[](https://arxiv.org/abs/2405.18991)
[](https://easyanimate.github.io/)
[](https://modelscope.cn/studios/PAI/EasyAnimate/summary)
[](https://huggingface.co/spaces/alibaba-pai/EasyAnimate)
[](https://discord.gg/UzkpB4Bn)
# Introduction
EasyAnimate is a pipeline based on the transformer architecture, designed for generating AI images and videos, and for training baseline models and Lora models for Diffusion Transformer. We support direct prediction from pre-trained EasyAnimate models, allowing for the generation of videos with various resolutions, approximately 6 seconds in length, at 8fps (EasyAnimateV5, 1 to 49 frames). Additionally, users can train their own baseline and Lora models for specific style transformations.
[English](./README_en.md) | [简体中文](./README.md)
# Model zoo
EasyAnimateV5.1:
12B:
| Name | Type | Storage Space | Hugging Face | Model Scope | Description |
|--|--|--|--|--|--|
| EasyAnimateV5.1-12b-zh-InP | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-InP) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5.1-12b-zh-InP) | Official image-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
| EasyAnimateV5.1-12b-zh-Control | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-Control) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5.1-12b-zh-Control) | Official video control weights, supporting various control conditions such as Canny, Depth, Pose, MLSD, and trajectory control. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
| EasyAnimateV5.1-12b-zh-Control-Camera | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-Control-Camera) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5.1-12b-zh-Control-Camera) | Official video camera control weights, supporting direction generation control by inputting camera motion trajectories. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
| EasyAnimateV5.1-12b-zh | EasyAnimateV5.1 | 39 GB | [🤗Link](https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh) | [😄Link](https://modelscope.cn/models/PAI/EasyAnimateV5.1-12b-zh) | Official text-to-video weights. Supports video prediction at multiple resolutions (512, 768, 1024), trained with 49 frames at 8 frames per second, and supports for multilingual prediction. |
# Video Result
### Image to Video with EasyAnimateV5.1-12b-zh-InP
### Text to Video with EasyAnimateV5.1-12b-zh
### Control Video with EasyAnimateV5.1-12b-zh-Control
Trajectory Control:
Generic Control Video (Canny, Pose, Depth, etc.):
### Camera Control with EasyAnimateV5.1-12b-zh-Control-Camera
|
Pan Up
|
Pan Left
|
Pan Right
|
|
|
|
|
|
Pan Down
|
Pan Up + Pan Left
|
Pan Up + Pan Right
|
|
|
|
|
# How to use
#### a. Memory-Saving Options
Since EasyAnimateV5 and V5.1 have very large parameters, we need to consider memory-saving options to adapt to consumer-grade graphics cards. We provide GPU_memory_mode for each prediction file, allowing you to choose from model_cpu_offload, model_cpu_offload_and_qfloat8, or sequential_cpu_offload.
- model_cpu_offload means the entire model will move to the CPU after use, saving some memory.
- model_cpu_offload_and_qfloat8 means the entire model will move to the CPU after use and applies float8 quantization to the transformer model, saving more memory.
- sequential_cpu_offload means each layer of the model moves to CPU after use, which is slower but saves a lot of memory.
qfloat8 may reduce model performance but saves more memory. If memory is sufficient, it's recommended to use model_cpu_offload.
#### b. Via ComfyUI
For more details, see the [ComfyUI README](https://github.com/aigc-apps/EasyAnimate/blob/main/comfyui/README.md).
#### c. Run Python Files
- Step 1: Download the corresponding [weights](#model-zoo) and place them in the models folder.
- Step 2: Use different files for predictions based on the weights and prediction goals.
- Text-to-Video:
- Modify the prompt, neg_prompt, guidance_scale, and seed in the predict_t2v.py file.
- Then run the predict_t2v.py file and wait for the results, which are stored in the samples/easyanimate-videos folder.
- Image-to-Video:
- Modify validation_image_start, validation_image_end, prompt, neg_prompt, guidance_scale, and seed in the predict_i2v.py file.
- validation_image_start is the starting image, and validation_image_end is the ending image of the video.
- Then run the predict_i2v.py file and wait for the results, which are stored in the samples/easyanimate-videos_i2v folder.
- Video-to-Video:
- Modify validation_video, validation_image_end, prompt, neg_prompt, guidance_scale, and seed in the predict_v2v.py file.
- validation_video is the reference video for video-to-video. You can run a demo with the following video: [Demo Video](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1/play_guitar.mp4)
- Then run the predict_v2v.py file and wait for the results, which are stored in samples/easyanimate-videos_v2v folder.
