# Wie kann ich ein Modell zu 🤗 Transformers hinzufügen?
Die 🤗 Transformers-Bibliothek ist dank der Beiträge der Community oft in der Lage, neue Modelle anzubieten. Aber das kann ein anspruchsvolles Projekt sein und erfordert eine eingehende Kenntnis der 🤗 Transformers-Bibliothek und des zu implementierenden Modells. Bei Hugging Face versuchen wir, mehr Mitgliedern der Community die Möglichkeit zu geben, aktiv Modelle hinzuzufügen, und wir haben diese Anleitung zusammengestellt, die Sie durch den Prozess des Hinzufügens eines PyTorch-Modells führt (stellen Sie sicher, dass Sie [PyTorch installiert haben](https://pytorch.org/get-started/locally/)).
Auf dem Weg dorthin, werden Sie:
- Einblicke in bewährte Open-Source-Verfahren erhalten
- die Konstruktionsprinzipien hinter einer der beliebtesten Deep-Learning-Bibliotheken verstehen
- lernen Sie, wie Sie große Modelle effizient testen können
- lernen Sie, wie Sie Python-Hilfsprogramme wie `black`, `ruff` und `make fix-copies` integrieren, um sauberen und lesbaren Code zu gewährleisten
Ein Mitglied des Hugging Face-Teams wird Ihnen dabei zur Seite stehen, damit Sie nicht alleine sind. 🤗 ❤️
Um loszulegen, öffnen Sie eine [New model addition](https://github.com/huggingface/transformers/issues/new?assignees=&labels=New+model&template=new-model-addition.yml) Ausgabe für das Modell, das Sie in 🤗 Transformers sehen möchten. Wenn Sie nicht besonders wählerisch sind, wenn es darum geht, ein bestimmtes Modell beizusteuern, können Sie nach dem [New model label](https://github.com/huggingface/transformers/labels/New%20model) filtern, um zu sehen, ob es noch unbeanspruchte Modellanfragen gibt, und daran arbeiten.
Sobald Sie eine neue Modellanfrage eröffnet haben, sollten Sie sich zunächst mit 🤗 Transformers vertraut machen, falls Sie das noch nicht sind!
## Allgemeiner Überblick über 🤗 Transformers
Zunächst sollten Sie sich einen allgemeinen Überblick über 🤗 Transformers verschaffen. 🤗 Transformers ist eine sehr meinungsfreudige Bibliothek, es ist also möglich, dass
Es besteht also die Möglichkeit, dass Sie mit einigen der Philosophien oder Designentscheidungen der Bibliothek nicht einverstanden sind. Aus unserer Erfahrung heraus haben wir jedoch
dass die grundlegenden Designentscheidungen und Philosophien der Bibliothek entscheidend sind, um 🤗 Transformers effizient zu skalieren.
Transformatoren zu skalieren und gleichzeitig die Wartungskosten auf einem vernünftigen Niveau zu halten.
Ein guter erster Ansatzpunkt, um die Bibliothek besser zu verstehen, ist die Lektüre der [Dokumentation unserer Philosophie](Philosophie). Als Ergebnis unserer Arbeitsweise gibt es einige Entscheidungen, die wir versuchen, auf alle Modelle anzuwenden:
- Komposition wird im Allgemeinen gegenüber Abstraktion bevorzugt
- Die Duplizierung von Code ist nicht immer schlecht, wenn sie die Lesbarkeit oder Zugänglichkeit eines Modells stark verbessert
- Modelldateien sind so in sich geschlossen wie möglich, so dass Sie, wenn Sie den Code eines bestimmten Modells lesen, idealerweise nur
in die entsprechende Datei `modeling_....py` schauen müssen.
Unserer Meinung nach ist der Code der Bibliothek nicht nur ein Mittel, um ein Produkt bereitzustellen, *z.B.* die Möglichkeit, BERT für
Inferenz zu verwenden, sondern auch als das Produkt selbst, das wir verbessern wollen. Wenn Sie also ein Modell hinzufügen, ist der Benutzer nicht nur die
Person, die Ihr Modell verwenden wird, sondern auch jeder, der Ihren Code liest, zu verstehen versucht und ihn möglicherweise verbessert.
Lassen Sie uns daher ein wenig tiefer in das allgemeine Design der Bibliothek einsteigen.
### Überblick über die Modelle
Um ein Modell erfolgreich hinzuzufügen, ist es wichtig, die Interaktion zwischen Ihrem Modell und seiner Konfiguration zu verstehen,
[`PreTrainedModel`] und [`PretrainedConfig`]. Als Beispiel werden wir
das Modell, das zu 🤗 Transformers hinzugefügt werden soll, `BrandNewBert` nennen.
Schauen wir uns das mal an:
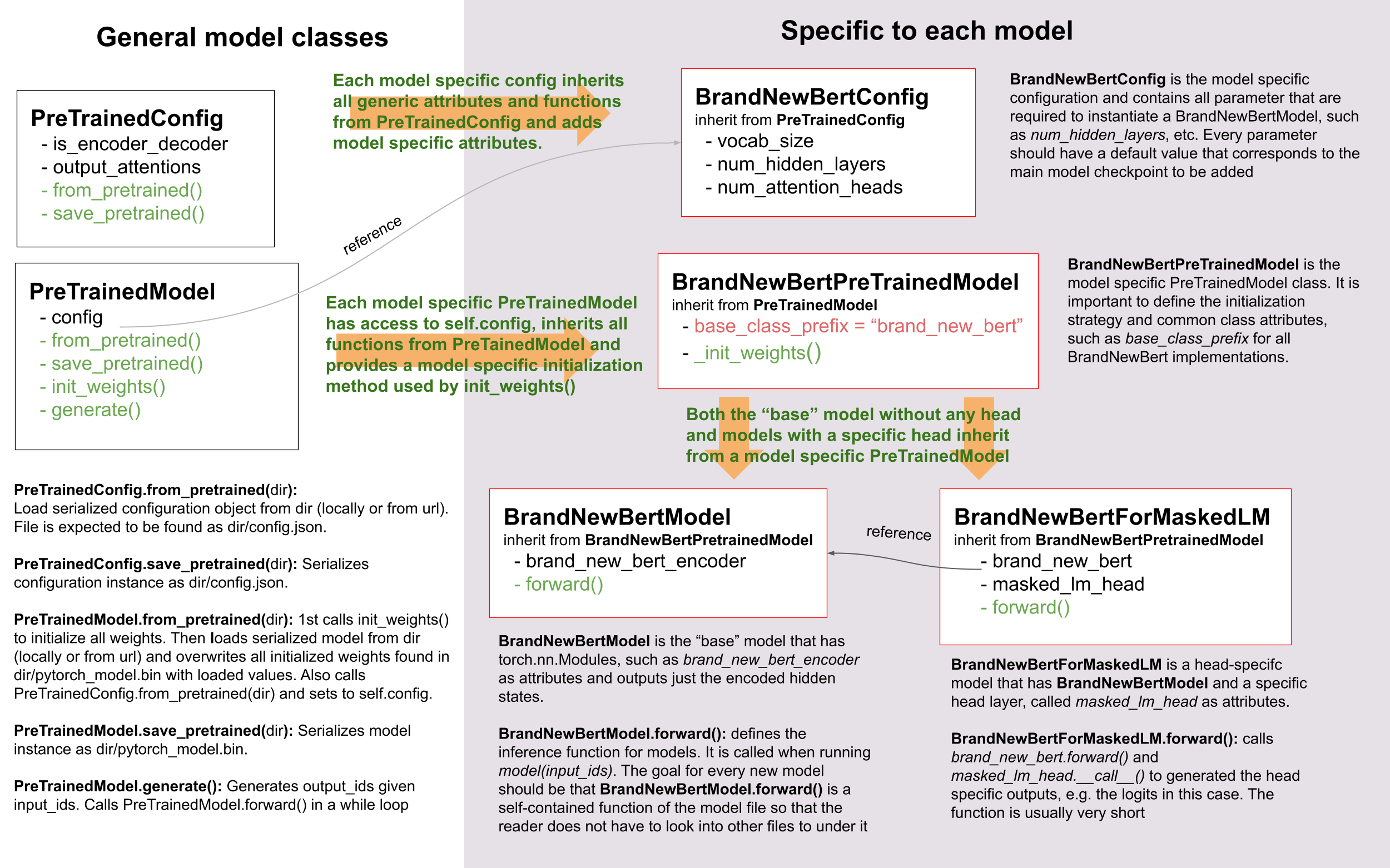 Wie Sie sehen, machen wir in 🤗 Transformers von der Vererbung Gebrauch, aber wir beschränken die Abstraktionsebene auf ein absolutes Minimum.
Minimum. Es gibt nie mehr als zwei Abstraktionsebenen für ein Modell in der Bibliothek. `BrandNewBertModel`
erbt von `BrandNewBertPreTrainedModel`, das wiederum von [`PreTrainedModel`] erbt und
das war's. In der Regel wollen wir sicherstellen, dass ein neues Modell nur von
[`PreTrainedModel`] abhängt. Die wichtigen Funktionalitäten, die jedem neuen Modell automatisch zur Verfügung gestellt werden, sind
Modell automatisch bereitgestellt werden, sind [`~PreTrainedModel.from_pretrained`] und
[`~PreTrainedModel.save_pretrained`], die für die Serialisierung und Deserialisierung verwendet werden. Alle
anderen wichtigen Funktionalitäten, wie `BrandNewBertModel.forward` sollten vollständig in der neuen
Skript `modeling_brand_new_bert.py` definiert werden. Als nächstes wollen wir sicherstellen, dass ein Modell mit einer bestimmten Kopfebene, wie z.B.
