__ドキュメント更新中のため記述に誤りがあるかもしれません。__
# 学習について、共通編
当リポジトリではモデルのfine tuning、DreamBooth、およびLoRAとTextual Inversion([XTI:P+](https://github.com/kohya-ss/sd-scripts/pull/327)を含む)の学習をサポートします。この文書ではそれらに共通する、学習データの準備方法やオプション等について説明します。
# 概要
あらかじめこのリポジトリのREADMEを参照し、環境整備を行ってください。
以下について説明します。
1. 学習データの準備について(設定ファイルを用いる新形式)
1. 学習で使われる用語のごく簡単な解説
1. 以前の指定形式(設定ファイルを用いずコマンドラインから指定)
1. 学習途中のサンプル画像生成
1. 各スクリプトで共通の、よく使われるオプション
1. fine tuning 方式のメタデータ準備:キャプションニングなど
1.だけ実行すればとりあえず学習は可能です(学習については各スクリプトのドキュメントを参照)。2.以降は必要に応じて参照してください。
# 学習データの準備について
任意のフォルダ(複数でも可)に学習データの画像ファイルを用意しておきます。`.png`, `.jpg`, `.jpeg`, `.webp`, `.bmp` をサポートします。リサイズなどの前処理は基本的に必要ありません。
ただし学習解像度(後述)よりも極端に小さい画像は使わないか、あらかじめ超解像AIなどで拡大しておくことをお勧めします。また極端に大きな画像(3000x3000ピクセル程度?)よりも大きな画像はエラーになる場合があるようですので事前に縮小してください。
学習時には、モデルに学ばせる画像データを整理し、スクリプトに対して指定する必要があります。学習データの数、学習対象、キャプション(画像の説明)が用意できるか否かなどにより、いくつかの方法で学習データを指定できます。以下の方式があります(それぞれの名前は一般的なものではなく、当リポジトリ独自の定義です)。正則化画像については後述します。
1. DreamBooth、class+identifier方式(正則化画像使用可)
特定の単語 (identifier) に学習対象を紐づけるように学習します。キャプションを用意する必要はありません。たとえば特定のキャラを学ばせる場合に使うとキャプションを用意する必要がない分、手軽ですが、髪型や服装、背景など学習データの全要素が identifier に紐づけられて学習されるため、生成時のプロンプトで服が変えられない、といった事態も起こりえます。
1. DreamBooth、キャプション方式(正則化画像使用可)
画像ごとにキャプションが記録されたテキストファイルを用意して学習します。たとえば特定のキャラを学ばせると、画像の詳細をキャプションに記述することで(白い服を着たキャラA、赤い服を着たキャラA、など)キャラとそれ以外の要素が分離され、より厳密にモデルがキャラだけを学ぶことが期待できます。
1. fine tuning方式(正則化画像使用不可)
あらかじめキャプションをメタデータファイルにまとめます。タグとキャプションを分けて管理したり、学習を高速化するためlatentsを事前キャッシュしたりなどの機能をサポートします(いずれも別文書で説明しています)。(fine tuning方式という名前ですが fine tuning 以外でも使えます。)
学習したいものと使用できる指定方法の組み合わせは以下の通りです。
| 学習対象または方法 | スクリプト | DB / class+identifier | DB / キャプション | fine tuning |
| ----- | ----- | ----- | ----- | ----- |
| モデルをfine tuning | `fine_tune.py`| x | x | o |
| モデルをDreamBooth | `train_db.py`| o | o | x |
| LoRA | `train_network.py`| o | o | o |
| Textual Invesion | `train_textual_inversion.py`| o | o | o |
## どれを選ぶか
LoRA、Textual Inversionについては、手軽にキャプションファイルを用意せずに学習したい場合はDreamBooth class+identifier、用意できるならDreamBooth キャプション方式がよいでしょう。学習データの枚数が多く、かつ正則化画像を使用しない場合はfine tuning方式も検討してください。
DreamBoothについても同様ですが、fine tuning方式は使えません。fine tuningの場合はfine tuning方式のみです。
# 各方式の指定方法について
ここではそれぞれの指定方法で典型的なパターンについてだけ説明します。より詳細な指定方法については [データセット設定](./config_README-ja.md) をご覧ください。
# DreamBooth、class+identifier方式(正則化画像使用可)
この方式では、各画像は `class identifier` というキャプションで学習されたのと同じことになります(`shs dog` など)。
## step 1. identifierとclassを決める
学ばせたい対象を結びつける単語identifierと、対象の属するclassを決めます。
(instanceなどいろいろな呼び方がありますが、とりあえず元の論文に合わせます。)
以下ごく簡単に説明します(詳しくは調べてください)。
classは学習対象の一般的な種別です。たとえば特定の犬種を学ばせる場合には、classはdogになります。アニメキャラならモデルによりboyやgirl、1boyや1girlになるでしょう。
identifierは学習対象を識別して学習するためのものです。任意の単語で構いませんが、元論文によると「tokinizerで1トークンになる3文字以下でレアな単語」が良いとのことです。
identifierとclassを使い、たとえば「shs dog」などでモデルを学習することで、学習させたい対象をclassから識別して学習できます。
画像生成時には「shs dog」とすれば学ばせた犬種の画像が生成されます。
(identifierとして私が最近使っているものを参考までに挙げると、``shs sts scs cpc coc cic msm usu ici lvl cic dii muk ori hru rik koo yos wny`` などです。本当は Danbooru Tag に含まれないやつがより望ましいです。)
## step 2. 正則化画像を使うか否かを決め、使う場合には正則化画像を生成する
正則化画像とは、前述のclass全体が、学習対象に引っ張られることを防ぐための画像です(language drift)。正則化画像を使わないと、たとえば `shs 1girl` で特定のキャラクタを学ばせると、単なる `1girl` というプロンプトで生成してもそのキャラに似てきます。これは `1girl` が学習時のキャプションに含まれているためです。
学習対象の画像と正則化画像を同時に学ばせることで、class は class のままで留まり、identifier をプロンプトにつけた時だけ学習対象が生成されるようになります。
LoRAやDreamBoothで特定のキャラだけ出てくればよい場合は、正則化画像を用いなくても良いといえます。
Textual Inversionでは用いなくてよいでしょう(学ばせる token string がキャプションに含まれない場合はなにも学習されないため)。
正則化画像としては、学習対象のモデルで、class 名だけで生成した画像を用いるのが一般的です(たとえば `1girl`)。ただし生成画像の品質が悪い場合には、プロンプトを工夫したり、ネットから別途ダウンロードした画像を用いることもできます。
(正則化画像も学習されるため、その品質はモデルに影響します。)
一般的には数百枚程度、用意するのが望ましいようです(枚数が少ないと class 画像が一般化されずそれらの特徴を学んでしまいます)。
生成画像を使う場合、通常、生成画像のサイズは学習解像度(より正確にはbucketの解像度、後述)にあわせてください。
## step 2. 設定ファイルの記述
テキストファイルを作成し、拡張子を `.toml` にします。たとえば以下のように記述します。
(`#` で始まっている部分はコメントですので、このままコピペしてそのままでもよいですし、削除しても問題ありません。)
```toml
[general]
enable_bucket = true # Aspect Ratio Bucketingを使うか否か
[[datasets]]
resolution = 512 # 学習解像度
batch_size = 4 # バッチサイズ
