---
license: apache-2.0
inference: false
---
# MegaBeam-Mistral-7B-512k Model
`MegaBeam-Mistral-7B-512k` is a Large-Context LLM that supports 524,288 tokens in its context. `MegaBeam-Mistral-7B-512k` was trained on [Mistral-7B Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2), and can be deployed using various serving frameworks like [vLLM](https://github.com/vllm-project/vllm) and Amazon SageMaker's [DJL](https://docs.aws.amazon.com/sagemaker/latest/dg/deploy-models-frameworks-djl-serving.html) endpoint.
## Evaluations
We evaluated `MegaBeam-Mistral-7B-512k` on three long-context benchmarks. For each benchmark, we deployed the `MegaBeam-Mistral-7B-512k` model with [vLLM (v0.5.1)](https://github.com/vllm-project/vllm/releases/tag/v0.5.1) on an EC2 instance and obtained LLM responses through the OpenAI API provided by vLLM.
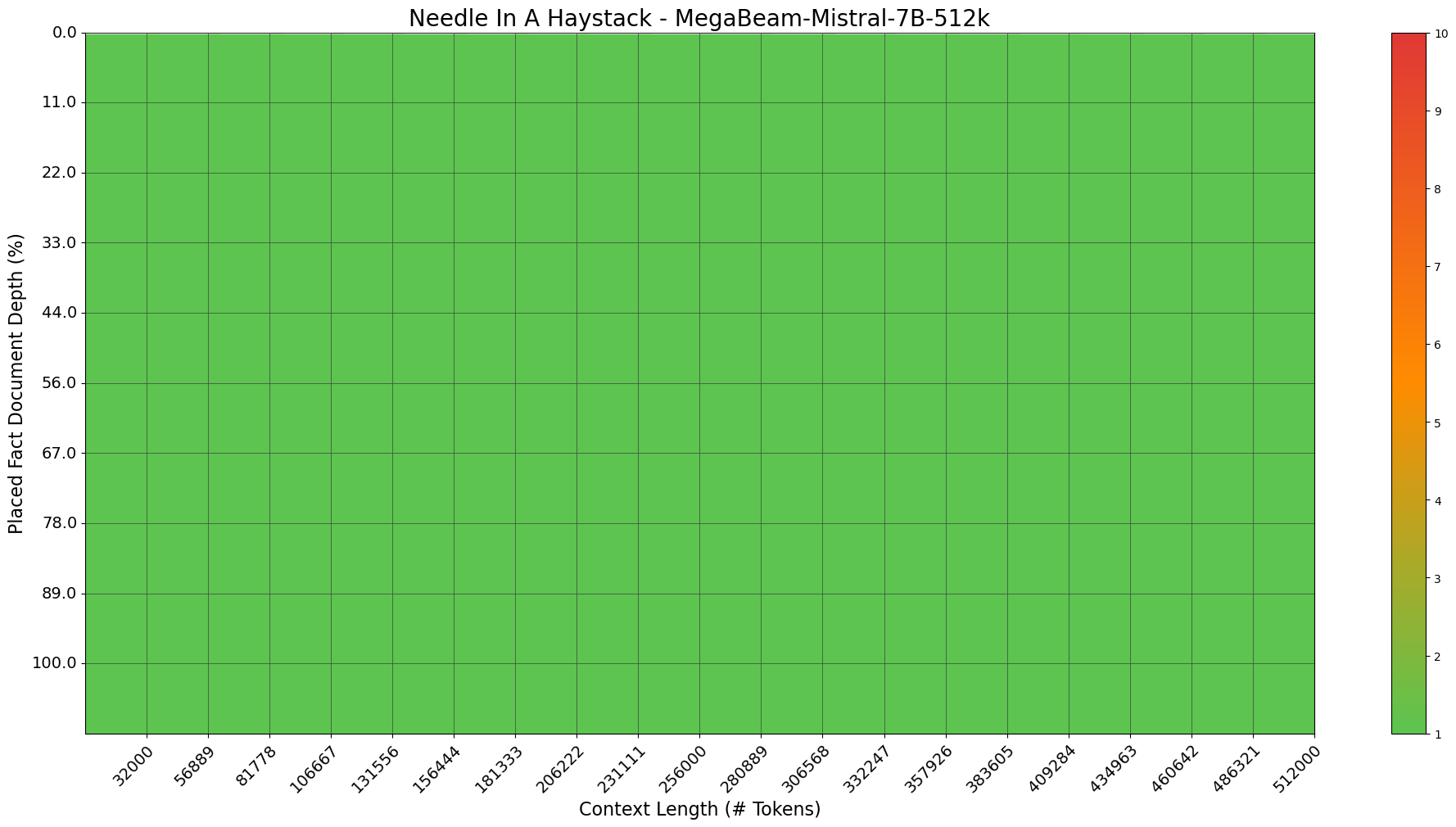
**[1. Needle In A Haystack - Pressure Testing LLMs](https://github.com/Arize-ai/LLMTest_NeedleInAHaystack)**
The [Arize-ai NIAH](https://github.com/Arize-ai/LLMTest_NeedleInAHaystack) varies the target random number and introduces a random city for each question, requiring the LLM to extract the random number from various selected context locations.
