self, df: pd.DataFrame, columns: List[str]) -> pd.DataFrame:
""" "
Calculates quantity per x, y and traces col
"""
return df.groupby(columns, as_index=False)["Dummy"].sum()
def join_dataframes(
self, df1: pd.DataFrame, df2: pd.DataFrame, on_columns: List[str]
) -> pd.DataFrame:
return (
df1.set_index(on_columns)
.join(df2.set_index(on_columns), rsuffix="_total")
.reset_index()
)
def to_categorical(self, column: str, categories: Category) -> pd.DataFrame:
cat_dtype = pd.api.types.CategoricalDtype(
categories=categories.value, ordered=True
)
self.metric_df[column] = self.metric_df[column].astype(cat_dtype)
return self.metric_df
def get_df(self):
"""
Returns a dataframe with or without lists exploded
"""
if self.explode:
return self.survey.df.explode(self.traces_col)
else:
return self.survey.df
def get_subplots(self, highlighted_traces: List[str]) -> List[MetricData]:
self.apply_categories()
self.metric_df["subplot_y_position"] = self.metric_df[self.y_col].cat.codes + 1
self.metric_df["subplot_x_position"] = 1
for index, row in self.metric_df.iterrows():
filtered_df = self.apply_filter(
df=self.metric_df, column=self.y_col, value=row[self.y_col]
)
filtered_df = self.apply_filter(
df=filtered_df, column=self.traces_col, value=row[self.traces_col]
)
metric_data = MetricData(
subplot_name=row[self.y_col],
trace_name=row[self.traces_col],
y_values=filtered_df["Metric"].values,
x_values=filtered_df[self.x_col].values,
subplot_y_position=row["subplot_y_position"],
subplot_x_position=row["subplot_x_position"],
highlighted_traces=row[self.traces_col] in highlighted_traces,
)
self.traces.append(metric_data)
class PercentageMetric(BaseMetric):
"""
Creates a plotly plot for slopegraphs
"""
def calculate_average(self, df=pd.DataFrame) -> pd.DataFrame:
detail = self.groupby(df=df, columns=[self.x_col, self.y_col])
total = self.groupby(df=df, columns=[self.x_col])
joined = self.join_dataframes(df1=detail, df2=total, on_columns=[self.x_col])
joined["Metric"] = (
joined["Dummy"] / joined["Dummy_total"] * 100
) # get percentage
joined[self.traces_col] = "Average"
return joined
def calculate(self, add_avg: bool = False) -> pd.DataFrame:
"""
Group the data by y_col, perform count and convert it to a list
Transforms absolute values into percentages
Yeld the metrics for a given trace
"""
df = self.get_df()
detail = self.groupby(df=df, columns=[self.x_col, self.y_col, self.traces_col])
total = self.groupby(df=df, columns=[self.x_col, self.traces_col])
joined = self.join_dataframes(
df1=detail, df2=total, on_columns=[self.x_col, self.traces_col]
)
joined["Metric"] = (
joined["Dummy"] / joined["Dummy_total"] * 100
) # get percentage
if add_avg:
avg_df = self.calculate_average(df=joined)
joined = joined.append(avg_df)
self.metric_df = joined
return joined
@abstractmethod
def apply_categories(self):
pass
class GenderProportionMetric(PercentageMetric):
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey, traces_col="Country", y_col="Gender", x_col="Survey Year"
)
def apply_categories(self):
self.to_categorical(column="Gender", categories=Category.GENDER)
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
class BasePlot(ABC):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(
self,
metric: Type[BaseMetric],
title: str,
yaxes_title: str,
shared_yaxes: bool,
yticks: List[float],
yticks_template: str,
annotation_template: str,
x_nticks: int,
hover_template: str,
) -> None:
pyo.init_notebook_mode()
self.metric = metric
self.yaxes_title = yaxes_title
self.shared_yaxes = shared_yaxes
self.hover_template = hover_template
self.title = title
self.yticks = yticks
self.yticks_template = yticks_template
self.annotation_template = annotation_template
self.x_nticks = x_nticks
self.figure = go.Figure()
self.range = (0, 0)
def make_subplots(self) -> None:
"""
Creates subplots in the figure and add titles
"""
self.figure = make_subplots(
cols=self.metric.subplots_qty, # our subplots will have the number of unique values for the select column
rows=1, # and 1 row
subplot_titles=self.metric.subplots_names, # Add titles to subplots
specs=[[{"type": "scatter"}] * self.metric.subplots_qty]
* 1, # Define chart type for each subplot
shared_yaxes=self.shared_yaxes,
shared_xaxes=True,
)
for idx, subplot_title in enumerate(self.figure["layout"]["annotations"]):
subplot_title["font"] = dict(
size=14, color="grey"
) # Size and color of subplot title
subplot_title["align"] = "left"
subplot_title["xanchor"] = "left"
subplot_title["x"] = 0
subplot_title["xref"] = "x" if idx == 0 else f"x{idx + 1}"
def update_common_layout(self) -> None:
"""
Updates general layout characteristics
"""
self.figure.update_layout(
showlegend=False,
plot_bgcolor="white",
title_text=self.title,
title_font_color="grey",
title_font_size=15,
title_x=0,
title_y=0.98,
margin_t=130,
margin_l=0,
margin_r=0,
height=600,
width=800,
yaxis_range=self.range,
)
def get_yticks_text(self) -> List[str]:
"""
Calculates the y_ticks text for charts
"""
return [self.yticks_template.format(i) for i in self.yticks]
def update_subplots_layout(self) -> None:
"""
Updates scatter subplots layout characteristics
"""
for subplot_idx in range(self.metric.subplots_qty):
self.figure.update_xaxes(
type="category",
color="lightgrey", # to not draw to much attention to axis
showgrid=False,
visible=subplot_idx == 0, # Visible only to the first subplot
row=1,
nticks=self.x_nticks,
col=subplot_idx + 1, # Subplots start at 1
)
self.figure.update_yaxes(
showgrid=False,
visible=subplot_idx == 0 or not self.shared_yaxes,
title=self.yaxes_title
if subplot_idx == 0
else None, # Visible only to the first subplot
color="grey",
row=1,
col=subplot_idx + 1,
tickvals=self.yticks, # show ticks ate 25, 50 and 75
ticktext=self.get_yticks_text(),
tickmode="array",
tickfont_color="lightgrey",
autorange=True,
)
def line_color(self, trace: MetricData) -> str:
"""
Sets color to the highlight color or to a tone of grey if not highlighted
"""
return (
self.highlight_color(trace=trace)
if trace.highlighted_traces
else "lightslategrey"
)
def highlight_color(self, trace: MetricData) -> str:
"""
Returns the highlight color
"""
return COLORS[trace.trace_name]
def line_width(self, trace: MetricData) -> str:
"""
Returns the line width of traces depending if trace is highlighted or not
"""
return 1.6 if trace.highlighted_traces else 0.6
def opacity(self, trace: MetricData) -> str:
"""
Returns the opacity depending if trace is highlighted or not
"""
return 0.8 if trace.highlighted_traces else 0.25
def add_trace(self, trace: MetricData) -> None:
"""
Adds a new trace to a figure
"""
self.figure.add_trace(
go.Scatter(
x=trace.x_values,
y=trace.y_values,
mode="lines",
name=trace.trace_name,
hoverinfo="name+text+y",
hovertemplate=self.hover_template,
text=trace.x_values,
line_color=self.line_color(trace=trace),
showlegend=False,
opacity=self.opacity(trace=trace),
line_shape="linear",
line_width=self.line_width(trace=trace),
connectgaps=True,
),
trace.subplot_x_position,
trace.subplot_y_position,
)
def get_annotation_text(self, trace: MetricData, idx: int) -> str:
"""
Calculates the annotation text to be added to the plot
"""
if trace.subplot_y_position == 1 and idx == 0:
template = "{}<br>" + f"{self.annotation_template}"
return template.format(trace.trace_name, trace.y_values[idx])
else:
return self.annotation_template.format(trace.y_values[idx])
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=0,
xshift=-3,
xanchor="right",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=self.get_annotation_text(trace=trace, idx=0),
showarrow=False,
)
# Add right annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=0,
xshift=3,
xanchor="left",
x=trace.x_values.codes[-1],
y=trace.y_values[-1],
text=self.get_annotation_text(trace=trace, idx=-1),
showarrow=False,
)
def add_subplot_axis_annotation(self) -> None:
"""
Add subplot axis annotation
"""
self.figure.add_annotation(
xref="x",
yref="paper",
font=dict(size=14, color="lightgrey"),
align="left",
x=0,
xanchor="left",
y=1.05,
yanchor="bottom",
text=f"{self.metric.y_col}",
showarrow=False,
)
def add_source_annotation(self) -> None:
"""
Add source annotation
"""
self.figure.add_annotation(
xref="paper",
yref="paper",
font=dict(size=11, color="lightgrey"),
align="left",
x=-0.07,
xanchor="left",
y=-0.13,
yanchor="bottom",
text="<b>Source:</b> Kaggle surveys from 2018 to 2020.",
showarrow=False,
)
def add_data(self) -> None:
"""
Adds a trace to the figure following the same standard for each trace
"""
# Add all non-highlighted traces.
for trace in self.metric.traces:
self.add_trace(trace=trace)
self.update_range(data=trace.y_values)
def update_range(self, data: List[float]) -> None:
"""
Updates the range to be 90% of minimum values and 110% of maximum value of all traces
"""
if len(data) == 0:
return self.range
max_range = max(data) * 1.2
min_range = min(data) * 0.8
self.range = (
(self.range[0], max_range) if max_range > self.range[1] else self.range
)
self.range = (
(min_range, self.range[1]) if min_range < self.range[0] else self.range
)
def show(self) -> None:
"""
Renders and shows the plot
"""
self.make_subplots()
self.update_common_layout()
self.add_data()
self.add_annotations()
self.add_subplot_axis_annotation()
self.update_subplots_layout()
self.add_source_annotation()
self.figure.show()
class GenderProportionPlot(BasePlot):
pass
kaggle_combined_survey = KaggleCombinedSurvey(
surveys=[Kaggle2018, Kaggle2019, Kaggle2020]
)
# The Gender Gap
# I wanted to start with something simple and important at the same time. So I questioned myself: over the past three years, did the proportion of Men and Women change? I knew there was a gap, but I would like to see it decreasing (and a lot) in the recent years.
#
metric = GenderProportionMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=True)
metric.get_subplots(highlighted_traces=["Average"])
GenderProportionPlot(
metric=metric,
yaxes_title="% of Respondents per Survey Year",
shared_yaxes=True,
yticks=[20, 40, 60, 80],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=3,
title="<b>Gender Gap: Kaggle members are mostly men. </b><br>And there are no signs of increase in women participation since 2018."
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents per country</i></span>',
).show()
#
# Unfortunately there is a huge gap in professionals participation in Kaggle: 84% of men against 16% of women.
# And what is worse than that is the fact that women participation did not increase over the past three years. I saw some other notebooks that showed an increase in female students. Maybe this will cause a increase in professionals next year, but need a lot more women to close this gap.
# Maybe Kaggle could host women only competitions, in a bid to attract more of them to the platform (and to Data Science).
# If we zoom-in using the same chart, we can see which countries are are getting more women into Data over the past few years.
metric = GenderProportionMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["India", "Brazil", "Canada"])
GenderProportionPlot(
metric=metric,
yaxes_title="% of Respondents per Survey Year",
shared_yaxes=False,
yticks=[5, 10, 15, 20, 75, 80, 85, 90],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=3,
title="<b>Gender Gap: India, Brazil and Canada are countries where the gender gap is reducing. </b><br>However changes are still very small to make any difference."
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents per country</i></span>',
).show()
#
# While most countries actually increased the gender gap in 2020, India is the country that is closing the gap faster. But remember that we are still talking about 18.5% women against 80.3% of men in India.
#
class AverageBaseMetric(BaseMetric):
"""
Creates a plotly plot for slopegraphs
"""
def groupby(self, df: pd.DataFrame, columns: List[str]) -> pd.DataFrame:
""" "
Calculates quantity per x, y and traces col
"""
return df.groupby(columns, as_index=False).agg(
{"Yearly Compensation Numeric": lambda x: x.mean(skipna=False)}
)
def calculate_average(self, df=pd.DataFrame) -> pd.DataFrame:
"""
Calculates the average trace
"""
detail = self.groupby(df=df, columns=[self.x_col, self.y_col])
detail["Metric"] = detail["Yearly Compensation Numeric"]
detail[self.traces_col] = "Average"
return detail
def calculate(self, add_avg: bool = False) -> pd.DataFrame:
"""
Group the data by y_col, perform count and convert it to a list
Transforms absolute values into percentages
Yeld the metrics for a given trace
"""
df = self.get_df()
detail = self.groupby(df=df, columns=[self.x_col, self.y_col, self.traces_col])
detail["Metric"] = detail["Yearly Compensation Numeric"]
if add_avg:
avg_df = self.calculate_average(df=detail)
detail = detail.append(avg_df)
self.metric_df = detail
return detail
class CompensationGenderMetric(AverageBaseMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey, traces_col="Gender", y_col="Education", x_col="Survey Year"
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Education", categories=Category.EDUCATION)
class CompensationPlot5(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=5,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
#
# Ok, there is a huge gap in participation, but the pay gap must be closing, no? We are past 2020 after all.
# To analyse the pay gap I decided to break down the average anual compensation of women and men for education levels. I was hoping to see the gap closing with higher degrees.
#
metric = CompensationGenderMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["Women", "Men"])
CompensationPlot5(
metric=metric,
yaxes_title="Average Yearly Compensation (USD)",
shared_yaxes=True,
yticks=[20, 40, 60],
yticks_template="U$ {}k",
hover_template="U$ %{y:0.1f}k",
annotation_template="U$ {:0.1f}k",
x_nticks=1,
title="<b>Gender Gap: In 2020 most women saw the pay gap increase regardless of their education.</b> "
"<br>The gap is greater at the extremes: those with either too little or too much education."
'<br><span style="font-size:14px;color:lightgrey"><i>Average Yearly Compensation in USD of professional respondents.</i></span>',
).show()
#
# I have to confess that seeing this chart was very disappointing. First the distance between women and men salaries increased in 2020 for most education levels. The sharp drop in 2020 could be partially explained by the pandemic, women having to leave their jobs or reduce hours to take care of children at home, for example. However the gap also slightly increased in 2019, we are in a bad trend.
# And the worst news is that even though the gap closes a little bit for Bachelor's and Master's degrees, it increases again for PhDs (Doctoral)! This was something that I really did not expect, and I feel sorry for all women that despite all effort to achieve the highest education title are still treated unequal to men.
# Let's do something to close the gap? Give more opportunities for women to ingress data careers even if they don't have all the required experience. And please, pay women the same you pay men for compatible education level and experience.
#
# Education vs Experience
# This is one that I love, because I dropped-off university and never got a degree. And I'm always curious to see if someone who got more formal education could be earning more than I do. Are you curious to see the results?
#
class CompensationEducationMetric(AverageBaseMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Tenure: Years Writing Code",
y_col="Education",
x_col="Survey Year",
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Education", categories=Category.EDUCATION)
class CompensationPlot4(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=10 if trace.trace_name == "10+ years" else -25,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = CompensationEducationMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["< 1 year", "10+ years"])
CompensationPlot4(
metric=metric,
yaxes_title="Average Yearly Compensation (USD)",
shared_yaxes=True,
yticks=[30, 60, 90, 120],
yticks_template="U$ {}k",
hover_template="U$ %{y:0.1f}k",
annotation_template="U$ {:0.1f}k",
x_nticks=1,
title="<b>Formal education has little impact on salary when compared to experience writing code.</b> <br>But dropping off university is better than no university at all."
'<br><span style="font-size:14px;color:lightgrey"><i>Average Yearly Compensation in USD of professional respondents. Lines are years of experience writing code.</i></span>',
).show()
#
# And the truth is that experience is much more important than formal education. Just look at people with less than 1 year of experience writing code, their salary did not increase with more education.
# A PhD with no experience writing code will earn the same as someone fresh from High School without experience.
# Now there is one curious thing about getting into a university. Those with more than 10 years of experience, but that never attended an university, tend to earn less than those who did at least some college. And there is no noticeable distinction between the salary of experienced people who didn't finish university and those who went all the way up to a doctoral degree.
# So if you are considering between getting more education or getting a job, the answer is crystal clear: get a job!
# Note: I swear I didn't tamper the results to confirm my bias :D (and you can always check the code as well)
# Why are salaries decreasing?
# From the previouis chart you might have noticed that salaries are dropping (a lot) since 2018. Let's have a closer look into that by breaking the data by Years of Experience Writing Code and Job Title.
#
class CompensationJobTitleMetric(AverageBaseMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Job Title",
y_col="Tenure: Years Writing Code",
x_col="Survey Year",
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(
column="Tenure: Years Writing Code", categories=Category.YEARS_WRITING_CODE
)
class CompensationPlot(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=8,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=self.get_annotation_text(trace=trace, idx=0),
showarrow=False,
)
# Add right annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=-8,
yanchor="top",
xshift=0,
xanchor="right",
x=trace.x_values.codes[-1],
y=trace.y_values[-1],
text=self.get_annotation_text(trace=trace, idx=-1),
showarrow=False,
)
metric = CompensationJobTitleMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=True)
metric.get_subplots(highlighted_traces=["Average"])
CompensationPlot(
metric=metric,
yaxes_title="Average Yearly Compensation (USD)",
shared_yaxes=True,
yticks=[30, 60, 90],
yticks_template="U$ {}k",
hover_template="U$ %{y:0.1f}k",
annotation_template="U$ {:0.1f}k",
x_nticks=1,
title="<b>The average salary increases with experience in writing code for all job titles.</b><br>But all salaries have been decreasing since 2018."
'<br><span style="font-size:14px;color:lightgrey"><i>Average Yearly Compensation in USD of professional respondents by job title</i></span>',
).show()
#
# We can clearly see that on average all salaries are decreasing since 2018, regardless of the experience level or job title, and that there is a sharper drop in 2020.
# 2020 as we all know was an exceptional year. By around March 2020 practically all countries went into some sort of lockdown because of COVID-19. As result of that, many employees started working from home and many others were dismissed due to the global economic crisis caused by the pandemic.
# If there are more professionals available, their market price will drop. Simple economics.
# Another effect here is due to **data science not being on the hype anymore**. A few years ago it was named the sexiest job of the century and there was a huge hype and inflated expectations around what data science could deliver to companies. Now business are starting to realise what is actually comercially viable. This well known as the technology hype cycle.
# Technology Hype Cycle. Adapted from Gartner
# We can check if this is true by looking at the actual Gartner Analysis for AI in 2020. Look at the Machine Learning position in the chart!
# What’s New In Gartner’s Hype Cycle For AI, 2020. Source: Forbes
# Given that we are past the peak of inflated expectations, I would expect salaries to continue decreasing over the next two to five years, until Machine Learning reaches the plateau of productivity.
# Continuing with the same chart I want to highlight two professions and show how experience writing code impacts their average salary.
#
class CompensationPlot2(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=-90 if trace.trace_name == "Data Scientist" else 45,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = CompensationJobTitleMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["Product/Project Manager", "Data Scientist"])
CompensationPlot2(
metric=metric,
yaxes_title="Average Yearly Compensation (USD)",
shared_yaxes=True,
yticks=[30, 60, 90],
yticks_template="U$ {}k",
hover_template="U$ %{y:0.1f}k",
annotation_template="U$ {:0.1f}k",
x_nticks=1,
title="<b>Data Scientists with coding skills benefit more from it than product managers.</b>"
"<br>Data Scientists with little coding experience are amongst the least paid professionals."
'<br><span style="font-size:14px;color:lightgrey"><i>Average Yearly Compensation in USD of professional respondents per job title</i></span>',
).show()
#
# We can clearly see that experience writing code increases salary for both Product/Project Managers (PMs) and for Data Scientists. A PM doesn't need to have coding experience and to earn more than a Data Scientist. However, because writing code is much more important for Data Science than for Product Management, the lines switch places after 5 years of experience and Data Scientists start earning more than PMs.
# Also note that in 2020 Data scientists wit less than 3 years of experience are the ones with worse salaries. This might also be an indication of our current position in the Hype Cycle.
# There are a lot of Data Science begginers available in the market, but companies want to hire experienced data scientists with proven records of delivering business results.
# The next charts will be ploted by Machine Learning Experience instead of Years of Experience Writing Code.
# How experience using machine learning methods change compensation?
# We had two questions in the survey asking about respondents experience, one was experienc writing code to analize data. The other one was experience using machine learning methods. I wanted to know how each country values ML experience in terms of salary. This is the chart:
class CompensationCountryMetric(AverageBaseMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Country",
y_col="Tenure: Years Using Machine Learning Methods",
x_col="Survey Year",
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(
column="Tenure: Years Using Machine Learning Methods",
categories=Category.YEARS_USING_ML,
)
metric = CompensationCountryMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=True)
metric.get_subplots(highlighted_traces=["Average"])
compensation_plot = CompensationPlot(
metric=metric,
yaxes_title="Average Yearly Compensation (USD)",
shared_yaxes=True,
yticks=[30, 60, 90, 120],
yticks_template="U$ {}k",
hover_template="U$ %{y:0.1f}k",
annotation_template="U$ {:0.1f}k",
x_nticks=1,
title="<b>Looking at ML experience, average salaries are stable over time.</b> <br>However, those with less experience saw a drop in earnings in 2020."
'<br><span style="font-size:14px;color:lightgrey"><i>Average Yearly Compensation in USD of professional respondents by country</i></span>',
)
compensation_plot.show()
#
# We can see straight away that on average experienced ML professionals did not notice reduction in their salaries. This is a sign that companies are finding professionals and that the global market is well balanced with offer and demand. However, different from experience writing code, gaining more ML experience does not increase your compensation so much.
# Now I want to focus in two countries. The united states because it's the one that pays more, and Brazil, because it's where I came from.
class CompensationPlot3(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=10 if trace.trace_name == "Brazil" else 50,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = CompensationCountryMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["Brazil", "United States"])
CompensationPlot3(
metric=metric,
yaxes_title="Average Yearly Compensation (USD)",
shared_yaxes=True,
yticks=[30, 60, 90, 120],
yticks_template="U$ {}k",
hover_template="U$ %{y:0.1f}k",
annotation_template="U$ {:0.1f}k",
x_nticks=1,
title="<b>The United States is certainly yhe country where ML experience is most valued (or overpriced).</b> <br>Other countries, such as Brazil, saw a decrease in compensation in 2020 even for the most experienced."
'<br><span style="font-size:14px;color:lightgrey"><i>Average Yearly Compensation in USD of professional respondents</i></span>',
).show()
#
# In The united States, experienced ML professionals are very well paid (I would probably say that they are overpriced). There is clearly high demand for such professionals and their salaries tend to increase in such situations. This high demand often also causes data professionals to stay for very short periods (often less than a year) at their jobs, because they receive better offers from other companies.
# I heard this once, and I think it describes this kind of professional. They are POC engineers - because in such short time before changing jobs the only thing possible to deliver is a proof of concept.
# Now in Brazil, we see a more stable trend over time and over experience, with some decrease in the salary of most professionals in 2020. There is a currency effect to be considered here, the Brazilian Real lost ~25% of its value against US Dollar in 2020.
# We see a bigger drop for experienced professionals, probably due to expensive employees that were laid off due to the pandemic effects on economy and had to find other jobs at a lower salary.
# Creating Professional Profiles
# For the rest of this analysis we will create data professional profiles to help us iunderstand some behaviours. To create those profiles I used the definition created by Teresa Kubacka on the winning submission of the 2019 Kaggle Survey.
# In her notebook Who codes what and how long - a story told through a heatmap she created professionals categories using the following two questions:
# How long have you been writing code to analyze data (at work or at school)?
# For how many years have you used machine learning methods?
# They are as follows:
# Professional subgroups based on the answers for the two questions. Author: Teresa Kubacka Source: A story told through a heatmap
# Here I'm just shortening their names for better visualization in the charts:
# Beginners: Those with less than 2 years of experience of both coding and ML methods.
# Coders: Those with lot's of coding experience, but that have started working with machine learning only recently.
# ML Veterans: Those that have been coding and doing machine learning for a very long time.
# Moodern DS: They have started their carreers in ML when it started to hype and have enough coding experience to provide measurable value.
# Now lets look at the yearly compensation for each profile!
#
class CompensationProfileMetric(AverageBaseMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey, traces_col="Job Title", y_col="Profile", x_col="Survey Year"
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Profile", categories=Category.PROFILES)
class CompensationPlot5(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=15
if trace.trace_name == "Product/Project Manager"
else -55,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = CompensationProfileMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["Data Engineer/DBA", "Product/Project Manager"])
CompensationPlot5(
metric=metric,
yaxes_title="Average Yearly Compensation (USD)",
shared_yaxes=True,
yticks=[20, 50, 100, 150],
yticks_template="U$ {}k",
hover_template="U$ %{y:0.1f}k",
annotation_template="U$ {:0.1f}k",
x_nticks=1,
title="<b>ML Veterans working in Data Engineering and Product Management are in high demand.</b>"
"<br>Salaries for both professions are the ones that increased the most since the first survey."
'<br><span style="font-size:14px;color:lightgrey"><i>Average Yearly Compensation in USD of professional respondents.</i></span>',
).show()
#
# While most of other profiles remained stable or had a drop in their earnings in 2020, salaries for ML veterans in Data Engineering and Product management continued to increase sharply. This means that those seasoned professionals are being requested to deliver real value to companies, and the problems they are facing have nothing to do with ML algorithms...
#
# The real problems in 2020 are:
# how to get and process data for ML
# how to manage projects so that they deliver what was promised
#
# Now let's have a look at what they think is the best language for an aspiring data scientist learn first.
#
class RecommendedLanguageMetric(PercentageMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Recommended Programming Language",
y_col="Profile",
x_col="Survey Year",
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Profile", categories=Category.PROFILES)
def calculate(self, add_avg: bool = False) -> pd.DataFrame:
"""
Group the data by y_col, perform count and convert it to a list
Transforms absolute values into percentages
Yeld the metrics for a given trace
"""
df = self.get_df()
df = df[df[self.y_col] != "None"]
detail = self.groupby(df=df, columns=[self.x_col, self.y_col, self.traces_col])
total = self.groupby(df=df, columns=[self.x_col, self.y_col])
joined = self.join_dataframes(
df1=detail, df2=total, on_columns=[self.x_col, self.y_col]
)
joined["Metric"] = (
joined["Dummy"] / joined["Dummy_total"] * 100
) # get percentage
if add_avg:
avg_df = self.calculate_average(df=joined)
joined = joined.append(avg_df)
self.metric_df = joined
return joined
class RecommendedLanguagePlot(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=-15 if trace.trace_name == "SQL" else 10,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = RecommendedLanguageMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["Python", "R", "SQL"])
RecommendedLanguagePlot(
metric=metric,
yaxes_title="% of Respondents",
shared_yaxes=True,
yticks=[0, 20, 40, 60, 80],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=1,
title="<b>R is losing space to Python as the most recommended language to learn first.</b> "
"<br>Those experienced in writing code are the ones that changed their minds the most over the past years."
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents that recommend '
"a programming language <br>for an aspiring data scientist to learn first.</i></span>",
).show()
#
# That old fight between Python fans and R lovers is in the past.Python has consolidated itself as the most recommended language to start with.
#
# Around 80% of Beginners recommend Python as the first language. Because this group has little experience coding, this probably means that Python is also their first language.
#
# The old ML veterans, that grew up using R for analysis, are also giving a chance to Python and started to recommend it more in the last year. SQL recommendations is consistent across all profiles.
# If you want to learn a programming language to do Data Science projects go with Python, you won't regret it.
#
#
class ListColumnsPercentageMetric(PercentageMetric):
"""
Creates a plotly plot for slopegraphs
"""
def calculate(self, add_avg: bool = False) -> pd.DataFrame:
"""
Group the data by y_col, perform count and convert it to a list
Transforms absolute values into percentages
Yeld the metrics for a given trace
"""
df = self.get_df()
detail = self.groupby(df=df, columns=[self.x_col, self.y_col, self.traces_col])
self.explode = False
df = self.get_df()
total = self.groupby(df=df, columns=[self.x_col, self.y_col])
joined = self.join_dataframes(
df1=detail, df2=total, on_columns=[self.x_col, self.y_col]
)
joined["Metric"] = (
joined["Dummy"] / joined["Dummy_total"] * 100
) # get percentage
if add_avg:
avg_df = self.calculate_average(df=joined)
joined = joined.append(avg_df)
self.metric_df = joined
return joined
class LanguagesMetric(ListColumnsPercentageMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Programming Languages",
y_col="Profile",
x_col="Survey Year",
explode=True,
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Profile", categories=Category.PROFILES)
class LanguagesPlot(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=-15 if trace.trace_name == "Python" else 10,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = LanguagesMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["Python", "C/C++"])
LanguagesPlot(
metric=metric,
yaxes_title="% of Professionals",
shared_yaxes=True,
yticks=[30, 60, 90],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=1,
title="<b>Python is the language most beginners use on a regular basis and adoption is increasing.</b> "
"<br>C/C++ usage is also increasing for all profiles, but specially for Coders."
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents that use a language on a regular basis.</i></span>',
).show()
#
# There is a noticeable increase in C/C++ usage for all profiles, but specially for Coders, a group tha has already lot's of experience in writing code, this means that more people coming from a C/C++ background (and that use it on a daily basis) want to dive in Machine Learning. They are coming to Kaggle to practice their skills and learn from the community.
#
# Now that we know the languages used on a regular basis for each profile let's have a look at the primary tool they use to analyse data.
#
class PrimaryToolMetric(ListColumnsPercentageMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Primary Tool to Analyze Data",
y_col="Profile",
x_col="Survey Year",
explode=True,
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Profile", categories=Category.PROFILES)
class PrimaryToolPlot(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=-20
if trace.trace_name == "Basic statistical software"
else 10,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = PrimaryToolMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(
highlighted_traces=[
"Basic statistical software",
"Local or hosted development environments",
]
)
PrimaryToolPlot(
metric=metric,
yaxes_title="% of Professionals",
shared_yaxes=True,
yticks=[15, 30, 45, 60],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=1,
title="<b>Basic statistical software gaining space in data analysis.</b> "
"<br>And Adoption of local or hosted dev environments is greater with Modern Data Scientists."
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents and their primary tool used to analyze data.</i></span>',
).show()
#
# And here again I was very surprised with the results. Who would imagine that in 2020 Modern Data Scientists and Beginners would use Basic Statistical Software (Such as Excel and Google Sheets) as their primary tool to analyse data instead of local or hosted development environments.
# I understand that Basic Statistical Software is common ground for everyone, and easy to use. But once I switched to writing code and gained experience, I could never conceive moving back to Spreadsheets as my primary tool. I can't remember of any release or market change in those tools that could justify moving back to them.
#
# I'm aware that both Google and Microsoft added some ML features into their products... But no... Once you start coding you should never move back to spreadsheets. Or should you?
#
#
class IDEMetric(ListColumnsPercentageMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="IDEs",
y_col="Profile",
x_col="Survey Year",
explode=True,
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Profile", categories=Category.PROFILES)
class IDEPlot(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=10,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = IDEMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["Jupyter/IPython", "Visual Studio"])
IDEPlot(
metric=metric,
yaxes_title="% of Professionals",
shared_yaxes=True,
yticks=[20, 40, 60, 80],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=1,
title="<b>Visual Studio gained adoption with all professional profiles in 2020</b> "
"<br>Overall IDE usage is decreasing with time."
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents and the IDEs they use.</i></span>',
).show()
#
# Jupyter/IPython is very popular with Beginners and Modern Data Scientists, and less popular with coders and ML Veterans. Interesting to note that regular use of Ipython is slowly decreasing over time an giving way to IDEs traditionally used by Software Developers. Here it's important to highlight the increase in Visual Studio adoption in 2020. I believe this movement is due to the native integration with notebooks released by mid 2020.
#
#
# Do you wanna try a proper IDE that has all good features such as code-completion, variable inspection, debugging, etc and still work on your loved notebook environment? Then I suggest you follow the lead and give a try to Visual Studio Code.
#
class CloudMetric(ListColumnsPercentageMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Cloud Computing Platforms",
y_col="Profile",
x_col="Survey Year",
explode=True,
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Profile", categories=Category.PROFILES)
class CloudPlot(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=-60 if trace.trace_name == "Azure" else 5,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = CloudMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["None"])
CloudPlot(
metric=metric,
yaxes_title="% of Professionals",
shared_yaxes=True,
yticks=[10, 30, 50],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=1,
title="<b>Cloud adoption is increasing amongst Kagglers since 2018!</b> "
"<br>Those who answered None for cloud platform are decreasing consistently."
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents and the cloud platforms they use.</i></span>',
).show()
#
# Here we are seeing how many persons answered None to cloud platforms (meaning that they don't use a cloud platform on a regular basis). And it is decreasing over time! So... Cloud adoption is increasing amongst professionals with Modern Data Scientists being the ones that use cloud services the most. This is very good news, meaning that everyone is having more access to the best Data Science tools and they are also getting closer to productionizing Data Science!
# Now there is one thing I think it's curious... I would expect ML Veterans to have a lot of experience with cloud, but they don't. Are they too cool for using the cloud?
# Hey Kaggle! This a good question for next years survey: How many years of experience with cloud platforms?
# Now how about we have a look at cloud adoption per provider?
#
metric = CloudMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["AWS", "Azure", "GCP"])
CloudPlot(
metric=metric,
yaxes_title="% of Professionals",
shared_yaxes=True,
yticks=[10, 30, 50],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=1,
title="<b>The three big providers remain the three big providers, with AWS losing marketshare.</b> "
"<br>GCP usage amongst coders has increased and now is above Azure"
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents and the cloud platforms they use.</i></span>',
).show()
#
# No big surprises in the cloud providers adoption. Google Cloud and Microsoft are increasing marketshare due to discounts and policies for both startups and large corporations. AWS is the biggest provider and usually adopted by business that were "cloud first" a few years ago.
#
class MLStatusMetric(ListColumnsPercentageMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Machine Learning Status in Company",
y_col="Profile",
x_col="Survey Year",
explode=True,
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Profile", categories=Category.PROFILES)
class MLStatusPlot(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=5 if trace.trace_name == "Exploring ML" else -30,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = MLStatusMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["Well established ML", "Exploring ML"])
MLStatusPlot(
metric=metric,
yaxes_title="% of Incorporation of ML Into Business",
shared_yaxes=True,
yticks=[15, 30, 45],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=1,
title="<b>Veterans usually work for companies that have well established models in production</b> "
"<br>Coders usually work for companies that are exploring ML an may one day put a model into production"
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents and the incorporation of ML methods into the business.</i></span>',
).show()
class MLFrameworksMetric(ListColumnsPercentageMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Machine Learning Frameworks",
y_col="Profile",
x_col="Survey Year",
explode=True,
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Profile", categories=Category.PROFILES)
class MLFrameworksPlot(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=-55 if trace.trace_name == "Scikit-learn" else -25,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = MLFrameworksMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["PyTorch", "Scikit-learn"])
MLFrameworksPlot(
metric=metric,
yaxes_title="% of ML Frameworks Usage",
shared_yaxes=True,
yticks=[25, 50, 75],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=1,
title="<b>PyTorch is gaining space and becoming much more popular!</b> "
"<br>The essential ML framework for every Modern Data Scientis is Scikit-learn"
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents and the usage of ML Frameworks.</i></span>',
).show()
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0051/274/51274129.ipynb | kaggle-survey-2017 | null | [{"Id": 51274129, "ScriptId": 13860086, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1549225, "CreationDate": "01/06/2021 22:51:51", "VersionNumber": 40.0, "Title": "One chart, many answers: Kaggle Surveys in Slopes", "EvaluationDate": "01/06/2021", "IsChange": true, "TotalLines": 2520.0, "LinesInsertedFromPrevious": 56.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 2464.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 63807751, "KernelVersionId": 51274129, "SourceDatasetVersionId": 5713}, {"Id": 63807752, "KernelVersionId": 51274129, "SourceDatasetVersionId": 161079}] | [{"Id": 5713, "DatasetId": 2733, "DatasourceVersionId": 5713, "CreatorUserId": 1056333, "LicenseName": "Database: Open Database, Contents: \u00a9 Original Authors", "CreationDate": "10/27/2017 22:03:03", "VersionNumber": 4.0, "Title": "2017 Kaggle Machine Learning & Data Science Survey", "Slug": "kaggle-survey-2017", "Subtitle": "A big picture view of the state of data science and machine learning.", "Description": "### Context\n\nFor the first time, Kaggle conducted an industry-wide survey to establish a comprehensive view of the state of data science and machine learning. The survey received over 16,000 responses and we learned a ton about who is working with data, what\u2019s happening at the cutting edge of machine learning across industries, and how new data scientists can best break into the field.\n\nTo share some of the initial insights from the survey, we\u2019ve worked with the folks from [The Pudding](https://pudding.cool/) to put together [this interactive report](https://kaggle.com/surveys/2017). They\u2019ve shared all of the kernels used in the report [here](https://www.kaggle.com/amberthomas/kaggle-2017-survey-results).\n\n### Content\n\nThe data includes 5 files: \n\n - `schema.csv`: a CSV file with survey schema. This schema includes the questions that correspond to each column name in both the `multipleChoiceResponses.csv` and `freeformResponses.csv`.\n - `multipleChoiceResponses.csv`: Respondents' answers to multiple choice and ranking questions. These are non-randomized and thus a single row does correspond to all of a single user's answers.\n -`freeformResponses.csv`: Respondents' freeform answers to Kaggle's survey questions. These responses are randomized within a column, so that reading across a single row does not give a single user's answers.\n - `conversionRates.csv`: Currency conversion rates (to USD) as accessed from the R package \"quantmod\" on September 14, 2017\n - `RespondentTypeREADME.txt`: This is a schema for decoding the responses in the \"Asked\" column of the `schema.csv` file.\n\n### Kernel Awards in November\nIn the month of November, we\u2019re awarding $1000 a week for code and analyses shared on this dataset via [Kaggle Kernels](https://www.kaggle.com/kaggle/kaggle-survey-2017/kernels). Read more about this month\u2019s [Kaggle Kernels Awards](https://www.kaggle.com/about/datasets-awards/kernels) and help us advance the state of machine learning and data science by exploring this one of a kind dataset.\n\n### Methodology\n - This survey received 16,716 usable respondents from 171 countries and territories. If a country or territory received less than 50 respondents, we grouped them into a group named \u201cOther\u201d for anonymity.\n - We excluded respondents who were flagged by our survey system as \u201cSpam\u201d or who did not answer the question regarding their employment status (this question was the first required question, so not answering it indicates that the respondent did not proceed past the 5th question in our survey).\n - Most of our respondents were found primarily through Kaggle channels, like our email list, discussion forums and social media channels.\n - The survey was live from August 7th to August 25th. The median response time for those who participated in the survey was 16.4 minutes. We allowed respondents to complete the survey at any time during that window.\n - We received salary data by first asking respondents for their day-to-day currency, and then asking them to write in either their total compensation.\n - We\u2019ve provided a csv with an exchange rate to USD for you to calculate the salary in US dollars on your own.\n - The question was optional\n - Not every question was shown to every respondent. In an attempt to ask relevant questions to each respondent, we generally asked work related questions to employed data scientists and learning related questions to students. There is a column in the `schema.csv` file called \"Asked\" that describes who saw each question. You can learn more about the different segments we used in the `schema.csv` file and `RespondentTypeREADME.txt` in the data tab.\n - To protect the respondents\u2019 identity, the answers to multiple choice questions have been separated into a separate data file from the open-ended responses. We do not provide a key to match up the multiple choice and free form responses. Further, the free form responses have been randomized column-wise such that the responses that appear on the same row did not necessarily come from the same survey-taker.", "VersionNotes": "Adjusted commas in multiple answer choices", "TotalCompressedBytes": 29225919.0, "TotalUncompressedBytes": 29225919.0}] | [{"Id": 2733, "CreatorUserId": 1056333, "OwnerUserId": NaN, "OwnerOrganizationId": 4.0, "CurrentDatasetVersionId": 5713.0, "CurrentDatasourceVersionId": 5713.0, "ForumId": 7077, "Type": 2, "CreationDate": "09/28/2017 17:11:06", "LastActivityDate": "02/06/2018", "TotalViews": 242960, "TotalDownloads": 28216, "TotalVotes": 869, "TotalKernels": 470}] | null | # # One chart, many answers: Kaggle Surveys in Slopes
# 
# On previous surveys I explored [What Makes a Kaggler Valuable](https://www.kaggle.com/andresionek/what-makes-a-kaggler-valuable) and a comparison between job posts and survey answers on [Is there any job out there? Kaggle vs Glassdoor](https://www.kaggle.com/andresionek/is-there-any-job-out-there-kaggle-vs-glassdoor).
# This is the 4th Kaggle Survey, so I decided to explore trends over time. Unfortunately The 2017 survey was very different from the others, so I decided to exclude it from the analysis. I was left with the 2018, 2019 and 2020 surveys and tried to extract as much value as possible.
# With one extra challenge: use only one chart type.
# I present to you Kaggle Surveys in Slopes! Enjoy!
# ## Slopegraphs - How to read them?
# Despite the fancy name, slopegraphs are simple line charts, the ones you are already familiar with. But lets give you an intro to how to read the charts I'm presenting here. I promise you only need to learn it only once!
# Let's look at this example:
# Here we have two slopegraphs, one for women and another for men. Note that they share the y axis.
#
# Each line in this chart represents a country. This information is available in the subtitle and also when you hover you mouse over the datapoints.
#
#
# Warning! For all charts in this study we applied a filter to select only Professionals (people who are actively working).
# Non-professionals were defined as those who answered Job Title (Q5) as either:
# Student
# Currently not employed
# those who didn't answer the question (NaN)
# Professionals were defined as everyone but the non-professionals.
# Now let's start the fun part!
#
"""
Prior to starting I created a spreadsheets mapping all questions from the 4 years of survey.
https://docs.google.com/spreadsheets/d/1HpVi0ipElWYxwXali7QlIbMWjCQWk6nuaZRAZLcksn4/edit?usp=sharing
Some questions were the same through the years and had exactly the same wording.
Others had changes that did not compromise too much the question meaning. For example:
2020 - For how many years have you been writing code and/or programming?
2019 - How long have you been writing code to analyze data (at work or at school)?
Or
2020 - Which of the following big data products (relational databases, data warehouses, data lakes, or similar) do you use on a regular basis?
2019 - Which specific big data / analytics products do you use on a regular basis?
Or
2020 - Which of the following big data products (relational databases, data warehouses, data lakes, or similar) do you use on a regular basis?
2019 - Which specific big data / analytics products do you use on a regular basis?
2018 - Which of the following big data and analytics products have you used at work or school in the last 5 years?
---
Other questions had a different wording that implied in a different meaning, so they were excluded from this analysis.
I picked only questions that were the same over the last 3 years (2020, 2019 and 2018).
The 2017 survey was very different from the others and only a few questions were useful, so I decided to exclude 2017 from the analysis.
## ## ## ## ##
I suggest that Kaggle keeps the survey consistent over the following years to allow better time-series analysis.
## ## ## ## ##
Note: I'm trying to write functions for all transformations following the single responsability principle.
"""
pass
from enum import Enum
import numpy as np
class Mapping(Enum):
"""
Contains dicts mapping values found in the surveys to values we want to replace with.
"""
COMPENSATION = {
"$0-999": "0-10k",
"1,000-1,999": "0-10k",
"2,000-2,999": "0-10k",
"3,000-3,999": "0-10k",
"4,000-4,999": "0-10k",
"5,000-7,499": "0-10k",
"7,500-9,999": "0-10k",
"10,000-14,999": "10-20k",
"15,000-19,999": "10-20k",
"20,000-24,999": "20-30k",
"25,000-29,999": "20-30k",
"30,000-39,999": "30-40k",
"40,000-49,999": "40-50k",
"50,000-59,999": "50-60k",
"60,000-69,999": "60-70k",
"70,000-79,999": "70-80k",
"80,000-89,999": "80-90k",
"90,000-99,999": "90-100k",
"100,000-124,999": "100-125k",
"125,000-149,999": "125-150k",
"150,000-199,999": "150-200k",
"200,000-249,999": "200-250k",
"300,000-500,000": "300-500k",
"> $500,000": np.nan,
"0-10,000": "0-10k",
"10-20,000": "10-20k",
"20-30,000": "20-30k",
"30-40,000": "30-40k",
"40-50,000": "40-50k",
"50-60,000": "50-60k",
"60-70,000": "60-70k",
"70-80,000": "70-80k",
"80-90,000": "80-90k",
"90-100,000": "90-100k",
"100-125,000": "100-125k",
"125-150,000": "125-150k",
"150-200,00": "150-200k",
"200-250,000": "200-250k",
"300-400,000": "300-500k",
"400-500,000": "300-500k",
"500,000+": np.nan,
"I do not wish to disclose my approximate yearly compensation": np.nan,
}
JOB_TITLE = {
"Data Scientist": "Data Scientist",
"Software Engineer": "Software Engineer",
"Data Analyst": "Data Analyst",
"Other": "Other",
"Research Scientist": "Research Scientist/Statistician",
"Business Analyst": "Business Analyst",
"Product/Project Manager": "Product/Project Manager",
"Data Engineer": "Data Engineer/DBA",
"Not employed": "Currently not employed",
"Machine Learning Engineer": "Machine Learning Engineer",
"Statistician": "Research Scientist/Statistician",
"Consultant": "Other",
"Research Assistant": "Research Scientist/Statistician",
"Manager": "Manager/C-level",
"DBA/Database Engineer": "Data Engineer/DBA",
"Chief Officer": "Manager/C-level",
"Developer Advocate": "Other",
"Marketing Analyst": "Business Analyst",
"Salesperson": "Other",
"Principal Investigator": "Research Scientist/Statistician",
"Data Journalist": "Other",
"Currently not employed": "Currently not employed",
"Student": "Student",
}
GENDER = {
"Male": "Men",
"Female": "Women",
"Man": "Men",
"Woman": "Women",
"Prefer not to say": np.nan, # Very few answers on those categories to do any meaningful analysis
"Prefer to self-describe": np.nan, # Very few answers on those categories to do any meaningful analysis
"Nonbinary": np.nan, # Very few answers on those categories to do any meaningful analysis
}
AGE = {
"18-21": "18-21",
"22-24": "22-24",
"25-29": "25-29",
"30-34": "30-34",
"35-39": "35-39",
"40-44": "40-44",
"45-49": "45-49",
"50-54": "50-54",
"55-59": "55-59",
"60-69": "60-69",
"70+": "70+",
"70-79": "70+",
"80+": "70+",
}
EDUCATION = {
"Master’s degree": "Master’s",
"Bachelor’s degree": "Bachelor’s",
"Some college/university study without earning a bachelor’s degree": "Some college",
"Doctoral degree": "Doctoral",
"Professional degree": "Professional",
"I prefer not to answer": np.nan,
"No formal education past high school": "High school",
}
YEARS_WRITING_CODE = {
"3-5 years": "3-5 years",
"1-2 years": "1-3 years",
"2-3 years": "1-3 years",
"5-10 years": "5-10 years",
"10-20 years": "10+ years",
"< 1 years": "< 1 year",
"< 1 year": "< 1 year",
"20+ years": "10+ years",
np.nan: "None",
"I have never written code": "None",
"I have never written code but I want to learn": "None",
"20-30 years": "10+ years",
"30-40 years": "10+ years",
"40+ years": "10+ years",
}
YEARS_WRITING_CODE_PROFILES = {
"3-5 years": "3-10 years",
"1-2 years": "1-2 years",
"2-3 years": "2-3 years",
"5-10 years": "3-10 years",
"10-20 years": "10+ years",
"< 1 years": "0-1 years",
"< 1 year": "0-1 years",
"20+ years": "10+ years",
np.nan: "None",
"I have never written code": "None",
"I have never written code but I want to learn": "None",
"20-30 years": "10+ years",
"30-40 years": "10+ years",
"40+ years": "10+ years",
}
RECOMMENDED_LANGUAGE = {
"Python": "Python",
"R": "R",
"SQL": "SQL",
"C++": "C++",
"MATLAB": "MATLAB",
"Other": "Other",
"Java": "Java",
"C": "C",
"None": "None",
"Javascript": "Javascript",
"Julia": "Julia",
"Scala": "Other",
"SAS": "Other",
"Bash": "Bash",
"VBA": "Other",
"Go": "Other",
"Swift": "Swift",
"TypeScript": "Other",
}
LANGUAGES = {
"SQL": "SQL",
"R": "R",
"Java": "Java",
"MATLAB": "MATLAB",
"Python": "Python",
"Javascript/Typescript": "Javascript/Typescript",
"Bash": "Bash",
"Visual Basic/VBA": "VBA",
"Scala": "Scala",
"PHP": "Other",
"C/C++": "C/C++",
"Other": "Other",
"C#/.NET": "Other",
"Go": "Other",
"SAS/STATA": "Other",
"Ruby": "Other",
"Julia": "Julia",
"None": "None",
np.nan: "None",
"Javascript": "Javascript/Typescript",
"C": "C/C++",
"TypeScript": "Javascript/Typescript",
"C++": "C/C++",
"Swift": "Swift",
}
YEARS_USING_ML = {
"1-2 years": "1-3 years",
"2-3 years": "1-3 years",
"< 1 year": "< 1 year",
"Under 1 year": "< 1 year",
"< 1 years": "< 1 year",
"3-4 years": "3-5 years",
"5-10 years": "5+ years",
"4-5 years": "3-5 years",
np.nan: "None",
"I have never studied machine learning but plan to learn in the future": "None",
"I do not use machine learning methods": "None",
"10-15 years": "5+ years",
"20+ years": "5+ years",
"10-20 years": "5+ years",
"20 or more years": "5+ years",
"I have never studied machine learning and I do not plan to": "None",
}
YEARS_USING_ML_PROFILES = {
"1-2 years": "1-2 years",
"2-3 years": "2-3 years",
"< 1 year": "0-1 years",
"Under 1 year": "0-3 years",
"< 1 years": "0-1 years",
"3-4 years": "3-10 years",
"5-10 years": "3-10 years",
"4-5 years": "3-10 years",
np.nan: "None",
"I have never studied machine learning but plan to learn in the future": "None",
"I do not use machine learning methods": "None",
"10-15 years": "10+ years",
"20+ years": "10+ years",
"10-20 years": "10+ years",
"20 or more years": "10+ years",
"I have never studied machine learning and I do not plan to": "None",
}
PRIMARY_TOOL = {
"Local development environments (RStudio, JupyterLab, etc.)": "Local or hosted development environments",
"Basic statistical software (Microsoft Excel, Google Sheets, etc.)": "Basic statistical software",
"Local or hosted development environments (RStudio, JupyterLab, etc.)": "Local or hosted development environments",
"Cloud-based data software & APIs (AWS, GCP, Azure, etc.)": "Cloud-based data software & APIs",
"Other": "Other",
"Advanced statistical software (SPSS, SAS, etc.)": "Advanced statistical software",
"Business intelligence software (Salesforce, Tableau, Spotfire, etc.)": "Business intelligence software",
}
COUNTRY = {
"India": "India",
"United States of America": "United States",
"Other": "Other",
"Brazil": "Brazil",
"Russia": "Russia",
"Japan": "Japan",
"United Kingdom of Great Britain and Northern Ireland": "United Kingdom",
"Germany": "Germany",
"China": "China",
"Spain": "Spain",
"France": "France",
"Canada": "Canada",
"Italy": "Italy",
"Nigeria": "Nigeria",
"Turkey": "Turkey",
"Australia": "Australia",
}
IDE = {
"None": "None",
"MATLAB": "MATLAB",
"RStudio": "RStudio",
"Jupyter/IPython": "Jupyter/IPython",
"PyCharm": "PyCharm",
"Atom": "Vim/Emacs/Atom",
"Visual Studio": "Visual Studio",
"Notepad++": "Notepad++/Sublime",
"Sublime Text": "Notepad++/Sublime",
"IntelliJ": "PyCharm",
"Spyder": "Spyder",
"Visual Studio Code": "Visual Studio",
"Vim": "Vim/Emacs/Atom",
"Other": "Other",
"nteract": "Other",
np.nan: "Other",
"Jupyter (JupyterLab, Jupyter Notebooks, etc) ": "Jupyter/IPython",
" RStudio ": "RStudio",
" PyCharm ": "PyCharm",
" MATLAB ": "MATLAB",
" Spyder ": "Spyder",
" Notepad++ ": "Notepad++/Sublime",
" Sublime Text ": "Notepad++/Sublime",
" Atom ": "Vim/Emacs/Atom",
" Visual Studio / Visual Studio Code ": "Visual Studio",
" Vim / Emacs ": "Vim/Emacs/Atom",
"Visual Studio Code (VSCode)": "Visual Studio",
}
CLOUD = {
"I have not used any cloud providers": "None",
"Microsoft Azure": "Azure",
"Google Cloud Platform (GCP)": "GCP",
"Amazon Web Services (AWS)": "AWS",
"IBM Cloud": "IBM/Red Hat",
"Other": "Other",
"Alibaba Cloud": "Alibaba",
np.nan: "None",
" Amazon Web Services (AWS) ": "AWS",
" Google Cloud Platform (GCP) ": "GCP",
" Microsoft Azure ": "Azure",
"None": "None",
" Salesforce Cloud ": "Other",
" Red Hat Cloud ": "IBM/Red Hat",
" VMware Cloud ": "Other",
" Alibaba Cloud ": "Alibaba",
" SAP Cloud ": "Other",
" IBM Cloud ": "IBM/Red Hat",
" Oracle Cloud ": "Other",
" IBM Cloud / Red Hat ": "IBM/Red Hat",
" Tencent Cloud ": "Other",
}
ML_STATUS = {
"No (we do not use ML methods)": "Do not use ML / Do not know",
"I do not know": "Do not use ML / Do not know",
"We recently started using ML methods (i.e., models in production for less than 2 years)": "Recently started using ML",
"We have well established ML methods (i.e., models in production for more than 2 years)": "Well established ML",
"We are exploring ML methods (and may one day put a model into production)": "Exploring ML",
"We use ML methods for generating insights (but do not put working models into production)": "Use ML for generating insights",
np.nan: "Do not use ML / Do not know",
}
ML_FRAMEWORKS = {
"None": "None",
"Prophet": "Prophet",
"Scikit-Learn": "Scikit-learn",
"Keras": "Keras",
"TensorFlow": "TensorFlow",
"Spark MLlib": "Other",
"Xgboost": "Xgboost",
"randomForest": "Other",
"lightgbm": "LightGBM",
"Caret": "Caret",
"mlr": "Other",
"PyTorch": "PyTorch",
"Mxnet": "Other",
"CNTK": "Other",
"Caffe": "Other",
"H20": "H2O",
"catboost": "CatBoost",
"Fastai": "Fast.ai",
"Other": "Other",
np.nan: "None",
" Scikit-learn ": "Scikit-learn",
" RandomForest": "Other",
" Xgboost ": "Xgboost",
" LightGBM ": "LightGBM",
" TensorFlow ": "TensorFlow",
" Keras ": "Keras",
" Caret ": "Caret",
" PyTorch ": "PyTorch",
" Spark MLib ": "Spark MLlib",
" Fast.ai ": "Fast.ai",
" Tidymodels ": "Other",
" CatBoost ": "CatBoost",
" JAX ": "Other",
" Prophet ": "Prophet",
" H2O 3 ": "H2O",
" MXNet ": "Other",
}
class Category(Enum):
COMPENSATION = [
"Not Disclosed",
"0-10k",
"10-20k",
"20-30k",
"30-40k",
"40-50k",
"50-60k",
"60-70k",
"70-80k",
"80-90k",
"90-100k",
"100-125k",
"125-150k",
"150-200k",
"200-250k",
"300-500k",
]
JOB_TITLE = [
"Other",
"Manager/C-level",
"Product/Project Manager",
"Business Analyst",
"Data Analyst",
"Research Scientist/Statistician",
"Data Scientist",
"Machine Learning Engineer",
"Data Engineer/DBA",
"Software Engineer",
]
GENDER = ["Women", "Men"]
AGE = [
"18-21",
"22-24",
"25-29",
"30-34",
"35-39",
"40-44",
"45-49",
"50-54",
"55-59",
"60-69",
"70+",
]
YEARS_WRITING_CODE = [
"None",
"< 1 year",
"1-3 years",
"3-5 years",
"5-10 years",
"10+ years",
]
YEARS_USING_ML = ["None", "< 1 year", "1-3 years", "3-5 years", "5+ years"]
SURVEY_YEAR = [2018, 2019, 2020]
EDUCATION = [
"High school",
"Some college",
"Professional",
"Bachelor’s",
"Master’s",
"Doctoral",
]
PROFILES = ["Beginners", "Others", "Modern DS", "Coders", "ML Veterans"]
COLORS = {
"India": "#FE9933",
"Brazil": "#179B3A",
"United States": "#002366",
"China": "#ED2124",
"Average": "blueviolet",
"Canada": "#F60B00",
"Data Scientist": "#13A4B4",
"Product/Project Manager": "#D70947",
"Software Engineer": "#E8743B",
"Data Analyst": "#BF399E",
"Data Engineer/DBA": "#144B7F",
"< 1 year": "lightgreen",
"10+ years": "green",
"Women": "hotpink",
"Men": "midnightblue",
"Python": "#FEC331",
"SQL": "#66B900",
"R": "#2063b7",
"C/C++": "slateblue",
"Basic statistical software": "#0D7036",
"Local or hosted development environments": "#36B5E2",
"Visual Studio": "#349FED",
"Jupyter/IPython": "#EC7426",
"AWS": "#F79500",
"GCP": "#1AA746",
"Azure": "#3278B1",
"Well established ML": "dodgerblue",
"Exploring ML": "slategrey",
"PyTorch": "orangered",
"Scikit-learn": "goldenrod",
"None": "darkblue",
}
from typing import List, Type, Tuple
import pandas as pd
from abc import ABC, abstractmethod
class BaseKaggle(ABC):
"""
Base class to handle cleaning and transformation of datasets from different years.
"""
def __init__(self) -> None:
self.df = None
self.non_professionals = ["Student", "Currently not employed", np.nan]
self.mapping = {}
self.questions_to_combine = []
self.survey_year = None
@property
def questions_to_keep(self) -> List[str]:
"""
Select which questions we should keep in the dataframe using the mapping keys
"""
return [key for key, value in self.mapping.items()]
def remove_non_professionals(self) -> pd.DataFrame:
"""
Non-professionals were defined as students, unemployed and NaNs.
Also removed those who didn't disclose compensation.
"""
self.df = self.df.drop(
self.df[self.df["Job Title"].isin(self.non_professionals)].index
)
self.df.dropna(subset=["Yearly Compensation"], inplace=True)
return self.df
@abstractmethod
def filter_question_columns(columns: List[str], question: str) -> List[str]:
pass
@staticmethod
def remove_nans_from_list(answers: List[str]) -> List[str]:
"""
This function removes all nans from a list
"""
return [x for x in answers if pd.notnull(x)]
def combine_answers_into_list(self, question: str) -> pd.DataFrame:
"""
This function will create a new column in the dataframe adding
all answers to a list and removing nans.
"""
filtered_columns = self.filter_question_columns(list(self.df.columns), question)
self.df[question] = self.df[filtered_columns].values.tolist()
self.df[question] = self.df[question].apply(self.remove_nans_from_list)
return self.df
def batch_combine_answers_into_list(
self, questions_to_combine: List[str]
) -> pd.DataFrame:
"""
Applyes combine_answers_into_list to multiple columns
"""
for question in questions_to_combine:
self.combine_answers_into_list(question=question)
return self.df
def rename_columns(self) -> pd.DataFrame:
"""
Renames columns using mapping
"""
self.df = self.df.rename(columns=self.mapping)
return self.df
def do_mapping(self, column: str, mapping: Mapping) -> pd.DataFrame:
"""
Maps values to have same classes accross all years
"""
self.df[column] = self.df[column].map(mapping.value)
return self.df
def do_list_mapping(self, column: str, mapping: Mapping) -> pd.DataFrame:
"""
Maps values to have same classes accross all years for columns that are list type
"""
mapping_dict = mapping.value
self.df[column] = self.df[column].apply(
lambda x: [mapping_dict[val] for val in x]
)
return self.df
def add_numeric_average_compensation(self) -> pd.DataFrame:
"""
Create a numeric value for compensation, taking the average between the max and min values for each class
We are summing up the lowest and highest value for each category, and then dividing by 2.
Some regex needed to clean the text
"""
compensation = (
self.df["Yearly Compensation"]
.str.replace(r"(?:(?!\d|\-).)*", "")
.str.replace("500", "500-500")
.str.split("-")
)
self.df["Yearly Compensation Numeric"] = compensation.apply(
lambda x: (int(x[0]) + int(x[1])) / 2
) # it is calculated in thousand of dollars
return self.df
def add_survey_year_column(self) -> pd.DataFrame:
"""
Adds the year the survey was taken as a column
"""
self.df["Survey Year"] = self.survey_year
return self.df
def add_dummy_column(self) -> pd.DataFrame:
"""
Adds Dummy = 1 to make easier to perform group by
"""
self.df["Dummy"] = 1
return self.df
def select_questions(self) -> pd.DataFrame:
"""
Selects only the relevant questions from each survey year
"""
self.df = self.df[self.questions_to_keep]
return self.df
def fill_na(self, column: str, value: str) -> pd.DataFrame:
"""
Fill column NaNs with a given value
"""
self.df[column] = self.df[column].fillna(value)
return self.df
def calculate_profile(self, values: tuple) -> str:
"""
This function creates profiles for professionals adapted from the work developed by Teresa Kubacka on last years survey
https://www.kaggle.com/tkubacka/a-story-told-through-a-heatmap
"""
years_code, years_ml = values
if years_code in ["0-1 years", "1-2 years"] and years_ml in [
"0-1 years",
"1-2 years",
]:
return "Beginners"
elif years_code in ["2-3 years", "3-10 years"] and years_ml in [
"1-2 years",
"2-3 years",
"3-10 years",
]:
return "Modern DS"
elif years_code == "10+ years" and years_ml in ["0-1 years", "1-2 years"]:
return "Coders"
elif years_code == "10+ years" and years_ml == "10+ years":
return "ML Veterans"
else:
return "Others"
def create_profiles(self) -> None:
"""
This function creates a new columns with profiles for professionals adapted from the work developed by Teresa Kubacka on last years survey
https://www.kaggle.com/tkubacka/a-story-told-through-a-heatmap
"""
self.df["Years Writing Code Profile"] = self.df[
"Tenure: Years Writing Code"
].map(Mapping.YEARS_WRITING_CODE_PROFILES.value)
self.df["Years Using ML Profile"] = self.df[
"Tenure: Years Using Machine Learning Methods"
].map(Mapping.YEARS_USING_ML_PROFILES.value)
self.df["Profile"] = self.df[
["Years Writing Code Profile", "Years Using ML Profile"]
].apply(self.calculate_profile, axis=1)
def transform(self) -> pd.DataFrame:
"""
Process and clean the dataset
"""
self.df.drop(
0, axis=0, inplace=True
) # dropping first row (questions) from processed data
self.batch_combine_answers_into_list(
questions_to_combine=self.questions_to_combine
)
self.select_questions()
self.rename_columns()
self.create_profiles()
self.do_mapping(column="Yearly Compensation", mapping=Mapping.COMPENSATION)
self.do_mapping(column="Job Title", mapping=Mapping.JOB_TITLE)
self.do_mapping(column="Gender", mapping=Mapping.GENDER)
self.do_mapping(column="Age", mapping=Mapping.AGE)
self.do_mapping(column="Education", mapping=Mapping.EDUCATION)
self.do_mapping(
column="Tenure: Years Writing Code", mapping=Mapping.YEARS_WRITING_CODE
)
self.do_mapping(
column="Recommended Programming Language",
mapping=Mapping.RECOMMENDED_LANGUAGE,
)
self.do_mapping(
column="Tenure: Years Using Machine Learning Methods",
mapping=Mapping.YEARS_USING_ML,
)
self.do_mapping(
column="Primary Tool to Analyze Data", mapping=Mapping.PRIMARY_TOOL
)
self.do_mapping(column="Country", mapping=Mapping.COUNTRY)
self.do_mapping(
column="Machine Learning Status in Company", mapping=Mapping.ML_STATUS
)
self.do_list_mapping(
column="Machine Learning Frameworks", mapping=Mapping.ML_FRAMEWORKS
)
self.do_list_mapping(column="Programming Languages", mapping=Mapping.LANGUAGES)
self.do_list_mapping(column="IDEs", mapping=Mapping.IDE)
self.do_list_mapping(column="Cloud Computing Platforms", mapping=Mapping.CLOUD)
self.fill_na(column="Country", value="Other")
self.remove_non_professionals()
self.add_numeric_average_compensation()
self.add_survey_year_column()
self.add_dummy_column()
self.df.reset_index(drop=True, inplace=True)
return self.df
class Kaggle2020(BaseKaggle):
"""
Processing and cleaning 2020 Dataset
Here we do the following:
* Group all multiple choice answers into a list in a single column.
* Remove Non-Professionals from the data set. Non-professionals were defined as students, unemployed and NaNs.
* Select the questions we want to keep, based on the spreadsheet analysis done previously.
* Remove all non-multiple choice answers
"""
def __init__(self) -> None:
super().__init__()
self.survey_year = 2020
self.df = pd.read_csv(
"/kaggle/input/kaggle-survey-2020/kaggle_survey_2020_responses.csv",
low_memory=False,
)
self.mapping = {
"Q1": "Age",
"Q2": "Gender",
"Q3": "Country",
"Q4": "Education",
"Q5": "Job Title",
"Q6": "Tenure: Years Writing Code",
"Q7": "Programming Languages",
"Q8": "Recommended Programming Language",
"Q9": "IDEs",
"Q10": "Hosted Notebooks",
"Q14": "Data Visualization Libraries",
"Q15": "Tenure: Years Using Machine Learning Methods",
"Q16": "Machine Learning Frameworks",
"Q22": "Machine Learning Status in Company",
"Q23": "Daily activities",
"Q24": "Yearly Compensation",
"Q26_A": "Cloud Computing Platforms",
"Q27_A": "Cloud Computing Products",
"Q28_A": "Machine Learning Products",
"Q29_A": "Big Data Products",
"Q37": "Data Science Courses",
"Q38": "Primary Tool to Analyze Data",
"Q39": "Media Sources",
}
self.questions_to_combine = [
"Q7",
"Q9",
"Q10",
"Q14",
"Q16",
"Q23",
"Q26_A",
"Q27_A",
"Q28_A",
"Q29_A",
"Q37",
"Q39",
]
@staticmethod
def filter_question_columns(columns: List[str], question: str) -> List[str]:
"""
Filters only questions that starts with the question_number and do not end with the string _OTHER
"""
return [
col
for col in columns
if col.startswith(f"{question}_P") and not col.endswith("_OTHER")
]
class Kaggle2019(BaseKaggle):
"""
Processing and cleaning 2019 Dataset
"""
def __init__(self) -> None:
super().__init__()
self.survey_year = 2019
self.df = pd.read_csv(
"/kaggle/input/kaggle-survey-2019/multiple_choice_responses.csv",
low_memory=False,
)
self.mapping = {
"Q1": "Age",
"Q2": "Gender",
"Q3": "Country",
"Q4": "Education",
"Q5": "Job Title",
"Q15": "Tenure: Years Writing Code",
"Q18": "Programming Languages",
"Q19": "Recommended Programming Language",
"Q16": "IDEs",
"Q17": "Hosted Notebooks",
"Q20": "Data Visualization Libraries",
"Q23": "Tenure: Years Using Machine Learning Methods",
"Q28": "Machine Learning Frameworks",
"Q8": "Machine Learning Status in Company",
"Q9": "Daily activities",
"Q10": "Yearly Compensation",
"Q29": "Cloud Computing Platforms",
"Q30": "Cloud Computing Products",
"Q32": "Machine Learning Products",
"Q31": "Big Data Products",
"Q13": "Data Science Courses",
"Q14": "Primary Tool to Analyze Data",
"Q12": "Media Sources",
}
self.questions_to_combine = [
"Q18",
"Q16",
"Q17",
"Q20",
"Q28",
"Q9",
"Q29",
"Q30",
"Q32",
"Q31",
"Q13",
"Q12",
]
@staticmethod
def filter_question_columns(columns: List[str], question: str) -> List[str]:
"""
Filters only questions that starts with the question_number and do not end with the string _OTHER_TEXT
"""
return [
col
for col in columns
if col.startswith(f"{question}_P") and not col.endswith("_OTHER_TEXT")
]
class Kaggle2018(BaseKaggle):
"""
Processing and cleaning 2019 Dataset
"""
def __init__(self) -> None:
super().__init__()
self.survey_year = 2018
self.df = pd.read_csv(
"/kaggle/input/kaggle-survey-2018/multipleChoiceResponses.csv",
low_memory=False,
)
self.mapping = {
"Q2": "Age",
"Q1": "Gender",
"Q3": "Country",
"Q4": "Education",
"Q6": "Job Title",
"Q24": "Tenure: Years Writing Code",
"Q16": "Programming Languages",
"Q18": "Recommended Programming Language",
"Q13": "IDEs",
"Q14": "Hosted Notebooks",
"Q21": "Data Visualization Libraries",
"Q25": "Tenure: Years Using Machine Learning Methods",
"Q19": "Machine Learning Frameworks",
"Q10": "Machine Learning Status in Company",
"Q11": "Daily activities",
"Q9": "Yearly Compensation",
"Q15": "Cloud Computing Platforms",
"Q27": "Cloud Computing Products",
"Q28": "Machine Learning Products",
"Q30": "Big Data Products",
"Q36": "Data Science Courses",
"Q12_MULTIPLE_CHOICE": "Primary Tool to Analyze Data",
"Q38": "Media Sources",
}
self.questions_to_combine = [
"Q16",
"Q13",
"Q14",
"Q21",
"Q19",
"Q11",
"Q15",
"Q27",
"Q28",
"Q30",
"Q36",
"Q38",
]
@staticmethod
def filter_question_columns(columns: List[str], question: str) -> List[str]:
"""
Filters only questions that starts with the question_number and do not end with the string _OTHER_TEXT
"""
return [
col
for col in columns
if col.startswith(f"{question}_P") and not col.endswith("_OTHER_TEXT")
]
class KaggleCombinedSurvey:
"""
This class combines surveys from multiple years into a concatenated dataframe.
"""
def __init__(self, surveys: List[Type[BaseKaggle]]) -> None:
self.surveys = surveys
self._cached_df = None
@property
def df(self) -> pd.DataFrame:
"""
If df was already processed get it from cache, otherwise process it and saves to cache.
"""
if isinstance(self._cached_df, type(None)):
self._cached_df = self._concatenate()
return self._cached_df
def _get_surveys_dfs(self) -> List[pd.DataFrame]:
"""
Applies the transform method for each survey and return the dfs in a list
"""
return [survey().transform() for survey in self.surveys]
def _concatenate(self) -> pd.DataFrame:
"""
Concatenate survey dataframes into a single dataframe
"""
df = pd.concat(self._get_surveys_dfs())
df = df.reset_index(drop=True)
return df
import plotly.graph_objects as go
import plotly.offline as pyo
import plotly.express as px
from plotly.subplots import make_subplots
from collections import namedtuple
MetricData = namedtuple(
"MetricData",
[
"subplot_name",
"trace_name",
"y_values",
"x_values",
"subplot_y_position",
"subplot_x_position",
"highlighted_traces",
],
)
class BaseMetric(ABC):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(
self,
survey: KaggleCombinedSurvey,
traces_col: str,
y_col: str,
x_col: str,
explode: bool = False,
) -> None:
"""
traces: the column name we want to creaate traces from
y: the column name we will be ploting
x: Will always be survey year for our slopegraphs.
"""
self.traces_col = traces_col
self.y_col = y_col
self.x_col = x_col
self.survey = survey
self.traces = []
self.explode = explode
self.metric_df = None
@property
def traces_names(self) -> List[str]:
"""
Calculate unique values of traces_col
"""
return self.metric_df[self.traces_col].cat.categories
@property
def subplots_names(self) -> List[str]:
"""
Calculate unique values of traces_col
"""
return self.metric_df[self.y_col].cat.categories
@property
def subplots_qty(self):
return len(self.subplots_names)
@property
def traces_qty(self):
return len(self.traces_names)
def apply_filter(self, df: pd.DataFrame, column: str, value: str) -> pd.DataFrame:
"""
filters data for a single trace
"""
return df[df[column] == value]
@abstractmethod
def calculate(self) -> pd.DataFrame:
"""
Group the data by y_col, perform count and convert it to a list
Transforms absolute values into percentages
Yeld the metrics for a given trace
"""
pass
def groupby(self, df: pd.DataFrame, columns: List[str]) -> pd.DataFrame:
""" "
Calculates quantity per x, y and traces col
"""
return df.groupby(columns, as_index=False)["Dummy"].sum()
def join_dataframes(
self, df1: pd.DataFrame, df2: pd.DataFrame, on_columns: List[str]
) -> pd.DataFrame:
return (
df1.set_index(on_columns)
.join(df2.set_index(on_columns), rsuffix="_total")
.reset_index()
)
def to_categorical(self, column: str, categories: Category) -> pd.DataFrame:
cat_dtype = pd.api.types.CategoricalDtype(
categories=categories.value, ordered=True
)
self.metric_df[column] = self.metric_df[column].astype(cat_dtype)
return self.metric_df
def get_df(self):
"""
Returns a dataframe with or without lists exploded
"""
if self.explode:
return self.survey.df.explode(self.traces_col)
else:
return self.survey.df
def get_subplots(self, highlighted_traces: List[str]) -> List[MetricData]:
self.apply_categories()
self.metric_df["subplot_y_position"] = self.metric_df[self.y_col].cat.codes + 1
self.metric_df["subplot_x_position"] = 1
for index, row in self.metric_df.iterrows():
filtered_df = self.apply_filter(
df=self.metric_df, column=self.y_col, value=row[self.y_col]
)
filtered_df = self.apply_filter(
df=filtered_df, column=self.traces_col, value=row[self.traces_col]
)
metric_data = MetricData(
subplot_name=row[self.y_col],
trace_name=row[self.traces_col],
y_values=filtered_df["Metric"].values,
x_values=filtered_df[self.x_col].values,
subplot_y_position=row["subplot_y_position"],
subplot_x_position=row["subplot_x_position"],
highlighted_traces=row[self.traces_col] in highlighted_traces,
)
self.traces.append(metric_data)
class PercentageMetric(BaseMetric):
"""
Creates a plotly plot for slopegraphs
"""
def calculate_average(self, df=pd.DataFrame) -> pd.DataFrame:
detail = self.groupby(df=df, columns=[self.x_col, self.y_col])
total = self.groupby(df=df, columns=[self.x_col])
joined = self.join_dataframes(df1=detail, df2=total, on_columns=[self.x_col])
joined["Metric"] = (
joined["Dummy"] / joined["Dummy_total"] * 100
) # get percentage
joined[self.traces_col] = "Average"
return joined
def calculate(self, add_avg: bool = False) -> pd.DataFrame:
"""
Group the data by y_col, perform count and convert it to a list
Transforms absolute values into percentages
Yeld the metrics for a given trace
"""
df = self.get_df()
detail = self.groupby(df=df, columns=[self.x_col, self.y_col, self.traces_col])
total = self.groupby(df=df, columns=[self.x_col, self.traces_col])
joined = self.join_dataframes(
df1=detail, df2=total, on_columns=[self.x_col, self.traces_col]
)
joined["Metric"] = (
joined["Dummy"] / joined["Dummy_total"] * 100
) # get percentage
if add_avg:
avg_df = self.calculate_average(df=joined)
joined = joined.append(avg_df)
self.metric_df = joined
return joined
@abstractmethod
def apply_categories(self):
pass
class GenderProportionMetric(PercentageMetric):
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey, traces_col="Country", y_col="Gender", x_col="Survey Year"
)
def apply_categories(self):
self.to_categorical(column="Gender", categories=Category.GENDER)
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
class BasePlot(ABC):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(
self,
metric: Type[BaseMetric],
title: str,
yaxes_title: str,
shared_yaxes: bool,
yticks: List[float],
yticks_template: str,
annotation_template: str,
x_nticks: int,
hover_template: str,
) -> None:
pyo.init_notebook_mode()
self.metric = metric
self.yaxes_title = yaxes_title
self.shared_yaxes = shared_yaxes
self.hover_template = hover_template
self.title = title
self.yticks = yticks
self.yticks_template = yticks_template
self.annotation_template = annotation_template
self.x_nticks = x_nticks
self.figure = go.Figure()
self.range = (0, 0)
def make_subplots(self) -> None:
"""
Creates subplots in the figure and add titles
"""
self.figure = make_subplots(
cols=self.metric.subplots_qty, # our subplots will have the number of unique values for the select column
rows=1, # and 1 row
subplot_titles=self.metric.subplots_names, # Add titles to subplots
specs=[[{"type": "scatter"}] * self.metric.subplots_qty]
* 1, # Define chart type for each subplot
shared_yaxes=self.shared_yaxes,
shared_xaxes=True,
)
for idx, subplot_title in enumerate(self.figure["layout"]["annotations"]):
subplot_title["font"] = dict(
size=14, color="grey"
) # Size and color of subplot title
subplot_title["align"] = "left"
subplot_title["xanchor"] = "left"
subplot_title["x"] = 0
subplot_title["xref"] = "x" if idx == 0 else f"x{idx + 1}"
def update_common_layout(self) -> None:
"""
Updates general layout characteristics
"""
self.figure.update_layout(
showlegend=False,
plot_bgcolor="white",
title_text=self.title,
title_font_color="grey",
title_font_size=15,
title_x=0,
title_y=0.98,
margin_t=130,
margin_l=0,
margin_r=0,
height=600,
width=800,
yaxis_range=self.range,
)
def get_yticks_text(self) -> List[str]:
"""
Calculates the y_ticks text for charts
"""
return [self.yticks_template.format(i) for i in self.yticks]
def update_subplots_layout(self) -> None:
"""
Updates scatter subplots layout characteristics
"""
for subplot_idx in range(self.metric.subplots_qty):
self.figure.update_xaxes(
type="category",
color="lightgrey", # to not draw to much attention to axis
showgrid=False,
visible=subplot_idx == 0, # Visible only to the first subplot
row=1,
nticks=self.x_nticks,
col=subplot_idx + 1, # Subplots start at 1
)
self.figure.update_yaxes(
showgrid=False,
visible=subplot_idx == 0 or not self.shared_yaxes,
title=self.yaxes_title
if subplot_idx == 0
else None, # Visible only to the first subplot
color="grey",
row=1,
col=subplot_idx + 1,
tickvals=self.yticks, # show ticks ate 25, 50 and 75
ticktext=self.get_yticks_text(),
tickmode="array",
tickfont_color="lightgrey",
autorange=True,
)
def line_color(self, trace: MetricData) -> str:
"""
Sets color to the highlight color or to a tone of grey if not highlighted
"""
return (
self.highlight_color(trace=trace)
if trace.highlighted_traces
else "lightslategrey"
)
def highlight_color(self, trace: MetricData) -> str:
"""
Returns the highlight color
"""
return COLORS[trace.trace_name]
def line_width(self, trace: MetricData) -> str:
"""
Returns the line width of traces depending if trace is highlighted or not
"""
return 1.6 if trace.highlighted_traces else 0.6
def opacity(self, trace: MetricData) -> str:
"""
Returns the opacity depending if trace is highlighted or not
"""
return 0.8 if trace.highlighted_traces else 0.25
def add_trace(self, trace: MetricData) -> None:
"""
Adds a new trace to a figure
"""
self.figure.add_trace(
go.Scatter(
x=trace.x_values,
y=trace.y_values,
mode="lines",
name=trace.trace_name,
hoverinfo="name+text+y",
hovertemplate=self.hover_template,
text=trace.x_values,
line_color=self.line_color(trace=trace),
showlegend=False,
opacity=self.opacity(trace=trace),
line_shape="linear",
line_width=self.line_width(trace=trace),
connectgaps=True,
),
trace.subplot_x_position,
trace.subplot_y_position,
)
def get_annotation_text(self, trace: MetricData, idx: int) -> str:
"""
Calculates the annotation text to be added to the plot
"""
if trace.subplot_y_position == 1 and idx == 0:
template = "{}<br>" + f"{self.annotation_template}"
return template.format(trace.trace_name, trace.y_values[idx])
else:
return self.annotation_template.format(trace.y_values[idx])
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=0,
xshift=-3,
xanchor="right",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=self.get_annotation_text(trace=trace, idx=0),
showarrow=False,
)
# Add right annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=0,
xshift=3,
xanchor="left",
x=trace.x_values.codes[-1],
y=trace.y_values[-1],
text=self.get_annotation_text(trace=trace, idx=-1),
showarrow=False,
)
def add_subplot_axis_annotation(self) -> None:
"""
Add subplot axis annotation
"""
self.figure.add_annotation(
xref="x",
yref="paper",
font=dict(size=14, color="lightgrey"),
align="left",
x=0,
xanchor="left",
y=1.05,
yanchor="bottom",
text=f"{self.metric.y_col}",
showarrow=False,
)
def add_source_annotation(self) -> None:
"""
Add source annotation
"""
self.figure.add_annotation(
xref="paper",
yref="paper",
font=dict(size=11, color="lightgrey"),
align="left",
x=-0.07,
xanchor="left",
y=-0.13,
yanchor="bottom",
text="<b>Source:</b> Kaggle surveys from 2018 to 2020.",
showarrow=False,
)
def add_data(self) -> None:
"""
Adds a trace to the figure following the same standard for each trace
"""
# Add all non-highlighted traces.
for trace in self.metric.traces:
self.add_trace(trace=trace)
self.update_range(data=trace.y_values)
def update_range(self, data: List[float]) -> None:
"""
Updates the range to be 90% of minimum values and 110% of maximum value of all traces
"""
if len(data) == 0:
return self.range
max_range = max(data) * 1.2
min_range = min(data) * 0.8
self.range = (
(self.range[0], max_range) if max_range > self.range[1] else self.range
)
self.range = (
(min_range, self.range[1]) if min_range < self.range[0] else self.range
)
def show(self) -> None:
"""
Renders and shows the plot
"""
self.make_subplots()
self.update_common_layout()
self.add_data()
self.add_annotations()
self.add_subplot_axis_annotation()
self.update_subplots_layout()
self.add_source_annotation()
self.figure.show()
class GenderProportionPlot(BasePlot):
pass
kaggle_combined_survey = KaggleCombinedSurvey(
surveys=[Kaggle2018, Kaggle2019, Kaggle2020]
)
# The Gender Gap
# I wanted to start with something simple and important at the same time. So I questioned myself: over the past three years, did the proportion of Men and Women change? I knew there was a gap, but I would like to see it decreasing (and a lot) in the recent years.
#
metric = GenderProportionMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=True)
metric.get_subplots(highlighted_traces=["Average"])
GenderProportionPlot(
metric=metric,
yaxes_title="% of Respondents per Survey Year",
shared_yaxes=True,
yticks=[20, 40, 60, 80],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=3,
title="<b>Gender Gap: Kaggle members are mostly men. </b><br>And there are no signs of increase in women participation since 2018."
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents per country</i></span>',
).show()
#
# Unfortunately there is a huge gap in professionals participation in Kaggle: 84% of men against 16% of women.
# And what is worse than that is the fact that women participation did not increase over the past three years. I saw some other notebooks that showed an increase in female students. Maybe this will cause a increase in professionals next year, but need a lot more women to close this gap.
# Maybe Kaggle could host women only competitions, in a bid to attract more of them to the platform (and to Data Science).
# If we zoom-in using the same chart, we can see which countries are are getting more women into Data over the past few years.
metric = GenderProportionMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["India", "Brazil", "Canada"])
GenderProportionPlot(
metric=metric,
yaxes_title="% of Respondents per Survey Year",
shared_yaxes=False,
yticks=[5, 10, 15, 20, 75, 80, 85, 90],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=3,
title="<b>Gender Gap: India, Brazil and Canada are countries where the gender gap is reducing. </b><br>However changes are still very small to make any difference."
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents per country</i></span>',
).show()
#
# While most countries actually increased the gender gap in 2020, India is the country that is closing the gap faster. But remember that we are still talking about 18.5% women against 80.3% of men in India.
#
class AverageBaseMetric(BaseMetric):
"""
Creates a plotly plot for slopegraphs
"""
def groupby(self, df: pd.DataFrame, columns: List[str]) -> pd.DataFrame:
""" "
Calculates quantity per x, y and traces col
"""
return df.groupby(columns, as_index=False).agg(
{"Yearly Compensation Numeric": lambda x: x.mean(skipna=False)}
)
def calculate_average(self, df=pd.DataFrame) -> pd.DataFrame:
"""
Calculates the average trace
"""
detail = self.groupby(df=df, columns=[self.x_col, self.y_col])
detail["Metric"] = detail["Yearly Compensation Numeric"]
detail[self.traces_col] = "Average"
return detail
def calculate(self, add_avg: bool = False) -> pd.DataFrame:
"""
Group the data by y_col, perform count and convert it to a list
Transforms absolute values into percentages
Yeld the metrics for a given trace
"""
df = self.get_df()
detail = self.groupby(df=df, columns=[self.x_col, self.y_col, self.traces_col])
detail["Metric"] = detail["Yearly Compensation Numeric"]
if add_avg:
avg_df = self.calculate_average(df=detail)
detail = detail.append(avg_df)
self.metric_df = detail
return detail
class CompensationGenderMetric(AverageBaseMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey, traces_col="Gender", y_col="Education", x_col="Survey Year"
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Education", categories=Category.EDUCATION)
class CompensationPlot5(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=5,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
#
# Ok, there is a huge gap in participation, but the pay gap must be closing, no? We are past 2020 after all.
# To analyse the pay gap I decided to break down the average anual compensation of women and men for education levels. I was hoping to see the gap closing with higher degrees.
#
metric = CompensationGenderMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["Women", "Men"])
CompensationPlot5(
metric=metric,
yaxes_title="Average Yearly Compensation (USD)",
shared_yaxes=True,
yticks=[20, 40, 60],
yticks_template="U$ {}k",
hover_template="U$ %{y:0.1f}k",
annotation_template="U$ {:0.1f}k",
x_nticks=1,
title="<b>Gender Gap: In 2020 most women saw the pay gap increase regardless of their education.</b> "
"<br>The gap is greater at the extremes: those with either too little or too much education."
'<br><span style="font-size:14px;color:lightgrey"><i>Average Yearly Compensation in USD of professional respondents.</i></span>',
).show()
#
# I have to confess that seeing this chart was very disappointing. First the distance between women and men salaries increased in 2020 for most education levels. The sharp drop in 2020 could be partially explained by the pandemic, women having to leave their jobs or reduce hours to take care of children at home, for example. However the gap also slightly increased in 2019, we are in a bad trend.
# And the worst news is that even though the gap closes a little bit for Bachelor's and Master's degrees, it increases again for PhDs (Doctoral)! This was something that I really did not expect, and I feel sorry for all women that despite all effort to achieve the highest education title are still treated unequal to men.
# Let's do something to close the gap? Give more opportunities for women to ingress data careers even if they don't have all the required experience. And please, pay women the same you pay men for compatible education level and experience.
#
# Education vs Experience
# This is one that I love, because I dropped-off university and never got a degree. And I'm always curious to see if someone who got more formal education could be earning more than I do. Are you curious to see the results?
#
class CompensationEducationMetric(AverageBaseMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Tenure: Years Writing Code",
y_col="Education",
x_col="Survey Year",
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Education", categories=Category.EDUCATION)
class CompensationPlot4(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=10 if trace.trace_name == "10+ years" else -25,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = CompensationEducationMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["< 1 year", "10+ years"])
CompensationPlot4(
metric=metric,
yaxes_title="Average Yearly Compensation (USD)",
shared_yaxes=True,
yticks=[30, 60, 90, 120],
yticks_template="U$ {}k",
hover_template="U$ %{y:0.1f}k",
annotation_template="U$ {:0.1f}k",
x_nticks=1,
title="<b>Formal education has little impact on salary when compared to experience writing code.</b> <br>But dropping off university is better than no university at all."
'<br><span style="font-size:14px;color:lightgrey"><i>Average Yearly Compensation in USD of professional respondents. Lines are years of experience writing code.</i></span>',
).show()
#
# And the truth is that experience is much more important than formal education. Just look at people with less than 1 year of experience writing code, their salary did not increase with more education.
# A PhD with no experience writing code will earn the same as someone fresh from High School without experience.
# Now there is one curious thing about getting into a university. Those with more than 10 years of experience, but that never attended an university, tend to earn less than those who did at least some college. And there is no noticeable distinction between the salary of experienced people who didn't finish university and those who went all the way up to a doctoral degree.
# So if you are considering between getting more education or getting a job, the answer is crystal clear: get a job!
# Note: I swear I didn't tamper the results to confirm my bias :D (and you can always check the code as well)
# Why are salaries decreasing?
# From the previouis chart you might have noticed that salaries are dropping (a lot) since 2018. Let's have a closer look into that by breaking the data by Years of Experience Writing Code and Job Title.
#
class CompensationJobTitleMetric(AverageBaseMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Job Title",
y_col="Tenure: Years Writing Code",
x_col="Survey Year",
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(
column="Tenure: Years Writing Code", categories=Category.YEARS_WRITING_CODE
)
class CompensationPlot(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=8,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=self.get_annotation_text(trace=trace, idx=0),
showarrow=False,
)
# Add right annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=-8,
yanchor="top",
xshift=0,
xanchor="right",
x=trace.x_values.codes[-1],
y=trace.y_values[-1],
text=self.get_annotation_text(trace=trace, idx=-1),
showarrow=False,
)
metric = CompensationJobTitleMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=True)
metric.get_subplots(highlighted_traces=["Average"])
CompensationPlot(
metric=metric,
yaxes_title="Average Yearly Compensation (USD)",
shared_yaxes=True,
yticks=[30, 60, 90],
yticks_template="U$ {}k",
hover_template="U$ %{y:0.1f}k",
annotation_template="U$ {:0.1f}k",
x_nticks=1,
title="<b>The average salary increases with experience in writing code for all job titles.</b><br>But all salaries have been decreasing since 2018."
'<br><span style="font-size:14px;color:lightgrey"><i>Average Yearly Compensation in USD of professional respondents by job title</i></span>',
).show()
#
# We can clearly see that on average all salaries are decreasing since 2018, regardless of the experience level or job title, and that there is a sharper drop in 2020.
# 2020 as we all know was an exceptional year. By around March 2020 practically all countries went into some sort of lockdown because of COVID-19. As result of that, many employees started working from home and many others were dismissed due to the global economic crisis caused by the pandemic.
# If there are more professionals available, their market price will drop. Simple economics.
# Another effect here is due to **data science not being on the hype anymore**. A few years ago it was named the sexiest job of the century and there was a huge hype and inflated expectations around what data science could deliver to companies. Now business are starting to realise what is actually comercially viable. This well known as the technology hype cycle.
# Technology Hype Cycle. Adapted from Gartner
# We can check if this is true by looking at the actual Gartner Analysis for AI in 2020. Look at the Machine Learning position in the chart!
# What’s New In Gartner’s Hype Cycle For AI, 2020. Source: Forbes
# Given that we are past the peak of inflated expectations, I would expect salaries to continue decreasing over the next two to five years, until Machine Learning reaches the plateau of productivity.
# Continuing with the same chart I want to highlight two professions and show how experience writing code impacts their average salary.
#
class CompensationPlot2(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=-90 if trace.trace_name == "Data Scientist" else 45,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = CompensationJobTitleMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["Product/Project Manager", "Data Scientist"])
CompensationPlot2(
metric=metric,
yaxes_title="Average Yearly Compensation (USD)",
shared_yaxes=True,
yticks=[30, 60, 90],
yticks_template="U$ {}k",
hover_template="U$ %{y:0.1f}k",
annotation_template="U$ {:0.1f}k",
x_nticks=1,
title="<b>Data Scientists with coding skills benefit more from it than product managers.</b>"
"<br>Data Scientists with little coding experience are amongst the least paid professionals."
'<br><span style="font-size:14px;color:lightgrey"><i>Average Yearly Compensation in USD of professional respondents per job title</i></span>',
).show()
#
# We can clearly see that experience writing code increases salary for both Product/Project Managers (PMs) and for Data Scientists. A PM doesn't need to have coding experience and to earn more than a Data Scientist. However, because writing code is much more important for Data Science than for Product Management, the lines switch places after 5 years of experience and Data Scientists start earning more than PMs.
# Also note that in 2020 Data scientists wit less than 3 years of experience are the ones with worse salaries. This might also be an indication of our current position in the Hype Cycle.
# There are a lot of Data Science begginers available in the market, but companies want to hire experienced data scientists with proven records of delivering business results.
# The next charts will be ploted by Machine Learning Experience instead of Years of Experience Writing Code.
# How experience using machine learning methods change compensation?
# We had two questions in the survey asking about respondents experience, one was experienc writing code to analize data. The other one was experience using machine learning methods. I wanted to know how each country values ML experience in terms of salary. This is the chart:
class CompensationCountryMetric(AverageBaseMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Country",
y_col="Tenure: Years Using Machine Learning Methods",
x_col="Survey Year",
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(
column="Tenure: Years Using Machine Learning Methods",
categories=Category.YEARS_USING_ML,
)
metric = CompensationCountryMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=True)
metric.get_subplots(highlighted_traces=["Average"])
compensation_plot = CompensationPlot(
metric=metric,
yaxes_title="Average Yearly Compensation (USD)",
shared_yaxes=True,
yticks=[30, 60, 90, 120],
yticks_template="U$ {}k",
hover_template="U$ %{y:0.1f}k",
annotation_template="U$ {:0.1f}k",
x_nticks=1,
title="<b>Looking at ML experience, average salaries are stable over time.</b> <br>However, those with less experience saw a drop in earnings in 2020."
'<br><span style="font-size:14px;color:lightgrey"><i>Average Yearly Compensation in USD of professional respondents by country</i></span>',
)
compensation_plot.show()
#
# We can see straight away that on average experienced ML professionals did not notice reduction in their salaries. This is a sign that companies are finding professionals and that the global market is well balanced with offer and demand. However, different from experience writing code, gaining more ML experience does not increase your compensation so much.
# Now I want to focus in two countries. The united states because it's the one that pays more, and Brazil, because it's where I came from.
class CompensationPlot3(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=10 if trace.trace_name == "Brazil" else 50,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = CompensationCountryMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["Brazil", "United States"])
CompensationPlot3(
metric=metric,
yaxes_title="Average Yearly Compensation (USD)",
shared_yaxes=True,
yticks=[30, 60, 90, 120],
yticks_template="U$ {}k",
hover_template="U$ %{y:0.1f}k",
annotation_template="U$ {:0.1f}k",
x_nticks=1,
title="<b>The United States is certainly yhe country where ML experience is most valued (or overpriced).</b> <br>Other countries, such as Brazil, saw a decrease in compensation in 2020 even for the most experienced."
'<br><span style="font-size:14px;color:lightgrey"><i>Average Yearly Compensation in USD of professional respondents</i></span>',
).show()
#
# In The united States, experienced ML professionals are very well paid (I would probably say that they are overpriced). There is clearly high demand for such professionals and their salaries tend to increase in such situations. This high demand often also causes data professionals to stay for very short periods (often less than a year) at their jobs, because they receive better offers from other companies.
# I heard this once, and I think it describes this kind of professional. They are POC engineers - because in such short time before changing jobs the only thing possible to deliver is a proof of concept.
# Now in Brazil, we see a more stable trend over time and over experience, with some decrease in the salary of most professionals in 2020. There is a currency effect to be considered here, the Brazilian Real lost ~25% of its value against US Dollar in 2020.
# We see a bigger drop for experienced professionals, probably due to expensive employees that were laid off due to the pandemic effects on economy and had to find other jobs at a lower salary.
# Creating Professional Profiles
# For the rest of this analysis we will create data professional profiles to help us iunderstand some behaviours. To create those profiles I used the definition created by Teresa Kubacka on the winning submission of the 2019 Kaggle Survey.
# In her notebook Who codes what and how long - a story told through a heatmap she created professionals categories using the following two questions:
# How long have you been writing code to analyze data (at work or at school)?
# For how many years have you used machine learning methods?
# They are as follows:
# Professional subgroups based on the answers for the two questions. Author: Teresa Kubacka Source: A story told through a heatmap
# Here I'm just shortening their names for better visualization in the charts:
# Beginners: Those with less than 2 years of experience of both coding and ML methods.
# Coders: Those with lot's of coding experience, but that have started working with machine learning only recently.
# ML Veterans: Those that have been coding and doing machine learning for a very long time.
# Moodern DS: They have started their carreers in ML when it started to hype and have enough coding experience to provide measurable value.
# Now lets look at the yearly compensation for each profile!
#
class CompensationProfileMetric(AverageBaseMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey, traces_col="Job Title", y_col="Profile", x_col="Survey Year"
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Profile", categories=Category.PROFILES)
class CompensationPlot5(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=15
if trace.trace_name == "Product/Project Manager"
else -55,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = CompensationProfileMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["Data Engineer/DBA", "Product/Project Manager"])
CompensationPlot5(
metric=metric,
yaxes_title="Average Yearly Compensation (USD)",
shared_yaxes=True,
yticks=[20, 50, 100, 150],
yticks_template="U$ {}k",
hover_template="U$ %{y:0.1f}k",
annotation_template="U$ {:0.1f}k",
x_nticks=1,
title="<b>ML Veterans working in Data Engineering and Product Management are in high demand.</b>"
"<br>Salaries for both professions are the ones that increased the most since the first survey."
'<br><span style="font-size:14px;color:lightgrey"><i>Average Yearly Compensation in USD of professional respondents.</i></span>',
).show()
#
# While most of other profiles remained stable or had a drop in their earnings in 2020, salaries for ML veterans in Data Engineering and Product management continued to increase sharply. This means that those seasoned professionals are being requested to deliver real value to companies, and the problems they are facing have nothing to do with ML algorithms...
#
# The real problems in 2020 are:
# how to get and process data for ML
# how to manage projects so that they deliver what was promised
#
# Now let's have a look at what they think is the best language for an aspiring data scientist learn first.
#
class RecommendedLanguageMetric(PercentageMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Recommended Programming Language",
y_col="Profile",
x_col="Survey Year",
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Profile", categories=Category.PROFILES)
def calculate(self, add_avg: bool = False) -> pd.DataFrame:
"""
Group the data by y_col, perform count and convert it to a list
Transforms absolute values into percentages
Yeld the metrics for a given trace
"""
df = self.get_df()
df = df[df[self.y_col] != "None"]
detail = self.groupby(df=df, columns=[self.x_col, self.y_col, self.traces_col])
total = self.groupby(df=df, columns=[self.x_col, self.y_col])
joined = self.join_dataframes(
df1=detail, df2=total, on_columns=[self.x_col, self.y_col]
)
joined["Metric"] = (
joined["Dummy"] / joined["Dummy_total"] * 100
) # get percentage
if add_avg:
avg_df = self.calculate_average(df=joined)
joined = joined.append(avg_df)
self.metric_df = joined
return joined
class RecommendedLanguagePlot(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=-15 if trace.trace_name == "SQL" else 10,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = RecommendedLanguageMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["Python", "R", "SQL"])
RecommendedLanguagePlot(
metric=metric,
yaxes_title="% of Respondents",
shared_yaxes=True,
yticks=[0, 20, 40, 60, 80],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=1,
title="<b>R is losing space to Python as the most recommended language to learn first.</b> "
"<br>Those experienced in writing code are the ones that changed their minds the most over the past years."
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents that recommend '
"a programming language <br>for an aspiring data scientist to learn first.</i></span>",
).show()
#
# That old fight between Python fans and R lovers is in the past.Python has consolidated itself as the most recommended language to start with.
#
# Around 80% of Beginners recommend Python as the first language. Because this group has little experience coding, this probably means that Python is also their first language.
#
# The old ML veterans, that grew up using R for analysis, are also giving a chance to Python and started to recommend it more in the last year. SQL recommendations is consistent across all profiles.
# If you want to learn a programming language to do Data Science projects go with Python, you won't regret it.
#
#
class ListColumnsPercentageMetric(PercentageMetric):
"""
Creates a plotly plot for slopegraphs
"""
def calculate(self, add_avg: bool = False) -> pd.DataFrame:
"""
Group the data by y_col, perform count and convert it to a list
Transforms absolute values into percentages
Yeld the metrics for a given trace
"""
df = self.get_df()
detail = self.groupby(df=df, columns=[self.x_col, self.y_col, self.traces_col])
self.explode = False
df = self.get_df()
total = self.groupby(df=df, columns=[self.x_col, self.y_col])
joined = self.join_dataframes(
df1=detail, df2=total, on_columns=[self.x_col, self.y_col]
)
joined["Metric"] = (
joined["Dummy"] / joined["Dummy_total"] * 100
) # get percentage
if add_avg:
avg_df = self.calculate_average(df=joined)
joined = joined.append(avg_df)
self.metric_df = joined
return joined
class LanguagesMetric(ListColumnsPercentageMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Programming Languages",
y_col="Profile",
x_col="Survey Year",
explode=True,
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Profile", categories=Category.PROFILES)
class LanguagesPlot(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=-15 if trace.trace_name == "Python" else 10,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = LanguagesMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["Python", "C/C++"])
LanguagesPlot(
metric=metric,
yaxes_title="% of Professionals",
shared_yaxes=True,
yticks=[30, 60, 90],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=1,
title="<b>Python is the language most beginners use on a regular basis and adoption is increasing.</b> "
"<br>C/C++ usage is also increasing for all profiles, but specially for Coders."
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents that use a language on a regular basis.</i></span>',
).show()
#
# There is a noticeable increase in C/C++ usage for all profiles, but specially for Coders, a group tha has already lot's of experience in writing code, this means that more people coming from a C/C++ background (and that use it on a daily basis) want to dive in Machine Learning. They are coming to Kaggle to practice their skills and learn from the community.
#
# Now that we know the languages used on a regular basis for each profile let's have a look at the primary tool they use to analyse data.
#
class PrimaryToolMetric(ListColumnsPercentageMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Primary Tool to Analyze Data",
y_col="Profile",
x_col="Survey Year",
explode=True,
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Profile", categories=Category.PROFILES)
class PrimaryToolPlot(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=-20
if trace.trace_name == "Basic statistical software"
else 10,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = PrimaryToolMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(
highlighted_traces=[
"Basic statistical software",
"Local or hosted development environments",
]
)
PrimaryToolPlot(
metric=metric,
yaxes_title="% of Professionals",
shared_yaxes=True,
yticks=[15, 30, 45, 60],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=1,
title="<b>Basic statistical software gaining space in data analysis.</b> "
"<br>And Adoption of local or hosted dev environments is greater with Modern Data Scientists."
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents and their primary tool used to analyze data.</i></span>',
).show()
#
# And here again I was very surprised with the results. Who would imagine that in 2020 Modern Data Scientists and Beginners would use Basic Statistical Software (Such as Excel and Google Sheets) as their primary tool to analyse data instead of local or hosted development environments.
# I understand that Basic Statistical Software is common ground for everyone, and easy to use. But once I switched to writing code and gained experience, I could never conceive moving back to Spreadsheets as my primary tool. I can't remember of any release or market change in those tools that could justify moving back to them.
#
# I'm aware that both Google and Microsoft added some ML features into their products... But no... Once you start coding you should never move back to spreadsheets. Or should you?
#
#
class IDEMetric(ListColumnsPercentageMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="IDEs",
y_col="Profile",
x_col="Survey Year",
explode=True,
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Profile", categories=Category.PROFILES)
class IDEPlot(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=10,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = IDEMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["Jupyter/IPython", "Visual Studio"])
IDEPlot(
metric=metric,
yaxes_title="% of Professionals",
shared_yaxes=True,
yticks=[20, 40, 60, 80],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=1,
title="<b>Visual Studio gained adoption with all professional profiles in 2020</b> "
"<br>Overall IDE usage is decreasing with time."
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents and the IDEs they use.</i></span>',
).show()
#
# Jupyter/IPython is very popular with Beginners and Modern Data Scientists, and less popular with coders and ML Veterans. Interesting to note that regular use of Ipython is slowly decreasing over time an giving way to IDEs traditionally used by Software Developers. Here it's important to highlight the increase in Visual Studio adoption in 2020. I believe this movement is due to the native integration with notebooks released by mid 2020.
#
#
# Do you wanna try a proper IDE that has all good features such as code-completion, variable inspection, debugging, etc and still work on your loved notebook environment? Then I suggest you follow the lead and give a try to Visual Studio Code.
#
class CloudMetric(ListColumnsPercentageMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Cloud Computing Platforms",
y_col="Profile",
x_col="Survey Year",
explode=True,
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Profile", categories=Category.PROFILES)
class CloudPlot(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=-60 if trace.trace_name == "Azure" else 5,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = CloudMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["None"])
CloudPlot(
metric=metric,
yaxes_title="% of Professionals",
shared_yaxes=True,
yticks=[10, 30, 50],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=1,
title="<b>Cloud adoption is increasing amongst Kagglers since 2018!</b> "
"<br>Those who answered None for cloud platform are decreasing consistently."
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents and the cloud platforms they use.</i></span>',
).show()
#
# Here we are seeing how many persons answered None to cloud platforms (meaning that they don't use a cloud platform on a regular basis). And it is decreasing over time! So... Cloud adoption is increasing amongst professionals with Modern Data Scientists being the ones that use cloud services the most. This is very good news, meaning that everyone is having more access to the best Data Science tools and they are also getting closer to productionizing Data Science!
# Now there is one thing I think it's curious... I would expect ML Veterans to have a lot of experience with cloud, but they don't. Are they too cool for using the cloud?
# Hey Kaggle! This a good question for next years survey: How many years of experience with cloud platforms?
# Now how about we have a look at cloud adoption per provider?
#
metric = CloudMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["AWS", "Azure", "GCP"])
CloudPlot(
metric=metric,
yaxes_title="% of Professionals",
shared_yaxes=True,
yticks=[10, 30, 50],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=1,
title="<b>The three big providers remain the three big providers, with AWS losing marketshare.</b> "
"<br>GCP usage amongst coders has increased and now is above Azure"
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents and the cloud platforms they use.</i></span>',
).show()
#
# No big surprises in the cloud providers adoption. Google Cloud and Microsoft are increasing marketshare due to discounts and policies for both startups and large corporations. AWS is the biggest provider and usually adopted by business that were "cloud first" a few years ago.
#
class MLStatusMetric(ListColumnsPercentageMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Machine Learning Status in Company",
y_col="Profile",
x_col="Survey Year",
explode=True,
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Profile", categories=Category.PROFILES)
class MLStatusPlot(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=5 if trace.trace_name == "Exploring ML" else -30,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = MLStatusMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["Well established ML", "Exploring ML"])
MLStatusPlot(
metric=metric,
yaxes_title="% of Incorporation of ML Into Business",
shared_yaxes=True,
yticks=[15, 30, 45],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=1,
title="<b>Veterans usually work for companies that have well established models in production</b> "
"<br>Coders usually work for companies that are exploring ML an may one day put a model into production"
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents and the incorporation of ML methods into the business.</i></span>',
).show()
class MLFrameworksMetric(ListColumnsPercentageMetric):
"""
Creates a plotly plot for slopegraphs
"""
def __init__(self, survey: KaggleCombinedSurvey) -> None:
super().__init__(
survey=survey,
traces_col="Machine Learning Frameworks",
y_col="Profile",
x_col="Survey Year",
explode=True,
)
def apply_categories(self):
self.to_categorical(column="Survey Year", categories=Category.SURVEY_YEAR)
self.to_categorical(column="Profile", categories=Category.PROFILES)
class MLFrameworksPlot(BasePlot):
def add_annotations(self) -> None:
"""
Adds annotations to the plot
"""
for trace in self.metric.traces:
if trace.highlighted_traces:
if trace.subplot_y_position == 1:
# Add left annotation
self.figure.add_annotation(
xref=f"x{trace.subplot_y_position}",
yref=f"y{trace.subplot_y_position}",
font=dict(size=11, color=self.highlight_color(trace=trace)),
opacity=0.8,
align="center",
yshift=-55 if trace.trace_name == "Scikit-learn" else -25,
yanchor="bottom",
xshift=0,
xanchor="left",
x=trace.x_values.codes[0],
y=trace.y_values[0],
text=trace.trace_name,
showarrow=False,
)
metric = MLFrameworksMetric(survey=kaggle_combined_survey)
metric.calculate(add_avg=False)
metric.get_subplots(highlighted_traces=["PyTorch", "Scikit-learn"])
MLFrameworksPlot(
metric=metric,
yaxes_title="% of ML Frameworks Usage",
shared_yaxes=True,
yticks=[25, 50, 75],
yticks_template="{}%",
hover_template="%{y:0.1f}%",
annotation_template="{:0.1f}%",
x_nticks=1,
title="<b>PyTorch is gaining space and becoming much more popular!</b> "
"<br>The essential ML framework for every Modern Data Scientis is Scikit-learn"
'<br><span style="font-size:14px;color:lightgrey"><i>Percentage of professional respondents and the usage of ML Frameworks.</i></span>',
).show()
| false | 0 | 26,853 | 0 | 1,021 | 26,853 |
||
51821409 | <kaggle_start><data_title>Skin Cancer MNIST: HAM10000<data_description># Overview
Another more interesting than digit classification dataset to use to get biology and medicine students more excited about machine learning and image processing.
## Original Data Source
- Original Challenge: https://challenge2018.isic-archive.com
- https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/DBW86T
[1] Noel Codella, Veronica Rotemberg, Philipp Tschandl, M. Emre Celebi, Stephen Dusza, David Gutman, Brian Helba, Aadi Kalloo, Konstantinos Liopyris, Michael Marchetti, Harald Kittler, Allan Halpern: “Skin Lesion Analysis Toward Melanoma Detection 2018: A Challenge Hosted by the International Skin Imaging Collaboration (ISIC)”, 2018; https://arxiv.org/abs/1902.03368
[2] Tschandl, P., Rosendahl, C. & Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 5, 180161 doi:10.1038/sdata.2018.161 (2018).
## From Authors
Training of neural networks for automated diagnosis of pigmented skin lesions is hampered by the small size and lack of diversity of available dataset of dermatoscopic images. We tackle this problem by releasing the HAM10000 ("Human Against Machine with 10000 training images") dataset. We collected dermatoscopic images from different populations, acquired and stored by different modalities. The final dataset consists of 10015 dermatoscopic images which can serve as a training set for academic machine learning purposes. Cases include a representative collection of all important diagnostic categories in the realm of pigmented lesions: Actinic keratoses and intraepithelial carcinoma / Bowen's disease (akiec), basal cell carcinoma (bcc), benign keratosis-like lesions (solar lentigines / seborrheic keratoses and lichen-planus like keratoses, bkl), dermatofibroma (df), melanoma (mel), melanocytic nevi (nv) and vascular lesions (angiomas, angiokeratomas, pyogenic granulomas and hemorrhage, vasc).
More than 50% of lesions are confirmed through histopathology (histo), the ground truth for the rest of the cases is either follow-up examination (follow_up), expert consensus (consensus), or confirmation by in-vivo confocal microscopy (confocal). The dataset includes lesions with multiple images, which can be tracked by the lesion_id-column within the HAM10000_metadata file.
The test set is not public, but the evaluation server remains running (see the challenge website). Any publications written using the HAM10000 data should be evaluated on the official test set hosted there, so that methods can be fairly compared.<data_name>skin-cancer-mnist-ham10000
<code>import numpy as np
import pandas as pd
import os
print(os.listdir("../input"))
import pandas as pd
df = pd.read_csv("../input/skin-cancer-mnist-ham10000/HAM10000_metadata.csv")
df.head()
from os.path import isfile
from PIL import Image as pil_image
df["num_images"] = df.groupby("lesion_id")["image_id"].transform("count")
classes = df["dx"].unique()
labeldict = {}
for num, name in enumerate(classes):
labeldict[name] = num
df["dx_id"] = df["dx"].map(lambda x: labeldict[x])
def expand_path(p):
if isfile(
"../input/skin-cancer-mnist-ham10000/ham10000_images_part_1/" + p + ".jpg"
):
return (
"../input/skin-cancer-mnist-ham10000/ham10000_images_part_1/" + p + ".jpg"
)
if isfile(
"../input/skin-cancer-mnist-ham10000/ham10000_images_part_2/" + p + ".jpg"
):
return (
"../input/skin-cancer-mnist-ham10000/ham10000_images_part_2/" + p + ".jpg"
)
return p
df["image_path"] = df["image_id"]
df["image_path"] = df["image_path"].apply(expand_path)
df["images"] = df["image_path"].map(
lambda x: np.asarray(pil_image.open(x).resize((150, 112)))
)
df.head()
from sklearn.model_selection import train_test_split
df_single = df[df["num_images"] == 1]
trainset1, testset = train_test_split(df_single, test_size=0.2, random_state=80)
trainset2, validationset = train_test_split(trainset1, test_size=0.2, random_state=600)
trainset3 = df[df["num_images"] != 1]
frames = [trainset2, trainset3]
trainset = pd.concat(frames)
def prepareimages(images):
# images is a list of images
images = np.asarray(images).astype(np.float64)
images = images[:, :, :, ::-1]
m0 = np.mean(images[:, :, :, 0])
m1 = np.mean(images[:, :, :, 1])
m2 = np.mean(images[:, :, :, 2])
images[:, :, :, 0] -= m0
images[:, :, :, 1] -= m1
images[:, :, :, 2] -= m2
return images
trainimages = prepareimages(list(trainset["images"]))
testimages = prepareimages(list(testset["images"]))
validationimages = prepareimages(list(validationset["images"]))
trainlabels = np.asarray(trainset["dx_id"])
testlabels = np.asarray(testset["dx_id"])
validationlabels = np.asarray(validationset["dx_id"])
import matplotlib.pyplot as plt
plt.hist(trainlabels, bins=7, density=True)
plt.show()
plt.hist(validationlabels, bins=7, density=True)
plt.show()
plt.hist(testlabels, bins=7, density=True)
plt.show()
from keras.preprocessing.image import ImageDataGenerator
trainimages = trainimages.reshape(trainimages.shape[0], *(112, 150, 3))
data_gen = ImageDataGenerator(
rotation_range=90, zoom_range=0.1, width_shift_range=0.1, height_shift_range=0.1
)
data_gen.fit(trainimages)
from keras.models import Sequential
from keras import optimizers
from keras.layers import Dense, Conv2D, Dropout, Flatten, MaxPooling2D
from keras.applications import ResNet50
from keras import regularizers
import numpy as np
model = Sequential()
num_labels = 7
base_model = ResNet50(
include_top=False, input_shape=(224, 224, 3), pooling="avg", weights="imagenet"
)
model = Sequential()
model.add(base_model)
model.add(Dropout(0.5))
model.add(Dense(128, activation="relu", kernel_regularizer=regularizers.l2(0.02)))
model.add(Dropout(0.5))
model.add(
Dense(num_labels, activation="softmax", kernel_regularizer=regularizers.l2(0.02))
)
for layer in base_model.layers:
layer.trainable = False
for layer in base_model.layers[-22:]:
layer.trainable = True
model.summary()
from tensorflow.keras.optimizers import Adam
optimizer = Adam(
lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=1e-6, amsgrad=False
)
model.compile(
optimizer=optimizer, loss="sparse_categorical_crossentropy", metrics=["accuracy"]
)
# Fit the model
import keras
from tensorflow.python.keras.callbacks import EarlyStopping, ModelCheckpoint
class CustomModelCheckPoint(keras.callbacks.Callback):
def __init__(self, **kargs):
super(CustomModelCheckPoint, self).__init__(**kargs)
self.epoch_accuracy = {} # loss at given epoch
self.epoch_loss = {} # accuracy at given epoch
def on_epoch_begin(self, epoch, logs={}):
# Things done on beginning of epoch.
return
def on_epoch_end(self, epoch, logs={}):
# things done on end of the epoch
self.epoch_accuracy[epoch] = logs.get("acc")
self.epoch_loss[epoch] = logs.get("loss")
self.model.save_weights("../output/resnet50/name-of-model-%d.h5" % epoch)
cb_early_stopper = EarlyStopping(monitor="val_loss", patience=4)
cb_checkpointer = ModelCheckpoint(
filepath="../working/best.hdf5",
monitor="val_loss",
save_best_only=True,
mode="auto",
)
epochs = 30
batch_size = 20
trainhistory = model.fit_generator(
data_gen.flow(trainimages, trainlabels, batch_size=batch_size),
epochs=epochs,
validation_data=(validationimages, validationlabels),
verbose=1,
steps_per_epoch=trainimages.shape[0] // batch_size,
callbacks=[cb_checkpointer, cb_early_stopper],
)
import matplotlib.pyplot as plt
acc = trainhistory.history["accuracy"]
val_acc = trainhistory.history["val_accuracy"]
loss = trainhistory.history["loss"]
val_loss = trainhistory.history["val_loss"]
epochs = range(1, len(acc) + 1)
plt.plot(epochs, loss, "", label="Training loss")
plt.plot(epochs, val_loss, "", label="Validation loss")
plt.title("Training and validation loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.figure()
plt.plot(epochs, acc, "", label="Training accuracy")
plt.plot(epochs, val_acc, "", label="Validation accuracy")
plt.title("Training and validation accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
model.load_weights("../working/best.hdf5")
test_loss, test_acc = model.evaluate(testimages, testlabels, verbose=1)
print("test_accuracy = %f ; test_loss = %f" % (test_acc, test_loss))
from sklearn.metrics import confusion_matrix
train_pred = model.predict(trainimages)
train_pred_classes = np.argmax(train_pred, axis=1)
test_pred = model.predict(testimages)
# Convert predictions classes to one hot vectors
test_pred_classes = np.argmax(test_pred, axis=1)
confusionmatrix = confusion_matrix(testlabels, test_pred_classes)
confusionmatrix
from sklearn.metrics import classification_report
labels = labeldict.keys()
# Generate a classification report
trainreport = classification_report(
trainlabels, train_pred_classes, target_names=list(labels)
)
testreport = classification_report(
testlabels, test_pred_classes, target_names=list(labels)
)
print(trainreport)
print(testreport)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0051/821/51821409.ipynb | skin-cancer-mnist-ham10000 | kmader | [{"Id": 51821409, "ScriptId": 14216919, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2669586, "CreationDate": "01/14/2021 02:49:07", "VersionNumber": 2.0, "Title": "skin_cancer-resnet50", "EvaluationDate": "01/14/2021", "IsChange": false, "TotalLines": 182.0, "LinesInsertedFromPrevious": 0.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 182.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 64608613, "KernelVersionId": 51821409, "SourceDatasetVersionId": 104884}] | [{"Id": 104884, "DatasetId": 54339, "DatasourceVersionId": 111874, "CreatorUserId": 67483, "LicenseName": "CC BY-NC-SA 4.0", "CreationDate": "09/20/2018 20:36:13", "VersionNumber": 2.0, "Title": "Skin Cancer MNIST: HAM10000", "Slug": "skin-cancer-mnist-ham10000", "Subtitle": "a large collection of multi-source dermatoscopic images of pigmented lesions", "Description": "# Overview\nAnother more interesting than digit classification dataset to use to get biology and medicine students more excited about machine learning and image processing. \n\n\n## Original Data Source\n- Original Challenge: https://challenge2018.isic-archive.com\n- https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/DBW86T\n[1] Noel Codella, Veronica Rotemberg, Philipp Tschandl, M. Emre Celebi, Stephen Dusza, David Gutman, Brian Helba, Aadi Kalloo, Konstantinos Liopyris, Michael Marchetti, Harald Kittler, Allan Halpern: \u201cSkin Lesion Analysis Toward Melanoma Detection 2018: A Challenge Hosted by the International Skin Imaging Collaboration (ISIC)\u201d, 2018; https://arxiv.org/abs/1902.03368\n\n[2] Tschandl, P., Rosendahl, C. & Kittler, H. The HAM10000 dataset, a large collection of multi-source dermatoscopic images of common pigmented skin lesions. Sci. Data 5, 180161 doi:10.1038/sdata.2018.161 (2018).\n\n## From Authors\n\nTraining of neural networks for automated diagnosis of pigmented skin lesions is hampered by the small size and lack of diversity of available dataset of dermatoscopic images. We tackle this problem by releasing the HAM10000 (\"Human Against Machine with 10000 training images\") dataset. We collected dermatoscopic images from different populations, acquired and stored by different modalities. The final dataset consists of 10015 dermatoscopic images which can serve as a training set for academic machine learning purposes. Cases include a representative collection of all important diagnostic categories in the realm of pigmented lesions: Actinic keratoses and intraepithelial carcinoma / Bowen's disease (akiec), basal cell carcinoma (bcc), benign keratosis-like lesions (solar lentigines / seborrheic keratoses and lichen-planus like keratoses, bkl), dermatofibroma (df), melanoma (mel), melanocytic nevi (nv) and vascular lesions (angiomas, angiokeratomas, pyogenic granulomas and hemorrhage, vasc).\n\nMore than 50% of lesions are confirmed through histopathology (histo), the ground truth for the rest of the cases is either follow-up examination (follow_up), expert consensus (consensus), or confirmation by in-vivo confocal microscopy (confocal). The dataset includes lesions with multiple images, which can be tracked by the lesion_id-column within the HAM10000_metadata file.\n\nThe test set is not public, but the evaluation server remains running (see the challenge website). Any publications written using the HAM10000 data should be evaluated on the official test set hosted there, so that methods can be fairly compared.", "VersionNotes": "addding mnist-style csv files", "TotalCompressedBytes": 2903343040.0, "TotalUncompressedBytes": 2808586677.0}] | [{"Id": 54339, "CreatorUserId": 67483, "OwnerUserId": 67483.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 104884.0, "CurrentDatasourceVersionId": 111874.0, "ForumId": 63066, "Type": 2, "CreationDate": "09/19/2018 13:42:20", "LastActivityDate": "09/19/2018", "TotalViews": 703251, "TotalDownloads": 90643, "TotalVotes": 1616, "TotalKernels": 430}] | [{"Id": 67483, "UserName": "kmader", "DisplayName": "K Scott Mader", "RegisterDate": "11/04/2012", "PerformanceTier": 4}] | import numpy as np
import pandas as pd
import os
print(os.listdir("../input"))
import pandas as pd
df = pd.read_csv("../input/skin-cancer-mnist-ham10000/HAM10000_metadata.csv")
df.head()
from os.path import isfile
from PIL import Image as pil_image
df["num_images"] = df.groupby("lesion_id")["image_id"].transform("count")
classes = df["dx"].unique()
labeldict = {}
for num, name in enumerate(classes):
labeldict[name] = num
df["dx_id"] = df["dx"].map(lambda x: labeldict[x])
def expand_path(p):
if isfile(
"../input/skin-cancer-mnist-ham10000/ham10000_images_part_1/" + p + ".jpg"
):
return (
"../input/skin-cancer-mnist-ham10000/ham10000_images_part_1/" + p + ".jpg"
)
if isfile(
"../input/skin-cancer-mnist-ham10000/ham10000_images_part_2/" + p + ".jpg"
):
return (
"../input/skin-cancer-mnist-ham10000/ham10000_images_part_2/" + p + ".jpg"
)
return p
df["image_path"] = df["image_id"]
df["image_path"] = df["image_path"].apply(expand_path)
df["images"] = df["image_path"].map(
lambda x: np.asarray(pil_image.open(x).resize((150, 112)))
)
df.head()
from sklearn.model_selection import train_test_split
df_single = df[df["num_images"] == 1]
trainset1, testset = train_test_split(df_single, test_size=0.2, random_state=80)
trainset2, validationset = train_test_split(trainset1, test_size=0.2, random_state=600)
trainset3 = df[df["num_images"] != 1]
frames = [trainset2, trainset3]
trainset = pd.concat(frames)
def prepareimages(images):
# images is a list of images
images = np.asarray(images).astype(np.float64)
images = images[:, :, :, ::-1]
m0 = np.mean(images[:, :, :, 0])
m1 = np.mean(images[:, :, :, 1])
m2 = np.mean(images[:, :, :, 2])
images[:, :, :, 0] -= m0
images[:, :, :, 1] -= m1
images[:, :, :, 2] -= m2
return images
trainimages = prepareimages(list(trainset["images"]))
testimages = prepareimages(list(testset["images"]))
validationimages = prepareimages(list(validationset["images"]))
trainlabels = np.asarray(trainset["dx_id"])
testlabels = np.asarray(testset["dx_id"])
validationlabels = np.asarray(validationset["dx_id"])
import matplotlib.pyplot as plt
plt.hist(trainlabels, bins=7, density=True)
plt.show()
plt.hist(validationlabels, bins=7, density=True)
plt.show()
plt.hist(testlabels, bins=7, density=True)
plt.show()
from keras.preprocessing.image import ImageDataGenerator
trainimages = trainimages.reshape(trainimages.shape[0], *(112, 150, 3))
data_gen = ImageDataGenerator(
rotation_range=90, zoom_range=0.1, width_shift_range=0.1, height_shift_range=0.1
)
data_gen.fit(trainimages)
from keras.models import Sequential
from keras import optimizers
from keras.layers import Dense, Conv2D, Dropout, Flatten, MaxPooling2D
from keras.applications import ResNet50
from keras import regularizers
import numpy as np
model = Sequential()
num_labels = 7
base_model = ResNet50(
include_top=False, input_shape=(224, 224, 3), pooling="avg", weights="imagenet"
)
model = Sequential()
model.add(base_model)
model.add(Dropout(0.5))
model.add(Dense(128, activation="relu", kernel_regularizer=regularizers.l2(0.02)))
model.add(Dropout(0.5))
model.add(
Dense(num_labels, activation="softmax", kernel_regularizer=regularizers.l2(0.02))
)
for layer in base_model.layers:
layer.trainable = False
for layer in base_model.layers[-22:]:
layer.trainable = True
model.summary()
from tensorflow.keras.optimizers import Adam
optimizer = Adam(
lr=0.001, beta_1=0.9, beta_2=0.999, epsilon=None, decay=1e-6, amsgrad=False
)
model.compile(
optimizer=optimizer, loss="sparse_categorical_crossentropy", metrics=["accuracy"]
)
# Fit the model
import keras
from tensorflow.python.keras.callbacks import EarlyStopping, ModelCheckpoint
class CustomModelCheckPoint(keras.callbacks.Callback):
def __init__(self, **kargs):
super(CustomModelCheckPoint, self).__init__(**kargs)
self.epoch_accuracy = {} # loss at given epoch
self.epoch_loss = {} # accuracy at given epoch
def on_epoch_begin(self, epoch, logs={}):
# Things done on beginning of epoch.
return
def on_epoch_end(self, epoch, logs={}):
# things done on end of the epoch
self.epoch_accuracy[epoch] = logs.get("acc")
self.epoch_loss[epoch] = logs.get("loss")
self.model.save_weights("../output/resnet50/name-of-model-%d.h5" % epoch)
cb_early_stopper = EarlyStopping(monitor="val_loss", patience=4)
cb_checkpointer = ModelCheckpoint(
filepath="../working/best.hdf5",
monitor="val_loss",
save_best_only=True,
mode="auto",
)
epochs = 30
batch_size = 20
trainhistory = model.fit_generator(
data_gen.flow(trainimages, trainlabels, batch_size=batch_size),
epochs=epochs,
validation_data=(validationimages, validationlabels),
verbose=1,
steps_per_epoch=trainimages.shape[0] // batch_size,
callbacks=[cb_checkpointer, cb_early_stopper],
)
import matplotlib.pyplot as plt
acc = trainhistory.history["accuracy"]
val_acc = trainhistory.history["val_accuracy"]
loss = trainhistory.history["loss"]
val_loss = trainhistory.history["val_loss"]
epochs = range(1, len(acc) + 1)
plt.plot(epochs, loss, "", label="Training loss")
plt.plot(epochs, val_loss, "", label="Validation loss")
plt.title("Training and validation loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.figure()
plt.plot(epochs, acc, "", label="Training accuracy")
plt.plot(epochs, val_acc, "", label="Validation accuracy")
plt.title("Training and validation accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
model.load_weights("../working/best.hdf5")
test_loss, test_acc = model.evaluate(testimages, testlabels, verbose=1)
print("test_accuracy = %f ; test_loss = %f" % (test_acc, test_loss))
from sklearn.metrics import confusion_matrix
train_pred = model.predict(trainimages)
train_pred_classes = np.argmax(train_pred, axis=1)
test_pred = model.predict(testimages)
# Convert predictions classes to one hot vectors
test_pred_classes = np.argmax(test_pred, axis=1)
confusionmatrix = confusion_matrix(testlabels, test_pred_classes)
confusionmatrix
from sklearn.metrics import classification_report
labels = labeldict.keys()
# Generate a classification report
trainreport = classification_report(
trainlabels, train_pred_classes, target_names=list(labels)
)
testreport = classification_report(
testlabels, test_pred_classes, target_names=list(labels)
)
print(trainreport)
print(testreport)
| false | 1 | 2,125 | 0 | 816 | 2,125 |
||
51184820 | <kaggle_start><code># # User define config
BATCH_SIZE = 8
EPOCH = 10
WD = 1e-4
LR = 0.0001
VAL_RATIO = 0.2
PHASE = ["train", "val"]
BETA = 1.0
CUTMIX_PROB = 1.0
TRAINING = False
# WEIGHT = '../input/cutmix-chacor-densenet/densenet_best_0.83.pkl'
K_FOLD = 5
# # Create Dataset
from torch.utils.data.dataset import Dataset
import glob
import pandas as pd
import os
from PIL import Image
class CLD_Dataset(Dataset):
def __init__(self, image_root, label_path=None, transform=None, return_name=False):
super(CLD_Dataset, self).__init__()
self.transform = transform
self.image_paths = glob.glob(os.path.join(image_root, "*.jpg"))
if not return_name:
self.label = pd.read_csv(label_path, index_col="image_id")
self.return_name = return_name
def set_transform(self, transform):
self.transform = transform
def __getitem__(self, x):
img = Image.open(self.image_paths[x])
if self.transform is not None:
img = self.transform(img)
if self.return_name:
return img, self.image_paths[x].split("/")[-1]
else:
label = self.label.loc[self.image_paths[x].split("/")[-1]].label
return img, label
def __len__(self):
return len(self.image_paths)
import torchvision.transforms as transform
from torch.utils.data import DataLoader
import torch
from sklearn.model_selection import KFold
train_transform = transform.Compose(
[
transform.Resize((448, 448)),
transform.RandomHorizontalFlip(),
transform.ToTensor(),
transform.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
val_transform = transform.Compose(
[
transform.Resize((448, 448)),
transform.ToTensor(),
transform.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
all_train_dataset = CLD_Dataset(
"/kaggle/input/cassava-leaf-disease-classification/train_images",
"/kaggle/input/cassava-leaf-disease-classification/train.csv",
train_transform,
)
dataset_size = len(all_train_dataset)
fold_dataloader = []
# all_train_dataset = DataLoader(all_train_dataset, batch_size = BATCH_SIZE, shuffle = True, num_workers = 4)
if K_FOLD != 1:
kf = KFold(K_FOLD, shuffle=True)
index = 0
for train_idx, val_idx in kf.split(all_train_dataset):
train_dataset = torch.utils.data.Subset(all_train_dataset, train_idx)
val_dataset = torch.utils.data.Subset(all_train_dataset, val_idx)
fold_dataloader.append(
{
"train": DataLoader(
train_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=4
),
"val": DataLoader(
val_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=4
),
}
)
index += 1
print(fold_dataloader)
else:
fold_dataloader.append(
{
"train": DataLoader(
all_train_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=4
),
"val": None,
}
)
# # Create Model
import re
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as cp
from collections import OrderedDict
from torch import Tensor
from torch.jit.annotations import List
__all__ = ["DenseNet", "densenet121", "densenet169", "densenet201", "densenet161"]
model_urls = {
"densenet121": "https://download.pytorch.org/models/densenet121-a639ec97.pth",
"densenet169": "https://download.pytorch.org/models/densenet169-b2777c0a.pth",
"densenet201": "https://download.pytorch.org/models/densenet201-c1103571.pth",
"densenet161": "https://download.pytorch.org/models/densenet161-8d451a50.pth",
}
class _DenseLayer(nn.Module):
def __init__(
self,
num_input_features,
growth_rate,
bn_size,
drop_rate,
memory_efficient=False,
):
super(_DenseLayer, self).__init__()
self.add_module("norm1", nn.BatchNorm2d(num_input_features)),
self.add_module("relu1", nn.ReLU(inplace=True)),
self.add_module(
"conv1",
nn.Conv2d(
num_input_features,
bn_size * growth_rate,
kernel_size=1,
stride=1,
bias=False,
),
),
self.add_module("norm2", nn.BatchNorm2d(bn_size * growth_rate)),
self.add_module("relu2", nn.ReLU(inplace=True)),
self.add_module(
"conv2",
nn.Conv2d(
bn_size * growth_rate,
growth_rate,
kernel_size=3,
stride=1,
padding=1,
bias=False,
),
),
self.drop_rate = float(drop_rate)
self.memory_efficient = memory_efficient
def bn_function(self, inputs):
# type: (List[Tensor]) -> Tensor
concated_features = torch.cat(inputs, 1)
bottleneck_output = self.conv1(
self.relu1(self.norm1(concated_features))
) # noqa: T484
return bottleneck_output
# todo: rewrite when torchscript supports any
def any_requires_grad(self, input):
# type: (List[Tensor]) -> bool
for tensor in input:
if tensor.requires_grad:
return True
return False
@torch.jit.unused # noqa: T484
def call_checkpoint_bottleneck(self, input):
# type: (List[Tensor]) -> Tensor
def closure(*inputs):
return self.bn_function(*inputs)
return cp.checkpoint(closure, input)
@torch.jit._overload_method # noqa: F811
def forward(self, input):
# type: (List[Tensor]) -> (Tensor)
pass
@torch.jit._overload_method # noqa: F811
def forward(self, input):
# type: (Tensor) -> (Tensor)
pass
# torchscript does not yet support *args, so we overload method
# allowing it to take either a List[Tensor] or single Tensor
def forward(self, input): # noqa: F811
if isinstance(input, Tensor):
prev_features = [input]
else:
prev_features = input
if self.memory_efficient and self.any_requires_grad(prev_features):
if torch.jit.is_scripting():
raise Exception("Memory Efficient not supported in JIT")
bottleneck_output = self.call_checkpoint_bottleneck(prev_features)
else:
bottleneck_output = self.bn_function(prev_features)
new_features = self.conv2(self.relu2(self.norm2(bottleneck_output)))
if self.drop_rate > 0:
new_features = F.dropout(
new_features, p=self.drop_rate, training=self.training
)
return new_features
class _DenseBlock(nn.ModuleDict):
_version = 2
def __init__(
self,
num_layers,
num_input_features,
bn_size,
growth_rate,
drop_rate,
memory_efficient=False,
):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(
num_input_features + i * growth_rate,
growth_rate=growth_rate,
bn_size=bn_size,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.add_module("denselayer%d" % (i + 1), layer)
def forward(self, init_features):
features = [init_features]
for name, layer in self.items():
new_features = layer(features)
features.append(new_features)
return torch.cat(features, 1)
class _Transition(nn.Sequential):
def __init__(self, num_input_features, num_output_features):
super(_Transition, self).__init__()
self.add_module("norm", nn.BatchNorm2d(num_input_features))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module(
"conv",
nn.Conv2d(
num_input_features,
num_output_features,
kernel_size=1,
stride=1,
bias=False,
),
)
self.add_module("pool", nn.AvgPool2d(kernel_size=2, stride=2))
class DenseNet(nn.Module):
r"""Densenet-BC model class, based on
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
growth_rate (int) - how many filters to add each layer (`k` in paper)
block_config (list of 4 ints) - how many layers in each pooling block
num_init_features (int) - the number of filters to learn in the first convolution layer
bn_size (int) - multiplicative factor for number of bottle neck layers
(i.e. bn_size * k features in the bottleneck layer)
drop_rate (float) - dropout rate after each dense layer
num_classes (int) - number of classification classes
memory_efficient (bool) - If True, uses checkpointing. Much more memory efficient,
but slower. Default: *False*. See `"paper" <https://arxiv.org/pdf/1707.06990.pdf>`_
"""
def __init__(
self,
growth_rate=32,
block_config=(6, 12, 24, 16),
num_init_features=64,
bn_size=4,
drop_rate=0,
num_classes=1000,
memory_efficient=False,
):
super(DenseNet, self).__init__()
# First convolution
self.features = nn.Sequential(
OrderedDict(
[
(
"conv0",
nn.Conv2d(
3,
num_init_features,
kernel_size=7,
stride=2,
padding=3,
bias=False,
),
),
("norm0", nn.BatchNorm2d(num_init_features)),
("relu0", nn.ReLU(inplace=True)),
("pool0", nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),
]
)
)
# Each denseblock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(
num_layers=num_layers,
num_input_features=num_features,
bn_size=bn_size,
growth_rate=growth_rate,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.features.add_module("denseblock%d" % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
trans = _Transition(
num_input_features=num_features,
num_output_features=num_features // 2,
)
self.features.add_module("transition%d" % (i + 1), trans)
num_features = num_features // 2
# Final batch norm
self.features.add_module("norm5", nn.BatchNorm2d(num_features))
# Linear layer
self.classifier = nn.Linear(num_features, num_classes)
# Official init from torch repo.
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def _construct_fc_layer(self, fc_dims, input_dim, dropout_p=None):
"""
Construct fully connected layer
- fc_dims (list or tuple): dimensions of fc layers, if None,
no fc layers are constructed
- input_dim (int): input dimension
- dropout_p (float): dropout probability, if None, dropout is unused
"""
if fc_dims is None:
self.feature_dim = input_dim
return None
assert isinstance(
fc_dims, (list, tuple)
), "fc_dims must be either list or tuple, but got {}".format(type(fc_dims))
layers = []
for dim in fc_dims:
layers.append(nn.Linear(input_dim, dim))
layers.append(nn.BatchNorm1d(dim))
layers.append(nn.ReLU(inplace=True))
if dropout_p is not None:
layers.append(nn.Dropout(p=dropout_p))
input_dim = dim
self.feature_dim = fc_dims[-1]
return nn.Sequential(*layers)
def feature_extract(self, x):
x = self.features.conv0(x)
x = self.features.norm0(x)
x = self.features.relu0(x)
x = self.features.pool0(x)
x = self.features.denseblock1(x)
x = self.features.transition1(x)
x = self.features.denseblock2(x)
x = self.features.transition2(x)
x = self.features.denseblock3(x)
x = self.features.transition3(x)
x = self.features.denseblock4(x)
x = self.features.norm5(x)
return x
def forward(self, x):
features = self.feature_extract(x)
out = F.relu(features, inplace=True)
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
def _load_state_dict(model, arch, progress):
# '.'s are no longer allowed in module names, but previous _DenseLayer
# has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'.
# They are also in the checkpoints in model_urls. This pattern is used
# to find such keys.
pattern = re.compile(
r"^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$"
)
state_dict = torch.load("../../pretrain/{}.pth".format(arch))
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
load = []
not_load = []
for name, param in state_dict.items():
if name in model.state_dict():
try:
model.state_dict()[name].copy_(param)
load.append(name)
except:
not_load.append(name)
print("Load pretrain : ")
print("Load : {} layers".format(len(load)))
print("Miss : {} layers".format(len(not_load)))
# model.load_state_dict(state_dict)
def _densenet(
arch, growth_rate, block_config, num_init_features, pretrained, progress, **kwargs
):
model = DenseNet(growth_rate, block_config, num_init_features, **kwargs)
if pretrained:
_load_state_dict(model, arch, progress)
return model
def densenet121(pretrained=False, progress=True, **kwargs):
r"""Densenet-121 model from
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
memory_efficient (bool) - If True, uses checkpointing. Much more memory efficient,
but slower. Default: *False*. See `"paper" <https://arxiv.org/pdf/1707.06990.pdf>`_
"""
return _densenet(
"densenet121", 32, (6, 12, 24, 16), 64, pretrained, progress, **kwargs
)
def densenet161(pretrained=False, progress=True, **kwargs):
r"""Densenet-161 model from
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
memory_efficient (bool) - If True, uses checkpointing. Much more memory efficient,
but slower. Default: *False*. See `"paper" <https://arxiv.org/pdf/1707.06990.pdf>`_
"""
return _densenet(
"densenet161", 48, (6, 12, 36, 24), 96, pretrained, progress, **kwargs
)
def densenet169(pretrained=False, progress=True, **kwargs):
r"""Densenet-169 model from
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
memory_efficient (bool) - If True, uses checkpointing. Much more memory efficient,
but slower. Default: *False*. See `"paper" <https://arxiv.org/pdf/1707.06990.pdf>`_
"""
return _densenet(
"densenet169", 32, (6, 12, 32, 32), 64, pretrained, progress, **kwargs
)
def densenet201(pretrained=False, progress=True, **kwargs):
r"""Densenet-201 model from
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
memory_efficient (bool) - If True, uses checkpointing. Much more memory efficient,
but slower. Default: *False*. See `"paper" <https://arxiv.org/pdf/1707.06990.pdf>`_
"""
return _densenet(
"densenet201", 32, (6, 12, 48, 32), 64, pretrained, progress, **kwargs
)
if torch.cuda.is_available():
device = "cuda:0"
else:
device = "cpu"
print(device)
def create_new_model(pretrained=True):
return densenet121(num_classes=5, pretrained=pretrained).to(device)
# # Define Loss function and Optimizer
def create_loss_opti():
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=LR, weight_decay=WD)
# lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 4, gamma=0.5, last_epoch=-1)
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(
optimizer, T_0=10, T_mult=1, eta_min=1e-6, last_epoch=-1
)
return criterion, optimizer, lr_scheduler
# # CutMix
def rand_bbox(size, lab):
W = size[2]
H = size[3]
cut_rat = np.sqrt(1.0 - lam)
cut_w = np.int(W * cut_rat)
cut_h = np.int(H * cut_rat)
# uniform
cx = np.random.randint(W)
cy = np.random.randint(H)
bbx1 = np.clip(cx - cut_w // 2, 0, W)
bby1 = np.clip(cy - cut_h // 2, 0, H)
bbx2 = np.clip(cx + cut_w // 2, 0, W)
bby2 = np.clip(cy + cut_h // 2, 0, H)
return bbx1, bby1, bbx2, bby2
# # Record
class AverageMeter:
"""Computes and stores the average and current value"""
def __init__(self, acc):
self.reset()
self.acc = acc
def reset(self):
self.value = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, value, batch):
self.value = value
if self.acc:
self.sum += value
else:
self.sum += value * batch
self.count += batch
self.avg = self.sum / self.count
# # Training
def train_step(model, criterion, optimizer, image, label, phase):
b_image = image.to(device)
b_label = label.to(device)
# CUTMIX -------------------------------------------
r = np.random.rand(1)
if BETA > 0 and r < CUTMIX_PROB:
lam = np.random.beta(BETA, BETA)
rand_index = torch.randperm(b_image.size()[0]).to(device)
target_a = b_label
target_b = b_label[rand_index]
bbx1, bby1, bbx2, bby2 = rand_bbox(b_image.size(), lam)
b_image[:, :, bbx1:bbx2, bby1:bby2] = b_image[
rand_index, :, bbx1:bbx2, bby1:bby2
]
lam = 1 - (
(bbx2 - bbx1) * (bby2 - bby1) / (b_image.size()[-1] * b_image.size()[-2])
)
output = model(b_image)
loss = criterion(output, target_a) * lam + criterion(output, target_b) * (
1.0 - lam
)
else:
output = model(b_image)
loss = criterion(output, b_label)
# --------------------------------------------------
_, predicted = torch.max(output.data, dim=1)
correct = (predicted.cpu() == label).sum().item()
if phase == "train":
optimizer.zero_grad()
loss.backward()
optimizer.step()
return correct, loss.item()
import numpy as np
from tqdm import tqdm
max_acc = 0.0
ACCMeter = []
LOSSMeter = []
for i in range(K_FOLD):
ACCMeter.append(AverageMeter(True))
LOSSMeter.append(AverageMeter(False))
if TRAINING:
for index, dataloader in enumerate(fold_dataloader):
model = create_new_model()
criterion, optimizer, lr_scheduler = create_loss_opti()
Best_ACC = 0.0
for epoch in range(1, EPOCH + 1):
tmp_ACCMeter = AverageMeter(True)
tmp_LOSSMeter = AverageMeter(False)
correct_t = 0
total = 0
loss_t = 0.0
for phase in PHASE:
if phase == "train":
model.train(True)
all_train_dataset.set_transform(train_transform)
else:
model.train(False)
all_train_dataset.set_transform(val_transform)
for image, label in tqdm(
dataloader[phase],
total=len(dataloader[phase]),
position=0,
leave=True,
):
correct, loss = train_step(
model, criterion, optimizer, image, label, phase
)
if phase == "val":
tmp_ACCMeter.update(correct, label.size(0))
tmp_LOSSMeter.update(loss, label.size(0))
total += label.size(0)
loss_t += loss * label.size(0)
correct_t += correct
if phase == "val" and Best_ACC < tmp_ACCMeter.avg:
Best_ACC = tmp_ACCMeter.avg
ACCMeter[index] = tmp_ACCMeter
LOSSMeter[index] = tmp_LOSSMeter
torch.save(
model.state_dict(),
"./resnet50_kfold_{}_{}_{:.2f}.pkl".format(
index + 1, epoch, tmp_ACCMeter.avg
),
)
print(
"Fold : {}/ {} Epoch : {} / {} loss : {:.6f} ACC : {:.6f}".format(
index + 1, K_FOLD, epoch, EPOCH, loss_t / total, correct_t / total
)
)
lr_scheduler.step()
# # Analyze K-fold result
acc_sum = 0
loss_sum = 0
for i in range(K_FOLD):
acc_sum += ACCMeter[i].avg
loss_sum += LOSSMeter[i].avg
print("K-fold {} ACC : {:.6f}".format(K_FOLD, acc_sum / K_FOLD))
print("K-fold {} ACC : {:.6f}".format(K_FOLD, loss_sum / K_FOLD))
# # Testing
import pandas as pd
test_dataset = CLD_Dataset(
"/kaggle/input/cassava-leaf-disease-classification/test_images",
transform=val_transform,
return_name=True,
)
test_dataloader = DataLoader(test_dataset, batch_size=1, shuffle=False, num_workers=4)
image_names = []
image_probs = []
for params_path in glob.glob("../input/densenet121-softtarget/*.pkl"):
model = create_new_model(pretrained=False)
params = torch.load(params_path)
load = []
not_load = []
image_name = []
image_prob = []
for name, param in params.items():
if name in model.state_dict():
try:
model.state_dict()[name].copy_(param)
load.append(name)
except:
not_load.append(name)
print("Trained weight load : {}".format(len(load)))
print("Trained weight not load : {}".format(len(not_load)))
print(not_load)
model.train(False)
for step, (img, img_name) in enumerate(test_dataloader):
b_img = img.to(device)
output = model(b_img)
_, predicted = torch.max(output, dim=1)
image_name.append(img_name[0])
image_prob.append(np.array(output[0].cpu().detach()))
image_names.append(image_name)
image_probs.append(image_prob)
image_names = np.array(image_names)
image_probs = np.array(image_probs)
image_labels = []
for img_idx in range(image_probs.shape[1]):
probs = 0.0
for fold in range(image_names.shape[0]):
prob = image_probs[fold][img_idx]
prob_e = np.exp(prob)
prob_e_sum = prob_e / sum(prob_e + 1e-4)
# probs += image_probs[fold][img_idx]
probs += prob_e_sum
label = np.argmax(probs)
image_labels.append(label)
image_labels = np.array(image_labels)
image_names = np.array(image_names)
df = pd.DataFrame({"image_id": image_names[0], "label": image_labels})
print(df)
df.to_csv("/kaggle/working/submission.csv", index=False)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0051/184/51184820.ipynb | null | null | [{"Id": 51184820, "ScriptId": 13532580, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2667025, "CreationDate": "01/06/2021 02:19:19", "VersionNumber": 13.0, "Title": "cassava-densenet121-softtarget", "EvaluationDate": "01/06/2021", "IsChange": true, "TotalLines": 647.0, "LinesInsertedFromPrevious": 8.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 639.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | # # User define config
BATCH_SIZE = 8
EPOCH = 10
WD = 1e-4
LR = 0.0001
VAL_RATIO = 0.2
PHASE = ["train", "val"]
BETA = 1.0
CUTMIX_PROB = 1.0
TRAINING = False
# WEIGHT = '../input/cutmix-chacor-densenet/densenet_best_0.83.pkl'
K_FOLD = 5
# # Create Dataset
from torch.utils.data.dataset import Dataset
import glob
import pandas as pd
import os
from PIL import Image
class CLD_Dataset(Dataset):
def __init__(self, image_root, label_path=None, transform=None, return_name=False):
super(CLD_Dataset, self).__init__()
self.transform = transform
self.image_paths = glob.glob(os.path.join(image_root, "*.jpg"))
if not return_name:
self.label = pd.read_csv(label_path, index_col="image_id")
self.return_name = return_name
def set_transform(self, transform):
self.transform = transform
def __getitem__(self, x):
img = Image.open(self.image_paths[x])
if self.transform is not None:
img = self.transform(img)
if self.return_name:
return img, self.image_paths[x].split("/")[-1]
else:
label = self.label.loc[self.image_paths[x].split("/")[-1]].label
return img, label
def __len__(self):
return len(self.image_paths)
import torchvision.transforms as transform
from torch.utils.data import DataLoader
import torch
from sklearn.model_selection import KFold
train_transform = transform.Compose(
[
transform.Resize((448, 448)),
transform.RandomHorizontalFlip(),
transform.ToTensor(),
transform.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
val_transform = transform.Compose(
[
transform.Resize((448, 448)),
transform.ToTensor(),
transform.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
all_train_dataset = CLD_Dataset(
"/kaggle/input/cassava-leaf-disease-classification/train_images",
"/kaggle/input/cassava-leaf-disease-classification/train.csv",
train_transform,
)
dataset_size = len(all_train_dataset)
fold_dataloader = []
# all_train_dataset = DataLoader(all_train_dataset, batch_size = BATCH_SIZE, shuffle = True, num_workers = 4)
if K_FOLD != 1:
kf = KFold(K_FOLD, shuffle=True)
index = 0
for train_idx, val_idx in kf.split(all_train_dataset):
train_dataset = torch.utils.data.Subset(all_train_dataset, train_idx)
val_dataset = torch.utils.data.Subset(all_train_dataset, val_idx)
fold_dataloader.append(
{
"train": DataLoader(
train_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=4
),
"val": DataLoader(
val_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=4
),
}
)
index += 1
print(fold_dataloader)
else:
fold_dataloader.append(
{
"train": DataLoader(
all_train_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=4
),
"val": None,
}
)
# # Create Model
import re
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as cp
from collections import OrderedDict
from torch import Tensor
from torch.jit.annotations import List
__all__ = ["DenseNet", "densenet121", "densenet169", "densenet201", "densenet161"]
model_urls = {
"densenet121": "https://download.pytorch.org/models/densenet121-a639ec97.pth",
"densenet169": "https://download.pytorch.org/models/densenet169-b2777c0a.pth",
"densenet201": "https://download.pytorch.org/models/densenet201-c1103571.pth",
"densenet161": "https://download.pytorch.org/models/densenet161-8d451a50.pth",
}
class _DenseLayer(nn.Module):
def __init__(
self,
num_input_features,
growth_rate,
bn_size,
drop_rate,
memory_efficient=False,
):
super(_DenseLayer, self).__init__()
self.add_module("norm1", nn.BatchNorm2d(num_input_features)),
self.add_module("relu1", nn.ReLU(inplace=True)),
self.add_module(
"conv1",
nn.Conv2d(
num_input_features,
bn_size * growth_rate,
kernel_size=1,
stride=1,
bias=False,
),
),
self.add_module("norm2", nn.BatchNorm2d(bn_size * growth_rate)),
self.add_module("relu2", nn.ReLU(inplace=True)),
self.add_module(
"conv2",
nn.Conv2d(
bn_size * growth_rate,
growth_rate,
kernel_size=3,
stride=1,
padding=1,
bias=False,
),
),
self.drop_rate = float(drop_rate)
self.memory_efficient = memory_efficient
def bn_function(self, inputs):
# type: (List[Tensor]) -> Tensor
concated_features = torch.cat(inputs, 1)
bottleneck_output = self.conv1(
self.relu1(self.norm1(concated_features))
) # noqa: T484
return bottleneck_output
# todo: rewrite when torchscript supports any
def any_requires_grad(self, input):
# type: (List[Tensor]) -> bool
for tensor in input:
if tensor.requires_grad:
return True
return False
@torch.jit.unused # noqa: T484
def call_checkpoint_bottleneck(self, input):
# type: (List[Tensor]) -> Tensor
def closure(*inputs):
return self.bn_function(*inputs)
return cp.checkpoint(closure, input)
@torch.jit._overload_method # noqa: F811
def forward(self, input):
# type: (List[Tensor]) -> (Tensor)
pass
@torch.jit._overload_method # noqa: F811
def forward(self, input):
# type: (Tensor) -> (Tensor)
pass
# torchscript does not yet support *args, so we overload method
# allowing it to take either a List[Tensor] or single Tensor
def forward(self, input): # noqa: F811
if isinstance(input, Tensor):
prev_features = [input]
else:
prev_features = input
if self.memory_efficient and self.any_requires_grad(prev_features):
if torch.jit.is_scripting():
raise Exception("Memory Efficient not supported in JIT")
bottleneck_output = self.call_checkpoint_bottleneck(prev_features)
else:
bottleneck_output = self.bn_function(prev_features)
new_features = self.conv2(self.relu2(self.norm2(bottleneck_output)))
if self.drop_rate > 0:
new_features = F.dropout(
new_features, p=self.drop_rate, training=self.training
)
return new_features
class _DenseBlock(nn.ModuleDict):
_version = 2
def __init__(
self,
num_layers,
num_input_features,
bn_size,
growth_rate,
drop_rate,
memory_efficient=False,
):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(
num_input_features + i * growth_rate,
growth_rate=growth_rate,
bn_size=bn_size,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.add_module("denselayer%d" % (i + 1), layer)
def forward(self, init_features):
features = [init_features]
for name, layer in self.items():
new_features = layer(features)
features.append(new_features)
return torch.cat(features, 1)
class _Transition(nn.Sequential):
def __init__(self, num_input_features, num_output_features):
super(_Transition, self).__init__()
self.add_module("norm", nn.BatchNorm2d(num_input_features))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module(
"conv",
nn.Conv2d(
num_input_features,
num_output_features,
kernel_size=1,
stride=1,
bias=False,
),
)
self.add_module("pool", nn.AvgPool2d(kernel_size=2, stride=2))
class DenseNet(nn.Module):
r"""Densenet-BC model class, based on
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
growth_rate (int) - how many filters to add each layer (`k` in paper)
block_config (list of 4 ints) - how many layers in each pooling block
num_init_features (int) - the number of filters to learn in the first convolution layer
bn_size (int) - multiplicative factor for number of bottle neck layers
(i.e. bn_size * k features in the bottleneck layer)
drop_rate (float) - dropout rate after each dense layer
num_classes (int) - number of classification classes
memory_efficient (bool) - If True, uses checkpointing. Much more memory efficient,
but slower. Default: *False*. See `"paper" <https://arxiv.org/pdf/1707.06990.pdf>`_
"""
def __init__(
self,
growth_rate=32,
block_config=(6, 12, 24, 16),
num_init_features=64,
bn_size=4,
drop_rate=0,
num_classes=1000,
memory_efficient=False,
):
super(DenseNet, self).__init__()
# First convolution
self.features = nn.Sequential(
OrderedDict(
[
(
"conv0",
nn.Conv2d(
3,
num_init_features,
kernel_size=7,
stride=2,
padding=3,
bias=False,
),
),
("norm0", nn.BatchNorm2d(num_init_features)),
("relu0", nn.ReLU(inplace=True)),
("pool0", nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),
]
)
)
# Each denseblock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(
num_layers=num_layers,
num_input_features=num_features,
bn_size=bn_size,
growth_rate=growth_rate,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.features.add_module("denseblock%d" % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
trans = _Transition(
num_input_features=num_features,
num_output_features=num_features // 2,
)
self.features.add_module("transition%d" % (i + 1), trans)
num_features = num_features // 2
# Final batch norm
self.features.add_module("norm5", nn.BatchNorm2d(num_features))
# Linear layer
self.classifier = nn.Linear(num_features, num_classes)
# Official init from torch repo.
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def _construct_fc_layer(self, fc_dims, input_dim, dropout_p=None):
"""
Construct fully connected layer
- fc_dims (list or tuple): dimensions of fc layers, if None,
no fc layers are constructed
- input_dim (int): input dimension
- dropout_p (float): dropout probability, if None, dropout is unused
"""
if fc_dims is None:
self.feature_dim = input_dim
return None
assert isinstance(
fc_dims, (list, tuple)
), "fc_dims must be either list or tuple, but got {}".format(type(fc_dims))
layers = []
for dim in fc_dims:
layers.append(nn.Linear(input_dim, dim))
layers.append(nn.BatchNorm1d(dim))
layers.append(nn.ReLU(inplace=True))
if dropout_p is not None:
layers.append(nn.Dropout(p=dropout_p))
input_dim = dim
self.feature_dim = fc_dims[-1]
return nn.Sequential(*layers)
def feature_extract(self, x):
x = self.features.conv0(x)
x = self.features.norm0(x)
x = self.features.relu0(x)
x = self.features.pool0(x)
x = self.features.denseblock1(x)
x = self.features.transition1(x)
x = self.features.denseblock2(x)
x = self.features.transition2(x)
x = self.features.denseblock3(x)
x = self.features.transition3(x)
x = self.features.denseblock4(x)
x = self.features.norm5(x)
return x
def forward(self, x):
features = self.feature_extract(x)
out = F.relu(features, inplace=True)
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
def _load_state_dict(model, arch, progress):
# '.'s are no longer allowed in module names, but previous _DenseLayer
# has keys 'norm.1', 'relu.1', 'conv.1', 'norm.2', 'relu.2', 'conv.2'.
# They are also in the checkpoints in model_urls. This pattern is used
# to find such keys.
pattern = re.compile(
r"^(.*denselayer\d+\.(?:norm|relu|conv))\.((?:[12])\.(?:weight|bias|running_mean|running_var))$"
)
state_dict = torch.load("../../pretrain/{}.pth".format(arch))
for key in list(state_dict.keys()):
res = pattern.match(key)
if res:
new_key = res.group(1) + res.group(2)
state_dict[new_key] = state_dict[key]
del state_dict[key]
load = []
not_load = []
for name, param in state_dict.items():
if name in model.state_dict():
try:
model.state_dict()[name].copy_(param)
load.append(name)
except:
not_load.append(name)
print("Load pretrain : ")
print("Load : {} layers".format(len(load)))
print("Miss : {} layers".format(len(not_load)))
# model.load_state_dict(state_dict)
def _densenet(
arch, growth_rate, block_config, num_init_features, pretrained, progress, **kwargs
):
model = DenseNet(growth_rate, block_config, num_init_features, **kwargs)
if pretrained:
_load_state_dict(model, arch, progress)
return model
def densenet121(pretrained=False, progress=True, **kwargs):
r"""Densenet-121 model from
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
memory_efficient (bool) - If True, uses checkpointing. Much more memory efficient,
but slower. Default: *False*. See `"paper" <https://arxiv.org/pdf/1707.06990.pdf>`_
"""
return _densenet(
"densenet121", 32, (6, 12, 24, 16), 64, pretrained, progress, **kwargs
)
def densenet161(pretrained=False, progress=True, **kwargs):
r"""Densenet-161 model from
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
memory_efficient (bool) - If True, uses checkpointing. Much more memory efficient,
but slower. Default: *False*. See `"paper" <https://arxiv.org/pdf/1707.06990.pdf>`_
"""
return _densenet(
"densenet161", 48, (6, 12, 36, 24), 96, pretrained, progress, **kwargs
)
def densenet169(pretrained=False, progress=True, **kwargs):
r"""Densenet-169 model from
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
memory_efficient (bool) - If True, uses checkpointing. Much more memory efficient,
but slower. Default: *False*. See `"paper" <https://arxiv.org/pdf/1707.06990.pdf>`_
"""
return _densenet(
"densenet169", 32, (6, 12, 32, 32), 64, pretrained, progress, **kwargs
)
def densenet201(pretrained=False, progress=True, **kwargs):
r"""Densenet-201 model from
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
memory_efficient (bool) - If True, uses checkpointing. Much more memory efficient,
but slower. Default: *False*. See `"paper" <https://arxiv.org/pdf/1707.06990.pdf>`_
"""
return _densenet(
"densenet201", 32, (6, 12, 48, 32), 64, pretrained, progress, **kwargs
)
if torch.cuda.is_available():
device = "cuda:0"
else:
device = "cpu"
print(device)
def create_new_model(pretrained=True):
return densenet121(num_classes=5, pretrained=pretrained).to(device)
# # Define Loss function and Optimizer
def create_loss_opti():
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=LR, weight_decay=WD)
# lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 4, gamma=0.5, last_epoch=-1)
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(
optimizer, T_0=10, T_mult=1, eta_min=1e-6, last_epoch=-1
)
return criterion, optimizer, lr_scheduler
# # CutMix
def rand_bbox(size, lab):
W = size[2]
H = size[3]
cut_rat = np.sqrt(1.0 - lam)
cut_w = np.int(W * cut_rat)
cut_h = np.int(H * cut_rat)
# uniform
cx = np.random.randint(W)
cy = np.random.randint(H)
bbx1 = np.clip(cx - cut_w // 2, 0, W)
bby1 = np.clip(cy - cut_h // 2, 0, H)
bbx2 = np.clip(cx + cut_w // 2, 0, W)
bby2 = np.clip(cy + cut_h // 2, 0, H)
return bbx1, bby1, bbx2, bby2
# # Record
class AverageMeter:
"""Computes and stores the average and current value"""
def __init__(self, acc):
self.reset()
self.acc = acc
def reset(self):
self.value = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, value, batch):
self.value = value
if self.acc:
self.sum += value
else:
self.sum += value * batch
self.count += batch
self.avg = self.sum / self.count
# # Training
def train_step(model, criterion, optimizer, image, label, phase):
b_image = image.to(device)
b_label = label.to(device)
# CUTMIX -------------------------------------------
r = np.random.rand(1)
if BETA > 0 and r < CUTMIX_PROB:
lam = np.random.beta(BETA, BETA)
rand_index = torch.randperm(b_image.size()[0]).to(device)
target_a = b_label
target_b = b_label[rand_index]
bbx1, bby1, bbx2, bby2 = rand_bbox(b_image.size(), lam)
b_image[:, :, bbx1:bbx2, bby1:bby2] = b_image[
rand_index, :, bbx1:bbx2, bby1:bby2
]
lam = 1 - (
(bbx2 - bbx1) * (bby2 - bby1) / (b_image.size()[-1] * b_image.size()[-2])
)
output = model(b_image)
loss = criterion(output, target_a) * lam + criterion(output, target_b) * (
1.0 - lam
)
else:
output = model(b_image)
loss = criterion(output, b_label)
# --------------------------------------------------
_, predicted = torch.max(output.data, dim=1)
correct = (predicted.cpu() == label).sum().item()
if phase == "train":
optimizer.zero_grad()
loss.backward()
optimizer.step()
return correct, loss.item()
import numpy as np
from tqdm import tqdm
max_acc = 0.0
ACCMeter = []
LOSSMeter = []
for i in range(K_FOLD):
ACCMeter.append(AverageMeter(True))
LOSSMeter.append(AverageMeter(False))
if TRAINING:
for index, dataloader in enumerate(fold_dataloader):
model = create_new_model()
criterion, optimizer, lr_scheduler = create_loss_opti()
Best_ACC = 0.0
for epoch in range(1, EPOCH + 1):
tmp_ACCMeter = AverageMeter(True)
tmp_LOSSMeter = AverageMeter(False)
correct_t = 0
total = 0
loss_t = 0.0
for phase in PHASE:
if phase == "train":
model.train(True)
all_train_dataset.set_transform(train_transform)
else:
model.train(False)
all_train_dataset.set_transform(val_transform)
for image, label in tqdm(
dataloader[phase],
total=len(dataloader[phase]),
position=0,
leave=True,
):
correct, loss = train_step(
model, criterion, optimizer, image, label, phase
)
if phase == "val":
tmp_ACCMeter.update(correct, label.size(0))
tmp_LOSSMeter.update(loss, label.size(0))
total += label.size(0)
loss_t += loss * label.size(0)
correct_t += correct
if phase == "val" and Best_ACC < tmp_ACCMeter.avg:
Best_ACC = tmp_ACCMeter.avg
ACCMeter[index] = tmp_ACCMeter
LOSSMeter[index] = tmp_LOSSMeter
torch.save(
model.state_dict(),
"./resnet50_kfold_{}_{}_{:.2f}.pkl".format(
index + 1, epoch, tmp_ACCMeter.avg
),
)
print(
"Fold : {}/ {} Epoch : {} / {} loss : {:.6f} ACC : {:.6f}".format(
index + 1, K_FOLD, epoch, EPOCH, loss_t / total, correct_t / total
)
)
lr_scheduler.step()
# # Analyze K-fold result
acc_sum = 0
loss_sum = 0
for i in range(K_FOLD):
acc_sum += ACCMeter[i].avg
loss_sum += LOSSMeter[i].avg
print("K-fold {} ACC : {:.6f}".format(K_FOLD, acc_sum / K_FOLD))
print("K-fold {} ACC : {:.6f}".format(K_FOLD, loss_sum / K_FOLD))
# # Testing
import pandas as pd
test_dataset = CLD_Dataset(
"/kaggle/input/cassava-leaf-disease-classification/test_images",
transform=val_transform,
return_name=True,
)
test_dataloader = DataLoader(test_dataset, batch_size=1, shuffle=False, num_workers=4)
image_names = []
image_probs = []
for params_path in glob.glob("../input/densenet121-softtarget/*.pkl"):
model = create_new_model(pretrained=False)
params = torch.load(params_path)
load = []
not_load = []
image_name = []
image_prob = []
for name, param in params.items():
if name in model.state_dict():
try:
model.state_dict()[name].copy_(param)
load.append(name)
except:
not_load.append(name)
print("Trained weight load : {}".format(len(load)))
print("Trained weight not load : {}".format(len(not_load)))
print(not_load)
model.train(False)
for step, (img, img_name) in enumerate(test_dataloader):
b_img = img.to(device)
output = model(b_img)
_, predicted = torch.max(output, dim=1)
image_name.append(img_name[0])
image_prob.append(np.array(output[0].cpu().detach()))
image_names.append(image_name)
image_probs.append(image_prob)
image_names = np.array(image_names)
image_probs = np.array(image_probs)
image_labels = []
for img_idx in range(image_probs.shape[1]):
probs = 0.0
for fold in range(image_names.shape[0]):
prob = image_probs[fold][img_idx]
prob_e = np.exp(prob)
prob_e_sum = prob_e / sum(prob_e + 1e-4)
# probs += image_probs[fold][img_idx]
probs += prob_e_sum
label = np.argmax(probs)
image_labels.append(label)
image_labels = np.array(image_labels)
image_names = np.array(image_names)
df = pd.DataFrame({"image_id": image_names[0], "label": image_labels})
print(df)
df.to_csv("/kaggle/working/submission.csv", index=False)
| false | 0 | 7,117 | 0 | 6 | 7,117 |
||
51826937 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
# # Unzipping Data
train_data_path = "/kaggle/temp/train/"
test_data_path = "/kaggle/temp/test1/"
sample_submission_path = "/kaggle/input/dogs-vs-cats/sampleSubmission.csv"
# # Loading Data
sample_submission = pd.read_csv(sample_submission_path)
sample_submission.head()
# ## Creating Dataset
import torch
import cv2
import pytorch_lightning as pl
from torch.utils.data import DataLoader, Dataset, random_split
import torchvision.transforms as T
from typing import Dict, Callable, Optional, Any, Tuple
import matplotlib.pyplot as plt
from PIL import Image
import matplotlib.pyplot as plt
import multiprocessing
class ResizeImage(object):
def __init__(self, image: Image, ratio: float, pad: Tuple[float, float]):
self.image = image
self.ratio = ratio
self.pad = pad
def load_image(path: str, new_shape: Tuple[int, int]) -> Tuple[Any, ResizeImage]:
# new_shape tuple [Height, Width]
img = Image.open(path)
w0, h0 = img.size # Pillow give us [Width, Height]
# Scale ratio (new / old) -> min(h_new/h_old, w_new/w_old)
# This secure to resize the large dimension first
r = min(new_shape[0] / h0, new_shape[1] / w0)
# new un_pad dimensions keeping aspec ratio
new_unpad = int(round(h0 * r)), int(round(w0 * r))
# Compute padding
dw, dh = new_shape[1] - new_unpad[1], new_shape[0] - new_unpad[0]
dw /= 2
dh /= 2
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
# First Stage Preprocessing Transforms
inteli_resize = T.Compose(
[T.Resize(new_unpad), T.Pad((left, top, right, bottom), fill=(0, 0, 0))]
)
return (img, ResizeImage(inteli_resize(img), r, (dw, dh)))
class CatsVsDogs(Dataset):
def __init__(
self,
path: str,
train: bool,
transforms: Optional[Callable] = None,
new_shape: Optional[Tuple[int, int]] = (224, 224),
) -> None:
self.img_paths = os.listdir(path)
self.name_classes = {"cat": 0, "dog": 1}
self.new_shape = new_shape
self.transforms = transforms
if train:
self.classes = [
self.name_classes[img_path.split(".")[0]] for img_path in self.img_paths
]
else:
# In this case classes will contains images ids
self.classes = [int(img_path.split(".")[0]) for img_path in self.img_paths]
self.img_paths = [os.path.join(path, img_path) for img_path in self.img_paths]
def __getitem__(self, index: int) -> Tuple[torch.Tensor, torch.Tensor]:
_, resize_image = load_image(self.img_paths[index], self.new_shape)
if self.transforms is not None:
tensor_img = self.transforms(resize_image.image)
else:
transforms = T.Compose(
[
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
tensor_img = transforms(resize_image.image)
return tensor_img, torch.tensor(self.classes[index], dtype=torch.float32)
def __len__(self) -> int:
return len(self.img_paths)
class CatsVsDogsDataModule(pl.LightningDataModule):
def __init__(self, train_dir: str, test_dir: str):
super().__init__()
self.train_dir = train_dir
self.test_dir = test_dir
self.transform = T.Compose(
[
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
# self.dims is returned when you call dm.size()
# Setting default dims here because we know them.
# Could optionally be assigned dynamically in dm.setup()
self.dims = (3, 224, 224)
def prepare_data(self):
# download
pass
def setup(self, stage=None):
# Assign train/val datasets for use in dataloaders
if stage == "fit" or stage is None:
dataset_full = CatsVsDogs(
self.train_dir,
train=True,
transforms=self.transform,
new_shape=self.dims[1:],
)
self.train_dataset, self.val_dataset = random_split(
dataset_full,
[
int(len(dataset_full) * 0.8),
len(dataset_full) - int(len(dataset_full) * 0.8),
],
)
# Assign test dataset for use in dataloader(s)
if stage == "test" or stage is None:
self.test_dataset = CatsVsDogs(
self.test_dir,
train=False,
transforms=self.transform,
new_shape=self.dims[1:],
)
def train_dataloader(self):
return DataLoader(
self.train_dataset,
batch_size=16,
shuffle=True,
num_workers=multiprocessing.cpu_count(),
)
def val_dataloader(self):
return DataLoader(
self.val_dataset,
batch_size=16,
shuffle=False,
num_workers=multiprocessing.cpu_count(),
)
def test_dataloader(self):
return DataLoader(
self.test_dataset,
batch_size=16,
shuffle=False,
num_workers=multiprocessing.cpu_count(),
)
# # Define Model
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import models
class VGG16(nn.Module):
def __init__(self):
super(VGG16, self).__init__()
self.vgg16 = models.vgg16(pretrained=True)
self.vgg16.classifier[-1] = nn.Linear(in_features=4096, out_features=1)
def forward(self, x):
x = self.vgg16(x)
return x.view(-1)
from pytorch_lightning.callbacks import LearningRateMonitor
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
class CatVsDogLitModel(pl.LightningModule):
def __init__(self, model: nn.Module, lr: int):
super(CatVsDogLitModel, self).__init__()
self.model = model
self.lr = lr
def forward(self, x):
y = self.model(x)
return y
def training_step(self, batch, batch_idx):
x, y = batch
bs, _, _, _ = x.size()
y_hat = self(x)
loss = F.binary_cross_entropy_with_logits(y_hat, y)
self.log("train_loss", loss, prog_bar=True)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
bs, _, _, _ = x.size()
y_hat = self(x)
loss = F.binary_cross_entropy_with_logits(y_hat, y)
self.log("val_loss", loss, prog_bar=True)
def configure_optimizers(self):
optimizer = optim.Adam(self.parameters(), lr=self.lr)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, "min", verbose=True)
return {
"optimizer": optimizer,
"lr_scheduler": scheduler, # Changed scheduler to lr_scheduler
"monitor": "val_loss",
}
data = CatsVsDogsDataModule(train_dir=train_data_path, test_dir=test_data_path)
ae_model = CatVsDogLitModel(VGG16(), 1e-3)
lr_monitor = LearningRateMonitor(logging_interval="step")
trainer = pl.Trainer(
gpus=1,
max_epochs=25,
amp_level="O2",
precision=16,
callbacks=[lr_monitor, EarlyStopping(monitor="val_loss")],
)
lr_finder = trainer.tuner.lr_find(ae_model, data)
lr_finder.results
fig = lr_finder.plot(suggest=True)
new_lr = lr_finder.suggestion()
ae_model.lr = new_lr
trainer.fit(ae_model, data)
# # Get Metrics results with validation dataset
from tqdm.notebook import tqdm
pbar = tqdm(total=len(data.val_dataset), desc="Metric")
ae_model.eval()
ae_model.cuda()
real_ = []
pred_ = []
for x, y in data.val_dataset:
with torch.no_grad():
y_hat = ae_model(x.unsqueeze(0).cuda()).sigmoid()
pred = (y_hat > 0.5).to(dtype=torch.float32)
real_.append(y.item())
pred_.append(pred.item())
pbar.update(1)
real_ = np.array(real_)
pred_ = np.array(pred_)
accuracy = sum(real_ == pred_) / len(real_) * 100
accuracy
import random
indexes = np.where(real_ != pred_)[0]
choices = random.choices(range(len(indexes)), k=10)
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
unormalize = T.Normalize(mean=-mean / std, std=1.0 / std)
print(choices)
data.setup(stage="test")
plt.figure(figsize=(45, 45), tight_layout=True)
for j, i in enumerate(choices):
plt.subplot(1, len(choices), j + 1)
x, y = data.val_dataset[indexes[i]]
plt.title(
f"class {list(data.test_dataset.name_classes.keys())[int(y.item())]},"
+ f" pred {list(data.test_dataset.name_classes.keys())[int(pred_[indexes[i]])]}"
)
plt.imshow(np.transpose(unormalize(x), (1, 2, 0)))
plt.show()
# # Get results
#
pbar = tqdm(total=len(data.test_dataset), desc="Test Set Predict")
ae_model.eval()
ae_model.cuda()
pred_ = []
idx_ = []
for x, y in data.test_dataset:
with torch.no_grad():
y_hat = ae_model(x.unsqueeze(0).cuda()).sigmoid()
pred = (y_hat > 0.5).to(dtype=torch.float32)
idx_.append(y.item())
pred_.append(pred.item())
pbar.update(1)
pred_ = np.array(pred_)
idx_ = np.array(idx_)
# # Save model
ae_model.eval()
ae_model.cpu()
ae_model.to_torchscript(
"/kaggle/working/model.torch.pt", example_inputs=torch.randn(1, 3, 224, 224)
)
# # Save submissions
pred_ = pred_.astype(np.int64)
idx_ = idx_.astype(np.int64)
submission = sample_submission.copy()
submission.head()
submission.set_index("id", inplace=True, drop=True)
submission.loc[idx_, "label"] = pred_
submission.reset_index(inplace=True)
submission.head()
submission.to_csv("/kaggle/working/submission.csv", index=False)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0051/826/51826937.ipynb | null | null | [{"Id": 51826937, "ScriptId": 14198413, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3607941, "CreationDate": "01/14/2021 04:59:38", "VersionNumber": 1.0, "Title": "dog-vs-cats", "EvaluationDate": "01/14/2021", "IsChange": true, "TotalLines": 322.0, "LinesInsertedFromPrevious": 322.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 4}] | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
# # Unzipping Data
train_data_path = "/kaggle/temp/train/"
test_data_path = "/kaggle/temp/test1/"
sample_submission_path = "/kaggle/input/dogs-vs-cats/sampleSubmission.csv"
# # Loading Data
sample_submission = pd.read_csv(sample_submission_path)
sample_submission.head()
# ## Creating Dataset
import torch
import cv2
import pytorch_lightning as pl
from torch.utils.data import DataLoader, Dataset, random_split
import torchvision.transforms as T
from typing import Dict, Callable, Optional, Any, Tuple
import matplotlib.pyplot as plt
from PIL import Image
import matplotlib.pyplot as plt
import multiprocessing
class ResizeImage(object):
def __init__(self, image: Image, ratio: float, pad: Tuple[float, float]):
self.image = image
self.ratio = ratio
self.pad = pad
def load_image(path: str, new_shape: Tuple[int, int]) -> Tuple[Any, ResizeImage]:
# new_shape tuple [Height, Width]
img = Image.open(path)
w0, h0 = img.size # Pillow give us [Width, Height]
# Scale ratio (new / old) -> min(h_new/h_old, w_new/w_old)
# This secure to resize the large dimension first
r = min(new_shape[0] / h0, new_shape[1] / w0)
# new un_pad dimensions keeping aspec ratio
new_unpad = int(round(h0 * r)), int(round(w0 * r))
# Compute padding
dw, dh = new_shape[1] - new_unpad[1], new_shape[0] - new_unpad[0]
dw /= 2
dh /= 2
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
# First Stage Preprocessing Transforms
inteli_resize = T.Compose(
[T.Resize(new_unpad), T.Pad((left, top, right, bottom), fill=(0, 0, 0))]
)
return (img, ResizeImage(inteli_resize(img), r, (dw, dh)))
class CatsVsDogs(Dataset):
def __init__(
self,
path: str,
train: bool,
transforms: Optional[Callable] = None,
new_shape: Optional[Tuple[int, int]] = (224, 224),
) -> None:
self.img_paths = os.listdir(path)
self.name_classes = {"cat": 0, "dog": 1}
self.new_shape = new_shape
self.transforms = transforms
if train:
self.classes = [
self.name_classes[img_path.split(".")[0]] for img_path in self.img_paths
]
else:
# In this case classes will contains images ids
self.classes = [int(img_path.split(".")[0]) for img_path in self.img_paths]
self.img_paths = [os.path.join(path, img_path) for img_path in self.img_paths]
def __getitem__(self, index: int) -> Tuple[torch.Tensor, torch.Tensor]:
_, resize_image = load_image(self.img_paths[index], self.new_shape)
if self.transforms is not None:
tensor_img = self.transforms(resize_image.image)
else:
transforms = T.Compose(
[
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
tensor_img = transforms(resize_image.image)
return tensor_img, torch.tensor(self.classes[index], dtype=torch.float32)
def __len__(self) -> int:
return len(self.img_paths)
class CatsVsDogsDataModule(pl.LightningDataModule):
def __init__(self, train_dir: str, test_dir: str):
super().__init__()
self.train_dir = train_dir
self.test_dir = test_dir
self.transform = T.Compose(
[
T.ToTensor(),
T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
# self.dims is returned when you call dm.size()
# Setting default dims here because we know them.
# Could optionally be assigned dynamically in dm.setup()
self.dims = (3, 224, 224)
def prepare_data(self):
# download
pass
def setup(self, stage=None):
# Assign train/val datasets for use in dataloaders
if stage == "fit" or stage is None:
dataset_full = CatsVsDogs(
self.train_dir,
train=True,
transforms=self.transform,
new_shape=self.dims[1:],
)
self.train_dataset, self.val_dataset = random_split(
dataset_full,
[
int(len(dataset_full) * 0.8),
len(dataset_full) - int(len(dataset_full) * 0.8),
],
)
# Assign test dataset for use in dataloader(s)
if stage == "test" or stage is None:
self.test_dataset = CatsVsDogs(
self.test_dir,
train=False,
transforms=self.transform,
new_shape=self.dims[1:],
)
def train_dataloader(self):
return DataLoader(
self.train_dataset,
batch_size=16,
shuffle=True,
num_workers=multiprocessing.cpu_count(),
)
def val_dataloader(self):
return DataLoader(
self.val_dataset,
batch_size=16,
shuffle=False,
num_workers=multiprocessing.cpu_count(),
)
def test_dataloader(self):
return DataLoader(
self.test_dataset,
batch_size=16,
shuffle=False,
num_workers=multiprocessing.cpu_count(),
)
# # Define Model
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torchvision import models
class VGG16(nn.Module):
def __init__(self):
super(VGG16, self).__init__()
self.vgg16 = models.vgg16(pretrained=True)
self.vgg16.classifier[-1] = nn.Linear(in_features=4096, out_features=1)
def forward(self, x):
x = self.vgg16(x)
return x.view(-1)
from pytorch_lightning.callbacks import LearningRateMonitor
from pytorch_lightning.callbacks.early_stopping import EarlyStopping
class CatVsDogLitModel(pl.LightningModule):
def __init__(self, model: nn.Module, lr: int):
super(CatVsDogLitModel, self).__init__()
self.model = model
self.lr = lr
def forward(self, x):
y = self.model(x)
return y
def training_step(self, batch, batch_idx):
x, y = batch
bs, _, _, _ = x.size()
y_hat = self(x)
loss = F.binary_cross_entropy_with_logits(y_hat, y)
self.log("train_loss", loss, prog_bar=True)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
bs, _, _, _ = x.size()
y_hat = self(x)
loss = F.binary_cross_entropy_with_logits(y_hat, y)
self.log("val_loss", loss, prog_bar=True)
def configure_optimizers(self):
optimizer = optim.Adam(self.parameters(), lr=self.lr)
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, "min", verbose=True)
return {
"optimizer": optimizer,
"lr_scheduler": scheduler, # Changed scheduler to lr_scheduler
"monitor": "val_loss",
}
data = CatsVsDogsDataModule(train_dir=train_data_path, test_dir=test_data_path)
ae_model = CatVsDogLitModel(VGG16(), 1e-3)
lr_monitor = LearningRateMonitor(logging_interval="step")
trainer = pl.Trainer(
gpus=1,
max_epochs=25,
amp_level="O2",
precision=16,
callbacks=[lr_monitor, EarlyStopping(monitor="val_loss")],
)
lr_finder = trainer.tuner.lr_find(ae_model, data)
lr_finder.results
fig = lr_finder.plot(suggest=True)
new_lr = lr_finder.suggestion()
ae_model.lr = new_lr
trainer.fit(ae_model, data)
# # Get Metrics results with validation dataset
from tqdm.notebook import tqdm
pbar = tqdm(total=len(data.val_dataset), desc="Metric")
ae_model.eval()
ae_model.cuda()
real_ = []
pred_ = []
for x, y in data.val_dataset:
with torch.no_grad():
y_hat = ae_model(x.unsqueeze(0).cuda()).sigmoid()
pred = (y_hat > 0.5).to(dtype=torch.float32)
real_.append(y.item())
pred_.append(pred.item())
pbar.update(1)
real_ = np.array(real_)
pred_ = np.array(pred_)
accuracy = sum(real_ == pred_) / len(real_) * 100
accuracy
import random
indexes = np.where(real_ != pred_)[0]
choices = random.choices(range(len(indexes)), k=10)
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
unormalize = T.Normalize(mean=-mean / std, std=1.0 / std)
print(choices)
data.setup(stage="test")
plt.figure(figsize=(45, 45), tight_layout=True)
for j, i in enumerate(choices):
plt.subplot(1, len(choices), j + 1)
x, y = data.val_dataset[indexes[i]]
plt.title(
f"class {list(data.test_dataset.name_classes.keys())[int(y.item())]},"
+ f" pred {list(data.test_dataset.name_classes.keys())[int(pred_[indexes[i]])]}"
)
plt.imshow(np.transpose(unormalize(x), (1, 2, 0)))
plt.show()
# # Get results
#
pbar = tqdm(total=len(data.test_dataset), desc="Test Set Predict")
ae_model.eval()
ae_model.cuda()
pred_ = []
idx_ = []
for x, y in data.test_dataset:
with torch.no_grad():
y_hat = ae_model(x.unsqueeze(0).cuda()).sigmoid()
pred = (y_hat > 0.5).to(dtype=torch.float32)
idx_.append(y.item())
pred_.append(pred.item())
pbar.update(1)
pred_ = np.array(pred_)
idx_ = np.array(idx_)
# # Save model
ae_model.eval()
ae_model.cpu()
ae_model.to_torchscript(
"/kaggle/working/model.torch.pt", example_inputs=torch.randn(1, 3, 224, 224)
)
# # Save submissions
pred_ = pred_.astype(np.int64)
idx_ = idx_.astype(np.int64)
submission = sample_submission.copy()
submission.head()
submission.set_index("id", inplace=True, drop=True)
submission.loc[idx_, "label"] = pred_
submission.reset_index(inplace=True)
submission.head()
submission.to_csv("/kaggle/working/submission.csv", index=False)
| false | 0 | 3,226 | 4 | 6 | 3,226 |
||
51143249 | <kaggle_start><code># **Импорт зависимостей**
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.layers import (
Dropout,
BatchNormalization,
SpatialDropout2D,
GaussianDropout,
)
from tensorflow.keras.layers import Conv2D, MaxPooling2D, AveragePooling2D
from tensorflow.keras.callbacks import (
EarlyStopping,
ModelCheckpoint,
ReduceLROnPlateau,
LearningRateScheduler,
CSVLogger,
LambdaCallback,
TerminateOnNaN,
)
from tensorflow.keras.preprocessing import image
import matplotlib.pyplot as plt
from tensorflow.keras import utils
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
classes = [
"самолет",
"автомобиль",
"птица",
"кот",
"олень",
"собака",
"лягушка",
"лошадь",
"корабль",
"грузовик",
]
# **Установка статических параметров**
batch_size = 200
nb_classes = 10
nb_epoch = 40
IMG_SIZE = [32, 32]
img_channels = 3
# **Нормализация данных**
x_train = x_train.astype("float32")
x_test = x_test.astype("float32")
x_train /= 255
x_test /= 255
y_train = utils.to_categorical(y_train, nb_classes)
y_test = utils.to_categorical(y_test, nb_classes)
# **Функция для получения последовательной модели для экспериментов с keras callbacks**
def get_model():
model = Sequential()
#
model.add(
Conv2D(
filters=32,
kernel_size=(3, 3),
padding="same",
input_shape=(*IMG_SIZE, img_channels),
activation="relu",
)
)
#
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding="same", activation="relu"))
#
model.add(AveragePooling2D(pool_size=(2, 2)))
#
model.add(BatchNormalization())
#
model.add(GaussianDropout(0.25))
#
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding="same", activation="relu"))
#
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding="same", activation="relu"))
#
model.add(AveragePooling2D(pool_size=(2, 2)))
#
model.add(Conv2D(filters=64, kernel_size=(4, 4), padding="same", activation="elu"))
#
model.add(Conv2D(filters=128, kernel_size=(3, 4), activation="relu"))
#
model.add(BatchNormalization())
#
model.add(GaussianDropout(0.4))
#
model.add(Flatten())
#
model.add(Dense(1024, activation="relu"))
#
model.add(Dropout(0.6))
#
model.add(Dense(nb_classes, activation="softmax"))
#
model.compile(
loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]
)
return model
# **Вспомогательная функция для представления графиков метрик**
def draw_model_plot(history, metric):
plt.plot(history[metric], label="{} на обучающем наборе".format(metric))
plt.plot(
history["val_{}".format(metric)],
label="val_{} на проверочном наборе".format(metric),
)
plt.xlabel("Эпоха обучения")
plt.ylabel(metric)
plt.legend()
plt.show()
# Имитация жизненного цикла модели для экспериментов
def model_life_cycle(callback_list, verbose=1):
model = get_model()
history = model.fit(
x=x_train,
y=y_train,
batch_size=batch_size,
epochs=nb_epoch,
callbacks=callback_list,
validation_split=0.1,
verbose=verbose,
)
#
scores = model.evaluate(x_test, y_test, verbose=0)
print("Evaluate val_accuracy: {}".format(scores[1] * 100))
#
draw_model_plot(history.history, "accuracy")
draw_model_plot(history.history, "loss")
# **Callback** – набор функций, применяемых в определенные моменты во время процедуры обучения. Вы можете использовать функции callback чтобы получить информацию о внутреннем состоянии модели в процессе обучения. Нужно передавать список callback’ов (именованным аргументом callbacks) методу .fit() Sequential или Model классов. Подходящие методы callback будут вызваны на каждой стадии обучения.
# **1) ModelCheckpoint**
# ModelCheckpoint используется для сохранения модели или весов (в файле) через некоторый интервал, чтобы модель или веса можно было загрузить позже, чтобы продолжить обучение из сохраненного состояния
# **Аргументы:**
# — filepath: строка, путь сохранения модели
# — monitor: параметр для мониторинга
# — verbose: режим отображения, 0 или 1
# — save_best_only: если save_best_only=True, если результат текущей эпохи хуже предыдущей, он не будет сохранен.
# — save_weights_only: если True, тогда будут сохраняться только веса модели (model.save_weights(filepath)), в противном случае будет сохраняться вся модель (model.save(filepath)).
# — mode: один из {auto, min, max}. Если save_best_only=True, решение о перезаписи текущего файла будет приниматься в зависимости от уменьшения/увеличения параметра мониторинга. Для val_acc, необходим max, для val_loss необходим min. В auto режиме, mode выбирается в зависимости от имени monitor.
# — period: Интервал (число эпох) между сохранениями.
modelCheckpoint = ModelCheckpoint(
filepath="best_model.h5",
monitor="val_loss",
mode="min",
save_best_only=True,
verbose=1,
period=1,
save_weights_only=False,
)
model_life_cycle(callback_list=[modelCheckpoint], verbose=0)
# **2) EarlyStopping**
# Используется для прекращение обучения, когда параметр monitor перестает улучшаться
# **Аргументы:**
# — monitor: параметр для мониторинга
# — min_delta: минимальное значение изменения величины monitor, расцениваемое как улучшение, то есть, если абсолютное изменение меньше min_delta, то улучшение не засчитывается
# — patience: число эпох, за которые величина monitor не улучшается, после которых обучение будет остановлено. Проверочные величины могут производиться не после каждой эпохи если validation_freq (model.fit(validation_freq=5)) больше единицы.
# — verbose: режим отображения, 0 или 1.
# — mode: один из {auto, min, max}. В режиме min, обучение остановится когда величина monitor перестанет уменьшаться; в режиме max, обучение остановится когда величина monitor перестанет увеличиваться; в режиме auto, mode выбирается в зависимости от имени monitor.
# — baseline: значение, которое должна достичь величина monitor, обучение прекращается по достижению этой величины[](http://)
# — restore_best_weights: восстанавливать ли веса модели с эпохи с лучшем значением параметра monitor. Если False, веса модели будут загружены из последней шага обучения.
earlyStopping = EarlyStopping(
monitor="val_loss",
min_delta=0,
patience=3,
verbose=1,
restore_best_weights=True,
mode="min",
)
model_life_cycle(callback_list=[earlyStopping], verbose=0)
# **3) LearningRateScheduler**
# Используется для регулировки скорости обучения с течением времени, используя schedule, эта функция возвращает желаемую скорость обучения. Входной параметр — индекс эпохи.
# **Аргументы:**
# — schedule: функция, принимающая индекс эпохи (integer, отсчет с нуля) и текущую скорость обучения, и возвращающая новую скорость обучения (float).
# — verbose: int. 0: «тихий» режим, 1: выводить сообщения
LR_START = 0.00001
LR_MAX = 0.0001
LR_MIN = 0.00001
LR_RAMPUP_EPOCHS = 10
LR_SUSTAIN_EPOCHS = 0
LR_EXP_DECAY = 0.8
def lrfn(epoch):
if epoch < LR_RAMPUP_EPOCHS:
lr = (LR_MAX - LR_START) / LR_RAMPUP_EPOCHS * epoch + LR_START
elif epoch < LR_RAMPUP_EPOCHS + LR_SUSTAIN_EPOCHS:
lr = LR_MAX
else:
lr = (LR_MAX - LR_MIN) * LR_EXP_DECAY ** (
epoch - LR_RAMPUP_EPOCHS - LR_SUSTAIN_EPOCHS
) + LR_MIN
return lr
rng = [i for i in range(nb_epoch)]
y = [lrfn(x) for x in rng]
plt.plot(rng, y)
plt.xlabel("Эпоха обучения")
plt.ylabel("Скорость обучения")
plt.show()
learningRateScheduler = LearningRateScheduler(schedule=lrfn, verbose=1)
model_life_cycle(callback_list=[learningRateScheduler], verbose=0)
# **4) ReduceLROnPlateau**
# Используется для изменения скорости обучения в factor раз, когда метрика перестала улучшаться patience эпох
# **Аргументы:**
# — monitor: параметр для мониторинга
# — factor: коэффициент уменьшения скорости обучения. new_lr = lr * factor
# — patience: число эпох, за которые величина monitor не улучшается, после которых обучение будет остановлено. Проверочные величины могут производиться не после каждой эпохи если validation_freq (model.fit(validation_freq=5)) больше единицы.
# — verbose: int. 0: «тихий» режим, 1: выводить сообщения
# — mode: один из {auto, min, max}. В режиме min, скорость обучения уменьшится когда величина monitor перестанет уменьшаться; в режиме max, скорость обучения уменьшится когда величина monitor перестанет увеличиваться; в режиме auto, mode выбирается в зависимости от имени monitor.
# — min_delta: минимальное значение изменения величины monitor, расцениваемое как улучшение, то есть, если абсолютное изменение меньше min_delta, то улучшение не засчитывается
# — cooldown: число эпох после уменьшения скорости обучения, которые должны пройти, прежде чем стандартный процесс уменьшения возобновится.
# — min_lr: нижняя граница скорости обучения
#
reduceLROnPlateau = ReduceLROnPlateau(
monitor="val_loss",
factor=0.2,
min_delta=0,
patience=2,
verbose=1,
cooldown=1,
mode="min",
)
model_life_cycle(callback_list=[reduceLROnPlateau], verbose=0)
# **5) CSVLogger**
# Callback, записывающий результаты эпох в csv файл
# **Аргументы:**
# — filename: имя csv файла (к примеру: ‘run/log.csv’)
# — separator: строка, используемая для разделения элементов в файле.
# — append: True: добавить к существующему файлу (если он существует). False: перезаписать существующий файл.
csvLogger = CSVLogger(filename="learning.csv", separator=",", append=False)
model_life_cycle(callback_list=[csvLogger])
# **6) LambdaCallback**
# Callback для создания простых пользовательских callback’ов «на лету»
# **Аргументы:**
# — on_epoch_begin: вызывается в начале каждой эпохи
# — on_epoch_end: вызывается в конце каждой эпохи
# — on_batch_begin: вызывается в начале каждого батча
# — on_batch_end: вызывается в конце каждого батча
# — on_train_begin: вызывается в начале обучения модели
# — on_train_end: вызывается в конце обучения модели
def foo(epochs, logs):
"""Любая пользовательская функция"""
return
lambdaCallback = LambdaCallback(
on_epoch_begin=foo,
on_epoch_end=foo,
on_batch_begin=foo,
on_batch_end=foo,
on_train_begin=lambda logs: print("on_train_begin"),
on_train_end=lambda logs: print("on_train_end"),
)
model_life_cycle(callback_list=[lambdaCallback], verbose=0)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0051/143/51143249.ipynb | null | null | [{"Id": 51143249, "ScriptId": 14026292, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5783242, "CreationDate": "01/05/2021 14:43:28", "VersionNumber": 2.0, "Title": "Keras Callbacks_1", "EvaluationDate": "01/05/2021", "IsChange": true, "TotalLines": 388.0, "LinesInsertedFromPrevious": 8.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 380.0, "LinesInsertedFromFork": 367.0, "LinesDeletedFromFork": 131.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 21.0, "TotalVotes": 0}] | null | null | null | null | # **Импорт зависимостей**
from tensorflow.keras.datasets import cifar10
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.layers import (
Dropout,
BatchNormalization,
SpatialDropout2D,
GaussianDropout,
)
from tensorflow.keras.layers import Conv2D, MaxPooling2D, AveragePooling2D
from tensorflow.keras.callbacks import (
EarlyStopping,
ModelCheckpoint,
ReduceLROnPlateau,
LearningRateScheduler,
CSVLogger,
LambdaCallback,
TerminateOnNaN,
)
from tensorflow.keras.preprocessing import image
import matplotlib.pyplot as plt
from tensorflow.keras import utils
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
classes = [
"самолет",
"автомобиль",
"птица",
"кот",
"олень",
"собака",
"лягушка",
"лошадь",
"корабль",
"грузовик",
]
# **Установка статических параметров**
batch_size = 200
nb_classes = 10
nb_epoch = 40
IMG_SIZE = [32, 32]
img_channels = 3
# **Нормализация данных**
x_train = x_train.astype("float32")
x_test = x_test.astype("float32")
x_train /= 255
x_test /= 255
y_train = utils.to_categorical(y_train, nb_classes)
y_test = utils.to_categorical(y_test, nb_classes)
# **Функция для получения последовательной модели для экспериментов с keras callbacks**
def get_model():
model = Sequential()
#
model.add(
Conv2D(
filters=32,
kernel_size=(3, 3),
padding="same",
input_shape=(*IMG_SIZE, img_channels),
activation="relu",
)
)
#
model.add(Conv2D(filters=32, kernel_size=(3, 3), padding="same", activation="relu"))
#
model.add(AveragePooling2D(pool_size=(2, 2)))
#
model.add(BatchNormalization())
#
model.add(GaussianDropout(0.25))
#
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding="same", activation="relu"))
#
model.add(Conv2D(filters=64, kernel_size=(3, 3), padding="same", activation="relu"))
#
model.add(AveragePooling2D(pool_size=(2, 2)))
#
model.add(Conv2D(filters=64, kernel_size=(4, 4), padding="same", activation="elu"))
#
model.add(Conv2D(filters=128, kernel_size=(3, 4), activation="relu"))
#
model.add(BatchNormalization())
#
model.add(GaussianDropout(0.4))
#
model.add(Flatten())
#
model.add(Dense(1024, activation="relu"))
#
model.add(Dropout(0.6))
#
model.add(Dense(nb_classes, activation="softmax"))
#
model.compile(
loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"]
)
return model
# **Вспомогательная функция для представления графиков метрик**
def draw_model_plot(history, metric):
plt.plot(history[metric], label="{} на обучающем наборе".format(metric))
plt.plot(
history["val_{}".format(metric)],
label="val_{} на проверочном наборе".format(metric),
)
plt.xlabel("Эпоха обучения")
plt.ylabel(metric)
plt.legend()
plt.show()
# Имитация жизненного цикла модели для экспериментов
def model_life_cycle(callback_list, verbose=1):
model = get_model()
history = model.fit(
x=x_train,
y=y_train,
batch_size=batch_size,
epochs=nb_epoch,
callbacks=callback_list,
validation_split=0.1,
verbose=verbose,
)
#
scores = model.evaluate(x_test, y_test, verbose=0)
print("Evaluate val_accuracy: {}".format(scores[1] * 100))
#
draw_model_plot(history.history, "accuracy")
draw_model_plot(history.history, "loss")
# **Callback** – набор функций, применяемых в определенные моменты во время процедуры обучения. Вы можете использовать функции callback чтобы получить информацию о внутреннем состоянии модели в процессе обучения. Нужно передавать список callback’ов (именованным аргументом callbacks) методу .fit() Sequential или Model классов. Подходящие методы callback будут вызваны на каждой стадии обучения.
# **1) ModelCheckpoint**
# ModelCheckpoint используется для сохранения модели или весов (в файле) через некоторый интервал, чтобы модель или веса можно было загрузить позже, чтобы продолжить обучение из сохраненного состояния
# **Аргументы:**
# — filepath: строка, путь сохранения модели
# — monitor: параметр для мониторинга
# — verbose: режим отображения, 0 или 1
# — save_best_only: если save_best_only=True, если результат текущей эпохи хуже предыдущей, он не будет сохранен.
# — save_weights_only: если True, тогда будут сохраняться только веса модели (model.save_weights(filepath)), в противном случае будет сохраняться вся модель (model.save(filepath)).
# — mode: один из {auto, min, max}. Если save_best_only=True, решение о перезаписи текущего файла будет приниматься в зависимости от уменьшения/увеличения параметра мониторинга. Для val_acc, необходим max, для val_loss необходим min. В auto режиме, mode выбирается в зависимости от имени monitor.
# — period: Интервал (число эпох) между сохранениями.
modelCheckpoint = ModelCheckpoint(
filepath="best_model.h5",
monitor="val_loss",
mode="min",
save_best_only=True,
verbose=1,
period=1,
save_weights_only=False,
)
model_life_cycle(callback_list=[modelCheckpoint], verbose=0)
# **2) EarlyStopping**
# Используется для прекращение обучения, когда параметр monitor перестает улучшаться
# **Аргументы:**
# — monitor: параметр для мониторинга
# — min_delta: минимальное значение изменения величины monitor, расцениваемое как улучшение, то есть, если абсолютное изменение меньше min_delta, то улучшение не засчитывается
# — patience: число эпох, за которые величина monitor не улучшается, после которых обучение будет остановлено. Проверочные величины могут производиться не после каждой эпохи если validation_freq (model.fit(validation_freq=5)) больше единицы.
# — verbose: режим отображения, 0 или 1.
# — mode: один из {auto, min, max}. В режиме min, обучение остановится когда величина monitor перестанет уменьшаться; в режиме max, обучение остановится когда величина monitor перестанет увеличиваться; в режиме auto, mode выбирается в зависимости от имени monitor.
# — baseline: значение, которое должна достичь величина monitor, обучение прекращается по достижению этой величины[](http://)
# — restore_best_weights: восстанавливать ли веса модели с эпохи с лучшем значением параметра monitor. Если False, веса модели будут загружены из последней шага обучения.
earlyStopping = EarlyStopping(
monitor="val_loss",
min_delta=0,
patience=3,
verbose=1,
restore_best_weights=True,
mode="min",
)
model_life_cycle(callback_list=[earlyStopping], verbose=0)
# **3) LearningRateScheduler**
# Используется для регулировки скорости обучения с течением времени, используя schedule, эта функция возвращает желаемую скорость обучения. Входной параметр — индекс эпохи.
# **Аргументы:**
# — schedule: функция, принимающая индекс эпохи (integer, отсчет с нуля) и текущую скорость обучения, и возвращающая новую скорость обучения (float).
# — verbose: int. 0: «тихий» режим, 1: выводить сообщения
LR_START = 0.00001
LR_MAX = 0.0001
LR_MIN = 0.00001
LR_RAMPUP_EPOCHS = 10
LR_SUSTAIN_EPOCHS = 0
LR_EXP_DECAY = 0.8
def lrfn(epoch):
if epoch < LR_RAMPUP_EPOCHS:
lr = (LR_MAX - LR_START) / LR_RAMPUP_EPOCHS * epoch + LR_START
elif epoch < LR_RAMPUP_EPOCHS + LR_SUSTAIN_EPOCHS:
lr = LR_MAX
else:
lr = (LR_MAX - LR_MIN) * LR_EXP_DECAY ** (
epoch - LR_RAMPUP_EPOCHS - LR_SUSTAIN_EPOCHS
) + LR_MIN
return lr
rng = [i for i in range(nb_epoch)]
y = [lrfn(x) for x in rng]
plt.plot(rng, y)
plt.xlabel("Эпоха обучения")
plt.ylabel("Скорость обучения")
plt.show()
learningRateScheduler = LearningRateScheduler(schedule=lrfn, verbose=1)
model_life_cycle(callback_list=[learningRateScheduler], verbose=0)
# **4) ReduceLROnPlateau**
# Используется для изменения скорости обучения в factor раз, когда метрика перестала улучшаться patience эпох
# **Аргументы:**
# — monitor: параметр для мониторинга
# — factor: коэффициент уменьшения скорости обучения. new_lr = lr * factor
# — patience: число эпох, за которые величина monitor не улучшается, после которых обучение будет остановлено. Проверочные величины могут производиться не после каждой эпохи если validation_freq (model.fit(validation_freq=5)) больше единицы.
# — verbose: int. 0: «тихий» режим, 1: выводить сообщения
# — mode: один из {auto, min, max}. В режиме min, скорость обучения уменьшится когда величина monitor перестанет уменьшаться; в режиме max, скорость обучения уменьшится когда величина monitor перестанет увеличиваться; в режиме auto, mode выбирается в зависимости от имени monitor.
# — min_delta: минимальное значение изменения величины monitor, расцениваемое как улучшение, то есть, если абсолютное изменение меньше min_delta, то улучшение не засчитывается
# — cooldown: число эпох после уменьшения скорости обучения, которые должны пройти, прежде чем стандартный процесс уменьшения возобновится.
# — min_lr: нижняя граница скорости обучения
#
reduceLROnPlateau = ReduceLROnPlateau(
monitor="val_loss",
factor=0.2,
min_delta=0,
patience=2,
verbose=1,
cooldown=1,
mode="min",
)
model_life_cycle(callback_list=[reduceLROnPlateau], verbose=0)
# **5) CSVLogger**
# Callback, записывающий результаты эпох в csv файл
# **Аргументы:**
# — filename: имя csv файла (к примеру: ‘run/log.csv’)
# — separator: строка, используемая для разделения элементов в файле.
# — append: True: добавить к существующему файлу (если он существует). False: перезаписать существующий файл.
csvLogger = CSVLogger(filename="learning.csv", separator=",", append=False)
model_life_cycle(callback_list=[csvLogger])
# **6) LambdaCallback**
# Callback для создания простых пользовательских callback’ов «на лету»
# **Аргументы:**
# — on_epoch_begin: вызывается в начале каждой эпохи
# — on_epoch_end: вызывается в конце каждой эпохи
# — on_batch_begin: вызывается в начале каждого батча
# — on_batch_end: вызывается в конце каждого батча
# — on_train_begin: вызывается в начале обучения модели
# — on_train_end: вызывается в конце обучения модели
def foo(epochs, logs):
"""Любая пользовательская функция"""
return
lambdaCallback = LambdaCallback(
on_epoch_begin=foo,
on_epoch_end=foo,
on_batch_begin=foo,
on_batch_end=foo,
on_train_begin=lambda logs: print("on_train_begin"),
on_train_end=lambda logs: print("on_train_end"),
)
model_life_cycle(callback_list=[lambdaCallback], verbose=0)
| false | 0 | 3,871 | 0 | 6 | 3,871 |
||
51802358 | <kaggle_start><code># # Lesson 11 (http://bit.ly/2WLy2cZ)
# Today we're going to cover:
# * Pass
# * None
# * List comprehensions
# * Is vs. ==
# * Iterables vs. lists
# * Modules:
# * Some useful modules
# * Name spaces
# * Making your own modules
# * Main()
#
# # Pass
#
x = 4
if x > 5:
pass # Pass acts as a placeholder for the code you will write
print(x)
# # None
x = print("hello")
print(x)
def helloWorld():
print("Hello, world!")
return None
x = helloWorld()
print(x)
# # List comprehensions
# These are a super useful mashup of a for loop a list and conditionals. I use these *all* the time.
x = ["a", 1, 2, "list"]
l = [i for i in x if type(i) == str] # Makes a new list, l, containing only the strings
# in x
# The basic structure is:
# [ EXPRESSION1 for x in ITERABLE (optionally) if EXPRESSION2 ]
# it is equivalent to writing:
# l = []
# for x in ITERABLE:
# if EXPRESSION2:
# l.append(EXPRESSION1)
print(l)
# Don't worry if this is too complicated to grok right now, just know that these shorthands exist and are really useful
# Consider the function we asked you to write last time and how
# a list comprehension could make it smaller
def how_many_strings(x):
"""
Returns the number of top-level strings in x, where x is a list or tuple.
DOES NOT need to count strings that are nested within nested tuples or lists.
"""
j = 0
for i in x:
if type(i) == str:
j += 1
return j
# This can be accomplished equivalently:
def how_many_strings2(x):
"""
Returns the number of top-level strings in x, where x is a list or tuple.
DOES NOT need to count strings that are nested within nested tuples or lists.
"""
return len([None for i in x if type(i) == str])
how_many_strings2([1, "a", "string", 6, (7,), [5, 6]])
# Note: play with making more examples to:
# * Double all the numbers in a list
# * Append a string to the strings in a list
# * etc.
[i * 2 for i in range(10)]
# # Is vs. ==
# So far we have seen == as a way to test if two things are equal.
# We can also ask if they represent the same object (i.e. same location in computer memory)
x = 1
y = 1
x == y # Clearly, 1 = 1.
# Under the hood Python is testing if x and y refer to are equivalent, even if they
# represent two separate instances in memory of the same thing.
x is y # This is asking if x is referring to the same thing in memory as y.
# Python is smart enough to cache numbers, strings, etc. so that it doesn't duplicate
# memory storing the same thing twice
# Because numbers, strings and tuples are immutable this caching does not affect
# the behavior of the program.
x = [1]
y = [1]
x == y # The two lists are equivalent
x is y # But they are not the same instance in memory, why?
# If Python decided to cache x and y to the same list in memory then changes to x would affect y and vice versa, leading to odd behaviour, e.g.
# Consider
x = [1]
y = [1]
x.append(2)
print(x, y) # The append to x did not affect y
# Now x neither 'is' or is 'equal to' y
x == y or x is y
# But there is nothing stopping you making multiple references
# to the same list
x = [1]
y = x
x == y # Yep, true.
x is y # Yep, also true.
y.append(2)
print(x)
# The take home here:
# * == is for equivalence
# * 'is' is for testing if references point to the same thing in memory
# # Iterables vs. lists
# Recall
list(range(10)) # Makes a list [ 0, 1, ... 9 ]
# What about ?
range(10) # What's the type?
type(range(10)) # So what is a range?
# A range, or iterable object, is a promise to produce a sequence when asked.
# Essentially, you can think of it like as a function you can call repeatedly to get
# successive values from an underlying sequence, e.g. 1, 2, ... etc.
# Why not just make a list? In a word: memory.
list(range(100)) # This requires allocating memory to store 100 integers
range(
100
) # This does not make the list, so the memory for the list is never allocated.
# This requires only the memory for j, i and the Python system
# Compute the sum of integers from 1 (inclusive) to 100 (exclusive)
j = 0
for i in range(100):
j += i
print(j)
# Alternatively, this requires memory for j, i and the list of 100 integers:
j = 0
for i in list(range(100)):
j += i
print(j)
# As a general guide, if we can be "lazy", and avoid ever building a complete sequence in memory, then we should be lazy about evaluation of sequences.
# # Modules
# From a user perspective, modules are variables, functions, objects etc. defined separately
# to the code we're working on.
import math # This line "imports" the math module, so that we can refer to it
math.log10(
100
) # Now we're calling a function from the math module to compute log_10(100)
# The math module contains lots of math functions and constants
dir(math) # Use dir to list the contents of an object or module
# Use help() to give you info (Note: this is great to use in the interactive interpretor)
help(math.sqrt) # e.g. get info on the math.sqrt function
# In general, the Python standard library provides loads of useful modules for all sorts of things: https://docs.python.org/3/py-modindex.html
# For example, the random module provides loads of functions for making random numbers/choices
import random
def make_random_ints(num, lower_bound, upper_bound):
"""
Generate a list containing num random ints between lower_bound
and upper_bound. upper_bound is an open bound.
"""
rng = random.Random() # Create a random number generator
# Makes a sequence of random numbers using rng.randrange()
return [rng.randrange(lower_bound, upper_bound) for i in range(num)]
make_random_ints(10, 0, 6) # Make a sequence of 10 random numbers, each in the
# interval (0 6]
# **Namespaces and '.' notation**
# To recap, the namespace is all the (identifiers variables, functions, classes (to be covered soon), and modules) available to a line of code (See Lecture 5 notes on scope and name space rules).
# In Python (like most programming languages), namespaces are organized hierarchically into subpieces using modules and functions and classes.
# If all identifiers were in one namespace without any hierarchy then we would get lots of collisions between names, and this would result in ambiguity. (see Module1.py and Module2.py example in textbook: http://openbookproject.net/thinkcs/python/english3e/modules.html)
# The upshot is if you want to use a function from another module you need to import it into the "namespace" of your code and use '.' notation:
import math # Imports the math module into the current namespace
# The '.' syntax is a way of indicating membership
math.sqrt(2) # sqrt is a function that "belongs" to the math module
# (Later we'll see this notation reused with objects)
# **Import from**
# You can import a specific function into your program's namespace using the import from syntax:
from math import sqrt
sqrt(2.0) # Now sqrt is a just a function in the current program's name space,
# no dot notation required
# If you want to import all the functions from a module you can use:
from math import * # Import all functions from math
# But, this is generally a BAD IDEA, because you need to be sure
# this doesn't bring in things that will collide with other things
# used by the program
log(10)
# etc.
# More useful is the "as" modifier
from math import sqrt as square_root # This imports the sqrt function from math
# but names it square_root. This is useful if you want to abbreviate a long function
# name, or if you want to import two separate things with the same name
square_root(2.0)
# **Writing your own modules**
# You can write your own modules.
# * Create a file whose name is
# x.py, where x is the name of the module you want to create.
# * Edit x.py to contain the stuff you want
# * Create a new python file, call it y.py, in the same directory as x.py and
# include "import x" at the top of y.py.
# (Note: do demo)
# If time permits, later we'll look more at environment setup to create more complex hierarchical module structures called "packages", but if you're curious see: https://docs.python.org/3/tutorial/modules.html#packages
# # main()
#
print(__name__) # The name of the current module
type(__name__)
def some_useful_function():
"""Define functions that would be useful to
other programs outside of main"""
pass
def main():
print("python main function")
if __name__ == "__main__":
main()
# # Homework
# Finish reading about is vs. == and iterables in Chapter 11: http://openbookproject.net/thinkcs/python/english3e/lists.html
# Read Chapter 12 on Modules: http://openbookproject.net/thinkcs/python/english3e/modules.html
# Complete the following challenge
# Lesson 11 challenge:
l = ["Yes", "You", "Can"]
# Write a list comprehension to create a new list in which each member of l is appended
# with an exclamation mark, i.e. resulting in [ "Yes!", "You!", "Can!"]
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0051/802/51802358.ipynb | null | null | [{"Id": 51802358, "ScriptId": 14213939, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 6505506, "CreationDate": "01/13/2021 18:55:04", "VersionNumber": 1.0, "Title": "Lesson 11", "EvaluationDate": "01/13/2021", "IsChange": true, "TotalLines": 335.0, "LinesInsertedFromPrevious": 335.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | # # Lesson 11 (http://bit.ly/2WLy2cZ)
# Today we're going to cover:
# * Pass
# * None
# * List comprehensions
# * Is vs. ==
# * Iterables vs. lists
# * Modules:
# * Some useful modules
# * Name spaces
# * Making your own modules
# * Main()
#
# # Pass
#
x = 4
if x > 5:
pass # Pass acts as a placeholder for the code you will write
print(x)
# # None
x = print("hello")
print(x)
def helloWorld():
print("Hello, world!")
return None
x = helloWorld()
print(x)
# # List comprehensions
# These are a super useful mashup of a for loop a list and conditionals. I use these *all* the time.
x = ["a", 1, 2, "list"]
l = [i for i in x if type(i) == str] # Makes a new list, l, containing only the strings
# in x
# The basic structure is:
# [ EXPRESSION1 for x in ITERABLE (optionally) if EXPRESSION2 ]
# it is equivalent to writing:
# l = []
# for x in ITERABLE:
# if EXPRESSION2:
# l.append(EXPRESSION1)
print(l)
# Don't worry if this is too complicated to grok right now, just know that these shorthands exist and are really useful
# Consider the function we asked you to write last time and how
# a list comprehension could make it smaller
def how_many_strings(x):
"""
Returns the number of top-level strings in x, where x is a list or tuple.
DOES NOT need to count strings that are nested within nested tuples or lists.
"""
j = 0
for i in x:
if type(i) == str:
j += 1
return j
# This can be accomplished equivalently:
def how_many_strings2(x):
"""
Returns the number of top-level strings in x, where x is a list or tuple.
DOES NOT need to count strings that are nested within nested tuples or lists.
"""
return len([None for i in x if type(i) == str])
how_many_strings2([1, "a", "string", 6, (7,), [5, 6]])
# Note: play with making more examples to:
# * Double all the numbers in a list
# * Append a string to the strings in a list
# * etc.
[i * 2 for i in range(10)]
# # Is vs. ==
# So far we have seen == as a way to test if two things are equal.
# We can also ask if they represent the same object (i.e. same location in computer memory)
x = 1
y = 1
x == y # Clearly, 1 = 1.
# Under the hood Python is testing if x and y refer to are equivalent, even if they
# represent two separate instances in memory of the same thing.
x is y # This is asking if x is referring to the same thing in memory as y.
# Python is smart enough to cache numbers, strings, etc. so that it doesn't duplicate
# memory storing the same thing twice
# Because numbers, strings and tuples are immutable this caching does not affect
# the behavior of the program.
x = [1]
y = [1]
x == y # The two lists are equivalent
x is y # But they are not the same instance in memory, why?
# If Python decided to cache x and y to the same list in memory then changes to x would affect y and vice versa, leading to odd behaviour, e.g.
# Consider
x = [1]
y = [1]
x.append(2)
print(x, y) # The append to x did not affect y
# Now x neither 'is' or is 'equal to' y
x == y or x is y
# But there is nothing stopping you making multiple references
# to the same list
x = [1]
y = x
x == y # Yep, true.
x is y # Yep, also true.
y.append(2)
print(x)
# The take home here:
# * == is for equivalence
# * 'is' is for testing if references point to the same thing in memory
# # Iterables vs. lists
# Recall
list(range(10)) # Makes a list [ 0, 1, ... 9 ]
# What about ?
range(10) # What's the type?
type(range(10)) # So what is a range?
# A range, or iterable object, is a promise to produce a sequence when asked.
# Essentially, you can think of it like as a function you can call repeatedly to get
# successive values from an underlying sequence, e.g. 1, 2, ... etc.
# Why not just make a list? In a word: memory.
list(range(100)) # This requires allocating memory to store 100 integers
range(
100
) # This does not make the list, so the memory for the list is never allocated.
# This requires only the memory for j, i and the Python system
# Compute the sum of integers from 1 (inclusive) to 100 (exclusive)
j = 0
for i in range(100):
j += i
print(j)
# Alternatively, this requires memory for j, i and the list of 100 integers:
j = 0
for i in list(range(100)):
j += i
print(j)
# As a general guide, if we can be "lazy", and avoid ever building a complete sequence in memory, then we should be lazy about evaluation of sequences.
# # Modules
# From a user perspective, modules are variables, functions, objects etc. defined separately
# to the code we're working on.
import math # This line "imports" the math module, so that we can refer to it
math.log10(
100
) # Now we're calling a function from the math module to compute log_10(100)
# The math module contains lots of math functions and constants
dir(math) # Use dir to list the contents of an object or module
# Use help() to give you info (Note: this is great to use in the interactive interpretor)
help(math.sqrt) # e.g. get info on the math.sqrt function
# In general, the Python standard library provides loads of useful modules for all sorts of things: https://docs.python.org/3/py-modindex.html
# For example, the random module provides loads of functions for making random numbers/choices
import random
def make_random_ints(num, lower_bound, upper_bound):
"""
Generate a list containing num random ints between lower_bound
and upper_bound. upper_bound is an open bound.
"""
rng = random.Random() # Create a random number generator
# Makes a sequence of random numbers using rng.randrange()
return [rng.randrange(lower_bound, upper_bound) for i in range(num)]
make_random_ints(10, 0, 6) # Make a sequence of 10 random numbers, each in the
# interval (0 6]
# **Namespaces and '.' notation**
# To recap, the namespace is all the (identifiers variables, functions, classes (to be covered soon), and modules) available to a line of code (See Lecture 5 notes on scope and name space rules).
# In Python (like most programming languages), namespaces are organized hierarchically into subpieces using modules and functions and classes.
# If all identifiers were in one namespace without any hierarchy then we would get lots of collisions between names, and this would result in ambiguity. (see Module1.py and Module2.py example in textbook: http://openbookproject.net/thinkcs/python/english3e/modules.html)
# The upshot is if you want to use a function from another module you need to import it into the "namespace" of your code and use '.' notation:
import math # Imports the math module into the current namespace
# The '.' syntax is a way of indicating membership
math.sqrt(2) # sqrt is a function that "belongs" to the math module
# (Later we'll see this notation reused with objects)
# **Import from**
# You can import a specific function into your program's namespace using the import from syntax:
from math import sqrt
sqrt(2.0) # Now sqrt is a just a function in the current program's name space,
# no dot notation required
# If you want to import all the functions from a module you can use:
from math import * # Import all functions from math
# But, this is generally a BAD IDEA, because you need to be sure
# this doesn't bring in things that will collide with other things
# used by the program
log(10)
# etc.
# More useful is the "as" modifier
from math import sqrt as square_root # This imports the sqrt function from math
# but names it square_root. This is useful if you want to abbreviate a long function
# name, or if you want to import two separate things with the same name
square_root(2.0)
# **Writing your own modules**
# You can write your own modules.
# * Create a file whose name is
# x.py, where x is the name of the module you want to create.
# * Edit x.py to contain the stuff you want
# * Create a new python file, call it y.py, in the same directory as x.py and
# include "import x" at the top of y.py.
# (Note: do demo)
# If time permits, later we'll look more at environment setup to create more complex hierarchical module structures called "packages", but if you're curious see: https://docs.python.org/3/tutorial/modules.html#packages
# # main()
#
print(__name__) # The name of the current module
type(__name__)
def some_useful_function():
"""Define functions that would be useful to
other programs outside of main"""
pass
def main():
print("python main function")
if __name__ == "__main__":
main()
# # Homework
# Finish reading about is vs. == and iterables in Chapter 11: http://openbookproject.net/thinkcs/python/english3e/lists.html
# Read Chapter 12 on Modules: http://openbookproject.net/thinkcs/python/english3e/modules.html
# Complete the following challenge
# Lesson 11 challenge:
l = ["Yes", "You", "Can"]
# Write a list comprehension to create a new list in which each member of l is appended
# with an exclamation mark, i.e. resulting in [ "Yes!", "You!", "Can!"]
| false | 0 | 2,589 | 0 | 6 | 2,589 |
||
70078015 | <kaggle_start><code># 上で説明したセットアップです。このコードが何をするのか、どのように動作するのかについては、今のところ心配する必要はありません。
from learntools.core import binder
binder.bind(globals())
from learntools.python.ex2 import *
print("Setup complete.")
# # 1.
# 次の関数のボディを,そのdocstringに従って完成させてください。
# HINT: Pythonには組み込み関数 `round` があります。
def round_to_two_places(num):
"""小数第2位に丸められた数値を返します。
>>> round_to_two_places(3.14159)
3.14
"""
# この関数(round_to_two_places)の中身にコードを書いてください。
# "pass"(この文字列の下部にあり)は、文字通り何もしないキーワードです。コードブロックを開始した後、
# Pythonは少なくとも1行のコード必要なので、仮として使用しました。
pass
# ここで正解か解答かを確認することができます。(このセルを実行すると確認できます)
q1.check()
# ヒントを見たい場合はコメントアウトを行ってください。
# q1.hint()
# この問題の解答を確認したい場合は以下のコメントアウトを削除してください。
# q1.solution()
# # 2.
# `round`のヘルプによると、`ndigits`(2番目の引数)が負の値になることがあると書かれています。
# 負の場合はどうなると思いますか?次のセルでいくつかの例を試してみましょう。
# コードをここに書いてください。
# これが役に立つのか思い浮かべてみてください。 準備ができたら、以下のコードセルを実行して、答えを確認し、問題を完了したことを確認してください。
# 答え合わせをする(このコードセルを実行してください!)
q2.solution()
# # 3.
# 前の演習では、友人のアリス、ボブ、キャロルがキャンディを均等に分けようとしました。分けた時に余ったキャンディは捨てます。例えば、全員で91個のキャンディを持ち帰った場合、30個ずつ取って1個を叩き潰します(捨てます)。
# 今回はキャンディの総数がどのような場合であっても、捨てるキャンディの数を計算できる関数を作成します。
# 以下にある関数を修正して、キャンディーを分ける友達の数を表す第2引数を任意に取るようにします。2番目の引数が提供されていない場合は、以前のように3人の友人で分けることを想定する必要があります。
# この新しい動作を反映してください。
def to_smash(total_candies):
"""与えられた数のキャンディを3人の友達に均等に配った後、捨てなければならない残りのキャンディの数を返します。
>>> to_smash(91)
1
"""
return total_candies % 3
# ここで正解か解答かを確認することができます。(このセルを実行すると確認できます)
q3.check()
# q3.hint()
# q3.solution()
# # 4. (Optional)
# 楽しいことではないかもしれませんが、エラーメッセージを読んで理解することは、Pythonを学ぶことにおいて重要な部分となります。
# 以下の各コードセルには、コメントされたバグのあるコードが含まれています。各セルには...
# 1. コードを読んで、実行したときに何が起こるかを予測してみてください。
# 2. その後、コードをコメントアウトして実行し、何が起こるかを確認してください。(**ヒント**。カーネルエディタでは、いくつかの行をハイライトして、`ctrl`+`/`を押すとコメントの表示を切り替えることができます)
# 3. コードを修正する(例外を発生させずに本来の目的を果たせるように)
#
# ruound_to_two_places(9.9999)
# x = -10
# y = 5
# # 上の2つの変数のうち、絶対値が小さいのはどれか?
# smallest_abs = min(abs(x, y))
# def f(x):
# y = abs(x)
# return y
# print(f(5))
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/078/70078015.ipynb | null | null | [{"Id": 70078015, "ScriptId": 19166323, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5973981, "CreationDate": "08/04/2021 15:16:55", "VersionNumber": 1.0, "Title": "[\u65e5\u672c\u8a9e\u8a33]Exercise: Functions and Getting Help", "EvaluationDate": "08/04/2021", "IsChange": true, "TotalLines": 108.0, "LinesInsertedFromPrevious": 35.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 73.0, "LinesInsertedFromFork": 35.0, "LinesDeletedFromFork": 38.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 73.0, "TotalVotes": 0}] | null | null | null | null | # 上で説明したセットアップです。このコードが何をするのか、どのように動作するのかについては、今のところ心配する必要はありません。
from learntools.core import binder
binder.bind(globals())
from learntools.python.ex2 import *
print("Setup complete.")
# # 1.
# 次の関数のボディを,そのdocstringに従って完成させてください。
# HINT: Pythonには組み込み関数 `round` があります。
def round_to_two_places(num):
"""小数第2位に丸められた数値を返します。
>>> round_to_two_places(3.14159)
3.14
"""
# この関数(round_to_two_places)の中身にコードを書いてください。
# "pass"(この文字列の下部にあり)は、文字通り何もしないキーワードです。コードブロックを開始した後、
# Pythonは少なくとも1行のコード必要なので、仮として使用しました。
pass
# ここで正解か解答かを確認することができます。(このセルを実行すると確認できます)
q1.check()
# ヒントを見たい場合はコメントアウトを行ってください。
# q1.hint()
# この問題の解答を確認したい場合は以下のコメントアウトを削除してください。
# q1.solution()
# # 2.
# `round`のヘルプによると、`ndigits`(2番目の引数)が負の値になることがあると書かれています。
# 負の場合はどうなると思いますか?次のセルでいくつかの例を試してみましょう。
# コードをここに書いてください。
# これが役に立つのか思い浮かべてみてください。 準備ができたら、以下のコードセルを実行して、答えを確認し、問題を完了したことを確認してください。
# 答え合わせをする(このコードセルを実行してください!)
q2.solution()
# # 3.
# 前の演習では、友人のアリス、ボブ、キャロルがキャンディを均等に分けようとしました。分けた時に余ったキャンディは捨てます。例えば、全員で91個のキャンディを持ち帰った場合、30個ずつ取って1個を叩き潰します(捨てます)。
# 今回はキャンディの総数がどのような場合であっても、捨てるキャンディの数を計算できる関数を作成します。
# 以下にある関数を修正して、キャンディーを分ける友達の数を表す第2引数を任意に取るようにします。2番目の引数が提供されていない場合は、以前のように3人の友人で分けることを想定する必要があります。
# この新しい動作を反映してください。
def to_smash(total_candies):
"""与えられた数のキャンディを3人の友達に均等に配った後、捨てなければならない残りのキャンディの数を返します。
>>> to_smash(91)
1
"""
return total_candies % 3
# ここで正解か解答かを確認することができます。(このセルを実行すると確認できます)
q3.check()
# q3.hint()
# q3.solution()
# # 4. (Optional)
# 楽しいことではないかもしれませんが、エラーメッセージを読んで理解することは、Pythonを学ぶことにおいて重要な部分となります。
# 以下の各コードセルには、コメントされたバグのあるコードが含まれています。各セルには...
# 1. コードを読んで、実行したときに何が起こるかを予測してみてください。
# 2. その後、コードをコメントアウトして実行し、何が起こるかを確認してください。(**ヒント**。カーネルエディタでは、いくつかの行をハイライトして、`ctrl`+`/`を押すとコメントの表示を切り替えることができます)
# 3. コードを修正する(例外を発生させずに本来の目的を果たせるように)
#
# ruound_to_two_places(9.9999)
# x = -10
# y = 5
# # 上の2つの変数のうち、絶対値が小さいのはどれか?
# smallest_abs = min(abs(x, y))
# def f(x):
# y = abs(x)
# return y
# print(f(5))
| false | 0 | 1,223 | 0 | 6 | 1,223 |
||
70542993 | <kaggle_start><code># # Hungry Geese - Agents Comparison
# - This notebook contains a lot of different agents from different sources for the [Hungry Geese](https://www.kaggle.com/c/hungry-geese).
# - In the [Comparison In Battle](#100) section, we also added a comparison of each pair of different agents (against two very simple additional agents so that real conditions are met). The agents fight for 100 rounds and then counts of the wins are calculated
# 
# # Simple Toward
from kaggle_environments.envs.hungry_geese.hungry_geese import (
Observation,
Configuration,
Action,
row_col,
)
def agent(obs_dict, config_dict):
"""This agent always moves toward observation.food[0] but does not take advantage of board wrapping"""
observation = Observation(obs_dict)
configuration = Configuration(config_dict)
player_index = observation.index
player_goose = observation.geese[player_index]
player_head = player_goose[0]
player_row, player_column = row_col(player_head, configuration.columns)
food = observation.food[0]
food_row, food_column = row_col(food, configuration.columns)
if food_row > player_row:
return Action.SOUTH.name
if food_row < player_row:
return Action.NORTH.name
if food_column > player_column:
return Action.EAST.name
return Action.WEST.name
# # Greedy Agent
from kaggle_environments.envs.hungry_geese.hungry_geese import (
Observation,
Configuration,
Action,
row_col,
)
from random import choice, sample
def random_agent():
return choice([action for action in Action]).name
def translate(position: int, direction: Action, columns: int, rows: int):
row, column = row_col(position, columns)
row_offset, column_offset = direction.to_row_col()
row = (row + row_offset) % rows
column = (column + column_offset) % columns
return row * columns + column
def adjacent_positions(position: int, columns: int, rows: int):
return [translate(position, action, columns, rows) for action in Action]
def min_distance(position: int, food: [int], columns: int):
row, column = row_col(position, columns)
return min(
abs(row - food_row) + abs(column - food_column)
for food_position in food
for food_row, food_column in [row_col(food_position, columns)]
)
def agent(observation, configuration):
observation = Observation(observation)
configuration = Configuration(configuration)
rows, columns = configuration.rows, configuration.columns
food = observation.food
geese = observation.geese
opponents = [
goose
for index, goose in enumerate(geese)
if index != observation.index and len(goose) > 0
]
# Don't move adjacent to any heads
head_adjacent_positions = {
opponent_head_adjacent
for opponent in opponents
for opponent_head in [opponent[0]]
for opponent_head_adjacent in adjacent_positions(opponent_head, rows, columns)
}
# Don't move into any bodies
bodies = {position for goose in geese for position in goose[0:-1]}
# Don't move into tails of heads that are adjacent to food
tails = {
opponent[-1]
for opponent in opponents
for opponent_head in [opponent[0]]
if any(
adjacent_position in food
# Head of opponent is adjacent to food so tail is not safe
for adjacent_position in adjacent_positions(opponent_head, rows, columns)
)
}
# Move to the closest food
position = geese[observation.index][0]
actions = {
action: min_distance(new_position, food, columns)
for action in Action
for new_position in [translate(position, action, columns, rows)]
if (
new_position not in head_adjacent_positions
and new_position not in bodies
and new_position not in tails
)
}
if any(actions):
return min(actions, key=actions.get).name
return random_agent()
# # Risk Adverse Greedy Goose
# Copy from kernel [Risk averse greedy goose](https://www.kaggle.com/ilialar/risk-averse-greedy-goose)
from kaggle_environments.envs.hungry_geese.hungry_geese import (
Observation,
Configuration,
Action,
row_col,
)
import numpy as np
import random
def get_nearest_cells(x, y):
# returns all cells reachable from the current one
result = []
for i in (-1, +1):
result.append(((x + i + 7) % 7, y))
result.append((x, (y + i + 11) % 11))
return result
def find_closest_food(table):
# returns the first step toward the closest food item
new_table = table.copy()
# (direction of the step, axis, code)
possible_moves = [(1, 0, 1), (-1, 0, 2), (1, 1, 3), (-1, 1, 4)]
# shuffle possible options to add variability
random.shuffle(possible_moves)
updated = False
for roll, axis, code in possible_moves:
shifted_table = np.roll(table, roll, axis)
if (table == -2).any() and (
shifted_table[table == -2] == -3
).any(): # we have found some food at the first step
return code
else:
mask = np.logical_and(new_table == 0, shifted_table == -3)
if mask.sum() > 0:
updated = True
new_table += code * mask
if (table == -2).any() and shifted_table[table == -2][
0
] > 0: # we have found some food
return shifted_table[table == -2][0]
# else - update new reachible cells
mask = np.logical_and(new_table == 0, shifted_table > 0)
if mask.sum() > 0:
updated = True
new_table += shifted_table * mask
# if we updated anything - continue reccurison
if updated:
return find_closest_food(new_table)
# if not - return some step
else:
return table.max()
last_step = None
def agent(obs_dict, config_dict):
global last_step
observation = Observation(obs_dict)
configuration = Configuration(config_dict)
player_index = observation.index
player_goose = observation.geese[player_index]
player_head = player_goose[0]
player_row, player_column = row_col(player_head, configuration.columns)
table = np.zeros((7, 11))
# 0 - emply cells
# -1 - obstacles
# -4 - possible obstacles
# -2 - food
# -3 - head
# 1,2,3,4 - reachable on the current step cell, number is the id of the first step direction
legend = {1: "SOUTH", 2: "NORTH", 3: "EAST", 4: "WEST"}
# let's add food to the map
for food in observation.food:
x, y = row_col(food, configuration.columns)
table[x, y] = -2 # food
# let's add all cells that are forbidden
for i in range(4):
opp_goose = observation.geese[i]
if len(opp_goose) == 0:
continue
is_close_to_food = False
if i != player_index:
x, y = row_col(opp_goose[0], configuration.columns)
possible_moves = get_nearest_cells(x, y) # head can move anywhere
for x, y in possible_moves:
if table[x, y] == -2:
is_close_to_food = True
table[x, y] = -4 # possibly forbidden cells
# usually we ignore the last tail cell but there are exceptions
tail_change = -1
if obs_dict["step"] % 40 == 39:
tail_change -= 1
# we assume that the goose will eat the food
if is_close_to_food:
tail_change += 1
if tail_change >= 0:
tail_change = None
for n in opp_goose[:tail_change]:
x, y = row_col(n, configuration.columns)
table[x, y] = -1 # forbidden cells
# going back is forbidden according to the new rules
x, y = row_col(player_head, configuration.columns)
if last_step is not None:
if last_step == 1:
table[(x + 6) % 7, y] = -1
elif last_step == 2:
table[(x + 8) % 7, y] = -1
elif last_step == 3:
table[x, (y + 10) % 11] = -1
elif last_step == 4:
table[x, (y + 12) % 11] = -1
# add head position
table[x, y] = -3
# the first step toward the nearest food
step = int(find_closest_food(table))
# if there is not available steps try to go to possibly dangerous cell
if step not in [1, 2, 3, 4]:
x, y = row_col(player_head, configuration.columns)
if table[(x + 8) % 7, y] == -4:
step = 1
elif table[(x + 6) % 7, y] == -4:
step = 2
elif table[x, (y + 12) % 11] == -4:
step = 3
elif table[x, (y + 10) % 11] == -4:
step = 4
# else - do a random step and lose
else:
step = np.random.randint(4) + 1
last_step = step
return legend[step]
# # Simple BFS
# Copy from kernel [Simple BFS- Starter Agent](https://www.kaggle.com/aatiffraz/simple-bfs-starter-agent)
from kaggle_environments.envs.hungry_geese.hungry_geese import (
Observation,
Configuration,
Action,
row_col,
)
import random
import numpy as np
directions = {
0: "EAST",
1: "NORTH",
2: "WEST",
3: "SOUTH",
"EAST": 0,
"NORTH": 1,
"WEST": 2,
"SOUTH": 3,
}
def move(loc, direction):
"""Move the whole snake in the given direction"""
global directions
direction = directions[direction]
new_loc = []
if direction == "EAST":
new_loc.append(int(11 * (loc[0] // 11) + (loc[0] % 11 + 1) % 11))
elif direction == "WEST":
new_loc.append(int(11 * (loc[0] // 11) + (loc[0] % 11 + 10) % 11))
elif direction == "NORTH":
new_loc.append(int(11 * ((loc[0] // 11 + 6) % 7) + loc[0] % 11))
else:
new_loc.append(int(11 * ((loc[0] // 11 + 1) % 7) + loc[0] % 11))
if len(loc) == 1:
return new_loc
return new_loc + loc[:-1]
def greedy_choose(head, board):
move_queue = []
visited = [[[100, "NA"] for _ in range(11)] for l in range(7)]
visited[head // 11][head % 11][0] = 0
for i in range(4):
move_queue.append([head, [i]])
while len(move_queue) > 0:
now_move = move_queue.pop(0)
next_step = move([now_move[0]], now_move[1][-1])[0]
if board[next_step // 11][next_step % 11] < 0:
continue
if len(now_move[1]) < visited[next_step // 11][next_step % 11][0]:
visited[next_step // 11][next_step % 11][0] = len(now_move[1])
visited[next_step // 11][next_step % 11][1] = now_move[1][0]
for i in range(4):
move_queue.append([next_step, now_move[1] + [i]])
if board[next_step // 11][next_step % 11] > 0:
return now_move[1][0]
return random.randint(0, 3)
def agent(obs, conf):
global directions
obs = Observation(obs)
conf = Configuration(conf)
board = np.zeros((7, 11), dtype=int)
# Obstacle-ize your opponents
for ind, goose in enumerate(obs.geese):
if ind == obs.index or len(goose) == 0:
continue
for direction in range(4):
moved = move(goose, direction)
for part in moved:
board[part // 11][part % 11] -= 1
# Obstacle-ize your body, except the last part
if len(obs.geese[obs.index]) > 1:
for k in obs.geese[obs.index][:-1]:
board[k // 11][k % 11] -= 1
# Count food only if there's no chance an opponent will meet you there
for f in obs.food:
board[f // 11][f % 11] += board[f // 11][f % 11] == 0
return directions[greedy_choose(obs.geese[obs.index][0], board)]
# # Straightforward BFS
from kaggle_environments.envs.hungry_geese.hungry_geese import (
Observation,
Configuration,
Action,
row_col,
)
import numpy as np
def bfs(start_x, start_y, mask, food_coords):
dist_matrix = np.zeros_like(mask)
vect_matrix = np.full_like(mask, -1)
queue = [(start_x, start_y, 0, None)]
while queue:
current_x, current_y, current_dist, vect = queue.pop(0)
vect_matrix[current_x, current_y] = vect
up_x = current_x + 1 if current_x != 6 else 0
down_x = current_x - 1 if current_x != 0 else 6
left_y = current_y - 1 if current_y != 0 else 10
right_y = current_y + 1 if current_y != 10 else 0
if mask[up_x, current_y] != -1 and not dist_matrix[up_x, current_y]:
dist_matrix[up_x, current_y] = current_dist + 1
if vect is None:
queue.append((up_x, current_y, current_dist + 1, 0))
else:
queue.append((up_x, current_y, current_dist + 1, vect))
if mask[down_x, current_y] != -1 and not dist_matrix[down_x, current_y]:
dist_matrix[down_x, current_y] = current_dist + 1
if vect is None:
queue.append((down_x, current_y, current_dist + 1, 1))
else:
queue.append((down_x, current_y, current_dist + 1, vect))
if mask[current_x, left_y] != -1 and not dist_matrix[current_x, left_y]:
dist_matrix[current_x, left_y] = current_dist + 1
if vect is None:
queue.append((current_x, left_y, current_dist + 1, 2))
else:
queue.append((current_x, left_y, current_dist + 1, vect))
if mask[current_x, right_y] != -1 and not dist_matrix[current_x, right_y]:
dist_matrix[current_x, right_y] = current_dist + 1
if vect is None:
queue.append((current_x, right_y, current_dist + 1, 3))
else:
queue.append((current_x, right_y, current_dist + 1, vect))
min_food_id = -1
min_food_dist = np.inf
for id_, food in enumerate(food_coords):
if (
dist_matrix[food[0], food[1]] != 0
and min_food_dist > dist_matrix[food[0], food[1]]
):
min_food_id = id_
min_food_dist = dist_matrix[food[0], food[1]]
if min_food_id == -1:
x, y = -1, -1
mn = 0
for i in range(dist_matrix.shape[0]):
for j in range(dist_matrix.shape[1]):
if dist_matrix[i, j] > mn:
x, y = i, j
mn = dist_matrix[i, j]
return vect_matrix[x, y]
food_x, food_y = food_coords[min_food_id]
return vect_matrix[food_x, food_y]
LAST_ACTION = None
def straightforward_bfs(obs_dict, config_dict):
observation = Observation(obs_dict)
configuration = Configuration(config_dict)
player_index = observation.index
player_goose = observation.geese[player_index]
player_head = player_goose[0]
start_row, start_col = row_col(player_head, configuration.columns)
mask = np.zeros((configuration.rows, configuration.columns))
for current_id in range(4):
current_goose = observation.geese[current_id]
for block in current_goose:
current_row, current_col = row_col(block, configuration.columns)
mask[current_row, current_col] = -1
food_coords = []
for food_id in range(configuration.min_food):
food = observation.food[food_id]
current_row, current_col = row_col(food, configuration.columns)
mask[current_row, current_col] = 2
food_coords.append((current_row, current_col))
last_action = bfs(start_row, start_col, mask, food_coords)
global LAST_ACTION
up_x = start_row + 1 if start_row != 6 else 0
down_x = start_row - 1 if start_row != 0 else 6
left_y = start_col - 1 if start_col != 0 else 10
right_y = start_col + 1 if start_col != 10 else 0
step = Action.NORTH.name
if last_action == 0:
step = Action.SOUTH.name
if LAST_ACTION == Action.NORTH.name:
if mask[down_x, start_col] != -1:
step = Action.NORTH.name
elif mask[start_row, left_y] != -1:
step = Action.WEST.name
elif mask[start_row, right_y] != -1:
step = Action.EAST.name
if last_action == 1:
step = Action.NORTH.name
if LAST_ACTION == Action.SOUTH.name:
if mask[up_x, start_col] != -1:
step = Action.SOUTH.name
elif mask[start_row, left_y] != -1:
step = Action.WEST.name
elif mask[start_row, right_y] != -1:
step = Action.EAST.name
if last_action == 2:
step = Action.WEST.name
if LAST_ACTION == Action.EAST.name:
if mask[up_x, start_col] != -1:
step = Action.SOUTH.name
elif mask[down_x, start_col] != -1:
step = Action.NORTH.name
elif mask[start_row, right_y] != -1:
step = Action.EAST.name
if last_action == 3:
step = Action.EAST.name
if LAST_ACTION == Action.WEST.name:
if mask[up_x, start_col] != -1:
step = Action.SOUTH.name
elif mask[down_x, start_col] != -1:
step = Action.NORTH.name
elif mask[start_row, left_y] != -1:
step = Action.WEST.name
LAST_ACTION = step
return step
# # BoilerGoose
# Copy from kernel [Mighty BoilerGoose with Flood fill](https://www.kaggle.com/superant/mighty-boilergoose-with-flood-fill)
import dataclasses
from dataclasses import dataclass
from typing import List, NamedTuple, Set, Dict, Optional, Tuple, Callable
import numpy as np
from kaggle_environments.envs.hungry_geese.hungry_geese import Action
from abc import ABC, abstractmethod
import sys
import traceback
trans_action_map: Dict[Tuple[int, int], Action] = {
(-1, 0): Action.NORTH,
(1, 0): Action.SOUTH,
(0, 1): Action.EAST,
(0, -1): Action.WEST,
}
class Pos(NamedTuple):
x: int
y: int
def __repr__(self):
return f"[{self.x}:{self.y}]"
@dataclass
class Goose:
head: Pos = dataclasses.field(init=False)
poses: List[Pos]
def __post_init__(self):
self.head = self.poses[0]
def __repr__(self):
return "Goose(" + "-".join(map(str, self.poses)) + ")"
def __iter__(self):
return iter(self.poses)
def __len__(self):
return len(self.poses)
def field_idx_to_pos(field_idx: int, *, num_cols: int, num_rows: int) -> Pos:
x = field_idx // num_cols
y = field_idx % num_cols
if not (0 <= x < num_rows and 0 <= y < num_cols):
raise ValueError("Illegal field_idx {field_idx} with x={x} and y={y}")
return Pos(x, y)
class Geometry:
def __init__(self, size_x, size_y):
self.size_x = size_x
self.size_y = size_y
@property
def shape(self) -> Tuple[int, int]:
return (self.size_x, self.size_y)
def prox(self, pos: Pos) -> Set[Pos]:
return {
self.translate(pos, direction)
for direction in [(0, 1), (1, 0), (0, -1), (-1, 0)]
}
def translate(self, pos: Pos, diff: Tuple[int, int]) -> Pos:
x, y = pos
dx, dy = diff
return Pos((x + dx) % self.size_x, (y + dy) % self.size_y)
def trans_to(self, pos1: Pos, pos2: Pos) -> Tuple[int, int]:
dx = pos2.x - pos1.x
dy = pos2.y - pos1.y
if dx <= self.size_x // 2:
dx += self.size_x
if dx > self.size_x // 2:
dx -= self.size_x
if dy <= self.size_y // 2:
dy += self.size_y
if dy > self.size_y // 2:
dy -= self.size_y
return (dx, dy)
def action_to(self, pos1, pos2):
diff = self.trans_to(pos1, pos2)
result = trans_action_map.get(diff)
if result is None:
raise ValueError(f"Cannot step from {pos1} to {pos2}")
return result
@dataclass
class State:
food: Set[Pos]
geese: Dict[int, Goose]
index: int
step: int
geo: Geometry
field: np.ndarray = dataclasses.field(init=False)
my_goose: Goose = dataclasses.field(init=False)
danger_poses: Set[Pos] = dataclasses.field(init=False)
def __post_init__(self):
self.field = np.full(fill_value=0, shape=self.geo.shape)
for goose in self.geese.values():
for pos in goose.poses[:-1]: # not considering tail!
self.field[pos.x, pos.y] = 1
if self.geo.prox(goose.head) & self.food:
tail = goose.poses[-1]
self.field[tail.x, tail.y] = 1
self.my_goose = self.geese[self.index]
self.danger_poses = {
pos
for i, goose in self.geese.items()
if i != self.index
for pos in self.geo.prox(goose.head)
}
@classmethod
def from_obs_conf(cls, obs, conf):
num_cols = conf["columns"]
num_rows = conf["rows"]
step = obs["step"]
index = obs["index"]
geese = {
idx: Goose(
poses=[
field_idx_to_pos(idx, num_cols=num_cols, num_rows=num_rows)
for idx in goose_data
]
)
for idx, goose_data in enumerate(obs["geese"])
if goose_data
}
food = {
field_idx_to_pos(idx, num_cols=num_cols, num_rows=num_rows)
for idx in obs["food"]
}
return cls(
food=food,
geese=geese,
index=index,
step=step,
geo=Geometry(size_x=num_rows, size_y=num_cols),
)
def __repr__(self):
return (
f"State(step:{self.step}, index:{self.index}, Geese("
+ ",".join(f"{idx}:{len(goose.poses)}" for idx, goose in self.geese.items())
+ f"), food:{len(self.food)})"
)
@dataclass
class FloodfillResult:
field_dist: np.ndarray
frontiers: List[List[Tuple[int, int]]]
def flood_fill(is_occupied: np.ndarray, seeds: List[Pos]) -> FloodfillResult:
"""
Flood will start with distance 0 at seeds and only flow where is_occupied[x,y]==0
"""
size_x, size_y = is_occupied.shape
field_dist = np.full(fill_value=-1, shape=(size_x, size_y))
frontier = [(s.x, s.y) for s in seeds]
frontiers = [frontier]
for seed in seeds:
field_dist[seed] = 0
dist = 1
while frontier:
new_frontier: List[Tuple[int, int]] = []
for x, y in frontier:
for dx, dy in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
new_x = (x + dx) % size_x
new_y = (y + dy) % size_y
if is_occupied[new_x, new_y] == 0 and field_dist[new_x, new_y] == -1:
field_dist[new_x, new_y] = dist
new_frontier.append((new_x, new_y))
frontier = new_frontier
frontiers.append(frontier)
dist += 1
return FloodfillResult(field_dist=field_dist, frontiers=frontiers)
def get_dist(
floodfill_result: FloodfillResult, test_func: Callable[[Tuple[int, int]], bool]
) -> Optional[int]:
for dist, frontier in enumerate(floodfill_result.frontiers):
for pos in frontier:
if test_func(pos):
return dist
return None
class BaseAgent(ABC):
def __init__(self):
self.last_pos: Optional[Pos] = None
def __call__(self, obs, conf):
try:
state = State.from_obs_conf(obs, conf)
next_pos = self.step(state)
action = state.geo.action_to(state.my_goose.head, next_pos)
self.last_pos = state.my_goose.head
return action.name
except Exception as exc:
traceback.print_exc(file=sys.stderr)
raise
@abstractmethod
def step(self, state: State) -> Pos:
"""
return: next position
Implement this
"""
pass
def next_poses(self, state: State) -> Set[Pos]:
head_next_poses = state.geo.prox(state.my_goose.head)
result = {
pos
for pos in head_next_poses
if pos != self.last_pos and state.field[pos] == 0
}
return result
from operator import itemgetter
import random
class FloodGoose(BaseAgent):
def __init__(self, min_length=13):
super().__init__()
self.min_length = min_length
def step(self, state):
result = None
if len(state.my_goose) < self.min_length:
result = self.goto(state, lambda pos: pos in state.food)
elif len(state.my_goose) >= 3:
result = self.goto(state, lambda pos: pos == state.my_goose.poses[-1])
if result is None:
result = self.random_step(state)
return result
def goto(self, state, test_func):
result = None
pos_dists = {}
for pos in self.next_poses(state):
flood = flood_fill(state.field, [pos])
dist = get_dist(flood, test_func)
if dist is not None:
pos_dists[pos] = dist
if pos_dists:
closest_pos, _ = min(pos_dists.items(), key=itemgetter(1))
if closest_pos not in state.danger_poses:
result = closest_pos
return result
def random_step(self, state):
next_poses = self.next_poses(state) - state.danger_poses - state.food
if not next_poses:
next_poses = self.next_poses(state) - state.danger_poses
if not next_poses:
next_poses = self.next_poses(state)
if not next_poses:
next_poses = state.geo.prox(state.my_goose.head)
result = random.choice(list(next_poses))
return result
agent = FloodGoose(min_length=8)
def call_agent(obs, conf):
return agent(obs, conf)
# # Crazy Goose
# Copy from kernel [Crazy Goose](https://www.kaggle.com/gabrielmilan/crazy-goose)
# Base code for this from
# https://www.kaggle.com/ilialar/risk-averse-greedy-goose
import numpy as np
from kaggle_environments.envs.hungry_geese.hungry_geese import (
Observation,
Configuration,
Action,
row_col,
)
# Moves constants
SOUTH = 1
NORTH = 2
EAST = 3
WEST = 4
REVERSE_MOVE = {
None: None,
SOUTH: NORTH,
NORTH: SOUTH,
EAST: WEST,
WEST: EAST,
}
CIRCLE_MOVE = {None: None, SOUTH: WEST, NORTH: EAST, EAST: SOUTH, WEST: NORTH}
# Board constants
MY_HEAD = 2
FOOD_CELL = 1
EMPTY = 0
HEAD_POSSIBLE_CELL = -1
BODY_CELL = -2
# Store last move
last_move = None
last_eaten = 0
last_size = 1
step = 0
# Returns a list of possible destinations in order to reach `dest_cell`
def move_towards(head_cell, neck_cell, dest_cell, configuration):
print("--- Computing food movements...")
destinations = []
x_head, y_head = row_col(head_cell, configuration.columns)
x_neck, y_neck = row_col(neck_cell, configuration.columns)
x_dest, y_dest = row_col(dest_cell, configuration.columns)
print("-> Head at ({}, {})".format(x_head, y_head))
print("-> Neck at ({}, {})".format(x_neck, y_neck))
print("-> Dest at ({}, {})".format(x_dest, y_dest))
dx = x_head - x_dest
dy = y_head - y_dest
if dx >= 4:
dx = 7 - dx
elif dx <= -4:
dx += 7
if dy >= 6:
dy = 11 - dy
elif dy <= -6:
dy += 11
print("dx={}, dy={}".format(dx, dy))
if dx > 0:
x_move = (x_head - 1 + 7) % 7
y_move = y_head
print("Move ({}, {}), Neck ({}, {})".format(x_move, y_move, x_neck, y_neck))
if not ((x_move == x_neck) and (y_move == y_neck)):
destinations.append((x_move, y_move, NORTH))
elif dx < 0:
x_move = (x_head + 1 + 7) % 7
y_move = y_head
print("Move ({}, {}), Neck ({}, {})".format(x_move, y_move, x_neck, y_neck))
if not ((x_move == x_neck) and (y_move == y_neck)):
destinations.append((x_move, y_move, SOUTH))
if dy > 0:
x_move = x_head
y_move = (y_head - 1 + 11) % 11
print("Move ({}, {}), Neck ({}, {})".format(x_move, y_move, x_neck, y_neck))
if not ((x_move == x_neck) and (y_move == y_neck)):
destinations.append((x_move, y_move, WEST))
elif dy < 0:
x_move = x_head
y_move = (y_head + 1 + 11) % 11
print("Move ({}, {}), Neck ({}, {})".format(x_move, y_move, x_neck, y_neck))
if not ((x_move == x_neck) and (y_move == y_neck)):
destinations.append((x_move, y_move, EAST))
return destinations
def get_all_movements(goose_head, configuration):
x_head, y_head = row_col(goose_head, configuration.columns)
movements = []
movements.append(((x_head - 1 + 7) % 7, y_head, NORTH))
movements.append(((x_head + 1 + 7) % 7, y_head, SOUTH))
movements.append((x_head, (y_head - 1 + 11) % 11, WEST))
movements.append((x_head, (y_head + 1 + 11) % 11, EAST))
return movements
def get_nearest_cells(x, y):
# Returns adjacent cells from the current one
result = []
for i in (-1, +1):
result.append(((x + i + 7) % 7, y))
result.append((x, (y + i + 11) % 11))
return result
# Compute L1 distance between cells
def cell_distance(a, b, configuration):
xa, ya = row_col(a, configuration.columns)
xb, yb = row_col(b, configuration.columns)
dx = abs(xa - xb)
dy = abs(ya - yb)
if dx >= 4:
dx = 7 - dx
if dy >= 6:
dy = 11 - dy
return dx + dy
# Tells if that particular cell forbids movement on the next step
def is_closed(movement, board):
return all(
[
board[x_adj, y_adj]
for (x_adj, y_adj) in get_nearest_cells(movement[0], movement[1])
]
)
def is_safe(movement, board):
return board[movement[0], movement[1]] >= 0
def is_half_safe(movement, board):
return board[movement[0], movement[1]] >= -1
def agent(obs_dict, config_dict):
global last_move
global last_eaten
global last_size
global step
print("==============================================")
observation = Observation(obs_dict)
configuration = Configuration(config_dict)
player_index = observation.index
player_goose = observation.geese[player_index]
player_head = player_goose[0]
player_row, player_column = row_col(player_head, configuration.columns)
if len(player_goose) > last_size:
last_size = len(player_goose)
last_eaten = step
step += 1
moves = {1: "SOUTH", 2: "NORTH", 3: "EAST", 4: "WEST"}
board = np.zeros((7, 11))
# Adding food to board
for food in observation.food:
x, y = row_col(food, configuration.columns)
print("Food cell on ({}, {})".format(x, y))
board[x, y] = FOOD_CELL
# Adding geese to the board
for i in range(4):
goose = observation.geese[i]
# Skip if goose is dead
if len(goose) == 0:
continue
# If it's an opponent
if i != player_index:
x, y = row_col(goose[0], configuration.columns)
# Add possible head movements for it
for px, py in get_nearest_cells(x, y):
print("Head possible cell on ({}, {})".format(px, py))
# If one of these head movements may lead the goose
# to eat, add tail as BODY_CELL, because it won't move.
if board[px, py] == FOOD_CELL:
x_tail, y_tail = row_col(goose[-1], configuration.columns)
print(
"Adding tail on ({}, {}) as the goose may eat".format(
x_tail, y_tail
)
)
board[x_tail, y_tail] = BODY_CELL
board[px, py] = HEAD_POSSIBLE_CELL
# Adds goose body without tail (tail is previously added only if goose may eat)
for n in goose[:-1]:
x, y = row_col(n, configuration.columns)
print("Body cell on ({}, {})".format(x, y))
board[x, y] = BODY_CELL
# Adding my head to the board
x, y = row_col(player_head, configuration.columns)
print("My head is at ({}, {})".format(x, y))
board[x, y] = MY_HEAD
# Debug board
print(board)
# Iterate over food and geese in order to compute distances for each one
food_race = {}
for food in observation.food:
food_race[food] = {}
for i in range(4):
goose = observation.geese[i]
if len(goose) == 0:
continue
food_race[food][i] = cell_distance(goose[0], food, configuration)
# The best food is the least coveted
best_food = None
best_distance = float("inf")
best_closest_geese = float("inf")
for food in food_race:
print("-> Food on {}".format(row_col(food, configuration.columns)))
my_distance = food_race[food][player_index]
print(" - My distance is {}".format(my_distance))
closest_geese = 0
for goose_id in food_race[food]:
if goose_id == player_index:
continue
if food_race[food][goose_id] <= my_distance:
closest_geese += 1
print(" - There are {} closest geese".format(closest_geese))
if closest_geese < best_closest_geese:
best_food = food
best_distance = my_distance
best_closest_geese = closest_geese
print(" * This food is better")
elif (closest_geese == best_closest_geese) and (my_distance <= best_distance):
best_food = food
best_distance = my_distance
best_closest_geese = closest_geese
print(" * This food is better")
# Now that the best food has been found, check if the movement towards it is safe.
# Computes every available move and then check for move priorities.
if len(player_goose) > 1:
food_movements = move_towards(
player_head, player_goose[1], best_food, configuration
)
else:
food_movements = move_towards(
player_head, player_head, best_food, configuration
)
all_movements = get_all_movements(player_head, configuration)
# Excluding last movement reverse
food_movements = [
move for move in food_movements if move[2] != REVERSE_MOVE[last_move]
]
all_movements = [
move for move in all_movements if move[2] != REVERSE_MOVE[last_move]
]
print("-> Available food moves: {}".format(food_movements))
print("-> All moves: {}".format(all_movements))
# Trying to reach goal size of 4
if len(player_goose) < 4:
# 1. Food movements that are safe and not closed
for food_movement in food_movements:
print("Food movement {}".format(food_movement))
if is_safe(food_movement, board) and not is_closed(food_movement, board):
print("It's safe! Let's move {}!".format(moves[food_movement[2]]))
last_move = food_movement[2]
return moves[food_movement[2]] # Move here
# 2. Any movement safe and not closed
for movement in all_movements:
print("Movement {}".format(movement))
if is_safe(movement, board) and not is_closed(movement, board):
print("It's safe! Let's move {}!".format(moves[movement[2]]))
last_move = movement[2]
return moves[movement[2]] # Move here
# 3. Food movements half safe and not closed
for food_movement in food_movements:
if is_half_safe(food_movement, board) and not is_closed(
food_movement, board
):
print(
"Food movement {} is half safe, I'm going {}!".format(
food_movement, moves[food_movement[2]]
)
)
last_move = food_movement[2]
return moves[food_movement[2]] # Move here
# 4. Any movement half safe and not closed
for movement in all_movements:
if is_half_safe(movement, board) and not is_closed(movement, board):
print(
"Movement {} is half safe, I'm going {}!".format(
movement, moves[movement[2]]
)
)
last_move = movement[2]
return moves[movement[2]] # Move here
# 5. Food movements that are safe
for food_movement in food_movements:
print("Food movement {}".format(food_movement))
if is_safe(food_movement, board):
print("It's safe! Let's move {}!".format(moves[food_movement[2]]))
last_move = food_movement[2]
return moves[food_movement[2]] # Move here
# 6. Any movement safe
for movement in all_movements:
print("Movement {}".format(movement))
if is_safe(movement, board):
print("It's safe! Let's move {}!".format(moves[movement[2]]))
last_move = movement[2]
return moves[movement[2]] # Move here
# 7. Food movements half safe
for food_movement in food_movements:
if is_half_safe(food_movement, board):
print(
"Food movement {} is half safe, I'm going {}!".format(
food_movement, moves[food_movement[2]]
)
)
last_move = food_movement[2]
return moves[food_movement[2]] # Move here
# 8. Any movement half safe
for movement in all_movements:
if is_half_safe(movement, board):
print(
"Movement {} is half safe, I'm going {}!".format(
movement, moves[movement[2]]
)
)
last_move = movement[2]
return moves[movement[2]] # Move here
# Just trying to walk in circles
else:
# Delete food moves
food_coordinates = []
for food in food_race:
x_food, y_food = row_col(food, configuration.columns)
food_coordinates.append((x_food, y_food))
available_moves = []
for move in all_movements:
for x_food, y_food in food_coordinates:
if (move[0] != x_food) or (move[1] != y_food):
available_moves.append(move)
# 1. Run in circles if you can
circle_move = CIRCLE_MOVE[last_move]
for move in available_moves:
if (
(move[2] == circle_move)
and (is_safe(move, board))
and not (is_closed(move, board))
):
last_move = move[2]
return moves[move[2]]
# 2. Any movement safe and not closed
for movement in all_movements:
print("Movement {}".format(movement))
if is_safe(movement, board) and not is_closed(movement, board):
print("It's safe! Let's move {}!".format(moves[movement[2]]))
last_move = movement[2]
return moves[movement[2]] # Move here
# 3. Any movement half safe and not closed
for movement in all_movements:
if is_half_safe(movement, board) and not is_closed(movement, board):
print(
"Movement {} is half safe, I'm going {}!".format(
movement, moves[movement[2]]
)
)
last_move = movement[2]
return moves[movement[2]] # Move here
# 4. Any movement safe
for movement in all_movements:
print("Movement {}".format(movement))
if is_safe(movement, board):
print("It's safe! Let's move {}!".format(moves[movement[2]]))
last_move = movement[2]
return moves[movement[2]] # Move here
# 5. Any movement half safe
for movement in all_movements:
if is_half_safe(movement, board):
print(
"Movement {} is half safe, I'm going {}!".format(
movement, moves[movement[2]]
)
)
last_move = movement[2]
return moves[movement[2]] # Move here
# Finally, if all moves are unsafe, randomly pick one
rand_pick = np.random.randint(4) + 1
last_move = rand_pick
print("Yeah whatever, I'm going {}".format(moves[rand_pick]))
return moves[rand_pick]
# # PubHRL
# Copy from kernel [Smart Geese Trained by Reinforcement Learning](https://www.kaggle.com/yuricat/smart-geese-trained-by-reinforcement-learning)
# This is a lightweight ML agent trained by self-play.
# After sharing this notebook,
# we will add Hungry Geese environment in our HandyRL library.
# https://github.com/DeNA/HandyRL
# We hope you enjoy reinforcement learning!
import pickle
import bz2
import base64
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
# Neural Network for Hungry Geese
class TorusConv2d(nn.Module):
def __init__(self, input_dim, output_dim, kernel_size, bn):
super().__init__()
self.edge_size = (kernel_size[0] // 2, kernel_size[1] // 2)
self.conv = nn.Conv2d(input_dim, output_dim, kernel_size=kernel_size)
self.bn = nn.BatchNorm2d(output_dim) if bn else None
def forward(self, x):
h = torch.cat(
[x[:, :, :, -self.edge_size[1] :], x, x[:, :, :, : self.edge_size[1]]],
dim=3,
)
h = torch.cat(
[h[:, :, -self.edge_size[0] :], h, h[:, :, : self.edge_size[0]]], dim=2
)
h = self.conv(h)
h = self.bn(h) if self.bn is not None else h
return h
class GeeseNet(nn.Module):
def __init__(self):
super().__init__()
layers, filters = 12, 32
self.conv0 = TorusConv2d(17, filters, (3, 3), True)
self.blocks = nn.ModuleList(
[TorusConv2d(filters, filters, (3, 3), True) for _ in range(layers)]
)
self.head_p = nn.Linear(filters, 4, bias=False)
self.head_v = nn.Linear(filters * 2, 1, bias=False)
def forward(self, x):
h = F.relu_(self.conv0(x))
for block in self.blocks:
h = F.relu_(h + block(h))
h_head = (h * x[:, :1]).view(h.size(0), h.size(1), -1).sum(-1)
h_avg = h.view(h.size(0), h.size(1), -1).mean(-1)
p = self.head_p(h_head)
v = torch.tanh(self.head_v(torch.cat([h_head, h_avg], 1)))
return {"policy": p, "value": v}
# Input for Neural Network
def make_input(obses):
b = np.zeros((17, 7 * 11), dtype=np.float32)
obs = obses[-1]
for p, pos_list in enumerate(obs["geese"]):
# head position
for pos in pos_list[:1]:
b[0 + (p - obs["index"]) % 4, pos] = 1
# tip position
for pos in pos_list[-1:]:
b[4 + (p - obs["index"]) % 4, pos] = 1
# whole position
for pos in pos_list:
b[8 + (p - obs["index"]) % 4, pos] = 1
# previous head position
if len(obses) > 1:
obs_prev = obses[-2]
for p, pos_list in enumerate(obs_prev["geese"]):
for pos in pos_list[:1]:
b[12 + (p - obs["index"]) % 4, pos] = 1
# food
for pos in obs["food"]:
b[16, pos] = 1
return b.reshape(-1, 7, 11)
# Load PyTorch Model
PARAM = b"XXXXX"
state_dict = pickle.loads(bz2.decompress(base64.b64decode(PARAM)))
model = GeeseNet()
model.load_state_dict(state_dict)
model.eval()
# Main Function of Agent
obses = []
def agent(obs, _):
obses.append(obs)
x = make_input(obses)
with torch.no_grad():
xt = torch.from_numpy(x).unsqueeze(0)
o = model(xt)
p = o["policy"].squeeze(0).detach().numpy()
actions = ["NORTH", "SOUTH", "WEST", "EAST"]
return actions[np.argmax(p)]
url = "https://tonghuikang.github.io/hungry-goose-training-logs/strings/pubhrl.txt"
import urllib
params = next(urllib.request.urlopen(url)).decode("utf-8")
with open("pubhrl.py", "r") as f:
s = f.read()
s = s.replace("XXXXX", params)
with open("pubhrl.py", "w") as f:
f.write(s)
# # PubHRL - trained
# This is a lightweight ML agent trained by self-play.
# After sharing this notebook,
# we will add Hungry Geese environment in our HandyRL library.
# https://github.com/DeNA/HandyRL
# We hope you enjoy reinforcement learning!
import pickle
import bz2
import base64
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
# Neural Network for Hungry Geese
class TorusConv2d(nn.Module):
def __init__(self, input_dim, output_dim, kernel_size, bn):
super().__init__()
self.edge_size = (kernel_size[0] // 2, kernel_size[1] // 2)
self.conv = nn.Conv2d(input_dim, output_dim, kernel_size=kernel_size)
self.bn = nn.BatchNorm2d(output_dim) if bn else None
def forward(self, x):
h = torch.cat(
[x[:, :, :, -self.edge_size[1] :], x, x[:, :, :, : self.edge_size[1]]],
dim=3,
)
h = torch.cat(
[h[:, :, -self.edge_size[0] :], h, h[:, :, : self.edge_size[0]]], dim=2
)
h = self.conv(h)
h = self.bn(h) if self.bn is not None else h
return h
class GeeseNet(nn.Module):
def __init__(self):
super().__init__()
layers, filters = 12, 32
self.conv0 = TorusConv2d(17, filters, (3, 3), True)
self.blocks = nn.ModuleList(
[TorusConv2d(filters, filters, (3, 3), True) for _ in range(layers)]
)
self.head_p = nn.Linear(filters, 4, bias=False)
self.head_v = nn.Linear(filters * 2, 1, bias=False)
def forward(self, x):
h = F.relu_(self.conv0(x))
for block in self.blocks:
h = F.relu_(h + block(h))
h_head = (h * x[:, :1]).view(h.size(0), h.size(1), -1).sum(-1)
h_avg = h.view(h.size(0), h.size(1), -1).mean(-1)
p = self.head_p(h_head)
v = torch.tanh(self.head_v(torch.cat([h_head, h_avg], 1)))
return {"policy": p, "value": v}
# Input for Neural Network
def make_input(obses):
b = np.zeros((17, 7 * 11), dtype=np.float32)
obs = obses[-1]
for p, pos_list in enumerate(obs["geese"]):
# head position
for pos in pos_list[:1]:
b[0 + (p - obs["index"]) % 4, pos] = 1
# tip position
for pos in pos_list[-1:]:
b[4 + (p - obs["index"]) % 4, pos] = 1
# whole position
for pos in pos_list:
b[8 + (p - obs["index"]) % 4, pos] = 1
# previous head position
if len(obses) > 1:
obs_prev = obses[-2]
for p, pos_list in enumerate(obs_prev["geese"]):
for pos in pos_list[:1]:
b[12 + (p - obs["index"]) % 4, pos] = 1
# food
for pos in obs["food"]:
b[16, pos] = 1
return b.reshape(-1, 7, 11)
# Load PyTorch Model
PARAM = b"XXXXX"
state_dict = pickle.loads(bz2.decompress(base64.b64decode(PARAM)))
model = GeeseNet()
model.load_state_dict(state_dict)
model.eval()
# Main Function of Agent
obses = []
def agent(obs, _):
obses.append(obs)
x = make_input(obses)
with torch.no_grad():
xt = torch.from_numpy(x).unsqueeze(0)
o = model(xt)
p = o["policy"].squeeze(0).detach().numpy()
actions = ["NORTH", "SOUTH", "WEST", "EAST"]
return actions[np.argmax(p)]
url = "https://tonghuikang.github.io/hungry-goose-training-logs/strings/pubhrl-trained-on-assorted-e4750.txt"
import urllib
params = next(urllib.request.urlopen(url)).decode("utf-8")
with open("pubhrl_trained.py", "r") as f:
s = f.read()
s = s.replace("XXXXX", params)
with open("pubhrl_trained.py", "w") as f:
f.write(s)
# # AlphaGeese
import pickle
import bz2
import base64
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import time
from copy import deepcopy
from kaggle_environments.envs.hungry_geese.hungry_geese import Action, translate
from kaggle_environments.helpers import histogram
# The model's parameters from https://www.kaggle.com/yuricat/smart-geese-trained-by-reinforcement-learning
PARAM = b"XXXXX"
class MCTS:
def __init__(self, game, nn_agent, eps=1e-8, cpuct=1.0):
self.game = game
self.nn_agent = nn_agent
self.eps = eps
self.cpuct = cpuct
self.Qsa = {} # stores Q values for s,a (as defined in the paper)
self.Nsa = {} # stores #times edge s,a was visited
self.Ns = {} # stores #times board s was visited
self.Ps = {} # stores initial policy (returned by neural net)
self.Vs = {} # stores game.getValidMoves for board s
self.last_obs = None
def getActionProb(self, obs, timelimit=1.0):
start_time = time.time()
while time.time() - start_time < timelimit:
self.search(obs, self.last_obs)
s = self.game.stringRepresentation(obs)
i = obs.index
counts = [
self.Nsa[(s, i, a)] if (s, i, a) in self.Nsa else 0
for a in range(self.game.getActionSize())
]
prob = counts / np.sum(counts)
self.last_obs = obs
return prob
def search(self, obs, last_obs):
s = self.game.stringRepresentation(obs)
if s not in self.Ns:
values = [-10] * 4
for i in range(4):
if len(obs.geese[i]) == 0:
continue
# leaf node
self.Ps[(s, i)], values[i] = self.nn_agent.predict(obs, last_obs, i)
valids = self.game.getValidMoves(obs, last_obs, i)
self.Ps[(s, i)] = self.Ps[(s, i)] * valids # masking invalid moves
sum_Ps_s = np.sum(self.Ps[(s, i)])
if sum_Ps_s > 0:
self.Ps[(s, i)] /= sum_Ps_s # renormalize
self.Vs[(s, i)] = valids
self.Ns[s] = 0
return values
best_acts = [None] * 4
for i in range(4):
if len(obs.geese[i]) == 0:
continue
valids = self.Vs[(s, i)]
cur_best = -float("inf")
best_act = self.game.actions[-1]
# pick the action with the highest upper confidence bound
for a in range(self.game.getActionSize()):
if valids[a]:
if (s, i, a) in self.Qsa:
u = self.Qsa[(s, i, a)] + self.cpuct * self.Ps[(s, i)][
a
] * math.sqrt(self.Ns[s]) / (1 + self.Nsa[(s, i, a)])
else:
u = (
self.cpuct
* self.Ps[(s, i)][a]
* math.sqrt(self.Ns[s] + self.eps)
) # Q = 0 ?
if u > cur_best:
cur_best = u
best_act = self.game.actions[a]
best_acts[i] = best_act
next_obs = self.game.getNextState(obs, last_obs, best_acts)
values = self.search(next_obs, obs)
for i in range(4):
if len(obs.geese[i]) == 0:
continue
a = self.game.actions.index(best_acts[i])
v = values[i]
if (s, i, a) in self.Qsa:
self.Qsa[(s, i, a)] = (
self.Nsa[(s, i, a)] * self.Qsa[(s, i, a)] + v
) / (self.Nsa[(s, i, a)] + 1)
self.Nsa[(s, i, a)] += 1
else:
self.Qsa[(s, i, a)] = v
self.Nsa[(s, i, a)] = 1
self.Ns[s] += 1
return values
class HungryGeese(object):
def __init__(
self,
rows=7,
columns=11,
actions=[Action.NORTH, Action.SOUTH, Action.WEST, Action.EAST],
hunger_rate=40,
):
self.rows = rows
self.columns = columns
self.actions = actions
self.hunger_rate = hunger_rate
def getActionSize(self):
return len(self.actions)
def getNextState(self, obs, last_obs, directions):
next_obs = deepcopy(obs)
next_obs.step += 1
geese = next_obs.geese
food = next_obs.food
for i in range(4):
goose = geese[i]
if len(goose) == 0:
continue
head = translate(goose[0], directions[i], self.columns, self.rows)
# Check action direction
if last_obs is not None and head == last_obs.geese[i][0]:
geese[i] = []
continue
# Consume food or drop a tail piece.
if head in food:
food.remove(head)
else:
goose.pop()
# Add New Head to the Goose.
goose.insert(0, head)
# If hunger strikes remove from the tail.
if next_obs.step % self.hunger_rate == 0:
if len(goose) > 0:
goose.pop()
goose_positions = histogram(position for goose in geese for position in goose)
# Check for collisions.
for i in range(4):
if len(geese[i]) > 0:
head = geese[i][0]
if goose_positions[head] > 1:
geese[i] = []
return next_obs
def getValidMoves(self, obs, last_obs, index):
geese = obs.geese
pos = geese[index][0]
obstacles = {position for goose in geese for position in goose[:-1]}
if last_obs is not None:
obstacles.add(last_obs.geese[index][0])
valid_moves = [
translate(pos, action, self.columns, self.rows) not in obstacles
for action in self.actions
]
return valid_moves
def stringRepresentation(self, obs):
return str(obs.geese + obs.food)
# Neural Network for Hungry Geese
class TorusConv2d(nn.Module):
def __init__(self, input_dim, output_dim, kernel_size, bn):
super().__init__()
self.edge_size = (kernel_size[0] // 2, kernel_size[1] // 2)
self.conv = nn.Conv2d(input_dim, output_dim, kernel_size=kernel_size)
self.bn = nn.BatchNorm2d(output_dim) if bn else None
def forward(self, x):
h = torch.cat(
[x[:, :, :, -self.edge_size[1] :], x, x[:, :, :, : self.edge_size[1]]],
dim=3,
)
h = torch.cat(
[h[:, :, -self.edge_size[0] :], h, h[:, :, : self.edge_size[0]]], dim=2
)
h = self.conv(h)
h = self.bn(h) if self.bn is not None else h
return h
class GeeseNet(nn.Module):
def __init__(self):
super().__init__()
layers, filters = 12, 32
self.conv0 = TorusConv2d(17, filters, (3, 3), True)
self.blocks = nn.ModuleList(
[TorusConv2d(filters, filters, (3, 3), True) for _ in range(layers)]
)
self.head_p = nn.Linear(filters, 4, bias=False)
self.head_v = nn.Linear(filters * 2, 1, bias=False)
def forward(self, x):
h = F.relu_(self.conv0(x))
for block in self.blocks:
h = F.relu_(h + block(h))
h_head = (h * x[:, :1]).view(h.size(0), h.size(1), -1).sum(-1)
h_avg = h.view(h.size(0), h.size(1), -1).mean(-1)
p = torch.softmax(self.head_p(h_head), 1)
v = torch.tanh(self.head_v(torch.cat([h_head, h_avg], 1)))
return p, v
class NNAgent:
def __init__(self, state_dict):
self.model = GeeseNet()
self.model.load_state_dict(state_dict)
self.model.eval()
def predict(self, obs, last_obs, index):
x = self._make_input(obs, last_obs, index)
with torch.no_grad():
xt = torch.from_numpy(x).unsqueeze(0)
p, v = self.model(xt)
return p.squeeze(0).detach().numpy(), v.item()
# Input for Neural Network
def _make_input(self, obs, last_obs, index):
b = np.zeros((17, 7 * 11), dtype=np.float32)
for p, pos_list in enumerate(obs.geese):
# head position
for pos in pos_list[:1]:
b[0 + (p - index) % 4, pos] = 1
# tip position
for pos in pos_list[-1:]:
b[4 + (p - index) % 4, pos] = 1
# whole position
for pos in pos_list:
b[8 + (p - index) % 4, pos] = 1
# previous head position
if last_obs is not None:
for p, pos_list in enumerate(last_obs.geese):
for pos in pos_list[:1]:
b[12 + (p - index) % 4, pos] = 1
# food
for pos in obs.food:
b[16, pos] = 1
return b.reshape(-1, 7, 11)
game = HungryGeese()
state_dict = pickle.loads(bz2.decompress(base64.b64decode(PARAM)))
agent = NNAgent(state_dict)
mcts = MCTS(game, agent)
def alphageese_agent(obs, config):
action = game.actions[
np.argmax(mcts.getActionProb(obs, timelimit=config.actTimeout))
]
return action.name
url = "https://tonghuikang.github.io/hungry-goose-training-logs/strings/pubhrl.txt"
import urllib
params = next(urllib.request.urlopen(url)).decode("utf-8")
with open("alphageese.py", "r") as f:
s = f.read()
s = s.replace("XXXXX", params)
with open("alphageese.py", "w") as f:
f.write(s)
# # AlphaGeese improved
import pickle
import bz2
import base64
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import time
import functools, collections
from copy import deepcopy
from kaggle_environments.envs.hungry_geese.hungry_geese import Action, translate
from kaggle_environments.helpers import histogram
sigmoid = lambda x: 1 / (1 + np.exp(-x))
eps = 10 ** (-6)
DEBUG = True
# The model’s parameters from https://www.kaggle.com/yuricat/smart-geese-trained-by-reinforcement-learning
PARAM = b"XXXXX"
PARAM_SELF = b"YYYYY"
class MCTS:
def __init__(
self,
game,
nn_agent_self,
nn_agent_pubhrl,
eps=1e-8,
cpuct_self=1.0,
cpuct_other=1.0,
):
self.game = game
self.nn_agent_self = nn_agent_self
self.nn_agent_pubhrl = nn_agent_pubhrl
self.eps = eps
self.cpuct_self = cpuct_self
self.cpuct_other = cpuct_other
self.Qsa = {} # stores Q values for s,a (as defined in the paper)
self.Nsa = {} # stores #times edge s,a was visited
self.Ns = {} # stores #times board s was visited
self.Ps = {} # stores initial policy (returned by neural net)
self.Pm = {} # masked initial policy (returned by neural net times masking)
self.Vs = {} # stores game.getValidMoves for board s
self.last_obs = None
def getActionProb(self, obs, timelimit=1.0):
extra_time = obs.remainingOverageTime
obs_step = obs.step
remaining_steps = 220 - obs.step
print(obs)
print(len(obs.geese[obs.index]), [len(goose) for goose in obs.geese])
s = self.game.stringRepresentation(obs)
i = obs.index
start_time = time.time()
while time.time() - start_time < timelimit + extra_time / (remaining_steps / 4):
self.search(obs, self.last_obs)
counts = [
self.Nsa[(s, i, a)] if (s, i, a) in self.Nsa else 0
for a in range(self.game.getActionSize())
]
prob = counts / (np.sum(counts) + eps)
target_prob = max(self.Ps[s, i])
if time.time() - start_time > timelimit and (
extra_time < 10 or max(prob) >= target_prob
):
break
self.last_obs = obs
a = np.argmax(prob)
if DEBUG:
print(s, i, a)
print(
len(self.Qsa), len(self.Nsa), len(self.Ns), len(self.Ps), len(self.Vs)
)
print("self.Qsa", self.Qsa[s, i, a])
print("self.Nsa", self.Nsa[s, i, a])
print("self.Ns", self.Ns[s])
print("self.Ps", " ".join(f"{x:.4f}" for x in self.Ps[s, i]))
print("self.Vs", self.Vs[s, i])
print("prob ", " ".join(f"{x:.4f}" for x in prob))
print()
return prob
def search(self, obs, last_obs, prev_v=0):
s = self.game.stringRepresentation(obs)
if obs.step >= 200:
lengths = sorted(len(goose) for goose in obs.geese)[::-1]
position = lengths.index(len(obs.geese[obs.index]))
scores = {0: 1, 1: 0.5, 2: -0.5, 3: -1}
return [scores[position]] * 4
if s not in self.Ns:
values = [-10] * 4
for i in range(4):
if len(obs.geese[i]) == 0:
continue
valids = self.game.getValidMoves(obs, last_obs, i)
# leaf node
if sum(v == 0 for v in valids) >= 3:
self.Ps[(s, i)], values[i] = valids, prev_v
elif obs.step >= 192: # random rollouts
self.Ps[(s, i)], values[i] = [0.25, 0.25, 0.25, 0.25], prev_v
elif i == obs.index:
self.Ps[(s, i)], values[i] = self.nn_agent_self.predict(
obs, last_obs, i
)
else:
self.Ps[(s, i)], values[i] = self.nn_agent_pubhrl.predict(
obs, last_obs, i
)
self.Pm[s, i] = (
valids + self.Ps[s, i]
) * valids # masking invalid moves
sum_Ps_s = np.sum(self.Pm[s, i])
if sum_Ps_s > 0:
self.Pm[(s, i)] /= sum_Ps_s # renormalize
self.Vs[(s, i)] = valids
self.Ns[s] = 0
return values
best_acts = [None] * 4
for i in range(4):
if len(obs.geese[i]) == 0:
continue
valids = self.Vs[(s, i)]
cur_best = -float("inf")
best_act = self.game.actions[-1]
# pick the action with the highest upper confidence bound
for a in range(self.game.getActionSize()):
if i == obs.index:
cpuct = self.cpuct_self
else:
cpuct = self.cpuct_other
if valids[a]:
if (s, i, a) in self.Qsa:
u = self.Qsa[(s, i, a)] + cpuct * self.Ps[(s, i)][
a
] * math.sqrt(self.Ns[s]) / (1 + self.Nsa[(s, i, a)])
else:
u = (
cpuct
* self.Ps[(s, i)][a]
* math.sqrt(self.Ns[s] + self.eps)
) # Q = 0 ?
if u > cur_best:
cur_best = u
best_act = self.game.actions[a]
best_acts[i] = best_act
next_obs = self.game.getNextState(obs, last_obs, best_acts)
values = self.search(next_obs, obs)
for i in range(4):
if len(obs.geese[i]) == 0:
continue
a = self.game.actions.index(best_acts[i])
v = values[i]
if (s, i, a) in self.Qsa:
self.Qsa[(s, i, a)] = (
self.Nsa[(s, i, a)] * self.Qsa[(s, i, a)] + v
) / (self.Nsa[(s, i, a)] + 1)
self.Nsa[(s, i, a)] += 1
else:
self.Qsa[(s, i, a)] = v
self.Nsa[(s, i, a)] = 1 + sigmoid(v) # to tie break when needed
self.Ns[s] += 1
return values
class HungryGeese(object):
def __init__(
self,
rows=7,
columns=11,
actions=[Action.NORTH, Action.SOUTH, Action.WEST, Action.EAST],
hunger_rate=40,
):
self.rows = rows
self.columns = columns
self.actions = actions
self.hunger_rate = hunger_rate
def getActionSize(self):
return len(self.actions)
def getNextState(self, obs, last_obs, directions):
next_obs = deepcopy(obs)
next_obs.step += 1
geese = next_obs.geese
food = next_obs.food
for i in range(4):
goose = geese[i]
if len(goose) == 0:
continue
head = translate(goose[0], directions[i], self.columns, self.rows)
# Check action direction
if last_obs is not None and head == last_obs.geese[i][0]:
geese[i] = []
continue
# Consume food or drop a tail piece.
if head in food:
food.remove(head)
else:
goose.pop()
# Add New Head to the Goose.
goose.insert(0, head)
# If hunger strikes remove from the tail.
if next_obs.step % self.hunger_rate == 0:
if len(goose) > 0:
goose.pop()
goose_positions = histogram(position for goose in geese for position in goose)
# Check for collisions.
for i in range(4):
if len(geese[i]) > 0:
head = geese[i][0]
if goose_positions[head] > 1:
geese[i] = []
return next_obs
def getValidMoves(self, obs, last_obs, index):
foods = obs.food
geese = deepcopy(obs.geese)
pos = geese[index][0]
maxlen_goose = max(len(goose) for goose in geese)
num_goose = sum(len(goose) > 0 for goose in geese)
potential_tail_strike = collections.defaultdict(lambda: 1)
potential_head_collision = collections.defaultdict(lambda: 1)
for goose_idx, goose in enumerate(geese):
if goose_idx == index or not goose:
continue
for action in self.actions:
nex_loc = translate(goose[0], action, self.columns, self.rows)
head_collision_factor = 1
if len(geese[index]) < len(goose):
potential_head_collision[
nex_loc
] = 0.111 # avoid because of definite loss
elif num_goose == 2 and len(geese[index]) >= maxlen_goose:
potential_head_collision[nex_loc] = 3.333 # secure first place
else:
potential_head_collision[
nex_loc
] = 0.888 # would prefer higher placing
if nex_loc in foods:
potential_tail_strike[goose[-1]] = 0.101
next_poss = [
translate(pos, action, self.columns, self.rows) for action in self.actions
]
mask_head_collision = np.array(
[potential_head_collision[next_pos] for next_pos in next_poss]
)
mask_tail_strike = np.array(
[potential_tail_strike[next_pos] for next_pos in next_poss]
)
obstacles = {position for goose in geese for position in goose[:-1]}
if last_obs:
obstacles.add(last_obs.geese[index][0])
mask_valid = np.array(
[1.0 if next_pos not in obstacles else 0 for next_pos in next_poss]
)
return mask_valid * mask_tail_strike * mask_head_collision
def stringRepresentation(self, obs):
return str(obs.geese + obs.food)
# Neural Network for Hungry Geese
class TorusConv2d(nn.Module):
def __init__(self, input_dim, output_dim, kernel_size, bn):
super().__init__()
self.edge_size = (kernel_size[0] // 2, kernel_size[1] // 2)
self.conv = nn.Conv2d(input_dim, output_dim, kernel_size=kernel_size)
self.bn = nn.BatchNorm2d(output_dim) if bn else None
def forward(self, x):
h = torch.cat(
[x[:, :, :, -self.edge_size[1] :], x, x[:, :, :, : self.edge_size[1]]],
dim=3,
)
h = torch.cat(
[h[:, :, -self.edge_size[0] :], h, h[:, :, : self.edge_size[0]]], dim=2
)
h = self.conv(h)
h = self.bn(h) if self.bn is not None else h
return h
class GeeseNet(nn.Module):
def __init__(self):
super().__init__()
layers, filters = 12, 32
self.conv0 = TorusConv2d(17, filters, (3, 3), True)
self.blocks = nn.ModuleList(
[TorusConv2d(filters, filters, (3, 3), True) for _ in range(layers)]
)
self.head_p = nn.Linear(filters, 4, bias=False)
self.head_v = nn.Linear(filters * 2, 1, bias=False)
def forward(self, x):
h = F.relu_(self.conv0(x))
for block in self.blocks:
h = F.relu_(h + block(h))
h_head = (h * x[:, :1]).view(h.size(0), h.size(1), -1).sum(-1)
h_avg = h.view(h.size(0), h.size(1), -1).mean(-1)
p = torch.softmax(self.head_p(h_head), 1)
v = torch.tanh(self.head_v(torch.cat([h_head, h_avg], 1)))
return p, v
class NNAgent:
def __init__(self, state_dict):
self.model = GeeseNet()
self.model.load_state_dict(state_dict)
self.model.eval()
def predict(self, obs, last_obs, index):
x = self._make_input(obs, last_obs, index)
with torch.no_grad():
xt = torch.from_numpy(x).unsqueeze(0)
p, v = self.model(xt)
return p.squeeze(0).detach().numpy(), v.item()
# Input for Neural Network
def _make_input(self, obs, last_obs, index):
b = np.zeros((17, 7 * 11), dtype=np.float32)
for p, pos_list in enumerate(obs.geese):
# head position
for pos in pos_list[:1]:
b[0 + (p - index) % 4, pos] = 1
# tip position
for pos in pos_list[-1:]:
b[4 + (p - index) % 4, pos] = 1
# whole position
for pos in pos_list:
b[8 + (p - index) % 4, pos] = 1
# previous head position
if last_obs is not None:
for p, pos_list in enumerate(last_obs.geese):
for pos in pos_list[:1]:
b[12 + (p - index) % 4, pos] = 1
# food
for pos in obs.food:
b[16, pos] = 1
return b.reshape(-1, 7, 11)
game = HungryGeese()
state_dict_self = pickle.loads(bz2.decompress(base64.b64decode(PARAM)))
agent_self = NNAgent(state_dict_self)
state_dict_pubhrl = pickle.loads(bz2.decompress(base64.b64decode(PARAM)))
agent_pubhrl = NNAgent(state_dict_pubhrl)
mcts = MCTS(game, agent_self, agent_pubhrl)
def alphageese_agent(obs, config):
action = game.actions[
np.argmax(mcts.getActionProb(obs, timelimit=config.actTimeout))
]
return action.name
# class Struct(object):
# # convert dictionary into object to allow instance.attribute notation
# def __init__(self, data):
# for name, value in data.items():
# setattr(self, name, self._wrap(value))
# def _wrap(self, value):
# if isinstance(value, (tuple, list, set, frozenset)):
# return type(value)([self._wrap(v) for v in value])
# else:
# return Struct(value) if isinstance(value, dict) else value
# ## test code
# config = {'episodeSteps': 200, 'actTimeout': 1, 'runTimeout': 1200,
# 'columns': 11, 'rows': 7, 'hunger_rate': 40, 'min_food': 2, 'max_length': 99}
# # [????] better to get stuck because game is ending
# obs = {'remainingOverageTime': 60, 'index': 1, 'step': 197, 'geese': [[],
# [36,35,24,25,14,3,4,15,16,27,38,39,40,29,28,17,18,7,6,5],
# [56,45,46,57,68,2,13,12,23,34,33,43,42,31,20,21,10,9,75,64,65],
# [30,41,52,63,62,51,50,49,48,59,60,61,72,73,74,8,19]], 'food': [26, 69]}
# alphageese_agent(Struct(obs), Struct(config))
# # [0100] https://www.kaggle.com/c/hungry-geese/submissions?dialog=episodes-episode-24354313
# obs = {'remainingOverageTime': 36.25855599999999, 'index': 3, 'step': 195, 'geese': [
# [76, 75, 74, 73, 72, 6, 7, 8, 9, 20, 21, 10],
# [3, 2, 13, 14, 25, 24, 23, 22, 11, 0, 66, 67, 68, 69, 70, 71, 5],
# [65, 64, 63, 52, 53, 42, 31, 32, 43, 54, 44, 45, 46, 57, 56],
# [36, 37, 38, 27, 26, 15, 16, 17, 28, 29, 18, 19, 30, 41, 40, 51, 62, 61, 50, 49, 48, 47]], 'food': [34, 39]}
# alphageese_agent(Struct(obs), Struct(config))
# # [0001] https://www.kaggle.com/c/hungry-geese/submissions?dialog=episodes-episode-24354751
# obs = {'remainingOverageTime': 8.744749000000029, 'index': 3, 'step': 159, 'geese': [
# [28, 17, 18, 7, 6, 5, 71, 70, 59, 48, 49, 38, 37],
# [57, 46, 47, 58, 69, 3, 14, 25, 36, 35, 24, 23, 12, 13, 2],
# [29, 30, 19, 20, 9, 8, 74, 73, 62, 61, 50, 51, 52, 63, 64, 53, 42, 41],
# [21, 32, 22, 33, 44, 45, 56, 67, 66, 76, 10, 0]], 'food': [60, 54]}
# alphageese_agent(Struct(obs), Struct(config))
url = "https://tonghuikang.github.io/hungry-goose-training-logs/strings/pubhrl.txt"
url_self = "https://tonghuikang.github.io/hungry-goose-training-logs/strings/pubhrl-trained-on-boiler-adverse.txt"
import urllib
params = next(urllib.request.urlopen(url)).decode("utf-8")
params_self = next(urllib.request.urlopen(url_self)).decode("utf-8")
with open("alphageese_improved.py", "r") as f:
s = f.read()
s = s.replace("YYYYY", params_self)
s = s.replace("XXXXX", params)
with open("alphageese_improved.py", "w") as f:
f.write(s)
"YYYYY" in params, "XXXXX" in params, "YYYYY" in params_self, "XXXXX" in params_self
# # Running
# Using The kaggle_environments For Testing Agents
import collections, os
import kaggle_environments
from kaggle_environments import evaluate, make, utils
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sn
kaggle_environments.__version__
env = make("hungry_geese")
vers = 13
env.reset()
env.run(
[
"../input/hungry-goose-alphageese-agents/v{}.py".format(vers),
"../input/hungry-goose-alphageese-agents/v1.py",
"../input/hungry-goose-alphageese-agents/v1.py",
"../input/hungry-goose-alphageese-agents/v1.py",
],
)
env.render(mode="ipython", width=800, height=700)
#
# Comparison In Battle
list_names = [
"../input/hungry-goose-alphageese-agents/v{}".format(vers),
"../input/hungry-goose-alphageese-agents/v1",
# "boilergoose",
# "risk_averse_greedy",
]
list_agents = [agent_name + ".py" for agent_name in list_names]
def one_on_one_with_two_simple(agents):
n_agents = len(agents)
scores = np.zeros((n_agents, n_agents), dtype=np.int)
print("Simulation of battles. It can take some time...")
for ind_1 in range(n_agents):
for ind_2 in range(ind_1 + 1, n_agents):
if ind_1 == ind_2:
continue
def threaded_evaluation(_):
print("x", end=" ")
current_score = evaluate(
"hungry_geese",
[
agents[ind_1],
agents[ind_2],
agents[ind_2],
agents[ind_2],
],
num_episodes=1,
)
print(_, end=" ")
episode_winners = np.argmax(current_score, axis=1)
episode_winner_counts = collections.Counter(episode_winners)
scores[ind_1, ind_2] += episode_winner_counts.get(0, 0)
# scores[ind_2, ind_1] += episode_winner_counts.get(1, 0)
for _ in range(25):
threaded_evaluation(_)
# from multiprocessing.pool import ThreadPool as Pool
# with Pool(max(2,os.cpu_count()-4)) as p:
# p.map(threaded_evaluation, list(range(20)))
return scores
def visualize_scores(scores, x_agents, y_agents, title):
df_scores = pd.DataFrame(
scores,
index=x_agents,
columns=y_agents,
)
plt.figure(figsize=(5, 5))
sn.heatmap(
df_scores,
annot=True,
cbar=False,
cmap="coolwarm",
linewidths=1,
linecolor="black",
fmt="d",
)
plt.xticks(rotation=90, fontsize=15)
plt.yticks(rotation=0, fontsize=15)
plt.title(title, fontsize=18)
plt.savefig(title + ".png")
plt.show()
scores = one_on_one_with_two_simple(list_agents)
visualize_scores(scores, list_names, list_names, "Number of wins: one versus one")
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/542/70542993.ipynb | null | null | [{"Id": 70542993, "ScriptId": 17985890, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1680925, "CreationDate": "08/07/2021 11:48:22", "VersionNumber": 66.0, "Title": "HG - Agents Comparison", "EvaluationDate": "08/07/2021", "IsChange": false, "TotalLines": 2292.0, "LinesInsertedFromPrevious": 0.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 2292.0, "LinesInsertedFromFork": 908.0, "LinesDeletedFromFork": 122.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 1384.0, "TotalVotes": 0}] | null | null | null | null | # # Hungry Geese - Agents Comparison
# - This notebook contains a lot of different agents from different sources for the [Hungry Geese](https://www.kaggle.com/c/hungry-geese).