`BrandNewBertForMaskedLM` nicht von `BrandNewBertModel` erbt, sondern `BrandNewBertModel` verwendet
als Komponente, die im Forward Pass aufgerufen werden kann, um die Abstraktionsebene niedrig zu halten. Jedes neue Modell erfordert eine
Konfigurationsklasse, genannt `BrandNewBertConfig`. Diese Konfiguration wird immer als ein Attribut in
[PreTrainedModel] gespeichert und kann daher über das Attribut `config` für alle Klassen aufgerufen werden
die von `BrandNewBertPreTrainedModel` erben:
```python
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # model has access to its config
```
Ähnlich wie das Modell erbt die Konfiguration grundlegende Serialisierungs- und Deserialisierungsfunktionalitäten von
[`PretrainedConfig`]. Beachten Sie, dass die Konfiguration und das Modell immer in zwei verschiedene Formate serialisiert werden
unterschiedliche Formate serialisiert werden - das Modell in eine *pytorch_model.bin* Datei und die Konfiguration in eine *config.json* Datei. Aufruf von
[`~PreTrainedModel.save_pretrained`] wird automatisch
[`~PretrainedConfig.save_pretrained`] auf, so dass sowohl das Modell als auch die Konfiguration gespeichert werden.
### Code-Stil
Wenn Sie Ihr neues Modell kodieren, sollten Sie daran denken, dass Transformers eine Bibliothek mit vielen Meinungen ist und dass wir selbst ein paar Macken haben
wie der Code geschrieben werden sollte :-)
1. Der Vorwärtsdurchlauf Ihres Modells sollte vollständig in die Modellierungsdatei geschrieben werden und dabei völlig unabhängig von anderen
Modellen in der Bibliothek. Wenn Sie einen Block aus einem anderen Modell wiederverwenden möchten, kopieren Sie den Code und fügen ihn mit einem
`# Kopiert von` ein (siehe [hier](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/models/roberta/modeling_roberta.py#L160)
für ein gutes Beispiel und [hier](pr_checks#check-copies) für weitere Dokumentation zu Copied from).
2. Der Code sollte vollständig verständlich sein, auch für einen Nicht-Muttersprachler. Das heißt, Sie sollten
beschreibende Variablennamen wählen und Abkürzungen vermeiden. Ein Beispiel: `activation` ist `act` vorzuziehen.
Von Variablennamen mit nur einem Buchstaben wird dringend abgeraten, es sei denn, es handelt sich um einen Index in einer for-Schleife.
3. Generell ziehen wir längeren expliziten Code einem kurzen magischen Code vor.
4. Vermeiden Sie die Unterklassifizierung von `nn.Sequential` in PyTorch, sondern unterklassifizieren Sie `nn.Module` und schreiben Sie den Vorwärtspass, so dass jeder
so dass jeder, der Ihren Code verwendet, ihn schnell debuggen kann, indem er Druckanweisungen oder Haltepunkte hinzufügt.
5. Ihre Funktionssignatur sollte mit einer Typ-Annotation versehen sein. Im Übrigen sind gute Variablennamen viel lesbarer und verständlicher
verständlicher als Typ-Anmerkungen.
### Übersicht der Tokenizer
Noch nicht ganz fertig :-( Dieser Abschnitt wird bald hinzugefügt!
## Schritt-für-Schritt-Rezept zum Hinzufügen eines Modells zu 🤗 Transformers
Jeder hat andere Vorlieben, was die Portierung eines Modells angeht. Daher kann es sehr hilfreich sein, wenn Sie sich Zusammenfassungen ansehen
wie andere Mitwirkende Modelle auf Hugging Face portiert haben. Hier ist eine Liste von Blogbeiträgen aus der Community, wie man ein Modell portiert:
1. [Portierung eines GPT2-Modells](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28) von [Thomas](https://huggingface.co/thomwolf)
2. [Portierung des WMT19 MT-Modells](https://huggingface.co/blog/porting-fsmt) von [Stas](https://huggingface.co/stas)
Aus Erfahrung können wir Ihnen sagen, dass die wichtigsten Dinge, die Sie beim Hinzufügen eines Modells beachten müssen, sind:
- Erfinden Sie das Rad nicht neu! Die meisten Teile des Codes, den Sie für das neue 🤗 Transformers-Modell hinzufügen werden, existieren bereits
irgendwo in 🤗 Transformers. Nehmen Sie sich etwas Zeit, um ähnliche, bereits vorhandene Modelle und Tokenizer zu finden, die Sie kopieren können
von. [grep](https://www.gnu.org/software/grep/) und [rg](https://github.com/BurntSushi/ripgrep) sind Ihre
Freunde. Beachten Sie, dass es sehr gut möglich ist, dass der Tokenizer Ihres Modells auf einer Modellimplementierung basiert und
und der Modellierungscode Ihres Modells auf einer anderen. *Z.B.* Der Modellierungscode von FSMT basiert auf BART, während der Tokenizer-Code von FSMT
auf XLM basiert.
- Es handelt sich eher um eine technische als um eine wissenschaftliche Herausforderung. Sie sollten mehr Zeit auf die Schaffung einer
eine effiziente Debugging-Umgebung zu schaffen, als zu versuchen, alle theoretischen Aspekte des Modells in dem Papier zu verstehen.
- Bitten Sie um Hilfe, wenn Sie nicht weiterkommen! Modelle sind der Kernbestandteil von 🤗 Transformers, so dass wir bei Hugging Face mehr als
mehr als glücklich, Ihnen bei jedem Schritt zu helfen, um Ihr Modell hinzuzufügen. Zögern Sie nicht zu fragen, wenn Sie merken, dass Sie nicht weiterkommen.
Fortschritte machen.
Im Folgenden versuchen wir, Ihnen ein allgemeines Rezept an die Hand zu geben, das uns bei der Portierung eines Modells auf 🤗 Transformers am nützlichsten erschien.
Die folgende Liste ist eine Zusammenfassung all dessen, was getan werden muss, um ein Modell hinzuzufügen und kann von Ihnen als To-Do verwendet werden
Liste verwenden:
☐ (Optional) Verstehen der theoretischen Aspekte des Modells
Wie Sie sehen, machen wir in 🤗 Transformers von der Vererbung Gebrauch, aber wir beschränken die Abstraktionsebene auf ein absolutes Minimum.
Minimum. Es gibt nie mehr als zwei Abstraktionsebenen für ein Modell in der Bibliothek. `BrandNewBertModel`
erbt von `BrandNewBertPreTrainedModel`, das wiederum von [`PreTrainedModel`] erbt und
das war's. In der Regel wollen wir sicherstellen, dass ein neues Modell nur von
[`PreTrainedModel`] abhängt. Die wichtigen Funktionalitäten, die jedem neuen Modell automatisch zur Verfügung gestellt werden, sind
Modell automatisch bereitgestellt werden, sind [`~PreTrainedModel.from_pretrained`] und
[`~PreTrainedModel.save_pretrained`], die für die Serialisierung und Deserialisierung verwendet werden. Alle
anderen wichtigen Funktionalitäten, wie `BrandNewBertModel.forward` sollten vollständig in der neuen
Skript `modeling_brand_new_bert.py` definiert werden. Als nächstes wollen wir sicherstellen, dass ein Modell mit einer bestimmten Kopfebene, wie z.B.
`BrandNewBertForMaskedLM` nicht von `BrandNewBertModel` erbt, sondern `BrandNewBertModel` verwendet
als Komponente, die im Forward Pass aufgerufen werden kann, um die Abstraktionsebene niedrig zu halten. Jedes neue Modell erfordert eine
Konfigurationsklasse, genannt `BrandNewBertConfig`. Diese Konfiguration wird immer als ein Attribut in
[PreTrainedModel] gespeichert und kann daher über das Attribut `config` für alle Klassen aufgerufen werden
die von `BrandNewBertPreTrainedModel` erben:
```python
model = BrandNewBertModel.from_pretrained("brandy/brand_new_bert")
model.config # model has access to its config
```
Ähnlich wie das Modell erbt die Konfiguration grundlegende Serialisierungs- und Deserialisierungsfunktionalitäten von
[`PretrainedConfig`]. Beachten Sie, dass die Konfiguration und das Modell immer in zwei verschiedene Formate serialisiert werden
unterschiedliche Formate serialisiert werden - das Modell in eine *pytorch_model.bin* Datei und die Konfiguration in eine *config.json* Datei. Aufruf von
[`~PreTrainedModel.save_pretrained`] wird automatisch
[`~PretrainedConfig.save_pretrained`] auf, so dass sowohl das Modell als auch die Konfiguration gespeichert werden.
### Code-Stil
Wenn Sie Ihr neues Modell kodieren, sollten Sie daran denken, dass Transformers eine Bibliothek mit vielen Meinungen ist und dass wir selbst ein paar Macken haben
wie der Code geschrieben werden sollte :-)
1. Der Vorwärtsdurchlauf Ihres Modells sollte vollständig in die Modellierungsdatei geschrieben werden und dabei völlig unabhängig von anderen
Modellen in der Bibliothek. Wenn Sie einen Block aus einem anderen Modell wiederverwenden möchten, kopieren Sie den Code und fügen ihn mit einem
`# Kopiert von` ein (siehe [hier](https://github.com/huggingface/transformers/blob/v4.17.0/src/transformers/models/roberta/modeling_roberta.py#L160)
für ein gutes Beispiel und [hier](pr_checks#check-copies) für weitere Dokumentation zu Copied from).
2. Der Code sollte vollständig verständlich sein, auch für einen Nicht-Muttersprachler. Das heißt, Sie sollten
beschreibende Variablennamen wählen und Abkürzungen vermeiden. Ein Beispiel: `activation` ist `act` vorzuziehen.
Von Variablennamen mit nur einem Buchstaben wird dringend abgeraten, es sei denn, es handelt sich um einen Index in einer for-Schleife.
3. Generell ziehen wir längeren expliziten Code einem kurzen magischen Code vor.
4. Vermeiden Sie die Unterklassifizierung von `nn.Sequential` in PyTorch, sondern unterklassifizieren Sie `nn.Module` und schreiben Sie den Vorwärtspass, so dass jeder
so dass jeder, der Ihren Code verwendet, ihn schnell debuggen kann, indem er Druckanweisungen oder Haltepunkte hinzufügt.
5. Ihre Funktionssignatur sollte mit einer Typ-Annotation versehen sein. Im Übrigen sind gute Variablennamen viel lesbarer und verständlicher
verständlicher als Typ-Anmerkungen.
