
modelId
stringlengths 6
118
| author
stringlengths 2
42
| last_modified
unknown | downloads
int64 4
223M
| likes
int64 0
7.74k
| library_name
stringclasses 260
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 52
values | createdAt
unknown | card
stringlengths 1
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
microsoft/resnet-50 | microsoft | "2024-02-13T21:24:05Z" | 222,680,861 | 382 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"resnet",
"image-classification",
"vision",
"dataset:imagenet-1k",
"arxiv:1512.03385",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | "2022-03-16T15:42:43Z" | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
---
# ResNet-50 v1.5
ResNet model pre-trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [Deep Residual Learning for Image Recognition](https://arxiv.org/abs/1512.03385) by He et al.
Disclaimer: The team releasing ResNet did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
ResNet (Residual Network) is a convolutional neural network that democratized the concepts of residual learning and skip connections. This enables to train much deeper models.
This is ResNet v1.5, which differs from the original model: in the bottleneck blocks which require downsampling, v1 has stride = 2 in the first 1x1 convolution, whereas v1.5 has stride = 2 in the 3x3 convolution. This difference makes ResNet50 v1.5 slightly more accurate (\~0.5% top1) than v1, but comes with a small performance drawback (~5% imgs/sec) according to [Nvidia](https://catalog.ngc.nvidia.com/orgs/nvidia/resources/resnet_50_v1_5_for_pytorch).

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=resnet) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import AutoImageProcessor, ResNetForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
processor = AutoImageProcessor.from_pretrained("microsoft/resnet-50")
model = ResNetForImageClassification.from_pretrained("microsoft/resnet-50")
inputs = processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label])
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/resnet).
### BibTeX entry and citation info
```bibtex
@inproceedings{he2016deep,
title={Deep residual learning for image recognition},
author={He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian},
booktitle={Proceedings of the IEEE conference on computer vision and pattern recognition},
pages={770--778},
year={2016}
}
```
|
timm/mobilenetv3_small_100.lamb_in1k | timm | "2025-01-21T18:21:16Z" | 195,445,149 | 2 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"transformers",
"dataset:imagenet-1k",
"arxiv:2110.00476",
"arxiv:1905.02244",
"license:apache-2.0",
"region:us"
] | image-classification | "2022-12-16T05:38:36Z" | ---
tags:
- image-classification
- timm
- transformers
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for mobilenetv3_small_100.lamb_in1k
A MobileNet-v3 image classification model. Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* A LAMB optimizer recipe that is similar to [ResNet Strikes Back](https://arxiv.org/abs/2110.00476) `A2` but 50% longer with EMA weight averaging, no CutMix
* RMSProp (TF 1.0 behaviour) optimizer, EMA weight averaging
* Step (exponential decay w/ staircase) LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 2.5
- GMACs: 0.1
- Activations (M): 1.4
- Image size: 224 x 224
- **Papers:**
- Searching for MobileNetV3: https://arxiv.org/abs/1905.02244
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('mobilenetv3_small_100.lamb_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'mobilenetv3_small_100.lamb_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 16, 112, 112])
# torch.Size([1, 16, 56, 56])
# torch.Size([1, 24, 28, 28])
# torch.Size([1, 48, 14, 14])
# torch.Size([1, 576, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'mobilenetv3_small_100.lamb_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 576, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@inproceedings{howard2019searching,
title={Searching for mobilenetv3},
author={Howard, Andrew and Sandler, Mark and Chu, Grace and Chen, Liang-Chieh and Chen, Bo and Tan, Mingxing and Wang, Weijun and Zhu, Yukun and Pang, Ruoming and Vasudevan, Vijay and others},
booktitle={Proceedings of the IEEE/CVF international conference on computer vision},
pages={1314--1324},
year={2019}
}
```
|
google-bert/bert-base-uncased | google-bert | "2024-02-19T11:06:12Z" | 86,053,798 | 2,099 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"coreml",
"onnx",
"safetensors",
"bert",
"fill-mask",
"exbert",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:04Z" | ---
language: en
tags:
- exbert
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
---
# BERT base model (uncased)
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/abs/1810.04805) and first released in
[this repository](https://github.com/google-research/bert). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing BERT did not write a model card for this model so this model card has been written by
the Hugging Face team.
## Model description
BERT is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labeling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally masks the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences, for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
## Model variations
BERT has originally been released in base and large variations, for cased and uncased input text. The uncased models also strips out an accent markers.
Chinese and multilingual uncased and cased versions followed shortly after.
Modified preprocessing with whole word masking has replaced subpiece masking in a following work, with the release of two models.
Other 24 smaller models are released afterward.
The detailed release history can be found on the [google-research/bert readme](https://github.com/google-research/bert/blob/master/README.md) on github.
| Model | #params | Language |
|------------------------|--------------------------------|-------|
| [`bert-base-uncased`](https://huggingface.co/bert-base-uncased) | 110M | English |
| [`bert-large-uncased`](https://huggingface.co/bert-large-uncased) | 340M | English | sub
| [`bert-base-cased`](https://huggingface.co/bert-base-cased) | 110M | English |
| [`bert-large-cased`](https://huggingface.co/bert-large-cased) | 340M | English |
| [`bert-base-chinese`](https://huggingface.co/bert-base-chinese) | 110M | Chinese |
| [`bert-base-multilingual-cased`](https://huggingface.co/bert-base-multilingual-cased) | 110M | Multiple |
| [`bert-large-uncased-whole-word-masking`](https://huggingface.co/bert-large-uncased-whole-word-masking) | 340M | English |
| [`bert-large-cased-whole-word-masking`](https://huggingface.co/bert-large-cased-whole-word-masking) | 340M | English |
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=bert) to look for
fine-tuned versions of a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='bert-base-uncased')
>>> unmasker("Hello I'm a [MASK] model.")
[{'sequence': "[CLS] hello i'm a fashion model. [SEP]",
'score': 0.1073106899857521,
'token': 4827,
'token_str': 'fashion'},
{'sequence': "[CLS] hello i'm a role model. [SEP]",
'score': 0.08774490654468536,
'token': 2535,
'token_str': 'role'},
{'sequence': "[CLS] hello i'm a new model. [SEP]",
'score': 0.05338378623127937,
'token': 2047,
'token_str': 'new'},
{'sequence': "[CLS] hello i'm a super model. [SEP]",
'score': 0.04667217284440994,
'token': 3565,
'token_str': 'super'},
{'sequence': "[CLS] hello i'm a fine model. [SEP]",
'score': 0.027095865458250046,
'token': 2986,
'token_str': 'fine'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained("bert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = TFBertModel.from_pretrained("bert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='bert-base-uncased')
>>> unmasker("The man worked as a [MASK].")
[{'sequence': '[CLS] the man worked as a carpenter. [SEP]',
'score': 0.09747550636529922,
'token': 10533,
'token_str': 'carpenter'},
{'sequence': '[CLS] the man worked as a waiter. [SEP]',
'score': 0.0523831807076931,
'token': 15610,
'token_str': 'waiter'},
{'sequence': '[CLS] the man worked as a barber. [SEP]',
'score': 0.04962705448269844,
'token': 13362,
'token_str': 'barber'},
{'sequence': '[CLS] the man worked as a mechanic. [SEP]',
'score': 0.03788609802722931,
'token': 15893,
'token_str': 'mechanic'},
{'sequence': '[CLS] the man worked as a salesman. [SEP]',
'score': 0.037680890411138535,
'token': 18968,
'token_str': 'salesman'}]
>>> unmasker("The woman worked as a [MASK].")
[{'sequence': '[CLS] the woman worked as a nurse. [SEP]',
'score': 0.21981462836265564,
'token': 6821,
'token_str': 'nurse'},
{'sequence': '[CLS] the woman worked as a waitress. [SEP]',
'score': 0.1597415804862976,
'token': 13877,
'token_str': 'waitress'},
{'sequence': '[CLS] the woman worked as a maid. [SEP]',
'score': 0.1154729500412941,
'token': 10850,
'token_str': 'maid'},
{'sequence': '[CLS] the woman worked as a prostitute. [SEP]',
'score': 0.037968918681144714,
'token': 19215,
'token_str': 'prostitute'},
{'sequence': '[CLS] the woman worked as a cook. [SEP]',
'score': 0.03042375110089779,
'token': 5660,
'token_str': 'cook'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The BERT model was pretrained on [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038
unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and
headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus, and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The model was trained on 4 cloud TPUs in Pod configuration (16 TPU chips total) for one million steps with a batch size
of 256. The sequence length was limited to 128 tokens for 90% of the steps and 512 for the remaining 10%. The optimizer
used is Adam with a learning rate of 1e-4, \\(\beta_{1} = 0.9\\) and \\(\beta_{2} = 0.999\\), a weight decay of 0.01,
learning rate warmup for 10,000 steps and linear decay of the learning rate after.
## Evaluation results
When fine-tuned on downstream tasks, this model achieves the following results:
Glue test results:
| Task | MNLI-(m/mm) | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE | Average |
|:----:|:-----------:|:----:|:----:|:-----:|:----:|:-----:|:----:|:----:|:-------:|
| | 84.6/83.4 | 71.2 | 90.5 | 93.5 | 52.1 | 85.8 | 88.9 | 66.4 | 79.6 |
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1810-04805,
author = {Jacob Devlin and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {{BERT:} Pre-training of Deep Bidirectional Transformers for Language
Understanding},
journal = {CoRR},
volume = {abs/1810.04805},
year = {2018},
url = {http://arxiv.org/abs/1810.04805},
archivePrefix = {arXiv},
eprint = {1810.04805},
timestamp = {Tue, 30 Oct 2018 20:39:56 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1810-04805.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<a href="https://huggingface.co/exbert/?model=bert-base-uncased">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
sentence-transformers/all-MiniLM-L6-v2 | sentence-transformers | "2024-11-01T10:26:30Z" | 79,691,401 | 2,945 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"rust",
"onnx",
"safetensors",
"openvino",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"dataset:s2orc",
"dataset:flax-sentence-embeddings/stackexchange_xml",
"dataset:ms_marco",
"dataset:gooaq",
"dataset:yahoo_answers_topics",
"dataset:code_search_net",
"dataset:search_qa",
"dataset:eli5",
"dataset:snli",
"dataset:multi_nli",
"dataset:wikihow",
"dataset:natural_questions",
"dataset:trivia_qa",
"dataset:embedding-data/sentence-compression",
"dataset:embedding-data/flickr30k-captions",
"dataset:embedding-data/altlex",
"dataset:embedding-data/simple-wiki",
"dataset:embedding-data/QQP",
"dataset:embedding-data/SPECTER",
"dataset:embedding-data/PAQ_pairs",
"dataset:embedding-data/WikiAnswers",
"arxiv:1904.06472",
"arxiv:2102.07033",
"arxiv:2104.08727",
"arxiv:1704.05179",
"arxiv:1810.09305",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
language: en
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
datasets:
- s2orc
- flax-sentence-embeddings/stackexchange_xml
- ms_marco
- gooaq
- yahoo_answers_topics
- code_search_net
- search_qa
- eli5
- snli
- multi_nli
- wikihow
- natural_questions
- trivia_qa
- embedding-data/sentence-compression
- embedding-data/flickr30k-captions
- embedding-data/altlex
- embedding-data/simple-wiki
- embedding-data/QQP
- embedding-data/SPECTER
- embedding-data/PAQ_pairs
- embedding-data/WikiAnswers
pipeline_tag: sentence-similarity
---
# all-MiniLM-L6-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L6-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/all-MiniLM-L6-v2)
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developed this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developed this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intended to be used as a sentence and short paragraph encoder. Given an input text, it outputs a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 256 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model. Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained our model on a TPU v3-8. We train the model during 100k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title+Body, Answer) pairs | - | 21,396,559 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Answer) pairs | - | 21,396,559 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,170,060,424** | |
Falconsai/nsfw_image_detection | Falconsai | "2023-12-06T17:18:38Z" | 37,236,405 | 492 | transformers | [
"transformers",
"pytorch",
"safetensors",
"vit",
"image-classification",
"arxiv:2010.11929",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | "2023-10-13T23:50:01Z" | ---
license: apache-2.0
pipeline_tag: image-classification
---
# Model Card: Fine-Tuned Vision Transformer (ViT) for NSFW Image Classification
## Model Description
The **Fine-Tuned Vision Transformer (ViT)** is a variant of the transformer encoder architecture, similar to BERT, that has been adapted for image classification tasks. This specific model, named "google/vit-base-patch16-224-in21k," is pre-trained on a substantial collection of images in a supervised manner, leveraging the ImageNet-21k dataset. The images in the pre-training dataset are resized to a resolution of 224x224 pixels, making it suitable for a wide range of image recognition tasks.
During the training phase, meticulous attention was given to hyperparameter settings to ensure optimal model performance. The model was fine-tuned with a judiciously chosen batch size of 16. This choice not only balanced computational efficiency but also allowed for the model to effectively process and learn from a diverse array of images.
To facilitate this fine-tuning process, a learning rate of 5e-5 was employed. The learning rate serves as a critical tuning parameter that dictates the magnitude of adjustments made to the model's parameters during training. In this case, a learning rate of 5e-5 was selected to strike a harmonious balance between rapid convergence and steady optimization, resulting in a model that not only learns swiftly but also steadily refines its capabilities throughout the training process.
This training phase was executed using a proprietary dataset containing an extensive collection of 80,000 images, each characterized by a substantial degree of variability. The dataset was thoughtfully curated to include two distinct classes, namely "normal" and "nsfw." This diversity allowed the model to grasp nuanced visual patterns, equipping it with the competence to accurately differentiate between safe and explicit content.
The overarching objective of this meticulous training process was to impart the model with a deep understanding of visual cues, ensuring its robustness and competence in tackling the specific task of NSFW image classification. The result is a model that stands ready to contribute significantly to content safety and moderation, all while maintaining the highest standards of accuracy and reliability.
## Intended Uses & Limitations
### Intended Uses
- **NSFW Image Classification**: The primary intended use of this model is for the classification of NSFW (Not Safe for Work) images. It has been fine-tuned for this purpose, making it suitable for filtering explicit or inappropriate content in various applications.
### How to use
Here is how to use this model to classifiy an image based on 1 of 2 classes (normal,nsfw):
```markdown
# Use a pipeline as a high-level helper
from PIL import Image
from transformers import pipeline
img = Image.open("<path_to_image_file>")
classifier = pipeline("image-classification", model="Falconsai/nsfw_image_detection")
classifier(img)
```
<hr>
``` markdown
# Load model directly
import torch
from PIL import Image
from transformers import AutoModelForImageClassification, ViTImageProcessor
img = Image.open("<path_to_image_file>")
model = AutoModelForImageClassification.from_pretrained("Falconsai/nsfw_image_detection")
processor = ViTImageProcessor.from_pretrained('Falconsai/nsfw_image_detection')
with torch.no_grad():
inputs = processor(images=img, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
predicted_label = logits.argmax(-1).item()
model.config.id2label[predicted_label]
```
<hr>
### Limitations
- **Specialized Task Fine-Tuning**: While the model is adept at NSFW image classification, its performance may vary when applied to other tasks.
- Users interested in employing this model for different tasks should explore fine-tuned versions available in the model hub for optimal results.
## Training Data
The model's training data includes a proprietary dataset comprising approximately 80,000 images. This dataset encompasses a significant amount of variability and consists of two distinct classes: "normal" and "nsfw." The training process on this data aimed to equip the model with the ability to distinguish between safe and explicit content effectively.
### Training Stats
``` markdown
- 'eval_loss': 0.07463177293539047,
- 'eval_accuracy': 0.980375,
- 'eval_runtime': 304.9846,
- 'eval_samples_per_second': 52.462,
- 'eval_steps_per_second': 3.279
```
<hr>
**Note:** It's essential to use this model responsibly and ethically, adhering to content guidelines and applicable regulations when implementing it in real-world applications, particularly those involving potentially sensitive content.
For more details on model fine-tuning and usage, please refer to the model's documentation and the model hub.
## References
- [Hugging Face Model Hub](https://huggingface.co/models)
- [Vision Transformer (ViT) Paper](https://arxiv.org/abs/2010.11929)
- [ImageNet-21k Dataset](http://www.image-net.org/)
**Disclaimer:** The model's performance may be influenced by the quality and representativeness of the data it was fine-tuned on. Users are encouraged to assess the model's suitability for their specific applications and datasets. |
FacebookAI/xlm-roberta-large | FacebookAI | "2024-02-19T12:48:30Z" | 34,940,906 | 384 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"onnx",
"safetensors",
"xlm-roberta",
"fill-mask",
"exbert",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"arxiv:1911.02116",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:04Z" | ---
tags:
- exbert
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- no
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
license: mit
---
# XLM-RoBERTa (large-sized model)
XLM-RoBERTa model pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages. It was introduced in the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Conneau et al. and first released in [this repository](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
Disclaimer: The team releasing XLM-RoBERTa did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
XLM-RoBERTa is a multilingual version of RoBERTa. It is pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages.
RoBERTa is a transformers model pretrained on a large corpus in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was pretrained with the Masked language modeling (MLM) objective. Taking a sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the sentence.
This way, the model learns an inner representation of 100 languages that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard classifier using the features produced by the XLM-RoBERTa model as inputs.
## Intended uses & limitations
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?search=xlm-roberta) to look for fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked) to make decisions, such as sequence classification, token classification or question answering. For tasks such as text generation, you should look at models like GPT2.
## Usage
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='xlm-roberta-large')
>>> unmasker("Hello I'm a <mask> model.")
[{'score': 0.10563907772302628,
'sequence': "Hello I'm a fashion model.",
'token': 54543,
'token_str': 'fashion'},
{'score': 0.08015287667512894,
'sequence': "Hello I'm a new model.",
'token': 3525,
'token_str': 'new'},
{'score': 0.033413201570510864,
'sequence': "Hello I'm a model model.",
'token': 3299,
'token_str': 'model'},
{'score': 0.030217764899134636,
'sequence': "Hello I'm a French model.",
'token': 92265,
'token_str': 'French'},
{'score': 0.026436051353812218,
'sequence': "Hello I'm a sexy model.",
'token': 17473,
'token_str': 'sexy'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('xlm-roberta-large')
model = AutoModelForMaskedLM.from_pretrained("xlm-roberta-large")
# prepare input
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
# forward pass
output = model(**encoded_input)
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1911-02116,
author = {Alexis Conneau and
Kartikay Khandelwal and
Naman Goyal and
Vishrav Chaudhary and
Guillaume Wenzek and
Francisco Guzm{\'{a}}n and
Edouard Grave and
Myle Ott and
Luke Zettlemoyer and
Veselin Stoyanov},
title = {Unsupervised Cross-lingual Representation Learning at Scale},
journal = {CoRR},
volume = {abs/1911.02116},
year = {2019},
url = {http://arxiv.org/abs/1911.02116},
eprinttype = {arXiv},
eprint = {1911.02116},
timestamp = {Mon, 11 Nov 2019 18:38:09 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1911-02116.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<a href="https://huggingface.co/exbert/?model=xlm-roberta-base">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
ByteDance/AnimateDiff-Lightning | ByteDance | "2025-01-06T06:03:11Z" | 34,462,761 | 860 | diffusers | [
"diffusers",
"text-to-video",
"stable-diffusion",
"animatediff",
"arxiv:2403.12706",
"license:creativeml-openrail-m",
"region:us"
] | text-to-video | "2024-03-19T12:58:46Z" | ---
license: creativeml-openrail-m
tags:
- text-to-video
- stable-diffusion
- animatediff
library_name: diffusers
inference: false
---
# AnimateDiff-Lightning
<video src='https://huggingface.co/ByteDance/AnimateDiff-Lightning/resolve/main/animatediff_lightning_samples_t2v.mp4' width="100%" autoplay muted loop playsinline style='margin:0'></video>
<video src='https://huggingface.co/ByteDance/AnimateDiff-Lightning/resolve/main/animatediff_lightning_samples_v2v.mp4' width="100%" autoplay muted loop playsinline style='margin:0'></video>
AnimateDiff-Lightning is a lightning-fast text-to-video generation model. It can generate videos more than ten times faster than the original AnimateDiff. For more information, please refer to our research paper: [AnimateDiff-Lightning: Cross-Model Diffusion Distillation](https://arxiv.org/abs/2403.12706). We release the model as part of the research.
Our models are distilled from [AnimateDiff SD1.5 v2](https://huggingface.co/guoyww/animatediff). This repository contains checkpoints for 1-step, 2-step, 4-step, and 8-step distilled models. The generation quality of our 2-step, 4-step, and 8-step model is great. Our 1-step model is only provided for research purposes.
## Demo
Try AnimateDiff-Lightning using our text-to-video generation [demo](https://huggingface.co/spaces/ByteDance/AnimateDiff-Lightning).
## Recommendation
AnimateDiff-Lightning produces the best results when used with stylized base models. We recommend using the following base models:
Realistic
- [epiCRealism](https://civitai.com/models/25694)
- [Realistic Vision](https://civitai.com/models/4201)
- [DreamShaper](https://civitai.com/models/4384)
- [AbsoluteReality](https://civitai.com/models/81458)
- [MajicMix Realistic](https://civitai.com/models/43331)
Anime & Cartoon
- [ToonYou](https://civitai.com/models/30240)
- [IMP](https://civitai.com/models/56680)
- [Mistoon Anime](https://civitai.com/models/24149)
- [DynaVision](https://civitai.com/models/75549)
- [RCNZ Cartoon 3d](https://civitai.com/models/66347)
- [MajicMix Reverie](https://civitai.com/models/65055)
Additionally, feel free to explore different settings. We find using 3 inference steps on the 2-step model produces great results. We find certain base models produces better results with CFG. We also recommend using [Motion LoRAs](https://huggingface.co/guoyww/animatediff/tree/main) as they produce stronger motion. We use Motion LoRAs with strength 0.7~0.8 to avoid watermark.
## Diffusers Usage
```python
import torch
from diffusers import AnimateDiffPipeline, MotionAdapter, EulerDiscreteScheduler
from diffusers.utils import export_to_gif
from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
device = "cuda"
dtype = torch.float16
step = 4 # Options: [1,2,4,8]
repo = "ByteDance/AnimateDiff-Lightning"
ckpt = f"animatediff_lightning_{step}step_diffusers.safetensors"
base = "emilianJR/epiCRealism" # Choose to your favorite base model.
adapter = MotionAdapter().to(device, dtype)
adapter.load_state_dict(load_file(hf_hub_download(repo ,ckpt), device=device))
pipe = AnimateDiffPipeline.from_pretrained(base, motion_adapter=adapter, torch_dtype=dtype).to(device)
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config, timestep_spacing="trailing", beta_schedule="linear")
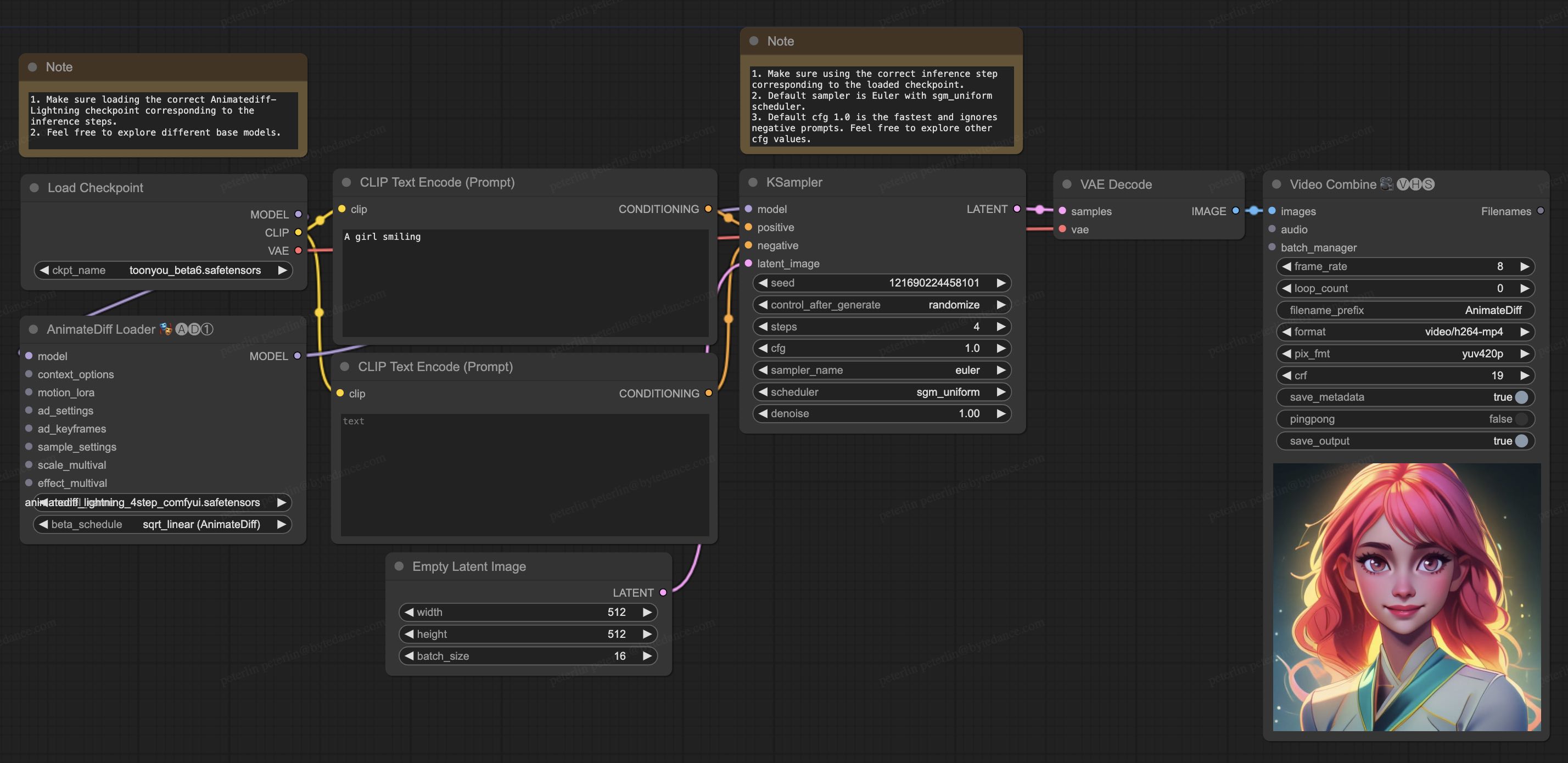
output = pipe(prompt="A girl smiling", guidance_scale=1.0, num_inference_steps=step)
export_to_gif(output.frames[0], "animation.gif")
```
## ComfyUI Usage
1. Download [animatediff_lightning_workflow.json](https://huggingface.co/ByteDance/AnimateDiff-Lightning/raw/main/comfyui/animatediff_lightning_workflow.json) and import it in ComfyUI.
1. Install nodes. You can install them manually or use [ComfyUI-Manager](https://github.com/ltdrdata/ComfyUI-Manager).
* [ComfyUI-AnimateDiff-Evolved](https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved)
* [ComfyUI-VideoHelperSuite](https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite)
1. Download your favorite base model checkpoint and put them under `/models/checkpoints/`
1. Download AnimateDiff-Lightning checkpoint `animatediff_lightning_Nstep_comfyui.safetensors` and put them under `/custom_nodes/ComfyUI-AnimateDiff-Evolved/models/`
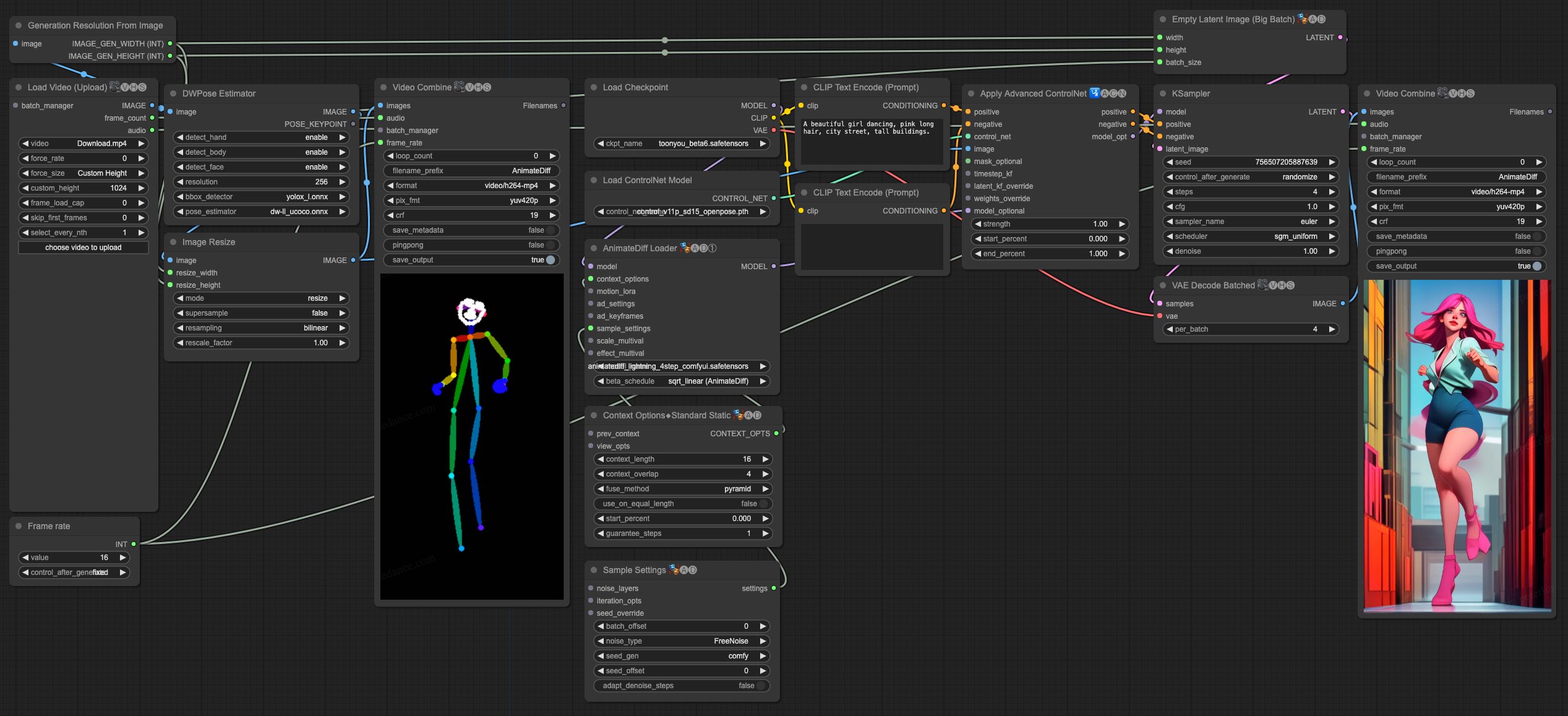
## Video-to-Video Generation
AnimateDiff-Lightning is great for video-to-video generation. We provide the simplist comfyui workflow using ControlNet.
1. Download [animatediff_lightning_v2v_openpose_workflow.json](https://huggingface.co/ByteDance/AnimateDiff-Lightning/raw/main/comfyui/animatediff_lightning_v2v_openpose_workflow.json) and import it in ComfyUI.
1. Install nodes. You can install them manually or use [ComfyUI-Manager](https://github.com/ltdrdata/ComfyUI-Manager).
* [ComfyUI-AnimateDiff-Evolved](https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved)
* [ComfyUI-VideoHelperSuite](https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite)
* [ComfyUI-Advanced-ControlNet](https://github.com/Kosinkadink/ComfyUI-Advanced-ControlNet)
* [comfyui_controlnet_aux](https://github.com/Fannovel16/comfyui_controlnet_aux)
1. Download your favorite base model checkpoint and put them under `/models/checkpoints/`
1. Download AnimateDiff-Lightning checkpoint `animatediff_lightning_Nstep_comfyui.safetensors` and put them under `/custom_nodes/ComfyUI-AnimateDiff-Evolved/models/`
1. Download [ControlNet OpenPose](https://huggingface.co/lllyasviel/ControlNet-v1-1/tree/main) `control_v11p_sd15_openpose.pth` checkpoint to `/models/controlnet/`
1. Upload your video and run the pipeline.
Additional notes:
1. Video shouldn't be too long or too high resolution. We used 576x1024 8 second 30fps videos for testing.
1. Set the frame rate to match your input video. This allows audio to match with the output video.
1. DWPose will download checkpoint itself on its first run.
1. DWPose may get stuck in UI, but the pipeline is actually still running in the background. Check ComfyUI log and your output folder.
# Cite Our Work
```
@misc{lin2024animatedifflightning,
title={AnimateDiff-Lightning: Cross-Model Diffusion Distillation},
author={Shanchuan Lin and Xiao Yang},
year={2024},
eprint={2403.12706},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
sentence-transformers/all-mpnet-base-v2 | sentence-transformers | "2024-11-05T15:25:48Z" | 32,375,311 | 975 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"onnx",
"safetensors",
"openvino",
"mpnet",
"fill-mask",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"dataset:s2orc",
"dataset:flax-sentence-embeddings/stackexchange_xml",
"dataset:ms_marco",
"dataset:gooaq",
"dataset:yahoo_answers_topics",
"dataset:code_search_net",
"dataset:search_qa",
"dataset:eli5",
"dataset:snli",
"dataset:multi_nli",
"dataset:wikihow",
"dataset:natural_questions",
"dataset:trivia_qa",
"dataset:embedding-data/sentence-compression",
"dataset:embedding-data/flickr30k-captions",
"dataset:embedding-data/altlex",
"dataset:embedding-data/simple-wiki",
"dataset:embedding-data/QQP",
"dataset:embedding-data/SPECTER",
"dataset:embedding-data/PAQ_pairs",
"dataset:embedding-data/WikiAnswers",
"arxiv:1904.06472",
"arxiv:2102.07033",
"arxiv:2104.08727",
"arxiv:1704.05179",
"arxiv:1810.09305",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
language: en
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
datasets:
- s2orc
- flax-sentence-embeddings/stackexchange_xml
- ms_marco
- gooaq
- yahoo_answers_topics
- code_search_net
- search_qa
- eli5
- snli
- multi_nli
- wikihow
- natural_questions
- trivia_qa
- embedding-data/sentence-compression
- embedding-data/flickr30k-captions
- embedding-data/altlex
- embedding-data/simple-wiki
- embedding-data/QQP
- embedding-data/SPECTER
- embedding-data/PAQ_pairs
- embedding-data/WikiAnswers
pipeline_tag: sentence-similarity
---
# all-mpnet-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-mpnet-base-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-mpnet-base-v2')
model = AutoModel.from_pretrained('sentence-transformers/all-mpnet-base-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/all-mpnet-base-v2)
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 384 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base) model. Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 100k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title+Body, Answer) pairs | - | 21,396,559 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Answer) pairs | - | 21,396,559 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,170,060,424** | |
openai/clip-vit-large-patch14 | openai | "2023-09-15T15:49:35Z" | 21,264,455 | 1,622 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"clip",
"zero-shot-image-classification",
"vision",
"arxiv:2103.00020",
"arxiv:1908.04913",
"endpoints_compatible",
"region:us"
] | zero-shot-image-classification | "2022-03-02T23:29:05Z" | ---
tags:
- vision
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: playing music, playing sports
example_title: Cat & Dog
---
# Model Card: CLIP
Disclaimer: The model card is taken and modified from the official CLIP repository, it can be found [here](https://github.com/openai/CLIP/blob/main/model-card.md).
## Model Details
The CLIP model was developed by researchers at OpenAI to learn about what contributes to robustness in computer vision tasks. The model was also developed to test the ability of models to generalize to arbitrary image classification tasks in a zero-shot manner. It was not developed for general model deployment - to deploy models like CLIP, researchers will first need to carefully study their capabilities in relation to the specific context they’re being deployed within.
### Model Date
January 2021
### Model Type
The base model uses a ViT-L/14 Transformer architecture as an image encoder and uses a masked self-attention Transformer as a text encoder. These encoders are trained to maximize the similarity of (image, text) pairs via a contrastive loss.
The original implementation had two variants: one using a ResNet image encoder and the other using a Vision Transformer. This repository has the variant with the Vision Transformer.
### Documents
- [Blog Post](https://openai.com/blog/clip/)
- [CLIP Paper](https://arxiv.org/abs/2103.00020)
### Use with Transformers
```python
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-large-patch14")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-large-patch14")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```
## Model Use
### Intended Use
The model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such models - the CLIP paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis.
#### Primary intended uses
The primary intended users of these models are AI researchers.
We primarily imagine the model will be used by researchers to better understand robustness, generalization, and other capabilities, biases, and constraints of computer vision models.
### Out-of-Scope Use Cases
**Any** deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP’s performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case currently potentially harmful.
Certain use cases which would fall under the domain of surveillance and facial recognition are always out-of-scope regardless of performance of the model. This is because the use of artificial intelligence for tasks such as these can be premature currently given the lack of testing norms and checks to ensure its fair use.
Since the model has not been purposefully trained in or evaluated on any languages other than English, its use should be limited to English language use cases.
## Data
The model was trained on publicly available image-caption data. This was done through a combination of crawling a handful of websites and using commonly-used pre-existing image datasets such as [YFCC100M](http://projects.dfki.uni-kl.de/yfcc100m/). A large portion of the data comes from our crawling of the internet. This means that the data is more representative of people and societies most connected to the internet which tend to skew towards more developed nations, and younger, male users.
### Data Mission Statement
Our goal with building this dataset was to test out robustness and generalizability in computer vision tasks. As a result, the focus was on gathering large quantities of data from different publicly-available internet data sources. The data was gathered in a mostly non-interventionist manner. However, we only crawled websites that had policies against excessively violent and adult images and allowed us to filter out such content. We do not intend for this dataset to be used as the basis for any commercial or deployed model and will not be releasing the dataset.
## Performance and Limitations
### Performance
We have evaluated the performance of CLIP on a wide range of benchmarks across a variety of computer vision datasets such as OCR to texture recognition to fine-grained classification. The paper describes model performance on the following datasets:
- Food101
- CIFAR10
- CIFAR100
- Birdsnap
- SUN397
- Stanford Cars
- FGVC Aircraft
- VOC2007
- DTD
- Oxford-IIIT Pet dataset
- Caltech101
- Flowers102
- MNIST
- SVHN
- IIIT5K
- Hateful Memes
- SST-2
- UCF101
- Kinetics700
- Country211
- CLEVR Counting
- KITTI Distance
- STL-10
- RareAct
- Flickr30
- MSCOCO
- ImageNet
- ImageNet-A
- ImageNet-R
- ImageNet Sketch
- ObjectNet (ImageNet Overlap)
- Youtube-BB
- ImageNet-Vid
## Limitations
CLIP and our analysis of it have a number of limitations. CLIP currently struggles with respect to certain tasks such as fine grained classification and counting objects. CLIP also poses issues with regards to fairness and bias which we discuss in the paper and briefly in the next section. Additionally, our approach to testing CLIP also has an important limitation- in many cases we have used linear probes to evaluate the performance of CLIP and there is evidence suggesting that linear probes can underestimate model performance.
### Bias and Fairness
We find that the performance of CLIP - and the specific biases it exhibits - can depend significantly on class design and the choices one makes for categories to include and exclude. We tested the risk of certain kinds of denigration with CLIP by classifying images of people from [Fairface](https://arxiv.org/abs/1908.04913) into crime-related and non-human animal categories. We found significant disparities with respect to race and gender. Additionally, we found that these disparities could shift based on how the classes were constructed. (Details captured in the Broader Impacts Section in the paper).
We also tested the performance of CLIP on gender, race and age classification using the Fairface dataset (We default to using race categories as they are constructed in the Fairface dataset.) in order to assess quality of performance across different demographics. We found accuracy >96% across all races for gender classification with ‘Middle Eastern’ having the highest accuracy (98.4%) and ‘White’ having the lowest (96.5%). Additionally, CLIP averaged ~93% for racial classification and ~63% for age classification. Our use of evaluations to test for gender, race and age classification as well as denigration harms is simply to evaluate performance of the model across people and surface potential risks and not to demonstrate an endorsement/enthusiasm for such tasks.
## Feedback
### Where to send questions or comments about the model
Please use [this Google Form](https://forms.gle/Uv7afRH5dvY34ZEs9) |
jonatasgrosman/wav2vec2-large-xlsr-53-english | jonatasgrosman | "2023-03-25T10:56:55Z" | 20,804,899 | 457 | transformers | [
"transformers",
"pytorch",
"jax",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"en",
"hf-asr-leaderboard",
"mozilla-foundation/common_voice_6_0",
"robust-speech-event",
"speech",
"xlsr-fine-tuning-week",
"dataset:common_voice",
"dataset:mozilla-foundation/common_voice_6_0",
"doi:10.57967/hf/3569",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-03-02T23:29:05Z" | ---
language: en
datasets:
- common_voice
- mozilla-foundation/common_voice_6_0
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- en
- hf-asr-leaderboard
- mozilla-foundation/common_voice_6_0
- robust-speech-event
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 English by Jonatas Grosman
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice en
type: common_voice
args: en
metrics:
- name: Test WER
type: wer
value: 19.06
- name: Test CER
type: cer
value: 7.69
- name: Test WER (+LM)
type: wer
value: 14.81
- name: Test CER (+LM)
type: cer
value: 6.84
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: en
metrics:
- name: Dev WER
type: wer
value: 27.72
- name: Dev CER
type: cer
value: 11.65
- name: Dev WER (+LM)
type: wer
value: 20.85
- name: Dev CER (+LM)
type: cer
value: 11.01
---
# Fine-tuned XLSR-53 large model for speech recognition in English
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on English using the train and validation splits of [Common Voice 6.1](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
The script used for training can be found here: https://github.com/jonatasgrosman/wav2vec2-sprint
## Usage
The model can be used directly (without a language model) as follows...
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-large-xlsr-53-english")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "en"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-english"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
for i, predicted_sentence in enumerate(predicted_sentences):
print("-" * 100)
print("Reference:", test_dataset[i]["sentence"])
print("Prediction:", predicted_sentence)
```
| Reference | Prediction |
| ------------- | ------------- |
| "SHE'LL BE ALL RIGHT." | SHE'LL BE ALL RIGHT |
| SIX | SIX |
| "ALL'S WELL THAT ENDS WELL." | ALL AS WELL THAT ENDS WELL |
| DO YOU MEAN IT? | DO YOU MEAN IT |
| THE NEW PATCH IS LESS INVASIVE THAN THE OLD ONE, BUT STILL CAUSES REGRESSIONS. | THE NEW PATCH IS LESS INVASIVE THAN THE OLD ONE BUT STILL CAUSES REGRESSION |
| HOW IS MOZILLA GOING TO HANDLE AMBIGUITIES LIKE QUEUE AND CUE? | HOW IS MOSLILLAR GOING TO HANDLE ANDBEWOOTH HIS LIKE Q AND Q |
| "I GUESS YOU MUST THINK I'M KINDA BATTY." | RUSTIAN WASTIN PAN ONTE BATTLY |
| NO ONE NEAR THE REMOTE MACHINE YOU COULD RING? | NO ONE NEAR THE REMOTE MACHINE YOU COULD RING |
| SAUCE FOR THE GOOSE IS SAUCE FOR THE GANDER. | SAUCE FOR THE GUICE IS SAUCE FOR THE GONDER |
| GROVES STARTED WRITING SONGS WHEN SHE WAS FOUR YEARS OLD. | GRAFS STARTED WRITING SONGS WHEN SHE WAS FOUR YEARS OLD |
## Evaluation
1. To evaluate on `mozilla-foundation/common_voice_6_0` with split `test`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-large-xlsr-53-english --dataset mozilla-foundation/common_voice_6_0 --config en --split test
```
2. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-large-xlsr-53-english --dataset speech-recognition-community-v2/dev_data --config en --split validation --chunk_length_s 5.0 --stride_length_s 1.0
```
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr53-large-english,
title={Fine-tuned {XLSR}-53 large model for speech recognition in {E}nglish},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-english}},
year={2021}
}
``` |
Bingsu/adetailer | Bingsu | "2024-11-21T12:40:27Z" | 20,130,249 | 536 | ultralytics | [
"ultralytics",
"pytorch",
"dataset:wider_face",
"dataset:skytnt/anime-segmentation",
"doi:10.57967/hf/3633",
"license:apache-2.0",
"region:us"
] | null | "2023-04-26T00:58:45Z" | ---
license: apache-2.0
library_name: ultralytics
datasets:
- wider_face
- skytnt/anime-segmentation
tags:
- pytorch
---
# YOLOv8 Detection Model
## Datasets
### Face
- [Anime Face CreateML](https://universe.roboflow.com/my-workspace-mph8o/anime-face-createml)
- [xml2txt](https://universe.roboflow.com/0oooooo0/xml2txt-njqx1)
- [AN](https://universe.roboflow.com/sed-b8vkf/an-lfg5i)
- [wider face](http://shuoyang1213.me/WIDERFACE/index.html)
### Hand
- [AnHDet](https://universe.roboflow.com/1-yshhi/anhdet)
- [hand-detection-fuao9](https://universe.roboflow.com/catwithawand/hand-detection-fuao9)
### Person
- [coco2017](https://cocodataset.org/#home) (only person)
- [AniSeg](https://github.com/jerryli27/AniSeg)
- [skytnt/anime-segmentation](https://huggingface.co/datasets/skytnt/anime-segmentation)
### deepfashion2
- [deepfashion2](https://github.com/switchablenorms/DeepFashion2)
| id | label |
| --- | --------------------- |
| 0 | short_sleeved_shirt |
| 1 | long_sleeved_shirt |
| 2 | short_sleeved_outwear |
| 3 | long_sleeved_outwear |
| 4 | vest |
| 5 | sling |
| 6 | shorts |
| 7 | trousers |
| 8 | skirt |
| 9 | short_sleeved_dress |
| 10 | long_sleeved_dress |
| 11 | vest_dress |
| 12 | sling_dress |
## Info
| Model | Target | mAP 50 | mAP 50-95 |
| --------------------------- | --------------------- | ----------------------------- | ----------------------------- |
| face_yolov8n.pt | 2D / realistic face | 0.660 | 0.366 |
| face_yolov8n_v2.pt | 2D / realistic face | 0.669 | 0.372 |
| face_yolov8s.pt | 2D / realistic face | 0.713 | 0.404 |
| face_yolov8m.pt | 2D / realistic face | 0.737 | 0.424 |
| face_yolov9c.pt | 2D / realistic face | 0.748 | 0.433 |
| hand_yolov8n.pt | 2D / realistic hand | 0.767 | 0.505 |
| hand_yolov8s.pt | 2D / realistic hand | 0.794 | 0.527 |
| hand_yolov9c.pt | 2D / realistic hand | 0.810 | 0.550 |
| person_yolov8n-seg.pt | 2D / realistic person | 0.782 (bbox)<br/>0.761 (mask) | 0.555 (bbox)<br/>0.460 (mask) |
| person_yolov8s-seg.pt | 2D / realistic person | 0.824 (bbox)<br/>0.809 (mask) | 0.605 (bbox)<br/>0.508 (mask) |
| person_yolov8m-seg.pt | 2D / realistic person | 0.849 (bbox)<br/>0.831 (mask) | 0.636 (bbox)<br/>0.533 (mask) |
| deepfashion2_yolov8s-seg.pt | realistic clothes | 0.849 (bbox)<br/>0.840 (mask) | 0.763 (bbox)<br/>0.675 (mask) |
## Usage
```python
from huggingface_hub import hf_hub_download
from ultralytics import YOLO
path = hf_hub_download("Bingsu/adetailer", "face_yolov8n.pt")
model = YOLO(path)
```
```python
import cv2
from PIL import Image
img = "https://farm5.staticflickr.com/4139/4887614566_6b57ec4422_z.jpg"
output = model(img)
pred = output[0].plot()
pred = cv2.cvtColor(pred, cv2.COLOR_BGR2RGB)
pred = Image.fromarray(pred)
pred
```

## Unsafe files

Since `getattr` is classified as a dangerous pickle function, any segmentation model that uses it is classified as unsafe.
All models were created and saved using the official [ultralytics](https://github.com/ultralytics/ultralytics) library, so it's okay to use files downloaded from a trusted source.
See also: https://huggingface.co/docs/hub/security-pickle
|
timm/resnet50.a1_in1k | timm | "2025-01-21T21:39:50Z" | 19,058,638 | 35 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"transformers",
"arxiv:2110.00476",
"arxiv:1512.03385",
"license:apache-2.0",
"region:us"
] | image-classification | "2023-04-05T18:07:45Z" | ---
license: apache-2.0
library_name: timm
tags:
- image-classification
- timm
- transformers
---
# Model card for resnet50.a1_in1k
A ResNet-B image classification model.
This model features:
* ReLU activations
* single layer 7x7 convolution with pooling
* 1x1 convolution shortcut downsample
Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* ResNet Strikes Back `A1` recipe
* LAMB optimizer with BCE loss
* Cosine LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 25.6
- GMACs: 4.1
- Activations (M): 11.1
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- ResNet strikes back: An improved training procedure in timm: https://arxiv.org/abs/2110.00476
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnet50.a1_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet50.a1_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 256, 56, 56])
# torch.Size([1, 512, 28, 28])
# torch.Size([1, 1024, 14, 14])
# torch.Size([1, 2048, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet50.a1_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 2048, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@inproceedings{wightman2021resnet,
title={ResNet strikes back: An improved training procedure in timm},
author={Wightman, Ross and Touvron, Hugo and Jegou, Herve},
booktitle={NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
```
|
distilbert/distilbert-base-uncased | distilbert | "2024-05-06T13:44:53Z" | 18,425,319 | 613 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"distilbert",
"fill-mask",
"exbert",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1910.01108",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:04Z" | ---
language: en
tags:
- exbert
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
---
# DistilBERT base model (uncased)
This model is a distilled version of the [BERT base model](https://huggingface.co/bert-base-uncased). It was
introduced in [this paper](https://arxiv.org/abs/1910.01108). The code for the distillation process can be found
[here](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation). This model is uncased: it does
not make a difference between english and English.
## Model description
DistilBERT is a transformers model, smaller and faster than BERT, which was pretrained on the same corpus in a
self-supervised fashion, using the BERT base model as a teacher. This means it was pretrained on the raw texts only,
with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic
process to generate inputs and labels from those texts using the BERT base model. More precisely, it was pretrained
with three objectives:
- Distillation loss: the model was trained to return the same probabilities as the BERT base model.
- Masked language modeling (MLM): this is part of the original training loss of the BERT base model. When taking a
sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the
model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that
usually see the words one after the other, or from autoregressive models like GPT which internally mask the future
tokens. It allows the model to learn a bidirectional representation of the sentence.
- Cosine embedding loss: the model was also trained to generate hidden states as close as possible as the BERT base
model.
This way, the model learns the same inner representation of the English language than its teacher model, while being
faster for inference or downstream tasks.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=distilbert) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='distilbert-base-uncased')
>>> unmasker("Hello I'm a [MASK] model.")
[{'sequence': "[CLS] hello i'm a role model. [SEP]",
'score': 0.05292855575680733,
'token': 2535,
'token_str': 'role'},
{'sequence': "[CLS] hello i'm a fashion model. [SEP]",
'score': 0.03968575969338417,
'token': 4827,
'token_str': 'fashion'},
{'sequence': "[CLS] hello i'm a business model. [SEP]",
'score': 0.034743521362543106,
'token': 2449,
'token_str': 'business'},
{'sequence': "[CLS] hello i'm a model model. [SEP]",
'score': 0.03462274372577667,
'token': 2944,
'token_str': 'model'},
{'sequence': "[CLS] hello i'm a modeling model. [SEP]",
'score': 0.018145186826586723,
'token': 11643,
'token_str': 'modeling'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import DistilBertTokenizer, DistilBertModel
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = DistilBertModel.from_pretrained("distilbert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import DistilBertTokenizer, TFDistilBertModel
tokenizer = DistilBertTokenizer.from_pretrained('distilbert-base-uncased')
model = TFDistilBertModel.from_pretrained("distilbert-base-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions. It also inherits some of
[the bias of its teacher model](https://huggingface.co/bert-base-uncased#limitations-and-bias).
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='distilbert-base-uncased')
>>> unmasker("The White man worked as a [MASK].")
[{'sequence': '[CLS] the white man worked as a blacksmith. [SEP]',
'score': 0.1235365942120552,
'token': 20987,
'token_str': 'blacksmith'},
{'sequence': '[CLS] the white man worked as a carpenter. [SEP]',
'score': 0.10142576694488525,
'token': 10533,
'token_str': 'carpenter'},
{'sequence': '[CLS] the white man worked as a farmer. [SEP]',
'score': 0.04985016956925392,
'token': 7500,
'token_str': 'farmer'},
{'sequence': '[CLS] the white man worked as a miner. [SEP]',
'score': 0.03932540491223335,
'token': 18594,
'token_str': 'miner'},
{'sequence': '[CLS] the white man worked as a butcher. [SEP]',
'score': 0.03351764753460884,
'token': 14998,
'token_str': 'butcher'}]
>>> unmasker("The Black woman worked as a [MASK].")
[{'sequence': '[CLS] the black woman worked as a waitress. [SEP]',
'score': 0.13283951580524445,
'token': 13877,
'token_str': 'waitress'},
{'sequence': '[CLS] the black woman worked as a nurse. [SEP]',
'score': 0.12586183845996857,
'token': 6821,
'token_str': 'nurse'},
{'sequence': '[CLS] the black woman worked as a maid. [SEP]',
'score': 0.11708822101354599,
'token': 10850,
'token_str': 'maid'},
{'sequence': '[CLS] the black woman worked as a prostitute. [SEP]',
'score': 0.11499975621700287,
'token': 19215,
'token_str': 'prostitute'},
{'sequence': '[CLS] the black woman worked as a housekeeper. [SEP]',
'score': 0.04722772538661957,
'token': 22583,
'token_str': 'housekeeper'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
DistilBERT pretrained on the same data as BERT, which is [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset
consisting of 11,038 unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia)
(excluding lists, tables and headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The model was trained on 8 16 GB V100 for 90 hours. See the
[training code](https://github.com/huggingface/transformers/tree/main/examples/research_projects/distillation) for all hyperparameters
details.
## Evaluation results
When fine-tuned on downstream tasks, this model achieves the following results:
Glue test results:
| Task | MNLI | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE |
|:----:|:----:|:----:|:----:|:-----:|:----:|:-----:|:----:|:----:|
| | 82.2 | 88.5 | 89.2 | 91.3 | 51.3 | 85.8 | 87.5 | 59.9 |
### BibTeX entry and citation info
```bibtex
@article{Sanh2019DistilBERTAD,
title={DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter},
author={Victor Sanh and Lysandre Debut and Julien Chaumond and Thomas Wolf},
journal={ArXiv},
year={2019},
volume={abs/1910.01108}
}
```
<a href="https://huggingface.co/exbert/?model=distilbert-base-uncased">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
openai-community/gpt2 | openai-community | "2024-02-19T10:57:45Z" | 17,932,522 | 2,552 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"tflite",
"rust",
"onnx",
"safetensors",
"gpt2",
"text-generation",
"exbert",
"en",
"doi:10.57967/hf/0039",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2022-03-02T23:29:04Z" | ---
language: en
tags:
- exbert
license: mit
---
# GPT-2
Test the whole generation capabilities here: https://transformer.huggingface.co/doc/gpt2-large
Pretrained model on English language using a causal language modeling (CLM) objective. It was introduced in
[this paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
and first released at [this page](https://openai.com/blog/better-language-models/).
Disclaimer: The team releasing GPT-2 also wrote a
[model card](https://github.com/openai/gpt-2/blob/master/model_card.md) for their model. Content from this model card
has been written by the Hugging Face team to complete the information they provided and give specific examples of bias.
## Model description
GPT-2 is a transformers model pretrained on a very large corpus of English data in a self-supervised fashion. This
means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots
of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely,
it was trained to guess the next word in sentences.
More precisely, inputs are sequences of continuous text of a certain length and the targets are the same sequence,
shifted one token (word or piece of word) to the right. The model uses internally a mask-mechanism to make sure the
predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a
prompt.
This is the **smallest** version of GPT-2, with 124M parameters.
**Related Models:** [GPT-Large](https://huggingface.co/gpt2-large), [GPT-Medium](https://huggingface.co/gpt2-medium) and [GPT-XL](https://huggingface.co/gpt2-xl)
## Intended uses & limitations
You can use the raw model for text generation or fine-tune it to a downstream task. See the
[model hub](https://huggingface.co/models?filter=gpt2) to look for fine-tuned versions on a task that interests you.
### How to use
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, we
set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='gpt2')
>>> set_seed(42)
>>> generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
[{'generated_text': "Hello, I'm a language model, a language for thinking, a language for expressing thoughts."},
{'generated_text': "Hello, I'm a language model, a compiler, a compiler library, I just want to know how I build this kind of stuff. I don"},
{'generated_text': "Hello, I'm a language model, and also have more than a few of your own, but I understand that they're going to need some help"},
{'generated_text': "Hello, I'm a language model, a system model. I want to know my language so that it might be more interesting, more user-friendly"},
{'generated_text': 'Hello, I\'m a language model, not a language model"\n\nThe concept of "no-tricks" comes in handy later with new'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2Model.from_pretrained('gpt2')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import GPT2Tokenizer, TFGPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = TFGPT2Model.from_pretrained('gpt2')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
The training data used for this model has not been released as a dataset one can browse. We know it contains a lot of
unfiltered content from the internet, which is far from neutral. As the openAI team themselves point out in their
[model card](https://github.com/openai/gpt-2/blob/master/model_card.md#out-of-scope-use-cases):
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases
> that require the generated text to be true.
>
> Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do
> not recommend that they be deployed into systems that interact with humans > unless the deployers first carry out a
> study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race,
> and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar
> levels of caution around use cases that are sensitive to biases around human attributes.
Here's an example of how the model can have biased predictions:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='gpt2')
>>> set_seed(42)
>>> generator("The White man worked as a", max_length=10, num_return_sequences=5)
[{'generated_text': 'The White man worked as a mannequin for'},
{'generated_text': 'The White man worked as a maniser of the'},
{'generated_text': 'The White man worked as a bus conductor by day'},
{'generated_text': 'The White man worked as a plumber at the'},
{'generated_text': 'The White man worked as a journalist. He had'}]
>>> set_seed(42)
>>> generator("The Black man worked as a", max_length=10, num_return_sequences=5)
[{'generated_text': 'The Black man worked as a man at a restaurant'},
{'generated_text': 'The Black man worked as a car salesman in a'},
{'generated_text': 'The Black man worked as a police sergeant at the'},
{'generated_text': 'The Black man worked as a man-eating monster'},
{'generated_text': 'The Black man worked as a slave, and was'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The OpenAI team wanted to train this model on a corpus as large as possible. To build it, they scraped all the web
pages from outbound links on Reddit which received at least 3 karma. Note that all Wikipedia pages were removed from
this dataset, so the model was not trained on any part of Wikipedia. The resulting dataset (called WebText) weights
40GB of texts but has not been publicly released. You can find a list of the top 1,000 domains present in WebText
[here](https://github.com/openai/gpt-2/blob/master/domains.txt).
## Training procedure
### Preprocessing
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a
vocabulary size of 50,257. The inputs are sequences of 1024 consecutive tokens.
The larger model was trained on 256 cloud TPU v3 cores. The training duration was not disclosed, nor were the exact
details of training.
## Evaluation results
The model achieves the following results without any fine-tuning (zero-shot):
| Dataset | LAMBADA | LAMBADA | CBT-CN | CBT-NE | WikiText2 | PTB | enwiki8 | text8 | WikiText103 | 1BW |
|:--------:|:-------:|:-------:|:------:|:------:|:---------:|:------:|:-------:|:------:|:-----------:|:-----:|
| (metric) | (PPL) | (ACC) | (ACC) | (ACC) | (PPL) | (PPL) | (BPB) | (BPC) | (PPL) | (PPL) |
| | 35.13 | 45.99 | 87.65 | 83.4 | 29.41 | 65.85 | 1.16 | 1,17 | 37.50 | 75.20 |
### BibTeX entry and citation info
```bibtex
@article{radford2019language,
title={Language Models are Unsupervised Multitask Learners},
author={Radford, Alec and Wu, Jeff and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya},
year={2019}
}
```
<a href="https://huggingface.co/exbert/?model=gpt2">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
facebook/dinov2-base | facebook | "2024-01-17T08:27:01Z" | 15,492,446 | 96 | transformers | [
"transformers",
"pytorch",
"safetensors",
"dinov2",
"image-feature-extraction",
"dino",
"vision",
"arxiv:2304.07193",
"license:apache-2.0",
"region:us"
] | image-feature-extraction | "2023-07-17T16:44:29Z" | ---
license: apache-2.0
tags:
- dino
- vision
inference: false
---
# Vision Transformer (base-sized model) trained using DINOv2
Vision Transformer (ViT) model trained using the DINOv2 method. It was introduced in the paper [DINOv2: Learning Robust Visual Features without Supervision](https://arxiv.org/abs/2304.07193) by Oquab et al. and first released in [this repository](https://github.com/facebookresearch/dinov2).
Disclaimer: The team releasing DINOv2 did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a self-supervised fashion.
Images are presented to the model as a sequence of fixed-size patches, which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
Note that this model does not include any fine-tuned heads.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for feature extraction. See the [model hub](https://huggingface.co/models?search=facebook/dinov2) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model:
```python
from transformers import AutoImageProcessor, AutoModel
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained('facebook/dinov2-base')
model = AutoModel.from_pretrained('facebook/dinov2-base')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
### BibTeX entry and citation info
```bibtex
misc{oquab2023dinov2,
title={DINOv2: Learning Robust Visual Features without Supervision},
author={Maxime Oquab and Timothée Darcet and Théo Moutakanni and Huy Vo and Marc Szafraniec and Vasil Khalidov and Pierre Fernandez and Daniel Haziza and Francisco Massa and Alaaeldin El-Nouby and Mahmoud Assran and Nicolas Ballas and Wojciech Galuba and Russell Howes and Po-Yao Huang and Shang-Wen Li and Ishan Misra and Michael Rabbat and Vasu Sharma and Gabriel Synnaeve and Hu Xu and Hervé Jegou and Julien Mairal and Patrick Labatut and Armand Joulin and Piotr Bojanowski},
year={2023},
eprint={2304.07193},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
FacebookAI/roberta-large | FacebookAI | "2024-02-19T12:47:04Z" | 14,963,144 | 204 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"onnx",
"safetensors",
"roberta",
"fill-mask",
"exbert",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1907.11692",
"arxiv:1806.02847",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:04Z" | ---
language: en
tags:
- exbert
license: mit
datasets:
- bookcorpus
- wikipedia
---
# RoBERTa large model
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/abs/1907.11692) and first released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/roberta). This model is case-sensitive: it
makes a difference between english and English.
Disclaimer: The team releasing RoBERTa did not write a model card for this model so this model card has been written by
the Hugging Face team.
## Model description
RoBERTa is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means
it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was pretrained with the Masked language modeling (MLM) objective. Taking a sentence, the model
randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict
the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one
after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to
learn a bidirectional representation of the sentence.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
## Intended uses & limitations
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task.
See the [model hub](https://huggingface.co/models?filter=roberta) to look for fine-tuned versions on a task that
interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='roberta-large')
>>> unmasker("Hello I'm a <mask> model.")
[{'sequence': "<s>Hello I'm a male model.</s>",
'score': 0.3317350447177887,
'token': 2943,
'token_str': 'Ġmale'},
{'sequence': "<s>Hello I'm a fashion model.</s>",
'score': 0.14171843230724335,
'token': 2734,
'token_str': 'Ġfashion'},
{'sequence': "<s>Hello I'm a professional model.</s>",
'score': 0.04291723668575287,
'token': 2038,
'token_str': 'Ġprofessional'},
{'sequence': "<s>Hello I'm a freelance model.</s>",
'score': 0.02134818211197853,
'token': 18150,
'token_str': 'Ġfreelance'},
{'sequence': "<s>Hello I'm a young model.</s>",
'score': 0.021098261699080467,
'token': 664,
'token_str': 'Ġyoung'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import RobertaTokenizer, RobertaModel
tokenizer = RobertaTokenizer.from_pretrained('roberta-large')
model = RobertaModel.from_pretrained('roberta-large')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import RobertaTokenizer, TFRobertaModel
tokenizer = RobertaTokenizer.from_pretrained('roberta-large')
model = TFRobertaModel.from_pretrained('roberta-large')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
The training data used for this model contains a lot of unfiltered content from the internet, which is far from
neutral. Therefore, the model can have biased predictions:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='roberta-large')
>>> unmasker("The man worked as a <mask>.")
[{'sequence': '<s>The man worked as a mechanic.</s>',
'score': 0.08260300755500793,
'token': 25682,
'token_str': 'Ġmechanic'},
{'sequence': '<s>The man worked as a driver.</s>',
'score': 0.05736079439520836,
'token': 1393,
'token_str': 'Ġdriver'},
{'sequence': '<s>The man worked as a teacher.</s>',
'score': 0.04709019884467125,
'token': 3254,
'token_str': 'Ġteacher'},
{'sequence': '<s>The man worked as a bartender.</s>',
'score': 0.04641604796051979,
'token': 33080,
'token_str': 'Ġbartender'},
{'sequence': '<s>The man worked as a waiter.</s>',
'score': 0.04239227622747421,
'token': 38233,
'token_str': 'Ġwaiter'}]
>>> unmasker("The woman worked as a <mask>.")
[{'sequence': '<s>The woman worked as a nurse.</s>',
'score': 0.2667474150657654,
'token': 9008,
'token_str': 'Ġnurse'},
{'sequence': '<s>The woman worked as a waitress.</s>',
'score': 0.12280137836933136,
'token': 35698,
'token_str': 'Ġwaitress'},
{'sequence': '<s>The woman worked as a teacher.</s>',
'score': 0.09747499972581863,
'token': 3254,
'token_str': 'Ġteacher'},
{'sequence': '<s>The woman worked as a secretary.</s>',
'score': 0.05783602222800255,
'token': 2971,
'token_str': 'Ġsecretary'},
{'sequence': '<s>The woman worked as a cleaner.</s>',
'score': 0.05576248839497566,
'token': 16126,
'token_str': 'Ġcleaner'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The RoBERTa model was pretrained on the reunion of five datasets:
- [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038 unpublished books;
- [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and headers) ;
- [CC-News](https://commoncrawl.org/2016/10/news-dataset-available/), a dataset containing 63 millions English news
articles crawled between September 2016 and February 2019.
- [OpenWebText](https://github.com/jcpeterson/openwebtext), an opensource recreation of the WebText dataset used to
train GPT-2,
- [Stories](https://arxiv.org/abs/1806.02847) a dataset containing a subset of CommonCrawl data filtered to match the
story-like style of Winograd schemas.
Together theses datasets weight 160GB of text.
## Training procedure
### Preprocessing
The texts are tokenized using a byte version of Byte-Pair Encoding (BPE) and a vocabulary size of 50,000. The inputs of
the model take pieces of 512 contiguous token that may span over documents. The beginning of a new document is marked
with `<s>` and the end of one by `</s>`
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `<mask>`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
Contrary to BERT, the masking is done dynamically during pretraining (e.g., it changes at each epoch and is not fixed).
### Pretraining
The model was trained on 1024 V100 GPUs for 500K steps with a batch size of 8K and a sequence length of 512. The
optimizer used is Adam with a learning rate of 4e-4, \\(\beta_{1} = 0.9\\), \\(\beta_{2} = 0.98\\) and
\\(\epsilon = 1e-6\\), a weight decay of 0.01, learning rate warmup for 30,000 steps and linear decay of the learning
rate after.
## Evaluation results
When fine-tuned on downstream tasks, this model achieves the following results:
Glue test results:
| Task | MNLI | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE |
|:----:|:----:|:----:|:----:|:-----:|:----:|:-----:|:----:|:----:|
| | 90.2 | 92.2 | 94.7 | 96.4 | 68.0 | 96.4 | 90.9 | 86.6 |
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1907-11692,
author = {Yinhan Liu and
Myle Ott and
Naman Goyal and
Jingfei Du and
Mandar Joshi and
Danqi Chen and
Omer Levy and
Mike Lewis and
Luke Zettlemoyer and
Veselin Stoyanov},
title = {RoBERTa: {A} Robustly Optimized {BERT} Pretraining Approach},
journal = {CoRR},
volume = {abs/1907.11692},
year = {2019},
url = {http://arxiv.org/abs/1907.11692},
archivePrefix = {arXiv},
eprint = {1907.11692},
timestamp = {Thu, 01 Aug 2019 08:59:33 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1907-11692.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<a href="https://huggingface.co/exbert/?model=roberta-base">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
pyannote/wespeaker-voxceleb-resnet34-LM | pyannote | "2024-05-10T19:36:24Z" | 14,292,981 | 50 | pyannote-audio | [
"pyannote-audio",
"pytorch",
"pyannote",
"pyannote-audio-model",
"wespeaker",
"audio",
"voice",
"speech",
"speaker",
"speaker-recognition",
"speaker-verification",
"speaker-identification",
"speaker-embedding",
"dataset:voxceleb",
"license:cc-by-4.0",
"region:us"
] | null | "2023-11-13T15:32:31Z" | ---
tags:
- pyannote
- pyannote-audio
- pyannote-audio-model
- wespeaker
- audio
- voice
- speech
- speaker
- speaker-recognition
- speaker-verification
- speaker-identification
- speaker-embedding
datasets:
- voxceleb
license: cc-by-4.0
inference: false
---
Using this open-source model in production?
Consider switching to [pyannoteAI](https://www.pyannote.ai) for better and faster options.
# 🎹 Wrapper around wespeaker-voxceleb-resnet34-LM
This model requires `pyannote.audio` version 3.1 or higher.
This is a wrapper around [WeSpeaker](https://github.com/wenet-e2e/wespeaker) `wespeaker-voxceleb-resnet34-LM` pretrained speaker embedding model, for use in `pyannote.audio`.
## Basic usage
```python
# instantiate pretrained model
from pyannote.audio import Model
model = Model.from_pretrained("pyannote/wespeaker-voxceleb-resnet34-LM")
```
```python
from pyannote.audio import Inference
inference = Inference(model, window="whole")
embedding1 = inference("speaker1.wav")
embedding2 = inference("speaker2.wav")
# `embeddingX` is (1 x D) numpy array extracted from the file as a whole.
from scipy.spatial.distance import cdist
distance = cdist(embedding1, embedding2, metric="cosine")[0,0]
# `distance` is a `float` describing how dissimilar speakers 1 and 2 are.
```
## Advanced usage
### Running on GPU
```python
import torch
inference.to(torch.device("cuda"))
embedding = inference("audio.wav")
```
### Extract embedding from an excerpt
```python
from pyannote.audio import Inference
from pyannote.core import Segment
inference = Inference(model, window="whole")
excerpt = Segment(13.37, 19.81)
embedding = inference.crop("audio.wav", excerpt)
# `embedding` is (1 x D) numpy array extracted from the file excerpt.
```
### Extract embeddings using a sliding window
```python
from pyannote.audio import Inference
inference = Inference(model, window="sliding",
duration=3.0, step=1.0)
embeddings = inference("audio.wav")
# `embeddings` is a (N x D) pyannote.core.SlidingWindowFeature
# `embeddings[i]` is the embedding of the ith position of the
# sliding window, i.e. from [i * step, i * step + duration].
```
## License
According to [this page](https://github.com/wenet-e2e/wespeaker/blob/master/docs/pretrained.md):
> The pretrained model in WeNet follows the license of it's corresponding dataset. For example, the pretrained model on VoxCeleb follows Creative Commons Attribution 4.0 International License., since it is used as license of the VoxCeleb dataset, see https://mm.kaist.ac.kr/datasets/voxceleb/.
## Citation
```bibtex
@inproceedings{Wang2023,
title={Wespeaker: A research and production oriented speaker embedding learning toolkit},
author={Wang, Hongji and Liang, Chengdong and Wang, Shuai and Chen, Zhengyang and Zhang, Binbin and Xiang, Xu and Deng, Yanlei and Qian, Yanmin},
booktitle={ICASSP 2023, IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={1--5},
year={2023},
organization={IEEE}
}
```
```bibtex
@inproceedings{Bredin23,
author={Hervé Bredin},
title={{pyannote.audio 2.1 speaker diarization pipeline: principle, benchmark, and recipe}},
year=2023,
booktitle={Proc. INTERSPEECH 2023},
pages={1983--1987},
doi={10.21437/Interspeech.2023-105}
}
```
|
openai/clip-vit-base-patch16 | openai | "2022-10-04T09:42:28Z" | 13,703,962 | 104 | transformers | [
"transformers",
"pytorch",
"jax",
"clip",
"zero-shot-image-classification",
"vision",
"arxiv:2103.00020",
"arxiv:1908.04913",
"endpoints_compatible",
"region:us"
] | zero-shot-image-classification | "2022-03-02T23:29:05Z" | ---
tags:
- vision
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: playing music, playing sports
example_title: Cat & Dog
---
# Model Card: CLIP
Disclaimer: The model card is taken and modified from the official CLIP repository, it can be found [here](https://github.com/openai/CLIP/blob/main/model-card.md).
## Model Details
The CLIP model was developed by researchers at OpenAI to learn about what contributes to robustness in computer vision tasks. The model was also developed to test the ability of models to generalize to arbitrary image classification tasks in a zero-shot manner. It was not developed for general model deployment - to deploy models like CLIP, researchers will first need to carefully study their capabilities in relation to the specific context they’re being deployed within.
### Model Date
January 2021
### Model Type
The base model uses a ViT-B/16 Transformer architecture as an image encoder and uses a masked self-attention Transformer as a text encoder. These encoders are trained to maximize the similarity of (image, text) pairs via a contrastive loss.
The original implementation had two variants: one using a ResNet image encoder and the other using a Vision Transformer. This repository has the variant with the Vision Transformer.
### Documents
- [Blog Post](https://openai.com/blog/clip/)
- [CLIP Paper](https://arxiv.org/abs/2103.00020)
### Use with Transformers
```python3
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch16")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch16")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```
## Model Use
### Intended Use
The model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such models - the CLIP paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis.
#### Primary intended uses
The primary intended users of these models are AI researchers.
We primarily imagine the model will be used by researchers to better understand robustness, generalization, and other capabilities, biases, and constraints of computer vision models.
### Out-of-Scope Use Cases
**Any** deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP’s performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case currently potentially harmful.
Certain use cases which would fall under the domain of surveillance and facial recognition are always out-of-scope regardless of performance of the model. This is because the use of artificial intelligence for tasks such as these can be premature currently given the lack of testing norms and checks to ensure its fair use.
Since the model has not been purposefully trained in or evaluated on any languages other than English, its use should be limited to English language use cases.
## Data
The model was trained on publicly available image-caption data. This was done through a combination of crawling a handful of websites and using commonly-used pre-existing image datasets such as [YFCC100M](http://projects.dfki.uni-kl.de/yfcc100m/). A large portion of the data comes from our crawling of the internet. This means that the data is more representative of people and societies most connected to the internet which tend to skew towards more developed nations, and younger, male users.
### Data Mission Statement
Our goal with building this dataset was to test out robustness and generalizability in computer vision tasks. As a result, the focus was on gathering large quantities of data from different publicly-available internet data sources. The data was gathered in a mostly non-interventionist manner. However, we only crawled websites that had policies against excessively violent and adult images and allowed us to filter out such content. We do not intend for this dataset to be used as the basis for any commercial or deployed model and will not be releasing the dataset.
## Performance and Limitations
### Performance
We have evaluated the performance of CLIP on a wide range of benchmarks across a variety of computer vision datasets such as OCR to texture recognition to fine-grained classification. The paper describes model performance on the following datasets:
- Food101
- CIFAR10
- CIFAR100
- Birdsnap
- SUN397
- Stanford Cars
- FGVC Aircraft
- VOC2007
- DTD
- Oxford-IIIT Pet dataset
- Caltech101
- Flowers102
- MNIST
- SVHN
- IIIT5K
- Hateful Memes
- SST-2
- UCF101
- Kinetics700
- Country211
- CLEVR Counting
- KITTI Distance
- STL-10
- RareAct
- Flickr30
- MSCOCO
- ImageNet
- ImageNet-A
- ImageNet-R
- ImageNet Sketch
- ObjectNet (ImageNet Overlap)
- Youtube-BB
- ImageNet-Vid
## Limitations
CLIP and our analysis of it have a number of limitations. CLIP currently struggles with respect to certain tasks such as fine grained classification and counting objects. CLIP also poses issues with regards to fairness and bias which we discuss in the paper and briefly in the next section. Additionally, our approach to testing CLIP also has an important limitation- in many cases we have used linear probes to evaluate the performance of CLIP and there is evidence suggesting that linear probes can underestimate model performance.
### Bias and Fairness
We find that the performance of CLIP - and the specific biases it exhibits - can depend significantly on class design and the choices one makes for categories to include and exclude. We tested the risk of certain kinds of denigration with CLIP by classifying images of people from [Fairface](https://arxiv.org/abs/1908.04913) into crime-related and non-human animal categories. We found significant disparities with respect to race and gender. Additionally, we found that these disparities could shift based on how the classes were constructed. (Details captured in the Broader Impacts Section in the paper).
We also tested the performance of CLIP on gender, race and age classification using the Fairface dataset (We default to using race categories as they are constructed in the Fairface dataset.) in order to assess quality of performance across different demographics. We found accuracy >96% across all races for gender classification with ‘Middle Eastern’ having the highest accuracy (98.4%) and ‘White’ having the lowest (96.5%). Additionally, CLIP averaged ~93% for racial classification and ~63% for age classification. Our use of evaluations to test for gender, race and age classification as well as denigration harms is simply to evaluate performance of the model across people and surface potential risks and not to demonstrate an endorsement/enthusiasm for such tasks.
## Feedback
### Where to send questions or comments about the model
Please use [this Google Form](https://forms.gle/Uv7afRH5dvY34ZEs9)
|
google-bert/bert-base-multilingual-cased | google-bert | "2024-02-19T11:05:41Z" | 12,989,177 | 473 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"multilingual",
"af",
"sq",
"ar",
"an",
"hy",
"ast",
"az",
"ba",
"eu",
"bar",
"be",
"bn",
"inc",
"bs",
"br",
"bg",
"my",
"ca",
"ceb",
"ce",
"zh",
"cv",
"hr",
"cs",
"da",
"nl",
"en",
"et",
"fi",
"fr",
"gl",
"ka",
"de",
"el",
"gu",
"ht",
"he",
"hi",
"hu",
"is",
"io",
"id",
"ga",
"it",
"ja",
"jv",
"kn",
"kk",
"ky",
"ko",
"la",
"lv",
"lt",
"roa",
"nds",
"lm",
"mk",
"mg",
"ms",
"ml",
"mr",
"mn",
"min",
"ne",
"new",
"nb",
"nn",
"oc",
"fa",
"pms",
"pl",
"pt",
"pa",
"ro",
"ru",
"sco",
"sr",
"scn",
"sk",
"sl",
"aze",
"es",
"su",
"sw",
"sv",
"tl",
"tg",
"th",
"ta",
"tt",
"te",
"tr",
"uk",
"ud",
"uz",
"vi",
"vo",
"war",
"cy",
"fry",
"pnb",
"yo",
"dataset:wikipedia",
"arxiv:1810.04805",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:04Z" | ---
language:
- multilingual
- af
- sq
- ar
- an
- hy
- ast
- az
- ba
- eu
- bar
- be
- bn
- inc
- bs
- br
- bg
- my
- ca
- ceb
- ce
- zh
- cv
- hr
- cs
- da
- nl
- en
- et
- fi
- fr
- gl
- ka
- de
- el
- gu
- ht
- he
- hi
- hu
- is
- io
- id
- ga
- it
- ja
- jv
- kn
- kk
- ky
- ko
- la
- lv
- lt
- roa
- nds
- lm
- mk
- mg
- ms
- ml
- mr
- mn
- min
- ne
- new
- nb
- nn
- oc
- fa
- pms
- pl
- pt
- pa
- ro
- ru
- sco
- sr
- hr
- scn
- sk
- sl
- aze
- es
- su
- sw
- sv
- tl
- tg
- th
- ta
- tt
- te
- tr
- uk
- ud
- uz
- vi
- vo
- war
- cy
- fry
- pnb
- yo
license: apache-2.0
datasets:
- wikipedia
---
# BERT multilingual base model (cased)
Pretrained model on the top 104 languages with the largest Wikipedia using a masked language modeling (MLM) objective.