[[datasets.subsets]]
image_dir = 'C:\hoge' # 学習用画像を入れたフォルダを指定
class_tokens = 'hoge girl' # identifier class を指定
num_repeats = 10 # 学習用画像の繰り返し回数
# 以下は正則化画像を用いる場合のみ記述する。用いない場合は削除する
[[datasets.subsets]]
is_reg = true
image_dir = 'C:\reg' # 正則化画像を入れたフォルダを指定
class_tokens = 'girl' # class を指定
num_repeats = 1 # 正則化画像の繰り返し回数、基本的には1でよい
```
基本的には以下の場所のみ書き換えれば学習できます。
1. 学習解像度
数値1つを指定すると正方形(`512`なら512x512)、鍵カッコカンマ区切りで2つ指定すると横×縦(`[512,768]`なら512x768)になります。SD1.x系ではもともとの学習解像度は512です。`[512,768]` 等の大きめの解像度を指定すると縦長、横長画像生成時の破綻を小さくできるかもしれません。SD2.x 768系では `768` です。
1. バッチサイズ
同時に何件のデータを学習するかを指定します。GPUのVRAMサイズ、学習解像度によって変わってきます。詳しくは後述します。またfine tuning/DreamBooth/LoRA等でも変わってきますので各スクリプトの説明もご覧ください。
1. フォルダ指定
学習用画像、正則化画像(使用する場合のみ)のフォルダを指定します。画像データが含まれているフォルダそのものを指定します。
1. identifier と class の指定
前述のサンプルの通りです。
1. 繰り返し回数
後述します。
### 繰り返し回数について
繰り返し回数は、正則化画像の枚数と学習用画像の枚数を調整するために用いられます。正則化画像の枚数は学習用画像よりも多いため、学習用画像を繰り返して枚数を合わせ、1対1の比率で学習できるようにします。
繰り返し回数は「 __学習用画像の繰り返し回数×学習用画像の枚数≧正則化画像の繰り返し回数×正則化画像の枚数__ 」となるように指定してください。
(1 epoch(データが一周すると1 epoch)のデータ数が「学習用画像の繰り返し回数×学習用画像の枚数」となります。正則化画像の枚数がそれより多いと、余った部分の正則化画像は使用されません。)
## step 3. 学習
それぞれのドキュメントを参考に学習を行ってください。
# DreamBooth、キャプション方式(正則化画像使用可)
この方式では各画像はキャプションで学習されます。
## step 1. キャプションファイルを準備する
学習用画像のフォルダに、画像と同じファイル名で、拡張子 `.caption`(設定で変えられます)のファイルを置いてください。それぞれのファイルは1行のみとしてください。エンコーディングは `UTF-8` です。
## step 2. 正則化画像を使うか否かを決め、使う場合には正則化画像を生成する
class+identifier形式と同様です。なお正則化画像にもキャプションを付けることができますが、通常は不要でしょう。
## step 2. 設定ファイルの記述
テキストファイルを作成し、拡張子を `.toml` にします。たとえば以下のように記述します。
```toml
[general]
enable_bucket = true # Aspect Ratio Bucketingを使うか否か
[[datasets]]
resolution = 512 # 学習解像度
batch_size = 4 # バッチサイズ
[[datasets.subsets]]
image_dir = 'C:\hoge' # 学習用画像を入れたフォルダを指定
caption_extension = '.caption' # キャプションファイルの拡張子 .txt を使う場合には書き換える
num_repeats = 10 # 学習用画像の繰り返し回数
# 以下は正則化画像を用いる場合のみ記述する。用いない場合は削除する
[[datasets.subsets]]
is_reg = true
image_dir = 'C:\reg' # 正則化画像を入れたフォルダを指定
class_tokens = 'girl' # class を指定
num_repeats = 1 # 正則化画像の繰り返し回数、基本的には1でよい
```
基本的には以下を場所のみ書き換えれば学習できます。特に記述がない部分は class+identifier 方式と同じです。
1. 学習解像度
1. バッチサイズ
1. フォルダ指定
1. キャプションファイルの拡張子
任意の拡張子を指定できます。
1. 繰り返し回数
## step 3. 学習
それぞれのドキュメントを参考に学習を行ってください。
# fine tuning 方式
## step 1. メタデータを準備する
キャプションやタグをまとめた管理用ファイルをメタデータと呼びます。json形式で拡張子は `.json`
です。作成方法は長くなりますのでこの文書の末尾に書きました。
## step 2. 設定ファイルの記述
テキストファイルを作成し、拡張子を `.toml` にします。たとえば以下のように記述します。
```toml
[general]
shuffle_caption = true
keep_tokens = 1
[[datasets]]
resolution = 512 # 学習解像度
batch_size = 4 # バッチサイズ
[[datasets.subsets]]
image_dir = 'C:\piyo' # 学習用画像を入れたフォルダを指定
metadata_file = 'C:\piyo\piyo_md.json' # メタデータファイル名
```
基本的には以下を場所のみ書き換えれば学習できます。特に記述がない部分は DreamBooth, class+identifier 方式と同じです。
1. 学習解像度
1. バッチサイズ
1. フォルダ指定
1. メタデータファイル名
後述の方法で作成したメタデータファイルを指定します。
## step 3. 学習
それぞれのドキュメントを参考に学習を行ってください。
# 学習で使われる用語のごく簡単な解説
細かいことは省略していますし私も完全には理解していないため、詳しくは各自お調べください。
## fine tuning(ファインチューニング)
モデルを学習して微調整することを指します。使われ方によって意味が異なってきますが、狭義のfine tuningはStable Diffusionの場合、モデルを画像とキャプションで学習することです。DreamBoothは狭義のfine tuningのひとつの特殊なやり方と言えます。広義のfine tuningは、LoRAやTextual Inversion、Hypernetworksなどを含み、モデルを学習することすべてを含みます。
## ステップ
ざっくりいうと学習データで1回計算すると1ステップです。「学習データのキャプションを今のモデルに流してみて、出てくる画像を学習データの画像と比較し、学習データに近づくようにモデルをわずかに変更する」のが1ステップです。
## バッチサイズ
バッチサイズは1ステップで何件のデータをまとめて計算するかを指定する値です。まとめて計算するため速度は相対的に向上します。また一般的には精度も高くなるといわれています。
`バッチサイズ×ステップ数` が学習に使われるデータの件数になります。そのため、バッチサイズを増やした分だけステップ数を減らすとよいでしょう。
(ただし、たとえば「バッチサイズ1で1600ステップ」と「バッチサイズ4で400ステップ」は同じ結果にはなりません。同じ学習率の場合、一般的には後者のほうが学習不足になります。学習率を多少大きくするか(たとえば `2e-6` など)、ステップ数をたとえば500ステップにするなどして工夫してください。)
バッチサイズを大きくするとその分だけGPUメモリを消費します。メモリが足りなくなるとエラーになりますし、エラーにならないギリギリでは学習速度が低下します。タスクマネージャーや `nvidia-smi` コマンドで使用メモリ量を確認しながら調整するとよいでしょう。
なお、バッチは「一塊のデータ」位の意味です。
## 学習率
ざっくりいうと1ステップごとにどのくらい変化させるかを表します。大きな値を指定するとそれだけ速く学習が進みますが、変化しすぎてモデルが壊れたり、最適な状態にまで至れない場合があります。小さい値を指定すると学習速度は遅くなり、また最適な状態にやはり至れない場合があります。
fine tuning、DreamBoooth、LoRAそれぞれで大きく異なり、また学習データや学習させたいモデル、バッチサイズやステップ数によっても変わってきます。一般的な値から初めて学習状態を見ながら増減してください。