### Übersicht der Tokenizer
Noch nicht ganz fertig :-( Dieser Abschnitt wird bald hinzugefügt!
## Schritt-für-Schritt-Rezept zum Hinzufügen eines Modells zu 🤗 Transformers
Jeder hat andere Vorlieben, was die Portierung eines Modells angeht. Daher kann es sehr hilfreich sein, wenn Sie sich Zusammenfassungen ansehen
wie andere Mitwirkende Modelle auf Hugging Face portiert haben. Hier ist eine Liste von Blogbeiträgen aus der Community, wie man ein Modell portiert:
1. [Portierung eines GPT2-Modells](https://medium.com/huggingface/from-tensorflow-to-pytorch-265f40ef2a28) von [Thomas](https://huggingface.co/thomwolf)
2. [Portierung des WMT19 MT-Modells](https://huggingface.co/blog/porting-fsmt) von [Stas](https://huggingface.co/stas)
Aus Erfahrung können wir Ihnen sagen, dass die wichtigsten Dinge, die Sie beim Hinzufügen eines Modells beachten müssen, sind:
- Erfinden Sie das Rad nicht neu! Die meisten Teile des Codes, den Sie für das neue 🤗 Transformers-Modell hinzufügen werden, existieren bereits
irgendwo in 🤗 Transformers. Nehmen Sie sich etwas Zeit, um ähnliche, bereits vorhandene Modelle und Tokenizer zu finden, die Sie kopieren können
von. [grep](https://www.gnu.org/software/grep/) und [rg](https://github.com/BurntSushi/ripgrep) sind Ihre
Freunde. Beachten Sie, dass es sehr gut möglich ist, dass der Tokenizer Ihres Modells auf einer Modellimplementierung basiert und
und der Modellierungscode Ihres Modells auf einer anderen. *Z.B.* Der Modellierungscode von FSMT basiert auf BART, während der Tokenizer-Code von FSMT
auf XLM basiert.
- Es handelt sich eher um eine technische als um eine wissenschaftliche Herausforderung. Sie sollten mehr Zeit auf die Schaffung einer
eine effiziente Debugging-Umgebung zu schaffen, als zu versuchen, alle theoretischen Aspekte des Modells in dem Papier zu verstehen.
- Bitten Sie um Hilfe, wenn Sie nicht weiterkommen! Modelle sind der Kernbestandteil von 🤗 Transformers, so dass wir bei Hugging Face mehr als
mehr als glücklich, Ihnen bei jedem Schritt zu helfen, um Ihr Modell hinzuzufügen. Zögern Sie nicht zu fragen, wenn Sie merken, dass Sie nicht weiterkommen.
Fortschritte machen.
Im Folgenden versuchen wir, Ihnen ein allgemeines Rezept an die Hand zu geben, das uns bei der Portierung eines Modells auf 🤗 Transformers am nützlichsten erschien.
Die folgende Liste ist eine Zusammenfassung all dessen, was getan werden muss, um ein Modell hinzuzufügen und kann von Ihnen als To-Do verwendet werden
Liste verwenden:
☐ (Optional) Verstehen der theoretischen Aspekte des Modells
☐ Vorbereiten der 🤗 Transformers-Entwicklungsumgebung
☐ Debugging-Umgebung des ursprünglichen Repositorys eingerichtet
☐ Skript erstellt, das den Durchlauf `forward()` unter Verwendung des ursprünglichen Repositorys und des Checkpoints erfolgreich durchführt
☐ Erfolgreich das Modellskelett zu 🤗 Transformers hinzugefügt
☐ Erfolgreiche Umwandlung des ursprünglichen Prüfpunkts in den 🤗 Transformers-Prüfpunkt
☐ Erfolgreich den Durchlauf `forward()` in 🤗 Transformers ausgeführt, der eine identische Ausgabe wie der ursprüngliche Prüfpunkt liefert
☐ Modell-Tests in 🤗 Transformers abgeschlossen
☐ Erfolgreich Tokenizer in 🤗 Transformers hinzugefügt
☐ End-to-End-Integrationstests ausgeführt
☐ Docs fertiggestellt
☐ Modellgewichte in den Hub hochgeladen
☐ Die Pull-Anfrage eingereicht
☐ (Optional) Hinzufügen eines Demo-Notizbuchs
Für den Anfang empfehlen wir in der Regel, mit einem guten theoretischen Verständnis von `BrandNewBert` zu beginnen. Wie auch immer,
wenn Sie es vorziehen, die theoretischen Aspekte des Modells *on-the-job* zu verstehen, dann ist es völlig in Ordnung, direkt in die
in die Code-Basis von `BrandNewBert` einzutauchen. Diese Option könnte für Sie besser geeignet sein, wenn Ihre technischen Fähigkeiten besser sind als
als Ihre theoretischen Fähigkeiten, wenn Sie Schwierigkeiten haben, die Arbeit von `BrandNewBert` zu verstehen, oder wenn Sie einfach Spaß am Programmieren
mehr Spaß am Programmieren haben als am Lesen wissenschaftlicher Abhandlungen.
### 1. (Optional) Theoretische Aspekte von BrandNewBert
Sie sollten sich etwas Zeit nehmen, um die Abhandlung von *BrandNewBert* zu lesen, falls eine solche Beschreibung existiert. Möglicherweise gibt es große
Abschnitte des Papiers, die schwer zu verstehen sind. Wenn das der Fall ist, ist das in Ordnung - machen Sie sich keine Sorgen! Das Ziel ist
ist es nicht, ein tiefes theoretisches Verständnis des Papiers zu erlangen, sondern die notwendigen Informationen zu extrahieren, um
das Modell effektiv in 🤗 Transformers zu implementieren. Das heißt, Sie müssen nicht zu viel Zeit auf die
theoretischen Aspekten verbringen, sondern sich lieber auf die praktischen Aspekte konzentrieren, nämlich:
- Welche Art von Modell ist *brand_new_bert*? BERT-ähnliches Modell nur für den Encoder? GPT2-ähnliches reines Decoder-Modell? BART-ähnliches
Encoder-Decoder-Modell? Sehen Sie sich die [model_summary](model_summary) an, wenn Sie mit den Unterschieden zwischen diesen Modellen nicht vertraut sind.
- Was sind die Anwendungen von *brand_new_bert*? Textklassifizierung? Texterzeugung? Seq2Seq-Aufgaben, *z.B.,*
Zusammenfassungen?
- Was ist die neue Eigenschaft des Modells, die es von BERT/GPT-2/BART unterscheidet?
- Welches der bereits existierenden [🤗 Transformers-Modelle](https://huggingface.co/transformers/#contents) ist am ähnlichsten
ähnlich wie *brand_new_bert*?
- Welche Art von Tokenizer wird verwendet? Ein Satzteil-Tokenisierer? Ein Wortstück-Tokenisierer? Ist es derselbe Tokenisierer, der für
für BERT oder BART?
Nachdem Sie das Gefühl haben, einen guten Überblick über die Architektur des Modells erhalten zu haben, können Sie dem
Hugging Face Team schreiben und Ihre Fragen stellen. Dazu können Fragen zur Architektur des Modells gehören,
seiner Aufmerksamkeitsebene usw. Wir werden Ihnen gerne weiterhelfen.
### 2. Bereiten Sie als nächstes Ihre Umgebung vor
1. Forken Sie das [Repository](https://github.com/huggingface/transformers), indem Sie auf der Seite des Repositorys auf die Schaltfläche 'Fork' klicken.
Seite des Repositorys klicken. Dadurch wird eine Kopie des Codes unter Ihrem GitHub-Benutzerkonto erstellt.
2. Klonen Sie Ihren `transformers` Fork auf Ihre lokale Festplatte und fügen Sie das Basis-Repository als Remote hinzu:
```bash
git clone https://github.com/[your Github handle]/transformers.git
cd transformers
git remote add upstream https://github.com/huggingface/transformers.git
```
3. Richten Sie eine Entwicklungsumgebung ein, indem Sie z.B. den folgenden Befehl ausführen:
```bash
python -m venv .env
source .env/bin/activate
pip install -e ".[dev]"
```
Abhängig von Ihrem Betriebssystem und da die Anzahl der optionalen Abhängigkeiten von Transformers wächst, kann es sein, dass Sie bei diesem Befehl einen
Fehler mit diesem Befehl. Stellen Sie in diesem Fall sicher, dass Sie das Deep Learning Framework, mit dem Sie arbeiten, installieren
(PyTorch, TensorFlow und/oder Flax) und führen Sie es aus:
```bash
pip install -e ".[quality]"
```
was für die meisten Anwendungsfälle ausreichend sein sollte. Sie können dann zum übergeordneten Verzeichnis zurückkehren
```bash
cd ..
```
4. Wir empfehlen, die PyTorch-Version von *brand_new_bert* zu Transformers hinzuzufügen. Um PyTorch zu installieren, folgen Sie bitte den
Anweisungen auf https://pytorch.org/get-started/locally/.
**Anmerkung:** Sie müssen CUDA nicht installiert haben. Es reicht aus, das neue Modell auf der CPU zum Laufen zu bringen.
5. Um *brand_new_bert* zu portieren, benötigen Sie außerdem Zugriff auf das Original-Repository:
```bash
git clone https://github.com/org_that_created_brand_new_bert_org/brand_new_bert.git
cd brand_new_bert
pip install -e .
```
Jetzt haben Sie eine Entwicklungsumgebung eingerichtet, um *brand_new_bert* auf 🤗 Transformers zu portieren.
### 3.-4. Führen Sie einen Pre-Training-Checkpoint mit dem Original-Repository durch
Zunächst werden Sie mit dem ursprünglichen *brand_new_bert* Repository arbeiten. Oft ist die ursprüngliche Implementierung sehr
"forschungslastig". Das bedeutet, dass es an Dokumentation mangeln kann und der Code schwer zu verstehen sein kann. Aber das sollte
genau Ihre Motivation sein, *brand_new_bert* neu zu implementieren. Eines unserer Hauptziele bei Hugging Face ist es, *die Menschen dazu zu bringen
auf den Schultern von Giganten zu stehen*, was sich hier sehr gut darin ausdrückt, dass wir ein funktionierendes Modell nehmen und es umschreiben, um es so
es so **zugänglich, benutzerfreundlich und schön** wie möglich zu machen. Dies ist die wichtigste Motivation für die Neuimplementierung von
Modelle in 🤗 Transformers umzuwandeln - der Versuch, komplexe neue NLP-Technologie für **jeden** zugänglich zu machen.
