

Commit
·
60a8f97
1
Parent(s):
e875200
Upload 7 files
Browse files- README.md +177 -0
- cc-arc-curve.png +0 -0
- cc-hellaswag-curve.png +0 -0
- cc-humaneval-curve.png +0 -0
- cc-mbpp-curve.png +0 -0
- cc-mmlu-cuve.png +0 -0
- cc-truthfulqa-curve.png +0 -0
README.md
ADDED
|
@@ -0,0 +1,177 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# CrystalCoder
|
| 2 |
+
|
| 3 |
+
CrystalCoder is a state-of-the-art 7B parameter language model, distinctively trained on the SlimPajama and StarCoder datasets. This model excels in balancing natural language processing and coding capabilities. Despite being trained on a smaller dataset of 1.4 trillion tokens—compared to LLaMA 2's 2 trillion—CrystalCoder surpasses LLaMA 2 in some challenging English and coding tasks. It demonstrates superior performance in benchmarks like MMLU, HumanEval, and MBPP.
|
| 4 |
+
|
| 5 |
+
| Model | Trained Tokens | MMLU (5-shot) | HumanEval (pass@1) | MBPP (pass@1) |
|
| 6 |
+
| --- | --- | --- | --- | --- |
|
| 7 |
+
| CrystalCoder 7B | 1.4T | **48.77%** | **28.38%** | **37.84%** |
|
| 8 |
+
| LLaMA 2 7B | 2T | 46.87% | 13.26% | 16.76% |
|
| 9 |
+
|
| 10 |
+
## About LLM360
|
| 11 |
+
LLM360 is an initiative for comprehensive and fully open-sourced LLMs,
|
| 12 |
+
where all training details, model checkpoints, intermediate results, and
|
| 13 |
+
additional analyses are made available to the community. Our goal is to advance
|
| 14 |
+
the field by inviting the community to deepen the understanding of LLMs
|
| 15 |
+
together. As the first step of the project LLM360, we release all intermediate
|
| 16 |
+
model checkpoints, our fully-prepared pre-training dataset, all source code and
|
| 17 |
+
configurations, and training details. We are
|
| 18 |
+
committed to continually pushing the boundaries of LLMs through this open-source
|
| 19 |
+
effort.
|
| 20 |
+
|
| 21 |
+
Get access now at [LLM360 site](https://www.llm360.ai/)
|
| 22 |
+
|
| 23 |
+
## Model Description
|
| 24 |
+
|
| 25 |
+
- **Model type:** Language model with the same architecture as LLaMA-7B
|
| 26 |
+
- **Language(s) (NLP):** English
|
| 27 |
+
- **License:** Apache 2.0
|
| 28 |
+
- **Resources for more information:**
|
| 29 |
+
- [Training Code](https://github.com/LLM360/crystalcoder-train)
|
| 30 |
+
- [Data Preparation](https://github.com/LLM360/crystalcoder-data-prep)
|
| 31 |
+
- [Metrics](https://github.com/LLM360/Analysis360)
|
| 32 |
+
- [Fully processed Amber pretraining data](https://huggingface.co/datasets/LLM360/CrystalCoderDatasets)
|
| 33 |
+
|
| 34 |
+
# Model Architecture
|
| 35 |
+
|
| 36 |
+
CrystalCoder leverages a GPT-like architecture, akin to LLaMA, but with the addition of maximal update parameterization (**muP**).
|
| 37 |
+
|
| 38 |
+
Key modifications introduced by muP include:
|
| 39 |
+
|
| 40 |
+
1. Input embeddings are scaled by `mup_embeddings_scale`.
|
| 41 |
+
2. Output logits are scaled by `mup_output_alpha` * `mup_width_scale`.
|
| 42 |
+
3. Attention weights scaling is refined to division by the hidden dimension size (`(QK^T)/d`) instead of its square root (`(QK^T)/sqrt(d)`).
|
| 43 |
+
4. Learning rates and weight decay are optimized for different parameter groups:
|
| 44 |
+
- Embedding layer: LR=`BASE_LR`, WD=`BASE_WD`.
|
| 45 |
+
- Normalization layers: LR=`BASE_LR`, WD=0.
|
| 46 |
+
- Other Parameters: LR=`BASE_LR` * `mup_width_scale`, WD=`BASE_WD`.