`MegaBeam-Mistral-7B-512k` scored `100%` on this NIAH benchmark as shown in this plot.
**[2. RULER: What’s the Real Context Size of Your Long-Context Language Models?](https://github.com/hsiehjackson/RULER)**
The [RULER](https://github.com/hsiehjackson/RULER) benchmark evaluates long-context language models across four task categories - Retrieval, Multi-hop Tracing, Aggregation, and Question Answering - with a total of 13 tasks. RULER goes beyond simple in-context recall by introducing more complex long-context scenarios.
`MegaBeam-Mistral-7B-512k` scored an average of `88.70` across different context lengths as shown in this table (*adapted from the [RULER project](https://github.com/hsiehjackson/RULER)*).
| Models | 4K | 8K | 16K | 32K | 64K | 128K | Avg. |
|------------------------------|------|------|------|------|------|------|------|
| **MegaBeam-Mistral-7B-512k** | 93.3 | 91.8 | 91.5 | 88.9 | 83.7 | 82.8 | 88.7 |
| | | | | | | | |
| [Gemini-1.5-pro](https://ai.google.dev/gemini-api/docs/models/gemini#:~:text=Gemini-,Gemini%201.5%20Pro%20(Preview%20only),-Text%20and%20images) | 96.7 | 95.8 | 96 | 95.9 | 95.9 | 94.4 | 95.8 |
| [GPT-4-1106-preview](https://platform.openai.com/docs/models/gpt-4-turbo-and-gpt-4#:~:text=gpt%2D4%2D1106%2Dpreview,Up%20to%20Apr%202023) | 96.6 | 96.3 | 95.2 | 93.2 | 87 | 81.2 | 91.6 |
[Llama3.1](https://huggingface.co/meta-llama/Meta-Llama-3.1-70B-Instruct) (70B)|96.5|95.8|95.4|94.8|88.4|66.6|89.6|
| [Qwen2](https://huggingface.co/Qwen/Qwen2-72B-Instruct) (72B) | 96.9 | 96.1 | 94.9 | 94.1 | 79.8 | 53.7 | 85.9 |
| [Command-R-plus](https://huggingface.co/CohereForAI/c4ai-command-r-plus) (104B) | 95.6 | 95.2 | 94.2 | 92 | 84.3 | 63.1 | 87.4 |
| [GLM4](https://huggingface.co/THUDM/glm-4-9b-chat-1m) (9B) | 94.7 | 92.8 | 92.1 | 89.9 | 86.7 | 83.1 | 89.9 |
[Llama3.1](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct) (8B)|95.5|93.8|91.6|87.4|84.7|77.0|88.3|
| [Command-R](https://huggingface.co/CohereForAI/c4ai-command-r-v01) (35B) | 93.8 | 93.3 | 92.4 | 89.5 | 84.9 | 76 | 88.3 |
| [GradientAI/Llama3](https://huggingface.co/gradientai/Llama-3-70B-Instruct-Gradient-1048k) (70B) | 95.1 | 94.4 | 90.8 | 85.4 | 82.9 | 72.1 | 86.5 |
| [Mixtral-8x22B](https://huggingface.co/mistralai/Mixtral-8x22B-instruct-v0.1) (39B/141B) | 95.6 | 94.9 | 93.4 | 90.9 | 84.7 | 31.7 | 81.9 |
| [Yi](https://huggingface.co/01-ai/Yi-34B-200K) (34B) | 93.3 | 92.2 | 91.3 | 87.5 | 83.2 | 77.3 | 87.5 |
| [Phi3-medium](https://huggingface.co/microsoft/Phi-3-medium-128K-instruct) (14B) | 93.3 | 93.2 | 91.1 | 86.8 | 78.6 | 46.1 | 81.5 |
