---
license: apache-2.0
datasets:
- AIDC-AI/Ovis-dataset
library_name: transformers
tags:
- MLLM
pipeline_tag: image-text-to-text
language:
- en
base_model:
- AIDC-AI/Ovis1.6-Llama3.2-3B
---
# Ovis1.6-Llama3.2-3B-GPTQ-Int4

## Introduction
[GitHub](https://github.com/AIDC-AI/Ovis) | [Paper](https://arxiv.org/abs/2405.20797)
We are excited to announce the open-sourcing of **Ovis-1.6**, our latest multi-modal large language model. Ovis is a novel Multimodal Large Language Model (MLLM) architecture, designed to structurally align visual and textual embeddings.
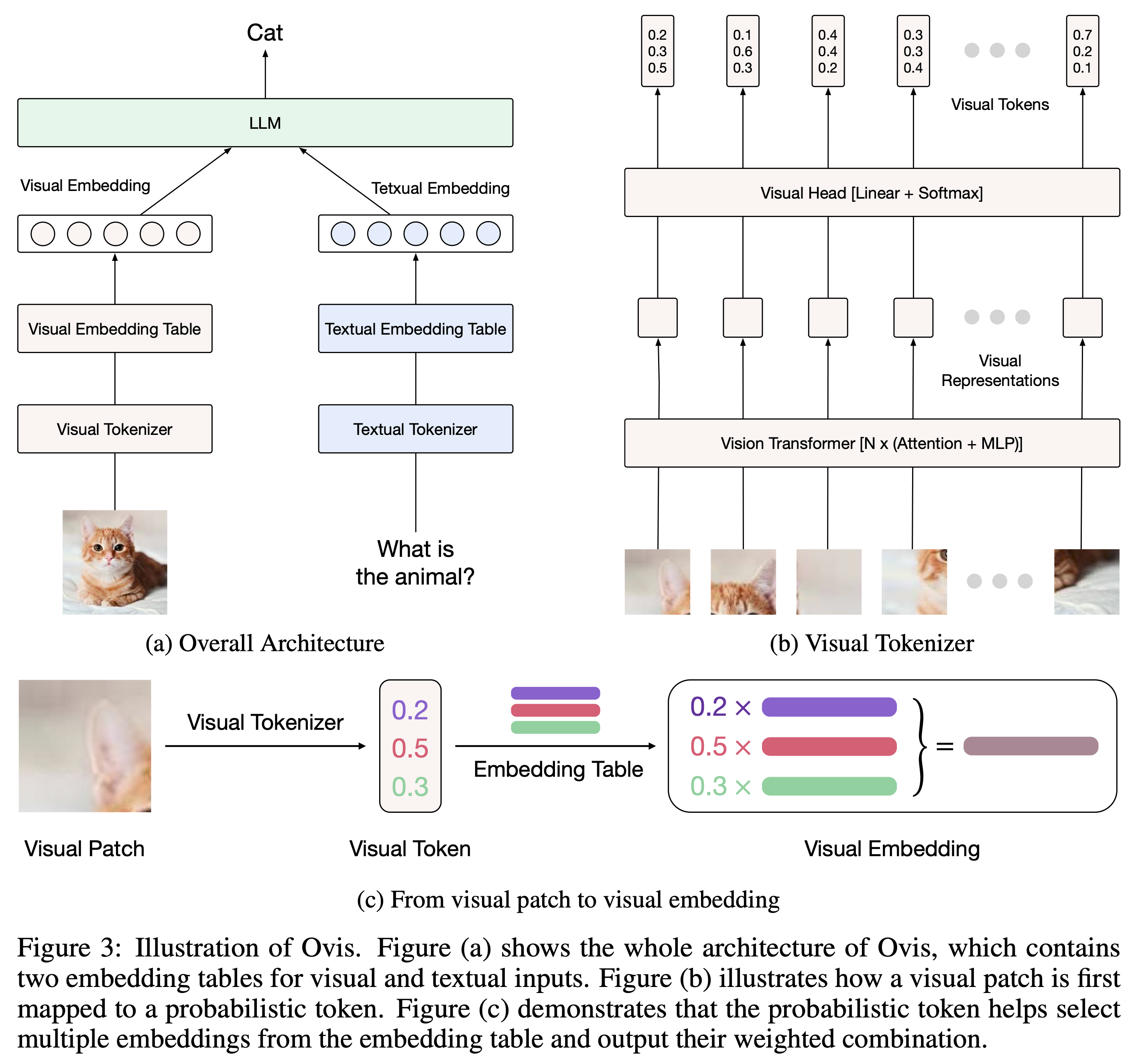
## Model
Built upon Ovis1.5, **Ovis1.6** further enhances high-resolution image processing, is trained on a larger, more diverse, and higher-quality dataset, and refines the training process with DPO training following instruction-tuning.