Sie sollten damit beginnen, indem Sie in das Original-Repository eintauchen.
Die erfolgreiche Ausführung des offiziellen Pre-Trainingsmodells im Original-Repository ist oft **der schwierigste** Schritt.
Unserer Erfahrung nach ist es sehr wichtig, dass Sie einige Zeit damit verbringen, sich mit der ursprünglichen Code-Basis vertraut zu machen. Sie müssen
das Folgende herausfinden:
- Wo finden Sie die vortrainierten Gewichte?
- Wie lädt man die vorab trainierten Gewichte in das entsprechende Modell?
- Wie kann der Tokenizer unabhängig vom Modell ausgeführt werden?
- Verfolgen Sie einen Forward Pass, damit Sie wissen, welche Klassen und Funktionen für einen einfachen Forward Pass erforderlich sind. Normalerweise,
müssen Sie nur diese Funktionen reimplementieren.
- Sie müssen in der Lage sein, die wichtigen Komponenten des Modells zu finden: Wo befindet sich die Klasse des Modells? Gibt es Unterklassen des Modells,
*z.B.* EncoderModel, DecoderModel? Wo befindet sich die Selbstaufmerksamkeitsschicht? Gibt es mehrere verschiedene Aufmerksamkeitsebenen,
*z.B.* *Selbstaufmerksamkeit*, *Kreuzaufmerksamkeit*...?
- Wie können Sie das Modell in der ursprünglichen Umgebung des Repo debuggen? Müssen Sie *print* Anweisungen hinzufügen, können Sie
mit einem interaktiven Debugger wie *ipdb* arbeiten oder sollten Sie eine effiziente IDE zum Debuggen des Modells verwenden, wie z.B. PyCharm?
Es ist sehr wichtig, dass Sie, bevor Sie mit der Portierung beginnen, den Code im Original-Repository **effizient** debuggen können
Repository können! Denken Sie auch daran, dass Sie mit einer Open-Source-Bibliothek arbeiten, also zögern Sie nicht, ein Problem oder
oder sogar eine Pull-Anfrage im Original-Repository zu stellen. Die Betreuer dieses Repositorys sind wahrscheinlich sehr froh darüber
dass jemand in ihren Code schaut!
An diesem Punkt liegt es wirklich an Ihnen, welche Debugging-Umgebung und Strategie Sie zum Debuggen des ursprünglichen
Modell zu debuggen. Wir raten dringend davon ab, eine kostspielige GPU-Umgebung einzurichten, sondern arbeiten Sie einfach auf einer CPU, sowohl wenn Sie mit dem
in das ursprüngliche Repository einzutauchen und auch, wenn Sie beginnen, die 🤗 Transformers-Implementierung des Modells zu schreiben. Nur
ganz am Ende, wenn das Modell bereits erfolgreich auf 🤗 Transformers portiert wurde, sollte man überprüfen, ob das
Modell auch auf der GPU wie erwartet funktioniert.
Im Allgemeinen gibt es zwei mögliche Debugging-Umgebungen für die Ausführung des Originalmodells
- [Jupyter notebooks](https://jupyter.org/) / [google colab](https://colab.research.google.com/notebooks/intro.ipynb)
- Lokale Python-Skripte.
Jupyter-Notebooks haben den Vorteil, dass sie eine zellenweise Ausführung ermöglichen, was hilfreich sein kann, um logische Komponenten besser voneinander zu trennen und
logische Komponenten voneinander zu trennen und schnellere Debugging-Zyklen zu haben, da Zwischenergebnisse gespeichert werden können. Außerdem,
Außerdem lassen sich Notebooks oft leichter mit anderen Mitwirkenden teilen, was sehr hilfreich sein kann, wenn Sie das Hugging Face Team um Hilfe bitten möchten.
Face Team um Hilfe bitten. Wenn Sie mit Jupyter-Notizbüchern vertraut sind, empfehlen wir Ihnen dringend, mit ihnen zu arbeiten.
Der offensichtliche Nachteil von Jupyter-Notizbüchern ist, dass Sie, wenn Sie nicht daran gewöhnt sind, mit ihnen zu arbeiten, einige Zeit damit verbringen müssen
einige Zeit damit verbringen müssen, sich an die neue Programmierumgebung zu gewöhnen, und dass Sie möglicherweise Ihre bekannten Debugging-Tools nicht mehr verwenden können
wie z.B. `ipdb` nicht mehr verwenden können.
Für jede Codebasis ist es immer ein guter erster Schritt, einen **kleinen** vortrainierten Checkpoint zu laden und in der Lage zu sein, einen
einzelnen Vorwärtsdurchlauf mit einem Dummy-Integer-Vektor von Eingabe-IDs als Eingabe zu reproduzieren. Ein solches Skript könnte wie folgt aussehen (in
Pseudocode):
```python
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = [0, 4, 5, 2, 3, 7, 9] # vector of input ids
original_output = model.predict(input_ids)
```
Was die Debugging-Strategie anbelangt, so können Sie im Allgemeinen aus mehreren Strategien wählen:
- Zerlegen Sie das ursprüngliche Modell in viele kleine testbare Komponenten und führen Sie für jede dieser Komponenten einen Vorwärtsdurchlauf zur
Überprüfung
- Zerlegen Sie das ursprüngliche Modell nur in den ursprünglichen *Tokenizer* und das ursprüngliche *Modell*, führen Sie einen Vorwärtsdurchlauf für diese Komponenten durch
und verwenden Sie dazwischenliegende Druckanweisungen oder Haltepunkte zur Überprüfung.
Auch hier bleibt es Ihnen überlassen, welche Strategie Sie wählen. Oft ist die eine oder die andere Strategie vorteilhaft, je nach der ursprünglichen Codebasis
Basis.
Wenn die ursprüngliche Codebasis es Ihnen erlaubt, das Modell in kleinere Teilkomponenten zu zerlegen, *z.B.* wenn die ursprüngliche
Code-Basis problemlos im Eager-Modus ausgeführt werden kann, lohnt es sich in der Regel, dies zu tun. Es gibt einige wichtige Vorteile
am Anfang den schwierigeren Weg zu gehen:
- Wenn Sie später das ursprüngliche Modell mit der Hugging Face-Implementierung vergleichen, können Sie automatisch überprüfen, ob
für jede Komponente einzeln überprüfen, ob die entsprechende Komponente der 🤗 Transformers-Implementierung übereinstimmt, anstatt sich auf
anstatt sich auf den visuellen Vergleich über Druckanweisungen zu verlassen
- können Sie das große Problem der Portierung eines Modells in kleinere Probleme der Portierung einzelner Komponenten zerlegen
einzelnen Komponenten zu zerlegen und so Ihre Arbeit besser zu strukturieren
- Die Aufteilung des Modells in logisch sinnvolle Komponenten hilft Ihnen, einen besseren Überblick über das Design des Modells zu bekommen
und somit das Modell besser zu verstehen
- In einem späteren Stadium helfen Ihnen diese komponentenweisen Tests dabei, sicherzustellen, dass keine Regressionen auftreten, während Sie fortfahren
Ihren Code ändern
[Lysandre's](https://gist.github.com/LysandreJik/db4c948f6b4483960de5cbac598ad4ed) Integrationstests für ELECTRA
gibt ein schönes Beispiel dafür, wie dies geschehen kann.
Wenn die ursprüngliche Codebasis jedoch sehr komplex ist oder nur die Ausführung von Zwischenkomponenten in einem kompilierten Modus erlaubt,
könnte es zu zeitaufwändig oder sogar unmöglich sein, das Modell in kleinere testbare Teilkomponenten zu zerlegen. Ein gutes
Beispiel ist die [T5's MeshTensorFlow](https://github.com/tensorflow/mesh/tree/master/mesh_tensorflow) Bibliothek, die sehr komplex ist
sehr komplex ist und keine einfache Möglichkeit bietet, das Modell in seine Unterkomponenten zu zerlegen. Bei solchen Bibliotheken ist man
oft auf die Überprüfung von Druckanweisungen angewiesen.
Unabhängig davon, welche Strategie Sie wählen, ist die empfohlene Vorgehensweise oft die gleiche, nämlich dass Sie mit der Fehlersuche in den
die Anfangsebenen zuerst und die Endebenen zuletzt debuggen.
Es wird empfohlen, dass Sie die Ausgaben der folgenden Ebenen abrufen, entweder durch Druckanweisungen oder Unterkomponentenfunktionen
Schichten in der folgenden Reihenfolge abrufen:
1. Rufen Sie die Eingabe-IDs ab, die an das Modell übergeben wurden
2. Rufen Sie die Worteinbettungen ab
3. Rufen Sie die Eingabe der ersten Transformer-Schicht ab
4. Rufen Sie die Ausgabe der ersten Transformer-Schicht ab
5. Rufen Sie die Ausgabe der folgenden n - 1 Transformer-Schichten ab
6. Rufen Sie die Ausgabe des gesamten BrandNewBert Modells ab
Die Eingabe-IDs sollten dabei aus einem Array von Ganzzahlen bestehen, *z.B.* `input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]`
Die Ausgaben der folgenden Schichten bestehen oft aus mehrdimensionalen Float-Arrays und können wie folgt aussehen:
```
[[
[-0.1465, -0.6501, 0.1993, ..., 0.1451, 0.3430, 0.6024],
[-0.4417, -0.5920, 0.3450, ..., -0.3062, 0.6182, 0.7132],
[-0.5009, -0.7122, 0.4548, ..., -0.3662, 0.6091, 0.7648],
...,
[-0.5613, -0.6332, 0.4324, ..., -0.3792, 0.7372, 0.9288],
[-0.5416, -0.6345, 0.4180, ..., -0.3564, 0.6992, 0.9191],
[-0.5334, -0.6403, 0.4271, ..., -0.3339, 0.6533, 0.8694]]],
```
Wir erwarten, dass jedes zu 🤗 Transformers hinzugefügte Modell eine Reihe von Integrationstests besteht, was bedeutet, dass das ursprüngliche
Modell und die neu implementierte Version in 🤗 Transformers exakt dieselbe Ausgabe liefern müssen, und zwar mit einer Genauigkeit von 0,001!