|
| 47 |
+
5. Initialization ranges are determined based on muP hyperparameters.
|
| 48 |
+
|
| 49 |
+
The muP hyperparameters are set as follows:
|
| 50 |
+
|
| 51 |
+
- `mup_embeddings_scale`: 14.6
|
| 52 |
+
- `mup_output_alpha`: 2.22
|
| 53 |
+
- `mup_width_scale`: 0.0625
|
| 54 |
+
|
| 55 |
+
For other architecture choices:
|
| 56 |
+
- We use `LayerNorm` instead of `RMSNorm`.
|
| 57 |
+
- Rotary position embeddings applied to only the first `25%` of hidden dimensions.
|
| 58 |
+
- Training sequence length is `2048`.
|
| 59 |
+
- Embedding dimension is `32032`.
|
| 60 |
+
|
| 61 |
+
# Tokenization
|
| 62 |
+
|
| 63 |
+
Our tokenizer is based on the LLaMA tokenizer, with 22 additional special tokens for the following usage:
|
| 64 |
+
- 4 filling-in-middle (FIM) tokens such as `<|fim_prefix|>` to support FIM inference.
|
| 65 |
+
- 14 spcial tokens such as `<|filename|>`, `<|jupyter_start|>`, `<|reponame|>` to support meta data for code dataset following StarCoder's method.
|
| 66 |
+
- 4 special tokens such as `<|sys_start|>`, `<|im_start|>` to support instruction tuning.
|
| 67 |
+
|
| 68 |
+
Therefore, we extended the LLaMA tokenizer vocabulary size from `32000` to `32032`. Some token ids are reserved and not used.
|
| 69 |
+
|
| 70 |
+
# Training
|
| 71 |
+
|
| 72 |
+
Our training has 3 stages:
|
| 73 |
+
- Stage 1: Pretraining on first half of SlimPajama (50% x 690B = 345B).
|
| 74 |
+
- Stage 2: Pretraining on the other half of SlimPajama (50% x 690B = 345B), plus two epochs of StarCoder Data (2 x 291B).
|
| 75 |
+
- Stage 3: Pretraining on `100B` additional Python and web-related data (HTML, JavaScript, CSS) sampled from StarCoder Data, and `10B` tokens sampled from SlimPajama.
|
| 76 |
+
|
| 77 |
+
For details of the training dataset for each stage, please refer to the Dataset section and our CrystalCoder Data Card.
|
| 78 |
+
|
| 79 |
+
For hyperparameters used in each stage, please refer to the following table:
|
| 80 |
+
<|TABLE_NEEDED|>
|
| 81 |
+
|
| 82 |
+
For more details of training, please refer to our future paper and blog.
|
| 83 |
+
|
| 84 |
+
# Dataset
|
| 85 |
+
|
| 86 |
+
Our tokenized datasets for all phases are available at [CrystalCoderDatasets](https://huggingface.co/datasets/LLM360/CrystalCoderDatasets).
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
# Model Usage
|
| 90 |
+
|
| 91 |
+
To load a specific checkpoint, use the revision argument as shown below, for example, `CrystalCoder_phase1_checkpoint_055500`. All the revisions can be seen from the branch dropdown in the "Files and versions" tab. If no revision argument is provided, it will load the phase 3 final checkpoint `CrystalCoder_phase3_checkpoint_027728`.
|
| 92 |
+
|
| 93 |
+
```python
|
| 94 |
+
from transformers import AutoModelForCausalLM, AutoTokenizer
|
| 95 |
+
|
| 96 |
+
tokenizer = AutoTokenizer.from_pretrained(
|
| 97 |
+
f"LLM360/CrystalCoder",
|
| 98 |
+
revision="CrystalCoder_phase1_checkpoint_055500",
|
| 99 |
+
trust_remote_code=True
|
| 100 |
+
)
|
| 101 |
+
model = AutoModelForCausalLM.from_pretrained(
|
| 102 |
+
f"LLM360/CrystalCoder",
|
| 103 |
+
revision="CrystalCoder_phase1_checkpoint_055500",
|
| 104 |
+
trust_remote_code=True
|
| 105 |
+
)
|
| 106 |
+
|
| 107 |
+
prompt = 'int add(int x, int y) {'
|
| 108 |
+
|
| 109 |
+
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
|
| 110 |
+
gen_tokens = model.generate(input_ids, do_sample=True, max_length=400)
|
| 111 |
+
|
| 112 |
+
print("-"*20 + "Output for model" + 20 * '-')
|
| 113 |
+
print(tokenizer.batch_decode(gen_tokens)[0])
|
| 114 |
+
```
|
| 115 |
+
|
| 116 |
+
## Completion Example:
|
| 117 |
+
|
| 118 |
+
### prompt:
|
| 119 |
+
|
| 120 |
+
```python
|
| 121 |
+
from typing import List
|
| 122 |
+
def has_close_elements(numbers: List[float], threshold: float) -> bool:
|
| 123 |
+
""" Check if in given list of numbers, are any two numbers closer to each other than given threshold.