- Generic Control Video (Canny, Pose, Depth, etc.):
- Modify control_video, validation_image_end, prompt, neg_prompt, guidance_scale, and seed in the predict_v2v_control.py file.
- control_video is the control video for video generation, extracted using Canny, Pose, Depth, etc. You can run a demo with the following video: [Demo Video](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1.1/pose.mp4)
- Then run the predict_v2v_control.py file and wait for the results, which are stored in samples/easyanimate-videos_v2v_control folder.
- Trajectory Control Video:
- Modify control_video, ref_image, validation_image_end, prompt, neg_prompt, guidance_scale, and seed in the predict_v2v_control.py file.
- control_video is the control video, and ref_image is the reference first frame image. You can run a demo with the following image and video: [Demo Image](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/v5.1/dog.png), [Demo Video](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/v5.1/trajectory_demo.mp4)
- Then run the predict_v2v_control.py file and wait for the results, which are stored in samples/easyanimate-videos_v2v_control folder.
- Interaction via ComfyUI is recommended.
- Camera Control Video:
- Modify control_video, ref_image, validation_image_end, prompt, neg_prompt, guidance_scale, and seed in the predict_v2v_control.py file.
- control_camera_txt is the control file for camera control video, and ref_image is the reference first frame image. You can run a demo with the following image and control file: [Demo Image](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/cogvideox_fun/asset/v1/firework.png), [Demo File (from CameraCtrl)](https://pai-aigc-photog.oss-cn-hangzhou.aliyuncs.com/easyanimate/asset/v5.1/0a3b5fb184936a83.txt)
- Then run the predict_v2v_control.py file and wait for the results, which are stored in samples/easyanimate-videos_v2v_control folder.
- Interaction via ComfyUI is recommended.
- Step 3: To combine with other backbones and Lora trained by yourself, modify predict_t2v.py and lora_path accordingly in the predict_t2v.py file.
#### d. Via WebUI Interface
WebUI supports text-to-video, image-to-video, video-to-video, and control-based video generation (such as Canny, Pose, Depth, etc.).
- Step 1: Download the corresponding [weights](#model-zoo) and place them in the models folder.
- Step 2: Run the app.py file to enter the Gradio page.