# - In the [Comparison In Battle](#100) section, we also added a comparison of each pair of different agents (against two very simple additional agents so that real conditions are met). The agents fight for 100 rounds and then counts of the wins are calculated
# 
# # Simple Toward
from kaggle_environments.envs.hungry_geese.hungry_geese import (
Observation,
Configuration,
Action,
row_col,
)
def agent(obs_dict, config_dict):
"""This agent always moves toward observation.food[0] but does not take advantage of board wrapping"""
observation = Observation(obs_dict)
configuration = Configuration(config_dict)
player_index = observation.index
player_goose = observation.geese[player_index]
player_head = player_goose[0]
player_row, player_column = row_col(player_head, configuration.columns)
food = observation.food[0]
food_row, food_column = row_col(food, configuration.columns)
if food_row > player_row:
return Action.SOUTH.name
if food_row < player_row:
return Action.NORTH.name
if food_column > player_column:
return Action.EAST.name
return Action.WEST.name
# # Greedy Agent
from kaggle_environments.envs.hungry_geese.hungry_geese import (
Observation,
Configuration,
Action,
row_col,
)
from random import choice, sample
def random_agent():
return choice([action for action in Action]).name
def translate(position: int, direction: Action, columns: int, rows: int):
row, column = row_col(position, columns)
row_offset, column_offset = direction.to_row_col()
row = (row + row_offset) % rows
column = (column + column_offset) % columns
return row * columns + column
def adjacent_positions(position: int, columns: int, rows: int):
return [translate(position, action, columns, rows) for action in Action]
def min_distance(position: int, food: [int], columns: int):
row, column = row_col(position, columns)
return min(
abs(row - food_row) + abs(column - food_column)
for food_position in food
for food_row, food_column in [row_col(food_position, columns)]
)
def agent(observation, configuration):
observation = Observation(observation)
configuration = Configuration(configuration)
rows, columns = configuration.rows, configuration.columns
food = observation.food
geese = observation.geese
opponents = [
goose
for index, goose in enumerate(geese)
if index != observation.index and len(goose) > 0
]
# Don't move adjacent to any heads
head_adjacent_positions = {
opponent_head_adjacent
for opponent in opponents
for opponent_head in [opponent[0]]
for opponent_head_adjacent in adjacent_positions(opponent_head, rows, columns)
}
# Don't move into any bodies
bodies = {position for goose in geese for position in goose[0:-1]}
# Don't move into tails of heads that are adjacent to food
tails = {
opponent[-1]
for opponent in opponents
for opponent_head in [opponent[0]]
if any(
adjacent_position in food
# Head of opponent is adjacent to food so tail is not safe
for adjacent_position in adjacent_positions(opponent_head, rows, columns)
)
}
# Move to the closest food
position = geese[observation.index][0]
actions = {
action: min_distance(new_position, food, columns)
for action in Action
for new_position in [translate(position, action, columns, rows)]
if (
new_position not in head_adjacent_positions
and new_position not in bodies
and new_position not in tails
)
}
if any(actions):
return min(actions, key=actions.get).name
return random_agent()
# # Risk Adverse Greedy Goose
# Copy from kernel [Risk averse greedy goose](https://www.kaggle.com/ilialar/risk-averse-greedy-goose)
from kaggle_environments.envs.hungry_geese.hungry_geese import (
Observation,
Configuration,
Action,
row_col,
)
import numpy as np
import random
def get_nearest_cells(x, y):
# returns all cells reachable from the current one
result = []
for i in (-1, +1):
result.append(((x + i + 7) % 7, y))
result.append((x, (y + i + 11) % 11))
return result
def find_closest_food(table):
# returns the first step toward the closest food item
new_table = table.copy()
# (direction of the step, axis, code)
possible_moves = [(1, 0, 1), (-1, 0, 2), (1, 1, 3), (-1, 1, 4)]
# shuffle possible options to add variability
random.shuffle(possible_moves)
updated = False
for roll, axis, code in possible_moves:
shifted_table = np.roll(table, roll, axis)
if (table == -2).any() and (
shifted_table[table == -2] == -3
).any(): # we have found some food at the first step
return code
else:
mask = np.logical_and(new_table == 0, shifted_table == -3)
if mask.sum() > 0:
updated = True
new_table += code * mask
if (table == -2).any() and shifted_table[table == -2][
0
] > 0: # we have found some food
return shifted_table[table == -2][0]
# else - update new reachible cells
mask = np.logical_and(new_table == 0, shifted_table > 0)
if mask.sum() > 0:
updated = True
new_table += shifted_table * mask
# if we updated anything - continue reccurison
if updated:
return find_closest_food(new_table)
# if not - return some step
else:
return table.max()
last_step = None
def agent(obs_dict, config_dict):
global last_step
observation = Observation(obs_dict)
configuration = Configuration(config_dict)
player_index = observation.index
player_goose = observation.geese[player_index]
player_head = player_goose[0]
player_row, player_column = row_col(player_head, configuration.columns)
table = np.zeros((7, 11))
# 0 - emply cells
# -1 - obstacles
# -4 - possible obstacles
# -2 - food
# -3 - head
# 1,2,3,4 - reachable on the current step cell, number is the id of the first step direction
legend = {1: "SOUTH", 2: "NORTH", 3: "EAST", 4: "WEST"}
# let's add food to the map
for food in observation.food:
x, y = row_col(food, configuration.columns)
table[x, y] = -2 # food
# let's add all cells that are forbidden
for i in range(4):
opp_goose = observation.geese[i]
if len(opp_goose) == 0:
continue
is_close_to_food = False
if i != player_index:
x, y = row_col(opp_goose[0], configuration.columns)
possible_moves = get_nearest_cells(x, y) # head can move anywhere
for x, y in possible_moves:
if table[x, y] == -2:
is_close_to_food = True
table[x, y] = -4 # possibly forbidden cells
# usually we ignore the last tail cell but there are exceptions
tail_change = -1
if obs_dict["step"] % 40 == 39:
tail_change -= 1
# we assume that the goose will eat the food
if is_close_to_food:
tail_change += 1
if tail_change >= 0:
tail_change = None
for n in opp_goose[:tail_change]:
x, y = row_col(n, configuration.columns)
table[x, y] = -1 # forbidden cells
# going back is forbidden according to the new rules
x, y = row_col(player_head, configuration.columns)
if last_step is not None:
if last_step == 1:
table[(x + 6) % 7, y] = -1
elif last_step == 2:
table[(x + 8) % 7, y] = -1
elif last_step == 3:
table[x, (y + 10) % 11] = -1
elif last_step == 4:
table[x, (y + 12) % 11] = -1
# add head position
table[x, y] = -3
# the first step toward the nearest food
step = int(find_closest_food(table))
# if there is not available steps try to go to possibly dangerous cell
if step not in [1, 2, 3, 4]:
x, y = row_col(player_head, configuration.columns)
if table[(x + 8) % 7, y] == -4:
step = 1
elif table[(x + 6) % 7, y] == -4:
step = 2
elif table[x, (y + 12) % 11] == -4:
step = 3
elif table[x, (y + 10) % 11] == -4:
step = 4
# else - do a random step and lose
else:
step = np.random.randint(4) + 1
last_step = step
return legend[step]
# # Simple BFS
# Copy from kernel [Simple BFS- Starter Agent](https://www.kaggle.com/aatiffraz/simple-bfs-starter-agent)
from kaggle_environments.envs.hungry_geese.hungry_geese import (
Observation,
Configuration,
Action,
row_col,
)
import random
import numpy as np
directions = {
0: "EAST",
1: "NORTH",
2: "WEST",
3: "SOUTH",
"EAST": 0,
"NORTH": 1,
"WEST": 2,
"SOUTH": 3,
}
def move(loc, direction):
"""Move the whole snake in the given direction"""
global directions
direction = directions[direction]
new_loc = []
if direction == "EAST":
new_loc.append(int(11 * (loc[0] // 11) + (loc[0] % 11 + 1) % 11))
elif direction == "WEST":
new_loc.append(int(11 * (loc[0] // 11) + (loc[0] % 11 + 10) % 11))
elif direction == "NORTH":
new_loc.append(int(11 * ((loc[0] // 11 + 6) % 7) + loc[0] % 11))
else:
new_loc.append(int(11 * ((loc[0] // 11 + 1) % 7) + loc[0] % 11))
if len(loc) == 1:
return new_loc
return new_loc + loc[:-1]
def greedy_choose(head, board):
move_queue = []
visited = [[[100, "NA"] for _ in range(11)] for l in range(7)]
visited[head // 11][head % 11][0] = 0
for i in range(4):
move_queue.append([head, [i]])
while len(move_queue) > 0:
now_move = move_queue.pop(0)
next_step = move([now_move[0]], now_move[1][-1])[0]
if board[next_step // 11][next_step % 11] < 0:
continue
if len(now_move[1]) < visited[next_step // 11][next_step % 11][0]:
visited[next_step // 11][next_step % 11][0] = len(now_move[1])
visited[next_step // 11][next_step % 11][1] = now_move[1][0]
for i in range(4):
move_queue.append([next_step, now_move[1] + [i]])
if board[next_step // 11][next_step % 11] > 0:
return now_move[1][0]
return random.randint(0, 3)
def agent(obs, conf):
global directions
obs = Observation(obs)
conf = Configuration(conf)
board = np.zeros((7, 11), dtype=int)
# Obstacle-ize your opponents
for ind, goose in enumerate(obs.geese):
if ind == obs.index or len(goose) == 0:
continue
for direction in range(4):
moved = move(goose, direction)
for part in moved:
board[part // 11][part % 11] -= 1
# Obstacle-ize your body, except the last part
if len(obs.geese[obs.index]) > 1:
for k in obs.geese[obs.index][:-1]:
board[k // 11][k % 11] -= 1
# Count food only if there's no chance an opponent will meet you there
for f in obs.food:
board[f // 11][f % 11] += board[f // 11][f % 11] == 0
return directions[greedy_choose(obs.geese[obs.index][0], board)]
# # Straightforward BFS
from kaggle_environments.envs.hungry_geese.hungry_geese import (
Observation,
Configuration,
Action,
row_col,
)
import numpy as np
def bfs(start_x, start_y, mask, food_coords):
dist_matrix = np.zeros_like(mask)
vect_matrix = np.full_like(mask, -1)
queue = [(start_x, start_y, 0, None)]
while queue:
current_x, current_y, current_dist, vect = queue.pop(0)
vect_matrix[current_x, current_y] = vect
up_x = current_x + 1 if current_x != 6 else 0
down_x = current_x - 1 if current_x != 0 else 6
left_y = current_y - 1 if current_y != 0 else 10
right_y = current_y + 1 if current_y != 10 else 0
if mask[up_x, current_y] != -1 and not dist_matrix[up_x, current_y]:
dist_matrix[up_x, current_y] = current_dist + 1
if vect is None:
queue.append((up_x, current_y, current_dist + 1, 0))
else:
queue.append((up_x, current_y, current_dist + 1, vect))
if mask[down_x, current_y] != -1 and not dist_matrix[down_x, current_y]:
dist_matrix[down_x, current_y] = current_dist + 1
if vect is None:
queue.append((down_x, current_y, current_dist + 1, 1))
else:
queue.append((down_x, current_y, current_dist + 1, vect))
if mask[current_x, left_y] != -1 and not dist_matrix[current_x, left_y]:
dist_matrix[current_x, left_y] = current_dist + 1
if vect is None:
queue.append((current_x, left_y, current_dist + 1, 2))
else:
queue.append((current_x, left_y, current_dist + 1, vect))
if mask[current_x, right_y] != -1 and not dist_matrix[current_x, right_y]:
dist_matrix[current_x, right_y] = current_dist + 1
if vect is None:
queue.append((current_x, right_y, current_dist + 1, 3))
else:
queue.append((current_x, right_y, current_dist + 1, vect))
min_food_id = -1
min_food_dist = np.inf
for id_, food in enumerate(food_coords):
if (
dist_matrix[food[0], food[1]] != 0
and min_food_dist > dist_matrix[food[0], food[1]]
):
min_food_id = id_
min_food_dist = dist_matrix[food[0], food[1]]
if min_food_id == -1:
x, y = -1, -1
mn = 0
for i in range(dist_matrix.shape[0]):
for j in range(dist_matrix.shape[1]):
if dist_matrix[i, j] > mn:
x, y = i, j
mn = dist_matrix[i, j]
return vect_matrix[x, y]
food_x, food_y = food_coords[min_food_id]
return vect_matrix[food_x, food_y]
LAST_ACTION = None
def straightforward_bfs(obs_dict, config_dict):
observation = Observation(obs_dict)
configuration = Configuration(config_dict)
player_index = observation.index
player_goose = observation.geese[player_index]
player_head = player_goose[0]
start_row, start_col = row_col(player_head, configuration.columns)
mask = np.zeros((configuration.rows, configuration.columns))
for current_id in range(4):
current_goose = observation.geese[current_id]
for block in current_goose:
current_row, current_col = row_col(block, configuration.columns)
mask[current_row, current_col] = -1
food_coords = []
for food_id in range(configuration.min_food):
food = observation.food[food_id]
current_row, current_col = row_col(food, configuration.columns)
mask[current_row, current_col] = 2
food_coords.append((current_row, current_col))
last_action = bfs(start_row, start_col, mask, food_coords)
global LAST_ACTION
up_x = start_row + 1 if start_row != 6 else 0
down_x = start_row - 1 if start_row != 0 else 6
left_y = start_col - 1 if start_col != 0 else 10
right_y = start_col + 1 if start_col != 10 else 0
step = Action.NORTH.name
if last_action == 0:
step = Action.SOUTH.name
if LAST_ACTION == Action.NORTH.name:
if mask[down_x, start_col] != -1:
step = Action.NORTH.name
elif mask[start_row, left_y] != -1:
step = Action.WEST.name
elif mask[start_row, right_y] != -1:
step = Action.EAST.name
if last_action == 1:
step = Action.NORTH.name
if LAST_ACTION == Action.SOUTH.name:
if mask[up_x, start_col] != -1:
step = Action.SOUTH.name
elif mask[start_row, left_y] != -1:
step = Action.WEST.name
elif mask[start_row, right_y] != -1:
step = Action.EAST.name
if last_action == 2:
step = Action.WEST.name
if LAST_ACTION == Action.EAST.name:
if mask[up_x, start_col] != -1:
step = Action.SOUTH.name
elif mask[down_x, start_col] != -1:
step = Action.NORTH.name
elif mask[start_row, right_y] != -1:
step = Action.EAST.name
if last_action == 3:
step = Action.EAST.name
if LAST_ACTION == Action.WEST.name:
if mask[up_x, start_col] != -1:
step = Action.SOUTH.name
elif mask[down_x, start_col] != -1:
step = Action.NORTH.name
elif mask[start_row, left_y] != -1:
step = Action.WEST.name
LAST_ACTION = step
return step
# # BoilerGoose
# Copy from kernel [Mighty BoilerGoose with Flood fill](https://www.kaggle.com/superant/mighty-boilergoose-with-flood-fill)
import dataclasses
from dataclasses import dataclass
from typing import List, NamedTuple, Set, Dict, Optional, Tuple, Callable
import numpy as np
from kaggle_environments.envs.hungry_geese.hungry_geese import Action
from abc import ABC, abstractmethod
import sys
import traceback
trans_action_map: Dict[Tuple[int, int], Action] = {
(-1, 0): Action.NORTH,
(1, 0): Action.SOUTH,
(0, 1): Action.EAST,
(0, -1): Action.WEST,
}
class Pos(NamedTuple):
x: int
y: int
def __repr__(self):
return f"[{self.x}:{self.y}]"
@dataclass
class Goose:
head: Pos = dataclasses.field(init=False)
poses: List[Pos]
def __post_init__(self):
self.head = self.poses[0]
def __repr__(self):
return "Goose(" + "-".join(map(str, self.poses)) + ")"
def __iter__(self):
return iter(self.poses)
def __len__(self):
return len(self.poses)
def field_idx_to_pos(field_idx: int, *, num_cols: int, num_rows: int) -> Pos:
x = field_idx // num_cols
y = field_idx % num_cols
if not (0 <= x < num_rows and 0 <= y < num_cols):
raise ValueError("Illegal field_idx {field_idx} with x={x} and y={y}")
return Pos(x, y)
class Geometry:
def __init__(self, size_x, size_y):
self.size_x = size_x
self.size_y = size_y
@property
def shape(self) -> Tuple[int, int]:
return (self.size_x, self.size_y)
def prox(self, pos: Pos) -> Set[Pos]:
return {
self.translate(pos, direction)
for direction in [(0, 1), (1, 0), (0, -1), (-1, 0)]
}
def translate(self, pos: Pos, diff: Tuple[int, int]) -> Pos:
x, y = pos
dx, dy = diff
return Pos((x + dx) % self.size_x, (y + dy) % self.size_y)
def trans_to(self, pos1: Pos, pos2: Pos) -> Tuple[int, int]:
dx = pos2.x - pos1.x
dy = pos2.y - pos1.y
if dx <= self.size_x // 2:
dx += self.size_x
if dx > self.size_x // 2:
dx -= self.size_x
if dy <= self.size_y // 2:
dy += self.size_y
if dy > self.size_y // 2:
dy -= self.size_y
return (dx, dy)
def action_to(self, pos1, pos2):
diff = self.trans_to(pos1, pos2)
result = trans_action_map.get(diff)
if result is None:
raise ValueError(f"Cannot step from {pos1} to {pos2}")
return result
@dataclass
class State:
food: Set[Pos]
geese: Dict[int, Goose]
index: int
step: int
geo: Geometry
field: np.ndarray = dataclasses.field(init=False)
my_goose: Goose = dataclasses.field(init=False)
danger_poses: Set[Pos] = dataclasses.field(init=False)
def __post_init__(self):
self.field = np.full(fill_value=0, shape=self.geo.shape)
for goose in self.geese.values():
for pos in goose.poses[:-1]: # not considering tail!
self.field[pos.x, pos.y] = 1
if self.geo.prox(goose.head) & self.food:
tail = goose.poses[-1]
self.field[tail.x, tail.y] = 1
self.my_goose = self.geese[self.index]
self.danger_poses = {
pos
for i, goose in self.geese.items()
if i != self.index
for pos in self.geo.prox(goose.head)
}
@classmethod
def from_obs_conf(cls, obs, conf):
num_cols = conf["columns"]
num_rows = conf["rows"]
step = obs["step"]
index = obs["index"]
geese = {
idx: Goose(
poses=[
field_idx_to_pos(idx, num_cols=num_cols, num_rows=num_rows)
for idx in goose_data
]
)
for idx, goose_data in enumerate(obs["geese"])
if goose_data
}
food = {
field_idx_to_pos(idx, num_cols=num_cols, num_rows=num_rows)
for idx in obs["food"]
}
return cls(
food=food,
geese=geese,
index=index,
step=step,
geo=Geometry(size_x=num_rows, size_y=num_cols),
)
def __repr__(self):
return (
f"State(step:{self.step}, index:{self.index}, Geese("
+ ",".join(f"{idx}:{len(goose.poses)}" for idx, goose in self.geese.items())
+ f"), food:{len(self.food)})"
)
@dataclass
class FloodfillResult:
field_dist: np.ndarray
frontiers: List[List[Tuple[int, int]]]
def flood_fill(is_occupied: np.ndarray, seeds: List[Pos]) -> FloodfillResult:
"""
Flood will start with distance 0 at seeds and only flow where is_occupied[x,y]==0
"""
size_x, size_y = is_occupied.shape
field_dist = np.full(fill_value=-1, shape=(size_x, size_y))
frontier = [(s.x, s.y) for s in seeds]
frontiers = [frontier]
for seed in seeds:
field_dist[seed] = 0
dist = 1
while frontier:
new_frontier: List[Tuple[int, int]] = []
for x, y in frontier:
for dx, dy in [(0, 1), (0, -1), (1, 0), (-1, 0)]:
new_x = (x + dx) % size_x
new_y = (y + dy) % size_y
if is_occupied[new_x, new_y] == 0 and field_dist[new_x, new_y] == -1:
field_dist[new_x, new_y] = dist
new_frontier.append((new_x, new_y))
frontier = new_frontier
frontiers.append(frontier)
dist += 1
return FloodfillResult(field_dist=field_dist, frontiers=frontiers)
def get_dist(
floodfill_result: FloodfillResult, test_func: Callable[[Tuple[int, int]], bool]
) -> Optional[int]:
for dist, frontier in enumerate(floodfill_result.frontiers):
for pos in frontier:
if test_func(pos):
return dist
return None
class BaseAgent(ABC):
def __init__(self):
self.last_pos: Optional[Pos] = None
def __call__(self, obs, conf):
try:
state = State.from_obs_conf(obs, conf)
next_pos = self.step(state)
action = state.geo.action_to(state.my_goose.head, next_pos)
self.last_pos = state.my_goose.head
return action.name
except Exception as exc:
traceback.print_exc(file=sys.stderr)
raise
@abstractmethod
def step(self, state: State) -> Pos:
"""
return: next position
Implement this
"""
pass
def next_poses(self, state: State) -> Set[Pos]:
head_next_poses = state.geo.prox(state.my_goose.head)
result = {
pos
for pos in head_next_poses
if pos != self.last_pos and state.field[pos] == 0
}
return result
from operator import itemgetter
import random
class FloodGoose(BaseAgent):
def __init__(self, min_length=13):
super().__init__()
self.min_length = min_length
def step(self, state):
result = None
if len(state.my_goose) < self.min_length:
result = self.goto(state, lambda pos: pos in state.food)
elif len(state.my_goose) >= 3:
result = self.goto(state, lambda pos: pos == state.my_goose.poses[-1])
if result is None:
result = self.random_step(state)
return result
def goto(self, state, test_func):
result = None
pos_dists = {}
for pos in self.next_poses(state):
flood = flood_fill(state.field, [pos])
dist = get_dist(flood, test_func)
if dist is not None:
pos_dists[pos] = dist
if pos_dists:
closest_pos, _ = min(pos_dists.items(), key=itemgetter(1))
if closest_pos not in state.danger_poses:
result = closest_pos
return result
def random_step(self, state):
next_poses = self.next_poses(state) - state.danger_poses - state.food
if not next_poses:
next_poses = self.next_poses(state) - state.danger_poses
if not next_poses:
next_poses = self.next_poses(state)
if not next_poses:
next_poses = state.geo.prox(state.my_goose.head)
result = random.choice(list(next_poses))
return result
agent = FloodGoose(min_length=8)
def call_agent(obs, conf):
return agent(obs, conf)
# # Crazy Goose
# Copy from kernel [Crazy Goose](https://www.kaggle.com/gabrielmilan/crazy-goose)
# Base code for this from
# https://www.kaggle.com/ilialar/risk-averse-greedy-goose
import numpy as np
from kaggle_environments.envs.hungry_geese.hungry_geese import (
Observation,
Configuration,
Action,
row_col,
)
# Moves constants
SOUTH = 1
NORTH = 2
EAST = 3
WEST = 4
REVERSE_MOVE = {
None: None,
SOUTH: NORTH,
NORTH: SOUTH,
EAST: WEST,
WEST: EAST,
}
CIRCLE_MOVE = {None: None, SOUTH: WEST, NORTH: EAST, EAST: SOUTH, WEST: NORTH}
# Board constants
MY_HEAD = 2
FOOD_CELL = 1
EMPTY = 0
HEAD_POSSIBLE_CELL = -1
BODY_CELL = -2
# Store last move
last_move = None
last_eaten = 0
last_size = 1
step = 0
# Returns a list of possible destinations in order to reach `dest_cell`
def move_towards(head_cell, neck_cell, dest_cell, configuration):
print("--- Computing food movements...")
destinations = []
x_head, y_head = row_col(head_cell, configuration.columns)
x_neck, y_neck = row_col(neck_cell, configuration.columns)
x_dest, y_dest = row_col(dest_cell, configuration.columns)
print("-> Head at ({}, {})".format(x_head, y_head))
print("-> Neck at ({}, {})".format(x_neck, y_neck))
print("-> Dest at ({}, {})".format(x_dest, y_dest))
dx = x_head - x_dest
dy = y_head - y_dest
if dx >= 4:
dx = 7 - dx
elif dx <= -4:
dx += 7
if dy >= 6:
dy = 11 - dy
elif dy <= -6:
dy += 11
print("dx={}, dy={}".format(dx, dy))
if dx > 0:
x_move = (x_head - 1 + 7) % 7
y_move = y_head
print("Move ({}, {}), Neck ({}, {})".format(x_move, y_move, x_neck, y_neck))
if not ((x_move == x_neck) and (y_move == y_neck)):
destinations.append((x_move, y_move, NORTH))
elif dx < 0:
x_move = (x_head + 1 + 7) % 7
y_move = y_head
print("Move ({}, {}), Neck ({}, {})".format(x_move, y_move, x_neck, y_neck))
if not ((x_move == x_neck) and (y_move == y_neck)):
destinations.append((x_move, y_move, SOUTH))
if dy > 0:
x_move = x_head
y_move = (y_head - 1 + 11) % 11
print("Move ({}, {}), Neck ({}, {})".format(x_move, y_move, x_neck, y_neck))
if not ((x_move == x_neck) and (y_move == y_neck)):
destinations.append((x_move, y_move, WEST))
elif dy < 0:
x_move = x_head
y_move = (y_head + 1 + 11) % 11
print("Move ({}, {}), Neck ({}, {})".format(x_move, y_move, x_neck, y_neck))
if not ((x_move == x_neck) and (y_move == y_neck)):
destinations.append((x_move, y_move, EAST))
return destinations
def get_all_movements(goose_head, configuration):
x_head, y_head = row_col(goose_head, configuration.columns)
movements = []
movements.append(((x_head - 1 + 7) % 7, y_head, NORTH))
movements.append(((x_head + 1 + 7) % 7, y_head, SOUTH))
movements.append((x_head, (y_head - 1 + 11) % 11, WEST))
movements.append((x_head, (y_head + 1 + 11) % 11, EAST))
return movements
def get_nearest_cells(x, y):
# Returns adjacent cells from the current one
result = []
for i in (-1, +1):
result.append(((x + i + 7) % 7, y))
result.append((x, (y + i + 11) % 11))
return result
# Compute L1 distance between cells
def cell_distance(a, b, configuration):
xa, ya = row_col(a, configuration.columns)
xb, yb = row_col(b, configuration.columns)
dx = abs(xa - xb)
dy = abs(ya - yb)
if dx >= 4:
dx = 7 - dx
if dy >= 6:
dy = 11 - dy
return dx + dy
# Tells if that particular cell forbids movement on the next step
def is_closed(movement, board):
return all(
[
board[x_adj, y_adj]
for (x_adj, y_adj) in get_nearest_cells(movement[0], movement[1])
]
)
def is_safe(movement, board):
return board[movement[0], movement[1]] >= 0
def is_half_safe(movement, board):
return board[movement[0], movement[1]] >= -1
def agent(obs_dict, config_dict):
global last_move
global last_eaten
global last_size
global step
print("==============================================")
observation = Observation(obs_dict)
configuration = Configuration(config_dict)
player_index = observation.index
player_goose = observation.geese[player_index]
player_head = player_goose[0]
player_row, player_column = row_col(player_head, configuration.columns)
if len(player_goose) > last_size:
last_size = len(player_goose)
last_eaten = step
step += 1
moves = {1: "SOUTH", 2: "NORTH", 3: "EAST", 4: "WEST"}
board = np.zeros((7, 11))
# Adding food to board
for food in observation.food:
x, y = row_col(food, configuration.columns)
print("Food cell on ({}, {})".format(x, y))
board[x, y] = FOOD_CELL
# Adding geese to the board
for i in range(4):
goose = observation.geese[i]
# Skip if goose is dead
if len(goose) == 0:
continue
# If it's an opponent
if i != player_index:
x, y = row_col(goose[0], configuration.columns)
# Add possible head movements for it
for px, py in get_nearest_cells(x, y):
print("Head possible cell on ({}, {})".format(px, py))
# If one of these head movements may lead the goose
# to eat, add tail as BODY_CELL, because it won't move.
if board[px, py] == FOOD_CELL:
x_tail, y_tail = row_col(goose[-1], configuration.columns)
print(
"Adding tail on ({}, {}) as the goose may eat".format(
x_tail, y_tail
)
)
board[x_tail, y_tail] = BODY_CELL
board[px, py] = HEAD_POSSIBLE_CELL
# Adds goose body without tail (tail is previously added only if goose may eat)
for n in goose[:-1]:
x, y = row_col(n, configuration.columns)
print("Body cell on ({}, {})".format(x, y))
board[x, y] = BODY_CELL
# Adding my head to the board
x, y = row_col(player_head, configuration.columns)
print("My head is at ({}, {})".format(x, y))
board[x, y] = MY_HEAD
# Debug board
print(board)
# Iterate over food and geese in order to compute distances for each one
food_race = {}
for food in observation.food:
food_race[food] = {}
for i in range(4):
goose = observation.geese[i]
if len(goose) == 0:
continue
food_race[food][i] = cell_distance(goose[0], food, configuration)
# The best food is the least coveted
best_food = None
best_distance = float("inf")
best_closest_geese = float("inf")
for food in food_race:
print("-> Food on {}".format(row_col(food, configuration.columns)))
my_distance = food_race[food][player_index]
print(" - My distance is {}".format(my_distance))
closest_geese = 0
for goose_id in food_race[food]:
if goose_id == player_index:
continue
if food_race[food][goose_id] <= my_distance:
closest_geese += 1
print(" - There are {} closest geese".format(closest_geese))
if closest_geese < best_closest_geese:
best_food = food
best_distance = my_distance
best_closest_geese = closest_geese
print(" * This food is better")
elif (closest_geese == best_closest_geese) and (my_distance <= best_distance):
best_food = food
best_distance = my_distance
best_closest_geese = closest_geese
print(" * This food is better")
# Now that the best food has been found, check if the movement towards it is safe.
# Computes every available move and then check for move priorities.
if len(player_goose) > 1:
food_movements = move_towards(
player_head, player_goose[1], best_food, configuration
)
else:
food_movements = move_towards(
player_head, player_head, best_food, configuration
)
all_movements = get_all_movements(player_head, configuration)
# Excluding last movement reverse
food_movements = [
move for move in food_movements if move[2] != REVERSE_MOVE[last_move]
]
all_movements = [
move for move in all_movements if move[2] != REVERSE_MOVE[last_move]
]
print("-> Available food moves: {}".format(food_movements))
print("-> All moves: {}".format(all_movements))
# Trying to reach goal size of 4
if len(player_goose) < 4:
# 1. Food movements that are safe and not closed
for food_movement in food_movements:
print("Food movement {}".format(food_movement))
if is_safe(food_movement, board) and not is_closed(food_movement, board):
print("It's safe! Let's move {}!".format(moves[food_movement[2]]))
last_move = food_movement[2]
return moves[food_movement[2]] # Move here
# 2. Any movement safe and not closed
for movement in all_movements:
print("Movement {}".format(movement))
if is_safe(movement, board) and not is_closed(movement, board):
print("It's safe! Let's move {}!".format(moves[movement[2]]))
last_move = movement[2]
return moves[movement[2]] # Move here
# 3. Food movements half safe and not closed
for food_movement in food_movements:
if is_half_safe(food_movement, board) and not is_closed(
food_movement, board
):
print(
"Food movement {} is half safe, I'm going {}!".format(
food_movement, moves[food_movement[2]]
)
)
last_move = food_movement[2]
return moves[food_movement[2]] # Move here
# 4. Any movement half safe and not closed
for movement in all_movements:
if is_half_safe(movement, board) and not is_closed(movement, board):
print(
"Movement {} is half safe, I'm going {}!".format(
movement, moves[movement[2]]
)
)
last_move = movement[2]
return moves[movement[2]] # Move here
# 5. Food movements that are safe
for food_movement in food_movements:
print("Food movement {}".format(food_movement))
if is_safe(food_movement, board):
print("It's safe! Let's move {}!".format(moves[food_movement[2]]))
last_move = food_movement[2]
return moves[food_movement[2]] # Move here
# 6. Any movement safe
for movement in all_movements:
print("Movement {}".format(movement))
if is_safe(movement, board):
print("It's safe! Let's move {}!".format(moves[movement[2]]))
last_move = movement[2]
return moves[movement[2]] # Move here
# 7. Food movements half safe
for food_movement in food_movements:
if is_half_safe(food_movement, board):
print(
"Food movement {} is half safe, I'm going {}!".format(
food_movement, moves[food_movement[2]]
)
)
last_move = food_movement[2]
return moves[food_movement[2]] # Move here
# 8. Any movement half safe
for movement in all_movements:
if is_half_safe(movement, board):
print(
"Movement {} is half safe, I'm going {}!".format(
movement, moves[movement[2]]
)
)
last_move = movement[2]
return moves[movement[2]] # Move here
# Just trying to walk in circles
else:
# Delete food moves
food_coordinates = []
for food in food_race:
x_food, y_food = row_col(food, configuration.columns)
food_coordinates.append((x_food, y_food))
available_moves = []
for move in all_movements:
for x_food, y_food in food_coordinates:
if (move[0] != x_food) or (move[1] != y_food):
available_moves.append(move)
# 1. Run in circles if you can
circle_move = CIRCLE_MOVE[last_move]
for move in available_moves:
if (
(move[2] == circle_move)
and (is_safe(move, board))
and not (is_closed(move, board))
):
last_move = move[2]
return moves[move[2]]
# 2. Any movement safe and not closed
for movement in all_movements:
print("Movement {}".format(movement))
if is_safe(movement, board) and not is_closed(movement, board):
print("It's safe! Let's move {}!".format(moves[movement[2]]))
last_move = movement[2]
return moves[movement[2]] # Move here
# 3. Any movement half safe and not closed
for movement in all_movements:
if is_half_safe(movement, board) and not is_closed(movement, board):
print(
"Movement {} is half safe, I'm going {}!".format(
movement, moves[movement[2]]
)
)
last_move = movement[2]
return moves[movement[2]] # Move here
# 4. Any movement safe
for movement in all_movements:
print("Movement {}".format(movement))
if is_safe(movement, board):
print("It's safe! Let's move {}!".format(moves[movement[2]]))
last_move = movement[2]
return moves[movement[2]] # Move here
# 5. Any movement half safe
for movement in all_movements:
if is_half_safe(movement, board):
print(
"Movement {} is half safe, I'm going {}!".format(
movement, moves[movement[2]]
)
)
last_move = movement[2]
return moves[movement[2]] # Move here
# Finally, if all moves are unsafe, randomly pick one
rand_pick = np.random.randint(4) + 1
last_move = rand_pick
print("Yeah whatever, I'm going {}".format(moves[rand_pick]))
return moves[rand_pick]
# # PubHRL
# Copy from kernel [Smart Geese Trained by Reinforcement Learning](https://www.kaggle.com/yuricat/smart-geese-trained-by-reinforcement-learning)
# This is a lightweight ML agent trained by self-play.
# After sharing this notebook,
# we will add Hungry Geese environment in our HandyRL library.
# https://github.com/DeNA/HandyRL
# We hope you enjoy reinforcement learning!
import pickle
import bz2
import base64
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
# Neural Network for Hungry Geese
class TorusConv2d(nn.Module):
def __init__(self, input_dim, output_dim, kernel_size, bn):
super().__init__()
self.edge_size = (kernel_size[0] // 2, kernel_size[1] // 2)
self.conv = nn.Conv2d(input_dim, output_dim, kernel_size=kernel_size)
self.bn = nn.BatchNorm2d(output_dim) if bn else None
def forward(self, x):
h = torch.cat(
[x[:, :, :, -self.edge_size[1] :], x, x[:, :, :, : self.edge_size[1]]],
dim=3,
)
h = torch.cat(
[h[:, :, -self.edge_size[0] :], h, h[:, :, : self.edge_size[0]]], dim=2
)
h = self.conv(h)
h = self.bn(h) if self.bn is not None else h
return h
class GeeseNet(nn.Module):
def __init__(self):
super().__init__()
layers, filters = 12, 32
self.conv0 = TorusConv2d(17, filters, (3, 3), True)
self.blocks = nn.ModuleList(
[TorusConv2d(filters, filters, (3, 3), True) for _ in range(layers)]
)
self.head_p = nn.Linear(filters, 4, bias=False)
self.head_v = nn.Linear(filters * 2, 1, bias=False)
def forward(self, x):
h = F.relu_(self.conv0(x))
for block in self.blocks:
h = F.relu_(h + block(h))
h_head = (h * x[:, :1]).view(h.size(0), h.size(1), -1).sum(-1)
h_avg = h.view(h.size(0), h.size(1), -1).mean(-1)
p = self.head_p(h_head)
v = torch.tanh(self.head_v(torch.cat([h_head, h_avg], 1)))
return {"policy": p, "value": v}
# Input for Neural Network
def make_input(obses):
b = np.zeros((17, 7 * 11), dtype=np.float32)
obs = obses[-1]
for p, pos_list in enumerate(obs["geese"]):
# head position
for pos in pos_list[:1]:
b[0 + (p - obs["index"]) % 4, pos] = 1
# tip position
for pos in pos_list[-1:]:
b[4 + (p - obs["index"]) % 4, pos] = 1
# whole position
for pos in pos_list:
b[8 + (p - obs["index"]) % 4, pos] = 1
# previous head position
if len(obses) > 1:
obs_prev = obses[-2]
for p, pos_list in enumerate(obs_prev["geese"]):
for pos in pos_list[:1]:
b[12 + (p - obs["index"]) % 4, pos] = 1
# food
for pos in obs["food"]:
b[16, pos] = 1
return b.reshape(-1, 7, 11)
# Load PyTorch Model
PARAM = b"XXXXX"
state_dict = pickle.loads(bz2.decompress(base64.b64decode(PARAM)))
model = GeeseNet()
model.load_state_dict(state_dict)
model.eval()
# Main Function of Agent
obses = []
def agent(obs, _):
obses.append(obs)
x = make_input(obses)
with torch.no_grad():
xt = torch.from_numpy(x).unsqueeze(0)
o = model(xt)
p = o["policy"].squeeze(0).detach().numpy()
actions = ["NORTH", "SOUTH", "WEST", "EAST"]
return actions[np.argmax(p)]
url = "https://tonghuikang.github.io/hungry-goose-training-logs/strings/pubhrl.txt"
import urllib
params = next(urllib.request.urlopen(url)).decode("utf-8")
with open("pubhrl.py", "r") as f:
s = f.read()
s = s.replace("XXXXX", params)
with open("pubhrl.py", "w") as f:
f.write(s)
# # PubHRL - trained
# This is a lightweight ML agent trained by self-play.
# After sharing this notebook,
# we will add Hungry Geese environment in our HandyRL library.
# https://github.com/DeNA/HandyRL
# We hope you enjoy reinforcement learning!
import pickle
import bz2
import base64
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
# Neural Network for Hungry Geese
class TorusConv2d(nn.Module):
def __init__(self, input_dim, output_dim, kernel_size, bn):
super().__init__()
self.edge_size = (kernel_size[0] // 2, kernel_size[1] // 2)
self.conv = nn.Conv2d(input_dim, output_dim, kernel_size=kernel_size)
self.bn = nn.BatchNorm2d(output_dim) if bn else None
def forward(self, x):
h = torch.cat(
[x[:, :, :, -self.edge_size[1] :], x, x[:, :, :, : self.edge_size[1]]],
dim=3,
)
h = torch.cat(
[h[:, :, -self.edge_size[0] :], h, h[:, :, : self.edge_size[0]]], dim=2
)
h = self.conv(h)
h = self.bn(h) if self.bn is not None else h
return h
class GeeseNet(nn.Module):
def __init__(self):
super().__init__()
layers, filters = 12, 32
self.conv0 = TorusConv2d(17, filters, (3, 3), True)
self.blocks = nn.ModuleList(
[TorusConv2d(filters, filters, (3, 3), True) for _ in range(layers)]
)
self.head_p = nn.Linear(filters, 4, bias=False)
self.head_v = nn.Linear(filters * 2, 1, bias=False)
def forward(self, x):
h = F.relu_(self.conv0(x))
for block in self.blocks:
h = F.relu_(h + block(h))
h_head = (h * x[:, :1]).view(h.size(0), h.size(1), -1).sum(-1)
h_avg = h.view(h.size(0), h.size(1), -1).mean(-1)
p = self.head_p(h_head)
v = torch.tanh(self.head_v(torch.cat([h_head, h_avg], 1)))
return {"policy": p, "value": v}
# Input for Neural Network
def make_input(obses):
b = np.zeros((17, 7 * 11), dtype=np.float32)
obs = obses[-1]
for p, pos_list in enumerate(obs["geese"]):
# head position
for pos in pos_list[:1]:
b[0 + (p - obs["index"]) % 4, pos] = 1
# tip position
for pos in pos_list[-1:]:
b[4 + (p - obs["index"]) % 4, pos] = 1
# whole position
for pos in pos_list:
b[8 + (p - obs["index"]) % 4, pos] = 1
# previous head position
if len(obses) > 1:
obs_prev = obses[-2]
for p, pos_list in enumerate(obs_prev["geese"]):
for pos in pos_list[:1]:
b[12 + (p - obs["index"]) % 4, pos] = 1
# food
for pos in obs["food"]:
b[16, pos] = 1
return b.reshape(-1, 7, 11)
# Load PyTorch Model
PARAM = b"XXXXX"
state_dict = pickle.loads(bz2.decompress(base64.b64decode(PARAM)))
model = GeeseNet()
model.load_state_dict(state_dict)
model.eval()
# Main Function of Agent
obses = []
def agent(obs, _):
obses.append(obs)
x = make_input(obses)
with torch.no_grad():
xt = torch.from_numpy(x).unsqueeze(0)
o = model(xt)
p = o["policy"].squeeze(0).detach().numpy()
actions = ["NORTH", "SOUTH", "WEST", "EAST"]
return actions[np.argmax(p)]
url = "https://tonghuikang.github.io/hungry-goose-training-logs/strings/pubhrl-trained-on-assorted-e4750.txt"
import urllib
params = next(urllib.request.urlopen(url)).decode("utf-8")
with open("pubhrl_trained.py", "r") as f:
s = f.read()
s = s.replace("XXXXX", params)
with open("pubhrl_trained.py", "w") as f:
f.write(s)
# # AlphaGeese
import pickle
import bz2
import base64
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import time
from copy import deepcopy
from kaggle_environments.envs.hungry_geese.hungry_geese import Action, translate
from kaggle_environments.helpers import histogram
# The model's parameters from https://www.kaggle.com/yuricat/smart-geese-trained-by-reinforcement-learning
PARAM = b"XXXXX"
class MCTS:
def __init__(self, game, nn_agent, eps=1e-8, cpuct=1.0):
self.game = game
self.nn_agent = nn_agent
self.eps = eps
self.cpuct = cpuct
self.Qsa = {} # stores Q values for s,a (as defined in the paper)
self.Nsa = {} # stores #times edge s,a was visited
self.Ns = {} # stores #times board s was visited
self.Ps = {} # stores initial policy (returned by neural net)
self.Vs = {} # stores game.getValidMoves for board s
self.last_obs = None
def getActionProb(self, obs, timelimit=1.0):
start_time = time.time()
while time.time() - start_time < timelimit:
self.search(obs, self.last_obs)
s = self.game.stringRepresentation(obs)
i = obs.index
counts = [
self.Nsa[(s, i, a)] if (s, i, a) in self.Nsa else 0
for a in range(self.game.getActionSize())
]
prob = counts / np.sum(counts)
self.last_obs = obs
return prob
def search(self, obs, last_obs):
s = self.game.stringRepresentation(obs)
if s not in self.Ns:
values = [-10] * 4
for i in range(4):
if len(obs.geese[i]) == 0:
continue
# leaf node
self.Ps[(s, i)], values[i] = self.nn_agent.predict(obs, last_obs, i)
valids = self.game.getValidMoves(obs, last_obs, i)
self.Ps[(s, i)] = self.Ps[(s, i)] * valids # masking invalid moves
sum_Ps_s = np.sum(self.Ps[(s, i)])
if sum_Ps_s > 0:
self.Ps[(s, i)] /= sum_Ps_s # renormalize
self.Vs[(s, i)] = valids
self.Ns[s] = 0
return values
best_acts = [None] * 4
for i in range(4):
if len(obs.geese[i]) == 0:
continue
valids = self.Vs[(s, i)]
cur_best = -float("inf")
best_act = self.game.actions[-1]
# pick the action with the highest upper confidence bound
for a in range(self.game.getActionSize()):
if valids[a]:
if (s, i, a) in self.Qsa:
u = self.Qsa[(s, i, a)] + self.cpuct * self.Ps[(s, i)][
a
] * math.sqrt(self.Ns[s]) / (1 + self.Nsa[(s, i, a)])
else:
u = (
self.cpuct
* self.Ps[(s, i)][a]
* math.sqrt(self.Ns[s] + self.eps)
) # Q = 0 ?
if u > cur_best:
cur_best = u
best_act = self.game.actions[a]
best_acts[i] = best_act
next_obs = self.game.getNextState(obs, last_obs, best_acts)
values = self.search(next_obs, obs)
for i in range(4):
if len(obs.geese[i]) == 0:
continue
a = self.game.actions.index(best_acts[i])
v = values[i]
if (s, i, a) in self.Qsa:
self.Qsa[(s, i, a)] = (
self.Nsa[(s, i, a)] * self.Qsa[(s, i, a)] + v
) / (self.Nsa[(s, i, a)] + 1)
self.Nsa[(s, i, a)] += 1
else:
self.Qsa[(s, i, a)] = v
self.Nsa[(s, i, a)] = 1
self.Ns[s] += 1
return values
class HungryGeese(object):
def __init__(
self,
rows=7,
columns=11,
actions=[Action.NORTH, Action.SOUTH, Action.WEST, Action.EAST],
hunger_rate=40,
):
self.rows = rows
self.columns = columns
self.actions = actions
self.hunger_rate = hunger_rate
def getActionSize(self):
return len(self.actions)
def getNextState(self, obs, last_obs, directions):
next_obs = deepcopy(obs)
next_obs.step += 1
geese = next_obs.geese
food = next_obs.food
for i in range(4):
goose = geese[i]
if len(goose) == 0:
continue
head = translate(goose[0], directions[i], self.columns, self.rows)
# Check action direction
if last_obs is not None and head == last_obs.geese[i][0]:
geese[i] = []
continue
# Consume food or drop a tail piece.
if head in food:
food.remove(head)
else:
goose.pop()
# Add New Head to the Goose.
goose.insert(0, head)
# If hunger strikes remove from the tail.
if next_obs.step % self.hunger_rate == 0:
if len(goose) > 0:
goose.pop()
goose_positions = histogram(position for goose in geese for position in goose)
# Check for collisions.
for i in range(4):
if len(geese[i]) > 0:
head = geese[i][0]
if goose_positions[head] > 1:
geese[i] = []
return next_obs
def getValidMoves(self, obs, last_obs, index):
geese = obs.geese
pos = geese[index][0]
obstacles = {position for goose in geese for position in goose[:-1]}
if last_obs is not None:
obstacles.add(last_obs.geese[index][0])
valid_moves = [
translate(pos, action, self.columns, self.rows) not in obstacles
for action in self.actions
]
return valid_moves
def stringRepresentation(self, obs):
return str(obs.geese + obs.food)
# Neural Network for Hungry Geese
class TorusConv2d(nn.Module):
def __init__(self, input_dim, output_dim, kernel_size, bn):
super().__init__()
self.edge_size = (kernel_size[0] // 2, kernel_size[1] // 2)
self.conv = nn.Conv2d(input_dim, output_dim, kernel_size=kernel_size)
self.bn = nn.BatchNorm2d(output_dim) if bn else None
def forward(self, x):
h = torch.cat(
[x[:, :, :, -self.edge_size[1] :], x, x[:, :, :, : self.edge_size[1]]],
dim=3,
)
h = torch.cat(
[h[:, :, -self.edge_size[0] :], h, h[:, :, : self.edge_size[0]]], dim=2
)
h = self.conv(h)
h = self.bn(h) if self.bn is not None else h
return h
class GeeseNet(nn.Module):
def __init__(self):
super().__init__()
layers, filters = 12, 32
self.conv0 = TorusConv2d(17, filters, (3, 3), True)
self.blocks = nn.ModuleList(
[TorusConv2d(filters, filters, (3, 3), True) for _ in range(layers)]
)
self.head_p = nn.Linear(filters, 4, bias=False)
self.head_v = nn.Linear(filters * 2, 1, bias=False)
def forward(self, x):
h = F.relu_(self.conv0(x))
for block in self.blocks:
h = F.relu_(h + block(h))
h_head = (h * x[:, :1]).view(h.size(0), h.size(1), -1).sum(-1)
h_avg = h.view(h.size(0), h.size(1), -1).mean(-1)
p = torch.softmax(self.head_p(h_head), 1)
v = torch.tanh(self.head_v(torch.cat([h_head, h_avg], 1)))
return p, v
class NNAgent:
def __init__(self, state_dict):
self.model = GeeseNet()
self.model.load_state_dict(state_dict)
self.model.eval()
def predict(self, obs, last_obs, index):
x = self._make_input(obs, last_obs, index)
with torch.no_grad():
xt = torch.from_numpy(x).unsqueeze(0)
p, v = self.model(xt)
return p.squeeze(0).detach().numpy(), v.item()
# Input for Neural Network
def _make_input(self, obs, last_obs, index):
b = np.zeros((17, 7 * 11), dtype=np.float32)
for p, pos_list in enumerate(obs.geese):
# head position
for pos in pos_list[:1]:
b[0 + (p - index) % 4, pos] = 1
# tip position
for pos in pos_list[-1:]:
b[4 + (p - index) % 4, pos] = 1
# whole position
for pos in pos_list:
b[8 + (p - index) % 4, pos] = 1
# previous head position
if last_obs is not None:
for p, pos_list in enumerate(last_obs.geese):
for pos in pos_list[:1]:
b[12 + (p - index) % 4, pos] = 1
# food
for pos in obs.food:
b[16, pos] = 1
return b.reshape(-1, 7, 11)
game = HungryGeese()
state_dict = pickle.loads(bz2.decompress(base64.b64decode(PARAM)))
agent = NNAgent(state_dict)
mcts = MCTS(game, agent)
def alphageese_agent(obs, config):
action = game.actions[
np.argmax(mcts.getActionProb(obs, timelimit=config.actTimeout))
]
return action.name
url = "https://tonghuikang.github.io/hungry-goose-training-logs/strings/pubhrl.txt"
import urllib
params = next(urllib.request.urlopen(url)).decode("utf-8")
with open("alphageese.py", "r") as f:
s = f.read()
s = s.replace("XXXXX", params)
with open("alphageese.py", "w") as f:
f.write(s)
# # AlphaGeese improved
import pickle
import bz2
import base64
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import time
import functools, collections
from copy import deepcopy
from kaggle_environments.envs.hungry_geese.hungry_geese import Action, translate
from kaggle_environments.helpers import histogram
sigmoid = lambda x: 1 / (1 + np.exp(-x))
eps = 10 ** (-6)
DEBUG = True
# The model’s parameters from https://www.kaggle.com/yuricat/smart-geese-trained-by-reinforcement-learning
PARAM = b"XXXXX"
PARAM_SELF = b"YYYYY"
class MCTS:
def __init__(
self,
game,
nn_agent_self,
nn_agent_pubhrl,
eps=1e-8,
cpuct_self=1.0,
cpuct_other=1.0,
):
self.game = game
self.nn_agent_self = nn_agent_self
self.nn_agent_pubhrl = nn_agent_pubhrl
self.eps = eps
self.cpuct_self = cpuct_self
self.cpuct_other = cpuct_other
self.Qsa = {} # stores Q values for s,a (as defined in the paper)
self.Nsa = {} # stores #times edge s,a was visited
self.Ns = {} # stores #times board s was visited
self.Ps = {} # stores initial policy (returned by neural net)
self.Pm = {} # masked initial policy (returned by neural net times masking)
self.Vs = {} # stores game.getValidMoves for board s
self.last_obs = None
def getActionProb(self, obs, timelimit=1.0):
extra_time = obs.remainingOverageTime
obs_step = obs.step
remaining_steps = 220 - obs.step
print(obs)
print(len(obs.geese[obs.index]), [len(goose) for goose in obs.geese])
s = self.game.stringRepresentation(obs)
i = obs.index
start_time = time.time()
while time.time() - start_time < timelimit + extra_time / (remaining_steps / 4):
self.search(obs, self.last_obs)
counts = [
self.Nsa[(s, i, a)] if (s, i, a) in self.Nsa else 0
for a in range(self.game.getActionSize())
]
prob = counts / (np.sum(counts) + eps)
target_prob = max(self.Ps[s, i])
if time.time() - start_time > timelimit and (
extra_time < 10 or max(prob) >= target_prob
):
break
self.last_obs = obs
a = np.argmax(prob)
if DEBUG:
print(s, i, a)
print(
len(self.Qsa), len(self.Nsa), len(self.Ns), len(self.Ps), len(self.Vs)
)
print("self.Qsa", self.Qsa[s, i, a])
print("self.Nsa", self.Nsa[s, i, a])
print("self.Ns", self.Ns[s])
print("self.Ps", " ".join(f"{x:.4f}" for x in self.Ps[s, i]))
print("self.Vs", self.Vs[s, i])
print("prob ", " ".join(f"{x:.4f}" for x in prob))
print()
return prob
def search(self, obs, last_obs, prev_v=0):
s = self.game.stringRepresentation(obs)
if obs.step >= 200:
lengths = sorted(len(goose) for goose in obs.geese)[::-1]
position = lengths.index(len(obs.geese[obs.index]))
scores = {0: 1, 1: 0.5, 2: -0.5, 3: -1}
return [scores[position]] * 4
if s not in self.Ns:
values = [-10] * 4
for i in range(4):
if len(obs.geese[i]) == 0:
continue
valids = self.game.getValidMoves(obs, last_obs, i)
# leaf node
if sum(v == 0 for v in valids) >= 3:
self.Ps[(s, i)], values[i] = valids, prev_v
elif obs.step >= 192: # random rollouts
self.Ps[(s, i)], values[i] = [0.25, 0.25, 0.25, 0.25], prev_v
elif i == obs.index:
self.Ps[(s, i)], values[i] = self.nn_agent_self.predict(
obs, last_obs, i
)
else:
self.Ps[(s, i)], values[i] = self.nn_agent_pubhrl.predict(
obs, last_obs, i
)
self.Pm[s, i] = (
valids + self.Ps[s, i]
) * valids # masking invalid moves
sum_Ps_s = np.sum(self.Pm[s, i])
if sum_Ps_s > 0:
self.Pm[(s, i)] /= sum_Ps_s # renormalize
self.Vs[(s, i)] = valids
self.Ns[s] = 0
return values
best_acts = [None] * 4
for i in range(4):
if len(obs.geese[i]) == 0:
continue
valids = self.Vs[(s, i)]
cur_best = -float("inf")
best_act = self.game.actions[-1]
# pick the action with the highest upper confidence bound
for a in range(self.game.getActionSize()):
if i == obs.index:
cpuct = self.cpuct_self
else:
cpuct = self.cpuct_other
if valids[a]:
if (s, i, a) in self.Qsa:
u = self.Qsa[(s, i, a)] + cpuct * self.Ps[(s, i)][
a
] * math.sqrt(self.Ns[s]) / (1 + self.Nsa[(s, i, a)])
else:
u = (
cpuct
* self.Ps[(s, i)][a]
* math.sqrt(self.Ns[s] + self.eps)
) # Q = 0 ?
if u > cur_best:
cur_best = u
best_act = self.game.actions[a]
best_acts[i] = best_act
next_obs = self.game.getNextState(obs, last_obs, best_acts)
values = self.search(next_obs, obs)
for i in range(4):
if len(obs.geese[i]) == 0:
continue
a = self.game.actions.index(best_acts[i])
v = values[i]
if (s, i, a) in self.Qsa:
self.Qsa[(s, i, a)] = (
self.Nsa[(s, i, a)] * self.Qsa[(s, i, a)] + v
) / (self.Nsa[(s, i, a)] + 1)
self.Nsa[(s, i, a)] += 1
else:
self.Qsa[(s, i, a)] = v
self.Nsa[(s, i, a)] = 1 + sigmoid(v) # to tie break when needed
self.Ns[s] += 1
return values
class HungryGeese(object):
def __init__(
self,
rows=7,
columns=11,
actions=[Action.NORTH, Action.SOUTH, Action.WEST, Action.EAST],
hunger_rate=40,
):
self.rows = rows
self.columns = columns
self.actions = actions
self.hunger_rate = hunger_rate
def getActionSize(self):
return len(self.actions)
def getNextState(self, obs, last_obs, directions):
next_obs = deepcopy(obs)
next_obs.step += 1
geese = next_obs.geese
food = next_obs.food
for i in range(4):
goose = geese[i]
if len(goose) == 0:
continue
head = translate(goose[0], directions[i], self.columns, self.rows)
# Check action direction
if last_obs is not None and head == last_obs.geese[i][0]:
geese[i] = []
continue
# Consume food or drop a tail piece.
if head in food:
food.remove(head)
else:
goose.pop()
# Add New Head to the Goose.
goose.insert(0, head)
# If hunger strikes remove from the tail.
if next_obs.step % self.hunger_rate == 0:
if len(goose) > 0:
goose.pop()
goose_positions = histogram(position for goose in geese for position in goose)
# Check for collisions.
for i in range(4):
if len(geese[i]) > 0:
head = geese[i][0]
if goose_positions[head] > 1:
geese[i] = []
return next_obs
def getValidMoves(self, obs, last_obs, index):
foods = obs.food
geese = deepcopy(obs.geese)
pos = geese[index][0]
maxlen_goose = max(len(goose) for goose in geese)
num_goose = sum(len(goose) > 0 for goose in geese)
potential_tail_strike = collections.defaultdict(lambda: 1)
potential_head_collision = collections.defaultdict(lambda: 1)
for goose_idx, goose in enumerate(geese):
if goose_idx == index or not goose:
continue
for action in self.actions:
nex_loc = translate(goose[0], action, self.columns, self.rows)
head_collision_factor = 1
if len(geese[index]) < len(goose):
potential_head_collision[
nex_loc
] = 0.111 # avoid because of definite loss
elif num_goose == 2 and len(geese[index]) >= maxlen_goose:
potential_head_collision[nex_loc] = 3.333 # secure first place
else:
potential_head_collision[
nex_loc
] = 0.888 # would prefer higher placing
if nex_loc in foods:
potential_tail_strike[goose[-1]] = 0.101
next_poss = [
translate(pos, action, self.columns, self.rows) for action in self.actions
]
mask_head_collision = np.array(
[potential_head_collision[next_pos] for next_pos in next_poss]
)
mask_tail_strike = np.array(
[potential_tail_strike[next_pos] for next_pos in next_poss]
)
obstacles = {position for goose in geese for position in goose[:-1]}
if last_obs:
obstacles.add(last_obs.geese[index][0])
mask_valid = np.array(
[1.0 if next_pos not in obstacles else 0 for next_pos in next_poss]
)
return mask_valid * mask_tail_strike * mask_head_collision
def stringRepresentation(self, obs):
return str(obs.geese + obs.food)
# Neural Network for Hungry Geese
class TorusConv2d(nn.Module):
def __init__(self, input_dim, output_dim, kernel_size, bn):
super().__init__()
self.edge_size = (kernel_size[0] // 2, kernel_size[1] // 2)
self.conv = nn.Conv2d(input_dim, output_dim, kernel_size=kernel_size)
self.bn = nn.BatchNorm2d(output_dim) if bn else None
def forward(self, x):
h = torch.cat(
[x[:, :, :, -self.edge_size[1] :], x, x[:, :, :, : self.edge_size[1]]],
dim=3,
)
h = torch.cat(
[h[:, :, -self.edge_size[0] :], h, h[:, :, : self.edge_size[0]]], dim=2
)
h = self.conv(h)
h = self.bn(h) if self.bn is not None else h
return h
class GeeseNet(nn.Module):
def __init__(self):
super().__init__()
layers, filters = 12, 32
self.conv0 = TorusConv2d(17, filters, (3, 3), True)
self.blocks = nn.ModuleList(
[TorusConv2d(filters, filters, (3, 3), True) for _ in range(layers)]
)
self.head_p = nn.Linear(filters, 4, bias=False)
self.head_v = nn.Linear(filters * 2, 1, bias=False)
def forward(self, x):
h = F.relu_(self.conv0(x))
for block in self.blocks:
h = F.relu_(h + block(h))
h_head = (h * x[:, :1]).view(h.size(0), h.size(1), -1).sum(-1)
h_avg = h.view(h.size(0), h.size(1), -1).mean(-1)
p = torch.softmax(self.head_p(h_head), 1)
v = torch.tanh(self.head_v(torch.cat([h_head, h_avg], 1)))
return p, v
class NNAgent:
def __init__(self, state_dict):
self.model = GeeseNet()
self.model.load_state_dict(state_dict)
self.model.eval()
def predict(self, obs, last_obs, index):
x = self._make_input(obs, last_obs, index)
with torch.no_grad():
xt = torch.from_numpy(x).unsqueeze(0)
p, v = self.model(xt)
return p.squeeze(0).detach().numpy(), v.item()
# Input for Neural Network
def _make_input(self, obs, last_obs, index):
b = np.zeros((17, 7 * 11), dtype=np.float32)
for p, pos_list in enumerate(obs.geese):
# head position
for pos in pos_list[:1]:
b[0 + (p - index) % 4, pos] = 1
# tip position
for pos in pos_list[-1:]:
b[4 + (p - index) % 4, pos] = 1
# whole position
for pos in pos_list:
b[8 + (p - index) % 4, pos] = 1
# previous head position
if last_obs is not None:
for p, pos_list in enumerate(last_obs.geese):
for pos in pos_list[:1]:
b[12 + (p - index) % 4, pos] = 1
# food
for pos in obs.food:
b[16, pos] = 1
return b.reshape(-1, 7, 11)
game = HungryGeese()
state_dict_self = pickle.loads(bz2.decompress(base64.b64decode(PARAM)))
agent_self = NNAgent(state_dict_self)
state_dict_pubhrl = pickle.loads(bz2.decompress(base64.b64decode(PARAM)))
agent_pubhrl = NNAgent(state_dict_pubhrl)
mcts = MCTS(game, agent_self, agent_pubhrl)
def alphageese_agent(obs, config):
action = game.actions[
np.argmax(mcts.getActionProb(obs, timelimit=config.actTimeout))
]
return action.name
# class Struct(object):
# # convert dictionary into object to allow instance.attribute notation
# def __init__(self, data):
# for name, value in data.items():
# setattr(self, name, self._wrap(value))
# def _wrap(self, value):
# if isinstance(value, (tuple, list, set, frozenset)):
# return type(value)([self._wrap(v) for v in value])
# else:
# return Struct(value) if isinstance(value, dict) else value
# ## test code
# config = {'episodeSteps': 200, 'actTimeout': 1, 'runTimeout': 1200,
# 'columns': 11, 'rows': 7, 'hunger_rate': 40, 'min_food': 2, 'max_length': 99}
# # [????] better to get stuck because game is ending
# obs = {'remainingOverageTime': 60, 'index': 1, 'step': 197, 'geese': [[],
# [36,35,24,25,14,3,4,15,16,27,38,39,40,29,28,17,18,7,6,5],
# [56,45,46,57,68,2,13,12,23,34,33,43,42,31,20,21,10,9,75,64,65],
# [30,41,52,63,62,51,50,49,48,59,60,61,72,73,74,8,19]], 'food': [26, 69]}
# alphageese_agent(Struct(obs), Struct(config))
# # [0100] https://www.kaggle.com/c/hungry-geese/submissions?dialog=episodes-episode-24354313
# obs = {'remainingOverageTime': 36.25855599999999, 'index': 3, 'step': 195, 'geese': [
# [76, 75, 74, 73, 72, 6, 7, 8, 9, 20, 21, 10],
# [3, 2, 13, 14, 25, 24, 23, 22, 11, 0, 66, 67, 68, 69, 70, 71, 5],
# [65, 64, 63, 52, 53, 42, 31, 32, 43, 54, 44, 45, 46, 57, 56],
# [36, 37, 38, 27, 26, 15, 16, 17, 28, 29, 18, 19, 30, 41, 40, 51, 62, 61, 50, 49, 48, 47]], 'food': [34, 39]}
# alphageese_agent(Struct(obs), Struct(config))
# # [0001] https://www.kaggle.com/c/hungry-geese/submissions?dialog=episodes-episode-24354751
# obs = {'remainingOverageTime': 8.744749000000029, 'index': 3, 'step': 159, 'geese': [
# [28, 17, 18, 7, 6, 5, 71, 70, 59, 48, 49, 38, 37],
# [57, 46, 47, 58, 69, 3, 14, 25, 36, 35, 24, 23, 12, 13, 2],
# [29, 30, 19, 20, 9, 8, 74, 73, 62, 61, 50, 51, 52, 63, 64, 53, 42, 41],
# [21, 32, 22, 33, 44, 45, 56, 67, 66, 76, 10, 0]], 'food': [60, 54]}
# alphageese_agent(Struct(obs), Struct(config))
url = "https://tonghuikang.github.io/hungry-goose-training-logs/strings/pubhrl.txt"
url_self = "https://tonghuikang.github.io/hungry-goose-training-logs/strings/pubhrl-trained-on-boiler-adverse.txt"
import urllib
params = next(urllib.request.urlopen(url)).decode("utf-8")
params_self = next(urllib.request.urlopen(url_self)).decode("utf-8")
with open("alphageese_improved.py", "r") as f:
s = f.read()
s = s.replace("YYYYY", params_self)
s = s.replace("XXXXX", params)
with open("alphageese_improved.py", "w") as f:
f.write(s)
"YYYYY" in params, "XXXXX" in params, "YYYYY" in params_self, "XXXXX" in params_self
# # Running
# Using The kaggle_environments For Testing Agents
import collections, os
import kaggle_environments
from kaggle_environments import evaluate, make, utils
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sn
kaggle_environments.__version__
env = make("hungry_geese")
vers = 13
env.reset()
env.run(
[
"../input/hungry-goose-alphageese-agents/v{}.py".format(vers),
"../input/hungry-goose-alphageese-agents/v1.py",
"../input/hungry-goose-alphageese-agents/v1.py",
"../input/hungry-goose-alphageese-agents/v1.py",
],
)
env.render(mode="ipython", width=800, height=700)
#
# Comparison In Battle
list_names = [
"../input/hungry-goose-alphageese-agents/v{}".format(vers),
"../input/hungry-goose-alphageese-agents/v1",
# "boilergoose",
# "risk_averse_greedy",
]
list_agents = [agent_name + ".py" for agent_name in list_names]
def one_on_one_with_two_simple(agents):
n_agents = len(agents)
scores = np.zeros((n_agents, n_agents), dtype=np.int)
print("Simulation of battles. It can take some time...")
for ind_1 in range(n_agents):
for ind_2 in range(ind_1 + 1, n_agents):
if ind_1 == ind_2:
continue
def threaded_evaluation(_):
print("x", end=" ")
current_score = evaluate(
"hungry_geese",
[
agents[ind_1],
agents[ind_2],
agents[ind_2],
agents[ind_2],
],
num_episodes=1,
)
print(_, end=" ")
episode_winners = np.argmax(current_score, axis=1)
episode_winner_counts = collections.Counter(episode_winners)
scores[ind_1, ind_2] += episode_winner_counts.get(0, 0)
# scores[ind_2, ind_1] += episode_winner_counts.get(1, 0)
for _ in range(25):
threaded_evaluation(_)
# from multiprocessing.pool import ThreadPool as Pool
# with Pool(max(2,os.cpu_count()-4)) as p:
# p.map(threaded_evaluation, list(range(20)))
return scores
def visualize_scores(scores, x_agents, y_agents, title):
df_scores = pd.DataFrame(
scores,
index=x_agents,
columns=y_agents,
)
plt.figure(figsize=(5, 5))
sn.heatmap(
df_scores,
annot=True,
cbar=False,
cmap="coolwarm",
linewidths=1,
linecolor="black",
fmt="d",
)
plt.xticks(rotation=90, fontsize=15)
plt.yticks(rotation=0, fontsize=15)
plt.title(title, fontsize=18)
plt.savefig(title + ".png")
plt.show()
scores = one_on_one_with_two_simple(list_agents)
visualize_scores(scores, list_names, list_names, "Number of wins: one versus one")
| false | 0 | 23,630 | 0 | 6 | 23,630 |
||
70262240 | <kaggle_start><code>from learntools.core import binder
binder.bind(globals())
from learntools.python.ex3 import *
print("Setup complete.")
# # 1.
# 多くのプログラミング言語では、[`sign`](https://ja.wikipedia.org/wiki/%E7%AC%A6%E5%8F%B7%E9%96%A2%E6%95%B0)が組み込み関数として用意されています。Pythonにはありませんが、自分で定義(作成)することができます。
# 下のセルに、数値を受け取り、それが負ならば-1、正ならば1、0ならば0を返す`sign`という関数を作成してください!
# コードはここに書いてください!"sign"という関数を作成します。
# Check your answer
q1.check()
# q1.solution()
# # 2.
# 前回の演習で作った`to_smash`関数に「logging(ログの出力、ここではprint関数を用います)」を追加しましょう!
def to_smash(total_candies):
"""与えられた数のキャンディを3人の友達に均等に配った後、捨てなければならない余りのキャンディの数を返します。
捨てなければならない余りのキャンディーの数を返します。
>>> to_smash(91)
1
"""
print("Splitting", total_candies, "candies")
return total_candies % 3
to_smash(91)
# `total_candies = 1`で実行するとどうなるでしょうか?
to_smash(1)
# それは素晴らしい文法ではありません!(=ベストプラクティスではありません)
# 下のセルの定義を変更して、プリント文の文法を修正してください。(キャンディが1つしかない場合は、複数形の"candies"ではなく、単数形の "candy"を使用しないといけません)
# (訳注: ひとつしかない時って a candyではないんですね〜〜)
def to_smash(total_candies):
"""与えられた数のキャンディを3人の友達に均等に配った後、捨てなければならない余りのキャンディの数を返します。
捨てなければならない余りのキャンディーの数を返します。
>>> to_smash(91)
1
"""
print("Splitting", total_candies, "candies")
return total_candies % 3
to_smash(91)
to_smash(1)
# この問題を正解したあと、解答を見る場合は、以下のコードセルを実行してください。
# 解答を見る(このコードセルを実行すると表示されます!)
q2.solution()
# # 3. 🌶️(難しめの問題です)
# チュートリアルでは、天気に対して外出する準備ができているかどうかを判断すること学びました。その時、私(作者)は、もし、、
# - 傘を持っていれば、雨に濡れたりする心配はないです。
# - または、雨がそれほど強くなく、フードがあれば、雨に濡れたりする心配はないです。
# - そうでなければ、雨が降っていて、仕事の日でなければ、私はまだ大丈夫です。(そもそも外出しないから)
# 以下の関数は、このことをPythonの式にしてます。このコードにはバグがあります。それを見つけることができますか?
# `prepared_for_weather`のコードが間違っていることを証明するには、次のいずれかを考えてください。
# - 関数が `False` を返す (しかし、本当は`True` を返すべきだった)、または
# - 関数が `True` を返した (しかし、本当は`False` を返すべきだった)。
# この問題に正解すると、Correctが出力(表示)されます。
def prepared_for_weather(have_umbrella, rain_level, have_hood, is_workday):
# このコードを変更しないでください。私たちの目的は、バグを見つけることだけで、修正することではありません
return (
have_umbrella
or rain_level < 5
and have_hood
or not rain_level > 0
and is_workday
)
# これらの入力の値を変更して、prepared_for_weatherのケースを表すようにします。
# これは間違っています。
have_umbrella = True
rain_level = 0.0
have_hood = True
is_workday = True
# 上の変数を利用して、prepared_for_weather関数が返す値を確認します。
actual = prepared_for_weather(have_umbrella, rain_level, have_hood, is_workday)
print(actual)
# 答え合わせをする
q3.check()
# q3.hint()
# q3.solution()
# # 4.
# 以下の関数 `is_negative` はうまく動いています。これは、与えられた数(入力された数)が負であれば`True`を、そうでなければ`False` を返します。
# 例) 5 が与えられると(つまり、`is_negative(5)` )、`True`
# -5が与えられると(つまり、`is_negative(-5)` )、`False`
# しかし、コードの長さが長すぎます。実はもっと短く書くことができるんです。なんと、この関数のコード行数を**75%**減らすことができます。
# たった**1行**のコードで同じことができます。それを関数 `concise_is_negative` に入れてみましょう。(HINT: Pythonの三項演算子は必要ありません)
# (訳注: これは、`def concise_is_negative(number):`これを含めずに1行です。)
def is_negative(number):
if number < 0:
return True
else:
return False
def concise_is_negative(number):
pass # ここに1行で書いてください。(これ以降の問題も)書くときはpassという文字は消してください。
# 答え合わせをします
q4.check()
# q4.hint()
# q4.solution()
# # 5a.
# bool型の変数(True or False) である`ketchup`, `mustard`, `onion` は,お客さんがホットドッグに特定のトッピングをしたいかどうかを表します.お客さんの注文に関するイエスかノーかの質問に対応するいくつかのbool型がreturnされる関数を実装したいと考えています。例えば、以下のようなものです。
def onionless(ketchup, mustard, onion):
"""お客様に玉ねぎのトッピングがいるかどうかを伺います。"""
return not onion
def wants_all_toppings(ketchup, mustard, onion):
"""お客様に "the works"(3つのトッピング)がいるかどうかを伺います。"""
pass
# 答え合わせをします
q5.a.check()
# q5.a.hint()
# q5.a.solution()
# # 5b.
# 次の関数では、docstring(def ..... の下にある赤い文字のこと)の説明に合わせて中身を書いていってください!
def wants_plain_hotdog(ketchup, mustard, onion):
"""お客様がトッピングなしのプレーンなホットドッグを注文しているかを返します。"""
pass
# 答え合わせをします
q5.b.check()
# q5.b.hint()
# q5.b.solution()
# # 5c.
# 次の関数では、docstring(def ..... の下にある赤い文字のこと)の説明に合わせて中身を書いていってください!
def exactly_one_sauce(ketchup, mustard, onion):
"""お客様がケチャップかマスタードのどちらか一方をトッピングするよう頼んでいます。
(この操作は「排他的論理和("exclusive or")」という名前でおなじみでしょう)
"""
pass
# 答え合わせをします
q5.c.check()
# q5.c.hint()
# q5.c.solution()
# # 6. 🌶️(難しめの問題です)
# 整数を入力し、`bool()`という関数を呼び出すと, 0に等しい場合は`False`を,そうでない場合は`True`を返すことを見てきました。
# ex) `bool(1)` -> `False`
# では、`int()`を呼び出すとどうなるでしょうか?下のノートブックセルで試してみてください。
# これを利用して,「お客さんはトッピングをちょうど1つ欲しいのか」という英文に対応する簡潔な関数を書くことができるでしょうか?
# 次の関数では、docstringの英語の説明に合わせてボディを記入します。
#
def exactly_one_topping(ketchup, mustard, onion):
"""お客様がホットドッグに3つのトッピングのうちどれか1つだけを希望しているかどうかを返します。"""
pass
# 答え合わせをします
q6.check()
# q6.hint()
# q6.solution()
# # 7. 🌶️(難しめ) (Optional)
# この問題では、[ブラックジャック](https://ja.wikipedia.org/wiki/%E3%83%96%E3%83%A9%E3%83%83%E3%82%AF%E3%82%B8%E3%83%A3%E3%83%83%E3%82%AF)の簡易版(通称:21)を扱います。このゲームは,プレイヤー1人(あなた)とディーラー1人がいます。プレイは次のように進みます。
# - プレイヤーには,表向きのカードが2枚配られます。ディーラーには表向きのカードが1枚配られます。
# - プレイヤーは何度でもディーラーにカードを配ってもらうことができます(「ヒット」)。カードの合計が21を超えた場合、このゲームは負けとなります。
# - その後、ディーラーは次のいずれかになるまで自分に追加のカードを配ります。
# - ディーラーのカードの合計が21を超えた場合 (この場合はプレイヤーの勝利となります)
# - ディーラーのカードの合計が17以上になる場合。(プレイヤーの合計がディーラーの合計より大きい場合は、プレイヤーの勝ちです。それ以外の場合は、ディーラーの勝ちです(同点の場合も同様))。
#
# カードの合計を計算するとき、ジャックJ、クイーンQ、キングKは10と数えます。エースAは1または11と数えます(上記のプレイヤーの「合計」という場合は、21を超えない最大の合計を意味します。例:A+8=19、A+8+8=17)。)
# この問題では、このゲームにおけるプレイヤーの意思決定戦略を表す関数を書きます。以下に、非常によくない、書き方が悪いコードを書きました。
def should_hit(dealer_total, player_total, player_low_aces, player_high_aces):
"""
現在のゲームの状態で、プレイヤーがHitする(別のカードを要求する)べきであればTrueを、プレイヤーがStayするのであればFalseを返します。
手元のカードの合計値を計算する際に、Aを11として数えた時に、21以上にならない場合はエースAを「high」(値が11)として数えます。
そうでない場合は「low」(値が1)として数えます。
例えば、プレイヤーの手札が{A, A, A, 7}の場合、11 + 1 + 1 + 7とカウントします。
となり、player_total=20、player_low_aces=2、player_high_aces=1となります。
"""
return False
# このゲームでは、カードが最初に配り終わると、そこからは常に2枚以上のカードを2人が持つことになります。
# あなたの関数を呼び出して,プレイヤーとディーラーのゲームをシュミレーションしてみましょう.
# 以下の関数を実行して,シュミレーションされたゲームを見てください.
q7.simulate_one_game()
# 多くのゲームにおける平均勝率が、プレイヤーの意思決定につながります。以下の関数を使って、50000回プレイしたブラックジャックをシミュレートしてみてください(実行するのに、数秒かかるかもしれません):
q7.simulate(n_games=50000)
# ゲームの状態を完全に無視したプレイヤーは、それでも衝撃的なほど頻繁に勝つことができます!!!
# `should_hit`関数にもう少し賢さを加えて、結果にどのような影響を与えるか試してみてください。
def should_hit(dealer_total, player_total, player_low_aces, player_high_aces):
"""現在のゲームの状態で、プレイヤーがHitする(別のカードを要求する)べきであればTrueを、プレイヤーがStayするのであればFalseを返します。
手元のカードの合計値を計算する際に、Aを11として数えた時に、21以上にならない場合はエースAを「high」(値が11)として数えます。
そうでない場合は「low」(値が1)として数えます。
例えば、プレイヤーの手札が{A, A, A, 7}の場合、11 + 1 + 1 + 7とカウントします。
となり、player_total=20、player_low_aces=2、player_high_aces=1となります。
"""
return False
q7.simulate(n_games=50000)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/262/70262240.ipynb | null | null | [{"Id": 70262240, "ScriptId": 19225433, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5973981, "CreationDate": "08/05/2021 15:15:06", "VersionNumber": 4.0, "Title": "(\u65e5\u672c\u8a9e\u8a33)Exercise: Booleans and Conditionals", "EvaluationDate": "08/05/2021", "IsChange": false, "TotalLines": 270.0, "LinesInsertedFromPrevious": 0.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 270.0, "LinesInsertedFromFork": 129.0, "LinesDeletedFromFork": 117.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 141.0, "TotalVotes": 9}] | null | null | null | null | from learntools.core import binder
binder.bind(globals())
from learntools.python.ex3 import *
print("Setup complete.")
# # 1.
# 多くのプログラミング言語では、[`sign`](https://ja.wikipedia.org/wiki/%E7%AC%A6%E5%8F%B7%E9%96%A2%E6%95%B0)が組み込み関数として用意されています。Pythonにはありませんが、自分で定義(作成)することができます。
# 下のセルに、数値を受け取り、それが負ならば-1、正ならば1、0ならば0を返す`sign`という関数を作成してください!
# コードはここに書いてください!"sign"という関数を作成します。
# Check your answer
q1.check()
# q1.solution()
# # 2.
# 前回の演習で作った`to_smash`関数に「logging(ログの出力、ここではprint関数を用います)」を追加しましょう!
def to_smash(total_candies):
"""与えられた数のキャンディを3人の友達に均等に配った後、捨てなければならない余りのキャンディの数を返します。
捨てなければならない余りのキャンディーの数を返します。
>>> to_smash(91)
1
"""
print("Splitting", total_candies, "candies")
return total_candies % 3
to_smash(91)
# `total_candies = 1`で実行するとどうなるでしょうか?
to_smash(1)
# それは素晴らしい文法ではありません!(=ベストプラクティスではありません)
# 下のセルの定義を変更して、プリント文の文法を修正してください。(キャンディが1つしかない場合は、複数形の"candies"ではなく、単数形の "candy"を使用しないといけません)
# (訳注: ひとつしかない時って a candyではないんですね〜〜)
def to_smash(total_candies):
"""与えられた数のキャンディを3人の友達に均等に配った後、捨てなければならない余りのキャンディの数を返します。
捨てなければならない余りのキャンディーの数を返します。
>>> to_smash(91)
1
"""
print("Splitting", total_candies, "candies")
return total_candies % 3
to_smash(91)
to_smash(1)
# この問題を正解したあと、解答を見る場合は、以下のコードセルを実行してください。
# 解答を見る(このコードセルを実行すると表示されます!)
q2.solution()
# # 3. 🌶️(難しめの問題です)
# チュートリアルでは、天気に対して外出する準備ができているかどうかを判断すること学びました。その時、私(作者)は、もし、、
# - 傘を持っていれば、雨に濡れたりする心配はないです。
# - または、雨がそれほど強くなく、フードがあれば、雨に濡れたりする心配はないです。
# - そうでなければ、雨が降っていて、仕事の日でなければ、私はまだ大丈夫です。(そもそも外出しないから)
# 以下の関数は、このことをPythonの式にしてます。このコードにはバグがあります。それを見つけることができますか?
# `prepared_for_weather`のコードが間違っていることを証明するには、次のいずれかを考えてください。
# - 関数が `False` を返す (しかし、本当は`True` を返すべきだった)、または
# - 関数が `True` を返した (しかし、本当は`False` を返すべきだった)。
# この問題に正解すると、Correctが出力(表示)されます。
def prepared_for_weather(have_umbrella, rain_level, have_hood, is_workday):
# このコードを変更しないでください。私たちの目的は、バグを見つけることだけで、修正することではありません
return (
have_umbrella
or rain_level < 5
and have_hood
or not rain_level > 0
and is_workday
)
# これらの入力の値を変更して、prepared_for_weatherのケースを表すようにします。
# これは間違っています。
have_umbrella = True
rain_level = 0.0
have_hood = True
is_workday = True
# 上の変数を利用して、prepared_for_weather関数が返す値を確認します。
actual = prepared_for_weather(have_umbrella, rain_level, have_hood, is_workday)
print(actual)
# 答え合わせをする
q3.check()
# q3.hint()
# q3.solution()
# # 4.
# 以下の関数 `is_negative` はうまく動いています。これは、与えられた数(入力された数)が負であれば`True`を、そうでなければ`False` を返します。
# 例) 5 が与えられると(つまり、`is_negative(5)` )、`True`
# -5が与えられると(つまり、`is_negative(-5)` )、`False`
# しかし、コードの長さが長すぎます。実はもっと短く書くことができるんです。なんと、この関数のコード行数を**75%**減らすことができます。
# たった**1行**のコードで同じことができます。それを関数 `concise_is_negative` に入れてみましょう。(HINT: Pythonの三項演算子は必要ありません)
# (訳注: これは、`def concise_is_negative(number):`これを含めずに1行です。)
def is_negative(number):
if number < 0:
return True
else:
return False
def concise_is_negative(number):
pass # ここに1行で書いてください。(これ以降の問題も)書くときはpassという文字は消してください。
# 答え合わせをします
q4.check()
# q4.hint()
# q4.solution()
# # 5a.
# bool型の変数(True or False) である`ketchup`, `mustard`, `onion` は,お客さんがホットドッグに特定のトッピングをしたいかどうかを表します.お客さんの注文に関するイエスかノーかの質問に対応するいくつかのbool型がreturnされる関数を実装したいと考えています。例えば、以下のようなものです。
def onionless(ketchup, mustard, onion):
"""お客様に玉ねぎのトッピングがいるかどうかを伺います。"""
return not onion
def wants_all_toppings(ketchup, mustard, onion):
"""お客様に "the works"(3つのトッピング)がいるかどうかを伺います。"""
pass
# 答え合わせをします
q5.a.check()
# q5.a.hint()
# q5.a.solution()
# # 5b.
# 次の関数では、docstring(def ..... の下にある赤い文字のこと)の説明に合わせて中身を書いていってください!
def wants_plain_hotdog(ketchup, mustard, onion):
"""お客様がトッピングなしのプレーンなホットドッグを注文しているかを返します。"""
pass
# 答え合わせをします
q5.b.check()
# q5.b.hint()
# q5.b.solution()
# # 5c.
# 次の関数では、docstring(def ..... の下にある赤い文字のこと)の説明に合わせて中身を書いていってください!
def exactly_one_sauce(ketchup, mustard, onion):
"""お客様がケチャップかマスタードのどちらか一方をトッピングするよう頼んでいます。
(この操作は「排他的論理和("exclusive or")」という名前でおなじみでしょう)
"""
pass
# 答え合わせをします
q5.c.check()
# q5.c.hint()
# q5.c.solution()
# # 6. 🌶️(難しめの問題です)
# 整数を入力し、`bool()`という関数を呼び出すと, 0に等しい場合は`False`を,そうでない場合は`True`を返すことを見てきました。
# ex) `bool(1)` -> `False`
# では、`int()`を呼び出すとどうなるでしょうか?下のノートブックセルで試してみてください。
# これを利用して,「お客さんはトッピングをちょうど1つ欲しいのか」という英文に対応する簡潔な関数を書くことができるでしょうか?
# 次の関数では、docstringの英語の説明に合わせてボディを記入します。
#
def exactly_one_topping(ketchup, mustard, onion):
"""お客様がホットドッグに3つのトッピングのうちどれか1つだけを希望しているかどうかを返します。"""
pass
# 答え合わせをします
q6.check()
# q6.hint()
# q6.solution()
# # 7. 🌶️(難しめ) (Optional)
# この問題では、[ブラックジャック](https://ja.wikipedia.org/wiki/%E3%83%96%E3%83%A9%E3%83%83%E3%82%AF%E3%82%B8%E3%83%A3%E3%83%83%E3%82%AF)の簡易版(通称:21)を扱います。このゲームは,プレイヤー1人(あなた)とディーラー1人がいます。プレイは次のように進みます。
# - プレイヤーには,表向きのカードが2枚配られます。ディーラーには表向きのカードが1枚配られます。
# - プレイヤーは何度でもディーラーにカードを配ってもらうことができます(「ヒット」)。カードの合計が21を超えた場合、このゲームは負けとなります。
# - その後、ディーラーは次のいずれかになるまで自分に追加のカードを配ります。
# - ディーラーのカードの合計が21を超えた場合 (この場合はプレイヤーの勝利となります)
# - ディーラーのカードの合計が17以上になる場合。(プレイヤーの合計がディーラーの合計より大きい場合は、プレイヤーの勝ちです。それ以外の場合は、ディーラーの勝ちです(同点の場合も同様))。
#
# カードの合計を計算するとき、ジャックJ、クイーンQ、キングKは10と数えます。エースAは1または11と数えます(上記のプレイヤーの「合計」という場合は、21を超えない最大の合計を意味します。例:A+8=19、A+8+8=17)。)
# この問題では、このゲームにおけるプレイヤーの意思決定戦略を表す関数を書きます。以下に、非常によくない、書き方が悪いコードを書きました。
def should_hit(dealer_total, player_total, player_low_aces, player_high_aces):
"""
現在のゲームの状態で、プレイヤーがHitする(別のカードを要求する)べきであればTrueを、プレイヤーがStayするのであればFalseを返します。
手元のカードの合計値を計算する際に、Aを11として数えた時に、21以上にならない場合はエースAを「high」(値が11)として数えます。
そうでない場合は「low」(値が1)として数えます。
例えば、プレイヤーの手札が{A, A, A, 7}の場合、11 + 1 + 1 + 7とカウントします。
となり、player_total=20、player_low_aces=2、player_high_aces=1となります。
"""
return False
# このゲームでは、カードが最初に配り終わると、そこからは常に2枚以上のカードを2人が持つことになります。
# あなたの関数を呼び出して,プレイヤーとディーラーのゲームをシュミレーションしてみましょう.
# 以下の関数を実行して,シュミレーションされたゲームを見てください.
q7.simulate_one_game()
# 多くのゲームにおける平均勝率が、プレイヤーの意思決定につながります。以下の関数を使って、50000回プレイしたブラックジャックをシミュレートしてみてください(実行するのに、数秒かかるかもしれません):
q7.simulate(n_games=50000)
# ゲームの状態を完全に無視したプレイヤーは、それでも衝撃的なほど頻繁に勝つことができます!!!
# `should_hit`関数にもう少し賢さを加えて、結果にどのような影響を与えるか試してみてください。
def should_hit(dealer_total, player_total, player_low_aces, player_high_aces):
"""現在のゲームの状態で、プレイヤーがHitする(別のカードを要求する)べきであればTrueを、プレイヤーがStayするのであればFalseを返します。
手元のカードの合計値を計算する際に、Aを11として数えた時に、21以上にならない場合はエースAを「high」(値が11)として数えます。
そうでない場合は「low」(値が1)として数えます。
例えば、プレイヤーの手札が{A, A, A, 7}の場合、11 + 1 + 1 + 7とカウントします。
となり、player_total=20、player_low_aces=2、player_high_aces=1となります。
"""
return False
q7.simulate(n_games=50000)
| false | 0 | 3,948 | 9 | 6 | 3,948 |
||
70254580 | <kaggle_start><data_title>covid19-512<data_name>covid19512
<code># # Warrning
# 1. This notebook only include public testset for faster testif you submit it you will get 0 score
# 2. Change wandb API KEY in training notebook to yours
# 3. colab free GPU is about 3x faster than kaggle
# # Approach and Refferences
# > efficientnetb3a with aux loss for study + efficientnetb5 for 2class + yolov5m for image
# ## Refferences
# 1. henhttps://www.kaggle.com/c/siim-covid19-detection/discussion/246586gk's aux loss https://www.kaggle.com/c/siim-covid19-detection/discussion/240233
# 2. alien's 2 class tricks https://www.kaggle.com/c/siim-covid19-detection/discussion/246586
# 3. darian's duplicate analysis https://www.kaggle.com/c/siim-covid19-detection/discussion/240878
# ## Training notebook
# 1. drop duplicate and create mask https://www.kaggle.com/drzhuzhe/siiim-covid-stratified-k-fold-and-create-mask
# 2. training study level https://www.kaggle.com/drzhuzhe/covid19-classify efficientnetb3a 1e-3 10 ep + 1e-4 5ep CV map*0.66 score (3.76 + 3.92 + 3.85 + 3.7 + 3.6)/5 avg 3.766
# 3. training yolo https://www.kaggle.com/drzhuzhe/covid19-det?scriptVersionId=67605495 efficientnetb5 only 10 epoch CV map score (0.4947 + 0.5103 + 0.4848 +0.4692 +0.5198)/5 avg 0.49575
# 4. 2 class https://www.kaggle.com/drzhuzhe/siim-covid19-efnb7-train-fold0-5-2class yolov5m 15 epoch (0.869 + 0.860 + 0.882 + 0.878 + 0.876)/5 avg 0.872
# ## Experiments
# 1. study level with 6 class is doable single fold LB 0.586 +
# 2. efficientnetV2-m got low result https://www.kaggle.com/c/siim-covid19-detection/discussion/248442 according to this disscus efficientnetV2 may need larger batchsize
# 3. aux CNN head attach to block 4 get mediocre result
#
import numpy as np, pandas as pd
from glob import glob
import shutil, os
import matplotlib.pyplot as plt
from sklearn.model_selection import GroupKFold
from tqdm.notebook import tqdm
import seaborn as sns
import cv2
import sys
import math
from timeit import default_timer as timer
from datetime import datetime
from numba import cuda
sys.path.append("../input/timm-pytorch-image-models/pytorch-image-models-master")
_det_model_path = "/kaggle/input/collect-submit-model/det/"
_classify_model1_path = "/kaggle/input/covidmodels/Archive/classify-ep12/"
_classify_model2_path = "/kaggle/input/covidmodels/"
_test_files_path = "/kaggle/input/covid19512/test/"
_data_dir = "/kaggle/input/covid19512/"
meta_df = pd.read_csv(_data_dir + "meta.csv")
IMG_SIZE = 512
# # Clssification
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.parallel.data_parallel import data_parallel
from torch.utils.data.dataset import Dataset
from torch.utils.data import DataLoader
from torch.utils.data.sampler import *
import collections
from collections import defaultdict
import timm
from timm.models.efficientnet import *
import torch.cuda.amp as amp
data_dir = _data_dir
image_size = IMG_SIZE
study_name_to_predict_string = {
"Negative for Pneumonia": "negative",
"Typical Appearance": "typical",
"Indeterminate Appearance": "indeterminate",
"Atypical Appearance": "atypical",
}
study_name_to_label = {
"Negative for Pneumonia": 0,
"Typical Appearance": 1,
"Indeterminate Appearance": 2,
"Atypical Appearance": 3,
}
study_label_to_name = {v: k for k, v in study_name_to_label.items()}
num_study_label = len(study_name_to_label)
def make_fold(mode="train-0"):
if "test" in mode:
df_meta = pd.read_csv(data_dir + "meta.csv")
df_valid = df_meta[df_meta["split"] == "test"].copy()
for l in study_name_to_label.keys():
df_valid.loc[:, l] = 0
df_valid = df_valid.reset_index(drop=True)
return df_valid
class SiimDataset(Dataset):
def __init__(self, df, augment=None):
super().__init__()
self.df = df
self.augment = augment
self.length = len(df)
def __str__(self):
string = ""
string += "\tlen = %d\n" % len(self)
string += "\tdf = %s\n" % str(self.df.shape)
string += "\tlabel distribution\n"
for i in range(num_study_label):
n = self.df[study_label_to_name[i]].sum()
string += "\t\t %d %26s: %5d (%0.4f)\n" % (
i,
study_label_to_name[i],
n,
n / len(self.df),
)
return string
def __len__(self):
return self.length
def __getitem__(self, index):
d = self.df.iloc[index]
image_file = data_dir + "/test/%s.png" % (d.image_id)
image = cv2.imread(image_file, cv2.IMREAD_GRAYSCALE)
onehot = d[study_name_to_label.keys()].values
mask = np.zeros_like(image)
r = {
"index": index,
"d": d,
"image": image,
"mask": mask,
"onehot": onehot,
}
if self.augment is not None:
r = self.augment(r)
return r
def null_collate(batch):
collate = defaultdict(list)
for r in batch:
for k, v in r.items():
collate[k].append(v)
# ---
batch_size = len(batch)
onehot = np.ascontiguousarray(np.stack(collate["onehot"])).astype(np.float32)
collate["onehot"] = torch.from_numpy(onehot)
image = np.stack(collate["image"])
image = image.reshape(batch_size, 1, image_size, image_size).repeat(3, 1)
image = np.ascontiguousarray(image)
image = image.astype(np.float32) / 255
collate["image"] = torch.from_numpy(image)
mask = np.stack(collate["mask"])
mask = mask.reshape(batch_size, 1, image_size, image_size)
mask = np.ascontiguousarray(mask)
mask = mask.astype(np.float32) / 255
collate["mask"] = torch.from_numpy(mask)
return collate
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
e = efficientnet_b3a(pretrained=False, drop_rate=0.3, drop_path_rate=0.2)
self.b0 = nn.Sequential(
e.conv_stem,
e.bn1,
e.act1,
)
self.b1 = e.blocks[0]
self.b2 = e.blocks[1]
self.b3 = e.blocks[2]
self.b4 = e.blocks[3]
self.b5 = e.blocks[4]
self.b6 = e.blocks[5]
self.b7 = e.blocks[6]
self.b8 = nn.Sequential(
e.conv_head, # 384, 1536
e.bn2,
e.act2,
)
self.logit = nn.Linear(1536, num_study_label)
self.mask = nn.Sequential(
nn.Conv2d(136, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 1, kernel_size=1, padding=0),
)
# @torch.cuda.amp.autocast()
def forward(self, image):
batch_size = len(image)
x = 2 * image - 1 # ; print('input ', x.shape)
x = self.b0(x) # ; print (x.shape) # torch.Size([2, 40, 256, 256])
x = self.b1(x) # ; print (x.shape) # torch.Size([2, 24, 256, 256])
x = self.b2(x) # ; print (x.shape) # torch.Size([2, 32, 128, 128])
x = self.b3(x) # ; print (x.shape) # torch.Size([2, 48, 64, 64])
x = self.b4(x) # ; print (x.shape) # torch.Size([2, 96, 32, 32])
x = self.b5(x) # ; print (x.shape) # torch.Size([2, 136, 32, 32])
# ------------
mask = self.mask(x)
# -------------
x = self.b6(x) # ; print (x.shape) # torch.Size([2, 232, 16, 16])
x = self.b7(x) # ; print (x.shape) # torch.Size([2, 384, 16, 16])
x = self.b8(x) # ; print (x.shape) # torch.Size([2, 1536, 16, 16])
x = F.adaptive_avg_pool2d(x, 1).reshape(batch_size, -1)
# x = F.dropout(x, 0.5, training=self.training)
logit = self.logit(x)
return logit, mask
class NetV2(nn.Module):
def __init__(self):
super(NetV2, self).__init__()
# e = efficientnet_b3a(pretrained=True, drop_rate=0.3, drop_path_rate=0.2)
# e = efficientnetv2_rw_m(pretrained=True, drop_rate=0.5, drop_path_rate=0.2)
# e = tf_efficientnetv2_m_in21ft1k(pretrained=True, drop_rate=0.3, drop_path_rate=0.2)
e = tf_efficientnetv2_m(pretrained=False, drop_path_rate=0.4)
self.b0 = nn.Sequential(
e.conv_stem,
e.bn1,
e.act1,
)
self.b1 = e.blocks[0]
self.b2 = e.blocks[1]
self.b3 = e.blocks[2]
self.b4 = e.blocks[3]
self.b5 = e.blocks[4]
self.b6 = e.blocks[5]
self.b7 = e.blocks[6]
self.b8 = nn.Sequential(
e.conv_head, # 384, 1536
e.bn2,
e.act2,
)
self.logit = nn.Linear(1280, num_study_label)
self.mask = nn.Sequential(
nn.Conv2d(176, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
# nn.Conv2d(128, 128, kernel_size=3, padding=1),
# nn.BatchNorm2d(128),
# nn.ReLU(inplace=True),
nn.Conv2d(128, 1, kernel_size=1, padding=0),
)
# @torch.cuda.amp.autocast()
def forward(self, image):
batch_size = len(image)
x = 2 * image - 1 # ; print('input ', x.shape)
"""
rw_m
torch.Size([2, 32, 256, 256])
torch.Size([2, 32, 256, 256])
torch.Size([2, 56, 128, 128])
torch.Size([2, 80, 64, 64])
torch.Size([2, 152, 32, 32])
torch.Size([2, 192, 32, 32])
torch.Size([2, 328, 16, 16])
torch.Size([2, 2152, 16, 16])
"""
x = self.b0(x)
# print (x.shape) # torch.Size([2, 32, 256, 256])
x = self.b1(x)
# print (x.shape) # torch.Size([2, 32, 256, 256])
x = self.b2(x)
# print (x.shape) # torch.Size([2, 56, 128, 128])
x = self.b3(x)
# print (x.shape) # torch.Size([2, 80, 64, 64])
x = self.b4(x)
# print (x.shape) # torch.Size([2, 152, 32, 32])
x = self.b5(x)
# print (x.shape) # torch.Size([2, 192, 32, 32])
# ------------
mask = self.mask(x)
# -------------
x = self.b6(x)
# print (x.shape) # torch.Size([2, 328, 16, 16])
x = self.b7(x)
# print (x.shape) # torch.Size([2, 512, 16, 16])
x = self.b8(x)
# print (x.shape) # torch.Size([2, 2152, 16, 16])
x = F.adaptive_avg_pool2d(x, 1).reshape(batch_size, -1)
x = F.dropout(x, 0.5, training=self.training)
logit = self.logit(x)
return logit, mask
def probability_to_df_study(df_valid, probability):
df_study = pd.DataFrame()
df_image = df_valid.copy()
df_study.loc[:, "id"] = df_valid.study + "_study"
for i in range(num_study_label):
df_study.loc[
:, study_name_to_predict_string[study_label_to_name[i]]
] = probability[:, i]
df_image.loc[
:, study_name_to_predict_string[study_label_to_name[i]]
] = probability[:, i]
df_study = df_study.groupby("id", as_index=False).mean()
df_study.loc[:, "PredictionString"] = (
"negative "
+ df_study.negative.apply(lambda x: "%0.6f" % x)
+ " 0 0 1 1"
+ " typical "
+ df_study.typical.apply(lambda x: "%0.6f" % x)
+ " 0 0 1 1"
+ " indeterminate "
+ df_study.indeterminate.apply(lambda x: "%0.6f" % x)
+ " 0 0 1 1"
+ " atypical "
+ df_study.atypical.apply(lambda x: "%0.6f" % x)
+ " 0 0 1 1"
)
df_study = df_study[["id", "PredictionString"]]
return df_study, df_image
def do_predict(net, valid_loader, tta=["flip", "scale"]): # flip
valid_probability = []
valid_num = 0
start_timer = timer()
for t, batch in enumerate(valid_loader):
batch_size = len(batch["index"])
image = batch["image"].cuda()
onehot = batch["onehot"]
label = onehot.argmax(-1)
# <todo> TTA
net.eval()
with torch.no_grad():
probability = []
logit, mask = net(image)
probability.append(F.softmax(logit, -1))
if "flip" in tta:
logit, mask = net(torch.flip(image, dims=(3,)))
probability.append(F.softmax(logit, -1))
if "scale" in tta:
# size=None, scale_factor=None, mode='nearest', align_corners=None, recompute_scale_factor=None):
logit, mask = net(
F.interpolate(
image, scale_factor=1.33, mode="bilinear", align_corners=False
)
)
probability.append(F.softmax(logit, -1))
# --------------
probability = torch.stack(probability, 0).mean(0)
valid_num += batch_size
valid_probability.append(probability.data.cpu().numpy())
print(
"\r %8d / %d %s"
% (
valid_num,
len(valid_loader.dataset),
time_to_str(timer() - start_timer, "sec"),
),
end="",
flush=True,
)
assert valid_num == len(valid_loader.dataset)
print("")
probability = np.concatenate(valid_probability)
return probability
class Logger(object):
def __init__(self):
self.terminal = sys.stdout # stdout
self.file = None
def open(self, file, mode=None):
if mode is None:
mode = "w"
self.file = open(file, mode)
def write(self, message, is_terminal=1, is_file=1):
if "\r" in message:
is_file = 0
if is_terminal == 1:
self.terminal.write(message)
self.terminal.flush()
# time.sleep(1)
if is_file == 1:
self.file.write(message)
self.file.flush()
def flush(self):
# this flush method is needed for python 3 compatibility.
# this handles the flush command by doing nothing.
# you might want to specify some extra behavior here.
pass
def time_to_str(t, mode="min"):
if mode == "min":
t = int(t) / 60
hr = t // 60
min = t % 60
return "%2d hr %02d min" % (hr, min)
elif mode == "sec":
t = int(t)
min = t // 60
sec = t % 60
return "%2d min %02d sec" % (min, sec)
else:
raise NotImplementedError
def run_submit():
for fold in [0, 1, 2, 3, 4]:
out_dir = "./study_predict/"
# initial_checkpoint = \
# _classify_model1_path + 'f' + str(fold) + '.pth'
# v2
initial_checkpoint = _classify_model2_path + "effv2-m-f" + str(fold) + ".pth"
## setup ----------------------------------------
# mode = 'local'
mode = "remote"
submit_dir = out_dir + "%s-fold%d" % (mode, fold)
os.makedirs(submit_dir, exist_ok=True)
log = Logger()
log.open(out_dir + "log.submit.txt", mode="a")
log.write("\n--- [START %s] %s\n\n" % (IDENTIFIER, "-" * 64))
# log.write('\t%s\n' % COMMON_STRING)
log.write("\n")
#
## dataset ------------------------------------
df_valid = make_fold("test")
valid_dataset = SiimDataset(df_valid)
valid_loader = DataLoader(
valid_dataset,
sampler=SequentialSampler(valid_dataset),
batch_size=32, # 128, #
drop_last=False,
num_workers=8,
pin_memory=True,
collate_fn=null_collate,
)
log.write("mode : %s\n" % (mode))
log.write("valid_dataset : \n%s\n" % (valid_dataset))
## net ----------------------------------------
if 1:
net = NetV2().cuda()
net.load_state_dict(
torch.load(initial_checkpoint)["state_dict"], strict=True
)
# ---
start_timer = timer()
probability = do_predict(net, valid_loader)
log.write("time %s \n" % time_to_str(timer() - start_timer, "min"))
log.write("probability %s \n" % str(probability.shape))
np.save(submit_dir + "/probability.npy", probability)
df_valid.to_csv(submit_dir + "/df_valid.csv", index=False)
else:
probability = np.load(submit_dir + "/probability.npy")
# ----
df_study, df_image = probability_to_df_study(df_valid, probability)
# df_image = probability_to_df_image(df_valid, None, None)
# df_submit = pd.concat([df_study,df_image])
df_submit = pd.concat([df_study])
df_submit.to_csv(submit_dir + "/submit.csv", index=False)
log.write("submit_dir : %s\n" % (submit_dir))
log.write("initial_checkpoint : %s\n" % (initial_checkpoint))
log.write("df_submit : %s\n" % str(df_submit.shape))
log.write("%s\n" % str(df_submit))
log.write("\n")
IDENTIFIER = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
run_submit()
# df_valid = make_fold('test')
# df_valid
def run_remote_ensemble():
out_dir = "./study_predict/"
log = Logger()
log.open(out_dir + "log.submit.txt", mode="a")
log.write("\n--- [START %s] %s\n\n" % (IDENTIFIER, "-" * 64))
# log.write('\t%s\n' % COMMON_STRING)
log.write("\n")
submit_dir = [
out_dir + "remote-fold0",
out_dir + "remote-fold1",
out_dir + "remote-fold2",
out_dir + "remote-fold3",
out_dir + "remote-fold4",
]
probability = 0
for d in submit_dir:
p = np.load(d + "/probability.npy")
probability += p**0.5
probability = probability / len(submit_dir)
# ----
df_valid = pd.read_csv(submit_dir[0] + "/df_valid.csv")
df_study, df_image = probability_to_df_study(df_valid, probability)
# df_image = probability_to_df_image(df_valid, None, None)
# df_submit = pd.concat([df_study, df_image])
df_submit = pd.concat([df_study])
# df_submit.to_csv(out_dir + '/effb3-full-512-mask-submit-ensemble1.csv', index=False)
log.write("submit_dir : %s\n" % (submit_dir))
log.write("df_submit : %s\n" % str(df_submit.shape))
log.write("%s\n" % str(df_submit))
log.write("\n")
return df_submit, df_image
IDENTIFIER = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
predict_study, df_image = run_remote_ensemble()
cuda.select_device(0)
cuda.close()
cuda.select_device(0)
# # Predict 2class
#!pip install /kaggle/input/kerasapplications -q
#!pip install /kaggle/input/efficientnet-keras-source-code/ -q --no-deps
# import efficientnet.tfkeras as efn
"""
import tensorflow as tf
def auto_select_accelerator():
try:
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.experimental.TPUStrategy(tpu)
print("Running on TPU:", tpu.master())
except ValueError:
strategy = tf.distribute.get_strategy()
print(f"Running on {strategy.num_replicas_in_sync} replicas")
return strategy
def build_decoder(with_labels=True, target_size=(300, 300), ext='jpg'):
def decode(path):
file_bytes = tf.io.read_file(path)
if ext == 'png':
img = tf.image.decode_png(file_bytes, channels=3)
elif ext in ['jpg', 'jpeg']:
img = tf.image.decode_jpeg(file_bytes, channels=3)
else:
raise ValueError("Image extension not supported")
img = tf.cast(img, tf.float32) / 255.0
img = tf.image.resize(img, target_size)
return img
def decode_with_labels(path, label):
return decode(path), label
return decode_with_labels if with_labels else decode
def build_augmenter(with_labels=True):
def augment(img):
img = tf.image.random_flip_left_right(img)
img = tf.image.random_flip_up_down(img)
return img
def augment_with_labels(img, label):
return augment(img), label
return augment_with_labels if with_labels else augment
def build_dataset(paths, labels=None, bsize=32, cache=True,
decode_fn=None, augment_fn=None,
augment=True, repeat=True, shuffle=1024,
cache_dir=""):
if cache_dir != "" and cache is True:
os.makedirs(cache_dir, exist_ok=True)
if decode_fn is None:
decode_fn = build_decoder(labels is not None)
if augment_fn is None:
augment_fn = build_augmenter(labels is not None)
AUTO = tf.data.experimental.AUTOTUNE
slices = paths if labels is None else (paths, labels)
dset = tf.data.Dataset.from_tensor_slices(slices)
dset = dset.map(decode_fn, num_parallel_calls=AUTO)
dset = dset.cache(cache_dir) if cache else dset
dset = dset.map(augment_fn, num_parallel_calls=AUTO) if augment else dset
dset = dset.repeat() if repeat else dset
dset = dset.shuffle(shuffle) if shuffle else dset
dset = dset.batch(bsize).prefetch(AUTO)
return dset
#COMPETITION_NAME = "siim-cov19-test-img512-study-600"
strategy = auto_select_accelerator()
BATCH_SIZE = strategy.num_replicas_in_sync * 16
IMSIZE = (224, 240, 260, 300, 380, 456, 528, 600, 512)
"""
submit_df = pd.read_csv("/kaggle/input/siim-covid19-detection/sample_submission.csv")
df_2class = meta_df.loc[meta_df.split == "test"].copy()
# test_paths = f'/kaggle/input/covid19512/test/' + df_2class['image_id'] +'.png'
df_2class["none"] = 0
# label_cols = df_2class.columns[5]
# label_cols
# 注意!!!!!! 这个模型训练时 没有 drop duplicate
"""
test_decoder = build_decoder(with_labels=False, target_size=(IMG_SIZE, IMG_SIZE), ext='png')
dtest = build_dataset(
test_paths, bsize=BATCH_SIZE, repeat=False,
shuffle=False, augment=False, cache=False,
decode_fn=test_decoder
)
with strategy.scope():
models = []
models0 = tf.keras.models.load_model(
'../input/siim-covid19-efnb7-train-fold0-5-2class/model0.h5'
)
models1 = tf.keras.models.load_model(
'../input/siim-covid19-efnb7-train-fold0-5-2class/model1.h5'
)
models2 = tf.keras.models.load_model(
'../input/siim-covid19-efnb7-train-fold0-5-2class/model2.h5'
)
models3 = tf.keras.models.load_model(
'../input/siim-covid19-efnb7-train-fold0-5-2class/model3.h5'
)
models4 = tf.keras.models.load_model(
'../input/siim-covid19-efnb7-train-fold0-5-2class/model4.h5'
)
models.append(models0)
models.append(models1)
models.append(models2)
models.append(models3)
models.append(models4)
df_2class[label_cols] = sum([model.predict(dtest, verbose=1) for model in models]) / len(models)
df_2class = df_2class.reset_index(drop=True)
"""
df_2class["none"] = df_image["negative"].values
df_2class.head()
# cuda.select_device(0)
# cuda.close()
# cuda.select_device(0)
# # Detect
shutil.copytree(
"/kaggle/input/yolov5-official-v31-dataset/yolov5", "/kaggle/working/yolov5"
)
os.chdir("/kaggle/working/yolov5")
MODEL_PATH = (
_det_model_path
+ "yolom-f0.pt"
+ " "
+ _det_model_path
+ "yolom-f1.pt"
+ " "
+ _det_model_path
+ "yolom-f2.pt"
+ " "
+ _det_model_path
+ "yolom-f3.pt"
+ " "
+ _det_model_path
+ "yolom-f4.pt"
)
"""
--source {_test_files_path} \
--img {IMG_SIZE} \
--conf 0.001 \
--iou-thres 0.5 \
--save-txt \
--save-conf
"""
"""
def yolo2voc(image_height, image_width, bboxes):
bboxes = bboxes.copy().astype(float) # otherwise all value will be 0 as voc_pascal dtype is np.int
bboxes[..., [0, 2]] = bboxes[..., [0, 2]]* image_width
bboxes[..., [1, 3]] = bboxes[..., [1, 3]]* image_height
bboxes[..., [0, 1]] = bboxes[..., [0, 1]] - bboxes[..., [2, 3]]/2
bboxes[..., [2, 3]] = bboxes[..., [0, 1]] + bboxes[..., [2, 3]]
return bboxes
image_ids = []
PredictionStrings = []
#for file_path in tqdm(glob('runs/detect/exp/labels/*.txt')):
for dir_path, _, filenames in os.walk(_test_files_path):
print(len(filenames))
for file in filenames:
file_path = 'runs/detect/exp/labels/' + file.replace(".png", '.txt')
image_id = file_path.split('/')[-1].split('.')[0]
w, h = meta_df.loc[meta_df.image_id == image_id,['dim1', 'dim0']].values[0]
if not os.path.exists(file_path):
bboxes = "none 1 0 0 1 1"
else:
f = open(file_path, 'r')
data = np.array(f.read().replace('\n', ' ').strip().split(' ')).astype(np.float32).reshape(-1, 6)
data = data[:, [0, 5, 1, 2, 3, 4]]
bboxes = list(np.round(np.concatenate((data[:, :2], np.round(yolo2voc(h, w, data[:, 2:]))), axis =1).reshape(-1), 12).astype(str))
for idx in range(len(bboxes)):
bboxes[idx] = str(int(float(bboxes[idx]))) if idx%6!=1 else bboxes[idx]
bboxes = ' '.join(bboxes)
image_id += "_image"
image_ids.append(image_id)
PredictionStrings.append(bboxes)
predict_image = pd.DataFrame({'id':image_ids,
'PredictionString':PredictionStrings})
"""
# # Submit
"""
for i in range(predict_image.shape[0]):
if predict_image.loc[i,'PredictionString'] == "none 1 0 0 1 1":
continue
sub_df_split = predict_image.loc[i,'PredictionString'].split()
sub_df_list = []
for j in range(int(len(sub_df_split) / 6)):
sub_df_list.append('opacity')
sub_df_list.append(sub_df_split[6 * j + 1])
sub_df_list.append(sub_df_split[6 * j + 2])
sub_df_list.append(sub_df_split[6 * j + 3])
sub_df_list.append(sub_df_split[6 * j + 4])
sub_df_list.append(sub_df_split[6 * j + 5])
predict_image.loc[i,'PredictionString'] = ' '.join(sub_df_list)
"""
"""
for i in range(predict_image.shape[0]):
if predict_image.loc[i,'PredictionString'] != 'none 1 0 0 1 1':
_none = str(df_2class.loc[df_2class.image_id + "_image" == predict_image.iloc[i].id]['none'].item())
predict_image.loc[i,'PredictionString'] = predict_image.loc[i,'PredictionString'] + ' none ' + _none + ' 0 0 1 1'
"""
for index, row in predict_study.iterrows():
submit_df.loc[submit_df.id == row.id, "PredictionString"] = row.PredictionString
# for index, row in predict_image.iterrows():
# submit_df.loc[submit_df.id == row.id, "PredictionString"] = row.PredictionString
submit_df.to_csv("/kaggle/working/submission.csv", index=False)
"""
sample = submit_df.iloc[-1]
print(sample.id, sample.PredictionString)
_study = meta_df.loc[meta_df.image_id + "_image" == sample.id].study.item()
print(_study)
_study_item = submit_df.loc[submit_df.id == _study + "_study"]
_study_item
"""
shutil.rmtree("/kaggle/working/yolov5")
shutil.rmtree("/kaggle/working/study_predict")
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/254/70254580.ipynb | covid19512 | drzhuzhe | [{"Id": 70254580, "ScriptId": 19223412, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4321793, "CreationDate": "08/05/2021 14:26:20", "VersionNumber": 2.0, "Title": "v2 covid-submit", "EvaluationDate": "08/05/2021", "IsChange": true, "TotalLines": 804.0, "LinesInsertedFromPrevious": 1.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 803.0, "LinesInsertedFromFork": 109.0, "LinesDeletedFromFork": 16.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 695.0, "TotalVotes": 0}] | [{"Id": 93595129, "KernelVersionId": 70254580, "SourceDatasetVersionId": 2411714}, {"Id": 93595128, "KernelVersionId": 70254580, "SourceDatasetVersionId": 1800778}, {"Id": 93595130, "KernelVersionId": 70254580, "SourceDatasetVersionId": 2417566}] | [{"Id": 2411714, "DatasetId": 1454561, "DatasourceVersionId": 2453830, "CreatorUserId": 4321793, "LicenseName": "Unknown", "CreationDate": "07/10/2021 07:49:01", "VersionNumber": 2.0, "Title": "covid19-512", "Slug": "covid19512", "Subtitle": NaN, "Description": NaN, "VersionNotes": "\u66f4\u65b0mate", "TotalCompressedBytes": 0.0, "TotalUncompressedBytes": 0.0}] | [{"Id": 1454561, "CreatorUserId": 4321793, "OwnerUserId": 4321793.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 2411714.0, "CurrentDatasourceVersionId": 2453830.0, "ForumId": 1474127, "Type": 2, "CreationDate": "07/08/2021 02:43:21", "LastActivityDate": "07/08/2021", "TotalViews": 860, "TotalDownloads": 309, "TotalVotes": 1, "TotalKernels": 4}] | [{"Id": 4321793, "UserName": "drzhuzhe", "DisplayName": "Drzhuzhe", "RegisterDate": "01/13/2020", "PerformanceTier": 2}] | # # Warrning
# 1. This notebook only include public testset for faster testif you submit it you will get 0 score
# 2. Change wandb API KEY in training notebook to yours
# 3. colab free GPU is about 3x faster than kaggle
# # Approach and Refferences
# > efficientnetb3a with aux loss for study + efficientnetb5 for 2class + yolov5m for image
# ## Refferences
# 1. henhttps://www.kaggle.com/c/siim-covid19-detection/discussion/246586gk's aux loss https://www.kaggle.com/c/siim-covid19-detection/discussion/240233
# 2. alien's 2 class tricks https://www.kaggle.com/c/siim-covid19-detection/discussion/246586
# 3. darian's duplicate analysis https://www.kaggle.com/c/siim-covid19-detection/discussion/240878
# ## Training notebook
# 1. drop duplicate and create mask https://www.kaggle.com/drzhuzhe/siiim-covid-stratified-k-fold-and-create-mask
# 2. training study level https://www.kaggle.com/drzhuzhe/covid19-classify efficientnetb3a 1e-3 10 ep + 1e-4 5ep CV map*0.66 score (3.76 + 3.92 + 3.85 + 3.7 + 3.6)/5 avg 3.766
# 3. training yolo https://www.kaggle.com/drzhuzhe/covid19-det?scriptVersionId=67605495 efficientnetb5 only 10 epoch CV map score (0.4947 + 0.5103 + 0.4848 +0.4692 +0.5198)/5 avg 0.49575
# 4. 2 class https://www.kaggle.com/drzhuzhe/siim-covid19-efnb7-train-fold0-5-2class yolov5m 15 epoch (0.869 + 0.860 + 0.882 + 0.878 + 0.876)/5 avg 0.872
# ## Experiments
# 1. study level with 6 class is doable single fold LB 0.586 +
# 2. efficientnetV2-m got low result https://www.kaggle.com/c/siim-covid19-detection/discussion/248442 according to this disscus efficientnetV2 may need larger batchsize
# 3. aux CNN head attach to block 4 get mediocre result
#
import numpy as np, pandas as pd
from glob import glob
import shutil, os
import matplotlib.pyplot as plt
from sklearn.model_selection import GroupKFold
from tqdm.notebook import tqdm
import seaborn as sns
import cv2
import sys
import math
from timeit import default_timer as timer
from datetime import datetime
from numba import cuda
sys.path.append("../input/timm-pytorch-image-models/pytorch-image-models-master")
_det_model_path = "/kaggle/input/collect-submit-model/det/"
_classify_model1_path = "/kaggle/input/covidmodels/Archive/classify-ep12/"
_classify_model2_path = "/kaggle/input/covidmodels/"
_test_files_path = "/kaggle/input/covid19512/test/"
_data_dir = "/kaggle/input/covid19512/"
meta_df = pd.read_csv(_data_dir + "meta.csv")
IMG_SIZE = 512
# # Clssification
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.parallel.data_parallel import data_parallel
from torch.utils.data.dataset import Dataset
from torch.utils.data import DataLoader
from torch.utils.data.sampler import *
import collections
from collections import defaultdict
import timm
from timm.models.efficientnet import *
import torch.cuda.amp as amp
data_dir = _data_dir
image_size = IMG_SIZE
study_name_to_predict_string = {
"Negative for Pneumonia": "negative",
"Typical Appearance": "typical",
"Indeterminate Appearance": "indeterminate",
"Atypical Appearance": "atypical",
}
study_name_to_label = {
"Negative for Pneumonia": 0,
"Typical Appearance": 1,
"Indeterminate Appearance": 2,
"Atypical Appearance": 3,
}
study_label_to_name = {v: k for k, v in study_name_to_label.items()}
num_study_label = len(study_name_to_label)
def make_fold(mode="train-0"):
if "test" in mode:
df_meta = pd.read_csv(data_dir + "meta.csv")
df_valid = df_meta[df_meta["split"] == "test"].copy()
for l in study_name_to_label.keys():
df_valid.loc[:, l] = 0
df_valid = df_valid.reset_index(drop=True)
return df_valid
class SiimDataset(Dataset):
def __init__(self, df, augment=None):
super().__init__()
self.df = df
self.augment = augment
self.length = len(df)
def __str__(self):
string = ""
string += "\tlen = %d\n" % len(self)
string += "\tdf = %s\n" % str(self.df.shape)
string += "\tlabel distribution\n"
for i in range(num_study_label):
n = self.df[study_label_to_name[i]].sum()
string += "\t\t %d %26s: %5d (%0.4f)\n" % (
i,
study_label_to_name[i],
n,
n / len(self.df),
)
return string
def __len__(self):
return self.length
def __getitem__(self, index):
d = self.df.iloc[index]
image_file = data_dir + "/test/%s.png" % (d.image_id)
image = cv2.imread(image_file, cv2.IMREAD_GRAYSCALE)
onehot = d[study_name_to_label.keys()].values
mask = np.zeros_like(image)
r = {
"index": index,
"d": d,
"image": image,
"mask": mask,
"onehot": onehot,
}
if self.augment is not None:
r = self.augment(r)
return r
def null_collate(batch):
collate = defaultdict(list)
for r in batch:
for k, v in r.items():
collate[k].append(v)
# ---
batch_size = len(batch)
onehot = np.ascontiguousarray(np.stack(collate["onehot"])).astype(np.float32)
collate["onehot"] = torch.from_numpy(onehot)
image = np.stack(collate["image"])
image = image.reshape(batch_size, 1, image_size, image_size).repeat(3, 1)
image = np.ascontiguousarray(image)
image = image.astype(np.float32) / 255
collate["image"] = torch.from_numpy(image)
mask = np.stack(collate["mask"])
mask = mask.reshape(batch_size, 1, image_size, image_size)
mask = np.ascontiguousarray(mask)
mask = mask.astype(np.float32) / 255
collate["mask"] = torch.from_numpy(mask)
return collate
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
e = efficientnet_b3a(pretrained=False, drop_rate=0.3, drop_path_rate=0.2)
self.b0 = nn.Sequential(
e.conv_stem,
e.bn1,
e.act1,
)
self.b1 = e.blocks[0]
self.b2 = e.blocks[1]
self.b3 = e.blocks[2]
self.b4 = e.blocks[3]
self.b5 = e.blocks[4]
self.b6 = e.blocks[5]
self.b7 = e.blocks[6]
self.b8 = nn.Sequential(
e.conv_head, # 384, 1536
e.bn2,
e.act2,
)
self.logit = nn.Linear(1536, num_study_label)
self.mask = nn.Sequential(
nn.Conv2d(136, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 1, kernel_size=1, padding=0),
)
# @torch.cuda.amp.autocast()
def forward(self, image):
batch_size = len(image)
x = 2 * image - 1 # ; print('input ', x.shape)
x = self.b0(x) # ; print (x.shape) # torch.Size([2, 40, 256, 256])
x = self.b1(x) # ; print (x.shape) # torch.Size([2, 24, 256, 256])
x = self.b2(x) # ; print (x.shape) # torch.Size([2, 32, 128, 128])
x = self.b3(x) # ; print (x.shape) # torch.Size([2, 48, 64, 64])
x = self.b4(x) # ; print (x.shape) # torch.Size([2, 96, 32, 32])
x = self.b5(x) # ; print (x.shape) # torch.Size([2, 136, 32, 32])
# ------------
mask = self.mask(x)
# -------------
x = self.b6(x) # ; print (x.shape) # torch.Size([2, 232, 16, 16])
x = self.b7(x) # ; print (x.shape) # torch.Size([2, 384, 16, 16])
x = self.b8(x) # ; print (x.shape) # torch.Size([2, 1536, 16, 16])
x = F.adaptive_avg_pool2d(x, 1).reshape(batch_size, -1)
# x = F.dropout(x, 0.5, training=self.training)
logit = self.logit(x)
return logit, mask
class NetV2(nn.Module):
def __init__(self):
super(NetV2, self).__init__()
# e = efficientnet_b3a(pretrained=True, drop_rate=0.3, drop_path_rate=0.2)
# e = efficientnetv2_rw_m(pretrained=True, drop_rate=0.5, drop_path_rate=0.2)
# e = tf_efficientnetv2_m_in21ft1k(pretrained=True, drop_rate=0.3, drop_path_rate=0.2)
e = tf_efficientnetv2_m(pretrained=False, drop_path_rate=0.4)
self.b0 = nn.Sequential(
e.conv_stem,
e.bn1,
e.act1,
)
self.b1 = e.blocks[0]
self.b2 = e.blocks[1]
self.b3 = e.blocks[2]
self.b4 = e.blocks[3]
self.b5 = e.blocks[4]
self.b6 = e.blocks[5]
self.b7 = e.blocks[6]
self.b8 = nn.Sequential(
e.conv_head, # 384, 1536
e.bn2,
e.act2,
)
self.logit = nn.Linear(1280, num_study_label)
self.mask = nn.Sequential(
nn.Conv2d(176, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
# nn.Conv2d(128, 128, kernel_size=3, padding=1),
# nn.BatchNorm2d(128),
# nn.ReLU(inplace=True),
nn.Conv2d(128, 1, kernel_size=1, padding=0),
)
# @torch.cuda.amp.autocast()
def forward(self, image):
batch_size = len(image)
x = 2 * image - 1 # ; print('input ', x.shape)
"""
rw_m
torch.Size([2, 32, 256, 256])
torch.Size([2, 32, 256, 256])
torch.Size([2, 56, 128, 128])
torch.Size([2, 80, 64, 64])
torch.Size([2, 152, 32, 32])
torch.Size([2, 192, 32, 32])
torch.Size([2, 328, 16, 16])
torch.Size([2, 2152, 16, 16])
"""
x = self.b0(x)
# print (x.shape) # torch.Size([2, 32, 256, 256])
x = self.b1(x)
# print (x.shape) # torch.Size([2, 32, 256, 256])
x = self.b2(x)
# print (x.shape) # torch.Size([2, 56, 128, 128])
x = self.b3(x)
# print (x.shape) # torch.Size([2, 80, 64, 64])
x = self.b4(x)
# print (x.shape) # torch.Size([2, 152, 32, 32])
x = self.b5(x)
# print (x.shape) # torch.Size([2, 192, 32, 32])
# ------------
mask = self.mask(x)
# -------------
x = self.b6(x)
# print (x.shape) # torch.Size([2, 328, 16, 16])
x = self.b7(x)
# print (x.shape) # torch.Size([2, 512, 16, 16])
x = self.b8(x)
# print (x.shape) # torch.Size([2, 2152, 16, 16])
x = F.adaptive_avg_pool2d(x, 1).reshape(batch_size, -1)
x = F.dropout(x, 0.5, training=self.training)
logit = self.logit(x)
return logit, mask
def probability_to_df_study(df_valid, probability):
df_study = pd.DataFrame()
df_image = df_valid.copy()
df_study.loc[:, "id"] = df_valid.study + "_study"
for i in range(num_study_label):
df_study.loc[
:, study_name_to_predict_string[study_label_to_name[i]]
] = probability[:, i]
df_image.loc[
:, study_name_to_predict_string[study_label_to_name[i]]
] = probability[:, i]
df_study = df_study.groupby("id", as_index=False).mean()
df_study.loc[:, "PredictionString"] = (
"negative "
+ df_study.negative.apply(lambda x: "%0.6f" % x)
+ " 0 0 1 1"
+ " typical "
+ df_study.typical.apply(lambda x: "%0.6f" % x)
+ " 0 0 1 1"
+ " indeterminate "
+ df_study.indeterminate.apply(lambda x: "%0.6f" % x)
+ " 0 0 1 1"
+ " atypical "
+ df_study.atypical.apply(lambda x: "%0.6f" % x)
+ " 0 0 1 1"
)
df_study = df_study[["id", "PredictionString"]]
return df_study, df_image
def do_predict(net, valid_loader, tta=["flip", "scale"]): # flip
valid_probability = []
valid_num = 0
start_timer = timer()
for t, batch in enumerate(valid_loader):
batch_size = len(batch["index"])
image = batch["image"].cuda()
onehot = batch["onehot"]
label = onehot.argmax(-1)
# <todo> TTA
net.eval()
with torch.no_grad():
probability = []
logit, mask = net(image)
probability.append(F.softmax(logit, -1))
if "flip" in tta:
logit, mask = net(torch.flip(image, dims=(3,)))
probability.append(F.softmax(logit, -1))
if "scale" in tta:
# size=None, scale_factor=None, mode='nearest', align_corners=None, recompute_scale_factor=None):
logit, mask = net(
F.interpolate(
image, scale_factor=1.33, mode="bilinear", align_corners=False
)
)
probability.append(F.softmax(logit, -1))
# --------------
probability = torch.stack(probability, 0).mean(0)
valid_num += batch_size
valid_probability.append(probability.data.cpu().numpy())
print(
"\r %8d / %d %s"
% (
valid_num,
len(valid_loader.dataset),
time_to_str(timer() - start_timer, "sec"),
),
end="",
flush=True,
)
assert valid_num == len(valid_loader.dataset)
print("")
probability = np.concatenate(valid_probability)
return probability
class Logger(object):
def __init__(self):
self.terminal = sys.stdout # stdout
self.file = None
def open(self, file, mode=None):
if mode is None:
mode = "w"
self.file = open(file, mode)
def write(self, message, is_terminal=1, is_file=1):
if "\r" in message:
is_file = 0
if is_terminal == 1:
self.terminal.write(message)
self.terminal.flush()
# time.sleep(1)
if is_file == 1:
self.file.write(message)
self.file.flush()
def flush(self):
# this flush method is needed for python 3 compatibility.
# this handles the flush command by doing nothing.
# you might want to specify some extra behavior here.
pass
def time_to_str(t, mode="min"):
if mode == "min":
t = int(t) / 60
hr = t // 60
min = t % 60
return "%2d hr %02d min" % (hr, min)
elif mode == "sec":
t = int(t)
min = t // 60
sec = t % 60
return "%2d min %02d sec" % (min, sec)
else:
raise NotImplementedError
def run_submit():
for fold in [0, 1, 2, 3, 4]:
out_dir = "./study_predict/"
# initial_checkpoint = \
# _classify_model1_path + 'f' + str(fold) + '.pth'
# v2
initial_checkpoint = _classify_model2_path + "effv2-m-f" + str(fold) + ".pth"
## setup ----------------------------------------
# mode = 'local'
mode = "remote"
submit_dir = out_dir + "%s-fold%d" % (mode, fold)
os.makedirs(submit_dir, exist_ok=True)
log = Logger()
log.open(out_dir + "log.submit.txt", mode="a")
log.write("\n--- [START %s] %s\n\n" % (IDENTIFIER, "-" * 64))
# log.write('\t%s\n' % COMMON_STRING)
log.write("\n")
#
## dataset ------------------------------------
df_valid = make_fold("test")
valid_dataset = SiimDataset(df_valid)
valid_loader = DataLoader(
valid_dataset,
sampler=SequentialSampler(valid_dataset),
batch_size=32, # 128, #
drop_last=False,
num_workers=8,
pin_memory=True,
collate_fn=null_collate,
)
log.write("mode : %s\n" % (mode))
log.write("valid_dataset : \n%s\n" % (valid_dataset))
## net ----------------------------------------
if 1:
net = NetV2().cuda()
net.load_state_dict(
torch.load(initial_checkpoint)["state_dict"], strict=True
)
# ---
start_timer = timer()
probability = do_predict(net, valid_loader)
log.write("time %s \n" % time_to_str(timer() - start_timer, "min"))
log.write("probability %s \n" % str(probability.shape))
np.save(submit_dir + "/probability.npy", probability)
df_valid.to_csv(submit_dir + "/df_valid.csv", index=False)
else:
probability = np.load(submit_dir + "/probability.npy")
# ----
df_study, df_image = probability_to_df_study(df_valid, probability)
# df_image = probability_to_df_image(df_valid, None, None)
# df_submit = pd.concat([df_study,df_image])
df_submit = pd.concat([df_study])
df_submit.to_csv(submit_dir + "/submit.csv", index=False)
log.write("submit_dir : %s\n" % (submit_dir))
log.write("initial_checkpoint : %s\n" % (initial_checkpoint))
log.write("df_submit : %s\n" % str(df_submit.shape))
log.write("%s\n" % str(df_submit))
log.write("\n")
IDENTIFIER = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
run_submit()
# df_valid = make_fold('test')
# df_valid
def run_remote_ensemble():
out_dir = "./study_predict/"
log = Logger()
log.open(out_dir + "log.submit.txt", mode="a")
log.write("\n--- [START %s] %s\n\n" % (IDENTIFIER, "-" * 64))
# log.write('\t%s\n' % COMMON_STRING)
log.write("\n")
submit_dir = [
out_dir + "remote-fold0",
out_dir + "remote-fold1",
out_dir + "remote-fold2",
out_dir + "remote-fold3",
out_dir + "remote-fold4",
]
probability = 0
for d in submit_dir:
p = np.load(d + "/probability.npy")
probability += p**0.5
probability = probability / len(submit_dir)
# ----
df_valid = pd.read_csv(submit_dir[0] + "/df_valid.csv")
df_study, df_image = probability_to_df_study(df_valid, probability)
# df_image = probability_to_df_image(df_valid, None, None)
# df_submit = pd.concat([df_study, df_image])
df_submit = pd.concat([df_study])
# df_submit.to_csv(out_dir + '/effb3-full-512-mask-submit-ensemble1.csv', index=False)
log.write("submit_dir : %s\n" % (submit_dir))
log.write("df_submit : %s\n" % str(df_submit.shape))
log.write("%s\n" % str(df_submit))
log.write("\n")
return df_submit, df_image
IDENTIFIER = datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
predict_study, df_image = run_remote_ensemble()
cuda.select_device(0)
cuda.close()
cuda.select_device(0)
# # Predict 2class
#!pip install /kaggle/input/kerasapplications -q
#!pip install /kaggle/input/efficientnet-keras-source-code/ -q --no-deps
# import efficientnet.tfkeras as efn
"""
import tensorflow as tf
def auto_select_accelerator():
try:
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.experimental.TPUStrategy(tpu)
print("Running on TPU:", tpu.master())
except ValueError:
strategy = tf.distribute.get_strategy()
print(f"Running on {strategy.num_replicas_in_sync} replicas")
return strategy
def build_decoder(with_labels=True, target_size=(300, 300), ext='jpg'):
def decode(path):
file_bytes = tf.io.read_file(path)
if ext == 'png':
img = tf.image.decode_png(file_bytes, channels=3)
elif ext in ['jpg', 'jpeg']:
img = tf.image.decode_jpeg(file_bytes, channels=3)
else:
raise ValueError("Image extension not supported")
img = tf.cast(img, tf.float32) / 255.0
img = tf.image.resize(img, target_size)
return img
def decode_with_labels(path, label):
return decode(path), label
return decode_with_labels if with_labels else decode
def build_augmenter(with_labels=True):
def augment(img):
img = tf.image.random_flip_left_right(img)
img = tf.image.random_flip_up_down(img)
return img
def augment_with_labels(img, label):
return augment(img), label
return augment_with_labels if with_labels else augment
def build_dataset(paths, labels=None, bsize=32, cache=True,
decode_fn=None, augment_fn=None,
augment=True, repeat=True, shuffle=1024,
cache_dir=""):
if cache_dir != "" and cache is True:
os.makedirs(cache_dir, exist_ok=True)
if decode_fn is None:
decode_fn = build_decoder(labels is not None)
if augment_fn is None:
augment_fn = build_augmenter(labels is not None)
AUTO = tf.data.experimental.AUTOTUNE
slices = paths if labels is None else (paths, labels)
dset = tf.data.Dataset.from_tensor_slices(slices)
dset = dset.map(decode_fn, num_parallel_calls=AUTO)
dset = dset.cache(cache_dir) if cache else dset
dset = dset.map(augment_fn, num_parallel_calls=AUTO) if augment else dset
dset = dset.repeat() if repeat else dset
dset = dset.shuffle(shuffle) if shuffle else dset
dset = dset.batch(bsize).prefetch(AUTO)
return dset
#COMPETITION_NAME = "siim-cov19-test-img512-study-600"
strategy = auto_select_accelerator()
BATCH_SIZE = strategy.num_replicas_in_sync * 16
IMSIZE = (224, 240, 260, 300, 380, 456, 528, 600, 512)
"""
submit_df = pd.read_csv("/kaggle/input/siim-covid19-detection/sample_submission.csv")
df_2class = meta_df.loc[meta_df.split == "test"].copy()
# test_paths = f'/kaggle/input/covid19512/test/' + df_2class['image_id'] +'.png'
df_2class["none"] = 0
# label_cols = df_2class.columns[5]
# label_cols
# 注意!!!!!! 这个模型训练时 没有 drop duplicate
"""
test_decoder = build_decoder(with_labels=False, target_size=(IMG_SIZE, IMG_SIZE), ext='png')
dtest = build_dataset(
test_paths, bsize=BATCH_SIZE, repeat=False,
shuffle=False, augment=False, cache=False,
decode_fn=test_decoder
)
with strategy.scope():
models = []
models0 = tf.keras.models.load_model(
'../input/siim-covid19-efnb7-train-fold0-5-2class/model0.h5'
)
models1 = tf.keras.models.load_model(
'../input/siim-covid19-efnb7-train-fold0-5-2class/model1.h5'
)
models2 = tf.keras.models.load_model(
'../input/siim-covid19-efnb7-train-fold0-5-2class/model2.h5'
)
models3 = tf.keras.models.load_model(
'../input/siim-covid19-efnb7-train-fold0-5-2class/model3.h5'
)
models4 = tf.keras.models.load_model(
'../input/siim-covid19-efnb7-train-fold0-5-2class/model4.h5'
)
models.append(models0)
models.append(models1)
models.append(models2)
models.append(models3)
models.append(models4)
df_2class[label_cols] = sum([model.predict(dtest, verbose=1) for model in models]) / len(models)
df_2class = df_2class.reset_index(drop=True)
"""
df_2class["none"] = df_image["negative"].values
df_2class.head()
# cuda.select_device(0)
# cuda.close()
# cuda.select_device(0)
# # Detect
shutil.copytree(
"/kaggle/input/yolov5-official-v31-dataset/yolov5", "/kaggle/working/yolov5"
)
os.chdir("/kaggle/working/yolov5")
MODEL_PATH = (
_det_model_path
+ "yolom-f0.pt"
+ " "
+ _det_model_path
+ "yolom-f1.pt"
+ " "
+ _det_model_path
+ "yolom-f2.pt"
+ " "
+ _det_model_path
+ "yolom-f3.pt"
+ " "
+ _det_model_path
+ "yolom-f4.pt"
)
"""
--source {_test_files_path} \
--img {IMG_SIZE} \
--conf 0.001 \
--iou-thres 0.5 \
--save-txt \
--save-conf
"""
"""
def yolo2voc(image_height, image_width, bboxes):
bboxes = bboxes.copy().astype(float) # otherwise all value will be 0 as voc_pascal dtype is np.int
bboxes[..., [0, 2]] = bboxes[..., [0, 2]]* image_width
bboxes[..., [1, 3]] = bboxes[..., [1, 3]]* image_height
bboxes[..., [0, 1]] = bboxes[..., [0, 1]] - bboxes[..., [2, 3]]/2
bboxes[..., [2, 3]] = bboxes[..., [0, 1]] + bboxes[..., [2, 3]]
return bboxes
image_ids = []
PredictionStrings = []
#for file_path in tqdm(glob('runs/detect/exp/labels/*.txt')):
for dir_path, _, filenames in os.walk(_test_files_path):
print(len(filenames))
for file in filenames:
file_path = 'runs/detect/exp/labels/' + file.replace(".png", '.txt')
image_id = file_path.split('/')[-1].split('.')[0]
w, h = meta_df.loc[meta_df.image_id == image_id,['dim1', 'dim0']].values[0]
if not os.path.exists(file_path):
bboxes = "none 1 0 0 1 1"
else:
f = open(file_path, 'r')
data = np.array(f.read().replace('\n', ' ').strip().split(' ')).astype(np.float32).reshape(-1, 6)
data = data[:, [0, 5, 1, 2, 3, 4]]
bboxes = list(np.round(np.concatenate((data[:, :2], np.round(yolo2voc(h, w, data[:, 2:]))), axis =1).reshape(-1), 12).astype(str))
for idx in range(len(bboxes)):
bboxes[idx] = str(int(float(bboxes[idx]))) if idx%6!=1 else bboxes[idx]
bboxes = ' '.join(bboxes)
image_id += "_image"
image_ids.append(image_id)
PredictionStrings.append(bboxes)
predict_image = pd.DataFrame({'id':image_ids,
'PredictionString':PredictionStrings})
"""
# # Submit
"""
for i in range(predict_image.shape[0]):
if predict_image.loc[i,'PredictionString'] == "none 1 0 0 1 1":
continue
sub_df_split = predict_image.loc[i,'PredictionString'].split()
sub_df_list = []
for j in range(int(len(sub_df_split) / 6)):
sub_df_list.append('opacity')
sub_df_list.append(sub_df_split[6 * j + 1])
sub_df_list.append(sub_df_split[6 * j + 2])
sub_df_list.append(sub_df_split[6 * j + 3])
sub_df_list.append(sub_df_split[6 * j + 4])
sub_df_list.append(sub_df_split[6 * j + 5])
predict_image.loc[i,'PredictionString'] = ' '.join(sub_df_list)
"""
"""
for i in range(predict_image.shape[0]):
if predict_image.loc[i,'PredictionString'] != 'none 1 0 0 1 1':
_none = str(df_2class.loc[df_2class.image_id + "_image" == predict_image.iloc[i].id]['none'].item())
predict_image.loc[i,'PredictionString'] = predict_image.loc[i,'PredictionString'] + ' none ' + _none + ' 0 0 1 1'
"""
for index, row in predict_study.iterrows():
submit_df.loc[submit_df.id == row.id, "PredictionString"] = row.PredictionString
# for index, row in predict_image.iterrows():
# submit_df.loc[submit_df.id == row.id, "PredictionString"] = row.PredictionString
submit_df.to_csv("/kaggle/working/submission.csv", index=False)
"""
sample = submit_df.iloc[-1]
print(sample.id, sample.PredictionString)
_study = meta_df.loc[meta_df.image_id + "_image" == sample.id].study.item()
print(_study)
_study_item = submit_df.loc[submit_df.id == _study + "_study"]
_study_item
"""
shutil.rmtree("/kaggle/working/yolov5")
shutil.rmtree("/kaggle/working/study_predict")
| false | 1 | 9,243 | 0 | 29 | 9,243 |
||
70417302 | <kaggle_start><code>from learntools.core import binder
binder.bind(globals())
from learntools.python.ex4 import *
print("Setup complete.")
# # 1.
# 以下の関数を、docstring(関数の下の赤い文字の部分)に従って完成させてください。
def select_second(L):
"""与えられたリスト(L)の2番目の要素を返します。もし、リストに2番目の要素がない場合は、Noneを返します。"""
pass
# 答え合わせをする
q1.check()
# q1.hint()
# q1.solution()
# # 2.
# あなたはスポーツチームを分析しています。 各チームのメンバーはリストに書いてあります。リストの最初にはコーチが、リストの2番目にはキャプテンが、その他の選手はその後に書かれています。
# このリストは大リストの中に存在します。(二次元配列)
# 大リストは最強のチームのリストから始まり、最弱のチームのリストが最後になるように並べられています。 最弱チームの**キャプテン**を選ぶために、以下の関数を作成してください。
def losing_team_captain(teams):
"""チームのリストが与えられ(上の説明で言うと、大リスト)、大リスト内に名前のリストがある場合、最後に並べられたチームの先頭から2番目のプレーヤー(キャプテン)を返します。"""
pass
# 答え合わせをする
q2.check()
# q2.hint()
# q2.solution()
# # 3.
# 次期『マリオカート』には、すごくムカつく新アイテム「パープルシェル」が登場します。使用すると、最下位の選手を1位に、1位の選手を最下位にすることができます。「パープルシェル」の効果を発揮させることができるような関数を作ってみましょう。
def purple_shell(racers):
"""レースするキャラクターのリストが与えられたとき、1位のキャラクター(リストの先頭)を最下位にして、その逆も同様です。
>>> r = ["Mario", "Bowser", "Luigi"]
>>> purple_shell(r)
>>> r
["Luigi", "Bowser", "Mario"]
"""
pass
# 答え合わせをする
q3.check()
# q3.hint()
# q3.solution()
# # 4.
# a, b, c, dのリストの長さを予想しましょう!
# あなたの予想を変数 `lengths` に記入してください。(`len()` を使ってもとめるのではなく**予測**を立てるようにしてください)
a = [1, 2, 3]
b = [1, [2, 3]]
c = []
d = [1, 2, 3][1:]
# 予測したものを下のリストに入れてください。4つの数字を入れて、1つ目はaの長さ、2つ目はbの長さ、というようにします。
lengths = []
# 答え合わせをする
q4.check()
# 以下の行で説明しています。
# q4.solution()
# # 5. 🌶️(難易度高め!)
# パーティーに参加した人たちがどのような順番で到着したかを記録するリストを使用しています。たとえば、次のリストは、7人のゲストが参加したパーティーで、アデラが最初に現れ、フォードが最後に到着したことを表しています。
# party_attendees = ['Adela', 'Fleda', 'Owen', 'May', 'Mona', 'Gilbert', 'Ford']
# パーティーに参加したゲストの半数以上が遅れて到着した場合、そのゲストは「適度な遅刻」とみなされます。ただし、一番最後のゲストであってはいけません(それはやりすぎです)。上の例では、Mona と Gilbert だけが適度に遅れてきたゲストです。
# パーティーの参加者のリストと遅れたかどうか知りたい人の名前を受け取り、その人が適度に遅れたかどうかを教えてくれる関数を以下に作成してください。
#
def fashionably_late(arrivals, name):
"""パーティーへの到着順のリストと名前が与えられると、その名前の人が適度に遅れたかどうかを返します。"""
pass
# 答え合わせをする
q5.check()
# q5.hint()
# q5.solution()
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/417/70417302.ipynb | null | null | [{"Id": 70417302, "ScriptId": 19271465, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5973981, "CreationDate": "08/06/2021 14:39:46", "VersionNumber": 2.0, "Title": "(\u65e5\u672c\u8a9e\u8a33)Exercise: Lists", "EvaluationDate": "08/06/2021", "IsChange": true, "TotalLines": 115.0, "LinesInsertedFromPrevious": 1.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 114.0, "LinesInsertedFromFork": 30.0, "LinesDeletedFromFork": 31.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 85.0, "TotalVotes": 0}] | null | null | null | null | from learntools.core import binder
binder.bind(globals())
from learntools.python.ex4 import *
print("Setup complete.")
# # 1.
# 以下の関数を、docstring(関数の下の赤い文字の部分)に従って完成させてください。
def select_second(L):
"""与えられたリスト(L)の2番目の要素を返します。もし、リストに2番目の要素がない場合は、Noneを返します。"""
pass
# 答え合わせをする
q1.check()
# q1.hint()
# q1.solution()
# # 2.
# あなたはスポーツチームを分析しています。 各チームのメンバーはリストに書いてあります。リストの最初にはコーチが、リストの2番目にはキャプテンが、その他の選手はその後に書かれています。
# このリストは大リストの中に存在します。(二次元配列)
# 大リストは最強のチームのリストから始まり、最弱のチームのリストが最後になるように並べられています。 最弱チームの**キャプテン**を選ぶために、以下の関数を作成してください。
def losing_team_captain(teams):
"""チームのリストが与えられ(上の説明で言うと、大リスト)、大リスト内に名前のリストがある場合、最後に並べられたチームの先頭から2番目のプレーヤー(キャプテン)を返します。"""
pass
# 答え合わせをする
q2.check()
# q2.hint()
# q2.solution()
# # 3.
# 次期『マリオカート』には、すごくムカつく新アイテム「パープルシェル」が登場します。使用すると、最下位の選手を1位に、1位の選手を最下位にすることができます。「パープルシェル」の効果を発揮させることができるような関数を作ってみましょう。
def purple_shell(racers):
"""レースするキャラクターのリストが与えられたとき、1位のキャラクター(リストの先頭)を最下位にして、その逆も同様です。
>>> r = ["Mario", "Bowser", "Luigi"]
>>> purple_shell(r)
>>> r
["Luigi", "Bowser", "Mario"]
"""
pass
# 答え合わせをする
q3.check()
# q3.hint()
# q3.solution()
# # 4.
# a, b, c, dのリストの長さを予想しましょう!
# あなたの予想を変数 `lengths` に記入してください。(`len()` を使ってもとめるのではなく**予測**を立てるようにしてください)
a = [1, 2, 3]
b = [1, [2, 3]]
c = []
d = [1, 2, 3][1:]
# 予測したものを下のリストに入れてください。4つの数字を入れて、1つ目はaの長さ、2つ目はbの長さ、というようにします。
lengths = []
# 答え合わせをする
q4.check()
# 以下の行で説明しています。
# q4.solution()
# # 5. 🌶️(難易度高め!)
# パーティーに参加した人たちがどのような順番で到着したかを記録するリストを使用しています。たとえば、次のリストは、7人のゲストが参加したパーティーで、アデラが最初に現れ、フォードが最後に到着したことを表しています。
# party_attendees = ['Adela', 'Fleda', 'Owen', 'May', 'Mona', 'Gilbert', 'Ford']
# パーティーに参加したゲストの半数以上が遅れて到着した場合、そのゲストは「適度な遅刻」とみなされます。ただし、一番最後のゲストであってはいけません(それはやりすぎです)。上の例では、Mona と Gilbert だけが適度に遅れてきたゲストです。
# パーティーの参加者のリストと遅れたかどうか知りたい人の名前を受け取り、その人が適度に遅れたかどうかを教えてくれる関数を以下に作成してください。
#
def fashionably_late(arrivals, name):
"""パーティーへの到着順のリストと名前が与えられると、その名前の人が適度に遅れたかどうかを返します。"""
pass
# 答え合わせをする
q5.check()
# q5.hint()
# q5.solution()
| false | 0 | 1,276 | 0 | 6 | 1,276 |
||
70261974 | <kaggle_start><code>from learntools.core import binder
binder.bind(globals())
from learntools.python.ex3 import *
print("Setup complete.")
# # 1.
# 多くのプログラミング言語では、[`sign`](https://ja.wikipedia.org/wiki/%E7%AC%A6%E5%8F%B7%E9%96%A2%E6%95%B0)が組み込み関数として用意されています。Pythonにはありませんが、自分で定義(作成)することができます。
# 下のセルに、数値を受け取り、それが負ならば-1、正ならば1、0ならば0を返す`sign`という関数を作成してください!
# コードはここに書いてください!"sign"という関数を作成します。
# Check your answer
q1.check()
# q1.solution()
# # 2.
# 前回の演習で作った`to_smash`関数に「logging(ログの出力、ここではprint関数を用います)」を追加しましょう!
def to_smash(total_candies):
"""与えられた数のキャンディを3人の友達に均等に配った後、捨てなければならない余りのキャンディの数を返します。
捨てなければならない余りのキャンディーの数を返します。
>>> to_smash(91)
1
"""
print("Splitting", total_candies, "candies")
return total_candies % 3
to_smash(91)
# `total_candies = 1`で実行するとどうなるでしょうか?
to_smash(1)
# それは素晴らしい文法ではありません!(=ベストプラクティスではありません)
# 下のセルの定義を変更して、プリント文の文法を修正してください。(キャンディが1つしかない場合は、複数形の"candies"ではなく、単数形の "candy"を使用しないといけません)
# (訳注: ひとつしかない時って a candyではないんですね〜〜)
def to_smash(total_candies):
"""与えられた数のキャンディを3人の友達に均等に配った後、捨てなければならない余りのキャンディの数を返します。
捨てなければならない余りのキャンディーの数を返します。
>>> to_smash(91)
1
"""
print("Splitting", total_candies, "candies")
return total_candies % 3
to_smash(91)
to_smash(1)
# この問題を正解したあと、解答を見る場合は、以下のコードセルを実行してください。
# 解答を見る(このコードセルを実行すると表示されます!)
q2.solution()
# # 3. 🌶️(難しめの問題です)
# チュートリアルでは、天気に対して外出する準備ができているかどうかを判断すること学びました。その時、私(作者)は、もし、、
# - 傘を持っていれば、雨に濡れたりする心配はないです。
# - または、雨がそれほど強くなく、フードがあれば、雨に濡れたりする心配はないです。
# - そうでなければ、雨が降っていて、仕事の日でなければ、私はまだ大丈夫です。(そもそも外出しないから)
# 以下の関数は、このことをPythonの式にしてます。このコードにはバグがあります。それを見つけることができますか?
# `prepared_for_weather`のコードが間違っていることを証明するには、次のいずれかを考えてください。
# - 関数が `False` を返す (しかし、本当は`True` を返すべきだった)、または
# - 関数が `True` を返した (しかし、本当は`False` を返すべきだった)。
# この問題に正解すると、Correctが出力(表示)されます。
def prepared_for_weather(have_umbrella, rain_level, have_hood, is_workday):
# このコードを変更しないでください。私たちの目的は、バグを見つけることだけで、修正することではありません
return (
have_umbrella
or rain_level < 5
and have_hood
or not rain_level > 0
and is_workday
)
# これらの入力の値を変更して、prepared_for_weatherのケースを表すようにします。
# これは間違っています。
have_umbrella = True
rain_level = 0.0
have_hood = True
is_workday = True
# 上の変数を利用して、prepared_for_weather関数が返す値を確認します。
actual = prepared_for_weather(have_umbrella, rain_level, have_hood, is_workday)
print(actual)
# 答え合わせをする
q3.check()
# q3.hint()
# q3.solution()
# # 4.
# 以下の関数 `is_negative` はうまく動いています。これは、与えられた数(入力された数)が負であれば`True`を、そうでなければ`False` を返します。
# 例) 5 が与えられると(つまり、`is_negative(5)` )、`True`
# -5が与えられると(つまり、`is_negative(-5)` )、`False`
# しかし、コードの長さが長すぎます。実はもっと短く書くことができるんです。なんと、この関数のコード行数を**75%**減らすことができます。
# たった**1行**のコードで同じことができます。それを関数 `concise_is_negative` に入れてみましょう。(HINT: Pythonの三項演算子は必要ありません)
# (訳注: これは、`def concise_is_negative(number):`これを含めずに1行です。)
def is_negative(number):
if number < 0:
return True
else:
return False
def concise_is_negative(number):
pass # ここに1行で書いてください。(これ以降の問題も)書くときはpassという文字は消してください。
# 答え合わせをします
q4.check()
# q4.hint()
# q4.solution()
# # 5a.
# The boolean variables `ketchup`, `mustard` and `onion` represent whether a customer wants a particular topping on their hot dog. We want to implement a number of boolean functions that correspond to some yes-or-no questions about the customer's order. For example:
# bool型の変数(True or False) である`ketchup`, `mustard`, `onion` は,お客さんがホットドッグに特定のトッピングをしたいかどうかを表します.お客さんの注文に関するイエスかノーかの質問に対応するいくつかのbool型がreturnされる関数を実装したいと考えています。例えば、以下のようなものです。
def onionless(ketchup, mustard, onion):
"""お客様に玉ねぎのトッピングがいるかどうかを伺います。"""
return not onion
def wants_all_toppings(ketchup, mustard, onion):
"""お客様に "the works"(3つのトッピング)がいるかどうかを伺います。"""
pass
# 答え合わせをします
q5.a.check()
# q5.a.hint()
# q5.a.solution()
# # 5b.
# 次の関数では、docstring(def ..... の下にある赤い文字のこと)の説明に合わせて中身を書いていってください!
def wants_plain_hotdog(ketchup, mustard, onion):
"""お客様がトッピングなしのプレーンなホットドッグを注文しているかを返します。"""
pass
# 答え合わせをします
q5.b.check()
# q5.b.hint()
# q5.b.solution()
# # 5c.
# 次の関数では、docstring(def ..... の下にある赤い文字のこと)の説明に合わせて中身を書いていってください!
def exactly_one_sauce(ketchup, mustard, onion):
"""お客様がケチャップかマスタードのどちらか一方をトッピングするよう頼んでいます。
(この操作は「排他的論理和("exclusive or")」という名前でおなじみでしょう)
"""
pass
# 答え合わせをします
q5.c.check()
# q5.c.hint()
# q5.c.solution()
# # 6. 🌶️(難しめの問題です)
# 整数を入力し、`bool()`という関数を呼び出すと, 0に等しい場合は`False`を,そうでない場合は`True`を返すことを見てきました。
# ex) `bool(1)` -> `False`
# では、`int()`を呼び出すとどうなるでしょうか?下のノートブックセルで試してみてください。
# これを利用して,「お客さんはトッピングをちょうど1つ欲しいのか」という英文に対応する簡潔な関数を書くことができるでしょうか?
# 次の関数では、docstringの英語の説明に合わせてボディを記入します。
#
def exactly_one_topping(ketchup, mustard, onion):
"""お客様がホットドッグに3つのトッピングのうちどれか1つだけを希望しているかどうかを返します。"""
pass
# 答え合わせをします
q6.check()
# q6.hint()
# q6.solution()
# # 7. 🌶️(難しめ) (Optional)
# In this problem we'll be working with a simplified version of [blackjack](https://en.wikipedia.org/wiki/Blackjack) (aka twenty-one). In this version there is one player (who you'll control) and a dealer. Play proceeds as follows:
# - The player is dealt two face-up cards. The dealer is dealt one face-up card.
# - The player may ask to be dealt another card ('hit') as many times as they wish. If the sum of their cards exceeds 21, they lose the round immediately.
# - The dealer then deals additional cards to himself until either:
# - the sum of the dealer's cards exceeds 21, in which case the player wins the round
# - the sum of the dealer's cards is greater than or equal to 17. If the player's total is greater than the dealer's, the player wins. Otherwise, the dealer wins (even in case of a tie).
#
# When calculating the sum of cards, Jack, Queen, and King count for 10. Aces can count as 1 or 11 (when referring to a player's "total" above, we mean the largest total that can be made without exceeding 21. So e.g. A+8 = 19, A+8+8 = 17)
# For this problem, you'll write a function representing the player's decision-making strategy in this game. We've provided a very unintelligent implementation below:
# この問題では、[ブラックジャック](https://ja.wikipedia.org/wiki/%E3%83%96%E3%83%A9%E3%83%83%E3%82%AF%E3%82%B8%E3%83%A3%E3%83%83%E3%82%AF)の簡易版(通称:21)を扱います。このゲームは,プレイヤー1人(あなた)とディーラー1人がいます。プレイは次のように進みます。
# - プレイヤーには,表向きのカードが2枚配られます。ディーラーには表向きのカードが1枚配られます。
# - プレイヤーは何度でもディーラーにカードを配ってもらうことができます(「ヒット」)。カードの合計が21を超えた場合、このゲームは負けとなります。
# - その後、ディーラーは次のいずれかになるまで自分に追加のカードを配ります。
# - ディーラーのカードの合計が21を超えた場合 (この場合はプレイヤーの勝利となります)
# - ディーラーのカードの合計が17以上になる場合。(プレイヤーの合計がディーラーの合計より大きい場合は、プレイヤーの勝ちです。それ以外の場合は、ディーラーの勝ちです(同点の場合も同様))。
#
# カードの合計を計算するとき、ジャックJ、クイーンQ、キングKは10と数えます。エースAは1または11と数えます(上記のプレイヤーの「合計」という場合は、21を超えない最大の合計を意味します。例:A+8=19、A+8+8=17)。)
# この問題では、このゲームにおけるプレイヤーの意思決定戦略を表す関数を書きます。以下に、非常によくない、書き方が悪いコードを書きました。
def should_hit(dealer_total, player_total, player_low_aces, player_high_aces):
"""
現在のゲームの状態で、プレイヤーがHitする(別のカードを要求する)べきであればTrueを、プレイヤーがStayするのであればFalseを返します。
手元のカードの合計値を計算する際に、Aを11として数えた時に、21以上にならない場合はエースAを「high」(値が11)として数えます。
そうでない場合は「low」(値が1)として数えます。
例えば、プレイヤーの手札が{A, A, A, 7}の場合、11 + 1 + 1 + 7とカウントします。
となり、player_total=20、player_low_aces=2、player_high_aces=1となります。
"""
return False
# このゲームでは、カードが最初に配り終わると、そこからは常に2枚以上のカードを2人が持つことになります。
# あなたの関数を呼び出して,プレイヤーとディーラーのゲームをシュミレーションしてみましょう.
# 以下の関数を実行して,シュミレーションされたゲームを見てください.
q7.simulate_one_game()
# 多くのゲームにおける平均勝率が、プレイヤーの意思決定につながります。以下の関数を使って、50000回プレイしたブラックジャックをシミュレートしてみてください(実行するのに、数秒かかるかもしれません):
q7.simulate(n_games=50000)
# ゲームの状態を完全に無視したプレイヤーは、それでも衝撃的なほど頻繁に勝つことができます!!!
# `should_hit`関数にもう少し賢さを加えて、結果にどのような影響を与えるか試してみてください。
def should_hit(dealer_total, player_total, player_low_aces, player_high_aces):
"""現在のゲームの状態で、プレイヤーがHitする(別のカードを要求する)べきであればTrueを、プレイヤーがStayするのであればFalseを返します。
手元のカードの合計値を計算する際に、Aを11として数えた時に、21以上にならない場合はエースAを「high」(値が11)として数えます。
そうでない場合は「low」(値が1)として数えます。
例えば、プレイヤーの手札が{A, A, A, 7}の場合、11 + 1 + 1 + 7とカウントします。
となり、player_total=20、player_low_aces=2、player_high_aces=1となります。
"""
return False
q7.simulate(n_games=50000)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/261/70261974.ipynb | null | null | [{"Id": 70261974, "ScriptId": 19225433, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5973981, "CreationDate": "08/05/2021 15:13:17", "VersionNumber": 2.0, "Title": "Exercise: Booleans and Conditionals", "EvaluationDate": "08/05/2021", "IsChange": false, "TotalLines": 284.0, "LinesInsertedFromPrevious": 0.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 284.0, "LinesInsertedFromFork": 131.0, "LinesDeletedFromFork": 105.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 153.0, "TotalVotes": 0}] | null | null | null | null | from learntools.core import binder
binder.bind(globals())
from learntools.python.ex3 import *
print("Setup complete.")
# # 1.
# 多くのプログラミング言語では、[`sign`](https://ja.wikipedia.org/wiki/%E7%AC%A6%E5%8F%B7%E9%96%A2%E6%95%B0)が組み込み関数として用意されています。Pythonにはありませんが、自分で定義(作成)することができます。
# 下のセルに、数値を受け取り、それが負ならば-1、正ならば1、0ならば0を返す`sign`という関数を作成してください!
# コードはここに書いてください!"sign"という関数を作成します。
# Check your answer
q1.check()
# q1.solution()
# # 2.
# 前回の演習で作った`to_smash`関数に「logging(ログの出力、ここではprint関数を用います)」を追加しましょう!
def to_smash(total_candies):
"""与えられた数のキャンディを3人の友達に均等に配った後、捨てなければならない余りのキャンディの数を返します。
捨てなければならない余りのキャンディーの数を返します。
>>> to_smash(91)
1
"""
print("Splitting", total_candies, "candies")
return total_candies % 3
to_smash(91)
# `total_candies = 1`で実行するとどうなるでしょうか?
to_smash(1)
# それは素晴らしい文法ではありません!(=ベストプラクティスではありません)
# 下のセルの定義を変更して、プリント文の文法を修正してください。(キャンディが1つしかない場合は、複数形の"candies"ではなく、単数形の "candy"を使用しないといけません)
# (訳注: ひとつしかない時って a candyではないんですね〜〜)
def to_smash(total_candies):
"""与えられた数のキャンディを3人の友達に均等に配った後、捨てなければならない余りのキャンディの数を返します。
捨てなければならない余りのキャンディーの数を返します。
>>> to_smash(91)
1
"""
print("Splitting", total_candies, "candies")
return total_candies % 3
to_smash(91)
to_smash(1)
# この問題を正解したあと、解答を見る場合は、以下のコードセルを実行してください。
# 解答を見る(このコードセルを実行すると表示されます!)
q2.solution()
# # 3. 🌶️(難しめの問題です)
# チュートリアルでは、天気に対して外出する準備ができているかどうかを判断すること学びました。その時、私(作者)は、もし、、
# - 傘を持っていれば、雨に濡れたりする心配はないです。
# - または、雨がそれほど強くなく、フードがあれば、雨に濡れたりする心配はないです。
# - そうでなければ、雨が降っていて、仕事の日でなければ、私はまだ大丈夫です。(そもそも外出しないから)
# 以下の関数は、このことをPythonの式にしてます。このコードにはバグがあります。それを見つけることができますか?
# `prepared_for_weather`のコードが間違っていることを証明するには、次のいずれかを考えてください。
# - 関数が `False` を返す (しかし、本当は`True` を返すべきだった)、または
# - 関数が `True` を返した (しかし、本当は`False` を返すべきだった)。
# この問題に正解すると、Correctが出力(表示)されます。
def prepared_for_weather(have_umbrella, rain_level, have_hood, is_workday):
# このコードを変更しないでください。私たちの目的は、バグを見つけることだけで、修正することではありません
return (
have_umbrella
or rain_level < 5
and have_hood
or not rain_level > 0
and is_workday
)
# これらの入力の値を変更して、prepared_for_weatherのケースを表すようにします。
# これは間違っています。
have_umbrella = True
rain_level = 0.0
have_hood = True
is_workday = True
# 上の変数を利用して、prepared_for_weather関数が返す値を確認します。
actual = prepared_for_weather(have_umbrella, rain_level, have_hood, is_workday)
print(actual)
# 答え合わせをする
q3.check()
# q3.hint()
# q3.solution()
# # 4.
# 以下の関数 `is_negative` はうまく動いています。これは、与えられた数(入力された数)が負であれば`True`を、そうでなければ`False` を返します。
# 例) 5 が与えられると(つまり、`is_negative(5)` )、`True`
# -5が与えられると(つまり、`is_negative(-5)` )、`False`
# しかし、コードの長さが長すぎます。実はもっと短く書くことができるんです。なんと、この関数のコード行数を**75%**減らすことができます。
# たった**1行**のコードで同じことができます。それを関数 `concise_is_negative` に入れてみましょう。(HINT: Pythonの三項演算子は必要ありません)
# (訳注: これは、`def concise_is_negative(number):`これを含めずに1行です。)
def is_negative(number):
if number < 0:
return True
else:
return False
def concise_is_negative(number):
pass # ここに1行で書いてください。(これ以降の問題も)書くときはpassという文字は消してください。
# 答え合わせをします
q4.check()
# q4.hint()
# q4.solution()
# # 5a.
# The boolean variables `ketchup`, `mustard` and `onion` represent whether a customer wants a particular topping on their hot dog. We want to implement a number of boolean functions that correspond to some yes-or-no questions about the customer's order. For example:
# bool型の変数(True or False) である`ketchup`, `mustard`, `onion` は,お客さんがホットドッグに特定のトッピングをしたいかどうかを表します.お客さんの注文に関するイエスかノーかの質問に対応するいくつかのbool型がreturnされる関数を実装したいと考えています。例えば、以下のようなものです。
def onionless(ketchup, mustard, onion):
"""お客様に玉ねぎのトッピングがいるかどうかを伺います。"""
return not onion
def wants_all_toppings(ketchup, mustard, onion):
"""お客様に "the works"(3つのトッピング)がいるかどうかを伺います。"""
pass
# 答え合わせをします
q5.a.check()
# q5.a.hint()
# q5.a.solution()
# # 5b.
# 次の関数では、docstring(def ..... の下にある赤い文字のこと)の説明に合わせて中身を書いていってください!
def wants_plain_hotdog(ketchup, mustard, onion):
"""お客様がトッピングなしのプレーンなホットドッグを注文しているかを返します。"""
pass
# 答え合わせをします
q5.b.check()
# q5.b.hint()
# q5.b.solution()
# # 5c.
# 次の関数では、docstring(def ..... の下にある赤い文字のこと)の説明に合わせて中身を書いていってください!
def exactly_one_sauce(ketchup, mustard, onion):
"""お客様がケチャップかマスタードのどちらか一方をトッピングするよう頼んでいます。
(この操作は「排他的論理和("exclusive or")」という名前でおなじみでしょう)
"""
pass
# 答え合わせをします
q5.c.check()
# q5.c.hint()
# q5.c.solution()
# # 6. 🌶️(難しめの問題です)
# 整数を入力し、`bool()`という関数を呼び出すと, 0に等しい場合は`False`を,そうでない場合は`True`を返すことを見てきました。
# ex) `bool(1)` -> `False`
# では、`int()`を呼び出すとどうなるでしょうか?下のノートブックセルで試してみてください。
# これを利用して,「お客さんはトッピングをちょうど1つ欲しいのか」という英文に対応する簡潔な関数を書くことができるでしょうか?
# 次の関数では、docstringの英語の説明に合わせてボディを記入します。
#
def exactly_one_topping(ketchup, mustard, onion):
"""お客様がホットドッグに3つのトッピングのうちどれか1つだけを希望しているかどうかを返します。"""
pass
# 答え合わせをします
q6.check()
# q6.hint()
# q6.solution()
# # 7. 🌶️(難しめ) (Optional)
# In this problem we'll be working with a simplified version of [blackjack](https://en.wikipedia.org/wiki/Blackjack) (aka twenty-one). In this version there is one player (who you'll control) and a dealer. Play proceeds as follows:
# - The player is dealt two face-up cards. The dealer is dealt one face-up card.
# - The player may ask to be dealt another card ('hit') as many times as they wish. If the sum of their cards exceeds 21, they lose the round immediately.
# - The dealer then deals additional cards to himself until either:
# - the sum of the dealer's cards exceeds 21, in which case the player wins the round
# - the sum of the dealer's cards is greater than or equal to 17. If the player's total is greater than the dealer's, the player wins. Otherwise, the dealer wins (even in case of a tie).
#
# When calculating the sum of cards, Jack, Queen, and King count for 10. Aces can count as 1 or 11 (when referring to a player's "total" above, we mean the largest total that can be made without exceeding 21. So e.g. A+8 = 19, A+8+8 = 17)
# For this problem, you'll write a function representing the player's decision-making strategy in this game. We've provided a very unintelligent implementation below:
# この問題では、[ブラックジャック](https://ja.wikipedia.org/wiki/%E3%83%96%E3%83%A9%E3%83%83%E3%82%AF%E3%82%B8%E3%83%A3%E3%83%83%E3%82%AF)の簡易版(通称:21)を扱います。このゲームは,プレイヤー1人(あなた)とディーラー1人がいます。プレイは次のように進みます。
# - プレイヤーには,表向きのカードが2枚配られます。ディーラーには表向きのカードが1枚配られます。
# - プレイヤーは何度でもディーラーにカードを配ってもらうことができます(「ヒット」)。カードの合計が21を超えた場合、このゲームは負けとなります。
# - その後、ディーラーは次のいずれかになるまで自分に追加のカードを配ります。
# - ディーラーのカードの合計が21を超えた場合 (この場合はプレイヤーの勝利となります)
# - ディーラーのカードの合計が17以上になる場合。(プレイヤーの合計がディーラーの合計より大きい場合は、プレイヤーの勝ちです。それ以外の場合は、ディーラーの勝ちです(同点の場合も同様))。
#
# カードの合計を計算するとき、ジャックJ、クイーンQ、キングKは10と数えます。エースAは1または11と数えます(上記のプレイヤーの「合計」という場合は、21を超えない最大の合計を意味します。例:A+8=19、A+8+8=17)。)
# この問題では、このゲームにおけるプレイヤーの意思決定戦略を表す関数を書きます。以下に、非常によくない、書き方が悪いコードを書きました。
def should_hit(dealer_total, player_total, player_low_aces, player_high_aces):
"""
現在のゲームの状態で、プレイヤーがHitする(別のカードを要求する)べきであればTrueを、プレイヤーがStayするのであればFalseを返します。
手元のカードの合計値を計算する際に、Aを11として数えた時に、21以上にならない場合はエースAを「high」(値が11)として数えます。
そうでない場合は「low」(値が1)として数えます。
例えば、プレイヤーの手札が{A, A, A, 7}の場合、11 + 1 + 1 + 7とカウントします。
となり、player_total=20、player_low_aces=2、player_high_aces=1となります。
"""
return False
# このゲームでは、カードが最初に配り終わると、そこからは常に2枚以上のカードを2人が持つことになります。
# あなたの関数を呼び出して,プレイヤーとディーラーのゲームをシュミレーションしてみましょう.
# 以下の関数を実行して,シュミレーションされたゲームを見てください.
q7.simulate_one_game()
# 多くのゲームにおける平均勝率が、プレイヤーの意思決定につながります。以下の関数を使って、50000回プレイしたブラックジャックをシミュレートしてみてください(実行するのに、数秒かかるかもしれません):
q7.simulate(n_games=50000)
# ゲームの状態を完全に無視したプレイヤーは、それでも衝撃的なほど頻繁に勝つことができます!!!
# `should_hit`関数にもう少し賢さを加えて、結果にどのような影響を与えるか試してみてください。
def should_hit(dealer_total, player_total, player_low_aces, player_high_aces):
"""現在のゲームの状態で、プレイヤーがHitする(別のカードを要求する)べきであればTrueを、プレイヤーがStayするのであればFalseを返します。
手元のカードの合計値を計算する際に、Aを11として数えた時に、21以上にならない場合はエースAを「high」(値が11)として数えます。
そうでない場合は「low」(値が1)として数えます。
例えば、プレイヤーの手札が{A, A, A, 7}の場合、11 + 1 + 1 + 7とカウントします。
となり、player_total=20、player_low_aces=2、player_high_aces=1となります。
"""
return False
q7.simulate(n_games=50000)
| false | 0 | 4,348 | 0 | 6 | 4,348 |
||
70782082 | <kaggle_start><code>from learntools.core import binder
binder.bind(globals())
from learntools.python.ex6 import *
print("Setup complete.")
# まずはウォーミングアップとして、文字列の長さを予想してみましょう。。
# 以下の5つの文字列のそれぞれについて、その文字列を `len()` に入れると何が返ってくるかを予測してください。変数 `length` を使ってそこに答えを入力し、セルを実行して予想が正しいかどうかを確認してください。
# # 0a.
a = ""
length = ____
q0.a.check()
# # 0b.
b = "it's ok"
length = ____
q0.b.check()
# # 0c.
c = "it's ok"
length = ____
q0.c.check()
# # 0d.
d = """hey"""
length = ____
q0.d.check()
# # 0e.
e = "\n"
length = ____
q0.e.check()
# # 1.
# "データサイエンティストは、80%の時間をデータのクリーニングに費やし、20%の時間をデータのクリーニングについての不満に費やす "という言葉があります。アメリカの郵便番号データを綺麗にするするための関数を書けるかどうか試してみましょう。文字列が与えられると、その文字列が有効な郵便番号であるかどうかを返す必要があります。ここでは、有効な郵便番号とは、正確に5桁の数字で構成される文字列のことです。
# ヒント: `str` には、実は隠された機能があります。(string型の後ろにくっつけるもの。c言語系をやった時に結構使いました)。その機能を見るには、`help(str)`を使ってください。
def is_valid_zip(zip_code):
"""Returns whether the input string is a valid (5 digit) zip code"""
pass
# 答え合わせをする
q1.check()
# q1.hint()
# q1.solution()
# # 2.
# ある研究者が何千ものニュース記事を集めました。しかし、彼女は特定の単語を含む記事に注目したいと考えています。彼女が記事のリストをフィルタリングできるように、以下の条件を満たす関数を作ってください!
# - キーワードの文字列が、より大きな単語の一部としてのみ表示される文書は含めません。例えば、彼女が "closed "というキーワードを探していた場合、"enclosed "という文字列は含めないようにします。
# - 大文字と小文字は区別する必要はありません。つまり、キーワードが "closed "の場合、"Closed the case. "というフレーズが含まれます。
# - ピリオドやカンマがマッチする内容に影響しないようにします。キーワードが "closed "の場合は、"It is closed. "も含まれます。しかし、他の種類の句読点はないと考えてよいでしょう。
#
def word_search(doc_list, keyword):
"""
ドキュメントのリスト(各ドキュメントは文字列)と検索するキーワードを受け取ります。 キーワードを含むドキュメントのインデックスの値のリスト(すべて)を返します。
例:
doc_list = ["The Learn Python Challenge Casino.", "They bought a car", "Casinoville"]
>>> word_search(doc_list, 'casino')
>>> [0]
"""
pass
# 答え合わせをする
q2.check()
# q2.hint()
# q2.solution()
# # 3.
# 今、研究者は、さっきとは違い、複数のキーワードを検索したいと考えています。先ほどのものに加え、検索キーワードを複数入力可能な関数を作成してください。
# (この関数を実装する際には、先ほど書いた `word_search` 関数を使うことをお勧めします。このようにコードを再利用することで、プログラムがより強固で読みやすくなり、タイピングの手間も省けます!)
def multi_word_search(doc_list, keywords):
"""
doc_list(各ドキュメントは文字列)とkeywords(検索キーワードのリスト)を受け取ります。
それぞれのキーワードで、検索結果として得られたインデックスのリスト(doc_listから)である辞書型の配列を返します。
>>> doc_list = ["The Learn Python Challenge Casino.", "They bought a car and a casino", "Casinoville"]
>>> keywords = ['casino', 'they']
>>> multi_word_search(doc_list, keywords)
{'casino': [0, 1], 'they': [1]}
"""
pass
# Check your answer
q3.check()
# q3.solution()
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/782/70782082.ipynb | null | null | [{"Id": 70782082, "ScriptId": 19340424, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5973981, "CreationDate": "08/09/2021 02:54:34", "VersionNumber": 3.0, "Title": "(\u65e5\u672c\u8a9e\u8a33) Exercise: Strings and Dictionaries", "EvaluationDate": "08/09/2021", "IsChange": false, "TotalLines": 129.0, "LinesInsertedFromPrevious": 0.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 129.0, "LinesInsertedFromFork": 25.0, "LinesDeletedFromFork": 26.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 104.0, "TotalVotes": 7}] | null | null | null | null | from learntools.core import binder
binder.bind(globals())
from learntools.python.ex6 import *
print("Setup complete.")
# まずはウォーミングアップとして、文字列の長さを予想してみましょう。。
# 以下の5つの文字列のそれぞれについて、その文字列を `len()` に入れると何が返ってくるかを予測してください。変数 `length` を使ってそこに答えを入力し、セルを実行して予想が正しいかどうかを確認してください。
# # 0a.
a = ""
length = ____
q0.a.check()
# # 0b.
b = "it's ok"
length = ____
q0.b.check()
# # 0c.
c = "it's ok"
length = ____
q0.c.check()
# # 0d.
d = """hey"""
length = ____
q0.d.check()
# # 0e.
e = "\n"
length = ____
q0.e.check()
# # 1.
# "データサイエンティストは、80%の時間をデータのクリーニングに費やし、20%の時間をデータのクリーニングについての不満に費やす "という言葉があります。アメリカの郵便番号データを綺麗にするするための関数を書けるかどうか試してみましょう。文字列が与えられると、その文字列が有効な郵便番号であるかどうかを返す必要があります。ここでは、有効な郵便番号とは、正確に5桁の数字で構成される文字列のことです。
# ヒント: `str` には、実は隠された機能があります。(string型の後ろにくっつけるもの。c言語系をやった時に結構使いました)。その機能を見るには、`help(str)`を使ってください。
def is_valid_zip(zip_code):
"""Returns whether the input string is a valid (5 digit) zip code"""
pass
# 答え合わせをする
q1.check()
# q1.hint()
# q1.solution()
# # 2.
# ある研究者が何千ものニュース記事を集めました。しかし、彼女は特定の単語を含む記事に注目したいと考えています。彼女が記事のリストをフィルタリングできるように、以下の条件を満たす関数を作ってください!
# - キーワードの文字列が、より大きな単語の一部としてのみ表示される文書は含めません。例えば、彼女が "closed "というキーワードを探していた場合、"enclosed "という文字列は含めないようにします。
# - 大文字と小文字は区別する必要はありません。つまり、キーワードが "closed "の場合、"Closed the case. "というフレーズが含まれます。
# - ピリオドやカンマがマッチする内容に影響しないようにします。キーワードが "closed "の場合は、"It is closed. "も含まれます。しかし、他の種類の句読点はないと考えてよいでしょう。
#
def word_search(doc_list, keyword):
"""
ドキュメントのリスト(各ドキュメントは文字列)と検索するキーワードを受け取ります。 キーワードを含むドキュメントのインデックスの値のリスト(すべて)を返します。
例:
doc_list = ["The Learn Python Challenge Casino.", "They bought a car", "Casinoville"]
>>> word_search(doc_list, 'casino')
>>> [0]
"""
pass
# 答え合わせをする
q2.check()
# q2.hint()
# q2.solution()
# # 3.
# 今、研究者は、さっきとは違い、複数のキーワードを検索したいと考えています。先ほどのものに加え、検索キーワードを複数入力可能な関数を作成してください。
# (この関数を実装する際には、先ほど書いた `word_search` 関数を使うことをお勧めします。このようにコードを再利用することで、プログラムがより強固で読みやすくなり、タイピングの手間も省けます!)
def multi_word_search(doc_list, keywords):
"""
doc_list(各ドキュメントは文字列)とkeywords(検索キーワードのリスト)を受け取ります。
それぞれのキーワードで、検索結果として得られたインデックスのリスト(doc_listから)である辞書型の配列を返します。
>>> doc_list = ["The Learn Python Challenge Casino.", "They bought a car and a casino", "Casinoville"]
>>> keywords = ['casino', 'they']
>>> multi_word_search(doc_list, keywords)
{'casino': [0, 1], 'they': [1]}
"""
pass
# Check your answer
q3.check()
# q3.solution()
| false | 0 | 1,313 | 7 | 6 | 1,313 |
||
70917348 | <kaggle_start><code># # Lux AI Season 1 Python Tutorial Notebook
# Welcome to Lux AI Season 1! We're glad you could make it! (TODO: add lore here?)
# This notebook takes you step by step on how to develop and compete using **Jupyter Notebooks and Python**. First things first, make sure you have these links at the ready
# - Competition Page: https://www.kaggle.com/c/lux-ai-2021/
# - Online Visualizer: https://2021vis.lux-ai.org/
# - Specifications: https://www.lux-ai.org/specs-2021
# - Github: https://github.com/Lux-AI-Challenge/Lux-Design-2021
# - Bot API: https://github.com/Lux-AI-Challenge/Lux-Design-2021/tree/master/kits
# And if you haven't done so already, we **highly recommend** you join our Discord server at https://discord.gg/aWJt3UAcgn or at the minimum follow the kaggle forums at https://www.kaggle.com/c/lux-ai-2021/discussion. We post important announcements there such as changes to rules, events, and opportunities from our sponsors!
# Now let's get started!
# ## Prerequisites
# We assume that you have a basic knowledge of Python and programming. It's okay if you don't know the game specifications yet! Feel free to always refer back to https://www.lux-ai.org/specs-2021.
# ## Basic Setup
# First thing to verify is that you have **Node.js v12 or above**. The engine for the competition runs on Node.js (for many good reasons including an awesome visualizer) and thus it is required. You can download it [here](https://nodejs.org/en/download/). You can then verify you have the appropriate version by running
#
# Next, we have to import the `make` function from the `kaggle_environments` package
from kaggle_environments import make
# The `make` function is used to create environments that can then run the game given agents. Agents refer to programmed bots that play the game given observations of the game itself.
# In addition to making the environment, you may also pass in special configurations such as the number of episode steps (capped at 361) and the seed.
# Now lets create our environment using `make` and watch a Episode! (We will be using the seed 562124210 because it's fun)
# create the environment
env = make("lux_ai_2021", configuration={"seed": 562124210})
# run a match between two simple agents, which are the agents we will walk you through on how to build!
steps = env.run(["simple_agent", "simple_agent"])
# render the game, feel free to change width and height to your liking. We recommend keeping them as large as possible for better quality.
env.render(mode="ipython", width=1200, height=800)
# Ok so woah, what just happened? We just ran a match, that's what :)
# There's a number of quality of life features in the visualizer, which you can also find embedded on the kaggle competition page when watching replays or on the online visualizer when using replay files.
# If you find this replay viewer slow, you can also download a local copy of this replay viewer in addition to lowering the graphics quality, see https://github.com/Lux-AI-Challenge/LuxViewer2021 for instructions.
# At this point, we recommend reading the [game specifications](https://www.lux-ai.org/specs-2021) a bit more to understand how to build a bot that tries to win the game.
# ## Building from Scratch
# The following bit of code is all you need for a empty agent that does nothing
# run this if using kaggle notebooks
from lux.game import Game
from lux.game_map import Cell, RESOURCE_TYPES
from lux.constants import Constants
from lux.game_constants import GAME_CONSTANTS
from lux import annotate
import math
# we declare this global game_state object so that state persists across turns so we do not need to reinitialize it all the time
game_state = None
def agent(observation, configuration):
global game_state
### Do not edit ###
if observation["step"] == 0:
game_state = Game()
game_state._initialize(observation["updates"])
game_state._update(observation["updates"][2:])
else:
game_state._update(observation["updates"])
actions = []
### AI Code goes down here! ###
player = game_state.players[observation.player]
opponent = game_state.players[(observation.player + 1) % 2]
width, height = game_state.map.width, game_state.map.height
return actions
# Unfortunately it's not that easy. This agent will eventually lose and all units and cities will fall to darkness! Let's write something to help the agent first find resources and then collect them.
def find_resources(game_state):
# TODO
pass
# Ok now that our agent finds and collects resources, what now? Well units can only carry so much resources before they can't collect anymore. And to keep your City alive, you must move your unit on top of any CityTile that is in that City. (Recall that a City is composed of connected CityTiles)
def return_to_nearest_city_tile(game_state):
# TODO
pass
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/917/70917348.ipynb | null | null | [{"Id": 70917348, "ScriptId": 19252428, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3353266, "CreationDate": "08/09/2021 19:33:13", "VersionNumber": 2.0, "Title": "Lux AI Season 1 Jupyter Notebook Tutorial", "EvaluationDate": "08/09/2021", "IsChange": true, "TotalLines": 106.0, "LinesInsertedFromPrevious": 2.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 104.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 1}] | null | null | null | null | # # Lux AI Season 1 Python Tutorial Notebook
# Welcome to Lux AI Season 1! We're glad you could make it! (TODO: add lore here?)
# This notebook takes you step by step on how to develop and compete using **Jupyter Notebooks and Python**. First things first, make sure you have these links at the ready
# - Competition Page: https://www.kaggle.com/c/lux-ai-2021/
# - Online Visualizer: https://2021vis.lux-ai.org/
# - Specifications: https://www.lux-ai.org/specs-2021
# - Github: https://github.com/Lux-AI-Challenge/Lux-Design-2021
# - Bot API: https://github.com/Lux-AI-Challenge/Lux-Design-2021/tree/master/kits
# And if you haven't done so already, we **highly recommend** you join our Discord server at https://discord.gg/aWJt3UAcgn or at the minimum follow the kaggle forums at https://www.kaggle.com/c/lux-ai-2021/discussion. We post important announcements there such as changes to rules, events, and opportunities from our sponsors!
# Now let's get started!
# ## Prerequisites
# We assume that you have a basic knowledge of Python and programming. It's okay if you don't know the game specifications yet! Feel free to always refer back to https://www.lux-ai.org/specs-2021.
# ## Basic Setup
# First thing to verify is that you have **Node.js v12 or above**. The engine for the competition runs on Node.js (for many good reasons including an awesome visualizer) and thus it is required. You can download it [here](https://nodejs.org/en/download/). You can then verify you have the appropriate version by running
#
# Next, we have to import the `make` function from the `kaggle_environments` package
from kaggle_environments import make
# The `make` function is used to create environments that can then run the game given agents. Agents refer to programmed bots that play the game given observations of the game itself.
# In addition to making the environment, you may also pass in special configurations such as the number of episode steps (capped at 361) and the seed.
# Now lets create our environment using `make` and watch a Episode! (We will be using the seed 562124210 because it's fun)
# create the environment
env = make("lux_ai_2021", configuration={"seed": 562124210})
# run a match between two simple agents, which are the agents we will walk you through on how to build!
steps = env.run(["simple_agent", "simple_agent"])
# render the game, feel free to change width and height to your liking. We recommend keeping them as large as possible for better quality.
env.render(mode="ipython", width=1200, height=800)
# Ok so woah, what just happened? We just ran a match, that's what :)
# There's a number of quality of life features in the visualizer, which you can also find embedded on the kaggle competition page when watching replays or on the online visualizer when using replay files.
# If you find this replay viewer slow, you can also download a local copy of this replay viewer in addition to lowering the graphics quality, see https://github.com/Lux-AI-Challenge/LuxViewer2021 for instructions.
# At this point, we recommend reading the [game specifications](https://www.lux-ai.org/specs-2021) a bit more to understand how to build a bot that tries to win the game.
# ## Building from Scratch
# The following bit of code is all you need for a empty agent that does nothing
# run this if using kaggle notebooks
from lux.game import Game
from lux.game_map import Cell, RESOURCE_TYPES
from lux.constants import Constants
from lux.game_constants import GAME_CONSTANTS
from lux import annotate
import math
# we declare this global game_state object so that state persists across turns so we do not need to reinitialize it all the time
game_state = None
def agent(observation, configuration):
global game_state
### Do not edit ###
if observation["step"] == 0:
game_state = Game()
game_state._initialize(observation["updates"])
game_state._update(observation["updates"][2:])
else:
game_state._update(observation["updates"])
actions = []
### AI Code goes down here! ###
player = game_state.players[observation.player]
opponent = game_state.players[(observation.player + 1) % 2]
width, height = game_state.map.width, game_state.map.height
return actions
# Unfortunately it's not that easy. This agent will eventually lose and all units and cities will fall to darkness! Let's write something to help the agent first find resources and then collect them.
def find_resources(game_state):
# TODO
pass
# Ok now that our agent finds and collects resources, what now? Well units can only carry so much resources before they can't collect anymore. And to keep your City alive, you must move your unit on top of any CityTile that is in that City. (Recall that a City is composed of connected CityTiles)
def return_to_nearest_city_tile(game_state):
# TODO
pass
| false | 0 | 1,299 | 1 | 6 | 1,299 |
||
70478747 | <kaggle_start><code>from learntools.core import binder
binder.bind(globals())
from learntools.python.ex5 import *
print("Setup complete.")
# # 1.
# デバッグには運も必要だと感じたことはありませんか? 次のプログラムにはバグがあります。そのバグを見つけ出して、正しいコードに修正してみてください!
def has_lucky_number(nums):
"""与えられた数字のリストがラッキーかどうかを返します。ラッキーリストには
7で割り切れる数字が1つ以上含まれている。
"""
for num in nums:
if num % 7 == 0:
return True
else:
return False
# バグを見つけ出して、下のセルに修正してみてください
def has_lucky_number(nums):
"""与えられた数字のリスト(nums)がラッキーかどうかを求めます。ラッキーなリストには
7で割り切れる数字が1つ以上含まれています。
"""
for num in nums:
if num % 7 == 0:
return True
else:
return False
# Check your answer
q1.check()
# q1.hint()
# q1.solution()
# # 2.
# 下のPythonの式を見てください。この式を実行すると、何が得られると思いますか?
# 予測ができたら、コードをコメントアウトしてセルを実行し、自分の答えが正しいかどうか判断してみてください。
# [1, 2, 3, 4] > 2
# RやPythonでは、(numpyやpandasなどの)いくつかのライブラリでは、リストの各要素を2と比較し(つまり、「要素ごと」の比較を行い)、`[False, False, True, True]`のようなbool型のリストを返します。
# この動作を関数を以下のセルで実装し、入力されたリストの数字それぞれがnより大きいかどうかを返すbool型のリストを作成してください。
def elementwise_greater_than(L, thresh):
"""Lと同じ長さのリストをreturnで返します。ここで、iをインデックス(番目の数)とすると
L[i]がthreshの数より大きければTrue、そうでなければFalseです。
>>> elementwise_greater_than([1, 2, 3, 4], 2)
[False, False, True, True]
"""
pass
# 答え合わせをする
q2.check()
# q2.solution()
# # 3.
# 以下の関数の中身を、docstring("""で囲まれている赤文字のもの)に従って完成させます。
def menu_is_boring(meals):
"""ある期間に提供された食事のリストが与えられ、同じ食事が2日連続で提供されたことがあればTrueを、そうでなければFalseを返す。"""
pass
# 答え合わせをする
q3.check()
# q3.hint()
# q3.solution()
# # 4. 🌶️(難しい問題)
# Python Challenge Casinoには、ブラックジャックテーブルの隣にスロットマシンがあります。スロットマシンの結果は、`play_slot_machine()`でわかります。返される数字はドルでの賞金です。通常は0が返されますが、たまに運が良ければ大金を手にすることができます。以下のように実行してみてください。
play_slot_machine()
# ところで、1回のプレイが1ドルだということをお伝えしましたか?後で請求書をお送りしますので、ご安心ください笑
# マシンをプレイするたびに、平均してどのくらいのお金が得られる(または失う)のでしょうか? カジノでは秘密にされていますが、**モンテカルロ法**と呼ばれる手法を使って、1回の獲得できるお金の平均値を推定することができます。平均的な結果を推定するには、シナリオを何度もシミュレーションして、その平均的な結果を返します。
# 次の関数を完成させて、スロットマシンの1回のプレイの平均値を計算してください。
def estimate_average_slot_payout(n_runs):
"""スロットマシンをn_runs回実行し、1回あたりの平均の純利益(得たお金 - スロットを回すのに使ったお金)を返します。
呼び出し例(戻り値は非決定論的であることに注意!):
>>> estimate_average_slot_payout(1)
-1
>>> estimate_average_slot_payout(1)
0.5
"""
pass
# 1スピンあたりの期待値がわかったら、下のセルを実行して解答を表示させてください。
# 答え合わせをする
q4.solution()
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/478/70478747.ipynb | null | null | [{"Id": 70478747, "ScriptId": 19293825, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5973981, "CreationDate": "08/07/2021 00:51:18", "VersionNumber": 3.0, "Title": "(\u65e5\u672c\u8a9e\u8a33)Exercise: Loops and List Comprehensions", "EvaluationDate": "08/07/2021", "IsChange": true, "TotalLines": 123.0, "LinesInsertedFromPrevious": 1.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 122.0, "LinesInsertedFromFork": 32.0, "LinesDeletedFromFork": 30.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 91.0, "TotalVotes": 7}] | null | null | null | null | from learntools.core import binder
binder.bind(globals())
from learntools.python.ex5 import *
print("Setup complete.")
# # 1.
# デバッグには運も必要だと感じたことはありませんか? 次のプログラムにはバグがあります。そのバグを見つけ出して、正しいコードに修正してみてください!
def has_lucky_number(nums):
"""与えられた数字のリストがラッキーかどうかを返します。ラッキーリストには
7で割り切れる数字が1つ以上含まれている。
"""
for num in nums:
if num % 7 == 0:
return True
else:
return False
# バグを見つけ出して、下のセルに修正してみてください
def has_lucky_number(nums):
"""与えられた数字のリスト(nums)がラッキーかどうかを求めます。ラッキーなリストには
7で割り切れる数字が1つ以上含まれています。
"""
for num in nums:
if num % 7 == 0:
return True
else:
return False
# Check your answer
q1.check()
# q1.hint()
# q1.solution()
# # 2.
# 下のPythonの式を見てください。この式を実行すると、何が得られると思いますか?
# 予測ができたら、コードをコメントアウトしてセルを実行し、自分の答えが正しいかどうか判断してみてください。
# [1, 2, 3, 4] > 2
# RやPythonでは、(numpyやpandasなどの)いくつかのライブラリでは、リストの各要素を2と比較し(つまり、「要素ごと」の比較を行い)、`[False, False, True, True]`のようなbool型のリストを返します。
# この動作を関数を以下のセルで実装し、入力されたリストの数字それぞれがnより大きいかどうかを返すbool型のリストを作成してください。
def elementwise_greater_than(L, thresh):
"""Lと同じ長さのリストをreturnで返します。ここで、iをインデックス(番目の数)とすると
L[i]がthreshの数より大きければTrue、そうでなければFalseです。
>>> elementwise_greater_than([1, 2, 3, 4], 2)
[False, False, True, True]
"""
pass
# 答え合わせをする
q2.check()
# q2.solution()
# # 3.
# 以下の関数の中身を、docstring("""で囲まれている赤文字のもの)に従って完成させます。
def menu_is_boring(meals):
"""ある期間に提供された食事のリストが与えられ、同じ食事が2日連続で提供されたことがあればTrueを、そうでなければFalseを返す。"""
pass
# 答え合わせをする
q3.check()
# q3.hint()
# q3.solution()
# # 4. 🌶️(難しい問題)
# Python Challenge Casinoには、ブラックジャックテーブルの隣にスロットマシンがあります。スロットマシンの結果は、`play_slot_machine()`でわかります。返される数字はドルでの賞金です。通常は0が返されますが、たまに運が良ければ大金を手にすることができます。以下のように実行してみてください。
play_slot_machine()
# ところで、1回のプレイが1ドルだということをお伝えしましたか?後で請求書をお送りしますので、ご安心ください笑
# マシンをプレイするたびに、平均してどのくらいのお金が得られる(または失う)のでしょうか? カジノでは秘密にされていますが、**モンテカルロ法**と呼ばれる手法を使って、1回の獲得できるお金の平均値を推定することができます。平均的な結果を推定するには、シナリオを何度もシミュレーションして、その平均的な結果を返します。
# 次の関数を完成させて、スロットマシンの1回のプレイの平均値を計算してください。
def estimate_average_slot_payout(n_runs):
"""スロットマシンをn_runs回実行し、1回あたりの平均の純利益(得たお金 - スロットを回すのに使ったお金)を返します。
呼び出し例(戻り値は非決定論的であることに注意!):
>>> estimate_average_slot_payout(1)
-1
>>> estimate_average_slot_payout(1)
0.5
"""
pass
# 1スピンあたりの期待値がわかったら、下のセルを実行して解答を表示させてください。
# 答え合わせをする
q4.solution()
| false | 0 | 1,304 | 7 | 6 | 1,304 |
||
70750057 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
base_path = "/kaggle/input/11-785-fall-20-homework-4-part-2/hw4p2"
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
from dataclasses import dataclass
from typing import List, Dict, Text
import torch
from torch.utils.data import Dataset
import torch
import torch.nn as nn
import tqdm
from torch.utils import data
from torch.nn.utils.rnn import pad_sequence
from torch.nn.utils.rnn import pack_padded_sequence
from torch.nn.utils.rnn import pad_packed_sequence
from torch import utils
print(torch.cuda.is_available())
cuda = torch.cuda.is_available()
if cuda:
dev = "cuda:0"
else:
dev = "cpu"
DEVICE = torch.device(dev)
print("Device:", DEVICE)
"""
Loading all the numpy files containing the utterance information and text information
"""
def load_data(base_path=""):
speech_train = np.load(
os.path.join(base_path, "train.npy"), allow_pickle=True, encoding="bytes"
)
speech_valid = np.load(
os.path.join(base_path, "dev.npy"), allow_pickle=True, encoding="bytes"
)
speech_test = np.load(
os.path.join(base_path, "test.npy"), allow_pickle=True, encoding="bytes"
)
transcript_train = np.load(
os.path.join(base_path, "train_transcripts.npy"),
allow_pickle=True,
encoding="bytes",
)
transcript_valid = np.load(
os.path.join(base_path, "./dev_transcripts.npy"),
allow_pickle=True,
encoding="bytes",
)
return speech_train, speech_valid, speech_test, transcript_train, transcript_valid
speech_train, speech_valid, speech_test, transcript_train, transcript_valid = load_data(
base_path
)
from torch.nn.utils.rnn import pad_sequence
from torch.nn.utils.rnn import pack_padded_sequence
from torch.nn.utils.rnn import pad_packed_sequence
from torch.utils.data import DataLoader
LETTER_LIST = [
"<pad>",
"a",
"b",
"c",
"d",
"e",
"f",
"g",
"h",
"i",
"j",
"k",
"l",
"m",
"n",
"o",
"p",
"q",
"r",
"s",
"t",
"u",
"v",
"w",
"x",
"y",
"z",
"-",
"'",
".",
"_",
"+",
" ",
"<sos>",
"<eos>",
"<unk>",
]
"""
Optional, create dictionaries for letter2index and index2letter transformations
"""
def create_dictionaries(letter_list):
index2letter = dict(enumerate(letter_list))
letter2index = dict()
for k, v in index2letter.items():
letter2index[v] = k
return letter2index, index2letter
letter2index, index2letter = create_dictionaries(LETTER_LIST)
"""
Transforms alphabetical input to numerical input, replace each letter by its corresponding
index from letter_list
"""
def transform_letter_to_index(transcript, letter_list) -> List:
"""
Transform letter to index. Adds <sos> and <eos> indexes.
:param transcript :(N, ) Transcripts are the text input
:param letter_list: Letter list defined above
:return letter_to_index_list: Returns a list for all the transcript sentence to index
"""
unk_idx = letter2index["<unk>"]
start_idx = letter2index["<sos>"]
end_idx = letter2index["<eos>"]
new_transcript = []
for sequence in transcript:
words = [word.decode("UTF-8") for word in sequence]
joined_words = " ".join(words)
new_seq = [start_idx]
for char in joined_words:
new_char = letter2index.get(char, unk_idx)
new_seq.append(new_char)
new_seq.append(end_idx)
new_seq = np.array(new_seq)
new_transcript.append(new_seq)
return new_transcript
class Speech2TextDataset(Dataset):
"""
Dataset class for the speech to text data, this may need some tweaking in the
getitem method as your implementation in the collate function may be different from
ours.
"""
def __init__(self, speech, text=None, isTrain=True):
self.speech = speech
self.isTrain = isTrain
if text is not None:
self.text = text
def __len__(self):
return self.speech.shape[0]
def __getitem__(self, index):
if self.isTrain == True:
return torch.tensor(self.speech[index].astype(np.float32)), torch.tensor(
self.text[index]
)
else:
return torch.tensor(self.speech[index].astype(np.float32))
# TODO: move to a params
INPUT_PADDING_VALUE = 0
LABEL_PADDING_VALUE = letter2index["<pad>"]
def collate_train(batch_data):
### Return the padded speech and text data, and the length of utterance and transcript ###
"""
Args:
:batch_data List[Tuple]: List of (input, label)
Returns
"""
batch_input, batch_label = zip(*batch_data)
input_lens = [len(seq) for seq in batch_input]
label_lens = [len(seq) for seq in batch_label]
batch_input_padded = torch.as_tensor(
pad_sequence(batch_input, batch_first=True, padding_value=INPUT_PADDING_VALUE)
)
batch_label_padded = torch.as_tensor(
pad_sequence(batch_label, batch_first=True, padding_value=LABEL_PADDING_VALUE)
)
return batch_input_padded, batch_label_padded, input_lens, label_lens
def collate_test(batch_data):
### Return padded speech and length of utterance ###
pass
character_text_train = transform_letter_to_index(transcript_train, LETTER_LIST)
character_text_valid = transform_letter_to_index(transcript_valid, LETTER_LIST)
print(index2letter[33])
print(index2letter[34])
print(character_text_train[9])
batch_size = 3
train_dataset = Speech2TextDataset(speech_train, character_text_train)
val_dataset = Speech2TextDataset(speech_valid, character_text_train)
test_dataset = Speech2TextDataset(speech_test, None, False)
# TODO: put in false just for debugging
train_loader = DataLoader(
train_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_train
)
val_loader = DataLoader(
val_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_train
)
test_loader = DataLoader(
test_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_test
)
class Attention(nn.Module):
"""
Attention is calculated using key, value and query from Encoder and decoder.
Below are the set of operations you need to perform for computing attention:
energy = bmm(key, query)
attention = softmax(energy)
context = bmm(attention, value)
"""
def __init__(self):
super(Attention, self).__init__()
def forward(self, query, key, value, lens):
"""
:param query :(batch_size, hidden_size) Query is the output of LSTMCell from Decoder
:param keys: (batch_size, max_len, encoder_size) Key Projection from Encoder
:param values: (batch_size, max_len, encoder_size) Value Projection from Encoder
:return context: (batch_size, encoder_size) Attended Context
:return attention_mask: (batch_size, max_len) Attention mask that can be plotted
"""
class pBLSTM(nn.Module):
"""
Pyramidal BiLSTM
The length of utterance (speech input) can be hundereds to thousands of frames long.
The Paper reports that a direct LSTM implementation as Encoder resulted in slow convergence,
and inferior results even after extensive training.
The major reason is inability of AttendAndSpell operation to extract relevant information
from a large number of input steps.
"""
def __init__(self, input_dim, hidden_dim, sample_rate=2):
super(pBLSTM, self).__init__()
self.blstm = nn.LSTM(
input_size=input_dim,
hidden_size=hidden_dim,
num_layers=1,
bidirectional=True,
)
self.sample_rate = sample_rate
def forward(self, x):
"""
:param x :(N, T) input to the pBLSTM: Packed Sequence
:return output: (N, T, H) encoded sequence from pyramidal Bi-LSTM
"""
padded_x, x_lens = pad_packed_sequence(
x, batch_first=True, padding_value=INPUT_PADDING_VALUE
)
batch_size, max_len, feature_dim = padded_x.shape
# Drop extra frames
if max_len % self.sample_rate != 0:
padded_x = padded_x[:, : -(max_len % self.sample_rate), :]
reshaped_x = padded_x.contiguous().view(
(
batch_size,
int(max_len / self.sample_rate),
feature_dim * self.sample_rate,
)
)
new_x_lens = x_lens / 2
new_x_lens = [int(np.floor(length)) for length in new_x_lens]
# TODO: Pack again
new_x = pack_padded_sequence(
reshaped_x, lengths=new_x_lens, batch_first=True, enforce_sorted=False
)
return self.blstm(new_x)
class Encoder(nn.Module):
"""
Encoder takes the utterances as inputs and returns the key and value.
Key and value are nothing but simple projections of the output from pBLSTM network.
"""
def __init__(self, input_dim, hidden_dim, value_size=128, key_size=128, p_layers=3):
super(Encoder, self).__init__()
self.lstm = nn.LSTM(
input_size=input_dim,
hidden_size=hidden_dim,
num_layers=1,
bidirectional=True,
batch_first=True,
)
### Add code to define the blocks of pBLSTMs! ###
pmodule_list = []
for l in range(p_layers):
# Input dim is hidden_dim*2 due to bidirectionality
# TODO: see if double because of concatenation
module = pBLSTM(hidden_dim * 2 * 2, hidden_dim)
pmodule_list.append(module)
self.p_layers = nn.ModuleList(pmodule_list)
self.key_network = nn.Linear(hidden_dim * 2, value_size)
self.value_network = nn.Linear(hidden_dim * 2, key_size)
def forward(self, x, lens):
rnn_inp = pack_padded_sequence(
x, lengths=lens, batch_first=True, enforce_sorted=False
)
outputs, _ = self.lstm(rnn_inp) # Packed Sequence
### Use the outputs and pass it through the pBLSTM blocks! ###
for layer in self.p_layers:
outputs, _ = layer(outputs)
# linear_input, _ = utils.rnn.pad_packed_sequence(outputs)
# keys = self.key_network(linear_input)
# value = self.value_network(linear_input)
# return keys, value
return outputs
encoder = Encoder(40, 512)
for batch_input, batch_labels, input_lens, label_lens in train_loader:
print("Input lens", input_lens)
print("Batch input", batch_input.shape)
outputs = encoder(batch_input, input_lens)
outputs_unpacked, seq_lens = pad_packed_sequence(
outputs, batch_first=True, padding_value=INPUT_PADDING_VALUE
)
print("Hello output", type(outputs_unpacked), outputs_unpacked.shape)
break
class Decoder(nn.Module):
"""
As mentioned in a previous recitation, each forward call of decoder deals with just one time step,
thus we use LSTMCell instead of LSLTM here.
The output from the second LSTMCell can be used as query here for attention module.
In place of value that we get from the attention, this can be replace by context we get from the attention.
Methods like Gumble noise and teacher forcing can also be incorporated for improving the performance.
"""
def __init__(
self, vocab_size, hidden_dim, value_size=128, key_size=128, isAttended=False
):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, hidden_dim, padding_idx=0)
self.lstm1 = nn.LSTMCell(
input_size=hidden_dim + value_size, hidden_size=hidden_dim
)
self.lstm2 = nn.LSTMCell(input_size=hidden_dim, hidden_size=key_size)
self.isAttended = isAttended
if isAttended == True:
self.attention = Attention()
self.character_prob = nn.Linear(key_size + value_size, vocab_size)
def forward(self, key, values, text=None, isTrain=True):
"""
:param key :(T, N, key_size) Output of the Encoder Key projection layer
:param values: (T, N, value_size) Output of the Encoder Value projection layer
:param text: (N, text_len) Batch input of text with text_length
:param isTrain: Train or eval mode
:return predictions: Returns the character prediction probability
"""
batch_size = key.shape[1]
if isTrain == True:
max_len = text.shape[1]
embeddings = self.embedding(text)
else:
max_len = 250
predictions = []
hidden_states = [None, None]
prediction = torch.zeros(batch_size, 1).to(
DEVICE
) # (torch.ones(batch_size, 1)*33).to(DEVICE)
for i in range(max_len):
# * Implement Gumble noise and teacher forcing techniques
# * When attention is True, replace values[i,:,:] with the context you get from attention.
# * If you haven't implemented attention yet, then you may want to check the index and break
# out of the loop so you do not get index out of range errors.
if isTrain:
char_embed = embeddings[:, i, :]
else:
char_embed = self.embedding(prediction.argmax(dim=-1))
inp = torch.cat([char_embed, values[i, :, :]], dim=1)
hidden_states[0] = self.lstm1(inp, hidden_states[0])
inp_2 = hidden_states[0][0]
hidden_states[1] = self.lstm2(inp_2, hidden_states[1])
### Compute attention from the output of the second LSTM Cell ###
output = hidden_states[1][0]
prediction = self.character_prob(
torch.cat([output, values[i, :, :]], dim=1)
)
predictions.append(prediction.unsqueeze(1))
return torch.cat(predictions, dim=1)
class Seq2Seq(nn.Module):
"""
We train an end-to-end sequence to sequence model comprising of Encoder and Decoder.
This is simply a wrapper "model" for your encoder and decoder.
"""
def __init__(
self,
input_dim,
vocab_size,
hidden_dim,
value_size=128,
key_size=128,
isAttended=False,
):
super(Seq2Seq, self).__init__()
self.encoder = Encoder(input_dim, hidden_dim)
self.decoder = Decoder(vocab_size, hidden_dim)
def forward(self, speech_input, speech_len, text_input=None, isTrain=True):
key, value = self.encoder(speech_input, speech_len)
if isTrain == True:
predictions = self.decoder(key, value, text_input)
else:
predictions = self.decoder(key, value, text=None, isTrain=False)
return predictions
import time
def train(model, train_loader, criterion, optimizer, epoch):
model.train()
model.to(DEVICE)
start = time.time()
# 1) Iterate through your loader
# 2) Use torch.autograd.set_detect_anomaly(True) to get notices about gradient explosion
# 3) Set the inputs to the device.
# 4) Pass your inputs, and length of speech into the model.
# 5) Generate a mask based on the lengths of the text to create a masked loss.
# 5.1) Ensure the mask is on the device and is the correct shape.
# 6) If necessary, reshape your predictions and origianl text input
# 6.1) Use .contiguous() if you need to.
# 7) Use the criterion to get the loss.
# 8) Use the mask to calculate a masked loss.
# 9) Run the backward pass on the masked loss.
# 10) Use torch.nn.utils.clip_grad_norm(model.parameters(), 2)
# 11) Take a step with your optimizer
# 12) Normalize the masked loss
# 13) Optionally print the training loss after every N batches
end = time.time()
def test(model, test_loader, epoch):
### Write your test code here! ###
pass
import torch.optim as optim
def main():
model = Seq2Seq(input_dim=40, vocab_size=len(LETTER_LIST), hidden_dim=128)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss(reduction="none")
nepochs = 25
batch_size = 64 if DEVICE == "cuda" else 1
character_text_train = transform_letter_to_index(transcript_train, LETTER_LIST)
character_text_valid = transform_letter_to_index(transcript_valid, LETTER_LIST)
train_dataset = Speech2TextDataset(speech_train, character_text_train)
# val_dataset =
test_dataset = Speech2TextDataset(speech_test, None, False)
train_loader = DataLoader(
train_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_train
)
# val_loader =
test_loader = DataLoader(
test_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_test
)
for epoch in range(nepochs):
train(model, train_loader, criterion, optimizer, epoch)
# val()
test(model, test_loader, epoch)
main()
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0070/750/70750057.ipynb | null | null | [{"Id": 70750057, "ScriptId": 18993126, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3452800, "CreationDate": "08/08/2021 19:56:23", "VersionNumber": 1.0, "Title": "H4P2 - Speech to Text with LAS", "EvaluationDate": "08/08/2021", "IsChange": true, "TotalLines": 447.0, "LinesInsertedFromPrevious": 447.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
base_path = "/kaggle/input/11-785-fall-20-homework-4-part-2/hw4p2"
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
from dataclasses import dataclass
from typing import List, Dict, Text
import torch
from torch.utils.data import Dataset
import torch
import torch.nn as nn
import tqdm
from torch.utils import data
from torch.nn.utils.rnn import pad_sequence
from torch.nn.utils.rnn import pack_padded_sequence
from torch.nn.utils.rnn import pad_packed_sequence
from torch import utils
print(torch.cuda.is_available())
cuda = torch.cuda.is_available()
if cuda:
dev = "cuda:0"
else:
dev = "cpu"
DEVICE = torch.device(dev)
print("Device:", DEVICE)
"""
Loading all the numpy files containing the utterance information and text information
"""
def load_data(base_path=""):
speech_train = np.load(
os.path.join(base_path, "train.npy"), allow_pickle=True, encoding="bytes"
)
speech_valid = np.load(
os.path.join(base_path, "dev.npy"), allow_pickle=True, encoding="bytes"
)
speech_test = np.load(
os.path.join(base_path, "test.npy"), allow_pickle=True, encoding="bytes"
)
transcript_train = np.load(
os.path.join(base_path, "train_transcripts.npy"),
allow_pickle=True,
encoding="bytes",
)
transcript_valid = np.load(
os.path.join(base_path, "./dev_transcripts.npy"),
allow_pickle=True,
encoding="bytes",
)
return speech_train, speech_valid, speech_test, transcript_train, transcript_valid
speech_train, speech_valid, speech_test, transcript_train, transcript_valid = load_data(
base_path
)
from torch.nn.utils.rnn import pad_sequence
from torch.nn.utils.rnn import pack_padded_sequence
from torch.nn.utils.rnn import pad_packed_sequence
from torch.utils.data import DataLoader
LETTER_LIST = [
"<pad>",
"a",
"b",
"c",
"d",
"e",
"f",
"g",
"h",
"i",
"j",
"k",
"l",
"m",
"n",
"o",
"p",
"q",
"r",
"s",
"t",
"u",
"v",
"w",
"x",
"y",
"z",
"-",
"'",
".",
"_",
"+",
" ",
"<sos>",
"<eos>",
"<unk>",
]
"""
Optional, create dictionaries for letter2index and index2letter transformations
"""
def create_dictionaries(letter_list):
index2letter = dict(enumerate(letter_list))
letter2index = dict()
for k, v in index2letter.items():
letter2index[v] = k
return letter2index, index2letter
letter2index, index2letter = create_dictionaries(LETTER_LIST)
"""
Transforms alphabetical input to numerical input, replace each letter by its corresponding
index from letter_list
"""
def transform_letter_to_index(transcript, letter_list) -> List:
"""
Transform letter to index. Adds <sos> and <eos> indexes.
:param transcript :(N, ) Transcripts are the text input
:param letter_list: Letter list defined above
:return letter_to_index_list: Returns a list for all the transcript sentence to index
"""
unk_idx = letter2index["<unk>"]
start_idx = letter2index["<sos>"]
end_idx = letter2index["<eos>"]
new_transcript = []
for sequence in transcript:
words = [word.decode("UTF-8") for word in sequence]
joined_words = " ".join(words)
new_seq = [start_idx]
for char in joined_words:
new_char = letter2index.get(char, unk_idx)
new_seq.append(new_char)
new_seq.append(end_idx)
new_seq = np.array(new_seq)
new_transcript.append(new_seq)
return new_transcript
class Speech2TextDataset(Dataset):
"""
Dataset class for the speech to text data, this may need some tweaking in the
getitem method as your implementation in the collate function may be different from
ours.
"""
def __init__(self, speech, text=None, isTrain=True):
self.speech = speech
self.isTrain = isTrain
if text is not None:
self.text = text
def __len__(self):
return self.speech.shape[0]
def __getitem__(self, index):
if self.isTrain == True:
return torch.tensor(self.speech[index].astype(np.float32)), torch.tensor(
self.text[index]
)
else:
return torch.tensor(self.speech[index].astype(np.float32))
# TODO: move to a params
INPUT_PADDING_VALUE = 0
LABEL_PADDING_VALUE = letter2index["<pad>"]
def collate_train(batch_data):
### Return the padded speech and text data, and the length of utterance and transcript ###
"""
Args:
:batch_data List[Tuple]: List of (input, label)
Returns
"""
batch_input, batch_label = zip(*batch_data)
input_lens = [len(seq) for seq in batch_input]
label_lens = [len(seq) for seq in batch_label]
batch_input_padded = torch.as_tensor(
pad_sequence(batch_input, batch_first=True, padding_value=INPUT_PADDING_VALUE)
)
batch_label_padded = torch.as_tensor(
pad_sequence(batch_label, batch_first=True, padding_value=LABEL_PADDING_VALUE)
)
return batch_input_padded, batch_label_padded, input_lens, label_lens
def collate_test(batch_data):
### Return padded speech and length of utterance ###
pass
character_text_train = transform_letter_to_index(transcript_train, LETTER_LIST)
character_text_valid = transform_letter_to_index(transcript_valid, LETTER_LIST)
print(index2letter[33])
print(index2letter[34])
print(character_text_train[9])
batch_size = 3
train_dataset = Speech2TextDataset(speech_train, character_text_train)
val_dataset = Speech2TextDataset(speech_valid, character_text_train)
test_dataset = Speech2TextDataset(speech_test, None, False)
# TODO: put in false just for debugging
train_loader = DataLoader(
train_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_train
)
val_loader = DataLoader(
val_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_train
)
test_loader = DataLoader(
test_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_test
)
class Attention(nn.Module):
"""
Attention is calculated using key, value and query from Encoder and decoder.
Below are the set of operations you need to perform for computing attention:
energy = bmm(key, query)
attention = softmax(energy)
context = bmm(attention, value)
"""
def __init__(self):
super(Attention, self).__init__()
def forward(self, query, key, value, lens):
"""
:param query :(batch_size, hidden_size) Query is the output of LSTMCell from Decoder
:param keys: (batch_size, max_len, encoder_size) Key Projection from Encoder
:param values: (batch_size, max_len, encoder_size) Value Projection from Encoder
:return context: (batch_size, encoder_size) Attended Context
:return attention_mask: (batch_size, max_len) Attention mask that can be plotted
"""
class pBLSTM(nn.Module):
"""
Pyramidal BiLSTM
The length of utterance (speech input) can be hundereds to thousands of frames long.
The Paper reports that a direct LSTM implementation as Encoder resulted in slow convergence,
and inferior results even after extensive training.
The major reason is inability of AttendAndSpell operation to extract relevant information
from a large number of input steps.
"""
def __init__(self, input_dim, hidden_dim, sample_rate=2):
super(pBLSTM, self).__init__()
self.blstm = nn.LSTM(
input_size=input_dim,
hidden_size=hidden_dim,
num_layers=1,
bidirectional=True,
)
self.sample_rate = sample_rate
def forward(self, x):
"""
:param x :(N, T) input to the pBLSTM: Packed Sequence
:return output: (N, T, H) encoded sequence from pyramidal Bi-LSTM
"""
padded_x, x_lens = pad_packed_sequence(
x, batch_first=True, padding_value=INPUT_PADDING_VALUE
)
batch_size, max_len, feature_dim = padded_x.shape
# Drop extra frames
if max_len % self.sample_rate != 0:
padded_x = padded_x[:, : -(max_len % self.sample_rate), :]
reshaped_x = padded_x.contiguous().view(
(
batch_size,
int(max_len / self.sample_rate),
feature_dim * self.sample_rate,
)
)
new_x_lens = x_lens / 2
new_x_lens = [int(np.floor(length)) for length in new_x_lens]
# TODO: Pack again
new_x = pack_padded_sequence(
reshaped_x, lengths=new_x_lens, batch_first=True, enforce_sorted=False
)
return self.blstm(new_x)
class Encoder(nn.Module):
"""
Encoder takes the utterances as inputs and returns the key and value.
Key and value are nothing but simple projections of the output from pBLSTM network.
"""
def __init__(self, input_dim, hidden_dim, value_size=128, key_size=128, p_layers=3):
super(Encoder, self).__init__()
self.lstm = nn.LSTM(
input_size=input_dim,
hidden_size=hidden_dim,
num_layers=1,
bidirectional=True,
batch_first=True,
)
### Add code to define the blocks of pBLSTMs! ###
pmodule_list = []
for l in range(p_layers):
# Input dim is hidden_dim*2 due to bidirectionality
# TODO: see if double because of concatenation
module = pBLSTM(hidden_dim * 2 * 2, hidden_dim)
pmodule_list.append(module)
self.p_layers = nn.ModuleList(pmodule_list)
self.key_network = nn.Linear(hidden_dim * 2, value_size)
self.value_network = nn.Linear(hidden_dim * 2, key_size)
def forward(self, x, lens):
rnn_inp = pack_padded_sequence(
x, lengths=lens, batch_first=True, enforce_sorted=False
)
outputs, _ = self.lstm(rnn_inp) # Packed Sequence
### Use the outputs and pass it through the pBLSTM blocks! ###
for layer in self.p_layers:
outputs, _ = layer(outputs)
# linear_input, _ = utils.rnn.pad_packed_sequence(outputs)
# keys = self.key_network(linear_input)
# value = self.value_network(linear_input)
# return keys, value
return outputs
encoder = Encoder(40, 512)
for batch_input, batch_labels, input_lens, label_lens in train_loader:
print("Input lens", input_lens)
print("Batch input", batch_input.shape)
outputs = encoder(batch_input, input_lens)
outputs_unpacked, seq_lens = pad_packed_sequence(
outputs, batch_first=True, padding_value=INPUT_PADDING_VALUE
)
print("Hello output", type(outputs_unpacked), outputs_unpacked.shape)
break
class Decoder(nn.Module):
"""
As mentioned in a previous recitation, each forward call of decoder deals with just one time step,
thus we use LSTMCell instead of LSLTM here.
The output from the second LSTMCell can be used as query here for attention module.
In place of value that we get from the attention, this can be replace by context we get from the attention.
Methods like Gumble noise and teacher forcing can also be incorporated for improving the performance.
"""
def __init__(
self, vocab_size, hidden_dim, value_size=128, key_size=128, isAttended=False
):
super(Decoder, self).__init__()
self.embedding = nn.Embedding(vocab_size, hidden_dim, padding_idx=0)
self.lstm1 = nn.LSTMCell(
input_size=hidden_dim + value_size, hidden_size=hidden_dim
)
self.lstm2 = nn.LSTMCell(input_size=hidden_dim, hidden_size=key_size)
self.isAttended = isAttended
if isAttended == True:
self.attention = Attention()
self.character_prob = nn.Linear(key_size + value_size, vocab_size)
def forward(self, key, values, text=None, isTrain=True):
"""
:param key :(T, N, key_size) Output of the Encoder Key projection layer
:param values: (T, N, value_size) Output of the Encoder Value projection layer
:param text: (N, text_len) Batch input of text with text_length
:param isTrain: Train or eval mode
:return predictions: Returns the character prediction probability
"""
batch_size = key.shape[1]
if isTrain == True:
max_len = text.shape[1]
embeddings = self.embedding(text)
else:
max_len = 250
predictions = []
hidden_states = [None, None]
prediction = torch.zeros(batch_size, 1).to(
DEVICE
) # (torch.ones(batch_size, 1)*33).to(DEVICE)
for i in range(max_len):
# * Implement Gumble noise and teacher forcing techniques
# * When attention is True, replace values[i,:,:] with the context you get from attention.
# * If you haven't implemented attention yet, then you may want to check the index and break
# out of the loop so you do not get index out of range errors.
if isTrain:
char_embed = embeddings[:, i, :]
else:
char_embed = self.embedding(prediction.argmax(dim=-1))
inp = torch.cat([char_embed, values[i, :, :]], dim=1)
hidden_states[0] = self.lstm1(inp, hidden_states[0])
inp_2 = hidden_states[0][0]
hidden_states[1] = self.lstm2(inp_2, hidden_states[1])
### Compute attention from the output of the second LSTM Cell ###
output = hidden_states[1][0]
prediction = self.character_prob(
torch.cat([output, values[i, :, :]], dim=1)
)
predictions.append(prediction.unsqueeze(1))
return torch.cat(predictions, dim=1)
class Seq2Seq(nn.Module):
"""
We train an end-to-end sequence to sequence model comprising of Encoder and Decoder.
This is simply a wrapper "model" for your encoder and decoder.
"""
def __init__(
self,
input_dim,
vocab_size,
hidden_dim,
value_size=128,
key_size=128,
isAttended=False,
):
super(Seq2Seq, self).__init__()
self.encoder = Encoder(input_dim, hidden_dim)
self.decoder = Decoder(vocab_size, hidden_dim)
def forward(self, speech_input, speech_len, text_input=None, isTrain=True):
key, value = self.encoder(speech_input, speech_len)
if isTrain == True:
predictions = self.decoder(key, value, text_input)
else:
predictions = self.decoder(key, value, text=None, isTrain=False)
return predictions
import time
def train(model, train_loader, criterion, optimizer, epoch):
model.train()
model.to(DEVICE)
start = time.time()
# 1) Iterate through your loader
# 2) Use torch.autograd.set_detect_anomaly(True) to get notices about gradient explosion
# 3) Set the inputs to the device.
# 4) Pass your inputs, and length of speech into the model.
# 5) Generate a mask based on the lengths of the text to create a masked loss.
# 5.1) Ensure the mask is on the device and is the correct shape.
# 6) If necessary, reshape your predictions and origianl text input
# 6.1) Use .contiguous() if you need to.
# 7) Use the criterion to get the loss.
# 8) Use the mask to calculate a masked loss.
# 9) Run the backward pass on the masked loss.
# 10) Use torch.nn.utils.clip_grad_norm(model.parameters(), 2)
# 11) Take a step with your optimizer
# 12) Normalize the masked loss
# 13) Optionally print the training loss after every N batches
end = time.time()
def test(model, test_loader, epoch):
### Write your test code here! ###
pass
import torch.optim as optim
def main():
model = Seq2Seq(input_dim=40, vocab_size=len(LETTER_LIST), hidden_dim=128)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss(reduction="none")
nepochs = 25
batch_size = 64 if DEVICE == "cuda" else 1
character_text_train = transform_letter_to_index(transcript_train, LETTER_LIST)
character_text_valid = transform_letter_to_index(transcript_valid, LETTER_LIST)
train_dataset = Speech2TextDataset(speech_train, character_text_train)
# val_dataset =
test_dataset = Speech2TextDataset(speech_test, None, False)
train_loader = DataLoader(
train_dataset, batch_size=batch_size, shuffle=True, collate_fn=collate_train
)
# val_loader =
test_loader = DataLoader(
test_dataset, batch_size=batch_size, shuffle=False, collate_fn=collate_test
)
for epoch in range(nepochs):
train(model, train_loader, criterion, optimizer, epoch)
# val()
test(model, test_loader, epoch)
main()
| false | 0 | 4,820 | 0 | 6 | 4,820 |
||
7074770 | <kaggle_start><code># # Hyperparameters and callbacks
# Source: https://github.com/fastai/fastai_docs/blob/master/dev_nb/004_callbacks.ipynb
# Clean up (to avoid errors)
# Install additional packages
# Download code from previous notebooks
# Download and unzip data
# Create data directories
# Clean up
from nb_003 import *
from torch import Tensor, tensor
from fastprogress import master_bar, progress_bar
from fastprogress.fastprogress import MasterBar, ProgressBar
from typing import Iterator
import fastprogress.fastprogress as fp2
import re
Floats = Union[float, Collection[float]]
PBar = Union[MasterBar, ProgressBar]
# ## Setup
DATA_PATH = Path("data")
PATH = DATA_PATH / "cifar10"
data_mean, data_std = map(tensor, ([0.491, 0.482, 0.447], [0.247, 0.243, 0.261]))
cifar_norm, cifar_denorm = normalize_funcs(data_mean, data_std)
tfms = [
flip_lr(p=0.5),
pad(padding=4),
crop(size=32, row_pct=(0, 1.0), col_pct=(0, 1.0)),
]
bs = 64
train_ds = ImageDataset.from_folder(PATH / "train", classes=["airplane", "dog"])
valid_ds = ImageDataset.from_folder(PATH / "test", classes=["airplane", "dog"])
len(train_ds), len(valid_ds)
data = DataBunch.create(
train_ds, valid_ds, bs=bs, train_tfm=tfms, num_workers=4, dl_tfms=cifar_norm
)
len(data.train_dl), len(data.valid_dl)
model = Darknet([1, 2, 4, 6, 3], num_classes=10, nf=16)
# ## Setting hyperparameters easily
# We want an optimizer with an easy way to set hyperparameters: they're all properties and we define custom setters to handle the different names in pytorch optimizers. We weill define a Wrapper for all optimizers within which we will define each parameter's setter functions. This allows us to set default value for each hyperparameter but to also easily edit it while experimenting.
class OptimWrapper:
"Normalize naming of parameters on wrapped optimizers"
def __init__(self, opt: optim.Optimizer, wd: float = 0.0, true_wd: bool = False):
"Create wrapper for `opt` and optionally (`true_wd`) set weight decay `wd`"
self.opt, self.true_wd = opt, true_wd
self.opt_keys = list(self.opt.param_groups[0].keys())
self.opt_keys.remove("params")
self.read_defaults()
self._wd = wd
# Pytorch optimizer methods
def step(self) -> None:
"Performs a single optimization step"
# weight decay outside of optimizer step (AdamW)
if self.true_wd:
for pg in self.opt.param_groups:
for p in pg["params"]:
p.data.mul_(1 - self._wd * pg["lr"])
self.set_val("weight_decay", 0)
self.opt.step()
def zero_grad(self) -> None:
"Clears the gradients of all optimized `Tensor`s"
self.opt.zero_grad()
# Hyperparameters as properties
@property
def lr(self) -> float:
"Learning rate"
return self._lr
@lr.setter
def lr(self, val: float) -> None:
self._lr = self.set_val("lr", val)
@property
def mom(self) -> float:
"Momentum if present on wrapped opt, else betas"
return self._mom
@mom.setter
def mom(self, val: float) -> None:
"Momentum if present on wrapped opt, else betas"
if "momentum" in self.opt_keys:
self.set_val("momentum", val)
elif "betas" in self.opt_keys:
self.set_val("betas", (val, self._beta))
self._mom = val
@property
def beta(self) -> float:
"Beta if present on wrapped opt, else it's alpha"
return self._beta
@beta.setter
def beta(self, val: float) -> None:
"Beta if present on wrapped opt, else it's alpha"
if "betas" in self.opt_keys:
self.set_val("betas", (self._mom, val))
elif "alpha" in self.opt_keys:
self.set_val("alpha", val)
self._beta = val
@property
def wd(self) -> float:
"Weight decay for wrapped opt"
return self._wd
@wd.setter
def wd(self, val: float) -> None:
"Weight decay for wrapped opt"
if not self.true_wd:
self.set_val("weight_decay", val)
self._wd = val
# Helper functions
def read_defaults(self):
"Reads in the default params from the wrapped optimizer"
self._beta = None
if "lr" in self.opt_keys:
self._lr = self.opt.param_groups[0]["lr"]
if "momentum" in self.opt_keys:
self._mom = self.opt.param_groups[0]["momentum"]
if "alpha" in self.opt_keys:
self._beta = self.opt.param_groups[0]["alpha"]
if "betas" in self.opt_keys:
self._mom, self._beta = self.opt.param_groups[0]["betas"]
if "weight_decay" in self.opt_keys:
self._wd = self.opt.param_groups[0]["weight_decay"]
def set_val(self, key: str, val: Any):
"Set parameter on wrapped optimizer"
for pg in self.opt.param_groups:
pg[key] = val
return val
opt_fn = partial(optim.Adam, betas=(0.95, 0.99))
opt = OptimWrapper(opt_fn(model.parameters(), 1e-2))
opt.lr, opt.mom, opt.wd, opt.beta
opt.lr = 0.2
opt.lr, opt.mom, opt.wd, opt.beta
# ## Callbacks
# Now that's it's easy to set and change the HP in the optimizer, we need a scheduler to change it. To keep the training loop readable as possible we don't want to handle of this stuff readable, so we'll use callbacks.
class Callback:
"Base class for callbacks that want to record values, dynamically change learner params, etc"
def on_train_begin(self, **kwargs: Any) -> None:
"To initialize constants in the callback."
pass
def on_epoch_begin(self, **kwargs: Any) -> None:
"At the beginning of each epoch"
pass
def on_batch_begin(self, **kwargs: Any) -> None:
"""To set HP before the step is done.
Returns xb, yb (which can allow us to modify the input at that step if needed)
"""
pass
def on_loss_begin(self, **kwargs: Any) -> None:
"""Called after the forward pass but before the loss has been computed.
Returns the output (which can allow us to modify it)"""
pass
def on_backward_begin(self, **kwargs: Any) -> None:
"""Called after the forward pass and the loss has been computed, but before the back propagation.
Returns the loss (which can allow us to modify it, for instance for reg functions)
"""
pass
def on_backward_end(self, **kwargs: Any) -> None:
"""Called after the back propagation had been done (and the gradients computed) but before the step of the optimizer.
Useful for true weight decay in AdamW"""
pass
def on_step_end(self, **kwargs: Any) -> None:
"Called after the step of the optimizer but before the gradients are zeroed (not sure this one is useful)"
pass
def on_batch_end(self, **kwargs: Any) -> None:
"Called at the end of the batch"
pass
def on_epoch_end(self, **kwargs: Any) -> bool:
"Called at the end of an epoch"
return False
def on_train_end(self, **kwargs: Any) -> None:
"Useful for cleaning up things and saving files/models"
pass
# To be more convenient and make the code of the training loop cleaner, we'll create a class to handle the callbacks. It will keep track of everything the training loop sends it, then pack itin the kwargs of each callback
class SmoothenValue:
"Creates a smooth moving average for a value (loss, etc)"
def __init__(self, beta: float) -> None:
"Create smoother for value, beta should be 0<beta<1"
self.beta, self.n, self.mov_avg = beta, 0, 0
def add_value(self, val: float) -> None:
"Add current value to calculate updated smoothed value"
self.n += 1
self.mov_avg = self.beta * self.mov_avg + (1 - self.beta) * val
self.smooth = self.mov_avg / (1 - self.beta**self.n)
TensorOrNumber = Union[Tensor, Number]
CallbackList = Collection[Callback]
MetricsList = Collection[TensorOrNumber]
TensorOrNumList = Collection[TensorOrNumber]
MetricFunc = Callable[[Tensor, Tensor], TensorOrNumber]
MetricFuncList = Collection[MetricFunc]
def _get_init_state():
return {"epoch": 0, "iteration": 0, "num_batch": 0}
@dataclass
class CallbackHandler:
"Manages all of the registered callback objects, beta is for smoothing loss"
callbacks: CallbackList
beta: float = 0.98
def __post_init__(self) -> None:
"InitInitializeitialize smoother and learning stats"
self.smoothener = SmoothenValue(self.beta)
self.state_dict: Dict[str, Union[int, float, Tensor]] = _get_init_state()
def __call__(self, cb_name, **kwargs) -> None:
"Call through to all of the callback handlers"
return [
getattr(cb, f"on_{cb_name}")(**self.state_dict, **kwargs)
for cb in self.callbacks
]
def on_train_begin(self, epochs: int, pbar: PBar, metrics: MetricFuncList) -> None:
"About to start learning"
self.state_dict = _get_init_state()
(
self.state_dict["n_epochs"],
self.state_dict["pbar"],
self.state_dict["metrics"],
) = (epochs, pbar, metrics)
self("train_begin")
def on_epoch_begin(self) -> None:
"Handle new epoch"
self.state_dict["num_batch"] = 0
self("epoch_begin")
def on_batch_begin(self, xb: Tensor, yb: Tensor) -> None:
"Handle new batch `xb`,`yb`"
self.state_dict["last_input"], self.state_dict["last_target"] = xb, yb
for cb in self.callbacks:
a = cb.on_batch_begin(**self.state_dict)
if a is not None:
self.state_dict["last_input"], self.state_dict["last_target"] = a
return self.state_dict["last_input"], self.state_dict["last_target"]
def on_loss_begin(self, out: Tensor) -> None:
"Handle start of loss calculation with model output `out`"
self.state_dict["last_output"] = out
for cb in self.callbacks:
a = cb.on_loss_begin(**self.state_dict)
if a is not None:
self.state_dict["last_output"] = a
return self.state_dict["last_output"]
def on_backward_begin(self, loss: Tensor) -> None:
"Handle gradient calculation on `loss`"
self.smoothener.add_value(loss.detach())
self.state_dict["last_loss"], self.state_dict["smooth_loss"] = (
loss,
self.smoothener.smooth,
)
for cb in self.callbacks:
a = cb.on_backward_begin(**self.state_dict)
if a is not None:
self.state_dict["last_loss"] = a
return self.state_dict["last_loss"]
def on_backward_end(self) -> None:
"Handle end of gradient calc"
self("backward_end")
def on_step_end(self) -> None:
"Handle end of optimization step"
self("step_end")
def on_batch_end(self, loss: Tensor) -> None:
"Handle end of processing one batch with `loss`"
self.state_dict["last_loss"] = loss
stop = np.any(self("batch_end"))
self.state_dict["iteration"] += 1
self.state_dict["num_batch"] += 1
return stop
def on_epoch_end(self, val_metrics: MetricsList) -> bool:
"Epoch is done, process `val_metrics`"
self.state_dict["last_metrics"] = val_metrics
stop = np.any(self("epoch_end"))
self.state_dict["epoch"] += 1
return stop
def on_train_end(self, exception: Union[bool, Exception]) -> None:
"Handle end of training, `exception` is an `Exception` or False if no exceptions during training"
self("train_end", exception=exception)
# The idea is to have a callback between every line of the training loop, that way every callback we need to add will be treated there and not inside. We also add metrics right after calculating the loss.
OptMetrics = Optional[Collection[Any]]
OptLossFunc = Optional[LossFunction]
OptCallbackHandler = Optional[CallbackHandler]
OptOptimizer = Optional[optim.Optimizer]
OptCallbackList = Optional[CallbackList]
def loss_batch(
model: Model,
xb: Tensor,
yb: Tensor,
loss_fn: OptLossFunc = None,
opt: OptOptimizer = None,
cb_handler: OptCallbackHandler = None,
metrics: OptMetrics = None,
) -> Tuple[Union[Tensor, int, float, str]]:
"Calculate loss for a batch, calculate metrics, call out to callbacks as necessary"
if cb_handler is None:
cb_handler = CallbackHandler([])
if not is_listy(xb):
xb = [xb]
if not is_listy(yb):
yb = [yb]
out = model(*xb)
out = cb_handler.on_loss_begin(out)
if not loss_fn:
return out.detach(), yb[0].detach()
loss = loss_fn(out, *yb)
mets = [f(out, *yb).detach().cpu() for f in metrics] if metrics is not None else []
if opt is not None:
loss = cb_handler.on_backward_begin(loss)
loss.backward()
cb_handler.on_backward_end()
opt.step()
cb_handler.on_step_end()
opt.zero_grad()
return (loss.detach().cpu(),) + tuple(mets) + (yb[0].shape[0],)
def validate(
model: Model,
dl: DataLoader,
loss_fn: OptLossFunc = None,
metrics: OptMetrics = None,
cb_handler: OptCallbackHandler = None,
pbar: Optional[PBar] = None,
) -> Iterator[Tuple[Union[Tensor, int], ...]]:
"Calculate loss and metrics for the validation set"
model.eval()
with torch.no_grad():
return zip(
*[
loss_batch(
model, xb, yb, loss_fn, cb_handler=cb_handler, metrics=metrics
)
for xb, yb in progress_bar(dl, parent=pbar)
]
)
def fit(
epochs: int,
model: Model,
loss_fn: LossFunction,
opt: optim.Optimizer,
data: DataBunch,
callbacks: OptCallbackList = None,
metrics: OptMetrics = None,
) -> None:
"Fit the `model` on `data` and learn using `loss` and `opt`"
cb_handler = CallbackHandler(callbacks)
pbar = master_bar(range(epochs))
cb_handler.on_train_begin(epochs, pbar=pbar, metrics=metrics)
exception = False
try:
for epoch in pbar:
model.train()
cb_handler.on_epoch_begin()
for xb, yb in progress_bar(data.train_dl, parent=pbar):
xb, yb = cb_handler.on_batch_begin(xb, yb)
loss, _ = loss_batch(model, xb, yb, loss_fn, opt, cb_handler)
if cb_handler.on_batch_end(loss):
break
if hasattr(data, "valid_dl") and data.valid_dl is not None:
*val_metrics, nums = validate(
model,
data.valid_dl,
loss_fn=loss_fn,
cb_handler=cb_handler,
metrics=metrics,
pbar=pbar,
)
nums = np.array(nums, dtype=np.float32)
val_metrics = [
(torch.stack(val).cpu().numpy() * nums).sum() / nums.sum()
for val in val_metrics
]
else:
val_metrics = None
if cb_handler.on_epoch_end(val_metrics):
break
except Exception as e:
exception = e
raise e
finally:
cb_handler.on_train_end(exception)
# First callback: it records the important values, updates the progress bar and prints out the epoch and validation loss as the training progresses. The important values we save during training such as losses and hyper-parameters will be used for future plots (lr_finder, plot of the LR/mom schedule). We will also add the plotting tools that will be used over and over again when training models.
_camel_re1 = re.compile("(.)([A-Z][a-z]+)")
_camel_re2 = re.compile("([a-z0-9])([A-Z])")
def camel2snake(name: str) -> str:
s1 = re.sub(_camel_re1, r"\1_\2", name)
return re.sub(_camel_re2, r"\1_\2", s1).lower()
@dataclass
class LearnerCallback(Callback):
"Base class for creating callbacks for the `Learner`"
learn: Learner
def __post_init__(self):
if self.cb_name:
setattr(self.learn, self.cb_name, self)
@property
def cb_name(self):
return camel2snake(self.__class__.__name__)
class Recorder(LearnerCallback):
"A `LearnerCallback` that records epoch,loss,opt and metric data during training"
def __init__(self, learn: Learner):
super().__init__(learn)
self.opt = self.learn.opt
self.train_dl = self.learn.data.train_dl
def on_train_begin(
self, pbar: PBar, metrics: MetricFuncList, **kwargs: Any
) -> None:
"Initialize recording status at beginning of training"
self.pbar = pbar
self.names = ["epoch", "train loss", "valid loss"] + [
fn.__name__ for fn in metrics
]
self.pbar.write(" ".join(self.names))
(
self.losses,
self.val_losses,
self.lrs,
self.moms,
self.metrics,
self.nb_batches,
) = ([], [], [], [], [], [])
def on_batch_begin(self, **kwargs: Any) -> None:
"Record learning rate and momentum at beginning of batch"
self.lrs.append(self.opt.lr)
self.moms.append(self.opt.mom)
def on_backward_begin(self, smooth_loss: Tensor, **kwargs: Any) -> None:
"Record the loss before any other callback has a chance to modify it."
self.losses.append(smooth_loss)
if self.pbar is not None and hasattr(self.pbar, "child"):
self.pbar.child.comment = f"{smooth_loss:.4f}"
def on_epoch_end(
self,
epoch: int,
num_batch: int,
smooth_loss: Tensor,
last_metrics=MetricsList,
**kwargs: Any,
) -> bool:
"Save epoch info: num_batch, smooth_loss, metrics"
self.nb_batches.append(num_batch)
if last_metrics is not None:
self.val_losses.append(last_metrics[0])
if len(last_metrics) > 1:
self.metrics.append(last_metrics[1:])
self.format_stats([epoch, smooth_loss] + last_metrics)
else:
self.format_stats([epoch, smooth_loss])
return False
def format_stats(self, stats: TensorOrNumList) -> None:
str_stats = []
for name, stat in zip(self.names, stats):
t = str(stat) if isinstance(stat, int) else f"{stat:.6f}"
t += " " * (len(name) - len(t))
str_stats.append(t)
self.pbar.write(" ".join(str_stats))
def plot_lr(self, show_moms=False) -> None:
"Plot learning rate, `show_moms` to include momentum"
iterations = list(range(len(self.lrs)))
if show_moms:
_, axs = plt.subplots(1, 2, figsize=(12, 4))
axs[0].plot(iterations, self.lrs)
axs[1].plot(iterations, self.moms)
else:
plt.plot(iterations, self.lrs)
def plot(self, skip_start: int = 10, skip_end: int = 5) -> None:
"Plot learning rate and losses, trimmed between `skip_start` and `skip_end`"
lrs = self.lrs[skip_start:-skip_end] if skip_end > 0 else self.lrs[skip_start:]
losses = (
self.losses[skip_start:-skip_end]
if skip_end > 0
else self.losses[skip_start:]
)
_, ax = plt.subplots(1, 1)
ax.plot(lrs, losses)
ax.set_xscale("log")
def plot_losses(self) -> None:
"Plot training and validation losses"
_, ax = plt.subplots(1, 1)
iterations = list(range(len(self.losses)))
ax.plot(iterations, self.losses)
val_iter = self.nb_batches
val_iter = np.cumsum(val_iter)
ax.plot(val_iter, self.val_losses)
def plot_metrics(self) -> None:
"Plot metrics collected during training"
assert len(self.metrics) != 0, "There are no metrics to plot."
_, axes = plt.subplots(
len(self.metrics[0]), 1, figsize=(6, 4 * len(self.metrics[0]))
)
val_iter = self.nb_batches
val_iter = np.cumsum(val_iter)
axes = axes.flatten() if len(self.metrics[0]) != 1 else [axes]
for i, ax in enumerate(axes):
values = [met[i] for met in self.metrics]
ax.plot(val_iter, values)
def accuracy(out: Tensor, yb: Tensor) -> TensorOrNumber:
"Calculate percentage of 1-hot `out` correctly predicted in `yb`"
preds = torch.argmax(out, dim=1)
return (preds == yb).float().mean()
AdamW = partial(optim.Adam, betas=(0.9, 0.99))
@dataclass
class Learner:
"""Trains `module` with `data` using `loss_fn` and `opt_fn`, collects `metrics` along the way
`true_wd` along with `wd` turn on weight decay, `path` specifies where models are stored
`callback_fns` is used to add custom callbacks beyond Recorder which is added by default
"""
data: DataBunch
model: nn.Module
opt_fn: Callable = AdamW
loss_fn: Callable = F.cross_entropy
metrics: Collection[Callable] = None
true_wd: bool = True
wd: Floats = 1e-2
path: str = "models"
callback_fns: Collection[Callable] = None
callbacks: Collection[Callback] = field(default_factory=list)
def __post_init__(self):
"Sets up internal learner variables"
self.path = Path(self.path)
self.metrics = listify(self.metrics)
self.path.mkdir(parents=True, exist_ok=True)
self.model = self.model.to(self.data.device)
self.callbacks = listify(self.callbacks)
self.callback_fns = [Recorder] + listify(self.callback_fns)
def fit(
self,
epochs: int,
lr: Optional[Floats],
wd: Optional[Floats] = None,
callbacks: OptCallbackList = None,
) -> None:
"Fit the model in this learner with `lr` learning rate and `wd` weight decay"
if wd is None:
wd = self.wd
self.create_opt(lr, wd)
callbacks = [cb(self) for cb in self.callback_fns] + listify(callbacks)
fit(
epochs,
self.model,
self.loss_fn,
self.opt,
self.data,
metrics=self.metrics,
callbacks=self.callbacks + callbacks,
)
def create_opt(self, lr: Floats, wd: Floats = 0.0) -> None:
"Binds a new optimizer each time `fit` is called with `lr` learning rate and `wd` weight decay"
self.opt = OptimWrapper(self.opt_fn(self.model.parameters(), lr))
def save(self, name: PathOrStr) -> None:
"Save the model bound to this learner in the `path` folder with `name`"
torch.save(self.model.state_dict(), self.path / f"{name}.pth")
def load(self, name: PathOrStr):
"Load the model bound to this learner with the `name` model params in the `path` folder"
self.model.load_state_dict(torch.load(self.path / f"{name}.pth"))
metrics = [accuracy]
model = Darknet([1, 2, 2, 2, 2], num_classes=2, nf=16)
learn = Learner(data, model, metrics=metrics)
learn.fit(10, 0.01)
learn.recorder.plot_losses()
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0007/074/7074770.ipynb | null | null | [{"Id": 7074770, "ScriptId": 2021162, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 959829, "CreationDate": "11/04/2018 21:05:40", "VersionNumber": 1.0, "Title": "fastai_docs/dev_nb/004_callbacks.ipynb", "EvaluationDate": "11/04/2018", "IsChange": true, "TotalLines": 530.0, "LinesInsertedFromPrevious": 530.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | # # Hyperparameters and callbacks
# Source: https://github.com/fastai/fastai_docs/blob/master/dev_nb/004_callbacks.ipynb
# Clean up (to avoid errors)
# Install additional packages
# Download code from previous notebooks
# Download and unzip data
# Create data directories
# Clean up
from nb_003 import *
from torch import Tensor, tensor
from fastprogress import master_bar, progress_bar
from fastprogress.fastprogress import MasterBar, ProgressBar
from typing import Iterator
import fastprogress.fastprogress as fp2
import re
Floats = Union[float, Collection[float]]
PBar = Union[MasterBar, ProgressBar]
# ## Setup
DATA_PATH = Path("data")
PATH = DATA_PATH / "cifar10"
data_mean, data_std = map(tensor, ([0.491, 0.482, 0.447], [0.247, 0.243, 0.261]))
cifar_norm, cifar_denorm = normalize_funcs(data_mean, data_std)
tfms = [
flip_lr(p=0.5),
pad(padding=4),
crop(size=32, row_pct=(0, 1.0), col_pct=(0, 1.0)),
]
bs = 64
train_ds = ImageDataset.from_folder(PATH / "train", classes=["airplane", "dog"])
valid_ds = ImageDataset.from_folder(PATH / "test", classes=["airplane", "dog"])
len(train_ds), len(valid_ds)
data = DataBunch.create(
train_ds, valid_ds, bs=bs, train_tfm=tfms, num_workers=4, dl_tfms=cifar_norm
)
len(data.train_dl), len(data.valid_dl)
model = Darknet([1, 2, 4, 6, 3], num_classes=10, nf=16)
# ## Setting hyperparameters easily
# We want an optimizer with an easy way to set hyperparameters: they're all properties and we define custom setters to handle the different names in pytorch optimizers. We weill define a Wrapper for all optimizers within which we will define each parameter's setter functions. This allows us to set default value for each hyperparameter but to also easily edit it while experimenting.
class OptimWrapper:
"Normalize naming of parameters on wrapped optimizers"
def __init__(self, opt: optim.Optimizer, wd: float = 0.0, true_wd: bool = False):
"Create wrapper for `opt` and optionally (`true_wd`) set weight decay `wd`"
self.opt, self.true_wd = opt, true_wd
self.opt_keys = list(self.opt.param_groups[0].keys())
self.opt_keys.remove("params")
self.read_defaults()
self._wd = wd
# Pytorch optimizer methods
def step(self) -> None:
"Performs a single optimization step"
# weight decay outside of optimizer step (AdamW)
if self.true_wd:
for pg in self.opt.param_groups:
for p in pg["params"]:
p.data.mul_(1 - self._wd * pg["lr"])
self.set_val("weight_decay", 0)
self.opt.step()
def zero_grad(self) -> None:
"Clears the gradients of all optimized `Tensor`s"
self.opt.zero_grad()
# Hyperparameters as properties
@property
def lr(self) -> float:
"Learning rate"
return self._lr
@lr.setter
def lr(self, val: float) -> None:
self._lr = self.set_val("lr", val)
@property
def mom(self) -> float:
"Momentum if present on wrapped opt, else betas"
return self._mom
@mom.setter
def mom(self, val: float) -> None:
"Momentum if present on wrapped opt, else betas"
if "momentum" in self.opt_keys:
self.set_val("momentum", val)
elif "betas" in self.opt_keys:
self.set_val("betas", (val, self._beta))
self._mom = val
@property
def beta(self) -> float:
"Beta if present on wrapped opt, else it's alpha"
return self._beta
@beta.setter
def beta(self, val: float) -> None:
"Beta if present on wrapped opt, else it's alpha"
if "betas" in self.opt_keys:
self.set_val("betas", (self._mom, val))
elif "alpha" in self.opt_keys:
self.set_val("alpha", val)
self._beta = val
@property
def wd(self) -> float:
"Weight decay for wrapped opt"
return self._wd
@wd.setter
def wd(self, val: float) -> None:
"Weight decay for wrapped opt"
if not self.true_wd:
self.set_val("weight_decay", val)
self._wd = val
# Helper functions
def read_defaults(self):
"Reads in the default params from the wrapped optimizer"
self._beta = None
if "lr" in self.opt_keys:
self._lr = self.opt.param_groups[0]["lr"]
if "momentum" in self.opt_keys:
self._mom = self.opt.param_groups[0]["momentum"]
if "alpha" in self.opt_keys:
self._beta = self.opt.param_groups[0]["alpha"]
if "betas" in self.opt_keys:
self._mom, self._beta = self.opt.param_groups[0]["betas"]
if "weight_decay" in self.opt_keys:
self._wd = self.opt.param_groups[0]["weight_decay"]
def set_val(self, key: str, val: Any):
"Set parameter on wrapped optimizer"
for pg in self.opt.param_groups:
pg[key] = val
return val
opt_fn = partial(optim.Adam, betas=(0.95, 0.99))
opt = OptimWrapper(opt_fn(model.parameters(), 1e-2))
opt.lr, opt.mom, opt.wd, opt.beta
opt.lr = 0.2
opt.lr, opt.mom, opt.wd, opt.beta
# ## Callbacks
# Now that's it's easy to set and change the HP in the optimizer, we need a scheduler to change it. To keep the training loop readable as possible we don't want to handle of this stuff readable, so we'll use callbacks.
class Callback:
"Base class for callbacks that want to record values, dynamically change learner params, etc"
def on_train_begin(self, **kwargs: Any) -> None:
"To initialize constants in the callback."
pass
def on_epoch_begin(self, **kwargs: Any) -> None:
"At the beginning of each epoch"
pass
def on_batch_begin(self, **kwargs: Any) -> None:
"""To set HP before the step is done.
Returns xb, yb (which can allow us to modify the input at that step if needed)
"""
pass
def on_loss_begin(self, **kwargs: Any) -> None:
"""Called after the forward pass but before the loss has been computed.