Da es normal ist, dass das exakt gleiche Modell, das in verschiedenen Bibliotheken geschrieben wurde, je nach Bibliotheksrahmen eine leicht unterschiedliche Ausgabe liefern kann
eine leicht unterschiedliche Ausgabe liefern kann, akzeptieren wir eine Fehlertoleranz von 1e-3 (0,001). Es reicht nicht aus, wenn das Modell
fast das gleiche Ergebnis liefert, sie müssen fast identisch sein. Daher werden Sie sicherlich die Zwischenergebnisse
Zwischenergebnisse der 🤗 Transformers-Version mehrfach mit den Zwischenergebnissen der ursprünglichen Implementierung von
*brand_new_bert* vergleichen. In diesem Fall ist eine **effiziente** Debugging-Umgebung des ursprünglichen Repositorys absolut
wichtig ist. Hier sind einige Ratschläge, um Ihre Debugging-Umgebung so effizient wie möglich zu gestalten.
- Finden Sie den besten Weg, um Zwischenergebnisse zu debuggen. Ist das ursprüngliche Repository in PyTorch geschrieben? Dann sollten Sie
dann sollten Sie sich wahrscheinlich die Zeit nehmen, ein längeres Skript zu schreiben, das das ursprüngliche Modell in kleinere Unterkomponenten zerlegt, um
Zwischenwerte abzurufen. Ist das ursprüngliche Repository in Tensorflow 1 geschrieben? Dann müssen Sie sich möglicherweise auf die
TensorFlow Druckoperationen wie [tf.print](https://www.tensorflow.org/api_docs/python/tf/print) verlassen, um die
Zwischenwerte auszugeben. Ist das ursprüngliche Repository in Jax geschrieben? Dann stellen Sie sicher, dass das Modell **nicht jitted** ist, wenn
wenn Sie den Vorwärtsdurchlauf ausführen, *z.B.* schauen Sie sich [dieser Link](https://github.com/google/jax/issues/196) an.
- Verwenden Sie den kleinsten vortrainierten Prüfpunkt, den Sie finden können. Je kleiner der Prüfpunkt ist, desto schneller wird Ihr Debugging-Zyklus
wird. Es ist nicht effizient, wenn Ihr vorab trainiertes Modell so groß ist, dass Ihr Vorwärtsdurchlauf mehr als 10 Sekunden dauert.
Falls nur sehr große Checkpoints verfügbar sind, kann es sinnvoller sein, ein Dummy-Modell in der neuen
Umgebung mit zufällig initialisierten Gewichten zu erstellen und diese Gewichte zum Vergleich mit der 🤗 Transformers-Version
Ihres Modells
- Vergewissern Sie sich, dass Sie den einfachsten Weg wählen, um einen Forward Pass im ursprünglichen Repository aufzurufen. Idealerweise sollten Sie
die Funktion im originalen Repository finden, die **nur** einen einzigen Vorwärtspass aufruft, *d.h.* die oft aufgerufen wird
Vorhersagen", "Auswerten", "Vorwärts" oder "Aufruf" genannt wird. Sie wollen keine Funktion debuggen, die `forward` aufruft
mehrfach aufruft, *z.B.* um Text zu erzeugen, wie `autoregressive_sample`, `generate`.
- Versuchen Sie, die Tokenisierung vom *Forward*-Pass des Modells zu trennen. Wenn das Original-Repository Beispiele zeigt, bei denen
Sie eine Zeichenkette eingeben müssen, dann versuchen Sie herauszufinden, an welcher Stelle im Vorwärtsaufruf die Zeichenketteneingabe in Eingabe-IDs geändert wird
geändert wird und beginnen Sie an dieser Stelle. Das könnte bedeuten, dass Sie möglicherweise selbst ein kleines Skript schreiben oder den
Originalcode so ändern müssen, dass Sie die ids direkt eingeben können, anstatt eine Zeichenkette einzugeben.
- Vergewissern Sie sich, dass sich das Modell in Ihrem Debugging-Setup **nicht** im Trainingsmodus befindet, der oft dazu führt, dass das Modell
Dies führt häufig zu zufälligen Ergebnissen, da das Modell mehrere Dropout-Schichten enthält. Stellen Sie sicher, dass der Vorwärtsdurchlauf in Ihrer Debugging
Umgebung **deterministisch** ist, damit die Dropout-Schichten nicht verwendet werden. Oder verwenden Sie *transformers.utils.set_seed*.
wenn sich die alte und die neue Implementierung im selben Framework befinden.
Im folgenden Abschnitt finden Sie genauere Details/Tipps, wie Sie dies für *brand_new_bert* tun können.
### 5.-14. Portierung von BrandNewBert auf 🤗 Transformatoren
Als nächstes können Sie endlich damit beginnen, neuen Code zu 🤗 Transformers hinzuzufügen. Gehen Sie in den Klon Ihres 🤗 Transformers Forks:
```bash
cd transformers
```
In dem speziellen Fall, dass Sie ein Modell hinzufügen, dessen Architektur genau mit der Modellarchitektur eines
Modells übereinstimmt, müssen Sie nur ein Konvertierungsskript hinzufügen, wie in [diesem Abschnitt](#write-a-conversion-script) beschrieben.
In diesem Fall können Sie einfach die gesamte Modellarchitektur des bereits vorhandenen Modells wiederverwenden.
Andernfalls beginnen wir mit der Erstellung eines neuen Modells. Wir empfehlen die Verwendung des folgenden Skripts, um ein Modell hinzuzufügen
ein bestehendes Modell:
```bash
transformers-cli add-new-model-like
```
Sie werden mit einem Fragebogen aufgefordert, die grundlegenden Informationen Ihres Modells einzugeben.
**Eröffnen Sie einen Pull Request auf dem Haupt-Repositorium huggingface/transformers**
Bevor Sie mit der Anpassung des automatisch generierten Codes beginnen, ist es nun an der Zeit, einen "Work in progress (WIP)" Pull
Anfrage, *z.B.* "[WIP] Add *brand_new_bert*", in 🤗 Transformers zu öffnen, damit Sie und das Hugging Face Team
Seite an Seite an der Integration des Modells in 🤗 Transformers arbeiten können.
Sie sollten Folgendes tun:
1. Erstellen Sie eine Verzweigung mit einem beschreibenden Namen von Ihrer Hauptverzweigung
```bash
git checkout -b add_brand_new_bert
```
2. Bestätigen Sie den automatisch generierten Code:
```bash
git add .
git commit
```
3. Abrufen und zurücksetzen auf die aktuelle Haupt
```bash
git fetch upstream
git rebase upstream/main
```
4. Übertragen Sie die Änderungen auf Ihr Konto mit:
```bash
git push -u origin a-descriptive-name-for-my-changes
```
5. Wenn Sie zufrieden sind, gehen Sie auf die Webseite Ihrer Abspaltung auf GitHub. Klicken Sie auf "Pull request". Stellen Sie sicher, dass Sie das
GitHub-Handle einiger Mitglieder des Hugging Face-Teams als Reviewer hinzuzufügen, damit das Hugging Face-Team über zukünftige Änderungen informiert wird.
zukünftige Änderungen benachrichtigt wird.
6. Ändern Sie den PR in einen Entwurf, indem Sie auf der rechten Seite der GitHub-Pull-Request-Webseite auf "In Entwurf umwandeln" klicken.
Vergessen Sie im Folgenden nicht, wenn Sie Fortschritte gemacht haben, Ihre Arbeit zu committen und in Ihr Konto zu pushen, damit sie in der Pull-Anfrage erscheint.
damit sie in der Pull-Anfrage angezeigt wird. Außerdem sollten Sie darauf achten, dass Sie Ihre Arbeit von Zeit zu Zeit mit dem aktuellen main
von Zeit zu Zeit zu aktualisieren, indem Sie dies tun:
```bash
git fetch upstream
git merge upstream/main
```
Generell sollten Sie alle Fragen, die Sie in Bezug auf das Modell oder Ihre Implementierung haben, in Ihrem PR stellen und
in der PR diskutiert/gelöst werden. Auf diese Weise wird das Hugging Face Team immer benachrichtigt, wenn Sie neuen Code einreichen oder
wenn Sie eine Frage haben. Es ist oft sehr hilfreich, das Hugging Face-Team auf Ihren hinzugefügten Code hinzuweisen, damit das Hugging Face-Team Ihr Problem oder Ihre Frage besser verstehen kann.
Face-Team Ihr Problem oder Ihre Frage besser verstehen kann.
Gehen Sie dazu auf die Registerkarte "Geänderte Dateien", auf der Sie alle Ihre Änderungen sehen, gehen Sie zu einer Zeile, zu der Sie eine Frage stellen möchten
eine Frage stellen möchten, und klicken Sie auf das "+"-Symbol, um einen Kommentar hinzuzufügen. Wenn eine Frage oder ein Problem gelöst wurde,
können Sie auf die Schaltfläche "Lösen" des erstellten Kommentars klicken.
Auf dieselbe Weise wird das Hugging Face-Team Kommentare öffnen, wenn es Ihren Code überprüft. Wir empfehlen, die meisten Fragen
auf GitHub in Ihrem PR zu stellen. Für einige sehr allgemeine Fragen, die für die Öffentlichkeit nicht sehr nützlich sind, können Sie das
Hugging Face Team per Slack oder E-Mail zu stellen.
**5. Passen Sie den Code der generierten Modelle für brand_new_bert** an.
Zunächst werden wir uns nur auf das Modell selbst konzentrieren und uns nicht um den Tokenizer kümmern. Den gesamten relevanten Code sollten Sie
finden Sie in den generierten Dateien `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` und
`src/transformers/models/brand_new_bert/configuration_brand_new_bert.py`.