| Ovis MLLMs | ViT | LLM | Model Weights | Demo |
|:------------------|:-----------:|:------------------:|:---------------------------------------------------------------:|:----------------------------------------------------------------:|
| Ovis1.6-Gemma2-9B | Siglip-400M | Gemma2-9B-It | [Huggingface](https://huggingface.co/AIDC-AI/Ovis1.6-Gemma2-9B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis1.6-Gemma2-9B) |
| Ovis1.6-Llama3.2-3B | Siglip-400M | Llama-3.2-3B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis1.6-Llama3.2-3B) | [Space](https://huggingface.co/spaces/AIDC-AI/Ovis1.6-Llama3.2-3B) |
| Ovis1.6-Gemma2-9B-GPTQ-Int4 | Siglip-400M | Gemma2-9B-It | [Huggingface](https://huggingface.co/AIDC-AI/Ovis1.6-Gemma2-9B-GPTQ-Int4) | - |
| Ovis1.6-Llama3.2-3B-GPTQ-Int4 | Siglip-400M | Llama-3.2-3B-Instruct | [Huggingface](https://huggingface.co/AIDC-AI/Ovis1.6-Llama3.2-3B-GPTQ-Int4) | - |
## Quantized Model
We quantized Ovis1.6 with AutoGPTQ. Follow these steps to run it.
### Installation
1. Run the following commands to get a basic environment. Be sure to run with CUDA 12.1.
```bash
conda create -n python=3.10
conda activate
pip install torch==2.2.1 torchvision==0.17.1 torchaudio==2.2.1 --index-url https://download.pytorch.org/whl/cu121
pip install numpy==1.24.3 transformers==4.44.2 pillow==10.3.0 gekko pandas
```
2. Build AutoGPTQ: We customized AutoGPTQ to support Ovis model quantization. You need to build from source to install the customized version.
```bash
git clone https://github.com/AIDC-AI/AutoGPTQ.git
cd AutoGPTQ
pip install -vvv --no-build-isolation -e .
```
Check [this](https://github.com/AutoGPTQ/AutoGPTQ/issues/194) first if you are building inside a Docker container.
### Usage
Below is a code snippet to run **Ovis1.6-Llama3.2-3B-GPTQ-Int4** with multimodal inputs. For additional usage instructions, including inference wrapper and Gradio UI, please refer to [Ovis GitHub](https://github.com/AIDC-AI/Ovis?tab=readme-ov-file#inference).
```python
import torch
from PIL import Image
from transformers import GenerationConfig
from auto_gptq.modeling import OvisLlamaGPTQForCausalLM
# load model
load_device = "cuda:0" # customize load device
model = OvisLlamaGPTQForCausalLM.from_pretrained(
"AIDC-AI/Ovis1.6-Llama3.2-3B-GPTQ-Int4",
device=load_device,
trust_remote_code=True
)
model.model.generation_config = GenerationConfig.from_pretrained("AIDC-AI/Ovis1.6-Llama3.2-3B-GPTQ-Int4")
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# enter image path and prompt
image_path = input("Enter image path: ")
image = Image.open(image_path)
text = input("Enter prompt: ")
query = f'\n{text}'
# format conversation
prompt, input_ids, pixel_values = model.preprocess_inputs(query, [image])
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
pixel_values = [pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'Output:\n{output}')
```
Batch inference
```python
batch_inputs = [
('example_image1.jpeg', 'Describe the content of this image.'),
('example_image2.jpeg', 'What is the equation in the image?')