Returns the output (which can allow us to modify it)"""
pass
def on_backward_begin(self, **kwargs: Any) -> None:
"""Called after the forward pass and the loss has been computed, but before the back propagation.
Returns the loss (which can allow us to modify it, for instance for reg functions)
"""
pass
def on_backward_end(self, **kwargs: Any) -> None:
"""Called after the back propagation had been done (and the gradients computed) but before the step of the optimizer.
Useful for true weight decay in AdamW"""
pass
def on_step_end(self, **kwargs: Any) -> None:
"Called after the step of the optimizer but before the gradients are zeroed (not sure this one is useful)"
pass
def on_batch_end(self, **kwargs: Any) -> None:
"Called at the end of the batch"
pass
def on_epoch_end(self, **kwargs: Any) -> bool:
"Called at the end of an epoch"
return False
def on_train_end(self, **kwargs: Any) -> None:
"Useful for cleaning up things and saving files/models"
pass
# To be more convenient and make the code of the training loop cleaner, we'll create a class to handle the callbacks. It will keep track of everything the training loop sends it, then pack itin the kwargs of each callback
class SmoothenValue:
"Creates a smooth moving average for a value (loss, etc)"
def __init__(self, beta: float) -> None:
"Create smoother for value, beta should be 0<beta<1"
self.beta, self.n, self.mov_avg = beta, 0, 0
def add_value(self, val: float) -> None:
"Add current value to calculate updated smoothed value"
self.n += 1
self.mov_avg = self.beta * self.mov_avg + (1 - self.beta) * val
self.smooth = self.mov_avg / (1 - self.beta**self.n)
TensorOrNumber = Union[Tensor, Number]
CallbackList = Collection[Callback]
MetricsList = Collection[TensorOrNumber]
TensorOrNumList = Collection[TensorOrNumber]
MetricFunc = Callable[[Tensor, Tensor], TensorOrNumber]
MetricFuncList = Collection[MetricFunc]
def _get_init_state():
return {"epoch": 0, "iteration": 0, "num_batch": 0}
@dataclass
class CallbackHandler:
"Manages all of the registered callback objects, beta is for smoothing loss"
callbacks: CallbackList
beta: float = 0.98
def __post_init__(self) -> None:
"InitInitializeitialize smoother and learning stats"
self.smoothener = SmoothenValue(self.beta)
self.state_dict: Dict[str, Union[int, float, Tensor]] = _get_init_state()
def __call__(self, cb_name, **kwargs) -> None:
"Call through to all of the callback handlers"
return [
getattr(cb, f"on_{cb_name}")(**self.state_dict, **kwargs)
for cb in self.callbacks
]
def on_train_begin(self, epochs: int, pbar: PBar, metrics: MetricFuncList) -> None:
"About to start learning"
self.state_dict = _get_init_state()
(
self.state_dict["n_epochs"],
self.state_dict["pbar"],
self.state_dict["metrics"],
) = (epochs, pbar, metrics)
self("train_begin")
def on_epoch_begin(self) -> None:
"Handle new epoch"
self.state_dict["num_batch"] = 0
self("epoch_begin")
def on_batch_begin(self, xb: Tensor, yb: Tensor) -> None:
"Handle new batch `xb`,`yb`"
self.state_dict["last_input"], self.state_dict["last_target"] = xb, yb
for cb in self.callbacks:
a = cb.on_batch_begin(**self.state_dict)
if a is not None:
self.state_dict["last_input"], self.state_dict["last_target"] = a
return self.state_dict["last_input"], self.state_dict["last_target"]
def on_loss_begin(self, out: Tensor) -> None:
"Handle start of loss calculation with model output `out`"
self.state_dict["last_output"] = out
for cb in self.callbacks:
a = cb.on_loss_begin(**self.state_dict)
if a is not None:
self.state_dict["last_output"] = a
return self.state_dict["last_output"]
def on_backward_begin(self, loss: Tensor) -> None:
"Handle gradient calculation on `loss`"
self.smoothener.add_value(loss.detach())
self.state_dict["last_loss"], self.state_dict["smooth_loss"] = (
loss,
self.smoothener.smooth,
)
for cb in self.callbacks:
a = cb.on_backward_begin(**self.state_dict)
if a is not None:
self.state_dict["last_loss"] = a
return self.state_dict["last_loss"]
def on_backward_end(self) -> None:
"Handle end of gradient calc"
self("backward_end")
def on_step_end(self) -> None:
"Handle end of optimization step"
self("step_end")
def on_batch_end(self, loss: Tensor) -> None:
"Handle end of processing one batch with `loss`"
self.state_dict["last_loss"] = loss
stop = np.any(self("batch_end"))
self.state_dict["iteration"] += 1
self.state_dict["num_batch"] += 1
return stop
def on_epoch_end(self, val_metrics: MetricsList) -> bool:
"Epoch is done, process `val_metrics`"
self.state_dict["last_metrics"] = val_metrics
stop = np.any(self("epoch_end"))
self.state_dict["epoch"] += 1
return stop
def on_train_end(self, exception: Union[bool, Exception]) -> None:
"Handle end of training, `exception` is an `Exception` or False if no exceptions during training"
self("train_end", exception=exception)
# The idea is to have a callback between every line of the training loop, that way every callback we need to add will be treated there and not inside. We also add metrics right after calculating the loss.
OptMetrics = Optional[Collection[Any]]
OptLossFunc = Optional[LossFunction]
OptCallbackHandler = Optional[CallbackHandler]
OptOptimizer = Optional[optim.Optimizer]
OptCallbackList = Optional[CallbackList]
def loss_batch(
model: Model,
xb: Tensor,
yb: Tensor,
loss_fn: OptLossFunc = None,
opt: OptOptimizer = None,
cb_handler: OptCallbackHandler = None,
metrics: OptMetrics = None,
) -> Tuple[Union[Tensor, int, float, str]]:
"Calculate loss for a batch, calculate metrics, call out to callbacks as necessary"
if cb_handler is None:
cb_handler = CallbackHandler([])
if not is_listy(xb):
xb = [xb]
if not is_listy(yb):
yb = [yb]
out = model(*xb)
out = cb_handler.on_loss_begin(out)
if not loss_fn:
return out.detach(), yb[0].detach()
loss = loss_fn(out, *yb)
mets = [f(out, *yb).detach().cpu() for f in metrics] if metrics is not None else []
if opt is not None:
loss = cb_handler.on_backward_begin(loss)
loss.backward()
cb_handler.on_backward_end()
opt.step()
cb_handler.on_step_end()
opt.zero_grad()
return (loss.detach().cpu(),) + tuple(mets) + (yb[0].shape[0],)
def validate(
model: Model,
dl: DataLoader,
loss_fn: OptLossFunc = None,
metrics: OptMetrics = None,
cb_handler: OptCallbackHandler = None,
pbar: Optional[PBar] = None,
) -> Iterator[Tuple[Union[Tensor, int], ...]]:
"Calculate loss and metrics for the validation set"
model.eval()
with torch.no_grad():
return zip(
*[
loss_batch(
model, xb, yb, loss_fn, cb_handler=cb_handler, metrics=metrics
)
for xb, yb in progress_bar(dl, parent=pbar)
]
)
def fit(
epochs: int,
model: Model,
loss_fn: LossFunction,
opt: optim.Optimizer,
data: DataBunch,
callbacks: OptCallbackList = None,
metrics: OptMetrics = None,
) -> None:
"Fit the `model` on `data` and learn using `loss` and `opt`"
cb_handler = CallbackHandler(callbacks)
pbar = master_bar(range(epochs))
cb_handler.on_train_begin(epochs, pbar=pbar, metrics=metrics)
exception = False
try:
for epoch in pbar:
model.train()
cb_handler.on_epoch_begin()
for xb, yb in progress_bar(data.train_dl, parent=pbar):
xb, yb = cb_handler.on_batch_begin(xb, yb)
loss, _ = loss_batch(model, xb, yb, loss_fn, opt, cb_handler)
if cb_handler.on_batch_end(loss):
break
if hasattr(data, "valid_dl") and data.valid_dl is not None:
*val_metrics, nums = validate(
model,
data.valid_dl,
loss_fn=loss_fn,
cb_handler=cb_handler,
metrics=metrics,
pbar=pbar,
)
nums = np.array(nums, dtype=np.float32)
val_metrics = [
(torch.stack(val).cpu().numpy() * nums).sum() / nums.sum()
for val in val_metrics
]
else:
val_metrics = None
if cb_handler.on_epoch_end(val_metrics):
break
except Exception as e:
exception = e
raise e
finally:
cb_handler.on_train_end(exception)
# First callback: it records the important values, updates the progress bar and prints out the epoch and validation loss as the training progresses. The important values we save during training such as losses and hyper-parameters will be used for future plots (lr_finder, plot of the LR/mom schedule). We will also add the plotting tools that will be used over and over again when training models.
_camel_re1 = re.compile("(.)([A-Z][a-z]+)")
_camel_re2 = re.compile("([a-z0-9])([A-Z])")
def camel2snake(name: str) -> str:
s1 = re.sub(_camel_re1, r"\1_\2", name)
return re.sub(_camel_re2, r"\1_\2", s1).lower()
@dataclass
class LearnerCallback(Callback):
"Base class for creating callbacks for the `Learner`"
learn: Learner
def __post_init__(self):
if self.cb_name:
setattr(self.learn, self.cb_name, self)
@property
def cb_name(self):
return camel2snake(self.__class__.__name__)
class Recorder(LearnerCallback):
"A `LearnerCallback` that records epoch,loss,opt and metric data during training"
def __init__(self, learn: Learner):
super().__init__(learn)
self.opt = self.learn.opt
self.train_dl = self.learn.data.train_dl
def on_train_begin(
self, pbar: PBar, metrics: MetricFuncList, **kwargs: Any
) -> None:
"Initialize recording status at beginning of training"
self.pbar = pbar
self.names = ["epoch", "train loss", "valid loss"] + [
fn.__name__ for fn in metrics
]
self.pbar.write(" ".join(self.names))
(
self.losses,
self.val_losses,
self.lrs,
self.moms,
self.metrics,
self.nb_batches,
) = ([], [], [], [], [], [])
def on_batch_begin(self, **kwargs: Any) -> None:
"Record learning rate and momentum at beginning of batch"
self.lrs.append(self.opt.lr)
self.moms.append(self.opt.mom)
def on_backward_begin(self, smooth_loss: Tensor, **kwargs: Any) -> None:
"Record the loss before any other callback has a chance to modify it."
self.losses.append(smooth_loss)
if self.pbar is not None and hasattr(self.pbar, "child"):
self.pbar.child.comment = f"{smooth_loss:.4f}"
def on_epoch_end(
self,
epoch: int,
num_batch: int,
smooth_loss: Tensor,
last_metrics=MetricsList,
**kwargs: Any,
) -> bool:
"Save epoch info: num_batch, smooth_loss, metrics"
self.nb_batches.append(num_batch)
if last_metrics is not None:
self.val_losses.append(last_metrics[0])
if len(last_metrics) > 1:
self.metrics.append(last_metrics[1:])
self.format_stats([epoch, smooth_loss] + last_metrics)
else:
self.format_stats([epoch, smooth_loss])
return False
def format_stats(self, stats: TensorOrNumList) -> None:
str_stats = []
for name, stat in zip(self.names, stats):
t = str(stat) if isinstance(stat, int) else f"{stat:.6f}"
t += " " * (len(name) - len(t))
str_stats.append(t)
self.pbar.write(" ".join(str_stats))
def plot_lr(self, show_moms=False) -> None:
"Plot learning rate, `show_moms` to include momentum"
iterations = list(range(len(self.lrs)))
if show_moms:
_, axs = plt.subplots(1, 2, figsize=(12, 4))
axs[0].plot(iterations, self.lrs)
axs[1].plot(iterations, self.moms)
else:
plt.plot(iterations, self.lrs)
def plot(self, skip_start: int = 10, skip_end: int = 5) -> None:
"Plot learning rate and losses, trimmed between `skip_start` and `skip_end`"
lrs = self.lrs[skip_start:-skip_end] if skip_end > 0 else self.lrs[skip_start:]
losses = (
self.losses[skip_start:-skip_end]
if skip_end > 0
else self.losses[skip_start:]
)
_, ax = plt.subplots(1, 1)
ax.plot(lrs, losses)
ax.set_xscale("log")
def plot_losses(self) -> None:
"Plot training and validation losses"
_, ax = plt.subplots(1, 1)
iterations = list(range(len(self.losses)))
ax.plot(iterations, self.losses)
val_iter = self.nb_batches
val_iter = np.cumsum(val_iter)
ax.plot(val_iter, self.val_losses)
def plot_metrics(self) -> None:
"Plot metrics collected during training"
assert len(self.metrics) != 0, "There are no metrics to plot."
_, axes = plt.subplots(
len(self.metrics[0]), 1, figsize=(6, 4 * len(self.metrics[0]))
)
val_iter = self.nb_batches
val_iter = np.cumsum(val_iter)
axes = axes.flatten() if len(self.metrics[0]) != 1 else [axes]
for i, ax in enumerate(axes):
values = [met[i] for met in self.metrics]
ax.plot(val_iter, values)
def accuracy(out: Tensor, yb: Tensor) -> TensorOrNumber:
"Calculate percentage of 1-hot `out` correctly predicted in `yb`"
preds = torch.argmax(out, dim=1)
return (preds == yb).float().mean()
AdamW = partial(optim.Adam, betas=(0.9, 0.99))
@dataclass
class Learner:
"""Trains `module` with `data` using `loss_fn` and `opt_fn`, collects `metrics` along the way
`true_wd` along with `wd` turn on weight decay, `path` specifies where models are stored
`callback_fns` is used to add custom callbacks beyond Recorder which is added by default
"""
data: DataBunch
model: nn.Module
opt_fn: Callable = AdamW
loss_fn: Callable = F.cross_entropy
metrics: Collection[Callable] = None
true_wd: bool = True
wd: Floats = 1e-2
path: str = "models"
callback_fns: Collection[Callable] = None
callbacks: Collection[Callback] = field(default_factory=list)
def __post_init__(self):
"Sets up internal learner variables"
self.path = Path(self.path)
self.metrics = listify(self.metrics)
self.path.mkdir(parents=True, exist_ok=True)
self.model = self.model.to(self.data.device)
self.callbacks = listify(self.callbacks)
self.callback_fns = [Recorder] + listify(self.callback_fns)
def fit(
self,
epochs: int,
lr: Optional[Floats],
wd: Optional[Floats] = None,
callbacks: OptCallbackList = None,
) -> None:
"Fit the model in this learner with `lr` learning rate and `wd` weight decay"
if wd is None:
wd = self.wd
self.create_opt(lr, wd)
callbacks = [cb(self) for cb in self.callback_fns] + listify(callbacks)
fit(
epochs,
self.model,
self.loss_fn,
self.opt,
self.data,
metrics=self.metrics,
callbacks=self.callbacks + callbacks,
)
def create_opt(self, lr: Floats, wd: Floats = 0.0) -> None:
"Binds a new optimizer each time `fit` is called with `lr` learning rate and `wd` weight decay"
self.opt = OptimWrapper(self.opt_fn(self.model.parameters(), lr))
def save(self, name: PathOrStr) -> None:
"Save the model bound to this learner in the `path` folder with `name`"
torch.save(self.model.state_dict(), self.path / f"{name}.pth")
def load(self, name: PathOrStr):
"Load the model bound to this learner with the `name` model params in the `path` folder"
self.model.load_state_dict(torch.load(self.path / f"{name}.pth"))
metrics = [accuracy]
model = Darknet([1, 2, 2, 2, 2], num_classes=2, nf=16)
learn = Learner(data, model, metrics=metrics)
learn.fit(10, 0.01)
learn.recorder.plot_losses()
| false | 0 | 6,528 | 0 | 6 | 6,528 |
||
94772222 | <kaggle_start><data_title>VOC2012<data_description>Image dataset,only use by learning
Image dataset,only use by learning
Image dataset,only use by learning
Image dataset,only use by learning
Image dataset,only use by learning
Image dataset,only use by learning
Image dataset,only use by learning<data_name>voc2012
<code># **导入必要的包**
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import PIL.Image as pil_image
import matplotlib.pyplot as plt
# **加载自定义的数据******
# * https://zhuanlan.zhihu.com/p/32506912
# 分割的类别
classes = [
"background",
"aeroplane",
"bicycle",
"bird",
"boat",
"bottle",
"bus",
"car",
"cat",
"chair",
"cow",
"diningtable",
"dog",
"horse",
"motorbike",
"person",
"potted plant",
"sheep",
"sofa",
"train",
"tv/monitor",
]
# 每个类别对应的RGB值
colormap = [
[0, 0, 0],
[128, 0, 0],
[0, 128, 0],
[128, 128, 0],
[0, 0, 128],
[128, 0, 128],
[0, 128, 128],
[128, 128, 128],
[64, 0, 0],
[192, 0, 0],
[64, 128, 0],
[192, 128, 0],
[64, 0, 128],
[192, 0, 128],
[64, 128, 128],
[192, 128, 128],
[0, 64, 0],
[128, 64, 0],
[0, 192, 0],
[128, 192, 0],
[0, 64, 128],
]
cm2lbl = np.zeros(256**3) # 每个像素点有 0 ~ 255 的选择,RGB 三个通道
for i, cm in enumerate(colormap):
cm2lbl[(cm[0] * 256 + cm[1]) * 256 + cm[2]] = i # 建立索引
# 将图片映射成索引数组
def image_to_label(image):
"""将图片映射成类别索引的数组"""
data = np.array(image, dtype="int32")
# 按照上面一样的计算规则,得到对应的值
index = (data[:, :, 0] * 256 + data[:, :, 1]) * 256 + data[:, :, 2]
return np.array(cm2lbl[index], dtype="int64")
def random_crop(image, width, height):
"""随机裁剪"""
pass
# 测试
image = pil_image.open(
"../input/voc2012/data/VOCdevkit/VOC2012/SegmentationClass/2007_000032.png"
).convert("RGB")
# image = transforms.RandomCrop((224, 224))(image)
# print(image)
# plt.imshow(image)
# label = transforms.FixedCrop(*rect)(label)
# image_array=image_to_label(image)
class VOCDataset(Dataset):
"""自定义数据类加载规则"""
def __init__(self, file_path=None, transform=None):
"""初始化函数"""
images_labels = []
file = open(file_path)
for name in file.readlines():
# 移除空格和换行符
name = name.strip()
image = (
"../input/voc2012/data/VOCdevkit/VOC2012/JPEGImages/" + name + ".jpg"
)
label = (
"../input/voc2012/data/VOCdevkit/VOC2012/SegmentationClass/"
+ name
+ ".png"
)
images_labels.append((image, label))
self.images_labels = images_labels
self.transform = transform
def __getitem__(self, index):
"""在DataLoader中会调用这个方法读取一个batch的数据"""
image_path, label_path = self.images_labels[index]
# 使用image.open加载目标图和特征图
image = pil_image.open(image_path)
label = pil_image.open(label_path).convert("RGB")
# # 裁剪图片,使其所有的图片输入一致
# x,y,width,height=transforms.RandomCrop.get_params(img=image,output_size=(224,224))
# image=function.crop(image,x,y,width,height)
# label=function.crop(label,x,y,width,height)
image = transforms.Resize((512, 512))(image)
label = transforms.Resize((512, 512))(label)
# 转化特征图
if self.transform is not None:
image = self.transform(image)
# 映射目标图
label = image_to_label(label)
# 从numpy数组转化成张量
label = torch.from_numpy(label)
# 返回
return image, label
def __len__(self):
"""获取整个dataset的数据大小"""
return len(self.images_labels)
# 数据预处理,增强,归一化
transform_train = transforms.Compose(
[
# 将数据转化成张量,并且归一化到[0,1]
transforms.ToTensor(),
# 将数据标准化到[-1,1],image=(image-mean)/std
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
transform_test = transforms.Compose(
[
# 将数据转化成张量,并且归一化到[0,1]
transforms.ToTensor(),
# 将数据标准化到[-1,1],image=(image-mean)/std
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
train_datasets = VOCDataset(
file_path="../input/voc2012/data/VOCdevkit/VOC2012/ImageSets/Segmentation/train.txt",
transform=transform_train,
)
test_datasets = VOCDataset(
file_path="../input/voc2012/data/VOCdevkit/VOC2012/ImageSets/Segmentation/val.txt",
transform=transform_test,
)
train_loader = DataLoader(
dataset=train_datasets, batch_size=8, shuffle=False, sampler=None
)
test_loader = DataLoader(
dataset=test_datasets, batch_size=8, shuffle=False, sampler=None
)
print(len(train_loader))
# print(next(iter(train_loader)))
# **FCN网络结构如下**
# 前面由VGG16组成,分5个卷积层,后面有3个(1,1)卷积层,输出32s,16s,8s,然后在进行融合,上采样得出结果
# https://github.com/wkentaro/pytorch-fcn/blob/main/torchfcn/models/fcn8s.py
# 
# **构建FCN网络模型**
class FCN8s(nn.Module):
def __init__(self):
super(FCN8s, self).__init__()
# 本项目有20个类别,一个背景,一共21类
n_class = 21
# conv1
# 输入图像为3通道,输出64个特征图,卷积核大小为(3,3),步长为1,padding为100(避免图片不兼容,其实也可以为1的)
# 卷积输出公式:output=(input+2*padding-kernel_size)/stride+1
# 512=(512+2*1-3)/1+1
self.conv1_1 = nn.Conv2d(
in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1
)
self.bn1_1 = nn.BatchNorm2d(num_features=64)
self.relu1_1 = nn.ReLU(inplace=True)
self.conv1_2 = nn.Conv2d(
in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1
)
self.bn1_2 = nn.BatchNorm2d(num_features=64)
self.relu1_2 = nn.ReLU(inplace=True)
# 最大池化层进行下采样
# 采样输出公式:output=(input+2*padding-kernel_size)/stride+1
# 256=(512+2*0-2)/2+1
self.maxpool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# conv2
self.conv2_1 = nn.Conv2d(
in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1
)
self.bn2_1 = nn.BatchNorm2d(num_features=128)
self.relu2_1 = nn.ReLU(inplace=True)
self.conv2_2 = nn.Conv2d(
in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1
)
self.bn2_2 = nn.BatchNorm2d(num_features=128)
self.relu2_2 = nn.ReLU(inplace=True)
# 最大池化层进行下采样
self.maxpool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# conv3
self.conv3_1 = nn.Conv2d(
in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1
)
self.bn3_1 = nn.BatchNorm2d(num_features=256)
self.relu3_1 = nn.ReLU(inplace=True)
self.conv3_2 = nn.Conv2d(
in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1
)
self.bn3_2 = nn.BatchNorm2d(num_features=256)
self.relu3_2 = nn.ReLU(inplace=True)
self.conv3_3 = nn.Conv2d(
in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1
)
self.bn3_3 = nn.BatchNorm2d(num_features=256)
self.relu3_3 = nn.ReLU(inplace=True)
# 最大池化层进行下采样
self.maxpool3 = nn.MaxPool2d(kernel_size=2, stride=2)
# conv4
self.conv4_1 = nn.Conv2d(
in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1
)
self.bn4_1 = nn.BatchNorm2d(num_features=512)
self.relu4_1 = nn.ReLU(inplace=True)
self.conv4_2 = nn.Conv2d(
in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1
)
self.bn4_2 = nn.BatchNorm2d(num_features=512)
self.relu4_2 = nn.ReLU(inplace=True)
self.conv4_3 = nn.Conv2d(
in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1
)
self.bn4_3 = nn.BatchNorm2d(num_features=512)
self.relu4_3 = nn.ReLU(inplace=True)
# 最大池化层进行下采样
self.maxpool4 = nn.MaxPool2d(kernel_size=2, stride=2)
# conv5
# 输入图像为3通道,输出64个特征图,卷积核大小为(3,3),步长为1,padding为100(避免图片不兼容)
self.conv5_1 = nn.Conv2d(
in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1
)
self.bn5_1 = nn.BatchNorm2d(num_features=512)
self.relu5_1 = nn.ReLU(inplace=True)
self.conv5_2 = nn.Conv2d(
in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1
)
self.bn5_2 = nn.BatchNorm2d(num_features=512)
self.relu5_2 = nn.ReLU(inplace=True)
self.conv5_3 = nn.Conv2d(
in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1
)
self.bn5_3 = nn.BatchNorm2d(num_features=512)
self.relu5_3 = nn.ReLU(inplace=True)
# 最大池化层进行下采样
self.maxpool5 = nn.MaxPool2d(kernel_size=2, stride=2)
# cnov6
self.conv6 = nn.Conv2d(
in_channels=512, out_channels=4096, kernel_size=7, stride=1, padding=1
)
self.bn6 = nn.BatchNorm2d(num_features=4096)
self.relu6 = nn.ReLU(inplace=True)
self.drop6 = nn.Dropout2d(p=0.5)
# cnov7
self.conv7 = nn.Conv2d(
in_channels=4096, out_channels=4096, kernel_size=1, stride=1, padding=1
)
self.bn7 = nn.BatchNorm2d(num_features=4096)
self.relu7 = nn.ReLU(inplace=True)
self.drop7 = nn.Dropout2d(p=0.5)
# cnov8,本项目有20个类别,一个背景,一共21类
self.conv8 = nn.Conv2d(
in_channels=4096, out_channels=n_class, kernel_size=1, stride=1, padding=1
)
# 上采样2倍(16,16,21)————>(32,32,21)
self.up_conv8_2 = nn.ConvTranspose2d(
in_channels=n_class,
out_channels=n_class,
kernel_size=2,
stride=2,
bias=False,
)
# 反卷积ConvTranspose2d操作输出宽高公式
# output=((input-1)*stride)+outputpadding-(2*padding)+kernelsize
# 34=(16-1)*2+0-(2*0)+4
# 第4层maxpool值做卷积运算
self.pool4_conv = nn.Conv2d(
in_channels=512, out_channels=n_class, kernel_size=1, stride=1
)
# 利用反卷积上采样2倍
self.up_pool4_2 = nn.ConvTranspose2d(
in_channels=n_class,
out_channels=n_class,
kernel_size=2,
stride=2,
bias=False,
)
# 第3层maxpool值做卷积运算
self.pool3_conv = nn.Conv2d(
in_channels=256, out_channels=n_class, kernel_size=1, stride=1
)
# 利用反卷积上采样8倍
self.up_pool3_8 = nn.ConvTranspose2d(
in_channels=n_class,
out_channels=n_class,
kernel_size=8,
stride=8,
bias=False,
)
def forward(self, x):
"""正向传播"""
# 记录初始图片的大小(32,21,512,512)
h = x
# conv1
x = self.relu1_1(self.bn1_1(self.conv1_1(x)))
x = self.relu1_2(self.bn1_2(self.conv1_2(x)))
x = self.maxpool1(x)
# conv2
x = self.relu2_1(self.bn2_1(self.conv2_1(x)))
x = self.relu2_2(self.bn2_2(self.conv2_2(x)))
x = self.maxpool2(x)
# conv3
x = self.relu3_1(self.bn3_1(self.conv3_1(x)))
x = self.relu3_2(self.bn3_2(self.conv3_2(x)))
x = self.relu3_3(self.bn3_3(self.conv3_3(x)))
x = self.maxpool3(x)
pool3 = x
# conv4
x = self.relu4_1(self.bn4_1(self.conv4_1(x)))
x = self.relu4_2(self.bn4_2(self.conv4_2(x)))
x = self.relu4_3(self.bn4_3(self.conv4_3(x)))
x = self.maxpool4(x)
pool4 = x
# conv5
x = self.relu5_1(self.bn5_1(self.conv5_1(x)))
x = self.relu5_2(self.bn5_2(self.conv5_2(x)))
x = self.relu5_3(self.bn5_3(self.conv5_3(x)))
x = self.maxpool5(x)
# conv6
# print(self.conv6(x).shape)
# print(self.bn6(self.conv6(x)).shape)
# print(self.relu6(self.bn6(self.conv6(x))).shape)
# print(self.drop6(self.relu6(self.bn6(self.conv6(x)))).shape)
x = self.drop6(self.relu6(self.bn6(self.conv6(x))))
# conv7
x = self.drop7(self.relu7(self.bn7(self.conv7(x))))
# conv8
x = self.up_conv8_2(self.conv8(x))
up_conv8 = x
# 计算第4层的值
x2 = self.pool4_conv(pool4)
# 相加融合
x2 = up_conv8 + x2
# 反卷积上采样8倍
x2 = self.up_pool4_2(x2)
up_pool4 = x2
# 计算第3层的值
x3 = self.pool3_conv(pool3)
x3 = up_pool4 + x3
# 反卷积上采样8倍
x3 = self.up_pool3_8(x3)
return x3
model = FCN8s()
# print(model)
# **模型训练**
# 配置训练参数
# 选择设置,优先GPU
device = torch.device("cuda" if torch.cuda.is_available else "cpu")
# 训练次数
epochs = 100
# 评判标准,损失函数
criterion = torch.nn.CrossEntropyLoss()
# 优化方法
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 将模型赋值到GPU中
model = model.to(device)
for epoch in range(epochs):
num = 1
loss_num = 0
for i, (image, label) in enumerate(train_loader):
# 将数据复制到GPU中
image = image.to(device)
label = label.to(device)
# 梯度清零
optimizer.zero_grad()
# 正向传播
output = model(image)
# 计算损失
loss = criterion(output, label)
# 反向传播
loss.backward()
# 更新梯度
optimizer.step()
# 获取当前损失
running_loss = loss.data.item()
loss_num += running_loss
num += i
epoch_loss = loss_num / len(train_loader)
print("次数", epoch, "平均损失", epoch_loss)
# 保存模型
torch.save(model.state_dict(), "./fcn8s.pt")
# **模型预测**
# 加载模型
# model=torch.load("./fcn8s.pt")
# 进入评估模式
model.eval()
cm = np.array(colormap).astype("uint8")
# 测试集梯度不更新
with torch.no_grad():
for image, label in test_loader:
# 将数据复制到GPU中
image = image.to(device)
label = label.to(device)
print("image", image.shape, "label", label.shape)
# 正向传播
output = model(image)
# 把数据从GPU复制到CPU中,plt才能调用
output = output.max(1)[1].squeeze().cpu().data.numpy()
pred = cm[output]
plt.imshow(pred[0])
# output=output.cpu().numpy()
# print(output.shape)
# for i,eval_image in enumerate(output):
# plt.imshow(eval_image)
break
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0094/772/94772222.ipynb | voc2012 | zhichengwen | [{"Id": 94772222, "ScriptId": 26481417, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3411147, "CreationDate": "05/04/2022 18:53:08", "VersionNumber": 7.0, "Title": "[\u56fe\u50cf\u5206\u5272]Pytorch-VGG/FCN-\u8bed\u4e49\u5206\u5272", "EvaluationDate": "05/04/2022", "IsChange": true, "TotalLines": 416.0, "LinesInsertedFromPrevious": 22.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 394.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 129113281, "KernelVersionId": 94772222, "SourceDatasetVersionId": 2887798}] | [{"Id": 2887798, "DatasetId": 1768994, "DatasourceVersionId": 2934854, "CreatorUserId": 7951664, "LicenseName": "U.S. Government Works", "CreationDate": "12/05/2021 02:55:48", "VersionNumber": 1.0, "Title": "VOC2012", "Slug": "voc2012", "Subtitle": "Image sets Image sets Image sets Image sets Image sets Image sets", "Description": "Image dataset\uff0conly use by learning \nImage dataset\uff0conly use by learning \nImage dataset\uff0conly use by learning \nImage dataset\uff0conly use by learning \nImage dataset\uff0conly use by learning \nImage dataset\uff0conly use by learning \nImage dataset\uff0conly use by learning", "VersionNotes": "Initial release", "TotalCompressedBytes": 0.0, "TotalUncompressedBytes": 0.0}] | [{"Id": 1768994, "CreatorUserId": 7951664, "OwnerUserId": 7951664.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 2887798.0, "CurrentDatasourceVersionId": 2934854.0, "ForumId": 1791237, "Type": 2, "CreationDate": "12/05/2021 02:55:48", "LastActivityDate": "12/05/2021", "TotalViews": 2390, "TotalDownloads": 235, "TotalVotes": 4, "TotalKernels": 1}] | [{"Id": 7951664, "UserName": "zhichengwen", "DisplayName": "Kprintf", "RegisterDate": "07/21/2021", "PerformanceTier": 1}] | # **导入必要的包**
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import torchvision.transforms as transforms
import PIL.Image as pil_image
import matplotlib.pyplot as plt
# **加载自定义的数据******
# * https://zhuanlan.zhihu.com/p/32506912
# 分割的类别
classes = [
"background",
"aeroplane",
"bicycle",
"bird",
"boat",
"bottle",
"bus",
"car",
"cat",
"chair",
"cow",
"diningtable",
"dog",
"horse",
"motorbike",
"person",
"potted plant",
"sheep",
"sofa",
"train",
"tv/monitor",
]
# 每个类别对应的RGB值
colormap = [
[0, 0, 0],
[128, 0, 0],
[0, 128, 0],
[128, 128, 0],
[0, 0, 128],
[128, 0, 128],
[0, 128, 128],
[128, 128, 128],
[64, 0, 0],
[192, 0, 0],
[64, 128, 0],
[192, 128, 0],
[64, 0, 128],
[192, 0, 128],
[64, 128, 128],
[192, 128, 128],
[0, 64, 0],
[128, 64, 0],
[0, 192, 0],
[128, 192, 0],
[0, 64, 128],
]
cm2lbl = np.zeros(256**3) # 每个像素点有 0 ~ 255 的选择,RGB 三个通道
for i, cm in enumerate(colormap):
cm2lbl[(cm[0] * 256 + cm[1]) * 256 + cm[2]] = i # 建立索引
# 将图片映射成索引数组
def image_to_label(image):
"""将图片映射成类别索引的数组"""
data = np.array(image, dtype="int32")
# 按照上面一样的计算规则,得到对应的值
index = (data[:, :, 0] * 256 + data[:, :, 1]) * 256 + data[:, :, 2]
return np.array(cm2lbl[index], dtype="int64")
def random_crop(image, width, height):
"""随机裁剪"""
pass
# 测试
image = pil_image.open(
"../input/voc2012/data/VOCdevkit/VOC2012/SegmentationClass/2007_000032.png"
).convert("RGB")
# image = transforms.RandomCrop((224, 224))(image)
# print(image)
# plt.imshow(image)
# label = transforms.FixedCrop(*rect)(label)
# image_array=image_to_label(image)
class VOCDataset(Dataset):
"""自定义数据类加载规则"""
def __init__(self, file_path=None, transform=None):
"""初始化函数"""
images_labels = []
file = open(file_path)
for name in file.readlines():
# 移除空格和换行符
name = name.strip()
image = (
"../input/voc2012/data/VOCdevkit/VOC2012/JPEGImages/" + name + ".jpg"
)
label = (
"../input/voc2012/data/VOCdevkit/VOC2012/SegmentationClass/"
+ name
+ ".png"
)
images_labels.append((image, label))
self.images_labels = images_labels
self.transform = transform
def __getitem__(self, index):
"""在DataLoader中会调用这个方法读取一个batch的数据"""
image_path, label_path = self.images_labels[index]
# 使用image.open加载目标图和特征图
image = pil_image.open(image_path)
label = pil_image.open(label_path).convert("RGB")
# # 裁剪图片,使其所有的图片输入一致
# x,y,width,height=transforms.RandomCrop.get_params(img=image,output_size=(224,224))
# image=function.crop(image,x,y,width,height)
# label=function.crop(label,x,y,width,height)
image = transforms.Resize((512, 512))(image)
label = transforms.Resize((512, 512))(label)
# 转化特征图
if self.transform is not None:
image = self.transform(image)
# 映射目标图
label = image_to_label(label)
# 从numpy数组转化成张量
label = torch.from_numpy(label)
# 返回
return image, label
def __len__(self):
"""获取整个dataset的数据大小"""
return len(self.images_labels)
# 数据预处理,增强,归一化
transform_train = transforms.Compose(
[
# 将数据转化成张量,并且归一化到[0,1]
transforms.ToTensor(),
# 将数据标准化到[-1,1],image=(image-mean)/std
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
transform_test = transforms.Compose(
[
# 将数据转化成张量,并且归一化到[0,1]
transforms.ToTensor(),
# 将数据标准化到[-1,1],image=(image-mean)/std
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
]
)
train_datasets = VOCDataset(
file_path="../input/voc2012/data/VOCdevkit/VOC2012/ImageSets/Segmentation/train.txt",
transform=transform_train,
)
test_datasets = VOCDataset(
file_path="../input/voc2012/data/VOCdevkit/VOC2012/ImageSets/Segmentation/val.txt",
transform=transform_test,
)
train_loader = DataLoader(
dataset=train_datasets, batch_size=8, shuffle=False, sampler=None
)
test_loader = DataLoader(
dataset=test_datasets, batch_size=8, shuffle=False, sampler=None
)
print(len(train_loader))
# print(next(iter(train_loader)))
# **FCN网络结构如下**
# 前面由VGG16组成,分5个卷积层,后面有3个(1,1)卷积层,输出32s,16s,8s,然后在进行融合,上采样得出结果
# https://github.com/wkentaro/pytorch-fcn/blob/main/torchfcn/models/fcn8s.py
# 
# **构建FCN网络模型**
class FCN8s(nn.Module):
def __init__(self):
super(FCN8s, self).__init__()
# 本项目有20个类别,一个背景,一共21类
n_class = 21
# conv1
# 输入图像为3通道,输出64个特征图,卷积核大小为(3,3),步长为1,padding为100(避免图片不兼容,其实也可以为1的)
# 卷积输出公式:output=(input+2*padding-kernel_size)/stride+1
# 512=(512+2*1-3)/1+1
self.conv1_1 = nn.Conv2d(
in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1
)
self.bn1_1 = nn.BatchNorm2d(num_features=64)
self.relu1_1 = nn.ReLU(inplace=True)
self.conv1_2 = nn.Conv2d(
in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1
)
self.bn1_2 = nn.BatchNorm2d(num_features=64)
self.relu1_2 = nn.ReLU(inplace=True)
# 最大池化层进行下采样
# 采样输出公式:output=(input+2*padding-kernel_size)/stride+1
# 256=(512+2*0-2)/2+1
self.maxpool1 = nn.MaxPool2d(kernel_size=2, stride=2)
# conv2
self.conv2_1 = nn.Conv2d(
in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1
)
self.bn2_1 = nn.BatchNorm2d(num_features=128)
self.relu2_1 = nn.ReLU(inplace=True)
self.conv2_2 = nn.Conv2d(
in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1
)
self.bn2_2 = nn.BatchNorm2d(num_features=128)
self.relu2_2 = nn.ReLU(inplace=True)
# 最大池化层进行下采样
self.maxpool2 = nn.MaxPool2d(kernel_size=2, stride=2)
# conv3
self.conv3_1 = nn.Conv2d(
in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1
)
self.bn3_1 = nn.BatchNorm2d(num_features=256)
self.relu3_1 = nn.ReLU(inplace=True)
self.conv3_2 = nn.Conv2d(
in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1
)
self.bn3_2 = nn.BatchNorm2d(num_features=256)
self.relu3_2 = nn.ReLU(inplace=True)
self.conv3_3 = nn.Conv2d(
in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1
)
self.bn3_3 = nn.BatchNorm2d(num_features=256)
self.relu3_3 = nn.ReLU(inplace=True)
# 最大池化层进行下采样
self.maxpool3 = nn.MaxPool2d(kernel_size=2, stride=2)
# conv4
self.conv4_1 = nn.Conv2d(
in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1
)
self.bn4_1 = nn.BatchNorm2d(num_features=512)
self.relu4_1 = nn.ReLU(inplace=True)
self.conv4_2 = nn.Conv2d(
in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1
)
self.bn4_2 = nn.BatchNorm2d(num_features=512)
self.relu4_2 = nn.ReLU(inplace=True)
self.conv4_3 = nn.Conv2d(
in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1
)
self.bn4_3 = nn.BatchNorm2d(num_features=512)
self.relu4_3 = nn.ReLU(inplace=True)
# 最大池化层进行下采样
self.maxpool4 = nn.MaxPool2d(kernel_size=2, stride=2)
# conv5
# 输入图像为3通道,输出64个特征图,卷积核大小为(3,3),步长为1,padding为100(避免图片不兼容)
self.conv5_1 = nn.Conv2d(
in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1
)
self.bn5_1 = nn.BatchNorm2d(num_features=512)
self.relu5_1 = nn.ReLU(inplace=True)
self.conv5_2 = nn.Conv2d(
in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1
)
self.bn5_2 = nn.BatchNorm2d(num_features=512)
self.relu5_2 = nn.ReLU(inplace=True)
self.conv5_3 = nn.Conv2d(
in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1
)
self.bn5_3 = nn.BatchNorm2d(num_features=512)
self.relu5_3 = nn.ReLU(inplace=True)
# 最大池化层进行下采样
self.maxpool5 = nn.MaxPool2d(kernel_size=2, stride=2)
# cnov6
self.conv6 = nn.Conv2d(
in_channels=512, out_channels=4096, kernel_size=7, stride=1, padding=1
)
self.bn6 = nn.BatchNorm2d(num_features=4096)
self.relu6 = nn.ReLU(inplace=True)
self.drop6 = nn.Dropout2d(p=0.5)
# cnov7
self.conv7 = nn.Conv2d(
in_channels=4096, out_channels=4096, kernel_size=1, stride=1, padding=1
)
self.bn7 = nn.BatchNorm2d(num_features=4096)
self.relu7 = nn.ReLU(inplace=True)
self.drop7 = nn.Dropout2d(p=0.5)
# cnov8,本项目有20个类别,一个背景,一共21类
self.conv8 = nn.Conv2d(
in_channels=4096, out_channels=n_class, kernel_size=1, stride=1, padding=1
)
# 上采样2倍(16,16,21)————>(32,32,21)
self.up_conv8_2 = nn.ConvTranspose2d(
in_channels=n_class,
out_channels=n_class,
kernel_size=2,
stride=2,
bias=False,
)
# 反卷积ConvTranspose2d操作输出宽高公式
# output=((input-1)*stride)+outputpadding-(2*padding)+kernelsize
# 34=(16-1)*2+0-(2*0)+4
# 第4层maxpool值做卷积运算
self.pool4_conv = nn.Conv2d(
in_channels=512, out_channels=n_class, kernel_size=1, stride=1
)
# 利用反卷积上采样2倍
self.up_pool4_2 = nn.ConvTranspose2d(
in_channels=n_class,
out_channels=n_class,
kernel_size=2,
stride=2,
bias=False,
)
# 第3层maxpool值做卷积运算
self.pool3_conv = nn.Conv2d(
in_channels=256, out_channels=n_class, kernel_size=1, stride=1
)
# 利用反卷积上采样8倍
self.up_pool3_8 = nn.ConvTranspose2d(
in_channels=n_class,
out_channels=n_class,
kernel_size=8,
stride=8,
bias=False,
)
def forward(self, x):
"""正向传播"""
# 记录初始图片的大小(32,21,512,512)
h = x
# conv1
x = self.relu1_1(self.bn1_1(self.conv1_1(x)))
x = self.relu1_2(self.bn1_2(self.conv1_2(x)))
x = self.maxpool1(x)
# conv2
x = self.relu2_1(self.bn2_1(self.conv2_1(x)))
x = self.relu2_2(self.bn2_2(self.conv2_2(x)))
x = self.maxpool2(x)
# conv3
x = self.relu3_1(self.bn3_1(self.conv3_1(x)))
x = self.relu3_2(self.bn3_2(self.conv3_2(x)))
x = self.relu3_3(self.bn3_3(self.conv3_3(x)))
x = self.maxpool3(x)
pool3 = x
# conv4
x = self.relu4_1(self.bn4_1(self.conv4_1(x)))
x = self.relu4_2(self.bn4_2(self.conv4_2(x)))
x = self.relu4_3(self.bn4_3(self.conv4_3(x)))
x = self.maxpool4(x)
pool4 = x
# conv5
x = self.relu5_1(self.bn5_1(self.conv5_1(x)))
x = self.relu5_2(self.bn5_2(self.conv5_2(x)))
x = self.relu5_3(self.bn5_3(self.conv5_3(x)))
x = self.maxpool5(x)
# conv6
# print(self.conv6(x).shape)
# print(self.bn6(self.conv6(x)).shape)
# print(self.relu6(self.bn6(self.conv6(x))).shape)
# print(self.drop6(self.relu6(self.bn6(self.conv6(x)))).shape)
x = self.drop6(self.relu6(self.bn6(self.conv6(x))))
# conv7
x = self.drop7(self.relu7(self.bn7(self.conv7(x))))
# conv8
x = self.up_conv8_2(self.conv8(x))
up_conv8 = x
# 计算第4层的值
x2 = self.pool4_conv(pool4)
# 相加融合
x2 = up_conv8 + x2
# 反卷积上采样8倍
x2 = self.up_pool4_2(x2)
up_pool4 = x2
# 计算第3层的值
x3 = self.pool3_conv(pool3)
x3 = up_pool4 + x3
# 反卷积上采样8倍
x3 = self.up_pool3_8(x3)
return x3
model = FCN8s()
# print(model)
# **模型训练**
# 配置训练参数
# 选择设置,优先GPU
device = torch.device("cuda" if torch.cuda.is_available else "cpu")
# 训练次数
epochs = 100
# 评判标准,损失函数
criterion = torch.nn.CrossEntropyLoss()
# 优化方法
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# 将模型赋值到GPU中
model = model.to(device)
for epoch in range(epochs):
num = 1
loss_num = 0
for i, (image, label) in enumerate(train_loader):
# 将数据复制到GPU中
image = image.to(device)
label = label.to(device)
# 梯度清零
optimizer.zero_grad()
# 正向传播
output = model(image)
# 计算损失
loss = criterion(output, label)
# 反向传播
loss.backward()
# 更新梯度
optimizer.step()
# 获取当前损失
running_loss = loss.data.item()
loss_num += running_loss
num += i
epoch_loss = loss_num / len(train_loader)
print("次数", epoch, "平均损失", epoch_loss)
# 保存模型
torch.save(model.state_dict(), "./fcn8s.pt")
# **模型预测**
# 加载模型
# model=torch.load("./fcn8s.pt")
# 进入评估模式
model.eval()
cm = np.array(colormap).astype("uint8")
# 测试集梯度不更新
with torch.no_grad():
for image, label in test_loader:
# 将数据复制到GPU中
image = image.to(device)
label = label.to(device)
print("image", image.shape, "label", label.shape)
# 正向传播
output = model(image)
# 把数据从GPU复制到CPU中,plt才能调用
output = output.max(1)[1].squeeze().cpu().data.numpy()
pred = cm[output]
plt.imshow(pred[0])
# output=output.cpu().numpy()
# print(output.shape)
# for i,eval_image in enumerate(output):
# plt.imshow(eval_image)
break
| false | 0 | 5,588 | 0 | 92 | 5,588 |
||
94659766 | <kaggle_start><code># # Pattern Recognition in Financial Market
# ## Initialization
# In this section, we initialize the environments with the following steps:
# 1. check all dependencies has been installed
# 2. if not installed, install the dependency with pip
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
# ### Common dependencies
# The following cell imports the dependencies required for the basic pipeline.
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
import os
import logging
import functools
import random
from datetime import datetime
from pprint import PrettyPrinter
from collections import OrderedDict
from typing import Tuple, Union, List, Iterable, Dict, Optional
import torch
import darts
import pandas as pd
import torch.nn as nn
import pytorch_lightning as pl
import matplotlib.pyplot as plt
from tqdm import tqdm
from darts.utils.missing_values import fill_missing_values, extract_subseries
from darts.utils.data import (
PastCovariatesTrainingDataset,
PastCovariatesInferenceDataset,
)
from darts.dataprocessing.transformers.scaler import Scaler
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s [%(levelname)s] line %(lineno)s, %(funcName)s: %(message)s",
)
os.makedirs("./output", exist_ok=True)
# ### Feature-model-specific dependencies
# The following cell imports the dependencies required for the feature engineering and for the algorithms. For instance, Pytorch for the RNN-CNN-based model.
# Generated by assemble.py (imports)
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import talib
import pandas as pd
# #### General Parameters
# --------------------------
# MODIFY CAREFULLY BASED ON RESPECITIVE USAGE!
# --------------------------
# Preprocessing Parameters
# -------------------------------------------------------------------------------------------------------------
# - GAP_SIZE: Remove weekend, holiday gaps with GAP_SIZE.
# Usually on weekends, data does not change, hence weekend time slot has no meaning
# Since most weekend gaps is ~48, GAP_SIZE is default as 40.
GAP_SIZE = 40
# - KEEP_MARKETS: A set containing the expected markets for testing. It could be left empty for using all markets.
# Each item is a string which could be a part of the market name,
# e.g. `Australia` for Australia 200 Cash -2022-04-26.csv
KEEP_MARKETS = ["Australia"]
# -------------------------------------------------------------------------------------------------------------
# Feature Engineering Parameters
# -------------------------------------------------------------------------------------------------------------
# - USE_FEATURE: whether to calculate features from the original dataset, default `True`.
USE_FEATURE = True
# -------------------------------------------------------------------------------------------------------------
# Model Parameters
# -------------------------------------------------------------------------------------------------------------
# - WINDOW_SIZE, HORIZON_SIZE: Determine the window and horizon for prediction, use window to predict horizon,
# e.g. window(10:00-16:00) --predict-> horizon(16:00-18:00),
# with WINDOW_SIZE as 6 and HORIZON_SIZE as 2
WINDOW_SIZE, HORIZON_SIZE = 64, 16
# - PRED_COLUMNS: the column(s) to be predicted by the model, usually `bid_close` or `ask_close`.
PRED_COLUMNS = ["bid_close"]
# - EPOCHS: the number of times to iterate on the dataset, default as 10
EPOCH = 300
# - STRIDE: the spacing of sampling steps. For instance, stride=1 means that slices will be like
# [(9:00-11:00), (10:00-12:00), ..., (22:00-24:00)]
# It could be set to `1` for full sampling, `HORIZON_SIZE` for prediction-covering sampling, and
# `WINDOW_SIZE+HORIZON_SIZE` for non-overlapping sampling
STRIDE = 1
# - USE_DIFF: whether to predict the difference instead of predicting the price itself, default `False`
USE_DIFF = False
# - SLICE_NORM: whether to normalize a slice to (0,1) based on window,
# the same scale is applied to the horizon as well, default `False`
SLICE_NORM = False
# - RANDOM_SPLIT: whether to split data randomly,
# if True, a slice(a pair of window & horizon) is randomly assigned to train/valid/test set;
# else, a slice is assigned to train/valid/test by its starting time;
RANDOM_SPLIT = False
# - FIX_RANDOM: whether to fix the random seed for fixed dataset split indices.
FIX_RANDOM = False
if FIX_RANDOM:
random.seed(0)
# - GENERAL_MODEL_PARAMS: general parameters for initialising the model, only modify the value when using
GENERAL_MODEL_PARAMS = {
"loss_fn": nn.MSELoss(),
"optimizer_cls": torch.optim.SGD,
"optimizer_kwargs": {"lr": 2e-3, "momentum": 0.5},
"lr_scheduler_cls": torch.optim.lr_scheduler.ReduceLROnPlateau,
"lr_scheduler_kwargs": {"factor": 0.5},
}
# -------------------------------------------------------------------------------------------------------------
# Pipeline Parameters
# -------------------------------------------------------------------------------------------------------------
# - MODE_LOAD_MODEL: whether to load model for prediction instead of training from scratch.
# if true, will not train model, the path of the model should be specified as well.
# if false, will train model
MODE_LOAD_MODEL = False
NAME_LOAD_MODEL = "./output/blockrnnmodel-0501-0601/epoch=74-step=9075.ckpt"
# ## Preprocessing
# Preprocessing in vital for the algorithms and features to work. The preprocessing step includes:
# 1. copy the data into designated folder and read it.
# 2. clean up missing values and outliers in the time-series data.
# ### Stage 1. Read data
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
DATA_SOURCE = "./data"
KAGGLE_DATASET_SOURCE = "../input/stock-indices-202103-202202"
if os.path.exists(DATA_SOURCE) and all(
fname.endswith(".csv") for fname in os.listdir(DATA_SOURCE)
):
logging.info(
f'Data already loaded into designated folder: [{", ".join(os.listdir(DATA_SOURCE)[:5])} ...]'
)
else:
DATA_SOURCE = KAGGLE_DATASET_SOURCE
logging.info(
f'Data copied into designated folder: [{", ".join(os.listdir(DATA_SOURCE)[:5])} ...]'
)
# #### Read Data
# Use pandas to read data
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
raw_data = OrderedDict()
def remove_gaps(ts: darts.TimeSeries) -> darts.TimeSeries:
tss = extract_subseries(ts, min_gap_size=GAP_SIZE)
return functools.reduce(lambda x, y: x.concatenate(y, ignore_time_axes=True), tss)
for fname in os.listdir(DATA_SOURCE):
if fname.endswith(".csv"):
market = fname[:-20].strip()
if KEEP_MARKETS and not any(i in market for i in KEEP_MARKETS):
continue
try:
ts = darts.TimeSeries.from_csv(
os.path.join(DATA_SOURCE, fname), time_col="time", freq="H"
)
raw_data[market] = remove_gaps(ts).pd_dataframe()
except:
logging.warning(f"{market} with incompatible data, skipping")
else:
logging.warning(f"unsupported file exists in data folder: {fname}")
logging.info(f'Testing markets: [{", ".join(raw_data.keys())}]')
# ### Stage 2. Missing value / outlier processing / normalisation
# If missing values are used in the prediction, it would cause the calculation of the error to become NaN. The missing values would be filled by two methods:
# 1. For prices, it would be filled by forefill method which use most-recent data on the left side. The consideration is that in this part, the
# 2. For volumes, average of a window is used to fill-in.
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
preprocessing_funcs = []
# Generated by assemble.py (preprocessing)
def normalize(df: pd.DataFrame) -> pd.DataFrame:
scaler = MinMaxScaler(feature_range=(0, 1))
scale_cols = list(filter(lambda x: "volume" not in x, df.columns))
df[scale_cols] = scaler.fit_transform(df[scale_cols])
return df
def volume_fillna(df: pd.DataFrame) -> pd.DataFrame:
fill_cols = list(filter(lambda x: "volume" not in x, df.columns))
df[fill_cols] = df[fill_cols].fillna(0.0)
return df
preprocessing_funcs = [normalize]
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
for market, df in raw_data.items():
for func in preprocessing_funcs:
raw_data[market] = func(df)
# ## Feature engineering
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
feature_funcs = []
# Generated by assemble.py (features)
def get_talib_overlap(df: pd.DataFrame) -> pd.DataFrame:
high = (df["bid_high"] + df["ask_high"]) / 2
low = (df["bid_low"] + df["ask_low"]) / 2
close = (df["bid_close"] + df["ask_close"]) / 2
open_ = (df["bid_open"] + df["ask_open"]) / 2
volume = df["last_volume"]
(
df["BBANDS.up.5.2.2"],
df["BBANDS.mid.5.2.2"],
df["BBANDS.low.5.2.2"],
) = talib.BBANDS(close, timeperiod=5, nbdevup=2, nbdevdn=2, matype=0)
df["DMA.30"] = talib.DEMA(close, timeperiod=30)
df["EMA.30"] = talib.EMA(close, timeperiod=30)
df["HT_TRENDLINE"] = talib.HT_TRENDLINE(close)
df["KAMA.30"] = talib.KAMA(close, timeperiod=30)
df["MA.30"] = talib.MA(close, timeperiod=30, matype=0)
df["MAMA.ma"], df["MAMA.fa"] = talib.MAMA(close)
df["MIDPOINT.14"] = talib.MIDPOINT(close, timeperiod=14)
df["MIDPRICE.14"] = talib.MIDPRICE(high, low, timeperiod=14)
df["SAR"] = talib.SAR(high, low, acceleration=0, maximum=0)
df["SAREXT"] = talib.SAREXT(
high,
low,
startvalue=0,
offsetonreverse=0,
accelerationinitlong=0,
accelerationlong=0,
accelerationmaxlong=0,
accelerationinitshort=0,
accelerationshort=0,
accelerationmaxshort=0,
)
df["SMA.30"] = talib.SMA(close, timeperiod=30)
df["T3.5"] = talib.T3(close, timeperiod=5, vfactor=0)
df["TEMA.30"] = talib.TEMA(close, timeperiod=30)
df["T3.5"] = talib.T3(close, timeperiod=5, vfactor=0)
df["TRIMA.30"] = talib.TRIMA(close, timeperiod=30)
df["WMA.30"] = talib.WMA(close, timeperiod=30)
df["ADX.14"] = talib.ADX(high, low, close, timeperiod=14)
df["ADXR.14"] = talib.ADXR(high, low, close, timeperiod=14)
df["APO.12.26"] = talib.APO(close, fastperiod=12, slowperiod=26, matype=0)
df["AROON.down.14"], df["AROON.up.14"] = talib.AROON(high, low, timeperiod=14)
df["AROONOSC.14"] = talib.AROONOSC(high, low, timeperiod=14)
df["BOP"] = talib.BOP(open_, high, low, close)
df["CCI.14"] = talib.CCI(high, low, close, timeperiod=14)
df["CMO.14"] = talib.CMO(close, timeperiod=14)
df["DX.14"] = talib.DX(high, low, close, timeperiod=14)
df["MACD.12.26"], df["MACD.12.26.sig"], df["MACD.12.26.hist"] = talib.MACD(
close, fastperiod=12, slowperiod=26, signalperiod=9
)
(
df["MACDEXT.12.26"],
df["MACDEXT.12.26.sig"],
df["MACDEXT.12.26.hist"],
) = talib.MACDEXT(
close,
fastperiod=12,
fastmatype=0,
slowperiod=26,
slowmatype=0,
signalperiod=9,
signalmatype=0,
)
(
df["MACDFIX.12.26"],
df["MACDFIX.12.26.sig"],
df["MACDFIX.12.26.hist"],
) = talib.MACDFIX(close, signalperiod=9)
df["MFI.14"] = talib.MFI(high, low, close, volume, timeperiod=14)
df["MINUS_DI.14"] = talib.MINUS_DI(high, low, close, timeperiod=14)
df["MINUS_DM.14"] = talib.MINUS_DM(high, low, timeperiod=14)
df["MOM.10"] = talib.MOM(close, timeperiod=10)
df["PLUS_DI.14"] = talib.PLUS_DI(high, low, close, timeperiod=14)
df["PLUS_DM.14"] = talib.PLUS_DM(high, low, timeperiod=14)
df["PPO.12.26"] = talib.PPO(close, fastperiod=12, slowperiod=26, matype=0)
df["ROC.10"] = talib.ROC(close, timeperiod=10)
df["ROCP.10"] = talib.ROCP(close, timeperiod=10)
df["ROCR.10"] = talib.ROCR(close, timeperiod=10)
df["ROCR100.10"] = talib.ROCR100(close, timeperiod=10)
df["RSI.14"] = talib.RSI(close, timeperiod=14)
df["STOCH.5.3.k"], df["STOCH.5.3.d"] = talib.STOCH(
high,
low,
close,
fastk_period=5,
slowk_period=3,
slowk_matype=0,
slowd_period=3,
slowd_matype=0,
)
df["STOCHF.5.3.k"], df["STOCHF.5.3.d"] = talib.STOCHF(
high, low, close, fastk_period=5, fastd_period=3, fastd_matype=0
)
df["STOCHRSI.5.3.k"], df["STOCHRSI.5.3.d"] = talib.STOCHRSI(
close, timeperiod=14, fastk_period=5, fastd_period=3, fastd_matype=0
)
df["TRIX.30"] = talib.TRIX(close, timeperiod=30)
df["ULTOSC.7.14.28"] = talib.ULTOSC(
high, low, close, timeperiod1=7, timeperiod2=14, timeperiod3=28
)
df["WILLR.14"] = talib.WILLR(high, low, close, timeperiod=14)
return df
feature_funcs = [get_talib_overlap]
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
if USE_FEATURE:
for market, df in raw_data.items():
for func in feature_funcs:
raw_data[market] = func(df)
# ## Prediction Models
# #### Convert data to time series
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
time_series = OrderedDict()
for market, df in raw_data.items():
ts = darts.timeseries.TimeSeries.from_dataframe(df, freq="1h")
if USE_DIFF:
ts = fill_missing_values(ts).diff(dropna=False)
time_series[market] = fill_missing_values(ts).astype(np.float32)
sample = time_series.values().__iter__().__next__()
# ### Creating train set, validation set and test set
# Since the dataset is rolling window based and behaves based on the model parameters, it should be split here.
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
class MarketDataset:
def __init__(
self,
data: Dict[str, darts.TimeSeries],
target_cols: Union[str, List[str]],
random_: bool = False,
window_size: int = WINDOW_SIZE,
horizon_size: int = HORIZON_SIZE,
stride: int = 1,
test_ratio: float = 0.25,
valid_ratio: float = 0.1,
) -> None:
super().__init__()
self.scaler = Scaler(MinMaxScaler())
self.rand = random_
self.window, self.horizon = window_size, horizon_size
self.data = data
self._init_ts_cov(target_cols)
self._build_indices(data, stride)
self._train_test_split(test_ratio, valid_ratio)
self._gen_idx_map()
def _init_ts_cov(self, target: Union[str, List[str]]) -> None:
sample = self.data.values().__iter__().__next__()
cols = set(sample.columns)
if isinstance(target, str) and target in set(ts.columns):
cols.remove(target)
target = [target]
elif isinstance(target, Iterable):
cols = cols.difference(target)
else:
raise ValueError(f"target time series has no column: {target}")
self.pred, self.covs = target, list(cols)
def _get_series_and_covariates(
self, ts: darts.TimeSeries
) -> Tuple[darts.TimeSeries, darts.TimeSeries]:
return ts[self.pred], ts[self.covs]
def _build_indices(self, data: Dict[str, darts.TimeSeries], stride: int) -> None:
rolling = self.window + self.horizon
indices = {}
for market, ts in data.items():
length = len(ts)
if length < rolling:
logging.error(
f"{market} does not have the length for the dataset, \
length is {length}, but should be larger than {rolling}"
)
elif stride > length - rolling:
logging.warning(
f"For {market}, stride({stride}) is bigger than a rolling window, will instead use {rolling}"
)
stride = rolling
indices[market] = set(range(0, length - rolling, stride))
self.indices = indices
def _train_test_split(
self, test_ratio: float = 0.25, valid_ratio: float = 0.1
) -> None:
train, test, valid = {}, {}, {}
# split dataset by market
for market, index in self.indices.items():
if self.rand:
_test = set(random.sample(index, int(len(index) * test_ratio)))
train_val = index.difference(test)
_valid = set(random.sample(train_val, int(len(index) * valid_ratio)))
_train = train_val.difference(_valid)
else: # traditional split method by entire segment slicing
idx_len, idx_sorted = len(index), sorted(index)
train_valid_boundary, valid_test_boundary = (
int(idx_len * (1 - valid_ratio - test_ratio)),
int(idx_len * (1 - valid_ratio)),
)
_train, _valid, _test = (
idx_sorted[:train_valid_boundary],
idx_sorted[train_valid_boundary:valid_test_boundary],
idx_sorted[valid_test_boundary:],
)
train[market], test[market], valid[market] = _train, _test, _valid
self.train, self.test, self.valid = train, test, valid
def _gen_idx_map(self):
def get_map(idx_dict: Dict[str, set]) -> Dict[int, Tuple[str, int]]:
count, res = 0, {}
for market, indices in idx_dict.items():
for idx in indices:
res[count] = (market, idx)
count += 1
return res
self._idx_map = {}
self._idx_map["train"] = get_map(self.train)
self._idx_map["test"] = get_map(self.test)
self._idx_map["valid"] = get_map(self.valid)
def inspect_dataset(self):
return (
self.indices,
(self.pred, self.covs),
self._idx_map,
{"train": self.train, "test": self.test, "valid": self.valid},
)
@functools.lru_cache()
def get_len(self, type_: str) -> int:
return len(self._idx_map[type_])
@functools.lru_cache(maxsize=None)
def get_sample(
self, idx: int, type_: str
) -> Tuple[darts.TimeSeries, darts.TimeSeries, darts.TimeSeries]:
market, start = self._idx_map[type_][idx]
ts = self.data[market]
window, horizon = start + self.window, start + self.window + self.horizon
slice = ts[start:window]
past, covs, truth = (
slice[self.pred],
slice[self.covs],
ts[window:horizon][self.pred],
)
if SLICE_NORM:
past = self.scaler.fit_transform(past)
truth = self.scaler.transform(truth)
return past, covs, truth
class PartialDataset(PastCovariatesTrainingDataset):
TRAIN, TEST, VALID = TYPES = ("train", "test", "valid")
def __init__(self, real_dataset: MarketDataset, type_: str) -> None:
super().__init__()
assert (
type_ in self.TYPES
), f"Type must be either of `train, test, valid` but {type_} was given"
self.type_ = type_
self.real_dataset = real_dataset
def __len__(self):
return self.real_dataset.get_len(self.type_)
def __getitem__(self, idx: int) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
return tuple(i.values() for i in self.real_dataset.get_sample(idx, self.type_))
class PartialInferenceDataset(PastCovariatesInferenceDataset):
def __init__(self, real_dataset: MarketDataset) -> None:
self.type_ = "test"
self.real_dataset = real_dataset
def __len__(self):
return self.real_dataset.get_len(self.type_)
def __getitem__(
self, idx: int
) -> Tuple[
np.ndarray, Optional[np.ndarray], Optional[np.ndarray], darts.TimeSeries
]:
past, covs, target = self.real_dataset.get_sample(idx, self.type_)
return past.values(), covs.values(), None, target
def get_ts_by_idx(
self, idx: int
) -> Tuple[darts.TimeSeries, darts.TimeSeries, darts.TimeSeries]:
return self.real_dataset.get_sample(idx, self.type_)
# Initialize the dataset
dataset = MarketDataset(
time_series, target_cols=PRED_COLUMNS, stride=STRIDE, random_=RANDOM_SPLIT
)
train = PartialDataset(dataset, PartialDataset.TRAIN)
valid = PartialDataset(dataset, PartialDataset.VALID)
test = PartialInferenceDataset(dataset)
# ### Model instantiating
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
from darts.models import NaiveDrift
from darts.models.forecasting.forecasting_model import ForecastingModel
model = NaiveDrift()
model.__not_initialized__ = True
# Generated by assemble.py (models)
from typing import List, Optional
from darts.models import BlockRNNModel
from darts.models.forecasting.pl_forecasting_module import PLPastCovariatesModule
import torch
import torch.nn as nn
class _ResidualBlock(nn.Module):
def __init__(self, input_dim: int, output_dim: int = None) -> None:
super(_ResidualBlock, self).__init__()
output_dim = output_dim or input_dim
self.cnn = nn.Conv1d(input_dim, output_dim, kernel_size=3, padding="same")
self.relu = nn.ReLU()
self.bn = nn.BatchNorm1d(output_dim)
def forward(self, x: torch.Tensor):
"""
args:
- x: Tensor(batch_size, signal_length, channels)
"""
residual = x
x = x.permute(0, 2, 1)
conv = self.cnn(x)
bn = self.bn(conv)
act = self.relu(bn)
act = act.permute(0, 2, 1)
return self.relu(act + residual)
@classmethod
def build_residual(
cls, input_dim: int, output_dim: int = None, block_nums: int = 4
) -> nn.Sequential:
blocks = [nn.Linear(input_dim, output_dim)]
for _ in range(block_nums - 1):
blocks.append(_ResidualBlock(output_dim, output_dim))
return nn.Sequential(*blocks)
class RNNCNNModel(PLPastCovariatesModule):
def __init__(
self,
name: str,
input_size: int,
hidden_dim: int,
num_layers: int,
target_size: int,
nr_params: int = None,
num_layers_out_fc: Optional[List] = None,
dropout: float = 0.0,
**kwargs,
) -> None:
super(RNNCNNModel, self).__init__(**kwargs)
self.name = name or "RNN-CNN"
self.target_size = target_size
self.lc_hidden_dim = 1024
self.residual = _ResidualBlock.build_residual(input_size, hidden_dim)
self.enc = nn.LSTM(input_size, hidden_dim, num_layers, dropout=dropout)
self.relu = nn.ReLU()
self.dec = nn.LSTM(hidden_dim * 2, hidden_dim, num_layers, dropout=dropout)
self.lc1 = nn.Linear(hidden_dim, self.lc_hidden_dim)
self.lc2 = nn.Linear(self.lc_hidden_dim, target_size, bias=False)
self.bias_lc = nn.Linear(input_size, target_size)
self.bias_acti = nn.Hardsigmoid()
self.bias_pool = nn.AdaptiveMaxPool1d(1)
def forward(self, x: torch.Tensor):
"""
args:
- x: Tensor(batch_size, signal_length, channels)
"""
# encoding
conv = self.residual(x)
recr, _ = self.enc(x)
hidden = self.relu(torch.cat((conv, recr), dim=-1))
# decoding
out, _ = self.dec(hidden)
relu = self.relu(out[:, : self.output_chunk_length, :])
lc_hidden = self.lc1(relu)
wb = self.relu(self.lc2(lc_hidden))
bias = self.bias_pool(self.bias_acti(self.bias_lc(x)).permute(0, 2, 1))
predictions = wb + bias
batch_size, out_len = x.size(0), self.output_chunk_length
return predictions.view(batch_size, out_len, self.target_size, 1)
_rnn_cnn = RNNCNNModel(
"RNN-CNN",
input_size=len(sample.columns),
input_chunk_length=WINDOW_SIZE,
output_chunk_length=HORIZON_SIZE,
hidden_dim=128,
num_layers=4,
target_size=len(PRED_COLUMNS),
)
model = BlockRNNModel(
input_chunk_length=WINDOW_SIZE,
output_chunk_length=HORIZON_SIZE,
model=_rnn_cnn,
**GENERAL_MODEL_PARAMS,
)
from darts.models.forecasting.nbeats import _Block, _TrendGenerator, _Stack
class NBeatsRNNModule(PLPastCovariatesModule):
def __init__(
self,
name: str,
input_size: int,
hidden_dim: int,
num_layers: int,
target_size: int,
nr_params: int = None,
num_layers_out_fc: Optional[List] = None,
dropout: float = 0.0,
**kwargs,
) -> None:
pass
def forward(self, x: torch.Tensor):
"""
args:
- x: Tensor(batch_size, signal_length, channels)
"""
return
# ### Model training
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
model_name = (
f'{model.__class__.__name__.lower()}-{datetime.utcnow().strftime("%m%d-%H%M")}'
)
def init_trainer() -> pl.Trainer:
train_args = {}
# Allow GPU is cuda available
if torch.cuda.is_available():
train_args["accelerator"] = "gpu"
train_args["gpus"] = torch.cuda.device_count()
# Add early stopping strategy and controlled checkpoints to the trainer
es = pl.callbacks.early_stopping.EarlyStopping(
monitor="val_loss", min_delta=0.001, patience=100
)
check_point = pl.callbacks.ModelCheckpoint(
dirpath=f"./output/{model_name}", save_top_k=1, monitor="val_loss"
)
train_args["callbacks"] = [es, check_point]
# Set max_epochs and precision
train_args["max_epochs"] = EPOCH
train_args["precision"] = 32
# Create the trainer with kwargs
trainer = pl.Trainer(**train_args)
return trainer
trainer = init_trainer()
# #### Start training
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
model_path = f"./output/{model_name}"
if MODE_LOAD_MODEL:
model.train_sample, model.output_dim = train[0], train[0][-1].shape[1]
model._init_model(trainer)
model.model = model.model.load_from_checkpoint(NAME_LOAD_MODEL)
logging.info(f"Successfully load model from: {NAME_LOAD_MODEL}")
else:
if isinstance(model, ForecastingModel) and not getattr(
model, "__not_initialized__", False
):
GENERAL_MODEL_PARAMS.update(
{
"work_dir": model_path,
}
)
model = model.fit_from_dataset(
train_dataset=train, val_dataset=valid, trainer=trainer, epochs=EPOCH
)
else:
logging.error("Model not defined")
# #### Save the model as ONNX format for future use
if (
isinstance(model, ForecastingModel)
and not getattr(model, "__not_initialized__", False)
and not MODE_LOAD_MODEL
):
try:
model.model.to_onnx(
os.path.join(model_path, "model.onnx"),
(torch.Tensor(np.concatenate(test[0][:2], axis=-1)).unsqueeze(0)),
export_params=True,
input_names=["input"],
output_names=["output"],
opset_version=11,
dynamic_axes={"input": {0: "batch_size"}, "output": {0: "batch_size"}},
)
except RuntimeError:
logging.warning("Model not able to be saved as onnx format")
# ## Evaluation
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
evaluation_funcs = []
# Generated by assemble.py (evaluation)
evaluation_funcs = [darts.metrics.rmse, darts.metrics.r2_score]
# --------------------------
# Aggregation Functions
# Could be defined here
# --------------------------
def avg(x):
return sum(x) / len(x)
agg_methods = [avg, np.std]
# ### Get Predictions
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
def get_prediction_pairs(
model: ForecastingModel, test_set: PartialInferenceDataset
) -> List[Tuple[darts.TimeSeries, darts.TimeSeries, darts.TimeSeries]]:
tester = pl.Trainer(
False, enable_progress_bar=False, accelerator="cpu", max_epochs=1
)
res = []
for i in tqdm(range(len(test_set))):
ts_, cov, truth = test.get_ts_by_idx(i)
pred = model.predict(HORIZON_SIZE, ts_, cov, trainer=tester)
res.append((ts_, truth, pred))
return res
predictions = get_prediction_pairs(model, test)
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
eval_res = {}
evaluation_funcs.append(darts.metrics.mae)
for metric in evaluation_funcs:
func_name = metric.__name__
losses = []
eval_res[func_name] = {}
for _, truth, pred in predictions:
losses.append(metric(truth, pred))
for agg in agg_methods:
eval_res[func_name][agg.__name__] = agg(losses)
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
def plot_predictions(
predictions: List[Tuple[darts.TimeSeries, darts.TimeSeries, darts.TimeSeries]],
sample_size: int = 10,
):
if sample_size > len(predictions):
sample_size = len(predictions)
sample_size = sample_size or len(predictions)
import time
random.seed(time.time())
predictions = random.sample(predictions, sample_size)
for i, (past, truth, pred) in enumerate(predictions):
past.plot(new_plot=True, label="truth")
truth.plot(label="truth")
pred.plot(label="pred")
if not MODE_LOAD_MODEL:
plt.savefig(os.path.join(model_path, f"pred-{i}.png"))
if FIX_RANDOM:
random.seed(0)
# ## Conclusion
# ### 1. Show the results of the experiment
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
pp = PrettyPrinter(indent=2, width=80)
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
pp.pprint(eval_res)
# ### 2. Plot Typical Prediction Results
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
plot_predictions(predictions, sample_size=20)
# ### 3. Save Hyperparameters to yaml
if not MODE_LOAD_MODEL:
import yaml
hyper_params = {
"KEEP_MARKETS": KEEP_MARKETS,
"USE_FEATURE": USE_FEATURE,
"USE_DIFF": USE_DIFF,
"WINDOW_SIZE": WINDOW_SIZE,
"HORIZON_SIZE": HORIZON_SIZE,
"PRED_COLUMNS": PRED_COLUMNS,
"EPOCH": EPOCH,
"STRIDE": STRIDE,
"USE_DIFF": USE_DIFF,
"SLICE_NORM": SLICE_NORM,
"RANDOM_SPLIT": RANDOM_SPLIT,
"FIX_RANDOM": FIX_RANDOM,
"GENERAL_MODEL_PARAMS": GENERAL_MODEL_PARAMS,
}
hyper_params.update(model.model.hparams)
with open(os.path.join(model_path, "hyper-params.yml"), "w") as f:
yaml.dump(hyper_params, f)
with open(os.path.join(model_path, "result.txt"), "w") as f:
PrettyPrinter(indent=2, stream=f).pprint(eval_res)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0094/659/94659766.ipynb | null | null | [{"Id": 94659766, "ScriptId": 26185548, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1452696, "CreationDate": "05/03/2022 12:56:18", "VersionNumber": 11.0, "Title": "Experiment of Stock Price Prediction", "EvaluationDate": "05/03/2022", "IsChange": true, "TotalLines": 804.0, "LinesInsertedFromPrevious": 195.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 609.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | # # Pattern Recognition in Financial Market
# ## Initialization
# In this section, we initialize the environments with the following steps:
# 1. check all dependencies has been installed
# 2. if not installed, install the dependency with pip
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
# ### Common dependencies
# The following cell imports the dependencies required for the basic pipeline.
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
import os
import logging
import functools
import random
from datetime import datetime
from pprint import PrettyPrinter
from collections import OrderedDict
from typing import Tuple, Union, List, Iterable, Dict, Optional
import torch
import darts
import pandas as pd
import torch.nn as nn
import pytorch_lightning as pl
import matplotlib.pyplot as plt
from tqdm import tqdm
from darts.utils.missing_values import fill_missing_values, extract_subseries
from darts.utils.data import (
PastCovariatesTrainingDataset,
PastCovariatesInferenceDataset,
)
from darts.dataprocessing.transformers.scaler import Scaler
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s [%(levelname)s] line %(lineno)s, %(funcName)s: %(message)s",
)
os.makedirs("./output", exist_ok=True)
# ### Feature-model-specific dependencies
# The following cell imports the dependencies required for the feature engineering and for the algorithms. For instance, Pytorch for the RNN-CNN-based model.
# Generated by assemble.py (imports)
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import talib
import pandas as pd
# #### General Parameters
# --------------------------
# MODIFY CAREFULLY BASED ON RESPECITIVE USAGE!
# --------------------------
# Preprocessing Parameters
# -------------------------------------------------------------------------------------------------------------
# - GAP_SIZE: Remove weekend, holiday gaps with GAP_SIZE.
# Usually on weekends, data does not change, hence weekend time slot has no meaning
# Since most weekend gaps is ~48, GAP_SIZE is default as 40.
GAP_SIZE = 40
# - KEEP_MARKETS: A set containing the expected markets for testing. It could be left empty for using all markets.
# Each item is a string which could be a part of the market name,
# e.g. `Australia` for Australia 200 Cash -2022-04-26.csv
KEEP_MARKETS = ["Australia"]
# -------------------------------------------------------------------------------------------------------------
# Feature Engineering Parameters
# -------------------------------------------------------------------------------------------------------------
# - USE_FEATURE: whether to calculate features from the original dataset, default `True`.
USE_FEATURE = True
# -------------------------------------------------------------------------------------------------------------
# Model Parameters
# -------------------------------------------------------------------------------------------------------------
# - WINDOW_SIZE, HORIZON_SIZE: Determine the window and horizon for prediction, use window to predict horizon,
# e.g. window(10:00-16:00) --predict-> horizon(16:00-18:00),
# with WINDOW_SIZE as 6 and HORIZON_SIZE as 2
WINDOW_SIZE, HORIZON_SIZE = 64, 16
# - PRED_COLUMNS: the column(s) to be predicted by the model, usually `bid_close` or `ask_close`.
PRED_COLUMNS = ["bid_close"]
# - EPOCHS: the number of times to iterate on the dataset, default as 10
EPOCH = 300
# - STRIDE: the spacing of sampling steps. For instance, stride=1 means that slices will be like
# [(9:00-11:00), (10:00-12:00), ..., (22:00-24:00)]
# It could be set to `1` for full sampling, `HORIZON_SIZE` for prediction-covering sampling, and
# `WINDOW_SIZE+HORIZON_SIZE` for non-overlapping sampling
STRIDE = 1
# - USE_DIFF: whether to predict the difference instead of predicting the price itself, default `False`
USE_DIFF = False
# - SLICE_NORM: whether to normalize a slice to (0,1) based on window,
# the same scale is applied to the horizon as well, default `False`
SLICE_NORM = False
# - RANDOM_SPLIT: whether to split data randomly,
# if True, a slice(a pair of window & horizon) is randomly assigned to train/valid/test set;
# else, a slice is assigned to train/valid/test by its starting time;
RANDOM_SPLIT = False
# - FIX_RANDOM: whether to fix the random seed for fixed dataset split indices.
FIX_RANDOM = False
if FIX_RANDOM:
random.seed(0)
# - GENERAL_MODEL_PARAMS: general parameters for initialising the model, only modify the value when using
GENERAL_MODEL_PARAMS = {
"loss_fn": nn.MSELoss(),
"optimizer_cls": torch.optim.SGD,
"optimizer_kwargs": {"lr": 2e-3, "momentum": 0.5},
"lr_scheduler_cls": torch.optim.lr_scheduler.ReduceLROnPlateau,
"lr_scheduler_kwargs": {"factor": 0.5},
}
# -------------------------------------------------------------------------------------------------------------
# Pipeline Parameters
# -------------------------------------------------------------------------------------------------------------
# - MODE_LOAD_MODEL: whether to load model for prediction instead of training from scratch.
# if true, will not train model, the path of the model should be specified as well.
# if false, will train model
MODE_LOAD_MODEL = False
NAME_LOAD_MODEL = "./output/blockrnnmodel-0501-0601/epoch=74-step=9075.ckpt"
# ## Preprocessing
# Preprocessing in vital for the algorithms and features to work. The preprocessing step includes:
# 1. copy the data into designated folder and read it.
# 2. clean up missing values and outliers in the time-series data.
# ### Stage 1. Read data
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
DATA_SOURCE = "./data"
KAGGLE_DATASET_SOURCE = "../input/stock-indices-202103-202202"
if os.path.exists(DATA_SOURCE) and all(
fname.endswith(".csv") for fname in os.listdir(DATA_SOURCE)
):
logging.info(
f'Data already loaded into designated folder: [{", ".join(os.listdir(DATA_SOURCE)[:5])} ...]'
)
else:
DATA_SOURCE = KAGGLE_DATASET_SOURCE
logging.info(
f'Data copied into designated folder: [{", ".join(os.listdir(DATA_SOURCE)[:5])} ...]'
)
# #### Read Data
# Use pandas to read data
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
raw_data = OrderedDict()
def remove_gaps(ts: darts.TimeSeries) -> darts.TimeSeries:
tss = extract_subseries(ts, min_gap_size=GAP_SIZE)
return functools.reduce(lambda x, y: x.concatenate(y, ignore_time_axes=True), tss)
for fname in os.listdir(DATA_SOURCE):
if fname.endswith(".csv"):
market = fname[:-20].strip()
if KEEP_MARKETS and not any(i in market for i in KEEP_MARKETS):
continue
try:
ts = darts.TimeSeries.from_csv(
os.path.join(DATA_SOURCE, fname), time_col="time", freq="H"
)
raw_data[market] = remove_gaps(ts).pd_dataframe()
except:
logging.warning(f"{market} with incompatible data, skipping")
else:
logging.warning(f"unsupported file exists in data folder: {fname}")
logging.info(f'Testing markets: [{", ".join(raw_data.keys())}]')
# ### Stage 2. Missing value / outlier processing / normalisation
# If missing values are used in the prediction, it would cause the calculation of the error to become NaN. The missing values would be filled by two methods:
# 1. For prices, it would be filled by forefill method which use most-recent data on the left side. The consideration is that in this part, the
# 2. For volumes, average of a window is used to fill-in.
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
preprocessing_funcs = []
# Generated by assemble.py (preprocessing)
def normalize(df: pd.DataFrame) -> pd.DataFrame:
scaler = MinMaxScaler(feature_range=(0, 1))
scale_cols = list(filter(lambda x: "volume" not in x, df.columns))
df[scale_cols] = scaler.fit_transform(df[scale_cols])
return df
def volume_fillna(df: pd.DataFrame) -> pd.DataFrame:
fill_cols = list(filter(lambda x: "volume" not in x, df.columns))
df[fill_cols] = df[fill_cols].fillna(0.0)
return df
preprocessing_funcs = [normalize]
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
for market, df in raw_data.items():
for func in preprocessing_funcs:
raw_data[market] = func(df)
# ## Feature engineering
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
feature_funcs = []
# Generated by assemble.py (features)
def get_talib_overlap(df: pd.DataFrame) -> pd.DataFrame:
high = (df["bid_high"] + df["ask_high"]) / 2
low = (df["bid_low"] + df["ask_low"]) / 2
close = (df["bid_close"] + df["ask_close"]) / 2
open_ = (df["bid_open"] + df["ask_open"]) / 2
volume = df["last_volume"]
(
df["BBANDS.up.5.2.2"],
df["BBANDS.mid.5.2.2"],
df["BBANDS.low.5.2.2"],
) = talib.BBANDS(close, timeperiod=5, nbdevup=2, nbdevdn=2, matype=0)
df["DMA.30"] = talib.DEMA(close, timeperiod=30)
df["EMA.30"] = talib.EMA(close, timeperiod=30)
df["HT_TRENDLINE"] = talib.HT_TRENDLINE(close)
df["KAMA.30"] = talib.KAMA(close, timeperiod=30)
df["MA.30"] = talib.MA(close, timeperiod=30, matype=0)
df["MAMA.ma"], df["MAMA.fa"] = talib.MAMA(close)
df["MIDPOINT.14"] = talib.MIDPOINT(close, timeperiod=14)
df["MIDPRICE.14"] = talib.MIDPRICE(high, low, timeperiod=14)
df["SAR"] = talib.SAR(high, low, acceleration=0, maximum=0)
df["SAREXT"] = talib.SAREXT(
high,
low,
startvalue=0,
offsetonreverse=0,
accelerationinitlong=0,
accelerationlong=0,
accelerationmaxlong=0,
accelerationinitshort=0,
accelerationshort=0,
accelerationmaxshort=0,
)
df["SMA.30"] = talib.SMA(close, timeperiod=30)
df["T3.5"] = talib.T3(close, timeperiod=5, vfactor=0)
df["TEMA.30"] = talib.TEMA(close, timeperiod=30)
df["T3.5"] = talib.T3(close, timeperiod=5, vfactor=0)
df["TRIMA.30"] = talib.TRIMA(close, timeperiod=30)
df["WMA.30"] = talib.WMA(close, timeperiod=30)
df["ADX.14"] = talib.ADX(high, low, close, timeperiod=14)
df["ADXR.14"] = talib.ADXR(high, low, close, timeperiod=14)
df["APO.12.26"] = talib.APO(close, fastperiod=12, slowperiod=26, matype=0)
df["AROON.down.14"], df["AROON.up.14"] = talib.AROON(high, low, timeperiod=14)
df["AROONOSC.14"] = talib.AROONOSC(high, low, timeperiod=14)
df["BOP"] = talib.BOP(open_, high, low, close)
df["CCI.14"] = talib.CCI(high, low, close, timeperiod=14)
df["CMO.14"] = talib.CMO(close, timeperiod=14)
df["DX.14"] = talib.DX(high, low, close, timeperiod=14)
df["MACD.12.26"], df["MACD.12.26.sig"], df["MACD.12.26.hist"] = talib.MACD(
close, fastperiod=12, slowperiod=26, signalperiod=9
)
(
df["MACDEXT.12.26"],
df["MACDEXT.12.26.sig"],
df["MACDEXT.12.26.hist"],
) = talib.MACDEXT(
close,
fastperiod=12,
fastmatype=0,
slowperiod=26,
slowmatype=0,
signalperiod=9,
signalmatype=0,
)
(
df["MACDFIX.12.26"],
df["MACDFIX.12.26.sig"],
df["MACDFIX.12.26.hist"],
) = talib.MACDFIX(close, signalperiod=9)
df["MFI.14"] = talib.MFI(high, low, close, volume, timeperiod=14)
df["MINUS_DI.14"] = talib.MINUS_DI(high, low, close, timeperiod=14)
df["MINUS_DM.14"] = talib.MINUS_DM(high, low, timeperiod=14)
df["MOM.10"] = talib.MOM(close, timeperiod=10)
df["PLUS_DI.14"] = talib.PLUS_DI(high, low, close, timeperiod=14)
df["PLUS_DM.14"] = talib.PLUS_DM(high, low, timeperiod=14)
df["PPO.12.26"] = talib.PPO(close, fastperiod=12, slowperiod=26, matype=0)
df["ROC.10"] = talib.ROC(close, timeperiod=10)
df["ROCP.10"] = talib.ROCP(close, timeperiod=10)
df["ROCR.10"] = talib.ROCR(close, timeperiod=10)
df["ROCR100.10"] = talib.ROCR100(close, timeperiod=10)
df["RSI.14"] = talib.RSI(close, timeperiod=14)
df["STOCH.5.3.k"], df["STOCH.5.3.d"] = talib.STOCH(
high,
low,
close,
fastk_period=5,
slowk_period=3,
slowk_matype=0,
slowd_period=3,
slowd_matype=0,
)
df["STOCHF.5.3.k"], df["STOCHF.5.3.d"] = talib.STOCHF(
high, low, close, fastk_period=5, fastd_period=3, fastd_matype=0
)
df["STOCHRSI.5.3.k"], df["STOCHRSI.5.3.d"] = talib.STOCHRSI(
close, timeperiod=14, fastk_period=5, fastd_period=3, fastd_matype=0
)
df["TRIX.30"] = talib.TRIX(close, timeperiod=30)
df["ULTOSC.7.14.28"] = talib.ULTOSC(
high, low, close, timeperiod1=7, timeperiod2=14, timeperiod3=28
)
df["WILLR.14"] = talib.WILLR(high, low, close, timeperiod=14)
return df
feature_funcs = [get_talib_overlap]
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
if USE_FEATURE:
for market, df in raw_data.items():
for func in feature_funcs:
raw_data[market] = func(df)
# ## Prediction Models
# #### Convert data to time series
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
time_series = OrderedDict()
for market, df in raw_data.items():
ts = darts.timeseries.TimeSeries.from_dataframe(df, freq="1h")
if USE_DIFF:
ts = fill_missing_values(ts).diff(dropna=False)
time_series[market] = fill_missing_values(ts).astype(np.float32)
sample = time_series.values().__iter__().__next__()
# ### Creating train set, validation set and test set
# Since the dataset is rolling window based and behaves based on the model parameters, it should be split here.
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
class MarketDataset:
def __init__(
self,
data: Dict[str, darts.TimeSeries],
target_cols: Union[str, List[str]],
random_: bool = False,
window_size: int = WINDOW_SIZE,
horizon_size: int = HORIZON_SIZE,
stride: int = 1,
test_ratio: float = 0.25,
valid_ratio: float = 0.1,
) -> None:
super().__init__()
self.scaler = Scaler(MinMaxScaler())
self.rand = random_
self.window, self.horizon = window_size, horizon_size
self.data = data
self._init_ts_cov(target_cols)
self._build_indices(data, stride)
self._train_test_split(test_ratio, valid_ratio)
self._gen_idx_map()
def _init_ts_cov(self, target: Union[str, List[str]]) -> None:
sample = self.data.values().__iter__().__next__()
cols = set(sample.columns)
if isinstance(target, str) and target in set(ts.columns):
cols.remove(target)
target = [target]
elif isinstance(target, Iterable):
cols = cols.difference(target)
else:
raise ValueError(f"target time series has no column: {target}")
self.pred, self.covs = target, list(cols)
def _get_series_and_covariates(
self, ts: darts.TimeSeries
) -> Tuple[darts.TimeSeries, darts.TimeSeries]:
return ts[self.pred], ts[self.covs]
def _build_indices(self, data: Dict[str, darts.TimeSeries], stride: int) -> None:
rolling = self.window + self.horizon
indices = {}
for market, ts in data.items():
length = len(ts)
if length < rolling:
logging.error(
f"{market} does not have the length for the dataset, \
length is {length}, but should be larger than {rolling}"
)
elif stride > length - rolling:
logging.warning(
f"For {market}, stride({stride}) is bigger than a rolling window, will instead use {rolling}"
)
stride = rolling
indices[market] = set(range(0, length - rolling, stride))
self.indices = indices
def _train_test_split(
self, test_ratio: float = 0.25, valid_ratio: float = 0.1
) -> None:
train, test, valid = {}, {}, {}
# split dataset by market
for market, index in self.indices.items():
if self.rand:
_test = set(random.sample(index, int(len(index) * test_ratio)))
train_val = index.difference(test)
_valid = set(random.sample(train_val, int(len(index) * valid_ratio)))
_train = train_val.difference(_valid)
else: # traditional split method by entire segment slicing
idx_len, idx_sorted = len(index), sorted(index)
train_valid_boundary, valid_test_boundary = (
int(idx_len * (1 - valid_ratio - test_ratio)),
int(idx_len * (1 - valid_ratio)),
)
_train, _valid, _test = (
idx_sorted[:train_valid_boundary],
idx_sorted[train_valid_boundary:valid_test_boundary],
idx_sorted[valid_test_boundary:],
)
train[market], test[market], valid[market] = _train, _test, _valid
self.train, self.test, self.valid = train, test, valid
def _gen_idx_map(self):
def get_map(idx_dict: Dict[str, set]) -> Dict[int, Tuple[str, int]]:
count, res = 0, {}
for market, indices in idx_dict.items():
for idx in indices:
res[count] = (market, idx)
count += 1
return res
self._idx_map = {}
self._idx_map["train"] = get_map(self.train)
self._idx_map["test"] = get_map(self.test)
self._idx_map["valid"] = get_map(self.valid)
def inspect_dataset(self):
return (
self.indices,
(self.pred, self.covs),
self._idx_map,
{"train": self.train, "test": self.test, "valid": self.valid},
)
@functools.lru_cache()
def get_len(self, type_: str) -> int:
return len(self._idx_map[type_])
@functools.lru_cache(maxsize=None)
def get_sample(
self, idx: int, type_: str
) -> Tuple[darts.TimeSeries, darts.TimeSeries, darts.TimeSeries]:
market, start = self._idx_map[type_][idx]
ts = self.data[market]
window, horizon = start + self.window, start + self.window + self.horizon
slice = ts[start:window]
past, covs, truth = (
slice[self.pred],
slice[self.covs],
ts[window:horizon][self.pred],
)
if SLICE_NORM:
past = self.scaler.fit_transform(past)
truth = self.scaler.transform(truth)
return past, covs, truth
class PartialDataset(PastCovariatesTrainingDataset):
TRAIN, TEST, VALID = TYPES = ("train", "test", "valid")
def __init__(self, real_dataset: MarketDataset, type_: str) -> None:
super().__init__()
assert (
type_ in self.TYPES
), f"Type must be either of `train, test, valid` but {type_} was given"
self.type_ = type_
self.real_dataset = real_dataset
def __len__(self):
return self.real_dataset.get_len(self.type_)
def __getitem__(self, idx: int) -> Tuple[np.ndarray, np.ndarray, np.ndarray]:
return tuple(i.values() for i in self.real_dataset.get_sample(idx, self.type_))
class PartialInferenceDataset(PastCovariatesInferenceDataset):
def __init__(self, real_dataset: MarketDataset) -> None:
self.type_ = "test"
self.real_dataset = real_dataset
def __len__(self):
return self.real_dataset.get_len(self.type_)
def __getitem__(
self, idx: int
) -> Tuple[
np.ndarray, Optional[np.ndarray], Optional[np.ndarray], darts.TimeSeries
]:
past, covs, target = self.real_dataset.get_sample(idx, self.type_)
return past.values(), covs.values(), None, target
def get_ts_by_idx(
self, idx: int
) -> Tuple[darts.TimeSeries, darts.TimeSeries, darts.TimeSeries]:
return self.real_dataset.get_sample(idx, self.type_)
# Initialize the dataset
dataset = MarketDataset(
time_series, target_cols=PRED_COLUMNS, stride=STRIDE, random_=RANDOM_SPLIT
)
train = PartialDataset(dataset, PartialDataset.TRAIN)
valid = PartialDataset(dataset, PartialDataset.VALID)
test = PartialInferenceDataset(dataset)
# ### Model instantiating
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
from darts.models import NaiveDrift
from darts.models.forecasting.forecasting_model import ForecastingModel
model = NaiveDrift()
model.__not_initialized__ = True
# Generated by assemble.py (models)
from typing import List, Optional
from darts.models import BlockRNNModel
from darts.models.forecasting.pl_forecasting_module import PLPastCovariatesModule
import torch
import torch.nn as nn
class _ResidualBlock(nn.Module):
def __init__(self, input_dim: int, output_dim: int = None) -> None:
super(_ResidualBlock, self).__init__()
output_dim = output_dim or input_dim
self.cnn = nn.Conv1d(input_dim, output_dim, kernel_size=3, padding="same")
self.relu = nn.ReLU()
self.bn = nn.BatchNorm1d(output_dim)
def forward(self, x: torch.Tensor):
"""
args:
- x: Tensor(batch_size, signal_length, channels)
"""
residual = x
x = x.permute(0, 2, 1)
conv = self.cnn(x)
bn = self.bn(conv)
act = self.relu(bn)
act = act.permute(0, 2, 1)
return self.relu(act + residual)
@classmethod
def build_residual(
cls, input_dim: int, output_dim: int = None, block_nums: int = 4
) -> nn.Sequential:
blocks = [nn.Linear(input_dim, output_dim)]
for _ in range(block_nums - 1):
blocks.append(_ResidualBlock(output_dim, output_dim))
return nn.Sequential(*blocks)
class RNNCNNModel(PLPastCovariatesModule):
def __init__(
self,
name: str,
input_size: int,
hidden_dim: int,
num_layers: int,
target_size: int,
nr_params: int = None,
num_layers_out_fc: Optional[List] = None,
dropout: float = 0.0,
**kwargs,
) -> None:
super(RNNCNNModel, self).__init__(**kwargs)
self.name = name or "RNN-CNN"
self.target_size = target_size
self.lc_hidden_dim = 1024
self.residual = _ResidualBlock.build_residual(input_size, hidden_dim)
self.enc = nn.LSTM(input_size, hidden_dim, num_layers, dropout=dropout)
self.relu = nn.ReLU()
self.dec = nn.LSTM(hidden_dim * 2, hidden_dim, num_layers, dropout=dropout)
self.lc1 = nn.Linear(hidden_dim, self.lc_hidden_dim)
self.lc2 = nn.Linear(self.lc_hidden_dim, target_size, bias=False)
self.bias_lc = nn.Linear(input_size, target_size)
self.bias_acti = nn.Hardsigmoid()
self.bias_pool = nn.AdaptiveMaxPool1d(1)
def forward(self, x: torch.Tensor):
"""
args:
- x: Tensor(batch_size, signal_length, channels)
"""
# encoding
conv = self.residual(x)
recr, _ = self.enc(x)
hidden = self.relu(torch.cat((conv, recr), dim=-1))
# decoding
out, _ = self.dec(hidden)
relu = self.relu(out[:, : self.output_chunk_length, :])
lc_hidden = self.lc1(relu)
wb = self.relu(self.lc2(lc_hidden))
bias = self.bias_pool(self.bias_acti(self.bias_lc(x)).permute(0, 2, 1))
predictions = wb + bias
batch_size, out_len = x.size(0), self.output_chunk_length
return predictions.view(batch_size, out_len, self.target_size, 1)
_rnn_cnn = RNNCNNModel(
"RNN-CNN",
input_size=len(sample.columns),
input_chunk_length=WINDOW_SIZE,
output_chunk_length=HORIZON_SIZE,
hidden_dim=128,
num_layers=4,
target_size=len(PRED_COLUMNS),
)
model = BlockRNNModel(
input_chunk_length=WINDOW_SIZE,
output_chunk_length=HORIZON_SIZE,
model=_rnn_cnn,
**GENERAL_MODEL_PARAMS,
)
from darts.models.forecasting.nbeats import _Block, _TrendGenerator, _Stack
class NBeatsRNNModule(PLPastCovariatesModule):
def __init__(
self,
name: str,
input_size: int,
hidden_dim: int,
num_layers: int,
target_size: int,
nr_params: int = None,
num_layers_out_fc: Optional[List] = None,
dropout: float = 0.0,
**kwargs,
) -> None:
pass
def forward(self, x: torch.Tensor):
"""
args:
- x: Tensor(batch_size, signal_length, channels)
"""
return
# ### Model training
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
model_name = (
f'{model.__class__.__name__.lower()}-{datetime.utcnow().strftime("%m%d-%H%M")}'
)
def init_trainer() -> pl.Trainer:
train_args = {}
# Allow GPU is cuda available
if torch.cuda.is_available():
train_args["accelerator"] = "gpu"
train_args["gpus"] = torch.cuda.device_count()
# Add early stopping strategy and controlled checkpoints to the trainer
es = pl.callbacks.early_stopping.EarlyStopping(
monitor="val_loss", min_delta=0.001, patience=100
)
check_point = pl.callbacks.ModelCheckpoint(
dirpath=f"./output/{model_name}", save_top_k=1, monitor="val_loss"
)
train_args["callbacks"] = [es, check_point]
# Set max_epochs and precision
train_args["max_epochs"] = EPOCH
train_args["precision"] = 32
# Create the trainer with kwargs
trainer = pl.Trainer(**train_args)
return trainer
trainer = init_trainer()
# #### Start training
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
model_path = f"./output/{model_name}"
if MODE_LOAD_MODEL:
model.train_sample, model.output_dim = train[0], train[0][-1].shape[1]
model._init_model(trainer)
model.model = model.model.load_from_checkpoint(NAME_LOAD_MODEL)
logging.info(f"Successfully load model from: {NAME_LOAD_MODEL}")
else:
if isinstance(model, ForecastingModel) and not getattr(
model, "__not_initialized__", False
):
GENERAL_MODEL_PARAMS.update(
{
"work_dir": model_path,
}
)
model = model.fit_from_dataset(
train_dataset=train, val_dataset=valid, trainer=trainer, epochs=EPOCH
)
else:
logging.error("Model not defined")
# #### Save the model as ONNX format for future use
if (
isinstance(model, ForecastingModel)
and not getattr(model, "__not_initialized__", False)
and not MODE_LOAD_MODEL
):
try:
model.model.to_onnx(
os.path.join(model_path, "model.onnx"),
(torch.Tensor(np.concatenate(test[0][:2], axis=-1)).unsqueeze(0)),
export_params=True,
input_names=["input"],
output_names=["output"],
opset_version=11,
dynamic_axes={"input": {0: "batch_size"}, "output": {0: "batch_size"}},
)
except RuntimeError:
logging.warning("Model not able to be saved as onnx format")
# ## Evaluation
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
evaluation_funcs = []
# Generated by assemble.py (evaluation)
evaluation_funcs = [darts.metrics.rmse, darts.metrics.r2_score]
# --------------------------
# Aggregation Functions
# Could be defined here
# --------------------------
def avg(x):
return sum(x) / len(x)
agg_methods = [avg, np.std]
# ### Get Predictions
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
def get_prediction_pairs(
model: ForecastingModel, test_set: PartialInferenceDataset
) -> List[Tuple[darts.TimeSeries, darts.TimeSeries, darts.TimeSeries]]:
tester = pl.Trainer(
False, enable_progress_bar=False, accelerator="cpu", max_epochs=1
)
res = []
for i in tqdm(range(len(test_set))):
ts_, cov, truth = test.get_ts_by_idx(i)
pred = model.predict(HORIZON_SIZE, ts_, cov, trainer=tester)
res.append((ts_, truth, pred))
return res
predictions = get_prediction_pairs(model, test)
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
eval_res = {}
evaluation_funcs.append(darts.metrics.mae)
for metric in evaluation_funcs:
func_name = metric.__name__
losses = []
eval_res[func_name] = {}
for _, truth, pred in predictions:
losses.append(metric(truth, pred))
for agg in agg_methods:
eval_res[func_name][agg.__name__] = agg(losses)
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
def plot_predictions(
predictions: List[Tuple[darts.TimeSeries, darts.TimeSeries, darts.TimeSeries]],
sample_size: int = 10,
):
if sample_size > len(predictions):
sample_size = len(predictions)
sample_size = sample_size or len(predictions)
import time
random.seed(time.time())
predictions = random.sample(predictions, sample_size)
for i, (past, truth, pred) in enumerate(predictions):
past.plot(new_plot=True, label="truth")
truth.plot(label="truth")
pred.plot(label="pred")
if not MODE_LOAD_MODEL:
plt.savefig(os.path.join(model_path, f"pred-{i}.png"))
if FIX_RANDOM:
random.seed(0)
# ## Conclusion
# ### 1. Show the results of the experiment
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
pp = PrettyPrinter(indent=2, width=80)
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
pp.pprint(eval_res)
# ### 2. Plot Typical Prediction Results
# --------------------------
# DO NOT MODIFY!!!
# --------------------------
plot_predictions(predictions, sample_size=20)
# ### 3. Save Hyperparameters to yaml
if not MODE_LOAD_MODEL:
import yaml
hyper_params = {
"KEEP_MARKETS": KEEP_MARKETS,
"USE_FEATURE": USE_FEATURE,
"USE_DIFF": USE_DIFF,
"WINDOW_SIZE": WINDOW_SIZE,
"HORIZON_SIZE": HORIZON_SIZE,
"PRED_COLUMNS": PRED_COLUMNS,
"EPOCH": EPOCH,
"STRIDE": STRIDE,
"USE_DIFF": USE_DIFF,
"SLICE_NORM": SLICE_NORM,
"RANDOM_SPLIT": RANDOM_SPLIT,
"FIX_RANDOM": FIX_RANDOM,
"GENERAL_MODEL_PARAMS": GENERAL_MODEL_PARAMS,
}
hyper_params.update(model.model.hparams)
with open(os.path.join(model_path, "hyper-params.yml"), "w") as f:
yaml.dump(hyper_params, f)
with open(os.path.join(model_path, "result.txt"), "w") as f:
PrettyPrinter(indent=2, stream=f).pprint(eval_res)
| false | 0 | 9,038 | 0 | 6 | 9,038 |
||
94040247 | <kaggle_start><data_title>kenh14-small<data_name>kenh14small
<code>import yaml
import os
import abc
import time
import numpy as np
import tensorflow as tf
import tensorflow.keras as keras
import pandas as pd
import pickle
import random
import re
from tqdm import tqdm
from tensorflow.keras import layers
from tensorflow.keras import backend as K
from collections import namedtuple
# detect and init the TPU
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
# instantiate a distribution strategy
tpu_strategy = tf.distribute.experimental.TPUStrategy(tpu)
def load_yaml(filename):
"""Load yaml file
Args:
filename
Returns:
dict
"""
try:
with open(filename, "r") as f:
config = yaml.load(f, yaml.SafeLoader)
return config
except FileNotFoundError:
raise
except Exception as e:
raise IOError(f"load {filename} error!")
def flat_config(config):
"""Flat config load tu yaml file to flat dict
Args:
config (dict): config load tu yaml file
Returns:
dict
"""
f_config = {}
category = config.keys()
for cate in category:
for key, val in config[cate].items():
f_config[key] = val
return f_config
def check_type(config):
int_parameters = [
"word_size",
"his_size",
"title_size",
"body_size",
"npratio",
"word_emb_dim",
"attention_hidden_dim",
"epochs",
"batch_size",
"show_step",
"save_epoch",
"head_num",
"head_dim",
"user_num",
"filter_num",
"window_size",
"gru_unit",
"user_emb_dim",
"vert_emb_dim",
"subvert_emb_dim",
]
for param in int_parameters:
if param in config and not isinstance(config[param], int):
raise TypeError("Parameters {0} must be int".format(param))
float_parameters = ["learning_rate", "dropout"]
for param in float_parameters:
if param in config and not isinstance(config[param], float):
raise TypeError("Parameters {0} must be float".format(param))
str_parameters = [
"wordEmb_file",
"wordDict_file",
"userDict_file",
"vertDict_file",
"subvertDict_file",
"method",
"loss",
"optimizer",
"cnn_activation",
"dense_activation" "type",
]
for param in str_parameters:
if param in config and not isinstance(config[param], str):
raise TypeError("Parameters {0} must be str".format(param))
list_parameters = ["layer_sizes", "activation"]
for param in list_parameters:
if param in config and not isinstance(config[param], list):
raise TypeError("Parameters {0} must be list".format(param))
bool_parameters = ["support_quick_scoring"]
for param in bool_parameters:
if param in config and not isinstance(config[param], bool):
raise TypeError("Parameters {0} must be bool".format(param))
def check_nn_config(f_config):
"""Check neural net config
Args:
f_config (dict): file config duoc flat tu yaml file
Raises:
ValueError: Neu params bi sai -> Raise error
"""
if f_config["model_type"] in ["nrms", "NRMS"]:
required_parameters = [
"title_size",
"his_size",
"wordEmb_file",
"wordDict_file",
"userDict_file",
"npratio",
"data_format",
"word_emb_dim",
"head_num",
"head_dim",
"attention_hidden_dim",
"loss",
"data_format",
"dropout",
]
else:
required_parameters = []
# check
for param in required_parameters:
if param not in f_config:
raise ValueError("Parameter {0} must be set!".format(param))
if f_config["model_type"] in ["nrms", "NRMS"]:
if f_config["data_format"] != "news":
raise ValueError(
"Voi NRMS model, dataformat phai la news, dua cai {0} vao lam gi".format(
f_config["data_format"]
)
)
check_type(f_config)
def get_hparams(**kwargs):
return namedtuple("GenericDict", kwargs.keys())(**kwargs)
def create_hparams(flags):
"""Create model's params
Args:
flags (dict): Dict co requirement
Returns:
object: namedtuple
"""
return get_hparams(
# data
data_format=flags.get("data_format", None),
iterator_type=flags.get("iterator_type", None),
support_quick_scoring=flags.get("support_quick_scoring", False),
wordEmb_file=flags.get("wordEmb_file", None),
wordDict_file=flags.get("wordDict_file", None),
userDict_file=flags.get("userDict_file", None),
vertDict_file=flags.get("vertDict_file", None),
subvertDict_file=flags.get("subvertDict_file", None),
# models
title_size=flags.get("title_size", None),
body_size=flags.get("body_size", None),
word_emb_dim=flags.get("word_emb_dim", None),
word_size=flags.get("word_size", None),
user_num=flags.get("user_num", None),
vert_num=flags.get("vert_num", None),
subvert_num=flags.get("subvert_num", None),
his_size=flags.get("his_size", None),
npratio=flags.get("npratio"),
dropout=flags.get("dropout", 0.0),
attention_hidden_dim=flags.get("attention_hidden_dim", 200),
# nrms
head_num=flags.get("head_num", 4),
head_dim=flags.get("head_dim", 100),
# train
learning_rate=flags.get("learning_rate", 0.001),
loss=flags.get("loss", None),
optimizer=flags.get("optimizer", "adam"),
epochs=flags.get("epochs", 10),
batch_size=flags.get("batch_size", 1),
# show info
show_step=flags.get("show_step", 1),
metrics=flags.get("metrics", None),
)
def prepare_hparams(yaml_file=None, **kwargs):
"""Prepare hyperparams and make sure it's ok
Args:
yaml_file: path to yaml file
Returns:
TF Hyperparams object (tf.contrib.training.HParams)
"""
if yaml_file is not None:
config = load_yaml(yaml_file)
config = flat_config(config)
else:
config = {}
config.update(kwargs)
check_nn_config(config)
return create_hparams(config)
yaml_file = "/kaggle/input/kenh14small/nrms.yaml"
wordEmb_file = "/kaggle/input/mindlike-final/embedding.npy"
wordDict_file = "/kaggle/input/mindlike-final/word_dict.pkl"
userDict_file = "/kaggle/input/mindlike-final/uid2index.pkl"
epochs = 1
seed = 42
batch_size = 1024
hparams = prepare_hparams(
yaml_file,
his_size=25,
wordEmb_file=wordEmb_file,
wordDict_file=wordDict_file,
userDict_file=userDict_file,
batch_size=batch_size,
epochs=epochs,
show_step=10,
)
print(hparams)
from sklearn.metrics import (
roc_auc_score,
log_loss,
mean_squared_error,
accuracy_score,
f1_score,
)
def mrr_score(y_true, y_score):
"""Computing mrr score metric.
Args:
y_true (np.ndarray): Ground-truth labels.
y_score (np.ndarray): Predicted labels.
Returns:
numpy.ndarray: mrr scores.
"""
order = np.argsort(y_score)[::-1]
y_true = np.take(y_true, order)
rr_score = y_true / (np.arange(len(y_true)) + 1)
return np.sum(rr_score) / np.sum(y_true)
def ndcg_score(y_true, y_score, k=10):
"""Computing ndcg score metric at k.
Args:
y_true (np.ndarray): Ground-truth labels.
y_score (np.ndarray): Predicted labels.
Returns:
numpy.ndarray: ndcg scores.
"""
best = dcg_score(y_true, y_true, k)
actual = dcg_score(y_true, y_score, k)
return actual / best
def hit_score(y_true, y_score, k=10):
"""Computing hit score metric at k.
Args:
y_true (np.ndarray): ground-truth labels.
y_score (np.ndarray): predicted labels.
Returns:
np.ndarray: hit score.
"""
ground_truth = np.where(y_true == 1)[0]
argsort = np.argsort(y_score)[::-1][:k]
for idx in argsort:
if idx in ground_truth:
return 1
return 0
def dcg_score(y_true, y_score, k=10):
"""Computing dcg score metric at k.
Args:
y_true (np.ndarray): Ground-truth labels.
y_score (np.ndarray): Predicted labels.
Returns:
np.ndarray: dcg scores.
"""
k = min(np.shape(y_true)[-1], k)
order = np.argsort(y_score)[::-1]
y_true = np.take(y_true, order[:k])
gains = 2**y_true - 1
discounts = np.log2(np.arange(len(y_true)) + 2)
return np.sum(gains / discounts)
def cal_metric(labels, preds, metrics):
print(labels)
print(preds)
"""Calculate metrics.
Available options are: `auc`, `rmse`, `logloss`, `acc` (accurary), `f1`, `mean_mrr`,
`ndcg` (format like: ndcg@2;4;6;8), `hit` (format like: hit@2;4;6;8), `group_auc`.
Args:
labels (array-like): Labels.
preds (array-like): Predictions.
metrics (list): List of metric names.
Return:
dict: Metrics.
Examples:
>>> cal_metric(labels, preds, ["ndcg@2;4;6", "group_auc"])
{'ndcg@2': 0.4026, 'ndcg@4': 0.4953, 'ndcg@6': 0.5346, 'group_auc': 0.8096}
"""
res = {}
for metric in metrics:
if metric == "auc":
auc = roc_auc_score(np.asarray(labels), np.asarray(preds))
res["auc"] = round(auc, 4)
elif metric == "rmse":
rmse = mean_squared_error(np.asarray(labels), np.asarray(preds))
res["rmse"] = np.sqrt(round(rmse, 4))
elif metric == "logloss":
# avoid logloss nan
preds = [max(min(p, 1.0 - 10e-12), 10e-12) for p in preds]
logloss = log_loss(np.asarray(labels), np.asarray(preds))
res["logloss"] = round(logloss, 4)
elif metric == "acc":
pred = np.asarray(preds)
pred[pred >= 0.5] = 1
pred[pred < 0.5] = 0
acc = accuracy_score(np.asarray(labels), pred)
res["acc"] = round(acc, 4)
elif metric == "f1":
pred = np.asarray(preds)
pred[pred >= 0.5] = 1
pred[pred < 0.5] = 0
f1 = f1_score(np.asarray(labels), pred)
res["f1"] = round(f1, 4)
elif metric == "mean_mrr":
mean_mrr = np.mean(
[
mrr_score(each_labels, each_preds)
for each_labels, each_preds in zip(labels, preds)
]
)
res["mean_mrr"] = round(mean_mrr, 4)
elif metric.startswith("ndcg"): # format like: ndcg@2;4;6;8
ndcg_list = [1, 2]
ks = metric.split("@")
if len(ks) > 1:
ndcg_list = [int(token) for token in ks[1].split(";")]
for k in ndcg_list:
ndcg_temp = np.mean(
[
ndcg_score(each_labels, each_preds, k)
for each_labels, each_preds in zip(labels, preds)
]
)
res["ndcg@{0}".format(k)] = round(ndcg_temp, 4)
elif metric.startswith("hit"): # format like: hit@2;4;6;8
hit_list = [1, 2]
ks = metric.split("@")
if len(ks) > 1:
hit_list = [int(token) for token in ks[1].split(";")]
for k in hit_list:
hit_temp = np.mean(
[
hit_score(each_labels, each_preds, k)
for each_labels, each_preds in zip(labels, preds)
]
)
res["hit@{0}".format(k)] = round(hit_temp, 4)
elif metric == "group_auc":
group_auc = np.mean(
[
roc_auc_score(each_labels, each_preds)
for each_labels, each_preds in zip(labels, preds)
]
)
res["group_auc"] = round(group_auc, 4)
else:
raise ValueError("Metric {0} not defined".format(metric))
return res
def word_tokenize(sent):
"""Split sentence into word list using regex.
Args:
sent (str): Input sentence
Return:
list: word list
"""
pat = re.compile(r"[\w]+|[.,!?;|]")
if isinstance(sent, str):
return pat.findall(sent.lower())
else:
return []
def newsample(news, ratio):
"""Sample ratio samples from news list.
If length of news is less than ratio, pad zeros.
Args:
news (list): input news list
ratio (int): sample number
Returns:
list: output of sample list.
"""
if ratio > len(news):
return news + [0] * (ratio - len(news))
else:
return random.sample(news, ratio)
def abstractmethod(funcobj):
"""A decorator indicating abstract methods.
Requires that the metaclass is ABCMeta or derived from it. A
class that has a metaclass derived from ABCMeta cannot be
instantiated unless all of its abstract methods are overridden.
The abstract methods can be called using any of the normal
'super' call mechanisms. abstractmethod() may be used to declare
abstract methods for properties and descriptors.
Usage:
class C(metaclass=ABCMeta):
@abstractmethod
def my_abstract_method(self, ...):
...
"""
funcobj.__isabstractmethod__ = True
return funcobj
class BaseIterator(object):
"""Abstract base iterator class"""
@abstractmethod
def parser_one_line(self, line):
"""Abstract method. Parse one string line into feature values.
Args:
line (str): A string indicating one instance.
"""
pass
@abstractmethod
def load_data_from_file(self, infile):
"""Abstract method. Read and parse data from a file.
Args:
infile (str): Text input file. Each line in this file is an instance.
"""
pass
@abstractmethod
def _convert_data(self, labels, features):
pass
@abstractmethod
def gen_feed_dict(self, data_dict):
"""Abstract method. Construct a dictionary that maps graph elements to values.
Args:
data_dict (dict): A dictionary that maps string name to numpy arrays.
"""
pass
def load_dict(file_path):
with open(file_path, "rb") as f:
return pickle.load(f)
class MINDIterator(BaseIterator):
"""Train data loader for NRMS model.
The model require a special type of data format, where each instance contains a label, impresion id, user id,
the candidate news articles and user's clicked news article. Articles are represented by title words,
body words, verts and subverts.
Iterator will not load the whole data into memory. Instead, it loads data into memory
per mini-batch, so that large files can be used as input data.
Attributes:
col_spliter (str): column spliter in one line.
ID_spliter (str): ID spliter in one line.
batch_size (int): the samples num in one batch.
title_size (int): max word num in news title.
his_size (int): max clicked news num in user click history.
npratio (int): negaive and positive ratio used in negative sampling. -1 means no need of negtive sampling.
"""
def __init__(
self,
hparams,
npratio=-1,
col_spliter="\t",
ID_spliter="%",
):
"""Initialize an iterator. Create necessary placeholders for the model.
Args:
hparams (object): Global hyper-parameters. Some key setttings such as head_num and head_dim are there.
npratio (int): negaive and positive ratio used in negative sampling. -1 means no need of negtive sampling.
col_spliter (str): column spliter in one line.
ID_spliter (str): ID spliter in one line.
"""
self.col_spliter = col_spliter
self.ID_spliter = ID_spliter
self.batch_size = hparams.batch_size
self.title_size = hparams.title_size
self.body_size = hparams.body_size
self.his_size = hparams.his_size
self.npratio = npratio
self.word_dict = self.load_dict(hparams.wordDict_file)
# self.cat_dict = self.load_dict(hparams.catDict_file)
# self.subcat_dict = self.load_dict(hparams.subcatDict_file)
# self.entity_dict = self.load_dict(hparams.entityDict_file)
# self.relation_dict = self.load_dict(hparams.relationDict_file)
self.uid2index = self.load_dict(hparams.userDict_file)
def load_dict(self, file_path):
"""load pickle file
Args:
file path (str): file path
Returns:
object: pickle loaded object
"""
with open(file_path, "rb") as f:
return pickle.load(f)
def init_news(self, news_file):
"""init news information given news file, such as news_title_index and nid2index.
Args:
news_file: path of news file
"""
self.nid2index = {}
news_title = [""]
# news_cat = [""]
# news_subcat = [""]
news_abstract = [""]
# news_entitites = [""]
# news_relation = [""]
with tf.io.gfile.GFile(news_file, "r") as rd:
for line in rd:
nid, cat, title, ab, content = line.strip("\n").split(self.col_spliter)
if nid in self.nid2index:
continue
self.nid2index[nid] = len(self.nid2index) + 1
title = word_tokenize(title)
if ab is None:
abstract = ""
else:
abstract = word_tokenize(ab)
news_title.append(title)
# news_cat.append(cat)
# news_subcat.append(subcat)
news_abstract.append(abstract)
# news_entities.append(entity)
# news_relation.append(relation)
self.news_title_index = np.zeros(
(len(news_title), self.title_size), dtype="int32"
)
self.news_abstract_index = np.zeros(
(len(news_abstract), self.body_size), dtype="int32"
)
# self.news_cat_index = np.zeros((len(news_cat), 1), dtype="int32")
# self.news_subcat_index = np.zeros((len(news_subcat, 1), dtype="int32")
for news_index in range(len(news_title)):
title = news_title[news_index]
abstract = news_abstract[news_index]
for word_index in range(min(self.title_size, len(title))):
if title[word_index] in self.word_dict:
self.news_title_index[news_index, word_index] = self.word_dict[
title[word_index].lower()
]
for word_index in range(min(self.body_size, len(abstract))):
if abstract[word_index] in self.word_dict:
self.news_abstract_index[news_index, word_index] = self.word_dict[
abstract[word_index].lower()
]
def init_behaviors(self, behaviors_file):
"""init behavior logs given behaviors file.
Args:
behaviors_file: path of behaviors file
"""
self.histories = []
self.imprs = []
self.labels = []
self.impr_indexes = []
self.uindexes = []
with tf.io.gfile.GFile(behaviors_file, "r") as rd:
impr_index = 0
for line in rd:
uid, history, impr, _ = line.strip("\n").split(self.col_spliter)[-4:]
history = [self.nid2index[i] for i in history.split()]
history = [0] * (self.his_size - len(history)) + history[
: self.his_size
]
impr_news = [self.nid2index[i.split("-")[0]] for i in impr.split()]
label = [int(i.split("-")[1]) for i in impr.split()]
uindex = self.uid2index[uid] if uid in self.uid2index else 0
self.histories.append(history)
self.imprs.append(impr_news)
self.labels.append(label)
self.impr_indexes.append(impr_index)
self.uindexes.append(uindex)
impr_index += 1
def parser_one_line(self, line):
"""Parse one behavior sample into feature values.
if npratio is larger than 0, return negtive sampled result.
Args:
line (int): sample index.
Yields:
list: Parsed results including label, impression id , user id,
candidate_title_index, clicked_title_index.
"""
if self.npratio > 0:
impr_label = self.labels[line]
impr = self.imprs[line]
poss = []
negs = []
for news, click in zip(impr, impr_label):
if click == 1:
poss.append(news)
else:
negs.append(news)
for p in poss:
candidate_title_index = []
candidate_abstract_index = []
impr_index = []
user_index = []
label = [1] + [0] * self.npratio
n = newsample(negs, self.npratio)
candidate_title_index = self.news_title_index[[p] + n]
candidate_abstract_index = self.news_abstract_index[[p] + n]
click_title_index = self.news_title_index[self.histories[line]]
click_abstract_index = self.news_abstract_index[self.histories[line]]
impr_index.append(self.impr_indexes[line])
user_index.append(self.uindexes[line])
yield (
label,
impr_index,
user_index,
candidate_title_index,
candidate_abstract_index,
click_title_index,
click_abstract_index,
)
else:
impr_label = self.labels[line]
impr = self.imprs[line]
for news, label in zip(impr, impr_label):
candidate_title_index = []
impr_index = []
user_index = []
label = [label]
candidate_title_index.append(self.news_title_index[news])
candidate_abstract_index = self.news_abstract_index[[p] + n]
click_title_index = self.news_title_index[self.histories[line]]
click_abstract_index = self.news_abstract_index[self.histories]
impr_index.append(self.impr_indexes[line])
user_index.append(self.uindexes[line])
yield (
label,
impr_index,
user_index,
candidate_title_index,
candidate_abstract_index,
click_title_index,
click_abstract_index,
)
def load_data_from_file(self, news_file, behavior_file):
"""Read and parse data from news file and behavior file.
Args:
news_file (str): A file contains several informations of news.
beahavior_file (str): A file contains information of user impressions.
Yields:
object: An iterator that yields parsed results, in the format of dict.
"""
if not hasattr(self, "news_title_index"):
self.init_news(news_file)
if not hasattr(self, "impr_indexes"):
self.init_behaviors(behavior_file)
label_list = []
imp_indexes = []
user_indexes = []
candidate_title_indexes = []
candidate_abstract_indexes = []
click_title_indexes = []
click_abstract_indexes = []
cnt = 0
indexes = np.arange(len(self.labels))
if self.npratio > 0:
np.random.shuffle(indexes)
for index in indexes:
for (
label,
imp_index,
user_index,
candidate_title_index,
candidate_abstract_index,
click_title_index,
click_abstract_index,
) in self.parser_one_line(index):
candidate_title_indexes.append(candidate_title_index)
candidate_abstract_indexes.append(candidate_abstract_index)
click_title_indexes.append(click_title_index)
click_abstract_indexes.append(click_abstract_index)
imp_indexes.append(imp_index)
user_indexes.append(user_index)
label_list.append(label)
cnt += 1
if cnt >= self.batch_size:
yield self._convert_data(
label_list,
imp_indexes,
user_indexes,
candidate_title_indexes,
candidate_abstract_indexes,
click_title_indexes,
click_abstract_indexes,
)
label_list = []
imp_indexes = []
user_indexes = []
candidate_title_indexes = []
candidate_abstract_indexes = []
click_title_indexes = []
click_abstract_indexes = []
cnt = 0
if cnt > 0:
yield self._convert_data(
label_list,
imp_indexes,
user_indexes,
candidate_title_indexes,
candidate_abstract_indexes,
click_title_indexes,
click_abstract_indexes,
)
def _convert_data(
self,
label_list,
imp_indexes,
user_indexes,
candidate_title_indexes,
candidate_abstract_indexes,
click_title_indexes,
click_abstract_indexes,
):
"""Convert data into numpy arrays that are good for further model operation.
Args:
label_list (list): a list of ground-truth labels.
imp_indexes (list): a list of impression indexes.
user_indexes (list): a list of user indexes.
candidate_title_indexes (list): the candidate news titles' words indices.
candidate_abstract_indexes (list): the candidate news abstract' words indices.
click_title_indexes (list): words indices for user's clicked news titles.
click_abstract_indexes (list): words indices for user's clicked news abstract.
Returns:
dict: A dictionary, containing multiple numpy arrays that are convenient for further operation.
"""
labels = np.asarray(label_list, dtype=np.float32)
imp_indexes = np.asarray(imp_indexes, dtype=np.int32)
user_indexes = np.asarray(user_indexes, dtype=np.int32)
candidate_title_index_batch = np.asarray(
candidate_title_indexes, dtype=np.int64
)
candidate_abstract_index_batch = np.asarray(
candidate_abstract_indexes, dtype=np.int64
)
click_title_index_batch = np.asarray(click_title_indexes, dtype=np.int64)
click_abstract_index_batch = np.asarray(click_abstract_indexes, dtype=np.int64)
return {
"impression_index_batch": imp_indexes,
"user_index_batch": user_indexes,
"clicked_title_batch": click_title_index_batch,
"clicked_abstract_batch": click_abstract_index_batch,
"candidate_title_batch": candidate_title_index_batch,
"candidate_abstract_batch": candidate_abstract_index_batch,
"labels": labels,
}
def load_user_from_file(self, news_file, behavior_file):
"""Read and parse user data from news file and behavior file.
Args:
news_file (str): A file contains several informations of news.
beahaviros_file (str): A file contains information of user impressions.
Yields:
object: An iterator that yields parsed user feature, in the format of dict.
"""
if not hasattr(self, "news_title_index"):
self.init_news(news_file)
if not hasattr(self, "impr_indexes"):
self.init_behaviors(behavior_file)
user_indexes = []
impr_indexes = []
click_title_indexes = []
click_abstract_indexes = []
cnt = 0
for index in range(len(self.impr_indexes)):
click_title_indexes.append(self.news_title_index[self.histories[index]])
click_abstract_indexes.append(
self.news_abstract_index[self.histories[index]]
)
user_indexes.append(self.uindexes[index])
impr_indexes.append(self.impr_indexes[index])
cnt += 1
if cnt >= self.batch_size:
yield self._convert_user_data(
user_indexes,
impr_indexes,
click_title_indexes,
click_abstract_indexes,
)
user_indexes = []
impr_indexes = []
click_title_indexes = []
click_abstract_indexes = []
cnt = 0
if cnt > 0:
yield self._convert_user_data(
user_indexes, impr_indexes, click_title_indexes, click_abstract_indexes
)
def _convert_user_data(
self, user_indexes, impr_indexes, click_title_indexes, click_abstract_indexes
):
"""Convert data into numpy arrays that are good for further model operation.
Args:
user_indexes (list): a list of user indexes.
click_title_indexes (list): words indices for user's clicked news titles.
Returns:
dict: A dictionary, containing multiple numpy arrays that are convenient for further operation.
"""
user_indexes = np.asarray(user_indexes, dtype=np.int32)
impr_indexes = np.asarray(impr_indexes, dtype=np.int32)
click_title_index_batch = np.asarray(click_title_indexes, dtype=np.int64)
click_abstract_index_batch = np.asarray(click_abstract_indexes, dtype=np.int64)
return {
"user_index_batch": user_indexes,
"impr_index_batch": impr_indexes,
"clicked_title_batch": click_title_index_batch,
"clicked_abstract_batch": click_abstract_index_batch,
}
def load_news_from_file(self, news_file):
"""Read and parse user data from news file.
Args:
news_file (str): A file contains several informations of news.
Yields:
object: An iterator that yields parsed news feature, in the format of dict.
"""
if not hasattr(self, "news_title_index"):
self.init_news(news_file)
news_indexes = []
candidate_title_indexes = []
candidate_abstract_indexes = []
cnt = 0
for index in range(len(self.news_title_index)):
news_indexes.append(index)
candidate_title_indexes.append(self.news_title_index[index])
candidate_abstract_indexes.append(self.news_abstract_index[index])
cnt += 1
if cnt >= self.batch_size:
yield self._convert_news_data(
news_indexes, candidate_title_indexes, candidate_abstract_indexes
)
news_indexes = []
candidate_title_indexes = []
candidate_abstract_indexes = []
cnt = 0
if cnt > 0:
yield self._convert_news_data(
news_indexes, candidate_title_indexes, candidate_abstract_indexes
)
def _convert_news_data(
self, news_indexes, candidate_title_indexes, candidate_abstract_indexes
):
"""Convert data into numpy arrays that are good for further model operation.
Args:
news_indexes (list): a list of news indexes.
candidate_title_indexes (list): the candidate news titles' words indices.
Returns:
dict: A dictionary, containing multiple numpy arrays that are convenient for further operation.
"""
news_indexes_batch = np.asarray(news_indexes, dtype=np.int32)
candidate_title_index_batch = np.asarray(
candidate_title_indexes, dtype=np.int32
)
candidate_abstract_index_batch = np.asarray(
candidate_abstract_indexes, dtype=np.int32
)
return {
"news_index_batch": news_indexes_batch,
"candidate_title_batch": candidate_title_index_batch,
"candidate_abstract_batch": candidate_abstract_index_batch,
}
def load_impression_from_file(self, behaivors_file):
"""Read and parse impression data from behaivors file.
Args:
behaivors_file (str): A file contains several informations of behaviros.
Yields:
object: An iterator that yields parsed impression data, in the format of dict.
"""
if not hasattr(self, "histories"):
self.init_behaviors(behaivors_file)
indexes = np.arange(len(self.labels))
for index in indexes:
impr_label = np.array(self.labels[index], dtype="int32")
impr_news = np.array(self.imprs[index], dtype="int32")
yield (
self.impr_indexes[index],
impr_news,
self.uindexes[index],
impr_label,
)
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License.
class AttLayer2(layers.Layer):
"""Soft alignment attention implement.
Attributes:
dim (int): attention hidden dim
"""
def __init__(self, dim=200, seed=0, **kwargs):
"""Initialization steps for AttLayer2.
Args:
dim (int): attention hidden dim
"""
self.dim = dim
self.seed = seed
super(AttLayer2, self).__init__(**kwargs)
def build(self, input_shape):
"""Initialization for variables in AttLayer2
There are there variables in AttLayer2, i.e. W, b and q.
Args:
input_shape (object): shape of input tensor.
"""
assert len(input_shape) == 3
dim = self.dim
self.W = self.add_weight(
name="W",
shape=(int(input_shape[-1]), dim),
initializer=keras.initializers.glorot_uniform(seed=self.seed),
trainable=True,
)
self.b = self.add_weight(
name="b",
shape=(dim,),
initializer=keras.initializers.Zeros(),
trainable=True,
)
self.q = self.add_weight(
name="q",
shape=(dim, 1),
initializer=keras.initializers.glorot_uniform(seed=self.seed),
trainable=True,
)
super(AttLayer2, self).build(input_shape) # be sure you call this somewhere!
def call(self, inputs, mask=None, **kwargs):
"""Core implemention of soft attention
Args:
inputs (object): input tensor.
Returns:
object: weighted sum of input tensors.
"""
attention = K.tanh(K.dot(inputs, self.W) + self.b)
attention = K.dot(attention, self.q)
attention = K.squeeze(attention, axis=2)
if mask == None:
attention = K.exp(attention)
else:
attention = K.exp(attention) * K.cast(mask, dtype="float32")
attention_weight = attention / (
K.sum(attention, axis=-1, keepdims=True) + K.epsilon()
)
attention_weight = K.expand_dims(attention_weight)
weighted_input = inputs * attention_weight
return K.sum(weighted_input, axis=1)
def compute_mask(self, input, input_mask=None):
"""Compte output mask value
Args:
input (object): input tensor.
input_mask: input mask
Returns:
object: output mask.
"""
return None
def compute_output_shape(self, input_shape):
"""Compute shape of output tensor
Args:
input_shape (tuple): shape of input tensor.
Returns:
tuple: shape of output tensor.
"""
return input_shape[0], input_shape[-1]
class SelfAttention(layers.Layer):
"""Multi-head self attention implement.
Args:
multiheads (int): The number of heads.
head_dim (object): Dimention of each head.
mask_right (boolean): whether to mask right words.
Returns:
object: Weighted sum after attention.
"""
def __init__(self, multiheads, head_dim, seed=0, mask_right=False, **kwargs):
"""Initialization steps for AttLayer2.
Args:
multiheads (int): The number of heads.
head_dim (object): Dimention of each head.
mask_right (boolean): whether to mask right words.
"""
self.multiheads = multiheads
self.head_dim = head_dim
self.output_dim = multiheads * head_dim
self.mask_right = mask_right
self.seed = seed
super(SelfAttention, self).__init__(**kwargs)
def compute_output_shape(self, input_shape):
"""Compute shape of output tensor.
Returns:
tuple: output shape tuple.
"""
return (input_shape[0][0], input_shape[0][1], self.output_dim)
def build(self, input_shape):
"""Initialization for variables in SelfAttention.
There are three variables in SelfAttention, i.e. WQ, WK ans WV.
WQ is used for linear transformation of query.
WK is used for linear transformation of key.
WV is used for linear transformation of value.
Args:
input_shape (object): shape of input tensor.
"""
self.WQ = self.add_weight(
name="WQ",
shape=(int(input_shape[0][-1]), self.output_dim),
initializer=keras.initializers.glorot_uniform(seed=self.seed),
trainable=True,
)
self.WK = self.add_weight(
name="WK",
shape=(int(input_shape[1][-1]), self.output_dim),
initializer=keras.initializers.glorot_uniform(seed=self.seed),
trainable=True,
)
self.WV = self.add_weight(
name="WV",
shape=(int(input_shape[2][-1]), self.output_dim),
initializer=keras.initializers.glorot_uniform(seed=self.seed),
trainable=True,
)
super(SelfAttention, self).build(input_shape)
def Mask(self, inputs, seq_len, mode="add"):
"""Mask operation used in multi-head self attention
Args:
seq_len (object): sequence length of inputs.
mode (str): mode of mask.
Returns:
object: tensors after masking.
"""
if seq_len == None:
return inputs
else:
mask = K.one_hot(indices=seq_len[:, 0], num_classes=K.shape(inputs)[1])
mask = 1 - K.cumsum(mask, axis=1)
for _ in range(len(inputs.shape) - 2):
mask = K.expand_dims(mask, 2)
if mode == "mul":
return inputs * mask
elif mode == "add":
return inputs - (1 - mask) * 1e12
def call(self, QKVs):
"""Core logic of multi-head self attention.
Args:
QKVs (list): inputs of multi-head self attention i.e. qeury, key and value.
Returns:
object: ouput tensors.
"""
if len(QKVs) == 3:
Q_seq, K_seq, V_seq = QKVs
Q_len, V_len = None, None
elif len(QKVs) == 5:
Q_seq, K_seq, V_seq, Q_len, V_len = QKVs
Q_seq = K.dot(Q_seq, self.WQ)
Q_seq = K.reshape(
Q_seq, shape=(-1, K.shape(Q_seq)[1], self.multiheads, self.head_dim)
)
Q_seq = K.permute_dimensions(Q_seq, pattern=(0, 2, 1, 3))
K_seq = K.dot(K_seq, self.WK)
K_seq = K.reshape(
K_seq, shape=(-1, K.shape(K_seq)[1], self.multiheads, self.head_dim)
)
K_seq = K.permute_dimensions(K_seq, pattern=(0, 2, 1, 3))
V_seq = K.dot(V_seq, self.WV)
V_seq = K.reshape(
V_seq, shape=(-1, K.shape(V_seq)[1], self.multiheads, self.head_dim)
)
V_seq = K.permute_dimensions(V_seq, pattern=(0, 2, 1, 3))
# tf.einsum('m b i k, m b j k -> m b i j', Q_seq , K_seq) # shape [10, 20, 50]
A = tf.einsum("m b i k, m b j k -> m b i j", Q_seq, K_seq) / K.sqrt(
K.cast(self.head_dim, dtype="float32")
)
A = K.permute_dimensions(
A, pattern=(0, 3, 2, 1)
) # A.shape=[batch_size,K_sequence_length,Q_sequence_length,self.multiheads]
A = self.Mask(A, V_len, "add")
A = K.permute_dimensions(A, pattern=(0, 3, 2, 1))
if self.mask_right:
ones = K.ones_like(A[:1, :1])
lower_triangular = K.tf.matrix_band_part(ones, num_lower=-1, num_upper=0)
mask = (ones - lower_triangular) * 1e12
A = A - mask
A = K.softmax(A)
# tf.einsum('m b i k, m b k j -> m b i j', A , V_seq)
O_seq = tf.einsum("m b i k, m b k j -> m b i j", A, V_seq)
O_seq = K.permute_dimensions(O_seq, pattern=(0, 2, 1, 3))
O_seq = K.reshape(O_seq, shape=(-1, K.shape(O_seq)[1], self.output_dim))
O_seq = self.Mask(O_seq, Q_len, "mul")
return O_seq
def get_config(self):
"""add multiheads, multiheads and mask_right into layer config.
Returns:
dict: config of SelfAttention layer.
"""
config = super(SelfAttention, self).get_config()
config.update(
{
"multiheads": self.multiheads,
"head_dim": self.head_dim,
"mask_right": self.mask_right,
}
)
return config
__all__ = ["BaseModel"]
class BaseModel:
"""Basic class of models
Attributes:
hparams (object): A tf.contrib.training.HParams object, hold the entire set of hyperparameters.
train_iterator (object): An iterator to load the data in training steps.
test_iterator (object): An iterator to load the data in testing steps.
graph (object): An optional graph.
seed (int): Random seed.
"""
def __init__(
self,
hparams,
iterator_creator,
seed=None,
):
"""Initializing the model. Create common logics which are needed by all deeprec models, such as loss function,
parameter set.
Args:
hparams (object): A tf.contrib.training.HParams object, hold the entire set of hyperparameters.
iterator_creator (object): An iterator to load the data.
graph (object): An optional graph.
seed (int): Random seed.
"""
self.seed = seed
tf.compat.v1.set_random_seed(seed)
np.random.seed(seed)
self.train_iterator = iterator_creator(
hparams,
hparams.npratio,
col_spliter="\t",
)
self.test_iterator = iterator_creator(
hparams,
col_spliter="\t",
)
self.hparams = hparams
self.support_quick_scoring = hparams.support_quick_scoring
self.model, self.scorer = self._build_graph()
self.loss = self._get_loss()
self.train_optimizer = self._get_opt()
self.model.compile(loss=self.loss, optimizer=self.train_optimizer)
def _init_embedding(self, file_path):
"""Load pre-trained embeddings as a constant tensor.
Args:
file_path (str): the pre-trained glove embeddings file path.
Returns:
numpy.ndarray: A constant numpy array.
"""
return np.load(file_path)
@abc.abstractmethod
def _build_graph(self):
"""Subclass will implement this."""
pass
@abc.abstractmethod
def _get_input_label_from_iter(self, batch_data):
"""Subclass will implement this"""
pass
def _get_loss(self):
"""Make loss function, consists of data loss and regularization loss
Returns:
object: Loss function or loss function name
"""
if self.hparams.loss == "cross_entropy_loss":
data_loss = "categorical_crossentropy"
elif self.hparams.loss == "log_loss":
data_loss = "binary_crossentropy"
else:
raise ValueError("this loss not defined {0}".format(self.hparams.loss))
return data_loss
def _get_opt(self):
"""Get the optimizer according to configuration. Usually we will use Adam.
Returns:
object: An optimizer.
"""
lr = self.hparams.learning_rate
optimizer = self.hparams.optimizer
if optimizer == "adam":
train_opt = tf.keras.optimizers.Adam(lr=lr)
return train_opt
def _get_pred(self, logit, task):
"""Make final output as prediction score, according to different tasks.
Args:
logit (object): Base prediction value.
task (str): A task (values: regression/classification)
Returns:
object: Transformed score
"""
if task == "regression":
pred = tf.identity(logit)
elif task == "classification":
pred = tf.sigmoid(logit)
else:
raise ValueError(
"method must be regression or classification, but now is {0}".format(
task
)
)
return pred
def train(self, train_batch_data):
"""Go through the optimization step once with training data in feed_dict.
Args:
sess (object): The model session object.
feed_dict (dict): Feed values to train the model. This is a dictionary that maps graph elements to values.
Returns:
list: A list of values, including update operation, total loss, data loss, and merged summary.
"""
train_input, train_label = self._get_input_label_from_iter(train_batch_data)
rslt = self.model.train_on_batch(train_input, train_label)
return rslt
def eval(self, eval_batch_data):
"""Evaluate the data in feed_dict with current model.
Args:
sess (object): The model session object.
feed_dict (dict): Feed values for evaluation. This is a dictionary that maps graph elements to values.
Returns:
list: A list of evaluated results, including total loss value, data loss value, predicted scores, and ground-truth labels.
"""
eval_input, eval_label = self._get_input_label_from_iter(eval_batch_data)
imp_index = eval_batch_data["impression_index_batch"]
pred_rslt = self.scorer.predict_on_batch(eval_input)
return pred_rslt, eval_label, imp_index
def fit(
self,
train_news_file,
train_behaviors_file,
valid_news_file,
valid_behaviors_file,
test_news_file=None,
test_behaviors_file=None,
):
"""Fit the model with train_file. Evaluate the model on valid_file per epoch to observe the training status.
If test_news_file is not None, evaluate it too.
Args:
train_file (str): training data set.
valid_file (str): validation set.
test_news_file (str): test set.
Returns:
object: An instance of self.
"""
self.history = {}
self.history["train_loss"] = []
self.history["val_loss"] = []
self.history["Val_auc"] = []
for epoch in range(1, self.hparams.epochs + 1):
step = 0
# self.hparams.current_epoch = epoch
epoch_loss = 0
train_start = time.time()
tqdm_util = tqdm(
self.train_iterator.load_data_from_file(
train_news_file, train_behaviors_file
)
)
for batch_data_input in tqdm_util:
step_result = self.train(batch_data_input)
step_data_loss = step_result
epoch_loss += step_data_loss
step += 1
if step % self.hparams.show_step == 0:
tqdm_util.set_description(
"step {0:d} , total_loss: {1:.4f}, data_loss: {2:.4f}".format(
step, epoch_loss / step, step_data_loss
)
)
self.history["train_loss"].append(epoch_loss / step)
self.history["val_loss"].append(step_data_loss)
train_end = time.time()
train_time = train_end - train_start
eval_start = time.time()
train_info = ",".join(
[
str(item[0]) + ":" + str(item[1])
for item in [("logloss loss", epoch_loss / step)]
]
)
eval_res = self.run_eval(valid_news_file, valid_behaviors_file)
eval_info = ", ".join(
[
str(item[0]) + ":" + str(item[1])
for item in sorted(eval_res.items(), key=lambda x: x[0])
]
)
if test_news_file is not None:
test_res = self.run_eval(test_news_file, test_behaviors_file)
test_info = ", ".join(
[
str(item[0]) + ":" + str(item[1])
for item in sorted(test_res.items(), key=lambda x: x[0])
]
)
eval_end = time.time()
eval_time = eval_end - eval_start
if test_news_file is not None:
print(
"at epoch {0:d}".format(epoch)
+ "\ntrain info: "
+ train_info
+ "\neval info: "
+ eval_info
+ "\ntest info: "
+ test_info
)
else:
print(
"at epoch {0:d}".format(epoch)
+ "\ntrain info: "
+ train_info
+ "\neval info: "
+ eval_info
)
print(
"at epoch {0:d} , train time: {1:.1f} eval time: {2:.1f}".format(
epoch, train_time, eval_time
)
)
return self
def group_labels(self, labels, preds, group_keys):
"""Devide labels and preds into several group according to values in group keys.
Args:
labels (list): ground truth label list.
preds (list): prediction score list.
group_keys (list): group key list.
Returns:
list, list, list:
- Keys after group.
- Labels after group.
- Preds after group.
"""
all_keys = list(set(group_keys))
all_keys.sort()
group_labels = {k: [] for k in all_keys}
group_preds = {k: [] for k in all_keys}
for l, p, k in zip(labels, preds, group_keys):
group_labels[k].append(l)
group_preds[k].append(p)
all_labels = []
all_preds = []
for k in all_keys:
all_labels.append(group_labels[k])
all_preds.append(group_preds[k])
return all_keys, all_labels, all_preds
def run_eval(self, news_filename, behaviors_file):
"""Evaluate the given file and returns some evaluation metrics.
Args:
filename (str): A file name that will be evaluated.
Returns:
dict: A dictionary that contains evaluation metrics.
"""
if self.support_quick_scoring:
_, group_labels, group_preds = self.run_fast_eval(
news_filename, behaviors_file
)
else:
_, group_labels, group_preds = self.run_slow_eval(
news_filename, behaviors_file
)
res = cal_metric(group_labels, group_preds, self.hparams.metrics)
return res
def user(self, batch_user_input):
user_input = self._get_user_feature_from_iter(batch_user_input)
user_vec = self.userencoder.predict_on_batch(user_input)
user_index = batch_user_input["impr_index_batch"]
return user_index, user_vec
def news(self, batch_news_input):
news_input = self._get_news_feature_from_iter(batch_news_input)
news_vec = self.newsencoder.predict_on_batch(news_input)
news_index = batch_news_input["news_index_batch"]
return news_index, news_vec
def run_user(self, news_filename, behaviors_file):
if not hasattr(self, "userencoder"):
raise ValueError("model must have attribute userencoder")
user_indexes = []
user_vecs = []
for batch_data_input in tqdm(
self.test_iterator.load_user_from_file(news_filename, behaviors_file)
):
# print("\nbatch_data_input:", batch_data_input)
user_index, user_vec = self.user(batch_data_input)
user_indexes.extend(np.reshape(user_index, -1))
user_vecs.extend(user_vec)
return dict(zip(user_indexes, user_vecs))
def run_news(self, news_filename):
if not hasattr(self, "newsencoder"):
raise ValueError("model must have attribute newsencoder")
news_indexes = []
news_vecs = []
for batch_data_input in tqdm(
self.test_iterator.load_news_from_file(news_filename)
):
news_index, news_vec = self.news(batch_data_input)
news_indexes.extend(np.reshape(news_index, -1))
news_vecs.extend(news_vec)
return dict(zip(news_indexes, news_vecs))
def run_slow_eval(self, news_filename, behaviors_file):
preds = []
labels = []
imp_indexes = []
for batch_data_input in tqdm(
self.test_iterator.load_data_from_file(news_filename, behaviors_file)
):
step_pred, step_labels, step_imp_index = self.eval(batch_data_input)
preds.extend(np.reshape(step_pred, -1))
labels.extend(np.reshape(step_labels, -1))
imp_indexes.extend(np.reshape(step_imp_index, -1))
group_impr_indexes, group_labels, group_preds = self.group_labels(
labels, preds, imp_indexes
)
return group_impr_indexes, group_labels, group_preds
def run_fast_eval(self, news_filename, behaviors_file):
news_vecs = self.run_news(news_filename)
user_vecs = self.run_user(news_filename, behaviors_file)
self.news_vecs = news_vecs
self.user_vecs = user_vecs
group_impr_indexes = []
group_labels = []
group_preds = []
for (
impr_index,
news_index,
user_index,
label,
) in tqdm(self.test_iterator.load_impression_from_file(behaviors_file)):
pred = np.dot(
np.stack([news_vecs[i] for i in news_index], axis=0),
user_vecs[impr_index],
)
group_impr_indexes.append(impr_index)
group_labels.append(label)
group_preds.append(pred)
return group_impr_indexes, group_labels, group_preds
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License.
__all__ = ["NRMSModel"]
class NRMSModel(BaseModel):
"""NRMS model(Neural News Recommendation with Multi-Head Self-Attention)
Chuhan Wu, Fangzhao Wu, Suyu Ge, Tao Qi, Yongfeng Huang,and Xing Xie, "Neural News
Recommendation with Multi-Head Self-Attention" in Proceedings of the 2019 Conference
on Empirical Methods in Natural Language Processing and the 9th International Joint Conference
on Natural Language Processing (EMNLP-IJCNLP)
Attributes:
word2vec_embedding (numpy.ndarray): Pretrained word embedding matrix.
hparam (object): Global hyper-parameters.
"""
def __init__(
self,
hparams,
iterator_creator,
seed=None,
):
"""Initialization steps for NRMS.
Compared with the BaseModel, NRMS need word embedding.
After creating word embedding matrix, BaseModel's __init__ method will be called.
Args:
hparams (object): Global hyper-parameters. Some key setttings such as head_num and head_dim are there.
iterator_creator_train (object): NRMS data loader class for train data.
iterator_creator_test (object): NRMS data loader class for test and validation data
"""
self.word2vec_embedding = self._init_embedding(hparams.wordEmb_file)
super().__init__(
hparams,
iterator_creator,
seed=seed,
)
def _get_input_label_from_iter(self, batch_data):
"""get input and labels for trainning from iterator
Args:
batch data: input batch data from iterator
Returns:
list: input feature fed into model (clicked_title_batch & candidate_title_batch)
numpy.ndarray: labels
"""
input_feat = [
batch_data["clicked_title_batch"],
batch_data["clicked_abstract_batch"],
batch_data["candidate_title_batch"],
batch_data["candidate_abstract_batch"],
]
input_label = batch_data["labels"]
return input_feat, input_label
def _get_user_feature_from_iter(self, batch_data):
"""get input of user encoder
Args:
batch_data: input batch data from user iterator
Returns:
numpy.ndarray: input user feature (clicked title batch)
"""
# print("\nclicked_title_batch:", batch_data["clicked_title_batch"].shape)
# print("\nclicked_abstract_batch:", batch_data["clicked_abstract_batch"].shape)
input_feature = [
batch_data["clicked_title_batch"],
batch_data["clicked_abstract_batch"],
]
input_feature = np.concatenate(input_feature, axis=-1)
# print("\ninput_feature:", input_feature.shape)
return input_feature
def _get_news_feature_from_iter(self, batch_data):
"""get input of news encoder
Args:
batch_data: input batch data from news iterator
Returns:
numpy.ndarray: input news feature (candidate title batch)
"""
input_feature = [
batch_data["candidate_title_batch"],
batch_data["candidate_abstract_batch"],
]
input_feature = np.concatenate(input_feature, axis=-1)
return input_feature
def _build_graph(self):
"""Build NRMS model and scorer.
Returns:
object: a model used to train.
object: a model used to evaluate and inference.
"""
hparams = self.hparams
model, scorer = self._build_nrms()
return model, scorer
def _build_userencoder(self, newsencoder):
"""The main function to create user encoder of NRMS.
Args:
newsencoder (object): the news encoder of NRMS.
Return:
object: the user encoder of NRMS.
"""
hparams = self.hparams
his_input_title_abstract = keras.Input(
shape=(hparams.his_size, hparams.title_size + hparams.body_size),
dtype="int32",
)
click_new_presents = layers.TimeDistributed(newsencoder)(
his_input_title_abstract
)
y = SelfAttention(hparams.head_num, hparams.head_dim, seed=self.seed)(
[click_new_presents] * 3
)
user_present = AttLayer2(hparams.attention_hidden_dim, seed=self.seed)(y)
model = keras.Model(his_input_title_abstract, user_present, name="user_encoder")
print("\n", model.summary())
return model
def _build_newsencoder(self, embedding_layer):
"""The main function to create news encoder of NRMS.
Args:
embedding_layer (object): a word embedding layer.
Return:
object: the news encoder of NRMS
"""
hparams = self.hparams
input_title_abstract = tf.keras.Input(
shape=(hparams.title_size + hparams.body_size,), dtype="int32"
)
# print("\ninput_title_abstract:", input_title_abstract)
sequences_input_title = layers.Lambda(lambda x: x[:, : hparams.title_size])(
input_title_abstract
)
# print("\nsequences_input_title:", sequences_input_title)
sequences_input_abstract = layers.Lambda(
lambda x: x[:, hparams.title_size : hparams.title_size + hparams.body_size]
)(input_title_abstract)
title_rep = self._build_titleencoder(embedding_layer)(sequences_input_title)
abstract_rep = self._build_abstractencoder(embedding_layer)(
sequences_input_abstract
)
# print("title_rep:", title_rep)
# print("abstract_rep:", abstract_rep)
concate_rep = layers.Concatenate(axis=-2)([title_rep, abstract_rep])
y = SelfAttention(hparams.head_num, hparams.head_dim, seed=self.seed)(
[concate_rep, concate_rep, concate_rep]
)
pred_title = AttLayer2(hparams.attention_hidden_dim, seed=self.seed)(y)
model = keras.Model(input_title_abstract, pred_title, name="news_encoder")
print("\n", model.summary())
return model
def _build_titleencoder(self, embedding_layer):
hparams = self.hparams
sequences_input_title = keras.Input(shape=(hparams.title_size,), dtype="int32")
embedded_sequences_title = embedding_layer(sequences_input_title)
y = layers.Dropout(hparams.dropout)(embedded_sequences_title)
y = SelfAttention(hparams.head_num, hparams.head_dim, seed=self.seed)([y, y, y])
y = layers.Dropout(hparams.dropout)(y)
pred_title = AttLayer2(hparams.attention_hidden_dim, seed=self.seed)(y)
pred_title = layers.Reshape((1, 400))(pred_title)
model = keras.Model(sequences_input_title, pred_title, name="title_encoder")
print("\n", model.summary())
return model
def _build_abstractencoder(self, embedding_layer):
hparams = self.hparams
sequences_input_abstract = keras.Input(
shape=(hparams.body_size,), dtype="int32"
)
embedded_sequences_abstract = embedding_layer(sequences_input_abstract)
y = layers.Dropout(hparams.dropout)(embedded_sequences_abstract)
y = SelfAttention(hparams.head_num, hparams.head_dim, seed=self.seed)([y, y, y])
y = layers.Dropout(hparams.dropout)(y)
pred_abstract = AttLayer2(hparams.attention_hidden_dim, seed=self.seed)(y)
pred_abstract = layers.Reshape((1, 400))(pred_abstract)
model = keras.Model(
sequences_input_abstract, pred_abstract, name="abstract_encoder"
)
print("\n", model.summary())
return model
def _build_nrms(self):
"""The main function to create NRMS's logic. The core of NRMS
is a user encoder and a news encoder.
Returns:
object: a model used to train.
object: a model used to evaluate and inference.
"""
hparams = self.hparams
his_input_title = keras.Input(
shape=(hparams.his_size, hparams.title_size), dtype="int32"
)
his_input_abstract = keras.Input(
shape=(hparams.his_size, hparams.body_size), dtype="int32"
)
pred_input_title = keras.Input(
shape=(hparams.npratio + 1, hparams.title_size), dtype="int32"
)
pred_input_abstract = keras.Input(
shape=(hparams.npratio + 1, hparams.body_size), dtype="int32"
)
pred_input_title_one = keras.Input(
shape=(
1,
hparams.title_size,
),
dtype="int32",
)
pred_input_abstract_one = keras.Input(
shape=(
1,
hparams.body_size,
),
dtype="int32",
)
his_title_abstract = layers.Concatenate(axis=-1)(
[his_input_title, his_input_abstract]
)
pred_title_abstract = layers.Concatenate(axis=-1)(
[pred_input_title, pred_input_abstract]
)
pred_title_abstract_one = layers.Concatenate(axis=-1)(
[
pred_input_title_one,
pred_input_abstract_one,
]
)
pred_title_abstract_one = layers.Reshape((-1,))(pred_title_abstract_one)
embedding_layer = layers.Embedding(
self.word2vec_embedding.shape[0],
hparams.word_emb_dim,
weights=[self.word2vec_embedding],
trainable=True,
)
self.newsencoder = self._build_newsencoder(embedding_layer)
self.userencoder = self._build_userencoder(self.newsencoder)
user_present = self.userencoder(his_title_abstract)
# print("\npred_title_abstract:", pred_title_abstract)
news_present = layers.TimeDistributed(self.newsencoder)(pred_title_abstract)
news_present_one = self.newsencoder(pred_title_abstract_one)
preds = layers.Dot(axes=-1)([news_present, user_present])
preds = layers.Activation(activation="softmax")(preds)
pred_one = layers.Dot(axes=-1)([news_present_one, user_present])
pred_one = layers.Activation(activation="sigmoid")(pred_one)
model = keras.Model(
[
his_input_title,
his_input_abstract,
pred_input_title,
pred_input_abstract,
],
preds,
)
scorer = keras.Model(
[
his_input_title,
his_input_abstract,
pred_input_title_one,
pred_input_abstract_one,
],
pred_one,
)
print("\n", model.summary())
return model, scorer
data_path = "/kaggle/input/mindlike-final/"
train_news_file = os.path.join(data_path, r"news_train.tsv")
train_behaviors_file = os.path.join(data_path, r"behaviors_train.tsv")
valid_news_file = os.path.join(data_path, r"news_val.tsv")
valid_behaviors_file = os.path.join(data_path, r"behaviors_val.tsv")
# test_news_file = os.path.join(data_path, r'news_test.tsv')
# est_behaviors_file = os.path.join(data_path, r'behaviors_test.tsv')
iterator = MINDIterator
with tpu_strategy.scope():
model = NRMSModel(hparams, iterator)
# print(model.run_eval(train_news_file, train_behaviors_file))
# print("\n", model.run_eval(valid_news_file, valid_behaviors_file))
# %%time
model.fit(train_news_file, train_behaviors_file, valid_news_file, valid_behaviors_file)
model.model.save_weights("/kaggle/working/models/nrms_ckpt")
# adsasd
# model.model.save("/kaggle/working/model.ckpt")
#!cd /kaggle/working
#!zip -r file1.zip /kaggle/working/model.ckpt
def init_behaviors2(iterator, behaviors_file):
"""init behavior logs given behaviors file.
Args:
behaviors_file: path of behaviors file
"""
iterator.histories = []
iterator.imprs = []
iterator.labels = []
iterator.impr_indexes = []
iterator.uindexes = []
with tf.io.gfile.GFile(behaviors_file, "r") as rd:
impr_index = 0
for line in rd:
uid, time, history, impr = line.strip("\n").split(iterator.col_spliter)[-4:]
history = [iterator.nid2index[i] for i in history.split()]
history = [0] * (iterator.his_size - len(history)) + history[
: iterator.his_size
]
impr_news = [iterator.nid2index[i.split("-")[0]] for i in impr.split()]
label = [0 for i in impr.split()]
uindex = iterator.uid2index[uid] if uid in iterator.uid2index else 0
iterator.histories.append(history)
iterator.imprs.append(impr_news)
iterator.labels.append(label)
iterator.impr_indexes.append(impr_index)
iterator.uindexes.append(uindex)
impr_index += 1
def load_impression_from_file2(iterator, behaivors_file):
"""Read and parse impression data from behaivors file.
Args:
behaivors_file (str): A file contains several informations of behaviros.
Yields:
object: An iterator that yields parsed impression data, in the format of dict.
"""
init_behaviors2(iterator, behaivors_file)
indexes = np.arange(len(iterator.labels))
for index in indexes:
impr_label = np.array(iterator.labels[index], dtype="int32")
impr_news = np.array(iterator.imprs[index], dtype="int32")
yield (
iterator.impr_indexes[index],
impr_news,
iterator.uindexes[index],
impr_label,
)
def load_user_from_file2(iterator, news_file, behavior_file):
"""Read and parse user data from news file and behavior file.
Args:
news_file (str): A file contains several informations of news.
beahaviros_file (str): A file contains information of user impressions.
Yields:
object: An iterator that yields parsed user feature, in the format of dict.
"""
iterator.init_news(news_file)
init_behaviors2(iterator, behavior_file)
user_indexes = []
impr_indexes = []
click_title_indexes = []
click_abstract_indexes = []
cnt = 0
for index in range(len(iterator.impr_indexes)):
click_title_indexes.append(iterator.news_title_index[iterator.histories[index]])
click_abstract_indexes.append(
iterator.news_abstract_index[iterator.histories[index]]
)
user_indexes.append(iterator.uindexes[index])
impr_indexes.append(iterator.impr_indexes[index])
cnt += 1
if cnt >= iterator.batch_size:
yield iterator._convert_user_data(
user_indexes, impr_indexes, click_title_indexes, click_abstract_indexes
)
user_indexes = []
impr_indexes = []
click_title_indexes = []
click_abstract_indexes = []
cnt = 0
if cnt > 0:
yield iterator._convert_user_data(
user_indexes, impr_indexes, click_title_indexes, click_abstract_indexes
)
def load_news_from_file2(iterator, news_file):
print(news_file)
"""Read and parse user data from news file.
Args:
news_file (str): A file contains several informations of news.
Yields:
object: An iterator that yields parsed news feature, in the format of dict.
"""
# if not hasattr(iterator, "news_title_index"):
iterator.init_news(news_file)
news_indexes = []
candidate_title_indexes = []
candidate_abstract_indexes = []
cnt = 0
for index in range(len(iterator.news_title_index)):
news_indexes.append(index)
candidate_title_indexes.append(iterator.news_title_index[index])
candidate_abstract_indexes.append(iterator.news_abstract_index[index])
cnt += 1
if cnt >= iterator.batch_size:
yield iterator._convert_news_data(
news_indexes, candidate_title_indexes, candidate_abstract_indexes
)
news_indexes = []
candidate_title_indexes = []
candidate_abstract_indexes = []
cnt = 0
if cnt > 0:
yield iterator._convert_news_data(
news_indexes, candidate_title_indexes, candidate_abstract_indexes
)
def run_news2(model, news_filename):
# print(news_filename)
if not hasattr(model, "newsencoder"):
raise ValueError("model must have attribute newsencoder")
news_indexes = []
news_vecs = []
for batch_data_input in tqdm(
load_news_from_file2(model.test_iterator, news_filename)
):
news_index, news_vec = model.news(batch_data_input)
news_indexes.extend(np.reshape(news_index, -1))
news_vecs.extend(news_vec)
return dict(zip(news_indexes, news_vecs))
def run_user2(model, news_filename, behaviors_file):
if not hasattr(model, "userencoder"):
raise ValueError("model must have attribute userencoder")
user_indexes = []
user_vecs = []
for batch_data_input in tqdm(
load_user_from_file2(model.test_iterator, news_filename, behaviors_file)
):
user_index, user_vec = model.user(batch_data_input)
user_indexes.extend(np.reshape(user_index, -1))
user_vecs.extend(user_vec)
return dict(zip(user_indexes, user_vecs))
def run_fast_eval2(model, news_filename, behaviors_file):
news_vecs = run_news2(model, news_filename)
# print(news_filename)
user_vecs = run_user2(model, news_filename, behaviors_file)
model.news_vecs = news_vecs
model.user_vecs = user_vecs
group_impr_indexes = []
group_labels = []
group_preds = []
for (
impr_index,
news_index,
user_index,
label,
) in tqdm(load_impression_from_file2(model.test_iterator, behaviors_file)):
pred = np.dot(
np.stack([news_vecs[i] for i in news_index], axis=0),
user_vecs[impr_index],
)
group_impr_indexes.append(impr_index)
group_labels.append(label)
group_preds.append(pred)
return group_impr_indexes, group_labels, group_preds
group_impr_indexes, group_labels, group_preds = run_fast_eval2(
model, test_news_file, test_behaviors_file
)
output_path = "/kaggle/working/"
with open(os.path.join(output_path, "prediction.txt"), "w") as f:
for impr_index, preds in tqdm(zip(group_impr_indexes, group_preds)):
impr_index += 1
pred_rank = (np.argsort(np.argsort(preds)[::-1]) + 1).tolist()
pred_rank = "[" + ",".join([str(i) for i in pred_rank]) + "]"
f.write(" ".join([str(impr_index), pred_rank]) + "\n")
import zipfile
f = zipfile.ZipFile(
os.path.join(output_path, "prediction.zip"), "w", zipfile.ZIP_DEFLATED
)
f.write(os.path.join(output_path, "prediction.txt"), arcname="prediction.txt")
f.close()
import matplotlib.pyplot as plt
fig = plt.figure()
plt.plot(np.arange(0, epochs), model.history["train_loss"], label="validation auc")
plt.plot(np.arange(0, epochs), model.history["val_loss"], label="validation auc")
plt.xticks(range(0, epochs))
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0094/040/94040247.ipynb | kenh14small | hieunm21 | [{"Id": 94040247, "ScriptId": 26386486, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 8375020, "CreationDate": "04/26/2022 09:21:58", "VersionNumber": 4.0, "Title": "nrms_tf2_k14", "EvaluationDate": "04/26/2022", "IsChange": false, "TotalLines": 2241.0, "LinesInsertedFromPrevious": 0.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 2241.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 127926474, "KernelVersionId": 94040247, "SourceDatasetVersionId": 3491230}] | [{"Id": 3491230, "DatasetId": 2101503, "DatasourceVersionId": 3543661, "CreatorUserId": 8375020, "LicenseName": "Unknown", "CreationDate": "04/19/2022 09:41:36", "VersionNumber": 1.0, "Title": "kenh14-small", "Slug": "kenh14small", "Subtitle": NaN, "Description": NaN, "VersionNotes": "Initial release", "TotalCompressedBytes": 0.0, "TotalUncompressedBytes": 0.0}] | [{"Id": 2101503, "CreatorUserId": 8375020, "OwnerUserId": 8375020.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 3491230.0, "CurrentDatasourceVersionId": 3543661.0, "ForumId": 2126900, "Type": 2, "CreationDate": "04/19/2022 09:41:36", "LastActivityDate": "04/19/2022", "TotalViews": 491, "TotalDownloads": 5, "TotalVotes": 0, "TotalKernels": 1}] | [{"Id": 8375020, "UserName": "hieunm21", "DisplayName": "Hieu Nguyen Minh", "RegisterDate": "09/17/2021", "PerformanceTier": 0}] | import yaml
import os
import abc
import time
import numpy as np
import tensorflow as tf
import tensorflow.keras as keras
import pandas as pd
import pickle
import random
import re
from tqdm import tqdm
from tensorflow.keras import layers
from tensorflow.keras import backend as K
from collections import namedtuple
# detect and init the TPU
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect()
# instantiate a distribution strategy
tpu_strategy = tf.distribute.experimental.TPUStrategy(tpu)
def load_yaml(filename):
"""Load yaml file
Args:
filename
Returns:
dict
"""
try:
with open(filename, "r") as f:
config = yaml.load(f, yaml.SafeLoader)
return config
except FileNotFoundError:
raise
except Exception as e:
raise IOError(f"load {filename} error!")
def flat_config(config):
"""Flat config load tu yaml file to flat dict
Args:
config (dict): config load tu yaml file
Returns:
dict
"""
f_config = {}
category = config.keys()
for cate in category:
for key, val in config[cate].items():
f_config[key] = val
return f_config
def check_type(config):
int_parameters = [
"word_size",
"his_size",
"title_size",
"body_size",
"npratio",
"word_emb_dim",
"attention_hidden_dim",
"epochs",
"batch_size",
"show_step",
"save_epoch",
"head_num",
"head_dim",
"user_num",
"filter_num",
"window_size",
"gru_unit",
"user_emb_dim",
"vert_emb_dim",
"subvert_emb_dim",
]
for param in int_parameters:
if param in config and not isinstance(config[param], int):
raise TypeError("Parameters {0} must be int".format(param))
float_parameters = ["learning_rate", "dropout"]
for param in float_parameters:
if param in config and not isinstance(config[param], float):
raise TypeError("Parameters {0} must be float".format(param))
str_parameters = [
"wordEmb_file",
"wordDict_file",
"userDict_file",
"vertDict_file",
"subvertDict_file",
"method",
"loss",
"optimizer",
"cnn_activation",
"dense_activation" "type",
]
for param in str_parameters:
if param in config and not isinstance(config[param], str):
raise TypeError("Parameters {0} must be str".format(param))
list_parameters = ["layer_sizes", "activation"]
for param in list_parameters:
if param in config and not isinstance(config[param], list):
raise TypeError("Parameters {0} must be list".format(param))
bool_parameters = ["support_quick_scoring"]
for param in bool_parameters:
if param in config and not isinstance(config[param], bool):
raise TypeError("Parameters {0} must be bool".format(param))
def check_nn_config(f_config):
"""Check neural net config
Args:
f_config (dict): file config duoc flat tu yaml file
Raises:
ValueError: Neu params bi sai -> Raise error
"""
if f_config["model_type"] in ["nrms", "NRMS"]:
required_parameters = [
"title_size",
"his_size",
"wordEmb_file",
"wordDict_file",
"userDict_file",
"npratio",
"data_format",
"word_emb_dim",
"head_num",
"head_dim",
"attention_hidden_dim",
"loss",
"data_format",
"dropout",
]
else:
required_parameters = []
# check
for param in required_parameters:
if param not in f_config:
raise ValueError("Parameter {0} must be set!".format(param))
if f_config["model_type"] in ["nrms", "NRMS"]:
if f_config["data_format"] != "news":
raise ValueError(
"Voi NRMS model, dataformat phai la news, dua cai {0} vao lam gi".format(
f_config["data_format"]
)
)
check_type(f_config)
def get_hparams(**kwargs):
return namedtuple("GenericDict", kwargs.keys())(**kwargs)
def create_hparams(flags):
"""Create model's params
Args:
flags (dict): Dict co requirement
Returns:
object: namedtuple
"""
return get_hparams(
# data
data_format=flags.get("data_format", None),
iterator_type=flags.get("iterator_type", None),
support_quick_scoring=flags.get("support_quick_scoring", False),
wordEmb_file=flags.get("wordEmb_file", None),
wordDict_file=flags.get("wordDict_file", None),
userDict_file=flags.get("userDict_file", None),
vertDict_file=flags.get("vertDict_file", None),
subvertDict_file=flags.get("subvertDict_file", None),
# models
title_size=flags.get("title_size", None),
body_size=flags.get("body_size", None),
word_emb_dim=flags.get("word_emb_dim", None),
word_size=flags.get("word_size", None),
user_num=flags.get("user_num", None),
vert_num=flags.get("vert_num", None),
subvert_num=flags.get("subvert_num", None),
his_size=flags.get("his_size", None),
npratio=flags.get("npratio"),
dropout=flags.get("dropout", 0.0),
attention_hidden_dim=flags.get("attention_hidden_dim", 200),
# nrms
head_num=flags.get("head_num", 4),
head_dim=flags.get("head_dim", 100),
# train
learning_rate=flags.get("learning_rate", 0.001),
loss=flags.get("loss", None),
optimizer=flags.get("optimizer", "adam"),
epochs=flags.get("epochs", 10),
batch_size=flags.get("batch_size", 1),
# show info
show_step=flags.get("show_step", 1),
metrics=flags.get("metrics", None),
)
def prepare_hparams(yaml_file=None, **kwargs):
"""Prepare hyperparams and make sure it's ok
Args:
yaml_file: path to yaml file
Returns:
TF Hyperparams object (tf.contrib.training.HParams)
"""
if yaml_file is not None:
config = load_yaml(yaml_file)
config = flat_config(config)
else:
config = {}
config.update(kwargs)
check_nn_config(config)
return create_hparams(config)
yaml_file = "/kaggle/input/kenh14small/nrms.yaml"
wordEmb_file = "/kaggle/input/mindlike-final/embedding.npy"
wordDict_file = "/kaggle/input/mindlike-final/word_dict.pkl"
userDict_file = "/kaggle/input/mindlike-final/uid2index.pkl"
epochs = 1
seed = 42
batch_size = 1024
hparams = prepare_hparams(
yaml_file,
his_size=25,
wordEmb_file=wordEmb_file,
wordDict_file=wordDict_file,
userDict_file=userDict_file,
batch_size=batch_size,
epochs=epochs,
show_step=10,
)
print(hparams)
from sklearn.metrics import (
roc_auc_score,
log_loss,
mean_squared_error,
accuracy_score,
f1_score,
)
def mrr_score(y_true, y_score):
"""Computing mrr score metric.
Args:
y_true (np.ndarray): Ground-truth labels.
y_score (np.ndarray): Predicted labels.
Returns:
numpy.ndarray: mrr scores.
"""
order = np.argsort(y_score)[::-1]
y_true = np.take(y_true, order)
rr_score = y_true / (np.arange(len(y_true)) + 1)
return np.sum(rr_score) / np.sum(y_true)
def ndcg_score(y_true, y_score, k=10):
"""Computing ndcg score metric at k.
Args:
y_true (np.ndarray): Ground-truth labels.
y_score (np.ndarray): Predicted labels.
Returns:
numpy.ndarray: ndcg scores.
"""
best = dcg_score(y_true, y_true, k)
actual = dcg_score(y_true, y_score, k)
return actual / best
def hit_score(y_true, y_score, k=10):
"""Computing hit score metric at k.
Args:
y_true (np.ndarray): ground-truth labels.
y_score (np.ndarray): predicted labels.
Returns:
np.ndarray: hit score.
"""
ground_truth = np.where(y_true == 1)[0]
argsort = np.argsort(y_score)[::-1][:k]
for idx in argsort:
if idx in ground_truth:
return 1
return 0
def dcg_score(y_true, y_score, k=10):
"""Computing dcg score metric at k.
Args:
y_true (np.ndarray): Ground-truth labels.
y_score (np.ndarray): Predicted labels.
Returns:
np.ndarray: dcg scores.
"""
k = min(np.shape(y_true)[-1], k)
order = np.argsort(y_score)[::-1]
y_true = np.take(y_true, order[:k])
gains = 2**y_true - 1
discounts = np.log2(np.arange(len(y_true)) + 2)
return np.sum(gains / discounts)
def cal_metric(labels, preds, metrics):
print(labels)
print(preds)
"""Calculate metrics.
Available options are: `auc`, `rmse`, `logloss`, `acc` (accurary), `f1`, `mean_mrr`,
`ndcg` (format like: ndcg@2;4;6;8), `hit` (format like: hit@2;4;6;8), `group_auc`.
Args:
labels (array-like): Labels.
preds (array-like): Predictions.
metrics (list): List of metric names.
Return:
dict: Metrics.
Examples:
>>> cal_metric(labels, preds, ["ndcg@2;4;6", "group_auc"])
{'ndcg@2': 0.4026, 'ndcg@4': 0.4953, 'ndcg@6': 0.5346, 'group_auc': 0.8096}
"""
res = {}
for metric in metrics:
if metric == "auc":
auc = roc_auc_score(np.asarray(labels), np.asarray(preds))
res["auc"] = round(auc, 4)
elif metric == "rmse":
rmse = mean_squared_error(np.asarray(labels), np.asarray(preds))
res["rmse"] = np.sqrt(round(rmse, 4))
elif metric == "logloss":
# avoid logloss nan
preds = [max(min(p, 1.0 - 10e-12), 10e-12) for p in preds]
logloss = log_loss(np.asarray(labels), np.asarray(preds))
res["logloss"] = round(logloss, 4)
elif metric == "acc":
pred = np.asarray(preds)
pred[pred >= 0.5] = 1
pred[pred < 0.5] = 0
acc = accuracy_score(np.asarray(labels), pred)
res["acc"] = round(acc, 4)
elif metric == "f1":
pred = np.asarray(preds)
pred[pred >= 0.5] = 1
pred[pred < 0.5] = 0
f1 = f1_score(np.asarray(labels), pred)
res["f1"] = round(f1, 4)
elif metric == "mean_mrr":
mean_mrr = np.mean(
[
mrr_score(each_labels, each_preds)
for each_labels, each_preds in zip(labels, preds)
]
)
res["mean_mrr"] = round(mean_mrr, 4)
elif metric.startswith("ndcg"): # format like: ndcg@2;4;6;8
ndcg_list = [1, 2]
ks = metric.split("@")
if len(ks) > 1:
ndcg_list = [int(token) for token in ks[1].split(";")]
for k in ndcg_list:
ndcg_temp = np.mean(
[
ndcg_score(each_labels, each_preds, k)
for each_labels, each_preds in zip(labels, preds)
]
)
res["ndcg@{0}".format(k)] = round(ndcg_temp, 4)
elif metric.startswith("hit"): # format like: hit@2;4;6;8
hit_list = [1, 2]
ks = metric.split("@")
if len(ks) > 1:
hit_list = [int(token) for token in ks[1].split(";")]
for k in hit_list:
hit_temp = np.mean(
[
hit_score(each_labels, each_preds, k)
for each_labels, each_preds in zip(labels, preds)
]
)
res["hit@{0}".format(k)] = round(hit_temp, 4)
elif metric == "group_auc":
group_auc = np.mean(
[
roc_auc_score(each_labels, each_preds)
for each_labels, each_preds in zip(labels, preds)
]
)
res["group_auc"] = round(group_auc, 4)
else:
raise ValueError("Metric {0} not defined".format(metric))
return res
def word_tokenize(sent):
"""Split sentence into word list using regex.
Args:
sent (str): Input sentence
Return:
list: word list
"""
pat = re.compile(r"[\w]+|[.,!?;|]")
if isinstance(sent, str):
return pat.findall(sent.lower())
else:
return []
def newsample(news, ratio):
"""Sample ratio samples from news list.
If length of news is less than ratio, pad zeros.
Args:
news (list): input news list
ratio (int): sample number
Returns:
list: output of sample list.
"""
if ratio > len(news):
return news + [0] * (ratio - len(news))
else:
return random.sample(news, ratio)
def abstractmethod(funcobj):
"""A decorator indicating abstract methods.
Requires that the metaclass is ABCMeta or derived from it. A
class that has a metaclass derived from ABCMeta cannot be
instantiated unless all of its abstract methods are overridden.
The abstract methods can be called using any of the normal
'super' call mechanisms. abstractmethod() may be used to declare
abstract methods for properties and descriptors.
Usage:
class C(metaclass=ABCMeta):
@abstractmethod
def my_abstract_method(self, ...):
...
"""
funcobj.__isabstractmethod__ = True
return funcobj
class BaseIterator(object):
"""Abstract base iterator class"""
@abstractmethod
def parser_one_line(self, line):
"""Abstract method. Parse one string line into feature values.
Args:
line (str): A string indicating one instance.
"""
pass
@abstractmethod
def load_data_from_file(self, infile):
"""Abstract method. Read and parse data from a file.
Args:
infile (str): Text input file. Each line in this file is an instance.
"""
pass
@abstractmethod
def _convert_data(self, labels, features):
pass
@abstractmethod
def gen_feed_dict(self, data_dict):
"""Abstract method. Construct a dictionary that maps graph elements to values.
Args:
data_dict (dict): A dictionary that maps string name to numpy arrays.
"""
pass
def load_dict(file_path):
with open(file_path, "rb") as f:
return pickle.load(f)
class MINDIterator(BaseIterator):
"""Train data loader for NRMS model.
The model require a special type of data format, where each instance contains a label, impresion id, user id,
the candidate news articles and user's clicked news article. Articles are represented by title words,
body words, verts and subverts.
Iterator will not load the whole data into memory. Instead, it loads data into memory
per mini-batch, so that large files can be used as input data.
Attributes:
col_spliter (str): column spliter in one line.
ID_spliter (str): ID spliter in one line.
batch_size (int): the samples num in one batch.
title_size (int): max word num in news title.
his_size (int): max clicked news num in user click history.
npratio (int): negaive and positive ratio used in negative sampling. -1 means no need of negtive sampling.
"""
def __init__(
self,
hparams,
npratio=-1,
col_spliter="\t",
ID_spliter="%",
):
"""Initialize an iterator. Create necessary placeholders for the model.
Args:
hparams (object): Global hyper-parameters. Some key setttings such as head_num and head_dim are there.
npratio (int): negaive and positive ratio used in negative sampling. -1 means no need of negtive sampling.
col_spliter (str): column spliter in one line.
ID_spliter (str): ID spliter in one line.
"""
self.col_spliter = col_spliter
self.ID_spliter = ID_spliter
self.batch_size = hparams.batch_size
self.title_size = hparams.title_size
self.body_size = hparams.body_size
self.his_size = hparams.his_size
self.npratio = npratio
self.word_dict = self.load_dict(hparams.wordDict_file)
# self.cat_dict = self.load_dict(hparams.catDict_file)
# self.subcat_dict = self.load_dict(hparams.subcatDict_file)
# self.entity_dict = self.load_dict(hparams.entityDict_file)
# self.relation_dict = self.load_dict(hparams.relationDict_file)
self.uid2index = self.load_dict(hparams.userDict_file)
def load_dict(self, file_path):
"""load pickle file
Args:
file path (str): file path
Returns:
object: pickle loaded object
"""
with open(file_path, "rb") as f:
return pickle.load(f)
def init_news(self, news_file):
"""init news information given news file, such as news_title_index and nid2index.
Args:
news_file: path of news file
"""
self.nid2index = {}
news_title = [""]
# news_cat = [""]
# news_subcat = [""]
news_abstract = [""]
# news_entitites = [""]
# news_relation = [""]
with tf.io.gfile.GFile(news_file, "r") as rd:
for line in rd:
nid, cat, title, ab, content = line.strip("\n").split(self.col_spliter)
if nid in self.nid2index:
continue
self.nid2index[nid] = len(self.nid2index) + 1
title = word_tokenize(title)
if ab is None:
abstract = ""
else:
abstract = word_tokenize(ab)
news_title.append(title)
# news_cat.append(cat)
# news_subcat.append(subcat)
news_abstract.append(abstract)
# news_entities.append(entity)
# news_relation.append(relation)
self.news_title_index = np.zeros(
(len(news_title), self.title_size), dtype="int32"
)
self.news_abstract_index = np.zeros(
(len(news_abstract), self.body_size), dtype="int32"
)
# self.news_cat_index = np.zeros((len(news_cat), 1), dtype="int32")
# self.news_subcat_index = np.zeros((len(news_subcat, 1), dtype="int32")
for news_index in range(len(news_title)):
title = news_title[news_index]
abstract = news_abstract[news_index]
for word_index in range(min(self.title_size, len(title))):
if title[word_index] in self.word_dict:
self.news_title_index[news_index, word_index] = self.word_dict[
title[word_index].lower()
]
for word_index in range(min(self.body_size, len(abstract))):
if abstract[word_index] in self.word_dict:
self.news_abstract_index[news_index, word_index] = self.word_dict[
abstract[word_index].lower()
]
def init_behaviors(self, behaviors_file):
"""init behavior logs given behaviors file.
Args:
behaviors_file: path of behaviors file
"""
self.histories = []
self.imprs = []
self.labels = []
self.impr_indexes = []
self.uindexes = []
with tf.io.gfile.GFile(behaviors_file, "r") as rd:
impr_index = 0
for line in rd:
uid, history, impr, _ = line.strip("\n").split(self.col_spliter)[-4:]
history = [self.nid2index[i] for i in history.split()]
history = [0] * (self.his_size - len(history)) + history[
: self.his_size
]
impr_news = [self.nid2index[i.split("-")[0]] for i in impr.split()]
label = [int(i.split("-")[1]) for i in impr.split()]
uindex = self.uid2index[uid] if uid in self.uid2index else 0
self.histories.append(history)
self.imprs.append(impr_news)
self.labels.append(label)
self.impr_indexes.append(impr_index)
self.uindexes.append(uindex)
impr_index += 1
def parser_one_line(self, line):
"""Parse one behavior sample into feature values.
if npratio is larger than 0, return negtive sampled result.
Args:
line (int): sample index.
Yields:
list: Parsed results including label, impression id , user id,
candidate_title_index, clicked_title_index.
"""
if self.npratio > 0:
impr_label = self.labels[line]
impr = self.imprs[line]
poss = []
negs = []
for news, click in zip(impr, impr_label):
if click == 1:
poss.append(news)
else:
negs.append(news)
for p in poss:
candidate_title_index = []
candidate_abstract_index = []
impr_index = []
user_index = []
label = [1] + [0] * self.npratio
n = newsample(negs, self.npratio)
candidate_title_index = self.news_title_index[[p] + n]
candidate_abstract_index = self.news_abstract_index[[p] + n]
click_title_index = self.news_title_index[self.histories[line]]
click_abstract_index = self.news_abstract_index[self.histories[line]]
impr_index.append(self.impr_indexes[line])
user_index.append(self.uindexes[line])
yield (
label,
impr_index,
user_index,
candidate_title_index,
candidate_abstract_index,
click_title_index,
click_abstract_index,
)
else:
impr_label = self.labels[line]
impr = self.imprs[line]
for news, label in zip(impr, impr_label):
candidate_title_index = []
impr_index = []
user_index = []
label = [label]
candidate_title_index.append(self.news_title_index[news])
candidate_abstract_index = self.news_abstract_index[[p] + n]
click_title_index = self.news_title_index[self.histories[line]]
click_abstract_index = self.news_abstract_index[self.histories]
impr_index.append(self.impr_indexes[line])
user_index.append(self.uindexes[line])
yield (
label,
impr_index,
user_index,
candidate_title_index,
candidate_abstract_index,
click_title_index,
click_abstract_index,
)
def load_data_from_file(self, news_file, behavior_file):
"""Read and parse data from news file and behavior file.
Args:
news_file (str): A file contains several informations of news.
beahavior_file (str): A file contains information of user impressions.
Yields:
object: An iterator that yields parsed results, in the format of dict.
"""
if not hasattr(self, "news_title_index"):
self.init_news(news_file)
if not hasattr(self, "impr_indexes"):
self.init_behaviors(behavior_file)
label_list = []
imp_indexes = []
user_indexes = []
candidate_title_indexes = []
candidate_abstract_indexes = []
click_title_indexes = []
click_abstract_indexes = []
cnt = 0
indexes = np.arange(len(self.labels))
if self.npratio > 0:
np.random.shuffle(indexes)
for index in indexes:
for (
label,
imp_index,
user_index,
candidate_title_index,
candidate_abstract_index,
click_title_index,
click_abstract_index,
) in self.parser_one_line(index):
candidate_title_indexes.append(candidate_title_index)
candidate_abstract_indexes.append(candidate_abstract_index)
click_title_indexes.append(click_title_index)
click_abstract_indexes.append(click_abstract_index)
imp_indexes.append(imp_index)
user_indexes.append(user_index)
label_list.append(label)
cnt += 1
if cnt >= self.batch_size:
yield self._convert_data(
label_list,
imp_indexes,
user_indexes,
candidate_title_indexes,
candidate_abstract_indexes,
click_title_indexes,
click_abstract_indexes,
)
label_list = []
imp_indexes = []
user_indexes = []
candidate_title_indexes = []
candidate_abstract_indexes = []
click_title_indexes = []
click_abstract_indexes = []
cnt = 0
if cnt > 0:
yield self._convert_data(
label_list,
imp_indexes,
user_indexes,
candidate_title_indexes,
candidate_abstract_indexes,
click_title_indexes,
click_abstract_indexes,
)
def _convert_data(
self,
label_list,
imp_indexes,
user_indexes,
candidate_title_indexes,
candidate_abstract_indexes,
click_title_indexes,
click_abstract_indexes,
):
"""Convert data into numpy arrays that are good for further model operation.
Args:
label_list (list): a list of ground-truth labels.
imp_indexes (list): a list of impression indexes.
user_indexes (list): a list of user indexes.
candidate_title_indexes (list): the candidate news titles' words indices.
candidate_abstract_indexes (list): the candidate news abstract' words indices.
click_title_indexes (list): words indices for user's clicked news titles.
click_abstract_indexes (list): words indices for user's clicked news abstract.
Returns:
dict: A dictionary, containing multiple numpy arrays that are convenient for further operation.
"""
labels = np.asarray(label_list, dtype=np.float32)
imp_indexes = np.asarray(imp_indexes, dtype=np.int32)
user_indexes = np.asarray(user_indexes, dtype=np.int32)
candidate_title_index_batch = np.asarray(
candidate_title_indexes, dtype=np.int64
)
candidate_abstract_index_batch = np.asarray(
candidate_abstract_indexes, dtype=np.int64
)
click_title_index_batch = np.asarray(click_title_indexes, dtype=np.int64)
click_abstract_index_batch = np.asarray(click_abstract_indexes, dtype=np.int64)
return {
"impression_index_batch": imp_indexes,
"user_index_batch": user_indexes,
"clicked_title_batch": click_title_index_batch,
"clicked_abstract_batch": click_abstract_index_batch,
"candidate_title_batch": candidate_title_index_batch,
"candidate_abstract_batch": candidate_abstract_index_batch,
"labels": labels,
}
def load_user_from_file(self, news_file, behavior_file):
"""Read and parse user data from news file and behavior file.
Args:
news_file (str): A file contains several informations of news.
beahaviros_file (str): A file contains information of user impressions.
Yields:
object: An iterator that yields parsed user feature, in the format of dict.
"""
if not hasattr(self, "news_title_index"):
self.init_news(news_file)
if not hasattr(self, "impr_indexes"):
self.init_behaviors(behavior_file)
user_indexes = []
impr_indexes = []
click_title_indexes = []
click_abstract_indexes = []
cnt = 0
for index in range(len(self.impr_indexes)):
click_title_indexes.append(self.news_title_index[self.histories[index]])
click_abstract_indexes.append(
self.news_abstract_index[self.histories[index]]
)
user_indexes.append(self.uindexes[index])
impr_indexes.append(self.impr_indexes[index])
cnt += 1
if cnt >= self.batch_size:
yield self._convert_user_data(
user_indexes,
impr_indexes,
click_title_indexes,
click_abstract_indexes,
)
user_indexes = []
impr_indexes = []
click_title_indexes = []
click_abstract_indexes = []
cnt = 0
if cnt > 0:
yield self._convert_user_data(
user_indexes, impr_indexes, click_title_indexes, click_abstract_indexes
)
def _convert_user_data(
self, user_indexes, impr_indexes, click_title_indexes, click_abstract_indexes
):
"""Convert data into numpy arrays that are good for further model operation.
Args:
user_indexes (list): a list of user indexes.
click_title_indexes (list): words indices for user's clicked news titles.
Returns:
dict: A dictionary, containing multiple numpy arrays that are convenient for further operation.
"""
user_indexes = np.asarray(user_indexes, dtype=np.int32)
impr_indexes = np.asarray(impr_indexes, dtype=np.int32)
click_title_index_batch = np.asarray(click_title_indexes, dtype=np.int64)
click_abstract_index_batch = np.asarray(click_abstract_indexes, dtype=np.int64)
return {
"user_index_batch": user_indexes,
"impr_index_batch": impr_indexes,
"clicked_title_batch": click_title_index_batch,
"clicked_abstract_batch": click_abstract_index_batch,
}
def load_news_from_file(self, news_file):
"""Read and parse user data from news file.
Args:
news_file (str): A file contains several informations of news.
Yields:
object: An iterator that yields parsed news feature, in the format of dict.
"""
if not hasattr(self, "news_title_index"):
self.init_news(news_file)
news_indexes = []
candidate_title_indexes = []
candidate_abstract_indexes = []
cnt = 0
for index in range(len(self.news_title_index)):
news_indexes.append(index)
candidate_title_indexes.append(self.news_title_index[index])
candidate_abstract_indexes.append(self.news_abstract_index[index])
cnt += 1
if cnt >= self.batch_size:
yield self._convert_news_data(
news_indexes, candidate_title_indexes, candidate_abstract_indexes
)
news_indexes = []
candidate_title_indexes = []
candidate_abstract_indexes = []
cnt = 0
if cnt > 0:
yield self._convert_news_data(
news_indexes, candidate_title_indexes, candidate_abstract_indexes
)
def _convert_news_data(
self, news_indexes, candidate_title_indexes, candidate_abstract_indexes
):
"""Convert data into numpy arrays that are good for further model operation.
Args:
news_indexes (list): a list of news indexes.
candidate_title_indexes (list): the candidate news titles' words indices.
Returns:
dict: A dictionary, containing multiple numpy arrays that are convenient for further operation.
"""
news_indexes_batch = np.asarray(news_indexes, dtype=np.int32)
candidate_title_index_batch = np.asarray(
candidate_title_indexes, dtype=np.int32
)
candidate_abstract_index_batch = np.asarray(
candidate_abstract_indexes, dtype=np.int32
)
return {
"news_index_batch": news_indexes_batch,
"candidate_title_batch": candidate_title_index_batch,
"candidate_abstract_batch": candidate_abstract_index_batch,
}
def load_impression_from_file(self, behaivors_file):
"""Read and parse impression data from behaivors file.
Args:
behaivors_file (str): A file contains several informations of behaviros.
Yields:
object: An iterator that yields parsed impression data, in the format of dict.
"""
if not hasattr(self, "histories"):
self.init_behaviors(behaivors_file)
indexes = np.arange(len(self.labels))
for index in indexes:
impr_label = np.array(self.labels[index], dtype="int32")
impr_news = np.array(self.imprs[index], dtype="int32")
yield (
self.impr_indexes[index],
impr_news,
self.uindexes[index],
impr_label,
)
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License.
class AttLayer2(layers.Layer):
"""Soft alignment attention implement.
Attributes:
dim (int): attention hidden dim
"""
def __init__(self, dim=200, seed=0, **kwargs):
"""Initialization steps for AttLayer2.
Args:
dim (int): attention hidden dim
"""
self.dim = dim
self.seed = seed
super(AttLayer2, self).__init__(**kwargs)
def build(self, input_shape):
"""Initialization for variables in AttLayer2
There are there variables in AttLayer2, i.e. W, b and q.
Args:
input_shape (object): shape of input tensor.
"""
assert len(input_shape) == 3
dim = self.dim
self.W = self.add_weight(
name="W",
shape=(int(input_shape[-1]), dim),
initializer=keras.initializers.glorot_uniform(seed=self.seed),
trainable=True,
)
self.b = self.add_weight(
name="b",
shape=(dim,),
initializer=keras.initializers.Zeros(),
trainable=True,
)
self.q = self.add_weight(
name="q",
shape=(dim, 1),
initializer=keras.initializers.glorot_uniform(seed=self.seed),
trainable=True,
)
super(AttLayer2, self).build(input_shape) # be sure you call this somewhere!
def call(self, inputs, mask=None, **kwargs):
"""Core implemention of soft attention
Args:
inputs (object): input tensor.
Returns:
object: weighted sum of input tensors.
"""
attention = K.tanh(K.dot(inputs, self.W) + self.b)
attention = K.dot(attention, self.q)
attention = K.squeeze(attention, axis=2)
if mask == None:
attention = K.exp(attention)
else:
attention = K.exp(attention) * K.cast(mask, dtype="float32")
attention_weight = attention / (
K.sum(attention, axis=-1, keepdims=True) + K.epsilon()
)
attention_weight = K.expand_dims(attention_weight)
weighted_input = inputs * attention_weight
return K.sum(weighted_input, axis=1)
def compute_mask(self, input, input_mask=None):
"""Compte output mask value
Args:
input (object): input tensor.
input_mask: input mask
Returns:
object: output mask.
"""
return None
def compute_output_shape(self, input_shape):
"""Compute shape of output tensor
Args:
input_shape (tuple): shape of input tensor.
Returns:
tuple: shape of output tensor.
"""
return input_shape[0], input_shape[-1]
class SelfAttention(layers.Layer):
"""Multi-head self attention implement.
Args:
multiheads (int): The number of heads.
head_dim (object): Dimention of each head.
mask_right (boolean): whether to mask right words.
Returns:
object: Weighted sum after attention.
"""
def __init__(self, multiheads, head_dim, seed=0, mask_right=False, **kwargs):
"""Initialization steps for AttLayer2.
Args:
multiheads (int): The number of heads.
head_dim (object): Dimention of each head.
mask_right (boolean): whether to mask right words.
"""
self.multiheads = multiheads
self.head_dim = head_dim
self.output_dim = multiheads * head_dim
self.mask_right = mask_right
self.seed = seed
super(SelfAttention, self).__init__(**kwargs)
def compute_output_shape(self, input_shape):
"""Compute shape of output tensor.
Returns:
tuple: output shape tuple.
"""
return (input_shape[0][0], input_shape[0][1], self.output_dim)
def build(self, input_shape):
"""Initialization for variables in SelfAttention.
There are three variables in SelfAttention, i.e. WQ, WK ans WV.
WQ is used for linear transformation of query.
WK is used for linear transformation of key.
WV is used for linear transformation of value.
Args:
input_shape (object): shape of input tensor.
"""
self.WQ = self.add_weight(
name="WQ",
shape=(int(input_shape[0][-1]), self.output_dim),
initializer=keras.initializers.glorot_uniform(seed=self.seed),
trainable=True,
)
self.WK = self.add_weight(
name="WK",
shape=(int(input_shape[1][-1]), self.output_dim),
initializer=keras.initializers.glorot_uniform(seed=self.seed),
trainable=True,
)
self.WV = self.add_weight(
name="WV",
shape=(int(input_shape[2][-1]), self.output_dim),
initializer=keras.initializers.glorot_uniform(seed=self.seed),
trainable=True,
)
super(SelfAttention, self).build(input_shape)
def Mask(self, inputs, seq_len, mode="add"):
"""Mask operation used in multi-head self attention
Args:
seq_len (object): sequence length of inputs.
mode (str): mode of mask.
Returns:
object: tensors after masking.
"""
if seq_len == None:
return inputs
else:
mask = K.one_hot(indices=seq_len[:, 0], num_classes=K.shape(inputs)[1])
mask = 1 - K.cumsum(mask, axis=1)
for _ in range(len(inputs.shape) - 2):
mask = K.expand_dims(mask, 2)
if mode == "mul":
return inputs * mask
elif mode == "add":
return inputs - (1 - mask) * 1e12
def call(self, QKVs):
"""Core logic of multi-head self attention.
Args:
QKVs (list): inputs of multi-head self attention i.e. qeury, key and value.
Returns:
object: ouput tensors.
"""
if len(QKVs) == 3:
Q_seq, K_seq, V_seq = QKVs
Q_len, V_len = None, None
elif len(QKVs) == 5:
Q_seq, K_seq, V_seq, Q_len, V_len = QKVs
Q_seq = K.dot(Q_seq, self.WQ)
Q_seq = K.reshape(
Q_seq, shape=(-1, K.shape(Q_seq)[1], self.multiheads, self.head_dim)
)
Q_seq = K.permute_dimensions(Q_seq, pattern=(0, 2, 1, 3))
K_seq = K.dot(K_seq, self.WK)
K_seq = K.reshape(
K_seq, shape=(-1, K.shape(K_seq)[1], self.multiheads, self.head_dim)
)
K_seq = K.permute_dimensions(K_seq, pattern=(0, 2, 1, 3))
V_seq = K.dot(V_seq, self.WV)
V_seq = K.reshape(
V_seq, shape=(-1, K.shape(V_seq)[1], self.multiheads, self.head_dim)
)
V_seq = K.permute_dimensions(V_seq, pattern=(0, 2, 1, 3))
# tf.einsum('m b i k, m b j k -> m b i j', Q_seq , K_seq) # shape [10, 20, 50]
A = tf.einsum("m b i k, m b j k -> m b i j", Q_seq, K_seq) / K.sqrt(
K.cast(self.head_dim, dtype="float32")
)
A = K.permute_dimensions(
A, pattern=(0, 3, 2, 1)
) # A.shape=[batch_size,K_sequence_length,Q_sequence_length,self.multiheads]
A = self.Mask(A, V_len, "add")
A = K.permute_dimensions(A, pattern=(0, 3, 2, 1))
if self.mask_right:
ones = K.ones_like(A[:1, :1])
lower_triangular = K.tf.matrix_band_part(ones, num_lower=-1, num_upper=0)
mask = (ones - lower_triangular) * 1e12
A = A - mask
A = K.softmax(A)
# tf.einsum('m b i k, m b k j -> m b i j', A , V_seq)
O_seq = tf.einsum("m b i k, m b k j -> m b i j", A, V_seq)
O_seq = K.permute_dimensions(O_seq, pattern=(0, 2, 1, 3))
O_seq = K.reshape(O_seq, shape=(-1, K.shape(O_seq)[1], self.output_dim))
O_seq = self.Mask(O_seq, Q_len, "mul")
return O_seq
def get_config(self):
"""add multiheads, multiheads and mask_right into layer config.
Returns:
dict: config of SelfAttention layer.
"""
config = super(SelfAttention, self).get_config()
config.update(
{
"multiheads": self.multiheads,
"head_dim": self.head_dim,
"mask_right": self.mask_right,
}
)
return config
__all__ = ["BaseModel"]
class BaseModel:
"""Basic class of models
Attributes:
hparams (object): A tf.contrib.training.HParams object, hold the entire set of hyperparameters.
train_iterator (object): An iterator to load the data in training steps.
test_iterator (object): An iterator to load the data in testing steps.
graph (object): An optional graph.
seed (int): Random seed.
"""
def __init__(
self,
hparams,
iterator_creator,
seed=None,
):
"""Initializing the model. Create common logics which are needed by all deeprec models, such as loss function,
parameter set.
Args:
hparams (object): A tf.contrib.training.HParams object, hold the entire set of hyperparameters.
iterator_creator (object): An iterator to load the data.
graph (object): An optional graph.
seed (int): Random seed.
"""
self.seed = seed
tf.compat.v1.set_random_seed(seed)
np.random.seed(seed)
self.train_iterator = iterator_creator(
hparams,
hparams.npratio,
col_spliter="\t",
)
self.test_iterator = iterator_creator(
hparams,
col_spliter="\t",
)
self.hparams = hparams
self.support_quick_scoring = hparams.support_quick_scoring
self.model, self.scorer = self._build_graph()
self.loss = self._get_loss()
self.train_optimizer = self._get_opt()
self.model.compile(loss=self.loss, optimizer=self.train_optimizer)
def _init_embedding(self, file_path):
"""Load pre-trained embeddings as a constant tensor.
Args:
file_path (str): the pre-trained glove embeddings file path.
Returns:
numpy.ndarray: A constant numpy array.
"""
return np.load(file_path)
@abc.abstractmethod
def _build_graph(self):
"""Subclass will implement this."""
pass
@abc.abstractmethod
def _get_input_label_from_iter(self, batch_data):
"""Subclass will implement this"""
pass
def _get_loss(self):
"""Make loss function, consists of data loss and regularization loss
Returns:
object: Loss function or loss function name
"""
if self.hparams.loss == "cross_entropy_loss":
data_loss = "categorical_crossentropy"
elif self.hparams.loss == "log_loss":
data_loss = "binary_crossentropy"
else:
raise ValueError("this loss not defined {0}".format(self.hparams.loss))
return data_loss
def _get_opt(self):
"""Get the optimizer according to configuration. Usually we will use Adam.
Returns:
object: An optimizer.
"""
lr = self.hparams.learning_rate
optimizer = self.hparams.optimizer
if optimizer == "adam":
train_opt = tf.keras.optimizers.Adam(lr=lr)
return train_opt
def _get_pred(self, logit, task):
"""Make final output as prediction score, according to different tasks.
Args:
logit (object): Base prediction value.
task (str): A task (values: regression/classification)
Returns:
object: Transformed score
"""
if task == "regression":
pred = tf.identity(logit)
elif task == "classification":
pred = tf.sigmoid(logit)
else:
raise ValueError(
"method must be regression or classification, but now is {0}".format(
task
)
)
return pred
def train(self, train_batch_data):
"""Go through the optimization step once with training data in feed_dict.
Args:
sess (object): The model session object.
feed_dict (dict): Feed values to train the model. This is a dictionary that maps graph elements to values.
Returns:
list: A list of values, including update operation, total loss, data loss, and merged summary.
"""
train_input, train_label = self._get_input_label_from_iter(train_batch_data)
rslt = self.model.train_on_batch(train_input, train_label)
return rslt
def eval(self, eval_batch_data):
"""Evaluate the data in feed_dict with current model.
Args:
sess (object): The model session object.
feed_dict (dict): Feed values for evaluation. This is a dictionary that maps graph elements to values.
Returns:
list: A list of evaluated results, including total loss value, data loss value, predicted scores, and ground-truth labels.
"""
eval_input, eval_label = self._get_input_label_from_iter(eval_batch_data)
imp_index = eval_batch_data["impression_index_batch"]
pred_rslt = self.scorer.predict_on_batch(eval_input)
return pred_rslt, eval_label, imp_index
def fit(
self,
train_news_file,
train_behaviors_file,
valid_news_file,
valid_behaviors_file,
test_news_file=None,
test_behaviors_file=None,
):
"""Fit the model with train_file. Evaluate the model on valid_file per epoch to observe the training status.
If test_news_file is not None, evaluate it too.
Args:
train_file (str): training data set.
valid_file (str): validation set.
test_news_file (str): test set.
Returns:
object: An instance of self.
"""
self.history = {}
self.history["train_loss"] = []
self.history["val_loss"] = []
self.history["Val_auc"] = []
for epoch in range(1, self.hparams.epochs + 1):
step = 0
# self.hparams.current_epoch = epoch
epoch_loss = 0
train_start = time.time()
tqdm_util = tqdm(
self.train_iterator.load_data_from_file(
train_news_file, train_behaviors_file
)
)
for batch_data_input in tqdm_util:
step_result = self.train(batch_data_input)
step_data_loss = step_result
epoch_loss += step_data_loss
step += 1
if step % self.hparams.show_step == 0:
tqdm_util.set_description(
"step {0:d} , total_loss: {1:.4f}, data_loss: {2:.4f}".format(
step, epoch_loss / step, step_data_loss
)
)
self.history["train_loss"].append(epoch_loss / step)
self.history["val_loss"].append(step_data_loss)
train_end = time.time()
train_time = train_end - train_start
eval_start = time.time()
train_info = ",".join(
[
str(item[0]) + ":" + str(item[1])
for item in [("logloss loss", epoch_loss / step)]
]
)
eval_res = self.run_eval(valid_news_file, valid_behaviors_file)
eval_info = ", ".join(
[
str(item[0]) + ":" + str(item[1])
for item in sorted(eval_res.items(), key=lambda x: x[0])
]
)
if test_news_file is not None:
test_res = self.run_eval(test_news_file, test_behaviors_file)
test_info = ", ".join(
[
str(item[0]) + ":" + str(item[1])
for item in sorted(test_res.items(), key=lambda x: x[0])
]
)
eval_end = time.time()
eval_time = eval_end - eval_start
if test_news_file is not None:
print(
"at epoch {0:d}".format(epoch)
+ "\ntrain info: "
+ train_info
+ "\neval info: "
+ eval_info
+ "\ntest info: "
+ test_info
)
else:
print(
"at epoch {0:d}".format(epoch)
+ "\ntrain info: "
+ train_info
+ "\neval info: "
+ eval_info
)
print(
"at epoch {0:d} , train time: {1:.1f} eval time: {2:.1f}".format(
epoch, train_time, eval_time
)
)
return self
def group_labels(self, labels, preds, group_keys):
"""Devide labels and preds into several group according to values in group keys.
Args:
labels (list): ground truth label list.
preds (list): prediction score list.
group_keys (list): group key list.
Returns:
list, list, list:
- Keys after group.
- Labels after group.
- Preds after group.
"""
all_keys = list(set(group_keys))
all_keys.sort()
group_labels = {k: [] for k in all_keys}
group_preds = {k: [] for k in all_keys}
for l, p, k in zip(labels, preds, group_keys):
group_labels[k].append(l)
group_preds[k].append(p)
all_labels = []
all_preds = []
for k in all_keys:
all_labels.append(group_labels[k])
all_preds.append(group_preds[k])
return all_keys, all_labels, all_preds
def run_eval(self, news_filename, behaviors_file):
"""Evaluate the given file and returns some evaluation metrics.
Args:
filename (str): A file name that will be evaluated.
Returns:
dict: A dictionary that contains evaluation metrics.
"""
if self.support_quick_scoring:
_, group_labels, group_preds = self.run_fast_eval(
news_filename, behaviors_file
)
else:
_, group_labels, group_preds = self.run_slow_eval(
news_filename, behaviors_file
)
res = cal_metric(group_labels, group_preds, self.hparams.metrics)
return res
def user(self, batch_user_input):
user_input = self._get_user_feature_from_iter(batch_user_input)
user_vec = self.userencoder.predict_on_batch(user_input)
user_index = batch_user_input["impr_index_batch"]
return user_index, user_vec
def news(self, batch_news_input):
news_input = self._get_news_feature_from_iter(batch_news_input)
news_vec = self.newsencoder.predict_on_batch(news_input)
news_index = batch_news_input["news_index_batch"]
return news_index, news_vec
def run_user(self, news_filename, behaviors_file):
if not hasattr(self, "userencoder"):
raise ValueError("model must have attribute userencoder")
user_indexes = []
user_vecs = []
for batch_data_input in tqdm(
self.test_iterator.load_user_from_file(news_filename, behaviors_file)
):
# print("\nbatch_data_input:", batch_data_input)
user_index, user_vec = self.user(batch_data_input)
user_indexes.extend(np.reshape(user_index, -1))
user_vecs.extend(user_vec)
return dict(zip(user_indexes, user_vecs))
def run_news(self, news_filename):
if not hasattr(self, "newsencoder"):
raise ValueError("model must have attribute newsencoder")
news_indexes = []
news_vecs = []
for batch_data_input in tqdm(
self.test_iterator.load_news_from_file(news_filename)
):
news_index, news_vec = self.news(batch_data_input)
news_indexes.extend(np.reshape(news_index, -1))
news_vecs.extend(news_vec)
return dict(zip(news_indexes, news_vecs))
def run_slow_eval(self, news_filename, behaviors_file):
preds = []
labels = []
imp_indexes = []
for batch_data_input in tqdm(
self.test_iterator.load_data_from_file(news_filename, behaviors_file)
):
step_pred, step_labels, step_imp_index = self.eval(batch_data_input)
preds.extend(np.reshape(step_pred, -1))
labels.extend(np.reshape(step_labels, -1))
imp_indexes.extend(np.reshape(step_imp_index, -1))
group_impr_indexes, group_labels, group_preds = self.group_labels(
labels, preds, imp_indexes
)
return group_impr_indexes, group_labels, group_preds
def run_fast_eval(self, news_filename, behaviors_file):
news_vecs = self.run_news(news_filename)
user_vecs = self.run_user(news_filename, behaviors_file)
self.news_vecs = news_vecs
self.user_vecs = user_vecs
group_impr_indexes = []
group_labels = []
group_preds = []
for (
impr_index,
news_index,
user_index,
label,
) in tqdm(self.test_iterator.load_impression_from_file(behaviors_file)):
pred = np.dot(
np.stack([news_vecs[i] for i in news_index], axis=0),
user_vecs[impr_index],
)
group_impr_indexes.append(impr_index)
group_labels.append(label)
group_preds.append(pred)
return group_impr_indexes, group_labels, group_preds
# Copyright (c) Microsoft Corporation. All rights reserved.
# Licensed under the MIT License.
__all__ = ["NRMSModel"]
class NRMSModel(BaseModel):
"""NRMS model(Neural News Recommendation with Multi-Head Self-Attention)
Chuhan Wu, Fangzhao Wu, Suyu Ge, Tao Qi, Yongfeng Huang,and Xing Xie, "Neural News
Recommendation with Multi-Head Self-Attention" in Proceedings of the 2019 Conference
on Empirical Methods in Natural Language Processing and the 9th International Joint Conference
on Natural Language Processing (EMNLP-IJCNLP)
Attributes:
word2vec_embedding (numpy.ndarray): Pretrained word embedding matrix.
hparam (object): Global hyper-parameters.
"""
def __init__(
self,
hparams,
iterator_creator,
seed=None,
):
"""Initialization steps for NRMS.
Compared with the BaseModel, NRMS need word embedding.
After creating word embedding matrix, BaseModel's __init__ method will be called.
Args:
hparams (object): Global hyper-parameters. Some key setttings such as head_num and head_dim are there.
iterator_creator_train (object): NRMS data loader class for train data.
iterator_creator_test (object): NRMS data loader class for test and validation data
"""
self.word2vec_embedding = self._init_embedding(hparams.wordEmb_file)
super().__init__(
hparams,
iterator_creator,
seed=seed,
)
def _get_input_label_from_iter(self, batch_data):
"""get input and labels for trainning from iterator
Args:
batch data: input batch data from iterator
Returns:
list: input feature fed into model (clicked_title_batch & candidate_title_batch)
numpy.ndarray: labels
"""
input_feat = [
batch_data["clicked_title_batch"],
batch_data["clicked_abstract_batch"],
batch_data["candidate_title_batch"],
batch_data["candidate_abstract_batch"],
]
input_label = batch_data["labels"]
return input_feat, input_label
def _get_user_feature_from_iter(self, batch_data):
"""get input of user encoder
Args:
batch_data: input batch data from user iterator
Returns:
numpy.ndarray: input user feature (clicked title batch)
"""
# print("\nclicked_title_batch:", batch_data["clicked_title_batch"].shape)
# print("\nclicked_abstract_batch:", batch_data["clicked_abstract_batch"].shape)
input_feature = [
batch_data["clicked_title_batch"],
batch_data["clicked_abstract_batch"],
]
input_feature = np.concatenate(input_feature, axis=-1)
# print("\ninput_feature:", input_feature.shape)
return input_feature
def _get_news_feature_from_iter(self, batch_data):
"""get input of news encoder
Args:
batch_data: input batch data from news iterator
Returns:
numpy.ndarray: input news feature (candidate title batch)
"""
input_feature = [
batch_data["candidate_title_batch"],
batch_data["candidate_abstract_batch"],
]
input_feature = np.concatenate(input_feature, axis=-1)
return input_feature
def _build_graph(self):
"""Build NRMS model and scorer.
Returns:
object: a model used to train.
object: a model used to evaluate and inference.
"""
hparams = self.hparams
model, scorer = self._build_nrms()
return model, scorer
def _build_userencoder(self, newsencoder):
"""The main function to create user encoder of NRMS.
Args:
newsencoder (object): the news encoder of NRMS.
Return:
object: the user encoder of NRMS.
"""
hparams = self.hparams
his_input_title_abstract = keras.Input(
shape=(hparams.his_size, hparams.title_size + hparams.body_size),
dtype="int32",
)
click_new_presents = layers.TimeDistributed(newsencoder)(
his_input_title_abstract
)
y = SelfAttention(hparams.head_num, hparams.head_dim, seed=self.seed)(
[click_new_presents] * 3
)
user_present = AttLayer2(hparams.attention_hidden_dim, seed=self.seed)(y)
model = keras.Model(his_input_title_abstract, user_present, name="user_encoder")
print("\n", model.summary())
return model
def _build_newsencoder(self, embedding_layer):
"""The main function to create news encoder of NRMS.
Args:
embedding_layer (object): a word embedding layer.
Return:
object: the news encoder of NRMS
"""
hparams = self.hparams
input_title_abstract = tf.keras.Input(
shape=(hparams.title_size + hparams.body_size,), dtype="int32"
)
# print("\ninput_title_abstract:", input_title_abstract)
sequences_input_title = layers.Lambda(lambda x: x[:, : hparams.title_size])(
input_title_abstract
)
# print("\nsequences_input_title:", sequences_input_title)
sequences_input_abstract = layers.Lambda(
lambda x: x[:, hparams.title_size : hparams.title_size + hparams.body_size]
)(input_title_abstract)
title_rep = self._build_titleencoder(embedding_layer)(sequences_input_title)
abstract_rep = self._build_abstractencoder(embedding_layer)(
sequences_input_abstract
)
# print("title_rep:", title_rep)
# print("abstract_rep:", abstract_rep)
concate_rep = layers.Concatenate(axis=-2)([title_rep, abstract_rep])
y = SelfAttention(hparams.head_num, hparams.head_dim, seed=self.seed)(
[concate_rep, concate_rep, concate_rep]
)
pred_title = AttLayer2(hparams.attention_hidden_dim, seed=self.seed)(y)
model = keras.Model(input_title_abstract, pred_title, name="news_encoder")
print("\n", model.summary())
return model
def _build_titleencoder(self, embedding_layer):
hparams = self.hparams
sequences_input_title = keras.Input(shape=(hparams.title_size,), dtype="int32")
embedded_sequences_title = embedding_layer(sequences_input_title)
y = layers.Dropout(hparams.dropout)(embedded_sequences_title)
y = SelfAttention(hparams.head_num, hparams.head_dim, seed=self.seed)([y, y, y])
y = layers.Dropout(hparams.dropout)(y)
pred_title = AttLayer2(hparams.attention_hidden_dim, seed=self.seed)(y)
pred_title = layers.Reshape((1, 400))(pred_title)
model = keras.Model(sequences_input_title, pred_title, name="title_encoder")
print("\n", model.summary())
return model
def _build_abstractencoder(self, embedding_layer):
hparams = self.hparams
sequences_input_abstract = keras.Input(
shape=(hparams.body_size,), dtype="int32"
)
embedded_sequences_abstract = embedding_layer(sequences_input_abstract)
y = layers.Dropout(hparams.dropout)(embedded_sequences_abstract)
y = SelfAttention(hparams.head_num, hparams.head_dim, seed=self.seed)([y, y, y])
y = layers.Dropout(hparams.dropout)(y)
pred_abstract = AttLayer2(hparams.attention_hidden_dim, seed=self.seed)(y)
pred_abstract = layers.Reshape((1, 400))(pred_abstract)
model = keras.Model(
sequences_input_abstract, pred_abstract, name="abstract_encoder"
)
print("\n", model.summary())
return model
def _build_nrms(self):
"""The main function to create NRMS's logic. The core of NRMS
is a user encoder and a news encoder.
Returns:
object: a model used to train.
object: a model used to evaluate and inference.
"""
hparams = self.hparams
his_input_title = keras.Input(
shape=(hparams.his_size, hparams.title_size), dtype="int32"
)
his_input_abstract = keras.Input(
shape=(hparams.his_size, hparams.body_size), dtype="int32"
)
pred_input_title = keras.Input(
shape=(hparams.npratio + 1, hparams.title_size), dtype="int32"
)
pred_input_abstract = keras.Input(
shape=(hparams.npratio + 1, hparams.body_size), dtype="int32"
)
pred_input_title_one = keras.Input(
shape=(
1,
hparams.title_size,
),
dtype="int32",
)
pred_input_abstract_one = keras.Input(
shape=(
1,
hparams.body_size,
),
dtype="int32",
)
his_title_abstract = layers.Concatenate(axis=-1)(
[his_input_title, his_input_abstract]
)
pred_title_abstract = layers.Concatenate(axis=-1)(
[pred_input_title, pred_input_abstract]
)
pred_title_abstract_one = layers.Concatenate(axis=-1)(
[
pred_input_title_one,
pred_input_abstract_one,
]
)
pred_title_abstract_one = layers.Reshape((-1,))(pred_title_abstract_one)
embedding_layer = layers.Embedding(
self.word2vec_embedding.shape[0],
hparams.word_emb_dim,
weights=[self.word2vec_embedding],
trainable=True,
)
self.newsencoder = self._build_newsencoder(embedding_layer)
self.userencoder = self._build_userencoder(self.newsencoder)
user_present = self.userencoder(his_title_abstract)
# print("\npred_title_abstract:", pred_title_abstract)
news_present = layers.TimeDistributed(self.newsencoder)(pred_title_abstract)
news_present_one = self.newsencoder(pred_title_abstract_one)
preds = layers.Dot(axes=-1)([news_present, user_present])
preds = layers.Activation(activation="softmax")(preds)
pred_one = layers.Dot(axes=-1)([news_present_one, user_present])
pred_one = layers.Activation(activation="sigmoid")(pred_one)
model = keras.Model(
[
his_input_title,
his_input_abstract,
pred_input_title,
pred_input_abstract,
],
preds,
)
scorer = keras.Model(
[
his_input_title,
his_input_abstract,
pred_input_title_one,
pred_input_abstract_one,
],
pred_one,
)
print("\n", model.summary())
return model, scorer
data_path = "/kaggle/input/mindlike-final/"
train_news_file = os.path.join(data_path, r"news_train.tsv")
train_behaviors_file = os.path.join(data_path, r"behaviors_train.tsv")
valid_news_file = os.path.join(data_path, r"news_val.tsv")
valid_behaviors_file = os.path.join(data_path, r"behaviors_val.tsv")
# test_news_file = os.path.join(data_path, r'news_test.tsv')
# est_behaviors_file = os.path.join(data_path, r'behaviors_test.tsv')
iterator = MINDIterator
with tpu_strategy.scope():
model = NRMSModel(hparams, iterator)
# print(model.run_eval(train_news_file, train_behaviors_file))
# print("\n", model.run_eval(valid_news_file, valid_behaviors_file))
# %%time
model.fit(train_news_file, train_behaviors_file, valid_news_file, valid_behaviors_file)
model.model.save_weights("/kaggle/working/models/nrms_ckpt")
# adsasd
# model.model.save("/kaggle/working/model.ckpt")
#!cd /kaggle/working
#!zip -r file1.zip /kaggle/working/model.ckpt
def init_behaviors2(iterator, behaviors_file):
"""init behavior logs given behaviors file.
Args:
behaviors_file: path of behaviors file
"""
iterator.histories = []
iterator.imprs = []
iterator.labels = []
iterator.impr_indexes = []
iterator.uindexes = []
with tf.io.gfile.GFile(behaviors_file, "r") as rd:
impr_index = 0
for line in rd:
uid, time, history, impr = line.strip("\n").split(iterator.col_spliter)[-4:]
history = [iterator.nid2index[i] for i in history.split()]
history = [0] * (iterator.his_size - len(history)) + history[
: iterator.his_size
]
impr_news = [iterator.nid2index[i.split("-")[0]] for i in impr.split()]
label = [0 for i in impr.split()]
uindex = iterator.uid2index[uid] if uid in iterator.uid2index else 0
iterator.histories.append(history)
iterator.imprs.append(impr_news)
iterator.labels.append(label)
iterator.impr_indexes.append(impr_index)
iterator.uindexes.append(uindex)
impr_index += 1
def load_impression_from_file2(iterator, behaivors_file):
"""Read and parse impression data from behaivors file.
Args:
behaivors_file (str): A file contains several informations of behaviros.
Yields:
object: An iterator that yields parsed impression data, in the format of dict.
"""
init_behaviors2(iterator, behaivors_file)
indexes = np.arange(len(iterator.labels))
for index in indexes:
impr_label = np.array(iterator.labels[index], dtype="int32")
impr_news = np.array(iterator.imprs[index], dtype="int32")
yield (
iterator.impr_indexes[index],
impr_news,
iterator.uindexes[index],
impr_label,
)
def load_user_from_file2(iterator, news_file, behavior_file):
"""Read and parse user data from news file and behavior file.
Args:
news_file (str): A file contains several informations of news.
beahaviros_file (str): A file contains information of user impressions.
Yields:
object: An iterator that yields parsed user feature, in the format of dict.
"""
iterator.init_news(news_file)
init_behaviors2(iterator, behavior_file)
user_indexes = []
impr_indexes = []
click_title_indexes = []
click_abstract_indexes = []
cnt = 0
for index in range(len(iterator.impr_indexes)):
click_title_indexes.append(iterator.news_title_index[iterator.histories[index]])
click_abstract_indexes.append(
iterator.news_abstract_index[iterator.histories[index]]
)
user_indexes.append(iterator.uindexes[index])
impr_indexes.append(iterator.impr_indexes[index])
cnt += 1
if cnt >= iterator.batch_size:
yield iterator._convert_user_data(
user_indexes, impr_indexes, click_title_indexes, click_abstract_indexes
)
user_indexes = []
impr_indexes = []
click_title_indexes = []
click_abstract_indexes = []
cnt = 0
if cnt > 0:
yield iterator._convert_user_data(
user_indexes, impr_indexes, click_title_indexes, click_abstract_indexes
)
def load_news_from_file2(iterator, news_file):
print(news_file)
"""Read and parse user data from news file.
Args:
news_file (str): A file contains several informations of news.
Yields:
object: An iterator that yields parsed news feature, in the format of dict.
"""
# if not hasattr(iterator, "news_title_index"):
iterator.init_news(news_file)
news_indexes = []
candidate_title_indexes = []
candidate_abstract_indexes = []
cnt = 0
for index in range(len(iterator.news_title_index)):
news_indexes.append(index)
candidate_title_indexes.append(iterator.news_title_index[index])
candidate_abstract_indexes.append(iterator.news_abstract_index[index])
cnt += 1
if cnt >= iterator.batch_size:
yield iterator._convert_news_data(
news_indexes, candidate_title_indexes, candidate_abstract_indexes
)
news_indexes = []
candidate_title_indexes = []
candidate_abstract_indexes = []
cnt = 0
if cnt > 0:
yield iterator._convert_news_data(
news_indexes, candidate_title_indexes, candidate_abstract_indexes
)
def run_news2(model, news_filename):
# print(news_filename)
if not hasattr(model, "newsencoder"):
raise ValueError("model must have attribute newsencoder")
news_indexes = []
news_vecs = []
for batch_data_input in tqdm(
load_news_from_file2(model.test_iterator, news_filename)
):
news_index, news_vec = model.news(batch_data_input)
news_indexes.extend(np.reshape(news_index, -1))
news_vecs.extend(news_vec)
return dict(zip(news_indexes, news_vecs))
def run_user2(model, news_filename, behaviors_file):
if not hasattr(model, "userencoder"):
raise ValueError("model must have attribute userencoder")
user_indexes = []
user_vecs = []
for batch_data_input in tqdm(
load_user_from_file2(model.test_iterator, news_filename, behaviors_file)
):
user_index, user_vec = model.user(batch_data_input)
user_indexes.extend(np.reshape(user_index, -1))
user_vecs.extend(user_vec)
return dict(zip(user_indexes, user_vecs))
def run_fast_eval2(model, news_filename, behaviors_file):
news_vecs = run_news2(model, news_filename)
# print(news_filename)
user_vecs = run_user2(model, news_filename, behaviors_file)
model.news_vecs = news_vecs
model.user_vecs = user_vecs
group_impr_indexes = []
group_labels = []
group_preds = []
for (
impr_index,
news_index,
user_index,
label,
) in tqdm(load_impression_from_file2(model.test_iterator, behaviors_file)):
pred = np.dot(
np.stack([news_vecs[i] for i in news_index], axis=0),
user_vecs[impr_index],
)
group_impr_indexes.append(impr_index)
group_labels.append(label)
group_preds.append(pred)
return group_impr_indexes, group_labels, group_preds
group_impr_indexes, group_labels, group_preds = run_fast_eval2(
model, test_news_file, test_behaviors_file
)
output_path = "/kaggle/working/"
with open(os.path.join(output_path, "prediction.txt"), "w") as f:
for impr_index, preds in tqdm(zip(group_impr_indexes, group_preds)):
impr_index += 1
pred_rank = (np.argsort(np.argsort(preds)[::-1]) + 1).tolist()
pred_rank = "[" + ",".join([str(i) for i in pred_rank]) + "]"
f.write(" ".join([str(impr_index), pred_rank]) + "\n")
import zipfile
f = zipfile.ZipFile(
os.path.join(output_path, "prediction.zip"), "w", zipfile.ZIP_DEFLATED
)
f.write(os.path.join(output_path, "prediction.txt"), arcname="prediction.txt")
f.close()
import matplotlib.pyplot as plt
fig = plt.figure()
plt.plot(np.arange(0, epochs), model.history["train_loss"], label="validation auc")
plt.plot(np.arange(0, epochs), model.history["val_loss"], label="validation auc")
plt.xticks(range(0, epochs))
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
| false | 0 | 19,583 | 0 | 27 | 19,583 |
||
100993508 | <kaggle_start><code># # **IMPORTING LIBRARIES**
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tifffile as tiff
import cv2
import tensorflow as tf
from tensorflow.keras import layers
from skimage.transform import resize
from sklearn.model_selection import train_test_split
# # **DATA GENERATOR**
class imageDataGen(tf.keras.utils.Sequence):
def __init__(
self, df, shuffle=True, training=True, imageSize=(512, 512), batchSize=8
):
self.df = df
self.shuffle = shuffle
self.training = training
self.imageSize = imageSize
self.batchSize = batchSize
self.N = len(self.df)
def on_epoch_end(self):
"""
This functions runs at end of every epoch.
"""
if self.shuffle:
self.df = self.df.sample(frac=1).reset_index(drop=True)
def __getitem__(self, index):
"""
input : index value of batch
output : returns the batch of training images and target images
"""
batchDF = self.df[index * self.batchSize : (index + 1) * self.batchSize]
X = self.__getInput(batchDF.id)
Y = self.__getOutput(batchDF[["rle", "img_width", "img_height"]])
return (X, Y)
def __len__(self):
"""
Calculates the length of data with batch size.
"""
return self.N // self.batchSize
# Public helper functions.
def mask2rle(self, img):
"""
input : image
output : return the run length encoding of given image
"""
pixels = img.T.flatten()
pixels = np.concatenate([[0], pixels, [0]])
runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
runs[1::2] -= runs[::2]
return " ".join(str(x) for x in runs)
def rle2img(self, mask_rle, width, height):
"""
input : run length encoding
output : return the image of given run length encoding.
"""
shape = (width, height)
s = mask_rle.split()
starts, lengths = [np.asarray(x, dtype=int) for x in (s[0:][::2], s[1:][::2])]
starts -= 1
ends = starts + lengths
img = np.zeros(shape[0] * shape[1], dtype=np.uint8)
for lo, hi in zip(starts, ends):
img[lo:hi] = 1
img = img.reshape(shape).T.reshape(shape[0], shape[1], 1)
return resize(img, self.imageSize)
# Private helper functions
def __loadImage(self, imgId):
"""
input : image id
output : return the array of tiff image
"""
img = tiff.imread(
"../input/hubmap-organ-segmentation/train_images/" + str(imgId) + ".tiff"
)
img = resize(img, self.imageSize)
img = tf.image.rgb_to_grayscale(img)
return img
def __augument(self, image):
"""
input : image
output : augumented image
"""
pass
def __getInput(self, imageIds):
"""
input : image ids of batch data
output : return the batch of training images
"""
images = imageIds.map(self.__loadImage)
if self.training:
# images = images.map(self.__augument)
pass
return images
def __getOutput(self, masksDf):
"""
input : RLE of batch data
output : return the batch of training label images
"""
maskImages = masksDf.apply(
lambda x: self.rle2img(x["rle"], x["img_width"], x["img_height"]), axis=1
)
return maskImages
# # **U-Net MArchitecture**
# It is the U-Net architecture with using same padding on all convolutional layers.
# The input is in grayscale and output layer is with the sigmoid activation function.
# Input shape of model : (512,512,1)
# Output shape of model : (512,512,1)
def buildModel():
Input = layers.Input(shape=(512, 512, 1))
# Feature extraction layers by conv layers
conv1 = layers.Conv2D(64, (3, 3), (1, 1), padding="same", activation="relu")(Input)
conv1 = layers.Conv2D(64, (3, 3), (1, 1), padding="same", activation="relu")(conv1)
pool1 = layers.MaxPooling2D()(conv1)
conv2 = layers.Conv2D(128, (3, 3), (1, 1), padding="same", activation="relu")(pool1)
conv2 = layers.Conv2D(128, (3, 3), (1, 1), padding="same", activation="relu")(conv2)
pool2 = layers.MaxPooling2D()(conv2)
conv3 = layers.Conv2D(256, (3, 3), (1, 1), padding="same", activation="relu")(pool2)
conv3 = layers.Conv2D(256, (3, 3), (1, 1), padding="same", activation="relu")(conv3)
pool3 = layers.MaxPooling2D()(conv3)
conv4 = layers.Conv2D(512, (3, 3), (1, 1), padding="same", activation="relu")(pool3)
conv4 = layers.Conv2D(512, (3, 3), (1, 1), padding="same", activation="relu")(conv4)
pool4 = layers.MaxPooling2D()(conv4)
conv5 = layers.Conv2D(1024, (3, 3), (1, 1), padding="same", activation="relu")(
pool4
)
conv5 = layers.Conv2D(1024, (3, 3), (1, 1), padding="same", activation="relu")(
conv5
)
# Creating a represented mask by deconv layers
dconv4 = layers.Conv2DTranspose(
512, (3, 3), (2, 2), padding="same", activation="relu"
)(conv5)
uconv4 = layers.Concatenate()([dconv4, conv4])
uconv4 = layers.Conv2D(512, (3, 3), (1, 1), padding="same", activation="relu")(
uconv4
)
uconv4 = layers.Conv2D(512, (3, 3), (1, 1), padding="same", activation="relu")(
uconv4
)
dconv3 = layers.Conv2DTranspose(
256, (3, 3), (2, 2), padding="same", activation="relu"
)(uconv4)
uconv3 = layers.Concatenate()([dconv3, conv3])
uconv3 = layers.Conv2D(256, (3, 3), (1, 1), padding="same", activation="relu")(
uconv3
)
uconv3 = layers.Conv2D(256, (3, 3), (1, 1), padding="same", activation="relu")(
uconv3
)
dconv2 = layers.Conv2DTranspose(
128, (3, 3), (2, 2), padding="same", activation="relu"
)(uconv3)
uconv2 = layers.Concatenate()([dconv2, conv2])
uconv2 = layers.Conv2D(128, (3, 3), (1, 1), padding="same", activation="relu")(
uconv2
)
uconv2 = layers.Conv2D(128, (3, 3), (1, 1), padding="same", activation="relu")(
uconv2
)
dconv1 = layers.Conv2DTranspose(
64, (3, 3), (2, 2), padding="same", activation="relu"
)(uconv2)
uconv1 = layers.Concatenate()([dconv1, conv1])
uconv1 = layers.Conv2D(64, (3, 3), (1, 1), padding="same", activation="relu")(
uconv1
)
uconv1 = layers.Conv2D(64, (3, 3), (1, 1), padding="same", activation="relu")(
uconv1
)
# Final output layer
Output = layers.Conv2D(1, (3, 3), (1, 1), padding="same", activation="sigmoid")(
uconv1
)
model = tf.keras.Model(inputs=[Input], outputs=[Output])
return model
# # **DATA LOADING**
DF = pd.read_csv("../input/hubmap-organ-segmentation/train.csv")
# Splitting the data for training and validation
trainDF, validDF = train_test_split(DF, test_size=0.2)
# Creating a train and validation generator
trainGen = imageDataGen(trainDF)
validGen = imageDataGen(validDF)
# # **DATA VISUALIZATION**
# Generating data from the data generator
batch1 = trainGen.__getitem__(0)
x = batch1[0].values[5].numpy()
y = batch1[1].values[5]
print(f"Training images shape : {x.shape}")
print(f"Target images shape : {y.shape}")
plt.figure(figsize=(5, 5))
plt.imshow(x)
plt.imshow(y, cmap="coolwarm", alpha=0.5)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0100/993/100993508.ipynb | null | null | [{"Id": 100993508, "ScriptId": 28234493, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5144785, "CreationDate": "07/16/2022 15:35:53", "VersionNumber": 1.0, "Title": "Hacking the Human Body [ Data Gen & Model Archi]", "EvaluationDate": "07/16/2022", "IsChange": true, "TotalLines": 211.0, "LinesInsertedFromPrevious": 211.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 1}] | null | null | null | null | # # **IMPORTING LIBRARIES**
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tifffile as tiff
import cv2
import tensorflow as tf
from tensorflow.keras import layers
from skimage.transform import resize
from sklearn.model_selection import train_test_split
# # **DATA GENERATOR**
class imageDataGen(tf.keras.utils.Sequence):
def __init__(
self, df, shuffle=True, training=True, imageSize=(512, 512), batchSize=8
):
self.df = df
self.shuffle = shuffle
self.training = training
self.imageSize = imageSize
self.batchSize = batchSize
self.N = len(self.df)
def on_epoch_end(self):
"""
This functions runs at end of every epoch.
"""
if self.shuffle:
self.df = self.df.sample(frac=1).reset_index(drop=True)
def __getitem__(self, index):
"""
input : index value of batch
output : returns the batch of training images and target images
"""
batchDF = self.df[index * self.batchSize : (index + 1) * self.batchSize]
X = self.__getInput(batchDF.id)
Y = self.__getOutput(batchDF[["rle", "img_width", "img_height"]])
return (X, Y)
def __len__(self):
"""
Calculates the length of data with batch size.
"""
return self.N // self.batchSize
# Public helper functions.
def mask2rle(self, img):
"""
input : image
output : return the run length encoding of given image
"""
pixels = img.T.flatten()
pixels = np.concatenate([[0], pixels, [0]])
runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
runs[1::2] -= runs[::2]
return " ".join(str(x) for x in runs)
def rle2img(self, mask_rle, width, height):
"""
input : run length encoding
output : return the image of given run length encoding.
"""
shape = (width, height)
s = mask_rle.split()
starts, lengths = [np.asarray(x, dtype=int) for x in (s[0:][::2], s[1:][::2])]
starts -= 1
ends = starts + lengths
img = np.zeros(shape[0] * shape[1], dtype=np.uint8)
for lo, hi in zip(starts, ends):
img[lo:hi] = 1
img = img.reshape(shape).T.reshape(shape[0], shape[1], 1)
return resize(img, self.imageSize)
# Private helper functions
def __loadImage(self, imgId):
"""
input : image id
output : return the array of tiff image
"""
img = tiff.imread(
"../input/hubmap-organ-segmentation/train_images/" + str(imgId) + ".tiff"
)
img = resize(img, self.imageSize)
img = tf.image.rgb_to_grayscale(img)
return img
def __augument(self, image):
"""
input : image
output : augumented image
"""
pass
def __getInput(self, imageIds):
"""
input : image ids of batch data
output : return the batch of training images
"""
images = imageIds.map(self.__loadImage)
if self.training:
# images = images.map(self.__augument)
pass
return images
def __getOutput(self, masksDf):
"""
input : RLE of batch data
output : return the batch of training label images
"""
maskImages = masksDf.apply(
lambda x: self.rle2img(x["rle"], x["img_width"], x["img_height"]), axis=1
)
return maskImages
# # **U-Net MArchitecture**
# It is the U-Net architecture with using same padding on all convolutional layers.
# The input is in grayscale and output layer is with the sigmoid activation function.
# Input shape of model : (512,512,1)
# Output shape of model : (512,512,1)
def buildModel():
Input = layers.Input(shape=(512, 512, 1))
# Feature extraction layers by conv layers
conv1 = layers.Conv2D(64, (3, 3), (1, 1), padding="same", activation="relu")(Input)
conv1 = layers.Conv2D(64, (3, 3), (1, 1), padding="same", activation="relu")(conv1)
pool1 = layers.MaxPooling2D()(conv1)
conv2 = layers.Conv2D(128, (3, 3), (1, 1), padding="same", activation="relu")(pool1)
conv2 = layers.Conv2D(128, (3, 3), (1, 1), padding="same", activation="relu")(conv2)
pool2 = layers.MaxPooling2D()(conv2)
conv3 = layers.Conv2D(256, (3, 3), (1, 1), padding="same", activation="relu")(pool2)
conv3 = layers.Conv2D(256, (3, 3), (1, 1), padding="same", activation="relu")(conv3)
pool3 = layers.MaxPooling2D()(conv3)
conv4 = layers.Conv2D(512, (3, 3), (1, 1), padding="same", activation="relu")(pool3)
conv4 = layers.Conv2D(512, (3, 3), (1, 1), padding="same", activation="relu")(conv4)
pool4 = layers.MaxPooling2D()(conv4)
conv5 = layers.Conv2D(1024, (3, 3), (1, 1), padding="same", activation="relu")(
pool4
)
conv5 = layers.Conv2D(1024, (3, 3), (1, 1), padding="same", activation="relu")(
conv5
)
# Creating a represented mask by deconv layers
dconv4 = layers.Conv2DTranspose(
512, (3, 3), (2, 2), padding="same", activation="relu"
)(conv5)
uconv4 = layers.Concatenate()([dconv4, conv4])
uconv4 = layers.Conv2D(512, (3, 3), (1, 1), padding="same", activation="relu")(
uconv4
)
uconv4 = layers.Conv2D(512, (3, 3), (1, 1), padding="same", activation="relu")(
uconv4
)
dconv3 = layers.Conv2DTranspose(
256, (3, 3), (2, 2), padding="same", activation="relu"
)(uconv4)
uconv3 = layers.Concatenate()([dconv3, conv3])
uconv3 = layers.Conv2D(256, (3, 3), (1, 1), padding="same", activation="relu")(
uconv3
)
uconv3 = layers.Conv2D(256, (3, 3), (1, 1), padding="same", activation="relu")(
uconv3
)
dconv2 = layers.Conv2DTranspose(
128, (3, 3), (2, 2), padding="same", activation="relu"
)(uconv3)
uconv2 = layers.Concatenate()([dconv2, conv2])
uconv2 = layers.Conv2D(128, (3, 3), (1, 1), padding="same", activation="relu")(
uconv2
)
uconv2 = layers.Conv2D(128, (3, 3), (1, 1), padding="same", activation="relu")(
uconv2
)
dconv1 = layers.Conv2DTranspose(
64, (3, 3), (2, 2), padding="same", activation="relu"
)(uconv2)
uconv1 = layers.Concatenate()([dconv1, conv1])
uconv1 = layers.Conv2D(64, (3, 3), (1, 1), padding="same", activation="relu")(
uconv1
)
uconv1 = layers.Conv2D(64, (3, 3), (1, 1), padding="same", activation="relu")(
uconv1
)
# Final output layer
Output = layers.Conv2D(1, (3, 3), (1, 1), padding="same", activation="sigmoid")(
uconv1
)
model = tf.keras.Model(inputs=[Input], outputs=[Output])
return model
# # **DATA LOADING**
DF = pd.read_csv("../input/hubmap-organ-segmentation/train.csv")
# Splitting the data for training and validation
trainDF, validDF = train_test_split(DF, test_size=0.2)
# Creating a train and validation generator
trainGen = imageDataGen(trainDF)
validGen = imageDataGen(validDF)
# # **DATA VISUALIZATION**
# Generating data from the data generator
batch1 = trainGen.__getitem__(0)
x = batch1[0].values[5].numpy()
y = batch1[1].values[5]
print(f"Training images shape : {x.shape}")
print(f"Target images shape : {y.shape}")
plt.figure(figsize=(5, 5))
plt.imshow(x)
plt.imshow(y, cmap="coolwarm", alpha=0.5)
| false | 0 | 2,341 | 1 | 6 | 2,341 |
||
138711824 | <kaggle_start><code># # Credit EDA Assignment
# # 1. Importing the Necessary Libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
import plotly.express as px
import plotly.figure_factory as ff
from plotly.subplots import make_subplots
from plotly.subplots import make_subplots
import plotly.graph_objects as go
warnings.filterwarnings(action="ignore")
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
AD = pd.read_csv(r"/kaggle/input/credit-eda-case-study/application_data.csv")
PD = pd.read_csv(r"/kaggle/input/credit-eda-case-study/previous_application.csv")
# # 2. Check the structure of data
# 2.1 Examining Application Data
AD.head()
AD.shape
AD.info()
AD.describe()
# 2.2 Examining Previous Application Data
PD.head()
PD.shape
PD.info()
AD.dtypes.value_counts()
# # 3.1 Data Qaulity Check and Missing Values
# 3.1.1 Checking missing values in Application Data
(AD.isnull().mean() * 100).sort_values(ascending=False)
# # 3.2 Dropping columns where missing values
# Note : Missing Values Consideration:
# Drop of the values of higher percentage -using certain criteria
# Columns Above 100 -->40%
# Columns in Range 50-100--> - 25%
# Columns in Range - 10%
#
s1 = (AD.isnull().mean() * 100).sort_values(ascending=False)[
AD.isnull().mean() * 100 > 40
]
s1
cols = (AD.isnull().mean() * 100 > 40)[AD.isnull().mean() * 100 > 40].index.tolist()
cols
len(cols)
# We are good to delete 49 columns because Null percentage for the columns is greater than 40%
# Dropping 49 columns
AD.drop(columns=cols, inplace=True)
AD.shape
# Null Value Percentage in new Data set
S2 = (AD.isnull().mean() * 100).sort_values(ascending=False)
S2
S2.head(10)
# # 3.3 Imputation of Missing Values
# Imputation in Categorical variables
AD.head()
# Imputation in numerical Variables
# Impute the Missing Values of below columns with mode
# - AMT_REQ_CREDIT_BUREAU_MON
# -AMT_REQ_CREDIT_BUREAU_WEEK
# -AMT_REQ_CREDIT_BUREAU_DAY
# -AMT_REQ_CREDIT_BUREAU_HOUR
# -AMT_REQ_CREDIT_BUREAU_QRT
#
for i in S2.head(10).index.to_list():
if "AMT_REQ_CREDIT" in i:
print("Most frequent value in {0} is : {1}".format(i, AD[i].mode()[0]))
print("Imputing the missing value with :{0}".format(i, AD[i].mode()[0]))
print("Null Values in {0} after imputation :{1}".format(i, AD[i].mode()[0]))
# Missing Value in percentage of missing columns
(AD.isnull().mean() * 100).sort_values(ascending=False)
# Impute Missing Value for occuption_type
# We can impute missing values in OCCUPTION_TYPE column with 'Laborers'
fig = px.bar(AD.OCCUPATION_TYPE.value_counts(), color=AD.OCCUPATION_TYPE.value_counts())
fig.update_traces(textposition="outside", marker_coloraxis=None)
fig.update_xaxes(title="Occuption Type")
fig.update_yaxes(title="Count")
fig.update_layout(
title=dict(text="Occuption Type Frequency", x=0.5, y=0.95),
title_font_size=20,
showlegend=False,
height=450,
)
fig.show()
# Impute Missing Values (XNA) in CODE_GENDER with mode
AD["CODE_GENDER"].value_counts()
AD["CODE_GENDER"].replace(
to_replace="XNA", value=AD["CODE_GENDER"].mode()[0], inplace=True
)
AD["CODE_GENDER"].value_counts()
# Impute Missing Values for EXT_SOURCE_3
#
AD.EXT_SOURCE_3.dtype
AD.EXT_SOURCE_3.fillna(AD.EXT_SOURCE_3.median(), inplace=True)
# Percentage of missing values after Imputation
(AD.isnull().mean() * 100).sort_values(ascending=False)
# Repalce 'XNA with NaN
AD = AD.replace("XNA", np.NaN)
# # Delete All flag columns
AD.columns
# Flag Columns
col = []
for i in AD.columns:
if "FLAG" in i:
col.append(i)
col
# Delete all flag columns as they won't be much useful in our analysis
AD = AD[[i for i in AD.columns if "FLAG" not in i]]
AD.head()
# # Impute Missing values for AMT_ANNUITY & AMT_GOODS_PRICE
col = ["AMT_INCOME_TOTAL", "AMT_CREDIT", "AMT_ANNUITY", "AMT_GOODS_PRICE"]
for i in col:
print("Null Values in {0} : {1}".format(i, AD[i].isnull().sum()))
AD["AMT_ANNUITY"].fillna(AD["AMT_ANNUITY"].median(), inplace=True)
AD["AMT_GOODS_PRICE"].fillna(AD["AMT_GOODS_PRICE"].median(), inplace=True)
AD["AMT_ANNUITY"].isnull().sum()
AD["AMT_GOODS_PRICE"].isnull().sum()
# # Correcting Data
days = []
for i in AD.columns:
if "DAYS" in i:
days.append(i)
print("Unique values in {0} column : {1}".format(i, AD[i].unique()))
print("NULL Values in {0} column : {1}".format(i, AD[i].isnull().sum()))
print()
AD[days]
# Use Absolute Values in DAYS columns
#
AD[days] = abs(AD[days])
AD[days]
# # Binning
# Lets do binning of these variables
for i in col:
AD[i + "_Range"] = pd.qcut(
AD[i], q=5, labels=["Very Low", "Low", "Medium", "High", "Very High"]
)
print(AD[i + "_Range"].value_counts())
print()
AD["YEARS_EMPLOYED"] = AD["DAYS_EMPLOYED"] / 365
AD["Client_Age"] = AD["DAYS_BIRTH"] / 365
# Drop 'DAYS_EMPLOYED' & 'DAYS_BIRTH' column as we will be performing analysis on Year basis
AD.drop(columns=["DAYS_EMPLOYED", "DAYS_BIRTH"], inplace=True)
AD["Age Group"] = pd.cut(
x=AD["Client_Age"],
bins=[0, 20, 30, 40, 50, 60, 100],
labels=["0-20", "20-30", "30-40", "40-50", "50-60", "60-100"],
)
AD[["SK_ID_CURR", "Client_Age", "Age Group"]]
AD["Work Experience"] = pd.cut(
x=AD["YEARS_EMPLOYED"],
bins=[0, 5, 10, 15, 20, 25, 30, 100],
labels=["0-5", "5-10", " 10-15", "15-20", "20-25", "25-30", "30-100"],
)
AD[["SK_ID_CURR", "YEARS_EMPLOYED", "Work Experience"]]
# # OUTLIER DETECTION
# Analyzing AMT columns for outliers
cols = ["AMT_INCOME_TOTAL", "AMT_CREDIT", "AMT_ANNUITY", "AMT_GOODS_PRICE"]
fig, axes = plt.subplots(ncols=2, nrows=2, figsize=(15, 15))
count = 0
for i in range(0, 2):
for j in range(0, 2):
sns.boxenplot(y=AD[cols[count]], ax=axes[i, j])
count += 1
plt.show()
# Below Columns have Outliers and those values can be dropped:-
# -- AMT_INCOME_TOTAL
# -AMT_ANNUITY
# REMOVE OUTLIERS FOR 'AMT_COLUMNS_TOTAL' COLUMN
AD = AD[AD["AMT_INCOME_TOTAL"] < AD["AMT_INCOME_TOTAL"].max()]
# REMOVE OUTLIERS FOR 'AMT_ANNUITY' COLUMN
AD = AD[AD["AMT_INCOME_TOTAL"] < AD["AMT_INCOME_TOTAL"].max()]
# Analysing CNT_CHILDREN column for Outliers
fig = px.box(AD["CNT_CHILDREN"])
fig.update_layout(
title=dict(text="Number of children", x=0.5, y=0.95),
title_font_size=20,
showlegend=False,
width=400,
height=400,
)
fig.show()
AD["CNT_CHILDREN"].value_counts()
AD.shape[0]
# Remove all data points where CNT_CHILDREN is greater than 10
AD = AD[AD["CNT_CHILDREN"] <= 10]
AD.shape[0]
# Around Eight values are dropped where number of children are greater than 10
# # Analysing YEARS_EMPLOYED columns for outliers
sns.boxplot(y=AD["YEARS_EMPLOYED"])
plt.show()
AD["YEARS_EMPLOYED"].value_counts()
AD.shape[0]
AD["YEARS_EMPLOYED"][AD["YEARS_EMPLOYED"] > 1000] = np.NaN
sns.boxplot(y=AD["YEARS_EMPLOYED"])
plt.show()
AD.isnull().sum().sort_values(ascending=False).head(10)
# # Analysing AMT_REQ_CREDIT columns for outliers
cols = [i for i in AD.columns if "AMT_REQ" in i]
cols
fig, axes = plt.subplots(ncols=3, nrows=2, figsize=(15, 15))
count = 0
for i in range(0, 2):
for j in range(0, 3):
sns.boxenplot(y=AD[cols[count]], ax=axes[i, j])
count += 1
plt.show()
# AMT_REQ_CREDIT_BUREAU_QRT contains an outlier
# Remove Outlier for AMT_REQ_CREDIT_BUREAU_QRT
AD = AD[AD["AMT_REQ_CREDIT_BUREAU_QRT"] < AD["AMT_REQ_CREDIT_BUREAU_QRT"].max()]
# # UNIVARIATE ANALYSIS
AD.columns
fig1 = px.bar(
AD["OCCUPATION_TYPE"].value_counts(), color=AD["OCCUPATION_TYPE"].value_counts()
)
fig1.update_traces(textposition="outside", marker_coloraxis=None)
fig1.update_xaxes(title="Occuption Type")
fig1.update_yaxes(title="Count")
fig1.update_layout(
title=dict(text="Occuption Typ", x=0.5, y=0.95),
title_font_size=20,
showlegend=False,
height=450,
)
fig1.show()
fig2 = px.bar(
AD["ORGANIZATION_TYPE"].value_counts(), color=AD["ORGANIZATION_TYPE"].value_counts()
)
fig2.update_traces(textposition="outside", marker_coloraxis=None)
fig2.update_xaxes(title="ORGANIZATION TYPE")
fig2.update_yaxes(title="Count")
fig2.update_layout(
title=dict(text="Organization Type Frequency", x=0.5, y=0.95),
title_font_size=20,
showlegend=False,
height=450,
)
fig2.show()
# Insights
# - Most People who applied for Loan Appliaction are Laborers
# - Most People who applied for Loan Application belong to either Business Entity Type3 or Self - Employed Organization Type.
cols = [
"Age Group",
"NAME_CONTRACT_TYPE",
"NAME_INCOME_TYPE",
"NAME_EDUCATION_TYPE",
"NAME_FAMILY_STATUS",
"NAME_HOUSING_TYPE",
"CODE_GENDER",
"Work Experience",
]
fig = make_subplots(
rows=4, cols=2, subplot_titles=cols, horizontal_spacing=0.1, vertical_spacing=0.13
)
count = 0
for i in range(4):
for j in range(2):
fig.add_trace(
go.Bar(
x=AD[cols[count]].value_counts().index,
y=AD[cols[count]].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (AD[cols[count]].value_counts(normalize=True) * 100)
.round(1)
.tolist()
],
),
row=i + 1,
col=j + 1,
)
count += 1
fig.update_layout(
title="Analyze Categorical variables (Frequency / Percentage)",
title_font_size=20,
showlegend=False,
width=960,
height=1600,
)
fig.show()
# Insights
# Banks has recieved majority of the loan application from 30-40 & 40-50Age groups.
# More than 50% of clients who have applied for the loan belong to Working Income Type.
# 88.7% clients with Secondary /Secondary Special education type have applied for the loan.
# Married people tend to apply more for loan i.e 63.9% clients who are have applied for loan are married.
# Female loan Application are more as compare to males. this may be because bank charges less rate of interest of females.
# Majority of the clients who have applied for the loan have their own house/apartment. Around 88.7% clients are owning either a house or an apartment.
# client with work expiernce between 0-5 years have applied most for loan application.
# 90.5% application have requested for a Cash Loans
#
AD.nunique().sort_values()
# # Checking Imbalance
AD["TARGET"].value_counts(normalize=True)
fig = px.pie(
values=AD["TARGET"].value_counts(normalize=True),
names=AD["TARGET"].value_counts(normalize=True).index,
hole=0.5,
)
fig.update_layout(
title=dict(text="Target Imbalance", x=0.5, y=0.95),
title_font_size=20,
showlegend=False,
)
fig.show()
app_target0 = AD.loc[AD.TARGET == 0]
app_target1 = AD.loc[AD.TARGET == 1]
app_target0.shape
app_target1.shape
cols = ["Age Group", "NAME_CONTRACT_TYPE", "NAME_INCOME_TYPE", "NAME_EDUCATION_TYPE"]
title = [None] * (2 * len(cols))
title[::2] = [i + "(Non - Payment Difficulties)" for i in cols]
title[1::2] = [i + "(Payment Difficulties)" for i in cols]
fig = make_subplots(
rows=4,
cols=2,
subplot_titles=title,
)
count = 0
for i in range(1, 5):
for j in range(1, 3):
if j == 1:
fig.add_trace(
go.Bar(
x=app_target0[cols[count]].value_counts().index,
y=app_target0[cols[count]].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (
app_target0[cols[count]].value_counts(normalize=True) * 100
)
.round(1)
.tolist()
],
),
row=i,
col=j,
)
else:
fig.add_trace(
go.Bar(
x=app_target1[cols[count]].value_counts().index,
y=app_target1[cols[count]].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (
app_target1[cols[count]].value_counts(normalize=True) * 100
)
.round(1)
.tolist()
],
),
row=i,
col=j,
)
count += 1
fig.update_layout(
title=dict(
text="Analyze Categorical variables (Payment/ Non-Payment Difficulties)",
x=0.5,
y=0.99,
),
title_font_size=20,
showlegend=False,
height=1600,
)
fig.show()
cols = ["NAME_FAMILY_STATUS", "NAME_HOUSING_TYPE", "CODE_GENDER", "Work Experience"]
title = [None] * (2 * len(cols))
title[::2] = [i + "(Non - Payment Difficulties)" for i in cols]
title[1::2] = [i + "(Payment Difficulties)" for i in cols]
fig = make_subplots(
rows=4,
cols=2,
subplot_titles=title,
)
count = 0
for i in range(1, 5):
for j in range(1, 3):
if j == 1:
fig.add_trace(
go.Bar(
x=app_target0[cols[count]].value_counts().index,
y=app_target0[cols[count]].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (
app_target0[cols[count]].value_counts(normalize=True) * 100
)
.round(1)
.tolist()
],
),
row=i,
col=j,
)
else:
fig.add_trace(
go.Bar(
x=app_target1[cols[count]].value_counts().index,
y=app_target1[cols[count]].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (
app_target1[cols[count]].value_counts(normalize=True) * 100
)
.round(1)
.tolist()
],
),
row=i,
col=j,
)
count += 1
fig.update_layout(
title=dict(
text="Analyze Categorical variables (Payment/ Non-Payment Difficulties)",
x=0.5,
y=0.99,
),
title_font_size=20,
showlegend=False,
height=1600,
)
fig.show()
# # Bivariate / Multivarite Analysis
# Group data by 'AMT_CREDIT_Range' & 'CODE_GENDER'
df1 = (
AD.groupby(by=["AMT_CREDIT_Range", "CODE_GENDER"])
.count()
.reset_index()[["AMT_CREDIT_Range", "CODE_GENDER", "SK_ID_CURR"]]
)
df1
# Group data by 'AMT_INCOME_TOTAL_Range' & 'CODE_GENDER'
fig1 = px.bar(
data_frame=df1,
x="AMT_CREDIT_Range",
y="SK_ID_CURR",
color="CODE_GENDER",
barmode="group",
text="SK_ID_CURR",
)
fig1.update_traces(textposition="outside")
fig1.update_xaxes(title="Day")
fig1.update_yaxes(title="Transaction count")
fig1.update_layout(
title=dict(text="Loan Applications by Gender & Credit Range", x=0.5, y=0.95),
title_font_size=20,
)
fig1.show()
# Insights
# Females are mostly applying for Very Low credit Loans.
# Males are applying for Medium & High credit loans.
# # Income Vs Credit Amount (Payment / Non Payment Difficulties)
fig = px.box(
app_target0,
x="AMT_INCOME_TOTAL_Range",
y="AMT_CREDIT",
color="NAME_FAMILY_STATUS",
title="Income Range Vs Credit Amount (Non- Payment Difficulties)",
)
fig.show()
fig = px.box(
app_target1,
x="AMT_INCOME_TOTAL_Range",
y="AMT_CREDIT",
color="NAME_FAMILY_STATUS",
title="Income Range Vs Credit Amount (Payment Difficulties)",
)
fig.show()
# # Age Group VS Credit Amount (Payment / Non Payment Diffculties)
fig = px.box(
app_target0,
x="Age Group",
y="AMT_CREDIT",
color="NAME_FAMILY_STATUS",
title="Age Group Vs Credit Amount (Non-Payment Difficulties)",
)
fig.show()
fig = px.box(
app_target1,
x="Age Group",
y="AMT_CREDIT",
color="NAME_FAMILY_STATUS",
title="Age Group Vs Credit Amount (Payment Difficulties)",
)
fig.show()
# # Numerical Vs Numerical Variables
sns.pairplot(
AD[
[
"AMT_INCOME_TOTAL",
"AMT_GOODS_PRICE",
"AMT_CREDIT",
"AMT_ANNUITY",
"Client_Age",
"YEARS_EMPLOYED",
]
].fillna(0)
)
plt.show()
# # Correlation in Target0 & Target1
plt.figure(figsize=(12, 8))
sns.heatmap(
app_target0[
[
"AMT_INCOME_TOTAL",
"AMT_GOODS_PRICE",
"AMT_CREDIT",
"AMT_ANNUITY",
"Client_Age",
"YEARS_EMPLOYED",
"DAYS_ID_PUBLISH",
"DAYS_REGISTRATION",
"EXT_SOURCE_2",
"EXT_SOURCE_3",
"REGION_POPULATION_RELATIVE",
]
].corr(),
annot=True,
cmap="RdYlGn",
)
plt.title("Correlation matrix for Non-Payment Difficulties")
plt.show()
plt.figure(figsize=(12, 8))
sns.heatmap(
app_target1[
[
"AMT_INCOME_TOTAL",
"AMT_GOODS_PRICE",
"AMT_CREDIT",
"AMT_ANNUITY",
"Client_Age",
"YEARS_EMPLOYED",
"DAYS_ID_PUBLISH",
"DAYS_REGISTRATION",
"EXT_SOURCE_2",
"EXT_SOURCE_3",
"REGION_POPULATION_RELATIVE",
]
].corr(),
annot=True,
cmap="RdYlGn",
)
plt.title("Correlation matrix for Payment Difficulties")
plt.show()
# # Data Analysis on Previous Appliaction Data Set
PD.head()
s1 = (PD.isnull().mean() * 100).sort_values(ascending=False)[
PD.isnull().mean() * 100 > 40
]
s1
PD.shape
PD.drop(columns=s1.index, inplace=True)
PD.shape
# # Changing Negative Values in the Days columns to positive Values
days = []
for i in PD.columns:
if "DAYS" in i:
days.append(i)
print("Unique values in {0} column : {1}".format(i, PD[i].unique()))
print("NULL Values in {0} column : {1}".format(i, PD[i].isnull().sum()))
print()
PD[days] = abs(PD[days])
PD[days]
PD = PD.replace("XNA", np.NaN)
PD = PD.replace("XAP", np.NaN)
# # Univariate Analysis on Previous App Data
PD.columns
cols = [
"NAME_CONTRACT_STATUS",
"WEEKDAY_APPR_PROCESS_START",
"NAME_PAYMENT_TYPE",
"CODE_REJECT_REASON",
"NAME_CONTRACT_TYPE",
"NAME_CLIENT_TYPE",
]
# Subplot initialization
fig = make_subplots(
rows=3, cols=2, subplot_titles=cols, horizontal_spacing=0.1, vertical_spacing=0.17
)
# Adding subplots
count = 0
for i in range(1, 4):
for j in range(1, 3):
fig.add_trace(
go.Bar(
x=PD[cols[count]].value_counts().index,
y=PD[cols[count]].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (PD[cols[count]].value_counts(normalize=True) * 100)
.round(1)
.tolist()
],
),
row=i,
col=j,
)
count += 1
fig.update_layout(
title=dict(
text="Analyze Categorical variables (Frequency / Percentage)", x=0.5, y=0.99
),
title_font_size=20,
showlegend=False,
width=960,
height=1200,
)
fig.show()
# # Approved Loan
Approved = PD[PD["NAME_CONTRACT_STATUS"] == "Approved"]
cols = [
"NAME_PORTFOLIO",
"NAME_GOODS_CATEGORY",
"CHANNEL_TYPE",
"NAME_YIELD_GROUP",
"NAME_PRODUCT_TYPE",
"NAME_CASH_LOAN_PURPOSE",
]
# Subplot initialization
fig = make_subplots(
rows=3, cols=2, subplot_titles=cols, horizontal_spacing=0.1, vertical_spacing=0.17
)
# Adding subplots
count = 0
for i in range(1, 4):
for j in range(1, 3):
fig.add_trace(
go.Bar(
x=PD[cols[count]].value_counts().index,
y=PD[cols[count]].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (PD[cols[count]].value_counts(normalize=True) * 100)
.round(1)
.tolist()
],
),
row=i,
col=j,
)
count += 1
fig.update_layout(
title=dict(
text="Analyze Categorical variables (Frequency / Percentage)", x=0.5, y=0.99
),
title_font_size=20,
showlegend=False,
width=960,
height=1200,
)
fig.show()
# # Refused Loans
Refused = PD[PD["NAME_CONTRACT_STATUS"] == "Refused"]
cols = [
"NAME_PORTFOLIO",
"NAME_GOODS_CATEGORY",
"CHANNEL_TYPE",
"NAME_YIELD_GROUP",
"NAME_PRODUCT_TYPE",
"NAME_CASH_LOAN_PURPOSE",
]
# Subplot initialization
fig = make_subplots(
rows=3, cols=2, subplot_titles=cols, horizontal_spacing=0.1, vertical_spacing=0.17
)
# Adding subplots
count = 0
for i in range(1, 4):
for j in range(1, 3):
fig.add_trace(
go.Bar(
x=PD[cols[count]].value_counts().index,
y=PD[cols[count]].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (PD[cols[count]].value_counts(normalize=True) * 100)
.round(1)
.tolist()
],
),
row=i,
col=j,
)
count += 1
fig.update_layout(
title=dict(
text="Analyze Categorical variables (Frequency / Percentage)", x=0.5, y=0.99
),
title_font_size=20,
showlegend=False,
width=960,
height=1200,
)
fig.show()
# # Merging Application & Previous Application Data
# Example of a custom function named mergereturn
def mergereturn(df1, df2, how="inner", on=None):
# Your function implementation here
pass
merged_df = pd.merge(AD, PD, on="SK_ID_CURR", how="inner")
merged_df
appdata_merge = AD.merge(PD, on="SK_ID_CURR", how="inner")
appdata_merge.shape
merged_df = pd.merge(
df1, df2, on="ID", how="inner"
) # You can choose 'how' to specify the type of join (inner, outer, left, right)
print(merged_df)
df_combine = AD.merge(PD, left_on="SK_ID_CURR", right_on="SK_ID_CURR", how="left")
df_combine
df_combine.shape
def plot_merge(df_combine, column_name):
col_value = ["Refused", "Approved", "Canceled", "Unused offer"]
fig = make_subplots(
rows=2,
cols=2,
subplot_titles=col_value,
horizontal_spacing=0.1,
vertical_spacing=0.3,
)
# Adding subplots
count = 0
for i in range(1, 3):
for j in range(1, 3):
fig.add_trace(
go.Bar(
x=df_combine[
df_combine["NAME_CONTRACT_STATUS"] == col_value[count]
][column_name]
.value_counts()
.index,
y=df_combine[
df_combine["NAME_CONTRACT_STATUS"] == col_value[count]
][column_name].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (
df_combine[
df_combine["NAME_CONTRACT_STATUS"] == col_value[count]
][column_name].value_counts(normalize=True)
* 100
)
.round(1)
.tolist()
],
),
row=i,
col=j,
)
count += 1
fig.update_layout(
title=dict(text="NAME_CONTRACT_STATUS VS " + column_name, x=0.5, y=0.99),
title_font_size=20,
showlegend=False,
width=960,
height=960,
)
fig.show()
def plot_pie_merge(df_combine, column_name):
col_value = ["Refused", "Approved", "Canceled", "Unused offer"]
# Subplot initialization
fig = make_subplots(
rows=2,
cols=2,
subplot_titles=col_value,
specs=[[{"type": "pie"}, {"type": "pie"}], [{"type": "pie"}, {"type": "pie"}]],
)
# Adding subplots
count = 0
for i in range(1, 3):
for j in range(1, 3):
fig.add_trace(
go.Pie(
labels=df_combine[
df_combine["NAME_CONTRACT_STATUS"] == col_value[count]
][column_name]
.value_counts()
.index,
values=df_combine[
df_combine["NAME_CONTRACT_STATUS"] == col_value[count]
][column_name].value_counts(),
textinfo="percent",
insidetextorientation="auto",
hole=0.3,
),
row=i,
col=j,
)
count += 1
fig.update_layout(
title=dict(text="NAME_CONTRACT_STATUS VS " + column_name, x=0.5, y=0.99),
title_font_size=20,
width=960,
height=960,
)
fig.show()
plot_pie_merge(df_combine, "NAME_CONTRACT_TYPE_y")
# Insights
# - Banks Mostly approve Consumer Loans
# - Most of the Refused_& Cancelled loans are cash loans.
plot_pie_merge(df_combine, "NAME_CLIENT_TYPE")
# Insights
# - Most of the Approved, refused & cancelled loans belong to the old clients.
# - Almost 27.4% loans were provided to new customers.
plot_pie_merge(df_combine, "CODE_GENDER")
# Insights
# - Approved percentage of loans provided to females is more as compared to refused percentage.
plot_merge(df_combine, "NAME_EDUCATION_TYPE")
# Insights
# - Most of the approved loans belong to applicants with Secondary / Secondary Special education type.
plot_merge(df_combine, "OCCUPATION_TYPE")
plot_merge(df_combine, "NAME_GOODS_CATEGORY")
plot_merge(df_combine, "PRODUCT_COMBINATION")
# Insights
# - Most of the approved loans belongs to POS household with interest & POS mobile with interest product combination.
# - 15% refused loans belong to Cash X - Sell:low product combination.
#
# - Most of the cancelled loan belong to cash category.
# 81.3% Unused offer loans belong to POS mobile with interest.
plot_merge(df_combine, "AMT_INCOME_TOTAL_Range")
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0138/711/138711824.ipynb | null | null | [{"Id": 138711824, "ScriptId": 41703939, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 15729532, "CreationDate": "08/02/2023 17:07:40", "VersionNumber": 1.0, "Title": "Credit EDA", "EvaluationDate": "08/02/2023", "IsChange": true, "TotalLines": 865.0, "LinesInsertedFromPrevious": 865.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 1}] | null | null | null | null | # # Credit EDA Assignment
# # 1. Importing the Necessary Libraries
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
import plotly.express as px
import plotly.figure_factory as ff
from plotly.subplots import make_subplots
from plotly.subplots import make_subplots
import plotly.graph_objects as go
warnings.filterwarnings(action="ignore")
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
AD = pd.read_csv(r"/kaggle/input/credit-eda-case-study/application_data.csv")
PD = pd.read_csv(r"/kaggle/input/credit-eda-case-study/previous_application.csv")
# # 2. Check the structure of data
# 2.1 Examining Application Data
AD.head()
AD.shape
AD.info()
AD.describe()
# 2.2 Examining Previous Application Data
PD.head()
PD.shape
PD.info()
AD.dtypes.value_counts()
# # 3.1 Data Qaulity Check and Missing Values
# 3.1.1 Checking missing values in Application Data
(AD.isnull().mean() * 100).sort_values(ascending=False)
# # 3.2 Dropping columns where missing values
# Note : Missing Values Consideration:
# Drop of the values of higher percentage -using certain criteria
# Columns Above 100 -->40%
# Columns in Range 50-100--> - 25%
# Columns in Range - 10%
#
s1 = (AD.isnull().mean() * 100).sort_values(ascending=False)[
AD.isnull().mean() * 100 > 40
]
s1
cols = (AD.isnull().mean() * 100 > 40)[AD.isnull().mean() * 100 > 40].index.tolist()
cols
len(cols)
# We are good to delete 49 columns because Null percentage for the columns is greater than 40%
# Dropping 49 columns
AD.drop(columns=cols, inplace=True)
AD.shape
# Null Value Percentage in new Data set
S2 = (AD.isnull().mean() * 100).sort_values(ascending=False)
S2
S2.head(10)
# # 3.3 Imputation of Missing Values
# Imputation in Categorical variables
AD.head()
# Imputation in numerical Variables
# Impute the Missing Values of below columns with mode
# - AMT_REQ_CREDIT_BUREAU_MON
# -AMT_REQ_CREDIT_BUREAU_WEEK
# -AMT_REQ_CREDIT_BUREAU_DAY
# -AMT_REQ_CREDIT_BUREAU_HOUR
# -AMT_REQ_CREDIT_BUREAU_QRT
#
for i in S2.head(10).index.to_list():
if "AMT_REQ_CREDIT" in i:
print("Most frequent value in {0} is : {1}".format(i, AD[i].mode()[0]))
print("Imputing the missing value with :{0}".format(i, AD[i].mode()[0]))
print("Null Values in {0} after imputation :{1}".format(i, AD[i].mode()[0]))
# Missing Value in percentage of missing columns
(AD.isnull().mean() * 100).sort_values(ascending=False)
# Impute Missing Value for occuption_type
# We can impute missing values in OCCUPTION_TYPE column with 'Laborers'
fig = px.bar(AD.OCCUPATION_TYPE.value_counts(), color=AD.OCCUPATION_TYPE.value_counts())
fig.update_traces(textposition="outside", marker_coloraxis=None)
fig.update_xaxes(title="Occuption Type")
fig.update_yaxes(title="Count")
fig.update_layout(
title=dict(text="Occuption Type Frequency", x=0.5, y=0.95),
title_font_size=20,
showlegend=False,
height=450,
)
fig.show()
# Impute Missing Values (XNA) in CODE_GENDER with mode
AD["CODE_GENDER"].value_counts()
AD["CODE_GENDER"].replace(
to_replace="XNA", value=AD["CODE_GENDER"].mode()[0], inplace=True
)
AD["CODE_GENDER"].value_counts()
# Impute Missing Values for EXT_SOURCE_3
#
AD.EXT_SOURCE_3.dtype
AD.EXT_SOURCE_3.fillna(AD.EXT_SOURCE_3.median(), inplace=True)
# Percentage of missing values after Imputation
(AD.isnull().mean() * 100).sort_values(ascending=False)
# Repalce 'XNA with NaN
AD = AD.replace("XNA", np.NaN)
# # Delete All flag columns
AD.columns
# Flag Columns
col = []
for i in AD.columns:
if "FLAG" in i:
col.append(i)
col
# Delete all flag columns as they won't be much useful in our analysis
AD = AD[[i for i in AD.columns if "FLAG" not in i]]
AD.head()
# # Impute Missing values for AMT_ANNUITY & AMT_GOODS_PRICE
col = ["AMT_INCOME_TOTAL", "AMT_CREDIT", "AMT_ANNUITY", "AMT_GOODS_PRICE"]
for i in col:
print("Null Values in {0} : {1}".format(i, AD[i].isnull().sum()))
AD["AMT_ANNUITY"].fillna(AD["AMT_ANNUITY"].median(), inplace=True)
AD["AMT_GOODS_PRICE"].fillna(AD["AMT_GOODS_PRICE"].median(), inplace=True)
AD["AMT_ANNUITY"].isnull().sum()
AD["AMT_GOODS_PRICE"].isnull().sum()
# # Correcting Data
days = []
for i in AD.columns:
if "DAYS" in i:
days.append(i)
print("Unique values in {0} column : {1}".format(i, AD[i].unique()))
print("NULL Values in {0} column : {1}".format(i, AD[i].isnull().sum()))
print()
AD[days]
# Use Absolute Values in DAYS columns
#
AD[days] = abs(AD[days])
AD[days]
# # Binning
# Lets do binning of these variables
for i in col:
AD[i + "_Range"] = pd.qcut(
AD[i], q=5, labels=["Very Low", "Low", "Medium", "High", "Very High"]
)
print(AD[i + "_Range"].value_counts())
print()
AD["YEARS_EMPLOYED"] = AD["DAYS_EMPLOYED"] / 365
AD["Client_Age"] = AD["DAYS_BIRTH"] / 365
# Drop 'DAYS_EMPLOYED' & 'DAYS_BIRTH' column as we will be performing analysis on Year basis
AD.drop(columns=["DAYS_EMPLOYED", "DAYS_BIRTH"], inplace=True)
AD["Age Group"] = pd.cut(
x=AD["Client_Age"],
bins=[0, 20, 30, 40, 50, 60, 100],
labels=["0-20", "20-30", "30-40", "40-50", "50-60", "60-100"],
)
AD[["SK_ID_CURR", "Client_Age", "Age Group"]]
AD["Work Experience"] = pd.cut(
x=AD["YEARS_EMPLOYED"],
bins=[0, 5, 10, 15, 20, 25, 30, 100],
labels=["0-5", "5-10", " 10-15", "15-20", "20-25", "25-30", "30-100"],
)
AD[["SK_ID_CURR", "YEARS_EMPLOYED", "Work Experience"]]
# # OUTLIER DETECTION
# Analyzing AMT columns for outliers
cols = ["AMT_INCOME_TOTAL", "AMT_CREDIT", "AMT_ANNUITY", "AMT_GOODS_PRICE"]
fig, axes = plt.subplots(ncols=2, nrows=2, figsize=(15, 15))
count = 0
for i in range(0, 2):
for j in range(0, 2):
sns.boxenplot(y=AD[cols[count]], ax=axes[i, j])
count += 1
plt.show()
# Below Columns have Outliers and those values can be dropped:-
# -- AMT_INCOME_TOTAL
# -AMT_ANNUITY
# REMOVE OUTLIERS FOR 'AMT_COLUMNS_TOTAL' COLUMN
AD = AD[AD["AMT_INCOME_TOTAL"] < AD["AMT_INCOME_TOTAL"].max()]
# REMOVE OUTLIERS FOR 'AMT_ANNUITY' COLUMN
AD = AD[AD["AMT_INCOME_TOTAL"] < AD["AMT_INCOME_TOTAL"].max()]
# Analysing CNT_CHILDREN column for Outliers
fig = px.box(AD["CNT_CHILDREN"])
fig.update_layout(
title=dict(text="Number of children", x=0.5, y=0.95),
title_font_size=20,
showlegend=False,
width=400,
height=400,
)
fig.show()
AD["CNT_CHILDREN"].value_counts()
AD.shape[0]
# Remove all data points where CNT_CHILDREN is greater than 10
AD = AD[AD["CNT_CHILDREN"] <= 10]
AD.shape[0]
# Around Eight values are dropped where number of children are greater than 10
# # Analysing YEARS_EMPLOYED columns for outliers
sns.boxplot(y=AD["YEARS_EMPLOYED"])
plt.show()
AD["YEARS_EMPLOYED"].value_counts()
AD.shape[0]
AD["YEARS_EMPLOYED"][AD["YEARS_EMPLOYED"] > 1000] = np.NaN
sns.boxplot(y=AD["YEARS_EMPLOYED"])
plt.show()
AD.isnull().sum().sort_values(ascending=False).head(10)
# # Analysing AMT_REQ_CREDIT columns for outliers
cols = [i for i in AD.columns if "AMT_REQ" in i]
cols
fig, axes = plt.subplots(ncols=3, nrows=2, figsize=(15, 15))
count = 0
for i in range(0, 2):
for j in range(0, 3):
sns.boxenplot(y=AD[cols[count]], ax=axes[i, j])
count += 1
plt.show()
# AMT_REQ_CREDIT_BUREAU_QRT contains an outlier
# Remove Outlier for AMT_REQ_CREDIT_BUREAU_QRT
AD = AD[AD["AMT_REQ_CREDIT_BUREAU_QRT"] < AD["AMT_REQ_CREDIT_BUREAU_QRT"].max()]
# # UNIVARIATE ANALYSIS
AD.columns
fig1 = px.bar(
AD["OCCUPATION_TYPE"].value_counts(), color=AD["OCCUPATION_TYPE"].value_counts()
)
fig1.update_traces(textposition="outside", marker_coloraxis=None)
fig1.update_xaxes(title="Occuption Type")
fig1.update_yaxes(title="Count")
fig1.update_layout(
title=dict(text="Occuption Typ", x=0.5, y=0.95),
title_font_size=20,
showlegend=False,
height=450,
)
fig1.show()
fig2 = px.bar(
AD["ORGANIZATION_TYPE"].value_counts(), color=AD["ORGANIZATION_TYPE"].value_counts()
)
fig2.update_traces(textposition="outside", marker_coloraxis=None)
fig2.update_xaxes(title="ORGANIZATION TYPE")
fig2.update_yaxes(title="Count")
fig2.update_layout(
title=dict(text="Organization Type Frequency", x=0.5, y=0.95),
title_font_size=20,
showlegend=False,
height=450,
)
fig2.show()
# Insights
# - Most People who applied for Loan Appliaction are Laborers
# - Most People who applied for Loan Application belong to either Business Entity Type3 or Self - Employed Organization Type.
cols = [
"Age Group",
"NAME_CONTRACT_TYPE",
"NAME_INCOME_TYPE",
"NAME_EDUCATION_TYPE",
"NAME_FAMILY_STATUS",
"NAME_HOUSING_TYPE",
"CODE_GENDER",
"Work Experience",
]
fig = make_subplots(
rows=4, cols=2, subplot_titles=cols, horizontal_spacing=0.1, vertical_spacing=0.13
)
count = 0
for i in range(4):
for j in range(2):
fig.add_trace(
go.Bar(
x=AD[cols[count]].value_counts().index,
y=AD[cols[count]].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (AD[cols[count]].value_counts(normalize=True) * 100)
.round(1)
.tolist()
],
),
row=i + 1,
col=j + 1,
)
count += 1
fig.update_layout(
title="Analyze Categorical variables (Frequency / Percentage)",
title_font_size=20,
showlegend=False,
width=960,
height=1600,
)
fig.show()
# Insights
# Banks has recieved majority of the loan application from 30-40 & 40-50Age groups.
# More than 50% of clients who have applied for the loan belong to Working Income Type.
# 88.7% clients with Secondary /Secondary Special education type have applied for the loan.
# Married people tend to apply more for loan i.e 63.9% clients who are have applied for loan are married.
# Female loan Application are more as compare to males. this may be because bank charges less rate of interest of females.