- Step 3: Choose the generation model from the page, fill in prompt, neg_prompt, guidance_scale, seed, etc., click generate, and wait for the results, which are stored in the sample folder.
# Quick Start
### 1. Cloud usage: AliyunDSW/Docker
#### a. From AliyunDSW
DSW has free GPU time, which can be applied once by a user and is valid for 3 months after applying.
Aliyun provide free GPU time in [Freetier](https://free.aliyun.com/?product=9602825&crowd=enterprise&spm=5176.28055625.J_5831864660.1.e939154aRgha4e&scm=20140722.M_9974135.P_110.MO_1806-ID_9974135-MID_9974135-CID_30683-ST_8512-V_1), get it and use in Aliyun PAI-DSW to start EasyAnimate within 5min!
[](https://gallery.pai-ml.com/#/preview/deepLearning/cv/easyanimate_v5)
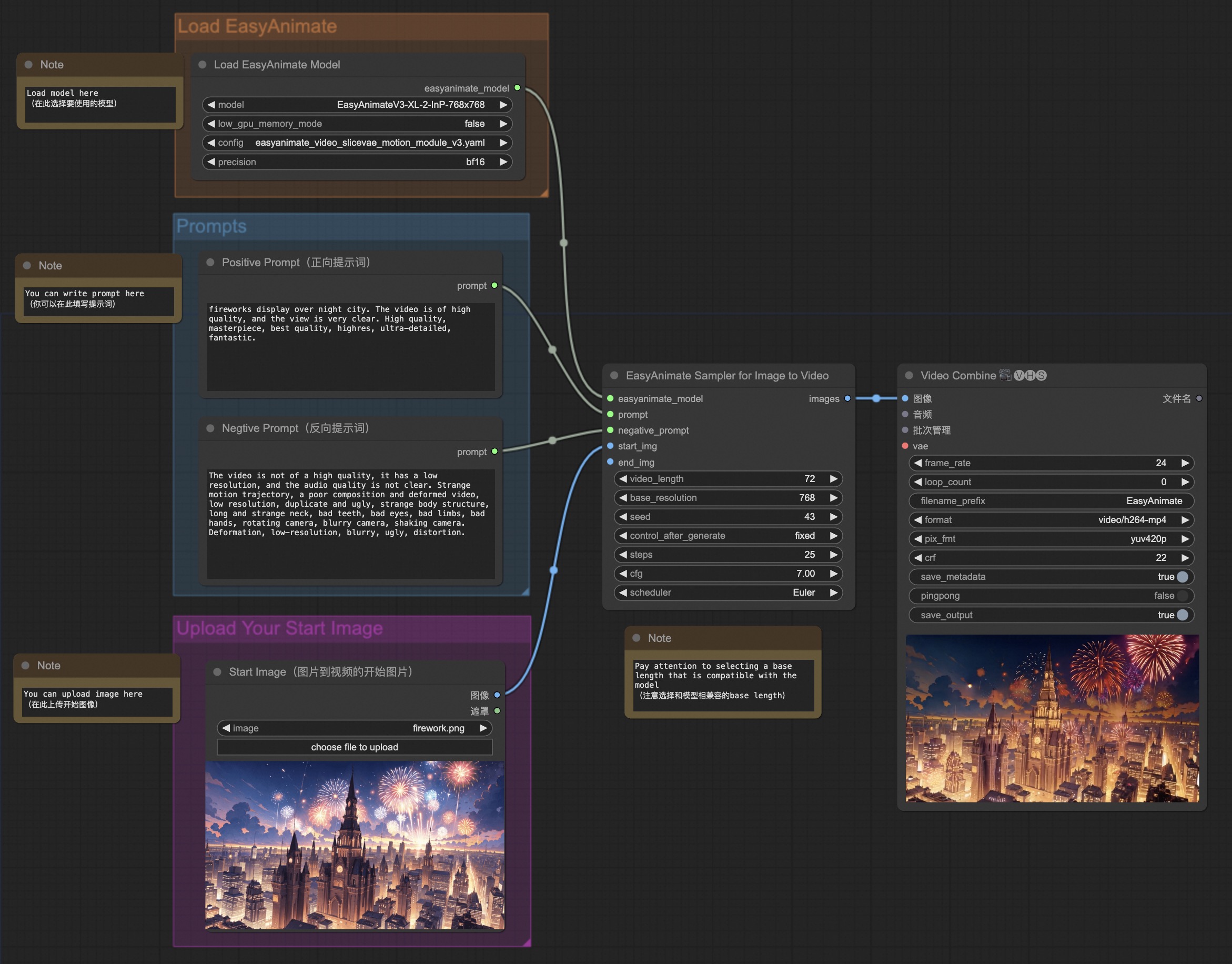
#### b. From ComfyUI
Our ComfyUI is as follows, please refer to [ComfyUI README](https://github.com/aigc-apps/EasyAnimate/blob/main/comfyui/README.md) for details.
#### c. From docker
If you are using docker, please make sure that the graphics card driver and CUDA environment have been installed correctly in your machine.
Then execute the following commands in this way:
```
# pull image
docker pull mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
# enter image
docker run -it -p 7860:7860 --network host --gpus all --security-opt seccomp:unconfined --shm-size 200g mybigpai-public-registry.cn-beijing.cr.aliyuncs.com/easycv/torch_cuda:easyanimate
# clone code
git clone https://github.com/aigc-apps/EasyAnimate.git
# enter EasyAnimate's dir
cd EasyAnimate
# download weights
mkdir models/Diffusion_Transformer
mkdir models/Motion_Module
mkdir models/Personalized_Model
# Please use the hugginface link or modelscope link to download the EasyAnimateV5.1 model.
# https://huggingface.co/alibaba-pai/EasyAnimateV5.1-12b-zh-InP
# https://modelscope.cn/models/PAI/EasyAnimateV5.1-12b-zh-InP
```
### 2. Local install: Environment Check/Downloading/Installation
#### a. Environment Check
We have verified EasyAnimate execution on the following environment:
The detailed of Windows:
- OS: Windows 10
- python: python3.10 & python3.11
- pytorch: torch2.2.0
- CUDA: 11.8 & 12.1
- CUDNN: 8+
- GPU: Nvidia-3060 12G
The detailed of Linux:
- OS: Ubuntu 20.04, CentOS
- python: python3.10 & python3.11
- pytorch: torch2.2.0
- CUDA: 11.8 & 12.1
- CUDNN: 8+
- GPU:Nvidia-V100 16G & Nvidia-A10 24G & Nvidia-A100 40G & Nvidia-A100 80G
We need about 60GB available on disk (for saving weights), please check!