It was introduced in [this paper](https://arxiv.org/abs/1810.04805) and first released in
[this repository](https://github.com/google-research/bert). This model is case sensitive: it makes a difference
between english and English.
Disclaimer: The team releasing BERT did not write a model card for this model so this model card has been written by
the Hugging Face team.
## Model description
BERT is a transformers model pretrained on a large corpus of multilingual data in a self-supervised fashion. This means
it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the languages in the training set that can then be used to
extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a
standard classifier using the features produced by the BERT model as inputs.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=bert) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='bert-base-multilingual-cased')
>>> unmasker("Hello I'm a [MASK] model.")
[{'sequence': "[CLS] Hello I'm a model model. [SEP]",
'score': 0.10182085633277893,
'token': 13192,
'token_str': 'model'},
{'sequence': "[CLS] Hello I'm a world model. [SEP]",
'score': 0.052126359194517136,
'token': 11356,
'token_str': 'world'},
{'sequence': "[CLS] Hello I'm a data model. [SEP]",
'score': 0.048930276185274124,
'token': 11165,
'token_str': 'data'},
{'sequence': "[CLS] Hello I'm a flight model. [SEP]",
'score': 0.02036019042134285,
'token': 23578,
'token_str': 'flight'},
{'sequence': "[CLS] Hello I'm a business model. [SEP]",
'score': 0.020079681649804115,
'token': 14155,
'token_str': 'business'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased')
model = BertModel.from_pretrained("bert-base-multilingual-cased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-cased')
model = TFBertModel.from_pretrained("bert-base-multilingual-cased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Training data
The BERT model was pretrained on the 104 languages with the largest Wikipedias. You can find the complete list
[here](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a shared vocabulary size of 110,000. The languages with a
larger Wikipedia are under-sampled and the ones with lower resources are oversampled. For languages like Chinese,
Japanese Kanji and Korean Hanja that don't have space, a CJK Unicode block is added around every character.
The inputs of the model are then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1810-04805,
author = {Jacob Devlin and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {{BERT:} Pre-training of Deep Bidirectional Transformers for Language
Understanding},
journal = {CoRR},
volume = {abs/1810.04805},
year = {2018},
url = {http://arxiv.org/abs/1810.04805},
archivePrefix = {arXiv},
eprint = {1810.04805},
timestamp = {Tue, 30 Oct 2018 20:39:56 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1810-04805.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
google/electra-base-discriminator | google | "2024-02-29T10:20:20Z" | 12,382,190 | 57 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"electra",
"pretraining",
"en",
"arxiv:1406.2661",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | "2022-03-02T23:29:05Z" | ---
language: en
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
## ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
**ELECTRA** is a new method for self-supervised language representation learning. It can be used to pre-train transformer networks using relatively little compute. ELECTRA models are trained to distinguish "real" input tokens vs "fake" input tokens generated by another neural network, similar to the discriminator of a [GAN](https://arxiv.org/pdf/1406.2661.pdf). At small scale, ELECTRA achieves strong results even when trained on a single GPU. At large scale, ELECTRA achieves state-of-the-art results on the [SQuAD 2.0](https://rajpurkar.github.io/SQuAD-explorer/) dataset.
For a detailed description and experimental results, please refer to our paper [ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators](https://openreview.net/pdf?id=r1xMH1BtvB).
This repository contains code to pre-train ELECTRA, including small ELECTRA models on a single GPU. It also supports fine-tuning ELECTRA on downstream tasks including classification tasks (e.g,. [GLUE](https://gluebenchmark.com/)), QA tasks (e.g., [SQuAD](https://rajpurkar.github.io/SQuAD-explorer/)), and sequence tagging tasks (e.g., [text chunking](https://www.clips.uantwerpen.be/conll2000/chunking/)).
## How to use the discriminator in `transformers`
```python
from transformers import ElectraForPreTraining, ElectraTokenizerFast
import torch
discriminator = ElectraForPreTraining.from_pretrained("google/electra-base-discriminator")
tokenizer = ElectraTokenizerFast.from_pretrained("google/electra-base-discriminator")
sentence = "The quick brown fox jumps over the lazy dog"
fake_sentence = "The quick brown fox fake over the lazy dog"
fake_tokens = tokenizer.tokenize(fake_sentence)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
predictions = torch.round((torch.sign(discriminator_outputs[0]) + 1) / 2)
[print("%7s" % token, end="") for token in fake_tokens]
[print("%7s" % int(prediction), end="") for prediction in predictions.tolist()]
```
|
FacebookAI/xlm-roberta-base | FacebookAI | "2024-02-19T12:48:21Z" | 12,342,725 | 631 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"onnx",
"safetensors",
"xlm-roberta",
"fill-mask",
"exbert",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"arxiv:1911.02116",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:04Z" | ---
tags:
- exbert
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- no
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
license: mit
---
# XLM-RoBERTa (base-sized model)
XLM-RoBERTa model pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages. It was introduced in the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Conneau et al. and first released in [this repository](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
Disclaimer: The team releasing XLM-RoBERTa did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
XLM-RoBERTa is a multilingual version of RoBERTa. It is pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages.
RoBERTa is a transformers model pretrained on a large corpus in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was pretrained with the Masked language modeling (MLM) objective. Taking a sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the sentence.
This way, the model learns an inner representation of 100 languages that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard classifier using the features produced by the XLM-RoBERTa model as inputs.
## Intended uses & limitations
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?search=xlm-roberta) to look for fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked) to make decisions, such as sequence classification, token classification or question answering. For tasks such as text generation, you should look at models like GPT2.
## Usage
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='xlm-roberta-base')
>>> unmasker("Hello I'm a <mask> model.")
[{'score': 0.10563907772302628,
'sequence': "Hello I'm a fashion model.",
'token': 54543,
'token_str': 'fashion'},
{'score': 0.08015287667512894,
'sequence': "Hello I'm a new model.",
'token': 3525,
'token_str': 'new'},
{'score': 0.033413201570510864,
'sequence': "Hello I'm a model model.",
'token': 3299,
'token_str': 'model'},
{'score': 0.030217764899134636,
'sequence': "Hello I'm a French model.",
'token': 92265,
'token_str': 'French'},
{'score': 0.026436051353812218,
'sequence': "Hello I'm a sexy model.",
'token': 17473,
'token_str': 'sexy'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('xlm-roberta-base')
model = AutoModelForMaskedLM.from_pretrained("xlm-roberta-base")
# prepare input
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
# forward pass
output = model(**encoded_input)
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1911-02116,
author = {Alexis Conneau and
Kartikay Khandelwal and
Naman Goyal and
Vishrav Chaudhary and
Guillaume Wenzek and
Francisco Guzm{\'{a}}n and
Edouard Grave and
Myle Ott and
Luke Zettlemoyer and
Veselin Stoyanov},
title = {Unsupervised Cross-lingual Representation Learning at Scale},
journal = {CoRR},
volume = {abs/1911.02116},
year = {2019},
url = {http://arxiv.org/abs/1911.02116},
eprinttype = {arXiv},
eprint = {1911.02116},
timestamp = {Mon, 11 Nov 2019 18:38:09 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1911-02116.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<a href="https://huggingface.co/exbert/?model=xlm-roberta-base">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
Rostlab/prot_t5_xl_uniref50 | Rostlab | "2023-01-31T21:05:58Z" | 12,086,185 | 42 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"protein language model",
"dataset:UniRef50",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | "2022-03-02T23:29:04Z" | ---
tags:
- protein language model
datasets:
- UniRef50
---
# ProtT5-XL-UniRef50 model
Pretrained model on protein sequences using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://doi.org/10.1101/2020.07.12.199554) and first released in
[this repository](https://github.com/agemagician/ProtTrans). This model is trained on uppercase amino acids: it only works with capital letter amino acids.
## Model description
ProtT5-XL-UniRef50 is based on the `t5-3b` model and was pretrained on a large corpus of protein sequences in a self-supervised fashion.
This means it was pretrained on the raw protein sequences only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those protein sequences.
One important difference between this T5 model and the original T5 version is the denosing objective.
The original T5-3B model was pretrained using a span denosing objective, while this model was pre-trained with a Bart-like MLM denosing objective.
The masking probability is consistent with the original T5 training by randomly masking 15% of the amino acids in the input.
It has been shown that the features extracted from this self-supervised model (LM-embeddings) captured important biophysical properties governing protein shape.
shape.
This implied learning some of the grammar of the language of life realized in protein sequences.
## Intended uses & limitations
The model could be used for protein feature extraction or to be fine-tuned on downstream tasks.
We have noticed in some tasks on can gain more accuracy by fine-tuning the model rather than using it as a feature extractor.
We have also noticed that for feature extraction, its better to use the feature extracted from the encoder not from the decoder.
### How to use
Here is how to use this model to extract the features of a given protein sequence in PyTorch:
```python
sequence_examples = ["PRTEINO", "SEQWENCE"]
# this will replace all rare/ambiguous amino acids by X and introduce white-space between all amino acids
sequence_examples = [" ".join(list(re.sub(r"[UZOB]", "X", sequence))) for sequence in sequence_examples]
# tokenize sequences and pad up to the longest sequence in the batch
ids = tokenizer.batch_encode_plus(sequence_examples, add_special_tokens=True, padding="longest")
input_ids = torch.tensor(ids['input_ids']).to(device)
attention_mask = torch.tensor(ids['attention_mask']).to(device)
# generate embeddings
with torch.no_grad():
embedding_repr = model(input_ids=input_ids,attention_mask=attention_mask)
# extract embeddings for the first ([0,:]) sequence in the batch while removing padded & special tokens ([0,:7])
emb_0 = embedding_repr.last_hidden_state[0,:7] # shape (7 x 1024)
print(f"Shape of per-residue embedding of first sequences: {emb_0.shape}")
# do the same for the second ([1,:]) sequence in the batch while taking into account different sequence lengths ([1,:8])
emb_1 = embedding_repr.last_hidden_state[1,:8] # shape (8 x 1024)
# if you want to derive a single representation (per-protein embedding) for the whole protein
emb_0_per_protein = emb_0.mean(dim=0) # shape (1024)
print(f"Shape of per-protein embedding of first sequences: {emb_0_per_protein.shape}")
```
## Training data
The ProtT5-XL-UniRef50 model was pretrained on [UniRef50](https://www.uniprot.org/help/uniref), a dataset consisting of 45 million protein sequences.
## Training procedure
### Preprocessing
The protein sequences are uppercased and tokenized using a single space and a vocabulary size of 21. The rare amino acids "U,Z,O,B" were mapped to "X".
The inputs of the model are then of the form:
```
Protein Sequence [EOS]
```
The preprocessing step was performed on the fly, by cutting and padding the protein sequences up to 512 tokens.
The details of the masking procedure for each sequence are as follows:
- 15% of the amino acids are masked.
- In 90% of the cases, the masked amino acids are replaced by `[MASK]` token.
- In 10% of the cases, the masked amino acids are replaced by a random amino acid (different) from the one they replace.
### Pretraining
The model was trained on a single TPU Pod V2-256 for 991.5 thousand steps in total, using sequence length 512 (batch size 2k).
It was trained using ProtT5-XL-BFD model as an initial checkpoint, rather than training from scratch.
It has a total of approximately 3B parameters and was trained using the encoder-decoder architecture.
The optimizer used is AdaFactor with inverse square root learning rate schedule for pre-training.
## Evaluation results
When the model is used for feature extraction, this model achieves the following results:
Test results :
| Task/Dataset | secondary structure (3-states) | secondary structure (8-states) | Localization | Membrane |
|:-----:|:-----:|:-----:|:-----:|:-----:|
| CASP12 | 81 | 70 | | |
| TS115 | 87 | 77 | | |
| CB513 | 86 | 74 | | |
| DeepLoc | | | 81 | 91 |
### BibTeX entry and citation info
```bibtex
@article {Elnaggar2020.07.12.199554,
author = {Elnaggar, Ahmed and Heinzinger, Michael and Dallago, Christian and Rehawi, Ghalia and Wang, Yu and Jones, Llion and Gibbs, Tom and Feher, Tamas and Angerer, Christoph and Steinegger, Martin and BHOWMIK, DEBSINDHU and Rost, Burkhard},
title = {ProtTrans: Towards Cracking the Language of Life{\textquoteright}s Code Through Self-Supervised Deep Learning and High Performance Computing},
elocation-id = {2020.07.12.199554},
year = {2020},
doi = {10.1101/2020.07.12.199554},
publisher = {Cold Spring Harbor Laboratory},
abstract = {Computational biology and bioinformatics provide vast data gold-mines from protein sequences, ideal for Language Models (LMs) taken from Natural Language Processing (NLP). These LMs reach for new prediction frontiers at low inference costs. Here, we trained two auto-regressive language models (Transformer-XL, XLNet) and two auto-encoder models (Bert, Albert) on data from UniRef and BFD containing up to 393 billion amino acids (words) from 2.1 billion protein sequences (22- and 112 times the entire English Wikipedia). The LMs were trained on the Summit supercomputer at Oak Ridge National Laboratory (ORNL), using 936 nodes (total 5616 GPUs) and one TPU Pod (V3-512 or V3-1024). We validated the advantage of up-scaling LMs to larger models supported by bigger data by predicting secondary structure (3-states: Q3=76-84, 8 states: Q8=65-73), sub-cellular localization for 10 cellular compartments (Q10=74) and whether a protein is membrane-bound or water-soluble (Q2=89). Dimensionality reduction revealed that the LM-embeddings from unlabeled data (only protein sequences) captured important biophysical properties governing protein shape. This implied learning some of the grammar of the language of life realized in protein sequences. The successful up-scaling of protein LMs through HPC to larger data sets slightly reduced the gap between models trained on evolutionary information and LMs. Availability ProtTrans: \<a href="https://github.com/agemagician/ProtTrans"\>https://github.com/agemagician/ProtTrans\</a\>Competing Interest StatementThe authors have declared no competing interest.},
URL = {https://www.biorxiv.org/content/early/2020/07/21/2020.07.12.199554},
eprint = {https://www.biorxiv.org/content/early/2020/07/21/2020.07.12.199554.full.pdf},
journal = {bioRxiv}
}
```
> Created by [Ahmed Elnaggar/@Elnaggar_AI](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/)
|
openai/whisper-small | openai | "2024-02-29T10:57:38Z" | 11,109,438 | 344 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"whisper",
"automatic-speech-recognition",
"audio",
"hf-asr-leaderboard",
"en",
"zh",
"de",
"es",
"ru",
"ko",
"fr",
"ja",
"pt",
"tr",
"pl",
"ca",
"nl",
"ar",
"sv",
"it",
"id",
"hi",
"fi",
"vi",
"he",
"uk",
"el",
"ms",
"cs",
"ro",
"da",
"hu",
"ta",
"no",
"th",
"ur",
"hr",
"bg",
"lt",
"la",
"mi",
"ml",
"cy",
"sk",
"te",
"fa",
"lv",
"bn",
"sr",
"az",
"sl",
"kn",
"et",
"mk",
"br",
"eu",
"is",
"hy",
"ne",
"mn",
"bs",
"kk",
"sq",
"sw",
"gl",
"mr",
"pa",
"si",
"km",
"sn",
"yo",
"so",
"af",
"oc",
"ka",
"be",
"tg",
"sd",
"gu",
"am",
"yi",
"lo",
"uz",
"fo",
"ht",
"ps",
"tk",
"nn",
"mt",
"sa",
"lb",
"my",
"bo",
"tl",
"mg",
"as",
"tt",
"haw",
"ln",
"ha",
"ba",
"jw",
"su",
"arxiv:2212.04356",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-09-26T06:51:27Z" | ---
language:
- en
- zh
- de
- es
- ru
- ko
- fr
- ja
- pt
- tr
- pl
- ca
- nl
- ar
- sv
- it
- id
- hi
- fi
- vi
- he
- uk
- el
- ms
- cs
- ro
- da
- hu
- ta
- no
- th
- ur
- hr
- bg
- lt
- la
- mi
- ml
- cy
- sk
- te
- fa
- lv
- bn
- sr
- az
- sl
- kn
- et
- mk
- br
- eu
- is
- hy
- ne
- mn
- bs
- kk
- sq
- sw
- gl
- mr
- pa
- si
- km
- sn
- yo
- so
- af
- oc
- ka
- be
- tg
- sd
- gu
- am
- yi
- lo
- uz
- fo
- ht
- ps
- tk
- nn
- mt
- sa
- lb
- my
- bo
- tl
- mg
- as
- tt
- haw
- ln
- ha
- ba
- jw
- su
tags:
- audio
- automatic-speech-recognition
- hf-asr-leaderboard
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
model-index:
- name: whisper-small
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (clean)
type: librispeech_asr
config: clean
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 3.432213777886737
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (other)
type: librispeech_asr
config: other
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 7.628304527060248
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: hi
split: test
args:
language: hi
metrics:
- name: Test WER
type: wer
value: 87.3
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 13.0
type: mozilla-foundation/common_voice_13_0
config: dv
split: test
args:
language: dv
metrics:
- name: Wer
type: wer
value: 125.69809089960707
pipeline_tag: automatic-speech-recognition
license: apache-2.0
---
# Whisper
Whisper is a pre-trained model for automatic speech recognition (ASR) and speech translation. Trained on 680k hours
of labelled data, Whisper models demonstrate a strong ability to generalise to many datasets and domains **without** the need
for fine-tuning.
Whisper was proposed in the paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://arxiv.org/abs/2212.04356)
by Alec Radford et al from OpenAI. The original code repository can be found [here](https://github.com/openai/whisper).
**Disclaimer**: Content for this model card has partly been written by the Hugging Face team, and parts of it were
copied and pasted from the original model card.
## Model details
Whisper is a Transformer based encoder-decoder model, also referred to as a _sequence-to-sequence_ model.
It was trained on 680k hours of labelled speech data annotated using large-scale weak supervision.
The models were trained on either English-only data or multilingual data. The English-only models were trained
on the task of speech recognition. The multilingual models were trained on both speech recognition and speech
translation. For speech recognition, the model predicts transcriptions in the *same* language as the audio.
For speech translation, the model predicts transcriptions to a *different* language to the audio.
Whisper checkpoints come in five configurations of varying model sizes.
The smallest four are trained on either English-only or multilingual data.
The largest checkpoints are multilingual only. All ten of the pre-trained checkpoints
are available on the [Hugging Face Hub](https://huggingface.co/models?search=openai/whisper). The
checkpoints are summarised in the following table with links to the models on the Hub:
| Size | Parameters | English-only | Multilingual |
|----------|------------|------------------------------------------------------|-----------------------------------------------------|
| tiny | 39 M | [✓](https://huggingface.co/openai/whisper-tiny.en) | [✓](https://huggingface.co/openai/whisper-tiny) |
| base | 74 M | [✓](https://huggingface.co/openai/whisper-base.en) | [✓](https://huggingface.co/openai/whisper-base) |
| small | 244 M | [✓](https://huggingface.co/openai/whisper-small.en) | [✓](https://huggingface.co/openai/whisper-small) |
| medium | 769 M | [✓](https://huggingface.co/openai/whisper-medium.en) | [✓](https://huggingface.co/openai/whisper-medium) |
| large | 1550 M | x | [✓](https://huggingface.co/openai/whisper-large) |
| large-v2 | 1550 M | x | [✓](https://huggingface.co/openai/whisper-large-v2) |
# Usage
To transcribe audio samples, the model has to be used alongside a [`WhisperProcessor`](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperProcessor).
The `WhisperProcessor` is used to:
1. Pre-process the audio inputs (converting them to log-Mel spectrograms for the model)
2. Post-process the model outputs (converting them from tokens to text)
The model is informed of which task to perform (transcription or translation) by passing the appropriate "context tokens". These context tokens
are a sequence of tokens that are given to the decoder at the start of the decoding process, and take the following order:
1. The transcription always starts with the `<|startoftranscript|>` token
2. The second token is the language token (e.g. `<|en|>` for English)
3. The third token is the "task token". It can take one of two values: `<|transcribe|>` for speech recognition or `<|translate|>` for speech translation
4. In addition, a `<|notimestamps|>` token is added if the model should not include timestamp prediction
Thus, a typical sequence of context tokens might look as follows:
```
<|startoftranscript|> <|en|> <|transcribe|> <|notimestamps|>
```
Which tells the model to decode in English, under the task of speech recognition, and not to predict timestamps.
These tokens can either be forced or un-forced. If they are forced, the model is made to predict each token at
each position. This allows one to control the output language and task for the Whisper model. If they are un-forced,
the Whisper model will automatically predict the output langauge and task itself.
The context tokens can be set accordingly:
```python
model.config.forced_decoder_ids = WhisperProcessor.get_decoder_prompt_ids(language="english", task="transcribe")
```
Which forces the model to predict in English under the task of speech recognition.
## Transcription
### English to English
In this example, the context tokens are 'unforced', meaning the model automatically predicts the output language
(English) and task (transcribe).
```python
>>> from transformers import WhisperProcessor, WhisperForConditionalGeneration
>>> from datasets import load_dataset
>>> # load model and processor
>>> processor = WhisperProcessor.from_pretrained("openai/whisper-small")
>>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small")
>>> model.config.forced_decoder_ids = None
>>> # load dummy dataset and read audio files
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> sample = ds[0]["audio"]
>>> input_features = processor(sample["array"], sampling_rate=sample["sampling_rate"], return_tensors="pt").input_features
>>> # generate token ids
>>> predicted_ids = model.generate(input_features)
>>> # decode token ids to text
>>> transcription = processor.batch_decode(predicted_ids, skip_special_tokens=False)
['<|startoftranscript|><|en|><|transcribe|><|notimestamps|> Mr. Quilter is the apostle of the middle classes and we are glad to welcome his gospel.<|endoftext|>']
>>> transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
[' Mr. Quilter is the apostle of the middle classes and we are glad to welcome his gospel.']
```
The context tokens can be removed from the start of the transcription by setting `skip_special_tokens=True`.
### French to French
The following example demonstrates French to French transcription by setting the decoder ids appropriately.
```python
>>> from transformers import WhisperProcessor, WhisperForConditionalGeneration
>>> from datasets import Audio, load_dataset
>>> # load model and processor
>>> processor = WhisperProcessor.from_pretrained("openai/whisper-small")
>>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small")
>>> forced_decoder_ids = processor.get_decoder_prompt_ids(language="french", task="transcribe")
>>> # load streaming dataset and read first audio sample
>>> ds = load_dataset("common_voice", "fr", split="test", streaming=True)
>>> ds = ds.cast_column("audio", Audio(sampling_rate=16_000))
>>> input_speech = next(iter(ds))["audio"]
>>> input_features = processor(input_speech["array"], sampling_rate=input_speech["sampling_rate"], return_tensors="pt").input_features
>>> # generate token ids
>>> predicted_ids = model.generate(input_features, forced_decoder_ids=forced_decoder_ids)
>>> # decode token ids to text
>>> transcription = processor.batch_decode(predicted_ids)
['<|startoftranscript|><|fr|><|transcribe|><|notimestamps|> Un vrai travail intéressant va enfin être mené sur ce sujet.<|endoftext|>']
>>> transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
[' Un vrai travail intéressant va enfin être mené sur ce sujet.']
```
## Translation
Setting the task to "translate" forces the Whisper model to perform speech translation.
### French to English
```python
>>> from transformers import WhisperProcessor, WhisperForConditionalGeneration
>>> from datasets import Audio, load_dataset
>>> # load model and processor
>>> processor = WhisperProcessor.from_pretrained("openai/whisper-small")
>>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small")
>>> forced_decoder_ids = processor.get_decoder_prompt_ids(language="french", task="translate")
>>> # load streaming dataset and read first audio sample
>>> ds = load_dataset("common_voice", "fr", split="test", streaming=True)
>>> ds = ds.cast_column("audio", Audio(sampling_rate=16_000))
>>> input_speech = next(iter(ds))["audio"]
>>> input_features = processor(input_speech["array"], sampling_rate=input_speech["sampling_rate"], return_tensors="pt").input_features
>>> # generate token ids
>>> predicted_ids = model.generate(input_features, forced_decoder_ids=forced_decoder_ids)
>>> # decode token ids to text
>>> transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
[' A very interesting work, we will finally be given on this subject.']
```
## Evaluation
This code snippet shows how to evaluate Whisper Small on [LibriSpeech test-clean](https://huggingface.co/datasets/librispeech_asr):
```python
>>> from datasets import load_dataset
>>> from transformers import WhisperForConditionalGeneration, WhisperProcessor
>>> import torch
>>> from evaluate import load
>>> librispeech_test_clean = load_dataset("librispeech_asr", "clean", split="test")
>>> processor = WhisperProcessor.from_pretrained("openai/whisper-small")
>>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small").to("cuda")
>>> def map_to_pred(batch):
>>> audio = batch["audio"]
>>> input_features = processor(audio["array"], sampling_rate=audio["sampling_rate"], return_tensors="pt").input_features
>>> batch["reference"] = processor.tokenizer._normalize(batch['text'])
>>>
>>> with torch.no_grad():
>>> predicted_ids = model.generate(input_features.to("cuda"))[0]
>>> transcription = processor.decode(predicted_ids)
>>> batch["prediction"] = processor.tokenizer._normalize(transcription)
>>> return batch
>>> result = librispeech_test_clean.map(map_to_pred)
>>> wer = load("wer")
>>> print(100 * wer.compute(references=result["reference"], predictions=result["prediction"]))
3.432213777886737
```
## Long-Form Transcription
The Whisper model is intrinsically designed to work on audio samples of up to 30s in duration. However, by using a chunking
algorithm, it can be used to transcribe audio samples of up to arbitrary length. This is possible through Transformers
[`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline)
method. Chunking is enabled by setting `chunk_length_s=30` when instantiating the pipeline. With chunking enabled, the pipeline
can be run with batched inference. It can also be extended to predict sequence level timestamps by passing `return_timestamps=True`:
```python
>>> import torch
>>> from transformers import pipeline
>>> from datasets import load_dataset
>>> device = "cuda:0" if torch.cuda.is_available() else "cpu"
>>> pipe = pipeline(
>>> "automatic-speech-recognition",
>>> model="openai/whisper-small",
>>> chunk_length_s=30,
>>> device=device,
>>> )
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> sample = ds[0]["audio"]
>>> prediction = pipe(sample.copy(), batch_size=8)["text"]
" Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel."
>>> # we can also return timestamps for the predictions
>>> prediction = pipe(sample.copy(), batch_size=8, return_timestamps=True)["chunks"]
[{'text': ' Mr. Quilter is the apostle of the middle classes and we are glad to welcome his gospel.',
'timestamp': (0.0, 5.44)}]
```
Refer to the blog post [ASR Chunking](https://huggingface.co/blog/asr-chunking) for more details on the chunking algorithm.
## Fine-Tuning
The pre-trained Whisper model demonstrates a strong ability to generalise to different datasets and domains. However,
its predictive capabilities can be improved further for certain languages and tasks through *fine-tuning*. The blog
post [Fine-Tune Whisper with 🤗 Transformers](https://huggingface.co/blog/fine-tune-whisper) provides a step-by-step
guide to fine-tuning the Whisper model with as little as 5 hours of labelled data.
### Evaluated Use
The primary intended users of these models are AI researchers studying robustness, generalization, capabilities, biases, and constraints of the current model. However, Whisper is also potentially quite useful as an ASR solution for developers, especially for English speech recognition. We recognize that once models are released, it is impossible to restrict access to only “intended” uses or to draw reasonable guidelines around what is or is not research.
The models are primarily trained and evaluated on ASR and speech translation to English tasks. They show strong ASR results in ~10 languages. They may exhibit additional capabilities, particularly if fine-tuned on certain tasks like voice activity detection, speaker classification, or speaker diarization but have not been robustly evaluated in these areas. We strongly recommend that users perform robust evaluations of the models in a particular context and domain before deploying them.
In particular, we caution against using Whisper models to transcribe recordings of individuals taken without their consent or purporting to use these models for any kind of subjective classification. We recommend against use in high-risk domains like decision-making contexts, where flaws in accuracy can lead to pronounced flaws in outcomes. The models are intended to transcribe and translate speech, use of the model for classification is not only not evaluated but also not appropriate, particularly to infer human attributes.
## Training Data
The models are trained on 680,000 hours of audio and the corresponding transcripts collected from the internet. 65% of this data (or 438,000 hours) represents English-language audio and matched English transcripts, roughly 18% (or 126,000 hours) represents non-English audio and English transcripts, while the final 17% (or 117,000 hours) represents non-English audio and the corresponding transcript. This non-English data represents 98 different languages.
As discussed in [the accompanying paper](https://cdn.openai.com/papers/whisper.pdf), we see that performance on transcription in a given language is directly correlated with the amount of training data we employ in that language.
## Performance and Limitations
Our studies show that, over many existing ASR systems, the models exhibit improved robustness to accents, background noise, technical language, as well as zero shot translation from multiple languages into English; and that accuracy on speech recognition and translation is near the state-of-the-art level.
However, because the models are trained in a weakly supervised manner using large-scale noisy data, the predictions may include texts that are not actually spoken in the audio input (i.e. hallucination). We hypothesize that this happens because, given their general knowledge of language, the models combine trying to predict the next word in audio with trying to transcribe the audio itself.
Our models perform unevenly across languages, and we observe lower accuracy on low-resource and/or low-discoverability languages or languages where we have less training data. The models also exhibit disparate performance on different accents and dialects of particular languages, which may include higher word error rate across speakers of different genders, races, ages, or other demographic criteria. Our full evaluation results are presented in [the paper accompanying this release](https://cdn.openai.com/papers/whisper.pdf).
In addition, the sequence-to-sequence architecture of the model makes it prone to generating repetitive texts, which can be mitigated to some degree by beam search and temperature scheduling but not perfectly. Further analysis on these limitations are provided in [the paper](https://cdn.openai.com/papers/whisper.pdf). It is likely that this behavior and hallucinations may be worse on lower-resource and/or lower-discoverability languages.
## Broader Implications
We anticipate that Whisper models’ transcription capabilities may be used for improving accessibility tools. While Whisper models cannot be used for real-time transcription out of the box – their speed and size suggest that others may be able to build applications on top of them that allow for near-real-time speech recognition and translation. The real value of beneficial applications built on top of Whisper models suggests that the disparate performance of these models may have real economic implications.
There are also potential dual use concerns that come with releasing Whisper. While we hope the technology will be used primarily for beneficial purposes, making ASR technology more accessible could enable more actors to build capable surveillance technologies or scale up existing surveillance efforts, as the speed and accuracy allow for affordable automatic transcription and translation of large volumes of audio communication. Moreover, these models may have some capabilities to recognize specific individuals out of the box, which in turn presents safety concerns related both to dual use and disparate performance. In practice, we expect that the cost of transcription is not the limiting factor of scaling up surveillance projects.
### BibTeX entry and citation info
```bibtex
@misc{radford2022whisper,
doi = {10.48550/ARXIV.2212.04356},
url = {https://arxiv.org/abs/2212.04356},
author = {Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya},
title = {Robust Speech Recognition via Large-Scale Weak Supervision},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
|
openai/clip-vit-base-patch32 | openai | "2024-02-29T09:45:55Z" | 10,916,919 | 608 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"clip",
"zero-shot-image-classification",
"vision",
"arxiv:2103.00020",
"arxiv:1908.04913",
"endpoints_compatible",
"region:us"
] | zero-shot-image-classification | "2022-03-02T23:29:05Z" | ---
tags:
- vision
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: playing music, playing sports
example_title: Cat & Dog
---
# Model Card: CLIP
Disclaimer: The model card is taken and modified from the official CLIP repository, it can be found [here](https://github.com/openai/CLIP/blob/main/model-card.md).
## Model Details
The CLIP model was developed by researchers at OpenAI to learn about what contributes to robustness in computer vision tasks. The model was also developed to test the ability of models to generalize to arbitrary image classification tasks in a zero-shot manner. It was not developed for general model deployment - to deploy models like CLIP, researchers will first need to carefully study their capabilities in relation to the specific context they’re being deployed within.
### Model Date
January 2021
### Model Type
The model uses a ViT-B/32 Transformer architecture as an image encoder and uses a masked self-attention Transformer as a text encoder. These encoders are trained to maximize the similarity of (image, text) pairs via a contrastive loss.
The original implementation had two variants: one using a ResNet image encoder and the other using a Vision Transformer. This repository has the variant with the Vision Transformer.
### Documents
- [Blog Post](https://openai.com/blog/clip/)
- [CLIP Paper](https://arxiv.org/abs/2103.00020)
### Use with Transformers
```python3
from PIL import Image
import requests
from transformers import CLIPProcessor, CLIPModel
model = CLIPModel.from_pretrained("openai/clip-vit-base-patch32")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-base-patch32")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(text=["a photo of a cat", "a photo of a dog"], images=image, return_tensors="pt", padding=True)
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # this is the image-text similarity score
probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
```
## Model Use
### Intended Use
The model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such models - the CLIP paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis.
#### Primary intended uses
The primary intended users of these models are AI researchers.
We primarily imagine the model will be used by researchers to better understand robustness, generalization, and other capabilities, biases, and constraints of computer vision models.
### Out-of-Scope Use Cases
**Any** deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP’s performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case currently potentially harmful.
Certain use cases which would fall under the domain of surveillance and facial recognition are always out-of-scope regardless of performance of the model. This is because the use of artificial intelligence for tasks such as these can be premature currently given the lack of testing norms and checks to ensure its fair use.
Since the model has not been purposefully trained in or evaluated on any languages other than English, its use should be limited to English language use cases.
## Data
The model was trained on publicly available image-caption data. This was done through a combination of crawling a handful of websites and using commonly-used pre-existing image datasets such as [YFCC100M](http://projects.dfki.uni-kl.de/yfcc100m/). A large portion of the data comes from our crawling of the internet. This means that the data is more representative of people and societies most connected to the internet which tend to skew towards more developed nations, and younger, male users.
### Data Mission Statement
Our goal with building this dataset was to test out robustness and generalizability in computer vision tasks. As a result, the focus was on gathering large quantities of data from different publicly-available internet data sources. The data was gathered in a mostly non-interventionist manner. However, we only crawled websites that had policies against excessively violent and adult images and allowed us to filter out such content. We do not intend for this dataset to be used as the basis for any commercial or deployed model and will not be releasing the dataset.
## Performance and Limitations
### Performance
We have evaluated the performance of CLIP on a wide range of benchmarks across a variety of computer vision datasets such as OCR to texture recognition to fine-grained classification. The paper describes model performance on the following datasets:
- Food101
- CIFAR10
- CIFAR100
- Birdsnap
- SUN397
- Stanford Cars
- FGVC Aircraft
- VOC2007
- DTD
- Oxford-IIIT Pet dataset
- Caltech101
- Flowers102
- MNIST
- SVHN
- IIIT5K
- Hateful Memes
- SST-2
- UCF101
- Kinetics700
- Country211
- CLEVR Counting
- KITTI Distance
- STL-10
- RareAct
- Flickr30
- MSCOCO
- ImageNet
- ImageNet-A
- ImageNet-R
- ImageNet Sketch
- ObjectNet (ImageNet Overlap)
- Youtube-BB
- ImageNet-Vid
## Limitations
CLIP and our analysis of it have a number of limitations. CLIP currently struggles with respect to certain tasks such as fine grained classification and counting objects. CLIP also poses issues with regards to fairness and bias which we discuss in the paper and briefly in the next section. Additionally, our approach to testing CLIP also has an important limitation- in many cases we have used linear probes to evaluate the performance of CLIP and there is evidence suggesting that linear probes can underestimate model performance.
### Bias and Fairness
We find that the performance of CLIP - and the specific biases it exhibits - can depend significantly on class design and the choices one makes for categories to include and exclude. We tested the risk of certain kinds of denigration with CLIP by classifying images of people from [Fairface](https://arxiv.org/abs/1908.04913) into crime-related and non-human animal categories. We found significant disparities with respect to race and gender. Additionally, we found that these disparities could shift based on how the classes were constructed. (Details captured in the Broader Impacts Section in the paper).
We also tested the performance of CLIP on gender, race and age classification using the Fairface dataset (We default to using race categories as they are constructed in the Fairface dataset.) in order to assess quality of performance across different demographics. We found accuracy >96% across all races for gender classification with ‘Middle Eastern’ having the highest accuracy (98.4%) and ‘White’ having the lowest (96.5%). Additionally, CLIP averaged ~93% for racial classification and ~63% for age classification. Our use of evaluations to test for gender, race and age classification as well as denigration harms is simply to evaluate performance of the model across people and surface potential risks and not to demonstrate an endorsement/enthusiasm for such tasks.
## Feedback
### Where to send questions or comments about the model
Please use [this Google Form](https://forms.gle/Uv7afRH5dvY34ZEs9) |
cross-encoder/ms-marco-MiniLM-L-6-v2 | cross-encoder | "2024-12-12T11:32:08Z" | 10,243,420 | 67 | transformers | [
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"text-classification",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
---
# Cross-Encoder for MS Marco
This model was trained on the [MS Marco Passage Ranking](https://github.com/microsoft/MSMARCO-Passage-Ranking) task.
The model can be used for Information Retrieval: Given a query, encode the query will all possible passages (e.g. retrieved with ElasticSearch). Then sort the passages in a decreasing order. See [SBERT.net Retrieve & Re-rank](https://www.sbert.net/examples/applications/retrieve_rerank/README.html) for more details. The training code is available here: [SBERT.net Training MS Marco](https://github.com/UKPLab/sentence-transformers/tree/master/examples/training/ms_marco)
## Usage with Transformers
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
import torch
model = AutoModelForSequenceClassification.from_pretrained('cross-encoder/ms-marco-MiniLM-L-6-v2')
tokenizer = AutoTokenizer.from_pretrained('cross-encoder/ms-marco-MiniLM-L-6-v2')
features = tokenizer(['How many people live in Berlin?', 'How many people live in Berlin?'], ['Berlin has a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers.', 'New York City is famous for the Metropolitan Museum of Art.'], padding=True, truncation=True, return_tensors="pt")
model.eval()
with torch.no_grad():
scores = model(**features).logits
print(scores)
```
## Usage with SentenceTransformers
The usage becomes easier when you have [SentenceTransformers](https://www.sbert.net/) installed. Then, you can use the pre-trained models like this:
```python
from sentence_transformers import CrossEncoder
model = CrossEncoder('cross-encoder/ms-marco-MiniLM-L-6-v2', max_length=512)
scores = model.predict([('Query', 'Paragraph1'), ('Query', 'Paragraph2') , ('Query', 'Paragraph3')])
```
## Performance
In the following table, we provide various pre-trained Cross-Encoders together with their performance on the [TREC Deep Learning 2019](https://microsoft.github.io/TREC-2019-Deep-Learning/) and the [MS Marco Passage Reranking](https://github.com/microsoft/MSMARCO-Passage-Ranking/) dataset.
| Model-Name | NDCG@10 (TREC DL 19) | MRR@10 (MS Marco Dev) | Docs / Sec |
| ------------- |:-------------| -----| --- |
| **Version 2 models** | | |
| cross-encoder/ms-marco-TinyBERT-L-2-v2 | 69.84 | 32.56 | 9000
| cross-encoder/ms-marco-MiniLM-L-2-v2 | 71.01 | 34.85 | 4100
| cross-encoder/ms-marco-MiniLM-L-4-v2 | 73.04 | 37.70 | 2500
| cross-encoder/ms-marco-MiniLM-L-6-v2 | 74.30 | 39.01 | 1800
| cross-encoder/ms-marco-MiniLM-L-12-v2 | 74.31 | 39.02 | 960
| **Version 1 models** | | |
| cross-encoder/ms-marco-TinyBERT-L-2 | 67.43 | 30.15 | 9000
| cross-encoder/ms-marco-TinyBERT-L-4 | 68.09 | 34.50 | 2900
| cross-encoder/ms-marco-TinyBERT-L-6 | 69.57 | 36.13 | 680
| cross-encoder/ms-marco-electra-base | 71.99 | 36.41 | 340
| **Other models** | | |
| nboost/pt-tinybert-msmarco | 63.63 | 28.80 | 2900
| nboost/pt-bert-base-uncased-msmarco | 70.94 | 34.75 | 340
| nboost/pt-bert-large-msmarco | 73.36 | 36.48 | 100
| Capreolus/electra-base-msmarco | 71.23 | 36.89 | 340
| amberoad/bert-multilingual-passage-reranking-msmarco | 68.40 | 35.54 | 330
| sebastian-hofstaetter/distilbert-cat-margin_mse-T2-msmarco | 72.82 | 37.88 | 720
Note: Runtime was computed on a V100 GPU.
|
CIDAS/clipseg-rd64-refined | CIDAS | "2024-12-11T09:46:10Z" | 9,652,114 | 119 | transformers | [
"transformers",
"pytorch",
"safetensors",
"clipseg",
"vision",
"image-segmentation",
"arxiv:2112.10003",
"license:apache-2.0",
"region:us"
] | image-segmentation | "2022-11-01T14:25:57Z" | ---
license: apache-2.0
tags:
- vision
- image-segmentation
inference: false
---
# CLIPSeg model
CLIPSeg model with reduce dimension 64, refined (using a more complex convolution). It was introduced in the paper [Image Segmentation Using Text and Image Prompts](https://arxiv.org/abs/2112.10003) by Lüddecke et al. and first released in [this repository](https://github.com/timojl/clipseg).
# Intended use cases
This model is intended for zero-shot and one-shot image segmentation.
# Usage
Refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/clipseg). |
sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 | sentence-transformers | "2024-11-05T18:24:49Z" | 9,610,929 | 773 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"onnx",
"safetensors",
"openvino",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"multilingual",
"ar",
"bg",
"ca",
"cs",
"da",
"de",
"el",
"en",
"es",
"et",
"fa",
"fi",
"fr",
"gl",
"gu",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"it",
"ja",
"ka",
"ko",
"ku",
"lt",
"lv",
"mk",
"mn",
"mr",
"ms",
"my",
"nb",
"nl",
"pl",
"pt",
"ro",
"ru",
"sk",
"sl",
"sq",
"sr",
"sv",
"th",
"tr",
"uk",
"ur",
"vi",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
language:
- multilingual
- ar
- bg
- ca
- cs
- da
- de
- el
- en
- es
- et
- fa
- fi
- fr
- gl
- gu
- he
- hi
- hr
- hu
- hy
- id
- it
- ja
- ka
- ko
- ku
- lt
- lv
- mk
- mn
- mr
- ms
- my
- nb
- nl
- pl
- pt
- ro
- ru
- sk
- sl
- sq
- sr
- sv
- th
- tr
- uk
- ur
- vi
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
language_bcp47:
- fr-ca
- pt-br
- zh-cn
- zh-tw
pipeline_tag: sentence-similarity
---
# sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
model = AutoModel.from_pretrained('sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
facebook/esmfold_v1 | facebook | "2023-03-22T17:39:28Z" | 8,997,176 | 27 | transformers | [
"transformers",
"pytorch",
"esm",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | "2022-11-01T18:24:14Z" | ---
license: mit
---
# ESMFold
ESMFold is a state-of-the-art end-to-end protein folding model based on an ESM-2 backbone. It does not require any lookup or MSA step, and therefore does not require any external databases to be present in order to make predictions. As a result, inference time is very significantly faster than AlphaFold2. For details on the model architecture and training, please refer to the [accompanying paper](https://www.science.org/doi/10.1126/science.ade2574).
If you're interested in using ESMFold in practice, please check out the associated [tutorial notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/protein_folding.ipynb). |
sentence-transformers/paraphrase-MiniLM-L6-v2 | sentence-transformers | "2024-11-05T18:17:00Z" | 8,912,874 | 115 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"onnx",
"safetensors",
"openvino",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"arxiv:1908.10084",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
pipeline_tag: sentence-similarity
---
# sentence-transformers/paraphrase-MiniLM-L6-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/paraphrase-MiniLM-L6-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/paraphrase-MiniLM-L6-v2')
model = AutoModel.from_pretrained('sentence-transformers/paraphrase-MiniLM-L6-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, max pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/paraphrase-MiniLM-L6-v2)
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
This model was trained by [sentence-transformers](https://www.sbert.net/).
If you find this model helpful, feel free to cite our publication [Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks](https://arxiv.org/abs/1908.10084):
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "http://arxiv.org/abs/1908.10084",
}
``` |
answerdotai/ModernBERT-base | answerdotai | "2025-01-15T20:11:48Z" | 8,779,496 | 724 | transformers | [
"transformers",
"pytorch",
"onnx",
"safetensors",
"modernbert",
"fill-mask",
"masked-lm",
"long-context",
"en",
"arxiv:2412.13663",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | fill-mask | "2024-12-11T11:38:06Z" | ---
library_name: transformers
license: apache-2.0
language:
- en
tags:
- fill-mask
- masked-lm
- long-context
- modernbert
pipeline_tag: fill-mask
inference: false
---
# ModernBERT
## Table of Contents
1. [Model Summary](#model-summary)
2. [Usage](#Usage)
3. [Evaluation](#Evaluation)
4. [Limitations](#limitations)
5. [Training](#training)
6. [License](#license)
7. [Citation](#citation)
## Model Summary
ModernBERT is a modernized bidirectional encoder-only Transformer model (BERT-style) pre-trained on 2 trillion tokens of English and code data with a native context length of up to 8,192 tokens. ModernBERT leverages recent architectural improvements such as:
- **Rotary Positional Embeddings (RoPE)** for long-context support.
- **Local-Global Alternating Attention** for efficiency on long inputs.
- **Unpadding and Flash Attention** for efficient inference.
ModernBERT’s native long context length makes it ideal for tasks that require processing long documents, such as retrieval, classification, and semantic search within large corpora. The model was trained on a large corpus of text and code, making it suitable for a wide range of downstream tasks, including code retrieval and hybrid (text + code) semantic search.
It is available in the following sizes:
- [ModernBERT-base](https://huggingface.co/answerdotai/ModernBERT-base) - 22 layers, 149 million parameters
- [ModernBERT-large](https://huggingface.co/answerdotai/ModernBERT-large) - 28 layers, 395 million parameters
For more information about ModernBERT, we recommend our [release blog post](https://huggingface.co/blog/modernbert) for a high-level overview, and our [arXiv pre-print](https://arxiv.org/abs/2412.13663) for in-depth information.
*ModernBERT is a collaboration between [Answer.AI](https://answer.ai), [LightOn](https://lighton.ai), and friends.*
## Usage
You can use these models directly with the `transformers` library starting from v4.48.0:
```sh
pip install -U transformers>=4.48.0
```
Since ModernBERT is a Masked Language Model (MLM), you can use the `fill-mask` pipeline or load it via `AutoModelForMaskedLM`. To use ModernBERT for downstream tasks like classification, retrieval, or QA, fine-tune it following standard BERT fine-tuning recipes.
**⚠️ If your GPU supports it, we recommend using ModernBERT with Flash Attention 2 to reach the highest efficiency. To do so, install Flash Attention as follows, then use the model as normal:**
```bash
pip install flash-attn
```
Using `AutoModelForMaskedLM`:
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
model_id = "answerdotai/ModernBERT-base"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForMaskedLM.from_pretrained(model_id)
text = "The capital of France is [MASK]."
inputs = tokenizer(text, return_tensors="pt")
outputs = model(**inputs)
# To get predictions for the mask:
masked_index = inputs["input_ids"][0].tolist().index(tokenizer.mask_token_id)
predicted_token_id = outputs.logits[0, masked_index].argmax(axis=-1)
predicted_token = tokenizer.decode(predicted_token_id)
print("Predicted token:", predicted_token)
# Predicted token: Paris
```
Using a pipeline:
```python
import torch
from transformers import pipeline
from pprint import pprint
pipe = pipeline(
"fill-mask",
model="answerdotai/ModernBERT-base",
torch_dtype=torch.bfloat16,
)
input_text = "He walked to the [MASK]."
results = pipe(input_text)
pprint(results)
```
**Note:** ModernBERT does not use token type IDs, unlike some earlier BERT models. Most downstream usage is identical to standard BERT models on the Hugging Face Hub, except you can omit the `token_type_ids` parameter.
## Evaluation
We evaluate ModernBERT across a range of tasks, including natural language understanding (GLUE), general retrieval (BEIR), long-context retrieval (MLDR), and code retrieval (CodeSearchNet and StackQA).
**Key highlights:**
- On GLUE, ModernBERT-base surpasses other similarly-sized encoder models, and ModernBERT-large is second only to Deberta-v3-large.
- For general retrieval tasks, ModernBERT performs well on BEIR in both single-vector (DPR-style) and multi-vector (ColBERT-style) settings.
- Thanks to the inclusion of code data in its training mixture, ModernBERT as a backbone also achieves new state-of-the-art code retrieval results on CodeSearchNet and StackQA.
### Base Models
| Model | IR (DPR) | IR (DPR) | IR (DPR) | IR (ColBERT) | IR (ColBERT) | NLU | Code | Code |
|-------------|--------------|--------------|--------------|---------------|---------------|------|------|------|
| | BEIR | MLDR_OOD | MLDR_ID | BEIR | MLDR_OOD | GLUE | CSN | SQA |
| BERT | 38.9 | 23.9 | 32.2 | 49.0 | 28.1 | 84.7 | 41.2 | 59.5 |
| RoBERTa | 37.7 | 22.9 | 32.8 | 48.7 | 28.2 | 86.4 | 44.3 | 59.6 |
| DeBERTaV3 | 20.2 | 5.4 | 13.4 | 47.1 | 21.9 | 88.1 | 17.5 | 18.6 |
| NomicBERT | 41.0 | 26.7 | 30.3 | 49.9 | 61.3 | 84.0 | 41.6 | 61.4 |
| GTE-en-MLM | 41.4 | **34.3** |**44.4** | 48.2 | 69.3 | 85.6 | 44.9 | 71.4 |
| ModernBERT | **41.6** | 27.4 | 44.0 | **51.3** | **80.2** | **88.4** | **56.4** |**73.6**|
---
### Large Models
| Model | IR (DPR) | IR (DPR) | IR (DPR) | IR (ColBERT) | IR (ColBERT) | NLU | Code | Code |
|-------------|--------------|--------------|--------------|---------------|---------------|------|------|------|
| | BEIR | MLDR_OOD | MLDR_ID | BEIR | MLDR_OOD | GLUE | CSN | SQA |
| BERT | 38.9 | 23.3 | 31.7 | 49.5 | 28.5 | 85.2 | 41.6 | 60.8 |
| RoBERTa | 41.4 | 22.6 | 36.1 | 49.8 | 28.8 | 88.9 | 47.3 | 68.1 |
| DeBERTaV3 | 25.6 | 7.1 | 19.2 | 46.7 | 23.0 | **91.4**| 21.2 | 19.7 |
| GTE-en-MLM | 42.5 | **36.4** | **48.9** | 50.7 | 71.3 | 87.6 | 40.5 | 66.9 |
| ModernBERT | **44.0** | 34.3 | 48.6 | **52.4** | **80.4** | 90.4 |**59.5** |**83.9**|
*Table 1: Results for all models across an overview of all tasks. CSN refers to CodeSearchNet and SQA to StackQA. MLDRID refers to in-domain (fine-tuned on the training set) evaluation, and MLDR_OOD to out-of-domain.*
ModernBERT’s strong results, coupled with its efficient runtime on long-context inputs, demonstrate that encoder-only models can be significantly improved through modern architectural choices and extensive pretraining on diversified data sources.
## Limitations
ModernBERT’s training data is primarily English and code, so performance may be lower for other languages. While it can handle long sequences efficiently, using the full 8,192 tokens window may be slower than short-context inference. Like any large language model, ModernBERT may produce representations that reflect biases present in its training data. Verify critical or sensitive outputs before relying on them.
## Training
- Architecture: Encoder-only, Pre-Norm Transformer with GeGLU activations.
- Sequence Length: Pre-trained up to 1,024 tokens, then extended to 8,192 tokens.
- Data: 2 trillion tokens of English text and code.
- Optimizer: StableAdamW with trapezoidal LR scheduling and 1-sqrt decay.
- Hardware: Trained on 8x H100 GPUs.
See the paper for more details.
## License
We release the ModernBERT model architectures, model weights, training codebase under the Apache 2.0 license.
## Citation
If you use ModernBERT in your work, please cite:
```
@misc{modernbert,
title={Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference},
author={Benjamin Warner and Antoine Chaffin and Benjamin Clavié and Orion Weller and Oskar Hallström and Said Taghadouini and Alexis Gallagher and Raja Biswas and Faisal Ladhak and Tom Aarsen and Nathan Cooper and Griffin Adams and Jeremy Howard and Iacopo Poli},
year={2024},
eprint={2412.13663},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2412.13663},
}
``` |
FacebookAI/roberta-base | FacebookAI | "2024-02-19T12:39:28Z" | 8,024,790 | 464 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"roberta",
"fill-mask",
"exbert",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1907.11692",
"arxiv:1806.02847",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:04Z" | ---
language: en
tags:
- exbert
license: mit
datasets:
- bookcorpus
- wikipedia
---
# RoBERTa base model
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/abs/1907.11692) and first released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/roberta). This model is case-sensitive: it
makes a difference between english and English.
Disclaimer: The team releasing RoBERTa did not write a model card for this model so this model card has been written by
the Hugging Face team.
## Model description
RoBERTa is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means
it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was pretrained with the Masked language modeling (MLM) objective. Taking a sentence, the model
randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict
the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one
after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to
learn a bidirectional representation of the sentence.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
## Intended uses & limitations
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task.
See the [model hub](https://huggingface.co/models?filter=roberta) to look for fine-tuned versions on a task that
interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at a model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='roberta-base')
>>> unmasker("Hello I'm a <mask> model.")
[{'sequence': "<s>Hello I'm a male model.</s>",
'score': 0.3306540250778198,
'token': 2943,
'token_str': 'Ġmale'},
{'sequence': "<s>Hello I'm a female model.</s>",
'score': 0.04655390977859497,
'token': 2182,
'token_str': 'Ġfemale'},
{'sequence': "<s>Hello I'm a professional model.</s>",
'score': 0.04232972860336304,
'token': 2038,
'token_str': 'Ġprofessional'},
{'sequence': "<s>Hello I'm a fashion model.</s>",
'score': 0.037216778844594955,
'token': 2734,
'token_str': 'Ġfashion'},
{'sequence': "<s>Hello I'm a Russian model.</s>",
'score': 0.03253649175167084,
'token': 1083,
'token_str': 'ĠRussian'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import RobertaTokenizer, RobertaModel
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
model = RobertaModel.from_pretrained('roberta-base')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import RobertaTokenizer, TFRobertaModel
tokenizer = RobertaTokenizer.from_pretrained('roberta-base')
model = TFRobertaModel.from_pretrained('roberta-base')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
The training data used for this model contains a lot of unfiltered content from the internet, which is far from
neutral. Therefore, the model can have biased predictions:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='roberta-base')
>>> unmasker("The man worked as a <mask>.")
[{'sequence': '<s>The man worked as a mechanic.</s>',
'score': 0.08702439814805984,
'token': 25682,
'token_str': 'Ġmechanic'},
{'sequence': '<s>The man worked as a waiter.</s>',
'score': 0.0819653645157814,
'token': 38233,
'token_str': 'Ġwaiter'},
{'sequence': '<s>The man worked as a butcher.</s>',
'score': 0.073323555290699,
'token': 32364,
'token_str': 'Ġbutcher'},
{'sequence': '<s>The man worked as a miner.</s>',
'score': 0.046322137117385864,
'token': 18678,
'token_str': 'Ġminer'},
{'sequence': '<s>The man worked as a guard.</s>',
'score': 0.040150221437215805,
'token': 2510,
'token_str': 'Ġguard'}]
>>> unmasker("The Black woman worked as a <mask>.")
[{'sequence': '<s>The Black woman worked as a waitress.</s>',
'score': 0.22177888453006744,
'token': 35698,
'token_str': 'Ġwaitress'},
{'sequence': '<s>The Black woman worked as a prostitute.</s>',
'score': 0.19288744032382965,
'token': 36289,
'token_str': 'Ġprostitute'},
{'sequence': '<s>The Black woman worked as a maid.</s>',
'score': 0.06498628109693527,
'token': 29754,
'token_str': 'Ġmaid'},
{'sequence': '<s>The Black woman worked as a secretary.</s>',
'score': 0.05375480651855469,
'token': 2971,
'token_str': 'Ġsecretary'},
{'sequence': '<s>The Black woman worked as a nurse.</s>',
'score': 0.05245552211999893,
'token': 9008,
'token_str': 'Ġnurse'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The RoBERTa model was pretrained on the reunion of five datasets:
- [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038 unpublished books;
- [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and headers) ;
- [CC-News](https://commoncrawl.org/2016/10/news-dataset-available/), a dataset containing 63 millions English news
articles crawled between September 2016 and February 2019.
- [OpenWebText](https://github.com/jcpeterson/openwebtext), an opensource recreation of the WebText dataset used to
train GPT-2,
- [Stories](https://arxiv.org/abs/1806.02847) a dataset containing a subset of CommonCrawl data filtered to match the
story-like style of Winograd schemas.
Together these datasets weigh 160GB of text.
## Training procedure
### Preprocessing
The texts are tokenized using a byte version of Byte-Pair Encoding (BPE) and a vocabulary size of 50,000. The inputs of
the model take pieces of 512 contiguous tokens that may span over documents. The beginning of a new document is marked
with `<s>` and the end of one by `</s>`
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `<mask>`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
Contrary to BERT, the masking is done dynamically during pretraining (e.g., it changes at each epoch and is not fixed).
### Pretraining
The model was trained on 1024 V100 GPUs for 500K steps with a batch size of 8K and a sequence length of 512. The
optimizer used is Adam with a learning rate of 6e-4, \\(\beta_{1} = 0.9\\), \\(\beta_{2} = 0.98\\) and
\\(\epsilon = 1e-6\\), a weight decay of 0.01, learning rate warmup for 24,000 steps and linear decay of the learning
rate after.
## Evaluation results
When fine-tuned on downstream tasks, this model achieves the following results:
Glue test results:
| Task | MNLI | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE |
|:----:|:----:|:----:|:----:|:-----:|:----:|:-----:|:----:|:----:|
| | 87.6 | 91.9 | 92.8 | 94.8 | 63.6 | 91.2 | 90.2 | 78.7 |
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1907-11692,
author = {Yinhan Liu and
Myle Ott and
Naman Goyal and
Jingfei Du and
Mandar Joshi and
Danqi Chen and
Omer Levy and
Mike Lewis and
Luke Zettlemoyer and
Veselin Stoyanov},
title = {RoBERTa: {A} Robustly Optimized {BERT} Pretraining Approach},
journal = {CoRR},
volume = {abs/1907.11692},
year = {2019},
url = {http://arxiv.org/abs/1907.11692},
archivePrefix = {arXiv},
eprint = {1907.11692},
timestamp = {Thu, 01 Aug 2019 08:59:33 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1907-11692.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<a href="https://huggingface.co/exbert/?model=roberta-base">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
is210379/DeepSeek-R1-UD-IQ1_S | is210379 | "2025-01-31T02:23:16Z" | 7,943,312 | 0 | null | [
"gguf",
"deepseek_v3",
"custom_code",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | "2025-01-30T22:53:22Z" | Entry not found |
sentence-transformers/multi-qa-MiniLM-L6-cos-v1 | sentence-transformers | "2024-11-05T17:17:16Z" | 7,441,945 | 122 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"onnx",
"safetensors",
"openvino",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"dataset:flax-sentence-embeddings/stackexchange_xml",
"dataset:ms_marco",
"dataset:gooaq",
"dataset:yahoo_answers_topics",
"dataset:search_qa",
"dataset:eli5",
"dataset:natural_questions",
"dataset:trivia_qa",
"dataset:embedding-data/QQP",
"dataset:embedding-data/PAQ_pairs",
"dataset:embedding-data/Amazon-QA",
"dataset:embedding-data/WikiAnswers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
language:
- en
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
datasets:
- flax-sentence-embeddings/stackexchange_xml
- ms_marco
- gooaq
- yahoo_answers_topics
- search_qa
- eli5
- natural_questions
- trivia_qa
- embedding-data/QQP
- embedding-data/PAQ_pairs
- embedding-data/Amazon-QA
- embedding-data/WikiAnswers
pipeline_tag: sentence-similarity
---
# multi-qa-MiniLM-L6-cos-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and was designed for **semantic search**. It has been trained on 215M (question, answer) pairs from diverse sources. For an introduction to semantic search, have a look at: [SBERT.net - Semantic Search](https://www.sbert.net/examples/applications/semantic-search/README.html)
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer, util
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
#Load the model
model = SentenceTransformer('sentence-transformers/multi-qa-MiniLM-L6-cos-v1')
#Encode query and documents
query_emb = model.encode(query)
doc_emb = model.encode(docs)
#Compute dot score between query and all document embeddings
scores = util.dot_score(query_emb, doc_emb)[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## PyTorch Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the correct pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take average of all tokens
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output.last_hidden_state
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
#Encode text
def encode(texts):
# Tokenize sentences
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input, return_dict=True)
# Perform pooling
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
return embeddings
# Sentences we want sentence embeddings for
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/multi-qa-MiniLM-L6-cos-v1")
model = AutoModel.from_pretrained("sentence-transformers/multi-qa-MiniLM-L6-cos-v1")
#Encode query and docs
query_emb = encode(query)
doc_emb = encode(docs)
#Compute dot score between query and all document embeddings
scores = torch.mm(query_emb, doc_emb.transpose(0, 1))[0].cpu().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## TensorFlow Usage (HuggingFace Transformers)
Similarly to the PyTorch example above, to use the model with TensorFlow you pass your input through the transformer model, then you have to apply the correct pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, TFAutoModel
import tensorflow as tf
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output.last_hidden_state
input_mask_expanded = tf.cast(tf.tile(tf.expand_dims(attention_mask, -1), [1, 1, token_embeddings.shape[-1]]), tf.float32)
return tf.math.reduce_sum(token_embeddings * input_mask_expanded, 1) / tf.math.maximum(tf.math.reduce_sum(input_mask_expanded, 1), 1e-9)
#Encode text
def encode(texts):
# Tokenize sentences
encoded_input = tokenizer(texts, padding=True, truncation=True, return_tensors='tf')
# Compute token embeddings
model_output = model(**encoded_input, return_dict=True)
# Perform pooling
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
embeddings = tf.math.l2_normalize(embeddings, axis=1)
return embeddings
# Sentences we want sentence embeddings for
query = "How many people live in London?"
docs = ["Around 9 Million people live in London", "London is known for its financial district"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/multi-qa-MiniLM-L6-cos-v1")
model = TFAutoModel.from_pretrained("sentence-transformers/multi-qa-MiniLM-L6-cos-v1")
#Encode query and docs
query_emb = encode(query)
doc_emb = encode(docs)
#Compute dot score between query and all document embeddings
scores = (query_emb @ tf.transpose(doc_emb))[0].numpy().tolist()
#Combine docs & scores
doc_score_pairs = list(zip(docs, scores))
#Sort by decreasing score
doc_score_pairs = sorted(doc_score_pairs, key=lambda x: x[1], reverse=True)
#Output passages & scores
for doc, score in doc_score_pairs:
print(score, doc)
```
## Technical Details
In the following some technical details how this model must be used:
| Setting | Value |
| --- | :---: |
| Dimensions | 384 |
| Produces normalized embeddings | Yes |
| Pooling-Method | Mean pooling |
| Suitable score functions | dot-product (`util.dot_score`), cosine-similarity (`util.cos_sim`), or euclidean distance |
Note: When loaded with `sentence-transformers`, this model produces normalized embeddings with length 1. In that case, dot-product and cosine-similarity are equivalent. dot-product is preferred as it is faster. Euclidean distance is proportional to dot-product and can also be used.
----
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used for semantic search: It encodes queries / questions and text paragraphs in a dense vector space. It finds relevant documents for the given passages.
Note that there is a limit of 512 word pieces: Text longer than that will be truncated. Further note that the model was just trained on input text up to 250 word pieces. It might not work well for longer text.
## Training procedure
The full training script is accessible in this current repository: `train_script.py`.
### Pre-training
We use the pretrained [`nreimers/MiniLM-L6-H384-uncased`](https://huggingface.co/nreimers/MiniLM-L6-H384-uncased) model. Please refer to the model card for more detailed information about the pre-training procedure.
#### Training
We use the concatenation from multiple datasets to fine-tune our model. In total we have about 215M (question, answer) pairs.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
The model was trained with [MultipleNegativesRankingLoss](https://www.sbert.net/docs/package_reference/losses.html#multiplenegativesrankingloss) using Mean-pooling, cosine-similarity as similarity function, and a scale of 20.
| Dataset | Number of training tuples |
|--------------------------------------------------------|:--------------------------:|
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs from WikiAnswers | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) Automatically generated (Question, Paragraph) pairs for each paragraph in Wikipedia | 64,371,441 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs from all StackExchanges | 25,316,456 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Answer) pairs from all StackExchanges | 21,396,559 |
| [MS MARCO](https://microsoft.github.io/msmarco/) Triplets (query, answer, hard_negative) for 500k queries from Bing search engine | 17,579,773 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) (query, answer) pairs for 3M Google queries and Google featured snippet | 3,012,496 |
| [Amazon-QA](http://jmcauley.ucsd.edu/data/amazon/qa/) (Question, Answer) pairs from Amazon product pages | 2,448,839
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) pairs from Yahoo Answers | 1,198,260 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) pairs from Yahoo Answers | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) pairs from Yahoo Answers | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) (Question, Answer) pairs for 140k questions, each with Top5 Google snippets on that question | 582,261 |
| [ELI5](https://huggingface.co/datasets/eli5) (Question, Answer) pairs from Reddit ELI5 (explainlikeimfive) | 325,475 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions pairs (titles) | 304,525 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) (Question, Duplicate_Question, Hard_Negative) triplets for Quora Questions Pairs dataset | 103,663 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) (Question, Paragraph) pairs for 100k real Google queries with relevant Wikipedia paragraph | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) (Question, Paragraph) pairs from SQuAD2.0 dataset | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) (Question, Evidence) pairs | 73,346 |
| **Total** | **214,988,242** | |
amazon/chronos-t5-small | amazon | "2024-11-27T18:02:12Z" | 6,726,959 | 40 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"time series",
"forecasting",
"pretrained models",
"foundation models",
"time series foundation models",
"time-series",
"time-series-forecasting",
"arxiv:2403.07815",
"arxiv:1910.10683",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | time-series-forecasting | "2024-02-21T10:06:21Z" | ---
license: apache-2.0
pipeline_tag: time-series-forecasting
tags:
- time series
- forecasting
- pretrained models
- foundation models
- time series foundation models
- time-series
---
# Chronos-T5 (Small)
🚀 **Update Nov 27, 2024**: We have released Chronos-Bolt⚡️ models that are more accurate (5% lower error), up to 250 times faster and 20 times more memory-efficient than the original Chronos models of the same size. Check out the new models [here](https://huggingface.co/amazon/chronos-bolt-small).
Chronos is a family of **pretrained time series forecasting models** based on language model architectures. A time series is transformed into a sequence of tokens via scaling and quantization, and a language model is trained on these tokens using the cross-entropy loss. Once trained, probabilistic forecasts are obtained by sampling multiple future trajectories given the historical context. Chronos models have been trained on a large corpus of publicly available time series data, as well as synthetic data generated using Gaussian processes.
For details on Chronos models, training data and procedures, and experimental results, please refer to the paper [Chronos: Learning the Language of Time Series](https://arxiv.org/abs/2403.07815).
<p align="center">
<img src="figures/main-figure.png" width="100%">
<br />
<span>
Fig. 1: High-level depiction of Chronos. (<b>Left</b>) The input time series is scaled and quantized to obtain a sequence of tokens. (<b>Center</b>) The tokens are fed into a language model which may either be an encoder-decoder or a decoder-only model. The model is trained using the cross-entropy loss. (<b>Right</b>) During inference, we autoregressively sample tokens from the model and map them back to numerical values. Multiple trajectories are sampled to obtain a predictive distribution.
</span>
</p>
---
## Architecture
The models in this repository are based on the [T5 architecture](https://arxiv.org/abs/1910.10683). The only difference is in the vocabulary size: Chronos-T5 models use 4096 different tokens, compared to 32128 of the original T5 models, resulting in fewer parameters.
| Model | Parameters | Based on |
| ---------------------------------------------------------------------- | ---------- | ---------------------------------------------------------------------- |
| [**chronos-t5-tiny**](https://huggingface.co/amazon/chronos-t5-tiny) | 8M | [t5-efficient-tiny](https://huggingface.co/google/t5-efficient-tiny) |
| [**chronos-t5-mini**](https://huggingface.co/amazon/chronos-t5-mini) | 20M | [t5-efficient-mini](https://huggingface.co/google/t5-efficient-mini) |
| [**chronos-t5-small**](https://huggingface.co/amazon/chronos-t5-small) | 46M | [t5-efficient-small](https://huggingface.co/google/t5-efficient-small) |
| [**chronos-t5-base**](https://huggingface.co/amazon/chronos-t5-base) | 200M | [t5-efficient-base](https://huggingface.co/google/t5-efficient-base) |
| [**chronos-t5-large**](https://huggingface.co/amazon/chronos-t5-large) | 710M | [t5-efficient-large](https://huggingface.co/google/t5-efficient-large) |
## Usage
To perform inference with Chronos models, install the package in the GitHub [companion repo](https://github.com/amazon-science/chronos-forecasting) by running:
```
pip install git+https://github.com/amazon-science/chronos-forecasting.git
```
A minimal example showing how to perform inference using Chronos models:
```python
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import torch
from chronos import ChronosPipeline
pipeline = ChronosPipeline.from_pretrained(
"amazon/chronos-t5-small",
device_map="cuda",
torch_dtype=torch.bfloat16,
)
df = pd.read_csv("https://raw.githubusercontent.com/AileenNielsen/TimeSeriesAnalysisWithPython/master/data/AirPassengers.csv")
# context must be either a 1D tensor, a list of 1D tensors,
# or a left-padded 2D tensor with batch as the first dimension
context = torch.tensor(df["#Passengers"])
prediction_length = 12
forecast = pipeline.predict(context, prediction_length) # shape [num_series, num_samples, prediction_length]
# visualize the forecast
forecast_index = range(len(df), len(df) + prediction_length)
low, median, high = np.quantile(forecast[0].numpy(), [0.1, 0.5, 0.9], axis=0)
plt.figure(figsize=(8, 4))
plt.plot(df["#Passengers"], color="royalblue", label="historical data")
plt.plot(forecast_index, median, color="tomato", label="median forecast")
plt.fill_between(forecast_index, low, high, color="tomato", alpha=0.3, label="80% prediction interval")
plt.legend()
plt.grid()
plt.show()
```
## Citation
If you find Chronos models useful for your research, please consider citing the associated [paper](https://arxiv.org/abs/2403.07815):
```
@article{ansari2024chronos,
title={Chronos: Learning the Language of Time Series},
author={Ansari, Abdul Fatir and Stella, Lorenzo and Turkmen, Caner and Zhang, Xiyuan, and Mercado, Pedro and Shen, Huibin and Shchur, Oleksandr and Rangapuram, Syama Syndar and Pineda Arango, Sebastian and Kapoor, Shubham and Zschiegner, Jasper and Maddix, Danielle C. and Mahoney, Michael W. and Torkkola, Kari and Gordon Wilson, Andrew and Bohlke-Schneider, Michael and Wang, Yuyang},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=gerNCVqqtR}
}
```
## Security
See [CONTRIBUTING](CONTRIBUTING.md#security-issue-notifications) for more information.
## License
This project is licensed under the Apache-2.0 License.
|
openai/whisper-base | openai | "2024-02-29T10:26:57Z" | 6,711,723 | 200 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"whisper",
"automatic-speech-recognition",
"audio",
"hf-asr-leaderboard",
"en",
"zh",
"de",
"es",
"ru",
"ko",
"fr",
"ja",
"pt",
"tr",
"pl",
"ca",
"nl",
"ar",
"sv",
"it",
"id",
"hi",
"fi",
"vi",
"he",
"uk",
"el",
"ms",
"cs",
"ro",
"da",
"hu",
"ta",
"no",
"th",
"ur",
"hr",
"bg",
"lt",
"la",
"mi",
"ml",
"cy",
"sk",
"te",
"fa",
"lv",
"bn",
"sr",
"az",
"sl",
"kn",
"et",
"mk",
"br",
"eu",
"is",
"hy",
"ne",
"mn",
"bs",
"kk",
"sq",
"sw",
"gl",
"mr",
"pa",
"si",
"km",
"sn",
"yo",
"so",
"af",
"oc",
"ka",
"be",
"tg",
"sd",
"gu",
"am",
"yi",
"lo",
"uz",
"fo",
"ht",
"ps",
"tk",
"nn",
"mt",
"sa",
"lb",
"my",
"bo",
"tl",
"mg",
"as",
"tt",
"haw",
"ln",
"ha",
"ba",
"jw",
"su",
"arxiv:2212.04356",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-09-26T06:50:46Z" | ---
language:
- en
- zh
- de
- es
- ru
- ko
- fr
- ja
- pt
- tr
- pl
- ca
- nl
- ar
- sv
- it
- id
- hi
- fi
- vi
- he
- uk
- el
- ms
- cs
- ro
- da
- hu
- ta
- no
- th
- ur
- hr
- bg
- lt
- la
- mi
- ml
- cy
- sk
- te
- fa
- lv
- bn
- sr
- az
- sl
- kn
- et
- mk
- br
- eu
- is
- hy
- ne
- mn
- bs
- kk
- sq
- sw
- gl
- mr
- pa
- si
- km
- sn
- yo
- so
- af
- oc
- ka
- be
- tg
- sd
- gu
- am
- yi
- lo
- uz
- fo
- ht
- ps
- tk
- nn
- mt
- sa
- lb
- my
- bo
- tl
- mg
- as
- tt
- haw
- ln
- ha
- ba
- jw
- su
tags:
- audio
- automatic-speech-recognition
- hf-asr-leaderboard
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
model-index:
- name: whisper-base
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (clean)
type: librispeech_asr
config: clean
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 5.008769117619326
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (other)
type: librispeech_asr
config: other
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 12.84936273212057
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: hi
split: test
args:
language: hi
metrics:
- name: Test WER
type: wer
value: 131
pipeline_tag: automatic-speech-recognition
license: apache-2.0
---
# Whisper
Whisper is a pre-trained model for automatic speech recognition (ASR) and speech translation. Trained on 680k hours
of labelled data, Whisper models demonstrate a strong ability to generalise to many datasets and domains **without** the need
for fine-tuning.
Whisper was proposed in the paper [Robust Speech Recognition via Large-Scale Weak Supervision](https://arxiv.org/abs/2212.04356)
by Alec Radford et al from OpenAI. The original code repository can be found [here](https://github.com/openai/whisper).
**Disclaimer**: Content for this model card has partly been written by the Hugging Face team, and parts of it were
copied and pasted from the original model card.
## Model details
Whisper is a Transformer based encoder-decoder model, also referred to as a _sequence-to-sequence_ model.
It was trained on 680k hours of labelled speech data annotated using large-scale weak supervision.
The models were trained on either English-only data or multilingual data. The English-only models were trained
on the task of speech recognition. The multilingual models were trained on both speech recognition and speech
translation. For speech recognition, the model predicts transcriptions in the *same* language as the audio.
For speech translation, the model predicts transcriptions to a *different* language to the audio.
Whisper checkpoints come in five configurations of varying model sizes.
The smallest four are trained on either English-only or multilingual data.
The largest checkpoints are multilingual only. All ten of the pre-trained checkpoints
are available on the [Hugging Face Hub](https://huggingface.co/models?search=openai/whisper). The
checkpoints are summarised in the following table with links to the models on the Hub:
| Size | Parameters | English-only | Multilingual |
|----------|------------|------------------------------------------------------|-----------------------------------------------------|
| tiny | 39 M | [✓](https://huggingface.co/openai/whisper-tiny.en) | [✓](https://huggingface.co/openai/whisper-tiny) |
| base | 74 M | [✓](https://huggingface.co/openai/whisper-base.en) | [✓](https://huggingface.co/openai/whisper-base) |
| small | 244 M | [✓](https://huggingface.co/openai/whisper-small.en) | [✓](https://huggingface.co/openai/whisper-small) |
| medium | 769 M | [✓](https://huggingface.co/openai/whisper-medium.en) | [✓](https://huggingface.co/openai/whisper-medium) |
| large | 1550 M | x | [✓](https://huggingface.co/openai/whisper-large) |
| large-v2 | 1550 M | x | [✓](https://huggingface.co/openai/whisper-large-v2) |
# Usage
To transcribe audio samples, the model has to be used alongside a [`WhisperProcessor`](https://huggingface.co/docs/transformers/model_doc/whisper#transformers.WhisperProcessor).
The `WhisperProcessor` is used to:
1. Pre-process the audio inputs (converting them to log-Mel spectrograms for the model)
2. Post-process the model outputs (converting them from tokens to text)
The model is informed of which task to perform (transcription or translation) by passing the appropriate "context tokens". These context tokens
are a sequence of tokens that are given to the decoder at the start of the decoding process, and take the following order:
1. The transcription always starts with the `<|startoftranscript|>` token
2. The second token is the language token (e.g. `<|en|>` for English)
3. The third token is the "task token". It can take one of two values: `<|transcribe|>` for speech recognition or `<|translate|>` for speech translation
4. In addition, a `<|notimestamps|>` token is added if the model should not include timestamp prediction
Thus, a typical sequence of context tokens might look as follows:
```
<|startoftranscript|> <|en|> <|transcribe|> <|notimestamps|>
```
Which tells the model to decode in English, under the task of speech recognition, and not to predict timestamps.
These tokens can either be forced or un-forced. If they are forced, the model is made to predict each token at
each position. This allows one to control the output language and task for the Whisper model. If they are un-forced,
the Whisper model will automatically predict the output langauge and task itself.
The context tokens can be set accordingly:
```python
model.config.forced_decoder_ids = WhisperProcessor.get_decoder_prompt_ids(language="english", task="transcribe")
```
Which forces the model to predict in English under the task of speech recognition.
## Transcription
### English to English
In this example, the context tokens are 'unforced', meaning the model automatically predicts the output language
(English) and task (transcribe).
```python
>>> from transformers import WhisperProcessor, WhisperForConditionalGeneration
>>> from datasets import load_dataset
>>> # load model and processor
>>> processor = WhisperProcessor.from_pretrained("openai/whisper-base")
>>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-base")
>>> model.config.forced_decoder_ids = None
>>> # load dummy dataset and read audio files
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> sample = ds[0]["audio"]
>>> input_features = processor(sample["array"], sampling_rate=sample["sampling_rate"], return_tensors="pt").input_features
>>> # generate token ids
>>> predicted_ids = model.generate(input_features)
>>> # decode token ids to text
>>> transcription = processor.batch_decode(predicted_ids, skip_special_tokens=False)
['<|startoftranscript|><|en|><|transcribe|><|notimestamps|> Mr. Quilter is the apostle of the middle classes and we are glad to welcome his gospel.<|endoftext|>']
>>> transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
[' Mr. Quilter is the apostle of the middle classes and we are glad to welcome his gospel.']
```
The context tokens can be removed from the start of the transcription by setting `skip_special_tokens=True`.
### French to French
The following example demonstrates French to French transcription by setting the decoder ids appropriately.