# Majority of the clients who have applied for the loan have their own house/apartment. Around 88.7% clients are owning either a house or an apartment.
# client with work expiernce between 0-5 years have applied most for loan application.
# 90.5% application have requested for a Cash Loans
#
AD.nunique().sort_values()
# # Checking Imbalance
AD["TARGET"].value_counts(normalize=True)
fig = px.pie(
values=AD["TARGET"].value_counts(normalize=True),
names=AD["TARGET"].value_counts(normalize=True).index,
hole=0.5,
)
fig.update_layout(
title=dict(text="Target Imbalance", x=0.5, y=0.95),
title_font_size=20,
showlegend=False,
)
fig.show()
app_target0 = AD.loc[AD.TARGET == 0]
app_target1 = AD.loc[AD.TARGET == 1]
app_target0.shape
app_target1.shape
cols = ["Age Group", "NAME_CONTRACT_TYPE", "NAME_INCOME_TYPE", "NAME_EDUCATION_TYPE"]
title = [None] * (2 * len(cols))
title[::2] = [i + "(Non - Payment Difficulties)" for i in cols]
title[1::2] = [i + "(Payment Difficulties)" for i in cols]
fig = make_subplots(
rows=4,
cols=2,
subplot_titles=title,
)
count = 0
for i in range(1, 5):
for j in range(1, 3):
if j == 1:
fig.add_trace(
go.Bar(
x=app_target0[cols[count]].value_counts().index,
y=app_target0[cols[count]].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (
app_target0[cols[count]].value_counts(normalize=True) * 100
)
.round(1)
.tolist()
],
),
row=i,
col=j,
)
else:
fig.add_trace(
go.Bar(
x=app_target1[cols[count]].value_counts().index,
y=app_target1[cols[count]].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (
app_target1[cols[count]].value_counts(normalize=True) * 100
)
.round(1)
.tolist()
],
),
row=i,
col=j,
)
count += 1
fig.update_layout(
title=dict(
text="Analyze Categorical variables (Payment/ Non-Payment Difficulties)",
x=0.5,
y=0.99,
),
title_font_size=20,
showlegend=False,
height=1600,
)
fig.show()
cols = ["NAME_FAMILY_STATUS", "NAME_HOUSING_TYPE", "CODE_GENDER", "Work Experience"]
title = [None] * (2 * len(cols))
title[::2] = [i + "(Non - Payment Difficulties)" for i in cols]
title[1::2] = [i + "(Payment Difficulties)" for i in cols]
fig = make_subplots(
rows=4,
cols=2,
subplot_titles=title,
)
count = 0
for i in range(1, 5):
for j in range(1, 3):
if j == 1:
fig.add_trace(
go.Bar(
x=app_target0[cols[count]].value_counts().index,
y=app_target0[cols[count]].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (
app_target0[cols[count]].value_counts(normalize=True) * 100
)
.round(1)
.tolist()
],
),
row=i,
col=j,
)
else:
fig.add_trace(
go.Bar(
x=app_target1[cols[count]].value_counts().index,
y=app_target1[cols[count]].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (
app_target1[cols[count]].value_counts(normalize=True) * 100
)
.round(1)
.tolist()
],
),
row=i,
col=j,
)
count += 1
fig.update_layout(
title=dict(
text="Analyze Categorical variables (Payment/ Non-Payment Difficulties)",
x=0.5,
y=0.99,
),
title_font_size=20,
showlegend=False,
height=1600,
)
fig.show()
# # Bivariate / Multivarite Analysis
# Group data by 'AMT_CREDIT_Range' & 'CODE_GENDER'
df1 = (
AD.groupby(by=["AMT_CREDIT_Range", "CODE_GENDER"])
.count()
.reset_index()[["AMT_CREDIT_Range", "CODE_GENDER", "SK_ID_CURR"]]
)
df1
# Group data by 'AMT_INCOME_TOTAL_Range' & 'CODE_GENDER'
fig1 = px.bar(
data_frame=df1,
x="AMT_CREDIT_Range",
y="SK_ID_CURR",
color="CODE_GENDER",
barmode="group",
text="SK_ID_CURR",
)
fig1.update_traces(textposition="outside")
fig1.update_xaxes(title="Day")
fig1.update_yaxes(title="Transaction count")
fig1.update_layout(
title=dict(text="Loan Applications by Gender & Credit Range", x=0.5, y=0.95),
title_font_size=20,
)
fig1.show()
# Insights
# Females are mostly applying for Very Low credit Loans.
# Males are applying for Medium & High credit loans.
# # Income Vs Credit Amount (Payment / Non Payment Difficulties)
fig = px.box(
app_target0,
x="AMT_INCOME_TOTAL_Range",
y="AMT_CREDIT",
color="NAME_FAMILY_STATUS",
title="Income Range Vs Credit Amount (Non- Payment Difficulties)",
)
fig.show()
fig = px.box(
app_target1,
x="AMT_INCOME_TOTAL_Range",
y="AMT_CREDIT",
color="NAME_FAMILY_STATUS",
title="Income Range Vs Credit Amount (Payment Difficulties)",
)
fig.show()
# # Age Group VS Credit Amount (Payment / Non Payment Diffculties)
fig = px.box(
app_target0,
x="Age Group",
y="AMT_CREDIT",
color="NAME_FAMILY_STATUS",
title="Age Group Vs Credit Amount (Non-Payment Difficulties)",
)
fig.show()
fig = px.box(
app_target1,
x="Age Group",
y="AMT_CREDIT",
color="NAME_FAMILY_STATUS",
title="Age Group Vs Credit Amount (Payment Difficulties)",
)
fig.show()
# # Numerical Vs Numerical Variables
sns.pairplot(
AD[
[
"AMT_INCOME_TOTAL",
"AMT_GOODS_PRICE",
"AMT_CREDIT",
"AMT_ANNUITY",
"Client_Age",
"YEARS_EMPLOYED",
]
].fillna(0)
)
plt.show()
# # Correlation in Target0 & Target1
plt.figure(figsize=(12, 8))
sns.heatmap(
app_target0[
[
"AMT_INCOME_TOTAL",
"AMT_GOODS_PRICE",
"AMT_CREDIT",
"AMT_ANNUITY",
"Client_Age",
"YEARS_EMPLOYED",
"DAYS_ID_PUBLISH",
"DAYS_REGISTRATION",
"EXT_SOURCE_2",
"EXT_SOURCE_3",
"REGION_POPULATION_RELATIVE",
]
].corr(),
annot=True,
cmap="RdYlGn",
)
plt.title("Correlation matrix for Non-Payment Difficulties")
plt.show()
plt.figure(figsize=(12, 8))
sns.heatmap(
app_target1[
[
"AMT_INCOME_TOTAL",
"AMT_GOODS_PRICE",
"AMT_CREDIT",
"AMT_ANNUITY",
"Client_Age",
"YEARS_EMPLOYED",
"DAYS_ID_PUBLISH",
"DAYS_REGISTRATION",
"EXT_SOURCE_2",
"EXT_SOURCE_3",
"REGION_POPULATION_RELATIVE",
]
].corr(),
annot=True,
cmap="RdYlGn",
)
plt.title("Correlation matrix for Payment Difficulties")
plt.show()
# # Data Analysis on Previous Appliaction Data Set
PD.head()
s1 = (PD.isnull().mean() * 100).sort_values(ascending=False)[
PD.isnull().mean() * 100 > 40
]
s1
PD.shape
PD.drop(columns=s1.index, inplace=True)
PD.shape
# # Changing Negative Values in the Days columns to positive Values
days = []
for i in PD.columns:
if "DAYS" in i:
days.append(i)
print("Unique values in {0} column : {1}".format(i, PD[i].unique()))
print("NULL Values in {0} column : {1}".format(i, PD[i].isnull().sum()))
print()
PD[days] = abs(PD[days])
PD[days]
PD = PD.replace("XNA", np.NaN)
PD = PD.replace("XAP", np.NaN)
# # Univariate Analysis on Previous App Data
PD.columns
cols = [
"NAME_CONTRACT_STATUS",
"WEEKDAY_APPR_PROCESS_START",
"NAME_PAYMENT_TYPE",
"CODE_REJECT_REASON",
"NAME_CONTRACT_TYPE",
"NAME_CLIENT_TYPE",
]
# Subplot initialization
fig = make_subplots(
rows=3, cols=2, subplot_titles=cols, horizontal_spacing=0.1, vertical_spacing=0.17
)
# Adding subplots
count = 0
for i in range(1, 4):
for j in range(1, 3):
fig.add_trace(
go.Bar(
x=PD[cols[count]].value_counts().index,
y=PD[cols[count]].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (PD[cols[count]].value_counts(normalize=True) * 100)
.round(1)
.tolist()
],
),
row=i,
col=j,
)
count += 1
fig.update_layout(
title=dict(
text="Analyze Categorical variables (Frequency / Percentage)", x=0.5, y=0.99
),
title_font_size=20,
showlegend=False,
width=960,
height=1200,
)
fig.show()
# # Approved Loan
Approved = PD[PD["NAME_CONTRACT_STATUS"] == "Approved"]
cols = [
"NAME_PORTFOLIO",
"NAME_GOODS_CATEGORY",
"CHANNEL_TYPE",
"NAME_YIELD_GROUP",
"NAME_PRODUCT_TYPE",
"NAME_CASH_LOAN_PURPOSE",
]
# Subplot initialization
fig = make_subplots(
rows=3, cols=2, subplot_titles=cols, horizontal_spacing=0.1, vertical_spacing=0.17
)
# Adding subplots
count = 0
for i in range(1, 4):
for j in range(1, 3):
fig.add_trace(
go.Bar(
x=PD[cols[count]].value_counts().index,
y=PD[cols[count]].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (PD[cols[count]].value_counts(normalize=True) * 100)
.round(1)
.tolist()
],
),
row=i,
col=j,
)
count += 1
fig.update_layout(
title=dict(
text="Analyze Categorical variables (Frequency / Percentage)", x=0.5, y=0.99
),
title_font_size=20,
showlegend=False,
width=960,
height=1200,
)
fig.show()
# # Refused Loans
Refused = PD[PD["NAME_CONTRACT_STATUS"] == "Refused"]
cols = [
"NAME_PORTFOLIO",
"NAME_GOODS_CATEGORY",
"CHANNEL_TYPE",
"NAME_YIELD_GROUP",
"NAME_PRODUCT_TYPE",
"NAME_CASH_LOAN_PURPOSE",
]
# Subplot initialization
fig = make_subplots(
rows=3, cols=2, subplot_titles=cols, horizontal_spacing=0.1, vertical_spacing=0.17
)
# Adding subplots
count = 0
for i in range(1, 4):
for j in range(1, 3):
fig.add_trace(
go.Bar(
x=PD[cols[count]].value_counts().index,
y=PD[cols[count]].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (PD[cols[count]].value_counts(normalize=True) * 100)
.round(1)
.tolist()
],
),
row=i,
col=j,
)
count += 1
fig.update_layout(
title=dict(
text="Analyze Categorical variables (Frequency / Percentage)", x=0.5, y=0.99
),
title_font_size=20,
showlegend=False,
width=960,
height=1200,
)
fig.show()
# # Merging Application & Previous Application Data
# Example of a custom function named mergereturn
def mergereturn(df1, df2, how="inner", on=None):
# Your function implementation here
pass
merged_df = pd.merge(AD, PD, on="SK_ID_CURR", how="inner")
merged_df
appdata_merge = AD.merge(PD, on="SK_ID_CURR", how="inner")
appdata_merge.shape
merged_df = pd.merge(
df1, df2, on="ID", how="inner"
) # You can choose 'how' to specify the type of join (inner, outer, left, right)
print(merged_df)
df_combine = AD.merge(PD, left_on="SK_ID_CURR", right_on="SK_ID_CURR", how="left")
df_combine
df_combine.shape
def plot_merge(df_combine, column_name):
col_value = ["Refused", "Approved", "Canceled", "Unused offer"]
fig = make_subplots(
rows=2,
cols=2,
subplot_titles=col_value,
horizontal_spacing=0.1,
vertical_spacing=0.3,
)
# Adding subplots
count = 0
for i in range(1, 3):
for j in range(1, 3):
fig.add_trace(
go.Bar(
x=df_combine[
df_combine["NAME_CONTRACT_STATUS"] == col_value[count]
][column_name]
.value_counts()
.index,
y=df_combine[
df_combine["NAME_CONTRACT_STATUS"] == col_value[count]
][column_name].value_counts(),
name=cols[count],
textposition="auto",
text=[
str(i) + "%"
for i in (
df_combine[
df_combine["NAME_CONTRACT_STATUS"] == col_value[count]
][column_name].value_counts(normalize=True)
* 100
)
.round(1)
.tolist()
],
),
row=i,
col=j,
)
count += 1
fig.update_layout(
title=dict(text="NAME_CONTRACT_STATUS VS " + column_name, x=0.5, y=0.99),
title_font_size=20,
showlegend=False,
width=960,
height=960,
)
fig.show()
def plot_pie_merge(df_combine, column_name):
col_value = ["Refused", "Approved", "Canceled", "Unused offer"]
# Subplot initialization
fig = make_subplots(
rows=2,
cols=2,
subplot_titles=col_value,
specs=[[{"type": "pie"}, {"type": "pie"}], [{"type": "pie"}, {"type": "pie"}]],
)
# Adding subplots
count = 0
for i in range(1, 3):
for j in range(1, 3):
fig.add_trace(
go.Pie(
labels=df_combine[
df_combine["NAME_CONTRACT_STATUS"] == col_value[count]
][column_name]
.value_counts()
.index,
values=df_combine[
df_combine["NAME_CONTRACT_STATUS"] == col_value[count]
][column_name].value_counts(),
textinfo="percent",
insidetextorientation="auto",
hole=0.3,
),
row=i,
col=j,
)
count += 1
fig.update_layout(
title=dict(text="NAME_CONTRACT_STATUS VS " + column_name, x=0.5, y=0.99),
title_font_size=20,
width=960,
height=960,
)
fig.show()
plot_pie_merge(df_combine, "NAME_CONTRACT_TYPE_y")
# Insights
# - Banks Mostly approve Consumer Loans
# - Most of the Refused_& Cancelled loans are cash loans.
plot_pie_merge(df_combine, "NAME_CLIENT_TYPE")
# Insights
# - Most of the Approved, refused & cancelled loans belong to the old clients.
# - Almost 27.4% loans were provided to new customers.
plot_pie_merge(df_combine, "CODE_GENDER")
# Insights
# - Approved percentage of loans provided to females is more as compared to refused percentage.
plot_merge(df_combine, "NAME_EDUCATION_TYPE")
# Insights
# - Most of the approved loans belong to applicants with Secondary / Secondary Special education type.
plot_merge(df_combine, "OCCUPATION_TYPE")
plot_merge(df_combine, "NAME_GOODS_CATEGORY")
plot_merge(df_combine, "PRODUCT_COMBINATION")
# Insights
# - Most of the approved loans belongs to POS household with interest & POS mobile with interest product combination.
# - 15% refused loans belong to Cash X - Sell:low product combination.
#
# - Most of the cancelled loan belong to cash category.
# 81.3% Unused offer loans belong to POS mobile with interest.
plot_merge(df_combine, "AMT_INCOME_TOTAL_Range")
| false | 0 | 8,498 | 1 | 6 | 8,498 |
||
35089966 | <kaggle_start><code>#
# # Table of Contents
# 1. [Align tasks](#align_tasks)
# 1. [Run @yukikubo123's DSL](#run_yuki_dsl)
# 1. [Rollback the predictions](#rollback_the_predictions)
# # Align tasks
# [Back to Table of Contents](#toc)
import warnings
warnings.filterwarnings("ignore")
import os
import json
import numpy as np
from pathlib import Path
import random
from collections import Counter
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
from tqdm import tqdm
import matplotlib.pyplot as plt
data_path = Path("../input/abstraction-and-reasoning-challenge")
train_path = data_path / "training"
valid_path = data_path / "evaluation"
test_path = data_path / "test"
def set_seeds(seed):
torch.manual_seed(seed)
np.random.seed(seed)
torch.cuda.manual_seed(seed)
random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
set_seeds(0)
paths = {"train": train_path, "eval": valid_path, "test": test_path}
def get_tasks(dataset="train"):
path = paths[dataset]
fns = sorted(os.listdir(path))
tasks = {}
for idx, fn in enumerate(fns):
fp = path / fn
with open(fp, "r") as f:
task = json.load(f)
tasks[fn.split(".")[0]] = task
return tasks
test_tasks = get_tasks("test")
train_tasks = get_tasks("train")
valid_tasks = get_tasks("eval")
from tqdm import tqdm
import matplotlib.pyplot as plt
from matplotlib import colors
from matplotlib import animation, rc
from IPython.display import HTML
cmap = colors.ListedColormap(
[
"#000000",
"#0074D9",
"#FF4136",
"#2ECC40",
"#FFDC00",
"#AAAAAA",
"#F012BE",
"#FF851B",
"#7FDBFF",
"#870C25",
]
)
norm = colors.Normalize(vmin=0, vmax=9)
def plot_pictures(pictures, labels):
fig, axs = plt.subplots(1, len(pictures), figsize=(2 * len(pictures), 32))
for i, (pict, label) in enumerate(zip(pictures, labels)):
axs[i].imshow(np.array(pict), cmap=cmap, norm=norm)
axs[i].set_title(label)
plt.show()
def plot_sample(sample, predict=None):
if predict is None:
plot_pictures([sample["input"], sample["output"]], ["Input", "Output"])
else:
plot_pictures(
[sample["input"], sample["output"], predict], ["Input", "Output", "Predict"]
)
norm = colors.Normalize(vmin=0, vmax=9)
# 0:black, 1:blue, 2:red, 3:greed, 4:yellow,
# 5:gray, 6:magenta, 7:orange, 8:sky, 9:brown
plt.figure(figsize=(3, 1), dpi=200)
plt.imshow([list(range(10))], cmap=cmap, norm=norm)
plt.xticks(list(range(10)))
plt.yticks([])
plt.show()
task = train_tasks["db3e9e38"]
for sample in task["train"]:
plot_sample(sample)
from skimage.transform import hough_line
def is_rotation(img):
tested_angles = np.array([0, np.pi / 2])
image = np.array(img)
h, theta, d = hough_line(image, theta=tested_angles)
rot = h[:, 0].max() > h[:, 1].max()
return rot
def get_color_counter(a, binary=False):
if binary:
unique, counts = np.unique((a > 0).astype(int), return_counts=True)
else:
unique, counts = np.unique(a, return_counts=True)
return dict(zip(unique, counts))
def similarity(da, db):
total = 0
for k, v in da.items():
if k in db:
total += min(v, db.get(k))
return total
def is_parts_aligned(da1, da2, db1, db2):
def get_most_color(dab):
c = 0
max_c = 0
for k, v in dab.items():
if k > 0:
if max_c < v:
max_c = v
c = k
return c
if True:
c1 = get_most_color(da1)
if (da1.get(c1, 0) >= da2.get(c1, 0)) and (db1.get(c1, 0) < db2.get(c1, 0)):
return False
if (da1.get(c1, 0) <= da2.get(c1, 0)) and (db1.get(c1, 0) > db2.get(c1, 0)):
return False
return True
def is_2images_aligned_updown(img0, img1):
a = np.array(img0)
a1 = a[0 : a.shape[0] // 2, :]
a2 = a[a.shape[0] // 2 :, :]
b = np.array(img1)
b1 = b[0 : b.shape[0] // 2, :]
b2 = b[b.shape[0] // 2 :, :]
da1 = get_color_counter(a1)
da2 = get_color_counter(a2)
db1 = get_color_counter(b1)
db2 = get_color_counter(b2)
return is_parts_aligned(da1, da2, db1, db2)
def is_2images_aligned_leftright(img0, img1):
a = np.array(img0)
a1 = a[:, 0 : a.shape[1] // 2] # a[0:a.shape[0]//2, :]
a2 = a[:, a.shape[1] // 2 :]
b = np.array(img1)
b1 = b[:, 0 : b.shape[1] // 2] # b[0:b.shape[0]//2, :]
b2 = b[:, b.shape[1] // 2 :]
da1 = get_color_counter(a1)
da2 = get_color_counter(a2)
db1 = get_color_counter(b1)
db2 = get_color_counter(b2)
return is_parts_aligned(da1, da2, db1, db2)
def align_task(task):
task_aligned = task.copy()
sample_trains = task["train"]
sample_tests = task["test"]
# Train
sample_trains_aligned = []
for sample in sample_trains:
img_input = sample["input"]
img_ouput = sample["output"]
sample_aligned = sample.copy()
if is_rotation(img_input):
sample_aligned["input"] = np.rot90(np.array(img_input), k=1).tolist()
sample_aligned["output"] = np.rot90(np.array(img_ouput), k=1).tolist()
sample_trains_aligned.append(sample_aligned)
sample_trains_aligned_2 = sample_trains_aligned[:1] # first element
img0_aligned = sample_trains_aligned_2[0]["input"]
for sample in sample_trains_aligned[1:]:
sample_aligned = sample.copy()
if not is_2images_aligned_updown(img0_aligned, sample_aligned["input"]):
sample_aligned["input"] = np.flipud(
np.array(sample_aligned["input"])
).tolist()
sample_aligned["output"] = np.flipud(
np.array(sample_aligned["output"])
).tolist()
if not is_2images_aligned_leftright(img0_aligned, sample_aligned["input"]):
sample_aligned["input"] = np.fliplr(
np.array(sample_aligned["input"])
).tolist()
sample_aligned["output"] = np.fliplr(
np.array(sample_aligned["output"])
).tolist()
sample_trains_aligned_2.append(sample_aligned)
task_aligned["train"] = sample_trains_aligned_2
# Test
sample_test_aligned = []
for sample in sample_tests:
img_input = sample["input"]
is_output_available = "output" in sample
sample_aligned = sample.copy()
sample_aligned["rot90"] = False
if is_rotation(img_input):
sample_aligned["input"] = np.rot90(np.array(img_input), k=1).tolist()
if is_output_available:
sample_aligned["output"] = np.rot90(
np.array(sample_aligned["output"]), k=1
).tolist()
sample_aligned["rot90"] = True
sample_test_aligned.append(sample_aligned)
sample_test_aligned_v2 = []
for sample in sample_test_aligned:
sample_aligned = sample.copy()
sample_aligned["flipud"] = False
if not is_2images_aligned_updown(img0_aligned, sample_aligned["input"]):
sample_aligned["input"] = np.flipud(
np.array(sample_aligned["input"])
).tolist()
if is_output_available:
sample_aligned["output"] = np.flipud(
np.array(sample_aligned["output"])
).tolist()
sample_aligned["flipud"] = True
sample_aligned["fliplr"] = False
if not is_2images_aligned_leftright(img0_aligned, sample_aligned["input"]):
sample_aligned["input"] = np.fliplr(
np.array(sample_aligned["input"])
).tolist()
if is_output_available:
sample_aligned["output"] = np.fliplr(
np.array(sample_aligned["output"])
).tolist()
sample_aligned["fliplr"] = True
sample_test_aligned_v2.append(sample_aligned)
task_aligned["test"] = sample_test_aligned_v2
return task_aligned
single_task = train_tasks["db3e9e38"]
single_task = valid_tasks["103eff5b"]
# single_task = valid_tasks["05a7bcf2"]
task_aligned = align_task(single_task)
for sample in task_aligned["train"]:
# print(sample['flipud'], sample['rot90'])
plot_sample(sample)
for sample in task_aligned["test"]:
print(sample["fliplr"], sample["flipud"], sample["rot90"])
plot_sample(sample)
test_aligned_path = Path("test_aligned")
test_tasks = get_tasks("test")
for task_id, task in tqdm(test_tasks.items()):
task_aligned = align_task(task)
task_filename = "{}.json".format(task_id)
with open(test_aligned_path / task_filename, "w") as outfile:
json.dump(task_aligned, outfile)
paths["test_aligned"] = test_aligned_path
test_aligned_tasks = get_tasks("test_aligned")
print(len(test_aligned_tasks))
#
# # Run @yukikubo123's DSL
# [Back to Table of Content](#toc)
""" This file was auto_generated by kernel_generator.py """
from typing import Set
from deap.tools import selNSGA2
from lightgbm import LGBMClassifier
from joblib import delayed
from scipy.ndimage import binary_erosion
from enum import auto
from collections import defaultdict
from scipy.ndimage import maximum_filter
from itertools import groupby
from skimage.measure import label
from sklearn.neural_network import MLPClassifier
from scipy.ndimage import binary_fill_holes
import json
import shutil
from typing import List
from enum import IntEnum
from pandas import DataFrame
from enum import unique
import cv2
import pandas as pd
from copy import deepcopy
from typing import Tuple
from itertools import product
from skimage.filters import try_all_threshold
from pathlib import Path
from heapq import heapify
from scipy.ndimage import generate_binary_structure
from sklearn.linear_model import LogisticRegression
from functools import partial
import copy
from typing import Any
from typing import Optional
from heapq import heappush
from category_encoders import OrdinalEncoder
import numpy as np
from typing import Dict
from tqdm import tqdm
from matplotlib import colors
import time
import random
from heapq import heappushpop
from typing import Iterable
from enum import Enum
import pickle
from matplotlib import pyplot as plt
from joblib import Parallel
from heapq import heappop
from itertools import chain
from dataclasses import asdict
from skimage.filters import threshold_minimum
from sklearn.linear_model import RidgeClassifier
from scipy.ndimage import binary_dilation
import optuna
from dataclasses import dataclass
from typing import Union
from typing import TypeVar
from optuna import Trial
import category_encoders
from sklearn.model_selection import KFold
from operator import itemgetter
# from ruamel import yaml
from collections import Counter
@dataclass
class OperationInconsistencyException(Exception):
message: str = ""
class Timer:
def __init__(self):
pass
def __enter__(self):
self.start_sec = time.perf_counter()
return self
def second(self):
return time.perf_counter() - self.start_sec
def __exit__(self, *exc):
return
class StrNameEnum(Enum):
def __str__(self):
return self.name
def __repr__(self):
return str(f"{self.__class__.__name__}.{self.name}")
class StrNameIntEnum(IntEnum):
def __str__(self):
return self.name
def __repr__(self):
return str(f"{self.__class__.__name__}.{self.name}")
@unique
class RunMode(Enum):
LOCAL_RUN_ALL = auto()
LOCAL_RUN = auto()
TREE_BASE_SEARCH_OPTIMIZATION = auto()
NODE_BASE_SEARCH_OPTIMIZATION = auto()
LOCAL_DATA_GENERATION = auto()
LOCAL_ML_TRAIN = auto()
TRAIN_OPERATION_ELEMENT_INCLUSION_PREDICTION = auto()
KERNEL = auto()
KERNEL_EMULATION = auto()
@unique
class TaskRange(Enum):
ALL = auto()
CAN_ANSWER_ONLY = auto()
EXCLUDE_GIVE_UPS = auto()
@unique
class FlipMode(StrNameEnum):
UD = auto()
LR = auto()
UL_DR = auto()
UR_DL = auto()
@unique
class EngineSchedulePattern(Enum):
DRY_RUN = auto()
HAND_MADE = auto()
ML = auto()
@unique
class EngineType(Enum):
NODE_BASED_SEARCH_ENGINE = auto()
TREE_BASED_SEARCH_ENGINE = auto()
class RunConfig:
RUN_MODE = RunMode.KERNEL # Usually, use "LOCAL_RUN" or "KERNEL"
TASK_RANGE = TaskRange.ALL # Limit the range to save time.
ENGINE_TYPE = EngineType.NODE_BASED_SEARCH_ENGINE
ENGINE_SCHEDULE_PATTERN = EngineSchedulePattern.HAND_MADE
USE_ML_GUIDE = False # DeepCoder-like strategy. Calculate the probability of inclusion of each DSL elements.
RUN_ONLY_PRIVATE_LB = False # Skip public kernel run to save time.
_KERNEL_N_JOB = 4
_LOCAL_N_JOB = 5
N_JOB = _KERNEL_N_JOB if RUN_MODE == RunMode.KERNEL else _LOCAL_N_JOB
@unique
class DepthSearchPattern(Enum):
BREADTH_FIRST = auto()
NORMAL = auto()
DEPTH_FIRST = auto()
@unique
class TrueOrFalse(StrNameEnum):
TRUE = auto()
FALSE = auto()
@unique
class Color(StrNameIntEnum):
BLACK = 0
BLUE = 1
RED = 2
GREEN = 3
YELLOW = 4
GRAY = 5
MAGENTA = 6
ORANGE = 7
SKY = 8
BROWN = 9
MASK_TAG = 10 # very special color. TODO unused?
@classmethod
def prepare(cls):
cls.mapping = {c.value: c for c in Color}
@classmethod
def of(cls, value: int) -> "Color":
try:
return cls.mapping[value]
except AttributeError:
cls.mapping = {c.value: c for c in Color}
return cls.mapping[value]
@unique
class Direction(StrNameEnum):
TOP = auto()
BOTTOM = auto()
RIGHT = auto()
LEFT = auto()
@unique
class PaddingMode(StrNameEnum):
REPEAT = auto()
MIRROR_1 = auto() # line-symmetric at the edge
MIRROR_2 = auto() # line-symmetric at the edge-pixel-line
EDGE = auto()
@unique
class Axis(StrNameEnum):
VERTICAL = auto()
HORIZONTAL = auto()
BOTH = auto()
@unique
class MultiColorSelectionMode(StrNameEnum):
# ANY_WITHOUT_FIXED_COLOR = auto() # TODO should define?
ANY_WITHOUT_MOST_COMMON = auto() # TODO ANY_WITHOUT_TOP2_MOST_COMMON
ANY_WITHOUT_LEAST_COMMON = auto()
@unique
class MaxOrMin(StrNameEnum):
MAX = max
MIN = min
@property
def func(self):
return self.value
@unique
class FillType(StrNameEnum):
NotOverride = auto()
Override = auto()
@unique
class LineEdgeType(StrNameEnum):
EdgeExclude = auto()
EdgeInclude = auto()
@unique
class ImageEdgeType(StrNameEnum):
EDGE_EXCLUDE = auto()
EDGE_INCLUDE = auto()
@unique
class ObjectFeature(StrNameEnum):
AREA = auto()
# PERIMETER_LEN = auto() # TODO difficult to implement?
HORIZONTAL_LEN = auto()
VERTICAL_LEN = auto()
@unique
class PixelConnectivity(StrNameEnum):
FOUR_DIRECTION = 1
EIGHT_DIRECTION = 2
@property
def value_for_skimage(self) -> int:
return self.value
@property
def structure_for_skimage(self) -> np.ndarray:
if self == PixelConnectivity.EIGHT_DIRECTION:
return generate_binary_structure(2, 2)
if self == PixelConnectivity.FOUR_DIRECTION:
return generate_binary_structure(2, 1)
raise NotImplementedError()
@unique
class HoleInclude(StrNameEnum):
INCLUDE = auto()
EXCLUDE = auto()
@unique
class SingleColorSelectionMode(StrNameEnum):
MOST_COMMON = auto()
SECOND_MOST_COMMON = auto()
LEAST_COMMON = auto()
@dataclass(frozen=True)
class ColorSelection:
def __call__(self, arr: np.ndarray) -> np.ndarray:
raise NotImplementedError()
@dataclass(frozen=True)
class MaskConversion:
def __call__(self, mask: np.ndarray) -> np.ndarray:
raise NotImplementedError()
@dataclass(frozen=True)
class NoMaskConversion(MaskConversion):
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
return color_mask
@dataclass(frozen=True)
class MaskOperation:
def __call__(self, arr: np.ndarray, mask: np.ndarray) -> np.ndarray:
raise NotImplementedError()
@dataclass(frozen=True)
class ColorChannelSelection:
def __call__(self, arr: np.ndarray) -> List[Tuple[Color, np.ndarray]]:
raise NotImplementedError()
@dataclass(frozen=True)
class ChannelMergeOperation:
def __call__(
self,
arr: np.ndarray,
original_color_mask_pairs: List[Tuple[Color, np.ndarray]],
color_mask_pairs: List[Tuple[Color, np.ndarray]],
) -> np.ndarray:
raise NotImplementedError()
@dataclass(frozen=True)
class ColorOperation:
color_selection: ColorSelection
mask_conversions: MaskConversion
mask_operation: MaskOperation
@dataclass(frozen=True)
class MultiColorChannelOperation:
channel_selection: ColorChannelSelection
mask_conversions: MaskConversion
channel_merge_operation: ChannelMergeOperation
@dataclass(frozen=True)
class PartitionedArraySelection:
def __call__(
self, arr: np.ndarray, partitioned_arrays: List[List[np.ndarray]]
) -> List[List[bool]]:
raise NotImplementedError()
@dataclass(frozen=True)
class PartitionOperation:
partition_selection: "PartitionSelection"
# partition_uniform_operation: PartitionUniformOperation # TODO implement
partition_merge_operation: "PartitionMergeOperation"
@dataclass(frozen=True)
class PartitionSelection:
# array -> (2d_partitioned_array, 2d_original_location_mask)
def __call__(
self, arr: np.ndarray
) -> Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]:
raise NotImplementedError()
@dataclass(frozen=True)
class PartitionMergeOperation:
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
raise NotImplementedError()
@dataclass
class DistanceEvaluatorParameter:
same_h_w_dim_between_input_output: float = 1500
all_dim_h_w_integer_multiple: float = 650
mean_lack_color_num: float = 30
mean_excess_color_num: float = 50
mean_hit_and_miss_histogram_diff: float = 50
mean_h_v_diff_input_arr_line_num: float = 40
mean_h_v_diff_output_arr_line_num: float = 60
mean_h_v_edge_sum_diff: float = 2
mean_h_v_edge_sum_diff_ratio: float = 0.5
mean_diff_color_cell_ratio: int = 1 # 基準
mean_diff_cell_where_no_need_to_change_count_ratio: float = 100
mean_wrong_change_cell_where_need_to_change_count_ratio: float = 100
@dataclass
class NodeBaseSearchEngineParameter:
breadth_first_cost: float = 3500
normal_first_cost: float = 400
depth_first_cost: float = 1.2
breadth_first_exp_cost: float = 0
normal_exp_cost: float = 0
depth_first_exp_cost: float = 0
element_inclusion_prob_factor: float = 0
pq_pop_mins_or_as_least_n: int = 20
@dataclass
class TreeBaseSearchEngineParameter:
population_num: int = 26
max_depth: int = 8
operation_mutation_prob: float = 0.19
operation_component_mutation_prob: float = 0.1
operation_param_mutation_prob: float = 0.0048
extend_mutation_prob: float = 0.044
shrink_mutation_prob: float = 0.0012
@dataclass
class AllParameter:
distance_evaluator_param: DistanceEvaluatorParameter = DistanceEvaluatorParameter()
node_base_engine_param: Optional[
NodeBaseSearchEngineParameter
] = NodeBaseSearchEngineParameter()
tree_base_engine_param: Optional[
TreeBaseSearchEngineParameter
] = TreeBaseSearchEngineParameter()
@dataclass()
class InputOutput:
input_arr: np.ndarray
output_arr: Optional[np.ndarray]
@staticmethod
def of(json_dict: dict) -> "InputOutput":
return InputOutput(
np.array(json_dict["input"], dtype=np.uint8),
np.array(json_dict["output"], dtype=np.uint8)
if "output" in json_dict
else None,
)
def get_all_arr(self) -> List[np.ndarray]:
if self.output_arr is None:
return [self.input_arr]
else:
return [self.input_arr, self.output_arr]
def candidate_color_mapping(self) -> List[Tuple[Color, Color]]:
input_colors = list(np.unique(self.input_arr)) + [
Color.ANY_WITHOUT_MOST,
Color.MOST,
Color.SECOND_MOST,
Color.LEAST,
]
output_colors = np.unique(self.output_arr)
return [
(Color.of(i), Color.of(o))
for i, o in product(input_colors, output_colors)
if i != o
]
@dataclass(frozen=True)
class UniformOperation:
def __call__(self, arr: np.ndarray) -> np.ndarray:
raise NotImplementedError()
@dataclass(frozen=True)
class OperationSet:
operations: List[
Union[
UniformOperation,
ColorOperation,
MultiColorChannelOperation,
PartitionOperation,
]
]
def __str__(self):
return repr(self)
def types(self):
results = []
for o in self.operations:
if isinstance(o, UniformOperation):
results.append(UniformOperation)
elif isinstance(o, ColorOperation):
results.append(ColorOperation)
elif isinstance(o, MultiColorChannelOperation):
results.append(MultiColorChannelOperation)
elif isinstance(o, PartitionOperation):
results.append(PartitionOperation)
else:
raise NotImplementedError()
return results
def elements(
self,
) -> List[
Union[
UniformOperation,
ColorSelection,
MaskConversion,
MaskOperation,
PartitionOperation,
]
]:
res = []
for o in self.operations:
if isinstance(o, UniformOperation):
res.append(o)
elif isinstance(o, ColorOperation):
res.append(o.color_selection)
res.append(o.mask_conversions)
res.append(o.mask_operation)
elif isinstance(o, MultiColorChannelOperation):
res.append(o.channel_selection)
res.append(o.mask_conversions)
res.append(o.channel_merge_operation)
elif isinstance(o, PartitionOperation):
res.append(o.partition_selection)
res.append(o.partition_merge_operation)
else:
raise NotImplementedError()
return res
@dataclass(frozen=True)
class Task:
name: str
train: Tuple[InputOutput]
test: Tuple[InputOutput]
@staticmethod
def of(name: str, json_dict: dict) -> "Task":
return Task(
name,
tuple(InputOutput.of(io) for io in json_dict["train"]),
tuple(InputOutput.of(io) for io in json_dict["test"]),
)
def get_all_arr(self) -> List[np.ndarray]:
return self.get_train_all_arr() + self.get_test_all_arr()
def get_train_all_arr(self) -> List[np.ndarray]:
return list(chain.from_iterable(map(lambda io: io.get_all_arr(), self.train)))
def get_test_all_arr(self) -> List[np.ndarray]:
return list(chain.from_iterable(map(lambda io: io.get_all_arr(), self.test)))
def get_input_all_arr(self) -> List[np.ndarray]:
return list(map(lambda io: io.input_arr, self.train + self.test))
def get_output_all_arr(self) -> List[np.ndarray]:
return list(
filter(
lambda arr: arr is not None,
map(lambda io: io.output_arr, self.train + self.test),
)
)
def test_arr_hash(self) -> int:
return hash(
self.__class__.__name__
+ "_".join(map(lambda io: str(io.input_arr), self.test))
)
@dataclass(frozen=True)
class ColorSelectedTask(Task):
train_masks: List[np.ndarray]
test_masks: List[np.ndarray]
@dataclass(frozen=True)
class MaskConvertedTask(Task):
train_masks: List[np.ndarray]
test_masks: List[np.ndarray]
@dataclass(frozen=True)
class ColorChannelSelectedTask(Task):
train_color_mask_pairs: List[List[Tuple[Color, np.ndarray]]]
test_color_mask_pairs: List[List[Tuple[Color, np.ndarray]]]
@dataclass(frozen=True)
class ColorChannelMaskConvertedTask(Task):
train_original_color_mask_pairs: List[List[Tuple[Color, np.ndarray]]]
train_color_mask_pairs: List[List[Tuple[Color, np.ndarray]]]
test_original_color_mask_pairs: List[List[Tuple[Color, np.ndarray]]]
test_color_mask_pairs: List[List[Tuple[Color, np.ndarray]]]
@dataclass(frozen=True)
class PartitionSelectionTask(Task):
train_partitioned_arrays_original_location_masks: List[
Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]
]
test_partitioned_arrays_original_location_masks: List[
Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]
]
@dataclass
class ImageFeature:
height: int
width: int
colors: List[Color]
hit_and_miss_histogram: List[int]
# most_common_color: Color
vertical_edge_num: int
horizontal_edge_num: int
@dataclass
class ImageDiffFeature:
input_image_feature: ImageFeature # TODO should not define here?
output_image_feature: ImageFeature # TODO should not define here?
dim_height_increase: int
dim_width_increase: int
dim_height_integer_multiple: bool
dim_width_integer_multiple: bool
dim_height_diff: int
dim_width_diff: int
dim_height_equal: bool
dim_width_equal: bool
lack_color_num: int
excess_color_num: int
hit_and_miss_histogram_diff: int
# vertical_diff_input_arr_line_num: Optional[int]
# horizontal_diff_input_arr_line_num: Optional[int]
# vertical_diff_output_arr_line_num: Optional[int]
# horizontal_diff_output_arr_line_num: Optional[int]
vertical_edge_sum_diff: int
horizontal_edge_sum_diff: int
vertical_edge_sum_diff_ratio: float
horizontal_edge_sum_diff_ratio: float
diff_color_cell_ratio: Optional[float] # None if different image size.
diff_cell_where_no_need_to_change_count_ratio: Optional[
float
] # None if different image size.
wrong_change_cell_where_need_to_change_count_ratio: Optional[
float
] # None if different image size.
# TODO cell_diff_num_except_formost_common_color
def same_dim(self) -> bool:
return self.dim_height_equal and self.dim_width_equal
@dataclass
class TaskFeature:
# image_diff_features: List[ImageDiffFeature]
same_dim_between_input_output: bool
same_height_dim_between_input_output: bool
same_width_dim_between_input_output: bool
all_dim_height_increased: bool
all_dim_height_decreased: bool
all_dim_width_increased: bool
all_dim_width_decreased: bool
all_dim_height_integer_multiple: bool
all_dim_width_integer_multiple: bool
mean_lack_color_num: float
mean_excess_color_num: float
mean_hit_and_miss_histogram_diff: float
# mean_vertical_diff_input_arr_line_num: Optional[float]
# mean_horizontal_diff_input_arr_line_num: Optional[float]
# mean_vertical_diff_output_arr_line_num: Optional[float]
# mean_horizontal_diff_output_arr_line_num: Optional[float]
mean_vertical_edge_sum_diff: float
mean_horizontal_edge_sum_diff: float
mean_vertical_edge_sum_diff_ratio: float
mean_horizontal_edge_sum_diff_ratio: float
mean_diff_color_cell_ratio: Optional[float] # None if different image size.
mean_diff_cell_where_no_need_to_change_count_ratio: Optional[
float
] # None if different image size.
mean_wrong_change_cell_where_need_to_change_count_ratio: Optional[float]
@dataclass
class ColorSelectedTaskFeature:
task_feature: TaskFeature
@dataclass
class MaskConvertedTaskFeature:
task_feature: TaskFeature
possible_improve_ratios: List[Optional[float]]
@dataclass
class DistanceEvaluator:
dist_eval_param: DistanceEvaluatorParameter
def evaluate_task_feature(self, task_feature: TaskFeature) -> float:
return (
0
+ self.dist_eval_param.same_h_w_dim_between_input_output
* (0 if task_feature.same_height_dim_between_input_output else 1)
+ self.dist_eval_param.same_h_w_dim_between_input_output
* (0 if task_feature.same_width_dim_between_input_output else 1)
+ self.dist_eval_param.all_dim_h_w_integer_multiple
* (0 if task_feature.all_dim_height_integer_multiple else 1)
+ self.dist_eval_param.all_dim_h_w_integer_multiple
* (0 if task_feature.all_dim_width_integer_multiple else 1)
+ self.dist_eval_param.mean_lack_color_num
* task_feature.mean_lack_color_num
+ self.dist_eval_param.mean_excess_color_num
* task_feature.mean_excess_color_num
+ self.dist_eval_param.mean_hit_and_miss_histogram_diff
* task_feature.mean_hit_and_miss_histogram_diff
+ self.dist_eval_param.mean_h_v_edge_sum_diff
* (task_feature.mean_vertical_edge_sum_diff)
+ self.dist_eval_param.mean_h_v_edge_sum_diff
* (task_feature.mean_horizontal_edge_sum_diff)
+ self.dist_eval_param.mean_h_v_edge_sum_diff_ratio
* (task_feature.mean_vertical_edge_sum_diff_ratio)
+ self.dist_eval_param.mean_h_v_edge_sum_diff_ratio
* (task_feature.mean_horizontal_edge_sum_diff_ratio)
+ self.dist_eval_param.mean_diff_color_cell_ratio
* (task_feature.mean_diff_color_cell_ratio or 0)
+ self.dist_eval_param.mean_diff_cell_where_no_need_to_change_count_ratio
* (task_feature.mean_diff_cell_where_no_need_to_change_count_ratio or 0)
+ self.dist_eval_param.mean_wrong_change_cell_where_need_to_change_count_ratio
* (
task_feature.mean_wrong_change_cell_where_need_to_change_count_ratio
or 0
)
)
# + self.dist_eval_param.mean_h_v_diff_input_arr_line_num * (task_feature.mean_horizontal_diff_input_arr_line_num or 0) \
# + self.dist_eval_param.mean_h_v_diff_input_arr_line_num * (task_feature.mean_vertical_diff_input_arr_line_num or 0) \
# + self.dist_eval_param.mean_h_v_diff_output_arr_line_num * (task_feature.mean_horizontal_diff_output_arr_line_num or 0) \
# + self.dist_eval_param.mean_h_v_diff_output_arr_line_num * (task_feature.mean_vertical_diff_output_arr_line_num or 0) \
def evaluate_task_feature_element(self, task_feature: TaskFeature) -> List[float]:
return [
(0 if task_feature.same_height_dim_between_input_output else 1),
(0 if task_feature.same_width_dim_between_input_output else 1),
(0 if task_feature.all_dim_height_integer_multiple else 1),
(0 if task_feature.all_dim_width_integer_multiple else 1),
task_feature.mean_lack_color_num,
task_feature.mean_excess_color_num,
task_feature.mean_hit_and_miss_histogram_diff,
(task_feature.mean_vertical_edge_sum_diff),
(task_feature.mean_horizontal_edge_sum_diff),
(task_feature.mean_vertical_edge_sum_diff_ratio),
(task_feature.mean_horizontal_edge_sum_diff_ratio),
(task_feature.mean_diff_color_cell_ratio or 0),
]
class Node:
def __repr__(self):
return str(self)
@dataclass
class WaitingNode(Node):
# This node will be added to priority queue.
parent_completed_node: "CompletedNode"
cache_pred_distance = None
def evaluation_features(self) -> Dict[str, Any]:
raise NotImplementedError()
def depth(self) -> int:
raise NotImplementedError()
def __le__(self, other: "WaitingNode") -> bool:
return self.cache_pred_distance <= other.cache_pred_distance
def __lt__(self, other: "WaitingNode") -> bool:
return self.cache_pred_distance < other.cache_pred_distance
@dataclass
class UniformOperationWaitingNode(WaitingNode):
original_task: Task
task: Task
task_feature: TaskFeature
base_operation_set: OperationSet
next_operation: UniformOperation
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, next_ope: {self.next_operation}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
def evaluation_features(self) -> Dict[str, Any]:
return {
"node_class": self.__class__.__name__,
"depth": len(self.base_operation_set.operations),
**asdict(self.task_feature),
"next_operation": self.next_operation.__class__.__name__,
**asdict(self.next_operation),
}
@dataclass
class ColorSelectionWaitingNode(WaitingNode):
original_task: Task
task: Task
task_feature: TaskFeature
base_operation_set: OperationSet
next_selection: ColorSelection
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, next_selection: {self.next_selection}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
def evaluation_features(self) -> Dict[str, Any]:
return {
"node_class": self.__class__.__name__,
"depth": len(self.base_operation_set.operations),
**asdict(self.task_feature),
"next_selection": self.next_selection.__class__.__name__,
**asdict(self.next_selection),
}
@dataclass
class MaskConversionWaitingNode(WaitingNode):
original_task: Task
color_selected_task: ColorSelectedTask
color_selected_task_feature: ColorSelectedTaskFeature
base_operation_set: OperationSet
color_selection: ColorSelection
next_mask_conversion: MaskConversion
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, color_selection: {self.color_selection}, next_add_selection: {self.next_mask_conversion}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
def evaluation_features(self) -> Dict[str, Any]:
return {
"node_class": self.__class__.__name__,
"depth": len(self.base_operation_set.operations),
**asdict(self.color_selected_task_feature.task_feature),
"next_mask_conversion": self.next_mask_conversion.__class__.__name__,
**asdict(self.next_mask_conversion),
}
@dataclass
class MaskOperationSelectionWaitingNode(WaitingNode):
original_task: Task
mask_converted_task: MaskConvertedTask
mask_converted_task_feature: MaskConvertedTaskFeature
base_operation_set: OperationSet
color_selection: ColorSelection
mask_conversion: MaskConversion
next_mask_operation: MaskOperation
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, color_selection: {self.color_selection}, add_selection: {self.mask_conversion}, next_mask_ope: {self.next_mask_operation}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
def evaluation_features(self) -> Dict[str, Any]:
return {
"node_class": self.__class__.__name__,
"depth": len(self.base_operation_set.operations),
**asdict(self.mask_converted_task_feature.task_feature),
"next_mask_operation": self.next_mask_operation.__class__.__name__,
**asdict(self.next_mask_operation),
}
@dataclass
class ColorChannelSelectionOperationWaitingNode(WaitingNode):
original_task: Task
task: Task
task_feature: TaskFeature
base_operation_set: OperationSet
next_color_channel_selection: ColorChannelSelection
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, next_color_channeling: {self.next_color_channel_selection}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
def evaluation_features(self) -> Dict[str, Any]:
return {
"node_class": self.__class__.__name__,
"depth": len(self.base_operation_set.operations),
**asdict(self.task_feature),
"next_operation": self.next_color_channel_selection.__class__.__name__,
**asdict(self.next_color_channel_selection),
}
@dataclass
class ColorChannelMaskConversionWaitingNode(WaitingNode):
original_task: Task
task: ColorChannelSelectedTask
task_feature: TaskFeature
base_operation_set: OperationSet
color_channel_selection: ColorChannelSelection
next_mask_conversion: MaskConversion
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, color_channel_selection: {self.color_channel_selection}, next_mask_conversion: {self.next_mask_conversion}, next_mask_ope: {self.next_mask_conversion}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
@dataclass
class ColorChannelMergeWaitingNode(WaitingNode):
original_task: Task
task: ColorChannelMaskConvertedTask
task_feature: TaskFeature
base_operation_set: OperationSet
color_channel_selection: ColorChannelSelection
mask_conversion: MaskConversion
next_merge_operation: ChannelMergeOperation
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, color_channel_selection: {self.color_channel_selection}, mask_conversion: {self.mask_conversion}, next_merge_operation: {self.next_merge_operation}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
@dataclass
class PartitionSelectionWaitingNode(WaitingNode):
original_task: Task
task: Task
task_feature: TaskFeature
base_operation_set: OperationSet
next_partition_selection: PartitionSelection
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, next_partition_sel: {self.next_partition_selection}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
@dataclass
class PartitionMergeWaitingNode(WaitingNode):
original_task: Task
task: PartitionSelectionTask
task_feature: TaskFeature
base_operation_set: OperationSet
partition_selection: PartitionSelection
next_partition_merge_operation: PartitionMergeOperation
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, partition_sel: {self.partition_selection}, partition_merge: {self.next_partition_merge_operation}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
@dataclass()
class CompletedNode(Node):
# This node won't be added to priority queue. This is processed immediately and converted to next List[WaitingNode].
parent_waiting_node: "WaitingNode"
def train_arr_hash(self) -> int:
raise NotImplementedError()
def all_arr_hash(self) -> int:
raise NotImplementedError()
@dataclass
class UniformOperationCompletedNode(CompletedNode):
original_task: Task
task: Task
task_feature: TaskFeature
base_operation_set: OperationSet
def __str__(self):
return f"depth: {len(self.base_operation_set.operations)}, class: {self.__class__.__name__}, ope_set: {self.base_operation_set}"
def train_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(map(lambda io: np_to_str(io.input_arr), self.task.train))
)
def all_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
map(
lambda io: np_to_str(io.input_arr), self.task.train + self.task.test
)
)
)
@dataclass
class ColorSelectionCompletedNode(CompletedNode):
original_task: Task
color_selected_task: ColorSelectedTask
color_selected_task_feature: ColorSelectedTaskFeature
base_operation_set: OperationSet
color_selection: ColorSelection
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}, class: {self.__class__.__name__}, "
f"base_ope: {self.base_operation_set}, color_sele: {self.color_selection}"
)
def train_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(
lambda io: np_to_str(io.input_arr),
self.color_selected_task.train,
),
map(lambda t: np_to_str(t), self.color_selected_task.train_masks),
)
)
)
def all_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(
lambda io: np_to_str(io.input_arr),
self.color_selected_task.train + self.color_selected_task.test,
),
map(
lambda t: np_to_str(t),
self.color_selected_task.train_masks
+ self.color_selected_task.test_masks,
),
)
)
)
@dataclass
class MaskConversionCompletedNode(CompletedNode):
original_task: Task
mask_converted_task: MaskConvertedTask
mask_converted_task_feature: MaskConvertedTaskFeature
base_operation_set: OperationSet
color_selection: ColorSelection
mask_conversion: MaskConversion
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}, class: {self.__class__.__name__}, "
f"base_ope: {self.base_operation_set}, color_sele: {self.color_selection}, add_sele: {self.mask_conversion}"
)
def train_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(
lambda io: np_to_str(io.input_arr),
self.mask_converted_task.train,
),
map(lambda t: np_to_str(t), self.mask_converted_task.train_masks),
)
)
)
def all_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(
lambda io: np_to_str(io.input_arr),
self.mask_converted_task.train + self.mask_converted_task.test,
),
map(
lambda t: np_to_str(t),
self.mask_converted_task.train_masks
+ self.mask_converted_task.test_masks,
),
)
)
)
@dataclass
class ColorChannelSelectionCompletedNode(CompletedNode):
original_task: Task
task: ColorChannelSelectedTask
feature: TaskFeature
base_operation_set: OperationSet
color_channel_selection: ColorChannelSelection
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}, class: {self.__class__.__name__}, "
f"base_ope: {self.base_operation_set}, color_sele: {self.color_channel_selection}"
)
def train_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(lambda io: np_to_str(io.input_arr), self.task.train),
chain.from_iterable(
[
(to_bytes(c), np_to_str(m))
for p_l in self.task.train_color_mask_pairs
for c, m in p_l
]
),
)
)
)
def all_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(lambda io: np_to_str(io.input_arr), self.task.test),
chain.from_iterable(
[
(to_bytes(c), np_to_str(m))
for p_l in self.task.train_color_mask_pairs
+ self.task.test_color_mask_pairs
for c, m in p_l
]
),
)
)
)
@dataclass
class ColorChannelMaskConversionCompletedNode(CompletedNode):
original_task: Task
task: ColorChannelMaskConvertedTask
feature: TaskFeature
base_operation_set: OperationSet
color_selection: ColorChannelSelection
mask_conversion: MaskConversion
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}, class: {self.__class__.__name__}, "
f"base_ope: {self.base_operation_set}, mask_conversion: {self.mask_conversion}"
)
def train_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(lambda io: np_to_str(io.input_arr), self.task.train),
chain.from_iterable(
[
(to_bytes(c), np_to_str(m))
for p_l in self.task.train_original_color_mask_pairs
for c, m in p_l
]
),
chain.from_iterable(
[
(to_bytes(c), np_to_str(m))
for p_l in self.task.train_color_mask_pairs
for c, m in p_l
]
),
)
)
)
def all_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(lambda io: np_to_str(io.input_arr), self.task.test),
chain.from_iterable(
[
(to_bytes(c), np_to_str(m))
for p_l in self.task.train_original_color_mask_pairs
+ self.task.test_original_color_mask_pairs
for c, m in p_l
]
),
chain.from_iterable(
[
(to_bytes(c), np_to_str(m))
for p_l in self.task.train_color_mask_pairs
+ self.task.test_color_mask_pairs
for c, m in p_l
]
),
)
)
)
@dataclass
class PartitionSelectionCompletedNode(CompletedNode):
original_task: Task
task: PartitionSelectionTask
feature: TaskFeature
base_operation_set: OperationSet
partition_selection: PartitionSelection
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}, class: {self.__class__.__name__}, "
f"base_ope: {self.base_operation_set}, partition_selection: {self.partition_selection}"
)
def train_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(lambda io: np_to_str(io.input_arr), self.task.train),
[
to_bytes(v)
for v in self.task.train_partitioned_arrays_original_location_masks
],
),
)
)
def all_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(lambda io: np_to_str(io.input_arr), self.task.test),
[
to_bytes(v)
for v in self.task.train_partitioned_arrays_original_location_masks
+ self.task.test_partitioned_arrays_original_location_masks
],
),
)
)
@dataclass(frozen=True)
class NodeTree:
completed_nodes: List[CompletedNode]
def __str__(self):
return "\n".join(map(str, self.completed_nodes))
@classmethod
def of(cls, completed_node: CompletedNode) -> "NodeTree":
completed_nodes = []
current_node = completed_node
while True:
if isinstance(current_node, CompletedNode):
completed_nodes.append(current_node)
current_node = current_node.parent_waiting_node
elif isinstance(current_node, WaitingNode):
current_node = current_node.parent_completed_node
elif current_node is None:
# TODO root node
break
else:
raise NotImplementedError()
return cls(list(reversed(completed_nodes)))
@classmethod
def replaced_new_node_tree(
cls, node_tree: "NodeTree", node_depth: int, node: CompletedNode
) -> "NodeTree":
copied_list = copy.copy(node_tree.completed_nodes)
copied_list[node_depth] = node
return cls(copied_list)
def to_operation_set(self) -> OperationSet:
# TODO found a bug related to MultiColorChannelOperation.
try:
operations = []
temp_color_selection = None
temp_mask_conversion = None
temp_color_channel_selection = None
temp_partition_selection = None
# TODO too dirty.
assert (
len(self.completed_nodes[0].base_operation_set.operations) == 0
), self.completed_nodes[0]
for n in self.completed_nodes[1:]: # first element is root.
if isinstance(n, UniformOperationCompletedNode):
if isinstance(
n.base_operation_set.operations[-1], UniformOperation
):
operations.append(n.base_operation_set.operations[-1])
else:
if temp_color_selection is not None:
operations.append(
ColorOperation(
temp_color_selection,
temp_mask_conversion,
n.base_operation_set.operations[-1].mask_operation,
)
)
temp_color_selection = None
temp_mask_conversion = None
temp_color_channel_selection = None
temp_partition_selection = None
elif temp_color_channel_selection is not None:
operations.append(
MultiColorChannelOperation(
temp_color_channel_selection,
temp_mask_conversion,
n.base_operation_set.operations[
-1
].channel_merge_operation,
)
)
temp_color_selection = None
temp_mask_conversion = None
temp_color_channel_selection = None
temp_partition_selection = None
elif temp_partition_selection is not None:
operations.append(
PartitionOperation(
temp_partition_selection,
n.base_operation_set.operations[
-1
].partition_merge_operation,
)
)
temp_color_selection = None
temp_mask_conversion = None
temp_color_channel_selection = None
temp_partition_selection = None
else:
raise NotImplementedError()
elif isinstance(n, ColorSelectionCompletedNode):
temp_color_selection = n.color_selection
elif isinstance(n, MaskConversionCompletedNode):
temp_mask_conversion = n.mask_conversion
elif isinstance(n, ColorChannelMaskConversionCompletedNode):
temp_mask_conversion = n.mask_conversion
elif isinstance(n, ColorChannelSelectionCompletedNode):
temp_color_channel_selection = n.color_channel_selection
elif isinstance(n, PartitionSelectionCompletedNode):
temp_partition_selection = n.partition_selection
else:
raise ValueError()
return OperationSet(operations)
except Exception as e:
print(f"error: {e}")
return OperationSet([])
def waiting_nodes(self) -> List[WaitingNode]:
return list(
filter(
lambda n: n is not None,
map(lambda n: n.parent_waiting_node, self.completed_nodes),
)
)
class NodeEvaluator:
def evaluate(self, node: WaitingNode):
raise NotImplementedError()
def evaluate_nodes(self, nodes: List[WaitingNode]):
raise NotImplementedError()
class RandomNodeEvaluator(NodeEvaluator):
def evaluate(self, node: WaitingNode):
node.cache_pred_distance = random.uniform(0, 1) * node.depth()
def evaluate_nodes(self, nodes: List[WaitingNode]):
for n in nodes:
self.evaluate(n)
@dataclass
class AnswerStorageElement:
task_name: str
correct: bool
depth: int
operation_set: OperationSet
def __post_init__(self):
self.depth = len(self.operation_set.operations)
def validate(self):
task = TaskLoader().get_task(self.task_name)
try:
a = AnswerMatcher.is_train_test_all_match_if_operated(
task, self.operation_set
)
if a != self.correct:
print(f"{self.task_name} correct inconsistency. {self.correct}_{a}")
return False
except OperationInconsistencyException as e:
print(f"{self.task_name} OperationInconsistencyException")
return False
return True
def __hash__(self):
return hash(repr(self))
@dataclass
class AnsweredSearchResult:
operation_set: OperationSet
test_output_arr: Tuple[np.ndarray] = None
test_correct: Optional[bool] = None
@dataclass
class AnsweredSearchResults:
task: Task
results: List[AnsweredSearchResult]
zero_depth_search_time: float
spent_time: float
searched_total_node: int
def summary(self):
summary_elements = [
f"{self.task.name}_{i}, "
f"correct: {str(r.test_correct):>5}, "
f"node: {self.searched_total_node:>6}, "
f"zero_depth_sec: {int(self.zero_depth_search_time):>5}, sec: {int(self.spent_time):>5}, "
f"depth: {len(r.operation_set.operations)}, operation_set: {r.operation_set}"
for i, r in enumerate(self.results)
]
return "\n".join(summary_elements)
def final_test_correct(self):
return any(map(lambda r: r.test_correct, self.results))
def to_answer_storage_elements(self) -> List[AnswerStorageElement]:
return [
AnswerStorageElement(
self.task.name,
r.test_correct,
len(r.operation_set.operations),
r.operation_set,
)
for r in self.results
]
@dataclass
class NotAnsweredSearchResult:
task: Task
exception: Exception
spent_time: float
searched_total_node: int
def final_test_correct(self):
return None
def summary(self):
return (
f"{self.task.name}__, "
f"correct: None, "
f"node: {self.searched_total_node:>6}, sec: {int(self.spent_time):>5}, "
f"exception: {self.exception.__class__.__name__}"
)
@dataclass
class AnswerStorage:
elements: Set[AnswerStorageElement]
def validate(self):
self.elements = set(filter(lambda e: e.validate(), self.elements))
def add(self, element: AnswerStorageElement):
self.elements.add(element)
def get_text(self) -> str:
return "\n".join(
repr(e)
for e in sorted(
self.elements, key=lambda e: (e.task_name, not e.correct, e.depth)
)
)
def get_only_correct_answer_storage(self) -> "AnswerStorage":
return AnswerStorage({e for e in self.elements if e.correct})
def get_task_grouped_elements(self) -> List[Tuple[str, List[AnswerStorageElement]]]:
elements = list(self.elements)
elements = sorted(elements, key=lambda e: e.task_name)
return [(k, list(g)) for k, g in groupby(elements, key=lambda e: e.task_name)]
def load_answer_storage() -> AnswerStorage:
if not PathConfig.OPERATION_ANSWER_STORAGE.exists():
return AnswerStorage(set())
elements: List[AnswerStorageElement] = []
with open(
str(PathConfig.OPERATION_ANSWER_STORAGE), mode="r", encoding="utf-8"
) as f:
for l in f.readlines():
try:
elements.append(str_to_AnswerStorageElement(l))
except:
pass
storage = AnswerStorage(set(elements))
storage.validate()
return storage
def save_answer_storage(storage: AnswerStorage):
PathConfig.OPERATION_ANSWER_STORAGE.unlink()
with open(
str(PathConfig.OPERATION_ANSWER_STORAGE), mode="w", encoding="utf-8"
) as f:
f.write(storage.get_text())
def update_answer_storage(elements: List[AnswerStorageElement], verbose: bool = False):
if verbose:
print("load_answer storage")
storage = load_answer_storage()
if verbose:
print(storage.get_text())
print("add answer storage")
for e in elements:
e.validate()
storage.add(e)
if verbose:
print("save answer storage")
print(storage.get_text())
save_answer_storage(storage)
@dataclass
class AnswerFoundException(Exception):
operation_set: OperationSet
class NoImprovementException(Exception):
MESSAGE = "No improve"
class MaxDepthExceededException(Exception):
MESSAGE = "Max depth"
class MaxNodeExceededException(Exception):
MESSAGE = "Max node"
class TimeoutException(Exception):
MESSAGE = "Timeout"
def get_all_operation_classes():
return [
UniformOperation,
ColorOperation,
MultiColorChannelOperation,
PartitionOperation,
]
def get_all_operation_element_classes():
classes = [
UniformOperation,
ColorSelection,
MaskConversion,
MaskOperation,
ColorChannelSelection,
ChannelMergeOperation,
PartitionSelection,
PartitionMergeOperation,
]
return chain.from_iterable([c.__subclasses__() for c in classes])
@unique
class BackGroundColorSelectionMode(StrNameEnum):
BLACK = auto()
MOST_COMMON = auto()
@unique
class AxisV2(StrNameEnum):
VERTICAL = auto()
HORIZONTAL = auto()
VERTICAL_HORIZONTAL = auto()
MAIN_DIAGONAL = auto()
ANTI_DIAGONAL = auto()
BOTH_DIAGONAL = auto()
@unique
class Corner(StrNameEnum):
TOP_LEFT = auto()
TOP_RIGHT = auto()
BOTTOM_RIGHT = auto()
BOTTOM_LEFT = auto()
@unique
class SpiralDirection(StrNameEnum):
CLOCKWISE = auto()
ANTICLOCKWISE = auto()
class DebugConfig:
OPERATION_DEBUG_TASK_NAME = "" # dae9d2b5
OPERATION_DEBUG_OPERATION_SET = ""
# solve debug
SOLVE_DEBUG_TASK_NAME = "" # dae9d2b5
# train_data_generator debug
TRAIN_DATA_GENERATION_DEBUG_TASK_NAME = ""
class PathConfig:
ROOT: Path = (
Path("") if RunConfig.RUN_MODE == RunMode.KERNEL else Path(__file__).parent
)
# input
INPUT_ROOT: Path = ROOT / "input"
TRAIN_ROOT: Path = INPUT_ROOT / "training" # training_and_evaluation
EVALUATION_ROOT: Path = INPUT_ROOT / "evaluation"
TEST_ROOT: Path = INPUT_ROOT / "test"
SAMPLE_SUBMISSION: Path = INPUT_ROOT / "sample_submission.csv"
# output
OUTPUT_SUBMISSION: Path = ROOT / "output" / "submission.csv"
# answer_memo
OPERATION_ANSWER_MEMO_ROOT: Path = ROOT / "answer_memo"
OPERATION_ANSWER_TAXONOMY_YAML: Path = (
OPERATION_ANSWER_MEMO_ROOT / "answer_taxonomy.yaml"
)
OPERATION_ANSWER_TAXONOMY_IMAGE_ROOT: Path = (
OPERATION_ANSWER_MEMO_ROOT / "answer_taxonomy"
)
OPERATION_ANSWER_STORAGE: Path = OPERATION_ANSWER_MEMO_ROOT / "answer_storage.txt"
WRONG_ANSWERS_ROOT: Path = OPERATION_ANSWER_MEMO_ROOT / "wrong_answers"
# kernel
KERNEL_SCRIPT_PATH: Path = ROOT / "kernel" / "kernel_script.py"
# run
LOG_ROOT: Path = ROOT / "log"
# ml_model
SAVED_MODEL: Path = ROOT / "saved_model"
NODE_EVALUATOR_FEATURES = SAVED_MODEL / "features.pkl"
NODE_EVALUATOR_CATEGORICAL_FEATURES = SAVED_MODEL / "categorical_features.pkl"
NODE_EVALUATOR_MODEL = SAVED_MODEL / "model.pkl"
NODE_EVALUATOR_ORDINAL_ENCODER = SAVED_MODEL / "ordinal_encoder.pkl"
NODE_EVALUATOR_SAMPLE_DF = SAVED_MODEL / "sample_df.pkl"
OPERATION_ELEMENT_INCLUSION_MODEL_ROOT = SAVED_MODEL / "operation_element_inclusion"
OPERATION_ELEMENT_INCLUSION_MODEL = (
OPERATION_ELEMENT_INCLUSION_MODEL_ROOT / "model.pkl"
)
OPERATION_ELEMENT_INCLUSION_MODEL_TARGET_COLUMNS = (
OPERATION_ELEMENT_INCLUSION_MODEL_ROOT / "target_columns.pkl"
)
OPERATION_ELEMENT_INCLUSION_MODEL_FEATURE_COLUMNS = (
OPERATION_ELEMENT_INCLUSION_MODEL_ROOT / "feature_columns.pkl"
)
# ml_training_data
LABELED_TRAINING_DATA_ROOT = ROOT / "training"
class KernelPathConfig:
INPUT_ROOT = Path("/kaggle/input/abstraction-and-reasoning-challenge/")
TRAIN_ROOT: Path = INPUT_ROOT / "training"
EVALUATION_ROOT: Path = INPUT_ROOT / "evaluation"
# TEST_ROOT: Path = INPUT_ROOT / 'test'
TEST_ROOT: Path = Path("test_aligned")
SAMPLE_SUBMISSION: Path = INPUT_ROOT / "sample_submission.csv"
SUBMISSION = "submission_yuki_alignment.csv"
def create_submission(
engine_results: List[Union[AnsweredSearchResults, NotAnsweredSearchResult]]
):
submission_df = DataFrame(columns=["output_id", "output"])
for result in engine_results:
test_arr_num = len(result.task.test)
for i in range(test_arr_num):
if isinstance(result, AnsweredSearchResults):
answers = [r.test_output_arr[i] for r in result.results]
answers += [None for _ in range(3 - len(answers))]
elif isinstance(result, NotAnsweredSearchResult):
answers = [None] * 3
else:
raise NotImplementedError()
output_str = " ".join(map(lambda a: parse_str(a), answers)) + " "
d = {"output_id": f"{result.task.name}_{i}", "output": output_str}
submission_df = submission_df.append([d])
return submission_df
def parse_str(arr: np.ndarray) -> str:
if arr is None:
return "|0|"
return "|" + "|".join(map(lambda row: "".join(str(v) for v in row), arr)) + "|"
def save_submission_df(submission_df: DataFrame):
if RunConfig.RUN_MODE == RunMode.KERNEL:
submission_df.to_csv(KernelPathConfig.SUBMISSION, index=False)
else:
PathConfig.OUTPUT_SUBMISSION.parent.mkdir(parents=True, exist_ok=True)
submission_df.to_csv(PathConfig.OUTPUT_SUBMISSION, index=False)
def plot_one(ax, arr: np.ndarray, i, train_or_test, input_or_output):
cmap = colors.ListedColormap(
[
"#000000",
"#0074D9",
"#FF4136",
"#2ECC40",
"#FFDC00",
"#AAAAAA",
"#F012BE",
"#FF851B",
"#7FDBFF",
"#870C25",
]
)
norm = colors.Normalize(vmin=0, vmax=9)
ax.imshow(arr, cmap=cmap, norm=norm)
ax.grid(True, which="both", color="lightgrey", linewidth=0.5)
ax.set_yticks([x - 0.5 for x in range(1 + len(arr))])
ax.set_xticks([x - 0.5 for x in range(1 + len(arr[0]))])
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_title(train_or_test + " " + input_or_output)
def plot_task(task: Task, show: bool, save_path: Optional[Path]):
input_output_num = len(task.train + task.test)
total_row = 2
fig, axs = plt.subplots(
total_row, input_output_num, figsize=(2 * input_output_num, 2 * total_row)
)
for i, (input_output, tag) in enumerate(
zip(
task.train + task.test,
["train"] * len(task.train) + ["test"] * len(task.test),
)
):
plot_one(axs[0, i], input_output.input_arr, i, tag, "input")
plot_one(axs[1, i], input_output.output_arr, i, tag, "output")
plt.tight_layout()
if save_path:
save_path.parent.mkdir(parents=True, exist_ok=True)
plt.savefig(save_path)
if show:
plt.show()
plt.close()
def plot_task_with_operation_set(
task: Task, operation_set: OperationSet, show: bool, save_path: Optional[Path]
):
input_output_num = len(task.train + task.test)
total_row = 3
applied_task = TaskOperationSetExecutor().execute(task, operation_set)
fig, axs = plt.subplots(
total_row, input_output_num, figsize=(3 * input_output_num, 3 * total_row)
)
for i, (raw_io, applied_io) in enumerate(
zip(task.train + task.test, applied_task.train + applied_task.test)
):
plot_one(axs[0, i], raw_io.input_arr, i, "train?", "input")
plot_one(axs[1, i], raw_io.output_arr, i, "train?", "output")
plot_one(axs[2, i], applied_io.input_arr, i, "train?", "operated")
plt.tight_layout()
if save_path:
save_path.parent.mkdir(parents=True, exist_ok=True)
plt.savefig(save_path)
if show:
plt.show()
plt.close()
def plot_task_with_result_set(
task: Task,
search_results: AnsweredSearchResults,
show: bool,
save_path: Optional[Path],
):
input_output_num = len(task.train + task.test)
total_row = 2 + len(search_results.results)
applied_tasks = [
TaskOperationSetExecutor().execute(task, r.operation_set)
for r in search_results.results
]
fig, axs = plt.subplots(
total_row, input_output_num, figsize=(3 * input_output_num, 3 * total_row)
)
for i, input_output in enumerate(task.train + task.test):
plot_one(axs[0, i], input_output.input_arr, i, "train?", "input")
plot_one(axs[1, i], input_output.output_arr, i, "train?", "output")
for i, t in enumerate(applied_tasks):
for j, input_output in enumerate(t.train + t.test):
plot_one(axs[i + 2, j], input_output.input_arr, i, "train?", "input")
plt.tight_layout()
if save_path:
save_path.parent.mkdir(parents=True, exist_ok=True)
plt.savefig(save_path)
if show:
plt.show()
plt.close()
@dataclass(frozen=True)
class Padding(UniformOperation):
padding_mode: PaddingMode
direction: Direction
k: int
def __call__(self, arr: np.ndarray) -> np.ndarray:
if self.padding_mode == PaddingMode.REPEAT:
np_pad_mode = "wrap"
elif self.padding_mode == PaddingMode.MIRROR_1:
np_pad_mode = "symmetric"
elif self.padding_mode == PaddingMode.MIRROR_2:
np_pad_mode = "reflect"
elif self.padding_mode == PaddingMode.EDGE:
np_pad_mode = "edge"
else:
raise ValueError(self.padding_mode)
h, w = arr.shape
if self.padding_mode == PaddingMode.MIRROR_2:
h, w = h - 1, w - 1
if self.direction == Direction.TOP:
pad_width = ((self.k * h, 0), (0, 0))
elif self.direction == Direction.BOTTOM:
pad_width = ((0, self.k * h), (0, 0))
elif self.direction == Direction.LEFT:
pad_width = ((0, 0), (self.k * w, 0))
elif self.direction == Direction.RIGHT:
pad_width = ((0, 0), (0, self.k * w))
else:
raise ValueError(self.direction)
return np.pad(arr, pad_width, mode=np_pad_mode)
@dataclass(frozen=True)
class Resize(UniformOperation):
axis: Axis
ratio: int # TODO int? How to resize 3/2?
def __call__(self, arr: np.ndarray) -> np.ndarray:
if self.axis == Axis.VERTICAL:
return np.repeat(arr, self.ratio, axis=0)
elif self.axis == Axis.HORIZONTAL:
return np.repeat(arr, self.ratio, axis=1)
elif self.axis == Axis.BOTH:
temp = np.repeat(arr, self.ratio, axis=0)
return np.repeat(temp, self.ratio, axis=1)
else:
raise ValueError(self.axis)
@dataclass(frozen=True)
class Flip(UniformOperation):
flip_mode: FlipMode
def __call__(self, arr: np.ndarray) -> np.ndarray:
if self.flip_mode == FlipMode.UD:
return np.flipud(arr)
elif self.flip_mode == FlipMode.LR:
return np.fliplr(arr)
elif self.flip_mode == FlipMode.UL_DR:
return arr.T
elif self.flip_mode == FlipMode.UR_DL:
return np.flipud(np.flipud(arr.T))
else:
raise ValueError(self.flip_mode)
@dataclass(frozen=True)
class Rotate(UniformOperation):
angle: int
def __call__(self, arr: np.ndarray) -> np.ndarray:
if self.angle not in [90, 180, 270]:
raise ValueError(self.angle)
return np.rot90(arr, self.angle // 90)
@dataclass(frozen=True)
class LineDeletion(UniformOperation):
line_color: Color
def __call__(self, arr: np.ndarray) -> np.ndarray:
if arr.size == 1:
raise OperationInconsistencyException("size == 1")
if 1 in arr.shape:
raise OperationInconsistencyException("can not separate")
color_hit: np.ndarray = arr == self.line_color
line_v_indices = np.where(color_hit.all(axis=1))[0]
line_h_indices = np.where(color_hit.all(axis=0))[0]
if len(line_v_indices) == len(line_h_indices) == 0:
raise OperationInconsistencyException("not line found")
arr = np.delete(arr, line_h_indices, axis=1)
arr = np.delete(arr, line_v_indices, axis=0)
if 0 in arr.shape:
raise OperationInconsistencyException("0 size")
return arr
@dataclass(frozen=True)
class FFTCompletion(UniformOperation):
# TODO GIVE UP implement.
# This is just a poc for "SYMMETRY" or "REPEAT" pattern tasks.
# If you're interested in this function, let me know. I'll translate it.
def __call__(self, arr: np.ndarray) -> np.ndarray:
revs = []
for color in Color:
print(color)
color_hit = arr == color
if color == Color.BLACK or not color_hit.any():
revs.append(np.full_like(color_hit, fill_value=False))
continue
rev_arr_int = self.complete_symmetric(color_hit)
rev_arr_int = self.complete_symmetric(rev_arr_int)
rev_arr_int = self.complete_symmetric(rev_arr_int)
revs.append(rev_arr_int)
for color, rev in zip(Color, revs):
arr[rev] = color
return arr
def complete_symmetric(self, hit_arr, verbose=False):
h, w = hit_arr.shape
if verbose:
print(hit_arr)
f = np.fft.fftshift(np.fft.fft2(hit_arr))
if verbose:
print(f)
amp = np.abs(f)
if verbose:
print(amp)
amp = amp / h / w * 2
if verbose:
print(amp)
print(f"sum {amp.sum()}")
print(f"mean {amp.mean()}")
print(f"max {amp.max()}")
# TODO detect peakのパラメータ調整
flags = np.array(self.detect_not_peaks_mask(amp))
if verbose:
print(flags)
f[flags] = 0
filtered_amp = amp.copy()
filtered_amp[f == 0] = 0
# F3_abs = np.abs(f) # 複素数を絶対値に変換
# F3_abs_amp = F3_abs / h / w * 2 # 交流成分はデータ数で割って2倍
# F3_abs_amp[0] = F3_abs_amp[0] / 2 # 直流成分(今回は扱わないけど)は2倍不要
F3_ifft = np.fft.ifft2(np.fft.ifftshift(f)) # IFFT
F3_ifft_real = F3_ifft.real # 実数部の取得
# TODO 2値化アルゴリズム検討
rev_arr_int = F3_ifft_real > threshold_minimum(F3_ifft_real)
if verbose:
fig, ax = try_all_threshold(F3_ifft_real, figsize=(10, 8), verbose=False)
plt.show()
# visualize
plt.subplot(171)
plt.imshow(hit_arr, cmap="gray")
plt.title("Input Image"), plt.xticks([]), plt.yticks([])
plt.subplot(172)
plt.hist(amp.ravel(), bins=100)
plt.title("Input Image"), plt.xticks([]), plt.yticks([])
plt.subplot(173)
plt.imshow(amp, cmap="gray")
plt.title("Magnitude Spectrum"), plt.xticks([]), plt.yticks([])
plt.subplot(174)
plt.imshow(filtered_amp, cmap="gray")
plt.title("Magnitude Spectrum"), plt.xticks([]), plt.yticks([])
plt.subplot(175)
plt.hist(F3_ifft_real.ravel(), bins=100)
plt.subplot(176)
plt.imshow(rev_arr_int, cmap="gray")
plt.title("rev"), plt.xticks([]), plt.yticks([])
plt.subplot(177)
plt.imshow(rev_arr_int | hit_arr, cmap="gray")
plt.title("and"), plt.xticks([]), plt.yticks([])
plt.show()
return rev_arr_int
def detect_not_peaks_mask(self, image, filter_size=3, order=0.05):
local_max = maximum_filter(
image, footprint=np.ones((filter_size, filter_size)), mode="constant"
)
detected_peaks = np.ma.array(image, mask=~(image == local_max))
# 小さいピーク値を排除(最大ピーク値のorder倍のピークは排除)
temp = np.ma.array(
detected_peaks, mask=~(detected_peaks >= detected_peaks.max() * order)
)
return temp.mask
@dataclass(frozen=True)
class FixedColorMaskFill(MaskOperation):
color: Color
def __call__(self, arr: np.ndarray, mask: np.ndarray) -> np.ndarray:
arr[mask] = self.color
return arr
@dataclass(frozen=True)
class SingleColorMaskFill(MaskOperation):
single_color_selection_mode: SingleColorSelectionMode
def __call__(self, arr: np.ndarray, mask: np.ndarray) -> np.ndarray:
color = ColorSelectionUtil().select_single_color(
arr, self.single_color_selection_mode
)
arr[mask] = color
return arr
@dataclass(frozen=True)
class MaskCoordsCrop(MaskOperation):
def __call__(self, arr: np.ndarray, mask: np.ndarray) -> np.ndarray:
# TODO raise OperationInconsistencyException?
if not mask.any():
return arr
coords = np.argwhere(mask)
x_min, y_min = coords.min(axis=0)
x_max, y_max = coords.max(axis=0)
return arr[x_min : x_max + 1, y_min : y_max + 1]
@dataclass(frozen=True)
class FixedSingleColorSelection(ColorSelection):
color: Color
def __call__(self, arr: np.ndarray) -> np.ndarray:
return arr == self.color
@dataclass(frozen=True)
class SingleColorSelection(ColorSelection):
single_color_selection_mode: SingleColorSelectionMode
def __call__(self, arr: np.ndarray) -> np.ndarray:
color = ColorSelectionUtil().select_single_color(
arr, self.single_color_selection_mode
)
return arr == color
@dataclass(frozen=True)
class MultiColorSelection(ColorSelection):
multi_color_selection_mode: MultiColorSelectionMode
def __call__(self, arr: np.ndarray) -> np.ndarray:
if (
self.multi_color_selection_mode
== MultiColorSelectionMode.ANY_WITHOUT_MOST_COMMON
):
most_common_color = ColorSelectionUtil().select_single_color(
arr, SingleColorSelectionMode.MOST_COMMON
)
return arr != most_common_color
elif (
self.multi_color_selection_mode
== MultiColorSelectionMode.ANY_WITHOUT_LEAST_COMMON
):
least_common_color = ColorSelectionUtil().select_single_color(
arr, SingleColorSelectionMode.LEAST_COMMON
)
return arr != least_common_color
else:
raise NotImplementedError()
class TaskLoader:
def get_task(self, name: str) -> Task:
try:
return self._get_task(PathConfig.TRAIN_ROOT / f"{name}.json")
except FileNotFoundError:
return self._get_task(PathConfig.EVALUATION_ROOT / f"{name}.json")
def get_training_tasks(self):
if RunConfig.RUN_MODE == RunMode.KERNEL:
return self._get_tasks(KernelPathConfig.TRAIN_ROOT)
else:
return self._get_tasks(PathConfig.TRAIN_ROOT)
def get_evaluation_tasks(self):
if RunConfig.RUN_MODE == RunMode.KERNEL:
return self._get_tasks(KernelPathConfig.EVALUATION_ROOT)
else:
return self._get_tasks(PathConfig.EVALUATION_ROOT)
def get_test_tasks(self):
if RunConfig.RUN_MODE == RunMode.KERNEL:
return self._get_tasks(KernelPathConfig.TEST_ROOT)
else:
return self._get_tasks(PathConfig.TEST_ROOT)
def _get_tasks(self, root_path: Path) -> List[Task]:
return [self._get_task(json_path) for json_path in root_path.iterdir()]
def _get_task(self, path: Path) -> Task:
with open(str(path), "r") as f:
return Task.of(path.stem, json.load(f))
def is_private_lb_run(self) -> bool:
eval_tasks = self._get_tasks(KernelPathConfig.EVALUATION_ROOT)
test_tasks = self._get_tasks(KernelPathConfig.TEST_ROOT)
eval_names = [t.name for t in eval_tasks]
if any(filter(lambda t: t.name in eval_names, test_tasks)):
return False
else:
return True
def create_image_feature(arr: np.ndarray) -> ImageFeature:
return ImageFeature(
height=arr.shape[0],
width=arr.shape[1],
colors=[Color.of(v) for v in ColorSelectionUtil().get_colors(arr)],
hit_and_miss_histogram=calculate_hit_and_miss_histogram(arr),
# most_common_color=ColorSelectionUtil().select_single_color(arr, SingleColorSelectionMode.MOST_COMMON),
vertical_edge_num=np.count_nonzero(
arr[1:] - arr[:-1]
), # faster than np.diff(arr, axis=0)
horizontal_edge_num=np.count_nonzero(
arr[:, 1:] - arr[:, :-1]
), # faster than np.diff(arr, axis=1)
)
def create_image_diff_feature(
original_input_arr: np.ndarray, input_arr: np.ndarray, output_arr: np.ndarray
) -> ImageDiffFeature:
util = FeatureUtil()
in_feature = create_image_feature(input_arr)
out_feature = create_image_feature(output_arr)
return ImageDiffFeature(
input_image_feature=in_feature,
output_image_feature=out_feature,
dim_height_increase=out_feature.height - in_feature.height,
dim_width_increase=out_feature.width - in_feature.width,
dim_height_integer_multiple=(
out_feature.height / in_feature.height
).is_integer()
or (in_feature.height / out_feature.height).is_integer(),
dim_width_integer_multiple=(out_feature.width / in_feature.width).is_integer()
or (in_feature.width / out_feature.width).is_integer(),
dim_height_diff=abs(out_feature.height - in_feature.height),
dim_width_diff=abs(out_feature.width - in_feature.width),
dim_height_equal=out_feature.height == in_feature.height,
dim_width_equal=out_feature.width == in_feature.width,
lack_color_num=len(set(out_feature.colors) - set(in_feature.colors)),
excess_color_num=len(set(in_feature.colors) - set(out_feature.colors)),
hit_and_miss_histogram_diff=sum(
abs(i_c - o_c)
for i_c, o_c in zip(
in_feature.hit_and_miss_histogram, out_feature.hit_and_miss_histogram
)
),
# vertical_diff_input_arr_line_num=util._vertical_diff_input_arr_line_num(input_arr, output_arr),
# horizontal_diff_input_arr_line_num=util._horizontal_diff_input_arr_line_num(input_arr, output_arr),
# vertical_diff_output_arr_line_num=util._vertical_diff_output_arr_line_num(input_arr, output_arr),
# horizontal_diff_output_arr_line_num=util._horizontal_diff_output_arr_line_num(input_arr, output_arr),
vertical_edge_sum_diff=abs(
out_feature.vertical_edge_num - in_feature.vertical_edge_num
),
horizontal_edge_sum_diff=abs(
out_feature.horizontal_edge_num - in_feature.horizontal_edge_num
),
vertical_edge_sum_diff_ratio=abs(
out_feature.vertical_edge_num - in_feature.vertical_edge_num
)
/ in_feature.width,
horizontal_edge_sum_diff_ratio=abs(
out_feature.horizontal_edge_num - in_feature.horizontal_edge_num
)
/ in_feature.height,
diff_color_cell_ratio=util._diff_cell_count_ratio(input_arr, output_arr),
diff_cell_where_no_need_to_change_count_ratio=util._diff_cell_where_no_need_to_change_count_ratio(
original_input_arr, input_arr, output_arr
),
wrong_change_cell_where_need_to_change_count_ratio=util._wrong_change_cell_where_need_to_change_count_ratio(
original_input_arr, input_arr, output_arr
),
)
def create_task_feature(original_task: Task, task: Task) -> TaskFeature:
diff_features = [
create_image_diff_feature(o_io.input_arr, io.input_arr, io.output_arr)
for o_io, io in zip(original_task.train, task.train)
]
return TaskFeature(
# image_diff_features=image_diff_features,
same_dim_between_input_output=all(f.same_dim() for f in diff_features),
same_height_dim_between_input_output=all(
f.dim_height_equal for f in diff_features
),
same_width_dim_between_input_output=all(
f.dim_width_equal for f in diff_features
),
all_dim_height_increased=all(f.dim_height_increase > 0 for f in diff_features),
all_dim_height_decreased=all(f.dim_height_increase < 0 for f in diff_features),
all_dim_width_increased=all(f.dim_width_increase > 0 for f in diff_features),
all_dim_width_decreased=all(f.dim_width_increase < 0 for f in diff_features),
all_dim_height_integer_multiple=all(
f.dim_height_integer_multiple for f in diff_features
),
all_dim_width_integer_multiple=all(
f.dim_width_integer_multiple for f in diff_features
),
mean_lack_color_num=mean([f.lack_color_num for f in diff_features]),
mean_excess_color_num=mean([f.excess_color_num for f in diff_features]),
mean_hit_and_miss_histogram_diff=mean(
[f.hit_and_miss_histogram_diff for f in diff_features]
),
# mean_vertical_diff_input_arr_line_num=nan_mean(f.vertical_diff_input_arr_line_num for f in diff_features),
# mean_horizontal_diff_input_arr_line_num=nan_mean(f.horizontal_diff_input_arr_line_num for f in diff_features),
# mean_vertical_diff_output_arr_line_num=nan_mean(f.vertical_diff_output_arr_line_num for f in diff_features),
# mean_horizontal_diff_output_arr_line_num=nan_mean(f.horizontal_diff_output_arr_line_num for f in diff_features),
mean_vertical_edge_sum_diff=mean(
[f.vertical_edge_sum_diff for f in diff_features]
),
mean_horizontal_edge_sum_diff=mean(
[f.horizontal_edge_sum_diff for f in diff_features]
),
mean_vertical_edge_sum_diff_ratio=mean(
[f.vertical_edge_sum_diff_ratio for f in diff_features]
),
mean_horizontal_edge_sum_diff_ratio=mean(
[f.horizontal_edge_sum_diff_ratio for f in diff_features]
),
mean_diff_color_cell_ratio=nan_mean(
f.diff_color_cell_ratio for f in diff_features
),
mean_diff_cell_where_no_need_to_change_count_ratio=nan_mean(
f.diff_cell_where_no_need_to_change_count_ratio for f in diff_features
),
mean_wrong_change_cell_where_need_to_change_count_ratio=nan_mean(
f.wrong_change_cell_where_need_to_change_count_ratio for f in diff_features
),
)
def create_color_selected_task_feature(
original_task: Task,
color_selected_task: ColorSelectedTask,
task_feature: TaskFeature = None,
) -> ColorSelectedTaskFeature:
if task_feature is None:
task_feature = create_task_feature(original_task, color_selected_task)
return ColorSelectedTaskFeature(task_feature)
def create_mask_conversion_task_feature(
original_task: Task,
mask_converted_task: MaskConvertedTask,
task_feature: TaskFeature = None,
) -> MaskConvertedTaskFeature:
if task_feature is None:
task_feature = create_task_feature(original_task, mask_converted_task)
possible_improve_ratios = [
_calculate_possible_improve_ratio(io.input_arr, io.output_arr, m)
for io, m in zip(mask_converted_task.train, mask_converted_task.train_masks)
]
return MaskConvertedTaskFeature(
task_feature=task_feature,
possible_improve_ratios=possible_improve_ratios,
)
def _calculate_possible_improve_ratio(
input_arr: np.ndarray, output_arr: np.ndarray, mask: np.ndarray
) -> Optional[float]:
if input_arr.shape != output_arr.shape:
return None
diff_arr = np.not_equal(input_arr, output_arr)
if not diff_arr.all():
return 1.0
else:
selected_diff_arr = np.logical_and(diff_arr, mask)
return 1 - selected_diff_arr.sum() / diff_arr.sum()
class FeatureUtil:
def _horizontal_diff_input_arr_line_num(
self, input_arr: np.ndarray, output_arr: np.ndarray
) -> Optional[float]:
if input_arr.shape[1] != output_arr.shape[1]:
return None
return abs(
input_arr.shape[0]
- np.array([(output_arr == h_l).all(axis=1) for h_l in input_arr])
.any(axis=1)
.sum()
)
def _horizontal_diff_output_arr_line_num(
self, input_arr: np.ndarray, output_arr: np.ndarray
) -> Optional[float]:
if input_arr.shape[1] != output_arr.shape[1]:
return None
return abs(
output_arr.shape[0]
- np.array([(output_arr == h_l).all(axis=1) for h_l in input_arr])
.any(axis=0)
.sum()
)
def _vertical_diff_input_arr_line_num(
self, input_arr: np.ndarray, output_arr: np.ndarray
) -> Optional[float]:
if input_arr.shape[0] != output_arr.shape[0]:
return None
return self._horizontal_diff_input_arr_line_num(input_arr.T, output_arr.T)
def _vertical_diff_output_arr_line_num(
self, input_arr: np.ndarray, output_arr: np.ndarray
) -> Optional[float]:
if input_arr.shape[0] != output_arr.shape[0]:
return None
return self._horizontal_diff_output_arr_line_num(input_arr.T, output_arr.T)
def _diff_cell_count_ratio(
self, input_arr: np.ndarray, output_arr: np.ndarray
) -> Optional[float]:
if input_arr.shape != output_arr.shape:
return None
diff_arr = np.not_equal(input_arr, output_arr)
return diff_arr.sum() / diff_arr.size
def _diff_cell_where_no_need_to_change_count_ratio(
self,
original_input_arr: np.ndarray,
input_arr: np.ndarray,
output_arr: np.ndarray,
) -> Optional[float]:
if not original_input_arr.shape == input_arr.shape == output_arr.shape:
return None
no_need_to_change_mask = np.equal(original_input_arr, output_arr)
diff_cell = np.not_equal(input_arr, output_arr)
diff_cell_where_no_need_to_change = diff_cell[no_need_to_change_mask]
return diff_cell_where_no_need_to_change.sum() / original_input_arr.size
def _wrong_change_cell_where_need_to_change_count_ratio(
self,
original_input_arr: np.ndarray,
input_arr: np.ndarray,
output_arr: np.ndarray,
) -> Optional[float]:
if not original_input_arr.shape == input_arr.shape == output_arr.shape:
return None
need_to_change_mask = np.not_equal(original_input_arr, output_arr)
change_mask = np.not_equal(original_input_arr, input_arr)
wrong_mask = np.not_equal(input_arr, output_arr)
wrong_change_cell_where_need_to_change_mask = (
need_to_change_mask & change_mask & wrong_mask
)
return (
wrong_change_cell_where_need_to_change_mask.sum() / original_input_arr.size
)
def get_hit_and_miss_kernels():
return [
# right top
np.array(
[
[0, -1, -1],
[1, 1, -1],
[0, 1, 0],
],
dtype=np.int8,
),
# right bottom
np.array(
[
[0, 1, 0],
[1, 1, -1],
[0, -1, -1],
],
dtype=np.int8,
),
# left bottom
np.array(
[
[0, 1, 0],
[-1, 1, 1],
[-1, -1, 0],
],
dtype=np.int8,
),
# left top
np.array(
[
[-1, -1, 0],
[-1, 1, 1],
[0, 1, 0],
],
dtype=np.int8,
),
# right protrusion
np.array(
[
[0, -1, -1],
[0, 1, -1],
[0, -1, -1],
],
dtype=np.int8,
),
# bottom protrusion
np.array(
[
[0, 0, 0],
[-1, 1, -1],
[-1, -1, -1],
],
dtype=np.int8,
),
# left protrusion
np.array(
[
[-1, -1, 0],
[-1, 1, 0],
[-1, -1, 0],
],
dtype=np.int8,
),
# top protrusion
np.array(
[
[-1, -1, -1],
[-1, 1, -1],
[0, 0, 0],
],
dtype=np.int8,
),
# TODO implement others?
]
def calculate_hit_and_miss_histogram(arr: np.ndarray):
kernels = get_hit_and_miss_kernels()
exist_colors = np.unique(arr)
counts = []
for color in range(10):
if color not in exist_colors:
for k in kernels:
counts.append(0)
else:
for k in kernels:
color_hit = (arr == color).astype(np.uint8)
hit_and_miss_result = cv2.morphologyEx(color_hit, cv2.MORPH_HITMISS, k)
counts.append(int(hit_and_miss_result.sum()))
# counts = []
# for k in kernels:
# for color in range(10):
# if color not in exist_colors:
# counts.append(0)
# else:
# color_hit = (arr == color).astype(np.uint8)
# hit_and_miss_result = cv2.morphologyEx(color_hit, cv2.MORPH_HITMISS, k)
# counts.append(int(hit_and_miss_result.sum()))
return counts
def summary_engine_results(
results: List[Union[AnsweredSearchResults, NotAnsweredSearchResult]]
):
if len(results) == 0:
return "0 result"
counts = Counter(r.final_test_correct() for r in results)
total_spent_time = np.sum([r.spent_time for r in results]) / 60
mean_spent_time = np.sum([r.spent_time for r in results])
max_spent_time = np.max([r.spent_time for r in results])
result_message = (
f"--- stats --- \n"
f"correct_count: {counts} \n"
f"total_spent_time: {total_spent_time} min \n"
f"mean_spent_time: {mean_spent_time} sec \n"
f"max_spent_time: {max_spent_time} sec \n\n"
)
result_message += "--- answered --- \n"
result_message += "\n".join(
r.summary() for r in results if isinstance(r, AnsweredSearchResults)
)
result_message += "\n--- all --- \n"
result_message += "\n".join(r.summary() for r in results)
return result_message
class ColorSelectionUtil:
def select_single_color(
self, arr: np.ndarray, mode: SingleColorSelectionMode
) -> Color:
if mode == SingleColorSelectionMode.MOST_COMMON:
color_counts = self.get_color_counts(arr)
if len(color_counts) <= 0:
raise OperationInconsistencyException("color <= 0")
try:
if color_counts[-1][1] == color_counts[-2][1]: # Two maximums.
raise OperationInconsistencyException("duplicated max color")
except IndexError:
pass
return Color.of(color_counts[-1][0])
elif mode == SingleColorSelectionMode.SECOND_MOST_COMMON:
color_counts = self.get_color_counts(arr)
if len(color_counts) <= 1:
raise OperationInconsistencyException("color <= 1")
if color_counts[-1][1] == color_counts[-2][1]: # Two maximums.
raise OperationInconsistencyException("duplicated max color")
try:
if color_counts[-2][1] == color_counts[-3][1]: # Two 2nd maximums.
raise OperationInconsistencyException("duplicated 2nd max color")
except IndexError:
pass
return Color.of(color_counts[-2][0])
elif mode == SingleColorSelectionMode.LEAST_COMMON:
color_counts = self.get_color_counts(arr)
if len(color_counts) <= 1:
raise OperationInconsistencyException("color <= 1")
if color_counts[0][1] == color_counts[1][1]: # Two minimum.
raise OperationInconsistencyException("duplicated 2nd max color")
return Color.of(color_counts[0][0])
else:
raise NotImplementedError()
def get_background_color(
self, arr: np.ndarray, mode: BackGroundColorSelectionMode
) -> Color:
if mode == BackGroundColorSelectionMode.BLACK:
return Color.BLACK
elif mode == BackGroundColorSelectionMode.MOST_COMMON:
return self.select_single_color(arr, SingleColorSelectionMode.MOST_COMMON)
else:
raise NotImplementedError()
def get_color_counts(self, arr: np.ndarray) -> List[Tuple[int, int]]:
color_counts = [
(color, count)
for color, count in enumerate(np.bincount(arr.ravel(), minlength=10))
if count != 0
]
return sorted(color_counts, key=itemgetter(1))
def get_colors(self, arr: np.ndarray) -> List[Color]:
return sorted(set(arr.ravel().tolist()))
def select_multi_color(self):
# TODO imple
raise
@dataclass(frozen=True)
class SplitLineSelection(MaskConversion):
axis: Axis
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
result_mask = np.full_like(color_mask, fill_value=False)
if self.axis in [Axis.VERTICAL, Axis.BOTH]:
vertical_line_hits = color_mask.all(axis=0)
result_mask[:, vertical_line_hits] = True
if self.axis in [Axis.HORIZONTAL, Axis.BOTH]:
horizontal_line_hits = color_mask.all(axis=1)
result_mask[horizontal_line_hits] = True
return result_mask
@dataclass(frozen=True)
class DotExistLineSelection(MaskConversion):
axis: Axis
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
result_mask = np.full_like(color_mask, fill_value=False)
if self.axis in [Axis.VERTICAL, Axis.BOTH]:
vertical_line_hits = color_mask.any(axis=0)
result_mask[:, vertical_line_hits] = True
if self.axis in [Axis.HORIZONTAL, Axis.BOTH]:
horizontal_line_hits = color_mask.any(axis=1)
result_mask[horizontal_line_hits] = True
return result_mask
@dataclass(frozen=True)
class ObjectsTouchingEdgeSelection(MaskConversion):
# TODO Direction or Axis property?
true_or_false: TrueOrFalse
connectivity: PixelConnectivity
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
label_array, max_label_index = label(
color_mask,
connectivity=self.connectivity.value_for_skimage,
background=False,
return_num=True,
)
if max_label_index == 0:
return np.full_like(color_mask, order="C", fill_value=False)
target_indices = [
i
for i in range(1, max_label_index + 1)
if self._is_target(label_array == i)
]
return np.isin(label_array, target_indices)
def _is_target(self, arr: np.ndarray) -> bool:
top_line = arr[0]
bottom_line = arr[-1]
left_line = arr[:, 0]
right_line = arr[:, -1]
if self.true_or_false == TrueOrFalse.TRUE:
return any(
[top_line.any(), bottom_line.any(), left_line.any(), right_line.any()]
)
else:
return not any(
[top_line.any(), bottom_line.any(), left_line.any(), right_line.any()]
)
@dataclass(frozen=True)
class ObjectsMaxMinSelection(MaskConversion):
"""Create a mask with max/min feature objects"""
true_or_false: TrueOrFalse
max_or_min: MaxOrMin
object_feature: ObjectFeature
connectivity: PixelConnectivity
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
label_array, max_label_index = label(
color_mask,
connectivity=self.connectivity.value_for_skimage,
background=False,
return_num=True,
)
if max_label_index == 0:
return np.full_like(color_mask, order="C", fill_value=False)
label_indices = list(range(1, max_label_index + 1))
label_index_feature_value_pairs = list(
map(
lambda l: (l, self._calculate_object_feature(label_array, l)),
label_indices,
)
)
target_feature_value = self.max_or_min.func(
label_index_feature_value_pairs, key=itemgetter(1)
)[1]
if self.true_or_false == TrueOrFalse.TRUE:
target_indices = [
l_i
for l_i, f in label_index_feature_value_pairs
if f == target_feature_value
]
else:
target_indices = [
l_i
for l_i, f in label_index_feature_value_pairs
if f != target_feature_value
]
return np.isin(label_array, target_indices)
def _calculate_object_feature(
self, label_array: np.ndarray, label_index: int
) -> int:
if self.object_feature == ObjectFeature.AREA:
return self._label_array_to_area(label_array, label_index)
if self.object_feature == ObjectFeature.HORIZONTAL_LEN:
return self._label_array_to_horizontal_len(label_array, label_index)
if self.object_feature == ObjectFeature.VERTICAL_LEN:
return self._label_array_to_vertical_len(label_array, label_index)
else:
raise NotImplementedError()
def _label_array_to_area(self, label_array: np.ndarray, label_index: int) -> int:
label_hit = label_array == label_index
return label_hit.sum()
def _label_array_to_horizontal_len(
self, label_array: np.ndarray, label_index: int
) -> int:
label_hit = label_array == label_index
horizontal_label_hit = label_hit.any(axis=0)
coords = np.where(horizontal_label_hit)[0]
return max(coords) - min(coords)
def _label_array_to_vertical_len(
self, label_array: np.ndarray, label_index: int
) -> int:
label_hit = label_array == label_index
vertical_label_hit = label_hit.any(axis=1)
coords = np.where(vertical_label_hit)[0]
return max(coords) - min(coords)
@dataclass(frozen=True)
class OldObjectsMaxMinSelection(MaskConversion):
# similar to ObjectsMaxMinSelection
# TODO Without this function, LB will be 0.97 -> 0.98
# TODO why???
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
# TODO should variate hierarchy?
contours, hierarchy = cv2.findContours(
np.ascontiguousarray(color_mask).astype(np.uint8),
cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE,
)
if len(contours) == 0:
return np.full_like(color_mask, order="C", fill_value=False)
max_area_contour = max(contours, key=lambda c: cv2.contourArea(c))
mask = np.full_like(color_mask, order="C", fill_value=False)
mask = cv2.drawContours(
mask.astype(np.uint8), max_area_contour, contourIdx=-1, color=1
)
if isinstance(
mask, cv2.UMat
): # mask sometimes becomes cv2.UMat class... I don't know why.
mask = mask.get()
return mask.astype(bool)
@dataclass(frozen=True)
class SquareObjectsSelection(MaskConversion):
"""Create a mask with only square objects"""
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
color_mask = color_mask.astype(np.uint8)
max_square_len = min(color_mask.shape)
# TODO
# if max_square_len == 1:
# return arr
square_hit = np.full_like(color_mask, fill_value=False, dtype=bool)
for l in range(1, max_square_len):
hit_and_miss_kernel = self._square_hit_and_miss_kenel(l)
filter_kernel = self._filter_kenel(l)
temp_square_hit = cv2.morphologyEx(
color_mask, cv2.MORPH_HITMISS, hit_and_miss_kernel, anchor=(1, 1)
)
temp_square_hit = cv2.filter2D(
temp_square_hit,
-1,
filter_kernel,
anchor=(l - 1, l - 1),
borderType=cv2.BORDER_CONSTANT,
)
square_hit = np.logical_or(square_hit, temp_square_hit.astype(bool))
return square_hit
def _square_hit_and_miss_kenel(self, l: int) -> np.ndarray:
kernel = np.full((l + 2, l + 2), fill_value=1, dtype=np.int8)
kernel[0, :] = -1
kernel[-1, :] = -1
kernel[:, 0] = -1
kernel[:, -1] = -1
return kernel
def _filter_kenel(self, l: int) -> np.ndarray:
return np.full((l, l), fill_value=1, dtype=np.int8)
@dataclass(frozen=True)
class HolesSelection(MaskConversion):
"""Select only the empty hole inside."""
connectivity: PixelConnectivity
# TODO Lack of consideration of the edges of the image?
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
filled = binary_fill_holes(
color_mask, structure=self.connectivity.structure_for_skimage
)
return filled ^ color_mask
@dataclass(frozen=True)
class ObjectInnerSelection(MaskConversion):
connectivity: PixelConnectivity
image_edge_type: ImageEdgeType
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
if self.image_edge_type == ImageEdgeType.EDGE_EXCLUDE:
border_value = 0
elif self.image_edge_type == ImageEdgeType.EDGE_INCLUDE:
border_value = 1
else:
raise NotImplementedError()
return binary_erosion(
color_mask,
structure=self.connectivity.structure_for_skimage,
border_value=border_value,
)
@dataclass(frozen=True)
class ContourSelection(MaskConversion):
"""Create a contour mask"""
connectivity: PixelConnectivity
image_edge_type: ImageEdgeType
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
inner_mask = ObjectInnerSelection(self.connectivity, self.image_edge_type)(
color_mask
)
return np.logical_xor(inner_mask, color_mask)
@dataclass(frozen=True)
class ContourOuterSelection(MaskConversion):
"""Create a mask one pixel outside the contour"""
connectivity: PixelConnectivity
hole_include: HoleInclude
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
if self.hole_include == HoleInclude.INCLUDE:
dilated = binary_dilation(
color_mask,
structure=self.connectivity.structure_for_skimage,
border_value=0,
)
return np.logical_xor(dilated, color_mask)
elif self.hole_include == HoleInclude.EXCLUDE:
dilated = binary_dilation(
color_mask,
structure=self.connectivity.structure_for_skimage,
border_value=0,
)
holes = HolesSelection(self.connectivity)(color_mask)
return np.logical_and(np.logical_xor(dilated, color_mask), ~holes)
else:
raise NotImplementedError()
@dataclass(frozen=True)
class ConnectDotSelection(MaskConversion):
# TODO This function spends much time.
axis: Axis
edge_type: LineEdgeType
fill_type: FillType
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
result_mask = np.full_like(color_mask, fill_value=False)
coords = np.argwhere(color_mask)
if self.axis in [Axis.HORIZONTAL, Axis.BOTH]:
# Calculate the min and max coordinates of the horizontal
horizontal_group = {
k: itemgetter(0, -1)(tuple(map(itemgetter(1), g)))
for k, g in groupby(coords, key=itemgetter(0))
}
# filter
horizontal_group = {
k: (v[0], v[1])
for k, v in horizontal_group.items()
if (v[1] - v[0]) >= 2
}
# maskを計算
for y, (x_min, x_max) in horizontal_group.items():
if self.edge_type == LineEdgeType.EdgeInclude:
pass
elif self.edge_type == LineEdgeType.EdgeExclude:
x_min += 1
x_max -= 1
else:
raise NotImplementedError()
result_mask[y, x_min : x_max + 1] = True
if self.axis in [Axis.VERTICAL, Axis.BOTH]:
# Calculate the min and max coordinates of the vertical
vertical_group = {
k: itemgetter(0, -1)(tuple(map(itemgetter(0), g)))
for k, g in groupby(
sorted(coords, key=itemgetter(1)), key=itemgetter(1)
)
}
# calculate mask
vertical_group = {
k: (v[0], v[1]) for k, v in vertical_group.items() if (v[1] - v[0]) >= 2
}
# generate mask
for x, (y_min, y_max) in vertical_group.items():
if self.edge_type == LineEdgeType.EdgeInclude:
pass
elif self.edge_type == LineEdgeType.EdgeExclude:
y_min += 1
y_max -= 1
else:
raise NotImplementedError()
result_mask[y_min : y_max + 1, x] = True
if self.fill_type == FillType.NotOverride:
result_mask = np.logical_xor(result_mask, color_mask)
return result_mask
class TaskOperationSetExecutor:
def execute(self, task: Task, operation_set: OperationSet) -> Task:
arrays = OperationSetExecutor.apply_operation_set(
[io.input_arr for io in task.train + task.test], operation_set
)
return Task(
task.name,
tuple(
[
InputOutput(a, io.output_arr)
for a, io in zip(arrays[: len(task.train)], task.train)
]
),
tuple(
[
InputOutput(a, io.output_arr)
for a, io in zip(arrays[len(task.train) :], task.test)
]
),
)
class ColorSelectionExecutor:
@staticmethod
def execute(task: Task, color_selection: ColorSelection) -> ColorSelectedTask:
masks = OperationSetExecutor.apply_color_selection(
[io.input_arr for io in task.train + task.test], color_selection
)
return ColorSelectedTask(
task.name,
task.train,
task.test,
masks[: len(task.train)],
masks[len(task.train) :],
)
class MaskConversionExecutor:
@staticmethod
def execute(
task: ColorSelectedTask, mask_conversion: MaskConversion
) -> MaskConvertedTask:
masks = OperationSetExecutor.apply_mask_conversion(
task.train_masks + task.test_masks, mask_conversion
)
return MaskConvertedTask(
task.name,
task.train,
task.test,
masks[: len(task.train_masks)],
masks[len(task.train_masks) :],
)
class MaskOperationExecutor:
@staticmethod
def execute(task: MaskConvertedTask, mask_operation: MaskOperation) -> Task:
new_arrays = OperationSetExecutor.apply_mask_operation(
[io.input_arr for io in task.train + task.test],
task.train_masks + task.test_masks,
mask_operation,
)
train_io = tuple(
[
InputOutput(n, io.output_arr)
for n, io, in zip(new_arrays[: len(task.train)], task.train)
]
)
test_io = tuple(
[
InputOutput(n, io.output_arr)
for n, io, in zip(new_arrays[len(task.train) :], task.train)
]
)
return Task(task.name, train_io, test_io)
class ColorChannelSelectionExecutor:
@staticmethod
def execute(
task: Task, color_channel_selection: ColorChannelSelection
) -> ColorChannelSelectedTask:
color_mask_pairs_list = OperationSetExecutor.apply_channel_selection(
[io.input_arr for io in task.train + task.test], color_channel_selection
)
return ColorChannelSelectedTask(
task.name,
task.train,
task.test,
color_mask_pairs_list[: len(task.train)],
color_mask_pairs_list[len(task.train) :],
)
class ColorChannelMaskConversionSelectionExecutor:
@staticmethod
def execute(
task: ColorChannelSelectedTask, mask_conversion: MaskConversion
) -> ColorChannelMaskConvertedTask:
color_mask_pairs_list = (
OperationSetExecutor.apply_color_channel_mask_conversion(
task.train_color_mask_pairs + task.test_color_mask_pairs,
mask_conversion,
)
)
return ColorChannelMaskConvertedTask(
task.name,
task.train,
task.test,
task.train_color_mask_pairs,
color_mask_pairs_list[: len(task.train_color_mask_pairs)],
task.test_color_mask_pairs,
color_mask_pairs_list[len(task.train_color_mask_pairs) :],
)
class ColorChannelMergeExecutor:
@staticmethod
def execute(
task: ColorChannelMaskConvertedTask, merge_operation: ChannelMergeOperation
) -> Task:
new_arrays = OperationSetExecutor.apply_channel_merge(
[io.input_arr for io in task.train + task.test],
task.train_original_color_mask_pairs + task.test_original_color_mask_pairs,
task.train_color_mask_pairs + task.test_color_mask_pairs,
merge_operation,
)
train_io = tuple(
[
InputOutput(n, io.output_arr)
for n, io, in zip(new_arrays[: len(task.train)], task.train)
]
)
test_io = tuple(
[
InputOutput(n, io.output_arr)
for n, io, in zip(new_arrays[len(task.train) :], task.train)
]
)
return Task(task.name, train_io, test_io)
class PartitionSelectionExecutor:
@staticmethod
def execute(
task: Task, partition_selection: PartitionSelection
) -> PartitionSelectionTask:
array_mask_list = OperationSetExecutor.apply_partition_selection(
[io.input_arr for io in task.train + task.test], partition_selection
)
return PartitionSelectionTask(
task.name,
task.train,
task.test,
array_mask_list[: len(task.train)],
array_mask_list[len(task.train) :],
)
class PartitionMergeExecutor:
@staticmethod
def execute(
task: PartitionSelectionTask, partition_merge_operation: PartitionMergeOperation
) -> Task:
new_arrays = OperationSetExecutor.apply_partition_merge_operation(
[io.input_arr for io in task.train + task.test],
task.train_partitioned_arrays_original_location_masks
+ task.test_partitioned_arrays_original_location_masks,
partition_merge_operation,
)
train_io = tuple(
[
InputOutput(n, io.output_arr)
for n, io, in zip(new_arrays[: len(task.train)], task.train)
]
)
test_io = tuple(
[
InputOutput(n, io.output_arr)
for n, io, in zip(new_arrays[len(task.train) :], task.train)
]
)
return Task(task.name, train_io, test_io)
class CompletedNodeProcessor:
@staticmethod
def process(node: CompletedNode) -> List[WaitingNode]:
mapping = {
UniformOperationCompletedNode: OperationCompletedNodeProcessor,
ColorSelectionCompletedNode: ColorSelectionCompletedNodeProcessor,
MaskConversionCompletedNode: MaskConversionCompletedNodeProcessor,
ColorChannelSelectionCompletedNode: ColorChannelSelectionCompletedNodeProcessor,
ColorChannelMaskConversionCompletedNode: ColorChannelMaskConversionCompletedNodeProcessor,
PartitionSelectionCompletedNode: PartitionSelectionCompletedNodeProcessor,
}
processor = mapping[node.__class__]
return processor.process(node)
class OperationCompletedNodeProcessor:
@classmethod
def process(
cls, node: UniformOperationCompletedNode
) -> List[
Union[
UniformOperationWaitingNode,
ColorSelectionWaitingNode,
ColorChannelSelectionOperationWaitingNode,
]
]:
res = [
*[
UniformOperationWaitingNode(
node,
node.original_task,
node.task,
node.task_feature,
node.base_operation_set,
new_operation,
)
for new_operation in cls._candidate_operations(
node.task, node.task_feature
)
],
*[
ColorSelectionWaitingNode(
node,
node.original_task,
node.task,
node.task_feature,
node.base_operation_set,
color_selection,
)
for color_selection in cls._candidate_color_selections(node.task)
],
*[
ColorChannelSelectionOperationWaitingNode(
node,
node.original_task,
node.task,
node.task_feature,
node.base_operation_set,
color_channel_selection,
)
for color_channel_selection in cls._candidate_color_channel_selection(
node.task
)
],
]
# first operation only
if len(node.base_operation_set.operations) == 0:
res.extend(
[
PartitionSelectionWaitingNode(
node,
node.original_task,
node.task,
node.task_feature,
node.base_operation_set,
partition_selection,
)
for partition_selection in cls._candidate_partition_selection(
node.task
)
]
)
return res
@staticmethod
def _candidate_operations(task: Task, task_feature: TaskFeature):
input_colors = list(
map(
lambda v: Color.of(v),
set(chain.from_iterable(chain.from_iterable(task.get_input_all_arr()))),
)
)
candidates = []
if task_feature.all_dim_height_increased:
candidates += [Resize(Axis.VERTICAL, r) for r in range(2, 5)]
candidates += [
Padding(m, d, k)
for m, d, k in product(
PaddingMode, [Direction.TOP, Direction.BOTTOM], range(1, 4)
)
]
if task_feature.all_dim_width_increased:
candidates += [Resize(Axis.HORIZONTAL, r) for r in range(2, 5)]
candidates += [
Padding(m, d, k)
for m, d, k in product(
PaddingMode, [Direction.LEFT, Direction.RIGHT], range(1, 4)
)
]
if (
task_feature.all_dim_height_decreased
or task_feature.all_dim_width_decreased
):
candidates += [LineDeletion(c) for c in input_colors]
candidates += [
*[Flip(m) for m in FlipMode],
*[Rotate(a) for a in [90, 180, 270]],
]
return candidates
@staticmethod
def _candidate_color_selections(task: Task) -> List[ColorSelection]:
input_colors = list(
map(
lambda v: Color.of(v),
set(chain.from_iterable(chain.from_iterable(task.get_input_all_arr()))),
)
)
return [
*[FixedSingleColorSelection(c) for c in input_colors],
*[SingleColorSelection(m) for m in SingleColorSelectionMode],
*[MultiColorSelection(m) for m in MultiColorSelectionMode],
]
@staticmethod
def _candidate_color_channel_selection(task: Task) -> List[ColorChannelSelection]:
return [
*[
WithOutMostCommonColorChannelSelection(m)
for m in BackGroundColorSelectionMode
]
]
@staticmethod
def _candidate_partition_selection(task: Task) -> List[PartitionSelection]:
input_colors = list(
map(
lambda v: Color.of(v),
set(chain.from_iterable(chain.from_iterable(task.get_input_all_arr()))),
)
)
return [
*[ColorNumIntegerDivisionPartition(axis=a) for a in Axis],
*[
IntegerDivisionPartition(axis=a, n_split=n)
for a, n in product(Axis, range(2, 5))
],
*[GeneralizedLinePartition(m) for m in BackGroundColorSelectionMode],
*[LinePartition(line_color=c) for c in input_colors],
]
class ColorSelectionCompletedNodeProcessor:
@classmethod
def process(
cls, node: ColorSelectionCompletedNode
) -> List[MaskConversionWaitingNode]:
return [
MaskConversionWaitingNode(
node,
node.original_task,
node.color_selected_task,
node.color_selected_task_feature,
node.base_operation_set,
node.color_selection,
mask_conversion,
)
for mask_conversion in cls._candidate_mask_conversions()
]
@staticmethod
def _candidate_mask_conversions() -> List[MaskConversion]:
return [
NoMaskConversion(),
SquareObjectsSelection(),
*[
ObjectsTouchingEdgeSelection(tf, c)
for tf, c in product(TrueOrFalse, PixelConnectivity)
],
*[
ObjectsMaxMinSelection(tf, m, t, c)
for tf, m, t, c in product(
TrueOrFalse, MaxOrMin, ObjectFeature, PixelConnectivity
)
],
OldObjectsMaxMinSelection(),
*[SplitLineSelection(a) for a in Axis],
*[DotExistLineSelection(a) for a in Axis],
*[HolesSelection(c) for c in PixelConnectivity],
*[
ObjectInnerSelection(c, e)
for c, e in product(PixelConnectivity, ImageEdgeType)
],
*[
ContourSelection(c, e)
for c, e in product(PixelConnectivity, ImageEdgeType)
],
*[
ContourOuterSelection(c, h)
for c, h in product(PixelConnectivity, HoleInclude)
],
*[
ConnectDotSelection(a, e, f)
for a, e, f in product(Axis, LineEdgeType, FillType)
],
]
class MaskConversionCompletedNodeProcessor:
@classmethod
def process(
cls, node: MaskConversionCompletedNode
) -> List[MaskOperationSelectionWaitingNode]:
return [
MaskOperationSelectionWaitingNode(
node,
node.original_task,
node.mask_converted_task,
node.mask_converted_task_feature,
node.base_operation_set,
node.color_selection,
node.mask_conversion,
mask_operation,
)
for mask_operation in cls._candidate(node)
]
@staticmethod
def _candidate(node: MaskConversionCompletedNode) -> List[MaskOperation]:
# TODO use
# color_mappings = set(chain.from_iterable(t.candidate_color_mapping() for t in task.train))
output_colors = list(
map(
lambda v: Color.of(v),
set(
chain.from_iterable(
chain.from_iterable(
node.mask_converted_task.get_output_all_arr()
)
)
),
)
)
candidates = []
if (
not node.mask_converted_task_feature.task_feature.same_dim_between_input_output
):
candidates += [MaskCoordsCrop()]
candidates += [
*[FixedColorMaskFill(c) for c in output_colors],
*[SingleColorMaskFill(m) for m in SingleColorSelectionMode],
]
return candidates
class ColorChannelSelectionCompletedNodeProcessor:
@classmethod
def process(
cls, node: ColorChannelSelectionCompletedNode
) -> List[ColorChannelMaskConversionWaitingNode]:
return [
ColorChannelMaskConversionWaitingNode(
node,
node.original_task,
node.task,
node.feature,
node.base_operation_set,
node.color_channel_selection,
mask_conversion,
)
for mask_conversion in cls._candidate_mask_conversions()
]
@staticmethod
def _candidate_mask_conversions() -> List[MaskConversion]:
return [
NoMaskConversion(),
SquareObjectsSelection(),
*[
ObjectsTouchingEdgeSelection(tf, c)
for tf, c in product(TrueOrFalse, PixelConnectivity)
],
*[
ObjectsMaxMinSelection(tf, m, t, c)
for tf, m, t, c in product(
TrueOrFalse, MaxOrMin, ObjectFeature, PixelConnectivity
)
],
OldObjectsMaxMinSelection(),
*[SplitLineSelection(a) for a in Axis],
*[DotExistLineSelection(a) for a in Axis],
*[HolesSelection(c) for c in PixelConnectivity],
*[
ObjectInnerSelection(c, e)
for c, e in product(PixelConnectivity, ImageEdgeType)
],
*[
ContourSelection(c, e)
for c, e in product(PixelConnectivity, ImageEdgeType)
],
*[
ContourOuterSelection(c, h)
for c, h in product(PixelConnectivity, HoleInclude)
],
*[
ConnectDotSelection(a, e, f)
for a, e, f in product(Axis, LineEdgeType, FillType)
],
]
class ColorChannelMaskConversionCompletedNodeProcessor:
@classmethod
def process(
cls, node: ColorChannelMaskConversionCompletedNode
) -> List[ColorChannelMergeWaitingNode]:
return [
ColorChannelMergeWaitingNode(
node,
node.original_task,
node.task,
node.feature,
node.base_operation_set,
node.color_selection,
node.mask_conversion,
merge_operation,
)
for merge_operation in cls._candidate()
]
@staticmethod
def _candidate() -> List[ChannelMergeOperation]:
return [ColorChannelOverrideOperation()]
class PartitionSelectionCompletedNodeProcessor:
@classmethod
def process(
cls, node: PartitionSelectionCompletedNode
) -> List[PartitionMergeWaitingNode]:
return [
PartitionMergeWaitingNode(
node,
node.original_task,
node.task,
node.feature,
node.base_operation_set,
node.partition_selection,
c,
)
for c in cls._candidate(node)
]
@staticmethod
def _candidate(
node: PartitionSelectionCompletedNode,
) -> List[PartitionMergeOperation]:
output_colors = list(
map(
lambda v: Color.of(v),
set(
chain.from_iterable(
chain.from_iterable(node.task.get_output_all_arr())
)
),
)
)
selections = [
*[UniqueColorNumberSelection(m) for m in MaxOrMin],
*[
ColoredCellNumberSelection(m, bg)
for m, bg in product(MaxOrMin, BackGroundColorSelectionMode)
],
*[SameShapeNumSelection(m) for m in MaxOrMin],
*[SymmetrySelection(a, tf) for a, tf in product(AxisV2, TrueOrFalse)],
]
return [
*[
AnySelectionMerge(m, c)
for m, c in product(BackGroundColorSelectionMode, output_colors)
],
*[
NotSelectionMerge(m, c)
for m, c in product(BackGroundColorSelectionMode, output_colors)
],
*[
AllSelectionMerge(m, c)
for m, c in product(BackGroundColorSelectionMode, output_colors)
],
*[
ModifiedXorSelectionMerge(m, c)
for m, c in product(BackGroundColorSelectionMode, output_colors)
],
*[
NaturalArrayOrderedOverrideMerge(m, c, a)
for m, c, a in product(
BackGroundColorSelectionMode,
Corner,
[Axis.VERTICAL, Axis.HORIZONTAL],
)
],
*[
DiagonalArrayOrderedOverrideMerge(m, c, a)
for m, c, a in product(
BackGroundColorSelectionMode,
Corner,
[Axis.VERTICAL, Axis.HORIZONTAL],
)
],
*[
SpiralArrayOrderedOverrideMerge(m, c, d)
for m, c, d in product(
BackGroundColorSelectionMode, Corner, SpiralDirection
)
],
*[UniquelySelectedArrayExtraction(s) for s in selections],
*[
RestoreOnlySelectedArray(m, s)
for m, s in product(BackGroundColorSelectionMode, selections)
],
ExtractOneValueFromPartitionedArray(),
]
class AnswerMatcher:
@staticmethod
def is_match_arr(arr1: np.ndarray, arr2: np.ndarray) -> bool:
return np.array_equal(arr1, arr2)
@classmethod
def is_train_all_match_if_operated(
cls, task: Task, operation_set: OperationSet
) -> bool:
try:
applied_task = TaskOperationSetExecutor().execute(task, operation_set)
return all(
cls.is_match_arr(io.input_arr, io.output_arr)
for io in applied_task.train
)
except OperationInconsistencyException:
return False
@classmethod
def is_train_test_all_match_if_operated(
cls, task: Task, operation_set: OperationSet
) -> bool:
try:
applied_task = TaskOperationSetExecutor().execute(task, operation_set)
return all(
cls.is_match_arr(io.input_arr, io.output_arr)
for io in applied_task.train + applied_task.test
)
except OperationInconsistencyException:
return False
# TODO ?
@classmethod
def is_train_all_match(cls, task: Task) -> bool:
return all(
map(lambda io: cls.is_match_arr(io.input_arr, io.output_arr), task.train)
)
def setup_df_display_options():
np.set_printoptions(threshold=10000)
np.set_printoptions(linewidth=10000)
pd.set_option("display.max_columns", 1000)
pd.set_option("display.max_rows", 1000)
pd.set_option("display.width", 800)
pd.set_option("display.max_colwidth", 300)
def mean(values: List[float]) -> float:
return sum(values) / len(values)
def nan_mean(val_iter: Iterable[Union[int, float]]) -> Optional[float]:
nan_filtered = [v for v in val_iter if v is not None]
if not nan_filtered:
return None
return mean(nan_filtered)
def initialize_path():
if RunConfig.RUN_MODE in [RunMode.LOCAL_RUN_ALL, RunMode.LOCAL_RUN]:
shutil.rmtree(PathConfig.WRONG_ANSWERS_ROOT, ignore_errors=True)
PathConfig.OUTPUT_SUBMISSION.unlink() if PathConfig.OUTPUT_SUBMISSION.exists() else None
@dataclass
class HandMadeNodeEvaluator(NodeEvaluator):
pattern: DepthSearchPattern
operation_element_prob_dict: Dict[str, float]
node_search_engine_param: NodeBaseSearchEngineParameter
dist_eval_param: DistanceEvaluatorParameter
def __post_init__(self):
self.class_mapping = {
UniformOperationWaitingNode: OperationWaitingNodeEvaluator(
self.operation_element_prob_dict
),
ColorSelectionWaitingNode: ColorSelectionWaitingNodeEvaluator(
self.operation_element_prob_dict
),
MaskConversionWaitingNode: MaskConversionWaitingNodeEvaluator(
self.operation_element_prob_dict
),
MaskOperationSelectionWaitingNode: MaskOperationSelectionWaitingNodeEvaluator(
self.operation_element_prob_dict
),
ColorChannelSelectionOperationWaitingNode: ColorChannelSelectionOperationWaitingNodeEvaluator(
self.operation_element_prob_dict
),
ColorChannelMaskConversionWaitingNode: ColorChannelMaskConversionWaitingNodeEvaluator(
self.operation_element_prob_dict
),
ColorChannelMergeWaitingNode: ColorChannelMergeWaitingNodeEvaluator(
self.operation_element_prob_dict
),
PartitionSelectionWaitingNode: PartitionSelectionWaitingNodeEvaluator(
self.operation_element_prob_dict
),
PartitionMergeWaitingNode: PartitionMergeWaitingNodeEvaluator(
self.operation_element_prob_dict
),
}
self.dist_evaluator = DistanceEvaluator(self.dist_eval_param)
def evaluate_nodes(self, nodes: List[WaitingNode]):
for n in nodes:
self.evaluate(n)
def evaluate(self, node: WaitingNode):
evaluator = self.class_mapping[node.__class__]
task_feature = evaluator.get_task_feature(node)
base_distance = self.dist_evaluator.evaluate_task_feature(task_feature)
element_including_prob = evaluator.get_element_inclusion_prob(node)
node.cache_pred_distance = self.calculate_final_distance(
base_distance, element_including_prob, node.depth()
)
def evaluate_base_distance_for_completed_node(self, node: CompletedNode):
return self.dist_evaluator.evaluate_task_feature(node.task_feature)
def calculate_final_distance(
self, base_distance: float, element_inclusion_prob: float, depth: int
) -> float:
prob_cost = self.node_search_engine_param.element_inclusion_prob_factor * (
1 - element_inclusion_prob
)
if self.pattern == DepthSearchPattern.BREADTH_FIRST:
return (
base_distance
** (1 + depth * self.node_search_engine_param.breadth_first_exp_cost)
+ prob_cost
+ self.node_search_engine_param.breadth_first_cost * depth
)
elif self.pattern == DepthSearchPattern.NORMAL:
return (
base_distance
** (1 + depth * self.node_search_engine_param.normal_exp_cost)
+ prob_cost
+ self.node_search_engine_param.normal_first_cost * depth
)
elif self.pattern == DepthSearchPattern.DEPTH_FIRST:
return (
base_distance
** (1 + depth * self.node_search_engine_param.depth_first_exp_cost)
+ prob_cost
+ self.node_search_engine_param.depth_first_cost * depth
)
else:
raise NotImplementedError()
@dataclass
class HandmadeNodeEvaluatorBase:
operation_element_prob_dict: Dict[str, float]
def get_task_feature(self, node) -> TaskFeature:
raise NotImplementedError()
def get_element_inclusion_prob(self, node) -> float:
raise NotImplementedError()
def calculate_dist_factor(self, node) -> float:
raise NotImplementedError()
class OperationWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(
self, operation_waiting_node: UniformOperationWaitingNode
) -> TaskFeature:
return operation_waiting_node.task_feature
def get_element_inclusion_prob(
self, operation_waiting_node: UniformOperationWaitingNode
) -> float:
return self.operation_element_prob_dict[
operation_waiting_node.next_operation.__class__.__name__
]
def calculate_dist_factor(
self, operation_waiting_node: UniformOperationWaitingNode
) -> float:
# TODO use height_integer_multiple?
operation = operation_waiting_node.next_operation
if isinstance(operation, (Flip, Rotate)):
if operation_waiting_node.task_feature.same_dim_between_input_output:
dist_factor = 0.8
else:
dist_factor = 1.2
elif isinstance(operation, (Resize, Padding)):
if operation_waiting_node.task_feature.same_dim_between_input_output:
dist_factor = 1.2
else:
dist_factor = 0.8
else:
raise NotImplementedError(operation)
return dist_factor
class ColorSelectionWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(
self, color_selection_waiting_node: ColorSelectionWaitingNode
) -> TaskFeature:
return color_selection_waiting_node.task_feature
def get_element_inclusion_prob(
self, color_selection_waiting_node: ColorSelectionWaitingNode
) -> float:
return self.operation_element_prob_dict[
color_selection_waiting_node.next_selection.__class__.__name__
]
def calculate_dist_factor(
self, color_selection_waiting_node: ColorSelectionWaitingNode
) -> float:
return 1.0
class MaskConversionWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(
self, mask_conversion_waiting_node: MaskConversionWaitingNode
) -> TaskFeature:
return mask_conversion_waiting_node.color_selected_task_feature.task_feature
def get_element_inclusion_prob(
self, mask_conversion_waiting_node: MaskConversionWaitingNode
) -> float:
return self.operation_element_prob_dict[
mask_conversion_waiting_node.next_mask_conversion.__class__.__name__
]
def calculate_dist_factor(
self, mask_conversion_waiting_node: MaskConversionWaitingNode
) -> float:
return 1.0
class MaskOperationSelectionWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(
self, mask_operation_waiting_node: MaskOperationSelectionWaitingNode
) -> TaskFeature:
return mask_operation_waiting_node.mask_converted_task_feature.task_feature
def get_element_inclusion_prob(
self, mask_operation_waiting_node: MaskOperationSelectionWaitingNode
) -> float:
return self.operation_element_prob_dict[
mask_operation_waiting_node.next_mask_operation.__class__.__name__
]
def calculate_dist_factor(
self, mask_operation_waiting_node: MaskOperationSelectionWaitingNode
) -> float:
return 1.0
class ColorChannelSelectionOperationWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(
self, node: ColorChannelSelectionOperationWaitingNode
) -> TaskFeature:
return node.task_feature
def get_element_inclusion_prob(
self, node: ColorChannelSelectionOperationWaitingNode
) -> float:
return self.operation_element_prob_dict[
node.next_color_channel_selection.__class__.__name__
]
class ColorChannelMaskConversionWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(
self, node: ColorChannelMaskConversionWaitingNode
) -> TaskFeature:
return node.task_feature
def get_element_inclusion_prob(
self, node: ColorChannelMaskConversionWaitingNode
) -> float:
return self.operation_element_prob_dict[
node.next_mask_conversion.__class__.__name__
]
class ColorChannelMergeWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(self, node: ColorChannelMergeWaitingNode) -> TaskFeature:
return node.task_feature
def get_element_inclusion_prob(self, node: ColorChannelMergeWaitingNode) -> float:
return self.operation_element_prob_dict[
node.next_merge_operation.__class__.__name__
]
class PartitionSelectionWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(self, node: PartitionSelectionWaitingNode) -> TaskFeature:
return node.task_feature
def get_element_inclusion_prob(self, node: PartitionSelectionWaitingNode) -> float:
return self.operation_element_prob_dict[
node.next_partition_selection.__class__.__name__
]
class PartitionMergeWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(self, node: PartitionMergeWaitingNode) -> TaskFeature:
return node.task_feature
def get_element_inclusion_prob(self, node: PartitionMergeWaitingNode) -> float:
return self.operation_element_prob_dict[
node.next_partition_merge_operation.__class__.__name__
]
def np_to_str(arr: np.ndarray) -> bytes:
return arr.tostring()
def to_bytes(obj):
return bytes(str(obj), encoding="utf-8")
def train_operation_element_inclusion_prediction():
storage = load_answer_storage()
save_answer_storage(storage)
storage = storage.get_only_correct_answer_storage()
print(storage.get_text())
type_classes = [c.__name__ for c in get_all_operation_classes()]
subclasses = [c.__name__ for c in get_all_operation_element_classes()]
record_dicts = []
for task_name, elements in storage.get_task_grouped_elements():
pseudo_operation_set = OperationSet(
list(chain.from_iterable([e.operation_set.operations for e in elements]))
)
task = TaskLoader().get_task(task_name)
task_feature = create_task_feature(task)
operation_type_classes = [
o_s_t.__name__ for o_s_t in pseudo_operation_set.types()
]
type_answer_dict = {c: c in operation_type_classes for c in type_classes}
operation_element_classes = [
o_s_e.__class__.__name__ for o_s_e in pseudo_operation_set.elements()
]
element_answer_dict = {c: c in operation_element_classes for c in subclasses}
record_dicts.append(
{**asdict(task_feature), **type_answer_dict, **element_answer_dict}
)
df = DataFrame(record_dicts)
df = df.fillna(10) # TODO do not use magic number
target_columns = type_classes + subclasses
feature_columns = list(set(df.columns) - set(target_columns))
x = df[feature_columns]
y = df[target_columns]
print(x)
print(y)
model = MLPClassifier(
# early_stopping=True, validation_fraction=0.3, n_iter_no_change=50,
hidden_layer_sizes=(50,),
solver="sgd",
learning_rate_init=0.003,
max_iter=40,
verbose=True,
)
model.fit(x, y)
shutil.rmtree(PathConfig.OPERATION_ELEMENT_INCLUSION_MODEL_ROOT, ignore_errors=True)
PathConfig.OPERATION_ELEMENT_INCLUSION_MODEL_ROOT.mkdir(parents=True, exist_ok=True)
pickle.dump(model, PathConfig.OPERATION_ELEMENT_INCLUSION_MODEL.open(mode="wb"))
pickle.dump(
feature_columns,
PathConfig.OPERATION_ELEMENT_INCLUSION_MODEL_FEATURE_COLUMNS.open(mode="wb"),
)
pickle.dump(
target_columns,
PathConfig.OPERATION_ELEMENT_INCLUSION_MODEL_TARGET_COLUMNS.open(mode="wb"),
)
temp_dicts = []
for e in sorted(storage.elements, key=lambda e: e.task_name):
task = TaskLoader().get_task(e.task_name)
task_feature = create_task_feature(task)
pred_dict = predict_operation_element_inclusion(task_feature)
operation_type_classes = [o_s_t.__name__ for o_s_t in e.operation_set.types()]
operation_element_classes = [
o_s_e.__class__.__name__ for o_s_e in e.operation_set.elements()
]
element_answer_dict = {
c: c in operation_type_classes + operation_element_classes
for c in type_classes + subclasses
}
temp_dicts.append(element_answer_dict)
temp_dicts.append(pred_dict)
temp_df = DataFrame(temp_dicts)
print(temp_df)
def predict_operation_element_inclusion(task_feature: TaskFeature) -> Dict[str, float]:
model: MLPClassifier = pickle.load(
PathConfig.OPERATION_ELEMENT_INCLUSION_MODEL.open(mode="rb")
)
feature_columns = pickle.load(
PathConfig.OPERATION_ELEMENT_INCLUSION_MODEL_FEATURE_COLUMNS.open(mode="rb")
)
target_columns = pickle.load(
PathConfig.OPERATION_ELEMENT_INCLUSION_MODEL_TARGET_COLUMNS.open(mode="rb")
)
df = DataFrame([asdict(task_feature)])
df = df.fillna(10)
x = df[feature_columns]
y = model.predict_proba(x)[0]
return {c: p for c, p in zip(target_columns, y)}
@dataclass
class NodeBaseSearchEngine:
MAX_NODE = 100000000
answer_limit_num: int = 3
def search(
self, task: Task, params: AllParameter, verbose: bool = False
) -> Union[AnsweredSearchResults, NotAnsweredSearchResult]:
task_feature = create_task_feature(task, task)
if RunConfig.USE_ML_GUIDE:
operation_element_prob_dict = predict_operation_element_inclusion(
task_feature
)
else:
operation_element_prob_dict = defaultdict(lambda: 1)
schedules: NodeEvaluatorSchedules = get_schedule(
operation_element_prob_dict,
params.node_base_engine_param,
params.distance_evaluator_param,
)
node_evaluator = schedules.pop_evaluator()
root_node = UniformOperationCompletedNode(
None, task, task, task_feature, OperationSet([])
)
first_waiting_nodes = CompletedNodeProcessor.process(root_node)
node_evaluator.evaluate_nodes(first_waiting_nodes)
zero_depth_pq = PriorityQueue([*first_waiting_nodes])
pq = PriorityQueue([])
zero_depth_completed_nodes = []
zero_depth_completed_node_eval_map = {}
visited_node_hashes = defaultdict(
dict
) # If same array is found, cache to save time.
if verbose:
print("search zero depth nodes")
with Timer() as timer:
for node_i in range(self.MAX_NODE):
if len(zero_depth_pq) == 0:
break
waiting_new_nodes = []
for same_cost_node_i, waiting_node in enumerate(
zero_depth_pq.pop_mins_or_as_least_n(
params.node_base_engine_param.pq_pop_mins_or_as_least_n
)
):
completed_node = WaitingNodeProcessor().process(waiting_node)
if isinstance(completed_node, Exception):
if verbose:
print(f"skipped: {completed_node}")
continue
if isinstance(completed_node, UniformOperationCompletedNode):
zero_depth_completed_nodes.append(completed_node)
zero_depth_completed_node_eval_map[
completed_node.base_operation_set.operations[0]
] = node_evaluator.evaluate_base_distance_for_completed_node(
completed_node
)
continue
temp_waiting_new_nodes = CompletedNodeProcessor.process(
completed_node
)
node_evaluator.evaluate_nodes(temp_waiting_new_nodes)
waiting_new_nodes += temp_waiting_new_nodes
for n in waiting_new_nodes:
zero_depth_pq.push(n)
one_depth_answer_nodes = [
k for k, v in zero_depth_completed_node_eval_map.items() if v == 0
]
if one_depth_answer_nodes:
answers = []
result_applied_tasks = []
for o in one_depth_answer_nodes:
try:
applied_task = TaskOperationSetExecutor().execute(
task, OperationSet([o])
)
except OperationInconsistencyException:
continue
if any(
applied_task.test_arr_hash() == t.test_arr_hash()
for t in result_applied_tasks
):
continue
result_applied_tasks.append(applied_task)
answers.append(AnsweredSearchResult(OperationSet([o])))
answers = answers[:3]
return AnsweredSearchResults(task, answers, timer.second(), 0, node_i)
zero_depth_search_time = timer.second()
for completed_node in zero_depth_completed_nodes:
train_node_hash = completed_node.train_arr_hash()
all_node_hash = completed_node.all_arr_hash()
if train_node_hash in visited_node_hashes:
if verbose:
print(
f'hash skipped. same node: {"_".join(map(str, (f"{k}:{v}" for k, v in visited_node_hashes[train_node_hash].items())))}'
)
visited_node_hashes[train_node_hash][all_node_hash] = completed_node
continue
visited_node_hashes[train_node_hash][all_node_hash] = completed_node
temp_waiting_new_nodes = CompletedNodeProcessor.process(completed_node)
node_evaluator.evaluate_nodes(temp_waiting_new_nodes)
for n in temp_waiting_new_nodes:
pq.push(n)
# TODO 1 depthものを使って評価関数をいい感じに
# TODO 同じoperationを含むとマイナスな補正をかけないと、まずいかも?
if verbose:
print("search none-zero depth nodes")
searched_total_node = 0
with Timer() as timer:
for node_i in range(self.MAX_NODE):
if len(pq) == 0:
return NotAnsweredSearchResult(
task,
NoImprovementException(),
timer.second(),
searched_total_node,
)
waiting_new_nodes = []
for same_cost_node_i, waiting_node in enumerate(
pq.pop_mins_or_as_least_n(
params.node_base_engine_param.pq_pop_mins_or_as_least_n
)
):
if verbose:
print(
f"total_node: {searched_total_node}, node: {node_i}_{same_cost_node_i}, pq_len: {len(pq)}, cost: {waiting_node.cache_pred_distance}, {waiting_node}"
)
searched_total_node += 1
completed_node = WaitingNodeProcessor().process(waiting_node)
if isinstance(completed_node, Exception):
if verbose:
print(f"skipped: {completed_node}")
continue
if isinstance(completed_node, UniformOperationCompletedNode):
if AnswerMatcher.is_train_all_match(completed_node.task):
answers = []
for t in get_alternative_operation_sets(
task, completed_node, visited_node_hashes, verbose
):
answers.append(
AnsweredSearchResult(t.to_operation_set())
)
if len(answers) == 3:
break
return AnsweredSearchResults(
task,
answers,
zero_depth_search_time,
timer.second(),
searched_total_node,
)
train_node_hash = completed_node.train_arr_hash()
all_node_hash = completed_node.all_arr_hash()
if train_node_hash in visited_node_hashes:
if verbose:
print(
f'hash skipped. same node: {"_".join(map(str, (f"{k}:{v}" for k, v in visited_node_hashes[train_node_hash].items())))}'
)
visited_node_hashes[train_node_hash][
all_node_hash
] = completed_node
continue
visited_node_hashes[train_node_hash][all_node_hash] = completed_node
temp_waiting_new_nodes = CompletedNodeProcessor.process(
completed_node
)
node_evaluator.evaluate_nodes(temp_waiting_new_nodes)
waiting_new_nodes += temp_waiting_new_nodes
if timer.second() > schedules.timeout_sec():
return NotAnsweredSearchResult(
task,
TimeoutException(),
timer.second(),
searched_total_node,
)
for n in waiting_new_nodes:
pq.push(n)
if timer.second() > schedules.next_timing():
if verbose:
print(
"=========================== evaluator switch!!! ==========================="
)
node_evaluator = schedules.pop_evaluator()
if node_evaluator is None:
return NotAnsweredSearchResult(
task,
TimeoutException(),
timer.second(),
searched_total_node,
)
node_evaluator.evaluate_nodes(pq.heap)
pq.refresh()
return NotAnsweredSearchResult(
task, MaxNodeExceededException(), timer.second(), searched_total_node
)
class WaitingNodeProcessor:
def process(
self, node: WaitingNode
) -> Union[CompletedNode, OperationInconsistencyException]:
mapping = {
UniformOperationWaitingNode: UniformOperationWaitingNodeProcessor(),
ColorSelectionWaitingNode: ColorSelectionWaitingNodeProcessor(),
MaskConversionWaitingNode: MaskConversionWaitingNodeProcessor(),
MaskOperationSelectionWaitingNode: MaskOperationSelectionWaitingNodeProcessor(),
ColorChannelSelectionOperationWaitingNode: ColorChannelSelectionOperationWaitingNodeProcessor(),
ColorChannelMaskConversionWaitingNode: ColorChannelMaskConversionWaitingNodeProcessor(),
ColorChannelMergeWaitingNode: ColorChannelMergeWaitingNodeProcessor(),
PartitionSelectionWaitingNode: PartitionSelectionWaitingNodeProcessor(),
PartitionMergeWaitingNode: PartitionMergeWaitingNodeProcessor(),
}
try:
processor = mapping[node.__class__]
return processor.process(node)
except OperationInconsistencyException as e:
return e
class UniformOperationWaitingNodeProcessor:
def process(
self, node: UniformOperationWaitingNode
) -> UniformOperationCompletedNode:
new_task = TaskOperationSetExecutor().execute(
node.task, OperationSet([node.next_operation])
)
if self.can_skip(node.task, new_task):
raise OperationInconsistencyException(f"can skip")
new_task_feature = create_task_feature(node.original_task, new_task)
new_base_operation_set = OperationSet(
node.base_operation_set.operations + [node.next_operation]
)
return UniformOperationCompletedNode(
node, node.original_task, new_task, new_task_feature, new_base_operation_set
)
def can_skip(self, prev_task: Task, next_task: Task) -> bool:
# TODO use OperationInconsistencyException?
if all(
AnswerMatcher.is_match_arr(prev_io.input_arr, next_io.input_arr)
for prev_io, next_io in zip(prev_task.train, next_task.train)
):
# no effect
return True
else:
return False
class ColorSelectionWaitingNodeProcessor:
def process(self, node: ColorSelectionWaitingNode) -> ColorSelectionCompletedNode:
color_selected_task = ColorSelectionExecutor.execute(
node.task, node.next_selection
)
if self.can_skip(color_selected_task):
raise OperationInconsistencyException(f"can skip")
color_selected_task_feature = create_color_selected_task_feature(
node.original_task, color_selected_task, node.task_feature
)
return ColorSelectionCompletedNode(
node,
node.original_task,
color_selected_task,
color_selected_task_feature,
node.base_operation_set,
node.next_selection,
)
def can_skip(self, color_selected_task: ColorSelectedTask) -> bool:
# TODO use OperationInconsistencyException?
if not any(m.any() for m in color_selected_task.train_masks):
# if no mask was generated, skip.
return True
elif all(m.all() for m in color_selected_task.train_masks):
# if mask covers all region, skip.
return True
else:
return False
class MaskConversionWaitingNodeProcessor:
def process(self, node: MaskConversionWaitingNode) -> MaskConversionCompletedNode:
mask_converted_task = MaskConversionExecutor.execute(
node.color_selected_task, node.next_mask_conversion
)
if self.can_skip(mask_converted_task):
raise OperationInconsistencyException(f"can skip")
mask_converted_task_feature = create_mask_conversion_task_feature(
node.original_task,
mask_converted_task,
node.color_selected_task_feature.task_feature,
)
return MaskConversionCompletedNode(
node,
node.original_task,
mask_converted_task,
mask_converted_task_feature,
node.base_operation_set,
node.color_selection,
node.next_mask_conversion,
)
def can_skip(self, mask_converted_task: MaskConvertedTask) -> bool:
if not any(m.any() for m in mask_converted_task.train_masks):
# if no mask was generated, skip.
return True
elif all(m.all() for m in mask_converted_task.train_masks):
# if mask covers all region, skip.
return True
else:
return False
class MaskOperationSelectionWaitingNodeProcessor:
def process(
self, node: MaskOperationSelectionWaitingNode
) -> UniformOperationCompletedNode:
new_task = MaskOperationExecutor.execute(
node.mask_converted_task, node.next_mask_operation
)
if self.can_skip(node.mask_converted_task, new_task):
raise OperationInconsistencyException(f"can skip")
new_task_feature = create_task_feature(node.original_task, new_task)
new_base_operation_set = OperationSet(
node.base_operation_set.operations
+ [
ColorOperation(
node.color_selection, node.mask_conversion, node.next_mask_operation
)
]
)
return UniformOperationCompletedNode(
node, node.original_task, new_task, new_task_feature, new_base_operation_set
)
def can_skip(self, prev_task: Task, next_task: Task) -> bool:
if all(
AnswerMatcher.is_match_arr(prev_io.input_arr, next_io.input_arr)
for prev_io, next_io in zip(prev_task.train, next_task.train)
):
# no effect
return True
else:
return False
class ColorChannelSelectionOperationWaitingNodeProcessor:
def process(
self, node: ColorChannelSelectionOperationWaitingNode
) -> ColorChannelSelectionCompletedNode:
new_task = ColorChannelSelectionExecutor().execute(
node.task, node.next_color_channel_selection
)
if self.can_skip(node.task, new_task):
raise OperationInconsistencyException(f"can skip")
# reuse old feature.
return ColorChannelSelectionCompletedNode(
node,
node.original_task,
new_task,
node.task_feature,
node.base_operation_set,
node.next_color_channel_selection,
)
def can_skip(self, prev_task: Task, next_task: Task) -> bool:
# TODO imple
return False
class ColorChannelMaskConversionWaitingNodeProcessor:
def process(
self, node: ColorChannelMaskConversionWaitingNode
) -> ColorChannelMaskConversionCompletedNode:
new_task = ColorChannelMaskConversionSelectionExecutor().execute(
node.task, node.next_mask_conversion
)
if self.can_skip(node.task, new_task):
raise OperationInconsistencyException(f"can skip")
# reuse old feature.
return ColorChannelMaskConversionCompletedNode(
node,
node.original_task,
new_task,
node.task_feature,
node.base_operation_set,
node.color_channel_selection,
node.next_mask_conversion,
)
def can_skip(self, prev_task: Task, next_task: Task) -> bool:
# TODO imple
return False
class ColorChannelMergeWaitingNodeProcessor:
def process(
self, node: ColorChannelMergeWaitingNode
) -> UniformOperationCompletedNode:
new_task = ColorChannelMergeExecutor.execute(
node.task, node.next_merge_operation
)
if self.can_skip(node.task, new_task):
raise OperationInconsistencyException(f"can skip")
new_task_feature = create_task_feature(node.original_task, new_task)
new_base_operation_set = OperationSet(
node.base_operation_set.operations
+ [
MultiColorChannelOperation(
node.color_channel_selection,
node.mask_conversion,
node.next_merge_operation,
)
]
)
return UniformOperationCompletedNode(
node, node.original_task, new_task, new_task_feature, new_base_operation_set
)
def can_skip(self, prev_task: Task, next_task: Task) -> bool:
# TODO imple
return False
class PartitionSelectionWaitingNodeProcessor:
def process(
self, node: PartitionSelectionWaitingNode
) -> PartitionSelectionCompletedNode:
new_task = PartitionSelectionExecutor().execute(
node.task, node.next_partition_selection
)
if self.can_skip(node.task, new_task):
raise OperationInconsistencyException(f"can skip")
# reuse old feature.
return PartitionSelectionCompletedNode(
node,
node.original_task,
new_task,
node.task_feature,
node.base_operation_set,
node.next_partition_selection,
)
def can_skip(self, prev_task: Task, next_task: Task) -> bool:
# TODO imple
return False
class PartitionMergeWaitingNodeProcessor:
def process(self, node: PartitionMergeWaitingNode) -> UniformOperationCompletedNode:
new_task = PartitionMergeExecutor().execute(
node.task, node.next_partition_merge_operation
)
if self.can_skip(node.task, new_task):
raise OperationInconsistencyException(f"can skip")
new_task_feature = create_task_feature(node.original_task, new_task)
new_base_operation_set = OperationSet(
node.base_operation_set.operations
+ [
PartitionOperation(
node.partition_selection, node.next_partition_merge_operation
)
]
)
return UniformOperationCompletedNode(
node, node.original_task, new_task, new_task_feature, new_base_operation_set
)
def can_skip(self, prev_task: Task, next_task: Task) -> bool:
# TODO imple
return False
@dataclass(frozen=True)
class WithOutMostCommonColorChannelSelection(ColorChannelSelection):
bg_selection_mode: BackGroundColorSelectionMode
def __call__(self, arr: np.ndarray) -> List[Tuple[Color, np.ndarray]]:
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
colors = ColorSelectionUtil().get_colors(arr)
results = [(c, arr == c) for c in colors if c != bg]
if len(results) <= 1:
raise OperationInconsistencyException("can not devide")
return results
@dataclass
class OperationSetExecutionResultHolder:
raw_task: Task
cache: Dict[str, Tuple[Task, TaskFeature]]
def get_result(self, operation_set: OperationSet) -> Tuple[Task, TaskFeature]:
if str(operation_set) in self.cache:
return self.cache[str(operation_set)]
for i in reversed(range(1, len(operation_set.operations))):
prev_o_s = OperationSet(operation_set.operations[:i])
post_o_s = OperationSet(operation_set.operations[i:])
assert len(prev_o_s.operations) + len(post_o_s.operations) == len(
operation_set.operations
)
if str(prev_o_s) in self.cache:
prev_task, _ = self.cache[str(prev_o_s)]
post_o_s_applied_task = TaskOperationSetExecutor().execute(
prev_task, post_o_s
)
post_o_s_applied_task_feature = create_task_feature(
post_o_s_applied_task
)
self.cache[str(operation_set)] = (
post_o_s_applied_task,
post_o_s_applied_task_feature,
)
return post_o_s_applied_task, post_o_s_applied_task_feature
applied_task = TaskOperationSetExecutor().execute(self.raw_task, operation_set)
applied_task_feature = create_task_feature(applied_task)
self.cache[str(operation_set)] = (applied_task, applied_task_feature)
return applied_task, applied_task_feature
@dataclass
class OperationSetMutator:
# TODO uniform(0, 1) is redundant. There must be easier way to do it.
# TODO I'd like to define procedure of probability. like albumentation.
# TODO should increase max_depth dynamically?
holder: OperationSetExecutionResultHolder
operation_element_prob_dict: Dict[str, float]
def mutate(self, operation_set: OperationSet):
new_operations = []
for o in operation_set.operations:
task, task_feature = self.holder.get_result(OperationSet(new_operations))
if (
random.uniform(0, 1)
< TreeBaseSearchEngineParameter.operation_mutation_prob
):
new_operations.append(self.get_random_one_operation(task, task_feature))
elif (
random.uniform(0, 1)
< TreeBaseSearchEngineParameter.operation_component_mutation_prob
):
if isinstance(o, UniformOperation):
new_operations.append(
self._uniform_operation_candidates(task_feature)
)
elif isinstance(o, ColorOperation):
color_sel, add_sels, mask_ope = (
o.color_selection,
o.mask_conversions,
o.mask_operation,
)
if random.uniform(0, 1) < 1 / 3:
color_sel = self._color_selection_candidates(task)
if random.uniform(0, 1) < 1 / 3:
add_sels = [self._mask_conversions()]
if random.uniform(0, 1) < 1 / 3:
mask_ope = self._mask_operation_candidates(task)
new_operations.append(ColorOperation(color_sel, add_sels, mask_ope))
else:
raise NotImplementedError()
elif (
random.uniform(0, 1)
< TreeBaseSearchEngineParameter.operation_param_mutation_prob
):
if isinstance(o, UniformOperation):
new_operations.append(self._mutate_parameter(o, task))
elif isinstance(o, ColorOperation):
color_sel, add_sels, mask_ope = (
o.color_selection,
o.mask_conversions,
o.mask_operation,
)
if random.uniform(0, 1) < 1 / 3:
color_sel = self._mutate_parameter(color_sel, task)
if random.uniform(0, 1) < 1 / 3:
add_sels = [self._mutate_parameter(add_sels[0], task)]
if random.uniform(0, 1) < 1 / 3:
mask_ope = self._mutate_parameter(mask_ope, task)
new_operations.append(ColorOperation(color_sel, add_sels, mask_ope))
else:
raise NotImplementedError()
elif (
random.uniform(0, 1)
< TreeBaseSearchEngineParameter.shrink_mutation_prob
):
continue
else:
new_operations.append(o)
if len(new_operations) < TreeBaseSearchEngineParameter.max_depth:
if (
random.uniform(0, 1)
< TreeBaseSearchEngineParameter.extend_mutation_prob
):
temp_new_set = OperationSet(new_operations)
task, task_feature = self.holder.get_result(temp_new_set)
new_operations.append(self.get_random_one_operation(task, task_feature))
return OperationSet(new_operations)
def get_random_one_operation(self, task: Task, task_feature: TaskFeature):
classes = [UniformOperation, ColorOperation]
class_probs = [self.operation_element_prob_dict[c.__name__] for c in classes]
total_prob = sum(class_probs)
class_probs = [p / total_prob for p in class_probs]
chosen_class = np.random.choice(classes, p=class_probs)
if chosen_class == UniformOperation:
operation = self._uniform_operation_candidates(task_feature)
elif chosen_class == ColorOperation:
color_sel = self._color_selection_candidates(task)
add_sels = self._mask_conversions()
mask_ope = self._mask_operation_candidates(task)
operation = ColorOperation(color_sel, add_sels, mask_ope)
else:
raise NotImplementedError()
return operation
def _uniform_operation_candidates(self, task_feature: TaskFeature):
classes = [Resize, Padding, Flip, Rotate]
class_probs = [self.operation_element_prob_dict[c.__name__] for c in classes]
total_prob = sum(class_probs)
class_probs = [p / total_prob for p in class_probs]
chosen_class = np.random.choice(classes, p=class_probs)
if chosen_class == Resize:
return random.choice([Resize(a, r) for a, r in product(Axis, range(2, 5))])
elif chosen_class == Padding:
return random.choice(
[
Padding(m, d, k)
for m, d, k in product(PaddingMode, Direction, range(1, 4))
]
)
elif chosen_class == Flip:
return random.choice([Flip(m) for m in FlipMode])
elif chosen_class == Rotate:
return random.choice([Rotate(a) for a in [90, 180, 270]])
else:
raise NotImplementedError()
def _color_selection_candidates(self, task: Task):
classes = [FixedSingleColorSelection, SingleColorSelection, MultiColorSelection]
class_probs = [self.operation_element_prob_dict[c.__name__] for c in classes]
total_prob = sum(class_probs)
class_probs = [p / total_prob for p in class_probs]
chosen_class = np.random.choice(classes, p=class_probs)
if chosen_class == FixedSingleColorSelection:
input_colors = list(
map(
lambda v: Color.of(v),
set(
chain.from_iterable(
chain.from_iterable(task.get_input_all_arr())
)
),
)
)
return random.choice([FixedSingleColorSelection(c) for c in input_colors])
elif chosen_class == SingleColorSelection:
return random.choice(
[SingleColorSelection(m) for m in SingleColorSelectionMode]
)
elif chosen_class == MultiColorSelection:
return random.choice(
[MultiColorSelection(m) for m in MultiColorSelectionMode]
)
else:
raise NotImplementedError()
def _mask_conversions(self):
classes = [
NoMaskConversion,
SquareObjectsSelection,
ObjectsMaxMinSelection,
SplitLineSelection,
DotExistLineSelection,
HolesSelection,
ObjectInnerSelection,
ContourSelection,
ContourOuterSelection,
ConnectDotSelection,
]
class_probs = [self.operation_element_prob_dict[c.__name__] for c in classes]
total_prob = sum(class_probs)
class_probs = [p / total_prob for p in class_probs]
chosen_class = np.random.choice(classes, p=class_probs)
if chosen_class == NoMaskConversion:
return NoMaskConversion()
elif chosen_class == SquareObjectsSelection:
return SquareObjectsSelection()
elif chosen_class == ObjectsMaxMinSelection:
return random.choice(
[
ObjectsMaxMinSelection(m, t, c)
for m, t, c in product(MaxOrMin, ObjectFeature, PixelConnectivity)
]
)
elif chosen_class == SplitLineSelection:
return random.choice([SplitLineSelection(a) for a in Axis])
elif chosen_class == DotExistLineSelection:
return random.choice([DotExistLineSelection(a) for a in Axis])
elif chosen_class == HolesSelection:
return random.choice([HolesSelection(c) for c in PixelConnectivity])
elif chosen_class == ObjectInnerSelection:
return random.choice(
[
ObjectInnerSelection(c, e)
for c, e in product(PixelConnectivity, ImageEdgeType)
]
)
elif chosen_class == ContourSelection:
return random.choice(
[
ContourSelection(c, e)
for c, e in product(PixelConnectivity, ImageEdgeType)
]
)
elif chosen_class == ContourOuterSelection:
return random.choice(
[
ContourOuterSelection(c, h)
for c, h in product(PixelConnectivity, HoleInclude)
]
)
elif chosen_class == ConnectDotSelection:
return random.choice(
[
ConnectDotSelection(a, e, f)
for a, e, f in product(Axis, LineEdgeType, FillType)
]
)
else:
raise NotImplementedError()
def _mask_operation_candidates(self, task: Task):
classes = [MaskCoordsCrop, FixedColorMaskFill, SingleColorMaskFill]
class_probs = [self.operation_element_prob_dict[c.__name__] for c in classes]
total_prob = sum(class_probs)
class_probs = [p / total_prob for p in class_probs]
chosen_class = np.random.choice(classes, p=class_probs)
if chosen_class == MaskCoordsCrop:
return MaskCoordsCrop()
elif chosen_class == FixedColorMaskFill:
output_colors = list(
map(
lambda v: Color.of(v),
set(
chain.from_iterable(
chain.from_iterable(task.get_output_all_arr())
)
),
)
)
return random.choice([FixedColorMaskFill(c) for c in output_colors])
elif chosen_class == SingleColorMaskFill:
return random.choice(
[SingleColorMaskFill(m) for m in SingleColorSelectionMode]
)
else:
raise NotImplementedError()
def _mutate_parameter(self, operation_element, task: Task):
# TODO Should mutate one property of operation_element.
if isinstance(operation_element, Resize):
return random.choice([Resize(Axis.VERTICAL, r) for r in range(2, 5)])
elif isinstance(operation_element, Padding):
return random.choice(
[
Padding(m, d, k)
for m, d, k in product(
PaddingMode, [Direction.TOP, Direction.BOTTOM], range(1, 4)
)
]
)
elif isinstance(operation_element, Flip):
return random.choice([Flip(m) for m in FlipMode])
elif isinstance(operation_element, Rotate):
return random.choice([Rotate(a) for a in [90, 180, 270]])
elif isinstance(operation_element, FixedSingleColorSelection):
input_colors = list(
map(
lambda v: Color.of(v),
set(
chain.from_iterable(
chain.from_iterable(task.get_input_all_arr())
)
),
)
)
return random.choice([FixedSingleColorSelection(c) for c in input_colors])
elif isinstance(operation_element, SingleColorSelection):
return random.choice(
[SingleColorSelection(m) for m in SingleColorSelectionMode]
)
elif isinstance(operation_element, MultiColorSelection):
return random.choice(
[MultiColorSelection(m) for m in MultiColorSelectionMode]
)
elif isinstance(operation_element, NoMaskConversion):
return random.choice([NoMaskConversion()])
elif isinstance(operation_element, SquareObjectsSelection):
return random.choice([SquareObjectsSelection()])
elif isinstance(operation_element, ObjectsMaxMinSelection):
return random.choice(
[
ObjectsMaxMinSelection(m, t, c)
for m, t, c in product(MaxOrMin, ObjectFeature, PixelConnectivity)
]
)
elif isinstance(operation_element, SplitLineSelection):
return random.choice([SplitLineSelection(a) for a in Axis])
elif isinstance(operation_element, DotExistLineSelection):
return random.choice([DotExistLineSelection(a) for a in Axis])
elif isinstance(operation_element, HolesSelection):
return random.choice([HolesSelection(c) for c in PixelConnectivity])
elif isinstance(operation_element, ObjectInnerSelection):
return random.choice(
[
ObjectInnerSelection(c, e)
for c, e in product(PixelConnectivity, ImageEdgeType)
]
)
elif isinstance(operation_element, ContourSelection):
return random.choice(
[
ContourSelection(c, e)
for c, e in product(PixelConnectivity, ImageEdgeType)
]
)
elif isinstance(operation_element, ContourOuterSelection):
return random.choice(
[
ContourOuterSelection(c, h)
for c, h in product(PixelConnectivity, HoleInclude)
]
)
elif isinstance(operation_element, ConnectDotSelection):
return random.choice(
[
ConnectDotSelection(a, e, f)
for a, e, f in product(Axis, LineEdgeType, FillType)
]
)
elif isinstance(operation_element, MaskCoordsCrop):
return random.choice([MaskCoordsCrop()])
elif isinstance(operation_element, FixedColorMaskFill):
output_colors = list(
map(
lambda v: Color.of(v),
set(
chain.from_iterable(
chain.from_iterable(task.get_output_all_arr())
)
),
)
)
return random.choice([FixedColorMaskFill(c) for c in output_colors])
elif isinstance(operation_element, SingleColorMaskFill):
return random.choice(
[SingleColorMaskFill(m) for m in SingleColorSelectionMode]
)
else:
raise NotImplementedError(operation_element)
@dataclass
class Individual:
operation_set: OperationSet
distance: float
task_feature: TaskFeature
def __str__(self):
return f"depth: {len(self.operation_set.operations)}, dist: {self.distance:.5f}, ope: {self.operation_set}"
@dataclass
class Population:
strategy: str
individuals: List[Individual]
def show(self):
self.sort()
for i in self.individuals:
print(i)
def sort(self):
random.shuffle(self.individuals)
self.individuals = sorted(self.individuals, key=lambda i: i.distance)
def get_elite(self):
# TODO Lack of consideration when there were multiple elites.
self.sort()
return self.individuals[0]
def get_dist0_if_exists(self) -> Optional[OperationSet]:
elite = min(self.individuals, key=lambda i: i.distance)
if elite.distance == 0:
return elite.operation_set
else:
return None
def mutate(self, mutator, holder, evaluator):
# 変異
self.sort()
mutated_individuals = [self.get_elite()]
for i in self.individuals[1:]:
for _ in range(1000000000000):
try:
mutated_operation_set = mutator.mutate(i.operation_set)
# チェックする。
task, task_feature = holder.get_result(mutated_operation_set)
break
except OperationInconsistencyException:
continue
applied_task, applied_task_feature = holder.get_result(
mutated_operation_set
)
mutation_distance = evaluator.evaluate_task_feature(applied_task_feature)
mutated_individuals.append(
Individual(
mutated_operation_set, mutation_distance, applied_task_feature
)
)
self.individuals = mutated_individuals
def select(self):
if self.strategy == "simple":
self.individuals = self.select_simple()
elif self.strategy == "nsga2":
self.individuals = self.select_nsga2()
else:
raise NotImplementedError()
def select_nsga2(self):
raw_len = len(self.individuals)
selected = selNSGA2(self.individuals, raw_len)
simple_selection = self.select_simple(include_elite=True)
return selected + simple_selection[: raw_len - len(selected)]
def select_simple(self, include_elite: bool = True):
# 選択
self.sort()
if include_elite:
next_individuals = [self.get_elite()]
else:
next_individuals = []
# score = 1 / distance # TODO Handle 0 division
score_sum = sum(map(lambda i: 1 / i.distance, self.individuals))
score_ratios = [1 / i.distance / score_sum for i in self.individuals]
score_roulette = np.cumsum(score_ratios)
for _ in range(len(self.individuals) - 1):
roulette_prob_hit = random.uniform(0, 1)
for i, roulette_prob in enumerate(score_roulette):
if roulette_prob_hit < roulette_prob:
next_individuals.append(self.individuals[i])
break
return next_individuals
@dataclass
class TreeBaseSearchEngine:
time_out: int = 60 # TODO
def get_first_individual(self, evaluator, mutator, holder, task, root_task_feature):
try:
operation = mutator.get_random_one_operation(task, root_task_feature)
operation_set = OperationSet([operation])
_, task_feature = holder.get_result(operation_set)
distance = evaluator.evaluate_task_feature(task_feature)
return Individual(operation_set, distance, task_feature)
except OperationInconsistencyException:
return self.get_first_individual(
evaluator, mutator, holder, task, root_task_feature
)
def search(
self, task: Task, params: AllParameter, verbose: bool = False
) -> Union[AnsweredSearchResults, NotAnsweredSearchResult]:
evaluator = DistanceEvaluator(params.distance_evaluator_param)
holder = OperationSetExecutionResultHolder(task, {})
root_operation_set = OperationSet([])
_, root_task_feature = holder.get_result(root_operation_set)
if RunConfig.USE_ML_GUIDE:
operation_element_prob_dict = predict_operation_element_inclusion()
else:
operation_element_prob_dict = defaultdict(lambda: 1)
if verbose:
print(operation_element_prob_dict)
mutator: OperationSetMutator = OperationSetMutator(
holder, operation_element_prob_dict
)
individuals = [
self.get_first_individual(
evaluator, mutator, holder, task, root_task_feature
)
for _ in range(TreeBaseSearchEngineParameter.population_num)
]
population = Population("simple", individuals)
with Timer() as timer:
for i in range(10000000):
if verbose:
print(f"============== generation: {i} population")
population.show()
population.mutate(mutator, holder, evaluator)
if verbose:
print(f"============== generation: {i}, mutation population")
population.show()
answer_operation_set = population.get_dist0_if_exists()
if answer_operation_set is not None:
if AnswerMatcher.is_train_all_match_if_operated(
task, answer_operation_set
):
return AnsweredSearchResults(
task,
[AnsweredSearchResult(answer_operation_set)],
timer.second(),
i,
)
else:
raise NotImplementedError()
population.select()
if timer.second() > self.time_out:
return NotAnsweredSearchResult(
task, TimeoutException(), timer.second(), i
)
return NotAnsweredSearchResult(
task, MaxNodeExceededException(), timer.second(), i
)
T = TypeVar("T")
class PriorityQueue:
def __init__(self, heap: List[T]):
self.heap = heap
heapify(self.heap)
def refresh(self):
heapify(self.heap)
def push(self, item: T):
heappush(self.heap, item)
def pop_min(self) -> T:
return heappop(self.heap)
def pop_mins(self) -> List[T]:
min_item = self.pop_min()
results = [min_item]
for _ in range(len(self.heap)):
item = self.pop_min()
if item <= min_item:
results.append(item)
else:
self.push(item)
return results
return results
def pop_mins_or_as_least_n(self, n: int) -> List[T]:
results = []
while len(results) < n:
if len(self) == 0:
break
results += self.pop_mins()
return results
def push_pop(self, item: T) -> T:
return heappushpop(self.heap, item)
def __len__(self) -> int:
return len(self.heap)
def sorted_list(self) -> List[T]:
return sorted(self.heap)
def str_to_operation_set(s: str) -> OperationSet:
# DSL string -> DSL object
return eval(s)
def str_to_AnswerStorageElement(s: str):
# noinspection PyUnresolvedReferences
# from abstraction_and_reasoning_challenge.src.answer_storage.answer_storage import AnswerStorageElement
return eval(s)
@dataclass(frozen=True)
class UniqueColorNumberSelection(PartitionedArraySelection):
max_or_min: MaxOrMin
def __call__(
self, arr: np.ndarray, partitioned_arrays: List[List[np.ndarray]]
) -> List[List[bool]]:
color_nums = _apply(self._color_num, partitioned_arrays)
if self.max_or_min == MaxOrMin.MAX:
target_color_num = max(map(max, color_nums))
elif self.max_or_min == MaxOrMin.MIN:
target_color_num = min(map(min, color_nums))
else:
raise NotImplementedError()
return _apply(lambda n: n == target_color_num, color_nums)
def _color_num(self, array: np.ndarray):
return len(np.unique(array))
@dataclass(frozen=True)
class ColoredCellNumberSelection(PartitionedArraySelection):
max_or_min: MaxOrMin
bg_selection_mode: BackGroundColorSelectionMode
def __call__(
self, arr: np.ndarray, partitioned_arrays: List[List[np.ndarray]]
) -> List[List[bool]]:
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
colored_cell_nums = _apply(
partial(self._colored_cell_nums, bg=bg), partitioned_arrays
)
if self.max_or_min == MaxOrMin.MAX:
target_color_num = max(map(max, colored_cell_nums))
elif self.max_or_min == MaxOrMin.MIN:
target_color_num = min(map(min, colored_cell_nums))
else:
raise NotImplementedError()
return _apply(lambda n: n == target_color_num, colored_cell_nums)
def _colored_cell_nums(self, array: np.ndarray, bg: Color):
return (array != bg).sum()
@dataclass(frozen=True)
class SameShapeNumSelection(PartitionedArraySelection):
max_or_min: MaxOrMin
def __call__(
self, arr: np.ndarray, partitioned_arrays: List[List[np.ndarray]]
) -> List[List[bool]]:
np_strings = _apply(lambda n: n.tostring(), partitioned_arrays)
c = Counter(_flatten(np_strings))
most_commons = c.most_common()
if len(most_commons) < 2:
raise OperationInconsistencyException("can not select")
if self.max_or_min == MaxOrMin.MAX:
if most_commons[0][1] == most_commons[1][1]:
raise OperationInconsistencyException("duplicated max")
target = most_commons[0][0]
elif self.max_or_min == MaxOrMin.MIN:
if most_commons[-1][1] == most_commons[-2][1]:
raise OperationInconsistencyException("duplicated min")
target = most_commons[-1][0]
else:
raise NotImplementedError()
return _apply(lambda n: n == target, np_strings)
@dataclass(frozen=True)
class SymmetrySelection(PartitionedArraySelection):
axis: AxisV2
true_or_false: TrueOrFalse
def __call__(
self, arr: np.ndarray, partitioned_arrays: List[List[np.ndarray]]
) -> List[List[bool]]:
return _apply(
partial(
self._is_symmetry, axis=self.axis, true_or_false=self.true_or_false
),
partitioned_arrays,
)
def _is_symmetry(
self, array: np.ndarray, axis: AxisV2, true_or_false: TrueOrFalse
) -> bool:
if axis == AxisV2.VERTICAL:
res = np.array_equal(array, Flip(FlipMode.UD)(array))
elif axis == AxisV2.HORIZONTAL:
res = np.array_equal(array, Flip(FlipMode.LR)(array))
elif axis == AxisV2.VERTICAL_HORIZONTAL:
res = self._is_symmetry(
array, AxisV2.VERTICAL, TrueOrFalse.TRUE
) and self._is_symmetry(array, AxisV2.HORIZONTAL, TrueOrFalse.TRUE)
elif axis == AxisV2.MAIN_DIAGONAL:
res = np.array_equal(array, Flip(FlipMode.UL_DR)(array))
elif axis == AxisV2.ANTI_DIAGONAL:
res = np.array_equal(array, Flip(FlipMode.UR_DL)(array))
elif axis == AxisV2.BOTH_DIAGONAL:
res = self._is_symmetry(
array, AxisV2.MAIN_DIAGONAL, TrueOrFalse.TRUE
) and self._is_symmetry(array, AxisV2.ANTI_DIAGONAL, TrueOrFalse.TRUE)
else:
raise NotImplementedError()
if true_or_false == TrueOrFalse.TRUE:
return res
else:
return not res
def _apply(func, partitioned_arrays: List[List[np.ndarray]]) -> List[List[Any]]:
results = []
for h_arrays in partitioned_arrays:
temp_masks = []
for array in h_arrays:
temp_masks.append(func(array))
results.append(temp_masks)
return results
def _flatten(partitioned: List[List[Any]]) -> List[Any]:
return list(chain.from_iterable(partitioned))
class OperationSetEvaluator:
# Evaluation function to choose three answers by ranking the OperationSet.
# Smaller is better.
def evaluate(self, operation_set: OperationSet) -> float:
score_map = {
FixedSingleColorSelection: 0.5,
}
return sum(score_map.get(e.__class__, 1) for e in operation_set.elements())
def get_alternative_operation_sets(
raw_task: Task,
last_completed_node: UniformOperationCompletedNode,
visited_node_hashes: Dict[int, Dict[int, Any]],
verbose: bool,
) -> Iterable[NodeTree]:
if verbose:
print("original_answer")
print(NodeTree.of(last_completed_node).to_operation_set())
print("===search other answers===")
node_tree = NodeTree.of(last_completed_node)
depth_alternative_nodes_pairs: List[Tuple[int, List[CompletedNode]]] = []
for i, node in enumerate(node_tree.completed_nodes):
if i == 0:
# no alternative for root node
continue
if node.train_arr_hash() in visited_node_hashes:
same_hash_node_dicts = visited_node_hashes[node.train_arr_hash()]
alternative_nodes = [
n
for all_hash, n in same_hash_node_dicts.items()
if all_hash != node.all_arr_hash()
]
depth_alternative_nodes_pairs.append((i, alternative_nodes))
if verbose:
print(f"alternative_nodes:")
for i, alternative_nodes in depth_alternative_nodes_pairs:
for n in alternative_nodes:
print(f"node_depth: {i}, {n}")
candidate_node_trees = [node_tree]
for i, alternative_nodes in depth_alternative_nodes_pairs:
if len(candidate_node_trees) > 1000:
break # TODO Too many candidate_node_trees causes Memory Error.
for n in alternative_nodes:
candidate_node_trees += [
NodeTree.replaced_new_node_tree(t, i, n) for t in candidate_node_trees
]
if verbose:
print("node_tree:")
print(node_tree)
print("candidate_node_trees:")
for c in candidate_node_trees:
print("===")
print(c)
# TODO unnecessary filter?
candidate_node_trees = [
t
for t in candidate_node_trees
if AnswerMatcher.is_train_all_match_if_operated(raw_task, t.to_operation_set())
]
candidate_node_trees = sorted(
candidate_node_trees,
key=lambda t: OperationSetEvaluator().evaluate(t.to_operation_set()),
)
result_applied_tasks = []
for t in candidate_node_trees:
try:
applied_task = TaskOperationSetExecutor().execute(
raw_task, t.to_operation_set()
)
except OperationInconsistencyException:
continue
if any(
applied_task.test_arr_hash() == t.test_arr_hash()
for t in result_applied_tasks
):
continue
result_applied_tasks.append(applied_task)
yield t
class ColorChannelOverrideOperation(ChannelMergeOperation):
def __call__(
self,
arr: np.ndarray,
original_color_mask_paris: List[Tuple[Color, np.ndarray]],
color_mask_pairs: List[Tuple[Color, np.ndarray]],
) -> np.ndarray:
diff_mask_paris = [
(c1, np.logical_and(np.logical_xor(o_m, c_m), c_m))
for (c1, o_m), (c2, c_m) in zip(
sorted(original_color_mask_paris, key=itemgetter(0)),
sorted(color_mask_pairs, key=itemgetter(0)),
)
] # TODO should groupby color?
check_mask = np.full_like(diff_mask_paris[0][1], fill_value=False)
# If duplicated, InconsistencyException
for _, m in diff_mask_paris:
if check_mask[m].any():
raise OperationInconsistencyException("failed channel merge")
check_mask[m] = True
for c, m in diff_mask_paris:
arr[m] = c
return arr
@dataclass
class NodeEvaluatorSchedule:
start_sec: int
evaluator: Optional[NodeEvaluator]
@dataclass
class NodeEvaluatorSchedules:
schedules: List[NodeEvaluatorSchedule]
def pop_evaluator(self) -> Optional[NodeEvaluator]:
evaluator = self.schedules[0].evaluator
self.schedules = self.schedules[1:]
return evaluator
def next_timing(self):
return self.schedules[0].start_sec
def timeout_sec(self):
return self.schedules[-1].start_sec
def get_schedule(
operation_element_prob_dict: Dict[str, float],
node_search_engine_param,
dist_eval_param,
) -> NodeEvaluatorSchedules:
if RunConfig.RUN_MODE == RunMode.KERNEL:
if RunConfig.ENGINE_SCHEDULE_PATTERN == EngineSchedulePattern.HAND_MADE:
return NodeEvaluatorSchedules(
[
NodeEvaluatorSchedule(
0,
HandMadeNodeEvaluator(
DepthSearchPattern.BREADTH_FIRST,
operation_element_prob_dict,
node_search_engine_param,
dist_eval_param,
),
),
NodeEvaluatorSchedule(
60 * 1,
HandMadeNodeEvaluator(
DepthSearchPattern.NORMAL,
operation_element_prob_dict,
node_search_engine_param,
dist_eval_param,
),
),
NodeEvaluatorSchedule(
60 * 2,
HandMadeNodeEvaluator(
DepthSearchPattern.DEPTH_FIRST,
operation_element_prob_dict,
node_search_engine_param,
dist_eval_param,
),
),
NodeEvaluatorSchedule(60 * 3, None),
]
)
if RunConfig.ENGINE_SCHEDULE_PATTERN == EngineSchedulePattern.DRY_RUN:
return NodeEvaluatorSchedules(
[
NodeEvaluatorSchedule(
0,
HandMadeNodeEvaluator(
DepthSearchPattern.BREADTH_FIRST,
operation_element_prob_dict,
node_search_engine_param,
dist_eval_param,
),
),
NodeEvaluatorSchedule(3, None),
]
)
else:
if RunConfig.ENGINE_SCHEDULE_PATTERN == EngineSchedulePattern.HAND_MADE:
return NodeEvaluatorSchedules(
[
NodeEvaluatorSchedule(
0,
HandMadeNodeEvaluator(
DepthSearchPattern.BREADTH_FIRST,
operation_element_prob_dict,
node_search_engine_param,
dist_eval_param,
),
),
NodeEvaluatorSchedule(
20,
HandMadeNodeEvaluator(
DepthSearchPattern.NORMAL,
operation_element_prob_dict,
node_search_engine_param,
dist_eval_param,
),
),
NodeEvaluatorSchedule(
40,
HandMadeNodeEvaluator(
DepthSearchPattern.DEPTH_FIRST,
operation_element_prob_dict,
node_search_engine_param,
dist_eval_param,
),
),
NodeEvaluatorSchedule(60, None),
]
)
if RunConfig.ENGINE_SCHEDULE_PATTERN == EngineSchedulePattern.ML:
return NodeEvaluatorSchedules(
[
NodeEvaluatorSchedule(
0, MLNodeEvaluator(DepthSearchPattern.BREADTH_FIRST)
),
NodeEvaluatorSchedule(
20, MLNodeEvaluator(DepthSearchPattern.NORMAL)
),
NodeEvaluatorSchedule(
40, MLNodeEvaluator(DepthSearchPattern.DEPTH_FIRST)
),
NodeEvaluatorSchedule(60, None),
]
)
if RunConfig.ENGINE_SCHEDULE_PATTERN == EngineSchedulePattern.DRY_RUN:
return NodeEvaluatorSchedules(
[
NodeEvaluatorSchedule(
0,
HandMadeNodeEvaluator(
DepthSearchPattern.BREADTH_FIRST,
operation_element_prob_dict,
node_search_engine_param,
dist_eval_param,
),
),
NodeEvaluatorSchedule(3, None),
]
)
raise NotImplementedError()
def optimize_node_base_search(tasks: List[Task]):
assert RunConfig.ENGINE_TYPE == EngineType.NODE_BASED_SEARCH_ENGINE
def objective(trial: Trial):
param = AllParameter(
# distance_evaluator_param=DistanceEvaluatorParameter(
# same_h_w_dim_between_input_output=trial.suggest_loguniform('same_h_w_dim_between_input_output', 100, 10000),
# all_dim_h_w_integer_multiple=trial.suggest_loguniform('all_dim_h_w_integer_multiple', 10, 1000),
# mean_lack_color_num=trial.suggest_loguniform('mean_lack_color_num', 1, 100),
# mean_excess_color_num=trial.suggest_loguniform('mean_excess_color_num', 1, 100),
# mean_hit_and_miss_histogram_diff=trial.suggest_loguniform('mean_hit_and_miss_histogram_diff', 1, 100),
# mean_h_v_diff_input_arr_line_num=trial.suggest_loguniform('mean_h_v_diff_input_arr_line_num', 1, 100),
# mean_h_v_diff_output_arr_line_num=trial.suggest_loguniform('mean_h_v_diff_output_arr_line_num', 1, 100),
# mean_h_v_edge_sum_diff=trial.suggest_discrete_uniform('mean_h_v_edge_sum_diff', 0, 2, 0.5),
# mean_h_v_edge_sum_diff_ratio=trial.suggest_discrete_uniform('mean_h_v_edge_sum_diff_ratio', 0, 2, 0.5),
# mean_diff_cell_where_no_need_to_change_count_ratio=trial.suggest_loguniform('mean_diff_cell_where_no_need_to_change_count_ratio', 1, 100000),
# ),
node_base_engine_param=NodeBaseSearchEngineParameter(
# breadth_first_cost=trial.suggest_loguniform('breadth_first_cost', 1000, 100000),
normal_first_cost=trial.suggest_loguniform(
"normal_first_cost", 10, 1000
),
depth_first_cost=trial.suggest_loguniform("depth_first_cost", 0.1, 10),
# breadth_first_exp_cost=trial.suggest_loguniform('exp_cost', 0.001, 3),
# normal_exp_cost=trial.params['exp_cost'],
# depth_first_exp_cost=trial.params['exp_cost'],
pq_pop_mins_or_as_least_n=trial.suggest_int(
"pq_pop_mins_or_as_least_n", 1, 10
),
# element_inclusion_prob_factor=trial.suggest_loguniform('element_inclusion_prob_factor', 0.001, 10000000),
)
)
print(trial.params)
engine_results = solve_tasks(tasks, param, add_answer_storage=True)
answered_results = [
r for r in engine_results if isinstance(r, AnsweredSearchResults)
]
true_results = [r for r in engine_results if r.final_test_correct()]
all_len = len(engine_results)
true_len = len(true_results)
false_len = len(answered_results) - len(true_results)
none_len = len(engine_results) - len(answered_results)
print(trial.params)
print(f"true: {true_len}, false: {false_len}, none: {none_len}, all: {all_len}")
return all_len - true_len - false_len / 2
study = optuna.create_study()
study.optimize(objective, n_trials=1000)
print(study.best_params)
def optimize_tree_base_search(tasks: List[Task]):
assert RunConfig.ENGINE_TYPE == EngineType.TREE_BASED_SEARCH_ENGINE
def objective(trial: Trial):
all_parameter = AllParameter(
tree_base_engine_param=TreeBaseSearchEngineParameter(
population_num=trial.suggest_int("population_num", 20, 80),
max_depth=trial.suggest_int("max_depth", 6, 10),
operation_mutation_prob=trial.suggest_loguniform(
"operation_mutation_prob", 0.01, 0.5
),
operation_component_mutation_prob=trial.suggest_loguniform(
"operation_component_mutation_prob", 0.005, 0.5
),
operation_param_mutation_prob=trial.suggest_loguniform(
"operation_param_mutation_prob", 0.001, 0.5
),
extend_mutation_prob=trial.suggest_loguniform(
"extend_mutation_prob", 0.01, 1
),
shrink_mutation_prob=trial.suggest_loguniform(
"shrink_mutation_prob", 0.001, 0.1
),
)
)
print(trial.params)
engine_results = solve_tasks(tasks, all_parameter, add_answer_storage=True)
answered_results = [
r for r in engine_results if isinstance(r, AnsweredSearchResults)
]
true_results = [r for r in engine_results if r.final_test_correct()]
all_len = len(engine_results)
true_len = len(true_results)
false_len = len(answered_results) - len(true_results)
none_len = len(engine_results) - len(answered_results)
print(f"true: {true_len}, false: {false_len}, none: {none_len}, all: {all_len}")
return all_len - true_len - false_len / 2
study = optuna.create_study()
study.optimize(objective, n_trials=1000)
print(study.best_params)
def solve_tasks(
tasks: List[Task],
params: AllParameter,
output_summary_path: Optional[Path] = None,
save_submission: bool = False,
copy_wrong_answers_root_tag: Optional[str] = None,
add_answer_storage: bool = False,
verbose: bool = False,
) -> List[Union[AnsweredSearchResults, NotAnsweredSearchResult]]:
print("===== start parallel solve tasks =====\n\n")
if RunConfig.N_JOB == 1 or len(tasks) == 1:
engine_results = [
solve_task(task, params, verbose)
for task in tqdm(tasks, miniters=0, mininterval=None, maxinterval=None)
]
else:
# with Pool(processes=RunConfig.N_JOB) as pool:
# args = ((task, verbose) for task in tqdm(tasks, miniters=0, mininterval=None, maxinterval=None))
# engine_results = pool.starmap(solve_task, args)
# 'multiprocessing' or 'threading'
engine_results = Parallel(n_jobs=RunConfig.N_JOB, backend="multiprocessing")(
delayed(solve_task)(task, params, verbose)
for task in tqdm(tasks, miniters=0, mininterval=None, maxinterval=None)
)
print("===== end parallel solve tasks =====\n\n")
summary = summary_engine_results(engine_results)
print(summary)
if output_summary_path:
output_summary_path.write_text(summary)
if save_submission:
print("start save submission")
submission_df = create_submission(engine_results)
save_submission_df(submission_df)
if add_answer_storage:
storage_elements = list(
chain.from_iterable(
[
r.to_answer_storage_elements()
for r in engine_results
if isinstance(r, AnsweredSearchResults)
]
)
)
update_answer_storage(storage_elements)
if copy_wrong_answers_root_tag:
print("start copy wrong answers")
for r in engine_results:
if not r.final_test_correct():
plot_task(
r.task,
show=False,
save_path=PathConfig.WRONG_ANSWERS_ROOT
/ copy_wrong_answers_root_tag
/ f"{r.task.name}.png",
)
return engine_results
def solve_task(
task: Task, params: AllParameter, verbose: bool = False
) -> Union[AnsweredSearchResults, NotAnsweredSearchResult]:
try:
engine = get_engine(RunConfig.ENGINE_TYPE)
engine_result = engine.search(task, params, verbose)
except Exception as e:
print(f"unknown error {task.name}")
raise e
if isinstance(engine_result, NotAnsweredSearchResult):
return engine_result
elif isinstance(engine_result, AnsweredSearchResults):
# calculate operation_set-executed task.
for result in engine_result.results:
applied_task = TaskOperationSetExecutor().execute(
task, result.operation_set
)
result.test_output_arr = [io.input_arr for io in applied_task.test]
result.test_correct = AnswerMatcher.is_train_test_all_match_if_operated(
task, result.operation_set
)
engine_result.results = sorted(
engine_result.results, key=lambda r: r.test_correct, reverse=True
)
print(engine_result.summary())
return engine_result
else:
raise NotImplementedError()
class OperationSetExecutor:
@classmethod
def apply_operation_set(
cls, arrays: List[np.ndarray], operation_set: OperationSet
) -> List[np.ndarray]:
for o in operation_set.operations:
arrays = cls.apply_operation(arrays, o)
return arrays
@classmethod
def apply_operation(
cls,
arrays: List[np.ndarray],
operation: Union[UniformOperation, ColorOperation, MultiColorChannelOperation],
) -> List[np.ndarray]:
if isinstance(operation, UniformOperation):
return cls.apply_uniform_operation(arrays, operation)
elif isinstance(operation, ColorOperation):
masks = cls.apply_color_selection(arrays, operation.color_selection)
masks = cls.apply_mask_conversion(masks, operation.mask_conversions)
return cls.apply_mask_operation(arrays, masks, operation.mask_operation)
elif isinstance(operation, MultiColorChannelOperation):
original_color_mask_pairs_list = cls.apply_channel_selection(
arrays, operation.channel_selection
)
color_mask_pairs_list = deepcopy(original_color_mask_pairs_list)
color_mask_pairs_list = cls.apply_color_channel_mask_conversion(
color_mask_pairs_list, operation.mask_conversions
)
return cls.apply_channel_merge(
arrays,
original_color_mask_pairs_list,
color_mask_pairs_list,
operation.channel_merge_operation,
)
elif isinstance(operation, PartitionOperation):
partitioned_arrays_original_location_masks = cls.apply_partition_selection(
arrays, operation.partition_selection
)
return cls.apply_partition_merge_operation(
arrays,
partitioned_arrays_original_location_masks,
operation.partition_merge_operation,
)
else:
raise NotImplementedError()
@classmethod
def apply_uniform_operation(
cls, arrays: List[np.ndarray], operation: UniformOperation
) -> List[np.ndarray]:
new_arrays = [cls._apply_uniform_operation(a, operation) for a in arrays]
if all(np.array_equal(n, r) for n, r in zip(new_arrays, arrays)):
raise OperationInconsistencyException(f"no effect. {operation}")
return new_arrays
@classmethod
def _apply_uniform_operation(
cls, arr: np.ndarray, operation: UniformOperation
) -> np.ndarray:
cls._check_arr(arr, operation)
temp_arr = deepcopy(arr)
new_arr = operation(temp_arr)
cls._check_arr(new_arr, operation)
return new_arr
@classmethod
def apply_color_selection(
cls, arrays: List[np.ndarray], selection: ColorSelection
) -> List[np.ndarray]:
return [cls._apply_color_selection(a, selection) for a in arrays]
@classmethod
def _apply_color_selection(
cls, arr: np.ndarray, selection: ColorSelection
) -> np.ndarray:
cls._check_arr(arr, None)
temp_arr = deepcopy(arr)
mask = selection(temp_arr)
cls._check_mask(mask, selection)
return mask
@classmethod
def apply_channel_selection(
cls, arrays: List[np.ndarray], channel_selection: ColorChannelSelection
) -> List[List[Tuple[Color, np.ndarray]]]:
return [cls._apply_channel_selection(a, channel_selection) for a in arrays]
@classmethod
def _apply_channel_selection(
cls, arr: np.ndarray, channel_selection: ColorChannelSelection
) -> List[Tuple[Color, np.ndarray]]:
cls._check_arr(arr, None)
temp_arr = deepcopy(arr)
color_mask_pairs = channel_selection(temp_arr)
for c, m in color_mask_pairs:
cls._check_mask(m, channel_selection)
return color_mask_pairs
@classmethod
def apply_color_channel_mask_conversion(
cls,
color_mask_pairs_list: List[List[Tuple[Color, np.ndarray]]],
mask_conversion: MaskConversion,
) -> List[List[Tuple[Color, np.ndarray]]]:
new_color_mask_pairs_list = [
cls._apply_color_channel_mask_conversion(p, mask_conversion)
for p in color_mask_pairs_list
]
# TODO imple
# if not isinstance(mask_conversion, NoMaskConversion):
# if all(np.array_equal(n, r) for n, r in zip(new_color_mask_pairs_list, color_mask_pairs_list)):
# raise OperationInconsistencyException(mask_conversion)
return new_color_mask_pairs_list
@classmethod
def _apply_color_channel_mask_conversion(
cls,
color_mask_pairs: List[Tuple[Color, np.ndarray]],
mask_conversion: MaskConversion,
) -> List[Tuple[Color, np.ndarray]]:
for c, m in color_mask_pairs:
cls._check_mask(m, None)
temp_color_mask_pairs = deepcopy(color_mask_pairs)
temp_color_mask_pairs = [
(c, mask_conversion(m)) for c, m in temp_color_mask_pairs
]
for c, m in temp_color_mask_pairs:
cls._check_mask(m, mask_conversion)
return temp_color_mask_pairs
@classmethod
def apply_channel_merge(
cls,
arrays: List[np.ndarray],
original_color_mask_pairs_list: List[List[Tuple[Color, np.ndarray]]],
color_mask_pairs_list: List[List[Tuple[Color, np.ndarray]]],
merge_operation: ChannelMergeOperation,
) -> List[np.ndarray]:
new_arrays = [
cls._apply_channel_merge(arr, o_p, p, merge_operation)
for arr, o_p, p in zip(
arrays, original_color_mask_pairs_list, color_mask_pairs_list
)
]
if all(np.array_equal(n, r) for n, r in zip(new_arrays, arrays)):
raise OperationInconsistencyException(f"no effect. {merge_operation}")
return new_arrays
@classmethod
def _apply_channel_merge(
cls,
arr: np.ndarray,
original_color_mask_pairs: List[Tuple[Color, np.ndarray]],
color_mask_pairs: List[Tuple[Color, np.ndarray]],
merge_operation: ChannelMergeOperation,
) -> np.ndarray:
cls._check_arr(arr, None)
for c, m in color_mask_pairs:
cls._check_mask(m, None)
temp_arr = deepcopy(arr)
temp_original_color_mask_pairs = deepcopy(original_color_mask_pairs)
temp_color_mask_pairs = deepcopy(color_mask_pairs)
new_arr = merge_operation(
temp_arr, temp_original_color_mask_pairs, temp_color_mask_pairs
)
cls._check_arr(new_arr, merge_operation)
return new_arr
@classmethod
def apply_mask_conversion(
cls, masks: List[np.ndarray], mask_conversion: MaskConversion
) -> List[np.ndarray]:
new_masks = [cls._mask_conversion(m, mask_conversion) for m in masks]
if not isinstance(mask_conversion, NoMaskConversion):
if all(np.array_equal(n, r) for n, r in zip(new_masks, masks)):
raise OperationInconsistencyException(f"no effect. {mask_conversion}")
return new_masks
@classmethod
def _mask_conversion(
cls, mask: np.ndarray, mask_conversion: MaskConversion
) -> np.ndarray:
cls._check_mask(mask, None)
temp_mask = deepcopy(mask)
applied_mask = mask_conversion(temp_mask)
cls._check_mask(applied_mask, mask_conversion)
return applied_mask
@classmethod
def apply_mask_operation(
cls,
arrays: List[np.ndarray],
masks: List[np.ndarray],
mask_operation: MaskOperation,
) -> List[np.ndarray]:
new_arrays = [
cls._apply_mask_operation(a, m, mask_operation)
for a, m in zip(arrays, masks)
]
if all(np.array_equal(n, r) for n, r in zip(new_arrays, arrays)):
raise OperationInconsistencyException(f"no effect. {mask_operation}")
return new_arrays
@classmethod
def _apply_mask_operation(
cls, arr: np.ndarray, mask: np.ndarray, mask_operation: MaskOperation
) -> np.ndarray:
cls._check_arr(arr, None)
cls._check_mask(mask, None)
temp_arr, temp_mask = deepcopy(arr), deepcopy(mask)
applied_arr = mask_operation(temp_arr, temp_mask)
cls._check_arr(applied_arr, mask_operation)
return applied_arr
@staticmethod
def _check_arr(arr: np.ndarray, operation: Optional[UniformOperation]):
# TODO Just for assertion and debug. This function spends some time. Should remove this function at the end of competition?
assert isinstance(arr, np.ndarray), f"operation: {operation}, type: {type(arr)}"
assert arr.dtype == np.uint8, f"operation: {operation}, dtype: {arr.dtype}"
assert arr.size != 0, f"operation: {operation}, operation_result: \n{arr}"
assert (
0 <= np.min(arr) <= np.max(arr) <= 10
), f"operation: {operation}, operation_result: \n{arr}"
assert len(arr.shape) == 2, f"operation: {operation}, operation_result: \n{arr}"
@staticmethod
def _check_mask(
mask: np.ndarray, operation: Union[ColorSelection, MaskConversion, None]
):
# TODO Just for assertion and debug. This function spends some time. Should remove this function at the end of competition?
assert isinstance(
mask, np.ndarray
), f"selection: {operation}, type: {type(mask)}"
assert mask.dtype == bool, f"selection: {operation}, dtype: {mask.dtype}"
assert len(mask.shape) == 2, f"selection: {operation}, result: \n{mask}"
@classmethod
def apply_partition_selection(
cls, arrays: List[np.ndarray], partition_selection: PartitionSelection
) -> List[Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]]:
return [cls._apply_partition_selection(a, partition_selection) for a in arrays]
@classmethod
def _apply_partition_selection(
cls, arr: np.ndarray, partition_selection: PartitionSelection
) -> Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]:
cls._check_arr(arr, None)
temp_arr = deepcopy(arr)
return partition_selection(temp_arr)
@classmethod
def apply_partition_merge_operation(
cls,
arrays: List[np.ndarray],
partitioned_arrays_original_location_masks: List[
Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]
],
partition_merge_operation: PartitionMergeOperation,
):
return [
cls._apply_partition_merge_operation(a, p, partition_merge_operation)
for a, p in zip(arrays, partitioned_arrays_original_location_masks)
]
@classmethod
def _apply_partition_merge_operation(
cls,
arr: np.ndarray,
partitioned_arrays_original_location_masks: Tuple[
List[List[np.ndarray]], List[List[np.ndarray]]
],
partition_merge_operation: PartitionMergeOperation,
):
(
partitioned_arrays,
original_location_masks,
) = partitioned_arrays_original_location_masks
cls._check_arr(arr, None)
temp_arr = deepcopy(arr)
temp_partitioned_arrays = deepcopy(partitioned_arrays)
temp_original_location_masks = deepcopy(original_location_masks)
res_arr = partition_merge_operation(
temp_arr, temp_partitioned_arrays, temp_original_location_masks
)
cls._check_arr(res_arr, partition_merge_operation)
return res_arr
class MLNodeEvaluator(NodeEvaluator):
def __init__(self, pattern: DepthSearchPattern):
self.pattern = pattern
self.features = pickle.load(PathConfig.NODE_EVALUATOR_FEATURES.open(mode="rb"))
self.categorical_features = pickle.load(
PathConfig.NODE_EVALUATOR_CATEGORICAL_FEATURES.open(mode="rb")
)
self.sample_df = pickle.load(
PathConfig.NODE_EVALUATOR_SAMPLE_DF.open(mode="rb")
)
self.model: LGBMClassifier = pickle.load(
PathConfig.NODE_EVALUATOR_MODEL.open(mode="rb")
)
self.model.n_jobs = 1
self.oe: OrdinalEncoder = pickle.load(
PathConfig.NODE_EVALUATOR_ORDINAL_ENCODER.open(mode="rb")
)
def evaluate(self, node: WaitingNode) -> float:
raise NotImplementedError()
def evaluate_nodes(self, nodes: List[WaitingNode]):
if len(nodes) == 0:
return
feature_dicts = [n.evaluation_features() for n in nodes]
feature_dicts = [
{
**{k: v for k, v in d.items() if k in self.features},
**{f: None for f in self.features if f not in d},
}
for d in feature_dicts
]
for d in feature_dicts:
for c_f in self.categorical_features:
d[c_f] = str(d[c_f])
df = DataFrame(columns=self.features)
df = df.append(feature_dicts)
df[self.categorical_features] = self.oe.transform(df[self.categorical_features])
df = df.fillna(-1)
x = df[self.features]
probs = self.model.predict_proba(x)[:, 0]
for n, p in zip(nodes, probs):
n.cache_pred_distance = self._add_cost(p, n.depth())
def _add_cost(self, prob: float, depth: int) -> float:
# Impose penalty. A* like algorithm.
if self.pattern == DepthSearchPattern.BREADTH_FIRST:
return prob ** (1 / (1 + (depth / 1))) + 0.3 * depth
elif self.pattern == DepthSearchPattern.NORMAL:
return prob ** (1 / (1 + (depth / 2))) + 0.1 * depth
elif self.pattern == DepthSearchPattern.DEPTH_FIRST:
return prob
else:
raise NotImplementedError()
@dataclass(frozen=True)
class LinePartition(PartitionSelection):
line_color: Color
def __call__(
self, arr: np.ndarray
) -> Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]:
if arr.size == 1:
raise OperationInconsistencyException("size == 1")
if 1 in arr.shape and len(np.unique(arr)) == 1:
raise OperationInconsistencyException("can not separate")
color_hit: np.ndarray = arr == self.line_color
line_v_indices = np.where(color_hit.all(axis=1))[0]
line_h_indices = np.where(color_hit.all(axis=0))[0]
if len(line_v_indices) == len(line_h_indices) == 0:
raise OperationInconsistencyException("not line found")
if 1 in np.diff(line_v_indices) or 1 in np.diff(line_h_indices):
raise OperationInconsistencyException("line duplicated")
partitioned_arrays = []
partitioned_masks = []
for start_v_i, end_v_i in zip(
[0] + list(line_v_indices + 1), list(line_v_indices) + [arr.shape[0]]
):
if start_v_i == end_v_i:
continue
partitioned_temp_arrays = []
partitioned_temp_masks = []
for start_h_i, end_h_i in zip(
[0] + list(line_h_indices + 1), list(line_h_indices) + [arr.shape[1]]
):
if start_h_i == end_h_i:
continue
partitioned_temp_arrays.append(
arr[start_v_i:end_v_i, start_h_i:end_h_i]
)
mask = np.full_like(arr, fill_value=False, dtype=bool)
mask[start_v_i:end_v_i, start_h_i:end_h_i] = True
partitioned_temp_masks.append(mask)
partitioned_arrays.append(partitioned_temp_arrays)
partitioned_masks.append(partitioned_temp_masks)
return partitioned_arrays, partitioned_masks
@dataclass(frozen=True)
class GeneralizedLinePartition(PartitionSelection):
bg_selection_mode: BackGroundColorSelectionMode
def __call__(
self, arr: np.ndarray
) -> Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]:
if arr.size == 1:
raise OperationInconsistencyException("size == 1")
if 1 in arr.shape and len(np.unique(arr)) == 1:
raise OperationInconsistencyException("can not separate")
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
colors = [Color.of(c) for c in np.unique(arr)]
color_lines = []
for c in colors:
if c == bg:
continue
color_hit: np.ndarray = arr == c
line_v_indices = np.where(color_hit.all(axis=1))[0]
line_h_indices = np.where(color_hit.all(axis=0))[0]
color_lines.append((c, len(line_v_indices) + len(line_h_indices)))
if len(color_lines) == 0:
raise OperationInconsistencyException("not colored")
target_color = max(color_lines, key=itemgetter(1))[0]
return LinePartition(target_color)(arr)
@dataclass(frozen=True)
class IntegerDivisionPartition(PartitionSelection):
axis: Axis
n_split: int
def __call__(
self, arr: np.ndarray
) -> Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]:
if self.axis == Axis.HORIZONTAL:
if arr.shape[1] % self.n_split != 0:
raise OperationInconsistencyException("can not divide")
masks = []
partition_len = arr.shape[1] // self.n_split
for i in range(self.n_split):
mask = np.full_like(arr, fill_value=False, dtype=bool)
start_i, end_i = i * partition_len, (i + 1) * partition_len
mask[:, start_i:end_i] = True
masks.append(mask)
masks = [masks]
partitioned_arrays = np.split(arr, self.n_split, axis=1)
partitioned_arrays = [partitioned_arrays]
elif self.axis == Axis.VERTICAL:
if arr.shape[0] % self.n_split != 0:
raise OperationInconsistencyException("can not divide")
masks = []
partition_len = arr.shape[0] // self.n_split
for i in range(self.n_split):
mask = np.full_like(arr, fill_value=False, dtype=bool)
start_i, end_i = i * partition_len, (i + 1) * partition_len
mask[start_i:end_i, :] = True
masks.append(mask)
masks = [[m] for m in masks]
partitioned_arrays = np.split(arr, self.n_split, axis=0)
partitioned_arrays = [[a] for a in partitioned_arrays]
elif self.axis == Axis.BOTH:
if arr.shape[0] % self.n_split != 0 or arr.shape[1] % self.n_split != 0:
raise OperationInconsistencyException("can not divide")
masks = []
v_partition_len = arr.shape[0] // self.n_split
h_partition_len = arr.shape[1] // self.n_split
for i in range(self.n_split):
temp_masks = []
v_start_i, v_end_i = i * v_partition_len, (i + 1) * v_partition_len
for j in range(self.n_split):
mask = np.full_like(arr, fill_value=False, dtype=bool)
h_start_i, h_end_i = j * h_partition_len, (j + 1) * h_partition_len
mask[v_start_i:v_end_i, h_start_i:h_end_i] = True
temp_masks.append(mask)
masks.append(temp_masks)
partitioned_arrays = np.split(arr, self.n_split, axis=0)
partitioned_arrays = [
np.split(a, self.n_split, axis=1) for a in partitioned_arrays
]
else:
raise NotImplementedError()
return partitioned_arrays, masks
@dataclass(frozen=True)
class ColorNumIntegerDivisionPartition(PartitionSelection):
axis: Axis
def __call__(
self, arr: np.ndarray
) -> Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]:
color_num = len(np.unique(arr))
color_num = color_num - 1 # bg
if color_num == 0:
raise OperationInconsistencyException("not colored")
return IntegerDivisionPartition(self.axis, color_num)(arr)
@dataclass
class RandomNodeTreeCreateEngine:
MAX_NODE = 30000
timeout_sec: int = 30
node_evaluator = RandomNodeEvaluator()
def search(self, task: Task, verbose: bool = False) -> List[NodeTree]:
task_feature = TaskFeature.of(task)
root_node = UniformOperationCompletedNode(
None, task, task_feature, OperationSet([])
)
first_waiting_nodes = CompletedNodeProcessor.process(root_node)
self.node_evaluator.evaluate_nodes(first_waiting_nodes)
pq = PriorityQueue([*first_waiting_nodes])
if verbose:
print("first pq nodes")
for n in pq.sorted_list():
print(f"cost: {n.cache_pred_distance}, {n}")
with Timer() as timer:
for node_i in range(self.MAX_NODE):
if len(pq) == 0:
# TODO What's the right thing to do?
raise NotImplementedError()
waiting_node = pq.pop_min()
completed_node = WaitingNodeProcessor().process(waiting_node)
if completed_node is None:
if verbose:
print("skipped")
continue
waiting_new_nodes = CompletedNodeProcessor.process(completed_node)
self.node_evaluator.evaluate_nodes(waiting_new_nodes)
for n in waiting_new_nodes:
pq.push(n)
if timer.second() > self.timeout_sec:
break
return [
NodeTree.of(waiting_node.parent_completed_node) for waiting_node in pq.heap
]
@dataclass(frozen=True)
class AnySelectionMerge(PartitionMergeOperation):
bg_selection_mode: BackGroundColorSelectionMode
fill_color: Color
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
shape = partitioned_arrays[0][0].shape
if not all(a.shape == shape for h_a in partitioned_arrays for a in h_a):
raise OperationInconsistencyException("not same shape")
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
result_mask = np.full_like(
partitioned_arrays[0][0], fill_value=False, dtype=bool
)
for horizontal_arrays in partitioned_arrays:
for a in horizontal_arrays:
result_mask[a != bg] = True
result_arr = np.full_like(partitioned_arrays[0][0], fill_value=bg)
result_arr[result_mask] = self.fill_color
return result_arr
@dataclass(frozen=True)
class NotSelectionMerge(PartitionMergeOperation):
bg_selection_mode: BackGroundColorSelectionMode
fill_color: Color
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
shape = partitioned_arrays[0][0].shape
if not all(a.shape == shape for h_a in partitioned_arrays for a in h_a):
raise OperationInconsistencyException("not same shape")
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
result_mask = np.full_like(
partitioned_arrays[0][0], fill_value=True, dtype=bool
)
for horizontal_arrays in partitioned_arrays:
for a in horizontal_arrays:
result_mask[a != bg] = False
result_arr = np.full_like(partitioned_arrays[0][0], fill_value=bg)
result_arr[result_mask] = self.fill_color
return result_arr
@dataclass(frozen=True)
class AllSelectionMerge(PartitionMergeOperation):
bg_selection_mode: BackGroundColorSelectionMode
fill_color: Color
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
shape = partitioned_arrays[0][0].shape
if not all(a.shape == shape for h_a in partitioned_arrays for a in h_a):
raise OperationInconsistencyException("not same shape")
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
result_mask = np.full_like(
partitioned_arrays[0][0], fill_value=True, dtype=bool
)
for horizontal_arrays in partitioned_arrays:
for a in horizontal_arrays:
result_mask[a == bg] = False
result_arr = np.full_like(partitioned_arrays[0][0], fill_value=bg)
result_arr[result_mask] = self.fill_color
return result_arr
@dataclass(frozen=True)
class ModifiedXorSelectionMerge(PartitionMergeOperation):
bg_selection_mode: BackGroundColorSelectionMode
fill_color: Color
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
shape = partitioned_arrays[0][0].shape
if not all(a.shape == shape for h_a in partitioned_arrays for a in h_a):
raise OperationInconsistencyException("not same shape")
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
any_result_mask = np.full_like(
partitioned_arrays[0][0], fill_value=False, dtype=bool
)
for horizontal_arrays in partitioned_arrays:
for a in horizontal_arrays:
any_result_mask[a != bg] = True
all_result_mask = np.full_like(
partitioned_arrays[0][0], fill_value=True, dtype=bool
)
for horizontal_arrays in partitioned_arrays:
for a in horizontal_arrays:
all_result_mask[a == bg] = False
# modified xor
result_mask = any_result_mask
result_mask[all_result_mask] = False
result_arr = np.full_like(partitioned_arrays[0][0], fill_value=bg)
result_arr[result_mask] = self.fill_color
return result_arr
@dataclass(frozen=True)
class NaturalArrayOrderedOverrideMerge(PartitionMergeOperation):
bg_selection_mode: BackGroundColorSelectionMode
start_corner: Corner
first_axis: Axis
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
shape = partitioned_arrays[0][0].shape
if not all(a.shape == shape for h_a in partitioned_arrays for a in h_a):
raise OperationInconsistencyException("not same shape")
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
result_arr = np.full_like(partitioned_arrays[0][0], fill_value=bg)
h, w = len(partitioned_arrays), len(partitioned_arrays[0])
for i, j in self.natural_array(h, w, self.start_corner, self.first_axis):
array = partitioned_arrays[i][j]
result_arr[array != bg] = array[array != bg]
return result_arr
def natural_array(
self, h: int, w: int, start_corner: Corner, first_axis: Axis
) -> List[Tuple[int, int]]:
start_ind = get_index(start_corner, h, w)
vertical_start_ind, horizontal_start_ind = start_ind
vertical_end_ind = h - 1 if vertical_start_ind == 0 else 0
horizontal_end_ind = w - 1 if horizontal_start_ind == 0 else 0
vertical_step = +1 if vertical_start_ind == 0 else -1
horizontal_step = +1 if horizontal_start_ind == 0 else -1
index_orders = []
if first_axis == Axis.HORIZONTAL:
for i in range_closed(vertical_start_ind, vertical_end_ind, vertical_step):
for j in range_closed(
horizontal_start_ind, horizontal_end_ind, horizontal_step
):
index_orders.append((i, j))
elif first_axis == Axis.VERTICAL:
for j in range_closed(
horizontal_start_ind, horizontal_end_ind, horizontal_step
):
for i in range_closed(
vertical_start_ind, vertical_end_ind, vertical_step
):
index_orders.append((i, j))
else:
raise NotImplementedError()
assert len(set(index_orders)) == len(index_orders) == h * w, index_orders
return index_orders
@dataclass(frozen=True)
class DiagonalArrayOrderedOverrideMerge(PartitionMergeOperation):
bg_selection_mode: BackGroundColorSelectionMode
start_corner: Corner
first_axis: Axis
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
shape = partitioned_arrays[0][0].shape
if not all(a.shape == shape for h_a in partitioned_arrays for a in h_a):
raise OperationInconsistencyException("not same shape")
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
result_arr = np.full_like(partitioned_arrays[0][0], fill_value=bg)
h, w = len(partitioned_arrays), len(partitioned_arrays[0])
for i, j in self.diagonal_array(h, w, self.start_corner, self.first_axis):
array = partitioned_arrays[i][j]
result_arr[array != bg] = array[array != bg]
return result_arr
def diagonal_array(
self, h: int, w: int, start_corner: Corner, first_axis: Axis
) -> List[Tuple[int, int]]:
start_ind = get_index(start_corner, h, w)
vertical_start_ind, horizontal_start_ind = start_ind
vertical_end_ind = h - 1 if vertical_start_ind == 0 else 0
horizontal_end_ind = w - 1 if horizontal_start_ind == 0 else 0
vertical_step = +1 if vertical_start_ind == 0 else -1
horizontal_step = +1 if horizontal_start_ind == 0 else -1
index_orders = []
if first_axis == Axis.HORIZONTAL:
for i in range_closed(vertical_start_ind, vertical_end_ind, vertical_step):
for h_num, j in enumerate(
range_closed(
horizontal_start_ind, horizontal_end_ind, horizontal_step
)
):
index_orders.append(((i + h_num) % h, j))
elif first_axis == Axis.VERTICAL:
for j in range_closed(
horizontal_start_ind, horizontal_end_ind, horizontal_step
):
for v_num, i in enumerate(
range_closed(vertical_start_ind, vertical_end_ind, vertical_step)
):
index_orders.append((i, (j + v_num) % w))
else:
raise NotImplementedError()
assert len(set(index_orders)) == len(index_orders) == h * w, index_orders
return index_orders
@dataclass(frozen=True)
class SpiralArrayOrderedOverrideMerge(PartitionMergeOperation):
bg_selection_mode: BackGroundColorSelectionMode
start_corner: Corner
spiral_direction: SpiralDirection
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
shape = partitioned_arrays[0][0].shape
if not all(a.shape == shape for h_a in partitioned_arrays for a in h_a):
raise OperationInconsistencyException("not same shape")
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
result_arr = np.full_like(partitioned_arrays[0][0], fill_value=bg)
h, w = len(partitioned_arrays), len(partitioned_arrays[0])
for i, j in self.spiral(h, w, self.start_corner, self.spiral_direction):
array = partitioned_arrays[i][j]
result_arr[array != bg] = array[array != bg]
return result_arr
def spiral(
self, h: int, w: int, start_corner: Corner, spiral_direction: SpiralDirection
) -> List[Tuple[int, int]]:
start_ind = get_index(start_corner, h, w)
index_orders = [start_ind]
current_ind = start_ind
while True:
if (
start_corner in [Corner.TOP_LEFT, Corner.TOP_RIGHT, Corner.BOTTOM_RIGHT]
and spiral_direction == SpiralDirection.CLOCKWISE
) or (
start_corner == Corner.BOTTOM_LEFT
and spiral_direction == SpiralDirection.ANTICLOCKWISE
):
if valid_index(
(current_ind[0], current_ind[1] + 1), h, w, index_orders
):
direction = Direction.RIGHT
elif valid_index(
(current_ind[0] + 1, current_ind[1]), h, w, index_orders
):
direction = Direction.BOTTOM
elif valid_index(
(current_ind[0], current_ind[1] - 1), h, w, index_orders
):
direction = Direction.LEFT
elif valid_index(
(current_ind[0] - 1, current_ind[1]), h, w, index_orders
):
direction = Direction.TOP
else:
break
else:
if valid_index(
(current_ind[0] - 1, current_ind[1]), h, w, index_orders
):
direction = Direction.TOP
elif valid_index(
(current_ind[0], current_ind[1] - 1), h, w, index_orders
):
direction = Direction.LEFT
elif valid_index(
(current_ind[0] + 1, current_ind[1]), h, w, index_orders
):
direction = Direction.BOTTOM
elif valid_index(
(current_ind[0], current_ind[1] + 1), h, w, index_orders
):
direction = Direction.RIGHT
else:
break
while True:
if direction == Direction.RIGHT:
next_ind = (current_ind[0], current_ind[1] + 1)
elif direction == Direction.BOTTOM:
next_ind = (current_ind[0] + 1, current_ind[1])
elif direction == Direction.LEFT:
next_ind = (current_ind[0], current_ind[1] - 1)
elif direction == Direction.TOP:
next_ind = (current_ind[0] - 1, current_ind[1])
else:
raise NotImplementedError()
if valid_index(next_ind, h, w, index_orders):
index_orders.append(next_ind)
current_ind = next_ind
else:
break
assert len(set(index_orders)) == len(index_orders) == h * w, index_orders
return index_orders
@dataclass(frozen=True)
class UniquelySelectedArrayExtraction(PartitionMergeOperation):
array_selection: PartitionedArraySelection
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
selections = self.array_selection(arr, partitioned_arrays)
results = []
for h_arrays, h_flags in zip(partitioned_arrays, selections):
for array, flag in zip(h_arrays, h_flags):
if flag:
results.append(array)
if len(set(map(lambda a: a.tostring(), results))) == 1:
return results[0]
else:
raise OperationInconsistencyException("not unique")
@dataclass(frozen=True)
class RestoreOnlySelectedArray(PartitionMergeOperation):
bg_selection_mode: BackGroundColorSelectionMode
array_selection: PartitionedArraySelection
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
selections = self.array_selection(arr, partitioned_arrays)
for h_arrays, h_flags, h_locations in zip(
partitioned_arrays, selections, original_location_masks
):
for array, flag, location in zip(h_arrays, h_flags, h_locations):
if flag:
arr[location] = array.ravel()
else:
arr[location] = bg
return arr
@dataclass(frozen=True)
class ExtractOneValueFromPartitionedArray(PartitionMergeOperation):
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
h, w = len(partitioned_arrays), len(partitioned_arrays[0])
result_arr = np.zeros_like(partitioned_arrays[0][0], shape=(h, w))
for i, j in product(range(h), range(w)):
array = partitioned_arrays[i][j]
extracted_value = ColorSelectionUtil().select_single_color(
array, SingleColorSelectionMode.MOST_COMMON
)
result_arr[i][j] = extracted_value
return result_arr
def range_closed(start, stop, step):
direction = 1 if (step > 0) else -1
return range(start, stop + direction, step)
def get_index(corner: Corner, h: int, w: int) -> Tuple[int, int]:
if corner == Corner.TOP_LEFT:
return 0, 0
elif corner == Corner.TOP_RIGHT:
return 0, w - 1
elif corner == Corner.BOTTOM_RIGHT:
return h - 1, w - 1
elif corner == Corner.BOTTOM_LEFT:
return h - 1, 0
else:
raise NotImplementedError()
def valid_index(
ind2d: Tuple[int, int], h: int, w: int, black_list: List[Tuple[int, int]]
) -> bool:
if ind2d in black_list:
return False
if ind2d[0] < 0 or h <= ind2d[0]:
return False
if ind2d[1] < 0 or w <= ind2d[1]:
return False
return True
def save_ml_training_data(task: Task, verbose: bool = False):
# 正解データ
correct_node_trees, exception, _ = NodeBaseSearchEngine(answer_limit_num=60).search(
task, verbose
)
print("search engine end")
if exception is not None:
print("answer not found")
return
correct_node_trees = [
t
for t in correct_node_trees
if AnswerMatcher.is_train_test_all_match_if_operated(task, t.to_operation_set())
]
if len(correct_node_trees) == 0:
print("answer not found")
return
correct_waiting_nodes = list(
chain.from_iterable([t.waiting_nodes() for t in correct_node_trees])
)
correct_feature_dicts = [n.evaluation_features() for n in correct_waiting_nodes]
correct_feature_dict_tuples = set(
tuple(sorted(d.items())) for d in correct_feature_dicts
)
correct_df = DataFrame(dict(t) for t in correct_feature_dict_tuples)
# 不正解データ
trees = RandomNodeTreeCreateEngine(timeout_sec=120).search(task, verbose)
print("random tree generated")
waiting_nodes = list(chain.from_iterable([t.waiting_nodes() for t in trees]))
feature_dicts = [n.evaluation_features() for n in waiting_nodes]
feature_dict_tuples = set(tuple(sorted(d.items())) for d in feature_dicts)
feature_dict_tuples = feature_dict_tuples - correct_feature_dict_tuples
wrong_df = DataFrame(dict(t) for t in feature_dict_tuples)
# ラベル付け
correct_df["label"] = 1
wrong_df["label"] = 0
all_df = correct_df.append(wrong_df, sort=False)
PathConfig.LABELED_TRAINING_DATA_ROOT.mkdir(parents=True, exist_ok=True)
pickle.dump(
all_df,
(PathConfig.LABELED_TRAINING_DATA_ROOT / f"{task.name}.pkl").open(mode="wb"),
)
print("save")
def train_ml():
x, y, feature_columns, categorical_features = prepare_train_data()
train_lgbm(x, y, feature_columns, categorical_features)
def prepare_train_data():
dfs = []
for pickle_path in PathConfig.LABELED_TRAINING_DATA_ROOT.iterdir():
print(pickle_path)
dfs.append(pickle.load((pickle_path.open(mode="rb"))))
all_df = pd.concat(dfs, ignore_index=True, sort=False)
print(
f'label1: {len(all_df[all_df["label"] == 1])}_label0: {len(all_df[all_df["label"] == 0])}'
)
# TODO Should we not use dsl properties(too detailed) features?
not_used_feature_columns = {
"label",
"depth",
"color",
"angle",
"direction",
"multi_color_selection_mode",
"single_color_selection_mode",
"edge_type",
"fill_type",
"flip_mode",
"k",
"ratio",
"padding_mode",
}
feature_columns = sorted(set(all_df.columns) - not_used_feature_columns)
all_df = all_df[feature_columns + ["label"]]
# process categorical
categorical_features = list(
filter(
lambda s: s in feature_columns,
map(str, all_df.select_dtypes(include="object").columns),
)
)
for c_f in categorical_features:
all_df[c_f] = all_df[c_f].fillna("None")
all_df[c_f] = all_df[c_f].apply(str)
# all_df[c_f] = all_df[c_f].astype(str)
# all_df[c_f] = all_df[c_f].apply(lambda v: str(v))
# all_df[c_f] = all_df[c_f].astype('category')
oe = category_encoders.OrdinalEncoder()
all_df[categorical_features] = oe.fit_transform(all_df[categorical_features])
# oe = category_encoders.OneHotEncoder(cols=[categorical_features])
# all_df = oe.fit_transform(all_df)
# all_df = all_df.fillna(-1)
# Relabel 0-labeled data in the neighborhood of 1 to 1
print("relabelling")
small_is_better_features = [
"mean_diff_color_cell_ratio",
"mean_excess_color_num",
"mean_lack_color_num",
"mean_horizontal_diff_input_arr_line_num",
"mean_horizontal_diff_output_arr_line_num",
"mean_horizontal_edge_sum_diff",
"mean_horizontal_edge_sum_diff_ratio",
"mean_vertical_diff_input_arr_line_num",
"mean_vertical_diff_output_arr_line_num",
"mean_vertical_edge_sum_diff",
"mean_vertical_edge_sum_diff_ratio",
]
for index, r in tqdm(all_df[all_df["label"] == 1].iterrows()):
temp_feature = sorted(set(feature_columns) - set(small_is_better_features))
near_rows = all_df[(all_df[temp_feature] == r[temp_feature]).all(axis=1)]
can_label_1 = near_rows[
(near_rows[small_is_better_features] <= r[small_is_better_features]).all(
axis=1
)
]
all_df.loc[can_label_1.index.values, "label"] = 1
print(
f'label1: {len(all_df[all_df["label"] == 1])}_label0: {len(all_df[all_df["label"] == 0])}'
)
print(f"feature_columns:")
for f in feature_columns:
print(f)
x = all_df[feature_columns]
y = all_df["label"]
print(f"len(x): {len(x)}, 1_labelled_len: {len(y[y == 1])}")
# x, y = RandomUnderSampler(sampling_strategy=0.01).fit_resample(x, y)
# x, y = EditedNearestNeighbours(sampling_strategy=0.01, n_jobs=RunConfig.N_JOB).fit_resample(x, y)
print(f"len(x): {len(x)}, 1_labelled_len: {len(y[y == 1])}")
# visualize
# scaled_x = StandardScaler().fit_transform(x)
# x_reduced = PCA(n_components=2).fit_transform(scaled_x)
# plt.scatter(x_reduced[y == 1, 0], x_reduced[y == 1, 1], alpha=0.1)
# plt.scatter(x_reduced[:, 0], x_reduced[:, 1], c=y, alpha=0.1)
# plt.show()
# plt.close()
pickle.dump(all_df, PathConfig.NODE_EVALUATOR_SAMPLE_DF.open(mode="wb"))
pickle.dump(oe, PathConfig.NODE_EVALUATOR_ORDINAL_ENCODER.open(mode="wb"))
pickle.dump(feature_columns, PathConfig.NODE_EVALUATOR_FEATURES.open(mode="wb"))
pickle.dump(
categorical_features,
PathConfig.NODE_EVALUATOR_CATEGORICAL_FEATURES.open(mode="wb"),
)
return x, y, feature_columns, categorical_features
def train_lg(feature_columns, x, y):
model = LogisticRegression(class_weight="balanced", n_jobs=RunConfig.N_JOB)
model.fit(x, y)
pred_y = model.predict_proba(x)
print(pred_y)
# cb = CatBoostClassifier(loss_function='Logloss', class_weights=[0.1, 1], cat_features=categorical_features)
# cb.fit(x, y)
# pred_y = cb.predict_proba(x)
PathConfig.SAVED_MODEL.mkdir(parents=True, exist_ok=True)
pickle.dump(model, PathConfig.NODE_EVALUATOR_MODEL.open(mode="wb"))
del model
print(x)
print(y)
print(pred_y)
# cb = CatBoostClassifier()
# cb.load_model(str(PathConfig.NODE_EVALUATOR_MODEL), format="cbm")
model = pickle.load(PathConfig.NODE_EVALUATOR_MODEL.open(mode="rb"))
pred_y = model.predict_proba(x)
print(pred_y)
coefs = np.abs(model.coef_[0])
for c, f in zip(coefs, feature_columns):
print(f"{f}_{c}")
def train_lgbm(x, y, feature_columns, categorical_features):
lgbm_params = {
"silent": False,
"n_jobs": RunConfig.N_JOB,
"class_weight": "balanced",
"max_depth": 3,
"learning_rate": 0.2,
}
best_iterations = []
folds = KFold(shuffle=False, n_splits=3)
for n_fold, (train_index, valid_index) in enumerate(folds.split(x, y)):
train_x, train_y = x.iloc[train_index], y.iloc[train_index]
valid_x, valid_y = x.iloc[valid_index], y.iloc[valid_index]
model = LGBMClassifier(n_estimators=1000, **lgbm_params)
model.fit(
train_x,
train_y,
eval_set=[(valid_x, valid_y), (train_x, train_y)],
early_stopping_rounds=10,
categorical_feature=categorical_features,
verbose=True,
)
best_iterations.append(model.best_iteration_)
print(best_iterations)
model = LGBMClassifier(n_estimators=min(best_iterations), **lgbm_params)
model.fit(x, y, verbose=True, categorical_feature=categorical_features)
pred_y = model.predict_proba(x)
print(pred_y)
PathConfig.SAVED_MODEL.mkdir(parents=True, exist_ok=True)
pickle.dump(model, PathConfig.NODE_EVALUATOR_MODEL.open(mode="wb"))
del model
print(x)
print(y)
print(pred_y)
model = pickle.load(PathConfig.NODE_EVALUATOR_MODEL.open(mode="rb"))
pred_y = model.predict_proba(x)
print(pred_y)
importance = pd.DataFrame(
model.feature_importances_, index=feature_columns, columns=["importance"]
)
print(importance)
def train_test_model(feature_columns, x, y):
try_cv = False
if try_cv:
folds = KFold(shuffle=True)
for n_fold, (train_index, valid_index) in enumerate(folds.split(x, y)):
train_x, train_y = x.iloc[train_index], y.iloc[train_index]
valid_x, valid_y = x.iloc[valid_index], y.iloc[valid_index]
model = LGBMClassifier(
class_weight="balanced",
learning_rate=0.2,
n_jobs=RunConfig.N_JOB,
n_estimators=1000,
silent=False,
)
model.fit(
train_x,
train_y,
eval_set=[(valid_x, valid_y), (train_x, train_y)],
early_stopping_rounds=10,
verbose=True,
)
# model = MLPClassifier(hidden_layer_sizes=(20, 20, 10))
model = RidgeClassifier(class_weight="balanced")
# model = LinearSVC(class_weight='balanced')
# model = LGBMClassifier(class_weight='balanced', learning_rate=0.2, n_estimators=50,
# silent=False)
model.fit(x, y)
pred_y = model.predict(x)
print(pred_y)
PathConfig.SAVED_MODEL.mkdir(parents=True, exist_ok=True)
pickle.dump(model, PathConfig.NODE_EVALUATOR_MODEL.open(mode="wb"))
del model
print(x)
print(y)
print(pred_y)
model = pickle.load(PathConfig.NODE_EVALUATOR_MODEL.open(mode="rb"))
pred_y = model.predict_proba(x)
print(pred_y)
importance = pd.DataFrame(
model.feature_importances_, index=feature_columns, columns=["importance"]
)
print(importance)
CATEGORIES = [
"PARTITION",
"SYMMETRY",
"REPEAT",
"DENOISE",
"SIMPLIFICATION",
"NUMBER",
"RANKING",
"SHAPE",
"FIND_FIT",
"LINE",
"OBJECT_TRANSFORM",
"OBJECT_MOVE",
"JIGSAW_PUZZLE",
"COLOR",
"PASTE",
"GUIDE",
"META",
"OTHERS",
"ONCE_ANSWERED",
]
GIVE_UPS = [
"SYMMETRY",
"REPEAT",
"DENOISE",
"SIMPLIFICATION",
"NUMBER",
"RANKING",
"SHAPE",
"FIND_FIT",
"OBJECT_MOVE",
"JIGSAW_PUZZLE",
"COLOR",
"PASTE",
"GUIDE",
"META",
]
class TaskTaxonomy:
def __init__(self):
with open(str(PathConfig.OPERATION_ANSWER_TAXONOMY_YAML), "r") as f:
yaml_dict = yaml.load(f, Loader=yaml.Loader)
self.trains: Dict[str, List[str]] = yaml_dict["1_train"]
self.evals: Dict[str, List[str]] = yaml_dict["2_eval"]
self.check()
def check(self):
assert len(self.trains) == len(self.evals) == 400
for task_name, categories in {**self.trains, **self.evals}.items():
assert len(categories) == len(set(categories))
for category in categories:
assert category in CATEGORIES, category
json_task_names = {
path.stem
for path in chain.from_iterable(
[PathConfig.TRAIN_ROOT.iterdir(), PathConfig.EVALUATION_ROOT.iterdir()]
)
}
df_task_names = set(list(self.trains.keys()) + list(self.evals.keys()))
assert json_task_names - df_task_names == set(), json_task_names - df_task_names
assert df_task_names - json_task_names == set(), df_task_names - json_task_names
def show_stats(self):
print("=== train stats ====")
for c in CATEGORIES:
num = len(list(filter(lambda v: c in v, self.trains.values())))
print(f"{c}: {num}")
print("\n=== eval stats ====")
for c in CATEGORIES:
num = len(list(filter(lambda v: c in v, self.evals.values())))
print(f"{c}: {num}")
def save_yaml(self):
self.check()
with open(str(PathConfig.OPERATION_ANSWER_TAXONOMY_YAML), "w") as f:
yaml.dump({"1_train": self.trains, "2_eval": self.evals}, f)
def save_categorized_fig(self):
# from abstraction_and_reasoning_challenge.src.loader.task_loader import TaskLoader # TODO fix local import?
shutil.rmtree(PathConfig.OPERATION_ANSWER_TAXONOMY_IMAGE_ROOT)
for (task_name, categories), tag in tqdm(
list(
zip(
list(self.trains.items()) + list(self.evals.items()),
["train"] * len(self.trains) + ["evals"] * len(self.evals),
)
)
):
if categories == []:
task = TaskLoader().get_task(task_name)
plot_task(
task,
show=False,
save_path=PathConfig.OPERATION_ANSWER_TAXONOMY_IMAGE_ROOT
/ tag
/ "not_categorized"
/ f"{task_name}.png",
)
for c in categories:
task = TaskLoader().get_task(task_name)
plot_task(
task,
show=False,
save_path=PathConfig.OPERATION_ANSWER_TAXONOMY_IMAGE_ROOT
/ tag
/ c
/ f"{task_name}.png",
)
def get_give_up_task_names(self) -> List[str]:
can_answers = self.get_can_answer_task_names()
give_up_task_names = []
for task_name, categories in {**self.trains, **self.evals}.items():
if task_name in can_answers:
continue
for c in categories:
if c in GIVE_UPS:
give_up_task_names.append(task_name)
break
return give_up_task_names
def get_can_answer_task_names(self) -> List[str]:
return [
task_name
for task_name, categories in {**self.trains, **self.evals}.items()
if "ONCE_ANSWERED" in categories
]
def filter_tasks(self, tasks: List[Task]) -> List[Task]:
if RunConfig.TASK_RANGE == TaskRange.ALL:
return tasks
elif RunConfig.TASK_RANGE == TaskRange.EXCLUDE_GIVE_UPS:
return list(
filter(lambda t: t.name not in self.get_give_up_task_names(), tasks)
)
elif RunConfig.TASK_RANGE == TaskRange.CAN_ANSWER_ONLY:
return list(
filter(lambda t: t.name in self.get_can_answer_task_names(), tasks)
)
else:
raise NotImplementedError()
def get_engine(engine_type: EngineType):
if engine_type == EngineType.NODE_BASED_SEARCH_ENGINE:
return NodeBaseSearchEngine()
elif engine_type == EngineType.TREE_BASED_SEARCH_ENGINE:
return TreeBaseSearchEngine()
else:
raise NotImplementedError()
def run():
if debug_run():
return
initialize_path()
if RunConfig.RUN_MODE == RunMode.LOCAL_RUN:
load_answer_storage() # debug validate
tt = TaskTaxonomy()
solve_tasks(
tt.filter_tasks(TaskLoader().get_training_tasks()),
AllParameter(),
output_summary_path=PathConfig.OPERATION_ANSWER_MEMO_ROOT
/ "answer_summary_train.txt",
copy_wrong_answers_root_tag="train",
add_answer_storage=True,
save_submission=True,
)
solve_tasks(
tt.filter_tasks(TaskLoader().get_evaluation_tasks()),
AllParameter(),
output_summary_path=PathConfig.OPERATION_ANSWER_MEMO_ROOT
/ "answer_summary_eval.txt",
copy_wrong_answers_root_tag="eval",
add_answer_storage=False,
save_submission=False,
)
elif RunConfig.RUN_MODE == RunMode.LOCAL_RUN_ALL:
solve_tasks(
TaskLoader().get_training_tasks(),
AllParameter(),
output_summary_path=PathConfig.OPERATION_ANSWER_MEMO_ROOT
/ "answer_summary_train.txt",
copy_wrong_answers_root_tag="train",
add_answer_storage=True,
save_submission=True,
)
solve_tasks(
TaskLoader().get_evaluation_tasks(),
AllParameter(),
output_summary_path=PathConfig.OPERATION_ANSWER_MEMO_ROOT
/ "answer_summary_eval.txt",
copy_wrong_answers_root_tag="eval",
add_answer_storage=False,
save_submission=False,
)
solve_tasks(TaskLoader().get_test_tasks(), AllParameter(), save_submission=True)
elif RunConfig.RUN_MODE == RunMode.KERNEL_EMULATION:
solve_tasks(TaskLoader().get_test_tasks(), AllParameter(), save_submission=True)
elif RunConfig.RUN_MODE == RunMode.NODE_BASE_SEARCH_OPTIMIZATION:
optimize_node_base_search(TaskLoader().get_training_tasks())
elif RunConfig.RUN_MODE == RunMode.TREE_BASE_SEARCH_OPTIMIZATION:
optimize_tree_base_search(TaskLoader().get_training_tasks())
elif RunConfig.RUN_MODE == RunMode.LOCAL_DATA_GENERATION:
for t in TaskLoader().get_training_tasks():
print(t.name)
save_ml_training_data(t)
elif RunConfig.RUN_MODE == RunMode.LOCAL_ML_TRAIN:
train_ml()
elif RunConfig.RUN_MODE == RunMode.TRAIN_OPERATION_ELEMENT_INCLUSION_PREDICTION:
train_operation_element_inclusion_prediction()
elif RunConfig.RUN_MODE == RunMode.KERNEL:
if RunConfig.RUN_ONLY_PRIVATE_LB and not TaskLoader().is_private_lb_run():
print("This is kernel public run. Skipped.")
shutil.copy(
str(KernelPathConfig.SAMPLE_SUBMISSION), KernelPathConfig.SUBMISSION
)
return
else:
print("This is private private run. Not skipped.")
solve_tasks(
TaskLoader().get_test_tasks(), AllParameter(), save_submission=True
)
else:
raise ValueError(RunConfig.RUN_MODE)
print("end")
def debug_run():
print("start")
if DebugConfig.OPERATION_DEBUG_TASK_NAME:
operation_set = str_to_operation_set(DebugConfig.OPERATION_DEBUG_OPERATION_SET)
print(operation_set)
task = TaskLoader().get_task(DebugConfig.OPERATION_DEBUG_TASK_NAME)
applied_task = TaskOperationSetExecutor().execute(task, operation_set)
original_task_feature = create_task_feature(task, task)
applied_task_feature = create_task_feature(task, applied_task)
original_df = DataFrame(asdict(original_task_feature), index=["index"]).T
applied_df = DataFrame(asdict(applied_task_feature), index=["index"]).T
merged_feature_df = pd.merge(
original_df,
applied_df,
left_index=True,
right_index=True,
suffixes=["original_", "appplied_"],
)
original_waiting_node = ColorSelectionWaitingNode(
None,
task,
task,
original_task_feature,
OperationSet([]),
MultiColorSelection(MultiColorSelectionMode.ANY_WITHOUT_MOST_COMMON),
)
# original_waiting_node2 = MaskConversionWaitingNode(None, None, task, original_task_feature, OperationSet([]), SingleColorSelection(SingleColorSelectionMode.LEAST_COMMON))
applied_waiting_node = ColorSelectionWaitingNode(
None,
task,
applied_task,
applied_task_feature,
operation_set,
MultiColorSelection(MultiColorSelectionMode.ANY_WITHOUT_MOST_COMMON),
)
print(merged_feature_df)
print("distance")
print(
DistanceEvaluator(DistanceEvaluatorParameter()).evaluate_task_feature(
original_task_feature
)
)
print(
DistanceEvaluator(DistanceEvaluatorParameter()).evaluate_task_feature(
applied_task_feature
)
)
print("breadth cost")
HandMadeNodeEvaluator(
DepthSearchPattern.BREADTH_FIRST,
defaultdict(lambda: 1),
NodeBaseSearchEngineParameter(),
DistanceEvaluatorParameter(),
).evaluate_nodes([original_waiting_node, original_waiting_node])
HandMadeNodeEvaluator(
DepthSearchPattern.BREADTH_FIRST,
defaultdict(lambda: 1),
NodeBaseSearchEngineParameter(),
DistanceEvaluatorParameter(),
).evaluate_nodes([original_waiting_node, applied_waiting_node])
print(original_waiting_node.cache_pred_distance)
print(applied_waiting_node.cache_pred_distance)
print("normal cost")
HandMadeNodeEvaluator(
DepthSearchPattern.NORMAL,
defaultdict(lambda: 1),
NodeBaseSearchEngineParameter(),
DistanceEvaluatorParameter(),
).evaluate_nodes([original_waiting_node, original_waiting_node])
HandMadeNodeEvaluator(
DepthSearchPattern.NORMAL,
defaultdict(lambda: 1),
NodeBaseSearchEngineParameter(),
DistanceEvaluatorParameter(),
).evaluate_nodes([original_waiting_node, applied_waiting_node])
print(original_waiting_node.cache_pred_distance)
print(applied_waiting_node.cache_pred_distance)
print("depth cost")
HandMadeNodeEvaluator(
DepthSearchPattern.DEPTH_FIRST,
defaultdict(lambda: 1),
NodeBaseSearchEngineParameter(),
DistanceEvaluatorParameter(),
).evaluate_nodes([original_waiting_node, original_waiting_node])
HandMadeNodeEvaluator(
DepthSearchPattern.DEPTH_FIRST,
defaultdict(lambda: 1),
NodeBaseSearchEngineParameter(),
DistanceEvaluatorParameter(),
).evaluate_nodes([original_waiting_node, applied_waiting_node])
print(original_waiting_node.cache_pred_distance)
print(applied_waiting_node.cache_pred_distance)
plot_task_with_operation_set(task, operation_set, show=True, save_path=None)
return True
if DebugConfig.SOLVE_DEBUG_TASK_NAME:
task = TaskLoader().get_task(DebugConfig.SOLVE_DEBUG_TASK_NAME)
engine_result = solve_tasks(
[task], AllParameter(), add_answer_storage=True, verbose=True
)[0]
if isinstance(engine_result, AnsweredSearchResults):
plot_task_with_result_set(task, engine_result, show=True, save_path=None)
return True
if DebugConfig.TRAIN_DATA_GENERATION_DEBUG_TASK_NAME:
task = TaskLoader().get_task(DebugConfig.TRAIN_DATA_GENERATION_DEBUG_TASK_NAME)
save_ml_training_data(task)
train_ml(task)
return True
return False
def performance_run():
# from line_profiler import LineProfiler
# from python_utils.src.library.print_line_profiler import print_stats
# from abstraction_and_reasoning_challenge import run as run_module
# from abstraction_and_reasoning_challenge.src.domain import task_solver
# from abstraction_and_reasoning_challenge.src.domain.search_engine.evaluation_functions import handmade_evaluator
# from abstraction_and_reasoning_challenge.src.domain.search_engine.node import waiting_node
# from abstraction_and_reasoning_challenge.src.domain.search_engine.node_processor import waiting_node_processor
# from abstraction_and_reasoning_challenge.src.domain.feature import task_feature
# from abstraction_and_reasoning_challenge.src.domain.search_engine.engine import node_base_search_engine
# from abstraction_and_reasoning_challenge.src.domain.search_engine.engine import tree_base_search_engine
#
# profiler = LineProfiler()
# profiler.add_module(run_module)
# profiler.add_module(task_solver)
# profiler.add_module(handmade_evaluator)
# profiler.add_module(waiting_node)
# profiler.add_module(waiting_node_processor)
# profiler.add_module(task_feature)
# profiler.add_module(node_base_search_engine)
# profiler.add_module(tree_base_search_engine)
#
# profiler.runcall(run)
# # profiler.print_stats()
# stats = profiler.get_stats()
# print_stats(stats, strip_seconds_limit=0., cost_sort=True)
pass
performance_profiling_mode = False
if __name__ == "__main__":
run()
#
# # Rollback the predictions
# [Back to Table of Content](#toc)
sub = pd.read_csv("./submission_yuki_alignment.csv")
print(sub.shape)
sub.head(3)
def get_string(pred):
str_pred = str([list(row) for row in pred])
str_pred = str_pred.replace(", ", "")
str_pred = str_pred.replace("[[", "|")
str_pred = str_pred.replace("][", "|")
str_pred = str_pred.replace("]]", "|")
return str_pred
def get_string_list(preds):
return " ".join([get_string(pred) for pred in preds])
def rollback_row(r, test_aligned_tasks=test_aligned_tasks, debug=False):
output_id = r["output_id"]
output_aligned = str(r["output_aligned"])
# |080000|808000|008088|000008| |0| |0|
if len(output_aligned) < 10:
return "|00|00| |00|00| |00|00|"
task_id = output_id.split("_")[0]
order_id = int(output_id.split("_")[1])
task_aligned = test_aligned_tasks[task_id]
sample_aligned = task_aligned["test"][order_id]
predictions_aligned = output_aligned.split(" ")
def str2list(s):
return [int(d) for d in s]
predictions_aligned = [
[str2list(s) for s in pred.split("|")[1:-1]]
for pred in predictions_aligned
if len(pred) > 5
]
predictions = []
modified = False
for pred_aligned in predictions_aligned:
pred = np.array(pred_aligned)
if sample_aligned["fliplr"]:
pred = np.fliplr(pred)
modified = True
if sample_aligned["flipud"]:
pred = np.flipud(pred)
modified = True
if sample_aligned["rot90"]:
pred = np.rot90(pred, k=3)
modified = True
predictions.append(pred.tolist())
output_final = get_string_list(predictions)
if debug and modified:
print(task_id, order_id)
return output_final
def rollback_sub(sub):
sub2 = sub.copy()
sub2["output_aligned"] = sub2["output"]
sub2["output"] = sub2.apply(lambda r: rollback_row(r), axis=1)
sub2["is_modified"] = sub2.apply(
lambda r: 1 if r["output_aligned"] != r["output"] else 0, axis=1
)
return sub2
sub2 = rollback_sub(sub)
print(sub2["is_modified"].sum())
sub2.head(3)
sub2[["output_id", "output"]].to_csv("./submission_yuki_rollback.csv", index=None)
sub2 = sub2[["output_id", "output"]]
sub2.set_index("output_id", inplace=True)
sample_submission = pd.read_csv(
"/kaggle/input/abstraction-and-reasoning-challenge/sample_submission.csv",
index_col="output_id",
)
for idx, row in sample_submission.iterrows():
if idx in sub2.index:
sample_submission.loc[idx, "output"] = sub2.loc[idx, "output"]
sample_submission.to_csv("submission.csv")
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0035/089/35089966.ipynb | null | null | [{"Id": 35089966, "ScriptId": 9793122, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1853329, "CreationDate": "05/30/2020 06:54:25", "VersionNumber": 2.0, "Title": "yukikubo123's DSL with Alignment", "EvaluationDate": "05/30/2020", "IsChange": true, "TotalLines": 6011.0, "LinesInsertedFromPrevious": 15.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 5996.0, "LinesInsertedFromFork": 17.0, "LinesDeletedFromFork": 58.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 5994.0, "TotalVotes": 9}] | null | null | null | null | #
# # Table of Contents
# 1. [Align tasks](#align_tasks)
# 1. [Run @yukikubo123's DSL](#run_yuki_dsl)
# 1. [Rollback the predictions](#rollback_the_predictions)
# # Align tasks
# [Back to Table of Contents](#toc)
import warnings
warnings.filterwarnings("ignore")
import os
import json
import numpy as np
from pathlib import Path
import random
from collections import Counter
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
from tqdm import tqdm
import matplotlib.pyplot as plt
data_path = Path("../input/abstraction-and-reasoning-challenge")
train_path = data_path / "training"
valid_path = data_path / "evaluation"
test_path = data_path / "test"
def set_seeds(seed):
torch.manual_seed(seed)
np.random.seed(seed)
torch.cuda.manual_seed(seed)
random.seed(seed)
os.environ["PYTHONHASHSEED"] = str(seed)
set_seeds(0)
paths = {"train": train_path, "eval": valid_path, "test": test_path}
def get_tasks(dataset="train"):
path = paths[dataset]
fns = sorted(os.listdir(path))
tasks = {}
for idx, fn in enumerate(fns):
fp = path / fn
with open(fp, "r") as f:
task = json.load(f)
tasks[fn.split(".")[0]] = task
return tasks
test_tasks = get_tasks("test")
train_tasks = get_tasks("train")
valid_tasks = get_tasks("eval")
from tqdm import tqdm
import matplotlib.pyplot as plt
from matplotlib import colors
from matplotlib import animation, rc
from IPython.display import HTML
cmap = colors.ListedColormap(
[
"#000000",
"#0074D9",
"#FF4136",
"#2ECC40",
"#FFDC00",
"#AAAAAA",
"#F012BE",
"#FF851B",
"#7FDBFF",
"#870C25",
]
)
norm = colors.Normalize(vmin=0, vmax=9)
def plot_pictures(pictures, labels):
fig, axs = plt.subplots(1, len(pictures), figsize=(2 * len(pictures), 32))
for i, (pict, label) in enumerate(zip(pictures, labels)):
axs[i].imshow(np.array(pict), cmap=cmap, norm=norm)
axs[i].set_title(label)
plt.show()
def plot_sample(sample, predict=None):
if predict is None:
plot_pictures([sample["input"], sample["output"]], ["Input", "Output"])
else:
plot_pictures(
[sample["input"], sample["output"], predict], ["Input", "Output", "Predict"]
)
norm = colors.Normalize(vmin=0, vmax=9)
# 0:black, 1:blue, 2:red, 3:greed, 4:yellow,
# 5:gray, 6:magenta, 7:orange, 8:sky, 9:brown
plt.figure(figsize=(3, 1), dpi=200)
plt.imshow([list(range(10))], cmap=cmap, norm=norm)
plt.xticks(list(range(10)))
plt.yticks([])
plt.show()
task = train_tasks["db3e9e38"]
for sample in task["train"]:
plot_sample(sample)
from skimage.transform import hough_line
def is_rotation(img):
tested_angles = np.array([0, np.pi / 2])
image = np.array(img)
h, theta, d = hough_line(image, theta=tested_angles)
rot = h[:, 0].max() > h[:, 1].max()
return rot
def get_color_counter(a, binary=False):
if binary:
unique, counts = np.unique((a > 0).astype(int), return_counts=True)
else:
unique, counts = np.unique(a, return_counts=True)
return dict(zip(unique, counts))
def similarity(da, db):
total = 0
for k, v in da.items():
if k in db:
total += min(v, db.get(k))
return total
def is_parts_aligned(da1, da2, db1, db2):
def get_most_color(dab):
c = 0
max_c = 0
for k, v in dab.items():
if k > 0:
if max_c < v:
max_c = v
c = k
return c
if True:
c1 = get_most_color(da1)
if (da1.get(c1, 0) >= da2.get(c1, 0)) and (db1.get(c1, 0) < db2.get(c1, 0)):
return False
if (da1.get(c1, 0) <= da2.get(c1, 0)) and (db1.get(c1, 0) > db2.get(c1, 0)):
return False
return True
def is_2images_aligned_updown(img0, img1):
a = np.array(img0)
a1 = a[0 : a.shape[0] // 2, :]
a2 = a[a.shape[0] // 2 :, :]
b = np.array(img1)
b1 = b[0 : b.shape[0] // 2, :]
b2 = b[b.shape[0] // 2 :, :]
da1 = get_color_counter(a1)
da2 = get_color_counter(a2)
db1 = get_color_counter(b1)
db2 = get_color_counter(b2)
return is_parts_aligned(da1, da2, db1, db2)
def is_2images_aligned_leftright(img0, img1):
a = np.array(img0)
a1 = a[:, 0 : a.shape[1] // 2] # a[0:a.shape[0]//2, :]
a2 = a[:, a.shape[1] // 2 :]
b = np.array(img1)
b1 = b[:, 0 : b.shape[1] // 2] # b[0:b.shape[0]//2, :]
b2 = b[:, b.shape[1] // 2 :]
da1 = get_color_counter(a1)
da2 = get_color_counter(a2)
db1 = get_color_counter(b1)
db2 = get_color_counter(b2)
return is_parts_aligned(da1, da2, db1, db2)
def align_task(task):
task_aligned = task.copy()
sample_trains = task["train"]
sample_tests = task["test"]
# Train
sample_trains_aligned = []
for sample in sample_trains:
img_input = sample["input"]
img_ouput = sample["output"]
sample_aligned = sample.copy()
if is_rotation(img_input):
sample_aligned["input"] = np.rot90(np.array(img_input), k=1).tolist()
sample_aligned["output"] = np.rot90(np.array(img_ouput), k=1).tolist()
sample_trains_aligned.append(sample_aligned)
sample_trains_aligned_2 = sample_trains_aligned[:1] # first element
img0_aligned = sample_trains_aligned_2[0]["input"]
for sample in sample_trains_aligned[1:]:
sample_aligned = sample.copy()
if not is_2images_aligned_updown(img0_aligned, sample_aligned["input"]):
sample_aligned["input"] = np.flipud(
np.array(sample_aligned["input"])
).tolist()
sample_aligned["output"] = np.flipud(
np.array(sample_aligned["output"])
).tolist()
if not is_2images_aligned_leftright(img0_aligned, sample_aligned["input"]):
sample_aligned["input"] = np.fliplr(
np.array(sample_aligned["input"])
).tolist()
sample_aligned["output"] = np.fliplr(
np.array(sample_aligned["output"])
).tolist()
sample_trains_aligned_2.append(sample_aligned)
task_aligned["train"] = sample_trains_aligned_2
# Test
sample_test_aligned = []
for sample in sample_tests:
img_input = sample["input"]
is_output_available = "output" in sample
sample_aligned = sample.copy()
sample_aligned["rot90"] = False
if is_rotation(img_input):
sample_aligned["input"] = np.rot90(np.array(img_input), k=1).tolist()
if is_output_available:
sample_aligned["output"] = np.rot90(
np.array(sample_aligned["output"]), k=1
).tolist()
sample_aligned["rot90"] = True
sample_test_aligned.append(sample_aligned)
sample_test_aligned_v2 = []
for sample in sample_test_aligned:
sample_aligned = sample.copy()
sample_aligned["flipud"] = False
if not is_2images_aligned_updown(img0_aligned, sample_aligned["input"]):
sample_aligned["input"] = np.flipud(
np.array(sample_aligned["input"])
).tolist()
if is_output_available:
sample_aligned["output"] = np.flipud(
np.array(sample_aligned["output"])
).tolist()
sample_aligned["flipud"] = True
sample_aligned["fliplr"] = False
if not is_2images_aligned_leftright(img0_aligned, sample_aligned["input"]):
sample_aligned["input"] = np.fliplr(
np.array(sample_aligned["input"])
).tolist()
if is_output_available:
sample_aligned["output"] = np.fliplr(
np.array(sample_aligned["output"])
).tolist()
sample_aligned["fliplr"] = True
sample_test_aligned_v2.append(sample_aligned)
task_aligned["test"] = sample_test_aligned_v2
return task_aligned
single_task = train_tasks["db3e9e38"]
single_task = valid_tasks["103eff5b"]
# single_task = valid_tasks["05a7bcf2"]
task_aligned = align_task(single_task)
for sample in task_aligned["train"]:
# print(sample['flipud'], sample['rot90'])
plot_sample(sample)
for sample in task_aligned["test"]:
print(sample["fliplr"], sample["flipud"], sample["rot90"])
plot_sample(sample)
test_aligned_path = Path("test_aligned")
test_tasks = get_tasks("test")
for task_id, task in tqdm(test_tasks.items()):
task_aligned = align_task(task)
task_filename = "{}.json".format(task_id)
with open(test_aligned_path / task_filename, "w") as outfile:
json.dump(task_aligned, outfile)
paths["test_aligned"] = test_aligned_path
test_aligned_tasks = get_tasks("test_aligned")
print(len(test_aligned_tasks))
#
# # Run @yukikubo123's DSL
# [Back to Table of Content](#toc)
""" This file was auto_generated by kernel_generator.py """
from typing import Set
from deap.tools import selNSGA2
from lightgbm import LGBMClassifier
from joblib import delayed
from scipy.ndimage import binary_erosion
from enum import auto
from collections import defaultdict
from scipy.ndimage import maximum_filter
from itertools import groupby
from skimage.measure import label
from sklearn.neural_network import MLPClassifier
from scipy.ndimage import binary_fill_holes
import json
import shutil
from typing import List
from enum import IntEnum
from pandas import DataFrame
from enum import unique
import cv2
import pandas as pd
from copy import deepcopy
from typing import Tuple
from itertools import product
from skimage.filters import try_all_threshold
from pathlib import Path
from heapq import heapify
from scipy.ndimage import generate_binary_structure
from sklearn.linear_model import LogisticRegression
from functools import partial
import copy
from typing import Any
from typing import Optional
from heapq import heappush
from category_encoders import OrdinalEncoder
import numpy as np
from typing import Dict
from tqdm import tqdm
from matplotlib import colors
import time
import random
from heapq import heappushpop
from typing import Iterable
from enum import Enum
import pickle
from matplotlib import pyplot as plt
from joblib import Parallel
from heapq import heappop
from itertools import chain
from dataclasses import asdict
from skimage.filters import threshold_minimum
from sklearn.linear_model import RidgeClassifier
from scipy.ndimage import binary_dilation
import optuna
from dataclasses import dataclass
from typing import Union
from typing import TypeVar
from optuna import Trial
import category_encoders
from sklearn.model_selection import KFold
from operator import itemgetter
# from ruamel import yaml
from collections import Counter
@dataclass
class OperationInconsistencyException(Exception):
message: str = ""
class Timer:
def __init__(self):
pass
def __enter__(self):
self.start_sec = time.perf_counter()
return self
def second(self):
return time.perf_counter() - self.start_sec
def __exit__(self, *exc):
return
class StrNameEnum(Enum):
def __str__(self):
return self.name
def __repr__(self):
return str(f"{self.__class__.__name__}.{self.name}")
class StrNameIntEnum(IntEnum):
def __str__(self):
return self.name
def __repr__(self):
return str(f"{self.__class__.__name__}.{self.name}")
@unique
class RunMode(Enum):
LOCAL_RUN_ALL = auto()
LOCAL_RUN = auto()
TREE_BASE_SEARCH_OPTIMIZATION = auto()
NODE_BASE_SEARCH_OPTIMIZATION = auto()
LOCAL_DATA_GENERATION = auto()
LOCAL_ML_TRAIN = auto()
TRAIN_OPERATION_ELEMENT_INCLUSION_PREDICTION = auto()
KERNEL = auto()
KERNEL_EMULATION = auto()
@unique
class TaskRange(Enum):
ALL = auto()
CAN_ANSWER_ONLY = auto()
EXCLUDE_GIVE_UPS = auto()
@unique
class FlipMode(StrNameEnum):
UD = auto()
LR = auto()
UL_DR = auto()
UR_DL = auto()
@unique
class EngineSchedulePattern(Enum):
DRY_RUN = auto()
HAND_MADE = auto()
ML = auto()
@unique
class EngineType(Enum):
NODE_BASED_SEARCH_ENGINE = auto()
TREE_BASED_SEARCH_ENGINE = auto()
class RunConfig:
RUN_MODE = RunMode.KERNEL # Usually, use "LOCAL_RUN" or "KERNEL"
TASK_RANGE = TaskRange.ALL # Limit the range to save time.
ENGINE_TYPE = EngineType.NODE_BASED_SEARCH_ENGINE
ENGINE_SCHEDULE_PATTERN = EngineSchedulePattern.HAND_MADE
USE_ML_GUIDE = False # DeepCoder-like strategy. Calculate the probability of inclusion of each DSL elements.
RUN_ONLY_PRIVATE_LB = False # Skip public kernel run to save time.
_KERNEL_N_JOB = 4
_LOCAL_N_JOB = 5
N_JOB = _KERNEL_N_JOB if RUN_MODE == RunMode.KERNEL else _LOCAL_N_JOB
@unique
class DepthSearchPattern(Enum):
BREADTH_FIRST = auto()
NORMAL = auto()
DEPTH_FIRST = auto()
@unique
class TrueOrFalse(StrNameEnum):
TRUE = auto()
FALSE = auto()
@unique
class Color(StrNameIntEnum):
BLACK = 0
BLUE = 1
RED = 2
GREEN = 3
YELLOW = 4
GRAY = 5
MAGENTA = 6
ORANGE = 7
SKY = 8
BROWN = 9
MASK_TAG = 10 # very special color. TODO unused?
@classmethod
def prepare(cls):
cls.mapping = {c.value: c for c in Color}
@classmethod
def of(cls, value: int) -> "Color":
try:
return cls.mapping[value]
except AttributeError:
cls.mapping = {c.value: c for c in Color}
return cls.mapping[value]
@unique
class Direction(StrNameEnum):
TOP = auto()
BOTTOM = auto()
RIGHT = auto()
LEFT = auto()
@unique
class PaddingMode(StrNameEnum):
REPEAT = auto()
MIRROR_1 = auto() # line-symmetric at the edge
MIRROR_2 = auto() # line-symmetric at the edge-pixel-line
EDGE = auto()
@unique
class Axis(StrNameEnum):
VERTICAL = auto()
HORIZONTAL = auto()
BOTH = auto()
@unique
class MultiColorSelectionMode(StrNameEnum):
# ANY_WITHOUT_FIXED_COLOR = auto() # TODO should define?
ANY_WITHOUT_MOST_COMMON = auto() # TODO ANY_WITHOUT_TOP2_MOST_COMMON
ANY_WITHOUT_LEAST_COMMON = auto()
@unique
class MaxOrMin(StrNameEnum):
MAX = max
MIN = min
@property
def func(self):
return self.value
@unique
class FillType(StrNameEnum):
NotOverride = auto()
Override = auto()
@unique
class LineEdgeType(StrNameEnum):
EdgeExclude = auto()
EdgeInclude = auto()
@unique
class ImageEdgeType(StrNameEnum):
EDGE_EXCLUDE = auto()
EDGE_INCLUDE = auto()
@unique
class ObjectFeature(StrNameEnum):
AREA = auto()
# PERIMETER_LEN = auto() # TODO difficult to implement?
HORIZONTAL_LEN = auto()
VERTICAL_LEN = auto()
@unique
class PixelConnectivity(StrNameEnum):
FOUR_DIRECTION = 1
EIGHT_DIRECTION = 2
@property
def value_for_skimage(self) -> int:
return self.value
@property
def structure_for_skimage(self) -> np.ndarray:
if self == PixelConnectivity.EIGHT_DIRECTION:
return generate_binary_structure(2, 2)
if self == PixelConnectivity.FOUR_DIRECTION:
return generate_binary_structure(2, 1)
raise NotImplementedError()
@unique
class HoleInclude(StrNameEnum):
INCLUDE = auto()
EXCLUDE = auto()
@unique
class SingleColorSelectionMode(StrNameEnum):
MOST_COMMON = auto()
SECOND_MOST_COMMON = auto()
LEAST_COMMON = auto()
@dataclass(frozen=True)
class ColorSelection:
def __call__(self, arr: np.ndarray) -> np.ndarray:
raise NotImplementedError()
@dataclass(frozen=True)
class MaskConversion:
def __call__(self, mask: np.ndarray) -> np.ndarray:
raise NotImplementedError()
@dataclass(frozen=True)
class NoMaskConversion(MaskConversion):
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
return color_mask
@dataclass(frozen=True)
class MaskOperation:
def __call__(self, arr: np.ndarray, mask: np.ndarray) -> np.ndarray:
raise NotImplementedError()
@dataclass(frozen=True)
class ColorChannelSelection:
def __call__(self, arr: np.ndarray) -> List[Tuple[Color, np.ndarray]]:
raise NotImplementedError()
@dataclass(frozen=True)
class ChannelMergeOperation:
def __call__(
self,
arr: np.ndarray,
original_color_mask_pairs: List[Tuple[Color, np.ndarray]],
color_mask_pairs: List[Tuple[Color, np.ndarray]],
) -> np.ndarray:
raise NotImplementedError()
@dataclass(frozen=True)
class ColorOperation:
color_selection: ColorSelection
mask_conversions: MaskConversion
mask_operation: MaskOperation
@dataclass(frozen=True)
class MultiColorChannelOperation:
channel_selection: ColorChannelSelection
mask_conversions: MaskConversion
channel_merge_operation: ChannelMergeOperation
@dataclass(frozen=True)
class PartitionedArraySelection:
def __call__(
self, arr: np.ndarray, partitioned_arrays: List[List[np.ndarray]]
) -> List[List[bool]]:
raise NotImplementedError()
@dataclass(frozen=True)
class PartitionOperation:
partition_selection: "PartitionSelection"
# partition_uniform_operation: PartitionUniformOperation # TODO implement
partition_merge_operation: "PartitionMergeOperation"
@dataclass(frozen=True)
class PartitionSelection:
# array -> (2d_partitioned_array, 2d_original_location_mask)
def __call__(
self, arr: np.ndarray
) -> Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]:
raise NotImplementedError()
@dataclass(frozen=True)
class PartitionMergeOperation:
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
raise NotImplementedError()
@dataclass
class DistanceEvaluatorParameter:
same_h_w_dim_between_input_output: float = 1500
all_dim_h_w_integer_multiple: float = 650
mean_lack_color_num: float = 30
mean_excess_color_num: float = 50
mean_hit_and_miss_histogram_diff: float = 50
mean_h_v_diff_input_arr_line_num: float = 40
mean_h_v_diff_output_arr_line_num: float = 60
mean_h_v_edge_sum_diff: float = 2
mean_h_v_edge_sum_diff_ratio: float = 0.5
mean_diff_color_cell_ratio: int = 1 # 基準
mean_diff_cell_where_no_need_to_change_count_ratio: float = 100
mean_wrong_change_cell_where_need_to_change_count_ratio: float = 100
@dataclass
class NodeBaseSearchEngineParameter:
breadth_first_cost: float = 3500
normal_first_cost: float = 400
depth_first_cost: float = 1.2
breadth_first_exp_cost: float = 0
normal_exp_cost: float = 0
depth_first_exp_cost: float = 0
element_inclusion_prob_factor: float = 0
pq_pop_mins_or_as_least_n: int = 20
@dataclass
class TreeBaseSearchEngineParameter:
population_num: int = 26
max_depth: int = 8
operation_mutation_prob: float = 0.19
operation_component_mutation_prob: float = 0.1
operation_param_mutation_prob: float = 0.0048
extend_mutation_prob: float = 0.044
shrink_mutation_prob: float = 0.0012
@dataclass
class AllParameter:
distance_evaluator_param: DistanceEvaluatorParameter = DistanceEvaluatorParameter()
node_base_engine_param: Optional[
NodeBaseSearchEngineParameter
] = NodeBaseSearchEngineParameter()
tree_base_engine_param: Optional[
TreeBaseSearchEngineParameter
] = TreeBaseSearchEngineParameter()
@dataclass()
class InputOutput:
input_arr: np.ndarray
output_arr: Optional[np.ndarray]
@staticmethod
def of(json_dict: dict) -> "InputOutput":
return InputOutput(
np.array(json_dict["input"], dtype=np.uint8),
np.array(json_dict["output"], dtype=np.uint8)
if "output" in json_dict
else None,
)
def get_all_arr(self) -> List[np.ndarray]:
if self.output_arr is None:
return [self.input_arr]
else:
return [self.input_arr, self.output_arr]
def candidate_color_mapping(self) -> List[Tuple[Color, Color]]:
input_colors = list(np.unique(self.input_arr)) + [
Color.ANY_WITHOUT_MOST,
Color.MOST,
Color.SECOND_MOST,
Color.LEAST,
]
output_colors = np.unique(self.output_arr)
return [
(Color.of(i), Color.of(o))
for i, o in product(input_colors, output_colors)
if i != o
]
@dataclass(frozen=True)
class UniformOperation:
def __call__(self, arr: np.ndarray) -> np.ndarray:
raise NotImplementedError()
@dataclass(frozen=True)
class OperationSet:
operations: List[
Union[
UniformOperation,
ColorOperation,
MultiColorChannelOperation,
PartitionOperation,
]
]
def __str__(self):
return repr(self)
def types(self):
results = []
for o in self.operations:
if isinstance(o, UniformOperation):
results.append(UniformOperation)
elif isinstance(o, ColorOperation):
results.append(ColorOperation)
elif isinstance(o, MultiColorChannelOperation):
results.append(MultiColorChannelOperation)
elif isinstance(o, PartitionOperation):
results.append(PartitionOperation)
else:
raise NotImplementedError()
return results
def elements(
self,
) -> List[
Union[
UniformOperation,
ColorSelection,
MaskConversion,
MaskOperation,
PartitionOperation,
]
]:
res = []
for o in self.operations:
if isinstance(o, UniformOperation):
res.append(o)
elif isinstance(o, ColorOperation):
res.append(o.color_selection)
res.append(o.mask_conversions)
res.append(o.mask_operation)
elif isinstance(o, MultiColorChannelOperation):
res.append(o.channel_selection)
res.append(o.mask_conversions)
res.append(o.channel_merge_operation)
elif isinstance(o, PartitionOperation):
res.append(o.partition_selection)
res.append(o.partition_merge_operation)
else:
raise NotImplementedError()
return res
@dataclass(frozen=True)
class Task:
name: str
train: Tuple[InputOutput]
test: Tuple[InputOutput]
@staticmethod
def of(name: str, json_dict: dict) -> "Task":
return Task(
name,
tuple(InputOutput.of(io) for io in json_dict["train"]),
tuple(InputOutput.of(io) for io in json_dict["test"]),
)
def get_all_arr(self) -> List[np.ndarray]:
return self.get_train_all_arr() + self.get_test_all_arr()
def get_train_all_arr(self) -> List[np.ndarray]:
return list(chain.from_iterable(map(lambda io: io.get_all_arr(), self.train)))
def get_test_all_arr(self) -> List[np.ndarray]:
return list(chain.from_iterable(map(lambda io: io.get_all_arr(), self.test)))
def get_input_all_arr(self) -> List[np.ndarray]:
return list(map(lambda io: io.input_arr, self.train + self.test))
def get_output_all_arr(self) -> List[np.ndarray]:
return list(
filter(
lambda arr: arr is not None,
map(lambda io: io.output_arr, self.train + self.test),
)
)
def test_arr_hash(self) -> int:
return hash(
self.__class__.__name__
+ "_".join(map(lambda io: str(io.input_arr), self.test))
)
@dataclass(frozen=True)
class ColorSelectedTask(Task):
train_masks: List[np.ndarray]
test_masks: List[np.ndarray]
@dataclass(frozen=True)
class MaskConvertedTask(Task):
train_masks: List[np.ndarray]
test_masks: List[np.ndarray]
@dataclass(frozen=True)
class ColorChannelSelectedTask(Task):
train_color_mask_pairs: List[List[Tuple[Color, np.ndarray]]]
test_color_mask_pairs: List[List[Tuple[Color, np.ndarray]]]
@dataclass(frozen=True)
class ColorChannelMaskConvertedTask(Task):
train_original_color_mask_pairs: List[List[Tuple[Color, np.ndarray]]]
train_color_mask_pairs: List[List[Tuple[Color, np.ndarray]]]
test_original_color_mask_pairs: List[List[Tuple[Color, np.ndarray]]]
test_color_mask_pairs: List[List[Tuple[Color, np.ndarray]]]
@dataclass(frozen=True)
class PartitionSelectionTask(Task):
train_partitioned_arrays_original_location_masks: List[
Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]
]
test_partitioned_arrays_original_location_masks: List[
Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]
]
@dataclass
class ImageFeature:
height: int
width: int
colors: List[Color]
hit_and_miss_histogram: List[int]
# most_common_color: Color
vertical_edge_num: int
horizontal_edge_num: int
@dataclass
class ImageDiffFeature:
input_image_feature: ImageFeature # TODO should not define here?
output_image_feature: ImageFeature # TODO should not define here?
dim_height_increase: int
dim_width_increase: int
dim_height_integer_multiple: bool
dim_width_integer_multiple: bool
dim_height_diff: int
dim_width_diff: int
dim_height_equal: bool
dim_width_equal: bool
lack_color_num: int
excess_color_num: int
hit_and_miss_histogram_diff: int
# vertical_diff_input_arr_line_num: Optional[int]
# horizontal_diff_input_arr_line_num: Optional[int]
# vertical_diff_output_arr_line_num: Optional[int]
# horizontal_diff_output_arr_line_num: Optional[int]
vertical_edge_sum_diff: int
horizontal_edge_sum_diff: int
vertical_edge_sum_diff_ratio: float
horizontal_edge_sum_diff_ratio: float
diff_color_cell_ratio: Optional[float] # None if different image size.
diff_cell_where_no_need_to_change_count_ratio: Optional[
float
] # None if different image size.
wrong_change_cell_where_need_to_change_count_ratio: Optional[
float
] # None if different image size.