Jetzt können Sie endlich mit dem Programmieren beginnen :). Der generierte Code in
`src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` wird entweder die gleiche Architektur wie BERT haben, wenn
wenn es sich um ein reines Encoder-Modell handelt oder BART, wenn es sich um ein Encoder-Decoder-Modell handelt. An diesem Punkt sollten Sie sich daran erinnern, was
was Sie am Anfang über die theoretischen Aspekte des Modells gelernt haben: *Wie unterscheidet sich das Modell von BERT oder
BART?*". Implementieren Sie diese Änderungen, was oft bedeutet, dass Sie die *Selbstaufmerksamkeitsschicht*, die Reihenfolge der Normalisierungsschicht usw. ändern müssen.
Schicht usw... Auch hier ist es oft nützlich, sich die ähnliche Architektur bereits bestehender Modelle in Transformers anzusehen, um ein besseres Gefühl dafür zu bekommen
ein besseres Gefühl dafür zu bekommen, wie Ihr Modell implementiert werden sollte.
**Beachten Sie**, dass Sie an diesem Punkt nicht sehr sicher sein müssen, dass Ihr Code völlig korrekt oder sauber ist. Vielmehr ist es
Sie sollten vielmehr eine erste *unbereinigte*, kopierte Version des ursprünglichen Codes in
src/transformers/models/brand_new_bert/modeling_brand_new_bert.py" hinzuzufügen, bis Sie das Gefühl haben, dass der gesamte notwendige Code
hinzugefügt wurde. Unserer Erfahrung nach ist es viel effizienter, schnell eine erste Version des erforderlichen Codes hinzuzufügen und
den Code iterativ mit dem Konvertierungsskript zu verbessern/korrigieren, wie im nächsten Abschnitt beschrieben. Das einzige, was
zu diesem Zeitpunkt funktionieren muss, ist, dass Sie die 🤗 Transformers-Implementierung von *brand_new_bert* instanziieren können, *d.h.* der
folgende Befehl sollte funktionieren:
```python
from transformers import BrandNewBertModel, BrandNewBertConfig
model = BrandNewBertModel(BrandNewBertConfig())
```
Der obige Befehl erstellt ein Modell gemäß den Standardparametern, die in `BrandNewBertConfig()` definiert sind, mit
zufälligen Gewichten und stellt damit sicher, dass die `init()` Methoden aller Komponenten funktionieren.
Beachten Sie, dass alle zufälligen Initialisierungen in der Methode `_init_weights` Ihres `BrandnewBertPreTrainedModel` stattfinden sollten.
Klasse erfolgen sollte. Sie sollte alle Blattmodule in Abhängigkeit von den Variablen der Konfiguration initialisieren. Hier ist ein Beispiel mit der
BERT `_init_weights` Methode:
```py
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
```
Sie können weitere benutzerdefinierte Schemata verwenden, wenn Sie eine spezielle Initialisierung für einige Module benötigen. Zum Beispiel in
`Wav2Vec2ForPreTraining` müssen die letzten beiden linearen Schichten die Initialisierung des regulären PyTorch `nn.Linear` haben.
aber alle anderen sollten eine Initialisierung wie oben verwenden. Dies ist wie folgt kodiert:
```py
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, Wav2Vec2ForPreTraining):
module.project_hid.reset_parameters()
module.project_q.reset_parameters()
module.project_hid._is_hf_initialized = True
module.project_q._is_hf_initialized = True
elif isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
```
Das Flag `_is_hf_initialized` wird intern verwendet, um sicherzustellen, dass wir ein Submodul nur einmal initialisieren. Wenn Sie es auf
`True` für `module.project_q` und `module.project_hid` setzen, stellen wir sicher, dass die benutzerdefinierte Initialisierung, die wir vorgenommen haben, später nicht überschrieben wird,
die Funktion `_init_weights` nicht auf sie angewendet wird.
**6. Schreiben Sie ein Konvertierungsskript**
Als nächstes sollten Sie ein Konvertierungsskript schreiben, mit dem Sie den Checkpoint, den Sie zum Debuggen von *brand_new_bert* im
im ursprünglichen Repository in einen Prüfpunkt konvertieren, der mit Ihrer gerade erstellten 🤗 Transformers-Implementierung von
*brand_new_bert*. Es ist nicht ratsam, das Konvertierungsskript von Grund auf neu zu schreiben, sondern die bereits
bestehenden Konvertierungsskripten in 🤗 Transformers nach einem Skript zu suchen, das für die Konvertierung eines ähnlichen Modells verwendet wurde, das im
demselben Framework wie *brand_new_bert* geschrieben wurde. Normalerweise reicht es aus, ein bereits vorhandenes Konvertierungsskript zu kopieren und
es für Ihren Anwendungsfall leicht anzupassen. Zögern Sie nicht, das Hugging Face Team zu bitten, Sie auf ein ähnliches, bereits vorhandenes
Konvertierungsskript für Ihr Modell zu finden.
- Wenn Sie ein Modell von TensorFlow nach PyTorch portieren, ist ein guter Ausgangspunkt das Konvertierungsskript von BERT [hier](https://github.com/huggingface/transformers/blob/7acfa95afb8194f8f9c1f4d2c6028224dbed35a2/src/transformers/models/bert/modeling_bert.py#L91)
- Wenn Sie ein Modell von PyTorch nach PyTorch portieren, ist ein guter Ausgangspunkt das Konvertierungsskript von BART [hier](https://github.com/huggingface/transformers/blob/main/src/transformers/models/bart/convert_bart_original_pytorch_checkpoint_to_pytorch.py)
Im Folgenden werden wir kurz erklären, wie PyTorch-Modelle Ebenengewichte speichern und Ebenennamen definieren. In PyTorch wird der
Name einer Ebene durch den Namen des Klassenattributs definiert, das Sie der Ebene geben. Lassen Sie uns ein Dummy-Modell in
PyTorch, das wir `SimpleModel` nennen, wie folgt:
```python
from torch import nn
class SimpleModel(nn.Module):
def __init__(self):
super().__init__()
self.dense = nn.Linear(10, 10)
self.intermediate = nn.Linear(10, 10)
self.layer_norm = nn.LayerNorm(10)
```
Jetzt können wir eine Instanz dieser Modelldefinition erstellen, die alle Gewichte ausfüllt: `dense`, `intermediate`,
`layer_norm` mit zufälligen Gewichten. Wir können das Modell ausdrucken, um seine Architektur zu sehen
```python
model = SimpleModel()
print(model)
```
Dies gibt folgendes aus:
```
SimpleModel(
(dense): Linear(in_features=10, out_features=10, bias=True)
(intermediate): Linear(in_features=10, out_features=10, bias=True)
(layer_norm): LayerNorm((10,), eps=1e-05, elementwise_affine=True)
)
```
Wir können sehen, dass die Ebenennamen durch den Namen des Klassenattributs in PyTorch definiert sind. Sie können die Gewichtswerte
Werte einer bestimmten Ebene anzeigen lassen:
```python
print(model.dense.weight.data)
```
um zu sehen, dass die Gewichte zufällig initialisiert wurden
```
tensor([[-0.0818, 0.2207, -0.0749, -0.0030, 0.0045, -0.1569, -0.1598, 0.0212,
-0.2077, 0.2157],
[ 0.1044, 0.0201, 0.0990, 0.2482, 0.3116, 0.2509, 0.2866, -0.2190,
0.2166, -0.0212],
[-0.2000, 0.1107, -0.1999, -0.3119, 0.1559, 0.0993, 0.1776, -0.1950,
-0.1023, -0.0447],
[-0.0888, -0.1092, 0.2281, 0.0336, 0.1817, -0.0115, 0.2096, 0.1415,
-0.1876, -0.2467],
[ 0.2208, -0.2352, -0.1426, -0.2636, -0.2889, -0.2061, -0.2849, -0.0465,
0.2577, 0.0402],
[ 0.1502, 0.2465, 0.2566, 0.0693, 0.2352, -0.0530, 0.1859, -0.0604,
0.2132, 0.1680],
[ 0.1733, -0.2407, -0.1721, 0.1484, 0.0358, -0.0633, -0.0721, -0.0090,
0.2707, -0.2509],
[-0.1173, 0.1561, 0.2945, 0.0595, -0.1996, 0.2988, -0.0802, 0.0407,
0.1829, -0.1568],
[-0.1164, -0.2228, -0.0403, 0.0428, 0.1339, 0.0047, 0.1967, 0.2923,
0.0333, -0.0536],
[-0.1492, -0.1616, 0.1057, 0.1950, -0.2807, -0.2710, -0.1586, 0.0739,
0.2220, 0.2358]]).
```
Im Konvertierungsskript sollten Sie diese zufällig initialisierten Gewichte mit den genauen Gewichten der
entsprechenden Ebene im Kontrollpunkt. *Z.B.*
```python
# retrieve matching layer weights, e.g. by
# recursive algorithm
layer_name = "dense"
pretrained_weight = array_of_dense_layer
model_pointer = getattr(model, "dense")
model_pointer.weight.data = torch.from_numpy(pretrained_weight)
```
Dabei müssen Sie sicherstellen, dass jedes zufällig initialisierte Gewicht Ihres PyTorch-Modells und sein entsprechendes
Checkpoint-Gewicht in **Form und Name** genau übereinstimmen. Zu diesem Zweck ist es **notwendig**, assert
Anweisungen für die Form hinzuzufügen und die Namen der Checkpoint-Gewichte auszugeben. Sie sollten z.B. Anweisungen hinzufügen wie:
```python
assert (
model_pointer.weight.shape == pretrained_weight.shape
), f"Pointer shape of random weight {model_pointer.shape} and array shape of checkpoint weight {pretrained_weight.shape} mismatched"
```
Außerdem sollten Sie die Namen der beiden Gewichte ausdrucken, um sicherzustellen, dass sie übereinstimmen, *z.B.*.