デフォルトでは学習全体を通して学習率は固定です。スケジューラの指定で学習率をどう変化させるか決められますので、それらによっても結果は変わってきます。
## エポック(epoch)
学習データが一通り学習されると(データが一周すると)1 epochです。繰り返し回数を指定した場合は、その繰り返し後のデータが一周すると1 epochです。
1 epochのステップ数は、基本的には `データ件数÷バッチサイズ` ですが、Aspect Ratio Bucketing を使うと微妙に増えます(異なるbucketのデータは同じバッチにできないため、ステップ数が増えます)。
## Aspect Ratio Bucketing
Stable Diffusion のv1は512\*512で学習されていますが、それに加えて256\*1024や384\*640といった解像度でも学習します。これによりトリミングされる部分が減り、より正しくキャプションと画像の関係が学習されることが期待されます。
また任意の解像度で学習するため、事前に画像データの縦横比を統一しておく必要がなくなります。
設定で有効、無効が切り替えられますが、ここまでの設定ファイルの記述例では有効になっています(`true` が設定されています)。
学習解像度はパラメータとして与えられた解像度の面積(=メモリ使用量)を超えない範囲で、64ピクセル単位(デフォルト、変更可)で縦横に調整、作成されます。
機械学習では入力サイズをすべて統一するのが一般的ですが、特に制約があるわけではなく、実際は同一のバッチ内で統一されていれば大丈夫です。NovelAIの言うbucketingは、あらかじめ教師データを、アスペクト比に応じた学習解像度ごとに分類しておくことを指しているようです。そしてバッチを各bucket内の画像で作成することで、バッチの画像サイズを統一します。
# 以前の指定形式(設定ファイルを用いずコマンドラインから指定)
`.toml` ファイルを指定せずコマンドラインオプションで指定する方法です。DreamBooth class+identifier方式、DreamBooth キャプション方式、fine tuning方式があります。
## DreamBooth、class+identifier方式
フォルダ名で繰り返し回数を指定します。また `train_data_dir` オプションと `reg_data_dir` オプションを用います。
### step 1. 学習用画像の準備
学習用画像を格納するフォルダを作成します。 __さらにその中に__ 、以下の名前でディレクトリを作成します。
```
<繰り返し回数>_<identifier> <class>
```
間の``_``を忘れないでください。
たとえば「sls frog」というプロンプトで、データを20回繰り返す場合、「20_sls frog」となります。以下のようになります。

### 複数class、複数対象(identifier)の学習
方法は単純で、学習用画像のフォルダ内に ``繰り返し回数_<identifier> <class>`` のフォルダを複数、正則化画像フォルダにも同様に ``繰り返し回数_<class>`` のフォルダを複数、用意してください。
たとえば「sls frog」と「cpc rabbit」を同時に学習する場合、以下のようになります。
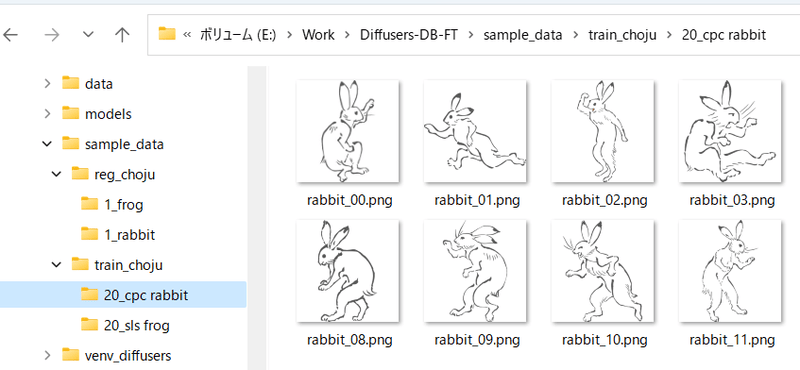
classがひとつで対象が複数の場合、正則化画像フォルダはひとつで構いません。たとえば1girlにキャラAとキャラBがいる場合は次のようにします。
- train_girls
- 10_sls 1girl
- 10_cpc 1girl
- reg_girls
- 1_1girl
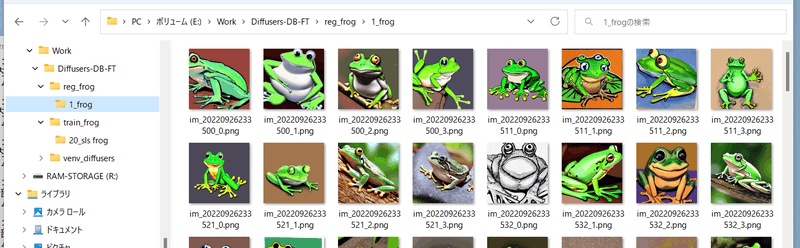
### step 2. 正則化画像の準備
正則化画像を使う場合の手順です。
正則化画像を格納するフォルダを作成します。 __さらにその中に__ ``<繰り返し回数>_<class>`` という名前でディレクトリを作成します。
たとえば「frog」というプロンプトで、データを繰り返さない(1回だけ)場合、以下のようになります。
### step 3. 学習の実行
各学習スクリプトを実行します。 `--train_data_dir` オプションで前述の学習用データのフォルダを(__画像を含むフォルダではなく、その親フォルダ__)、`--reg_data_dir` オプションで正則化画像のフォルダ(__画像を含むフォルダではなく、その親フォルダ__)を指定してください。
## DreamBooth、キャプション方式
学習用画像、正則化画像のフォルダに、画像と同じファイル名で、拡張子.caption(オプションで変えられます)のファイルを置くと、そのファイルからキャプションを読み込みプロンプトとして学習します。
※それらの画像の学習に、フォルダ名(identifier class)は使用されなくなります。
キャプションファイルの拡張子はデフォルトで.captionです。学習スクリプトの `--caption_extension` オプションで変更できます。`--shuffle_caption` オプションで学習時のキャプションについて、カンマ区切りの各部分をシャッフルしながら学習します。
## fine tuning 方式
メタデータを作るところまでは設定ファイルを使う場合と同様です。`in_json` オプションでメタデータファイルを指定します。
# 学習途中でのサンプル出力
学習中のモデルで試しに画像生成することで学習の進み方を確認できます。学習スクリプトに以下のオプションを指定します。
- `--sample_every_n_steps` / `--sample_every_n_epochs`
サンプル出力するステップ数またはエポック数を指定します。この数ごとにサンプル出力します。両方指定するとエポック数が優先されます。
- `--sample_at_first`
学習開始前にサンプル出力します。学習前との比較ができます。
- `--sample_prompts`
サンプル出力用プロンプトのファイルを指定します。
- `--sample_sampler`
サンプル出力に使うサンプラーを指定します。
`'ddim', 'pndm', 'heun', 'dpmsolver', 'dpmsolver++', 'dpmsingle', 'k_lms', 'k_euler', 'k_euler_a', 'k_dpm_2', 'k_dpm_2_a'`が選べます。
サンプル出力を行うにはあらかじめプロンプトを記述したテキストファイルを用意しておく必要があります。1行につき1プロンプトで記述します。
たとえば以下のようになります。
```txt
# prompt 1
masterpiece, best quality, 1girl, in white shirts, upper body, looking at viewer, simple background --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 768 --h 768 --d 1 --l 7.5 --s 28
# prompt 2
masterpiece, best quality, 1boy, in business suit, standing at street, looking back --n low quality, worst quality, bad anatomy,bad composition, poor, low effort --w 576 --h 832 --d 2 --l 5.5 --s 40
```
先頭が `#` の行はコメントになります。`--n` のように 「`--` + 英小文字」で生成画像へのオプションを指定できます。以下が使えます。
- `--n` 次のオプションまでをネガティブプロンプトとします。
- `--w` 生成画像の横幅を指定します。
- `--h` 生成画像の高さを指定します。
- `--d` 生成画像のseedを指定します。
- `--l` 生成画像のCFG scaleを指定します。
- `--s` 生成時のステップ数を指定します。
# 各スクリプトで共通の、よく使われるオプション
スクリプトの更新後、ドキュメントの更新が追い付いていない場合があります。その場合は `--help` オプションで使用できるオプションを確認してください。
## 学習に使うモデル指定
- `--v2` / `--v_parameterization`
学習対象モデルとしてHugging Faceのstable-diffusion-2-base、またはそこからのfine tuningモデルを使う場合(推論時に `v2-inference.yaml` を使うように指示されているモデルの場合)は `--v2` オプションを、stable-diffusion-2や768-v-ema.ckpt、およびそれらのfine tuningモデルを使う場合(推論時に `v2-inference-v.yaml` を使うモデルの場合)は `--v2` と `--v_parameterization` の両方のオプションを指定してください。