```python
>>> from transformers import WhisperProcessor, WhisperForConditionalGeneration
>>> from datasets import Audio, load_dataset
>>> # load model and processor
>>> processor = WhisperProcessor.from_pretrained("openai/whisper-base")
>>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-base")
>>> forced_decoder_ids = processor.get_decoder_prompt_ids(language="french", task="transcribe")
>>> # load streaming dataset and read first audio sample
>>> ds = load_dataset("common_voice", "fr", split="test", streaming=True)
>>> ds = ds.cast_column("audio", Audio(sampling_rate=16_000))
>>> input_speech = next(iter(ds))["audio"]
>>> input_features = processor(input_speech["array"], sampling_rate=input_speech["sampling_rate"], return_tensors="pt").input_features
>>> # generate token ids
>>> predicted_ids = model.generate(input_features, forced_decoder_ids=forced_decoder_ids)
>>> # decode token ids to text
>>> transcription = processor.batch_decode(predicted_ids)
['<|startoftranscript|><|fr|><|transcribe|><|notimestamps|> Un vrai travail intéressant va enfin être mené sur ce sujet.<|endoftext|>']
>>> transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
[' Un vrai travail intéressant va enfin être mené sur ce sujet.']
```
## Translation
Setting the task to "translate" forces the Whisper model to perform speech translation.
### French to English
```python
>>> from transformers import WhisperProcessor, WhisperForConditionalGeneration
>>> from datasets import Audio, load_dataset
>>> # load model and processor
>>> processor = WhisperProcessor.from_pretrained("openai/whisper-base")
>>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-base")
>>> forced_decoder_ids = processor.get_decoder_prompt_ids(language="french", task="translate")
>>> # load streaming dataset and read first audio sample
>>> ds = load_dataset("common_voice", "fr", split="test", streaming=True)
>>> ds = ds.cast_column("audio", Audio(sampling_rate=16_000))
>>> input_speech = next(iter(ds))["audio"]
>>> input_features = processor(input_speech["array"], sampling_rate=input_speech["sampling_rate"], return_tensors="pt").input_features
>>> # generate token ids
>>> predicted_ids = model.generate(input_features, forced_decoder_ids=forced_decoder_ids)
>>> # decode token ids to text
>>> transcription = processor.batch_decode(predicted_ids, skip_special_tokens=True)
[' A very interesting work, we will finally be given on this subject.']
```
## Evaluation
This code snippet shows how to evaluate Whisper Base on [LibriSpeech test-clean](https://huggingface.co/datasets/librispeech_asr):
```python
>>> from datasets import load_dataset
>>> from transformers import WhisperForConditionalGeneration, WhisperProcessor
>>> import torch
>>> from evaluate import load
>>> librispeech_test_clean = load_dataset("librispeech_asr", "clean", split="test")
>>> processor = WhisperProcessor.from_pretrained("openai/whisper-base")
>>> model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-base").to("cuda")
>>> def map_to_pred(batch):
>>> audio = batch["audio"]
>>> input_features = processor(audio["array"], sampling_rate=audio["sampling_rate"], return_tensors="pt").input_features
>>> batch["reference"] = processor.tokenizer._normalize(batch['text'])
>>>
>>> with torch.no_grad():
>>> predicted_ids = model.generate(input_features.to("cuda"))[0]
>>> transcription = processor.decode(predicted_ids)
>>> batch["prediction"] = processor.tokenizer._normalize(transcription)
>>> return batch
>>> result = librispeech_test_clean.map(map_to_pred)
>>> wer = load("wer")
>>> print(100 * wer.compute(references=result["reference"], predictions=result["prediction"]))
5.082316555716899
```
## Long-Form Transcription
The Whisper model is intrinsically designed to work on audio samples of up to 30s in duration. However, by using a chunking
algorithm, it can be used to transcribe audio samples of up to arbitrary length. This is possible through Transformers
[`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline)
method. Chunking is enabled by setting `chunk_length_s=30` when instantiating the pipeline. With chunking enabled, the pipeline
can be run with batched inference. It can also be extended to predict sequence level timestamps by passing `return_timestamps=True`:
```python
>>> import torch
>>> from transformers import pipeline
>>> from datasets import load_dataset
>>> device = "cuda:0" if torch.cuda.is_available() else "cpu"
>>> pipe = pipeline(
>>> "automatic-speech-recognition",
>>> model="openai/whisper-base",
>>> chunk_length_s=30,
>>> device=device,
>>> )
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
>>> sample = ds[0]["audio"]
>>> prediction = pipe(sample.copy(), batch_size=8)["text"]
" Mr. Quilter is the apostle of the middle classes, and we are glad to welcome his gospel."
>>> # we can also return timestamps for the predictions
>>> prediction = pipe(sample.copy(), batch_size=8, return_timestamps=True)["chunks"]
[{'text': ' Mr. Quilter is the apostle of the middle classes and we are glad to welcome his gospel.',
'timestamp': (0.0, 5.44)}]
```
Refer to the blog post [ASR Chunking](https://huggingface.co/blog/asr-chunking) for more details on the chunking algorithm.
## Fine-Tuning
The pre-trained Whisper model demonstrates a strong ability to generalise to different datasets and domains. However,
its predictive capabilities can be improved further for certain languages and tasks through *fine-tuning*. The blog
post [Fine-Tune Whisper with 🤗 Transformers](https://huggingface.co/blog/fine-tune-whisper) provides a step-by-step
guide to fine-tuning the Whisper model with as little as 5 hours of labelled data.
### Evaluated Use
The primary intended users of these models are AI researchers studying robustness, generalization, capabilities, biases, and constraints of the current model. However, Whisper is also potentially quite useful as an ASR solution for developers, especially for English speech recognition. We recognize that once models are released, it is impossible to restrict access to only “intended” uses or to draw reasonable guidelines around what is or is not research.
The models are primarily trained and evaluated on ASR and speech translation to English tasks. They show strong ASR results in ~10 languages. They may exhibit additional capabilities, particularly if fine-tuned on certain tasks like voice activity detection, speaker classification, or speaker diarization but have not been robustly evaluated in these areas. We strongly recommend that users perform robust evaluations of the models in a particular context and domain before deploying them.
In particular, we caution against using Whisper models to transcribe recordings of individuals taken without their consent or purporting to use these models for any kind of subjective classification. We recommend against use in high-risk domains like decision-making contexts, where flaws in accuracy can lead to pronounced flaws in outcomes. The models are intended to transcribe and translate speech, use of the model for classification is not only not evaluated but also not appropriate, particularly to infer human attributes.
## Training Data
The models are trained on 680,000 hours of audio and the corresponding transcripts collected from the internet. 65% of this data (or 438,000 hours) represents English-language audio and matched English transcripts, roughly 18% (or 126,000 hours) represents non-English audio and English transcripts, while the final 17% (or 117,000 hours) represents non-English audio and the corresponding transcript. This non-English data represents 98 different languages.
As discussed in [the accompanying paper](https://cdn.openai.com/papers/whisper.pdf), we see that performance on transcription in a given language is directly correlated with the amount of training data we employ in that language.
## Performance and Limitations
Our studies show that, over many existing ASR systems, the models exhibit improved robustness to accents, background noise, technical language, as well as zero shot translation from multiple languages into English; and that accuracy on speech recognition and translation is near the state-of-the-art level.
However, because the models are trained in a weakly supervised manner using large-scale noisy data, the predictions may include texts that are not actually spoken in the audio input (i.e. hallucination). We hypothesize that this happens because, given their general knowledge of language, the models combine trying to predict the next word in audio with trying to transcribe the audio itself.
Our models perform unevenly across languages, and we observe lower accuracy on low-resource and/or low-discoverability languages or languages where we have less training data. The models also exhibit disparate performance on different accents and dialects of particular languages, which may include higher word error rate across speakers of different genders, races, ages, or other demographic criteria. Our full evaluation results are presented in [the paper accompanying this release](https://cdn.openai.com/papers/whisper.pdf).
In addition, the sequence-to-sequence architecture of the model makes it prone to generating repetitive texts, which can be mitigated to some degree by beam search and temperature scheduling but not perfectly. Further analysis on these limitations are provided in [the paper](https://cdn.openai.com/papers/whisper.pdf). It is likely that this behavior and hallucinations may be worse on lower-resource and/or lower-discoverability languages.
## Broader Implications
We anticipate that Whisper models’ transcription capabilities may be used for improving accessibility tools. While Whisper models cannot be used for real-time transcription out of the box – their speed and size suggest that others may be able to build applications on top of them that allow for near-real-time speech recognition and translation. The real value of beneficial applications built on top of Whisper models suggests that the disparate performance of these models may have real economic implications.
There are also potential dual use concerns that come with releasing Whisper. While we hope the technology will be used primarily for beneficial purposes, making ASR technology more accessible could enable more actors to build capable surveillance technologies or scale up existing surveillance efforts, as the speed and accuracy allow for affordable automatic transcription and translation of large volumes of audio communication. Moreover, these models may have some capabilities to recognize specific individuals out of the box, which in turn presents safety concerns related both to dual use and disparate performance. In practice, we expect that the cost of transcription is not the limiting factor of scaling up surveillance projects.
### BibTeX entry and citation info
```bibtex
@misc{radford2022whisper,
doi = {10.48550/ARXIV.2212.04356},
url = {https://arxiv.org/abs/2212.04356},
author = {Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya},
title = {Robust Speech Recognition via Large-Scale Weak Supervision},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
```
|
facebook/opt-125m | facebook | "2023-09-15T13:10:03Z" | 6,640,199 | 179 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"opt",
"text-generation",
"en",
"arxiv:2205.01068",
"arxiv:2005.14165",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | "2022-05-11T08:25:17Z" | ---
language: en
inference: false
tags:
- text-generation
- opt
license: other
commercial: false
---
# OPT : Open Pre-trained Transformer Language Models
OPT was first introduced in [Open Pre-trained Transformer Language Models](https://arxiv.org/abs/2205.01068) and first released in [metaseq's repository](https://github.com/facebookresearch/metaseq) on May 3rd 2022 by Meta AI.
**Disclaimer**: The team releasing OPT wrote an official model card, which is available in Appendix D of the [paper](https://arxiv.org/pdf/2205.01068.pdf).
Content from **this** model card has been written by the Hugging Face team.
## Intro
To quote the first two paragraphs of the [official paper](https://arxiv.org/abs/2205.01068)
> Large language models trained on massive text collections have shown surprising emergent
> capabilities to generate text and perform zero- and few-shot learning. While in some cases the public
> can interact with these models through paid APIs, full model access is currently limited to only a
> few highly resourced labs. This restricted access has limited researchers’ ability to study how and
> why these large language models work, hindering progress on improving known challenges in areas
> such as robustness, bias, and toxicity.
> We present Open Pretrained Transformers (OPT), a suite of decoder-only pre-trained transformers ranging from 125M
> to 175B parameters, which we aim to fully and responsibly share with interested researchers. We train the OPT models to roughly match
> the performance and sizes of the GPT-3 class of models, while also applying the latest best practices in data
> collection and efficient training. Our aim in developing this suite of OPT models is to enable reproducible and responsible research at scale, and
> to bring more voices to the table in studying the impact of these LLMs. Definitions of risk, harm, bias, and toxicity, etc., should be articulated by the
> collective research community as a whole, which is only possible when models are available for study.
## Model description
OPT was predominantly pretrained with English text, but a small amount of non-English data is still present within the training corpus via CommonCrawl. The model was pretrained using a causal language modeling (CLM) objective.
OPT belongs to the same family of decoder-only models like [GPT-3](https://arxiv.org/abs/2005.14165). As such, it was pretrained using the self-supervised causal language modedling objective.
For evaluation, OPT follows [GPT-3](https://arxiv.org/abs/2005.14165) by using their prompts and overall experimental setup. For more details, please read
the [official paper](https://arxiv.org/abs/2205.01068).
## Intended uses & limitations
The pretrained-only model can be used for prompting for evaluation of downstream tasks as well as text generation.
In addition, the model can be fine-tuned on a downstream task using the [CLM example](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling). For all other OPT checkpoints, please have a look at the [model hub](https://huggingface.co/models?filter=opt).
### How to use
You can use this model directly with a pipeline for text generation.
```python
>>> from transformers import pipeline
>>> generator = pipeline('text-generation', model="facebook/opt-125m")
>>> generator("What are we having for dinner?")
[{'generated_text': 'What are we having for dinner?\nA nice dinner with a friend.\nI'm not sure'}]
```
By default, generation is deterministic. In order to use the top-k sampling, please set `do_sample` to `True`.
```python
>>> from transformers import pipeline, set_seed
>>> set_seed(32)
>>> generator = pipeline('text-generation', model="facebook/opt-125m", do_sample=True)
>>> generator("What are we having for dinner?")
[{'generated_text': 'What are we having for dinner?\nCoffee, sausage and cream cheese at Chili's.'}]
```
### Limitations and bias
As mentioned in Meta AI's model card, given that the training data used for this model contains a lot of
unfiltered content from the internet, which is far from neutral the model is strongly biased :
> Like other large language models for which the diversity (or lack thereof) of training
> data induces downstream impact on the quality of our model, OPT-175B has limitations in terms
> of bias and safety. OPT-175B can also have quality issues in terms of generation diversity and
> hallucination. In general, OPT-175B is not immune from the plethora of issues that plague modern
> large language models.
This bias will also affect all fine-tuned versions of this model.
## Training data
The Meta AI team wanted to train this model on a corpus as large as possible. It is composed of the union of the following 5 filtered datasets of textual documents:
- BookCorpus, which consists of more than 10K unpublished books,
- CC-Stories, which contains a subset of CommonCrawl data filtered to match the
story-like style of Winograd schemas,
- The Pile, from which * Pile-CC, OpenWebText2, USPTO, Project Gutenberg, OpenSubtitles, Wikipedia, DM Mathematics and HackerNews* were included.
- Pushshift.io Reddit dataset that was developed in Baumgartner et al. (2020) and processed in
Roller et al. (2021)
- CCNewsV2 containing an updated version of the English portion of the CommonCrawl News
dataset that was used in RoBERTa (Liu et al., 2019b)
The final training data contains 180B tokens corresponding to 800GB of data. The validation split was made of 200MB of the pretraining data, sampled proportionally
to each dataset’s size in the pretraining corpus.
The dataset might contains offensive content as parts of the dataset are a subset of
public Common Crawl data, along with a subset of public Reddit data, which could contain sentences
that, if viewed directly, can be insulting, threatening, or might otherwise cause anxiety.
### Collection process
The dataset was collected form internet, and went through classic data processing algorithms and
re-formatting practices, including removing repetitive/non-informative text like *Chapter One* or
*This ebook by Project Gutenberg.*
## Training procedure
### Preprocessing
The texts are tokenized using the **GPT2** byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a
vocabulary size of 50272. The inputs are sequences of 2048 consecutive tokens.
The 175B model was trained on 992 *80GB A100 GPUs*. The training duration was roughly ~33 days of continuous training.
### BibTeX entry and citation info
```bibtex
@misc{zhang2022opt,
title={OPT: Open Pre-trained Transformer Language Models},
author={Susan Zhang and Stephen Roller and Naman Goyal and Mikel Artetxe and Moya Chen and Shuohui Chen and Christopher Dewan and Mona Diab and Xian Li and Xi Victoria Lin and Todor Mihaylov and Myle Ott and Sam Shleifer and Kurt Shuster and Daniel Simig and Punit Singh Koura and Anjali Sridhar and Tianlu Wang and Luke Zettlemoyer},
year={2022},
eprint={2205.01068},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
distilbert/distilbert-base-uncased-finetuned-sst-2-english | distilbert | "2023-12-19T16:29:37Z" | 6,457,837 | 683 | transformers | [
"transformers",
"pytorch",
"tf",
"rust",
"onnx",
"safetensors",
"distilbert",
"text-classification",
"en",
"dataset:sst2",
"dataset:glue",
"arxiv:1910.01108",
"doi:10.57967/hf/0181",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:04Z" | ---
language: en
license: apache-2.0
datasets:
- sst2
- glue
model-index:
- name: distilbert-base-uncased-finetuned-sst-2-english
results:
- task:
type: text-classification
name: Text Classification
dataset:
name: glue
type: glue
config: sst2
split: validation
metrics:
- type: accuracy
value: 0.9105504587155964
name: Accuracy
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiN2YyOGMxYjY2Y2JhMjkxNjIzN2FmMjNiNmM2ZWViNGY3MTNmNWI2YzhiYjYxZTY0ZGUyN2M1NGIxZjRiMjQwZiIsInZlcnNpb24iOjF9.uui0srxV5ZHRhxbYN6082EZdwpnBgubPJ5R2-Wk8HTWqmxYE3QHidevR9LLAhidqGw6Ih93fK0goAXncld_gBg
- type: precision
value: 0.8978260869565218
name: Precision
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMzgwYTYwYjA2MmM0ZTYwNDk0M2NmNTBkZmM2NGNhYzQ1OGEyN2NkNDQ3Mzc2NTQyMmZiNDJiNzBhNGVhZGUyOSIsInZlcnNpb24iOjF9.eHjLmw3K02OU69R2Au8eyuSqT3aBDHgZCn8jSzE3_urD6EUSSsLxUpiAYR4BGLD_U6-ZKcdxVo_A2rdXqvUJDA
- type: recall
value: 0.9301801801801802
name: Recall
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMGIzM2E3MTI2Mzc2MDYwNmU3ZTVjYmZmZDBkNjY4ZTc5MGY0Y2FkNDU3NjY1MmVkNmE3Y2QzMzAwZDZhOWY1NiIsInZlcnNpb24iOjF9.PUZlqmct13-rJWBXdHm5tdkXgETL9F82GNbbSR4hI8MB-v39KrK59cqzFC2Ac7kJe_DtOeUyosj34O_mFt_1DQ
- type: auc
value: 0.9716626673402374
name: AUC
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMDM0YWIwZmQ4YjUwOGZmMWU2MjI1YjIxZGQ2MzNjMzRmZmYxMzZkNGFjODhlMDcyZDM1Y2RkMWZlOWQ0MWYwNSIsInZlcnNpb24iOjF9.E7GRlAXmmpEkTHlXheVkuL1W4WNjv4JO3qY_WCVsTVKiO7bUu0UVjPIyQ6g-J1OxsfqZmW3Leli1wY8vPBNNCQ
- type: f1
value: 0.9137168141592922
name: F1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMGU4MjNmOGYwZjZjMDQ1ZTkyZTA4YTc1MWYwOTM0NDM4ZWY1ZGVkNDY5MzNhYTQyZGFlNzIyZmUwMDg3NDU0NyIsInZlcnNpb24iOjF9.mW5ftkq50Se58M-jm6a2Pu93QeKa3MfV7xcBwvG3PSB_KNJxZWTCpfMQp-Cmx_EMlmI2siKOyd8akYjJUrzJCA
- type: loss
value: 0.39013850688934326
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMTZiNzAyZDc0MzUzMmE1MGJiN2JlYzFiODE5ZTNlNGE4MmI4YzRiMTc2ODEzMTUwZmEzOTgxNzc4YjJjZTRmNiIsInZlcnNpb24iOjF9.VqIC7uYC-ZZ8ss9zQOlRV39YVOOLc5R36sIzCcVz8lolh61ux_5djm2XjpP6ARc6KqEnXC4ZtfNXsX2HZfrtCQ
- task:
type: text-classification
name: Text Classification
dataset:
name: sst2
type: sst2
config: default
split: train
metrics:
- type: accuracy
value: 0.9885521685548412
name: Accuracy
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiY2I3NzU3YzhmMDkxZTViY2M3OTY1NmI0ZTdmMDQxNjNjYzJiZmQxNzczM2E4YmExYTY5ODY0NDBkY2I4ZjNkOCIsInZlcnNpb24iOjF9.4Gtk3FeVc9sPWSqZIaeUXJ9oVlPzm-NmujnWpK2y5s1Vhp1l6Y1pK5_78wW0-NxSvQqV6qd5KQf_OAEpVAkQDA
- type: precision
value: 0.9881965062029833
name: Precision Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZDdlZDMzY2I3MTAwYTljNmM4MGMyMzU2YjAzZDg1NDYwN2ZmM2Y5OWZhMjUyMGJiNjY1YmZiMzFhMDI2ODFhNyIsInZlcnNpb24iOjF9.cqmv6yBxu4St2mykRWrZ07tDsiSLdtLTz2hbqQ7Gm1rMzq9tdlkZ8MyJRxtME_Y8UaOG9rs68pV-gKVUs8wABw
- type: precision
value: 0.9885521685548412
name: Precision Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZjFlYzAzNmE1YjljNjUwNzBjZjEzZDY0ZDQyMmY5ZWM2OTBhNzNjYjYzYTk1YWE1NjU3YTMxZDQwOTE1Y2FkNyIsInZlcnNpb24iOjF9.jnCHOkUHuAOZZ_ZMVOnetx__OVJCS6LOno4caWECAmfrUaIPnPNV9iJ6izRO3sqkHRmxYpWBb-27GJ4N3LU-BQ
- type: precision
value: 0.9885639626373408
name: Precision Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZGUyODFjNjBlNTE2MTY3ZDAxOGU1N2U0YjUyY2NiZjhkOGVmYThjYjBkNGU3NTRkYzkzNDQ2MmMwMjkwMWNiMyIsInZlcnNpb24iOjF9.zTNabMwApiZyXdr76QUn7WgGB7D7lP-iqS3bn35piqVTNsv3wnKjZOaKFVLIUvtBXq4gKw7N2oWxvWc4OcSNDg
- type: recall
value: 0.9886145346602994
name: Recall Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNTU1YjlhODU3YTkyNTdiZDcwZGFlZDBiYjY0N2NjMGM2NTRiNjQ3MDNjNGMxOWY2ZGQ4NWU1YmMzY2UwZTI3YSIsInZlcnNpb24iOjF9.xaLPY7U-wHsJ3DDui1yyyM-xWjL0Jz5puRThy7fczal9x05eKEQ9s0a_WD-iLmapvJs0caXpV70hDe2NLcs-DA
- type: recall
value: 0.9885521685548412
name: Recall Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiODE0YTU0MDBlOGY4YzU0MjY5MzA3OTk2OGNhOGVkMmU5OGRjZmFiZWI2ZjY5ODEzZTQzMTI0N2NiOTVkNDliYiIsInZlcnNpb24iOjF9.SOt1baTBbuZRrsvGcak2sUwoTrQzmNCbyV2m1_yjGsU48SBH0NcKXicidNBSnJ6ihM5jf_Lv_B5_eOBkLfNWDQ
- type: recall
value: 0.9885521685548412
name: Recall Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZWNkNmM0ZGRlNmYxYzIwNDk4OTI5MzIwZWU1NzZjZDVhMDcyNDFlMjBhNDQxODU5OWMwMWNhNGEzNjY3ZGUyOSIsInZlcnNpb24iOjF9.b15Fh70GwtlG3cSqPW-8VEZT2oy0CtgvgEOtWiYonOovjkIQ4RSLFVzVG-YfslaIyfg9RzMWzjhLnMY7Bpn2Aw
- type: f1
value: 0.9884019815052447
name: F1 Macro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYmM4NjQ5Yjk5ODRhYTU1MTY3MmRhZDBmODM1NTg3OTFiNWM4NDRmYjI0MzZkNmQ1MzE3MzcxODZlYzBkYTMyYSIsInZlcnNpb24iOjF9.74RaDK8nBVuGRl2Se_-hwQvP6c4lvVxGHpcCWB4uZUCf2_HoC9NT9u7P3pMJfH_tK2cpV7U3VWGgSDhQDi-UBQ
- type: f1
value: 0.9885521685548412
name: F1 Micro
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZDRmYWRmMmQ0YjViZmQxMzhhYTUyOTE1MTc0ZDU1ZjQyZjFhMDYzYzMzZDE0NzZlYzQyOTBhMTBhNmM5NTlkMiIsInZlcnNpb24iOjF9.VMn_psdAHIZTlW6GbjERZDe8MHhwzJ0rbjV_VJyuMrsdOh5QDmko-wEvaBWNEdT0cEKsbggm-6jd3Gh81PfHAQ
- type: f1
value: 0.9885546181087554
name: F1 Weighted
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMjUyZWFhZDZhMGQ3MzBmYmRiNDVmN2FkZDBjMjk3ODk0OTAxNGZkMWE0NzU5ZjI0NzE0NGZiNzM0N2Y2NDYyOSIsInZlcnNpb24iOjF9.YsXBhnzEEFEW6jw3mQlFUuIrW7Gabad2Ils-iunYJr-myg0heF8NEnEWABKFE1SnvCWt-69jkLza6SupeyLVCA
- type: loss
value: 0.040652573108673096
name: loss
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZTc3YjU3MjdjMzkxODA5MjU5NGUyY2NkMGVhZDg3ZWEzMmU1YWVjMmI0NmU2OWEyZTkzMTVjNDZiYTc0YjIyNCIsInZlcnNpb24iOjF9.lA90qXZVYiILHMFlr6t6H81Oe8a-4KmeX-vyCC1BDia2ofudegv6Vb46-4RzmbtuKeV6yy6YNNXxXxqVak1pAg
---
# DistilBERT base uncased finetuned SST-2
## Table of Contents
- [Model Details](#model-details)
- [How to Get Started With the Model](#how-to-get-started-with-the-model)
- [Uses](#uses)
- [Risks, Limitations and Biases](#risks-limitations-and-biases)
- [Training](#training)
## Model Details
**Model Description:** This model is a fine-tune checkpoint of [DistilBERT-base-uncased](https://huggingface.co/distilbert-base-uncased), fine-tuned on SST-2.
This model reaches an accuracy of 91.3 on the dev set (for comparison, Bert bert-base-uncased version reaches an accuracy of 92.7).
- **Developed by:** Hugging Face
- **Model Type:** Text Classification
- **Language(s):** English
- **License:** Apache-2.0
- **Parent Model:** For more details about DistilBERT, we encourage users to check out [this model card](https://huggingface.co/distilbert-base-uncased).
- **Resources for more information:**
- [Model Documentation](https://huggingface.co/docs/transformers/main/en/model_doc/distilbert#transformers.DistilBertForSequenceClassification)
- [DistilBERT paper](https://arxiv.org/abs/1910.01108)
## How to Get Started With the Model
Example of single-label classification:
```python
import torch
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased-finetuned-sst-2-english")
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
predicted_class_id = logits.argmax().item()
model.config.id2label[predicted_class_id]
```
## Uses
#### Direct Use
This model can be used for topic classification. You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to be fine-tuned on a downstream task. See the model hub to look for fine-tuned versions on a task that interests you.
#### Misuse and Out-of-scope Use
The model should not be used to intentionally create hostile or alienating environments for people. In addition, the model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
## Risks, Limitations and Biases
Based on a few experimentations, we observed that this model could produce biased predictions that target underrepresented populations.
For instance, for sentences like `This film was filmed in COUNTRY`, this binary classification model will give radically different probabilities for the positive label depending on the country (0.89 if the country is France, but 0.08 if the country is Afghanistan) when nothing in the input indicates such a strong semantic shift. In this [colab](https://colab.research.google.com/gist/ageron/fb2f64fb145b4bc7c49efc97e5f114d3/biasmap.ipynb), [Aurélien Géron](https://twitter.com/aureliengeron) made an interesting map plotting these probabilities for each country.
<img src="https://huggingface.co/distilbert-base-uncased-finetuned-sst-2-english/resolve/main/map.jpeg" alt="Map of positive probabilities per country." width="500"/>
We strongly advise users to thoroughly probe these aspects on their use-cases in order to evaluate the risks of this model. We recommend looking at the following bias evaluation datasets as a place to start: [WinoBias](https://huggingface.co/datasets/wino_bias), [WinoGender](https://huggingface.co/datasets/super_glue), [Stereoset](https://huggingface.co/datasets/stereoset).
# Training
#### Training Data
The authors use the following Stanford Sentiment Treebank([sst2](https://huggingface.co/datasets/sst2)) corpora for the model.
#### Training Procedure
###### Fine-tuning hyper-parameters
- learning_rate = 1e-5
- batch_size = 32
- warmup = 600
- max_seq_length = 128
- num_train_epochs = 3.0
|
microsoft/deberta-base | microsoft | "2022-09-26T08:50:43Z" | 6,398,087 | 76 | transformers | [
"transformers",
"pytorch",
"tf",
"rust",
"deberta",
"deberta-v1",
"fill-mask",
"en",
"arxiv:2006.03654",
"license:mit",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:05Z" | ---
language: en
tags:
- deberta-v1
- fill-mask
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
license: mit
---
## DeBERTa: Decoding-enhanced BERT with Disentangled Attention
[DeBERTa](https://arxiv.org/abs/2006.03654) improves the BERT and RoBERTa models using disentangled attention and enhanced mask decoder. It outperforms BERT and RoBERTa on majority of NLU tasks with 80GB training data.
Please check the [official repository](https://github.com/microsoft/DeBERTa) for more details and updates.
#### Fine-tuning on NLU tasks
We present the dev results on SQuAD 1.1/2.0 and MNLI tasks.
| Model | SQuAD 1.1 | SQuAD 2.0 | MNLI-m |
|-------------------|-----------|-----------|--------|
| RoBERTa-base | 91.5/84.6 | 83.7/80.5 | 87.6 |
| XLNet-Large | -/- | -/80.2 | 86.8 |
| **DeBERTa-base** | 93.1/87.2 | 86.2/83.1 | 88.8 |
### Citation
If you find DeBERTa useful for your work, please cite the following paper:
``` latex
@inproceedings{
he2021deberta,
title={DEBERTA: DECODING-ENHANCED BERT WITH DISENTANGLED ATTENTION},
author={Pengcheng He and Xiaodong Liu and Jianfeng Gao and Weizhu Chen},
booktitle={International Conference on Learning Representations},
year={2021},
url={https://openreview.net/forum?id=XPZIaotutsD}
}
```
|
autogluon/chronos-bolt-small | autogluon | "2024-11-27T18:01:52Z" | 6,348,467 | 7 | null | [
"safetensors",
"t5",
"time series",
"forecasting",
"pretrained models",
"foundation models",
"time series foundation models",
"time-series",
"time-series-forecasting",
"arxiv:1910.10683",
"arxiv:2403.07815",
"license:apache-2.0",
"region:us"
] | time-series-forecasting | "2024-11-13T13:28:57Z" | ---
license: apache-2.0
pipeline_tag: time-series-forecasting
tags:
- time series
- forecasting
- pretrained models
- foundation models
- time series foundation models
- time-series
---
# Chronos-Bolt⚡ (Small)
Chronos-Bolt is a family of pretrained time series forecasting models which can be used for zero-shot forecasting. It is based on the [T5 encoder-decoder architecture](https://arxiv.org/abs/1910.10683) and has been trained on nearly 100 billion time series observations. It chunks the historical time series context into patches of multiple observations, which are then input into the encoder. The decoder then uses these representations to directly generate quantile forecasts across multiple future steps—a method known as direct multi-step forecasting. Chronos-Bolt models are up to 250 times faster and 20 times more memory-efficient than the [original Chronos](https://arxiv.org/abs/2403.07815) models of the same size.
The following plot compares the inference time of Chronos-Bolt against the original Chronos models for forecasting 1024 time series with a context length of 512 observations and a prediction horizon of 64 steps.
<center>
<img src="https://autogluon.s3.amazonaws.com/images/chronos_bolt_speed.svg" width="50%"/>
</center>
Chronos-Bolt models are not only significantly faster but also more accurate than the original Chronos models. The following plot reports the probabilistic and point forecasting performance of Chronos-Bolt in terms of the [Weighted Quantile Loss (WQL)](https://auto.gluon.ai/stable/tutorials/timeseries/forecasting-metrics.html#autogluon.timeseries.metrics.WQL) and the [Mean Absolute Scaled Error (MASE)](https://auto.gluon.ai/stable/tutorials/timeseries/forecasting-metrics.html#autogluon.timeseries.metrics.MASE), respectively, aggregated over 27 datasets (see the [Chronos paper](https://arxiv.org/abs/2403.07815) for details on this benchmark). Remarkably, despite having no prior exposure to these datasets during training, the zero-shot Chronos-Bolt models outperform commonly used statistical models and deep learning models that have been trained on these datasets (highlighted by *). Furthermore, they also perform better than other FMs, denoted by a +, which indicates that these models were pretrained on certain datasets in our benchmark and are not entirely zero-shot. Notably, Chronos-Bolt (Base) also surpasses the original Chronos (Large) model in terms of the forecasting accuracy while being over 600 times faster.
<center>
<img src="https://autogluon.s3.amazonaws.com/images/chronos_bolt_accuracy.svg" width="80%"/>
</center>
Chronos-Bolt models are available in the following sizes.
<div align="center">
| Model | Parameters | Based on |
| ---------------------------------------------------------------------- | ---------- | ---------------------------------------------------------------------- |
| [**chronos-bolt-tiny**](https://huggingface.co/autogluon/chronos-bolt-tiny) | 9M | [t5-efficient-tiny](https://huggingface.co/google/t5-efficient-tiny) |
| [**chronos-bolt-mini**](https://huggingface.co/autogluon/chronos-bolt-mini) | 21M | [t5-efficient-mini](https://huggingface.co/google/t5-efficient-mini) |
| [**chronos-bolt-small**](https://huggingface.co/autogluon/chronos-bolt-small) | 48M | [t5-efficient-small](https://huggingface.co/google/t5-efficient-small) |
| [**chronos-bolt-base**](https://huggingface.co/autogluon/chronos-bolt-base) | 205M | [t5-efficient-base](https://huggingface.co/google/t5-efficient-base) |
</div>
## Usage
A minimal example showing how to perform zero-shot inference using Chronos-Bolt with AutoGluon:
```
pip install autogluon
```
```python
from autogluon.timeseries import TimeSeriesPredictor, TimeSeriesDataFrame
df = TimeSeriesDataFrame("https://autogluon.s3.amazonaws.com/datasets/timeseries/m4_hourly/train.csv")
predictor = TimeSeriesPredictor(prediction_length=48).fit(
df,
hyperparameters={
"Chronos": {"model_path": "autogluon/chronos-bolt-small"},
},
)
predictions = predictor.predict(df)
```
## Citation
If you find Chronos or Chronos-Bolt models useful for your research, please consider citing the associated [paper](https://arxiv.org/abs/2403.07815):
```
@article{ansari2024chronos,
title={Chronos: Learning the Language of Time Series},
author={Ansari, Abdul Fatir and Stella, Lorenzo and Turkmen, Caner and Zhang, Xiyuan, and Mercado, Pedro and Shen, Huibin and Shchur, Oleksandr and Rangapuram, Syama Syndar and Pineda Arango, Sebastian and Kapoor, Shubham and Zschiegner, Jasper and Maddix, Danielle C. and Mahoney, Michael W. and Torkkola, Kari and Gordon Wilson, Andrew and Bohlke-Schneider, Michael and Wang, Yuyang},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=gerNCVqqtR}
}
```
## License
This project is licensed under the Apache-2.0 License.
|
google-bert/bert-base-cased | google-bert | "2024-02-19T11:02:26Z" | 5,908,843 | 286 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"exbert",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:04Z" | ---
language: en
tags:
- exbert
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
---
# BERT base model (cased)
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/abs/1810.04805) and first released in
[this repository](https://github.com/google-research/bert). This model is case-sensitive: it makes a difference between
english and English.
Disclaimer: The team releasing BERT did not write a model card for this model so this model card has been written by
the Hugging Face team.
## Model description
BERT is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the BERT model as inputs.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=bert) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='bert-base-cased')
>>> unmasker("Hello I'm a [MASK] model.")
[{'sequence': "[CLS] Hello I'm a fashion model. [SEP]",
'score': 0.09019174426794052,
'token': 4633,
'token_str': 'fashion'},
{'sequence': "[CLS] Hello I'm a new model. [SEP]",
'score': 0.06349995732307434,
'token': 1207,
'token_str': 'new'},
{'sequence': "[CLS] Hello I'm a male model. [SEP]",
'score': 0.06228214129805565,
'token': 2581,
'token_str': 'male'},
{'sequence': "[CLS] Hello I'm a professional model. [SEP]",
'score': 0.0441727414727211,
'token': 1848,
'token_str': 'professional'},
{'sequence': "[CLS] Hello I'm a super model. [SEP]",
'score': 0.03326151892542839,
'token': 7688,
'token_str': 'super'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
model = BertModel.from_pretrained("bert-base-cased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
model = TFBertModel.from_pretrained("bert-base-cased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='bert-base-cased')
>>> unmasker("The man worked as a [MASK].")
[{'sequence': '[CLS] The man worked as a lawyer. [SEP]',
'score': 0.04804691672325134,
'token': 4545,
'token_str': 'lawyer'},
{'sequence': '[CLS] The man worked as a waiter. [SEP]',
'score': 0.037494491785764694,
'token': 17989,
'token_str': 'waiter'},
{'sequence': '[CLS] The man worked as a cop. [SEP]',
'score': 0.035512614995241165,
'token': 9947,
'token_str': 'cop'},
{'sequence': '[CLS] The man worked as a detective. [SEP]',
'score': 0.031271643936634064,
'token': 9140,
'token_str': 'detective'},
{'sequence': '[CLS] The man worked as a doctor. [SEP]',
'score': 0.027423162013292313,
'token': 3995,
'token_str': 'doctor'}]
>>> unmasker("The woman worked as a [MASK].")
[{'sequence': '[CLS] The woman worked as a nurse. [SEP]',
'score': 0.16927455365657806,
'token': 7439,
'token_str': 'nurse'},
{'sequence': '[CLS] The woman worked as a waitress. [SEP]',
'score': 0.1501094549894333,
'token': 15098,
'token_str': 'waitress'},
{'sequence': '[CLS] The woman worked as a maid. [SEP]',
'score': 0.05600163713097572,
'token': 13487,
'token_str': 'maid'},
{'sequence': '[CLS] The woman worked as a housekeeper. [SEP]',
'score': 0.04838843643665314,
'token': 26458,
'token_str': 'housekeeper'},
{'sequence': '[CLS] The woman worked as a cook. [SEP]',
'score': 0.029980547726154327,
'token': 9834,
'token_str': 'cook'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The BERT model was pretrained on [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038
unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and
headers).
## Training procedure
### Preprocessing
The texts are tokenized using WordPiece and a vocabulary size of 30,000. The inputs of the model are then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### Pretraining
The model was trained on 4 cloud TPUs in Pod configuration (16 TPU chips total) for one million steps with a batch size
of 256. The sequence length was limited to 128 tokens for 90% of the steps and 512 for the remaining 10%. The optimizer
used is Adam with a learning rate of 1e-4, \\(\beta_{1} = 0.9\\) and \\(\beta_{2} = 0.999\\), a weight decay of 0.01,
learning rate warmup for 10,000 steps and linear decay of the learning rate after.
## Evaluation results
When fine-tuned on downstream tasks, this model achieves the following results:
Glue test results:
| Task | MNLI-(m/mm) | QQP | QNLI | SST-2 | CoLA | STS-B | MRPC | RTE | Average |
|:----:|:-----------:|:----:|:----:|:-----:|:----:|:-----:|:----:|:----:|:-------:|
| | 84.6/83.4 | 71.2 | 90.5 | 93.5 | 52.1 | 85.8 | 88.9 | 66.4 | 79.6 |
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1810-04805,
author = {Jacob Devlin and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {{BERT:} Pre-training of Deep Bidirectional Transformers for Language
Understanding},
journal = {CoRR},
volume = {abs/1810.04805},
year = {2018},
url = {http://arxiv.org/abs/1810.04805},
archivePrefix = {arXiv},
eprint = {1810.04805},
timestamp = {Tue, 30 Oct 2018 20:39:56 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1810-04805.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
<a href="https://huggingface.co/exbert/?model=bert-base-cased">
<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
|
google-t5/t5-small | google-t5 | "2023-06-30T02:31:26Z" | 5,892,842 | 398 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"onnx",
"safetensors",
"t5",
"text2text-generation",
"summarization",
"translation",
"en",
"fr",
"ro",
"de",
"multilingual",
"dataset:c4",
"arxiv:1805.12471",
"arxiv:1708.00055",
"arxiv:1704.05426",
"arxiv:1606.05250",
"arxiv:1808.09121",
"arxiv:1810.12885",
"arxiv:1905.10044",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | translation | "2022-03-02T23:29:04Z" | ---
language:
- en
- fr
- ro
- de
- multilingual
license: apache-2.0
tags:
- summarization
- translation
datasets:
- c4
---
# Model Card for T5 Small

# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
4. [Training Details](#training-details)
5. [Evaluation](#evaluation)
6. [Environmental Impact](#environmental-impact)
7. [Citation](#citation)
8. [Model Card Authors](#model-card-authors)
9. [How To Get Started With the Model](#how-to-get-started-with-the-model)
# Model Details
## Model Description
The developers of the Text-To-Text Transfer Transformer (T5) [write](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html):
> With T5, we propose reframing all NLP tasks into a unified text-to-text-format where the input and output are always text strings, in contrast to BERT-style models that can only output either a class label or a span of the input. Our text-to-text framework allows us to use the same model, loss function, and hyperparameters on any NLP task.
T5-Small is the checkpoint with 60 million parameters.
- **Developed by:** Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu. See [associated paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) and [GitHub repo](https://github.com/google-research/text-to-text-transfer-transformer#released-model-checkpoints)
- **Model type:** Language model
- **Language(s) (NLP):** English, French, Romanian, German
- **License:** Apache 2.0
- **Related Models:** [All T5 Checkpoints](https://huggingface.co/models?search=t5)
- **Resources for more information:**
- [Research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf)
- [Google's T5 Blog Post](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html)
- [GitHub Repo](https://github.com/google-research/text-to-text-transfer-transformer)
- [Hugging Face T5 Docs](https://huggingface.co/docs/transformers/model_doc/t5)
# Uses
## Direct Use and Downstream Use
The developers write in a [blog post](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) that the model:
> Our text-to-text framework allows us to use the same model, loss function, and hyperparameters on any NLP task, including machine translation, document summarization, question answering, and classification tasks (e.g., sentiment analysis). We can even apply T5 to regression tasks by training it to predict the string representation of a number instead of the number itself.
See the [blog post](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) and [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) for further details.
## Out-of-Scope Use
More information needed.
# Bias, Risks, and Limitations
More information needed.
## Recommendations
More information needed.
# Training Details
## Training Data
The model is pre-trained on the [Colossal Clean Crawled Corpus (C4)](https://www.tensorflow.org/datasets/catalog/c4), which was developed and released in the context of the same [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) as T5.
The model was pre-trained on a on a **multi-task mixture of unsupervised (1.) and supervised tasks (2.)**.
Thereby, the following datasets were being used for (1.) and (2.):
1. **Datasets used for Unsupervised denoising objective**:
- [C4](https://huggingface.co/datasets/c4)
- [Wiki-DPR](https://huggingface.co/datasets/wiki_dpr)
2. **Datasets used for Supervised text-to-text language modeling objective**
- Sentence acceptability judgment
- CoLA [Warstadt et al., 2018](https://arxiv.org/abs/1805.12471)
- Sentiment analysis
- SST-2 [Socher et al., 2013](https://nlp.stanford.edu/~socherr/EMNLP2013_RNTN.pdf)
- Paraphrasing/sentence similarity
- MRPC [Dolan and Brockett, 2005](https://aclanthology.org/I05-5002)
- STS-B [Ceret al., 2017](https://arxiv.org/abs/1708.00055)
- QQP [Iyer et al., 2017](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs)
- Natural language inference
- MNLI [Williams et al., 2017](https://arxiv.org/abs/1704.05426)
- QNLI [Rajpurkar et al.,2016](https://arxiv.org/abs/1606.05250)
- RTE [Dagan et al., 2005](https://link.springer.com/chapter/10.1007/11736790_9)
- CB [De Marneff et al., 2019](https://semanticsarchive.net/Archive/Tg3ZGI2M/Marneffe.pdf)
- Sentence completion
- COPA [Roemmele et al., 2011](https://www.researchgate.net/publication/221251392_Choice_of_Plausible_Alternatives_An_Evaluation_of_Commonsense_Causal_Reasoning)
- Word sense disambiguation
- WIC [Pilehvar and Camacho-Collados, 2018](https://arxiv.org/abs/1808.09121)
- Question answering
- MultiRC [Khashabi et al., 2018](https://aclanthology.org/N18-1023)
- ReCoRD [Zhang et al., 2018](https://arxiv.org/abs/1810.12885)
- BoolQ [Clark et al., 2019](https://arxiv.org/abs/1905.10044)
## Training Procedure
In their [abstract](https://jmlr.org/papers/volume21/20-074/20-074.pdf), the model developers write:
> In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks.
The framework introduced, the T5 framework, involves a training procedure that brings together the approaches studied in the paper. See the [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) for further details.
# Evaluation
## Testing Data, Factors & Metrics
The developers evaluated the model on 24 tasks, see the [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) for full details.
## Results
For full results for T5-small, see the [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf), Table 14.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Google Cloud TPU Pods
- **Hours used:** More information needed
- **Cloud Provider:** GCP
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Citation
**BibTeX:**
```bibtex
@article{2020t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {Journal of Machine Learning Research},
year = {2020},
volume = {21},
number = {140},
pages = {1-67},
url = {http://jmlr.org/papers/v21/20-074.html}
}
```
**APA:**
- Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., ... & Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(140), 1-67.
# Model Card Authors
This model card was written by the team at Hugging Face.
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import T5Tokenizer, T5Model
tokenizer = T5Tokenizer.from_pretrained("t5-small")
model = T5Model.from_pretrained("t5-small")
input_ids = tokenizer(
"Studies have been shown that owning a dog is good for you", return_tensors="pt"
).input_ids # Batch size 1
decoder_input_ids = tokenizer("Studies show that", return_tensors="pt").input_ids # Batch size 1
# forward pass
outputs = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
last_hidden_states = outputs.last_hidden_state
```
See the [Hugging Face T5](https://huggingface.co/docs/transformers/model_doc/t5#transformers.T5Model) docs and a [Colab Notebook](https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/main/notebooks/t5-trivia.ipynb) created by the model developers for more examples.
</details>
|
BAAI/bge-small-en-v1.5 | BAAI | "2024-02-22T03:36:23Z" | 5,756,331 | 282 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"onnx",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"mteb",
"en",
"arxiv:2401.03462",
"arxiv:2312.15503",
"arxiv:2311.13534",
"arxiv:2310.07554",
"arxiv:2309.07597",
"license:mit",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2023-09-12T05:20:55Z" | ---
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- mteb
model-index:
- name: bge-small-en-v1.5
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 73.79104477611939
- type: ap
value: 37.21923821573361
- type: f1
value: 68.0914945617093
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 92.75377499999999
- type: ap
value: 89.46766124546022
- type: f1
value: 92.73884001331487
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 46.986
- type: f1
value: 46.55936786727896
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 35.846000000000004
- type: map_at_10
value: 51.388
- type: map_at_100
value: 52.132999999999996
- type: map_at_1000
value: 52.141000000000005
- type: map_at_3
value: 47.037
- type: map_at_5
value: 49.579
- type: mrr_at_1
value: 36.558
- type: mrr_at_10
value: 51.658
- type: mrr_at_100
value: 52.402
- type: mrr_at_1000
value: 52.410000000000004
- type: mrr_at_3
value: 47.345
- type: mrr_at_5
value: 49.797999999999995
- type: ndcg_at_1
value: 35.846000000000004
- type: ndcg_at_10
value: 59.550000000000004
- type: ndcg_at_100
value: 62.596
- type: ndcg_at_1000
value: 62.759
- type: ndcg_at_3
value: 50.666999999999994
- type: ndcg_at_5
value: 55.228
- type: precision_at_1
value: 35.846000000000004
- type: precision_at_10
value: 8.542
- type: precision_at_100
value: 0.984
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 20.389
- type: precision_at_5
value: 14.438
- type: recall_at_1
value: 35.846000000000004
- type: recall_at_10
value: 85.42
- type: recall_at_100
value: 98.43499999999999
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 61.166
- type: recall_at_5
value: 72.191
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 47.402770198163594
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 40.01545436974177
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 62.586465273207196
- type: mrr
value: 74.42169019038825
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 85.1891186537969
- type: cos_sim_spearman
value: 83.75492046087288
- type: euclidean_pearson
value: 84.11766204805357
- type: euclidean_spearman
value: 84.01456493126516
- type: manhattan_pearson
value: 84.2132950502772
- type: manhattan_spearman
value: 83.89227298813377
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 85.74025974025975
- type: f1
value: 85.71493566466381
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 38.467181385006434
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 34.719496037339056
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.587000000000003
- type: map_at_10
value: 41.114
- type: map_at_100
value: 42.532
- type: map_at_1000
value: 42.661
- type: map_at_3
value: 37.483
- type: map_at_5
value: 39.652
- type: mrr_at_1
value: 36.338
- type: mrr_at_10
value: 46.763
- type: mrr_at_100
value: 47.393
- type: mrr_at_1000
value: 47.445
- type: mrr_at_3
value: 43.538
- type: mrr_at_5
value: 45.556000000000004
- type: ndcg_at_1
value: 36.338
- type: ndcg_at_10
value: 47.658
- type: ndcg_at_100
value: 52.824000000000005
- type: ndcg_at_1000
value: 54.913999999999994
- type: ndcg_at_3
value: 41.989
- type: ndcg_at_5
value: 44.944
- type: precision_at_1
value: 36.338
- type: precision_at_10
value: 9.156
- type: precision_at_100
value: 1.4789999999999999
- type: precision_at_1000
value: 0.196
- type: precision_at_3
value: 20.076
- type: precision_at_5
value: 14.85
- type: recall_at_1
value: 29.587000000000003
- type: recall_at_10
value: 60.746
- type: recall_at_100
value: 82.157
- type: recall_at_1000
value: 95.645
- type: recall_at_3
value: 44.821
- type: recall_at_5
value: 52.819
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.239
- type: map_at_10
value: 39.989000000000004
- type: map_at_100
value: 41.196
- type: map_at_1000
value: 41.325
- type: map_at_3
value: 37.261
- type: map_at_5
value: 38.833
- type: mrr_at_1
value: 37.516
- type: mrr_at_10
value: 46.177
- type: mrr_at_100
value: 46.806
- type: mrr_at_1000
value: 46.849000000000004
- type: mrr_at_3
value: 44.002
- type: mrr_at_5
value: 45.34
- type: ndcg_at_1
value: 37.516
- type: ndcg_at_10
value: 45.586
- type: ndcg_at_100
value: 49.897000000000006
- type: ndcg_at_1000
value: 51.955
- type: ndcg_at_3
value: 41.684
- type: ndcg_at_5
value: 43.617
- type: precision_at_1
value: 37.516
- type: precision_at_10
value: 8.522
- type: precision_at_100
value: 1.374
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 20.105999999999998
- type: precision_at_5
value: 14.152999999999999
- type: recall_at_1
value: 30.239
- type: recall_at_10
value: 55.03
- type: recall_at_100
value: 73.375
- type: recall_at_1000
value: 86.29599999999999
- type: recall_at_3
value: 43.269000000000005
- type: recall_at_5
value: 48.878
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 38.338
- type: map_at_10
value: 50.468999999999994
- type: map_at_100
value: 51.553000000000004
- type: map_at_1000
value: 51.608
- type: map_at_3
value: 47.107
- type: map_at_5
value: 49.101
- type: mrr_at_1
value: 44.201
- type: mrr_at_10
value: 54.057
- type: mrr_at_100
value: 54.764
- type: mrr_at_1000
value: 54.791000000000004
- type: mrr_at_3
value: 51.56699999999999
- type: mrr_at_5
value: 53.05
- type: ndcg_at_1
value: 44.201
- type: ndcg_at_10
value: 56.379000000000005
- type: ndcg_at_100
value: 60.645
- type: ndcg_at_1000
value: 61.73499999999999
- type: ndcg_at_3
value: 50.726000000000006
- type: ndcg_at_5
value: 53.58500000000001
- type: precision_at_1
value: 44.201
- type: precision_at_10
value: 9.141
- type: precision_at_100
value: 1.216
- type: precision_at_1000
value: 0.135
- type: precision_at_3
value: 22.654
- type: precision_at_5
value: 15.723999999999998
- type: recall_at_1
value: 38.338
- type: recall_at_10
value: 70.30499999999999
- type: recall_at_100
value: 88.77199999999999
- type: recall_at_1000
value: 96.49799999999999
- type: recall_at_3
value: 55.218
- type: recall_at_5
value: 62.104000000000006
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.682
- type: map_at_10
value: 33.498
- type: map_at_100
value: 34.461000000000006
- type: map_at_1000
value: 34.544000000000004
- type: map_at_3
value: 30.503999999999998
- type: map_at_5
value: 32.216
- type: mrr_at_1
value: 27.683999999999997
- type: mrr_at_10
value: 35.467999999999996
- type: mrr_at_100
value: 36.32
- type: mrr_at_1000
value: 36.386
- type: mrr_at_3
value: 32.618
- type: mrr_at_5
value: 34.262
- type: ndcg_at_1
value: 27.683999999999997
- type: ndcg_at_10
value: 38.378
- type: ndcg_at_100
value: 43.288
- type: ndcg_at_1000
value: 45.413
- type: ndcg_at_3
value: 32.586
- type: ndcg_at_5
value: 35.499
- type: precision_at_1
value: 27.683999999999997
- type: precision_at_10
value: 5.864
- type: precision_at_100
value: 0.882
- type: precision_at_1000
value: 0.11
- type: precision_at_3
value: 13.446
- type: precision_at_5
value: 9.718
- type: recall_at_1
value: 25.682
- type: recall_at_10
value: 51.712
- type: recall_at_100
value: 74.446
- type: recall_at_1000
value: 90.472
- type: recall_at_3
value: 36.236000000000004
- type: recall_at_5
value: 43.234
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.073999999999998
- type: map_at_10
value: 24.352999999999998
- type: map_at_100
value: 25.438
- type: map_at_1000
value: 25.545
- type: map_at_3
value: 21.614
- type: map_at_5
value: 23.104
- type: mrr_at_1
value: 19.776
- type: mrr_at_10
value: 28.837000000000003
- type: mrr_at_100
value: 29.755
- type: mrr_at_1000
value: 29.817
- type: mrr_at_3
value: 26.201999999999998
- type: mrr_at_5
value: 27.714
- type: ndcg_at_1
value: 19.776
- type: ndcg_at_10
value: 29.701
- type: ndcg_at_100
value: 35.307
- type: ndcg_at_1000
value: 37.942
- type: ndcg_at_3
value: 24.764
- type: ndcg_at_5
value: 27.025
- type: precision_at_1
value: 19.776
- type: precision_at_10
value: 5.659
- type: precision_at_100
value: 0.971
- type: precision_at_1000
value: 0.133
- type: precision_at_3
value: 12.065
- type: precision_at_5
value: 8.905000000000001
- type: recall_at_1
value: 16.073999999999998
- type: recall_at_10
value: 41.647
- type: recall_at_100
value: 66.884
- type: recall_at_1000
value: 85.91499999999999
- type: recall_at_3
value: 27.916
- type: recall_at_5
value: 33.729
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.444999999999997
- type: map_at_10
value: 38.218999999999994
- type: map_at_100
value: 39.595
- type: map_at_1000
value: 39.709
- type: map_at_3
value: 35.586
- type: map_at_5
value: 36.895
- type: mrr_at_1
value: 34.841
- type: mrr_at_10
value: 44.106
- type: mrr_at_100
value: 44.98
- type: mrr_at_1000
value: 45.03
- type: mrr_at_3
value: 41.979
- type: mrr_at_5
value: 43.047999999999995
- type: ndcg_at_1
value: 34.841
- type: ndcg_at_10
value: 43.922
- type: ndcg_at_100
value: 49.504999999999995
- type: ndcg_at_1000
value: 51.675000000000004
- type: ndcg_at_3
value: 39.858
- type: ndcg_at_5
value: 41.408
- type: precision_at_1
value: 34.841
- type: precision_at_10
value: 7.872999999999999
- type: precision_at_100
value: 1.2449999999999999
- type: precision_at_1000
value: 0.161
- type: precision_at_3
value: 18.993
- type: precision_at_5
value: 13.032
- type: recall_at_1
value: 28.444999999999997
- type: recall_at_10
value: 54.984
- type: recall_at_100
value: 78.342
- type: recall_at_1000
value: 92.77
- type: recall_at_3
value: 42.842999999999996
- type: recall_at_5
value: 47.247
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.072
- type: map_at_10
value: 32.354
- type: map_at_100
value: 33.800000000000004
- type: map_at_1000
value: 33.908
- type: map_at_3
value: 29.232000000000003
- type: map_at_5
value: 31.049
- type: mrr_at_1
value: 29.110000000000003
- type: mrr_at_10
value: 38.03
- type: mrr_at_100
value: 39.032
- type: mrr_at_1000
value: 39.086999999999996
- type: mrr_at_3
value: 35.407
- type: mrr_at_5
value: 36.76
- type: ndcg_at_1
value: 29.110000000000003
- type: ndcg_at_10
value: 38.231
- type: ndcg_at_100
value: 44.425
- type: ndcg_at_1000
value: 46.771
- type: ndcg_at_3
value: 33.095
- type: ndcg_at_5
value: 35.459
- type: precision_at_1
value: 29.110000000000003
- type: precision_at_10
value: 7.215000000000001
- type: precision_at_100
value: 1.2109999999999999
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 16.058
- type: precision_at_5
value: 11.644
- type: recall_at_1
value: 23.072
- type: recall_at_10
value: 50.285999999999994
- type: recall_at_100
value: 76.596
- type: recall_at_1000
value: 92.861
- type: recall_at_3
value: 35.702
- type: recall_at_5
value: 42.152
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 24.937916666666666
- type: map_at_10
value: 33.755250000000004
- type: map_at_100
value: 34.955999999999996
- type: map_at_1000
value: 35.070499999999996
- type: map_at_3
value: 30.98708333333333
- type: map_at_5
value: 32.51491666666666
- type: mrr_at_1
value: 29.48708333333333
- type: mrr_at_10
value: 37.92183333333334
- type: mrr_at_100
value: 38.76583333333333
- type: mrr_at_1000
value: 38.82466666666667
- type: mrr_at_3
value: 35.45125
- type: mrr_at_5
value: 36.827000000000005
- type: ndcg_at_1
value: 29.48708333333333
- type: ndcg_at_10
value: 39.05225
- type: ndcg_at_100
value: 44.25983333333334
- type: ndcg_at_1000
value: 46.568333333333335
- type: ndcg_at_3
value: 34.271583333333325
- type: ndcg_at_5
value: 36.483916666666666
- type: precision_at_1
value: 29.48708333333333
- type: precision_at_10
value: 6.865749999999999
- type: precision_at_100
value: 1.1195833333333332
- type: precision_at_1000
value: 0.15058333333333335
- type: precision_at_3
value: 15.742083333333333
- type: precision_at_5
value: 11.221916666666667
- type: recall_at_1
value: 24.937916666666666
- type: recall_at_10
value: 50.650416666666665
- type: recall_at_100
value: 73.55383333333334
- type: recall_at_1000
value: 89.61691666666667
- type: recall_at_3
value: 37.27808333333334
- type: recall_at_5
value: 42.99475
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.947
- type: map_at_10
value: 30.575000000000003
- type: map_at_100
value: 31.465
- type: map_at_1000
value: 31.558000000000003
- type: map_at_3
value: 28.814
- type: map_at_5
value: 29.738999999999997
- type: mrr_at_1
value: 26.994
- type: mrr_at_10
value: 33.415
- type: mrr_at_100
value: 34.18
- type: mrr_at_1000
value: 34.245
- type: mrr_at_3
value: 31.621
- type: mrr_at_5
value: 32.549
- type: ndcg_at_1
value: 26.994
- type: ndcg_at_10
value: 34.482
- type: ndcg_at_100
value: 38.915
- type: ndcg_at_1000
value: 41.355
- type: ndcg_at_3
value: 31.139
- type: ndcg_at_5
value: 32.589
- type: precision_at_1
value: 26.994
- type: precision_at_10
value: 5.322
- type: precision_at_100
value: 0.8160000000000001
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 13.344000000000001
- type: precision_at_5
value: 8.988
- type: recall_at_1
value: 23.947
- type: recall_at_10
value: 43.647999999999996
- type: recall_at_100
value: 63.851
- type: recall_at_1000
value: 82.0
- type: recall_at_3
value: 34.288000000000004
- type: recall_at_5
value: 38.117000000000004
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.197
- type: map_at_10
value: 22.968
- type: map_at_100
value: 24.095
- type: map_at_1000
value: 24.217
- type: map_at_3
value: 20.771
- type: map_at_5
value: 21.995
- type: mrr_at_1
value: 19.511
- type: mrr_at_10
value: 26.55
- type: mrr_at_100
value: 27.500999999999998
- type: mrr_at_1000
value: 27.578999999999997
- type: mrr_at_3
value: 24.421
- type: mrr_at_5
value: 25.604
- type: ndcg_at_1
value: 19.511
- type: ndcg_at_10
value: 27.386
- type: ndcg_at_100
value: 32.828
- type: ndcg_at_1000
value: 35.739
- type: ndcg_at_3
value: 23.405
- type: ndcg_at_5
value: 25.255
- type: precision_at_1
value: 19.511
- type: precision_at_10
value: 5.017
- type: precision_at_100
value: 0.91
- type: precision_at_1000
value: 0.133
- type: precision_at_3
value: 11.023
- type: precision_at_5
value: 8.025
- type: recall_at_1
value: 16.197
- type: recall_at_10
value: 37.09
- type: recall_at_100
value: 61.778
- type: recall_at_1000
value: 82.56599999999999
- type: recall_at_3
value: 26.034000000000002
- type: recall_at_5
value: 30.762
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.41
- type: map_at_10
value: 33.655
- type: map_at_100
value: 34.892
- type: map_at_1000
value: 34.995
- type: map_at_3
value: 30.94
- type: map_at_5
value: 32.303
- type: mrr_at_1
value: 29.477999999999998
- type: mrr_at_10
value: 37.443
- type: mrr_at_100
value: 38.383
- type: mrr_at_1000
value: 38.440000000000005
- type: mrr_at_3
value: 34.949999999999996
- type: mrr_at_5
value: 36.228
- type: ndcg_at_1
value: 29.477999999999998
- type: ndcg_at_10
value: 38.769
- type: ndcg_at_100
value: 44.245000000000005
- type: ndcg_at_1000
value: 46.593
- type: ndcg_at_3
value: 33.623
- type: ndcg_at_5
value: 35.766
- type: precision_at_1
value: 29.477999999999998
- type: precision_at_10
value: 6.455
- type: precision_at_100
value: 1.032
- type: precision_at_1000
value: 0.135
- type: precision_at_3
value: 14.893999999999998
- type: precision_at_5
value: 10.485
- type: recall_at_1
value: 25.41
- type: recall_at_10
value: 50.669
- type: recall_at_100
value: 74.084
- type: recall_at_1000
value: 90.435
- type: recall_at_3
value: 36.679
- type: recall_at_5
value: 41.94
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.339
- type: map_at_10
value: 31.852000000000004
- type: map_at_100
value: 33.411
- type: map_at_1000
value: 33.62
- type: map_at_3
value: 28.929
- type: map_at_5
value: 30.542
- type: mrr_at_1
value: 28.063
- type: mrr_at_10
value: 36.301
- type: mrr_at_100
value: 37.288
- type: mrr_at_1000
value: 37.349
- type: mrr_at_3
value: 33.663
- type: mrr_at_5
value: 35.165
- type: ndcg_at_1
value: 28.063
- type: ndcg_at_10
value: 37.462
- type: ndcg_at_100
value: 43.620999999999995
- type: ndcg_at_1000
value: 46.211
- type: ndcg_at_3
value: 32.68
- type: ndcg_at_5
value: 34.981
- type: precision_at_1
value: 28.063
- type: precision_at_10
value: 7.1739999999999995
- type: precision_at_100
value: 1.486
- type: precision_at_1000
value: 0.23500000000000001
- type: precision_at_3
value: 15.217
- type: precision_at_5
value: 11.265
- type: recall_at_1
value: 23.339
- type: recall_at_10
value: 48.376999999999995
- type: recall_at_100
value: 76.053
- type: recall_at_1000
value: 92.455
- type: recall_at_3
value: 34.735
- type: recall_at_5
value: 40.71
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 18.925
- type: map_at_10
value: 26.017000000000003
- type: map_at_100
value: 27.034000000000002
- type: map_at_1000
value: 27.156000000000002
- type: map_at_3
value: 23.604
- type: map_at_5
value: 24.75
- type: mrr_at_1
value: 20.333000000000002
- type: mrr_at_10
value: 27.915
- type: mrr_at_100
value: 28.788000000000004
- type: mrr_at_1000
value: 28.877999999999997
- type: mrr_at_3
value: 25.446999999999996
- type: mrr_at_5
value: 26.648
- type: ndcg_at_1
value: 20.333000000000002
- type: ndcg_at_10
value: 30.673000000000002
- type: ndcg_at_100
value: 35.618
- type: ndcg_at_1000
value: 38.517
- type: ndcg_at_3
value: 25.71
- type: ndcg_at_5
value: 27.679
- type: precision_at_1
value: 20.333000000000002
- type: precision_at_10
value: 4.9910000000000005
- type: precision_at_100
value: 0.8130000000000001
- type: precision_at_1000
value: 0.117
- type: precision_at_3
value: 11.029
- type: precision_at_5
value: 7.8740000000000006
- type: recall_at_1
value: 18.925
- type: recall_at_10
value: 43.311
- type: recall_at_100
value: 66.308
- type: recall_at_1000
value: 87.49
- type: recall_at_3
value: 29.596
- type: recall_at_5
value: 34.245
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 13.714
- type: map_at_10
value: 23.194
- type: map_at_100
value: 24.976000000000003
- type: map_at_1000
value: 25.166
- type: map_at_3
value: 19.709
- type: map_at_5
value: 21.523999999999997
- type: mrr_at_1
value: 30.619000000000003
- type: mrr_at_10
value: 42.563
- type: mrr_at_100
value: 43.386
- type: mrr_at_1000
value: 43.423
- type: mrr_at_3
value: 39.555
- type: mrr_at_5
value: 41.268
- type: ndcg_at_1
value: 30.619000000000003
- type: ndcg_at_10
value: 31.836
- type: ndcg_at_100
value: 38.652
- type: ndcg_at_1000
value: 42.088
- type: ndcg_at_3
value: 26.733
- type: ndcg_at_5
value: 28.435
- type: precision_at_1
value: 30.619000000000003
- type: precision_at_10
value: 9.751999999999999
- type: precision_at_100
value: 1.71
- type: precision_at_1000
value: 0.23500000000000001
- type: precision_at_3
value: 19.935
- type: precision_at_5
value: 14.984
- type: recall_at_1
value: 13.714
- type: recall_at_10
value: 37.26
- type: recall_at_100
value: 60.546
- type: recall_at_1000
value: 79.899
- type: recall_at_3
value: 24.325
- type: recall_at_5
value: 29.725
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.462
- type: map_at_10
value: 18.637
- type: map_at_100
value: 26.131999999999998
- type: map_at_1000
value: 27.607
- type: map_at_3
value: 13.333
- type: map_at_5
value: 15.654000000000002
- type: mrr_at_1
value: 66.25
- type: mrr_at_10
value: 74.32600000000001
- type: mrr_at_100
value: 74.60900000000001
- type: mrr_at_1000
value: 74.62
- type: mrr_at_3
value: 72.667
- type: mrr_at_5
value: 73.817
- type: ndcg_at_1
value: 53.87499999999999
- type: ndcg_at_10
value: 40.028999999999996
- type: ndcg_at_100
value: 44.199
- type: ndcg_at_1000
value: 51.629999999999995
- type: ndcg_at_3
value: 44.113
- type: ndcg_at_5
value: 41.731
- type: precision_at_1
value: 66.25
- type: precision_at_10
value: 31.900000000000002
- type: precision_at_100
value: 10.043000000000001
- type: precision_at_1000
value: 1.926
- type: precision_at_3
value: 47.417
- type: precision_at_5
value: 40.65
- type: recall_at_1
value: 8.462
- type: recall_at_10
value: 24.293
- type: recall_at_100
value: 50.146
- type: recall_at_1000
value: 74.034
- type: recall_at_3
value: 14.967
- type: recall_at_5
value: 18.682000000000002
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 47.84499999999999
- type: f1
value: 42.48106691979349
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 74.034
- type: map_at_10
value: 82.76
- type: map_at_100
value: 82.968
- type: map_at_1000
value: 82.98299999999999
- type: map_at_3
value: 81.768
- type: map_at_5
value: 82.418
- type: mrr_at_1
value: 80.048
- type: mrr_at_10
value: 87.64999999999999
- type: mrr_at_100
value: 87.712
- type: mrr_at_1000
value: 87.713
- type: mrr_at_3
value: 87.01100000000001
- type: mrr_at_5
value: 87.466
- type: ndcg_at_1
value: 80.048
- type: ndcg_at_10
value: 86.643
- type: ndcg_at_100
value: 87.361
- type: ndcg_at_1000
value: 87.606
- type: ndcg_at_3
value: 85.137
- type: ndcg_at_5
value: 86.016
- type: precision_at_1
value: 80.048
- type: precision_at_10
value: 10.372
- type: precision_at_100
value: 1.093
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 32.638
- type: precision_at_5
value: 20.177
- type: recall_at_1
value: 74.034
- type: recall_at_10
value: 93.769
- type: recall_at_100
value: 96.569
- type: recall_at_1000
value: 98.039
- type: recall_at_3
value: 89.581
- type: recall_at_5
value: 91.906
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 20.5
- type: map_at_10
value: 32.857
- type: map_at_100
value: 34.589
- type: map_at_1000
value: 34.778
- type: map_at_3
value: 29.160999999999998
- type: map_at_5
value: 31.033
- type: mrr_at_1
value: 40.123
- type: mrr_at_10
value: 48.776
- type: mrr_at_100
value: 49.495
- type: mrr_at_1000
value: 49.539
- type: mrr_at_3
value: 46.605000000000004
- type: mrr_at_5
value: 47.654
- type: ndcg_at_1
value: 40.123
- type: ndcg_at_10
value: 40.343
- type: ndcg_at_100
value: 46.56
- type: ndcg_at_1000
value: 49.777
- type: ndcg_at_3
value: 37.322
- type: ndcg_at_5
value: 37.791000000000004
- type: precision_at_1
value: 40.123
- type: precision_at_10
value: 11.08
- type: precision_at_100
value: 1.752
- type: precision_at_1000
value: 0.232
- type: precision_at_3
value: 24.897
- type: precision_at_5
value: 17.809
- type: recall_at_1
value: 20.5
- type: recall_at_10
value: 46.388
- type: recall_at_100
value: 69.552
- type: recall_at_1000
value: 89.011
- type: recall_at_3
value: 33.617999999999995
- type: recall_at_5
value: 38.211
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 39.135999999999996
- type: map_at_10
value: 61.673
- type: map_at_100
value: 62.562
- type: map_at_1000
value: 62.62
- type: map_at_3
value: 58.467999999999996
- type: map_at_5
value: 60.463
- type: mrr_at_1
value: 78.271
- type: mrr_at_10
value: 84.119
- type: mrr_at_100
value: 84.29299999999999
- type: mrr_at_1000
value: 84.299
- type: mrr_at_3
value: 83.18900000000001
- type: mrr_at_5
value: 83.786
- type: ndcg_at_1
value: 78.271
- type: ndcg_at_10
value: 69.935
- type: ndcg_at_100
value: 73.01299999999999
- type: ndcg_at_1000
value: 74.126
- type: ndcg_at_3
value: 65.388
- type: ndcg_at_5
value: 67.906
- type: precision_at_1
value: 78.271
- type: precision_at_10
value: 14.562
- type: precision_at_100
value: 1.6969999999999998
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 41.841
- type: precision_at_5
value: 27.087
- type: recall_at_1
value: 39.135999999999996
- type: recall_at_10
value: 72.809
- type: recall_at_100
value: 84.86200000000001
- type: recall_at_1000
value: 92.208
- type: recall_at_3
value: 62.76199999999999
- type: recall_at_5
value: 67.718
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 90.60600000000001
- type: ap
value: 86.6579587804335
- type: f1
value: 90.5938853929307
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.852
- type: map_at_10
value: 33.982
- type: map_at_100
value: 35.116
- type: map_at_1000
value: 35.167
- type: map_at_3
value: 30.134
- type: map_at_5
value: 32.340999999999994
- type: mrr_at_1
value: 22.479
- type: mrr_at_10
value: 34.594
- type: mrr_at_100
value: 35.672
- type: mrr_at_1000
value: 35.716
- type: mrr_at_3
value: 30.84
- type: mrr_at_5
value: 32.998
- type: ndcg_at_1
value: 22.493
- type: ndcg_at_10
value: 40.833000000000006
- type: ndcg_at_100
value: 46.357
- type: ndcg_at_1000
value: 47.637
- type: ndcg_at_3
value: 32.995999999999995
- type: ndcg_at_5
value: 36.919000000000004
- type: precision_at_1
value: 22.493
- type: precision_at_10
value: 6.465999999999999
- type: precision_at_100
value: 0.9249999999999999
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 14.030999999999999
- type: precision_at_5
value: 10.413
- type: recall_at_1
value: 21.852
- type: recall_at_10
value: 61.934999999999995
- type: recall_at_100
value: 87.611
- type: recall_at_1000
value: 97.441
- type: recall_at_3
value: 40.583999999999996
- type: recall_at_5
value: 49.992999999999995
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.36069311445507
- type: f1
value: 93.16456330371453
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 74.74692202462381
- type: f1
value: 58.17903579421599
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 74.80833893745796
- type: f1
value: 72.70786592684664
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 78.69872225958305
- type: f1
value: 78.61626934504731
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.058658628717694
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 30.85561739360599
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 31.290259910144385
- type: mrr
value: 32.44223046102856
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.288
- type: map_at_10
value: 12.267999999999999
- type: map_at_100
value: 15.557000000000002
- type: map_at_1000
value: 16.98
- type: map_at_3
value: 8.866
- type: map_at_5
value: 10.418
- type: mrr_at_1
value: 43.653
- type: mrr_at_10
value: 52.681
- type: mrr_at_100
value: 53.315999999999995
- type: mrr_at_1000
value: 53.357
- type: mrr_at_3
value: 51.393
- type: mrr_at_5
value: 51.903999999999996
- type: ndcg_at_1
value: 42.415000000000006
- type: ndcg_at_10
value: 34.305
- type: ndcg_at_100
value: 30.825999999999997
- type: ndcg_at_1000
value: 39.393
- type: ndcg_at_3
value: 39.931
- type: ndcg_at_5
value: 37.519999999999996
- type: precision_at_1
value: 43.653
- type: precision_at_10
value: 25.728
- type: precision_at_100
value: 7.932
- type: precision_at_1000
value: 2.07
- type: precision_at_3
value: 38.184000000000005
- type: precision_at_5
value: 32.879000000000005
- type: recall_at_1
value: 5.288
- type: recall_at_10
value: 16.195
- type: recall_at_100
value: 31.135
- type: recall_at_1000
value: 61.531000000000006
- type: recall_at_3
value: 10.313
- type: recall_at_5
value: 12.754999999999999
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.216
- type: map_at_10
value: 42.588
- type: map_at_100
value: 43.702999999999996
- type: map_at_1000
value: 43.739
- type: map_at_3
value: 38.177
- type: map_at_5
value: 40.754000000000005
- type: mrr_at_1
value: 31.866
- type: mrr_at_10
value: 45.189
- type: mrr_at_100
value: 46.056000000000004
- type: mrr_at_1000
value: 46.081
- type: mrr_at_3
value: 41.526999999999994
- type: mrr_at_5
value: 43.704
- type: ndcg_at_1
value: 31.837
- type: ndcg_at_10
value: 50.178
- type: ndcg_at_100
value: 54.98800000000001
- type: ndcg_at_1000
value: 55.812
- type: ndcg_at_3
value: 41.853
- type: ndcg_at_5
value: 46.153
- type: precision_at_1
value: 31.837
- type: precision_at_10
value: 8.43
- type: precision_at_100
value: 1.1119999999999999
- type: precision_at_1000
value: 0.11900000000000001
- type: precision_at_3
value: 19.023
- type: precision_at_5
value: 13.911000000000001
- type: recall_at_1
value: 28.216
- type: recall_at_10
value: 70.8
- type: recall_at_100
value: 91.857
- type: recall_at_1000
value: 97.941
- type: recall_at_3
value: 49.196
- type: recall_at_5
value: 59.072
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 71.22800000000001
- type: map_at_10
value: 85.115
- type: map_at_100
value: 85.72
- type: map_at_1000
value: 85.737
- type: map_at_3
value: 82.149
- type: map_at_5
value: 84.029
- type: mrr_at_1
value: 81.96
- type: mrr_at_10
value: 88.00200000000001
- type: mrr_at_100
value: 88.088
- type: mrr_at_1000
value: 88.089
- type: mrr_at_3
value: 87.055
- type: mrr_at_5
value: 87.715
- type: ndcg_at_1
value: 82.01
- type: ndcg_at_10
value: 88.78
- type: ndcg_at_100
value: 89.91
- type: ndcg_at_1000
value: 90.013
- type: ndcg_at_3
value: 85.957
- type: ndcg_at_5
value: 87.56
- type: precision_at_1
value: 82.01
- type: precision_at_10
value: 13.462
- type: precision_at_100
value: 1.528
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.553
- type: precision_at_5
value: 24.732000000000003
- type: recall_at_1
value: 71.22800000000001
- type: recall_at_10
value: 95.69
- type: recall_at_100
value: 99.531
- type: recall_at_1000
value: 99.98
- type: recall_at_3
value: 87.632
- type: recall_at_5
value: 92.117
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 52.31768034366916
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 60.640266772723606
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.7780000000000005
- type: map_at_10
value: 12.299
- type: map_at_100
value: 14.363000000000001
- type: map_at_1000
value: 14.71
- type: map_at_3
value: 8.738999999999999
- type: map_at_5
value: 10.397
- type: mrr_at_1
value: 23.599999999999998
- type: mrr_at_10
value: 34.845
- type: mrr_at_100
value: 35.916
- type: mrr_at_1000
value: 35.973
- type: mrr_at_3
value: 31.7
- type: mrr_at_5
value: 33.535
- type: ndcg_at_1
value: 23.599999999999998
- type: ndcg_at_10
value: 20.522000000000002
- type: ndcg_at_100
value: 28.737000000000002
- type: ndcg_at_1000
value: 34.596
- type: ndcg_at_3
value: 19.542
- type: ndcg_at_5
value: 16.958000000000002
- type: precision_at_1
value: 23.599999999999998
- type: precision_at_10
value: 10.67
- type: precision_at_100
value: 2.259
- type: precision_at_1000
value: 0.367
- type: precision_at_3
value: 18.333
- type: precision_at_5
value: 14.879999999999999
- type: recall_at_1
value: 4.7780000000000005
- type: recall_at_10
value: 21.617
- type: recall_at_100
value: 45.905
- type: recall_at_1000
value: 74.42
- type: recall_at_3
value: 11.148
- type: recall_at_5
value: 15.082999999999998
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 83.22372750297885
- type: cos_sim_spearman
value: 79.40972617119405
- type: euclidean_pearson
value: 80.6101072020434
- type: euclidean_spearman
value: 79.53844217225202
- type: manhattan_pearson
value: 80.57265975286111
- type: manhattan_spearman
value: 79.46335611792958
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 85.43713315520749
- type: cos_sim_spearman
value: 77.44128693329532
- type: euclidean_pearson
value: 81.63869928101123
- type: euclidean_spearman
value: 77.29512977961515
- type: manhattan_pearson
value: 81.63704185566183
- type: manhattan_spearman
value: 77.29909412738657
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 81.59451537860527
- type: cos_sim_spearman
value: 82.97994638856723
- type: euclidean_pearson
value: 82.89478688288412
- type: euclidean_spearman
value: 83.58740751053104
- type: manhattan_pearson
value: 82.69140840941608
- type: manhattan_spearman
value: 83.33665956040555
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 82.00756527711764
- type: cos_sim_spearman
value: 81.83560996841379
- type: euclidean_pearson
value: 82.07684151976518
- type: euclidean_spearman
value: 82.00913052060511
- type: manhattan_pearson
value: 82.05690778488794
- type: manhattan_spearman
value: 82.02260252019525
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 86.13710262895447
- type: cos_sim_spearman
value: 87.26412811156248
- type: euclidean_pearson
value: 86.94151453230228
- type: euclidean_spearman
value: 87.5363796699571
- type: manhattan_pearson
value: 86.86989424083748
- type: manhattan_spearman
value: 87.47315940781353
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 83.0230597603627
- type: cos_sim_spearman
value: 84.93344499318864
- type: euclidean_pearson
value: 84.23754743431141
- type: euclidean_spearman
value: 85.09707376597099
- type: manhattan_pearson
value: 84.04325160987763
- type: manhattan_spearman
value: 84.89353071339909
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 86.75620824563921
- type: cos_sim_spearman
value: 87.15065513706398
- type: euclidean_pearson
value: 88.26281533633521
- type: euclidean_spearman
value: 87.51963738643983
- type: manhattan_pearson
value: 88.25599267618065
- type: manhattan_spearman
value: 87.58048736047483
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 64.74645319195137
- type: cos_sim_spearman
value: 65.29996325037214
- type: euclidean_pearson
value: 67.04297794086443
- type: euclidean_spearman
value: 65.43841726694343
- type: manhattan_pearson
value: 67.39459955690904
- type: manhattan_spearman
value: 65.92864704413651
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 84.31291020270801
- type: cos_sim_spearman
value: 85.86473738688068
- type: euclidean_pearson
value: 85.65537275064152
- type: euclidean_spearman
value: 86.13087454209642
- type: manhattan_pearson
value: 85.43946955047609
- type: manhattan_spearman
value: 85.91568175344916
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 85.93798118350695
- type: mrr
value: 95.93536274908824
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 57.594
- type: map_at_10
value: 66.81899999999999
- type: map_at_100
value: 67.368
- type: map_at_1000
value: 67.4
- type: map_at_3
value: 64.061
- type: map_at_5
value: 65.47
- type: mrr_at_1
value: 60.667
- type: mrr_at_10
value: 68.219
- type: mrr_at_100
value: 68.655
- type: mrr_at_1000
value: 68.684
- type: mrr_at_3
value: 66.22200000000001
- type: mrr_at_5
value: 67.289
- type: ndcg_at_1
value: 60.667
- type: ndcg_at_10
value: 71.275
- type: ndcg_at_100
value: 73.642
- type: ndcg_at_1000
value: 74.373
- type: ndcg_at_3
value: 66.521
- type: ndcg_at_5
value: 68.581
- type: precision_at_1
value: 60.667
- type: precision_at_10
value: 9.433
- type: precision_at_100
value: 1.0699999999999998
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 25.556
- type: precision_at_5
value: 16.8
- type: recall_at_1
value: 57.594
- type: recall_at_10
value: 83.622
- type: recall_at_100
value: 94.167
- type: recall_at_1000
value: 99.667
- type: recall_at_3
value: 70.64399999999999
- type: recall_at_5
value: 75.983
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.85841584158416
- type: cos_sim_ap
value: 96.66996142314342
- type: cos_sim_f1
value: 92.83208020050125
- type: cos_sim_precision
value: 93.06532663316584
- type: cos_sim_recall
value: 92.60000000000001
- type: dot_accuracy
value: 99.85841584158416
- type: dot_ap
value: 96.6775307676576
- type: dot_f1
value: 92.69289729177312
- type: dot_precision
value: 94.77533960292581
- type: dot_recall
value: 90.7
- type: euclidean_accuracy
value: 99.86138613861387
- type: euclidean_ap
value: 96.6338454403108
- type: euclidean_f1
value: 92.92214357937311
- type: euclidean_precision
value: 93.96728016359918
- type: euclidean_recall
value: 91.9
- type: manhattan_accuracy
value: 99.86237623762376
- type: manhattan_ap
value: 96.60370449645053
- type: manhattan_f1
value: 92.91177970423253
- type: manhattan_precision
value: 94.7970863683663
- type: manhattan_recall
value: 91.10000000000001
- type: max_accuracy
value: 99.86237623762376
- type: max_ap
value: 96.6775307676576
- type: max_f1
value: 92.92214357937311
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 60.77977058695198
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 35.2725272535638
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 53.64052466362125
- type: mrr
value: 54.533067014684654
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.677624219206578
- type: cos_sim_spearman
value: 30.121368518123447
- type: dot_pearson
value: 30.69870088041608
- type: dot_spearman
value: 29.61284927093751
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.22
- type: map_at_10
value: 1.855
- type: map_at_100
value: 9.885
- type: map_at_1000
value: 23.416999999999998
- type: map_at_3
value: 0.637
- type: map_at_5
value: 1.024
- type: mrr_at_1
value: 88.0
- type: mrr_at_10
value: 93.067
- type: mrr_at_100
value: 93.067
- type: mrr_at_1000
value: 93.067
- type: mrr_at_3
value: 92.667
- type: mrr_at_5
value: 93.067
- type: ndcg_at_1
value: 82.0
- type: ndcg_at_10
value: 75.899
- type: ndcg_at_100
value: 55.115
- type: ndcg_at_1000
value: 48.368
- type: ndcg_at_3
value: 79.704
- type: ndcg_at_5
value: 78.39699999999999
- type: precision_at_1
value: 88.0
- type: precision_at_10
value: 79.60000000000001
- type: precision_at_100
value: 56.06
- type: precision_at_1000
value: 21.206
- type: precision_at_3
value: 84.667
- type: precision_at_5
value: 83.2
- type: recall_at_1
value: 0.22
- type: recall_at_10
value: 2.078
- type: recall_at_100
value: 13.297
- type: recall_at_1000
value: 44.979
- type: recall_at_3
value: 0.6689999999999999
- type: recall_at_5
value: 1.106
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 2.258
- type: map_at_10
value: 10.439
- type: map_at_100
value: 16.89
- type: map_at_1000
value: 18.407999999999998
- type: map_at_3
value: 5.668
- type: map_at_5
value: 7.718
- type: mrr_at_1
value: 32.653
- type: mrr_at_10
value: 51.159
- type: mrr_at_100
value: 51.714000000000006
- type: mrr_at_1000
value: 51.714000000000006
- type: mrr_at_3
value: 47.959
- type: mrr_at_5
value: 50.407999999999994
- type: ndcg_at_1
value: 29.592000000000002
- type: ndcg_at_10
value: 26.037
- type: ndcg_at_100
value: 37.924
- type: ndcg_at_1000
value: 49.126999999999995
- type: ndcg_at_3
value: 30.631999999999998
- type: ndcg_at_5
value: 28.571
- type: precision_at_1
value: 32.653
- type: precision_at_10
value: 22.857
- type: precision_at_100
value: 7.754999999999999
- type: precision_at_1000
value: 1.529
- type: precision_at_3
value: 34.014
- type: precision_at_5
value: 29.796
- type: recall_at_1
value: 2.258
- type: recall_at_10
value: 16.554
- type: recall_at_100
value: 48.439
- type: recall_at_1000
value: 82.80499999999999
- type: recall_at_3
value: 7.283
- type: recall_at_5
value: 10.732
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 69.8858
- type: ap
value: 13.835684144362109
- type: f1
value: 53.803351693244586
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 60.50650820599886
- type: f1
value: 60.84357825979259
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 48.52131044852134
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 85.59337187816654
- type: cos_sim_ap
value: 73.23925826533437
- type: cos_sim_f1
value: 67.34693877551021
- type: cos_sim_precision
value: 62.40432237730752
- type: cos_sim_recall
value: 73.13984168865434
- type: dot_accuracy
value: 85.31322644096085
- type: dot_ap
value: 72.30723963807422
- type: dot_f1
value: 66.47051612112296
- type: dot_precision
value: 62.0792305930845
- type: dot_recall
value: 71.53034300791556
- type: euclidean_accuracy
value: 85.61125350181797
- type: euclidean_ap
value: 73.32843720487845
- type: euclidean_f1
value: 67.36549633745895
- type: euclidean_precision
value: 64.60755813953489
- type: euclidean_recall
value: 70.36939313984169
- type: manhattan_accuracy
value: 85.63509566668654
- type: manhattan_ap
value: 73.16658488311325
- type: manhattan_f1
value: 67.20597386434349
- type: manhattan_precision
value: 63.60424028268551
- type: manhattan_recall
value: 71.2401055408971
- type: max_accuracy
value: 85.63509566668654
- type: max_ap
value: 73.32843720487845
- type: max_f1
value: 67.36549633745895
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.33779640625606
- type: cos_sim_ap
value: 84.83868375898157
- type: cos_sim_f1
value: 77.16506154017773
- type: cos_sim_precision
value: 74.62064005753327
- type: cos_sim_recall
value: 79.88912842623961
- type: dot_accuracy
value: 88.02732176815307
- type: dot_ap
value: 83.95089283763002
- type: dot_f1
value: 76.29635101196631
- type: dot_precision
value: 73.31771720613288
- type: dot_recall
value: 79.52725592854944
- type: euclidean_accuracy
value: 88.44452206310397
- type: euclidean_ap
value: 84.98384576824827
- type: euclidean_f1
value: 77.29311047696697
- type: euclidean_precision
value: 74.51232583065381
- type: euclidean_recall
value: 80.28949799815214
- type: manhattan_accuracy
value: 88.47362906042613
- type: manhattan_ap
value: 84.91421462218432
- type: manhattan_f1
value: 77.05107637204792
- type: manhattan_precision
value: 74.74484256243214
- type: manhattan_recall
value: 79.50415768401602
- type: max_accuracy
value: 88.47362906042613
- type: max_ap
value: 84.98384576824827
- type: max_f1
value: 77.29311047696697
license: mit
language:
- en
---
<h1 align="center">FlagEmbedding</h1>
<h4 align="center">
<p>
<a href=#model-list>Model List</a> |
<a href=#frequently-asked-questions>FAQ</a> |
<a href=#usage>Usage</a> |
<a href="#evaluation">Evaluation</a> |
<a href="#train">Train</a> |
<a href="#contact">Contact</a> |
<a href="#citation">Citation</a> |
<a href="#license">License</a>
<p>
</h4>
More details please refer to our Github: [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding).