```python
logger.info(f"Initialize PyTorch weight {layer_name} from {pretrained_weight.name}")
```
Wenn entweder die Form oder der Name nicht übereinstimmt, haben Sie wahrscheinlich das falsche Kontrollpunktgewicht einer zufällig
Ebene der 🤗 Transformers-Implementierung zugewiesen.
Eine falsche Form ist höchstwahrscheinlich auf eine falsche Einstellung der Konfigurationsparameter in `BrandNewBertConfig()` zurückzuführen, die
nicht genau mit denen übereinstimmen, die für den zu konvertierenden Prüfpunkt verwendet wurden. Es könnte aber auch sein, dass
die PyTorch-Implementierung eines Layers erfordert, dass das Gewicht vorher transponiert wird.
Schließlich sollten Sie auch überprüfen, ob **alle** erforderlichen Gewichte initialisiert sind und alle Checkpoint-Gewichte ausgeben, die
die nicht zur Initialisierung verwendet wurden, um sicherzustellen, dass das Modell korrekt konvertiert wurde. Es ist völlig normal, dass die
Konvertierungsversuche entweder mit einer falschen Shape-Anweisung oder einer falschen Namenszuweisung fehlschlagen. Das liegt höchstwahrscheinlich daran, dass entweder
Sie haben falsche Parameter in `BrandNewBertConfig()` verwendet, haben eine falsche Architektur in der 🤗 Transformers
Implementierung, Sie haben einen Fehler in den `init()` Funktionen einer der Komponenten der 🤗 Transformers
Implementierung oder Sie müssen eine der Kontrollpunktgewichte transponieren.
Dieser Schritt sollte mit dem vorherigen Schritt wiederholt werden, bis alle Gewichte des Kontrollpunkts korrekt in das
Transformers-Modell geladen sind. Nachdem Sie den Prüfpunkt korrekt in die 🤗 Transformers-Implementierung geladen haben, können Sie das Modell
das Modell unter einem Ordner Ihrer Wahl `/path/to/converted/checkpoint/folder` speichern, der dann sowohl ein
Datei `pytorch_model.bin` und eine Datei `config.json` enthalten sollte:
```python
model.save_pretrained("/path/to/converted/checkpoint/folder")
```
**7. Implementieren Sie den Vorwärtspass**
Nachdem es Ihnen gelungen ist, die trainierten Gewichte korrekt in die 🤗 Transformers-Implementierung zu laden, sollten Sie nun dafür sorgen
sicherstellen, dass der Forward Pass korrekt implementiert ist. In [Machen Sie sich mit dem ursprünglichen Repository vertraut](#3-4-führen-sie-einen-pre-training-checkpoint-mit-dem-original-repository-durch) haben Sie bereits ein Skript erstellt, das einen Forward Pass
Durchlauf des Modells unter Verwendung des Original-Repositorys durchführt. Jetzt sollten Sie ein analoges Skript schreiben, das die 🤗 Transformers
Implementierung anstelle der Originalimplementierung verwenden. Es sollte wie folgt aussehen:
```python
model = BrandNewBertModel.from_pretrained("/path/to/converted/checkpoint/folder")
input_ids = [0, 4, 4, 3, 2, 4, 1, 7, 19]
output = model(input_ids).last_hidden_states
```
Es ist sehr wahrscheinlich, dass die 🤗 Transformers-Implementierung und die ursprüngliche Modell-Implementierung nicht genau die gleiche Ausgabe liefern.
beim ersten Mal nicht die gleiche Ausgabe liefern oder dass der Vorwärtsdurchlauf einen Fehler auslöst. Seien Sie nicht enttäuscht - das ist zu erwarten! Erstens,
sollten Sie sicherstellen, dass der Vorwärtsdurchlauf keine Fehler auslöst. Es passiert oft, dass die falschen Dimensionen verwendet werden
verwendet werden, was zu einem *Dimensionality mismatch* Fehler führt oder dass der falsche Datentyp verwendet wird, *z.B.* `torch.long`
anstelle von `torch.float32`. Zögern Sie nicht, das Hugging Face Team um Hilfe zu bitten, wenn Sie bestimmte Fehler nicht lösen können.
bestimmte Fehler nicht lösen können.
Um sicherzustellen, dass die Implementierung von 🤗 Transformers korrekt funktioniert, müssen Sie sicherstellen, dass die Ausgaben
einer Genauigkeit von `1e-3` entsprechen. Zunächst sollten Sie sicherstellen, dass die Ausgabeformen identisch sind, *d.h.*.
Die Ausgabeform *outputs.shape* sollte für das Skript der 🤗 Transformers-Implementierung und die ursprüngliche
Implementierung ergeben. Als nächstes sollten Sie sicherstellen, dass auch die Ausgabewerte identisch sind. Dies ist einer der schwierigsten
Teile des Hinzufügens eines neuen Modells. Häufige Fehler, warum die Ausgaben nicht identisch sind, sind:
- Einige Ebenen wurden nicht hinzugefügt, *d.h.* eine *Aktivierungsebene* wurde nicht hinzugefügt, oder die Restverbindung wurde vergessen
- Die Worteinbettungsmatrix wurde nicht gebunden
- Es werden die falschen Positionseinbettungen verwendet, da die ursprüngliche Implementierung einen Offset verwendet
- Dropout wird während des Vorwärtsdurchlaufs angewendet. Um dies zu beheben, stellen Sie sicher, dass *model.training auf False* steht und dass keine Dropout
Schicht während des Vorwärtsdurchlaufs fälschlicherweise aktiviert wird, *d.h.* übergeben Sie *self.training* an [PyTorch's functional dropout](https://pytorch.org/docs/stable/nn.functional.html?highlight=dropout#torch.nn.functional.dropout)
Der beste Weg, das Problem zu beheben, besteht normalerweise darin, sich den Vorwärtsdurchlauf der ursprünglichen Implementierung und die 🤗
Transformers-Implementierung nebeneinander zu sehen und zu prüfen, ob es Unterschiede gibt. Idealerweise sollten Sie die
Zwischenergebnisse beider Implementierungen des Vorwärtsdurchlaufs debuggen/ausdrucken, um die genaue Position im Netzwerk zu finden, an der die 🤗
Transformers-Implementierung eine andere Ausgabe zeigt als die ursprüngliche Implementierung. Stellen Sie zunächst sicher, dass die
hartcodierten `input_ids` in beiden Skripten identisch sind. Überprüfen Sie dann, ob die Ausgaben der ersten Transformation von
der `input_ids` (normalerweise die Worteinbettungen) identisch sind. Und dann arbeiten Sie sich bis zur allerletzten Schicht des
Netzwerks. Irgendwann werden Sie einen Unterschied zwischen den beiden Implementierungen feststellen, der Sie auf den Fehler
in der Implementierung von 🤗 Transformers hinweist. Unserer Erfahrung nach ist ein einfacher und effizienter Weg, viele Druckanweisungen hinzuzufügen
sowohl in der Original-Implementierung als auch in der 🤗 Transformers-Implementierung an den gleichen Stellen im Netzwerk
hinzuzufügen und nacheinander Druckanweisungen zu entfernen, die dieselben Werte für Zwischenpräsentationen anzeigen.
Wenn Sie sicher sind, dass beide Implementierungen die gleiche Ausgabe liefern, überprüfen Sie die Ausgaben mit
`torch.allclose(original_output, output, atol=1e-3)` überprüfen, haben Sie den schwierigsten Teil hinter sich! Herzlichen Glückwunsch - die
Arbeit, die noch zu erledigen ist, sollte ein Kinderspiel sein 😊.
**8. Hinzufügen aller notwendigen Modelltests**
An diesem Punkt haben Sie erfolgreich ein neues Modell hinzugefügt. Es ist jedoch sehr gut möglich, dass das Modell noch nicht
noch nicht vollständig mit dem erforderlichen Design übereinstimmt. Um sicherzustellen, dass die Implementierung vollständig kompatibel mit 🤗 Transformers ist, sollten alle
gemeinsamen Tests bestehen. Der Cookiecutter sollte automatisch eine Testdatei für Ihr Modell hinzugefügt haben, wahrscheinlich unter
demselben `tests/models/brand_new_bert/test_modeling_brand_new_bert.py`. Führen Sie diese Testdatei aus, um zu überprüfen, ob alle gängigen
Tests bestehen:
```bash
pytest tests/models/brand_new_bert/test_modeling_brand_new_bert.py
```
Nachdem Sie alle allgemeinen Tests festgelegt haben, müssen Sie nun sicherstellen, dass all die schöne Arbeit, die Sie geleistet haben, gut getestet ist, damit
- a) die Community Ihre Arbeit leicht nachvollziehen kann, indem sie sich spezifische Tests von *brand_new_bert* ansieht
- b) zukünftige Änderungen an Ihrem Modell keine wichtigen Funktionen des Modells zerstören.
Als erstes sollten Sie Integrationstests hinzufügen. Diese Integrationstests tun im Wesentlichen dasselbe wie die Debugging-Skripte
die Sie zuvor zur Implementierung des Modells in 🤗 Transformers verwendet haben. Eine Vorlage für diese Modelltests wurde bereits von dem
Cookiecutter hinzugefügt, die `BrandNewBertModelIntegrationTests` heißt und nur noch von Ihnen ausgefüllt werden muss. Um sicherzustellen, dass diese
Tests erfolgreich sind, führen Sie
```bash
RUN_SLOW=1 pytest -sv tests/models/brand_new_bert/test_modeling_brand_new_bert.py::BrandNewBertModelIntegrationTests
```
Falls Sie Windows verwenden, sollten Sie `RUN_SLOW=1` durch `SET RUN_SLOW=1` ersetzen.
Zweitens sollten alle Funktionen, die speziell für *brand_new_bert* sind, zusätzlich in einem separaten Test getestet werden unter
`BrandNewBertModelTester`/`BrandNewBertModelTest`. Dieser Teil wird oft vergessen, ist aber in zweierlei Hinsicht äußerst nützlich
Weise:
- Er hilft dabei, das Wissen, das Sie während der Modellerweiterung erworben haben, an die Community weiterzugeben, indem er zeigt, wie die
speziellen Funktionen von *brand_new_bert* funktionieren sollten.