|
| 124 |
+
>>> has_close_elements([1.0, 2.0, 3.0], 0.5) False
|
| 125 |
+
>>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3) True """
|
| 126 |
+
```
|
| 127 |
+
|
| 128 |
+
### response:
|
| 129 |
+
|
| 130 |
+
```python
|
| 131 |
+
from typing import List
|
| 132 |
+
def has_close_elements(numbers: List[float], threshold: float) -> bool:
|
| 133 |
+
""" Check if in given list of numbers, are any two numbers closer to each other than given threshold.
|
| 134 |
+
>>> has_close_elements([1.0, 2.0, 3.0], 0.5) False
|
| 135 |
+
>>> has_close_elements([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.3) True """
|
| 136 |
+
pass
|
| 137 |
+
|
| 138 |
+
# Fill in this function. It should return the index into `numbers` where the closest pair should be inserted.
|
| 139 |
+
def closest_pair(numbers: List[float], threshold: float) -> int:
|
| 140 |
+
""" Find the closest pair in a given list ofalso numbers.
|
| 141 |
+
|
| 142 |
+
Assumes all the numbers are numbers in the list are positive.
|
| 143 |
+
Returns the correct index into `numbers` where the closest pair should be inserted. This
|
| 144 |
+
number is the *first* element of the closest pair.
|
| 145 |
+
|
| 146 |
+
>>> closest_pair([1.0, 2.8, 3.0, 4.0, 5.0, 2.0], 0.25) 1
|
| 147 |
+
>>> closest_pair([12.8, 12.0], 0.0) 0
|
| 148 |
+
>>> closest_pair([12.8, 12.0, 12.5, 12.1], 0.0) 1
|
| 149 |
+
>>> closest_pair([12.8, 11.5, 12.0, 12.5, 12.1], 0.0) 2 """
|
| 150 |
+
pass
|
| 151 |
+
|
| 152 |
+
<unk> import torch
|
| 153 |
+
import numpy as np
|
| 154 |
+
```
|
| 155 |
+
# Training Logs and Evaluation Results
|
| 156 |
+
|
| 157 |
+
Please refer to our [W&B project page](https://wandb.ai/llm360/CrystalCoder) for complete training logs and evaluation results.
|
| 158 |
+
|
| 159 |
+
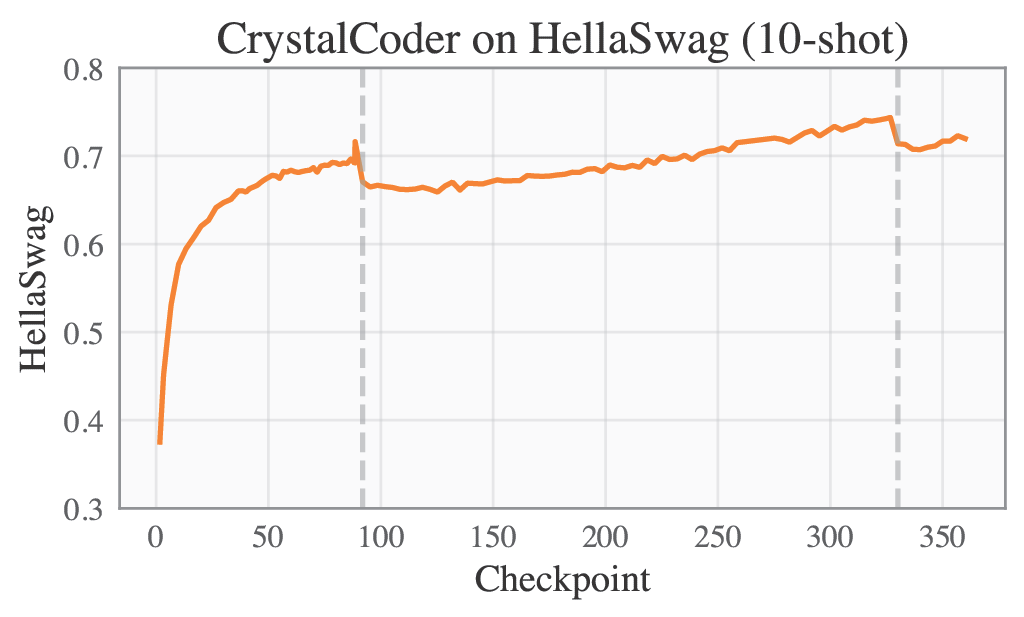
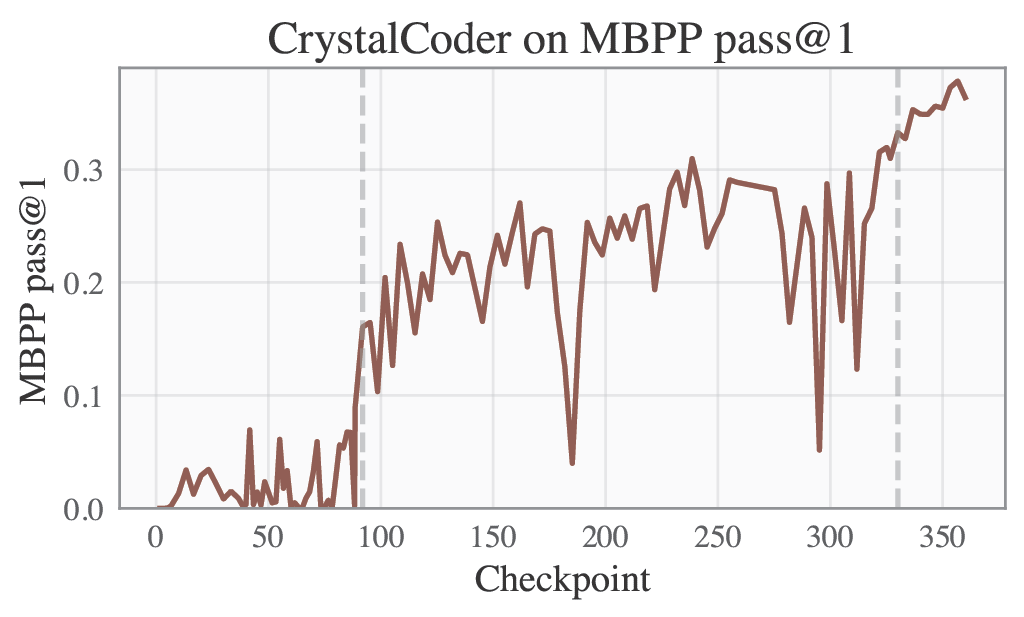
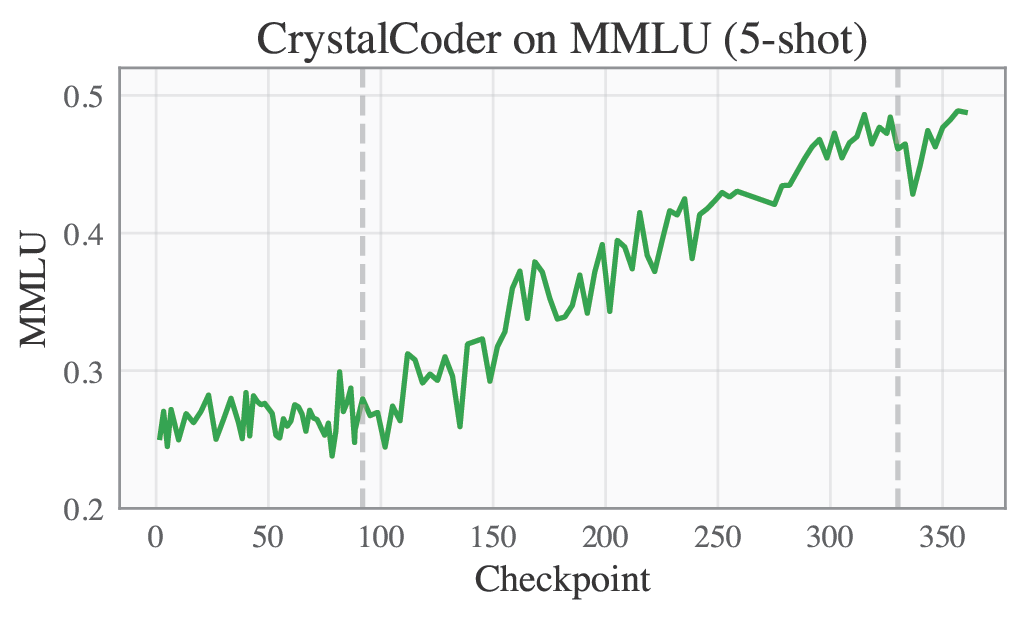
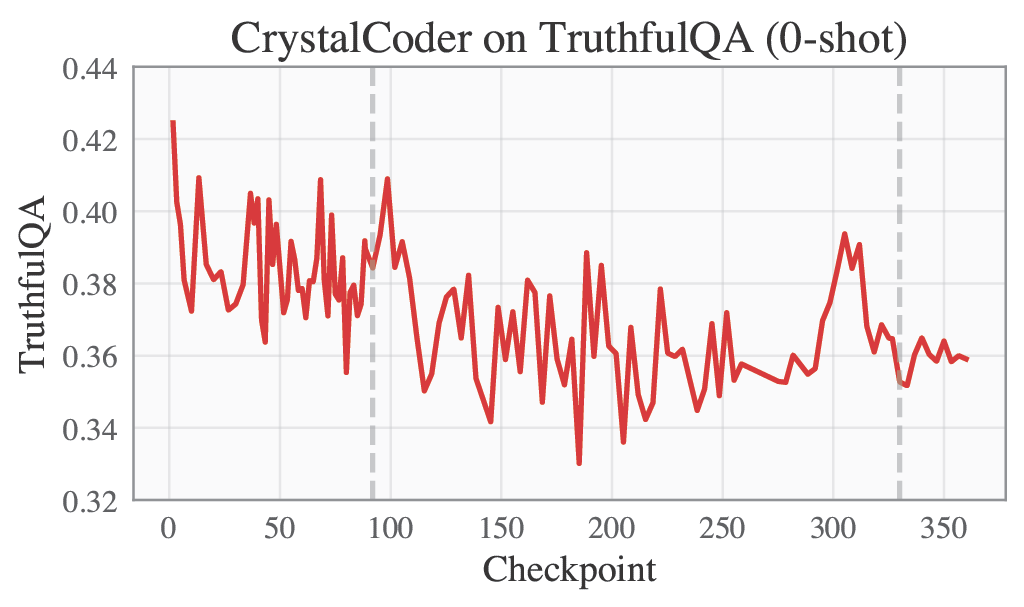
Selected Metrics are displayed below.
|
| 160 |
+
|
| 161 |
+
|HumanEval | MBPP |
|
| 162 |
+
|-----------------------------------------------------|-----------------------------------------------------------|
|
| 163 |
+