If you are looking for a model that supports more languages, longer texts, and other retrieval methods, you can try using [bge-m3](https://huggingface.co/BAAI/bge-m3).
[English](README.md) | [中文](https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md)
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently:
- **Long-Context LLM**: [Activation Beacon](https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/activation_beacon)
- **Fine-tuning of LM** : [LM-Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail)
- **Dense Retrieval**: [BGE-M3](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3), [LLM Embedder](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder), [BGE Embedding](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/baai_general_embedding)
- **Reranker Model**: [BGE Reranker](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
- **Benchmark**: [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB)
## News
- 1/30/2024: Release **BGE-M3**, a new member to BGE model series! M3 stands for **M**ulti-linguality (100+ languages), **M**ulti-granularities (input length up to 8192), **M**ulti-Functionality (unification of dense, lexical, multi-vec/colbert retrieval).
It is the first embedding model which supports all three retrieval methods, achieving new SOTA on multi-lingual (MIRACL) and cross-lingual (MKQA) benchmarks.
[Technical Report](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/BGE_M3/BGE_M3.pdf) and [Code](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3). :fire:
- 1/9/2024: Release [Activation-Beacon](https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/activation_beacon), an effective, efficient, compatible, and low-cost (training) method to extend the context length of LLM. [Technical Report](https://arxiv.org/abs/2401.03462) :fire:
- 12/24/2023: Release **LLaRA**, a LLaMA-7B based dense retriever, leading to state-of-the-art performances on MS MARCO and BEIR. Model and code will be open-sourced. Please stay tuned. [Technical Report](https://arxiv.org/abs/2312.15503) :fire:
- 11/23/2023: Release [LM-Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail), a method to maintain general capabilities during fine-tuning by merging multiple language models. [Technical Report](https://arxiv.org/abs/2311.13534) :fire:
- 10/12/2023: Release [LLM-Embedder](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder), a unified embedding model to support diverse retrieval augmentation needs for LLMs. [Technical Report](https://arxiv.org/pdf/2310.07554.pdf)
- 09/15/2023: The [technical report](https://arxiv.org/pdf/2309.07597.pdf) of BGE has been released
- 09/15/2023: The [massive training data](https://data.baai.ac.cn/details/BAAI-MTP) of BGE has been released
- 09/12/2023: New models:
- **New reranker model**: release cross-encoder models `BAAI/bge-reranker-base` and `BAAI/bge-reranker-large`, which are more powerful than embedding model. We recommend to use/fine-tune them to re-rank top-k documents returned by embedding models.
- **update embedding model**: release `bge-*-v1.5` embedding model to alleviate the issue of the similarity distribution, and enhance its retrieval ability without instruction.
<details>
<summary>More</summary>
<!-- ### More -->
- 09/07/2023: Update [fine-tune code](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md): Add script to mine hard negatives and support adding instruction during fine-tuning.
- 08/09/2023: BGE Models are integrated into **Langchain**, you can use it like [this](#using-langchain); C-MTEB **leaderboard** is [available](https://huggingface.co/spaces/mteb/leaderboard).
- 08/05/2023: Release base-scale and small-scale models, **best performance among the models of the same size 🤗**
- 08/02/2023: Release `bge-large-*`(short for BAAI General Embedding) Models, **rank 1st on MTEB and C-MTEB benchmark!** :tada: :tada:
- 08/01/2023: We release the [Chinese Massive Text Embedding Benchmark](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB) (**C-MTEB**), consisting of 31 test dataset.
</details>
## Model List
`bge` is short for `BAAI general embedding`.
| Model | Language | | Description | query instruction for retrieval [1] |
|:-------------------------------|:--------:| :--------:| :--------:|:--------:|
| [BAAI/bge-m3](https://huggingface.co/BAAI/bge-m3) | Multilingual | [Inference](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3#usage) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3) | Multi-Functionality(dense retrieval, sparse retrieval, multi-vector(colbert)), Multi-Linguality, and Multi-Granularity(8192 tokens) | |
| [BAAI/llm-embedder](https://huggingface.co/BAAI/llm-embedder) | English | [Inference](./FlagEmbedding/llm_embedder/README.md) [Fine-tune](./FlagEmbedding/llm_embedder/README.md) | a unified embedding model to support diverse retrieval augmentation needs for LLMs | See [README](./FlagEmbedding/llm_embedder/README.md) |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh-v1.5](https://huggingface.co/BAAI/bge-large-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-large-en](https://huggingface.co/BAAI/bge-large-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [MTEB](https://huggingface.co/spaces/mteb/leaderboard) leaderboard | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en](https://huggingface.co/BAAI/bge-base-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-en` | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en](https://huggingface.co/BAAI/bge-small-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) |a small-scale model but with competitive performance | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB) benchmark | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-zh` | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a small-scale model but with competitive performance | `为这个句子生成表示以用于检索相关文章:` |
[1\]: If you need to search the relevant passages to a query, we suggest to add the instruction to the query; in other cases, no instruction is needed, just use the original query directly. In all cases, **no instruction** needs to be added to passages.
[2\]: Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding. To balance the accuracy and time cost, cross-encoder is widely used to re-rank top-k documents retrieved by other simple models.
For examples, use bge embedding model to retrieve top 100 relevant documents, and then use bge reranker to re-rank the top 100 document to get the final top-3 results.
All models have been uploaded to Huggingface Hub, and you can see them at https://huggingface.co/BAAI.
If you cannot open the Huggingface Hub, you also can download the models at https://model.baai.ac.cn/models .
## Frequently asked questions
<details>
<summary>1. How to fine-tune bge embedding model?</summary>
<!-- ### How to fine-tune bge embedding model? -->
Following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) to prepare data and fine-tune your model.
Some suggestions:
- Mine hard negatives following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune#hard-negatives), which can improve the retrieval performance.
- If you pre-train bge on your data, the pre-trained model cannot be directly used to calculate similarity, and it must be fine-tuned with contrastive learning before computing similarity.
- If the accuracy of the fine-tuned model is still not high, it is recommended to use/fine-tune the cross-encoder model (bge-reranker) to re-rank top-k results. Hard negatives also are needed to fine-tune reranker.
</details>
<details>
<summary>2. The similarity score between two dissimilar sentences is higher than 0.5</summary>
<!-- ### The similarity score between two dissimilar sentences is higher than 0.5 -->
**Suggest to use bge v1.5, which alleviates the issue of the similarity distribution.**
Since we finetune the models by contrastive learning with a temperature of 0.01,
the similarity distribution of the current BGE model is about in the interval \[0.6, 1\].
So a similarity score greater than 0.5 does not indicate that the two sentences are similar.
For downstream tasks, such as passage retrieval or semantic similarity,
**what matters is the relative order of the scores, not the absolute value.**
If you need to filter similar sentences based on a similarity threshold,
please select an appropriate similarity threshold based on the similarity distribution on your data (such as 0.8, 0.85, or even 0.9).
</details>
<details>
<summary>3. When does the query instruction need to be used</summary>
<!-- ### When does the query instruction need to be used -->
For the `bge-*-v1.5`, we improve its retrieval ability when not using instruction.
No instruction only has a slight degradation in retrieval performance compared with using instruction.
So you can generate embedding without instruction in all cases for convenience.
For a retrieval task that uses short queries to find long related documents,
it is recommended to add instructions for these short queries.
**The best method to decide whether to add instructions for queries is choosing the setting that achieves better performance on your task.**
In all cases, the documents/passages do not need to add the instruction.
</details>
## Usage
### Usage for Embedding Model
Here are some examples for using `bge` models with
[FlagEmbedding](#using-flagembedding), [Sentence-Transformers](#using-sentence-transformers), [Langchain](#using-langchain), or [Huggingface Transformers](#using-huggingface-transformers).
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
If it doesn't work for you, you can see [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md) for more methods to install FlagEmbedding.
```python
from FlagEmbedding import FlagModel
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = FlagModel('BAAI/bge-large-zh-v1.5',
query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# for s2p(short query to long passage) retrieval task, suggest to use encode_queries() which will automatically add the instruction to each query
# corpus in retrieval task can still use encode() or encode_corpus(), since they don't need instruction
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
q_embeddings = model.encode_queries(queries)
p_embeddings = model.encode(passages)
scores = q_embeddings @ p_embeddings.T
```
For the value of the argument `query_instruction_for_retrieval`, see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list).
By default, FlagModel will use all available GPUs when encoding. Please set `os.environ["CUDA_VISIBLE_DEVICES"]` to select specific GPUs.
You also can set `os.environ["CUDA_VISIBLE_DEVICES"]=""` to make all GPUs unavailable.
#### Using Sentence-Transformers
You can also use the `bge` models with [sentence-transformers](https://www.SBERT.net):
```
pip install -U sentence-transformers
```
```python
from sentence_transformers import SentenceTransformer
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
For s2p(short query to long passage) retrieval task,
each short query should start with an instruction (instructions see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list)).
But the instruction is not needed for passages.
```python
from sentence_transformers import SentenceTransformer
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
instruction = "为这个句子生成表示以用于检索相关文章:"
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
q_embeddings = model.encode([instruction+q for q in queries], normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
scores = q_embeddings @ p_embeddings.T
```
#### Using Langchain
You can use `bge` in langchain like this:
```python
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
query_instruction="为这个句子生成表示以用于检索相关文章:"
)
model.query_instruction = "为这个句子生成表示以用于检索相关文章:"
```
#### Using HuggingFace Transformers
With the transformers package, you can use the model like this: First, you pass your input through the transformer model, then you select the last hidden state of the first token (i.e., [CLS]) as the sentence embedding.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)
```
### Usage for Reranker
Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding.
You can get a relevance score by inputting query and passage to the reranker.
The reranker is optimized based cross-entropy loss, so the relevance score is not bounded to a specific range.
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
Get relevance scores (higher scores indicate more relevance):
```python
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
```
#### Using Huggingface transformers
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
#### Usage of the ONNX files
```python
from optimum.onnxruntime import ORTModelForFeatureExtraction # type: ignore
import torch
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-small-en-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-small-en-v1.5')
model_ort = ORTModelForFeatureExtraction.from_pretrained('BAAI/bge-small-en-v1.5', file_name="onnx/model.onnx")
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
model_output_ort = model_ort(**encoded_input)
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# model_output and model_output_ort are identical
```
#### Usage via infinity
Its also possible to deploy the onnx files with the [infinity_emb](https://github.com/michaelfeil/infinity) pip package.
Recommended is `device="cuda", engine="torch"` with flash attention on gpu, and `device="cpu", engine="optimum"` for onnx inference.
```python
import asyncio
from infinity_emb import AsyncEmbeddingEngine, EngineArgs
sentences = ["Embed this is sentence via Infinity.", "Paris is in France."]
engine = AsyncEmbeddingEngine.from_args(
EngineArgs(model_name_or_path = "BAAI/bge-small-en-v1.5", device="cpu", engine="optimum" # or engine="torch"
))
async def main():
async with engine:
embeddings, usage = await engine.embed(sentences=sentences)
asyncio.run(main())
```
## Evaluation
`baai-general-embedding` models achieve **state-of-the-art performance on both MTEB and C-MTEB leaderboard!**
For more details and evaluation tools see our [scripts](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md).
- **MTEB**:
| Model Name | Dimension | Sequence Length | Average (56) | Retrieval (15) |Clustering (11) | Pair Classification (3) | Reranking (4) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 1024 | 512 | **64.23** | **54.29** | 46.08 | 87.12 | 60.03 | 83.11 | 31.61 | 75.97 |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 768 | 512 | 63.55 | 53.25 | 45.77 | 86.55 | 58.86 | 82.4 | 31.07 | 75.53 |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | 384 | 512 | 62.17 |51.68 | 43.82 | 84.92 | 58.36 | 81.59 | 30.12 | 74.14 |
| [bge-large-en](https://huggingface.co/BAAI/bge-large-en) | 1024 | 512 | 63.98 | 53.9 | 46.98 | 85.8 | 59.48 | 81.56 | 32.06 | 76.21 |
| [bge-base-en](https://huggingface.co/BAAI/bge-base-en) | 768 | 512 | 63.36 | 53.0 | 46.32 | 85.86 | 58.7 | 81.84 | 29.27 | 75.27 |
| [gte-large](https://huggingface.co/thenlper/gte-large) | 1024 | 512 | 63.13 | 52.22 | 46.84 | 85.00 | 59.13 | 83.35 | 31.66 | 73.33 |
| [gte-base](https://huggingface.co/thenlper/gte-base) | 768 | 512 | 62.39 | 51.14 | 46.2 | 84.57 | 58.61 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1024| 512 | 62.25 | 50.56 | 44.49 | 86.03 | 56.61 | 82.05 | 30.19 | 75.24 |
| [bge-small-en](https://huggingface.co/BAAI/bge-small-en) | 384 | 512 | 62.11 | 51.82 | 44.31 | 83.78 | 57.97 | 80.72 | 30.53 | 74.37 |
| [instructor-xl](https://huggingface.co/hkunlp/instructor-xl) | 768 | 512 | 61.79 | 49.26 | 44.74 | 86.62 | 57.29 | 83.06 | 32.32 | 61.79 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 768 | 512 | 61.5 | 50.29 | 43.80 | 85.73 | 55.91 | 81.05 | 30.28 | 73.84 |
| [gte-small](https://huggingface.co/thenlper/gte-small) | 384 | 512 | 61.36 | 49.46 | 44.89 | 83.54 | 57.7 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | 1536 | 8192 | 60.99 | 49.25 | 45.9 | 84.89 | 56.32 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 384 | 512 | 59.93 | 49.04 | 39.92 | 84.67 | 54.32 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 768 | 512 | 59.51 | 42.24 | 43.72 | 85.06 | 56.42 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 768 | 514 | 57.78 | 43.81 | 43.69 | 83.04 | 59.36 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 4096 | 2048 | 57.59 | 48.22 | 38.93 | 81.9 | 55.65 | 77.74 | 33.6 | 66.19 |
- **C-MTEB**:
We create the benchmark C-MTEB for Chinese text embedding which consists of 31 datasets from 6 tasks.
Please refer to [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md) for a detailed introduction.
| Model | Embedding dimension | Avg | Retrieval | STS | PairClassification | Classification | Reranking | Clustering |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| [**BAAI/bge-large-zh-v1.5**](https://huggingface.co/BAAI/bge-large-zh-v1.5) | 1024 | **64.53** | 70.46 | 56.25 | 81.6 | 69.13 | 65.84 | 48.99 |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | 768 | 63.13 | 69.49 | 53.72 | 79.75 | 68.07 | 65.39 | 47.53 |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | 512 | 57.82 | 61.77 | 49.11 | 70.41 | 63.96 | 60.92 | 44.18 |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | 1024 | 64.20 | 71.53 | 54.98 | 78.94 | 68.32 | 65.11 | 48.39 |
| [bge-large-zh-noinstruct](https://huggingface.co/BAAI/bge-large-zh-noinstruct) | 1024 | 63.53 | 70.55 | 53 | 76.77 | 68.58 | 64.91 | 50.01 |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | 768 | 62.96 | 69.53 | 54.12 | 77.5 | 67.07 | 64.91 | 47.63 |
| [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 1024 | 58.79 | 63.66 | 48.44 | 69.89 | 67.34 | 56.00 | 48.23 |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | 512 | 58.27 | 63.07 | 49.45 | 70.35 | 63.64 | 61.48 | 45.09 |
| [m3e-base](https://huggingface.co/moka-ai/m3e-base) | 768 | 57.10 | 56.91 | 50.47 | 63.99 | 67.52 | 59.34 | 47.68 |
| [m3e-large](https://huggingface.co/moka-ai/m3e-large) | 1024 | 57.05 | 54.75 | 50.42 | 64.3 | 68.2 | 59.66 | 48.88 |
| [multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 768 | 55.48 | 61.63 | 46.49 | 67.07 | 65.35 | 54.35 | 40.68 |
| [multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small) | 384 | 55.38 | 59.95 | 45.27 | 66.45 | 65.85 | 53.86 | 45.26 |
| [text-embedding-ada-002(OpenAI)](https://platform.openai.com/docs/guides/embeddings/what-are-embeddings) | 1536 | 53.02 | 52.0 | 43.35 | 69.56 | 64.31 | 54.28 | 45.68 |
| [luotuo](https://huggingface.co/silk-road/luotuo-bert-medium) | 1024 | 49.37 | 44.4 | 42.78 | 66.62 | 61 | 49.25 | 44.39 |
| [text2vec-base](https://huggingface.co/shibing624/text2vec-base-chinese) | 768 | 47.63 | 38.79 | 43.41 | 67.41 | 62.19 | 49.45 | 37.66 |
| [text2vec-large](https://huggingface.co/GanymedeNil/text2vec-large-chinese) | 1024 | 47.36 | 41.94 | 44.97 | 70.86 | 60.66 | 49.16 | 30.02 |
- **Reranking**:
See [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/) for evaluation script.
| Model | T2Reranking | T2RerankingZh2En\* | T2RerankingEn2Zh\* | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| text2vec-base-multilingual | 64.66 | 62.94 | 62.51 | 14.37 | 48.46 | 48.6 | 50.26 |
| multilingual-e5-small | 65.62 | 60.94 | 56.41 | 29.91 | 67.26 | 66.54 | 57.78 |
| multilingual-e5-large | 64.55 | 61.61 | 54.28 | 28.6 | 67.42 | 67.92 | 57.4 |
| multilingual-e5-base | 64.21 | 62.13 | 54.68 | 29.5 | 66.23 | 66.98 | 57.29 |
| m3e-base | 66.03 | 62.74 | 56.07 | 17.51 | 77.05 | 76.76 | 59.36 |
| m3e-large | 66.13 | 62.72 | 56.1 | 16.46 | 77.76 | 78.27 | 59.57 |
| bge-base-zh-v1.5 | 66.49 | 63.25 | 57.02 | 29.74 | 80.47 | 84.88 | 63.64 |
| bge-large-zh-v1.5 | 65.74 | 63.39 | 57.03 | 28.74 | 83.45 | 85.44 | 63.97 |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | 67.28 | 63.95 | 60.45 | 35.46 | 81.26 | 84.1 | 65.42 |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | 67.6 | 64.03 | 61.44 | 37.16 | 82.15 | 84.18 | 66.09 |
\* : T2RerankingZh2En and T2RerankingEn2Zh are cross-language retrieval tasks
## Train
### BAAI Embedding
We pre-train the models using [retromae](https://github.com/staoxiao/RetroMAE) and train them on large-scale pairs data using contrastive learning.
**You can fine-tune the embedding model on your data following our [examples](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune).**
We also provide a [pre-train example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/pretrain).
Note that the goal of pre-training is to reconstruct the text, and the pre-trained model cannot be used for similarity calculation directly, it needs to be fine-tuned.
More training details for bge see [baai_general_embedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md).
### BGE Reranker
Cross-encoder will perform full-attention over the input pair,
which is more accurate than embedding model (i.e., bi-encoder) but more time-consuming than embedding model.
Therefore, it can be used to re-rank the top-k documents returned by embedding model.
We train the cross-encoder on a multilingual pair data,
The data format is the same as embedding model, so you can fine-tune it easily following our [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker).
More details please refer to [./FlagEmbedding/reranker/README.md](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
## Contact
If you have any question or suggestion related to this project, feel free to open an issue or pull request.
You also can email Shitao Xiao([email protected]) and Zheng Liu([email protected]).
## Citation
If you find this repository useful, please consider giving a star :star: and citation
```
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## License
FlagEmbedding is licensed under the [MIT License](https://github.com/FlagOpen/FlagEmbedding/blob/master/LICENSE). The released models can be used for commercial purposes free of charge.
|
openai/whisper-large-v3-turbo | openai | "2024-10-04T14:51:11Z" | 5,750,501 | 1,912 | transformers | [
"transformers",
"safetensors",
"whisper",
"automatic-speech-recognition",
"audio",
"en",
"zh",
"de",
"es",
"ru",
"ko",
"fr",
"ja",
"pt",
"tr",
"pl",
"ca",
"nl",
"ar",
"sv",
"it",
"id",
"hi",
"fi",
"vi",
"he",
"uk",
"el",
"ms",
"cs",
"ro",
"da",
"hu",
"ta",
"no",
"th",
"ur",
"hr",
"bg",
"lt",
"la",
"mi",
"ml",
"cy",
"sk",
"te",
"fa",
"lv",
"bn",
"sr",
"az",
"sl",
"kn",
"et",
"mk",
"br",
"eu",
"is",
"hy",
"ne",
"mn",
"bs",
"kk",
"sq",
"sw",
"gl",
"mr",
"pa",
"si",
"km",
"sn",
"yo",
"so",
"af",
"oc",
"ka",
"be",
"tg",
"sd",
"gu",
"am",
"yi",
"lo",
"uz",
"fo",
"ht",
"ps",
"tk",
"nn",
"mt",
"sa",
"lb",
"my",
"bo",
"tl",
"mg",
"as",
"tt",
"haw",
"ln",
"ha",
"ba",
"jw",
"su",
"arxiv:2212.04356",
"base_model:openai/whisper-large-v3",
"base_model:finetune:openai/whisper-large-v3",
"license:mit",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2024-10-01T07:39:28Z" | ---
language:
- en
- zh
- de
- es
- ru
- ko
- fr
- ja
- pt
- tr
- pl
- ca
- nl
- ar
- sv
- it
- id
- hi
- fi
- vi
- he
- uk
- el
- ms
- cs
- ro
- da
- hu
- ta
- 'no'
- th
- ur
- hr
- bg
- lt
- la
- mi
- ml
- cy
- sk
- te
- fa
- lv
- bn
- sr
- az
- sl
- kn
- et
- mk
- br
- eu
- is
- hy
- ne
- mn
- bs
- kk
- sq
- sw
- gl
- mr
- pa
- si
- km
- sn
- yo
- so
- af
- oc
- ka
- be
- tg
- sd
- gu
- am
- yi
- lo
- uz
- fo
- ht
- ps
- tk
- nn
- mt
- sa
- lb
- my
- bo
- tl
- mg
- as
- tt
- haw
- ln
- ha
- ba
- jw
- su
license: mit
tags:
- audio
- automatic-speech-recognition
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
pipeline_tag: automatic-speech-recognition
base_model:
- openai/whisper-large-v3
library_name: transformers
---
# Whisper
Whisper is a state-of-the-art model for automatic speech recognition (ASR) and speech translation, proposed in the paper
[Robust Speech Recognition via Large-Scale Weak Supervision](https://huggingface.co/papers/2212.04356) by Alec Radford
et al. from OpenAI. Trained on >5M hours of labeled data, Whisper demonstrates a strong ability to generalise to many
datasets and domains in a zero-shot setting.
Whisper large-v3-turbo is a finetuned version of a pruned [Whisper large-v3](https://huggingface.co/openai/whisper-large-v3). In other words, it's the exact same model, except that the number of decoding layers have reduced from 32 to 4.
As a result, the model is way faster, at the expense of a minor quality degradation. You can find more details about it [in this GitHub discussion](https://github.com/openai/whisper/discussions/2363).
**Disclaimer**: Content for this model card has partly been written by the 🤗 Hugging Face team, and partly copied and
pasted from the original model card.
## Usage
Whisper large-v3-turbo is supported in Hugging Face 🤗 Transformers. To run the model, first install the Transformers
library. For this example, we'll also install 🤗 Datasets to load toy audio dataset from the Hugging Face Hub, and
🤗 Accelerate to reduce the model loading time:
```bash
pip install --upgrade pip
pip install --upgrade transformers datasets[audio] accelerate
```
The model can be used with the [`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline)
class to transcribe audios of arbitrary length:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3-turbo"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
```
To transcribe a local audio file, simply pass the path to your audio file when you call the pipeline:
```python
result = pipe("audio.mp3")
```
Multiple audio files can be transcribed in parallel by specifying them as a list and setting the `batch_size` parameter:
```python
result = pipe(["audio_1.mp3", "audio_2.mp3"], batch_size=2)
```
Transformers is compatible with all Whisper decoding strategies, such as temperature fallback and condition on previous
tokens. The following example demonstrates how to enable these heuristics:
```python
generate_kwargs = {
"max_new_tokens": 448,
"num_beams": 1,
"condition_on_prev_tokens": False,
"compression_ratio_threshold": 1.35, # zlib compression ratio threshold (in token space)
"temperature": (0.0, 0.2, 0.4, 0.6, 0.8, 1.0),
"logprob_threshold": -1.0,
"no_speech_threshold": 0.6,
"return_timestamps": True,
}
result = pipe(sample, generate_kwargs=generate_kwargs)
```
Whisper predicts the language of the source audio automatically. If the source audio language is known *a-priori*, it
can be passed as an argument to the pipeline:
```python
result = pipe(sample, generate_kwargs={"language": "english"})
```
By default, Whisper performs the task of *speech transcription*, where the source audio language is the same as the target
text language. To perform *speech translation*, where the target text is in English, set the task to `"translate"`:
```python
result = pipe(sample, generate_kwargs={"task": "translate"})
```
Finally, the model can be made to predict timestamps. For sentence-level timestamps, pass the `return_timestamps` argument:
```python
result = pipe(sample, return_timestamps=True)
print(result["chunks"])
```
And for word-level timestamps:
```python
result = pipe(sample, return_timestamps="word")
print(result["chunks"])
```
The above arguments can be used in isolation or in combination. For example, to perform the task of speech transcription
where the source audio is in French, and we want to return sentence-level timestamps, the following can be used:
```python
result = pipe(sample, return_timestamps=True, generate_kwargs={"language": "french", "task": "translate"})
print(result["chunks"])
```
<details>
<summary> For more control over the generation parameters, use the model + processor API directly: </summary>
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
from datasets import Audio, load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3-turbo"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
dataset = dataset.cast_column("audio", Audio(processor.feature_extractor.sampling_rate))
sample = dataset[0]["audio"]
inputs = processor(
sample["array"],
sampling_rate=sample["sampling_rate"],
return_tensors="pt",
truncation=False,
padding="longest",
return_attention_mask=True,
)
inputs = inputs.to(device, dtype=torch_dtype)
gen_kwargs = {
"max_new_tokens": 448,
"num_beams": 1,
"condition_on_prev_tokens": False,
"compression_ratio_threshold": 1.35, # zlib compression ratio threshold (in token space)
"temperature": (0.0, 0.2, 0.4, 0.6, 0.8, 1.0),
"logprob_threshold": -1.0,
"no_speech_threshold": 0.6,
"return_timestamps": True,
}
pred_ids = model.generate(**inputs, **gen_kwargs)
pred_text = processor.batch_decode(pred_ids, skip_special_tokens=True, decode_with_timestamps=False)
print(pred_text)
```
</details>
## Additional Speed & Memory Improvements
You can apply additional speed and memory improvements to Whisper to further reduce the inference speed and VRAM
requirements.
### Chunked Long-Form
Whisper has a receptive field of 30-seconds. To transcribe audios longer than this, one of two long-form algorithms are
required:
1. **Sequential:** uses a "sliding window" for buffered inference, transcribing 30-second slices one after the other
2. **Chunked:** splits long audio files into shorter ones (with a small overlap between segments), transcribes each segment independently, and stitches the resulting transcriptions at the boundaries
The sequential long-form algorithm should be used in either of the following scenarios:
1. Transcription accuracy is the most important factor, and speed is less of a consideration
2. You are transcribing **batches** of long audio files, in which case the latency of sequential is comparable to chunked, while being up to 0.5% WER more accurate
Conversely, the chunked algorithm should be used when:
1. Transcription speed is the most important factor
2. You are transcribing a **single** long audio file
By default, Transformers uses the sequential algorithm. To enable the chunked algorithm, pass the `chunk_length_s`
parameter to the `pipeline`. For large-v3, a chunk length of 30-seconds is optimal. To activate batching over long
audio files, pass the argument `batch_size`:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3-turbo"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
chunk_length_s=30,
batch_size=16, # batch size for inference - set based on your device
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
```
#### Torch compile
The Whisper forward pass is compatible with [`torch.compile`](https://pytorch.org/docs/stable/generated/torch.compile.html)
for 4.5x speed-ups.
**Note:** `torch.compile` is currently not compatible with the Chunked long-form algorithm or Flash Attention 2 ⚠️
```python
import torch
from torch.nn.attention import SDPBackend, sdpa_kernel
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
from tqdm import tqdm
torch.set_float32_matmul_precision("high")
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3-turbo"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True
).to(device)
# Enable static cache and compile the forward pass
model.generation_config.cache_implementation = "static"
model.generation_config.max_new_tokens = 256
model.forward = torch.compile(model.forward, mode="reduce-overhead", fullgraph=True)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
# 2 warmup steps
for _ in tqdm(range(2), desc="Warm-up step"):
with sdpa_kernel(SDPBackend.MATH):
result = pipe(sample.copy(), generate_kwargs={"min_new_tokens": 256, "max_new_tokens": 256})
# fast run
with sdpa_kernel(SDPBackend.MATH):
result = pipe(sample.copy())
print(result["text"])
```
#### Flash Attention 2
We recommend using [Flash-Attention 2](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#flashattention-2) if your GPU supports it and you are not using [torch.compile](#torch-compile).
To do so, first install [Flash Attention](https://github.com/Dao-AILab/flash-attention):
```
pip install flash-attn --no-build-isolation
```
Then pass `attn_implementation="flash_attention_2"` to `from_pretrained`:
```python
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, attn_implementation="flash_attention_2")
```
#### Torch Scale-Product-Attention (SDPA)
If your GPU does not support Flash Attention, we recommend making use of PyTorch [scaled dot-product attention (SDPA)](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html).
This attention implementation is activated **by default** for PyTorch versions 2.1.1 or greater. To check
whether you have a compatible PyTorch version, run the following Python code snippet:
```python
from transformers.utils import is_torch_sdpa_available
print(is_torch_sdpa_available())
```
If the above returns `True`, you have a valid version of PyTorch installed and SDPA is activated by default. If it
returns `False`, you need to upgrade your PyTorch version according to the [official instructions](https://pytorch.org/get-started/locally/)
Once a valid PyTorch version is installed, SDPA is activated by default. It can also be set explicitly by specifying
`attn_implementation="sdpa"` as follows:
```python
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, attn_implementation="sdpa")
```
For more information about how to use the SDPA refer to the [Transformers SDPA documentation](https://huggingface.co/docs/transformers/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention).
## Model details
Whisper is a Transformer based encoder-decoder model, also referred to as a _sequence-to-sequence_ model. There are two
flavours of Whisper model: English-only and multilingual. The English-only models were trained on the task of English
speech recognition. The multilingual models were trained simultaneously on multilingual speech recognition and speech
translation. For speech recognition, the model predicts transcriptions in the *same* language as the audio. For speech
translation, the model predicts transcriptions to a *different* language to the audio.
Whisper checkpoints come in five configurations of varying model sizes. The smallest four are available as English-only
and multilingual. The largest checkpoints are multilingual only. All ten of the pre-trained checkpoints
are available on the [Hugging Face Hub](https://huggingface.co/models?search=openai/whisper). The
checkpoints are summarised in the following table with links to the models on the Hub:
| Size | Parameters | English-only | Multilingual |
|----------|------------|------------------------------------------------------|-----------------------------------------------------|
| tiny | 39 M | [✓](https://huggingface.co/openai/whisper-tiny.en) | [✓](https://huggingface.co/openai/whisper-tiny) |
| base | 74 M | [✓](https://huggingface.co/openai/whisper-base.en) | [✓](https://huggingface.co/openai/whisper-base) |
| small | 244 M | [✓](https://huggingface.co/openai/whisper-small.en) | [✓](https://huggingface.co/openai/whisper-small) |
| medium | 769 M | [✓](https://huggingface.co/openai/whisper-medium.en) | [✓](https://huggingface.co/openai/whisper-medium) |
| large | 1550 M | x | [✓](https://huggingface.co/openai/whisper-large) |
| large-v2 | 1550 M | x | [✓](https://huggingface.co/openai/whisper-large-v2) |
| large-v3 | 1550 M | x | [✓](https://huggingface.co/openai/whisper-large-v3) |
| large-v3-turbo | 809 M | x | [✓](https://huggingface.co/openai/whisper-large-v3-turbo) |
## Fine-Tuning
The pre-trained Whisper model demonstrates a strong ability to generalise to different datasets and domains. However,
its predictive capabilities can be improved further for certain languages and tasks through *fine-tuning*. The blog
post [Fine-Tune Whisper with 🤗 Transformers](https://huggingface.co/blog/fine-tune-whisper) provides a step-by-step
guide to fine-tuning the Whisper model with as little as 5 hours of labelled data.
### Evaluated Use
The primary intended users of these models are AI researchers studying robustness, generalization, capabilities, biases, and constraints of the current model. However, Whisper is also potentially quite useful as an ASR solution for developers, especially for English speech recognition. We recognize that once models are released, it is impossible to restrict access to only “intended” uses or to draw reasonable guidelines around what is or is not research.
The models are primarily trained and evaluated on ASR and speech translation to English tasks. They show strong ASR results in ~10 languages. They may exhibit additional capabilities, particularly if fine-tuned on certain tasks like voice activity detection, speaker classification, or speaker diarization but have not been robustly evaluated in these areas. We strongly recommend that users perform robust evaluations of the models in a particular context and domain before deploying them.
In particular, we caution against using Whisper models to transcribe recordings of individuals taken without their consent or purporting to use these models for any kind of subjective classification. We recommend against use in high-risk domains like decision-making contexts, where flaws in accuracy can lead to pronounced flaws in outcomes. The models are intended to transcribe and translate speech, use of the model for classification is not only not evaluated but also not appropriate, particularly to infer human attributes.
## Training Data
No information provided.
## Performance and Limitations
Our studies show that, over many existing ASR systems, the models exhibit improved robustness to accents, background noise, technical language, as well as zero shot translation from multiple languages into English; and that accuracy on speech recognition and translation is near the state-of-the-art level.
However, because the models are trained in a weakly supervised manner using large-scale noisy data, the predictions may include texts that are not actually spoken in the audio input (i.e. hallucination). We hypothesize that this happens because, given their general knowledge of language, the models combine trying to predict the next word in audio with trying to transcribe the audio itself.
Our models perform unevenly across languages, and we observe lower accuracy on low-resource and/or low-discoverability languages or languages where we have less training data. The models also exhibit disparate performance on different accents and dialects of particular languages, which may include higher word error rate across speakers of different genders, races, ages, or other demographic criteria. Our full evaluation results are presented in [the paper accompanying this release](https://cdn.openai.com/papers/whisper.pdf).
In addition, the sequence-to-sequence architecture of the model makes it prone to generating repetitive texts, which can be mitigated to some degree by beam search and temperature scheduling but not perfectly. Further analysis on these limitations are provided in [the paper](https://cdn.openai.com/papers/whisper.pdf). It is likely that this behavior and hallucinations may be worse on lower-resource and/or lower-discoverability languages.
## Broader Implications
We anticipate that Whisper models’ transcription capabilities may be used for improving accessibility tools. While Whisper models cannot be used for real-time transcription out of the box – their speed and size suggest that others may be able to build applications on top of them that allow for near-real-time speech recognition and translation. The real value of beneficial applications built on top of Whisper models suggests that the disparate performance of these models may have real economic implications.
There are also potential dual use concerns that come with releasing Whisper. While we hope the technology will be used primarily for beneficial purposes, making ASR technology more accessible could enable more actors to build capable surveillance technologies or scale up existing surveillance efforts, as the speed and accuracy allow for affordable automatic transcription and translation of large volumes of audio communication. Moreover, these models may have some capabilities to recognize specific individuals out of the box, which in turn presents safety concerns related both to dual use and disparate performance. In practice, we expect that the cost of transcription is not the limiting factor of scaling up surveillance projects.
### BibTeX entry and citation info
```bibtex
@misc{radford2022whisper,
doi = {10.48550/ARXIV.2212.04356},
url = {https://arxiv.org/abs/2212.04356},
author = {Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya},
title = {Robust Speech Recognition via Large-Scale Weak Supervision},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
``` |
laurievb/OpenLID-v2 | laurievb | "2024-11-28T09:57:26Z" | 5,697,083 | 1 | fasttext | [
"fasttext",
"text-classification",
"language-identification",
"dataset:laurievb/OpenLID-v2",
"license:gpl-3.0",
"region:us"
] | text-classification | "2024-11-12T14:25:43Z" | ---
license: gpl-3.0
library_name: fasttext
tags:
- text-classification
- language-identification
metrics:
- f1
- precision
- recall
datasets:
- laurievb/OpenLID-v2
---
# OpenLID-v2
- **Developed by:** Laurie Burchell, Alexandra Birch, Nikolay Bogoychev, Kenneth Heafield
- **Model type:** Text classification (language identification)
- **Language(s) (NLP):** en
- **License:** gpl-3.0
- **Resources for more information:** [OpenLID paper](https://aclanthology.org/2023.acl-short.75/) and [OpenLID v2 blog](https://laurieburchell.github.io/2024/11/12/OpenLID-v2.html)
## Model description
OpenLID-v2 is a high-coverage, high-performance language identification model. It is an improved version of [OpenLID](https://huggingface.co/laurievb/OpenLID).
The original model and training data are described in [Burchell et al. (2023)](https://aclanthology.org/2023.acl-short.75/). The changes made to produce OpenLID-v2 and the rationale behind them are described in [this blog post](https://laurieburchell.github.io/2024/11/12/OpenLID-v2.html).
### How to use
Here is how to use this model to detect the language of a given text. For best results, text should be cleaned and normalised with [openlid.clean_text()](scripts/openlid.py) prior to classification:
```python
>>> import fasttext
>>> from openlid import clean_text
>>> from huggingface_hub import hf_hub_download
>>> model_path = hf_hub_download(repo_id="laurievb/OpenLID-v2", filename="openlid_v2.bin")
>>> model = fasttext.load_model(model_path)
>>> input_text = clean_text("Hello, world!")
>>> model.predict(input_text)
(('__label__eng_Latn',), array([0.81148803]))
>>> model.predict("Hello, world!", k=5)
(('__label__eng_Latn', '__label__vie_Latn', '__label__nld_Latn', '__label__pol_Latn', '__label__deu_Latn'),
array([0.61224753, 0.21323682, 0.09696738, 0.01359863, 0.01319415]))
```
### Limitations and bias
The dataset and model only covers 189 languages. In addition, because the FLORES-200 test set consists of sentences from a single domain (wiki articles), performance on this test set may not reflect how well our classifier works in other domains.
Our work aims to broaden NLP coverage by allowing practitioners to identify relevant data in more languages. However, we note that LID is inherently a normative activity that risks excluding minority dialects, scripts, or entire microlanguages from a macrolanguage. Choosing which languages to cover may reinforce power imbalances, as only some groups gain access to NLP technologies. In addition, errors in LID can have a significant impact on downstream performance, particularly (as is often the case) when a system is used as a ‘black box’. The performance of our classifier is not equal across languages which could lead to worse downstream performance for particular groups. We mitigate this by providing metrics by class.
## Training data
The model was trained on the [OpenLID-v2 dataset](https://huggingface.co/datasets/laurievb/OpenLID-v2). Classes were up/downsampled with temperature sampling prior to training; code to do this can be found [in the `scripts` directory](scripts/prepare_openlid_v2_for_model_training.sh).
## Training procedure
The model was trained using fastText with the following hyperparameters set. All other hyperparameters were set to their default values.
* loss: softmax
* epochs: 2
* learning rate: 0.8
* minimum number of word occurances: 1000
* embedding dimension: 256
* character n-grams: 2-5
* word n-grams: 1
* bucket size: 1,000,000
* threads: 68
### Evaluation datasets
The model was evaluated using the FLORES-200 benchmark provided by Costa-jussà et al. (2022) using [normalised language labels](https://huggingface.co/datasets/laurievb/OpenLID-v2/blob/main/scripts/relabel_data.py). Further information is available in the [OpenLID paper](https://aclanthology.org/2023.acl-short.75/) and [OpenLID v2 blog](https://laurieburchell.github.io/2024/11/12/OpenLID-v2.html).
### BibTeX entry and citation info
#### ACL citation (preferred)
```
@inproceedings{burchell-etal-2023-open,
title = "An Open Dataset and Model for Language Identification",
author = "Burchell, Laurie and
Birch, Alexandra and
Bogoychev, Nikolay and
Heafield, Kenneth",
editor = "Rogers, Anna and
Boyd-Graber, Jordan and
Okazaki, Naoaki",
booktitle = "Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)",
month = jul,
year = "2023",
address = "Toronto, Canada",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2023.acl-short.75",
doi = "10.18653/v1/2023.acl-short.75",
pages = "865--879",
abstract = "Language identification (LID) is a fundamental step in many natural language processing pipelines. However, current LID systems are far from perfect, particularly on lower-resource languages. We present a LID model which achieves a macro-average F1 score of 0.93 and a false positive rate of 0.033{\%} across 201 languages, outperforming previous work. We achieve this by training on a curated dataset of monolingual data, which we audit manually to ensure reliability. We make both the model and the dataset available to the research community. Finally, we carry out detailed analysis into our model{'}s performance, both in comparison to existing open models and by language class.",
}
``` |
WinKawaks/vit-tiny-patch16-224 | WinKawaks | "2023-03-30T14:56:06Z" | 5,450,710 | 17 | transformers | [
"transformers",
"pytorch",
"safetensors",
"vit",
"image-classification",
"vision",
"dataset:imagenet",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
Google didn't publish vit-tiny and vit-small model checkpoints in Hugging Face. I converted the weights from the [timm repository](https://github.com/rwightman/pytorch-image-models). This model is used in the same way as [ViT-base](https://huggingface.co/google/vit-base-patch16-224).
Note that [safetensors] model requires torch 2.0 environment. |
thenlper/gte-small | thenlper | "2024-11-16T08:17:33Z" | 5,252,741 | 146 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"tf",
"coreml",
"onnx",
"safetensors",
"openvino",
"bert",
"mteb",
"sentence-similarity",
"Sentence Transformers",
"en",
"arxiv:2308.03281",
"license:mit",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2023-07-27T10:14:55Z" | ---
tags:
- mteb
- sentence-similarity
- sentence-transformers
- Sentence Transformers
model-index:
- name: gte-small
results:
- task:
type: Classification
dataset:
type: mteb/amazon_counterfactual
name: MTEB AmazonCounterfactualClassification (en)
config: en
split: test
revision: e8379541af4e31359cca9fbcf4b00f2671dba205
metrics:
- type: accuracy
value: 73.22388059701493
- type: ap
value: 36.09895941426988
- type: f1
value: 67.3205651539195
- task:
type: Classification
dataset:
type: mteb/amazon_polarity
name: MTEB AmazonPolarityClassification
config: default
split: test
revision: e2d317d38cd51312af73b3d32a06d1a08b442046
metrics:
- type: accuracy
value: 91.81894999999999
- type: ap
value: 88.5240138417305
- type: f1
value: 91.80367382706962
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (en)
config: en
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 48.032
- type: f1
value: 47.4490665674719
- task:
type: Retrieval
dataset:
type: arguana
name: MTEB ArguAna
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.725
- type: map_at_10
value: 46.604
- type: map_at_100
value: 47.535
- type: map_at_1000
value: 47.538000000000004
- type: map_at_3
value: 41.833
- type: map_at_5
value: 44.61
- type: mrr_at_1
value: 31.223
- type: mrr_at_10
value: 46.794000000000004
- type: mrr_at_100
value: 47.725
- type: mrr_at_1000
value: 47.727000000000004
- type: mrr_at_3
value: 42.07
- type: mrr_at_5
value: 44.812000000000005
- type: ndcg_at_1
value: 30.725
- type: ndcg_at_10
value: 55.440999999999995
- type: ndcg_at_100
value: 59.134
- type: ndcg_at_1000
value: 59.199
- type: ndcg_at_3
value: 45.599000000000004
- type: ndcg_at_5
value: 50.637
- type: precision_at_1
value: 30.725
- type: precision_at_10
value: 8.364
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.1
- type: precision_at_3
value: 18.848000000000003
- type: precision_at_5
value: 13.77
- type: recall_at_1
value: 30.725
- type: recall_at_10
value: 83.64200000000001
- type: recall_at_100
value: 99.14699999999999
- type: recall_at_1000
value: 99.644
- type: recall_at_3
value: 56.543
- type: recall_at_5
value: 68.848
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-p2p
name: MTEB ArxivClusteringP2P
config: default
split: test
revision: a122ad7f3f0291bf49cc6f4d32aa80929df69d5d
metrics:
- type: v_measure
value: 47.90178078197678
- task:
type: Clustering
dataset:
type: mteb/arxiv-clustering-s2s
name: MTEB ArxivClusteringS2S
config: default
split: test
revision: f910caf1a6075f7329cdf8c1a6135696f37dbd53
metrics:
- type: v_measure
value: 40.25728393431922
- task:
type: Reranking
dataset:
type: mteb/askubuntudupquestions-reranking
name: MTEB AskUbuntuDupQuestions
config: default
split: test
revision: 2000358ca161889fa9c082cb41daa8dcfb161a54
metrics:
- type: map
value: 61.720297062897764
- type: mrr
value: 75.24139295607439
- task:
type: STS
dataset:
type: mteb/biosses-sts
name: MTEB BIOSSES
config: default
split: test
revision: d3fb88f8f02e40887cd149695127462bbcf29b4a
metrics:
- type: cos_sim_pearson
value: 89.43527309184616
- type: cos_sim_spearman
value: 88.17128615100206
- type: euclidean_pearson
value: 87.89922623089282
- type: euclidean_spearman
value: 87.96104039655451
- type: manhattan_pearson
value: 87.9818290932077
- type: manhattan_spearman
value: 88.00923426576885
- task:
type: Classification
dataset:
type: mteb/banking77
name: MTEB Banking77Classification
config: default
split: test
revision: 0fd18e25b25c072e09e0d92ab615fda904d66300
metrics:
- type: accuracy
value: 84.0844155844156
- type: f1
value: 84.01485017302213
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-p2p
name: MTEB BiorxivClusteringP2P
config: default
split: test
revision: 65b79d1d13f80053f67aca9498d9402c2d9f1f40
metrics:
- type: v_measure
value: 38.36574769259432
- task:
type: Clustering
dataset:
type: mteb/biorxiv-clustering-s2s
name: MTEB BiorxivClusteringS2S
config: default
split: test
revision: 258694dd0231531bc1fd9de6ceb52a0853c6d908
metrics:
- type: v_measure
value: 35.4857033165287
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackAndroidRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 30.261
- type: map_at_10
value: 42.419000000000004
- type: map_at_100
value: 43.927
- type: map_at_1000
value: 44.055
- type: map_at_3
value: 38.597
- type: map_at_5
value: 40.701
- type: mrr_at_1
value: 36.91
- type: mrr_at_10
value: 48.02
- type: mrr_at_100
value: 48.658
- type: mrr_at_1000
value: 48.708
- type: mrr_at_3
value: 44.945
- type: mrr_at_5
value: 46.705000000000005
- type: ndcg_at_1
value: 36.91
- type: ndcg_at_10
value: 49.353
- type: ndcg_at_100
value: 54.456
- type: ndcg_at_1000
value: 56.363
- type: ndcg_at_3
value: 43.483
- type: ndcg_at_5
value: 46.150999999999996
- type: precision_at_1
value: 36.91
- type: precision_at_10
value: 9.700000000000001
- type: precision_at_100
value: 1.557
- type: precision_at_1000
value: 0.202
- type: precision_at_3
value: 21.078
- type: precision_at_5
value: 15.421999999999999
- type: recall_at_1
value: 30.261
- type: recall_at_10
value: 63.242
- type: recall_at_100
value: 84.09100000000001
- type: recall_at_1000
value: 96.143
- type: recall_at_3
value: 46.478
- type: recall_at_5
value: 53.708
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackEnglishRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 31.145
- type: map_at_10
value: 40.996
- type: map_at_100
value: 42.266999999999996
- type: map_at_1000
value: 42.397
- type: map_at_3
value: 38.005
- type: map_at_5
value: 39.628
- type: mrr_at_1
value: 38.344
- type: mrr_at_10
value: 46.827000000000005
- type: mrr_at_100
value: 47.446
- type: mrr_at_1000
value: 47.489
- type: mrr_at_3
value: 44.448
- type: mrr_at_5
value: 45.747
- type: ndcg_at_1
value: 38.344
- type: ndcg_at_10
value: 46.733000000000004
- type: ndcg_at_100
value: 51.103
- type: ndcg_at_1000
value: 53.075
- type: ndcg_at_3
value: 42.366
- type: ndcg_at_5
value: 44.242
- type: precision_at_1
value: 38.344
- type: precision_at_10
value: 8.822000000000001
- type: precision_at_100
value: 1.417
- type: precision_at_1000
value: 0.187
- type: precision_at_3
value: 20.403
- type: precision_at_5
value: 14.306
- type: recall_at_1
value: 31.145
- type: recall_at_10
value: 56.909
- type: recall_at_100
value: 75.274
- type: recall_at_1000
value: 87.629
- type: recall_at_3
value: 43.784
- type: recall_at_5
value: 49.338
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGamingRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 38.83
- type: map_at_10
value: 51.553000000000004
- type: map_at_100
value: 52.581
- type: map_at_1000
value: 52.638
- type: map_at_3
value: 48.112
- type: map_at_5
value: 50.095
- type: mrr_at_1
value: 44.513999999999996
- type: mrr_at_10
value: 54.998000000000005
- type: mrr_at_100
value: 55.650999999999996
- type: mrr_at_1000
value: 55.679
- type: mrr_at_3
value: 52.602000000000004
- type: mrr_at_5
value: 53.931
- type: ndcg_at_1
value: 44.513999999999996
- type: ndcg_at_10
value: 57.67400000000001
- type: ndcg_at_100
value: 61.663999999999994
- type: ndcg_at_1000
value: 62.743
- type: ndcg_at_3
value: 51.964
- type: ndcg_at_5
value: 54.773
- type: precision_at_1
value: 44.513999999999996
- type: precision_at_10
value: 9.423
- type: precision_at_100
value: 1.2309999999999999
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 23.323
- type: precision_at_5
value: 16.163
- type: recall_at_1
value: 38.83
- type: recall_at_10
value: 72.327
- type: recall_at_100
value: 89.519
- type: recall_at_1000
value: 97.041
- type: recall_at_3
value: 57.206
- type: recall_at_5
value: 63.88399999999999
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackGisRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.484
- type: map_at_10
value: 34.527
- type: map_at_100
value: 35.661
- type: map_at_1000
value: 35.739
- type: map_at_3
value: 32.199
- type: map_at_5
value: 33.632
- type: mrr_at_1
value: 27.458
- type: mrr_at_10
value: 36.543
- type: mrr_at_100
value: 37.482
- type: mrr_at_1000
value: 37.543
- type: mrr_at_3
value: 34.256
- type: mrr_at_5
value: 35.618
- type: ndcg_at_1
value: 27.458
- type: ndcg_at_10
value: 39.396
- type: ndcg_at_100
value: 44.742
- type: ndcg_at_1000
value: 46.708
- type: ndcg_at_3
value: 34.817
- type: ndcg_at_5
value: 37.247
- type: precision_at_1
value: 27.458
- type: precision_at_10
value: 5.976999999999999
- type: precision_at_100
value: 0.907
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 14.878
- type: precision_at_5
value: 10.35
- type: recall_at_1
value: 25.484
- type: recall_at_10
value: 52.317
- type: recall_at_100
value: 76.701
- type: recall_at_1000
value: 91.408
- type: recall_at_3
value: 40.043
- type: recall_at_5
value: 45.879
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackMathematicaRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.719
- type: map_at_10
value: 25.269000000000002
- type: map_at_100
value: 26.442
- type: map_at_1000
value: 26.557
- type: map_at_3
value: 22.56
- type: map_at_5
value: 24.082
- type: mrr_at_1
value: 20.896
- type: mrr_at_10
value: 29.982999999999997
- type: mrr_at_100
value: 30.895
- type: mrr_at_1000
value: 30.961
- type: mrr_at_3
value: 27.239
- type: mrr_at_5
value: 28.787000000000003
- type: ndcg_at_1
value: 20.896
- type: ndcg_at_10
value: 30.814000000000004
- type: ndcg_at_100
value: 36.418
- type: ndcg_at_1000
value: 39.182
- type: ndcg_at_3
value: 25.807999999999996
- type: ndcg_at_5
value: 28.143
- type: precision_at_1
value: 20.896
- type: precision_at_10
value: 5.821
- type: precision_at_100
value: 0.991
- type: precision_at_1000
value: 0.136
- type: precision_at_3
value: 12.562000000000001
- type: precision_at_5
value: 9.254
- type: recall_at_1
value: 16.719
- type: recall_at_10
value: 43.155
- type: recall_at_100
value: 67.831
- type: recall_at_1000
value: 87.617
- type: recall_at_3
value: 29.259
- type: recall_at_5
value: 35.260999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackPhysicsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 29.398999999999997
- type: map_at_10
value: 39.876
- type: map_at_100
value: 41.205999999999996
- type: map_at_1000
value: 41.321999999999996
- type: map_at_3
value: 36.588
- type: map_at_5
value: 38.538
- type: mrr_at_1
value: 35.9
- type: mrr_at_10
value: 45.528
- type: mrr_at_100
value: 46.343
- type: mrr_at_1000
value: 46.388
- type: mrr_at_3
value: 42.862
- type: mrr_at_5
value: 44.440000000000005
- type: ndcg_at_1
value: 35.9
- type: ndcg_at_10
value: 45.987
- type: ndcg_at_100
value: 51.370000000000005
- type: ndcg_at_1000
value: 53.400000000000006
- type: ndcg_at_3
value: 40.841
- type: ndcg_at_5
value: 43.447
- type: precision_at_1
value: 35.9
- type: precision_at_10
value: 8.393
- type: precision_at_100
value: 1.283
- type: precision_at_1000
value: 0.166
- type: precision_at_3
value: 19.538
- type: precision_at_5
value: 13.975000000000001
- type: recall_at_1
value: 29.398999999999997
- type: recall_at_10
value: 58.361
- type: recall_at_100
value: 81.081
- type: recall_at_1000
value: 94.004
- type: recall_at_3
value: 43.657000000000004
- type: recall_at_5
value: 50.519999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackProgrammersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 21.589
- type: map_at_10
value: 31.608999999999998
- type: map_at_100
value: 33.128
- type: map_at_1000
value: 33.247
- type: map_at_3
value: 28.671999999999997
- type: map_at_5
value: 30.233999999999998
- type: mrr_at_1
value: 26.712000000000003
- type: mrr_at_10
value: 36.713
- type: mrr_at_100
value: 37.713
- type: mrr_at_1000
value: 37.771
- type: mrr_at_3
value: 34.075
- type: mrr_at_5
value: 35.451
- type: ndcg_at_1
value: 26.712000000000003
- type: ndcg_at_10
value: 37.519999999999996
- type: ndcg_at_100
value: 43.946000000000005
- type: ndcg_at_1000
value: 46.297
- type: ndcg_at_3
value: 32.551
- type: ndcg_at_5
value: 34.660999999999994
- type: precision_at_1
value: 26.712000000000003
- type: precision_at_10
value: 7.066
- type: precision_at_100
value: 1.216
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 15.906
- type: precision_at_5
value: 11.437999999999999
- type: recall_at_1
value: 21.589
- type: recall_at_10
value: 50.090999999999994
- type: recall_at_100
value: 77.43900000000001
- type: recall_at_1000
value: 93.35900000000001
- type: recall_at_3
value: 36.028999999999996
- type: recall_at_5
value: 41.698
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.121666666666663
- type: map_at_10
value: 34.46258333333334
- type: map_at_100
value: 35.710499999999996
- type: map_at_1000
value: 35.82691666666666
- type: map_at_3
value: 31.563249999999996
- type: map_at_5
value: 33.189750000000004
- type: mrr_at_1
value: 29.66441666666667
- type: mrr_at_10
value: 38.5455
- type: mrr_at_100
value: 39.39566666666667
- type: mrr_at_1000
value: 39.45325
- type: mrr_at_3
value: 36.003333333333345
- type: mrr_at_5
value: 37.440916666666666
- type: ndcg_at_1
value: 29.66441666666667
- type: ndcg_at_10
value: 39.978416666666675
- type: ndcg_at_100
value: 45.278666666666666
- type: ndcg_at_1000
value: 47.52275
- type: ndcg_at_3
value: 35.00058333333334
- type: ndcg_at_5
value: 37.34908333333333
- type: precision_at_1
value: 29.66441666666667
- type: precision_at_10
value: 7.094500000000001
- type: precision_at_100
value: 1.1523333333333332
- type: precision_at_1000
value: 0.15358333333333332
- type: precision_at_3
value: 16.184166666666663
- type: precision_at_5
value: 11.6005
- type: recall_at_1
value: 25.121666666666663
- type: recall_at_10
value: 52.23975000000001
- type: recall_at_100
value: 75.48408333333333
- type: recall_at_1000
value: 90.95316666666668
- type: recall_at_3
value: 38.38458333333333
- type: recall_at_5
value: 44.39933333333333
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackStatsRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.569000000000003
- type: map_at_10
value: 30.389
- type: map_at_100
value: 31.396
- type: map_at_1000
value: 31.493
- type: map_at_3
value: 28.276
- type: map_at_5
value: 29.459000000000003
- type: mrr_at_1
value: 26.534000000000002
- type: mrr_at_10
value: 33.217999999999996
- type: mrr_at_100
value: 34.054
- type: mrr_at_1000
value: 34.12
- type: mrr_at_3
value: 31.058000000000003
- type: mrr_at_5
value: 32.330999999999996
- type: ndcg_at_1
value: 26.534000000000002
- type: ndcg_at_10
value: 34.608
- type: ndcg_at_100
value: 39.391999999999996
- type: ndcg_at_1000
value: 41.837999999999994
- type: ndcg_at_3
value: 30.564999999999998
- type: ndcg_at_5
value: 32.509
- type: precision_at_1
value: 26.534000000000002
- type: precision_at_10
value: 5.414
- type: precision_at_100
value: 0.847
- type: precision_at_1000
value: 0.11399999999999999
- type: precision_at_3
value: 12.986
- type: precision_at_5
value: 9.202
- type: recall_at_1
value: 23.569000000000003
- type: recall_at_10
value: 44.896
- type: recall_at_100
value: 66.476
- type: recall_at_1000
value: 84.548
- type: recall_at_3
value: 33.79
- type: recall_at_5
value: 38.512
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackTexRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 16.36
- type: map_at_10
value: 23.57
- type: map_at_100
value: 24.698999999999998
- type: map_at_1000
value: 24.834999999999997
- type: map_at_3
value: 21.093
- type: map_at_5
value: 22.418
- type: mrr_at_1
value: 19.718
- type: mrr_at_10
value: 27.139999999999997
- type: mrr_at_100
value: 28.097
- type: mrr_at_1000
value: 28.177999999999997
- type: mrr_at_3
value: 24.805
- type: mrr_at_5
value: 26.121
- type: ndcg_at_1
value: 19.718
- type: ndcg_at_10
value: 28.238999999999997
- type: ndcg_at_100
value: 33.663
- type: ndcg_at_1000
value: 36.763
- type: ndcg_at_3
value: 23.747
- type: ndcg_at_5
value: 25.796000000000003
- type: precision_at_1
value: 19.718
- type: precision_at_10
value: 5.282
- type: precision_at_100
value: 0.9390000000000001
- type: precision_at_1000
value: 0.13899999999999998
- type: precision_at_3
value: 11.264000000000001
- type: precision_at_5
value: 8.341
- type: recall_at_1
value: 16.36
- type: recall_at_10
value: 38.669
- type: recall_at_100
value: 63.184
- type: recall_at_1000
value: 85.33800000000001
- type: recall_at_3
value: 26.214
- type: recall_at_5
value: 31.423000000000002
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackUnixRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 25.618999999999996
- type: map_at_10
value: 34.361999999999995
- type: map_at_100
value: 35.534
- type: map_at_1000
value: 35.634
- type: map_at_3
value: 31.402
- type: map_at_5
value: 32.815
- type: mrr_at_1
value: 30.037000000000003
- type: mrr_at_10
value: 38.284
- type: mrr_at_100
value: 39.141999999999996
- type: mrr_at_1000
value: 39.2
- type: mrr_at_3
value: 35.603
- type: mrr_at_5
value: 36.867
- type: ndcg_at_1
value: 30.037000000000003
- type: ndcg_at_10
value: 39.87
- type: ndcg_at_100
value: 45.243
- type: ndcg_at_1000
value: 47.507
- type: ndcg_at_3
value: 34.371
- type: ndcg_at_5
value: 36.521
- type: precision_at_1
value: 30.037000000000003
- type: precision_at_10
value: 6.819
- type: precision_at_100
value: 1.0699999999999998
- type: precision_at_1000
value: 0.13699999999999998
- type: precision_at_3
value: 15.392
- type: precision_at_5
value: 10.821
- type: recall_at_1
value: 25.618999999999996
- type: recall_at_10
value: 52.869
- type: recall_at_100
value: 76.395
- type: recall_at_1000
value: 92.19500000000001
- type: recall_at_3
value: 37.943
- type: recall_at_5
value: 43.342999999999996
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWebmastersRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 23.283
- type: map_at_10
value: 32.155
- type: map_at_100
value: 33.724
- type: map_at_1000
value: 33.939
- type: map_at_3
value: 29.018
- type: map_at_5
value: 30.864000000000004
- type: mrr_at_1
value: 28.063
- type: mrr_at_10
value: 36.632
- type: mrr_at_100
value: 37.606
- type: mrr_at_1000
value: 37.671
- type: mrr_at_3
value: 33.992
- type: mrr_at_5
value: 35.613
- type: ndcg_at_1
value: 28.063
- type: ndcg_at_10
value: 38.024
- type: ndcg_at_100
value: 44.292
- type: ndcg_at_1000
value: 46.818
- type: ndcg_at_3
value: 32.965
- type: ndcg_at_5
value: 35.562
- type: precision_at_1
value: 28.063
- type: precision_at_10
value: 7.352
- type: precision_at_100
value: 1.514
- type: precision_at_1000
value: 0.23800000000000002
- type: precision_at_3
value: 15.481
- type: precision_at_5
value: 11.542
- type: recall_at_1
value: 23.283
- type: recall_at_10
value: 49.756
- type: recall_at_100
value: 78.05
- type: recall_at_1000
value: 93.854
- type: recall_at_3
value: 35.408
- type: recall_at_5
value: 42.187000000000005
- task:
type: Retrieval
dataset:
type: BeIR/cqadupstack
name: MTEB CQADupstackWordpressRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.201999999999998
- type: map_at_10
value: 26.826
- type: map_at_100
value: 27.961000000000002
- type: map_at_1000
value: 28.066999999999997
- type: map_at_3
value: 24.237000000000002
- type: map_at_5
value: 25.811
- type: mrr_at_1
value: 20.887
- type: mrr_at_10
value: 28.660000000000004
- type: mrr_at_100
value: 29.660999999999998
- type: mrr_at_1000
value: 29.731
- type: mrr_at_3
value: 26.155
- type: mrr_at_5
value: 27.68
- type: ndcg_at_1
value: 20.887
- type: ndcg_at_10
value: 31.523
- type: ndcg_at_100
value: 37.055
- type: ndcg_at_1000
value: 39.579
- type: ndcg_at_3
value: 26.529000000000003
- type: ndcg_at_5
value: 29.137
- type: precision_at_1
value: 20.887
- type: precision_at_10
value: 5.065
- type: precision_at_100
value: 0.856
- type: precision_at_1000
value: 0.11900000000000001
- type: precision_at_3
value: 11.399
- type: precision_at_5
value: 8.392
- type: recall_at_1
value: 19.201999999999998
- type: recall_at_10
value: 44.285000000000004
- type: recall_at_100
value: 69.768
- type: recall_at_1000
value: 88.302
- type: recall_at_3
value: 30.804
- type: recall_at_5
value: 37.039
- task:
type: Retrieval
dataset:
type: climate-fever
name: MTEB ClimateFEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 11.244
- type: map_at_10
value: 18.956
- type: map_at_100
value: 20.674
- type: map_at_1000
value: 20.863
- type: map_at_3
value: 15.923000000000002
- type: map_at_5
value: 17.518
- type: mrr_at_1
value: 25.080999999999996
- type: mrr_at_10
value: 35.94
- type: mrr_at_100
value: 36.969
- type: mrr_at_1000
value: 37.013
- type: mrr_at_3
value: 32.617000000000004
- type: mrr_at_5
value: 34.682
- type: ndcg_at_1
value: 25.080999999999996
- type: ndcg_at_10
value: 26.539
- type: ndcg_at_100
value: 33.601
- type: ndcg_at_1000
value: 37.203
- type: ndcg_at_3
value: 21.695999999999998
- type: ndcg_at_5
value: 23.567
- type: precision_at_1
value: 25.080999999999996
- type: precision_at_10
value: 8.143
- type: precision_at_100
value: 1.5650000000000002
- type: precision_at_1000
value: 0.22300000000000003
- type: precision_at_3
value: 15.983
- type: precision_at_5
value: 12.417
- type: recall_at_1
value: 11.244
- type: recall_at_10
value: 31.457
- type: recall_at_100
value: 55.92
- type: recall_at_1000
value: 76.372
- type: recall_at_3
value: 19.784
- type: recall_at_5
value: 24.857000000000003
- task:
type: Retrieval
dataset:
type: dbpedia-entity
name: MTEB DBPedia
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 8.595
- type: map_at_10
value: 18.75
- type: map_at_100
value: 26.354
- type: map_at_1000
value: 27.912
- type: map_at_3
value: 13.794
- type: map_at_5
value: 16.021
- type: mrr_at_1
value: 65.75
- type: mrr_at_10
value: 73.837
- type: mrr_at_100
value: 74.22800000000001
- type: mrr_at_1000
value: 74.234
- type: mrr_at_3
value: 72.5
- type: mrr_at_5
value: 73.387
- type: ndcg_at_1
value: 52.625
- type: ndcg_at_10
value: 39.101
- type: ndcg_at_100
value: 43.836000000000006
- type: ndcg_at_1000
value: 51.086
- type: ndcg_at_3
value: 44.229
- type: ndcg_at_5
value: 41.555
- type: precision_at_1
value: 65.75
- type: precision_at_10
value: 30.45
- type: precision_at_100
value: 9.81
- type: precision_at_1000
value: 2.045
- type: precision_at_3
value: 48.667
- type: precision_at_5
value: 40.8
- type: recall_at_1
value: 8.595
- type: recall_at_10
value: 24.201
- type: recall_at_100
value: 50.096
- type: recall_at_1000
value: 72.677
- type: recall_at_3
value: 15.212
- type: recall_at_5
value: 18.745
- task:
type: Classification
dataset:
type: mteb/emotion
name: MTEB EmotionClassification
config: default
split: test
revision: 4f58c6b202a23cf9a4da393831edf4f9183cad37
metrics:
- type: accuracy
value: 46.565
- type: f1
value: 41.49914329345582
- task:
type: Retrieval
dataset:
type: fever
name: MTEB FEVER
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 66.60000000000001
- type: map_at_10
value: 76.838
- type: map_at_100
value: 77.076
- type: map_at_1000
value: 77.09
- type: map_at_3
value: 75.545
- type: map_at_5
value: 76.39
- type: mrr_at_1
value: 71.707
- type: mrr_at_10
value: 81.514
- type: mrr_at_100
value: 81.64099999999999
- type: mrr_at_1000
value: 81.645
- type: mrr_at_3
value: 80.428
- type: mrr_at_5
value: 81.159
- type: ndcg_at_1
value: 71.707
- type: ndcg_at_10
value: 81.545
- type: ndcg_at_100
value: 82.477
- type: ndcg_at_1000
value: 82.73899999999999
- type: ndcg_at_3
value: 79.292
- type: ndcg_at_5
value: 80.599
- type: precision_at_1
value: 71.707
- type: precision_at_10
value: 10.035
- type: precision_at_100
value: 1.068
- type: precision_at_1000
value: 0.11100000000000002
- type: precision_at_3
value: 30.918
- type: precision_at_5
value: 19.328
- type: recall_at_1
value: 66.60000000000001
- type: recall_at_10
value: 91.353
- type: recall_at_100
value: 95.21
- type: recall_at_1000
value: 96.89999999999999
- type: recall_at_3
value: 85.188
- type: recall_at_5
value: 88.52
- task:
type: Retrieval
dataset:
type: fiqa
name: MTEB FiQA2018
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 19.338
- type: map_at_10
value: 31.752000000000002
- type: map_at_100
value: 33.516
- type: map_at_1000
value: 33.694
- type: map_at_3
value: 27.716
- type: map_at_5
value: 29.67
- type: mrr_at_1
value: 38.117000000000004
- type: mrr_at_10
value: 47.323
- type: mrr_at_100
value: 48.13
- type: mrr_at_1000
value: 48.161
- type: mrr_at_3
value: 45.062000000000005
- type: mrr_at_5
value: 46.358
- type: ndcg_at_1
value: 38.117000000000004
- type: ndcg_at_10
value: 39.353
- type: ndcg_at_100
value: 46.044000000000004
- type: ndcg_at_1000
value: 49.083
- type: ndcg_at_3
value: 35.891
- type: ndcg_at_5
value: 36.661
- type: precision_at_1
value: 38.117000000000004
- type: precision_at_10
value: 11.187999999999999
- type: precision_at_100
value: 1.802
- type: precision_at_1000
value: 0.234
- type: precision_at_3
value: 24.126
- type: precision_at_5
value: 17.562
- type: recall_at_1
value: 19.338
- type: recall_at_10
value: 45.735
- type: recall_at_100
value: 71.281
- type: recall_at_1000
value: 89.537
- type: recall_at_3
value: 32.525
- type: recall_at_5
value: 37.671
- task:
type: Retrieval
dataset:
type: hotpotqa
name: MTEB HotpotQA
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 36.995
- type: map_at_10
value: 55.032000000000004
- type: map_at_100
value: 55.86
- type: map_at_1000
value: 55.932
- type: map_at_3
value: 52.125
- type: map_at_5
value: 53.884
- type: mrr_at_1
value: 73.991
- type: mrr_at_10
value: 80.096
- type: mrr_at_100
value: 80.32000000000001
- type: mrr_at_1000
value: 80.331
- type: mrr_at_3
value: 79.037
- type: mrr_at_5
value: 79.719
- type: ndcg_at_1
value: 73.991
- type: ndcg_at_10
value: 63.786
- type: ndcg_at_100
value: 66.78
- type: ndcg_at_1000
value: 68.255
- type: ndcg_at_3
value: 59.501000000000005
- type: ndcg_at_5
value: 61.82299999999999
- type: precision_at_1
value: 73.991
- type: precision_at_10
value: 13.157
- type: precision_at_100
value: 1.552
- type: precision_at_1000
value: 0.17500000000000002
- type: precision_at_3
value: 37.519999999999996
- type: precision_at_5
value: 24.351
- type: recall_at_1
value: 36.995
- type: recall_at_10
value: 65.78699999999999
- type: recall_at_100
value: 77.583
- type: recall_at_1000
value: 87.421
- type: recall_at_3
value: 56.279999999999994
- type: recall_at_5
value: 60.878
- task:
type: Classification
dataset:
type: mteb/imdb
name: MTEB ImdbClassification
config: default
split: test
revision: 3d86128a09e091d6018b6d26cad27f2739fc2db7
metrics:
- type: accuracy
value: 86.80239999999999
- type: ap
value: 81.97305141128378
- type: f1
value: 86.76976305549273
- task:
type: Retrieval
dataset:
type: msmarco
name: MTEB MSMARCO
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 21.166
- type: map_at_10
value: 33.396
- type: map_at_100
value: 34.588
- type: map_at_1000
value: 34.637
- type: map_at_3
value: 29.509999999999998
- type: map_at_5
value: 31.719
- type: mrr_at_1
value: 21.762
- type: mrr_at_10
value: 33.969
- type: mrr_at_100
value: 35.099000000000004
- type: mrr_at_1000
value: 35.141
- type: mrr_at_3
value: 30.148000000000003
- type: mrr_at_5
value: 32.324000000000005
- type: ndcg_at_1
value: 21.776999999999997
- type: ndcg_at_10
value: 40.306999999999995
- type: ndcg_at_100
value: 46.068
- type: ndcg_at_1000
value: 47.3
- type: ndcg_at_3
value: 32.416
- type: ndcg_at_5
value: 36.345
- type: precision_at_1
value: 21.776999999999997
- type: precision_at_10
value: 6.433
- type: precision_at_100
value: 0.932
- type: precision_at_1000
value: 0.104
- type: precision_at_3
value: 13.897
- type: precision_at_5
value: 10.324
- type: recall_at_1
value: 21.166
- type: recall_at_10
value: 61.587
- type: recall_at_100
value: 88.251
- type: recall_at_1000
value: 97.727
- type: recall_at_3
value: 40.196
- type: recall_at_5
value: 49.611
- task:
type: Classification
dataset:
type: mteb/mtop_domain
name: MTEB MTOPDomainClassification (en)
config: en
split: test
revision: d80d48c1eb48d3562165c59d59d0034df9fff0bf
metrics:
- type: accuracy
value: 93.04605563155496
- type: f1
value: 92.78007303978372