- Künftige Mitwirkende können Änderungen am Modell schnell testen, indem sie diese speziellen Tests ausführen.
**9. Implementieren Sie den Tokenizer**
Als nächstes sollten wir den Tokenizer von *brand_new_bert* hinzufügen. Normalerweise ist der Tokenizer äquivalent oder sehr ähnlich zu einem
bereits vorhandenen Tokenizer von 🤗 Transformers.
Es ist sehr wichtig, die ursprüngliche Tokenizer-Datei zu finden/extrahieren und es zu schaffen, diese Datei in die 🤗
Transformers Implementierung des Tokenizers zu laden.
Um sicherzustellen, dass der Tokenizer korrekt funktioniert, empfiehlt es sich, zunächst ein Skript im ursprünglichen Repository zu erstellen
zu erstellen, das eine Zeichenkette eingibt und die `input_ids` zurückgibt. Es könnte etwa so aussehen (in Pseudocode):
```python
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
model = BrandNewBertModel.load_pretrained_checkpoint("/path/to/checkpoint/")
input_ids = model.tokenize(input_str)
```
Möglicherweise müssen Sie noch einmal einen Blick in das ursprüngliche Repository werfen, um die richtige Tokenizer-Funktion zu finden, oder Sie müssen
Sie müssen vielleicht sogar Änderungen an Ihrem Klon des Original-Repositorys vornehmen, um nur die `input_ids` auszugeben. Nach dem Schreiben
ein funktionierendes Tokenisierungsskript geschrieben, das das ursprüngliche Repository verwendet, sollten Sie ein analoges Skript für 🤗 Transformers
erstellt werden. Es sollte ähnlich wie dieses aussehen:
```python
from transformers import BrandNewBertTokenizer
input_str = "This is a long example input string containing special characters .$?-, numbers 2872 234 12 and words."
tokenizer = BrandNewBertTokenizer.from_pretrained("/path/to/tokenizer/folder/")
input_ids = tokenizer(input_str).input_ids
```
Wenn beide `input_ids` die gleichen Werte ergeben, sollte als letzter Schritt auch eine Tokenizer-Testdatei hinzugefügt werden.
Analog zu den Modellierungstestdateien von *brand_new_bert* sollten auch die Tokenisierungs-Testdateien von *brand_new_bert*
eine Reihe von fest kodierten Integrationstests enthalten.
**10. Führen Sie End-to-End-Integrationstests aus**
Nachdem Sie den Tokenizer hinzugefügt haben, sollten Sie auch ein paar End-to-End-Integrationstests, die sowohl das Modell als auch den
Tokenizer zu `tests/models/brand_new_bert/test_modeling_brand_new_bert.py` in 🤗 Transformers.
Ein solcher Test sollte bei einem aussagekräftigen
Text-zu-Text-Beispiel zeigen, dass die Implementierung von 🤗 Transformers wie erwartet funktioniert. Ein aussagekräftiges Text-zu-Text-Beispiel kann
z.B. *ein Quell-zu-Ziel-Übersetzungspaar, ein Artikel-zu-Zusammenfassung-Paar, ein Frage-zu-Antwort-Paar, usw... Wenn keiner der
der portierten Prüfpunkte in einer nachgelagerten Aufgabe feinabgestimmt wurde, genügt es, sich einfach auf die Modelltests zu verlassen. In einem
letzten Schritt, um sicherzustellen, dass das Modell voll funktionsfähig ist, sollten Sie alle Tests auch auf der GPU durchführen. Es kann
Es kann vorkommen, dass Sie vergessen haben, einige `.to(self.device)` Anweisungen zu internen Tensoren des Modells hinzuzufügen, was in einem solchen
Test zu einem Fehler führen würde. Falls Sie keinen Zugang zu einem Grafikprozessor haben, kann das Hugging Face Team diese Tests für Sie durchführen.
Tests für Sie übernehmen.
**11. Docstring hinzufügen**
Nun sind alle notwendigen Funktionen für *brand_new_bert* hinzugefügt - Sie sind fast fertig! Das Einzige, was Sie noch hinzufügen müssen, ist
ein schöner Docstring und eine Doku-Seite. Der Cookiecutter sollte eine Vorlagendatei namens
`docs/source/model_doc/brand_new_bert.md` hinzugefügt haben, die Sie ausfüllen sollten. Die Benutzer Ihres Modells werden in der Regel zuerst einen Blick auf
diese Seite ansehen, bevor sie Ihr Modell verwenden. Daher muss die Dokumentation verständlich und prägnant sein. Es ist sehr nützlich für
die Gemeinschaft, einige *Tipps* hinzuzufügen, um zu zeigen, wie das Modell verwendet werden sollte. Zögern Sie nicht, das Hugging Face-Team anzupingen
bezüglich der Docstrings.
Stellen Sie als nächstes sicher, dass der zu `src/transformers/models/brand_new_bert/modeling_brand_new_bert.py` hinzugefügte docstring
korrekt ist und alle erforderlichen Eingaben und Ausgaben enthält. Wir haben eine ausführliche Anleitung zum Schreiben von Dokumentationen und unserem Docstring-Format [hier](writing-documentation). Es ist immer gut, sich daran zu erinnern, dass die Dokumentation
mindestens so sorgfältig behandelt werden sollte wie der Code in 🤗 Transformers, denn die Dokumentation ist in der Regel der erste Kontaktpunkt der
Berührungspunkt der Community mit dem Modell ist.
**Code refactor**
Großartig, jetzt haben Sie den gesamten erforderlichen Code für *brand_new_bert* hinzugefügt. An diesem Punkt sollten Sie einige mögliche
falschen Codestil korrigieren, indem Sie ausführen:
```bash
make style
```
und überprüfen Sie, ob Ihr Kodierungsstil die Qualitätsprüfung besteht:
```bash
make quality
```
Es gibt noch ein paar andere sehr strenge Designtests in 🤗 Transformers, die möglicherweise noch fehlschlagen, was sich in den
den Tests Ihres Pull Requests. Dies liegt oft an fehlenden Informationen im Docstring oder an einer falschen
Benennung. Das Hugging Face Team wird Ihnen sicherlich helfen, wenn Sie hier nicht weiterkommen.
Und schließlich ist es immer eine gute Idee, den eigenen Code zu refaktorisieren, nachdem man sichergestellt hat, dass er korrekt funktioniert. Wenn alle
Tests bestanden haben, ist es nun an der Zeit, den hinzugefügten Code noch einmal durchzugehen und einige Überarbeitungen vorzunehmen.
Sie haben nun den Codierungsteil abgeschlossen, herzlichen Glückwunsch! 🎉 Sie sind großartig! 😎
**12. Laden Sie die Modelle in den Model Hub hoch**
In diesem letzten Teil sollten Sie alle Checkpoints konvertieren und in den Modell-Hub hochladen und eine Modellkarte für jeden
hochgeladenen Modell-Kontrollpunkt. Sie können sich mit den Hub-Funktionen vertraut machen, indem Sie unsere [Model sharing and uploading Page](model_sharing) lesen. Hier sollten Sie mit dem Hugging Face-Team zusammenarbeiten, um einen passenden Namen für jeden
Checkpoint festzulegen und die erforderlichen Zugriffsrechte zu erhalten, um das Modell unter der Organisation des Autors *brand_new_bert* hochladen zu können.
*brand_new_bert*. Die Methode `push_to_hub`, die in allen Modellen in `transformers` vorhanden ist, ist ein schneller und effizienter Weg, Ihren Checkpoint in den Hub zu pushen. Ein kleines Snippet ist unten eingefügt:
```python
brand_new_bert.push_to_hub("brand_new_bert")
# Uncomment the following line to push to an organization.
# brand_new_bert.push_to_hub("/brand_new_bert")
```
Es lohnt sich, etwas Zeit darauf zu verwenden, für jeden Kontrollpunkt passende Musterkarten zu erstellen. Die Modellkarten sollten die
spezifischen Merkmale dieses bestimmten Prüfpunkts hervorheben, * z.B.* auf welchem Datensatz wurde der Prüfpunkt
vortrainiert/abgestimmt? Für welche nachgelagerte Aufgabe sollte das Modell verwendet werden? Und fügen Sie auch etwas Code bei, wie Sie
wie das Modell korrekt verwendet wird.
**13. (Optional) Notizbuch hinzufügen**
Es ist sehr hilfreich, ein Notizbuch hinzuzufügen, in dem im Detail gezeigt wird, wie *brand_new_bert* für Schlussfolgerungen verwendet werden kann und/oder
bei einer nachgelagerten Aufgabe feinabgestimmt wird. Dies ist nicht zwingend erforderlich, um Ihren PR zusammenzuführen, aber sehr nützlich für die Gemeinschaft.
**14. Reichen Sie Ihren fertigen PR ein**
Sie sind jetzt mit der Programmierung fertig und können zum letzten Schritt übergehen, nämlich der Zusammenführung Ihres PR mit main. Normalerweise hat das
Hugging Face Team Ihnen an diesem Punkt bereits geholfen haben, aber es lohnt sich, sich etwas Zeit zu nehmen, um Ihrem fertigen
PR eine schöne Beschreibung zu geben und eventuell Kommentare zu Ihrem Code hinzuzufügen, wenn Sie Ihren Gutachter auf bestimmte Designentscheidungen hinweisen wollen.
Gutachter hinweisen wollen.
### Teilen Sie Ihre Arbeit!!
Jetzt ist es an der Zeit, von der Community Anerkennung für Ihre Arbeit zu bekommen! Die Fertigstellung einer Modellergänzung ist ein wichtiger
Beitrag zu Transformers und der gesamten NLP-Gemeinschaft. Ihr Code und die portierten vortrainierten Modelle werden sicherlich
von Hunderten und vielleicht sogar Tausenden von Entwicklern und Forschern genutzt werden. Sie sollten stolz auf Ihre Arbeit sein und Ihre
Ihre Leistung mit der Gemeinschaft teilen.
**Sie haben ein weiteres Modell erstellt, das für jeden in der Community super einfach zugänglich ist! 🤯**