]
batch_input_ids = []
batch_attention_mask = []
batch_pixel_values = []
for image_path, text in batch_inputs:
image = Image.open(image_path)
query = f'\n{text}'
prompt, input_ids, pixel_values = model.preprocess_inputs(query, [image])
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
pixel_values = [pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)]
batch_input_ids.append(input_ids.squeeze())
batch_attention_mask.append(attention_mask.squeeze())
batch_pixel_values.append(pixel_values)
pad_batch_input_ids = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_input_ids],batch_first=True, padding_value=0.0).flip(dims=[1])
pad_batch_input_ids = pad_batch_input_ids[:,-model.config.multimodal_max_length:]
pad_batch_attention_mask = torch.nn.utils.rnn.pad_sequence([i.flip(dims=[0]) for i in batch_attention_mask],batch_first=True, padding_value=False).flip(dims=[1])
pad_batch_attention_mask = pad_batch_attention_mask[:,-model.config.multimodal_max_length:]
pad_batch_pixel_values = [item for sublist in batch_pixel_values for item in sublist]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(pad_batch_input_ids, pixel_values=pad_batch_pixel_values, attention_mask=pad_batch_attention_mask, **gen_kwargs)
for i in range(len(batch_input_ids)):
output = text_tokenizer.decode(output_ids[i], skip_special_tokens=True)
print(f'Output_{i}:\n{output}')
```
## Quantize Your Own Ovis Model with AutoGPTQ
We provide a demonstration code snippet for you to quantize your own fine-tuned **Ovis1.6-Llama3.2-3B** model. Before running the code, you need to **follow the ABOVE installation steps** to obtain an environment for quantization.
```python
from typing import Dict, Sequence, Union, List
import copy
import logging
from auto_gptq import BaseQuantizeConfig
from auto_gptq.modeling import OvisLlamaGPTQForCausalLM
import torch
from torch.utils.data import Dataset, DataLoader
from PIL import Image
# Specify paths and hyperparameters for quantization
model_path = "path/to/finetuned/model"
quantize_save_path = "path/to/save/quantized/model"
IGNORE_ID = -100
device_idx = 2 # you customize
torch.cuda.set_device(device_idx)
quantize_config = BaseQuantizeConfig(
bits=4, # 4 or 8
group_size=128,
damp_percent=0.1,
desc_act=False, # set to False can significantly speed up inference but the perplexity may slightly bad
static_groups=False,
sym=True,
true_sequential=True,
)
# Load model
model = OvisLlamaGPTQForCausalLM.from_pretrained(
model_path,
quantize_config,
torch_dtype=torch.bfloat16,
multimodal_max_length=2624,
llm_attn_implementation='eager',
trust_remote_code=True
).cuda()
print(f"Model Loaded!")
# prepare calibration samples
class CalibrationDataset(Dataset):
"""
Dataset class for calibration. Initialize with the loaded Ovis model, and a sample list in the following format:
data_list = [
{
"image": "path/to/image/of/this/sample",
"conversations": [
{
"from": "human",
"value": "\n[Your sample prompt]"
},
{
"from": "gpt",
"value": "[Anything]"
}
]
},
...