| [Mixtral-8x7B](https://huggingface.co/mistralai/Mixtral-8x7B-instruct-v0.1) (12.9B/46.7B) | 94.9 | 92.1 | 92.5 | 85.9 | 72.4 | 44.5 | 80.4 |
| [GradientAI/Llama3](https://huggingface.co/gradientai/Llama-3-8B-Instruct-Gradient-1048k) (8B) | 92.8 | 90.3 | 85.7 | 79.9 | 76.3 | 69.5 | 82.4 |
| [FILM-7B](https://huggingface.co/In2Training/FILM-7B) (7B) | 92.8 | 88.2 | 88.1 | 86.9 | 70.1 | 27.1 | 75.5 |
| [Mistral-7B-instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-instruct-v0.2) (7B) | 93.6 | 91.2 | 87.2 | 75.4 | 49 | 13.8 | 68.4 |
[Mistral-Nemo](https://huggingface.co/mistralai/Mistral-Nemo-Instruct-2407)|87.8|87.2|87.7|69.0|46.8|19.0|66.2|
| [GLM3](https://huggingface.co/THUDM/chatglm3-6b-128K) (6B) | 87.8 | 83.4 | 78.6 | 69.9 | 56 | 42 | 69.6 |
| [LWM](https://huggingface.co/LargeWorldModel/LWM-Text-Chat-1M) (7B) | 82.3 | 78.4 | 73.7 | 69.1 | 68.1 | 65 | 72.8 |
This table shows how `MegaBeam-Mistral-7B-512k` performed on 13 RULER tasks with increasing context lengths.
| Task | Category | 4096 | 8192 | 16384 | 32768 | 65536 | 131072 |
|------------------|--------------------|------|-------|-------|-------|-------|--------|
| niah_single_1 | Retrieval | 100 | 100 | 100 | 100 | 100 | 100 |
| niah_single_2 | Retrieval | 98.6 | 97.8 | 98.8 | 98.2 | 99.4 | 99.6 |
| niah_single_3 | Retrieval | 100 | 100 | 100 | 99.8 | 100 | 99.8 |
| niah_multikey_1 | Retrieval | 98.8 | 99.6 | 99.2 | 99 | 99.6 | 99.6 |
| niah_multikey_2 | Retrieval | 100 | 100 | 100 | 99.8 | 99.4 | 98.6 |
| niah_multikey_3 | Retrieval | 99.8 | 99.4 | 99.8 | 100 | 98.6 | 97.8 |
| niah_multivalue | Retrieval | 97.1 | 93.8 | 91.85 | 83.5 | 80.3 | 71.45 |
| niah_multiquery | Retrieval | 99.95| 99.9 | 99.85 | 99.3 | 99.55 | 99.3 |
| vt | Multi-hop Tracing | 99.2 | 97.88 | 96.44 | 96.12 | 91.6 | 89.08 |
| cwe | Aggregation | 98.2 | 90.62 | 75.6 | 52.72 | 5.9 | 0.94 |
| fwe | Aggregation | 81.47| 80.07 | 95.87 | 96.33 | 83.73 | 96.87 |
| qa_1 | Q & A | 85.6 | 82 | 80.6 | 83 | 80.6 | 77.4 |
| qa_2 | Q & A | 53.8 | 52 | 51.6 | 48.4 | 49.2 | 45.8 |
| average | ALL | 93.3 | 91.8 | 91.5 | 88.9 | 83.7 | 82.8 |
| Total Average | 88.7 | | | | | | |
**[3. InfiniteBench: Extending Long Context Evaluation Beyond 100K Tokens](https://github.com/OpenBMB/InfiniteBench)**
[InfiniteBench](https://github.com/OpenBMB/InfiniteBench) developed 12 tasks to evaluate an LLM's capability to process, comprehend, and reason with extended contexts, specifically those with over 100,000 tokens.