# TODO cell_diff_num_except_formost_common_color
def same_dim(self) -> bool:
return self.dim_height_equal and self.dim_width_equal
@dataclass
class TaskFeature:
# image_diff_features: List[ImageDiffFeature]
same_dim_between_input_output: bool
same_height_dim_between_input_output: bool
same_width_dim_between_input_output: bool
all_dim_height_increased: bool
all_dim_height_decreased: bool
all_dim_width_increased: bool
all_dim_width_decreased: bool
all_dim_height_integer_multiple: bool
all_dim_width_integer_multiple: bool
mean_lack_color_num: float
mean_excess_color_num: float
mean_hit_and_miss_histogram_diff: float
# mean_vertical_diff_input_arr_line_num: Optional[float]
# mean_horizontal_diff_input_arr_line_num: Optional[float]
# mean_vertical_diff_output_arr_line_num: Optional[float]
# mean_horizontal_diff_output_arr_line_num: Optional[float]
mean_vertical_edge_sum_diff: float
mean_horizontal_edge_sum_diff: float
mean_vertical_edge_sum_diff_ratio: float
mean_horizontal_edge_sum_diff_ratio: float
mean_diff_color_cell_ratio: Optional[float] # None if different image size.
mean_diff_cell_where_no_need_to_change_count_ratio: Optional[
float
] # None if different image size.
mean_wrong_change_cell_where_need_to_change_count_ratio: Optional[float]
@dataclass
class ColorSelectedTaskFeature:
task_feature: TaskFeature
@dataclass
class MaskConvertedTaskFeature:
task_feature: TaskFeature
possible_improve_ratios: List[Optional[float]]
@dataclass
class DistanceEvaluator:
dist_eval_param: DistanceEvaluatorParameter
def evaluate_task_feature(self, task_feature: TaskFeature) -> float:
return (
0
+ self.dist_eval_param.same_h_w_dim_between_input_output
* (0 if task_feature.same_height_dim_between_input_output else 1)
+ self.dist_eval_param.same_h_w_dim_between_input_output
* (0 if task_feature.same_width_dim_between_input_output else 1)
+ self.dist_eval_param.all_dim_h_w_integer_multiple
* (0 if task_feature.all_dim_height_integer_multiple else 1)
+ self.dist_eval_param.all_dim_h_w_integer_multiple
* (0 if task_feature.all_dim_width_integer_multiple else 1)
+ self.dist_eval_param.mean_lack_color_num
* task_feature.mean_lack_color_num
+ self.dist_eval_param.mean_excess_color_num
* task_feature.mean_excess_color_num
+ self.dist_eval_param.mean_hit_and_miss_histogram_diff
* task_feature.mean_hit_and_miss_histogram_diff
+ self.dist_eval_param.mean_h_v_edge_sum_diff
* (task_feature.mean_vertical_edge_sum_diff)
+ self.dist_eval_param.mean_h_v_edge_sum_diff
* (task_feature.mean_horizontal_edge_sum_diff)
+ self.dist_eval_param.mean_h_v_edge_sum_diff_ratio
* (task_feature.mean_vertical_edge_sum_diff_ratio)
+ self.dist_eval_param.mean_h_v_edge_sum_diff_ratio
* (task_feature.mean_horizontal_edge_sum_diff_ratio)
+ self.dist_eval_param.mean_diff_color_cell_ratio
* (task_feature.mean_diff_color_cell_ratio or 0)
+ self.dist_eval_param.mean_diff_cell_where_no_need_to_change_count_ratio
* (task_feature.mean_diff_cell_where_no_need_to_change_count_ratio or 0)
+ self.dist_eval_param.mean_wrong_change_cell_where_need_to_change_count_ratio
* (
task_feature.mean_wrong_change_cell_where_need_to_change_count_ratio
or 0
)
)
# + self.dist_eval_param.mean_h_v_diff_input_arr_line_num * (task_feature.mean_horizontal_diff_input_arr_line_num or 0) \
# + self.dist_eval_param.mean_h_v_diff_input_arr_line_num * (task_feature.mean_vertical_diff_input_arr_line_num or 0) \
# + self.dist_eval_param.mean_h_v_diff_output_arr_line_num * (task_feature.mean_horizontal_diff_output_arr_line_num or 0) \
# + self.dist_eval_param.mean_h_v_diff_output_arr_line_num * (task_feature.mean_vertical_diff_output_arr_line_num or 0) \
def evaluate_task_feature_element(self, task_feature: TaskFeature) -> List[float]:
return [
(0 if task_feature.same_height_dim_between_input_output else 1),
(0 if task_feature.same_width_dim_between_input_output else 1),
(0 if task_feature.all_dim_height_integer_multiple else 1),
(0 if task_feature.all_dim_width_integer_multiple else 1),
task_feature.mean_lack_color_num,
task_feature.mean_excess_color_num,
task_feature.mean_hit_and_miss_histogram_diff,
(task_feature.mean_vertical_edge_sum_diff),
(task_feature.mean_horizontal_edge_sum_diff),
(task_feature.mean_vertical_edge_sum_diff_ratio),
(task_feature.mean_horizontal_edge_sum_diff_ratio),
(task_feature.mean_diff_color_cell_ratio or 0),
]
class Node:
def __repr__(self):
return str(self)
@dataclass
class WaitingNode(Node):
# This node will be added to priority queue.
parent_completed_node: "CompletedNode"
cache_pred_distance = None
def evaluation_features(self) -> Dict[str, Any]:
raise NotImplementedError()
def depth(self) -> int:
raise NotImplementedError()
def __le__(self, other: "WaitingNode") -> bool:
return self.cache_pred_distance <= other.cache_pred_distance
def __lt__(self, other: "WaitingNode") -> bool:
return self.cache_pred_distance < other.cache_pred_distance
@dataclass
class UniformOperationWaitingNode(WaitingNode):
original_task: Task
task: Task
task_feature: TaskFeature
base_operation_set: OperationSet
next_operation: UniformOperation
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, next_ope: {self.next_operation}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
def evaluation_features(self) -> Dict[str, Any]:
return {
"node_class": self.__class__.__name__,
"depth": len(self.base_operation_set.operations),
**asdict(self.task_feature),
"next_operation": self.next_operation.__class__.__name__,
**asdict(self.next_operation),
}
@dataclass
class ColorSelectionWaitingNode(WaitingNode):
original_task: Task
task: Task
task_feature: TaskFeature
base_operation_set: OperationSet
next_selection: ColorSelection
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, next_selection: {self.next_selection}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
def evaluation_features(self) -> Dict[str, Any]:
return {
"node_class": self.__class__.__name__,
"depth": len(self.base_operation_set.operations),
**asdict(self.task_feature),
"next_selection": self.next_selection.__class__.__name__,
**asdict(self.next_selection),
}
@dataclass
class MaskConversionWaitingNode(WaitingNode):
original_task: Task
color_selected_task: ColorSelectedTask
color_selected_task_feature: ColorSelectedTaskFeature
base_operation_set: OperationSet
color_selection: ColorSelection
next_mask_conversion: MaskConversion
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, color_selection: {self.color_selection}, next_add_selection: {self.next_mask_conversion}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
def evaluation_features(self) -> Dict[str, Any]:
return {
"node_class": self.__class__.__name__,
"depth": len(self.base_operation_set.operations),
**asdict(self.color_selected_task_feature.task_feature),
"next_mask_conversion": self.next_mask_conversion.__class__.__name__,
**asdict(self.next_mask_conversion),
}
@dataclass
class MaskOperationSelectionWaitingNode(WaitingNode):
original_task: Task
mask_converted_task: MaskConvertedTask
mask_converted_task_feature: MaskConvertedTaskFeature
base_operation_set: OperationSet
color_selection: ColorSelection
mask_conversion: MaskConversion
next_mask_operation: MaskOperation
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, color_selection: {self.color_selection}, add_selection: {self.mask_conversion}, next_mask_ope: {self.next_mask_operation}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
def evaluation_features(self) -> Dict[str, Any]:
return {
"node_class": self.__class__.__name__,
"depth": len(self.base_operation_set.operations),
**asdict(self.mask_converted_task_feature.task_feature),
"next_mask_operation": self.next_mask_operation.__class__.__name__,
**asdict(self.next_mask_operation),
}
@dataclass
class ColorChannelSelectionOperationWaitingNode(WaitingNode):
original_task: Task
task: Task
task_feature: TaskFeature
base_operation_set: OperationSet
next_color_channel_selection: ColorChannelSelection
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, next_color_channeling: {self.next_color_channel_selection}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
def evaluation_features(self) -> Dict[str, Any]:
return {
"node_class": self.__class__.__name__,
"depth": len(self.base_operation_set.operations),
**asdict(self.task_feature),
"next_operation": self.next_color_channel_selection.__class__.__name__,
**asdict(self.next_color_channel_selection),
}
@dataclass
class ColorChannelMaskConversionWaitingNode(WaitingNode):
original_task: Task
task: ColorChannelSelectedTask
task_feature: TaskFeature
base_operation_set: OperationSet
color_channel_selection: ColorChannelSelection
next_mask_conversion: MaskConversion
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, color_channel_selection: {self.color_channel_selection}, next_mask_conversion: {self.next_mask_conversion}, next_mask_ope: {self.next_mask_conversion}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
@dataclass
class ColorChannelMergeWaitingNode(WaitingNode):
original_task: Task
task: ColorChannelMaskConvertedTask
task_feature: TaskFeature
base_operation_set: OperationSet
color_channel_selection: ColorChannelSelection
mask_conversion: MaskConversion
next_merge_operation: ChannelMergeOperation
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, color_channel_selection: {self.color_channel_selection}, mask_conversion: {self.mask_conversion}, next_merge_operation: {self.next_merge_operation}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
@dataclass
class PartitionSelectionWaitingNode(WaitingNode):
original_task: Task
task: Task
task_feature: TaskFeature
base_operation_set: OperationSet
next_partition_selection: PartitionSelection
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, next_partition_sel: {self.next_partition_selection}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
@dataclass
class PartitionMergeWaitingNode(WaitingNode):
original_task: Task
task: PartitionSelectionTask
task_feature: TaskFeature
base_operation_set: OperationSet
partition_selection: PartitionSelection
next_partition_merge_operation: PartitionMergeOperation
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}+1, class: {self.__class__.__name__}, "
f"ope_set: {self.base_operation_set}, partition_sel: {self.partition_selection}, partition_merge: {self.next_partition_merge_operation}"
)
def depth(self) -> int:
return len(self.base_operation_set.operations)
@dataclass()
class CompletedNode(Node):
# This node won't be added to priority queue. This is processed immediately and converted to next List[WaitingNode].
parent_waiting_node: "WaitingNode"
def train_arr_hash(self) -> int:
raise NotImplementedError()
def all_arr_hash(self) -> int:
raise NotImplementedError()
@dataclass
class UniformOperationCompletedNode(CompletedNode):
original_task: Task
task: Task
task_feature: TaskFeature
base_operation_set: OperationSet
def __str__(self):
return f"depth: {len(self.base_operation_set.operations)}, class: {self.__class__.__name__}, ope_set: {self.base_operation_set}"
def train_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(map(lambda io: np_to_str(io.input_arr), self.task.train))
)
def all_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
map(
lambda io: np_to_str(io.input_arr), self.task.train + self.task.test
)
)
)
@dataclass
class ColorSelectionCompletedNode(CompletedNode):
original_task: Task
color_selected_task: ColorSelectedTask
color_selected_task_feature: ColorSelectedTaskFeature
base_operation_set: OperationSet
color_selection: ColorSelection
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}, class: {self.__class__.__name__}, "
f"base_ope: {self.base_operation_set}, color_sele: {self.color_selection}"
)
def train_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(
lambda io: np_to_str(io.input_arr),
self.color_selected_task.train,
),
map(lambda t: np_to_str(t), self.color_selected_task.train_masks),
)
)
)
def all_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(
lambda io: np_to_str(io.input_arr),
self.color_selected_task.train + self.color_selected_task.test,
),
map(
lambda t: np_to_str(t),
self.color_selected_task.train_masks
+ self.color_selected_task.test_masks,
),
)
)
)
@dataclass
class MaskConversionCompletedNode(CompletedNode):
original_task: Task
mask_converted_task: MaskConvertedTask
mask_converted_task_feature: MaskConvertedTaskFeature
base_operation_set: OperationSet
color_selection: ColorSelection
mask_conversion: MaskConversion
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}, class: {self.__class__.__name__}, "
f"base_ope: {self.base_operation_set}, color_sele: {self.color_selection}, add_sele: {self.mask_conversion}"
)
def train_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(
lambda io: np_to_str(io.input_arr),
self.mask_converted_task.train,
),
map(lambda t: np_to_str(t), self.mask_converted_task.train_masks),
)
)
)
def all_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(
lambda io: np_to_str(io.input_arr),
self.mask_converted_task.train + self.mask_converted_task.test,
),
map(
lambda t: np_to_str(t),
self.mask_converted_task.train_masks
+ self.mask_converted_task.test_masks,
),
)
)
)
@dataclass
class ColorChannelSelectionCompletedNode(CompletedNode):
original_task: Task
task: ColorChannelSelectedTask
feature: TaskFeature
base_operation_set: OperationSet
color_channel_selection: ColorChannelSelection
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}, class: {self.__class__.__name__}, "
f"base_ope: {self.base_operation_set}, color_sele: {self.color_channel_selection}"
)
def train_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(lambda io: np_to_str(io.input_arr), self.task.train),
chain.from_iterable(
[
(to_bytes(c), np_to_str(m))
for p_l in self.task.train_color_mask_pairs
for c, m in p_l
]
),
)
)
)
def all_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(lambda io: np_to_str(io.input_arr), self.task.test),
chain.from_iterable(
[
(to_bytes(c), np_to_str(m))
for p_l in self.task.train_color_mask_pairs
+ self.task.test_color_mask_pairs
for c, m in p_l
]
),
)
)
)
@dataclass
class ColorChannelMaskConversionCompletedNode(CompletedNode):
original_task: Task
task: ColorChannelMaskConvertedTask
feature: TaskFeature
base_operation_set: OperationSet
color_selection: ColorChannelSelection
mask_conversion: MaskConversion
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}, class: {self.__class__.__name__}, "
f"base_ope: {self.base_operation_set}, mask_conversion: {self.mask_conversion}"
)
def train_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(lambda io: np_to_str(io.input_arr), self.task.train),
chain.from_iterable(
[
(to_bytes(c), np_to_str(m))
for p_l in self.task.train_original_color_mask_pairs
for c, m in p_l
]
),
chain.from_iterable(
[
(to_bytes(c), np_to_str(m))
for p_l in self.task.train_color_mask_pairs
for c, m in p_l
]
),
)
)
)
def all_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(lambda io: np_to_str(io.input_arr), self.task.test),
chain.from_iterable(
[
(to_bytes(c), np_to_str(m))
for p_l in self.task.train_original_color_mask_pairs
+ self.task.test_original_color_mask_pairs
for c, m in p_l
]
),
chain.from_iterable(
[
(to_bytes(c), np_to_str(m))
for p_l in self.task.train_color_mask_pairs
+ self.task.test_color_mask_pairs
for c, m in p_l
]
),
)
)
)
@dataclass
class PartitionSelectionCompletedNode(CompletedNode):
original_task: Task
task: PartitionSelectionTask
feature: TaskFeature
base_operation_set: OperationSet
partition_selection: PartitionSelection
def __str__(self):
return (
f"depth: {len(self.base_operation_set.operations)}, class: {self.__class__.__name__}, "
f"base_ope: {self.base_operation_set}, partition_selection: {self.partition_selection}"
)
def train_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(lambda io: np_to_str(io.input_arr), self.task.train),
[
to_bytes(v)
for v in self.task.train_partitioned_arrays_original_location_masks
],
),
)
)
def all_arr_hash(self) -> int:
return hash(
bytes(self.__class__.__name__, encoding="utf-8")
+ b"_".join(
chain(
map(lambda io: np_to_str(io.input_arr), self.task.test),
[
to_bytes(v)
for v in self.task.train_partitioned_arrays_original_location_masks
+ self.task.test_partitioned_arrays_original_location_masks
],
),
)
)
@dataclass(frozen=True)
class NodeTree:
completed_nodes: List[CompletedNode]
def __str__(self):
return "\n".join(map(str, self.completed_nodes))
@classmethod
def of(cls, completed_node: CompletedNode) -> "NodeTree":
completed_nodes = []
current_node = completed_node
while True:
if isinstance(current_node, CompletedNode):
completed_nodes.append(current_node)
current_node = current_node.parent_waiting_node
elif isinstance(current_node, WaitingNode):
current_node = current_node.parent_completed_node
elif current_node is None:
# TODO root node
break
else:
raise NotImplementedError()
return cls(list(reversed(completed_nodes)))
@classmethod
def replaced_new_node_tree(
cls, node_tree: "NodeTree", node_depth: int, node: CompletedNode
) -> "NodeTree":
copied_list = copy.copy(node_tree.completed_nodes)
copied_list[node_depth] = node
return cls(copied_list)
def to_operation_set(self) -> OperationSet:
# TODO found a bug related to MultiColorChannelOperation.
try:
operations = []
temp_color_selection = None
temp_mask_conversion = None
temp_color_channel_selection = None
temp_partition_selection = None
# TODO too dirty.
assert (
len(self.completed_nodes[0].base_operation_set.operations) == 0
), self.completed_nodes[0]
for n in self.completed_nodes[1:]: # first element is root.
if isinstance(n, UniformOperationCompletedNode):
if isinstance(
n.base_operation_set.operations[-1], UniformOperation
):
operations.append(n.base_operation_set.operations[-1])
else:
if temp_color_selection is not None:
operations.append(
ColorOperation(
temp_color_selection,
temp_mask_conversion,
n.base_operation_set.operations[-1].mask_operation,
)
)
temp_color_selection = None
temp_mask_conversion = None
temp_color_channel_selection = None
temp_partition_selection = None
elif temp_color_channel_selection is not None:
operations.append(
MultiColorChannelOperation(
temp_color_channel_selection,
temp_mask_conversion,
n.base_operation_set.operations[
-1
].channel_merge_operation,
)
)
temp_color_selection = None
temp_mask_conversion = None
temp_color_channel_selection = None
temp_partition_selection = None
elif temp_partition_selection is not None:
operations.append(
PartitionOperation(
temp_partition_selection,
n.base_operation_set.operations[
-1
].partition_merge_operation,
)
)
temp_color_selection = None
temp_mask_conversion = None
temp_color_channel_selection = None
temp_partition_selection = None
else:
raise NotImplementedError()
elif isinstance(n, ColorSelectionCompletedNode):
temp_color_selection = n.color_selection
elif isinstance(n, MaskConversionCompletedNode):
temp_mask_conversion = n.mask_conversion
elif isinstance(n, ColorChannelMaskConversionCompletedNode):
temp_mask_conversion = n.mask_conversion
elif isinstance(n, ColorChannelSelectionCompletedNode):
temp_color_channel_selection = n.color_channel_selection
elif isinstance(n, PartitionSelectionCompletedNode):
temp_partition_selection = n.partition_selection
else:
raise ValueError()
return OperationSet(operations)
except Exception as e:
print(f"error: {e}")
return OperationSet([])
def waiting_nodes(self) -> List[WaitingNode]:
return list(
filter(
lambda n: n is not None,
map(lambda n: n.parent_waiting_node, self.completed_nodes),
)
)
class NodeEvaluator:
def evaluate(self, node: WaitingNode):
raise NotImplementedError()
def evaluate_nodes(self, nodes: List[WaitingNode]):
raise NotImplementedError()
class RandomNodeEvaluator(NodeEvaluator):
def evaluate(self, node: WaitingNode):
node.cache_pred_distance = random.uniform(0, 1) * node.depth()
def evaluate_nodes(self, nodes: List[WaitingNode]):
for n in nodes:
self.evaluate(n)
@dataclass
class AnswerStorageElement:
task_name: str
correct: bool
depth: int
operation_set: OperationSet
def __post_init__(self):
self.depth = len(self.operation_set.operations)
def validate(self):
task = TaskLoader().get_task(self.task_name)
try:
a = AnswerMatcher.is_train_test_all_match_if_operated(
task, self.operation_set
)
if a != self.correct:
print(f"{self.task_name} correct inconsistency. {self.correct}_{a}")
return False
except OperationInconsistencyException as e:
print(f"{self.task_name} OperationInconsistencyException")
return False
return True
def __hash__(self):
return hash(repr(self))
@dataclass
class AnsweredSearchResult:
operation_set: OperationSet
test_output_arr: Tuple[np.ndarray] = None
test_correct: Optional[bool] = None
@dataclass
class AnsweredSearchResults:
task: Task
results: List[AnsweredSearchResult]
zero_depth_search_time: float
spent_time: float
searched_total_node: int
def summary(self):
summary_elements = [
f"{self.task.name}_{i}, "
f"correct: {str(r.test_correct):>5}, "
f"node: {self.searched_total_node:>6}, "
f"zero_depth_sec: {int(self.zero_depth_search_time):>5}, sec: {int(self.spent_time):>5}, "
f"depth: {len(r.operation_set.operations)}, operation_set: {r.operation_set}"
for i, r in enumerate(self.results)
]
return "\n".join(summary_elements)
def final_test_correct(self):
return any(map(lambda r: r.test_correct, self.results))
def to_answer_storage_elements(self) -> List[AnswerStorageElement]:
return [
AnswerStorageElement(
self.task.name,
r.test_correct,
len(r.operation_set.operations),
r.operation_set,
)
for r in self.results
]
@dataclass
class NotAnsweredSearchResult:
task: Task
exception: Exception
spent_time: float
searched_total_node: int
def final_test_correct(self):
return None
def summary(self):
return (
f"{self.task.name}__, "
f"correct: None, "
f"node: {self.searched_total_node:>6}, sec: {int(self.spent_time):>5}, "
f"exception: {self.exception.__class__.__name__}"
)
@dataclass
class AnswerStorage:
elements: Set[AnswerStorageElement]
def validate(self):
self.elements = set(filter(lambda e: e.validate(), self.elements))
def add(self, element: AnswerStorageElement):
self.elements.add(element)
def get_text(self) -> str:
return "\n".join(
repr(e)
for e in sorted(
self.elements, key=lambda e: (e.task_name, not e.correct, e.depth)
)
)
def get_only_correct_answer_storage(self) -> "AnswerStorage":
return AnswerStorage({e for e in self.elements if e.correct})
def get_task_grouped_elements(self) -> List[Tuple[str, List[AnswerStorageElement]]]:
elements = list(self.elements)
elements = sorted(elements, key=lambda e: e.task_name)
return [(k, list(g)) for k, g in groupby(elements, key=lambda e: e.task_name)]
def load_answer_storage() -> AnswerStorage:
if not PathConfig.OPERATION_ANSWER_STORAGE.exists():
return AnswerStorage(set())
elements: List[AnswerStorageElement] = []
with open(
str(PathConfig.OPERATION_ANSWER_STORAGE), mode="r", encoding="utf-8"
) as f:
for l in f.readlines():
try:
elements.append(str_to_AnswerStorageElement(l))
except:
pass
storage = AnswerStorage(set(elements))
storage.validate()
return storage
def save_answer_storage(storage: AnswerStorage):
PathConfig.OPERATION_ANSWER_STORAGE.unlink()
with open(
str(PathConfig.OPERATION_ANSWER_STORAGE), mode="w", encoding="utf-8"
) as f:
f.write(storage.get_text())
def update_answer_storage(elements: List[AnswerStorageElement], verbose: bool = False):
if verbose:
print("load_answer storage")
storage = load_answer_storage()
if verbose:
print(storage.get_text())
print("add answer storage")
for e in elements:
e.validate()
storage.add(e)
if verbose:
print("save answer storage")
print(storage.get_text())
save_answer_storage(storage)
@dataclass
class AnswerFoundException(Exception):
operation_set: OperationSet
class NoImprovementException(Exception):
MESSAGE = "No improve"
class MaxDepthExceededException(Exception):
MESSAGE = "Max depth"
class MaxNodeExceededException(Exception):
MESSAGE = "Max node"
class TimeoutException(Exception):
MESSAGE = "Timeout"
def get_all_operation_classes():
return [
UniformOperation,
ColorOperation,
MultiColorChannelOperation,
PartitionOperation,
]
def get_all_operation_element_classes():
classes = [
UniformOperation,
ColorSelection,
MaskConversion,
MaskOperation,
ColorChannelSelection,
ChannelMergeOperation,
PartitionSelection,
PartitionMergeOperation,
]
return chain.from_iterable([c.__subclasses__() for c in classes])
@unique
class BackGroundColorSelectionMode(StrNameEnum):
BLACK = auto()
MOST_COMMON = auto()
@unique
class AxisV2(StrNameEnum):
VERTICAL = auto()
HORIZONTAL = auto()
VERTICAL_HORIZONTAL = auto()
MAIN_DIAGONAL = auto()
ANTI_DIAGONAL = auto()
BOTH_DIAGONAL = auto()
@unique
class Corner(StrNameEnum):
TOP_LEFT = auto()
TOP_RIGHT = auto()
BOTTOM_RIGHT = auto()
BOTTOM_LEFT = auto()
@unique
class SpiralDirection(StrNameEnum):
CLOCKWISE = auto()
ANTICLOCKWISE = auto()
class DebugConfig:
OPERATION_DEBUG_TASK_NAME = "" # dae9d2b5
OPERATION_DEBUG_OPERATION_SET = ""
# solve debug
SOLVE_DEBUG_TASK_NAME = "" # dae9d2b5
# train_data_generator debug
TRAIN_DATA_GENERATION_DEBUG_TASK_NAME = ""
class PathConfig:
ROOT: Path = (
Path("") if RunConfig.RUN_MODE == RunMode.KERNEL else Path(__file__).parent
)
# input
INPUT_ROOT: Path = ROOT / "input"
TRAIN_ROOT: Path = INPUT_ROOT / "training" # training_and_evaluation
EVALUATION_ROOT: Path = INPUT_ROOT / "evaluation"
TEST_ROOT: Path = INPUT_ROOT / "test"
SAMPLE_SUBMISSION: Path = INPUT_ROOT / "sample_submission.csv"
# output
OUTPUT_SUBMISSION: Path = ROOT / "output" / "submission.csv"
# answer_memo
OPERATION_ANSWER_MEMO_ROOT: Path = ROOT / "answer_memo"
OPERATION_ANSWER_TAXONOMY_YAML: Path = (
OPERATION_ANSWER_MEMO_ROOT / "answer_taxonomy.yaml"
)
OPERATION_ANSWER_TAXONOMY_IMAGE_ROOT: Path = (
OPERATION_ANSWER_MEMO_ROOT / "answer_taxonomy"
)
OPERATION_ANSWER_STORAGE: Path = OPERATION_ANSWER_MEMO_ROOT / "answer_storage.txt"
WRONG_ANSWERS_ROOT: Path = OPERATION_ANSWER_MEMO_ROOT / "wrong_answers"
# kernel
KERNEL_SCRIPT_PATH: Path = ROOT / "kernel" / "kernel_script.py"
# run
LOG_ROOT: Path = ROOT / "log"
# ml_model
SAVED_MODEL: Path = ROOT / "saved_model"
NODE_EVALUATOR_FEATURES = SAVED_MODEL / "features.pkl"
NODE_EVALUATOR_CATEGORICAL_FEATURES = SAVED_MODEL / "categorical_features.pkl"
NODE_EVALUATOR_MODEL = SAVED_MODEL / "model.pkl"
NODE_EVALUATOR_ORDINAL_ENCODER = SAVED_MODEL / "ordinal_encoder.pkl"
NODE_EVALUATOR_SAMPLE_DF = SAVED_MODEL / "sample_df.pkl"
OPERATION_ELEMENT_INCLUSION_MODEL_ROOT = SAVED_MODEL / "operation_element_inclusion"
OPERATION_ELEMENT_INCLUSION_MODEL = (
OPERATION_ELEMENT_INCLUSION_MODEL_ROOT / "model.pkl"
)
OPERATION_ELEMENT_INCLUSION_MODEL_TARGET_COLUMNS = (
OPERATION_ELEMENT_INCLUSION_MODEL_ROOT / "target_columns.pkl"
)
OPERATION_ELEMENT_INCLUSION_MODEL_FEATURE_COLUMNS = (
OPERATION_ELEMENT_INCLUSION_MODEL_ROOT / "feature_columns.pkl"
)
# ml_training_data
LABELED_TRAINING_DATA_ROOT = ROOT / "training"
class KernelPathConfig:
INPUT_ROOT = Path("/kaggle/input/abstraction-and-reasoning-challenge/")
TRAIN_ROOT: Path = INPUT_ROOT / "training"
EVALUATION_ROOT: Path = INPUT_ROOT / "evaluation"
# TEST_ROOT: Path = INPUT_ROOT / 'test'
TEST_ROOT: Path = Path("test_aligned")
SAMPLE_SUBMISSION: Path = INPUT_ROOT / "sample_submission.csv"
SUBMISSION = "submission_yuki_alignment.csv"
def create_submission(
engine_results: List[Union[AnsweredSearchResults, NotAnsweredSearchResult]]
):
submission_df = DataFrame(columns=["output_id", "output"])
for result in engine_results:
test_arr_num = len(result.task.test)
for i in range(test_arr_num):
if isinstance(result, AnsweredSearchResults):
answers = [r.test_output_arr[i] for r in result.results]
answers += [None for _ in range(3 - len(answers))]
elif isinstance(result, NotAnsweredSearchResult):
answers = [None] * 3
else:
raise NotImplementedError()
output_str = " ".join(map(lambda a: parse_str(a), answers)) + " "
d = {"output_id": f"{result.task.name}_{i}", "output": output_str}
submission_df = submission_df.append([d])
return submission_df
def parse_str(arr: np.ndarray) -> str:
if arr is None:
return "|0|"
return "|" + "|".join(map(lambda row: "".join(str(v) for v in row), arr)) + "|"
def save_submission_df(submission_df: DataFrame):
if RunConfig.RUN_MODE == RunMode.KERNEL:
submission_df.to_csv(KernelPathConfig.SUBMISSION, index=False)
else:
PathConfig.OUTPUT_SUBMISSION.parent.mkdir(parents=True, exist_ok=True)
submission_df.to_csv(PathConfig.OUTPUT_SUBMISSION, index=False)
def plot_one(ax, arr: np.ndarray, i, train_or_test, input_or_output):
cmap = colors.ListedColormap(
[
"#000000",
"#0074D9",
"#FF4136",
"#2ECC40",
"#FFDC00",
"#AAAAAA",
"#F012BE",
"#FF851B",
"#7FDBFF",
"#870C25",
]
)
norm = colors.Normalize(vmin=0, vmax=9)
ax.imshow(arr, cmap=cmap, norm=norm)
ax.grid(True, which="both", color="lightgrey", linewidth=0.5)
ax.set_yticks([x - 0.5 for x in range(1 + len(arr))])
ax.set_xticks([x - 0.5 for x in range(1 + len(arr[0]))])
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_title(train_or_test + " " + input_or_output)
def plot_task(task: Task, show: bool, save_path: Optional[Path]):
input_output_num = len(task.train + task.test)
total_row = 2
fig, axs = plt.subplots(
total_row, input_output_num, figsize=(2 * input_output_num, 2 * total_row)
)
for i, (input_output, tag) in enumerate(
zip(
task.train + task.test,
["train"] * len(task.train) + ["test"] * len(task.test),
)
):
plot_one(axs[0, i], input_output.input_arr, i, tag, "input")
plot_one(axs[1, i], input_output.output_arr, i, tag, "output")
plt.tight_layout()
if save_path:
save_path.parent.mkdir(parents=True, exist_ok=True)
plt.savefig(save_path)
if show:
plt.show()
plt.close()
def plot_task_with_operation_set(
task: Task, operation_set: OperationSet, show: bool, save_path: Optional[Path]
):
input_output_num = len(task.train + task.test)
total_row = 3
applied_task = TaskOperationSetExecutor().execute(task, operation_set)
fig, axs = plt.subplots(
total_row, input_output_num, figsize=(3 * input_output_num, 3 * total_row)
)
for i, (raw_io, applied_io) in enumerate(
zip(task.train + task.test, applied_task.train + applied_task.test)
):
plot_one(axs[0, i], raw_io.input_arr, i, "train?", "input")
plot_one(axs[1, i], raw_io.output_arr, i, "train?", "output")
plot_one(axs[2, i], applied_io.input_arr, i, "train?", "operated")
plt.tight_layout()
if save_path:
save_path.parent.mkdir(parents=True, exist_ok=True)
plt.savefig(save_path)
if show:
plt.show()
plt.close()
def plot_task_with_result_set(
task: Task,
search_results: AnsweredSearchResults,
show: bool,
save_path: Optional[Path],
):
input_output_num = len(task.train + task.test)
total_row = 2 + len(search_results.results)
applied_tasks = [
TaskOperationSetExecutor().execute(task, r.operation_set)
for r in search_results.results
]
fig, axs = plt.subplots(
total_row, input_output_num, figsize=(3 * input_output_num, 3 * total_row)
)
for i, input_output in enumerate(task.train + task.test):
plot_one(axs[0, i], input_output.input_arr, i, "train?", "input")
plot_one(axs[1, i], input_output.output_arr, i, "train?", "output")
for i, t in enumerate(applied_tasks):
for j, input_output in enumerate(t.train + t.test):
plot_one(axs[i + 2, j], input_output.input_arr, i, "train?", "input")
plt.tight_layout()
if save_path:
save_path.parent.mkdir(parents=True, exist_ok=True)
plt.savefig(save_path)
if show:
plt.show()
plt.close()
@dataclass(frozen=True)
class Padding(UniformOperation):
padding_mode: PaddingMode
direction: Direction
k: int
def __call__(self, arr: np.ndarray) -> np.ndarray:
if self.padding_mode == PaddingMode.REPEAT:
np_pad_mode = "wrap"
elif self.padding_mode == PaddingMode.MIRROR_1:
np_pad_mode = "symmetric"
elif self.padding_mode == PaddingMode.MIRROR_2:
np_pad_mode = "reflect"
elif self.padding_mode == PaddingMode.EDGE:
np_pad_mode = "edge"
else:
raise ValueError(self.padding_mode)
h, w = arr.shape
if self.padding_mode == PaddingMode.MIRROR_2:
h, w = h - 1, w - 1
if self.direction == Direction.TOP:
pad_width = ((self.k * h, 0), (0, 0))
elif self.direction == Direction.BOTTOM:
pad_width = ((0, self.k * h), (0, 0))
elif self.direction == Direction.LEFT:
pad_width = ((0, 0), (self.k * w, 0))
elif self.direction == Direction.RIGHT:
pad_width = ((0, 0), (0, self.k * w))
else:
raise ValueError(self.direction)
return np.pad(arr, pad_width, mode=np_pad_mode)
@dataclass(frozen=True)
class Resize(UniformOperation):
axis: Axis
ratio: int # TODO int? How to resize 3/2?
def __call__(self, arr: np.ndarray) -> np.ndarray:
if self.axis == Axis.VERTICAL:
return np.repeat(arr, self.ratio, axis=0)
elif self.axis == Axis.HORIZONTAL:
return np.repeat(arr, self.ratio, axis=1)
elif self.axis == Axis.BOTH:
temp = np.repeat(arr, self.ratio, axis=0)
return np.repeat(temp, self.ratio, axis=1)
else:
raise ValueError(self.axis)
@dataclass(frozen=True)
class Flip(UniformOperation):
flip_mode: FlipMode
def __call__(self, arr: np.ndarray) -> np.ndarray:
if self.flip_mode == FlipMode.UD:
return np.flipud(arr)
elif self.flip_mode == FlipMode.LR:
return np.fliplr(arr)
elif self.flip_mode == FlipMode.UL_DR:
return arr.T
elif self.flip_mode == FlipMode.UR_DL:
return np.flipud(np.flipud(arr.T))
else:
raise ValueError(self.flip_mode)
@dataclass(frozen=True)
class Rotate(UniformOperation):
angle: int
def __call__(self, arr: np.ndarray) -> np.ndarray:
if self.angle not in [90, 180, 270]:
raise ValueError(self.angle)
return np.rot90(arr, self.angle // 90)
@dataclass(frozen=True)
class LineDeletion(UniformOperation):
line_color: Color
def __call__(self, arr: np.ndarray) -> np.ndarray:
if arr.size == 1:
raise OperationInconsistencyException("size == 1")
if 1 in arr.shape:
raise OperationInconsistencyException("can not separate")
color_hit: np.ndarray = arr == self.line_color
line_v_indices = np.where(color_hit.all(axis=1))[0]
line_h_indices = np.where(color_hit.all(axis=0))[0]
if len(line_v_indices) == len(line_h_indices) == 0:
raise OperationInconsistencyException("not line found")
arr = np.delete(arr, line_h_indices, axis=1)
arr = np.delete(arr, line_v_indices, axis=0)
if 0 in arr.shape:
raise OperationInconsistencyException("0 size")
return arr
@dataclass(frozen=True)
class FFTCompletion(UniformOperation):
# TODO GIVE UP implement.
# This is just a poc for "SYMMETRY" or "REPEAT" pattern tasks.
# If you're interested in this function, let me know. I'll translate it.
def __call__(self, arr: np.ndarray) -> np.ndarray:
revs = []
for color in Color:
print(color)
color_hit = arr == color
if color == Color.BLACK or not color_hit.any():
revs.append(np.full_like(color_hit, fill_value=False))
continue
rev_arr_int = self.complete_symmetric(color_hit)
rev_arr_int = self.complete_symmetric(rev_arr_int)
rev_arr_int = self.complete_symmetric(rev_arr_int)
revs.append(rev_arr_int)
for color, rev in zip(Color, revs):
arr[rev] = color
return arr
def complete_symmetric(self, hit_arr, verbose=False):
h, w = hit_arr.shape
if verbose:
print(hit_arr)
f = np.fft.fftshift(np.fft.fft2(hit_arr))
if verbose:
print(f)
amp = np.abs(f)
if verbose:
print(amp)
amp = amp / h / w * 2
if verbose:
print(amp)
print(f"sum {amp.sum()}")
print(f"mean {amp.mean()}")
print(f"max {amp.max()}")
# TODO detect peakのパラメータ調整
flags = np.array(self.detect_not_peaks_mask(amp))
if verbose:
print(flags)
f[flags] = 0
filtered_amp = amp.copy()
filtered_amp[f == 0] = 0
# F3_abs = np.abs(f) # 複素数を絶対値に変換
# F3_abs_amp = F3_abs / h / w * 2 # 交流成分はデータ数で割って2倍
# F3_abs_amp[0] = F3_abs_amp[0] / 2 # 直流成分(今回は扱わないけど)は2倍不要
F3_ifft = np.fft.ifft2(np.fft.ifftshift(f)) # IFFT
F3_ifft_real = F3_ifft.real # 実数部の取得
# TODO 2値化アルゴリズム検討
rev_arr_int = F3_ifft_real > threshold_minimum(F3_ifft_real)
if verbose:
fig, ax = try_all_threshold(F3_ifft_real, figsize=(10, 8), verbose=False)
plt.show()
# visualize
plt.subplot(171)
plt.imshow(hit_arr, cmap="gray")
plt.title("Input Image"), plt.xticks([]), plt.yticks([])
plt.subplot(172)
plt.hist(amp.ravel(), bins=100)
plt.title("Input Image"), plt.xticks([]), plt.yticks([])
plt.subplot(173)
plt.imshow(amp, cmap="gray")
plt.title("Magnitude Spectrum"), plt.xticks([]), plt.yticks([])
plt.subplot(174)
plt.imshow(filtered_amp, cmap="gray")
plt.title("Magnitude Spectrum"), plt.xticks([]), plt.yticks([])
plt.subplot(175)
plt.hist(F3_ifft_real.ravel(), bins=100)
plt.subplot(176)
plt.imshow(rev_arr_int, cmap="gray")
plt.title("rev"), plt.xticks([]), plt.yticks([])
plt.subplot(177)
plt.imshow(rev_arr_int | hit_arr, cmap="gray")
plt.title("and"), plt.xticks([]), plt.yticks([])
plt.show()
return rev_arr_int
def detect_not_peaks_mask(self, image, filter_size=3, order=0.05):
local_max = maximum_filter(
image, footprint=np.ones((filter_size, filter_size)), mode="constant"
)
detected_peaks = np.ma.array(image, mask=~(image == local_max))
# 小さいピーク値を排除(最大ピーク値のorder倍のピークは排除)
temp = np.ma.array(
detected_peaks, mask=~(detected_peaks >= detected_peaks.max() * order)
)
return temp.mask
@dataclass(frozen=True)
class FixedColorMaskFill(MaskOperation):
color: Color
def __call__(self, arr: np.ndarray, mask: np.ndarray) -> np.ndarray:
arr[mask] = self.color
return arr
@dataclass(frozen=True)
class SingleColorMaskFill(MaskOperation):
single_color_selection_mode: SingleColorSelectionMode
def __call__(self, arr: np.ndarray, mask: np.ndarray) -> np.ndarray:
color = ColorSelectionUtil().select_single_color(
arr, self.single_color_selection_mode
)
arr[mask] = color
return arr
@dataclass(frozen=True)
class MaskCoordsCrop(MaskOperation):
def __call__(self, arr: np.ndarray, mask: np.ndarray) -> np.ndarray:
# TODO raise OperationInconsistencyException?
if not mask.any():
return arr
coords = np.argwhere(mask)
x_min, y_min = coords.min(axis=0)
x_max, y_max = coords.max(axis=0)
return arr[x_min : x_max + 1, y_min : y_max + 1]
@dataclass(frozen=True)
class FixedSingleColorSelection(ColorSelection):
color: Color
def __call__(self, arr: np.ndarray) -> np.ndarray:
return arr == self.color
@dataclass(frozen=True)
class SingleColorSelection(ColorSelection):
single_color_selection_mode: SingleColorSelectionMode
def __call__(self, arr: np.ndarray) -> np.ndarray:
color = ColorSelectionUtil().select_single_color(
arr, self.single_color_selection_mode
)
return arr == color
@dataclass(frozen=True)
class MultiColorSelection(ColorSelection):
multi_color_selection_mode: MultiColorSelectionMode
def __call__(self, arr: np.ndarray) -> np.ndarray:
if (
self.multi_color_selection_mode
== MultiColorSelectionMode.ANY_WITHOUT_MOST_COMMON
):
most_common_color = ColorSelectionUtil().select_single_color(
arr, SingleColorSelectionMode.MOST_COMMON
)
return arr != most_common_color
elif (
self.multi_color_selection_mode
== MultiColorSelectionMode.ANY_WITHOUT_LEAST_COMMON
):
least_common_color = ColorSelectionUtil().select_single_color(
arr, SingleColorSelectionMode.LEAST_COMMON
)
return arr != least_common_color
else:
raise NotImplementedError()
class TaskLoader:
def get_task(self, name: str) -> Task:
try:
return self._get_task(PathConfig.TRAIN_ROOT / f"{name}.json")
except FileNotFoundError:
return self._get_task(PathConfig.EVALUATION_ROOT / f"{name}.json")
def get_training_tasks(self):
if RunConfig.RUN_MODE == RunMode.KERNEL:
return self._get_tasks(KernelPathConfig.TRAIN_ROOT)
else:
return self._get_tasks(PathConfig.TRAIN_ROOT)
def get_evaluation_tasks(self):
if RunConfig.RUN_MODE == RunMode.KERNEL:
return self._get_tasks(KernelPathConfig.EVALUATION_ROOT)
else:
return self._get_tasks(PathConfig.EVALUATION_ROOT)
def get_test_tasks(self):
if RunConfig.RUN_MODE == RunMode.KERNEL:
return self._get_tasks(KernelPathConfig.TEST_ROOT)
else:
return self._get_tasks(PathConfig.TEST_ROOT)
def _get_tasks(self, root_path: Path) -> List[Task]:
return [self._get_task(json_path) for json_path in root_path.iterdir()]
def _get_task(self, path: Path) -> Task:
with open(str(path), "r") as f:
return Task.of(path.stem, json.load(f))
def is_private_lb_run(self) -> bool:
eval_tasks = self._get_tasks(KernelPathConfig.EVALUATION_ROOT)
test_tasks = self._get_tasks(KernelPathConfig.TEST_ROOT)
eval_names = [t.name for t in eval_tasks]
if any(filter(lambda t: t.name in eval_names, test_tasks)):
return False
else:
return True
def create_image_feature(arr: np.ndarray) -> ImageFeature:
return ImageFeature(
height=arr.shape[0],
width=arr.shape[1],
colors=[Color.of(v) for v in ColorSelectionUtil().get_colors(arr)],
hit_and_miss_histogram=calculate_hit_and_miss_histogram(arr),
# most_common_color=ColorSelectionUtil().select_single_color(arr, SingleColorSelectionMode.MOST_COMMON),
vertical_edge_num=np.count_nonzero(
arr[1:] - arr[:-1]
), # faster than np.diff(arr, axis=0)
horizontal_edge_num=np.count_nonzero(
arr[:, 1:] - arr[:, :-1]
), # faster than np.diff(arr, axis=1)
)
def create_image_diff_feature(
original_input_arr: np.ndarray, input_arr: np.ndarray, output_arr: np.ndarray
) -> ImageDiffFeature:
util = FeatureUtil()
in_feature = create_image_feature(input_arr)
out_feature = create_image_feature(output_arr)
return ImageDiffFeature(
input_image_feature=in_feature,
output_image_feature=out_feature,
dim_height_increase=out_feature.height - in_feature.height,
dim_width_increase=out_feature.width - in_feature.width,
dim_height_integer_multiple=(
out_feature.height / in_feature.height
).is_integer()
or (in_feature.height / out_feature.height).is_integer(),
dim_width_integer_multiple=(out_feature.width / in_feature.width).is_integer()
or (in_feature.width / out_feature.width).is_integer(),
dim_height_diff=abs(out_feature.height - in_feature.height),
dim_width_diff=abs(out_feature.width - in_feature.width),
dim_height_equal=out_feature.height == in_feature.height,
dim_width_equal=out_feature.width == in_feature.width,
lack_color_num=len(set(out_feature.colors) - set(in_feature.colors)),
excess_color_num=len(set(in_feature.colors) - set(out_feature.colors)),
hit_and_miss_histogram_diff=sum(
abs(i_c - o_c)
for i_c, o_c in zip(
in_feature.hit_and_miss_histogram, out_feature.hit_and_miss_histogram
)
),
# vertical_diff_input_arr_line_num=util._vertical_diff_input_arr_line_num(input_arr, output_arr),
# horizontal_diff_input_arr_line_num=util._horizontal_diff_input_arr_line_num(input_arr, output_arr),
# vertical_diff_output_arr_line_num=util._vertical_diff_output_arr_line_num(input_arr, output_arr),
# horizontal_diff_output_arr_line_num=util._horizontal_diff_output_arr_line_num(input_arr, output_arr),
vertical_edge_sum_diff=abs(
out_feature.vertical_edge_num - in_feature.vertical_edge_num
),
horizontal_edge_sum_diff=abs(
out_feature.horizontal_edge_num - in_feature.horizontal_edge_num
),
vertical_edge_sum_diff_ratio=abs(
out_feature.vertical_edge_num - in_feature.vertical_edge_num
)
/ in_feature.width,
horizontal_edge_sum_diff_ratio=abs(
out_feature.horizontal_edge_num - in_feature.horizontal_edge_num
)
/ in_feature.height,
diff_color_cell_ratio=util._diff_cell_count_ratio(input_arr, output_arr),
diff_cell_where_no_need_to_change_count_ratio=util._diff_cell_where_no_need_to_change_count_ratio(
original_input_arr, input_arr, output_arr
),
wrong_change_cell_where_need_to_change_count_ratio=util._wrong_change_cell_where_need_to_change_count_ratio(
original_input_arr, input_arr, output_arr
),
)
def create_task_feature(original_task: Task, task: Task) -> TaskFeature:
diff_features = [
create_image_diff_feature(o_io.input_arr, io.input_arr, io.output_arr)
for o_io, io in zip(original_task.train, task.train)
]
return TaskFeature(
# image_diff_features=image_diff_features,
same_dim_between_input_output=all(f.same_dim() for f in diff_features),
same_height_dim_between_input_output=all(
f.dim_height_equal for f in diff_features
),
same_width_dim_between_input_output=all(
f.dim_width_equal for f in diff_features
),
all_dim_height_increased=all(f.dim_height_increase > 0 for f in diff_features),
all_dim_height_decreased=all(f.dim_height_increase < 0 for f in diff_features),
all_dim_width_increased=all(f.dim_width_increase > 0 for f in diff_features),
all_dim_width_decreased=all(f.dim_width_increase < 0 for f in diff_features),
all_dim_height_integer_multiple=all(
f.dim_height_integer_multiple for f in diff_features
),
all_dim_width_integer_multiple=all(
f.dim_width_integer_multiple for f in diff_features
),
mean_lack_color_num=mean([f.lack_color_num for f in diff_features]),
mean_excess_color_num=mean([f.excess_color_num for f in diff_features]),
mean_hit_and_miss_histogram_diff=mean(
[f.hit_and_miss_histogram_diff for f in diff_features]
),
# mean_vertical_diff_input_arr_line_num=nan_mean(f.vertical_diff_input_arr_line_num for f in diff_features),
# mean_horizontal_diff_input_arr_line_num=nan_mean(f.horizontal_diff_input_arr_line_num for f in diff_features),
# mean_vertical_diff_output_arr_line_num=nan_mean(f.vertical_diff_output_arr_line_num for f in diff_features),
# mean_horizontal_diff_output_arr_line_num=nan_mean(f.horizontal_diff_output_arr_line_num for f in diff_features),
mean_vertical_edge_sum_diff=mean(
[f.vertical_edge_sum_diff for f in diff_features]
),
mean_horizontal_edge_sum_diff=mean(
[f.horizontal_edge_sum_diff for f in diff_features]
),
mean_vertical_edge_sum_diff_ratio=mean(
[f.vertical_edge_sum_diff_ratio for f in diff_features]
),
mean_horizontal_edge_sum_diff_ratio=mean(
[f.horizontal_edge_sum_diff_ratio for f in diff_features]
),
mean_diff_color_cell_ratio=nan_mean(
f.diff_color_cell_ratio for f in diff_features
),
mean_diff_cell_where_no_need_to_change_count_ratio=nan_mean(
f.diff_cell_where_no_need_to_change_count_ratio for f in diff_features
),
mean_wrong_change_cell_where_need_to_change_count_ratio=nan_mean(
f.wrong_change_cell_where_need_to_change_count_ratio for f in diff_features
),
)
def create_color_selected_task_feature(
original_task: Task,
color_selected_task: ColorSelectedTask,
task_feature: TaskFeature = None,
) -> ColorSelectedTaskFeature:
if task_feature is None:
task_feature = create_task_feature(original_task, color_selected_task)
return ColorSelectedTaskFeature(task_feature)
def create_mask_conversion_task_feature(
original_task: Task,
mask_converted_task: MaskConvertedTask,
task_feature: TaskFeature = None,
) -> MaskConvertedTaskFeature:
if task_feature is None:
task_feature = create_task_feature(original_task, mask_converted_task)
possible_improve_ratios = [
_calculate_possible_improve_ratio(io.input_arr, io.output_arr, m)
for io, m in zip(mask_converted_task.train, mask_converted_task.train_masks)
]
return MaskConvertedTaskFeature(
task_feature=task_feature,
possible_improve_ratios=possible_improve_ratios,
)
def _calculate_possible_improve_ratio(
input_arr: np.ndarray, output_arr: np.ndarray, mask: np.ndarray
) -> Optional[float]:
if input_arr.shape != output_arr.shape:
return None
diff_arr = np.not_equal(input_arr, output_arr)
if not diff_arr.all():
return 1.0
else:
selected_diff_arr = np.logical_and(diff_arr, mask)
return 1 - selected_diff_arr.sum() / diff_arr.sum()
class FeatureUtil:
def _horizontal_diff_input_arr_line_num(
self, input_arr: np.ndarray, output_arr: np.ndarray
) -> Optional[float]:
if input_arr.shape[1] != output_arr.shape[1]:
return None
return abs(
input_arr.shape[0]
- np.array([(output_arr == h_l).all(axis=1) for h_l in input_arr])
.any(axis=1)
.sum()
)
def _horizontal_diff_output_arr_line_num(
self, input_arr: np.ndarray, output_arr: np.ndarray
) -> Optional[float]:
if input_arr.shape[1] != output_arr.shape[1]:
return None
return abs(
output_arr.shape[0]
- np.array([(output_arr == h_l).all(axis=1) for h_l in input_arr])
.any(axis=0)
.sum()
)
def _vertical_diff_input_arr_line_num(
self, input_arr: np.ndarray, output_arr: np.ndarray
) -> Optional[float]:
if input_arr.shape[0] != output_arr.shape[0]:
return None
return self._horizontal_diff_input_arr_line_num(input_arr.T, output_arr.T)
def _vertical_diff_output_arr_line_num(
self, input_arr: np.ndarray, output_arr: np.ndarray
) -> Optional[float]:
if input_arr.shape[0] != output_arr.shape[0]:
return None
return self._horizontal_diff_output_arr_line_num(input_arr.T, output_arr.T)
def _diff_cell_count_ratio(
self, input_arr: np.ndarray, output_arr: np.ndarray
) -> Optional[float]:
if input_arr.shape != output_arr.shape:
return None
diff_arr = np.not_equal(input_arr, output_arr)
return diff_arr.sum() / diff_arr.size
def _diff_cell_where_no_need_to_change_count_ratio(
self,
original_input_arr: np.ndarray,
input_arr: np.ndarray,
output_arr: np.ndarray,
) -> Optional[float]:
if not original_input_arr.shape == input_arr.shape == output_arr.shape:
return None
no_need_to_change_mask = np.equal(original_input_arr, output_arr)
diff_cell = np.not_equal(input_arr, output_arr)
diff_cell_where_no_need_to_change = diff_cell[no_need_to_change_mask]
return diff_cell_where_no_need_to_change.sum() / original_input_arr.size
def _wrong_change_cell_where_need_to_change_count_ratio(
self,
original_input_arr: np.ndarray,
input_arr: np.ndarray,
output_arr: np.ndarray,
) -> Optional[float]:
if not original_input_arr.shape == input_arr.shape == output_arr.shape:
return None
need_to_change_mask = np.not_equal(original_input_arr, output_arr)
change_mask = np.not_equal(original_input_arr, input_arr)
wrong_mask = np.not_equal(input_arr, output_arr)
wrong_change_cell_where_need_to_change_mask = (
need_to_change_mask & change_mask & wrong_mask
)
return (
wrong_change_cell_where_need_to_change_mask.sum() / original_input_arr.size
)
def get_hit_and_miss_kernels():
return [
# right top
np.array(
[
[0, -1, -1],
[1, 1, -1],
[0, 1, 0],
],
dtype=np.int8,
),
# right bottom
np.array(
[
[0, 1, 0],
[1, 1, -1],
[0, -1, -1],
],
dtype=np.int8,
),
# left bottom
np.array(
[
[0, 1, 0],
[-1, 1, 1],
[-1, -1, 0],
],
dtype=np.int8,
),
# left top
np.array(
[
[-1, -1, 0],
[-1, 1, 1],
[0, 1, 0],
],
dtype=np.int8,
),
# right protrusion
np.array(
[
[0, -1, -1],
[0, 1, -1],
[0, -1, -1],
],
dtype=np.int8,
),
# bottom protrusion
np.array(
[
[0, 0, 0],
[-1, 1, -1],
[-1, -1, -1],
],
dtype=np.int8,
),
# left protrusion
np.array(
[
[-1, -1, 0],
[-1, 1, 0],
[-1, -1, 0],
],
dtype=np.int8,
),
# top protrusion
np.array(
[
[-1, -1, -1],
[-1, 1, -1],
[0, 0, 0],
],
dtype=np.int8,
),
# TODO implement others?
]
def calculate_hit_and_miss_histogram(arr: np.ndarray):
kernels = get_hit_and_miss_kernels()
exist_colors = np.unique(arr)
counts = []
for color in range(10):
if color not in exist_colors:
for k in kernels:
counts.append(0)
else:
for k in kernels:
color_hit = (arr == color).astype(np.uint8)
hit_and_miss_result = cv2.morphologyEx(color_hit, cv2.MORPH_HITMISS, k)
counts.append(int(hit_and_miss_result.sum()))
# counts = []
# for k in kernels:
# for color in range(10):
# if color not in exist_colors:
# counts.append(0)
# else:
# color_hit = (arr == color).astype(np.uint8)
# hit_and_miss_result = cv2.morphologyEx(color_hit, cv2.MORPH_HITMISS, k)
# counts.append(int(hit_and_miss_result.sum()))
return counts
def summary_engine_results(
results: List[Union[AnsweredSearchResults, NotAnsweredSearchResult]]
):
if len(results) == 0:
return "0 result"
counts = Counter(r.final_test_correct() for r in results)
total_spent_time = np.sum([r.spent_time for r in results]) / 60
mean_spent_time = np.sum([r.spent_time for r in results])
max_spent_time = np.max([r.spent_time for r in results])
result_message = (
f"--- stats --- \n"
f"correct_count: {counts} \n"
f"total_spent_time: {total_spent_time} min \n"
f"mean_spent_time: {mean_spent_time} sec \n"
f"max_spent_time: {max_spent_time} sec \n\n"
)
result_message += "--- answered --- \n"
result_message += "\n".join(
r.summary() for r in results if isinstance(r, AnsweredSearchResults)
)
result_message += "\n--- all --- \n"
result_message += "\n".join(r.summary() for r in results)
return result_message
class ColorSelectionUtil:
def select_single_color(
self, arr: np.ndarray, mode: SingleColorSelectionMode
) -> Color:
if mode == SingleColorSelectionMode.MOST_COMMON:
color_counts = self.get_color_counts(arr)
if len(color_counts) <= 0:
raise OperationInconsistencyException("color <= 0")
try:
if color_counts[-1][1] == color_counts[-2][1]: # Two maximums.
raise OperationInconsistencyException("duplicated max color")
except IndexError:
pass
return Color.of(color_counts[-1][0])
elif mode == SingleColorSelectionMode.SECOND_MOST_COMMON:
color_counts = self.get_color_counts(arr)
if len(color_counts) <= 1:
raise OperationInconsistencyException("color <= 1")
if color_counts[-1][1] == color_counts[-2][1]: # Two maximums.
raise OperationInconsistencyException("duplicated max color")
try:
if color_counts[-2][1] == color_counts[-3][1]: # Two 2nd maximums.
raise OperationInconsistencyException("duplicated 2nd max color")
except IndexError:
pass
return Color.of(color_counts[-2][0])
elif mode == SingleColorSelectionMode.LEAST_COMMON:
color_counts = self.get_color_counts(arr)
if len(color_counts) <= 1:
raise OperationInconsistencyException("color <= 1")
if color_counts[0][1] == color_counts[1][1]: # Two minimum.
raise OperationInconsistencyException("duplicated 2nd max color")
return Color.of(color_counts[0][0])
else:
raise NotImplementedError()
def get_background_color(
self, arr: np.ndarray, mode: BackGroundColorSelectionMode
) -> Color:
if mode == BackGroundColorSelectionMode.BLACK:
return Color.BLACK
elif mode == BackGroundColorSelectionMode.MOST_COMMON:
return self.select_single_color(arr, SingleColorSelectionMode.MOST_COMMON)
else:
raise NotImplementedError()
def get_color_counts(self, arr: np.ndarray) -> List[Tuple[int, int]]:
color_counts = [
(color, count)
for color, count in enumerate(np.bincount(arr.ravel(), minlength=10))
if count != 0
]
return sorted(color_counts, key=itemgetter(1))
def get_colors(self, arr: np.ndarray) -> List[Color]:
return sorted(set(arr.ravel().tolist()))
def select_multi_color(self):
# TODO imple
raise
@dataclass(frozen=True)
class SplitLineSelection(MaskConversion):
axis: Axis
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
result_mask = np.full_like(color_mask, fill_value=False)
if self.axis in [Axis.VERTICAL, Axis.BOTH]:
vertical_line_hits = color_mask.all(axis=0)
result_mask[:, vertical_line_hits] = True
if self.axis in [Axis.HORIZONTAL, Axis.BOTH]:
horizontal_line_hits = color_mask.all(axis=1)
result_mask[horizontal_line_hits] = True
return result_mask
@dataclass(frozen=True)
class DotExistLineSelection(MaskConversion):
axis: Axis
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
result_mask = np.full_like(color_mask, fill_value=False)
if self.axis in [Axis.VERTICAL, Axis.BOTH]:
vertical_line_hits = color_mask.any(axis=0)
result_mask[:, vertical_line_hits] = True
if self.axis in [Axis.HORIZONTAL, Axis.BOTH]:
horizontal_line_hits = color_mask.any(axis=1)
result_mask[horizontal_line_hits] = True
return result_mask
@dataclass(frozen=True)
class ObjectsTouchingEdgeSelection(MaskConversion):
# TODO Direction or Axis property?
true_or_false: TrueOrFalse
connectivity: PixelConnectivity
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
label_array, max_label_index = label(
color_mask,
connectivity=self.connectivity.value_for_skimage,
background=False,
return_num=True,
)
if max_label_index == 0:
return np.full_like(color_mask, order="C", fill_value=False)
target_indices = [
i
for i in range(1, max_label_index + 1)
if self._is_target(label_array == i)
]
return np.isin(label_array, target_indices)
def _is_target(self, arr: np.ndarray) -> bool:
top_line = arr[0]
bottom_line = arr[-1]
left_line = arr[:, 0]
right_line = arr[:, -1]
if self.true_or_false == TrueOrFalse.TRUE:
return any(
[top_line.any(), bottom_line.any(), left_line.any(), right_line.any()]
)
else:
return not any(
[top_line.any(), bottom_line.any(), left_line.any(), right_line.any()]
)
@dataclass(frozen=True)
class ObjectsMaxMinSelection(MaskConversion):
"""Create a mask with max/min feature objects"""
true_or_false: TrueOrFalse
max_or_min: MaxOrMin
object_feature: ObjectFeature
connectivity: PixelConnectivity
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
label_array, max_label_index = label(
color_mask,
connectivity=self.connectivity.value_for_skimage,
background=False,
return_num=True,
)
if max_label_index == 0:
return np.full_like(color_mask, order="C", fill_value=False)
label_indices = list(range(1, max_label_index + 1))
label_index_feature_value_pairs = list(
map(
lambda l: (l, self._calculate_object_feature(label_array, l)),
label_indices,
)
)
target_feature_value = self.max_or_min.func(
label_index_feature_value_pairs, key=itemgetter(1)
)[1]
if self.true_or_false == TrueOrFalse.TRUE:
target_indices = [
l_i
for l_i, f in label_index_feature_value_pairs
if f == target_feature_value
]
else:
target_indices = [
l_i
for l_i, f in label_index_feature_value_pairs
if f != target_feature_value
]
return np.isin(label_array, target_indices)
def _calculate_object_feature(
self, label_array: np.ndarray, label_index: int
) -> int:
if self.object_feature == ObjectFeature.AREA:
return self._label_array_to_area(label_array, label_index)
if self.object_feature == ObjectFeature.HORIZONTAL_LEN:
return self._label_array_to_horizontal_len(label_array, label_index)
if self.object_feature == ObjectFeature.VERTICAL_LEN:
return self._label_array_to_vertical_len(label_array, label_index)
else:
raise NotImplementedError()
def _label_array_to_area(self, label_array: np.ndarray, label_index: int) -> int:
label_hit = label_array == label_index
return label_hit.sum()
def _label_array_to_horizontal_len(
self, label_array: np.ndarray, label_index: int
) -> int:
label_hit = label_array == label_index
horizontal_label_hit = label_hit.any(axis=0)
coords = np.where(horizontal_label_hit)[0]
return max(coords) - min(coords)
def _label_array_to_vertical_len(
self, label_array: np.ndarray, label_index: int
) -> int:
label_hit = label_array == label_index
vertical_label_hit = label_hit.any(axis=1)
coords = np.where(vertical_label_hit)[0]
return max(coords) - min(coords)
@dataclass(frozen=True)
class OldObjectsMaxMinSelection(MaskConversion):
# similar to ObjectsMaxMinSelection
# TODO Without this function, LB will be 0.97 -> 0.98
# TODO why???
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
# TODO should variate hierarchy?
contours, hierarchy = cv2.findContours(
np.ascontiguousarray(color_mask).astype(np.uint8),
cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE,
)
if len(contours) == 0:
return np.full_like(color_mask, order="C", fill_value=False)
max_area_contour = max(contours, key=lambda c: cv2.contourArea(c))
mask = np.full_like(color_mask, order="C", fill_value=False)
mask = cv2.drawContours(
mask.astype(np.uint8), max_area_contour, contourIdx=-1, color=1
)
if isinstance(
mask, cv2.UMat
): # mask sometimes becomes cv2.UMat class... I don't know why.
mask = mask.get()
return mask.astype(bool)
@dataclass(frozen=True)
class SquareObjectsSelection(MaskConversion):
"""Create a mask with only square objects"""
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
color_mask = color_mask.astype(np.uint8)
max_square_len = min(color_mask.shape)
# TODO
# if max_square_len == 1:
# return arr
square_hit = np.full_like(color_mask, fill_value=False, dtype=bool)
for l in range(1, max_square_len):
hit_and_miss_kernel = self._square_hit_and_miss_kenel(l)
filter_kernel = self._filter_kenel(l)
temp_square_hit = cv2.morphologyEx(
color_mask, cv2.MORPH_HITMISS, hit_and_miss_kernel, anchor=(1, 1)
)
temp_square_hit = cv2.filter2D(
temp_square_hit,
-1,
filter_kernel,
anchor=(l - 1, l - 1),
borderType=cv2.BORDER_CONSTANT,
)
square_hit = np.logical_or(square_hit, temp_square_hit.astype(bool))
return square_hit
def _square_hit_and_miss_kenel(self, l: int) -> np.ndarray:
kernel = np.full((l + 2, l + 2), fill_value=1, dtype=np.int8)
kernel[0, :] = -1
kernel[-1, :] = -1
kernel[:, 0] = -1
kernel[:, -1] = -1
return kernel
def _filter_kenel(self, l: int) -> np.ndarray:
return np.full((l, l), fill_value=1, dtype=np.int8)
@dataclass(frozen=True)
class HolesSelection(MaskConversion):
"""Select only the empty hole inside."""
connectivity: PixelConnectivity
# TODO Lack of consideration of the edges of the image?
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
filled = binary_fill_holes(
color_mask, structure=self.connectivity.structure_for_skimage
)
return filled ^ color_mask
@dataclass(frozen=True)
class ObjectInnerSelection(MaskConversion):
connectivity: PixelConnectivity
image_edge_type: ImageEdgeType
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
if self.image_edge_type == ImageEdgeType.EDGE_EXCLUDE:
border_value = 0
elif self.image_edge_type == ImageEdgeType.EDGE_INCLUDE:
border_value = 1
else:
raise NotImplementedError()
return binary_erosion(
color_mask,
structure=self.connectivity.structure_for_skimage,
border_value=border_value,
)
@dataclass(frozen=True)
class ContourSelection(MaskConversion):
"""Create a contour mask"""
connectivity: PixelConnectivity
image_edge_type: ImageEdgeType
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
inner_mask = ObjectInnerSelection(self.connectivity, self.image_edge_type)(
color_mask
)
return np.logical_xor(inner_mask, color_mask)
@dataclass(frozen=True)
class ContourOuterSelection(MaskConversion):
"""Create a mask one pixel outside the contour"""
connectivity: PixelConnectivity
hole_include: HoleInclude
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
if self.hole_include == HoleInclude.INCLUDE:
dilated = binary_dilation(
color_mask,
structure=self.connectivity.structure_for_skimage,
border_value=0,
)
return np.logical_xor(dilated, color_mask)
elif self.hole_include == HoleInclude.EXCLUDE:
dilated = binary_dilation(
color_mask,
structure=self.connectivity.structure_for_skimage,
border_value=0,
)
holes = HolesSelection(self.connectivity)(color_mask)
return np.logical_and(np.logical_xor(dilated, color_mask), ~holes)
else:
raise NotImplementedError()
@dataclass(frozen=True)
class ConnectDotSelection(MaskConversion):
# TODO This function spends much time.
axis: Axis
edge_type: LineEdgeType
fill_type: FillType
def __call__(self, color_mask: np.ndarray) -> np.ndarray:
result_mask = np.full_like(color_mask, fill_value=False)
coords = np.argwhere(color_mask)
if self.axis in [Axis.HORIZONTAL, Axis.BOTH]:
# Calculate the min and max coordinates of the horizontal
horizontal_group = {
k: itemgetter(0, -1)(tuple(map(itemgetter(1), g)))
for k, g in groupby(coords, key=itemgetter(0))
}
# filter
horizontal_group = {
k: (v[0], v[1])
for k, v in horizontal_group.items()
if (v[1] - v[0]) >= 2
}
# maskを計算
for y, (x_min, x_max) in horizontal_group.items():
if self.edge_type == LineEdgeType.EdgeInclude:
pass
elif self.edge_type == LineEdgeType.EdgeExclude:
x_min += 1
x_max -= 1
else:
raise NotImplementedError()
result_mask[y, x_min : x_max + 1] = True
if self.axis in [Axis.VERTICAL, Axis.BOTH]:
# Calculate the min and max coordinates of the vertical
vertical_group = {
k: itemgetter(0, -1)(tuple(map(itemgetter(0), g)))
for k, g in groupby(
sorted(coords, key=itemgetter(1)), key=itemgetter(1)
)
}
# calculate mask
vertical_group = {
k: (v[0], v[1]) for k, v in vertical_group.items() if (v[1] - v[0]) >= 2
}
# generate mask
for x, (y_min, y_max) in vertical_group.items():
if self.edge_type == LineEdgeType.EdgeInclude:
pass
elif self.edge_type == LineEdgeType.EdgeExclude:
y_min += 1
y_max -= 1
else:
raise NotImplementedError()
result_mask[y_min : y_max + 1, x] = True
if self.fill_type == FillType.NotOverride:
result_mask = np.logical_xor(result_mask, color_mask)
return result_mask
class TaskOperationSetExecutor:
def execute(self, task: Task, operation_set: OperationSet) -> Task:
arrays = OperationSetExecutor.apply_operation_set(
[io.input_arr for io in task.train + task.test], operation_set
)
return Task(
task.name,
tuple(
[
InputOutput(a, io.output_arr)
for a, io in zip(arrays[: len(task.train)], task.train)
]
),
tuple(
[
InputOutput(a, io.output_arr)
for a, io in zip(arrays[len(task.train) :], task.test)
]
),
)
class ColorSelectionExecutor:
@staticmethod
def execute(task: Task, color_selection: ColorSelection) -> ColorSelectedTask:
masks = OperationSetExecutor.apply_color_selection(
[io.input_arr for io in task.train + task.test], color_selection
)
return ColorSelectedTask(
task.name,
task.train,
task.test,
masks[: len(task.train)],
masks[len(task.train) :],
)
class MaskConversionExecutor:
@staticmethod
def execute(
task: ColorSelectedTask, mask_conversion: MaskConversion
) -> MaskConvertedTask:
masks = OperationSetExecutor.apply_mask_conversion(
task.train_masks + task.test_masks, mask_conversion
)
return MaskConvertedTask(
task.name,
task.train,
task.test,
masks[: len(task.train_masks)],
masks[len(task.train_masks) :],
)
class MaskOperationExecutor:
@staticmethod
def execute(task: MaskConvertedTask, mask_operation: MaskOperation) -> Task:
new_arrays = OperationSetExecutor.apply_mask_operation(
[io.input_arr for io in task.train + task.test],
task.train_masks + task.test_masks,
mask_operation,
)
train_io = tuple(
[
InputOutput(n, io.output_arr)
for n, io, in zip(new_arrays[: len(task.train)], task.train)
]
)
test_io = tuple(
[
InputOutput(n, io.output_arr)
for n, io, in zip(new_arrays[len(task.train) :], task.train)
]
)
return Task(task.name, train_io, test_io)
class ColorChannelSelectionExecutor:
@staticmethod
def execute(
task: Task, color_channel_selection: ColorChannelSelection
) -> ColorChannelSelectedTask:
color_mask_pairs_list = OperationSetExecutor.apply_channel_selection(
[io.input_arr for io in task.train + task.test], color_channel_selection
)
return ColorChannelSelectedTask(
task.name,
task.train,
task.test,
color_mask_pairs_list[: len(task.train)],
color_mask_pairs_list[len(task.train) :],
)
class ColorChannelMaskConversionSelectionExecutor:
@staticmethod
def execute(
task: ColorChannelSelectedTask, mask_conversion: MaskConversion
) -> ColorChannelMaskConvertedTask:
color_mask_pairs_list = (
OperationSetExecutor.apply_color_channel_mask_conversion(
task.train_color_mask_pairs + task.test_color_mask_pairs,
mask_conversion,
)
)
return ColorChannelMaskConvertedTask(
task.name,
task.train,
task.test,
task.train_color_mask_pairs,
color_mask_pairs_list[: len(task.train_color_mask_pairs)],
task.test_color_mask_pairs,
color_mask_pairs_list[len(task.train_color_mask_pairs) :],
)
class ColorChannelMergeExecutor:
@staticmethod
def execute(
task: ColorChannelMaskConvertedTask, merge_operation: ChannelMergeOperation
) -> Task:
new_arrays = OperationSetExecutor.apply_channel_merge(
[io.input_arr for io in task.train + task.test],
task.train_original_color_mask_pairs + task.test_original_color_mask_pairs,
task.train_color_mask_pairs + task.test_color_mask_pairs,
merge_operation,
)
train_io = tuple(
[
InputOutput(n, io.output_arr)
for n, io, in zip(new_arrays[: len(task.train)], task.train)
]
)
test_io = tuple(
[
InputOutput(n, io.output_arr)
for n, io, in zip(new_arrays[len(task.train) :], task.train)
]
)
return Task(task.name, train_io, test_io)
class PartitionSelectionExecutor:
@staticmethod
def execute(
task: Task, partition_selection: PartitionSelection
) -> PartitionSelectionTask:
array_mask_list = OperationSetExecutor.apply_partition_selection(
[io.input_arr for io in task.train + task.test], partition_selection
)
return PartitionSelectionTask(
task.name,
task.train,
task.test,
array_mask_list[: len(task.train)],
array_mask_list[len(task.train) :],
)
class PartitionMergeExecutor:
@staticmethod
def execute(
task: PartitionSelectionTask, partition_merge_operation: PartitionMergeOperation
) -> Task:
new_arrays = OperationSetExecutor.apply_partition_merge_operation(
[io.input_arr for io in task.train + task.test],
task.train_partitioned_arrays_original_location_masks
+ task.test_partitioned_arrays_original_location_masks,
partition_merge_operation,
)
train_io = tuple(
[
InputOutput(n, io.output_arr)
for n, io, in zip(new_arrays[: len(task.train)], task.train)
]
)
test_io = tuple(
[
InputOutput(n, io.output_arr)
for n, io, in zip(new_arrays[len(task.train) :], task.train)
]
)
return Task(task.name, train_io, test_io)
class CompletedNodeProcessor:
@staticmethod
def process(node: CompletedNode) -> List[WaitingNode]:
mapping = {
UniformOperationCompletedNode: OperationCompletedNodeProcessor,
ColorSelectionCompletedNode: ColorSelectionCompletedNodeProcessor,
MaskConversionCompletedNode: MaskConversionCompletedNodeProcessor,
ColorChannelSelectionCompletedNode: ColorChannelSelectionCompletedNodeProcessor,
ColorChannelMaskConversionCompletedNode: ColorChannelMaskConversionCompletedNodeProcessor,
PartitionSelectionCompletedNode: PartitionSelectionCompletedNodeProcessor,
}
processor = mapping[node.__class__]
return processor.process(node)
class OperationCompletedNodeProcessor:
@classmethod
def process(
cls, node: UniformOperationCompletedNode
) -> List[
Union[
UniformOperationWaitingNode,
ColorSelectionWaitingNode,
ColorChannelSelectionOperationWaitingNode,
]
]:
res = [
*[
UniformOperationWaitingNode(
node,
node.original_task,
node.task,
node.task_feature,
node.base_operation_set,
new_operation,
)
for new_operation in cls._candidate_operations(
node.task, node.task_feature
)
],
*[
ColorSelectionWaitingNode(
node,
node.original_task,
node.task,
node.task_feature,
node.base_operation_set,
color_selection,
)
for color_selection in cls._candidate_color_selections(node.task)
],
*[
ColorChannelSelectionOperationWaitingNode(
node,
node.original_task,
node.task,
node.task_feature,
node.base_operation_set,
color_channel_selection,
)
for color_channel_selection in cls._candidate_color_channel_selection(
node.task
)
],
]
# first operation only
if len(node.base_operation_set.operations) == 0:
res.extend(
[
PartitionSelectionWaitingNode(
node,
node.original_task,
node.task,
node.task_feature,
node.base_operation_set,
partition_selection,
)
for partition_selection in cls._candidate_partition_selection(
node.task
)
]
)
return res
@staticmethod
def _candidate_operations(task: Task, task_feature: TaskFeature):
input_colors = list(
map(
lambda v: Color.of(v),
set(chain.from_iterable(chain.from_iterable(task.get_input_all_arr()))),
)
)
candidates = []
if task_feature.all_dim_height_increased:
candidates += [Resize(Axis.VERTICAL, r) for r in range(2, 5)]
candidates += [
Padding(m, d, k)
for m, d, k in product(
PaddingMode, [Direction.TOP, Direction.BOTTOM], range(1, 4)
)
]
if task_feature.all_dim_width_increased:
candidates += [Resize(Axis.HORIZONTAL, r) for r in range(2, 5)]
candidates += [
Padding(m, d, k)
for m, d, k in product(
PaddingMode, [Direction.LEFT, Direction.RIGHT], range(1, 4)
)
]
if (
task_feature.all_dim_height_decreased
or task_feature.all_dim_width_decreased
):
candidates += [LineDeletion(c) for c in input_colors]
candidates += [
*[Flip(m) for m in FlipMode],
*[Rotate(a) for a in [90, 180, 270]],
]
return candidates
@staticmethod
def _candidate_color_selections(task: Task) -> List[ColorSelection]:
input_colors = list(
map(
lambda v: Color.of(v),
set(chain.from_iterable(chain.from_iterable(task.get_input_all_arr()))),
)
)
return [
*[FixedSingleColorSelection(c) for c in input_colors],
*[SingleColorSelection(m) for m in SingleColorSelectionMode],
*[MultiColorSelection(m) for m in MultiColorSelectionMode],
]
@staticmethod
def _candidate_color_channel_selection(task: Task) -> List[ColorChannelSelection]:
return [
*[
WithOutMostCommonColorChannelSelection(m)
for m in BackGroundColorSelectionMode
]
]
@staticmethod
def _candidate_partition_selection(task: Task) -> List[PartitionSelection]:
input_colors = list(
map(
lambda v: Color.of(v),
set(chain.from_iterable(chain.from_iterable(task.get_input_all_arr()))),
)
)
return [
*[ColorNumIntegerDivisionPartition(axis=a) for a in Axis],
*[
IntegerDivisionPartition(axis=a, n_split=n)
for a, n in product(Axis, range(2, 5))
],
*[GeneralizedLinePartition(m) for m in BackGroundColorSelectionMode],
*[LinePartition(line_color=c) for c in input_colors],
]
class ColorSelectionCompletedNodeProcessor:
@classmethod
def process(
cls, node: ColorSelectionCompletedNode
) -> List[MaskConversionWaitingNode]:
return [
MaskConversionWaitingNode(
node,
node.original_task,
node.color_selected_task,
node.color_selected_task_feature,
node.base_operation_set,
node.color_selection,
mask_conversion,
)
for mask_conversion in cls._candidate_mask_conversions()
]
@staticmethod
def _candidate_mask_conversions() -> List[MaskConversion]:
return [
NoMaskConversion(),
SquareObjectsSelection(),
*[
ObjectsTouchingEdgeSelection(tf, c)
for tf, c in product(TrueOrFalse, PixelConnectivity)
],
*[
ObjectsMaxMinSelection(tf, m, t, c)
for tf, m, t, c in product(
TrueOrFalse, MaxOrMin, ObjectFeature, PixelConnectivity
)
],
OldObjectsMaxMinSelection(),
*[SplitLineSelection(a) for a in Axis],
*[DotExistLineSelection(a) for a in Axis],
*[HolesSelection(c) for c in PixelConnectivity],
*[
ObjectInnerSelection(c, e)
for c, e in product(PixelConnectivity, ImageEdgeType)
],
*[
ContourSelection(c, e)
for c, e in product(PixelConnectivity, ImageEdgeType)
],
*[
ContourOuterSelection(c, h)
for c, h in product(PixelConnectivity, HoleInclude)
],
*[
ConnectDotSelection(a, e, f)
for a, e, f in product(Axis, LineEdgeType, FillType)
],
]
class MaskConversionCompletedNodeProcessor:
@classmethod
def process(
cls, node: MaskConversionCompletedNode
) -> List[MaskOperationSelectionWaitingNode]:
return [
MaskOperationSelectionWaitingNode(
node,
node.original_task,
node.mask_converted_task,
node.mask_converted_task_feature,
node.base_operation_set,
node.color_selection,
node.mask_conversion,
mask_operation,
)
for mask_operation in cls._candidate(node)
]
@staticmethod
def _candidate(node: MaskConversionCompletedNode) -> List[MaskOperation]:
# TODO use
# color_mappings = set(chain.from_iterable(t.candidate_color_mapping() for t in task.train))
output_colors = list(
map(
lambda v: Color.of(v),
set(
chain.from_iterable(
chain.from_iterable(
node.mask_converted_task.get_output_all_arr()
)
)
),
)
)
candidates = []
if (
not node.mask_converted_task_feature.task_feature.same_dim_between_input_output
):
candidates += [MaskCoordsCrop()]
candidates += [
*[FixedColorMaskFill(c) for c in output_colors],
*[SingleColorMaskFill(m) for m in SingleColorSelectionMode],
]
return candidates
class ColorChannelSelectionCompletedNodeProcessor:
@classmethod
def process(
cls, node: ColorChannelSelectionCompletedNode
) -> List[ColorChannelMaskConversionWaitingNode]:
return [
ColorChannelMaskConversionWaitingNode(
node,
node.original_task,
node.task,
node.feature,
node.base_operation_set,
node.color_channel_selection,
mask_conversion,
)
for mask_conversion in cls._candidate_mask_conversions()
]
@staticmethod
def _candidate_mask_conversions() -> List[MaskConversion]:
return [
NoMaskConversion(),
SquareObjectsSelection(),
*[
ObjectsTouchingEdgeSelection(tf, c)
for tf, c in product(TrueOrFalse, PixelConnectivity)
],
*[
ObjectsMaxMinSelection(tf, m, t, c)
for tf, m, t, c in product(
TrueOrFalse, MaxOrMin, ObjectFeature, PixelConnectivity
)
],
OldObjectsMaxMinSelection(),
*[SplitLineSelection(a) for a in Axis],
*[DotExistLineSelection(a) for a in Axis],
*[HolesSelection(c) for c in PixelConnectivity],
*[
ObjectInnerSelection(c, e)
for c, e in product(PixelConnectivity, ImageEdgeType)
],
*[
ContourSelection(c, e)
for c, e in product(PixelConnectivity, ImageEdgeType)
],
*[
ContourOuterSelection(c, h)
for c, h in product(PixelConnectivity, HoleInclude)
],
*[
ConnectDotSelection(a, e, f)
for a, e, f in product(Axis, LineEdgeType, FillType)
],
]
class ColorChannelMaskConversionCompletedNodeProcessor:
@classmethod
def process(
cls, node: ColorChannelMaskConversionCompletedNode
) -> List[ColorChannelMergeWaitingNode]:
return [
ColorChannelMergeWaitingNode(
node,
node.original_task,
node.task,
node.feature,
node.base_operation_set,
node.color_selection,
node.mask_conversion,
merge_operation,
)
for merge_operation in cls._candidate()
]
@staticmethod
def _candidate() -> List[ChannelMergeOperation]:
return [ColorChannelOverrideOperation()]
class PartitionSelectionCompletedNodeProcessor:
@classmethod
def process(
cls, node: PartitionSelectionCompletedNode
) -> List[PartitionMergeWaitingNode]:
return [
PartitionMergeWaitingNode(
node,
node.original_task,
node.task,
node.feature,
node.base_operation_set,
node.partition_selection,
c,
)
for c in cls._candidate(node)
]
@staticmethod
def _candidate(
node: PartitionSelectionCompletedNode,
) -> List[PartitionMergeOperation]:
output_colors = list(
map(
lambda v: Color.of(v),
set(
chain.from_iterable(
chain.from_iterable(node.task.get_output_all_arr())
)
),
)
)
selections = [
*[UniqueColorNumberSelection(m) for m in MaxOrMin],
*[
ColoredCellNumberSelection(m, bg)
for m, bg in product(MaxOrMin, BackGroundColorSelectionMode)
],
*[SameShapeNumSelection(m) for m in MaxOrMin],
*[SymmetrySelection(a, tf) for a, tf in product(AxisV2, TrueOrFalse)],
]
return [
*[
AnySelectionMerge(m, c)
for m, c in product(BackGroundColorSelectionMode, output_colors)
],
*[
NotSelectionMerge(m, c)
for m, c in product(BackGroundColorSelectionMode, output_colors)
],
*[
AllSelectionMerge(m, c)
for m, c in product(BackGroundColorSelectionMode, output_colors)
],
*[
ModifiedXorSelectionMerge(m, c)
for m, c in product(BackGroundColorSelectionMode, output_colors)
],
*[
NaturalArrayOrderedOverrideMerge(m, c, a)
for m, c, a in product(
BackGroundColorSelectionMode,
Corner,
[Axis.VERTICAL, Axis.HORIZONTAL],
)
],
*[
DiagonalArrayOrderedOverrideMerge(m, c, a)
for m, c, a in product(
BackGroundColorSelectionMode,
Corner,
[Axis.VERTICAL, Axis.HORIZONTAL],
)
],
*[
SpiralArrayOrderedOverrideMerge(m, c, d)
for m, c, d in product(
BackGroundColorSelectionMode, Corner, SpiralDirection
)
],
*[UniquelySelectedArrayExtraction(s) for s in selections],
*[
RestoreOnlySelectedArray(m, s)
for m, s in product(BackGroundColorSelectionMode, selections)
],
ExtractOneValueFromPartitionedArray(),
]
class AnswerMatcher:
@staticmethod
def is_match_arr(arr1: np.ndarray, arr2: np.ndarray) -> bool:
return np.array_equal(arr1, arr2)
@classmethod
def is_train_all_match_if_operated(
cls, task: Task, operation_set: OperationSet
) -> bool:
try:
applied_task = TaskOperationSetExecutor().execute(task, operation_set)
return all(
cls.is_match_arr(io.input_arr, io.output_arr)
for io in applied_task.train
)
except OperationInconsistencyException:
return False
@classmethod
def is_train_test_all_match_if_operated(
cls, task: Task, operation_set: OperationSet
) -> bool:
try:
applied_task = TaskOperationSetExecutor().execute(task, operation_set)
return all(
cls.is_match_arr(io.input_arr, io.output_arr)
for io in applied_task.train + applied_task.test
)
except OperationInconsistencyException:
return False
# TODO ?
@classmethod
def is_train_all_match(cls, task: Task) -> bool:
return all(
map(lambda io: cls.is_match_arr(io.input_arr, io.output_arr), task.train)
)
def setup_df_display_options():
np.set_printoptions(threshold=10000)
np.set_printoptions(linewidth=10000)
pd.set_option("display.max_columns", 1000)
pd.set_option("display.max_rows", 1000)
pd.set_option("display.width", 800)
pd.set_option("display.max_colwidth", 300)
def mean(values: List[float]) -> float:
return sum(values) / len(values)
def nan_mean(val_iter: Iterable[Union[int, float]]) -> Optional[float]:
nan_filtered = [v for v in val_iter if v is not None]
if not nan_filtered:
return None
return mean(nan_filtered)
def initialize_path():
if RunConfig.RUN_MODE in [RunMode.LOCAL_RUN_ALL, RunMode.LOCAL_RUN]:
shutil.rmtree(PathConfig.WRONG_ANSWERS_ROOT, ignore_errors=True)
PathConfig.OUTPUT_SUBMISSION.unlink() if PathConfig.OUTPUT_SUBMISSION.exists() else None
@dataclass
class HandMadeNodeEvaluator(NodeEvaluator):
pattern: DepthSearchPattern
operation_element_prob_dict: Dict[str, float]
node_search_engine_param: NodeBaseSearchEngineParameter
dist_eval_param: DistanceEvaluatorParameter
def __post_init__(self):
self.class_mapping = {
UniformOperationWaitingNode: OperationWaitingNodeEvaluator(
self.operation_element_prob_dict
),
ColorSelectionWaitingNode: ColorSelectionWaitingNodeEvaluator(
self.operation_element_prob_dict
),
MaskConversionWaitingNode: MaskConversionWaitingNodeEvaluator(
self.operation_element_prob_dict
),
MaskOperationSelectionWaitingNode: MaskOperationSelectionWaitingNodeEvaluator(
self.operation_element_prob_dict
),
ColorChannelSelectionOperationWaitingNode: ColorChannelSelectionOperationWaitingNodeEvaluator(
self.operation_element_prob_dict
),
ColorChannelMaskConversionWaitingNode: ColorChannelMaskConversionWaitingNodeEvaluator(
self.operation_element_prob_dict
),
ColorChannelMergeWaitingNode: ColorChannelMergeWaitingNodeEvaluator(
self.operation_element_prob_dict
),
PartitionSelectionWaitingNode: PartitionSelectionWaitingNodeEvaluator(
self.operation_element_prob_dict
),
PartitionMergeWaitingNode: PartitionMergeWaitingNodeEvaluator(
self.operation_element_prob_dict
),
}
self.dist_evaluator = DistanceEvaluator(self.dist_eval_param)
def evaluate_nodes(self, nodes: List[WaitingNode]):
for n in nodes:
self.evaluate(n)
def evaluate(self, node: WaitingNode):
evaluator = self.class_mapping[node.__class__]
task_feature = evaluator.get_task_feature(node)
base_distance = self.dist_evaluator.evaluate_task_feature(task_feature)
element_including_prob = evaluator.get_element_inclusion_prob(node)
node.cache_pred_distance = self.calculate_final_distance(
base_distance, element_including_prob, node.depth()
)
def evaluate_base_distance_for_completed_node(self, node: CompletedNode):
return self.dist_evaluator.evaluate_task_feature(node.task_feature)
def calculate_final_distance(
self, base_distance: float, element_inclusion_prob: float, depth: int
) -> float:
prob_cost = self.node_search_engine_param.element_inclusion_prob_factor * (
1 - element_inclusion_prob
)
if self.pattern == DepthSearchPattern.BREADTH_FIRST:
return (
base_distance
** (1 + depth * self.node_search_engine_param.breadth_first_exp_cost)
+ prob_cost
+ self.node_search_engine_param.breadth_first_cost * depth
)
elif self.pattern == DepthSearchPattern.NORMAL:
return (
base_distance
** (1 + depth * self.node_search_engine_param.normal_exp_cost)
+ prob_cost
+ self.node_search_engine_param.normal_first_cost * depth
)
elif self.pattern == DepthSearchPattern.DEPTH_FIRST:
return (
base_distance
** (1 + depth * self.node_search_engine_param.depth_first_exp_cost)
+ prob_cost
+ self.node_search_engine_param.depth_first_cost * depth
)
else:
raise NotImplementedError()
@dataclass
class HandmadeNodeEvaluatorBase:
operation_element_prob_dict: Dict[str, float]
def get_task_feature(self, node) -> TaskFeature:
raise NotImplementedError()
def get_element_inclusion_prob(self, node) -> float:
raise NotImplementedError()
def calculate_dist_factor(self, node) -> float:
raise NotImplementedError()
class OperationWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(
self, operation_waiting_node: UniformOperationWaitingNode
) -> TaskFeature:
return operation_waiting_node.task_feature
def get_element_inclusion_prob(
self, operation_waiting_node: UniformOperationWaitingNode
) -> float:
return self.operation_element_prob_dict[
operation_waiting_node.next_operation.__class__.__name__
]
def calculate_dist_factor(
self, operation_waiting_node: UniformOperationWaitingNode
) -> float:
# TODO use height_integer_multiple?
operation = operation_waiting_node.next_operation
if isinstance(operation, (Flip, Rotate)):
if operation_waiting_node.task_feature.same_dim_between_input_output:
dist_factor = 0.8
else:
dist_factor = 1.2
elif isinstance(operation, (Resize, Padding)):
if operation_waiting_node.task_feature.same_dim_between_input_output:
dist_factor = 1.2
else:
dist_factor = 0.8
else:
raise NotImplementedError(operation)
return dist_factor
class ColorSelectionWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(
self, color_selection_waiting_node: ColorSelectionWaitingNode
) -> TaskFeature:
return color_selection_waiting_node.task_feature
def get_element_inclusion_prob(
self, color_selection_waiting_node: ColorSelectionWaitingNode
) -> float:
return self.operation_element_prob_dict[
color_selection_waiting_node.next_selection.__class__.__name__
]
def calculate_dist_factor(
self, color_selection_waiting_node: ColorSelectionWaitingNode
) -> float:
return 1.0
class MaskConversionWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(
self, mask_conversion_waiting_node: MaskConversionWaitingNode
) -> TaskFeature:
return mask_conversion_waiting_node.color_selected_task_feature.task_feature
def get_element_inclusion_prob(
self, mask_conversion_waiting_node: MaskConversionWaitingNode
) -> float:
return self.operation_element_prob_dict[
mask_conversion_waiting_node.next_mask_conversion.__class__.__name__
]
def calculate_dist_factor(
self, mask_conversion_waiting_node: MaskConversionWaitingNode
) -> float:
return 1.0
class MaskOperationSelectionWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(
self, mask_operation_waiting_node: MaskOperationSelectionWaitingNode
) -> TaskFeature:
return mask_operation_waiting_node.mask_converted_task_feature.task_feature
def get_element_inclusion_prob(
self, mask_operation_waiting_node: MaskOperationSelectionWaitingNode
) -> float:
return self.operation_element_prob_dict[
mask_operation_waiting_node.next_mask_operation.__class__.__name__
]
def calculate_dist_factor(
self, mask_operation_waiting_node: MaskOperationSelectionWaitingNode
) -> float:
return 1.0
class ColorChannelSelectionOperationWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(
self, node: ColorChannelSelectionOperationWaitingNode
) -> TaskFeature:
return node.task_feature
def get_element_inclusion_prob(
self, node: ColorChannelSelectionOperationWaitingNode
) -> float:
return self.operation_element_prob_dict[
node.next_color_channel_selection.__class__.__name__
]
class ColorChannelMaskConversionWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(
self, node: ColorChannelMaskConversionWaitingNode
) -> TaskFeature:
return node.task_feature
def get_element_inclusion_prob(
self, node: ColorChannelMaskConversionWaitingNode
) -> float:
return self.operation_element_prob_dict[
node.next_mask_conversion.__class__.__name__
]
class ColorChannelMergeWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(self, node: ColorChannelMergeWaitingNode) -> TaskFeature:
return node.task_feature
def get_element_inclusion_prob(self, node: ColorChannelMergeWaitingNode) -> float:
return self.operation_element_prob_dict[
node.next_merge_operation.__class__.__name__
]
class PartitionSelectionWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(self, node: PartitionSelectionWaitingNode) -> TaskFeature:
return node.task_feature
def get_element_inclusion_prob(self, node: PartitionSelectionWaitingNode) -> float:
return self.operation_element_prob_dict[
node.next_partition_selection.__class__.__name__
]
class PartitionMergeWaitingNodeEvaluator(HandmadeNodeEvaluatorBase):
def get_task_feature(self, node: PartitionMergeWaitingNode) -> TaskFeature:
return node.task_feature
def get_element_inclusion_prob(self, node: PartitionMergeWaitingNode) -> float:
return self.operation_element_prob_dict[
node.next_partition_merge_operation.__class__.__name__
]
def np_to_str(arr: np.ndarray) -> bytes:
return arr.tostring()
def to_bytes(obj):
return bytes(str(obj), encoding="utf-8")
def train_operation_element_inclusion_prediction():
storage = load_answer_storage()
save_answer_storage(storage)
storage = storage.get_only_correct_answer_storage()
print(storage.get_text())
type_classes = [c.__name__ for c in get_all_operation_classes()]
subclasses = [c.__name__ for c in get_all_operation_element_classes()]
record_dicts = []
for task_name, elements in storage.get_task_grouped_elements():
pseudo_operation_set = OperationSet(
list(chain.from_iterable([e.operation_set.operations for e in elements]))
)
task = TaskLoader().get_task(task_name)
task_feature = create_task_feature(task)
operation_type_classes = [
o_s_t.__name__ for o_s_t in pseudo_operation_set.types()
]
type_answer_dict = {c: c in operation_type_classes for c in type_classes}
operation_element_classes = [
o_s_e.__class__.__name__ for o_s_e in pseudo_operation_set.elements()
]
element_answer_dict = {c: c in operation_element_classes for c in subclasses}
record_dicts.append(
{**asdict(task_feature), **type_answer_dict, **element_answer_dict}
)
df = DataFrame(record_dicts)
df = df.fillna(10) # TODO do not use magic number
target_columns = type_classes + subclasses
feature_columns = list(set(df.columns) - set(target_columns))
x = df[feature_columns]
y = df[target_columns]
print(x)
print(y)
model = MLPClassifier(
# early_stopping=True, validation_fraction=0.3, n_iter_no_change=50,
hidden_layer_sizes=(50,),
solver="sgd",
learning_rate_init=0.003,
max_iter=40,
verbose=True,
)
model.fit(x, y)
shutil.rmtree(PathConfig.OPERATION_ELEMENT_INCLUSION_MODEL_ROOT, ignore_errors=True)
PathConfig.OPERATION_ELEMENT_INCLUSION_MODEL_ROOT.mkdir(parents=True, exist_ok=True)
pickle.dump(model, PathConfig.OPERATION_ELEMENT_INCLUSION_MODEL.open(mode="wb"))
pickle.dump(
feature_columns,
PathConfig.OPERATION_ELEMENT_INCLUSION_MODEL_FEATURE_COLUMNS.open(mode="wb"),
)
pickle.dump(
target_columns,
PathConfig.OPERATION_ELEMENT_INCLUSION_MODEL_TARGET_COLUMNS.open(mode="wb"),
)
temp_dicts = []
for e in sorted(storage.elements, key=lambda e: e.task_name):
task = TaskLoader().get_task(e.task_name)
task_feature = create_task_feature(task)
pred_dict = predict_operation_element_inclusion(task_feature)
operation_type_classes = [o_s_t.__name__ for o_s_t in e.operation_set.types()]
operation_element_classes = [
o_s_e.__class__.__name__ for o_s_e in e.operation_set.elements()
]
element_answer_dict = {
c: c in operation_type_classes + operation_element_classes
for c in type_classes + subclasses
}
temp_dicts.append(element_answer_dict)
temp_dicts.append(pred_dict)
temp_df = DataFrame(temp_dicts)
print(temp_df)
def predict_operation_element_inclusion(task_feature: TaskFeature) -> Dict[str, float]:
model: MLPClassifier = pickle.load(
PathConfig.OPERATION_ELEMENT_INCLUSION_MODEL.open(mode="rb")
)
feature_columns = pickle.load(
PathConfig.OPERATION_ELEMENT_INCLUSION_MODEL_FEATURE_COLUMNS.open(mode="rb")
)
target_columns = pickle.load(
PathConfig.OPERATION_ELEMENT_INCLUSION_MODEL_TARGET_COLUMNS.open(mode="rb")
)
df = DataFrame([asdict(task_feature)])
df = df.fillna(10)
x = df[feature_columns]
y = model.predict_proba(x)[0]
return {c: p for c, p in zip(target_columns, y)}
@dataclass
class NodeBaseSearchEngine:
MAX_NODE = 100000000
answer_limit_num: int = 3
def search(
self, task: Task, params: AllParameter, verbose: bool = False
) -> Union[AnsweredSearchResults, NotAnsweredSearchResult]:
task_feature = create_task_feature(task, task)
if RunConfig.USE_ML_GUIDE:
operation_element_prob_dict = predict_operation_element_inclusion(
task_feature
)
else:
operation_element_prob_dict = defaultdict(lambda: 1)
schedules: NodeEvaluatorSchedules = get_schedule(
operation_element_prob_dict,
params.node_base_engine_param,
params.distance_evaluator_param,
)
node_evaluator = schedules.pop_evaluator()
root_node = UniformOperationCompletedNode(
None, task, task, task_feature, OperationSet([])
)
first_waiting_nodes = CompletedNodeProcessor.process(root_node)
node_evaluator.evaluate_nodes(first_waiting_nodes)
zero_depth_pq = PriorityQueue([*first_waiting_nodes])
pq = PriorityQueue([])
zero_depth_completed_nodes = []
zero_depth_completed_node_eval_map = {}
visited_node_hashes = defaultdict(
dict
) # If same array is found, cache to save time.
if verbose:
print("search zero depth nodes")
with Timer() as timer:
for node_i in range(self.MAX_NODE):
if len(zero_depth_pq) == 0:
break
waiting_new_nodes = []
for same_cost_node_i, waiting_node in enumerate(
zero_depth_pq.pop_mins_or_as_least_n(
params.node_base_engine_param.pq_pop_mins_or_as_least_n
)
):
completed_node = WaitingNodeProcessor().process(waiting_node)
if isinstance(completed_node, Exception):
if verbose:
print(f"skipped: {completed_node}")
continue
if isinstance(completed_node, UniformOperationCompletedNode):
zero_depth_completed_nodes.append(completed_node)
zero_depth_completed_node_eval_map[
completed_node.base_operation_set.operations[0]
] = node_evaluator.evaluate_base_distance_for_completed_node(
completed_node
)
continue
temp_waiting_new_nodes = CompletedNodeProcessor.process(
completed_node
)
node_evaluator.evaluate_nodes(temp_waiting_new_nodes)
waiting_new_nodes += temp_waiting_new_nodes
for n in waiting_new_nodes:
zero_depth_pq.push(n)
one_depth_answer_nodes = [
k for k, v in zero_depth_completed_node_eval_map.items() if v == 0
]
if one_depth_answer_nodes:
answers = []
result_applied_tasks = []
for o in one_depth_answer_nodes:
try:
applied_task = TaskOperationSetExecutor().execute(
task, OperationSet([o])
)
except OperationInconsistencyException:
continue
if any(
applied_task.test_arr_hash() == t.test_arr_hash()
for t in result_applied_tasks
):
continue
result_applied_tasks.append(applied_task)
answers.append(AnsweredSearchResult(OperationSet([o])))
answers = answers[:3]
return AnsweredSearchResults(task, answers, timer.second(), 0, node_i)
zero_depth_search_time = timer.second()
for completed_node in zero_depth_completed_nodes:
train_node_hash = completed_node.train_arr_hash()
all_node_hash = completed_node.all_arr_hash()
if train_node_hash in visited_node_hashes:
if verbose:
print(
f'hash skipped. same node: {"_".join(map(str, (f"{k}:{v}" for k, v in visited_node_hashes[train_node_hash].items())))}'
)
visited_node_hashes[train_node_hash][all_node_hash] = completed_node
continue
visited_node_hashes[train_node_hash][all_node_hash] = completed_node
temp_waiting_new_nodes = CompletedNodeProcessor.process(completed_node)
node_evaluator.evaluate_nodes(temp_waiting_new_nodes)
for n in temp_waiting_new_nodes:
pq.push(n)
# TODO 1 depthものを使って評価関数をいい感じに
# TODO 同じoperationを含むとマイナスな補正をかけないと、まずいかも?
if verbose:
print("search none-zero depth nodes")
searched_total_node = 0
with Timer() as timer:
for node_i in range(self.MAX_NODE):
if len(pq) == 0:
return NotAnsweredSearchResult(
task,
NoImprovementException(),
timer.second(),
searched_total_node,
)
waiting_new_nodes = []
for same_cost_node_i, waiting_node in enumerate(
pq.pop_mins_or_as_least_n(
params.node_base_engine_param.pq_pop_mins_or_as_least_n
)
):
if verbose:
print(
f"total_node: {searched_total_node}, node: {node_i}_{same_cost_node_i}, pq_len: {len(pq)}, cost: {waiting_node.cache_pred_distance}, {waiting_node}"
)
searched_total_node += 1
completed_node = WaitingNodeProcessor().process(waiting_node)
if isinstance(completed_node, Exception):
if verbose:
print(f"skipped: {completed_node}")
continue
if isinstance(completed_node, UniformOperationCompletedNode):
if AnswerMatcher.is_train_all_match(completed_node.task):
answers = []
for t in get_alternative_operation_sets(
task, completed_node, visited_node_hashes, verbose
):
answers.append(
AnsweredSearchResult(t.to_operation_set())
)
if len(answers) == 3:
break
return AnsweredSearchResults(
task,
answers,
zero_depth_search_time,
timer.second(),
searched_total_node,
)
train_node_hash = completed_node.train_arr_hash()
all_node_hash = completed_node.all_arr_hash()
if train_node_hash in visited_node_hashes:
if verbose:
print(
f'hash skipped. same node: {"_".join(map(str, (f"{k}:{v}" for k, v in visited_node_hashes[train_node_hash].items())))}'
)
visited_node_hashes[train_node_hash][
all_node_hash
] = completed_node
continue
visited_node_hashes[train_node_hash][all_node_hash] = completed_node
temp_waiting_new_nodes = CompletedNodeProcessor.process(
completed_node
)
node_evaluator.evaluate_nodes(temp_waiting_new_nodes)
waiting_new_nodes += temp_waiting_new_nodes
if timer.second() > schedules.timeout_sec():
return NotAnsweredSearchResult(
task,
TimeoutException(),
timer.second(),
searched_total_node,
)
for n in waiting_new_nodes:
pq.push(n)
if timer.second() > schedules.next_timing():
if verbose:
print(
"=========================== evaluator switch!!! ==========================="
)
node_evaluator = schedules.pop_evaluator()
if node_evaluator is None:
return NotAnsweredSearchResult(
task,
TimeoutException(),
timer.second(),
searched_total_node,
)
node_evaluator.evaluate_nodes(pq.heap)
pq.refresh()
return NotAnsweredSearchResult(
task, MaxNodeExceededException(), timer.second(), searched_total_node
)
class WaitingNodeProcessor:
def process(
self, node: WaitingNode
) -> Union[CompletedNode, OperationInconsistencyException]:
mapping = {
UniformOperationWaitingNode: UniformOperationWaitingNodeProcessor(),
ColorSelectionWaitingNode: ColorSelectionWaitingNodeProcessor(),
MaskConversionWaitingNode: MaskConversionWaitingNodeProcessor(),
MaskOperationSelectionWaitingNode: MaskOperationSelectionWaitingNodeProcessor(),
ColorChannelSelectionOperationWaitingNode: ColorChannelSelectionOperationWaitingNodeProcessor(),
ColorChannelMaskConversionWaitingNode: ColorChannelMaskConversionWaitingNodeProcessor(),
ColorChannelMergeWaitingNode: ColorChannelMergeWaitingNodeProcessor(),
PartitionSelectionWaitingNode: PartitionSelectionWaitingNodeProcessor(),
PartitionMergeWaitingNode: PartitionMergeWaitingNodeProcessor(),
}
try:
processor = mapping[node.__class__]
return processor.process(node)
except OperationInconsistencyException as e:
return e
class UniformOperationWaitingNodeProcessor:
def process(
self, node: UniformOperationWaitingNode
) -> UniformOperationCompletedNode:
new_task = TaskOperationSetExecutor().execute(
node.task, OperationSet([node.next_operation])
)
if self.can_skip(node.task, new_task):
raise OperationInconsistencyException(f"can skip")
new_task_feature = create_task_feature(node.original_task, new_task)
new_base_operation_set = OperationSet(
node.base_operation_set.operations + [node.next_operation]
)
return UniformOperationCompletedNode(
node, node.original_task, new_task, new_task_feature, new_base_operation_set
)
def can_skip(self, prev_task: Task, next_task: Task) -> bool:
# TODO use OperationInconsistencyException?
if all(
AnswerMatcher.is_match_arr(prev_io.input_arr, next_io.input_arr)
for prev_io, next_io in zip(prev_task.train, next_task.train)
):
# no effect
return True
else:
return False
class ColorSelectionWaitingNodeProcessor:
def process(self, node: ColorSelectionWaitingNode) -> ColorSelectionCompletedNode:
color_selected_task = ColorSelectionExecutor.execute(
node.task, node.next_selection
)
if self.can_skip(color_selected_task):
raise OperationInconsistencyException(f"can skip")
color_selected_task_feature = create_color_selected_task_feature(
node.original_task, color_selected_task, node.task_feature
)
return ColorSelectionCompletedNode(
node,
node.original_task,
color_selected_task,
color_selected_task_feature,
node.base_operation_set,
node.next_selection,
)
def can_skip(self, color_selected_task: ColorSelectedTask) -> bool:
# TODO use OperationInconsistencyException?
if not any(m.any() for m in color_selected_task.train_masks):
# if no mask was generated, skip.
return True
elif all(m.all() for m in color_selected_task.train_masks):
# if mask covers all region, skip.
return True
else:
return False
class MaskConversionWaitingNodeProcessor:
def process(self, node: MaskConversionWaitingNode) -> MaskConversionCompletedNode:
mask_converted_task = MaskConversionExecutor.execute(
node.color_selected_task, node.next_mask_conversion
)
if self.can_skip(mask_converted_task):
raise OperationInconsistencyException(f"can skip")
mask_converted_task_feature = create_mask_conversion_task_feature(
node.original_task,
mask_converted_task,
node.color_selected_task_feature.task_feature,
)
return MaskConversionCompletedNode(
node,
node.original_task,
mask_converted_task,
mask_converted_task_feature,
node.base_operation_set,
node.color_selection,
node.next_mask_conversion,
)
def can_skip(self, mask_converted_task: MaskConvertedTask) -> bool:
if not any(m.any() for m in mask_converted_task.train_masks):
# if no mask was generated, skip.
return True
elif all(m.all() for m in mask_converted_task.train_masks):
# if mask covers all region, skip.
return True
else:
return False
class MaskOperationSelectionWaitingNodeProcessor:
def process(
self, node: MaskOperationSelectionWaitingNode
) -> UniformOperationCompletedNode:
new_task = MaskOperationExecutor.execute(
node.mask_converted_task, node.next_mask_operation
)
if self.can_skip(node.mask_converted_task, new_task):
raise OperationInconsistencyException(f"can skip")
new_task_feature = create_task_feature(node.original_task, new_task)
new_base_operation_set = OperationSet(
node.base_operation_set.operations
+ [
ColorOperation(
node.color_selection, node.mask_conversion, node.next_mask_operation
)
]
)
return UniformOperationCompletedNode(
node, node.original_task, new_task, new_task_feature, new_base_operation_set
)
def can_skip(self, prev_task: Task, next_task: Task) -> bool:
if all(
AnswerMatcher.is_match_arr(prev_io.input_arr, next_io.input_arr)
for prev_io, next_io in zip(prev_task.train, next_task.train)
):
# no effect
return True
else:
return False
class ColorChannelSelectionOperationWaitingNodeProcessor:
def process(
self, node: ColorChannelSelectionOperationWaitingNode
) -> ColorChannelSelectionCompletedNode:
new_task = ColorChannelSelectionExecutor().execute(
node.task, node.next_color_channel_selection
)
if self.can_skip(node.task, new_task):
raise OperationInconsistencyException(f"can skip")
# reuse old feature.
return ColorChannelSelectionCompletedNode(
node,
node.original_task,
new_task,
node.task_feature,
node.base_operation_set,
node.next_color_channel_selection,
)
def can_skip(self, prev_task: Task, next_task: Task) -> bool:
# TODO imple
return False
class ColorChannelMaskConversionWaitingNodeProcessor:
def process(
self, node: ColorChannelMaskConversionWaitingNode
) -> ColorChannelMaskConversionCompletedNode:
new_task = ColorChannelMaskConversionSelectionExecutor().execute(
node.task, node.next_mask_conversion
)
if self.can_skip(node.task, new_task):
raise OperationInconsistencyException(f"can skip")
# reuse old feature.
return ColorChannelMaskConversionCompletedNode(
node,
node.original_task,
new_task,
node.task_feature,
node.base_operation_set,
node.color_channel_selection,
node.next_mask_conversion,
)
def can_skip(self, prev_task: Task, next_task: Task) -> bool:
# TODO imple
return False
class ColorChannelMergeWaitingNodeProcessor:
def process(
self, node: ColorChannelMergeWaitingNode
) -> UniformOperationCompletedNode:
new_task = ColorChannelMergeExecutor.execute(
node.task, node.next_merge_operation
)
if self.can_skip(node.task, new_task):
raise OperationInconsistencyException(f"can skip")
new_task_feature = create_task_feature(node.original_task, new_task)
new_base_operation_set = OperationSet(
node.base_operation_set.operations
+ [
MultiColorChannelOperation(
node.color_channel_selection,
node.mask_conversion,
node.next_merge_operation,
)
]
)
return UniformOperationCompletedNode(
node, node.original_task, new_task, new_task_feature, new_base_operation_set
)
def can_skip(self, prev_task: Task, next_task: Task) -> bool:
# TODO imple
return False
class PartitionSelectionWaitingNodeProcessor:
def process(
self, node: PartitionSelectionWaitingNode
) -> PartitionSelectionCompletedNode:
new_task = PartitionSelectionExecutor().execute(
node.task, node.next_partition_selection
)
if self.can_skip(node.task, new_task):
raise OperationInconsistencyException(f"can skip")
# reuse old feature.
return PartitionSelectionCompletedNode(
node,
node.original_task,
new_task,
node.task_feature,
node.base_operation_set,
node.next_partition_selection,
)
def can_skip(self, prev_task: Task, next_task: Task) -> bool:
# TODO imple
return False
class PartitionMergeWaitingNodeProcessor:
def process(self, node: PartitionMergeWaitingNode) -> UniformOperationCompletedNode:
new_task = PartitionMergeExecutor().execute(
node.task, node.next_partition_merge_operation
)
if self.can_skip(node.task, new_task):
raise OperationInconsistencyException(f"can skip")
new_task_feature = create_task_feature(node.original_task, new_task)
new_base_operation_set = OperationSet(
node.base_operation_set.operations
+ [
PartitionOperation(
node.partition_selection, node.next_partition_merge_operation
)
]
)
return UniformOperationCompletedNode(
node, node.original_task, new_task, new_task_feature, new_base_operation_set
)
def can_skip(self, prev_task: Task, next_task: Task) -> bool:
# TODO imple
return False
@dataclass(frozen=True)
class WithOutMostCommonColorChannelSelection(ColorChannelSelection):
bg_selection_mode: BackGroundColorSelectionMode
def __call__(self, arr: np.ndarray) -> List[Tuple[Color, np.ndarray]]:
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
colors = ColorSelectionUtil().get_colors(arr)
results = [(c, arr == c) for c in colors if c != bg]
if len(results) <= 1:
raise OperationInconsistencyException("can not devide")
return results
@dataclass
class OperationSetExecutionResultHolder:
raw_task: Task
cache: Dict[str, Tuple[Task, TaskFeature]]
def get_result(self, operation_set: OperationSet) -> Tuple[Task, TaskFeature]:
if str(operation_set) in self.cache:
return self.cache[str(operation_set)]
for i in reversed(range(1, len(operation_set.operations))):
prev_o_s = OperationSet(operation_set.operations[:i])
post_o_s = OperationSet(operation_set.operations[i:])
assert len(prev_o_s.operations) + len(post_o_s.operations) == len(
operation_set.operations
)
if str(prev_o_s) in self.cache:
prev_task, _ = self.cache[str(prev_o_s)]
post_o_s_applied_task = TaskOperationSetExecutor().execute(
prev_task, post_o_s
)
post_o_s_applied_task_feature = create_task_feature(
post_o_s_applied_task
)
self.cache[str(operation_set)] = (
post_o_s_applied_task,
post_o_s_applied_task_feature,
)
return post_o_s_applied_task, post_o_s_applied_task_feature
applied_task = TaskOperationSetExecutor().execute(self.raw_task, operation_set)
applied_task_feature = create_task_feature(applied_task)
self.cache[str(operation_set)] = (applied_task, applied_task_feature)
return applied_task, applied_task_feature
@dataclass
class OperationSetMutator:
# TODO uniform(0, 1) is redundant. There must be easier way to do it.
# TODO I'd like to define procedure of probability. like albumentation.
# TODO should increase max_depth dynamically?
holder: OperationSetExecutionResultHolder
operation_element_prob_dict: Dict[str, float]
def mutate(self, operation_set: OperationSet):
new_operations = []
for o in operation_set.operations:
task, task_feature = self.holder.get_result(OperationSet(new_operations))
if (
random.uniform(0, 1)
< TreeBaseSearchEngineParameter.operation_mutation_prob
):
new_operations.append(self.get_random_one_operation(task, task_feature))
elif (
random.uniform(0, 1)
< TreeBaseSearchEngineParameter.operation_component_mutation_prob
):
if isinstance(o, UniformOperation):
new_operations.append(
self._uniform_operation_candidates(task_feature)
)
elif isinstance(o, ColorOperation):
color_sel, add_sels, mask_ope = (
o.color_selection,
o.mask_conversions,
o.mask_operation,
)
if random.uniform(0, 1) < 1 / 3:
color_sel = self._color_selection_candidates(task)
if random.uniform(0, 1) < 1 / 3:
add_sels = [self._mask_conversions()]
if random.uniform(0, 1) < 1 / 3:
mask_ope = self._mask_operation_candidates(task)
new_operations.append(ColorOperation(color_sel, add_sels, mask_ope))
else:
raise NotImplementedError()
elif (
random.uniform(0, 1)
< TreeBaseSearchEngineParameter.operation_param_mutation_prob
):
if isinstance(o, UniformOperation):
new_operations.append(self._mutate_parameter(o, task))
elif isinstance(o, ColorOperation):
color_sel, add_sels, mask_ope = (
o.color_selection,
o.mask_conversions,
o.mask_operation,
)
if random.uniform(0, 1) < 1 / 3:
color_sel = self._mutate_parameter(color_sel, task)
if random.uniform(0, 1) < 1 / 3:
add_sels = [self._mutate_parameter(add_sels[0], task)]
if random.uniform(0, 1) < 1 / 3:
mask_ope = self._mutate_parameter(mask_ope, task)
new_operations.append(ColorOperation(color_sel, add_sels, mask_ope))
else:
raise NotImplementedError()
elif (
random.uniform(0, 1)
< TreeBaseSearchEngineParameter.shrink_mutation_prob
):
continue
else:
new_operations.append(o)
if len(new_operations) < TreeBaseSearchEngineParameter.max_depth:
if (
random.uniform(0, 1)
< TreeBaseSearchEngineParameter.extend_mutation_prob
):
temp_new_set = OperationSet(new_operations)
task, task_feature = self.holder.get_result(temp_new_set)
new_operations.append(self.get_random_one_operation(task, task_feature))
return OperationSet(new_operations)
def get_random_one_operation(self, task: Task, task_feature: TaskFeature):
classes = [UniformOperation, ColorOperation]
class_probs = [self.operation_element_prob_dict[c.__name__] for c in classes]
total_prob = sum(class_probs)
class_probs = [p / total_prob for p in class_probs]
chosen_class = np.random.choice(classes, p=class_probs)
if chosen_class == UniformOperation:
operation = self._uniform_operation_candidates(task_feature)
elif chosen_class == ColorOperation:
color_sel = self._color_selection_candidates(task)
add_sels = self._mask_conversions()
mask_ope = self._mask_operation_candidates(task)
operation = ColorOperation(color_sel, add_sels, mask_ope)
else:
raise NotImplementedError()
return operation
def _uniform_operation_candidates(self, task_feature: TaskFeature):
classes = [Resize, Padding, Flip, Rotate]
class_probs = [self.operation_element_prob_dict[c.__name__] for c in classes]
total_prob = sum(class_probs)
class_probs = [p / total_prob for p in class_probs]
chosen_class = np.random.choice(classes, p=class_probs)
if chosen_class == Resize:
return random.choice([Resize(a, r) for a, r in product(Axis, range(2, 5))])
elif chosen_class == Padding:
return random.choice(
[
Padding(m, d, k)
for m, d, k in product(PaddingMode, Direction, range(1, 4))
]
)
elif chosen_class == Flip:
return random.choice([Flip(m) for m in FlipMode])
elif chosen_class == Rotate:
return random.choice([Rotate(a) for a in [90, 180, 270]])
else:
raise NotImplementedError()
def _color_selection_candidates(self, task: Task):
classes = [FixedSingleColorSelection, SingleColorSelection, MultiColorSelection]
class_probs = [self.operation_element_prob_dict[c.__name__] for c in classes]
total_prob = sum(class_probs)
class_probs = [p / total_prob for p in class_probs]
chosen_class = np.random.choice(classes, p=class_probs)
if chosen_class == FixedSingleColorSelection:
input_colors = list(
map(
lambda v: Color.of(v),
set(
chain.from_iterable(
chain.from_iterable(task.get_input_all_arr())
)
),
)
)
return random.choice([FixedSingleColorSelection(c) for c in input_colors])
elif chosen_class == SingleColorSelection:
return random.choice(
[SingleColorSelection(m) for m in SingleColorSelectionMode]
)
elif chosen_class == MultiColorSelection:
return random.choice(
[MultiColorSelection(m) for m in MultiColorSelectionMode]
)
else:
raise NotImplementedError()
def _mask_conversions(self):
classes = [
NoMaskConversion,
SquareObjectsSelection,
ObjectsMaxMinSelection,
SplitLineSelection,
DotExistLineSelection,
HolesSelection,
ObjectInnerSelection,
ContourSelection,
ContourOuterSelection,
ConnectDotSelection,
]
class_probs = [self.operation_element_prob_dict[c.__name__] for c in classes]
total_prob = sum(class_probs)
class_probs = [p / total_prob for p in class_probs]
chosen_class = np.random.choice(classes, p=class_probs)
if chosen_class == NoMaskConversion:
return NoMaskConversion()
elif chosen_class == SquareObjectsSelection:
return SquareObjectsSelection()
elif chosen_class == ObjectsMaxMinSelection:
return random.choice(
[
ObjectsMaxMinSelection(m, t, c)
for m, t, c in product(MaxOrMin, ObjectFeature, PixelConnectivity)
]
)
elif chosen_class == SplitLineSelection:
return random.choice([SplitLineSelection(a) for a in Axis])
elif chosen_class == DotExistLineSelection:
return random.choice([DotExistLineSelection(a) for a in Axis])
elif chosen_class == HolesSelection:
return random.choice([HolesSelection(c) for c in PixelConnectivity])
elif chosen_class == ObjectInnerSelection:
return random.choice(
[
ObjectInnerSelection(c, e)
for c, e in product(PixelConnectivity, ImageEdgeType)
]
)
elif chosen_class == ContourSelection:
return random.choice(
[
ContourSelection(c, e)
for c, e in product(PixelConnectivity, ImageEdgeType)
]
)
elif chosen_class == ContourOuterSelection:
return random.choice(
[
ContourOuterSelection(c, h)
for c, h in product(PixelConnectivity, HoleInclude)
]
)
elif chosen_class == ConnectDotSelection:
return random.choice(
[
ConnectDotSelection(a, e, f)
for a, e, f in product(Axis, LineEdgeType, FillType)
]
)
else:
raise NotImplementedError()
def _mask_operation_candidates(self, task: Task):
classes = [MaskCoordsCrop, FixedColorMaskFill, SingleColorMaskFill]
class_probs = [self.operation_element_prob_dict[c.__name__] for c in classes]
total_prob = sum(class_probs)
class_probs = [p / total_prob for p in class_probs]
chosen_class = np.random.choice(classes, p=class_probs)
if chosen_class == MaskCoordsCrop:
return MaskCoordsCrop()
elif chosen_class == FixedColorMaskFill:
output_colors = list(
map(
lambda v: Color.of(v),
set(
chain.from_iterable(
chain.from_iterable(task.get_output_all_arr())
)
),
)
)
return random.choice([FixedColorMaskFill(c) for c in output_colors])
elif chosen_class == SingleColorMaskFill:
return random.choice(
[SingleColorMaskFill(m) for m in SingleColorSelectionMode]
)
else:
raise NotImplementedError()
def _mutate_parameter(self, operation_element, task: Task):
# TODO Should mutate one property of operation_element.
if isinstance(operation_element, Resize):
return random.choice([Resize(Axis.VERTICAL, r) for r in range(2, 5)])
elif isinstance(operation_element, Padding):
return random.choice(
[
Padding(m, d, k)
for m, d, k in product(
PaddingMode, [Direction.TOP, Direction.BOTTOM], range(1, 4)
)
]
)
elif isinstance(operation_element, Flip):
return random.choice([Flip(m) for m in FlipMode])
elif isinstance(operation_element, Rotate):
return random.choice([Rotate(a) for a in [90, 180, 270]])
elif isinstance(operation_element, FixedSingleColorSelection):
input_colors = list(
map(
lambda v: Color.of(v),
set(
chain.from_iterable(
chain.from_iterable(task.get_input_all_arr())
)
),
)
)
return random.choice([FixedSingleColorSelection(c) for c in input_colors])
elif isinstance(operation_element, SingleColorSelection):
return random.choice(
[SingleColorSelection(m) for m in SingleColorSelectionMode]
)
elif isinstance(operation_element, MultiColorSelection):
return random.choice(
[MultiColorSelection(m) for m in MultiColorSelectionMode]
)
elif isinstance(operation_element, NoMaskConversion):
return random.choice([NoMaskConversion()])
elif isinstance(operation_element, SquareObjectsSelection):
return random.choice([SquareObjectsSelection()])
elif isinstance(operation_element, ObjectsMaxMinSelection):
return random.choice(
[
ObjectsMaxMinSelection(m, t, c)
for m, t, c in product(MaxOrMin, ObjectFeature, PixelConnectivity)
]
)
elif isinstance(operation_element, SplitLineSelection):
return random.choice([SplitLineSelection(a) for a in Axis])
elif isinstance(operation_element, DotExistLineSelection):
return random.choice([DotExistLineSelection(a) for a in Axis])
elif isinstance(operation_element, HolesSelection):
return random.choice([HolesSelection(c) for c in PixelConnectivity])
elif isinstance(operation_element, ObjectInnerSelection):
return random.choice(
[
ObjectInnerSelection(c, e)
for c, e in product(PixelConnectivity, ImageEdgeType)
]
)
elif isinstance(operation_element, ContourSelection):
return random.choice(
[
ContourSelection(c, e)
for c, e in product(PixelConnectivity, ImageEdgeType)
]
)
elif isinstance(operation_element, ContourOuterSelection):
return random.choice(
[
ContourOuterSelection(c, h)
for c, h in product(PixelConnectivity, HoleInclude)
]
)
elif isinstance(operation_element, ConnectDotSelection):
return random.choice(
[
ConnectDotSelection(a, e, f)
for a, e, f in product(Axis, LineEdgeType, FillType)
]
)
elif isinstance(operation_element, MaskCoordsCrop):
return random.choice([MaskCoordsCrop()])
elif isinstance(operation_element, FixedColorMaskFill):
output_colors = list(
map(
lambda v: Color.of(v),
set(
chain.from_iterable(
chain.from_iterable(task.get_output_all_arr())
)
),
)
)
return random.choice([FixedColorMaskFill(c) for c in output_colors])
elif isinstance(operation_element, SingleColorMaskFill):
return random.choice(
[SingleColorMaskFill(m) for m in SingleColorSelectionMode]
)
else:
raise NotImplementedError(operation_element)
@dataclass
class Individual:
operation_set: OperationSet
distance: float
task_feature: TaskFeature
def __str__(self):
return f"depth: {len(self.operation_set.operations)}, dist: {self.distance:.5f}, ope: {self.operation_set}"
@dataclass
class Population:
strategy: str
individuals: List[Individual]
def show(self):
self.sort()
for i in self.individuals:
print(i)
def sort(self):
random.shuffle(self.individuals)
self.individuals = sorted(self.individuals, key=lambda i: i.distance)
def get_elite(self):
# TODO Lack of consideration when there were multiple elites.
self.sort()
return self.individuals[0]
def get_dist0_if_exists(self) -> Optional[OperationSet]:
elite = min(self.individuals, key=lambda i: i.distance)
if elite.distance == 0:
return elite.operation_set
else:
return None
def mutate(self, mutator, holder, evaluator):
# 変異
self.sort()
mutated_individuals = [self.get_elite()]
for i in self.individuals[1:]:
for _ in range(1000000000000):
try:
mutated_operation_set = mutator.mutate(i.operation_set)
# チェックする。
task, task_feature = holder.get_result(mutated_operation_set)
break
except OperationInconsistencyException:
continue
applied_task, applied_task_feature = holder.get_result(
mutated_operation_set
)
mutation_distance = evaluator.evaluate_task_feature(applied_task_feature)
mutated_individuals.append(
Individual(
mutated_operation_set, mutation_distance, applied_task_feature
)
)
self.individuals = mutated_individuals
def select(self):
if self.strategy == "simple":
self.individuals = self.select_simple()
elif self.strategy == "nsga2":
self.individuals = self.select_nsga2()
else:
raise NotImplementedError()
def select_nsga2(self):
raw_len = len(self.individuals)
selected = selNSGA2(self.individuals, raw_len)
simple_selection = self.select_simple(include_elite=True)
return selected + simple_selection[: raw_len - len(selected)]
def select_simple(self, include_elite: bool = True):
# 選択
self.sort()
if include_elite:
next_individuals = [self.get_elite()]
else:
next_individuals = []
# score = 1 / distance # TODO Handle 0 division
score_sum = sum(map(lambda i: 1 / i.distance, self.individuals))
score_ratios = [1 / i.distance / score_sum for i in self.individuals]
score_roulette = np.cumsum(score_ratios)
for _ in range(len(self.individuals) - 1):
roulette_prob_hit = random.uniform(0, 1)
for i, roulette_prob in enumerate(score_roulette):
if roulette_prob_hit < roulette_prob:
next_individuals.append(self.individuals[i])
break
return next_individuals
@dataclass
class TreeBaseSearchEngine:
time_out: int = 60 # TODO
def get_first_individual(self, evaluator, mutator, holder, task, root_task_feature):
try:
operation = mutator.get_random_one_operation(task, root_task_feature)
operation_set = OperationSet([operation])
_, task_feature = holder.get_result(operation_set)
distance = evaluator.evaluate_task_feature(task_feature)
return Individual(operation_set, distance, task_feature)
except OperationInconsistencyException:
return self.get_first_individual(
evaluator, mutator, holder, task, root_task_feature
)
def search(
self, task: Task, params: AllParameter, verbose: bool = False
) -> Union[AnsweredSearchResults, NotAnsweredSearchResult]:
evaluator = DistanceEvaluator(params.distance_evaluator_param)
holder = OperationSetExecutionResultHolder(task, {})
root_operation_set = OperationSet([])
_, root_task_feature = holder.get_result(root_operation_set)
if RunConfig.USE_ML_GUIDE:
operation_element_prob_dict = predict_operation_element_inclusion()
else:
operation_element_prob_dict = defaultdict(lambda: 1)
if verbose:
print(operation_element_prob_dict)
mutator: OperationSetMutator = OperationSetMutator(
holder, operation_element_prob_dict
)
individuals = [
self.get_first_individual(
evaluator, mutator, holder, task, root_task_feature
)
for _ in range(TreeBaseSearchEngineParameter.population_num)
]
population = Population("simple", individuals)
with Timer() as timer:
for i in range(10000000):
if verbose:
print(f"============== generation: {i} population")
population.show()
population.mutate(mutator, holder, evaluator)
if verbose:
print(f"============== generation: {i}, mutation population")
population.show()
answer_operation_set = population.get_dist0_if_exists()
if answer_operation_set is not None:
if AnswerMatcher.is_train_all_match_if_operated(
task, answer_operation_set
):
return AnsweredSearchResults(
task,
[AnsweredSearchResult(answer_operation_set)],
timer.second(),
i,
)
else:
raise NotImplementedError()
population.select()
if timer.second() > self.time_out:
return NotAnsweredSearchResult(
task, TimeoutException(), timer.second(), i
)
return NotAnsweredSearchResult(
task, MaxNodeExceededException(), timer.second(), i
)
T = TypeVar("T")
class PriorityQueue:
def __init__(self, heap: List[T]):
self.heap = heap
heapify(self.heap)
def refresh(self):
heapify(self.heap)
def push(self, item: T):
heappush(self.heap, item)
def pop_min(self) -> T:
return heappop(self.heap)
def pop_mins(self) -> List[T]:
min_item = self.pop_min()
results = [min_item]
for _ in range(len(self.heap)):
item = self.pop_min()
if item <= min_item:
results.append(item)
else:
self.push(item)
return results
return results
def pop_mins_or_as_least_n(self, n: int) -> List[T]:
results = []
while len(results) < n:
if len(self) == 0:
break
results += self.pop_mins()
return results
def push_pop(self, item: T) -> T:
return heappushpop(self.heap, item)
def __len__(self) -> int:
return len(self.heap)
def sorted_list(self) -> List[T]:
return sorted(self.heap)
def str_to_operation_set(s: str) -> OperationSet:
# DSL string -> DSL object
return eval(s)
def str_to_AnswerStorageElement(s: str):
# noinspection PyUnresolvedReferences
# from abstraction_and_reasoning_challenge.src.answer_storage.answer_storage import AnswerStorageElement
return eval(s)
@dataclass(frozen=True)
class UniqueColorNumberSelection(PartitionedArraySelection):
max_or_min: MaxOrMin
def __call__(
self, arr: np.ndarray, partitioned_arrays: List[List[np.ndarray]]
) -> List[List[bool]]:
color_nums = _apply(self._color_num, partitioned_arrays)
if self.max_or_min == MaxOrMin.MAX:
target_color_num = max(map(max, color_nums))
elif self.max_or_min == MaxOrMin.MIN:
target_color_num = min(map(min, color_nums))
else:
raise NotImplementedError()
return _apply(lambda n: n == target_color_num, color_nums)
def _color_num(self, array: np.ndarray):
return len(np.unique(array))
@dataclass(frozen=True)
class ColoredCellNumberSelection(PartitionedArraySelection):
max_or_min: MaxOrMin
bg_selection_mode: BackGroundColorSelectionMode
def __call__(
self, arr: np.ndarray, partitioned_arrays: List[List[np.ndarray]]
) -> List[List[bool]]:
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
colored_cell_nums = _apply(
partial(self._colored_cell_nums, bg=bg), partitioned_arrays
)
if self.max_or_min == MaxOrMin.MAX:
target_color_num = max(map(max, colored_cell_nums))
elif self.max_or_min == MaxOrMin.MIN:
target_color_num = min(map(min, colored_cell_nums))
else:
raise NotImplementedError()
return _apply(lambda n: n == target_color_num, colored_cell_nums)
def _colored_cell_nums(self, array: np.ndarray, bg: Color):
return (array != bg).sum()
@dataclass(frozen=True)
class SameShapeNumSelection(PartitionedArraySelection):
max_or_min: MaxOrMin
def __call__(
self, arr: np.ndarray, partitioned_arrays: List[List[np.ndarray]]
) -> List[List[bool]]:
np_strings = _apply(lambda n: n.tostring(), partitioned_arrays)
c = Counter(_flatten(np_strings))
most_commons = c.most_common()
if len(most_commons) < 2:
raise OperationInconsistencyException("can not select")
if self.max_or_min == MaxOrMin.MAX:
if most_commons[0][1] == most_commons[1][1]:
raise OperationInconsistencyException("duplicated max")
target = most_commons[0][0]
elif self.max_or_min == MaxOrMin.MIN:
if most_commons[-1][1] == most_commons[-2][1]:
raise OperationInconsistencyException("duplicated min")
target = most_commons[-1][0]
else:
raise NotImplementedError()
return _apply(lambda n: n == target, np_strings)
@dataclass(frozen=True)
class SymmetrySelection(PartitionedArraySelection):
axis: AxisV2
true_or_false: TrueOrFalse
def __call__(
self, arr: np.ndarray, partitioned_arrays: List[List[np.ndarray]]
) -> List[List[bool]]:
return _apply(
partial(
self._is_symmetry, axis=self.axis, true_or_false=self.true_or_false
),
partitioned_arrays,
)
def _is_symmetry(
self, array: np.ndarray, axis: AxisV2, true_or_false: TrueOrFalse
) -> bool:
if axis == AxisV2.VERTICAL:
res = np.array_equal(array, Flip(FlipMode.UD)(array))
elif axis == AxisV2.HORIZONTAL:
res = np.array_equal(array, Flip(FlipMode.LR)(array))
elif axis == AxisV2.VERTICAL_HORIZONTAL:
res = self._is_symmetry(
array, AxisV2.VERTICAL, TrueOrFalse.TRUE
) and self._is_symmetry(array, AxisV2.HORIZONTAL, TrueOrFalse.TRUE)
elif axis == AxisV2.MAIN_DIAGONAL:
res = np.array_equal(array, Flip(FlipMode.UL_DR)(array))
elif axis == AxisV2.ANTI_DIAGONAL:
res = np.array_equal(array, Flip(FlipMode.UR_DL)(array))
elif axis == AxisV2.BOTH_DIAGONAL:
res = self._is_symmetry(
array, AxisV2.MAIN_DIAGONAL, TrueOrFalse.TRUE
) and self._is_symmetry(array, AxisV2.ANTI_DIAGONAL, TrueOrFalse.TRUE)
else:
raise NotImplementedError()
if true_or_false == TrueOrFalse.TRUE:
return res
else:
return not res
def _apply(func, partitioned_arrays: List[List[np.ndarray]]) -> List[List[Any]]:
results = []
for h_arrays in partitioned_arrays:
temp_masks = []
for array in h_arrays:
temp_masks.append(func(array))
results.append(temp_masks)
return results
def _flatten(partitioned: List[List[Any]]) -> List[Any]:
return list(chain.from_iterable(partitioned))
class OperationSetEvaluator:
# Evaluation function to choose three answers by ranking the OperationSet.
# Smaller is better.
def evaluate(self, operation_set: OperationSet) -> float:
score_map = {
FixedSingleColorSelection: 0.5,
}
return sum(score_map.get(e.__class__, 1) for e in operation_set.elements())
def get_alternative_operation_sets(
raw_task: Task,
last_completed_node: UniformOperationCompletedNode,
visited_node_hashes: Dict[int, Dict[int, Any]],
verbose: bool,
) -> Iterable[NodeTree]:
if verbose:
print("original_answer")
print(NodeTree.of(last_completed_node).to_operation_set())
print("===search other answers===")
node_tree = NodeTree.of(last_completed_node)
depth_alternative_nodes_pairs: List[Tuple[int, List[CompletedNode]]] = []
for i, node in enumerate(node_tree.completed_nodes):
if i == 0:
# no alternative for root node
continue
if node.train_arr_hash() in visited_node_hashes:
same_hash_node_dicts = visited_node_hashes[node.train_arr_hash()]
alternative_nodes = [
n
for all_hash, n in same_hash_node_dicts.items()
if all_hash != node.all_arr_hash()
]
depth_alternative_nodes_pairs.append((i, alternative_nodes))
if verbose:
print(f"alternative_nodes:")
for i, alternative_nodes in depth_alternative_nodes_pairs:
for n in alternative_nodes:
print(f"node_depth: {i}, {n}")
candidate_node_trees = [node_tree]
for i, alternative_nodes in depth_alternative_nodes_pairs:
if len(candidate_node_trees) > 1000:
break # TODO Too many candidate_node_trees causes Memory Error.
for n in alternative_nodes:
candidate_node_trees += [
NodeTree.replaced_new_node_tree(t, i, n) for t in candidate_node_trees
]
if verbose:
print("node_tree:")
print(node_tree)
print("candidate_node_trees:")
for c in candidate_node_trees:
print("===")
print(c)
# TODO unnecessary filter?
candidate_node_trees = [
t
for t in candidate_node_trees
if AnswerMatcher.is_train_all_match_if_operated(raw_task, t.to_operation_set())
]
candidate_node_trees = sorted(
candidate_node_trees,
key=lambda t: OperationSetEvaluator().evaluate(t.to_operation_set()),
)
result_applied_tasks = []
for t in candidate_node_trees:
try:
applied_task = TaskOperationSetExecutor().execute(
raw_task, t.to_operation_set()
)
except OperationInconsistencyException:
continue
if any(
applied_task.test_arr_hash() == t.test_arr_hash()
for t in result_applied_tasks
):
continue
result_applied_tasks.append(applied_task)
yield t
class ColorChannelOverrideOperation(ChannelMergeOperation):
def __call__(
self,
arr: np.ndarray,
original_color_mask_paris: List[Tuple[Color, np.ndarray]],
color_mask_pairs: List[Tuple[Color, np.ndarray]],
) -> np.ndarray:
diff_mask_paris = [
(c1, np.logical_and(np.logical_xor(o_m, c_m), c_m))
for (c1, o_m), (c2, c_m) in zip(
sorted(original_color_mask_paris, key=itemgetter(0)),
sorted(color_mask_pairs, key=itemgetter(0)),
)
] # TODO should groupby color?
check_mask = np.full_like(diff_mask_paris[0][1], fill_value=False)
# If duplicated, InconsistencyException
for _, m in diff_mask_paris:
if check_mask[m].any():
raise OperationInconsistencyException("failed channel merge")
check_mask[m] = True
for c, m in diff_mask_paris:
arr[m] = c
return arr
@dataclass
class NodeEvaluatorSchedule:
start_sec: int
evaluator: Optional[NodeEvaluator]
@dataclass
class NodeEvaluatorSchedules:
schedules: List[NodeEvaluatorSchedule]
def pop_evaluator(self) -> Optional[NodeEvaluator]:
evaluator = self.schedules[0].evaluator
self.schedules = self.schedules[1:]
return evaluator
def next_timing(self):
return self.schedules[0].start_sec
def timeout_sec(self):
return self.schedules[-1].start_sec
def get_schedule(
operation_element_prob_dict: Dict[str, float],
node_search_engine_param,
dist_eval_param,
) -> NodeEvaluatorSchedules:
if RunConfig.RUN_MODE == RunMode.KERNEL:
if RunConfig.ENGINE_SCHEDULE_PATTERN == EngineSchedulePattern.HAND_MADE:
return NodeEvaluatorSchedules(
[
NodeEvaluatorSchedule(
0,
HandMadeNodeEvaluator(
DepthSearchPattern.BREADTH_FIRST,
operation_element_prob_dict,
node_search_engine_param,
dist_eval_param,
),
),
NodeEvaluatorSchedule(
60 * 1,
HandMadeNodeEvaluator(
DepthSearchPattern.NORMAL,
operation_element_prob_dict,
node_search_engine_param,
dist_eval_param,
),
),
NodeEvaluatorSchedule(
60 * 2,
HandMadeNodeEvaluator(
DepthSearchPattern.DEPTH_FIRST,
operation_element_prob_dict,
node_search_engine_param,
dist_eval_param,
),
),
NodeEvaluatorSchedule(60 * 3, None),
]
)
if RunConfig.ENGINE_SCHEDULE_PATTERN == EngineSchedulePattern.DRY_RUN:
return NodeEvaluatorSchedules(
[
NodeEvaluatorSchedule(
0,
HandMadeNodeEvaluator(
DepthSearchPattern.BREADTH_FIRST,
operation_element_prob_dict,
node_search_engine_param,
dist_eval_param,
),
),
NodeEvaluatorSchedule(3, None),
]
)
else:
if RunConfig.ENGINE_SCHEDULE_PATTERN == EngineSchedulePattern.HAND_MADE:
return NodeEvaluatorSchedules(
[
NodeEvaluatorSchedule(
0,
HandMadeNodeEvaluator(
DepthSearchPattern.BREADTH_FIRST,
operation_element_prob_dict,
node_search_engine_param,
dist_eval_param,
),
),
NodeEvaluatorSchedule(
20,
HandMadeNodeEvaluator(
DepthSearchPattern.NORMAL,
operation_element_prob_dict,
node_search_engine_param,
dist_eval_param,
),
),
NodeEvaluatorSchedule(
40,
HandMadeNodeEvaluator(
DepthSearchPattern.DEPTH_FIRST,
operation_element_prob_dict,
node_search_engine_param,
dist_eval_param,
),
),
NodeEvaluatorSchedule(60, None),
]
)
if RunConfig.ENGINE_SCHEDULE_PATTERN == EngineSchedulePattern.ML:
return NodeEvaluatorSchedules(
[
NodeEvaluatorSchedule(
0, MLNodeEvaluator(DepthSearchPattern.BREADTH_FIRST)
),
NodeEvaluatorSchedule(
20, MLNodeEvaluator(DepthSearchPattern.NORMAL)
),
NodeEvaluatorSchedule(
40, MLNodeEvaluator(DepthSearchPattern.DEPTH_FIRST)
),
NodeEvaluatorSchedule(60, None),
]
)
if RunConfig.ENGINE_SCHEDULE_PATTERN == EngineSchedulePattern.DRY_RUN:
return NodeEvaluatorSchedules(
[
NodeEvaluatorSchedule(
0,
HandMadeNodeEvaluator(
DepthSearchPattern.BREADTH_FIRST,
operation_element_prob_dict,
node_search_engine_param,
dist_eval_param,
),
),
NodeEvaluatorSchedule(3, None),
]
)
raise NotImplementedError()
def optimize_node_base_search(tasks: List[Task]):
assert RunConfig.ENGINE_TYPE == EngineType.NODE_BASED_SEARCH_ENGINE
def objective(trial: Trial):
param = AllParameter(
# distance_evaluator_param=DistanceEvaluatorParameter(
# same_h_w_dim_between_input_output=trial.suggest_loguniform('same_h_w_dim_between_input_output', 100, 10000),
# all_dim_h_w_integer_multiple=trial.suggest_loguniform('all_dim_h_w_integer_multiple', 10, 1000),
# mean_lack_color_num=trial.suggest_loguniform('mean_lack_color_num', 1, 100),
# mean_excess_color_num=trial.suggest_loguniform('mean_excess_color_num', 1, 100),
# mean_hit_and_miss_histogram_diff=trial.suggest_loguniform('mean_hit_and_miss_histogram_diff', 1, 100),
# mean_h_v_diff_input_arr_line_num=trial.suggest_loguniform('mean_h_v_diff_input_arr_line_num', 1, 100),
# mean_h_v_diff_output_arr_line_num=trial.suggest_loguniform('mean_h_v_diff_output_arr_line_num', 1, 100),
# mean_h_v_edge_sum_diff=trial.suggest_discrete_uniform('mean_h_v_edge_sum_diff', 0, 2, 0.5),
# mean_h_v_edge_sum_diff_ratio=trial.suggest_discrete_uniform('mean_h_v_edge_sum_diff_ratio', 0, 2, 0.5),
# mean_diff_cell_where_no_need_to_change_count_ratio=trial.suggest_loguniform('mean_diff_cell_where_no_need_to_change_count_ratio', 1, 100000),
# ),
node_base_engine_param=NodeBaseSearchEngineParameter(
# breadth_first_cost=trial.suggest_loguniform('breadth_first_cost', 1000, 100000),
normal_first_cost=trial.suggest_loguniform(
"normal_first_cost", 10, 1000
),
depth_first_cost=trial.suggest_loguniform("depth_first_cost", 0.1, 10),
# breadth_first_exp_cost=trial.suggest_loguniform('exp_cost', 0.001, 3),
# normal_exp_cost=trial.params['exp_cost'],
# depth_first_exp_cost=trial.params['exp_cost'],
pq_pop_mins_or_as_least_n=trial.suggest_int(
"pq_pop_mins_or_as_least_n", 1, 10
),
# element_inclusion_prob_factor=trial.suggest_loguniform('element_inclusion_prob_factor', 0.001, 10000000),
)
)
print(trial.params)
engine_results = solve_tasks(tasks, param, add_answer_storage=True)
answered_results = [
r for r in engine_results if isinstance(r, AnsweredSearchResults)
]
true_results = [r for r in engine_results if r.final_test_correct()]
all_len = len(engine_results)
true_len = len(true_results)
false_len = len(answered_results) - len(true_results)
none_len = len(engine_results) - len(answered_results)
print(trial.params)
print(f"true: {true_len}, false: {false_len}, none: {none_len}, all: {all_len}")
return all_len - true_len - false_len / 2
study = optuna.create_study()
study.optimize(objective, n_trials=1000)
print(study.best_params)
def optimize_tree_base_search(tasks: List[Task]):
assert RunConfig.ENGINE_TYPE == EngineType.TREE_BASED_SEARCH_ENGINE
def objective(trial: Trial):
all_parameter = AllParameter(
tree_base_engine_param=TreeBaseSearchEngineParameter(
population_num=trial.suggest_int("population_num", 20, 80),
max_depth=trial.suggest_int("max_depth", 6, 10),
operation_mutation_prob=trial.suggest_loguniform(
"operation_mutation_prob", 0.01, 0.5
),
operation_component_mutation_prob=trial.suggest_loguniform(
"operation_component_mutation_prob", 0.005, 0.5
),
operation_param_mutation_prob=trial.suggest_loguniform(
"operation_param_mutation_prob", 0.001, 0.5
),
extend_mutation_prob=trial.suggest_loguniform(
"extend_mutation_prob", 0.01, 1
),
shrink_mutation_prob=trial.suggest_loguniform(
"shrink_mutation_prob", 0.001, 0.1
),
)
)
print(trial.params)
engine_results = solve_tasks(tasks, all_parameter, add_answer_storage=True)
answered_results = [
r for r in engine_results if isinstance(r, AnsweredSearchResults)
]
true_results = [r for r in engine_results if r.final_test_correct()]
all_len = len(engine_results)
true_len = len(true_results)
false_len = len(answered_results) - len(true_results)
none_len = len(engine_results) - len(answered_results)
print(f"true: {true_len}, false: {false_len}, none: {none_len}, all: {all_len}")
return all_len - true_len - false_len / 2
study = optuna.create_study()
study.optimize(objective, n_trials=1000)
print(study.best_params)
def solve_tasks(
tasks: List[Task],
params: AllParameter,
output_summary_path: Optional[Path] = None,
save_submission: bool = False,
copy_wrong_answers_root_tag: Optional[str] = None,
add_answer_storage: bool = False,
verbose: bool = False,
) -> List[Union[AnsweredSearchResults, NotAnsweredSearchResult]]:
print("===== start parallel solve tasks =====\n\n")
if RunConfig.N_JOB == 1 or len(tasks) == 1:
engine_results = [
solve_task(task, params, verbose)
for task in tqdm(tasks, miniters=0, mininterval=None, maxinterval=None)
]
else:
# with Pool(processes=RunConfig.N_JOB) as pool:
# args = ((task, verbose) for task in tqdm(tasks, miniters=0, mininterval=None, maxinterval=None))
# engine_results = pool.starmap(solve_task, args)
# 'multiprocessing' or 'threading'
engine_results = Parallel(n_jobs=RunConfig.N_JOB, backend="multiprocessing")(
delayed(solve_task)(task, params, verbose)
for task in tqdm(tasks, miniters=0, mininterval=None, maxinterval=None)
)
print("===== end parallel solve tasks =====\n\n")
summary = summary_engine_results(engine_results)
print(summary)
if output_summary_path:
output_summary_path.write_text(summary)
if save_submission:
print("start save submission")
submission_df = create_submission(engine_results)
save_submission_df(submission_df)
if add_answer_storage:
storage_elements = list(
chain.from_iterable(
[
r.to_answer_storage_elements()
for r in engine_results
if isinstance(r, AnsweredSearchResults)
]
)
)
update_answer_storage(storage_elements)
if copy_wrong_answers_root_tag:
print("start copy wrong answers")
for r in engine_results:
if not r.final_test_correct():
plot_task(
r.task,
show=False,
save_path=PathConfig.WRONG_ANSWERS_ROOT
/ copy_wrong_answers_root_tag
/ f"{r.task.name}.png",
)
return engine_results
def solve_task(
task: Task, params: AllParameter, verbose: bool = False
) -> Union[AnsweredSearchResults, NotAnsweredSearchResult]:
try:
engine = get_engine(RunConfig.ENGINE_TYPE)
engine_result = engine.search(task, params, verbose)
except Exception as e:
print(f"unknown error {task.name}")
raise e
if isinstance(engine_result, NotAnsweredSearchResult):
return engine_result
elif isinstance(engine_result, AnsweredSearchResults):
# calculate operation_set-executed task.
for result in engine_result.results:
applied_task = TaskOperationSetExecutor().execute(
task, result.operation_set
)
result.test_output_arr = [io.input_arr for io in applied_task.test]
result.test_correct = AnswerMatcher.is_train_test_all_match_if_operated(
task, result.operation_set
)
engine_result.results = sorted(
engine_result.results, key=lambda r: r.test_correct, reverse=True
)
print(engine_result.summary())
return engine_result
else:
raise NotImplementedError()
class OperationSetExecutor:
@classmethod
def apply_operation_set(
cls, arrays: List[np.ndarray], operation_set: OperationSet
) -> List[np.ndarray]:
for o in operation_set.operations:
arrays = cls.apply_operation(arrays, o)
return arrays
@classmethod
def apply_operation(
cls,
arrays: List[np.ndarray],
operation: Union[UniformOperation, ColorOperation, MultiColorChannelOperation],
) -> List[np.ndarray]:
if isinstance(operation, UniformOperation):
return cls.apply_uniform_operation(arrays, operation)
elif isinstance(operation, ColorOperation):
masks = cls.apply_color_selection(arrays, operation.color_selection)
masks = cls.apply_mask_conversion(masks, operation.mask_conversions)
return cls.apply_mask_operation(arrays, masks, operation.mask_operation)
elif isinstance(operation, MultiColorChannelOperation):
original_color_mask_pairs_list = cls.apply_channel_selection(
arrays, operation.channel_selection
)
color_mask_pairs_list = deepcopy(original_color_mask_pairs_list)
color_mask_pairs_list = cls.apply_color_channel_mask_conversion(
color_mask_pairs_list, operation.mask_conversions
)
return cls.apply_channel_merge(
arrays,
original_color_mask_pairs_list,
color_mask_pairs_list,
operation.channel_merge_operation,
)
elif isinstance(operation, PartitionOperation):
partitioned_arrays_original_location_masks = cls.apply_partition_selection(
arrays, operation.partition_selection
)
return cls.apply_partition_merge_operation(
arrays,
partitioned_arrays_original_location_masks,
operation.partition_merge_operation,
)
else:
raise NotImplementedError()
@classmethod
def apply_uniform_operation(
cls, arrays: List[np.ndarray], operation: UniformOperation
) -> List[np.ndarray]:
new_arrays = [cls._apply_uniform_operation(a, operation) for a in arrays]
if all(np.array_equal(n, r) for n, r in zip(new_arrays, arrays)):
raise OperationInconsistencyException(f"no effect. {operation}")
return new_arrays
@classmethod
def _apply_uniform_operation(
cls, arr: np.ndarray, operation: UniformOperation
) -> np.ndarray:
cls._check_arr(arr, operation)
temp_arr = deepcopy(arr)
new_arr = operation(temp_arr)
cls._check_arr(new_arr, operation)
return new_arr
@classmethod
def apply_color_selection(
cls, arrays: List[np.ndarray], selection: ColorSelection
) -> List[np.ndarray]:
return [cls._apply_color_selection(a, selection) for a in arrays]
@classmethod
def _apply_color_selection(
cls, arr: np.ndarray, selection: ColorSelection
) -> np.ndarray:
cls._check_arr(arr, None)
temp_arr = deepcopy(arr)
mask = selection(temp_arr)
cls._check_mask(mask, selection)
return mask
@classmethod
def apply_channel_selection(
cls, arrays: List[np.ndarray], channel_selection: ColorChannelSelection
) -> List[List[Tuple[Color, np.ndarray]]]:
return [cls._apply_channel_selection(a, channel_selection) for a in arrays]
@classmethod
def _apply_channel_selection(
cls, arr: np.ndarray, channel_selection: ColorChannelSelection
) -> List[Tuple[Color, np.ndarray]]:
cls._check_arr(arr, None)
temp_arr = deepcopy(arr)
color_mask_pairs = channel_selection(temp_arr)
for c, m in color_mask_pairs:
cls._check_mask(m, channel_selection)
return color_mask_pairs
@classmethod
def apply_color_channel_mask_conversion(
cls,
color_mask_pairs_list: List[List[Tuple[Color, np.ndarray]]],
mask_conversion: MaskConversion,
) -> List[List[Tuple[Color, np.ndarray]]]:
new_color_mask_pairs_list = [
cls._apply_color_channel_mask_conversion(p, mask_conversion)
for p in color_mask_pairs_list
]
# TODO imple
# if not isinstance(mask_conversion, NoMaskConversion):
# if all(np.array_equal(n, r) for n, r in zip(new_color_mask_pairs_list, color_mask_pairs_list)):
# raise OperationInconsistencyException(mask_conversion)
return new_color_mask_pairs_list
@classmethod
def _apply_color_channel_mask_conversion(
cls,
color_mask_pairs: List[Tuple[Color, np.ndarray]],
mask_conversion: MaskConversion,
) -> List[Tuple[Color, np.ndarray]]:
for c, m in color_mask_pairs:
cls._check_mask(m, None)
temp_color_mask_pairs = deepcopy(color_mask_pairs)
temp_color_mask_pairs = [
(c, mask_conversion(m)) for c, m in temp_color_mask_pairs
]
for c, m in temp_color_mask_pairs:
cls._check_mask(m, mask_conversion)
return temp_color_mask_pairs
@classmethod
def apply_channel_merge(
cls,
arrays: List[np.ndarray],
original_color_mask_pairs_list: List[List[Tuple[Color, np.ndarray]]],
color_mask_pairs_list: List[List[Tuple[Color, np.ndarray]]],
merge_operation: ChannelMergeOperation,
) -> List[np.ndarray]:
new_arrays = [
cls._apply_channel_merge(arr, o_p, p, merge_operation)
for arr, o_p, p in zip(
arrays, original_color_mask_pairs_list, color_mask_pairs_list
)
]
if all(np.array_equal(n, r) for n, r in zip(new_arrays, arrays)):
raise OperationInconsistencyException(f"no effect. {merge_operation}")
return new_arrays
@classmethod
def _apply_channel_merge(
cls,
arr: np.ndarray,
original_color_mask_pairs: List[Tuple[Color, np.ndarray]],
color_mask_pairs: List[Tuple[Color, np.ndarray]],
merge_operation: ChannelMergeOperation,
) -> np.ndarray:
cls._check_arr(arr, None)
for c, m in color_mask_pairs:
cls._check_mask(m, None)
temp_arr = deepcopy(arr)
temp_original_color_mask_pairs = deepcopy(original_color_mask_pairs)
temp_color_mask_pairs = deepcopy(color_mask_pairs)
new_arr = merge_operation(
temp_arr, temp_original_color_mask_pairs, temp_color_mask_pairs
)
cls._check_arr(new_arr, merge_operation)
return new_arr
@classmethod
def apply_mask_conversion(
cls, masks: List[np.ndarray], mask_conversion: MaskConversion
) -> List[np.ndarray]:
new_masks = [cls._mask_conversion(m, mask_conversion) for m in masks]
if not isinstance(mask_conversion, NoMaskConversion):
if all(np.array_equal(n, r) for n, r in zip(new_masks, masks)):
raise OperationInconsistencyException(f"no effect. {mask_conversion}")
return new_masks
@classmethod
def _mask_conversion(
cls, mask: np.ndarray, mask_conversion: MaskConversion
) -> np.ndarray:
cls._check_mask(mask, None)
temp_mask = deepcopy(mask)
applied_mask = mask_conversion(temp_mask)
cls._check_mask(applied_mask, mask_conversion)
return applied_mask
@classmethod
def apply_mask_operation(
cls,
arrays: List[np.ndarray],
masks: List[np.ndarray],
mask_operation: MaskOperation,
) -> List[np.ndarray]:
new_arrays = [
cls._apply_mask_operation(a, m, mask_operation)
for a, m in zip(arrays, masks)
]
if all(np.array_equal(n, r) for n, r in zip(new_arrays, arrays)):
raise OperationInconsistencyException(f"no effect. {mask_operation}")
return new_arrays
@classmethod
def _apply_mask_operation(
cls, arr: np.ndarray, mask: np.ndarray, mask_operation: MaskOperation
) -> np.ndarray:
cls._check_arr(arr, None)
cls._check_mask(mask, None)
temp_arr, temp_mask = deepcopy(arr), deepcopy(mask)
applied_arr = mask_operation(temp_arr, temp_mask)
cls._check_arr(applied_arr, mask_operation)
return applied_arr
@staticmethod
def _check_arr(arr: np.ndarray, operation: Optional[UniformOperation]):
# TODO Just for assertion and debug. This function spends some time. Should remove this function at the end of competition?
assert isinstance(arr, np.ndarray), f"operation: {operation}, type: {type(arr)}"
assert arr.dtype == np.uint8, f"operation: {operation}, dtype: {arr.dtype}"
assert arr.size != 0, f"operation: {operation}, operation_result: \n{arr}"
assert (
0 <= np.min(arr) <= np.max(arr) <= 10
), f"operation: {operation}, operation_result: \n{arr}"
assert len(arr.shape) == 2, f"operation: {operation}, operation_result: \n{arr}"
@staticmethod
def _check_mask(
mask: np.ndarray, operation: Union[ColorSelection, MaskConversion, None]
):
# TODO Just for assertion and debug. This function spends some time. Should remove this function at the end of competition?
assert isinstance(
mask, np.ndarray
), f"selection: {operation}, type: {type(mask)}"
assert mask.dtype == bool, f"selection: {operation}, dtype: {mask.dtype}"
assert len(mask.shape) == 2, f"selection: {operation}, result: \n{mask}"
@classmethod
def apply_partition_selection(
cls, arrays: List[np.ndarray], partition_selection: PartitionSelection
) -> List[Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]]:
return [cls._apply_partition_selection(a, partition_selection) for a in arrays]
@classmethod
def _apply_partition_selection(
cls, arr: np.ndarray, partition_selection: PartitionSelection
) -> Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]:
cls._check_arr(arr, None)
temp_arr = deepcopy(arr)
return partition_selection(temp_arr)
@classmethod
def apply_partition_merge_operation(
cls,
arrays: List[np.ndarray],
partitioned_arrays_original_location_masks: List[
Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]
],
partition_merge_operation: PartitionMergeOperation,
):
return [
cls._apply_partition_merge_operation(a, p, partition_merge_operation)
for a, p in zip(arrays, partitioned_arrays_original_location_masks)
]
@classmethod
def _apply_partition_merge_operation(
cls,
arr: np.ndarray,
partitioned_arrays_original_location_masks: Tuple[
List[List[np.ndarray]], List[List[np.ndarray]]
],
partition_merge_operation: PartitionMergeOperation,
):
(
partitioned_arrays,
original_location_masks,
) = partitioned_arrays_original_location_masks
cls._check_arr(arr, None)
temp_arr = deepcopy(arr)
temp_partitioned_arrays = deepcopy(partitioned_arrays)
temp_original_location_masks = deepcopy(original_location_masks)
res_arr = partition_merge_operation(
temp_arr, temp_partitioned_arrays, temp_original_location_masks
)
cls._check_arr(res_arr, partition_merge_operation)
return res_arr
class MLNodeEvaluator(NodeEvaluator):
def __init__(self, pattern: DepthSearchPattern):
self.pattern = pattern
self.features = pickle.load(PathConfig.NODE_EVALUATOR_FEATURES.open(mode="rb"))
self.categorical_features = pickle.load(
PathConfig.NODE_EVALUATOR_CATEGORICAL_FEATURES.open(mode="rb")
)
self.sample_df = pickle.load(
PathConfig.NODE_EVALUATOR_SAMPLE_DF.open(mode="rb")
)
self.model: LGBMClassifier = pickle.load(
PathConfig.NODE_EVALUATOR_MODEL.open(mode="rb")
)
self.model.n_jobs = 1
self.oe: OrdinalEncoder = pickle.load(
PathConfig.NODE_EVALUATOR_ORDINAL_ENCODER.open(mode="rb")
)
def evaluate(self, node: WaitingNode) -> float:
raise NotImplementedError()
def evaluate_nodes(self, nodes: List[WaitingNode]):
if len(nodes) == 0:
return
feature_dicts = [n.evaluation_features() for n in nodes]
feature_dicts = [
{
**{k: v for k, v in d.items() if k in self.features},
**{f: None for f in self.features if f not in d},
}
for d in feature_dicts
]
for d in feature_dicts:
for c_f in self.categorical_features:
d[c_f] = str(d[c_f])
df = DataFrame(columns=self.features)
df = df.append(feature_dicts)
df[self.categorical_features] = self.oe.transform(df[self.categorical_features])
df = df.fillna(-1)
x = df[self.features]
probs = self.model.predict_proba(x)[:, 0]
for n, p in zip(nodes, probs):
n.cache_pred_distance = self._add_cost(p, n.depth())
def _add_cost(self, prob: float, depth: int) -> float:
# Impose penalty. A* like algorithm.
if self.pattern == DepthSearchPattern.BREADTH_FIRST:
return prob ** (1 / (1 + (depth / 1))) + 0.3 * depth
elif self.pattern == DepthSearchPattern.NORMAL:
return prob ** (1 / (1 + (depth / 2))) + 0.1 * depth
elif self.pattern == DepthSearchPattern.DEPTH_FIRST:
return prob
else:
raise NotImplementedError()
@dataclass(frozen=True)
class LinePartition(PartitionSelection):
line_color: Color
def __call__(
self, arr: np.ndarray
) -> Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]:
if arr.size == 1:
raise OperationInconsistencyException("size == 1")
if 1 in arr.shape and len(np.unique(arr)) == 1:
raise OperationInconsistencyException("can not separate")
color_hit: np.ndarray = arr == self.line_color
line_v_indices = np.where(color_hit.all(axis=1))[0]
line_h_indices = np.where(color_hit.all(axis=0))[0]
if len(line_v_indices) == len(line_h_indices) == 0:
raise OperationInconsistencyException("not line found")
if 1 in np.diff(line_v_indices) or 1 in np.diff(line_h_indices):
raise OperationInconsistencyException("line duplicated")
partitioned_arrays = []
partitioned_masks = []
for start_v_i, end_v_i in zip(
[0] + list(line_v_indices + 1), list(line_v_indices) + [arr.shape[0]]
):
if start_v_i == end_v_i:
continue
partitioned_temp_arrays = []
partitioned_temp_masks = []
for start_h_i, end_h_i in zip(
[0] + list(line_h_indices + 1), list(line_h_indices) + [arr.shape[1]]
):
if start_h_i == end_h_i:
continue
partitioned_temp_arrays.append(
arr[start_v_i:end_v_i, start_h_i:end_h_i]
)
mask = np.full_like(arr, fill_value=False, dtype=bool)
mask[start_v_i:end_v_i, start_h_i:end_h_i] = True
partitioned_temp_masks.append(mask)
partitioned_arrays.append(partitioned_temp_arrays)
partitioned_masks.append(partitioned_temp_masks)
return partitioned_arrays, partitioned_masks
@dataclass(frozen=True)
class GeneralizedLinePartition(PartitionSelection):
bg_selection_mode: BackGroundColorSelectionMode
def __call__(
self, arr: np.ndarray
) -> Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]:
if arr.size == 1:
raise OperationInconsistencyException("size == 1")
if 1 in arr.shape and len(np.unique(arr)) == 1:
raise OperationInconsistencyException("can not separate")
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
colors = [Color.of(c) for c in np.unique(arr)]
color_lines = []
for c in colors:
if c == bg:
continue
color_hit: np.ndarray = arr == c
line_v_indices = np.where(color_hit.all(axis=1))[0]
line_h_indices = np.where(color_hit.all(axis=0))[0]
color_lines.append((c, len(line_v_indices) + len(line_h_indices)))
if len(color_lines) == 0:
raise OperationInconsistencyException("not colored")
target_color = max(color_lines, key=itemgetter(1))[0]
return LinePartition(target_color)(arr)
@dataclass(frozen=True)
class IntegerDivisionPartition(PartitionSelection):
axis: Axis
n_split: int
def __call__(
self, arr: np.ndarray
) -> Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]:
if self.axis == Axis.HORIZONTAL:
if arr.shape[1] % self.n_split != 0:
raise OperationInconsistencyException("can not divide")
masks = []
partition_len = arr.shape[1] // self.n_split
for i in range(self.n_split):
mask = np.full_like(arr, fill_value=False, dtype=bool)
start_i, end_i = i * partition_len, (i + 1) * partition_len
mask[:, start_i:end_i] = True
masks.append(mask)
masks = [masks]
partitioned_arrays = np.split(arr, self.n_split, axis=1)
partitioned_arrays = [partitioned_arrays]
elif self.axis == Axis.VERTICAL:
if arr.shape[0] % self.n_split != 0:
raise OperationInconsistencyException("can not divide")
masks = []
partition_len = arr.shape[0] // self.n_split
for i in range(self.n_split):
mask = np.full_like(arr, fill_value=False, dtype=bool)
start_i, end_i = i * partition_len, (i + 1) * partition_len
mask[start_i:end_i, :] = True
masks.append(mask)
masks = [[m] for m in masks]
partitioned_arrays = np.split(arr, self.n_split, axis=0)
partitioned_arrays = [[a] for a in partitioned_arrays]
elif self.axis == Axis.BOTH:
if arr.shape[0] % self.n_split != 0 or arr.shape[1] % self.n_split != 0:
raise OperationInconsistencyException("can not divide")
masks = []
v_partition_len = arr.shape[0] // self.n_split
h_partition_len = arr.shape[1] // self.n_split
for i in range(self.n_split):
temp_masks = []
v_start_i, v_end_i = i * v_partition_len, (i + 1) * v_partition_len
for j in range(self.n_split):
mask = np.full_like(arr, fill_value=False, dtype=bool)
h_start_i, h_end_i = j * h_partition_len, (j + 1) * h_partition_len
mask[v_start_i:v_end_i, h_start_i:h_end_i] = True
temp_masks.append(mask)
masks.append(temp_masks)
partitioned_arrays = np.split(arr, self.n_split, axis=0)
partitioned_arrays = [
np.split(a, self.n_split, axis=1) for a in partitioned_arrays
]
else:
raise NotImplementedError()
return partitioned_arrays, masks
@dataclass(frozen=True)
class ColorNumIntegerDivisionPartition(PartitionSelection):
axis: Axis
def __call__(
self, arr: np.ndarray
) -> Tuple[List[List[np.ndarray]], List[List[np.ndarray]]]:
color_num = len(np.unique(arr))
color_num = color_num - 1 # bg
if color_num == 0:
raise OperationInconsistencyException("not colored")
return IntegerDivisionPartition(self.axis, color_num)(arr)
@dataclass
class RandomNodeTreeCreateEngine:
MAX_NODE = 30000
timeout_sec: int = 30
node_evaluator = RandomNodeEvaluator()
def search(self, task: Task, verbose: bool = False) -> List[NodeTree]:
task_feature = TaskFeature.of(task)
root_node = UniformOperationCompletedNode(
None, task, task_feature, OperationSet([])
)
first_waiting_nodes = CompletedNodeProcessor.process(root_node)
self.node_evaluator.evaluate_nodes(first_waiting_nodes)
pq = PriorityQueue([*first_waiting_nodes])
if verbose:
print("first pq nodes")
for n in pq.sorted_list():
print(f"cost: {n.cache_pred_distance}, {n}")
with Timer() as timer:
for node_i in range(self.MAX_NODE):
if len(pq) == 0:
# TODO What's the right thing to do?
raise NotImplementedError()
waiting_node = pq.pop_min()
completed_node = WaitingNodeProcessor().process(waiting_node)
if completed_node is None:
if verbose:
print("skipped")
continue
waiting_new_nodes = CompletedNodeProcessor.process(completed_node)
self.node_evaluator.evaluate_nodes(waiting_new_nodes)
for n in waiting_new_nodes:
pq.push(n)
if timer.second() > self.timeout_sec:
break
return [
NodeTree.of(waiting_node.parent_completed_node) for waiting_node in pq.heap
]
@dataclass(frozen=True)
class AnySelectionMerge(PartitionMergeOperation):
bg_selection_mode: BackGroundColorSelectionMode
fill_color: Color
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
shape = partitioned_arrays[0][0].shape
if not all(a.shape == shape for h_a in partitioned_arrays for a in h_a):
raise OperationInconsistencyException("not same shape")
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
result_mask = np.full_like(
partitioned_arrays[0][0], fill_value=False, dtype=bool
)
for horizontal_arrays in partitioned_arrays:
for a in horizontal_arrays:
result_mask[a != bg] = True
result_arr = np.full_like(partitioned_arrays[0][0], fill_value=bg)
result_arr[result_mask] = self.fill_color
return result_arr
@dataclass(frozen=True)
class NotSelectionMerge(PartitionMergeOperation):
bg_selection_mode: BackGroundColorSelectionMode
fill_color: Color
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
shape = partitioned_arrays[0][0].shape
if not all(a.shape == shape for h_a in partitioned_arrays for a in h_a):
raise OperationInconsistencyException("not same shape")
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
result_mask = np.full_like(
partitioned_arrays[0][0], fill_value=True, dtype=bool
)
for horizontal_arrays in partitioned_arrays:
for a in horizontal_arrays:
result_mask[a != bg] = False
result_arr = np.full_like(partitioned_arrays[0][0], fill_value=bg)
result_arr[result_mask] = self.fill_color
return result_arr
@dataclass(frozen=True)
class AllSelectionMerge(PartitionMergeOperation):
bg_selection_mode: BackGroundColorSelectionMode
fill_color: Color
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
shape = partitioned_arrays[0][0].shape
if not all(a.shape == shape for h_a in partitioned_arrays for a in h_a):
raise OperationInconsistencyException("not same shape")
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
result_mask = np.full_like(
partitioned_arrays[0][0], fill_value=True, dtype=bool
)
for horizontal_arrays in partitioned_arrays:
for a in horizontal_arrays:
result_mask[a == bg] = False
result_arr = np.full_like(partitioned_arrays[0][0], fill_value=bg)
result_arr[result_mask] = self.fill_color
return result_arr
@dataclass(frozen=True)
class ModifiedXorSelectionMerge(PartitionMergeOperation):
bg_selection_mode: BackGroundColorSelectionMode
fill_color: Color
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
shape = partitioned_arrays[0][0].shape
if not all(a.shape == shape for h_a in partitioned_arrays for a in h_a):
raise OperationInconsistencyException("not same shape")
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
any_result_mask = np.full_like(
partitioned_arrays[0][0], fill_value=False, dtype=bool
)
for horizontal_arrays in partitioned_arrays:
for a in horizontal_arrays:
any_result_mask[a != bg] = True
all_result_mask = np.full_like(
partitioned_arrays[0][0], fill_value=True, dtype=bool
)
for horizontal_arrays in partitioned_arrays:
for a in horizontal_arrays:
all_result_mask[a == bg] = False
# modified xor
result_mask = any_result_mask
result_mask[all_result_mask] = False
result_arr = np.full_like(partitioned_arrays[0][0], fill_value=bg)
result_arr[result_mask] = self.fill_color
return result_arr
@dataclass(frozen=True)
class NaturalArrayOrderedOverrideMerge(PartitionMergeOperation):
bg_selection_mode: BackGroundColorSelectionMode
start_corner: Corner
first_axis: Axis
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
shape = partitioned_arrays[0][0].shape
if not all(a.shape == shape for h_a in partitioned_arrays for a in h_a):
raise OperationInconsistencyException("not same shape")
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
result_arr = np.full_like(partitioned_arrays[0][0], fill_value=bg)
h, w = len(partitioned_arrays), len(partitioned_arrays[0])
for i, j in self.natural_array(h, w, self.start_corner, self.first_axis):
array = partitioned_arrays[i][j]
result_arr[array != bg] = array[array != bg]
return result_arr
def natural_array(
self, h: int, w: int, start_corner: Corner, first_axis: Axis
) -> List[Tuple[int, int]]:
start_ind = get_index(start_corner, h, w)
vertical_start_ind, horizontal_start_ind = start_ind
vertical_end_ind = h - 1 if vertical_start_ind == 0 else 0
horizontal_end_ind = w - 1 if horizontal_start_ind == 0 else 0
vertical_step = +1 if vertical_start_ind == 0 else -1
horizontal_step = +1 if horizontal_start_ind == 0 else -1
index_orders = []
if first_axis == Axis.HORIZONTAL:
for i in range_closed(vertical_start_ind, vertical_end_ind, vertical_step):
for j in range_closed(
horizontal_start_ind, horizontal_end_ind, horizontal_step
):
index_orders.append((i, j))
elif first_axis == Axis.VERTICAL:
for j in range_closed(
horizontal_start_ind, horizontal_end_ind, horizontal_step
):
for i in range_closed(
vertical_start_ind, vertical_end_ind, vertical_step
):
index_orders.append((i, j))
else:
raise NotImplementedError()
assert len(set(index_orders)) == len(index_orders) == h * w, index_orders
return index_orders
@dataclass(frozen=True)
class DiagonalArrayOrderedOverrideMerge(PartitionMergeOperation):
bg_selection_mode: BackGroundColorSelectionMode
start_corner: Corner
first_axis: Axis
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
shape = partitioned_arrays[0][0].shape
if not all(a.shape == shape for h_a in partitioned_arrays for a in h_a):
raise OperationInconsistencyException("not same shape")
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
result_arr = np.full_like(partitioned_arrays[0][0], fill_value=bg)
h, w = len(partitioned_arrays), len(partitioned_arrays[0])
for i, j in self.diagonal_array(h, w, self.start_corner, self.first_axis):
array = partitioned_arrays[i][j]
result_arr[array != bg] = array[array != bg]
return result_arr
def diagonal_array(
self, h: int, w: int, start_corner: Corner, first_axis: Axis
) -> List[Tuple[int, int]]:
start_ind = get_index(start_corner, h, w)
vertical_start_ind, horizontal_start_ind = start_ind
vertical_end_ind = h - 1 if vertical_start_ind == 0 else 0
horizontal_end_ind = w - 1 if horizontal_start_ind == 0 else 0
vertical_step = +1 if vertical_start_ind == 0 else -1
horizontal_step = +1 if horizontal_start_ind == 0 else -1
index_orders = []
if first_axis == Axis.HORIZONTAL:
for i in range_closed(vertical_start_ind, vertical_end_ind, vertical_step):
for h_num, j in enumerate(
range_closed(
horizontal_start_ind, horizontal_end_ind, horizontal_step
)
):
index_orders.append(((i + h_num) % h, j))
elif first_axis == Axis.VERTICAL:
for j in range_closed(
horizontal_start_ind, horizontal_end_ind, horizontal_step
):
for v_num, i in enumerate(
range_closed(vertical_start_ind, vertical_end_ind, vertical_step)
):
index_orders.append((i, (j + v_num) % w))
else:
raise NotImplementedError()
assert len(set(index_orders)) == len(index_orders) == h * w, index_orders
return index_orders
@dataclass(frozen=True)
class SpiralArrayOrderedOverrideMerge(PartitionMergeOperation):
bg_selection_mode: BackGroundColorSelectionMode
start_corner: Corner
spiral_direction: SpiralDirection
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
shape = partitioned_arrays[0][0].shape
if not all(a.shape == shape for h_a in partitioned_arrays for a in h_a):
raise OperationInconsistencyException("not same shape")
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
result_arr = np.full_like(partitioned_arrays[0][0], fill_value=bg)
h, w = len(partitioned_arrays), len(partitioned_arrays[0])
for i, j in self.spiral(h, w, self.start_corner, self.spiral_direction):
array = partitioned_arrays[i][j]
result_arr[array != bg] = array[array != bg]
return result_arr
def spiral(
self, h: int, w: int, start_corner: Corner, spiral_direction: SpiralDirection
) -> List[Tuple[int, int]]:
start_ind = get_index(start_corner, h, w)
index_orders = [start_ind]
current_ind = start_ind
while True:
if (
start_corner in [Corner.TOP_LEFT, Corner.TOP_RIGHT, Corner.BOTTOM_RIGHT]
and spiral_direction == SpiralDirection.CLOCKWISE
) or (
start_corner == Corner.BOTTOM_LEFT
and spiral_direction == SpiralDirection.ANTICLOCKWISE
):
if valid_index(
(current_ind[0], current_ind[1] + 1), h, w, index_orders
):
direction = Direction.RIGHT
elif valid_index(
(current_ind[0] + 1, current_ind[1]), h, w, index_orders
):
direction = Direction.BOTTOM
elif valid_index(
(current_ind[0], current_ind[1] - 1), h, w, index_orders
):
direction = Direction.LEFT
elif valid_index(
(current_ind[0] - 1, current_ind[1]), h, w, index_orders
):
direction = Direction.TOP
else:
break
else:
if valid_index(
(current_ind[0] - 1, current_ind[1]), h, w, index_orders
):
direction = Direction.TOP
elif valid_index(
(current_ind[0], current_ind[1] - 1), h, w, index_orders
):
direction = Direction.LEFT
elif valid_index(
(current_ind[0] + 1, current_ind[1]), h, w, index_orders
):
direction = Direction.BOTTOM
elif valid_index(
(current_ind[0], current_ind[1] + 1), h, w, index_orders
):
direction = Direction.RIGHT
else:
break
while True:
if direction == Direction.RIGHT:
next_ind = (current_ind[0], current_ind[1] + 1)
elif direction == Direction.BOTTOM:
next_ind = (current_ind[0] + 1, current_ind[1])
elif direction == Direction.LEFT:
next_ind = (current_ind[0], current_ind[1] - 1)
elif direction == Direction.TOP:
next_ind = (current_ind[0] - 1, current_ind[1])
else:
raise NotImplementedError()
if valid_index(next_ind, h, w, index_orders):
index_orders.append(next_ind)
current_ind = next_ind
else:
break
assert len(set(index_orders)) == len(index_orders) == h * w, index_orders
return index_orders
@dataclass(frozen=True)
class UniquelySelectedArrayExtraction(PartitionMergeOperation):
array_selection: PartitionedArraySelection
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
selections = self.array_selection(arr, partitioned_arrays)
results = []
for h_arrays, h_flags in zip(partitioned_arrays, selections):
for array, flag in zip(h_arrays, h_flags):
if flag:
results.append(array)
if len(set(map(lambda a: a.tostring(), results))) == 1:
return results[0]
else:
raise OperationInconsistencyException("not unique")
@dataclass(frozen=True)
class RestoreOnlySelectedArray(PartitionMergeOperation):
bg_selection_mode: BackGroundColorSelectionMode
array_selection: PartitionedArraySelection
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
bg = ColorSelectionUtil().get_background_color(arr, self.bg_selection_mode)
selections = self.array_selection(arr, partitioned_arrays)
for h_arrays, h_flags, h_locations in zip(
partitioned_arrays, selections, original_location_masks
):
for array, flag, location in zip(h_arrays, h_flags, h_locations):
if flag:
arr[location] = array.ravel()
else:
arr[location] = bg
return arr
@dataclass(frozen=True)
class ExtractOneValueFromPartitionedArray(PartitionMergeOperation):
def __call__(
self,
arr: np.ndarray,
partitioned_arrays: List[List[np.ndarray]],
original_location_masks: List[List[np.ndarray]],
) -> np.ndarray:
h, w = len(partitioned_arrays), len(partitioned_arrays[0])
result_arr = np.zeros_like(partitioned_arrays[0][0], shape=(h, w))
for i, j in product(range(h), range(w)):
array = partitioned_arrays[i][j]
extracted_value = ColorSelectionUtil().select_single_color(
array, SingleColorSelectionMode.MOST_COMMON
)
result_arr[i][j] = extracted_value
return result_arr
def range_closed(start, stop, step):
direction = 1 if (step > 0) else -1
return range(start, stop + direction, step)
def get_index(corner: Corner, h: int, w: int) -> Tuple[int, int]:
if corner == Corner.TOP_LEFT:
return 0, 0
elif corner == Corner.TOP_RIGHT:
return 0, w - 1
elif corner == Corner.BOTTOM_RIGHT:
return h - 1, w - 1
elif corner == Corner.BOTTOM_LEFT:
return h - 1, 0
else:
raise NotImplementedError()
def valid_index(
ind2d: Tuple[int, int], h: int, w: int, black_list: List[Tuple[int, int]]
) -> bool:
if ind2d in black_list:
return False
if ind2d[0] < 0 or h <= ind2d[0]:
return False
if ind2d[1] < 0 or w <= ind2d[1]:
return False
return True
def save_ml_training_data(task: Task, verbose: bool = False):
# 正解データ
correct_node_trees, exception, _ = NodeBaseSearchEngine(answer_limit_num=60).search(
task, verbose
)
print("search engine end")
if exception is not None:
print("answer not found")
return
correct_node_trees = [
t
for t in correct_node_trees
if AnswerMatcher.is_train_test_all_match_if_operated(task, t.to_operation_set())
]
if len(correct_node_trees) == 0:
print("answer not found")
return
correct_waiting_nodes = list(
chain.from_iterable([t.waiting_nodes() for t in correct_node_trees])
)
correct_feature_dicts = [n.evaluation_features() for n in correct_waiting_nodes]
correct_feature_dict_tuples = set(
tuple(sorted(d.items())) for d in correct_feature_dicts
)
correct_df = DataFrame(dict(t) for t in correct_feature_dict_tuples)
# 不正解データ
trees = RandomNodeTreeCreateEngine(timeout_sec=120).search(task, verbose)
print("random tree generated")
waiting_nodes = list(chain.from_iterable([t.waiting_nodes() for t in trees]))
feature_dicts = [n.evaluation_features() for n in waiting_nodes]
feature_dict_tuples = set(tuple(sorted(d.items())) for d in feature_dicts)
feature_dict_tuples = feature_dict_tuples - correct_feature_dict_tuples
wrong_df = DataFrame(dict(t) for t in feature_dict_tuples)
# ラベル付け
correct_df["label"] = 1
wrong_df["label"] = 0
all_df = correct_df.append(wrong_df, sort=False)
PathConfig.LABELED_TRAINING_DATA_ROOT.mkdir(parents=True, exist_ok=True)
pickle.dump(
all_df,
(PathConfig.LABELED_TRAINING_DATA_ROOT / f"{task.name}.pkl").open(mode="wb"),
)
print("save")
def train_ml():
x, y, feature_columns, categorical_features = prepare_train_data()
train_lgbm(x, y, feature_columns, categorical_features)
def prepare_train_data():
dfs = []
for pickle_path in PathConfig.LABELED_TRAINING_DATA_ROOT.iterdir():
print(pickle_path)
dfs.append(pickle.load((pickle_path.open(mode="rb"))))
all_df = pd.concat(dfs, ignore_index=True, sort=False)
print(
f'label1: {len(all_df[all_df["label"] == 1])}_label0: {len(all_df[all_df["label"] == 0])}'
)
# TODO Should we not use dsl properties(too detailed) features?
not_used_feature_columns = {
"label",
"depth",
"color",
"angle",
"direction",
"multi_color_selection_mode",
"single_color_selection_mode",
"edge_type",
"fill_type",
"flip_mode",
"k",
"ratio",
"padding_mode",
}
feature_columns = sorted(set(all_df.columns) - not_used_feature_columns)
all_df = all_df[feature_columns + ["label"]]
# process categorical
categorical_features = list(
filter(
lambda s: s in feature_columns,
map(str, all_df.select_dtypes(include="object").columns),
)
)
for c_f in categorical_features:
all_df[c_f] = all_df[c_f].fillna("None")
all_df[c_f] = all_df[c_f].apply(str)
# all_df[c_f] = all_df[c_f].astype(str)
# all_df[c_f] = all_df[c_f].apply(lambda v: str(v))
# all_df[c_f] = all_df[c_f].astype('category')
oe = category_encoders.OrdinalEncoder()
all_df[categorical_features] = oe.fit_transform(all_df[categorical_features])
# oe = category_encoders.OneHotEncoder(cols=[categorical_features])
# all_df = oe.fit_transform(all_df)
# all_df = all_df.fillna(-1)
# Relabel 0-labeled data in the neighborhood of 1 to 1
print("relabelling")
small_is_better_features = [
"mean_diff_color_cell_ratio",
"mean_excess_color_num",
"mean_lack_color_num",
"mean_horizontal_diff_input_arr_line_num",
"mean_horizontal_diff_output_arr_line_num",
"mean_horizontal_edge_sum_diff",
"mean_horizontal_edge_sum_diff_ratio",
"mean_vertical_diff_input_arr_line_num",
"mean_vertical_diff_output_arr_line_num",
"mean_vertical_edge_sum_diff",
"mean_vertical_edge_sum_diff_ratio",
]
for index, r in tqdm(all_df[all_df["label"] == 1].iterrows()):
temp_feature = sorted(set(feature_columns) - set(small_is_better_features))
near_rows = all_df[(all_df[temp_feature] == r[temp_feature]).all(axis=1)]
can_label_1 = near_rows[
(near_rows[small_is_better_features] <= r[small_is_better_features]).all(
axis=1
)
]
all_df.loc[can_label_1.index.values, "label"] = 1
print(
f'label1: {len(all_df[all_df["label"] == 1])}_label0: {len(all_df[all_df["label"] == 0])}'
)
print(f"feature_columns:")
for f in feature_columns:
print(f)
x = all_df[feature_columns]
y = all_df["label"]
print(f"len(x): {len(x)}, 1_labelled_len: {len(y[y == 1])}")
# x, y = RandomUnderSampler(sampling_strategy=0.01).fit_resample(x, y)
# x, y = EditedNearestNeighbours(sampling_strategy=0.01, n_jobs=RunConfig.N_JOB).fit_resample(x, y)
print(f"len(x): {len(x)}, 1_labelled_len: {len(y[y == 1])}")
# visualize
# scaled_x = StandardScaler().fit_transform(x)
# x_reduced = PCA(n_components=2).fit_transform(scaled_x)
# plt.scatter(x_reduced[y == 1, 0], x_reduced[y == 1, 1], alpha=0.1)
# plt.scatter(x_reduced[:, 0], x_reduced[:, 1], c=y, alpha=0.1)
# plt.show()
# plt.close()
pickle.dump(all_df, PathConfig.NODE_EVALUATOR_SAMPLE_DF.open(mode="wb"))
pickle.dump(oe, PathConfig.NODE_EVALUATOR_ORDINAL_ENCODER.open(mode="wb"))
pickle.dump(feature_columns, PathConfig.NODE_EVALUATOR_FEATURES.open(mode="wb"))
pickle.dump(
categorical_features,
PathConfig.NODE_EVALUATOR_CATEGORICAL_FEATURES.open(mode="wb"),
)
return x, y, feature_columns, categorical_features
def train_lg(feature_columns, x, y):
model = LogisticRegression(class_weight="balanced", n_jobs=RunConfig.N_JOB)
model.fit(x, y)
pred_y = model.predict_proba(x)
print(pred_y)
# cb = CatBoostClassifier(loss_function='Logloss', class_weights=[0.1, 1], cat_features=categorical_features)
# cb.fit(x, y)
# pred_y = cb.predict_proba(x)
PathConfig.SAVED_MODEL.mkdir(parents=True, exist_ok=True)
pickle.dump(model, PathConfig.NODE_EVALUATOR_MODEL.open(mode="wb"))
del model
print(x)
print(y)
print(pred_y)
# cb = CatBoostClassifier()
# cb.load_model(str(PathConfig.NODE_EVALUATOR_MODEL), format="cbm")
model = pickle.load(PathConfig.NODE_EVALUATOR_MODEL.open(mode="rb"))
pred_y = model.predict_proba(x)
print(pred_y)
coefs = np.abs(model.coef_[0])
for c, f in zip(coefs, feature_columns):
print(f"{f}_{c}")
def train_lgbm(x, y, feature_columns, categorical_features):
lgbm_params = {
"silent": False,
"n_jobs": RunConfig.N_JOB,
"class_weight": "balanced",
"max_depth": 3,
"learning_rate": 0.2,
}
best_iterations = []
folds = KFold(shuffle=False, n_splits=3)
for n_fold, (train_index, valid_index) in enumerate(folds.split(x, y)):
train_x, train_y = x.iloc[train_index], y.iloc[train_index]
valid_x, valid_y = x.iloc[valid_index], y.iloc[valid_index]
model = LGBMClassifier(n_estimators=1000, **lgbm_params)
model.fit(
train_x,
train_y,
eval_set=[(valid_x, valid_y), (train_x, train_y)],
early_stopping_rounds=10,
categorical_feature=categorical_features,
verbose=True,
)
best_iterations.append(model.best_iteration_)
print(best_iterations)
model = LGBMClassifier(n_estimators=min(best_iterations), **lgbm_params)
model.fit(x, y, verbose=True, categorical_feature=categorical_features)
pred_y = model.predict_proba(x)
print(pred_y)
PathConfig.SAVED_MODEL.mkdir(parents=True, exist_ok=True)
pickle.dump(model, PathConfig.NODE_EVALUATOR_MODEL.open(mode="wb"))
del model
print(x)
print(y)
print(pred_y)
model = pickle.load(PathConfig.NODE_EVALUATOR_MODEL.open(mode="rb"))
pred_y = model.predict_proba(x)
print(pred_y)
importance = pd.DataFrame(
model.feature_importances_, index=feature_columns, columns=["importance"]
)
print(importance)
def train_test_model(feature_columns, x, y):
try_cv = False
if try_cv:
folds = KFold(shuffle=True)
for n_fold, (train_index, valid_index) in enumerate(folds.split(x, y)):
train_x, train_y = x.iloc[train_index], y.iloc[train_index]
valid_x, valid_y = x.iloc[valid_index], y.iloc[valid_index]
model = LGBMClassifier(
class_weight="balanced",
learning_rate=0.2,
n_jobs=RunConfig.N_JOB,
n_estimators=1000,
silent=False,
)
model.fit(
train_x,
train_y,
eval_set=[(valid_x, valid_y), (train_x, train_y)],
early_stopping_rounds=10,
verbose=True,
)
# model = MLPClassifier(hidden_layer_sizes=(20, 20, 10))
model = RidgeClassifier(class_weight="balanced")
# model = LinearSVC(class_weight='balanced')
# model = LGBMClassifier(class_weight='balanced', learning_rate=0.2, n_estimators=50,
# silent=False)
model.fit(x, y)
pred_y = model.predict(x)
print(pred_y)
PathConfig.SAVED_MODEL.mkdir(parents=True, exist_ok=True)
pickle.dump(model, PathConfig.NODE_EVALUATOR_MODEL.open(mode="wb"))
del model
print(x)
print(y)
print(pred_y)
model = pickle.load(PathConfig.NODE_EVALUATOR_MODEL.open(mode="rb"))
pred_y = model.predict_proba(x)
print(pred_y)
importance = pd.DataFrame(
model.feature_importances_, index=feature_columns, columns=["importance"]
)
print(importance)
CATEGORIES = [
"PARTITION",
"SYMMETRY",
"REPEAT",
"DENOISE",
"SIMPLIFICATION",
"NUMBER",
"RANKING",
"SHAPE",
"FIND_FIT",
"LINE",
"OBJECT_TRANSFORM",
"OBJECT_MOVE",
"JIGSAW_PUZZLE",
"COLOR",
"PASTE",
"GUIDE",
"META",
"OTHERS",
"ONCE_ANSWERED",
]
GIVE_UPS = [
"SYMMETRY",
"REPEAT",
"DENOISE",
"SIMPLIFICATION",
"NUMBER",
"RANKING",
"SHAPE",
"FIND_FIT",
"OBJECT_MOVE",
"JIGSAW_PUZZLE",
"COLOR",
"PASTE",
"GUIDE",
"META",
]
class TaskTaxonomy:
def __init__(self):
with open(str(PathConfig.OPERATION_ANSWER_TAXONOMY_YAML), "r") as f:
yaml_dict = yaml.load(f, Loader=yaml.Loader)
self.trains: Dict[str, List[str]] = yaml_dict["1_train"]
self.evals: Dict[str, List[str]] = yaml_dict["2_eval"]
self.check()
def check(self):
assert len(self.trains) == len(self.evals) == 400
for task_name, categories in {**self.trains, **self.evals}.items():
assert len(categories) == len(set(categories))
for category in categories:
assert category in CATEGORIES, category
json_task_names = {
path.stem
for path in chain.from_iterable(
[PathConfig.TRAIN_ROOT.iterdir(), PathConfig.EVALUATION_ROOT.iterdir()]
)
}
df_task_names = set(list(self.trains.keys()) + list(self.evals.keys()))
assert json_task_names - df_task_names == set(), json_task_names - df_task_names
assert df_task_names - json_task_names == set(), df_task_names - json_task_names
def show_stats(self):
print("=== train stats ====")
for c in CATEGORIES:
num = len(list(filter(lambda v: c in v, self.trains.values())))
print(f"{c}: {num}")
print("\n=== eval stats ====")
for c in CATEGORIES:
num = len(list(filter(lambda v: c in v, self.evals.values())))
print(f"{c}: {num}")
def save_yaml(self):
self.check()
with open(str(PathConfig.OPERATION_ANSWER_TAXONOMY_YAML), "w") as f:
yaml.dump({"1_train": self.trains, "2_eval": self.evals}, f)
def save_categorized_fig(self):
# from abstraction_and_reasoning_challenge.src.loader.task_loader import TaskLoader # TODO fix local import?
shutil.rmtree(PathConfig.OPERATION_ANSWER_TAXONOMY_IMAGE_ROOT)
for (task_name, categories), tag in tqdm(
list(
zip(
list(self.trains.items()) + list(self.evals.items()),
["train"] * len(self.trains) + ["evals"] * len(self.evals),
)
)
):
if categories == []:
task = TaskLoader().get_task(task_name)
plot_task(
task,
show=False,
save_path=PathConfig.OPERATION_ANSWER_TAXONOMY_IMAGE_ROOT
/ tag
/ "not_categorized"
/ f"{task_name}.png",
)
for c in categories:
task = TaskLoader().get_task(task_name)
plot_task(
task,
show=False,
save_path=PathConfig.OPERATION_ANSWER_TAXONOMY_IMAGE_ROOT
/ tag
/ c
/ f"{task_name}.png",
)
def get_give_up_task_names(self) -> List[str]:
can_answers = self.get_can_answer_task_names()
give_up_task_names = []
for task_name, categories in {**self.trains, **self.evals}.items():
if task_name in can_answers:
continue
for c in categories:
if c in GIVE_UPS:
give_up_task_names.append(task_name)
break
return give_up_task_names
def get_can_answer_task_names(self) -> List[str]:
return [
task_name
for task_name, categories in {**self.trains, **self.evals}.items()
if "ONCE_ANSWERED" in categories
]
def filter_tasks(self, tasks: List[Task]) -> List[Task]:
if RunConfig.TASK_RANGE == TaskRange.ALL:
return tasks
elif RunConfig.TASK_RANGE == TaskRange.EXCLUDE_GIVE_UPS:
return list(
filter(lambda t: t.name not in self.get_give_up_task_names(), tasks)
)
elif RunConfig.TASK_RANGE == TaskRange.CAN_ANSWER_ONLY:
return list(
filter(lambda t: t.name in self.get_can_answer_task_names(), tasks)
)
else:
raise NotImplementedError()
def get_engine(engine_type: EngineType):
if engine_type == EngineType.NODE_BASED_SEARCH_ENGINE:
return NodeBaseSearchEngine()
elif engine_type == EngineType.TREE_BASED_SEARCH_ENGINE:
return TreeBaseSearchEngine()
else:
raise NotImplementedError()
def run():
if debug_run():
return
initialize_path()
if RunConfig.RUN_MODE == RunMode.LOCAL_RUN:
load_answer_storage() # debug validate
tt = TaskTaxonomy()
solve_tasks(
tt.filter_tasks(TaskLoader().get_training_tasks()),
AllParameter(),
output_summary_path=PathConfig.OPERATION_ANSWER_MEMO_ROOT
/ "answer_summary_train.txt",
copy_wrong_answers_root_tag="train",
add_answer_storage=True,
save_submission=True,
)
solve_tasks(
tt.filter_tasks(TaskLoader().get_evaluation_tasks()),
AllParameter(),
output_summary_path=PathConfig.OPERATION_ANSWER_MEMO_ROOT
/ "answer_summary_eval.txt",
copy_wrong_answers_root_tag="eval",
add_answer_storage=False,
save_submission=False,
)
elif RunConfig.RUN_MODE == RunMode.LOCAL_RUN_ALL:
solve_tasks(
TaskLoader().get_training_tasks(),
AllParameter(),
output_summary_path=PathConfig.OPERATION_ANSWER_MEMO_ROOT
/ "answer_summary_train.txt",
copy_wrong_answers_root_tag="train",
add_answer_storage=True,
save_submission=True,
)
solve_tasks(
TaskLoader().get_evaluation_tasks(),
AllParameter(),
output_summary_path=PathConfig.OPERATION_ANSWER_MEMO_ROOT
/ "answer_summary_eval.txt",
copy_wrong_answers_root_tag="eval",
add_answer_storage=False,
save_submission=False,
)
solve_tasks(TaskLoader().get_test_tasks(), AllParameter(), save_submission=True)
elif RunConfig.RUN_MODE == RunMode.KERNEL_EMULATION:
solve_tasks(TaskLoader().get_test_tasks(), AllParameter(), save_submission=True)
elif RunConfig.RUN_MODE == RunMode.NODE_BASE_SEARCH_OPTIMIZATION:
optimize_node_base_search(TaskLoader().get_training_tasks())
elif RunConfig.RUN_MODE == RunMode.TREE_BASE_SEARCH_OPTIMIZATION:
optimize_tree_base_search(TaskLoader().get_training_tasks())
elif RunConfig.RUN_MODE == RunMode.LOCAL_DATA_GENERATION:
for t in TaskLoader().get_training_tasks():
print(t.name)
save_ml_training_data(t)
elif RunConfig.RUN_MODE == RunMode.LOCAL_ML_TRAIN:
train_ml()
elif RunConfig.RUN_MODE == RunMode.TRAIN_OPERATION_ELEMENT_INCLUSION_PREDICTION:
train_operation_element_inclusion_prediction()
elif RunConfig.RUN_MODE == RunMode.KERNEL:
if RunConfig.RUN_ONLY_PRIVATE_LB and not TaskLoader().is_private_lb_run():
print("This is kernel public run. Skipped.")
shutil.copy(
str(KernelPathConfig.SAMPLE_SUBMISSION), KernelPathConfig.SUBMISSION
)
return
else:
print("This is private private run. Not skipped.")
solve_tasks(
TaskLoader().get_test_tasks(), AllParameter(), save_submission=True
)
else:
raise ValueError(RunConfig.RUN_MODE)
print("end")
def debug_run():
print("start")
if DebugConfig.OPERATION_DEBUG_TASK_NAME:
operation_set = str_to_operation_set(DebugConfig.OPERATION_DEBUG_OPERATION_SET)
print(operation_set)
task = TaskLoader().get_task(DebugConfig.OPERATION_DEBUG_TASK_NAME)
applied_task = TaskOperationSetExecutor().execute(task, operation_set)
original_task_feature = create_task_feature(task, task)
applied_task_feature = create_task_feature(task, applied_task)
original_df = DataFrame(asdict(original_task_feature), index=["index"]).T
applied_df = DataFrame(asdict(applied_task_feature), index=["index"]).T
merged_feature_df = pd.merge(
original_df,
applied_df,
left_index=True,
right_index=True,
suffixes=["original_", "appplied_"],
)
original_waiting_node = ColorSelectionWaitingNode(
None,
task,
task,
original_task_feature,
OperationSet([]),
MultiColorSelection(MultiColorSelectionMode.ANY_WITHOUT_MOST_COMMON),
)
# original_waiting_node2 = MaskConversionWaitingNode(None, None, task, original_task_feature, OperationSet([]), SingleColorSelection(SingleColorSelectionMode.LEAST_COMMON))
applied_waiting_node = ColorSelectionWaitingNode(
None,
task,
applied_task,
applied_task_feature,
operation_set,
MultiColorSelection(MultiColorSelectionMode.ANY_WITHOUT_MOST_COMMON),
)
print(merged_feature_df)
print("distance")
print(
DistanceEvaluator(DistanceEvaluatorParameter()).evaluate_task_feature(
original_task_feature
)
)
print(
DistanceEvaluator(DistanceEvaluatorParameter()).evaluate_task_feature(
applied_task_feature
)
)
print("breadth cost")
HandMadeNodeEvaluator(
DepthSearchPattern.BREADTH_FIRST,
defaultdict(lambda: 1),
NodeBaseSearchEngineParameter(),
DistanceEvaluatorParameter(),
).evaluate_nodes([original_waiting_node, original_waiting_node])
HandMadeNodeEvaluator(
DepthSearchPattern.BREADTH_FIRST,
defaultdict(lambda: 1),
NodeBaseSearchEngineParameter(),
DistanceEvaluatorParameter(),
).evaluate_nodes([original_waiting_node, applied_waiting_node])
print(original_waiting_node.cache_pred_distance)
print(applied_waiting_node.cache_pred_distance)
print("normal cost")
HandMadeNodeEvaluator(
DepthSearchPattern.NORMAL,
defaultdict(lambda: 1),
NodeBaseSearchEngineParameter(),
DistanceEvaluatorParameter(),
).evaluate_nodes([original_waiting_node, original_waiting_node])
HandMadeNodeEvaluator(
DepthSearchPattern.NORMAL,
defaultdict(lambda: 1),
NodeBaseSearchEngineParameter(),
DistanceEvaluatorParameter(),
).evaluate_nodes([original_waiting_node, applied_waiting_node])
print(original_waiting_node.cache_pred_distance)
print(applied_waiting_node.cache_pred_distance)
print("depth cost")
HandMadeNodeEvaluator(
DepthSearchPattern.DEPTH_FIRST,
defaultdict(lambda: 1),
NodeBaseSearchEngineParameter(),
DistanceEvaluatorParameter(),
).evaluate_nodes([original_waiting_node, original_waiting_node])
HandMadeNodeEvaluator(
DepthSearchPattern.DEPTH_FIRST,
defaultdict(lambda: 1),
NodeBaseSearchEngineParameter(),
DistanceEvaluatorParameter(),
).evaluate_nodes([original_waiting_node, applied_waiting_node])
print(original_waiting_node.cache_pred_distance)
print(applied_waiting_node.cache_pred_distance)
plot_task_with_operation_set(task, operation_set, show=True, save_path=None)
return True
if DebugConfig.SOLVE_DEBUG_TASK_NAME:
task = TaskLoader().get_task(DebugConfig.SOLVE_DEBUG_TASK_NAME)
engine_result = solve_tasks(
[task], AllParameter(), add_answer_storage=True, verbose=True
)[0]
if isinstance(engine_result, AnsweredSearchResults):
plot_task_with_result_set(task, engine_result, show=True, save_path=None)
return True
if DebugConfig.TRAIN_DATA_GENERATION_DEBUG_TASK_NAME:
task = TaskLoader().get_task(DebugConfig.TRAIN_DATA_GENERATION_DEBUG_TASK_NAME)
save_ml_training_data(task)
train_ml(task)
return True
return False
def performance_run():
# from line_profiler import LineProfiler
# from python_utils.src.library.print_line_profiler import print_stats
# from abstraction_and_reasoning_challenge import run as run_module
# from abstraction_and_reasoning_challenge.src.domain import task_solver
# from abstraction_and_reasoning_challenge.src.domain.search_engine.evaluation_functions import handmade_evaluator
# from abstraction_and_reasoning_challenge.src.domain.search_engine.node import waiting_node
# from abstraction_and_reasoning_challenge.src.domain.search_engine.node_processor import waiting_node_processor
# from abstraction_and_reasoning_challenge.src.domain.feature import task_feature
# from abstraction_and_reasoning_challenge.src.domain.search_engine.engine import node_base_search_engine
# from abstraction_and_reasoning_challenge.src.domain.search_engine.engine import tree_base_search_engine
#
# profiler = LineProfiler()
# profiler.add_module(run_module)
# profiler.add_module(task_solver)
# profiler.add_module(handmade_evaluator)
# profiler.add_module(waiting_node)
# profiler.add_module(waiting_node_processor)
# profiler.add_module(task_feature)
# profiler.add_module(node_base_search_engine)
# profiler.add_module(tree_base_search_engine)
#
# profiler.runcall(run)
# # profiler.print_stats()
# stats = profiler.get_stats()
# print_stats(stats, strip_seconds_limit=0., cost_sort=True)
pass
performance_profiling_mode = False
if __name__ == "__main__":
run()
#
# # Rollback the predictions
# [Back to Table of Content](#toc)
sub = pd.read_csv("./submission_yuki_alignment.csv")
print(sub.shape)
sub.head(3)
def get_string(pred):
str_pred = str([list(row) for row in pred])
str_pred = str_pred.replace(", ", "")
str_pred = str_pred.replace("[[", "|")
str_pred = str_pred.replace("][", "|")
str_pred = str_pred.replace("]]", "|")
return str_pred
def get_string_list(preds):
return " ".join([get_string(pred) for pred in preds])
def rollback_row(r, test_aligned_tasks=test_aligned_tasks, debug=False):
output_id = r["output_id"]
output_aligned = str(r["output_aligned"])
# |080000|808000|008088|000008| |0| |0|
if len(output_aligned) < 10:
return "|00|00| |00|00| |00|00|"
task_id = output_id.split("_")[0]
order_id = int(output_id.split("_")[1])
task_aligned = test_aligned_tasks[task_id]
sample_aligned = task_aligned["test"][order_id]
predictions_aligned = output_aligned.split(" ")
def str2list(s):
return [int(d) for d in s]
predictions_aligned = [
[str2list(s) for s in pred.split("|")[1:-1]]
for pred in predictions_aligned
if len(pred) > 5
]
predictions = []
modified = False
for pred_aligned in predictions_aligned:
pred = np.array(pred_aligned)
if sample_aligned["fliplr"]:
pred = np.fliplr(pred)
modified = True
if sample_aligned["flipud"]:
pred = np.flipud(pred)
modified = True
if sample_aligned["rot90"]:
pred = np.rot90(pred, k=3)
modified = True
predictions.append(pred.tolist())
output_final = get_string_list(predictions)
if debug and modified:
print(task_id, order_id)
return output_final
def rollback_sub(sub):
sub2 = sub.copy()
sub2["output_aligned"] = sub2["output"]
sub2["output"] = sub2.apply(lambda r: rollback_row(r), axis=1)
sub2["is_modified"] = sub2.apply(
lambda r: 1 if r["output_aligned"] != r["output"] else 0, axis=1
)
return sub2
sub2 = rollback_sub(sub)
print(sub2["is_modified"].sum())
sub2.head(3)
sub2[["output_id", "output"]].to_csv("./submission_yuki_rollback.csv", index=None)
sub2 = sub2[["output_id", "output"]]
sub2.set_index("output_id", inplace=True)
sample_submission = pd.read_csv(
"/kaggle/input/abstraction-and-reasoning-challenge/sample_submission.csv",
index_col="output_id",
)
for idx, row in sample_submission.iterrows():
if idx in sub2.index:
sample_submission.loc[idx, "output"] = sub2.loc[idx, "output"]
sample_submission.to_csv("submission.csv")
| false | 0 | 71,693 | 9 | 6 | 71,693 |
||
35900759 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
import os
def log(*args):
os.system(f'echo "{args}"')
print(*args)
# In the [Data preparation notebook](https://www.kaggle.com/tchaye59/data-preparation), we've prepared the dataset in a suitable format ready to feed into a machine learning pipeline. In this one, we will use tf.data API to build our transformations pipeline and feed our network.
# ### We install the TFDS library and import required modules:
import tensorflow as tf
from tensorflow import keras
import pickle
import pandas
import numpy as np
from matplotlib import pyplot as plt
import gc
import threading
import time
import tensorflow_datasets.public_api as tfds
from tensorflow.keras import backend as K
from sklearn import metrics
tf.random.set_seed(1234)
np.random.seed(1234)
# The columns give us an idea of what our data looks like
columns = pickle.load(open("/kaggle/input/data-preparation/columns.pkl", "rb"))
max_day = 1941
print(f"Columns-{len(columns)} : {columns}")
print("Target: ", columns[5])
target_col = 5
# ## Let define some utils
# This function is just a wrapper to a function that calls add_time_steps
def preprocess(
lookback,
delay,
target_col=target_col,
lookback_step=1,
test=False,
val_days=0,
return_key=False,
val=False,
):
# It takes as input a single time series data and applies some transformations to add time step
def fn(inputs):
# Remember _generate_examples of MyFullDataset we yielded a dictionary containing key and input
values = inputs["input"]
key = inputs["key"]
return add_time_steps_ntarget(
(key, values),
lookback,
delay,
lookback_step=lookback_step,
target_col=target_col,
val_days=val_days,
val=val,
test=test,
return_key=return_key,
)
return fn
# This function takes an item with all it 1941 days salles, prices, and calendar data adds lookback
# and generate the inputs and targets.
def add_time_steps(
inputs,
lookback,
delay,
target_col=target_col,
test=False,
lookback_step=1,
val=False,
val_days=0,
return_key=False,
):
key, values = inputs
max_index = values.shape[0] - 1
min_index = 0
y = None
idx = tf.signal.frame(tf.range(min_index, max_index), lookback, lookback_step)
if not test:
idx = idx[tf.reduce_all(idx + delay <= max_index, axis=-1)]
if val:
idx = idx[-val_days:]
else:
if val_days:
idx = idx[:-val_days]
y_idx = idx[..., -1] + delay
y = tf.gather(values, y_idx)[..., target_col]
else:
idx = idx[-delay:]
X = tf.gather(values, idx)
if not test and return_key:
return (key, X, y)
return (X, y) if not test else (key, X)
# This function takes an item with all it 1941 days salles, prices, and calendar data adds lookback
# and generate the inputs and targets.
def add_time_steps_ntarget(
inputs,
lookback,
delay,
target_col=target_col,
test=False,
lookback_step=1,
val=False,
val_days=0,
return_key=False,
):
key, values = inputs
max_index = values.shape[0] - 1
min_index = 0
val_steps = val_days // delay
y = None
idx = tf.signal.frame(tf.range(min_index, max_index), lookback, lookback_step)
if not test:
y_idx = idx[:, -1]
y_idx = tf.map_fn(lambda x: tf.range(x, x + delay), y_idx)
select = tf.reduce_all(y_idx <= max_index, axis=-1)
idx = idx[select]
y_idx = y_idx[select]
if val:
y_idx = y_idx[-val_steps:]
idx = idx[-val_steps:]
else:
if val_days:
idx = idx[:-val_steps]
y_idx = y_idx[:-val_steps]
y = tf.gather(values[..., target_col], y_idx)
else:
idx = idx[-1:]
X = tf.gather(values, idx)
if not test and return_key:
return (key, X, y)
return (X, y) if not test else (key, X)
# We need again this class
class MyFullDataset(tfds.core.GeneratorBasedBuilder):
VERSION = tfds.core.Version("0.1.0")
def _split_generators(self, dl_manager):
return [
tfds.core.SplitGenerator(
name=f"train",
gen_kwargs={},
)
]
def _info(self):
shape = (max_day, len(columns))
return tfds.core.DatasetInfo(
builder=self,
description=(""),
features=tfds.features.FeaturesDict(
{
"input": tfds.features.Tensor(shape=shape, dtype=tf.float32),
"key": tfds.features.Tensor(shape=(), dtype=tf.int32),
}
),
)
def _generate_examples(self, **args):
# We no longer need this function because we already build our dataset
pass
# Now we are ready to build our pipelines 😋️
# ### Let create our source
# The code is the same as what we did to prepare the dataset but since the dataset is already available TFDS will not try to create it
log("Download dataset")
gs_path = "gs://bucket59"
builder = MyFullDataset(data_dir=gs_path)
builder.download_and_prepare()
dataset_ = builder.as_dataset()["train"].repeat()
# Amazing right look at your dataset info : we only have one split named train.
# No need to worry we will use our preprocess and build differents pipelines to access the training, validation and test data from this single split
log(builder.info)
# This an example of how to access split's data by getting it as a tf.data.Dataset object
log("Try data access")
dataset = builder.as_dataset()["train"]
for item in dataset.take(1):
# We access 2 time-series
log("key: ", item["key"])
log("input: ", item["input"].shape)
# We apply some transformations: add lookback and get the input and target
lookback = 5
delay = 28
preprocessor = preprocess(lookback, delay)
dataset = dataset.map(preprocessor)
for X, y in dataset.take(1):
log(X.shape, y.shape)
# del dataset
gc.collect()
# ## Prepare for training
val_days = 28 # we use last 28 days of each time step for validation
lookback = 28 # time steps
lookback_step = 1
delay = 28 # We we are forecasting 28 days in the future
batch_size = 2**11
buffer_size = batch_size * 100
prefetch = 100 #
total_num_examples = 30490
ds_name = "train" # The split name
load_weights = False
train = False
log(batch_size)
# Since our dataset is not normalized, we need our first layer to be a normalization layer
def build_model():
input_ = keras.layers.Input(
shape=(
lookback,
len(columns),
)
)
bn = keras.layers.BatchNormalization()(input_)
lstm = keras.layers.Bidirectional(
keras.layers.LSTM(256, return_sequences=True, recurrent_dropout=0.1)
)(bn)
lstm = keras.layers.Bidirectional(keras.layers.LSTM(256, recurrent_dropout=0.1))(
lstm
)
dense = keras.layers.Dense(delay, activation=keras.activations.relu)(lstm)
dense = keras.layers.Activation("relu")(dense)
model = keras.models.Model(input_, dense)
log(model.summary())
model.compile(
optimizer=keras.optimizers.Adam(0.01),
loss=keras.losses.mean_squared_error,
metrics=["mse", tf.keras.metrics.RootMeanSquaredError()],
)
return model
# detect and init the TPU
tpu_strategy = None
try:
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
log("Running on TPU ", tpu.cluster_spec().as_dict()["worker"])
# instantiate a distribution strategy
tpu_strategy = tf.distribute.experimental.TPUStrategy(tpu)
except:
pass
if tpu_strategy:
with tpu_strategy.scope():
model = build_model()
else:
model = build_model()
# Let Try to load weight from the previous commit
if load_weights and os.path.exists("/kaggle/input/modelh5/model.h5"):
log("Loading weights")
# model.load_weights('/kaggle/input/training/model.h5')
model.load_weights("/kaggle/input/modelh5/model.h5")
# ### Training & Validation pipelines
#
# This pipeline provides training dataset
preprocessor = preprocess(
lookback, delay, lookback_step=lookback_step, val_days=val_days
)
train_dataset = (
dataset_.take(total_num_examples)
.repeat()
.shuffle(buffer_size=1000)
.map(preprocessor)
.unbatch()
)
train_dataset = (
train_dataset.shuffle(buffer_size=buffer_size).batch(batch_size).prefetch(prefetch)
)
train_steps = (
(total_num_examples * max_day - val_days - delay) // batch_size // lookback_step
)
log(train_steps)
# This one provides validation dataset
val_preprocessor = preprocess(
lookback, delay, val_days=val_days, val=True, lookback_step=lookback_step
)
val_dataset = dataset_.take(total_num_examples).repeat().map(val_preprocessor).unbatch()
val_dataset = val_dataset.batch(total_num_examples).prefetch(prefetch)
val_steps = val_days // delay # (total_num_examples*val_days)//batch_size
log(val_steps)
# # Training
if train:
log("Start training")
history = model.fit(
train_dataset,
steps_per_epoch=train_steps,
epochs=30,
validation_data=val_dataset,
validation_steps=val_steps,
callbacks=[
keras.callbacks.EarlyStopping(
monitor="loss",
patience=50,
restore_best_weights=True,
),
keras.callbacks.ModelCheckpoint(
filepath=f"model.h5",
monitor="val_loss",
save_best_only=True,
save_weights_only=True,
),
keras.callbacks.ReduceLROnPlateau(
monitor="val_loss",
factor=0.5,
patience=10,
min_lr=0.001,
),
],
)
if train:
pd.DataFrame(history.history).plot(figsize=(15, 8))
del train_dataset
del val_dataset
gc.collect()
model.load_weights(f"model.h5")
# Evaluate our validation data with the leaderboard
df_val = pd.read_csv(
"/kaggle/input/m5-forecasting-accuracy/sample_submission.csv", index_col=0
)
df_val.iloc[total_num_examples:] = 0 # set evaluation to 0
val_preprocessor = preprocess(
lookback,
delay,
val_days=val_days,
val=True,
lookback_step=lookback_step,
return_key=True,
)
# fn_predict takes time-series data and generates predictions
fn_predict = lambda k, x, y: (k, model(x), y)
dataset = dataset_.take(total_num_examples)
dataset = dataset.map(
val_preprocessor, num_parallel_calls=tf.data.experimental.AUTOTUNE
).prefetch(1000)
dataset = dataset.map(
fn_predict, num_parallel_calls=tf.data.experimental.AUTOTUNE
).batch(total_num_examples)
for keys, y_pred, y in dataset:
log(f"y_pred: {y_pred.shape}, y: {y.shape}, keys: {keys.shape}")
y_pred = y_pred.numpy()
keys = np.argsort(keys.numpy()) # retrieve items ordering
df_val.iloc[:total_num_examples, :] = y_pred[keys]
df_val.to_csv("validation_submission.csv")
def generate_submission(
model, lookback, lookback_step, delay, out_path="submission.csv"
):
preprocessor = preprocess(lookback, delay, lookback_step=lookback_step, test=True)
df_sub = pd.read_csv(
"/kaggle/input/m5-forecasting-accuracy/sample_submission.csv", index_col=0
)
df_sub.iloc[:30490, :] = (
pd.read_csv(
"/kaggle/input/m5-forecasting-accuracy/sales_train_evaluation.csv",
index_col=0,
)
.iloc[:, -28:]
.values
)
fn_predict = lambda k, x: (k, model(x))
dataset = dataset_.take(total_num_examples)
dataset = dataset.map(
preprocessor, num_parallel_calls=tf.data.experimental.AUTOTUNE
).prefetch(1000)
dataset = dataset.map(
fn_predict, num_parallel_calls=tf.data.experimental.AUTOTUNE
).batch(30490)
for keys, y in dataset:
y = y.numpy()
log("y: ", y.shape)
keys = np.argsort(keys.numpy())
df_sub.iloc[total_num_examples:, :] = y[keys]
df_sub.to_csv(out_path)
del dataset
log("Generate Submission")
generate_submission(model, lookback, lookback_step, delay)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0035/900/35900759.ipynb | null | null | [{"Id": 35900759, "ScriptId": 9817381, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3699565, "CreationDate": "06/10/2020 17:34:57", "VersionNumber": 23.0, "Title": "M5-acc lstm model", "EvaluationDate": "06/10/2020", "IsChange": true, "TotalLines": 349.0, "LinesInsertedFromPrevious": 76.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 273.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
import os
def log(*args):
os.system(f'echo "{args}"')
print(*args)
# In the [Data preparation notebook](https://www.kaggle.com/tchaye59/data-preparation), we've prepared the dataset in a suitable format ready to feed into a machine learning pipeline. In this one, we will use tf.data API to build our transformations pipeline and feed our network.
# ### We install the TFDS library and import required modules:
import tensorflow as tf
from tensorflow import keras
import pickle
import pandas
import numpy as np
from matplotlib import pyplot as plt
import gc
import threading
import time
import tensorflow_datasets.public_api as tfds
from tensorflow.keras import backend as K
from sklearn import metrics
tf.random.set_seed(1234)
np.random.seed(1234)
# The columns give us an idea of what our data looks like
columns = pickle.load(open("/kaggle/input/data-preparation/columns.pkl", "rb"))
max_day = 1941
print(f"Columns-{len(columns)} : {columns}")
print("Target: ", columns[5])
target_col = 5
# ## Let define some utils
# This function is just a wrapper to a function that calls add_time_steps
def preprocess(
lookback,
delay,
target_col=target_col,
lookback_step=1,
test=False,
val_days=0,
return_key=False,
val=False,
):
# It takes as input a single time series data and applies some transformations to add time step
def fn(inputs):
# Remember _generate_examples of MyFullDataset we yielded a dictionary containing key and input
values = inputs["input"]
key = inputs["key"]
return add_time_steps_ntarget(
(key, values),
lookback,
delay,
lookback_step=lookback_step,
target_col=target_col,
val_days=val_days,
val=val,
test=test,
return_key=return_key,
)
return fn
# This function takes an item with all it 1941 days salles, prices, and calendar data adds lookback
# and generate the inputs and targets.
def add_time_steps(
inputs,
lookback,
delay,
target_col=target_col,
test=False,
lookback_step=1,
val=False,
val_days=0,
return_key=False,
):
key, values = inputs
max_index = values.shape[0] - 1
min_index = 0
y = None
idx = tf.signal.frame(tf.range(min_index, max_index), lookback, lookback_step)
if not test:
idx = idx[tf.reduce_all(idx + delay <= max_index, axis=-1)]
if val:
idx = idx[-val_days:]
else:
if val_days:
idx = idx[:-val_days]
y_idx = idx[..., -1] + delay
y = tf.gather(values, y_idx)[..., target_col]
else:
idx = idx[-delay:]
X = tf.gather(values, idx)
if not test and return_key:
return (key, X, y)
return (X, y) if not test else (key, X)
# This function takes an item with all it 1941 days salles, prices, and calendar data adds lookback
# and generate the inputs and targets.
def add_time_steps_ntarget(
inputs,
lookback,
delay,
target_col=target_col,
test=False,
lookback_step=1,
val=False,
val_days=0,
return_key=False,
):
key, values = inputs
max_index = values.shape[0] - 1
min_index = 0
val_steps = val_days // delay
y = None
idx = tf.signal.frame(tf.range(min_index, max_index), lookback, lookback_step)
if not test:
y_idx = idx[:, -1]
y_idx = tf.map_fn(lambda x: tf.range(x, x + delay), y_idx)
select = tf.reduce_all(y_idx <= max_index, axis=-1)
idx = idx[select]
y_idx = y_idx[select]
if val:
y_idx = y_idx[-val_steps:]
idx = idx[-val_steps:]
else:
if val_days:
idx = idx[:-val_steps]
y_idx = y_idx[:-val_steps]
y = tf.gather(values[..., target_col], y_idx)
else:
idx = idx[-1:]
X = tf.gather(values, idx)
if not test and return_key:
return (key, X, y)
return (X, y) if not test else (key, X)
# We need again this class
class MyFullDataset(tfds.core.GeneratorBasedBuilder):
VERSION = tfds.core.Version("0.1.0")
def _split_generators(self, dl_manager):
return [
tfds.core.SplitGenerator(
name=f"train",
gen_kwargs={},
)
]
def _info(self):
shape = (max_day, len(columns))
return tfds.core.DatasetInfo(
builder=self,
description=(""),
features=tfds.features.FeaturesDict(
{
"input": tfds.features.Tensor(shape=shape, dtype=tf.float32),
"key": tfds.features.Tensor(shape=(), dtype=tf.int32),
}
),
)
def _generate_examples(self, **args):
# We no longer need this function because we already build our dataset
pass
# Now we are ready to build our pipelines 😋️
# ### Let create our source
# The code is the same as what we did to prepare the dataset but since the dataset is already available TFDS will not try to create it
log("Download dataset")
gs_path = "gs://bucket59"
builder = MyFullDataset(data_dir=gs_path)
builder.download_and_prepare()
dataset_ = builder.as_dataset()["train"].repeat()
# Amazing right look at your dataset info : we only have one split named train.
# No need to worry we will use our preprocess and build differents pipelines to access the training, validation and test data from this single split
log(builder.info)
# This an example of how to access split's data by getting it as a tf.data.Dataset object
log("Try data access")
dataset = builder.as_dataset()["train"]
for item in dataset.take(1):
# We access 2 time-series
log("key: ", item["key"])
log("input: ", item["input"].shape)
# We apply some transformations: add lookback and get the input and target
lookback = 5
delay = 28
preprocessor = preprocess(lookback, delay)
dataset = dataset.map(preprocessor)
for X, y in dataset.take(1):
log(X.shape, y.shape)
# del dataset
gc.collect()
# ## Prepare for training
val_days = 28 # we use last 28 days of each time step for validation
lookback = 28 # time steps
lookback_step = 1
delay = 28 # We we are forecasting 28 days in the future
batch_size = 2**11
buffer_size = batch_size * 100
prefetch = 100 #
total_num_examples = 30490
ds_name = "train" # The split name
load_weights = False
train = False
log(batch_size)
# Since our dataset is not normalized, we need our first layer to be a normalization layer
def build_model():
input_ = keras.layers.Input(
shape=(
lookback,
len(columns),
)
)
bn = keras.layers.BatchNormalization()(input_)
lstm = keras.layers.Bidirectional(
keras.layers.LSTM(256, return_sequences=True, recurrent_dropout=0.1)
)(bn)
lstm = keras.layers.Bidirectional(keras.layers.LSTM(256, recurrent_dropout=0.1))(
lstm
)
dense = keras.layers.Dense(delay, activation=keras.activations.relu)(lstm)
dense = keras.layers.Activation("relu")(dense)
model = keras.models.Model(input_, dense)
log(model.summary())
model.compile(
optimizer=keras.optimizers.Adam(0.01),
loss=keras.losses.mean_squared_error,
metrics=["mse", tf.keras.metrics.RootMeanSquaredError()],
)
return model
# detect and init the TPU
tpu_strategy = None
try:
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
log("Running on TPU ", tpu.cluster_spec().as_dict()["worker"])
# instantiate a distribution strategy
tpu_strategy = tf.distribute.experimental.TPUStrategy(tpu)
except:
pass
if tpu_strategy:
with tpu_strategy.scope():
model = build_model()
else:
model = build_model()
# Let Try to load weight from the previous commit
if load_weights and os.path.exists("/kaggle/input/modelh5/model.h5"):
log("Loading weights")
# model.load_weights('/kaggle/input/training/model.h5')
model.load_weights("/kaggle/input/modelh5/model.h5")
# ### Training & Validation pipelines
#
# This pipeline provides training dataset
preprocessor = preprocess(
lookback, delay, lookback_step=lookback_step, val_days=val_days
)
train_dataset = (
dataset_.take(total_num_examples)
.repeat()
.shuffle(buffer_size=1000)
.map(preprocessor)
.unbatch()
)
train_dataset = (
train_dataset.shuffle(buffer_size=buffer_size).batch(batch_size).prefetch(prefetch)
)
train_steps = (
(total_num_examples * max_day - val_days - delay) // batch_size // lookback_step
)
log(train_steps)
# This one provides validation dataset
val_preprocessor = preprocess(
lookback, delay, val_days=val_days, val=True, lookback_step=lookback_step
)
val_dataset = dataset_.take(total_num_examples).repeat().map(val_preprocessor).unbatch()
val_dataset = val_dataset.batch(total_num_examples).prefetch(prefetch)
val_steps = val_days // delay # (total_num_examples*val_days)//batch_size
log(val_steps)
# # Training
if train:
log("Start training")
history = model.fit(
train_dataset,
steps_per_epoch=train_steps,
epochs=30,
validation_data=val_dataset,
validation_steps=val_steps,
callbacks=[
keras.callbacks.EarlyStopping(
monitor="loss",
patience=50,
restore_best_weights=True,
),
keras.callbacks.ModelCheckpoint(
filepath=f"model.h5",
monitor="val_loss",
save_best_only=True,
save_weights_only=True,
),
keras.callbacks.ReduceLROnPlateau(
monitor="val_loss",
factor=0.5,
patience=10,
min_lr=0.001,
),
],
)
if train:
pd.DataFrame(history.history).plot(figsize=(15, 8))
del train_dataset
del val_dataset
gc.collect()
model.load_weights(f"model.h5")
# Evaluate our validation data with the leaderboard
df_val = pd.read_csv(
"/kaggle/input/m5-forecasting-accuracy/sample_submission.csv", index_col=0
)
df_val.iloc[total_num_examples:] = 0 # set evaluation to 0
val_preprocessor = preprocess(
lookback,
delay,
val_days=val_days,
val=True,
lookback_step=lookback_step,
return_key=True,
)
# fn_predict takes time-series data and generates predictions
fn_predict = lambda k, x, y: (k, model(x), y)
dataset = dataset_.take(total_num_examples)
dataset = dataset.map(
val_preprocessor, num_parallel_calls=tf.data.experimental.AUTOTUNE
).prefetch(1000)
dataset = dataset.map(
fn_predict, num_parallel_calls=tf.data.experimental.AUTOTUNE
).batch(total_num_examples)
for keys, y_pred, y in dataset:
log(f"y_pred: {y_pred.shape}, y: {y.shape}, keys: {keys.shape}")
y_pred = y_pred.numpy()
keys = np.argsort(keys.numpy()) # retrieve items ordering
df_val.iloc[:total_num_examples, :] = y_pred[keys]
df_val.to_csv("validation_submission.csv")
def generate_submission(
model, lookback, lookback_step, delay, out_path="submission.csv"
):
preprocessor = preprocess(lookback, delay, lookback_step=lookback_step, test=True)
df_sub = pd.read_csv(
"/kaggle/input/m5-forecasting-accuracy/sample_submission.csv", index_col=0
)
df_sub.iloc[:30490, :] = (
pd.read_csv(
"/kaggle/input/m5-forecasting-accuracy/sales_train_evaluation.csv",
index_col=0,
)
.iloc[:, -28:]
.values
)
fn_predict = lambda k, x: (k, model(x))
dataset = dataset_.take(total_num_examples)
dataset = dataset.map(
preprocessor, num_parallel_calls=tf.data.experimental.AUTOTUNE
).prefetch(1000)
dataset = dataset.map(
fn_predict, num_parallel_calls=tf.data.experimental.AUTOTUNE
).batch(30490)
for keys, y in dataset:
y = y.numpy()
log("y: ", y.shape)
keys = np.argsort(keys.numpy())
df_sub.iloc[total_num_examples:, :] = y[keys]
df_sub.to_csv(out_path)
del dataset
log("Generate Submission")
generate_submission(model, lookback, lookback_step, delay)
| false | 0 | 3,721 | 0 | 6 | 3,721 |
||
35919897 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
import os
def log(*args):
os.system(f'echo "{args}"')
print(*args)
# We will use different split of the dataset we've prepared this kernel, to build boosting models
# ### We install the TFDS library and import required modules:
import os
import pickle
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from joblib import dump, load
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.base import BaseEstimator, RegressorMixin
from sklearn.preprocessing import PolynomialFeatures
import multiprocessing as mp
import gc
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest, f_regression
import tensorflow as tf
import lightgbm as lgb
import tensorflow_datasets.public_api as tfds
np.random.seed(12345)
tf.random.set_seed(12345)
encoders = pickle.load(open("/kaggle/input/data-preparation/encoders.pkl", "rb"))
columns = pickle.load(open("/kaggle/input/data-preparation/columns.pkl", "rb"))
max_day = 1941
# We will build one model for each store
print(columns[3]) # The store id is the third columns
group_index = 3 # We will group our data by this column
n_groups = len(encoders["store_id"].classes_)
keys = list(range(n_groups))
encoders["store_id"].classes_
log(columns)
log(columns[5]) # We retrieve our target column
target_col = 5
# ### Let define some utils
# This function is just a wrapper to a function that calls add_time_steps
def preprocess(
lookback,
delay,
target_col=target_col,
lookback_step=1,
test=False,
val_days=0,
return_key=False,
):
# It takes as input a single time series data and applies some transformations to add time step
def fn(inputs):
# Remember _generate_examples of MyFullDataset we yielded a dictionary containing key and input
values = inputs["input"]
key = inputs["key"]
return add_time_steps(
(key, values),
lookback,
delay,
lookback_step=lookback_step,
target_col=target_col,
val_days=val_days,
test=test,
return_key=return_key,
)
return fn
# This function takes an item with all it 1941 days salles, prices, and calendar data adds lookback
# and generate the inputs and targets.
def add_time_steps(
inputs,
lookback,
delay,
target_col=target_col,
test=False,
lookback_step=1,
val_days=0,
return_key=False,
):
key, values = inputs
max_index = values.shape[0] - 1
min_index = 0
y = None
idx = tf.signal.frame(tf.range(min_index, max_index), lookback, lookback_step)
if not test:
idx = idx[tf.reduce_all(idx + delay <= max_index, axis=-1)]
if val_days:
val_idx = idx[-val_days:]
val_y_idx = val_idx[..., -1] + delay
y_val = tf.gather(values, val_y_idx)[..., target_col]
X_val = tf.gather(values, val_idx)
# remove val_days from training
idx = idx[:-val_days]
y_idx = idx[..., -1] + delay
y = tf.gather(values, y_idx)[..., target_col]
else:
idx = idx[-delay:]
X = tf.gather(values, idx)
if not test and return_key:
return (key, (X, y), (X_val, y_val))
return ((X, y), (X_val, y_val)) if not test else (key, X)
# We need again this class
class MyFullDataset(tfds.core.GeneratorBasedBuilder):
VERSION = tfds.core.Version("0.1.0")
def _split_generators(self, dl_manager):
return [
tfds.core.SplitGenerator(
name=f"train",
gen_kwargs={},
)
]
def _info(self):
shape = (max_day, len(columns))
return tfds.core.DatasetInfo(
builder=self,
description=(""),
features=tfds.features.FeaturesDict(
{
"input": tfds.features.Tensor(shape=shape, dtype=tf.float32),
"key": tfds.features.Tensor(shape=(), dtype=tf.int32),
}
),
)
def _generate_examples(self, **args):
# We no longer need this function because we already build our dataset
pass
# ## Prepare for training
log("Download dataset")
gs_path = "gs://bucket59"
builder = MyFullDataset(data_dir=gs_path)
dataset_ = builder.as_dataset()[f"train"].repeat()
builder.download_and_prepare()
log(builder.info)
total_num_examples = 30490
val_days = 28
lookback = 1
lookback_step = 1
delay = 28
gpu = False
def train(key, nthread=1, save=True, verbose_eval=False, gpu=False):
params = {
"boosting_type": "gbdt",
"objective": "poisson", # regression
"metric": {
"rmse",
},
"tree": "feature_parallel",
"num_leaves": 100,
"learning_rate": 0.01,
"feature_fraction": 0.2,
"bagging_fraction": 0.8,
"min_data_in_leaf": 100,
"bagging_freq": 5,
"bagging_seed": 1234,
"seed": 1234,
"verbosity": 1,
}
if gpu:
params["device"] = "gpu"
params["gpu_platform_id"] = 0
params["gpu_device_id"] = 0
else:
params["nthread"] = nthread
path = f"regressor-{key}.model"
pipe = Pipeline(
[
("scaller", StandardScaler()),
("kbest", SelectKBest(f_regression, k=30)),
]
)
preprocessor = preprocess(
lookback, delay, lookback_step=lookback_step, val_days=val_days
)
fn_key_filter = lambda item: item["input"][0][group_index] == key
dataset = dataset_.take(total_num_examples).filter(fn_key_filter)
dataset = dataset.map(
preprocessor, num_parallel_calls=tf.data.experimental.AUTOTUNE
)
dataset = dataset.batch(3049)
for (X_train, y_train), (X_val, y_val) in dataset:
log("X_train : ", X_train.shape, "; y_train : ", y_train.shape)
log("X_val : ", X_val.shape, "; y_train : ", y_val.shape)
X_train, y_train = X_train.numpy(), y_train.numpy()
X_val, y_val = X_val.numpy(), y_val.numpy()
del dataset
tf.keras.backend.clear_session()
gc.collect()
# Let correct the shape
X_train = X_train.reshape(-1, X_train.shape[-1] * lookback)
y_train = y_train.reshape((-1,))
idx = np.arange(X_train.shape[0])
# We shuffle
np.random.shuffle(idx)
X_train, y_train = X_train[idx], y_train[idx]
log("X_train : ", X_train.shape)
X_train = pipe.fit_transform(X_train, y_train)
log("X_train : ", X_train.shape)
# log("Scores : ",pipe.named_steps['kbest'].scores_)
# No need to shuffle validation data
X_val = X_val.reshape(-1, X_val.shape[-1] * lookback)
y_val = y_val.reshape((-1,))
X_val = pipe.transform(X_val)
log("X_val : ", X_val.shape)
# Training
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_val, label=y_val)
model = lgb.train(
params,
train_data,
valid_sets=[test_data],
num_boost_round=3000,
early_stopping_rounds=100,
verbose_eval=verbose_eval,
)
mse = mean_squared_error(
y_train, model.predict(X_train, num_iteration_predict=model.best_iteration)
)
val_mse = mean_squared_error(
y_val, model.predict(X_val, num_iteration_predict=model.best_iteration)
)
log(f"Key {key}; MSE: {mse}, VAL_MSE: {val_mse}")
if not save:
return (key, model)
else:
with open(path, "wb") as f:
dump(
{
"model": model,
"num_iteration_predict": model.best_iteration,
"pipe": pipe,
},
f,
compress=9,
)
del model
gc.collect()
# ### Train
for key in keys:
tf.keras.backend.clear_session()
gc.collect()
train(key, nthread=-1, verbose_eval=True, gpu=gpu)
gc.collect()
gc.collect()
log("Loading models")
models = {}
for key in keys:
path = f"regressor-{key}.model"
models[key] = load(path)
# ### Submission
# Evaluate our validation data with the leaderboard
df_val = pd.read_csv(
"/kaggle/input/m5-forecasting-accuracy/sample_submission.csv", index_col=0
)
df_val.iloc[total_num_examples:] = 0 # set evaluation to 0
preprocessor = preprocess(
lookback, delay, lookback_step=lookback_step, val_days=val_days, return_key=True
)
dataset = dataset_.take(total_num_examples)
dataset = dataset.map(
preprocessor, num_parallel_calls=tf.data.experimental.AUTOTUNE
).prefetch(1000)
c = 1
for idx, _, (X_val, y_val) in dataset:
idx = idx.numpy()
X_val, y_val = X_val.numpy(), y_val.numpy()
X_val = X_val.reshape(-1, X_val.shape[-1] * lookback)
group_key = X_val[0][group_index]
pipe = models[group_key]["pipe"]
model = models[group_key]["model"]
num_iteration_predict = models[group_key]["num_iteration_predict"]
X_val = pipe.transform(X_val)
df_val.iloc[idx] = model.predict(
X_val, num_iteration_predict=num_iteration_predict
).flatten()
print(f"{c}\r", end="")
c += 1
df_val.to_csv("validation_submission.csv")
del dataset
gc.collect()
def generate_submission(
models,
group_index,
lookback,
delay,
lookback_step,
xgb=False,
out_path="submission.csv",
):
df_sub = pd.read_csv(
"/kaggle/input/m5-forecasting-accuracy/sample_submission.csv", index_col=0
)
df_sub.iloc[:30490, :] = (
pd.read_csv(
"/kaggle/input/m5-forecasting-accuracy/sales_train_evaluation.csv",
index_col=0,
)
.iloc[:, -28:]
.values
)
df_sub.iloc[30490:] = 0
preprocessor = preprocess(
lookback, delay, lookback_step=lookback_step, val_days=val_days, test=True
)
dataset = dataset_.take(total_num_examples)
dataset = dataset.map(
preprocessor, num_parallel_calls=tf.data.experimental.AUTOTUNE
).prefetch(1000)
c = 1
for idx, X in dataset:
idx = idx.numpy()
X = X.numpy()
X = X.reshape(-1, X.shape[-1] * lookback)
group_key = X[0][group_index]
pipe = models[group_key]["pipe"]
model = models[group_key]["model"]
num_iteration_predict = models[group_key]["num_iteration_predict"]
X = pipe.transform(X)
df_sub.iloc[total_num_examples + idx] = model.predict(
X, num_iteration_predict=num_iteration_predict
).flatten()
print(f"{c}\r", end="")
c += 1
df_sub.to_csv(out_path)
log("Generate submission")
generate_submission(models, group_index, lookback, delay, lookback_step)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0035/919/35919897.ipynb | null | null | [{"Id": 35919897, "ScriptId": 9817086, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3699565, "CreationDate": "06/11/2020 01:08:25", "VersionNumber": 22.0, "Title": "M5-acc boosting", "EvaluationDate": "06/11/2020", "IsChange": true, "TotalLines": 314.0, "LinesInsertedFromPrevious": 4.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 310.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
import os
def log(*args):
os.system(f'echo "{args}"')
print(*args)
# We will use different split of the dataset we've prepared this kernel, to build boosting models
# ### We install the TFDS library and import required modules:
import os
import pickle
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from joblib import dump, load
import numpy as np
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.base import BaseEstimator, RegressorMixin
from sklearn.preprocessing import PolynomialFeatures
import multiprocessing as mp
import gc
from sklearn.decomposition import PCA
from sklearn.feature_selection import SelectKBest, f_regression
import tensorflow as tf
import lightgbm as lgb
import tensorflow_datasets.public_api as tfds
np.random.seed(12345)
tf.random.set_seed(12345)
encoders = pickle.load(open("/kaggle/input/data-preparation/encoders.pkl", "rb"))
columns = pickle.load(open("/kaggle/input/data-preparation/columns.pkl", "rb"))
max_day = 1941
# We will build one model for each store
print(columns[3]) # The store id is the third columns
group_index = 3 # We will group our data by this column
n_groups = len(encoders["store_id"].classes_)
keys = list(range(n_groups))
encoders["store_id"].classes_
log(columns)
log(columns[5]) # We retrieve our target column
target_col = 5
# ### Let define some utils
# This function is just a wrapper to a function that calls add_time_steps
def preprocess(
lookback,
delay,
target_col=target_col,
lookback_step=1,
test=False,
val_days=0,
return_key=False,
):
# It takes as input a single time series data and applies some transformations to add time step
def fn(inputs):
# Remember _generate_examples of MyFullDataset we yielded a dictionary containing key and input
values = inputs["input"]
key = inputs["key"]
return add_time_steps(
(key, values),
lookback,
delay,
lookback_step=lookback_step,
target_col=target_col,
val_days=val_days,
test=test,
return_key=return_key,
)
return fn
# This function takes an item with all it 1941 days salles, prices, and calendar data adds lookback
# and generate the inputs and targets.
def add_time_steps(
inputs,
lookback,
delay,
target_col=target_col,
test=False,
lookback_step=1,
val_days=0,
return_key=False,
):
key, values = inputs
max_index = values.shape[0] - 1
min_index = 0
y = None
idx = tf.signal.frame(tf.range(min_index, max_index), lookback, lookback_step)
if not test:
idx = idx[tf.reduce_all(idx + delay <= max_index, axis=-1)]
if val_days:
val_idx = idx[-val_days:]
val_y_idx = val_idx[..., -1] + delay
y_val = tf.gather(values, val_y_idx)[..., target_col]
X_val = tf.gather(values, val_idx)
# remove val_days from training
idx = idx[:-val_days]
y_idx = idx[..., -1] + delay
y = tf.gather(values, y_idx)[..., target_col]
else:
idx = idx[-delay:]
X = tf.gather(values, idx)
if not test and return_key:
return (key, (X, y), (X_val, y_val))
return ((X, y), (X_val, y_val)) if not test else (key, X)
# We need again this class
class MyFullDataset(tfds.core.GeneratorBasedBuilder):
VERSION = tfds.core.Version("0.1.0")
def _split_generators(self, dl_manager):
return [
tfds.core.SplitGenerator(
name=f"train",
gen_kwargs={},
)
]
def _info(self):
shape = (max_day, len(columns))
return tfds.core.DatasetInfo(
builder=self,
description=(""),
features=tfds.features.FeaturesDict(
{
"input": tfds.features.Tensor(shape=shape, dtype=tf.float32),
"key": tfds.features.Tensor(shape=(), dtype=tf.int32),
}
),
)
def _generate_examples(self, **args):
# We no longer need this function because we already build our dataset
pass
# ## Prepare for training
log("Download dataset")
gs_path = "gs://bucket59"
builder = MyFullDataset(data_dir=gs_path)
dataset_ = builder.as_dataset()[f"train"].repeat()
builder.download_and_prepare()
log(builder.info)
total_num_examples = 30490
val_days = 28
lookback = 1
lookback_step = 1
delay = 28
gpu = False
def train(key, nthread=1, save=True, verbose_eval=False, gpu=False):
params = {
"boosting_type": "gbdt",
"objective": "poisson", # regression
"metric": {
"rmse",
},
"tree": "feature_parallel",
"num_leaves": 100,
"learning_rate": 0.01,
"feature_fraction": 0.2,
"bagging_fraction": 0.8,
"min_data_in_leaf": 100,
"bagging_freq": 5,
"bagging_seed": 1234,
"seed": 1234,
"verbosity": 1,
}
if gpu:
params["device"] = "gpu"
params["gpu_platform_id"] = 0
params["gpu_device_id"] = 0
else:
params["nthread"] = nthread
path = f"regressor-{key}.model"
pipe = Pipeline(
[
("scaller", StandardScaler()),
("kbest", SelectKBest(f_regression, k=30)),
]
)
preprocessor = preprocess(
lookback, delay, lookback_step=lookback_step, val_days=val_days
)
fn_key_filter = lambda item: item["input"][0][group_index] == key
dataset = dataset_.take(total_num_examples).filter(fn_key_filter)
dataset = dataset.map(
preprocessor, num_parallel_calls=tf.data.experimental.AUTOTUNE
)
dataset = dataset.batch(3049)
for (X_train, y_train), (X_val, y_val) in dataset:
log("X_train : ", X_train.shape, "; y_train : ", y_train.shape)
log("X_val : ", X_val.shape, "; y_train : ", y_val.shape)
X_train, y_train = X_train.numpy(), y_train.numpy()
X_val, y_val = X_val.numpy(), y_val.numpy()
del dataset
tf.keras.backend.clear_session()
gc.collect()
# Let correct the shape
X_train = X_train.reshape(-1, X_train.shape[-1] * lookback)
y_train = y_train.reshape((-1,))
idx = np.arange(X_train.shape[0])
# We shuffle
np.random.shuffle(idx)
X_train, y_train = X_train[idx], y_train[idx]
log("X_train : ", X_train.shape)
X_train = pipe.fit_transform(X_train, y_train)
log("X_train : ", X_train.shape)
# log("Scores : ",pipe.named_steps['kbest'].scores_)
# No need to shuffle validation data
X_val = X_val.reshape(-1, X_val.shape[-1] * lookback)
y_val = y_val.reshape((-1,))
X_val = pipe.transform(X_val)
log("X_val : ", X_val.shape)
# Training
train_data = lgb.Dataset(X_train, label=y_train)
test_data = lgb.Dataset(X_val, label=y_val)
model = lgb.train(
params,
train_data,
valid_sets=[test_data],
num_boost_round=3000,
early_stopping_rounds=100,
verbose_eval=verbose_eval,
)
mse = mean_squared_error(
y_train, model.predict(X_train, num_iteration_predict=model.best_iteration)
)
val_mse = mean_squared_error(
y_val, model.predict(X_val, num_iteration_predict=model.best_iteration)
)
log(f"Key {key}; MSE: {mse}, VAL_MSE: {val_mse}")
if not save:
return (key, model)
else:
with open(path, "wb") as f:
dump(
{
"model": model,
"num_iteration_predict": model.best_iteration,
"pipe": pipe,
},
f,
compress=9,
)
del model
gc.collect()
# ### Train
for key in keys:
tf.keras.backend.clear_session()
gc.collect()
train(key, nthread=-1, verbose_eval=True, gpu=gpu)
gc.collect()
gc.collect()
log("Loading models")
models = {}
for key in keys:
path = f"regressor-{key}.model"
models[key] = load(path)
# ### Submission
# Evaluate our validation data with the leaderboard
df_val = pd.read_csv(
"/kaggle/input/m5-forecasting-accuracy/sample_submission.csv", index_col=0
)
df_val.iloc[total_num_examples:] = 0 # set evaluation to 0
preprocessor = preprocess(
lookback, delay, lookback_step=lookback_step, val_days=val_days, return_key=True
)
dataset = dataset_.take(total_num_examples)
dataset = dataset.map(
preprocessor, num_parallel_calls=tf.data.experimental.AUTOTUNE
).prefetch(1000)
c = 1
for idx, _, (X_val, y_val) in dataset:
idx = idx.numpy()
X_val, y_val = X_val.numpy(), y_val.numpy()
X_val = X_val.reshape(-1, X_val.shape[-1] * lookback)
group_key = X_val[0][group_index]
pipe = models[group_key]["pipe"]
model = models[group_key]["model"]
num_iteration_predict = models[group_key]["num_iteration_predict"]
X_val = pipe.transform(X_val)
df_val.iloc[idx] = model.predict(
X_val, num_iteration_predict=num_iteration_predict
).flatten()
print(f"{c}\r", end="")
c += 1
df_val.to_csv("validation_submission.csv")
del dataset
gc.collect()
def generate_submission(
models,
group_index,
lookback,
delay,
lookback_step,
xgb=False,
out_path="submission.csv",
):
df_sub = pd.read_csv(
"/kaggle/input/m5-forecasting-accuracy/sample_submission.csv", index_col=0
)
df_sub.iloc[:30490, :] = (
pd.read_csv(
"/kaggle/input/m5-forecasting-accuracy/sales_train_evaluation.csv",
index_col=0,
)
.iloc[:, -28:]
.values
)
df_sub.iloc[30490:] = 0
preprocessor = preprocess(
lookback, delay, lookback_step=lookback_step, val_days=val_days, test=True
)
dataset = dataset_.take(total_num_examples)
dataset = dataset.map(
preprocessor, num_parallel_calls=tf.data.experimental.AUTOTUNE
).prefetch(1000)
c = 1
for idx, X in dataset:
idx = idx.numpy()
X = X.numpy()
X = X.reshape(-1, X.shape[-1] * lookback)
group_key = X[0][group_index]
pipe = models[group_key]["pipe"]
model = models[group_key]["model"]
num_iteration_predict = models[group_key]["num_iteration_predict"]
X = pipe.transform(X)
df_sub.iloc[total_num_examples + idx] = model.predict(
X, num_iteration_predict=num_iteration_predict
).flatten()
print(f"{c}\r", end="")
c += 1
df_sub.to_csv(out_path)
log("Generate submission")
generate_submission(models, group_index, lookback, delay, lookback_step)
| false | 0 | 3,398 | 0 | 6 | 3,398 |
||
35433526 | <kaggle_start><data_title>ResNet-50<data_description># ResNet-50
---
## Deep Residual Learning for Image Recognition
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity.
An ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers.
The depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.<br>
**Authors: Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun**<br>
**https://arxiv.org/abs/1512.03385**
---
Architecture visualization: http://ethereon.github.io/netscope/#/gist/db945b393d40bfa26006
![Resnet][1]
---
### What is a Pre-trained Model?
A pre-trained model has been previously trained on a dataset and contains the weights and biases that represent the features of whichever dataset it was trained on. Learned features are often transferable to different data. For example, a model trained on a large dataset of bird images will contain learned features like edges or horizontal lines that you would be transferable your dataset.
### Why use a Pre-trained Model?
Pre-trained models are beneficial to us for many reasons. By using a pre-trained model you are saving time. Someone else has already spent the time and compute resources to learn a lot of features and your model will likely benefit from it.
[1]: https://imgur.com/nyYh5xH.jpg<data_name>resnet50
<code># #------------------code for training------------------
#!pip install easydict
#!cp -r ../input/cascadercnn .
# cd cascadercnn/lib
#!python setup.py build develop
# cd ..
#!ls .
# #lr = 0.00125 for one card and one image per batch
#!python train_cascade_fpn.py --dataset pascal_voc --net res50 --epoch 30 --lr_decay_step 9 --disp_interval 1 --bs 6 --nw 16 --lr 0.001 --lr_decay_step 8 --cuda --mGPUs
#!rm -rf ../cascadercnn
# #------------------code for testing------------------
import cv2
import math
import os
import numpy as np
import pandas as pd
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Function
from torch.autograd.function import once_differentiable
from torch.nn.modules.utils import _pair
from torch.nn.functional import avg_pool2d
from torch.autograd import Variable
classes = np.asarray(["__background__", "wheat"])
pascal_classes = ["__background__", "wheat"]
categoryList = {"bg": 0, "wheat": 1}
cfg = {
"ANCHOR_RATIOS": [0.5, 1, 2],
"ANCHOR_SCALES": [4, 8, 16, 32],
"FEAT_STRIDE": [
16,
],
"POOLING_SIZE": 7,
"TRAIN_TRUNCATED": False,
"POOLING_MODE": "align",
"CROP_RESIZE_WITH_MAX_POOL": False,
"FPN_ANCHOR_SCALES": [32, 64, 128, 256, 512],
"FPN_FEAT_STRIDES": [4, 8, 16, 32, 64],
"FPN_ANCHOR_STRIDE": 1,
"RPN_PRE_NMS_TOP_N": 6000,
"RPN_POST_NMS_TOP_N": 300,
"RPN_NMS_THRESH": 0.7,
"RPN_MIN_SIZE": 16,
"TRAIN_RPN_NEGATIVE_OVERLAP": 0.3,
"TRAIN_RPN_POSITIVE_OVERLAP": 0.7,
"TRAIN_RPN_FG_FRACTION": 0.5,
"TRAIN_RPN_BATCHSIZE": 256,
"TRAIN_RPN_BBOX_INSIDE_WEIGHTS": (1.0, 1.0, 1.0, 1.0),
"TRAIN_RPN_POSITIVE_WEIGHT": -1.0,
"TRAIN_FG_THRESH": 0.5,
"TRAIN_BG_THRESH_HI": 0.5,
"TRAIN_BG_THRESH_LO": 0.1,
"TRAIN_FG_THRESH_2ND": 0.6,
"TRAIN_FG_THRESH_3RD": 0.7,
"TRAIN_BBOX_NORMALIZE_TARGETS_PRECOMPUTED": True,
"TRAIN_BATCH_SIZE": 128,
"TRAIN_FG_FRACTION": 0.25,
"TRAIN_BBOX_NORMALIZE_MEANS": (0.0, 0.0, 0.0, 0.0),
"TRAIN_BBOX_NORMALIZE_STDS": (0.1, 0.1, 0.2, 0.2),
"TRAIN_BBOX_INSIDE_WEIGHTS": (1.0, 1.0, 1.0, 1.0),
"RESNET_FIXED_BLOCKS": 1,
#'PIXEL_MEANS': np.array([[[0.485, 0.456, 0.406]]]),
"PIXEL_MEANS": np.array([[[122.7717, 115.9465, 102.9801]]]), # RGB
#'PIXEL_MEANS': np.array([[[102.9801, 115.9465, 122.7717]]]), # BGR
"TEST_SCALES": (1024,),
"TEST_MAX_SIZE": 1024,
"TEST_BBOX_REG": True,
}
# --------------------------------------------------#
def clip_boxes(boxes, im_shape, batch_size):
for i in range(batch_size):
boxes[i, :, 0::4].clamp_(0, im_shape[i, 1] - 1)
boxes[i, :, 1::4].clamp_(0, im_shape[i, 0] - 1)
boxes[i, :, 2::4].clamp_(0, im_shape[i, 1] - 1)
boxes[i, :, 3::4].clamp_(0, im_shape[i, 0] - 1)
return boxes
def bbox_transform_inv(boxes, deltas, batch_size):
# print(" bbox_transform_inv ")
# print("bbox shape:",boxes.shape)
# print("deltas shape:",deltas.shape)
widths = boxes[:, :, 2] - boxes[:, :, 0] + 1.0
heights = boxes[:, :, 3] - boxes[:, :, 1] + 1.0
ctr_x = boxes[:, :, 0] + 0.5 * widths
ctr_y = boxes[:, :, 1] + 0.5 * heights
dx = deltas[:, :, 0::4]
dy = deltas[:, :, 1::4]
dw = deltas[:, :, 2::4]
dh = deltas[:, :, 3::4]
# print(dx.shape)
pred_ctr_x = dx * widths.unsqueeze(2) + ctr_x.unsqueeze(2)
pred_ctr_y = dy * heights.unsqueeze(2) + ctr_y.unsqueeze(2)
pred_w = torch.exp(dw) * widths.unsqueeze(2)
pred_h = torch.exp(dh) * heights.unsqueeze(2)
pred_boxes = deltas.clone()
# x1
pred_boxes[:, :, 0::4] = pred_ctr_x - 0.5 * pred_w
# y1
pred_boxes[:, :, 1::4] = pred_ctr_y - 0.5 * pred_h
# x2
pred_boxes[:, :, 2::4] = pred_ctr_x + 0.5 * pred_w
# y2
pred_boxes[:, :, 3::4] = pred_ctr_y + 0.5 * pred_h
return pred_boxes
def generate_anchors_single_pyramid(
scales, ratios, shape, feature_stride, anchor_stride
):
"""
scales: 1D array of anchor sizes in pixels. Example: [32, 64, 128]
ratios: 1D array of anchor ratios of width/height. Example: [0.5, 1, 2]
shape: [height, width] spatial shape of the feature map over which
to generate anchors.
feature_stride: Stride of the feature map relative to the image in pixels.
anchor_stride: Stride of anchors on the feature map. For example, if the
value is 2 then generate anchors for every other feature map pixel.
"""
# Get all combinations of scales and ratios
scales, ratios = np.meshgrid(np.array(scales), np.array(ratios))
scales = scales.flatten()
ratios = ratios.flatten()
# Enumerate heights and widths from scales and ratios
heights = scales / np.sqrt(ratios)
widths = scales * np.sqrt(ratios)
# Enumerate shifts in feature space
shifts_y = np.arange(0, shape[0], anchor_stride) * feature_stride
shifts_x = np.arange(0, shape[1], anchor_stride) * feature_stride
shifts_x, shifts_y = np.meshgrid(shifts_x, shifts_y)
# Enumerate combinations of shifts, widths, and heights
box_widths, box_centers_x = np.meshgrid(widths, shifts_x)
box_heights, box_centers_y = np.meshgrid(heights, shifts_y)
# # Reshape to get a list of (y, x) and a list of (h, w)
# box_centers = np.stack(
# [box_centers_y, box_centers_x], axis=2).reshape([-1, 2])
# box_sizes = np.stack([box_heights, box_widths], axis=2).reshape([-1, 2])
# NOTE: the original order is (y, x), we changed it to (x, y) for our code
# Reshape to get a list of (x, y) and a list of (w, h)
box_centers = np.stack([box_centers_x, box_centers_y], axis=2).reshape([-1, 2])
box_sizes = np.stack([box_widths, box_heights], axis=2).reshape([-1, 2])
# Convert to corner coordinates (x1, y1, x2, y2)
boxes = np.concatenate(
[box_centers - 0.5 * box_sizes, box_centers + 0.5 * box_sizes], axis=1
)
# print(boxes)
return boxes
def generate_anchors_all_pyramids(
scales, ratios, feature_shapes, feature_strides, anchor_stride
):
"""Generate anchors at different levels of a feature pyramid. Each scale
is associated with a level of the pyramid, but each ratio is used in
all levels of the pyramid.
Returns:
anchors: [N, (y1, x1, y2, x2)]. All generated anchors in one array. Sorted
with the same order of the given scales. So, anchors of scale[0] come
first, then anchors of scale[1], and so on.
"""
# Anchors
# [anchor_count, (y1, x1, y2, x2)]
anchors = []
for i in range(len(scales)):
anchors.append(
generate_anchors_single_pyramid(
scales[i], ratios, feature_shapes[i], feature_strides[i], anchor_stride
)
)
return np.concatenate(anchors, axis=0)
class _ProposalTargetLayer(nn.Module):
"""
Assign object detection proposals to ground-truth targets. Produces proposal
classification labels and bounding-box regression targets.
"""
def __init__(self, nclasses):
super(_ProposalTargetLayer, self).__init__()
self._num_classes = nclasses
self.BBOX_NORMALIZE_MEANS = torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_MEANS"])
self.BBOX_NORMALIZE_STDS = torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_STDS"])
self.BBOX_INSIDE_WEIGHTS = torch.FloatTensor(cfg["TRAIN_BBOX_INSIDE_WEIGHTS"])
def forward(self, all_rois, gt_boxes, num_boxes, stage=1):
self.BBOX_NORMALIZE_MEANS = self.BBOX_NORMALIZE_MEANS.type_as(gt_boxes)
self.BBOX_NORMALIZE_STDS = self.BBOX_NORMALIZE_STDS.type_as(gt_boxes)
self.BBOX_INSIDE_WEIGHTS = self.BBOX_INSIDE_WEIGHTS.type_as(gt_boxes)
gt_boxes_append = gt_boxes.new(gt_boxes.size()).zero_()
gt_boxes_append[:, :, 1:5] = gt_boxes[:, :, :4]
# Include ground-truth boxes in the set of candidate rois
all_rois = torch.cat([all_rois, gt_boxes_append], 1)
num_images = 1
rois_per_image = int(cfg["TRAIN_BATCH_SIZE"] / num_images)
fg_rois_per_image = int(np.round(cfg["TRAIN_FG_FRACTION"] * rois_per_image))
fg_rois_per_image = 1 if fg_rois_per_image == 0 else fg_rois_per_image
(
labels,
rois,
gt_assign,
bbox_targets,
bbox_inside_weights,
) = self._sample_rois_pytorch(
all_rois,
gt_boxes,
fg_rois_per_image,
rois_per_image,
self._num_classes,
stage=stage,
)
bbox_outside_weights = (bbox_inside_weights > 0).float()
return (
rois,
labels,
gt_assign,
bbox_targets,
bbox_inside_weights,
bbox_outside_weights,
)
def backward(self, top, propagate_down, bottom):
"""This layer does not propagate gradients."""
pass
def reshape(self, bottom, top):
"""Reshaping happens during the call to forward."""
pass
def _get_bbox_regression_labels_pytorch(
self, bbox_target_data, labels_batch, num_classes
):
"""Bounding-box regression targets (bbox_target_data) are stored in a
compact form b x N x (class, tx, ty, tw, th)
This function expands those targets into the 4-of-4*K representation used
by the network (i.e. only one class has non-zero targets).
Returns:
bbox_target (ndarray): b x N x 4K blob of regression targets
bbox_inside_weights (ndarray): b x N x 4K blob of loss weights
"""
batch_size = labels_batch.size(0)
rois_per_image = labels_batch.size(1)
clss = labels_batch
bbox_targets = bbox_target_data.new(batch_size, rois_per_image, 4).zero_()
bbox_inside_weights = bbox_target_data.new(bbox_targets.size()).zero_()
for b in range(batch_size):
# assert clss[b].sum() > 0
if clss[b].sum() == 0:
continue
inds = torch.nonzero(clss[b] > 0).view(-1)
for i in range(inds.numel()):
ind = inds[i]
bbox_targets[b, ind, :] = bbox_target_data[b, ind, :]
bbox_inside_weights[b, ind, :] = self.BBOX_INSIDE_WEIGHTS
return bbox_targets, bbox_inside_weights
def _compute_targets_pytorch(self, ex_rois, gt_rois):
"""Compute bounding-box regression targets for an image."""
assert ex_rois.size(1) == gt_rois.size(1)
assert ex_rois.size(2) == 4
assert gt_rois.size(2) == 4
batch_size = ex_rois.size(0)
rois_per_image = ex_rois.size(1)
targets = bbox_transform_batch(ex_rois, gt_rois)
if cfg["TRAIN_BBOX_NORMALIZE_TARGETS_PRECOMPUTED"]:
# Optionally normalize targets by a precomputed mean and stdev
targets = (
targets - self.BBOX_NORMALIZE_MEANS.expand_as(targets)
) / self.BBOX_NORMALIZE_STDS.expand_as(targets)
return targets
def _sample_rois_pytorch(
self,
all_rois,
gt_boxes,
fg_rois_per_image,
rois_per_image,
num_classes,
stage=1,
):
"""Generate a random sample of RoIs comprising foreground and background
examples.
"""
# overlaps: (rois x gt_boxes)
overlaps = bbox_overlaps_batch(all_rois, gt_boxes)
max_overlaps, gt_assignment = torch.max(overlaps, 2)
batch_size = overlaps.size(0)
num_proposal = overlaps.size(1)
num_boxes_per_img = overlaps.size(2)
offset = torch.arange(0, batch_size) * gt_boxes.size(1)
offset = offset.view(-1, 1).type_as(gt_assignment) + gt_assignment
labels = (
gt_boxes[:, :, 4]
.contiguous()
.view(-1)[(offset.view(-1),)]
.view(batch_size, -1)
)
labels_batch = labels.new(batch_size, rois_per_image).zero_()
rois_batch = all_rois.new(batch_size, rois_per_image, 5).zero_()
gt_assign_batch = all_rois.new(batch_size, rois_per_image).zero_()
gt_rois_batch = all_rois.new(batch_size, rois_per_image, 5).zero_()
# Guard against the case when an image has fewer than max_fg_rois_per_image
# foreground RoIs
if stage == 1:
fg_thresh = cfg["TRAIN_FG_THRESH"]
bg_thresh_hi = cfg["TRAIN_BG_THRESH_HI"]
bg_thresh_lo = cfg["TRAIN_BG_THRESH_LO"]
elif stage == 2:
fg_thresh = cfg["TRAIN_FG_THRESH_2ND"]
bg_thresh_hi = cfg["TRAIN_FG_THRESH_2ND"]
bg_thresh_lo = cfg["TRAIN_BG_THRESH_LO"]
elif stage == 3:
fg_thresh = cfg["TRAIN_FG_THRESH_3RD"]
bg_thresh_hi = cfg["TRAIN_FG_THRESH_3RD"]
bg_thresh_lo = cfg["TRAIN_BG_THRESH_LO"]
else:
raise RuntimeError("stage must be in [1, 2, 3]")
for i in range(batch_size):
fg_inds = torch.nonzero(max_overlaps[i] >= fg_thresh).view(-1)
fg_num_rois = fg_inds.numel()
# Select background RoIs as those within [BG_THRESH_LO, BG_THRESH_HI)
bg_inds = torch.nonzero(
(max_overlaps[i] < bg_thresh_hi) & (max_overlaps[i] >= bg_thresh_lo)
).view(-1)
bg_num_rois = bg_inds.numel()
if fg_num_rois > 0 and bg_num_rois > 0:
# sampling fg
fg_rois_per_this_image = min(fg_rois_per_image, fg_num_rois)
# torch.randperm seems has a bug on multi-gpu setting that cause the segfault.
# See https://github.com/pytorch/pytorch/issues/1868 for more details.
# use numpy instead.
# rand_num = torch.randperm(fg_num_rois).long().cuda()
rand_num = (
torch.from_numpy(np.random.permutation(fg_num_rois))
.type_as(gt_boxes)
.long()
)
fg_inds = fg_inds[rand_num[:fg_rois_per_this_image]]
# sampling bg
bg_rois_per_this_image = rois_per_image - fg_rois_per_this_image
# Seems torch.rand has a bug, it will generate very large number and make an error.
# We use numpy rand instead.
# rand_num = (torch.rand(bg_rois_per_this_image) * bg_num_rois).long().cuda()
rand_num = np.floor(
np.random.rand(bg_rois_per_this_image) * bg_num_rois
)
rand_num = torch.from_numpy(rand_num).type_as(gt_boxes).long()
bg_inds = bg_inds[rand_num]
elif fg_num_rois > 0 and bg_num_rois == 0:
# sampling fg
# rand_num = torch.floor(torch.rand(rois_per_image) * fg_num_rois).long().cuda()
rand_num = np.floor(np.random.rand(rois_per_image) * fg_num_rois)
rand_num = torch.from_numpy(rand_num).type_as(gt_boxes).long()
fg_inds = fg_inds[rand_num]
fg_rois_per_this_image = rois_per_image
bg_rois_per_this_image = 0
elif bg_num_rois > 0 and fg_num_rois == 0:
# sampling bg
# rand_num = torch.floor(torch.rand(rois_per_image) * bg_num_rois).long().cuda()
rand_num = np.floor(np.random.rand(rois_per_image) * bg_num_rois)
rand_num = torch.from_numpy(rand_num).type_as(gt_boxes).long()
bg_inds = bg_inds[rand_num]
bg_rois_per_this_image = rois_per_image
fg_rois_per_this_image = 0
else:
print(i, overlaps[i], max_overlaps[i], gt_boxes[i])
raise ValueError(
"bg_num_rois = 0 and fg_num_rois = 0, this should not happen!"
)
# The indices that we're selecting (both fg and bg)
keep_inds = torch.cat([fg_inds, bg_inds], 0)
# Select sampled values from various arrays:
labels_batch[i].copy_(labels[i][keep_inds])
# Clamp labels for the background RoIs to 0
if fg_rois_per_this_image < rois_per_image:
labels_batch[i][fg_rois_per_this_image:] = 0
rois_batch[i] = all_rois[i][keep_inds]
rois_batch[i, :, 0] = i
# TODO: check the below line when batch_size > 1, no need to add offset here
gt_assign_batch[i] = gt_assignment[i][keep_inds]
gt_rois_batch[i] = gt_boxes[i][gt_assignment[i][keep_inds]]
bbox_target_data = self._compute_targets_pytorch(
rois_batch[:, :, 1:5], gt_rois_batch[:, :, :4]
)
bbox_targets, bbox_inside_weights = self._get_bbox_regression_labels_pytorch(
bbox_target_data, labels_batch, num_classes
)
return (
labels_batch,
rois_batch,
gt_assign_batch,
bbox_targets,
bbox_inside_weights,
)
class _AnchorTargetLayer_FPN(nn.Module):
"""
Assign anchors to ground-truth targets. Produces anchor classification
labels and bounding-box regression targets.
