---
language:
- en
---
# VeCLIP: Improving CLIP Training via Visual-enriched Captions
* A novel CLIP training scheme that achieves the SoTA performance on zero-shot ImageNet classification and COCO image text retreival using limited visual-enriched captions.* [[Paper](https://arxiv.org/abs/2310.07699)]
[Zhengfeng Lai*](https://zjujefflai.github.io/), [Haotian Zhang*](https://haotian-zhang.github.io/) , [Bowen Zhang](https://zbwglory.github.io/), Wentao Wu, Haoping Bai, Aleksei Timofeev, Xianzhi Du, [Zhe Gan](https://zhegan27.github.io/), Jiulong Shan, [Chen-Nee Chuah](https://www.ece.ucdavis.edu/~chuah/rubinet/people/chuah/bio.html), Yinfei Yang, Meng Cao [*: equal contribution]
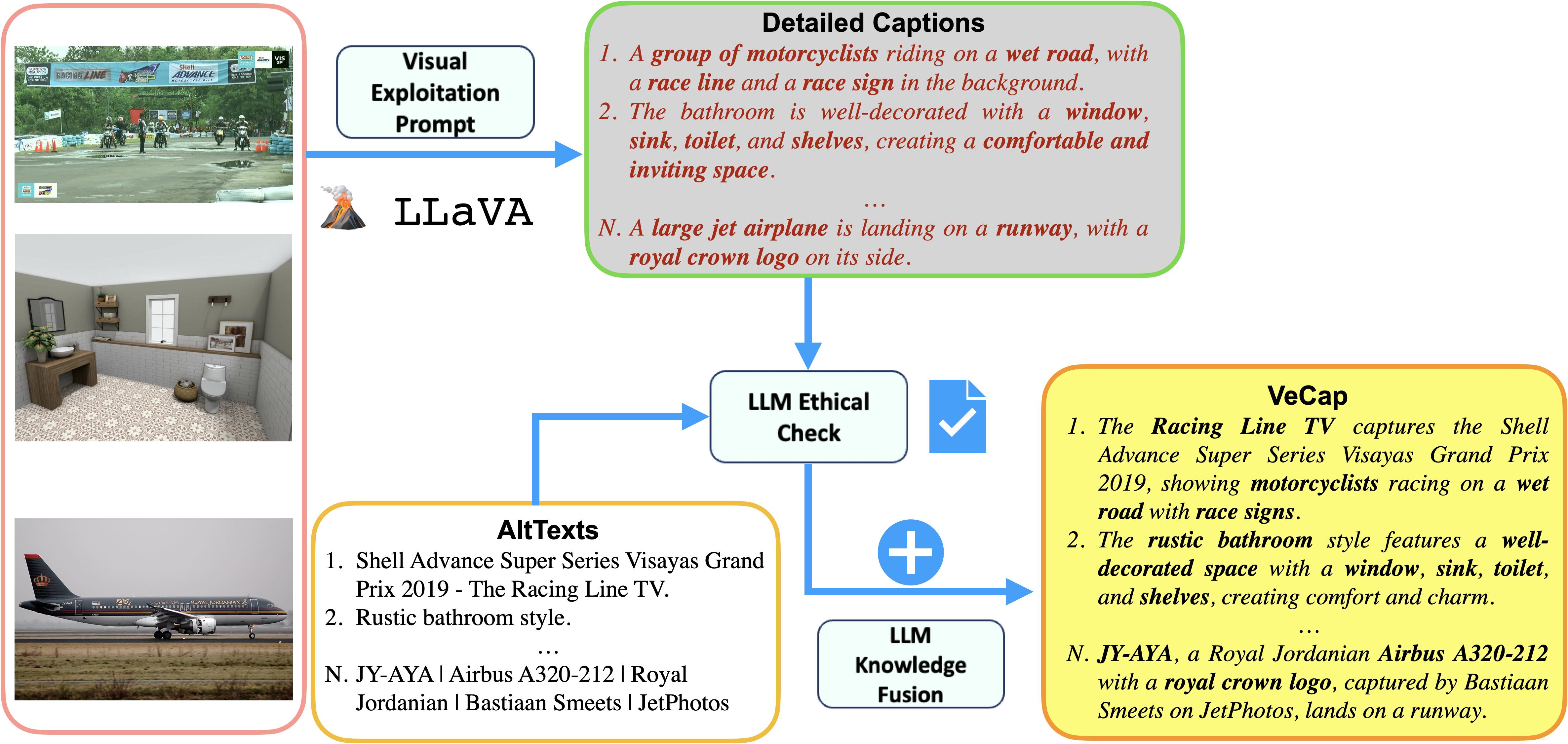
Diagram of VeCap.