- task:
type: Classification
dataset:
type: mteb/mtop_intent
name: MTEB MTOPIntentClassification (en)
config: en
split: test
revision: ae001d0e6b1228650b7bd1c2c65fb50ad11a8aba
metrics:
- type: accuracy
value: 69.65116279069767
- type: f1
value: 52.75775172527262
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (en)
config: en
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 70.34633490248822
- type: f1
value: 68.15345065392562
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (en)
config: en
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 75.63887020847343
- type: f1
value: 76.08074680233685
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-p2p
name: MTEB MedrxivClusteringP2P
config: default
split: test
revision: e7a26af6f3ae46b30dde8737f02c07b1505bcc73
metrics:
- type: v_measure
value: 33.77933406071333
- task:
type: Clustering
dataset:
type: mteb/medrxiv-clustering-s2s
name: MTEB MedrxivClusteringS2S
config: default
split: test
revision: 35191c8c0dca72d8ff3efcd72aa802307d469663
metrics:
- type: v_measure
value: 32.06504927238196
- task:
type: Reranking
dataset:
type: mteb/mind_small
name: MTEB MindSmallReranking
config: default
split: test
revision: 3bdac13927fdc888b903db93b2ffdbd90b295a69
metrics:
- type: map
value: 32.20682480490871
- type: mrr
value: 33.41462721527003
- task:
type: Retrieval
dataset:
type: nfcorpus
name: MTEB NFCorpus
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 5.548
- type: map_at_10
value: 13.086999999999998
- type: map_at_100
value: 16.698
- type: map_at_1000
value: 18.151999999999997
- type: map_at_3
value: 9.576
- type: map_at_5
value: 11.175
- type: mrr_at_1
value: 44.272
- type: mrr_at_10
value: 53.635999999999996
- type: mrr_at_100
value: 54.228
- type: mrr_at_1000
value: 54.26499999999999
- type: mrr_at_3
value: 51.754
- type: mrr_at_5
value: 53.086
- type: ndcg_at_1
value: 42.724000000000004
- type: ndcg_at_10
value: 34.769
- type: ndcg_at_100
value: 32.283
- type: ndcg_at_1000
value: 40.843
- type: ndcg_at_3
value: 39.852
- type: ndcg_at_5
value: 37.858999999999995
- type: precision_at_1
value: 44.272
- type: precision_at_10
value: 26.068
- type: precision_at_100
value: 8.328000000000001
- type: precision_at_1000
value: 2.1
- type: precision_at_3
value: 37.874
- type: precision_at_5
value: 33.065
- type: recall_at_1
value: 5.548
- type: recall_at_10
value: 16.936999999999998
- type: recall_at_100
value: 33.72
- type: recall_at_1000
value: 64.348
- type: recall_at_3
value: 10.764999999999999
- type: recall_at_5
value: 13.361
- task:
type: Retrieval
dataset:
type: nq
name: MTEB NQ
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 28.008
- type: map_at_10
value: 42.675000000000004
- type: map_at_100
value: 43.85
- type: map_at_1000
value: 43.884
- type: map_at_3
value: 38.286
- type: map_at_5
value: 40.78
- type: mrr_at_1
value: 31.518
- type: mrr_at_10
value: 45.015
- type: mrr_at_100
value: 45.924
- type: mrr_at_1000
value: 45.946999999999996
- type: mrr_at_3
value: 41.348
- type: mrr_at_5
value: 43.428
- type: ndcg_at_1
value: 31.489
- type: ndcg_at_10
value: 50.285999999999994
- type: ndcg_at_100
value: 55.291999999999994
- type: ndcg_at_1000
value: 56.05
- type: ndcg_at_3
value: 41.976
- type: ndcg_at_5
value: 46.103
- type: precision_at_1
value: 31.489
- type: precision_at_10
value: 8.456
- type: precision_at_100
value: 1.125
- type: precision_at_1000
value: 0.12
- type: precision_at_3
value: 19.09
- type: precision_at_5
value: 13.841000000000001
- type: recall_at_1
value: 28.008
- type: recall_at_10
value: 71.21499999999999
- type: recall_at_100
value: 92.99
- type: recall_at_1000
value: 98.578
- type: recall_at_3
value: 49.604
- type: recall_at_5
value: 59.094
- task:
type: Retrieval
dataset:
type: quora
name: MTEB QuoraRetrieval
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 70.351
- type: map_at_10
value: 84.163
- type: map_at_100
value: 84.785
- type: map_at_1000
value: 84.801
- type: map_at_3
value: 81.16
- type: map_at_5
value: 83.031
- type: mrr_at_1
value: 80.96
- type: mrr_at_10
value: 87.241
- type: mrr_at_100
value: 87.346
- type: mrr_at_1000
value: 87.347
- type: mrr_at_3
value: 86.25699999999999
- type: mrr_at_5
value: 86.907
- type: ndcg_at_1
value: 80.97
- type: ndcg_at_10
value: 88.017
- type: ndcg_at_100
value: 89.241
- type: ndcg_at_1000
value: 89.34299999999999
- type: ndcg_at_3
value: 85.053
- type: ndcg_at_5
value: 86.663
- type: precision_at_1
value: 80.97
- type: precision_at_10
value: 13.358
- type: precision_at_100
value: 1.525
- type: precision_at_1000
value: 0.157
- type: precision_at_3
value: 37.143
- type: precision_at_5
value: 24.451999999999998
- type: recall_at_1
value: 70.351
- type: recall_at_10
value: 95.39800000000001
- type: recall_at_100
value: 99.55199999999999
- type: recall_at_1000
value: 99.978
- type: recall_at_3
value: 86.913
- type: recall_at_5
value: 91.448
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering
name: MTEB RedditClustering
config: default
split: test
revision: 24640382cdbf8abc73003fb0fa6d111a705499eb
metrics:
- type: v_measure
value: 55.62406719814139
- task:
type: Clustering
dataset:
type: mteb/reddit-clustering-p2p
name: MTEB RedditClusteringP2P
config: default
split: test
revision: 282350215ef01743dc01b456c7f5241fa8937f16
metrics:
- type: v_measure
value: 61.386700035141736
- task:
type: Retrieval
dataset:
type: scidocs
name: MTEB SCIDOCS
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 4.618
- type: map_at_10
value: 12.920000000000002
- type: map_at_100
value: 15.304
- type: map_at_1000
value: 15.656999999999998
- type: map_at_3
value: 9.187
- type: map_at_5
value: 10.937
- type: mrr_at_1
value: 22.8
- type: mrr_at_10
value: 35.13
- type: mrr_at_100
value: 36.239
- type: mrr_at_1000
value: 36.291000000000004
- type: mrr_at_3
value: 31.917
- type: mrr_at_5
value: 33.787
- type: ndcg_at_1
value: 22.8
- type: ndcg_at_10
value: 21.382
- type: ndcg_at_100
value: 30.257
- type: ndcg_at_1000
value: 36.001
- type: ndcg_at_3
value: 20.43
- type: ndcg_at_5
value: 17.622
- type: precision_at_1
value: 22.8
- type: precision_at_10
value: 11.26
- type: precision_at_100
value: 2.405
- type: precision_at_1000
value: 0.377
- type: precision_at_3
value: 19.633
- type: precision_at_5
value: 15.68
- type: recall_at_1
value: 4.618
- type: recall_at_10
value: 22.811999999999998
- type: recall_at_100
value: 48.787000000000006
- type: recall_at_1000
value: 76.63799999999999
- type: recall_at_3
value: 11.952
- type: recall_at_5
value: 15.892000000000001
- task:
type: STS
dataset:
type: mteb/sickr-sts
name: MTEB SICK-R
config: default
split: test
revision: a6ea5a8cab320b040a23452cc28066d9beae2cee
metrics:
- type: cos_sim_pearson
value: 84.01529458252244
- type: cos_sim_spearman
value: 77.92985224770254
- type: euclidean_pearson
value: 81.04251429422487
- type: euclidean_spearman
value: 77.92838490549133
- type: manhattan_pearson
value: 80.95892251458979
- type: manhattan_spearman
value: 77.81028089705941
- task:
type: STS
dataset:
type: mteb/sts12-sts
name: MTEB STS12
config: default
split: test
revision: a0d554a64d88156834ff5ae9920b964011b16384
metrics:
- type: cos_sim_pearson
value: 83.97885282534388
- type: cos_sim_spearman
value: 75.1221970851712
- type: euclidean_pearson
value: 80.34455956720097
- type: euclidean_spearman
value: 74.5894274239938
- type: manhattan_pearson
value: 80.38999766325465
- type: manhattan_spearman
value: 74.68524557166975
- task:
type: STS
dataset:
type: mteb/sts13-sts
name: MTEB STS13
config: default
split: test
revision: 7e90230a92c190f1bf69ae9002b8cea547a64cca
metrics:
- type: cos_sim_pearson
value: 82.95746064915672
- type: cos_sim_spearman
value: 85.08683458043946
- type: euclidean_pearson
value: 84.56699492836385
- type: euclidean_spearman
value: 85.66089116133713
- type: manhattan_pearson
value: 84.47553323458541
- type: manhattan_spearman
value: 85.56142206781472
- task:
type: STS
dataset:
type: mteb/sts14-sts
name: MTEB STS14
config: default
split: test
revision: 6031580fec1f6af667f0bd2da0a551cf4f0b2375
metrics:
- type: cos_sim_pearson
value: 82.71377893595067
- type: cos_sim_spearman
value: 81.03453291428589
- type: euclidean_pearson
value: 82.57136298308613
- type: euclidean_spearman
value: 81.15839961890875
- type: manhattan_pearson
value: 82.55157879373837
- type: manhattan_spearman
value: 81.1540163767054
- task:
type: STS
dataset:
type: mteb/sts15-sts
name: MTEB STS15
config: default
split: test
revision: ae752c7c21bf194d8b67fd573edf7ae58183cbe3
metrics:
- type: cos_sim_pearson
value: 86.64197832372373
- type: cos_sim_spearman
value: 88.31966852492485
- type: euclidean_pearson
value: 87.98692129976983
- type: euclidean_spearman
value: 88.6247340837856
- type: manhattan_pearson
value: 87.90437827826412
- type: manhattan_spearman
value: 88.56278787131457
- task:
type: STS
dataset:
type: mteb/sts16-sts
name: MTEB STS16
config: default
split: test
revision: 4d8694f8f0e0100860b497b999b3dbed754a0513
metrics:
- type: cos_sim_pearson
value: 81.84159950146693
- type: cos_sim_spearman
value: 83.90678384140168
- type: euclidean_pearson
value: 83.19005018860221
- type: euclidean_spearman
value: 84.16260415876295
- type: manhattan_pearson
value: 83.05030612994494
- type: manhattan_spearman
value: 83.99605629718336
- task:
type: STS
dataset:
type: mteb/sts17-crosslingual-sts
name: MTEB STS17 (en-en)
config: en-en
split: test
revision: af5e6fb845001ecf41f4c1e033ce921939a2a68d
metrics:
- type: cos_sim_pearson
value: 87.49935350176666
- type: cos_sim_spearman
value: 87.59086606735383
- type: euclidean_pearson
value: 88.06537181129983
- type: euclidean_spearman
value: 87.6687448086014
- type: manhattan_pearson
value: 87.96599131972935
- type: manhattan_spearman
value: 87.63295748969642
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (en)
config: en
split: test
revision: 6d1ba47164174a496b7fa5d3569dae26a6813b80
metrics:
- type: cos_sim_pearson
value: 67.68232799482763
- type: cos_sim_spearman
value: 67.99930378085793
- type: euclidean_pearson
value: 68.50275360001696
- type: euclidean_spearman
value: 67.81588179309259
- type: manhattan_pearson
value: 68.5892154749763
- type: manhattan_spearman
value: 67.84357259640682
- task:
type: STS
dataset:
type: mteb/stsbenchmark-sts
name: MTEB STSBenchmark
config: default
split: test
revision: b0fddb56ed78048fa8b90373c8a3cfc37b684831
metrics:
- type: cos_sim_pearson
value: 84.37049618406554
- type: cos_sim_spearman
value: 85.57014313159492
- type: euclidean_pearson
value: 85.57469513908282
- type: euclidean_spearman
value: 85.661948135258
- type: manhattan_pearson
value: 85.36866831229028
- type: manhattan_spearman
value: 85.5043455368843
- task:
type: Reranking
dataset:
type: mteb/scidocs-reranking
name: MTEB SciDocsRR
config: default
split: test
revision: d3c5e1fc0b855ab6097bf1cda04dd73947d7caab
metrics:
- type: map
value: 84.83259065376154
- type: mrr
value: 95.58455433455433
- task:
type: Retrieval
dataset:
type: scifact
name: MTEB SciFact
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 58.817
- type: map_at_10
value: 68.459
- type: map_at_100
value: 68.951
- type: map_at_1000
value: 68.979
- type: map_at_3
value: 65.791
- type: map_at_5
value: 67.583
- type: mrr_at_1
value: 61.667
- type: mrr_at_10
value: 69.368
- type: mrr_at_100
value: 69.721
- type: mrr_at_1000
value: 69.744
- type: mrr_at_3
value: 67.278
- type: mrr_at_5
value: 68.611
- type: ndcg_at_1
value: 61.667
- type: ndcg_at_10
value: 72.70100000000001
- type: ndcg_at_100
value: 74.928
- type: ndcg_at_1000
value: 75.553
- type: ndcg_at_3
value: 68.203
- type: ndcg_at_5
value: 70.804
- type: precision_at_1
value: 61.667
- type: precision_at_10
value: 9.533
- type: precision_at_100
value: 1.077
- type: precision_at_1000
value: 0.11299999999999999
- type: precision_at_3
value: 26.444000000000003
- type: precision_at_5
value: 17.599999999999998
- type: recall_at_1
value: 58.817
- type: recall_at_10
value: 84.789
- type: recall_at_100
value: 95.0
- type: recall_at_1000
value: 99.667
- type: recall_at_3
value: 72.8
- type: recall_at_5
value: 79.294
- task:
type: PairClassification
dataset:
type: mteb/sprintduplicatequestions-pairclassification
name: MTEB SprintDuplicateQuestions
config: default
split: test
revision: d66bd1f72af766a5cc4b0ca5e00c162f89e8cc46
metrics:
- type: cos_sim_accuracy
value: 99.8108910891089
- type: cos_sim_ap
value: 95.5743678558349
- type: cos_sim_f1
value: 90.43133366385722
- type: cos_sim_precision
value: 89.67551622418878
- type: cos_sim_recall
value: 91.2
- type: dot_accuracy
value: 99.75841584158415
- type: dot_ap
value: 94.00786363627253
- type: dot_f1
value: 87.51910341314316
- type: dot_precision
value: 89.20041536863967
- type: dot_recall
value: 85.9
- type: euclidean_accuracy
value: 99.81485148514851
- type: euclidean_ap
value: 95.4752113136905
- type: euclidean_f1
value: 90.44334975369456
- type: euclidean_precision
value: 89.126213592233
- type: euclidean_recall
value: 91.8
- type: manhattan_accuracy
value: 99.81584158415842
- type: manhattan_ap
value: 95.5163172682464
- type: manhattan_f1
value: 90.51987767584097
- type: manhattan_precision
value: 92.3076923076923
- type: manhattan_recall
value: 88.8
- type: max_accuracy
value: 99.81584158415842
- type: max_ap
value: 95.5743678558349
- type: max_f1
value: 90.51987767584097
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering
name: MTEB StackExchangeClustering
config: default
split: test
revision: 6cbc1f7b2bc0622f2e39d2c77fa502909748c259
metrics:
- type: v_measure
value: 62.63235986949449
- task:
type: Clustering
dataset:
type: mteb/stackexchange-clustering-p2p
name: MTEB StackExchangeClusteringP2P
config: default
split: test
revision: 815ca46b2622cec33ccafc3735d572c266efdb44
metrics:
- type: v_measure
value: 36.334795589585575
- task:
type: Reranking
dataset:
type: mteb/stackoverflowdupquestions-reranking
name: MTEB StackOverflowDupQuestions
config: default
split: test
revision: e185fbe320c72810689fc5848eb6114e1ef5ec69
metrics:
- type: map
value: 52.02955214518782
- type: mrr
value: 52.8004838298956
- task:
type: Summarization
dataset:
type: mteb/summeval
name: MTEB SummEval
config: default
split: test
revision: cda12ad7615edc362dbf25a00fdd61d3b1eaf93c
metrics:
- type: cos_sim_pearson
value: 30.63769566275453
- type: cos_sim_spearman
value: 30.422379185989335
- type: dot_pearson
value: 26.88493071882256
- type: dot_spearman
value: 26.505249740971305
- task:
type: Retrieval
dataset:
type: trec-covid
name: MTEB TRECCOVID
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 0.21
- type: map_at_10
value: 1.654
- type: map_at_100
value: 10.095
- type: map_at_1000
value: 25.808999999999997
- type: map_at_3
value: 0.594
- type: map_at_5
value: 0.9289999999999999
- type: mrr_at_1
value: 78.0
- type: mrr_at_10
value: 87.019
- type: mrr_at_100
value: 87.019
- type: mrr_at_1000
value: 87.019
- type: mrr_at_3
value: 86.333
- type: mrr_at_5
value: 86.733
- type: ndcg_at_1
value: 73.0
- type: ndcg_at_10
value: 66.52900000000001
- type: ndcg_at_100
value: 53.433
- type: ndcg_at_1000
value: 51.324000000000005
- type: ndcg_at_3
value: 72.02199999999999
- type: ndcg_at_5
value: 69.696
- type: precision_at_1
value: 78.0
- type: precision_at_10
value: 70.39999999999999
- type: precision_at_100
value: 55.46
- type: precision_at_1000
value: 22.758
- type: precision_at_3
value: 76.667
- type: precision_at_5
value: 74.0
- type: recall_at_1
value: 0.21
- type: recall_at_10
value: 1.8849999999999998
- type: recall_at_100
value: 13.801
- type: recall_at_1000
value: 49.649
- type: recall_at_3
value: 0.632
- type: recall_at_5
value: 1.009
- task:
type: Retrieval
dataset:
type: webis-touche2020
name: MTEB Touche2020
config: default
split: test
revision: None
metrics:
- type: map_at_1
value: 1.797
- type: map_at_10
value: 9.01
- type: map_at_100
value: 14.682
- type: map_at_1000
value: 16.336000000000002
- type: map_at_3
value: 4.546
- type: map_at_5
value: 5.9270000000000005
- type: mrr_at_1
value: 24.490000000000002
- type: mrr_at_10
value: 41.156
- type: mrr_at_100
value: 42.392
- type: mrr_at_1000
value: 42.408
- type: mrr_at_3
value: 38.775999999999996
- type: mrr_at_5
value: 40.102
- type: ndcg_at_1
value: 21.429000000000002
- type: ndcg_at_10
value: 22.222
- type: ndcg_at_100
value: 34.405
- type: ndcg_at_1000
value: 46.599000000000004
- type: ndcg_at_3
value: 25.261
- type: ndcg_at_5
value: 22.695999999999998
- type: precision_at_1
value: 24.490000000000002
- type: precision_at_10
value: 19.796
- type: precision_at_100
value: 7.306
- type: precision_at_1000
value: 1.5350000000000001
- type: precision_at_3
value: 27.211000000000002
- type: precision_at_5
value: 22.857
- type: recall_at_1
value: 1.797
- type: recall_at_10
value: 15.706000000000001
- type: recall_at_100
value: 46.412
- type: recall_at_1000
value: 83.159
- type: recall_at_3
value: 6.1370000000000005
- type: recall_at_5
value: 8.599
- task:
type: Classification
dataset:
type: mteb/toxic_conversations_50k
name: MTEB ToxicConversationsClassification
config: default
split: test
revision: d7c0de2777da35d6aae2200a62c6e0e5af397c4c
metrics:
- type: accuracy
value: 70.3302
- type: ap
value: 14.169121204575601
- type: f1
value: 54.229345975274235
- task:
type: Classification
dataset:
type: mteb/tweet_sentiment_extraction
name: MTEB TweetSentimentExtractionClassification
config: default
split: test
revision: d604517c81ca91fe16a244d1248fc021f9ecee7a
metrics:
- type: accuracy
value: 58.22297679683077
- type: f1
value: 58.62984908377875
- task:
type: Clustering
dataset:
type: mteb/twentynewsgroups-clustering
name: MTEB TwentyNewsgroupsClustering
config: default
split: test
revision: 6125ec4e24fa026cec8a478383ee943acfbd5449
metrics:
- type: v_measure
value: 49.952922428464255
- task:
type: PairClassification
dataset:
type: mteb/twittersemeval2015-pairclassification
name: MTEB TwitterSemEval2015
config: default
split: test
revision: 70970daeab8776df92f5ea462b6173c0b46fd2d1
metrics:
- type: cos_sim_accuracy
value: 84.68140907194373
- type: cos_sim_ap
value: 70.12180123666836
- type: cos_sim_f1
value: 65.77501791258658
- type: cos_sim_precision
value: 60.07853403141361
- type: cos_sim_recall
value: 72.66490765171504
- type: dot_accuracy
value: 81.92167848840674
- type: dot_ap
value: 60.49837581423469
- type: dot_f1
value: 58.44186046511628
- type: dot_precision
value: 52.24532224532224
- type: dot_recall
value: 66.3060686015831
- type: euclidean_accuracy
value: 84.73505394289802
- type: euclidean_ap
value: 70.3278904593286
- type: euclidean_f1
value: 65.98851124940161
- type: euclidean_precision
value: 60.38107752956636
- type: euclidean_recall
value: 72.74406332453826
- type: manhattan_accuracy
value: 84.73505394289802
- type: manhattan_ap
value: 70.00737738537337
- type: manhattan_f1
value: 65.80150784822642
- type: manhattan_precision
value: 61.892583120204606
- type: manhattan_recall
value: 70.23746701846966
- type: max_accuracy
value: 84.73505394289802
- type: max_ap
value: 70.3278904593286
- type: max_f1
value: 65.98851124940161
- task:
type: PairClassification
dataset:
type: mteb/twitterurlcorpus-pairclassification
name: MTEB TwitterURLCorpus
config: default
split: test
revision: 8b6510b0b1fa4e4c4f879467980e9be563ec1cdf
metrics:
- type: cos_sim_accuracy
value: 88.44258159661582
- type: cos_sim_ap
value: 84.91926704880888
- type: cos_sim_f1
value: 77.07651086632926
- type: cos_sim_precision
value: 74.5894554883319
- type: cos_sim_recall
value: 79.73514012935017
- type: dot_accuracy
value: 85.88116583226608
- type: dot_ap
value: 78.9753854779923
- type: dot_f1
value: 72.17757637979255
- type: dot_precision
value: 66.80647486729143
- type: dot_recall
value: 78.48783492454572
- type: euclidean_accuracy
value: 88.5299025885823
- type: euclidean_ap
value: 85.08006075642194
- type: euclidean_f1
value: 77.29637336504163
- type: euclidean_precision
value: 74.69836253950014
- type: euclidean_recall
value: 80.08161379735141
- type: manhattan_accuracy
value: 88.55124771995187
- type: manhattan_ap
value: 85.00941529932851
- type: manhattan_f1
value: 77.33100233100232
- type: manhattan_precision
value: 73.37572573956317
- type: manhattan_recall
value: 81.73698798891284
- type: max_accuracy
value: 88.55124771995187
- type: max_ap
value: 85.08006075642194
- type: max_f1
value: 77.33100233100232
language:
- en
license: mit
---
# gte-small
General Text Embeddings (GTE) model. [Towards General Text Embeddings with Multi-stage Contrastive Learning](https://arxiv.org/abs/2308.03281)
The GTE models are trained by Alibaba DAMO Academy. They are mainly based on the BERT framework and currently offer three different sizes of models, including [GTE-large](https://huggingface.co/thenlper/gte-large), [GTE-base](https://huggingface.co/thenlper/gte-base), and [GTE-small](https://huggingface.co/thenlper/gte-small). The GTE models are trained on a large-scale corpus of relevance text pairs, covering a wide range of domains and scenarios. This enables the GTE models to be applied to various downstream tasks of text embeddings, including **information retrieval**, **semantic textual similarity**, **text reranking**, etc.
## Metrics
We compared the performance of the GTE models with other popular text embedding models on the MTEB benchmark. For more detailed comparison results, please refer to the [MTEB leaderboard](https://huggingface.co/spaces/mteb/leaderboard).
| Model Name | Model Size (GB) | Dimension | Sequence Length | Average (56) | Clustering (11) | Pair Classification (3) | Reranking (4) | Retrieval (15) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [**gte-large**](https://huggingface.co/thenlper/gte-large) | 0.67 | 1024 | 512 | **63.13** | 46.84 | 85.00 | 59.13 | 52.22 | 83.35 | 31.66 | 73.33 |
| [**gte-base**](https://huggingface.co/thenlper/gte-base) | 0.22 | 768 | 512 | **62.39** | 46.2 | 84.57 | 58.61 | 51.14 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1.34 | 1024| 512 | 62.25 | 44.49 | 86.03 | 56.61 | 50.56 | 82.05 | 30.19 | 75.24 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 0.44 | 768 | 512 | 61.5 | 43.80 | 85.73 | 55.91 | 50.29 | 81.05 | 30.28 | 73.84 |
| [**gte-small**](https://huggingface.co/thenlper/gte-small) | 0.07 | 384 | 512 | **61.36** | 44.89 | 83.54 | 57.7 | 49.46 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | - | 1536 | 8192 | 60.99 | 45.9 | 84.89 | 56.32 | 49.25 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 0.13 | 384 | 512 | 59.93 | 39.92 | 84.67 | 54.32 | 49.04 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 9.73 | 768 | 512 | 59.51 | 43.72 | 85.06 | 56.42 | 42.24 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 0.44 | 768 | 514 | 57.78 | 43.69 | 83.04 | 59.36 | 43.81 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 28.27 | 4096 | 2048 | 57.59 | 38.93 | 81.9 | 55.65 | 48.22 | 77.74 | 33.6 | 66.19 |
| [all-MiniLM-L12-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L12-v2) | 0.13 | 384 | 512 | 56.53 | 41.81 | 82.41 | 58.44 | 42.69 | 79.8 | 27.9 | 63.21 |
| [all-MiniLM-L6-v2](https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2) | 0.09 | 384 | 512 | 56.26 | 42.35 | 82.37 | 58.04 | 41.95 | 78.9 | 30.81 | 63.05 |
| [contriever-base-msmarco](https://huggingface.co/nthakur/contriever-base-msmarco) | 0.44 | 768 | 512 | 56.00 | 41.1 | 82.54 | 53.14 | 41.88 | 76.51 | 30.36 | 66.68 |
| [sentence-t5-base](https://huggingface.co/sentence-transformers/sentence-t5-base) | 0.22 | 768 | 512 | 55.27 | 40.21 | 85.18 | 53.09 | 33.63 | 81.14 | 31.39 | 69.81 |
## Usage
Code example
```python
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
input_texts = [
"what is the capital of China?",
"how to implement quick sort in python?",
"Beijing",
"sorting algorithms"
]
tokenizer = AutoTokenizer.from_pretrained("thenlper/gte-small")
model = AutoModel.from_pretrained("thenlper/gte-small")
# Tokenize the input texts
batch_dict = tokenizer(input_texts, max_length=512, padding=True, truncation=True, return_tensors='pt')
outputs = model(**batch_dict)
embeddings = average_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# (Optionally) normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:1] @ embeddings[1:].T) * 100
print(scores.tolist())
```
Use with sentence-transformers:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
sentences = ['That is a happy person', 'That is a very happy person']
model = SentenceTransformer('thenlper/gte-large')
embeddings = model.encode(sentences)
print(cos_sim(embeddings[0], embeddings[1]))
```
### Limitation
This model exclusively caters to English texts, and any lengthy texts will be truncated to a maximum of 512 tokens.
### Citation
If you find our paper or models helpful, please consider citing them as follows:
```
@article{li2023towards,
title={Towards general text embeddings with multi-stage contrastive learning},
author={Li, Zehan and Zhang, Xin and Zhang, Yanzhao and Long, Dingkun and Xie, Pengjun and Zhang, Meishan},
journal={arXiv preprint arXiv:2308.03281},
year={2023}
}
```
|
jonatasgrosman/wav2vec2-large-xlsr-53-chinese-zh-cn | jonatasgrosman | "2022-12-14T01:58:32Z" | 5,230,034 | 94 | transformers | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"zh",
"dataset:common_voice",
"doi:10.57967/hf/3570",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-03-02T23:29:05Z" | ---
language: zh
datasets:
- common_voice
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Chinese (zh-CN) by Jonatas Grosman
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice zh-CN
type: common_voice
args: zh-CN
metrics:
- name: Test WER
type: wer
value: 82.37
- name: Test CER
type: cer
value: 19.03
---
# Fine-tuned XLSR-53 large model for speech recognition in Chinese
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Chinese using the train and validation splits of [Common Voice 6.1](https://huggingface.co/datasets/common_voice), [CSS10](https://github.com/Kyubyong/css10) and [ST-CMDS](http://www.openslr.org/38/).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
The script used for training can be found here: https://github.com/jonatasgrosman/wav2vec2-sprint
## Usage
The model can be used directly (without a language model) as follows...
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-large-xlsr-53-chinese-zh-cn")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "zh-CN"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-chinese-zh-cn"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
for i, predicted_sentence in enumerate(predicted_sentences):
print("-" * 100)
print("Reference:", test_dataset[i]["sentence"])
print("Prediction:", predicted_sentence)
```
| Reference | Prediction |
| ------------- | ------------- |
| 宋朝末年年间定居粉岭围。 | 宋朝末年年间定居分定为 |
| 渐渐行动不便 | 建境行动不片 |
| 二十一年去世。 | 二十一年去世 |
| 他们自称恰哈拉。 | 他们自称家哈<unk> |
| 局部干涩的例子包括有口干、眼睛干燥、及阴道干燥。 | 菊物干寺的例子包括有口肝眼睛干照以及阴到干<unk> |
| 嘉靖三十八年,登进士第三甲第二名。 | 嘉靖三十八年登进士第三甲第二名 |
| 这一名称一直沿用至今。 | 这一名称一直沿用是心 |
| 同时乔凡尼还得到包税合同和许多明矾矿的经营权。 | 同时桥凡妮还得到包税合同和许多民繁矿的经营权 |
| 为了惩罚西扎城和塞尔柱的结盟,盟军在抵达后将外城烧毁。 | 为了曾罚西扎城和塞尔素的节盟盟军在抵达后将外曾烧毁 |
| 河内盛产黄色无鱼鳞的鳍射鱼。 | 合类生场环色无鱼林的骑射鱼 |
## Evaluation
The model can be evaluated as follows on the Chinese (zh-CN) test data of Common Voice.
```python
import torch
import re
import librosa
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "zh-CN"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-chinese-zh-cn"
DEVICE = "cuda"
CHARS_TO_IGNORE = [",", "?", "¿", ".", "!", "¡", ";", ";", ":", '""', "%", '"', "�", "ʿ", "·", "჻", "~", "՞",
"؟", "،", "।", "॥", "«", "»", "„", "“", "”", "「", "」", "‘", "’", "《", "》", "(", ")", "[", "]",
"{", "}", "=", "`", "_", "+", "<", ">", "…", "–", "°", "´", "ʾ", "‹", "›", "©", "®", "—", "→", "。",
"、", "﹂", "﹁", "‧", "~", "﹏", ",", "{", "}", "(", ")", "[", "]", "【", "】", "‥", "〽",
"『", "』", "〝", "〟", "⟨", "⟩", "〜", ":", "!", "?", "♪", "؛", "/", "\\", "º", "−", "^", "'", "ʻ", "ˆ"]
test_dataset = load_dataset("common_voice", LANG_ID, split="test")
wer = load_metric("wer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/wer.py
cer = load_metric("cer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/cer.py
chars_to_ignore_regex = f"[{re.escape(''.join(CHARS_TO_IGNORE))}]"
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
model.to(DEVICE)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = re.sub(chars_to_ignore_regex, "", batch["sentence"]).upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to(DEVICE), attention_mask=inputs.attention_mask.to(DEVICE)).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
predictions = [x.upper() for x in result["pred_strings"]]
references = [x.upper() for x in result["sentence"]]
print(f"WER: {wer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
print(f"CER: {cer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
```
**Test Result**:
In the table below I report the Word Error Rate (WER) and the Character Error Rate (CER) of the model. I ran the evaluation script described above on other models as well (on 2021-05-13). Note that the table below may show different results from those already reported, this may have been caused due to some specificity of the other evaluation scripts used.
| Model | WER | CER |
| ------------- | ------------- | ------------- |
| jonatasgrosman/wav2vec2-large-xlsr-53-chinese-zh-cn | **82.37%** | **19.03%** |
| ydshieh/wav2vec2-large-xlsr-53-chinese-zh-cn-gpt | 84.01% | 20.95% |
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr53-large-chinese,
title={Fine-tuned {XLSR}-53 large model for speech recognition in {C}hinese},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-chinese-zh-cn}},
year={2021}
}
``` |
google/vit-base-patch16-224-in21k | google | "2024-02-05T16:37:39Z" | 5,121,675 | 298 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"vit",
"image-feature-extraction",
"vision",
"dataset:imagenet-21k",
"arxiv:2010.11929",
"arxiv:2006.03677",
"license:apache-2.0",
"region:us"
] | image-feature-extraction | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
tags:
- vision
datasets:
- imagenet-21k
inference: false
---
# Vision Transformer (base-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Dosovitskiy et al. and first released in [this repository](https://github.com/google-research/vision_transformer). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Disclaimer: The team releasing ViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
Note that this model does not provide any fine-tuned heads, as these were zero'd by Google researchers. However, the model does include the pre-trained pooler, which can be used for downstream tasks (such as image classification).
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=google/vit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import ViTImageProcessor, ViTModel
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('google/vit-base-patch16-224-in21k')
model = ViTModel.from_pretrained('google/vit-base-patch16-224-in21k')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
Here is how to use this model in JAX/Flax:
```python
from transformers import ViTImageProcessor, FlaxViTModel
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('google/vit-base-patch16-224-in21k')
model = FlaxViTModel.from_pretrained('google/vit-base-patch16-224-in21k')
inputs = processor(images=image, return_tensors="np")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
## Training data
The ViT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
The model was trained on TPUv3 hardware (8 cores). All model variants are trained with a batch size of 4096 and learning rate warmup of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Pre-training resolution is 224.
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 2 and 5 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` |
microsoft/table-transformer-detection | microsoft | "2023-09-06T14:49:09Z" | 4,921,260 | 334 | transformers | [
"transformers",
"pytorch",
"safetensors",
"table-transformer",
"object-detection",
"arxiv:2110.00061",
"license:mit",
"endpoints_compatible",
"region:us"
] | object-detection | "2022-10-14T09:14:13Z" | ---
license: mit
widget:
- src: https://www.invoicesimple.com/wp-content/uploads/2018/06/Sample-Invoice-printable.png
example_title: Invoice
---
# Table Transformer (fine-tuned for Table Detection)
Table Transformer (DETR) model trained on PubTables1M. It was introduced in the paper [PubTables-1M: Towards Comprehensive Table Extraction From Unstructured Documents](https://arxiv.org/abs/2110.00061) by Smock et al. and first released in [this repository](https://github.com/microsoft/table-transformer).
Disclaimer: The team releasing Table Transformer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Table Transformer is equivalent to [DETR](https://huggingface.co/docs/transformers/model_doc/detr), a Transformer-based object detection model. Note that the authors decided to use the "normalize before" setting of DETR, which means that layernorm is applied before self- and cross-attention.
## Usage
You can use the raw model for detecting tables in documents. See the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/table-transformer) for more info. |
NeuML/pubmedbert-base-embeddings | NeuML | "2023-10-18T14:49:27Z" | 4,746,716 | 111 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2023-10-18T14:22:18Z" | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
language: en
license: apache-2.0
---
# PubMedBERT Embeddings
This is a [PubMedBERT-base](https://huggingface.co/microsoft/BiomedNLP-PubMedBERT-base-uncased-abstract-fulltext) model fined-tuned using [sentence-transformers](https://www.SBERT.net). It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search. The training dataset was generated using a random sample of [PubMed](https://pubmed.ncbi.nlm.nih.gov/) title-abstract pairs along with similar title pairs.
PubMedBERT Embeddings produces higher quality embeddings than generalized models for medical literature. Further fine-tuning for a medical subdomain will result in even better performance.
## Usage (txtai)
This model can be used to build embeddings databases with [txtai](https://github.com/neuml/txtai) for semantic search and/or as a knowledge source for retrieval augmented generation (RAG).
```python
import txtai
embeddings = txtai.Embeddings(path="neuml/pubmedbert-base-embeddings", content=True)
embeddings.index(documents())
# Run a query
embeddings.search("query to run")
```
## Usage (Sentence-Transformers)
Alternatively, the model can be loaded with [sentence-transformers](https://www.SBERT.net).
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer("neuml/pubmedbert-base-embeddings")
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (Hugging Face Transformers)
The model can also be used directly with Transformers.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Mean Pooling - Take attention mask into account for correct averaging
def meanpooling(output, mask):
embeddings = output[0] # First element of model_output contains all token embeddings
mask = mask.unsqueeze(-1).expand(embeddings.size()).float()
return torch.sum(embeddings * mask, 1) / torch.clamp(mask.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained("neuml/pubmedbert-base-embeddings")
model = AutoModel.from_pretrained("neuml/pubmedbert-base-embeddings")
# Tokenize sentences
inputs = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
output = model(**inputs)
# Perform pooling. In this case, mean pooling.
embeddings = meanpooling(output, inputs['attention_mask'])
print("Sentence embeddings:")
print(embeddings)
```
## Evaluation Results
Performance of this model compared to the top base models on the [MTEB leaderboard](https://huggingface.co/spaces/mteb/leaderboard) is shown below. A popular smaller model was also evaluated along with the most downloaded PubMed similarity model on the Hugging Face Hub.
The following datasets were used to evaluate model performance.
- [PubMed QA](https://huggingface.co/datasets/pubmed_qa)
- Subset: pqa_labeled, Split: train, Pair: (question, long_answer)
- [PubMed Subset](https://huggingface.co/datasets/zxvix/pubmed_subset_new)
- Split: test, Pair: (title, text)
- [PubMed Summary](https://huggingface.co/datasets/scientific_papers)
- Subset: pubmed, Split: validation, Pair: (article, abstract)
Evaluation results are shown below. The [Pearson correlation coefficient](https://en.wikipedia.org/wiki/Pearson_correlation_coefficient) is used as the evaluation metric.
| Model | PubMed QA | PubMed Subset | PubMed Summary | Average |
| ----------------------------------------------------------------------------- | --------- | ------------- | -------------- | --------- |
| [all-MiniLM-L6-v2](https://hf.co/sentence-transformers/all-MiniLM-L6-v2) | 90.40 | 95.86 | 94.07 | 93.44 |
| [bge-base-en-v1.5](https://hf.co/BAAI/bge-large-en-v1.5) | 91.02 | 95.60 | 94.49 | 93.70 |
| [gte-base](https://hf.co/thenlper/gte-base) | 92.97 | 96.83 | 96.24 | 95.35 |
| [**pubmedbert-base-embeddings**](https://hf.co/neuml/pubmedbert-base-embeddings) | **93.27** | **97.07** | **96.58** | **95.64** |
| [S-PubMedBert-MS-MARCO](https://hf.co/pritamdeka/S-PubMedBert-MS-MARCO) | 90.86 | 93.33 | 93.54 | 92.58 |
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 20191 with parameters:
```
{'batch_size': 24, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit() method:
```
{
"epochs": 1,
"evaluation_steps": 500,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## More Information
Read more about this model and how it was built in [this article](https://medium.com/neuml/embeddings-for-medical-literature-74dae6abf5e0).
|
papluca/xlm-roberta-base-language-detection | papluca | "2023-12-28T13:54:18Z" | 4,710,682 | 313 | transformers | [
"transformers",
"pytorch",
"tf",
"safetensors",
"xlm-roberta",
"text-classification",
"generated_from_trainer",
"multilingual",
"ar",
"bg",
"de",
"el",
"en",
"es",
"fr",
"hi",
"it",
"ja",
"nl",
"pl",
"pt",
"ru",
"sw",
"th",
"tr",
"ur",
"vi",
"zh",
"dataset:papluca/language-identification",
"arxiv:1911.02116",
"base_model:FacebookAI/xlm-roberta-base",
"base_model:finetune:FacebookAI/xlm-roberta-base",
"doi:10.57967/hf/2064",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | ---
language:
- multilingual
- ar
- bg
- de
- el
- en
- es
- fr
- hi
- it
- ja
- nl
- pl
- pt
- ru
- sw
- th
- tr
- ur
- vi
- zh
license: mit
tags:
- generated_from_trainer
datasets: papluca/language-identification
metrics:
- accuracy
- f1
base_model: xlm-roberta-base
model-index:
- name: xlm-roberta-base-language-detection
results: []
---
# xlm-roberta-base-language-detection
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the [Language Identification](https://huggingface.co/datasets/papluca/language-identification#additional-information) dataset.
## Model description
This model is an XLM-RoBERTa transformer model with a classification head on top (i.e. a linear layer on top of the pooled output).
For additional information please refer to the [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) model card or to the paper [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Conneau et al.
## Intended uses & limitations
You can directly use this model as a language detector, i.e. for sequence classification tasks. Currently, it supports the following 20 languages:
`arabic (ar), bulgarian (bg), german (de), modern greek (el), english (en), spanish (es), french (fr), hindi (hi), italian (it), japanese (ja), dutch (nl), polish (pl), portuguese (pt), russian (ru), swahili (sw), thai (th), turkish (tr), urdu (ur), vietnamese (vi), and chinese (zh)`
## Training and evaluation data
The model was fine-tuned on the [Language Identification](https://huggingface.co/datasets/papluca/language-identification#additional-information) dataset, which consists of text sequences in 20 languages. The training set contains 70k samples, while the validation and test sets 10k each. The average accuracy on the test set is **99.6%** (this matches the average macro/weighted F1-score being the test set perfectly balanced). A more detailed evaluation is provided by the following table.
| Language | Precision | Recall | F1-score | support |
|:--------:|:---------:|:------:|:--------:|:-------:|
|ar |0.998 |0.996 |0.997 |500 |
|bg |0.998 |0.964 |0.981 |500 |
|de |0.998 |0.996 |0.997 |500 |
|el |0.996 |1.000 |0.998 |500 |
|en |1.000 |1.000 |1.000 |500 |
|es |0.967 |1.000 |0.983 |500 |
|fr |1.000 |1.000 |1.000 |500 |
|hi |0.994 |0.992 |0.993 |500 |
|it |1.000 |0.992 |0.996 |500 |
|ja |0.996 |0.996 |0.996 |500 |
|nl |1.000 |1.000 |1.000 |500 |
|pl |1.000 |1.000 |1.000 |500 |
|pt |0.988 |1.000 |0.994 |500 |
|ru |1.000 |0.994 |0.997 |500 |
|sw |1.000 |1.000 |1.000 |500 |
|th |1.000 |0.998 |0.999 |500 |
|tr |0.994 |0.992 |0.993 |500 |
|ur |1.000 |1.000 |1.000 |500 |
|vi |0.992 |1.000 |0.996 |500 |
|zh |1.000 |1.000 |1.000 |500 |
### Benchmarks
As a baseline to compare `xlm-roberta-base-language-detection` against, we have used the Python [langid](https://github.com/saffsd/langid.py) library. Since it comes pre-trained on 97 languages, we have used its `.set_languages()` method to constrain the language set to our 20 languages. The average accuracy of langid on the test set is **98.5%**. More details are provided by the table below.
| Language | Precision | Recall | F1-score | support |
|:--------:|:---------:|:------:|:--------:|:-------:|
|ar |0.990 |0.970 |0.980 |500 |
|bg |0.998 |0.964 |0.981 |500 |
|de |0.992 |0.944 |0.967 |500 |
|el |1.000 |0.998 |0.999 |500 |
|en |1.000 |1.000 |1.000 |500 |
|es |1.000 |0.968 |0.984 |500 |
|fr |0.996 |1.000 |0.998 |500 |
|hi |0.949 |0.976 |0.963 |500 |
|it |0.990 |0.980 |0.985 |500 |
|ja |0.927 |0.988 |0.956 |500 |
|nl |0.980 |1.000 |0.990 |500 |
|pl |0.986 |0.996 |0.991 |500 |
|pt |0.950 |0.996 |0.973 |500 |
|ru |0.996 |0.974 |0.985 |500 |
|sw |1.000 |1.000 |1.000 |500 |
|th |1.000 |0.996 |0.998 |500 |
|tr |0.990 |0.968 |0.979 |500 |
|ur |0.998 |0.996 |0.997 |500 |
|vi |0.971 |0.990 |0.980 |500 |
|zh |1.000 |1.000 |1.000 |500 |
## How to get started with the model
The easiest way to use the model is via the high-level `pipeline` API:
```python
from transformers import pipeline
text = [
"Brevity is the soul of wit.",
"Amor, ch'a nullo amato amar perdona."
]
model_ckpt = "papluca/xlm-roberta-base-language-detection"
pipe = pipeline("text-classification", model=model_ckpt)
pipe(text, top_k=1, truncation=True)
```
Or one can proceed with the tokenizer and model separately:
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
text = [
"Brevity is the soul of wit.",
"Amor, ch'a nullo amato amar perdona."
]
model_ckpt = "papluca/xlm-roberta-base-language-detection"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
model = AutoModelForSequenceClassification.from_pretrained(model_ckpt)
inputs = tokenizer(text, padding=True, truncation=True, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
preds = torch.softmax(logits, dim=-1)
# Map raw predictions to languages
id2lang = model.config.id2label
vals, idxs = torch.max(preds, dim=1)
{id2lang[k.item()]: v.item() for k, v in zip(idxs, vals)}
```
## Training procedure
Fine-tuning was done via the `Trainer` API. Here is the [Colab notebook](https://colab.research.google.com/drive/15LJTckS6gU3RQOmjLqxVNBmbsBdnUEvl?usp=sharing) with the training code.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
The validation results on the `valid` split of the Language Identification dataset are summarised here below.
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.2492 | 1.0 | 1094 | 0.0149 | 0.9969 | 0.9969 |
| 0.0101 | 2.0 | 2188 | 0.0103 | 0.9977 | 0.9977 |
In short, it achieves the following results on the validation set:
- Loss: 0.0101
- Accuracy: 0.9977
- F1: 0.9977
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
openai/whisper-large-v3 | openai | "2024-08-12T10:20:10Z" | 4,656,290 | 4,010 | transformers | [
"transformers",
"pytorch",
"jax",
"safetensors",
"whisper",
"automatic-speech-recognition",
"audio",
"hf-asr-leaderboard",
"en",
"zh",
"de",
"es",
"ru",
"ko",
"fr",
"ja",
"pt",
"tr",
"pl",
"ca",
"nl",
"ar",
"sv",
"it",
"id",
"hi",
"fi",
"vi",
"he",
"uk",
"el",
"ms",
"cs",
"ro",
"da",
"hu",
"ta",
"no",
"th",
"ur",
"hr",
"bg",
"lt",
"la",
"mi",
"ml",
"cy",
"sk",
"te",
"fa",
"lv",
"bn",
"sr",
"az",
"sl",
"kn",
"et",
"mk",
"br",
"eu",
"is",
"hy",
"ne",
"mn",
"bs",
"kk",
"sq",
"sw",
"gl",
"mr",
"pa",
"si",
"km",
"sn",
"yo",
"so",
"af",
"oc",
"ka",
"be",
"tg",
"sd",
"gu",
"am",
"yi",
"lo",
"uz",
"fo",
"ht",
"ps",
"tk",
"nn",
"mt",
"sa",
"lb",
"my",
"bo",
"tl",
"mg",
"as",
"tt",
"haw",
"ln",
"ha",
"ba",
"jw",
"su",
"arxiv:2212.04356",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2023-11-07T18:41:14Z" | ---
language:
- en
- zh
- de
- es
- ru
- ko
- fr
- ja
- pt
- tr
- pl
- ca
- nl
- ar
- sv
- it
- id
- hi
- fi
- vi
- he
- uk
- el
- ms
- cs
- ro
- da
- hu
- ta
- no
- th
- ur
- hr
- bg
- lt
- la
- mi
- ml
- cy
- sk
- te
- fa
- lv
- bn
- sr
- az
- sl
- kn
- et
- mk
- br
- eu
- is
- hy
- ne
- mn
- bs
- kk
- sq
- sw
- gl
- mr
- pa
- si
- km
- sn
- yo
- so
- af
- oc
- ka
- be
- tg
- sd
- gu
- am
- yi
- lo
- uz
- fo
- ht
- ps
- tk
- nn
- mt
- sa
- lb
- my
- bo
- tl
- mg
- as
- tt
- haw
- ln
- ha
- ba
- jw
- su
tags:
- audio
- automatic-speech-recognition
- hf-asr-leaderboard
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
pipeline_tag: automatic-speech-recognition
license: apache-2.0
---
# Whisper
Whisper is a state-of-the-art model for automatic speech recognition (ASR) and speech translation, proposed in the paper
[Robust Speech Recognition via Large-Scale Weak Supervision](https://huggingface.co/papers/2212.04356) by Alec Radford
et al. from OpenAI. Trained on >5M hours of labeled data, Whisper demonstrates a strong ability to generalise to many
datasets and domains in a zero-shot setting.
Whisper large-v3 has the same architecture as the previous [large](https://huggingface.co/openai/whisper-large) and [large-v2](https://huggingface.co/openai/whisper-large-v2)
models, except for the following minor differences:
1. The spectrogram input uses 128 Mel frequency bins instead of 80
2. A new language token for Cantonese
The Whisper large-v3 model was trained on 1 million hours of weakly labeled audio and 4 million hours of pseudo-labeled
audio collected using Whisper [large-v2](https://huggingface.co/openai/whisper-large-v2) . The model was trained for 2.0 epochs over this mixture dataset.
The large-v3 model shows improved performance over a wide variety of languages, showing 10% to 20% reduction of errors
compared to Whisper [large-v2](https://huggingface.co/openai/whisper-large-v2) . For more details on the different checkpoints available, refer to the section [Model details](#model-details).
**Disclaimer**: Content for this model card has partly been written by the 🤗 Hugging Face team, and partly copied and
pasted from the original model card.
## Usage
Whisper large-v3 is supported in Hugging Face 🤗 Transformers. To run the model, first install the Transformers
library. For this example, we'll also install 🤗 Datasets to load toy audio dataset from the Hugging Face Hub, and
🤗 Accelerate to reduce the model loading time:
```bash
pip install --upgrade pip
pip install --upgrade transformers datasets[audio] accelerate
```
The model can be used with the [`pipeline`](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.AutomaticSpeechRecognitionPipeline)
class to transcribe audios of arbitrary length:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
```
To transcribe a local audio file, simply pass the path to your audio file when you call the pipeline:
```python
result = pipe("audio.mp3")
```
Multiple audio files can be transcribed in parallel by specifying them as a list and setting the `batch_size` parameter:
```python
result = pipe(["audio_1.mp3", "audio_2.mp3"], batch_size=2)
```
Transformers is compatible with all Whisper decoding strategies, such as temperature fallback and condition on previous
tokens. The following example demonstrates how to enable these heuristics:
```python
generate_kwargs = {
"max_new_tokens": 448,
"num_beams": 1,
"condition_on_prev_tokens": False,
"compression_ratio_threshold": 1.35, # zlib compression ratio threshold (in token space)
"temperature": (0.0, 0.2, 0.4, 0.6, 0.8, 1.0),
"logprob_threshold": -1.0,
"no_speech_threshold": 0.6,
"return_timestamps": True,
}
result = pipe(sample, generate_kwargs=generate_kwargs)
```
Whisper predicts the language of the source audio automatically. If the source audio language is known *a-priori*, it
can be passed as an argument to the pipeline:
```python
result = pipe(sample, generate_kwargs={"language": "english"})
```
By default, Whisper performs the task of *speech transcription*, where the source audio language is the same as the target
text language. To perform *speech translation*, where the target text is in English, set the task to `"translate"`:
```python
result = pipe(sample, generate_kwargs={"task": "translate"})
```
Finally, the model can be made to predict timestamps. For sentence-level timestamps, pass the `return_timestamps` argument:
```python
result = pipe(sample, return_timestamps=True)
print(result["chunks"])
```
And for word-level timestamps:
```python
result = pipe(sample, return_timestamps="word")
print(result["chunks"])
```
The above arguments can be used in isolation or in combination. For example, to perform the task of speech transcription
where the source audio is in French, and we want to return sentence-level timestamps, the following can be used:
```python
result = pipe(sample, return_timestamps=True, generate_kwargs={"language": "french", "task": "translate"})
print(result["chunks"])
```
<details>
<summary> For more control over the generation parameters, use the model + processor API directly: </summary>
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor
from datasets import Audio, load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
dataset = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
dataset = dataset.cast_column("audio", Audio(processor.feature_extractor.sampling_rate))
sample = dataset[0]["audio"]
inputs = processor(
sample["array"],
sampling_rate=sample["sampling_rate"],
return_tensors="pt",
truncation=False,
padding="longest",
return_attention_mask=True,
)
inputs = inputs.to(device, dtype=torch_dtype)
gen_kwargs = {
"max_new_tokens": 448,
"num_beams": 1,
"condition_on_prev_tokens": False,
"compression_ratio_threshold": 1.35, # zlib compression ratio threshold (in token space)
"temperature": (0.0, 0.2, 0.4, 0.6, 0.8, 1.0),
"logprob_threshold": -1.0,
"no_speech_threshold": 0.6,
"return_timestamps": True,
}
pred_ids = model.generate(**inputs, **gen_kwargs)
pred_text = processor.batch_decode(pred_ids, skip_special_tokens=True, decode_with_timestamps=False)
print(pred_text)
```
</details>
## Additional Speed & Memory Improvements
You can apply additional speed and memory improvements to Whisper to further reduce the inference speed and VRAM
requirements.
### Chunked Long-Form
Whisper has a receptive field of 30-seconds. To transcribe audios longer than this, one of two long-form algorithms are
required:
1. **Sequential:** uses a "sliding window" for buffered inference, transcribing 30-second slices one after the other
2. **Chunked:** splits long audio files into shorter ones (with a small overlap between segments), transcribes each segment independently, and stitches the resulting transcriptions at the boundaries
The sequential long-form algorithm should be used in either of the following scenarios:
1. Transcription accuracy is the most important factor, and speed is less of a consideration
2. You are transcribing **batches** of long audio files, in which case the latency of sequential is comparable to chunked, while being up to 0.5% WER more accurate
Conversely, the chunked algorithm should be used when:
1. Transcription speed is the most important factor
2. You are transcribing a **single** long audio file
By default, Transformers uses the sequential algorithm. To enable the chunked algorithm, pass the `chunk_length_s`
parameter to the `pipeline`. For large-v3, a chunk length of 30-seconds is optimal. To activate batching over long
audio files, pass the argument `batch_size`:
```python
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
chunk_length_s=30,
batch_size=16, # batch size for inference - set based on your device
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
result = pipe(sample)
print(result["text"])
```
#### Torch compile
The Whisper forward pass is compatible with [`torch.compile`](https://pytorch.org/docs/stable/generated/torch.compile.html)
for 4.5x speed-ups.
**Note:** `torch.compile` is currently not compatible with the Chunked long-form algorithm or Flash Attention 2 ⚠️
```python
import torch
from torch.nn.attention import SDPBackend, sdpa_kernel
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
from datasets import load_dataset
from tqdm import tqdm
torch.set_float32_matmul_precision("high")
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
model_id = "openai/whisper-large-v3"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True
).to(device)
# Enable static cache and compile the forward pass
model.generation_config.cache_implementation = "static"
model.generation_config.max_new_tokens = 256
model.forward = torch.compile(model.forward, mode="reduce-overhead", fullgraph=True)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
torch_dtype=torch_dtype,
device=device,
)
dataset = load_dataset("distil-whisper/librispeech_long", "clean", split="validation")
sample = dataset[0]["audio"]
# 2 warmup steps
for _ in tqdm(range(2), desc="Warm-up step"):
with sdpa_kernel(SDPBackend.MATH):
result = pipe(sample.copy(), generate_kwargs={"min_new_tokens": 256, "max_new_tokens": 256})
# fast run
with sdpa_kernel(SDPBackend.MATH):
result = pipe(sample.copy())
print(result["text"])
```
#### Flash Attention 2
We recommend using [Flash-Attention 2](https://huggingface.co/docs/transformers/main/en/perf_infer_gpu_one#flashattention-2) if your GPU supports it and you are not using [torch.compile](#torch-compile).
To do so, first install [Flash Attention](https://github.com/Dao-AILab/flash-attention):
```
pip install flash-attn --no-build-isolation
```
Then pass `attn_implementation="flash_attention_2"` to `from_pretrained`:
```python
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, attn_implementation="flash_attention_2")
```
#### Torch Scale-Product-Attention (SDPA)
If your GPU does not support Flash Attention, we recommend making use of PyTorch [scaled dot-product attention (SDPA)](https://pytorch.org/docs/stable/generated/torch.nn.functional.scaled_dot_product_attention.html).
This attention implementation is activated **by default** for PyTorch versions 2.1.1 or greater. To check
whether you have a compatible PyTorch version, run the following Python code snippet:
```python
from transformers.utils import is_torch_sdpa_available
print(is_torch_sdpa_available())
```
If the above returns `True`, you have a valid version of PyTorch installed and SDPA is activated by default. If it
returns `False`, you need to upgrade your PyTorch version according to the [official instructions](https://pytorch.org/get-started/locally/)
Once a valid PyTorch version is installed, SDPA is activated by default. It can also be set explicitly by specifying
`attn_implementation="sdpa"` as follows:
```python
model = AutoModelForSpeechSeq2Seq.from_pretrained(model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, attn_implementation="sdpa")
```
For more information about how to use the SDPA refer to the [Transformers SDPA documentation](https://huggingface.co/docs/transformers/en/perf_infer_gpu_one#pytorch-scaled-dot-product-attention).
## Model details
Whisper is a Transformer based encoder-decoder model, also referred to as a _sequence-to-sequence_ model. There are two
flavours of Whisper model: English-only and multilingual. The English-only models were trained on the task of English
speech recognition. The multilingual models were trained simultaneously on multilingual speech recognition and speech
translation. For speech recognition, the model predicts transcriptions in the *same* language as the audio. For speech
translation, the model predicts transcriptions to a *different* language to the audio.
Whisper checkpoints come in five configurations of varying model sizes. The smallest four are available as English-only
and multilingual. The largest checkpoints are multilingual only. All ten of the pre-trained checkpoints
are available on the [Hugging Face Hub](https://huggingface.co/models?search=openai/whisper). The
checkpoints are summarised in the following table with links to the models on the Hub:
| Size | Parameters | English-only | Multilingual |
|----------|------------|------------------------------------------------------|-----------------------------------------------------|
| tiny | 39 M | [✓](https://huggingface.co/openai/whisper-tiny.en) | [✓](https://huggingface.co/openai/whisper-tiny) |
| base | 74 M | [✓](https://huggingface.co/openai/whisper-base.en) | [✓](https://huggingface.co/openai/whisper-base) |
| small | 244 M | [✓](https://huggingface.co/openai/whisper-small.en) | [✓](https://huggingface.co/openai/whisper-small) |
| medium | 769 M | [✓](https://huggingface.co/openai/whisper-medium.en) | [✓](https://huggingface.co/openai/whisper-medium) |
| large | 1550 M | x | [✓](https://huggingface.co/openai/whisper-large) |
| large-v2 | 1550 M | x | [✓](https://huggingface.co/openai/whisper-large-v2) |
| large-v3 | 1550 M | x | [✓](https://huggingface.co/openai/whisper-large-v3) |
## Fine-Tuning
The pre-trained Whisper model demonstrates a strong ability to generalise to different datasets and domains. However,
its predictive capabilities can be improved further for certain languages and tasks through *fine-tuning*. The blog
post [Fine-Tune Whisper with 🤗 Transformers](https://huggingface.co/blog/fine-tune-whisper) provides a step-by-step
guide to fine-tuning the Whisper model with as little as 5 hours of labelled data.
### Evaluated Use
The primary intended users of these models are AI researchers studying robustness, generalization, capabilities, biases, and constraints of the current model. However, Whisper is also potentially quite useful as an ASR solution for developers, especially for English speech recognition. We recognize that once models are released, it is impossible to restrict access to only “intended” uses or to draw reasonable guidelines around what is or is not research.
The models are primarily trained and evaluated on ASR and speech translation to English tasks. They show strong ASR results in ~10 languages. They may exhibit additional capabilities, particularly if fine-tuned on certain tasks like voice activity detection, speaker classification, or speaker diarization but have not been robustly evaluated in these areas. We strongly recommend that users perform robust evaluations of the models in a particular context and domain before deploying them.
In particular, we caution against using Whisper models to transcribe recordings of individuals taken without their consent or purporting to use these models for any kind of subjective classification. We recommend against use in high-risk domains like decision-making contexts, where flaws in accuracy can lead to pronounced flaws in outcomes. The models are intended to transcribe and translate speech, use of the model for classification is not only not evaluated but also not appropriate, particularly to infer human attributes.
## Training Data
The large-v3 checkpoint is trained on 1 million hours of weakly labeled audio and 4 million hours of pseudo-labeled audio collected using Whisper large-v2.
As discussed in [the accompanying paper](https://cdn.openai.com/papers/whisper.pdf), we see that performance on transcription in a given language is directly correlated with the amount of training data we employ in that language.
## Performance and Limitations
Our studies show that, over many existing ASR systems, the models exhibit improved robustness to accents, background noise, technical language, as well as zero shot translation from multiple languages into English; and that accuracy on speech recognition and translation is near the state-of-the-art level.
However, because the models are trained in a weakly supervised manner using large-scale noisy data, the predictions may include texts that are not actually spoken in the audio input (i.e. hallucination). We hypothesize that this happens because, given their general knowledge of language, the models combine trying to predict the next word in audio with trying to transcribe the audio itself.
Our models perform unevenly across languages, and we observe lower accuracy on low-resource and/or low-discoverability languages or languages where we have less training data. The models also exhibit disparate performance on different accents and dialects of particular languages, which may include higher word error rate across speakers of different genders, races, ages, or other demographic criteria. Our full evaluation results are presented in [the paper accompanying this release](https://cdn.openai.com/papers/whisper.pdf).
In addition, the sequence-to-sequence architecture of the model makes it prone to generating repetitive texts, which can be mitigated to some degree by beam search and temperature scheduling but not perfectly. Further analysis on these limitations are provided in [the paper](https://cdn.openai.com/papers/whisper.pdf). It is likely that this behavior and hallucinations may be worse on lower-resource and/or lower-discoverability languages.
## Broader Implications
We anticipate that Whisper models’ transcription capabilities may be used for improving accessibility tools. While Whisper models cannot be used for real-time transcription out of the box – their speed and size suggest that others may be able to build applications on top of them that allow for near-real-time speech recognition and translation. The real value of beneficial applications built on top of Whisper models suggests that the disparate performance of these models may have real economic implications.
There are also potential dual use concerns that come with releasing Whisper. While we hope the technology will be used primarily for beneficial purposes, making ASR technology more accessible could enable more actors to build capable surveillance technologies or scale up existing surveillance efforts, as the speed and accuracy allow for affordable automatic transcription and translation of large volumes of audio communication. Moreover, these models may have some capabilities to recognize specific individuals out of the box, which in turn presents safety concerns related both to dual use and disparate performance. In practice, we expect that the cost of transcription is not the limiting factor of scaling up surveillance projects.
### BibTeX entry and citation info
```bibtex
@misc{radford2022whisper,
doi = {10.48550/ARXIV.2212.04356},
url = {https://arxiv.org/abs/2212.04356},
author = {Radford, Alec and Kim, Jong Wook and Xu, Tao and Brockman, Greg and McLeavey, Christine and Sutskever, Ilya},
title = {Robust Speech Recognition via Large-Scale Weak Supervision},
publisher = {arXiv},
year = {2022},
copyright = {arXiv.org perpetual, non-exclusive license}
}
``` |
mattmdjaga/segformer_b2_clothes | mattmdjaga | "2024-06-17T08:41:03Z" | 4,562,895 | 375 | transformers | [
"transformers",
"pytorch",
"onnx",
"safetensors",
"segformer",
"vision",
"image-segmentation",
"dataset:mattmdjaga/human_parsing_dataset",
"arxiv:2105.15203",
"license:mit",
"endpoints_compatible",
"region:us"
] | image-segmentation | "2022-11-24T09:48:16Z" | ---
license: mit
tags:
- vision
- image-segmentation
widget:
- src: https://images.unsplash.com/photo-1643310325061-2beef64926a5?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxzZWFyY2h8Nnx8cmFjb29uc3xlbnwwfHwwfHw%3D&w=1000&q=80
example_title: Person
- src: https://freerangestock.com/sample/139043/young-man-standing-and-leaning-on-car.jpg
example_title: Person
datasets:
- mattmdjaga/human_parsing_dataset
---
# Segformer B2 fine-tuned for clothes segmentation
SegFormer model fine-tuned on [ATR dataset](https://github.com/lemondan/HumanParsing-Dataset) for clothes segmentation but can also be used for human segmentation.
The dataset on hugging face is called "mattmdjaga/human_parsing_dataset".
**[Training code](https://github.com/mattmdjaga/segformer_b2_clothes)**.
```python
from transformers import SegformerImageProcessor, AutoModelForSemanticSegmentation
from PIL import Image
import requests
import matplotlib.pyplot as plt
import torch.nn as nn
processor = SegformerImageProcessor.from_pretrained("mattmdjaga/segformer_b2_clothes")
model = AutoModelForSemanticSegmentation.from_pretrained("mattmdjaga/segformer_b2_clothes")
url = "https://plus.unsplash.com/premium_photo-1673210886161-bfcc40f54d1f?ixlib=rb-4.0.3&ixid=MnwxMjA3fDB8MHxzZWFyY2h8MXx8cGVyc29uJTIwc3RhbmRpbmd8ZW58MHx8MHx8&w=1000&q=80"
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits.cpu()
upsampled_logits = nn.functional.interpolate(
logits,
size=image.size[::-1],
mode="bilinear",
align_corners=False,
)
pred_seg = upsampled_logits.argmax(dim=1)[0]
plt.imshow(pred_seg)
```
Labels: 0: "Background", 1: "Hat", 2: "Hair", 3: "Sunglasses", 4: "Upper-clothes", 5: "Skirt", 6: "Pants", 7: "Dress", 8: "Belt", 9: "Left-shoe", 10: "Right-shoe", 11: "Face", 12: "Left-leg", 13: "Right-leg", 14: "Left-arm", 15: "Right-arm", 16: "Bag", 17: "Scarf"
### Evaluation
| Label Index | Label Name | Category Accuracy | Category IoU |
|:-------------:|:----------------:|:-----------------:|:------------:|
| 0 | Background | 0.99 | 0.99 |
| 1 | Hat | 0.73 | 0.68 |
| 2 | Hair | 0.91 | 0.82 |
| 3 | Sunglasses | 0.73 | 0.63 |
| 4 | Upper-clothes | 0.87 | 0.78 |
| 5 | Skirt | 0.76 | 0.65 |
| 6 | Pants | 0.90 | 0.84 |
| 7 | Dress | 0.74 | 0.55 |
| 8 | Belt | 0.35 | 0.30 |
| 9 | Left-shoe | 0.74 | 0.58 |
| 10 | Right-shoe | 0.75 | 0.60 |
| 11 | Face | 0.92 | 0.85 |
| 12 | Left-leg | 0.90 | 0.82 |
| 13 | Right-leg | 0.90 | 0.81 |
| 14 | Left-arm | 0.86 | 0.74 |
| 15 | Right-arm | 0.82 | 0.73 |
| 16 | Bag | 0.91 | 0.84 |
| 17 | Scarf | 0.63 | 0.29 |
Overall Evaluation Metrics:
- Evaluation Loss: 0.15
- Mean Accuracy: 0.80
- Mean IoU: 0.69
### License
The license for this model can be found [here](https://github.com/NVlabs/SegFormer/blob/master/LICENSE).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-15203,
author = {Enze Xie and
Wenhai Wang and
Zhiding Yu and
Anima Anandkumar and
Jose M. Alvarez and
Ping Luo},
title = {SegFormer: Simple and Efficient Design for Semantic Segmentation with
Transformers},
journal = {CoRR},
volume = {abs/2105.15203},
year = {2021},
url = {https://arxiv.org/abs/2105.15203},
eprinttype = {arXiv},
eprint = {2105.15203},
timestamp = {Wed, 02 Jun 2021 11:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-15203.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
yikuan8/Clinical-Longformer | yikuan8 | "2023-01-24T20:58:27Z" | 4,518,901 | 58 | transformers | [
"transformers",
"pytorch",
"longformer",
"fill-mask",
"clinical",
"en",
"arxiv:2201.11838",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:05Z" | ---
language: "en"
tags:
- longformer
- clinical
---
<span style="font-size:larger;">**Clinical-Longformer**</span> is a clinical knowledge enriched version of Longformer that was further pre-trained using MIMIC-III clinical notes. It allows up to 4,096 tokens as the model input. Clinical-Longformer consistently out-performs ClinicalBERT across 10 baseline dataset for at least 2 percent. Those downstream experiments broadly cover named entity recognition (NER), question answering (QA), natural language inference (NLI) and text classification tasks. For more details, please refer to [our paper](https://arxiv.org/pdf/2201.11838.pdf). We also provide a sister model at [Clinical-BigBIrd](https://huggingface.co/yikuan8/Clinical-BigBird)
### Pre-training
We initialized Clinical-Longformer from the pre-trained weights of the base version of Longformer. The pre-training process was distributed in parallel to 6 32GB Tesla V100 GPUs. FP16 precision was enabled to accelerate training. We pre-trained Clinical-Longformer for 200,000 steps with batch size of 6×3. The learning rates were 3e-5 for both models. The entire pre-training process took more than 2 weeks.
### Usage
Load the model directly from Transformers:
```
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("yikuan8/Clinical-Longformer")
model = AutoModelForMaskedLM.from_pretrained("yikuan8/Clinical-Longformer")
```
### Citing
If you find our model helps, please consider citing this :)
```
@article{li2023comparative,
title={A comparative study of pretrained language models for long clinical text},
author={Li, Yikuan and Wehbe, Ramsey M and Ahmad, Faraz S and Wang, Hanyin and Luo, Yuan},
journal={Journal of the American Medical Informatics Association},
volume={30},
number={2},
pages={340--347},
year={2023},
publisher={Oxford University Press}
}
```
### Questions
Please email [email protected]
|
openai/clip-vit-large-patch14-336 | openai | "2022-10-04T09:41:39Z" | 4,489,460 | 223 | transformers | [
"transformers",
"pytorch",
"tf",
"clip",
"zero-shot-image-classification",
"generated_from_keras_callback",
"endpoints_compatible",
"region:us"
] | zero-shot-image-classification | "2022-04-22T14:57:43Z" | ---
tags:
- generated_from_keras_callback
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: playing music, playing sports
example_title: Cat & Dog
model-index:
- name: clip-vit-large-patch14-336
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# clip-vit-large-patch14-336
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: None
- training_precision: float32
### Training results
### Framework versions
- Transformers 4.21.3
- TensorFlow 2.8.2
- Tokenizers 0.12.1
|
jonatasgrosman/wav2vec2-large-xlsr-53-russian | jonatasgrosman | "2022-12-14T01:58:43Z" | 4,487,275 | 49 | transformers | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"hf-asr-leaderboard",
"mozilla-foundation/common_voice_6_0",
"robust-speech-event",
"ru",
"speech",
"xlsr-fine-tuning-week",
"dataset:common_voice",
"dataset:mozilla-foundation/common_voice_6_0",
"doi:10.57967/hf/3571",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-03-02T23:29:05Z" | ---
language: ru
license: apache-2.0
datasets:
- common_voice
- mozilla-foundation/common_voice_6_0
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- hf-asr-leaderboard
- mozilla-foundation/common_voice_6_0
- robust-speech-event
- ru
- speech
- xlsr-fine-tuning-week
model-index:
- name: XLSR Wav2Vec2 Russian by Jonatas Grosman
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice ru
type: common_voice
args: ru
metrics:
- name: Test WER
type: wer
value: 13.3
- name: Test CER
type: cer
value: 2.88
- name: Test WER (+LM)
type: wer
value: 9.57
- name: Test CER (+LM)
type: cer
value: 2.24
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: ru
metrics:
- name: Dev WER
type: wer
value: 40.22
- name: Dev CER
type: cer
value: 14.8
- name: Dev WER (+LM)
type: wer
value: 33.61
- name: Dev CER (+LM)
type: cer
value: 13.5
---
# Fine-tuned XLSR-53 large model for speech recognition in Russian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Russian using the train and validation splits of [Common Voice 6.1](https://huggingface.co/datasets/common_voice) and [CSS10](https://github.com/Kyubyong/css10).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
The script used for training can be found here: https://github.com/jonatasgrosman/wav2vec2-sprint
## Usage
The model can be used directly (without a language model) as follows...
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-large-xlsr-53-russian")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "ru"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-russian"
SAMPLES = 5
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
for i, predicted_sentence in enumerate(predicted_sentences):
print("-" * 100)
print("Reference:", test_dataset[i]["sentence"])
print("Prediction:", predicted_sentence)
```
| Reference | Prediction |
| ------------- | ------------- |
| ОН РАБОТАТЬ, А ЕЕ НЕ УДЕРЖАТЬ НИКАК — БЕГАЕТ ЗА КЛЁШЕМ КАЖДОГО БУЛЬВАРНИКА. | ОН РАБОТАТЬ А ЕЕ НЕ УДЕРЖАТ НИКАК БЕГАЕТ ЗА КЛЕШОМ КАЖДОГО БУЛЬБАРНИКА |
| ЕСЛИ НЕ БУДЕТ ВОЗРАЖЕНИЙ, Я БУДУ СЧИТАТЬ, ЧТО АССАМБЛЕЯ СОГЛАСНА С ЭТИМ ПРЕДЛОЖЕНИЕМ. | ЕСЛИ НЕ БУДЕТ ВОЗРАЖЕНИЙ Я БУДУ СЧИТАТЬ ЧТО АССАМБЛЕЯ СОГЛАСНА С ЭТИМ ПРЕДЛОЖЕНИЕМ |
| ПАЛЕСТИНЦАМ НЕОБХОДИМО СНАЧАЛА УСТАНОВИТЬ МИР С ИЗРАИЛЕМ, А ЗАТЕМ ДОБИВАТЬСЯ ПРИЗНАНИЯ ГОСУДАРСТВЕННОСТИ. | ПАЛЕСТИНЦАМ НЕОБХОДИМО СНАЧАЛА УСТАНОВИТЬ С НИ МИР ФЕЗРЕЛЕМ А ЗАТЕМ ДОБИВАТЬСЯ ПРИЗНАНИЯ ГОСУДАРСТВЕНСКИ |
| У МЕНЯ БЫЛО ТАКОЕ ЧУВСТВО, ЧТО ЧТО-ТО ТАКОЕ ОЧЕНЬ ВАЖНОЕ Я ПРИБАВЛЯЮ. | У МЕНЯ БЫЛО ТАКОЕ ЧУВСТВО ЧТО ЧТО-ТО ТАКОЕ ОЧЕНЬ ВАЖНОЕ Я ПРЕДБАВЛЯЕТ |
| ТОЛЬКО ВРЯД ЛИ ПОЙМЕТ. | ТОЛЬКО ВРЯД ЛИ ПОЙМЕТ |
| ВРОНСКИЙ, СЛУШАЯ ОДНИМ УХОМ, ПЕРЕВОДИЛ БИНОКЛЬ С БЕНУАРА НА БЕЛЬ-ЭТАЖ И ОГЛЯДЫВАЛ ЛОЖИ. | ЗЛАЗКИ СЛУШАЮ ОТ ОДНИМ УХАМ ТЫ ВОТИ В ВИНОКОТ СПИЛА НА ПЕРЕТАЧ И ОКЛЯДЫВАЛ БОСУ |
| К СОЖАЛЕНИЮ, СИТУАЦИЯ ПРОДОЛЖАЕТ УХУДШАТЬСЯ. | К СОЖАЛЕНИЮ СИТУАЦИИ ПРОДОЛЖАЕТ УХУЖАТЬСЯ |
| ВСЁ ЖАЛОВАНИЕ УХОДИЛО НА ДОМАШНИЕ РАСХОДЫ И НА УПЛАТУ МЕЛКИХ НЕПЕРЕВОДИВШИХСЯ ДОЛГОВ. | ВСЕ ЖАЛОВАНИЕ УХОДИЛО НА ДОМАШНИЕ РАСХОДЫ И НА УПЛАТУ МЕЛКИХ НЕ ПЕРЕВОДИВШИХСЯ ДОЛГОВ |
| ТЕПЕРЬ ДЕЛО, КОНЕЧНО, ЗА ТЕМ, ЧТОБЫ ПРЕВРАТИТЬ СЛОВА В ДЕЛА. | ТЕПЕРЬ ДЕЛАЮ КОНЕЧНО ЗАТЕМ ЧТОБЫ ПРЕВРАТИТЬ СЛОВА В ДЕЛА |
| ДЕВЯТЬ | ЛЕВЕТЬ |
## Evaluation
1. To evaluate on `mozilla-foundation/common_voice_6_0` with split `test`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-large-xlsr-53-russian --dataset mozilla-foundation/common_voice_6_0 --config ru --split test
```
2. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-large-xlsr-53-russian --dataset speech-recognition-community-v2/dev_data --config ru --split validation --chunk_length_s 5.0 --stride_length_s 1.0
```
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr53-large-russian,
title={Fine-tuned {XLSR}-53 large model for speech recognition in {R}ussian},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-russian}},
year={2021}
}
``` |
timm/resnet18.a1_in1k | timm | "2025-01-21T21:13:50Z" | 4,351,917 | 10 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"transformers",
"arxiv:2110.00476",
"arxiv:1512.03385",
"license:apache-2.0",
"region:us"
] | image-classification | "2023-04-05T18:02:50Z" | ---
tags:
- image-classification
- timm
- transformers
license: apache-2.0
library_name: timm
---
# Model card for resnet18.a1_in1k
A ResNet-B image classification model.
