FuseAI
FuseAI is an open-source research community focused on model fusion topics.
The community members currently applying model fusion on Foundation, Chat, o1-like LLMs.
Welcome to join us!
News
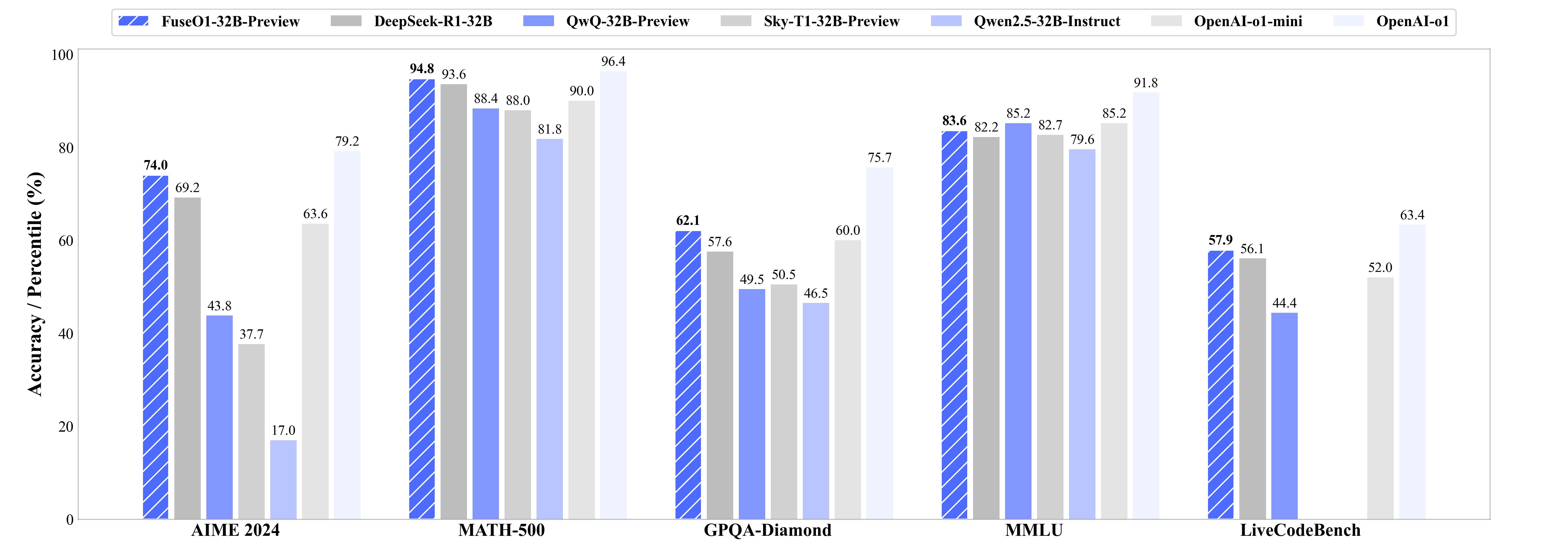
FuseO1-Preview [74.0 on AIME24, approaching OpenAI o1's 79.2]
- Jan 21, 2025: 🔥 FuseO1-Preview is our initial endeavor to enhance the System-II reasoning capabilities of large language models (LLMs) through innovative model fusion techniques. By employing our advanced SCE merging methodologies, we integrate multiple open-source o1-like LLMs into a unified model. Our goal is to incorporate the distinct knowledge and strengths from different reasoning LLMs into a single, unified model with strong System-II reasoning abilities, particularly in mathematics, coding, and science domains.
To achieve this, we conduct two types of model merging:
- Long-Long Reasoning Merging: This approach involves model fusion across LLMs that utilize long-CoT reasoning, with the goal of enhancing long-CoT reasoning capabilities. The resulted FuseAI/FuseO1-DeepSeekR1-QwQ-SkyT1-32B-Preview achieves a Pass@1 accuracy of 74.0 on AIME24, demonstrating significant performance improvements compared to the OpenAI o1-preview (44.6) and OpenAI o1-mini (63.4), even approaching OpenAI o1 (79.2).
- Long-Short Reasoning Merging: This approach involves model fusion between long-CoT and short-CoT LLMs, aiming to improve reasoning capabilities in both long and short reasoning processes. The resulted FuseAI/FuseO1-DeepSeekR1-Qwen2.5-Instruct-32B-Preview and FuseAI/FuseO1-DeepSeekR1-Qwen2.5-Coder-32B-Preview is capable of utilizing both long and short reasoning processes and demonstrates relatively strong performance in long reasoning tasks.
FuseChat-3.0 [SOTA 8B LLM on AlpacaEval-2 & Arena-Hard]
- Dec 12, 2024: 🔥 We release FuseChat-3.0 and Blog Post. FuseChat-3.0 contains a series of models crafted to enhance performance by integrating the strengths of multiple source LLMs into more compact target LLMs. To achieve this fusion, we utilized four powerful source LLMs: Gemma-2-27b-It, Mistral-Large-Instruct-2407, Qwen-2.5-72B-Instruct, and Llama-3.1-70B-Instruct. For the target LLMs, we employed three widely-used smaller models—Llama-3.1-8B-Instruct, Gemma-2-9B-It, and Qwen-2.5-7B-Instruct—along with two even more compact models—Llama-3.2-3B-Instruct and Llama-3.2-1B-Instruct. . The implicit model fusion process involves a two-stage training pipeline comprising Supervised Fine-Tuning (SFT) to mitigate distribution discrepancies between target and source LLMs, and Direct Preference Optimization (DPO) for learning preferences from multiple source LLMs. The resulting FuseChat-3.0 models demonstrated substantial improvements in tasks related to general conversation, instruction following, mathematics, and coding. Notably, when Llama-3.1-8B-Instruct served as the target LLM, our fusion approach achieved an average improvement of 6.8 points across 14 benchmarks. Moreover, it showed significant improvements of 37.1 and 30.1 points on instruction-following test sets AlpacaEval-2 and Arena-Hard respectively.

