

Update README.md
Browse files
README.md
CHANGED
|
@@ -49,11 +49,12 @@ scores = model.predict([(Query, Paragraph1), (Query, Paragraph2)])
|
|
| 49 |
|
| 50 |
We evaluate our model on two different datasets using the metrics **MAP**, **MRR** and **NDCG@10**:
|
| 51 |
|
| 52 |
-
The purpose of this evaluation is to highlight the performance of our model with regards to: Relevant/Irrelevant labels and
|
| 53 |
|
| 54 |
-
|
| 55 |
-
2 - Dataset 2: [NAMAA-Space/Ar-Reranking-Eval](https://huggingface.co/datasets/NAMAA-Space/Ar-Reranking-Eval)
|
| 56 |
|
| 57 |
-
|
| 58 |
|
| 59 |
-
|
|
|
|
|
|
|
|
|
| 49 |
|
| 50 |
We evaluate our model on two different datasets using the metrics **MAP**, **MRR** and **NDCG@10**:
|
| 51 |
|
| 52 |
+
The purpose of this evaluation is to highlight the performance of our model with regards to: Relevant/Irrelevant labels and positive/multiple negatives documents:
|
| 53 |
|
| 54 |
+
Dataset 1: [NAMAA-Space/Ar-Reranking-Eval](https://huggingface.co/datasets/NAMAA-Space/Ar-Reranking-Eval)
|
|
|
|
| 55 |
|
| 56 |
+
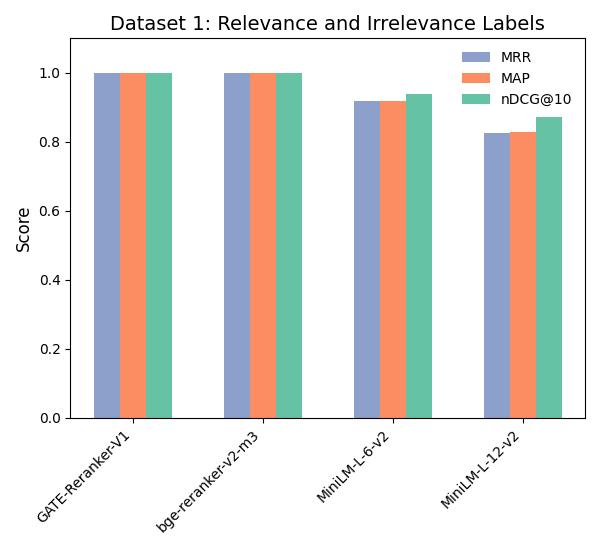
|
| 57 |
|
| 58 |
+
Dataset 2: [NAMAA-Space/Arabic-Reranking-Triplet-5-Eval](https://huggingface.co/datasets/NAMAA-Space/Arabic-Reranking-Triplet-5-Eval)
|
| 59 |
+
|
| 60 |
+
and compare it to other famous models on the hub
|