Stable Diffusion 2.0では大きく以下の点が変わっています。
1. 使用するTokenizer
2. 使用するText Encoderおよび使用する出力層(2.0は最後から二番目の層を使う)
3. Text Encoderの出力次元数(768->1024)
4. U-Netの構造(CrossAttentionのhead数など)
5. v-parameterization(サンプリング方法が変更されているらしい)
このうちbaseでは1~4が、baseのつかない方(768-v)では1~5が採用されています。1~4を有効にするのがv2オプション、5を有効にするのがv_parameterizationオプションです。
- `--pretrained_model_name_or_path`
追加学習を行う元となるモデルを指定します。Stable Diffusionのcheckpointファイル(.ckptまたは.safetensors)、Diffusersのローカルディスクにあるモデルディレクトリ、DiffusersのモデルID("stabilityai/stable-diffusion-2"など)が指定できます。
## 学習に関する設定
- `--output_dir`
学習後のモデルを保存するフォルダを指定します。
- `--output_name`
モデルのファイル名を拡張子を除いて指定します。
- `--dataset_config`
データセットの設定を記述した `.toml` ファイルを指定します。
- `--max_train_steps` / `--max_train_epochs`
学習するステップ数やエポック数を指定します。両方指定するとエポック数のほうが優先されます。
- `--mixed_precision`
省メモリ化のため mixed precision (混合精度)で学習します。`--mixed_precision="fp16"` のように指定します。mixed precision なし(デフォルト)と比べて精度が低くなる可能性がありますが、学習に必要なGPUメモリ量が大きく減ります。
(RTX30 シリーズ以降では `bf16` も指定できます。環境整備時にaccelerateに行った設定と合わせてください)。
- `--gradient_checkpointing`
学習時の重みの計算をまとめて行うのではなく少しずつ行うことで、学習に必要なGPUメモリ量を減らします。オンオフは精度には影響しませんが、オンにするとバッチサイズを大きくできるため、そちらでの影響はあります。
また一般的にはオンにすると速度は低下しますが、バッチサイズを大きくできるので、トータルでの学習時間はむしろ速くなるかもしれません。
- `--xformers` / `--mem_eff_attn`
xformersオプションを指定するとxformersのCrossAttentionを用います。xformersをインストールしていない場合やエラーとなる場合(環境にもよりますが `mixed_precision="no"` の場合など)、代わりに `mem_eff_attn` オプションを指定すると省メモリ版CrossAttentionを使用します(xformersよりも速度は遅くなります)。
- `--clip_skip`
`2` を指定すると、Text Encoder (CLIP) の後ろから二番目の層の出力を用います。1またはオプション省略時は最後の層を用います。
※SD2.0はデフォルトで後ろから二番目の層を使うため、SD2.0の学習では指定しないでください。
学習対象のモデルがもともと二番目の層を使うように学習されている場合は、2を指定するとよいでしょう。
そうではなく最後の層を使用していた場合はモデル全体がそれを前提に学習されています。そのため改めて二番目の層を使用して学習すると、望ましい学習結果を得るにはある程度の枚数の教師データ、長めの学習が必要になるかもしれません。
- `--max_token_length`
デフォルトは75です。`150` または `225` を指定することでトークン長を拡張して学習できます。長いキャプションで学習する場合に指定してください。
ただし学習時のトークン拡張の仕様は Automatic1111 氏のWeb UIとは微妙に異なるため(分割の仕様など)、必要なければ75で学習することをお勧めします。
clip_skipと同様に、モデルの学習状態と異なる長さで学習するには、ある程度の教師データ枚数、長めの学習時間が必要になると思われます。
- `--weighted_captions`
指定するとAutomatic1111氏のWeb UIと同様の重み付きキャプションが有効になります。「Textual Inversion と XTI」以外の学習に使用できます。キャプションだけでなく DreamBooth 手法の token string でも有効です。
重みづけキャプションの記法はWeb UIとほぼ同じで、(abc)や[abc]、(abc:1.23)などが使用できます。入れ子も可能です。括弧内にカンマを含めるとプロンプトのshuffle/dropoutで括弧の対応付けがおかしくなるため、括弧内にはカンマを含めないでください。
- `--persistent_data_loader_workers`
Windows環境で指定するとエポック間の待ち時間が大幅に短縮されます。
- `--max_data_loader_n_workers`
データ読み込みのプロセス数を指定します。プロセス数が多いとデータ読み込みが速くなりGPUを効率的に利用できますが、メインメモリを消費します。デフォルトは「`8` または `CPU同時実行スレッド数-1` の小さいほう」なので、メインメモリに余裕がない場合や、GPU使用率が90%程度以上なら、それらの数値を見ながら `2` または `1` 程度まで下げてください。
- `--logging_dir` / `--log_prefix`
学習ログの保存に関するオプションです。logging_dirオプションにログ保存先フォルダを指定してください。TensorBoard形式のログが保存されます。
たとえば--logging_dir=logsと指定すると、作業フォルダにlogsフォルダが作成され、その中の日時フォルダにログが保存されます。
また--log_prefixオプションを指定すると、日時の前に指定した文字列が追加されます。「--logging_dir=logs --log_prefix=db_style1_」などとして識別用にお使いください。
TensorBoardでログを確認するには、別のコマンドプロンプトを開き、作業フォルダで以下のように入力します。
```
tensorboard --logdir=logs
```
(tensorboardは環境整備時にあわせてインストールされると思いますが、もし入っていないなら `pip install tensorboard` で入れてください。)
その後ブラウザを開き、http://localhost:6006/ へアクセスすると表示されます。
- `--log_with` / `--log_tracker_name`
学習ログの保存に関するオプションです。`tensorboard` だけでなく `wandb`への保存が可能です。詳細は [PR#428](https://github.com/kohya-ss/sd-scripts/pull/428)をご覧ください。
- `--noise_offset`
こちらの記事の実装になります: https://www.crosslabs.org//blog/diffusion-with-offset-noise
全体的に暗い、明るい画像の生成結果が良くなる可能性があるようです。LoRA学習でも有効なようです。`0.1` 程度の値を指定するとよいようです。
- `--adaptive_noise_scale` (実験的オプション)
Noise offsetの値を、latentsの各チャネルの平均値の絶対値に応じて自動調整するオプションです。`--noise_offset` と同時に指定することで有効になります。Noise offsetの値は `noise_offset + abs(mean(latents, dim=(2,3))) * adaptive_noise_scale` で計算されます。latentは正規分布に近いためnoise_offsetの1/10~同程度の値を指定するとよいかもしれません。
負の値も指定でき、その場合はnoise offsetは0以上にclipされます。
- `--multires_noise_iterations` / `--multires_noise_discount`