FuseChat [SOTA 7B LLM on MT-Bench]
Aug 16, 2024: 🔥🔥🔥🔥 We update the FuseChat tech report and release FuseChat-7B-v2.0, which is the fusion of six prominent chat LLMs with diverse architectures and scales, namely OpenChat-3.5-7B, Starling-LM-7B-alpha, NH2-Solar-10.7B, InternLM2-Chat-20B, Mixtral-8x7B-Instruct, and Qwen1.5-Chat-72B. FuseChat-7B-v2.0 achieves an average performance of 7.38 on MT-Bench (GPT-4-0125-Preview as judge LLM), which is comparable to Mixtral-8x7B-Instruct and approaches GPT-3.5-Turbo-1106.
Mar 13, 2024: 🔥🔥🔥 We release a HuggingFace Space for FuseChat-7B, try it now!
Feb 26, 2024: 🔥🔥 We release FuseChat-7B-VaRM, which is the fusion of three prominent chat LLMs with diverse architectures and scales, namely NH2-Mixtral-8x7B, NH2-Solar-10.7B, and OpenChat-3.5-7B. FuseChat-7B-VaRM achieves an average performance of 8.22 on MT-Bench, outperforming various powerful chat LLMs like Starling-7B, Yi-34B-Chat, and Tulu-2-DPO-70B, even surpassing GPT-3.5 (March), Claude-2.1, and approaching Mixtral-8x7B-Instruct.
Feb 25, 2024: 🔥 We release FuseChat-Mixture, which is a comprehensive training dataset covers different styles and capabilities, featuring both human-written and model-generated, and spanning general instruction-following and specific skills.


FuseLLM [Surpassing Llama-2-7B]


Citation
Please cite the following paper if you reference our model, code, data, or paper related to FuseLLM.
@inproceedings{wan2024knowledge,
title={Knowledge Fusion of Large Language Models},
author={Fanqi Wan and Xinting Huang and Deng Cai and Xiaojun Quan and Wei Bi and Shuming Shi},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/pdf?id=jiDsk12qcz}
}
Please cite the following paper if you reference our model, code, data, or paper related to FuseChat.
@article{wan2024fusechat,
title={FuseChat: Knowledge Fusion of Chat Models},
author={Fanqi Wan and Longguang Zhong and Ziyi Yang and Ruijun Chen and Xiaojun Quan},
journal={arXiv preprint arXiv:2408.07990},
year={2024}
}
Please cite the following paper if you reference our model, code, data, or paper related to WRPO.
@inproceedings{yang2025weightedreward,
title={Weighted-Reward Preference Optimization for Implicit Model Fusion},
author={Ziyi Yang and Fanqi Wan and Longguang Zhong and Tianyuan Shi and Xiaojun Quan},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=fq24pEb8SL}
}
Please cite the following paper if you reference our model, code, data, or paper related to FuseChat-3.0.
@article{yang2025fusechat,
title={FuseChat-3.0: Preference Optimization Meets Heterogeneous Model Fusion},
author={Ziyi Yang and Fanqi Wan and Longguang Zhong and Canbin Huang and Guosheng Liang and Xiaojun Quan},
journal={arXiv preprint arXiv:2503.04222},
year={2025},
}