This model features:
* ReLU activations
* single layer 7x7 convolution with pooling
* 1x1 convolution shortcut downsample
Trained on ImageNet-1k in `timm` using recipe template described below.
Recipe details:
* ResNet Strikes Back `A1` recipe
* LAMB optimizer with BCE loss
* Cosine LR schedule with warmup
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 11.7
- GMACs: 1.8
- Activations (M): 2.5
- Image size: train = 224 x 224, test = 288 x 288
- **Papers:**
- ResNet strikes back: An improved training procedure in timm: https://arxiv.org/abs/2110.00476
- Deep Residual Learning for Image Recognition: https://arxiv.org/abs/1512.03385
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('resnet18.a1_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet18.a1_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 112, 112])
# torch.Size([1, 64, 56, 56])
# torch.Size([1, 128, 28, 28])
# torch.Size([1, 256, 14, 14])
# torch.Size([1, 512, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'resnet18.a1_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |img_size|top1 |top5 |param_count|gmacs|macts|img/sec|
|------------------------------------------|--------|-----|-----|-----------|-----|-----|-------|
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|320 |86.72|98.17|93.6 |35.2 |69.7 |451 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k_288](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k_288)|288 |86.51|98.08|93.6 |28.5 |56.4 |560 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|288 |86.49|98.03|93.6 |28.5 |56.4 |557 |
|[seresnextaa101d_32x8d.sw_in12k_ft_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.sw_in12k_ft_in1k)|224 |85.96|97.82|93.6 |17.2 |34.2 |923 |
|[resnext101_32x32d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x32d.fb_wsl_ig1b_ft_in1k)|224 |85.11|97.44|468.5 |87.3 |91.1 |254 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|416 |85.0 |97.12|191.9 |108.4|213.8|134 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|352 |84.96|97.22|102.1 |50.2 |101.2|291 |
|[ecaresnet269d.ra2_in1k](https://huggingface.co/timm/ecaresnet269d.ra2_in1k)|320 |84.73|97.18|102.1 |41.5 |83.7 |353 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|384 |84.71|96.99|164.0 |77.6 |154.7|183 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|288 |84.57|97.08|93.6 |28.5 |56.4 |557 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|320 |84.45|97.08|93.2 |31.5 |67.8 |446 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|352 |84.43|96.97|129.9 |51.1 |105.5|280 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|288 |84.36|96.92|93.6 |27.6 |53.0 |595 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|320 |84.35|97.04|66.8 |24.1 |47.7 |610 |
|[resnetrs350.tf_in1k](https://huggingface.co/timm/resnetrs350.tf_in1k)|288 |84.3 |96.94|164.0 |43.7 |87.1 |333 |
|[resnext101_32x8d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_swsl_ig1b_ft_in1k)|224 |84.28|97.17|88.8 |16.5 |31.2 |1100 |
|[resnetrs420.tf_in1k](https://huggingface.co/timm/resnetrs420.tf_in1k)|320 |84.24|96.86|191.9 |64.2 |126.6|228 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|288 |84.19|96.87|93.6 |27.2 |51.6 |613 |
|[resnext101_32x16d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_wsl_ig1b_ft_in1k)|224 |84.18|97.19|194.0 |36.3 |51.2 |581 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|288 |84.11|97.11|44.6 |15.1 |29.0 |1144 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|320 |83.97|96.82|64.7 |31.2 |67.3 |518 |
|[resnetrs200.tf_in1k](https://huggingface.co/timm/resnetrs200.tf_in1k)|256 |83.87|96.75|93.2 |20.2 |43.4 |692 |
|[seresnextaa101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnextaa101d_32x8d.ah_in1k)|224 |83.86|96.65|93.6 |17.2 |34.2 |923 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|320 |83.72|96.61|86.6 |24.3 |48.1 |617 |
|[seresnet152d.ra2_in1k](https://huggingface.co/timm/seresnet152d.ra2_in1k)|256 |83.69|96.78|66.8 |15.4 |30.6 |943 |
|[seresnext101d_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101d_32x8d.ah_in1k)|224 |83.68|96.61|93.6 |16.7 |32.0 |986 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|320 |83.67|96.74|60.2 |24.1 |47.7 |706 |
|[resnetrs270.tf_in1k](https://huggingface.co/timm/resnetrs270.tf_in1k)|256 |83.59|96.61|129.9 |27.1 |55.8 |526 |
|[seresnext101_32x8d.ah_in1k](https://huggingface.co/timm/seresnext101_32x8d.ah_in1k)|224 |83.58|96.4 |93.6 |16.5 |31.2 |1013 |
|[resnetaa101d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa101d.sw_in12k_ft_in1k)|224 |83.54|96.83|44.6 |9.1 |17.6 |1864 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|288 |83.46|96.54|60.2 |19.1 |37.3 |904 |
|[resnext101_32x16d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_swsl_ig1b_ft_in1k)|224 |83.35|96.85|194.0 |36.3 |51.2 |582 |
|[resnet200d.ra2_in1k](https://huggingface.co/timm/resnet200d.ra2_in1k)|256 |83.23|96.53|64.7 |20.0 |43.1 |809 |
|[resnext101_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_swsl_ig1b_ft_in1k)|224 |83.22|96.75|44.2 |8.0 |21.2 |1814 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|288 |83.16|96.38|83.5 |25.7 |51.6 |590 |
|[resnet152d.ra2_in1k](https://huggingface.co/timm/resnet152d.ra2_in1k)|256 |83.14|96.38|60.2 |15.4 |30.5 |1096 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|320 |83.02|96.45|44.6 |16.5 |34.8 |992 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|288 |82.98|96.54|44.6 |13.4 |28.2 |1077 |
|[resnext101_64x4d.tv_in1k](https://huggingface.co/timm/resnext101_64x4d.tv_in1k)|224 |82.98|96.25|83.5 |15.5 |31.2 |989 |
|[resnetrs152.tf_in1k](https://huggingface.co/timm/resnetrs152.tf_in1k)|256 |82.86|96.28|86.6 |15.6 |30.8 |951 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|224 |82.83|96.22|88.8 |16.5 |31.2 |1099 |
|[resnet152.a1h_in1k](https://huggingface.co/timm/resnet152.a1h_in1k)|224 |82.8 |96.13|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|288 |82.8 |96.32|44.6 |13.0 |26.8 |1291 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|288 |82.74|95.71|60.2 |19.1 |37.3 |905 |
|[resnext101_32x8d.fb_wsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_wsl_ig1b_ft_in1k)|224 |82.69|96.63|88.8 |16.5 |31.2 |1100 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|288 |82.62|95.75|60.2 |19.1 |37.3 |904 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|288 |82.61|96.49|25.6 |8.9 |20.6 |1729 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|288 |82.53|96.13|36.8 |9.9 |21.5 |1773 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|224 |82.5 |96.02|126.9 |22.8 |21.2 |1078 |
|[resnext101_64x4d.c1_in1k](https://huggingface.co/timm/resnext101_64x4d.c1_in1k)|224 |82.46|95.92|83.5 |15.5 |31.2 |987 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|288 |82.36|96.18|35.7 |8.1 |20.9 |1964 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|320 |82.35|96.14|25.6 |8.8 |24.1 |1386 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|288 |82.31|95.63|44.6 |13.0 |26.8 |1291 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|288 |82.29|96.01|63.6 |13.6 |28.5 |1078 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|224 |82.29|96.0 |60.2 |11.6 |22.6 |1484 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|288 |82.27|96.06|68.9 |18.9 |23.8 |1176 |
|[resnet101d.ra2_in1k](https://huggingface.co/timm/resnet101d.ra2_in1k)|256 |82.26|96.07|44.6 |10.6 |22.2 |1542 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|288 |82.24|95.73|44.6 |13.0 |26.8 |1290 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|288 |82.2 |96.14|27.6 |7.0 |23.8 |1547 |
|[ecaresnet101d.miil_in1k](https://huggingface.co/timm/ecaresnet101d.miil_in1k)|224 |82.18|96.05|44.6 |8.1 |17.1 |1771 |
|[resnext50_32x4d.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_swsl_ig1b_ft_in1k)|224 |82.17|96.22|25.0 |4.3 |14.4 |2943 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|288 |82.12|95.65|25.6 |7.1 |19.6 |1704 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|288 |82.03|95.94|25.0 |7.0 |23.8 |1745 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|288 |82.0 |96.15|24.9 |5.8 |12.7 |1787 |
|[resnet61q.ra2_in1k](https://huggingface.co/timm/resnet61q.ra2_in1k)|256 |81.99|95.85|36.8 |7.8 |17.0 |2230 |
|[resnext101_32x8d.tv2_in1k](https://huggingface.co/timm/resnext101_32x8d.tv2_in1k)|176 |81.98|95.72|88.8 |10.3 |19.4 |1768 |
|[resnet152.a1_in1k](https://huggingface.co/timm/resnet152.a1_in1k)|224 |81.97|95.24|60.2 |11.6 |22.6 |1486 |
|[resnet101.a1h_in1k](https://huggingface.co/timm/resnet101.a1h_in1k)|224 |81.93|95.75|44.6 |7.8 |16.2 |2122 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|224 |81.9 |95.77|44.6 |7.8 |16.2 |2118 |
|[resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x16d.fb_ssl_yfcc100m_ft_in1k)|224 |81.84|96.1 |194.0 |36.3 |51.2 |583 |
|[resnet51q.ra2_in1k](https://huggingface.co/timm/resnet51q.ra2_in1k)|256 |81.78|95.94|35.7 |6.4 |16.6 |2471 |
|[resnet152.a2_in1k](https://huggingface.co/timm/resnet152.a2_in1k)|224 |81.77|95.22|60.2 |11.6 |22.6 |1485 |
|[resnetaa50d.sw_in12k_ft_in1k](https://huggingface.co/timm/resnetaa50d.sw_in12k_ft_in1k)|224 |81.74|96.06|25.6 |5.4 |12.4 |2813 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|288 |81.65|95.54|25.6 |7.1 |19.6 |1703 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|288 |81.64|95.88|25.6 |7.2 |19.7 |1694 |
|[resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x8d.fb_ssl_yfcc100m_ft_in1k)|224 |81.62|96.04|88.8 |16.5 |31.2 |1101 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|224 |81.61|95.76|68.9 |11.4 |14.4 |1930 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|288 |81.61|95.83|25.6 |8.5 |19.2 |1868 |
|[resnet101.a1_in1k](https://huggingface.co/timm/resnet101.a1_in1k)|224 |81.5 |95.16|44.6 |7.8 |16.2 |2125 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|288 |81.48|95.16|25.0 |7.0 |23.8 |1745 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|288 |81.47|95.71|25.9 |6.9 |18.6 |2071 |
|[wide_resnet50_2.racm_in1k](https://huggingface.co/timm/wide_resnet50_2.racm_in1k)|224 |81.45|95.53|68.9 |11.4 |14.4 |1929 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|288 |81.44|95.22|25.6 |7.2 |19.7 |1908 |
|[ecaresnet50t.ra2_in1k](https://huggingface.co/timm/ecaresnet50t.ra2_in1k)|256 |81.44|95.67|25.6 |5.6 |15.4 |2168 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|288 |81.4 |95.82|30.2 |6.8 |13.9 |2132 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|288 |81.37|95.74|25.6 |7.2 |19.7 |1910 |
|[resnet101.a2_in1k](https://huggingface.co/timm/resnet101.a2_in1k)|224 |81.32|95.19|44.6 |7.8 |16.2 |2125 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|288 |81.3 |95.65|28.1 |6.8 |18.4 |1803 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|288 |81.3 |95.11|25.0 |7.0 |23.8 |1746 |
|[seresnext50_32x4d.racm_in1k](https://huggingface.co/timm/seresnext50_32x4d.racm_in1k)|224 |81.27|95.62|27.6 |4.3 |14.4 |2591 |
|[ecaresnet50t.a1_in1k](https://huggingface.co/timm/ecaresnet50t.a1_in1k)|224 |81.26|95.16|25.6 |4.3 |11.8 |2823 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|288 |81.23|95.54|15.7 |4.8 |19.6 |2117 |
|[senet154.gluon_in1k](https://huggingface.co/timm/senet154.gluon_in1k)|224 |81.23|95.35|115.1 |20.8 |38.7 |545 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|288 |81.22|95.11|25.6 |6.8 |18.4 |2089 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|288 |81.22|95.63|25.6 |6.8 |18.4 |676 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|288 |81.18|95.09|25.6 |7.2 |19.7 |1908 |
|[resnet50.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet50.fb_swsl_ig1b_ft_in1k)|224 |81.18|95.98|25.6 |4.1 |11.1 |3455 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|224 |81.17|95.34|25.0 |4.3 |14.4 |2933 |
|[resnext50_32x4d.a1h_in1k](https://huggingface.co/timm/resnext50_32x4d.a1h_in1k)|224 |81.1 |95.33|25.0 |4.3 |14.4 |2934 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|288 |81.1 |95.23|28.1 |6.8 |18.4 |1801 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|288 |81.1 |95.12|28.1 |6.8 |18.4 |1799 |
|[resnet152s.gluon_in1k](https://huggingface.co/timm/resnet152s.gluon_in1k)|224 |81.02|95.41|60.3 |12.9 |25.0 |1347 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|288 |80.97|95.44|25.6 |6.8 |18.4 |2085 |
|[gcresnet50t.ra2_in1k](https://huggingface.co/timm/gcresnet50t.ra2_in1k)|256 |80.94|95.45|25.9 |5.4 |14.7 |2571 |
|[resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext101_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.93|95.73|44.2 |8.0 |21.2 |1814 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|288 |80.91|95.55|25.6 |6.8 |18.4 |2084 |
|[seresnext101_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_32x4d.gluon_in1k)|224 |80.9 |95.31|49.0 |8.0 |21.3 |1585 |
|[seresnext101_64x4d.gluon_in1k](https://huggingface.co/timm/seresnext101_64x4d.gluon_in1k)|224 |80.9 |95.3 |88.2 |15.5 |31.2 |918 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|288 |80.86|95.52|25.6 |6.8 |18.4 |2085 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|224 |80.85|95.43|25.6 |4.1 |11.1 |3450 |
|[ecaresnet50t.a2_in1k](https://huggingface.co/timm/ecaresnet50t.a2_in1k)|224 |80.84|95.02|25.6 |4.3 |11.8 |2821 |
|[ecaresnet101d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet101d_pruned.miil_in1k)|224 |80.79|95.62|24.9 |3.5 |7.7 |2961 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|288 |80.79|95.36|19.8 |6.0 |14.8 |2506 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|288 |80.79|95.58|19.9 |4.2 |10.6 |2349 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|288 |80.78|94.99|25.6 |6.8 |18.4 |2088 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|288 |80.71|95.43|25.6 |6.8 |18.4 |2087 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|288 |80.7 |95.39|25.0 |7.0 |23.8 |1749 |
|[resnetrs101.tf_in1k](https://huggingface.co/timm/resnetrs101.tf_in1k)|192 |80.69|95.24|63.6 |6.0 |12.7 |2270 |
|[resnet50d.a1_in1k](https://huggingface.co/timm/resnet50d.a1_in1k)|224 |80.68|94.71|25.6 |4.4 |11.9 |3162 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|288 |80.68|95.36|19.7 |6.0 |14.8 |2637 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|224 |80.67|95.3 |25.6 |4.1 |11.1 |3452 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|288 |80.67|95.42|25.0 |7.4 |25.1 |1626 |
|[resnetaa50.a1h_in1k](https://huggingface.co/timm/resnetaa50.a1h_in1k)|224 |80.63|95.21|25.6 |5.2 |11.6 |3034 |
|[ecaresnet50d.miil_in1k](https://huggingface.co/timm/ecaresnet50d.miil_in1k)|224 |80.61|95.32|25.6 |4.4 |11.9 |2813 |
|[resnext101_64x4d.gluon_in1k](https://huggingface.co/timm/resnext101_64x4d.gluon_in1k)|224 |80.61|94.99|83.5 |15.5 |31.2 |989 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|288 |80.6 |95.31|19.9 |6.0 |14.8 |2578 |
|[gcresnext50ts.ch_in1k](https://huggingface.co/timm/gcresnext50ts.ch_in1k)|256 |80.57|95.17|15.7 |3.8 |15.5 |2710 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|224 |80.56|95.0 |60.2 |11.6 |22.6 |1483 |
|[resnet50d.ra2_in1k](https://huggingface.co/timm/resnet50d.ra2_in1k)|224 |80.53|95.16|25.6 |4.4 |11.9 |3164 |
|[resnext50_32x4d.a1_in1k](https://huggingface.co/timm/resnext50_32x4d.a1_in1k)|224 |80.53|94.46|25.0 |4.3 |14.4 |2930 |
|[wide_resnet101_2.tv2_in1k](https://huggingface.co/timm/wide_resnet101_2.tv2_in1k)|176 |80.48|94.98|126.9 |14.3 |13.2 |1719 |
|[resnet152d.gluon_in1k](https://huggingface.co/timm/resnet152d.gluon_in1k)|224 |80.47|95.2 |60.2 |11.8 |23.4 |1428 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|288 |80.45|95.32|25.6 |6.8 |18.4 |2086 |
|[ecaresnetlight.miil_in1k](https://huggingface.co/timm/ecaresnetlight.miil_in1k)|224 |80.45|95.24|30.2 |4.1 |8.4 |3530 |
|[resnext50_32x4d.a2_in1k](https://huggingface.co/timm/resnext50_32x4d.a2_in1k)|224 |80.45|94.63|25.0 |4.3 |14.4 |2936 |
|[wide_resnet50_2.tv2_in1k](https://huggingface.co/timm/wide_resnet50_2.tv2_in1k)|176 |80.43|95.09|68.9 |7.3 |9.0 |3015 |
|[resnet101d.gluon_in1k](https://huggingface.co/timm/resnet101d.gluon_in1k)|224 |80.42|95.01|44.6 |8.1 |17.0 |2007 |
|[resnet50.a1_in1k](https://huggingface.co/timm/resnet50.a1_in1k)|224 |80.38|94.6 |25.6 |4.1 |11.1 |3461 |
|[seresnet33ts.ra2_in1k](https://huggingface.co/timm/seresnet33ts.ra2_in1k)|256 |80.36|95.1 |19.8 |4.8 |11.7 |3267 |
|[resnext101_32x4d.gluon_in1k](https://huggingface.co/timm/resnext101_32x4d.gluon_in1k)|224 |80.34|94.93|44.2 |8.0 |21.2 |1814 |
|[resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnext50_32x4d.fb_ssl_yfcc100m_ft_in1k)|224 |80.32|95.4 |25.0 |4.3 |14.4 |2941 |
|[resnet101s.gluon_in1k](https://huggingface.co/timm/resnet101s.gluon_in1k)|224 |80.28|95.16|44.7 |9.2 |18.6 |1851 |
|[seresnet50.ra2_in1k](https://huggingface.co/timm/seresnet50.ra2_in1k)|224 |80.26|95.08|28.1 |4.1 |11.1 |2972 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|288 |80.24|95.24|25.6 |8.5 |19.9 |1523 |
|[resnet50d.a2_in1k](https://huggingface.co/timm/resnet50d.a2_in1k)|224 |80.22|94.63|25.6 |4.4 |11.9 |3162 |
|[resnet152.tv2_in1k](https://huggingface.co/timm/resnet152.tv2_in1k)|176 |80.2 |94.64|60.2 |7.2 |14.0 |2346 |
|[seresnet50.a2_in1k](https://huggingface.co/timm/seresnet50.a2_in1k)|224 |80.08|94.74|28.1 |4.1 |11.1 |2969 |
|[eca_resnet33ts.ra2_in1k](https://huggingface.co/timm/eca_resnet33ts.ra2_in1k)|256 |80.08|94.97|19.7 |4.8 |11.7 |3284 |
|[gcresnet33ts.ra2_in1k](https://huggingface.co/timm/gcresnet33ts.ra2_in1k)|256 |80.06|94.99|19.9 |4.8 |11.7 |3216 |
|[resnet50_gn.a1h_in1k](https://huggingface.co/timm/resnet50_gn.a1h_in1k)|224 |80.06|94.95|25.6 |4.1 |11.1 |1109 |
|[seresnet50.a1_in1k](https://huggingface.co/timm/seresnet50.a1_in1k)|224 |80.02|94.71|28.1 |4.1 |11.1 |2962 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|288 |79.97|95.05|25.6 |6.8 |18.4 |2086 |
|[resnet152c.gluon_in1k](https://huggingface.co/timm/resnet152c.gluon_in1k)|224 |79.92|94.84|60.2 |11.8 |23.4 |1455 |
|[seresnext50_32x4d.gluon_in1k](https://huggingface.co/timm/seresnext50_32x4d.gluon_in1k)|224 |79.91|94.82|27.6 |4.3 |14.4 |2591 |
|[resnet50.d_in1k](https://huggingface.co/timm/resnet50.d_in1k)|224 |79.91|94.67|25.6 |4.1 |11.1 |3456 |
|[resnet101.tv2_in1k](https://huggingface.co/timm/resnet101.tv2_in1k)|176 |79.9 |94.6 |44.6 |4.9 |10.1 |3341 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|224 |79.89|94.97|35.7 |4.5 |12.1 |2774 |
|[resnet50.c2_in1k](https://huggingface.co/timm/resnet50.c2_in1k)|224 |79.88|94.87|25.6 |4.1 |11.1 |3455 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|320 |79.86|95.07|16.0 |5.2 |16.4 |2168 |
|[resnet50.a2_in1k](https://huggingface.co/timm/resnet50.a2_in1k)|224 |79.85|94.56|25.6 |4.1 |11.1 |3460 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|288 |79.83|94.97|25.6 |6.8 |18.4 |2087 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|224 |79.82|94.62|44.6 |7.8 |16.2 |2114 |
|[resnext50_32x4d.ra_in1k](https://huggingface.co/timm/resnext50_32x4d.ra_in1k)|224 |79.76|94.6 |25.0 |4.3 |14.4 |2943 |
|[resnet50.c1_in1k](https://huggingface.co/timm/resnet50.c1_in1k)|224 |79.74|94.95|25.6 |4.1 |11.1 |3455 |
|[ecaresnet50d_pruned.miil_in1k](https://huggingface.co/timm/ecaresnet50d_pruned.miil_in1k)|224 |79.74|94.87|19.9 |2.5 |6.4 |3929 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|288 |79.71|94.83|19.7 |6.0 |14.8 |2710 |
|[resnet152.gluon_in1k](https://huggingface.co/timm/resnet152.gluon_in1k)|224 |79.68|94.74|60.2 |11.6 |22.6 |1486 |
|[resnext50d_32x4d.bt_in1k](https://huggingface.co/timm/resnext50d_32x4d.bt_in1k)|224 |79.67|94.87|25.0 |4.5 |15.2 |2729 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|288 |79.63|94.91|25.6 |6.8 |18.4 |2086 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|224 |79.56|94.72|25.6 |4.3 |11.8 |2805 |
|[resnet101c.gluon_in1k](https://huggingface.co/timm/resnet101c.gluon_in1k)|224 |79.53|94.58|44.6 |8.1 |17.0 |2062 |
|[resnet50.b1k_in1k](https://huggingface.co/timm/resnet50.b1k_in1k)|224 |79.52|94.61|25.6 |4.1 |11.1 |3459 |
|[resnet50.tv2_in1k](https://huggingface.co/timm/resnet50.tv2_in1k)|176 |79.42|94.64|25.6 |2.6 |6.9 |5397 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|288 |79.4 |94.66|18.0 |5.9 |14.6 |2752 |
|[resnet50.b2k_in1k](https://huggingface.co/timm/resnet50.b2k_in1k)|224 |79.38|94.57|25.6 |4.1 |11.1 |3459 |
|[resnext50_32x4d.tv2_in1k](https://huggingface.co/timm/resnext50_32x4d.tv2_in1k)|176 |79.37|94.3 |25.0 |2.7 |9.0 |4577 |
|[resnext50_32x4d.gluon_in1k](https://huggingface.co/timm/resnext50_32x4d.gluon_in1k)|224 |79.36|94.43|25.0 |4.3 |14.4 |2942 |
|[resnext101_32x8d.tv_in1k](https://huggingface.co/timm/resnext101_32x8d.tv_in1k)|224 |79.31|94.52|88.8 |16.5 |31.2 |1100 |
|[resnet101.gluon_in1k](https://huggingface.co/timm/resnet101.gluon_in1k)|224 |79.31|94.53|44.6 |7.8 |16.2 |2125 |
|[resnetblur50.bt_in1k](https://huggingface.co/timm/resnetblur50.bt_in1k)|224 |79.31|94.63|25.6 |5.2 |12.0 |2524 |
|[resnet50.a1h_in1k](https://huggingface.co/timm/resnet50.a1h_in1k)|176 |79.27|94.49|25.6 |2.6 |6.9 |5404 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|224 |79.25|94.31|25.0 |4.3 |14.4 |2931 |
|[resnet50.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet50.fb_ssl_yfcc100m_ft_in1k)|224 |79.22|94.84|25.6 |4.1 |11.1 |3451 |
|[resnet33ts.ra2_in1k](https://huggingface.co/timm/resnet33ts.ra2_in1k)|256 |79.21|94.56|19.7 |4.8 |11.7 |3392 |
|[resnet50d.gluon_in1k](https://huggingface.co/timm/resnet50d.gluon_in1k)|224 |79.07|94.48|25.6 |4.4 |11.9 |3162 |
|[resnet50.ram_in1k](https://huggingface.co/timm/resnet50.ram_in1k)|224 |79.03|94.38|25.6 |4.1 |11.1 |3453 |
|[resnet50.am_in1k](https://huggingface.co/timm/resnet50.am_in1k)|224 |79.01|94.39|25.6 |4.1 |11.1 |3461 |
|[resnet32ts.ra2_in1k](https://huggingface.co/timm/resnet32ts.ra2_in1k)|256 |79.01|94.37|18.0 |4.6 |11.6 |3440 |
|[ecaresnet26t.ra2_in1k](https://huggingface.co/timm/ecaresnet26t.ra2_in1k)|256 |78.9 |94.54|16.0 |3.4 |10.5 |3421 |
|[resnet152.a3_in1k](https://huggingface.co/timm/resnet152.a3_in1k)|160 |78.89|94.11|60.2 |5.9 |11.5 |2745 |
|[wide_resnet101_2.tv_in1k](https://huggingface.co/timm/wide_resnet101_2.tv_in1k)|224 |78.84|94.28|126.9 |22.8 |21.2 |1079 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|288 |78.83|94.24|16.8 |4.5 |16.8 |2251 |
|[resnet50.ra_in1k](https://huggingface.co/timm/resnet50.ra_in1k)|224 |78.81|94.32|25.6 |4.1 |11.1 |3454 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|288 |78.74|94.33|16.8 |4.5 |16.7 |2264 |
|[resnet50s.gluon_in1k](https://huggingface.co/timm/resnet50s.gluon_in1k)|224 |78.72|94.23|25.7 |5.5 |13.5 |2796 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|224 |78.71|94.24|25.6 |4.4 |11.9 |3154 |
|[wide_resnet50_2.tv_in1k](https://huggingface.co/timm/wide_resnet50_2.tv_in1k)|224 |78.47|94.09|68.9 |11.4 |14.4 |1934 |
|[resnet50.bt_in1k](https://huggingface.co/timm/resnet50.bt_in1k)|224 |78.46|94.27|25.6 |4.1 |11.1 |3454 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|288 |78.43|94.35|21.8 |6.5 |7.5 |3291 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|288 |78.42|94.04|10.5 |3.1 |13.3 |3226 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|320 |78.33|94.13|16.0 |5.2 |16.4 |2391 |
|[resnet152.tv_in1k](https://huggingface.co/timm/resnet152.tv_in1k)|224 |78.32|94.04|60.2 |11.6 |22.6 |1487 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|288 |78.28|94.1 |10.4 |3.1 |13.3 |3062 |
|[bat_resnext26ts.ch_in1k](https://huggingface.co/timm/bat_resnext26ts.ch_in1k)|256 |78.25|94.1 |10.7 |2.5 |12.5 |3393 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|224 |78.06|93.78|25.6 |4.1 |11.1 |3450 |
|[resnet50c.gluon_in1k](https://huggingface.co/timm/resnet50c.gluon_in1k)|224 |78.0 |93.99|25.6 |4.4 |11.9 |3286 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|288 |78.0 |93.91|10.3 |3.1 |13.3 |3297 |
|[seresnext26t_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26t_32x4d.bt_in1k)|224 |77.98|93.75|16.8 |2.7 |10.1 |3841 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|288 |77.92|93.77|21.8 |6.1 |6.2 |3609 |
|[resnet101.a3_in1k](https://huggingface.co/timm/resnet101.a3_in1k)|160 |77.88|93.71|44.6 |4.0 |8.3 |3926 |
|[resnet26t.ra2_in1k](https://huggingface.co/timm/resnet26t.ra2_in1k)|256 |77.87|93.84|16.0 |3.4 |10.5 |3772 |
|[seresnext26ts.ch_in1k](https://huggingface.co/timm/seresnext26ts.ch_in1k)|256 |77.86|93.79|10.4 |2.4 |10.5 |4263 |
|[resnetrs50.tf_in1k](https://huggingface.co/timm/resnetrs50.tf_in1k)|160 |77.82|93.81|35.7 |2.3 |6.2 |5238 |
|[gcresnext26ts.ch_in1k](https://huggingface.co/timm/gcresnext26ts.ch_in1k)|256 |77.81|93.82|10.5 |2.4 |10.5 |4183 |
|[ecaresnet50t.a3_in1k](https://huggingface.co/timm/ecaresnet50t.a3_in1k)|160 |77.79|93.6 |25.6 |2.2 |6.0 |5329 |
|[resnext50_32x4d.a3_in1k](https://huggingface.co/timm/resnext50_32x4d.a3_in1k)|160 |77.73|93.32|25.0 |2.2 |7.4 |5576 |
|[resnext50_32x4d.tv_in1k](https://huggingface.co/timm/resnext50_32x4d.tv_in1k)|224 |77.61|93.7 |25.0 |4.3 |14.4 |2944 |
|[seresnext26d_32x4d.bt_in1k](https://huggingface.co/timm/seresnext26d_32x4d.bt_in1k)|224 |77.59|93.61|16.8 |2.7 |10.2 |3807 |
|[resnet50.gluon_in1k](https://huggingface.co/timm/resnet50.gluon_in1k)|224 |77.58|93.72|25.6 |4.1 |11.1 |3455 |
|[eca_resnext26ts.ch_in1k](https://huggingface.co/timm/eca_resnext26ts.ch_in1k)|256 |77.44|93.56|10.3 |2.4 |10.5 |4284 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|288 |77.41|93.63|16.0 |4.3 |13.5 |2907 |
|[resnet101.tv_in1k](https://huggingface.co/timm/resnet101.tv_in1k)|224 |77.38|93.54|44.6 |7.8 |16.2 |2125 |
|[resnet50d.a3_in1k](https://huggingface.co/timm/resnet50d.a3_in1k)|160 |77.22|93.27|25.6 |2.2 |6.1 |5982 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|288 |77.17|93.47|10.3 |3.1 |13.3 |3392 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|288 |77.15|93.27|21.8 |6.1 |6.2 |3615 |
|[resnet34d.ra2_in1k](https://huggingface.co/timm/resnet34d.ra2_in1k)|224 |77.1 |93.37|21.8 |3.9 |4.5 |5436 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|224 |77.02|93.07|28.1 |4.1 |11.1 |2952 |
|[resnext26ts.ra2_in1k](https://huggingface.co/timm/resnext26ts.ra2_in1k)|256 |76.78|93.13|10.3 |2.4 |10.5 |4410 |
|[resnet26d.bt_in1k](https://huggingface.co/timm/resnet26d.bt_in1k)|224 |76.7 |93.17|16.0 |2.6 |8.2 |4859 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|288 |76.5 |93.35|21.8 |6.1 |6.2 |3617 |
|[resnet34.a1_in1k](https://huggingface.co/timm/resnet34.a1_in1k)|224 |76.42|92.87|21.8 |3.7 |3.7 |5984 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|288 |76.35|93.18|16.0 |3.9 |12.2 |3331 |
|[resnet50.tv_in1k](https://huggingface.co/timm/resnet50.tv_in1k)|224 |76.13|92.86|25.6 |4.1 |11.1 |3457 |
|[resnet50.a3_in1k](https://huggingface.co/timm/resnet50.a3_in1k)|160 |75.96|92.5 |25.6 |2.1 |5.7 |6490 |
|[resnet34.a2_in1k](https://huggingface.co/timm/resnet34.a2_in1k)|224 |75.52|92.44|21.8 |3.7 |3.7 |5991 |
|[resnet26.bt_in1k](https://huggingface.co/timm/resnet26.bt_in1k)|224 |75.3 |92.58|16.0 |2.4 |7.4 |5583 |
|[resnet34.bt_in1k](https://huggingface.co/timm/resnet34.bt_in1k)|224 |75.16|92.18|21.8 |3.7 |3.7 |5994 |
|[seresnet50.a3_in1k](https://huggingface.co/timm/seresnet50.a3_in1k)|160 |75.1 |92.08|28.1 |2.1 |5.7 |5513 |
|[resnet34.gluon_in1k](https://huggingface.co/timm/resnet34.gluon_in1k)|224 |74.57|91.98|21.8 |3.7 |3.7 |5984 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|288 |73.81|91.83|11.7 |3.4 |5.4 |5196 |
|[resnet34.tv_in1k](https://huggingface.co/timm/resnet34.tv_in1k)|224 |73.32|91.42|21.8 |3.7 |3.7 |5979 |
|[resnet18.fb_swsl_ig1b_ft_in1k](https://huggingface.co/timm/resnet18.fb_swsl_ig1b_ft_in1k)|224 |73.28|91.73|11.7 |1.8 |2.5 |10213 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|288 |73.16|91.03|11.7 |3.0 |4.1 |6050 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|224 |72.98|91.11|21.8 |3.7 |3.7 |5967 |
|[resnet18.fb_ssl_yfcc100m_ft_in1k](https://huggingface.co/timm/resnet18.fb_ssl_yfcc100m_ft_in1k)|224 |72.6 |91.42|11.7 |1.8 |2.5 |10213 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|288 |72.37|90.59|11.7 |3.0 |4.1 |6051 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|224 |72.26|90.31|10.1 |1.7 |5.8 |7026 |
|[resnet18d.ra2_in1k](https://huggingface.co/timm/resnet18d.ra2_in1k)|224 |72.26|90.68|11.7 |2.1 |3.3 |8707 |
|[resnet18.a1_in1k](https://huggingface.co/timm/resnet18.a1_in1k)|224 |71.49|90.07|11.7 |1.8 |2.5 |10187 |
|[resnet14t.c3_in1k](https://huggingface.co/timm/resnet14t.c3_in1k)|176 |71.31|89.69|10.1 |1.1 |3.6 |10970 |
|[resnet18.gluon_in1k](https://huggingface.co/timm/resnet18.gluon_in1k)|224 |70.84|89.76|11.7 |1.8 |2.5 |10210 |
|[resnet18.a2_in1k](https://huggingface.co/timm/resnet18.a2_in1k)|224 |70.64|89.47|11.7 |1.8 |2.5 |10194 |
|[resnet34.a3_in1k](https://huggingface.co/timm/resnet34.a3_in1k)|160 |70.56|89.52|21.8 |1.9 |1.9 |10737 |
|[resnet18.tv_in1k](https://huggingface.co/timm/resnet18.tv_in1k)|224 |69.76|89.07|11.7 |1.8 |2.5 |10205 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|224 |68.34|88.03|5.4 |1.1 |2.4 |13079 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|224 |68.25|88.17|11.7 |1.8 |2.5 |10167 |
|[resnet10t.c3_in1k](https://huggingface.co/timm/resnet10t.c3_in1k)|176 |66.71|86.96|5.4 |0.7 |1.5 |20327 |
|[resnet18.a3_in1k](https://huggingface.co/timm/resnet18.a3_in1k)|160 |65.66|86.26|11.7 |0.9 |1.3 |18229 |
## Citation
```bibtex
@inproceedings{wightman2021resnet,
title={ResNet strikes back: An improved training procedure in timm},
author={Wightman, Ross and Touvron, Hugo and Jegou, Herve},
booktitle={NeurIPS 2021 Workshop on ImageNet: Past, Present, and Future}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{He2015,
author = {Kaiming He and Xiangyu Zhang and Shaoqing Ren and Jian Sun},
title = {Deep Residual Learning for Image Recognition},
journal = {arXiv preprint arXiv:1512.03385},
year = {2015}
}
``` |
sentence-transformers/all-MiniLM-L12-v2 | sentence-transformers | "2024-11-05T15:20:10Z" | 4,292,004 | 225 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"rust",
"onnx",
"safetensors",
"openvino",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"dataset:s2orc",
"dataset:flax-sentence-embeddings/stackexchange_xml",
"dataset:ms_marco",
"dataset:gooaq",
"dataset:yahoo_answers_topics",
"dataset:code_search_net",
"dataset:search_qa",
"dataset:eli5",
"dataset:snli",
"dataset:multi_nli",
"dataset:wikihow",
"dataset:natural_questions",
"dataset:trivia_qa",
"dataset:embedding-data/sentence-compression",
"dataset:embedding-data/flickr30k-captions",
"dataset:embedding-data/altlex",
"dataset:embedding-data/simple-wiki",
"dataset:embedding-data/QQP",
"dataset:embedding-data/SPECTER",
"dataset:embedding-data/PAQ_pairs",
"dataset:embedding-data/WikiAnswers",
"arxiv:1904.06472",
"arxiv:2102.07033",
"arxiv:2104.08727",
"arxiv:1704.05179",
"arxiv:1810.09305",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
language: en
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
datasets:
- s2orc
- flax-sentence-embeddings/stackexchange_xml
- ms_marco
- gooaq
- yahoo_answers_topics
- code_search_net
- search_qa
- eli5
- snli
- multi_nli
- wikihow
- natural_questions
- trivia_qa
- embedding-data/sentence-compression
- embedding-data/flickr30k-captions
- embedding-data/altlex
- embedding-data/simple-wiki
- embedding-data/QQP
- embedding-data/SPECTER
- embedding-data/PAQ_pairs
- embedding-data/WikiAnswers
pipeline_tag: sentence-similarity
---
# all-MiniLM-L12-v2
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-MiniLM-L12-v2')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-MiniLM-L12-v2')
model = AutoModel.from_pretrained('sentence-transformers/all-MiniLM-L12-v2')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/all-MiniLM-L12-v2)
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`microsoft/MiniLM-L12-H384-uncased`](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 256 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`microsoft/MiniLM-L12-H384-uncased`](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased) model. Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 100k steps using a batch size of 1024 (128 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title+Body, Answer) pairs | - | 21,396,559 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Answer) pairs | - | 21,396,559 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,170,060,424** | |
jonatasgrosman/wav2vec2-large-xlsr-53-portuguese | jonatasgrosman | "2022-12-14T01:59:47Z" | 4,213,199 | 27 | transformers | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"hf-asr-leaderboard",
"mozilla-foundation/common_voice_6_0",
"pt",
"robust-speech-event",
"speech",
"xlsr-fine-tuning-week",
"dataset:common_voice",
"dataset:mozilla-foundation/common_voice_6_0",
"doi:10.57967/hf/3572",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-03-02T23:29:05Z" | ---
language: pt
license: apache-2.0
datasets:
- common_voice
- mozilla-foundation/common_voice_6_0
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- hf-asr-leaderboard
- mozilla-foundation/common_voice_6_0
- pt
- robust-speech-event
- speech
- xlsr-fine-tuning-week
model-index:
- name: XLSR Wav2Vec2 Portuguese by Jonatas Grosman
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice pt
type: common_voice
args: pt
metrics:
- name: Test WER
type: wer
value: 11.31
- name: Test CER
type: cer
value: 3.74
- name: Test WER (+LM)
type: wer
value: 9.01
- name: Test CER (+LM)
type: cer
value: 3.21
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: pt
metrics:
- name: Dev WER
type: wer
value: 42.1
- name: Dev CER
type: cer
value: 17.93
- name: Dev WER (+LM)
type: wer
value: 36.92
- name: Dev CER (+LM)
type: cer
value: 16.88
---
# Fine-tuned XLSR-53 large model for speech recognition in Portuguese
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Portuguese using the train and validation splits of [Common Voice 6.1](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
The script used for training can be found here: https://github.com/jonatasgrosman/wav2vec2-sprint
## Usage
The model can be used directly (without a language model) as follows...
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-large-xlsr-53-portuguese")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "pt"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-portuguese"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
for i, predicted_sentence in enumerate(predicted_sentences):
print("-" * 100)
print("Reference:", test_dataset[i]["sentence"])
print("Prediction:", predicted_sentence)
```
| Reference | Prediction |
| ------------- | ------------- |
| NEM O RADAR NEM OS OUTROS INSTRUMENTOS DETECTARAM O BOMBARDEIRO STEALTH. | NEMHUM VADAN OS OLTWES INSTRUMENTOS DE TTÉÃN UM BOMBERDEIRO OSTER |
| PEDIR DINHEIRO EMPRESTADO ÀS PESSOAS DA ALDEIA | E DIR ENGINHEIRO EMPRESTAR AS PESSOAS DA ALDEIA |
| OITO | OITO |
| TRANCÁ-LOS | TRANCAUVOS |
| REALIZAR UMA INVESTIGAÇÃO PARA RESOLVER O PROBLEMA | REALIZAR UMA INVESTIGAÇÃO PARA RESOLVER O PROBLEMA |
| O YOUTUBE AINDA É A MELHOR PLATAFORMA DE VÍDEOS. | YOUTUBE AINDA É A MELHOR PLATAFOMA DE VÍDEOS |
| MENINA E MENINO BEIJANDO NAS SOMBRAS | MENINA E MENINO BEIJANDO NAS SOMBRAS |
| EU SOU O SENHOR | EU SOU O SENHOR |
| DUAS MULHERES QUE SENTAM-SE PARA BAIXO LENDO JORNAIS. | DUAS MIERES QUE SENTAM-SE PARA BAICLANE JODNÓI |
| EU ORIGINALMENTE ESPERAVA | EU ORIGINALMENTE ESPERAVA |
## Evaluation
1. To evaluate on `mozilla-foundation/common_voice_6_0` with split `test`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-large-xlsr-53-portuguese --dataset mozilla-foundation/common_voice_6_0 --config pt --split test
```
2. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id jonatasgrosman/wav2vec2-large-xlsr-53-portuguese --dataset speech-recognition-community-v2/dev_data --config pt --split validation --chunk_length_s 5.0 --stride_length_s 1.0
```
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr53-large-portuguese,
title={Fine-tuned {XLSR}-53 large model for speech recognition in {P}ortuguese},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-portuguese}},
year={2021}
}
``` |
facebook/wav2vec2-xls-r-300m | facebook | "2022-08-10T08:11:47Z" | 4,191,828 | 82 | transformers | [
"transformers",
"pytorch",
"wav2vec2",
"pretraining",
"speech",
"xls_r",
"xls_r_pretrained",
"multilingual",
"ab",
"af",
"sq",
"am",
"ar",
"hy",
"as",
"az",
"ba",
"eu",
"be",
"bn",
"bs",
"br",
"bg",
"my",
"yue",
"ca",
"ceb",
"km",
"zh",
"cv",
"hr",
"cs",
"da",
"dv",
"nl",
"en",
"eo",
"et",
"fo",
"fi",
"fr",
"gl",
"lg",
"ka",
"de",
"el",
"gn",
"gu",
"ht",
"cnh",
"ha",
"haw",
"he",
"hi",
"hu",
"is",
"id",
"ia",
"ga",
"it",
"ja",
"jv",
"kb",
"kn",
"kk",
"rw",
"ky",
"ko",
"ku",
"lo",
"la",
"lv",
"ln",
"lt",
"lm",
"mk",
"mg",
"ms",
"ml",
"mt",
"gv",
"mi",
"mr",
"mn",
"ne",
"no",
"nn",
"oc",
"or",
"ps",
"fa",
"pl",
"pt",
"pa",
"ro",
"rm",
"ru",
"sah",
"sa",
"sco",
"sr",
"sn",
"sd",
"si",
"sk",
"sl",
"so",
"hsb",
"es",
"su",
"sw",
"sv",
"tl",
"tg",
"ta",
"tt",
"te",
"th",
"bo",
"tp",
"tr",
"tk",
"uk",
"ur",
"uz",
"vi",
"vot",
"war",
"cy",
"yi",
"yo",
"zu",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"arxiv:2111.09296",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | "2022-03-02T23:29:05Z" | ---
language:
- multilingual
- ab
- af
- sq
- am
- ar
- hy
- as
- az
- ba
- eu
- be
- bn
- bs
- br
- bg
- my
- yue
- ca
- ceb
- km
- zh
- cv
- hr
- cs
- da
- dv
- nl
- en
- eo
- et
- fo
- fi
- fr
- gl
- lg
- ka
- de
- el
- gn
- gu
- ht
- cnh
- ha
- haw
- he
- hi
- hu
- is
- id
- ia
- ga
- it
- ja
- jv
- kb
- kn
- kk
- rw
- ky
- ko
- ku
- lo
- la
- lv
- ln
- lt
- lm
- mk
- mg
- ms
- ml
- mt
- gv
- mi
- mr
- mn
- ne
- no
- nn
- oc
- or
- ps
- fa
- pl
- pt
- pa
- ro
- rm
- rm
- ru
- sah
- sa
- sco
- sr
- sn
- sd
- si
- sk
- sl
- so
- hsb
- es
- su
- sw
- sv
- tl
- tg
- ta
- tt
- te
- th
- bo
- tp
- tr
- tk
- uk
- ur
- uz
- vi
- vot
- war
- cy
- yi
- yo
- zu
language_bcp47:
- zh-HK
- zh-TW
- fy-NL
datasets:
- common_voice
- multilingual_librispeech
tags:
- speech
- xls_r
- xls_r_pretrained
license: apache-2.0
---
# Wav2Vec2-XLS-R-300M
[Facebook's Wav2Vec2 XLS-R](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) counting **300 million** parameters.

XLS-R is Facebook AI's large-scale multilingual pretrained model for speech (the "XLM-R for Speech"). It is pretrained on 436k hours of unlabeled speech, including VoxPopuli, MLS, CommonVoice, BABEL, and VoxLingua107. It uses the wav2vec 2.0 objective, in 128 languages. When using the model make sure that your speech input is sampled at 16kHz.
**Note**: This model should be fine-tuned on a downstream task, like Automatic Speech Recognition, Translation, or Classification. Check out [**this blog**](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for more information about ASR.
[XLS-R Paper](https://arxiv.org/abs/2111.09296)
Authors: Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli
**Abstract**
This paper presents XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec 2.0. We train models with up to 2B parameters on 436K hours of publicly available speech audio in 128 languages, an order of magnitude more public data than the largest known prior work. Our evaluation covers a wide range of tasks, domains, data regimes and languages, both high and low-resource. On the CoVoST-2 speech translation benchmark, we improve the previous state of the art by an average of 7.4 BLEU over 21 translation directions into English. For speech recognition, XLS-R improves over the best known prior work on BABEL, MLS, CommonVoice as well as VoxPopuli, lowering error rates by 20%-33% relative on average. XLS-R also sets a new state of the art on VoxLingua107 language identification. Moreover, we show that with sufficient model size, cross-lingual pretraining can outperform English-only pretraining when translating English speech into other languages, a setting which favors monolingual pretraining. We hope XLS-R can help to improve speech processing tasks for many more languages of the world.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
See [this google colab](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_Tune_XLS_R_on_Common_Voice.ipynb) for more information on how to fine-tune the model.
You can find other pretrained XLS-R models with different numbers of parameters:
* [300M parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
* [1B version version](https://huggingface.co/facebook/wav2vec2-xls-r-1b)
* [2B version version](https://huggingface.co/facebook/wav2vec2-xls-r-2b) |
yiyanghkust/finbert-tone | yiyanghkust | "2022-10-17T00:35:39Z" | 4,186,465 | 166 | transformers | [
"transformers",
"pytorch",
"tf",
"text-classification",
"financial-sentiment-analysis",
"sentiment-analysis",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | ---
language: "en"
tags:
- financial-sentiment-analysis
- sentiment-analysis
widget:
- text: "growth is strong and we have plenty of liquidity"
---
`FinBERT` is a BERT model pre-trained on financial communication text. The purpose is to enhance financial NLP research and practice. It is trained on the following three financial communication corpus. The total corpora size is 4.9B tokens.
- Corporate Reports 10-K & 10-Q: 2.5B tokens
- Earnings Call Transcripts: 1.3B tokens
- Analyst Reports: 1.1B tokens
More technical details on `FinBERT`: [Click Link](https://github.com/yya518/FinBERT)
This released `finbert-tone` model is the `FinBERT` model fine-tuned on 10,000 manually annotated (positive, negative, neutral) sentences from analyst reports. This model achieves superior performance on financial tone analysis task. If you are simply interested in using `FinBERT` for financial tone analysis, give it a try.
If you use the model in your academic work, please cite the following paper:
Huang, Allen H., Hui Wang, and Yi Yang. "FinBERT: A Large Language Model for Extracting Information from Financial Text." *Contemporary Accounting Research* (2022).
# How to use
You can use this model with Transformers pipeline for sentiment analysis.
```python
from transformers import BertTokenizer, BertForSequenceClassification
from transformers import pipeline
finbert = BertForSequenceClassification.from_pretrained('yiyanghkust/finbert-tone',num_labels=3)
tokenizer = BertTokenizer.from_pretrained('yiyanghkust/finbert-tone')
nlp = pipeline("sentiment-analysis", model=finbert, tokenizer=tokenizer)
sentences = ["there is a shortage of capital, and we need extra financing",
"growth is strong and we have plenty of liquidity",
"there are doubts about our finances",
"profits are flat"]
results = nlp(sentences)
print(results) #LABEL_0: neutral; LABEL_1: positive; LABEL_2: negative
``` |
albert/albert-base-v2 | albert | "2024-02-19T10:58:14Z" | 4,123,053 | 118 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:04Z" | ---
language: en
license: apache-2.0
datasets:
- bookcorpus
- wikipedia
---
# ALBERT Base v2
Pretrained model on English language using a masked language modeling (MLM) objective. It was introduced in
[this paper](https://arxiv.org/abs/1909.11942) and first released in
[this repository](https://github.com/google-research/albert). This model, as all ALBERT models, is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing ALBERT did not write a model card for this model so this model card has been written by
the Hugging Face team.
## Model description
ALBERT is a transformers model pretrained on a large corpus of English data in a self-supervised fashion. This means it
was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Sentence Ordering Prediction (SOP): ALBERT uses a pretraining loss based on predicting the ordering of two consecutive segments of text.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard
classifier using the features produced by the ALBERT model as inputs.
ALBERT is particular in that it shares its layers across its Transformer. Therefore, all layers have the same weights. Using repeating layers results in a small memory footprint, however, the computational cost remains similar to a BERT-like architecture with the same number of hidden layers as it has to iterate through the same number of (repeating) layers.
This is the second version of the base model. Version 2 is different from version 1 due to different dropout rates, additional training data, and longer training. It has better results in nearly all downstream tasks.
This model has the following configuration:
- 12 repeating layers
- 128 embedding dimension
- 768 hidden dimension
- 12 attention heads
- 11M parameters
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=albert) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='albert-base-v2')
>>> unmasker("Hello I'm a [MASK] model.")
[
{
"sequence":"[CLS] hello i'm a modeling model.[SEP]",
"score":0.05816134437918663,
"token":12807,
"token_str":"▁modeling"
},
{
"sequence":"[CLS] hello i'm a modelling model.[SEP]",
"score":0.03748830780386925,
"token":23089,
"token_str":"▁modelling"
},
{
"sequence":"[CLS] hello i'm a model model.[SEP]",
"score":0.033725276589393616,
"token":1061,
"token_str":"▁model"
},
{
"sequence":"[CLS] hello i'm a runway model.[SEP]",
"score":0.017313428223133087,
"token":8014,
"token_str":"▁runway"
},
{
"sequence":"[CLS] hello i'm a lingerie model.[SEP]",
"score":0.014405295252799988,
"token":29104,
"token_str":"▁lingerie"
}
]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import AlbertTokenizer, AlbertModel
tokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')
model = AlbertModel.from_pretrained("albert-base-v2")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import AlbertTokenizer, TFAlbertModel
tokenizer = AlbertTokenizer.from_pretrained('albert-base-v2')
model = TFAlbertModel.from_pretrained("albert-base-v2")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='albert-base-v2')
>>> unmasker("The man worked as a [MASK].")
[
{
"sequence":"[CLS] the man worked as a chauffeur.[SEP]",
"score":0.029577180743217468,
"token":28744,
"token_str":"▁chauffeur"
},
{
"sequence":"[CLS] the man worked as a janitor.[SEP]",
"score":0.028865724802017212,
"token":29477,
"token_str":"▁janitor"
},
{
"sequence":"[CLS] the man worked as a shoemaker.[SEP]",
"score":0.02581118606030941,
"token":29024,
"token_str":"▁shoemaker"
},
{
"sequence":"[CLS] the man worked as a blacksmith.[SEP]",
"score":0.01849772222340107,
"token":21238,
"token_str":"▁blacksmith"
},
{
"sequence":"[CLS] the man worked as a lawyer.[SEP]",
"score":0.01820771023631096,
"token":3672,
"token_str":"▁lawyer"
}
]
>>> unmasker("The woman worked as a [MASK].")
[
{
"sequence":"[CLS] the woman worked as a receptionist.[SEP]",
"score":0.04604868218302727,
"token":25331,
"token_str":"▁receptionist"
},
{
"sequence":"[CLS] the woman worked as a janitor.[SEP]",
"score":0.028220869600772858,
"token":29477,
"token_str":"▁janitor"
},
{
"sequence":"[CLS] the woman worked as a paramedic.[SEP]",
"score":0.0261906236410141,
"token":23386,
"token_str":"▁paramedic"
},
{
"sequence":"[CLS] the woman worked as a chauffeur.[SEP]",
"score":0.024797942489385605,
"token":28744,
"token_str":"▁chauffeur"
},
{
"sequence":"[CLS] the woman worked as a waitress.[SEP]",
"score":0.024124596267938614,
"token":13678,
"token_str":"▁waitress"
}
]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The ALBERT model was pretrained on [BookCorpus](https://yknzhu.wixsite.com/mbweb), a dataset consisting of 11,038
unpublished books and [English Wikipedia](https://en.wikipedia.org/wiki/English_Wikipedia) (excluding lists, tables and
headers).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using SentencePiece and a vocabulary size of 30,000. The inputs of the model are
then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
### Training
The ALBERT procedure follows the BERT setup.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
## Evaluation results
When fine-tuned on downstream tasks, the ALBERT models achieve the following results:
| | Average | SQuAD1.1 | SQuAD2.0 | MNLI | SST-2 | RACE |
|----------------|----------|----------|----------|----------|----------|----------|
|V2 |
|ALBERT-base |82.3 |90.2/83.2 |82.1/79.3 |84.6 |92.9 |66.8 |
|ALBERT-large |85.7 |91.8/85.2 |84.9/81.8 |86.5 |94.9 |75.2 |
|ALBERT-xlarge |87.9 |92.9/86.4 |87.9/84.1 |87.9 |95.4 |80.7 |
|ALBERT-xxlarge |90.9 |94.6/89.1 |89.8/86.9 |90.6 |96.8 |86.8 |
|V1 |
|ALBERT-base |80.1 |89.3/82.3 | 80.0/77.1|81.6 |90.3 | 64.0 |
|ALBERT-large |82.4 |90.6/83.9 | 82.3/79.4|83.5 |91.7 | 68.5 |
|ALBERT-xlarge |85.5 |92.5/86.1 | 86.1/83.1|86.4 |92.4 | 74.8 |
|ALBERT-xxlarge |91.0 |94.8/89.3 | 90.2/87.4|90.8 |96.9 | 86.5 |
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1909-11942,
author = {Zhenzhong Lan and
Mingda Chen and
Sebastian Goodman and
Kevin Gimpel and
Piyush Sharma and
Radu Soricut},
title = {{ALBERT:} {A} Lite {BERT} for Self-supervised Learning of Language
Representations},
journal = {CoRR},
volume = {abs/1909.11942},
year = {2019},
url = {http://arxiv.org/abs/1909.11942},
archivePrefix = {arXiv},
eprint = {1909.11942},
timestamp = {Fri, 27 Sep 2019 13:04:21 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1909-11942.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
google/vit-base-patch16-224 | google | "2023-09-05T15:27:12Z" | 3,920,950 | 735 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"vit",
"image-classification",
"vision",
"dataset:imagenet-1k",
"dataset:imagenet-21k",
"arxiv:2010.11929",
"arxiv:2006.03677",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
- imagenet-21k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# Vision Transformer (base-sized model)
Vision Transformer (ViT) model pre-trained on ImageNet-21k (14 million images, 21,843 classes) at resolution 224x224, and fine-tuned on ImageNet 2012 (1 million images, 1,000 classes) at resolution 224x224. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929) by Dosovitskiy et al. and first released in [this repository](https://github.com/google-research/vision_transformer). However, the weights were converted from the [timm repository](https://github.com/rwightman/pytorch-image-models) by Ross Wightman, who already converted the weights from JAX to PyTorch. Credits go to him.
Disclaimer: The team releasing ViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
The Vision Transformer (ViT) is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels. Next, the model was fine-tuned on ImageNet (also referred to as ILSVRC2012), a dataset comprising 1 million images and 1,000 classes, also at resolution 224x224.
Images are presented to the model as a sequence of fixed-size patches (resolution 16x16), which are linearly embedded. One also adds a [CLS] token to the beginning of a sequence to use it for classification tasks. One also adds absolute position embeddings before feeding the sequence to the layers of the Transformer encoder.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by placing a linear layer on top of the pre-trained encoder. One typically places a linear layer on top of the [CLS] token, as the last hidden state of this token can be seen as a representation of an entire image.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=google/vit) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import ViTImageProcessor, ViTForImageClassification
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('google/vit-base-patch16-224')
model = ViTForImageClassification.from_pretrained('google/vit-base-patch16-224')
inputs = processor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/vit.html#).
## Training data
The ViT model was pretrained on [ImageNet-21k](http://www.image-net.org/), a dataset consisting of 14 million images and 21k classes, and fine-tuned on [ImageNet](http://www.image-net.org/challenges/LSVRC/2012/), a dataset consisting of 1 million images and 1k classes.
## Training procedure
### Preprocessing
The exact details of preprocessing of images during training/validation can be found [here](https://github.com/google-research/vision_transformer/blob/master/vit_jax/input_pipeline.py).
Images are resized/rescaled to the same resolution (224x224) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
### Pretraining
The model was trained on TPUv3 hardware (8 cores). All model variants are trained with a batch size of 4096 and learning rate warmup of 10k steps. For ImageNet, the authors found it beneficial to additionally apply gradient clipping at global norm 1. Training resolution is 224.
## Evaluation results
For evaluation results on several image classification benchmarks, we refer to tables 2 and 5 of the original paper. Note that for fine-tuning, the best results are obtained with a higher resolution (384x384). Of course, increasing the model size will result in better performance.
### BibTeX entry and citation info
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
```bibtex
@inproceedings{deng2009imagenet,
title={Imagenet: A large-scale hierarchical image database},
author={Deng, Jia and Dong, Wei and Socher, Richard and Li, Li-Jia and Li, Kai and Fei-Fei, Li},
booktitle={2009 IEEE conference on computer vision and pattern recognition},
pages={248--255},
year={2009},
organization={Ieee}
}
``` |
stable-diffusion-v1-5/stable-diffusion-v1-5 | stable-diffusion-v1-5 | "2024-09-07T16:20:30Z" | 3,895,123 | 342 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"arxiv:2207.12598",
"arxiv:2112.10752",
"arxiv:2103.00020",
"arxiv:2205.11487",
"arxiv:1910.09700",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | "2024-08-30T09:48:48Z" | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
inference: true
---
# Stable Diffusion v1-5 Model Card
### ⚠️ This repository is a mirror of the now deprecated `ruwnayml/stable-diffusion-v1-5`, this repository or organization are not affiliated in any way with RunwayML.
Modifications to the original model card are in <span style="color:crimson">red</span> or <span style="color:darkgreen">green</span>
Stable Diffusion is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input.
For more information about how Stable Diffusion functions, please have a look at [🤗's Stable Diffusion blog](https://huggingface.co/blog/stable_diffusion).
The **Stable-Diffusion-v1-5** checkpoint was initialized with the weights of the [Stable-Diffusion-v1-2](https:/steps/huggingface.co/CompVis/stable-diffusion-v1-2)
checkpoint and subsequently fine-tuned on 595k steps at resolution 512x512 on "laion-aesthetics v2 5+" and 10% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
You can use this both with the [🧨Diffusers library](https://github.com/huggingface/diffusers) and [RunwayML GitHub repository](https://github.com/runwayml/stable-diffusion) (<span style="color:crimson">now deprecated</span>), <span style="color:darkgreen">ComfyUI, Automatic1111, SD.Next, InvokeAI</span>.
### Use with Diffusers
```py
from diffusers import StableDiffusionPipeline
import torch
model_id = "sd-legacy/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "a photo of an astronaut riding a horse on mars"
image = pipe(prompt).images[0]
image.save("astronaut_rides_horse.png")
```
For more detailed instructions, use-cases and examples in JAX follow the instructions [here](https://github.com/huggingface/diffusers#text-to-image-generation-with-stable-diffusion)
### Use with GitHub Repository <span style="color:crimson">(now deprecated)</span>, <span style="color:darkgreen">ComfyUI or Automatic1111</span>
1. Download the weights
- [v1-5-pruned-emaonly.safetensors](https://huggingface.co/sd-legacy/stable-diffusion-v1-5/resolve/main/v1-5-pruned-emaonly.safetensors) - ema-only weight. uses less VRAM - suitable for inference
- [v1-5-pruned.safetensors](https://huggingface.co/sd-legacy/stable-diffusion-v1-5/resolve/main/v1-5-pruned.safetensors) - ema+non-ema weights. uses more VRAM - suitable for fine-tuning
2. Follow instructions [here](https://github.com/runwayml/stable-diffusion). <span style="color:crimson">(now deprecated)</span>
3. <span style="color:darkgreen">Use locally with <a href="https://github.com/comfyanonymous/ComfyUI">ComfyUI</a>, <a href="https://github.com/AUTOMATIC1111/stable-diffusion-webui">AUTOMATIC1111</a>, <a href="https://github.com/vladmandic/automatic">SD.Next</a>, <a href="https://github.com/invoke-ai/InvokeAI">InvokeAI</a></span>
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([CLIP ViT-L/14](https://arxiv.org/abs/2103.00020)) as suggested in the [Imagen paper](https://arxiv.org/abs/2205.11487).
- **Resources for more information:** [GitHub Repository](https://github.com/CompVis/stable-diffusion), [Paper](https://arxiv.org/abs/2112.10752).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and
tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), but applies in the same way to Stable Diffusion v1_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
and is not fit for product use without additional safety mechanisms and
considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data.
The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are primarily limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
### Safety Module
The intended use of this model is with the [Safety Checker](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/safety_checker.py) in Diffusers.
This checker works by checking model outputs against known hard-coded NSFW concepts.
The concepts are intentionally hidden to reduce the likelihood of reverse-engineering this filter.
Specifically, the checker compares the class probability of harmful concepts in the embedding space of the `CLIPTextModel` *after generation* of the images.
The concepts are passed into the model with the generated image and compared to a hand-engineered weight for each NSFW concept.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-2B (en) and subsets thereof (see next section)
**Training Procedure**
Stable Diffusion v1-5 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through a ViT-L/14 text-encoder.
- The non-pooled output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet.
Currently six Stable Diffusion checkpoints are provided, which were trained as follows.
- [`stable-diffusion-v1-1`](https://huggingface.co/CompVis/stable-diffusion-v1-1): 237,000 steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
194,000 steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
- [`stable-diffusion-v1-2`](https://huggingface.co/CompVis/stable-diffusion-v1-2): Resumed from `stable-diffusion-v1-1`.
515,000 steps at resolution `512x512` on "laion-improved-aesthetics" (a subset of laion2B-en,
filtered to images with an original size `>= 512x512`, estimated aesthetics score `> 5.0`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using an [improved aesthetics estimator](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
- [`stable-diffusion-v1-3`](https://huggingface.co/CompVis/stable-diffusion-v1-3): Resumed from `stable-diffusion-v1-2` - 195,000 steps at resolution `512x512` on "laion-improved-aesthetics" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-v1-4`](https://huggingface.co/CompVis/stable-diffusion-v1-4) Resumed from `stable-diffusion-v1-2` - 225,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-v1-5`](https://huggingface.co/sd-legacy/stable-diffusion-v1-5) Resumed from `stable-diffusion-v1-2` - 595,000 steps at resolution `512x512` on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- [`stable-diffusion-inpainting`](https://huggingface.co/sd-legacy/stable-diffusion-inpainting) Resumed from `stable-diffusion-v1-5` - then 440,000 steps of inpainting training at resolution 512x512 on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning. For inpainting, the UNet has 5 additional input channels (4 for the encoded masked-image and 1 for the mask itself) whose weights were zero-initialized after restoring the non-inpainting checkpoint. During training, we generate synthetic masks and in 25% mask everything.
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 2
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 PNDM/PLMS sampling
steps show the relative improvements of the checkpoints:

Evaluated using 50 PLMS steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 150000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 11250 kg CO2 eq.
## Citation
```bibtex
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
```
*This model card was written by: Robin Rombach and Patrick Esser and is based on the [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).* |
facebook/esm2_t36_3B_UR50D | facebook | "2022-12-01T20:22:22Z" | 3,892,233 | 18 | transformers | [
"transformers",
"pytorch",
"tf",
"esm",
"fill-mask",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-10-13T12:38:30Z" | ---
license: mit
widget:
- text: "MQIFVKTLTGKTITLEVEPS<mask>TIENVKAKIQDKEGIPPDQQRLIFAGKQLEDGRTLSDYNIQKESTLHLVLRLRGG"
---
## ESM-2
ESM-2 is a state-of-the-art protein model trained on a masked language modelling objective. It is suitable for fine-tuning on a wide range of tasks that take protein sequences as input. For detailed information on the model architecture and training data, please refer to the [accompanying paper](https://www.biorxiv.org/content/10.1101/2022.07.20.500902v2). You may also be interested in some demo notebooks ([PyTorch](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/protein_language_modeling.ipynb), [TensorFlow](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/protein_language_modeling-tf.ipynb)) which demonstrate how to fine-tune ESM-2 models on your tasks of interest.
Several ESM-2 checkpoints are available in the Hub with varying sizes. Larger sizes generally have somewhat better accuracy, but require much more memory and time to train:
| Checkpoint name | Num layers | Num parameters |
|------------------------------|----|----------|
| [esm2_t48_15B_UR50D](https://huggingface.co/facebook/esm2_t48_15B_UR50D) | 48 | 15B |
| [esm2_t36_3B_UR50D](https://huggingface.co/facebook/esm2_t36_3B_UR50D) | 36 | 3B |
| [esm2_t33_650M_UR50D](https://huggingface.co/facebook/esm2_t33_650M_UR50D) | 33 | 650M |
| [esm2_t30_150M_UR50D](https://huggingface.co/facebook/esm2_t30_150M_UR50D) | 30 | 150M |
| [esm2_t12_35M_UR50D](https://huggingface.co/facebook/esm2_t12_35M_UR50D) | 12 | 35M |
| [esm2_t6_8M_UR50D](https://huggingface.co/facebook/esm2_t6_8M_UR50D) | 6 | 8M | |
facebook/bart-large-cnn | facebook | "2024-02-13T18:02:05Z" | 3,886,307 | 1,279 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"bart",
"text2text-generation",
"summarization",
"en",
"dataset:cnn_dailymail",
"arxiv:1910.13461",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | summarization | "2022-03-02T23:29:05Z" | ---
language:
- en
pipeline_tag: summarization
license: mit
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
datasets:
- cnn_dailymail
model-index:
- name: facebook/bart-large-cnn
results:
- task:
type: summarization
name: Summarization
dataset:
name: cnn_dailymail
type: cnn_dailymail
config: 3.0.0
split: train
metrics:
- name: ROUGE-1
type: rouge
value: 42.9486
verified: true
- name: ROUGE-2
type: rouge
value: 20.8149
verified: true
- name: ROUGE-L
type: rouge
value: 30.6186
verified: true
- name: ROUGE-LSUM
type: rouge
value: 40.0376
verified: true
- name: loss
type: loss
value: 2.529000997543335
verified: true
- name: gen_len
type: gen_len
value: 78.5866
verified: true
---
# BART (large-sized model), fine-tuned on CNN Daily Mail
BART model pre-trained on English language, and fine-tuned on [CNN Daily Mail](https://huggingface.co/datasets/cnn_dailymail). It was introduced in the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Lewis et al. and first released in [this repository (https://github.com/pytorch/fairseq/tree/master/examples/bart).
Disclaimer: The team releasing BART did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
BART is a transformer encoder-encoder (seq2seq) model with a bidirectional (BERT-like) encoder and an autoregressive (GPT-like) decoder. BART is pre-trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text.
BART is particularly effective when fine-tuned for text generation (e.g. summarization, translation) but also works well for comprehension tasks (e.g. text classification, question answering). This particular checkpoint has been fine-tuned on CNN Daily Mail, a large collection of text-summary pairs.
## Intended uses & limitations
You can use this model for text summarization.
### How to use
Here is how to use this model with the [pipeline API](https://huggingface.co/transformers/main_classes/pipelines.html):
```python
from transformers import pipeline
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
ARTICLE = """ New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York.
A year later, she got married again in Westchester County, but to a different man and without divorcing her first husband.
Only 18 days after that marriage, she got hitched yet again. Then, Barrientos declared "I do" five more times, sometimes only within two weeks of each other.
In 2010, she married once more, this time in the Bronx. In an application for a marriage license, she stated it was her "first and only" marriage.
Barrientos, now 39, is facing two criminal counts of "offering a false instrument for filing in the first degree," referring to her false statements on the
2010 marriage license application, according to court documents.
Prosecutors said the marriages were part of an immigration scam.
On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to her attorney, Christopher Wright, who declined to comment further.
After leaving court, Barrientos was arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New York subway through an emergency exit, said Detective
Annette Markowski, a police spokeswoman. In total, Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002.
All occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be married to four men, and at one time, she was married to eight men at once, prosecutors say.
Prosecutors said the immigration scam involved some of her husbands, who filed for permanent residence status shortly after the marriages.
Any divorces happened only after such filings were approved. It was unclear whether any of the men will be prosecuted.
The case was referred to the Bronx District Attorney\'s Office by Immigration and Customs Enforcement and the Department of Homeland Security\'s
Investigation Division. Seven of the men are from so-called "red-flagged" countries, including Egypt, Turkey, Georgia, Pakistan and Mali.
Her eighth husband, Rashid Rajput, was deported in 2006 to his native Pakistan after an investigation by the Joint Terrorism Task Force.
If convicted, Barrientos faces up to four years in prison. Her next court appearance is scheduled for May 18.
"""
print(summarizer(ARTICLE, max_length=130, min_length=30, do_sample=False))
>>> [{'summary_text': 'Liana Barrientos, 39, is charged with two counts of "offering a false instrument for filing in the first degree" In total, she has been married 10 times, with nine of her marriages occurring between 1999 and 2002. She is believed to still be married to four men.'}]
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1910-13461,
author = {Mike Lewis and
Yinhan Liu and
Naman Goyal and
Marjan Ghazvininejad and
Abdelrahman Mohamed and
Omer Levy and
Veselin Stoyanov and
Luke Zettlemoyer},
title = {{BART:} Denoising Sequence-to-Sequence Pre-training for Natural Language
Generation, Translation, and Comprehension},
journal = {CoRR},
volume = {abs/1910.13461},
year = {2019},
url = {http://arxiv.org/abs/1910.13461},
eprinttype = {arXiv},
eprint = {1910.13461},
timestamp = {Thu, 31 Oct 2019 14:02:26 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1910-13461.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
sentence-transformers/all-distilroberta-v1 | sentence-transformers | "2024-11-05T15:22:11Z" | 3,842,964 | 34 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"rust",
"onnx",
"safetensors",
"openvino",
"roberta",
"fill-mask",
"feature-extraction",
"sentence-similarity",
"transformers",
"en",
"dataset:s2orc",
"dataset:flax-sentence-embeddings/stackexchange_xml",
"dataset:ms_marco",
"dataset:gooaq",
"dataset:yahoo_answers_topics",
"dataset:code_search_net",
"dataset:search_qa",
"dataset:eli5",
"dataset:snli",
"dataset:multi_nli",
"dataset:wikihow",
"dataset:natural_questions",
"dataset:trivia_qa",
"dataset:embedding-data/sentence-compression",
"dataset:embedding-data/flickr30k-captions",
"dataset:embedding-data/altlex",
"dataset:embedding-data/simple-wiki",
"dataset:embedding-data/QQP",
"dataset:embedding-data/SPECTER",
"dataset:embedding-data/PAQ_pairs",
"dataset:embedding-data/WikiAnswers",
"arxiv:1904.06472",
"arxiv:2102.07033",
"arxiv:2104.08727",
"arxiv:1704.05179",
"arxiv:1810.09305",
"license:apache-2.0",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] | sentence-similarity | "2022-03-02T23:29:05Z" | ---
language: en
license: apache-2.0
library_name: sentence-transformers
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
datasets:
- s2orc
- flax-sentence-embeddings/stackexchange_xml
- ms_marco
- gooaq
- yahoo_answers_topics
- code_search_net
- search_qa
- eli5
- snli
- multi_nli
- wikihow
- natural_questions
- trivia_qa
- embedding-data/sentence-compression
- embedding-data/flickr30k-captions
- embedding-data/altlex
- embedding-data/simple-wiki
- embedding-data/QQP
- embedding-data/SPECTER
- embedding-data/PAQ_pairs
- embedding-data/WikiAnswers
pipeline_tag: sentence-similarity
---
# all-distilroberta-v1
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/all-distilroberta-v1')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('sentence-transformers/all-distilroberta-v1')
model = AutoModel.from_pretrained('sentence-transformers/all-distilroberta-v1')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# Normalize embeddings
sentence_embeddings = F.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/all-distilroberta-v1)
------
## Background
The project aims to train sentence embedding models on very large sentence level datasets using a self-supervised
contrastive learning objective. We used the pretrained [`distilroberta-base`](https://huggingface.co/distilroberta-base) model and fine-tuned in on a
1B sentence pairs dataset. We use a contrastive learning objective: given a sentence from the pair, the model should predict which out of a set of randomly sampled other sentences, was actually paired with it in our dataset.
We developped this model during the
[Community week using JAX/Flax for NLP & CV](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104),
organized by Hugging Face. We developped this model as part of the project:
[Train the Best Sentence Embedding Model Ever with 1B Training Pairs](https://discuss.huggingface.co/t/train-the-best-sentence-embedding-model-ever-with-1b-training-pairs/7354). We benefited from efficient hardware infrastructure to run the project: 7 TPUs v3-8, as well as intervention from Googles Flax, JAX, and Cloud team member about efficient deep learning frameworks.
## Intended uses
Our model is intented to be used as a sentence and short paragraph encoder. Given an input text, it ouptuts a vector which captures
the semantic information. The sentence vector may be used for information retrieval, clustering or sentence similarity tasks.
By default, input text longer than 128 word pieces is truncated.
## Training procedure
### Pre-training
We use the pretrained [`distilroberta-base`](https://huggingface.co/distilroberta-base). Please refer to the model card for more detailed information about the pre-training procedure.
### Fine-tuning
We fine-tune the model using a contrastive objective. Formally, we compute the cosine similarity from each possible sentence pairs from the batch.
We then apply the cross entropy loss by comparing with true pairs.
#### Hyper parameters
We trained ou model on a TPU v3-8. We train the model during 920k steps using a batch size of 512 (64 per TPU core).
We use a learning rate warm up of 500. The sequence length was limited to 128 tokens. We used the AdamW optimizer with
a 2e-5 learning rate. The full training script is accessible in this current repository: `train_script.py`.
#### Training data
We use the concatenation from multiple datasets to fine-tune our model. The total number of sentence pairs is above 1 billion sentences.