"""
def __init__(self, feat_stride, scales, ratios):
super(_AnchorTargetLayer_FPN, self).__init__()
self._anchor_ratios = ratios
self._feat_stride = feat_stride
self._fpn_scales = np.array(cfg["FPN_ANCHOR_SCALES"])
self._fpn_feature_strides = np.array(cfg["FPN_FEAT_STRIDES"])
self._fpn_anchor_stride = cfg["FPN_ANCHOR_STRIDE"]
# allow boxes to sit over the edge by a small amount
self._allowed_border = 0 # default is 0
def forward(self, input):
# Algorithm:
#
# for each (H, W) location i
# generate 9 anchor boxes centered on cell i
# apply predicted bbox deltas at cell i to each of the 9 anchors
# filter out-of-image anchors
#
scores = input[0]
gt_boxes = input[1]
im_info = input[2]
num_boxes = input[3]
feat_shapes = input[4]
# NOTE: need to change
# height, width = scores.size(2), scores.size(3)
height, width = 0, 0
batch_size = gt_boxes.size(0)
anchors = torch.from_numpy(
generate_anchors_all_pyramids(
self._fpn_scales,
self._anchor_ratios,
feat_shapes,
self._fpn_feature_strides,
self._fpn_anchor_stride,
)
).type_as(scores)
total_anchors = anchors.size(0)
# print(self._fpn_feature_strides)
# print(anchors.shape)
keep = (
(anchors[:, 0] >= -self._allowed_border)
& (anchors[:, 1] >= -self._allowed_border)
& (anchors[:, 2] < long(im_info[0][1]) + self._allowed_border)
& (anchors[:, 3] < long(im_info[0][0]) + self._allowed_border)
)
inds_inside = torch.nonzero(keep).view(-1)
# keep only inside anchors
anchors = anchors[inds_inside, :]
# label: 1 is positive, 0 is negative, -1 is dont care
labels = gt_boxes.new(batch_size, inds_inside.size(0)).fill_(-1)
bbox_inside_weights = gt_boxes.new(batch_size, inds_inside.size(0)).zero_()
bbox_outside_weights = gt_boxes.new(batch_size, inds_inside.size(0)).zero_()
overlaps = bbox_overlaps_batch(anchors, gt_boxes)
max_overlaps, argmax_overlaps = torch.max(overlaps, 2)
gt_max_overlaps, _ = torch.max(overlaps, 1)
labels[max_overlaps < cfg["TRAIN_RPN_NEGATIVE_OVERLAP"]] = 0
gt_max_overlaps[gt_max_overlaps == 0] = 1e-5
keep = torch.sum(
overlaps.eq(gt_max_overlaps.view(batch_size, 1, -1).expand_as(overlaps)), 2
)
if torch.sum(keep) > 0:
labels[keep > 0] = 1
# fg label: above threshold IOU
labels[max_overlaps >= cfg["TRAIN_RPN_POSITIVE_OVERLAP"]] = 1
num_fg = int(cfg["TRAIN_RPN_FG_FRACTION"] * cfg["TRAIN_RPN_BATCHSIZE"])
sum_fg = torch.sum((labels == 1).int(), 1)
sum_bg = torch.sum((labels == 0).int(), 1)
for i in range(batch_size):
# subsample positive labels if we have too many
if sum_fg[i] > num_fg:
fg_inds = torch.nonzero(labels[i] == 1).view(-1)
# torch.randperm seems has a bug on multi-gpu setting that cause the segfault.
# See https://github.com/pytorch/pytorch/issues/1868 for more details.
# use numpy instead.
# rand_num = torch.randperm(fg_inds.size(0)).type_as(gt_boxes).long()
rand_num = (
torch.from_numpy(np.random.permutation(fg_inds.size(0)))
.type_as(gt_boxes)
.long()
)
disable_inds = fg_inds[rand_num[: fg_inds.size(0) - num_fg]]
labels[i][disable_inds] = -1
num_bg = cfg["TRAIN_RPN_BATCHSIZE"] - sum_fg[i]
# subsample negative labels if we have too many
if sum_bg[i] > num_bg:
bg_inds = torch.nonzero(labels[i] == 0).view(-1)
# rand_num = torch.randperm(bg_inds.size(0)).type_as(gt_boxes).long()
rand_num = (
torch.from_numpy(np.random.permutation(bg_inds.size(0)))
.type_as(gt_boxes)
.long()
)
disable_inds = bg_inds[rand_num[: bg_inds.size(0) - num_bg]]
labels[i][disable_inds] = -1
offset = torch.arange(0, batch_size) * gt_boxes.size(1)
argmax_overlaps = argmax_overlaps + offset.view(batch_size, 1).type_as(
argmax_overlaps
)
bbox_targets = _compute_targets_batch(
anchors,
gt_boxes.view(-1, 5)[argmax_overlaps.view(-1), :].view(batch_size, -1, 5),
)
# use a single value instead of 4 values for easy index.
bbox_inside_weights[labels == 1] = cfg["TRAIN_RPN_BBOX_INSIDE_WEIGHTS"][0]
if cfg["TRAIN_RPN_POSITIVE_WEIGHT"] < 0:
num_examples = torch.sum(labels[i] >= 0)
positive_weights = 1.0 / num_examples.item()
negative_weights = 1.0 / num_examples.item()
else:
assert (cfg["TRAIN_RPN_POSITIVE_WEIGHT"] > 0) & (
cfg["TRAIN_RPN_POSITIVE_WEIGHT"] < 1
)
bbox_outside_weights[labels == 1] = positive_weights
bbox_outside_weights[labels == 0] = negative_weights
labels = _unmap(labels, total_anchors, inds_inside, batch_size, fill=-1)
bbox_targets = _unmap(
bbox_targets, total_anchors, inds_inside, batch_size, fill=0
)
bbox_inside_weights = _unmap(
bbox_inside_weights, total_anchors, inds_inside, batch_size, fill=0
)
bbox_outside_weights = _unmap(
bbox_outside_weights, total_anchors, inds_inside, batch_size, fill=0
)
outputs = []
# labels = labels.view(batch_size, height, width, A).permute(0,3,1,2).contiguous()
# labels = labels.view(batch_size, 1, A * height, width)
outputs.append(labels)
# bbox_targets = bbox_targets.view(batch_size, height, width, A*4).permute(0,3,1,2).contiguous()
outputs.append(bbox_targets)
# anchors_count = bbox_inside_weights.size(1)
# bbox_inside_weights = bbox_inside_weights.view(batch_size,anchors_count,1).expand(batch_size, anchors_count, 4)
# bbox_inside_weights = bbox_inside_weights.contiguous().view(batch_size, height, width, 4*A)\
# .permute(0,3,1,2).contiguous()
outputs.append(bbox_inside_weights)
# bbox_outside_weights = bbox_outside_weights.view(batch_size,anchors_count,1).expand(batch_size, anchors_count, 4)
# bbox_outside_weights = bbox_outside_weights.contiguous().view(batch_size, height, width, 4*A)\
# .permute(0,3,1,2).contiguous()
outputs.append(bbox_outside_weights)
return outputs
def backward(self, top, propagate_down, bottom):
"""This layer does not propagate gradients."""
pass
def reshape(self, bottom, top):
"""Reshaping happens during the call to forward."""
pass
class _ProposalLayer_FPN(nn.Module):
"""
Outputs object detection proposals by applying estimated bounding-box
transformations to a set of regular boxes (called "anchors").
"""
def __init__(self, feat_stride, scales, ratios):
super(_ProposalLayer_FPN, self).__init__()
self._anchor_ratios = ratios
self._feat_stride = feat_stride
self._fpn_scales = np.array(cfg["FPN_ANCHOR_SCALES"])
self._fpn_feature_strides = np.array(cfg["FPN_FEAT_STRIDES"])
self._fpn_anchor_stride = cfg["FPN_ANCHOR_STRIDE"]
# self._anchors = torch.from_numpy(generate_anchors_all_pyramids(self._fpn_scales, ratios, self._fpn_feature_strides, fpn_anchor_stride))
# self._num_anchors = self._anchors.size(0)
def forward(self, input):
# Algorithm:
#
# for each (H, W) location i
# generate A anchor boxes centered on cell i
# apply predicted bbox deltas at cell i to each of the A anchors
# clip predicted boxes to image
# remove predicted boxes with either height or width < threshold
# sort all (proposal, score) pairs by score from highest to lowest
# take top pre_nms_topN proposals before NMS
# apply NMS with threshold 0.7 to remaining proposals
# take after_nms_topN proposals after NMS
# return the top proposals (-> RoIs top, scores top)
# the first set of _num_anchors channels are bg probs
# the second set are the fg probs
scores = input[0][:, :, 1] # batch_size x num_rois x 1
bbox_deltas = input[1] # batch_size x num_rois x 4
im_info = input[2]
cfg_key = input[3]
feat_shapes = input[4]
pre_nms_topN = cfg["RPN_PRE_NMS_TOP_N"]
post_nms_topN = cfg["RPN_POST_NMS_TOP_N"]
nms_thresh = cfg["RPN_NMS_THRESH"]
min_size = cfg["RPN_MIN_SIZE"]
batch_size = bbox_deltas.size(0)
anchors = torch.from_numpy(
generate_anchors_all_pyramids(
self._fpn_scales,
self._anchor_ratios,
feat_shapes,
self._fpn_feature_strides,
self._fpn_anchor_stride,
)
).type_as(scores)
num_anchors = anchors.size(0)
anchors = anchors.view(1, num_anchors, 4).expand(batch_size, num_anchors, 4)
# Convert anchors into proposals via bbox transformations
proposals = bbox_transform_inv(anchors, bbox_deltas, batch_size)
# 2. clip predicted boxes to image
proposals = clip_boxes(proposals, im_info, batch_size)
# keep_idx = self._filter_boxes(proposals, min_size).squeeze().long().nonzero().squeeze()
scores_keep = scores
proposals_keep = proposals
_, order = torch.sort(scores_keep, 1, True)
output = scores.new(batch_size, post_nms_topN, 5).zero_()
for i in range(batch_size):
# # 3. remove predicted boxes with either height or width < threshold
# # (NOTE: convert min_size to input image scale stored in im_info[2])
proposals_single = proposals_keep[i]
scores_single = scores_keep[i]
# # 4. sort all (proposal, score) pairs by score from highest to lowest
# # 5. take top pre_nms_topN (e.g. 6000)
order_single = order[i]
if pre_nms_topN > 0 and pre_nms_topN < scores_keep.numel():
order_single = order_single[:pre_nms_topN]
proposals_single = proposals_single[order_single, :]
scores_single = scores_single[order_single].view(-1, 1)
# print("-------------------------")
# print(type(proposals_single))
# print(proposals_single.shape)
# print(type(scores_single))
# print(scores_single.shape)
# print("-------------------------")
# # 6. apply nms (e.g. threshold = 0.7)
# # 7. take after_nms_topN (e.g. 300)
# # 8. return the top proposals (-> RoIs top)
# print(proposals_single)
# print('------------------------')
# print(proposals_single.cpu().numpy())
keep_idx_i = soft_nms(
proposals_single,
scores_single.squeeze(1),
sigma=0.5,
thresh=0.001,
cuda=1,
)
# keep_idx_i = soft_nms(proposals_single.cpu().numpy(), scores_single.cpu().numpy(), 0, thresh = 0.2, Nt = nms_thresh)
# keep_idx_i = torch.from_numpy(keep_idx_i)
# keep_idx_i = nms(proposals_single, scores_single.squeeze(1), nms_thresh)
# keep_idx_i = nms(proposals_single, scores_single, nms_thresh)
keep_idx_i = keep_idx_i.long().view(-1)
if post_nms_topN > 0:
keep_idx_i = keep_idx_i[:post_nms_topN]
proposals_single = proposals_single[keep_idx_i, :]
scores_single = scores_single[keep_idx_i, :]
# padding 0 at the end.
num_proposal = proposals_single.size(0)
output[i, :, 0] = i
output[i, :num_proposal, 1:] = proposals_single
return output
def backward(self, top, propagate_down, bottom):
"""This layer does not propagate gradients."""
pass
def reshape(self, bottom, top):
"""Reshaping happens during the call to forward."""
pass
def _filter_boxes(self, boxes, min_size):
"""Remove all boxes with any side smaller than min_size."""
ws = boxes[:, :, 2] - boxes[:, :, 0] + 1
hs = boxes[:, :, 3] - boxes[:, :, 1] + 1
keep = (ws >= min_size) & (hs >= min_size)
return keep
class _RPN_FPN(nn.Module):
"""region proposal network"""
def __init__(self, din):
super(_RPN_FPN, self).__init__()
self.din = din # get depth of input feature map, e.g., 512
self.anchor_ratios = cfg["ANCHOR_RATIOS"]
self.anchor_scales = cfg["ANCHOR_SCALES"]
self.feat_stride = cfg["FEAT_STRIDE"]
# define the convrelu layers processing input feature map
self.RPN_Conv = nn.Conv2d(self.din, 512, 3, 1, 1, bias=True)
# define bg/fg classifcation score layer
# self.nc_score_out = len(self.anchor_scales) * len(self.anchor_ratios) * 2 # 2(bg/fg) * 9 (anchors)
self.nc_score_out = (
1 * len(self.anchor_ratios) * 2
) # 2(bg/fg) * 3 (anchor ratios) * 1 (anchor scale)
self.RPN_cls_score = nn.Conv2d(512, self.nc_score_out, 1, 1, 0)
# define anchor box offset prediction layer
# self.nc_bbox_out = len(self.anchor_scales) * len(self.anchor_ratios) * 4 # 4(coords) * 9 (anchors)
self.nc_bbox_out = (
1 * len(self.anchor_ratios) * 4
) # 4(coords) * 3 (anchors) * 1 (anchor scale)
self.RPN_bbox_pred = nn.Conv2d(512, self.nc_bbox_out, 1, 1, 0)
# define proposal layer
self.RPN_proposal = _ProposalLayer_FPN(
self.feat_stride, self.anchor_scales, self.anchor_ratios
)
# define anchor target layer
self.RPN_anchor_target = _AnchorTargetLayer_FPN(
self.feat_stride, self.anchor_scales, self.anchor_ratios
)
self.rpn_loss_cls = 0
self.rpn_loss_box = 0
@staticmethod
def reshape(x, d):
input_shape = x.size()
x = x.contiguous().view(
input_shape[0],
int(d),
int(float(input_shape[1] * input_shape[2]) / float(d)),
input_shape[3],
)
return x
def forward(self, rpn_feature_maps, im_info, gt_boxes, num_boxes):
n_feat_maps = len(rpn_feature_maps)
rpn_cls_scores = []
rpn_cls_probs = []
rpn_bbox_preds = []
rpn_shapes = []
for i in range(n_feat_maps):
feat_map = rpn_feature_maps[i]
batch_size = feat_map.size(0)
# return feature map after convrelu layer
rpn_conv1 = F.relu(self.RPN_Conv(feat_map), inplace=True)
# get rpn classification score
rpn_cls_score = self.RPN_cls_score(rpn_conv1)
rpn_cls_score_reshape = self.reshape(rpn_cls_score, 2)
rpn_cls_prob_reshape = F.softmax(rpn_cls_score_reshape, 1)
rpn_cls_prob = self.reshape(rpn_cls_prob_reshape, self.nc_score_out)
# get rpn offsets to the anchor boxes
rpn_bbox_pred = self.RPN_bbox_pred(rpn_conv1)
rpn_shapes.append([rpn_cls_score.size()[2], rpn_cls_score.size()[3]])
rpn_cls_scores.append(
rpn_cls_score.permute(0, 2, 3, 1).contiguous().view(batch_size, -1, 2)
)
rpn_cls_probs.append(
rpn_cls_prob.permute(0, 2, 3, 1).contiguous().view(batch_size, -1, 2)
)
rpn_bbox_preds.append(
rpn_bbox_pred.permute(0, 2, 3, 1).contiguous().view(batch_size, -1, 4)
)
rpn_cls_score_alls = torch.cat(rpn_cls_scores, 1)
rpn_cls_prob_alls = torch.cat(rpn_cls_probs, 1)
rpn_bbox_pred_alls = torch.cat(rpn_bbox_preds, 1)
n_rpn_pred = rpn_cls_score_alls.size(1)
# proposal layer
cfg_key = "TRAIN" if self.training else "TEST"
rois = self.RPN_proposal(
(
rpn_cls_prob_alls.data,
rpn_bbox_pred_alls.data,
im_info,
cfg_key,
rpn_shapes,
)
)
self.rpn_loss_cls = 0
self.rpn_loss_box = 0
# generating training labels and build the rpn loss
if self.training:
assert gt_boxes is not None
rpn_data = self.RPN_anchor_target(
(rpn_cls_score_alls.data, gt_boxes, im_info, num_boxes, rpn_shapes)
)
# compute classification loss
rpn_label = rpn_data[0].view(batch_size, -1)
rpn_keep = Variable(rpn_label.view(-1).ne(-1).nonzero().view(-1))
rpn_cls_score = torch.index_select(
rpn_cls_score_alls.view(-1, 2), 0, rpn_keep
)
rpn_label = torch.index_select(rpn_label.view(-1), 0, rpn_keep.data)
rpn_label = Variable(rpn_label.long())
self.rpn_loss_cls = F.cross_entropy(rpn_cls_score, rpn_label)
fg_cnt = torch.sum(rpn_label.data.ne(0))
(
rpn_bbox_targets,
rpn_bbox_inside_weights,
rpn_bbox_outside_weights,
) = rpn_data[1:]
# print(rpn_bbox_targets.shape)
# compute bbox regression loss
rpn_bbox_inside_weights = Variable(
rpn_bbox_inside_weights.unsqueeze(2).expand(
batch_size, rpn_bbox_inside_weights.size(1), 4
)
)
rpn_bbox_outside_weights = Variable(
rpn_bbox_outside_weights.unsqueeze(2).expand(
batch_size, rpn_bbox_outside_weights.size(1), 4
)
)
rpn_bbox_targets = Variable(rpn_bbox_targets)
self.rpn_loss_box = _smooth_l1_loss(
rpn_bbox_pred_alls,
rpn_bbox_targets,
rpn_bbox_inside_weights,
rpn_bbox_outside_weights,
sigma=3,
)
return rois, self.rpn_loss_cls, self.rpn_loss_box
class _ROIPool(Function):
@staticmethod
def forward(ctx, input, roi, output_size, spatial_scale):
ctx.output_size = _pair(output_size)
ctx.spatial_scale = spatial_scale
ctx.input_shape = input.size()
output, argmax = _C.roi_pool_forward(
input, roi, spatial_scale, output_size[0], output_size[1]
)
ctx.save_for_backward(input, roi, argmax)
return output
@staticmethod
@once_differentiable
def backward(ctx, grad_output):
input, rois, argmax = ctx.saved_tensors
output_size = ctx.output_size
spatial_scale = ctx.spatial_scale
bs, ch, h, w = ctx.input_shape
grad_input = _C.roi_pool_backward(
grad_output,
input,
rois,
argmax,
spatial_scale,
output_size[0],
output_size[1],
bs,
ch,
h,
w,
)
return grad_input, None, None, None
roi_pool = _ROIPool.apply
class ROIPool(nn.Module):
def __init__(self, output_size, spatial_scale):
super(ROIPool, self).__init__()
self.output_size = output_size
self.spatial_scale = spatial_scale
def forward(self, input, rois):
return roi_pool(input, rois, self.output_size, self.spatial_scale)
def __repr__(self):
tmpstr = self.__class__.__name__ + "("
tmpstr += "output_size=" + str(self.output_size)
tmpstr += ", spatial_scale=" + str(self.spatial_scale)
tmpstr += ")"
return tmpstr
class _ROIAlign(Function):
@staticmethod
def forward(ctx, input, roi, output_size, spatial_scale, sampling_ratio):
ctx.save_for_backward(roi)
ctx.output_size = _pair(output_size)
ctx.spatial_scale = spatial_scale
ctx.sampling_ratio = sampling_ratio
ctx.input_shape = input.size()
output = _C.roi_align_forward(
input, roi, spatial_scale, output_size[0], output_size[1], sampling_ratio
)
return output
@staticmethod
@once_differentiable
def backward(ctx, grad_output):
(rois,) = ctx.saved_tensors
output_size = ctx.output_size
spatial_scale = ctx.spatial_scale
sampling_ratio = ctx.sampling_ratio
bs, ch, h, w = ctx.input_shape
grad_input = _C.roi_align_backward(
grad_output,
rois,
spatial_scale,
output_size[0],
output_size[1],
bs,
ch,
h,
w,
sampling_ratio,
)
return grad_input, None, None, None, None
roi_align = _ROIAlign.apply
def bbox_decode(
rois, bbox_pred, batch_size, class_agnostic, classes, im_info, training, cls_prob
):
boxes = rois.data[:, :, 1:5]
if cfg["TEST_BBOX_REG"]:
# Apply bounding-box regression deltas
box_deltas = bbox_pred.data
if cfg["TRAIN_BBOX_NORMALIZE_TARGETS_PRECOMPUTED"]:
# Optionally normalize targets by a precomputed mean and stdev
if class_agnostic or training:
box_deltas = (
box_deltas.view(-1, 4)
* torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_STDS"]).cuda()
+ torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_MEANS"]).cuda()
)
box_deltas = box_deltas.view(batch_size, -1, 4)
else:
cls_prob[:, 0] = 0
bbox_pred_cls_argmax = torch.argmax(cls_prob, dim=1)
# print(bbox_pred_cls_argmax)
for i in range(bbox_pred.size(1)):
bbox_pred_cls_argmax[i] = bbox_pred_cls_argmax[i] + i * classes
bbox_pred_max = bbox_pred.view(batch_size, -1, 4)
bbox_pred_max = torch.index_select(
bbox_pred_max, 1, bbox_pred_cls_argmax
)
box_deltas = bbox_pred_max.data
box_deltas = (
box_deltas.view(-1, 4)
* torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_STDS"]).cuda()
+ torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_MEANS"]).cuda()
)
box_deltas = box_deltas.view(batch_size, -1, 4)
pred_boxes = bbox_transform_inv(boxes, box_deltas, batch_size)
pred_boxes = clip_boxes(pred_boxes, im_info, batch_size)
else:
# Simply repeat the boxes, once for each class
pred_boxes = boxes
pred_boxes = pred_boxes.view(batch_size, -1, 4)
ret_boxes = torch.zeros(pred_boxes.size(0), pred_boxes.size(1), 5).cuda()
ret_boxes[:, :, 1:] = pred_boxes
for b in range(batch_size):
ret_boxes[b, :, 0] = b
return ret_boxes
class ROIAlignAvg(nn.Module):
def __init__(self, output_size, spatial_scale, sampling_ratio):
super(ROIAlignAvg, self).__init__()
self.output_size = output_size
self.spatial_scale = spatial_scale
self.sampling_ratio = sampling_ratio
def forward(self, input, rois, spatial_scale):
self.spatial_scale = spatial_scale
# x= roi_align(
# input, rois, self.output_size, self.spatial_scale, self.sampling_ratio
# )
x = torchvision.ops.roi_align(
input, rois, self.output_size, self.spatial_scale, self.sampling_ratio
)
return avg_pool2d(x, kernel_size=2, stride=1)
def __repr__(self):
tmpstr = self.__class__.__name__ + "("
tmpstr += "output_size=" + str(self.output_size)
tmpstr += ", spatial_scale=" + str(self.spatial_scale)
tmpstr += ", sampling_ratio=" + str(self.sampling_ratio)
tmpstr += ")"
return tmpstr
class _FPN(nn.Module):
"""FPN"""
def __init__(self, classes, class_agnostic):
super(_FPN, self).__init__()
self.classes = classes
self.n_classes = len(classes)
self.class_agnostic = class_agnostic
# loss
self.RCNN_loss_cls = 0
self.RCNN_loss_bbox = 0
self.maxpool2d = nn.MaxPool2d(1, stride=2)
# define rpn
self.RCNN_rpn = _RPN_FPN(self.dout_base_model)
self.RCNN_proposal_target = _ProposalTargetLayer(self.n_classes)
# NOTE: the original paper used pool_size = 7 for cls branch, and 14 for mask branch, to save the
# computation time, we first use 14 as the pool_size, and then do stride=2 pooling for cls branch.
self.RCNN_roi_pool = ROIPool(
(cfg["POOLING_SIZE"], cfg["POOLING_SIZE"]), 1.0 / 16.0
)
self.RCNN_roi_align = ROIAlignAvg(
(cfg["POOLING_SIZE"] + 1, cfg["POOLING_SIZE"] + 1), 1.0 / 16.0, 0
)
# self.RCNN_roi_pool = ROIPool(cfg['POOLING_SIZE'], cfg['POOLING_SIZE'], 1.0/16.0)
# self.RCNN_roi_align = ROIAlignAvg(cfg['POOLING_SIZE'], cfg['POOLING_SIZE'], 1.0/16.0)
self.grid_size = (
cfg["POOLING_SIZE"] * 2
if cfg["CROP_RESIZE_WITH_MAX_POOL"]
else cfg["POOLING_SIZE"]
)
def _init_weights(self):
def normal_init(m, mean, stddev, truncated=False):
"""
weight initalizer: truncated normal and random normal.
"""
# x is a parameter
if truncated:
m.weight.data.normal_().fmod_(2).mul_(stddev).add_(
mean
) # not a perfect approximation
else:
m.weight.data.normal_(mean, stddev)
m.bias.data.zero_()
# custom weights initialization called on netG and netD
def weights_init(m, mean, stddev, truncated=False):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
m.weight.data.normal_(0.0, 0.02)
m.bias.data.fill_(0)
elif classname.find("BatchNorm") != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
normal_init(self.RCNN_toplayer, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_smooth1, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_smooth2, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_smooth3, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_latlayer1, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_latlayer2, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_latlayer3, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_rpn.RPN_Conv, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_rpn.RPN_cls_score, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_rpn.RPN_bbox_pred, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_cls_score, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_bbox_pred, 0, 0.001, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_cls_score_2nd, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_bbox_pred_2nd, 0, 0.001, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_cls_score_3rd, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_bbox_pred_3rd, 0, 0.001, cfg["TRAIN_TRUNCATED"])
weights_init(self.RCNN_top, 0, 0.01, cfg["TRAIN_TRUNCATED"])
weights_init(self.RCNN_top_2nd, 0, 0.01, cfg["TRAIN_TRUNCATED"])
weights_init(self.RCNN_top_3rd, 0, 0.01, cfg["TRAIN_TRUNCATED"])
def create_architecture(self):
self._init_modules()
self._init_weights()
def _upsample_add(self, x, y):
"""Upsample and add two feature maps.
Args:
x: (Variable) top feature map to be upsampled.
y: (Variable) lateral feature map.
Returns:
(Variable) added feature map.
Note in PyTorch, when input size is odd, the upsampled feature map
with `F.upsample(..., scale_factor=2, mode='nearest')`
maybe not equal to the lateral feature map size.
e.g.
original input size: [N,_,15,15] ->
conv2d feature map size: [N,_,8,8] ->
upsampled feature map size: [N,_,16,16]
So we choose bilinear upsample which supports arbitrary output sizes.
"""
_, _, H, W = y.size()
return F.interpolate(x, size=(H, W), mode="bilinear", align_corners=True) + y
def _PyramidRoI_Feat(self, feat_maps, rois, im_info):
"""roi pool on pyramid feature maps"""
# do roi pooling based on predicted rois
# print("rois shape",rois.shape)
# print("feat_maps",feat_maps.shape)
img_area = im_info[0][0] * im_info[0][1]
h = rois.data[:, 4] - rois.data[:, 2] + 1
w = rois.data[:, 3] - rois.data[:, 1] + 1
# print(h)
# print(w)
roi_level = torch.log2(torch.sqrt(h * w) / 224.0)
roi_level = torch.round(roi_level + 4)
roi_level[roi_level < 2] = 2
roi_level[roi_level > 5] = 5
# roi_level.fill_(5)
# print("roi_level",roi_level)
if cfg["POOLING_MODE"] == "align":
roi_pool_feats = []
box_to_levels = []
for i, l in enumerate(range(2, 6)):
# print(i, l)
# print(roi_level)
if (roi_level == l).sum() == 0:
continue
idx_l = (roi_level == l).nonzero().squeeze()
# print(idx_l.dim())
# print((idx_l.cpu().numpy()))
if idx_l.dim() == 0:
idx_l = idx_l.unsqueeze(0)
# continue
# print("^^^^^^^^^^^^^^^^^^^^^^",idx_l.dim())
box_to_levels.append(idx_l)
scale = feat_maps[i].size(2) / im_info[0][0]
# self.RCNN_roi_align.scale=scale
feat = self.RCNN_roi_align(feat_maps[i], rois[idx_l], scale)
roi_pool_feats.append(feat)
# print("box_to_levels")
# print(box_to_levels)
roi_pool_feat = torch.cat(roi_pool_feats, 0)
box_to_level = torch.cat(box_to_levels, 0)
idx_sorted, order = torch.sort(box_to_level)
roi_pool_feat = roi_pool_feat[order]
elif cfg["POOLING_MODE"] == "pool":
roi_pool_feats = []
box_to_levels = []
for i, l in enumerate(range(2, 6)):
if (roi_level == l).sum() == 0:
continue
idx_l = (roi_level == l).nonzero().squeeze()
box_to_levels.append(idx_l)
scale = feat_maps[i].size(2) / im_info[0][0]
self.RCNN_roi_pool.scale = scale
feat = self.RCNN_roi_pool(feat_maps[i], rois[idx_l])
roi_pool_feats.append(feat)
roi_pool_feat = torch.cat(roi_pool_feats, 0)
box_to_level = torch.cat(box_to_levels, 0)
idx_sorted, order = torch.sort(box_to_level)
roi_pool_feat = roi_pool_feat[order]
return roi_pool_feat
def forward(self, im_data, im_info, gt_boxes, num_boxes):
batch_size = im_data.size(0)
im_info = im_info.data
gt_boxes = gt_boxes.data
num_boxes = num_boxes.data
# feed image data to base model to obtain base feature map
# Bottom-up
c1 = self.RCNN_layer0(im_data)
c2 = self.RCNN_layer1(c1)
c3 = self.RCNN_layer2(c2)
c4 = self.RCNN_layer3(c3)
c5 = self.RCNN_layer4(c4)
# Top-down
p5 = self.RCNN_toplayer(c5)
p4 = self._upsample_add(p5, self.RCNN_latlayer1(c4))
p4 = self.RCNN_smooth1(p4)
p3 = self._upsample_add(p4, self.RCNN_latlayer2(c3))
p3 = self.RCNN_smooth2(p3)
p2 = self._upsample_add(p3, self.RCNN_latlayer3(c2))
p2 = self.RCNN_smooth3(p2)
p6 = self.maxpool2d(p5)
rpn_feature_maps = [p2, p3, p4, p5, p6]
mrcnn_feature_maps = [p2, p3, p4, p5]
rois, rpn_loss_cls, rpn_loss_bbox = self.RCNN_rpn(
rpn_feature_maps, im_info, gt_boxes, num_boxes
)
# print("rois shape stage1:",rois.shape)
# if it is training phrase, then use ground trubut bboxes for refining
if self.training:
roi_data = self.RCNN_proposal_target(rois, gt_boxes, num_boxes)
(
rois,
rois_label,
gt_assign,
rois_target,
rois_inside_ws,
rois_outside_ws,
) = roi_data
## NOTE: additionally, normalize proposals to range [0, 1],
# this is necessary so that the following roi pooling
# is correct on different feature maps
# rois[:, :, 1::2] /= im_info[0][1]
# rois[:, :, 2::2] /= im_info[0][0]
rois = rois.view(-1, 5)
rois_label = rois_label.view(-1).long()
gt_assign = gt_assign.view(-1).long()
pos_id = rois_label.nonzero().squeeze()
gt_assign_pos = gt_assign[pos_id]
rois_label_pos = rois_label[pos_id]
rois_label_pos_ids = pos_id
rois_pos = Variable(rois[pos_id])
rois = Variable(rois)
rois_label = Variable(rois_label)
rois_target = Variable(rois_target.view(-1, rois_target.size(2)))
rois_inside_ws = Variable(rois_inside_ws.view(-1, rois_inside_ws.size(2)))
rois_outside_ws = Variable(
rois_outside_ws.view(-1, rois_outside_ws.size(2))
)
else:
## NOTE: additionally, normalize proposals to range [0, 1],
# this is necessary so that the following roi pooling
# is correct on different feature maps
# rois[:, :, 1::2] /= im_info[0][1]
# rois[:, :, 2::2] /= im_info[0][0]
rois_label = None
gt_assign = None
rois_target = None
rois_inside_ws = None
rois_outside_ws = None
rpn_loss_cls = 0
rpn_loss_bbox = 0
rois = rois.view(-1, 5)
pos_id = torch.arange(0, rois.size(0)).long().type_as(rois).long()
rois_label_pos_ids = pos_id
rois_pos = Variable(rois[pos_id])
rois = Variable(rois)
roi_pool_feat = self._PyramidRoI_Feat(mrcnn_feature_maps, rois, im_info)
# feed pooled features to top model
pooled_feat = self._head_to_tail(roi_pool_feat)
bbox_pred = self.RCNN_bbox_pred(pooled_feat)
if self.training and not self.class_agnostic:
# select the corresponding columns according to roi labels
bbox_pred_view = bbox_pred.view(
bbox_pred.size(0), int(bbox_pred.size(1) / 4), 4
)
bbox_pred_select = torch.gather(
bbox_pred_view,
1,
rois_label.long()
.view(rois_label.size(0), 1, 1)
.expand(rois_label.size(0), 1, 4),
)
bbox_pred = bbox_pred_select.squeeze(1)
cls_score = self.RCNN_cls_score(pooled_feat)
cls_prob = F.softmax(cls_score, 1)
# print(cls_prob)
# print("*******************cls prob shape",cls_prob.shape)
RCNN_loss_cls = 0
RCNN_loss_bbox = 0
if self.training:
RCNN_loss_cls = F.cross_entropy(cls_score, rois_label)
# loss (l1-norm) for bounding box regression
RCNN_loss_bbox = _smooth_l1_loss(
bbox_pred, rois_target, rois_inside_ws, rois_outside_ws
)
rois = rois.view(batch_size, -1, rois.size(1))
bbox_pred = bbox_pred.view(batch_size, -1, bbox_pred.size(1))
if self.training:
rois_label = rois_label.view(batch_size, -1)
# 2nd-----------------------------
# decode
rois = bbox_decode(
rois,
bbox_pred,
batch_size,
self.class_agnostic,
self.n_classes,
im_info,
self.training,
cls_prob,
)
if self.training:
roi_data = self.RCNN_proposal_target(rois, gt_boxes, num_boxes, stage=2)
(
rois,
rois_label,
gt_assign,
rois_target,
rois_inside_ws,
rois_outside_ws,
) = roi_data
rois = rois.view(-1, 5)
rois_label = rois_label.view(-1).long()
gt_assign = gt_assign.view(-1).long()
pos_id = rois_label.nonzero().squeeze()
gt_assign_pos = gt_assign[pos_id]
rois_label_pos = rois_label[pos_id]
rois_label_pos_ids = pos_id
rois_pos = Variable(rois[pos_id])
rois = Variable(rois)
rois_label = Variable(rois_label)
rois_target = Variable(rois_target.view(-1, rois_target.size(2)))
rois_inside_ws = Variable(rois_inside_ws.view(-1, rois_inside_ws.size(2)))
rois_outside_ws = Variable(
rois_outside_ws.view(-1, rois_outside_ws.size(2))
)
else:
rois_label = None
gt_assign = None
rois_target = None
rois_inside_ws = None
rois_outside_ws = None
rpn_loss_cls = 0
rpn_loss_bbox = 0
rois = rois.view(-1, 5)
pos_id = torch.arange(0, rois.size(0)).long().type_as(rois).long()
# print(pos_id)
rois_label_pos_ids = pos_id
rois_pos = Variable(rois[pos_id])
rois = Variable(rois)
roi_pool_feat = self._PyramidRoI_Feat(mrcnn_feature_maps, rois, im_info)
# feed pooled features to top model
pooled_feat = self._head_to_tail_2nd(roi_pool_feat)
# compute bbox offset
bbox_pred = self.RCNN_bbox_pred_2nd(pooled_feat)
if self.training and not self.class_agnostic:
# select the corresponding columns according to roi labels
bbox_pred_view = bbox_pred.view(
bbox_pred.size(0), int(bbox_pred.size(1) / 4), 4
)
bbox_pred_select = torch.gather(
bbox_pred_view,
1,
rois_label.long()
.view(rois_label.size(0), 1, 1)
.expand(rois_label.size(0), 1, 4),
)
bbox_pred = bbox_pred_select.squeeze(1)
# compute object classification probability
cls_score = self.RCNN_cls_score_2nd(pooled_feat)
cls_prob_2nd = F.softmax(cls_score, 1)
RCNN_loss_cls_2nd = 0
RCNN_loss_bbox_2nd = 0
if self.training:
# loss (cross entropy) for object classification
RCNN_loss_cls_2nd = F.cross_entropy(cls_score, rois_label)
# loss (l1-norm) for bounding box regression
RCNN_loss_bbox_2nd = _smooth_l1_loss(
bbox_pred, rois_target, rois_inside_ws, rois_outside_ws
)
rois = rois.view(batch_size, -1, rois.size(1))
# cls_prob_2nd = cls_prob_2nd.view(batch_size, -1, cls_prob_2nd.size(1)) ----------------not be used ---------
bbox_pred_2nd = bbox_pred.view(batch_size, -1, bbox_pred.size(1))
if self.training:
rois_label = rois_label.view(batch_size, -1)
# 3rd---------------
# decode
rois = bbox_decode(
rois,
bbox_pred_2nd,
batch_size,
self.class_agnostic,
self.n_classes,
im_info,
self.training,
cls_prob_2nd,
)
# proposal_target
# if it is training phrase, then use ground trubut bboxes for refining
if self.training:
roi_data = self.RCNN_proposal_target(rois, gt_boxes, num_boxes, stage=3)
(
rois,
rois_label,
gt_assign,
rois_target,
rois_inside_ws,
rois_outside_ws,
) = roi_data
rois = rois.view(-1, 5)
rois_label = rois_label.view(-1).long()
gt_assign = gt_assign.view(-1).long()
pos_id = rois_label.nonzero().squeeze()
gt_assign_pos = gt_assign[pos_id]
rois_label_pos = rois_label[pos_id]
rois_label_pos_ids = pos_id
rois_pos = Variable(rois[pos_id])
rois = Variable(rois)
rois_label = Variable(rois_label)
rois_target = Variable(rois_target.view(-1, rois_target.size(2)))
rois_inside_ws = Variable(rois_inside_ws.view(-1, rois_inside_ws.size(2)))
rois_outside_ws = Variable(
rois_outside_ws.view(-1, rois_outside_ws.size(2))
)
else:
rois_label = None
gt_assign = None
rois_target = None
rois_inside_ws = None
rois_outside_ws = None
rpn_loss_cls = 0
rpn_loss_bbox = 0
rois = rois.view(-1, 5)
pos_id = torch.arange(0, rois.size(0)).long().type_as(rois).long()
rois_label_pos_ids = pos_id
rois_pos = Variable(rois[pos_id])
rois = Variable(rois)
roi_pool_feat = self._PyramidRoI_Feat(mrcnn_feature_maps, rois, im_info)
# feed pooled features to top model
pooled_feat = self._head_to_tail_3rd(roi_pool_feat)
# compute bbox offset
bbox_pred = self.RCNN_bbox_pred_3rd(pooled_feat)
if self.training and not self.class_agnostic:
# select the corresponding columns according to roi labels
bbox_pred_view = bbox_pred.view(
bbox_pred.size(0), int(bbox_pred.size(1) / 4), 4
)
bbox_pred_select = torch.gather(
bbox_pred_view,
1,
rois_label.long()
.view(rois_label.size(0), 1, 1)
.expand(rois_label.size(0), 1, 4),
)
bbox_pred = bbox_pred_select.squeeze(1)
# compute object classification probability
cls_score = self.RCNN_cls_score_3rd(pooled_feat)
cls_prob_3rd = F.softmax(cls_score, 1)
RCNN_loss_cls_3rd = 0
RCNN_loss_bbox_3rd = 0
if self.training:
# loss (cross entropy) for object classification
RCNN_loss_cls_3rd = F.cross_entropy(cls_score, rois_label)
# loss (l1-norm) for bounding box regression
RCNN_loss_bbox_3rd = _smooth_l1_loss(
bbox_pred, rois_target, rois_inside_ws, rois_outside_ws
)
rois = rois.view(batch_size, -1, rois.size(1))
cls_prob_3rd = cls_prob_3rd.view(batch_size, -1, cls_prob_3rd.size(1))
bbox_pred_3rd = bbox_pred.view(batch_size, -1, bbox_pred.size(1))
if self.training:
rois_label = rois_label.view(batch_size, -1)
if not self.training:
# 3rd_avg
# 1st_3rd
pooled_feat_1st_3rd = self._head_to_tail(roi_pool_feat)
cls_score_1st_3rd = self.RCNN_cls_score(pooled_feat_1st_3rd)
cls_prob_1st_3rd = F.softmax(cls_score_1st_3rd, 1)
cls_prob_1st_3rd = cls_prob_1st_3rd.view(
batch_size, -1, cls_prob_1st_3rd.size(1)
)
# 2nd_3rd
pooled_feat_2nd_3rd = self._head_to_tail_2nd(roi_pool_feat)
cls_score_2nd_3rd = self.RCNN_cls_score_2nd(pooled_feat_2nd_3rd)
cls_prob_2nd_3rd = F.softmax(cls_score_2nd_3rd, 1)
cls_prob_2nd_3rd = cls_prob_2nd_3rd.view(
batch_size, -1, cls_prob_2nd_3rd.size(1)
)
cls_prob_3rd_avg = (cls_prob_1st_3rd + cls_prob_2nd_3rd + cls_prob_3rd) / 3
else:
cls_prob_3rd_avg = cls_prob_3rd
return (
rois,
cls_prob_3rd_avg,
bbox_pred_3rd,
rpn_loss_cls,
rpn_loss_bbox,
RCNN_loss_cls,
RCNN_loss_bbox,
RCNN_loss_cls_2nd,
RCNN_loss_bbox_2nd,
RCNN_loss_cls_3rd,
RCNN_loss_bbox_3rd,
rois_label,
)
def conv3x3(in_planes, out_planes, stride=1):
"3x3 convolution with padding"
return nn.Conv2d(
in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False
)
# class BasicBlock(nn.Module):
# expansion = 1
# def __init__(self, inplanes, planes, stride=1, downsample=None):
# super(BasicBlock, self).__init__()
# self.conv1 = conv3x3(inplanes, planes, stride)
# self.bn1 = nn.BatchNorm2d(planes)
# self.relu = nn.ReLU(inplace=True)
# self.conv2 = conv3x3(planes, planes)
# self.bn2 = nn.BatchNorm2d(planes)
# self.downsample = downsample
# self.stride = stride
# def forward(self, x):
# residual = x
# out = self.conv1(x)
# out = self.bn1(out)
# out = self.relu(out)
# out = self.conv2(out)
# out = self.bn2(out)
# if self.downsample is not None:
# residual = self.downsample(x)
# out += residual
# out = self.relu(out)
# return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(
inplanes, planes, kernel_size=1, stride=stride, bias=False
) # change
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(
planes, planes, kernel_size=3, stride=1, padding=1, bias=False # change
)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(
kernel_size=3, stride=2, padding=0, ceil_mode=True
) # change
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2) # different
self.avgpool = nn.AvgPool2d(7)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2.0 / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(
self.inplanes,
planes * block.expansion,
kernel_size=1,
stride=stride,
bias=False,
),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def resnet50(pretrained=False):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 6, 3])
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls["resnet50"]))
return model
def resnet101(pretrained=False):
"""Constructs a ResNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 23, 3])
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls["resnet101"]))
return model
class resnet(_FPN):
def __init__(self, classes, num_layers=101, pretrained=False, class_agnostic=False):
self.dout_base_model = 256
self.pretrained = pretrained
self.class_agnostic = class_agnostic
self.num_layers = num_layers
if num_layers == 101:
self.model_path = "data/pretrained_model/resnet101.pth"
elif num_layers == 50:
self.model_path = "data/pretrained_model/resnet50.pth"
_FPN.__init__(self, classes, class_agnostic)
def _init_modules(self):
if self.num_layers == 101:
resnet = resnet101()
elif self.num_layers == 50:
resnet = resnet50()
if self.pretrained == True:
print("Loading pretrained weights from %s" % (self.model_path))
state_dict = torch.load(self.model_path)
resnet.load_state_dict(
{k: v for k, v in state_dict.items() if k in resnet.state_dict()}
)
self.RCNN_layer0 = nn.Sequential(
resnet.conv1, resnet.bn1, resnet.relu, resnet.maxpool
)
self.RCNN_layer1 = nn.Sequential(resnet.layer1)
self.RCNN_layer2 = nn.Sequential(resnet.layer2)
self.RCNN_layer3 = nn.Sequential(resnet.layer3)
self.RCNN_layer4 = nn.Sequential(resnet.layer4)
# Top layer
self.RCNN_toplayer = nn.Conv2d(
2048, 256, kernel_size=1, stride=1, padding=0
) # reduce channel
# Smooth layers
self.RCNN_smooth1 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.RCNN_smooth2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.RCNN_smooth3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
# Lateral layers
self.RCNN_latlayer1 = nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0)
self.RCNN_latlayer2 = nn.Conv2d(512, 256, kernel_size=1, stride=1, padding=0)
self.RCNN_latlayer3 = nn.Conv2d(256, 256, kernel_size=1, stride=1, padding=0)
# ROI Pool feature downsampling
self.RCNN_roi_feat_ds = nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1)
self.RCNN_top = nn.Sequential(
nn.Conv2d(
256,
1024,
kernel_size=cfg["POOLING_SIZE"],
stride=cfg["POOLING_SIZE"],
padding=0,
),
nn.ReLU(True),
nn.Conv2d(1024, 1024, kernel_size=1, stride=1, padding=0),
nn.ReLU(True),
)
self.RCNN_top_2nd = nn.Sequential(
nn.Conv2d(
256,
1024,
kernel_size=cfg["POOLING_SIZE"],
stride=cfg["POOLING_SIZE"],
padding=0,
),
nn.ReLU(True),
nn.Conv2d(1024, 1024, kernel_size=1, stride=1, padding=0),
nn.ReLU(True),
)
self.RCNN_top_3rd = nn.Sequential(
nn.Conv2d(
256,
1024,
kernel_size=cfg["POOLING_SIZE"],
stride=cfg["POOLING_SIZE"],
padding=0,
),
nn.ReLU(True),
nn.Conv2d(1024, 1024, kernel_size=1, stride=1, padding=0),
nn.ReLU(True),
)
self.RCNN_cls_score = nn.Linear(1024, self.n_classes)
if self.class_agnostic:
self.RCNN_bbox_pred = nn.Linear(1024, 4)
else:
self.RCNN_bbox_pred = nn.Linear(1024, 4 * self.n_classes)
self.RCNN_cls_score_2nd = nn.Linear(1024, self.n_classes)
if self.class_agnostic:
self.RCNN_bbox_pred_2nd = nn.Linear(1024, 4)
else:
self.RCNN_bbox_pred_2nd = nn.Linear(1024, 4 * self.n_classes)
self.RCNN_cls_score_3rd = nn.Linear(1024, self.n_classes)
if self.class_agnostic:
self.RCNN_bbox_pred_3rd = nn.Linear(1024, 4)
else:
self.RCNN_bbox_pred_3rd = nn.Linear(1024, 4 * self.n_classes)
# Fix blocks
for p in self.RCNN_layer0[0].parameters():
p.requires_grad = False
for p in self.RCNN_layer0[1].parameters():
p.requires_grad = False
if cfg["RESNET_FIXED_BLOCKS"] >= 3:
for p in self.RCNN_layer3.parameters():
p.requires_grad = False
if cfg["RESNET_FIXED_BLOCKS"] >= 2:
for p in self.RCNN_layer2.parameters():
p.requires_grad = False
if cfg["RESNET_FIXED_BLOCKS"] >= 1:
for p in self.RCNN_layer1.parameters():
p.requires_grad = False
def set_bn_fix(m):
classname = m.__class__.__name__
if classname.find("BatchNorm") != -1:
for p in m.parameters():
p.requires_grad = False
self.RCNN_layer0.apply(set_bn_fix)
self.RCNN_layer1.apply(set_bn_fix)
self.RCNN_layer2.apply(set_bn_fix)
self.RCNN_layer3.apply(set_bn_fix)
self.RCNN_layer4.apply(set_bn_fix)
def train(self, mode=True):
# Override train so that the training mode is set as we want
nn.Module.train(self, mode)
if mode:
# Set fixed blocks to be in eval mode
self.RCNN_layer0.eval()
self.RCNN_layer1.eval()
self.RCNN_layer2.train()
self.RCNN_layer3.train()
self.RCNN_layer4.train()
self.RCNN_smooth1.train()
self.RCNN_smooth2.train()
self.RCNN_smooth3.train()
self.RCNN_latlayer1.train()
self.RCNN_latlayer2.train()
self.RCNN_latlayer3.train()
self.RCNN_toplayer.train()
def set_bn_eval(m):
classname = m.__class__.__name__
if classname.find("BatchNorm") != -1:
m.eval()
self.RCNN_layer0.apply(set_bn_eval)
self.RCNN_layer1.apply(set_bn_eval)
self.RCNN_layer2.apply(set_bn_eval)
self.RCNN_layer3.apply(set_bn_eval)
self.RCNN_layer4.apply(set_bn_eval)
def _head_to_tail(self, pool5):
block5 = self.RCNN_top(pool5)
fc7 = block5.mean(3).mean(2)
return fc7
def _head_to_tail_2nd(self, pool5):
block5 = self.RCNN_top_2nd(pool5)
fc7 = block5.mean(3).mean(2)
return fc7
def _head_to_tail_3rd(self, pool5):
block5 = self.RCNN_top_3rd(pool5)
fc7 = block5.mean(3).mean(2)
return fc7
# -----------------------------------------------------------------------#
P_img_ext = ["jpg", "png"]
def file_list(path, allfile):
filelist = os.listdir(path)
for filename in filelist:
filepath = os.path.join(path, filename)
if os.path.isdir(filepath):
file_list(filepath, allfile)
else:
if filepath.split(".")[-1] in P_img_ext:
# if filepath.endswith('xml'):
# allfile.append(filepath[0:-4].strip())
allfile.append(filepath.strip())
return allfile
def im_list_to_blob(ims):
"""Convert a list of images into a network input.
Assumes images are already prepared (means subtracted, BGR order, ...).
"""
max_shape = np.array([im.shape for im in ims]).max(axis=0)
num_images = len(ims)
blob = np.zeros((num_images, max_shape[0], max_shape[1], 3), dtype=np.float32)
for i in range(num_images):
im = ims[i]
blob[i, 0 : im.shape[0], 0 : im.shape[1], :] = im
return blob
def _get_image_blob(im):
"""Converts an image into a network input.
Arguments:
im (ndarray): a color image in BGR order
Returns:
blob (ndarray): a data blob holding an image pyramid
im_scale_factors (list): list of image scales (relative to im) used
in the image pyramid
"""
im_orig = im.astype(np.float32, copy=True)
im_orig -= cfg["PIXEL_MEANS"]
im_shape = im_orig.shape
im_size_min = np.min(im_shape[0:2])
im_size_max = np.max(im_shape[0:2])
processed_ims = []
im_scale_factors = []
for target_size in cfg["TEST_SCALES"]:
im_scale = float(target_size) / float(im_size_min)
# Prevent the biggest axis from being more than MAX_SIZE
if np.round(im_scale * im_size_max) > cfg["TEST_MAX_SIZE"]:
im_scale = float(cfg["TEST_MAX_SIZE"]) / float(im_size_max)
im = cv2.resize(
im_orig,
None,
None,
fx=im_scale,
fy=im_scale,
interpolation=cv2.INTER_LINEAR,
)
im_scale_factors.append(im_scale)
processed_ims.append(im)
# Create a blob to hold the input images
blob = im_list_to_blob(processed_ims)
return blob, np.array(im_scale_factors)
def soft_nms(dets, box_scores, sigma=0.5, thresh=0.001, cuda=0):
"""
Build a pytorch implement of Soft NMS algorithm.
# Augments
dets: boxes coordinate tensor (format:[y1, x1, y2, x2])
box_scores: box score tensors
sigma: variance of Gaussian function
thresh: score thresh
cuda: CUDA flag
# Return
the index of the selected boxes
"""
# Indexes concatenate boxes with the last column
N = dets.shape[0]
if cuda:
indexes = torch.arange(0, N, dtype=torch.float).cuda().view(N, 1)
else:
indexes = torch.arange(0, N, dtype=torch.float).view(N, 1)
dets = torch.cat((dets, indexes), dim=1)
# The order of boxes coordinate is [y1,x1,y2,x2]
y1 = dets[:, 0]
x1 = dets[:, 1]
y2 = dets[:, 2]
x2 = dets[:, 3]
scores = box_scores
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
for i in range(N):
# intermediate parameters for later parameters exchange
tscore = scores[i].clone()
pos = i + 1
if i != N - 1:
maxscore, maxpos = torch.max(scores[pos:], dim=0)
if tscore < maxscore:
dets[i], dets[maxpos.item() + i + 1] = (
dets[maxpos.item() + i + 1].clone(),
dets[i].clone(),
)
scores[i], scores[maxpos.item() + i + 1] = (
scores[maxpos.item() + i + 1].clone(),
scores[i].clone(),
)
areas[i], areas[maxpos + i + 1] = (
areas[maxpos + i + 1].clone(),
areas[i].clone(),
)
# IoU calculate
yy1 = np.maximum(dets[i, 0].to("cpu").numpy(), dets[pos:, 0].to("cpu").numpy())
xx1 = np.maximum(dets[i, 1].to("cpu").numpy(), dets[pos:, 1].to("cpu").numpy())
yy2 = np.minimum(dets[i, 2].to("cpu").numpy(), dets[pos:, 2].to("cpu").numpy())
xx2 = np.minimum(dets[i, 3].to("cpu").numpy(), dets[pos:, 3].to("cpu").numpy())
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = torch.tensor(w * h).cuda() if cuda else torch.tensor(w * h)
ovr = torch.div(inter, (areas[i] + areas[pos:] - inter))
# Gaussian decay
weight = torch.exp(-(ovr * ovr) / sigma)
scores[pos:] = weight * scores[pos:]
# select the boxes and keep the corresponding indexes
keep = dets[:, 4][scores > thresh].int()
return keep
def soft_nms_old(det_proposal, detr_scores, method, thresh, Nt, sigma=0.5):
"""
the soft nms implement using python
:param dets: the pred_bboxes
:param method: the policy of decay pred_bbox score in soft nms
:param thresh: the threshold
:param Nt: Nt
:return: the index of pred_bbox after soft nms
"""
# print(det_proposal)
x1 = det_proposal[:, 0]
y1 = det_proposal[:, 1]
x2 = det_proposal[:, 2]
y2 = det_proposal[:, 3]
scores = detr_scores.squeeze(1)
areas = (y2 - y1 + 1.0) * (x2 - x1 + 1.0)
orders = scores.argsort()[::-1]
keep = []
while orders.size > 0:
i = orders[0]
keep.append(i)
for j in orders[1:]:
xx1 = np.maximum(x1[i], x1[j])
yy1 = np.maximum(y1[i], y1[j])
xx2 = np.minimum(x2[i], x2[j])
yy2 = np.minimum(y2[i], y2[j])
w = np.maximum(xx2 - xx1 + 1.0, 0.0)
h = np.maximum(yy2 - yy1 + 1.0, 0.0)
inter = w * h
overlap = inter / (areas[i] + areas[j] - inter)
if method == 1: # linear
if overlap > Nt:
weight = 1 - overlap
else:
weight = 1
elif method == 2: # gaussian
weight = np.exp(-(overlap * overlap) / sigma)
else: # original NMS
if overlap > Nt:
weight = 0
else:
weight = 1
# print('weight:', weight)
scores[j] = weight * scores[j]
# print('scores[j]:', scores[j])
# print('thresh:', thresh)
if scores[j] < thresh:
orders = np.delete(orders, np.where(orders == j))
orders = np.delete(orders, 0)
return keep
def vis_detections(im, class_name, dets, thresh=0.0):
"""Visual debugging of detections."""
for i in range(dets.shape[0]):
bbox = tuple(int(np.round(x)) for x in dets[i, :4])
score = dets[i, -1]
if score > thresh:
cv2.rectangle(im, bbox[0:2], bbox[2:4], (0, 204, 0), 4)
cv2.putText(
im,
"%s: %.3f" % (class_name, score),
(bbox[0], bbox[1] + 15),
cv2.FONT_HERSHEY_PLAIN,
2.0,
(0, 0, 255),
thickness=2,
)
return im
if __name__ == "__main__":
# params
num_layers = 50
num_session = 1
num_epoch = 72
checkpoint = 1686
thresh_score_final = 0.05
thresh_score_final_soft_nms = 0.5
model_dir = os.path.join("models", "res" + str(num_layers), "pascal_voc")
data_dir = "../input/global-wheat-detection/test"
Flag_vis = True
# model name
load_name = os.path.join(
"../input/mymodels",
"cascade_fpn_{}_{}_{}.pth".format(num_session, num_epoch, checkpoint),
)
# load_name = 'cascade_fpn_{}_{}_{}.pth'.format(num_session, num_epoch, checkpoint)
# Network
FPN = resnet(classes, num_layers, pretrained=False, class_agnostic=False)
FPN.create_architecture()
# load model
checkpoint = torch.load(load_name)
FPN.load_state_dict(checkpoint["model"])
# set mode
FPN.cuda()
FPN.eval()
print("load checkpoin---->", load_name)
# get test images
imgs_list = []
file_list(data_dir, imgs_list)
# commit submission
submission = []
for idx, img in enumerate(imgs_list):
str_print = "total:{}--currnet:{}--img:{}".format(
len(imgs_list), idx, os.path.basename(img)
)
print(img)
# load an image
im = cv2.imread(img)
if Flag_vis:
img_show = im.copy()
prediction_string = []
# prepare im for forward
im = im[:, :, ::-1] # BGR--->RGB
blobs, im_scales = _get_image_blob(im)
im_blob = blobs
im_info_np = np.array(
[[im_blob.shape[1], im_blob.shape[2], im_scales[0]]], dtype=np.float32
)
im_data_pt = torch.from_numpy(im_blob) # numpy to tensor
im_data_pt = im_data_pt.permute(0, 3, 1, 2) # NHWC --> NCHW
im_info_pt = torch.from_numpy(im_info_np) # numpy to tensor
with torch.no_grad():
im_data = im_data_pt.cuda()
im_info = im_info_pt.cuda()
num_boxes = torch.zeros((1), dtype=torch.int64).cuda()
gt_boxes = torch.zeros((1, 1, 5), dtype=torch.float32).cuda()
# forward
(
rois,
cls_prob,
bbox_pred,
rpn_loss_cls,
rpn_loss_box,
RCNN_loss_cls,
RCNN_loss_bbox,
RCNN_loss_cls_2nd,
RCNN_loss_bbox_2nd,
RCNN_loss_cls_3rd,
RCNN_loss_bbox_3rd,
roi_labels,
) = FPN(im_data, im_info, gt_boxes, num_boxes)
# parse result
scores = cls_prob.data
boxes = rois.data[:, :, 1:5]
# box transform
class_agnostic = False
args_cuda = True
if cfg["TEST_BBOX_REG"]:
# Apply bounding-box regression deltas
box_deltas = bbox_pred.data
if cfg["TRAIN_BBOX_NORMALIZE_TARGETS_PRECOMPUTED"]:
# Optionally normalize targets by a precomputed mean and stdev
if class_agnostic:
if args_cuda > 0:
box_deltas = (
box_deltas.view(-1, 4)
* torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_STDS"]).cuda()
+ torch.FloatTensor(
cfg["TRAIN_BBOX_NORMALIZE_MEANS"]
).cuda()
)
else:
box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(
cfg["TRAIN_BBOX_NORMALIZE_STDS"]
) + torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_MEANS"])
box_deltas = box_deltas.view(1, -1, 4)
else:
if args_cuda > 0:
box_deltas = (
box_deltas.view(-1, 4)
* torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_STDS"]).cuda()
+ torch.FloatTensor(
cfg["TRAIN_BBOX_NORMALIZE_MEANS"]
).cuda()
)
else:
box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(
cfg["TRAIN_BBOX_NORMALIZE_STDS"]
) + torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_MEANS"])
box_deltas = box_deltas.view(1, -1, 4 * len(pascal_classes))
pred_boxes = bbox_transform_inv(boxes, box_deltas, 1)
pred_boxes = clip_boxes(pred_boxes, im_info.data, 1)
else:
# Simply repeat the boxes, once for each class
pred_boxes = np.tile(boxes, (1, scores.shape[1]))
pred_boxes /= im_scales[0]
scores = scores.squeeze()
pred_boxes = pred_boxes.squeeze()
# filter boxes
for j in range(1, len(pascal_classes)):
inds = torch.nonzero(scores[:, j] > thresh_score_final).view(-1)
# if there is det
if inds.numel() == 0:
prediction_string.append("")
else:
cls_scores = scores[:, j][inds]
_, order = torch.sort(cls_scores, 0, True)
if class_agnostic:
cls_boxes = pred_boxes[inds, :]
else:
cls_boxes = pred_boxes[inds][:, j * 4 : (j + 1) * 4]
cls_dets = torch.cat((cls_boxes, cls_scores.unsqueeze(1)), 1)
cls_dets = cls_dets[order]
keep = soft_nms(
cls_boxes[order, :],
cls_scores[order],
thresh=thresh_score_final_soft_nms,
cuda=1,
)
cls_dets = cls_dets[keep.view(-1).long()]
det_final = cls_dets.cpu().numpy()
if det_final.shape[0] == 0:
prediction_string.append("")
else:
for i in range(det_final.shape[0]):
bbox = tuple(int(np.round(x)) for x in det_final[i, :4])
score = det_final[i, -1]
x = int(bbox[0])
y = int(bbox[1])
w = int(bbox[2] - bbox[0])
h = int(bbox[3] - bbox[1])
s = float(score)
prediction_string.append("{} {} {} {} {}".format(s, x, y, w, h))
if Flag_vis:
im2show = vis_detections(img_show, pascal_classes[j], det_final)
img_name_save = os.path.basename(img)[:-4]
prediction_string = " ".join(prediction_string)
submission.append([img_name_save, prediction_string])
# if Flag_vis:
# result_path = os.path.join("results_vis", os.path.basename(img)) # chagne here
# cv2.imwrite(result_path, im2show)
sample_submission = pd.DataFrame(
submission, columns=["image_id", "PredictionString"]
)
sample_submission.to_csv("submission.csv", index=False)
print("\n----------------------END----------------------")
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0035/433/35433526.ipynb | resnet50 | null | [{"Id": 35433526, "ScriptId": 9682236, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5079964, "CreationDate": "06/04/2020 09:01:41", "VersionNumber": 13.0, "Title": "kernel54beb4b767", "EvaluationDate": "06/04/2020", "IsChange": true, "TotalLines": 2092.0, "LinesInsertedFromPrevious": 1.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 2091.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 39328011, "KernelVersionId": 35433526, "SourceDatasetVersionId": 10040}] | [{"Id": 10040, "DatasetId": 6979, "DatasourceVersionId": 10040, "CreatorUserId": 484516, "LicenseName": "CC0: Public Domain", "CreationDate": "12/13/2017 20:46:19", "VersionNumber": 1.0, "Title": "ResNet-50", "Slug": "resnet50", "Subtitle": "ResNet-50 Pre-trained Model for PyTorch", "Description": "# ResNet-50\n\n---\n\n## Deep Residual Learning for Image Recognition\nDeeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously. We explicitly reformulate the layers as learning residual functions with reference to the layer inputs, instead of learning unreferenced functions. We provide comprehensive empirical evidence showing that these residual networks are easier to optimize, and can gain accuracy from considerably increased depth. On the ImageNet dataset we evaluate residual nets with a depth of up to 152 layers---8x deeper than VGG nets but still having lower complexity. \n\nAn ensemble of these residual nets achieves 3.57% error on the ImageNet test set. This result won the 1st place on the ILSVRC 2015 classification task. We also present analysis on CIFAR-10 with 100 and 1000 layers. \n\nThe depth of representations is of central importance for many visual recognition tasks. Solely due to our extremely deep representations, we obtain a 28% relative improvement on the COCO object detection dataset. Deep residual nets are foundations of our submissions to ILSVRC & COCO 2015 competitions, where we also won the 1st places on the tasks of ImageNet detection, ImageNet localization, COCO detection, and COCO segmentation.<br>\n\n**Authors: Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun**<br>\n**https://arxiv.org/abs/1512.03385**\n\n---\n\n\nArchitecture visualization: http://ethereon.github.io/netscope/#/gist/db945b393d40bfa26006\n\n![Resnet][1]\n\n---\n\n### What is a Pre-trained Model?\nA pre-trained model has been previously trained on a dataset and contains the weights and biases that represent the features of whichever dataset it was trained on. Learned features are often transferable to different data. For example, a model trained on a large dataset of bird images will contain learned features like edges or horizontal lines that you would be transferable your dataset. \n\n### Why use a Pre-trained Model?\nPre-trained models are beneficial to us for many reasons. By using a pre-trained model you are saving time. Someone else has already spent the time and compute resources to learn a lot of features and your model will likely benefit from it. \n\n\n [1]: https://imgur.com/nyYh5xH.jpg", "VersionNotes": "Initial release", "TotalCompressedBytes": 95165345.0, "TotalUncompressedBytes": 95165345.0}] | [{"Id": 6979, "CreatorUserId": 484516, "OwnerUserId": NaN, "OwnerOrganizationId": 1212.0, "CurrentDatasetVersionId": 10040.0, "CurrentDatasourceVersionId": 10040.0, "ForumId": 13659, "Type": 2, "CreationDate": "12/13/2017 20:46:19", "LastActivityDate": "01/12/2018", "TotalViews": 19757, "TotalDownloads": 1912, "TotalVotes": 55, "TotalKernels": 141}] | null | # #------------------code for training------------------
#!pip install easydict
#!cp -r ../input/cascadercnn .
# cd cascadercnn/lib
#!python setup.py build develop
# cd ..
#!ls .
# #lr = 0.00125 for one card and one image per batch
#!python train_cascade_fpn.py --dataset pascal_voc --net res50 --epoch 30 --lr_decay_step 9 --disp_interval 1 --bs 6 --nw 16 --lr 0.001 --lr_decay_step 8 --cuda --mGPUs
#!rm -rf ../cascadercnn
# #------------------code for testing------------------
import cv2
import math
import os
import numpy as np
import pandas as pd
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
import torch
import torchvision
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Function
from torch.autograd.function import once_differentiable
from torch.nn.modules.utils import _pair
from torch.nn.functional import avg_pool2d
from torch.autograd import Variable
classes = np.asarray(["__background__", "wheat"])
pascal_classes = ["__background__", "wheat"]
categoryList = {"bg": 0, "wheat": 1}
cfg = {
"ANCHOR_RATIOS": [0.5, 1, 2],
"ANCHOR_SCALES": [4, 8, 16, 32],
"FEAT_STRIDE": [
16,
],
"POOLING_SIZE": 7,
"TRAIN_TRUNCATED": False,
"POOLING_MODE": "align",
"CROP_RESIZE_WITH_MAX_POOL": False,
"FPN_ANCHOR_SCALES": [32, 64, 128, 256, 512],
"FPN_FEAT_STRIDES": [4, 8, 16, 32, 64],
"FPN_ANCHOR_STRIDE": 1,
"RPN_PRE_NMS_TOP_N": 6000,
"RPN_POST_NMS_TOP_N": 300,
"RPN_NMS_THRESH": 0.7,
"RPN_MIN_SIZE": 16,
"TRAIN_RPN_NEGATIVE_OVERLAP": 0.3,
"TRAIN_RPN_POSITIVE_OVERLAP": 0.7,
"TRAIN_RPN_FG_FRACTION": 0.5,
"TRAIN_RPN_BATCHSIZE": 256,
"TRAIN_RPN_BBOX_INSIDE_WEIGHTS": (1.0, 1.0, 1.0, 1.0),
"TRAIN_RPN_POSITIVE_WEIGHT": -1.0,
"TRAIN_FG_THRESH": 0.5,
"TRAIN_BG_THRESH_HI": 0.5,
"TRAIN_BG_THRESH_LO": 0.1,
"TRAIN_FG_THRESH_2ND": 0.6,
"TRAIN_FG_THRESH_3RD": 0.7,
"TRAIN_BBOX_NORMALIZE_TARGETS_PRECOMPUTED": True,
"TRAIN_BATCH_SIZE": 128,
"TRAIN_FG_FRACTION": 0.25,
"TRAIN_BBOX_NORMALIZE_MEANS": (0.0, 0.0, 0.0, 0.0),
"TRAIN_BBOX_NORMALIZE_STDS": (0.1, 0.1, 0.2, 0.2),
"TRAIN_BBOX_INSIDE_WEIGHTS": (1.0, 1.0, 1.0, 1.0),
"RESNET_FIXED_BLOCKS": 1,
#'PIXEL_MEANS': np.array([[[0.485, 0.456, 0.406]]]),
"PIXEL_MEANS": np.array([[[122.7717, 115.9465, 102.9801]]]), # RGB
#'PIXEL_MEANS': np.array([[[102.9801, 115.9465, 122.7717]]]), # BGR
"TEST_SCALES": (1024,),
"TEST_MAX_SIZE": 1024,
"TEST_BBOX_REG": True,
}
# --------------------------------------------------#
def clip_boxes(boxes, im_shape, batch_size):
for i in range(batch_size):
boxes[i, :, 0::4].clamp_(0, im_shape[i, 1] - 1)
boxes[i, :, 1::4].clamp_(0, im_shape[i, 0] - 1)
boxes[i, :, 2::4].clamp_(0, im_shape[i, 1] - 1)
boxes[i, :, 3::4].clamp_(0, im_shape[i, 0] - 1)
return boxes
def bbox_transform_inv(boxes, deltas, batch_size):
# print(" bbox_transform_inv ")
# print("bbox shape:",boxes.shape)
# print("deltas shape:",deltas.shape)
widths = boxes[:, :, 2] - boxes[:, :, 0] + 1.0
heights = boxes[:, :, 3] - boxes[:, :, 1] + 1.0
ctr_x = boxes[:, :, 0] + 0.5 * widths
ctr_y = boxes[:, :, 1] + 0.5 * heights
dx = deltas[:, :, 0::4]
dy = deltas[:, :, 1::4]
dw = deltas[:, :, 2::4]
dh = deltas[:, :, 3::4]
# print(dx.shape)
pred_ctr_x = dx * widths.unsqueeze(2) + ctr_x.unsqueeze(2)
pred_ctr_y = dy * heights.unsqueeze(2) + ctr_y.unsqueeze(2)
pred_w = torch.exp(dw) * widths.unsqueeze(2)
pred_h = torch.exp(dh) * heights.unsqueeze(2)
pred_boxes = deltas.clone()
# x1
pred_boxes[:, :, 0::4] = pred_ctr_x - 0.5 * pred_w
# y1
pred_boxes[:, :, 1::4] = pred_ctr_y - 0.5 * pred_h
# x2
pred_boxes[:, :, 2::4] = pred_ctr_x + 0.5 * pred_w
# y2
pred_boxes[:, :, 3::4] = pred_ctr_y + 0.5 * pred_h
return pred_boxes
def generate_anchors_single_pyramid(
scales, ratios, shape, feature_stride, anchor_stride
):
"""
scales: 1D array of anchor sizes in pixels. Example: [32, 64, 128]
ratios: 1D array of anchor ratios of width/height. Example: [0.5, 1, 2]
shape: [height, width] spatial shape of the feature map over which
to generate anchors.
feature_stride: Stride of the feature map relative to the image in pixels.
anchor_stride: Stride of anchors on the feature map. For example, if the
value is 2 then generate anchors for every other feature map pixel.
"""
# Get all combinations of scales and ratios
scales, ratios = np.meshgrid(np.array(scales), np.array(ratios))
scales = scales.flatten()
ratios = ratios.flatten()
# Enumerate heights and widths from scales and ratios
heights = scales / np.sqrt(ratios)
widths = scales * np.sqrt(ratios)
# Enumerate shifts in feature space
shifts_y = np.arange(0, shape[0], anchor_stride) * feature_stride
shifts_x = np.arange(0, shape[1], anchor_stride) * feature_stride
shifts_x, shifts_y = np.meshgrid(shifts_x, shifts_y)
# Enumerate combinations of shifts, widths, and heights
box_widths, box_centers_x = np.meshgrid(widths, shifts_x)
box_heights, box_centers_y = np.meshgrid(heights, shifts_y)
# # Reshape to get a list of (y, x) and a list of (h, w)
# box_centers = np.stack(
# [box_centers_y, box_centers_x], axis=2).reshape([-1, 2])
# box_sizes = np.stack([box_heights, box_widths], axis=2).reshape([-1, 2])
# NOTE: the original order is (y, x), we changed it to (x, y) for our code
# Reshape to get a list of (x, y) and a list of (w, h)
box_centers = np.stack([box_centers_x, box_centers_y], axis=2).reshape([-1, 2])
box_sizes = np.stack([box_widths, box_heights], axis=2).reshape([-1, 2])
# Convert to corner coordinates (x1, y1, x2, y2)
boxes = np.concatenate(
[box_centers - 0.5 * box_sizes, box_centers + 0.5 * box_sizes], axis=1
)
# print(boxes)
return boxes
def generate_anchors_all_pyramids(
scales, ratios, feature_shapes, feature_strides, anchor_stride
):
"""Generate anchors at different levels of a feature pyramid. Each scale
is associated with a level of the pyramid, but each ratio is used in
all levels of the pyramid.
Returns:
anchors: [N, (y1, x1, y2, x2)]. All generated anchors in one array. Sorted
with the same order of the given scales. So, anchors of scale[0] come
first, then anchors of scale[1], and so on.
"""
# Anchors
# [anchor_count, (y1, x1, y2, x2)]
anchors = []
for i in range(len(scales)):
anchors.append(
generate_anchors_single_pyramid(
scales[i], ratios, feature_shapes[i], feature_strides[i], anchor_stride
)
)
return np.concatenate(anchors, axis=0)
class _ProposalTargetLayer(nn.Module):
"""
Assign object detection proposals to ground-truth targets. Produces proposal
classification labels and bounding-box regression targets.
"""
def __init__(self, nclasses):
super(_ProposalTargetLayer, self).__init__()
self._num_classes = nclasses
self.BBOX_NORMALIZE_MEANS = torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_MEANS"])
self.BBOX_NORMALIZE_STDS = torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_STDS"])
self.BBOX_INSIDE_WEIGHTS = torch.FloatTensor(cfg["TRAIN_BBOX_INSIDE_WEIGHTS"])
def forward(self, all_rois, gt_boxes, num_boxes, stage=1):
self.BBOX_NORMALIZE_MEANS = self.BBOX_NORMALIZE_MEANS.type_as(gt_boxes)
self.BBOX_NORMALIZE_STDS = self.BBOX_NORMALIZE_STDS.type_as(gt_boxes)
self.BBOX_INSIDE_WEIGHTS = self.BBOX_INSIDE_WEIGHTS.type_as(gt_boxes)
gt_boxes_append = gt_boxes.new(gt_boxes.size()).zero_()
gt_boxes_append[:, :, 1:5] = gt_boxes[:, :, :4]
# Include ground-truth boxes in the set of candidate rois
all_rois = torch.cat([all_rois, gt_boxes_append], 1)
num_images = 1
rois_per_image = int(cfg["TRAIN_BATCH_SIZE"] / num_images)
fg_rois_per_image = int(np.round(cfg["TRAIN_FG_FRACTION"] * rois_per_image))
fg_rois_per_image = 1 if fg_rois_per_image == 0 else fg_rois_per_image
(
labels,
rois,
gt_assign,
bbox_targets,
bbox_inside_weights,
) = self._sample_rois_pytorch(
all_rois,
gt_boxes,
fg_rois_per_image,
rois_per_image,
self._num_classes,
stage=stage,
)
bbox_outside_weights = (bbox_inside_weights > 0).float()
return (
rois,
labels,
gt_assign,
bbox_targets,
bbox_inside_weights,
bbox_outside_weights,
)
def backward(self, top, propagate_down, bottom):
"""This layer does not propagate gradients."""
pass
def reshape(self, bottom, top):
"""Reshaping happens during the call to forward."""
pass
def _get_bbox_regression_labels_pytorch(
self, bbox_target_data, labels_batch, num_classes
):
"""Bounding-box regression targets (bbox_target_data) are stored in a
compact form b x N x (class, tx, ty, tw, th)
This function expands those targets into the 4-of-4*K representation used
by the network (i.e. only one class has non-zero targets).
Returns:
bbox_target (ndarray): b x N x 4K blob of regression targets
bbox_inside_weights (ndarray): b x N x 4K blob of loss weights
"""
batch_size = labels_batch.size(0)
rois_per_image = labels_batch.size(1)
clss = labels_batch
bbox_targets = bbox_target_data.new(batch_size, rois_per_image, 4).zero_()
bbox_inside_weights = bbox_target_data.new(bbox_targets.size()).zero_()
for b in range(batch_size):
# assert clss[b].sum() > 0
if clss[b].sum() == 0:
continue
inds = torch.nonzero(clss[b] > 0).view(-1)
for i in range(inds.numel()):
ind = inds[i]
bbox_targets[b, ind, :] = bbox_target_data[b, ind, :]
bbox_inside_weights[b, ind, :] = self.BBOX_INSIDE_WEIGHTS
return bbox_targets, bbox_inside_weights
def _compute_targets_pytorch(self, ex_rois, gt_rois):
"""Compute bounding-box regression targets for an image."""
assert ex_rois.size(1) == gt_rois.size(1)
assert ex_rois.size(2) == 4
assert gt_rois.size(2) == 4
batch_size = ex_rois.size(0)
rois_per_image = ex_rois.size(1)
targets = bbox_transform_batch(ex_rois, gt_rois)
if cfg["TRAIN_BBOX_NORMALIZE_TARGETS_PRECOMPUTED"]:
# Optionally normalize targets by a precomputed mean and stdev
targets = (
targets - self.BBOX_NORMALIZE_MEANS.expand_as(targets)
) / self.BBOX_NORMALIZE_STDS.expand_as(targets)
return targets
def _sample_rois_pytorch(
self,
all_rois,
gt_boxes,
fg_rois_per_image,
rois_per_image,
num_classes,
stage=1,
):
"""Generate a random sample of RoIs comprising foreground and background
examples.
"""
# overlaps: (rois x gt_boxes)
overlaps = bbox_overlaps_batch(all_rois, gt_boxes)
max_overlaps, gt_assignment = torch.max(overlaps, 2)
batch_size = overlaps.size(0)
num_proposal = overlaps.size(1)
num_boxes_per_img = overlaps.size(2)
offset = torch.arange(0, batch_size) * gt_boxes.size(1)
offset = offset.view(-1, 1).type_as(gt_assignment) + gt_assignment
labels = (
gt_boxes[:, :, 4]
.contiguous()
.view(-1)[(offset.view(-1),)]
.view(batch_size, -1)
)
labels_batch = labels.new(batch_size, rois_per_image).zero_()
rois_batch = all_rois.new(batch_size, rois_per_image, 5).zero_()
gt_assign_batch = all_rois.new(batch_size, rois_per_image).zero_()
gt_rois_batch = all_rois.new(batch_size, rois_per_image, 5).zero_()
# Guard against the case when an image has fewer than max_fg_rois_per_image
# foreground RoIs
if stage == 1:
fg_thresh = cfg["TRAIN_FG_THRESH"]
bg_thresh_hi = cfg["TRAIN_BG_THRESH_HI"]
bg_thresh_lo = cfg["TRAIN_BG_THRESH_LO"]
elif stage == 2:
fg_thresh = cfg["TRAIN_FG_THRESH_2ND"]
bg_thresh_hi = cfg["TRAIN_FG_THRESH_2ND"]
bg_thresh_lo = cfg["TRAIN_BG_THRESH_LO"]
elif stage == 3:
fg_thresh = cfg["TRAIN_FG_THRESH_3RD"]
bg_thresh_hi = cfg["TRAIN_FG_THRESH_3RD"]
bg_thresh_lo = cfg["TRAIN_BG_THRESH_LO"]
else:
raise RuntimeError("stage must be in [1, 2, 3]")
for i in range(batch_size):
fg_inds = torch.nonzero(max_overlaps[i] >= fg_thresh).view(-1)
fg_num_rois = fg_inds.numel()
# Select background RoIs as those within [BG_THRESH_LO, BG_THRESH_HI)
bg_inds = torch.nonzero(
(max_overlaps[i] < bg_thresh_hi) & (max_overlaps[i] >= bg_thresh_lo)
).view(-1)
bg_num_rois = bg_inds.numel()
if fg_num_rois > 0 and bg_num_rois > 0:
# sampling fg
fg_rois_per_this_image = min(fg_rois_per_image, fg_num_rois)
# torch.randperm seems has a bug on multi-gpu setting that cause the segfault.
# See https://github.com/pytorch/pytorch/issues/1868 for more details.
# use numpy instead.
# rand_num = torch.randperm(fg_num_rois).long().cuda()
rand_num = (
torch.from_numpy(np.random.permutation(fg_num_rois))
.type_as(gt_boxes)
.long()
)
fg_inds = fg_inds[rand_num[:fg_rois_per_this_image]]
# sampling bg
bg_rois_per_this_image = rois_per_image - fg_rois_per_this_image
# Seems torch.rand has a bug, it will generate very large number and make an error.
# We use numpy rand instead.
# rand_num = (torch.rand(bg_rois_per_this_image) * bg_num_rois).long().cuda()
rand_num = np.floor(
np.random.rand(bg_rois_per_this_image) * bg_num_rois
)
rand_num = torch.from_numpy(rand_num).type_as(gt_boxes).long()
bg_inds = bg_inds[rand_num]
elif fg_num_rois > 0 and bg_num_rois == 0:
# sampling fg
# rand_num = torch.floor(torch.rand(rois_per_image) * fg_num_rois).long().cuda()
rand_num = np.floor(np.random.rand(rois_per_image) * fg_num_rois)
rand_num = torch.from_numpy(rand_num).type_as(gt_boxes).long()
fg_inds = fg_inds[rand_num]
fg_rois_per_this_image = rois_per_image
bg_rois_per_this_image = 0
elif bg_num_rois > 0 and fg_num_rois == 0:
# sampling bg
# rand_num = torch.floor(torch.rand(rois_per_image) * bg_num_rois).long().cuda()
rand_num = np.floor(np.random.rand(rois_per_image) * bg_num_rois)
rand_num = torch.from_numpy(rand_num).type_as(gt_boxes).long()
bg_inds = bg_inds[rand_num]
bg_rois_per_this_image = rois_per_image
fg_rois_per_this_image = 0
else:
print(i, overlaps[i], max_overlaps[i], gt_boxes[i])
raise ValueError(
"bg_num_rois = 0 and fg_num_rois = 0, this should not happen!"
)
# The indices that we're selecting (both fg and bg)
keep_inds = torch.cat([fg_inds, bg_inds], 0)
# Select sampled values from various arrays:
labels_batch[i].copy_(labels[i][keep_inds])
# Clamp labels for the background RoIs to 0
if fg_rois_per_this_image < rois_per_image:
labels_batch[i][fg_rois_per_this_image:] = 0
rois_batch[i] = all_rois[i][keep_inds]
rois_batch[i, :, 0] = i
# TODO: check the below line when batch_size > 1, no need to add offset here
gt_assign_batch[i] = gt_assignment[i][keep_inds]
gt_rois_batch[i] = gt_boxes[i][gt_assignment[i][keep_inds]]
bbox_target_data = self._compute_targets_pytorch(
rois_batch[:, :, 1:5], gt_rois_batch[:, :, :4]
)
bbox_targets, bbox_inside_weights = self._get_bbox_regression_labels_pytorch(
bbox_target_data, labels_batch, num_classes
)
return (
labels_batch,
rois_batch,
gt_assign_batch,
bbox_targets,
bbox_inside_weights,
)
class _AnchorTargetLayer_FPN(nn.Module):
"""
Assign anchors to ground-truth targets. Produces anchor classification
labels and bounding-box regression targets.
"""
def __init__(self, feat_stride, scales, ratios):
super(_AnchorTargetLayer_FPN, self).__init__()
self._anchor_ratios = ratios
self._feat_stride = feat_stride
self._fpn_scales = np.array(cfg["FPN_ANCHOR_SCALES"])
self._fpn_feature_strides = np.array(cfg["FPN_FEAT_STRIDES"])
self._fpn_anchor_stride = cfg["FPN_ANCHOR_STRIDE"]
# allow boxes to sit over the edge by a small amount
self._allowed_border = 0 # default is 0
def forward(self, input):
# Algorithm:
#
# for each (H, W) location i
# generate 9 anchor boxes centered on cell i
# apply predicted bbox deltas at cell i to each of the 9 anchors
# filter out-of-image anchors
#
scores = input[0]
gt_boxes = input[1]
im_info = input[2]
num_boxes = input[3]
feat_shapes = input[4]
# NOTE: need to change
# height, width = scores.size(2), scores.size(3)
height, width = 0, 0
batch_size = gt_boxes.size(0)
anchors = torch.from_numpy(
generate_anchors_all_pyramids(
self._fpn_scales,
self._anchor_ratios,
feat_shapes,
self._fpn_feature_strides,
self._fpn_anchor_stride,
)
).type_as(scores)
total_anchors = anchors.size(0)
# print(self._fpn_feature_strides)
# print(anchors.shape)
keep = (
(anchors[:, 0] >= -self._allowed_border)
& (anchors[:, 1] >= -self._allowed_border)
& (anchors[:, 2] < long(im_info[0][1]) + self._allowed_border)
& (anchors[:, 3] < long(im_info[0][0]) + self._allowed_border)
)
inds_inside = torch.nonzero(keep).view(-1)
# keep only inside anchors
anchors = anchors[inds_inside, :]
# label: 1 is positive, 0 is negative, -1 is dont care
labels = gt_boxes.new(batch_size, inds_inside.size(0)).fill_(-1)
bbox_inside_weights = gt_boxes.new(batch_size, inds_inside.size(0)).zero_()
bbox_outside_weights = gt_boxes.new(batch_size, inds_inside.size(0)).zero_()
overlaps = bbox_overlaps_batch(anchors, gt_boxes)
max_overlaps, argmax_overlaps = torch.max(overlaps, 2)
gt_max_overlaps, _ = torch.max(overlaps, 1)
labels[max_overlaps < cfg["TRAIN_RPN_NEGATIVE_OVERLAP"]] = 0
gt_max_overlaps[gt_max_overlaps == 0] = 1e-5
keep = torch.sum(
overlaps.eq(gt_max_overlaps.view(batch_size, 1, -1).expand_as(overlaps)), 2
)
if torch.sum(keep) > 0:
labels[keep > 0] = 1
# fg label: above threshold IOU
labels[max_overlaps >= cfg["TRAIN_RPN_POSITIVE_OVERLAP"]] = 1
num_fg = int(cfg["TRAIN_RPN_FG_FRACTION"] * cfg["TRAIN_RPN_BATCHSIZE"])
sum_fg = torch.sum((labels == 1).int(), 1)
sum_bg = torch.sum((labels == 0).int(), 1)
for i in range(batch_size):
# subsample positive labels if we have too many
if sum_fg[i] > num_fg:
fg_inds = torch.nonzero(labels[i] == 1).view(-1)
# torch.randperm seems has a bug on multi-gpu setting that cause the segfault.
# See https://github.com/pytorch/pytorch/issues/1868 for more details.
# use numpy instead.
# rand_num = torch.randperm(fg_inds.size(0)).type_as(gt_boxes).long()
rand_num = (
torch.from_numpy(np.random.permutation(fg_inds.size(0)))
.type_as(gt_boxes)
.long()
)
disable_inds = fg_inds[rand_num[: fg_inds.size(0) - num_fg]]
labels[i][disable_inds] = -1
num_bg = cfg["TRAIN_RPN_BATCHSIZE"] - sum_fg[i]
# subsample negative labels if we have too many
if sum_bg[i] > num_bg:
bg_inds = torch.nonzero(labels[i] == 0).view(-1)
# rand_num = torch.randperm(bg_inds.size(0)).type_as(gt_boxes).long()
rand_num = (
torch.from_numpy(np.random.permutation(bg_inds.size(0)))
.type_as(gt_boxes)
.long()
)
disable_inds = bg_inds[rand_num[: bg_inds.size(0) - num_bg]]
labels[i][disable_inds] = -1
offset = torch.arange(0, batch_size) * gt_boxes.size(1)
argmax_overlaps = argmax_overlaps + offset.view(batch_size, 1).type_as(
argmax_overlaps
)
bbox_targets = _compute_targets_batch(
anchors,
gt_boxes.view(-1, 5)[argmax_overlaps.view(-1), :].view(batch_size, -1, 5),
)
# use a single value instead of 4 values for easy index.
bbox_inside_weights[labels == 1] = cfg["TRAIN_RPN_BBOX_INSIDE_WEIGHTS"][0]
if cfg["TRAIN_RPN_POSITIVE_WEIGHT"] < 0:
num_examples = torch.sum(labels[i] >= 0)
positive_weights = 1.0 / num_examples.item()
negative_weights = 1.0 / num_examples.item()
else:
assert (cfg["TRAIN_RPN_POSITIVE_WEIGHT"] > 0) & (
cfg["TRAIN_RPN_POSITIVE_WEIGHT"] < 1
)
bbox_outside_weights[labels == 1] = positive_weights
bbox_outside_weights[labels == 0] = negative_weights
labels = _unmap(labels, total_anchors, inds_inside, batch_size, fill=-1)
bbox_targets = _unmap(
bbox_targets, total_anchors, inds_inside, batch_size, fill=0
)
bbox_inside_weights = _unmap(
bbox_inside_weights, total_anchors, inds_inside, batch_size, fill=0
)
bbox_outside_weights = _unmap(
bbox_outside_weights, total_anchors, inds_inside, batch_size, fill=0
)
outputs = []
# labels = labels.view(batch_size, height, width, A).permute(0,3,1,2).contiguous()
# labels = labels.view(batch_size, 1, A * height, width)
outputs.append(labels)
# bbox_targets = bbox_targets.view(batch_size, height, width, A*4).permute(0,3,1,2).contiguous()
outputs.append(bbox_targets)
# anchors_count = bbox_inside_weights.size(1)
# bbox_inside_weights = bbox_inside_weights.view(batch_size,anchors_count,1).expand(batch_size, anchors_count, 4)
# bbox_inside_weights = bbox_inside_weights.contiguous().view(batch_size, height, width, 4*A)\
# .permute(0,3,1,2).contiguous()
outputs.append(bbox_inside_weights)
# bbox_outside_weights = bbox_outside_weights.view(batch_size,anchors_count,1).expand(batch_size, anchors_count, 4)
# bbox_outside_weights = bbox_outside_weights.contiguous().view(batch_size, height, width, 4*A)\
# .permute(0,3,1,2).contiguous()
outputs.append(bbox_outside_weights)
return outputs
def backward(self, top, propagate_down, bottom):
"""This layer does not propagate gradients."""
pass
def reshape(self, bottom, top):
"""Reshaping happens during the call to forward."""
pass
class _ProposalLayer_FPN(nn.Module):
"""
Outputs object detection proposals by applying estimated bounding-box
transformations to a set of regular boxes (called "anchors").
"""
def __init__(self, feat_stride, scales, ratios):
super(_ProposalLayer_FPN, self).__init__()
self._anchor_ratios = ratios
self._feat_stride = feat_stride
self._fpn_scales = np.array(cfg["FPN_ANCHOR_SCALES"])
self._fpn_feature_strides = np.array(cfg["FPN_FEAT_STRIDES"])
self._fpn_anchor_stride = cfg["FPN_ANCHOR_STRIDE"]
# self._anchors = torch.from_numpy(generate_anchors_all_pyramids(self._fpn_scales, ratios, self._fpn_feature_strides, fpn_anchor_stride))
# self._num_anchors = self._anchors.size(0)
def forward(self, input):
# Algorithm:
#
# for each (H, W) location i
# generate A anchor boxes centered on cell i
# apply predicted bbox deltas at cell i to each of the A anchors
# clip predicted boxes to image
# remove predicted boxes with either height or width < threshold
# sort all (proposal, score) pairs by score from highest to lowest
# take top pre_nms_topN proposals before NMS
# apply NMS with threshold 0.7 to remaining proposals
# take after_nms_topN proposals after NMS
# return the top proposals (-> RoIs top, scores top)
# the first set of _num_anchors channels are bg probs
# the second set are the fg probs
scores = input[0][:, :, 1] # batch_size x num_rois x 1
bbox_deltas = input[1] # batch_size x num_rois x 4
im_info = input[2]
cfg_key = input[3]
feat_shapes = input[4]
pre_nms_topN = cfg["RPN_PRE_NMS_TOP_N"]
post_nms_topN = cfg["RPN_POST_NMS_TOP_N"]
nms_thresh = cfg["RPN_NMS_THRESH"]
min_size = cfg["RPN_MIN_SIZE"]
batch_size = bbox_deltas.size(0)
anchors = torch.from_numpy(
generate_anchors_all_pyramids(
self._fpn_scales,
self._anchor_ratios,
feat_shapes,
self._fpn_feature_strides,
self._fpn_anchor_stride,
)
).type_as(scores)
num_anchors = anchors.size(0)
anchors = anchors.view(1, num_anchors, 4).expand(batch_size, num_anchors, 4)
# Convert anchors into proposals via bbox transformations
proposals = bbox_transform_inv(anchors, bbox_deltas, batch_size)
# 2. clip predicted boxes to image
proposals = clip_boxes(proposals, im_info, batch_size)
# keep_idx = self._filter_boxes(proposals, min_size).squeeze().long().nonzero().squeeze()
scores_keep = scores
proposals_keep = proposals
_, order = torch.sort(scores_keep, 1, True)
output = scores.new(batch_size, post_nms_topN, 5).zero_()
for i in range(batch_size):
# # 3. remove predicted boxes with either height or width < threshold
# # (NOTE: convert min_size to input image scale stored in im_info[2])
proposals_single = proposals_keep[i]
scores_single = scores_keep[i]
# # 4. sort all (proposal, score) pairs by score from highest to lowest
# # 5. take top pre_nms_topN (e.g. 6000)
order_single = order[i]
if pre_nms_topN > 0 and pre_nms_topN < scores_keep.numel():
order_single = order_single[:pre_nms_topN]
proposals_single = proposals_single[order_single, :]
scores_single = scores_single[order_single].view(-1, 1)
# print("-------------------------")
# print(type(proposals_single))
# print(proposals_single.shape)
# print(type(scores_single))
# print(scores_single.shape)
# print("-------------------------")
# # 6. apply nms (e.g. threshold = 0.7)
# # 7. take after_nms_topN (e.g. 300)
# # 8. return the top proposals (-> RoIs top)
# print(proposals_single)
# print('------------------------')
# print(proposals_single.cpu().numpy())
keep_idx_i = soft_nms(
proposals_single,
scores_single.squeeze(1),
sigma=0.5,
thresh=0.001,
cuda=1,
)
# keep_idx_i = soft_nms(proposals_single.cpu().numpy(), scores_single.cpu().numpy(), 0, thresh = 0.2, Nt = nms_thresh)
# keep_idx_i = torch.from_numpy(keep_idx_i)
# keep_idx_i = nms(proposals_single, scores_single.squeeze(1), nms_thresh)
# keep_idx_i = nms(proposals_single, scores_single, nms_thresh)
keep_idx_i = keep_idx_i.long().view(-1)
if post_nms_topN > 0:
keep_idx_i = keep_idx_i[:post_nms_topN]
proposals_single = proposals_single[keep_idx_i, :]
scores_single = scores_single[keep_idx_i, :]
# padding 0 at the end.
num_proposal = proposals_single.size(0)
output[i, :, 0] = i
output[i, :num_proposal, 1:] = proposals_single
return output
def backward(self, top, propagate_down, bottom):
"""This layer does not propagate gradients."""
pass
def reshape(self, bottom, top):
"""Reshaping happens during the call to forward."""
pass
def _filter_boxes(self, boxes, min_size):
"""Remove all boxes with any side smaller than min_size."""
ws = boxes[:, :, 2] - boxes[:, :, 0] + 1
hs = boxes[:, :, 3] - boxes[:, :, 1] + 1
keep = (ws >= min_size) & (hs >= min_size)
return keep
class _RPN_FPN(nn.Module):
"""region proposal network"""
def __init__(self, din):
super(_RPN_FPN, self).__init__()
self.din = din # get depth of input feature map, e.g., 512
self.anchor_ratios = cfg["ANCHOR_RATIOS"]
self.anchor_scales = cfg["ANCHOR_SCALES"]
self.feat_stride = cfg["FEAT_STRIDE"]
# define the convrelu layers processing input feature map
self.RPN_Conv = nn.Conv2d(self.din, 512, 3, 1, 1, bias=True)
# define bg/fg classifcation score layer
# self.nc_score_out = len(self.anchor_scales) * len(self.anchor_ratios) * 2 # 2(bg/fg) * 9 (anchors)
self.nc_score_out = (
1 * len(self.anchor_ratios) * 2
) # 2(bg/fg) * 3 (anchor ratios) * 1 (anchor scale)
self.RPN_cls_score = nn.Conv2d(512, self.nc_score_out, 1, 1, 0)
# define anchor box offset prediction layer
# self.nc_bbox_out = len(self.anchor_scales) * len(self.anchor_ratios) * 4 # 4(coords) * 9 (anchors)
self.nc_bbox_out = (
1 * len(self.anchor_ratios) * 4
) # 4(coords) * 3 (anchors) * 1 (anchor scale)
self.RPN_bbox_pred = nn.Conv2d(512, self.nc_bbox_out, 1, 1, 0)
# define proposal layer
self.RPN_proposal = _ProposalLayer_FPN(
self.feat_stride, self.anchor_scales, self.anchor_ratios
)
# define anchor target layer
self.RPN_anchor_target = _AnchorTargetLayer_FPN(
self.feat_stride, self.anchor_scales, self.anchor_ratios
)
self.rpn_loss_cls = 0
self.rpn_loss_box = 0
@staticmethod
def reshape(x, d):
input_shape = x.size()
x = x.contiguous().view(
input_shape[0],
int(d),
int(float(input_shape[1] * input_shape[2]) / float(d)),
input_shape[3],
)
return x
def forward(self, rpn_feature_maps, im_info, gt_boxes, num_boxes):
n_feat_maps = len(rpn_feature_maps)
rpn_cls_scores = []
rpn_cls_probs = []
rpn_bbox_preds = []
rpn_shapes = []
for i in range(n_feat_maps):
feat_map = rpn_feature_maps[i]
batch_size = feat_map.size(0)
# return feature map after convrelu layer
rpn_conv1 = F.relu(self.RPN_Conv(feat_map), inplace=True)
# get rpn classification score
rpn_cls_score = self.RPN_cls_score(rpn_conv1)
rpn_cls_score_reshape = self.reshape(rpn_cls_score, 2)
rpn_cls_prob_reshape = F.softmax(rpn_cls_score_reshape, 1)
rpn_cls_prob = self.reshape(rpn_cls_prob_reshape, self.nc_score_out)
# get rpn offsets to the anchor boxes
rpn_bbox_pred = self.RPN_bbox_pred(rpn_conv1)
rpn_shapes.append([rpn_cls_score.size()[2], rpn_cls_score.size()[3]])
rpn_cls_scores.append(
rpn_cls_score.permute(0, 2, 3, 1).contiguous().view(batch_size, -1, 2)
)
rpn_cls_probs.append(
rpn_cls_prob.permute(0, 2, 3, 1).contiguous().view(batch_size, -1, 2)
)
rpn_bbox_preds.append(
rpn_bbox_pred.permute(0, 2, 3, 1).contiguous().view(batch_size, -1, 4)
)
rpn_cls_score_alls = torch.cat(rpn_cls_scores, 1)
rpn_cls_prob_alls = torch.cat(rpn_cls_probs, 1)
rpn_bbox_pred_alls = torch.cat(rpn_bbox_preds, 1)
n_rpn_pred = rpn_cls_score_alls.size(1)
# proposal layer
cfg_key = "TRAIN" if self.training else "TEST"
rois = self.RPN_proposal(
(
rpn_cls_prob_alls.data,
rpn_bbox_pred_alls.data,
im_info,
cfg_key,
rpn_shapes,
)
)
self.rpn_loss_cls = 0
self.rpn_loss_box = 0
# generating training labels and build the rpn loss
if self.training:
assert gt_boxes is not None
rpn_data = self.RPN_anchor_target(
(rpn_cls_score_alls.data, gt_boxes, im_info, num_boxes, rpn_shapes)
)
# compute classification loss
rpn_label = rpn_data[0].view(batch_size, -1)
rpn_keep = Variable(rpn_label.view(-1).ne(-1).nonzero().view(-1))
rpn_cls_score = torch.index_select(
rpn_cls_score_alls.view(-1, 2), 0, rpn_keep
)
rpn_label = torch.index_select(rpn_label.view(-1), 0, rpn_keep.data)
rpn_label = Variable(rpn_label.long())
self.rpn_loss_cls = F.cross_entropy(rpn_cls_score, rpn_label)
fg_cnt = torch.sum(rpn_label.data.ne(0))
(
rpn_bbox_targets,
rpn_bbox_inside_weights,
rpn_bbox_outside_weights,
) = rpn_data[1:]
# print(rpn_bbox_targets.shape)
# compute bbox regression loss
rpn_bbox_inside_weights = Variable(
rpn_bbox_inside_weights.unsqueeze(2).expand(
batch_size, rpn_bbox_inside_weights.size(1), 4
)
)
rpn_bbox_outside_weights = Variable(
rpn_bbox_outside_weights.unsqueeze(2).expand(
batch_size, rpn_bbox_outside_weights.size(1), 4
)
)
rpn_bbox_targets = Variable(rpn_bbox_targets)
self.rpn_loss_box = _smooth_l1_loss(
rpn_bbox_pred_alls,
rpn_bbox_targets,
rpn_bbox_inside_weights,
rpn_bbox_outside_weights,
sigma=3,
)
return rois, self.rpn_loss_cls, self.rpn_loss_box
class _ROIPool(Function):
@staticmethod
def forward(ctx, input, roi, output_size, spatial_scale):
ctx.output_size = _pair(output_size)
ctx.spatial_scale = spatial_scale
ctx.input_shape = input.size()
output, argmax = _C.roi_pool_forward(
input, roi, spatial_scale, output_size[0], output_size[1]
)
ctx.save_for_backward(input, roi, argmax)
return output
@staticmethod
@once_differentiable
def backward(ctx, grad_output):
input, rois, argmax = ctx.saved_tensors
output_size = ctx.output_size
spatial_scale = ctx.spatial_scale
bs, ch, h, w = ctx.input_shape
grad_input = _C.roi_pool_backward(
grad_output,
input,
rois,
argmax,
spatial_scale,
output_size[0],
output_size[1],
bs,
ch,
h,
w,
)
return grad_input, None, None, None
roi_pool = _ROIPool.apply
class ROIPool(nn.Module):
def __init__(self, output_size, spatial_scale):
super(ROIPool, self).__init__()
self.output_size = output_size
self.spatial_scale = spatial_scale
def forward(self, input, rois):
return roi_pool(input, rois, self.output_size, self.spatial_scale)
def __repr__(self):
tmpstr = self.__class__.__name__ + "("
tmpstr += "output_size=" + str(self.output_size)
tmpstr += ", spatial_scale=" + str(self.spatial_scale)
tmpstr += ")"
return tmpstr
class _ROIAlign(Function):
@staticmethod
def forward(ctx, input, roi, output_size, spatial_scale, sampling_ratio):
ctx.save_for_backward(roi)
ctx.output_size = _pair(output_size)
ctx.spatial_scale = spatial_scale
ctx.sampling_ratio = sampling_ratio
ctx.input_shape = input.size()
output = _C.roi_align_forward(
input, roi, spatial_scale, output_size[0], output_size[1], sampling_ratio
)
return output
@staticmethod
@once_differentiable
def backward(ctx, grad_output):
(rois,) = ctx.saved_tensors
output_size = ctx.output_size
spatial_scale = ctx.spatial_scale
sampling_ratio = ctx.sampling_ratio
bs, ch, h, w = ctx.input_shape
grad_input = _C.roi_align_backward(
grad_output,
rois,
spatial_scale,
output_size[0],
output_size[1],
bs,
ch,
h,
w,
sampling_ratio,
)
return grad_input, None, None, None, None
roi_align = _ROIAlign.apply
def bbox_decode(
rois, bbox_pred, batch_size, class_agnostic, classes, im_info, training, cls_prob
):
boxes = rois.data[:, :, 1:5]
if cfg["TEST_BBOX_REG"]:
# Apply bounding-box regression deltas
box_deltas = bbox_pred.data
if cfg["TRAIN_BBOX_NORMALIZE_TARGETS_PRECOMPUTED"]:
# Optionally normalize targets by a precomputed mean and stdev
if class_agnostic or training:
box_deltas = (
box_deltas.view(-1, 4)
* torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_STDS"]).cuda()
+ torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_MEANS"]).cuda()
)
box_deltas = box_deltas.view(batch_size, -1, 4)
else:
cls_prob[:, 0] = 0
bbox_pred_cls_argmax = torch.argmax(cls_prob, dim=1)
# print(bbox_pred_cls_argmax)
for i in range(bbox_pred.size(1)):
bbox_pred_cls_argmax[i] = bbox_pred_cls_argmax[i] + i * classes
bbox_pred_max = bbox_pred.view(batch_size, -1, 4)
bbox_pred_max = torch.index_select(
bbox_pred_max, 1, bbox_pred_cls_argmax
)
box_deltas = bbox_pred_max.data
box_deltas = (
box_deltas.view(-1, 4)
* torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_STDS"]).cuda()
+ torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_MEANS"]).cuda()
)
box_deltas = box_deltas.view(batch_size, -1, 4)
pred_boxes = bbox_transform_inv(boxes, box_deltas, batch_size)
pred_boxes = clip_boxes(pred_boxes, im_info, batch_size)
else:
# Simply repeat the boxes, once for each class
pred_boxes = boxes
pred_boxes = pred_boxes.view(batch_size, -1, 4)
ret_boxes = torch.zeros(pred_boxes.size(0), pred_boxes.size(1), 5).cuda()
ret_boxes[:, :, 1:] = pred_boxes
for b in range(batch_size):
ret_boxes[b, :, 0] = b
return ret_boxes
class ROIAlignAvg(nn.Module):
def __init__(self, output_size, spatial_scale, sampling_ratio):
super(ROIAlignAvg, self).__init__()
self.output_size = output_size
self.spatial_scale = spatial_scale
self.sampling_ratio = sampling_ratio
def forward(self, input, rois, spatial_scale):
self.spatial_scale = spatial_scale
# x= roi_align(
# input, rois, self.output_size, self.spatial_scale, self.sampling_ratio
# )
x = torchvision.ops.roi_align(
input, rois, self.output_size, self.spatial_scale, self.sampling_ratio
)
return avg_pool2d(x, kernel_size=2, stride=1)
def __repr__(self):
tmpstr = self.__class__.__name__ + "("
tmpstr += "output_size=" + str(self.output_size)
tmpstr += ", spatial_scale=" + str(self.spatial_scale)
tmpstr += ", sampling_ratio=" + str(self.sampling_ratio)
tmpstr += ")"
return tmpstr
class _FPN(nn.Module):
"""FPN"""
def __init__(self, classes, class_agnostic):
super(_FPN, self).__init__()
self.classes = classes
self.n_classes = len(classes)
self.class_agnostic = class_agnostic
# loss
self.RCNN_loss_cls = 0
self.RCNN_loss_bbox = 0
self.maxpool2d = nn.MaxPool2d(1, stride=2)
# define rpn
self.RCNN_rpn = _RPN_FPN(self.dout_base_model)
self.RCNN_proposal_target = _ProposalTargetLayer(self.n_classes)
# NOTE: the original paper used pool_size = 7 for cls branch, and 14 for mask branch, to save the
# computation time, we first use 14 as the pool_size, and then do stride=2 pooling for cls branch.
self.RCNN_roi_pool = ROIPool(
(cfg["POOLING_SIZE"], cfg["POOLING_SIZE"]), 1.0 / 16.0
)
self.RCNN_roi_align = ROIAlignAvg(
(cfg["POOLING_SIZE"] + 1, cfg["POOLING_SIZE"] + 1), 1.0 / 16.0, 0
)
# self.RCNN_roi_pool = ROIPool(cfg['POOLING_SIZE'], cfg['POOLING_SIZE'], 1.0/16.0)
# self.RCNN_roi_align = ROIAlignAvg(cfg['POOLING_SIZE'], cfg['POOLING_SIZE'], 1.0/16.0)
self.grid_size = (
cfg["POOLING_SIZE"] * 2
if cfg["CROP_RESIZE_WITH_MAX_POOL"]
else cfg["POOLING_SIZE"]
)
def _init_weights(self):
def normal_init(m, mean, stddev, truncated=False):
"""
weight initalizer: truncated normal and random normal.
"""
# x is a parameter
if truncated:
m.weight.data.normal_().fmod_(2).mul_(stddev).add_(
mean
) # not a perfect approximation
else:
m.weight.data.normal_(mean, stddev)
m.bias.data.zero_()
# custom weights initialization called on netG and netD
def weights_init(m, mean, stddev, truncated=False):
classname = m.__class__.__name__
if classname.find("Conv") != -1:
m.weight.data.normal_(0.0, 0.02)
m.bias.data.fill_(0)
elif classname.find("BatchNorm") != -1:
m.weight.data.normal_(1.0, 0.02)
m.bias.data.fill_(0)
normal_init(self.RCNN_toplayer, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_smooth1, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_smooth2, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_smooth3, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_latlayer1, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_latlayer2, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_latlayer3, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_rpn.RPN_Conv, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_rpn.RPN_cls_score, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_rpn.RPN_bbox_pred, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_cls_score, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_bbox_pred, 0, 0.001, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_cls_score_2nd, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_bbox_pred_2nd, 0, 0.001, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_cls_score_3rd, 0, 0.01, cfg["TRAIN_TRUNCATED"])
normal_init(self.RCNN_bbox_pred_3rd, 0, 0.001, cfg["TRAIN_TRUNCATED"])
weights_init(self.RCNN_top, 0, 0.01, cfg["TRAIN_TRUNCATED"])
weights_init(self.RCNN_top_2nd, 0, 0.01, cfg["TRAIN_TRUNCATED"])
weights_init(self.RCNN_top_3rd, 0, 0.01, cfg["TRAIN_TRUNCATED"])
def create_architecture(self):
self._init_modules()
self._init_weights()
def _upsample_add(self, x, y):
"""Upsample and add two feature maps.
Args:
x: (Variable) top feature map to be upsampled.
y: (Variable) lateral feature map.
Returns:
(Variable) added feature map.
Note in PyTorch, when input size is odd, the upsampled feature map
with `F.upsample(..., scale_factor=2, mode='nearest')`
maybe not equal to the lateral feature map size.
e.g.
original input size: [N,_,15,15] ->
conv2d feature map size: [N,_,8,8] ->
upsampled feature map size: [N,_,16,16]
So we choose bilinear upsample which supports arbitrary output sizes.
"""
_, _, H, W = y.size()
return F.interpolate(x, size=(H, W), mode="bilinear", align_corners=True) + y
def _PyramidRoI_Feat(self, feat_maps, rois, im_info):
"""roi pool on pyramid feature maps"""
# do roi pooling based on predicted rois
# print("rois shape",rois.shape)
# print("feat_maps",feat_maps.shape)
img_area = im_info[0][0] * im_info[0][1]
h = rois.data[:, 4] - rois.data[:, 2] + 1
w = rois.data[:, 3] - rois.data[:, 1] + 1
# print(h)
# print(w)
roi_level = torch.log2(torch.sqrt(h * w) / 224.0)
roi_level = torch.round(roi_level + 4)
roi_level[roi_level < 2] = 2
roi_level[roi_level > 5] = 5
# roi_level.fill_(5)
# print("roi_level",roi_level)
if cfg["POOLING_MODE"] == "align":
roi_pool_feats = []
box_to_levels = []
for i, l in enumerate(range(2, 6)):
# print(i, l)
# print(roi_level)
if (roi_level == l).sum() == 0:
continue
idx_l = (roi_level == l).nonzero().squeeze()
# print(idx_l.dim())
# print((idx_l.cpu().numpy()))
if idx_l.dim() == 0:
idx_l = idx_l.unsqueeze(0)
# continue
# print("^^^^^^^^^^^^^^^^^^^^^^",idx_l.dim())
box_to_levels.append(idx_l)
scale = feat_maps[i].size(2) / im_info[0][0]
# self.RCNN_roi_align.scale=scale
feat = self.RCNN_roi_align(feat_maps[i], rois[idx_l], scale)
roi_pool_feats.append(feat)
# print("box_to_levels")
# print(box_to_levels)
roi_pool_feat = torch.cat(roi_pool_feats, 0)
box_to_level = torch.cat(box_to_levels, 0)
idx_sorted, order = torch.sort(box_to_level)
roi_pool_feat = roi_pool_feat[order]
elif cfg["POOLING_MODE"] == "pool":
roi_pool_feats = []
box_to_levels = []
for i, l in enumerate(range(2, 6)):
if (roi_level == l).sum() == 0:
continue
idx_l = (roi_level == l).nonzero().squeeze()
box_to_levels.append(idx_l)
scale = feat_maps[i].size(2) / im_info[0][0]
self.RCNN_roi_pool.scale = scale
feat = self.RCNN_roi_pool(feat_maps[i], rois[idx_l])
roi_pool_feats.append(feat)
roi_pool_feat = torch.cat(roi_pool_feats, 0)
box_to_level = torch.cat(box_to_levels, 0)
idx_sorted, order = torch.sort(box_to_level)
roi_pool_feat = roi_pool_feat[order]
return roi_pool_feat
def forward(self, im_data, im_info, gt_boxes, num_boxes):
batch_size = im_data.size(0)
im_info = im_info.data
gt_boxes = gt_boxes.data
num_boxes = num_boxes.data
# feed image data to base model to obtain base feature map
# Bottom-up
c1 = self.RCNN_layer0(im_data)
c2 = self.RCNN_layer1(c1)
c3 = self.RCNN_layer2(c2)
c4 = self.RCNN_layer3(c3)
c5 = self.RCNN_layer4(c4)
# Top-down
p5 = self.RCNN_toplayer(c5)
p4 = self._upsample_add(p5, self.RCNN_latlayer1(c4))
p4 = self.RCNN_smooth1(p4)
p3 = self._upsample_add(p4, self.RCNN_latlayer2(c3))
p3 = self.RCNN_smooth2(p3)
p2 = self._upsample_add(p3, self.RCNN_latlayer3(c2))
p2 = self.RCNN_smooth3(p2)
p6 = self.maxpool2d(p5)
rpn_feature_maps = [p2, p3, p4, p5, p6]
mrcnn_feature_maps = [p2, p3, p4, p5]
rois, rpn_loss_cls, rpn_loss_bbox = self.RCNN_rpn(
rpn_feature_maps, im_info, gt_boxes, num_boxes
)
# print("rois shape stage1:",rois.shape)
# if it is training phrase, then use ground trubut bboxes for refining
if self.training:
roi_data = self.RCNN_proposal_target(rois, gt_boxes, num_boxes)
(
rois,
rois_label,
gt_assign,
rois_target,
rois_inside_ws,
rois_outside_ws,
) = roi_data
## NOTE: additionally, normalize proposals to range [0, 1],
# this is necessary so that the following roi pooling
# is correct on different feature maps
# rois[:, :, 1::2] /= im_info[0][1]
# rois[:, :, 2::2] /= im_info[0][0]
rois = rois.view(-1, 5)
rois_label = rois_label.view(-1).long()
gt_assign = gt_assign.view(-1).long()
pos_id = rois_label.nonzero().squeeze()
gt_assign_pos = gt_assign[pos_id]
rois_label_pos = rois_label[pos_id]
rois_label_pos_ids = pos_id
rois_pos = Variable(rois[pos_id])
rois = Variable(rois)
rois_label = Variable(rois_label)
rois_target = Variable(rois_target.view(-1, rois_target.size(2)))
rois_inside_ws = Variable(rois_inside_ws.view(-1, rois_inside_ws.size(2)))
rois_outside_ws = Variable(
rois_outside_ws.view(-1, rois_outside_ws.size(2))
)
else:
## NOTE: additionally, normalize proposals to range [0, 1],
# this is necessary so that the following roi pooling
# is correct on different feature maps
# rois[:, :, 1::2] /= im_info[0][1]
# rois[:, :, 2::2] /= im_info[0][0]
rois_label = None
gt_assign = None
rois_target = None
rois_inside_ws = None
rois_outside_ws = None
rpn_loss_cls = 0
rpn_loss_bbox = 0
rois = rois.view(-1, 5)
pos_id = torch.arange(0, rois.size(0)).long().type_as(rois).long()
rois_label_pos_ids = pos_id
rois_pos = Variable(rois[pos_id])
rois = Variable(rois)
roi_pool_feat = self._PyramidRoI_Feat(mrcnn_feature_maps, rois, im_info)
# feed pooled features to top model
pooled_feat = self._head_to_tail(roi_pool_feat)
bbox_pred = self.RCNN_bbox_pred(pooled_feat)
if self.training and not self.class_agnostic:
# select the corresponding columns according to roi labels
bbox_pred_view = bbox_pred.view(
bbox_pred.size(0), int(bbox_pred.size(1) / 4), 4
)
bbox_pred_select = torch.gather(
bbox_pred_view,
1,
rois_label.long()
.view(rois_label.size(0), 1, 1)
.expand(rois_label.size(0), 1, 4),
)
bbox_pred = bbox_pred_select.squeeze(1)
cls_score = self.RCNN_cls_score(pooled_feat)
cls_prob = F.softmax(cls_score, 1)
# print(cls_prob)
# print("*******************cls prob shape",cls_prob.shape)
RCNN_loss_cls = 0
RCNN_loss_bbox = 0
if self.training:
RCNN_loss_cls = F.cross_entropy(cls_score, rois_label)
# loss (l1-norm) for bounding box regression
RCNN_loss_bbox = _smooth_l1_loss(
bbox_pred, rois_target, rois_inside_ws, rois_outside_ws
)
rois = rois.view(batch_size, -1, rois.size(1))
bbox_pred = bbox_pred.view(batch_size, -1, bbox_pred.size(1))
if self.training:
rois_label = rois_label.view(batch_size, -1)
# 2nd-----------------------------
# decode
rois = bbox_decode(
rois,
bbox_pred,
batch_size,
self.class_agnostic,
self.n_classes,
im_info,
self.training,
cls_prob,
)
if self.training:
roi_data = self.RCNN_proposal_target(rois, gt_boxes, num_boxes, stage=2)
(
rois,
rois_label,
gt_assign,
rois_target,
rois_inside_ws,
rois_outside_ws,
) = roi_data
rois = rois.view(-1, 5)
rois_label = rois_label.view(-1).long()
gt_assign = gt_assign.view(-1).long()
pos_id = rois_label.nonzero().squeeze()
gt_assign_pos = gt_assign[pos_id]
rois_label_pos = rois_label[pos_id]
rois_label_pos_ids = pos_id
rois_pos = Variable(rois[pos_id])
rois = Variable(rois)
rois_label = Variable(rois_label)
rois_target = Variable(rois_target.view(-1, rois_target.size(2)))
rois_inside_ws = Variable(rois_inside_ws.view(-1, rois_inside_ws.size(2)))
rois_outside_ws = Variable(
rois_outside_ws.view(-1, rois_outside_ws.size(2))
)
else:
rois_label = None
gt_assign = None
rois_target = None
rois_inside_ws = None
rois_outside_ws = None
rpn_loss_cls = 0
rpn_loss_bbox = 0
rois = rois.view(-1, 5)
pos_id = torch.arange(0, rois.size(0)).long().type_as(rois).long()
# print(pos_id)
rois_label_pos_ids = pos_id
rois_pos = Variable(rois[pos_id])
rois = Variable(rois)
roi_pool_feat = self._PyramidRoI_Feat(mrcnn_feature_maps, rois, im_info)
# feed pooled features to top model
pooled_feat = self._head_to_tail_2nd(roi_pool_feat)
# compute bbox offset
bbox_pred = self.RCNN_bbox_pred_2nd(pooled_feat)
if self.training and not self.class_agnostic:
# select the corresponding columns according to roi labels
bbox_pred_view = bbox_pred.view(
bbox_pred.size(0), int(bbox_pred.size(1) / 4), 4
)
bbox_pred_select = torch.gather(
bbox_pred_view,
1,
rois_label.long()
.view(rois_label.size(0), 1, 1)
.expand(rois_label.size(0), 1, 4),
)
bbox_pred = bbox_pred_select.squeeze(1)
# compute object classification probability
cls_score = self.RCNN_cls_score_2nd(pooled_feat)
cls_prob_2nd = F.softmax(cls_score, 1)
RCNN_loss_cls_2nd = 0
RCNN_loss_bbox_2nd = 0
if self.training:
# loss (cross entropy) for object classification
RCNN_loss_cls_2nd = F.cross_entropy(cls_score, rois_label)
# loss (l1-norm) for bounding box regression
RCNN_loss_bbox_2nd = _smooth_l1_loss(
bbox_pred, rois_target, rois_inside_ws, rois_outside_ws
)
rois = rois.view(batch_size, -1, rois.size(1))
# cls_prob_2nd = cls_prob_2nd.view(batch_size, -1, cls_prob_2nd.size(1)) ----------------not be used ---------
bbox_pred_2nd = bbox_pred.view(batch_size, -1, bbox_pred.size(1))
if self.training:
rois_label = rois_label.view(batch_size, -1)
# 3rd---------------
# decode
rois = bbox_decode(
rois,
bbox_pred_2nd,
batch_size,
self.class_agnostic,
self.n_classes,
im_info,
self.training,
cls_prob_2nd,
)
# proposal_target
# if it is training phrase, then use ground trubut bboxes for refining
if self.training:
roi_data = self.RCNN_proposal_target(rois, gt_boxes, num_boxes, stage=3)
(
rois,
rois_label,
gt_assign,
rois_target,
rois_inside_ws,
rois_outside_ws,
) = roi_data
rois = rois.view(-1, 5)
rois_label = rois_label.view(-1).long()
gt_assign = gt_assign.view(-1).long()
pos_id = rois_label.nonzero().squeeze()
gt_assign_pos = gt_assign[pos_id]
rois_label_pos = rois_label[pos_id]
rois_label_pos_ids = pos_id
rois_pos = Variable(rois[pos_id])
rois = Variable(rois)
rois_label = Variable(rois_label)
rois_target = Variable(rois_target.view(-1, rois_target.size(2)))
rois_inside_ws = Variable(rois_inside_ws.view(-1, rois_inside_ws.size(2)))
rois_outside_ws = Variable(
rois_outside_ws.view(-1, rois_outside_ws.size(2))
)
else:
rois_label = None
gt_assign = None
rois_target = None
rois_inside_ws = None
rois_outside_ws = None
rpn_loss_cls = 0
rpn_loss_bbox = 0
rois = rois.view(-1, 5)
pos_id = torch.arange(0, rois.size(0)).long().type_as(rois).long()
rois_label_pos_ids = pos_id
rois_pos = Variable(rois[pos_id])
rois = Variable(rois)
roi_pool_feat = self._PyramidRoI_Feat(mrcnn_feature_maps, rois, im_info)
# feed pooled features to top model
pooled_feat = self._head_to_tail_3rd(roi_pool_feat)
# compute bbox offset
bbox_pred = self.RCNN_bbox_pred_3rd(pooled_feat)
if self.training and not self.class_agnostic:
# select the corresponding columns according to roi labels
bbox_pred_view = bbox_pred.view(
bbox_pred.size(0), int(bbox_pred.size(1) / 4), 4
)
bbox_pred_select = torch.gather(
bbox_pred_view,
1,
rois_label.long()
.view(rois_label.size(0), 1, 1)
.expand(rois_label.size(0), 1, 4),
)
bbox_pred = bbox_pred_select.squeeze(1)
# compute object classification probability
cls_score = self.RCNN_cls_score_3rd(pooled_feat)
cls_prob_3rd = F.softmax(cls_score, 1)
RCNN_loss_cls_3rd = 0
RCNN_loss_bbox_3rd = 0
if self.training:
# loss (cross entropy) for object classification
RCNN_loss_cls_3rd = F.cross_entropy(cls_score, rois_label)
# loss (l1-norm) for bounding box regression
RCNN_loss_bbox_3rd = _smooth_l1_loss(
bbox_pred, rois_target, rois_inside_ws, rois_outside_ws
)
rois = rois.view(batch_size, -1, rois.size(1))
cls_prob_3rd = cls_prob_3rd.view(batch_size, -1, cls_prob_3rd.size(1))
bbox_pred_3rd = bbox_pred.view(batch_size, -1, bbox_pred.size(1))
if self.training:
rois_label = rois_label.view(batch_size, -1)
if not self.training:
# 3rd_avg
# 1st_3rd
pooled_feat_1st_3rd = self._head_to_tail(roi_pool_feat)
cls_score_1st_3rd = self.RCNN_cls_score(pooled_feat_1st_3rd)
cls_prob_1st_3rd = F.softmax(cls_score_1st_3rd, 1)
cls_prob_1st_3rd = cls_prob_1st_3rd.view(
batch_size, -1, cls_prob_1st_3rd.size(1)
)
# 2nd_3rd
pooled_feat_2nd_3rd = self._head_to_tail_2nd(roi_pool_feat)
cls_score_2nd_3rd = self.RCNN_cls_score_2nd(pooled_feat_2nd_3rd)
cls_prob_2nd_3rd = F.softmax(cls_score_2nd_3rd, 1)
cls_prob_2nd_3rd = cls_prob_2nd_3rd.view(
batch_size, -1, cls_prob_2nd_3rd.size(1)
)
cls_prob_3rd_avg = (cls_prob_1st_3rd + cls_prob_2nd_3rd + cls_prob_3rd) / 3
else:
cls_prob_3rd_avg = cls_prob_3rd
return (
rois,
cls_prob_3rd_avg,
bbox_pred_3rd,
rpn_loss_cls,
rpn_loss_bbox,
RCNN_loss_cls,
RCNN_loss_bbox,
RCNN_loss_cls_2nd,
RCNN_loss_bbox_2nd,
RCNN_loss_cls_3rd,
RCNN_loss_bbox_3rd,
rois_label,
)
def conv3x3(in_planes, out_planes, stride=1):
"3x3 convolution with padding"
return nn.Conv2d(
in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False
)
# class BasicBlock(nn.Module):
# expansion = 1
# def __init__(self, inplanes, planes, stride=1, downsample=None):
# super(BasicBlock, self).__init__()
# self.conv1 = conv3x3(inplanes, planes, stride)
# self.bn1 = nn.BatchNorm2d(planes)
# self.relu = nn.ReLU(inplace=True)
# self.conv2 = conv3x3(planes, planes)
# self.bn2 = nn.BatchNorm2d(planes)
# self.downsample = downsample
# self.stride = stride
# def forward(self, x):
# residual = x
# out = self.conv1(x)
# out = self.bn1(out)
# out = self.relu(out)
# out = self.conv2(out)
# out = self.bn2(out)
# if self.downsample is not None:
# residual = self.downsample(x)
# out += residual
# out = self.relu(out)
# return out
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(
inplanes, planes, kernel_size=1, stride=stride, bias=False
) # change
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(
planes, planes, kernel_size=3, stride=1, padding=1, bias=False # change
)
self.bn2 = nn.BatchNorm2d(planes)
self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, layers, num_classes=1000):
self.inplanes = 64
super(ResNet, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(
kernel_size=3, stride=2, padding=0, ceil_mode=True
) # change
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2) # different
self.avgpool = nn.AvgPool2d(7)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2.0 / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(
self.inplanes,
planes * block.expansion,
kernel_size=1,
stride=stride,
bias=False,
),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def resnet50(pretrained=False):
"""Constructs a ResNet-50 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 6, 3])
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls["resnet50"]))
return model
def resnet101(pretrained=False):
"""Constructs a ResNet-101 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(Bottleneck, [3, 4, 23, 3])
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls["resnet101"]))
return model
class resnet(_FPN):
def __init__(self, classes, num_layers=101, pretrained=False, class_agnostic=False):
self.dout_base_model = 256
self.pretrained = pretrained
self.class_agnostic = class_agnostic
self.num_layers = num_layers
if num_layers == 101:
self.model_path = "data/pretrained_model/resnet101.pth"
elif num_layers == 50:
self.model_path = "data/pretrained_model/resnet50.pth"
_FPN.__init__(self, classes, class_agnostic)
def _init_modules(self):
if self.num_layers == 101:
resnet = resnet101()
elif self.num_layers == 50:
resnet = resnet50()
if self.pretrained == True:
print("Loading pretrained weights from %s" % (self.model_path))
state_dict = torch.load(self.model_path)
resnet.load_state_dict(
{k: v for k, v in state_dict.items() if k in resnet.state_dict()}
)
self.RCNN_layer0 = nn.Sequential(
resnet.conv1, resnet.bn1, resnet.relu, resnet.maxpool
)
self.RCNN_layer1 = nn.Sequential(resnet.layer1)
self.RCNN_layer2 = nn.Sequential(resnet.layer2)
self.RCNN_layer3 = nn.Sequential(resnet.layer3)
self.RCNN_layer4 = nn.Sequential(resnet.layer4)
# Top layer
self.RCNN_toplayer = nn.Conv2d(
2048, 256, kernel_size=1, stride=1, padding=0
) # reduce channel
# Smooth layers
self.RCNN_smooth1 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.RCNN_smooth2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.RCNN_smooth3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
# Lateral layers
self.RCNN_latlayer1 = nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0)
self.RCNN_latlayer2 = nn.Conv2d(512, 256, kernel_size=1, stride=1, padding=0)
self.RCNN_latlayer3 = nn.Conv2d(256, 256, kernel_size=1, stride=1, padding=0)
# ROI Pool feature downsampling
self.RCNN_roi_feat_ds = nn.Conv2d(256, 256, kernel_size=3, stride=2, padding=1)
self.RCNN_top = nn.Sequential(
nn.Conv2d(
256,
1024,
kernel_size=cfg["POOLING_SIZE"],
stride=cfg["POOLING_SIZE"],
padding=0,
),
nn.ReLU(True),
nn.Conv2d(1024, 1024, kernel_size=1, stride=1, padding=0),
nn.ReLU(True),
)
self.RCNN_top_2nd = nn.Sequential(
nn.Conv2d(
256,
1024,
kernel_size=cfg["POOLING_SIZE"],
stride=cfg["POOLING_SIZE"],
padding=0,
),
nn.ReLU(True),
nn.Conv2d(1024, 1024, kernel_size=1, stride=1, padding=0),
nn.ReLU(True),
)
self.RCNN_top_3rd = nn.Sequential(
nn.Conv2d(
256,
1024,
kernel_size=cfg["POOLING_SIZE"],
stride=cfg["POOLING_SIZE"],
padding=0,
),
nn.ReLU(True),
nn.Conv2d(1024, 1024, kernel_size=1, stride=1, padding=0),
nn.ReLU(True),
)
self.RCNN_cls_score = nn.Linear(1024, self.n_classes)
if self.class_agnostic:
self.RCNN_bbox_pred = nn.Linear(1024, 4)
else:
self.RCNN_bbox_pred = nn.Linear(1024, 4 * self.n_classes)
self.RCNN_cls_score_2nd = nn.Linear(1024, self.n_classes)
if self.class_agnostic:
self.RCNN_bbox_pred_2nd = nn.Linear(1024, 4)
else:
self.RCNN_bbox_pred_2nd = nn.Linear(1024, 4 * self.n_classes)
self.RCNN_cls_score_3rd = nn.Linear(1024, self.n_classes)
if self.class_agnostic:
self.RCNN_bbox_pred_3rd = nn.Linear(1024, 4)
else:
self.RCNN_bbox_pred_3rd = nn.Linear(1024, 4 * self.n_classes)
# Fix blocks
for p in self.RCNN_layer0[0].parameters():
p.requires_grad = False
for p in self.RCNN_layer0[1].parameters():
p.requires_grad = False
if cfg["RESNET_FIXED_BLOCKS"] >= 3:
for p in self.RCNN_layer3.parameters():
p.requires_grad = False
if cfg["RESNET_FIXED_BLOCKS"] >= 2:
for p in self.RCNN_layer2.parameters():
p.requires_grad = False
if cfg["RESNET_FIXED_BLOCKS"] >= 1:
for p in self.RCNN_layer1.parameters():
p.requires_grad = False
def set_bn_fix(m):
classname = m.__class__.__name__
if classname.find("BatchNorm") != -1:
for p in m.parameters():
p.requires_grad = False
self.RCNN_layer0.apply(set_bn_fix)
self.RCNN_layer1.apply(set_bn_fix)
self.RCNN_layer2.apply(set_bn_fix)
self.RCNN_layer3.apply(set_bn_fix)
self.RCNN_layer4.apply(set_bn_fix)
def train(self, mode=True):
# Override train so that the training mode is set as we want
nn.Module.train(self, mode)
if mode:
# Set fixed blocks to be in eval mode
self.RCNN_layer0.eval()
self.RCNN_layer1.eval()
self.RCNN_layer2.train()
self.RCNN_layer3.train()
self.RCNN_layer4.train()
self.RCNN_smooth1.train()
self.RCNN_smooth2.train()
self.RCNN_smooth3.train()
self.RCNN_latlayer1.train()
self.RCNN_latlayer2.train()
self.RCNN_latlayer3.train()
self.RCNN_toplayer.train()
def set_bn_eval(m):
classname = m.__class__.__name__
if classname.find("BatchNorm") != -1:
m.eval()
self.RCNN_layer0.apply(set_bn_eval)
self.RCNN_layer1.apply(set_bn_eval)
self.RCNN_layer2.apply(set_bn_eval)
self.RCNN_layer3.apply(set_bn_eval)
self.RCNN_layer4.apply(set_bn_eval)
def _head_to_tail(self, pool5):
block5 = self.RCNN_top(pool5)
fc7 = block5.mean(3).mean(2)
return fc7
def _head_to_tail_2nd(self, pool5):
block5 = self.RCNN_top_2nd(pool5)
fc7 = block5.mean(3).mean(2)
return fc7
def _head_to_tail_3rd(self, pool5):
block5 = self.RCNN_top_3rd(pool5)
fc7 = block5.mean(3).mean(2)
return fc7
# -----------------------------------------------------------------------#
P_img_ext = ["jpg", "png"]
def file_list(path, allfile):
filelist = os.listdir(path)
for filename in filelist:
filepath = os.path.join(path, filename)
if os.path.isdir(filepath):
file_list(filepath, allfile)
else:
if filepath.split(".")[-1] in P_img_ext:
# if filepath.endswith('xml'):
# allfile.append(filepath[0:-4].strip())
allfile.append(filepath.strip())
return allfile
def im_list_to_blob(ims):
"""Convert a list of images into a network input.
Assumes images are already prepared (means subtracted, BGR order, ...).
"""
max_shape = np.array([im.shape for im in ims]).max(axis=0)
num_images = len(ims)
blob = np.zeros((num_images, max_shape[0], max_shape[1], 3), dtype=np.float32)
for i in range(num_images):
im = ims[i]
blob[i, 0 : im.shape[0], 0 : im.shape[1], :] = im
return blob
def _get_image_blob(im):
"""Converts an image into a network input.
Arguments:
im (ndarray): a color image in BGR order
Returns:
blob (ndarray): a data blob holding an image pyramid
im_scale_factors (list): list of image scales (relative to im) used
in the image pyramid
"""
im_orig = im.astype(np.float32, copy=True)
im_orig -= cfg["PIXEL_MEANS"]
im_shape = im_orig.shape
im_size_min = np.min(im_shape[0:2])
im_size_max = np.max(im_shape[0:2])
processed_ims = []
im_scale_factors = []
for target_size in cfg["TEST_SCALES"]:
im_scale = float(target_size) / float(im_size_min)
# Prevent the biggest axis from being more than MAX_SIZE
if np.round(im_scale * im_size_max) > cfg["TEST_MAX_SIZE"]:
im_scale = float(cfg["TEST_MAX_SIZE"]) / float(im_size_max)
im = cv2.resize(
im_orig,
None,
None,
fx=im_scale,
fy=im_scale,
interpolation=cv2.INTER_LINEAR,
)
im_scale_factors.append(im_scale)
processed_ims.append(im)
# Create a blob to hold the input images
blob = im_list_to_blob(processed_ims)
return blob, np.array(im_scale_factors)
def soft_nms(dets, box_scores, sigma=0.5, thresh=0.001, cuda=0):
"""
Build a pytorch implement of Soft NMS algorithm.
# Augments
dets: boxes coordinate tensor (format:[y1, x1, y2, x2])
box_scores: box score tensors
sigma: variance of Gaussian function
thresh: score thresh
cuda: CUDA flag
# Return
the index of the selected boxes
"""
# Indexes concatenate boxes with the last column
N = dets.shape[0]
if cuda:
indexes = torch.arange(0, N, dtype=torch.float).cuda().view(N, 1)
else:
indexes = torch.arange(0, N, dtype=torch.float).view(N, 1)
dets = torch.cat((dets, indexes), dim=1)
# The order of boxes coordinate is [y1,x1,y2,x2]
y1 = dets[:, 0]
x1 = dets[:, 1]
y2 = dets[:, 2]
x2 = dets[:, 3]
scores = box_scores
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
for i in range(N):
# intermediate parameters for later parameters exchange
tscore = scores[i].clone()
pos = i + 1
if i != N - 1:
maxscore, maxpos = torch.max(scores[pos:], dim=0)
if tscore < maxscore:
dets[i], dets[maxpos.item() + i + 1] = (
dets[maxpos.item() + i + 1].clone(),
dets[i].clone(),
)
scores[i], scores[maxpos.item() + i + 1] = (
scores[maxpos.item() + i + 1].clone(),
scores[i].clone(),
)
areas[i], areas[maxpos + i + 1] = (
areas[maxpos + i + 1].clone(),
areas[i].clone(),
)
# IoU calculate
yy1 = np.maximum(dets[i, 0].to("cpu").numpy(), dets[pos:, 0].to("cpu").numpy())
xx1 = np.maximum(dets[i, 1].to("cpu").numpy(), dets[pos:, 1].to("cpu").numpy())
yy2 = np.minimum(dets[i, 2].to("cpu").numpy(), dets[pos:, 2].to("cpu").numpy())
xx2 = np.minimum(dets[i, 3].to("cpu").numpy(), dets[pos:, 3].to("cpu").numpy())
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = torch.tensor(w * h).cuda() if cuda else torch.tensor(w * h)
ovr = torch.div(inter, (areas[i] + areas[pos:] - inter))
# Gaussian decay
weight = torch.exp(-(ovr * ovr) / sigma)
scores[pos:] = weight * scores[pos:]
# select the boxes and keep the corresponding indexes
keep = dets[:, 4][scores > thresh].int()
return keep
def soft_nms_old(det_proposal, detr_scores, method, thresh, Nt, sigma=0.5):
"""
the soft nms implement using python
:param dets: the pred_bboxes
:param method: the policy of decay pred_bbox score in soft nms
:param thresh: the threshold
:param Nt: Nt
:return: the index of pred_bbox after soft nms
"""
# print(det_proposal)
x1 = det_proposal[:, 0]
y1 = det_proposal[:, 1]
x2 = det_proposal[:, 2]
y2 = det_proposal[:, 3]
scores = detr_scores.squeeze(1)
areas = (y2 - y1 + 1.0) * (x2 - x1 + 1.0)
orders = scores.argsort()[::-1]
keep = []
while orders.size > 0:
i = orders[0]
keep.append(i)
for j in orders[1:]:
xx1 = np.maximum(x1[i], x1[j])
yy1 = np.maximum(y1[i], y1[j])
xx2 = np.minimum(x2[i], x2[j])
yy2 = np.minimum(y2[i], y2[j])
w = np.maximum(xx2 - xx1 + 1.0, 0.0)
h = np.maximum(yy2 - yy1 + 1.0, 0.0)
inter = w * h
overlap = inter / (areas[i] + areas[j] - inter)
if method == 1: # linear
if overlap > Nt:
weight = 1 - overlap
else:
weight = 1
elif method == 2: # gaussian
weight = np.exp(-(overlap * overlap) / sigma)
else: # original NMS
if overlap > Nt:
weight = 0
else:
weight = 1
# print('weight:', weight)
scores[j] = weight * scores[j]
# print('scores[j]:', scores[j])
# print('thresh:', thresh)
if scores[j] < thresh:
orders = np.delete(orders, np.where(orders == j))
orders = np.delete(orders, 0)
return keep
def vis_detections(im, class_name, dets, thresh=0.0):
"""Visual debugging of detections."""
for i in range(dets.shape[0]):
bbox = tuple(int(np.round(x)) for x in dets[i, :4])
score = dets[i, -1]
if score > thresh:
cv2.rectangle(im, bbox[0:2], bbox[2:4], (0, 204, 0), 4)
cv2.putText(
im,
"%s: %.3f" % (class_name, score),
(bbox[0], bbox[1] + 15),
cv2.FONT_HERSHEY_PLAIN,
2.0,
(0, 0, 255),
thickness=2,
)
return im
if __name__ == "__main__":
# params
num_layers = 50
num_session = 1
num_epoch = 72
checkpoint = 1686
thresh_score_final = 0.05
thresh_score_final_soft_nms = 0.5
model_dir = os.path.join("models", "res" + str(num_layers), "pascal_voc")
data_dir = "../input/global-wheat-detection/test"
Flag_vis = True
# model name
load_name = os.path.join(
"../input/mymodels",
"cascade_fpn_{}_{}_{}.pth".format(num_session, num_epoch, checkpoint),
)
# load_name = 'cascade_fpn_{}_{}_{}.pth'.format(num_session, num_epoch, checkpoint)
# Network
FPN = resnet(classes, num_layers, pretrained=False, class_agnostic=False)
FPN.create_architecture()
# load model
checkpoint = torch.load(load_name)
FPN.load_state_dict(checkpoint["model"])
# set mode
FPN.cuda()
FPN.eval()
print("load checkpoin---->", load_name)
# get test images
imgs_list = []
file_list(data_dir, imgs_list)
# commit submission
submission = []
for idx, img in enumerate(imgs_list):
str_print = "total:{}--currnet:{}--img:{}".format(
len(imgs_list), idx, os.path.basename(img)
)
print(img)
# load an image
im = cv2.imread(img)
if Flag_vis:
img_show = im.copy()
prediction_string = []
# prepare im for forward
im = im[:, :, ::-1] # BGR--->RGB
blobs, im_scales = _get_image_blob(im)
im_blob = blobs
im_info_np = np.array(
[[im_blob.shape[1], im_blob.shape[2], im_scales[0]]], dtype=np.float32
)
im_data_pt = torch.from_numpy(im_blob) # numpy to tensor
im_data_pt = im_data_pt.permute(0, 3, 1, 2) # NHWC --> NCHW
im_info_pt = torch.from_numpy(im_info_np) # numpy to tensor
with torch.no_grad():
im_data = im_data_pt.cuda()
im_info = im_info_pt.cuda()
num_boxes = torch.zeros((1), dtype=torch.int64).cuda()
gt_boxes = torch.zeros((1, 1, 5), dtype=torch.float32).cuda()
# forward
(
rois,
cls_prob,
bbox_pred,
rpn_loss_cls,
rpn_loss_box,
RCNN_loss_cls,
RCNN_loss_bbox,
RCNN_loss_cls_2nd,
RCNN_loss_bbox_2nd,
RCNN_loss_cls_3rd,
RCNN_loss_bbox_3rd,
roi_labels,
) = FPN(im_data, im_info, gt_boxes, num_boxes)
# parse result
scores = cls_prob.data
boxes = rois.data[:, :, 1:5]
# box transform
class_agnostic = False
args_cuda = True
if cfg["TEST_BBOX_REG"]:
# Apply bounding-box regression deltas
box_deltas = bbox_pred.data
if cfg["TRAIN_BBOX_NORMALIZE_TARGETS_PRECOMPUTED"]:
# Optionally normalize targets by a precomputed mean and stdev
if class_agnostic:
if args_cuda > 0:
box_deltas = (
box_deltas.view(-1, 4)
* torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_STDS"]).cuda()
+ torch.FloatTensor(
cfg["TRAIN_BBOX_NORMALIZE_MEANS"]
).cuda()
)
else:
box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(
cfg["TRAIN_BBOX_NORMALIZE_STDS"]
) + torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_MEANS"])
box_deltas = box_deltas.view(1, -1, 4)
else:
if args_cuda > 0:
box_deltas = (
box_deltas.view(-1, 4)
* torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_STDS"]).cuda()
+ torch.FloatTensor(
cfg["TRAIN_BBOX_NORMALIZE_MEANS"]
).cuda()
)
else:
box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(
cfg["TRAIN_BBOX_NORMALIZE_STDS"]
) + torch.FloatTensor(cfg["TRAIN_BBOX_NORMALIZE_MEANS"])
box_deltas = box_deltas.view(1, -1, 4 * len(pascal_classes))
pred_boxes = bbox_transform_inv(boxes, box_deltas, 1)
pred_boxes = clip_boxes(pred_boxes, im_info.data, 1)
else:
# Simply repeat the boxes, once for each class
pred_boxes = np.tile(boxes, (1, scores.shape[1]))
pred_boxes /= im_scales[0]
scores = scores.squeeze()
pred_boxes = pred_boxes.squeeze()
# filter boxes
for j in range(1, len(pascal_classes)):
inds = torch.nonzero(scores[:, j] > thresh_score_final).view(-1)
# if there is det
if inds.numel() == 0:
prediction_string.append("")
else:
cls_scores = scores[:, j][inds]
_, order = torch.sort(cls_scores, 0, True)
if class_agnostic:
cls_boxes = pred_boxes[inds, :]
else:
cls_boxes = pred_boxes[inds][:, j * 4 : (j + 1) * 4]
cls_dets = torch.cat((cls_boxes, cls_scores.unsqueeze(1)), 1)
cls_dets = cls_dets[order]
keep = soft_nms(
cls_boxes[order, :],
cls_scores[order],
thresh=thresh_score_final_soft_nms,
cuda=1,
)
cls_dets = cls_dets[keep.view(-1).long()]
det_final = cls_dets.cpu().numpy()
if det_final.shape[0] == 0:
prediction_string.append("")
else:
for i in range(det_final.shape[0]):
bbox = tuple(int(np.round(x)) for x in det_final[i, :4])
score = det_final[i, -1]
x = int(bbox[0])
y = int(bbox[1])
w = int(bbox[2] - bbox[0])
h = int(bbox[3] - bbox[1])
s = float(score)
prediction_string.append("{} {} {} {} {}".format(s, x, y, w, h))
if Flag_vis:
im2show = vis_detections(img_show, pascal_classes[j], det_final)
img_name_save = os.path.basename(img)[:-4]
prediction_string = " ".join(prediction_string)
submission.append([img_name_save, prediction_string])
# if Flag_vis:
# result_path = os.path.join("results_vis", os.path.basename(img)) # chagne here
# cv2.imwrite(result_path, im2show)
sample_submission = pd.DataFrame(
submission, columns=["image_id", "PredictionString"]
)
sample_submission.to_csv("submission.csv", index=False)
print("\n----------------------END----------------------")
| false | 0 | 26,913 | 0 | 608 | 26,913 |
||
35056588 | <kaggle_start><data_title>SIIM ISIC - 224x224 images<data_name>siic-isic-224x224-images
<code># Note: The io with original images is awful. Therefore I created a dataset https://www.kaggle.com/arroqc/siic-isic-224x224-images of images preprocessed to 224x224 size and saved in png (lossless).
# If you train on original jpeg large imagesm I have put the right lines of code in comments with the added comments : # Use this when training with original images
# # Pytorch Lightning Starter - SSIM Melanoma competition
# I use pytorch lightning both for this competition and in my day to day work. I hope it can serve as a useful tutorial for fellow kagglers.
# Why use Pytorch-Lightning ?
# Pytorch lighntning is designed to help you easily follow a pytorch based training loop and ease modifications that you may want. Want to use a new scheduler ? Then simply modify the configure_optimizer method ! The beauty of it is that it automates all the boring stuff that clogs a pure pytorch code. All these loops, .zero_grad(), .eval(), torch.save etc. are gone and handled by the framework. You just have to focus on the ML part of it. The best things for researchers is that it comes with automated logs through tensorboard to compare your many experiments and easy switches between GPU, DataParallel, TPU mixed precision etc. Obviously kaggle is not very friendly with logs so I suggest reproducing the code of this kernel in a local environment and use tensorboard there.
# You may ask why not simply use fastai. This is now a matter of preference. Fastai automates a lot of stuff with best practices like .fit_one_cycle. But on the other hand unless you have a lot of experience with it I find it rather opaque in what is happening behind the scenes. It's a framework designed to go with doing the fastai course so that you understand the options. If like me you learnt deep learning in a more academic environment in pure pytorch or pure tensorflow then you may find fastai hard to understand without listening to J. Howard courses. Similarly as soon as you want to do something a bit different it can become hard to understand how to change anything. On a personal note, I'll wait for the fastai v2 course before delving into it.
#
# Let's install it as it not in kaggle by default.
#
# ## Loading data
# First let's open the csv. One thing we need to make sure when splitting data in a medical context is to split by patient ID rather than image ID. Otherwise you run the risk of having some data leakage.
#
import os
import random
import argparse
from pathlib import Path
import PIL.Image as Image
import pandas as pd
import numpy as np
import cv2
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import train_test_split
import pytorch_lightning as pl
import torch.utils.data as tdata
import torch
import torch.nn as nn
import torchvision.models as models
from torchvision import transforms
# Reproductibility
SEED = 33
random.seed(SEED)
os.environ["PYTHONHASHSEED"] = str(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
def dict_to_args(d):
args = argparse.Namespace()
def dict_to_args_recursive(args, d, prefix=""):
for k, v in d.items():
if type(v) == dict:
dict_to_args_recursive(args, v, prefix=k)
elif type(v) in [tuple, list]:
continue
else:
if prefix:
args.__setattr__(prefix + "_" + k, v)
else:
args.__setattr__(k, v)
dict_to_args_recursive(args, d)
return args
CSV_DIR = Path("/kaggle/input/siim-isic-melanoma-classification/")
train_df = pd.read_csv(CSV_DIR / "train.csv")
test_df = pd.read_csv(CSV_DIR / "test.csv")
# IMAGE_DIR = Path('/kaggle/input/siim-isic-melanoma-classification/jpeg') # Use this when training with original images
IMAGE_DIR = Path("/kaggle/input/siic-isic-224x224-images/")
train_df.head()
train_df.groupby(by=["patient_id"])["image_name"].count()
train_df.groupby(by=["patient_id"])["target"].mean()
# So you have patients that have multiple images. Also apparently the data is imbalanced. Let's verify:
train_df.groupby(["target"]).count()
# so we have approx 60 times more negatives than positives. We need to make sure we split good/bad patients equally.
patient_means = train_df.groupby(["patient_id"])["target"].mean()
patient_ids = train_df["patient_id"].unique()
# Now let's make our split
train_idx, val_idx = train_test_split(
np.arange(len(patient_ids)), stratify=(patient_means > 0), test_size=0.2
) # KFold + averaging should be much better considering how small the dataset is for malignant cases
pid_train = patient_ids[train_idx]
pid_val = patient_ids[val_idx]
# Let's verify the split was correct
train_df[train_df["patient_id"].isin(pid_train)].groupby(["target"]).count()
train_df[train_df["patient_id"].isin(pid_val)].groupby(["target"]).count()
# ## Pytorch Dataset
# A dataset should simply return all the information necessary for a sample by defining the getitem and len magic methods.
class SIIMDataset(tdata.Dataset):
def __init__(self, df, transform, test=False):
self.df = df
self.transform = transform
self.test = test
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
meta = self.df.iloc[idx]
# image_fn = meta['image_name'] + '.jpg' # Use this when training with original images
image_fn = meta["image_name"] + ".png"
if self.test:
img = Image.open(str(IMAGE_DIR / ("test/" + image_fn)))
else:
img = Image.open(str(IMAGE_DIR / ("train/" + image_fn)))
if self.transform is not None:
img = self.transform(img)
if self.test:
return {"image": img}
else:
return {"image": img, "target": meta["target"]}
# ## Model
class AdaptiveConcatPool2d(nn.Module):
def __init__(self):
super().__init__()
self.avg = nn.AdaptiveAvgPool2d(output_size=(1, 1))
self.max = nn.AdaptiveMaxPool2d(output_size=(1, 1))
def forward(self, x):
avg_x = self.avg(x)
max_x = self.max(x)
return torch.cat([avg_x, max_x], dim=1)
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.shape[0], -1)
class Model(nn.Module):
def __init__(self, c_out=1, arch="resnet34"):
super().__init__()
if arch == "resnet34":
remove_range = 2
m = models.resnet34(pretrained=True)
elif arch == "seresnext50":
m = torch.hub.load(
"facebookresearch/semi-supervised-ImageNet1K-models",
"resnext50_32x4d_ssl",
)
remove_range = 2
c_feature = list(m.children())[-1].in_features
self.base = nn.Sequential(*list(m.children())[:-remove_range])
self.head = nn.Sequential(
AdaptiveConcatPool2d(), Flatten(), nn.Linear(c_feature * 2, c_out)
)
def forward(self, x):
h = self.base(x)
logits = self.head(h).squeeze(1)
return logits
#
# ## Pytorch Lightning module definition
# In a normal pytorch code you probably would instantiate the model, dataloaders and make a nested for loop for epochs and batches. Pytorch lightning automates the engineering parts like the loops so that you focus on the ML part. To do that you create a pytorch lightning model and then define every ML step inside of it. To help you understand I have added comments under every method you need to implement.
#
import torch.nn.functional as F
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2, logits=False, reduce=True):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.logits = logits
self.reduce = reduce
def forward(self, inputs, targets):
if self.logits:
BCE_loss = F.binary_cross_entropy_with_logits(
inputs, targets, reduction="none"
)
else:
BCE_loss = F.binary_cross_entropy(inputs, targets, reduction="none")
pt = torch.exp(-BCE_loss)
F_loss = self.alpha * (1 - pt) ** self.gamma * BCE_loss
if self.reduce:
return torch.mean(F_loss)
else:
return F_loss
class LightModel(pl.LightningModule):
def __init__(self, df_train, df_test, pid_train, pid_val, hparams):
# This is where paths and options should be stored. I also store the
# train_idx, val_idx for cross validation since the dataset are defined
# in the module !
super().__init__()
self.pid_train = pid_train
self.pid_val = pid_val
self.df_train = df_train
self.model = Model(
arch=hparams.arch
) # You will obviously want to make the model better :)
self.hparams = hparams
# Defining datasets here instead of in prepare_data usually solves a lot of problems for me...
self.transform_train = transforms.Compose(
[ # transforms.Resize((224, 224)), # Use this when training with original images
transforms.RandomHorizontalFlip(0.5),
transforms.RandomVerticalFlip(0.5),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
),
]
)
self.transform_test = transforms.Compose(
[ # transforms.Resize((224, 224)), # Use this when training with original images
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
),
]
)
self.trainset = SIIMDataset(
self.df_train[self.df_train["patient_id"].isin(pid_train)],
self.transform_train,
)
self.valset = SIIMDataset(
self.df_train[self.df_train["patient_id"].isin(pid_val)],
self.transform_test,
)
self.testset = SIIMDataset(df_test, self.transform_test, test=True)
def forward(self, batch):
# What to do with a batch in a forward. Usually simple if everything is already defined in the model.
return self.model(batch["image"])
def prepare_data(self):
# This is called at the start of training
pass
def train_dataloader(self):
# Simply define a pytorch dataloader here that will take care of batching. Note it works well with dictionnaries !
train_dl = tdata.DataLoader(
self.trainset,
batch_size=self.hparams.batch_size,
shuffle=True,
num_workers=os.cpu_count(),
)
return train_dl
def val_dataloader(self):
# Same but for validation. Pytorch lightning allows multiple validation dataloaders hence why I return a list.
val_dl = tdata.DataLoader(
self.valset,
batch_size=self.hparams.batch_size,
shuffle=False,
num_workers=os.cpu_count(),
)
return [val_dl]
def test_dataloader(self):
test_dl = tdata.DataLoader(
self.testset,
batch_size=self.hparams.batch_size,
shuffle=False,
num_workers=os.cpu_count(),
)
return [test_dl]
def loss_function(self, logits, gt):
# How to calculate the loss. Note this method is actually not a part of pytorch lightning ! It's only good practice
# loss_fn = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([32542/584]).to(logits.device)) # Let's rebalance the weights for each class here.
loss_fn = FocalLoss(logits=True)
gt = gt.float()
loss = loss_fn(logits, gt)
return loss
def configure_optimizers(self):
# Optimizers and schedulers. Note that each are in lists of equal length to allow multiple optimizers (for GAN for example)
optimizer = torch.optim.Adam(
self.model.parameters(), lr=self.hparams.lr, weight_decay=3e-6
)
scheduler = torch.optim.lr_scheduler.OneCycleLR(
optimizer,
max_lr=10 * self.hparams.lr,
epochs=self.hparams.epochs,
steps_per_epoch=len(self.train_dataloader()),
)
return [optimizer], [scheduler]
def training_step(self, batch, batch_idx):
# This is where you must define what happens during a training step (per batch)
logits = self(batch)
loss = self.loss_function(logits, batch["target"]).unsqueeze(
0
) # You need to unsqueeze in case you do multi-gpu training
# Pytorch lightning will call .backward on what is called 'loss' in output
# 'log' is reserved for tensorboard and will log everything define in the dictionary
return {"loss": loss, "log": {"train_loss": loss}}
def validation_step(self, batch, batch_idx):
# This is where you must define what happens during a validation step (per batch)
logits = self(batch)
loss = self.loss_function(logits, batch["target"]).unsqueeze(0)
probs = torch.sigmoid(logits)
return {"val_loss": loss, "probs": probs, "gt": batch["target"]}
def test_step(self, batch, batch_idx):
logits = self(batch)
probs = torch.sigmoid(logits)
return {"probs": probs}
def validation_epoch_end(self, outputs):
# This is what happens at the end of validation epoch. Usually gathering all predictions
# outputs is a list of dictionary from each step.
avg_loss = torch.cat([out["val_loss"] for out in outputs], dim=0).mean()
probs = torch.cat([out["probs"] for out in outputs], dim=0)
gt = torch.cat([out["gt"] for out in outputs], dim=0)
probs = probs.detach().cpu().numpy()
gt = gt.detach().cpu().numpy()
auc_roc = torch.tensor(roc_auc_score(gt, probs))
tensorboard_logs = {"val_loss": avg_loss, "auc": auc_roc}
print(f"Epoch {self.current_epoch}: {avg_loss:.2f}, auc: {auc_roc:.4f}")
return {"avg_val_loss": avg_loss, "log": tensorboard_logs}
def test_epoch_end(self, outputs):
probs = torch.cat([out["probs"] for out in outputs], dim=0)
probs = probs.detach().cpu().numpy()
self.test_predicts = probs # Save prediction internally for easy access
# We need to return something
return {"dummy_item": 0}
#
# ## Training
# Let's start by specifying parameters, the seed and output folder.
#
# dict_to_args is a simple helper to make hparams act like args from argparse. This makes it trivial to then use argparse
OUTPUT_DIR = "./lightning_logs"
hparams = dict_to_args(
{
"batch_size": 64,
"lr": 1e-4, # common when using pretrained
"epochs": 10,
"arch": "seresnext50",
}
)
# For training we just need to instantiate the pytorch lightning module and a trainer with a few options. Most importantly this is where you specify how many GPU to use (or TPU) and if you want to do mixed precision training (with apex). For the purpose of this kernel I just do FP32 1GPU training but please read the pytorch lightning doc if you want to try TPU and/or mixed precision.
# Initiate model
model = LightModel(train_df, test_df, pid_train, pid_val, hparams)
tb_logger = pl.loggers.TensorBoardLogger(
save_dir="./",
name=f"baseline", # This will create different subfolders for your models
version=f"0",
) # If you use KFold you can specify here the fold number like f'fold_{fold+1}'
checkpoint_callback = pl.callbacks.ModelCheckpoint(
filepath=tb_logger.log_dir + "/{epoch:02d}-{auc:.4f}", monitor="auc", mode="max"
)
# Define trainer
# Here you can
trainer = pl.Trainer(
max_nb_epochs=hparams.epochs,
auto_lr_find=False, # Usually the auto is pretty bad. You should instead plot and pick manually.
gradient_clip_val=1,
nb_sanity_val_steps=0, # Comment that out to reactivate sanity but the ROC will fail if the sample has only class 0
checkpoint_callback=checkpoint_callback,
gpus=1,
early_stop_callback=False,
progress_bar_refresh_rate=0,
)
trainer.fit(model)
# ## Test time
# The easy part :)
# Grab best checkpoint file
out = Path(tb_logger.log_dir)
aucs = [ckpt.stem[-4:] for ckpt in out.iterdir()]
best_auc_idx = aucs.index(max(aucs))
best_ckpt = list(out.iterdir())[best_auc_idx]
print("Using ", best_ckpt)
trainer = pl.Trainer(resume_from_checkpoint=str(best_ckpt), gpus=1)
trainer.test(model)
preds = model.test_predicts
test_df["target"] = preds
submission = test_df[["image_name", "target"]]
submission.to_csv("submission.csv", index=False)
submission.head()
submission.head(20)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0035/056/35056588.ipynb | siic-isic-224x224-images | arroqc | [{"Id": 35056588, "ScriptId": 9744592, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1609480, "CreationDate": "05/29/2020 15:48:29", "VersionNumber": 1.0, "Title": "SIIM ISIC- Pytorch Lightning Starter SEResnext50", "EvaluationDate": "05/29/2020", "IsChange": true, "TotalLines": 380.0, "LinesInsertedFromPrevious": 380.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 38779547, "KernelVersionId": 35056588, "SourceDatasetVersionId": 1195048}] | [{"Id": 1195048, "DatasetId": 680469, "DatasourceVersionId": 1226267, "CreatorUserId": 1609480, "LicenseName": "Unknown", "CreationDate": "05/28/2020 16:27:52", "VersionNumber": 1.0, "Title": "SIIM ISIC - 224x224 images", "Slug": "siic-isic-224x224-images", "Subtitle": "Preprocessed jpeg images for SIIM ISIC competition", "Description": NaN, "VersionNotes": "Initial release", "TotalCompressedBytes": 0.0, "TotalUncompressedBytes": 0.0}] | [{"Id": 680469, "CreatorUserId": 1609480, "OwnerUserId": 1609480.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 1195048.0, "CurrentDatasourceVersionId": 1226267.0, "ForumId": 695012, "Type": 2, "CreationDate": "05/28/2020 16:27:52", "LastActivityDate": "05/28/2020", "TotalViews": 8881, "TotalDownloads": 1527, "TotalVotes": 67, "TotalKernels": 47}] | [{"Id": 1609480, "UserName": "arroqc", "DisplayName": "Arnaud Roussel", "RegisterDate": "02/04/2018", "PerformanceTier": 3}] | # Note: The io with original images is awful. Therefore I created a dataset https://www.kaggle.com/arroqc/siic-isic-224x224-images of images preprocessed to 224x224 size and saved in png (lossless).
# If you train on original jpeg large imagesm I have put the right lines of code in comments with the added comments : # Use this when training with original images
# # Pytorch Lightning Starter - SSIM Melanoma competition
# I use pytorch lightning both for this competition and in my day to day work. I hope it can serve as a useful tutorial for fellow kagglers.
# Why use Pytorch-Lightning ?
# Pytorch lighntning is designed to help you easily follow a pytorch based training loop and ease modifications that you may want. Want to use a new scheduler ? Then simply modify the configure_optimizer method ! The beauty of it is that it automates all the boring stuff that clogs a pure pytorch code. All these loops, .zero_grad(), .eval(), torch.save etc. are gone and handled by the framework. You just have to focus on the ML part of it. The best things for researchers is that it comes with automated logs through tensorboard to compare your many experiments and easy switches between GPU, DataParallel, TPU mixed precision etc. Obviously kaggle is not very friendly with logs so I suggest reproducing the code of this kernel in a local environment and use tensorboard there.
# You may ask why not simply use fastai. This is now a matter of preference. Fastai automates a lot of stuff with best practices like .fit_one_cycle. But on the other hand unless you have a lot of experience with it I find it rather opaque in what is happening behind the scenes. It's a framework designed to go with doing the fastai course so that you understand the options. If like me you learnt deep learning in a more academic environment in pure pytorch or pure tensorflow then you may find fastai hard to understand without listening to J. Howard courses. Similarly as soon as you want to do something a bit different it can become hard to understand how to change anything. On a personal note, I'll wait for the fastai v2 course before delving into it.
#
# Let's install it as it not in kaggle by default.
#
# ## Loading data
# First let's open the csv. One thing we need to make sure when splitting data in a medical context is to split by patient ID rather than image ID. Otherwise you run the risk of having some data leakage.
#
import os
import random
import argparse
from pathlib import Path
import PIL.Image as Image
import pandas as pd
import numpy as np
import cv2
from sklearn.metrics import roc_auc_score
from sklearn.model_selection import train_test_split
import pytorch_lightning as pl
import torch.utils.data as tdata
import torch
import torch.nn as nn
import torchvision.models as models
from torchvision import transforms
# Reproductibility
SEED = 33
random.seed(SEED)
os.environ["PYTHONHASHSEED"] = str(SEED)
np.random.seed(SEED)
torch.manual_seed(SEED)
torch.cuda.manual_seed(SEED)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
def dict_to_args(d):
args = argparse.Namespace()
def dict_to_args_recursive(args, d, prefix=""):
for k, v in d.items():
if type(v) == dict:
dict_to_args_recursive(args, v, prefix=k)
elif type(v) in [tuple, list]:
continue
else:
if prefix:
args.__setattr__(prefix + "_" + k, v)
else:
args.__setattr__(k, v)
dict_to_args_recursive(args, d)
return args
CSV_DIR = Path("/kaggle/input/siim-isic-melanoma-classification/")
train_df = pd.read_csv(CSV_DIR / "train.csv")
test_df = pd.read_csv(CSV_DIR / "test.csv")
# IMAGE_DIR = Path('/kaggle/input/siim-isic-melanoma-classification/jpeg') # Use this when training with original images
IMAGE_DIR = Path("/kaggle/input/siic-isic-224x224-images/")
train_df.head()
train_df.groupby(by=["patient_id"])["image_name"].count()
train_df.groupby(by=["patient_id"])["target"].mean()
# So you have patients that have multiple images. Also apparently the data is imbalanced. Let's verify:
train_df.groupby(["target"]).count()
# so we have approx 60 times more negatives than positives. We need to make sure we split good/bad patients equally.
patient_means = train_df.groupby(["patient_id"])["target"].mean()
patient_ids = train_df["patient_id"].unique()
# Now let's make our split
train_idx, val_idx = train_test_split(
np.arange(len(patient_ids)), stratify=(patient_means > 0), test_size=0.2
) # KFold + averaging should be much better considering how small the dataset is for malignant cases
pid_train = patient_ids[train_idx]
pid_val = patient_ids[val_idx]
# Let's verify the split was correct
train_df[train_df["patient_id"].isin(pid_train)].groupby(["target"]).count()
train_df[train_df["patient_id"].isin(pid_val)].groupby(["target"]).count()
# ## Pytorch Dataset
# A dataset should simply return all the information necessary for a sample by defining the getitem and len magic methods.
class SIIMDataset(tdata.Dataset):
def __init__(self, df, transform, test=False):
self.df = df
self.transform = transform
self.test = test
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
meta = self.df.iloc[idx]
# image_fn = meta['image_name'] + '.jpg' # Use this when training with original images
image_fn = meta["image_name"] + ".png"
if self.test:
img = Image.open(str(IMAGE_DIR / ("test/" + image_fn)))
else:
img = Image.open(str(IMAGE_DIR / ("train/" + image_fn)))
if self.transform is not None:
img = self.transform(img)
if self.test:
return {"image": img}
else:
return {"image": img, "target": meta["target"]}
# ## Model
class AdaptiveConcatPool2d(nn.Module):
def __init__(self):
super().__init__()
self.avg = nn.AdaptiveAvgPool2d(output_size=(1, 1))
self.max = nn.AdaptiveMaxPool2d(output_size=(1, 1))
def forward(self, x):
avg_x = self.avg(x)
max_x = self.max(x)
return torch.cat([avg_x, max_x], dim=1)
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.shape[0], -1)
class Model(nn.Module):
def __init__(self, c_out=1, arch="resnet34"):
super().__init__()
if arch == "resnet34":
remove_range = 2
m = models.resnet34(pretrained=True)
elif arch == "seresnext50":
m = torch.hub.load(
"facebookresearch/semi-supervised-ImageNet1K-models",
"resnext50_32x4d_ssl",
)
remove_range = 2
c_feature = list(m.children())[-1].in_features
self.base = nn.Sequential(*list(m.children())[:-remove_range])
self.head = nn.Sequential(
AdaptiveConcatPool2d(), Flatten(), nn.Linear(c_feature * 2, c_out)
)
def forward(self, x):
h = self.base(x)
logits = self.head(h).squeeze(1)
return logits
#
# ## Pytorch Lightning module definition
# In a normal pytorch code you probably would instantiate the model, dataloaders and make a nested for loop for epochs and batches. Pytorch lightning automates the engineering parts like the loops so that you focus on the ML part. To do that you create a pytorch lightning model and then define every ML step inside of it. To help you understand I have added comments under every method you need to implement.
#
import torch.nn.functional as F
class FocalLoss(nn.Module):
def __init__(self, alpha=1, gamma=2, logits=False, reduce=True):
super(FocalLoss, self).__init__()
self.alpha = alpha
self.gamma = gamma
self.logits = logits
self.reduce = reduce
def forward(self, inputs, targets):
if self.logits:
BCE_loss = F.binary_cross_entropy_with_logits(
inputs, targets, reduction="none"
)
else:
BCE_loss = F.binary_cross_entropy(inputs, targets, reduction="none")
pt = torch.exp(-BCE_loss)
F_loss = self.alpha * (1 - pt) ** self.gamma * BCE_loss
if self.reduce:
return torch.mean(F_loss)
else:
return F_loss
class LightModel(pl.LightningModule):
def __init__(self, df_train, df_test, pid_train, pid_val, hparams):
# This is where paths and options should be stored. I also store the
# train_idx, val_idx for cross validation since the dataset are defined
# in the module !
super().__init__()
self.pid_train = pid_train
self.pid_val = pid_val
self.df_train = df_train
self.model = Model(
arch=hparams.arch
) # You will obviously want to make the model better :)
self.hparams = hparams
# Defining datasets here instead of in prepare_data usually solves a lot of problems for me...
self.transform_train = transforms.Compose(
[ # transforms.Resize((224, 224)), # Use this when training with original images
transforms.RandomHorizontalFlip(0.5),
transforms.RandomVerticalFlip(0.5),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
),
]
)
self.transform_test = transforms.Compose(
[ # transforms.Resize((224, 224)), # Use this when training with original images
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
),
]
)
self.trainset = SIIMDataset(
self.df_train[self.df_train["patient_id"].isin(pid_train)],
self.transform_train,
)
self.valset = SIIMDataset(
self.df_train[self.df_train["patient_id"].isin(pid_val)],
self.transform_test,
)
self.testset = SIIMDataset(df_test, self.transform_test, test=True)
def forward(self, batch):
# What to do with a batch in a forward. Usually simple if everything is already defined in the model.
return self.model(batch["image"])
def prepare_data(self):
# This is called at the start of training
pass
def train_dataloader(self):
# Simply define a pytorch dataloader here that will take care of batching. Note it works well with dictionnaries !
train_dl = tdata.DataLoader(
self.trainset,
batch_size=self.hparams.batch_size,
shuffle=True,
num_workers=os.cpu_count(),
)
return train_dl
def val_dataloader(self):
# Same but for validation. Pytorch lightning allows multiple validation dataloaders hence why I return a list.
val_dl = tdata.DataLoader(
self.valset,
batch_size=self.hparams.batch_size,
shuffle=False,
num_workers=os.cpu_count(),
)
return [val_dl]
def test_dataloader(self):
test_dl = tdata.DataLoader(
self.testset,
batch_size=self.hparams.batch_size,
shuffle=False,
num_workers=os.cpu_count(),
)
return [test_dl]
def loss_function(self, logits, gt):
# How to calculate the loss. Note this method is actually not a part of pytorch lightning ! It's only good practice
# loss_fn = nn.BCEWithLogitsLoss(pos_weight=torch.tensor([32542/584]).to(logits.device)) # Let's rebalance the weights for each class here.
loss_fn = FocalLoss(logits=True)
gt = gt.float()
loss = loss_fn(logits, gt)
return loss
def configure_optimizers(self):
# Optimizers and schedulers. Note that each are in lists of equal length to allow multiple optimizers (for GAN for example)
optimizer = torch.optim.Adam(
self.model.parameters(), lr=self.hparams.lr, weight_decay=3e-6
)
scheduler = torch.optim.lr_scheduler.OneCycleLR(
optimizer,
max_lr=10 * self.hparams.lr,
epochs=self.hparams.epochs,
steps_per_epoch=len(self.train_dataloader()),
)
return [optimizer], [scheduler]
def training_step(self, batch, batch_idx):
# This is where you must define what happens during a training step (per batch)
logits = self(batch)
loss = self.loss_function(logits, batch["target"]).unsqueeze(
0
) # You need to unsqueeze in case you do multi-gpu training
# Pytorch lightning will call .backward on what is called 'loss' in output
# 'log' is reserved for tensorboard and will log everything define in the dictionary
return {"loss": loss, "log": {"train_loss": loss}}
def validation_step(self, batch, batch_idx):
# This is where you must define what happens during a validation step (per batch)
logits = self(batch)
loss = self.loss_function(logits, batch["target"]).unsqueeze(0)
probs = torch.sigmoid(logits)
return {"val_loss": loss, "probs": probs, "gt": batch["target"]}
def test_step(self, batch, batch_idx):
logits = self(batch)
probs = torch.sigmoid(logits)
return {"probs": probs}
def validation_epoch_end(self, outputs):
# This is what happens at the end of validation epoch. Usually gathering all predictions
# outputs is a list of dictionary from each step.
avg_loss = torch.cat([out["val_loss"] for out in outputs], dim=0).mean()
probs = torch.cat([out["probs"] for out in outputs], dim=0)
gt = torch.cat([out["gt"] for out in outputs], dim=0)
probs = probs.detach().cpu().numpy()
gt = gt.detach().cpu().numpy()
auc_roc = torch.tensor(roc_auc_score(gt, probs))
tensorboard_logs = {"val_loss": avg_loss, "auc": auc_roc}
print(f"Epoch {self.current_epoch}: {avg_loss:.2f}, auc: {auc_roc:.4f}")
return {"avg_val_loss": avg_loss, "log": tensorboard_logs}
def test_epoch_end(self, outputs):
probs = torch.cat([out["probs"] for out in outputs], dim=0)
probs = probs.detach().cpu().numpy()
self.test_predicts = probs # Save prediction internally for easy access
# We need to return something
return {"dummy_item": 0}
#
# ## Training
# Let's start by specifying parameters, the seed and output folder.
#
# dict_to_args is a simple helper to make hparams act like args from argparse. This makes it trivial to then use argparse
OUTPUT_DIR = "./lightning_logs"
hparams = dict_to_args(
{
"batch_size": 64,
"lr": 1e-4, # common when using pretrained
"epochs": 10,
"arch": "seresnext50",
}
)
# For training we just need to instantiate the pytorch lightning module and a trainer with a few options. Most importantly this is where you specify how many GPU to use (or TPU) and if you want to do mixed precision training (with apex). For the purpose of this kernel I just do FP32 1GPU training but please read the pytorch lightning doc if you want to try TPU and/or mixed precision.
# Initiate model
model = LightModel(train_df, test_df, pid_train, pid_val, hparams)
tb_logger = pl.loggers.TensorBoardLogger(
save_dir="./",
name=f"baseline", # This will create different subfolders for your models
version=f"0",
) # If you use KFold you can specify here the fold number like f'fold_{fold+1}'
checkpoint_callback = pl.callbacks.ModelCheckpoint(
filepath=tb_logger.log_dir + "/{epoch:02d}-{auc:.4f}", monitor="auc", mode="max"
)
# Define trainer
# Here you can
trainer = pl.Trainer(
max_nb_epochs=hparams.epochs,
auto_lr_find=False, # Usually the auto is pretty bad. You should instead plot and pick manually.
gradient_clip_val=1,
nb_sanity_val_steps=0, # Comment that out to reactivate sanity but the ROC will fail if the sample has only class 0
checkpoint_callback=checkpoint_callback,
gpus=1,
early_stop_callback=False,
progress_bar_refresh_rate=0,
)
trainer.fit(model)
# ## Test time
# The easy part :)
# Grab best checkpoint file
out = Path(tb_logger.log_dir)
aucs = [ckpt.stem[-4:] for ckpt in out.iterdir()]
best_auc_idx = aucs.index(max(aucs))
best_ckpt = list(out.iterdir())[best_auc_idx]
print("Using ", best_ckpt)
trainer = pl.Trainer(resume_from_checkpoint=str(best_ckpt), gpus=1)
trainer.test(model)
preds = model.test_predicts
test_df["target"] = preds
submission = test_df[["image_name", "target"]]
submission.to_csv("submission.csv", index=False)
submission.head()
submission.head(20)
| false | 0 | 4,576 | 0 | 45 | 4,576 |
||
35538162 | <kaggle_start><code># Install `tensorflow-datasets`.
# Define wrapper.
# adapted from https://www.tensorflow.org/datasets/add_dataset
import tensorflow_datasets.public_api as tfds
class MyDataset(tfds.core.GeneratorBasedBuilder):
"""Short description of my dataset."""
VERSION = tfds.core.Version("0.1.0")
def _info(self):
# metadata goes here
pass # TODO
def _split_generators(self, dl_manager):
# specifies what data goes into train, validation, test (or whatever)
pass # TODO
def _generate_examples(self):
# Yields examples from the dataset
yield "key", {}
# Supposing the above had been attached as a utility script `dataset.py`, we just import the wrapper to make the loader aware of it, and then point it to wherever the dataset is living on Kaggle.
from dataset import MyDataset
from kaggle_datasets import KaggleDatasets
if tpu:
DATA_DIR = KaggleDatasets().get_gcs_path("my-dataset")
else:
DATA_DIR = "/kaggle/input/my-dataset"
# And now we're set!
ds = tfds.load("my_dataset", split=["train", "test"], data_dir=DATA_DIR)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0035/538/35538162.ipynb | null | null | [{"Id": 35538162, "ScriptId": 9936942, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2003505, "CreationDate": "06/05/2020 18:23:26", "VersionNumber": 3.0, "Title": "TFDS Example", "EvaluationDate": "06/05/2020", "IsChange": true, "TotalLines": 40.0, "LinesInsertedFromPrevious": 4.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 36.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | # Install `tensorflow-datasets`.
# Define wrapper.
# adapted from https://www.tensorflow.org/datasets/add_dataset
import tensorflow_datasets.public_api as tfds
class MyDataset(tfds.core.GeneratorBasedBuilder):
"""Short description of my dataset."""
VERSION = tfds.core.Version("0.1.0")
def _info(self):
# metadata goes here
pass # TODO
def _split_generators(self, dl_manager):
# specifies what data goes into train, validation, test (or whatever)
pass # TODO
def _generate_examples(self):
# Yields examples from the dataset
yield "key", {}
# Supposing the above had been attached as a utility script `dataset.py`, we just import the wrapper to make the loader aware of it, and then point it to wherever the dataset is living on Kaggle.
from dataset import MyDataset
from kaggle_datasets import KaggleDatasets
if tpu:
DATA_DIR = KaggleDatasets().get_gcs_path("my-dataset")
else:
DATA_DIR = "/kaggle/input/my-dataset"
# And now we're set!
ds = tfds.load("my_dataset", split=["train", "test"], data_dir=DATA_DIR)
| false | 0 | 300 | 0 | 6 | 300 |
||
35536478 | <kaggle_start><code># Install `tensorflow-datasets`.
# Define wrapper.
# from https://www.tensorflow.org/datasets/add_dataset
import tensorflow_datasets.public_api as tfds
class MyDataset(tfds.core.GeneratorBasedBuilder):
"""Short description of my dataset."""
VERSION = tfds.core.Version("0.1.0")
def _info(self):
# Specifies the tfds.core.DatasetInfo object
pass # TODO
def _split_generators(self, dl_manager):
# Downloads the data and defines the splits
# dl_manager is a tfds.download.DownloadManager that can be used to
# download and extract URLs
pass # TODO
def _generate_examples(self):
# Yields examples from the dataset
yield "key", {}
# Supposing the above had been attached as a utility script `dataset.py`, we just import the wrapper to make the loader aware of it, and then point it to wherever the it's living on Kaggle.
from dataset import MyDataset
from kaggle_datasets import KaggleDatasets
if tpu:
DATA_DIR = KaggleDatasets().get_gcs_path("my-dataset")
else:
DATA_DIR = "/kaggle/input/my-dataset"
# And now we're set!
ds = tfds.load("my_dataset", split=["train", "test"], data_dir=DATA_DIR)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0035/536/35536478.ipynb | null | null | [{"Id": 35536478, "ScriptId": 9936942, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2003505, "CreationDate": "06/05/2020 17:52:48", "VersionNumber": 1.0, "Title": "TFDS Example", "EvaluationDate": "06/05/2020", "IsChange": true, "TotalLines": 42.0, "LinesInsertedFromPrevious": 42.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | # Install `tensorflow-datasets`.
# Define wrapper.
# from https://www.tensorflow.org/datasets/add_dataset
import tensorflow_datasets.public_api as tfds
class MyDataset(tfds.core.GeneratorBasedBuilder):
"""Short description of my dataset."""
VERSION = tfds.core.Version("0.1.0")
def _info(self):
# Specifies the tfds.core.DatasetInfo object
pass # TODO
def _split_generators(self, dl_manager):
# Downloads the data and defines the splits
# dl_manager is a tfds.download.DownloadManager that can be used to
# download and extract URLs
pass # TODO
def _generate_examples(self):
# Yields examples from the dataset
yield "key", {}
# Supposing the above had been attached as a utility script `dataset.py`, we just import the wrapper to make the loader aware of it, and then point it to wherever the it's living on Kaggle.
from dataset import MyDataset
from kaggle_datasets import KaggleDatasets
if tpu:
DATA_DIR = KaggleDatasets().get_gcs_path("my-dataset")
else:
DATA_DIR = "/kaggle/input/my-dataset"
# And now we're set!
ds = tfds.load("my_dataset", split=["train", "test"], data_dir=DATA_DIR)
| false | 0 | 325 | 0 | 6 | 325 |
||
42613117 | <kaggle_start><code># # Project Assignment Problem Statement
# * There are S students, P projects, and each project should have at least R students ( R < S/P)
# * Each student rank orders at most K (K < P, for example K = 5) projects according to their preferences
# * After a student is assigned to a project, the quality of assignment from that student’s perspective is Q ( 1 <= Q <= K). Lower the Q, better it is for the student
# * We want low class-wise average Q so that the performance is good at the class lever
# * We also want a low variance in class wise Q so that the assignment is fairer
# local file path stuff (skip if need be)
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
# print(os.path.join(dirname, filename))
pass
# ### Main Classroom obj to deal with manipulation
import collections
class Classroom:
def __init__(self, P, S, R, K):
self.P, self.S, self.K, self.R, self.Q = P, S, K, R, -1
self.projects = collections.OrderedDict()
self.students = collections.OrderedDict()
def generate_data(self):
"""Generates mock project and random student preferences based on P,S,K values"""
for i in range(0, self.P):
proj_name = ""
if i > 25:
temp = i
while temp >= 0:
proj_name = chr(ord("a") + (temp % 26)) + proj_name
temp = int(temp / 26) - 1
print(proj_name)
else:
proj_name = chr(ord("a") + i)
self.projects[proj_name] = []
for i in range(0, self.S):
sname = "s" + str(i)
import random
assignments = random.sample(range(self.P), self.K)
items = list(self.projects.items())
preferences = []
for n in assignments:
preferences.append(items[n][0])
self.students[sname] = {"Preferences": preferences, "Q": -1}
def pretty_print(self, only_projects=False):
print("\nProjects and Assignments")
for project in self.projects:
print("project: %s %s" % (project, self.projects[project]))
if not only_projects:
print("\nStudents and Preferences")
for student in self.students:
print(
"%s, pref: %s, Q: %s"
% (
student,
self.students[student]["Preferences"],
self.students[student]["Q"],
)
)
def assign_1(self):
# iterate through each project, for each project find best candidate student
# check remaining projects to see if students fits with better project
pass
# ## Approach 1
classroom = Classroom(P=13, S=65, R=5, K=5)
classroom.generate_data()
classroom.pretty_print()
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0042/613/42613117.ipynb | null | null | [{"Id": 42613117, "ScriptId": 11715103, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1892767, "CreationDate": "09/13/2020 22:09:58", "VersionNumber": 1.0, "Title": "project assignment", "EvaluationDate": "09/13/2020", "IsChange": true, "TotalLines": 70.0, "LinesInsertedFromPrevious": 70.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 1}] | null | null | null | null | # # Project Assignment Problem Statement
# * There are S students, P projects, and each project should have at least R students ( R < S/P)
# * Each student rank orders at most K (K < P, for example K = 5) projects according to their preferences
# * After a student is assigned to a project, the quality of assignment from that student’s perspective is Q ( 1 <= Q <= K). Lower the Q, better it is for the student
# * We want low class-wise average Q so that the performance is good at the class lever
# * We also want a low variance in class wise Q so that the assignment is fairer
# local file path stuff (skip if need be)
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
# print(os.path.join(dirname, filename))
pass
# ### Main Classroom obj to deal with manipulation
import collections
class Classroom:
def __init__(self, P, S, R, K):
self.P, self.S, self.K, self.R, self.Q = P, S, K, R, -1
self.projects = collections.OrderedDict()
self.students = collections.OrderedDict()
def generate_data(self):
"""Generates mock project and random student preferences based on P,S,K values"""
for i in range(0, self.P):
proj_name = ""
if i > 25:
temp = i
while temp >= 0:
proj_name = chr(ord("a") + (temp % 26)) + proj_name
temp = int(temp / 26) - 1
print(proj_name)
else:
proj_name = chr(ord("a") + i)
self.projects[proj_name] = []
for i in range(0, self.S):
sname = "s" + str(i)
import random
assignments = random.sample(range(self.P), self.K)
items = list(self.projects.items())
preferences = []
for n in assignments:
preferences.append(items[n][0])
self.students[sname] = {"Preferences": preferences, "Q": -1}
def pretty_print(self, only_projects=False):
print("\nProjects and Assignments")
for project in self.projects:
print("project: %s %s" % (project, self.projects[project]))
if not only_projects:
print("\nStudents and Preferences")
for student in self.students:
print(
"%s, pref: %s, Q: %s"
% (
student,
self.students[student]["Preferences"],
self.students[student]["Q"],
)
)
def assign_1(self):
# iterate through each project, for each project find best candidate student
# check remaining projects to see if students fits with better project
pass
# ## Approach 1
classroom = Classroom(P=13, S=65, R=5, K=5)
classroom.generate_data()
classroom.pretty_print()
| false | 0 | 722 | 1 | 6 | 722 |
||
42552163 | <kaggle_start><code># # Tic Tac Toe
# BMS College of Engineering - Dr Kavitha Sooda
# Create a 3x3 tic tac toe board of "" strings for each value
board = None
# Create a function to display your board
def display_board(board):
pass
display_board(board)
# Create a function to check if anyone won, Use marks "X" or "O"
def check_win(player_mark, board):
## If the player has won then there must be 3 consecutive Player values
pass
check_win("X", board)
# # The AI agent
# ## Create and agent
# 1. Check the immediate move to see if anyone wins
# 2. Check if there are fork moves for anyone
# 3. Create a stategy if no fork or immediate moves
# Immediate move checker
def test_win_move(move, player_mark, board):
test_b = board.copy() # Test board to try the new move
pass
# Fork move checker
def test_fork_move(move, player_mark, board):
test_b = board.copy() # Test board to try the new move
pass
# Strategy if others fail
def final_strategy(board):
pass
# Agents move
def get_agent_move(board):
# Check Agent win or Player win
# Check Agent fork or Player fork
# Final Strategy
pass
# Assemble the game
def tictactoe(board):
pass
# Play!!!
tictactoe(board)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0042/552/42552163.ipynb | null | null | [{"Id": 42552163, "ScriptId": 11684452, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3482267, "CreationDate": "09/13/2020 02:31:24", "VersionNumber": 1.0, "Title": "AI-Lab Program 1", "EvaluationDate": "09/13/2020", "IsChange": true, "TotalLines": 57.0, "LinesInsertedFromPrevious": 57.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | # # Tic Tac Toe
# BMS College of Engineering - Dr Kavitha Sooda
# Create a 3x3 tic tac toe board of "" strings for each value
board = None
# Create a function to display your board
def display_board(board):
pass
display_board(board)
# Create a function to check if anyone won, Use marks "X" or "O"
def check_win(player_mark, board):
## If the player has won then there must be 3 consecutive Player values
pass
check_win("X", board)
# # The AI agent
# ## Create and agent
# 1. Check the immediate move to see if anyone wins
# 2. Check if there are fork moves for anyone
# 3. Create a stategy if no fork or immediate moves
# Immediate move checker
def test_win_move(move, player_mark, board):
test_b = board.copy() # Test board to try the new move
pass
# Fork move checker
def test_fork_move(move, player_mark, board):
test_b = board.copy() # Test board to try the new move
pass
# Strategy if others fail
def final_strategy(board):
pass
# Agents move
def get_agent_move(board):
# Check Agent win or Player win
# Check Agent fork or Player fork
# Final Strategy
pass
# Assemble the game
def tictactoe(board):
pass
# Play!!!
tictactoe(board)
| false | 0 | 362 | 0 | 6 | 362 |
||
42448247 | <kaggle_start><code>import os
import warnings
from tqdm import tqdm
import pandas as pd
import numpy as np
from ml_stratifiers import MultilabelStratifiedKFold
from sklearn.preprocessing import StandardScaler
from sklearn.base import clone
from sklearn.linear_model import LogisticRegression
from sklearn.multioutput import MultiOutputClassifier
from sklearn.pipeline import Pipeline
from sklearn.decomposition import PCA
warnings.filterwarnings("ignore")
def load_datasets(data_path):
train_features = pd.read_csv(os.path.join(data_path, "train_features.csv"))
train_targets_s = pd.read_csv(os.path.join(data_path, "train_targets_scored.csv"))
train_targets_n = pd.read_csv(
os.path.join(data_path, "train_targets_nonscored.csv")
)
test_features = pd.read_csv(os.path.join(data_path, "test_features.csv"))
sample_submission = pd.read_csv(os.path.join(data_path, "sample_submission.csv"))
train_features.set_index("sig_id", inplace=True)
train_targets_s.set_index("sig_id", inplace=True)
test_features.set_index("sig_id", inplace=True)
sample_submission.set_index("sig_id", inplace=True)
assert np.all(test_features.index == sample_submission.index)
return (
train_features,
train_targets_s,
train_targets_n,
test_features,
sample_submission,
)
def preprocess(X, y, test, random_state=2020):
X, y, test = X.copy(), y.copy(), test.copy()
# 1. Filter cp_type=ctl_vehicle
X = X[X.cp_type != "ctl_vehicle"]
X.drop("cp_type", axis=1, inplace=True)
test_control = test.cp_type == "ctl_vehicle"
test.drop("cp_type", axis=1, inplace=True)
# 2. Standard scale continuous features [train + test non-control]
scaler = StandardScaler()
scaler.fit(pd.concat([X.iloc[:, 2:], test.loc[~test_control].iloc[:, 2:]]))
X.iloc[:, 2:] = scaler.transform(X.iloc[:, 2:])
test.iloc[:, 2:] = scaler.transform(test.iloc[:, 2:])
# 3. Encode cp_time & cp_dose
X["cp_dose"] = X["cp_dose"].map({"D1": 0, "D2": 1})
X["cp_time"] = X["cp_time"] // 24 - 1
test["cp_dose"] = test["cp_dose"].map({"D1": 0, "D2": 1})
test["cp_time"] = test["cp_time"] // 24 - 1
# 4. Shuffle data
X = X.sample(frac=1.0, random_state=random_state)
y = y.loc[X.index, :]
assert np.all(y.index == X.index)
return X, y, test, test_control
def split(X, y, n_folds=6, holdout=True):
# remove too rare classes
rare_columns = y.loc[:, y.sum(axis=0) < n_folds].columns
y.drop(rare_columns, axis=1, inplace=True)
# build stratified split index
split_index = np.zeros(len(X)) - 1
cv = MultilabelStratifiedKFold(n_splits=n_folds)
for fold, (index_train, index_test) in enumerate(cv.split(X, y)):
split_index[index_test] = fold
classnames = y.columns.tolist()
X, y = X.values, y.values
# make holdout
X_holdout, y_holdout = None, None
if holdout:
X_holdout, y_holdout = (
X[split_index == n_folds - 1].copy(),
y[split_index == n_folds - 1].copy(),
)
X, y = X[split_index < n_folds - 1], y[split_index < n_folds - 1]
split_index = split_index[split_index < n_folds - 1]
return X, y, split_index, X_holdout, y_holdout, classnames
def logloss(y_true, y_pred, eps=1e-15):
y_pred[y_pred == 0] = eps
y_pred[y_pred == 1] = 1 - eps
return -(y_true * np.log(y_pred) + (1 - y_true) * (np.log(1 - y_pred))).mean()
class OOFTrainer:
def __init__(
self, estimator, metric, hparams=dict(), fit_params=dict(), predict_proba=True
):
"""
Out-of-fold trainer
Training data doesn't persisted
Args:
metric -- function computing loss/metric
hparams -- estimator hyperparameters
"""
self.estimator = estimator
self.metric = metric
self.hparams = hparams
self.fit_params = fit_params
self.predict_proba = predict_proba
self.models_ = None
self.prediction_ = None
self.valid_loss_ = None
def finetune_hparams(self, grid, X, y):
"""Hyperparameters grid search"""
pass
def fit(self, X, y, split_index, verbose=True):
"""Fit models on each fold, validate and predict folds"""
assert len(X) == len(y) == len(split_index)
assert len(y.shape) > 1
self.models_, self.valid_loss_ = [], []
cv_prediction = np.zeros_like(y, dtype=np.float64)
for fold in np.unique(split_index):
if verbose:
print(f"Fold {int(fold)}")
# train|valid split
train, valid = split_index != fold, split_index == fold
x_train, y_train, x_valid, y_valid = X[train], y[train], X[valid], y[valid]
# build and fit model
model = clone(self.estimator)
model = model.set_params(**self.hparams)
model.fit(x_train, y_train, **self.fit_params)
# predict and evaluate validation fold
if self.predict_proba:
prediction = model.predict_proba(x_valid)
else:
prediction = model.predict(x_valid)
cv_prediction[valid] = prediction
# save result
self.models_.append(model)
loss = self.metric(y_valid, prediction)
self.valid_loss_.append(loss)
if verbose:
print(f"Loss={loss}")
self.prediction_ = cv_prediction
return self
def predict(self, X):
"""Predict new data by all models and average"""
prediction = np.zeros((len(X), self.prediction_.shape[1]), dtype=np.float64)
for model in self.models_:
prediction += model.predict_proba(X)
prediction /= len(self.models_)
return prediction
X, y, y_nonscored, test, submission = load_datasets("../input/lish-moa")
X, y, test, test_control = preprocess(X, y, test)
X, y, split_index, X_holdout, y_holdout, classnames = split(
X, y, n_folds=5, holdout=False
)
# X, y, split_index, X_holdout, y_holdout, classnames = split(X, y, n_folds=6, holdout=True)
print("train :", X.shape, y.shape, split_index.shape)
if X_holdout:
print("holdout:", X_holdout.shape, y_holdout.shape)
print("test :", test.shape, submission.shape)
# multioutput wrapper
class MultiLabelClassfifier(MultiOutputClassifier):
def _predict_proba(self, X):
results = [estimator.predict_proba(X) for estimator in self.estimators_]
return np.moveaxis(results, 0, 1)[:, :, 1]
pca = PCA(n_components=50)
logistic = LogisticRegression(max_iter=150, tol=0.1, C=0.01, verbose=0)
base_model = Pipeline(steps=[("pca", pca), ("logistic", logistic)])
multilabel_model = MultiLabelClassfifier(base_model, n_jobs=-1)
oof_model = OOFTrainer(multilabel_model, logloss)
oof_model.fit(X, y, split_index, verbose=True)
result.append((p, np.mean(oof_model.valid_loss_)))
# todo: different hparams for different classes to MultiLabel
# from sklearn.base import BaseEstimator
# class MultiLabel(BaseEstimator):
# def __init__(self, estimator, hparams, verbose=0):
# """ """
# self.estimator = estimator
# self.hparams = hparams
# self.verbose = verbose
# self.models_ = []
# def fit(self, X, y, **fit_params):
# labels_iterator = range(y.shape[1])
# for target in (tqdm(labels_iterator) if self.verbose else labels_iterator):
# model = self.estimator(**self.hparams)
# model.fit(X, y[:, target], **fit_params)
# self.models_.append(model)
# return self
# def predict(self, X):
# raise NotImplementedError
# def predict_proba(self, X):
# results = [model.predict_proba(X) for model in self.models_]
# return np.moveaxis(results, 0, 1)[:, :, 1]
# pca = PCA(n_components=50)
# X_pca = pca.fit_transform(X)
# multilabel_lr = MultiLabel(LogisticRegression, dict(max_iter=300, tol=0.01, C=0.2, verbose=0), 1)
# multilabel_lr.fit(X_pca[split_index>0], y[split_index>0])
# logloss(y[split_index==0], multilabel_lr.predict_proba(X_pca[split_index==0]))
# def grid_search(estimator, hparams):
# multilabel_lr = MultiLabel(estimator, hparams, verbose=1)
# multilabel_lr.fit(X_pca[split_index>0], y[split_index>0])
# loss = logloss(y[split_index==0], multilabel_lr.predict_proba(X_pca[split_index==0]))
# return loss
# result = []
# grid = [1e-5, 1e-4, 1e-3, 1e-2]
# for p in grid:
# loss = grid_search(LogisticRegression,
# dict(max_iter=100, tol=0.1, C=p, verbose=0))
# result.append((p, loss))
# save result
prediction = oof_model.predict(test)
submission[:] = 0.0
for i, c in enumerate(classnames):
submission[c] = prediction[:, i]
submission[test_control] = 0.0
submission.to_csv("submission.csv")
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0042/448/42448247.ipynb | null | null | [{"Id": 42448247, "ScriptId": 11620414, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1309204, "CreationDate": "09/11/2020 11:59:42", "VersionNumber": 7.0, "Title": "MoA :: OOF & non-DL models", "EvaluationDate": "09/11/2020", "IsChange": true, "TotalLines": 241.0, "LinesInsertedFromPrevious": 54.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 187.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | import os
import warnings
from tqdm import tqdm
import pandas as pd
import numpy as np
from ml_stratifiers import MultilabelStratifiedKFold
from sklearn.preprocessing import StandardScaler
from sklearn.base import clone
from sklearn.linear_model import LogisticRegression
from sklearn.multioutput import MultiOutputClassifier
from sklearn.pipeline import Pipeline
from sklearn.decomposition import PCA
warnings.filterwarnings("ignore")
def load_datasets(data_path):
train_features = pd.read_csv(os.path.join(data_path, "train_features.csv"))
train_targets_s = pd.read_csv(os.path.join(data_path, "train_targets_scored.csv"))
train_targets_n = pd.read_csv(
os.path.join(data_path, "train_targets_nonscored.csv")
)
test_features = pd.read_csv(os.path.join(data_path, "test_features.csv"))
sample_submission = pd.read_csv(os.path.join(data_path, "sample_submission.csv"))
train_features.set_index("sig_id", inplace=True)
train_targets_s.set_index("sig_id", inplace=True)
test_features.set_index("sig_id", inplace=True)
sample_submission.set_index("sig_id", inplace=True)
assert np.all(test_features.index == sample_submission.index)
return (
train_features,
train_targets_s,
train_targets_n,
test_features,
sample_submission,
)
def preprocess(X, y, test, random_state=2020):
X, y, test = X.copy(), y.copy(), test.copy()
# 1. Filter cp_type=ctl_vehicle
X = X[X.cp_type != "ctl_vehicle"]
X.drop("cp_type", axis=1, inplace=True)
test_control = test.cp_type == "ctl_vehicle"
test.drop("cp_type", axis=1, inplace=True)
# 2. Standard scale continuous features [train + test non-control]
scaler = StandardScaler()
scaler.fit(pd.concat([X.iloc[:, 2:], test.loc[~test_control].iloc[:, 2:]]))
X.iloc[:, 2:] = scaler.transform(X.iloc[:, 2:])
test.iloc[:, 2:] = scaler.transform(test.iloc[:, 2:])
# 3. Encode cp_time & cp_dose
X["cp_dose"] = X["cp_dose"].map({"D1": 0, "D2": 1})
X["cp_time"] = X["cp_time"] // 24 - 1
test["cp_dose"] = test["cp_dose"].map({"D1": 0, "D2": 1})
test["cp_time"] = test["cp_time"] // 24 - 1
# 4. Shuffle data
X = X.sample(frac=1.0, random_state=random_state)
y = y.loc[X.index, :]
assert np.all(y.index == X.index)
return X, y, test, test_control
def split(X, y, n_folds=6, holdout=True):
# remove too rare classes
rare_columns = y.loc[:, y.sum(axis=0) < n_folds].columns
y.drop(rare_columns, axis=1, inplace=True)
# build stratified split index
split_index = np.zeros(len(X)) - 1
cv = MultilabelStratifiedKFold(n_splits=n_folds)
for fold, (index_train, index_test) in enumerate(cv.split(X, y)):
split_index[index_test] = fold
classnames = y.columns.tolist()
X, y = X.values, y.values
# make holdout
X_holdout, y_holdout = None, None
if holdout:
X_holdout, y_holdout = (
X[split_index == n_folds - 1].copy(),
y[split_index == n_folds - 1].copy(),
)
X, y = X[split_index < n_folds - 1], y[split_index < n_folds - 1]
split_index = split_index[split_index < n_folds - 1]
return X, y, split_index, X_holdout, y_holdout, classnames
def logloss(y_true, y_pred, eps=1e-15):
y_pred[y_pred == 0] = eps
y_pred[y_pred == 1] = 1 - eps
return -(y_true * np.log(y_pred) + (1 - y_true) * (np.log(1 - y_pred))).mean()
class OOFTrainer:
def __init__(
self, estimator, metric, hparams=dict(), fit_params=dict(), predict_proba=True
):
"""
Out-of-fold trainer
Training data doesn't persisted
Args:
metric -- function computing loss/metric
hparams -- estimator hyperparameters
"""
self.estimator = estimator
self.metric = metric
self.hparams = hparams
self.fit_params = fit_params
self.predict_proba = predict_proba
self.models_ = None
self.prediction_ = None
self.valid_loss_ = None
def finetune_hparams(self, grid, X, y):
"""Hyperparameters grid search"""
pass
def fit(self, X, y, split_index, verbose=True):
"""Fit models on each fold, validate and predict folds"""
assert len(X) == len(y) == len(split_index)
assert len(y.shape) > 1
self.models_, self.valid_loss_ = [], []
cv_prediction = np.zeros_like(y, dtype=np.float64)
for fold in np.unique(split_index):
if verbose:
print(f"Fold {int(fold)}")
# train|valid split
train, valid = split_index != fold, split_index == fold
x_train, y_train, x_valid, y_valid = X[train], y[train], X[valid], y[valid]
# build and fit model
model = clone(self.estimator)
model = model.set_params(**self.hparams)
model.fit(x_train, y_train, **self.fit_params)
# predict and evaluate validation fold
if self.predict_proba:
prediction = model.predict_proba(x_valid)
else:
prediction = model.predict(x_valid)
cv_prediction[valid] = prediction
# save result
self.models_.append(model)
loss = self.metric(y_valid, prediction)
self.valid_loss_.append(loss)
if verbose:
print(f"Loss={loss}")
self.prediction_ = cv_prediction
return self
def predict(self, X):
"""Predict new data by all models and average"""
prediction = np.zeros((len(X), self.prediction_.shape[1]), dtype=np.float64)
for model in self.models_:
prediction += model.predict_proba(X)
prediction /= len(self.models_)
return prediction
X, y, y_nonscored, test, submission = load_datasets("../input/lish-moa")
X, y, test, test_control = preprocess(X, y, test)
X, y, split_index, X_holdout, y_holdout, classnames = split(
X, y, n_folds=5, holdout=False
)
# X, y, split_index, X_holdout, y_holdout, classnames = split(X, y, n_folds=6, holdout=True)
print("train :", X.shape, y.shape, split_index.shape)
if X_holdout:
print("holdout:", X_holdout.shape, y_holdout.shape)
print("test :", test.shape, submission.shape)
# multioutput wrapper
class MultiLabelClassfifier(MultiOutputClassifier):
def _predict_proba(self, X):
results = [estimator.predict_proba(X) for estimator in self.estimators_]
return np.moveaxis(results, 0, 1)[:, :, 1]
pca = PCA(n_components=50)
logistic = LogisticRegression(max_iter=150, tol=0.1, C=0.01, verbose=0)
base_model = Pipeline(steps=[("pca", pca), ("logistic", logistic)])
multilabel_model = MultiLabelClassfifier(base_model, n_jobs=-1)
oof_model = OOFTrainer(multilabel_model, logloss)
oof_model.fit(X, y, split_index, verbose=True)
result.append((p, np.mean(oof_model.valid_loss_)))
# todo: different hparams for different classes to MultiLabel
# from sklearn.base import BaseEstimator
# class MultiLabel(BaseEstimator):
# def __init__(self, estimator, hparams, verbose=0):
# """ """
# self.estimator = estimator
# self.hparams = hparams
# self.verbose = verbose
# self.models_ = []
# def fit(self, X, y, **fit_params):
# labels_iterator = range(y.shape[1])
# for target in (tqdm(labels_iterator) if self.verbose else labels_iterator):
# model = self.estimator(**self.hparams)
# model.fit(X, y[:, target], **fit_params)
# self.models_.append(model)
# return self
# def predict(self, X):
# raise NotImplementedError
# def predict_proba(self, X):
# results = [model.predict_proba(X) for model in self.models_]
# return np.moveaxis(results, 0, 1)[:, :, 1]
# pca = PCA(n_components=50)
# X_pca = pca.fit_transform(X)
# multilabel_lr = MultiLabel(LogisticRegression, dict(max_iter=300, tol=0.01, C=0.2, verbose=0), 1)
# multilabel_lr.fit(X_pca[split_index>0], y[split_index>0])
# logloss(y[split_index==0], multilabel_lr.predict_proba(X_pca[split_index==0]))
# def grid_search(estimator, hparams):
# multilabel_lr = MultiLabel(estimator, hparams, verbose=1)
# multilabel_lr.fit(X_pca[split_index>0], y[split_index>0])
# loss = logloss(y[split_index==0], multilabel_lr.predict_proba(X_pca[split_index==0]))
# return loss
# result = []
# grid = [1e-5, 1e-4, 1e-3, 1e-2]
# for p in grid:
# loss = grid_search(LogisticRegression,
# dict(max_iter=100, tol=0.1, C=p, verbose=0))
# result.append((p, loss))
# save result
prediction = oof_model.predict(test)
submission[:] = 0.0
for i, c in enumerate(classnames):
submission[c] = prediction[:, i]
submission[test_control] = 0.0
submission.to_csv("submission.csv")
| false | 0 | 2,832 | 0 | 6 | 2,832 |
||
42711809 | <kaggle_start><data_title>Grid Loss Prediction Dataset<data_description>### Context
A power grid transports the electricity from power producers to the consumers. But all that is produced is not delivered to the customers. Some parts of it are lost in either transmission or distribution. In Norway, the grid companies are responsible for reporting this grid loss to the institutes responsible for national transmission networks. They have to nominate the expected loss day ahead to the market so that the electricity price can be decided.
The physics of grid losses are well understood and can be calculated quite accurately given the grid configuration. Still, as these are not known or changes all the time, calculating grid losses is not straight forward.
### Content
Grid loss is directly correlated with the total amount of power in the grid, which is also known as the grid load.
We provide data for three different grids from Norway that are owned by Tensio (Previously Trønderenergi Nett).
Features:
In this dataset, we provide the hourly values of all the features we found relevant for predicting the grid loss.
For each of the grids, we have:
1. Grid loss: historical measurements of grid loss in MWh
2. Grid load: historical measurements of grid load in MWh
3. Temperature forecast in Kelvin
4. Predictions using the Prophet model in MWh
5. Trend, daily, weekly and yearly components of the grid loss, also from the Prophet Model.
Other than these grid specific features, we provide:
1. Calendar features: year, season, month, week, weekday, hour, in the cyclic form (see Notes 1.) and whether it is a holiday or not.
2. Incorrect data: whether the data was marked incorrect by the experts, in retrospective. We recommend removing this data before training your model.
3. Estimated demand in Trondheim: predicted demand for electricity in Trondheim, a big city in the middle of Norway, in MWh (see Note 2.)
We have split the dataset into two parts: training and testing set.
Training set:
This file (train.csv) contains two years of data (December 2017 to November 2019). All the features mentioned above are provided for this duration.
Test set:
This file (test.csv) contains six months of data (December 2019 to May 2020). All the features from training data are provided for the test set as well. Occasionally, some of the features could be missing.
Additionally, we provide a copy of test dataset (test\_backfilled\_missing\_features.csv) where the missing features are backfilled.
Note:
1. Calendar features are cyclic in nature. If we encode the weekdays (Monday to Sunday) as 0 to 6, we find that while Sunday and Monday are next to each other, the distance between their embeddings does not reflect it. To reflect this cyclic nature of the calendar features, we created cyclic calendar features based on cosine and sine which together place the highest and lowest value of the features close to each other in the feature space.
2. We don't have an estimate of demand for all the grids. We used the demand predictions for Trondheim, the biggest city closest to the three grids.
3. The grid load is directly proportional to the grid loss. While we don't have predictions for grid load, but since we have historical measurements for them, it makes sense to predict it and use it as a feature for predicting the grid loss.
4. While the Prophet Model did not perform nicely as a prediction tool for our dataset, we found it useful to include its prediction and other components as features in our model.
5. Grid 3 has less training data than grid 1 and grid 2.
6. We published our solution. For more details, please refer to:
Dalal, N., Mølnå, M., Herrem, M., Røen, M., & Gundersen, O. E. (2020). Day-Ahead Forecasting of Losses in the Distribution Network. In AAAI (pp. 13148-13155).
Bibtex format for citation:
@incollection{dalal2020a,
author = {Dalal, N. and Mølnå, M. and Herrem, M. and Røen, M. and Gundersen, O.E.},
date = {2020},
title = {Day-Ahead Forecasting of Losses in the Distribution Network},
pages = {13148–13155},
language = {en},
booktitle = {AAAI}
}
### Challenges
Working with clean and processed data often hides the complexity of running the model in deployment. Some of the challenges we had while predicting grid loss in deployment are:
1. Day-ahead predictions: We need to predict the grid loss for the next day before 10 am the current day at an hourly resolution i.e on 10:00 May 26, 2020, we need to predict the grid loss on May 27, 2020, from midnight to 23:00 May 28, 2020, at an hourly resolution (24 values) for each grid.
2. Delayed measurements: We don't receive the measured values of load and loss immediately. We receive them 5 days after. Sometimes, there can be additional delays for a few more days. While grid loss and load are provided for the test data set as well, DO NOT USE them as features, unless they are 6 days old i.e while predicting grid loss for 27th January 2020, you can use the grid loss values will 20th January 2020. Using grid loss or grid load data after that date is unfair and will be discarded.
3. Missing data: Sometimes, we don't receive some of the features. For example, weather client might be out of service. You should make sure that your model should work even when some features are unavailable/missing.
4. Incorrect data: There have been times when the measurements we received were incorrect, by a big margin. They have been marked in the dataset in the incorrect_data column. It is recommended to remove those data points before you start analysing the data.
5. Less training data: For one of the grids, grid 3, we only have a few months of data.
6. Changes in the grids: Grid structures can keep changing. Sometimes new big consumers are added, or small grids can be merged into big ones.<data_name>grid-loss-time-series-dataset
<code># # Grid loss demonstration and Persistence model
# This notebook will give a demo for how to use the dataset. The pupose of this notebook is to provide the persistence model for predicting the grid loss.
# **Persistence model:**
# Persistence model is a well used baseline time series perdiction. It assumes that time series data does not change rapidly from day to day. Under this assumption, the persistence models 'predicts' that the values in the future will be a repitition of the last observed values. In this project, persistence model assumes that the grid loss for today will be same as the grid loss last week, the same day. Hence, in the model implementation, training is not needed. For prediction, it just returns the last week's measured grid loss values.
# As you will notice, Persistence model is not the best model. Feel free to explore other features and beat its performance with your models.
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import datetime as dt # date time
import matplotlib.pyplot as plt # for plotting
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 5GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
# For this demonstration, we used the test.csv file from the dataset. Persistence model was tested on this whole file in this demo, but feel free to play around the start date, duration and end date. We predicted grid loss for grid 1 here.
## Add dates and grid number you are interested in
start_date = dt.datetime(2019, 12, 1)
end_date = dt.datetime(2020, 5, 31)
grid_nr = 1
grid_col = f"grid{grid_nr}-loss"
# Load the test dataset. Training dataset is not needed here as Persistence model just returns the grid loss values from the week before, hence no training is needed.
test_data = pd.read_csv("../input/grid-loss-time-series-dataset/test.csv", index_col=0)
x_test = test_data[grid_col]
display(x_test.head())
# Persistence model was defined below. To use the model in the similar fashion as other sklearn models, we used the same prototype for our model.
# Defining the Persistence model, in line with other sklearn models
class PersistenceModel:
def __init__(self):
pass
def train(self, x_train, y_train):
# No training needed
pass
def predict(self, x_test):
# returns the values shifted back by 7 days (i.e. 24*7 hourly values)
return x_test.shift(24 * 7)
## Other helful functions
# Calculating the model performance. MAE, RMSE and MAPE are calculated.
def calculate_error(pred, target):
target = target.loc[pred.index[0] : pred.index[-1]]
metrics = {
"mae": np.mean(np.abs(pred - target)), # Mean absolute error
"rmse": np.sqrt(np.mean((pred - target) ** 2)), # Root mean squared error
"mape": 100 * np.sum(np.abs(pred - target)) / np.sum(target),
} # Mean absolute percentage error
return metrics
# Visualizing the target and predictions
def plot_predictions(pred, target):
target.plot(figsize=(30, 10), label="target", linewidth=2)
pred.plot(label="prediction", linewidth=2)
plt.title("Persistence model performance", fontsize=20)
plt.xlabel("Date and time", fontsize=18)
plt.ylabel("Grid loss", fontsize=18)
plt.xticks(fontsize=14)
plt.legend()
# Initializing the model
model = PersistenceModel()
# Returns the last week's values
y_test = model.predict(x_test)
# Check model's performance
error_metrics = calculate_error(x_test, y_test)
print(f"Model performance for predicting loss for grid {grid_nr} is: {error_metrics}")
# Visualize the performance
plot_predictions(y_test, x_test)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0042/711/42711809.ipynb | grid-loss-time-series-dataset | trnderenergikraft | [{"Id": 42711809, "ScriptId": 11740565, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1203660, "CreationDate": "09/15/2020 07:29:31", "VersionNumber": 2.0, "Title": "Grid loss demo and persistence model", "EvaluationDate": "09/15/2020", "IsChange": false, "TotalLines": 93.0, "LinesInsertedFromPrevious": 0.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 93.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 52282979, "KernelVersionId": 42711809, "SourceDatasetVersionId": 1487717}] | [{"Id": 1487717, "DatasetId": 746802, "DatasourceVersionId": 1521634, "CreatorUserId": 5773405, "LicenseName": "CC BY-SA 4.0", "CreationDate": "09/14/2020 14:35:19", "VersionNumber": 2.0, "Title": "Grid Loss Prediction Dataset", "Slug": "grid-loss-time-series-dataset", "Subtitle": "A time series dataset for predicting loss in three electrical grids in Norway", "Description": "### Context\n\nA power grid transports the electricity from power producers to the consumers. But all that is produced is not delivered to the customers. Some parts of it are lost in either transmission or distribution. In Norway, the grid companies are responsible for reporting this grid loss to the institutes responsible for national transmission networks. They have to nominate the expected loss day ahead to the market so that the electricity price can be decided.\n\nThe physics of grid losses are well understood and can be calculated quite accurately given the grid configuration. Still, as these are not known or changes all the time, calculating grid losses is not straight forward. \n\n\n### Content\n\nGrid loss is directly correlated with the total amount of power in the grid, which is also known as the grid load.\n\nWe provide data for three different grids from Norway that are owned by Tensio (Previously Tr\u00f8nderenergi Nett).\n\nFeatures:\nIn this dataset, we provide the hourly values of all the features we found relevant for predicting the grid loss. \n\nFor each of the grids, we have:\n1. Grid loss: historical measurements of grid loss in MWh\n2. Grid load: historical measurements of grid load in MWh\n3. Temperature forecast in Kelvin\n4. Predictions using the Prophet model in MWh\n5. Trend, daily, weekly and yearly components of the grid loss, also from the Prophet Model.\n\nOther than these grid specific features, we provide:\n1. Calendar features: year, season, month, week, weekday, hour, in the cyclic form (see Notes 1.) and whether it is a holiday or not.\n2. Incorrect data: whether the data was marked incorrect by the experts, in retrospective. We recommend removing this data before training your model.\n3. Estimated demand in Trondheim: predicted demand for electricity in Trondheim, a big city in the middle of Norway, in MWh (see Note 2.)\n\nWe have split the dataset into two parts: training and testing set.\n\nTraining set:\nThis file (train.csv) contains two years of data (December 2017 to November 2019). All the features mentioned above are provided for this duration.\n\nTest set:\nThis file (test.csv) contains six months of data (December 2019 to May 2020). All the features from training data are provided for the test set as well. Occasionally, some of the features could be missing.\n\nAdditionally, we provide a copy of test dataset (test\\_backfilled\\_missing\\_features.csv) where the missing features are backfilled.\n\n\nNote:\n1. Calendar features are cyclic in nature. If we encode the weekdays (Monday to Sunday) as 0 to 6, we find that while Sunday and Monday are next to each other, the distance between their embeddings does not reflect it. To reflect this cyclic nature of the calendar features, we created cyclic calendar features based on cosine and sine which together place the highest and lowest value of the features close to each other in the feature space. \n2. We don't have an estimate of demand for all the grids. We used the demand predictions for Trondheim, the biggest city closest to the three grids.\n3. The grid load is directly proportional to the grid loss. While we don't have predictions for grid load, but since we have historical measurements for them, it makes sense to predict it and use it as a feature for predicting the grid loss.\n4. While the Prophet Model did not perform nicely as a prediction tool for our dataset, we found it useful to include its prediction and other components as features in our model.\n5. Grid 3 has less training data than grid 1 and grid 2.\n6. We published our solution. For more details, please refer to:\n\nDalal, N., M\u00f8ln\u00e5, M., Herrem, M., R\u00f8en, M., & Gundersen, O. E. (2020). Day-Ahead Forecasting of Losses in the Distribution Network. In AAAI (pp. 13148-13155).\n\nBibtex format for citation:\n\n@incollection{dalal2020a,\n author = {Dalal, N. and M\u00f8ln\u00e5, M. and Herrem, M. and R\u00f8en, M. and Gundersen, O.E.},\n date = {2020},\n title = {Day-Ahead Forecasting of Losses in the Distribution Network},\n pages = {13148\u201313155},\n language = {en},\n booktitle = {AAAI}\n}\n\n\n### Challenges\n\nWorking with clean and processed data often hides the complexity of running the model in deployment. Some of the challenges we had while predicting grid loss in deployment are:\n\n1. Day-ahead predictions: We need to predict the grid loss for the next day before 10 am the current day at an hourly resolution i.e on 10:00 May 26, 2020, we need to predict the grid loss on May 27, 2020, from midnight to 23:00 May 28, 2020, at an hourly resolution (24 values) for each grid.\n2. Delayed measurements: We don't receive the measured values of load and loss immediately. We receive them 5 days after. Sometimes, there can be additional delays for a few more days. While grid loss and load are provided for the test data set as well, DO NOT USE them as features, unless they are 6 days old i.e while predicting grid loss for 27th January 2020, you can use the grid loss values will 20th January 2020. Using grid loss or grid load data after that date is unfair and will be discarded.\n3. Missing data: Sometimes, we don't receive some of the features. For example, weather client might be out of service. You should make sure that your model should work even when some features are unavailable/missing.\n4. Incorrect data: There have been times when the measurements we received were incorrect, by a big margin. They have been marked in the dataset in the incorrect_data column. It is recommended to remove those data points before you start analysing the data.\n5. Less training data: For one of the grids, grid 3, we only have a few months of data.\n6. Changes in the grids: Grid structures can keep changing. Sometimes new big consumers are added, or small grids can be merged into big ones.\n\n\n### Acknowledgements\n\nWe wouldn't be here without the help of others. We would like to thank Tensio for allowing us to make their grid data public in the interest of open science and research. We would also like to thank the AI group in NTNU for strong collaborations and scientific discussions.\nIf you use this dataset, please cite the following paper:\nDalal, N., M\u00f8ln\u00e5, M., Herrem, M., R\u00f8en, M., & Gundersen, O. E. (2020). Day-Ahead Forecasting of Losses in the Distribution Network. In AAAI (pp. 13148-13155).", "VersionNotes": "Split the data into train and test", "TotalCompressedBytes": 0.0, "TotalUncompressedBytes": 0.0}] | [{"Id": 746802, "CreatorUserId": 1203660, "OwnerUserId": 5773405.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 1546931.0, "CurrentDatasourceVersionId": 1581682.0, "ForumId": 761702, "Type": 2, "CreationDate": "06/30/2020 08:44:25", "LastActivityDate": "06/30/2020", "TotalViews": 6191, "TotalDownloads": 433, "TotalVotes": 10, "TotalKernels": 3}] | [{"Id": 5773405, "UserName": "trnderenergikraft", "DisplayName": "Tr\u00f8nderEnergi Kraft", "RegisterDate": "09/14/2020", "PerformanceTier": 0}] | # # Grid loss demonstration and Persistence model
# This notebook will give a demo for how to use the dataset. The pupose of this notebook is to provide the persistence model for predicting the grid loss.
# **Persistence model:**
# Persistence model is a well used baseline time series perdiction. It assumes that time series data does not change rapidly from day to day. Under this assumption, the persistence models 'predicts' that the values in the future will be a repitition of the last observed values. In this project, persistence model assumes that the grid loss for today will be same as the grid loss last week, the same day. Hence, in the model implementation, training is not needed. For prediction, it just returns the last week's measured grid loss values.
# As you will notice, Persistence model is not the best model. Feel free to explore other features and beat its performance with your models.
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import datetime as dt # date time
import matplotlib.pyplot as plt # for plotting
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 5GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
# For this demonstration, we used the test.csv file from the dataset. Persistence model was tested on this whole file in this demo, but feel free to play around the start date, duration and end date. We predicted grid loss for grid 1 here.
## Add dates and grid number you are interested in
start_date = dt.datetime(2019, 12, 1)
end_date = dt.datetime(2020, 5, 31)
grid_nr = 1
grid_col = f"grid{grid_nr}-loss"
# Load the test dataset. Training dataset is not needed here as Persistence model just returns the grid loss values from the week before, hence no training is needed.
test_data = pd.read_csv("../input/grid-loss-time-series-dataset/test.csv", index_col=0)
x_test = test_data[grid_col]
display(x_test.head())
# Persistence model was defined below. To use the model in the similar fashion as other sklearn models, we used the same prototype for our model.
# Defining the Persistence model, in line with other sklearn models
class PersistenceModel:
def __init__(self):
pass
def train(self, x_train, y_train):
# No training needed
pass
def predict(self, x_test):
# returns the values shifted back by 7 days (i.e. 24*7 hourly values)
return x_test.shift(24 * 7)
## Other helful functions
# Calculating the model performance. MAE, RMSE and MAPE are calculated.
def calculate_error(pred, target):
target = target.loc[pred.index[0] : pred.index[-1]]
metrics = {
"mae": np.mean(np.abs(pred - target)), # Mean absolute error
"rmse": np.sqrt(np.mean((pred - target) ** 2)), # Root mean squared error
"mape": 100 * np.sum(np.abs(pred - target)) / np.sum(target),
} # Mean absolute percentage error
return metrics
# Visualizing the target and predictions
def plot_predictions(pred, target):
target.plot(figsize=(30, 10), label="target", linewidth=2)
pred.plot(label="prediction", linewidth=2)
plt.title("Persistence model performance", fontsize=20)
plt.xlabel("Date and time", fontsize=18)
plt.ylabel("Grid loss", fontsize=18)
plt.xticks(fontsize=14)
plt.legend()
# Initializing the model
model = PersistenceModel()
# Returns the last week's values
y_test = model.predict(x_test)
# Check model's performance
error_metrics = calculate_error(x_test, y_test)
print(f"Model performance for predicting loss for grid {grid_nr} is: {error_metrics}")
# Visualize the performance
plot_predictions(y_test, x_test)
| false | 1 | 1,101 | 0 | 1,513 | 1,101 |
||
132007580 | <kaggle_start><code># # **Titanic survival prediction with Decision Tree**
# Hello there, this notebook will go through the process of my data preprocessing approach and building a decision tree using sklearn. What you can expect from this notebook:
# 1. Feature enginneering with pipeline
# 2. Building a simple decision tree using sklearn
# 3. Improving our model with cost-complexity pruning using sklearn
# I will be importing libraries from different sections so you can understand what each libraries are correspond to, feel free to leave any kind of comments if you see any problems/improvements that I can make, it will be very much appreciated!
import pandas as pd
import numpy as np
train_df = pd.read_csv("/kaggle/input/titanic/train.csv")
test_df = pd.read_csv("/kaggle/input/titanic/test.csv")
train_df.head()
# I have already done my EDA on a seperate notebook,
# https://www.kaggle.com/code/crxxom/titanic-survival-rate-interactive-dashboard-eda which is an interactive tableau dashboard you can interact with the find valuable insight, feel free to go check it out!
# # **Data Preprocessing and feature selection**
# I am going to build a simple pipeline to preprocess the dataframe. What you could expect in the following section:
# 1. Imputing Age, Embarked and Fare
# 2. 'Companion' feature based on the 'SibSp' and 'Parch' Feature
# 3. 'Title' feature based on the 'Name' feature
# 4. Binarizing Sex, Companion and Title
# 5. One hot encoding of Embarked feature
# 6. Dropping features
# libraries we will be using in this section
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.preprocessing import OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
import math
# The general structure of building a pipeline
class Name_of_your_estimator(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
# Your code
return # what you are going to return
# ### 1. Impute (NaN handling)
# Here we are imputing age using the mean, imputing embarked using mode, imputing fare using mean
class Imputer(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
# Impute Age
imputer = SimpleImputer(strategy="mean")
X["Age"] = imputer.fit_transform(X["Age"].values.reshape(-1, 1))[:, 0]
# Impute Embarked
imputer = SimpleImputer(strategy="most_frequent")
X["Embarked"] = imputer.fit_transform(X["Embarked"].values.reshape(-1, 1))[:, 0]
# Impute Fare
imputer = SimpleImputer(strategy="mean")
X["Fare"] = imputer.fit_transform(X["Fare"].values.reshape(-1, 1))[:, 0]
return X
# ### 2. 'Companion' feature
# Basically we are creating a companion feature to classify between people travelling alone and people travelling with a companion.
class Companion(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
X["companion"] = X["SibSp"] + X["Parch"]
return X.drop(["SibSp", "Parch"], axis=1)
# ### 3. 'Title' feature
# By extracting the title from the Name column, we classify people with special titles (eg. Master)
class TitleFeature(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
lr = ["Mr", "Mrs", "Miss", "Ms", "Mlle"] # Ms and Mlle both means Miss
# Basically we classify people with special titles and people that do not
def rank_title(x):
if x in lr:
return "LR"
else:
return "HR"
X["title"] = (
X["Name"]
.str.split(",", expand=True)[1]
.str.split(".", expand=True)[0]
.str.strip()
)
X["title"] = X["title"].apply(rank_title)
return X
# ### 4. Binarize
# Since most ML model do not read string values, we need to binarize the values with 0 and 1.
class FeatureBinarize(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
# Gender binarize
gender_dct = {"male": 0, "female": 1}
X["Sex"] = [gender_dct[g] for g in X["Sex"]]
# Title binarize - Classify low rank and high rank
title_dct = {"LR": 0, "HR": 1}
X["title"] = [title_dct[t] for t in X["title"]]
# Companion binarize
def is_alone(x):
if x > 0:
return 1
else:
return 0
X["companion"] = X["companion"].apply(is_alone)
return X
# ### 5. One hot encoding
# 'One-hot encoding in machine learning is the **conversion of categorical information** into a format that may be fed into machine learning algorithms to improve prediction accuracy. One-hot encoding is a common method for dealing with categorical data in machine learning.'
# From my understanding, basically why we don't simply plug in 1,2,3,4 for 4 different categories to label them (just an example) is because the 'distance' between 1 and 2 is smaller between 1 and 4, and it will be more likely that the model will cluster category 1 with category 2, but it doesn't make sense in this scenario, so we use one hot encoding to deal with categorical information in this case. Note, there are a lot of different methods other than one hot encoding, also please let me know if my understanding on this topic is wrong, thanks!
class FeatureEncoder(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
encoder = OneHotEncoder()
matrix = encoder.fit_transform(X["Embarked"].values.reshape(-1, 1)).toarray()
column_name = ["C", "Q", "S"]
for i in range(len(matrix.T)):
X[column_name[i]] = matrix.T[i]
return X.drop(["Embarked"], axis=1)
# ### 6. Dropping features
# We will be dropping Name, PassengerId, Ticket and Cabin from our dataset since they are either irrelavent or too many NaN data (Cabin).
class FeatureDropper(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
return X.drop(["Name", "PassengerId", "Ticket", "Cabin"], axis=1)
# ### Extra: Unit adjusting
class UnitAdjust(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
X["Age"] = X["Age"].apply(lambda y: math.floor(y))
X["Fare"] = X["Fare"].apply(lambda f: round(f, 1))
return X
# ### Run the dataset through the pipeline
pipe = Pipeline(
[
("imputer", Imputer()),
("title", TitleFeature()),
("companion", Companion()),
("binarize", FeatureBinarize()),
("encoder", FeatureEncoder()),
("dropper", FeatureDropper()),
("unit", UnitAdjust()),
]
)
train_ab = pipe.fit_transform(train_df.copy())
train_ab.head()
# And we scale it using StandardScaler. (Feel free to let me know if there are better ways to do it)
from sklearn.preprocessing import StandardScaler
X = train_ab.drop(["Survived"], axis=1)
y = train_ab["Survived"]
scaler = StandardScaler()
train = scaler.fit_transform(X)
y = y.to_numpy()
# # **Decision Tree Model Building**
# Libraries we will be using
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import ConfusionMatrixDisplay
# ### 1. Building the preliminary classification tree
X_train, X_test, y_train, y_test = train_test_split(train, y, random_state=42)
clf_dt = DecisionTreeClassifier(random_state=42)
clf_dt = clf_dt.fit(X_train, y_train)
# I found an interesting article of why we set random_state to 42, https://stackoverflow.com/questions/49147774/what-is-random-state-in-sklearn-model-selection-train-test-split-example.
# We can visualize our decision tree with the plot_tree library we just imported.
plt.figure(figsize=(15, 7.5))
plot_tree(
clf_dt,
filled=True,
rounded=True,
class_names=["Dead", "Survived"],
feature_names=X.columns,
)
# Damn that's a pretty huge tree, we can also see the performance of the tree with a confusion matrix.
ConfusionMatrixDisplay.from_estimator(
clf_dt, X_test, y_test, display_labels=["Dead", "Survived"]
)
# We can calculate that the sensitivity of the model is (108/(108+24)) = 81.8%, while the specificity of the model is (65/(65+26)) = 71.4%, the model is relatively better at correctly predicting people that are dead. (Intuitively it might be better to swap the dead and survived position in the matrix since we are trying to find the survival rate, but it's similar)
# ### 2. Cost-complexity pruning with cross validation
# We will apply cost complexity pruning to reduce the overfitting which will occur frequently when it comes to decision tree. If you don't know what pruning is, I highly recommend you to watch this video https://www.youtube.com/watch?v=D0efHEJsfHo&list=PLblh5JKOoLUICTaGLRoHQDuF_7q2GfuJF&index=50 which discuss the use of pruning in decision tree. In fact, a lot of the code that I used building this model is from another video from this series!
path = clf_dt.cost_complexity_pruning_path(X_train, y_train)
ccp_alphas = path.ccp_alphas
ccp_alphas = ccp_alphas[:-1] # remove the maximum alpha value from the dataset
alpha_loop_value = []
for ccp_alpha in ccp_alphas:
clf_dt = DecisionTreeClassifier(random_state=0, ccp_alpha=ccp_alpha)
scores = cross_val_score(clf_dt, X_train, y_train, cv=5)
alpha_loop_value.append([ccp_alpha, np.mean(scores), np.std(scores)])
alpha_results = pd.DataFrame(
alpha_loop_value, columns=["alpha", "mean_accuracy", "std"]
)
alpha_results.sort_values(by="mean_accuracy", ascending=False)
alpha_results.plot(x="alpha", y="mean_accuracy", yerr="std", marker="o", linestyle="--")
optimal_ccp_alpha = alpha_results.iloc[63, 0]
# Now that we get the optimal alpha value for the model, we can build our modified decision tree!
clf_dt_pruned = DecisionTreeClassifier(random_state=42, ccp_alpha=optimal_ccp_alpha)
clf_dt_pruned = clf_dt_pruned.fit(X_train, y_train)
plt.figure(figsize=(15, 7.5))
plot_tree(
clf_dt_pruned,
filled=True,
rounded=True,
class_names=["Dead", "Survived"],
feature_names=X.columns,
)
ConfusionMatrixDisplay.from_estimator(
clf_dt_pruned, X_test, y_test, display_labels=["Dead", "Survived"]
)
# We notice that the sensitivity worsen a bit while the specificity have improved.
# # **Submission**
# We first run our test set through our pipeline.
pipe = Pipeline(
[
("imputer", Imputer()),
("title", TitleFeature()),
("companion", Companion()),
("binarize", FeatureBinarize()),
("encoder", FeatureEncoder()),
("dropper", FeatureDropper()),
("unit", UnitAdjust()),
]
)
test_ab = pipe.fit_transform(test_df.copy())
test_ab.head()
scaler = StandardScaler()
X_test = scaler.fit_transform(test_ab)
# Then we run our filtered dataset to our pruned decision tree.
Y_pred = clf_dt_pruned.predict(X_test)
Y_pred
# Check if the predicted output fullfill the requirement.
Y_pred.shape
# And now we only need to put our results in a dataframe for submission!
submission = pd.DataFrame(
{"PassengerId": test_df.PassengerId.values, "Survived": Y_pred}
)
submission.to_csv("Titanic_DT.csv", index=False)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0132/007/132007580.ipynb | null | null | [{"Id": 132007580, "ScriptId": 39373078, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 12917908, "CreationDate": "06/02/2023 16:54:28", "VersionNumber": 3.0, "Title": "Prediction with Decision Tree", "EvaluationDate": "06/02/2023", "IsChange": true, "TotalLines": 304.0, "LinesInsertedFromPrevious": 1.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 303.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 2}] | null | null | null | null | # # **Titanic survival prediction with Decision Tree**
# Hello there, this notebook will go through the process of my data preprocessing approach and building a decision tree using sklearn. What you can expect from this notebook:
# 1. Feature enginneering with pipeline
# 2. Building a simple decision tree using sklearn
# 3. Improving our model with cost-complexity pruning using sklearn
# I will be importing libraries from different sections so you can understand what each libraries are correspond to, feel free to leave any kind of comments if you see any problems/improvements that I can make, it will be very much appreciated!
import pandas as pd
import numpy as np
train_df = pd.read_csv("/kaggle/input/titanic/train.csv")
test_df = pd.read_csv("/kaggle/input/titanic/test.csv")
train_df.head()
# I have already done my EDA on a seperate notebook,
# https://www.kaggle.com/code/crxxom/titanic-survival-rate-interactive-dashboard-eda which is an interactive tableau dashboard you can interact with the find valuable insight, feel free to go check it out!
# # **Data Preprocessing and feature selection**
# I am going to build a simple pipeline to preprocess the dataframe. What you could expect in the following section:
# 1. Imputing Age, Embarked and Fare
# 2. 'Companion' feature based on the 'SibSp' and 'Parch' Feature
# 3. 'Title' feature based on the 'Name' feature
# 4. Binarizing Sex, Companion and Title
# 5. One hot encoding of Embarked feature
# 6. Dropping features
# libraries we will be using in this section
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.preprocessing import OneHotEncoder
from sklearn.impute import SimpleImputer
from sklearn.pipeline import Pipeline
import math
# The general structure of building a pipeline
class Name_of_your_estimator(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
# Your code
return # what you are going to return
# ### 1. Impute (NaN handling)
# Here we are imputing age using the mean, imputing embarked using mode, imputing fare using mean
class Imputer(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
# Impute Age
imputer = SimpleImputer(strategy="mean")
X["Age"] = imputer.fit_transform(X["Age"].values.reshape(-1, 1))[:, 0]
# Impute Embarked
imputer = SimpleImputer(strategy="most_frequent")
X["Embarked"] = imputer.fit_transform(X["Embarked"].values.reshape(-1, 1))[:, 0]
# Impute Fare
imputer = SimpleImputer(strategy="mean")
X["Fare"] = imputer.fit_transform(X["Fare"].values.reshape(-1, 1))[:, 0]
return X
# ### 2. 'Companion' feature
# Basically we are creating a companion feature to classify between people travelling alone and people travelling with a companion.
class Companion(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
X["companion"] = X["SibSp"] + X["Parch"]
return X.drop(["SibSp", "Parch"], axis=1)
# ### 3. 'Title' feature
# By extracting the title from the Name column, we classify people with special titles (eg. Master)
class TitleFeature(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
lr = ["Mr", "Mrs", "Miss", "Ms", "Mlle"] # Ms and Mlle both means Miss
# Basically we classify people with special titles and people that do not
def rank_title(x):
if x in lr:
return "LR"
else:
return "HR"
X["title"] = (
X["Name"]
.str.split(",", expand=True)[1]
.str.split(".", expand=True)[0]
.str.strip()
)
X["title"] = X["title"].apply(rank_title)
return X
# ### 4. Binarize
# Since most ML model do not read string values, we need to binarize the values with 0 and 1.
class FeatureBinarize(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
# Gender binarize
gender_dct = {"male": 0, "female": 1}
X["Sex"] = [gender_dct[g] for g in X["Sex"]]
# Title binarize - Classify low rank and high rank
title_dct = {"LR": 0, "HR": 1}
X["title"] = [title_dct[t] for t in X["title"]]
# Companion binarize
def is_alone(x):
if x > 0:
return 1
else:
return 0
X["companion"] = X["companion"].apply(is_alone)
return X
# ### 5. One hot encoding
# 'One-hot encoding in machine learning is the **conversion of categorical information** into a format that may be fed into machine learning algorithms to improve prediction accuracy. One-hot encoding is a common method for dealing with categorical data in machine learning.'
# From my understanding, basically why we don't simply plug in 1,2,3,4 for 4 different categories to label them (just an example) is because the 'distance' between 1 and 2 is smaller between 1 and 4, and it will be more likely that the model will cluster category 1 with category 2, but it doesn't make sense in this scenario, so we use one hot encoding to deal with categorical information in this case. Note, there are a lot of different methods other than one hot encoding, also please let me know if my understanding on this topic is wrong, thanks!
class FeatureEncoder(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
encoder = OneHotEncoder()
matrix = encoder.fit_transform(X["Embarked"].values.reshape(-1, 1)).toarray()
column_name = ["C", "Q", "S"]
for i in range(len(matrix.T)):
X[column_name[i]] = matrix.T[i]
return X.drop(["Embarked"], axis=1)
# ### 6. Dropping features
# We will be dropping Name, PassengerId, Ticket and Cabin from our dataset since they are either irrelavent or too many NaN data (Cabin).
class FeatureDropper(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
return X.drop(["Name", "PassengerId", "Ticket", "Cabin"], axis=1)
# ### Extra: Unit adjusting
class UnitAdjust(BaseEstimator, TransformerMixin):
def fit(self, X, y=None):
return self
def transform(self, X):
X["Age"] = X["Age"].apply(lambda y: math.floor(y))
X["Fare"] = X["Fare"].apply(lambda f: round(f, 1))
return X
# ### Run the dataset through the pipeline
pipe = Pipeline(
[
("imputer", Imputer()),
("title", TitleFeature()),
("companion", Companion()),
("binarize", FeatureBinarize()),
("encoder", FeatureEncoder()),
("dropper", FeatureDropper()),
("unit", UnitAdjust()),
]
)
train_ab = pipe.fit_transform(train_df.copy())
train_ab.head()
# And we scale it using StandardScaler. (Feel free to let me know if there are better ways to do it)
from sklearn.preprocessing import StandardScaler
X = train_ab.drop(["Survived"], axis=1)
y = train_ab["Survived"]
scaler = StandardScaler()
train = scaler.fit_transform(X)
y = y.to_numpy()
# # **Decision Tree Model Building**
# Libraries we will be using
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import ConfusionMatrixDisplay
# ### 1. Building the preliminary classification tree
X_train, X_test, y_train, y_test = train_test_split(train, y, random_state=42)
clf_dt = DecisionTreeClassifier(random_state=42)
clf_dt = clf_dt.fit(X_train, y_train)
# I found an interesting article of why we set random_state to 42, https://stackoverflow.com/questions/49147774/what-is-random-state-in-sklearn-model-selection-train-test-split-example.
# We can visualize our decision tree with the plot_tree library we just imported.
plt.figure(figsize=(15, 7.5))
plot_tree(
clf_dt,
filled=True,
rounded=True,
class_names=["Dead", "Survived"],
feature_names=X.columns,
)
# Damn that's a pretty huge tree, we can also see the performance of the tree with a confusion matrix.
ConfusionMatrixDisplay.from_estimator(
clf_dt, X_test, y_test, display_labels=["Dead", "Survived"]
)
# We can calculate that the sensitivity of the model is (108/(108+24)) = 81.8%, while the specificity of the model is (65/(65+26)) = 71.4%, the model is relatively better at correctly predicting people that are dead. (Intuitively it might be better to swap the dead and survived position in the matrix since we are trying to find the survival rate, but it's similar)
# ### 2. Cost-complexity pruning with cross validation
# We will apply cost complexity pruning to reduce the overfitting which will occur frequently when it comes to decision tree. If you don't know what pruning is, I highly recommend you to watch this video https://www.youtube.com/watch?v=D0efHEJsfHo&list=PLblh5JKOoLUICTaGLRoHQDuF_7q2GfuJF&index=50 which discuss the use of pruning in decision tree. In fact, a lot of the code that I used building this model is from another video from this series!
path = clf_dt.cost_complexity_pruning_path(X_train, y_train)
ccp_alphas = path.ccp_alphas
ccp_alphas = ccp_alphas[:-1] # remove the maximum alpha value from the dataset
alpha_loop_value = []
for ccp_alpha in ccp_alphas:
clf_dt = DecisionTreeClassifier(random_state=0, ccp_alpha=ccp_alpha)
scores = cross_val_score(clf_dt, X_train, y_train, cv=5)
alpha_loop_value.append([ccp_alpha, np.mean(scores), np.std(scores)])
alpha_results = pd.DataFrame(
alpha_loop_value, columns=["alpha", "mean_accuracy", "std"]
)
alpha_results.sort_values(by="mean_accuracy", ascending=False)
alpha_results.plot(x="alpha", y="mean_accuracy", yerr="std", marker="o", linestyle="--")
optimal_ccp_alpha = alpha_results.iloc[63, 0]
# Now that we get the optimal alpha value for the model, we can build our modified decision tree!
clf_dt_pruned = DecisionTreeClassifier(random_state=42, ccp_alpha=optimal_ccp_alpha)
clf_dt_pruned = clf_dt_pruned.fit(X_train, y_train)
plt.figure(figsize=(15, 7.5))
plot_tree(
clf_dt_pruned,
filled=True,
rounded=True,
class_names=["Dead", "Survived"],
feature_names=X.columns,
)
ConfusionMatrixDisplay.from_estimator(
clf_dt_pruned, X_test, y_test, display_labels=["Dead", "Survived"]
)
# We notice that the sensitivity worsen a bit while the specificity have improved.
# # **Submission**
# We first run our test set through our pipeline.
pipe = Pipeline(
[
("imputer", Imputer()),
("title", TitleFeature()),
("companion", Companion()),
("binarize", FeatureBinarize()),
("encoder", FeatureEncoder()),
("dropper", FeatureDropper()),
("unit", UnitAdjust()),
]
)
test_ab = pipe.fit_transform(test_df.copy())
test_ab.head()
scaler = StandardScaler()
X_test = scaler.fit_transform(test_ab)
# Then we run our filtered dataset to our pruned decision tree.
Y_pred = clf_dt_pruned.predict(X_test)
Y_pred
# Check if the predicted output fullfill the requirement.
Y_pred.shape
# And now we only need to put our results in a dataframe for submission!
submission = pd.DataFrame(
{"PassengerId": test_df.PassengerId.values, "Survived": Y_pred}
)
submission.to_csv("Titanic_DT.csv", index=False)
| false | 0 | 3,319 | 2 | 6 | 3,319 |
||
132554970 | <kaggle_start><data_title>Flickr-Faces-HQ (FFHQ) small<data_description>This is a small version of FFHQ with 3143 photos.
Flickr-Faces-HQ (FFHQ) is an image dataset containing high-quality images of human faces. It is provided by NVIDIA under the Creative Commons BY-NC-SA 4.0 license. It offers 70,000 PNG images at 1024×1024 resolution that display diverse ages, ethnicities, image backgrounds, and accessories like hats and eyeglasses.<data_name>faces-dataset-small
<code>#
# Школа глубокого обучения ФПМИ МФТИ
# Домашнее задание. Generative adversarial networks
# В этом домашнем задании вы обучите GAN генерировать лица людей и посмотрите на то, как можно оценивать качество генерации
import os
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
import torchvision.transforms as tt
import torchvision
import torch
import torch.nn as nn
import cv2
from tqdm.notebook import tqdm
from torchvision.utils import save_image
from torchvision.utils import make_grid
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from torch.utils.data import Dataset
import multiprocessing as mp
from PIL import Image
from IPython.display import clear_output
sns.set(style="darkgrid", font_scale=1.2)
sns.set_style("darkgrid")
# ## Часть 1. Подготовка данных (1 балл)
# В качестве обучающей выборки возьмем часть датасета [Flickr Faces](https://github.com/NVlabs/ffhq-dataset), который содержит изображения лиц людей в высоком разрешении (1024х1024). Оригинальный датасет очень большой, поэтому мы возьмем его часть. Скачать датасет можно [здесь](https://www.kaggle.com/datasets/tommykamaz/faces-dataset-small?resource=download-directory) и [здесь](https://drive.google.com/drive/folders/14H7LQWzd09SaM11oLfGtd455sWH2rmRW?usp=share_link)
# Давайте загрузим наши изображения. Напишите функцию, которая строит DataLoader для изображений, при этом меняя их размер до нужного значения (размер 1024 слишком большой, поэтому мы рекомендуем взять размер 128 либо немного больше)
class FacesDataset(Dataset):
"""
Dataset for Flickr-Faces-HQ (FFHQ) small
"""
def __init__(self, path, input_transform=None):
super().__init__()
self.path = path
self.input_transform = input_transform
self.paths = os.listdir(self.path)
self.data = []
self._read_images()
def _read_image(self, image_name):
"""
Read image and use input_transforms
"""
image = Image.open(os.path.join(self.path, image_name))
if self.input_transform:
image = self.input_transform(image)
return image
def _read_images(self):
"""
Pool of _read_image functions
"""
with mp.Pool(processes=mp.cpu_count()) as pool:
self.data = list(
tqdm(
pool.imap_unordered(self._read_image, self.paths),
total=len(self.paths),
)
)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def to_device(data, device):
"""
Move data to self.device
"""
if isinstance(data, (list, tuple)):
return [to_device(x, device) for x in data]
return data.to(device, non_blocking=True)
class DeviceDataLoader:
def __init__(self, dataloader, device):
self.dataloader = dataloader
self.device = device
def __iter__(self):
for batch in self.dataloader:
yield to_device(batch, self.device)
def __len__(self):
return len(self.dataloader)
def get_dataloader(path, device, input_transform, image_size, batch_size):
"""
Builds dataloader for training data.
Use tt.Compose and tt.Resize for transformations
:param image_size: height and wdith of the image
:param batch_size: batch_size of the dataloader
:returns: DataLoader object
"""
# TODO: resize images, convert them to tensors and build dataloader
faces_dataset = FacesDataset(path, input_transform)
return DeviceDataLoader(
DataLoader(faces_dataset, batch_size=batch_size, drop_last=True), device
)
# !ls /kaggle/input/faces-dataset-small/faces_dataset_small
image_size = (128, 128)
batch_size = 64
path = "/kaggle/input/faces-dataset-small/faces_dataset_small"
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
input_transform = tt.Compose(
[
tt.RandomHorizontalFlip(p=0.5),
tt.Resize(image_size),
tt.ToTensor(),
tt.ConvertImageDtype(torch.float),
]
)
faces_dataloader = get_dataloader(path, device, input_transform, image_size, batch_size)
faces = next(iter(faces_dataloader))
grid = torchvision.utils.make_grid(faces, nrow=8, padding=0, scale_each=True)
fig = plt.figure(figsize=(16, 8))
plt.imshow(grid.cpu().permute(1, 2, 0))
plt.axis("off")
plt.show()
# ## Часть 2. Построение и обучение модели (2 балла)
# Сконструируйте генератор и дискриминатор. Помните, что:
# * дискриминатор принимает на вход изображение (тензор размера `3 x image_size x image_size`) и выдает вероятность того, что изображение настоящее (тензор размера 1)
# * генератор принимает на вход тензор шумов размера `latent_size x 1 x 1` и генерирует изображение размера `3 x image_size x image_size`
# ### PixelNorm
# to avoid training BatchNorm module
class PixelNorm(nn.Module):
"""
Nontrainable pixel normalization layer
"""
def __init__(self, eps=1e-8):
super(PixelNorm, self).__init__()
self.eps = eps
def forward(self, x):
return (
x
/ torch.sqrt(torch.mean(x**2, dim=1, keepdim=True) + self.eps)
/ x.shape[0]
)
# Что же такое PixelNorm?
# В [статье по ProGAN]("https://towardsdatascience.com/progan-how-nvidia-generated-images-of-unprecedented-quality-51c98ec2cbd2") предлагается использовать такую нормализация вместо BatchNorm. Главным отличием от BatchNorm является отсутствие тренировочных весов у этого слоя.
# $$b_{x,y}=\frac{a_{x,y}}{\sqrt{\frac{1}{C}\sum\limits_{j=0}^C (a_{x,y}^j)^2 + \varepsilon}}$$
# Но как же влияет PixelNorm на фотографию?
faces = next(iter(faces_dataloader))
grid = torchvision.utils.make_grid(faces, nrow=8, padding=0, scale_each=True)
fig = plt.figure(figsize=(16, 8))
# Using PixelNorm
plt.imshow(PixelNorm()(grid).cpu().permute(1, 2, 0))
plt.axis("off")
plt.show()
# Норм, однако давайте не использовать нормализацию на последнем слое генератора, чтобы он смог восстанавливать цвета.
# ### Generator
class DCGenerator(nn.Module):
"""
Generator of Deep Convolution GAN
"""
def __init__(self, z_dim=96, channels_image=3, features_g=8):
super(DCGenerator, self).__init__()
self.channels_image = channels_image
self.latent_size = z_dim
self._block1 = self._block(
z_dim, features_g * 32, 4, 1, 0
) # N x f_g*16 x 4 x 4
self._block2 = self._block(
features_g * 32, features_g * 16, 3, 2, 1, output_padding=1
) # 8 x 8
self._block3 = self._block(
features_g * 16, features_g * 8, 3, 2, 1, output_padding=1
) # 16 x 16
self._block4 = self._block(
features_g * 8, features_g * 4, 3, 2, 1, output_padding=1
) # 32 x 32
self._block5 = self._block(features_g * 4, features_g * 2, 4, 2, 1) # 64 x 64
self.end_block = nn.Sequential(
nn.ConvTranspose2d(
features_g * 2, self.channels_image, 4, 2, 1, output_padding=0
), # 128 x 128
nn.Tanh(), # [0, +inf] -> [0, 1]
)
def _block(
self, in_channels, out_channels, kernel_size, stride, padding, output_padding=0
):
"""
Generator block consist such elems as
nn.ConvTranspose2d
PixelNorm()
nn.ReLU()
"""
return nn.Sequential(
nn.ConvTranspose2d(
in_channels,
out_channels,
kernel_size,
stride,
padding,
output_padding=output_padding,
bias=False,
),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
def _get_input_tensor_shape(self):
"""
Return input tensor size
"""
return self.latent_size
def forward(self, x):
x = self._block1(x)
x = self._block2(x)
x = tt.GaussianBlur(3)(x) # Blur Image
x = self._block3(x)
# x = tt.GaussianBlur(3)(x) # Blur image
x = self._block4(x)
x = self._block5(x)
x = self.end_block(x)
return x
# ### Disciminator
class DCDiscriminator(nn.Module):
"""
Discriminator of Deep Convolution GAN
"""
def __init__(self, channels_image, features_d, H, W):
super(DCDiscriminator, self).__init__()
self.channels_image = channels_image
self.H = H
self.W = W
self.disc = nn.Sequential(
# N x channels_image x 128 x 128
nn.Conv2d(
channels_image, features_d, kernel_size=4, stride=2, padding=1
), # 64 x 64
nn.LeakyReLU(0.2),
self._block(features_d, features_d * 2, 4, 2, 1), # 32 x 32
self._block(features_d * 2, features_d * 4, 4, 2, 1), # 16 x 16
self._block(features_d * 4, features_d * 8, 4, 2, 1), # 8 x 8
self._block(features_d * 8, features_d * 16, 4, 2, 1), # 4 x 4
nn.Conv2d(features_d * 16, 1, kernel_size=4, stride=2, padding=0), # 1 x 1
nn.Sigmoid(),
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
"""
Discriminator block consist such elems as
nn.Conv2d
nn.BatchNorm2d
nn.LeakyReLU
"""
return nn.Sequential(
nn.Conv2d(
in_channels, out_channels, kernel_size, stride, padding, bias=False
),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.1),
)
def _get_input_tensor_shape(self):
"""
Return input tensor size
"""
return self.channels_image, self.H, self.W
def forward(self, x):
return self.disc(x)
# Проинизицализируем веса нормальным распределением с стандартным отлонением 0 и дисперсией 0.02
def initialize_weights(model):
"""
Model normal initialization
Args:
model: nn.Module object
"""
for m in model.modules():
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.BatchNorm2d)):
nn.init.normal_(m.weight, 0.0, 0.02)
# Проверим размерности выходов генератора и дискриминатора
def checkout(gen, disc, latent_size, N, in_channels, H, W):
"""
Checking right shape of generator and discriminator
Args:
gen: initilized generator
disc: initilized discriminator
latent_size: lenght of latent vector
N: batch size
in_channels: source image channels
(H, W): source image size
"""
x = torch.randn((N, in_channels, H, W))
assert disc(x).shape == (N, 1, 1, 1), "Discriminator has wrong output shape"
z = torch.randn((N, latent_size, 1, 1))
assert gen(z).shape == (
N,
in_channels,
H,
W,
), "Generator has wrong output shape: {}. \nExpected ({}, {}, {}, {})".format(
gen(z).shape, N, in_channels, H, W
)
print("Success")
latent_size = 96 # choose latent size
batch_size = 8
image_channels = 3
H, W = 128, 128
features = 32
DCdisc = DCDiscriminator(image_channels, features, H, W)
initialize_weights(DCdisc)
DCgen = DCGenerator(latent_size, image_channels, features)
initialize_weights(DCgen)
# do some test
checkout(DCgen, DCdisc, latent_size, batch_size, image_channels, H, W)
# ### Trainer
# Перейдем теперь к обучению нашего GANа. Алгоритм обучения следующий:
# 1. Учим дискриминатор:
# * берем реальные изображения и присваиваем им метку 1
# * генерируем изображения генератором и присваиваем им метку 0
# * обучаем классификатор на два класса
# 2. Учим генератор:
# * генерируем изображения генератором и присваиваем им метку 0
# * предсказываем дискриминаторором, реальное это изображение или нет
# В качестве функции потерь берем бинарную кросс-энтропию
class GANTrainer:
def __init__(
self,
models,
optimizers,
criterions,
latent_size,
batch_size,
device,
plot_step=10,
):
self.device = device
# init and move to device
self.model = {name: model.to(self.device) for name, model in models.items()}
self.criterion = {
name: criterion.to(self.device) for name, criterion in criterions.items()
}
self.optimizer = optimizers
self.latent_size = latent_size
self.batch_size = batch_size
# Plot settings
self.plot_step = plot_step
# Losses
self.losses = {"discriminator": [], "generator": []}
self.score = {"real": [0], "fake": [0]}
def train(self, dataloader, epochs):
"""
Main train GAN function
"""
self.model["discriminator"].train()
self.model["generator"].train()
torch.cuda.empty_cache()
for epoch in range(epochs):
self.__prepare_stat()
print("Epoch {} out of {}".format(epoch + 1, epochs))
for i, real_image in enumerate(tqdm(dataloader)):
# Train discriminator
if i < 5 or self.score["real"][-2] < 0.9:
self.optimizer["discriminator"].zero_grad() # Clear grads
loss_d = self.__train_disc(
real_image, self._get_fake_images(self.batch_size)
)
loss_d.backward() # Calculate gradients
self.optimizer["discriminator"].step() # Doing optimazer step
# Train Generator
self.optimizer["generator"].zero_grad()
loss_g = self.__train_gen(self._get_fake_images(self.batch_size))
loss_g.backward()
self.optimizer["generator"].step()
# Plot Stats
self.__calculate_stat()
self._print_last_stats()
if (epoch + 1) % self.plot_step == 0:
clear_output()
self._plot_fake_images()
def __train_disc(self, real_image, fake_images):
"""
Epoch training discriminator
Args:
real_image: torch.Tensor (batch_size, image_channles, H, W)
fake_image: the same
"""
# Pass real images through discriminator
real_pred = self.model["discriminator"](real_image)
real_target = torch.ones(real_image.size(0), 1, 1, 1, device=self.device)
real_loss = self.criterion["discriminator"](real_pred, real_target)
self.score["real"][-1].append(torch.mean(real_pred.detach().cpu()))
fake_pred = self.model["discriminator"](fake_images)
fake_target = torch.zeros(fake_images.size(0), 1, 1, 1, device=self.device)
fake_loss = self.criterion["discriminator"](fake_pred, fake_target)
self.score["fake"][-1].append(torch.mean(fake_pred.detach().cpu()))
loss_d = real_loss + fake_loss
self.losses["discriminator"][-1].append(loss_d.detach().item())
return loss_d
def __train_gen(self, fake_images):
"""
Epoch training generator
Args:
real_image: torch.Tensor (batch_size, image_channles, H, W)
fake_image: the same
"""
fake_image = self._get_fake_images(self.batch_size)
pred = self.model["discriminator"](fake_image)
target = torch.ones(self.batch_size, 1, 1, 1, device=self.device)
loss_g = self.criterion["generator"](pred, target)
self.losses["generator"][-1].append(loss_g.detach().item())
return loss_g
def __prepare_stat(self):
"""
Aappend empty array to losses and scores history:
[1, 2, 3, ..., [stats_per_epochs]]
and at the end we calculate np.mean to get ONE number instead ARRAY
[1, 2, 3, ..., []] -> [1, 2, 3, ..., n]
"""
self.losses["discriminator"].append([])
self.losses["generator"].append([])
self.score["real"].append([])
self.score["fake"].append([])
def __calculate_stat(self):
"""
[1, 2, 3, ..., [stats_per_epochs]] -> [1, 2, 3, ..., n]
"""
self.losses["discriminator"][-1] = np.mean(self.losses["discriminator"][-1])
self.losses["generator"][-1] = np.mean(self.losses["generator"][-1])
self.score["real"][-1] = np.mean(self.score["real"][-1])
self.score["fake"][-1] = np.mean(self.score["fake"][-1])
def _get_fake_images(self, N):
latent = torch.randn(N, self.latent_size, 1, 1, device=self.device)
fake_images = self.model["generator"](latent)
return fake_images
def _print_last_stats(self):
"""
Warning: you should use self.__calculate_stat() before this function
"""
print(
"Epoch {}, loss_g {:.4f}, loss_d {:.4f}, fake_score {:.4f}, real_score {:.4f}".format(
len(self.score["real"]),
self.losses["generator"][-1],
self.losses["discriminator"][-1],
self.score["fake"][-1],
self.score["real"][-1],
)
)
def _plot_fake_images(self, nrow=8):
"""
Showing the generator's results
"""
grid = torchvision.utils.make_grid(
self._get_fake_images(nrow**2), nrow=nrow, padding=0, scale_each=True
)
fig = plt.figure(figsize=(16, 8))
plt.imshow(grid.cpu().permute(1, 2, 0))
plt.axis("off")
plt.show()
def _plot_stats(self):
"""
Plotting stats of history training
"""
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
sns.lineplot(self.losses["discriminator"], label="discriminator", ax=axes[0])
sns.lineplot(self.losses["generator"], label="generator", ax=axes[0])
sns.lineplot(self.score["real"], label="real", ax=axes[1])
sns.lineplot(self.score["fake"], label="fake", ax=axes[1])
plt.tight_layout()
plt.show()
lr = 0.0001
models = {"discriminator": DCdisc, "generator": DCgen}
criterions = {"discriminator": nn.BCELoss(), "generator": nn.BCELoss()}
optimizers = {
"discriminator": torch.optim.Adam(
models["discriminator"].parameters(), lr=lr, betas=(0.5, 0.999)
),
"generator": torch.optim.Adam(
models["generator"].parameters(), lr=lr, betas=(0.5, 0.999)
),
}
trainer = GANTrainer(models, optimizers, criterions, latent_size, batch_size, device)
trainer._plot_fake_images()
trainer.train(faces_dataloader, 100)
trainer._plot_stats()
# Постройте графики лосса для генератора и дискриминатора. Что вы можете сказать про эти графики?
# ## Часть 3. Генерация изображений (1 балл)
# Теперь давайте оценим качество получившихся изображений. Напишите функцию, которая выводит изображения, сгенерированные нашим генератором
n_images = 4
fixed_latent = torch.randn(n_images, latent_size, 1, 1, device=device)
fake_images = model["generator"](fixed_latent)
def show_images(generated):
# TODO: show generated images
pass
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0132/554/132554970.ipynb | faces-dataset-small | tommykamaz | [{"Id": 132554970, "ScriptId": 39497739, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 3910696, "CreationDate": "06/06/2023 18:55:17", "VersionNumber": 3.0, "Title": "faceDCGAN", "EvaluationDate": "06/06/2023", "IsChange": true, "TotalLines": 599.0, "LinesInsertedFromPrevious": 86.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 513.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 1}] | [{"Id": 190049945, "KernelVersionId": 132554970, "SourceDatasetVersionId": 3684316}] | [{"Id": 3684316, "DatasetId": 2204890, "DatasourceVersionId": 3738480, "CreatorUserId": 8975186, "LicenseName": "Attribution 4.0 International (CC BY 4.0)", "CreationDate": "05/23/2022 17:12:59", "VersionNumber": 1.0, "Title": "Flickr-Faces-HQ (FFHQ) small", "Slug": "faces-dataset-small", "Subtitle": "3143 photos of Flickr-Faces-HQ (1024px)", "Description": "This is a small version of FFHQ with 3143 photos. \nFlickr-Faces-HQ (FFHQ) is an image dataset containing high-quality images of human faces. It is provided by NVIDIA under the Creative Commons BY-NC-SA 4.0 license. It offers 70,000 PNG images at 1024\u00d71024 resolution that display diverse ages, ethnicities, image backgrounds, and accessories like hats and eyeglasses.", "VersionNotes": "Initial release", "TotalCompressedBytes": 0.0, "TotalUncompressedBytes": 0.0}] | [{"Id": 2204890, "CreatorUserId": 8975186, "OwnerUserId": 8975186.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 3684316.0, "CurrentDatasourceVersionId": 3738480.0, "ForumId": 2231003, "Type": 2, "CreationDate": "05/23/2022 17:12:59", "LastActivityDate": "05/23/2022", "TotalViews": 2531, "TotalDownloads": 1206, "TotalVotes": 13, "TotalKernels": 12}] | [{"Id": 8975186, "UserName": "tommykamaz", "DisplayName": "Grigory Soldatov", "RegisterDate": "11/23/2021", "PerformanceTier": 1}] | #
# Школа глубокого обучения ФПМИ МФТИ
# Домашнее задание. Generative adversarial networks
# В этом домашнем задании вы обучите GAN генерировать лица людей и посмотрите на то, как можно оценивать качество генерации
import os
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
import torchvision.transforms as tt
import torchvision
import torch
import torch.nn as nn
import cv2
from tqdm.notebook import tqdm
from torchvision.utils import save_image
from torchvision.utils import make_grid
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from torch.utils.data import Dataset
import multiprocessing as mp
from PIL import Image
from IPython.display import clear_output
sns.set(style="darkgrid", font_scale=1.2)
sns.set_style("darkgrid")
# ## Часть 1. Подготовка данных (1 балл)
# В качестве обучающей выборки возьмем часть датасета [Flickr Faces](https://github.com/NVlabs/ffhq-dataset), который содержит изображения лиц людей в высоком разрешении (1024х1024). Оригинальный датасет очень большой, поэтому мы возьмем его часть. Скачать датасет можно [здесь](https://www.kaggle.com/datasets/tommykamaz/faces-dataset-small?resource=download-directory) и [здесь](https://drive.google.com/drive/folders/14H7LQWzd09SaM11oLfGtd455sWH2rmRW?usp=share_link)
# Давайте загрузим наши изображения. Напишите функцию, которая строит DataLoader для изображений, при этом меняя их размер до нужного значения (размер 1024 слишком большой, поэтому мы рекомендуем взять размер 128 либо немного больше)
class FacesDataset(Dataset):
"""
Dataset for Flickr-Faces-HQ (FFHQ) small
"""
def __init__(self, path, input_transform=None):
super().__init__()
self.path = path
self.input_transform = input_transform
self.paths = os.listdir(self.path)
self.data = []
self._read_images()
def _read_image(self, image_name):
"""
Read image and use input_transforms
"""
image = Image.open(os.path.join(self.path, image_name))
if self.input_transform:
image = self.input_transform(image)
return image
def _read_images(self):
"""
Pool of _read_image functions
"""
with mp.Pool(processes=mp.cpu_count()) as pool:
self.data = list(
tqdm(
pool.imap_unordered(self._read_image, self.paths),
total=len(self.paths),
)
)
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]
def to_device(data, device):
"""
Move data to self.device
"""
if isinstance(data, (list, tuple)):
return [to_device(x, device) for x in data]
return data.to(device, non_blocking=True)
class DeviceDataLoader:
def __init__(self, dataloader, device):
self.dataloader = dataloader
self.device = device
def __iter__(self):
for batch in self.dataloader:
yield to_device(batch, self.device)
def __len__(self):
return len(self.dataloader)
def get_dataloader(path, device, input_transform, image_size, batch_size):
"""
Builds dataloader for training data.
Use tt.Compose and tt.Resize for transformations
:param image_size: height and wdith of the image
:param batch_size: batch_size of the dataloader
:returns: DataLoader object
"""
# TODO: resize images, convert them to tensors and build dataloader
faces_dataset = FacesDataset(path, input_transform)
return DeviceDataLoader(
DataLoader(faces_dataset, batch_size=batch_size, drop_last=True), device
)
# !ls /kaggle/input/faces-dataset-small/faces_dataset_small
image_size = (128, 128)
batch_size = 64
path = "/kaggle/input/faces-dataset-small/faces_dataset_small"
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
input_transform = tt.Compose(
[
tt.RandomHorizontalFlip(p=0.5),
tt.Resize(image_size),
tt.ToTensor(),
tt.ConvertImageDtype(torch.float),
]
)
faces_dataloader = get_dataloader(path, device, input_transform, image_size, batch_size)
faces = next(iter(faces_dataloader))
grid = torchvision.utils.make_grid(faces, nrow=8, padding=0, scale_each=True)
fig = plt.figure(figsize=(16, 8))
plt.imshow(grid.cpu().permute(1, 2, 0))
plt.axis("off")
plt.show()
# ## Часть 2. Построение и обучение модели (2 балла)
# Сконструируйте генератор и дискриминатор. Помните, что:
# * дискриминатор принимает на вход изображение (тензор размера `3 x image_size x image_size`) и выдает вероятность того, что изображение настоящее (тензор размера 1)
# * генератор принимает на вход тензор шумов размера `latent_size x 1 x 1` и генерирует изображение размера `3 x image_size x image_size`
# ### PixelNorm
# to avoid training BatchNorm module
class PixelNorm(nn.Module):
"""
Nontrainable pixel normalization layer
"""
def __init__(self, eps=1e-8):
super(PixelNorm, self).__init__()
self.eps = eps
def forward(self, x):
return (
x
/ torch.sqrt(torch.mean(x**2, dim=1, keepdim=True) + self.eps)
/ x.shape[0]
)
# Что же такое PixelNorm?
# В [статье по ProGAN]("https://towardsdatascience.com/progan-how-nvidia-generated-images-of-unprecedented-quality-51c98ec2cbd2") предлагается использовать такую нормализация вместо BatchNorm. Главным отличием от BatchNorm является отсутствие тренировочных весов у этого слоя.
# $$b_{x,y}=\frac{a_{x,y}}{\sqrt{\frac{1}{C}\sum\limits_{j=0}^C (a_{x,y}^j)^2 + \varepsilon}}$$
# Но как же влияет PixelNorm на фотографию?
faces = next(iter(faces_dataloader))
grid = torchvision.utils.make_grid(faces, nrow=8, padding=0, scale_each=True)
fig = plt.figure(figsize=(16, 8))
# Using PixelNorm
plt.imshow(PixelNorm()(grid).cpu().permute(1, 2, 0))
plt.axis("off")
plt.show()
# Норм, однако давайте не использовать нормализацию на последнем слое генератора, чтобы он смог восстанавливать цвета.
# ### Generator
class DCGenerator(nn.Module):
"""
Generator of Deep Convolution GAN
"""
def __init__(self, z_dim=96, channels_image=3, features_g=8):
super(DCGenerator, self).__init__()
self.channels_image = channels_image
self.latent_size = z_dim
self._block1 = self._block(
z_dim, features_g * 32, 4, 1, 0
) # N x f_g*16 x 4 x 4
self._block2 = self._block(
features_g * 32, features_g * 16, 3, 2, 1, output_padding=1
) # 8 x 8
self._block3 = self._block(
features_g * 16, features_g * 8, 3, 2, 1, output_padding=1
) # 16 x 16
self._block4 = self._block(
features_g * 8, features_g * 4, 3, 2, 1, output_padding=1
) # 32 x 32
self._block5 = self._block(features_g * 4, features_g * 2, 4, 2, 1) # 64 x 64
self.end_block = nn.Sequential(
nn.ConvTranspose2d(
features_g * 2, self.channels_image, 4, 2, 1, output_padding=0
), # 128 x 128
nn.Tanh(), # [0, +inf] -> [0, 1]
)
def _block(
self, in_channels, out_channels, kernel_size, stride, padding, output_padding=0
):
"""
Generator block consist such elems as
nn.ConvTranspose2d
PixelNorm()
nn.ReLU()
"""
return nn.Sequential(
nn.ConvTranspose2d(
in_channels,
out_channels,
kernel_size,
stride,
padding,
output_padding=output_padding,
bias=False,
),
nn.BatchNorm2d(out_channels),
nn.ReLU(),
)
def _get_input_tensor_shape(self):
"""
Return input tensor size
"""
return self.latent_size
def forward(self, x):
x = self._block1(x)
x = self._block2(x)
x = tt.GaussianBlur(3)(x) # Blur Image
x = self._block3(x)
# x = tt.GaussianBlur(3)(x) # Blur image
x = self._block4(x)
x = self._block5(x)
x = self.end_block(x)
return x
# ### Disciminator
class DCDiscriminator(nn.Module):
"""
Discriminator of Deep Convolution GAN
"""
def __init__(self, channels_image, features_d, H, W):
super(DCDiscriminator, self).__init__()
self.channels_image = channels_image
self.H = H
self.W = W
self.disc = nn.Sequential(
# N x channels_image x 128 x 128
nn.Conv2d(
channels_image, features_d, kernel_size=4, stride=2, padding=1
), # 64 x 64
nn.LeakyReLU(0.2),
self._block(features_d, features_d * 2, 4, 2, 1), # 32 x 32
self._block(features_d * 2, features_d * 4, 4, 2, 1), # 16 x 16
self._block(features_d * 4, features_d * 8, 4, 2, 1), # 8 x 8
self._block(features_d * 8, features_d * 16, 4, 2, 1), # 4 x 4
nn.Conv2d(features_d * 16, 1, kernel_size=4, stride=2, padding=0), # 1 x 1
nn.Sigmoid(),
)
def _block(self, in_channels, out_channels, kernel_size, stride, padding):
"""
Discriminator block consist such elems as
nn.Conv2d
nn.BatchNorm2d
nn.LeakyReLU
"""
return nn.Sequential(
nn.Conv2d(
in_channels, out_channels, kernel_size, stride, padding, bias=False
),
nn.BatchNorm2d(out_channels),
nn.LeakyReLU(0.1),
)
def _get_input_tensor_shape(self):
"""
Return input tensor size
"""
return self.channels_image, self.H, self.W
def forward(self, x):
return self.disc(x)
# Проинизицализируем веса нормальным распределением с стандартным отлонением 0 и дисперсией 0.02
def initialize_weights(model):
"""
Model normal initialization
Args:
model: nn.Module object
"""
for m in model.modules():
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.BatchNorm2d)):
nn.init.normal_(m.weight, 0.0, 0.02)
# Проверим размерности выходов генератора и дискриминатора
def checkout(gen, disc, latent_size, N, in_channels, H, W):
"""
Checking right shape of generator and discriminator
Args:
gen: initilized generator
disc: initilized discriminator
latent_size: lenght of latent vector
N: batch size
in_channels: source image channels
(H, W): source image size
"""
x = torch.randn((N, in_channels, H, W))
assert disc(x).shape == (N, 1, 1, 1), "Discriminator has wrong output shape"
z = torch.randn((N, latent_size, 1, 1))
assert gen(z).shape == (
N,
in_channels,
H,
W,
), "Generator has wrong output shape: {}. \nExpected ({}, {}, {}, {})".format(
gen(z).shape, N, in_channels, H, W
)
print("Success")
latent_size = 96 # choose latent size
batch_size = 8
image_channels = 3
H, W = 128, 128
features = 32
DCdisc = DCDiscriminator(image_channels, features, H, W)
initialize_weights(DCdisc)
DCgen = DCGenerator(latent_size, image_channels, features)
initialize_weights(DCgen)
# do some test
checkout(DCgen, DCdisc, latent_size, batch_size, image_channels, H, W)
# ### Trainer
# Перейдем теперь к обучению нашего GANа. Алгоритм обучения следующий:
# 1. Учим дискриминатор:
# * берем реальные изображения и присваиваем им метку 1
# * генерируем изображения генератором и присваиваем им метку 0
# * обучаем классификатор на два класса
# 2. Учим генератор:
# * генерируем изображения генератором и присваиваем им метку 0
# * предсказываем дискриминаторором, реальное это изображение или нет
# В качестве функции потерь берем бинарную кросс-энтропию
class GANTrainer:
def __init__(
self,
models,
optimizers,
criterions,
latent_size,
batch_size,
device,
plot_step=10,
):
self.device = device
# init and move to device
self.model = {name: model.to(self.device) for name, model in models.items()}
self.criterion = {
name: criterion.to(self.device) for name, criterion in criterions.items()
}
self.optimizer = optimizers
self.latent_size = latent_size
self.batch_size = batch_size
# Plot settings
self.plot_step = plot_step
# Losses
self.losses = {"discriminator": [], "generator": []}
self.score = {"real": [0], "fake": [0]}
def train(self, dataloader, epochs):
"""
Main train GAN function
"""
self.model["discriminator"].train()
self.model["generator"].train()
torch.cuda.empty_cache()
for epoch in range(epochs):
self.__prepare_stat()
print("Epoch {} out of {}".format(epoch + 1, epochs))
for i, real_image in enumerate(tqdm(dataloader)):
# Train discriminator
if i < 5 or self.score["real"][-2] < 0.9:
self.optimizer["discriminator"].zero_grad() # Clear grads
loss_d = self.__train_disc(
real_image, self._get_fake_images(self.batch_size)
)
loss_d.backward() # Calculate gradients
self.optimizer["discriminator"].step() # Doing optimazer step
# Train Generator
self.optimizer["generator"].zero_grad()
loss_g = self.__train_gen(self._get_fake_images(self.batch_size))
loss_g.backward()
self.optimizer["generator"].step()
# Plot Stats
self.__calculate_stat()
self._print_last_stats()
if (epoch + 1) % self.plot_step == 0:
clear_output()
self._plot_fake_images()
def __train_disc(self, real_image, fake_images):
"""
Epoch training discriminator
Args:
real_image: torch.Tensor (batch_size, image_channles, H, W)
fake_image: the same
"""
# Pass real images through discriminator
real_pred = self.model["discriminator"](real_image)
real_target = torch.ones(real_image.size(0), 1, 1, 1, device=self.device)
real_loss = self.criterion["discriminator"](real_pred, real_target)
self.score["real"][-1].append(torch.mean(real_pred.detach().cpu()))
fake_pred = self.model["discriminator"](fake_images)
fake_target = torch.zeros(fake_images.size(0), 1, 1, 1, device=self.device)
fake_loss = self.criterion["discriminator"](fake_pred, fake_target)
self.score["fake"][-1].append(torch.mean(fake_pred.detach().cpu()))
loss_d = real_loss + fake_loss
self.losses["discriminator"][-1].append(loss_d.detach().item())
return loss_d
def __train_gen(self, fake_images):
"""
Epoch training generator
Args:
real_image: torch.Tensor (batch_size, image_channles, H, W)
fake_image: the same
"""
fake_image = self._get_fake_images(self.batch_size)
pred = self.model["discriminator"](fake_image)
target = torch.ones(self.batch_size, 1, 1, 1, device=self.device)
loss_g = self.criterion["generator"](pred, target)
self.losses["generator"][-1].append(loss_g.detach().item())
return loss_g
def __prepare_stat(self):
"""
Aappend empty array to losses and scores history:
[1, 2, 3, ..., [stats_per_epochs]]
and at the end we calculate np.mean to get ONE number instead ARRAY
[1, 2, 3, ..., []] -> [1, 2, 3, ..., n]
"""
self.losses["discriminator"].append([])
self.losses["generator"].append([])
self.score["real"].append([])
self.score["fake"].append([])
def __calculate_stat(self):
"""
[1, 2, 3, ..., [stats_per_epochs]] -> [1, 2, 3, ..., n]
"""
self.losses["discriminator"][-1] = np.mean(self.losses["discriminator"][-1])
self.losses["generator"][-1] = np.mean(self.losses["generator"][-1])
self.score["real"][-1] = np.mean(self.score["real"][-1])
self.score["fake"][-1] = np.mean(self.score["fake"][-1])
def _get_fake_images(self, N):
latent = torch.randn(N, self.latent_size, 1, 1, device=self.device)
fake_images = self.model["generator"](latent)
return fake_images
def _print_last_stats(self):
"""
Warning: you should use self.__calculate_stat() before this function
"""
print(
"Epoch {}, loss_g {:.4f}, loss_d {:.4f}, fake_score {:.4f}, real_score {:.4f}".format(
len(self.score["real"]),
self.losses["generator"][-1],
self.losses["discriminator"][-1],
self.score["fake"][-1],
self.score["real"][-1],
)
)
def _plot_fake_images(self, nrow=8):
"""
Showing the generator's results
"""
grid = torchvision.utils.make_grid(
self._get_fake_images(nrow**2), nrow=nrow, padding=0, scale_each=True
)
fig = plt.figure(figsize=(16, 8))
plt.imshow(grid.cpu().permute(1, 2, 0))
plt.axis("off")
plt.show()
def _plot_stats(self):
"""
Plotting stats of history training
"""
fig, axes = plt.subplots(1, 2, figsize=(10, 4))
sns.lineplot(self.losses["discriminator"], label="discriminator", ax=axes[0])
sns.lineplot(self.losses["generator"], label="generator", ax=axes[0])
sns.lineplot(self.score["real"], label="real", ax=axes[1])
sns.lineplot(self.score["fake"], label="fake", ax=axes[1])
plt.tight_layout()
plt.show()
lr = 0.0001
models = {"discriminator": DCdisc, "generator": DCgen}
criterions = {"discriminator": nn.BCELoss(), "generator": nn.BCELoss()}
optimizers = {
"discriminator": torch.optim.Adam(
models["discriminator"].parameters(), lr=lr, betas=(0.5, 0.999)
),
"generator": torch.optim.Adam(
models["generator"].parameters(), lr=lr, betas=(0.5, 0.999)
),
}
trainer = GANTrainer(models, optimizers, criterions, latent_size, batch_size, device)
trainer._plot_fake_images()
trainer.train(faces_dataloader, 100)
trainer._plot_stats()
# Постройте графики лосса для генератора и дискриминатора. Что вы можете сказать про эти графики?
# ## Часть 3. Генерация изображений (1 балл)
# Теперь давайте оценим качество получившихся изображений. Напишите функцию, которая выводит изображения, сгенерированные нашим генератором
n_images = 4
fixed_latent = torch.randn(n_images, latent_size, 1, 1, device=device)
fake_images = model["generator"](fixed_latent)
def show_images(generated):
# TODO: show generated images
pass
| false | 0 | 5,959 | 1 | 146 | 5,959 |
||
48305609 | <kaggle_start><code># This is a two part tutorial series on TF-Agents
# Part 1 : https://www.kaggle.com/usharengaraju/tfagents-environment-policy-driver
# Part 2 : https://www.kaggle.com/usharengaraju/tf-agents-replay-buffer-network-checkpointer
# Credit : The article series has been adapted from the official tensorflow documentation.
# ## Reinforcement Learning
# Reinforcement learning (RL) is a machine learning framework where agents takes action in an environment in order to maximize the cumulative reward .