]
"""
def __init__(self, model, text_max_length, data_list: List[Dict]):
self.data = data_list
self.model = model
self.visual_tokenizer = model.get_visual_tokenizer()
self.text_max_length = text_max_length
def __len__(self):
return len(self.data)
def __getitem__(self, i: int) -> Dict[str, torch.Tensor]:
sample = self.data[i]
conversations = copy.deepcopy(sample["conversations"])
images = [Image.open(sample['image'])]
max_partition = 9
prompt, input_ids, pixel_values, labels = self.model.preprocess_inputs(
conversations,
images,
max_partition=max_partition,
generation_preface=None,
return_labels=True,
propagate_exception=False
)
if pixel_values is None:
pixel_values, _ = self.visual_tokenizer.mock_input()
input_ids = input_ids[:self.text_max_length]
labels = labels[:self.text_max_length]
return dict(
pixel_values=pixel_values,
input_ids=input_ids,
labels=labels
)
class DataCollatorForMultimodalDatasetGPTQ:
def __init__(self, text_tokenizer):
self.text_tokenizer = text_tokenizer
def __call__(self, instances: Sequence[Dict]) -> Dict[str, Union[torch.Tensor, List[torch.Tensor]]]:
pixel_values, input_ids, labels = tuple([instance[key] for instance in instances]
for key in ("pixel_values", "input_ids", "labels"))
input_ids = torch.nn.utils.rnn.pad_sequence(
input_ids,
batch_first=True,
padding_value=self.text_tokenizer.pad_token_id)
attention_mask = torch.ne(input_ids, self.text_tokenizer.pad_token_id)
labels = torch.nn.utils.rnn.pad_sequence(
labels,
batch_first=True,
padding_value=IGNORE_ID)
num_valid_label = torch.not_equal(labels, IGNORE_ID).sum().item()
if num_valid_label == 0:
logging.warning(
f'[DataCollatorForMultimodalDatasetGPTQ] All labels are ignored, may causing training instability\n{input_ids=}\n{attention_mask=}\n{labels=}')
return dict(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels,
pixel_values=pixel_values
)
class MyDataLoader(DataLoader):
def __len__(self):
return len(self.dataset) // self.batch_size # must set drop last=True
# prepare your own calibration samples here
data_list = [
{
"image": "path/to/image/of/this/sample",
"conversations": [
{
"from": "human",
"value": "\n[Your sample prompt]"
},
{
"from": "gpt",
"value": "[Anything]"
}
]
}
]
train_dataset = CalibrationDataset(model, text_max_length=832, data_list=data_list)
print(f"Dataset Loaded!")
print(f"Total length of the training set: {len(train_dataset)}")
train_loader = MyDataLoader(
train_dataset,
collate_fn=DataCollatorForMultimodalDatasetGPTQ(model.get_text_tokenizer()),
shuffle=False,
batch_size=4,
drop_last=True,
pin_memory=True,
num_workers=8
)
print(f"Dataloader Loaded!")
# start quantizing
model.quantize(train_loader, cache_examples_on_gpu=False)
print(f"Model Quantized! Now Saving...")
model.save_quantized(quantize_save_path, use_safetensors=True)
print(f"ALL Done!")
```
## Performance
Here we report the performance of Ovis1.6-Llama3.2-3B-GPTQ-Int4. The results are obtained with VLMEvalkit.
Benchmark:

VRAM usage:

## Citation
If you find Ovis useful, please cite the paper
```
@article{lu2024ovis,
title={Ovis: Structural Embedding Alignment for Multimodal Large Language Model},
author={Shiyin Lu and Yang Li and Qing-Guo Chen and Zhao Xu and Weihua Luo and Kaifu Zhang and Han-Jia Ye},
year={2024},
journal={arXiv:2405.20797}
}
```
## License
This project is licensed under the [Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0.txt) (SPDX-License-Identifier: Apache-2.0).
## Disclaimer
We used compliance-checking algorithms during the training process, to ensure the compliance of the trained model to the best of our ability. Due to the complexity of the data and the diversity of language model usage scenarios, we cannot guarantee that the model is completely free of copyright issues or improper content. If you believe anything infringes on your rights or generates improper content, please contact us, and we will promptly address the matter.