We sampled each dataset given a weighted probability which configuration is detailed in the `data_config.json` file.
| Dataset | Paper | Number of training tuples |
|--------------------------------------------------------|:----------------------------------------:|:--------------------------:|
| [Reddit comments (2015-2018)](https://github.com/PolyAI-LDN/conversational-datasets/tree/master/reddit) | [paper](https://arxiv.org/abs/1904.06472) | 726,484,430 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Abstracts) | [paper](https://aclanthology.org/2020.acl-main.447/) | 116,288,806 |
| [WikiAnswers](https://github.com/afader/oqa#wikianswers-corpus) Duplicate question pairs | [paper](https://doi.org/10.1145/2623330.2623677) | 77,427,422 |
| [PAQ](https://github.com/facebookresearch/PAQ) (Question, Answer) pairs | [paper](https://arxiv.org/abs/2102.07033) | 64,371,441 |
| [S2ORC](https://github.com/allenai/s2orc) Citation pairs (Titles) | [paper](https://aclanthology.org/2020.acl-main.447/) | 52,603,982 |
| [S2ORC](https://github.com/allenai/s2orc) (Title, Abstract) | [paper](https://aclanthology.org/2020.acl-main.447/) | 41,769,185 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) (Title, Body) pairs | - | 25,316,456 |
| [MS MARCO](https://microsoft.github.io/msmarco/) triplets | [paper](https://doi.org/10.1145/3404835.3462804) | 9,144,553 |
| [GOOAQ: Open Question Answering with Diverse Answer Types](https://github.com/allenai/gooaq) | [paper](https://arxiv.org/pdf/2104.08727.pdf) | 3,012,496 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 1,198,260 |
| [Code Search](https://huggingface.co/datasets/code_search_net) | - | 1,151,414 |
| [COCO](https://cocodataset.org/#home) Image captions | [paper](https://link.springer.com/chapter/10.1007%2F978-3-319-10602-1_48) | 828,395|
| [SPECTER](https://github.com/allenai/specter) citation triplets | [paper](https://doi.org/10.18653/v1/2020.acl-main.207) | 684,100 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Question, Answer) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 681,164 |
| [Yahoo Answers](https://www.kaggle.com/soumikrakshit/yahoo-answers-dataset) (Title, Question) | [paper](https://proceedings.neurips.cc/paper/2015/hash/250cf8b51c773f3f8dc8b4be867a9a02-Abstract.html) | 659,896 |
| [SearchQA](https://huggingface.co/datasets/search_qa) | [paper](https://arxiv.org/abs/1704.05179) | 582,261 |
| [Eli5](https://huggingface.co/datasets/eli5) | [paper](https://doi.org/10.18653/v1/p19-1346) | 325,475 |
| [Flickr 30k](https://shannon.cs.illinois.edu/DenotationGraph/) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/229/33) | 317,695 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles) | | 304,525 |
| AllNLI ([SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) | [paper SNLI](https://doi.org/10.18653/v1/d15-1075), [paper MultiNLI](https://doi.org/10.18653/v1/n18-1101) | 277,230 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (bodies) | | 250,519 |
| [Stack Exchange](https://huggingface.co/datasets/flax-sentence-embeddings/stackexchange_xml) Duplicate questions (titles+bodies) | | 250,460 |
| [Sentence Compression](https://github.com/google-research-datasets/sentence-compression) | [paper](https://www.aclweb.org/anthology/D13-1155/) | 180,000 |
| [Wikihow](https://github.com/pvl/wikihow_pairs_dataset) | [paper](https://arxiv.org/abs/1810.09305) | 128,542 |
| [Altlex](https://github.com/chridey/altlex/) | [paper](https://aclanthology.org/P16-1135.pdf) | 112,696 |
| [Quora Question Triplets](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs) | - | 103,663 |
| [Simple Wikipedia](https://cs.pomona.edu/~dkauchak/simplification/) | [paper](https://www.aclweb.org/anthology/P11-2117/) | 102,225 |
| [Natural Questions (NQ)](https://ai.google.com/research/NaturalQuestions) | [paper](https://transacl.org/ojs/index.php/tacl/article/view/1455) | 100,231 |
| [SQuAD2.0](https://rajpurkar.github.io/SQuAD-explorer/) | [paper](https://aclanthology.org/P18-2124.pdf) | 87,599 |
| [TriviaQA](https://huggingface.co/datasets/trivia_qa) | - | 73,346 |
| **Total** | | **1,124,818,467** | |
dima806/fairface_age_image_detection | dima806 | "2024-12-15T19:54:53Z" | 3,786,157 | 1 | transformers | [
"transformers",
"safetensors",
"vit",
"image-classification",
"dataset:nateraw/fairface",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | "2024-12-06T14:59:20Z" | ---
license: apache-2.0
metrics:
- accuracy
- f1
base_model:
- google/vit-base-patch16-224-in21k
pipeline_tag: image-classification
library_name: transformers
datasets:
- nateraw/fairface
---
Detects age group with about 59% accuracy based on an image.
See https://www.kaggle.com/code/dima806/age-group-image-classification-vit for details.

```
Classification report:
precision recall f1-score support
0-2 0.7803 0.7500 0.7649 180
3-9 0.7998 0.7998 0.7998 1249
10-19 0.5361 0.4236 0.4733 1086
20-29 0.6402 0.7221 0.6787 3026
30-39 0.4935 0.5083 0.5008 2099
40-49 0.4848 0.4386 0.4606 1238
50-59 0.5000 0.4814 0.4905 725
60-69 0.4497 0.4685 0.4589 286
more than 70 0.6897 0.1802 0.2857 111
accuracy 0.5892 10000
macro avg 0.5971 0.5303 0.5459 10000
weighted avg 0.5863 0.5892 0.5844 10000
``` |
google/bert_uncased_L-2_H-128_A-2 | google | "2023-09-05T15:25:24Z" | 3,627,010 | 30 | transformers | [
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"arxiv:1908.08962",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | "2022-03-02T23:29:05Z" | ---
thumbnail: https://huggingface.co/front/thumbnails/google.png
license: apache-2.0
---
BERT Miniatures
===
This is the set of 24 BERT models referenced in [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962) (English only, uncased, trained with WordPiece masking).
We have shown that the standard BERT recipe (including model architecture and training objective) is effective on a wide range of model sizes, beyond BERT-Base and BERT-Large. The smaller BERT models are intended for environments with restricted computational resources. They can be fine-tuned in the same manner as the original BERT models. However, they are most effective in the context of knowledge distillation, where the fine-tuning labels are produced by a larger and more accurate teacher.
Our goal is to enable research in institutions with fewer computational resources and encourage the community to seek directions of innovation alternative to increasing model capacity.
You can download the 24 BERT miniatures either from the [official BERT Github page](https://github.com/google-research/bert/), or via HuggingFace from the links below:
| |H=128|H=256|H=512|H=768|
|---|:---:|:---:|:---:|:---:|
| **L=2** |[**2/128 (BERT-Tiny)**][2_128]|[2/256][2_256]|[2/512][2_512]|[2/768][2_768]|
| **L=4** |[4/128][4_128]|[**4/256 (BERT-Mini)**][4_256]|[**4/512 (BERT-Small)**][4_512]|[4/768][4_768]|
| **L=6** |[6/128][6_128]|[6/256][6_256]|[6/512][6_512]|[6/768][6_768]|
| **L=8** |[8/128][8_128]|[8/256][8_256]|[**8/512 (BERT-Medium)**][8_512]|[8/768][8_768]|
| **L=10** |[10/128][10_128]|[10/256][10_256]|[10/512][10_512]|[10/768][10_768]|
| **L=12** |[12/128][12_128]|[12/256][12_256]|[12/512][12_512]|[**12/768 (BERT-Base)**][12_768]|
Note that the BERT-Base model in this release is included for completeness only; it was re-trained under the same regime as the original model.
Here are the corresponding GLUE scores on the test set:
|Model|Score|CoLA|SST-2|MRPC|STS-B|QQP|MNLI-m|MNLI-mm|QNLI(v2)|RTE|WNLI|AX|
|---|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
|BERT-Tiny|64.2|0.0|83.2|81.1/71.1|74.3/73.6|62.2/83.4|70.2|70.3|81.5|57.2|62.3|21.0|
|BERT-Mini|65.8|0.0|85.9|81.1/71.8|75.4/73.3|66.4/86.2|74.8|74.3|84.1|57.9|62.3|26.1|
|BERT-Small|71.2|27.8|89.7|83.4/76.2|78.8/77.0|68.1/87.0|77.6|77.0|86.4|61.8|62.3|28.6|
|BERT-Medium|73.5|38.0|89.6|86.6/81.6|80.4/78.4|69.6/87.9|80.0|79.1|87.7|62.2|62.3|30.5|
For each task, we selected the best fine-tuning hyperparameters from the lists below, and trained for 4 epochs:
- batch sizes: 8, 16, 32, 64, 128
- learning rates: 3e-4, 1e-4, 5e-5, 3e-5
If you use these models, please cite the following paper:
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
[2_128]: https://huggingface.co/google/bert_uncased_L-2_H-128_A-2
[2_256]: https://huggingface.co/google/bert_uncased_L-2_H-256_A-4
[2_512]: https://huggingface.co/google/bert_uncased_L-2_H-512_A-8
[2_768]: https://huggingface.co/google/bert_uncased_L-2_H-768_A-12
[4_128]: https://huggingface.co/google/bert_uncased_L-4_H-128_A-2
[4_256]: https://huggingface.co/google/bert_uncased_L-4_H-256_A-4
[4_512]: https://huggingface.co/google/bert_uncased_L-4_H-512_A-8
[4_768]: https://huggingface.co/google/bert_uncased_L-4_H-768_A-12
[6_128]: https://huggingface.co/google/bert_uncased_L-6_H-128_A-2
[6_256]: https://huggingface.co/google/bert_uncased_L-6_H-256_A-4
[6_512]: https://huggingface.co/google/bert_uncased_L-6_H-512_A-8
[6_768]: https://huggingface.co/google/bert_uncased_L-6_H-768_A-12
[8_128]: https://huggingface.co/google/bert_uncased_L-8_H-128_A-2
[8_256]: https://huggingface.co/google/bert_uncased_L-8_H-256_A-4
[8_512]: https://huggingface.co/google/bert_uncased_L-8_H-512_A-8
[8_768]: https://huggingface.co/google/bert_uncased_L-8_H-768_A-12
[10_128]: https://huggingface.co/google/bert_uncased_L-10_H-128_A-2
[10_256]: https://huggingface.co/google/bert_uncased_L-10_H-256_A-4
[10_512]: https://huggingface.co/google/bert_uncased_L-10_H-512_A-8
[10_768]: https://huggingface.co/google/bert_uncased_L-10_H-768_A-12
[12_128]: https://huggingface.co/google/bert_uncased_L-12_H-128_A-2
[12_256]: https://huggingface.co/google/bert_uncased_L-12_H-256_A-4
[12_512]: https://huggingface.co/google/bert_uncased_L-12_H-512_A-8
[12_768]: https://huggingface.co/google/bert_uncased_L-12_H-768_A-12
|
openai-community/gpt2-large | openai-community | "2024-02-19T11:11:02Z" | 3,600,082 | 283 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"onnx",
"safetensors",
"gpt2",
"text-generation",
"en",
"arxiv:1910.09700",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2022-03-02T23:29:04Z" | ---
language: en
license: mit
---
# GPT-2 Large
## Table of Contents
- [Model Details](#model-details)
- [How To Get Started With the Model](#how-to-get-started-with-the-model)
- [Uses](#uses)
- [Risks, Limitations and Biases](#risks-limitations-and-biases)
- [Training](#training)
- [Evaluation](#evaluation)
- [Environmental Impact](#environmental-impact)
- [Technical Specifications](#technical-specifications)
- [Citation Information](#citation-information)
- [Model Card Authors](#model-card-author)
## Model Details
**Model Description:** GPT-2 Large is the **774M parameter** version of GPT-2, a transformer-based language model created and released by OpenAI. The model is a pretrained model on English language using a causal language modeling (CLM) objective.
- **Developed by:** OpenAI, see [associated research paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) and [GitHub repo](https://github.com/openai/gpt-2) for model developers.
- **Model Type:** Transformer-based language model
- **Language(s):** English
- **License:** [Modified MIT License](https://github.com/openai/gpt-2/blob/master/LICENSE)
- **Related Models:** [GPT-2](https://huggingface.co/gpt2), [GPT-Medium](https://huggingface.co/gpt2-medium) and [GPT-XL](https://huggingface.co/gpt2-xl)
- **Resources for more information:**
- [Research Paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
- [OpenAI Blog Post](https://openai.com/blog/better-language-models/)
- [GitHub Repo](https://github.com/openai/gpt-2)
- [OpenAI Model Card for GPT-2](https://github.com/openai/gpt-2/blob/master/model_card.md)
- Test the full generation capabilities here: https://transformer.huggingface.co/doc/gpt2-large
## How to Get Started with the Model
Use the code below to get started with the model. You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, we
set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='gpt2-large')
>>> set_seed(42)
>>> generator("Hello, I'm a language model,", max_length=30, num_return_sequences=5)
[{'generated_text': "Hello, I'm a language model, I can do language modeling. In fact, this is one of the reasons I use languages. To get a"},
{'generated_text': "Hello, I'm a language model, which in its turn implements a model of how a human can reason about a language, and is in turn an"},
{'generated_text': "Hello, I'm a language model, why does this matter for you?\n\nWhen I hear new languages, I tend to start thinking in terms"},
{'generated_text': "Hello, I'm a language model, a functional language...\n\nI don't need to know anything else. If I want to understand about how"},
{'generated_text': "Hello, I'm a language model, not a toolbox.\n\nIn a nutshell, a language model is a set of attributes that define how"}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-large')
model = GPT2Model.from_pretrained('gpt2-large')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import GPT2Tokenizer, TFGPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('gpt2-large')
model = TFGPT2Model.from_pretrained('gpt2-large')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Uses
#### Direct Use
In their [model card about GPT-2](https://github.com/openai/gpt-2/blob/master/model_card.md), OpenAI wrote:
> The primary intended users of these models are AI researchers and practitioners.
>
> We primarily imagine these language models will be used by researchers to better understand the behaviors, capabilities, biases, and constraints of large-scale generative language models.
#### Downstream Use
In their [model card about GPT-2](https://github.com/openai/gpt-2/blob/master/model_card.md), OpenAI wrote:
> Here are some secondary use cases we believe are likely:
>
> - Writing assistance: Grammar assistance, autocompletion (for normal prose or code)
> - Creative writing and art: exploring the generation of creative, fictional texts; aiding creation of poetry and other literary art.
> - Entertainment: Creation of games, chat bots, and amusing generations.
#### Misuse and Out-of-scope Use
In their [model card about GPT-2](https://github.com/openai/gpt-2/blob/master/model_card.md), OpenAI wrote:
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases that require the generated text to be true.
>
> Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do not recommend that they be deployed into systems that interact with humans unless the deployers first carry out a study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race, and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar levels of caution around use cases that are sensitive to biases around human attributes.
## Risks, Limitations and Biases
**CONTENT WARNING: Readers should be aware this section contains content that is disturbing, offensive, and can propogate historical and current stereotypes.**
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
The training data used for this model has not been released as a dataset one can browse. We know it contains a lot of unfiltered content from the internet, which is far from neutral. Predictions generated by the model can include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups. For example:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='gpt2-large')
>>> set_seed(42)
>>> generator("The man worked as a", max_length=10, num_return_sequences=5)
[{'generated_text': 'The man worked as a security guard in a hotel'},
{'generated_text': 'The man worked as a salesman in Mexico and in'},
{'generated_text': 'The man worked as a supervisor at the warehouse for'},
{'generated_text': "The man worked as a cleaner for the store's"},
{'generated_text': 'The man worked as a barbershop apprentice.'}]
>>> set_seed(42)
>>> generator("The woman worked as a", max_length=10, num_return_sequences=5)
[{'generated_text': 'The woman worked as a clerk at the bank.'},
{'generated_text': 'The woman worked as a caregiver, and her'},
{'generated_text': 'The woman worked as a customer service agent for a'},
{'generated_text': 'The woman worked as a cleaner at the store,'},
{'generated_text': 'The woman worked as a barista and was "'}]
```
This bias will also affect all fine-tuned versions of this model. Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model.
## Training
#### Training Data
The OpenAI team wanted to train this model on a corpus as large as possible. To build it, they scraped all the web
pages from outbound links on Reddit which received at least 3 karma. Note that all Wikipedia pages were removed from
this dataset, so the model was not trained on any part of Wikipedia. The resulting dataset (called WebText) weights
40GB of texts but has not been publicly released. You can find a list of the top 1,000 domains present in WebText
[here](https://github.com/openai/gpt-2/blob/master/domains.txt).
#### Training Procedure
The model is pretrained on a very large corpus of English data in a self-supervised fashion. This
means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots
of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely,
it was trained to guess the next word in sentences.
More precisely, inputs are sequences of continuous text of a certain length and the targets are the same sequence,
shifted one token (word or piece of word) to the right. The model uses internally a mask-mechanism to make sure the
predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the English language that can then be used to extract features
useful for downstream tasks.
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a
vocabulary size of 50,257. The inputs are sequences of 1024 consecutive tokens.
## Evaluation
The following evaluation information is extracted from the [associated paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf).
#### Testing Data, Factors and Metrics
The model authors write in the [associated paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) that:
> Since our model operates on a byte level and does not require lossy pre-processing or tokenization, we can evaluate it on any language model benchmark. Results on language modeling datasets are commonly reported in a quantity which is a scaled or ex- ponentiated version of the average negative log probability per canonical prediction unit - usually a character, a byte, or a word. We evaluate the same quantity by computing the log-probability of a dataset according to a WebText LM and dividing by the number of canonical units. For many of these datasets, WebText LMs would be tested significantly out- of-distribution, having to predict aggressively standardized text, tokenization artifacts such as disconnected punctuation and contractions, shuffled sentences, and even the string <UNK> which is extremely rare in WebText - occurring only 26 times in 40 billion bytes. We report our main results...using invertible de-tokenizers which remove as many of these tokenization / pre-processing artifacts as possible. Since these de-tokenizers are invertible, we can still calculate the log probability of a dataset and they can be thought of as a simple form of domain adaptation.
#### Results
The model achieves the following results without any fine-tuning (zero-shot):
| Dataset | LAMBADA | LAMBADA | CBT-CN | CBT-NE | WikiText2 | PTB | enwiki8 | text8 | WikiText103 | 1BW |
|:--------:|:-------:|:-------:|:------:|:------:|:---------:|:------:|:-------:|:------:|:-----------:|:-----:|
| (metric) | (PPL) | (ACC) | (ACC) | (ACC) | (PPL) | (PPL) | (BPB) | (BPC) | (PPL) | (PPL) |
| | 10.87 | 60.12 | 93.45 | 88.0 | 19.93 | 40.31 | 0.97 | 1.02 | 22.05 | 44.575|
## Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Unknown
- **Hours used:** Unknown
- **Cloud Provider:** Unknown
- **Compute Region:** Unknown
- **Carbon Emitted:** Unknown
## Technical Specifications
See the [associated paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) for details on the modeling architecture, objective, compute infrastructure, and training details.
## Citation Information
```bibtex
@article{radford2019language,
title={Language models are unsupervised multitask learners},
author={Radford, Alec and Wu, Jeffrey and Child, Rewon and Luan, David and Amodei, Dario and Sutskever, Ilya and others},
journal={OpenAI blog},
volume={1},
number={8},
pages={9},
year={2019}
}
```
## Model Card Authors
This model card was written by the Hugging Face team. |
microsoft/infoxlm-large | microsoft | "2021-08-04T11:43:05Z" | 3,535,155 | 12 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"fill-mask",
"arxiv:2007.07834",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:05Z" | # InfoXLM
**InfoXLM** (NAACL 2021, [paper](https://arxiv.org/pdf/2007.07834.pdf), [repo](https://github.com/microsoft/unilm/tree/master/infoxlm), [model](https://huggingface.co/microsoft/infoxlm-base)) InfoXLM: An Information-Theoretic Framework for Cross-Lingual Language Model Pre-Training.
**MD5**
```
05b95b7d977450b364f8ea3269391953 config.json
c19438359fed6d36b0c1bbb107929579 pytorch_model.bin
bf25eb5120ad92ef5c7d8596b5dc4046 sentencepiece.bpe.model
eedbd60a7268b9fc45981b849664f747 tokenizer.json
```
**BibTeX**
```
@inproceedings{chi-etal-2021-infoxlm,
title = "{I}nfo{XLM}: An Information-Theoretic Framework for Cross-Lingual Language Model Pre-Training",
author={Chi, Zewen and Dong, Li and Wei, Furu and Yang, Nan and Singhal, Saksham and Wang, Wenhui and Song, Xia and Mao, Xian-Ling and Huang, Heyan and Zhou, Ming},
booktitle = "Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jun,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.naacl-main.280",
doi = "10.18653/v1/2021.naacl-main.280",
pages = "3576--3588",}
``` |
mlx-community/Llama-3.2-1B-Instruct-4bit | mlx-community | "2024-10-07T22:41:58Z" | 3,505,109 | 12 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"llama-3",
"mlx",
"conversational",
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"base_model:meta-llama/Llama-3.2-1B-Instruct",
"base_model:quantized:meta-llama/Llama-3.2-1B-Instruct",
"license:llama3.2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"region:us"
] | text-generation | "2024-09-25T18:35:40Z" | ---
base_model: meta-llama/Llama-3.2-1B-Instruct
language:
- en
- de
- fr
- it
- pt
- hi
- es
- th
library_name: transformers
license: llama3.2
pipeline_tag: text-generation
tags:
- facebook
- meta
- llama
- llama-3
- mlx
extra_gated_prompt: "### LLAMA 3.2 COMMUNITY LICENSE AGREEMENT\n\nLlama 3.2 Version Release Date: September 25, 2024\n\n“Agreement” means the terms and conditions for use, reproduction, distribution and modification of the Llama Materials set forth herein.\n\n“Documentation” means the specifications, manuals and documentation accompanying Llama 3.2 distributed by Meta at https://llama.meta.com/doc/overview.\n\n“Licensee” or “you” means you, or your employer or any other person or entity (if you are entering into this Agreement on such person or entity’s behalf), of the age required under applicable laws, rules or regulations to provide legal consent and that has legal authority to bind your employer or such other person or entity if you are entering in this Agreement on their behalf.\n\n“Llama 3.2” means the foundational large language models and software and algorithms, including machine-learning model code, trained model weights, inference-enabling code, training-enabling code, fine-tuning enabling code and other elements of the foregoing distributed by Meta at https://www.llama.com/llama-downloads.\n\n“Llama Materials” means, collectively, Meta’s proprietary Llama 3.2 and Documentation (and any portion thereof) made available under this Agreement.\n\n“Meta” or “we” means Meta Platforms Ireland Limited (if you are located in or, if you are an entity, your principal place of business is in the EEA or Switzerland) and Meta Platforms, Inc. (if you are located outside of the EEA or Switzerland). \n\nBy clicking “I Accept” below or by using or distributing any portion or element of the Llama Materials, you agree to be bound by this Agreement.\n\n1. License Rights and Redistribution.\na. Grant of Rights. You are granted a non-exclusive, worldwide, non-transferable and royalty-free limited license under Meta’s intellectual property or other rights owned by Meta embodied in the Llama Materials to use, reproduce, distribute, copy, create derivative works of, and make modifications to the Llama Materials. \nb. Redistribution and Use. \ni. If you distribute or make available the Llama Materials (or any derivative works thereof), or a product or service (including another AI model) that contains any of them, you shall (A) provide a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Llama” on a related website, user interface, blogpost, about page, or product documentation. If you use the Llama Materials or any outputs or results of the Llama Materials to create, train, fine tune, or otherwise improve an AI model, which is distributed or made available, you shall also include “Llama” at the beginning of any such AI model name.\nii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part of an integrated end user product, then Section 2 of this Agreement will not apply to you. \niii. You must retain in all copies of the Llama Materials that you distribute the following attribution notice within a “Notice” text file distributed as a part of such copies: “Llama 3.2 is licensed under the Llama 3.2 Community License, Copyright © Meta Platforms, Inc. All Rights Reserved.”\niv. Your use of the Llama Materials must comply with applicable laws and regulations (including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for the Llama Materials (available at https://www.llama.com/llama3_2/use-policy), which is hereby incorporated by reference into this Agreement.\n \n2. Additional Commercial Terms. If, on the Llama 3.2 version release date, the monthly active users of the products or services made available by or for Licensee, or Licensee’s affiliates, is greater than 700 million monthly active users in the preceding calendar month, you must request a license from Meta, which Meta may grant to you in its sole discretion, and you are not authorized to exercise any of the rights under this Agreement unless or until Meta otherwise expressly grants you such rights.\n3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.\n4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.\n5. Intellectual Property.\na. No trademark licenses are granted under this Agreement, and in connection with the Llama Materials, neither Meta nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates, except as required for reasonable and customary use in describing and redistributing the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you a license to use “Llama” (the “Mark”) solely as required to comply with the last sentence of Section 1.b.i. You will comply with Meta’s brand guidelines (currently accessible at https://about.meta.com/brand/resources/meta/company-brand/). All goodwill arising out of your use of the Mark will inure to the benefit of Meta.\nb. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with respect to any derivative works and modifications of the Llama Materials that are made by you, as between you and Meta, you are and will be the owner of such derivative works and modifications.\nc. If you institute litigation or other proceedings against Meta or any entity (including a cross-claim or counterclaim in a lawsuit) alleging that the Llama Materials or Llama 3.2 outputs or results, or any portion of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or claim is filed or instituted. You will indemnify and hold harmless Meta from and against any claim by any third party arising out of or related to your use or distribution of the Llama Materials.\n6. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access to the Llama Materials and will continue in full force and effect until terminated in accordance with the terms and conditions herein. Meta may terminate this Agreement if you are in breach of any term or condition of this Agreement. Upon termination of this Agreement, you shall delete and cease use of the Llama Materials. Sections 3, 4 and 7 shall survive the termination of this Agreement. \n7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of California without regard to choice of law principles, and the UN Convention on Contracts for the International Sale of Goods does not apply to this Agreement. The courts of California shall have exclusive jurisdiction of any dispute arising out of this Agreement. \n### Llama 3.2 Acceptable Use Policy\nMeta is committed to promoting safe and fair use of its tools and features, including Llama 3.2. If you access or use Llama 3.2, you agree to this Acceptable Use Policy (“**Policy**”). The most recent copy of this policy can be found at [https://www.llama.com/llama3_2/use-policy](https://www.llama.com/llama3_2/use-policy).\n#### Prohibited Uses\nWe want everyone to use Llama 3.2 safely and responsibly. You agree you will not use, or allow others to use, Llama 3.2 to:\n1. Violate the law or others’ rights, including to:\n 1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:\n 1. Violence or terrorism\n 2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material\n 3. Human trafficking, exploitation, and sexual violence\n 4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.\n 5. Sexual solicitation\n 6. Any other criminal activity\n 1. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals\n 2. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services\n 3. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices\n 4. Collect, process, disclose, generate, or infer private or sensitive information about individuals, including information about individuals’ identity, health, or demographic information, unless you have obtained the right to do so in accordance with applicable law\n 5. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials\n 6. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system\n 7. Engage in any action, or facilitate any action, to intentionally circumvent or remove usage restrictions or other safety measures, or to enable functionality disabled by Meta\_\n2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Llama 3.2 related to the following:\n 8. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State or to the U.S. Biological Weapons Anti-Terrorism Act of 1989 or the Chemical Weapons Convention Implementation Act of 1997\n 9. Guns and illegal weapons (including weapon development)\n 10. Illegal drugs and regulated/controlled substances\n 11. Operation of critical infrastructure, transportation technologies, or heavy machinery\n 12. Self-harm or harm to others, including suicide, cutting, and eating disorders\n 13. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual\n3. Intentionally deceive or mislead others, including use of Llama 3.2 related to the following:\n 14. Generating, promoting, or furthering fraud or the creation or promotion of disinformation\n 15. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content\n 16. Generating, promoting, or further distributing spam\n 17. Impersonating another individual without consent, authorization, or legal right\n 18. Representing that the use of Llama 3.2 or outputs are human-generated\n 19. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement\_\n4. Fail to appropriately disclose to end users any known dangers of your AI system 5. Interact with third party tools, models, or software designed to generate unlawful content or engage in unlawful or harmful conduct and/or represent that the outputs of such tools, models, or software are associated with Meta or Llama 3.2\n\nWith respect to any multimodal models included in Llama 3.2, the rights granted under Section 1(a) of the Llama 3.2 Community License Agreement are not being granted to you if you are an individual domiciled in, or a company with a principal place of business in, the European Union. This restriction does not apply to end users of a product or service that incorporates any such multimodal models.\n\nPlease report any violation of this Policy, software “bug,” or other problems that could lead to a violation of this Policy through one of the following means:\n\n* Reporting issues with the model: [https://github.com/meta-llama/llama-models/issues](https://l.workplace.com/l.php?u=https%3A%2F%2Fgithub.com%2Fmeta-llama%2Fllama-models%2Fissues&h=AT0qV8W9BFT6NwihiOHRuKYQM_UnkzN_NmHMy91OT55gkLpgi4kQupHUl0ssR4dQsIQ8n3tfd0vtkobvsEvt1l4Ic6GXI2EeuHV8N08OG2WnbAmm0FL4ObkazC6G_256vN0lN9DsykCvCqGZ)\n* Reporting risky content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)\n* Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)\n* Reporting violations of the Acceptable Use Policy or unlicensed uses of Llama 3.2: [email protected]"
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
Job title:
type: select
options:
- Student
- Research Graduate
- AI researcher
- AI developer/engineer
- Reporter
- Other
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: >-
The information you provide will be collected, stored, processed and shared in
accordance with the [Meta Privacy
Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
# mlx-community/Llama-3.2-1B-Instruct-4bit
The Model [mlx-community/Llama-3.2-1B-Instruct-4bit](https://huggingface.co/mlx-community/Llama-3.2-1B-Instruct-4bit) was converted to MLX format from [meta-llama/Llama-3.2-1B-Instruct](https://huggingface.co/meta-llama/Llama-3.2-1B-Instruct) using mlx-lm version **0.18.2**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/Llama-3.2-1B-Instruct-4bit")
prompt="hello"
if hasattr(tokenizer, "apply_chat_template") and tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
``` |
Bingsu/yolo-world-mirror | Bingsu | "2024-03-16T10:43:40Z" | 3,397,696 | 4 | ultralytics | [
"ultralytics",
"license:agpl-3.0",
"region:us"
] | null | "2024-03-01T01:56:11Z" | ---
license: agpl-3.0
tags:
- ultralytics
---
# YOLO World Mirror
https://docs.ultralytics.com/models/yolo-world/#available-models-supported-tasks-and-operating-modes
model weights for ultralytics yolo models
|
patrickjohncyh/fashion-clip | patrickjohncyh | "2024-09-17T15:19:43Z" | 3,374,114 | 206 | transformers | [
"transformers",
"pytorch",
"onnx",
"safetensors",
"clip",
"zero-shot-image-classification",
"vision",
"language",
"fashion",
"ecommerce",
"en",
"license:mit",
"endpoints_compatible",
"region:us"
] | zero-shot-image-classification | "2023-02-21T19:51:47Z" | ---
license: mit
tags:
- vision
- language
- fashion
- ecommerce
library_name: transformers
language:
- en
widget:
- src: https://cdn-images.farfetch-contents.com/19/76/05/56/19760556_44221665_1000.jpg
candidate_labels: black shoe, red shoe, a cat
example_title: Black Shoe
---
[](https://www.youtube.com/watch?v=uqRSc-KSA1Y) [](https://huggingface.co/patrickjohncyh/fashion-clip) [](https://colab.research.google.com/drive/1Z1hAxBnWjF76bEi9KQ6CMBBEmI_FVDrW?usp=sharing) [](https://towardsdatascience.com/teaching-clip-some-fashion-3005ac3fdcc3) [](https://huggingface.co/spaces/vinid/fashion-clip-app)
# Model Card: Fashion CLIP
Disclaimer: The model card adapts the model card from [here](https://huggingface.co/openai/clip-vit-base-patch32).
## Model Details
UPDATE (10/03/23): We have updated the model! We found that [laion/CLIP-ViT-B-32-laion2B-s34B-b79K](https://huggingface.co/laion/CLIP-ViT-B-32-laion2B-s34B-b79K) checkpoint (thanks [Bin](https://www.linkedin.com/in/bin-duan-56205310/)!) worked better than original OpenAI CLIP on Fashion. We thus fine-tune a newer (and better!) version of FashionCLIP (henceforth FashionCLIP 2.0), while keeping the architecture the same. We postulate that the perofrmance gains afforded by `laion/CLIP-ViT-B-32-laion2B-s34B-b79K` are due to the increased training data (5x OpenAI CLIP data). Our [thesis](https://www.nature.com/articles/s41598-022-23052-9), however, remains the same -- fine-tuning `laion/CLIP` on our fashion dataset improved zero-shot perofrmance across our benchmarks. See the below table comparing weighted macro F1 score across models.
| Model | FMNIST | KAGL | DEEP |
| ------------- | ------------- | ------------- | ------------- |
| OpenAI CLIP | 0.66 | 0.63 | 0.45 |
| FashionCLIP | 0.74 | 0.67 | 0.48 |
| Laion CLIP | 0.78 | 0.71 | 0.58 |
| FashionCLIP 2.0 | __0.83__ | __0.73__ | __0.62__ |
---
FashionCLIP is a CLIP-based model developed to produce general product representations for fashion concepts. Leveraging the pre-trained checkpoint (ViT-B/32) released by [OpenAI](https://github.com/openai/CLIP), we train FashionCLIP on a large, high-quality novel fashion dataset to study whether domain specific fine-tuning of CLIP-like models is sufficient to produce product representations that are zero-shot transferable to entirely new datasets and tasks. FashionCLIP was not developed for model deplyoment - to do so, researchers will first need to carefully study their capabilities in relation to the specific context they’re being deployed within.
### Model Date
March 2023
### Model Type
The model uses a ViT-B/32 Transformer architecture as an image encoder and uses a masked self-attention Transformer as a text encoder. These encoders are trained, starting from a pre-trained checkpoint, to maximize the similarity of (image, text) pairs via a contrastive loss on a fashion dataset containing 800K products.
### Documents
- [FashionCLIP Github Repo](https://github.com/patrickjohncyh/fashion-clip)
- [FashionCLIP Paper](https://www.nature.com/articles/s41598-022-23052-9)
## Data
The model was trained on (image, text) pairs obtained from the Farfecth dataset[^1 Awaiting official release.], an English dataset comprising over 800K fashion products, with more than 3K brands across dozens of object types. The image used for encoding is the standard product image, which is a picture of the item over a white background, with no humans. The text used is a concatenation of the _highlight_ (e.g., “stripes”, “long sleeves”, “Armani”) and _short description_ (“80s styled t-shirt”)) available in the Farfetch dataset.
## Limitations, Bias and Fiarness
We acknowledge certain limitations of FashionCLIP and expect that it inherits certain limitations and biases present in the original CLIP model. We do not expect our fine-tuning to significantly augment these limitations: we acknowledge that the fashion data we use makes explicit assumptions about the notion of gender as in "blue shoes for a woman" that inevitably associate aspects of clothing with specific people.
Our investigations also suggest that the data used introduces certain limitations in FashionCLIP. From the textual modality, given that most captions derived from the Farfetch dataset are long, we observe that FashionCLIP may be more performant in longer queries than shorter ones. From the image modality, FashionCLIP is also biased towards standard product images (centered, white background).
Model selection, i.e. selecting an appropariate stopping critera during fine-tuning, remains an open challenge. We observed that using loss on an in-domain (i.e. same distribution as test) validation dataset is a poor selection critera when out-of-domain generalization (i.e. across different datasets) is desired, even when the dataset used is relatively diverse and large.
## Citation
```
@Article{Chia2022,
title="Contrastive language and vision learning of general fashion concepts",
author="Chia, Patrick John
and Attanasio, Giuseppe
and Bianchi, Federico
and Terragni, Silvia
and Magalh{\~a}es, Ana Rita
and Goncalves, Diogo
and Greco, Ciro
and Tagliabue, Jacopo",
journal="Scientific Reports",
year="2022",
month="Nov",
day="08",
volume="12",
number="1",
abstract="The steady rise of online shopping goes hand in hand with the development of increasingly complex ML and NLP models. While most use cases are cast as specialized supervised learning problems, we argue that practitioners would greatly benefit from general and transferable representations of products. In this work, we build on recent developments in contrastive learning to train FashionCLIP, a CLIP-like model adapted for the fashion industry. We demonstrate the effectiveness of the representations learned by FashionCLIP with extensive tests across a variety of tasks, datasets and generalization probes. We argue that adaptations of large pre-trained models such as CLIP offer new perspectives in terms of scalability and sustainability for certain types of players in the industry. Finally, we detail the costs and environmental impact of training, and release the model weights and code as open source contribution to the community.",
issn="2045-2322",
doi="10.1038/s41598-022-23052-9",
url="https://doi.org/10.1038/s41598-022-23052-9"
}
``` |
neuralmind/bert-base-portuguese-cased | neuralmind | "2022-06-14T14:37:09Z" | 3,326,509 | 174 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"pt",
"dataset:brWaC",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:05Z" | ---
language: pt
license: mit
tags:
- bert
- pytorch
datasets:
- brWaC
---
# BERTimbau Base (aka "bert-base-portuguese-cased")

## Introduction
BERTimbau Base is a pretrained BERT model for Brazilian Portuguese that achieves state-of-the-art performances on three downstream NLP tasks: Named Entity Recognition, Sentence Textual Similarity and Recognizing Textual Entailment. It is available in two sizes: Base and Large.
For further information or requests, please go to [BERTimbau repository](https://github.com/neuralmind-ai/portuguese-bert/).
## Available models
| Model | Arch. | #Layers | #Params |
| ---------------------------------------- | ---------- | ------- | ------- |
| `neuralmind/bert-base-portuguese-cased` | BERT-Base | 12 | 110M |
| `neuralmind/bert-large-portuguese-cased` | BERT-Large | 24 | 335M |
## Usage
```python
from transformers import AutoTokenizer # Or BertTokenizer
from transformers import AutoModelForPreTraining # Or BertForPreTraining for loading pretraining heads
from transformers import AutoModel # or BertModel, for BERT without pretraining heads
model = AutoModelForPreTraining.from_pretrained('neuralmind/bert-base-portuguese-cased')
tokenizer = AutoTokenizer.from_pretrained('neuralmind/bert-base-portuguese-cased', do_lower_case=False)
```
### Masked language modeling prediction example
```python
from transformers import pipeline
pipe = pipeline('fill-mask', model=model, tokenizer=tokenizer)
pipe('Tinha uma [MASK] no meio do caminho.')
# [{'score': 0.14287759363651276,
# 'sequence': '[CLS] Tinha uma pedra no meio do caminho. [SEP]',
# 'token': 5028,
# 'token_str': 'pedra'},
# {'score': 0.06213393807411194,
# 'sequence': '[CLS] Tinha uma árvore no meio do caminho. [SEP]',
# 'token': 7411,
# 'token_str': 'árvore'},
# {'score': 0.05515013635158539,
# 'sequence': '[CLS] Tinha uma estrada no meio do caminho. [SEP]',
# 'token': 5675,
# 'token_str': 'estrada'},
# {'score': 0.0299188531935215,
# 'sequence': '[CLS] Tinha uma casa no meio do caminho. [SEP]',
# 'token': 1105,
# 'token_str': 'casa'},
# {'score': 0.025660505518317223,
# 'sequence': '[CLS] Tinha uma cruz no meio do caminho. [SEP]',
# 'token': 3466,
# 'token_str': 'cruz'}]
```
### For BERT embeddings
```python
import torch
model = AutoModel.from_pretrained('neuralmind/bert-base-portuguese-cased')
input_ids = tokenizer.encode('Tinha uma pedra no meio do caminho.', return_tensors='pt')
with torch.no_grad():
outs = model(input_ids)
encoded = outs[0][0, 1:-1] # Ignore [CLS] and [SEP] special tokens
# encoded.shape: (8, 768)
# tensor([[-0.0398, -0.3057, 0.2431, ..., -0.5420, 0.1857, -0.5775],
# [-0.2926, -0.1957, 0.7020, ..., -0.2843, 0.0530, -0.4304],
# [ 0.2463, -0.1467, 0.5496, ..., 0.3781, -0.2325, -0.5469],
# ...,
# [ 0.0662, 0.7817, 0.3486, ..., -0.4131, -0.2852, -0.2819],
# [ 0.0662, 0.2845, 0.1871, ..., -0.2542, -0.2933, -0.0661],
# [ 0.2761, -0.1657, 0.3288, ..., -0.2102, 0.0029, -0.2009]])
```
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{souza2020bertimbau,
author = {F{\'a}bio Souza and
Rodrigo Nogueira and
Roberto Lotufo},
title = {{BERT}imbau: pretrained {BERT} models for {B}razilian {P}ortuguese},
booktitle = {9th Brazilian Conference on Intelligent Systems, {BRACIS}, Rio Grande do Sul, Brazil, October 20-23 (to appear)},
year = {2020}
}
```
|
unslothai/1 | unslothai | "2024-07-14T03:07:01Z" | 3,325,034 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"feature-extraction",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2024-07-14T03:05:31Z" | ---
library_name: transformers
tags: []
--- |
facebook/bart-large-mnli | facebook | "2023-09-05T14:49:34Z" | 3,203,665 | 1,290 | transformers | [
"transformers",
"pytorch",
"jax",
"rust",
"safetensors",
"bart",
"text-classification",
"zero-shot-classification",
"dataset:multi_nli",
"arxiv:1910.13461",
"arxiv:1909.00161",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | zero-shot-classification | "2022-03-02T23:29:05Z" | ---
license: mit
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
pipeline_tag: zero-shot-classification
datasets:
- multi_nli
---
# bart-large-mnli
This is the checkpoint for [bart-large](https://huggingface.co/facebook/bart-large) after being trained on the [MultiNLI (MNLI)](https://huggingface.co/datasets/multi_nli) dataset.
Additional information about this model:
- The [bart-large](https://huggingface.co/facebook/bart-large) model page
- [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
](https://arxiv.org/abs/1910.13461)
- [BART fairseq implementation](https://github.com/pytorch/fairseq/tree/master/fairseq/models/bart)
## NLI-based Zero Shot Text Classification
[Yin et al.](https://arxiv.org/abs/1909.00161) proposed a method for using pre-trained NLI models as a ready-made zero-shot sequence classifiers. The method works by posing the sequence to be classified as the NLI premise and to construct a hypothesis from each candidate label. For example, if we want to evaluate whether a sequence belongs to the class "politics", we could construct a hypothesis of `This text is about politics.`. The probabilities for entailment and contradiction are then converted to label probabilities.
This method is surprisingly effective in many cases, particularly when used with larger pre-trained models like BART and Roberta. See [this blog post](https://joeddav.github.io/blog/2020/05/29/ZSL.html) for a more expansive introduction to this and other zero shot methods, and see the code snippets below for examples of using this model for zero-shot classification both with Hugging Face's built-in pipeline and with native Transformers/PyTorch code.
#### With the zero-shot classification pipeline
The model can be loaded with the `zero-shot-classification` pipeline like so:
```python
from transformers import pipeline
classifier = pipeline("zero-shot-classification",
model="facebook/bart-large-mnli")
```
You can then use this pipeline to classify sequences into any of the class names you specify.
```python
sequence_to_classify = "one day I will see the world"
candidate_labels = ['travel', 'cooking', 'dancing']
classifier(sequence_to_classify, candidate_labels)
#{'labels': ['travel', 'dancing', 'cooking'],
# 'scores': [0.9938651323318481, 0.0032737774308770895, 0.002861034357920289],
# 'sequence': 'one day I will see the world'}
```
If more than one candidate label can be correct, pass `multi_label=True` to calculate each class independently:
```python
candidate_labels = ['travel', 'cooking', 'dancing', 'exploration']
classifier(sequence_to_classify, candidate_labels, multi_label=True)
#{'labels': ['travel', 'exploration', 'dancing', 'cooking'],
# 'scores': [0.9945111274719238,
# 0.9383890628814697,
# 0.0057061901316046715,
# 0.0018193122232332826],
# 'sequence': 'one day I will see the world'}
```
#### With manual PyTorch
```python
# pose sequence as a NLI premise and label as a hypothesis
from transformers import AutoModelForSequenceClassification, AutoTokenizer
nli_model = AutoModelForSequenceClassification.from_pretrained('facebook/bart-large-mnli')
tokenizer = AutoTokenizer.from_pretrained('facebook/bart-large-mnli')
premise = sequence
hypothesis = f'This example is {label}.'
# run through model pre-trained on MNLI
x = tokenizer.encode(premise, hypothesis, return_tensors='pt',
truncation_strategy='only_first')
logits = nli_model(x.to(device))[0]
# we throw away "neutral" (dim 1) and take the probability of
# "entailment" (2) as the probability of the label being true
entail_contradiction_logits = logits[:,[0,2]]
probs = entail_contradiction_logits.softmax(dim=1)
prob_label_is_true = probs[:,1]
```
|
autogluon/chronos-bolt-base | autogluon | "2024-11-27T18:01:47Z" | 3,200,266 | 22 | null | [
"safetensors",
"t5",
"time series",
"forecasting",
"pretrained models",
"foundation models",
"time series foundation models",
"time-series",
"time-series-forecasting",
"arxiv:1910.10683",
"arxiv:2403.07815",
"license:apache-2.0",
"region:us"
] | time-series-forecasting | "2024-11-13T13:07:57Z" | ---
license: apache-2.0
pipeline_tag: time-series-forecasting
tags:
- time series
- forecasting
- pretrained models
- foundation models
- time series foundation models
- time-series
---
# Chronos-Bolt⚡ (Base)
Chronos-Bolt is a family of pretrained time series forecasting models which can be used for zero-shot forecasting. It is based on the [T5 encoder-decoder architecture](https://arxiv.org/abs/1910.10683) and has been trained on nearly 100 billion time series observations. It chunks the historical time series context into patches of multiple observations, which are then input into the encoder. The decoder then uses these representations to directly generate quantile forecasts across multiple future steps—a method known as direct multi-step forecasting. Chronos-Bolt models are up to 250 times faster and 20 times more memory-efficient than the [original Chronos](https://arxiv.org/abs/2403.07815) models of the same size.
The following plot compares the inference time of Chronos-Bolt against the original Chronos models for forecasting 1024 time series with a context length of 512 observations and a prediction horizon of 64 steps.
<center>
<img src="https://autogluon.s3.amazonaws.com/images/chronos_bolt_speed.svg" width="50%"/>
</center>
Chronos-Bolt models are not only significantly faster but also more accurate than the original Chronos models. The following plot reports the probabilistic and point forecasting performance of Chronos-Bolt in terms of the [Weighted Quantile Loss (WQL)](https://auto.gluon.ai/stable/tutorials/timeseries/forecasting-metrics.html#autogluon.timeseries.metrics.WQL) and the [Mean Absolute Scaled Error (MASE)](https://auto.gluon.ai/stable/tutorials/timeseries/forecasting-metrics.html#autogluon.timeseries.metrics.MASE), respectively, aggregated over 27 datasets (see the [Chronos paper](https://arxiv.org/abs/2403.07815) for details on this benchmark). Remarkably, despite having no prior exposure to these datasets during training, the zero-shot Chronos-Bolt models outperform commonly used statistical models and deep learning models that have been trained on these datasets (highlighted by *). Furthermore, they also perform better than other FMs, denoted by a +, which indicates that these models were pretrained on certain datasets in our benchmark and are not entirely zero-shot. Notably, Chronos-Bolt (Base) also surpasses the original Chronos (Large) model in terms of the forecasting accuracy while being over 600 times faster.
<center>
<img src="https://autogluon.s3.amazonaws.com/images/chronos_bolt_accuracy.svg" width="80%"/>
</center>
Chronos-Bolt models are available in the following sizes.
<div align="center">
| Model | Parameters | Based on |
| ---------------------------------------------------------------------- | ---------- | ---------------------------------------------------------------------- |
| [**chronos-bolt-tiny**](https://huggingface.co/autogluon/chronos-bolt-tiny) | 9M | [t5-efficient-tiny](https://huggingface.co/google/t5-efficient-tiny) |
| [**chronos-bolt-mini**](https://huggingface.co/autogluon/chronos-bolt-mini) | 21M | [t5-efficient-mini](https://huggingface.co/google/t5-efficient-mini) |
| [**chronos-bolt-small**](https://huggingface.co/autogluon/chronos-bolt-small) | 48M | [t5-efficient-small](https://huggingface.co/google/t5-efficient-small) |
| [**chronos-bolt-base**](https://huggingface.co/autogluon/chronos-bolt-base) | 205M | [t5-efficient-base](https://huggingface.co/google/t5-efficient-base) |
</div>
## Usage
A minimal example showing how to perform zero-shot inference using Chronos-Bolt with AutoGluon:
```
pip install autogluon
```
```python
from autogluon.timeseries import TimeSeriesPredictor, TimeSeriesDataFrame
df = TimeSeriesDataFrame("https://autogluon.s3.amazonaws.com/datasets/timeseries/m4_hourly/train.csv")
predictor = TimeSeriesPredictor(prediction_length=48).fit(
df,
hyperparameters={
"Chronos": {"model_path": "autogluon/chronos-bolt-base"},
},
)
predictions = predictor.predict(df)
```
## Citation
If you find Chronos or Chronos-Bolt models useful for your research, please consider citing the associated [paper](https://arxiv.org/abs/2403.07815):
```
@article{ansari2024chronos,
title={Chronos: Learning the Language of Time Series},
author={Ansari, Abdul Fatir and Stella, Lorenzo and Turkmen, Caner and Zhang, Xiyuan, and Mercado, Pedro and Shen, Huibin and Shchur, Oleksandr and Rangapuram, Syama Syndar and Pineda Arango, Sebastian and Kapoor, Shubham and Zschiegner, Jasper and Maddix, Danielle C. and Mahoney, Michael W. and Torkkola, Kari and Gordon Wilson, Andrew and Bohlke-Schneider, Michael and Wang, Yuyang},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=gerNCVqqtR}
}
```
## License
This project is licensed under the Apache-2.0 License.
|
nateraw/vit-age-classifier | nateraw | "2024-07-28T23:24:56Z" | 3,183,235 | 125 | transformers | [
"transformers",
"pytorch",
"safetensors",
"vit",
"image-classification",
"dataset:nateraw/fairface",
"doi:10.57967/hf/1259",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | "2022-03-02T23:29:05Z" | ---
tags:
- image-classification
- pytorch
datasets:
- nateraw/fairface
---
A vision transformer finetuned to classify the age of a given person's face.
```python
import requests
from PIL import Image
from io import BytesIO
from transformers import ViTFeatureExtractor, ViTForImageClassification
# Get example image from official fairface repo + read it in as an image
r = requests.get('https://github.com/dchen236/FairFace/blob/master/detected_faces/race_Asian_face0.jpg?raw=true')
im = Image.open(BytesIO(r.content))
# Init model, transforms
model = ViTForImageClassification.from_pretrained('nateraw/vit-age-classifier')
transforms = ViTFeatureExtractor.from_pretrained('nateraw/vit-age-classifier')
# Transform our image and pass it through the model
inputs = transforms(im, return_tensors='pt')
output = model(**inputs)
# Predicted Class probabilities
proba = output.logits.softmax(1)
# Predicted Classes
preds = proba.argmax(1)
``` |
allenai/longformer-base-4096 | allenai | "2023-04-05T18:24:00Z" | 3,175,159 | 185 | transformers | [
"transformers",
"pytorch",
"tf",
"rust",
"longformer",
"en",
"arxiv:2004.05150",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | "2022-03-02T23:29:05Z" | ---
language: en
license: apache-2.0
---
# longformer-base-4096
[Longformer](https://arxiv.org/abs/2004.05150) is a transformer model for long documents.
`longformer-base-4096` is a BERT-like model started from the RoBERTa checkpoint and pretrained for MLM on long documents. It supports sequences of length up to 4,096.
Longformer uses a combination of a sliding window (local) attention and global attention. Global attention is user-configured based on the task to allow the model to learn task-specific representations.
Please refer to the examples in `modeling_longformer.py` and the paper for more details on how to set global attention.
### Citing
If you use `Longformer` in your research, please cite [Longformer: The Long-Document Transformer](https://arxiv.org/abs/2004.05150).
```
@article{Beltagy2020Longformer,
title={Longformer: The Long-Document Transformer},
author={Iz Beltagy and Matthew E. Peters and Arman Cohan},
journal={arXiv:2004.05150},
year={2020},
}
```
`Longformer` is an open-source project developed by [the Allen Institute for Artificial Intelligence (AI2)](http://www.allenai.org).
AI2 is a non-profit institute with the mission to contribute to humanity through high-impact AI research and engineering. |
emilyalsentzer/Bio_ClinicalBERT | emilyalsentzer | "2024-12-03T20:22:45Z" | 3,120,362 | 308 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"en",
"arxiv:1904.03323",
"arxiv:1901.08746",
"license:mit",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:05Z" | ---
language: "en"
tags:
- fill-mask
license: mit
---
# ClinicalBERT - Bio + Clinical BERT Model
The [Publicly Available Clinical BERT Embeddings](https://arxiv.org/abs/1904.03323) paper contains four unique clinicalBERT models: initialized with BERT-Base (`cased_L-12_H-768_A-12`) or BioBERT (`BioBERT-Base v1.0 + PubMed 200K + PMC 270K`) & trained on either all MIMIC notes or only discharge summaries.
This model card describes the Bio+Clinical BERT model, which was initialized from [BioBERT](https://arxiv.org/abs/1901.08746) & trained on all MIMIC notes.
## Pretraining Data
The `Bio_ClinicalBERT` model was trained on all notes from [MIMIC III](https://www.nature.com/articles/sdata201635), a database containing electronic health records from ICU patients at the Beth Israel Hospital in Boston, MA. For more details on MIMIC, see [here](https://mimic.physionet.org/). All notes from the `NOTEEVENTS` table were included (~880M words).
## Model Pretraining
### Note Preprocessing
Each note in MIMIC was first split into sections using a rules-based section splitter (e.g. discharge summary notes were split into "History of Present Illness", "Family History", "Brief Hospital Course", etc. sections). Then each section was split into sentences using SciSpacy (`en core sci md` tokenizer).
### Pretraining Procedures
The model was trained using code from [Google's BERT repository](https://github.com/google-research/bert) on a GeForce GTX TITAN X 12 GB GPU. Model parameters were initialized with BioBERT (`BioBERT-Base v1.0 + PubMed 200K + PMC 270K`).
### Pretraining Hyperparameters
We used a batch size of 32, a maximum sequence length of 128, and a learning rate of 5 · 10−5 for pre-training our models. The models trained on all MIMIC notes were trained for 150,000 steps. The dup factor for duplicating input data with different masks was set to 5. All other default parameters were used (specifically, masked language model probability = 0.15
and max predictions per sequence = 20).
## How to use the model
Load the model via the transformers library:
```
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("emilyalsentzer/Bio_ClinicalBERT")
model = AutoModel.from_pretrained("emilyalsentzer/Bio_ClinicalBERT")
```
## More Information
Refer to the original paper, [Publicly Available Clinical BERT Embeddings](https://arxiv.org/abs/1904.03323) (NAACL Clinical NLP Workshop 2019) for additional details and performance on NLI and NER tasks.
## Questions?
Post a Github issue on the [clinicalBERT repo](https://github.com/EmilyAlsentzer/clinicalBERT) or email [email protected] with any questions.
|
answerdotai/answerai-colbert-small-v1 | answerdotai | "2024-11-18T23:45:37Z" | 3,092,673 | 141 | null | [
"onnx",
"safetensors",
"bert",
"ColBERT",
"RAGatouille",
"passage-retrieval",
"en",
"arxiv:2407.20750",
"license:apache-2.0",
"region:us"
] | null | "2024-08-12T13:02:24Z" | ---
license: apache-2.0
language:
- en
tags:
- ColBERT
- RAGatouille
- passage-retrieval
---
# answerai-colbert-small-v1
**answerai-colbert-small-v1** is a new, proof-of-concept model by [Answer.AI](https://answer.ai), showing the strong performance multi-vector models with the new [JaColBERTv2.5 training recipe](https://arxiv.org/abs/2407.20750) and some extra tweaks can reach, even with just **33 million parameters**.
While being MiniLM-sized, it outperforms all previous similarly-sized models on common benchmarks, and even outperforms much larger popular models such as e5-large-v2 or bge-base-en-v1.5.
For more information about this model or how it was trained, head over to the [announcement blogpost](https://www.answer.ai/posts/2024-08-13-small-but-mighty-colbert.html).
## Usage
### Installation
This model was designed with the upcoming RAGatouille overhaul in mind. However, it's compatible with all recent ColBERT implementations!
To use it, you can either use the Stanford ColBERT library, or RAGatouille. You can install both or either by simply running.
```sh
pip install --upgrade ragatouille
pip install --upgrade colbert-ai
```
If you're interested in using this model as a re-ranker (it vastly outperforms cross-encoders its size!), you can do so via the [rerankers](https://github.com/AnswerDotAI/rerankers) library:
```sh
pip install --upgrade rerankers[transformers]
```
### Rerankers
```python
from rerankers import Reranker
ranker = Reranker("answerdotai/answerai-colbert-small-v1", model_type='colbert')
docs = ['Hayao Miyazaki is a Japanese director, born on [...]', 'Walt Disney is an American author, director and [...]', ...]
query = 'Who directed spirited away?'
ranker.rank(query=query, docs=docs)
```
### RAGatouille
```python
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("answerdotai/answerai-colbert-small-v1")
docs = ['Hayao Miyazaki is a Japanese director, born on [...]', 'Walt Disney is an American author, director and [...]', ...]
RAG.index(docs, index_name="ghibli")
query = 'Who directed spirited away?'
results = RAG.search(query)
```
### Stanford ColBERT
#### Indexing
```python
from colbert import Indexer
from colbert.infra import Run, RunConfig, ColBERTConfig
INDEX_NAME = "DEFINE_HERE"
if __name__ == "__main__":
config = ColBERTConfig(
doc_maxlen=512,
nbits=2
)
indexer = Indexer(
checkpoint="answerdotai/answerai-colbert-small-v1",
config=config,
)
docs = ['Hayao Miyazaki is a Japanese director, born on [...]', 'Walt Disney is an American author, director and [...]', ...]
indexer.index(name=INDEX_NAME, collection=docs)
```
#### Querying
```python
from colbert import Searcher
from colbert.infra import Run, RunConfig, ColBERTConfig
INDEX_NAME = "THE_INDEX_YOU_CREATED"
k = 10
if __name__ == "__main__":
config = ColBERTConfig(
query_maxlen=32 # Adjust as needed, we recommend the nearest higher multiple of 16 to your query
)
searcher = Searcher(
index=index_name,
config=config
)
query = 'Who directed spirited away?'
results = searcher.search(query, k=k)
```
#### Extracting Vectors
Finally, if you want to extract individula vectors, you can use the model this way:
```python
from colbert.modeling.checkpoint import Checkpoint
ckpt = Checkpoint("answerdotai/answerai-colbert-small-v1", colbert_config=ColBERTConfig())
embedded_query = ckpt.queryFromText(["Who dubs Howl's in English?"], bsize=16)
```
## Results
### Against single-vector models
| Dataset / Model | answer-colbert-s | snowflake-s | bge-small-en | bge-base-en |
|:-----------------|:-----------------:|:-------------:|:-------------:|:-------------:|
| **Size** | 33M (1x) | 33M (1x) | 33M (1x) | **109M (3.3x)** |
| **BEIR AVG** | **53.79** | 51.99 | 51.68 | 53.25 |
| **FiQA2018** | **41.15** | 40.65 | 40.34 | 40.65 |
| **HotpotQA** | **76.11** | 66.54 | 69.94 | 72.6 |
| **MSMARCO** | **43.5** | 40.23 | 40.83 | 41.35 |
| **NQ** | **59.1** | 50.9 | 50.18 | 54.15 |
| **TRECCOVID** | **84.59** | 80.12 | 75.9 | 78.07 |
| **ArguAna** | 50.09 | 57.59 | 59.55 | **63.61** |
| **ClimateFEVER**| 33.07 | **35.2** | 31.84 | 31.17 |
| **CQADupstackRetrieval** | 38.75 | 39.65 | 39.05 | **42.35** |
| **DBPedia** | **45.58** | 41.02 | 40.03 | 40.77 |
| **FEVER** | **90.96** | 87.13 | 86.64 | 86.29 |
| **NFCorpus** | 37.3 | 34.92 | 34.3 | **37.39** |
| **QuoraRetrieval** | 87.72 | 88.41 | 88.78 | **88.9** |
| **SCIDOCS** | 18.42 | **21.82** | 20.52 | 21.73 |
| **SciFact** | **74.77** | 72.22 | 71.28 | 74.04 |
| **Touche2020** | 25.69 | 23.48 | **26.04** | 25.7 |
### Against ColBERTv2.0
| Dataset / Model | answerai-colbert-small-v1 | ColBERTv2.0 |
|:-----------------|:-----------------------:|:------------:|
| **BEIR AVG** | **53.79** | 50.02 |
| **DBPedia** | **45.58** | 44.6 |
| **FiQA2018** | **41.15** | 35.6 |
| **NQ** | **59.1** | 56.2 |
| **HotpotQA** | **76.11** | 66.7 |
| **NFCorpus** | **37.3** | 33.8 |
| **TRECCOVID** | **84.59** | 73.3 |
| **Touche2020** | 25.69 | **26.3** |
| **ArguAna** | **50.09** | 46.3 |
| **ClimateFEVER**| **33.07** | 17.6 |
| **FEVER** | **90.96** | 78.5 |
| **QuoraRetrieval** | **87.72** | 85.2 |
| **SCIDOCS** | **18.42** | 15.4 |
| **SciFact** | **74.77** | 69.3 |
## Referencing
We'll most likely eventually release a technical report. In the meantime, if you use this model or other models following the JaColBERTv2.5 recipe and would like to give us credit, please cite the JaColBERTv2.5 journal pre-print:
```
@article{clavie2024jacolbertv2,
title={JaColBERTv2.5: Optimising Multi-Vector Retrievers to Create State-of-the-Art Japanese Retrievers with Constrained Resources},
author={Clavi{\'e}, Benjamin},
journal={arXiv preprint arXiv:2407.20750},
year={2024}
}
```
|
google-t5/t5-base | google-t5 | "2024-02-14T17:21:55Z" | 3,088,643 | 663 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"t5",
"text2text-generation",
"summarization",
"translation",
"en",
"fr",
"ro",
"de",
"dataset:c4",
"arxiv:1805.12471",
"arxiv:1708.00055",
"arxiv:1704.05426",
"arxiv:1606.05250",
"arxiv:1808.09121",
"arxiv:1810.12885",
"arxiv:1905.10044",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | translation | "2022-03-02T23:29:04Z" | ---
pipeline_tag: translation
language:
- en
- fr
- ro
- de
datasets:
- c4
tags:
- summarization
- translation
license: apache-2.0
---
# Model Card for T5 Base

# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
4. [Training Details](#training-details)
5. [Evaluation](#evaluation)
6. [Environmental Impact](#environmental-impact)
7. [Citation](#citation)
8. [Model Card Authors](#model-card-authors)
9. [How To Get Started With the Model](#how-to-get-started-with-the-model)
# Model Details
## Model Description
The developers of the Text-To-Text Transfer Transformer (T5) [write](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html):
> With T5, we propose reframing all NLP tasks into a unified text-to-text-format where the input and output are always text strings, in contrast to BERT-style models that can only output either a class label or a span of the input. Our text-to-text framework allows us to use the same model, loss function, and hyperparameters on any NLP task.
T5-Base is the checkpoint with 220 million parameters.
- **Developed by:** Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu. See [associated paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) and [GitHub repo](https://github.com/google-research/text-to-text-transfer-transformer#released-model-checkpoints)
- **Model type:** Language model
- **Language(s) (NLP):** English, French, Romanian, German
- **License:** Apache 2.0
- **Related Models:** [All T5 Checkpoints](https://huggingface.co/models?search=t5)
- **Resources for more information:**
- [Research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf)
- [Google's T5 Blog Post](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html)
- [GitHub Repo](https://github.com/google-research/text-to-text-transfer-transformer)
- [Hugging Face T5 Docs](https://huggingface.co/docs/transformers/model_doc/t5)
# Uses
## Direct Use and Downstream Use
The developers write in a [blog post](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) that the model:
> Our text-to-text framework allows us to use the same model, loss function, and hyperparameters on any NLP task, including machine translation, document summarization, question answering, and classification tasks (e.g., sentiment analysis). We can even apply T5 to regression tasks by training it to predict the string representation of a number instead of the number itself.
See the [blog post](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) and [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) for further details.
## Out-of-Scope Use
More information needed.
# Bias, Risks, and Limitations
More information needed.
## Recommendations
More information needed.
# Training Details
## Training Data
The model is pre-trained on the [Colossal Clean Crawled Corpus (C4)](https://www.tensorflow.org/datasets/catalog/c4), which was developed and released in the context of the same [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) as T5.
The model was pre-trained on a on a **multi-task mixture of unsupervised (1.) and supervised tasks (2.)**.
Thereby, the following datasets were being used for (1.) and (2.):
1. **Datasets used for Unsupervised denoising objective**:
- [C4](https://huggingface.co/datasets/c4)
- [Wiki-DPR](https://huggingface.co/datasets/wiki_dpr)
2. **Datasets used for Supervised text-to-text language modeling objective**
- Sentence acceptability judgment
- CoLA [Warstadt et al., 2018](https://arxiv.org/abs/1805.12471)
- Sentiment analysis
- SST-2 [Socher et al., 2013](https://nlp.stanford.edu/~socherr/EMNLP2013_RNTN.pdf)
- Paraphrasing/sentence similarity
- MRPC [Dolan and Brockett, 2005](https://aclanthology.org/I05-5002)
- STS-B [Ceret al., 2017](https://arxiv.org/abs/1708.00055)
- QQP [Iyer et al., 2017](https://quoradata.quora.com/First-Quora-Dataset-Release-Question-Pairs)
- Natural language inference
- MNLI [Williams et al., 2017](https://arxiv.org/abs/1704.05426)
- QNLI [Rajpurkar et al.,2016](https://arxiv.org/abs/1606.05250)
- RTE [Dagan et al., 2005](https://link.springer.com/chapter/10.1007/11736790_9)
- CB [De Marneff et al., 2019](https://semanticsarchive.net/Archive/Tg3ZGI2M/Marneffe.pdf)
- Sentence completion
- COPA [Roemmele et al., 2011](https://www.researchgate.net/publication/221251392_Choice_of_Plausible_Alternatives_An_Evaluation_of_Commonsense_Causal_Reasoning)
- Word sense disambiguation
- WIC [Pilehvar and Camacho-Collados, 2018](https://arxiv.org/abs/1808.09121)
- Question answering
- MultiRC [Khashabi et al., 2018](https://aclanthology.org/N18-1023)
- ReCoRD [Zhang et al., 2018](https://arxiv.org/abs/1810.12885)
- BoolQ [Clark et al., 2019](https://arxiv.org/abs/1905.10044)
## Training Procedure
In their [abstract](https://jmlr.org/papers/volume21/20-074/20-074.pdf), the model developers write:
> In this paper, we explore the landscape of transfer learning techniques for NLP by introducing a unified framework that converts every language problem into a text-to-text format. Our systematic study compares pre-training objectives, architectures, unlabeled datasets, transfer approaches, and other factors on dozens of language understanding tasks.
The framework introduced, the T5 framework, involves a training procedure that brings together the approaches studied in the paper. See the [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) for further details.
# Evaluation
## Testing Data, Factors & Metrics
The developers evaluated the model on 24 tasks, see the [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf) for full details.
## Results
For full results for T5-Base, see the [research paper](https://jmlr.org/papers/volume21/20-074/20-074.pdf), Table 14.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Google Cloud TPU Pods
- **Hours used:** More information needed
- **Cloud Provider:** GCP
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Citation
**BibTeX:**
```bibtex
@article{2020t5,
author = {Colin Raffel and Noam Shazeer and Adam Roberts and Katherine Lee and Sharan Narang and Michael Matena and Yanqi Zhou and Wei Li and Peter J. Liu},
title = {Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer},
journal = {Journal of Machine Learning Research},
year = {2020},
volume = {21},
number = {140},
pages = {1-67},
url = {http://jmlr.org/papers/v21/20-074.html}
}
```
**APA:**
- Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., ... & Liu, P. J. (2020). Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(140), 1-67.
# Model Card Authors
This model card was written by the team at Hugging Face.
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import T5Tokenizer, T5Model
tokenizer = T5Tokenizer.from_pretrained("t5-base")
model = T5Model.from_pretrained("t5-base")
input_ids = tokenizer(
"Studies have been shown that owning a dog is good for you", return_tensors="pt"
).input_ids # Batch size 1
decoder_input_ids = tokenizer("Studies show that", return_tensors="pt").input_ids # Batch size 1
# forward pass
outputs = model(input_ids=input_ids, decoder_input_ids=decoder_input_ids)
last_hidden_states = outputs.last_hidden_state
```
See the [Hugging Face T5](https://huggingface.co/docs/transformers/model_doc/t5#transformers.T5Model) docs and a [Colab Notebook](https://colab.research.google.com/github/google-research/text-to-text-transfer-transformer/blob/main/notebooks/t5-trivia.ipynb) created by the model developers for more examples.
</details> |
stable-diffusion-v1-5/stable-diffusion-inpainting | stable-diffusion-v1-5 | "2024-09-06T18:58:07Z" | 3,080,128 | 25 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"arxiv:2207.12598",
"arxiv:2112.10752",
"arxiv:2103.00020",
"arxiv:2205.11487",
"arxiv:1910.09700",
"license:creativeml-openrail-m",
"diffusers:StableDiffusionInpaintPipeline",
"region:us"
] | text-to-image | "2024-08-30T10:08:03Z" | ---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
inference: false
library_name: diffusers
---
# Stable Diffusion Inpainting model card
### ⚠️ This repository is a mirror of the now deprecated `ruwnayml/stable-diffusion-inpainting`, this repository or oganization are not affiliated in any way with RunwayML.
Modifications to the original model card are in <span style="color:crimson">red</span> or <span style="color:darkgreen">green</span>
Stable Diffusion Inpainting is a latent text-to-image diffusion model capable of generating photo-realistic images given any text input, with the extra capability of inpainting the pictures by using a mask.
The **Stable-Diffusion-Inpainting** was initialized with the weights of the [Stable-Diffusion-v-1-2](https://steps/huggingface.co/CompVis/stable-diffusion-v-1-2-original). First 595k steps regular training, then 440k steps of inpainting training at resolution 512x512 on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning to improve classifier-free [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598). For inpainting, the UNet has 5 additional input channels (4 for the encoded masked-image and 1 for the mask itself) whose weights were zero-initialized after restoring the non-inpainting checkpoint. During training, we generate synthetic masks and in 25% mask everything.
[Open In Spaces](https://huggingface.co/spaces/sd-legacy/stable-diffusion-inpainting) | [](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/in_painting_with_stable_diffusion_using_diffusers.ipynb)
:-------------------------:|:-------------------------:|
## Examples:
You can use this both with the [🧨Diffusers library](https://github.com/huggingface/diffusers) and [RunwayML GitHub repository](https://github.com/runwayml/stable-diffusion) (<span style="color:crimson">now deprecated</span>), <span style="color:darkgreen">Automatic1111</span>.
### Use with Diffusers
```python
from diffusers import StableDiffusionInpaintPipeline
pipe = StableDiffusionInpaintPipeline.from_pretrained(
"sd-legacy/stable-diffusion-inpainting",
revision="fp16",
torch_dtype=torch.float16,
)
prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
#image and mask_image should be PIL images.
#The mask structure is white for inpainting and black for keeping as is
image = pipe(prompt=prompt, image=image, mask_image=mask_image).images[0]
image.save("./yellow_cat_on_park_bench.png")
```
**How it works:**
`image` | `mask_image`
:-------------------------:|:-------------------------:|
<img src="https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo.png" alt="drawing" width="300"/> | <img src="https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/overture-creations-5sI6fQgYIuo_mask.png" alt="drawing" width="300"/>
`prompt` | `Output`
:-------------------------:|:-------------------------:|
<span style="position: relative;bottom: 150px;">Face of a yellow cat, high resolution, sitting on a park bench</span> | <img src="https://huggingface.co/datasets/patrickvonplaten/images/resolve/main/test.png" alt="drawing" width="300"/>
### Use with Original GitHub Repository <span style="color:darkgreen">or AUTOMATIC1111</span>
1. Download the weights [sd-v1-5-inpainting.ckpt](https://huggingface.co/sd-legacy/stable-diffusion-inpainting/resolve/main/sd-v1-5-inpainting.ckpt)
2. Follow instructions [here](https://github.com/runwayml/stable-diffusion#inpainting-with-stable-diffusion) (<span style="color:crimson">now deprecated</span>).
3. <span style="color:darkgreen">Use it with <a href="https://github.com/AUTOMATIC1111/stable-diffusion-webui">AUTOMATIC1111</a></span>
## Model Details
- **Developed by:** Robin Rombach, Patrick Esser
- **Model type:** Diffusion-based text-to-image generation model
- **Language(s):** English
- **License:** [The CreativeML OpenRAIL M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) is an [Open RAIL M license](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses), adapted from the work that [BigScience](https://bigscience.huggingface.co/) and [the RAIL Initiative](https://www.licenses.ai/) are jointly carrying in the area of responsible AI licensing. See also [the article about the BLOOM Open RAIL license](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) on which our license is based.
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses a fixed, pretrained text encoder ([CLIP ViT-L/14](https://arxiv.org/abs/2103.00020)) as suggested in the [Imagen paper](https://arxiv.org/abs/2205.11487).
- **Resources for more information:** [GitHub Repository](https://github.com/runwayml/stable-diffusion), [Paper](https://arxiv.org/abs/2112.10752).
- **Cite as:**
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
# Uses
## Direct Use
The model is intended for research purposes only. Possible research areas and
tasks include
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
Excluded uses are described below.
### Misuse, Malicious Use, and Out-of-Scope Use
_Note: This section is taken from the [DALLE-MINI model card](https://huggingface.co/dalle-mini/dalle-mini), but applies in the same way to Stable Diffusion v1_.
The model should not be used to intentionally create or disseminate images that create hostile or alienating environments for people. This includes generating images that people would foreseeably find disturbing, distressing, or offensive; or content that propagates historical or current stereotypes.
#### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
#### Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
- Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
- Intentionally promoting or propagating discriminatory content or harmful stereotypes.
- Impersonating individuals without their consent.
- Sexual content without consent of the people who might see it.
- Mis- and disinformation
- Representations of egregious violence and gore
- Sharing of copyrighted or licensed material in violation of its terms of use.
- Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model does not perform well on more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The model was trained mainly with English captions and will not work as well in other languages.
- The autoencoding part of the model is lossy
- The model was trained on a large-scale dataset
[LAION-5B](https://laion.ai/blog/laion-5b/) which contains adult material
and is not fit for product use without additional safety mechanisms and
considerations.
- No additional measures were used to deduplicate the dataset. As a result, we observe some degree of memorization for images that are duplicated in the training data.
The training data can be searched at [https://rom1504.github.io/clip-retrieval/](https://rom1504.github.io/clip-retrieval/) to possibly assist in the detection of memorized images.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
Stable Diffusion v1 was trained on subsets of [LAION-2B(en)](https://laion.ai/blog/laion-5b/),
which consists of images that are primarily limited to English descriptions.
Texts and images from communities and cultures that use other languages are likely to be insufficiently accounted for.
This affects the overall output of the model, as white and western cultures are often set as the default. Further, the
ability of the model to generate content with non-English prompts is significantly worse than with English-language prompts.
## Training
**Training Data**
The model developers used the following dataset for training the model:
- LAION-2B (en) and subsets thereof (see next section)
**Training Procedure**
Stable Diffusion v1 is a latent diffusion model which combines an autoencoder with a diffusion model that is trained in the latent space of the autoencoder. During training,
- Images are encoded through an encoder, which turns images into latent representations. The autoencoder uses a relative downsampling factor of 8 and maps images of shape H x W x 3 to latents of shape H/f x W/f x 4
- Text prompts are encoded through a ViT-L/14 text-encoder.
- The non-pooled output of the text encoder is fed into the UNet backbone of the latent diffusion model via cross-attention.
- The loss is a reconstruction objective between the noise that was added to the latent and the prediction made by the UNet.
We currently provide six checkpoints, `sd-v1-1.ckpt`, `sd-v1-2.ckpt` and `sd-v1-3.ckpt`, `sd-v1-4.ckpt`, `sd-v1-5.ckpt` and `sd-v1-5-inpainting.ckpt`
which were trained as follows,
- `sd-v1-1.ckpt`: 237k steps at resolution `256x256` on [laion2B-en](https://huggingface.co/datasets/laion/laion2B-en).
194k steps at resolution `512x512` on [laion-high-resolution](https://huggingface.co/datasets/laion/laion-high-resolution) (170M examples from LAION-5B with resolution `>= 1024x1024`).
- `sd-v1-2.ckpt`: Resumed from `sd-v1-1.ckpt`.
515k steps at resolution `512x512` on "laion-improved-aesthetics" (a subset of laion2B-en,
filtered to images with an original size `>= 512x512`, estimated aesthetics score `> 5.0`, and an estimated watermark probability `< 0.5`. The watermark estimate is from the LAION-5B metadata, the aesthetics score is estimated using an [improved aesthetics estimator](https://github.com/christophschuhmann/improved-aesthetic-predictor)).
- `sd-v1-3.ckpt`: Resumed from `sd-v1-2.ckpt`. 195k steps at resolution `512x512` on "laion-improved-aesthetics" and 10\% dropping of the text-conditioning to improve [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- `sd-v1-4.ckpt`: Resumed from stable-diffusion-v1-2.225,000 steps at resolution 512x512 on "laion-aesthetics v2 5+" and 10 % dropping of the text-conditioning to [classifier-free guidance sampling](https://arxiv.org/abs/2207.12598).
- `sd-v1-5.ckpt`: Resumed from sd-v1-2.ckpt. 595k steps at resolution 512x512 on "laion-aesthetics v2 5+" and 10% dropping of the text-conditioning to improve classifier-free guidance sampling.
- `sd-v1-5-inpaint.ckpt`: Resumed from sd-v1-2.ckpt. 595k steps at resolution 512x512 on "laion-aesthetics v2 5+" and 10% dropping of the text-conditioning to improve classifier-free guidance sampling. Then 440k steps of inpainting training at resolution 512x512 on “laion-aesthetics v2 5+” and 10% dropping of the text-conditioning. For inpainting, the UNet has 5 additional input channels (4 for the encoded masked-image and 1 for the mask itself) whose weights were zero-initialized after restoring the non-inpainting checkpoint. During training, we generate synthetic masks and in 25% mask everything.
- **Hardware:** 32 x 8 x A100 GPUs
- **Optimizer:** AdamW
- **Gradient Accumulations**: 2
- **Batch:** 32 x 8 x 2 x 4 = 2048
- **Learning rate:** warmup to 0.0001 for 10,000 steps and then kept constant
## Evaluation Results
Evaluations with different classifier-free guidance scales (1.5, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0) and 50 PLMS sampling
steps show the relative improvements of the checkpoints:

Evaluated using 50 PLMS steps and 10000 random prompts from the COCO2017 validation set, evaluated at 512x512 resolution. Not optimized for FID scores.
## Inpainting Evaluation
To assess the performance of the inpainting model, we used the same evaluation
protocol as in our [LDM paper](https://arxiv.org/abs/2112.10752). Since the
Stable Diffusion Inpainting Model acccepts a text input, we simply used a fixed
prompt of `photograph of a beautiful empty scene, highest quality settings`.
| Model | FID | LPIPS |
|-----------------------------|------|------------------|
| Stable Diffusion Inpainting | 1.00 | 0.141 (+- 0.082) |
| Latent Diffusion Inpainting | 1.50 | 0.137 (+- 0.080) |
| CoModGAN | 1.82 | 0.15 |
| LaMa | 2.21 | 0.134 (+- 0.080) |
## Environmental Impact
**Stable Diffusion v1** **Estimated Emissions**
Based on that information, we estimate the following CO2 emissions using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700). The hardware, runtime, cloud provider, and compute region were utilized to estimate the carbon impact.
- **Hardware Type:** A100 PCIe 40GB
- **Hours used:** 150000
- **Cloud Provider:** AWS
- **Compute Region:** US-east
- **Carbon Emitted (Power consumption x Time x Carbon produced based on location of power grid):** 11250 kg CO2 eq.
## Citation
```bibtex
@InProceedings{Rombach_2022_CVPR,
author = {Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn},
title = {High-Resolution Image Synthesis With Latent Diffusion Models},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {10684-10695}
}
```
*This model card was written by: Robin Rombach and Patrick Esser and is based on the [DALL-E Mini model card](https://huggingface.co/dalle-mini/dalle-mini).* |
google/siglip-so400m-patch14-384 | google | "2024-09-26T08:21:46Z" | 3,071,244 | 455 | transformers | [
"transformers",
"safetensors",
"siglip",
"zero-shot-image-classification",
"vision",
"arxiv:2303.15343",
"arxiv:2305.13035",
"arxiv:2209.06794",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | zero-shot-image-classification | "2024-01-08T13:38:32Z" | ---
license: apache-2.0
tags:
- vision
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: playing music, playing sports
example_title: Cat & Dog
---
# SigLIP (shape-optimized model)
SigLIP model pre-trained on WebLi at resolution 384x384. It was introduced in the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Zhai et al. and first released in [this repository](https://github.com/google-research/big_vision).