Multi resolution noise (pyramid noise)の設定です。詳細は [PR#471](https://github.com/kohya-ss/sd-scripts/pull/471) およびこちらのページ [Multi-Resolution Noise for Diffusion Model Training](https://wandb.ai/johnowhitaker/multires_noise/reports/Multi-Resolution-Noise-for-Diffusion-Model-Training--VmlldzozNjYyOTU2) を参照してください。
`--multires_noise_iterations` に数値を指定すると有効になります。6~10程度の値が良いようです。`--multires_noise_discount` に0.1~0.3 程度の値(LoRA学習等比較的データセットが小さい場合のPR作者の推奨)、ないしは0.8程度の値(元記事の推奨)を指定してください(デフォルトは 0.3)。
- `--debug_dataset`
このオプションを付けることで学習を行う前に事前にどのような画像データ、キャプションで学習されるかを確認できます。Escキーを押すと終了してコマンドラインに戻ります。`S`キーで次のステップ(バッチ)、`E`キーで次のエポックに進みます。
※Linux環境(Colabを含む)では画像は表示されません。
- `--vae`
vaeオプションにStable Diffusionのcheckpoint、VAEのcheckpointファイル、DiffusesのモデルまたはVAE(ともにローカルまたはHugging FaceのモデルIDが指定できます)のいずれかを指定すると、そのVAEを使って学習します(latentsのキャッシュ時または学習中のlatents取得時)。
DreamBoothおよびfine tuningでは、保存されるモデルはこのVAEを組み込んだものになります。
- `--cache_latents` / `--cache_latents_to_disk`
使用VRAMを減らすためVAEの出力をメインメモリにキャッシュします。`flip_aug` 以外のaugmentationは使えなくなります。また全体の学習速度が若干速くなります。
cache_latents_to_diskを指定するとキャッシュをディスクに保存します。スクリプトを終了し、再度起動した場合もキャッシュが有効になります。
- `--min_snr_gamma`
Min-SNR Weighting strategyを指定します。詳細は[こちら](https://github.com/kohya-ss/sd-scripts/pull/308)を参照してください。論文では`5`が推奨されています。
## モデルの保存に関する設定
- `--save_precision`
保存時のデータ精度を指定します。save_precisionオプションにfloat、fp16、bf16のいずれかを指定すると、その形式でモデルを保存します(DreamBooth、fine tuningでDiffusers形式でモデルを保存する場合は無効です)。モデルのサイズを削減したい場合などにお使いください。
- `--save_every_n_epochs` / `--save_state` / `--resume`
save_every_n_epochsオプションに数値を指定すると、そのエポックごとに学習途中のモデルを保存します。
save_stateオプションを同時に指定すると、optimizer等の状態も含めた学習状態を合わせて保存します(保存したモデルからも学習再開できますが、それに比べると精度の向上、学習時間の短縮が期待できます)。保存先はフォルダになります。
学習状態は保存先フォルダに `<output_name>-??????-state`(??????はエポック数)という名前のフォルダで出力されます。長時間にわたる学習時にご利用ください。
保存された学習状態から学習を再開するにはresumeオプションを使います。学習状態のフォルダ(`output_dir` ではなくその中のstateのフォルダ)を指定してください。
なおAcceleratorの仕様により、エポック数、global stepは保存されておらず、resumeしたときにも1からになりますがご容赦ください。
- `--save_every_n_steps`
save_every_n_stepsオプションに数値を指定すると、そのステップごとに学習途中のモデルを保存します。save_every_n_epochsと同時に指定できます。
- `--save_model_as` (DreamBooth, fine tuning のみ)
モデルの保存形式を`ckpt, safetensors, diffusers, diffusers_safetensors` から選べます。
`--save_model_as=safetensors` のように指定します。Stable Diffusion形式(ckptまたはsafetensors)を読み込み、Diffusers形式で保存する場合、不足する情報はHugging Faceからv1.5またはv2.1の情報を落としてきて補完します。
- `--huggingface_repo_id` 等
huggingface_repo_idが指定されているとモデル保存時に同時にHuggingFaceにアップロードします。アクセストークンの取り扱いに注意してください(HuggingFaceのドキュメントを参照してください)。
他の引数をたとえば以下のように指定してください。
- `--huggingface_repo_id "your-hf-name/your-model" --huggingface_path_in_repo "path" --huggingface_repo_type model --huggingface_repo_visibility private --huggingface_token hf_YourAccessTokenHere`
huggingface_repo_visibilityに`public`を指定するとリポジトリが公開されます。省略時または`private`(などpublic以外)を指定すると非公開になります。
`--save_state`オプション指定時に`--save_state_to_huggingface`を指定するとstateもアップロードします。
`--resume`オプション指定時に`--resume_from_huggingface`を指定するとHuggingFaceからstateをダウンロードして再開します。その時の --resumeオプションは `--resume {repo_id}/{path_in_repo}:{revision}:{repo_type}`になります。
例: `--resume_from_huggingface --resume your-hf-name/your-model/path/test-000002-state:main:model`
`--async_upload`オプションを指定するとアップロードを非同期で行います。
## オプティマイザ関係
- `--optimizer_type`
--オプティマイザの種類を指定します。以下が指定できます。
- AdamW : [torch.optim.AdamW](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html)
- 過去のバージョンのオプション未指定時と同じ
- AdamW8bit : 引数は同上
- PagedAdamW8bit : 引数は同上
- 過去のバージョンの--use_8bit_adam指定時と同じ
- Lion : https://github.com/lucidrains/lion-pytorch
- 過去のバージョンの--use_lion_optimizer指定時と同じ
- Lion8bit : 引数は同上
- PagedLion8bit : 引数は同上
- SGDNesterov : [torch.optim.SGD](https://pytorch.org/docs/stable/generated/torch.optim.SGD.html), nesterov=True
- SGDNesterov8bit : 引数は同上
- DAdaptation(DAdaptAdamPreprint) : https://github.com/facebookresearch/dadaptation
- DAdaptAdam : 引数は同上
- DAdaptAdaGrad : 引数は同上
- DAdaptAdan : 引数は同上
- DAdaptAdanIP : 引数は同上
- DAdaptLion : 引数は同上
- DAdaptSGD : 引数は同上
- Prodigy : https://github.com/konstmish/prodigy