## Release
- [03/06/2024] 🔥 We released the VeCLIP & VeCap-DFN [checkpoints](#checkpoints).
## Contents
- [Install](#install)
- [Getting Started](#getting-started)
- [Checkpoints](#checkpoints)
## Install
1. Clone this repository
```Shell
git clone https://github.com/apple/ml-veclip
cd ml-veclip
```
2. Create an environment and install related packages
```Shell
conda create -n veclip python=3.9 -y
conda activate veclip
pip install -r requirements.txt
```
## Getting Started
See the [example notebook](https://github.com/apple/ml-veclip/blob/main/load_veclip.ipynb) for details on how to simply load the different checkpoints using HuggingFace transformers.
## Checkpoints
We release the checkpoints for **VeCLIP**, which are trained from scratch on visual-enriched captions VeCap 3M/12M/100M/200M, as reported in the paper. The models are evaluated on COCO/Flickr30k image-text retrieval and ImageNet/ImageNetv2 classification in a zero-shot fashion. Use `wget` or `curl` to download the below checkpoints.
| Data |
Model |
Resolution |
COCO (R@1) |
Flickr30k (R@1) |
ImageNet |
ImageNetv2 |
| I2T |
T2I |
I2T |
T2I |
| VeCap 3M |
CLIP-B/16 |
224x224 |
5.46 |
3.28 |
12.20 |
6.36 |
5.46 |
7.09 |
| VeCLIP-B/16 |
224x224 |
22.30 |
13.01 |
40.60 |
27.58 |
15.98 |
13.51 |
| VeCap 12M |
CLIP-B/16 |
224x224 |
24.52 |
14.28 |
44.70 |
290.6 |
31.60 |
27.03 |
| VeCLIP-B/16 |
224x224 |
47.78 |
31.62 |
73.90 |
55.68 |
38.11 |
32.53 |
| VeCap 100M |
CLIP-B/16 |
224x224 |
47.24 |
30.61 |
74.40 |
57.16 |
58.64 |
50.96 |
| VeCLIP-B/16 |
224x224 |
64.82 |
46.12 |
89.30 |
73.10 |
60.77 |
54.17 |
| VeCap 200M |
CLIP-B/16 |
224x224 |
52.20 |
34.97 |
80.90 |
63.26 |
63.72 |
56.84 |
| VeCLIP-B/16 |
224x224 |
67.20 |
48.40 |
91.10 |
76.32 |
64.64 |
57.67 |
We further found our VeCap can also be complementary to other well-established filtering methods, e.g., [Data Filtering Network (DFN)](https://arxiv.org/abs/2309.17425). We also provide thosse checkpoints (referred to as **VeCap-DFN**) and report their performance below.
| Backbone |
Resolution |
Data |
COCO (R@1) |
Flickr30k (R@1) |
ImageNet |
ImageNetV2 |
| I2T |
T2I |
I2T |
T2I |
| VeCap-DFN-B/16 |
224x224 |
DFN |
62.96 |
43.20 |
87.10 |
70.44 |
76.15 |
68.19 |
| VeCap 300M |
64.74 |
44.58 |
90.10 |
73.14 |
46.43 |
41.15 |
| DFN + VeCap 300M |
66.28 |
45.12 |
88.80 |
73.56 |
76.19 |
69.58 |
| VeCap-DFN-L/14 |
224x224 |
DFN + VeCap 300M |
71.06 |
51.13 |
93.10 |
80.96 |
81.95 |
75.48 |
| VeCap-DFN-H/14 |
336x336 |
DFN + VeCap 300M |
72.78 |
52.33 |
93.60 |
82.64 |
83.07 |
76.37 |
## Citation
If you find VeCLIP useful, please cite using this BibTeX:
```bibtex
@article{lai2023scarcity,
title={From scarcity to efficiency: Improving clip training via visual-enriched captions},
author={Lai, Zhengfeng and Zhang, Haotian and Zhang, Bowen and Wu, Wentao and Bai, Haoping and Timofeev, Aleksei and Du, Xianzhi and Gan, Zhe and Shan, Jiulong and Chuah, Chen-Nee and Yang, Yinfei and others},
journal={arXiv preprint arXiv:2310.07699},
year={2023}
}
@article{fang2023data,
title={Data filtering networks},
author={Fang, Alex and Jose, Albin Madappally and Jain, Amit and Schmidt, Ludwig and Toshev, Alexander and Shankar, Vaishaal},
journal={arXiv preprint arXiv:2309.17425},
year={2023}
}
```
## Acknowledgement
- [axlearn](https://github.com/apple/axlearn): the codebase we use to train the models.
- [huggingface transformers](https://huggingface.co/docs/transformers/en/index): Transformers provides APIs to load our trained models.