We combine the InfiniteBench project's evaluation results for SOTA LLMs with `MegaBeam-Mistral-7B-512k`'s result in this table.
| Task Name | MegaBeam-Mistral
-7B-512k | GPT-4-1106
-preview | YaRN-Mistral
-7B | Kimi-Chat | Claude 2 | Yi-34B
-200K |
|----------------|--------------------------|--------------------|-----------------|-----------|-----------|-------------|
| PassKey | 100% | 100% | 92.71% | 98.14% | 97.80% | 100.00% |
| Retrv.Num | 99.49% | 100% | 56.61% | 95.42% | 98.14% | 100.00% |
| Retrv.KV | 24.20% | 89.00% | < 5% | 53.60% | 65.40% | < 5% |
| En.Sum | 34.66% | 14.73% | 9.09% | 17.93% | 14.45% | < 5% |
| En.QA | 20.32% | 22.22% | 9.55% | 16.52% | 11.97% | 12.17% |
| En.MC | 61.57% | 67.25% | 27.95% | 72.49% | 62.88% | 38.43% |
| En.Dia | 10.50% | 8.50% | 7.50% | 11.50% | 46.50% | < 5% |
| Zh.QA | 19.54% | 25.96% | 14.43% | 17.93% | 9.64% | 13.61% |
| Code.Debug | 26.14% | 39.59% | < 5% | 18.02% | < 5% | < 5% |
| Code.Run | 2% | 23.25% | < 5% | < 5% | < 5% | < 5% |
| Math.Calc | 0% | < 5% | < 5% | < 5% | < 5% | < 5% |
| Math.Find | 20% | 60.00% | 17.14% | 12.57% | 32.29% | 25.71% |
| Average | 34.87% | 46.08% | 20.41% | 34.93% | 37.21% | 25.41% |
## Example use case
This example demonstrates `MegaBeam-Mistral-7B-512k`'s long context capability by processing a large file that includes hundreds of files from a single [Git repository](https://github.com/awslabs/amazon-accessible-rl-sdk). This can be useful for onboarding new developers.

## Serve MegaBeam-Mistral-7B-512k on EC2 instances ##
On an AWS `g5.48xlarge` instance, install vLLM as per [vLLM docs](https://vllm.readthedocs.io/en/latest/).
```shell
pip install vllm==0.5.1
```
### Start the server
```shell
VLLM_ENGINE_ITERATION_TIMEOUT_S=3600 python3 -m vllm.entrypoints.openai.api_server \
--model aws-prototyping/MegaBeam-Mistral-7B-512k \
--tensor-parallel-size 8 \
--revision g5-48x
```
**Important Note** - In the repo revision `g5-48x`, `config.json` has been updated to set `max_position_embeddings` to 288,800, fitting the model's KV cache on a single `g5.48xlarge` instance with 8 A10 GPUs (24GB RAM per GPU).