- AdaFactor : [Transformers AdaFactor](https://huggingface.co/docs/transformers/main_classes/optimizer_schedules)
- 任意のオプティマイザ
- `--learning_rate`
学習率を指定します。適切な学習率は学習スクリプトにより異なりますので、それぞれの説明を参照してください。
- `--lr_scheduler` / `--lr_warmup_steps` / `--lr_scheduler_num_cycles` / `--lr_scheduler_power`
学習率のスケジューラ関連の指定です。
lr_schedulerオプションで学習率のスケジューラをlinear, cosine, cosine_with_restarts, polynomial, constant, constant_with_warmup, 任意のスケジューラから選べます。デフォルトはconstantです。
lr_warmup_stepsでスケジューラのウォームアップ(だんだん学習率を変えていく)ステップ数を指定できます。
lr_scheduler_num_cycles は cosine with restartsスケジューラでのリスタート回数、lr_scheduler_power は polynomialスケジューラでのpolynomial power です。
詳細については各自お調べください。
任意のスケジューラを使う場合、任意のオプティマイザと同様に、`--scheduler_args`でオプション引数を指定してください。
### オプティマイザの指定について
オプティマイザのオプション引数は--optimizer_argsオプションで指定してください。key=valueの形式で、複数の値が指定できます。また、valueはカンマ区切りで複数の値が指定できます。たとえばAdamWオプティマイザに引数を指定する場合は、``--optimizer_args weight_decay=0.01 betas=.9,.999``のようになります。
オプション引数を指定する場合は、それぞれのオプティマイザの仕様をご確認ください。
一部のオプティマイザでは必須の引数があり、省略すると自動的に追加されます(SGDNesterovのmomentumなど)。コンソールの出力を確認してください。
D-Adaptationオプティマイザは学習率を自動調整します。学習率のオプションに指定した値は学習率そのものではなくD-Adaptationが決定した学習率の適用率になりますので、通常は1.0を指定してください。Text EncoderにU-Netの半分の学習率を指定したい場合は、``--text_encoder_lr=0.5 --unet_lr=1.0``と指定します。
AdaFactorオプティマイザはrelative_step=Trueを指定すると学習率を自動調整できます(省略時はデフォルトで追加されます)。自動調整する場合は学習率のスケジューラにはadafactor_schedulerが強制的に使用されます。またscale_parameterとwarmup_initを指定するとよいようです。
自動調整する場合のオプション指定はたとえば ``--optimizer_args "relative_step=True" "scale_parameter=True" "warmup_init=True"`` のようになります。
学習率を自動調整しない場合はオプション引数 ``relative_step=False`` を追加してください。その場合、学習率のスケジューラにはconstant_with_warmupが、また勾配のclip normをしないことが推奨されているようです。そのため引数は ``--optimizer_type=adafactor --optimizer_args "relative_step=False" --lr_scheduler="constant_with_warmup" --max_grad_norm=0.0`` のようになります。
### 任意のオプティマイザを使う
``torch.optim`` のオプティマイザを使う場合にはクラス名のみを(``--optimizer_type=RMSprop``など)、他のモジュールのオプティマイザを使う時は「モジュール名.クラス名」を指定してください(``--optimizer_type=bitsandbytes.optim.lamb.LAMB``など)。
(内部でimportlibしているだけで動作は未確認です。必要ならパッケージをインストールしてください。)
<!--
## 任意サイズの画像での学習 --resolution
正方形以外で学習できます。resolutionに「448,640」のように「幅,高さ」で指定してください。幅と高さは64で割り切れる必要があります。学習用画像、正則化画像のサイズを合わせてください。
個人的には縦長の画像を生成することが多いため「448,640」などで学習することもあります。
## Aspect Ratio Bucketing --enable_bucket / --min_bucket_reso / --max_bucket_reso
enable_bucketオプションを指定すると有効になります。Stable Diffusionは512x512で学習されていますが、それに加えて256x768や384x640といった解像度でも学習します。
このオプションを指定した場合は、学習用画像、正則化画像を特定の解像度に統一する必要はありません。いくつかの解像度(アスペクト比)から最適なものを選び、その解像度で学習します。
解像度は64ピクセル単位のため、元画像とアスペクト比が完全に一致しない場合がありますが、その場合は、はみ出した部分がわずかにトリミングされます。
解像度の最小サイズをmin_bucket_resoオプションで、最大サイズをmax_bucket_resoで指定できます。デフォルトはそれぞれ256、1024です。
たとえば最小サイズに384を指定すると、256x1024や320x768などの解像度は使わなくなります。
解像度を768x768のように大きくした場合、最大サイズに1280などを指定しても良いかもしれません。
なおAspect Ratio Bucketingを有効にするときには、正則化画像についても、学習用画像と似た傾向の様々な解像度を用意した方がいいかもしれません。
(ひとつのバッチ内の画像が学習用画像、正則化画像に偏らなくなるため。そこまで大きな影響はないと思いますが……。)
## augmentation --color_aug / --flip_aug
augmentationは学習時に動的にデータを変化させることで、モデルの性能を上げる手法です。color_augで色合いを微妙に変えつつ、flip_augで左右反転をしつつ、学習します。
動的にデータを変化させるため、cache_latentsオプションと同時に指定できません。
## 勾配をfp16とした学習(実験的機能) --full_fp16
full_fp16オプションを指定すると勾配を通常のfloat32からfloat16(fp16)に変更して学習します(mixed precisionではなく完全なfp16学習になるようです)。
これによりSD1.xの512x512サイズでは8GB未満、SD2.xの512x512サイズで12GB未満のVRAM使用量で学習できるようです。
あらかじめaccelerate configでfp16を指定し、オプションで ``mixed_precision="fp16"`` としてください(bf16では動作しません)。
メモリ使用量を最小化するためには、xformers、use_8bit_adam、cache_latents、gradient_checkpointingの各オプションを指定し、train_batch_sizeを1としてください。
(余裕があるようならtrain_batch_sizeを段階的に増やすと若干精度が上がるはずです。)
PyTorchのソースにパッチを当てて無理やり実現しています(PyTorch 1.12.1と1.13.0で確認)。精度はかなり落ちますし、途中で学習失敗する確率も高くなります。
学習率やステップ数の設定もシビアなようです。それらを認識したうえで自己責任でお使いください。
-->
# メタデータファイルの作成
## 教師データの用意
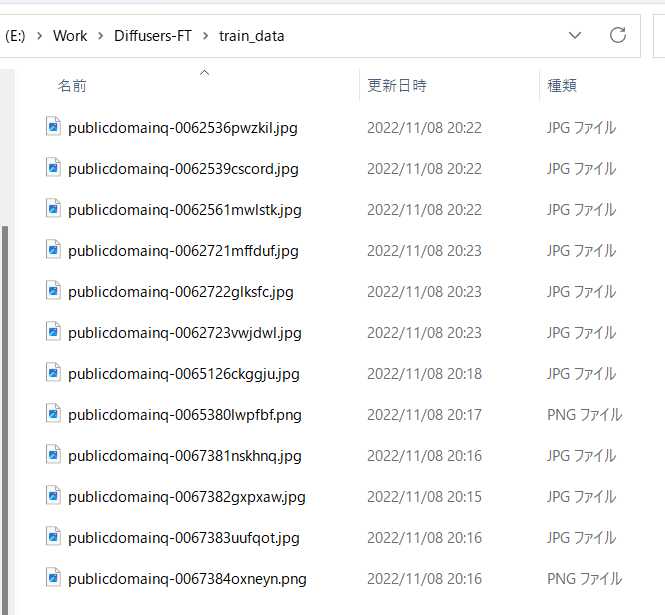
前述のように学習させたい画像データを用意し、任意のフォルダに入れてください。
たとえば以下のように画像を格納します。
## 自動キャプショニング
キャプションを使わずタグだけで学習する場合はスキップしてください。
また手動でキャプションを用意する場合、キャプションは教師データ画像と同じディレクトリに、同じファイル名、拡張子.caption等で用意してください。各ファイルは1行のみのテキストファイルとします。