This model has the SoViT-400m architecture, which is the shape-optimized version as presented in [Getting ViT in Shape: Scaling Laws for Compute-Optimal Model Design](https://arxiv.org/abs/2305.13035) by Alabdulmohsin et al.
Disclaimer: The team releasing SigLIP did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SigLIP is [CLIP](https://huggingface.co/docs/transformers/model_doc/clip), a multimodal model, with a better loss function. The sigmoid loss operates solely on image-text pairs and does not require a global view of the pairwise similarities for normalization. This allows further scaling up the batch size, while also performing better at smaller batch sizes.
A TLDR of SigLIP by one of the authors can be found [here](https://twitter.com/giffmana/status/1692641733459267713).
## Intended uses & limitations
You can use the raw model for tasks like zero-shot image classification and image-text retrieval. See the [model hub](https://huggingface.co/models?search=google/siglip) to look for
other versions on a task that interests you.
### How to use
Here is how to use this model to perform zero-shot image classification:
```python
from PIL import Image
import requests
from transformers import AutoProcessor, AutoModel
import torch
model = AutoModel.from_pretrained("google/siglip-so400m-patch14-384")
processor = AutoProcessor.from_pretrained("google/siglip-so400m-patch14-384")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["a photo of 2 cats", "a photo of 2 dogs"]
inputs = processor(text=texts, images=image, padding="max_length", return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image
probs = torch.sigmoid(logits_per_image) # these are the probabilities
print(f"{probs[0][0]:.1%} that image 0 is '{texts[0]}'")
```
Alternatively, one can leverage the pipeline API which abstracts away the complexity for the user:
```python
from transformers import pipeline
from PIL import Image
import requests
# load pipe
image_classifier = pipeline(task="zero-shot-image-classification", model="google/siglip-so400m-patch14-384")
# load image
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
# inference
outputs = image_classifier(image, candidate_labels=["2 cats", "a plane", "a remote"])
outputs = [{"score": round(output["score"], 4), "label": output["label"] } for output in outputs]
print(outputs)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/main/model_doc/siglip.html#).
## Training procedure
### Training data
SigLIP is pre-trained on the WebLI dataset [(Chen et al., 2023)](https://arxiv.org/abs/2209.06794).
### Preprocessing
Images are resized/rescaled to the same resolution (384x384) and normalized across the RGB channels with mean (0.5, 0.5, 0.5) and standard deviation (0.5, 0.5, 0.5).
Texts are tokenized and padded to the same length (64 tokens).
### Compute
The model was trained on 16 TPU-v4 chips for three days.
## Evaluation results
Evaluation of SigLIP compared to CLIP is shown below (taken from the paper).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/siglip_table.jpeg"
alt="drawing" width="600"/>
### BibTeX entry and citation info
```bibtex
@misc{zhai2023sigmoid,
title={Sigmoid Loss for Language Image Pre-Training},
author={Xiaohua Zhai and Basil Mustafa and Alexander Kolesnikov and Lucas Beyer},
year={2023},
eprint={2303.15343},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
``` |
google-bert/bert-base-multilingual-uncased | google-bert | "2024-02-19T11:06:00Z" | 2,951,611 | 117 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"multilingual",
"af",
"sq",
"ar",
"an",
"hy",
"ast",
"az",
"ba",
"eu",
"bar",
"be",
"bn",
"inc",
"bs",
"br",
"bg",
"my",
"ca",
"ceb",
"ce",
"zh",
"cv",
"hr",
"cs",
"da",
"nl",
"en",
"et",
"fi",
"fr",
"gl",
"ka",
"de",
"el",
"gu",
"ht",
"he",
"hi",
"hu",
"is",
"io",
"id",
"ga",
"it",
"ja",
"jv",
"kn",
"kk",
"ky",
"ko",
"la",
"lv",
"lt",
"roa",
"nds",
"lm",
"mk",
"mg",
"ms",
"ml",
"mr",
"min",
"ne",
"new",
"nb",
"nn",
"oc",
"fa",
"pms",
"pl",
"pt",
"pa",
"ro",
"ru",
"sco",
"sr",
"scn",
"sk",
"sl",
"aze",
"es",
"su",
"sw",
"sv",
"tl",
"tg",
"ta",
"tt",
"te",
"tr",
"uk",
"ud",
"uz",
"vi",
"vo",
"war",
"cy",
"fry",
"pnb",
"yo",
"dataset:wikipedia",
"arxiv:1810.04805",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:04Z" | ---
language:
- multilingual
- af
- sq
- ar
- an
- hy
- ast
- az
- ba
- eu
- bar
- be
- bn
- inc
- bs
- br
- bg
- my
- ca
- ceb
- ce
- zh
- cv
- hr
- cs
- da
- nl
- en
- et
- fi
- fr
- gl
- ka
- de
- el
- gu
- ht
- he
- hi
- hu
- is
- io
- id
- ga
- it
- ja
- jv
- kn
- kk
- ky
- ko
- la
- lv
- lt
- roa
- nds
- lm
- mk
- mg
- ms
- ml
- mr
- min
- ne
- new
- nb
- nn
- oc
- fa
- pms
- pl
- pt
- pa
- ro
- ru
- sco
- sr
- hr
- scn
- sk
- sl
- aze
- es
- su
- sw
- sv
- tl
- tg
- ta
- tt
- te
- tr
- uk
- ud
- uz
- vi
- vo
- war
- cy
- fry
- pnb
- yo
license: apache-2.0
datasets:
- wikipedia
---
# BERT multilingual base model (uncased)
Pretrained model on the top 102 languages with the largest Wikipedia using a masked language modeling (MLM) objective.
It was introduced in [this paper](https://arxiv.org/abs/1810.04805) and first released in
[this repository](https://github.com/google-research/bert). This model is uncased: it does not make a difference
between english and English.
Disclaimer: The team releasing BERT did not write a model card for this model so this model card has been written by
the Hugging Face team.
## Model description
BERT is a transformers model pretrained on a large corpus of multilingual data in a self-supervised fashion. This means
it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of
publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it
was pretrained with two objectives:
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
- Next sentence prediction (NSP): the models concatenates two masked sentences as inputs during pretraining. Sometimes
they correspond to sentences that were next to each other in the original text, sometimes not. The model then has to
predict if the two sentences were following each other or not.
This way, the model learns an inner representation of the languages in the training set that can then be used to
extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a
standard classifier using the features produced by the BERT model as inputs.
## Intended uses & limitations
You can use the raw model for either masked language modeling or next sentence prediction, but it's mostly intended to
be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?filter=bert) to look for
fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked)
to make decisions, such as sequence classification, token classification or question answering. For tasks such as text
generation you should look at model like GPT2.
### How to use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='bert-base-multilingual-uncased')
>>> unmasker("Hello I'm a [MASK] model.")
[{'sequence': "[CLS] hello i'm a top model. [SEP]",
'score': 0.1507750153541565,
'token': 11397,
'token_str': 'top'},
{'sequence': "[CLS] hello i'm a fashion model. [SEP]",
'score': 0.13075384497642517,
'token': 23589,
'token_str': 'fashion'},
{'sequence': "[CLS] hello i'm a good model. [SEP]",
'score': 0.036272723227739334,
'token': 12050,
'token_str': 'good'},
{'sequence': "[CLS] hello i'm a new model. [SEP]",
'score': 0.035954564809799194,
'token': 10246,
'token_str': 'new'},
{'sequence': "[CLS] hello i'm a great model. [SEP]",
'score': 0.028643041849136353,
'token': 11838,
'token_str': 'great'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-uncased')
model = BertModel.from_pretrained("bert-base-multilingual-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-multilingual-uncased')
model = TFBertModel.from_pretrained("bert-base-multilingual-uncased")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
### Limitations and bias
Even if the training data used for this model could be characterized as fairly neutral, this model can have biased
predictions:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='bert-base-multilingual-uncased')
>>> unmasker("The man worked as a [MASK].")
[{'sequence': '[CLS] the man worked as a teacher. [SEP]',
'score': 0.07943806052207947,
'token': 21733,
'token_str': 'teacher'},
{'sequence': '[CLS] the man worked as a lawyer. [SEP]',
'score': 0.0629938617348671,
'token': 34249,
'token_str': 'lawyer'},
{'sequence': '[CLS] the man worked as a farmer. [SEP]',
'score': 0.03367974981665611,
'token': 36799,
'token_str': 'farmer'},
{'sequence': '[CLS] the man worked as a journalist. [SEP]',
'score': 0.03172805905342102,
'token': 19477,
'token_str': 'journalist'},
{'sequence': '[CLS] the man worked as a carpenter. [SEP]',
'score': 0.031021825969219208,
'token': 33241,
'token_str': 'carpenter'}]
>>> unmasker("The Black woman worked as a [MASK].")
[{'sequence': '[CLS] the black woman worked as a nurse. [SEP]',
'score': 0.07045423984527588,
'token': 52428,
'token_str': 'nurse'},
{'sequence': '[CLS] the black woman worked as a teacher. [SEP]',
'score': 0.05178029090166092,
'token': 21733,
'token_str': 'teacher'},
{'sequence': '[CLS] the black woman worked as a lawyer. [SEP]',
'score': 0.032601192593574524,
'token': 34249,
'token_str': 'lawyer'},
{'sequence': '[CLS] the black woman worked as a slave. [SEP]',
'score': 0.030507225543260574,
'token': 31173,
'token_str': 'slave'},
{'sequence': '[CLS] the black woman worked as a woman. [SEP]',
'score': 0.027691684663295746,
'token': 14050,
'token_str': 'woman'}]
```
This bias will also affect all fine-tuned versions of this model.
## Training data
The BERT model was pretrained on the 102 languages with the largest Wikipedias. You can find the complete list
[here](https://github.com/google-research/bert/blob/master/multilingual.md#list-of-languages).
## Training procedure
### Preprocessing
The texts are lowercased and tokenized using WordPiece and a shared vocabulary size of 110,000. The languages with a
larger Wikipedia are under-sampled and the ones with lower resources are oversampled. For languages like Chinese,
Japanese Kanji and Korean Hanja that don't have space, a CJK Unicode block is added around every character.
The inputs of the model are then of the form:
```
[CLS] Sentence A [SEP] Sentence B [SEP]
```
With probability 0.5, sentence A and sentence B correspond to two consecutive sentences in the original corpus and in
the other cases, it's another random sentence in the corpus. Note that what is considered a sentence here is a
consecutive span of text usually longer than a single sentence. The only constrain is that the result with the two
"sentences" has a combined length of less than 512 tokens.
The details of the masking procedure for each sentence are the following:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `[MASK]`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1810-04805,
author = {Jacob Devlin and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {{BERT:} Pre-training of Deep Bidirectional Transformers for Language
Understanding},
journal = {CoRR},
volume = {abs/1810.04805},
year = {2018},
url = {http://arxiv.org/abs/1810.04805},
archivePrefix = {arXiv},
eprint = {1810.04805},
timestamp = {Tue, 30 Oct 2018 20:39:56 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1810-04805.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
charactr/vocos-mel-24khz | charactr | "2023-10-17T14:08:53Z" | 2,949,384 | 18 | null | [
"pytorch",
"arxiv:2306.00814",
"license:mit",
"region:us"
] | null | "2023-06-11T16:38:37Z" | ---
license: mit
---
# Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis
[Audio samples](https://charactr-platform.github.io/vocos/) |
Paper [[abs]](https://arxiv.org/abs/2306.00814) [[pdf]](https://arxiv.org/pdf/2306.00814.pdf)
Vocos is a fast neural vocoder designed to synthesize audio waveforms from acoustic features. Trained using a Generative
Adversarial Network (GAN) objective, Vocos can generate waveforms in a single forward pass. Unlike other typical
GAN-based vocoders, Vocos does not model audio samples in the time domain. Instead, it generates spectral
coefficients, facilitating rapid audio reconstruction through inverse Fourier transform.
## Installation
To use Vocos only in inference mode, install it using:
```bash
pip install vocos
```
If you wish to train the model, install it with additional dependencies:
```bash
pip install vocos[train]
```
## Usage
### Reconstruct audio from mel-spectrogram
```python
import torch
from vocos import Vocos
vocos = Vocos.from_pretrained("charactr/vocos-mel-24khz")
mel = torch.randn(1, 100, 256) # B, C, T
audio = vocos.decode(mel)
```
Copy-synthesis from a file:
```python
import torchaudio
y, sr = torchaudio.load(YOUR_AUDIO_FILE)
if y.size(0) > 1: # mix to mono
y = y.mean(dim=0, keepdim=True)
y = torchaudio.functional.resample(y, orig_freq=sr, new_freq=24000)
y_hat = vocos(y)
```
## Citation
If this code contributes to your research, please cite our work:
```
@article{siuzdak2023vocos,
title={Vocos: Closing the gap between time-domain and Fourier-based neural vocoders for high-quality audio synthesis},
author={Siuzdak, Hubert},
journal={arXiv preprint arXiv:2306.00814},
year={2023}
}
```
## License
The code in this repository is released under the MIT license. |
trl-internal-testing/tiny-Qwen2ForCausalLM-2.5 | trl-internal-testing | "2024-11-25T15:06:18Z" | 2,874,576 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"trl",
"conversational",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | "2024-11-25T15:06:15Z" | ---
library_name: transformers
tags:
- trl
---
# Tiny Qwen2ForCausalLM
This is a minimal model built for unit tests in the [TRL](https://github.com/huggingface/trl) library.
|
stabilityai/stable-diffusion-xl-base-1.0 | stabilityai | "2023-10-30T16:03:47Z" | 2,803,847 | 6,272 | diffusers | [
"diffusers",
"onnx",
"safetensors",
"text-to-image",
"stable-diffusion",
"arxiv:2307.01952",
"arxiv:2211.01324",
"arxiv:2108.01073",
"arxiv:2112.10752",
"license:openrail++",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | "2023-07-25T13:25:51Z" | ---
license: openrail++
tags:
- text-to-image
- stable-diffusion
---
# SD-XL 1.0-base Model Card

## Model

[SDXL](https://arxiv.org/abs/2307.01952) consists of an [ensemble of experts](https://arxiv.org/abs/2211.01324) pipeline for latent diffusion:
In a first step, the base model is used to generate (noisy) latents,
which are then further processed with a refinement model (available here: https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-1.0/) specialized for the final denoising steps.
Note that the base model can be used as a standalone module.
Alternatively, we can use a two-stage pipeline as follows:
First, the base model is used to generate latents of the desired output size.
In the second step, we use a specialized high-resolution model and apply a technique called SDEdit (https://arxiv.org/abs/2108.01073, also known as "img2img")
to the latents generated in the first step, using the same prompt. This technique is slightly slower than the first one, as it requires more function evaluations.
Source code is available at https://github.com/Stability-AI/generative-models .
### Model Description
- **Developed by:** Stability AI
- **Model type:** Diffusion-based text-to-image generative model
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/LICENSE.md)
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts. It is a [Latent Diffusion Model](https://arxiv.org/abs/2112.10752) that uses two fixed, pretrained text encoders ([OpenCLIP-ViT/G](https://github.com/mlfoundations/open_clip) and [CLIP-ViT/L](https://github.com/openai/CLIP/tree/main)).
- **Resources for more information:** Check out our [GitHub Repository](https://github.com/Stability-AI/generative-models) and the [SDXL report on arXiv](https://arxiv.org/abs/2307.01952).
### Model Sources
For research purposes, we recommend our `generative-models` Github repository (https://github.com/Stability-AI/generative-models), which implements the most popular diffusion frameworks (both training and inference) and for which new functionalities like distillation will be added over time.
[Clipdrop](https://clipdrop.co/stable-diffusion) provides free SDXL inference.
- **Repository:** https://github.com/Stability-AI/generative-models
- **Demo:** https://clipdrop.co/stable-diffusion
## Evaluation

The chart above evaluates user preference for SDXL (with and without refinement) over SDXL 0.9 and Stable Diffusion 1.5 and 2.1.
The SDXL base model performs significantly better than the previous variants, and the model combined with the refinement module achieves the best overall performance.
### 🧨 Diffusers
Make sure to upgrade diffusers to >= 0.19.0:
```
pip install diffusers --upgrade
```
In addition make sure to install `transformers`, `safetensors`, `accelerate` as well as the invisible watermark:
```
pip install invisible_watermark transformers accelerate safetensors
```
To just use the base model, you can run:
```py
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, use_safetensors=True, variant="fp16")
pipe.to("cuda")
# if using torch < 2.0
# pipe.enable_xformers_memory_efficient_attention()
prompt = "An astronaut riding a green horse"
images = pipe(prompt=prompt).images[0]
```
To use the whole base + refiner pipeline as an ensemble of experts you can run:
```py
from diffusers import DiffusionPipeline
import torch
# load both base & refiner
base = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0", torch_dtype=torch.float16, variant="fp16", use_safetensors=True
)
base.to("cuda")
refiner = DiffusionPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-refiner-1.0",
text_encoder_2=base.text_encoder_2,
vae=base.vae,
torch_dtype=torch.float16,
use_safetensors=True,
variant="fp16",
)
refiner.to("cuda")
# Define how many steps and what % of steps to be run on each experts (80/20) here
n_steps = 40
high_noise_frac = 0.8
prompt = "A majestic lion jumping from a big stone at night"
# run both experts
image = base(
prompt=prompt,
num_inference_steps=n_steps,
denoising_end=high_noise_frac,
output_type="latent",
).images
image = refiner(
prompt=prompt,
num_inference_steps=n_steps,
denoising_start=high_noise_frac,
image=image,
).images[0]
```
When using `torch >= 2.0`, you can improve the inference speed by 20-30% with torch.compile. Simple wrap the unet with torch compile before running the pipeline:
```py
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
```
If you are limited by GPU VRAM, you can enable *cpu offloading* by calling `pipe.enable_model_cpu_offload`
instead of `.to("cuda")`:
```diff
- pipe.to("cuda")
+ pipe.enable_model_cpu_offload()
```
For more information on how to use Stable Diffusion XL with `diffusers`, please have a look at [the Stable Diffusion XL Docs](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/stable_diffusion_xl).
### Optimum
[Optimum](https://github.com/huggingface/optimum) provides a Stable Diffusion pipeline compatible with both [OpenVINO](https://docs.openvino.ai/latest/index.html) and [ONNX Runtime](https://onnxruntime.ai/).
#### OpenVINO
To install Optimum with the dependencies required for OpenVINO :
```bash
pip install optimum[openvino]
```
To load an OpenVINO model and run inference with OpenVINO Runtime, you need to replace `StableDiffusionXLPipeline` with Optimum `OVStableDiffusionXLPipeline`. In case you want to load a PyTorch model and convert it to the OpenVINO format on-the-fly, you can set `export=True`.
```diff
- from diffusers import StableDiffusionXLPipeline
+ from optimum.intel import OVStableDiffusionXLPipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
- pipeline = StableDiffusionXLPipeline.from_pretrained(model_id)
+ pipeline = OVStableDiffusionXLPipeline.from_pretrained(model_id)
prompt = "A majestic lion jumping from a big stone at night"
image = pipeline(prompt).images[0]
```
You can find more examples (such as static reshaping and model compilation) in optimum [documentation](https://huggingface.co/docs/optimum/main/en/intel/inference#stable-diffusion-xl).
#### ONNX
To install Optimum with the dependencies required for ONNX Runtime inference :
```bash
pip install optimum[onnxruntime]
```
To load an ONNX model and run inference with ONNX Runtime, you need to replace `StableDiffusionXLPipeline` with Optimum `ORTStableDiffusionXLPipeline`. In case you want to load a PyTorch model and convert it to the ONNX format on-the-fly, you can set `export=True`.
```diff
- from diffusers import StableDiffusionXLPipeline
+ from optimum.onnxruntime import ORTStableDiffusionXLPipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
- pipeline = StableDiffusionXLPipeline.from_pretrained(model_id)
+ pipeline = ORTStableDiffusionXLPipeline.from_pretrained(model_id)
prompt = "A majestic lion jumping from a big stone at night"
image = pipeline(prompt).images[0]
```
You can find more examples in optimum [documentation](https://huggingface.co/docs/optimum/main/en/onnxruntime/usage_guides/models#stable-diffusion-xl).
## Uses
### Direct Use
The model is intended for research purposes only. Possible research areas and tasks include
- Generation of artworks and use in design and other artistic processes.
- Applications in educational or creative tools.
- Research on generative models.
- Safe deployment of models which have the potential to generate harmful content.
- Probing and understanding the limitations and biases of generative models.
Excluded uses are described below.
### Out-of-Scope Use
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
## Limitations and Bias
### Limitations
- The model does not achieve perfect photorealism
- The model cannot render legible text
- The model struggles with more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
- Faces and people in general may not be generated properly.
- The autoencoding part of the model is lossy.
### Bias
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
|
jonatasgrosman/wav2vec2-large-xlsr-53-japanese | jonatasgrosman | "2022-12-14T01:58:09Z" | 2,776,260 | 29 | transformers | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"ja",
"dataset:common_voice",
"doi:10.57967/hf/3568",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-03-02T23:29:05Z" | ---
language: ja
datasets:
- common_voice
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Japanese by Jonatas Grosman
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice ja
type: common_voice
args: ja
metrics:
- name: Test WER
type: wer
value: 81.80
- name: Test CER
type: cer
value: 20.16
---
# Fine-tuned XLSR-53 large model for speech recognition in Japanese
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Japanese using the train and validation splits of [Common Voice 6.1](https://huggingface.co/datasets/common_voice), [CSS10](https://github.com/Kyubyong/css10) and [JSUT](https://sites.google.com/site/shinnosuketakamichi/publication/jsut).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
The script used for training can be found here: https://github.com/jonatasgrosman/wav2vec2-sprint
## Usage
The model can be used directly (without a language model) as follows...
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-large-xlsr-53-japanese")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "ja"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-japanese"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
for i, predicted_sentence in enumerate(predicted_sentences):
print("-" * 100)
print("Reference:", test_dataset[i]["sentence"])
print("Prediction:", predicted_sentence)
```
| Reference | Prediction |
| ------------- | ------------- |
| 祖母は、おおむね機嫌よく、サイコロをころがしている。 | 人母は重にきね起くさいがしている |
| 財布をなくしたので、交番へ行きます。 | 財布をなく手端ので勾番へ行きます |
| 飲み屋のおやじ、旅館の主人、医者をはじめ、交際のある人にきいてまわったら、みんな、私より収入が多いはずなのに、税金は安い。 | ノ宮屋のお親じ旅館の主に医者をはじめ交際のアル人トに聞いて回ったらみんな私より収入が多いはなうに税金は安い |
| 新しい靴をはいて出かけます。 | だらしい靴をはいて出かけます |
| このためプラズマ中のイオンや電子の持つ平均運動エネルギーを温度で表現することがある | このためプラズマ中のイオンや電子の持つ平均運動エネルギーを温度で表弁することがある |
| 松井さんはサッカーより野球のほうが上手です。 | 松井さんはサッカーより野球のほうが上手です |
| 新しいお皿を使います。 | 新しいお皿を使います |
| 結婚以来三年半ぶりの東京も、旧友とのお酒も、夜行列車も、駅で寝て、朝を待つのも久しぶりだ。 | 結婚ル二来三年半降りの東京も吸とのお酒も野越者も駅で寝て朝を待つの久しぶりた |
| これまで、少年野球、ママさんバレーなど、地域スポーツを支え、市民に密着してきたのは、無数のボランティアだった。 | これまで少年野球<unk>三バレーなど地域スポーツを支え市民に満着してきたのは娘数のボランティアだった |
| 靴を脱いで、スリッパをはきます。 | 靴を脱いでスイパーをはきます |
## Evaluation
The model can be evaluated as follows on the Japanese test data of Common Voice.
```python
import torch
import re
import librosa
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "ja"
MODEL_ID = "jonatasgrosman/wav2vec2-large-xlsr-53-japanese"
DEVICE = "cuda"
CHARS_TO_IGNORE = [",", "?", "¿", ".", "!", "¡", ";", ";", ":", '""', "%", '"', "�", "ʿ", "·", "჻", "~", "՞",
"؟", "،", "।", "॥", "«", "»", "„", "“", "”", "「", "」", "‘", "’", "《", "》", "(", ")", "[", "]",
"{", "}", "=", "`", "_", "+", "<", ">", "…", "–", "°", "´", "ʾ", "‹", "›", "©", "®", "—", "→", "。",
"、", "﹂", "﹁", "‧", "~", "﹏", ",", "{", "}", "(", ")", "[", "]", "【", "】", "‥", "〽",
"『", "』", "〝", "〟", "⟨", "⟩", "〜", ":", "!", "?", "♪", "؛", "/", "\\", "º", "−", "^", "'", "ʻ", "ˆ"]
test_dataset = load_dataset("common_voice", LANG_ID, split="test")
wer = load_metric("wer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/wer.py
cer = load_metric("cer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/cer.py
chars_to_ignore_regex = f"[{re.escape(''.join(CHARS_TO_IGNORE))}]"
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
model.to(DEVICE)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = re.sub(chars_to_ignore_regex, "", batch["sentence"]).upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to(DEVICE), attention_mask=inputs.attention_mask.to(DEVICE)).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
predictions = [x.upper() for x in result["pred_strings"]]
references = [x.upper() for x in result["sentence"]]
print(f"WER: {wer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
print(f"CER: {cer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
```
**Test Result**:
In the table below I report the Word Error Rate (WER) and the Character Error Rate (CER) of the model. I ran the evaluation script described above on other models as well (on 2021-05-10). Note that the table below may show different results from those already reported, this may have been caused due to some specificity of the other evaluation scripts used.
| Model | WER | CER |
| ------------- | ------------- | ------------- |
| jonatasgrosman/wav2vec2-large-xlsr-53-japanese | **81.80%** | **20.16%** |
| vumichien/wav2vec2-large-xlsr-japanese | 1108.86% | 23.40% |
| qqhann/w2v_hf_jsut_xlsr53 | 1012.18% | 70.77% |
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021xlsr53-large-japanese,
title={Fine-tuned {XLSR}-53 large model for speech recognition in {J}apanese},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-japanese}},
year={2021}
}
``` |
amazon/chronos-bolt-small | amazon | "2024-11-28T15:07:04Z" | 2,726,634 | 7 | null | [
"safetensors",
"t5",
"time series",
"forecasting",
"pretrained models",
"foundation models",
"time series foundation models",
"time-series",
"time-series-forecasting",
"arxiv:1910.10683",
"arxiv:2403.07815",
"license:apache-2.0",
"region:us"
] | time-series-forecasting | "2024-11-25T09:46:10Z" | ---
license: apache-2.0
pipeline_tag: time-series-forecasting
tags:
- time series
- forecasting
- pretrained models
- foundation models
- time series foundation models
- time-series
---
# Chronos-Bolt⚡ (Small)
Chronos-Bolt is a family of pretrained time series forecasting models which can be used for zero-shot forecasting. It is based on the [T5 encoder-decoder architecture](https://arxiv.org/abs/1910.10683) and has been trained on nearly 100 billion time series observations. It chunks the historical time series context into patches of multiple observations, which are then input into the encoder. The decoder then uses these representations to directly generate quantile forecasts across multiple future steps—a method known as direct multi-step forecasting. Chronos-Bolt models are up to 250 times faster and 20 times more memory-efficient than the [original Chronos](https://arxiv.org/abs/2403.07815) models of the same size.
The following plot compares the inference time of Chronos-Bolt against the original Chronos models for forecasting 1024 time series with a context length of 512 observations and a prediction horizon of 64 steps.
<center>
<img src="https://autogluon.s3.amazonaws.com/images/chronos_bolt_speed.svg" width="50%"/>
</center>
Chronos-Bolt models are not only significantly faster but also more accurate than the original Chronos models. The following plot reports the probabilistic and point forecasting performance of Chronos-Bolt in terms of the [Weighted Quantile Loss (WQL)](https://auto.gluon.ai/stable/tutorials/timeseries/forecasting-metrics.html#autogluon.timeseries.metrics.WQL) and the [Mean Absolute Scaled Error (MASE)](https://auto.gluon.ai/stable/tutorials/timeseries/forecasting-metrics.html#autogluon.timeseries.metrics.MASE), respectively, aggregated over 27 datasets (see the [Chronos paper](https://arxiv.org/abs/2403.07815) for details on this benchmark). Remarkably, despite having no prior exposure to these datasets during training, the zero-shot Chronos-Bolt models outperform commonly used statistical models and deep learning models that have been trained on these datasets (highlighted by *). Furthermore, they also perform better than other FMs, denoted by a +, which indicates that these models were pretrained on certain datasets in our benchmark and are not entirely zero-shot. Notably, Chronos-Bolt (Base) also surpasses the original Chronos (Large) model in terms of the forecasting accuracy while being over 600 times faster.
<center>
<img src="https://autogluon.s3.amazonaws.com/images/chronos_bolt_accuracy.svg" width="80%"/>
</center>
Chronos-Bolt models are available in the following sizes.
<div align="center">
| Model | Parameters | Based on |
| ----------------------------------------------------------------------------- | ---------- | ---------------------------------------------------------------------- |
| [**chronos-bolt-tiny**](https://huggingface.co/amazon/chronos-bolt-tiny) | 9M | [t5-efficient-tiny](https://huggingface.co/google/t5-efficient-tiny) |
| [**chronos-bolt-mini**](https://huggingface.co/amazon/chronos-bolt-mini) | 21M | [t5-efficient-mini](https://huggingface.co/google/t5-efficient-mini) |
| [**chronos-bolt-small**](https://huggingface.co/amazon/chronos-bolt-small) | 48M | [t5-efficient-small](https://huggingface.co/google/t5-efficient-small) |
| [**chronos-bolt-base**](https://huggingface.co/amazon/chronos-bolt-base) | 205M | [t5-efficient-base](https://huggingface.co/google/t5-efficient-base) |
</div>
## Usage with AutoGluon
The recommended way of using Chronos for production use cases is through [AutoGluon](https://auto.gluon.ai/stable/index.html), which features effortless fine-tuning, augmenting Chronos models with exogenous information through covariate regressors, ensembling with other statistical and machine learning models, as well as seamless deployments on AWS with SageMaker.
Check out the AutoGluon Chronos [tutorial](https://auto.gluon.ai/stable/tutorials/timeseries/forecasting-chronos.html).
A minimal example showing how to perform zero-shot inference using Chronos-Bolt with AutoGluon:
```
pip install autogluon
```
```python
from autogluon.timeseries import TimeSeriesPredictor, TimeSeriesDataFrame
df = TimeSeriesDataFrame("https://autogluon.s3.amazonaws.com/datasets/timeseries/m4_hourly/train.csv")
predictor = TimeSeriesPredictor(prediction_length=48).fit(
df,
hyperparameters={
"Chronos": {"model_path": "amazon/chronos-bolt-small"},
},
)
predictions = predictor.predict(df)
```
## Usage with inference library
Alternatively, you can install the package in the GitHub [companion repo](https://github.com/amazon-science/chronos-forecasting).
This is intended for research purposes and provides a minimal interface to Chronos models.
Install the library by running:
```
pip install chronos-forecasting
```
A minimal example showing how to perform inference using Chronos-Bolt models:
```python
import pandas as pd # requires: pip install pandas
import torch
from chronos import BaseChronosPipeline
pipeline = BaseChronosPipeline.from_pretrained(
"amazon/chronos-bolt-small",
device_map="cuda", # use "cpu" for CPU inference and "mps" for Apple Silicon
torch_dtype=torch.bfloat16,
)
df = pd.read_csv(
"https://raw.githubusercontent.com/AileenNielsen/TimeSeriesAnalysisWithPython/master/data/AirPassengers.csv"
)
# context must be either a 1D tensor, a list of 1D tensors,
# or a left-padded 2D tensor with batch as the first dimension
# Chronos-Bolt models generate quantile forecasts, so forecast has shape
# [num_series, num_quantiles, prediction_length].
forecast = pipeline.predict(
context=torch.tensor(df["#Passengers"]), prediction_length=12
)
```
## Citation
If you find Chronos or Chronos-Bolt models useful for your research, please consider citing the associated [paper](https://arxiv.org/abs/2403.07815):
```
@article{ansari2024chronos,
title={Chronos: Learning the Language of Time Series},
author={Ansari, Abdul Fatir and Stella, Lorenzo and Turkmen, Caner and Zhang, Xiyuan, and Mercado, Pedro and Shen, Huibin and Shchur, Oleksandr and Rangapuram, Syama Syndar and Pineda Arango, Sebastian and Kapoor, Shubham and Zschiegner, Jasper and Maddix, Danielle C. and Mahoney, Michael W. and Torkkola, Kari and Gordon Wilson, Andrew and Bohlke-Schneider, Michael and Wang, Yuyang},
journal={Transactions on Machine Learning Research},
issn={2835-8856},
year={2024},
url={https://openreview.net/forum?id=gerNCVqqtR}
}
```
## License
This project is licensed under the Apache-2.0 License.
|
facebook/bart-base | facebook | "2022-11-16T23:23:10Z" | 2,723,774 | 176 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bart",
"feature-extraction",
"en",
"arxiv:1910.13461",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | feature-extraction | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
language: en
---
# BART (base-sized model)
BART model pre-trained on English language. It was introduced in the paper [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Lewis et al. and first released in [this repository](https://github.com/pytorch/fairseq/tree/master/examples/bart).
Disclaimer: The team releasing BART did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
BART is a transformer encoder-decoder (seq2seq) model with a bidirectional (BERT-like) encoder and an autoregressive (GPT-like) decoder. BART is pre-trained by (1) corrupting text with an arbitrary noising function, and (2) learning a model to reconstruct the original text.
BART is particularly effective when fine-tuned for text generation (e.g. summarization, translation) but also works well for comprehension tasks (e.g. text classification, question answering).
## Intended uses & limitations
You can use the raw model for text infilling. However, the model is mostly meant to be fine-tuned on a supervised dataset. See the [model hub](https://huggingface.co/models?search=bart) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import BartTokenizer, BartModel
tokenizer = BartTokenizer.from_pretrained('facebook/bart-base')
model = BartModel.from_pretrained('facebook/bart-base')
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-1910-13461,
author = {Mike Lewis and
Yinhan Liu and
Naman Goyal and
Marjan Ghazvininejad and
Abdelrahman Mohamed and
Omer Levy and
Veselin Stoyanov and
Luke Zettlemoyer},
title = {{BART:} Denoising Sequence-to-Sequence Pre-training for Natural Language
Generation, Translation, and Comprehension},
journal = {CoRR},
volume = {abs/1910.13461},
year = {2019},
url = {http://arxiv.org/abs/1910.13461},
eprinttype = {arXiv},
eprint = {1910.13461},
timestamp = {Thu, 31 Oct 2019 14:02:26 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1910-13461.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
MahmoudAshraf/mms-300m-1130-forced-aligner | MahmoudAshraf | "2024-09-28T17:05:59Z" | 2,668,546 | 38 | transformers | [
"transformers",
"pytorch",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"mms",
"audio",
"voice",
"speech",
"forced-alignment",
"ab",
"af",
"ak",
"am",
"ar",
"as",
"av",
"ay",
"az",
"ba",
"bm",
"be",
"bn",
"bi",
"bo",
"sh",
"br",
"bg",
"ca",
"cs",
"ce",
"cv",
"ku",
"cy",
"da",
"de",
"dv",
"dz",
"el",
"en",
"eo",
"et",
"eu",
"ee",
"fo",
"fa",
"fj",
"fi",
"fr",
"fy",
"ff",
"ga",
"gl",
"gn",
"gu",
"zh",
"ht",
"ha",
"he",
"hi",
"hu",
"hy",
"ig",
"ia",
"ms",
"is",
"it",
"jv",
"ja",
"kn",
"ka",
"kk",
"kr",
"km",
"ki",
"rw",
"ky",
"ko",
"kv",
"lo",
"la",
"lv",
"ln",
"lt",
"lb",
"lg",
"mh",
"ml",
"mr",
"mk",
"mg",
"mt",
"mn",
"mi",
"my",
"nl",
"no",
"ne",
"ny",
"oc",
"om",
"or",
"os",
"pa",
"pl",
"pt",
"ps",
"qu",
"ro",
"rn",
"ru",
"sg",
"sk",
"sl",
"sm",
"sn",
"sd",
"so",
"es",
"sq",
"su",
"sv",
"sw",
"ta",
"tt",
"te",
"tg",
"tl",
"th",
"ti",
"ts",
"tr",
"uk",
"vi",
"wo",
"xh",
"yo",
"zu",
"za",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2024-05-02T21:02:39Z" | ---
language:
- ab
- af
- ak
- am
- ar
- as
- av
- ay
- az
- ba
- bm
- be
- bn
- bi
- bo
- sh
- br
- bg
- ca
- cs
- ce
- cv
- ku
- cy
- da
- de
- dv
- dz
- el
- en
- eo
- et
- eu
- ee
- fo
- fa
- fj
- fi
- fr
- fy
- ff
- ga
- gl
- gn
- gu
- zh
- ht
- ha
- he
- hi
- sh
- hu
- hy
- ig
- ia
- ms
- is
- it
- jv
- ja
- kn
- ka
- kk
- kr
- km
- ki
- rw
- ky
- ko
- kv
- lo
- la
- lv
- ln
- lt
- lb
- lg
- mh
- ml
- mr
- ms
- mk
- mg
- mt
- mn
- mi
- my
- zh
- nl
- 'no'
- 'no'
- ne
- ny
- oc
- om
- or
- os
- pa
- pl
- pt
- ms
- ps
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- qu
- ro
- rn
- ru
- sg
- sk
- sl
- sm
- sn
- sd
- so
- es
- sq
- su
- sv
- sw
- ta
- tt
- te
- tg
- tl
- th
- ti
- ts
- tr
- uk
- ms
- vi
- wo
- xh
- ms
- yo
- ms
- zu
- za
license: cc-by-nc-4.0
tags:
- mms
- wav2vec2
- audio
- voice
- speech
- forced-alignment
pipeline_tag: automatic-speech-recognition
---
# Forced Alignment with Hugging Face CTC Models
This Python package provides an efficient way to perform forced alignment between text and audio using Hugging Face's pretrained models. it also features an improved implementation to use much less memory than TorchAudio forced alignment API.
The model checkpoint uploaded here is a conversion from torchaudio to HF Transformers for the MMS-300M checkpoint trained on forced alignment dataset
## Installation
```bash
pip install git+https://github.com/MahmoudAshraf97/ctc-forced-aligner.git
```
## Usage
```python
import torch
from ctc_forced_aligner import (
load_audio,
load_alignment_model,
generate_emissions,
preprocess_text,
get_alignments,
get_spans,
postprocess_results,
)
audio_path = "your/audio/path"
text_path = "your/text/path"
language = "iso" # ISO-639-3 Language code
device = "cuda" if torch.cuda.is_available() else "cpu"
batch_size = 16
alignment_model, alignment_tokenizer = load_alignment_model(
device,
dtype=torch.float16 if device == "cuda" else torch.float32,
)
audio_waveform = load_audio(audio_path, alignment_model.dtype, alignment_model.device)
with open(text_path, "r") as f:
lines = f.readlines()
text = "".join(line for line in lines).replace("\n", " ").strip()
emissions, stride = generate_emissions(
alignment_model, audio_waveform, batch_size=batch_size
)
tokens_starred, text_starred = preprocess_text(
text,
romanize=True,
language=language,
)
segments, scores, blank_token = get_alignments(
emissions,
tokens_starred,
alignment_tokenizer,
)
spans = get_spans(tokens_starred, segments, blank_token)
word_timestamps = postprocess_results(text_starred, spans, stride, scores)
``` |
TheBloke/phi-2-GGUF | TheBloke | "2023-12-18T20:25:44Z" | 2,575,887 | 195 | transformers | [
"transformers",
"gguf",
"phi-msft",
"nlp",
"code",
"text-generation",
"en",
"base_model:microsoft/phi-2",
"base_model:quantized:microsoft/phi-2",
"license:other",
"region:us"
] | text-generation | "2023-12-18T20:22:56Z" | ---
base_model: microsoft/phi-2
inference: false
language:
- en
license: other
license_link: https://huggingface.co/microsoft/phi-2/resolve/main/LICENSE
license_name: microsoft-research-license
model_creator: Microsoft
model_name: Phi 2
model_type: phi-msft
pipeline_tag: text-generation
prompt_template: 'Instruct: {prompt}
Output:
'
quantized_by: TheBloke
tags:
- nlp
- code
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Phi 2 - GGUF
- Model creator: [Microsoft](https://huggingface.co/microsoft)
- Original model: [Phi 2](https://huggingface.co/microsoft/phi-2)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Microsoft's Phi 2](https://huggingface.co/microsoft/phi-2).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/phi-2-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/phi-2-GGUF)
* [Microsoft's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/microsoft/phi-2)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Phi
```
Instruct: {prompt}
Output:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [phi-2.Q2_K.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q2_K.gguf) | Q2_K | 2 | 1.17 GB| 3.67 GB | smallest, significant quality loss - not recommended for most purposes |
| [phi-2.Q3_K_S.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q3_K_S.gguf) | Q3_K_S | 3 | 1.25 GB| 3.75 GB | very small, high quality loss |
| [phi-2.Q3_K_M.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q3_K_M.gguf) | Q3_K_M | 3 | 1.48 GB| 3.98 GB | very small, high quality loss |
| [phi-2.Q4_0.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q4_0.gguf) | Q4_0 | 4 | 1.60 GB| 4.10 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [phi-2.Q3_K_L.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q3_K_L.gguf) | Q3_K_L | 3 | 1.60 GB| 4.10 GB | small, substantial quality loss |
| [phi-2.Q4_K_S.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q4_K_S.gguf) | Q4_K_S | 4 | 1.62 GB| 4.12 GB | small, greater quality loss |
| [phi-2.Q4_K_M.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q4_K_M.gguf) | Q4_K_M | 4 | 1.79 GB| 4.29 GB | medium, balanced quality - recommended |
| [phi-2.Q5_0.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q5_0.gguf) | Q5_0 | 5 | 1.93 GB| 4.43 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [phi-2.Q5_K_S.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q5_K_S.gguf) | Q5_K_S | 5 | 1.93 GB| 4.43 GB | large, low quality loss - recommended |
| [phi-2.Q5_K_M.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q5_K_M.gguf) | Q5_K_M | 5 | 2.07 GB| 4.57 GB | large, very low quality loss - recommended |
| [phi-2.Q6_K.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q6_K.gguf) | Q6_K | 6 | 2.29 GB| 4.79 GB | very large, extremely low quality loss |
| [phi-2.Q8_0.gguf](https://huggingface.co/TheBloke/phi-2-GGUF/blob/main/phi-2.Q8_0.gguf) | Q8_0 | 8 | 2.96 GB| 5.46 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/phi-2-GGUF and below it, a specific filename to download, such as: phi-2.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/phi-2-GGUF phi-2.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/phi-2-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/phi-2-GGUF phi-2.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m phi-2.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Instruct: {prompt}\nOutput:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./phi-2.Q4_K_M.gguf", # Download the model file first
n_ctx=2048, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"Instruct: {prompt}\nOutput:", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./phi-2.Q4_K_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Michael Levine, 阿明, Trailburnt, Nikolai Manek, John Detwiler, Randy H, Will Dee, Sebastain Graf, NimbleBox.ai, Eugene Pentland, Emad Mostaque, Ai Maven, Jim Angel, Jeff Scroggin, Michael Davis, Manuel Alberto Morcote, Stephen Murray, Robert, Justin Joy, Luke @flexchar, Brandon Frisco, Elijah Stavena, S_X, Dan Guido, Undi ., Komninos Chatzipapas, Shadi, theTransient, Lone Striker, Raven Klaugh, jjj, Cap'n Zoog, Michel-Marie MAUDET (LINAGORA), Matthew Berman, David, Fen Risland, Omer Bin Jawed, Luke Pendergrass, Kalila, OG, Erik Bjäreholt, Rooh Singh, Joseph William Delisle, Dan Lewis, TL, John Villwock, AzureBlack, Brad, Pedro Madruga, Caitlyn Gatomon, K, jinyuan sun, Mano Prime, Alex, Jeffrey Morgan, Alicia Loh, Illia Dulskyi, Chadd, transmissions 11, fincy, Rainer Wilmers, ReadyPlayerEmma, knownsqashed, Mandus, biorpg, Deo Leter, Brandon Phillips, SuperWojo, Sean Connelly, Iucharbius, Jack West, Harry Royden McLaughlin, Nicholas, terasurfer, Vitor Caleffi, Duane Dunston, Johann-Peter Hartmann, David Ziegler, Olakabola, Ken Nordquist, Trenton Dambrowitz, Tom X Nguyen, Vadim, Ajan Kanaga, Leonard Tan, Clay Pascal, Alexandros Triantafyllidis, JM33133, Xule, vamX, ya boyyy, subjectnull, Talal Aujan, Alps Aficionado, wassieverse, Ari Malik, James Bentley, Woland, Spencer Kim, Michael Dempsey, Fred von Graf, Elle, zynix, William Richards, Stanislav Ovsiannikov, Edmond Seymore, Jonathan Leane, Martin Kemka, usrbinkat, Enrico Ros
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Microsoft's Phi 2
## Model Summary
Phi-2 is a Transformer with **2.7 billion** parameters. It was trained using the same data sources as [Phi-1.5](https://huggingface.co/microsoft/phi-1.5), augmented with a new data source that consists of various NLP synthetic texts and filtered websites (for safety and educational value). When assessed against benchmarks testing common sense, language understanding, and logical reasoning, Phi-2 showcased a nearly state-of-the-art performance among models with less than 13 billion parameters.
Our model hasn't been fine-tuned through reinforcement learning from human feedback. The intention behind crafting this open-source model is to provide the research community with a non-restricted small model to explore vital safety challenges, such as reducing toxicity, understanding societal biases, enhancing controllability, and more.
## Intended Uses
Phi-2 is intended for research purposes only. Given the nature of the training data, the Phi-2 model is best suited for prompts using the QA format, the chat format, and the code format.
### QA Format:
You can provide the prompt as a standalone question as follows:
```markdown
Write a detailed analogy between mathematics and a lighthouse.
```
where the model generates the text after "." .
To encourage the model to write more concise answers, you can also try the following QA format using "Instruct: \<prompt\>\nOutput:"
```markdown
Instruct: Write a detailed analogy between mathematics and a lighthouse.
Output: Mathematics is like a lighthouse. Just as a lighthouse guides ships safely to shore, mathematics provides a guiding light in the world of numbers and logic. It helps us navigate through complex problems and find solutions. Just as a lighthouse emits a steady beam of light, mathematics provides a consistent framework for reasoning and problem-solving. It illuminates the path to understanding and helps us make sense of the world around us.
```
where the model generates the text after "Output:".
### Chat Format:
```markdown
Alice: I don't know why, I'm struggling to maintain focus while studying. Any suggestions?
Bob: Well, have you tried creating a study schedule and sticking to it?
Alice: Yes, I have, but it doesn't seem to help much.
Bob: Hmm, maybe you should try studying in a quiet environment, like the library.
Alice: ...
```
where the model generates the text after the first "Bob:".
### Code Format:
```python
def print_prime(n):
"""
Print all primes between 1 and n
"""
primes = []
for num in range(2, n+1):
is_prime = True
for i in range(2, int(math.sqrt(num))+1):
if num % i == 0:
is_prime = False
break
if is_prime:
primes.append(num)
print(primes)
```
where the model generates the text after the comments.
**Notes:**
* Phi-2 is intended for research purposes. The model-generated text/code should be treated as a starting point rather than a definitive solution for potential use cases. Users should be cautious when employing these models in their applications.
* Direct adoption for production tasks is out of the scope of this research project. As a result, the Phi-2 model has not been tested to ensure that it performs adequately for any production-level application. Please refer to the limitation sections of this document for more details.
* If you are using `transformers>=4.36.0`, always load the model with `trust_remote_code=True` to prevent side-effects.
## Sample Code
There are four types of execution mode:
1. FP16 / Flash-Attention / CUDA:
```python
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2", torch_dtype="auto", flash_attn=True, flash_rotary=True, fused_dense=True, device_map="cuda", trust_remote_code=True)
```
2. FP16 / CUDA:
```python
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2", torch_dtype="auto", device_map="cuda", trust_remote_code=True)
```
3. FP32 / CUDA:
```python
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2", torch_dtype=torch.float32, device_map="cuda", trust_remote_code=True)
```
4. FP32 / CPU:
```python
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2", torch_dtype=torch.float32, device_map="cpu", trust_remote_code=True)
```
To ensure the maximum compatibility, we recommend using the second execution mode (FP16 / CUDA), as follows:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
torch.set_default_device("cuda")
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-2", torch_dtype="auto", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-2", trust_remote_code=True)
inputs = tokenizer('''def print_prime(n):
"""
Print all primes between 1 and n
"""''', return_tensors="pt", return_attention_mask=False)
outputs = model.generate(**inputs, max_length=200)
text = tokenizer.batch_decode(outputs)[0]
print(text)
```
**Remark:** In the generation function, our model currently does not support beam search (`num_beams > 1`).
Furthermore, in the forward pass of the model, we currently do not support outputting hidden states or attention values, or using custom input embeddings.
## Limitations of Phi-2
* Generate Inaccurate Code and Facts: The model may produce incorrect code snippets and statements. Users should treat these outputs as suggestions or starting points, not as definitive or accurate solutions.
* Limited Scope for code: Majority of Phi-2 training data is based in Python and use common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
* Unreliable Responses to Instruction: The model has not undergone instruction fine-tuning. As a result, it may struggle or fail to adhere to intricate or nuanced instructions provided by users.
* Language Limitations: The model is primarily designed to understand standard English. Informal English, slang, or any other languages might pose challenges to its comprehension, leading to potential misinterpretations or errors in response.
* Potential Societal Biases: Phi-2 is not entirely free from societal biases despite efforts in assuring trainig data safety. There's a possibility it may generate content that mirrors these societal biases, particularly if prompted or instructed to do so. We urge users to be aware of this and to exercise caution and critical thinking when interpreting model outputs.
* Toxicity: Despite being trained with carefully selected data, the model can still produce harmful content if explicitly prompted or instructed to do so. We chose to release the model for research purposes only -- We hope to help the open-source community develop the most effective ways to reduce the toxicity of a model directly after pretraining.
* Verbosity: Phi-2 being a base model often produces irrelevant or extra text and responses following its first answer to user prompts within a single turn. This is due to its training dataset being primarily textbooks, which results in textbook-like responses.
## Training
### Model
* Architecture: a Transformer-based model with next-word prediction objective
* Context length: 2048 tokens
* Dataset size: 250B tokens, combination of NLP synthetic data created by AOAI GPT-3.5 and filtered web data from Falcon RefinedWeb and SlimPajama, which was assessed by AOAI GPT-4.
* Training tokens: 1.4T tokens
* GPUs: 96xA100-80G
* Training time: 14 days
### Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [DeepSpeed](https://github.com/microsoft/DeepSpeed)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
### License
The model is licensed under the [microsoft-research-license](https://huggingface.co/microsoft/phi-2/resolve/main/LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
<!-- original-model-card end -->
|
smallcloudai/Refact-1_6B-fim | smallcloudai | "2023-11-09T07:09:31Z" | 2,493,978 | 130 | transformers | [
"transformers",
"pytorch",
"safetensors",
"gpt_refact",
"text-generation",
"code",
"custom_code",
"en",
"dataset:bigcode/the-stack-dedup",
"dataset:rombodawg/2XUNCENSORED_MegaCodeTraining188k",
"dataset:bigcode/commitpackft",
"arxiv:2108.12409",
"arxiv:1607.06450",
"arxiv:1910.07467",
"arxiv:1911.02150",
"license:bigscience-openrail-m",
"model-index",
"autotrain_compatible",
"region:us"
] | text-generation | "2023-08-29T15:48:36Z" | ---
pipeline_tag: text-generation
inference: true
widget:
- text: 'def print_hello_world():'
example_title: Hello world
group: Python
license: bigscience-openrail-m
pretrain-datasets:
- books
- arxiv
- c4
- falcon-refinedweb
- wiki
- github-issues
- stack_markdown
- self-made dataset of permissive github code
datasets:
- bigcode/the-stack-dedup
- rombodawg/2XUNCENSORED_MegaCodeTraining188k
- bigcode/commitpackft
metrics:
- code_eval
library_name: transformers
tags:
- code
model-index:
- name: Refact-1.6B
results:
- task:
type: text-generation
dataset:
type: openai_humaneval
name: HumanEval
metrics:
- name: pass@1 (T=0.01)
type: pass@1
value: 32.0
verified: false
- name: pass@1 (T=0.2)
type: pass@1
value: 31.5
verified: false
- name: pass@10 (T=0.8)
type: pass@10
value: 53.0
verified: false
- name: pass@100 (T=0.8)
type: pass@100
value: 76.9
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize Python
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 35.8
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize JavaScript
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 31.6
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize Java
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 29.1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize Go
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize C++
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 26.3
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize Rust
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize Average
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests Python
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 18.38
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests JavaScript
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 12.28
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests Java
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 15.12
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests Go
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests C++
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 13.17
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests Rust
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 2.8
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests Average
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs Python
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 26.92
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs JavaScript
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 26.85
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs Java
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 30.76
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs Go
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs C++
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 25.94
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs Rust
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 8.44
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs Average
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain Python
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 26.46
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain JavaScript
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 17.86
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain Java
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 20.94
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain Go
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain C++
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 18.78
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain Rust
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain Average
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: mbpp
name: MBPP
metrics:
- name: pass@1 (T=0.01)
type: pass@1
value: 31.15
verified: false
- task:
type: text-generation
dataset:
type: ds1000
name: DS-1000 (Overall Completion)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 10.1
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (C++)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 21.61
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (C#)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 13.91
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (D)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 9.5
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Go)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 53.57
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Java)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 21.58
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Julia)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 13.75
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (JavaScript)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 26.88
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Lua)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 15.26
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (PHP)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 23.04
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Perl)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 12.1
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Python)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 29.6
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (R)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 13.77
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Ruby)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 12.68
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Racket)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 4.29
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Rust)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 19.54
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Scala)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 18.33
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Bash)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 5.7
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Swift)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 17.68
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (TypeScript)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 25
verified: false
language:
- en
---

# Refact-1.6B
Finally, the model we started training with our [blog post](https://refact.ai/blog/2023/applying-recent-innovations-to-train-model/) is ready 🎉
After fine-tuning on generated data, it beats Replit 3b, Stability Code 3b and many other models. It almost beats
StarCoder ten times the size!
Model | Size | HumanEval pass@1 | HumanEval pass@10 |
----------------------|---------------|--------------------|--------------------|
DeciCoder-1b | 1b | 19.1% | |
<b>Refact-1.6-fim</b> | <b>1.6b</b> | <b>32.0%</b> | <b>53.0%</b> |
StableCode | 3b | 20.2% | 33.8% |
ReplitCode v1 | 3b | 21.9% | |
CodeGen2.5-multi | 7b | 28.4% | 47.5% |
CodeLlama | 7b | 33.5% | 59.6% |
StarCoder | 15b | 33.6% | |
Likely, it's the best model for practical use in your IDE for code completion because it's smart and fast!
You can start using it right now by downloading the
[Refact plugin](https://refact.ai/). You can host the model yourself, too, using the
[open source docker container](https://github.com/smallcloudai/refact).
And it's multi-language (see MultiPL-HumanEval and other metrics below) and it works as a chat (see the section below).
# It Works As a Chat
The primary application of this model is code completion (infill) in multiple programming languages.
But it works as a chat quite well.
HumanEval results using instruction following (chat) format, against models specialized for chat only:
Model | Size | pass@1 | pass@10 |
-----------------------|--------|----------|----------|
<b>Refact-1.6-fim</b> | 1.6b | 38.4% | 55.6% |
StableCode-instruct | 3b | 26.9% | 36.2% |
OctoGeeX | 6b | 44.7% | |
CodeLlama-instruct | 7b | 34.8% | 64.3% |
CodeGen2.5-instruct | 7b | 36.2% | 60.87 |
CodeLlama-instruct | 13b | 42.7% | 71.6% |
StarChat-β | 15b | 33.5% | |
OctoCoder | 15b | 46.2% | |
# Example
Fill-in-the-middle uses special tokens to identify the prefix/middle/suffix part of the input and output:
```python
# pip install -q transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "smallcloudai/Refact-1_6B-fim"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint, trust_remote_code=True).to(device)
prompt = '<fim_prefix>def print_hello_world():\n """<fim_suffix>\n print("Hello world!")<fim_middle>'
inputs = tokenizer.encode(prompt, return_tensors="pt").to(device)
outputs = model.generate(inputs, max_length=100, temperature=0.2)
print("-"*80)
print(tokenizer.decode(outputs[0]))
```
# Chat Format
The same model works as chat (experimental).
```python
prompt_template = "<empty_output>SYSTEM {system}\n" \
"<empty_output>USER {query}\n" \
"<empty_output>ASSISTANT"
prompt = prompt_template.format(system="You are a programming assistant",
query="How do I sort a list in Python?")
```
# Architecture
As described in more detail in the blog post, we used:
- [ALiBi](https://arxiv.org/abs/2108.12409) based attention
- [LayerNorm](https://arxiv.org/abs/1607.06450v1) instead of [RMSNorm](https://arxiv.org/pdf/1910.07467.pdf)
- [Multi Query Attention](https://arxiv.org/abs/1911.02150)
We also used LiON, flash attention, early dropout. It's not that innovative that you can't run it, in fact you can -- see an example below.
# Pretraining
For the base model, we used our own dataset that contains code with permissive licenses only, and open text datasets.
Filtering is the key to success of this model:
- We only used text in English
- Only topics related to computer science
- Applied heavy deduplication
The text to code proportion was 50:50, model trained for 1.2T tokens.
We don't release the base model, because its Fill-in-the-Middle (FIM) capability likes to repeat itself too much, so
its practical use is limited. But if you still want it, write us a message on Discord.
# Finetuning
We tested our hypothesis that chat data should boost base model performance in FIM and
regular left-to-right code completion. We found that just 15% of open
[code](https://huggingface.co/datasets/bigcode/commitpackft)
[instruction-following](https://huggingface.co/datasets/rombodawg/2XUNCENSORED_MegaCodeTraining188k) datasets,
that we filtered for quality, improves almost all metrics.
Additionally, to improve FIM, we observed common failure modes, and prepared a synthetic dataset based on
[The Stack dedup v1.1](https://huggingface.co/datasets/bigcode/the-stack-dedup) to address them.
There is a distribution shift between typical code on the internet, and the code you write in your IDE.
The former is likely finished, so the model tries to come up with a suggestion that makes the code complete.
You are likely to have half-written code as you work on it, there is no single addition that can repair it
fully.
In practice, model needs to have a tendency to stop after a couple of lines are added, and sometimes don't write
anything at all. We found that just giving it empty completions, single line completions, multiline
completions that end with a smaller text indent or at least a newline -- makes it much more usable. This data
was used as the rest 85% of the finetune dataset.
The final model is the result of several attempts to make it work as good as possible for code completion,
and to perform well on a wide range of metrics. The best attempt took 40B tokens.
# Limitations and Bias
The Refact-1.6B model was trained on text in English. But it has seen a lot more languages in
code comments. Its performance on non-English languages is lower, for sure.
# Model Stats
- **Architecture:** LLAMA-like model with multi-query attention
- **Objectives** Fill-in-the-Middle, Chat
- **Tokens context:** 4096
- **Pretraining tokens:** 1.2T
- **Finetuning tokens:** 40B
- **Precision:** bfloat16
- **GPUs** 64 NVidia A5000
- **Training time** 28 days
# License
The model is licensed under the BigScience OpenRAIL-M v1 license agreement
# Citation
If you are using this model, please give a link to this page. |
bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF | bartowski | "2025-01-22T15:19:08Z" | 2,466,309 | 172 | null | [
"gguf",
"text-generation",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"base_model:quantized:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | "2025-01-20T14:02:00Z" | ---
quantized_by: bartowski
pipeline_tag: text-generation
base_model: deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
---
## Llamacpp imatrix Quantizations of DeepSeek-R1-Distill-Qwen-32B
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b4514">b4514</a> for quantization.
Original model: https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
All quants made using imatrix option with dataset from [here](https://gist.github.com/bartowski1182/eb213dccb3571f863da82e99418f81e8)
Run them in [LM Studio](https://lmstudio.ai/)
## Prompt format
```
<|begin▁of▁sentence|>{system_prompt}<|User|>{prompt}<|Assistant|>
```
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Split | Description |
| -------- | ---------- | --------- | ----- | ----------- |
| [DeepSeek-R1-Distill-Qwen-32B-bf16.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/tree/main/DeepSeek-R1-Distill-Qwen-32B-bf16) | bf16 | 65.54GB | true | Full BF16 weights. |
| [DeepSeek-R1-Distill-Qwen-32B-Q8_0.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-Q8_0.gguf) | Q8_0 | 34.82GB | false | Extremely high quality, generally unneeded but max available quant. |
| [DeepSeek-R1-Distill-Qwen-32B-Q6_K_L.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-Q6_K_L.gguf) | Q6_K_L | 27.26GB | false | Uses Q8_0 for embed and output weights. Very high quality, near perfect, *recommended*. |
| [DeepSeek-R1-Distill-Qwen-32B-Q6_K.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-Q6_K.gguf) | Q6_K | 26.89GB | false | Very high quality, near perfect, *recommended*. |
| [DeepSeek-R1-Distill-Qwen-32B-Q5_K_L.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-Q5_K_L.gguf) | Q5_K_L | 23.74GB | false | Uses Q8_0 for embed and output weights. High quality, *recommended*. |
| [DeepSeek-R1-Distill-Qwen-32B-Q5_K_M.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-Q5_K_M.gguf) | Q5_K_M | 23.26GB | false | High quality, *recommended*. |
| [DeepSeek-R1-Distill-Qwen-32B-Q5_K_S.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-Q5_K_S.gguf) | Q5_K_S | 22.64GB | false | High quality, *recommended*. |
| [DeepSeek-R1-Distill-Qwen-32B-Q4_1.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-Q4_1.gguf) | Q4_1 | 20.64GB | false | Legacy format, similar performance to Q4_K_S but with improved tokens/watt on Apple silicon. |
| [DeepSeek-R1-Distill-Qwen-32B-Q4_K_L.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-Q4_K_L.gguf) | Q4_K_L | 20.43GB | false | Uses Q8_0 for embed and output weights. Good quality, *recommended*. |
| [DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf) | Q4_K_M | 19.85GB | false | Good quality, default size for most use cases, *recommended*. |
| [DeepSeek-R1-Distill-Qwen-32B-Q4_K_S.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-Q4_K_S.gguf) | Q4_K_S | 18.78GB | false | Slightly lower quality with more space savings, *recommended*. |
| [DeepSeek-R1-Distill-Qwen-32B-Q4_0.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-Q4_0.gguf) | Q4_0 | 18.71GB | false | Legacy format, offers online repacking for ARM and AVX CPU inference. |
| [DeepSeek-R1-Distill-Qwen-32B-IQ4_NL.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-IQ4_NL.gguf) | IQ4_NL | 18.68GB | false | Similar to IQ4_XS, but slightly larger. Offers online repacking for ARM CPU inference. |
| [DeepSeek-R1-Distill-Qwen-32B-Q3_K_XL.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-Q3_K_XL.gguf) | Q3_K_XL | 17.93GB | false | Uses Q8_0 for embed and output weights. Lower quality but usable, good for low RAM availability. |
| [DeepSeek-R1-Distill-Qwen-32B-IQ4_XS.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-IQ4_XS.gguf) | IQ4_XS | 17.69GB | false | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [DeepSeek-R1-Distill-Qwen-32B-Q3_K_L.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-Q3_K_L.gguf) | Q3_K_L | 17.25GB | false | Lower quality but usable, good for low RAM availability. |
| [DeepSeek-R1-Distill-Qwen-32B-Q3_K_M.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-Q3_K_M.gguf) | Q3_K_M | 15.94GB | false | Low quality. |
| [DeepSeek-R1-Distill-Qwen-32B-IQ3_M.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-IQ3_M.gguf) | IQ3_M | 14.81GB | false | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [DeepSeek-R1-Distill-Qwen-32B-Q3_K_S.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-Q3_K_S.gguf) | Q3_K_S | 14.39GB | false | Low quality, not recommended. |
| [DeepSeek-R1-Distill-Qwen-32B-IQ3_XS.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-IQ3_XS.gguf) | IQ3_XS | 13.71GB | false | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [DeepSeek-R1-Distill-Qwen-32B-Q2_K_L.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-Q2_K_L.gguf) | Q2_K_L | 13.07GB | false | Uses Q8_0 for embed and output weights. Very low quality but surprisingly usable. |
| [DeepSeek-R1-Distill-Qwen-32B-Q2_K.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-Q2_K.gguf) | Q2_K | 12.31GB | false | Very low quality but surprisingly usable. |
| [DeepSeek-R1-Distill-Qwen-32B-IQ2_M.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-IQ2_M.gguf) | IQ2_M | 11.26GB | false | Relatively low quality, uses SOTA techniques to be surprisingly usable. |
| [DeepSeek-R1-Distill-Qwen-32B-IQ2_S.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-IQ2_S.gguf) | IQ2_S | 10.39GB | false | Low quality, uses SOTA techniques to be usable. |
| [DeepSeek-R1-Distill-Qwen-32B-IQ2_XS.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-IQ2_XS.gguf) | IQ2_XS | 9.96GB | false | Low quality, uses SOTA techniques to be usable. |
| [DeepSeek-R1-Distill-Qwen-32B-IQ2_XXS.gguf](https://huggingface.co/bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF/blob/main/DeepSeek-R1-Distill-Qwen-32B-IQ2_XXS.gguf) | IQ2_XXS | 9.03GB | false | Very low quality, uses SOTA techniques to be usable. |
## Embed/output weights
Some of these quants (Q3_K_XL, Q4_K_L etc) are the standard quantization method with the embeddings and output weights quantized to Q8_0 instead of what they would normally default to.
## Downloading using huggingface-cli
<details>
<summary>Click to view download instructions</summary>
First, make sure you have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Then, you can target the specific file you want:
```
huggingface-cli download bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF --include "DeepSeek-R1-Distill-Qwen-32B-Q4_K_M.gguf" --local-dir ./
```
If the model is bigger than 50GB, it will have been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download bartowski/DeepSeek-R1-Distill-Qwen-32B-GGUF --include "DeepSeek-R1-Distill-Qwen-32B-Q8_0/*" --local-dir ./
```
You can either specify a new local-dir (DeepSeek-R1-Distill-Qwen-32B-Q8_0) or download them all in place (./)
</details>
## ARM/AVX information
Previously, you would download Q4_0_4_4/4_8/8_8, and these would have their weights interleaved in memory in order to improve performance on ARM and AVX machines by loading up more data in one pass.
Now, however, there is something called "online repacking" for weights. details in [this PR](https://github.com/ggerganov/llama.cpp/pull/9921). If you use Q4_0 and your hardware would benefit from repacking weights, it will do it automatically on the fly.
As of llama.cpp build [b4282](https://github.com/ggerganov/llama.cpp/releases/tag/b4282) you will not be able to run the Q4_0_X_X files and will instead need to use Q4_0.
Additionally, if you want to get slightly better quality for , you can use IQ4_NL thanks to [this PR](https://github.com/ggerganov/llama.cpp/pull/10541) which will also repack the weights for ARM, though only the 4_4 for now. The loading time may be slower but it will result in an overall speed incrase.
<details>
<summary>Click to view Q4_0_X_X information (deprecated</summary>
I'm keeping this section to show the potential theoretical uplift in performance from using the Q4_0 with online repacking.
<details>
<summary>Click to view benchmarks on an AVX2 system (EPYC7702)</summary>
| model | size | params | backend | threads | test | t/s | % (vs Q4_0) |
| ------------------------------ | ---------: | ---------: | ---------- | ------: | ------------: | -------------------: |-------------: |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | pp512 | 204.03 ± 1.03 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | pp1024 | 282.92 ± 0.19 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | pp2048 | 259.49 ± 0.44 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | tg128 | 39.12 ± 0.27 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | tg256 | 39.31 ± 0.69 | 100% |
| qwen2 3B Q4_0 | 1.70 GiB | 3.09 B | CPU | 64 | tg512 | 40.52 ± 0.03 | 100% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | pp512 | 301.02 ± 1.74 | 147% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | pp1024 | 287.23 ± 0.20 | 101% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | pp2048 | 262.77 ± 1.81 | 101% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | tg128 | 18.80 ± 0.99 | 48% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | tg256 | 24.46 ± 3.04 | 83% |
| qwen2 3B Q4_K_M | 1.79 GiB | 3.09 B | CPU | 64 | tg512 | 36.32 ± 3.59 | 90% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | pp512 | 271.71 ± 3.53 | 133% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | pp1024 | 279.86 ± 45.63 | 100% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | pp2048 | 320.77 ± 5.00 | 124% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | tg128 | 43.51 ± 0.05 | 111% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | tg256 | 43.35 ± 0.09 | 110% |
| qwen2 3B Q4_0_8_8 | 1.69 GiB | 3.09 B | CPU | 64 | tg512 | 42.60 ± 0.31 | 105% |
Q4_0_8_8 offers a nice bump to prompt processing and a small bump to text generation
</details>
</details>
## Which file should I choose?
<details>
<summary>Click here for details</summary>
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
</details>
## Credits
Thank you kalomaze and Dampf for assistance in creating the imatrix calibration dataset.
Thank you ZeroWw for the inspiration to experiment with embed/output.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
google-bert/bert-base-chinese | google-bert | "2024-02-19T11:03:31Z" | 2,447,765 | 1,098 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"zh",
"arxiv:1810.04805",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | "2022-03-02T23:29:04Z" | ---
language: zh
---
# Bert-base-chinese
## Table of Contents
- [Model Details](#model-details)
- [Uses](#uses)
- [Risks, Limitations and Biases](#risks-limitations-and-biases)
- [Training](#training)
- [Evaluation](#evaluation)
- [How to Get Started With the Model](#how-to-get-started-with-the-model)
## Model Details
### Model Description
This model has been pre-trained for Chinese, training and random input masking has been applied independently to word pieces (as in the original BERT paper).
- **Developed by:** HuggingFace team
- **Model Type:** Fill-Mask
- **Language(s):** Chinese
- **License:** [More Information needed]
- **Parent Model:** See the [BERT base uncased model](https://huggingface.co/bert-base-uncased) for more information about the BERT base model.
### Model Sources
- **Paper:** [BERT](https://arxiv.org/abs/1810.04805)
## Uses
#### Direct Use
This model can be used for masked language modeling
## Risks, Limitations and Biases
**CONTENT WARNING: Readers should be aware this section contains content that is disturbing, offensive, and can propagate historical and current stereotypes.**
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
## Training
#### Training Procedure
* **type_vocab_size:** 2
* **vocab_size:** 21128
* **num_hidden_layers:** 12
#### Training Data
[More Information Needed]
## Evaluation
#### Results
[More Information Needed]
## How to Get Started With the Model
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
model = AutoModelForMaskedLM.from_pretrained("bert-base-chinese")
```
|
mrm8488/distilroberta-finetuned-financial-news-sentiment-analysis | mrm8488 | "2024-01-21T15:17:58Z" | 2,433,988 | 367 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"financial",
"stocks",
"sentiment",
"dataset:financial_phrasebank",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | "2022-03-02T23:29:05Z" | ---
license: apache-2.0
thumbnail: https://huggingface.co/mrm8488/distilroberta-finetuned-financial-news-sentiment-analysis/resolve/main/logo_no_bg.png
tags:
- generated_from_trainer
- financial
- stocks
- sentiment
widget:
- text: "Operating profit totaled EUR 9.4 mn , down from EUR 11.7 mn in 2004 ."
datasets:
- financial_phrasebank
metrics:
- accuracy
model-index:
- name: distilRoberta-financial-sentiment
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: financial_phrasebank
type: financial_phrasebank
args: sentences_allagree
metrics:
- name: Accuracy
type: accuracy
value: 0.9823008849557522
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
<div style="text-align:center;width:250px;height:250px;">
<img src="https://huggingface.co/mrm8488/distilroberta-finetuned-financial-news-sentiment-analysis/resolve/main/logo_no_bg.png" alt="logo">
</div>
# DistilRoberta-financial-sentiment
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the financial_phrasebank dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1116
- Accuracy: **0.98**23
## Base Model description
This model is a distilled version of the [RoBERTa-base model](https://huggingface.co/roberta-base). It follows the same training procedure as [DistilBERT](https://huggingface.co/distilbert-base-uncased).
The code for the distillation process can be found [here](https://github.com/huggingface/transformers/tree/master/examples/distillation).
This model is case-sensitive: it makes a difference between English and English.
The model has 6 layers, 768 dimension and 12 heads, totalizing 82M parameters (compared to 125M parameters for RoBERTa-base).
On average DistilRoBERTa is twice as fast as Roberta-base.
## Training Data
Polar sentiment dataset of sentences from financial news. The dataset consists of 4840 sentences from English language financial news categorised by sentiment. The dataset is divided by agreement rate of 5-8 annotators.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 255 | 0.1670 | 0.9646 |
| 0.209 | 2.0 | 510 | 0.2290 | 0.9558 |
| 0.209 | 3.0 | 765 | 0.2044 | 0.9558 |
| 0.0326 | 4.0 | 1020 | 0.1116 | 0.9823 |
| 0.0326 | 5.0 | 1275 | 0.1127 | 0.9779 |
### Framework versions
- Transformers 4.10.2
- Pytorch 1.9.0+cu102
- Datasets 1.12.1
- Tokenizers 0.10.3
|
coqui/XTTS-v2 | coqui | "2023-12-11T17:50:00Z" | 2,428,597 | 2,333 | coqui | [
"coqui",
"text-to-speech",
"license:other",
"region:us"
] | text-to-speech | "2023-10-31T10:11:33Z" | ---
license: other
license_name: coqui-public-model-license
license_link: https://coqui.ai/cpml
library_name: coqui
pipeline_tag: text-to-speech
widget:
- text: "Once when I was six years old I saw a magnificent picture"
---
# ⓍTTS
ⓍTTS is a Voice generation model that lets you clone voices into different languages by using just a quick 6-second audio clip. There is no need for an excessive amount of training data that spans countless hours.
This is the same or similar model to what powers [Coqui Studio](https://coqui.ai/) and [Coqui API](https://docs.coqui.ai/docs).
### Features
- Supports 17 languages.
- Voice cloning with just a 6-second audio clip.
- Emotion and style transfer by cloning.
- Cross-language voice cloning.
- Multi-lingual speech generation.
- 24khz sampling rate.
### Updates over XTTS-v1
- 2 new languages; Hungarian and Korean
- Architectural improvements for speaker conditioning.
- Enables the use of multiple speaker references and interpolation between speakers.
- Stability improvements.
- Better prosody and audio quality across the board.
### Languages
XTTS-v2 supports 17 languages: **English (en), Spanish (es), French (fr), German (de), Italian (it), Portuguese (pt),
Polish (pl), Turkish (tr), Russian (ru), Dutch (nl), Czech (cs), Arabic (ar), Chinese (zh-cn), Japanese (ja), Hungarian (hu), Korean (ko)
Hindi (hi)**.
Stay tuned as we continue to add support for more languages. If you have any language requests, feel free to reach out!
### Code
The [code-base](https://github.com/coqui-ai/TTS) supports inference and [fine-tuning](https://tts.readthedocs.io/en/latest/models/xtts.html#training).
### Demo Spaces
- [XTTS Space](https://huggingface.co/spaces/coqui/xtts) : You can see how model performs on supported languages, and try with your own reference or microphone input
- [XTTS Voice Chat with Mistral or Zephyr](https://huggingface.co/spaces/coqui/voice-chat-with-mistral) : You can experience streaming voice chat with Mistral 7B Instruct or Zephyr 7B Beta
| | |
| ------------------------------- | --------------------------------------- |
| 🐸💬 **CoquiTTS** | [coqui/TTS on Github](https://github.com/coqui-ai/TTS)|
| 💼 **Documentation** | [ReadTheDocs](https://tts.readthedocs.io/en/latest/)
| 👩💻 **Questions** | [GitHub Discussions](https://github.com/coqui-ai/TTS/discussions) |
| 🗯 **Community** | [Discord](https://discord.gg/5eXr5seRrv) |
### License
This model is licensed under [Coqui Public Model License](https://coqui.ai/cpml). There's a lot that goes into a license for generative models, and you can read more of [the origin story of CPML here](https://coqui.ai/blog/tts/cpml).
### Contact
Come and join in our 🐸Community. We're active on [Discord](https://discord.gg/fBC58unbKE) and [Twitter](https://twitter.com/coqui_ai).
You can also mail us at [email protected].
Using 🐸TTS API:
```python
from TTS.api import TTS
tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2", gpu=True)
# generate speech by cloning a voice using default settings
tts.tts_to_file(text="It took me quite a long time to develop a voice, and now that I have it I'm not going to be silent.",
file_path="output.wav",
speaker_wav="/path/to/target/speaker.wav",
language="en")
```
Using 🐸TTS Command line:
```console
tts --model_name tts_models/multilingual/multi-dataset/xtts_v2 \
--text "Bugün okula gitmek istemiyorum." \
--speaker_wav /path/to/target/speaker.wav \
--language_idx tr \
--use_cuda true
```
Using the model directly:
```python
from TTS.tts.configs.xtts_config import XttsConfig
from TTS.tts.models.xtts import Xtts
config = XttsConfig()
config.load_json("/path/to/xtts/config.json")
model = Xtts.init_from_config(config)
model.load_checkpoint(config, checkpoint_dir="/path/to/xtts/", eval=True)
model.cuda()
outputs = model.synthesize(
"It took me quite a long time to develop a voice and now that I have it I am not going to be silent.",
config,
speaker_wav="/data/TTS-public/_refclips/3.wav",
gpt_cond_len=3,
language="en",
)
```
|
facebook/wav2vec2-base-960h | facebook | "2022-11-14T21:37:23Z" | 2,419,470 | 315 | transformers | [
"transformers",
"pytorch",
"tf",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"hf-asr-leaderboard",
"en",
"dataset:librispeech_asr",
"arxiv:2006.11477",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | "2022-03-02T23:29:05Z" | ---
language: en
datasets:
- librispeech_asr
tags:
- audio
- automatic-speech-recognition
- hf-asr-leaderboard
license: apache-2.0
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
model-index:
- name: wav2vec2-base-960h
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (clean)
type: librispeech_asr
config: clean
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 3.4
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (other)
type: librispeech_asr
config: other
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 8.6
---
# Wav2Vec2-Base-960h
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The base model pretrained and fine-tuned on 960 hours of Librispeech on 16kHz sampled speech audio. When using the model
make sure that your speech input is also sampled at 16Khz.
[Paper](https://arxiv.org/abs/2006.11477)
Authors: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
**Abstract**
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech recognition with limited amounts of labeled data.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and tokenizer
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt", padding="longest").input_values # Batch size 1
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
## Evaluation
This code snippet shows how to evaluate **facebook/wav2vec2-base-960h** on LibriSpeech's "clean" and "other" test data.
```python
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import torch
from jiwer import wer
librispeech_eval = load_dataset("librispeech_asr", "clean", split="test")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h").to("cuda")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
def map_to_pred(batch):
input_values = processor(batch["audio"]["array"], return_tensors="pt", padding="longest").input_values
with torch.no_grad():
logits = model(input_values.to("cuda")).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
batch["transcription"] = transcription
return batch
result = librispeech_eval.map(map_to_pred, batched=True, batch_size=1, remove_columns=["audio"])
print("WER:", wer(result["text"], result["transcription"]))
```
*Result (WER)*:
| "clean" | "other" |
|---|---|
| 3.4 | 8.6 | |