# 
# Pic Credit : ai.googleblog.com
# ### TF-Agents :
# A reliable, scalable and easy to use TensorFlow library for Contextual Bandits and Reinforcement Learning.
# 
# Pic Credit : Tensorflow Dev Summit
# ### Advantages of TF-Agents :
# 🎯 Great Resources to get started with Reinforcement Learning like colab , documentation and resources
# 🎯 Well suited to handle complex RL problems
# 🎯 Helps in developing RL algorithms quickly
# 🎯 Can be configured easily with gin-config
# 
# Pic Credit : Tensorflow Dev Summit
# In this notebook , we will be discussing three concepts - Environment , Policy and Driver
# ### Environment
# The agent receives an observation and chooses an action which it applies on the environment and gets back reward
# and a observation from the environment. The goal of the agent is to train a policy to choose actions which will
# maximize the cumulative rewards.
# TF-Agents has both Python and TensorFlow implentation of environments .
#
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import abc
import tensorflow as tf
import numpy as np
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.environments import utils
from tf_agents.specs import array_spec
from tf_agents.environments import wrappers
from tf_agents.environments import suite_gym
from tf_agents.trajectories import time_step as ts
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.networks import network
from tf_agents.policies import py_policy
from tf_agents.policies import random_py_policy
from tf_agents.policies import scripted_py_policy
from tf_agents.policies import tf_policy
from tf_agents.policies import random_tf_policy
from tf_agents.policies import actor_policy
from tf_agents.policies import q_policy
from tf_agents.policies import greedy_policy
from tf_agents.environments import suite_gym
from tf_agents.metrics import py_metrics
from tf_agents.metrics import tf_metrics
from tf_agents.drivers import py_driver
from tf_agents.drivers import dynamic_episode_driver
tf.compat.v1.enable_v2_behavior()
from tf_agents.trajectories import time_step as ts
tf.compat.v1.enable_v2_behavior()
tf.compat.v1.enable_v2_behavior()
# ### Python Environments :
# The interface that all python environments must implement is in environments/py_environment.PyEnvironment.
# After interaction with the environment the following information about the next step are available
# 📌 **observation:** This is the part of the environment state that the agent can observe to choose its actions at the next step.
# 📌 **reward:** The agent is learning to maximize the sum of these rewards across multiple steps.
# 📌 **step_type:** Interactions with the environment are usually part of a sequence/episode. e.g. multiple moves in a game of chess. step_type can be either FIRST, MID or LAST to indicate whether this time step is the first, intermediate or last step in a sequence.
# 📌 **discount:** This is a float representing how much to weight the reward at the next time step relative to the reward at the current time step.
#
class PyEnvironment(object):
def reset(self):
"""Return initial_time_step."""
self._current_time_step = self._reset()
return self._current_time_step
def step(self, action):
"""Apply action and return new time_step."""
if self._current_time_step is None:
return self.reset()
self._current_time_step = self._step(action)
return self._current_time_step
def current_time_step(self):
return self._current_time_step
def time_step_spec(self):
"""Return time_step_spec."""
@abc.abstractmethod
def observation_spec(self):
"""Return observation_spec."""
@abc.abstractmethod
def action_spec(self):
"""Return action_spec."""
@abc.abstractmethod
def _reset(self):
"""Return initial_time_step."""
@abc.abstractmethod
def _step(self, action):
"""Apply action and return new time_step."""
self._current_time_step = self._step(action)
return self._current_time_step
# ### Standard Environments :
# TF Agents has built-in wrappers for many standard environments like the OpenAI Gym, DeepMind-control and Atari, which can be easily loaded using our environment suites. The code below loads the CartPole environment from the OpenAI gym
#
environment = suite_gym.load("CartPole-v0")
print("action_spec:", environment.action_spec())
print("time_step_spec.observation:", environment.time_step_spec().observation)
print("time_step_spec.step_type:", environment.time_step_spec().step_type)
print("time_step_spec.discount:", environment.time_step_spec().discount)
print("time_step_spec.reward:", environment.time_step_spec().reward)
# ## Policy
# Policies map an observation from the environment to an action or a distribution over actions.Most policies have a neural network to compute actions and/or distributions over actions from TimeSteps.Policies can be saved/restored, and can be used indepedently of the agent for data collection, evaluation etc.
# Policies contain the following information
# 📌 **action:** The action to be applied to the environment.
# 📌 **state:** The state of the policy (e.g. RNN state) to be fed into the next call to action.
# 📌 **info:** Optional side information such as action log probabilities.
#
class Base(object):
@abc.abstractmethod
def __init__(self, time_step_spec, action_spec, policy_state_spec=()):
self._time_step_spec = time_step_spec
self._action_spec = action_spec
self._policy_state_spec = policy_state_spec
@abc.abstractmethod
def reset(self, policy_state=()):
# return initial_policy_state.
pass
@abc.abstractmethod
def action(self, time_step, policy_state=()):
# return a PolicyStep(action, state, info) named tuple.
pass
@abc.abstractmethod
def distribution(self, time_step, policy_state=()):
# Not implemented in python, only for TF policies.
pass
@abc.abstractmethod
def update(self, policy):
# update self to be similar to the input `policy`.
pass
@property
def time_step_spec(self):
return self._time_step_spec
@property
def action_spec(self):
return self._action_spec
@property
def policy_state_spec(self):
return self._policy_state_spec
# ## Random Python Policy
# RandomPyPolicy generates random actions for the discrete/continuous given action_spec.
action_spec = array_spec.BoundedArraySpec((2,), np.int32, -10, 10)
my_random_py_policy = random_py_policy.RandomPyPolicy(
time_step_spec=None, action_spec=action_spec
)
time_step = None
action_step = my_random_py_policy.action(time_step)
print(action_step)
action_step = my_random_py_policy.action(time_step)
print(action_step)
# ## Drivers
# Drivers are abstraction for the process of executing a policy in an environment for a specified number of steps during data collection, evaluation and generating a video of the agent.The data encountered by the driver at each step like observation , action , reward , current and next step is saved in Trajectory and broadcast to a set of observers such as replay buffers and metrics.
# Implementations for drivers are available both in Python and TensorFlow
# **Python Drivers :**
# The PyDriver class takes a python environment, a python policy and a list of observers to update at each step.
class PyDriver(object):
def __init__(self, env, policy, observers, max_steps=1, max_episodes=1):
self._env = env
self._policy = policy
self._observers = observers or []
self._max_steps = max_steps or np.inf
self._max_episodes = max_episodes or np.inf
def run(self, time_step, policy_state=()):
num_steps = 0
num_episodes = 0
while num_steps < self._max_steps and num_episodes < self._max_episodes:
# Compute an action using the policy for the given time_step
action_step = self._policy.action(time_step, policy_state)
# Apply the action to the environment and get the next step
next_time_step = self._env.step(action_step.action)
# Package information into a trajectory
traj = trajectory.Trajectory(
time_step.step_type,
time_step.observation,
action_step.action,
action_step.info,
next_time_step.step_type,
next_time_step.reward,
next_time_step.discount,
)
for observer in self._observers:
observer(traj)
# Update statistics to check termination
num_episodes += np.sum(traj.is_last())
num_steps += np.sum(~traj.is_boundary())
time_step = next_time_step
policy_state = action_step.state
return time_step, policy_state
# The code below runs a random policy on the CartPole environment, saving the results to a **replay buffer**.
#
env = suite_gym.load("CartPole-v0")
policy = random_py_policy.RandomPyPolicy(
time_step_spec=env.time_step_spec(), action_spec=env.action_spec()
)
replay_buffer = []
metric = py_metrics.AverageReturnMetric()
observers = [replay_buffer.append, metric]
driver = py_driver.PyDriver(env, policy, observers, max_steps=20, max_episodes=1)
initial_time_step = env.reset()
final_time_step, _ = driver.run(initial_time_step)
print("Replay Buffer:")
for traj in replay_buffer:
print(traj)
print("Average Return: ", metric.result())
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0048/305/48305609.ipynb | null | null | [{"Id": 48305609, "ScriptId": 7934748, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 373959, "CreationDate": "12/01/2020 20:53:25", "VersionNumber": 43.0, "Title": "TFAgents-Environment , Policy , Driver", "EvaluationDate": "12/01/2020", "IsChange": false, "TotalLines": 320.0, "LinesInsertedFromPrevious": 0.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 320.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 26}] | null | null | null | null | # This is a two part tutorial series on TF-Agents
# Part 1 : https://www.kaggle.com/usharengaraju/tfagents-environment-policy-driver
# Part 2 : https://www.kaggle.com/usharengaraju/tf-agents-replay-buffer-network-checkpointer
# Credit : The article series has been adapted from the official tensorflow documentation.
# ## Reinforcement Learning
# Reinforcement learning (RL) is a machine learning framework where agents takes action in an environment in order to maximize the cumulative reward .
# 
# Pic Credit : ai.googleblog.com
# ### TF-Agents :
# A reliable, scalable and easy to use TensorFlow library for Contextual Bandits and Reinforcement Learning.
# 
# Pic Credit : Tensorflow Dev Summit
# ### Advantages of TF-Agents :
# 🎯 Great Resources to get started with Reinforcement Learning like colab , documentation and resources
# 🎯 Well suited to handle complex RL problems
# 🎯 Helps in developing RL algorithms quickly
# 🎯 Can be configured easily with gin-config
# 
# Pic Credit : Tensorflow Dev Summit
# In this notebook , we will be discussing three concepts - Environment , Policy and Driver
# ### Environment
# The agent receives an observation and chooses an action which it applies on the environment and gets back reward
# and a observation from the environment. The goal of the agent is to train a policy to choose actions which will
# maximize the cumulative rewards.
# TF-Agents has both Python and TensorFlow implentation of environments .
#
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import abc
import tensorflow as tf
import numpy as np
from tf_agents.environments import py_environment
from tf_agents.environments import tf_environment
from tf_agents.environments import tf_py_environment
from tf_agents.environments import utils
from tf_agents.specs import array_spec
from tf_agents.environments import wrappers
from tf_agents.environments import suite_gym
from tf_agents.trajectories import time_step as ts
from tf_agents.specs import array_spec
from tf_agents.specs import tensor_spec
from tf_agents.networks import network
from tf_agents.policies import py_policy
from tf_agents.policies import random_py_policy
from tf_agents.policies import scripted_py_policy
from tf_agents.policies import tf_policy
from tf_agents.policies import random_tf_policy
from tf_agents.policies import actor_policy
from tf_agents.policies import q_policy
from tf_agents.policies import greedy_policy
from tf_agents.environments import suite_gym
from tf_agents.metrics import py_metrics
from tf_agents.metrics import tf_metrics
from tf_agents.drivers import py_driver
from tf_agents.drivers import dynamic_episode_driver
tf.compat.v1.enable_v2_behavior()
from tf_agents.trajectories import time_step as ts
tf.compat.v1.enable_v2_behavior()
tf.compat.v1.enable_v2_behavior()
# ### Python Environments :
# The interface that all python environments must implement is in environments/py_environment.PyEnvironment.
# After interaction with the environment the following information about the next step are available
# 📌 **observation:** This is the part of the environment state that the agent can observe to choose its actions at the next step.
# 📌 **reward:** The agent is learning to maximize the sum of these rewards across multiple steps.
# 📌 **step_type:** Interactions with the environment are usually part of a sequence/episode. e.g. multiple moves in a game of chess. step_type can be either FIRST, MID or LAST to indicate whether this time step is the first, intermediate or last step in a sequence.
# 📌 **discount:** This is a float representing how much to weight the reward at the next time step relative to the reward at the current time step.
#
class PyEnvironment(object):
def reset(self):
"""Return initial_time_step."""
self._current_time_step = self._reset()
return self._current_time_step
def step(self, action):
"""Apply action and return new time_step."""
if self._current_time_step is None:
return self.reset()
self._current_time_step = self._step(action)
return self._current_time_step
def current_time_step(self):
return self._current_time_step
def time_step_spec(self):
"""Return time_step_spec."""
@abc.abstractmethod
def observation_spec(self):
"""Return observation_spec."""
@abc.abstractmethod
def action_spec(self):
"""Return action_spec."""
@abc.abstractmethod
def _reset(self):
"""Return initial_time_step."""
@abc.abstractmethod
def _step(self, action):
"""Apply action and return new time_step."""
self._current_time_step = self._step(action)
return self._current_time_step
# ### Standard Environments :
# TF Agents has built-in wrappers for many standard environments like the OpenAI Gym, DeepMind-control and Atari, which can be easily loaded using our environment suites. The code below loads the CartPole environment from the OpenAI gym
#
environment = suite_gym.load("CartPole-v0")
print("action_spec:", environment.action_spec())
print("time_step_spec.observation:", environment.time_step_spec().observation)
print("time_step_spec.step_type:", environment.time_step_spec().step_type)
print("time_step_spec.discount:", environment.time_step_spec().discount)
print("time_step_spec.reward:", environment.time_step_spec().reward)
# ## Policy
# Policies map an observation from the environment to an action or a distribution over actions.Most policies have a neural network to compute actions and/or distributions over actions from TimeSteps.Policies can be saved/restored, and can be used indepedently of the agent for data collection, evaluation etc.
# Policies contain the following information
# 📌 **action:** The action to be applied to the environment.
# 📌 **state:** The state of the policy (e.g. RNN state) to be fed into the next call to action.
# 📌 **info:** Optional side information such as action log probabilities.
#
class Base(object):
@abc.abstractmethod
def __init__(self, time_step_spec, action_spec, policy_state_spec=()):
self._time_step_spec = time_step_spec
self._action_spec = action_spec
self._policy_state_spec = policy_state_spec
@abc.abstractmethod
def reset(self, policy_state=()):
# return initial_policy_state.
pass
@abc.abstractmethod
def action(self, time_step, policy_state=()):
# return a PolicyStep(action, state, info) named tuple.
pass
@abc.abstractmethod
def distribution(self, time_step, policy_state=()):
# Not implemented in python, only for TF policies.
pass
@abc.abstractmethod
def update(self, policy):
# update self to be similar to the input `policy`.
pass
@property
def time_step_spec(self):
return self._time_step_spec
@property
def action_spec(self):
return self._action_spec
@property
def policy_state_spec(self):
return self._policy_state_spec
# ## Random Python Policy
# RandomPyPolicy generates random actions for the discrete/continuous given action_spec.
action_spec = array_spec.BoundedArraySpec((2,), np.int32, -10, 10)
my_random_py_policy = random_py_policy.RandomPyPolicy(
time_step_spec=None, action_spec=action_spec
)
time_step = None
action_step = my_random_py_policy.action(time_step)
print(action_step)
action_step = my_random_py_policy.action(time_step)
print(action_step)
# ## Drivers
# Drivers are abstraction for the process of executing a policy in an environment for a specified number of steps during data collection, evaluation and generating a video of the agent.The data encountered by the driver at each step like observation , action , reward , current and next step is saved in Trajectory and broadcast to a set of observers such as replay buffers and metrics.
# Implementations for drivers are available both in Python and TensorFlow
# **Python Drivers :**
# The PyDriver class takes a python environment, a python policy and a list of observers to update at each step.
class PyDriver(object):
def __init__(self, env, policy, observers, max_steps=1, max_episodes=1):
self._env = env
self._policy = policy
self._observers = observers or []
self._max_steps = max_steps or np.inf
self._max_episodes = max_episodes or np.inf
def run(self, time_step, policy_state=()):
num_steps = 0
num_episodes = 0
while num_steps < self._max_steps and num_episodes < self._max_episodes:
# Compute an action using the policy for the given time_step
action_step = self._policy.action(time_step, policy_state)
# Apply the action to the environment and get the next step
next_time_step = self._env.step(action_step.action)
# Package information into a trajectory
traj = trajectory.Trajectory(
time_step.step_type,
time_step.observation,
action_step.action,
action_step.info,
next_time_step.step_type,
next_time_step.reward,
next_time_step.discount,
)
for observer in self._observers:
observer(traj)
# Update statistics to check termination
num_episodes += np.sum(traj.is_last())
num_steps += np.sum(~traj.is_boundary())
time_step = next_time_step
policy_state = action_step.state
return time_step, policy_state
# The code below runs a random policy on the CartPole environment, saving the results to a **replay buffer**.
#
env = suite_gym.load("CartPole-v0")
policy = random_py_policy.RandomPyPolicy(
time_step_spec=env.time_step_spec(), action_spec=env.action_spec()
)
replay_buffer = []
metric = py_metrics.AverageReturnMetric()
observers = [replay_buffer.append, metric]
driver = py_driver.PyDriver(env, policy, observers, max_steps=20, max_episodes=1)
initial_time_step = env.reset()
final_time_step, _ = driver.run(initial_time_step)
print("Replay Buffer:")
for traj in replay_buffer:
print(traj)
print("Average Return: ", metric.result())
| false | 0 | 2,714 | 26 | 6 | 2,714 |
||
48202409 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
# # Lists
# Lists in Python represent ordered sequences of values.
# -1 : It means to increment the index every time by -1, meaning it will traverse the list by going backwards.
#
planets = [
"Mercury",
"Venus",
"Earth",
"Mars",
"Jupiter",
"Saturn",
"Uranus",
"Neptune",
]
planets[1]
# list[start:exlusive]
planets[2:5]
# list[start:stop:step]
planets[1:6:2]
# All the planets except the first and last
print(planets)
# The last 3 planets
planets[-3:]
# Reversing the list
planets[::-1]
# # Changing lists
# Lists are "mutable", meaning they can be modified "in place".
# One way to modify a list is to assign to an index or slice expression.
#
planets = [
"Mercury",
"Venus",
"Earth",
"Mars",
"Jupiter",
"Saturn",
"Uranus",
"Neptune",
]
# planets[3] = 'Malacandra'
# print(planets)
planets[:3] = ["Mur", "Vee", "Ur"]
print(planets)
# # List functions
#
# How many planets are there?
len(planets)
# The planets sorted in alphabetical order
planets = [
"Mercury",
"Venus",
"Earth",
"Mars",
"Jupiter",
"Saturn",
"Uranus",
"Neptune",
]
print(sorted(planets))
print(planets)
planets.sort() # list.sort()
print(planets)
planets = [
"Mercury",
"Venus",
"Earth",
"Mars",
"Jupiter",
"Saturn",
"Uranus",
"Neptune",
]
print(planets)
primes = [2, 3, 5, 7]
sum([1, 2, 3])
print(max(primes))
print(min(primes))
# # Interlude - Objects
# **Using the dot notation**
#
# x = 12
# # x is a real number, so its imaginary part is 0.
# print(x.imag)
# Here's how to make a complex number:
c = 12 + 3j
print(c.imag)
# # List methods
#
planets = [
"Mercury",
"Venus",
"Earth",
"Mars",
"Jupiter",
"Saturn",
"Uranus",
"Neptune",
]
emptyList = []
print(planets)
planets.append("Corellia")
print(planets)
planets.pop()
print(planets)
planets.remove("Venus")
print(planets)
planets = [
"Mercury",
"Venus",
"Earth",
"Mars",
"Jupiter",
"Saturn",
"Uranus",
"Neptune",
]
planets.index("Earth")
planets.index("fsdfsd")
"Venus" in planets
"fsdfsd" in planets
#
# Append() Add an element to the end of the list
# Extend() Add all elements of a list to the another list
# Insert() Insert an item at the defined index
# Remove() Removes an item from the list
# Pop() Removes and returns an element at the given index
# Clear() Removes all items from the list
# Index() Returns the index of the first matched item
# Count() Returns the count of number of items passed as an argument
# Sort() Sort items in a list in ascending order
# Reverse() Reverse the order of items in the list
# copy() Returns a copy of the list
# [https://www.geeksforgeeks.org/python-list/#urm](http://)
# # Tuples
# Tuples are almost exactly the same as lists. They differ in just two ways.
# * The syntax for creating them uses parentheses instead of square brackets.
# * They cannot be modified (they are immutable).
tup = (1, 2, 3)
tup
# Activity - Write a Python program to Swap two variables
a = 1
b = 0
print(a, b)
a, b = b, a
print(a, b)
# # Slicing in tuples
# Slicing in tuples
a = (1, 2, 3, 4, 5)
sliceObj = slice(1, 3)
a[slice(1, 3)]
# # Practice questions
# Complete the function below according to its docstring.
def select_second(L):
"""Return the second element of the given list. If the list has no second
element, return None.
"""
pass
# Solution
def select_second(L):
if len(L) < 2:
return None
return L[1]
# What are the lengths of the following lists? Fill in the variable lengths with your predictions. (Try to make a prediction for each list without just calling len() on it.)
a = [1, 2, 3]
b = [1, [2, 3]]
c = []
d = [1, 2, 3][1:]
# Put your predictions in the list below. Lengths should contain 4 numbers, the
# first being the length of a, the second being the length of b and so on.
lengths = []
# # Solution:
# #
# a: There are three items in this list. Nothing tricky yet.
# b: The list [2, 3] counts as a single item. It has one item before it. So we have 2 items in the list
# c: The empty list has 0 items
# d: The expression is the same as the list [2, 3], which has length 2.
# We're using lists to record people who attended our party and what order they arrived in. For example, the following list represents a party with 7 guests, in which Adela showed up first and Ford was the last to arrive:
# party_attendees = ['Adela', 'Fleda', 'Owen', 'May', 'Mona', 'Gilbert', 'Ford']
# A guest is considered 'fashionably late' if they arrived after at least half of the party's guests. However, they must not be the very last guest (that's taking it too far). In the above example, Mona and Gilbert are the only guests who were fashionably late.
# Complete the function below which takes a list of party attendees as well as a person, and tells us whether that person is fashionably late.
def fashionably_late(arrivals, name):
"""Given an ordered list of arrivals to the party and a name, return whether the guest with that
name was fashionably late.
"""
pass
def fashionably_late(arrivals, name):
order = arrivals.index(name)
return order >= len(arrivals) / 2 and order != len(arrivals) - 1
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0048/202/48202409.ipynb | null | null | [{"Id": 48202409, "ScriptId": 13002333, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 6204353, "CreationDate": "11/30/2020 15:56:58", "VersionNumber": 2.0, "Title": "notebook05985af1f6", "EvaluationDate": "11/30/2020", "IsChange": false, "TotalLines": 238.0, "LinesInsertedFromPrevious": 0.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 238.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
# # Lists
# Lists in Python represent ordered sequences of values.
# -1 : It means to increment the index every time by -1, meaning it will traverse the list by going backwards.
#
planets = [
"Mercury",
"Venus",
"Earth",
"Mars",
"Jupiter",
"Saturn",
"Uranus",
"Neptune",
]
planets[1]
# list[start:exlusive]
planets[2:5]
# list[start:stop:step]
planets[1:6:2]
# All the planets except the first and last
print(planets)
# The last 3 planets
planets[-3:]
# Reversing the list
planets[::-1]
# # Changing lists
# Lists are "mutable", meaning they can be modified "in place".
# One way to modify a list is to assign to an index or slice expression.
#
planets = [
"Mercury",
"Venus",
"Earth",
"Mars",
"Jupiter",
"Saturn",
"Uranus",
"Neptune",
]
# planets[3] = 'Malacandra'
# print(planets)
planets[:3] = ["Mur", "Vee", "Ur"]
print(planets)
# # List functions
#
# How many planets are there?
len(planets)
# The planets sorted in alphabetical order
planets = [
"Mercury",
"Venus",
"Earth",
"Mars",
"Jupiter",
"Saturn",
"Uranus",
"Neptune",
]
print(sorted(planets))
print(planets)
planets.sort() # list.sort()
print(planets)
planets = [
"Mercury",
"Venus",
"Earth",
"Mars",
"Jupiter",
"Saturn",
"Uranus",
"Neptune",
]
print(planets)
primes = [2, 3, 5, 7]
sum([1, 2, 3])
print(max(primes))
print(min(primes))
# # Interlude - Objects
# **Using the dot notation**
#
# x = 12
# # x is a real number, so its imaginary part is 0.
# print(x.imag)
# Here's how to make a complex number:
c = 12 + 3j
print(c.imag)
# # List methods
#
planets = [
"Mercury",
"Venus",
"Earth",
"Mars",
"Jupiter",
"Saturn",
"Uranus",
"Neptune",
]
emptyList = []
print(planets)
planets.append("Corellia")
print(planets)
planets.pop()
print(planets)
planets.remove("Venus")
print(planets)
planets = [
"Mercury",
"Venus",
"Earth",
"Mars",
"Jupiter",
"Saturn",
"Uranus",
"Neptune",
]
planets.index("Earth")
planets.index("fsdfsd")
"Venus" in planets
"fsdfsd" in planets
#
# Append() Add an element to the end of the list
# Extend() Add all elements of a list to the another list
# Insert() Insert an item at the defined index
# Remove() Removes an item from the list
# Pop() Removes and returns an element at the given index
# Clear() Removes all items from the list
# Index() Returns the index of the first matched item
# Count() Returns the count of number of items passed as an argument
# Sort() Sort items in a list in ascending order
# Reverse() Reverse the order of items in the list
# copy() Returns a copy of the list
# [https://www.geeksforgeeks.org/python-list/#urm](http://)
# # Tuples
# Tuples are almost exactly the same as lists. They differ in just two ways.
# * The syntax for creating them uses parentheses instead of square brackets.
# * They cannot be modified (they are immutable).
tup = (1, 2, 3)
tup
# Activity - Write a Python program to Swap two variables
a = 1
b = 0
print(a, b)
a, b = b, a
print(a, b)
# # Slicing in tuples
# Slicing in tuples
a = (1, 2, 3, 4, 5)
sliceObj = slice(1, 3)
a[slice(1, 3)]
# # Practice questions
# Complete the function below according to its docstring.
def select_second(L):
"""Return the second element of the given list. If the list has no second
element, return None.
"""
pass
# Solution
def select_second(L):
if len(L) < 2:
return None
return L[1]
# What are the lengths of the following lists? Fill in the variable lengths with your predictions. (Try to make a prediction for each list without just calling len() on it.)
a = [1, 2, 3]
b = [1, [2, 3]]
c = []
d = [1, 2, 3][1:]
# Put your predictions in the list below. Lengths should contain 4 numbers, the
# first being the length of a, the second being the length of b and so on.
lengths = []
# # Solution:
# #
# a: There are three items in this list. Nothing tricky yet.
# b: The list [2, 3] counts as a single item. It has one item before it. So we have 2 items in the list
# c: The empty list has 0 items
# d: The expression is the same as the list [2, 3], which has length 2.
# We're using lists to record people who attended our party and what order they arrived in. For example, the following list represents a party with 7 guests, in which Adela showed up first and Ford was the last to arrive:
# party_attendees = ['Adela', 'Fleda', 'Owen', 'May', 'Mona', 'Gilbert', 'Ford']
# A guest is considered 'fashionably late' if they arrived after at least half of the party's guests. However, they must not be the very last guest (that's taking it too far). In the above example, Mona and Gilbert are the only guests who were fashionably late.
# Complete the function below which takes a list of party attendees as well as a person, and tells us whether that person is fashionably late.
def fashionably_late(arrivals, name):
"""Given an ordered list of arrivals to the party and a name, return whether the guest with that
name was fashionably late.
"""
pass
def fashionably_late(arrivals, name):
order = arrivals.index(name)
return order >= len(arrivals) / 2 and order != len(arrivals) - 1
| false | 0 | 1,897 | 0 | 6 | 1,897 |
||
48950175 | <kaggle_start><code>## This is course material for Introduction to Python Scientific Programming
## Class 13 Example code: person.py
## Author: Allen Y. Yang, Intelligent Racing Inc.
##
## (c) Copyright 2020. Intelligent Racing Inc. Not permitted for commercial use
class Person:
"""An example class to show Python Class definitions"""
retirement_age = 65 # Class attribute
def __init__(self, first_name, last_name):
if type(first_name) != str or type(last_name) != str:
raise TypeError("Person class initailzed with the unsupported types.")
self.first_name = first_name
self.last_name = last_name
self.age = None
def set_age(self, age):
if age < 0:
raise ValueError("age attribute in Person must be nonnegative.")
self.age = age
def print_name(selfish):
print(
"First Name: {0}, Last Name: {1}".format(
selfish.first_name, selfish.last_name
)
)
def years_until_retirement(self):
until_retirement_year = Person.retirement_age - self.age
if until_retirement_year <= 0:
print("This person has retired")
else:
print(
"This person has {0} years until retirement".format(
until_retirement_year
)
)
@classmethod
def set_retirement_age(cls, retirement_age):
if retirement_age < 0:
raise ValueError("age attribute in Person must be nonnegative.")
cls.retirement_age = retirement_age
@staticmethod
def copyright():
print("This class is for noncommercial use only!")
print(os.listdir("../input"))
import os
os.getcwd()
## This is course material for Introduction to Python Scientific Programming
## Class 13 Example code: shape_class.py
## Author: Allen Y. Yang, Intelligent Racing Inc.
##
## (c) Copyright 2020. Intelligent Racing Inc. Not permitted for commercial use
class Shape:
"""An example class that defines an empty abstract shape"""
initiated = False
def get_area(self):
"""virtual method to calculate area of a shape"""
pass
@classmethod
def is_init(cls):
"""return True if a shape has been assigned to the class"""
return cls.initiated
class Square(Shape):
"""A subclass of Shape, specifically for calculating square area"""
def __init__(self, width):
self.width = width
self.get_area()
self.__class__.initiated = True
def get_area(self):
"""Area of a square is its width times width"""
self.area = self.width * self.width
return self.area
## This is course material for Introduction to Python Scientific Programming
## Class 13 Example code: student_class.py
## Author: Allen Y. Yang, Intelligent Racing Inc.
##
## (c) Copyright 2020. Intelligent Racing Inc. Not permitted for commercial use
from person import Person
class Student(Person):
next_ID = 0
def __init__(self, first_name, last_name):
super().__init__(first_name, last_name)
self.student_ID = Student.next_ID
Student.next_ID += 1
def __del__(self):
print(self.student_ID, "deleted")
def __add__(self, other):
return [self, other]
def print_ID(self):
print(
"{0} {1}'s student ID is: {2}".format(
self.first_name, self.last_name, self.student_ID
)
)
## This is course material for Introduction to Python Scientific Programming
## Class 13 Example code: test_person_class.py
## Author: Allen Y. Yang, Intelligent Racing Inc.
##
## (c) Copyright 2020. Intelligent Racing Inc. Not permitted for commercial use
import person
from person import Person
x1 = Person("John", "Smith")
x1.print_name()
x2 = Person("Jane", "Doe")
x2.print_name()
print(x2.first_name, "Retirement Age: ", x1.retirement_age)
x1.set_age(42)
x1.years_until_retirement()
print(x1.first_name, "Retirement Age:", x1.retirement_age)
x1.retirement_age = 80
print(x1.first_name, "Retirement Age:", x1.retirement_age)
x1.set_retirement_age(80)
print("Class Retirement Age:", Person.retirement_age)
Person.copyright()
## This is course material for Introduction to Python Scientific Programming
## Class 13 Example code: test_shape_class.py
## Author: Allen Y. Yang, Intelligent Racing Inc.
##
## (c) Copyright 2020. Intelligent Racing Inc. Not permitted for commercial use
from shape_class import Square
s = Square(6)
print(s.is_init())
print(s.get_area())
## This is course material for Introduction to Python Scientific Programming
## Class 13 Example code: test_student_class.py
## Author: Allen Y. Yang, Intelligent Racing Inc.
##
## (c) Copyright 2020. Intelligent Racing Inc. Not permitted for commercial use
from student_class import Student
s1 = Student("John", "Smith")
s2 = Student("Jane", "Doe")
enroll = s1 + s2
enroll[0].print_name()
enroll[0].print_ID()
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0048/950/48950175.ipynb | null | null | [{"Id": 48950175, "ScriptId": 13334608, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5756551, "CreationDate": "12/10/2020 02:55:34", "VersionNumber": 1.0, "Title": "lecture_13", "EvaluationDate": "12/10/2020", "IsChange": true, "TotalLines": 165.0, "LinesInsertedFromPrevious": 165.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 1}] | null | null | null | null | ## This is course material for Introduction to Python Scientific Programming
## Class 13 Example code: person.py
## Author: Allen Y. Yang, Intelligent Racing Inc.
##
## (c) Copyright 2020. Intelligent Racing Inc. Not permitted for commercial use
class Person:
"""An example class to show Python Class definitions"""
retirement_age = 65 # Class attribute
def __init__(self, first_name, last_name):
if type(first_name) != str or type(last_name) != str:
raise TypeError("Person class initailzed with the unsupported types.")
self.first_name = first_name
self.last_name = last_name
self.age = None
def set_age(self, age):
if age < 0:
raise ValueError("age attribute in Person must be nonnegative.")
self.age = age
def print_name(selfish):
print(
"First Name: {0}, Last Name: {1}".format(
selfish.first_name, selfish.last_name
)
)
def years_until_retirement(self):
until_retirement_year = Person.retirement_age - self.age
if until_retirement_year <= 0:
print("This person has retired")
else:
print(
"This person has {0} years until retirement".format(
until_retirement_year
)
)
@classmethod
def set_retirement_age(cls, retirement_age):
if retirement_age < 0:
raise ValueError("age attribute in Person must be nonnegative.")
cls.retirement_age = retirement_age
@staticmethod
def copyright():
print("This class is for noncommercial use only!")
print(os.listdir("../input"))
import os
os.getcwd()
## This is course material for Introduction to Python Scientific Programming
## Class 13 Example code: shape_class.py
## Author: Allen Y. Yang, Intelligent Racing Inc.
##
## (c) Copyright 2020. Intelligent Racing Inc. Not permitted for commercial use
class Shape:
"""An example class that defines an empty abstract shape"""
initiated = False
def get_area(self):
"""virtual method to calculate area of a shape"""
pass
@classmethod
def is_init(cls):
"""return True if a shape has been assigned to the class"""
return cls.initiated
class Square(Shape):
"""A subclass of Shape, specifically for calculating square area"""
def __init__(self, width):
self.width = width
self.get_area()
self.__class__.initiated = True
def get_area(self):
"""Area of a square is its width times width"""
self.area = self.width * self.width
return self.area
## This is course material for Introduction to Python Scientific Programming
## Class 13 Example code: student_class.py
## Author: Allen Y. Yang, Intelligent Racing Inc.
##
## (c) Copyright 2020. Intelligent Racing Inc. Not permitted for commercial use
from person import Person
class Student(Person):
next_ID = 0
def __init__(self, first_name, last_name):
super().__init__(first_name, last_name)
self.student_ID = Student.next_ID
Student.next_ID += 1
def __del__(self):
print(self.student_ID, "deleted")
def __add__(self, other):
return [self, other]
def print_ID(self):
print(
"{0} {1}'s student ID is: {2}".format(
self.first_name, self.last_name, self.student_ID
)
)
## This is course material for Introduction to Python Scientific Programming
## Class 13 Example code: test_person_class.py
## Author: Allen Y. Yang, Intelligent Racing Inc.
##
## (c) Copyright 2020. Intelligent Racing Inc. Not permitted for commercial use
import person
from person import Person
x1 = Person("John", "Smith")
x1.print_name()
x2 = Person("Jane", "Doe")
x2.print_name()
print(x2.first_name, "Retirement Age: ", x1.retirement_age)
x1.set_age(42)
x1.years_until_retirement()
print(x1.first_name, "Retirement Age:", x1.retirement_age)
x1.retirement_age = 80
print(x1.first_name, "Retirement Age:", x1.retirement_age)
x1.set_retirement_age(80)
print("Class Retirement Age:", Person.retirement_age)
Person.copyright()
## This is course material for Introduction to Python Scientific Programming
## Class 13 Example code: test_shape_class.py
## Author: Allen Y. Yang, Intelligent Racing Inc.
##
## (c) Copyright 2020. Intelligent Racing Inc. Not permitted for commercial use
from shape_class import Square
s = Square(6)
print(s.is_init())
print(s.get_area())
## This is course material for Introduction to Python Scientific Programming
## Class 13 Example code: test_student_class.py
## Author: Allen Y. Yang, Intelligent Racing Inc.
##
## (c) Copyright 2020. Intelligent Racing Inc. Not permitted for commercial use
from student_class import Student
s1 = Student("John", "Smith")
s2 = Student("Jane", "Doe")
enroll = s1 + s2
enroll[0].print_name()
enroll[0].print_ID()
| false | 0 | 1,396 | 1 | 6 | 1,396 |
||
48225430 | <kaggle_start><data_title>The Enron Email Dataset<data_description>The Enron email dataset contains approximately 500,000 emails generated by employees of the Enron Corporation. It was obtained by the Federal Energy Regulatory Commission during its investigation of Enron's collapse.
This is the May 7, 2015 Version of dataset, as published at [https://www.cs.cmu.edu/~./enron/][1]
[1]: https://www.cs.cmu.edu/~./enron/<data_name>enron-email-dataset
<code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from sklearn.cluster import KMeans
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import PCA
from sklearn.preprocessing import normalize
from sklearn.metrics import pairwise_distances
from nltk.tokenize import word_tokenize
from nltk.stem.porter import PorterStemmer
from nltk.corpus import stopwords
from bs4 import BeautifulSoup
from scipy.stats import multivariate_normal as mvn
import nltk
import os
import random
import string
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
# email module has some useful functions
import matplotlib.pyplot as plt
plt.style.use("fivethirtyeight")
import os, sys, email, re
print(os.listdir("../input"))
# Any results you write to the current directory are saved as output.
df = pd.read_csv("../input/emails.csv", nrows=35000)
df.shape
# # Main Analysis Starts Here
# ## Use the Email module to extract raw text
# create list of email objects
emails = list(map(email.parser.Parser().parsestr, df["message"]))
# extract headings such as subject, from, to etc..
headings = emails[0].keys()
# Goes through each email and grabs info for each key
# doc['From'] grabs who sent email in all emails
for key in headings:
df[key] = [doc[key] for doc in emails]
##Useful functions
def get_raw_text(emails):
email_text = []
for email in emails.walk():
if email.get_content_type() == "text/plain":
email_text.append(email.get_payload())
return "".join(email_text)
df["body"] = list(map(get_raw_text, emails))
df.head()
df["user"] = df["file"].map(lambda x: x.split("/")[0])
df["Date"] = pd.to_datetime(df["Date"], infer_datetime_format=True)
df.head()
df.dtypes
df["Month"] = df["Date"].dt.month
df["Year"] = df["Date"].dt.year
df["Day"] = df["Date"].dt.dayofweek
# reduce the sample period
# looks like the total number of emails really ramped up in 2000 and 2001
indices = (df["Year"] > 1995) & (df["Year"] <= 2004)
plt.figure(figsize=(10, 6))
figure1 = df.loc[indices].groupby("Year")["body"].count().plot()
df.Year.agg({"max": max, "min": min})
# really should not be dates up to 2044
df[df["Year"] == 2044]
plt.figure(figsize=(10, 6))
figure2 = df.groupby("Month")["body"].count().plot()
plt.figure(figsize=(10, 6))
figure3 = df.groupby("Day")["body"].count().plot()
# Unique to and From
print("Total number of emails: %d" % len(df))
print("------------")
print("Number of unique received: %d " % df["To"].nunique())
print("------------")
print("Number of unique Sent: %d " % df["From"].nunique())
# ### Most frequent Senders and receivers of Emails
top_10_frequent = df.groupby("user")["file"].count().sort_values(ascending=False)[:30]
top_10_frequent
plt.figure(figsize=(10, 6))
top_10_frequent.plot(kind="bar")
# ## Users and number of emails they sent by year.
# - huge increase in quantity of emails in the early 2000's
df.groupby(["user", "Year"])["file"].count()
# ## Check whether emails were to a single person or multiple people
def split_data(data):
if data is not None:
temp = data.split(",")
if len(temp) == 1:
return "Direct"
else:
return "Multiple"
else:
return "Empty"
df["Direct_or_multi"] = df["To"].apply(split_data)
# ## Top 10 most frequent emailers
# - Interestingly all kaminski's emails were sent directly to people
# - This could warrent a closer look: who were the ppl he was emailing.
df.groupby("user")["Direct_or_multi"].value_counts().sort_values(ascending=False)[:15]
# ## Clean the subject columns
def clean_column(data):
if data is not None:
stopwords_list = stopwords.words("english")
# exclusions = ['RE:', 'Re:', 're:']
# exclusions = '|'.join(exclusions)
data = data.lower()
data = re.sub("re:", "", data)
data = re.sub("-", "", data)
data = re.sub("_", "", data)
# Remove data between square brackets
data = re.sub("\[[^]]*\]", "", data)
# removes punctuation
data = re.sub(r"[^\w\s]", "", data)
data = re.sub(r"\n", " ", data)
data = re.sub(r"[0-9]+", "", data)
# strip html
p = re.compile(r"<.*?>")
data = re.sub(r"\'ve", " have ", data)
data = re.sub(r"can't", "cannot ", data)
data = re.sub(r"n't", " not ", data)
data = re.sub(r"I'm", "I am", data)
data = re.sub(r" m ", " am ", data)
data = re.sub(r"\'re", " are ", data)
data = re.sub(r"\'d", " would ", data)
data = re.sub(r"\'ll", " will ", data)
data = re.sub("forwarded by phillip k allenhouect on pm", "", data)
data = re.sub(r"httpitcappscorpenroncomsrrsauthemaillinkaspidpage", "", data)
data = p.sub("", data)
if "forwarded by:" in data:
data = data.split("subject")[1]
data = data.strip()
return data
return "No Subject"
df["Subject_new"] = df["Subject"].apply(clean_column)
df["body_new"] = df["body"].apply(clean_column)
df["body_new"].head(5)
from wordcloud import WordCloud, STOPWORDS
stopwords = set(STOPWORDS)
to_add = [
"FW",
"ga",
"httpitcappscorpenroncomsrrsauthemaillinkaspidpage",
"cc",
"aa",
"aaa",
"aaaa",
"hou",
"cc",
"etc",
"subject",
"pm",
]
for i in to_add:
stopwords.add(i)
# ## Visualise Email Subject
wordcloud = WordCloud(
collocations=False,
width=1600,
height=800,
background_color="white",
stopwords=stopwords,
max_words=150,
# max_font_size=40,
random_state=42,
).generate(
" ".join(df["Subject_new"])
) # can't pass a series, needs to be strings and function computes frequencies
print(wordcloud)
plt.figure(figsize=(9, 8))
fig = plt.figure(1)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
stemmer = PorterStemmer()
def stemming_tokenizer(str_input):
words = re.sub(r"[^A-Za-z0-9\-]", " ", str_input).lower().split()
words = [porter_stemmer.stem(word) for word in words]
return words
def tokenize_and_stem(text):
# first tokenize by sentence, then by word to ensure that punctuation is caught as it's own token
tokens = [
word for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent)
]
filtered_tokens = []
# filter out any tokens not containing letters (e.g., numeric tokens, raw punctuation)
for token in tokens:
if re.search("[a-zA-Z]", token):
filtered_tokens.append(token)
stems = [stemmer.stem(t) for t in filtered_tokens]
return stems
# ## TF-IDF tranformation for K-means algorithm
from sklearn.feature_extraction.text import TfidfVectorizer
data = df["body_new"]
# data.head()
tf_idf_vectorizor = TfidfVectorizer(
stop_words=stopwords, max_features=5000 # tokenizer = tokenize_and_stem,
)
tf_idf_norm = normalize(tf_idf)
tf_idf_array = tf_idf_norm.toarray()
pd.DataFrame(tf_idf_array, columns=tf_idf_vectorizor.get_feature_names()).head()
# # Kmeans Class
# ## test pairwise function
# initial_centroids = np.random.permutation(tf_idf_array.shape[0])[:3]
# initial_centroids
# centroids = tf_idf_array[initial_centroids]
# centroids.shape
# dist_to_centroid = pairwise_distances(tf_idf_array,centroids, metric = 'euclidean')
# cluster_labels = np.argmin(dist_to_centroid, axis = 1)
class Kmeans:
"""K Means Clustering
Parameters
-----------
k: int , number of clusters
seed: int, will be randomly set if None
max_iter: int, number of iterations to run algorithm, default: 200
Attributes
-----------
centroids: array, k, number_features
cluster_labels: label for each data point
"""
def __init__(self, k, seed=None, max_iter=200):
self.k = k
self.seed = seed
if self.seed is not None:
np.random.seed(self.seed)
self.max_iter = max_iter
def initialise_centroids(self, data):
"""Randomly Initialise Centroids
Parameters
----------
data: array or matrix, number_rows, number_features
Returns
--------
centroids: array of k centroids chosen as random data points
"""
initial_centroids = np.random.permutation(data.shape[0])[: self.k]
self.centroids = data[initial_centroids]
return self.centroids
def assign_clusters(self, data):
"""Compute distance of data from clusters and assign data point
to closest cluster.
Parameters
----------
data: array or matrix, number_rows, number_features
Returns
--------
cluster_labels: index which minmises the distance of data to each
cluster
"""
if data.ndim == 1:
data = data.reshape(-1, 1)
dist_to_centroid = pairwise_distances(data, self.centroids, metric="euclidean")
self.cluster_labels = np.argmin(dist_to_centroid, axis=1)
return self.cluster_labels
def update_centroids(self, data):
"""Computes average of all data points in cluster and
assigns new centroids as average of data points
Parameters
-----------
data: array or matrix, number_rows, number_features
Returns
-----------
centroids: array, k, number_features
"""
self.centroids = np.array(
[data[self.cluster_labels == i].mean(axis=0) for i in range(self.k)]
)
return self.centroids
def convergence_calculation(self):
"""
Calculates
"""
pass
def predict(self, data):
"""Predict which cluster data point belongs to
Parameters
----------
data: array or matrix, number_rows, number_features
Returns
--------
cluster_labels: index which minmises the distance of data to each
cluster
"""
return self.assign_clusters(data)
def fit_kmeans(self, data):
"""
This function contains the main loop to fit the algorithm
Implements initialise centroids and update_centroids
according to max_iter
-----------------------
Returns
-------
instance of kmeans class
"""
self.centroids = self.initialise_centroids(data)
# Main kmeans loop
for iter in range(self.max_iter):
self.cluster_labels = self.assign_clusters(data)
self.centroids = self.update_centroids(data)
if iter % 100 == 0:
print("Running Model Iteration %d " % iter)
print("Model finished running")
return self
# # My Implementation
from sklearn.datasets import make_blobs
# create blobs
data = make_blobs(
n_samples=200, n_features=2, centers=4, cluster_std=1.6, random_state=50
)
# create np array for data points
points = data[0]
# create scatter plot
plt.scatter(data[0][:, 0], data[0][:, 1], c=data[1], cmap="viridis")
plt.xlim(-15, 15)
plt.ylim(-15, 15)
X = data[0]
X[2]
temp_k = Kmeans(4, 1, 600)
temp_fitted = temp_k.fit_kmeans(X)
new_data = np.array(
[[1.066, -8.66], [1.87876, -6.516], [-1.59728965, 8.45369045], [1.87876, -6.516]]
)
temp_fitted.predict(new_data)
sklearn_pca = PCA(n_components=2)
Y_sklearn = sklearn_pca.fit_transform(tf_idf_array)
test_e = Kmeans(3, 1, 600)
predicted_values = test_e.predict(Y_sklearn)
plt.scatter(Y_sklearn[:, 0], Y_sklearn[:, 1], c=predicted_values, s=50, cmap="viridis")
centers = fitted.centroids
plt.scatter(centers[:, 0], centers[:, 1], c="black", s=300, alpha=0.6)
# # SK learn Implementation
from sklearn.cluster import KMeans
n_clusters = 3
sklearn_pca = PCA(n_components=2)
Y_sklearn = sklearn_pca.fit_transform(tf_idf_array)
kmeans = KMeans(n_clusters=n_clusters, max_iter=600, algorithm="auto")
prediction = kmeans.predict(Y_sklearn)
plt.scatter(Y_sklearn[:, 0], Y_sklearn[:, 1], c=prediction, s=50, cmap="viridis")
centers2 = fitted.cluster_centers_
plt.scatter(centers2[:, 0], centers2[:, 1], c="black", s=300, alpha=0.6)
# # Optimal Clusters
number_clusters = range(1, 7)
kmeans = [KMeans(n_clusters=i, max_iter=600) for i in number_clusters]
kmeans
score = [kmeans[i].fit(Y_sklearn).score(Y_sklearn) for i in range(len(kmeans))]
score = [i * -1 for i in score]
plt.plot(number_clusters, score)
plt.xlabel("Number of Clusters")
plt.ylabel("Score")
plt.title("Elbow Method")
plt.show()
# # Extracting top features
def get_top_features_cluster(tf_idf_array, prediction, n_feats):
labels = np.unique(prediction)
dfs = []
for label in labels:
id_temp = np.where(prediction == label) # indices for each cluster
x_means = np.mean(
tf_idf_array[id_temp], axis=0
) # returns average score across cluster
sorted_means = np.argsort(x_means)[::-1][:n_feats] # indices with top 20 scores
features = tf_idf_vectorizor.get_feature_names()
best_features = [(features[i], x_means[i]) for i in sorted_means]
df = pd.DataFrame(best_features, columns=["features", "score"])
dfs.append(df)
return dfs
dfs = get_top_features_cluster(tf_idf_array, prediction, 20)
import seaborn as sns
plt.figure(figsize=(8, 6))
sns.barplot(x="score", y="features", orient="h", data=dfs[0][:15])
plt.figure(figsize=(8, 6))
sns.barplot(x="score", y="features", orient="h", data=dfs[1][:15])
plt.figure(figsize=(8, 6))
sns.barplot(x="score", y="features", orient="h", data=dfs[2][:15])
for i, df in enumerate(dfs):
df.to_csv("df_" + str(i) + ".csv")
def plot_features(dfs):
fig = plt.figure(figsize=(14, 12))
x = np.arange(len(dfs[0]))
for i, df in enumerate(dfs):
ax = fig.add_subplot(1, len(dfs), i + 1)
ax.set_title("Cluster: " + str(i), fontsize=14)
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.set_frame_on(False)
ax.get_xaxis().tick_bottom()
ax.get_yaxis().tick_left()
ax.ticklabel_format(axis="x", style="sci", scilimits=(-2, 2))
ax.barh(x, df.score, align="center", color="#40826d")
yticks = ax.set_yticklabels(df.features)
plt.show()
plot_features(dfs)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0048/225/48225430.ipynb | enron-email-dataset | wcukierski | [{"Id": 48225430, "ScriptId": 13228744, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4409920, "CreationDate": "11/30/2020 21:33:21", "VersionNumber": 1.0, "Title": "MIS 437 Module 9", "EvaluationDate": "11/30/2020", "IsChange": false, "TotalLines": 487.0, "LinesInsertedFromPrevious": 0.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 487.0, "LinesInsertedFromFork": 0.0, "LinesDeletedFromFork": 0.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 487.0, "TotalVotes": 0}] | [{"Id": 59521244, "KernelVersionId": 48225430, "SourceDatasetVersionId": 120}] | [{"Id": 120, "DatasetId": 55, "DatasourceVersionId": 120, "CreatorUserId": 3258, "LicenseName": "Data files \u00a9 Original Authors", "CreationDate": "06/16/2016 20:55:19", "VersionNumber": 2.0, "Title": "The Enron Email Dataset", "Slug": "enron-email-dataset", "Subtitle": "500,000+ emails from 150 employees of the Enron Corporation", "Description": "The Enron email dataset contains approximately 500,000 emails generated by employees of the Enron Corporation. It was obtained by the Federal Energy Regulatory Commission during its investigation of Enron's collapse.\n\nThis is the May 7, 2015 Version of dataset, as published at [https://www.cs.cmu.edu/~./enron/][1]\n\n\n [1]: https://www.cs.cmu.edu/~./enron/", "VersionNotes": "Line endings fix", "TotalCompressedBytes": 1426122219.0, "TotalUncompressedBytes": 1426122219.0}] | [{"Id": 55, "CreatorUserId": 3258, "OwnerUserId": 3258.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 120.0, "CurrentDatasourceVersionId": 120.0, "ForumId": 1322, "Type": 2, "CreationDate": "06/07/2016 16:46:57", "LastActivityDate": "02/05/2018", "TotalViews": 370722, "TotalDownloads": 41492, "TotalVotes": 674, "TotalKernels": 246}] | [{"Id": 3258, "UserName": "wcukierski", "DisplayName": "Will Cukierski", "RegisterDate": "10/13/2010", "PerformanceTier": 5}] | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from sklearn.cluster import KMeans
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import PCA
from sklearn.preprocessing import normalize
from sklearn.metrics import pairwise_distances
from nltk.tokenize import word_tokenize
from nltk.stem.porter import PorterStemmer
from nltk.corpus import stopwords
from bs4 import BeautifulSoup
from scipy.stats import multivariate_normal as mvn
import nltk
import os
import random
import string
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list the files in the input directory
# email module has some useful functions
import matplotlib.pyplot as plt
plt.style.use("fivethirtyeight")
import os, sys, email, re
print(os.listdir("../input"))
# Any results you write to the current directory are saved as output.
df = pd.read_csv("../input/emails.csv", nrows=35000)
df.shape
# # Main Analysis Starts Here
# ## Use the Email module to extract raw text
# create list of email objects
emails = list(map(email.parser.Parser().parsestr, df["message"]))
# extract headings such as subject, from, to etc..
headings = emails[0].keys()
# Goes through each email and grabs info for each key
# doc['From'] grabs who sent email in all emails
for key in headings:
df[key] = [doc[key] for doc in emails]
##Useful functions
def get_raw_text(emails):
email_text = []
for email in emails.walk():
if email.get_content_type() == "text/plain":
email_text.append(email.get_payload())
return "".join(email_text)
df["body"] = list(map(get_raw_text, emails))
df.head()
df["user"] = df["file"].map(lambda x: x.split("/")[0])
df["Date"] = pd.to_datetime(df["Date"], infer_datetime_format=True)
df.head()
df.dtypes
df["Month"] = df["Date"].dt.month
df["Year"] = df["Date"].dt.year
df["Day"] = df["Date"].dt.dayofweek
# reduce the sample period
# looks like the total number of emails really ramped up in 2000 and 2001
indices = (df["Year"] > 1995) & (df["Year"] <= 2004)
plt.figure(figsize=(10, 6))
figure1 = df.loc[indices].groupby("Year")["body"].count().plot()
df.Year.agg({"max": max, "min": min})
# really should not be dates up to 2044
df[df["Year"] == 2044]
plt.figure(figsize=(10, 6))
figure2 = df.groupby("Month")["body"].count().plot()
plt.figure(figsize=(10, 6))
figure3 = df.groupby("Day")["body"].count().plot()
# Unique to and From
print("Total number of emails: %d" % len(df))
print("------------")
print("Number of unique received: %d " % df["To"].nunique())
print("------------")
print("Number of unique Sent: %d " % df["From"].nunique())
# ### Most frequent Senders and receivers of Emails
top_10_frequent = df.groupby("user")["file"].count().sort_values(ascending=False)[:30]
top_10_frequent
plt.figure(figsize=(10, 6))
top_10_frequent.plot(kind="bar")
# ## Users and number of emails they sent by year.
# - huge increase in quantity of emails in the early 2000's
df.groupby(["user", "Year"])["file"].count()
# ## Check whether emails were to a single person or multiple people
def split_data(data):
if data is not None:
temp = data.split(",")
if len(temp) == 1:
return "Direct"
else:
return "Multiple"
else:
return "Empty"
df["Direct_or_multi"] = df["To"].apply(split_data)
# ## Top 10 most frequent emailers
# - Interestingly all kaminski's emails were sent directly to people
# - This could warrent a closer look: who were the ppl he was emailing.
df.groupby("user")["Direct_or_multi"].value_counts().sort_values(ascending=False)[:15]
# ## Clean the subject columns
def clean_column(data):
if data is not None:
stopwords_list = stopwords.words("english")
# exclusions = ['RE:', 'Re:', 're:']
# exclusions = '|'.join(exclusions)
data = data.lower()
data = re.sub("re:", "", data)
data = re.sub("-", "", data)
data = re.sub("_", "", data)
# Remove data between square brackets
data = re.sub("\[[^]]*\]", "", data)
# removes punctuation
data = re.sub(r"[^\w\s]", "", data)
data = re.sub(r"\n", " ", data)
data = re.sub(r"[0-9]+", "", data)
# strip html
p = re.compile(r"<.*?>")
data = re.sub(r"\'ve", " have ", data)
data = re.sub(r"can't", "cannot ", data)
data = re.sub(r"n't", " not ", data)
data = re.sub(r"I'm", "I am", data)
data = re.sub(r" m ", " am ", data)
data = re.sub(r"\'re", " are ", data)
data = re.sub(r"\'d", " would ", data)
data = re.sub(r"\'ll", " will ", data)
data = re.sub("forwarded by phillip k allenhouect on pm", "", data)
data = re.sub(r"httpitcappscorpenroncomsrrsauthemaillinkaspidpage", "", data)
data = p.sub("", data)
if "forwarded by:" in data:
data = data.split("subject")[1]
data = data.strip()
return data
return "No Subject"
df["Subject_new"] = df["Subject"].apply(clean_column)
df["body_new"] = df["body"].apply(clean_column)
df["body_new"].head(5)
from wordcloud import WordCloud, STOPWORDS
stopwords = set(STOPWORDS)
to_add = [
"FW",
"ga",
"httpitcappscorpenroncomsrrsauthemaillinkaspidpage",
"cc",
"aa",
"aaa",
"aaaa",
"hou",
"cc",
"etc",
"subject",
"pm",
]
for i in to_add:
stopwords.add(i)
# ## Visualise Email Subject
wordcloud = WordCloud(
collocations=False,
width=1600,
height=800,
background_color="white",
stopwords=stopwords,
max_words=150,
# max_font_size=40,
random_state=42,
).generate(
" ".join(df["Subject_new"])
) # can't pass a series, needs to be strings and function computes frequencies
print(wordcloud)
plt.figure(figsize=(9, 8))
fig = plt.figure(1)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
stemmer = PorterStemmer()
def stemming_tokenizer(str_input):
words = re.sub(r"[^A-Za-z0-9\-]", " ", str_input).lower().split()
words = [porter_stemmer.stem(word) for word in words]
return words
def tokenize_and_stem(text):
# first tokenize by sentence, then by word to ensure that punctuation is caught as it's own token
tokens = [
word for sent in nltk.sent_tokenize(text) for word in nltk.word_tokenize(sent)
]
filtered_tokens = []
# filter out any tokens not containing letters (e.g., numeric tokens, raw punctuation)
for token in tokens:
if re.search("[a-zA-Z]", token):
filtered_tokens.append(token)
stems = [stemmer.stem(t) for t in filtered_tokens]
return stems
# ## TF-IDF tranformation for K-means algorithm
from sklearn.feature_extraction.text import TfidfVectorizer
data = df["body_new"]
# data.head()
tf_idf_vectorizor = TfidfVectorizer(
stop_words=stopwords, max_features=5000 # tokenizer = tokenize_and_stem,
)
tf_idf_norm = normalize(tf_idf)
tf_idf_array = tf_idf_norm.toarray()
pd.DataFrame(tf_idf_array, columns=tf_idf_vectorizor.get_feature_names()).head()
# # Kmeans Class
# ## test pairwise function
# initial_centroids = np.random.permutation(tf_idf_array.shape[0])[:3]
# initial_centroids
# centroids = tf_idf_array[initial_centroids]
# centroids.shape
# dist_to_centroid = pairwise_distances(tf_idf_array,centroids, metric = 'euclidean')
# cluster_labels = np.argmin(dist_to_centroid, axis = 1)
class Kmeans:
"""K Means Clustering
Parameters
-----------
k: int , number of clusters
seed: int, will be randomly set if None
max_iter: int, number of iterations to run algorithm, default: 200
Attributes
-----------
centroids: array, k, number_features
cluster_labels: label for each data point
"""
def __init__(self, k, seed=None, max_iter=200):
self.k = k
self.seed = seed
if self.seed is not None:
np.random.seed(self.seed)
self.max_iter = max_iter
def initialise_centroids(self, data):
"""Randomly Initialise Centroids
Parameters
----------
data: array or matrix, number_rows, number_features
Returns
--------
centroids: array of k centroids chosen as random data points
"""
initial_centroids = np.random.permutation(data.shape[0])[: self.k]
self.centroids = data[initial_centroids]
return self.centroids
def assign_clusters(self, data):
"""Compute distance of data from clusters and assign data point
to closest cluster.
Parameters
----------
data: array or matrix, number_rows, number_features
Returns
--------
cluster_labels: index which minmises the distance of data to each
cluster
"""
if data.ndim == 1:
data = data.reshape(-1, 1)
dist_to_centroid = pairwise_distances(data, self.centroids, metric="euclidean")
self.cluster_labels = np.argmin(dist_to_centroid, axis=1)
return self.cluster_labels
def update_centroids(self, data):
"""Computes average of all data points in cluster and
assigns new centroids as average of data points
Parameters
-----------
data: array or matrix, number_rows, number_features
Returns
-----------
centroids: array, k, number_features
"""
self.centroids = np.array(
[data[self.cluster_labels == i].mean(axis=0) for i in range(self.k)]
)
return self.centroids
def convergence_calculation(self):
"""
Calculates
"""
pass
def predict(self, data):
"""Predict which cluster data point belongs to
Parameters
----------
data: array or matrix, number_rows, number_features
Returns
--------
cluster_labels: index which minmises the distance of data to each
cluster
"""
return self.assign_clusters(data)
def fit_kmeans(self, data):
"""
This function contains the main loop to fit the algorithm
Implements initialise centroids and update_centroids
according to max_iter
-----------------------
Returns
-------
instance of kmeans class
"""
self.centroids = self.initialise_centroids(data)
# Main kmeans loop
for iter in range(self.max_iter):
self.cluster_labels = self.assign_clusters(data)
self.centroids = self.update_centroids(data)
if iter % 100 == 0:
print("Running Model Iteration %d " % iter)
print("Model finished running")
return self
# # My Implementation
from sklearn.datasets import make_blobs
# create blobs
data = make_blobs(
n_samples=200, n_features=2, centers=4, cluster_std=1.6, random_state=50
)
# create np array for data points
points = data[0]
# create scatter plot
plt.scatter(data[0][:, 0], data[0][:, 1], c=data[1], cmap="viridis")
plt.xlim(-15, 15)
plt.ylim(-15, 15)
X = data[0]
X[2]
temp_k = Kmeans(4, 1, 600)
temp_fitted = temp_k.fit_kmeans(X)
new_data = np.array(
[[1.066, -8.66], [1.87876, -6.516], [-1.59728965, 8.45369045], [1.87876, -6.516]]
)
temp_fitted.predict(new_data)
sklearn_pca = PCA(n_components=2)
Y_sklearn = sklearn_pca.fit_transform(tf_idf_array)
test_e = Kmeans(3, 1, 600)
predicted_values = test_e.predict(Y_sklearn)
plt.scatter(Y_sklearn[:, 0], Y_sklearn[:, 1], c=predicted_values, s=50, cmap="viridis")
centers = fitted.centroids
plt.scatter(centers[:, 0], centers[:, 1], c="black", s=300, alpha=0.6)
# # SK learn Implementation
from sklearn.cluster import KMeans
n_clusters = 3
sklearn_pca = PCA(n_components=2)
Y_sklearn = sklearn_pca.fit_transform(tf_idf_array)
kmeans = KMeans(n_clusters=n_clusters, max_iter=600, algorithm="auto")
prediction = kmeans.predict(Y_sklearn)
plt.scatter(Y_sklearn[:, 0], Y_sklearn[:, 1], c=prediction, s=50, cmap="viridis")
centers2 = fitted.cluster_centers_
plt.scatter(centers2[:, 0], centers2[:, 1], c="black", s=300, alpha=0.6)
# # Optimal Clusters
number_clusters = range(1, 7)
kmeans = [KMeans(n_clusters=i, max_iter=600) for i in number_clusters]
kmeans
score = [kmeans[i].fit(Y_sklearn).score(Y_sklearn) for i in range(len(kmeans))]
score = [i * -1 for i in score]
plt.plot(number_clusters, score)
plt.xlabel("Number of Clusters")
plt.ylabel("Score")
plt.title("Elbow Method")
plt.show()
# # Extracting top features
def get_top_features_cluster(tf_idf_array, prediction, n_feats):
labels = np.unique(prediction)
dfs = []
for label in labels:
id_temp = np.where(prediction == label) # indices for each cluster
x_means = np.mean(
tf_idf_array[id_temp], axis=0
) # returns average score across cluster
sorted_means = np.argsort(x_means)[::-1][:n_feats] # indices with top 20 scores
features = tf_idf_vectorizor.get_feature_names()
best_features = [(features[i], x_means[i]) for i in sorted_means]
df = pd.DataFrame(best_features, columns=["features", "score"])
dfs.append(df)
return dfs
dfs = get_top_features_cluster(tf_idf_array, prediction, 20)
import seaborn as sns
plt.figure(figsize=(8, 6))
sns.barplot(x="score", y="features", orient="h", data=dfs[0][:15])
plt.figure(figsize=(8, 6))
sns.barplot(x="score", y="features", orient="h", data=dfs[1][:15])
plt.figure(figsize=(8, 6))
sns.barplot(x="score", y="features", orient="h", data=dfs[2][:15])
for i, df in enumerate(dfs):
df.to_csv("df_" + str(i) + ".csv")
def plot_features(dfs):
fig = plt.figure(figsize=(14, 12))
x = np.arange(len(dfs[0]))
for i, df in enumerate(dfs):
ax = fig.add_subplot(1, len(dfs), i + 1)
ax.set_title("Cluster: " + str(i), fontsize=14)
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.set_frame_on(False)
ax.get_xaxis().tick_bottom()
ax.get_yaxis().tick_left()
ax.ticklabel_format(axis="x", style="sci", scilimits=(-2, 2))
ax.barh(x, df.score, align="center", color="#40826d")
yticks = ax.set_yticklabels(df.features)
plt.show()
plot_features(dfs)
| false | 0 | 4,449 | 0 | 136 | 4,449 |
||
45894332 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from functools import partial
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
class Gradient_Decent:
"""
Calculates the local minimum
accuracy, how close you want the output x to be to the proper value
Lambda, the gradient decent rate
"""
def __init__(self, grad_func, func=None, Lambda=0.1, accuracy=0.001):
self.func = func
self.grad_func = grad_func
self.Lambda = Lambda
self.accuracy = accuracy
def sample(start, end):
pass
def start(self, x_0, iterations=3000):
x_k = x_0
for k in range(iterations):
grad_val = self.grad_func(x_k)
x_k = x_k - self.Lambda * grad_val
if np.linalg.norm(self.grad_func(x_k)) < self.accuracy:
# Found solution
print("Yes")
return x_k
print("No")
return x_k
# Easy Tests
def f(x):
x_1 = x[0]
x_2 = x[1]
return (x_1 - 3) ** 2 + y_2**2
def grad_f(x):
x_1 = x[0]
x_2 = x[1]
return np.array([2 * (x_1 - 3), 2 * x_2])
test_gradient_decent = Gradient_Decent(grad_func=grad_f)
result = test_gradient_decent.start(np.array([5, 4]))
assert max(abs(result - np.array([3, 0]))) < 1e-2
result = test_gradient_decent.start(np.array([-50, 23]))
assert max(abs(result - np.array([3, 0]))) < 1e-2
# Harder Tests
def grad_f(x):
x_1 = x[0]
x_2 = x[1]
x_3 = x[2]
y_1 = 2 * x_2**2 * x_3**2 * x_1 + 2 * x_1 * x_3**2
y_2 = 2 * x_2 * x_3**2 * x_1**2
y_3 = 2 * x_2**2 * x_3 * x_1**2 + 2 * x_3 * x_1**2
return np.array([y_1, y_2, y_3])
test_gradient_decent = Gradient_Decent(grad_func=grad_f, Lambda=0.0001)
result = test_gradient_decent.start(np.array([5, 4, 10]))
assert abs(result[0]) < 1e-2
a = np.array(result)
grad_f(a)
result
9.9e-4
# Neural Net Section
def sigmoid(x):
if x > 700:
return 1
if x < -700:
return 0
return 1 / (1 + np.e ** (-x))
def dsigmoid(x):
if (x < -700) or (700 < x):
return 0
return np.e ** (-x) * sigmoid(x) ** 2
assert dsigmoid(0) == 1 / 4
class BasicNeuralNet:
"""
1 layer neural network
"""
def __init__(self):
pass
def fit(self, X, y):
"""X,y pandas data frames"""
X = X.assign(_BIAS_=[1] * len(X)) # Add bias weight
num_X = X.to_numpy()
self.n = len(num_X[0])
self.a = np.zeros(self.n)
self.my_grad_MSE = partial(grad_MSE, x=num_X, y=y.to_numpy())
my_gradient_decent = Gradient_Decent(grad_func=self.my_grad_MSE, Lambda=0.1)
# partail function
# use gradient decent
new_a = my_gradient_decent.start(x_0=self.a, iterations=7000)
self.a = new_a
# get the weights and make a predict function
def predict(self, X):
"""X is 2D array"""
m = len(X) # records
X = np.append(X, np.array([[1]] * m), axis=1)
y = np.zeros(m)
for record_id in range(len(X)):
y[record_id] = sigmoid(sum(self.a * X[record_id]))
return y
def MSE(self, x):
"""The cost function"""
pass
def grad_MSE(a, x, y):
"""x is a 2D numpy array
a are the weights
y is the actual value"""
n = len(x[0])
m = len(x)
grad = np.zeros(n)
for grad_position in range(n):
total = 0
for i in range(m):
# i is the record ID
total += (
2
* dsigmoid(sum(a * x[i]))
* x[i][grad_position]
* (sigmoid(sum(a * x[i])) - y[i])
)
grad[grad_position] = total
return grad
# Test
test_X = [[1, 2, 3, 1], [3, 2, 1, 0], [2, 2, 2, 0]]
test_Xdf = pd.DataFrame(data=test_X)
test_y = [0, 1, 0]
test_ydf = pd.DataFrame(data=test_y)
test_NeuralNet = BasicNeuralNet()
test_NeuralNet.fit(X=test_Xdf, y=test_ydf)
print(test_NeuralNet.my_grad_MSE(test_NeuralNet.a))
assert max(abs(test_NeuralNet.predict(test_X) - [0, 1, 0])) < 0.1
test_NeuralNet.predict(test_X)
test_ydf
test_a = np.array([0, 0, 3, 0, 0])
test_x = np.array([[1, 1, 3, 4, 5], [5, 4, 3, 2, 1], [1, 2, 3, 4, 5]])
test_y = np.array([1, 0, 1])
grad_MSE(test_a, test_x, test_y)
titanic_file_path = "../input/titanic/train.csv"
titanic_data = pd.read_csv(titanic_file_path)
titanic_data.head()
y = titanic_data.Survived
feature_columns = ["Pclass", "Sex", "Age", "Fare"] # , "Cabin"]
X = titanic_data[feature_columns]
new_columns = ["Pclass", "isMale", "isFemale", "Age", "Fare"]
# is_First = (X["Pclass"]==1)
# is_Second = (X["Pclass"]==2)
# is_Third = (X["Pclass"]==3)
is_Male = X["Sex"] == "male"
is_Female = X["Sex"] == "female"
the_data = [X["Pclass"], is_Male, is_Female, X["Age"], X["Fare"]]
new_X = pd.concat(the_data, axis=1, keys=new_columns)
# Remove NAN and change to 0
new_X = new_X.replace(np.nan, 0)
new_X
titanicNeuralNet = BasicNeuralNet()
X_train = new_X[0:800]
y_train = y[0:800]
titanicNeuralNet.fit(X_train, y_train)
titanicNeuralNet.a
# Mean average error
sum(abs(titanicNeuralNet.predict(new_X[0:10]) - y[0:10]))
# Number wrong
sum(abs(np.round(titanicNeuralNet.predict(new_X[0:880])) - y[0:880]))
# Number incorrect
sum((np.round(titanicNeuralNet.predict(new_X[0:300])).astype(np.int) - y[0:300]) ** 2)
# now for test data
# path to file you will use for predictions
test_data_path = "../input/titanic/test.csv"
# read test data file using pandas
test_data = pd.read_csv(test_data_path)
# create test_X which comes from test_data but includes only the columns you used for prediction.
# The list of columns is stored in a variable called features
feature_columns = ["Pclass", "Sex", "Age", "Fare"]
test_X = test_data[feature_columns]
new_columns = ["Pclass", "isMale", "isFemale", "Age", "Fare"]
is_Male = test_X["Sex"] == "male"
is_Female = test_X["Sex"] == "female"
the_data = [test_X["Pclass"], is_Male, is_Female, test_X["Age"], test_X["Fare"]]
test_new_X = pd.concat(the_data, axis=1, keys=new_columns)
# Remove NAN and change to 0
test_new_X = test_new_X.replace(np.nan, 0)
# make predictions which we will submit.
test_preds = np.round(titanicNeuralNet.predict(test_new_X)).astype(np.int)
# The lines below shows how to save predictions in format used for competition scoring
# Just uncomment them.
output = pd.DataFrame({"PassengerId": test_data.PassengerId, "Survived": test_preds})
output.to_csv("submission.csv", index=False)
output[0:20]
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0045/894/45894332.ipynb | null | null | [{"Id": 45894332, "ScriptId": 12596012, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 6065461, "CreationDate": "10/31/2020 15:28:39", "VersionNumber": 2.0, "Title": "Gradient Decent", "EvaluationDate": "10/31/2020", "IsChange": true, "TotalLines": 256.0, "LinesInsertedFromPrevious": 7.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 249.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
from functools import partial
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
class Gradient_Decent:
"""
Calculates the local minimum
accuracy, how close you want the output x to be to the proper value
Lambda, the gradient decent rate
"""
def __init__(self, grad_func, func=None, Lambda=0.1, accuracy=0.001):
self.func = func
self.grad_func = grad_func
self.Lambda = Lambda
self.accuracy = accuracy
def sample(start, end):
pass
def start(self, x_0, iterations=3000):
x_k = x_0
for k in range(iterations):
grad_val = self.grad_func(x_k)
x_k = x_k - self.Lambda * grad_val
if np.linalg.norm(self.grad_func(x_k)) < self.accuracy:
# Found solution
print("Yes")
return x_k
print("No")
return x_k
# Easy Tests
def f(x):
x_1 = x[0]
x_2 = x[1]
return (x_1 - 3) ** 2 + y_2**2
def grad_f(x):
x_1 = x[0]
x_2 = x[1]
return np.array([2 * (x_1 - 3), 2 * x_2])
test_gradient_decent = Gradient_Decent(grad_func=grad_f)
result = test_gradient_decent.start(np.array([5, 4]))
assert max(abs(result - np.array([3, 0]))) < 1e-2
result = test_gradient_decent.start(np.array([-50, 23]))
assert max(abs(result - np.array([3, 0]))) < 1e-2
# Harder Tests
def grad_f(x):
x_1 = x[0]
x_2 = x[1]
x_3 = x[2]
y_1 = 2 * x_2**2 * x_3**2 * x_1 + 2 * x_1 * x_3**2
y_2 = 2 * x_2 * x_3**2 * x_1**2
y_3 = 2 * x_2**2 * x_3 * x_1**2 + 2 * x_3 * x_1**2
return np.array([y_1, y_2, y_3])
test_gradient_decent = Gradient_Decent(grad_func=grad_f, Lambda=0.0001)
result = test_gradient_decent.start(np.array([5, 4, 10]))
assert abs(result[0]) < 1e-2
a = np.array(result)
grad_f(a)
result
9.9e-4
# Neural Net Section
def sigmoid(x):
if x > 700:
return 1
if x < -700:
return 0
return 1 / (1 + np.e ** (-x))
def dsigmoid(x):
if (x < -700) or (700 < x):
return 0
return np.e ** (-x) * sigmoid(x) ** 2
assert dsigmoid(0) == 1 / 4
class BasicNeuralNet:
"""
1 layer neural network
"""
def __init__(self):
pass
def fit(self, X, y):
"""X,y pandas data frames"""
X = X.assign(_BIAS_=[1] * len(X)) # Add bias weight
num_X = X.to_numpy()
self.n = len(num_X[0])
self.a = np.zeros(self.n)
self.my_grad_MSE = partial(grad_MSE, x=num_X, y=y.to_numpy())
my_gradient_decent = Gradient_Decent(grad_func=self.my_grad_MSE, Lambda=0.1)
# partail function
# use gradient decent
new_a = my_gradient_decent.start(x_0=self.a, iterations=7000)
self.a = new_a
# get the weights and make a predict function
def predict(self, X):
"""X is 2D array"""
m = len(X) # records
X = np.append(X, np.array([[1]] * m), axis=1)
y = np.zeros(m)
for record_id in range(len(X)):
y[record_id] = sigmoid(sum(self.a * X[record_id]))
return y
def MSE(self, x):
"""The cost function"""
pass
def grad_MSE(a, x, y):
"""x is a 2D numpy array
a are the weights
y is the actual value"""
n = len(x[0])
m = len(x)
grad = np.zeros(n)
for grad_position in range(n):
total = 0
for i in range(m):
# i is the record ID
total += (
2
* dsigmoid(sum(a * x[i]))
* x[i][grad_position]
* (sigmoid(sum(a * x[i])) - y[i])
)
grad[grad_position] = total
return grad
# Test
test_X = [[1, 2, 3, 1], [3, 2, 1, 0], [2, 2, 2, 0]]
test_Xdf = pd.DataFrame(data=test_X)
test_y = [0, 1, 0]
test_ydf = pd.DataFrame(data=test_y)
test_NeuralNet = BasicNeuralNet()
test_NeuralNet.fit(X=test_Xdf, y=test_ydf)
print(test_NeuralNet.my_grad_MSE(test_NeuralNet.a))
assert max(abs(test_NeuralNet.predict(test_X) - [0, 1, 0])) < 0.1
test_NeuralNet.predict(test_X)
test_ydf
test_a = np.array([0, 0, 3, 0, 0])
test_x = np.array([[1, 1, 3, 4, 5], [5, 4, 3, 2, 1], [1, 2, 3, 4, 5]])
test_y = np.array([1, 0, 1])
grad_MSE(test_a, test_x, test_y)
titanic_file_path = "../input/titanic/train.csv"
titanic_data = pd.read_csv(titanic_file_path)
titanic_data.head()
y = titanic_data.Survived
feature_columns = ["Pclass", "Sex", "Age", "Fare"] # , "Cabin"]
X = titanic_data[feature_columns]
new_columns = ["Pclass", "isMale", "isFemale", "Age", "Fare"]
# is_First = (X["Pclass"]==1)
# is_Second = (X["Pclass"]==2)
# is_Third = (X["Pclass"]==3)
is_Male = X["Sex"] == "male"
is_Female = X["Sex"] == "female"
the_data = [X["Pclass"], is_Male, is_Female, X["Age"], X["Fare"]]
new_X = pd.concat(the_data, axis=1, keys=new_columns)
# Remove NAN and change to 0
new_X = new_X.replace(np.nan, 0)
new_X
titanicNeuralNet = BasicNeuralNet()
X_train = new_X[0:800]
y_train = y[0:800]
titanicNeuralNet.fit(X_train, y_train)
titanicNeuralNet.a
# Mean average error
sum(abs(titanicNeuralNet.predict(new_X[0:10]) - y[0:10]))
# Number wrong
sum(abs(np.round(titanicNeuralNet.predict(new_X[0:880])) - y[0:880]))
# Number incorrect
sum((np.round(titanicNeuralNet.predict(new_X[0:300])).astype(np.int) - y[0:300]) ** 2)
# now for test data
# path to file you will use for predictions
test_data_path = "../input/titanic/test.csv"
# read test data file using pandas
test_data = pd.read_csv(test_data_path)
# create test_X which comes from test_data but includes only the columns you used for prediction.
# The list of columns is stored in a variable called features
feature_columns = ["Pclass", "Sex", "Age", "Fare"]
test_X = test_data[feature_columns]
new_columns = ["Pclass", "isMale", "isFemale", "Age", "Fare"]
is_Male = test_X["Sex"] == "male"
is_Female = test_X["Sex"] == "female"
the_data = [test_X["Pclass"], is_Male, is_Female, test_X["Age"], test_X["Fare"]]
test_new_X = pd.concat(the_data, axis=1, keys=new_columns)
# Remove NAN and change to 0
test_new_X = test_new_X.replace(np.nan, 0)
# make predictions which we will submit.
test_preds = np.round(titanicNeuralNet.predict(test_new_X)).astype(np.int)
# The lines below shows how to save predictions in format used for competition scoring
# Just uncomment them.
output = pd.DataFrame({"PassengerId": test_data.PassengerId, "Survived": test_preds})
output.to_csv("submission.csv", index=False)
output[0:20]
| false | 0 | 2,622 | 0 | 6 | 2,622 |
||
45605603 | <kaggle_start><code># # Deep Q-learner starter code
# **Work in progress!** Please forgive lack of clarity, bugs, and typos.
# This notebook aims to demonstrate creating a deep Q-learner using Keras and train it on the GFootball enviroment. It will focus on the coded need to train a deep q-learner agent, rather than theory. Hopefully it will provide a starting point developing models and testing them out on the GFootball enviroment, and show how to train and evaluate them using the Gym API. I have no idea at this point how well a Q-learner is likely to perform in this competition, though! It'll certainly take a lot of training and tweaking, and and a large replay buffer to perform well. See also [Convolutional Deep-Q learner](https://www.kaggle.com/garethjns/convolutional-deep-q-learner) for a convolutional version using the SMM environment wrapper.
# The code will be based on a package I've been working on while learning about RL myself. It's available here: [reinforcement-learning-keras](https://github.com/garethjns/reinforcement-learning-keras), and includes configs for solving other Gym enviroments including Cart-pole, Pong, Space invaders, Doom etc. It also handles running experiments with different agents, and some of the diffulties of working with Tensorflow. I've stripped a lot of that out here to try and keep the code simple. For those interested in theory, check the readme on github, there's a list of useful resources. There's an example using this package at the end of this notebook.
# GFootball environment.
# Some helper code
import collections
from typing import Union, Callable, List, Tuple, Iterable, Any
from dataclasses import dataclass
from IPython.display import Image
import matplotlib.pyplot as plt
import numpy as np
from tensorflow import keras
import tensorflow as tf
import seaborn as sns
import gym
import gfootball
import sys
sns.set()
# Training keras models in a loop with eager execution on causes memory leaks and terrible performance.
tf.compat.v1.disable_eager_execution()
sys.path.append("/kaggle/working/kaggle-football/")
# # Q-Learning
# Q-learners are off-policy temporal difference learners, have a look [here](https://lilianweng.github.io/lil-log/2018/02/19/a-long-peek-into-reinforcement-learning.html#model-transition-and-reward) for details and context within the RL world.
# ## Components
# - Agent
# - Model, usually a neural network
# - Replay buffer (the agent's memory)
# - Exploration method, such as episilon greedy
#
# ## Model
# We'll use the GFootball enviroment with the Simple115StateWrapper which returns observations (state) as a (115,) array. This will be used as the input to a very simple neural network wtih 3 layers, which will output an estimated value for every possible action. The agent will either select the action with the highest value as estimated from this model, or randomly (chance depending on epsilon) select a random action.
# To make learning more stable with deep-q learners, two copies of this model are used by the agent.
# - "Action" model This copy is updated every training step and is used to estimate the value of actions for the current state.
# - "Target" model" The copy is updated by copying the weights of the value model, this is done less frequently in order to keep the training target more stable.
#
# The model is defined in this class, feel free to play with the arcitecture! Also note that unit_scale is set to make the model very small, this makes running in the notebook easier, but should be increased for real training.
class DenseNN:
def __init__(
self,
observation_shape: List[int],
n_actions: int,
output_activation: Union[None, str] = None,
unit_scale: int = 1,
learning_rate: float = 0.0001,
opt: str = "Adam",
) -> None:
"""
:param observation_shape: Tuple specifying input shape.
:param n_actions: Int specifying number of outputs
:param output_activation: Activation function for output. Eg.
None for value estimation (off-policy methods).
:param unit_scale: Multiplier for all units in FC layers in network
(not used here at the moment).
:param opt: Keras optimiser to use. Should be string.
This is to avoid storing TF/Keras objects here.
:param learning_rate: Learning rate for optimiser.
"""
self.observation_shape = observation_shape
self.n_actions = n_actions
self.unit_scale = unit_scale
self.output_activation = output_activation
self.learning_rate = learning_rate
self.opt = opt
def _model_architecture(self) -> Tuple[keras.layers.Layer, keras.layers.Layer]:
frame_input = keras.layers.Input(name="input", shape=self.observation_shape)
fc1 = keras.layers.Dense(
int(self.observation_shape[0] / 1.5 * self.unit_scale),
name="fc1",
activation="relu",
)(frame_input)
fc2 = keras.layers.Dense(
int(self.observation_shape[0] / 3 * self.unit_scale),
name="fc2",
activation="relu",
)(fc1)
fc3 = keras.layers.Dense(self.n_actions * 2, name="fc3", activation="relu")(fc2)
action_output = keras.layers.Dense(
units=self.n_actions, name="output", activation=self.output_activation
)(fc3)
return frame_input, action_output
def compile(
self, model_name: str = "model", loss: Union[str, Callable] = "mse"
) -> keras.Model:
"""
Compile a copy of the model using the provided loss.
:param model_name: Name of model
:param loss: Model loss. Default 'mse'. Can be custom callable.
"""
# Get optimiser
if self.opt.lower() == "adam":
opt = keras.optimizers.Adam
elif self.opt.lower() == "rmsprop":
opt = keras.optimizers.RMSprop
else:
raise ValueError(f"Invalid optimiser {self.opt}")
state_input, action_output = self._model_architecture()
model = keras.Model(
inputs=[state_input], outputs=[action_output], name=model_name
)
model.compile(optimizer=opt(learning_rate=self.learning_rate), loss=loss)
return model
def plot(self, model_name: str = "model") -> None:
keras.utils.plot_model(
self.compile(model_name), to_file=f"{model_name}.png", show_shapes=True
)
plt.show()
DenseNN(observation_shape=(115,), unit_scale=0.25, n_actions=19).plot()
Image(filename="model.png")
# ## Replay buffer
# The replay buffer records previous state, actions, and rewards. When the agent is updated, it samples a batch from the replay buffer to create the training set. These samples can come from different episodes if the buffer is long enough. This is necessary to reduce the correlation in the training data, which would be extremely high if, for example, the model was trained with just the last observation on each step. Neural networks don't do well with highly correlated training data.
@dataclass
class ContinuousBuffer:
buffer_size: int = 250
def __post_init__(self) -> None:
self._state_queue = collections.deque(maxlen=self.buffer_size)
self._other_queue = collections.deque(maxlen=self.buffer_size)
self.queue = collections.deque(maxlen=self.buffer_size)
def __len__(self) -> int:
return self.n if (self.n > 0) else 0
@property
def full(self) -> bool:
return len(self._state_queue) == self.buffer_size
@property
def n(self) -> int:
return len(self._state_queue) - 1
def append(self, items: Tuple[Any, int, float, bool]) -> None:
"""
:param items: Tuple containing (s, a, r, d).
"""
self._state_queue.append(items[0])
self._other_queue.append(items[1::])
def get_batch(
self, idxs: Iterable[int]
) -> Tuple[
List[np.ndarray], List[np.ndarray], List[float], List[bool], List[np.ndarray]
]:
ss = [self._state_queue[i] for i in idxs]
ss_ = [self._state_queue[i + 1] for i in idxs]
ard = [self._other_queue[i] for i in idxs]
aa = [a for (a, _, _) in ard]
rr = [r for (_, r, _) in ard]
dd = [d for (_, _, d) in ard]
return ss, aa, rr, dd, ss_
def sample_batch(
self, n: int
) -> Tuple[
List[np.ndarray], List[np.ndarray], List[float], List[bool], List[np.ndarray]
]:
if n > self.n:
raise ValueError
idxs = np.random.randint(0, self.n, n)
return self.get_batch(idxs)
# ## Epsilon greedy
# Epsilon greedy is used to force the agent to explore the environment. When the agent is asked for an action, it draws a random sample between 0-1. If this value is >epsilon, the agent simply selects a random action. Typically epsilon is set high at the beginning of training, and is slowly decayed over time. This class tracks it and handles the random action selection.
@dataclass
class EpsilonGreedy:
"""
Handles epsilon-greedy action selection, decay of epsilon during training.
:param eps_initial: Initial epsilon value.
:param decay: Decay rate in percent (should be positive to decay).
:param decay_schedule: 'linear' or 'compound'.
:param eps_min: The min value epsilon can fall to.
:param state: Random state, used to pick between the greedy or random options.
"""
eps_initial: float = 0.2
decay: float = 0.0001
decay_schedule: str = "compound"
eps_min: float = 0.01
state = None
def __post_init__(self) -> None:
self._step: int = 0
self.eps_current = self.eps_initial
valid_decay = ("linear", "compound")
if self.decay_schedule.lower() not in valid_decay:
raise ValueError(
f"Invalid decay schedule {self.decay_schedule}. "
"Pick from {valid_decay}."
)
self._set_random_state()
def _set_random_state(self) -> None:
self._state = np.random.RandomState(self.state)
def _linear_decay(self) -> float:
return self.eps_current - self.decay
def _compound_decay(self) -> float:
return self.eps_current - self.eps_current * self.decay
def _decay(self):
new_eps = np.nan
if self.decay_schedule.lower() == "linear":
new_eps = self._linear_decay()
if self.decay_schedule.lower() == "compound":
new_eps = self._compound_decay()
self._step += 1
return max(self.eps_min, new_eps)
def select(
self, greedy_option: Callable, random_option: Callable, training: bool = False
) -> Any:
"""
Apply epsilon greedy selection.
If training, decay epsilon, and return selected option.
If not training, just return greedy_option.
Use of lambdas is to avoid unnecessarily picking between
two pre-computed options.
:param greedy_option: Function to evaluate if random option
is NOT picked.
:param random_option: Function to evaluate if random option
IS picked.
:param training: Bool indicating if call is during training
and to use epsilon greedy and decay.
:return: Evaluated selected option.
"""
if training:
self.eps_current = self._decay()
if self._state.random() < self.eps_current:
return random_option()
return greedy_option()
# ## Agent
# The agent estimates actions values from states, and learns from its experience. Most of the magic happens in the .update_model, where the problem is formulated into something that can be learned by the DenseNN model.
@dataclass
class DeepQAgent:
replay_buffer: ContinuousBuffer
eps: EpsilonGreedy
model_architecture: DenseNN
name: str = "DQNAgent"
double: bool = False
noisy: bool = False
gamma: float = 0.99
replay_buffer_samples: int = 75
final_reward: Union[float, None] = None
def __post_init__(self) -> None:
self._build_model()
def _build_model(self) -> None:
"""
Prepare two of the same model.
The action model is used to pick actions and the target model
is used to predict value of Q(s', a). Action model
weights are updated on every buffer sample + training step.
The target model is never directly trained, but it's
weights are updated to match the action model at the end of
each episode.
"""
self._action_model = self.model_architecture.compile(
model_name="action_model", loss="mse"
)
self._target_model = self.model_architecture.compile(
model_name="target_model", loss="mse"
)
def transform(self, s: np.ndarray) -> np.ndarray:
"""Check input shape, add Row dimension if required."""
if len(s.shape) < len(self._action_model.input.shape):
s = np.expand_dims(s, 0)
return s
def update_experience(self, s: np.ndarray, a: int, r: float, d: bool) -> None:
"""
First the most recent step is added to the buffer.
Note that s' isn't saved because there's no need.
It'll be added next step. s' for any s is always index + 1 in
the buffer.
"""
# Add s, a, r, d to experience buffer
self.replay_buffer.append((s, a, r, d))
def update_model(self) -> None:
"""
Sample a batch from the replay buffer, calculate targets using
target model, and train action model.
If the buffer is below its minimum size, no training is done.
If the buffer has reached its minimum size, a training batch
from the replay buffer and the action model is updated.
This update samples random (s, a, r, s') sets from the buffer
and calculates the discounted reward for each set.
The value of the actions at states s and s' are predicted from
the value model. The action model is updated using these value
predictions as the targets. The value of performed action is
updated with the discounted reward (using its value prediction
at s'). ie. x=s, y=[action value 1, action value 2].
"""
# If buffer isn't full, don't train
if not self.replay_buffer.full:
return
# Else sample batch from buffer
ss, aa, rr, dd, ss_ = self.replay_buffer.sample_batch(
self.replay_buffer_samples
)
# Calculate estimated S,A values for current states and next states.
# These are stacked together first to avoid making two separate
# predict calls (which is slow on GPU).
ss = np.array(ss)
ss_ = np.array(ss_)
y_now_and_future = self._target_model.predict_on_batch(np.vstack((ss, ss_)))
# Separate again
y_now = y_now_and_future[0 : self.replay_buffer_samples]
y_future = y_now_and_future[self.replay_buffer_samples : :]
# Update rewards where not done with y_future predictions
dd_mask = np.array(dd, dtype=bool).squeeze()
rr = np.array(rr, dtype=float).squeeze()
# Gather max action indexes and update relevant actions in y
if self.double:
# If using double dqn select best actions using the action model,
# but the value of those action using the
# target model (already have in y_future).
y_future_action_model = self._action_model.predict_on_batch(ss_)
selected_actions = np.argmax(y_future_action_model[~dd_mask, :], axis=1)
else:
# If normal dqn select targets using target model,
# and value of those from target model too
selected_actions = np.argmax(y_future[~dd_mask, :], axis=1)
# Update reward values with estimated values (where not done)
# and final rewards (where done)
rr[~dd_mask] += y_future[~dd_mask, selected_actions]
if self.final_reward is not None:
# If self.final_reward is set, set done cases to this value.
# Else leave as observed reward.
rr[dd_mask] = self.final_reward
aa = np.array(aa, dtype=int)
np.put_along_axis(y_now, aa.reshape(-1, 1), rr.reshape(-1, 1), axis=1)
# Fit model with updated y_now values
self._action_model.train_on_batch(ss, y_now)
def get_best_action(self, s: np.ndarray) -> np.ndarray:
"""
Get best action(s) from model - the one with the highest predicted value.
:param s: A single or multiple rows of state observations.
:return: The selected action.
"""
preds = self._action_model.predict(self.transform(s))
return np.argmax(preds)
def get_action(self, s: np.ndarray, training: bool = False) -> int:
"""
Get an action using get_best_action or epsilon greedy.
Epsilon decays every time a random action is chosen.
:param s: The raw state observation.
:param training: Bool to indicate whether or not to use this
experience to update the model. If False, just
returns best action.
:return: The selected action.
"""
action = self.eps.select(
greedy_option=lambda: self.get_best_action(s),
random_option=lambda: self.env.action_space.sample(),
training=training,
)
return action
def update_target_model(self) -> None:
"""
Update the value model with the weights of the action model
(which is updated each step).
The value model is updated less often to aid stability.
"""
self._target_model.set_weights(self._action_model.get_weights())
def after_episode_update(self) -> None:
"""Value model synced with action model at the end of each episode."""
self.update_target_model()
def _discounted_reward(
self, reward: float, estimated_future_action_rewards: np.ndarray
) -> float:
"""
Use this to define the discounted reward for unfinished episodes,
default is 1 step TD.
"""
return reward + self.gamma * np.max(estimated_future_action_rewards)
def _get_reward(
self, reward: float, estimated_future_action_rewards: np.ndarray, done: bool
) -> float:
"""
Calculate discounted reward for a single step.
:param reward: Last real reward.
:param estimated_future_action_rewards: Estimated future values
of actions taken on next step.
:param done: Flag indicating if this is the last step on an episode.
:return: Reward.
"""
if done:
# If done, reward is just this step. Can finish because agent has won or lost.
return self._final_reward(reward)
else:
# Otherwise, it's the reward plus the predicted max value of next action
return self._discounted_reward(reward, estimated_future_action_rewards)
# # Play single episode
# An episode refers to one play through an enviroment. It will take many episodes to train an agent
def play_episode(
env: gym.Env, agent, n_steps: int = 10, pr: bool = False, training: bool = False
) -> Tuple[List[float], List[int]]:
episode_rewards = []
episode_actions = []
obs = env.reset()
done = False
for s in range(n_steps):
if done:
break
# Select action
action = agent.get_action(obs)
episode_actions.append(action)
# Take action
prev_obs = obs
obs, reward, done, info = env.step(action)
episode_rewards.append(reward)
# Update model
if training:
agent.update_experience(s=prev_obs, a=action, r=reward, d=done)
agent.update_model()
if pr:
print(f"Step {s}: Action taken {action}, " f"reward recieved {reward}")
last_step = s
if training:
agent.after_episode_update()
return episode_rewards, episode_actions
env = gym.make("GFootball-11_vs_11_kaggle-simple115v2-v0")
agent = DeepQAgent(
# Realistically this should be more like 100,000!
replay_buffer=ContinuousBuffer(buffer_size=2000),
eps=EpsilonGreedy(),
model_architecture=DenseNN(
observation_shape=env.observation_space.shape,
# This is also set too low to make running in a notebook easier
unit_scale=0.3,
n_actions=env.action_space.n,
),
)
_ = play_episode(env, agent, n_steps=100, pr=True, training=True)
#
# # Play multiple episodes
def run_multiple_episodes(
env: gym.Env,
agent,
n_episodes: int = 10,
n_steps: int = 10,
pr: bool = False,
training: bool = False,
) -> List[float]:
total_episode_rewards = []
for ep in range(n_episodes):
episode_rewards, _ = play_episode(env, agent, n_steps, pr=False, training=True)
total_episode_rewards.append(sum(episode_rewards))
if pr:
print(
f"Episode {ep} finished after {len(episode_rewards)} "
f"steps, total reward: {sum(episode_rewards)}"
)
return total_episode_rewards
env = gym.make("GFootball-11_vs_11_kaggle-simple115v2-v0")
agent = DeepQAgent(
replay_buffer=ContinuousBuffer(buffer_size=1000),
eps=EpsilonGreedy(eps_initial=0.7),
model_architecture=DenseNN(
observation_shape=env.observation_space.shape,
unit_scale=0.25,
n_actions=env.action_space.n,
),
)
# Both n_episodes and n_steps need to
reward_history = run_multiple_episodes(
env,
agent,
n_episodes=10,
# Use 3000 for 90 minute games
n_steps=3000,
training=True,
pr=True,
)
plt.plot(reward_history)
plt.xlabel("Episode")
plt.ylabel("Reward")
plt.show()
# # Compare to a random agent
class RandomModel:
def __init__(self, n_actions: int):
self.n_actions = n_actions
def predict(self) -> int:
return int(np.random.randint(0, self.n_actions, 1))
@dataclass
class RandomAgent:
"""A random agent that acts randomly and learns nothing."""
n_actions: int
name: str = "RandomAgent"
def __post_init__(self) -> None:
self._build_model()
def _build_model(self) -> None:
"""Set model function."""
self.model = RandomModel(self.n_actions)
def update_model(self, *args, **kwargs) -> None:
"""No model to update."""
pass
def get_action(self, s: Any, **kwargs) -> int:
return self.model.predict()
env = gym.make("GFootball-11_vs_11_kaggle-simple115v2-v0")
obs = env.reset()
random_agent = RandomAgent(n_actions=env.action_space.n)
ra_reward_history = run_multiple_episodes(
env, agent, n_episodes=25, n_steps=3000, training=False
)
dqn_reward_history = run_multiple_episodes(
env, agent, n_episodes=25, n_steps=3000, training=False
)
plt.plot(ra_reward_history, label="Random")
plt.plot(dqn_reward_history, label="DQN")
plt.xlabel("Episode")
plt.ylabel("Reward")
plt.legend(title="Agent")
plt.show()
# # Prepare submission
# This is covered in a bit more detail in the next notebook: https://www.kaggle.com/garethjns/convolutional-deep-q-learner . In short, we need to create a single file containing the agent components we need for inference, including the serialsed model weights. We also need to add to agent function that acts given an environment observation.
# ## Get model weights
import zlib
import pickle
weights_bytes = zlib.compress(pickle.dumps(agent._action_model.get_weights()))
# ## Create submission.py
# Copy and paste the contents of weight_bytes into WEIGHTS_BYTES
import zlib
import pickle
import tensorflow as tf
import numpy as np
from tensorflow import keras
from typing import List, Tuple, Union, Callable
from gfootball.env.wrappers import Simple115StateWrapper
class DenseNN:
def __init__(
self,
observation_shape: List[int],
n_actions: int,
output_activation: Union[None, str] = None,
unit_scale: int = 1,
learning_rate: float = 0.0001,
opt: str = "Adam",
) -> None:
"""
:param observation_shape: Tuple specifying input shape.
:param n_actions: Int specifying number of outputs
:param output_activation: Activation function for output. Eg.
None for value estimation (off-policy methods).
:param unit_scale: Multiplier for all units in FC layers in network
(not used here at the moment).
:param opt: Keras optimiser to use. Should be string.
This is to avoid storing TF/Keras objects here.
:param learning_rate: Learning rate for optimiser.
"""
self.observation_shape = observation_shape
self.n_actions = n_actions
self.unit_scale = unit_scale
self.output_activation = output_activation
self.learning_rate = learning_rate
self.opt = opt
def _model_architecture(self) -> Tuple[keras.layers.Layer, keras.layers.Layer]:
frame_input = keras.layers.Input(name="input", shape=self.observation_shape)
fc1 = keras.layers.Dense(
int(self.observation_shape[0] / 1.5 * self.unit_scale),
name="fc1",
activation="relu",
)(frame_input)
fc2 = keras.layers.Dense(
int(self.observation_shape[0] / 3 * self.unit_scale),
name="fc2",
activation="relu",
)(fc1)
fc3 = keras.layers.Dense(self.n_actions * 2, name="fc3", activation="relu")(fc2)
action_output = keras.layers.Dense(
units=self.n_actions, name="output", activation=self.output_activation
)(fc3)
return frame_input, action_output
def compile(
self, model_name: str = "model", loss: Union[str, Callable] = "mse"
) -> keras.Model:
"""
Compile a copy of the model using the provided loss.
:param model_name: Name of model
:param loss: Model loss. Default 'mse'. Can be custom callable.
"""
# Get optimiser
if self.opt.lower() == "adam":
opt = keras.optimizers.Adam
elif self.opt.lower() == "rmsprop":
opt = keras.optimizers.RMSprop
else:
raise ValueError(f"Invalid optimiser {self.opt}")
state_input, action_output = self._model_architecture()
model = keras.Model(
inputs=[state_input], outputs=[action_output], name=model_name
)
model.compile(optimizer=opt(learning_rate=self.learning_rate), loss=loss)
return model
def plot(self, model_name: str = "model") -> None:
keras.utils.plot_model(
self.compile(model_name), to_file=f"{model_name}.png", show_shapes=True
)
plt.show()
tf_mod = DenseNN(
observation_shape=(115,),
# This needs to match the number from training
unit_scale=0.25,
n_actions=19,
).compile()
tf_mod.set_weights(pickle.loads(zlib.decompress(WEIGHTS_BYTES)))
def agent(obs):
# Use the existing model and obs buffer on each call to agent
global tf_mod
# Convert these to the same output as the Simple115StateWrapper we used in training
obs = Simple115StateWrapper.convert_observation(
obs["players_raw"], fixed_positions=False
)
# Predict actions from keras model
actions = tf_mod.predict(obs)
action = np.argmax(actions)
return [action]
# # Test submission.py
# The written submission file can be tested with the following block.
# See here: https://github.com/garethjns/kaggle-football/blob/main/scripts/debug_agent.py for a version that can be used to run locally, but also maintain debugability.
from kaggle_environments import make
env = make(
"football", configuration={"save_video": True, "scenario_name": "11_vs_11_kaggle"}
)
# Define players
left_player = "submission.py" # A custom agent, eg. random_agent.py or example_agent.py
right_player = "run_right" # eg. A built in 'AI' agent or the agent again
output = env.run([left_player, right_player])
print(
f"Final score: {sum([r['reward'] for r in output[0]])} : {sum([r['reward'] for r in output[1]])}"
)
env.render(mode="human", width=800, height=600)
# # Conclusions and next steps
# The DQN performs currently extremely poorly, which is expected given the totally inadequate training done so far here. However, it seems to be running, so that's a start.
# A few things to try:
# - Increase number of training iterations
# - Increase size of replay buffer
# - Increase number of units in network (set unit_scale higher)
# - Increase depth of NN (modify architecture)
# # Appendix
# ## Training with reinforcement-learning-keras
# Follows the same logic as above, but is a bit more fancy. https://github.com/garethjns/reinforcement-learning-keras
import gfootball
from reinforcement_learning_keras.agents.components.history.training_history import (
TrainingHistory,
)
from reinforcement_learning_keras.agents.components.replay_buffers.continuous_buffer import (
ContinuousBuffer,
)
from reinforcement_learning_keras.agents.models.dense_nn import DenseNN
from reinforcement_learning_keras.agents.q_learning.deep_q_agent import DeepQAgent
from reinforcement_learning_keras.agents.q_learning.exploration.epsilon_greedy import (
EpsilonGreedy,
)
agent = DeepQAgent(
name="deep_q",
model_architecture=DenseNN(observation_shape=(115,), n_actions=19),
replay_buffer=ContinuousBuffer(buffer_size=30000),
env_spec="GFootball-11_vs_11_kaggle-simple115v2-v0",
eps=EpsilonGreedy(
eps_initial=0.9, decay=0.0001, eps_min=0.01, decay_schedule="linear"
),
training_history=TrainingHistory(
agent_name="deep_q", rolling_average=1, plotting_on=True, plot_every=5
),
)
agent.train(
verbose=True,
render=False,
n_episodes=10,
max_episode_steps=3000,
update_every=2,
checkpoint_every=1,
)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0045/605/45605603.ipynb | null | null | [{"Id": 45605603, "ScriptId": 12495311, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4999684, "CreationDate": "10/27/2020 12:44:35", "VersionNumber": 3.0, "Title": "Wstawic115v3", "EvaluationDate": "10/27/2020", "IsChange": true, "TotalLines": 794.0, "LinesInsertedFromPrevious": 4.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 790.0, "LinesInsertedFromFork": 4.0, "LinesDeletedFromFork": 4.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 790.0, "TotalVotes": 0}] | null | null | null | null | # # Deep Q-learner starter code
# **Work in progress!** Please forgive lack of clarity, bugs, and typos.
# This notebook aims to demonstrate creating a deep Q-learner using Keras and train it on the GFootball enviroment. It will focus on the coded need to train a deep q-learner agent, rather than theory. Hopefully it will provide a starting point developing models and testing them out on the GFootball enviroment, and show how to train and evaluate them using the Gym API. I have no idea at this point how well a Q-learner is likely to perform in this competition, though! It'll certainly take a lot of training and tweaking, and and a large replay buffer to perform well. See also [Convolutional Deep-Q learner](https://www.kaggle.com/garethjns/convolutional-deep-q-learner) for a convolutional version using the SMM environment wrapper.
# The code will be based on a package I've been working on while learning about RL myself. It's available here: [reinforcement-learning-keras](https://github.com/garethjns/reinforcement-learning-keras), and includes configs for solving other Gym enviroments including Cart-pole, Pong, Space invaders, Doom etc. It also handles running experiments with different agents, and some of the diffulties of working with Tensorflow. I've stripped a lot of that out here to try and keep the code simple. For those interested in theory, check the readme on github, there's a list of useful resources. There's an example using this package at the end of this notebook.
# GFootball environment.
# Some helper code
import collections
from typing import Union, Callable, List, Tuple, Iterable, Any
from dataclasses import dataclass
from IPython.display import Image
import matplotlib.pyplot as plt
import numpy as np
from tensorflow import keras
import tensorflow as tf
import seaborn as sns
import gym
import gfootball
import sys
sns.set()
# Training keras models in a loop with eager execution on causes memory leaks and terrible performance.
tf.compat.v1.disable_eager_execution()
sys.path.append("/kaggle/working/kaggle-football/")
# # Q-Learning
# Q-learners are off-policy temporal difference learners, have a look [here](https://lilianweng.github.io/lil-log/2018/02/19/a-long-peek-into-reinforcement-learning.html#model-transition-and-reward) for details and context within the RL world.
# ## Components
# - Agent
# - Model, usually a neural network
# - Replay buffer (the agent's memory)
# - Exploration method, such as episilon greedy
#
# ## Model
# We'll use the GFootball enviroment with the Simple115StateWrapper which returns observations (state) as a (115,) array. This will be used as the input to a very simple neural network wtih 3 layers, which will output an estimated value for every possible action. The agent will either select the action with the highest value as estimated from this model, or randomly (chance depending on epsilon) select a random action.
# To make learning more stable with deep-q learners, two copies of this model are used by the agent.
# - "Action" model This copy is updated every training step and is used to estimate the value of actions for the current state.
# - "Target" model" The copy is updated by copying the weights of the value model, this is done less frequently in order to keep the training target more stable.
#
# The model is defined in this class, feel free to play with the arcitecture! Also note that unit_scale is set to make the model very small, this makes running in the notebook easier, but should be increased for real training.
class DenseNN:
def __init__(
self,
observation_shape: List[int],
n_actions: int,
output_activation: Union[None, str] = None,
unit_scale: int = 1,
learning_rate: float = 0.0001,
opt: str = "Adam",
) -> None:
"""
:param observation_shape: Tuple specifying input shape.
:param n_actions: Int specifying number of outputs
:param output_activation: Activation function for output. Eg.
None for value estimation (off-policy methods).
:param unit_scale: Multiplier for all units in FC layers in network
(not used here at the moment).
:param opt: Keras optimiser to use. Should be string.
This is to avoid storing TF/Keras objects here.
:param learning_rate: Learning rate for optimiser.
"""
self.observation_shape = observation_shape
self.n_actions = n_actions
self.unit_scale = unit_scale
self.output_activation = output_activation
self.learning_rate = learning_rate
self.opt = opt
def _model_architecture(self) -> Tuple[keras.layers.Layer, keras.layers.Layer]:
frame_input = keras.layers.Input(name="input", shape=self.observation_shape)
fc1 = keras.layers.Dense(
int(self.observation_shape[0] / 1.5 * self.unit_scale),
name="fc1",
activation="relu",
)(frame_input)
fc2 = keras.layers.Dense(
int(self.observation_shape[0] / 3 * self.unit_scale),
name="fc2",
activation="relu",
)(fc1)
fc3 = keras.layers.Dense(self.n_actions * 2, name="fc3", activation="relu")(fc2)
action_output = keras.layers.Dense(
units=self.n_actions, name="output", activation=self.output_activation
)(fc3)
return frame_input, action_output
def compile(
self, model_name: str = "model", loss: Union[str, Callable] = "mse"
) -> keras.Model:
"""
Compile a copy of the model using the provided loss.
:param model_name: Name of model
:param loss: Model loss. Default 'mse'. Can be custom callable.
"""
# Get optimiser
if self.opt.lower() == "adam":
opt = keras.optimizers.Adam
elif self.opt.lower() == "rmsprop":
opt = keras.optimizers.RMSprop
else:
raise ValueError(f"Invalid optimiser {self.opt}")
state_input, action_output = self._model_architecture()
model = keras.Model(
inputs=[state_input], outputs=[action_output], name=model_name
)
model.compile(optimizer=opt(learning_rate=self.learning_rate), loss=loss)
return model
def plot(self, model_name: str = "model") -> None:
keras.utils.plot_model(
self.compile(model_name), to_file=f"{model_name}.png", show_shapes=True
)
plt.show()
DenseNN(observation_shape=(115,), unit_scale=0.25, n_actions=19).plot()
Image(filename="model.png")
# ## Replay buffer
# The replay buffer records previous state, actions, and rewards. When the agent is updated, it samples a batch from the replay buffer to create the training set. These samples can come from different episodes if the buffer is long enough. This is necessary to reduce the correlation in the training data, which would be extremely high if, for example, the model was trained with just the last observation on each step. Neural networks don't do well with highly correlated training data.
@dataclass
class ContinuousBuffer:
buffer_size: int = 250
def __post_init__(self) -> None:
self._state_queue = collections.deque(maxlen=self.buffer_size)
self._other_queue = collections.deque(maxlen=self.buffer_size)
self.queue = collections.deque(maxlen=self.buffer_size)
def __len__(self) -> int:
return self.n if (self.n > 0) else 0
@property
def full(self) -> bool:
return len(self._state_queue) == self.buffer_size
@property
def n(self) -> int:
return len(self._state_queue) - 1
def append(self, items: Tuple[Any, int, float, bool]) -> None:
"""
:param items: Tuple containing (s, a, r, d).
"""
self._state_queue.append(items[0])
self._other_queue.append(items[1::])
def get_batch(
self, idxs: Iterable[int]
) -> Tuple[
List[np.ndarray], List[np.ndarray], List[float], List[bool], List[np.ndarray]
]:
ss = [self._state_queue[i] for i in idxs]
ss_ = [self._state_queue[i + 1] for i in idxs]
ard = [self._other_queue[i] for i in idxs]
aa = [a for (a, _, _) in ard]
rr = [r for (_, r, _) in ard]
dd = [d for (_, _, d) in ard]
return ss, aa, rr, dd, ss_
def sample_batch(
self, n: int
) -> Tuple[
List[np.ndarray], List[np.ndarray], List[float], List[bool], List[np.ndarray]
]:
if n > self.n:
raise ValueError
idxs = np.random.randint(0, self.n, n)
return self.get_batch(idxs)
# ## Epsilon greedy
# Epsilon greedy is used to force the agent to explore the environment. When the agent is asked for an action, it draws a random sample between 0-1. If this value is >epsilon, the agent simply selects a random action. Typically epsilon is set high at the beginning of training, and is slowly decayed over time. This class tracks it and handles the random action selection.
@dataclass
class EpsilonGreedy:
"""
Handles epsilon-greedy action selection, decay of epsilon during training.
:param eps_initial: Initial epsilon value.
:param decay: Decay rate in percent (should be positive to decay).
:param decay_schedule: 'linear' or 'compound'.
:param eps_min: The min value epsilon can fall to.
:param state: Random state, used to pick between the greedy or random options.
"""
eps_initial: float = 0.2
decay: float = 0.0001
decay_schedule: str = "compound"
eps_min: float = 0.01
state = None
def __post_init__(self) -> None:
self._step: int = 0
self.eps_current = self.eps_initial
valid_decay = ("linear", "compound")
if self.decay_schedule.lower() not in valid_decay:
raise ValueError(
f"Invalid decay schedule {self.decay_schedule}. "
"Pick from {valid_decay}."
)
self._set_random_state()
def _set_random_state(self) -> None:
self._state = np.random.RandomState(self.state)
def _linear_decay(self) -> float:
return self.eps_current - self.decay
def _compound_decay(self) -> float:
return self.eps_current - self.eps_current * self.decay
def _decay(self):
new_eps = np.nan
if self.decay_schedule.lower() == "linear":
new_eps = self._linear_decay()
if self.decay_schedule.lower() == "compound":
new_eps = self._compound_decay()
self._step += 1
return max(self.eps_min, new_eps)
def select(
self, greedy_option: Callable, random_option: Callable, training: bool = False
) -> Any:
"""
Apply epsilon greedy selection.
If training, decay epsilon, and return selected option.
If not training, just return greedy_option.
Use of lambdas is to avoid unnecessarily picking between
two pre-computed options.
:param greedy_option: Function to evaluate if random option
is NOT picked.
:param random_option: Function to evaluate if random option
IS picked.
:param training: Bool indicating if call is during training
and to use epsilon greedy and decay.
:return: Evaluated selected option.
"""
if training:
self.eps_current = self._decay()
if self._state.random() < self.eps_current:
return random_option()
return greedy_option()
# ## Agent
# The agent estimates actions values from states, and learns from its experience. Most of the magic happens in the .update_model, where the problem is formulated into something that can be learned by the DenseNN model.
@dataclass
class DeepQAgent:
replay_buffer: ContinuousBuffer
eps: EpsilonGreedy
model_architecture: DenseNN
name: str = "DQNAgent"
double: bool = False
noisy: bool = False
gamma: float = 0.99
replay_buffer_samples: int = 75
final_reward: Union[float, None] = None
def __post_init__(self) -> None:
self._build_model()
def _build_model(self) -> None:
"""
Prepare two of the same model.
The action model is used to pick actions and the target model
is used to predict value of Q(s', a). Action model
weights are updated on every buffer sample + training step.
The target model is never directly trained, but it's
weights are updated to match the action model at the end of
each episode.
"""
self._action_model = self.model_architecture.compile(
model_name="action_model", loss="mse"
)
self._target_model = self.model_architecture.compile(
model_name="target_model", loss="mse"
)
def transform(self, s: np.ndarray) -> np.ndarray:
"""Check input shape, add Row dimension if required."""
if len(s.shape) < len(self._action_model.input.shape):
s = np.expand_dims(s, 0)
return s
def update_experience(self, s: np.ndarray, a: int, r: float, d: bool) -> None:
"""
First the most recent step is added to the buffer.
Note that s' isn't saved because there's no need.
It'll be added next step. s' for any s is always index + 1 in
the buffer.
"""
# Add s, a, r, d to experience buffer
self.replay_buffer.append((s, a, r, d))
def update_model(self) -> None:
"""
Sample a batch from the replay buffer, calculate targets using
target model, and train action model.
If the buffer is below its minimum size, no training is done.
If the buffer has reached its minimum size, a training batch
from the replay buffer and the action model is updated.
This update samples random (s, a, r, s') sets from the buffer
and calculates the discounted reward for each set.
The value of the actions at states s and s' are predicted from
the value model. The action model is updated using these value
predictions as the targets. The value of performed action is
updated with the discounted reward (using its value prediction
at s'). ie. x=s, y=[action value 1, action value 2].
"""
# If buffer isn't full, don't train
if not self.replay_buffer.full:
return
# Else sample batch from buffer
ss, aa, rr, dd, ss_ = self.replay_buffer.sample_batch(
self.replay_buffer_samples
)
# Calculate estimated S,A values for current states and next states.
# These are stacked together first to avoid making two separate
# predict calls (which is slow on GPU).
ss = np.array(ss)
ss_ = np.array(ss_)
y_now_and_future = self._target_model.predict_on_batch(np.vstack((ss, ss_)))
# Separate again
y_now = y_now_and_future[0 : self.replay_buffer_samples]
y_future = y_now_and_future[self.replay_buffer_samples : :]
# Update rewards where not done with y_future predictions
dd_mask = np.array(dd, dtype=bool).squeeze()
rr = np.array(rr, dtype=float).squeeze()
# Gather max action indexes and update relevant actions in y
if self.double:
# If using double dqn select best actions using the action model,
# but the value of those action using the
# target model (already have in y_future).
y_future_action_model = self._action_model.predict_on_batch(ss_)
selected_actions = np.argmax(y_future_action_model[~dd_mask, :], axis=1)
else:
# If normal dqn select targets using target model,
# and value of those from target model too
selected_actions = np.argmax(y_future[~dd_mask, :], axis=1)
# Update reward values with estimated values (where not done)
# and final rewards (where done)
rr[~dd_mask] += y_future[~dd_mask, selected_actions]
if self.final_reward is not None:
# If self.final_reward is set, set done cases to this value.
# Else leave as observed reward.
rr[dd_mask] = self.final_reward
aa = np.array(aa, dtype=int)
np.put_along_axis(y_now, aa.reshape(-1, 1), rr.reshape(-1, 1), axis=1)
# Fit model with updated y_now values
self._action_model.train_on_batch(ss, y_now)
def get_best_action(self, s: np.ndarray) -> np.ndarray:
"""
Get best action(s) from model - the one with the highest predicted value.
:param s: A single or multiple rows of state observations.
:return: The selected action.
"""
preds = self._action_model.predict(self.transform(s))
return np.argmax(preds)
def get_action(self, s: np.ndarray, training: bool = False) -> int:
"""
Get an action using get_best_action or epsilon greedy.
Epsilon decays every time a random action is chosen.
:param s: The raw state observation.
:param training: Bool to indicate whether or not to use this
experience to update the model. If False, just
returns best action.
:return: The selected action.
"""
action = self.eps.select(
greedy_option=lambda: self.get_best_action(s),
random_option=lambda: self.env.action_space.sample(),
training=training,
)
return action
def update_target_model(self) -> None:
"""
Update the value model with the weights of the action model
(which is updated each step).
The value model is updated less often to aid stability.
"""
self._target_model.set_weights(self._action_model.get_weights())
def after_episode_update(self) -> None:
"""Value model synced with action model at the end of each episode."""
self.update_target_model()
def _discounted_reward(
self, reward: float, estimated_future_action_rewards: np.ndarray
) -> float:
"""
Use this to define the discounted reward for unfinished episodes,
default is 1 step TD.
"""
return reward + self.gamma * np.max(estimated_future_action_rewards)
def _get_reward(
self, reward: float, estimated_future_action_rewards: np.ndarray, done: bool
) -> float:
"""
Calculate discounted reward for a single step.
:param reward: Last real reward.
:param estimated_future_action_rewards: Estimated future values
of actions taken on next step.
:param done: Flag indicating if this is the last step on an episode.
:return: Reward.
"""
if done:
# If done, reward is just this step. Can finish because agent has won or lost.
return self._final_reward(reward)
else:
# Otherwise, it's the reward plus the predicted max value of next action
return self._discounted_reward(reward, estimated_future_action_rewards)
# # Play single episode
# An episode refers to one play through an enviroment. It will take many episodes to train an agent
def play_episode(
env: gym.Env, agent, n_steps: int = 10, pr: bool = False, training: bool = False
) -> Tuple[List[float], List[int]]:
episode_rewards = []
episode_actions = []
obs = env.reset()
done = False
for s in range(n_steps):
if done:
break
# Select action
action = agent.get_action(obs)
episode_actions.append(action)
# Take action
prev_obs = obs
obs, reward, done, info = env.step(action)
episode_rewards.append(reward)
# Update model
if training:
agent.update_experience(s=prev_obs, a=action, r=reward, d=done)
agent.update_model()
if pr:
print(f"Step {s}: Action taken {action}, " f"reward recieved {reward}")
last_step = s
if training:
agent.after_episode_update()
return episode_rewards, episode_actions
env = gym.make("GFootball-11_vs_11_kaggle-simple115v2-v0")
agent = DeepQAgent(
# Realistically this should be more like 100,000!
replay_buffer=ContinuousBuffer(buffer_size=2000),
eps=EpsilonGreedy(),
model_architecture=DenseNN(
observation_shape=env.observation_space.shape,
# This is also set too low to make running in a notebook easier
unit_scale=0.3,
n_actions=env.action_space.n,
),
)
_ = play_episode(env, agent, n_steps=100, pr=True, training=True)
#
# # Play multiple episodes
def run_multiple_episodes(
env: gym.Env,
agent,
n_episodes: int = 10,
n_steps: int = 10,
pr: bool = False,
training: bool = False,
) -> List[float]:
total_episode_rewards = []
for ep in range(n_episodes):
episode_rewards, _ = play_episode(env, agent, n_steps, pr=False, training=True)
total_episode_rewards.append(sum(episode_rewards))
if pr:
print(
f"Episode {ep} finished after {len(episode_rewards)} "
f"steps, total reward: {sum(episode_rewards)}"
)
return total_episode_rewards
env = gym.make("GFootball-11_vs_11_kaggle-simple115v2-v0")
agent = DeepQAgent(
replay_buffer=ContinuousBuffer(buffer_size=1000),
eps=EpsilonGreedy(eps_initial=0.7),
model_architecture=DenseNN(
observation_shape=env.observation_space.shape,
unit_scale=0.25,
n_actions=env.action_space.n,
),
)
# Both n_episodes and n_steps need to
reward_history = run_multiple_episodes(
env,
agent,
n_episodes=10,
# Use 3000 for 90 minute games
n_steps=3000,
training=True,
pr=True,
)
plt.plot(reward_history)
plt.xlabel("Episode")
plt.ylabel("Reward")
plt.show()
# # Compare to a random agent
class RandomModel:
def __init__(self, n_actions: int):
self.n_actions = n_actions
def predict(self) -> int:
return int(np.random.randint(0, self.n_actions, 1))
@dataclass
class RandomAgent:
"""A random agent that acts randomly and learns nothing."""
n_actions: int
name: str = "RandomAgent"
def __post_init__(self) -> None:
self._build_model()
def _build_model(self) -> None:
"""Set model function."""
self.model = RandomModel(self.n_actions)
def update_model(self, *args, **kwargs) -> None:
"""No model to update."""
pass
def get_action(self, s: Any, **kwargs) -> int:
return self.model.predict()
env = gym.make("GFootball-11_vs_11_kaggle-simple115v2-v0")
obs = env.reset()
random_agent = RandomAgent(n_actions=env.action_space.n)
ra_reward_history = run_multiple_episodes(
env, agent, n_episodes=25, n_steps=3000, training=False
)
dqn_reward_history = run_multiple_episodes(
env, agent, n_episodes=25, n_steps=3000, training=False
)
plt.plot(ra_reward_history, label="Random")
plt.plot(dqn_reward_history, label="DQN")
plt.xlabel("Episode")
plt.ylabel("Reward")
plt.legend(title="Agent")
plt.show()
# # Prepare submission
# This is covered in a bit more detail in the next notebook: https://www.kaggle.com/garethjns/convolutional-deep-q-learner . In short, we need to create a single file containing the agent components we need for inference, including the serialsed model weights. We also need to add to agent function that acts given an environment observation.
# ## Get model weights
import zlib
import pickle
weights_bytes = zlib.compress(pickle.dumps(agent._action_model.get_weights()))
# ## Create submission.py
# Copy and paste the contents of weight_bytes into WEIGHTS_BYTES
import zlib
import pickle
import tensorflow as tf
import numpy as np
from tensorflow import keras
from typing import List, Tuple, Union, Callable
from gfootball.env.wrappers import Simple115StateWrapper
class DenseNN:
def __init__(
self,
observation_shape: List[int],
n_actions: int,
output_activation: Union[None, str] = None,
unit_scale: int = 1,
learning_rate: float = 0.0001,
opt: str = "Adam",
) -> None:
"""
:param observation_shape: Tuple specifying input shape.
:param n_actions: Int specifying number of outputs
:param output_activation: Activation function for output. Eg.
None for value estimation (off-policy methods).
:param unit_scale: Multiplier for all units in FC layers in network
(not used here at the moment).
:param opt: Keras optimiser to use. Should be string.
This is to avoid storing TF/Keras objects here.
:param learning_rate: Learning rate for optimiser.
"""
self.observation_shape = observation_shape
self.n_actions = n_actions
self.unit_scale = unit_scale
self.output_activation = output_activation
self.learning_rate = learning_rate
self.opt = opt
def _model_architecture(self) -> Tuple[keras.layers.Layer, keras.layers.Layer]:
frame_input = keras.layers.Input(name="input", shape=self.observation_shape)
fc1 = keras.layers.Dense(
int(self.observation_shape[0] / 1.5 * self.unit_scale),
name="fc1",
activation="relu",
)(frame_input)
fc2 = keras.layers.Dense(
int(self.observation_shape[0] / 3 * self.unit_scale),
name="fc2",
activation="relu",
)(fc1)
fc3 = keras.layers.Dense(self.n_actions * 2, name="fc3", activation="relu")(fc2)
action_output = keras.layers.Dense(
units=self.n_actions, name="output", activation=self.output_activation
)(fc3)
return frame_input, action_output
def compile(
self, model_name: str = "model", loss: Union[str, Callable] = "mse"
) -> keras.Model:
"""
Compile a copy of the model using the provided loss.
:param model_name: Name of model
:param loss: Model loss. Default 'mse'. Can be custom callable.
"""
# Get optimiser
if self.opt.lower() == "adam":
opt = keras.optimizers.Adam
elif self.opt.lower() == "rmsprop":
opt = keras.optimizers.RMSprop
else:
raise ValueError(f"Invalid optimiser {self.opt}")
state_input, action_output = self._model_architecture()
model = keras.Model(
inputs=[state_input], outputs=[action_output], name=model_name
)
model.compile(optimizer=opt(learning_rate=self.learning_rate), loss=loss)
return model
def plot(self, model_name: str = "model") -> None:
keras.utils.plot_model(
self.compile(model_name), to_file=f"{model_name}.png", show_shapes=True
)
plt.show()
tf_mod = DenseNN(
observation_shape=(115,),
# This needs to match the number from training
unit_scale=0.25,
n_actions=19,
).compile()
tf_mod.set_weights(pickle.loads(zlib.decompress(WEIGHTS_BYTES)))
def agent(obs):
# Use the existing model and obs buffer on each call to agent
global tf_mod
# Convert these to the same output as the Simple115StateWrapper we used in training
obs = Simple115StateWrapper.convert_observation(
obs["players_raw"], fixed_positions=False
)
# Predict actions from keras model
actions = tf_mod.predict(obs)
action = np.argmax(actions)
return [action]
# # Test submission.py
# The written submission file can be tested with the following block.
# See here: https://github.com/garethjns/kaggle-football/blob/main/scripts/debug_agent.py for a version that can be used to run locally, but also maintain debugability.
from kaggle_environments import make
env = make(
"football", configuration={"save_video": True, "scenario_name": "11_vs_11_kaggle"}
)
# Define players
left_player = "submission.py" # A custom agent, eg. random_agent.py or example_agent.py
right_player = "run_right" # eg. A built in 'AI' agent or the agent again
output = env.run([left_player, right_player])
print(
f"Final score: {sum([r['reward'] for r in output[0]])} : {sum([r['reward'] for r in output[1]])}"
)
env.render(mode="human", width=800, height=600)
# # Conclusions and next steps
# The DQN performs currently extremely poorly, which is expected given the totally inadequate training done so far here. However, it seems to be running, so that's a start.
# A few things to try:
# - Increase number of training iterations
# - Increase size of replay buffer
# - Increase number of units in network (set unit_scale higher)
# - Increase depth of NN (modify architecture)
# # Appendix
# ## Training with reinforcement-learning-keras
# Follows the same logic as above, but is a bit more fancy. https://github.com/garethjns/reinforcement-learning-keras
import gfootball
from reinforcement_learning_keras.agents.components.history.training_history import (
TrainingHistory,
)
from reinforcement_learning_keras.agents.components.replay_buffers.continuous_buffer import (
ContinuousBuffer,
)
from reinforcement_learning_keras.agents.models.dense_nn import DenseNN
from reinforcement_learning_keras.agents.q_learning.deep_q_agent import DeepQAgent
from reinforcement_learning_keras.agents.q_learning.exploration.epsilon_greedy import (
EpsilonGreedy,
)
agent = DeepQAgent(
name="deep_q",
model_architecture=DenseNN(observation_shape=(115,), n_actions=19),
replay_buffer=ContinuousBuffer(buffer_size=30000),
env_spec="GFootball-11_vs_11_kaggle-simple115v2-v0",
eps=EpsilonGreedy(
eps_initial=0.9, decay=0.0001, eps_min=0.01, decay_schedule="linear"
),
training_history=TrainingHistory(
agent_name="deep_q", rolling_average=1, plotting_on=True, plot_every=5
),
)
agent.train(
verbose=True,
render=False,
n_episodes=10,
max_episode_steps=3000,
update_every=2,
checkpoint_every=1,
)
| false | 0 | 7,968 | 0 | 6 | 7,968 |
||
45449554 | <kaggle_start><code># El problema de la mochila (Knapsack problem - KSP) consiste en encontrar, a partir de los objetos disponibles, el conjunto de objetos que quepa en la mochila cuyo valor acumulado sea máximo. Al igual que en el problema anterior, este problema es fácilmente resoluble haciendo una comprobación de todas las posibles combinaciones de objetos y tomando aquella que más valor tenga. Sin embargo, estos métodos basados en la fuerza bruta son imposibles de aplicar cuando la lista de objetos que se pueden introducir en la mochila crece mucho.
# En esta práctica se trabajará el problema de la mochila, teniendo como objetivo alcanzar una solución que permita calcular conjuntos de objetos óptimos a partir de una lista pequeña de objetos. Como en la práctica anterior, y siguiendo este notebook, se tendrá que hacer uso del lenguaje de programación Python para realizar la práctica, rellenando o modificando el código que se indique a lo largo del notebook. **Se debe realizar una implementación programación dinámica con tabulation**.
# En este notebook se han incluido distintos datasets que representan diferentes configuraciones del problema del KSP, con distintas listas de objetos y tamaños de mochila. El código que acompaña a este notebook permite realizar la lectura de estos ficheros para su procesamiento. Existen varios códigos a lo largo del notebook que deben ser completados o modificados para terminar esta practica. Concretamente, se debe realizar las siguientes implementaciones:
# * Algoritmo de programación dinámica con memoization
# NOTA: los códigos implementados por el alumno deben utilizar [funciones lambda](https://www.w3schools.com/python/python_lambda.asp) en la medida de lo posible.
# Adding imports that will be used
import numpy as np # linear algebra
# The following code takes all files in the given directory and print the paths of the files
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Definition of the tuples that will be read from the input files. These tuples of three positions represent the item index, its value and its weight
import sys
import csv
csv.field_size_limit(sys.maxsize)
from collections import namedtuple
Item = namedtuple(
"Item", ["index", "value", "weight"]
) # check https://docs.python.org/3/library/collections.html#collections.namedtuple
# This method checks that the solution is a valid solution. It is that the selected list of items does not weight more than the knapsack capacity
def check_solution(capacity, items, taken):
weight = 0
value = 0
for item in items:
if taken[item.index] == 1:
weight += item.weight
value += item.value
if weight > capacity:
print(
"Incorrect solution, the knapsack capacity is exceeded: Capacity = %f, Weight = %f"
% (capacity, weight)
)
return 0
return value
# El código a continuación debe ser modificado para implementar una solución basada en [**programación dinámica**](https://es.wikipedia.org/wiki/Programaci%C3%B3n_din%C3%A1mica) que utilice en la medida de lo posible funciones lambda
def solve_with_dp_tabulation(items, capacity):
"""Write here your implementation of dynamic programming with tabulation"""
value = 0
weight = 0
taken = [0] * len(items)
# write here your implementation of dynamic programming
# prepare the solution in the specified output format
output_data = str(value) + " " + str(0) + "\n"
output_data += " ".join(map(str, taken))
return output_data, check_solution(capacity, items, taken)
# Optativamente, puede implementar programación dinámica con memoization. Recuerde modificar las condiciones de llamada a estas funciones en solve_it
def solve_with_dp_memoization(items, capacity):
"""Write here your implementation of dynamic programming with memoization. This part is optional but will improve your scoring"""
value = 0
weight = 0
taken = [0] * len(items)
# write here your implementation of dynamic programming
# prepare the solution in the specified output format
output_data = str(value) + " " + str(0) + "\n"
output_data += " ".join(map(str, taken))
return output_data, check_solution(capacity, items, taken)
# Aquí debe copiar el código implementado en la P2 para que sea invocado cuando la tabla de la programación dinámica se estime muy grande
def solve_with_greedy(items, capacity):
"""Copy here the implementation of greedy you did in P2"""
pass
# Aquí debe copiar el código implementado del sort de la P2
def sort(items, cmp):
"""Copy here the implementation of sort you did in P2"""
pass
# This function takes input data that describes a specific problem of TSP and solve it
def solve_it(input_data):
# parse the input
lines = input_data.split("\n")
firstLine = lines[0].split()
item_count = int(firstLine[0])
capacity = int(firstLine[1])
items = []
for i in range(1, item_count + 1):
line = lines[i]
parts = line.split()
items.append(Item(i - 1, int(parts[0]), int(parts[1])))
# Modify this code to adapt it to your solution. Currently
# tabulation is unconditionally invoked, and therefore it
# will fail with cases requiring a large table.
# In order to avoid that problem, add here code which helps
# deciding what approach must be taken (for example, depending
# on the number of elements of the table), and adjust the
# conditions of the following if-statement to choose what
# function must be dynamically invoked: tabulation,
# memoization or greedy.
if True:
return solve_with_dp_tabulation(items, capacity)
# elif True:
# return solve_with_dp_memoization(items, capacity)
else:
return solve_with_greedy(items, capacity)
# For each input file, solve_it is called and the result serialized in the ouputs for kaggle and moodle
str_output_kaggle = [["Filename", "Max_value"]]
str_output_moodle = [["Filename", "Max_value", "Solution"]]
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
full_name = dirname + "/" + filename
with open(full_name, "r") as input_data_file:
input_data = input_data_file.read()
output, value = solve_it(input_data)
str_output_kaggle.append([filename, str(value)])
str_output_moodle.append([filename, str(value), output.split("\n")[1]])
from IPython.display import FileLink
def submission_generation(filename, str_output):
os.chdir(r"/kaggle/working")
with open(filename, "w", newline="") as file:
writer = csv.writer(file)
for item in str_output:
writer.writerow(item)
return FileLink(filename)
submission_generation("NAME_P4_kaggle.csv", str_output_kaggle)
# The file generated by this method must be uploaded in the task of the "campus virtual". The file to upload in the "campus virtual" must be the one related to one submitted to Kaggle. That is, both submitted files must be generated in the same run
submission_generation("NAME_P4_moodle.csv", str_output_moodle)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0045/449/45449554.ipynb | null | null | [{"Id": 45449554, "ScriptId": 12486770, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1743598, "CreationDate": "10/25/2020 09:27:07", "VersionNumber": 1.0, "Title": "Practica 4 AP KS 2020", "EvaluationDate": "10/25/2020", "IsChange": false, "TotalLines": 148.0, "LinesInsertedFromPrevious": 0.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 148.0, "LinesInsertedFromFork": 0.0, "LinesDeletedFromFork": 0.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 148.0, "TotalVotes": 0}] | null | null | null | null | # El problema de la mochila (Knapsack problem - KSP) consiste en encontrar, a partir de los objetos disponibles, el conjunto de objetos que quepa en la mochila cuyo valor acumulado sea máximo. Al igual que en el problema anterior, este problema es fácilmente resoluble haciendo una comprobación de todas las posibles combinaciones de objetos y tomando aquella que más valor tenga. Sin embargo, estos métodos basados en la fuerza bruta son imposibles de aplicar cuando la lista de objetos que se pueden introducir en la mochila crece mucho.
# En esta práctica se trabajará el problema de la mochila, teniendo como objetivo alcanzar una solución que permita calcular conjuntos de objetos óptimos a partir de una lista pequeña de objetos. Como en la práctica anterior, y siguiendo este notebook, se tendrá que hacer uso del lenguaje de programación Python para realizar la práctica, rellenando o modificando el código que se indique a lo largo del notebook. **Se debe realizar una implementación programación dinámica con tabulation**.
# En este notebook se han incluido distintos datasets que representan diferentes configuraciones del problema del KSP, con distintas listas de objetos y tamaños de mochila. El código que acompaña a este notebook permite realizar la lectura de estos ficheros para su procesamiento. Existen varios códigos a lo largo del notebook que deben ser completados o modificados para terminar esta practica. Concretamente, se debe realizar las siguientes implementaciones:
# * Algoritmo de programación dinámica con memoization
# NOTA: los códigos implementados por el alumno deben utilizar [funciones lambda](https://www.w3schools.com/python/python_lambda.asp) en la medida de lo posible.
# Adding imports that will be used
import numpy as np # linear algebra
# The following code takes all files in the given directory and print the paths of the files
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Definition of the tuples that will be read from the input files. These tuples of three positions represent the item index, its value and its weight
import sys
import csv
csv.field_size_limit(sys.maxsize)
from collections import namedtuple
Item = namedtuple(
"Item", ["index", "value", "weight"]
) # check https://docs.python.org/3/library/collections.html#collections.namedtuple
# This method checks that the solution is a valid solution. It is that the selected list of items does not weight more than the knapsack capacity
def check_solution(capacity, items, taken):
weight = 0
value = 0
for item in items:
if taken[item.index] == 1:
weight += item.weight
value += item.value
if weight > capacity:
print(
"Incorrect solution, the knapsack capacity is exceeded: Capacity = %f, Weight = %f"
% (capacity, weight)
)
return 0
return value
# El código a continuación debe ser modificado para implementar una solución basada en [**programación dinámica**](https://es.wikipedia.org/wiki/Programaci%C3%B3n_din%C3%A1mica) que utilice en la medida de lo posible funciones lambda
def solve_with_dp_tabulation(items, capacity):
"""Write here your implementation of dynamic programming with tabulation"""
value = 0
weight = 0
taken = [0] * len(items)
# write here your implementation of dynamic programming
# prepare the solution in the specified output format
output_data = str(value) + " " + str(0) + "\n"
output_data += " ".join(map(str, taken))
return output_data, check_solution(capacity, items, taken)
# Optativamente, puede implementar programación dinámica con memoization. Recuerde modificar las condiciones de llamada a estas funciones en solve_it
def solve_with_dp_memoization(items, capacity):
"""Write here your implementation of dynamic programming with memoization. This part is optional but will improve your scoring"""
value = 0
weight = 0
taken = [0] * len(items)
# write here your implementation of dynamic programming
# prepare the solution in the specified output format
output_data = str(value) + " " + str(0) + "\n"
output_data += " ".join(map(str, taken))
return output_data, check_solution(capacity, items, taken)
# Aquí debe copiar el código implementado en la P2 para que sea invocado cuando la tabla de la programación dinámica se estime muy grande
def solve_with_greedy(items, capacity):
"""Copy here the implementation of greedy you did in P2"""
pass
# Aquí debe copiar el código implementado del sort de la P2
def sort(items, cmp):
"""Copy here the implementation of sort you did in P2"""
pass
# This function takes input data that describes a specific problem of TSP and solve it
def solve_it(input_data):
# parse the input
lines = input_data.split("\n")
firstLine = lines[0].split()
item_count = int(firstLine[0])
capacity = int(firstLine[1])
items = []
for i in range(1, item_count + 1):
line = lines[i]
parts = line.split()
items.append(Item(i - 1, int(parts[0]), int(parts[1])))
# Modify this code to adapt it to your solution. Currently
# tabulation is unconditionally invoked, and therefore it
# will fail with cases requiring a large table.
# In order to avoid that problem, add here code which helps
# deciding what approach must be taken (for example, depending
# on the number of elements of the table), and adjust the
# conditions of the following if-statement to choose what
# function must be dynamically invoked: tabulation,
# memoization or greedy.
if True:
return solve_with_dp_tabulation(items, capacity)
# elif True:
# return solve_with_dp_memoization(items, capacity)
else:
return solve_with_greedy(items, capacity)
# For each input file, solve_it is called and the result serialized in the ouputs for kaggle and moodle
str_output_kaggle = [["Filename", "Max_value"]]
str_output_moodle = [["Filename", "Max_value", "Solution"]]
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
full_name = dirname + "/" + filename
with open(full_name, "r") as input_data_file:
input_data = input_data_file.read()
output, value = solve_it(input_data)
str_output_kaggle.append([filename, str(value)])
str_output_moodle.append([filename, str(value), output.split("\n")[1]])
from IPython.display import FileLink
def submission_generation(filename, str_output):
os.chdir(r"/kaggle/working")
with open(filename, "w", newline="") as file:
writer = csv.writer(file)
for item in str_output:
writer.writerow(item)
return FileLink(filename)
submission_generation("NAME_P4_kaggle.csv", str_output_kaggle)
# The file generated by this method must be uploaded in the task of the "campus virtual". The file to upload in the "campus virtual" must be the one related to one submitted to Kaggle. That is, both submitted files must be generated in the same run
submission_generation("NAME_P4_moodle.csv", str_output_moodle)
| false | 0 | 1,909 | 0 | 6 | 1,909 |
||
45013469 | <kaggle_start><code># # 8 Puzzle Problem
# BMS College of Engineering - Dr Kavitha Sooda
# BMS College of Engineering - Dr Nagarathna N
# BMS College of Engineering - Prof G R Asha
# ##### Class 5C
# ## Objective
# Given a 3×3 board with 8 tiles and one empty space
# - Move the numbers around to match the final configuration using the empty spot
# - You can slide the numbers from above, below, left and right tiles into the empty space.
# 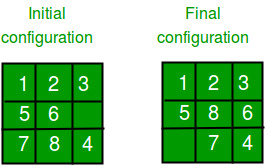
# # Use A* Algorithm
# 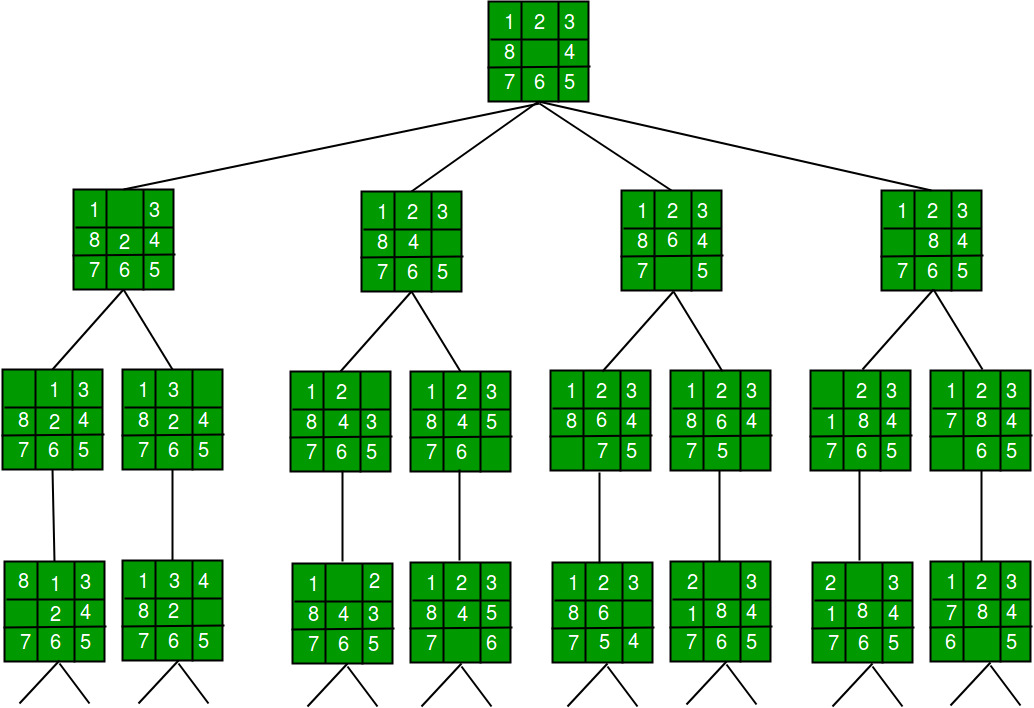
# ## 1. Create the function that finds us the total estimated cost of path through node n - F(n)
# - Create a way to find cost so far to reach node n - G(n)
# - Create a heuristic function to estimate cost from n to goal - H(n)
def G_n(state):
# Note: You can skip this step if you feel you have a better way of getting G(n)
pass
def H_n(state, target, g):
cost = 0
for i in state:
d1, d2 = state.index(i), target.index(i)
p, q = d1 % 3, d1 // 3
x, y = d2 % 3, d2 // 3
cost += abs(p - x) + abs(q - y)
return cost + g
def F_n(poss_moves, target, g): # Fill inputs as necessary
return [
sorted([(i, H_n(i, target, g)) for i in poss_moves], key=lambda x: x[1])[0][0]
]
# ## 2. Create a Search function
# ### To traverse across the tree using F(n) to select the next node
# 1. Make sure it to discard visited sites
# 2. Create possible moves function
# 3. Create move generator function
#
def astar(state, target): # Add inputs if more are required
visited_states = []
visited_states.append(src)
g = 0
arr = [src]
c = 0
while arr:
c += 1 # Calculate Number of Iterations # Print current state to check
if arr[0] == target: # break if target found
return True
arr += F_n(
possible_moves(arr[0], visited_states), target, g
) # else Add all possible moves to arr
visited_states.append(arr[0])
print("Level {} : {}".format(g, arr[0]))
arr.pop(0) # remove checked move from arr
g += 1
return False
def possible_moves(state, visited_states): # Add inputs if more are required
ind = state.index(-1)
d = []
if ind + 3 in range(9):
d.append("d")
if ind - 3 in range(9):
d.append("u")
if ind not in [0, 3, 6]:
d.append("l")
if ind not in [2, 5, 8]:
d.append("r")
pos_moves = []
for move in d:
pos_moves.append(gen(state, move, ind))
return [move for move in pos_moves if move not in visited_states]
def gen(state, direction, b):
temp = state.copy()
if direction == "d":
a = temp[b + 3]
temp[b + 3] = temp[b]
temp[b] = a
elif direction == "u":
a = temp[b - 3]
temp[b - 3] = temp[b]
temp[b] = a
elif direction == "l":
a = temp[b - 1]
temp[b - 1] = temp[b]
temp[b] = a
elif direction == "r":
a = temp[b + 1]
temp[b + 1] = temp[b]
temp[b] = a
return temp
# Test 1
src = [1, 2, 3, -1, 4, 5, 6, 7, 8]
target = [1, 2, 3, 4, 5, -1, 6, 7, 8]
astar(src, target)
# Test 2
src = [1, 2, 3, -1, 4, 5, 6, 7, 8]
target = [1, 2, 3, 6, 4, 5, -1, 7, 8]
astar(src, target)
# # Test 3
# src = [1,2,3,7,4,5,6,-1,8]
# target=[1,2,3,6,4,5,-1,7,8]
# astar(src, target)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0045/013/45013469.ipynb | null | null | [{"Id": 45013469, "ScriptId": 12365973, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 5817315, "CreationDate": "10/19/2020 05:15:12", "VersionNumber": 1.0, "Title": "AI - Lab Program 4", "EvaluationDate": "10/19/2020", "IsChange": true, "TotalLines": 121.0, "LinesInsertedFromPrevious": 63.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 58.0, "LinesInsertedFromFork": 63.0, "LinesDeletedFromFork": 14.0, "LinesChangedFromFork": 0.0, "LinesUnchangedFromFork": 58.0, "TotalVotes": 0}] | null | null | null | null | # # 8 Puzzle Problem
# BMS College of Engineering - Dr Kavitha Sooda
# BMS College of Engineering - Dr Nagarathna N
# BMS College of Engineering - Prof G R Asha
# ##### Class 5C
# ## Objective
# Given a 3×3 board with 8 tiles and one empty space
# - Move the numbers around to match the final configuration using the empty spot
# - You can slide the numbers from above, below, left and right tiles into the empty space.
# 
# # Use A* Algorithm
# 
# ## 1. Create the function that finds us the total estimated cost of path through node n - F(n)
# - Create a way to find cost so far to reach node n - G(n)
# - Create a heuristic function to estimate cost from n to goal - H(n)
def G_n(state):
# Note: You can skip this step if you feel you have a better way of getting G(n)
pass
def H_n(state, target, g):
cost = 0
for i in state:
d1, d2 = state.index(i), target.index(i)
p, q = d1 % 3, d1 // 3
x, y = d2 % 3, d2 // 3
cost += abs(p - x) + abs(q - y)
return cost + g
def F_n(poss_moves, target, g): # Fill inputs as necessary
return [
sorted([(i, H_n(i, target, g)) for i in poss_moves], key=lambda x: x[1])[0][0]
]
# ## 2. Create a Search function
# ### To traverse across the tree using F(n) to select the next node
# 1. Make sure it to discard visited sites
# 2. Create possible moves function
# 3. Create move generator function
#
def astar(state, target): # Add inputs if more are required
visited_states = []
visited_states.append(src)
g = 0
arr = [src]
c = 0
while arr:
c += 1 # Calculate Number of Iterations # Print current state to check
if arr[0] == target: # break if target found
return True
arr += F_n(
possible_moves(arr[0], visited_states), target, g
) # else Add all possible moves to arr
visited_states.append(arr[0])
print("Level {} : {}".format(g, arr[0]))
arr.pop(0) # remove checked move from arr
g += 1
return False
def possible_moves(state, visited_states): # Add inputs if more are required
ind = state.index(-1)
d = []
if ind + 3 in range(9):
d.append("d")
if ind - 3 in range(9):
d.append("u")
if ind not in [0, 3, 6]:
d.append("l")
if ind not in [2, 5, 8]:
d.append("r")
pos_moves = []
for move in d:
pos_moves.append(gen(state, move, ind))
return [move for move in pos_moves if move not in visited_states]
def gen(state, direction, b):
temp = state.copy()
if direction == "d":
a = temp[b + 3]
temp[b + 3] = temp[b]
temp[b] = a
elif direction == "u":
a = temp[b - 3]
temp[b - 3] = temp[b]
temp[b] = a
elif direction == "l":
a = temp[b - 1]
temp[b - 1] = temp[b]
temp[b] = a
elif direction == "r":
a = temp[b + 1]
temp[b + 1] = temp[b]
temp[b] = a
return temp
# Test 1
src = [1, 2, 3, -1, 4, 5, 6, 7, 8]
target = [1, 2, 3, 4, 5, -1, 6, 7, 8]
astar(src, target)
# Test 2
src = [1, 2, 3, -1, 4, 5, 6, 7, 8]
target = [1, 2, 3, 6, 4, 5, -1, 7, 8]
astar(src, target)
# # Test 3
# src = [1,2,3,7,4,5,6,-1,8]
# target=[1,2,3,6,4,5,-1,7,8]
# astar(src, target)
| false | 0 | 1,199 | 0 | 6 | 1,199 |
||
32923749 | <kaggle_start><data_title>densenet121_256<data_name>densenet121-256
<code>import os
import math
import openslide
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import albumentations
from tqdm import tqdm
from joblib import Parallel, delayed
from matplotlib import pyplot as plt
from PIL import Image, ImageChops
import cv2
import torch
import torch.utils.data as data_utils
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from torch.optim import lr_scheduler
from torch import nn
from torchvision import transforms, models
import torch.nn.functional as F
from tqdm.auto import tqdm
from torch import Tensor
from collections import OrderedDict
BASE_DIR = "/kaggle/input/prostate-cancer-grade-assessment"
# DATA_DIR = os.path.join(BASE_DIR, 'train_images')
DATA_DIR = os.path.join(BASE_DIR, "test_images")
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# test_df = pd.read_csv(os.path.join(BASE_DIR, 'train.csv'))[['image_id', 'data_provider']].loc[:1]
# test_df
test_df = pd.read_csv(os.path.join(BASE_DIR, "test.csv"))
sample_sub_df = pd.read_csv(os.path.join(BASE_DIR, "sample_submission.csv"))
org_test_df = test_df.copy()
org_test_df
crop_size = 256 # Size of resultant images
crop_level = 2 # The level of slide used to get the images (you can use 0 to get very high resolution images)
down_samples = [1, 4, 16] # List of down samples available in any tiff image file
def split_image(openslide_image):
"""
Splits the given image into multiple images if 256x256
"""
# Get the size of the given image
width, height = openslide_image.level_dimensions[crop_level]
# Get the dimensions of level 0 resolution, as it's required in "read_region()" function
base_height = down_samples[crop_level] * height # height of level 0
base_width = down_samples[crop_level] * width # width of level 0
# Get the number of smaller images
h_crops = math.ceil(width / crop_size)
v_crops = math.ceil(height / crop_size)
splits = []
for v in range(v_crops):
for h in range(h_crops):
x_location = h * crop_size * down_samples[crop_level]
y_location = v * crop_size * down_samples[crop_level]
patch = openslide_image.read_region(
(x_location, y_location), crop_level, (crop_size, crop_size)
)
splits.append(patch)
return splits, h_crops, v_crops
def get_emptiness(arr):
total_ele = arr.size
white_ele = np.count_nonzero(arr == 255) + np.count_nonzero(arr == 0)
return white_ele / total_ele
ignore_threshold = (
0.95 # If the image is more than 95% empty, consider it as white and ignore
)
def filter_white_images(images):
non_empty_crops = []
for image in images:
image_arr = np.array(image)[..., :3] # Discard the alpha channel
emptiness = get_emptiness(image_arr)
if emptiness < ignore_threshold:
non_empty_crops.append(image)
return non_empty_crops
dataset = []
def create_dataset(count):
img = os.path.join(DATA_DIR, f'{test_df["image_id"].iloc[count]}.tiff')
img = openslide.OpenSlide(img)
crops, _, _ = split_image(img)
img.close()
non_empty_crops = filter_white_images(crops)
image_id = test_df["image_id"].iloc[count]
for index, img in enumerate(non_empty_crops):
img_metadata = {}
img = img.convert("RGB")
img_metadata["image_id"] = f"{image_id}_{index}"
img_metadata["data_provider"] = test_df["data_provider"].iloc[count]
img_metadata["group"] = count
img.save(
f"{image_id}_{index}.jpg",
"JPEG",
quality=100,
optimize=True,
progressive=True,
)
dataset.append(img_metadata)
return dataset
if os.path.exists(DATA_DIR):
dataset = Parallel(n_jobs=8)(
delayed(create_dataset)(count) for count in tqdm(range(len(test_df)))
)
dataset = [item for sublist in dataset for item in sublist]
dataset = pd.DataFrame(dataset)
dataset.to_csv("new_test.csv", index=False)
test_df = pd.read_csv("new_test.csv")
class _Transition(nn.Sequential):
def __init__(self, num_input_features, num_output_features):
super(_Transition, self).__init__()
self.add_module("norm", nn.BatchNorm2d(num_input_features))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module(
"conv",
nn.Conv2d(
num_input_features,
num_output_features,
kernel_size=1,
stride=1,
bias=False,
),
)
self.add_module("pool", nn.AvgPool2d(kernel_size=2, stride=2))
class _DenseLayer(nn.Module):
def __init__(
self,
num_input_features,
growth_rate,
bn_size,
drop_rate,
memory_efficient=False,
):
super(_DenseLayer, self).__init__()
self.add_module("norm1", nn.BatchNorm2d(num_input_features)),
self.add_module("relu1", nn.ReLU(inplace=True)),
self.add_module(
"conv1",
nn.Conv2d(
num_input_features,
bn_size * growth_rate,
kernel_size=1,
stride=1,
bias=False,
),
),
self.add_module("norm2", nn.BatchNorm2d(bn_size * growth_rate)),
self.add_module("relu2", nn.ReLU(inplace=True)),
self.add_module(
"conv2",
nn.Conv2d(
bn_size * growth_rate,
growth_rate,
kernel_size=3,
stride=1,
padding=1,
bias=False,
),
),
self.drop_rate = float(drop_rate)
self.memory_efficient = memory_efficient
def bn_function(self, inputs):
# type: (List[Tensor]) -> Tensor
concated_features = torch.cat(inputs, 1)
bottleneck_output = self.conv1(
self.relu1(self.norm1(concated_features))
) # noqa: T484
return bottleneck_output
# todo: rewrite when torchscript supports any
def any_requires_grad(self, input):
# type: (List[Tensor]) -> bool
for tensor in input:
if tensor.requires_grad:
return True
return False
@torch.jit.unused # noqa: T484
def call_checkpoint_bottleneck(self, input):
# type: (List[Tensor]) -> Tensor
def closure(*inputs):
return self.bn_function(*inputs)
return cp.checkpoint(closure, input)
@torch.jit._overload_method # noqa: F811
def forward(self, input):
# type: (List[Tensor]) -> (Tensor)
pass
@torch.jit._overload_method # noqa: F811
def forward(self, input):
# type: (Tensor) -> (Tensor)
pass
# torchscript does not yet support *args, so we overload method
# allowing it to take either a List[Tensor] or single Tensor
def forward(self, input): # noqa: F811
if isinstance(input, Tensor):
prev_features = [input]
else:
prev_features = input
if self.memory_efficient and self.any_requires_grad(prev_features):
if torch.jit.is_scripting():
raise Exception("Memory Efficient not supported in JIT")
bottleneck_output = self.call_checkpoint_bottleneck(prev_features)
else:
bottleneck_output = self.bn_function(prev_features)
new_features = self.conv2(self.relu2(self.norm2(bottleneck_output)))
if self.drop_rate > 0:
new_features = F.dropout(
new_features, p=self.drop_rate, training=self.training
)
return new_features
class _DenseBlock(nn.ModuleDict):
_version = 2
def __init__(
self,
num_layers,
num_input_features,
bn_size,
growth_rate,
drop_rate,
memory_efficient=False,
):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(
num_input_features + i * growth_rate,
growth_rate=growth_rate,
bn_size=bn_size,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.add_module("denselayer%d" % (i + 1), layer)
def forward(self, init_features):
features = [init_features]
for name, layer in self.items():
new_features = layer(features)
features.append(new_features)
return torch.cat(features, 1)
class DenseNet(nn.Module):
r"""Densenet-BC model class, based on
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
growth_rate (int) - how many filters to add each layer (`k` in paper)
block_config (list of 4 ints) - how many layers in each pooling block
num_init_features (int) - the number of filters to learn in the first convolution layer
bn_size (int) - multiplicative factor for number of bottle neck layers
(i.e. bn_size * k features in the bottleneck layer)
drop_rate (float) - dropout rate after each dense layer
num_classes (int) - number of classification classes
memory_efficient (bool) - If True, uses checkpointing. Much more memory efficient,
but slower. Default: *False*. See `"paper" <https://arxiv.org/pdf/1707.06990.pdf>`_
"""
__constants__ = ["features"]
def __init__(
self,
growth_rate=32,
block_config=(6, 12, 24, 16),
num_init_features=64,
bn_size=4,
drop_rate=0,
num_classes=1000,
memory_efficient=False,
):
super(DenseNet, self).__init__()
# First convolution
self.features = nn.Sequential(
OrderedDict(
[
(
"conv0",
nn.Conv2d(
3,
num_init_features,
kernel_size=7,
stride=2,
padding=3,
bias=False,
),
), # 3 is number of channels in input image
("norm0", nn.BatchNorm2d(num_init_features)),
("relu0", nn.ReLU(inplace=True)),
("pool0", nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),
]
)
)
# Each denseblock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(
num_layers=num_layers,
num_input_features=num_features,
bn_size=bn_size,
growth_rate=growth_rate,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.features.add_module("denseblock%d" % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
trans = _Transition(
num_input_features=num_features,
num_output_features=num_features // 2,
)
self.features.add_module("transition%d" % (i + 1), trans)
num_features = num_features // 2
# Final batch norm
self.features.add_module("norm5", nn.BatchNorm2d(num_features))
# Linear layer
self.classifier = nn.Linear(num_features, num_classes)
# Official init from torch repo.
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
def _densenet(growth_rate, block_config, num_init_features, **kwargs):
return DenseNet(growth_rate, block_config, num_init_features, **kwargs)
def densenet121(**kwargs):
r"""Densenet-121 model from
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
"""
return _densenet(32, (6, 12, 24, 16), 64, **kwargs)
class DenseNet121Wrapper(nn.Module):
def __init__(self):
super(DenseNet121Wrapper, self).__init__()
# Load imagenet pre-trained model
self.dense_net = densenet121()
# Appdend output layers based on our date
self.out = nn.Linear(in_features=1000, out_features=6)
def forward(self, X):
output = self.dense_net(X)
output = self.out(output)
return output
model = DenseNet121Wrapper()
model = nn.DataParallel(model)
model.load_state_dict(
torch.load("/kaggle/input/densenet121-256/densenet121_256.pth", map_location=DEVICE)
)
model.eval()
WORKING_DIR = os.path.join("/", "kaggle", "working")
class PandaDataset(Dataset):
"""Custom dataset for PANDA Tests"""
def __init__(self, df, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
self.df = df
self.aug = albumentations.Compose(
[
albumentations.ShiftScaleRotate(
shift_limit=0.0625, scale_limit=0.15, rotate_limit=10, p=0.9
),
albumentations.HorizontalFlip(p=0.5),
albumentations.VerticalFlip(p=0.5),
]
)
def __len__(self):
return len(self.df)
def __getitem__(self, index):
image_id = self.df.loc[index]["image_id"]
image = cv2.imread(os.path.join(WORKING_DIR, f"{image_id}.jpg"))
image = self.aug(image=image)["image"]
# Convert from NHWC to NCHW as pytorch expects images in NCHW format
image = np.transpose(image, (2, 0, 1))
# For now, just return image and ISUP grades
return image
BATCH_SIZE = 16
def inference(model, test_loader, device):
preds = []
for i, images in tqdm(enumerate(test_loader)):
images = images.to(device, dtype=torch.float)
with torch.no_grad():
y_preds = model(images)
preds.append(y_preds.to("cpu").numpy().argmax(1))
preds = np.concatenate(preds)
return preds
def submit(sample):
global sample_sub_df
if os.path.exists(DATA_DIR):
test_dataset = PandaDataset(test_df)
test_loader = data_utils.DataLoader(
test_dataset, batch_size=BATCH_SIZE, shuffle=False
)
preds = inference(model, test_loader, DEVICE)
test_df["preds"] = preds
sample = sample.drop(["data_provider"], axis=1)
sample["isup_grade"] = test_df.groupby("group")["preds"].agg(
lambda x: x.value_counts().index[0]
)
return sample
return sample_sub_df
submission = submit(org_test_df)
submission["isup_grade"] = submission["isup_grade"].astype(int)
submission.head()
submission.to_csv("submission.csv", index=False)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0032/923/32923749.ipynb | densenet121-256 | kaushal2896 | [{"Id": 32923749, "ScriptId": 9153730, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 1905996, "CreationDate": "04/29/2020 10:12:59", "VersionNumber": 13.0, "Title": "PANDA: DenseNet121 Inference", "EvaluationDate": "04/29/2020", "IsChange": true, "TotalLines": 391.0, "LinesInsertedFromPrevious": 3.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 388.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 35791690, "KernelVersionId": 32923749, "SourceDatasetVersionId": 1117024}] | [{"Id": 1117024, "DatasetId": 625369, "DatasourceVersionId": 1147361, "CreatorUserId": 1905996, "LicenseName": "Unknown", "CreationDate": "04/29/2020 09:31:01", "VersionNumber": 3.0, "Title": "densenet121_256", "Slug": "densenet121-256", "Subtitle": NaN, "Description": NaN, "VersionNotes": "v3", "TotalCompressedBytes": 0.0, "TotalUncompressedBytes": 0.0}] | [{"Id": 625369, "CreatorUserId": 1905996, "OwnerUserId": 1905996.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 1121883.0, "CurrentDatasourceVersionId": 1152271.0, "ForumId": 639561, "Type": 2, "CreationDate": "04/28/2020 12:06:07", "LastActivityDate": "04/28/2020", "TotalViews": 1439, "TotalDownloads": 4, "TotalVotes": 1, "TotalKernels": 1}] | [{"Id": 1905996, "UserName": "kaushal2896", "DisplayName": "Kaushal Shah", "RegisterDate": "05/12/2018", "PerformanceTier": 2}] | import os
import math
import openslide
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import albumentations
from tqdm import tqdm
from joblib import Parallel, delayed
from matplotlib import pyplot as plt
from PIL import Image, ImageChops
import cv2
import torch
import torch.utils.data as data_utils
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from torch.optim import lr_scheduler
from torch import nn
from torchvision import transforms, models
import torch.nn.functional as F
from tqdm.auto import tqdm
from torch import Tensor
from collections import OrderedDict
BASE_DIR = "/kaggle/input/prostate-cancer-grade-assessment"
# DATA_DIR = os.path.join(BASE_DIR, 'train_images')
DATA_DIR = os.path.join(BASE_DIR, "test_images")
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# test_df = pd.read_csv(os.path.join(BASE_DIR, 'train.csv'))[['image_id', 'data_provider']].loc[:1]
# test_df
test_df = pd.read_csv(os.path.join(BASE_DIR, "test.csv"))
sample_sub_df = pd.read_csv(os.path.join(BASE_DIR, "sample_submission.csv"))
org_test_df = test_df.copy()
org_test_df
crop_size = 256 # Size of resultant images
crop_level = 2 # The level of slide used to get the images (you can use 0 to get very high resolution images)
down_samples = [1, 4, 16] # List of down samples available in any tiff image file
def split_image(openslide_image):
"""
Splits the given image into multiple images if 256x256
"""
# Get the size of the given image
width, height = openslide_image.level_dimensions[crop_level]
# Get the dimensions of level 0 resolution, as it's required in "read_region()" function
base_height = down_samples[crop_level] * height # height of level 0
base_width = down_samples[crop_level] * width # width of level 0
# Get the number of smaller images
h_crops = math.ceil(width / crop_size)
v_crops = math.ceil(height / crop_size)
splits = []
for v in range(v_crops):
for h in range(h_crops):
x_location = h * crop_size * down_samples[crop_level]
y_location = v * crop_size * down_samples[crop_level]
patch = openslide_image.read_region(
(x_location, y_location), crop_level, (crop_size, crop_size)
)
splits.append(patch)
return splits, h_crops, v_crops
def get_emptiness(arr):
total_ele = arr.size
white_ele = np.count_nonzero(arr == 255) + np.count_nonzero(arr == 0)
return white_ele / total_ele
ignore_threshold = (
0.95 # If the image is more than 95% empty, consider it as white and ignore
)
def filter_white_images(images):
non_empty_crops = []
for image in images:
image_arr = np.array(image)[..., :3] # Discard the alpha channel
emptiness = get_emptiness(image_arr)
if emptiness < ignore_threshold:
non_empty_crops.append(image)
return non_empty_crops
dataset = []
def create_dataset(count):
img = os.path.join(DATA_DIR, f'{test_df["image_id"].iloc[count]}.tiff')
img = openslide.OpenSlide(img)
crops, _, _ = split_image(img)
img.close()
non_empty_crops = filter_white_images(crops)
image_id = test_df["image_id"].iloc[count]
for index, img in enumerate(non_empty_crops):
img_metadata = {}
img = img.convert("RGB")
img_metadata["image_id"] = f"{image_id}_{index}"
img_metadata["data_provider"] = test_df["data_provider"].iloc[count]
img_metadata["group"] = count
img.save(
f"{image_id}_{index}.jpg",
"JPEG",
quality=100,
optimize=True,
progressive=True,
)
dataset.append(img_metadata)
return dataset
if os.path.exists(DATA_DIR):
dataset = Parallel(n_jobs=8)(
delayed(create_dataset)(count) for count in tqdm(range(len(test_df)))
)
dataset = [item for sublist in dataset for item in sublist]
dataset = pd.DataFrame(dataset)
dataset.to_csv("new_test.csv", index=False)
test_df = pd.read_csv("new_test.csv")
class _Transition(nn.Sequential):
def __init__(self, num_input_features, num_output_features):
super(_Transition, self).__init__()
self.add_module("norm", nn.BatchNorm2d(num_input_features))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module(
"conv",
nn.Conv2d(
num_input_features,
num_output_features,
kernel_size=1,
stride=1,
bias=False,
),
)
self.add_module("pool", nn.AvgPool2d(kernel_size=2, stride=2))
class _DenseLayer(nn.Module):
def __init__(
self,
num_input_features,
growth_rate,
bn_size,
drop_rate,
memory_efficient=False,
):
super(_DenseLayer, self).__init__()
self.add_module("norm1", nn.BatchNorm2d(num_input_features)),
self.add_module("relu1", nn.ReLU(inplace=True)),
self.add_module(
"conv1",
nn.Conv2d(
num_input_features,
bn_size * growth_rate,
kernel_size=1,
stride=1,
bias=False,
),
),
self.add_module("norm2", nn.BatchNorm2d(bn_size * growth_rate)),
self.add_module("relu2", nn.ReLU(inplace=True)),
self.add_module(
"conv2",
nn.Conv2d(
bn_size * growth_rate,
growth_rate,
kernel_size=3,
stride=1,
padding=1,
bias=False,
),
),
self.drop_rate = float(drop_rate)
self.memory_efficient = memory_efficient
def bn_function(self, inputs):
# type: (List[Tensor]) -> Tensor
concated_features = torch.cat(inputs, 1)
bottleneck_output = self.conv1(
self.relu1(self.norm1(concated_features))
) # noqa: T484
return bottleneck_output
# todo: rewrite when torchscript supports any
def any_requires_grad(self, input):
# type: (List[Tensor]) -> bool
for tensor in input:
if tensor.requires_grad:
return True
return False
@torch.jit.unused # noqa: T484
def call_checkpoint_bottleneck(self, input):
# type: (List[Tensor]) -> Tensor
def closure(*inputs):
return self.bn_function(*inputs)
return cp.checkpoint(closure, input)
@torch.jit._overload_method # noqa: F811
def forward(self, input):
# type: (List[Tensor]) -> (Tensor)
pass
@torch.jit._overload_method # noqa: F811
def forward(self, input):
# type: (Tensor) -> (Tensor)
pass
# torchscript does not yet support *args, so we overload method
# allowing it to take either a List[Tensor] or single Tensor
def forward(self, input): # noqa: F811
if isinstance(input, Tensor):
prev_features = [input]
else:
prev_features = input
if self.memory_efficient and self.any_requires_grad(prev_features):
if torch.jit.is_scripting():
raise Exception("Memory Efficient not supported in JIT")
bottleneck_output = self.call_checkpoint_bottleneck(prev_features)
else:
bottleneck_output = self.bn_function(prev_features)
new_features = self.conv2(self.relu2(self.norm2(bottleneck_output)))
if self.drop_rate > 0:
new_features = F.dropout(
new_features, p=self.drop_rate, training=self.training
)
return new_features
class _DenseBlock(nn.ModuleDict):
_version = 2
def __init__(
self,
num_layers,
num_input_features,
bn_size,
growth_rate,
drop_rate,
memory_efficient=False,
):
super(_DenseBlock, self).__init__()
for i in range(num_layers):
layer = _DenseLayer(
num_input_features + i * growth_rate,
growth_rate=growth_rate,
bn_size=bn_size,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.add_module("denselayer%d" % (i + 1), layer)
def forward(self, init_features):
features = [init_features]
for name, layer in self.items():
new_features = layer(features)
features.append(new_features)
return torch.cat(features, 1)
class DenseNet(nn.Module):
r"""Densenet-BC model class, based on
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
Args:
growth_rate (int) - how many filters to add each layer (`k` in paper)
block_config (list of 4 ints) - how many layers in each pooling block
num_init_features (int) - the number of filters to learn in the first convolution layer
bn_size (int) - multiplicative factor for number of bottle neck layers
(i.e. bn_size * k features in the bottleneck layer)
drop_rate (float) - dropout rate after each dense layer
num_classes (int) - number of classification classes
memory_efficient (bool) - If True, uses checkpointing. Much more memory efficient,
but slower. Default: *False*. See `"paper" <https://arxiv.org/pdf/1707.06990.pdf>`_
"""
__constants__ = ["features"]
def __init__(
self,
growth_rate=32,
block_config=(6, 12, 24, 16),
num_init_features=64,
bn_size=4,
drop_rate=0,
num_classes=1000,
memory_efficient=False,
):
super(DenseNet, self).__init__()
# First convolution
self.features = nn.Sequential(
OrderedDict(
[
(
"conv0",
nn.Conv2d(
3,
num_init_features,
kernel_size=7,
stride=2,
padding=3,
bias=False,
),
), # 3 is number of channels in input image
("norm0", nn.BatchNorm2d(num_init_features)),
("relu0", nn.ReLU(inplace=True)),
("pool0", nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),
]
)
)
# Each denseblock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(
num_layers=num_layers,
num_input_features=num_features,
bn_size=bn_size,
growth_rate=growth_rate,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.features.add_module("denseblock%d" % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
trans = _Transition(
num_input_features=num_features,
num_output_features=num_features // 2,
)
self.features.add_module("transition%d" % (i + 1), trans)
num_features = num_features // 2
# Final batch norm
self.features.add_module("norm5", nn.BatchNorm2d(num_features))
# Linear layer
self.classifier = nn.Linear(num_features, num_classes)
# Official init from torch repo.
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
def _densenet(growth_rate, block_config, num_init_features, **kwargs):
return DenseNet(growth_rate, block_config, num_init_features, **kwargs)
def densenet121(**kwargs):
r"""Densenet-121 model from
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_
"""
return _densenet(32, (6, 12, 24, 16), 64, **kwargs)
class DenseNet121Wrapper(nn.Module):
def __init__(self):
super(DenseNet121Wrapper, self).__init__()
# Load imagenet pre-trained model
self.dense_net = densenet121()
# Appdend output layers based on our date
self.out = nn.Linear(in_features=1000, out_features=6)
def forward(self, X):
output = self.dense_net(X)
output = self.out(output)
return output
model = DenseNet121Wrapper()
model = nn.DataParallel(model)
model.load_state_dict(
torch.load("/kaggle/input/densenet121-256/densenet121_256.pth", map_location=DEVICE)
)
model.eval()
WORKING_DIR = os.path.join("/", "kaggle", "working")
class PandaDataset(Dataset):
"""Custom dataset for PANDA Tests"""
def __init__(self, df, mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)):
self.df = df
self.aug = albumentations.Compose(
[
albumentations.ShiftScaleRotate(
shift_limit=0.0625, scale_limit=0.15, rotate_limit=10, p=0.9
),
albumentations.HorizontalFlip(p=0.5),
albumentations.VerticalFlip(p=0.5),
]
)
def __len__(self):
return len(self.df)
def __getitem__(self, index):
image_id = self.df.loc[index]["image_id"]
image = cv2.imread(os.path.join(WORKING_DIR, f"{image_id}.jpg"))
image = self.aug(image=image)["image"]
# Convert from NHWC to NCHW as pytorch expects images in NCHW format
image = np.transpose(image, (2, 0, 1))
# For now, just return image and ISUP grades
return image
BATCH_SIZE = 16
def inference(model, test_loader, device):
preds = []
for i, images in tqdm(enumerate(test_loader)):
images = images.to(device, dtype=torch.float)
with torch.no_grad():
y_preds = model(images)
preds.append(y_preds.to("cpu").numpy().argmax(1))
preds = np.concatenate(preds)
return preds
def submit(sample):
global sample_sub_df
if os.path.exists(DATA_DIR):
test_dataset = PandaDataset(test_df)
test_loader = data_utils.DataLoader(
test_dataset, batch_size=BATCH_SIZE, shuffle=False
)
preds = inference(model, test_loader, DEVICE)
test_df["preds"] = preds
sample = sample.drop(["data_provider"], axis=1)
sample["isup_grade"] = test_df.groupby("group")["preds"].agg(
lambda x: x.value_counts().index[0]
)
return sample
return sample_sub_df
submission = submit(org_test_df)
submission["isup_grade"] = submission["isup_grade"].astype(int)
submission.head()
submission.to_csv("submission.csv", index=False)
| false | 0 | 4,297 | 0 | 34 | 4,297 |
||
32853136 | <kaggle_start><data_title>MNIST Dataset<data_description>### Context
MNIST is a subset of a larger set available from NIST (it's copied from http://yann.lecun.com/exdb/mnist/)
### Content
The MNIST database of handwritten digits has a training set of 60,000 examples, and a test set of 10,000 examples. .
Four files are available:
- train-images-idx3-ubyte.gz: training set images (9912422 bytes)
- train-labels-idx1-ubyte.gz: training set labels (28881 bytes)
- t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
- t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
### How to read
See [sample MNIST reader][1]<data_name>mnist-dataset
<code># 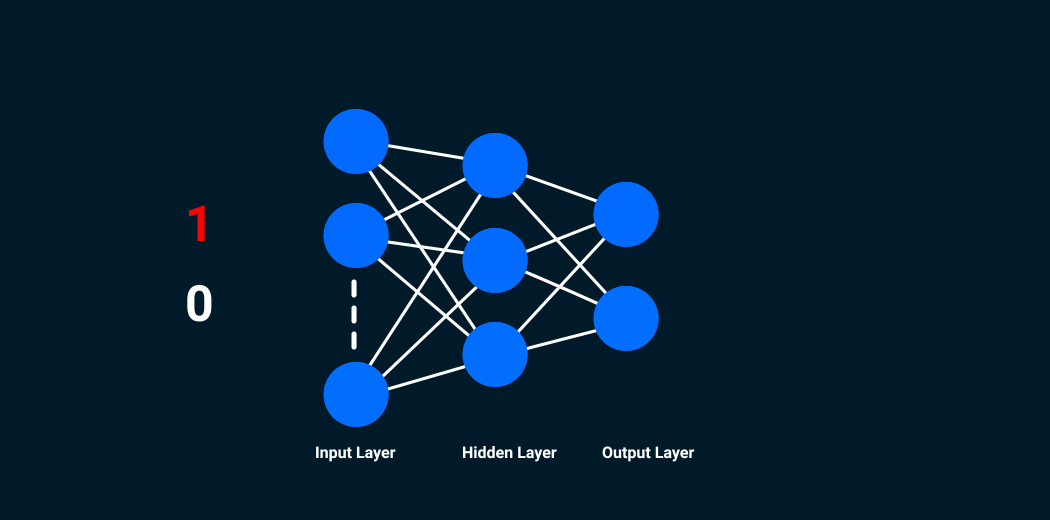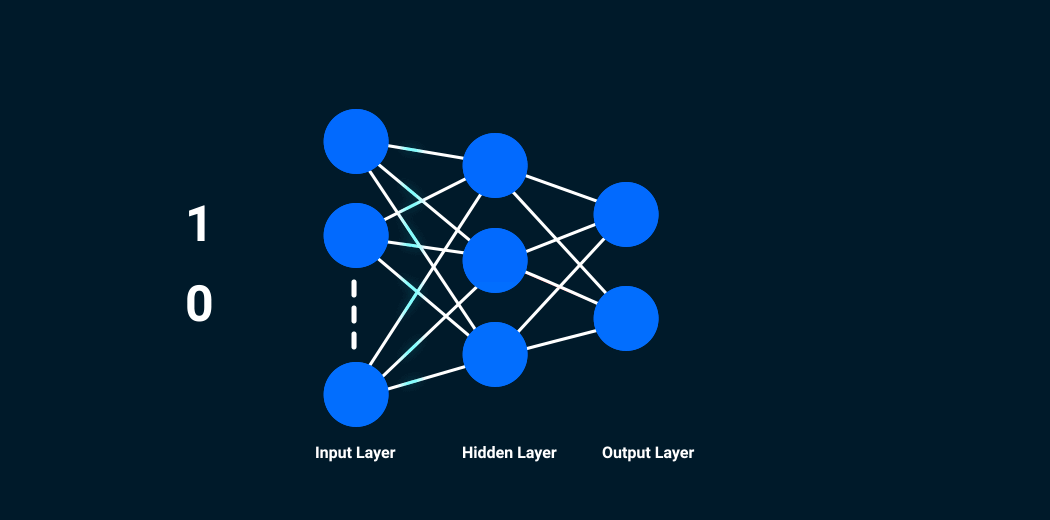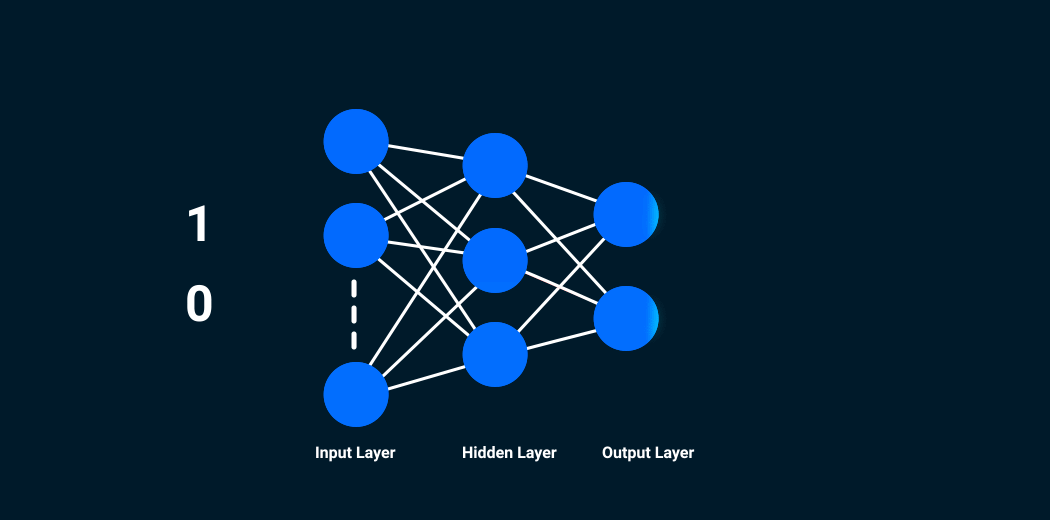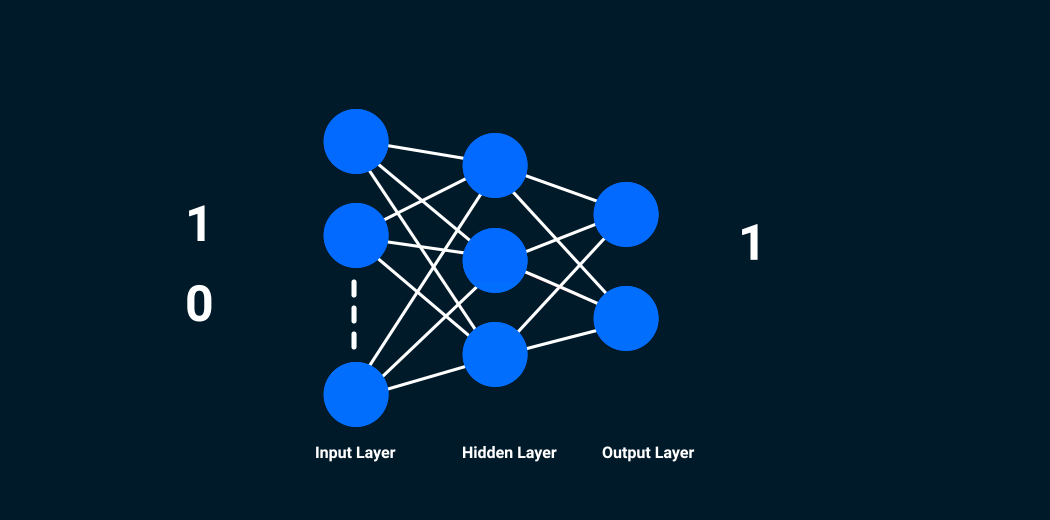
# # Setup
# Import Libraries
import numpy as np
import math
import matplotlib.pyplot as plt
import seaborn as sns
from pylab import rcParams
from preprocessing import *
from mathutils import *
sns.set(style="whitegrid")
rcParams["figure.figsize"] = 12, 6
RANDOM_SEED = 42
np.random.seed(RANDOM_SEED)
# # Let us start by answering this key question: What is a neural network?
# It is a biologically-inspired method of building computer programs that are able to learn and independently find connections in data. As Figure shows, nets are a collection of software ‘neurons’ arranged in layers, connected together in a way that allows communication.
# # Single neuron
# Each neuron receives a set of x-values (numbered from 1 to n) as an input and compute the predicted y-hat value. Vector x actually contains the values of the features in one of m examples from the training set. What is more each of units has its own set of parameters, usually referred to as w (column vector of weights) and b (bias) which changes during the learning process. In each iteration, the neuron calculates a weighted average of the values of the vector x, based on its current weight vector w and adds bias. Finally, the result of this calculation is passed through a non-linear activation function g. I will mention a bit about the most popular activation functions in the following part of the article.
# 
# # Perceptrons
# invented by Frank Rosenblatt in 1957, are the simplest neural network that consist of n number of inputs, only one neuron and one output, where n is the number of features of our dataset. The process of passing the data through the neural network is know as forward propagation and the forward propagation carried out in a Perceptron is explained in the following three steps:
# Step 1 : For each input, multiply the input value xᵢ with weights wᵢ and sum all the multiplied values. Weights — represent the strength of the connection between neurons and decides how much influence the given input will have on the neuron’s output. If the weight w₁ has higher value than the weight w₂, then the input x₁ will have higher influence on the output than w₂.
# 
# The row vectors of the inputs and weights are x = [x₁, x₂, … , xₙ] and w =[w₁, w₂, … , wₙ] respectively and their dot product is given by
# 
# Hence, the summation is equal to the dot product of the vectors x and w
# 
# Step 2: Add bias b to the summation of multiplied values and let’s call this z. Bias — also know as offset is necessary in most of the cases, to move the entire activation function to the left or right to generate the required output values .
# 
# Step 3 : Pass the value of z to a non-linear activation function. Activation functions — are used to introduce non-linearity into the output of the neurons, without which the neural network will just be a linear function. Moreover, they have a significant impact on the learning speed of the neural network. Perceptrons have binary step function as their activation function. However, we shall use Sigmoid — also know as logistic function as our activation function.
# 
# where, σ denotes the Sigmoid activation function and the output we get after the forward prorogation is know as the predicted value ŷ.
# # Learning Algorithm
# The learning algorithm consist of two parts — Backpropagation and Optimization.
# Backpropagation : Backpropagation, short for backward propagation of errors, refers to the algorithm for computing the gradient of the loss function with respect to the weights. However, the term is often used to refer to the entire learning algorithm. The backpropagation carried out in a Perceptron is explained in the following two steps:
# **Step 1** : To know an estimation of how far are we from our desired solution a loss function is used. Generally, Mean Squared Error is chosen as loss function for regression problems and cross entropy for classification problems. Let’s take a regression problem and its loss function be Mean Squared Error, which squares the difference between actual (yᵢ) and predicted value ( ŷᵢ ).
# 
# Loss function is calculated for the entire training dataset and their average is called the Cost function C.
# 
# **Step 2** : In order to find the best weights and bias for our Perceptron, we need to know how the cost function changes in relation to weights and bias. This is done with the help the gradients (rate of change) — how one quantity changes in relation to another quantity. In our case, we need to find the gradient of the cost function with respect to the weights and bias.
# Let’s calculate the gradient of cost function C with respect to the weight wᵢ using partial derivation. Since the cost function is not directly related to the weight wᵢ, let’s use the chain rule.
# 
# Now we need to find the following three gradients
# 
# Let’s start with the gradient of the Cost function (C) with respect to the predicted value ( ŷ )
# 
# Let y = [y₁ , y₂ , … yₙ] and ŷ =[ ŷ₁ , ŷ₂ , … ŷₙ] be the row vectors of actual and predicted values. Hence the above equation is simplifies as
# 
# Now let’s find the the gradient of the predicted value with respect to the z. This will be a bit lengthy.
# 
# The gradient of z with respect to the weight wᵢ is
# 
# Therefore we get,
# 
# What about Bias? — Bias is theoretically considered to have an input of constant value 1. Hence,
# 
# # Optimization :
# Optimization is the selection of a best element from some set of available alternatives, which in our case, is the selection of best weights and bias of the perceptron. Let’s choose gradient descent as our optimization algorithm, which changes the weights and bias, proportional to the negative of the gradient of the Cost function with respect to the corresponding weight or bias. Learning rate (α) is a hyperparameter which is used to control how much the weights and bias are changed.
# The weights and bias are updated as follows and the Backporpagation and gradient descent is repeated until convergence.
# 
# # Single layer
# Now let’s zoom out a little and consider how calculations are performed for a whole layer of the neural network. We will use our knowledge of what is happening inside a single unit and vectorize across full layer to combine those calculations in into matrix equations. To unify the notation, the equations will be written for the selected layer. By the way, subscript i mark the index of a neuron in that layer.
# 
# # One more important remark:
# When we wrote the equations for a single unit, we used x and y-hat, which were respectively the column vector of features and the predicted value. When switching to the general notation for layer, we use the vector a — meaning the activation of the corresponding layer. The x vector is therefore the activation for layer 0 — input layer. Each neuron in the layer performs a similar calculation according to the following equations:
# 
# For the sake of clarity, let’s write down the equations for example for layer 2:
# 
# As you can see, for each of the layers we have to perform a number of very similar operations. Using for-loop for this purpose is not very efficient, so to speed up the calculation we will use vectorization. First of all, by stacking together horizontal vectors of weights w (transposed) we will build matrix W. Similarly, we will stack together bias of each neuron in the layer creating vertical vector b. Now there is nothing to stop us from building a single matrix equations that allows us to perform calculations for all the neurons of the layer at once. Let’s also write down the dimensions of the matrices and vectors we have used.
# 
# 
# 
# # Vectorizing across multiple examples
# The equation that we have drawn up so far involves only one example. During the learning process of a neural network, you usually work with huge sets of data, up to millions of entries. The next step will therefore be vectorisation across multiple examples. Let’s assume that our data set has m entries with nx features each. First of all, we will put together the vertical vectors x, a, and z of each layer creating the X, A and Z matrices, respectively. Then we rewrite the previously laid-out equation, taking into account the newly created matrices.
# 
# 
# # What is activation function and why do we need it?
# Activation functions are one of the key elements of the neural network. Without them, our neural network would become a combination of linear functions, so it would be just a linear function itself. Our model would have limited expansiveness, no greater than logistic regression. The non-linearity element allows for greater flexibility and creation of complex functions during the learning process. The activation function also has a significant impact on the speed of learning, which is one of the main criteria for their selection. Figure 6 shows some of the commonly used activation functions. Currently, the most popular one for hidden layers is probably ReLU. We still sometimes use sigmoid, especially in the output layer, when we are dealing with a binary classification and we want the values returned from the model to be in the range from 0 to 1.
# 
# # Sigmoid (and it’s derivative)
# The sigmoid function is used quite commonly in the realm of deep learning, at least it was until recently. It has distinct S shape and it is a differentiable real function for any real input value. Additionally, it has a positive derivative at each point. More importantly, we will use it as an activation function for the hidden layer of our model. Here’s how it is defined:
# 
# It’s first derivative (which we will use during the backpropagation step of our training algorithm) has the following formula:
# 
# So, the derivative can be expressed using the original sigmoid function. Pretty cool, right? Don’t like formulas? Let’s look at a picture:
# 
# The derivative shows us the rate of change of a function. We can use it to determine the “slope” of that function. The highest rate of change for the sigmoid function is when x=0x=0, as it is evident from the derivative graph (in green).
# # Softmax
# The softmax function can be easily differentiated, it is pure (output depends only on input) and the elements of the resulting vector sum to 1.
# Here it is:
# 
# In probability theory, the output of the softmax function is sometimes used as a representation of a categorical distribution. Let’s see an example result:
def softmax(x):
"""Compute softmax values for each sets of scores in x."""
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum()
softmax(np.array([[2, 4, 6, 8]]))
# The output has most of its weight corresponding to the input 8. The softmax function highlights the largest value(s) and suppresses the smaller ones.
# # Loss function
# The basic source of information on the progress of the learning process is the value of the loss function. Generally speaking, the loss function is designed to show how far we are from the ‘ideal’ solution. In our case we used binary crossentropy, but depending on the problem we are dealing with different functions can be applied. The function used by us is described by the following formula, and the change of its value during the learning process is visualised in the next Figure. It shows how with each iteration the value of the loss function decreases and accuracy increases.
# 
# 
# # How do neural networks learn?
# The learning process is about changing the values of the W and b parameters so that the loss function is minimized. In order to achieve this goal, we will turn for help to calculus and use gradient descent method to find a function minimum. In each iteration we will calculate the values of the loss function partial derivatives with respect to each of the parameters of our neural network. For those who are less familiar with this type of calculations, I will just mention that the derivative has a fantastic ability to describe the slope of the function. Thanks to that we know how to manipulate variables in order to move downhill in the graph. Aiming to form an intuition about how the gradient descent works (and stop you from falling asleep once again) I prepared a small visualization. You can see how with each successive epoch we are heading towards the minimum. In our NN it works in the same way — the gradient calculated on each iteration shows us the direction in which we should move. The main difference is that in our exemplary neural network, we have many more parameters to manipulate. Exactly… How to calculate such complex derivatives?
# 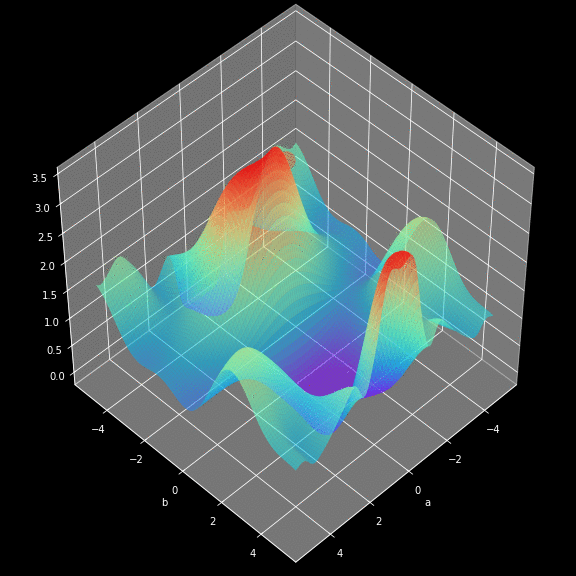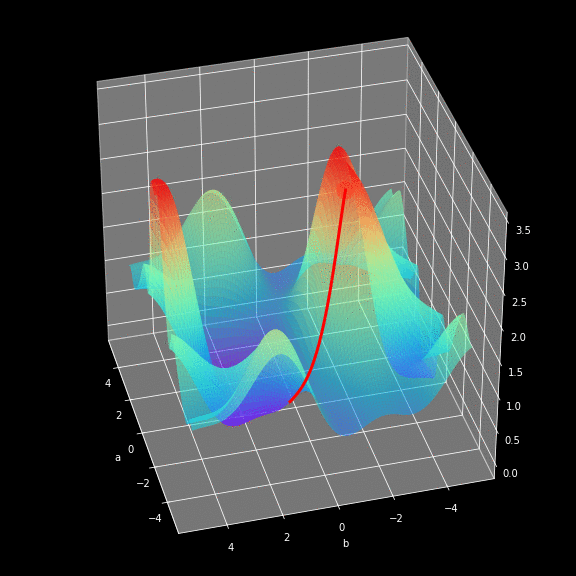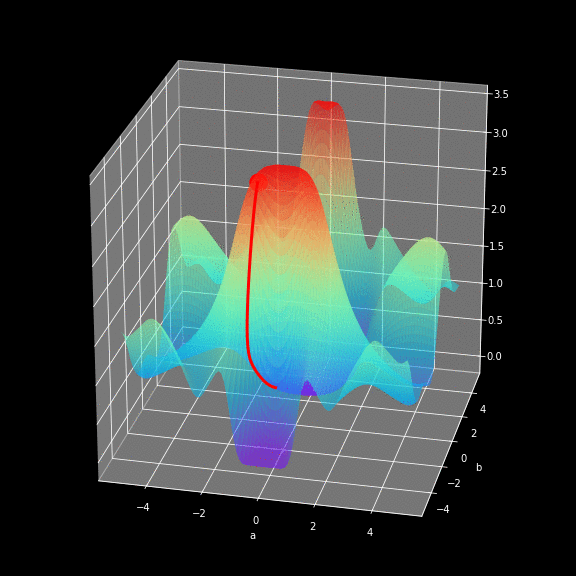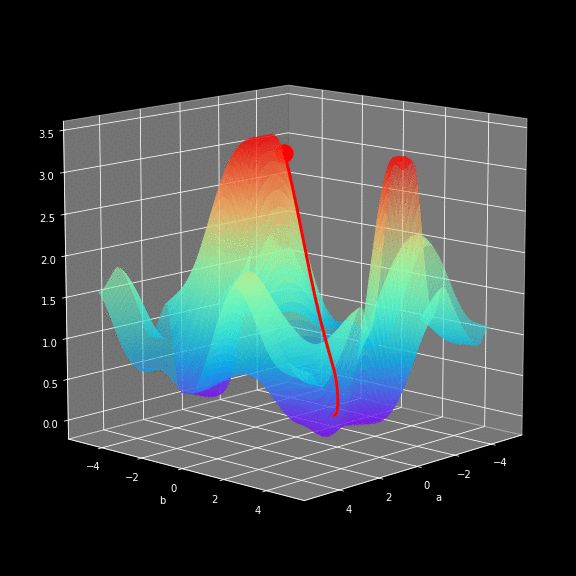
# # Backpropagation
# Backpropagation is an algorithm that allows us to calculate a very complicated gradient, like the one we need. The parameters of the neural network are adjusted according to the following formulae.
# 
# In the equations above, α represents learning rate - a hyperparameter which allows you to control the value of performed adjustment. Choosing a learning rate is crucial — we set it too low, our NN will be learning very slowly, we set it too high and we will not be able to hit the minimum. dW and db are calculated using the chain rule, partial derivatives of loss function with respect to W and b. The size of dW and db are the same as that of W and b respectively. The next figure shows the sequence of operations within the neural network. We see clearly how forward and backward propagation work together to optimize the loss function.
# 
# 
# Backpropagation is the backbone of almost anything we do when using Neural Networks. The algorithm consists of 3 subtasks:
# * Make a forward pass
# * Calculate the error
# * Make backward pass (backpropagation)
# In the first step, backprop uses the data and the weights of the network to compute a prediction. Next, the error is computed based on the prediction and the provided labels. The final step propagates the error through the network, starting from the final layer. Thus, the weights get updated based on the error, little by little.
# # We will try to create a Neural Network (NN) that can properly predict values from the XOR function.
# Here is its truth table:
# 
# visual representation:
# 
# Let's start by defining some parameters:
epochs = 60000 # Number of iterations
inputLayerSize, hiddenLayerSize, outputLayerSize = 2, 3, 1
LR = 0.1 # learning rate
# Our data
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([[0], [1], [1], [0]])
# Initialize the weights of our NN to random numbers :
# weights on layer inputs
w_hidden = np.random.uniform(size=(inputLayerSize, hiddenLayerSize))
w_output = np.random.uniform(size=(hiddenLayerSize, outputLayerSize))
# Finally, implementation of the Backprop algorithm:
def sigmoid(x):
return 1 / (1 + np.exp(-x)) # activation function
def sigmoid_prime(x):
return x * (1 - x) # derivative of sigmoid
for epoch in range(epochs):
# Forward
act_hidden = sigmoid(np.dot(X, w_hidden))
output = np.dot(act_hidden, w_output)
# Calculate error
error = y - output
if epoch % 5000 == 0:
print(f"error sum {sum(error)}")
# Backward
dZ = error * LR
w_output += act_hidden.T.dot(dZ)
dH = dZ.dot(w_output.T) * sigmoid_prime(act_hidden)
w_hidden += X.T.dot(dH)
# That error seems to be decreasing! Yay! And the implementation is not that scary, isn’t it? We just multiply the matrix containing our training data with the matrix of the weights of the hidden layer. Then, we apply the activation function (sigmoid) to the result and multiply that with the weight matrix of the output layer.
# The error is computed by doing simple subtraction. During the backpropagation step, we adjust the weight matrices using the already computed error and use the derivative of the sigmoid function.
# Let’s try to predict using our trained model (doing just the forward step):
X_test = X[1] # [0, 1]
act_hidden = sigmoid(np.dot(X_test, w_hidden))
np.round(np.dot(act_hidden, w_output))
# What is this sorcery? The prediction is correct! You can try some of the other input examples.
# # Building our own Neural Network Classifier
# The “hello world” dataset MNIST (“Modified National Institute of Standards and Technology”), released in 1999, contains images of handwritten digits. Our goal is to build a model that correctly identify digits from a dataset of tens of thousands of handwritten digits.
# We will build our own “vanilla” Neural Network classifier that learns from raw pixels using only Python and NumPy. Let’s start by reading the data:
from mlxtend.data import loadlocal_mnist
import pandas as pd
import os
import random
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# # Model
# Let’s define a class, called NNClassifier that does all the dirty work for us. We will implement a somewhat more sophisticated version of our training algorithm shown above along with some handy methods:
# # Loading data & Showing image:
from os.path import join
import struct
from array import array
class MnistDataloader(object):
def __init__(
self,
training_images_filepath,
training_labels_filepath,
test_images_filepath,
test_labels_filepath,
):
self.training_images_filepath = training_images_filepath
self.training_labels_filepath = training_labels_filepath
self.test_images_filepath = test_images_filepath
self.test_labels_filepath = test_labels_filepath
def read_images_labels(self, images_filepath, labels_filepath):
labels = []
with open(labels_filepath, "rb") as file:
magic, size = struct.unpack(">II", file.read(8))
if magic != 2049:
raise ValueError(
"Magic number mismatch, expected 2049, got {}".format(magic)
)
labels = array("B", file.read())
with open(images_filepath, "rb") as file:
magic, size, rows, cols = struct.unpack(">IIII", file.read(16))
if magic != 2051:
raise ValueError(
"Magic number mismatch, expected 2051, got {}".format(magic)
)
image_data = array("B", file.read())
images = []
for i in range(size):
images.append([0] * rows * cols)
for i in range(size):
img = np.array(image_data[i * rows * cols : (i + 1) * rows * cols])
img = img.reshape(28, 28)
images[i][:] = img
return images, labels
def load_data(self):
x_train, y_train = self.read_images_labels(
self.training_images_filepath, self.training_labels_filepath
)
x_test, y_test = self.read_images_labels(
self.test_images_filepath, self.test_labels_filepath
)
return (x_train, y_train), (x_test, y_test)
# Set file paths based on added MNIST Datasets
training_images_filepath = "/kaggle/input/mnist-dataset/train-images.idx3-ubyte"
training_labels_filepath = "/kaggle/input/mnist-dataset/train-labels.idx1-ubyte"
test_images_filepath = "/kaggle/input/mnist-dataset/t10k-images.idx3-ubyte"
test_labels_filepath = "/kaggle/input/mnist-dataset/t10k-labels.idx1-ubyte"
# Load MINST dataset
print("Loading MNIST dataset...")
mnist_dataloader = MnistDataloader(
training_images_filepath,
training_labels_filepath,
test_images_filepath,
test_labels_filepath,
)
(x_train, y_train), (x_test, y_test) = mnist_dataloader.load_data()
print("MNIST dataset loaded.")
# Show example images
def show_images(images, title_texts):
cols = 5
rows = int(len(images) / cols) + 1
plt.figure(figsize=(28, 28))
index = 1
for x in zip(images, title_texts):
image = x[0]
title_text = x[1]
plt.subplot(rows, cols, index)
plt.imshow(image, cmap=plt.cm.gray)
if title_text != "":
plt.title(title_text, fontsize=15)
index += 1
random_images = []
for i in range(0, 10):
r = random.randint(1, 60000)
random_images.append(
(x_train[r], "training image [" + str(r) + "] = " + str(y_train[r]))
)
for i in range(0, 5):
r = random.randint(1, 10000)
random_images.append((x_test[r], "test image [" + str(r) + "] = " + str(y_test[r])))
show_images(
list(map(lambda x: x[0], random_images)), list(map(lambda x: x[1], random_images))
)
# Building functions:
def softmax_crossentropy_with_logits(logits, reference_answers):
# Compute crossentropy from logits[batch,n_classes] and ids of correct answers
logits_for_answers = logits[np.arange(len(logits)), reference_answers]
xentropy = -logits_for_answers + np.log(np.sum(np.exp(logits), axis=-1))
return xentropy
def grad_softmax_crossentropy_with_logits(logits, reference_answers):
# Compute crossentropy gradient from logits[batch,n_classes] and ids of correct answers
ones_for_answers = np.zeros_like(logits)
ones_for_answers[np.arange(len(logits)), reference_answers] = 1
softmax = np.exp(logits) / np.exp(logits).sum(axis=-1, keepdims=True)
return (-ones_for_answers + softmax) / logits.shape[0]
# A building block. Each layer is capable of performing two things:
# - Process input to get output: output = layer.forward(input)
# - Propagate gradients through itself: grad_input = layer.backward(input, grad_output)
# Some layers also have learnable parameters which they update during layer.backward.
class Layer(object):
def __init__(self):
pass
def forward(self, input):
# Takes input data of shape [batch, input_units], returns output data [batch, output_units]
# A dummy layer just returns whatever it gets as input.
return input
def backward(self, input, grad_output):
# Performs a backpropagation step through the layer, with respect to the given input.
# To compute loss gradients w.r.t input, we need to apply chain rule (backprop):
# d loss / d x = (d loss / d layer) * (d layer / d x)
# Luckily, we already receive d loss / d layer as input, so you only need to multiply it by d layer / d x.
# If our layer has parameters (e.g. dense layer), we also need to update them here using d loss / d layer
# The gradient of a dummy layer is precisely grad_output, but we'll write it more explicitly
num_units = input.shape[1]
d_layer_d_input = np.eye(num_units)
return np.dot(grad_output, d_layer_d_input) # chain rule
class ReLU(Layer):
def __init__(self):
# ReLU layer simply applies elementwise rectified linear unit to all inputs
pass
def forward(self, input):
# Apply elementwise ReLU to [batch, input_units] matrix
relu_forward = np.maximum(0, input)
return relu_forward
def backward(self, input, grad_output):
# Compute gradient of loss w.r.t. ReLU input
relu_grad = input > 0
return grad_output * relu_grad
class Dense(Layer):
def __init__(self, input_units, output_units, learning_rate=0.1):
# A dense layer is a layer which performs a learned affine transformation: f(x) = <W*x> + b
self.learning_rate = learning_rate
self.weights = np.random.normal(
loc=0.0,
scale=np.sqrt(2 / (input_units + output_units)),
size=(input_units, output_units),
)
self.biases = np.zeros(output_units)
def forward(self, input):
# Perform an affine transformation: f(x) = <W*x> + b
# input shape: [batch, input_units]
# output shape: [batch, output units]
return np.dot(input, self.weights) + self.biases
def backward(self, input, grad_output):
# compute d f / d x = d f / d dense * d dense / d x where d dense/ d x = weights transposed
grad_input = np.dot(grad_output, self.weights.T)
# compute gradient w.r.t. weights and biases
grad_weights = np.dot(input.T, grad_output)
grad_biases = grad_output.mean(axis=0) * input.shape[0]
assert (
grad_weights.shape == self.weights.shape
and grad_biases.shape == self.biases.shape
)
# Here we perform a stochastic gradient descent step.
self.weights = self.weights - self.learning_rate * grad_weights
self.biases = self.biases - self.learning_rate * grad_biases
return grad_input
class MCP(object):
def __init__(self):
self.layers = []
def add_layer(self, layer):
self.layers.append(layer)
def forward(self, X):
# Compute activations of all network layers by applying them sequentially.
# Return a list of activations for each layer.
activations = []
input = X
# Looping through each layer
for l in self.layers:
activations.append(l.forward(input))
# Updating input to last layer output
input = activations[-1]
assert len(activations) == len(self.layers)
return activations
def train_batch(self, X, y):
# Train our network on a given batch of X and y.
# We first need to run forward to get all layer activations.
# Then we can run layer.backward going from last to first layer.
# After we have called backward for all layers, all Dense layers have already made one gradient step.
layer_activations = self.forward(X)
layer_inputs = [
X
] + layer_activations # layer_input[i] is an input for layer[i]
logits = layer_activations[-1]
# Compute the loss and the initial gradient
y_argmax = y.argmax(axis=1)
loss = softmax_crossentropy_with_logits(logits, y_argmax)
loss_grad = grad_softmax_crossentropy_with_logits(logits, y_argmax)
# Propagate gradients through the network
# Reverse propogation as this is backprop
for layer_index in range(len(self.layers))[::-1]:
layer = self.layers[layer_index]
loss_grad = layer.backward(
layer_inputs[layer_index], loss_grad
) # grad w.r.t. input, also weight updates
return np.mean(loss)
def train(self, X_train, y_train, n_epochs=25, batch_size=32):
train_log = []
for epoch in range(n_epochs):
for i in range(0, X_train.shape[0], batch_size):
# Get pair of (X, y) of the current minibatch/chunk
x_batch = np.array([x.flatten() for x in X_train[i : i + batch_size]])
y_batch = np.array([y for y in y_train[i : i + batch_size]])
self.train_batch(x_batch, y_batch)
train_log.append(np.mean(self.predict(X_train) == y_train.argmax(axis=-1)))
print(f"Epoch: {epoch + 1}, Train accuracy: {train_log[-1]}")
return train_log
def predict(self, X):
# Compute network predictions. Returning indices of largest Logit probability
logits = self.forward(X)[-1]
return logits.argmax(axis=-1)
# Building Model and Fitting :
def normalize(X):
X_normalize = (X - np.min(X)) / (np.max(X) - np.min(X))
return X_normalize
def one_hot(a, num_classes):
return np.squeeze(np.eye(num_classes)[a.reshape(-1)])
X_train = normalize(np.array([np.ravel(x) for x in x_train]))
X_test = normalize(np.array([np.ravel(x) for x in x_test]))
Y_train = np.array([one_hot(np.array(y, dtype=int), 10) for y in y_train], dtype=int)
Y_test = np.array([one_hot(np.array(y, dtype=int), 10) for y in y_test], dtype=int)
print("X_train.shape", X_train.shape)
print("Y_train.shape", Y_train.shape)
input_size = X_train.shape[1]
output_size = Y_train.shape[1]
network = MCP()
network.add_layer(Dense(input_size, 100, learning_rate=0.05))
network.add_layer(ReLU())
network.add_layer(Dense(100, 200, learning_rate=0.05))
network.add_layer(ReLU())
network.add_layer(Dense(200, output_size))
train_log = network.train(X_train, Y_train, n_epochs=32, batch_size=64)
plt.plot(train_log, label="train accuracy")
plt.legend(loc="best")
plt.grid()
plt.show()
test_corrects = len(
list(filter(lambda x: x == True, network.predict(X_test) == Y_test.argmax(axis=-1)))
)
test_all = len(X_test)
test_accuracy = test_corrects / test_all # np.mean(test_errors)
print(f"Test accuracy = {test_corrects}/{test_all} = {test_accuracy}")
# # Evaluation
network.predict(X_test[1:2])
# You can “clearly” see that the most probable digit is 2
# Let’s look at the image itself:
def visualize_input(img, ax):
ax.imshow(img, cmap="gray")
width, height = img.shape
thresh = img.max() / 2.5
for x in range(width):
for y in range(height):
ax.annotate(
str(round(img[x][y], 2)),
xy=(y, x),
horizontalalignment="center",
verticalalignment="center",
color="white" if img[x][y] < thresh else "black",
)
fig = plt.figure(figsize=(12, 12))
ax = fig.add_subplot(111)
visualize_input(X_test[1:2].reshape(28, 28), ax)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0032/853/32853136.ipynb | mnist-dataset | hojjatk | [{"Id": 32853136, "ScriptId": 9080374, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2708391, "CreationDate": "04/28/2020 11:04:59", "VersionNumber": 6.0, "Title": "No tf, pytorch: Create Neural Network From Scratch", "EvaluationDate": "04/28/2020", "IsChange": true, "TotalLines": 593.0, "LinesInsertedFromPrevious": 0.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 593.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 1}] | [{"Id": 35697682, "KernelVersionId": 32853136, "SourceDatasetVersionId": 242592}] | [{"Id": 242592, "DatasetId": 102285, "DatasourceVersionId": 254413, "CreatorUserId": 1840515, "LicenseName": "Data files \u00a9 Original Authors", "CreationDate": "01/08/2019 13:01:57", "VersionNumber": 1.0, "Title": "MNIST Dataset", "Slug": "mnist-dataset", "Subtitle": "The MNIST database of handwritten digits (http://yann.lecun.com)", "Description": "### Context\n\nMNIST is a subset of a larger set available from NIST (it's copied from http://yann.lecun.com/exdb/mnist/)\n\n\n### Content\nThe MNIST database of handwritten digits has a training set of 60,000 examples, and a test set of 10,000 examples. .\nFour files are available:\n\n - train-images-idx3-ubyte.gz: training set images (9912422 bytes) \n - train-labels-idx1-ubyte.gz: training set labels (28881 bytes)\n - t10k-images-idx3-ubyte.gz: test set images (1648877 bytes) \n - t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)\n\n### How to read\nSee [sample MNIST reader][1]\n\n### Acknowledgements\n* Yann LeCun, Courant Institute, NYU\n* Corinna Cortes, Google Labs, New York\n* Christopher J.C. Burges, Microsoft Research, Redmond\n\n### Inspiration\nMany methods have been tested with this training set and test set (see http://yann.lecun.com/exdb/mnist/ for more details)\n\n\n [1]: https://www.kaggle.com/hojjatk/read-mnist-dataset", "VersionNotes": "Initial release", "TotalCompressedBytes": 11594722.0, "TotalUncompressedBytes": 11594722.0}] | [{"Id": 102285, "CreatorUserId": 1840515, "OwnerUserId": 1840515.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 242592.0, "CurrentDatasourceVersionId": 254413.0, "ForumId": 111993, "Type": 2, "CreationDate": "01/08/2019 13:01:57", "LastActivityDate": "01/08/2019", "TotalViews": 113247, "TotalDownloads": 16600, "TotalVotes": 111, "TotalKernels": 67}] | [{"Id": 1840515, "UserName": "hojjatk", "DisplayName": "Hojjat Khodabakhsh", "RegisterDate": "04/20/2018", "PerformanceTier": 0}] | # 
# # Setup
# Import Libraries
import numpy as np
import math
import matplotlib.pyplot as plt
import seaborn as sns
from pylab import rcParams
from preprocessing import *
from mathutils import *
sns.set(style="whitegrid")
rcParams["figure.figsize"] = 12, 6
RANDOM_SEED = 42
np.random.seed(RANDOM_SEED)
# # Let us start by answering this key question: What is a neural network?
# It is a biologically-inspired method of building computer programs that are able to learn and independently find connections in data. As Figure shows, nets are a collection of software ‘neurons’ arranged in layers, connected together in a way that allows communication.
# # Single neuron
# Each neuron receives a set of x-values (numbered from 1 to n) as an input and compute the predicted y-hat value. Vector x actually contains the values of the features in one of m examples from the training set. What is more each of units has its own set of parameters, usually referred to as w (column vector of weights) and b (bias) which changes during the learning process. In each iteration, the neuron calculates a weighted average of the values of the vector x, based on its current weight vector w and adds bias. Finally, the result of this calculation is passed through a non-linear activation function g. I will mention a bit about the most popular activation functions in the following part of the article.
# 
# # Perceptrons
# invented by Frank Rosenblatt in 1957, are the simplest neural network that consist of n number of inputs, only one neuron and one output, where n is the number of features of our dataset. The process of passing the data through the neural network is know as forward propagation and the forward propagation carried out in a Perceptron is explained in the following three steps:
# Step 1 : For each input, multiply the input value xᵢ with weights wᵢ and sum all the multiplied values. Weights — represent the strength of the connection between neurons and decides how much influence the given input will have on the neuron’s output. If the weight w₁ has higher value than the weight w₂, then the input x₁ will have higher influence on the output than w₂.
# 
# The row vectors of the inputs and weights are x = [x₁, x₂, … , xₙ] and w =[w₁, w₂, … , wₙ] respectively and their dot product is given by
# 
# Hence, the summation is equal to the dot product of the vectors x and w
# 
# Step 2: Add bias b to the summation of multiplied values and let’s call this z. Bias — also know as offset is necessary in most of the cases, to move the entire activation function to the left or right to generate the required output values .
# 
# Step 3 : Pass the value of z to a non-linear activation function. Activation functions — are used to introduce non-linearity into the output of the neurons, without which the neural network will just be a linear function. Moreover, they have a significant impact on the learning speed of the neural network. Perceptrons have binary step function as their activation function. However, we shall use Sigmoid — also know as logistic function as our activation function.
# 
# where, σ denotes the Sigmoid activation function and the output we get after the forward prorogation is know as the predicted value ŷ.
# # Learning Algorithm
# The learning algorithm consist of two parts — Backpropagation and Optimization.
# Backpropagation : Backpropagation, short for backward propagation of errors, refers to the algorithm for computing the gradient of the loss function with respect to the weights. However, the term is often used to refer to the entire learning algorithm. The backpropagation carried out in a Perceptron is explained in the following two steps:
# **Step 1** : To know an estimation of how far are we from our desired solution a loss function is used. Generally, Mean Squared Error is chosen as loss function for regression problems and cross entropy for classification problems. Let’s take a regression problem and its loss function be Mean Squared Error, which squares the difference between actual (yᵢ) and predicted value ( ŷᵢ ).
# 
# Loss function is calculated for the entire training dataset and their average is called the Cost function C.
# 
# **Step 2** : In order to find the best weights and bias for our Perceptron, we need to know how the cost function changes in relation to weights and bias. This is done with the help the gradients (rate of change) — how one quantity changes in relation to another quantity. In our case, we need to find the gradient of the cost function with respect to the weights and bias.
# Let’s calculate the gradient of cost function C with respect to the weight wᵢ using partial derivation. Since the cost function is not directly related to the weight wᵢ, let’s use the chain rule.
# 
# Now we need to find the following three gradients
# 
# Let’s start with the gradient of the Cost function (C) with respect to the predicted value ( ŷ )
# 
# Let y = [y₁ , y₂ , … yₙ] and ŷ =[ ŷ₁ , ŷ₂ , … ŷₙ] be the row vectors of actual and predicted values. Hence the above equation is simplifies as
# 
# Now let’s find the the gradient of the predicted value with respect to the z. This will be a bit lengthy.
# 
# The gradient of z with respect to the weight wᵢ is
# 
# Therefore we get,
# 
# What about Bias? — Bias is theoretically considered to have an input of constant value 1. Hence,
# 
# # Optimization :
# Optimization is the selection of a best element from some set of available alternatives, which in our case, is the selection of best weights and bias of the perceptron. Let’s choose gradient descent as our optimization algorithm, which changes the weights and bias, proportional to the negative of the gradient of the Cost function with respect to the corresponding weight or bias. Learning rate (α) is a hyperparameter which is used to control how much the weights and bias are changed.
# The weights and bias are updated as follows and the Backporpagation and gradient descent is repeated until convergence.
# 
# # Single layer
# Now let’s zoom out a little and consider how calculations are performed for a whole layer of the neural network. We will use our knowledge of what is happening inside a single unit and vectorize across full layer to combine those calculations in into matrix equations. To unify the notation, the equations will be written for the selected layer. By the way, subscript i mark the index of a neuron in that layer.
# 
# # One more important remark:
# When we wrote the equations for a single unit, we used x and y-hat, which were respectively the column vector of features and the predicted value. When switching to the general notation for layer, we use the vector a — meaning the activation of the corresponding layer. The x vector is therefore the activation for layer 0 — input layer. Each neuron in the layer performs a similar calculation according to the following equations:
# 
# For the sake of clarity, let’s write down the equations for example for layer 2:
# 
# As you can see, for each of the layers we have to perform a number of very similar operations. Using for-loop for this purpose is not very efficient, so to speed up the calculation we will use vectorization. First of all, by stacking together horizontal vectors of weights w (transposed) we will build matrix W. Similarly, we will stack together bias of each neuron in the layer creating vertical vector b. Now there is nothing to stop us from building a single matrix equations that allows us to perform calculations for all the neurons of the layer at once. Let’s also write down the dimensions of the matrices and vectors we have used.
# 
# 
# 
# # Vectorizing across multiple examples
# The equation that we have drawn up so far involves only one example. During the learning process of a neural network, you usually work with huge sets of data, up to millions of entries. The next step will therefore be vectorisation across multiple examples. Let’s assume that our data set has m entries with nx features each. First of all, we will put together the vertical vectors x, a, and z of each layer creating the X, A and Z matrices, respectively. Then we rewrite the previously laid-out equation, taking into account the newly created matrices.
# 
# 
# # What is activation function and why do we need it?
# Activation functions are one of the key elements of the neural network. Without them, our neural network would become a combination of linear functions, so it would be just a linear function itself. Our model would have limited expansiveness, no greater than logistic regression. The non-linearity element allows for greater flexibility and creation of complex functions during the learning process. The activation function also has a significant impact on the speed of learning, which is one of the main criteria for their selection. Figure 6 shows some of the commonly used activation functions. Currently, the most popular one for hidden layers is probably ReLU. We still sometimes use sigmoid, especially in the output layer, when we are dealing with a binary classification and we want the values returned from the model to be in the range from 0 to 1.
# 
# # Sigmoid (and it’s derivative)
# The sigmoid function is used quite commonly in the realm of deep learning, at least it was until recently. It has distinct S shape and it is a differentiable real function for any real input value. Additionally, it has a positive derivative at each point. More importantly, we will use it as an activation function for the hidden layer of our model. Here’s how it is defined:
# 
# It’s first derivative (which we will use during the backpropagation step of our training algorithm) has the following formula:
# 
# So, the derivative can be expressed using the original sigmoid function. Pretty cool, right? Don’t like formulas? Let’s look at a picture:
# 
# The derivative shows us the rate of change of a function. We can use it to determine the “slope” of that function. The highest rate of change for the sigmoid function is when x=0x=0, as it is evident from the derivative graph (in green).
# # Softmax
# The softmax function can be easily differentiated, it is pure (output depends only on input) and the elements of the resulting vector sum to 1.
# Here it is:
# 
# In probability theory, the output of the softmax function is sometimes used as a representation of a categorical distribution. Let’s see an example result:
def softmax(x):
"""Compute softmax values for each sets of scores in x."""
e_x = np.exp(x - np.max(x))
return e_x / e_x.sum()
softmax(np.array([[2, 4, 6, 8]]))
# The output has most of its weight corresponding to the input 8. The softmax function highlights the largest value(s) and suppresses the smaller ones.
# # Loss function
# The basic source of information on the progress of the learning process is the value of the loss function. Generally speaking, the loss function is designed to show how far we are from the ‘ideal’ solution. In our case we used binary crossentropy, but depending on the problem we are dealing with different functions can be applied. The function used by us is described by the following formula, and the change of its value during the learning process is visualised in the next Figure. It shows how with each iteration the value of the loss function decreases and accuracy increases.
# 
# 
# # How do neural networks learn?
# The learning process is about changing the values of the W and b parameters so that the loss function is minimized. In order to achieve this goal, we will turn for help to calculus and use gradient descent method to find a function minimum. In each iteration we will calculate the values of the loss function partial derivatives with respect to each of the parameters of our neural network. For those who are less familiar with this type of calculations, I will just mention that the derivative has a fantastic ability to describe the slope of the function. Thanks to that we know how to manipulate variables in order to move downhill in the graph. Aiming to form an intuition about how the gradient descent works (and stop you from falling asleep once again) I prepared a small visualization. You can see how with each successive epoch we are heading towards the minimum. In our NN it works in the same way — the gradient calculated on each iteration shows us the direction in which we should move. The main difference is that in our exemplary neural network, we have many more parameters to manipulate. Exactly… How to calculate such complex derivatives?
# 
# # Backpropagation
# Backpropagation is an algorithm that allows us to calculate a very complicated gradient, like the one we need. The parameters of the neural network are adjusted according to the following formulae.
# 
# In the equations above, α represents learning rate - a hyperparameter which allows you to control the value of performed adjustment. Choosing a learning rate is crucial — we set it too low, our NN will be learning very slowly, we set it too high and we will not be able to hit the minimum. dW and db are calculated using the chain rule, partial derivatives of loss function with respect to W and b. The size of dW and db are the same as that of W and b respectively. The next figure shows the sequence of operations within the neural network. We see clearly how forward and backward propagation work together to optimize the loss function.
# 
# 
# Backpropagation is the backbone of almost anything we do when using Neural Networks. The algorithm consists of 3 subtasks:
# * Make a forward pass
# * Calculate the error
# * Make backward pass (backpropagation)
# In the first step, backprop uses the data and the weights of the network to compute a prediction. Next, the error is computed based on the prediction and the provided labels. The final step propagates the error through the network, starting from the final layer. Thus, the weights get updated based on the error, little by little.
# # We will try to create a Neural Network (NN) that can properly predict values from the XOR function.
# Here is its truth table:
# 
# visual representation:
# 
# Let's start by defining some parameters:
epochs = 60000 # Number of iterations
inputLayerSize, hiddenLayerSize, outputLayerSize = 2, 3, 1
LR = 0.1 # learning rate
# Our data
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([[0], [1], [1], [0]])
# Initialize the weights of our NN to random numbers :
# weights on layer inputs
w_hidden = np.random.uniform(size=(inputLayerSize, hiddenLayerSize))
w_output = np.random.uniform(size=(hiddenLayerSize, outputLayerSize))
# Finally, implementation of the Backprop algorithm:
def sigmoid(x):
return 1 / (1 + np.exp(-x)) # activation function
def sigmoid_prime(x):
return x * (1 - x) # derivative of sigmoid
for epoch in range(epochs):
# Forward
act_hidden = sigmoid(np.dot(X, w_hidden))
output = np.dot(act_hidden, w_output)
# Calculate error
error = y - output
if epoch % 5000 == 0:
print(f"error sum {sum(error)}")
# Backward
dZ = error * LR
w_output += act_hidden.T.dot(dZ)
dH = dZ.dot(w_output.T) * sigmoid_prime(act_hidden)
w_hidden += X.T.dot(dH)
# That error seems to be decreasing! Yay! And the implementation is not that scary, isn’t it? We just multiply the matrix containing our training data with the matrix of the weights of the hidden layer. Then, we apply the activation function (sigmoid) to the result and multiply that with the weight matrix of the output layer.
# The error is computed by doing simple subtraction. During the backpropagation step, we adjust the weight matrices using the already computed error and use the derivative of the sigmoid function.
# Let’s try to predict using our trained model (doing just the forward step):
X_test = X[1] # [0, 1]
act_hidden = sigmoid(np.dot(X_test, w_hidden))
np.round(np.dot(act_hidden, w_output))
# What is this sorcery? The prediction is correct! You can try some of the other input examples.
# # Building our own Neural Network Classifier
# The “hello world” dataset MNIST (“Modified National Institute of Standards and Technology”), released in 1999, contains images of handwritten digits. Our goal is to build a model that correctly identify digits from a dataset of tens of thousands of handwritten digits.
# We will build our own “vanilla” Neural Network classifier that learns from raw pixels using only Python and NumPy. Let’s start by reading the data:
from mlxtend.data import loadlocal_mnist
import pandas as pd
import os
import random
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# # Model
# Let’s define a class, called NNClassifier that does all the dirty work for us. We will implement a somewhat more sophisticated version of our training algorithm shown above along with some handy methods:
# # Loading data & Showing image:
from os.path import join
import struct
from array import array
class MnistDataloader(object):
def __init__(
self,
training_images_filepath,
training_labels_filepath,
test_images_filepath,
test_labels_filepath,
):
self.training_images_filepath = training_images_filepath
self.training_labels_filepath = training_labels_filepath
self.test_images_filepath = test_images_filepath
self.test_labels_filepath = test_labels_filepath
def read_images_labels(self, images_filepath, labels_filepath):
labels = []
with open(labels_filepath, "rb") as file:
magic, size = struct.unpack(">II", file.read(8))
if magic != 2049:
raise ValueError(
"Magic number mismatch, expected 2049, got {}".format(magic)
)
labels = array("B", file.read())
with open(images_filepath, "rb") as file:
magic, size, rows, cols = struct.unpack(">IIII", file.read(16))
if magic != 2051:
raise ValueError(
"Magic number mismatch, expected 2051, got {}".format(magic)
)
image_data = array("B", file.read())
images = []
for i in range(size):
images.append([0] * rows * cols)
for i in range(size):
img = np.array(image_data[i * rows * cols : (i + 1) * rows * cols])
img = img.reshape(28, 28)
images[i][:] = img
return images, labels
def load_data(self):
x_train, y_train = self.read_images_labels(
self.training_images_filepath, self.training_labels_filepath
)
x_test, y_test = self.read_images_labels(
self.test_images_filepath, self.test_labels_filepath
)
return (x_train, y_train), (x_test, y_test)
# Set file paths based on added MNIST Datasets
training_images_filepath = "/kaggle/input/mnist-dataset/train-images.idx3-ubyte"
training_labels_filepath = "/kaggle/input/mnist-dataset/train-labels.idx1-ubyte"
test_images_filepath = "/kaggle/input/mnist-dataset/t10k-images.idx3-ubyte"
test_labels_filepath = "/kaggle/input/mnist-dataset/t10k-labels.idx1-ubyte"
# Load MINST dataset
print("Loading MNIST dataset...")
mnist_dataloader = MnistDataloader(
training_images_filepath,
training_labels_filepath,
test_images_filepath,
test_labels_filepath,
)
(x_train, y_train), (x_test, y_test) = mnist_dataloader.load_data()
print("MNIST dataset loaded.")
# Show example images
def show_images(images, title_texts):
cols = 5
rows = int(len(images) / cols) + 1
plt.figure(figsize=(28, 28))
index = 1
for x in zip(images, title_texts):
image = x[0]
title_text = x[1]
plt.subplot(rows, cols, index)
plt.imshow(image, cmap=plt.cm.gray)
if title_text != "":
plt.title(title_text, fontsize=15)
index += 1
random_images = []
for i in range(0, 10):
r = random.randint(1, 60000)
random_images.append(
(x_train[r], "training image [" + str(r) + "] = " + str(y_train[r]))
)
for i in range(0, 5):
r = random.randint(1, 10000)
random_images.append((x_test[r], "test image [" + str(r) + "] = " + str(y_test[r])))
show_images(
list(map(lambda x: x[0], random_images)), list(map(lambda x: x[1], random_images))
)
# Building functions:
def softmax_crossentropy_with_logits(logits, reference_answers):
# Compute crossentropy from logits[batch,n_classes] and ids of correct answers
logits_for_answers = logits[np.arange(len(logits)), reference_answers]
xentropy = -logits_for_answers + np.log(np.sum(np.exp(logits), axis=-1))
return xentropy
def grad_softmax_crossentropy_with_logits(logits, reference_answers):
# Compute crossentropy gradient from logits[batch,n_classes] and ids of correct answers
ones_for_answers = np.zeros_like(logits)
ones_for_answers[np.arange(len(logits)), reference_answers] = 1
softmax = np.exp(logits) / np.exp(logits).sum(axis=-1, keepdims=True)
return (-ones_for_answers + softmax) / logits.shape[0]
# A building block. Each layer is capable of performing two things:
# - Process input to get output: output = layer.forward(input)
# - Propagate gradients through itself: grad_input = layer.backward(input, grad_output)
# Some layers also have learnable parameters which they update during layer.backward.
class Layer(object):
def __init__(self):
pass
def forward(self, input):
# Takes input data of shape [batch, input_units], returns output data [batch, output_units]
# A dummy layer just returns whatever it gets as input.
return input
def backward(self, input, grad_output):
# Performs a backpropagation step through the layer, with respect to the given input.
# To compute loss gradients w.r.t input, we need to apply chain rule (backprop):
# d loss / d x = (d loss / d layer) * (d layer / d x)
# Luckily, we already receive d loss / d layer as input, so you only need to multiply it by d layer / d x.
# If our layer has parameters (e.g. dense layer), we also need to update them here using d loss / d layer
# The gradient of a dummy layer is precisely grad_output, but we'll write it more explicitly
num_units = input.shape[1]
d_layer_d_input = np.eye(num_units)
return np.dot(grad_output, d_layer_d_input) # chain rule
class ReLU(Layer):
def __init__(self):
# ReLU layer simply applies elementwise rectified linear unit to all inputs
pass
def forward(self, input):
# Apply elementwise ReLU to [batch, input_units] matrix
relu_forward = np.maximum(0, input)
return relu_forward
def backward(self, input, grad_output):
# Compute gradient of loss w.r.t. ReLU input
relu_grad = input > 0
return grad_output * relu_grad
class Dense(Layer):
def __init__(self, input_units, output_units, learning_rate=0.1):
# A dense layer is a layer which performs a learned affine transformation: f(x) = <W*x> + b
self.learning_rate = learning_rate
self.weights = np.random.normal(
loc=0.0,
scale=np.sqrt(2 / (input_units + output_units)),
size=(input_units, output_units),
)
self.biases = np.zeros(output_units)
def forward(self, input):
# Perform an affine transformation: f(x) = <W*x> + b
# input shape: [batch, input_units]
# output shape: [batch, output units]
return np.dot(input, self.weights) + self.biases
def backward(self, input, grad_output):
# compute d f / d x = d f / d dense * d dense / d x where d dense/ d x = weights transposed
grad_input = np.dot(grad_output, self.weights.T)
# compute gradient w.r.t. weights and biases
grad_weights = np.dot(input.T, grad_output)
grad_biases = grad_output.mean(axis=0) * input.shape[0]
assert (
grad_weights.shape == self.weights.shape
and grad_biases.shape == self.biases.shape
)
# Here we perform a stochastic gradient descent step.
self.weights = self.weights - self.learning_rate * grad_weights
self.biases = self.biases - self.learning_rate * grad_biases
return grad_input
class MCP(object):
def __init__(self):
self.layers = []
def add_layer(self, layer):
self.layers.append(layer)
def forward(self, X):
# Compute activations of all network layers by applying them sequentially.
# Return a list of activations for each layer.
activations = []
input = X
# Looping through each layer
for l in self.layers:
activations.append(l.forward(input))
# Updating input to last layer output
input = activations[-1]
assert len(activations) == len(self.layers)
return activations
def train_batch(self, X, y):
# Train our network on a given batch of X and y.
# We first need to run forward to get all layer activations.
# Then we can run layer.backward going from last to first layer.
# After we have called backward for all layers, all Dense layers have already made one gradient step.
layer_activations = self.forward(X)
layer_inputs = [
X
] + layer_activations # layer_input[i] is an input for layer[i]
logits = layer_activations[-1]
# Compute the loss and the initial gradient
y_argmax = y.argmax(axis=1)
loss = softmax_crossentropy_with_logits(logits, y_argmax)
loss_grad = grad_softmax_crossentropy_with_logits(logits, y_argmax)
# Propagate gradients through the network
# Reverse propogation as this is backprop
for layer_index in range(len(self.layers))[::-1]:
layer = self.layers[layer_index]
loss_grad = layer.backward(
layer_inputs[layer_index], loss_grad
) # grad w.r.t. input, also weight updates
return np.mean(loss)
def train(self, X_train, y_train, n_epochs=25, batch_size=32):
train_log = []
for epoch in range(n_epochs):
for i in range(0, X_train.shape[0], batch_size):
# Get pair of (X, y) of the current minibatch/chunk
x_batch = np.array([x.flatten() for x in X_train[i : i + batch_size]])
y_batch = np.array([y for y in y_train[i : i + batch_size]])
self.train_batch(x_batch, y_batch)
train_log.append(np.mean(self.predict(X_train) == y_train.argmax(axis=-1)))
print(f"Epoch: {epoch + 1}, Train accuracy: {train_log[-1]}")
return train_log
def predict(self, X):
# Compute network predictions. Returning indices of largest Logit probability
logits = self.forward(X)[-1]
return logits.argmax(axis=-1)
# Building Model and Fitting :
def normalize(X):
X_normalize = (X - np.min(X)) / (np.max(X) - np.min(X))
return X_normalize
def one_hot(a, num_classes):
return np.squeeze(np.eye(num_classes)[a.reshape(-1)])
X_train = normalize(np.array([np.ravel(x) for x in x_train]))
X_test = normalize(np.array([np.ravel(x) for x in x_test]))
Y_train = np.array([one_hot(np.array(y, dtype=int), 10) for y in y_train], dtype=int)
Y_test = np.array([one_hot(np.array(y, dtype=int), 10) for y in y_test], dtype=int)
print("X_train.shape", X_train.shape)
print("Y_train.shape", Y_train.shape)
input_size = X_train.shape[1]
output_size = Y_train.shape[1]
network = MCP()
network.add_layer(Dense(input_size, 100, learning_rate=0.05))
network.add_layer(ReLU())
network.add_layer(Dense(100, 200, learning_rate=0.05))
network.add_layer(ReLU())
network.add_layer(Dense(200, output_size))
train_log = network.train(X_train, Y_train, n_epochs=32, batch_size=64)
plt.plot(train_log, label="train accuracy")
plt.legend(loc="best")
plt.grid()
plt.show()
test_corrects = len(
list(filter(lambda x: x == True, network.predict(X_test) == Y_test.argmax(axis=-1)))
)
test_all = len(X_test)
test_accuracy = test_corrects / test_all # np.mean(test_errors)
print(f"Test accuracy = {test_corrects}/{test_all} = {test_accuracy}")
# # Evaluation
network.predict(X_test[1:2])
# You can “clearly” see that the most probable digit is 2
# Let’s look at the image itself:
def visualize_input(img, ax):
ax.imshow(img, cmap="gray")
width, height = img.shape
thresh = img.max() / 2.5
for x in range(width):
for y in range(height):
ax.annotate(
str(round(img[x][y], 2)),
xy=(y, x),
horizontalalignment="center",
verticalalignment="center",
color="white" if img[x][y] < thresh else "black",
)
fig = plt.figure(figsize=(12, 12))
ax = fig.add_subplot(111)
visualize_input(X_test[1:2].reshape(28, 28), ax)
| false | 0 | 9,046 | 1 | 237 | 9,046 |
||
32195719 | <kaggle_start><data_title>COVID-19 Open Research Dataset Challenge (CORD-19)<data_description>### Dataset Description
In response to the COVID-19 pandemic, the White House and a coalition of leading research groups have prepared the COVID-19 Open Research Dataset (CORD-19). CORD-19 is a resource of over 51,000 scholarly articles, including over 40,000 with full text, about COVID-19, SARS-CoV-2, and related coronaviruses. This freely available dataset is provided to the global research community to apply recent advances in natural language processing and other AI techniques to generate new insights in support of the ongoing fight against this infectious disease. There is a growing urgency for these approaches because of the rapid acceleration in new coronavirus literature, making it difficult for the medical research community to keep up.
### Call to Action
We are issuing a call to action to the world's artificial intelligence experts to develop text and data mining tools that can help the medical community develop answers to high priority scientific questions. The CORD-19 dataset represents the most extensive machine-readable coronavirus literature collection available for data mining to date. This allows the worldwide AI research community the opportunity to apply text and data mining approaches to find answers to questions within, and connect insights across, this content in support of the ongoing COVID-19 response efforts worldwide. There is a growing urgency for these approaches because of the rapid increase in coronavirus literature, making it difficult for the medical community to keep up.
A list of our initial key questions can be found under the **[Tasks](https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge/tasks)** section of this dataset. These key scientific questions are drawn from the NASEM’s SCIED (National Academies of Sciences, Engineering, and Medicine’s Standing Committee on Emerging Infectious Diseases and 21st Century Health Threats) [research topics](https://www.nationalacademies.org/event/03-11-2020/standing-committee-on-emerging-infectious-diseases-and-21st-century-health-threats-virtual-meeting-1) and the World Health Organization’s [R&D Blueprint](https://www.who.int/blueprint/priority-diseases/key-action/Global_Research_Forum_FINAL_VERSION_for_web_14_feb_2020.pdf?ua=1) for COVID-19.
Many of these questions are suitable for text mining, and we encourage researchers to develop text mining tools to provide insights on these questions.
We are maintaining a summary of the [community's contributions](https://www.kaggle.com/covid-19-contributions). For guidance on how to make your contributions useful, we're maintaining a [forum thread](https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge/discussion/138484) with the feedback we're getting from the medical and health policy communities.
### Prizes
Kaggle is sponsoring a *$1,000 per task* award to the winner whose submission is identified as best meeting the evaluation criteria. The winner may elect to receive this award as a charitable donation to COVID-19 relief/research efforts or as a monetary payment. More details on the prizes and timeline can be found on the [discussion post](https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge/discussion/135826).
### Accessing the Dataset
We have made this dataset available on Kaggle. Watch out for [periodic updates](https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge/discussion/137474).
The dataset is also hosted on [AI2's Semantic Scholar](https://pages.semanticscholar.org/coronavirus-research). And you can search the dataset using AI2's new [COVID-19 explorer](https://cord-19.apps.allenai.org/).
The licenses for each dataset can be found in the all _ sources _ metadata csv file.<data_name>CORD-19-research-challenge
<code># # Introduction
# This project uses pretrained text classifier model to get the embedding in order to find the nearest texts (or sentences) in a collection of articles. The texts to find are from the following questions.
# - Real-time tracking of whole genomes and a mechanism for coordinating the rapid dissemination of that information to inform the development of diagnostics and therapeutics and to track variations of the virus over time. [Q1](#Q1)
# - Access to geographic and temporal diverse sample sets to understand geographic distribution and genomic differences, and determine whether there is more than one strain in circulation. Multi-lateral agreements such as the Nagoya Protocol could be leveraged. [Q2](#Q2)
# - Evidence that livestock could be infected (e.g., field surveillance, genetic sequencing, receptor binding) and serve as a reservoir after the epidemic appears to be over. [Q3](#Q3)
# - Evidence of whether farmers are infected, and whether farmers could have played a role in the origin. [Q3a](#Q3a)
# - Surveillance of mixed wildlife-livestock farms for SARS-CoV-2 and other coronaviruses in Southeast Asia. [Q3b](#Q3b)
# - Experimental infections to test host range for this pathogen. [Q3c](#Q3c)
# - Animal host(s) and any evidence of continued spill-over to humans. [Q4](#Q4)
# - Socioeconomic and behavioral risk factors for this spill-over. [Q5](#Q5)
# - Sustainable risk reduction strategies. [Q6](#Q6)
# This project uses models and datasets from the following works.
# - [CORD-19: Abstract and Conclusion Word Embedding (version 17)](https://www.kaggle.com/ekaakurniawan/cord-19-abstract-and-conclusion-word-embedding?scriptVersionId=31434959) or [`skip-gram__CORD-19` dataset (version 1)](https://www.kaggle.com/ekaakurniawan/skipgram-cord19-v17/version/1).
# - [CORD-19: Abstract and Conclusion Classification (version 20)](https://www.kaggle.com/ekaakurniawan/cord-19-abstract-and-conclusion-classification?scriptVersionId=31732781) or [`brnn-gru__CORD-19` dataset (version 2)](https://www.kaggle.com/ekaakurniawan/brnngru-cord19-v19/version/2).
# Instead of using the full classification architecture, the text embedding architecture will extract text features from bottleneck layer without the fully connected layers.
# # Software Versions
import sys
print("Python %s" % sys.version)
import os
import time
import math
import random
import gc
from pathlib import Path
from abc import ABC, abstractmethod
from typing import List, Dict
from collections import Counter
import json
from pprint import pprint # for debugging
import numpy as np
print("NumPy %s" % np.__version__)
import matplotlib
print("matplotlib %s" % matplotlib.__version__)
import matplotlib.pyplot as plt
# Set plotting options
import tensorflow as tf
print("TensorFlow %s" % tf.__version__)
from tensorflow.keras.preprocessing.text import text_to_word_sequence
from tensorflow import keras
from tensorflow.keras import layers
import pandas as pd
print("Pandas %s" % pd.__version__)
pd.set_option("display.max_colwidth", 400)
import spacy
print("spaCy %s" % spacy.__version__)
# Get ScispaCy trained model for processing biomedical, scientific or clinical text.`[1]`
import en_core_sci_md
print("en_core_sci_md %s" % en_core_sci_md.__version__)
# # Hyperparameters
# ## Word Embedding Hyperparameters
# Taken from [CORD-19: Abstract and Conclusion Word Embedding](https://www.kaggle.com/ekaakurniawan/cord-19-abstract-and-conclusion-word-embedding).
# Data
WE_DATA_NAME = "CORD-19"
WE_INPUT_DIRECTORY = "/kaggle/input/skipgram-cord19-v17/embedding"
WE_WORKING_DIRECTORY = "/kaggle/working/embedding"
# Preprocessing
WE_TEXT_PROCESSING_MODEL = en_core_sci_md
# Training
WE_MODEL_ARCHITECTURE_NAME = "skip-gram"
WE_VOCABULARY_SIZE = 147843 + 1 # Vocabulary size + UNK
WE_EMBEDDING_DIM = 256
WE_WORD_BATCH_SIZE = 128 # How many words in one batch
WE_TOTAL_NEG_SAMPLES = 64 # Number of negative examples to sample
WE_LEARNING_RATE = 1.0
WE_EPOCHS = 150
WE_REPORT_EVERY = 50000
# Validation
WE_VALIDATION_SIZE = 16 # Random set of words to evaluate similarity on
WE_VALIDATION_WINDOW = 100 # Only pick dev samples in the head of the distribution
# ## Classification Hyperparameters
# Taken from [CORD-19: Abstract and Conclusion Classification](https://www.kaggle.com/ekaakurniawan/cord-19-abstract-and-conclusion-classification).
# Data
CL_DATA_NAME = "CORD-19"
CL_INPUT_DIRECTORY = "/kaggle/input/brnngru-cord19-v19/classification"
CL_WORKING_DIRECTORY = "/kaggle/working/classification"
# Preprocessing
CL_SEQUENCE_LENGTH = 400 # Feature fixed sequence length
CL_NUM_PARALLEL_CALLS = 4
# Training
CL_MODEL_ARCHITECTURES = [
"brnn-gru", # Bidirectional Recurrent Neural Networks using GRU
]
CL_MODEL_ARCHITECTURE_NAME = "brnn-gru"
CL_PRETRAINED_EMBEDDING_FLAG = True # Use pretrained embedding
CL_VOCABULARY_SIZE = 147843 + 1 # Vocabulary size + UNK
CL_EMBEDDING_DIM = 256 # Embedding dimension
CL_HIDDEN_LAYER_UNITS = 256
CL_TOTAL_CLASSES = 6 # Total classes
CL_BATCH_SIZE = 128 # Bach size
CL_EPOCHS = 60 # Number of epochs
CL_NUM_WORKERS = 4
# ## Text Embedding Hyperparameters
# Data
TE_DATA_NAME = "CORD-19"
TE_INPUT_DIRECTORY = "/kaggle/input"
TE_WORKING_DIRECTORY = "/kaggle/working/text_embedding"
# Inference
TE_BATCH_SIZE = 128 # How many texts in one batch
TE_NUM_WORKERS = 4
# ## Text Finder Hyperparameters
# Application
TF_APPLICATION_NAME = "text-finder"
# Data
TF_DATA_NAME = "CORD-19"
TF_INPUT_DIRECTORY = "/kaggle/input"
TF_WORKING_DIRECTORY = "/kaggle/working/text_finder"
# Preprocessing
TF_NUM_PARALLEL_CALLS = 4
# Model
TF_MODEL_ARCHITECTURE_NAME = "brnn-gru"
# Inference
TF_BATCH_SIZE = 1 # How many texts in one batch
TF_NUM_WORKERS = 4
# # Analyze Dataset
# Dataset source is from [COVID-19 Open Research Dataset (CORD-19)](https://pages.semanticscholar.org/coronavirus-research).`[2]` Check the website for new updates.
# List all directories in the dataset.
for dirname, _, _ in os.walk(TE_INPUT_DIRECTORY):
print(dirname)
publication_directory = os.path.join(TE_INPUT_DIRECTORY, "CORD-19-research-challenge")
publication_directory
publication_names = [
"custom_license",
"biorxiv_medrxiv",
"comm_use_subset",
"noncomm_use_subset",
]
# ## Create Publication Model
class PublicationModel(object):
"""Publication class to store and process publication information."""
def __init__(self, name: str, directory: str):
"""Initialize publication object.
Arguments:
name {str} -- the name of the publication.
directory {str} -- the directory of the publication.
"""
self.name = name
self.directory = directory
self.article_filenames: List[str] = []
def collect_articles(self):
"""Collect all article filenames in publication directory."""
self.article_filenames = os.listdir(
os.path.join(self.directory, self.name, self.name, "pdf_json")
)
def __repr__(self):
"""Return publication short information."""
return f"{self.name} with {len(self.article_filenames)} articles."
publications: List[PublicationModel] = []
for publication_name in publication_names:
publication = PublicationModel(publication_name, publication_directory)
publication.collect_articles()
print(publication.__repr__())
publications.append(publication)
total_articles = 0
for publication in publications:
total_articles += len(publication.article_filenames)
print("total articles:", total_articles)
# ## Create Article Model
class ArticleModel(object):
"""Article class to store the entire article information."""
def __init__(self, paper_id: str, title: str, abstract: str, conclusion: str):
"""Initialize article object.
Arguments:
paper_id {str} -- 40-character sha1 of the PDF.
title {str} -- the title of the article.
abstract {str} -- the text abstract of the article.
conclusion {str} -- the text conclusion of the article.
"""
self.paper_id = paper_id
self.title = title
self.abstract = abstract
self.conclusion = conclusion
def __repr__(self):
"""Return article in readable string."""
return (
f"{self.paper_id}\n{self.title}\n\n"
+ f"Abstract:\n{self.abstract}\n\n"
+ f"Conclusion:\n{self.conclusion}\n"
)
# ## Create Article Ingestor
class ArticleIngestorInterface(ABC):
"""Abstract class for ingestor classes."""
allowed_extensions: List[str] = []
@classmethod
def can_ingest(cls, path: str) -> bool:
"""Check if file extension is supported for ingestion.
Arguments:
path {str} -- article file location.
Returns:
bool -- True if the extension is supported and False otherwise.
"""
ext = path.split(".")[-1].lower()
return ext in cls.allowed_extensions
@classmethod
@abstractmethod
def parse(cls, path: str) -> ArticleModel:
"""Parse article from file and store them in ArticleModel object.
Arguments:
path {str} -- article file location.
Returns:
ArticleModel -- article object.
"""
pass
class JsonArticleIngestor(ArticleIngestorInterface):
"""Object that ingests JSON file into article model."""
allowed_extensions: List[str] = ["json"]
@classmethod
def parse(cls, path: str) -> ArticleModel:
"""Parse article from file and store them in ArticleModel object.
Arguments:
path {str} -- article file location.
Returns:
ArticleModel -- article object.
"""
if not cls.can_ingest(path):
raise Exception(f"Cannot ingest exception for {path}")
with open(path, "r", encoding="utf-8-sig") as fh:
article_json = json.load(fh)
title = article_json.get("metadata", {}).get("title", "")
abstract = " ".join(
[p.get("text", "") for p in article_json.get("abstract", "")]
)
conclusion = " ".join(
[
p.get("text", "")
for p in article_json.get("body_text", "")
if "conclusion" in p.get("section", "").lower()
]
)
article = ArticleModel(
paper_id=article_json.get("paper_id", ""),
title=title.strip(),
abstract=abstract.strip(),
conclusion=conclusion.strip(),
)
return article
# ## Check Article Ingestor
sample_json_article_path = os.path.join(
publication_directory,
"custom_license",
"custom_license",
"pdf_json",
"0a52a3d2793f8ca8a4d6f6630e986ea1da115f80.json",
)
sample_article = JsonArticleIngestor.parse(sample_json_article_path)
sample_article
# System monitoring:
# - RAM usage up to this point: 1 GB
# ## Get Sentences
tic = time.time()
nlp = WE_TEXT_PROCESSING_MODEL.load()
toc = time.time()
print(f"Runtime: {int(toc-tic)} seconds.")
# System monitoring:
# - RAM usage up to this point: 1.3 GB
# Check getting sentences.
text = sample_article.abstract
[str(sentence).strip() for sentence in list(nlp(text).sents)]
text = sample_article.conclusion
[str(sentence).strip() for sentence in list(nlp(text).sents)]
# Get sentences from abstract and conclusion of all articles.
def get_sentences():
"""Get sentences from all articles."""
paper_ids: List[str] = []
publication_names: List[str] = []
sections: List[str] = []
sentences: List[str] = []
for publication in publications:
article_filenames = publication.article_filenames
for article_filename in article_filenames:
# Get and parse article
article_path = os.path.join(
publication.directory,
publication.name,
publication.name,
"pdf_json",
article_filename,
)
article = JsonArticleIngestor.parse(article_path)
for section_name in ["abstract", "conclusion"]:
if section_name == "abstract":
text = article.abstract
elif section_name == "conclusion":
text = article.conclusion
else:
continue
# Get sentences.
for sentence in list(nlp(text).sents):
sentence = str(sentence).strip()
# Ignore sentences lesser than three words
# (subject, predicate and object).
if len(sentence.split()) < 3:
continue
paper_ids.append(article.paper_id)
publication_names.append(publication.name)
sections.append(section_name)
sentences.append(sentence)
sentences_df = pd.DataFrame(
{
"paper_id": paper_ids,
"publication_name": publication_names,
"section": sections,
"sentence": sentences,
}
)
return sentences_df
tic = time.time()
sentences_df = get_sentences()
toc = time.time()
print(f"Runtime: {int((toc-tic)/60)} minutes.")
# System monitoring:
# - CPU utilization: 100%
# - RAM usage up to this point: 6.4 GB
sentences = sentences_df["sentence"].values.tolist()
# Total sentences.
total_sentences = len(sentences)
total_sentences
# Sentence lengths.
sentence_lengths = [len(sentence.split()) for sentence in sentences]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.boxplot([sentence_lengths])
plt.title("Sentence Lengths")
plt.xlabel("Sentence")
plt.ylabel("# Words")
plt.show()
# Mean value of sentence lengths.
int(np.mean(sentence_lengths))
# Sample of sentences table.
sentences_df.head(10)
# Save sentences table to file.
if not os.path.isdir(TF_WORKING_DIRECTORY):
print(f"Creating directory... {TF_WORKING_DIRECTORY}")
os.makedirs(TF_WORKING_DIRECTORY)
sentences_path = os.path.join(TF_WORKING_DIRECTORY, "sentences.csv")
sentences_path
sentences_df.to_csv(sentences_path, index=False)
# System monitoring:
# - Disk usage up to this point: 115 MB
# Remove `sentences_df` to free some memory.
if "sentences_df" in globals():
del sentences_df
gc.collect()
# System monitoring:
# - RAM usage up to this point: 6.4 GB
# # Build Dataset
sentences_dataset = tf.data.Dataset.from_generator(
lambda: sentences, (tf.string), (tf.TensorShape([]))
)
for sentence in sentences_dataset.take(10):
print(f"{sentence}")
# # Create Data Pipeline
# ## Tokenize
def tokenize(words: str) -> List[str]:
"""Tokenize text of words into a list of individual words.
Arguments:
words {srt} -- tensor of words.
Returns:
List(str) -- list of words.
"""
return text_to_word_sequence(words)
# ## Generate Words Dictionaries
def load_pretrained_words_dictionaries():
"""Get words dictionaries used by pretrained model."""
print(f"Load dictionaries...")
dictionary_path = os.path.join(WE_INPUT_DIRECTORY, "words.txt")
with open(dictionary_path, "r") as fh:
sorted_words = fh.readlines()
sorted_words = [word.strip() for word in sorted_words]
# Generate dictionaries
int_to_word = {i + 1: word for i, word in enumerate(sorted_words)}
int_to_word[0] = "<UNK>"
word_to_int = {word: i for i, word in int_to_word.items()}
vocabulary_size = len(int_to_word)
if vocabulary_size != WE_VOCABULARY_SIZE:
raise Exception(
f"Vocabulary size is not the same "
+ f"({vocabulary_size} and {WE_VOCABULARY_SIZE})"
)
return int_to_word, word_to_int, vocabulary_size
int_to_word, word_to_int, vocabulary_size = load_pretrained_words_dictionaries()
vocabulary_size
word_to_int["<UNK>"]
word_to_int["the"]
int_to_word[0]
int_to_word[1]
assert int_to_word[word_to_int["the"]] == "the"
# ## Preprocess Dataset
sequence_length = CL_SEQUENCE_LENGTH
sequence_length
def preprocess(text: str) -> List[int]:
"""Pad/turncate and encode text of words from strings into integers.
Arguments:
text {str} -- input text.
Returns:
List[int] -- features in integers.
"""
if type(text) is not str:
# Convert tensor to string
text = text.numpy().decode("utf-8")
# Tokenize text
tokenized_text = tokenize(text)
# Turncate text
if len(tokenized_text) >= sequence_length:
features = tokenized_text[:sequence_length]
# Pad text
else:
features = ["<UNK>"] * (sequence_length - len(tokenized_text))
features += tokenized_text
# Encode text
features_int = [word_to_int.get(feature, 0) for feature in features]
features_int = np.array(features_int)
return features_int
features_int = preprocess(text=" ".join(["the"] * (sequence_length - 26)))
features_int.shape
features_int
# Check labeled dataset text smaller than sequence length.
features_int = preprocess(text=" ".join(["the"] * (sequence_length - 26)))
assert len(features_int) == sequence_length
assert Counter(features_int)[1] == sequence_length - 26
assert Counter(features_int)[0] == 26
# Check labeled dataset text equal sequence length.
features_int = preprocess(text=" ".join(["the"] * sequence_length))
assert len(features_int) == sequence_length
assert Counter(features_int)[1] == sequence_length
assert Counter(features_int)[0] == 0
# Check labeled dataset text bigger than sequence length.
features_int = preprocess(text=" ".join(["the"] * (sequence_length + 16)))
assert len(features_int) == sequence_length
assert Counter(features_int)[1] == sequence_length
assert Counter(features_int)[0] == 0
# ## Data Pipeline
num_parallel_calls = CL_NUM_PARALLEL_CALLS
preprocessing_lambda = lambda x: tf.py_function(
func=preprocess, inp=(x,), Tout=(tf.int32)
)
sentences_features = (
sentences_dataset.map(preprocessing_lambda, num_parallel_calls=num_parallel_calls)
.batch(total_sentences)
.prefetch(buffer_size=num_parallel_calls)
.cache()
.repeat()
)
sentences_features_iter = iter(sentences_features)
tic = time.time()
sentences_features_int = sentences_features_iter.get_next()
toc = time.time()
print(f"Runtime: {int((toc-tic)/60)} minutes.")
# Initial runtime is 4 minutes.
# System monitoring:
# - CPU utilization: 165%
# - RAM usage up to this point: 7.1 GB
sentences_features_int.shape
assert sentences_features_int.shape == (total_sentences, sequence_length)
# # Build Models
# Models to build are:
# - Pretrained word embedding model.
# - Pretrained classifier model that uses pretrained word embedding model.
# - Text embedding model is pretrained classifier model up to the bottleneck features without the dense or classifier layers. This model will be used to extract bottleneck features from all sentences in the articles.
# - Text finder model gets the input from questions being asked to produce questions bottleneck features from text embedding model. Then, this model performs cosine similarity of the questions bottleneck features against article sentences bottleneck features.
# ## Load Pretrained Word Embedding Model
class PretrainedWordEmbeddingModel(object):
"""Pretrained word embedding model."""
def __init__(
self,
input_directory: str,
data_name: str,
model_architecture_name: str,
vocabulary_size: int,
embedding_dim: int,
total_neg_samples: int,
learning_rate: float,
word_batch_size: int,
):
"""Initialize pretrained word embedding model.
Arguments:
input_directory {str} -- input directory.
data_name {str} -- input data name.
model_architecture_name {str} -- name of model architecture.
vocabulary_size {int} -- vocabulary size.
embedding_dim {int} -- embedding dimension.
total_neg_samples {int} -- total negative samples.
learning_rate {float} -- learning rate.
word_batch_size {int} -- training batch size.
"""
self.input_directory = input_directory
# Dataset
self.data_name = data_name
# Model
self.graph = tf.Graph()
self.model_architecture_name = model_architecture_name
self.vocabulary_size = vocabulary_size
self.embedding_dim = embedding_dim
self.total_neg_samples = total_neg_samples
self.learning_rate = learning_rate
self.word_batch_size = word_batch_size
self.model_checkpoint_directory = os.path.join(
self.input_directory, "models/checkpoint"
)
self.model_checkpoint_file_name = "%s__%s" % (
self.model_architecture_name,
self.data_name,
)
self.model_checkpoint_path = os.path.join(
self.model_checkpoint_directory, self.model_checkpoint_file_name
)
self.train_dataset = None
self.train_labels = None
self.loss = None
self.optimizer = None
# Initial processing
self.build_model()
def build_model(self):
"""Build model."""
with self.graph.as_default():
# Input data
self.train_dataset = tf.compat.v1.placeholder(
shape=(self.word_batch_size), dtype=tf.int32
)
self.train_labels = tf.compat.v1.placeholder(
shape=(self.word_batch_size, 1), dtype=tf.int32
)
# Variables
embeddings = tf.compat.v1.Variable(
tf.random.uniform([self.vocabulary_size, self.embedding_dim], -1.0, 1.0)
)
softmax_weights = tf.compat.v1.Variable(
tf.random.truncated_normal(
[self.vocabulary_size, self.embedding_dim],
stddev=1.0 / math.sqrt(self.embedding_dim),
)
)
softmax_biases = tf.compat.v1.Variable(tf.zeros([self.vocabulary_size]))
# Model
# Look up embeddings for inputs.
embed = tf.compat.v1.nn.embedding_lookup(embeddings, self.train_dataset)
# Compute the softmax loss, using a sample of the negative labels
# each time.
self.loss = tf.compat.v1.reduce_mean(
tf.nn.sampled_softmax_loss(
weights=softmax_weights,
biases=softmax_biases,
inputs=embed,
labels=self.train_labels,
num_sampled=self.total_neg_samples,
num_classes=self.vocabulary_size,
)
)
# Optimizer
# Note: The optimizer will optimize the softmax_weights AND
# the embeddings.
# This is because the embeddings are defined as a variable quantity
# and the optimizer's `minimize` method will by default modify all
# variable quantities that contribute to the tensor it is passed.
# See docs on `tf.train.Optimizer.minimize()` for more details.
self.optimizer = tf.compat.v1.train.AdagradOptimizer(
learning_rate=self.learning_rate
).minimize(self.loss)
def get_embedding_variable(self):
with tf.compat.v1.Session(graph=self.graph) as sess:
saver = tf.compat.v1.train.Saver()
saver.restore(sess, self.model_checkpoint_path)
return sess.graph.get_collection("variables")[0].eval()
word_embedding = PretrainedWordEmbeddingModel(
input_directory=WE_INPUT_DIRECTORY,
data_name=WE_DATA_NAME,
vocabulary_size=WE_VOCABULARY_SIZE,
embedding_dim=WE_EMBEDDING_DIM,
total_neg_samples=WE_TOTAL_NEG_SAMPLES,
learning_rate=WE_LEARNING_RATE,
model_architecture_name=WE_MODEL_ARCHITECTURE_NAME,
word_batch_size=WE_WORD_BATCH_SIZE,
)
word_embedding_variable = word_embedding.get_embedding_variable()
type(word_embedding_variable)
word_embedding_variable.shape
# Check if the variable is pretrained. Initialization values are in between -1.0 and 1.0. Any maximum and minimum values beyond initial values indicates pretrained variable.
np.min(word_embedding_variable)
np.max(word_embedding_variable)
# ## Load Pretrained Text Classifier Model
class PretrainedClassifierModel(object):
"""Pretrained classifier model."""
def __init__(
self,
input_directory: str,
data_name: str,
model_architecture_name: str,
pretrained_embedding_flag: bool,
vocabulary_size: int,
embedding_dim: int,
hidden_layer_units: int,
total_classes: int,
pretrained_embedding_variable: np.ndarray = None,
):
"""Initialize pretrained word embedding.
Arguments:
input_directory {str} -- input directory.
data_name {str} -- input data name.
model_architecture_name {str} -- name of model architecture.
pretrained_embedding_flag {bool} -- use pretrained embedding.
vocabulary_size {int} -- vocabulary size.
embedding_dim {int} -- embedding dimension.
hidden_layer_units {int} -- hidden layer units.
total_classes {int} -- total classes.
pretrained_embedding_variable {numpy.ndarray} -- pretrained embedding.
"""
self.input_directory = input_directory
# Dataset
self.data_name = data_name
# Model
self.model = None
self.model_architecture_name = model_architecture_name
self.pretrained_embedding_flag = pretrained_embedding_flag
self.pretrained_embedding_variable = pretrained_embedding_variable
self.vocabulary_size = vocabulary_size
self.embedding_dim = embedding_dim
self.hidden_layer_units = hidden_layer_units
self.total_classes = total_classes
self.model_checkpoint_directory = os.path.join(
self.input_directory, "models/checkpoint"
)
self.model_checkpoint_file_name = "%s__%s.h5" % (
self.model_architecture_name,
self.data_name,
)
self.model_checkpoint_path = os.path.join(
self.model_checkpoint_directory, self.model_checkpoint_file_name
)
# Initial processing
self.build_model()
def build_model(self):
"""Build model."""
if self.model_architecture_name == "brnn-gru":
if self.pretrained_embedding_flag:
self.model = keras.Sequential(
[
keras.layers.Embedding(
self.vocabulary_size,
self.embedding_dim,
weights=[self.pretrained_embedding_variable],
trainable=False,
),
keras.layers.Bidirectional(
keras.layers.GRU(self.hidden_layer_units)
),
keras.layers.Dense(self.hidden_layer_units, activation="relu"),
keras.layers.Dense(self.total_classes),
]
)
else:
self.model = keras.Sequential(
[
keras.layers.Embedding(
self.vocabulary_size,
self.embedding_dim,
embeddings_initializer="uniform",
),
keras.layers.Bidirectional(
keras.layers.GRU(self.hidden_layer_units)
),
keras.layers.Dense(self.hidden_layer_units, activation="relu"),
keras.layers.Dense(self.total_classes),
]
)
self.model.compile(
optimizer="adam",
loss=tf.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
def load_weights(self):
self.model.load_weights(self.model_checkpoint_path)
text_classifier = PretrainedClassifierModel(
input_directory=CL_INPUT_DIRECTORY,
data_name=CL_DATA_NAME,
model_architecture_name=CL_MODEL_ARCHITECTURE_NAME,
pretrained_embedding_flag=CL_PRETRAINED_EMBEDDING_FLAG,
vocabulary_size=CL_VOCABULARY_SIZE,
embedding_dim=CL_EMBEDDING_DIM,
hidden_layer_units=CL_HIDDEN_LAYER_UNITS,
total_classes=CL_TOTAL_CLASSES,
pretrained_embedding_variable=word_embedding_variable,
)
text_classifier.model.summary()
# ### Load Pretrained Model
text_classifier.load_weights()
# ## Build Text Embedding Model
text_embedding = keras.Model(
inputs=text_classifier.model.input,
outputs=text_classifier.model.get_layer("bidirectional").output,
)
text_embedding.summary()
# ## Extract Bottleneck Features using Text Embedding
def extract_bottleneck_features(model, features_int, batch_size, num_workers):
bottleneck_features = model.predict(
x=features_int,
batch_size=batch_size,
verbose=1,
workers=num_workers,
use_multiprocessing=True,
)
return bottleneck_features
bottleneck_features = extract_bottleneck_features(
model=text_embedding,
features_int=sentences_features_int,
batch_size=TE_BATCH_SIZE,
num_workers=TE_NUM_WORKERS,
)
# Runtime is 53 minutes.
# System monitoring:
# - CPU utilization: 386%
# - RAM usage up to this point: 9.3 GB
# Delete sentences and NLP variables to free some memory.
if "sentences" in globals():
del sentences
if "sentences_dataset" in globals():
del sentences_dataset
if "sentences_features" in globals():
del sentences_features
if "sentences_features_iter" in globals():
del sentences_features_iter
if "sentences_features_int" in globals():
del sentences_features_int
if "nlp" in globals():
del nlp
gc.collect()
# System monitoring:
# - RAM usage up to this point: 8.4 GB
type(bottleneck_features)
bottleneck_features.shape
np.max(bottleneck_features)
np.min(bottleneck_features)
# Normalize bottleneck features for cosine similarity.
normalized_bottleneck_features = (
bottleneck_features
/ tf.sqrt(tf.reduce_sum(tf.square(bottleneck_features), 1, keepdims=True))
).numpy()
type(normalized_bottleneck_features)
normalized_bottleneck_features.shape
np.min(normalized_bottleneck_features)
np.max(normalized_bottleneck_features)
# System monitoring:
# - RAM usage up to this point: 9.2 GB
# Save normalized bottleneck features to file.
normalized_bottleneck_features_path = os.path.join(
TF_WORKING_DIRECTORY, "normalized_bottleneck_features.npy"
)
normalized_bottleneck_features_path
normalized_bottleneck_features.save(normalized_bottleneck_features_path)
# ## Build Nearest Text Finder Model
normalized_bottleneck_features_tensor = tf.Variable(
normalized_bottleneck_features, trainable=False, dtype=tf.float32
)
normalized_bottleneck_features_tensor
normalized_text_embedding_tensor = text_embedding.output / tf.sqrt(
tf.reduce_sum(tf.square(text_embedding.output), 1, keepdims=True)
)
normalized_text_embedding_tensor
cosine_similarity_tensor = tf.matmul(
normalized_text_embedding_tensor,
tf.transpose(normalized_bottleneck_features_tensor),
)
cosine_similarity_tensor
text_finder = keras.Model(inputs=text_embedding.input, outputs=cosine_similarity_tensor)
text_finder.summary()
# System monitoring:
# - RAM usage up to this point: 10.8 GB
# Delete unused models and the variables to free some memory.
if "word_embedding" in globals():
del word_embedding
if "word_embedding_variable" in globals():
del word_embedding_variable
if "text_classifier" in globals():
del text_classifier
if "text_embedding" in globals():
del text_embedding
if "bottleneck_features" in globals():
del bottleneck_features
if "normalized_bottleneck_features" in globals():
del normalized_bottleneck_features
gc.collect()
# System monitoring:
# - RAM usage up to this point: 9 GB
# Save text finder model to file.
model_directory = os.path.join(TF_WORKING_DIRECTORY, "models")
model_directory
if not os.path.isdir(model_directory):
print(f"Creating directory... {model_directory}")
os.makedirs(model_directory)
model_checkpoint_directory = os.path.join(model_directory, "checkpoint")
model_checkpoint_directory
if not os.path.isdir(model_checkpoint_directory):
print(f"Creating directory... {model_checkpoint_directory}")
os.makedirs(model_checkpoint_directory)
model_architecture_name = TF_MODEL_ARCHITECTURE_NAME
model_architecture_name
data_name = TF_DATA_NAME
data_name
application_name = TF_APPLICATION_NAME
application_name
model_checkpoint_file_name = "%s__%s__%s.h5" % (
model_architecture_name,
data_name,
application_name,
)
model_checkpoint_file_name
model_checkpoint_path = os.path.join(
model_checkpoint_directory, model_checkpoint_file_name
)
model_checkpoint_path
tic = time.time()
text_finder.save(model_checkpoint_path)
toc = time.time()
print(f"Runtime: {int((toc-tic)/60)} minutes.")
# System monitoring:
# - RAM usage up to this point: 5.1 GB
# - Disk usage up to this point: 700 MB
# # Make Similarity Prediction
def make_similarity_prediction(
dataset,
dataset_size,
preprocessing_lambda,
model,
num_parallel_calls,
batch_size,
num_workers,
):
"""Make prediction on text finder."""