### BLIPによるキャプショニング
最新版ではBLIPのダウンロード、重みのダウンロード、仮想環境の追加は不要になりました。そのままで動作します。
finetuneフォルダ内のmake_captions.pyを実行します。
```
python finetune\make_captions.py --batch_size <バッチサイズ> <教師データフォルダ>
```
バッチサイズ8、教師データを親フォルダのtrain_dataに置いた場合、以下のようになります。
```
python finetune\make_captions.py --batch_size 8 ..\train_data
```
キャプションファイルが教師データ画像と同じディレクトリに、同じファイル名、拡張子.captionで作成されます。
batch_sizeはGPUのVRAM容量に応じて増減してください。大きいほうが速くなります(VRAM 12GBでももう少し増やせると思います)。
max_lengthオプションでキャプションの最大長を指定できます。デフォルトは75です。モデルをトークン長225で学習する場合には長くしても良いかもしれません。
caption_extensionオプションでキャプションの拡張子を変更できます。デフォルトは.captionです(.txtにすると後述のDeepDanbooruと競合します)。
複数の教師データフォルダがある場合には、それぞれのフォルダに対して実行してください。
なお、推論にランダム性があるため、実行するたびに結果が変わります。固定する場合には--seedオプションで `--seed 42` のように乱数seedを指定してください。
その他のオプションは `--help` でヘルプをご参照ください(パラメータの意味についてはドキュメントがまとまっていないようで、ソースを見るしかないようです)。
デフォルトでは拡張子.captionでキャプションファイルが生成されます。
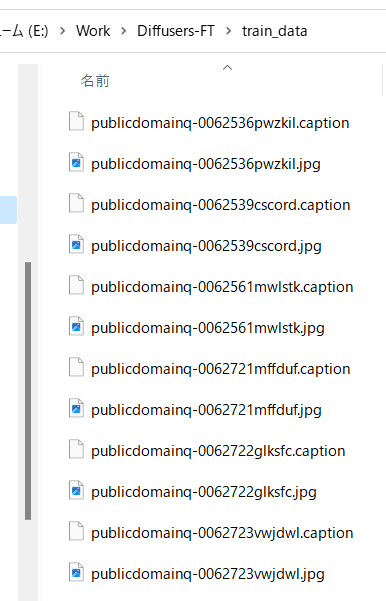
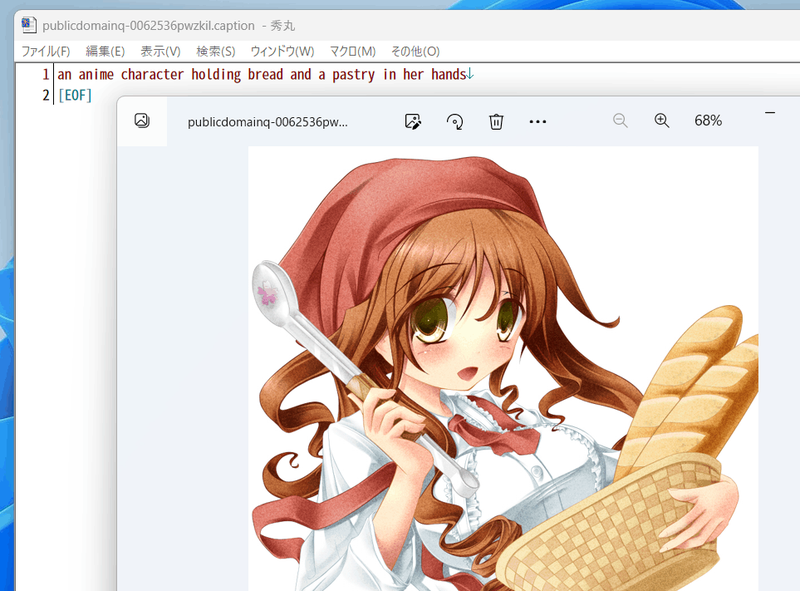
たとえば以下のようなキャプションが付きます。
## DeepDanbooruによるタグ付け
danbooruタグのタグ付け自体を行わない場合は「キャプションとタグ情報の前処理」に進んでください。
タグ付けはDeepDanbooruまたはWD14Taggerで行います。WD14Taggerのほうが精度が良いようです。WD14Taggerでタグ付けする場合は、次の章へ進んでください。
### 環境整備
DeepDanbooru https://github.com/KichangKim/DeepDanbooru を作業フォルダにcloneしてくるか、zipをダウンロードして展開します。私はzipで展開しました。
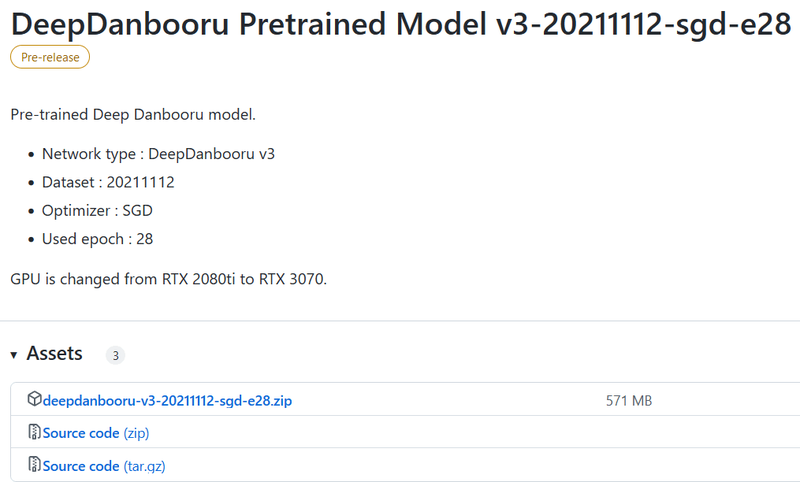
またDeepDanbooruのReleasesのページ https://github.com/KichangKim/DeepDanbooru/releases の「DeepDanbooru Pretrained Model v3-20211112-sgd-e28」のAssetsから、deepdanbooru-v3-20211112-sgd-e28.zipをダウンロードしてきてDeepDanbooruのフォルダに展開します。
以下からダウンロードします。Assetsをクリックして開き、そこからダウンロードします。
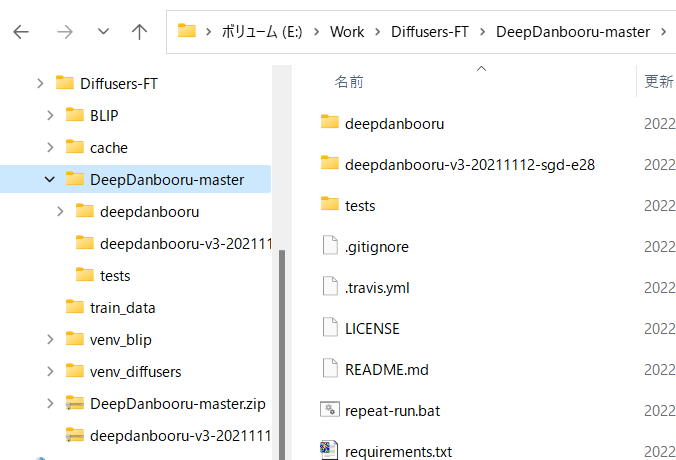
以下のようなこういうディレクトリ構造にしてください
Diffusersの環境に必要なライブラリをインストールします。DeepDanbooruのフォルダに移動してインストールします(実質的にはtensorflow-ioが追加されるだけだと思います)。
```
pip install -r requirements.txt
```
続いてDeepDanbooru自体をインストールします。
```
pip install .
```
以上でタグ付けの環境整備は完了です。
### タグ付けの実施
DeepDanbooruのフォルダに移動し、deepdanbooruを実行してタグ付けを行います。
```
deepdanbooru evaluate <教師データフォルダ> --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
```
教師データを親フォルダのtrain_dataに置いた場合、以下のようになります。
```
deepdanbooru evaluate ../train_data --project-path deepdanbooru-v3-20211112-sgd-e28 --allow-folder --save-txt
```
タグファイルが教師データ画像と同じディレクトリに、同じファイル名、拡張子.txtで作成されます。1件ずつ処理されるためわりと遅いです。
複数の教師データフォルダがある場合には、それぞれのフォルダに対して実行してください。
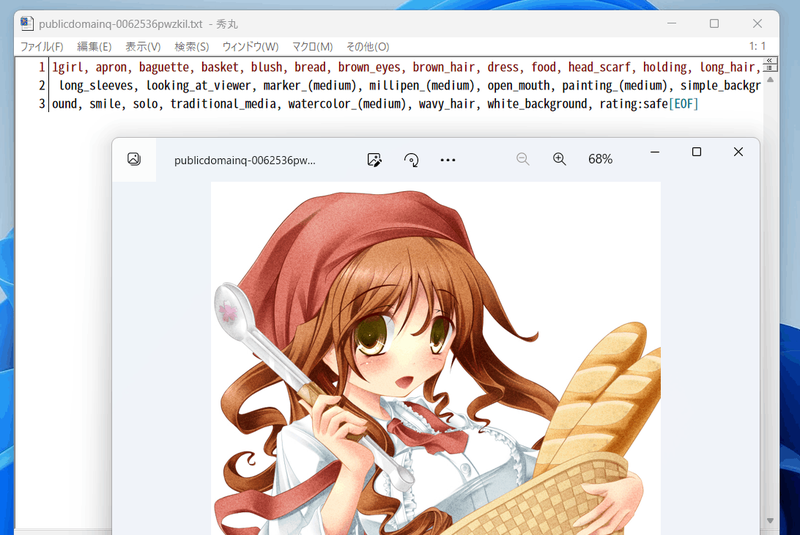
以下のように生成されます。
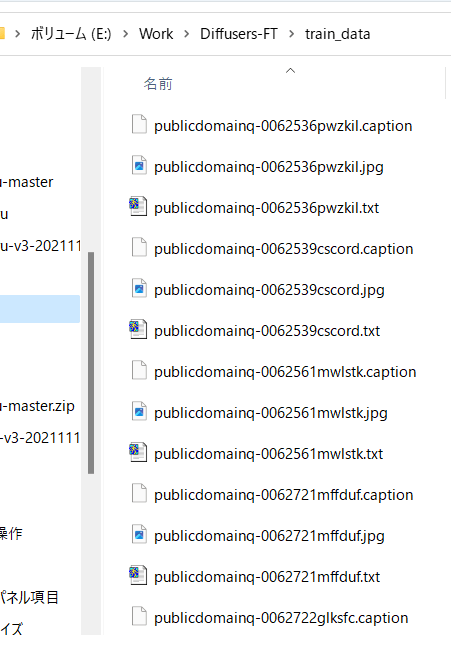
こんな感じにタグが付きます(すごい情報量……)。
## WD14Taggerによるタグ付け
DeepDanbooruの代わりにWD14Taggerを用いる手順です。
Automatic1111氏のWebUIで使用しているtaggerを利用します。こちらのgithubページ(https://github.com/toriato/stable-diffusion-webui-wd14-tagger#mrsmilingwolfs-model-aka-waifu-diffusion-14-tagger )の情報を参考にさせていただきました。
最初の環境整備で必要なモジュールはインストール済みです。また重みはHugging Faceから自動的にダウンロードしてきます。
### タグ付けの実施
スクリプトを実行してタグ付けを行います。
```
python tag_images_by_wd14_tagger.py --batch_size <バッチサイズ> <教師データフォルダ>
```
教師データを親フォルダのtrain_dataに置いた場合、以下のようになります。
```
python tag_images_by_wd14_tagger.py --batch_size 4 ..\train_data
```
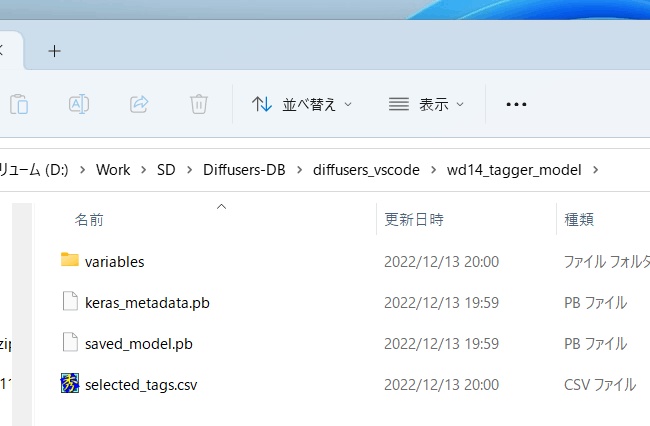
初回起動時にはモデルファイルがwd14_tagger_modelフォルダに自動的にダウンロードされます(フォルダはオプションで変えられます)。以下のようになります。
タグファイルが教師データ画像と同じディレクトリに、同じファイル名、拡張子.txtで作成されます。


threshオプションで、判定されたタグのconfidence(確信度)がいくつ以上でタグをつけるかが指定できます。デフォルトはWD14Taggerのサンプルと同じ0.35です。値を下げるとより多くのタグが付与されますが、精度は下がります。
batch_sizeはGPUのVRAM容量に応じて増減してください。大きいほうが速くなります(VRAM 12GBでももう少し増やせると思います)。caption_extensionオプションでタグファイルの拡張子を変更できます。デフォルトは.txtです。
model_dirオプションでモデルの保存先フォルダを指定できます。
またforce_downloadオプションを指定すると保存先フォルダがあってもモデルを再ダウンロードします。
複数の教師データフォルダがある場合には、それぞれのフォルダに対して実行してください。
## キャプションとタグ情報の前処理
スクリプトから処理しやすいようにキャプションとタグをメタデータとしてひとつのファイルにまとめます。
### キャプションの前処理
キャプションをメタデータに入れるには、作業フォルダ内で以下を実行してください(キャプションを学習に使わない場合は実行不要です)(実際は1行で記述します、以下同様)。`--full_path` オプションを指定してメタデータに画像ファイルの場所をフルパスで格納します。このオプションを省略すると相対パスで記録されますが、フォルダ指定が `.toml` ファイル内で別途必要になります。
```
python merge_captions_to_metadata.py --full_path <教師データフォルダ>
--in_json <読み込むメタデータファイル名> <メタデータファイル名>
```
メタデータファイル名は任意の名前です。
教師データがtrain_data、読み込むメタデータファイルなし、メタデータファイルがmeta_cap.jsonの場合、以下のようになります。