The video size for EasyAnimateV5.1-12B can be generated by different GPU Memory, including:
| GPU memory | 384x672x72 | 384x672x49 | 576x1008x25 | 576x1008x49 | 768x1344x25 | 768x1344x49 |
|------------|------------|------------|------------|------------|------------|------------|
| 16GB | 🧡 | 🧡 | ❌ | ❌ | ❌ | ❌ |
| 24GB | 🧡 | 🧡 | 🧡 | 🧡 | ❌ | ❌ |
| 40GB | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ |
| 80GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
The video size for EasyAnimateV5.1-7B can be generated by different GPU Memory, including:
| GPU memory | 384x672x72 | 384x672x49 | 576x1008x25 | 576x1008x49 | 768x1344x25 | 768x1344x49 |
|------------|------------|------------|------------|------------|------------|------------|
| 16GB | 🧡 | 🧡 | ❌ | ❌ | ❌ | ❌ |
| 24GB | ✅ | ✅ | 🧡 | 🧡 | ❌ | ❌ |
| 40GB | ✅ | ✅ | ✅ | ✅ | ❌ | ❌ |
| 80GB | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Due to the float16 weights of qwen2-vl-7b, it cannot run on a 16GB GPU. If your GPU memory is 16GB, please visit [Huggingface](https://huggingface.co/Qwen/Qwen2-VL-7B-Instruct-GPTQ-Int8) or [Modelscope](https://modelscope.cn/models/Qwen/Qwen2-VL-7B-Instruct-GPTQ-Int8) to download the quantized version of qwen2-vl-7b to replace the original text encoder, and install the corresponding dependency libraries (auto-gptq, optimum).
✅ indicates it can run under "model_cpu_offload", 🧡 represents it can run under "model_cpu_offload_and_qfloat8", ⭕️ indicates it can run under "sequential_cpu_offload", ❌ means it can't run. Please note that running with sequential_cpu_offload will be slower.
Some GPUs that do not support torch.bfloat16, such as 2080ti and V100, require changing the weight_dtype in app.py and predict files to torch.float16 in order to run.
The generation time for EasyAnimateV5.1-12B using different GPUs over 25 steps is as follows:
| GPU | 384x672x72 | 384x672x49 | 576x1008x25 | 576x1008x49 | 768x1344x25 | 768x1344x49 |
|-----------|------------------|------------------|------------------|------------------|------------------|-----------------|
| A10 24GB | ~120s (4.8s/it) | ~240s (9.6s/it) | ~320s (12.7s/it) | ~750s (29.8s/it) | ❌ | ❌ |
| A100 80GB | ~45s (1.75s/it) | ~90s (3.7s/it) | ~120s (4.7s/it) | ~300s (11.4s/it) | ~265s (10.6s/it) | ~710s (28.3s/it) |
#### b. Weights
We'd better place the [weights](#model-zoo) along the specified path:
EasyAnimateV5.1:
```
📦 models/
├── 📂 Diffusion_Transformer/
│ ├── 📂 EasyAnimateV5.1-12b-zh-InP/
│ ├── 📂 EasyAnimateV5.1-12b-zh-Control/
│ ├── 📂 EasyAnimateV5.1-12b-zh-Control-Camera/
│ └── 📂 EasyAnimateV5.1-12b-zh/
├── 📂 Personalized_Model/
│ └── your trained trainformer model / your trained lora model (for UI load)
```
# Contact Us
1. Use Dingding to search group 77450006752 or Scan to join
2. You need to scan the image to join the WeChat group or if it is expired, add this student as a friend first to invite you.


 # Reference
- CogVideo: https://github.com/THUDM/CogVideo/
- Flux: https://github.com/black-forest-labs/flux
- magvit: https://github.com/google-research/magvit
- PixArt: https://github.com/PixArt-alpha/PixArt-alpha
- Open-Sora-Plan: https://github.com/PKU-YuanGroup/Open-Sora-Plan
- Open-Sora: https://github.com/hpcaitech/Open-Sora
- Animatediff: https://github.com/guoyww/AnimateDiff
- ComfyUI-EasyAnimateWrapper: https://github.com/kijai/ComfyUI-EasyAnimateWrapper
- HunYuan DiT: https://github.com/tencent/HunyuanDiT
# License
This project is licensed under the [Apache License (Version 2.0)](https://github.com/modelscope/modelscope/blob/master/LICENSE).
# Reference
- CogVideo: https://github.com/THUDM/CogVideo/
- Flux: https://github.com/black-forest-labs/flux
- magvit: https://github.com/google-research/magvit
- PixArt: https://github.com/PixArt-alpha/PixArt-alpha
- Open-Sora-Plan: https://github.com/PKU-YuanGroup/Open-Sora-Plan
- Open-Sora: https://github.com/hpcaitech/Open-Sora
- Animatediff: https://github.com/guoyww/AnimateDiff
- ComfyUI-EasyAnimateWrapper: https://github.com/kijai/ComfyUI-EasyAnimateWrapper
- HunYuan DiT: https://github.com/tencent/HunyuanDiT
# License
This project is licensed under the [Apache License (Version 2.0)](https://github.com/modelscope/modelscope/blob/master/LICENSE).