On an instance with larger GPU RAM (e.g. `p4d.24xlarge`), simply remove the `revision` argument in order to support the full sequence length of 524,288 tokens:
```shell
VLLM_ENGINE_ITERATION_TIMEOUT_S=3600 python3 -m vllm.entrypoints.openai.api_server \
--model aws-prototyping/MegaBeam-Mistral-7B-512k \
--tensor-parallel-size 8 \
```
### Run the client
```python
from openai import OpenAI
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
# defaults to os.environ.get("OPENAI_API_KEY")
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
chat_completion = client.chat.completions.create(
messages = [
{"role": "user", "content": "What is your favourite condiment?"}, # insert your long context here
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"} # insert your long context here
],
model=model,
)
print("Chat completion results:")
print(chat_completion)
```
### Deploy the model on a SageMaker Endpoint ###
To deploy MegaBeam-Mistral-7B-512k on a SageMaker endpoint, please follow this [SageMaker DJL deployment guide](https://docs.djl.ai/docs/demos/aws/sagemaker/large-model-inference/sample-llm/vllm_deploy_mistral_7b.html).
Run the following Python code in a SageMaker notebook (with each block running in a separate cell)
```python
import sagemaker
from sagemaker import Model, image_uris, serializers, deserializers
sagemaker_session = sagemaker.Session()
region = sagemaker_session.boto_region_name
role = sagemaker.get_execution_role()
%%writefile serving.properties
engine=Python
option.model_id=aws-prototyping/MegaBeam-Mistral-7B-512k
option.revision=g5-48x
option.dtype=bf16
option.task=text-generation
option.rolling_batch=vllm
option.tensor_parallel_degree=8
option.device_map=auto
%%sh
mkdir mymodel
mv serving.properties mymodel/
tar czvf mymodel.tar.gz mymodel/
rm -rf mymodel
image_uri = image_uris.retrieve(
framework="djl-deepspeed",
region=region,
version="0.27.0"
)
s3_code_prefix = "megaBeam-mistral-7b-512k/code"
bucket = sagemaker_session.default_bucket() # bucket to house artifacts
code_artifact = sagemaker_session.upload_data("mymodel.tar.gz", bucket, s3_code_prefix)
print(f"S3 Code or Model tar ball uploaded to --- > {code_artifact}")
model = Model(image_uri=image_uri, model_data=code_artifact, role=role)
instance_type = "ml.g5.48xlarge"
endpoint_name = sagemaker.utils.name_from_base("megaBeam-mistral-7b-512k")
model.deploy(initial_instance_count=1,
instance_type=instance_type,
endpoint_name=endpoint_name
)
# our requests and responses will be in json format so we specify the serializer and the deserializer
predictor = sagemaker.Predictor(
endpoint_name=endpoint_name,
sagemaker_session=sagemaker_session,
serializer=serializers.JSONSerializer(),
)
# test the endpoint
input_str = """[INST] What is your favourite condiment? [/INST]
Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen! "
[INST] Do you have mayonnaise recipes? [/INST]"""
predictor.predict(
{"inputs": input_str, "parameters": {"max_new_tokens": 75}}
)
```
### Invoke the model on a SageMaker Endpoint ###
To use MegaBeam-Mistral-7B-512k on a SageMaker endpoint, please try following this example:
```python
import boto3
import json
def call_endpoint(text:str, endpoint_name:str):
client = boto3.client("sagemaker-runtime")
parameters = {
"max_new_tokens": 450,
"do_sample": True,
"temperature": 0.7,
}
payload = {"inputs": text, "parameters": parameters}
response = client.invoke_endpoint(
EndpointName=endpoint_name, Body=json.dumps(payload), ContentType="application/json"
)
output = json.loads(response["Body"].read().decode())
result = output["generated_text"]
return result
# please insert your long prompt/document content here
prompt = """[INST] What are the main challenges to support long contexts for a Large Language Model? [/INST]"""
#print(prompt)
endpoint_name = "megaBeam-mistral-7b-512k-2024-05-13-14-23-41-219" # please use a valid endpoint name
result = call_endpoint(prompt, endpoint_name)
print(result)
```
## Limitations ##
Before using the MegaBeam-Mistral-7B-512k model, it is important to perform your own independent assessment, and take measures to ensure that your use would comply with your own specific quality control practices and standards, and that your use would comply with the local rules, laws, regulations, licenses and terms that apply to you, and your content.
## The AWS Contributors ##
Chen Wu, Yin Song, Eden Duthie