|<img src="cc-humaneval-curve.png" alt="humaneval" width="400"/> | <img src="cc-mbpp-curve.png" alt="mbpp" width="400"/> |
|
| 164 |
+
|
| 165 |
+
| ARC | HellSwag |
|
| 166 |
+
|------------------------------------------------------|------------------------------------------------------------|
|
| 167 |
+
| <img src="cc-arc-curve.png" alt="arc" width="400"/> | <img src="cc-hellaswag-curve.png" alt="hellaswag" width="400"/> |
|
| 168 |
+
|
| 169 |
+
|MMLU | TruthfulQA |
|
| 170 |
+
|-----------------------------------------------------|-----------------------------------------------------------|
|
| 171 |
+
|<img src="cc-mmlu-cuve.png" alt="mmlu" width="400"/> | <img src="cc-truthfulqa-curve.png" alt="truthfulqa" width="400"/> |
|
| 172 |
+
|
| 173 |
+
|
| 174 |
+
# CrystalCoder-Instruct
|
| 175 |
+
|
| 176 |
+
We also have instruction tuned versions of CrystalCoder, based on stage 2 and stage 3 final checkpoints. The Instruct version will be released later.
|
| 177 |
+
|
cc-arc-curve.png
ADDED

|
cc-hellaswag-curve.png
ADDED
|
cc-humaneval-curve.png
ADDED

|
cc-mbpp-curve.png
ADDED
|
cc-mmlu-cuve.png
ADDED
|
cc-truthfulqa-curve.png
ADDED
|