# Free some memory
if "sentences_df" in globals():
del sentences_df
gc.collect()
# Make data pipeline
features = (
dataset.map(preprocessing_lambda, num_parallel_calls=num_parallel_calls)
.batch(dataset_size)
.prefetch(buffer_size=num_parallel_calls)
)
features_iter = iter(features)
features_int = features_iter.get_next()
# Make prediction
predictions = model.predict(
x=features_int,
batch_size=batch_size,
verbose=1,
workers=num_workers,
use_multiprocessing=True,
)
return predictions
def get_prediction_info(prediction: List[int], idx: int = 0, top_k: int = 10):
"""Get sentences info from prediction index."""
if "sentences_df" not in globals():
sentences_df = pd.read_csv(sentences_path)
nearest = (-prediction[idx]).argsort()[:top_k]
return sentences_df[sentences_df.index.isin(nearest)]
# ## Initialize Model
# Initializing model may take some time (72 seconds) to initiate the model graph.
questions = [
"Much",
]
questions_dataset = tf.data.Dataset.from_generator(
lambda: questions, (tf.string), (tf.TensorShape([]))
)
similarity_prediction = make_similarity_prediction(
dataset=questions_dataset,
dataset_size=len(questions),
preprocessing_lambda=preprocessing_lambda,
model=text_finder,
num_parallel_calls=TF_NUM_PARALLEL_CALLS,
batch_size=TF_BATCH_SIZE,
num_workers=TF_NUM_WORKERS,
)
type(similarity_prediction)
similarity_prediction.shape
get_prediction_info(prediction=similarity_prediction)
# ## Test using Existing Text in the Articles
questions = [
"Much progress has been made in understanding the role of structural and accessory proteins in the pathogenesis of severe acute respiratory syndrome coronavirus (SARS-CoV) infections.",
]
questions_dataset = tf.data.Dataset.from_generator(
lambda: questions, (tf.string), (tf.TensorShape([]))
)
similarity_prediction = make_similarity_prediction(
dataset=questions_dataset,
dataset_size=len(questions),
preprocessing_lambda=preprocessing_lambda,
model=text_finder,
num_parallel_calls=TF_NUM_PARALLEL_CALLS,
batch_size=TF_BATCH_SIZE,
num_workers=TF_NUM_WORKERS,
)
get_prediction_info(prediction=similarity_prediction)
# ## Find Nearest Sentences to the Questions
questions = [
"Real-time tracking of whole genomes and a mechanism for coordinating the rapid dissemination of that information to inform the development of diagnostics and therapeutics and to track variations of the virus over time.",
"Access to geographic and temporal diverse sample sets to understand geographic distribution and genomic differences, and determine whether there is more than one strain in circulation. Multi-lateral agreements such as the Nagoya Protocol could be leveraged.",
"Evidence that livestock could be infected (e.g., field surveillance, genetic sequencing, receptor binding) and serve as a reservoir after the epidemic appears to be over.",
"Evidence of whether farmers are infected, and whether farmers could have played a role in the origin.",
"Surveillance of mixed wildlife-livestock farms for SARS-CoV-2 and other coronaviruses in Southeast Asia.",
"Experimental infections to test host range for this pathogen.",
"Animal host(s) and any evidence of continued spill-over to humans.",
"Socioeconomic and behavioral risk factors for this spill-over.",
"Sustainable risk reduction strategies.",
]
questions_dataset = tf.data.Dataset.from_generator(
lambda: questions, (tf.string), (tf.TensorShape([]))
)
similarity_prediction = make_similarity_prediction(
dataset=questions_dataset,
dataset_size=len(questions),
preprocessing_lambda=preprocessing_lambda,
model=text_finder,
num_parallel_calls=TF_NUM_PARALLEL_CALLS,
batch_size=TF_BATCH_SIZE,
num_workers=TF_NUM_WORKERS,
)
# # Q1
# #### Real-time tracking of whole genomes and a mechanism for coordinating the rapid dissemination of that information to inform the development of diagnostics and therapeutics and to track variations of the virus over time.
get_prediction_info(prediction=similarity_prediction, idx=0)
# # Q2
# #### Access to geographic and temporal diverse sample sets to understand geographic distribution and genomic differences, and determine whether there is more than one strain in circulation. Multi-lateral agreements such as the Nagoya Protocol could be leveraged.
get_prediction_info(prediction=similarity_prediction, idx=1)
# # Q3
# #### Evidence that livestock could be infected (e.g., field surveillance, genetic sequencing, receptor binding) and serve as a reservoir after the epidemic appears to be over.
get_prediction_info(prediction=similarity_prediction, idx=2)
# # Q3a
# #### Evidence of whether farmers are infected, and whether farmers could have played a role in the origin.
get_prediction_info(prediction=similarity_prediction, idx=3)
# # Q3b
# #### Surveillance of mixed wildlife-livestock farms for SARS-CoV-2 and other coronaviruses in Southeast Asia.
get_prediction_info(prediction=similarity_prediction, idx=4)
# # Q3c
# #### Experimental infections to test host range for this pathogen.
get_prediction_info(prediction=similarity_prediction, idx=5)
# # Q4
# #### Animal host(s) and any evidence of continued spill-over to humans.
get_prediction_info(prediction=similarity_prediction, idx=6)
# # Q5
# #### Socioeconomic and behavioral risk factors for this spill-over.
get_prediction_info(prediction=similarity_prediction, idx=7)
# # Q6
# #### Sustainable risk reduction strategies.
get_prediction_info(prediction=similarity_prediction, idx=8)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0032/195/32195719.ipynb | CORD-19-research-challenge | null | [{"Id": 32195719, "ScriptId": 8850712, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 273193, "CreationDate": "04/17/2020 18:31:59", "VersionNumber": 8.0, "Title": "CORD-19: Abstract and Conclusion Text Embedding", "EvaluationDate": "04/17/2020", "IsChange": true, "TotalLines": 1268.0, "LinesInsertedFromPrevious": 10.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 1258.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 34837114, "KernelVersionId": 32195719, "SourceDatasetVersionId": 1073914}, {"Id": 34837113, "KernelVersionId": 32195719, "SourceDatasetVersionId": 1071857}, {"Id": 34837112, "KernelVersionId": 32195719, "SourceDatasetVersionId": 1063983}] | [{"Id": 1073914, "DatasetId": 551982, "DatasourceVersionId": 1103617, "CreatorUserId": 1314380, "LicenseName": "Other (specified in description)", "CreationDate": "04/11/2020 13:32:24", "VersionNumber": 7.0, "Title": "COVID-19 Open Research Dataset Challenge (CORD-19)", "Slug": "CORD-19-research-challenge", "Subtitle": "An AI challenge with AI2, CZI, MSR, Georgetown, NIH & The White House", "Description": "### Dataset Description\n\nIn response to the COVID-19 pandemic, the White House and a coalition of leading research groups have prepared the COVID-19 Open Research Dataset (CORD-19). CORD-19 is a resource of over 51,000 scholarly articles, including over 40,000 with full text, about COVID-19, SARS-CoV-2, and related coronaviruses. This freely available dataset is provided to the global research community to apply recent advances in natural language processing and other AI techniques to generate new insights in support of the ongoing fight against this infectious disease. There is a growing urgency for these approaches because of the rapid acceleration in new coronavirus literature, making it difficult for the medical research community to keep up.\n\n### Call to Action\n\nWe are issuing a call to action to the world's artificial intelligence experts to develop text and data mining tools that can help the medical community develop answers to high priority scientific questions. The CORD-19 dataset represents the most extensive machine-readable coronavirus literature collection available for data mining to date. This allows the worldwide AI research community the opportunity to apply text and data mining approaches to find answers to questions within, and connect insights across, this content in support of the ongoing COVID-19 response efforts worldwide. There is a growing urgency for these approaches because of the rapid increase in coronavirus literature, making it difficult for the medical community to keep up.\n\nA list of our initial key questions can be found under the **[Tasks](https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge/tasks)** section of this dataset. These key scientific questions are drawn from the NASEM\u2019s SCIED (National Academies of Sciences, Engineering, and Medicine\u2019s Standing Committee on Emerging Infectious Diseases and 21st Century Health Threats) [research topics](https://www.nationalacademies.org/event/03-11-2020/standing-committee-on-emerging-infectious-diseases-and-21st-century-health-threats-virtual-meeting-1) and the World Health Organization\u2019s [R&D Blueprint](https://www.who.int/blueprint/priority-diseases/key-action/Global_Research_Forum_FINAL_VERSION_for_web_14_feb_2020.pdf?ua=1) for COVID-19. \n\nMany of these questions are suitable for text mining, and we encourage researchers to develop text mining tools to provide insights on these questions. \n\nWe are maintaining a summary of the [community's contributions](https://www.kaggle.com/covid-19-contributions). For guidance on how to make your contributions useful, we're maintaining a [forum thread](https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge/discussion/138484) with the feedback we're getting from the medical and health policy communities. \n\n### Prizes\n\nKaggle is sponsoring a *$1,000 per task* award to the winner whose submission is identified as best meeting the evaluation criteria. The winner may elect to receive this award as a charitable donation to COVID-19 relief/research efforts or as a monetary payment. More details on the prizes and timeline can be found on the [discussion post](https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge/discussion/135826).\n\n### Accessing the Dataset\n\nWe have made this dataset available on Kaggle. Watch out for [periodic updates](https://www.kaggle.com/allen-institute-for-ai/CORD-19-research-challenge/discussion/137474). \n\nThe dataset is also hosted on [AI2's Semantic Scholar](https://pages.semanticscholar.org/coronavirus-research). And you can search the dataset using AI2's new [COVID-19 explorer](https://cord-19.apps.allenai.org/).\n\nThe licenses for each dataset can be found in the all _ sources _ metadata csv file.\n\n### Acknowledgements\n\n\n\nThis dataset was created by the Allen Institute for AI in partnership with the Chan Zuckerberg Initiative, Georgetown University\u2019s Center for Security and Emerging Technology, Microsoft Research, and the National Library of Medicine - National Institutes of Health, in coordination with The White House Office of Science and Technology Policy.", "VersionNotes": "2020-04-10", "TotalCompressedBytes": 0.0, "TotalUncompressedBytes": 0.0}] | [{"Id": 551982, "CreatorUserId": 2931338, "OwnerUserId": NaN, "OwnerOrganizationId": 3737.0, "CurrentDatasetVersionId": 3756201.0, "CurrentDatasourceVersionId": 3810704.0, "ForumId": 565591, "Type": 2, "CreationDate": "03/12/2020 20:05:08", "LastActivityDate": "03/12/2020", "TotalViews": 4468011, "TotalDownloads": 163921, "TotalVotes": 10518, "TotalKernels": 1717}] | null | # # Introduction
# This project uses pretrained text classifier model to get the embedding in order to find the nearest texts (or sentences) in a collection of articles. The texts to find are from the following questions.
# - Real-time tracking of whole genomes and a mechanism for coordinating the rapid dissemination of that information to inform the development of diagnostics and therapeutics and to track variations of the virus over time. [Q1](#Q1)
# - Access to geographic and temporal diverse sample sets to understand geographic distribution and genomic differences, and determine whether there is more than one strain in circulation. Multi-lateral agreements such as the Nagoya Protocol could be leveraged. [Q2](#Q2)
# - Evidence that livestock could be infected (e.g., field surveillance, genetic sequencing, receptor binding) and serve as a reservoir after the epidemic appears to be over. [Q3](#Q3)
# - Evidence of whether farmers are infected, and whether farmers could have played a role in the origin. [Q3a](#Q3a)
# - Surveillance of mixed wildlife-livestock farms for SARS-CoV-2 and other coronaviruses in Southeast Asia. [Q3b](#Q3b)
# - Experimental infections to test host range for this pathogen. [Q3c](#Q3c)
# - Animal host(s) and any evidence of continued spill-over to humans. [Q4](#Q4)
# - Socioeconomic and behavioral risk factors for this spill-over. [Q5](#Q5)
# - Sustainable risk reduction strategies. [Q6](#Q6)
# This project uses models and datasets from the following works.
# - [CORD-19: Abstract and Conclusion Word Embedding (version 17)](https://www.kaggle.com/ekaakurniawan/cord-19-abstract-and-conclusion-word-embedding?scriptVersionId=31434959) or [`skip-gram__CORD-19` dataset (version 1)](https://www.kaggle.com/ekaakurniawan/skipgram-cord19-v17/version/1).
# - [CORD-19: Abstract and Conclusion Classification (version 20)](https://www.kaggle.com/ekaakurniawan/cord-19-abstract-and-conclusion-classification?scriptVersionId=31732781) or [`brnn-gru__CORD-19` dataset (version 2)](https://www.kaggle.com/ekaakurniawan/brnngru-cord19-v19/version/2).
# Instead of using the full classification architecture, the text embedding architecture will extract text features from bottleneck layer without the fully connected layers.
# # Software Versions
import sys
print("Python %s" % sys.version)
import os
import time
import math
import random
import gc
from pathlib import Path
from abc import ABC, abstractmethod
from typing import List, Dict
from collections import Counter
import json
from pprint import pprint # for debugging
import numpy as np
print("NumPy %s" % np.__version__)
import matplotlib
print("matplotlib %s" % matplotlib.__version__)
import matplotlib.pyplot as plt
# Set plotting options
import tensorflow as tf
print("TensorFlow %s" % tf.__version__)
from tensorflow.keras.preprocessing.text import text_to_word_sequence
from tensorflow import keras
from tensorflow.keras import layers
import pandas as pd
print("Pandas %s" % pd.__version__)
pd.set_option("display.max_colwidth", 400)
import spacy
print("spaCy %s" % spacy.__version__)
# Get ScispaCy trained model for processing biomedical, scientific or clinical text.`[1]`
import en_core_sci_md
print("en_core_sci_md %s" % en_core_sci_md.__version__)
# # Hyperparameters
# ## Word Embedding Hyperparameters
# Taken from [CORD-19: Abstract and Conclusion Word Embedding](https://www.kaggle.com/ekaakurniawan/cord-19-abstract-and-conclusion-word-embedding).
# Data
WE_DATA_NAME = "CORD-19"
WE_INPUT_DIRECTORY = "/kaggle/input/skipgram-cord19-v17/embedding"
WE_WORKING_DIRECTORY = "/kaggle/working/embedding"
# Preprocessing
WE_TEXT_PROCESSING_MODEL = en_core_sci_md
# Training
WE_MODEL_ARCHITECTURE_NAME = "skip-gram"
WE_VOCABULARY_SIZE = 147843 + 1 # Vocabulary size + UNK
WE_EMBEDDING_DIM = 256
WE_WORD_BATCH_SIZE = 128 # How many words in one batch
WE_TOTAL_NEG_SAMPLES = 64 # Number of negative examples to sample
WE_LEARNING_RATE = 1.0
WE_EPOCHS = 150
WE_REPORT_EVERY = 50000
# Validation
WE_VALIDATION_SIZE = 16 # Random set of words to evaluate similarity on
WE_VALIDATION_WINDOW = 100 # Only pick dev samples in the head of the distribution
# ## Classification Hyperparameters
# Taken from [CORD-19: Abstract and Conclusion Classification](https://www.kaggle.com/ekaakurniawan/cord-19-abstract-and-conclusion-classification).
# Data
CL_DATA_NAME = "CORD-19"
CL_INPUT_DIRECTORY = "/kaggle/input/brnngru-cord19-v19/classification"
CL_WORKING_DIRECTORY = "/kaggle/working/classification"
# Preprocessing
CL_SEQUENCE_LENGTH = 400 # Feature fixed sequence length
CL_NUM_PARALLEL_CALLS = 4
# Training
CL_MODEL_ARCHITECTURES = [
"brnn-gru", # Bidirectional Recurrent Neural Networks using GRU
]
CL_MODEL_ARCHITECTURE_NAME = "brnn-gru"
CL_PRETRAINED_EMBEDDING_FLAG = True # Use pretrained embedding
CL_VOCABULARY_SIZE = 147843 + 1 # Vocabulary size + UNK
CL_EMBEDDING_DIM = 256 # Embedding dimension
CL_HIDDEN_LAYER_UNITS = 256
CL_TOTAL_CLASSES = 6 # Total classes
CL_BATCH_SIZE = 128 # Bach size
CL_EPOCHS = 60 # Number of epochs
CL_NUM_WORKERS = 4
# ## Text Embedding Hyperparameters
# Data
TE_DATA_NAME = "CORD-19"
TE_INPUT_DIRECTORY = "/kaggle/input"
TE_WORKING_DIRECTORY = "/kaggle/working/text_embedding"
# Inference
TE_BATCH_SIZE = 128 # How many texts in one batch
TE_NUM_WORKERS = 4
# ## Text Finder Hyperparameters
# Application
TF_APPLICATION_NAME = "text-finder"
# Data
TF_DATA_NAME = "CORD-19"
TF_INPUT_DIRECTORY = "/kaggle/input"
TF_WORKING_DIRECTORY = "/kaggle/working/text_finder"
# Preprocessing
TF_NUM_PARALLEL_CALLS = 4
# Model
TF_MODEL_ARCHITECTURE_NAME = "brnn-gru"
# Inference
TF_BATCH_SIZE = 1 # How many texts in one batch
TF_NUM_WORKERS = 4
# # Analyze Dataset
# Dataset source is from [COVID-19 Open Research Dataset (CORD-19)](https://pages.semanticscholar.org/coronavirus-research).`[2]` Check the website for new updates.
# List all directories in the dataset.
for dirname, _, _ in os.walk(TE_INPUT_DIRECTORY):
print(dirname)
publication_directory = os.path.join(TE_INPUT_DIRECTORY, "CORD-19-research-challenge")
publication_directory
publication_names = [
"custom_license",
"biorxiv_medrxiv",
"comm_use_subset",
"noncomm_use_subset",
]
# ## Create Publication Model
class PublicationModel(object):
"""Publication class to store and process publication information."""
def __init__(self, name: str, directory: str):
"""Initialize publication object.
Arguments:
name {str} -- the name of the publication.
directory {str} -- the directory of the publication.
"""
self.name = name
self.directory = directory
self.article_filenames: List[str] = []
def collect_articles(self):
"""Collect all article filenames in publication directory."""
self.article_filenames = os.listdir(
os.path.join(self.directory, self.name, self.name, "pdf_json")
)
def __repr__(self):
"""Return publication short information."""
return f"{self.name} with {len(self.article_filenames)} articles."
publications: List[PublicationModel] = []
for publication_name in publication_names:
publication = PublicationModel(publication_name, publication_directory)
publication.collect_articles()
print(publication.__repr__())
publications.append(publication)
total_articles = 0
for publication in publications:
total_articles += len(publication.article_filenames)
print("total articles:", total_articles)
# ## Create Article Model
class ArticleModel(object):
"""Article class to store the entire article information."""
def __init__(self, paper_id: str, title: str, abstract: str, conclusion: str):
"""Initialize article object.
Arguments:
paper_id {str} -- 40-character sha1 of the PDF.
title {str} -- the title of the article.
abstract {str} -- the text abstract of the article.
conclusion {str} -- the text conclusion of the article.
"""
self.paper_id = paper_id
self.title = title
self.abstract = abstract
self.conclusion = conclusion
def __repr__(self):
"""Return article in readable string."""
return (
f"{self.paper_id}\n{self.title}\n\n"
+ f"Abstract:\n{self.abstract}\n\n"
+ f"Conclusion:\n{self.conclusion}\n"
)
# ## Create Article Ingestor
class ArticleIngestorInterface(ABC):
"""Abstract class for ingestor classes."""
allowed_extensions: List[str] = []
@classmethod
def can_ingest(cls, path: str) -> bool:
"""Check if file extension is supported for ingestion.
Arguments:
path {str} -- article file location.
Returns:
bool -- True if the extension is supported and False otherwise.
"""
ext = path.split(".")[-1].lower()
return ext in cls.allowed_extensions
@classmethod
@abstractmethod
def parse(cls, path: str) -> ArticleModel:
"""Parse article from file and store them in ArticleModel object.
Arguments:
path {str} -- article file location.
Returns:
ArticleModel -- article object.
"""
pass
class JsonArticleIngestor(ArticleIngestorInterface):
"""Object that ingests JSON file into article model."""
allowed_extensions: List[str] = ["json"]
@classmethod
def parse(cls, path: str) -> ArticleModel:
"""Parse article from file and store them in ArticleModel object.
Arguments:
path {str} -- article file location.
Returns:
ArticleModel -- article object.
"""
if not cls.can_ingest(path):
raise Exception(f"Cannot ingest exception for {path}")
with open(path, "r", encoding="utf-8-sig") as fh:
article_json = json.load(fh)
title = article_json.get("metadata", {}).get("title", "")
abstract = " ".join(
[p.get("text", "") for p in article_json.get("abstract", "")]
)
conclusion = " ".join(
[
p.get("text", "")
for p in article_json.get("body_text", "")
if "conclusion" in p.get("section", "").lower()
]
)
article = ArticleModel(
paper_id=article_json.get("paper_id", ""),
title=title.strip(),
abstract=abstract.strip(),
conclusion=conclusion.strip(),
)
return article
# ## Check Article Ingestor
sample_json_article_path = os.path.join(
publication_directory,
"custom_license",
"custom_license",
"pdf_json",
"0a52a3d2793f8ca8a4d6f6630e986ea1da115f80.json",
)
sample_article = JsonArticleIngestor.parse(sample_json_article_path)
sample_article
# System monitoring:
# - RAM usage up to this point: 1 GB
# ## Get Sentences
tic = time.time()
nlp = WE_TEXT_PROCESSING_MODEL.load()
toc = time.time()
print(f"Runtime: {int(toc-tic)} seconds.")
# System monitoring:
# - RAM usage up to this point: 1.3 GB
# Check getting sentences.
text = sample_article.abstract
[str(sentence).strip() for sentence in list(nlp(text).sents)]
text = sample_article.conclusion
[str(sentence).strip() for sentence in list(nlp(text).sents)]
# Get sentences from abstract and conclusion of all articles.
def get_sentences():
"""Get sentences from all articles."""
paper_ids: List[str] = []
publication_names: List[str] = []
sections: List[str] = []
sentences: List[str] = []
for publication in publications:
article_filenames = publication.article_filenames
for article_filename in article_filenames:
# Get and parse article
article_path = os.path.join(
publication.directory,
publication.name,
publication.name,
"pdf_json",
article_filename,
)
article = JsonArticleIngestor.parse(article_path)
for section_name in ["abstract", "conclusion"]:
if section_name == "abstract":
text = article.abstract
elif section_name == "conclusion":
text = article.conclusion
else:
continue
# Get sentences.
for sentence in list(nlp(text).sents):
sentence = str(sentence).strip()
# Ignore sentences lesser than three words
# (subject, predicate and object).
if len(sentence.split()) < 3:
continue
paper_ids.append(article.paper_id)
publication_names.append(publication.name)
sections.append(section_name)
sentences.append(sentence)
sentences_df = pd.DataFrame(
{
"paper_id": paper_ids,
"publication_name": publication_names,
"section": sections,
"sentence": sentences,
}
)
return sentences_df
tic = time.time()
sentences_df = get_sentences()
toc = time.time()
print(f"Runtime: {int((toc-tic)/60)} minutes.")
# System monitoring:
# - CPU utilization: 100%
# - RAM usage up to this point: 6.4 GB
sentences = sentences_df["sentence"].values.tolist()
# Total sentences.
total_sentences = len(sentences)
total_sentences
# Sentence lengths.
sentence_lengths = [len(sentence.split()) for sentence in sentences]
fig = plt.figure()
ax = fig.add_subplot(111)
ax.boxplot([sentence_lengths])
plt.title("Sentence Lengths")
plt.xlabel("Sentence")
plt.ylabel("# Words")
plt.show()
# Mean value of sentence lengths.
int(np.mean(sentence_lengths))
# Sample of sentences table.
sentences_df.head(10)
# Save sentences table to file.
if not os.path.isdir(TF_WORKING_DIRECTORY):
print(f"Creating directory... {TF_WORKING_DIRECTORY}")
os.makedirs(TF_WORKING_DIRECTORY)
sentences_path = os.path.join(TF_WORKING_DIRECTORY, "sentences.csv")
sentences_path
sentences_df.to_csv(sentences_path, index=False)
# System monitoring:
# - Disk usage up to this point: 115 MB
# Remove `sentences_df` to free some memory.
if "sentences_df" in globals():
del sentences_df
gc.collect()
# System monitoring:
# - RAM usage up to this point: 6.4 GB
# # Build Dataset
sentences_dataset = tf.data.Dataset.from_generator(
lambda: sentences, (tf.string), (tf.TensorShape([]))
)
for sentence in sentences_dataset.take(10):
print(f"{sentence}")
# # Create Data Pipeline
# ## Tokenize
def tokenize(words: str) -> List[str]:
"""Tokenize text of words into a list of individual words.
Arguments:
words {srt} -- tensor of words.
Returns:
List(str) -- list of words.
"""
return text_to_word_sequence(words)
# ## Generate Words Dictionaries
def load_pretrained_words_dictionaries():
"""Get words dictionaries used by pretrained model."""
print(f"Load dictionaries...")
dictionary_path = os.path.join(WE_INPUT_DIRECTORY, "words.txt")
with open(dictionary_path, "r") as fh:
sorted_words = fh.readlines()
sorted_words = [word.strip() for word in sorted_words]
# Generate dictionaries
int_to_word = {i + 1: word for i, word in enumerate(sorted_words)}
int_to_word[0] = "<UNK>"
word_to_int = {word: i for i, word in int_to_word.items()}
vocabulary_size = len(int_to_word)
if vocabulary_size != WE_VOCABULARY_SIZE:
raise Exception(
f"Vocabulary size is not the same "
+ f"({vocabulary_size} and {WE_VOCABULARY_SIZE})"
)
return int_to_word, word_to_int, vocabulary_size
int_to_word, word_to_int, vocabulary_size = load_pretrained_words_dictionaries()
vocabulary_size
word_to_int["<UNK>"]
word_to_int["the"]
int_to_word[0]
int_to_word[1]
assert int_to_word[word_to_int["the"]] == "the"
# ## Preprocess Dataset
sequence_length = CL_SEQUENCE_LENGTH
sequence_length
def preprocess(text: str) -> List[int]:
"""Pad/turncate and encode text of words from strings into integers.
Arguments:
text {str} -- input text.
Returns:
List[int] -- features in integers.
"""
if type(text) is not str:
# Convert tensor to string
text = text.numpy().decode("utf-8")
# Tokenize text
tokenized_text = tokenize(text)
# Turncate text
if len(tokenized_text) >= sequence_length:
features = tokenized_text[:sequence_length]
# Pad text
else:
features = ["<UNK>"] * (sequence_length - len(tokenized_text))
features += tokenized_text
# Encode text
features_int = [word_to_int.get(feature, 0) for feature in features]
features_int = np.array(features_int)
return features_int
features_int = preprocess(text=" ".join(["the"] * (sequence_length - 26)))
features_int.shape
features_int
# Check labeled dataset text smaller than sequence length.
features_int = preprocess(text=" ".join(["the"] * (sequence_length - 26)))
assert len(features_int) == sequence_length
assert Counter(features_int)[1] == sequence_length - 26
assert Counter(features_int)[0] == 26
# Check labeled dataset text equal sequence length.
features_int = preprocess(text=" ".join(["the"] * sequence_length))
assert len(features_int) == sequence_length
assert Counter(features_int)[1] == sequence_length
assert Counter(features_int)[0] == 0
# Check labeled dataset text bigger than sequence length.
features_int = preprocess(text=" ".join(["the"] * (sequence_length + 16)))
assert len(features_int) == sequence_length
assert Counter(features_int)[1] == sequence_length
assert Counter(features_int)[0] == 0
# ## Data Pipeline
num_parallel_calls = CL_NUM_PARALLEL_CALLS
preprocessing_lambda = lambda x: tf.py_function(
func=preprocess, inp=(x,), Tout=(tf.int32)
)
sentences_features = (
sentences_dataset.map(preprocessing_lambda, num_parallel_calls=num_parallel_calls)
.batch(total_sentences)
.prefetch(buffer_size=num_parallel_calls)
.cache()
.repeat()
)
sentences_features_iter = iter(sentences_features)
tic = time.time()
sentences_features_int = sentences_features_iter.get_next()
toc = time.time()
print(f"Runtime: {int((toc-tic)/60)} minutes.")
# Initial runtime is 4 minutes.
# System monitoring:
# - CPU utilization: 165%
# - RAM usage up to this point: 7.1 GB
sentences_features_int.shape
assert sentences_features_int.shape == (total_sentences, sequence_length)
# # Build Models
# Models to build are:
# - Pretrained word embedding model.
# - Pretrained classifier model that uses pretrained word embedding model.
# - Text embedding model is pretrained classifier model up to the bottleneck features without the dense or classifier layers. This model will be used to extract bottleneck features from all sentences in the articles.
# - Text finder model gets the input from questions being asked to produce questions bottleneck features from text embedding model. Then, this model performs cosine similarity of the questions bottleneck features against article sentences bottleneck features.
# ## Load Pretrained Word Embedding Model
class PretrainedWordEmbeddingModel(object):
"""Pretrained word embedding model."""
def __init__(
self,
input_directory: str,
data_name: str,
model_architecture_name: str,
vocabulary_size: int,
embedding_dim: int,
total_neg_samples: int,
learning_rate: float,
word_batch_size: int,
):
"""Initialize pretrained word embedding model.
Arguments:
input_directory {str} -- input directory.
data_name {str} -- input data name.
model_architecture_name {str} -- name of model architecture.
vocabulary_size {int} -- vocabulary size.
embedding_dim {int} -- embedding dimension.
total_neg_samples {int} -- total negative samples.
learning_rate {float} -- learning rate.
word_batch_size {int} -- training batch size.
"""
self.input_directory = input_directory
# Dataset
self.data_name = data_name
# Model
self.graph = tf.Graph()
self.model_architecture_name = model_architecture_name
self.vocabulary_size = vocabulary_size
self.embedding_dim = embedding_dim
self.total_neg_samples = total_neg_samples
self.learning_rate = learning_rate
self.word_batch_size = word_batch_size
self.model_checkpoint_directory = os.path.join(
self.input_directory, "models/checkpoint"
)
self.model_checkpoint_file_name = "%s__%s" % (
self.model_architecture_name,
self.data_name,
)
self.model_checkpoint_path = os.path.join(
self.model_checkpoint_directory, self.model_checkpoint_file_name
)
self.train_dataset = None
self.train_labels = None
self.loss = None
self.optimizer = None
# Initial processing
self.build_model()
def build_model(self):
"""Build model."""
with self.graph.as_default():
# Input data
self.train_dataset = tf.compat.v1.placeholder(
shape=(self.word_batch_size), dtype=tf.int32
)
self.train_labels = tf.compat.v1.placeholder(
shape=(self.word_batch_size, 1), dtype=tf.int32
)
# Variables
embeddings = tf.compat.v1.Variable(
tf.random.uniform([self.vocabulary_size, self.embedding_dim], -1.0, 1.0)
)
softmax_weights = tf.compat.v1.Variable(
tf.random.truncated_normal(
[self.vocabulary_size, self.embedding_dim],
stddev=1.0 / math.sqrt(self.embedding_dim),
)
)
softmax_biases = tf.compat.v1.Variable(tf.zeros([self.vocabulary_size]))
# Model
# Look up embeddings for inputs.
embed = tf.compat.v1.nn.embedding_lookup(embeddings, self.train_dataset)
# Compute the softmax loss, using a sample of the negative labels
# each time.
self.loss = tf.compat.v1.reduce_mean(
tf.nn.sampled_softmax_loss(
weights=softmax_weights,
biases=softmax_biases,
inputs=embed,
labels=self.train_labels,
num_sampled=self.total_neg_samples,
num_classes=self.vocabulary_size,
)
)
# Optimizer
# Note: The optimizer will optimize the softmax_weights AND
# the embeddings.
# This is because the embeddings are defined as a variable quantity
# and the optimizer's `minimize` method will by default modify all
# variable quantities that contribute to the tensor it is passed.
# See docs on `tf.train.Optimizer.minimize()` for more details.
self.optimizer = tf.compat.v1.train.AdagradOptimizer(
learning_rate=self.learning_rate
).minimize(self.loss)
def get_embedding_variable(self):
with tf.compat.v1.Session(graph=self.graph) as sess:
saver = tf.compat.v1.train.Saver()
saver.restore(sess, self.model_checkpoint_path)
return sess.graph.get_collection("variables")[0].eval()
word_embedding = PretrainedWordEmbeddingModel(
input_directory=WE_INPUT_DIRECTORY,
data_name=WE_DATA_NAME,
vocabulary_size=WE_VOCABULARY_SIZE,
embedding_dim=WE_EMBEDDING_DIM,
total_neg_samples=WE_TOTAL_NEG_SAMPLES,
learning_rate=WE_LEARNING_RATE,
model_architecture_name=WE_MODEL_ARCHITECTURE_NAME,
word_batch_size=WE_WORD_BATCH_SIZE,
)
word_embedding_variable = word_embedding.get_embedding_variable()
type(word_embedding_variable)
word_embedding_variable.shape
# Check if the variable is pretrained. Initialization values are in between -1.0 and 1.0. Any maximum and minimum values beyond initial values indicates pretrained variable.
np.min(word_embedding_variable)
np.max(word_embedding_variable)
# ## Load Pretrained Text Classifier Model
class PretrainedClassifierModel(object):
"""Pretrained classifier model."""
def __init__(
self,
input_directory: str,
data_name: str,
model_architecture_name: str,
pretrained_embedding_flag: bool,
vocabulary_size: int,
embedding_dim: int,
hidden_layer_units: int,
total_classes: int,
pretrained_embedding_variable: np.ndarray = None,
):
"""Initialize pretrained word embedding.
Arguments:
input_directory {str} -- input directory.
data_name {str} -- input data name.
model_architecture_name {str} -- name of model architecture.
pretrained_embedding_flag {bool} -- use pretrained embedding.
vocabulary_size {int} -- vocabulary size.
embedding_dim {int} -- embedding dimension.
hidden_layer_units {int} -- hidden layer units.
total_classes {int} -- total classes.
pretrained_embedding_variable {numpy.ndarray} -- pretrained embedding.
"""
self.input_directory = input_directory
# Dataset
self.data_name = data_name
# Model
self.model = None
self.model_architecture_name = model_architecture_name
self.pretrained_embedding_flag = pretrained_embedding_flag
self.pretrained_embedding_variable = pretrained_embedding_variable
self.vocabulary_size = vocabulary_size
self.embedding_dim = embedding_dim
self.hidden_layer_units = hidden_layer_units
self.total_classes = total_classes
self.model_checkpoint_directory = os.path.join(
self.input_directory, "models/checkpoint"
)
self.model_checkpoint_file_name = "%s__%s.h5" % (
self.model_architecture_name,
self.data_name,
)
self.model_checkpoint_path = os.path.join(
self.model_checkpoint_directory, self.model_checkpoint_file_name
)
# Initial processing
self.build_model()
def build_model(self):
"""Build model."""
if self.model_architecture_name == "brnn-gru":
if self.pretrained_embedding_flag:
self.model = keras.Sequential(
[
keras.layers.Embedding(
self.vocabulary_size,
self.embedding_dim,
weights=[self.pretrained_embedding_variable],
trainable=False,
),
keras.layers.Bidirectional(
keras.layers.GRU(self.hidden_layer_units)
),
keras.layers.Dense(self.hidden_layer_units, activation="relu"),
keras.layers.Dense(self.total_classes),
]
)
else:
self.model = keras.Sequential(
[
keras.layers.Embedding(
self.vocabulary_size,
self.embedding_dim,
embeddings_initializer="uniform",
),
keras.layers.Bidirectional(
keras.layers.GRU(self.hidden_layer_units)
),
keras.layers.Dense(self.hidden_layer_units, activation="relu"),
keras.layers.Dense(self.total_classes),
]
)
self.model.compile(
optimizer="adam",
loss=tf.losses.BinaryCrossentropy(from_logits=True),
metrics=["accuracy"],
)
def load_weights(self):
self.model.load_weights(self.model_checkpoint_path)
text_classifier = PretrainedClassifierModel(
input_directory=CL_INPUT_DIRECTORY,
data_name=CL_DATA_NAME,
model_architecture_name=CL_MODEL_ARCHITECTURE_NAME,
pretrained_embedding_flag=CL_PRETRAINED_EMBEDDING_FLAG,
vocabulary_size=CL_VOCABULARY_SIZE,
embedding_dim=CL_EMBEDDING_DIM,
hidden_layer_units=CL_HIDDEN_LAYER_UNITS,
total_classes=CL_TOTAL_CLASSES,
pretrained_embedding_variable=word_embedding_variable,
)
text_classifier.model.summary()
# ### Load Pretrained Model
text_classifier.load_weights()
# ## Build Text Embedding Model
text_embedding = keras.Model(
inputs=text_classifier.model.input,
outputs=text_classifier.model.get_layer("bidirectional").output,
)
text_embedding.summary()
# ## Extract Bottleneck Features using Text Embedding
def extract_bottleneck_features(model, features_int, batch_size, num_workers):
bottleneck_features = model.predict(
x=features_int,
batch_size=batch_size,
verbose=1,
workers=num_workers,
use_multiprocessing=True,
)
return bottleneck_features
bottleneck_features = extract_bottleneck_features(
model=text_embedding,
features_int=sentences_features_int,
batch_size=TE_BATCH_SIZE,
num_workers=TE_NUM_WORKERS,
)
# Runtime is 53 minutes.
# System monitoring:
# - CPU utilization: 386%
# - RAM usage up to this point: 9.3 GB
# Delete sentences and NLP variables to free some memory.
if "sentences" in globals():
del sentences
if "sentences_dataset" in globals():
del sentences_dataset
if "sentences_features" in globals():
del sentences_features
if "sentences_features_iter" in globals():
del sentences_features_iter
if "sentences_features_int" in globals():
del sentences_features_int
if "nlp" in globals():
del nlp
gc.collect()
# System monitoring:
# - RAM usage up to this point: 8.4 GB
type(bottleneck_features)
bottleneck_features.shape
np.max(bottleneck_features)
np.min(bottleneck_features)
# Normalize bottleneck features for cosine similarity.
normalized_bottleneck_features = (
bottleneck_features
/ tf.sqrt(tf.reduce_sum(tf.square(bottleneck_features), 1, keepdims=True))
).numpy()
type(normalized_bottleneck_features)
normalized_bottleneck_features.shape
np.min(normalized_bottleneck_features)
np.max(normalized_bottleneck_features)
# System monitoring:
# - RAM usage up to this point: 9.2 GB
# Save normalized bottleneck features to file.
normalized_bottleneck_features_path = os.path.join(
TF_WORKING_DIRECTORY, "normalized_bottleneck_features.npy"
)
normalized_bottleneck_features_path
normalized_bottleneck_features.save(normalized_bottleneck_features_path)
# ## Build Nearest Text Finder Model
normalized_bottleneck_features_tensor = tf.Variable(
normalized_bottleneck_features, trainable=False, dtype=tf.float32
)
normalized_bottleneck_features_tensor
normalized_text_embedding_tensor = text_embedding.output / tf.sqrt(
tf.reduce_sum(tf.square(text_embedding.output), 1, keepdims=True)
)
normalized_text_embedding_tensor
cosine_similarity_tensor = tf.matmul(
normalized_text_embedding_tensor,
tf.transpose(normalized_bottleneck_features_tensor),
)
cosine_similarity_tensor
text_finder = keras.Model(inputs=text_embedding.input, outputs=cosine_similarity_tensor)
text_finder.summary()
# System monitoring:
# - RAM usage up to this point: 10.8 GB
# Delete unused models and the variables to free some memory.
if "word_embedding" in globals():
del word_embedding
if "word_embedding_variable" in globals():
del word_embedding_variable
if "text_classifier" in globals():
del text_classifier
if "text_embedding" in globals():
del text_embedding
if "bottleneck_features" in globals():
del bottleneck_features
if "normalized_bottleneck_features" in globals():
del normalized_bottleneck_features
gc.collect()
# System monitoring:
# - RAM usage up to this point: 9 GB
# Save text finder model to file.
model_directory = os.path.join(TF_WORKING_DIRECTORY, "models")
model_directory
if not os.path.isdir(model_directory):
print(f"Creating directory... {model_directory}")
os.makedirs(model_directory)
model_checkpoint_directory = os.path.join(model_directory, "checkpoint")
model_checkpoint_directory
if not os.path.isdir(model_checkpoint_directory):
print(f"Creating directory... {model_checkpoint_directory}")
os.makedirs(model_checkpoint_directory)
model_architecture_name = TF_MODEL_ARCHITECTURE_NAME
model_architecture_name
data_name = TF_DATA_NAME
data_name
application_name = TF_APPLICATION_NAME
application_name
model_checkpoint_file_name = "%s__%s__%s.h5" % (
model_architecture_name,
data_name,
application_name,
)
model_checkpoint_file_name
model_checkpoint_path = os.path.join(
model_checkpoint_directory, model_checkpoint_file_name
)
model_checkpoint_path
tic = time.time()
text_finder.save(model_checkpoint_path)
toc = time.time()
print(f"Runtime: {int((toc-tic)/60)} minutes.")
# System monitoring:
# - RAM usage up to this point: 5.1 GB
# - Disk usage up to this point: 700 MB
# # Make Similarity Prediction
def make_similarity_prediction(
dataset,
dataset_size,
preprocessing_lambda,
model,
num_parallel_calls,
batch_size,
num_workers,
):
"""Make prediction on text finder."""
# Free some memory
if "sentences_df" in globals():
del sentences_df
gc.collect()
# Make data pipeline
features = (
dataset.map(preprocessing_lambda, num_parallel_calls=num_parallel_calls)
.batch(dataset_size)
.prefetch(buffer_size=num_parallel_calls)
)
features_iter = iter(features)
features_int = features_iter.get_next()
# Make prediction
predictions = model.predict(
x=features_int,
batch_size=batch_size,
verbose=1,
workers=num_workers,
use_multiprocessing=True,
)
return predictions
def get_prediction_info(prediction: List[int], idx: int = 0, top_k: int = 10):
"""Get sentences info from prediction index."""
if "sentences_df" not in globals():
sentences_df = pd.read_csv(sentences_path)
nearest = (-prediction[idx]).argsort()[:top_k]
return sentences_df[sentences_df.index.isin(nearest)]
# ## Initialize Model
# Initializing model may take some time (72 seconds) to initiate the model graph.
questions = [
"Much",
]
questions_dataset = tf.data.Dataset.from_generator(
lambda: questions, (tf.string), (tf.TensorShape([]))
)
similarity_prediction = make_similarity_prediction(
dataset=questions_dataset,
dataset_size=len(questions),
preprocessing_lambda=preprocessing_lambda,
model=text_finder,
num_parallel_calls=TF_NUM_PARALLEL_CALLS,
batch_size=TF_BATCH_SIZE,
num_workers=TF_NUM_WORKERS,
)
type(similarity_prediction)
similarity_prediction.shape
get_prediction_info(prediction=similarity_prediction)
# ## Test using Existing Text in the Articles
questions = [
"Much progress has been made in understanding the role of structural and accessory proteins in the pathogenesis of severe acute respiratory syndrome coronavirus (SARS-CoV) infections.",
]
questions_dataset = tf.data.Dataset.from_generator(
lambda: questions, (tf.string), (tf.TensorShape([]))
)
similarity_prediction = make_similarity_prediction(
dataset=questions_dataset,
dataset_size=len(questions),
preprocessing_lambda=preprocessing_lambda,
model=text_finder,
num_parallel_calls=TF_NUM_PARALLEL_CALLS,
batch_size=TF_BATCH_SIZE,
num_workers=TF_NUM_WORKERS,
)
get_prediction_info(prediction=similarity_prediction)
# ## Find Nearest Sentences to the Questions
questions = [
"Real-time tracking of whole genomes and a mechanism for coordinating the rapid dissemination of that information to inform the development of diagnostics and therapeutics and to track variations of the virus over time.",
"Access to geographic and temporal diverse sample sets to understand geographic distribution and genomic differences, and determine whether there is more than one strain in circulation. Multi-lateral agreements such as the Nagoya Protocol could be leveraged.",
"Evidence that livestock could be infected (e.g., field surveillance, genetic sequencing, receptor binding) and serve as a reservoir after the epidemic appears to be over.",
"Evidence of whether farmers are infected, and whether farmers could have played a role in the origin.",
"Surveillance of mixed wildlife-livestock farms for SARS-CoV-2 and other coronaviruses in Southeast Asia.",
"Experimental infections to test host range for this pathogen.",
"Animal host(s) and any evidence of continued spill-over to humans.",
"Socioeconomic and behavioral risk factors for this spill-over.",
"Sustainable risk reduction strategies.",
]
questions_dataset = tf.data.Dataset.from_generator(
lambda: questions, (tf.string), (tf.TensorShape([]))
)
similarity_prediction = make_similarity_prediction(
dataset=questions_dataset,
dataset_size=len(questions),
preprocessing_lambda=preprocessing_lambda,
model=text_finder,
num_parallel_calls=TF_NUM_PARALLEL_CALLS,
batch_size=TF_BATCH_SIZE,
num_workers=TF_NUM_WORKERS,
)
# # Q1
# #### Real-time tracking of whole genomes and a mechanism for coordinating the rapid dissemination of that information to inform the development of diagnostics and therapeutics and to track variations of the virus over time.
get_prediction_info(prediction=similarity_prediction, idx=0)
# # Q2
# #### Access to geographic and temporal diverse sample sets to understand geographic distribution and genomic differences, and determine whether there is more than one strain in circulation. Multi-lateral agreements such as the Nagoya Protocol could be leveraged.
get_prediction_info(prediction=similarity_prediction, idx=1)
# # Q3
# #### Evidence that livestock could be infected (e.g., field surveillance, genetic sequencing, receptor binding) and serve as a reservoir after the epidemic appears to be over.
get_prediction_info(prediction=similarity_prediction, idx=2)
# # Q3a
# #### Evidence of whether farmers are infected, and whether farmers could have played a role in the origin.
get_prediction_info(prediction=similarity_prediction, idx=3)
# # Q3b
# #### Surveillance of mixed wildlife-livestock farms for SARS-CoV-2 and other coronaviruses in Southeast Asia.
get_prediction_info(prediction=similarity_prediction, idx=4)
# # Q3c
# #### Experimental infections to test host range for this pathogen.
get_prediction_info(prediction=similarity_prediction, idx=5)
# # Q4
# #### Animal host(s) and any evidence of continued spill-over to humans.
get_prediction_info(prediction=similarity_prediction, idx=6)
# # Q5
# #### Socioeconomic and behavioral risk factors for this spill-over.
get_prediction_info(prediction=similarity_prediction, idx=7)
# # Q6
# #### Sustainable risk reduction strategies.
get_prediction_info(prediction=similarity_prediction, idx=8)
| false | 0 | 10,448 | 0 | 1,020 | 10,448 |
||
32224913 | <kaggle_start><code># # Preperation
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
# # Introduction
# If you are not yet familiar with the basic concepts of pipelines, I recommend you to have a look on following lesson first: https://www.kaggle.com/alexisbcook/pipelines
# Due to performance reasons sklearn transforms returns numpy ndarrays when provided with Dataframes. Unfortunatly like this the column and index information is lost. For some operations, like the OneHotEncoder, this has the risk of mixing up columns. During set up of the preprocessor it would be handy to return pandas dataframes. After this is finished you could switch to the "standard" performant numpy ndarrays.
# This brings the best of both worlds:
# - All nice featurers of dataframes during development
# - Performant sklearn transformes during fitting
# - The ability to easily adapt preprocessing steps and revalidate those.
# This notebook is inspired by lucabasas Notebook on pipelines.
# https://www.kaggle.com/lucabasa/understand-and-use-a-pipeline
# and following article on medium:
# https://medium.com/bigdatarepublic/integrating-pandas-and-scikit-learn-with-pipelines-f70eb6183696
# Herein I suggest further "dataframe transformers" and apply those on the titanic machine learning dataset.
# With this dataframe transformers I developed a full preprocessing pipeline without loosing the dataframe informiation (column and index)
# ## Required packages
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import numpy as np
# ## Load data as Dataframe
# It is important that the test and train data is not concatenated to a complete set and preprocesses together for followig reason:
# For validation a reduced dataset of the train data is used. If we fill emplty values in the train data using information of the test data. We introduced data to the validation that is actually not part of it. Pipelines allow us to develop a preprocessor which can be applied to all datasets seperatly. In turn the validation result will be bether than the exctual prediction.****
# For this reason, only the train data is loaded for now.
df_train = pd.read_csv("../input/titanic/train.csv")
df_train.head()
# ## Take care if nans (imputation)
# create copy for further processing
df = df_train.copy()
df.isnull().sum()
# ## Try and error sklearn transformers with Dataframes
# To keep the dataframe structure we can simply fill the dataframe columns with the ndarray returned by the sklearn transformers.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer()
df[["Age"]] = imputer.fit_transform(df[["Age"]])
df.isnull().sum()
# Alternatively we can create a modified Imputer, which recreates a the original Dataframe from the ndarray after imputation.
class df_SimpleImputer(SimpleImputer): # (BaseEstimator, TransformerMixin):
"""
Just a wrapper for the SimpleImputer that keeps the dataframe structure
"""
def transform(self, X, **kwargs):
Array = SimpleImputer.transform(self, X, **kwargs)
return pd.DataFrame(Array, index=X.index, columns=X.columns)
imputer = df_SimpleImputer()
imputer.fit_transform(df[["Age"]]).transpose()
# ## Use ColumnTransformer
# The ColumnTransformer is ideal to process the individual data columns seperatly.However we use the ColumnTransformer, we cannot simply passthrough unprocessed columns and reload the result in the previous dataframe, as the chronology of the ndarray is different from the dataframe. This is shown in following example.
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
preprocessor = ColumnTransformer(
transformers=[("num", df_SimpleImputer(), ["Age"])], remainder="passthrough"
)
df = df_train.copy()
array = preprocessor.fit_transform(df)
moddf = pd.DataFrame(array, index=df.index, columns=df.columns)
moddf.head()
# Note!: Columns are incorrectly assigned, chronology of column needs to be modified!
# Using the sklearn transformer can be complicated as the column names and indexes are lost. The representation of the data lacks sufficient overview:
preprocessor = ColumnTransformer(
transformers=[("num", df_SimpleImputer(), ["Age"])], remainder="passthrough"
)
df = df_train.copy()
nparray = preprocessor.fit_transform(df)
nparray
# ## Modified ColumnTransformer for dataframes
# To solve this problem I created a modified ColumnsTransformer which returns dataframes instead of numpy ndarrays.
class df_ColumnTransformer(ColumnTransformer):
"""
I cannot garanty that this Transformer works well in combination all sklearn Transformers
Tested with: SimpleImputer, OneHotEncoder, OrdinalEncoder
Applies transformers to columns of an array or pandas DataFrame.
In contrast to the sklearn ColumnTransfromer, this transfomer returns a pandas Dataframe
This estimator allows different columns or column subsets of the input
to be transformed separately and the features generated by each transformer
will be concatenated to form a single feature space.
This is useful for heterogeneous or columnar data, to combine several
feature extraction mechanisms or transformations into a single transformer.
"""
def fit_transform(self, X, *args, **kwargs):
ColumnTransformer.fit_transform(self, X)
return df_ColumnTransformer.transform(self, X, *args, **kwargs)
def transform(self, X, *args, **kwargs):
ret_df = pd.DataFrame(index=X.index) # columns=cols)
for (
row
) in (
self.transformers_
): # row includes all information for one transformer step.
transformer = row[1] # tranformer to be applied
lst_of_cols_transformed = row[
2
] # columns to be transformed with this transformer
if isinstance(transformer, str):
# passthrough other elments if passthrough is set
if transformer == "passthrough":
cols = []
for index in lst_of_cols_transformed:
cols.append(X.columns[index])
ret_df[cols] = X[cols]
else:
transformed = transformer.transform(+X[lst_of_cols_transformed])
if transformed.shape[1] == len(lst_of_cols_transformed):
# Set provided DataFrame columns as given in the cols
for i, col in enumerate(lst_of_cols_transformed):
if isinstance(transformed, pd.DataFrame):
transformed = transformed.values
ret_df[col] = transformed[:, i]
else:
# e.g. with OneHotEncoder, more columns are provided, in this case it is not always possible to find
# out which output column is related to which input column
if isinstance(transformed, pd.DataFrame):
ret_df = pd.concat([ret_df, transformed], axis=1)
else:
cols = []
for i in range(1, transformed.shape[1] + 1):
cols.append(
"-".join(lst_of_cols_transformed) + "_" + str(i)
)
print(type(transformed))
# if tranformer returns ndarray convert to Dataframe
if isinstance(transformed, np.ndarray):
temp_df = pd.DataFrame(
transformed, index=X.index, columns=cols
)
else:
# if sparse matrix is returned by transformer
temp_df = pd.DataFrame.sparse.from_spmatrix(
transformed, index=X.index, columns=cols
)
temp_df = temp_df.sparse.to_dense()
ret_df = pd.concat([ret_df, temp_df], axis=1)
return ret_df
# Now we can test it. Here we only need to rename the ColumnTransformer to df_ColumnTransformer. The chronology of the column is according to the transfomer steps, but now the assignment is correct:
#
# Preprocessor #1
preprocessor = df_ColumnTransformer(
transformers=[("num", df_SimpleImputer(), ["Age"])], remainder="passthrough"
)
df = df_train.copy()
moddf = preprocessor.fit_transform(df)
moddf.head(3)
# Checking for nans the combination of both seems to impute all nans correctly.
moddf.isnull().sum()
# ### Further preprocessing steps
# Now we have a ColumnTransfromer for DataFrames, which allows us to work on the preprocessing column by column.
# To present that, we additionally use a different Imputer and an OrdinalEncoder to process the 'Embarked' column.
from sklearn.preprocessing import OrdinalEncoder
# Preprocessor #2
process_embarked = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("label_encoder", OrdinalEncoder()),
]
)
preprocessor = df_ColumnTransformer(
transformers=[
("num", df_SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
],
remainder="passthrough",
)
df = df_train.copy()
moddf = preprocessor.fit_transform(df)
moddf.head()
# Now we can use dataframe operations to inspect hte modified columns. e.g. We can get the average age per 'Pclass'.
df[["Age", "Pclass"]].groupby("Pclass").mean()
# We can als use the OneHotEncoder instead of the OrdinalEncoder to encode the 'Embarked' column. As the ColumnTransformer does not know which labels were used by the OneHotEncoder, it simply names those Embarked_1, Embarked_2 and Embarked_3.
from sklearn.preprocessing import OneHotEncoder
# Preprocessor #3
process_embarked = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("label_encoder", OneHotEncoder()),
]
)
preprocessor = df_ColumnTransformer(
transformers=[
("num", df_SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
],
remainder="passthrough",
)
df = df_train.copy()
moddf = preprocessor.fit_transform(df)
moddf.head()
# ## df_OneHotEncoder
# To solve this problem we can write write our own OneHotEncoder, which builds up on top of the original one.
#
class df_OneHotEncoder(OneHotEncoder):
def transform(self, X, *args, **kwargs):
uniquedict = {}
for col in X.columns:
lst = list(X[col].unique())
lst.sort()
uniquedict[col] = lst
Array = OneHotEncoder.transform(self, X, *args, **kwargs)
newcolumns = []
for key in uniquedict:
for value in uniquedict[key]:
newcolumns.append(str(key) + "_" + str(value))
temp_df = pd.DataFrame.sparse.from_spmatrix(
Array, columns=newcolumns, index=X.index
)
temp_df = temp_df.sparse.to_dense()
return temp_df
# This includes the lables in the columns (Embarked_C, Embarked_Q and Embarked_S).
# Preprocessor #4
process_embarked = Pipeline(
steps=[
("imputer", df_SimpleImputer(strategy="most_frequent")),
# The df_OneHotEncoder requires a Dataframe as input, therefore df_SimpleImputer must be used instead of the SimpleImputer.
("label_encoder", df_OneHotEncoder()),
]
)
preprocessor = df_ColumnTransformer(
transformers=[
("num", df_SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
],
remainder="passthrough",
)
df = df_train.copy()
moddf = preprocessor.fit_transform(df)
moddf.head()
# The df_ColumnTransformer is especially handy if we create our own transformes. In this example we generate one for the Cabin column.
# From that we want to generate a column called 'Cabine_Deck' which extractes the Deck from the cabine numner and a Columns 'Cabine' that indicates if a person had a cabin or not.
# Here is a guideline, which shows how to write your own tranformers/estimators: https://scikit-learn.org/stable/developers/develop.html
from sklearn.base import BaseEstimator, TransformerMixin
class df_Process_Cabin(BaseEstimator, TransformerMixin):
"""
If a value is given in cell it is set to 1, if nan cell is set to 0
Empty cabine fields are assigned with 'None'
"""
def fit(self, *args, **kwargs):
return self
def transform(self, X):
for col in X.columns:
X[col + "_Deck"] = X[col].str.extract("([A-Za-z]).", expand=False)
X[col + "_Deck"] = X[col + "_Deck"].fillna("None")
X[col] = X[col].notnull().astype("int")
return X
# Just to have this without df as well
class Process_Cabin(df_Process_Cabin):
# no changes the sklearn transformes will convert this to numpy arrays anyway
def fit(self, *args, **kwargs):
return self
# We can use that transformer in the ColumnTransform just as we would use an ordinary sklearn transformers. See column 'Cabin' and 'Cabin_Deck'.
# Preprocessor #5
process_embarked = Pipeline(
steps=[
("imputer", df_SimpleImputer(strategy="most_frequent")),
# The df_OneHotEncoder requires a Dataframe as input, therefore df_SimpleImputer must be used instead of the SimpleImputer.
("label_encoder", df_OneHotEncoder()),
]
)
preprocessor = df_ColumnTransformer(
transformers=[
("num", df_SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
("cabin", df_Process_Cabin(), ["Cabin"]),
],
remainder="passthrough",
)
df = df_train.copy()
moddf = preprocessor.fit_transform(df)
moddf.head(6)
# Now the the new feature 'Cabin_Deck' can be easily analized using the Dataframe functionality. There seems to be some relation between the deck and the Survial rate.
sns.barplot(x="Cabin_Deck", y="Survived", data=moddf)
# As you can see from the dataframe above, the newly genereated column 'Cabin_Deck' still needs to be processed with a OrdinalEncoder or a OneHotEncoder. I coosed the OrdinalEncoder and introduce a Pipeline and another ColumnTransformer for this procedure.
# Preprocessor #6
process_cabin = Pipeline(
steps=[
("cab", df_Process_Cabin()),
(
"label_encoder",
df_ColumnTransformer(
transformers=[
("deck", OrdinalEncoder(), ["Cabin_Deck"]),
],
remainder="passthrough",
),
),
]
)
process_embarked = Pipeline(
steps=[
("imputer", df_SimpleImputer(strategy="most_frequent")),
# The df_OneHotEncoder requires a Dataframe as input, therefore df_SimpleImputer must be used instead of the SimpleImputer.
("label_encoder", df_OneHotEncoder()),
]
)
preprocessor = df_ColumnTransformer(
transformers=[
("num", df_SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
("cabin", process_cabin, ["Cabin"]),
],
remainder="passthrough",
)
df = df_train.copy()
moddf = preprocessor.fit_transform(df)
moddf.head(6)
# ## Extract Title from name
# As a next stepy I extract the title from the name. To do that, I generate a specific transformer.
class ExtractTitle(BaseEstimator, TransformerMixin):
"""
Extracts title from name in titanic machine learning competion
Basic extraction reused from:
https://www.kaggle.com/muhammetcimci/easy-titanic-survival-prediction-notebook
"""
def fit(*args, **kwargs):
# Nothing to do
return
def fit_transform(self, X, *args):
# Just transform
return self.transform(X)
def transform(self, X):
# Create a list of series from input data.
# This is needed, as the ColumnTransformer will provide a numpy array
# I included several options for flexibility, Normally one would be sufficient.
list_of_Series = []
if isinstance(X, pd.core.series.Series):
list_of_Series = [X]
elif isinstance(X, np.ndarray):
for i in range(0, X.shape[1]):
list_of_Series.append(pd.Series(X[:, i]))
elif isinstance(X, pd.core.frame.DataFrame):
for col in X.columns:
list_of_Series.append(X[col])
else:
warnings.warn('Datatype "' + str(type(X)) + '" not suppoted!')
# Create empty numpy array, which holds result later.
result = np.empty(
shape=(len(list_of_Series[0]), len(list_of_Series)), dtype="O"
)
for i, series in enumerate(list_of_Series):
title = series.str.extract(" ([A-Za-z]+)\.", expand=False)
title = title.replace(
[
"Lady",
"Capt",
"Col",
"Don",
"Dr",
"Major",
"Rev",
"Jonkheer",
"Dona",
],
"Rare",
)
title = title.replace(["Countess", "Lady", "Sir"], "Royal")
title = title.replace("Mlle", "Miss")
title = title.replace("Ms", "Miss")
title = title.replace("Mme", "Mrs")
result[:, i] = title.values
return result
#
class df_ExtractTitle(ExtractTitle):
"""
Extracts title from name in titanic machine learning competion
Returns Dataframe
"""
def transform(self, X):
columns = list(X.columns)
for i, col in enumerate(columns):
columns[i] = col + "_Title"
matrix = ExtractTitle.transform(self, X)
return pd.DataFrame(matrix, index=X.index, columns=columns)
# Lets apply the newly created tranformer. Further I include an OrdinalEncoder for the column 'Sex'. I guess you can imagine how complicated it would be to evaluate the correct behavior using the numpy arrays.
# Preprocessor #7
process_cabin = Pipeline(
steps=[
("cab", df_Process_Cabin()),
(
"label_encoder",
df_ColumnTransformer(
transformers=[
("deck", OrdinalEncoder(), ["Cabin_Deck"]),
],
remainder="passthrough",
),
),
]
)
process_embarked = Pipeline(
steps=[
("imputer", df_SimpleImputer(strategy="most_frequent")),
# The df_OneHotEncoder requires a Dataframe as input, therefore df_SimpleImputer must be used instead of the SimpleImputer.
("label_encoder", df_OneHotEncoder()),
]
)
process_title = Pipeline(
steps=[("title_extract", df_ExtractTitle()), ("encode", df_OneHotEncoder())]
)
preprocessor = df_ColumnTransformer(
transformers=[
("num", df_SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
("cabin", process_cabin, ["Cabin"]),
("name", process_title, ["Name"]),
("sex", OrdinalEncoder(), ["Sex"]),
],
remainder="passthrough",
)
df = df_train.copy()
moddf = preprocessor.fit_transform(df)
moddf.head(4)
# The column 'Ticket' is not needed in my prediction. Also the column 'Survived' should not be processed. Instead of passing all unprocessed columns (remainder = passthrough), I will copy unchanged columns. To do so I created a transformer copier. For sure I could as well just use an Imputer, which has nothing to do for those columns. For the column 'Pclass' I will include a OneHotEncoder, later I will test if that provides better results during validation. this is the last preprocessing step I will apply.
class Copier(BaseEstimator, TransformerMixin):
"""
Simply takes over column as they are.
"""
def fit(*args, **kwargs):
# Nothing to do
return
def fit_transform(self, X, *args):
# Just transform
return self.transform(X)
def transform(self, X):
return X
# Here you can see the complete preprocessing Pipeline using the Dataframes.
# Preprocessor #8
process_cabin = Pipeline(
steps=[
("cab", df_Process_Cabin()),
(
"label_encoder",
df_ColumnTransformer(
transformers=[
("deck", OrdinalEncoder(), ["Cabin_Deck"]),
],
remainder="passthrough",
),
),
]
)
process_embarked = Pipeline(
steps=[
("imputer", df_SimpleImputer(strategy="most_frequent")),
# The df_OneHotEncoder requires a Dataframe as input, therefore df_SimpleImputer must be used instead of the SimpleImputer.
("label_encoder", df_OneHotEncoder()),
]
)
process_title = Pipeline(
steps=[("title_extract", df_ExtractTitle()), ("encode", df_OneHotEncoder())]
)
preprocessor = df_ColumnTransformer(
transformers=[
("num", df_SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
("cabin", process_cabin, ["Cabin"]),
("name", process_title, ["Name"]),
("sex", OrdinalEncoder(), ["Sex"]),
("onehot", df_OneHotEncoder(), ["Pclass"]),
("unmodified", Copier(), ["Fare", "Parch", "SibSp"]),
],
remainder="drop",
) # drops ticket
df = df_train.copy()
# I will make a time measurment on the compete preprocessing.
moddf = preprocessor.fit_transform(df)
moddf.head(3)
# ## Switch back to the performant numpy arrays
# Now that the preprocessing is successfully developed, the pipeline can be modified to work with the perfromant numpy arrays. To do that, from the previous pipeline I removed all 'df_'s, switching to the ordinary sklearn transformers.
# Sklearn Preprocessor
process_cabin = Pipeline(
steps=[
("cab", Process_Cabin()),
(
"label_encoder",
ColumnTransformer(
transformers=[
("deck", OrdinalEncoder(), ["Cabin_Deck"]),
],
remainder="passthrough",
),
),
]
)
process_embarked = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("label_encoder", OneHotEncoder()),
]
)
process_title = Pipeline(
steps=[("title_extract", ExtractTitle()), ("encode", OneHotEncoder())]
)
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
("cabin", process_cabin, ["Cabin"]),
("name", process_title, ["Name"]),
("sex", OrdinalEncoder(), ["Sex"]),
("onehot", OneHotEncoder(), ["Pclass"]),
("unmodified", Copier(), ["Fare", "Parch", "SibSp"]),
],
remainder="drop",
) # drops ticket
df = df_train.copy()
nparray = preprocessor.fit_transform(df)
nparray[1, :]
# Compared to our previous preprocessing pipeline we were significantly faster. From ~125 ms down to ~44.8 ms.
# We can also show that the df_ version and the numpy array version returned the same result. From now on we will not need the Dataframe version anymore.
if np.sum(np.equal(nparray, moddf.values)) == nparray.size:
print("All elements are equal!")
# # Create Pipeline with Model
# Now that preprocessor is finished we can create a complete pipeline to include our model as well.
# Preproccesing-Modeling Pipeline #1
from sklearn.ensemble import GradientBoostingClassifier
process_cabin = Pipeline(
steps=[
("cab", Process_Cabin()),
(
"label_encoder",
ColumnTransformer(
transformers=[
("deck", OrdinalEncoder(), ["Cabin_Deck"]),
],
remainder="passthrough",
),
),
]
)
process_embarked = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("label_encoder", OneHotEncoder(handle_unknown="ignore")),
]
)
process_title = Pipeline(
steps=[("title_extract", ExtractTitle()), ("encode", OneHotEncoder())]
)
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
("cabin", process_cabin, ["Cabin"]),
("name", process_title, ["Name"]),
("sex", OrdinalEncoder(), ["Sex"]),
("onehot", OneHotEncoder(handle_unknown="ignore"), ["Pclass"]),
("unmodified", Copier(), ["Fare", "Parch", "SibSp"]),
],
remainder="drop",
) # drops ticket
model = GradientBoostingClassifier(random_state=0)
process = Pipeline(steps=[("preprocessor", preprocessor), ("model", model)])
from sklearn.model_selection import cross_val_score
df = df_train.copy()
y = df["Survived"]
df = df.drop(
"Survived", axis=1
) # make sure that Survived is really not used in fitting
X = df
cross_val_score(process, X, y).mean()
# Now we can play around with the Pipeline and see which features and which models perform best in cross validation.
# Preproccesing-Modeling Pipeline #2
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
process_cabin = Pipeline(
steps=[
("cab", Process_Cabin()),
(
"label_encoder",
ColumnTransformer(
transformers=[
(
"deck",
OneHotEncoder(handle_unknown="ignore", categories="auto"),
["Cabin_Deck"],
),
],
remainder="passthrough",
),
),
]
)
process_embarked = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("label_encoder", OneHotEncoder(handle_unknown="ignore", categories="auto")),
]
)
process_title = Pipeline(
steps=[
("title_extract", ExtractTitle()),
("encode", OneHotEncoder(handle_unknown="ignore", categories="auto")),
]
)
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(), ["Age", "Fare"]), # Fare has nan in the test data
("cab", cabine, ["Cabin"]), # Categorize and imputes at the same time
("cat", OrdinalEncoder(), ["Sex"]),
("class", OrdinalEncoder(), ["Pclass"]),
("parch", impute_onehot, ["Parch"]),
("embarked", impute_onehot, ["Embarked"]),
("name", title_onehot, ["Name"]),
("copy", Copier(), ["SibSp"]),
],
remainder="drop",
) # drops ticket
# Validate
df = df_train.copy()
y = df["Survived"].astype(int).values
df = df.drop(
"Survived", axis=1
) # make sure that Survived is really not used in fitting
X = preprocessor.fit_transform(df)
# Validation set for stopping round of XGBclassifier
__, val_x, __, val_y = train_test_split(X, y, test_size=0.30, random_state=4)
model = XGBClassifier(
early_stopping_round=5, eval_set=(val_x, val_y), learning_rate=0.08, random_state=8
)
cross_val_score(model, X, y, cv=4).mean()
# At the end we can use our final pipeline to predict the Survived feature in the test data.
# train
df = df_train.copy()
y_train = df_train["Survived"].values
df = df.drop(["Survived"], axis=1)
X_train = df
X_test = pd.read_csv("../input/titanic/test.csv")
# Validation set for stopping round of XGBclassifier -> Complete X_train and y_train can be used.
X_train_class = preprocessor.fit_transform(
X_train
) # preprocessor should be performed on this data as well.
model = XGBClassifier(
early_stopping_round=8,
eval_set=(X_train_class, y_train),
learning_rate=0.08,
random_state=8,
)
process = Pipeline(steps=[("preprocessor", preprocessor), ("model", model)])
process.fit(X_train, y_train)
y_pred = process.predict(X_test)
y_pred
output = pd.DataFrame({"PassengerId": X_test["PassengerId"].values, "Survived": y_pred})
output
output.to_csv("submission.csv", index=False)
def auto_model_cross_val(
X,
y,
preprocessor,
model_class_ptr,
optimize_param,
param_list,
model_kwargs=dict(),
cross_val_kwargs={"scoring": "accuracy", "cv": 5},
):
"""
Preform multiple cross_validations of model with modified model parameter
:param val_set:
:param y_name:
:param model_class_ptr:
:param optimize_param:
:param param_list:
:param model_kwargs:
:return:
"""
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import Pipeline
import pandas as pd
score_df = pd.DataFrame()
score_df[optimize_param] = param_list
score_df = score_df.set_index(optimize_param)
score_list = []
for param in param_list:
model_kwargs[optimize_param] = param
model_instance = model_class_ptr(**model_kwargs)
process = Pipeline(
steps=[("preprocessor", preprocessor), ("model", model_instance)]
)
score = cross_val_score(process, X, y, **cross_val_kwargs).mean()
score_list.append(score)
score_df[cross_val_kwargs["scoring"]] = score_list
return score_df
from xgboost import XGBClassifier
y_train = df_train["Survived"].astype(int).values
impute_onehot = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("label_encoder", OneHotEncoder(handle_unknown="ignore", categories="auto")),
]
)
title_onehot = Pipeline(
steps=[
("title_extract", ExtractTitle()),
("one_hot", OneHotEncoder(handle_unknown="ignore", categories="auto")),
]
)
cabine = Pipeline(
steps=[
("cab", Process_Cabin()),
(
"label_encoder",
ColumnTransformer(
transformers=[
("deck", OneHotEncoder(handle_unknown="ignore"), ["Cabin_Deck"])
],
remainder="passthrough",
),
),
]
)
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(), ["Age", "Fare"]), # Fare has nan in the test data
("cab", cabine, ["Cabin"]), # Categorize and imputes at the same time
("cat", OrdinalEncoder(), ["Sex"]),
("class", OrdinalEncoder(), ["Pclass"]),
("parch", impute_onehot, ["Parch"]),
("embarked", impute_onehot, ["Embarked"]),
("name", title_onehot, ["Name"]),
("copy", Copier(), ["SibSp"]),
]
)
__, val_x, __, val_y = train_test_split(
df_train, y_train, test_size=0.30, random_state=8
)
auto_model_cross_val(
df_train,
y_train,
preprocessor,
XGBClassifier,
"learning_rate",
param_list=[0.06, 0.07, 0.08, 0.09, 0.1],
model_kwargs={"early_stopping_rounds": 8, "eval_set": [(val_x, val_y)]},
)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0032/224/32224913.ipynb | null | null | [{"Id": 32224913, "ScriptId": 8825052, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4714017, "CreationDate": "04/18/2020 09:04:12", "VersionNumber": 7.0, "Title": "Step by step Pipeline with pandas Dataframes", "EvaluationDate": "04/18/2020", "IsChange": true, "TotalLines": 751.0, "LinesInsertedFromPrevious": 0.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 751.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | # # Preperation
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the "../input/" directory.
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# Any results you write to the current directory are saved as output.
# # Introduction
# If you are not yet familiar with the basic concepts of pipelines, I recommend you to have a look on following lesson first: https://www.kaggle.com/alexisbcook/pipelines
# Due to performance reasons sklearn transforms returns numpy ndarrays when provided with Dataframes. Unfortunatly like this the column and index information is lost. For some operations, like the OneHotEncoder, this has the risk of mixing up columns. During set up of the preprocessor it would be handy to return pandas dataframes. After this is finished you could switch to the "standard" performant numpy ndarrays.
# This brings the best of both worlds:
# - All nice featurers of dataframes during development
# - Performant sklearn transformes during fitting
# - The ability to easily adapt preprocessing steps and revalidate those.
# This notebook is inspired by lucabasas Notebook on pipelines.
# https://www.kaggle.com/lucabasa/understand-and-use-a-pipeline
# and following article on medium:
# https://medium.com/bigdatarepublic/integrating-pandas-and-scikit-learn-with-pipelines-f70eb6183696
# Herein I suggest further "dataframe transformers" and apply those on the titanic machine learning dataset.
# With this dataframe transformers I developed a full preprocessing pipeline without loosing the dataframe informiation (column and index)
# ## Required packages
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
import numpy as np
# ## Load data as Dataframe
# It is important that the test and train data is not concatenated to a complete set and preprocesses together for followig reason:
# For validation a reduced dataset of the train data is used. If we fill emplty values in the train data using information of the test data. We introduced data to the validation that is actually not part of it. Pipelines allow us to develop a preprocessor which can be applied to all datasets seperatly. In turn the validation result will be bether than the exctual prediction.****
# For this reason, only the train data is loaded for now.
df_train = pd.read_csv("../input/titanic/train.csv")
df_train.head()
# ## Take care if nans (imputation)
# create copy for further processing
df = df_train.copy()
df.isnull().sum()
# ## Try and error sklearn transformers with Dataframes
# To keep the dataframe structure we can simply fill the dataframe columns with the ndarray returned by the sklearn transformers.
from sklearn.impute import SimpleImputer
imputer = SimpleImputer()
df[["Age"]] = imputer.fit_transform(df[["Age"]])
df.isnull().sum()
# Alternatively we can create a modified Imputer, which recreates a the original Dataframe from the ndarray after imputation.
class df_SimpleImputer(SimpleImputer): # (BaseEstimator, TransformerMixin):
"""
Just a wrapper for the SimpleImputer that keeps the dataframe structure
"""
def transform(self, X, **kwargs):
Array = SimpleImputer.transform(self, X, **kwargs)
return pd.DataFrame(Array, index=X.index, columns=X.columns)
imputer = df_SimpleImputer()
imputer.fit_transform(df[["Age"]]).transpose()
# ## Use ColumnTransformer
# The ColumnTransformer is ideal to process the individual data columns seperatly.However we use the ColumnTransformer, we cannot simply passthrough unprocessed columns and reload the result in the previous dataframe, as the chronology of the ndarray is different from the dataframe. This is shown in following example.
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
preprocessor = ColumnTransformer(
transformers=[("num", df_SimpleImputer(), ["Age"])], remainder="passthrough"
)
df = df_train.copy()
array = preprocessor.fit_transform(df)
moddf = pd.DataFrame(array, index=df.index, columns=df.columns)
moddf.head()
# Note!: Columns are incorrectly assigned, chronology of column needs to be modified!
# Using the sklearn transformer can be complicated as the column names and indexes are lost. The representation of the data lacks sufficient overview:
preprocessor = ColumnTransformer(
transformers=[("num", df_SimpleImputer(), ["Age"])], remainder="passthrough"
)
df = df_train.copy()
nparray = preprocessor.fit_transform(df)
nparray
# ## Modified ColumnTransformer for dataframes
# To solve this problem I created a modified ColumnsTransformer which returns dataframes instead of numpy ndarrays.
class df_ColumnTransformer(ColumnTransformer):
"""
I cannot garanty that this Transformer works well in combination all sklearn Transformers
Tested with: SimpleImputer, OneHotEncoder, OrdinalEncoder
Applies transformers to columns of an array or pandas DataFrame.
In contrast to the sklearn ColumnTransfromer, this transfomer returns a pandas Dataframe
This estimator allows different columns or column subsets of the input
to be transformed separately and the features generated by each transformer
will be concatenated to form a single feature space.
This is useful for heterogeneous or columnar data, to combine several
feature extraction mechanisms or transformations into a single transformer.
"""
def fit_transform(self, X, *args, **kwargs):
ColumnTransformer.fit_transform(self, X)
return df_ColumnTransformer.transform(self, X, *args, **kwargs)
def transform(self, X, *args, **kwargs):
ret_df = pd.DataFrame(index=X.index) # columns=cols)
for (
row
) in (
self.transformers_
): # row includes all information for one transformer step.
transformer = row[1] # tranformer to be applied
lst_of_cols_transformed = row[
2
] # columns to be transformed with this transformer
if isinstance(transformer, str):
# passthrough other elments if passthrough is set
if transformer == "passthrough":
cols = []
for index in lst_of_cols_transformed:
cols.append(X.columns[index])
ret_df[cols] = X[cols]
else:
transformed = transformer.transform(+X[lst_of_cols_transformed])
if transformed.shape[1] == len(lst_of_cols_transformed):
# Set provided DataFrame columns as given in the cols
for i, col in enumerate(lst_of_cols_transformed):
if isinstance(transformed, pd.DataFrame):
transformed = transformed.values
ret_df[col] = transformed[:, i]
else:
# e.g. with OneHotEncoder, more columns are provided, in this case it is not always possible to find
# out which output column is related to which input column
if isinstance(transformed, pd.DataFrame):
ret_df = pd.concat([ret_df, transformed], axis=1)
else:
cols = []
for i in range(1, transformed.shape[1] + 1):
cols.append(
"-".join(lst_of_cols_transformed) + "_" + str(i)
)
print(type(transformed))
# if tranformer returns ndarray convert to Dataframe
if isinstance(transformed, np.ndarray):
temp_df = pd.DataFrame(
transformed, index=X.index, columns=cols
)
else:
# if sparse matrix is returned by transformer
temp_df = pd.DataFrame.sparse.from_spmatrix(
transformed, index=X.index, columns=cols
)
temp_df = temp_df.sparse.to_dense()
ret_df = pd.concat([ret_df, temp_df], axis=1)
return ret_df
# Now we can test it. Here we only need to rename the ColumnTransformer to df_ColumnTransformer. The chronology of the column is according to the transfomer steps, but now the assignment is correct:
#
# Preprocessor #1
preprocessor = df_ColumnTransformer(
transformers=[("num", df_SimpleImputer(), ["Age"])], remainder="passthrough"
)
df = df_train.copy()
moddf = preprocessor.fit_transform(df)
moddf.head(3)
# Checking for nans the combination of both seems to impute all nans correctly.
moddf.isnull().sum()
# ### Further preprocessing steps
# Now we have a ColumnTransfromer for DataFrames, which allows us to work on the preprocessing column by column.
# To present that, we additionally use a different Imputer and an OrdinalEncoder to process the 'Embarked' column.
from sklearn.preprocessing import OrdinalEncoder
# Preprocessor #2
process_embarked = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("label_encoder", OrdinalEncoder()),
]
)
preprocessor = df_ColumnTransformer(
transformers=[
("num", df_SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
],
remainder="passthrough",
)
df = df_train.copy()
moddf = preprocessor.fit_transform(df)
moddf.head()
# Now we can use dataframe operations to inspect hte modified columns. e.g. We can get the average age per 'Pclass'.
df[["Age", "Pclass"]].groupby("Pclass").mean()
# We can als use the OneHotEncoder instead of the OrdinalEncoder to encode the 'Embarked' column. As the ColumnTransformer does not know which labels were used by the OneHotEncoder, it simply names those Embarked_1, Embarked_2 and Embarked_3.
from sklearn.preprocessing import OneHotEncoder
# Preprocessor #3
process_embarked = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("label_encoder", OneHotEncoder()),
]
)
preprocessor = df_ColumnTransformer(
transformers=[
("num", df_SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
],
remainder="passthrough",
)
df = df_train.copy()
moddf = preprocessor.fit_transform(df)
moddf.head()
# ## df_OneHotEncoder
# To solve this problem we can write write our own OneHotEncoder, which builds up on top of the original one.
#
class df_OneHotEncoder(OneHotEncoder):
def transform(self, X, *args, **kwargs):
uniquedict = {}
for col in X.columns:
lst = list(X[col].unique())
lst.sort()
uniquedict[col] = lst
Array = OneHotEncoder.transform(self, X, *args, **kwargs)
newcolumns = []
for key in uniquedict:
for value in uniquedict[key]:
newcolumns.append(str(key) + "_" + str(value))
temp_df = pd.DataFrame.sparse.from_spmatrix(
Array, columns=newcolumns, index=X.index
)
temp_df = temp_df.sparse.to_dense()
return temp_df
# This includes the lables in the columns (Embarked_C, Embarked_Q and Embarked_S).
# Preprocessor #4
process_embarked = Pipeline(
steps=[
("imputer", df_SimpleImputer(strategy="most_frequent")),
# The df_OneHotEncoder requires a Dataframe as input, therefore df_SimpleImputer must be used instead of the SimpleImputer.
("label_encoder", df_OneHotEncoder()),
]
)
preprocessor = df_ColumnTransformer(
transformers=[
("num", df_SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
],
remainder="passthrough",
)
df = df_train.copy()
moddf = preprocessor.fit_transform(df)
moddf.head()
# The df_ColumnTransformer is especially handy if we create our own transformes. In this example we generate one for the Cabin column.
# From that we want to generate a column called 'Cabine_Deck' which extractes the Deck from the cabine numner and a Columns 'Cabine' that indicates if a person had a cabin or not.
# Here is a guideline, which shows how to write your own tranformers/estimators: https://scikit-learn.org/stable/developers/develop.html
from sklearn.base import BaseEstimator, TransformerMixin
class df_Process_Cabin(BaseEstimator, TransformerMixin):
"""
If a value is given in cell it is set to 1, if nan cell is set to 0
Empty cabine fields are assigned with 'None'
"""
def fit(self, *args, **kwargs):
return self
def transform(self, X):
for col in X.columns:
X[col + "_Deck"] = X[col].str.extract("([A-Za-z]).", expand=False)
X[col + "_Deck"] = X[col + "_Deck"].fillna("None")
X[col] = X[col].notnull().astype("int")
return X
# Just to have this without df as well
class Process_Cabin(df_Process_Cabin):
# no changes the sklearn transformes will convert this to numpy arrays anyway
def fit(self, *args, **kwargs):
return self
# We can use that transformer in the ColumnTransform just as we would use an ordinary sklearn transformers. See column 'Cabin' and 'Cabin_Deck'.
# Preprocessor #5
process_embarked = Pipeline(
steps=[
("imputer", df_SimpleImputer(strategy="most_frequent")),
# The df_OneHotEncoder requires a Dataframe as input, therefore df_SimpleImputer must be used instead of the SimpleImputer.
("label_encoder", df_OneHotEncoder()),
]
)
preprocessor = df_ColumnTransformer(
transformers=[
("num", df_SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
("cabin", df_Process_Cabin(), ["Cabin"]),
],
remainder="passthrough",
)
df = df_train.copy()
moddf = preprocessor.fit_transform(df)
moddf.head(6)
# Now the the new feature 'Cabin_Deck' can be easily analized using the Dataframe functionality. There seems to be some relation between the deck and the Survial rate.
sns.barplot(x="Cabin_Deck", y="Survived", data=moddf)
# As you can see from the dataframe above, the newly genereated column 'Cabin_Deck' still needs to be processed with a OrdinalEncoder or a OneHotEncoder. I coosed the OrdinalEncoder and introduce a Pipeline and another ColumnTransformer for this procedure.
# Preprocessor #6
process_cabin = Pipeline(
steps=[
("cab", df_Process_Cabin()),
(
"label_encoder",
df_ColumnTransformer(
transformers=[
("deck", OrdinalEncoder(), ["Cabin_Deck"]),
],
remainder="passthrough",
),
),
]
)
process_embarked = Pipeline(
steps=[
("imputer", df_SimpleImputer(strategy="most_frequent")),
# The df_OneHotEncoder requires a Dataframe as input, therefore df_SimpleImputer must be used instead of the SimpleImputer.
("label_encoder", df_OneHotEncoder()),
]
)
preprocessor = df_ColumnTransformer(
transformers=[
("num", df_SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
("cabin", process_cabin, ["Cabin"]),
],
remainder="passthrough",
)
df = df_train.copy()
moddf = preprocessor.fit_transform(df)
moddf.head(6)
# ## Extract Title from name
# As a next stepy I extract the title from the name. To do that, I generate a specific transformer.
class ExtractTitle(BaseEstimator, TransformerMixin):
"""
Extracts title from name in titanic machine learning competion
Basic extraction reused from:
https://www.kaggle.com/muhammetcimci/easy-titanic-survival-prediction-notebook
"""
def fit(*args, **kwargs):
# Nothing to do
return
def fit_transform(self, X, *args):
# Just transform
return self.transform(X)
def transform(self, X):
# Create a list of series from input data.
# This is needed, as the ColumnTransformer will provide a numpy array
# I included several options for flexibility, Normally one would be sufficient.
list_of_Series = []
if isinstance(X, pd.core.series.Series):
list_of_Series = [X]
elif isinstance(X, np.ndarray):
for i in range(0, X.shape[1]):
list_of_Series.append(pd.Series(X[:, i]))
elif isinstance(X, pd.core.frame.DataFrame):
for col in X.columns:
list_of_Series.append(X[col])
else:
warnings.warn('Datatype "' + str(type(X)) + '" not suppoted!')
# Create empty numpy array, which holds result later.
result = np.empty(
shape=(len(list_of_Series[0]), len(list_of_Series)), dtype="O"
)
for i, series in enumerate(list_of_Series):
title = series.str.extract(" ([A-Za-z]+)\.", expand=False)
title = title.replace(
[
"Lady",
"Capt",
"Col",
"Don",
"Dr",
"Major",
"Rev",
"Jonkheer",
"Dona",
],
"Rare",
)
title = title.replace(["Countess", "Lady", "Sir"], "Royal")
title = title.replace("Mlle", "Miss")
title = title.replace("Ms", "Miss")
title = title.replace("Mme", "Mrs")
result[:, i] = title.values
return result
#
class df_ExtractTitle(ExtractTitle):
"""
Extracts title from name in titanic machine learning competion
Returns Dataframe
"""
def transform(self, X):
columns = list(X.columns)
for i, col in enumerate(columns):
columns[i] = col + "_Title"
matrix = ExtractTitle.transform(self, X)
return pd.DataFrame(matrix, index=X.index, columns=columns)
# Lets apply the newly created tranformer. Further I include an OrdinalEncoder for the column 'Sex'. I guess you can imagine how complicated it would be to evaluate the correct behavior using the numpy arrays.
# Preprocessor #7
process_cabin = Pipeline(
steps=[
("cab", df_Process_Cabin()),
(
"label_encoder",
df_ColumnTransformer(
transformers=[
("deck", OrdinalEncoder(), ["Cabin_Deck"]),
],
remainder="passthrough",
),
),
]
)
process_embarked = Pipeline(
steps=[
("imputer", df_SimpleImputer(strategy="most_frequent")),
# The df_OneHotEncoder requires a Dataframe as input, therefore df_SimpleImputer must be used instead of the SimpleImputer.
("label_encoder", df_OneHotEncoder()),
]
)
process_title = Pipeline(
steps=[("title_extract", df_ExtractTitle()), ("encode", df_OneHotEncoder())]
)
preprocessor = df_ColumnTransformer(
transformers=[
("num", df_SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
("cabin", process_cabin, ["Cabin"]),
("name", process_title, ["Name"]),
("sex", OrdinalEncoder(), ["Sex"]),
],
remainder="passthrough",
)
df = df_train.copy()
moddf = preprocessor.fit_transform(df)
moddf.head(4)
# The column 'Ticket' is not needed in my prediction. Also the column 'Survived' should not be processed. Instead of passing all unprocessed columns (remainder = passthrough), I will copy unchanged columns. To do so I created a transformer copier. For sure I could as well just use an Imputer, which has nothing to do for those columns. For the column 'Pclass' I will include a OneHotEncoder, later I will test if that provides better results during validation. this is the last preprocessing step I will apply.
class Copier(BaseEstimator, TransformerMixin):
"""
Simply takes over column as they are.
"""
def fit(*args, **kwargs):
# Nothing to do
return
def fit_transform(self, X, *args):
# Just transform
return self.transform(X)
def transform(self, X):
return X
# Here you can see the complete preprocessing Pipeline using the Dataframes.
# Preprocessor #8
process_cabin = Pipeline(
steps=[
("cab", df_Process_Cabin()),
(
"label_encoder",
df_ColumnTransformer(
transformers=[
("deck", OrdinalEncoder(), ["Cabin_Deck"]),
],
remainder="passthrough",
),
),
]
)
process_embarked = Pipeline(
steps=[
("imputer", df_SimpleImputer(strategy="most_frequent")),
# The df_OneHotEncoder requires a Dataframe as input, therefore df_SimpleImputer must be used instead of the SimpleImputer.
("label_encoder", df_OneHotEncoder()),
]
)
process_title = Pipeline(
steps=[("title_extract", df_ExtractTitle()), ("encode", df_OneHotEncoder())]
)
preprocessor = df_ColumnTransformer(
transformers=[
("num", df_SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
("cabin", process_cabin, ["Cabin"]),
("name", process_title, ["Name"]),
("sex", OrdinalEncoder(), ["Sex"]),
("onehot", df_OneHotEncoder(), ["Pclass"]),
("unmodified", Copier(), ["Fare", "Parch", "SibSp"]),
],
remainder="drop",
) # drops ticket
df = df_train.copy()
# I will make a time measurment on the compete preprocessing.
moddf = preprocessor.fit_transform(df)
moddf.head(3)
# ## Switch back to the performant numpy arrays
# Now that the preprocessing is successfully developed, the pipeline can be modified to work with the perfromant numpy arrays. To do that, from the previous pipeline I removed all 'df_'s, switching to the ordinary sklearn transformers.
# Sklearn Preprocessor
process_cabin = Pipeline(
steps=[
("cab", Process_Cabin()),
(
"label_encoder",
ColumnTransformer(
transformers=[
("deck", OrdinalEncoder(), ["Cabin_Deck"]),
],
remainder="passthrough",
),
),
]
)
process_embarked = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("label_encoder", OneHotEncoder()),
]
)
process_title = Pipeline(
steps=[("title_extract", ExtractTitle()), ("encode", OneHotEncoder())]
)
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
("cabin", process_cabin, ["Cabin"]),
("name", process_title, ["Name"]),
("sex", OrdinalEncoder(), ["Sex"]),
("onehot", OneHotEncoder(), ["Pclass"]),
("unmodified", Copier(), ["Fare", "Parch", "SibSp"]),
],
remainder="drop",
) # drops ticket
df = df_train.copy()
nparray = preprocessor.fit_transform(df)
nparray[1, :]
# Compared to our previous preprocessing pipeline we were significantly faster. From ~125 ms down to ~44.8 ms.
# We can also show that the df_ version and the numpy array version returned the same result. From now on we will not need the Dataframe version anymore.
if np.sum(np.equal(nparray, moddf.values)) == nparray.size:
print("All elements are equal!")
# # Create Pipeline with Model
# Now that preprocessor is finished we can create a complete pipeline to include our model as well.
# Preproccesing-Modeling Pipeline #1
from sklearn.ensemble import GradientBoostingClassifier
process_cabin = Pipeline(
steps=[
("cab", Process_Cabin()),
(
"label_encoder",
ColumnTransformer(
transformers=[
("deck", OrdinalEncoder(), ["Cabin_Deck"]),
],
remainder="passthrough",
),
),
]
)
process_embarked = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("label_encoder", OneHotEncoder(handle_unknown="ignore")),
]
)
process_title = Pipeline(
steps=[("title_extract", ExtractTitle()), ("encode", OneHotEncoder())]
)
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(), ["Age"]),
("embarked", process_embarked, ["Embarked"]),
("cabin", process_cabin, ["Cabin"]),
("name", process_title, ["Name"]),
("sex", OrdinalEncoder(), ["Sex"]),
("onehot", OneHotEncoder(handle_unknown="ignore"), ["Pclass"]),
("unmodified", Copier(), ["Fare", "Parch", "SibSp"]),
],
remainder="drop",
) # drops ticket
model = GradientBoostingClassifier(random_state=0)
process = Pipeline(steps=[("preprocessor", preprocessor), ("model", model)])
from sklearn.model_selection import cross_val_score
df = df_train.copy()
y = df["Survived"]
df = df.drop(
"Survived", axis=1
) # make sure that Survived is really not used in fitting
X = df
cross_val_score(process, X, y).mean()
# Now we can play around with the Pipeline and see which features and which models perform best in cross validation.
# Preproccesing-Modeling Pipeline #2
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
process_cabin = Pipeline(
steps=[
("cab", Process_Cabin()),
(
"label_encoder",
ColumnTransformer(
transformers=[
(
"deck",
OneHotEncoder(handle_unknown="ignore", categories="auto"),
["Cabin_Deck"],
),
],
remainder="passthrough",
),
),
]
)
process_embarked = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("label_encoder", OneHotEncoder(handle_unknown="ignore", categories="auto")),
]
)
process_title = Pipeline(
steps=[
("title_extract", ExtractTitle()),
("encode", OneHotEncoder(handle_unknown="ignore", categories="auto")),
]
)
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(), ["Age", "Fare"]), # Fare has nan in the test data
("cab", cabine, ["Cabin"]), # Categorize and imputes at the same time
("cat", OrdinalEncoder(), ["Sex"]),
("class", OrdinalEncoder(), ["Pclass"]),
("parch", impute_onehot, ["Parch"]),
("embarked", impute_onehot, ["Embarked"]),
("name", title_onehot, ["Name"]),
("copy", Copier(), ["SibSp"]),
],
remainder="drop",
) # drops ticket
# Validate
df = df_train.copy()
y = df["Survived"].astype(int).values
df = df.drop(
"Survived", axis=1
) # make sure that Survived is really not used in fitting
X = preprocessor.fit_transform(df)
# Validation set for stopping round of XGBclassifier
__, val_x, __, val_y = train_test_split(X, y, test_size=0.30, random_state=4)
model = XGBClassifier(
early_stopping_round=5, eval_set=(val_x, val_y), learning_rate=0.08, random_state=8
)
cross_val_score(model, X, y, cv=4).mean()
# At the end we can use our final pipeline to predict the Survived feature in the test data.
# train
df = df_train.copy()
y_train = df_train["Survived"].values
df = df.drop(["Survived"], axis=1)
X_train = df
X_test = pd.read_csv("../input/titanic/test.csv")
# Validation set for stopping round of XGBclassifier -> Complete X_train and y_train can be used.
X_train_class = preprocessor.fit_transform(
X_train
) # preprocessor should be performed on this data as well.
model = XGBClassifier(
early_stopping_round=8,
eval_set=(X_train_class, y_train),
learning_rate=0.08,
random_state=8,
)
process = Pipeline(steps=[("preprocessor", preprocessor), ("model", model)])
process.fit(X_train, y_train)
y_pred = process.predict(X_test)
y_pred
output = pd.DataFrame({"PassengerId": X_test["PassengerId"].values, "Survived": y_pred})
output
output.to_csv("submission.csv", index=False)
def auto_model_cross_val(
X,
y,
preprocessor,
model_class_ptr,
optimize_param,
param_list,
model_kwargs=dict(),
cross_val_kwargs={"scoring": "accuracy", "cv": 5},
):
"""
Preform multiple cross_validations of model with modified model parameter
:param val_set:
:param y_name:
:param model_class_ptr:
:param optimize_param:
:param param_list:
:param model_kwargs:
:return:
"""
from sklearn.model_selection import cross_val_score
from sklearn.pipeline import Pipeline
import pandas as pd
score_df = pd.DataFrame()
score_df[optimize_param] = param_list
score_df = score_df.set_index(optimize_param)
score_list = []
for param in param_list:
model_kwargs[optimize_param] = param
model_instance = model_class_ptr(**model_kwargs)
process = Pipeline(
steps=[("preprocessor", preprocessor), ("model", model_instance)]
)
score = cross_val_score(process, X, y, **cross_val_kwargs).mean()
score_list.append(score)
score_df[cross_val_kwargs["scoring"]] = score_list
return score_df
from xgboost import XGBClassifier
y_train = df_train["Survived"].astype(int).values
impute_onehot = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="most_frequent")),
("label_encoder", OneHotEncoder(handle_unknown="ignore", categories="auto")),
]
)
title_onehot = Pipeline(
steps=[
("title_extract", ExtractTitle()),
("one_hot", OneHotEncoder(handle_unknown="ignore", categories="auto")),
]
)
cabine = Pipeline(
steps=[
("cab", Process_Cabin()),
(
"label_encoder",
ColumnTransformer(
transformers=[
("deck", OneHotEncoder(handle_unknown="ignore"), ["Cabin_Deck"])
],
remainder="passthrough",
),
),
]
)
preprocessor = ColumnTransformer(
transformers=[
("num", SimpleImputer(), ["Age", "Fare"]), # Fare has nan in the test data
("cab", cabine, ["Cabin"]), # Categorize and imputes at the same time
("cat", OrdinalEncoder(), ["Sex"]),
("class", OrdinalEncoder(), ["Pclass"]),
("parch", impute_onehot, ["Parch"]),
("embarked", impute_onehot, ["Embarked"]),
("name", title_onehot, ["Name"]),
("copy", Copier(), ["SibSp"]),
]
)
__, val_x, __, val_y = train_test_split(
df_train, y_train, test_size=0.30, random_state=8
)
auto_model_cross_val(
df_train,
y_train,
preprocessor,
XGBClassifier,
"learning_rate",
param_list=[0.06, 0.07, 0.08, 0.09, 0.1],
model_kwargs={"early_stopping_rounds": 8, "eval_set": [(val_x, val_y)]},
)
| false | 0 | 7,966 | 0 | 6 | 7,966 |
||
32525073 | <kaggle_start><code># > # M5 Statistical Benchmarks with Python classes
# This notebook provides some of the **statistical benchmark models** proposed by **M5 organizers** (for more details about these models and for more general information on the M5 competition, please refer to the [M5 Competitors Guide](https://mk0mcompetitiont8ake.kinstacdn.com/wp-content/uploads/2020/02/M5-Competitors-Guide_Final-1.pdf)).
# Bonus part: a benchmark using facebook prophet has also been provided.
# Althaugh more efficient packages already exists for some the following models, the aim of this notebook is to present how we can easily **implement these benchmark models from scratch** so as to better **understand how they work**.
# Moreover, I decided to use simple Python classes for each one of the model for making the code more modular.
# A final submission file is created by averaging the predictions of the top 2 (with respect to WRMSSE on the validation set) benchmark models.
# If you found the notebook useful, please upvote it ;-)
# If you have any remarks/questions, do not hesitate to comment, I'll be more than happy to discuss with you.
# ## LOAD LIBRARIES
from tqdm import tqdm
import matplotlib.pyplot as plt
import os
import seaborn as sns
import pandas as pd
import numpy as np
from itertools import cycle
from scipy.stats import hmean
import plotly.express as px
import plotly.graph_objects as go
import plotly.offline as pyo
from scipy.optimize import minimize_scalar
from statsmodels.tsa.api import ExponentialSmoothing, SimpleExpSmoothing
import itertools
from functools import partial
from multiprocessing import Pool
import statsmodels.api as sm
import warnings
from statsmodels.tsa.api import SimpleExpSmoothing
from scipy.ndimage.interpolation import shift
pyo.init_notebook_mode(connected=True)
import math
from typing import Union
from tqdm.auto import tqdm as tqdm
import constants as cnt
pd.set_option("max_columns", 50)
def reduce_mem_usage(df, verbose=True):
"""
from M5 Forecast: Keras with Categorical Embeddings V2
https://www.kaggle.com/mayer79/m5-forecast-keras-with-categorical-embeddings-v2
"""
numerics = ["int16", "int32", "int64", "float16", "float32", "float64"]
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == "int":
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if (
c_min > np.finfo(np.float16).min
and c_max < np.finfo(np.float16).max
):
df[col] = df[col].astype(np.float16)
elif (
c_min > np.finfo(np.float32).min
and c_max < np.finfo(np.float32).max
):
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
if verbose:
print(
"Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)".format(
end_mem, 100 * (start_mem - end_mem) / start_mem
)
)
return df
def load_raw_data():
"""
Load raw input data. Paths are in the constant.py file
Return:
- df_train_val : sales train val data-frame
- df_calendar : calendar data-frame
- df_price : price data-frame
- df_sample_sub : sample submission data-frame
"""
df_train_val = pd.read_csv(cnt.SALES_TRAIN_VAL_PATH)
df_calendar = pd.read_csv(cnt.CALENDAR_PATH)
df_price = pd.read_csv(cnt.SELL_PRICE_PATH)
df_sample_sub = pd.read_csv(cnt.SAMPLE_SUBMISSION)
df_train_val = reduce_mem_usage(df_train_val)
df_calendar = reduce_mem_usage(df_calendar)
df_price = reduce_mem_usage(df_price)
df_sample_sub = reduce_mem_usage(df_sample_sub)
print("df_train_val shape: ", df_train_val.shape)
print("df_calendar shape: ", df_calendar.shape)
print("df_price shape: ", df_price.shape)
print("df_sample_sub shape: ", df_sample_sub.shape)
return df_train_val, df_calendar, df_price, df_sample_sub
def split_train_val_sales(df_sales, horizon):
"""
train-val split of sales data according to the horizon parameter
"""
df_sales_train = df_sales.iloc[:, :-horizon]
df_val_item = df_sales[
["id", "item_id", "dept_id", "cat_id", "store_id", "state_id"]
]
df_val_qty = df_sales.iloc[:, -cnt.HORIZON :]
df_sales_val = pd.concat([df_val_item, df_val_qty], axis=1)
print("df_sales_train shape: ", df_sales_train.shape)
print("df_sales_val shape: ", df_sales_val.shape)
return df_sales_train, df_sales_val
# ## Load Data
# Load Raw input data
df_train_val, df_calendar, df_price, df_sample_sub = load_raw_data()
# ## Split Train-Val
# Split train val sales
df_train, df_val = split_train_val_sales(df_sales=df_train_val, horizon=cnt.HORIZON)
df_train.head()
df_val.head()
df_calendar.head()
df_price.head()
df_sample_sub.head()
df_sample_sub.tail()
def plot_time_series(index, df_train, calendar, df_eval=None, preds=None):
df_eval = df_val.copy()
id_columns = [i for i in df_train_val.columns if not i.startswith("d_")]
d_columns_train = [i for i in df_train.columns if i.startswith("d_")]
if df_eval is not None:
d_columns_eval = [i for i in df_eval.columns if i.startswith("d_")]
calendar = calendar[["d", "date"]]
# Train
train_serie = df_train.iloc[[index], :]
train_serie = pd.melt(train_serie, id_vars=id_columns, value_vars=d_columns_train)
train_serie.columns = id_columns + ["d", "sales"]
train_serie = train_serie.merge(calendar, on="d", how="left")
# Eval
if df_eval is not None:
eval_serie = df_eval.iloc[[index], :]
eval_serie = pd.melt(eval_serie, id_vars=id_columns, value_vars=d_columns_eval)
eval_serie.columns = id_columns + ["d", "sales"]
eval_serie = eval_serie.merge(calendar, on="d", how="left")
# Pred
if preds is not None:
pred_serie = pd.concat(
[
eval_serie[["date"]],
pd.DataFrame(preds[index, :].ravel(), columns=["sales"]),
],
axis=1,
)
fig = go.Figure()
fig.add_trace(
go.Scatter(
x=train_serie.date,
y=train_serie["sales"],
name="train",
line_color="deepskyblue",
)
)
if df_eval is not None:
fig.add_trace(
go.Scatter(
x=eval_serie.date,
y=eval_serie["sales"],
name="eval",
line_color="dimgray",
)
)
if preds is not None:
fig.add_trace(
go.Scatter(
x=pred_serie.date,
y=pred_serie["sales"],
name="pred",
line_color="darkmagenta",
)
)
fig.update_layout(
title_text="Time Series: " + df_train.iloc[index, 0],
xaxis_rangeslider_visible=True,
)
fig.show()
# ## WRMSSEEvaluator
class WRMSSEEvaluator(object):
"""
From WRMSSE Evaluator with extra feature
https://www.kaggle.com/dhananjay3/wrmsse-evaluator-with-extra-features
"""
group_ids = (
"all_id",
"state_id",
"store_id",
"cat_id",
"dept_id",
"item_id",
["state_id", "cat_id"],
["state_id", "dept_id"],
["store_id", "cat_id"],
["store_id", "dept_id"],
["item_id", "state_id"],
["item_id", "store_id"],
)
def __init__(
self,
train_df: pd.DataFrame,
valid_df: pd.DataFrame,
calendar: pd.DataFrame,
prices: pd.DataFrame,
):
"""
intialize and calculate weights
"""
self.calendar = calendar
self.prices = prices
self.train_df = train_df
self.valid_df = valid_df
self.train_target_columns = [
i for i in self.train_df.columns if i.startswith("d_")
]
self.weight_columns = self.train_df.iloc[:, -28:].columns.tolist()
self.train_df["all_id"] = "all"
self.id_columns = [i for i in self.train_df.columns if not i.startswith("d_")]
self.valid_target_columns = [
i for i in self.valid_df.columns if i.startswith("d_")
]
if not all([c in self.valid_df.columns for c in self.id_columns]):
self.valid_df = pd.concat(
[self.train_df[self.id_columns], self.valid_df], axis=1, sort=False
)
self.train_series = self.trans_30490_to_42840(
self.train_df, self.train_target_columns, self.group_ids
)
self.valid_series = self.trans_30490_to_42840(
self.valid_df, self.valid_target_columns, self.group_ids
)
self.weights = self.get_weight_df()
self.scale = self.get_scale()
self.train_series = None
self.train_df = None
self.prices = None
self.calendar = None
def get_scale(self):
"""
scaling factor for each series ignoring starting zeros
"""
scales = []
for i in tqdm(range(len(self.train_series))):
series = self.train_series.iloc[i].values
series = series[np.argmax(series != 0) :]
scale = ((series[1:] - series[:-1]) ** 2).mean()
scales.append(scale)
return np.array(scales)
def get_name(self, i):
"""
convert a str or list of strings to unique string
used for naming each of 42840 series
"""
if type(i) == str or type(i) == int:
return str(i)
else:
return "--".join(i)
def get_weight_df(self) -> pd.DataFrame:
"""
returns weights for each of 42840 series in a dataFrame
"""
day_to_week = self.calendar.set_index("d")["wm_yr_wk"].to_dict()
weight_df = self.train_df[
["item_id", "store_id"] + self.weight_columns
].set_index(["item_id", "store_id"])
weight_df = (
weight_df.stack().reset_index().rename(columns={"level_2": "d", 0: "value"})
)
weight_df["wm_yr_wk"] = weight_df["d"].map(day_to_week)
weight_df = weight_df.merge(
self.prices, how="left", on=["item_id", "store_id", "wm_yr_wk"]
)
weight_df["value"] = weight_df["value"] * weight_df["sell_price"]
weight_df = weight_df.set_index(["item_id", "store_id", "d"]).unstack(level=2)[
"value"
]
weight_df = weight_df.loc[
zip(self.train_df.item_id, self.train_df.store_id), :
].reset_index(drop=True)
weight_df = pd.concat(
[self.train_df[self.id_columns], weight_df], axis=1, sort=False
)
weights_map = {}
for i, group_id in enumerate(tqdm(self.group_ids, leave=False)):
lv_weight = (
weight_df.groupby(group_id)[self.weight_columns].sum().sum(axis=1)
)
lv_weight = lv_weight / lv_weight.sum()
for i in range(len(lv_weight)):
weights_map[self.get_name(lv_weight.index[i])] = np.array(
[lv_weight.iloc[i]]
)
weights = pd.DataFrame(weights_map).T / len(self.group_ids)
return weights
def trans_30490_to_42840(self, df, cols, group_ids, dis=False):
"""
transform 30490 sries to all 42840 series
"""
series_map = {}
for i, group_id in enumerate(tqdm(self.group_ids, leave=False, disable=dis)):
tr = df.groupby(group_id)[cols].sum()
for i in range(len(tr)):
series_map[self.get_name(tr.index[i])] = tr.iloc[i].values
return pd.DataFrame(series_map).T
def get_rmsse(self, valid_preds) -> pd.Series:
"""
returns rmsse scores for all 42840 series
"""
score = ((self.valid_series - valid_preds) ** 2).mean(axis=1)
rmsse = (score / self.scale).map(np.sqrt)
return rmsse
def score(self, valid_preds: Union[pd.DataFrame, np.ndarray]) -> float:
assert self.valid_df[self.valid_target_columns].shape == valid_preds.shape
if isinstance(valid_preds, np.ndarray):
valid_preds = pd.DataFrame(valid_preds, columns=self.valid_target_columns)
valid_preds = pd.concat(
[self.valid_df[self.id_columns], valid_preds], axis=1, sort=False
)
valid_preds = self.trans_30490_to_42840(
valid_preds, self.valid_target_columns, self.group_ids, True
)
self.rmsse = self.get_rmsse(valid_preds)
self.contributors = pd.concat(
[self.weights, self.rmsse], axis=1, sort=False
).prod(axis=1)
return np.sum(self.contributors)
id_columns = [i for i in df_train_val.columns if not i.startswith("d_")]
d_columns_train = [i for i in df_train.columns if i.startswith("d_")]
d_columns_val = [i for i in df_val.columns if i.startswith("d_")]
train_fold_df = df_train.copy()
valid_fold_df = df_val.copy()
error_eval = WRMSSEEvaluator(
train_fold_df, valid_fold_df[d_columns_val], df_calendar, df_price
)
l = list([train_fold_df, valid_fold_df])
del l
# # Statistical Benchmarks
# ## Generic Class
class M5model(object):
"""
Generic class for representing M5 Benchmark statistical models
"""
def __init__(self, horizon):
"""
horizon : integer, horizon of prediction.
"""
self.horizon = horizon
def _remove_starting_zeros(self, serie):
"""
Remove starting zeros from serie
"""
start_index = np.argmax(serie != 0)
return serie[start_index:]
def predict(self, serie):
pass
def predict_all(self, df_train):
"""
Predict using the Naive (persistence) method on a DataFrame of time series.
Parameters
----------
df_train : pd.DataFrame, shape (nb_series, ids+d_) d_{i} columns contains sales
Returns
-------
preds : array, shape (nb_series, horizon)
Returns predicted values.
"""
nb_series = df_train.shape[0]
preds = np.zeros((nb_series, self.horizon))
d_columns = [i for i in df_train.columns if i.startswith("d_")]
for index, row in enumerate(
tqdm(df_train[d_columns].itertuples(index=False), total=len(df_train))
):
series = self._remove_starting_zeros(row)
preds[index, :] = self.predict(series)
return preds
def create_submission_file(self, df, file_name):
"""
Create submission file with the predictions
NB: We double the horizon to take into accoint validation & evaluation forcasts as requested in the submission file
"""
single_horizon = self.horizon
# double horizon to take into accoint validation & evaluation forcast in the submission file
self.horizon = 2 * single_horizon
preds = self.predict_all(df)
sample_submission = pd.read_csv(cnt.SAMPLE_SUBMISSION)
sample_submission.iloc[0 : preds.shape[0], 1:] = preds[:, 0:single_horizon]
sample_submission.iloc[-preds.shape[0] :, 1:] = preds[:, -single_horizon:]
sample_submission.to_csv(file_name, index=False, compression="gzip")
# ## Naive
class M5Naive(M5model):
"""
Naive (persistence) method for time series forecasting.
Last known value will be persisted.
"""
def predict(self, serie):
"""
Predict using the Naive (persistence) method.
Returns
-------
predictions : array, shape (horizon,)
Returns predicted values.
"""
last_value = serie[-1]
predictions = np.ones(self.horizon) * last_value
return predictions
naive_preds_val = M5Naive(horizon=cnt.HORIZON).predict_all(df_train)
naive_error = error_eval.score(naive_preds_val)
naive_error
naive_preds_val.shape
naive_preds_val[:, 0 : cnt.HORIZON].shape, naive_preds_val[:, -cnt.HORIZON :].shape
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=naive_preds_val,
calendar=df_calendar,
)
# ## Seasonal Naive
class M5SeasonalNaive(M5model):
"""
Seasinal Naive (persistence) method for time series forecasting.
Last known values in the given seasonal perdiod (expressed in number of days) will be persisted.
"""
def __init__(self, horizon, seasonal_days):
"""
Initialization
Parameters
----------
horizon : integer, horizon of prediction.
seasonal_days: int, number of day determining the series seasonality (ex: 7 for weekly)
"""
self.horizon = horizon
self.seasonal_days = seasonal_days
def predict(self, sequence):
"""
Predict using the Seasonal Naive method.
Returns
-------
predictions : array, shape (horizon,)
Returns predicted values.
"""
last_seasonal_values = sequence[-self.seasonal_days :]
predictions = np.tile(
last_seasonal_values, math.ceil(self.horizon / self.seasonal_days)
)[: self.horizon]
return predictions
snaive_preds_val = M5SeasonalNaive(horizon=cnt.HORIZON, seasonal_days=7).predict_all(
df_train
)
snaive_error = error_eval.score(snaive_preds_val)
snaive_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=snaive_preds_val,
calendar=df_calendar,
)
# ## Simple Exponential Smoothing
class M5SimpleExponentialSmoothing(M5model):
"""
Simple Exponential Smooting method for time series forecasting.
"""
def __init__(self, horizon=1, alpha=0.1, optimized=False, bounds=(0, 1), maxiter=3):
"""
Params:
----------
horizon : integer, horizon of prediction.
alpha : float,Exponential smoothing parameter, range(0,1)
optimized: boolean, if True alpha is calculated and optimized automatically
bounds: 2D-tuple, (lower_bound, upper_bound) for alpha param
maxiter: int, max number of iteration for finding the optimal alpha (the higher the more accurate, but also the slower)
"""
self.horizon = horizon
self.alpha = alpha
self.optimized = optimized
self.bounds = bounds
self.maxiter = maxiter
def _fit(self, ts, alpha):
"""
Fit Simple Exponential Smoothing
"""
len_ts = len(ts)
es = np.zeros(len_ts) # exponential-smoothing array
# init
es[0] = ts[0]
for i in range(1, len_ts):
es[i] = alpha * ts[i - 1] + (1 - alpha) * es[i - 1]
return es
def _mse(self, ts, alpha):
es = self._fit(ts, alpha)
mse = np.mean(np.square(ts - es))
return mse
def _best_alpha(self, ts):
"""
Calculate best alpha parameter based on MSE
"""
res = minimize_scalar(
lambda alpha: self._mse(ts, alpha),
bounds=self.bounds,
method="bounded",
options={"xatol": 1e-05, "maxiter": self.maxiter},
)
return res.x
def predict(self, ts):
"""
Predict with Simple Exponential Smoothing method
Parameters
----------
ts : array, time series array
Returns
-------
preds : array, shape (horizon,)
Returns predicted values.
"""
if self.optimized:
alpha = self._best_alpha(ts)
self.alpha = alpha
len_ts = len(ts)
es = np.zeros(len_ts) # exponential-smoothing array
# init
es[0] = ts[0]
for i in range(1, len_ts):
es[i] = self.alpha * ts[i] + (1 - self.alpha) * es[i - 1]
preds = np.repeat(es[-1], self.horizon)
return preds
ses_preds_val = M5SimpleExponentialSmoothing(
horizon=cnt.HORIZON, alpha=0.1, optimized=False, bounds=(0.1, 0.3), maxiter=1
).predict_all(df_train)
ses_error = error_eval.score(ses_preds_val)
ses_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=ses_preds_val,
calendar=df_calendar,
)
# ## Moving Average
class M5MovingAverage(M5model):
"""
Moving Average method for time series forecasting.
"""
def __init__(self, horizon, k, optimized=False, k_lb=2, k_ub=5, last_n_values=None):
"""
horizon : integer, horizon of prediction.
k : integer, moving average is calculated from the moving last k elements
optimized boolean, if True parameter k is calculated and optimized automatically
k_lb : integer, lower bound of k paramter
k_ub : integer, upper bound of k paramter
last_n_values : int, default None, take last n values of the serie to calculate best k param (to speed up)
"""
self.horizon = horizon
self.k = k
self.optimized = optimized
self.k_lb = k_lb
self.k_ub = k_ub
self.last_n_values = last_n_values
def calculate_best_k_parameter(self, serie):
"""
Calulate the optimal (in terms of mse) paramter k for moving average.
Paramter k determines the last k elements of the serie that have to be taken to calculate the (moving) average
Parameters
----------
serie : array, vector containing the serie's values
Returns
-------
best_k : int
Returns the best k value selected from the range [k_lb, k_ub] by minimizing the insample MSE.
"""
serie = self._remove_starting_zeros(serie)
if self.last_n_values is not None:
serie = serie[-self.last_n_values :] # reduce serie to its last_n_values
serie_len = len(serie)
mse = np.zeros(self.k_ub - self.k_lb + 1)
all_k = list(range(self.k_lb, self.k_ub + 1))
for ind, k in enumerate(all_k):
moving_average_values = np.zeros((serie_len - k))
for i in range(k, serie_len):
sliding_window = serie[i - k : i]
moving_average_values[i - k] = np.average(sliding_window)
mse[ind] = np.average(np.square(serie[k:] - moving_average_values))
best_k = all_k[np.argmin(mse)]
return best_k
def predict(self, serie):
"""
Predict using the Moving Average method.
Parameters
----------
serie : array, vector of serie values
Returns
-------
predictions : array, shape (horizon,)
Returns predicted values.
"""
if self.optimized:
serie_optimized = serie
if self.last_n_values is not None:
# To speed up calcuation, best k param is calculated from last_n_values
serie_optimized = serie_optimized[-self.last_n_values :]
best_k = self.calculate_best_k_parameter(serie_optimized)
self.k = best_k
working_serie = np.concatenate((serie[-self.k :], np.zeros(self.horizon)))
for i in range(self.horizon):
working_serie[self.k + i] = np.average(working_serie[i : self.k + i])
return working_serie[self.k :]
ma_preds_val = M5MovingAverage(
k=3, horizon=cnt.HORIZON, optimized=True, k_lb=3, k_ub=5, last_n_values=28
).predict_all(df_train)
ma_error = error_eval.score(ma_preds_val)
ma_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=ma_preds_val,
calendar=df_calendar,
)
# # Croston
class M5Croston(M5model):
def __init__(self, horizon):
self.horizon = horizon
self.smoothing_level = 0.1
self.optimized = False
self.maxiter = 3
self.debiasing = 1
def _inter_demand_intervals(self, ts):
"""
Calculate inter-demand intervals of serie
"""
demand_times = np.argwhere(ts > 0).ravel() + 1
a = demand_times - shift(demand_times, 1, cval=0)
return a
def _positive_demand(self, ts):
"""
Calculates non-zero demand (values) of a serie
"""
return ts[ts > 0]
def predict(self, ts):
"""
Predict using the Croston method.
Parameters
----------
ts : array, vector of time-series values
horizon : integer, horizon of prediction.
Returns
-------
predictions : array, shape (horizon,)
Returns predicted values.
"""
ts = np.array(ts)
p = self._inter_demand_intervals(ts)
a = self._positive_demand(ts)
p_est = M5SimpleExponentialSmoothing(
horizon=self.horizon, alpha=0.1, optimized=self.optimized, bounds=(0.1, 0.3)
).predict(p)
a_est = M5SimpleExponentialSmoothing(
horizon=self.horizon, alpha=0.1, optimized=self.optimized, bounds=(0.1, 0.3)
).predict(a)
# Future Forecast
future_forecasts = self.debiasing * np.divide(a_est, p_est)
return future_forecasts
cro_preds_val = M5Croston(horizon=cnt.HORIZON).predict_all(df_train)
cro_error = error_eval.score(cro_preds_val)
cro_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=cro_preds_val,
calendar=df_calendar,
)
# ## Optimized Croston
class M5OptCroston(M5Croston):
"""
Optimized Croston model
"""
def __init__(self, horizon, maxiter):
super().__init__(horizon)
self.optimized = True
self.maxiter = maxiter
optcro_preds_val = M5OptCroston(horizon=cnt.HORIZON, maxiter=3).predict_all(df_train)
optcro_error = error_eval.score(optcro_preds_val)
optcro_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=optcro_preds_val,
calendar=df_calendar,
)
# ## Syntetos-Boylan Approximation (SBA)
class M5SBA(M5Croston):
"""
Syntetos-Boylan Approximation (SBA) model
"""
def __init__(self, horizon):
super().__init__(horizon)
self.debiasing = 0.95
sba_preds_val = M5SBA(horizon=cnt.HORIZON).predict_all(df_train)
sba_error = error_eval.score(sba_preds_val)
sba_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=sba_preds_val,
calendar=df_calendar,
)
# ## Teunter-Syntetos-Babai method (TSB)
class M5TSB(M5model):
"""
Teunter-Syntetos-Babai method (TSB)
Inspired by https://medium.com/analytics-vidhya/croston-forecast-model-for-intermittent-demand-360287a17f5f
"""
def __init__(self, horizon, alpha, beta):
self.horizon = horizon
self.alpha = alpha
self.beta = beta
def predict(self, ts):
ts = np.array(ts) # Transform the input into a numpy array
len_ts = len(ts) # Historical period length
# level (a), probability(p) and forecast (f)
a = np.zeros(len_ts + 1)
p = np.zeros(len_ts + 1)
f = np.zeros(len_ts + 1)
first_occurence = np.argmax(ts > 0)
a[0] = ts[first_occurence]
p[0] = 1 / (1 + first_occurence)
f[0] = p[0] * a[0]
# Create all the t+1 forecasts
for t in range(0, len_ts):
if ts[t] > 0:
a[t + 1] = self.alpha * ts[t] + (1 - self.alpha) * a[t]
p[t + 1] = self.beta * (1) + (1 - self.beta) * p[t]
else:
a[t + 1] = a[t]
p[t + 1] = (1 - self.beta) * p[t]
f[t + 1] = p[t + 1] * a[t + 1]
# Future Forecast
preds = np.repeat(f[-1], self.horizon)
return preds
tsb_preds_val = M5TSB(horizon=cnt.HORIZON, alpha=0.1, beta=0.1).predict_all(df_train)
tsb_error = error_eval.score(tsb_preds_val)
tsb_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=tsb_preds_val,
calendar=df_calendar,
)
# ## Exponential Smoothing
class M5TopDown(object):
"""
Base class to model Top-DOwn approach:
- predicting top-level time-series and
- disaggregating predictions proportional to bottom time-series values
"""
def __init__(self, horizon, df_train, df_calendar):
self.horizon = horizon
self.df_train = df_train
self.df_calendar = df_calendar
self.top_level = self._get_top_level_timeserie()
def _get_top_level_timeserie(self):
"""
Calculate top level time series by aggregating low level time-series
"""
data = np.sum(self.df_train.iloc[:, 6:].values, axis=0)
index = pd.date_range(
start=self.df_calendar["date"][0],
end=self.df_calendar["date"][len(data) - 1],
freq="D",
)
top_level = pd.Series(data, index)
return top_level
def _get_weights(self):
"""
Claculate weights based on the last 28 days for each time series;
These weights will be used to disaggregate the top level time-series
"""
w = np.sum(self.df_train.iloc[:, -28:].values, axis=1) / sum(
self.top_level[-28:]
)
w = w.reshape(len(w), 1)
return w
def _parameters_tuning(self):
"""
Tuning hyper-parameters of the model used for predicting the top-level time-series future horizon.
The implenetation will depend on the method used (ex: Expontial Smoothign, ARIMA, etc)
"""
pass
def predict_top_level(self):
"""
Predict the future horizon of top level time-series
"""
pass
def predict_bottom_levels(self):
"""
Predict the future horizon of the bottom level time-series by disaggregating the the top level predictions
"""
w = self._get_weights()
top_level_preds = self.predict_top_level().values
top_level_preds = top_level_preds.reshape(1, len(top_level_preds))
preds = np.multiply(top_level_preds, w)
return preds
def create_submission_file(self, file_name):
"""
Create submission file with the predictions
NB: We double the horizon to take into account validation & evaluation forcasts as requested in the submission file
"""
single_horizon = self.horizon
# double horizon to take into accoint validation & evaluation forcast in the submission file
self.horizon = 2 * single_horizon
preds = self.predict_bottom_levels()
sample_submission = pd.read_csv(cnt.SAMPLE_SUBMISSION)
sample_submission.iloc[0 : preds.shape[0], 1:] = preds[:, 0:single_horizon]
sample_submission.iloc[-preds.shape[0] :, 1:] = preds[:, -single_horizon:]
sample_submission.to_csv(file_name, index=False, compression="gzip")
class M5ExponentialSmoothing(M5TopDown):
"""
An algorithm is used to select the most appropriate exponential smoothing model
for predicting the top level of the hierarchy (level 1 of Table 1), indicated through information criteria (AIC).
The top-down method will be used for obtaining reconciled forecasts
at the rest of the hierarchical levels (based on historical proportions, estimated for the last 28 days).
"""
def __init__(self, horizon, df_train, df_calendar):
self.horizon = horizon
self.df_train = df_train
self.df_calendar = df_calendar
self.top_level = self._get_top_level_timeserie()
def _parameters_tuning(self):
# prepare param grid
trend_param = ["add", "mul", None]
seasonal_param = ["add", "mul", None]
damped_param = [True, False]
params = [trend_param, seasonal_param, damped_param]
grid_param = list(itertools.product(*params))
grid_param = [
(trend, seasonal, damped)
for trend, seasonal, damped in grid_param
if not (trend == None and damped == True)
]
aic = np.ones(len(grid_param)) * np.nan
# grid-search
for i, (trend, seasonal, damped) in enumerate(grid_param):
ES = ExponentialSmoothing(
self.top_level,
trend=trend,
seasonal=seasonal,
damped=damped,
seasonal_periods=7,
freq="D",
).fit(optimized=True, use_brute=True)
aic[i] = ES.aic
# best parameters & AIC
best_index = np.nanargmin(aic)
best_params = grid_param[best_index]
best_aic = aic[best_index]
return best_params, best_aic
def predict_top_level(self):
(best_trend, best_seas, best_dumped), best_aic = self._parameters_tuning()
ES = ExponentialSmoothing(
self.top_level,
trend=best_trend,
damped=best_dumped,
seasonal=best_seas,
seasonal_periods=7,
freq="D",
).fit(optimized=True, use_brute=True)
top_level_preds = ES.forecast(self.horizon)
return top_level_preds
es_preds_val = M5ExponentialSmoothing(
horizon=cnt.HORIZON, df_train=df_train, df_calendar=df_calendar
).predict_bottom_levels()
es_error = error_eval.score(es_preds_val)
es_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=es_preds_val,
calendar=df_calendar,
)
# ## ARIMA
class M5ARIMA(M5TopDown):
def __init__(self, horizon, df_train, df_calendar):
self.horizon = horizon
self.df_train = df_train
self.df_calendar = df_calendar
self.top_level = self._get_top_level_timeserie()
self.exog_fit = None
self.exog_pred = None
def _get_aic(self, order):
"""
Because some parameter combinations may lead to numerical misspecifications,
we explicitly disabled warning messages in order to avoid an overload of warning messages.
These misspecifications can also lead to errors and throw an exception,
so we make sure to catch these exceptions and ignore the parameter combinations that cause these issues.
"""
aic = np.nan
try:
with warnings.catch_warnings():
warnings.filterwarnings(
"ignore",
message="Maximum Likelihood optimization failed to converge. Check mle_retvals",
)
arima_mod = sm.tsa.statespace.SARIMAX(
endog=self.top_level,
exog=self.exog_fit,
order=order,
enforce_stationarity=False,
enforce_invertibility=False,
).fit()
aic = arima_mod.aic
except:
pass
return aic
def _parameters_tuning(self, n_jobs=7):
d = range(3)
p = range(12)
q = range(12)
params = [p, d, q]
pdq_params = list(itertools.product(*params))
get_aic_partial = partial(self._get_aic)
p = Pool(n_jobs)
res_aic = p.map(get_aic_partial, pdq_params)
p.close()
best_aic_index = np.nanargmin(res_aic)
best_aic = res_aic[best_aic_index]
best_pdq = pdq_params[best_aic_index]
return best_pdq, best_aic
def predict_top_level(self):
best_pdq, best_aic = self._parameters_tuning()
arima_mod = sm.tsa.statespace.SARIMAX(
endog=self.top_level,
exog=self.exog_fit,
order=best_pdq,
enforce_stationarity=False,
enforce_invertibility=False,
).fit()
top_level_preds = arima_mod.forecast(self.horizon, exog=self.exog_pred)
return top_level_preds
arima_preds_val = M5ARIMA(
horizon=cnt.HORIZON, df_train=df_train, df_calendar=df_calendar
).predict_bottom_levels()
arima_error = error_eval.score(arima_preds_val)
arima_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=arima_preds_val,
calendar=df_calendar,
)
# ## ARIMAX
class M5ARIMAX(M5ARIMA):
def __init__(self, horizon, df_train, df_calendar):
self.horizon = horizon
self.df_train = df_train
self.df_calendar = df_calendar
self.train_len = len([x for x in self.df_train.columns if x.startswith("d_")])
self.top_level = self._get_top_level_timeserie()
self.exog_fit, self.exog_pred = self._get_exploratory_variables()
def _get_exploratory_variables(self):
calendar = self.df_calendar[
["date", "snap_CA", "snap_TX", "snap_WI", "event_name_1", "event_name_2"]
].copy()
calendar["snap_count"] = calendar[["snap_CA", "snap_TX", "snap_WI"]].apply(
np.sum, axis=1
)
calendar["is_event_1"] = [
isinstance(x, str) * 1 for x in calendar["event_name_1"]
]
calendar["is_event_2"] = [
isinstance(x, str) * 1 for x in calendar["event_name_2"]
]
calendar["is_event"] = calendar[["is_event_1", "is_event_2"]].apply(
np.sum, axis=1
)
calendar["is_event"] = np.where(calendar["is_event"] > 0, 1, 0)
exog_fit = calendar[["snap_count", "is_event"]].iloc[: self.train_len, :].values
exog_pred = (
calendar[["snap_count", "is_event"]]
.iloc[self.train_len : self.train_len + self.horizon, :]
.values
)
return exog_fit, exog_pred
def create_submission_file(self, file_name):
"""
Create submission file with the predictions
NB: We double the horizon to take into account validation & evaluation forcasts as requested in the submission file
"""
single_horizon = self.horizon
# double horizon to take into accoint validation & evaluation forcast in the submission file
# self.horizon = 2 * single_horizon
# Ri-Calculate Ex Variables to take into account 2*horizon
self.exog_fit, self.exog_pred = self._get_exploratory_variables()
preds = self.predict_bottom_levels()
sample_submission = pd.read_csv(cnt.SAMPLE_SUBMISSION)
sample_submission.iloc[0 : preds.shape[0], 1:] = preds[:, 0:single_horizon]
sample_submission.iloc[-preds.shape[0] :, 1:] = preds[:, -single_horizon:]
sample_submission.to_csv(file_name, index=False, compression="gzip")
arimax_preds_val = M5ARIMAX(
horizon=cnt.HORIZON, df_train=df_train, df_calendar=df_calendar
).predict_bottom_levels()
arimax_error = error_eval.score(arimax_preds_val)
arimax_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=arimax_preds_val,
calendar=df_calendar,
)
# ## Bonus: Facebook Prophet
# Eventhough Facebook Prophet method is not an official benchmark provided by the M5 organizers, I decided to give it a try.
# As for ARIMAX, I added the exploratory variables as well as the built it holidays.
from fbprophet import Prophet
class M5Prophet(M5ARIMAX):
def __init__(self, horizon, df_train, df_calendar):
self.horizon = horizon
self.df_train = df_train
self.df_calendar = df_calendar
self.train_len = len([x for x in self.df_train.columns if x.startswith("d_")])
self.top_level = self._get_top_level_timeserie()
self.exog_fit, self.exog_pred = self._get_exploratory_variables()
def predict_top_level(self):
df = pd.DataFrame({"ds": self.top_level.index, "y": self.top_level.values})
df["snap_count"] = self.exog_fit[:, 0]
df["is_event"] = self.exog_fit[:, 1]
m = Prophet()
m.add_regressor("snap_count")
m.add_regressor("is_event")
m.add_country_holidays(country_name="US")
m.fit(df)
future = m.make_future_dataframe(periods=self.horizon)
future["snap_count"] = np.concatenate(
(self.exog_fit[:, 0], self.exog_pred[:, 0])
)
future["is_event"] = np.concatenate((self.exog_fit[:, 1], self.exog_pred[:, 1]))
preds = m.predict(future)
top_level_preds = pd.Series(
preds["yhat"].values[-self.horizon :],
index=preds["ds"].values[-self.horizon :],
)
return top_level_preds
fp_preds_val = M5Prophet(
horizon=cnt.HORIZON, df_train=df_train, df_calendar=df_calendar
).predict_bottom_levels()
fp_error = error_eval.score(fp_preds_val)
fp_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=fp_preds_val,
calendar=df_calendar,
)
# # Validation Scores
method = [
"Naive",
"sNaive",
"SES",
"MA",
"CRO",
"optCRO",
"SBA",
"TSB",
"ES",
"ARIMA",
"ARIMAX",
"prophet",
]
error = [
naive_error,
snaive_error,
ses_error,
ma_error,
cro_error,
optcro_error,
sba_error,
tsb_error,
es_error,
arima_error,
arimax_error,
fp_error,
]
validation_errors = (
pd.DataFrame({"method": method, "WRMSSE": error})
.sort_values("WRMSSE")
.reset_index(drop=True)
)
validation_errors
# ## Submission files for all methods
M5Naive(horizon=cnt.HORIZON).create_submission_file(
df_train_val, file_name="submission_naive.csv.gz"
)
M5SeasonalNaive(horizon=cnt.HORIZON, seasonal_days=7).create_submission_file(
df_train_val, file_name="submission_snaive.csv.gz"
)
M5SimpleExponentialSmoothing(
horizon=cnt.HORIZON, alpha=0.1, optimized=True, bounds=(0.1, 0.3), maxiter=10
).create_submission_file(df_train_val, file_name="submission_ses.csv.gz")
M5MovingAverage(
k=3, horizon=cnt.HORIZON, optimized=True, k_lb=3, k_ub=5, last_n_values=100
).create_submission_file(df_train_val, file_name="submission_ma.csv.gz")
M5Croston(horizon=cnt.HORIZON).create_submission_file(
df_train_val, file_name="submission_cro.csv.gz"
)
M5OptCroston(horizon=cnt.HORIZON, maxiter=10).create_submission_file(
df_train_val, file_name="submission_optcro.csv.gz"
)
M5SBA(horizon=cnt.HORIZON).create_submission_file(
df_train_val, file_name="submission_sba.csv.gz"
)
M5TSB(horizon=cnt.HORIZON, alpha=0.1, beta=0.1).create_submission_file(
df_train_val, file_name="submission_tsb.csv.gz"
)
M5ExponentialSmoothing(
horizon=cnt.HORIZON, df_train=df_train_val, df_calendar=df_calendar
).create_submission_file(file_name="submission_es.csv.gz")
M5ARIMA(
horizon=cnt.HORIZON, df_train=df_train_val, df_calendar=df_calendar
).create_submission_file("submission_arima.csv.gz")
M5ARIMAX(
horizon=cnt.HORIZON, df_train=df_train_val, df_calendar=df_calendar
).create_submission_file("submission_arimax.csv.gz")
M5Prophet(
horizon=cnt.HORIZON, df_train=df_train, df_calendar=df_calendar
).create_submission_file("submission_prophet.csv.gz")
# ## Final Submission
# Final submission is calculated by averaging the best 3 methods with respct to WRMSSE on the validaation set.
top_methods = validation_errors["method"].head(3).values
submission_files = [
"submission_" + method.lower() + ".csv.gz" for method in top_methods
]
all_preds = np.zeros((60980, cnt.HORIZON, len(submission_files)))
for i, file in tqdm(enumerate(submission_files)):
sub_df = pd.read_csv(file)
all_preds[:, :, i] = sub_df.iloc[:, 1:].values
final_pred = np.mean(all_preds, axis=2)
final_pred.shape
# ### Write final submission
final_submission = pd.read_csv(cnt.SAMPLE_SUBMISSION)
final_submission.iloc[0 : final_pred.shape[0], 1:] = final_pred
final_submission.to_csv("submission.csv.gz", index=False, compression="gzip")
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0032/525/32525073.ipynb | null | null | [{"Id": 32525073, "ScriptId": 8511938, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 493741, "CreationDate": "04/23/2020 09:45:55", "VersionNumber": 14.0, "Title": "M5 Statistical Benchmarks with Python classes", "EvaluationDate": "04/23/2020", "IsChange": true, "TotalLines": 1295.0, "LinesInsertedFromPrevious": 122.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 1173.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 2}] | null | null | null | null | # > # M5 Statistical Benchmarks with Python classes
# This notebook provides some of the **statistical benchmark models** proposed by **M5 organizers** (for more details about these models and for more general information on the M5 competition, please refer to the [M5 Competitors Guide](https://mk0mcompetitiont8ake.kinstacdn.com/wp-content/uploads/2020/02/M5-Competitors-Guide_Final-1.pdf)).
# Bonus part: a benchmark using facebook prophet has also been provided.
# Althaugh more efficient packages already exists for some the following models, the aim of this notebook is to present how we can easily **implement these benchmark models from scratch** so as to better **understand how they work**.
# Moreover, I decided to use simple Python classes for each one of the model for making the code more modular.
# A final submission file is created by averaging the predictions of the top 2 (with respect to WRMSSE on the validation set) benchmark models.
# If you found the notebook useful, please upvote it ;-)
# If you have any remarks/questions, do not hesitate to comment, I'll be more than happy to discuss with you.
# ## LOAD LIBRARIES
from tqdm import tqdm
import matplotlib.pyplot as plt
import os
import seaborn as sns
import pandas as pd
import numpy as np
from itertools import cycle
from scipy.stats import hmean
import plotly.express as px
import plotly.graph_objects as go
import plotly.offline as pyo
from scipy.optimize import minimize_scalar
from statsmodels.tsa.api import ExponentialSmoothing, SimpleExpSmoothing
import itertools
from functools import partial
from multiprocessing import Pool
import statsmodels.api as sm
import warnings
from statsmodels.tsa.api import SimpleExpSmoothing
from scipy.ndimage.interpolation import shift
pyo.init_notebook_mode(connected=True)
import math
from typing import Union
from tqdm.auto import tqdm as tqdm
import constants as cnt
pd.set_option("max_columns", 50)
def reduce_mem_usage(df, verbose=True):
"""
from M5 Forecast: Keras with Categorical Embeddings V2
https://www.kaggle.com/mayer79/m5-forecast-keras-with-categorical-embeddings-v2
"""
numerics = ["int16", "int32", "int64", "float16", "float32", "float64"]
start_mem = df.memory_usage().sum() / 1024**2
for col in df.columns:
col_type = df[col].dtypes
if col_type in numerics:
c_min = df[col].min()
c_max = df[col].max()
if str(col_type)[:3] == "int":
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
else:
if (
c_min > np.finfo(np.float16).min
and c_max < np.finfo(np.float16).max
):
df[col] = df[col].astype(np.float16)
elif (
c_min > np.finfo(np.float32).min
and c_max < np.finfo(np.float32).max
):
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
if verbose:
print(
"Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)".format(
end_mem, 100 * (start_mem - end_mem) / start_mem
)
)
return df
def load_raw_data():
"""
Load raw input data. Paths are in the constant.py file
Return:
- df_train_val : sales train val data-frame
- df_calendar : calendar data-frame
- df_price : price data-frame
- df_sample_sub : sample submission data-frame
"""
df_train_val = pd.read_csv(cnt.SALES_TRAIN_VAL_PATH)
df_calendar = pd.read_csv(cnt.CALENDAR_PATH)
df_price = pd.read_csv(cnt.SELL_PRICE_PATH)
df_sample_sub = pd.read_csv(cnt.SAMPLE_SUBMISSION)
df_train_val = reduce_mem_usage(df_train_val)
df_calendar = reduce_mem_usage(df_calendar)
df_price = reduce_mem_usage(df_price)
df_sample_sub = reduce_mem_usage(df_sample_sub)
print("df_train_val shape: ", df_train_val.shape)
print("df_calendar shape: ", df_calendar.shape)
print("df_price shape: ", df_price.shape)
print("df_sample_sub shape: ", df_sample_sub.shape)
return df_train_val, df_calendar, df_price, df_sample_sub
def split_train_val_sales(df_sales, horizon):
"""
train-val split of sales data according to the horizon parameter
"""
df_sales_train = df_sales.iloc[:, :-horizon]
df_val_item = df_sales[
["id", "item_id", "dept_id", "cat_id", "store_id", "state_id"]
]
df_val_qty = df_sales.iloc[:, -cnt.HORIZON :]
df_sales_val = pd.concat([df_val_item, df_val_qty], axis=1)
print("df_sales_train shape: ", df_sales_train.shape)
print("df_sales_val shape: ", df_sales_val.shape)
return df_sales_train, df_sales_val
# ## Load Data
# Load Raw input data
df_train_val, df_calendar, df_price, df_sample_sub = load_raw_data()
# ## Split Train-Val
# Split train val sales
df_train, df_val = split_train_val_sales(df_sales=df_train_val, horizon=cnt.HORIZON)
df_train.head()
df_val.head()
df_calendar.head()
df_price.head()
df_sample_sub.head()
df_sample_sub.tail()
def plot_time_series(index, df_train, calendar, df_eval=None, preds=None):
df_eval = df_val.copy()
id_columns = [i for i in df_train_val.columns if not i.startswith("d_")]
d_columns_train = [i for i in df_train.columns if i.startswith("d_")]
if df_eval is not None:
d_columns_eval = [i for i in df_eval.columns if i.startswith("d_")]
calendar = calendar[["d", "date"]]
# Train
train_serie = df_train.iloc[[index], :]
train_serie = pd.melt(train_serie, id_vars=id_columns, value_vars=d_columns_train)
train_serie.columns = id_columns + ["d", "sales"]
train_serie = train_serie.merge(calendar, on="d", how="left")
# Eval
if df_eval is not None:
eval_serie = df_eval.iloc[[index], :]
eval_serie = pd.melt(eval_serie, id_vars=id_columns, value_vars=d_columns_eval)
eval_serie.columns = id_columns + ["d", "sales"]
eval_serie = eval_serie.merge(calendar, on="d", how="left")
# Pred
if preds is not None:
pred_serie = pd.concat(
[
eval_serie[["date"]],
pd.DataFrame(preds[index, :].ravel(), columns=["sales"]),
],
axis=1,
)
fig = go.Figure()
fig.add_trace(
go.Scatter(
x=train_serie.date,
y=train_serie["sales"],
name="train",
line_color="deepskyblue",
)
)
if df_eval is not None:
fig.add_trace(
go.Scatter(
x=eval_serie.date,
y=eval_serie["sales"],
name="eval",
line_color="dimgray",
)
)
if preds is not None:
fig.add_trace(
go.Scatter(
x=pred_serie.date,
y=pred_serie["sales"],
name="pred",
line_color="darkmagenta",
)
)
fig.update_layout(
title_text="Time Series: " + df_train.iloc[index, 0],
xaxis_rangeslider_visible=True,
)
fig.show()
# ## WRMSSEEvaluator
class WRMSSEEvaluator(object):
"""
From WRMSSE Evaluator with extra feature
https://www.kaggle.com/dhananjay3/wrmsse-evaluator-with-extra-features
"""
group_ids = (
"all_id",
"state_id",
"store_id",
"cat_id",
"dept_id",
"item_id",
["state_id", "cat_id"],
["state_id", "dept_id"],
["store_id", "cat_id"],
["store_id", "dept_id"],
["item_id", "state_id"],
["item_id", "store_id"],
)
def __init__(
self,
train_df: pd.DataFrame,
valid_df: pd.DataFrame,
calendar: pd.DataFrame,
prices: pd.DataFrame,
):
"""
intialize and calculate weights
"""
self.calendar = calendar
self.prices = prices
self.train_df = train_df
self.valid_df = valid_df
self.train_target_columns = [
i for i in self.train_df.columns if i.startswith("d_")
]
self.weight_columns = self.train_df.iloc[:, -28:].columns.tolist()
self.train_df["all_id"] = "all"
self.id_columns = [i for i in self.train_df.columns if not i.startswith("d_")]
self.valid_target_columns = [
i for i in self.valid_df.columns if i.startswith("d_")
]
if not all([c in self.valid_df.columns for c in self.id_columns]):
self.valid_df = pd.concat(
[self.train_df[self.id_columns], self.valid_df], axis=1, sort=False
)
self.train_series = self.trans_30490_to_42840(
self.train_df, self.train_target_columns, self.group_ids
)
self.valid_series = self.trans_30490_to_42840(
self.valid_df, self.valid_target_columns, self.group_ids
)
self.weights = self.get_weight_df()
self.scale = self.get_scale()
self.train_series = None
self.train_df = None
self.prices = None
self.calendar = None
def get_scale(self):
"""
scaling factor for each series ignoring starting zeros
"""
scales = []
for i in tqdm(range(len(self.train_series))):
series = self.train_series.iloc[i].values
series = series[np.argmax(series != 0) :]
scale = ((series[1:] - series[:-1]) ** 2).mean()
scales.append(scale)
return np.array(scales)
def get_name(self, i):
"""
convert a str or list of strings to unique string
used for naming each of 42840 series
"""
if type(i) == str or type(i) == int:
return str(i)
else:
return "--".join(i)
def get_weight_df(self) -> pd.DataFrame:
"""
returns weights for each of 42840 series in a dataFrame
"""
day_to_week = self.calendar.set_index("d")["wm_yr_wk"].to_dict()
weight_df = self.train_df[
["item_id", "store_id"] + self.weight_columns
].set_index(["item_id", "store_id"])
weight_df = (
weight_df.stack().reset_index().rename(columns={"level_2": "d", 0: "value"})
)
weight_df["wm_yr_wk"] = weight_df["d"].map(day_to_week)
weight_df = weight_df.merge(
self.prices, how="left", on=["item_id", "store_id", "wm_yr_wk"]
)
weight_df["value"] = weight_df["value"] * weight_df["sell_price"]
weight_df = weight_df.set_index(["item_id", "store_id", "d"]).unstack(level=2)[
"value"
]
weight_df = weight_df.loc[
zip(self.train_df.item_id, self.train_df.store_id), :
].reset_index(drop=True)
weight_df = pd.concat(
[self.train_df[self.id_columns], weight_df], axis=1, sort=False
)
weights_map = {}
for i, group_id in enumerate(tqdm(self.group_ids, leave=False)):
lv_weight = (
weight_df.groupby(group_id)[self.weight_columns].sum().sum(axis=1)
)
lv_weight = lv_weight / lv_weight.sum()
for i in range(len(lv_weight)):
weights_map[self.get_name(lv_weight.index[i])] = np.array(
[lv_weight.iloc[i]]
)
weights = pd.DataFrame(weights_map).T / len(self.group_ids)
return weights
def trans_30490_to_42840(self, df, cols, group_ids, dis=False):
"""
transform 30490 sries to all 42840 series
"""
series_map = {}
for i, group_id in enumerate(tqdm(self.group_ids, leave=False, disable=dis)):
tr = df.groupby(group_id)[cols].sum()
for i in range(len(tr)):
series_map[self.get_name(tr.index[i])] = tr.iloc[i].values
return pd.DataFrame(series_map).T
def get_rmsse(self, valid_preds) -> pd.Series:
"""
returns rmsse scores for all 42840 series
"""
score = ((self.valid_series - valid_preds) ** 2).mean(axis=1)
rmsse = (score / self.scale).map(np.sqrt)
return rmsse
def score(self, valid_preds: Union[pd.DataFrame, np.ndarray]) -> float:
assert self.valid_df[self.valid_target_columns].shape == valid_preds.shape
if isinstance(valid_preds, np.ndarray):
valid_preds = pd.DataFrame(valid_preds, columns=self.valid_target_columns)
valid_preds = pd.concat(
[self.valid_df[self.id_columns], valid_preds], axis=1, sort=False
)
valid_preds = self.trans_30490_to_42840(
valid_preds, self.valid_target_columns, self.group_ids, True
)
self.rmsse = self.get_rmsse(valid_preds)
self.contributors = pd.concat(
[self.weights, self.rmsse], axis=1, sort=False
).prod(axis=1)
return np.sum(self.contributors)
id_columns = [i for i in df_train_val.columns if not i.startswith("d_")]
d_columns_train = [i for i in df_train.columns if i.startswith("d_")]
d_columns_val = [i for i in df_val.columns if i.startswith("d_")]
train_fold_df = df_train.copy()
valid_fold_df = df_val.copy()
error_eval = WRMSSEEvaluator(
train_fold_df, valid_fold_df[d_columns_val], df_calendar, df_price
)
l = list([train_fold_df, valid_fold_df])
del l
# # Statistical Benchmarks
# ## Generic Class
class M5model(object):
"""
Generic class for representing M5 Benchmark statistical models
"""
def __init__(self, horizon):
"""
horizon : integer, horizon of prediction.
"""
self.horizon = horizon
def _remove_starting_zeros(self, serie):
"""
Remove starting zeros from serie
"""
start_index = np.argmax(serie != 0)
return serie[start_index:]
def predict(self, serie):
pass
def predict_all(self, df_train):
"""
Predict using the Naive (persistence) method on a DataFrame of time series.
Parameters
----------
df_train : pd.DataFrame, shape (nb_series, ids+d_) d_{i} columns contains sales
Returns
-------
preds : array, shape (nb_series, horizon)
Returns predicted values.
"""
nb_series = df_train.shape[0]
preds = np.zeros((nb_series, self.horizon))
d_columns = [i for i in df_train.columns if i.startswith("d_")]
for index, row in enumerate(
tqdm(df_train[d_columns].itertuples(index=False), total=len(df_train))
):
series = self._remove_starting_zeros(row)
preds[index, :] = self.predict(series)
return preds
def create_submission_file(self, df, file_name):
"""
Create submission file with the predictions
NB: We double the horizon to take into accoint validation & evaluation forcasts as requested in the submission file
"""
single_horizon = self.horizon
# double horizon to take into accoint validation & evaluation forcast in the submission file
self.horizon = 2 * single_horizon
preds = self.predict_all(df)
sample_submission = pd.read_csv(cnt.SAMPLE_SUBMISSION)
sample_submission.iloc[0 : preds.shape[0], 1:] = preds[:, 0:single_horizon]
sample_submission.iloc[-preds.shape[0] :, 1:] = preds[:, -single_horizon:]
sample_submission.to_csv(file_name, index=False, compression="gzip")
# ## Naive
class M5Naive(M5model):
"""
Naive (persistence) method for time series forecasting.
Last known value will be persisted.
"""
def predict(self, serie):
"""
Predict using the Naive (persistence) method.
Returns
-------
predictions : array, shape (horizon,)
Returns predicted values.
"""
last_value = serie[-1]
predictions = np.ones(self.horizon) * last_value
return predictions
naive_preds_val = M5Naive(horizon=cnt.HORIZON).predict_all(df_train)
naive_error = error_eval.score(naive_preds_val)
naive_error
naive_preds_val.shape
naive_preds_val[:, 0 : cnt.HORIZON].shape, naive_preds_val[:, -cnt.HORIZON :].shape
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=naive_preds_val,
calendar=df_calendar,
)
# ## Seasonal Naive
class M5SeasonalNaive(M5model):
"""
Seasinal Naive (persistence) method for time series forecasting.
Last known values in the given seasonal perdiod (expressed in number of days) will be persisted.
"""
def __init__(self, horizon, seasonal_days):
"""
Initialization
Parameters
----------
horizon : integer, horizon of prediction.
seasonal_days: int, number of day determining the series seasonality (ex: 7 for weekly)
"""
self.horizon = horizon
self.seasonal_days = seasonal_days
def predict(self, sequence):
"""
Predict using the Seasonal Naive method.
Returns
-------
predictions : array, shape (horizon,)
Returns predicted values.
"""
last_seasonal_values = sequence[-self.seasonal_days :]
predictions = np.tile(
last_seasonal_values, math.ceil(self.horizon / self.seasonal_days)
)[: self.horizon]
return predictions
snaive_preds_val = M5SeasonalNaive(horizon=cnt.HORIZON, seasonal_days=7).predict_all(
df_train
)
snaive_error = error_eval.score(snaive_preds_val)
snaive_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=snaive_preds_val,
calendar=df_calendar,
)
# ## Simple Exponential Smoothing
class M5SimpleExponentialSmoothing(M5model):
"""
Simple Exponential Smooting method for time series forecasting.
"""
def __init__(self, horizon=1, alpha=0.1, optimized=False, bounds=(0, 1), maxiter=3):
"""
Params:
----------
horizon : integer, horizon of prediction.
alpha : float,Exponential smoothing parameter, range(0,1)
optimized: boolean, if True alpha is calculated and optimized automatically
bounds: 2D-tuple, (lower_bound, upper_bound) for alpha param
maxiter: int, max number of iteration for finding the optimal alpha (the higher the more accurate, but also the slower)
"""
self.horizon = horizon
self.alpha = alpha
self.optimized = optimized
self.bounds = bounds
self.maxiter = maxiter
def _fit(self, ts, alpha):
"""
Fit Simple Exponential Smoothing
"""
len_ts = len(ts)
es = np.zeros(len_ts) # exponential-smoothing array
# init
es[0] = ts[0]
for i in range(1, len_ts):
es[i] = alpha * ts[i - 1] + (1 - alpha) * es[i - 1]
return es
def _mse(self, ts, alpha):
es = self._fit(ts, alpha)
mse = np.mean(np.square(ts - es))
return mse
def _best_alpha(self, ts):
"""
Calculate best alpha parameter based on MSE
"""
res = minimize_scalar(
lambda alpha: self._mse(ts, alpha),
bounds=self.bounds,
method="bounded",
options={"xatol": 1e-05, "maxiter": self.maxiter},
)
return res.x
def predict(self, ts):
"""
Predict with Simple Exponential Smoothing method
Parameters
----------
ts : array, time series array
Returns
-------
preds : array, shape (horizon,)
Returns predicted values.
"""
if self.optimized:
alpha = self._best_alpha(ts)
self.alpha = alpha
len_ts = len(ts)
es = np.zeros(len_ts) # exponential-smoothing array
# init
es[0] = ts[0]
for i in range(1, len_ts):
es[i] = self.alpha * ts[i] + (1 - self.alpha) * es[i - 1]
preds = np.repeat(es[-1], self.horizon)
return preds
ses_preds_val = M5SimpleExponentialSmoothing(
horizon=cnt.HORIZON, alpha=0.1, optimized=False, bounds=(0.1, 0.3), maxiter=1
).predict_all(df_train)
ses_error = error_eval.score(ses_preds_val)
ses_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=ses_preds_val,
calendar=df_calendar,
)
# ## Moving Average
class M5MovingAverage(M5model):
"""
Moving Average method for time series forecasting.
"""
def __init__(self, horizon, k, optimized=False, k_lb=2, k_ub=5, last_n_values=None):
"""
horizon : integer, horizon of prediction.
k : integer, moving average is calculated from the moving last k elements
optimized boolean, if True parameter k is calculated and optimized automatically
k_lb : integer, lower bound of k paramter
k_ub : integer, upper bound of k paramter
last_n_values : int, default None, take last n values of the serie to calculate best k param (to speed up)
"""
self.horizon = horizon
self.k = k
self.optimized = optimized
self.k_lb = k_lb
self.k_ub = k_ub
self.last_n_values = last_n_values
def calculate_best_k_parameter(self, serie):
"""
Calulate the optimal (in terms of mse) paramter k for moving average.
Paramter k determines the last k elements of the serie that have to be taken to calculate the (moving) average
Parameters
----------
serie : array, vector containing the serie's values
Returns
-------
best_k : int
Returns the best k value selected from the range [k_lb, k_ub] by minimizing the insample MSE.
"""
serie = self._remove_starting_zeros(serie)
if self.last_n_values is not None:
serie = serie[-self.last_n_values :] # reduce serie to its last_n_values
serie_len = len(serie)
mse = np.zeros(self.k_ub - self.k_lb + 1)
all_k = list(range(self.k_lb, self.k_ub + 1))
for ind, k in enumerate(all_k):
moving_average_values = np.zeros((serie_len - k))
for i in range(k, serie_len):
sliding_window = serie[i - k : i]
moving_average_values[i - k] = np.average(sliding_window)
mse[ind] = np.average(np.square(serie[k:] - moving_average_values))
best_k = all_k[np.argmin(mse)]
return best_k
def predict(self, serie):
"""
Predict using the Moving Average method.
Parameters
----------
serie : array, vector of serie values
Returns
-------
predictions : array, shape (horizon,)
Returns predicted values.
"""
if self.optimized:
serie_optimized = serie
if self.last_n_values is not None:
# To speed up calcuation, best k param is calculated from last_n_values
serie_optimized = serie_optimized[-self.last_n_values :]
best_k = self.calculate_best_k_parameter(serie_optimized)
self.k = best_k
working_serie = np.concatenate((serie[-self.k :], np.zeros(self.horizon)))
for i in range(self.horizon):
working_serie[self.k + i] = np.average(working_serie[i : self.k + i])
return working_serie[self.k :]
ma_preds_val = M5MovingAverage(
k=3, horizon=cnt.HORIZON, optimized=True, k_lb=3, k_ub=5, last_n_values=28
).predict_all(df_train)
ma_error = error_eval.score(ma_preds_val)
ma_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=ma_preds_val,
calendar=df_calendar,
)
# # Croston
class M5Croston(M5model):
def __init__(self, horizon):
self.horizon = horizon
self.smoothing_level = 0.1
self.optimized = False
self.maxiter = 3
self.debiasing = 1
def _inter_demand_intervals(self, ts):
"""
Calculate inter-demand intervals of serie
"""
demand_times = np.argwhere(ts > 0).ravel() + 1
a = demand_times - shift(demand_times, 1, cval=0)
return a
def _positive_demand(self, ts):
"""
Calculates non-zero demand (values) of a serie
"""
return ts[ts > 0]
def predict(self, ts):
"""
Predict using the Croston method.
Parameters
----------
ts : array, vector of time-series values
horizon : integer, horizon of prediction.
Returns
-------
predictions : array, shape (horizon,)
Returns predicted values.
"""
ts = np.array(ts)
p = self._inter_demand_intervals(ts)
a = self._positive_demand(ts)
p_est = M5SimpleExponentialSmoothing(
horizon=self.horizon, alpha=0.1, optimized=self.optimized, bounds=(0.1, 0.3)
).predict(p)
a_est = M5SimpleExponentialSmoothing(
horizon=self.horizon, alpha=0.1, optimized=self.optimized, bounds=(0.1, 0.3)
).predict(a)
# Future Forecast
future_forecasts = self.debiasing * np.divide(a_est, p_est)
return future_forecasts
cro_preds_val = M5Croston(horizon=cnt.HORIZON).predict_all(df_train)
cro_error = error_eval.score(cro_preds_val)
cro_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=cro_preds_val,
calendar=df_calendar,
)
# ## Optimized Croston
class M5OptCroston(M5Croston):
"""
Optimized Croston model
"""
def __init__(self, horizon, maxiter):
super().__init__(horizon)
self.optimized = True
self.maxiter = maxiter
optcro_preds_val = M5OptCroston(horizon=cnt.HORIZON, maxiter=3).predict_all(df_train)
optcro_error = error_eval.score(optcro_preds_val)
optcro_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=optcro_preds_val,
calendar=df_calendar,
)
# ## Syntetos-Boylan Approximation (SBA)
class M5SBA(M5Croston):
"""
Syntetos-Boylan Approximation (SBA) model
"""
def __init__(self, horizon):
super().__init__(horizon)
self.debiasing = 0.95
sba_preds_val = M5SBA(horizon=cnt.HORIZON).predict_all(df_train)
sba_error = error_eval.score(sba_preds_val)
sba_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=sba_preds_val,
calendar=df_calendar,
)
# ## Teunter-Syntetos-Babai method (TSB)
class M5TSB(M5model):
"""
Teunter-Syntetos-Babai method (TSB)
Inspired by https://medium.com/analytics-vidhya/croston-forecast-model-for-intermittent-demand-360287a17f5f
"""
def __init__(self, horizon, alpha, beta):
self.horizon = horizon
self.alpha = alpha
self.beta = beta
def predict(self, ts):
ts = np.array(ts) # Transform the input into a numpy array
len_ts = len(ts) # Historical period length
# level (a), probability(p) and forecast (f)
a = np.zeros(len_ts + 1)
p = np.zeros(len_ts + 1)
f = np.zeros(len_ts + 1)
first_occurence = np.argmax(ts > 0)
a[0] = ts[first_occurence]
p[0] = 1 / (1 + first_occurence)
f[0] = p[0] * a[0]
# Create all the t+1 forecasts
for t in range(0, len_ts):
if ts[t] > 0:
a[t + 1] = self.alpha * ts[t] + (1 - self.alpha) * a[t]
p[t + 1] = self.beta * (1) + (1 - self.beta) * p[t]
else:
a[t + 1] = a[t]
p[t + 1] = (1 - self.beta) * p[t]
f[t + 1] = p[t + 1] * a[t + 1]
# Future Forecast
preds = np.repeat(f[-1], self.horizon)
return preds
tsb_preds_val = M5TSB(horizon=cnt.HORIZON, alpha=0.1, beta=0.1).predict_all(df_train)
tsb_error = error_eval.score(tsb_preds_val)
tsb_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=tsb_preds_val,
calendar=df_calendar,
)
# ## Exponential Smoothing
class M5TopDown(object):
"""
Base class to model Top-DOwn approach:
- predicting top-level time-series and
- disaggregating predictions proportional to bottom time-series values
"""
def __init__(self, horizon, df_train, df_calendar):
self.horizon = horizon
self.df_train = df_train
self.df_calendar = df_calendar
self.top_level = self._get_top_level_timeserie()
def _get_top_level_timeserie(self):
"""
Calculate top level time series by aggregating low level time-series
"""
data = np.sum(self.df_train.iloc[:, 6:].values, axis=0)
index = pd.date_range(
start=self.df_calendar["date"][0],
end=self.df_calendar["date"][len(data) - 1],
freq="D",
)
top_level = pd.Series(data, index)
return top_level
def _get_weights(self):
"""
Claculate weights based on the last 28 days for each time series;
These weights will be used to disaggregate the top level time-series
"""
w = np.sum(self.df_train.iloc[:, -28:].values, axis=1) / sum(
self.top_level[-28:]
)
w = w.reshape(len(w), 1)
return w
def _parameters_tuning(self):
"""
Tuning hyper-parameters of the model used for predicting the top-level time-series future horizon.
The implenetation will depend on the method used (ex: Expontial Smoothign, ARIMA, etc)
"""
pass
def predict_top_level(self):
"""
Predict the future horizon of top level time-series
"""
pass
def predict_bottom_levels(self):
"""
Predict the future horizon of the bottom level time-series by disaggregating the the top level predictions
"""
w = self._get_weights()
top_level_preds = self.predict_top_level().values
top_level_preds = top_level_preds.reshape(1, len(top_level_preds))
preds = np.multiply(top_level_preds, w)
return preds
def create_submission_file(self, file_name):
"""
Create submission file with the predictions
NB: We double the horizon to take into account validation & evaluation forcasts as requested in the submission file
"""
single_horizon = self.horizon
# double horizon to take into accoint validation & evaluation forcast in the submission file
self.horizon = 2 * single_horizon
preds = self.predict_bottom_levels()
sample_submission = pd.read_csv(cnt.SAMPLE_SUBMISSION)
sample_submission.iloc[0 : preds.shape[0], 1:] = preds[:, 0:single_horizon]
sample_submission.iloc[-preds.shape[0] :, 1:] = preds[:, -single_horizon:]
sample_submission.to_csv(file_name, index=False, compression="gzip")
class M5ExponentialSmoothing(M5TopDown):
"""
An algorithm is used to select the most appropriate exponential smoothing model
for predicting the top level of the hierarchy (level 1 of Table 1), indicated through information criteria (AIC).
The top-down method will be used for obtaining reconciled forecasts
at the rest of the hierarchical levels (based on historical proportions, estimated for the last 28 days).
"""
def __init__(self, horizon, df_train, df_calendar):
self.horizon = horizon
self.df_train = df_train
self.df_calendar = df_calendar
self.top_level = self._get_top_level_timeserie()
def _parameters_tuning(self):
# prepare param grid
trend_param = ["add", "mul", None]
seasonal_param = ["add", "mul", None]
damped_param = [True, False]
params = [trend_param, seasonal_param, damped_param]
grid_param = list(itertools.product(*params))
grid_param = [
(trend, seasonal, damped)
for trend, seasonal, damped in grid_param
if not (trend == None and damped == True)
]
aic = np.ones(len(grid_param)) * np.nan
# grid-search
for i, (trend, seasonal, damped) in enumerate(grid_param):
ES = ExponentialSmoothing(
self.top_level,
trend=trend,
seasonal=seasonal,
damped=damped,
seasonal_periods=7,
freq="D",
).fit(optimized=True, use_brute=True)
aic[i] = ES.aic
# best parameters & AIC
best_index = np.nanargmin(aic)
best_params = grid_param[best_index]
best_aic = aic[best_index]
return best_params, best_aic
def predict_top_level(self):
(best_trend, best_seas, best_dumped), best_aic = self._parameters_tuning()
ES = ExponentialSmoothing(
self.top_level,
trend=best_trend,
damped=best_dumped,
seasonal=best_seas,
seasonal_periods=7,
freq="D",
).fit(optimized=True, use_brute=True)
top_level_preds = ES.forecast(self.horizon)
return top_level_preds
es_preds_val = M5ExponentialSmoothing(
horizon=cnt.HORIZON, df_train=df_train, df_calendar=df_calendar
).predict_bottom_levels()
es_error = error_eval.score(es_preds_val)
es_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=es_preds_val,
calendar=df_calendar,
)
# ## ARIMA
class M5ARIMA(M5TopDown):
def __init__(self, horizon, df_train, df_calendar):
self.horizon = horizon
self.df_train = df_train
self.df_calendar = df_calendar
self.top_level = self._get_top_level_timeserie()
self.exog_fit = None
self.exog_pred = None
def _get_aic(self, order):
"""
Because some parameter combinations may lead to numerical misspecifications,
we explicitly disabled warning messages in order to avoid an overload of warning messages.
These misspecifications can also lead to errors and throw an exception,
so we make sure to catch these exceptions and ignore the parameter combinations that cause these issues.
"""
aic = np.nan
try:
with warnings.catch_warnings():
warnings.filterwarnings(
"ignore",
message="Maximum Likelihood optimization failed to converge. Check mle_retvals",
)
arima_mod = sm.tsa.statespace.SARIMAX(
endog=self.top_level,
exog=self.exog_fit,
order=order,
enforce_stationarity=False,
enforce_invertibility=False,
).fit()
aic = arima_mod.aic
except:
pass
return aic
def _parameters_tuning(self, n_jobs=7):
d = range(3)
p = range(12)
q = range(12)
params = [p, d, q]
pdq_params = list(itertools.product(*params))
get_aic_partial = partial(self._get_aic)
p = Pool(n_jobs)
res_aic = p.map(get_aic_partial, pdq_params)
p.close()
best_aic_index = np.nanargmin(res_aic)
best_aic = res_aic[best_aic_index]
best_pdq = pdq_params[best_aic_index]
return best_pdq, best_aic
def predict_top_level(self):
best_pdq, best_aic = self._parameters_tuning()
arima_mod = sm.tsa.statespace.SARIMAX(
endog=self.top_level,
exog=self.exog_fit,
order=best_pdq,
enforce_stationarity=False,
enforce_invertibility=False,
).fit()
top_level_preds = arima_mod.forecast(self.horizon, exog=self.exog_pred)
return top_level_preds
arima_preds_val = M5ARIMA(
horizon=cnt.HORIZON, df_train=df_train, df_calendar=df_calendar
).predict_bottom_levels()
arima_error = error_eval.score(arima_preds_val)
arima_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=arima_preds_val,
calendar=df_calendar,
)
# ## ARIMAX
class M5ARIMAX(M5ARIMA):
def __init__(self, horizon, df_train, df_calendar):
self.horizon = horizon
self.df_train = df_train
self.df_calendar = df_calendar
self.train_len = len([x for x in self.df_train.columns if x.startswith("d_")])
self.top_level = self._get_top_level_timeserie()
self.exog_fit, self.exog_pred = self._get_exploratory_variables()
def _get_exploratory_variables(self):
calendar = self.df_calendar[
["date", "snap_CA", "snap_TX", "snap_WI", "event_name_1", "event_name_2"]
].copy()
calendar["snap_count"] = calendar[["snap_CA", "snap_TX", "snap_WI"]].apply(
np.sum, axis=1
)
calendar["is_event_1"] = [
isinstance(x, str) * 1 for x in calendar["event_name_1"]
]
calendar["is_event_2"] = [
isinstance(x, str) * 1 for x in calendar["event_name_2"]
]
calendar["is_event"] = calendar[["is_event_1", "is_event_2"]].apply(
np.sum, axis=1
)
calendar["is_event"] = np.where(calendar["is_event"] > 0, 1, 0)
exog_fit = calendar[["snap_count", "is_event"]].iloc[: self.train_len, :].values
exog_pred = (
calendar[["snap_count", "is_event"]]
.iloc[self.train_len : self.train_len + self.horizon, :]
.values
)
return exog_fit, exog_pred
def create_submission_file(self, file_name):
"""
Create submission file with the predictions
NB: We double the horizon to take into account validation & evaluation forcasts as requested in the submission file
"""
single_horizon = self.horizon
# double horizon to take into accoint validation & evaluation forcast in the submission file
# self.horizon = 2 * single_horizon
# Ri-Calculate Ex Variables to take into account 2*horizon
self.exog_fit, self.exog_pred = self._get_exploratory_variables()
preds = self.predict_bottom_levels()
sample_submission = pd.read_csv(cnt.SAMPLE_SUBMISSION)
sample_submission.iloc[0 : preds.shape[0], 1:] = preds[:, 0:single_horizon]
sample_submission.iloc[-preds.shape[0] :, 1:] = preds[:, -single_horizon:]
sample_submission.to_csv(file_name, index=False, compression="gzip")
arimax_preds_val = M5ARIMAX(
horizon=cnt.HORIZON, df_train=df_train, df_calendar=df_calendar
).predict_bottom_levels()
arimax_error = error_eval.score(arimax_preds_val)
arimax_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=arimax_preds_val,
calendar=df_calendar,
)
# ## Bonus: Facebook Prophet
# Eventhough Facebook Prophet method is not an official benchmark provided by the M5 organizers, I decided to give it a try.
# As for ARIMAX, I added the exploratory variables as well as the built it holidays.
from fbprophet import Prophet
class M5Prophet(M5ARIMAX):
def __init__(self, horizon, df_train, df_calendar):
self.horizon = horizon
self.df_train = df_train
self.df_calendar = df_calendar
self.train_len = len([x for x in self.df_train.columns if x.startswith("d_")])
self.top_level = self._get_top_level_timeserie()
self.exog_fit, self.exog_pred = self._get_exploratory_variables()
def predict_top_level(self):
df = pd.DataFrame({"ds": self.top_level.index, "y": self.top_level.values})
df["snap_count"] = self.exog_fit[:, 0]
df["is_event"] = self.exog_fit[:, 1]
m = Prophet()
m.add_regressor("snap_count")
m.add_regressor("is_event")
m.add_country_holidays(country_name="US")
m.fit(df)
future = m.make_future_dataframe(periods=self.horizon)
future["snap_count"] = np.concatenate(
(self.exog_fit[:, 0], self.exog_pred[:, 0])
)
future["is_event"] = np.concatenate((self.exog_fit[:, 1], self.exog_pred[:, 1]))
preds = m.predict(future)
top_level_preds = pd.Series(
preds["yhat"].values[-self.horizon :],
index=preds["ds"].values[-self.horizon :],
)
return top_level_preds
fp_preds_val = M5Prophet(
horizon=cnt.HORIZON, df_train=df_train, df_calendar=df_calendar
).predict_bottom_levels()
fp_error = error_eval.score(fp_preds_val)
fp_error
plot_time_series(
index=24,
df_train=df_train,
df_eval=df_val,
preds=fp_preds_val,
calendar=df_calendar,
)
# # Validation Scores
method = [
"Naive",
"sNaive",
"SES",
"MA",
"CRO",
"optCRO",
"SBA",
"TSB",
"ES",
"ARIMA",
"ARIMAX",
"prophet",
]
error = [
naive_error,
snaive_error,
ses_error,
ma_error,
cro_error,
optcro_error,
sba_error,
tsb_error,
es_error,
arima_error,
arimax_error,
fp_error,
]
validation_errors = (
pd.DataFrame({"method": method, "WRMSSE": error})
.sort_values("WRMSSE")
.reset_index(drop=True)
)
validation_errors
# ## Submission files for all methods
M5Naive(horizon=cnt.HORIZON).create_submission_file(
df_train_val, file_name="submission_naive.csv.gz"
)
M5SeasonalNaive(horizon=cnt.HORIZON, seasonal_days=7).create_submission_file(
df_train_val, file_name="submission_snaive.csv.gz"
)
M5SimpleExponentialSmoothing(
horizon=cnt.HORIZON, alpha=0.1, optimized=True, bounds=(0.1, 0.3), maxiter=10
).create_submission_file(df_train_val, file_name="submission_ses.csv.gz")
M5MovingAverage(
k=3, horizon=cnt.HORIZON, optimized=True, k_lb=3, k_ub=5, last_n_values=100
).create_submission_file(df_train_val, file_name="submission_ma.csv.gz")
M5Croston(horizon=cnt.HORIZON).create_submission_file(
df_train_val, file_name="submission_cro.csv.gz"
)
M5OptCroston(horizon=cnt.HORIZON, maxiter=10).create_submission_file(
df_train_val, file_name="submission_optcro.csv.gz"
)
M5SBA(horizon=cnt.HORIZON).create_submission_file(
df_train_val, file_name="submission_sba.csv.gz"
)
M5TSB(horizon=cnt.HORIZON, alpha=0.1, beta=0.1).create_submission_file(
df_train_val, file_name="submission_tsb.csv.gz"
)
M5ExponentialSmoothing(
horizon=cnt.HORIZON, df_train=df_train_val, df_calendar=df_calendar
).create_submission_file(file_name="submission_es.csv.gz")
M5ARIMA(
horizon=cnt.HORIZON, df_train=df_train_val, df_calendar=df_calendar
).create_submission_file("submission_arima.csv.gz")
M5ARIMAX(
horizon=cnt.HORIZON, df_train=df_train_val, df_calendar=df_calendar
).create_submission_file("submission_arimax.csv.gz")
M5Prophet(
horizon=cnt.HORIZON, df_train=df_train, df_calendar=df_calendar
).create_submission_file("submission_prophet.csv.gz")
# ## Final Submission
# Final submission is calculated by averaging the best 3 methods with respct to WRMSSE on the validaation set.
top_methods = validation_errors["method"].head(3).values
submission_files = [
"submission_" + method.lower() + ".csv.gz" for method in top_methods
]
all_preds = np.zeros((60980, cnt.HORIZON, len(submission_files)))
for i, file in tqdm(enumerate(submission_files)):
sub_df = pd.read_csv(file)
all_preds[:, :, i] = sub_df.iloc[:, 1:].values
final_pred = np.mean(all_preds, axis=2)
final_pred.shape
# ### Write final submission
final_submission = pd.read_csv(cnt.SAMPLE_SUBMISSION)
final_submission.iloc[0 : final_pred.shape[0], 1:] = final_pred
final_submission.to_csv("submission.csv.gz", index=False, compression="gzip")
| false | 0 | 13,144 | 2 | 6 | 13,144 |
||
32085077 | <kaggle_start><data_title>country health indicators<data_description>This dataset combines multiple open data sets for Covid-19 cases and deaths ([kaggle1](https://www.kaggle.com/c/covid19-global-forecasting-week-3/data)), Death causes ([ourworldindata1](https://ourworldindata.org/grapher/share-of-total-disease-burden-by-cause), [ourworldindata2](https://ourworldindata.org/grapher/share-deaths-smoking), [ourworldindata3]((https://ourworldindata.org/grapher/pneumonia-death-rates-age-standardized)), Food sources ([FAO1](http://www.fao.org/faostat/en/#data/FBS)), Health Care System ([WHO1](https://apps.who.int/gho/data/node.main.HWFGRP_0020?lang=en), [WHO2](https://www.who.int/data/gho/data/indicators/indicator-details/GHO/hospital-beds-(per-10-000-population)), [WHO3](https://www.who.int/data/gho/data/indicators/indicator-details/GHO/total-density-per-100-000-population-specialized-hospitals)), TB vaccine status ([BCG1](http://www.bcgatlas.org/index.php)) School closures ([UNESCO1](https://en.unesco.org/themes/education-emergencies/coronavirus-school-closures)), and People/Society facts ([CIA1](https://www.cia.gov/library/publications/the-world-factbook/docs/rankorderguide.html)).<data_name>country-health-indicators
<code># ## Imports
# Imports
import os
from abc import ABCMeta, abstractmethod
from typing import Dict, List, Tuple, Union
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import mean_squared_log_error
from scipy.optimize.minpack import curve_fit
from scipy.optimize import curve_fit, OptimizeWarning
from scipy.optimize import least_squares
from xgboost import XGBRegressor
# ## Helpers
# First the Root Mean Square Log Error cost function:
# $$\mathrm{RMSLE}=\sqrt{\left}$$
# where, $y$ is actual value and $\hat(y)$ is predicted. Luckily the MSLE is implemented in [sklearn](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.mean_squared_log_error.html#sklearn.metrics.mean_squared_log_error) so all that is needed is a square root. However, as the predictor may be silly and give values just below 0, we force positive values or 0.
def RMSLE(actual: np.ndarray, prediction: np.ndarray) -> float:
"""Calculate Root Mean Square Log Error between actual and predicted values"""
return np.sqrt(mean_squared_log_error(actual, np.maximum(0, prediction)))
# ## Prepare data set
def load_kaggle_csv(dataset: str, datadir: str) -> pd.DataFrame:
"""Load andt preprocess kaggle covid-19 csv dataset."""
df = pd.read_csv(f"{os.path.join(datadir,dataset)}.csv", parse_dates=["Date"])
df["country"] = df["Country_Region"]
if "Province_State" in df:
df["Country_Region"] = np.where(
df["Province_State"].isnull(),
df["Country_Region"],
df["Country_Region"] + "_" + df["Province_State"],
)
df.drop(columns="Province_State", inplace=True)
if "ConfirmedCases" in df:
df["ConfirmedCases"] = df.groupby("Country_Region")["ConfirmedCases"].cummax()
if "Fatalities" in df:
df["Fatalities"] = df.groupby("Country_Region")["Fatalities"].cummax()
if "DayOfYear" not in df:
df["DayOfYear"] = df["Date"].dt.dayofyear
df["Date"] = df["Date"].dt.date
return df
def dateparse(x):
try:
return pd.datetime.strptime(x, "%Y-%m-%d")
except:
return pd.NaT
def prepare_lat_long(df):
df["Country_Region"] = np.where(
df["Province/State"].isnull(),
df["Country/Region"],
df["Country/Region"] + "_" + df["Province/State"],
)
return df[["Country_Region", "Lat", "Long"]].drop_duplicates()
def get_extra_features(df):
df["school_closure_status_daily"] = np.where(
df["school_closure"] < df["Date"], 1, 0
)
df["school_closure_first_fatality"] = np.where(
df["school_closure"] < df["first_1Fatalities"], 1, 0
)
df["school_closure_first_10cases"] = np.where(
df["school_closure"] < df["first_10ConfirmedCases"], 1, 0
)
#
df["case_delta1_10"] = (
df["first_10ConfirmedCases"] - df["first_1ConfirmedCases"]
).dt.days
df["case_death_delta1"] = (
df["first_1Fatalities"] - df["first_1ConfirmedCases"]
).dt.days
df["case_delta1_100"] = (
df["first_100ConfirmedCases"] - df["first_1ConfirmedCases"]
).dt.days
df["days_since"] = df["DayOfYear"] - df["case1_DayOfYear"]
df["weekday"] = pd.to_datetime(df["Date"]).dt.weekday
col = df.isnull().mean()
rm_null_col = col[col > 0.2].index.tolist()
return df
# * ## Load train data
# We use week 1 [train data](https://www.kaggle.com/c/covid19-global-forecasting-week-1/data) to get lat/long of geographic locations, then we use our [country health indicators](https://www.kaggle.com/nxpnsv/country-health-indicators) dataset.
### Train data
# Take lat/long from week 1 data set
df_lat = prepare_lat_long(
pd.read_csv("/kaggle/input/covid19-global-forecasting-week-1/train.csv")
)
# Get current train data
train = load_kaggle_csv("train", "/kaggle/input/covid19-global-forecasting-week-4")
# Insert augmentations
country_health_indicators = (
pd.read_csv(
"/kaggle/input/country-health-indicators/country_health_indicators_v3.csv",
parse_dates=[
"first_1ConfirmedCases",
"first_10ConfirmedCases",
"first_50ConfirmedCases",
"first_100ConfirmedCases",
"first_1Fatalities",
"school_closure",
],
date_parser=dateparse,
)
).rename(columns={"Country_Region": "country"})
# Merge augmentation to kaggle input
train = (pd.merge(train, country_health_indicators, on="country", how="left")).merge(
df_lat, on="Country_Region", how="left"
)
train = get_extra_features(train)
# train=train.fillna(0)
train.head(3)
### TEST DATA
test = load_kaggle_csv("test", "/kaggle/input/covid19-global-forecasting-week-4")
test = (pd.merge(test, country_health_indicators, on="country", how="left")).merge(
df_lat, on="Country_Region", how="left"
)
test = get_extra_features(test)
del country_health_indicators
# # Curve fitting
# First we add a helper class to fit functions. In previous weeks we went with a [Logistic](https://en.wikipedia.org/wiki/Logistic_function) function, but this is increasingly insuffucient. Instead we tried with a [generalized logistic function](https://en.wikipedia.org/wiki/Generalised_logistic_function) (GLF). However, actions like social distances dramatically change rates, so we create a new model DiXGLF which is a linear interpolation between 2 GLF, where the interpolation term $\alpha$ is a logistic function.
class Fitter(metaclass=ABCMeta):
"""
Helper class for 1D fits using scipy fit.
This version assumes y-data is positive and increasing.
"""
def __init__(self, name):
"""Make fitter instance."""
self.kwargs = {
"method": "trf",
"max_nfev": 20000,
"x_scale": "jac",
"loss": "linear",
"jac": self.jacobian,
}
self.name = name
self.rmsle = None
self.fit_params = None
self.fit_cov = None
self.y_hat = None
self.p0 = None
self.bounds = None
@abstractmethod
def function(self, x: np.ndarray, *args) -> np.ndarray:
"""Mathematical function to fit."""
pass
@abstractmethod
def jacobian(self, x: np.ndarray, *args) -> np.ndarray:
"""Jacobian of funciton."""
pass
@abstractmethod
def guess(self) -> Tuple[List[float], List]:
"""First guess for fit optimium."""
pass
def fit(self, x: np.ndarray, y: np.ndarray, **kwargs) -> Union[None, Tuple]:
"""Fit function to y over x."""
# Update extra keywords for fit
kwargs.update(self.kwargs)
# Reset fit results
self.rmsle = None
self.fit_params = None
self.fit_cov = None
self.y_hat = None
self.p0 = None
self.bounds = None
if len(x) <= 3:
return
# Guess params
self.p0, self.bounds = self.guess(x, y)
# Perform fit
try:
res = curve_fit(
f=self.function,
xdata=np.array(x, dtype=np.float128),
ydata=np.array(y, dtype=np.float128),
p0=self.p0,
bounds=self.bounds,
sigma=np.maximum(1, np.sqrt(y)),
**kwargs,
)
except (ValueError, RuntimeError, OptimizeWarning) as e:
print(e)
return
# Update fit results
self.y_hat = self.function(x, *res[0])
self.rmsle = np.sqrt(mean_squared_log_error(y, self.y_hat))
self.fit_params = res[0]
self.fit_cov = res[1]
def plot_fit(self, x, y, ax=None, title=None, **kwargs):
"""Fit and plot."""
self.fit(x, y, **kwargs)
if self.fit_params is None:
print("No result, cannot plot")
return
if ax is None:
_, ax = plt.subplots()
ax.set_title(f"{title or ''} {self.name}: rmsle={self.rmsle:.2f}")
color = "g"
ax.plot(x, y, "o", color=color, alpha=0.9)
ax.plot(x, self.y_hat, "-", color="r")
ax.set_ylabel("Counts", color=color)
ax.set_xlabel("Day of Year")
ax.tick_params(axis="y", labelcolor=color)
ax2 = ax.twinx()
color = "b"
ax2.set_ylabel("Residual", color=color)
ax2.plot(x, y - self.y_hat, ".", color=color)
ax2.tick_params(axis="y", labelcolor=color)
ax.text(
0.05,
0.95,
"\n".join([f"$p_{i}$={x:0.2f}" for i, x in enumerate(self.fit_params)]),
horizontalalignment="left",
verticalalignment="top",
transform=ax.transAxes,
)
class Logistic(Fitter):
def __init__(self):
super().__init__(name="Logistic")
def function(self, x: np.ndarray, K: float, B: float, M: float) -> np.ndarray:
return K / (1 + np.exp(-B * (x - M)))
def jacobian(self, x: np.ndarray, K: float, B: float, M: float) -> np.ndarray:
dK = 1 / (1 + np.exp(-B * (x - M)))
dB = K * (x - M) * np.exp(-B * (x - M)) / np.square(1 + np.exp(-B * (x - M)))
dM = K * B * np.exp(-B * (x - M)) / np.square(1 + np.exp(-B * (x - M)))
return np.transpose([dK, dB, dM])
def guess(self, x: np.ndarray, y: np.ndarray) -> Tuple[List[float], List[float]]:
K = y[-1]
B = 0.1
M = x[np.argmax(y >= 0.5 * K)]
p0 = [K, B, M]
bounds = [[y[-1], 1e-4, x[0]], [y[-1] * 8, 0.5, (1 + x[-1]) * 2]]
return p0, bounds
class GLF(Fitter):
def __init__(self):
super().__init__(name="GLF")
def function(self, x, K, B, M, nu):
return K / np.power((1 + np.exp(-B * (x - M))), 1 / nu)
def jacobian(self, x, K, B, M, nu):
nu1 = 1.0 / nu
xM = x - M
exp_BxM = np.exp(-B * xM)
pow0 = np.power(1 + exp_BxM, -nu1)
pow1 = K * exp_BxM / (nu * np.power(1 + exp_BxM, nu1 + 1))
dK = pow0
dB = xM * pow1
dnu = K * np.log1p(exp_BxM) * pow0 / nu
dM = B * pow1
return np.transpose([dK, dB, dnu, dM])
def guess(self, x, y):
# Guess params and param bounds
K = y[-1]
B = 0.1
M = x[np.argmax(y >= 0.5 * K)]
nu = 0.5
p0 = [K, B, M, nu]
bounds = [
[y[-1], 1e-3, x[0], 1e-2],
[(y[-1] + 1) * 10, 0.5, (x[-1] + 1) * 2, 1.0],
]
return p0, bounds
class DiXGLF(Fitter):
"""Interpolation between 2 logistic function.
First guess is split by y_max/2 so the first and second logistic
start on different partitions of data.
Uses 3-point estimator in place of explicit jacobian because of numeric stability.
"""
def __init__(self):
super().__init__(name="DiXGLF")
self.glf = GLF()
self.logistic = Logistic()
self.kwargs.update({"jac": "3-point"})
def function(self, x, B0, M0, K1, B1, M1, nu1, K2, B2, M2, nu2):
alpha = self.logistic.function(x, 1, B0, M0)
return alpha * self.glf.function(x, K1, B1, M1, nu1) + (
1 - alpha
) * self.glf.function(x, K2, B2, M2, nu2)
def jacobian(self, x, B0, M0, K1, B1, M1, nu1, K2, B2, M2, nu2):
raise RuntimeError("%s jacobian not implemented", self.name)
def guess(self, x, y):
split = min(max(1, np.argmax(y >= 0.5 * y[-1])), len(x) - 2)
p01, bounds1 = self.glf.guess(x[:split], y[:split])
p02, bounds2 = self.glf.guess(x[split:], y[split:])
p0, bounds = self.logistic.guess(x, y)
p0 = p0[1:]
bounds = [bounds[0][1:], bounds[1][1:]]
p0.extend(p01)
p0.extend(p02)
bounds[0].extend(bounds1[0])
bounds[0].extend(bounds2[0])
bounds[1].extend(bounds1[1])
bounds[1].extend(bounds2[1])
return p0, bounds
def apply_fitter(
df: pd.DataFrame,
fitter: Fitter,
x_col: str = "DayOfYear",
y_cols: List[str] = ["ConfirmedCases", "Fatalities"],
) -> pd.DataFrame:
"""Helper to apply fitter to dataframe groups"""
x = df[x_col].astype(np.float128).to_numpy()
result = {}
for y_col in y_cols:
y = df[y_col].astype(np.float128).to_numpy()
fitter.fit(x, y)
if fitter.rmsle is None:
continue
result[f"{y_col}_rmsle"] = fitter.rmsle
df[f"y_hat_fitter_{y_col}"] = fitter.y_hat
result.update({f"{y_col}_p_{i}": p for i, p in enumerate(fitter.fit_params)})
return pd.DataFrame([result])
plt.style.use("seaborn-white")
sns.set_color_codes()
dixglf = DiXGLF()
train["y_hat_fitter_ConfirmedCases"] = 0
train["y_hat_fitter_Fatalities"] = 0
fig, ax = plt.subplots(2, 4, figsize=(16, 8))
ax = ax.flatten()
for i, country in enumerate(("Italy", "Austria", "Korea, South", "Germany")):
c = train[train["Country_Region"] == country]
x = c["DayOfYear"].astype(np.float128).to_numpy()
dixglf.plot_fit(
x,
c["ConfirmedCases"].astype(np.float128).to_numpy(),
ax=ax[i],
title=f"Cases {country}",
)
dixglf.plot_fit(
x,
c["Fatalities"].astype(np.float128).to_numpy(),
ax=ax[i + 4],
title=f"Deaths {country}",
)
fig.tight_layout()
train = pd.merge(
train,
train.groupby(["Country_Region"], observed=True, sort=False)
.apply(lambda x: apply_fitter(x, fitter=dixglf))
.reset_index(),
on=["Country_Region"],
how="left",
)
train["y_hat_fitter_ConfirmedCases"] = dixglf.function(
train["DayOfYear"],
train["ConfirmedCases_p_0"],
train["ConfirmedCases_p_1"],
train["ConfirmedCases_p_2"],
train["ConfirmedCases_p_3"],
train["ConfirmedCases_p_4"],
train["ConfirmedCases_p_5"],
train["ConfirmedCases_p_6"],
train["ConfirmedCases_p_7"],
train["ConfirmedCases_p_8"],
train["ConfirmedCases_p_9"],
)
train["y_hat_fitter_Fatalities"] = dixglf.function(
train["DayOfYear"],
train["Fatalities_p_0"],
train["Fatalities_p_1"],
train["Fatalities_p_2"],
train["Fatalities_p_3"],
train["Fatalities_p_4"],
train["Fatalities_p_5"],
train["Fatalities_p_6"],
train["Fatalities_p_7"],
train["Fatalities_p_8"],
train["Fatalities_p_9"],
)
train.head()
# # XGB boost regression
def apply_xgb_model(train, x_columns, y_column, xgb_params):
X = train[x_columns].astype(np.float32).fillna(0).to_numpy()
y = train[y_column].astype(np.float32).fillna(0).to_numpy()
xgb_fit = XGBRegressor(**xgb_params).fit(X, y)
y_hat = xgb_fit.predict(X)
train[f"yhat_xgb_{y_column}"] = y_hat
return RMSLE(y, y_hat), xgb_fit
xgb_params_c = dict(
gamma=0.1,
learning_rate=0.35,
n_estimators=221,
max_depth=15,
min_child_weight=1,
nthread=8,
objective="reg:squarederror",
)
xgb_params_f = dict(
gamma=0.1022,
learning_rate=0.338,
n_estimators=292,
max_depth=14,
min_child_weight=1,
nthread=8,
objective="reg:squarederror",
)
x_columns = [
"DayOfYear",
"Diabetes, blood, & endocrine diseases (%)",
"Respiratory diseases (%)",
"Diarrhea & common infectious diseases (%)",
"Nutritional deficiencies (%)",
"obesity - adult prevalence rate",
"pneumonia-death-rates",
"animal_fats",
"animal_products",
"eggs",
"offals",
"treenuts",
"vegetable_oils",
"nbr_surgeons",
"nbr_anaesthesiologists",
"population",
"school_shutdown_1case",
"school_shutdown_10case",
"school_shutdown_50case",
"school_shutdown_1death",
"case1_DayOfYear",
"case10_DayOfYear",
"case50_DayOfYear",
"school_closure_status_daily",
"case_delta1_10",
"case_death_delta1",
"case_delta1_100",
"days_since",
"Lat",
"Long",
"weekday",
"y_hat_fitter_ConfirmedCases",
"y_hat_fitter_Fatalities",
]
xgb_c_rmsle, xgb_c_fit = apply_xgb_model(
train, x_columns, "ConfirmedCases", xgb_params_c
)
xgb_f_rmsle, xgb_f_fit = apply_xgb_model(train, x_columns, "Fatalities", xgb_params_f)
# # Hybrid fit
# From logistic curve fit we have $\hat{y}_L$: `y_hat_fitter_ConfirmedCases`,and from XGB boost regression $\hat{y}_X$: `yhat_xgb_ConfirmedCases`.
# Here we make a hybrid predictor
# $\hat{y}_H = \alpha \hat{y}_L + (1-\alpha) \hat{y}_X$
#
# by fitting alpha with `scipy.optmize.least_squares`. Similarly for `Fatalities`. First we define a few functions to do the work:
def interpolate(alpha, x0, x1):
return x0 * alpha + x1 * (1 - alpha)
def RMSLE_interpolate(alpha, y, x0, x1):
return RMSLE(y, interpolate(alpha, x0, x1))
def fit_hybrid(
train: pd.DataFrame, y_cols: List[str] = ["ConfirmedCases", "Fatalities"]
) -> pd.DataFrame:
def fit_one(y_col: str):
opt = least_squares(
fun=RMSLE_interpolate,
args=(
train[y_col],
train[f"y_hat_fitter_{y_col}"],
train[f"yhat_xgb_{y_col}"],
),
x0=(0.5,),
bounds=((0.0), (1.0,)),
)
return {f"{y_col}_alpha": opt.x[0], f"{y_col}_cost": opt.cost}
result = {}
for y_col in y_cols:
result.update(fit_one(y_col))
return pd.DataFrame([result])
def predict_hybrid(
df: pd.DataFrame,
x_col: str = "DayOfYear",
y_cols: List[str] = ["ConfirmedCases", "Fatalities"],
):
def predict_one(col):
df[f"yhat_hybrid_{col}"] = interpolate(
df[f"{y_col}_alpha"].to_numpy(),
df[f"y_hat_fitter_{y_col}"].to_numpy(),
df[f"yhat_xgb_{y_col}"].to_numpy(),
)
for y_col in y_cols:
predict_one(y_col)
# Now apply to each `Country_Region`:
train = pd.merge(
train,
train.groupby(["Country_Region"], observed=True, sort=False)
.apply(lambda x: fit_hybrid(x))
.reset_index(),
on=["Country_Region"],
how="left",
)
predict_hybrid(train)
# # Compare approaches
print(
"Confirmed:\n"
f'Fitter\t{RMSLE(train["ConfirmedCases"], train["y_hat_fitter_ConfirmedCases"])}\n'
f'XGBoost\t{RMSLE(train["ConfirmedCases"], train["yhat_xgb_ConfirmedCases"])}\n'
f'Hybrid\t{RMSLE(train["ConfirmedCases"], train["yhat_hybrid_ConfirmedCases"])}\n'
f"Fatalities:\n"
f'Fitter\t{RMSLE(train["Fatalities"], train["y_hat_fitter_Fatalities"])}\n'
f'XGBoost\t{RMSLE(train["Fatalities"], train["yhat_xgb_Fatalities"])}\n'
f'Hybrid\t{RMSLE(train["Fatalities"], train["yhat_hybrid_Fatalities"])}\n'
)
# # Predict test cases
# Merge logistic and hybrid fit into test
test = pd.merge(
test,
train[
["Country_Region"]
+ [
"ConfirmedCases_p_0",
"ConfirmedCases_p_1",
"ConfirmedCases_p_2",
"ConfirmedCases_p_3",
"ConfirmedCases_p_4",
"ConfirmedCases_p_5",
"ConfirmedCases_p_6",
"ConfirmedCases_p_7",
"ConfirmedCases_p_8",
"ConfirmedCases_p_9",
]
+ [
"Fatalities_p_0",
"Fatalities_p_1",
"Fatalities_p_2",
"Fatalities_p_3",
"Fatalities_p_4",
"Fatalities_p_5",
"Fatalities_p_6",
"Fatalities_p_7",
"Fatalities_p_8",
"Fatalities_p_9",
]
+ ["Fatalities_alpha"]
+ ["ConfirmedCases_alpha"]
]
.groupby(["Country_Region"])
.head(1),
on="Country_Region",
how="left",
)
# Test predictions
test["y_hat_fitter_ConfirmedCases"] = dixglf.function(
test["DayOfYear"],
test["ConfirmedCases_p_0"],
test["ConfirmedCases_p_1"],
test["ConfirmedCases_p_2"],
test["ConfirmedCases_p_3"],
test["ConfirmedCases_p_4"],
test["ConfirmedCases_p_5"],
test["ConfirmedCases_p_6"],
test["ConfirmedCases_p_7"],
test["ConfirmedCases_p_8"],
test["ConfirmedCases_p_9"],
)
test["y_hat_fitter_Fatalities"] = dixglf.function(
test["DayOfYear"],
test["Fatalities_p_0"],
test["Fatalities_p_1"],
test["Fatalities_p_2"],
test["Fatalities_p_3"],
test["Fatalities_p_4"],
test["Fatalities_p_5"],
test["Fatalities_p_6"],
test["Fatalities_p_7"],
test["Fatalities_p_8"],
test["Fatalities_p_9"],
)
test["yhat_xgb_ConfirmedCases"] = xgb_c_fit.predict(test[x_columns].to_numpy())
test["yhat_xgb_Fatalities"] = xgb_f_fit.predict(test[x_columns].to_numpy())
predict_hybrid(test)
# # Prepare submission
submission = (
test[["ForecastId", "yhat_hybrid_ConfirmedCases", "yhat_hybrid_Fatalities"]]
.round(2)
.rename(
columns={
"yhat_hybrid_ConfirmedCases": "ConfirmedCases",
"yhat_hybrid_Fatalities": "Fatalities",
}
)
)
submission["ConfirmedCases"] = np.maximum(0, submission["ConfirmedCases"])
submission["Fatalities"] = np.maximum(0, submission["Fatalities"])
submission.head()
submission.to_csv("submission.csv", index=False)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0032/085/32085077.ipynb | country-health-indicators | nxpnsv | [{"Id": 32085077, "ScriptId": 8950160, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 85138, "CreationDate": "04/15/2020 23:30:59", "VersionNumber": 2.0, "Title": "TBTB-W4", "EvaluationDate": "04/15/2020", "IsChange": true, "TotalLines": 584.0, "LinesInsertedFromPrevious": 58.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 526.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 34667158, "KernelVersionId": 32085077, "SourceDatasetVersionId": 1064891}] | [{"Id": 1064891, "DatasetId": 585107, "DatasourceVersionId": 1094467, "CreatorUserId": 85138, "LicenseName": "CC BY-NC-SA 4.0", "CreationDate": "04/07/2020 11:12:41", "VersionNumber": 6.0, "Title": "country health indicators", "Slug": "country-health-indicators", "Subtitle": "Health indicator relevant to covid19 death and infection risk", "Description": "This dataset combines multiple open data sets for Covid-19 cases and deaths ([kaggle1](https://www.kaggle.com/c/covid19-global-forecasting-week-3/data)), Death causes ([ourworldindata1](https://ourworldindata.org/grapher/share-of-total-disease-burden-by-cause), [ourworldindata2](https://ourworldindata.org/grapher/share-deaths-smoking), [ourworldindata3]((https://ourworldindata.org/grapher/pneumonia-death-rates-age-standardized)), Food sources ([FAO1](http://www.fao.org/faostat/en/#data/FBS)), Health Care System ([WHO1](https://apps.who.int/gho/data/node.main.HWFGRP_0020?lang=en), [WHO2](https://www.who.int/data/gho/data/indicators/indicator-details/GHO/hospital-beds-(per-10-000-population)), [WHO3](https://www.who.int/data/gho/data/indicators/indicator-details/GHO/total-density-per-100-000-population-specialized-hospitals)), TB vaccine status ([BCG1](http://www.bcgatlas.org/index.php)) School closures ([UNESCO1](https://en.unesco.org/themes/education-emergencies/coronavirus-school-closures)), and People/Society facts ([CIA1](https://www.cia.gov/library/publications/the-world-factbook/docs/rankorderguide.html)).", "VersionNotes": "Updated version", "TotalCompressedBytes": 0.0, "TotalUncompressedBytes": 0.0}] | [{"Id": 585107, "CreatorUserId": 85138, "OwnerUserId": 85138.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 1064891.0, "CurrentDatasourceVersionId": 1094467.0, "ForumId": 598971, "Type": 2, "CreationDate": "04/03/2020 11:40:29", "LastActivityDate": "04/03/2020", "TotalViews": 16569, "TotalDownloads": 1478, "TotalVotes": 22, "TotalKernels": 7}] | [{"Id": 85138, "UserName": "nxpnsv", "DisplayName": "nxpnsv", "RegisterDate": "02/14/2013", "PerformanceTier": 1}] | # ## Imports
# Imports
import os
from abc import ABCMeta, abstractmethod
from typing import Dict, List, Tuple, Union
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import mean_squared_log_error
from scipy.optimize.minpack import curve_fit
from scipy.optimize import curve_fit, OptimizeWarning
from scipy.optimize import least_squares
from xgboost import XGBRegressor
# ## Helpers
# First the Root Mean Square Log Error cost function:
# $$\mathrm{RMSLE}=\sqrt{\left}$$
# where, $y$ is actual value and $\hat(y)$ is predicted. Luckily the MSLE is implemented in [sklearn](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.mean_squared_log_error.html#sklearn.metrics.mean_squared_log_error) so all that is needed is a square root. However, as the predictor may be silly and give values just below 0, we force positive values or 0.
def RMSLE(actual: np.ndarray, prediction: np.ndarray) -> float:
"""Calculate Root Mean Square Log Error between actual and predicted values"""
return np.sqrt(mean_squared_log_error(actual, np.maximum(0, prediction)))
# ## Prepare data set
def load_kaggle_csv(dataset: str, datadir: str) -> pd.DataFrame:
"""Load andt preprocess kaggle covid-19 csv dataset."""
df = pd.read_csv(f"{os.path.join(datadir,dataset)}.csv", parse_dates=["Date"])
df["country"] = df["Country_Region"]
if "Province_State" in df:
df["Country_Region"] = np.where(
df["Province_State"].isnull(),
df["Country_Region"],
df["Country_Region"] + "_" + df["Province_State"],
)
df.drop(columns="Province_State", inplace=True)
if "ConfirmedCases" in df:
df["ConfirmedCases"] = df.groupby("Country_Region")["ConfirmedCases"].cummax()
if "Fatalities" in df:
df["Fatalities"] = df.groupby("Country_Region")["Fatalities"].cummax()
if "DayOfYear" not in df:
df["DayOfYear"] = df["Date"].dt.dayofyear
df["Date"] = df["Date"].dt.date
return df
def dateparse(x):
try:
return pd.datetime.strptime(x, "%Y-%m-%d")
except:
return pd.NaT
def prepare_lat_long(df):
df["Country_Region"] = np.where(
df["Province/State"].isnull(),
df["Country/Region"],
df["Country/Region"] + "_" + df["Province/State"],
)
return df[["Country_Region", "Lat", "Long"]].drop_duplicates()
def get_extra_features(df):
df["school_closure_status_daily"] = np.where(
df["school_closure"] < df["Date"], 1, 0
)
df["school_closure_first_fatality"] = np.where(
df["school_closure"] < df["first_1Fatalities"], 1, 0
)
df["school_closure_first_10cases"] = np.where(
df["school_closure"] < df["first_10ConfirmedCases"], 1, 0
)
#
df["case_delta1_10"] = (
df["first_10ConfirmedCases"] - df["first_1ConfirmedCases"]
).dt.days
df["case_death_delta1"] = (
df["first_1Fatalities"] - df["first_1ConfirmedCases"]
).dt.days
df["case_delta1_100"] = (
df["first_100ConfirmedCases"] - df["first_1ConfirmedCases"]
).dt.days
df["days_since"] = df["DayOfYear"] - df["case1_DayOfYear"]
df["weekday"] = pd.to_datetime(df["Date"]).dt.weekday
col = df.isnull().mean()
rm_null_col = col[col > 0.2].index.tolist()
return df
# * ## Load train data
# We use week 1 [train data](https://www.kaggle.com/c/covid19-global-forecasting-week-1/data) to get lat/long of geographic locations, then we use our [country health indicators](https://www.kaggle.com/nxpnsv/country-health-indicators) dataset.
### Train data
# Take lat/long from week 1 data set
df_lat = prepare_lat_long(
pd.read_csv("/kaggle/input/covid19-global-forecasting-week-1/train.csv")
)
# Get current train data
train = load_kaggle_csv("train", "/kaggle/input/covid19-global-forecasting-week-4")
# Insert augmentations
country_health_indicators = (
pd.read_csv(
"/kaggle/input/country-health-indicators/country_health_indicators_v3.csv",
parse_dates=[
"first_1ConfirmedCases",
"first_10ConfirmedCases",
"first_50ConfirmedCases",
"first_100ConfirmedCases",
"first_1Fatalities",
"school_closure",
],
date_parser=dateparse,
)
).rename(columns={"Country_Region": "country"})
# Merge augmentation to kaggle input
train = (pd.merge(train, country_health_indicators, on="country", how="left")).merge(
df_lat, on="Country_Region", how="left"
)
train = get_extra_features(train)
# train=train.fillna(0)
train.head(3)
### TEST DATA
test = load_kaggle_csv("test", "/kaggle/input/covid19-global-forecasting-week-4")
test = (pd.merge(test, country_health_indicators, on="country", how="left")).merge(
df_lat, on="Country_Region", how="left"
)
test = get_extra_features(test)
del country_health_indicators
# # Curve fitting
# First we add a helper class to fit functions. In previous weeks we went with a [Logistic](https://en.wikipedia.org/wiki/Logistic_function) function, but this is increasingly insuffucient. Instead we tried with a [generalized logistic function](https://en.wikipedia.org/wiki/Generalised_logistic_function) (GLF). However, actions like social distances dramatically change rates, so we create a new model DiXGLF which is a linear interpolation between 2 GLF, where the interpolation term $\alpha$ is a logistic function.
class Fitter(metaclass=ABCMeta):
"""
Helper class for 1D fits using scipy fit.
This version assumes y-data is positive and increasing.
"""
def __init__(self, name):
"""Make fitter instance."""
self.kwargs = {
"method": "trf",
"max_nfev": 20000,
"x_scale": "jac",
"loss": "linear",
"jac": self.jacobian,
}
self.name = name
self.rmsle = None
self.fit_params = None
self.fit_cov = None
self.y_hat = None
self.p0 = None
self.bounds = None
@abstractmethod
def function(self, x: np.ndarray, *args) -> np.ndarray:
"""Mathematical function to fit."""
pass
@abstractmethod
def jacobian(self, x: np.ndarray, *args) -> np.ndarray:
"""Jacobian of funciton."""
pass
@abstractmethod
def guess(self) -> Tuple[List[float], List]:
"""First guess for fit optimium."""
pass
def fit(self, x: np.ndarray, y: np.ndarray, **kwargs) -> Union[None, Tuple]:
"""Fit function to y over x."""
# Update extra keywords for fit
kwargs.update(self.kwargs)
# Reset fit results
self.rmsle = None
self.fit_params = None
self.fit_cov = None
self.y_hat = None
self.p0 = None
self.bounds = None
if len(x) <= 3:
return
# Guess params
self.p0, self.bounds = self.guess(x, y)
# Perform fit
try:
res = curve_fit(
f=self.function,
xdata=np.array(x, dtype=np.float128),
ydata=np.array(y, dtype=np.float128),
p0=self.p0,
bounds=self.bounds,
sigma=np.maximum(1, np.sqrt(y)),
**kwargs,
)
except (ValueError, RuntimeError, OptimizeWarning) as e:
print(e)
return
# Update fit results
self.y_hat = self.function(x, *res[0])
self.rmsle = np.sqrt(mean_squared_log_error(y, self.y_hat))
self.fit_params = res[0]
self.fit_cov = res[1]
def plot_fit(self, x, y, ax=None, title=None, **kwargs):
"""Fit and plot."""
self.fit(x, y, **kwargs)
if self.fit_params is None:
print("No result, cannot plot")
return
if ax is None:
_, ax = plt.subplots()
ax.set_title(f"{title or ''} {self.name}: rmsle={self.rmsle:.2f}")
color = "g"
ax.plot(x, y, "o", color=color, alpha=0.9)
ax.plot(x, self.y_hat, "-", color="r")
ax.set_ylabel("Counts", color=color)
ax.set_xlabel("Day of Year")
ax.tick_params(axis="y", labelcolor=color)
ax2 = ax.twinx()
color = "b"
ax2.set_ylabel("Residual", color=color)
ax2.plot(x, y - self.y_hat, ".", color=color)
ax2.tick_params(axis="y", labelcolor=color)
ax.text(
0.05,
0.95,
"\n".join([f"$p_{i}$={x:0.2f}" for i, x in enumerate(self.fit_params)]),
horizontalalignment="left",
verticalalignment="top",
transform=ax.transAxes,
)
class Logistic(Fitter):
def __init__(self):
super().__init__(name="Logistic")
def function(self, x: np.ndarray, K: float, B: float, M: float) -> np.ndarray:
return K / (1 + np.exp(-B * (x - M)))
def jacobian(self, x: np.ndarray, K: float, B: float, M: float) -> np.ndarray:
dK = 1 / (1 + np.exp(-B * (x - M)))
dB = K * (x - M) * np.exp(-B * (x - M)) / np.square(1 + np.exp(-B * (x - M)))
dM = K * B * np.exp(-B * (x - M)) / np.square(1 + np.exp(-B * (x - M)))
return np.transpose([dK, dB, dM])
def guess(self, x: np.ndarray, y: np.ndarray) -> Tuple[List[float], List[float]]:
K = y[-1]
B = 0.1
M = x[np.argmax(y >= 0.5 * K)]
p0 = [K, B, M]
bounds = [[y[-1], 1e-4, x[0]], [y[-1] * 8, 0.5, (1 + x[-1]) * 2]]
return p0, bounds
class GLF(Fitter):
def __init__(self):
super().__init__(name="GLF")
def function(self, x, K, B, M, nu):
return K / np.power((1 + np.exp(-B * (x - M))), 1 / nu)
def jacobian(self, x, K, B, M, nu):
nu1 = 1.0 / nu
xM = x - M
exp_BxM = np.exp(-B * xM)
pow0 = np.power(1 + exp_BxM, -nu1)
pow1 = K * exp_BxM / (nu * np.power(1 + exp_BxM, nu1 + 1))
dK = pow0
dB = xM * pow1
dnu = K * np.log1p(exp_BxM) * pow0 / nu
dM = B * pow1
return np.transpose([dK, dB, dnu, dM])
def guess(self, x, y):
# Guess params and param bounds
K = y[-1]
B = 0.1
M = x[np.argmax(y >= 0.5 * K)]
nu = 0.5
p0 = [K, B, M, nu]
bounds = [
[y[-1], 1e-3, x[0], 1e-2],
[(y[-1] + 1) * 10, 0.5, (x[-1] + 1) * 2, 1.0],
]
return p0, bounds
class DiXGLF(Fitter):
"""Interpolation between 2 logistic function.
First guess is split by y_max/2 so the first and second logistic
start on different partitions of data.
Uses 3-point estimator in place of explicit jacobian because of numeric stability.
"""
def __init__(self):
super().__init__(name="DiXGLF")
self.glf = GLF()
self.logistic = Logistic()
self.kwargs.update({"jac": "3-point"})
def function(self, x, B0, M0, K1, B1, M1, nu1, K2, B2, M2, nu2):
alpha = self.logistic.function(x, 1, B0, M0)
return alpha * self.glf.function(x, K1, B1, M1, nu1) + (
1 - alpha
) * self.glf.function(x, K2, B2, M2, nu2)
def jacobian(self, x, B0, M0, K1, B1, M1, nu1, K2, B2, M2, nu2):
raise RuntimeError("%s jacobian not implemented", self.name)
def guess(self, x, y):
split = min(max(1, np.argmax(y >= 0.5 * y[-1])), len(x) - 2)
p01, bounds1 = self.glf.guess(x[:split], y[:split])
p02, bounds2 = self.glf.guess(x[split:], y[split:])
p0, bounds = self.logistic.guess(x, y)
p0 = p0[1:]
bounds = [bounds[0][1:], bounds[1][1:]]
p0.extend(p01)
p0.extend(p02)
bounds[0].extend(bounds1[0])
bounds[0].extend(bounds2[0])
bounds[1].extend(bounds1[1])
bounds[1].extend(bounds2[1])
return p0, bounds
def apply_fitter(
df: pd.DataFrame,
fitter: Fitter,
x_col: str = "DayOfYear",
y_cols: List[str] = ["ConfirmedCases", "Fatalities"],
) -> pd.DataFrame:
"""Helper to apply fitter to dataframe groups"""
x = df[x_col].astype(np.float128).to_numpy()
result = {}
for y_col in y_cols:
y = df[y_col].astype(np.float128).to_numpy()
fitter.fit(x, y)
if fitter.rmsle is None:
continue
result[f"{y_col}_rmsle"] = fitter.rmsle
df[f"y_hat_fitter_{y_col}"] = fitter.y_hat
result.update({f"{y_col}_p_{i}": p for i, p in enumerate(fitter.fit_params)})
return pd.DataFrame([result])
plt.style.use("seaborn-white")
sns.set_color_codes()
dixglf = DiXGLF()
train["y_hat_fitter_ConfirmedCases"] = 0
train["y_hat_fitter_Fatalities"] = 0
fig, ax = plt.subplots(2, 4, figsize=(16, 8))
ax = ax.flatten()
for i, country in enumerate(("Italy", "Austria", "Korea, South", "Germany")):
c = train[train["Country_Region"] == country]
x = c["DayOfYear"].astype(np.float128).to_numpy()
dixglf.plot_fit(
x,
c["ConfirmedCases"].astype(np.float128).to_numpy(),
ax=ax[i],
title=f"Cases {country}",
)
dixglf.plot_fit(
x,
c["Fatalities"].astype(np.float128).to_numpy(),
ax=ax[i + 4],
title=f"Deaths {country}",
)
fig.tight_layout()
train = pd.merge(
train,
train.groupby(["Country_Region"], observed=True, sort=False)
.apply(lambda x: apply_fitter(x, fitter=dixglf))
.reset_index(),
on=["Country_Region"],
how="left",
)
train["y_hat_fitter_ConfirmedCases"] = dixglf.function(
train["DayOfYear"],
train["ConfirmedCases_p_0"],
train["ConfirmedCases_p_1"],
train["ConfirmedCases_p_2"],
train["ConfirmedCases_p_3"],
train["ConfirmedCases_p_4"],
train["ConfirmedCases_p_5"],
train["ConfirmedCases_p_6"],
train["ConfirmedCases_p_7"],
train["ConfirmedCases_p_8"],
train["ConfirmedCases_p_9"],
)
train["y_hat_fitter_Fatalities"] = dixglf.function(
train["DayOfYear"],
train["Fatalities_p_0"],
train["Fatalities_p_1"],
train["Fatalities_p_2"],
train["Fatalities_p_3"],
train["Fatalities_p_4"],
train["Fatalities_p_5"],
train["Fatalities_p_6"],
train["Fatalities_p_7"],
train["Fatalities_p_8"],
train["Fatalities_p_9"],
)
train.head()
# # XGB boost regression
def apply_xgb_model(train, x_columns, y_column, xgb_params):
X = train[x_columns].astype(np.float32).fillna(0).to_numpy()
y = train[y_column].astype(np.float32).fillna(0).to_numpy()
xgb_fit = XGBRegressor(**xgb_params).fit(X, y)
y_hat = xgb_fit.predict(X)
train[f"yhat_xgb_{y_column}"] = y_hat
return RMSLE(y, y_hat), xgb_fit
xgb_params_c = dict(
gamma=0.1,
learning_rate=0.35,
n_estimators=221,
max_depth=15,
min_child_weight=1,
nthread=8,
objective="reg:squarederror",
)
xgb_params_f = dict(
gamma=0.1022,
learning_rate=0.338,
n_estimators=292,
max_depth=14,
min_child_weight=1,
nthread=8,
objective="reg:squarederror",
)
x_columns = [
"DayOfYear",
"Diabetes, blood, & endocrine diseases (%)",
"Respiratory diseases (%)",
"Diarrhea & common infectious diseases (%)",
"Nutritional deficiencies (%)",
"obesity - adult prevalence rate",
"pneumonia-death-rates",
"animal_fats",
"animal_products",
"eggs",
"offals",
"treenuts",
"vegetable_oils",
"nbr_surgeons",
"nbr_anaesthesiologists",
"population",
"school_shutdown_1case",
"school_shutdown_10case",
"school_shutdown_50case",
"school_shutdown_1death",
"case1_DayOfYear",
"case10_DayOfYear",
"case50_DayOfYear",
"school_closure_status_daily",
"case_delta1_10",
"case_death_delta1",
"case_delta1_100",
"days_since",
"Lat",
"Long",
"weekday",
"y_hat_fitter_ConfirmedCases",
"y_hat_fitter_Fatalities",
]
xgb_c_rmsle, xgb_c_fit = apply_xgb_model(
train, x_columns, "ConfirmedCases", xgb_params_c
)
xgb_f_rmsle, xgb_f_fit = apply_xgb_model(train, x_columns, "Fatalities", xgb_params_f)
# # Hybrid fit
# From logistic curve fit we have $\hat{y}_L$: `y_hat_fitter_ConfirmedCases`,and from XGB boost regression $\hat{y}_X$: `yhat_xgb_ConfirmedCases`.
# Here we make a hybrid predictor
# $\hat{y}_H = \alpha \hat{y}_L + (1-\alpha) \hat{y}_X$
#
# by fitting alpha with `scipy.optmize.least_squares`. Similarly for `Fatalities`. First we define a few functions to do the work:
def interpolate(alpha, x0, x1):
return x0 * alpha + x1 * (1 - alpha)
def RMSLE_interpolate(alpha, y, x0, x1):
return RMSLE(y, interpolate(alpha, x0, x1))
def fit_hybrid(
train: pd.DataFrame, y_cols: List[str] = ["ConfirmedCases", "Fatalities"]
) -> pd.DataFrame:
def fit_one(y_col: str):
opt = least_squares(
fun=RMSLE_interpolate,
args=(
train[y_col],
train[f"y_hat_fitter_{y_col}"],
train[f"yhat_xgb_{y_col}"],
),
x0=(0.5,),
bounds=((0.0), (1.0,)),
)
return {f"{y_col}_alpha": opt.x[0], f"{y_col}_cost": opt.cost}
result = {}
for y_col in y_cols:
result.update(fit_one(y_col))
return pd.DataFrame([result])
def predict_hybrid(
df: pd.DataFrame,
x_col: str = "DayOfYear",
y_cols: List[str] = ["ConfirmedCases", "Fatalities"],
):
def predict_one(col):
df[f"yhat_hybrid_{col}"] = interpolate(
df[f"{y_col}_alpha"].to_numpy(),
df[f"y_hat_fitter_{y_col}"].to_numpy(),
df[f"yhat_xgb_{y_col}"].to_numpy(),
)
for y_col in y_cols:
predict_one(y_col)
# Now apply to each `Country_Region`:
train = pd.merge(
train,
train.groupby(["Country_Region"], observed=True, sort=False)
.apply(lambda x: fit_hybrid(x))
.reset_index(),
on=["Country_Region"],
how="left",
)
predict_hybrid(train)
# # Compare approaches
print(
"Confirmed:\n"
f'Fitter\t{RMSLE(train["ConfirmedCases"], train["y_hat_fitter_ConfirmedCases"])}\n'
f'XGBoost\t{RMSLE(train["ConfirmedCases"], train["yhat_xgb_ConfirmedCases"])}\n'
f'Hybrid\t{RMSLE(train["ConfirmedCases"], train["yhat_hybrid_ConfirmedCases"])}\n'
f"Fatalities:\n"
f'Fitter\t{RMSLE(train["Fatalities"], train["y_hat_fitter_Fatalities"])}\n'
f'XGBoost\t{RMSLE(train["Fatalities"], train["yhat_xgb_Fatalities"])}\n'
f'Hybrid\t{RMSLE(train["Fatalities"], train["yhat_hybrid_Fatalities"])}\n'
)
# # Predict test cases
# Merge logistic and hybrid fit into test
test = pd.merge(
test,
train[
["Country_Region"]
+ [
"ConfirmedCases_p_0",
"ConfirmedCases_p_1",
"ConfirmedCases_p_2",
"ConfirmedCases_p_3",
"ConfirmedCases_p_4",
"ConfirmedCases_p_5",
"ConfirmedCases_p_6",
"ConfirmedCases_p_7",
"ConfirmedCases_p_8",
"ConfirmedCases_p_9",
]
+ [
"Fatalities_p_0",
"Fatalities_p_1",
"Fatalities_p_2",
"Fatalities_p_3",
"Fatalities_p_4",
"Fatalities_p_5",
"Fatalities_p_6",
"Fatalities_p_7",
"Fatalities_p_8",
"Fatalities_p_9",
]
+ ["Fatalities_alpha"]
+ ["ConfirmedCases_alpha"]
]
.groupby(["Country_Region"])
.head(1),
on="Country_Region",
how="left",
)
# Test predictions
test["y_hat_fitter_ConfirmedCases"] = dixglf.function(
test["DayOfYear"],
test["ConfirmedCases_p_0"],
test["ConfirmedCases_p_1"],
test["ConfirmedCases_p_2"],
test["ConfirmedCases_p_3"],
test["ConfirmedCases_p_4"],
test["ConfirmedCases_p_5"],
test["ConfirmedCases_p_6"],
test["ConfirmedCases_p_7"],
test["ConfirmedCases_p_8"],
test["ConfirmedCases_p_9"],
)
test["y_hat_fitter_Fatalities"] = dixglf.function(
test["DayOfYear"],
test["Fatalities_p_0"],
test["Fatalities_p_1"],
test["Fatalities_p_2"],
test["Fatalities_p_3"],
test["Fatalities_p_4"],
test["Fatalities_p_5"],
test["Fatalities_p_6"],
test["Fatalities_p_7"],
test["Fatalities_p_8"],
test["Fatalities_p_9"],
)
test["yhat_xgb_ConfirmedCases"] = xgb_c_fit.predict(test[x_columns].to_numpy())
test["yhat_xgb_Fatalities"] = xgb_f_fit.predict(test[x_columns].to_numpy())
predict_hybrid(test)
# # Prepare submission
submission = (
test[["ForecastId", "yhat_hybrid_ConfirmedCases", "yhat_hybrid_Fatalities"]]
.round(2)
.rename(
columns={
"yhat_hybrid_ConfirmedCases": "ConfirmedCases",
"yhat_hybrid_Fatalities": "Fatalities",
}
)
)
submission["ConfirmedCases"] = np.maximum(0, submission["ConfirmedCases"])
submission["Fatalities"] = np.maximum(0, submission["Fatalities"])
submission.head()
submission.to_csv("submission.csv", index=False)
| false | 2 | 6,792 | 0 | 434 | 6,792 |
||
32437219 | <kaggle_start><code>import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
def weights_init(m):
if type(m) == nn.Linear:
m.weight.data.normal_(0.0, 1e-3)
m.bias.data.fill_(0.0)
def update_lr(optimizer, lr):
for param_group in optimizer.param_groups:
param_group["lr"] = lr
# --------------------------------
# Device configuration
# --------------------------------
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using device: %s" % device)
# --------------------------------
# Hyper-parameters
# --------------------------------
input_size = 3
num_classes = 10
hidden_size = [128, 512, 512, 512, 512]
num_epochs = 20
batch_size = 200
learning_rate = 2e-3
learning_rate_decay = 0.95
reg = 0.001
num_training = 49000
num_validation = 1000
norm_layer = None # norm_layer = 'BN'
print(hidden_size)
# -------------------------------------------------
# Load the CIFAR-10 dataset
# -------------------------------------------------
#################################################################################
# TODO: Q3.a Choose the right data augmentation transforms with the right #
# hyper-parameters and put them in the data_aug_transforms variable #
#################################################################################
data_aug_transforms = []
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
norm_transform = transforms.Compose(
data_aug_transforms
+ [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
test_transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
cifar_dataset = torchvision.datasets.CIFAR10(
root="datasets/", train=True, transform=norm_transform, download=True
)
test_dataset = torchvision.datasets.CIFAR10(
root="datasets/", train=False, transform=test_transform
)
# -------------------------------------------------
# Prepare the training and validation splits
# -------------------------------------------------
mask = list(range(num_training))
train_dataset = torch.utils.data.Subset(cifar_dataset, mask)
mask = list(range(num_training, num_training + num_validation))
val_dataset = torch.utils.data.Subset(cifar_dataset, mask)
# -------------------------------------------------
# Data loader
# -------------------------------------------------
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset, batch_size=batch_size, shuffle=True
)
val_loader = torch.utils.data.DataLoader(
dataset=val_dataset, batch_size=batch_size, shuffle=False
)
test_loader = torch.utils.data.DataLoader(
dataset=test_dataset, batch_size=batch_size, shuffle=False
)
# -------------------------------------------------
# Convolutional neural network (Q1.a and Q2.a)
# Set norm_layer for different networks whether using batch normalization
# -------------------------------------------------
class ConvNet(nn.Module):
def __init__(self, input_size, hidden_layers, num_classes, norm_layer=None):
super(ConvNet, self).__init__()
#################################################################################
# TODO: Initialize the modules required to implement the convolutional layer #
# described in the exercise. #
# For Q1.a make use of conv2d and relu layers from the torch.nn module. #
# For Q2.a make use of BatchNorm2d layer from the torch.nn module. #
# For Q3.b Use Dropout layer from the torch.nn module. #
#################################################################################
layers = []
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
layers.append(nn.Conv2d(3, hidden_layers[0], 3))
layers.append(nn.ReLU())
layers.append(nn.MaxPool2d(2, 2))
for i in range(len(hidden_layers[1:-1])):
layers.append(
nn.Conv2d(hidden_layers[i], hidden_layers[i + 1], 3, padding=1)
)
layers.append(nn.ReLU())
layers.append(nn.MaxPool2d(2, 2))
layers.append(nn.Linear(512, 10))
# layers.append(nn.Linear(16 * 5 * 5, input_size))
# layers.append(nn.Linear(input_size, *hidden_layers))
# layers.append(nn.Linear(*hidden_layers, num_classes))
self.layers = nn.Sequential(*layers)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
def forward(self, x):
#################################################################################
# TODO: Implement the forward pass computations #
#################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
out = self.layers[:-1](x)
out = out.squeeze(-1).squeeze(-1)
print(out.shape)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return out
# -------------------------------------------------
# Calculate the model size (Q1.b)
# if disp is true, print the model parameters, otherwise, only return the number of parameters.
# -------------------------------------------------
def PrintModelSize(model, disp=True):
#################################################################################
# TODO: Implement the function to count the number of trainable parameters in #
# the input model. This useful to track the capacity of the model you are #
# training #
#################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# return model_sz
pass
# -------------------------------------------------
# Calculate the model size (Q1.c)
# visualize the convolution filters of the first convolution layer of the input model
# -------------------------------------------------
def VisualizeFilter(model):
#################################################################################
# TODO: Implement the functiont to visualize the weights in the first conv layer#
# in the model. Visualize them as a single image of stacked filters. #
# You can use matlplotlib.imshow to visualize an image in python #
#################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
pass
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# ======================================================================================
# Q1.a: Implementing convolutional neural net in PyTorch
# ======================================================================================
# In this question we will implement a convolutional neural networks using the PyTorch
# library. Please complete the code for the ConvNet class evaluating the model
# --------------------------------------------------------------------------------------
model = ConvNet(input_size, hidden_size, num_classes, norm_layer=norm_layer).to(device)
# Q2.a - Initialize the model with correct batch norm layer
model.apply(weights_init)
# Print the model
print(model)
# Print model size
# ======================================================================================
# Q1.b: Implementing the function to count the number of trainable parameters in the model
# ======================================================================================
PrintModelSize(model)
# ======================================================================================
# Q1.a: Implementing the function to visualize the filters in the first conv layers.
# Visualize the filters before training
# ======================================================================================
VisualizeFilter(model)
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=reg)
# Train the model
lr = learning_rate
total_step = len(train_loader)
loss_train = []
loss_val = []
best_accuracy = None
accuracy_val = []
best_model = type(model)(
input_size, hidden_size, num_classes, norm_layer=norm_layer
) # get a new instance
# best_model = ConvNet(input_size, hidden_size, num_classes, norm_layer=norm_layer)
for epoch in range(num_epochs):
model.train()
loss_iter = 0
for i, (images, labels) in enumerate(train_loader):
# Move tensors to the configured device
images = images.to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_iter += loss.item()
if (i + 1) % 100 == 0:
print(
"Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}".format(
epoch + 1, num_epochs, i + 1, total_step, loss.item()
)
)
loss_train.append(loss_iter / (len(train_loader) * batch_size))
# Code to update the lr
lr *= learning_rate_decay
update_lr(optimizer, lr)
model.eval()
with torch.no_grad():
correct = 0
total = 0
loss_iter = 0
for images, labels in val_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
loss = criterion(outputs, labels)
loss_iter += loss.item()
loss_val.append(loss_iter / (len(val_loader) * batch_size))
accuracy = 100 * correct / total
accuracy_val.append(accuracy)
print("Validation accuracy is: {} %".format(accuracy))
#################################################################################
# TODO: Q2.b Implement the early stopping mechanism to save the model which has #
# the model with the best validation accuracy so-far (use best_model). #
#################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# Test the model
# In test phase, we don't need to compute gradients (for memory efficiency)
model.eval()
plt.figure(2)
plt.plot(loss_train, "r", label="Train loss")
plt.plot(loss_val, "g", label="Val loss")
plt.legend()
plt.show()
plt.figure(3)
plt.plot(accuracy_val, "r", label="Val accuracy")
plt.legend()
plt.show()
#################################################################################
# TODO: Q2.b Implement the early stopping mechanism to load the weights from the#
# best model so far and perform testing with this model. #
#################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# Compute accuracy on the test set
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
if total == 1000:
break
print(
"Accuracy of the network on the {} test images: {} %".format(
total, 100 * correct / total
)
)
# Q1.c: Implementing the function to visualize the filters in the first conv layers.
# Visualize the filters before training
VisualizeFilter(model)
# Save the model checkpoint
# torch.save(model.state_dict(), 'model.ckpt')
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0032/437/32437219.ipynb | null | null | [{"Id": 32437219, "ScriptId": 9050975, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 2853217, "CreationDate": "04/21/2020 21:12:46", "VersionNumber": 1.0, "Title": "AMLHW3", "EvaluationDate": "04/21/2020", "IsChange": true, "TotalLines": 346.0, "LinesInsertedFromPrevious": 346.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 0.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
def weights_init(m):
if type(m) == nn.Linear:
m.weight.data.normal_(0.0, 1e-3)
m.bias.data.fill_(0.0)
def update_lr(optimizer, lr):
for param_group in optimizer.param_groups:
param_group["lr"] = lr
# --------------------------------
# Device configuration
# --------------------------------
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using device: %s" % device)
# --------------------------------
# Hyper-parameters
# --------------------------------
input_size = 3
num_classes = 10
hidden_size = [128, 512, 512, 512, 512]
num_epochs = 20
batch_size = 200
learning_rate = 2e-3
learning_rate_decay = 0.95
reg = 0.001
num_training = 49000
num_validation = 1000
norm_layer = None # norm_layer = 'BN'
print(hidden_size)
# -------------------------------------------------
# Load the CIFAR-10 dataset
# -------------------------------------------------
#################################################################################
# TODO: Q3.a Choose the right data augmentation transforms with the right #
# hyper-parameters and put them in the data_aug_transforms variable #
#################################################################################
data_aug_transforms = []
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
norm_transform = transforms.Compose(
data_aug_transforms
+ [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
test_transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
)
cifar_dataset = torchvision.datasets.CIFAR10(
root="datasets/", train=True, transform=norm_transform, download=True
)
test_dataset = torchvision.datasets.CIFAR10(
root="datasets/", train=False, transform=test_transform
)
# -------------------------------------------------
# Prepare the training and validation splits
# -------------------------------------------------
mask = list(range(num_training))
train_dataset = torch.utils.data.Subset(cifar_dataset, mask)
mask = list(range(num_training, num_training + num_validation))
val_dataset = torch.utils.data.Subset(cifar_dataset, mask)
# -------------------------------------------------
# Data loader
# -------------------------------------------------
train_loader = torch.utils.data.DataLoader(
dataset=train_dataset, batch_size=batch_size, shuffle=True
)
val_loader = torch.utils.data.DataLoader(
dataset=val_dataset, batch_size=batch_size, shuffle=False
)
test_loader = torch.utils.data.DataLoader(
dataset=test_dataset, batch_size=batch_size, shuffle=False
)
# -------------------------------------------------
# Convolutional neural network (Q1.a and Q2.a)
# Set norm_layer for different networks whether using batch normalization
# -------------------------------------------------
class ConvNet(nn.Module):
def __init__(self, input_size, hidden_layers, num_classes, norm_layer=None):
super(ConvNet, self).__init__()
#################################################################################
# TODO: Initialize the modules required to implement the convolutional layer #
# described in the exercise. #
# For Q1.a make use of conv2d and relu layers from the torch.nn module. #
# For Q2.a make use of BatchNorm2d layer from the torch.nn module. #
# For Q3.b Use Dropout layer from the torch.nn module. #
#################################################################################
layers = []
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
layers.append(nn.Conv2d(3, hidden_layers[0], 3))
layers.append(nn.ReLU())
layers.append(nn.MaxPool2d(2, 2))
for i in range(len(hidden_layers[1:-1])):
layers.append(
nn.Conv2d(hidden_layers[i], hidden_layers[i + 1], 3, padding=1)
)
layers.append(nn.ReLU())
layers.append(nn.MaxPool2d(2, 2))
layers.append(nn.Linear(512, 10))
# layers.append(nn.Linear(16 * 5 * 5, input_size))
# layers.append(nn.Linear(input_size, *hidden_layers))
# layers.append(nn.Linear(*hidden_layers, num_classes))
self.layers = nn.Sequential(*layers)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
def forward(self, x):
#################################################################################
# TODO: Implement the forward pass computations #
#################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
out = self.layers[:-1](x)
out = out.squeeze(-1).squeeze(-1)
print(out.shape)
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
return out
# -------------------------------------------------
# Calculate the model size (Q1.b)
# if disp is true, print the model parameters, otherwise, only return the number of parameters.
# -------------------------------------------------
def PrintModelSize(model, disp=True):
#################################################################################
# TODO: Implement the function to count the number of trainable parameters in #
# the input model. This useful to track the capacity of the model you are #
# training #
#################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# return model_sz
pass
# -------------------------------------------------
# Calculate the model size (Q1.c)
# visualize the convolution filters of the first convolution layer of the input model
# -------------------------------------------------
def VisualizeFilter(model):
#################################################################################
# TODO: Implement the functiont to visualize the weights in the first conv layer#
# in the model. Visualize them as a single image of stacked filters. #
# You can use matlplotlib.imshow to visualize an image in python #
#################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
pass
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# ======================================================================================
# Q1.a: Implementing convolutional neural net in PyTorch
# ======================================================================================
# In this question we will implement a convolutional neural networks using the PyTorch
# library. Please complete the code for the ConvNet class evaluating the model
# --------------------------------------------------------------------------------------
model = ConvNet(input_size, hidden_size, num_classes, norm_layer=norm_layer).to(device)
# Q2.a - Initialize the model with correct batch norm layer
model.apply(weights_init)
# Print the model
print(model)
# Print model size
# ======================================================================================
# Q1.b: Implementing the function to count the number of trainable parameters in the model
# ======================================================================================
PrintModelSize(model)
# ======================================================================================
# Q1.a: Implementing the function to visualize the filters in the first conv layers.
# Visualize the filters before training
# ======================================================================================
VisualizeFilter(model)
# Loss and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=reg)
# Train the model
lr = learning_rate
total_step = len(train_loader)
loss_train = []
loss_val = []
best_accuracy = None
accuracy_val = []
best_model = type(model)(
input_size, hidden_size, num_classes, norm_layer=norm_layer
) # get a new instance
# best_model = ConvNet(input_size, hidden_size, num_classes, norm_layer=norm_layer)
for epoch in range(num_epochs):
model.train()
loss_iter = 0
for i, (images, labels) in enumerate(train_loader):
# Move tensors to the configured device
images = images.to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels)
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_iter += loss.item()
if (i + 1) % 100 == 0:
print(
"Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}".format(
epoch + 1, num_epochs, i + 1, total_step, loss.item()
)
)
loss_train.append(loss_iter / (len(train_loader) * batch_size))
# Code to update the lr
lr *= learning_rate_decay
update_lr(optimizer, lr)
model.eval()
with torch.no_grad():
correct = 0
total = 0
loss_iter = 0
for images, labels in val_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
loss = criterion(outputs, labels)
loss_iter += loss.item()
loss_val.append(loss_iter / (len(val_loader) * batch_size))
accuracy = 100 * correct / total
accuracy_val.append(accuracy)
print("Validation accuracy is: {} %".format(accuracy))
#################################################################################
# TODO: Q2.b Implement the early stopping mechanism to save the model which has #
# the model with the best validation accuracy so-far (use best_model). #
#################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# Test the model
# In test phase, we don't need to compute gradients (for memory efficiency)
model.eval()
plt.figure(2)
plt.plot(loss_train, "r", label="Train loss")
plt.plot(loss_val, "g", label="Val loss")
plt.legend()
plt.show()
plt.figure(3)
plt.plot(accuracy_val, "r", label="Val accuracy")
plt.legend()
plt.show()
#################################################################################
# TODO: Q2.b Implement the early stopping mechanism to load the weights from the#
# best model so far and perform testing with this model. #
#################################################################################
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# Compute accuracy on the test set
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
if total == 1000:
break
print(
"Accuracy of the network on the {} test images: {} %".format(
total, 100 * correct / total
)
)
# Q1.c: Implementing the function to visualize the filters in the first conv layers.
# Visualize the filters before training
VisualizeFilter(model)
# Save the model checkpoint
# torch.save(model.state_dict(), 'model.ckpt')
| false | 0 | 2,876 | 0 | 6 | 2,876 |
||
32970077 | <kaggle_start><data_title>Face Detection in Images<data_description>### Context
Faces in images marked with bounding boxes. Have around 500 images with around 1100 faces manually tagged via bounding box.
To visualize the dataset and see how the dataset looks (actual images with tags) please see: https://dataturks.com/projects/devika.mishra/face_detection
### Content
Some examples from the dataset:
![enter image description here][1]
![enter image description here][2]<data_name>face-detection-in-images
<code>import numpy as np
import pandas as pd
import cv2 as cv
import os
import matplotlib.pyplot as plt
from tqdm.notebook import tqdm
import glob
# https://realpython.com/traditional-face-detection-python/
face_cascade = cv.CascadeClassifier(
"/kaggle/input/haarcascades/haarcascade_frontalface_alt.xml"
)
def detect_faces(img):
grey_image = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
detected_faces = face_cascade.detectMultiScale(grey_image)
return detected_faces
def crop_face(img):
faces = detect_faces(img)
if len(faces) == 0:
return img
else:
column, row, width, height = faces[0]
cropped = img[row : row + height, column : column + width]
return cv.resize(cropped, img.shape[0:2][::-1])
image = cv.imread(
"/kaggle/input/celeba-dataset/img_align_celeba/img_align_celeba/000001.jpg"
)
fig, ax = plt.subplots(1, 2)
ax[0].imshow(image)
ax[1].imshow(crop_face(image))
# # Importing Data
# Each identity has to have its own folder
import pandas as pd
from shutil import copyfile
train_size = 20
file = "/kaggle/input/identity-celeba/identity_CelebA.txt"
identities = pd.read_csv(file, delimiter=" ", names=["file", "identity"])
source_dir = "/kaggle/input/celeba-dataset/img_align_celeba/img_align_celeba/%s"
target_dir_train = "/kaggle/working/train/%d/"
target_dir_test = "/kaggle/working/test/%d/"
for _, file, identity in tqdm(list(identities.itertuples())):
if identity <= train_size:
dest_dir = target_dir_train if identity <= train_size else target_dir_test
dest_dir = dest_dir % identity
os.makedirs(dest_dir, exist_ok=True)
copyfile(source_dir % file, dest_dir + file)
def show_class(class_name, cl="train"):
# Check to make sure that all files in each directory are of the same person (sanity check)
files = glob.glob("/kaggle/working/%s/%s/*" % (cl, class_name))
fig, ax = plt.subplots(1, len(files), figsize=(20, 10))
for index, file in enumerate(files):
ax[index].imshow(cv.imread(file))
ax[index].axis("off")
plt.show()
show_class(7)
# Create the image preprocessor
from keras.preprocessing.image import ImageDataGenerator
import random
def preprocess_image(img):
# image must be an int for cropping and float for Keras
return
train_directory = "/kaggle/working/train/"
test_directory = "/kaggle/working/train/"
batch_size = 16
class DirectoryFlow:
def __init__(self, directory, batch_size):
self.directory = directory
self.batch_size = batch_size
self.file_structure = {
int(f): [
directory + "%s/%s" % (f, file_name)
for file_name in os.listdir(directory + f)
]
for f in os.listdir(directory)
}
self.classes = list(self.file_structure.keys())
print("Loaded %d classes" % len(self.classes))
def read_image(self, file):
img = cv.imread(file)
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
return crop_face(img.astype("uint8")).astype("float32") / 255
def next(self, class_name=None):
if class_name is None:
class_name = random.choice(self.classes)
item = random.choice(self.file_structure[class_name])
return self.read_image(item), class_name
def next_batch(self):
images = []
labels = np.zeros((self.batch_size))
for i in range(self.batch_size):
image, class_name = self.next()
images.append(image)
labels[i] = class_name
return np.array(images), labels
datagen_train = DirectoryFlow(train_directory, batch_size)
# datagen_test = DirectoryFlow(test_directory)
# # Modeling
# https://github.com/aleju/face-comparer/blob/master/train.py#L252
from keras.layers import (
Input,
Dense,
Activation,
Dropout,
Flatten,
Dense,
Add,
Conv2D,
MaxPooling2D,
Lambda,
)
from keras.models import Model
input_shape = (218, 178, 3)
input_face_left = Input(shape=input_shape, name="model_face_left")
input_face_right = Input(shape=input_shape, name="model_face_right")
input_face = Input(shape=input_shape)
face = Conv2D(32, kernel_size=(3, 3), activation="relu", padding="same", name="conv1")(
input_face
)
face = MaxPooling2D((2, 2), name="mp1")(face)
face = Conv2D(32, kernel_size=(3, 3), activation="relu", padding="same", name="conv2")(
face
)
face = MaxPooling2D((3, 3), name="mp2")(face)
output_face = Flatten(name="f1")(face)
model_face = Model(input_face, output_face)
model_face_left = model_face(input_face_left)
model_face_right = model_face(input_face_right)
merged_model = Lambda(
lambda tensors: abs(tensors[0] - tensors[1]), name="absolute_difference"
)([model_face_left, model_face_right])
merged_model = Dense(64, activation="relu", name="d1")(merged_model)
merged_model = Dropout(0.1, name="drop1")(merged_model)
merged_model = Dense(64, activation="relu", name="d2")(merged_model)
merged_model = Dense(1, activation="sigmoid", name="out")(merged_model)
model = Model(
inputs=[input_face_left, input_face_right], outputs=merged_model, name="lr_merger"
)
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
model.summary()
from IPython.display import Image
from keras.utils import plot_model
plot_model(model, to_file="/kaggle/working/model.png", show_shapes=True)
Image("/kaggle/working/model.png")
class CustomBatchIterator:
def __init__(self, datagen, batch_size):
self.datagen = datagen
self.batch_size = batch_size
def make_batch(self):
images, labels = self.datagen.next_batch()
output_pairs = [np.zeros((self.batch_size, *images[0].shape)) for i in range(2)]
output_labels = np.zeros(self.batch_size)
output_labels[: self.batch_size // 2] = 1
for i in range(self.batch_size // 2):
label = labels[i]
random_image, _ = self.datagen.next(label)
output_pairs[0][i] = images[i]
output_pairs[1][i] = random_image
for i in range(self.batch_size // 2, self.batch_size):
label = labels[i]
while True:
random_label = random.choice(self.datagen.classes)
if random_label != label:
break
random_image, _ = self.datagen.next(random_label)
output_pairs[0][i] = images[i]
output_pairs[1][i] = random_image
return output_pairs, output_labels
def __iter__(self):
return self
def __next__(self):
return self.make_batch()
def show_batch_pairs(image_batch_pairs, label_batch):
fig, ax = plt.subplots(len(image_batch_pairs[0]), 2, figsize=(20, 20))
for r in range(len(image_batch_pairs[0])):
for c in [0, 1]:
ax[r, c].imshow(image_batch_pairs[c][r])
ax[r, c].axis("off")
ax[r, c].set_title("y=%d" % label_batch[r])
train_it = CustomBatchIterator(datagen_train, batch_size)
show_batch_pairs(*next(train_it))
model.fit_generator(train_it, steps_per_epoch=10, epochs=200)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0032/970/32970077.ipynb | face-detection-in-images | dataturks | [{"Id": 32970077, "ScriptId": 9086782, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 4456277, "CreationDate": "04/30/2020 01:26:28", "VersionNumber": 8.0, "Title": "CSCI 4622: Final Project", "EvaluationDate": "04/30/2020", "IsChange": true, "TotalLines": 200.0, "LinesInsertedFromPrevious": 118.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 82.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | [{"Id": 35851505, "KernelVersionId": 32970077, "SourceDatasetVersionId": 54972}, {"Id": 35851504, "KernelVersionId": 32970077, "SourceDatasetVersionId": 37705}, {"Id": 35851503, "KernelVersionId": 32970077, "SourceDatasetVersionId": 18147}, {"Id": 35851506, "KernelVersionId": 32970077, "SourceDatasetVersionId": 1104205}] | [{"Id": 54972, "DatasetId": 36341, "DatasourceVersionId": 57374, "CreatorUserId": 1853660, "LicenseName": "Unknown", "CreationDate": "07/12/2018 09:34:14", "VersionNumber": 1.0, "Title": "Face Detection in Images", "Slug": "face-detection-in-images", "Subtitle": "Image bounding box dataset to detect faces in images", "Description": "### Context\n\nFaces in images marked with bounding boxes. Have around 500 images with around 1100 faces manually tagged via bounding box.\n\nTo visualize the dataset and see how the dataset looks (actual images with tags) please see: https://dataturks.com/projects/devika.mishra/face_detection\n\n\n### Content\n\nSome examples from the dataset:\n\n![enter image description here][1]\n\n![enter image description here][2]\n\n### Acknowledgements\n\nOriginal location: https://dataturks.com/projects/devika.mishra/face_detection\n\n\n [1]: https://storage.googleapis.com/bonsai-b808c.appspot.com/dataturks/extras/face_detection_dataset1.png\n [2]: https://storage.googleapis.com/bonsai-b808c.appspot.com/dataturks/extras/face_detection_datatset_image2.png", "VersionNotes": "Initial release", "TotalCompressedBytes": 273830.0, "TotalUncompressedBytes": 273830.0}] | [{"Id": 36341, "CreatorUserId": 1853660, "OwnerUserId": 1853660.0, "OwnerOrganizationId": NaN, "CurrentDatasetVersionId": 54972.0, "CurrentDatasourceVersionId": 57374.0, "ForumId": 44755, "Type": 2, "CreationDate": "07/12/2018 09:34:14", "LastActivityDate": "07/12/2018", "TotalViews": 598479, "TotalDownloads": 23774, "TotalVotes": 536, "TotalKernels": 13}] | [{"Id": 1853660, "UserName": "dataturks", "DisplayName": "DataTurks", "RegisterDate": "04/24/2018", "PerformanceTier": 2}] | import numpy as np
import pandas as pd
import cv2 as cv
import os
import matplotlib.pyplot as plt
from tqdm.notebook import tqdm
import glob
# https://realpython.com/traditional-face-detection-python/
face_cascade = cv.CascadeClassifier(
"/kaggle/input/haarcascades/haarcascade_frontalface_alt.xml"
)
def detect_faces(img):
grey_image = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
detected_faces = face_cascade.detectMultiScale(grey_image)
return detected_faces
def crop_face(img):
faces = detect_faces(img)
if len(faces) == 0:
return img
else:
column, row, width, height = faces[0]
cropped = img[row : row + height, column : column + width]
return cv.resize(cropped, img.shape[0:2][::-1])
image = cv.imread(
"/kaggle/input/celeba-dataset/img_align_celeba/img_align_celeba/000001.jpg"
)
fig, ax = plt.subplots(1, 2)
ax[0].imshow(image)
ax[1].imshow(crop_face(image))
# # Importing Data
# Each identity has to have its own folder
import pandas as pd
from shutil import copyfile
train_size = 20
file = "/kaggle/input/identity-celeba/identity_CelebA.txt"
identities = pd.read_csv(file, delimiter=" ", names=["file", "identity"])
source_dir = "/kaggle/input/celeba-dataset/img_align_celeba/img_align_celeba/%s"
target_dir_train = "/kaggle/working/train/%d/"
target_dir_test = "/kaggle/working/test/%d/"
for _, file, identity in tqdm(list(identities.itertuples())):
if identity <= train_size:
dest_dir = target_dir_train if identity <= train_size else target_dir_test
dest_dir = dest_dir % identity
os.makedirs(dest_dir, exist_ok=True)
copyfile(source_dir % file, dest_dir + file)
def show_class(class_name, cl="train"):
# Check to make sure that all files in each directory are of the same person (sanity check)
files = glob.glob("/kaggle/working/%s/%s/*" % (cl, class_name))
fig, ax = plt.subplots(1, len(files), figsize=(20, 10))
for index, file in enumerate(files):
ax[index].imshow(cv.imread(file))
ax[index].axis("off")
plt.show()
show_class(7)
# Create the image preprocessor
from keras.preprocessing.image import ImageDataGenerator
import random
def preprocess_image(img):
# image must be an int for cropping and float for Keras
return
train_directory = "/kaggle/working/train/"
test_directory = "/kaggle/working/train/"
batch_size = 16
class DirectoryFlow:
def __init__(self, directory, batch_size):
self.directory = directory
self.batch_size = batch_size
self.file_structure = {
int(f): [
directory + "%s/%s" % (f, file_name)
for file_name in os.listdir(directory + f)
]
for f in os.listdir(directory)
}
self.classes = list(self.file_structure.keys())
print("Loaded %d classes" % len(self.classes))
def read_image(self, file):
img = cv.imread(file)
img = cv.cvtColor(img, cv.COLOR_BGR2RGB)
return crop_face(img.astype("uint8")).astype("float32") / 255
def next(self, class_name=None):
if class_name is None:
class_name = random.choice(self.classes)
item = random.choice(self.file_structure[class_name])
return self.read_image(item), class_name
def next_batch(self):
images = []
labels = np.zeros((self.batch_size))
for i in range(self.batch_size):
image, class_name = self.next()
images.append(image)
labels[i] = class_name
return np.array(images), labels
datagen_train = DirectoryFlow(train_directory, batch_size)
# datagen_test = DirectoryFlow(test_directory)
# # Modeling
# https://github.com/aleju/face-comparer/blob/master/train.py#L252
from keras.layers import (
Input,
Dense,
Activation,
Dropout,
Flatten,
Dense,
Add,
Conv2D,
MaxPooling2D,
Lambda,
)
from keras.models import Model
input_shape = (218, 178, 3)
input_face_left = Input(shape=input_shape, name="model_face_left")
input_face_right = Input(shape=input_shape, name="model_face_right")
input_face = Input(shape=input_shape)
face = Conv2D(32, kernel_size=(3, 3), activation="relu", padding="same", name="conv1")(
input_face
)
face = MaxPooling2D((2, 2), name="mp1")(face)
face = Conv2D(32, kernel_size=(3, 3), activation="relu", padding="same", name="conv2")(
face
)
face = MaxPooling2D((3, 3), name="mp2")(face)
output_face = Flatten(name="f1")(face)
model_face = Model(input_face, output_face)
model_face_left = model_face(input_face_left)
model_face_right = model_face(input_face_right)
merged_model = Lambda(
lambda tensors: abs(tensors[0] - tensors[1]), name="absolute_difference"
)([model_face_left, model_face_right])
merged_model = Dense(64, activation="relu", name="d1")(merged_model)
merged_model = Dropout(0.1, name="drop1")(merged_model)
merged_model = Dense(64, activation="relu", name="d2")(merged_model)
merged_model = Dense(1, activation="sigmoid", name="out")(merged_model)
model = Model(
inputs=[input_face_left, input_face_right], outputs=merged_model, name="lr_merger"
)
model.compile(loss="binary_crossentropy", optimizer="adam", metrics=["accuracy"])
model.summary()
from IPython.display import Image
from keras.utils import plot_model
plot_model(model, to_file="/kaggle/working/model.png", show_shapes=True)
Image("/kaggle/working/model.png")
class CustomBatchIterator:
def __init__(self, datagen, batch_size):
self.datagen = datagen
self.batch_size = batch_size
def make_batch(self):
images, labels = self.datagen.next_batch()
output_pairs = [np.zeros((self.batch_size, *images[0].shape)) for i in range(2)]
output_labels = np.zeros(self.batch_size)
output_labels[: self.batch_size // 2] = 1
for i in range(self.batch_size // 2):
label = labels[i]
random_image, _ = self.datagen.next(label)
output_pairs[0][i] = images[i]
output_pairs[1][i] = random_image
for i in range(self.batch_size // 2, self.batch_size):
label = labels[i]
while True:
random_label = random.choice(self.datagen.classes)
if random_label != label:
break
random_image, _ = self.datagen.next(random_label)
output_pairs[0][i] = images[i]
output_pairs[1][i] = random_image
return output_pairs, output_labels
def __iter__(self):
return self
def __next__(self):
return self.make_batch()
def show_batch_pairs(image_batch_pairs, label_batch):
fig, ax = plt.subplots(len(image_batch_pairs[0]), 2, figsize=(20, 20))
for r in range(len(image_batch_pairs[0])):
for c in [0, 1]:
ax[r, c].imshow(image_batch_pairs[c][r])
ax[r, c].axis("off")
ax[r, c].set_title("y=%d" % label_batch[r])
train_it = CustomBatchIterator(datagen_train, batch_size)
show_batch_pairs(*next(train_it))
model.fit_generator(train_it, steps_per_epoch=10, epochs=200)
| false | 0 | 2,220 | 0 | 137 | 2,220 |
||
135796633 | <kaggle_start><code>import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
X = pd.read_csv("/kaggle/input/playground-series-s3e18/train.csv")
# Drop EC3-6 to prevent leakage
X = X.drop(["id", "EC3", "EC4", "EC5", "EC6"], axis=1)
# remove -666 row
idxs = X[
(X["FpDensityMorgan1"] == -666)
| (X["FpDensityMorgan2"] == -666)
| (X["FpDensityMorgan3"] == -666)
].index
X = X.drop(idxs, axis=0)
y1 = X.pop("EC1")
y2 = X.pop("EC2")
X.shape
# I decide to trian models on EC1 and EC2 separately. The objective is to maximize the cv score.
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import BaggingClassifier, VotingClassifier
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, FunctionTransformer
# Use optuna to tune the hp
import optuna
def add_features():
# add several features
pass
# # EC1
# Use LGBM to predict EC1
from lightgbm import LGBMClassifier
param1_distributions = {
"learning_rate": optuna.distributions.FloatDistribution(1e-3, 0.05),
"n_estimators": optuna.distributions.IntDistribution(80, 500),
"min_child_samples": optuna.distributions.IntDistribution(10, 90),
"reg_alpha": optuna.distributions.FloatDistribution(1e-3, 10.0),
"subsample": optuna.distributions.FloatDistribution(0.6, 1.0),
"colsample_bytree": optuna.distributions.FloatDistribution(0.6, 1.0),
}
optuna_search1 = optuna.integration.OptunaSearchCV(
LGBMClassifier(random_state=100),
param1_distributions,
scoring="roc_auc",
refit=True,
random_state=1289,
verbose=0,
)
# optuna_search1.fit(X,y1)
# Tuned by optuna
clf1 = LGBMClassifier(
random_state=100,
n_estimators=160,
learning_rate=0.04,
min_child_samples=50,
reg_alpha=1.06,
reg_lambda=2,
)
gcv1 = GridSearchCV(clf1, {}, refit=True, scoring="roc_auc")
gcv1.fit(X, y1)
gcv1.best_score_
# # EC2
from sklearn.neighbors import KNeighborsClassifier
model = make_pipeline(
StandardScaler(),
BaggingClassifier(
KNeighborsClassifier(n_neighbors=500, weights="distance"),
n_estimators=100,
bootstrap=False,
max_features=9,
random_state=1,
),
)
gcv2 = GridSearchCV(model, {}, refit=True, scoring="roc_auc")
gcv2.fit(X, y2)
gcv2.best_score_
# # Submission
X_test = pd.read_csv("/kaggle/input/playground-series-s3e18/test.csv")
ids = X_test.pop("id")
y1_test = gcv1.predict_proba(X_test)[:, 1]
y2_test = gcv2.predict_proba(X_test)[:, 1]
submit = pd.DataFrame({"id": ids, "EC1": y1_test, "EC2": y2_test})
submit.to_csv("submission.csv", index=False)
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0135/796/135796633.ipynb | null | null | [{"Id": 135796633, "ScriptId": 40539752, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 13503132, "CreationDate": "07/05/2023 10:09:03", "VersionNumber": 4.0, "Title": "Enzyme\ud83e\udda0", "EvaluationDate": "07/05/2023", "IsChange": true, "TotalLines": 115.0, "LinesInsertedFromPrevious": 74.0, "LinesChangedFromPrevious": 0.0, "LinesUnchangedFromPrevious": 41.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk("/kaggle/input"):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
X = pd.read_csv("/kaggle/input/playground-series-s3e18/train.csv")
# Drop EC3-6 to prevent leakage
X = X.drop(["id", "EC3", "EC4", "EC5", "EC6"], axis=1)
# remove -666 row
idxs = X[
(X["FpDensityMorgan1"] == -666)
| (X["FpDensityMorgan2"] == -666)
| (X["FpDensityMorgan3"] == -666)
].index
X = X.drop(idxs, axis=0)
y1 = X.pop("EC1")
y2 = X.pop("EC2")
X.shape
# I decide to trian models on EC1 and EC2 separately. The objective is to maximize the cv score.
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.model_selection import GridSearchCV
from sklearn.ensemble import BaggingClassifier, VotingClassifier
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, FunctionTransformer
# Use optuna to tune the hp
import optuna
def add_features():
# add several features
pass
# # EC1
# Use LGBM to predict EC1
from lightgbm import LGBMClassifier
param1_distributions = {
"learning_rate": optuna.distributions.FloatDistribution(1e-3, 0.05),
"n_estimators": optuna.distributions.IntDistribution(80, 500),
"min_child_samples": optuna.distributions.IntDistribution(10, 90),
"reg_alpha": optuna.distributions.FloatDistribution(1e-3, 10.0),
"subsample": optuna.distributions.FloatDistribution(0.6, 1.0),
"colsample_bytree": optuna.distributions.FloatDistribution(0.6, 1.0),
}
optuna_search1 = optuna.integration.OptunaSearchCV(
LGBMClassifier(random_state=100),
param1_distributions,
scoring="roc_auc",
refit=True,
random_state=1289,
verbose=0,
)
# optuna_search1.fit(X,y1)
# Tuned by optuna
clf1 = LGBMClassifier(
random_state=100,
n_estimators=160,
learning_rate=0.04,
min_child_samples=50,
reg_alpha=1.06,
reg_lambda=2,
)
gcv1 = GridSearchCV(clf1, {}, refit=True, scoring="roc_auc")
gcv1.fit(X, y1)
gcv1.best_score_
# # EC2
from sklearn.neighbors import KNeighborsClassifier
model = make_pipeline(
StandardScaler(),
BaggingClassifier(
KNeighborsClassifier(n_neighbors=500, weights="distance"),
n_estimators=100,
bootstrap=False,
max_features=9,
random_state=1,
),
)
gcv2 = GridSearchCV(model, {}, refit=True, scoring="roc_auc")
gcv2.fit(X, y2)
gcv2.best_score_
# # Submission
X_test = pd.read_csv("/kaggle/input/playground-series-s3e18/test.csv")
ids = X_test.pop("id")
y1_test = gcv1.predict_proba(X_test)[:, 1]
y2_test = gcv2.predict_proba(X_test)[:, 1]
submit = pd.DataFrame({"id": ids, "EC1": y1_test, "EC2": y2_test})
submit.to_csv("submission.csv", index=False)
| false | 0 | 1,099 | 0 | 6 | 1,099 |
||
469856 | <kaggle_start><code># # @author Julien WUTHRICH
import pandas as pd
import numpy as np
df = pd.read_csv("../input/train_ver2.csv", nrows=100000)
import time
def timeit(method):
def timed(*args, **kw):
ts = time.time()
result = method(*args, **kw)
te = time.time()
print("Duration = {}".format(te - ts))
return result
return timed
cols = {
"fecha_dato": "Day",
"ncodpers": "Id",
"ind_empleado": "Employee",
"pais_residenca": "Country",
"sexo": "Sexe",
"cod_prov": "CountryId",
"age": "Age",
"fecha_alta": "RegistrationDate",
"ind_nuevo": "NewCustomer",
"antiguedad": "Seniority",
"indrel": "Premium",
"ult_fec_cli_1t": "EndPremium",
"indrel_1mes": "CustomerType",
"tiprel_1mes": "RelationType",
"indresi": "CountryBank",
"indext": "CountryBirth",
"conyuemp": "Spouse",
"canal_entrada": "Channel",
"indfall": "Deceased",
"tipodom": "PrimaryAdress",
"nomprov": "ProvinceName",
"ind_actividad_cliente": "CustomerActivity",
"renta": "Income",
"segmento": "Job",
}
df = df.rename(columns=cols)
from collections import namedtuple
TRAPEZE = namedtuple("SubCategory", ["x1", "x2", "x3", "x4"])
class Tools(object):
"""All tools needed for this exp."""
def __init__(self):
"""Constructor."""
pass
def count_frequency(df, col, new_col="Freq"):
"""Count the occurence of a value, in a column.
:params df: train dataset
:type df: dataframe
:params col: column to work on
:type col: str or list
:return: dataframe with new col, Frequency
:rtype: dataframe
"""
df[new_col] = df.groupby(col)[col].transform("count")
return df
def change_nan_value(df, new_value):
"""Change the nan into new value.
:params df: dataset
:params new_val: value to change from NaN
:return: df or serie without NaN
"""
return df.where((pd.notnull(df)), new_value)
def pairwise(data, last=False):
"""Generator for pair data.
:rparams data: dataframe or list
:params last: pair btw last and first ?
:return: generator of pair
:rtype: list
"""
res = None
if isinstance(data, pd.DataFrame):
res = [(x[1], y[1]) for x, y in zip(data.iterrows(), data[1:].iterrows())]
if last:
res = res + [
(x[1], y[1])
for x, y in zip(data[-1:].iterrows(), data[:1].iterrows())
]
elif isinstance(data, list):
res = [(x, y) for x, y in zip(data, data[1:])]
if last:
res = res + [(x, y) for x, y in zip(data[-1:], data[:1])]
return res
def select_cols_after_one(df, col):
"""Select cols after the one given.
:params df: dataset
:params col: after this one
:return: subset df
"""
return df.ix[:, col:]
def remove_rows_contains_null(df, col):
"""
Remove all rows which contain a None in the dataframe column
"""
return df[df[col].notnull()]
class Fuzzy(object):
"""Generate the fuzzy value."""
def __init__(self, df):
"""Constructor."""
self.df = df
self.remove_row_without_age
@property
def remove_row_without_age(self):
"""."""
self.df = self.df[self.df["Age"] != " NA"]
def belong_line(self, pt1, pt2, value):
"""Belong line btw the pt1 and pt2.
:params pt1: (x1, y1)
:params pt2: (x2, y2)
"""
x1 = pt1[0]
x2 = pt2[0]
contains = range(x1, x2)
if value in contains:
return 1
else:
return 0
def belong_fall(self, pt1, pt2, value):
"""Find slope of the line and calc the ordonate of the value.
:params pt1: (x1, y1)
:params pt2: (x2, y2)
"""
if value > pt1[0] and value > pt2[0]:
return 0
elif value < pt1[0] and value < pt2[0]:
return 0
alpha = (pt2[1] - pt1[1]) / (pt2[0] - pt1[0])
b = pt1[1] - alpha * pt1[0]
y = value * alpha + b
y = abs(round(y, 2))
if 0 <= y <= 1:
return y
else:
return 0
def function_membership(self, value, trapeze):
"""Belong of a value.
:params value: value to define the origin
:params trapeze: the value of the behaviour
"""
left_bot = (trapeze.x1, 0.0)
left_top = (trapeze.x2, 1.0)
right_top = (trapeze.x3, 1.0)
right_bot = (trapeze.x4, 0.0)
res1 = self.belong_fall(left_bot, left_top, value)
res2 = self.belong_line(left_top, right_top, value)
res3 = self.belong_fall(right_top, right_bot, value)
val = [x for x in [res1, res2, res3] if 0 < x <= 1]
try:
return val[0]
except:
return 0
@timeit
def main(self):
"""Compute the new cols with values."""
kid = TRAPEZE(0, 3, 18, 22)
student = TRAPEZE(18, 22, 26, 28)
worker = TRAPEZE(26, 28, 55, 60)
retired = TRAPEZE(55, 60, 95, 120)
lst_first, lst_second, lst_third, lst_last, lst_id = [], [], [], [], []
for idx, row in self.df.iterrows():
age = int(row["Age"])
lst_first.append(self.function_membership(age, kid))
lst_second.append(self.function_membership(age, student))
lst_third.append(self.function_membership(age, worker))
lst_last.append(self.function_membership(age, retired))
lst_id.append(row["Id"])
df_age = pd.DataFrame([lst_first, lst_second, lst_third, lst_last, lst_id]).T
df_age.columns = ["Kid", "Student", "Worker", "Retired", "Id"]
return pd.merge(self.df, df_age, on="Id")
df = Fuzzy(df).main()
class TransformCols(object):
"""Transform cols qualitative to quantitative."""
def __init__(self, df):
"""Constructor."""
self.df = df
@timeit
def main(self):
"""Create for sexe and job for now."""
self.df["_Sexe"] = self.df["Sexe"].apply(lambda x: 1 if x == "H" else 0)
self.df["Job"] = Tools.change_nan_value(self.df["Job"], "05")
self.df["_Job"] = self.df["Job"].apply(lambda x: x[:2])
self.df["_Job"] = self.df["_Job"].astype(int)
self.df["Seniority"] = self.df["Seniority"].astype(int)
self.df["Age"] = self.df["Age"].astype(int)
return self.df
df = TransformCols(df).main()
df.head()
available_cols = [
"Age",
"NewCustomer",
"Seniority",
"Premium",
"CustomerType",
"CountryId",
"CustomerActivity",
"Income",
"Kid",
"Student",
"Worker",
"Retired",
"_Sexe",
"_Job",
]
cols_to_pred = [
"ind_cco_fin_ult1",
"ind_recibo_ult1",
"ind_cder_fin_ult1",
"ind_cno_fin_ult1",
"ind_ctju_fin_ult1",
"ind_ctma_fin_ult1",
"ind_ctop_fin_ult1",
"ind_ctpp_fin_ult1",
"ind_deco_fin_ult1",
"ind_deme_fin_ult1",
"ind_dela_fin_ult1",
"ind_ecue_fin_ult1",
"ind_fond_fin_ult1",
"ind_hip_fin_ult1",
"ind_plan_fin_ult1",
"ind_pres_fin_ult1",
"ind_reca_fin_ult1",
"ind_tjcr_fin_ult1",
"ind_valo_fin_ult1",
"ind_viv_fin_ult1",
"ind_nomina_ult1",
"ind_nom_pens_ult1",
]
df = df.drop(["Spouse", "PrimaryAdress"], 1)
df_corr = df.corr(method="spearman")
<|endoftext|> | /fsx/loubna/kaggle_data/kaggle-code-data/data/0000/469/469856.ipynb | null | null | [{"Id": 469856, "ScriptId": 123325, "ParentScriptVersionId": NaN, "ScriptLanguageId": 9, "AuthorUserId": 576054, "CreationDate": "11/27/2016 16:45:54", "VersionNumber": 8.0, "Title": "Create new columns based on fuzzy logic", "EvaluationDate": "11/27/2016", "IsChange": true, "TotalLines": NaN, "LinesInsertedFromPrevious": 0.0, "LinesChangedFromPrevious": 2.0, "LinesUnchangedFromPrevious": 439.0, "LinesInsertedFromFork": NaN, "LinesDeletedFromFork": NaN, "LinesChangedFromFork": NaN, "LinesUnchangedFromFork": NaN, "TotalVotes": 0}] | null | null | null | null | # # @author Julien WUTHRICH
import pandas as pd
import numpy as np
df = pd.read_csv("../input/train_ver2.csv", nrows=100000)
import time
def timeit(method):
def timed(*args, **kw):
ts = time.time()
result = method(*args, **kw)
te = time.time()
print("Duration = {}".format(te - ts))
return result
return timed
cols = {
"fecha_dato": "Day",
"ncodpers": "Id",
"ind_empleado": "Employee",
"pais_residenca": "Country",
"sexo": "Sexe",
"cod_prov": "CountryId",
"age": "Age",
"fecha_alta": "RegistrationDate",
"ind_nuevo": "NewCustomer",
"antiguedad": "Seniority",
"indrel": "Premium",
"ult_fec_cli_1t": "EndPremium",
"indrel_1mes": "CustomerType",
"tiprel_1mes": "RelationType",
"indresi": "CountryBank",
"indext": "CountryBirth",
"conyuemp": "Spouse",
"canal_entrada": "Channel",
"indfall": "Deceased",
"tipodom": "PrimaryAdress",
"nomprov": "ProvinceName",
"ind_actividad_cliente": "CustomerActivity",
"renta": "Income",
"segmento": "Job",
}
df = df.rename(columns=cols)
from collections import namedtuple
TRAPEZE = namedtuple("SubCategory", ["x1", "x2", "x3", "x4"])
class Tools(object):
"""All tools needed for this exp."""
def __init__(self):
"""Constructor."""
pass
def count_frequency(df, col, new_col="Freq"):
"""Count the occurence of a value, in a column.
:params df: train dataset
:type df: dataframe
:params col: column to work on
:type col: str or list
:return: dataframe with new col, Frequency
:rtype: dataframe
"""
df[new_col] = df.groupby(col)[col].transform("count")
return df
def change_nan_value(df, new_value):
"""Change the nan into new value.
:params df: dataset
:params new_val: value to change from NaN
:return: df or serie without NaN
"""
return df.where((pd.notnull(df)), new_value)
def pairwise(data, last=False):
"""Generator for pair data.
:rparams data: dataframe or list
:params last: pair btw last and first ?
:return: generator of pair
:rtype: list
"""
res = None
if isinstance(data, pd.DataFrame):
res = [(x[1], y[1]) for x, y in zip(data.iterrows(), data[1:].iterrows())]
if last:
res = res + [
(x[1], y[1])
for x, y in zip(data[-1:].iterrows(), data[:1].iterrows())
]
elif isinstance(data, list):
res = [(x, y) for x, y in zip(data, data[1:])]
if last:
res = res + [(x, y) for x, y in zip(data[-1:], data[:1])]
return res
def select_cols_after_one(df, col):
"""Select cols after the one given.
:params df: dataset
:params col: after this one
:return: subset df
"""
return df.ix[:, col:]
def remove_rows_contains_null(df, col):
"""
Remove all rows which contain a None in the dataframe column
"""
return df[df[col].notnull()]
class Fuzzy(object):
"""Generate the fuzzy value."""
def __init__(self, df):
"""Constructor."""
self.df = df
self.remove_row_without_age
@property
def remove_row_without_age(self):
"""."""
self.df = self.df[self.df["Age"] != " NA"]
def belong_line(self, pt1, pt2, value):
"""Belong line btw the pt1 and pt2.
:params pt1: (x1, y1)
:params pt2: (x2, y2)
"""
x1 = pt1[0]
x2 = pt2[0]
contains = range(x1, x2)
if value in contains:
return 1
else:
return 0
def belong_fall(self, pt1, pt2, value):
"""Find slope of the line and calc the ordonate of the value.
:params pt1: (x1, y1)
:params pt2: (x2, y2)
"""
if value > pt1[0] and value > pt2[0]:
return 0
elif value < pt1[0] and value < pt2[0]:
return 0
alpha = (pt2[1] - pt1[1]) / (pt2[0] - pt1[0])
b = pt1[1] - alpha * pt1[0]
y = value * alpha + b
y = abs(round(y, 2))
if 0 <= y <= 1:
return y
else:
return 0
def function_membership(self, value, trapeze):
"""Belong of a value.
:params value: value to define the origin
:params trapeze: the value of the behaviour
"""
left_bot = (trapeze.x1, 0.0)
left_top = (trapeze.x2, 1.0)
right_top = (trapeze.x3, 1.0)
right_bot = (trapeze.x4, 0.0)
res1 = self.belong_fall(left_bot, left_top, value)
res2 = self.belong_line(left_top, right_top, value)
res3 = self.belong_fall(right_top, right_bot, value)
val = [x for x in [res1, res2, res3] if 0 < x <= 1]
try:
return val[0]
except:
return 0
@timeit
def main(self):
"""Compute the new cols with values."""
kid = TRAPEZE(0, 3, 18, 22)
student = TRAPEZE(18, 22, 26, 28)
worker = TRAPEZE(26, 28, 55, 60)
retired = TRAPEZE(55, 60, 95, 120)
lst_first, lst_second, lst_third, lst_last, lst_id = [], [], [], [], []
for idx, row in self.df.iterrows():
age = int(row["Age"])
lst_first.append(self.function_membership(age, kid))
lst_second.append(self.function_membership(age, student))
lst_third.append(self.function_membership(age, worker))
lst_last.append(self.function_membership(age, retired))
lst_id.append(row["Id"])
df_age = pd.DataFrame([lst_first, lst_second, lst_third, lst_last, lst_id]).T
df_age.columns = ["Kid", "Student", "Worker", "Retired", "Id"]
return pd.merge(self.df, df_age, on="Id")
df = Fuzzy(df).main()
class TransformCols(object):
"""Transform cols qualitative to quantitative."""
def __init__(self, df):
"""Constructor."""
self.df = df
@timeit
def main(self):
"""Create for sexe and job for now."""
self.df["_Sexe"] = self.df["Sexe"].apply(lambda x: 1 if x == "H" else 0)
self.df["Job"] = Tools.change_nan_value(self.df["Job"], "05")
self.df["_Job"] = self.df["Job"].apply(lambda x: x[:2])
self.df["_Job"] = self.df["_Job"].astype(int)
self.df["Seniority"] = self.df["Seniority"].astype(int)
self.df["Age"] = self.df["Age"].astype(int)
return self.df
df = TransformCols(df).main()
df.head()
available_cols = [
"Age",
"NewCustomer",
"Seniority",
"Premium",
"CustomerType",
"CountryId",
"CustomerActivity",
"Income",
"Kid",
"Student",
"Worker",
"Retired",
"_Sexe",
"_Job",
]
cols_to_pred = [
"ind_cco_fin_ult1",
"ind_recibo_ult1",
"ind_cder_fin_ult1",
"ind_cno_fin_ult1",
"ind_ctju_fin_ult1",
"ind_ctma_fin_ult1",
"ind_ctop_fin_ult1",
"ind_ctpp_fin_ult1",
"ind_deco_fin_ult1",
"ind_deme_fin_ult1",
"ind_dela_fin_ult1",
"ind_ecue_fin_ult1",
"ind_fond_fin_ult1",
"ind_hip_fin_ult1",
"ind_plan_fin_ult1",
"ind_pres_fin_ult1",
"ind_reca_fin_ult1",
"ind_tjcr_fin_ult1",
"ind_valo_fin_ult1",
"ind_viv_fin_ult1",
"ind_nomina_ult1",
"ind_nom_pens_ult1",
]
df = df.drop(["Spouse", "PrimaryAdress"], 1)
df_corr = df.corr(method="spearman")
| false | 0 | 2,423 | 0 | 6 | 2,423 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.