```
python merge_captions_to_metadata.py --full_path train_data meta_cap.json
```
caption_extensionオプションでキャプションの拡張子を指定できます。
複数の教師データフォルダがある場合には、full_path引数を指定しつつ、それぞれのフォルダに対して実行してください。
```
python merge_captions_to_metadata.py --full_path
train_data1 meta_cap1.json
python merge_captions_to_metadata.py --full_path --in_json meta_cap1.json
train_data2 meta_cap2.json
```
in_jsonを省略すると書き込み先メタデータファイルがあるとそこから読み込み、そこに上書きします。
__※in_jsonオプションと書き込み先を都度書き換えて、別のメタデータファイルへ書き出すようにすると安全です。__
### タグの前処理
同様にタグもメタデータにまとめます(タグを学習に使わない場合は実行不要です)。
```
python merge_dd_tags_to_metadata.py --full_path <教師データフォルダ>
--in_json <読み込むメタデータファイル名> <書き込むメタデータファイル名>
```
先と同じディレクトリ構成で、meta_cap.jsonを読み、meta_cap_dd.jsonに書きだす場合、以下となります。
```
python merge_dd_tags_to_metadata.py --full_path train_data --in_json meta_cap.json meta_cap_dd.json
```
複数の教師データフォルダがある場合には、full_path引数を指定しつつ、それぞれのフォルダに対して実行してください。
```
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap2.json
train_data1 meta_cap_dd1.json
python merge_dd_tags_to_metadata.py --full_path --in_json meta_cap_dd1.json
train_data2 meta_cap_dd2.json
```
in_jsonを省略すると書き込み先メタデータファイルがあるとそこから読み込み、そこに上書きします。
__※in_jsonオプションと書き込み先を都度書き換えて、別のメタデータファイルへ書き出すようにすると安全です。__
### キャプションとタグのクリーニング
ここまででメタデータファイルにキャプションとDeepDanbooruのタグがまとめられています。ただ自動キャプショニングにしたキャプションは表記ゆれなどがあり微妙(※)ですし、タグにはアンダースコアが含まれていたりratingが付いていたりしますので(DeepDanbooruの場合)、エディタの置換機能などを用いてキャプションとタグのクリーニングをしたほうがいいでしょう。
※たとえばアニメ絵の少女を学習する場合、キャプションにはgirl/girls/woman/womenなどのばらつきがあります。また「anime girl」なども単に「girl」としたほうが適切かもしれません。
クリーニング用のスクリプトが用意してありますので、スクリプトの内容を状況に応じて編集してお使いください。
(教師データフォルダの指定は不要になりました。メタデータ内の全データをクリーニングします。)
```
python clean_captions_and_tags.py <読み込むメタデータファイル名> <書き込むメタデータファイル名>
```
--in_jsonは付きませんのでご注意ください。たとえば次のようになります。
```
python clean_captions_and_tags.py meta_cap_dd.json meta_clean.json
```
以上でキャプションとタグの前処理は完了です。
## latentsの事前取得
※ このステップは必須ではありません。省略しても学習時にlatentsを取得しながら学習できます。
また学習時に `random_crop` や `color_aug` などを行う場合にはlatentsの事前取得はできません(画像を毎回変えながら学習するため)。事前取得をしない場合、ここまでのメタデータで学習できます。
あらかじめ画像の潜在表現を取得しディスクに保存しておきます。それにより、学習を高速に進めることができます。あわせてbucketing(教師データをアスペクト比に応じて分類する)を行います。
作業フォルダで以下のように入力してください。
```
python prepare_buckets_latents.py --full_path <教師データフォルダ>
<読み込むメタデータファイル名> <書き込むメタデータファイル名>
<fine tuningするモデル名またはcheckpoint>
--batch_size <バッチサイズ>
--max_resolution <解像度 幅,高さ>
--mixed_precision <精度>
```
モデルがmodel.ckpt、バッチサイズ4、学習解像度は512\*512、精度no(float32)で、meta_clean.jsonからメタデータを読み込み、meta_lat.jsonに書き込む場合、以下のようになります。
```
python prepare_buckets_latents.py --full_path
train_data meta_clean.json meta_lat.json model.ckpt
--batch_size 4 --max_resolution 512,512 --mixed_precision no
```
教師データフォルダにnumpyのnpz形式でlatentsが保存されます。
解像度の最小サイズを--min_bucket_resoオプションで、最大サイズを--max_bucket_resoで指定できます。デフォルトはそれぞれ256、1024です。たとえば最小サイズに384を指定すると、256\*1024や320\*768などの解像度は使わなくなります。
解像度を768\*768のように大きくした場合、最大サイズに1280などを指定すると良いでしょう。
--flip_augオプションを指定すると左右反転のaugmentation(データ拡張)を行います。疑似的にデータ量を二倍に増やすことができますが、データが左右対称でない場合に指定すると(例えばキャラクタの外見、髪型など)学習がうまく行かなくなります。
(反転した画像についてもlatentsを取得し、\*\_flip.npzファイルを保存する単純な実装です。fline_tune.pyには特にオプション指定は必要ありません。\_flip付きのファイルがある場合、flip付き・なしのファイルを、ランダムに読み込みます。)
バッチサイズはVRAM 12GBでももう少し増やせるかもしれません。
解像度は64で割り切れる数字で、"幅,高さ"で指定します。解像度はfine tuning時のメモリサイズに直結します。VRAM 12GBでは512,512が限界と思われます(※)。16GBなら512,704や512,768まで上げられるかもしれません。なお256,256等にしてもVRAM 8GBでは厳しいようです(パラメータやoptimizerなどは解像度に関係せず一定のメモリが必要なため)。
※batch size 1の学習で12GB VRAM、640,640で動いたとの報告もありました。
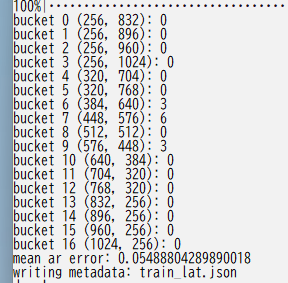
以下のようにbucketingの結果が表示されます。
複数の教師データフォルダがある場合には、full_path引数を指定しつつ、それぞれのフォルダに対して実行してください。
```
python prepare_buckets_latents.py --full_path
train_data1 meta_clean.json meta_lat1.json model.ckpt
--batch_size 4 --max_resolution 512,512 --mixed_precision no
python prepare_buckets_latents.py --full_path
train_data2 meta_lat1.json meta_lat2.json model.ckpt
--batch_size 4 --max_resolution 512,512 --mixed_precision no
```
読み込み元と書き込み先を同じにすることも可能ですが別々の方が安全です。
__※引数を都度書き換えて、別のメタデータファイルに書き込むと安全です。__